Manually sync'd code from upstream TF. (#2)
Confirmed that the following command passes:
```
./tensorflow/lite/micro/tools/ci_build/test_all_new.sh GITHUB_PRESUBMIT
```
diff --git a/.bazelrc b/.bazelrc
new file mode 100644
index 0000000..55ffeb4
--- /dev/null
+++ b/.bazelrc
@@ -0,0 +1,52 @@
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# TFLM Bazel configuration file.
+#
+# Other build options:
+# asan: Build with the clang address sanitizer
+# msan: Build with the clang memory sanitizer
+# ubsan: Build with the clang undefined behavior sanitizer
+#
+
+# Address sanitizer
+# CC=clang bazel build --config asan
+build:asan --strip=never
+build:asan --copt -fsanitize=address
+build:asan --copt -DADDRESS_SANITIZER
+build:asan --copt -g
+build:asan --copt -O3
+build:asan --copt -fno-omit-frame-pointer
+build:asan --linkopt -fsanitize=address
+
+# Memory sanitizer
+# CC=clang bazel build --config msan
+build:msan --strip=never
+build:msan --copt -fsanitize=memory
+build:msan --copt -DADDRESS_SANITIZER
+build:msan --copt -g
+build:msan --copt -O3
+build:msan --copt -fno-omit-frame-pointer
+build:msan --linkopt -fsanitize=memory
+
+# Undefined Behavior Sanitizer
+# CC=clang bazel build --config ubsan
+build:ubsan --strip=never
+build:ubsan --copt -fsanitize=undefined
+build:ubsan --copt -g
+build:ubsan --copt -O3
+build:ubsan --copt -fno-omit-frame-pointer
+build:ubsan --linkopt -fsanitize=undefined
+build:ubsan --linkopt -lubsan
diff --git a/WORKSPACE b/WORKSPACE
new file mode 100644
index 0000000..b289b13
--- /dev/null
+++ b/WORKSPACE
@@ -0,0 +1,20 @@
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+workspace(name = "org_tensorflow")
+
+load("@//tensorflow:workspace.bzl", "workspace")
+
+workspace()
diff --git a/tensorflow/BUILD b/tensorflow/BUILD
new file mode 100644
index 0000000..2eab80a
--- /dev/null
+++ b/tensorflow/BUILD
@@ -0,0 +1,540 @@
+load("@bazel_skylib//lib:selects.bzl", "selects")
+load("@bazel_skylib//rules:common_settings.bzl", "bool_setting")
+
+licenses(["notice"])
+
+# Config setting used when building for products
+# which requires restricted licenses to be avoided.
+config_setting(
+ name = "no_lgpl_deps",
+ define_values = {"__TENSORFLOW_NO_LGPL_DEPS__": "1"},
+ visibility = ["//visibility:public"],
+)
+
+# Config setting that disables the default logger, only logging
+# to registered TFLogSinks
+config_setting(
+ name = "no_default_logger",
+ define_values = {"no_default_logger": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# Config setting for determining if we are building for Android.
+config_setting(
+ name = "android",
+ values = {"crosstool_top": "//external:android/crosstool"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "android_x86",
+ values = {
+ "crosstool_top": "//external:android/crosstool",
+ "cpu": "x86",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "android_x86_64",
+ values = {
+ "crosstool_top": "//external:android/crosstool",
+ "cpu": "x86_64",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "android_armeabi",
+ values = {
+ "crosstool_top": "//external:android/crosstool",
+ "cpu": "armeabi",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "emscripten",
+ values = {"crosstool_top": "//external:android/emscripten"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "raspberry_pi_armeabi",
+ values = {
+ "crosstool_top": "@local_config_arm_compiler//:toolchain",
+ "cpu": "armeabi",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "android_arm",
+ values = {
+ "crosstool_top": "//external:android/crosstool",
+ "cpu": "armeabi-v7a",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "android_arm64",
+ values = {
+ "crosstool_top": "//external:android/crosstool",
+ "cpu": "arm64-v8a",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "android_mips",
+ values = {
+ "crosstool_top": "//external:android/crosstool",
+ "cpu": "mips",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "android_mips64",
+ values = {
+ "crosstool_top": "//external:android/crosstool",
+ "cpu": "mips64",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "windows",
+ values = {"cpu": "x64_windows"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "no_tensorflow_py_deps",
+ define_values = {"no_tensorflow_py_deps": "true"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "macos_x86_64",
+ values = {
+ "apple_platform_type": "macos",
+ "cpu": "darwin",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "macos_arm64",
+ values = {
+ "apple_platform_type": "macos",
+ "cpu": "darwin_arm64",
+ },
+ visibility = ["//visibility:public"],
+)
+
+selects.config_setting_group(
+ name = "macos",
+ match_any = [
+ ":macos_x86_64",
+ ":macos_arm64",
+ ],
+)
+
+config_setting(
+ name = "ios",
+ values = {"apple_platform_type": "ios"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "fuchsia",
+ values = {"cpu": "fuchsia"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "ios_x86_64",
+ values = {
+ "crosstool_top": "//tools/osx/crosstool:crosstool",
+ "cpu": "ios_x86_64",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "chromiumos",
+ values = {"crosstool_top": "//external:android/chromiumos"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "linux_aarch64",
+ values = {"cpu": "aarch64"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "linux_armhf",
+ values = {"cpu": "armhf"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "linux_x86_64",
+ values = {"cpu": "k8"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "linux_ppc64le",
+ values = {"cpu": "ppc"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "linux_s390x",
+ values = {"cpu": "s390x"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "linux_mips64",
+ values = {"cpu": "mips64"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "debug",
+ values = {
+ "compilation_mode": "dbg",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "optimized",
+ values = {
+ "compilation_mode": "opt",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "arm",
+ values = {"cpu": "arm"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "armeabi",
+ values = {"cpu": "armeabi"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "armeabi-v7a",
+ values = {"cpu": "armeabi-v7a"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "arm64-v8a",
+ values = {"cpu": "arm64-v8a"},
+ visibility = ["//visibility:public"],
+)
+
+selects.config_setting_group(
+ name = "arm_any",
+ match_any = [
+ ":arm",
+ ":armeabi",
+ ":armeabi-v7a",
+ ":arm64-v8a",
+ ":linux_aarch64",
+ ":linux_armhf",
+ ],
+)
+
+config_setting(
+ name = "freebsd",
+ values = {"cpu": "freebsd"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "with_default_optimizations",
+ define_values = {"with_default_optimizations": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# Features that are default ON are handled differently below.
+#
+config_setting(
+ name = "no_aws_support",
+ define_values = {"no_aws_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "no_gcp_support",
+ define_values = {"no_gcp_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "no_hdfs_support",
+ define_values = {"no_hdfs_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "no_nccl_support",
+ define_values = {"no_nccl_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# Experimental features
+config_setting(
+ name = "stackdriver_support",
+ define_values = {"stackdriver_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# Crosses between platforms and file system libraries not supported on those
+# platforms due to limitations in nested select() statements.
+config_setting(
+ name = "with_cuda_support_windows_override",
+ define_values = {"using_cuda_nvcc": "true"},
+ values = {"cpu": "x64_windows"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "with_xla_support",
+ define_values = {"with_xla_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# By default, XLA GPU is compiled into tensorflow when building with
+# --config=cuda even when `with_xla_support` is false. The config setting
+# here allows us to override the behavior if needed.
+config_setting(
+ name = "no_xla_deps_in_cuda",
+ define_values = {"no_xla_deps_in_cuda": "true"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "with_numa_support",
+ define_values = {"with_numa_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# Crosses between framework_shared_object and a bunch of other configurations
+# due to limitations in nested select() statements.
+config_setting(
+ name = "framework_shared_object",
+ define_values = {"framework_shared_object": "true"},
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "macos_x86_64_with_framework_shared_object",
+ define_values = {
+ "framework_shared_object": "true",
+ },
+ values = {
+ "apple_platform_type": "macos",
+ "cpu": "darwin",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "macos_arm64_with_framework_shared_object",
+ define_values = {
+ "framework_shared_object": "true",
+ },
+ values = {
+ "apple_platform_type": "macos",
+ "cpu": "darwin_arm64",
+ },
+ visibility = ["//visibility:public"],
+)
+
+selects.config_setting_group(
+ name = "macos_with_framework_shared_object",
+ match_any = [
+ ":macos_x86_64_with_framework_shared_object",
+ ":macos_arm64_with_framework_shared_object",
+ ],
+)
+
+config_setting(
+ name = "using_cuda_clang",
+ define_values = {"using_cuda_clang": "true"},
+)
+
+# Config setting to use in select()s to distinguish open source build from
+# google internal build on configurable attributes.
+config_setting(
+ name = "oss",
+ flag_values = {":oss_setting": "True"},
+ visibility = ["//visibility:public"],
+)
+
+# Fixed setting to indicate open source build.
+bool_setting(
+ name = "oss_setting",
+ build_setting_default = True,
+)
+
+config_setting(
+ name = "using_cuda_clang_with_dynamic_build",
+ define_values = {
+ "using_cuda_clang": "true",
+ "framework_shared_object": "true",
+ },
+)
+
+selects.config_setting_group(
+ name = "build_oss_using_cuda_clang",
+ match_all = [
+ ":using_cuda_clang",
+ ":oss",
+ ],
+)
+
+# Setting to use when loading kernels dynamically
+config_setting(
+ name = "dynamic_loaded_kernels",
+ define_values = {
+ "dynamic_loaded_kernels": "true",
+ "framework_shared_object": "true",
+ },
+ visibility = ["//visibility:public"],
+)
+
+config_setting(
+ name = "using_cuda_nvcc",
+ define_values = {"using_cuda_nvcc": "true"},
+)
+
+config_setting(
+ name = "using_cuda_nvcc_with_dynamic_build",
+ define_values = {
+ "using_cuda_nvcc": "true",
+ "framework_shared_object": "true",
+ },
+)
+
+selects.config_setting_group(
+ name = "build_oss_using_cuda_nvcc",
+ match_all = [
+ ":using_cuda_nvcc",
+ ":oss",
+ ],
+)
+
+config_setting(
+ name = "using_rocm_hipcc",
+ define_values = {"using_rocm_hipcc": "true"},
+)
+
+config_setting(
+ name = "override_eigen_strong_inline",
+ define_values = {"override_eigen_strong_inline": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# This flag specifies whether TensorFlow 2.0 API should be built instead
+# of 1.* API. Note that TensorFlow 2.0 API is currently under development.
+config_setting(
+ name = "api_version_2",
+ define_values = {"tf_api_version": "2"},
+ visibility = ["//visibility:public"],
+)
+
+# This flag is defined for select statements that match both
+# on 'windows' and 'api_version_2'. In this case, bazel requires
+# having a flag which is a superset of these two.
+config_setting(
+ name = "windows_and_api_version_2",
+ define_values = {"tf_api_version": "2"},
+ values = {"cpu": "x64_windows"},
+)
+
+# This flag enables experimental MLIR support.
+config_setting(
+ name = "with_mlir_support",
+ define_values = {"with_mlir_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# This flag forcibly enables experimental MLIR bridge support.
+config_setting(
+ name = "enable_mlir_bridge",
+ define_values = {"enable_mlir_bridge": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# This flag forcibly disables experimental MLIR bridge support.
+config_setting(
+ name = "disable_mlir_bridge",
+ define_values = {"enable_mlir_bridge": "false"},
+ visibility = ["//visibility:public"],
+)
+
+# This flag enables experimental TPU support
+config_setting(
+ name = "with_tpu_support",
+ define_values = {"with_tpu_support": "true"},
+ visibility = ["//visibility:public"],
+)
+
+# Specifies via a config setting if this is a mobile build or not, makes
+# it easier to combine settings later.
+selects.config_setting_group(
+ name = "mobile",
+ match_any = [
+ ":android",
+ ":chromiumos",
+ ":emscripten",
+ ":ios",
+ ],
+)
+
+config_setting(
+ name = "lite_protos_legacy",
+ define_values = {"TENSORFLOW_PROTOS": "lite"},
+ visibility = ["//visibility:private"],
+)
+
+config_setting(
+ name = "full_protos",
+ define_values = {"TENSORFLOW_PROTOS": "full"},
+ visibility = ["//visibility:public"],
+)
+
+selects.config_setting_group(
+ name = "lite_protos",
+ match_any = [":lite_protos_legacy"],
+)
+
+selects.config_setting_group(
+ name = "mobile_lite_protos",
+ match_all = [
+ ":lite_protos",
+ ":mobile",
+ ],
+)
+
+selects.config_setting_group(
+ name = "mobile_full_protos",
+ match_all = [
+ ":full_protos",
+ ":mobile",
+ ],
+)
diff --git a/tensorflow/lite/BUILD b/tensorflow/lite/BUILD
new file mode 100644
index 0000000..4d02054
--- /dev/null
+++ b/tensorflow/lite/BUILD
@@ -0,0 +1,13 @@
+package(
+ default_visibility = ["//visibility:public"],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "type_to_tflitetype",
+ hdrs = [
+ "portable_type_to_tflitetype.h",
+ ],
+ deps = ["//tensorflow/lite/c:common"],
+)
+
diff --git a/tensorflow/lite/build_def.bzl b/tensorflow/lite/build_def.bzl
new file mode 100644
index 0000000..82c6653
--- /dev/null
+++ b/tensorflow/lite/build_def.bzl
@@ -0,0 +1,13 @@
+load(
+ "//tensorflow:tensorflow.bzl",
+ "clean_dep",
+)
+
+def tflite_copts():
+ """Defines common compile time flags for TFLite libraries."""
+ copts = [
+ "-DFARMHASH_NO_CXX_STRING",
+ "-Wno-sign-compare",
+ "-fno-exceptions", # Exceptions are unused in TFLite.
+ ]
+ return copts
diff --git a/tensorflow/lite/c/BUILD b/tensorflow/lite/c/BUILD
new file mode 100644
index 0000000..fbb8641
--- /dev/null
+++ b/tensorflow/lite/c/BUILD
@@ -0,0 +1,29 @@
+load(
+ "//tensorflow/lite:build_def.bzl",
+ "tflite_copts",
+)
+
+package(
+ default_visibility = ["//visibility:public"],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "common",
+ srcs = ["common.c"],
+ hdrs = [
+ "builtin_op_data.h",
+ "common.h",
+ ],
+ copts = tflite_copts(),
+ deps = [
+ ":c_api_types",
+ ],
+)
+
+cc_library(
+ name = "c_api_types",
+ hdrs = ["c_api_types.h"],
+ copts = tflite_copts(),
+)
+
diff --git a/tensorflow/lite/c/builtin_op_data.h b/tensorflow/lite/c/builtin_op_data.h
new file mode 100644
index 0000000..a0167c3
--- /dev/null
+++ b/tensorflow/lite/c/builtin_op_data.h
@@ -0,0 +1,502 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_C_BUILTIN_OP_DATA_H_
+#define TENSORFLOW_LITE_C_BUILTIN_OP_DATA_H_
+
+#include <stdint.h>
+
+#include "tensorflow/lite/c/common.h"
+
+#ifdef __cplusplus
+extern "C" {
+#endif // __cplusplus
+
+// TfLiteReshapeParams can't have dynamic data so we fix the maximum possible
+// number of dimensions.
+#define TFLITE_RESHAPE_PARAMS_MAX_DIMENSION_COUNT 8
+
+// TODO(aselle): Consider using "if this then that" for testing.
+
+// Useful placeholder to put in otherwise empty structs to avoid size warnings.
+typedef struct {
+ char dummy;
+} EmptyStructPlaceholder;
+
+// IMPORTANT: All new members of structs must be added at the end to ensure
+// backwards compatibility.
+
+// Possible padding types (for convolutions)
+typedef enum {
+ kTfLitePaddingUnknown = 0,
+ kTfLitePaddingSame,
+ kTfLitePaddingValid,
+} TfLitePadding;
+
+typedef enum {
+ kTfLiteMirrorPaddingUnknown = 0,
+ kTfLiteMirrorPaddingReflect,
+ kTfLiteMirrorPaddingSymmetric,
+} TfLiteMirrorPaddingMode;
+
+// TODO(b/130259536): We should move this out of builtin_op_data.
+typedef struct {
+ int width;
+ int height;
+ int width_offset;
+ int height_offset;
+} TfLitePaddingValues;
+
+typedef struct {
+ TfLiteMirrorPaddingMode mode;
+} TfLiteMirrorPaddingParams;
+
+// Possible fused activation functions.
+// TODO(aselle): rename to TfLiteActivation
+typedef enum {
+ kTfLiteActNone = 0,
+ kTfLiteActRelu,
+ kTfLiteActReluN1To1, // min(max(-1, x), 1)
+ kTfLiteActRelu6, // min(max(0, x), 6)
+ kTfLiteActTanh,
+ kTfLiteActSignBit,
+ kTfLiteActSigmoid,
+} TfLiteFusedActivation;
+
+typedef struct {
+ // Parameters for CONV_2D version 1.
+ TfLitePadding padding;
+ int stride_width;
+ int stride_height;
+ TfLiteFusedActivation activation;
+
+ // Parameters for CONV_2D version 2.
+ // Note: Version 2 supports dilation values not equal to 1.
+ int dilation_width_factor;
+ int dilation_height_factor;
+} TfLiteConvParams;
+
+typedef struct {
+ TfLitePadding padding;
+ int stride_width;
+ int stride_height;
+ int stride_depth;
+ int dilation_width_factor;
+ int dilation_height_factor;
+ int dilation_depth_factor;
+ TfLiteFusedActivation activation;
+} TfLiteConv3DParams;
+
+typedef struct {
+ TfLitePadding padding;
+ int stride_width;
+ int stride_height;
+ int filter_width;
+ int filter_height;
+ TfLiteFusedActivation activation;
+ struct {
+ TfLitePaddingValues padding;
+ } computed;
+} TfLitePoolParams;
+
+typedef struct {
+ // Parameters for DepthwiseConv version 1 or above.
+ TfLitePadding padding;
+ int stride_width;
+ int stride_height;
+ // `depth_multiplier` is redundant. It's used by CPU kernels in
+ // TensorFlow 2.0 or below, but ignored in versions above.
+ //
+ // The information can be deduced from the shape of input and the shape of
+ // weights. Since the TFLiteConverter toolchain doesn't support partially
+ // specified shapes, relying on `depth_multiplier` stops us from supporting
+ // graphs with dynamic shape tensors.
+ //
+ // Note: Some of the delegates (e.g. NNAPI, GPU) are still relying on this
+ // field.
+ int depth_multiplier;
+ TfLiteFusedActivation activation;
+ // Parameters for DepthwiseConv version 2 or above.
+ int dilation_width_factor;
+ int dilation_height_factor;
+} TfLiteDepthwiseConvParams;
+
+typedef struct {
+ int rank;
+ TfLiteFusedActivation activation;
+
+ // Parameter for SVDF version 4.
+ bool asymmetric_quantize_inputs;
+} TfLiteSVDFParams;
+
+typedef struct {
+ TfLiteFusedActivation activation;
+
+ // Parameter for RNN version 3.
+ bool asymmetric_quantize_inputs;
+} TfLiteRNNParams;
+
+typedef struct {
+ bool time_major;
+ TfLiteFusedActivation activation;
+
+ // Parameter for Sequence RNN version 3.
+ bool asymmetric_quantize_inputs;
+} TfLiteSequenceRNNParams;
+
+typedef struct {
+ bool time_major;
+ TfLiteFusedActivation activation;
+ bool merge_outputs;
+
+ // Parameter for Bidirectional RNN verison 3.
+ bool asymmetric_quantize_inputs;
+} TfLiteBidirectionalSequenceRNNParams;
+
+typedef enum {
+ kTfLiteFullyConnectedWeightsFormatDefault = 0,
+ kTfLiteFullyConnectedWeightsFormatShuffled4x16Int8 = 1,
+} TfLiteFullyConnectedWeightsFormat;
+
+typedef struct {
+ // Parameters for FullyConnected version 1 or above.
+ TfLiteFusedActivation activation;
+
+ // Parameters for FullyConnected version 2 or above.
+ TfLiteFullyConnectedWeightsFormat weights_format;
+
+ // Parameters for FullyConnected version 5 or above.
+ // If set to true, then the number of dimensions in the input and the output
+ // tensors are the same. Furthermore, all but the last dimension of the input
+ // and output shapes will be equal.
+ bool keep_num_dims;
+
+ // Parameters for FullyConnected version 7 or above.
+ // If set to true and the weights are quantized, then non constant inputs
+ // are quantized at evaluation time with asymmetric quantization.
+ bool asymmetric_quantize_inputs;
+} TfLiteFullyConnectedParams;
+
+typedef enum {
+ kTfLiteLshProjectionUnknown = 0,
+ kTfLiteLshProjectionSparse = 1,
+ kTfLiteLshProjectionDense = 2,
+} TfLiteLSHProjectionType;
+
+typedef struct {
+ TfLiteLSHProjectionType type;
+} TfLiteLSHProjectionParams;
+
+typedef struct {
+ float beta;
+} TfLiteSoftmaxParams;
+
+typedef struct {
+ int axis;
+ TfLiteFusedActivation activation;
+} TfLiteConcatenationParams;
+
+typedef struct {
+ TfLiteFusedActivation activation;
+ // Parameter added for the version 4.
+ bool pot_scale_int16;
+} TfLiteAddParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLiteSpaceToBatchNDParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLiteBatchToSpaceNDParams;
+
+typedef struct {
+ bool adj_x;
+ bool adj_y;
+ // Parameters for BatchMatMul version 4 or above.
+ // If set to true and the weights are quantized, then non constant inputs
+ // are quantized at evaluation time with asymmetric quantization.
+ bool asymmetric_quantize_inputs;
+} TfLiteBatchMatMulParams;
+
+typedef struct {
+ TfLiteFusedActivation activation;
+} TfLiteMulParams;
+
+typedef struct {
+ TfLiteFusedActivation activation;
+ // Parameter added for the version 5.
+ bool pot_scale_int16;
+} TfLiteSubParams;
+
+typedef struct {
+ TfLiteFusedActivation activation;
+} TfLiteDivParams;
+
+typedef struct {
+ TfLiteFusedActivation activation;
+} TfLiteL2NormParams;
+
+typedef struct {
+ int radius;
+ float bias;
+ float alpha;
+ float beta;
+} TfLiteLocalResponseNormParams;
+
+typedef enum {
+ kTfLiteLSTMFullKernel = 0,
+ kTfLiteLSTMBasicKernel
+} TfLiteLSTMKernelType;
+
+typedef struct {
+ // Parameters for LSTM version 1.
+ TfLiteFusedActivation activation;
+ float cell_clip;
+ float proj_clip;
+
+ // Parameters for LSTM version 2.
+ // kTfLiteLSTMBasicKernel is only supported in version 2 or above.
+ TfLiteLSTMKernelType kernel_type;
+
+ // Parameters for LSTM version 4.
+ bool asymmetric_quantize_inputs;
+} TfLiteLSTMParams;
+
+typedef struct {
+ // Parameters needed for the underlying LSTM.
+ TfLiteFusedActivation activation;
+ float cell_clip;
+ float proj_clip;
+
+ // If set to true then the first dimension is time, otherwise batch.
+ bool time_major;
+
+ // Parameter for unidirectional sequence RNN version 3.
+ bool asymmetric_quantize_inputs;
+} TfLiteUnidirectionalSequenceLSTMParams;
+
+typedef struct {
+ // Parameters supported by version 1:
+ // Parameters inherited for the LSTM kernel.
+ TfLiteFusedActivation activation;
+ float cell_clip;
+ float proj_clip;
+
+ // If true, store the outputs of both directions in the first output.
+ bool merge_outputs;
+
+ // Parameters supported by version 2:
+ // If set to true then the first dimension is time, otherwise batch.
+ bool time_major;
+
+ // Parameters supported by version 4:
+ // If set to true, then hybrid ops use asymmetric quantization for inputs.
+ bool asymmetric_quantize_inputs;
+} TfLiteBidirectionalSequenceLSTMParams;
+
+typedef struct {
+ bool align_corners;
+ // half_pixel_centers assumes pixels are of half the actual dimensions, and
+ // yields more accurate resizes. Corresponds to the same argument for the
+ // original TensorFlow op in TF2.0.
+ bool half_pixel_centers;
+} TfLiteResizeBilinearParams;
+
+typedef struct {
+ bool align_corners;
+ bool half_pixel_centers;
+} TfLiteResizeNearestNeighborParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLitePadParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLitePadV2Params;
+
+typedef struct {
+ // TODO(ahentz): We can't have dynamic data in this struct, at least not yet.
+ // For now we will fix the maximum possible number of dimensions.
+ int shape[TFLITE_RESHAPE_PARAMS_MAX_DIMENSION_COUNT];
+ int num_dimensions;
+} TfLiteReshapeParams;
+
+typedef struct {
+ int ngram_size;
+ int max_skip_size;
+ bool include_all_ngrams;
+} TfLiteSkipGramParams;
+
+typedef struct {
+ int block_size;
+} TfLiteSpaceToDepthParams;
+
+typedef struct {
+ int block_size;
+} TfLiteDepthToSpaceParams;
+
+typedef struct {
+ TfLiteType in_data_type;
+ TfLiteType out_data_type;
+} TfLiteCastParams;
+
+typedef enum {
+ kTfLiteCombinerTypeSum = 0,
+ kTfLiteCombinerTypeMean = 1,
+ kTfLiteCombinerTypeSqrtn = 2,
+} TfLiteCombinerType;
+
+typedef struct {
+ TfLiteCombinerType combiner;
+} TfLiteEmbeddingLookupSparseParams;
+
+typedef struct {
+ int axis;
+ int batch_dims;
+} TfLiteGatherParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLiteTransposeParams;
+
+typedef struct {
+ bool keep_dims;
+} TfLiteReducerParams;
+
+typedef struct {
+ int num_splits;
+} TfLiteSplitParams;
+
+typedef struct {
+ int num_splits;
+} TfLiteSplitVParams;
+
+typedef struct {
+ // TODO(ahentz): We can't have dynamic data in this struct, at least not yet.
+ // For now we will fix the maximum possible number of dimensions.
+ int squeeze_dims[8];
+ int num_squeeze_dims;
+} TfLiteSqueezeParams;
+
+typedef struct {
+ int begin_mask;
+ int end_mask;
+ int ellipsis_mask;
+ int new_axis_mask;
+ int shrink_axis_mask;
+} TfLiteStridedSliceParams;
+
+typedef struct {
+ TfLiteType output_type;
+} TfLiteArgMaxParams;
+
+typedef struct {
+ TfLiteType output_type;
+} TfLiteArgMinParams;
+
+typedef struct {
+ TfLitePadding padding;
+ int stride_width;
+ int stride_height;
+} TfLiteTransposeConvParams;
+
+typedef struct {
+ bool validate_indices;
+} TfLiteSparseToDenseParams;
+
+typedef struct {
+ TfLiteType out_type;
+} TfLiteShapeParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLiteRankParams;
+
+typedef struct {
+ // Parameters supported by version 1:
+ float min;
+ float max;
+ int num_bits;
+
+ // Parameters supported by version 2:
+ bool narrow_range;
+} TfLiteFakeQuantParams;
+
+typedef struct {
+ int values_count;
+ int axis;
+} TfLitePackParams;
+
+typedef struct {
+ int axis;
+} TfLiteOneHotParams;
+
+typedef struct {
+ int num;
+ int axis;
+} TfLiteUnpackParams;
+
+typedef struct {
+ float alpha;
+} TfLiteLeakyReluParams;
+
+typedef struct {
+ TfLiteType index_out_type;
+} TfLiteUniqueParams;
+
+typedef struct {
+ int seq_dim;
+ int batch_dim;
+} TfLiteReverseSequenceParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLiteMatrixDiagParams;
+
+typedef struct {
+ EmptyStructPlaceholder placeholder;
+} TfLiteMatrixSetDiagParams;
+
+typedef struct {
+ int then_subgraph_index;
+ int else_subgraph_index;
+} TfLiteIfParams;
+
+typedef struct {
+ int cond_subgraph_index;
+ int body_subgraph_index;
+} TfLiteWhileParams;
+
+typedef struct {
+ bool exclusive;
+ bool reverse;
+} TfLiteCumsumParams;
+
+typedef struct {
+ int init_subgraph_index;
+} TfLiteCallOnceParams;
+
+typedef struct {
+ int table_id;
+ TfLiteType key_dtype;
+ TfLiteType value_dtype;
+} TfLiteHashtableParams;
+
+#ifdef __cplusplus
+} // extern "C"
+#endif // __cplusplus
+
+#endif // TENSORFLOW_LITE_C_BUILTIN_OP_DATA_H_
diff --git a/tensorflow/lite/c/c_api_types.h b/tensorflow/lite/c/c_api_types.h
new file mode 100644
index 0000000..02eccd7
--- /dev/null
+++ b/tensorflow/lite/c/c_api_types.h
@@ -0,0 +1,97 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This file declares types used by the pure C inference API defined in c_api.h,
+// some of which are also used in the C++ and C kernel and interpreter APIs.
+
+#ifndef TENSORFLOW_LITE_C_C_API_TYPES_H_
+#define TENSORFLOW_LITE_C_C_API_TYPES_H_
+
+#include <stdint.h>
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+// Define TFL_CAPI_EXPORT macro to export a function properly with a shared
+// library.
+#ifdef SWIG
+#define TFL_CAPI_EXPORT
+#elif defined(TFL_STATIC_LIBRARY_BUILD)
+#define TFL_CAPI_EXPORT
+#else // not definded TFL_STATIC_LIBRARY_BUILD
+#if defined(_WIN32)
+#ifdef TFL_COMPILE_LIBRARY
+#define TFL_CAPI_EXPORT __declspec(dllexport)
+#else
+#define TFL_CAPI_EXPORT __declspec(dllimport)
+#endif // TFL_COMPILE_LIBRARY
+#else
+#define TFL_CAPI_EXPORT __attribute__((visibility("default")))
+#endif // _WIN32
+#endif // SWIG
+
+typedef enum TfLiteStatus {
+ kTfLiteOk = 0,
+
+ // Generally referring to an error in the runtime (i.e. interpreter)
+ kTfLiteError = 1,
+
+ // Generally referring to an error from a TfLiteDelegate itself.
+ kTfLiteDelegateError = 2,
+
+ // Generally referring to an error in applying a delegate due to
+ // incompatibility between runtime and delegate, e.g., this error is returned
+ // when trying to apply a TfLite delegate onto a model graph that's already
+ // immutable.
+ kTfLiteApplicationError = 3
+} TfLiteStatus;
+
+// Types supported by tensor
+typedef enum {
+ kTfLiteNoType = 0,
+ kTfLiteFloat32 = 1,
+ kTfLiteInt32 = 2,
+ kTfLiteUInt8 = 3,
+ kTfLiteInt64 = 4,
+ kTfLiteString = 5,
+ kTfLiteBool = 6,
+ kTfLiteInt16 = 7,
+ kTfLiteComplex64 = 8,
+ kTfLiteInt8 = 9,
+ kTfLiteFloat16 = 10,
+ kTfLiteFloat64 = 11,
+ kTfLiteComplex128 = 12,
+ kTfLiteUInt64 = 13,
+ kTfLiteResource = 14,
+ kTfLiteVariant = 15,
+ kTfLiteUInt32 = 16,
+} TfLiteType;
+
+// Legacy. Will be deprecated in favor of TfLiteAffineQuantization.
+// If per-layer quantization is specified this field will still be populated in
+// addition to TfLiteAffineQuantization.
+// Parameters for asymmetric quantization. Quantized values can be converted
+// back to float using:
+// real_value = scale * (quantized_value - zero_point)
+typedef struct TfLiteQuantizationParams {
+ float scale;
+ int32_t zero_point;
+} TfLiteQuantizationParams;
+
+#ifdef __cplusplus
+} // extern C
+#endif
+#endif // TENSORFLOW_LITE_C_C_API_TYPES_H_
diff --git a/tensorflow/lite/c/common.c b/tensorflow/lite/c/common.c
new file mode 100644
index 0000000..aaa98a9
--- /dev/null
+++ b/tensorflow/lite/c/common.c
@@ -0,0 +1,242 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/c/c_api_types.h"
+
+#ifndef TF_LITE_STATIC_MEMORY
+#include <stdlib.h>
+#include <string.h>
+#endif // TF_LITE_STATIC_MEMORY
+
+int TfLiteIntArrayGetSizeInBytes(int size) {
+ static TfLiteIntArray dummy;
+ return sizeof(dummy) + sizeof(dummy.data[0]) * size;
+}
+
+int TfLiteIntArrayEqual(const TfLiteIntArray* a, const TfLiteIntArray* b) {
+ if (a == b) return 1;
+ if (a == NULL || b == NULL) return 0;
+ return TfLiteIntArrayEqualsArray(a, b->size, b->data);
+}
+
+int TfLiteIntArrayEqualsArray(const TfLiteIntArray* a, int b_size,
+ const int b_data[]) {
+ if (a == NULL) return (b_size == 0);
+ if (a->size != b_size) return 0;
+ int i = 0;
+ for (; i < a->size; i++)
+ if (a->data[i] != b_data[i]) return 0;
+ return 1;
+}
+
+#ifndef TF_LITE_STATIC_MEMORY
+
+TfLiteIntArray* TfLiteIntArrayCreate(int size) {
+ TfLiteIntArray* ret =
+ (TfLiteIntArray*)malloc(TfLiteIntArrayGetSizeInBytes(size));
+ ret->size = size;
+ return ret;
+}
+
+TfLiteIntArray* TfLiteIntArrayCopy(const TfLiteIntArray* src) {
+ if (!src) return NULL;
+ TfLiteIntArray* ret = TfLiteIntArrayCreate(src->size);
+ if (ret) {
+ memcpy(ret->data, src->data, src->size * sizeof(int));
+ }
+ return ret;
+}
+
+void TfLiteIntArrayFree(TfLiteIntArray* a) { free(a); }
+
+#endif // TF_LITE_STATIC_MEMORY
+
+int TfLiteFloatArrayGetSizeInBytes(int size) {
+ static TfLiteFloatArray dummy;
+ return sizeof(dummy) + sizeof(dummy.data[0]) * size;
+}
+
+#ifndef TF_LITE_STATIC_MEMORY
+
+TfLiteFloatArray* TfLiteFloatArrayCreate(int size) {
+ TfLiteFloatArray* ret =
+ (TfLiteFloatArray*)malloc(TfLiteFloatArrayGetSizeInBytes(size));
+ ret->size = size;
+ return ret;
+}
+
+void TfLiteFloatArrayFree(TfLiteFloatArray* a) { free(a); }
+
+void TfLiteTensorDataFree(TfLiteTensor* t) {
+ if (t->allocation_type == kTfLiteDynamic ||
+ t->allocation_type == kTfLitePersistentRo) {
+ free(t->data.raw);
+ }
+ t->data.raw = NULL;
+}
+
+void TfLiteQuantizationFree(TfLiteQuantization* quantization) {
+ if (quantization->type == kTfLiteAffineQuantization) {
+ TfLiteAffineQuantization* q_params =
+ (TfLiteAffineQuantization*)(quantization->params);
+ if (q_params->scale) {
+ TfLiteFloatArrayFree(q_params->scale);
+ q_params->scale = NULL;
+ }
+ if (q_params->zero_point) {
+ TfLiteIntArrayFree(q_params->zero_point);
+ q_params->zero_point = NULL;
+ }
+ free(q_params);
+ }
+ quantization->params = NULL;
+ quantization->type = kTfLiteNoQuantization;
+}
+
+void TfLiteSparsityFree(TfLiteSparsity* sparsity) {
+ if (sparsity == NULL) {
+ return;
+ }
+
+ if (sparsity->traversal_order) {
+ TfLiteIntArrayFree(sparsity->traversal_order);
+ sparsity->traversal_order = NULL;
+ }
+
+ if (sparsity->block_map) {
+ TfLiteIntArrayFree(sparsity->block_map);
+ sparsity->block_map = NULL;
+ }
+
+ if (sparsity->dim_metadata) {
+ int i = 0;
+ for (; i < sparsity->dim_metadata_size; i++) {
+ TfLiteDimensionMetadata metadata = sparsity->dim_metadata[i];
+ if (metadata.format == kTfLiteDimSparseCSR) {
+ TfLiteIntArrayFree(metadata.array_segments);
+ metadata.array_segments = NULL;
+ TfLiteIntArrayFree(metadata.array_indices);
+ metadata.array_indices = NULL;
+ }
+ }
+ free(sparsity->dim_metadata);
+ sparsity->dim_metadata = NULL;
+ }
+
+ free(sparsity);
+}
+
+void TfLiteTensorFree(TfLiteTensor* t) {
+ TfLiteTensorDataFree(t);
+ if (t->dims) TfLiteIntArrayFree(t->dims);
+ t->dims = NULL;
+
+ if (t->dims_signature) {
+ TfLiteIntArrayFree((TfLiteIntArray *) t->dims_signature);
+ }
+ t->dims_signature = NULL;
+
+ TfLiteQuantizationFree(&t->quantization);
+ TfLiteSparsityFree(t->sparsity);
+ t->sparsity = NULL;
+}
+
+void TfLiteTensorReset(TfLiteType type, const char* name, TfLiteIntArray* dims,
+ TfLiteQuantizationParams quantization, char* buffer,
+ size_t size, TfLiteAllocationType allocation_type,
+ const void* allocation, bool is_variable,
+ TfLiteTensor* tensor) {
+ TfLiteTensorFree(tensor);
+ tensor->type = type;
+ tensor->name = name;
+ tensor->dims = dims;
+ tensor->params = quantization;
+ tensor->data.raw = buffer;
+ tensor->bytes = size;
+ tensor->allocation_type = allocation_type;
+ tensor->allocation = allocation;
+ tensor->is_variable = is_variable;
+
+ tensor->quantization.type = kTfLiteNoQuantization;
+ tensor->quantization.params = NULL;
+}
+
+void TfLiteTensorRealloc(size_t num_bytes, TfLiteTensor* tensor) {
+ if (tensor->allocation_type != kTfLiteDynamic &&
+ tensor->allocation_type != kTfLitePersistentRo) {
+ return;
+ }
+ // TODO(b/145340303): Tensor data should be aligned.
+ if (!tensor->data.raw) {
+ tensor->data.raw = malloc(num_bytes);
+ } else if (num_bytes > tensor->bytes) {
+ tensor->data.raw = realloc(tensor->data.raw, num_bytes);
+ }
+ tensor->bytes = num_bytes;
+}
+#endif // TF_LITE_STATIC_MEMORY
+
+const char* TfLiteTypeGetName(TfLiteType type) {
+ switch (type) {
+ case kTfLiteNoType:
+ return "NOTYPE";
+ case kTfLiteFloat32:
+ return "FLOAT32";
+ case kTfLiteInt16:
+ return "INT16";
+ case kTfLiteInt32:
+ return "INT32";
+ case kTfLiteUInt32:
+ return "UINT32";
+ case kTfLiteUInt8:
+ return "UINT8";
+ case kTfLiteInt8:
+ return "INT8";
+ case kTfLiteInt64:
+ return "INT64";
+ case kTfLiteUInt64:
+ return "UINT64";
+ case kTfLiteBool:
+ return "BOOL";
+ case kTfLiteComplex64:
+ return "COMPLEX64";
+ case kTfLiteComplex128:
+ return "COMPLEX128";
+ case kTfLiteString:
+ return "STRING";
+ case kTfLiteFloat16:
+ return "FLOAT16";
+ case kTfLiteFloat64:
+ return "FLOAT64";
+ case kTfLiteResource:
+ return "RESOURCE";
+ case kTfLiteVariant:
+ return "VARIANT";
+ }
+ return "Unknown type";
+}
+
+TfLiteDelegate TfLiteDelegateCreate() {
+ TfLiteDelegate d = {
+ .data_ = NULL,
+ .Prepare = NULL,
+ .CopyFromBufferHandle = NULL,
+ .CopyToBufferHandle = NULL,
+ .FreeBufferHandle = NULL,
+ .flags = kTfLiteDelegateFlagsNone,
+ };
+ return d;
+}
diff --git a/tensorflow/lite/c/common.h b/tensorflow/lite/c/common.h
new file mode 100644
index 0000000..56e0f8d
--- /dev/null
+++ b/tensorflow/lite/c/common.h
@@ -0,0 +1,926 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This file defines common C types and APIs for implementing operations,
+// delegates and other constructs in TensorFlow Lite. The actual operations and
+// delegates can be defined using C++, but the interface between the interpreter
+// and the operations are C.
+//
+// Summary of abstractions
+// TF_LITE_ENSURE - Self-sufficient error checking
+// TfLiteStatus - Status reporting
+// TfLiteIntArray - stores tensor shapes (dims),
+// TfLiteContext - allows an op to access the tensors
+// TfLiteTensor - tensor (a multidimensional array)
+// TfLiteNode - a single node or operation
+// TfLiteRegistration - the implementation of a conceptual operation.
+// TfLiteDelegate - allows delegation of nodes to alternative backends.
+//
+// Some abstractions in this file are created and managed by Interpreter.
+//
+// NOTE: The order of values in these structs are "semi-ABI stable". New values
+// should be added only to the end of structs and never reordered.
+
+#ifndef TENSORFLOW_LITE_C_COMMON_H_
+#define TENSORFLOW_LITE_C_COMMON_H_
+
+#include <stdbool.h>
+#include <stddef.h>
+#include <stdint.h>
+
+#include "tensorflow/lite/c/c_api_types.h" // IWYU pragma: export
+
+#ifdef __cplusplus
+extern "C" {
+#endif // __cplusplus
+
+// The list of external context types known to TF Lite. This list exists solely
+// to avoid conflicts and to ensure ops can share the external contexts they
+// need. Access to the external contexts is controlled by one of the
+// corresponding support files.
+typedef enum TfLiteExternalContextType {
+ kTfLiteEigenContext = 0, // include eigen_support.h to use.
+ kTfLiteGemmLowpContext = 1, // include gemm_support.h to use.
+ kTfLiteEdgeTpuContext = 2, // Placeholder for Edge TPU support.
+ kTfLiteCpuBackendContext = 3, // include cpu_backend_context.h to use.
+ kTfLiteMaxExternalContexts = 4
+} TfLiteExternalContextType;
+
+// Forward declare so dependent structs and methods can reference these types
+// prior to the struct definitions.
+struct TfLiteContext;
+struct TfLiteDelegate;
+struct TfLiteRegistration;
+
+// An external context is a collection of information unrelated to the TF Lite
+// framework, but useful to a subset of the ops. TF Lite knows very little
+// about the actual contexts, but it keeps a list of them, and is able to
+// refresh them if configurations like the number of recommended threads
+// change.
+typedef struct TfLiteExternalContext {
+ TfLiteExternalContextType type;
+ TfLiteStatus (*Refresh)(struct TfLiteContext* context);
+} TfLiteExternalContext;
+
+#define kTfLiteOptionalTensor (-1)
+
+// Fixed size list of integers. Used for dimensions and inputs/outputs tensor
+// indices
+typedef struct TfLiteIntArray {
+ int size;
+// gcc 6.1+ have a bug where flexible members aren't properly handled
+// https://github.com/google/re2/commit/b94b7cd42e9f02673cd748c1ac1d16db4052514c
+#if (!defined(__clang__) && defined(__GNUC__) && __GNUC__ == 6 && \
+ __GNUC_MINOR__ >= 1) || \
+ defined(HEXAGON) || \
+ (defined(__clang__) && __clang_major__ == 7 && __clang_minor__ == 1)
+ int data[0];
+#else
+ int data[];
+#endif
+} TfLiteIntArray;
+
+// Given the size (number of elements) in a TfLiteIntArray, calculate its size
+// in bytes.
+int TfLiteIntArrayGetSizeInBytes(int size);
+
+#ifndef TF_LITE_STATIC_MEMORY
+// Create a array of a given `size` (uninitialized entries).
+// This returns a pointer, that you must free using TfLiteIntArrayFree().
+TfLiteIntArray* TfLiteIntArrayCreate(int size);
+#endif
+
+// Check if two intarrays are equal. Returns 1 if they are equal, 0 otherwise.
+int TfLiteIntArrayEqual(const TfLiteIntArray* a, const TfLiteIntArray* b);
+
+// Check if an intarray equals an array. Returns 1 if equals, 0 otherwise.
+int TfLiteIntArrayEqualsArray(const TfLiteIntArray* a, int b_size,
+ const int b_data[]);
+
+#ifndef TF_LITE_STATIC_MEMORY
+// Create a copy of an array passed as `src`.
+// You are expected to free memory with TfLiteIntArrayFree
+TfLiteIntArray* TfLiteIntArrayCopy(const TfLiteIntArray* src);
+
+// Free memory of array `a`.
+void TfLiteIntArrayFree(TfLiteIntArray* a);
+#endif // TF_LITE_STATIC_MEMORY
+
+// Fixed size list of floats. Used for per-channel quantization.
+typedef struct TfLiteFloatArray {
+ int size;
+// gcc 6.1+ have a bug where flexible members aren't properly handled
+// https://github.com/google/re2/commit/b94b7cd42e9f02673cd748c1ac1d16db4052514c
+// This also applies to the toolchain used for Qualcomm Hexagon DSPs.
+#if !defined(__clang__) && defined(__GNUC__) && __GNUC__ == 6 && \
+ __GNUC_MINOR__ >= 1
+ float data[0];
+#else
+ float data[];
+#endif
+} TfLiteFloatArray;
+
+// Given the size (number of elements) in a TfLiteFloatArray, calculate its size
+// in bytes.
+int TfLiteFloatArrayGetSizeInBytes(int size);
+
+#ifndef TF_LITE_STATIC_MEMORY
+// Create a array of a given `size` (uninitialized entries).
+// This returns a pointer, that you must free using TfLiteFloatArrayFree().
+TfLiteFloatArray* TfLiteFloatArrayCreate(int size);
+
+// Free memory of array `a`.
+void TfLiteFloatArrayFree(TfLiteFloatArray* a);
+#endif // TF_LITE_STATIC_MEMORY
+
+// Since we must not depend on any libraries, define a minimal subset of
+// error macros while avoiding names that have pre-conceived meanings like
+// assert and check.
+
+// Try to make all reporting calls through TF_LITE_KERNEL_LOG rather than
+// calling the context->ReportError function directly, so that message strings
+// can be stripped out if the binary size needs to be severely optimized.
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+#define TF_LITE_KERNEL_LOG(context, ...) \
+ do { \
+ (context)->ReportError((context), __VA_ARGS__); \
+ } while (false)
+
+#define TF_LITE_MAYBE_KERNEL_LOG(context, ...) \
+ do { \
+ if ((context) != nullptr) { \
+ (context)->ReportError((context), __VA_ARGS__); \
+ } \
+ } while (false)
+#else // TF_LITE_STRIP_ERROR_STRINGS
+#define TF_LITE_KERNEL_LOG(context, ...)
+#define TF_LITE_MAYBE_KERNEL_LOG(context, ...)
+#endif // TF_LITE_STRIP_ERROR_STRINGS
+
+// Check whether value is true, and if not return kTfLiteError from
+// the current function (and report the error string msg).
+#define TF_LITE_ENSURE_MSG(context, value, msg) \
+ do { \
+ if (!(value)) { \
+ TF_LITE_KERNEL_LOG((context), __FILE__ " " msg); \
+ return kTfLiteError; \
+ } \
+ } while (0)
+
+// Check whether the value `a` is true, and if not return kTfLiteError from
+// the current function, while also reporting the location of the error.
+#define TF_LITE_ENSURE(context, a) \
+ do { \
+ if (!(a)) { \
+ TF_LITE_KERNEL_LOG((context), "%s:%d %s was not true.", __FILE__, \
+ __LINE__, #a); \
+ return kTfLiteError; \
+ } \
+ } while (0)
+
+#define TF_LITE_ENSURE_STATUS(a) \
+ do { \
+ const TfLiteStatus s = (a); \
+ if (s != kTfLiteOk) { \
+ return s; \
+ } \
+ } while (0)
+
+// Check whether the value `a == b` is true, and if not return kTfLiteError from
+// the current function, while also reporting the location of the error.
+// `a` and `b` may be evaluated more than once, so no side effects or
+// extremely expensive computations should be done.
+// NOTE: Use TF_LITE_ENSURE_TYPES_EQ if comparing TfLiteTypes.
+#define TF_LITE_ENSURE_EQ(context, a, b) \
+ do { \
+ if ((a) != (b)) { \
+ TF_LITE_KERNEL_LOG((context), "%s:%d %s != %s (%d != %d)", __FILE__, \
+ __LINE__, #a, #b, (a), (b)); \
+ return kTfLiteError; \
+ } \
+ } while (0)
+
+#define TF_LITE_ENSURE_TYPES_EQ(context, a, b) \
+ do { \
+ if ((a) != (b)) { \
+ TF_LITE_KERNEL_LOG((context), "%s:%d %s != %s (%s != %s)", __FILE__, \
+ __LINE__, #a, #b, TfLiteTypeGetName(a), \
+ TfLiteTypeGetName(b)); \
+ return kTfLiteError; \
+ } \
+ } while (0)
+
+#define TF_LITE_ENSURE_NEAR(context, a, b, epsilon) \
+ do { \
+ auto delta = ((a) > (b)) ? ((a) - (b)) : ((b) - (a)); \
+ if (delta > epsilon) { \
+ TF_LITE_KERNEL_LOG((context), "%s:%d %s not near %s (%f != %f)", \
+ __FILE__, __LINE__, #a, #b, static_cast<double>(a), \
+ static_cast<double>(b)); \
+ return kTfLiteError; \
+ } \
+ } while (0)
+
+#define TF_LITE_ENSURE_OK(context, status) \
+ do { \
+ const TfLiteStatus s = (status); \
+ if ((s) != kTfLiteOk) { \
+ return s; \
+ } \
+ } while (0)
+
+// Single-precision complex data type compatible with the C99 definition.
+typedef struct TfLiteComplex64 {
+ float re, im; // real and imaginary parts, respectively.
+} TfLiteComplex64;
+
+// Double-precision complex data type compatible with the C99 definition.
+typedef struct TfLiteComplex128 {
+ double re, im; // real and imaginary parts, respectively.
+} TfLiteComplex128;
+
+// Half precision data type compatible with the C99 definition.
+typedef struct TfLiteFloat16 {
+ uint16_t data;
+} TfLiteFloat16;
+
+// Return the name of a given type, for error reporting purposes.
+const char* TfLiteTypeGetName(TfLiteType type);
+
+// SupportedQuantizationTypes.
+typedef enum TfLiteQuantizationType {
+ // No quantization.
+ kTfLiteNoQuantization = 0,
+ // Affine quantization (with support for per-channel quantization).
+ // Corresponds to TfLiteAffineQuantization.
+ kTfLiteAffineQuantization = 1,
+} TfLiteQuantizationType;
+
+// Structure specifying the quantization used by the tensor, if-any.
+typedef struct TfLiteQuantization {
+ // The type of quantization held by params.
+ TfLiteQuantizationType type;
+ // Holds an optional reference to a quantization param structure. The actual
+ // type depends on the value of the `type` field (see the comment there for
+ // the values and corresponding types).
+ void* params;
+} TfLiteQuantization;
+
+// Parameters for asymmetric quantization across a dimension (i.e per output
+// channel quantization).
+// quantized_dimension specifies which dimension the scales and zero_points
+// correspond to.
+// For a particular value in quantized_dimension, quantized values can be
+// converted back to float using:
+// real_value = scale * (quantized_value - zero_point)
+typedef struct TfLiteAffineQuantization {
+ TfLiteFloatArray* scale;
+ TfLiteIntArray* zero_point;
+ int32_t quantized_dimension;
+} TfLiteAffineQuantization;
+
+/* A union of pointers that points to memory for a given tensor. */
+typedef union TfLitePtrUnion {
+ /* Do not access these members directly, if possible, use
+ * GetTensorData<TYPE>(tensor) instead, otherwise only access .data, as other
+ * members are deprecated. */
+ int32_t* i32;
+ uint32_t* u32;
+ int64_t* i64;
+ uint64_t* u64;
+ float* f;
+ TfLiteFloat16* f16;
+ double* f64;
+ char* raw;
+ const char* raw_const;
+ uint8_t* uint8;
+ bool* b;
+ int16_t* i16;
+ TfLiteComplex64* c64;
+ TfLiteComplex128* c128;
+ int8_t* int8;
+ /* Only use this member. */
+ void* data;
+} TfLitePtrUnion;
+
+// Memory allocation strategies.
+// * kTfLiteMmapRo: Read-only memory-mapped data, or data externally allocated.
+// * kTfLiteArenaRw: Arena allocated with no guarantees about persistence,
+// and available during eval.
+// * kTfLiteArenaRwPersistent: Arena allocated but persistent across eval, and
+// only available during eval.
+// * kTfLiteDynamic: Allocated during eval, or for string tensors.
+// * kTfLitePersistentRo: Allocated and populated during prepare. This is
+// useful for tensors that can be computed during prepare and treated
+// as constant inputs for downstream ops (also in prepare).
+// * kTfLiteCustom: Custom memory allocation provided by the user. See
+// TfLiteCustomAllocation below.
+typedef enum TfLiteAllocationType {
+ kTfLiteMemNone = 0,
+ kTfLiteMmapRo,
+ kTfLiteArenaRw,
+ kTfLiteArenaRwPersistent,
+ kTfLiteDynamic,
+ kTfLitePersistentRo,
+ kTfLiteCustom,
+} TfLiteAllocationType;
+
+// The delegates should use zero or positive integers to represent handles.
+// -1 is reserved from unallocated status.
+typedef int TfLiteBufferHandle;
+enum {
+ kTfLiteNullBufferHandle = -1,
+};
+
+// Storage format of each dimension in a sparse tensor.
+typedef enum TfLiteDimensionType {
+ kTfLiteDimDense = 0,
+ kTfLiteDimSparseCSR,
+} TfLiteDimensionType;
+
+// Metadata to encode each dimension in a sparse tensor.
+typedef struct TfLiteDimensionMetadata {
+ TfLiteDimensionType format;
+ int dense_size;
+ TfLiteIntArray* array_segments;
+ TfLiteIntArray* array_indices;
+} TfLiteDimensionMetadata;
+
+// Parameters used to encode a sparse tensor. For detailed explanation of each
+// field please refer to lite/schema/schema.fbs.
+typedef struct TfLiteSparsity {
+ TfLiteIntArray* traversal_order;
+ TfLiteIntArray* block_map;
+ TfLiteDimensionMetadata* dim_metadata;
+ int dim_metadata_size;
+} TfLiteSparsity;
+
+// Defines a custom memory allocation not owned by the runtime.
+// `data` should be aligned to kDefaultTensorAlignment defined in
+// lite/util.h. (Currently 64 bytes)
+// NOTE: See Interpreter.SetCustomAllocationForTensor for details on usage.
+typedef struct TfLiteCustomAllocation {
+ void* data;
+ size_t bytes;
+} TfLiteCustomAllocation;
+
+// The flags used in `Interpreter::SetCustomAllocationForTensor`.
+// Note that this is a bitmask, so the values should be 1, 2, 4, 8, ...etc.
+typedef enum TfLiteCustomAllocationFlags {
+ kTfLiteCustomAllocationFlagsNone = 0,
+ // Skips checking whether allocation.data points to an aligned buffer as
+ // expected by the TFLite runtime.
+ // NOTE: Setting this flag can cause crashes when calling Invoke().
+ // Use with caution.
+ kTfLiteCustomAllocationFlagsSkipAlignCheck = 1,
+} TfLiteCustomAllocationFlags;
+
+// A tensor in the interpreter system which is a wrapper around a buffer of
+// data including a dimensionality (or NULL if not currently defined).
+#ifndef TF_LITE_STATIC_MEMORY
+typedef struct TfLiteTensor {
+ // The data type specification for data stored in `data`. This affects
+ // what member of `data` union should be used.
+ TfLiteType type;
+ // A union of data pointers. The appropriate type should be used for a typed
+ // tensor based on `type`.
+ TfLitePtrUnion data;
+ // A pointer to a structure representing the dimensionality interpretation
+ // that the buffer should have. NOTE: the product of elements of `dims`
+ // and the element datatype size should be equal to `bytes` below.
+ TfLiteIntArray* dims;
+ // Quantization information.
+ TfLiteQuantizationParams params;
+ // How memory is mapped
+ // kTfLiteMmapRo: Memory mapped read only.
+ // i.e. weights
+ // kTfLiteArenaRw: Arena allocated read write memory
+ // (i.e. temporaries, outputs).
+ TfLiteAllocationType allocation_type;
+ // The number of bytes required to store the data of this Tensor. I.e.
+ // (bytes of each element) * dims[0] * ... * dims[n-1]. For example, if
+ // type is kTfLiteFloat32 and dims = {3, 2} then
+ // bytes = sizeof(float) * 3 * 2 = 4 * 3 * 2 = 24.
+ size_t bytes;
+
+ // An opaque pointer to a tflite::MMapAllocation
+ const void* allocation;
+
+ // Null-terminated name of this tensor.
+ const char* name;
+
+ // The delegate which knows how to handle `buffer_handle`.
+ // WARNING: This is an experimental interface that is subject to change.
+ struct TfLiteDelegate* delegate;
+
+ // An integer buffer handle that can be handled by `delegate`.
+ // The value is valid only when delegate is not null.
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteBufferHandle buffer_handle;
+
+ // If the delegate uses its own buffer (e.g. GPU memory), the delegate is
+ // responsible to set data_is_stale to true.
+ // `delegate->CopyFromBufferHandle` can be called to copy the data from
+ // delegate buffer.
+ // WARNING: This is an // experimental interface that is subject to change.
+ bool data_is_stale;
+
+ // True if the tensor is a variable.
+ bool is_variable;
+
+ // Quantization information. Replaces params field above.
+ TfLiteQuantization quantization;
+
+ // Parameters used to encode a sparse tensor.
+ // This is optional. The field is NULL if a tensor is dense.
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteSparsity* sparsity;
+
+ // Optional. Encodes shapes with unknown dimensions with -1. This field is
+ // only populated when unknown dimensions exist in a read-write tensor (i.e.
+ // an input or output tensor). (e.g. `dims` contains [1, 1, 1, 3] and
+ // `dims_signature` contains [1, -1, -1, 3]).
+ const TfLiteIntArray* dims_signature;
+} TfLiteTensor;
+
+// A structure representing an instance of a node.
+// This structure only exhibits the inputs, outputs and user defined data, not
+// other features like the type.
+typedef struct TfLiteNode {
+ // Inputs to this node expressed as indices into the simulator's tensors.
+ TfLiteIntArray* inputs;
+
+ // Outputs to this node expressed as indices into the simulator's tensors.
+ TfLiteIntArray* outputs;
+
+ // intermediate tensors to this node expressed as indices into the simulator's
+ // tensors.
+ TfLiteIntArray* intermediates;
+
+ // Temporary tensors uses during the computations. This usually contains no
+ // tensors, but ops are allowed to change that if they need scratch space of
+ // any sort.
+ TfLiteIntArray* temporaries;
+
+ // Opaque data provided by the node implementer through `Registration.init`.
+ void* user_data;
+
+ // Opaque data provided to the node if the node is a builtin. This is usually
+ // a structure defined in builtin_op_data.h
+ void* builtin_data;
+
+ // Custom initial data. This is the opaque data provided in the flatbuffer.
+ // WARNING: This is an experimental interface that is subject to change.
+ const void* custom_initial_data;
+ int custom_initial_data_size;
+
+ // The pointer to the delegate. This is non-null only when the node is
+ // created by calling `interpreter.ModifyGraphWithDelegate`.
+ // WARNING: This is an experimental interface that is subject to change.
+ struct TfLiteDelegate* delegate;
+} TfLiteNode;
+#else // defined(TF_LITE_STATIC_MEMORY)?
+// NOTE: This flag is opt-in only at compile time.
+//
+// Specific reduced TfLiteTensor struct for TF Micro runtime. This struct
+// contains only the minimum fields required to initialize and prepare a micro
+// inference graph. The fields in this struct have been ordered from
+// largest-to-smallest for optimal struct sizeof.
+//
+// This struct does not use:
+// - allocation
+// - buffer_handle
+// - data_is_stale
+// - delegate
+// - dims_signature
+// - name
+// - sparsity
+typedef struct TfLiteTensor {
+ // TODO(b/155784997): Consider consolidating these quantization fields:
+ // Quantization information. Replaces params field above.
+ TfLiteQuantization quantization;
+
+ // Quantization information.
+ TfLiteQuantizationParams params;
+
+ // A union of data pointers. The appropriate type should be used for a typed
+ // tensor based on `type`.
+ TfLitePtrUnion data;
+
+ // A pointer to a structure representing the dimensionality interpretation
+ // that the buffer should have. NOTE: the product of elements of `dims`
+ // and the element datatype size should be equal to `bytes` below.
+ TfLiteIntArray* dims;
+
+ // The number of bytes required to store the data of this Tensor. I.e.
+ // (bytes of each element) * dims[0] * ... * dims[n-1]. For example, if
+ // type is kTfLiteFloat32 and dims = {3, 2} then
+ // bytes = sizeof(float) * 3 * 2 = 4 * 3 * 2 = 24.
+ size_t bytes;
+
+ // The data type specification for data stored in `data`. This affects
+ // what member of `data` union should be used.
+ TfLiteType type;
+
+ // How memory is mapped
+ // kTfLiteMmapRo: Memory mapped read only.
+ // i.e. weights
+ // kTfLiteArenaRw: Arena allocated read write memory
+ // (i.e. temporaries, outputs).
+ TfLiteAllocationType allocation_type;
+
+ // True if the tensor is a variable.
+ bool is_variable;
+} TfLiteTensor;
+
+// Specific reduced TfLiteNode struct for TF Micro runtime. This struct contains
+// only the minimum fields required to represent a node.
+//
+// This struct does not use:
+// - delegate
+// - intermediates
+// - temporaries
+typedef struct TfLiteNode {
+ // Inputs to this node expressed as indices into the simulator's tensors.
+ TfLiteIntArray* inputs;
+
+ // Outputs to this node expressed as indices into the simulator's tensors.
+ TfLiteIntArray* outputs;
+
+ // Opaque data provided by the node implementer through `Registration.init`.
+ void* user_data;
+
+ // Opaque data provided to the node if the node is a builtin. This is usually
+ // a structure defined in builtin_op_data.h
+ void* builtin_data;
+
+ // Custom initial data. This is the opaque data provided in the flatbuffer.
+ // WARNING: This is an experimental interface that is subject to change.
+ const void* custom_initial_data;
+ int custom_initial_data_size;
+} TfLiteNode;
+#endif // TF_LITE_STATIC_MEMORY
+
+// Light-weight tensor struct for TF Micro runtime. Provides the minimal amount
+// of information required for a kernel to run during TfLiteRegistration::Eval.
+// TODO(b/160955687): Move this field into TF_LITE_STATIC_MEMORY when TFLM
+// builds with this flag by default internally.
+typedef struct TfLiteEvalTensor {
+ // A union of data pointers. The appropriate type should be used for a typed
+ // tensor based on `type`.
+ TfLitePtrUnion data;
+
+ // A pointer to a structure representing the dimensionality interpretation
+ // that the buffer should have.
+ TfLiteIntArray* dims;
+
+ // The data type specification for data stored in `data`. This affects
+ // what member of `data` union should be used.
+ TfLiteType type;
+} TfLiteEvalTensor;
+
+#ifndef TF_LITE_STATIC_MEMORY
+// Free data memory of tensor `t`.
+void TfLiteTensorDataFree(TfLiteTensor* t);
+
+// Free quantization data.
+void TfLiteQuantizationFree(TfLiteQuantization* quantization);
+
+// Free sparsity parameters.
+void TfLiteSparsityFree(TfLiteSparsity* sparsity);
+
+// Free memory of tensor `t`.
+void TfLiteTensorFree(TfLiteTensor* t);
+
+// Set all of a tensor's fields (and free any previously allocated data).
+void TfLiteTensorReset(TfLiteType type, const char* name, TfLiteIntArray* dims,
+ TfLiteQuantizationParams quantization, char* buffer,
+ size_t size, TfLiteAllocationType allocation_type,
+ const void* allocation, bool is_variable,
+ TfLiteTensor* tensor);
+
+// Resize the allocated data of a (dynamic) tensor. Tensors with allocation
+// types other than kTfLiteDynamic will be ignored.
+void TfLiteTensorRealloc(size_t num_bytes, TfLiteTensor* tensor);
+#endif // TF_LITE_STATIC_MEMORY
+
+// WARNING: This is an experimental interface that is subject to change.
+//
+// Currently, TfLiteDelegateParams has to be allocated in a way that it's
+// trivially destructable. It will be stored as `builtin_data` field in
+// `TfLiteNode` of the delegate node.
+//
+// See also the `CreateDelegateParams` function in `interpreter.cc` details.
+typedef struct TfLiteDelegateParams {
+ struct TfLiteDelegate* delegate;
+ TfLiteIntArray* nodes_to_replace;
+ TfLiteIntArray* input_tensors;
+ TfLiteIntArray* output_tensors;
+} TfLiteDelegateParams;
+
+typedef struct TfLiteContext {
+ // Number of tensors in the context.
+ size_t tensors_size;
+
+ // The execution plan contains a list of the node indices in execution
+ // order. execution_plan->size is the current number of nodes. And,
+ // execution_plan->data[0] is the first node that needs to be run.
+ // TfLiteDelegates can traverse the current execution plan by iterating
+ // through each member of this array and using GetNodeAndRegistration() to
+ // access details about a node. i.e.
+ // TfLiteIntArray* execution_plan;
+ // TF_LITE_ENSURE_STATUS(context->GetExecutionPlan(context, &execution_plan));
+ // for (int exec_index = 0; exec_index < execution_plan->size; exec_index++) {
+ // int node_index = execution_plan->data[exec_index];
+ // TfLiteNode* node;
+ // TfLiteRegistration* reg;
+ // context->GetNodeAndRegistration(context, node_index, &node, ®);
+ // }
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteStatus (*GetExecutionPlan)(struct TfLiteContext* context,
+ TfLiteIntArray** execution_plan);
+
+ // An array of tensors in the interpreter context (of length `tensors_size`)
+ TfLiteTensor* tensors;
+
+ // opaque full context ptr (an opaque c++ data structure)
+ void* impl_;
+
+ // Request memory pointer be resized. Updates dimensions on the tensor.
+ // NOTE: ResizeTensor takes ownership of newSize.
+ TfLiteStatus (*ResizeTensor)(struct TfLiteContext*, TfLiteTensor* tensor,
+ TfLiteIntArray* new_size);
+ // Request that an error be reported with format string msg.
+ void (*ReportError)(struct TfLiteContext*, const char* msg, ...);
+
+ // Add `tensors_to_add` tensors, preserving pre-existing Tensor entries. If
+ // non-null, the value pointed to by `first_new_tensor_index` will be set to
+ // the index of the first new tensor.
+ TfLiteStatus (*AddTensors)(struct TfLiteContext*, int tensors_to_add,
+ int* first_new_tensor_index);
+
+ // Get a Tensor node by node_index.
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteStatus (*GetNodeAndRegistration)(
+ struct TfLiteContext*, int node_index, TfLiteNode** node,
+ struct TfLiteRegistration** registration);
+
+ // Replace ops with one or more stub delegate operations. This function
+ // does not take ownership of `nodes_to_replace`.
+ TfLiteStatus (*ReplaceNodeSubsetsWithDelegateKernels)(
+ struct TfLiteContext*, struct TfLiteRegistration registration,
+ const TfLiteIntArray* nodes_to_replace, struct TfLiteDelegate* delegate);
+
+ // Number of threads that are recommended to subsystems like gemmlowp and
+ // eigen.
+ int recommended_num_threads;
+
+ // Access external contexts by type.
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteExternalContext* (*GetExternalContext)(struct TfLiteContext*,
+ TfLiteExternalContextType);
+ // Set the value of a external context. Does not take ownership of the
+ // pointer.
+ // WARNING: This is an experimental interface that is subject to change.
+ void (*SetExternalContext)(struct TfLiteContext*, TfLiteExternalContextType,
+ TfLiteExternalContext*);
+
+ // Flag for allowing float16 precision for FP32 calculation.
+ // default: false.
+ // WARNING: This is an experimental API and subject to change.
+ bool allow_fp32_relax_to_fp16;
+
+ // Pointer to the op-level profiler, if set; nullptr otherwise.
+ void* profiler;
+
+ // Allocate persistent buffer which has the same life time as the interpreter.
+ // Returns nullptr on failure.
+ // The memory is allocated from heap for TFL, and from tail in TFLM.
+ // This method is only available in Init or Prepare stage.
+ // WARNING: This is an experimental interface that is subject to change.
+ void* (*AllocatePersistentBuffer)(struct TfLiteContext* ctx, size_t bytes);
+
+ // Allocate a buffer which will be deallocated right after invoke phase.
+ // The memory is allocated from heap in TFL, and from volatile arena in TFLM.
+ // This method is only available in invoke stage.
+ // NOTE: If possible use RequestScratchBufferInArena method to avoid memory
+ // allocation during inference time.
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteStatus (*AllocateBufferForEval)(struct TfLiteContext* ctx, size_t bytes,
+ void** ptr);
+
+ // Request a scratch buffer in the arena through static memory planning.
+ // This method is only available in Prepare stage and the buffer is allocated
+ // by the interpreter between Prepare and Eval stage. In Eval stage,
+ // GetScratchBuffer API can be used to fetch the address.
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteStatus (*RequestScratchBufferInArena)(struct TfLiteContext* ctx,
+ size_t bytes, int* buffer_idx);
+
+ // Get the scratch buffer pointer.
+ // This method is only available in Eval stage.
+ // WARNING: This is an experimental interface that is subject to change.
+ void* (*GetScratchBuffer)(struct TfLiteContext* ctx, int buffer_idx);
+
+ // Resize the memory pointer of the `tensor`. This method behaves the same as
+ // `ResizeTensor`, except that it makes a copy of the shape array internally
+ // so the shape array could be deallocated right afterwards.
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteStatus (*ResizeTensorExplicit)(struct TfLiteContext* ctx,
+ TfLiteTensor* tensor, int dims,
+ const int* shape);
+
+ // This method provides a preview of post-delegation partitioning. Each
+ // TfLiteDelegateParams in the referenced array corresponds to one instance of
+ // the delegate kernel.
+ // Example usage:
+ //
+ // TfLiteIntArray* nodes_to_replace = ...;
+ // TfLiteDelegateParams* params_array;
+ // int num_partitions = 0;
+ // TF_LITE_ENSURE_STATUS(context->PreviewDelegatePartitioning(
+ // context, delegate, nodes_to_replace, ¶ms_array, &num_partitions));
+ // for (int idx = 0; idx < num_partitions; idx++) {
+ // const auto& partition_params = params_array[idx];
+ // ...
+ // }
+ //
+ // NOTE: The context owns the memory referenced by partition_params_array. It
+ // will be cleared with another call to PreviewDelegateParitioning, or after
+ // TfLiteDelegateParams::Prepare returns.
+ //
+ // WARNING: This is an experimental interface that is subject to change.
+ TfLiteStatus (*PreviewDelegatePartitioning)(
+ struct TfLiteContext* context, const TfLiteIntArray* nodes_to_replace,
+ TfLiteDelegateParams** partition_params_array, int* num_partitions);
+
+ // Returns a TfLiteTensor struct for a given index.
+ // WARNING: This is an experimental interface that is subject to change.
+ // WARNING: This method may not be available on all platforms.
+ TfLiteTensor* (*GetTensor)(const struct TfLiteContext* context,
+ int tensor_idx);
+
+ // Returns a TfLiteEvalTensor struct for a given index.
+ // WARNING: This is an experimental interface that is subject to change.
+ // WARNING: This method may not be available on all platforms.
+ TfLiteEvalTensor* (*GetEvalTensor)(const struct TfLiteContext* context,
+ int tensor_idx);
+} TfLiteContext;
+
+typedef struct TfLiteRegistration {
+ // Initializes the op from serialized data.
+ // If a built-in op:
+ // `buffer` is the op's params data (TfLiteLSTMParams*).
+ // `length` is zero.
+ // If custom op:
+ // `buffer` is the op's `custom_options`.
+ // `length` is the size of the buffer.
+ //
+ // Returns a type-punned (i.e. void*) opaque data (e.g. a primitive pointer
+ // or an instance of a struct).
+ //
+ // The returned pointer will be stored with the node in the `user_data` field,
+ // accessible within prepare and invoke functions below.
+ // NOTE: if the data is already in the desired format, simply implement this
+ // function to return `nullptr` and implement the free function to be a no-op.
+ void* (*init)(TfLiteContext* context, const char* buffer, size_t length);
+
+ // The pointer `buffer` is the data previously returned by an init invocation.
+ void (*free)(TfLiteContext* context, void* buffer);
+
+ // prepare is called when the inputs this node depends on have been resized.
+ // context->ResizeTensor() can be called to request output tensors to be
+ // resized.
+ //
+ // Returns kTfLiteOk on success.
+ TfLiteStatus (*prepare)(TfLiteContext* context, TfLiteNode* node);
+
+ // Execute the node (should read node->inputs and output to node->outputs).
+ // Returns kTfLiteOk on success.
+ TfLiteStatus (*invoke)(TfLiteContext* context, TfLiteNode* node);
+
+ // profiling_string is called during summarization of profiling information
+ // in order to group executions together. Providing a value here will cause a
+ // given op to appear multiple times is the profiling report. This is
+ // particularly useful for custom ops that can perform significantly
+ // different calculations depending on their `user-data`.
+ const char* (*profiling_string)(const TfLiteContext* context,
+ const TfLiteNode* node);
+
+ // Builtin codes. If this kernel refers to a builtin this is the code
+ // of the builtin. This is so we can do marshaling to other frameworks like
+ // NN API.
+ // Note: It is the responsibility of the registration binder to set this
+ // properly.
+ int32_t builtin_code;
+
+ // Custom op name. If the op is a builtin, this will be null.
+ // Note: It is the responsibility of the registration binder to set this
+ // properly.
+ // WARNING: This is an experimental interface that is subject to change.
+ const char* custom_name;
+
+ // The version of the op.
+ // Note: It is the responsibility of the registration binder to set this
+ // properly.
+ int version;
+} TfLiteRegistration;
+
+// The flags used in `TfLiteDelegate`. Note that this is a bitmask, so the
+// values should be 1, 2, 4, 8, ...etc.
+typedef enum TfLiteDelegateFlags {
+ kTfLiteDelegateFlagsNone = 0,
+ // The flag is set if the delegate can handle dynamic sized tensors.
+ // For example, the output shape of a `Resize` op with non-constant shape
+ // can only be inferred when the op is invoked.
+ // In this case, the Delegate is responsible for calling
+ // `SetTensorToDynamic` to mark the tensor as a dynamic tensor, and calling
+ // `ResizeTensor` when invoking the op.
+ //
+ // If the delegate isn't capable to handle dynamic tensors, this flag need
+ // to be set to false.
+ kTfLiteDelegateFlagsAllowDynamicTensors = 1,
+
+ // This flag can be used by delegates (that allow dynamic tensors) to ensure
+ // applicable tensor shapes are automatically propagated in the case of tensor
+ // resizing.
+ // This means that non-dynamic (allocation_type != kTfLiteDynamic) I/O tensors
+ // of a delegate kernel will have correct shapes before its Prepare() method
+ // is called. The runtime leverages TFLite builtin ops in the original
+ // execution plan to propagate shapes.
+ //
+ // A few points to note:
+ // 1. This requires kTfLiteDelegateFlagsAllowDynamicTensors. If that flag is
+ // false, this one is redundant since the delegate kernels are re-initialized
+ // every time tensors are resized.
+ // 2. Enabling this flag adds some overhead to AllocateTensors(), since extra
+ // work is required to prepare the original execution plan.
+ // 3. This flag requires that the original execution plan only have ops with
+ // valid registrations (and not 'dummy' custom ops like with Flex).
+ // WARNING: This feature is experimental and subject to change.
+ kTfLiteDelegateFlagsRequirePropagatedShapes = 2
+} TfLiteDelegateFlags;
+
+// WARNING: This is an experimental interface that is subject to change.
+typedef struct TfLiteDelegate {
+ // Data that delegate needs to identify itself. This data is owned by the
+ // delegate. The delegate is owned in the user code, so the delegate is
+ // responsible for doing this when it is destroyed.
+ void* data_;
+
+ // Invoked by ModifyGraphWithDelegate. This prepare is called, giving the
+ // delegate a view of the current graph through TfLiteContext*. It typically
+ // will look at the nodes and call ReplaceNodeSubsetsWithDelegateKernels()
+ // to ask the TensorFlow lite runtime to create macro-nodes to represent
+ // delegated subgraphs of the original graph.
+ TfLiteStatus (*Prepare)(TfLiteContext* context,
+ struct TfLiteDelegate* delegate);
+
+ // Copy the data from delegate buffer handle into raw memory of the given
+ // 'tensor'. Note that the delegate is allowed to allocate the raw bytes as
+ // long as it follows the rules for kTfLiteDynamic tensors, in which case this
+ // cannot be null.
+ TfLiteStatus (*CopyFromBufferHandle)(TfLiteContext* context,
+ struct TfLiteDelegate* delegate,
+ TfLiteBufferHandle buffer_handle,
+ TfLiteTensor* tensor);
+
+ // Copy the data from raw memory of the given 'tensor' to delegate buffer
+ // handle. This can be null if the delegate doesn't use its own buffer.
+ TfLiteStatus (*CopyToBufferHandle)(TfLiteContext* context,
+ struct TfLiteDelegate* delegate,
+ TfLiteBufferHandle buffer_handle,
+ TfLiteTensor* tensor);
+
+ // Free the Delegate Buffer Handle. Note: This only frees the handle, but
+ // this doesn't release the underlying resource (e.g. textures). The
+ // resources are either owned by application layer or the delegate.
+ // This can be null if the delegate doesn't use its own buffer.
+ void (*FreeBufferHandle)(TfLiteContext* context,
+ struct TfLiteDelegate* delegate,
+ TfLiteBufferHandle* handle);
+
+ // Bitmask flags. See the comments in `TfLiteDelegateFlags`.
+ int64_t flags;
+} TfLiteDelegate;
+
+// Build a 'null' delegate, with all the fields properly set to their default
+// values.
+TfLiteDelegate TfLiteDelegateCreate();
+
+#ifdef __cplusplus
+} // extern "C"
+#endif // __cplusplus
+#endif // TENSORFLOW_LITE_C_COMMON_H_
diff --git a/tensorflow/lite/core/api/BUILD b/tensorflow/lite/core/api/BUILD
new file mode 100644
index 0000000..bcf1a3d
--- /dev/null
+++ b/tensorflow/lite/core/api/BUILD
@@ -0,0 +1,66 @@
+load("//tensorflow/lite:build_def.bzl", "tflite_copts")
+load("//tensorflow/lite/micro:build_def.bzl", "micro_copts")
+
+package(
+ default_visibility = ["//visibility:private"],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "api",
+ srcs = [
+ "flatbuffer_conversions.cc",
+ "tensor_utils.cc",
+ ],
+ hdrs = [
+ "error_reporter.h",
+ "flatbuffer_conversions.h",
+ "op_resolver.h",
+ "tensor_utils.h",
+ ],
+ copts = tflite_copts() + micro_copts(),
+ visibility = ["//visibility:public"],
+ deps = [
+ ":error_reporter",
+ ":op_resolver",
+ "@flatbuffers//:runtime_cc",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "//tensorflow/lite/schema:schema_fbs",
+ "//tensorflow/lite/schema:schema_utils",
+ ],
+)
+
+# We define separate targets for "op_resolver" and "error_reporter",
+# even though those headers are also exported by the "api" target,
+# so that targets which only want to depend on these small abstract base
+# class modules can express more fine-grained dependencies without
+# pulling in tensor_utils and flatbuffer_conversions.
+
+cc_library(
+ name = "op_resolver",
+ srcs = ["op_resolver.cc"],
+ hdrs = ["op_resolver.h"],
+ copts = tflite_copts() + micro_copts(),
+ visibility = [
+ "//visibility:public",
+ ],
+ deps = [
+ ":error_reporter",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/schema:schema_fbs",
+ "//tensorflow/lite/schema:schema_utils",
+ "@flatbuffers//:runtime_cc",
+ ],
+)
+
+cc_library(
+ name = "error_reporter",
+ srcs = ["error_reporter.cc"],
+ hdrs = ["error_reporter.h"],
+ copts = tflite_copts() + micro_copts(),
+ visibility = [
+ "//visibility:public",
+ ],
+ deps = [],
+)
diff --git a/tensorflow/lite/core/api/error_reporter.cc b/tensorflow/lite/core/api/error_reporter.cc
new file mode 100644
index 0000000..7070eaa
--- /dev/null
+++ b/tensorflow/lite/core/api/error_reporter.cc
@@ -0,0 +1,38 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include <cstdarg>
+
+namespace tflite {
+
+int ErrorReporter::Report(const char* format, ...) {
+ va_list args;
+ va_start(args, format);
+ int code = Report(format, args);
+ va_end(args);
+ return code;
+}
+
+// TODO(aselle): Make the name of ReportError on context the same, so
+// we can use the ensure functions w/o a context and w/ a reporter.
+int ErrorReporter::ReportError(void*, const char* format, ...) {
+ va_list args;
+ va_start(args, format);
+ int code = Report(format, args);
+ va_end(args);
+ return code;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/core/api/error_reporter.h b/tensorflow/lite/core/api/error_reporter.h
new file mode 100644
index 0000000..05839a6
--- /dev/null
+++ b/tensorflow/lite/core/api/error_reporter.h
@@ -0,0 +1,59 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_CORE_API_ERROR_REPORTER_H_
+#define TENSORFLOW_LITE_CORE_API_ERROR_REPORTER_H_
+
+#include <cstdarg>
+
+namespace tflite {
+
+/// A functor that reports error to supporting system. Invoked similar to
+/// printf.
+///
+/// Usage:
+/// ErrorReporter foo;
+/// foo.Report("test %d", 5);
+/// or
+/// va_list args;
+/// foo.Report("test %d", args); // where args is va_list
+///
+/// Subclass ErrorReporter to provide another reporting destination.
+/// For example, if you have a GUI program, you might redirect to a buffer
+/// that drives a GUI error log box.
+class ErrorReporter {
+ public:
+ virtual ~ErrorReporter() {}
+ virtual int Report(const char* format, va_list args) = 0;
+ int Report(const char* format, ...);
+ int ReportError(void*, const char* format, ...);
+};
+
+} // namespace tflite
+
+// You should not make bare calls to the error reporter, instead use the
+// TF_LITE_REPORT_ERROR macro, since this allows message strings to be
+// stripped when the binary size has to be optimized. If you are looking to
+// reduce binary size, define TF_LITE_STRIP_ERROR_STRINGS when compiling and
+// every call will be stubbed out, taking no memory.
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+#define TF_LITE_REPORT_ERROR(reporter, ...) \
+ do { \
+ static_cast<tflite::ErrorReporter*>(reporter)->Report(__VA_ARGS__); \
+ } while (false)
+#else // TF_LITE_STRIP_ERROR_STRINGS
+#define TF_LITE_REPORT_ERROR(reporter, ...)
+#endif // TF_LITE_STRIP_ERROR_STRINGS
+
+#endif // TENSORFLOW_LITE_CORE_API_ERROR_REPORTER_H_
diff --git a/tensorflow/lite/core/api/flatbuffer_conversions.cc b/tensorflow/lite/core/api/flatbuffer_conversions.cc
new file mode 100644
index 0000000..a1f2e73
--- /dev/null
+++ b/tensorflow/lite/core/api/flatbuffer_conversions.cc
@@ -0,0 +1,2163 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/core/api/flatbuffer_conversions.h"
+
+#include <cstddef>
+#include <cstdint>
+#include <memory>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+namespace {
+
+// Utility class for safely allocating POD data. This is useful for avoiding
+// leaks in cases where op params are allocated but fail to propagate to the
+// parsed op data (e.g., when model parameters are invalid).
+class SafeBuiltinDataAllocator {
+ public:
+ class BuiltinDataDeleter {
+ public:
+ explicit BuiltinDataDeleter(BuiltinDataAllocator* allocator)
+ : allocator_(allocator) {}
+
+ void operator()(void* data) { allocator_->Deallocate(data); }
+
+ private:
+ BuiltinDataAllocator* allocator_;
+ };
+
+ template <typename T>
+ using BuiltinDataPtr = std::unique_ptr<T, BuiltinDataDeleter>;
+
+ explicit SafeBuiltinDataAllocator(BuiltinDataAllocator* allocator)
+ : allocator_(allocator) {}
+
+ template <typename T>
+ BuiltinDataPtr<T> Allocate() {
+ return BuiltinDataPtr<T>(allocator_->AllocatePOD<T>(),
+ BuiltinDataDeleter(allocator_));
+ }
+
+ private:
+ BuiltinDataAllocator* allocator_;
+};
+
+// All the Parse functions take some pointers as params and this function has
+// the common DCHECKs to catch if any of those are nullptr.
+void CheckParsePointerParams(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ TFLITE_DCHECK(op != nullptr);
+ TFLITE_DCHECK(error_reporter != nullptr);
+ TFLITE_DCHECK(allocator != nullptr);
+ TFLITE_DCHECK(builtin_data != nullptr);
+}
+
+// Copies the contents from the flatbuffer int vector `flatbuffer` into the
+// int array `buffer`. `flat_vector` and `buffer` represent the same
+// configuration operation for a given operation.
+TfLiteStatus FlatBufferIntVectorToArray(
+ int max_size_of_buffer, const flatbuffers::Vector<int32_t>* flat_vector,
+ int* buffer, ErrorReporter* error_reporter, const char* op_name) {
+ if (!flat_vector) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Input array not provided for operation '%s'.\n",
+ op_name);
+ return kTfLiteError;
+ } else {
+ size_t num_dimensions = flat_vector->size();
+ if (num_dimensions > max_size_of_buffer / sizeof(int)) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "Found too many dimensions in the input array of operation '%s'.\n",
+ op_name);
+ return kTfLiteError;
+ } else {
+ for (size_t i = 0; i < num_dimensions; ++i) {
+ buffer[i] = flat_vector->Get(i);
+ }
+ }
+ }
+ return kTfLiteOk;
+}
+
+// Converts the flatbuffer activation to what is used at runtime.
+TfLiteFusedActivation ConvertActivation(ActivationFunctionType activation) {
+ switch (activation) {
+ case ActivationFunctionType_NONE:
+ return kTfLiteActNone;
+ case ActivationFunctionType_RELU:
+ return kTfLiteActRelu;
+ case ActivationFunctionType_RELU_N1_TO_1:
+ return kTfLiteActReluN1To1;
+ case ActivationFunctionType_RELU6:
+ return kTfLiteActRelu6;
+ case ActivationFunctionType_TANH:
+ return kTfLiteActTanh;
+ case ActivationFunctionType_SIGN_BIT:
+ return kTfLiteActSignBit;
+ }
+ return kTfLiteActNone;
+}
+
+// Converts the flatbuffer padding enum to what is used at runtime.
+TfLitePadding ConvertPadding(Padding padding) {
+ switch (padding) {
+ case Padding_SAME:
+ return kTfLitePaddingSame;
+ case Padding_VALID:
+ return kTfLitePaddingValid;
+ }
+ return kTfLitePaddingUnknown;
+}
+
+#ifndef TF_LITE_STATIC_MEMORY
+TfLiteStatus ParseOpDataTfLite(const Operator* op, BuiltinOperator op_type,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ auto parseLSHProjectionType = [](LSHProjectionType type) {
+ switch (type) {
+ case LSHProjectionType_SPARSE:
+ return kTfLiteLshProjectionSparse;
+ case LSHProjectionType_DENSE:
+ return kTfLiteLshProjectionDense;
+ default:
+ return kTfLiteLshProjectionUnknown;
+ }
+ };
+ auto parseCombinerType = [](CombinerType type) {
+ switch (type) {
+ case CombinerType_MEAN:
+ return kTfLiteCombinerTypeMean;
+ case CombinerType_SQRTN:
+ return kTfLiteCombinerTypeSqrtn;
+ case CombinerType_SUM:
+ default:
+ return kTfLiteCombinerTypeSum;
+ }
+ };
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ *builtin_data = nullptr;
+ switch (op_type) {
+ case BuiltinOperator_ABS: {
+ return ParseAbs(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_ADD: {
+ return ParseAdd(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_ADD_N: {
+ return ParseAddN(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_ARG_MAX: {
+ return ParseArgMax(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_ARG_MIN: {
+ return ParseArgMin(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_AVERAGE_POOL_2D: {
+ return ParsePool(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_BATCH_MATMUL: {
+ return ParseBatchMatMul(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_BATCH_TO_SPACE_ND: {
+ return ParseBatchToSpaceNd(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_CEIL: {
+ return ParseCeil(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_CONCATENATION: {
+ return ParseConcatenation(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_CONV_2D: {
+ return ParseConv2D(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_CUMSUM: {
+ return ParseCumsum(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_DEPTH_TO_SPACE: {
+ return ParseDepthToSpace(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_DEPTHWISE_CONV_2D: {
+ return ParseDepthwiseConv2D(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_DEQUANTIZE: {
+ return ParseDequantize(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_DIV: {
+ return ParseDiv(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_ELU: {
+ return ParseElu(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_EXP: {
+ return ParseExp(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_EXPAND_DIMS: {
+ return ParseExpandDims(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_FILL: {
+ return ParseFill(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_FLOOR: {
+ return ParseFloor(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_FLOOR_DIV: {
+ return ParseFloorDiv(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_FLOOR_MOD: {
+ return ParseFloorMod(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_FULLY_CONNECTED: {
+ return ParseFullyConnected(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_GATHER_ND: {
+ return ParseGatherNd(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_GREATER: {
+ return ParseGreater(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_GREATER_EQUAL: {
+ return ParseGreaterEqual(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_HARD_SWISH: {
+ return ParseHardSwish(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_L2_NORMALIZATION: {
+ return ParseL2Normalization(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_L2_POOL_2D: {
+ return ParsePool(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LEAKY_RELU: {
+ return ParseLeakyRelu(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LESS: {
+ return ParseLess(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LESS_EQUAL: {
+ return ParseLessEqual(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LOG: {
+ return ParseLog(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LOGICAL_AND: {
+ return ParseLogicalAnd(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LOGICAL_NOT: {
+ return ParseLogicalNot(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LOGICAL_OR: {
+ return ParseLogicalOr(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LOGISTIC: {
+ return ParseLogistic(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_LOG_SOFTMAX: {
+ return ParseLogSoftmax(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_MAXIMUM: {
+ return ParseMaximum(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_MAX_POOL_2D: {
+ return ParsePool(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_MEAN: {
+ return ParseReducer(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_MINIMUM: {
+ return ParseMinimum(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_MUL: {
+ return ParseMul(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_NEG: {
+ return ParseNeg(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_NOT_EQUAL: {
+ return ParseNotEqual(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_PACK: {
+ return ParsePack(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_PAD: {
+ return ParsePad(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_PADV2: {
+ return ParsePadV2(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_POW: {
+ return ParsePow(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_PRELU: {
+ return ParsePrelu(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_QUANTIZE: {
+ return ParseQuantize(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_REDUCE_ANY: {
+ return ParseReducer(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_REDUCE_ALL: {
+ return ParseReducer(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_REDUCE_MAX: {
+ return ParseReducer(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_REDUCE_MIN: {
+ return ParseReducer(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_REDUCE_PROD: {
+ return ParseReducer(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_RELU: {
+ return ParseRelu(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_RELU6: {
+ return ParseRelu6(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_RESHAPE: {
+ return ParseReshape(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_RESIZE_BILINEAR: {
+ return ParseResizeBilinear(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_RESIZE_NEAREST_NEIGHBOR: {
+ return ParseResizeNearestNeighbor(op, error_reporter, allocator,
+ builtin_data);
+ }
+
+ case BuiltinOperator_ROUND: {
+ return ParseRound(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_RSQRT: {
+ return ParseRsqrt(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SHAPE: {
+ return ParseShape(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SIN: {
+ return ParseSin(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SOFTMAX: {
+ return ParseSoftmax(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SPACE_TO_BATCH_ND: {
+ return ParseSpaceToBatchNd(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SPACE_TO_DEPTH: {
+ return ParseSpaceToDepth(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SPLIT: {
+ return ParseSplit(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SPLIT_V: {
+ return ParseSplitV(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SQRT: {
+ return ParseSqrt(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SQUARE: {
+ return ParseSquare(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SQUEEZE: {
+ return ParseSqueeze(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_STRIDED_SLICE: {
+ return ParseStridedSlice(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SUB: {
+ return ParseSub(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SUM: {
+ return ParseReducer(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_SVDF: {
+ return ParseSvdf(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_TANH: {
+ return ParseTanh(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_TRANSPOSE_CONV: {
+ return ParseTransposeConv(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_UNPACK: {
+ return ParseUnpack(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_ZEROS_LIKE: {
+ return ParseZerosLike(op, error_reporter, allocator, builtin_data);
+ }
+
+ case BuiltinOperator_CAST: {
+ return ParseCast(op, error_reporter, allocator, builtin_data);
+ }
+ case BuiltinOperator_LSH_PROJECTION: {
+ auto params = safe_allocator.Allocate<TfLiteLSHProjectionParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* lshParams =
+ op->builtin_options_as_LSHProjectionOptions()) {
+ params->type = parseLSHProjectionType(lshParams->type());
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_RNN: {
+ auto params = safe_allocator.Allocate<TfLiteSequenceRNNParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* sequence_rnn_params =
+ op->builtin_options_as_SequenceRNNOptions()) {
+ params->activation =
+ ConvertActivation(sequence_rnn_params->fused_activation_function());
+ params->time_major = sequence_rnn_params->time_major();
+ params->asymmetric_quantize_inputs =
+ sequence_rnn_params->asymmetric_quantize_inputs();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_BIDIRECTIONAL_SEQUENCE_RNN: {
+ auto params =
+ safe_allocator.Allocate<TfLiteBidirectionalSequenceRNNParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* bidi_sequence_rnn_params =
+ op->builtin_options_as_BidirectionalSequenceRNNOptions()) {
+ params->activation = ConvertActivation(
+ bidi_sequence_rnn_params->fused_activation_function());
+ params->time_major = bidi_sequence_rnn_params->time_major();
+ params->merge_outputs = bidi_sequence_rnn_params->merge_outputs();
+ params->asymmetric_quantize_inputs =
+ bidi_sequence_rnn_params->asymmetric_quantize_inputs();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_RNN: {
+ auto params = safe_allocator.Allocate<TfLiteRNNParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* rnn_params = op->builtin_options_as_RNNOptions()) {
+ params->activation =
+ ConvertActivation(rnn_params->fused_activation_function());
+ params->asymmetric_quantize_inputs =
+ rnn_params->asymmetric_quantize_inputs();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_EMBEDDING_LOOKUP_SPARSE: {
+ auto params =
+ safe_allocator.Allocate<TfLiteEmbeddingLookupSparseParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* embedding_params =
+ op->builtin_options_as_EmbeddingLookupSparseOptions()) {
+ params->combiner = parseCombinerType(embedding_params->combiner());
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+
+ case BuiltinOperator_HASHTABLE_LOOKUP:
+ // no-op.
+ return kTfLiteOk;
+
+ case BuiltinOperator_LOCAL_RESPONSE_NORMALIZATION: {
+ auto params = safe_allocator.Allocate<TfLiteLocalResponseNormParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* schema_params =
+ op->builtin_options_as_LocalResponseNormalizationOptions()) {
+ params->radius = schema_params->radius();
+ params->bias = schema_params->bias();
+ params->alpha = schema_params->alpha();
+ params->beta = schema_params->beta();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_LSTM: {
+ auto params = safe_allocator.Allocate<TfLiteLSTMParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* lstm_params = op->builtin_options_as_LSTMOptions()) {
+ params->activation =
+ ConvertActivation(lstm_params->fused_activation_function());
+ params->cell_clip = lstm_params->cell_clip();
+ params->proj_clip = lstm_params->proj_clip();
+ switch (lstm_params->kernel_type()) {
+ case LSTMKernelType_FULL:
+ params->kernel_type = kTfLiteLSTMFullKernel;
+ break;
+ case LSTMKernelType_BASIC:
+ params->kernel_type = kTfLiteLSTMBasicKernel;
+ break;
+ default:
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Unhandled LSTM kernel type: %d",
+ lstm_params->kernel_type());
+ return kTfLiteError;
+ }
+ params->asymmetric_quantize_inputs =
+ lstm_params->asymmetric_quantize_inputs();
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "No valid LSTM builtin options exist");
+ return kTfLiteError;
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_LSTM: {
+ auto params =
+ safe_allocator.Allocate<TfLiteUnidirectionalSequenceLSTMParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* seq_lstm_params =
+ op->builtin_options_as_UnidirectionalSequenceLSTMOptions()) {
+ params->activation =
+ ConvertActivation(seq_lstm_params->fused_activation_function());
+ params->cell_clip = seq_lstm_params->cell_clip();
+ params->proj_clip = seq_lstm_params->proj_clip();
+ params->time_major = seq_lstm_params->time_major();
+ params->asymmetric_quantize_inputs =
+ seq_lstm_params->asymmetric_quantize_inputs();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_BIDIRECTIONAL_SEQUENCE_LSTM: {
+ auto params =
+ safe_allocator.Allocate<TfLiteBidirectionalSequenceLSTMParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* bidi_lstm_params =
+ op->builtin_options_as_BidirectionalSequenceLSTMOptions()) {
+ params->activation =
+ ConvertActivation(bidi_lstm_params->fused_activation_function());
+ params->cell_clip = bidi_lstm_params->cell_clip();
+ params->proj_clip = bidi_lstm_params->proj_clip();
+ params->merge_outputs = bidi_lstm_params->merge_outputs();
+ params->time_major = bidi_lstm_params->time_major();
+ params->asymmetric_quantize_inputs =
+ bidi_lstm_params->asymmetric_quantize_inputs();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_SKIP_GRAM: {
+ auto params = safe_allocator.Allocate<TfLiteSkipGramParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* skip_gram_params =
+ op->builtin_options_as_SkipGramOptions()) {
+ params->ngram_size = skip_gram_params->ngram_size();
+ params->max_skip_size = skip_gram_params->max_skip_size();
+ params->include_all_ngrams = skip_gram_params->include_all_ngrams();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+
+ case BuiltinOperator_GATHER: {
+ return ParseGather(op, error_reporter, allocator, builtin_data);
+ }
+ case BuiltinOperator_SPARSE_TO_DENSE: {
+ auto params = safe_allocator.Allocate<TfLiteSparseToDenseParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* sparse_to_dense_params =
+ op->builtin_options_as_SparseToDenseOptions()) {
+ params->validate_indices = sparse_to_dense_params->validate_indices();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_DELEGATE: {
+ // TODO(ycling): Revisit when supporting saving delegated models.
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "DELEGATE op shouldn't exist in model.");
+ return kTfLiteError;
+ }
+ case BuiltinOperator_FAKE_QUANT: {
+ auto params = safe_allocator.Allocate<TfLiteFakeQuantParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* schema_params =
+ op->builtin_options_as_FakeQuantOptions()) {
+ params->min = schema_params->min();
+ params->max = schema_params->max();
+ params->num_bits = schema_params->num_bits();
+ params->narrow_range = schema_params->narrow_range();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_ONE_HOT: {
+ auto params = safe_allocator.Allocate<TfLiteOneHotParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* schema_params = op->builtin_options_as_OneHotOptions()) {
+ params->axis = schema_params->axis();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_MIRROR_PAD: {
+ auto params = safe_allocator.Allocate<TfLiteMirrorPaddingParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ const auto* mirror_pad_params = op->builtin_options_as_MirrorPadOptions();
+ if (mirror_pad_params != nullptr) {
+ params->mode =
+ mirror_pad_params->mode() == tflite::MirrorPadMode_REFLECT
+ ? TfLiteMirrorPaddingMode::kTfLiteMirrorPaddingReflect
+ : TfLiteMirrorPaddingMode::kTfLiteMirrorPaddingSymmetric;
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_UNIQUE: {
+ auto params = safe_allocator.Allocate<TfLiteUniqueParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ const auto* unique_params = op->builtin_options_as_UniqueOptions();
+ if (unique_params != nullptr) {
+ params->index_out_type =
+ unique_params->idx_out_type() == tflite::TensorType_INT64
+ ? TfLiteType::kTfLiteInt64
+ : TfLiteType::kTfLiteInt32;
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_REVERSE_SEQUENCE: {
+ auto params = safe_allocator.Allocate<TfLiteReverseSequenceParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* reverse_seq_params =
+ op->builtin_options_as_ReverseSequenceOptions()) {
+ params->seq_dim = reverse_seq_params->seq_dim();
+ params->batch_dim = reverse_seq_params->batch_dim();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_IF: {
+ auto params = safe_allocator.Allocate<TfLiteIfParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* if_params = op->builtin_options_as_IfOptions()) {
+ params->then_subgraph_index = if_params->then_subgraph_index();
+ params->else_subgraph_index = if_params->else_subgraph_index();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_WHILE: {
+ auto params = safe_allocator.Allocate<TfLiteWhileParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* while_params = op->builtin_options_as_WhileOptions()) {
+ params->cond_subgraph_index = while_params->cond_subgraph_index();
+ params->body_subgraph_index = while_params->body_subgraph_index();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_CALL_ONCE: {
+ auto params = safe_allocator.Allocate<TfLiteCallOnceParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* call_once_params =
+ op->builtin_options_as_CallOnceOptions()) {
+ params->init_subgraph_index = call_once_params->init_subgraph_index();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_CONV_3D: {
+ auto params = safe_allocator.Allocate<TfLiteConv3DParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* conv3d_params = op->builtin_options_as_Conv3DOptions()) {
+ params->padding = ConvertPadding(conv3d_params->padding());
+ params->activation =
+ ConvertActivation(conv3d_params->fused_activation_function());
+ params->stride_depth = conv3d_params->stride_d();
+ params->stride_height = conv3d_params->stride_h();
+ params->stride_width = conv3d_params->stride_w();
+ params->dilation_depth_factor = conv3d_params->dilation_d_factor();
+ params->dilation_height_factor = conv3d_params->dilation_h_factor();
+ params->dilation_width_factor = conv3d_params->dilation_w_factor();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ case BuiltinOperator_HASHTABLE: {
+ auto params = safe_allocator.Allocate<TfLiteHashtableParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* hashtable_params =
+ op->builtin_options_as_HashtableOptions()) {
+ params->table_id = hashtable_params->table_id();
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(
+ hashtable_params->key_dtype(), ¶ms->key_dtype, error_reporter));
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(hashtable_params->value_dtype(),
+ ¶ms->value_dtype,
+ error_reporter));
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+ }
+ // Below are the ops with no builtin_data structure.
+ // TODO(aselle): Implement call in BuiltinOptions, but nullptrs are
+ // ok for now, since there is no call implementation either.
+ case BuiltinOperator_CALL:
+ case BuiltinOperator_CONCAT_EMBEDDINGS:
+ case BuiltinOperator_COS:
+ case BuiltinOperator_CUSTOM:
+ case BuiltinOperator_EMBEDDING_LOOKUP:
+ case BuiltinOperator_EQUAL:
+ case BuiltinOperator_MATRIX_DIAG:
+ case BuiltinOperator_MATRIX_SET_DIAG:
+ case BuiltinOperator_RELU_N1_TO_1:
+ case BuiltinOperator_SELECT:
+ case BuiltinOperator_SELECT_V2:
+ case BuiltinOperator_SLICE:
+ case BuiltinOperator_TILE:
+ case BuiltinOperator_TOPK_V2:
+ case BuiltinOperator_TRANSPOSE:
+ case BuiltinOperator_RANGE:
+ case BuiltinOperator_SQUARED_DIFFERENCE:
+ case BuiltinOperator_REVERSE_V2:
+ case BuiltinOperator_WHERE:
+ case BuiltinOperator_RANK:
+ case BuiltinOperator_NON_MAX_SUPPRESSION_V4:
+ case BuiltinOperator_NON_MAX_SUPPRESSION_V5:
+ case BuiltinOperator_SCATTER_ND:
+ case BuiltinOperator_DENSIFY:
+ case BuiltinOperator_SEGMENT_SUM:
+ case BuiltinOperator_BROADCAST_TO:
+ case BuiltinOperator_RFFT2D:
+ case BuiltinOperator_IMAG:
+ case BuiltinOperator_REAL:
+ case BuiltinOperator_COMPLEX_ABS:
+ case BuiltinOperator_HASHTABLE_FIND:
+ case BuiltinOperator_HASHTABLE_IMPORT:
+ case BuiltinOperator_HASHTABLE_SIZE:
+ return kTfLiteOk;
+ case BuiltinOperator_PLACEHOLDER_FOR_GREATER_OP_CODES:
+ return kTfLiteError;
+ }
+ return kTfLiteError;
+} // NOLINT[readability/fn_size]
+#endif // !defined(TF_LITE_STATIC_MEMORY)
+} // namespace
+
+TfLiteStatus ConvertTensorType(TensorType tensor_type, TfLiteType* type,
+ ErrorReporter* error_reporter) {
+ switch (tensor_type) {
+ case TensorType_FLOAT16:
+ *type = kTfLiteFloat16;
+ return kTfLiteOk;
+ case TensorType_FLOAT32:
+ *type = kTfLiteFloat32;
+ return kTfLiteOk;
+ case TensorType_FLOAT64:
+ *type = kTfLiteFloat64;
+ return kTfLiteOk;
+ case TensorType_INT16:
+ *type = kTfLiteInt16;
+ return kTfLiteOk;
+ case TensorType_INT32:
+ *type = kTfLiteInt32;
+ return kTfLiteOk;
+ case TensorType_UINT32:
+ *type = kTfLiteUInt32;
+ return kTfLiteOk;
+ case TensorType_UINT8:
+ *type = kTfLiteUInt8;
+ return kTfLiteOk;
+ case TensorType_INT8:
+ *type = kTfLiteInt8;
+ return kTfLiteOk;
+ case TensorType_INT64:
+ *type = kTfLiteInt64;
+ return kTfLiteOk;
+ case TensorType_UINT64:
+ *type = kTfLiteUInt64;
+ return kTfLiteOk;
+ case TensorType_STRING:
+ *type = kTfLiteString;
+ return kTfLiteOk;
+ case TensorType_BOOL:
+ *type = kTfLiteBool;
+ return kTfLiteOk;
+ case TensorType_COMPLEX64:
+ *type = kTfLiteComplex64;
+ return kTfLiteOk;
+ case TensorType_COMPLEX128:
+ *type = kTfLiteComplex128;
+ return kTfLiteOk;
+ case TensorType_RESOURCE:
+ *type = kTfLiteResource;
+ return kTfLiteOk;
+ case TensorType_VARIANT:
+ *type = kTfLiteVariant;
+ return kTfLiteOk;
+ default:
+ *type = kTfLiteNoType;
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Unsupported data type %d in tensor\n", tensor_type);
+ return kTfLiteError;
+ }
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseAbs(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseAdd(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteAddParams, SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteAddParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const AddOptions* schema_params = op->builtin_options_as_AddOptions();
+
+ if (schema_params != nullptr) {
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ params->pot_scale_int16 = schema_params->pot_scale_int16();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseAddN(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseArgMax(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteArgMaxParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteArgMaxParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ArgMaxOptions* schema_params = op->builtin_options_as_ArgMaxOptions();
+
+ if (schema_params != nullptr) {
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(
+ schema_params->output_type(), ¶ms->output_type, error_reporter));
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseArgMin(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteArgMinParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteArgMinParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ArgMinOptions* schema_params = op->builtin_options_as_ArgMinOptions();
+
+ if (schema_params != nullptr) {
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(
+ schema_params->output_type(), ¶ms->output_type, error_reporter));
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseBatchMatMul(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ auto params = safe_allocator.Allocate<TfLiteBatchMatMulParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* bmm_params = op->builtin_options_as_BatchMatMulOptions()) {
+ params->adj_x = bmm_params->adj_x();
+ params->adj_y = bmm_params->adj_y();
+ params->asymmetric_quantize_inputs =
+ bmm_params->asymmetric_quantize_inputs();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseBatchToSpaceNd(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseCast(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ auto params = safe_allocator.Allocate<TfLiteCastParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* schema_params = op->builtin_options_as_CastOptions()) {
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(
+ schema_params->in_data_type(), ¶ms->in_data_type, error_reporter));
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(schema_params->out_data_type(),
+ ¶ms->out_data_type,
+ error_reporter));
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseCeil(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseConcatenation(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteConcatenationParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteConcatenationParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ConcatenationOptions* schema_params =
+ op->builtin_options_as_ConcatenationOptions();
+
+ if (schema_params != nullptr) {
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ params->axis = schema_params->axis();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseConv2D(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteConvParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteConvParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const Conv2DOptions* schema_params = op->builtin_options_as_Conv2DOptions();
+
+ if (schema_params != nullptr) {
+ params->padding = ConvertPadding(schema_params->padding());
+ params->stride_width = schema_params->stride_w();
+ params->stride_height = schema_params->stride_h();
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+
+ params->dilation_width_factor = schema_params->dilation_w_factor();
+ params->dilation_height_factor = schema_params->dilation_h_factor();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseCumsum(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ auto params = safe_allocator.Allocate<TfLiteCumsumParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* cumsum_params = op->builtin_options_as_CumsumOptions()) {
+ params->exclusive = cumsum_params->exclusive();
+ params->reverse = cumsum_params->reverse();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseCos(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseDepthToSpace(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteDepthToSpaceParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteDepthToSpaceParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const auto* schema_params = op->builtin_options_as_DepthToSpaceOptions();
+ if (schema_params != nullptr) {
+ params->block_size = schema_params->block_size();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseDepthwiseConv2D(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+
+ std::unique_ptr<TfLiteDepthwiseConvParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteDepthwiseConvParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const DepthwiseConv2DOptions* schema_params =
+ op->builtin_options_as_DepthwiseConv2DOptions();
+
+ if (schema_params != nullptr) {
+ params->padding = ConvertPadding(schema_params->padding());
+ params->stride_width = schema_params->stride_w();
+ params->stride_height = schema_params->stride_h();
+ params->depth_multiplier = schema_params->depth_multiplier();
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+
+ params->dilation_width_factor = schema_params->dilation_w_factor();
+ params->dilation_height_factor = schema_params->dilation_h_factor();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseDequantize(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseDiv(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ auto params = safe_allocator.Allocate<TfLiteDivParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* schema_params = op->builtin_options_as_DivOptions()) {
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseElu(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseEqual(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseExp(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseExpandDims(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseFill(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseFloor(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseFloorDiv(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseFloorMod(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseFullyConnected(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+
+ std::unique_ptr<TfLiteFullyConnectedParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteFullyConnectedParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const FullyConnectedOptions* schema_params =
+ op->builtin_options_as_FullyConnectedOptions();
+
+ if (schema_params != nullptr) {
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ params->keep_num_dims = schema_params->keep_num_dims();
+ params->asymmetric_quantize_inputs =
+ schema_params->asymmetric_quantize_inputs();
+
+ switch (schema_params->weights_format()) {
+ case FullyConnectedOptionsWeightsFormat_DEFAULT:
+ params->weights_format = kTfLiteFullyConnectedWeightsFormatDefault;
+ break;
+ case FullyConnectedOptionsWeightsFormat_SHUFFLED4x16INT8:
+ params->weights_format =
+ kTfLiteFullyConnectedWeightsFormatShuffled4x16Int8;
+ break;
+ default:
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Unhandled fully-connected weights format.");
+ return kTfLiteError;
+ }
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseGather(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ auto params = safe_allocator.Allocate<TfLiteGatherParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ params->axis = 0;
+ params->batch_dims = 0;
+ if (const auto* gather_params = op->builtin_options_as_GatherOptions()) {
+ params->axis = gather_params->axis();
+ params->batch_dims = gather_params->batch_dims();
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseGatherNd(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseGreater(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseGreaterEqual(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseHardSwish(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseL2Normalization(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteL2NormParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteL2NormParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const L2NormOptions* schema_params = op->builtin_options_as_L2NormOptions();
+
+ if (schema_params != nullptr) {
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseLeakyRelu(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ auto params = safe_allocator.Allocate<TfLiteLeakyReluParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ if (const auto* leaky_relu_params =
+ op->builtin_options_as_LeakyReluOptions()) {
+ params->alpha = leaky_relu_params->alpha();
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLess(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLessEqual(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLog(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLogicalAnd(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLogicalNot(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLogicalOr(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLogistic(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseLogSoftmax(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseMaximum(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseMinimum(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseMul(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteMulParams, SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteMulParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const MulOptions* schema_params = op->builtin_options_as_MulOptions();
+
+ if (schema_params != nullptr) {
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseNeg(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseNotEqual(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParsePack(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLitePackParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLitePackParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const PackOptions* schema_params = op->builtin_options_as_PackOptions();
+
+ if (schema_params != nullptr) {
+ params->values_count = schema_params->values_count();
+ params->axis = schema_params->axis();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParsePad(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParsePadV2(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParsePool(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLitePoolParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLitePoolParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const Pool2DOptions* schema_params = op->builtin_options_as_Pool2DOptions();
+
+ if (schema_params != nullptr) {
+ params->padding = ConvertPadding(schema_params->padding());
+ params->stride_width = schema_params->stride_w();
+ params->stride_height = schema_params->stride_h();
+ params->filter_width = schema_params->filter_width();
+ params->filter_height = schema_params->filter_height();
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParsePow(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParsePrelu(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseQuantize(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseReducer(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+
+ std::unique_ptr<TfLiteReducerParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteReducerParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ReducerOptions* schema_params = op->builtin_options_as_ReducerOptions();
+
+ if (schema_params != nullptr) {
+ params->keep_dims = schema_params->keep_dims();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseRelu(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseRelu6(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseReshape(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+
+ std::unique_ptr<TfLiteReshapeParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteReshapeParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ReshapeOptions* schema_params = op->builtin_options_as_ReshapeOptions();
+
+ if (schema_params != nullptr) {
+ const flatbuffers::Vector<int32_t>* new_shape = schema_params->new_shape();
+ if (new_shape != nullptr) {
+ TF_LITE_ENSURE_STATUS(
+ FlatBufferIntVectorToArray(sizeof(params->shape), new_shape,
+ params->shape, error_reporter, "reshape"));
+ params->num_dimensions = new_shape->size();
+ } else {
+ // TODO(b/157480169) TODO(b/147203660): We should either return
+ // kTfLiteError or fill in some reasonable defaults in the params struct.
+ // We are not doing so until we better undertand the ramifications of
+ // changing the legacy behavior.
+ }
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseResizeBilinear(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteResizeBilinearParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteResizeBilinearParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ResizeBilinearOptions* schema_params =
+ op->builtin_options_as_ResizeBilinearOptions();
+
+ if (schema_params != nullptr) {
+ params->align_corners = schema_params->align_corners();
+ params->half_pixel_centers = schema_params->half_pixel_centers();
+ } else {
+ params->align_corners = false;
+ params->half_pixel_centers = false;
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseResizeNearestNeighbor(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteResizeNearestNeighborParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteResizeNearestNeighborParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ResizeNearestNeighborOptions* schema_params =
+ op->builtin_options_as_ResizeNearestNeighborOptions();
+
+ if (schema_params != nullptr) {
+ params->align_corners = schema_params->align_corners();
+ params->half_pixel_centers = schema_params->half_pixel_centers();
+ } else {
+ params->align_corners = false;
+ params->half_pixel_centers = false;
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseRound(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseRsqrt(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseShape(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteShapeParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteShapeParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const ShapeOptions* schema_params = op->builtin_options_as_ShapeOptions();
+
+ if (schema_params != nullptr) {
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(schema_params->out_type(),
+ ¶ms->out_type, error_reporter));
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseSin(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseSoftmax(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteSoftmaxParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteSoftmaxParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const SoftmaxOptions* schema_params = op->builtin_options_as_SoftmaxOptions();
+
+ if (schema_params != nullptr) {
+ params->beta = schema_params->beta();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseSpaceToBatchNd(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseSpaceToDepth(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteSpaceToDepthParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteSpaceToDepthParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const auto* schema_params = op->builtin_options_as_SpaceToDepthOptions();
+ if (schema_params != nullptr) {
+ params->block_size = schema_params->block_size();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseSplit(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteSplitParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteSplitParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const SplitOptions* schema_params = op->builtin_options_as_SplitOptions();
+
+ if (schema_params != nullptr) {
+ params->num_splits = schema_params->num_splits();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseSplitV(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+
+ std::unique_ptr<TfLiteSplitVParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteSplitVParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const SplitVOptions* schema_params = op->builtin_options_as_SplitVOptions();
+
+ if (schema_params != nullptr) {
+ params->num_splits = schema_params->num_splits();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseSqueeze(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+
+ std::unique_ptr<TfLiteSqueezeParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteSqueezeParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const SqueezeOptions* schema_params = op->builtin_options_as_SqueezeOptions();
+
+ if (schema_params != nullptr) {
+ const auto* squeeze_dims = schema_params->squeeze_dims();
+ if (squeeze_dims != nullptr) {
+ TF_LITE_ENSURE_STATUS(FlatBufferIntVectorToArray(
+ sizeof(params->squeeze_dims), squeeze_dims, params->squeeze_dims,
+ error_reporter, "squeeze"));
+ params->num_squeeze_dims = squeeze_dims->size();
+ } else {
+ params->num_squeeze_dims = 0;
+ }
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseSqrt(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseSquare(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseStridedSlice(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteStridedSliceParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteStridedSliceParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const StridedSliceOptions* schema_params =
+ op->builtin_options_as_StridedSliceOptions();
+
+ if (schema_params != nullptr) {
+ params->begin_mask = schema_params->begin_mask();
+ params->end_mask = schema_params->end_mask();
+ params->ellipsis_mask = schema_params->ellipsis_mask();
+ params->new_axis_mask = schema_params->new_axis_mask();
+ params->shrink_axis_mask = schema_params->shrink_axis_mask();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseSub(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteSubParams, SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteSubParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const SubOptions* schema_params = op->builtin_options_as_SubOptions();
+
+ if (schema_params != nullptr) {
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ params->pot_scale_int16 = schema_params->pot_scale_int16();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseSvdf(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteSVDFParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteSVDFParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const SVDFOptions* schema_params = op->builtin_options_as_SVDFOptions();
+ if (schema_params != nullptr) {
+ params->rank = schema_params->rank();
+ params->activation =
+ ConvertActivation(schema_params->fused_activation_function());
+ params->asymmetric_quantize_inputs =
+ schema_params->asymmetric_quantize_inputs();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseTanh(const Operator*, ErrorReporter*, BuiltinDataAllocator*,
+ void**) {
+ return kTfLiteOk;
+}
+//
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseTranspose(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseTransposeConv(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteTransposeConvParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteTransposeConvParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+ const TransposeConvOptions* transpose_conv_params =
+ op->builtin_options_as_TransposeConvOptions();
+ if (transpose_conv_params != nullptr) {
+ params->padding = ConvertPadding(transpose_conv_params->padding());
+ params->stride_width = transpose_conv_params->stride_w();
+ params->stride_height = transpose_conv_params->stride_h();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseUnpack(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+ CheckParsePointerParams(op, error_reporter, allocator, builtin_data);
+
+ SafeBuiltinDataAllocator safe_allocator(allocator);
+ std::unique_ptr<TfLiteUnpackParams,
+ SafeBuiltinDataAllocator::BuiltinDataDeleter>
+ params = safe_allocator.Allocate<TfLiteUnpackParams>();
+ TF_LITE_ENSURE(error_reporter, params != nullptr);
+
+ const UnpackOptions* schema_params = op->builtin_options_as_UnpackOptions();
+
+ if (schema_params != nullptr) {
+ params->num = schema_params->num();
+ params->axis = schema_params->axis();
+ } else {
+ // TODO(b/157480169): We should either return kTfLiteError or fill in some
+ // reasonable defaults in the params struct. We are not doing so until we
+ // better undertand the ramifications of changing the legacy behavior.
+ }
+
+ *builtin_data = params.release();
+ return kTfLiteOk;
+}
+
+// We have this parse function instead of directly returning kTfLiteOk from the
+// switch-case in ParseOpData because this function is used as part of the
+// selective registration for the OpResolver implementation in micro.
+TfLiteStatus ParseZerosLike(const Operator*, ErrorReporter*,
+ BuiltinDataAllocator*, void**) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus ParseOpData(const Operator* op, BuiltinOperator op_type,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data) {
+// TODO(b/145762662): It would be preferable to have the build graph for TF Lite
+// Micro not have the ParseOpData function at all. This would require splitting
+// the current file into two separate files, one of which defines the
+// ParseOpData function and the other that defines the operator specific parse
+// functions (e.g. ParseAdd).
+//
+// Such a split was attempted but was not worth the effort at the time because
+// of the following reasons:
+// * We could either duplicate the functions and the SafeBuiltinDataAllocator
+// class in the anonymous namespace of this file, or attempt to make a common
+// library with these helper functions and class.
+// * Making a common library with a separate build target was not feasible as
+// it introduced circular dependencies due to the ErrorReporter and a common
+// .cc and .h within the same api build target the also cause circular
+// dependencies due to the BuiltinDataAllocator class.
+// * If all the builtin operators were to have their own parse functions, or we
+// were ok with some amount of code duplication, then this split of the .cc
+// files would be a lot more feasible.
+#ifdef TF_LITE_STATIC_MEMORY
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "ParseOpData is unsupported on TfLiteMicro, please use the operator "
+ "specific parse functions (e.g. ParseAdd etc.).\n");
+ return kTfLiteError;
+#else
+ return ParseOpDataTfLite(op, op_type, error_reporter, allocator,
+ builtin_data);
+#endif
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/core/api/flatbuffer_conversions.h b/tensorflow/lite/core/api/flatbuffer_conversions.h
new file mode 100644
index 0000000..b4a6883
--- /dev/null
+++ b/tensorflow/lite/core/api/flatbuffer_conversions.h
@@ -0,0 +1,355 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_CORE_API_FLATBUFFER_CONVERSIONS_H_
+#define TENSORFLOW_LITE_CORE_API_FLATBUFFER_CONVERSIONS_H_
+
+// These functions transform codes and data structures that are defined in the
+// flatbuffer serialization format into in-memory values that are used by the
+// runtime API and interpreter.
+
+#include <cstddef>
+#include <new>
+#include <type_traits>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+// Interface class for builtin data allocations.
+class BuiltinDataAllocator {
+ public:
+ virtual void* Allocate(size_t size, size_t alignment_hint) = 0;
+ virtual void Deallocate(void* data) = 0;
+
+ // Allocate a structure, but make sure it is a POD structure that doesn't
+ // require constructors to run. The reason we do this, is that Interpreter's C
+ // extension part will take ownership so destructors will not be run during
+ // deallocation.
+ template <typename T>
+ T* AllocatePOD() {
+ // TODO(b/154346074): Change this to is_trivially_destructible when all
+ // platform targets support that properly.
+ static_assert(std::is_pod<T>::value, "Builtin data structure must be POD.");
+ void* allocated_memory = this->Allocate(sizeof(T), alignof(T));
+ return new (allocated_memory) T();
+ }
+
+ virtual ~BuiltinDataAllocator() {}
+};
+
+// Parse the appropriate data out of the op.
+//
+// This handles builtin data explicitly as there are flatbuffer schemas.
+// If it returns kTfLiteOk, it passes the data out with `builtin_data`. The
+// calling function has to pass in an allocator object, and this allocator
+// will be called to reserve space for the output data. If the calling
+// function's allocator reserves memory on the heap, then it's the calling
+// function's responsibility to free it.
+// If it returns kTfLiteError, `builtin_data` will be `nullptr`.
+TfLiteStatus ParseOpData(const Operator* op, BuiltinOperator op_type,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+// Converts the tensor data type used in the flat buffer to the representation
+// used by the runtime.
+TfLiteStatus ConvertTensorType(TensorType tensor_type, TfLiteType* type,
+ ErrorReporter* error_reporter);
+
+TfLiteStatus ParseAbs(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseAdd(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseAddN(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseArgMax(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseArgMin(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseBatchMatMul(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseBatchToSpaceNd(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseCeil(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseCast(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseConcatenation(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseConv2D(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseCos(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseCumsum(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseDepthToSpace(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseDepthwiseConv2D(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseDequantize(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseDiv(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseElu(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseEqual(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseExp(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseExpandDims(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseFill(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseFloor(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseFloorDiv(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseFloorMod(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseFullyConnected(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseGather(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseGatherNd(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseGreater(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseGreaterEqual(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseHardSwish(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseL2Normalization(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseLeakyRelu(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseLess(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseLessEqual(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseLog(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseLogicalAnd(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseLogicalNot(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseLogicalOr(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseLogistic(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseLogSoftmax(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseMaximum(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseMinimum(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseMul(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseNeg(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseNotEqual(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParsePack(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParsePad(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParsePadV2(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParsePool(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParsePow(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParsePrelu(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseQuantize(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseReducer(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseRelu(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseRelu6(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseReshape(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseResizeBilinear(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseResizeNearestNeighbor(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseRound(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseRsqrt(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseShape(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSin(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSoftmax(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSpaceToBatchNd(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseSpaceToDepth(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseSplit(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSplitV(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSqueeze(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSqrt(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSquare(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseStridedSlice(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseSub(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseSvdf(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseTanh(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseTranspose(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseTransposeConv(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+TfLiteStatus ParseUnpack(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator, void** builtin_data);
+
+TfLiteStatus ParseZerosLike(const Operator* op, ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_CORE_API_FLATBUFFER_CONVERSIONS_H_
diff --git a/tensorflow/lite/core/api/op_resolver.cc b/tensorflow/lite/core/api/op_resolver.cc
new file mode 100644
index 0000000..04ebd9a
--- /dev/null
+++ b/tensorflow/lite/core/api/op_resolver.cc
@@ -0,0 +1,69 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/core/api/op_resolver.h"
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/schema/schema_utils.h"
+
+namespace tflite {
+
+TfLiteStatus GetRegistrationFromOpCode(
+ const OperatorCode* opcode, const OpResolver& op_resolver,
+ ErrorReporter* error_reporter, const TfLiteRegistration** registration) {
+ TfLiteStatus status = kTfLiteOk;
+ *registration = nullptr;
+ auto builtin_code = GetBuiltinCode(opcode);
+ int version = opcode->version();
+
+ if (builtin_code > BuiltinOperator_MAX ||
+ builtin_code < BuiltinOperator_MIN) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "Op builtin_code out of range: %d. Are you using old TFLite binary "
+ "with newer model?",
+ builtin_code);
+ status = kTfLiteError;
+ } else if (builtin_code != BuiltinOperator_CUSTOM) {
+ *registration = op_resolver.FindOp(builtin_code, version);
+ if (*registration == nullptr) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "Didn't find op for builtin opcode '%s' version '%d'. "
+ "An older version of this builtin might be supported. "
+ "Are you using an old TFLite binary with a newer model?\n",
+ EnumNameBuiltinOperator(builtin_code), version);
+ status = kTfLiteError;
+ }
+ } else if (!opcode->custom_code()) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "Operator with CUSTOM builtin_code has no custom_code.\n");
+ status = kTfLiteError;
+ } else {
+ const char* name = opcode->custom_code()->c_str();
+ *registration = op_resolver.FindOp(name, version);
+ if (*registration == nullptr) {
+ // Do not report error for unresolved custom op, we do the final check
+ // while preparing ops.
+ status = kTfLiteError;
+ }
+ }
+ return status;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/core/api/op_resolver.h b/tensorflow/lite/core/api/op_resolver.h
new file mode 100644
index 0000000..f43c6ba
--- /dev/null
+++ b/tensorflow/lite/core/api/op_resolver.h
@@ -0,0 +1,61 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_CORE_API_OP_RESOLVER_H_
+#define TENSORFLOW_LITE_CORE_API_OP_RESOLVER_H_
+
+#include <memory>
+#include <vector>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+/// Abstract interface that returns TfLiteRegistrations given op codes or custom
+/// op names. This is the mechanism that ops being referenced in the flatbuffer
+/// model are mapped to executable function pointers (TfLiteRegistrations).
+class OpResolver {
+ public:
+ /// Finds the op registration for a builtin operator by enum code.
+ virtual const TfLiteRegistration* FindOp(tflite::BuiltinOperator op,
+ int version) const = 0;
+ /// Finds the op registration of a custom operator by op name.
+ virtual const TfLiteRegistration* FindOp(const char* op,
+ int version) const = 0;
+
+ // Returns optional delegates for resolving and handling ops in the flatbuffer
+ // model. This may be used in addition to the standard TfLiteRegistration
+ // lookup for graph resolution.
+ using TfLiteDelegatePtrVector =
+ std::vector<std::unique_ptr<TfLiteDelegate, void (*)(TfLiteDelegate*)>>;
+ virtual TfLiteDelegatePtrVector GetDelegates(int num_threads) const {
+ return TfLiteDelegatePtrVector();
+ }
+
+ virtual ~OpResolver() {}
+};
+
+// Handles the logic for converting between an OperatorCode structure extracted
+// from a flatbuffer and information about a registered operator
+// implementation.
+TfLiteStatus GetRegistrationFromOpCode(const OperatorCode* opcode,
+ const OpResolver& op_resolver,
+ ErrorReporter* error_reporter,
+ const TfLiteRegistration** registration);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_CORE_API_OP_RESOLVER_H_
diff --git a/tensorflow/lite/core/api/tensor_utils.cc b/tensorflow/lite/core/api/tensor_utils.cc
new file mode 100644
index 0000000..3aac16b
--- /dev/null
+++ b/tensorflow/lite/core/api/tensor_utils.cc
@@ -0,0 +1,50 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/core/api/tensor_utils.h"
+
+#include <string.h>
+
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+TfLiteStatus ResetVariableTensor(TfLiteTensor* tensor) {
+ if (!tensor->is_variable) {
+ return kTfLiteOk;
+ }
+ // TODO(b/115961645): Implement - If a variable tensor has a buffer, reset it
+ // to the value of the buffer.
+ int value = 0;
+ if (tensor->type == kTfLiteInt8) {
+ value = tensor->params.zero_point;
+ }
+ // TODO(b/139446230): Provide a platform header to better handle these
+ // specific scenarios.
+#if __ANDROID__ || defined(__x86_64__) || defined(__i386__) || \
+ defined(__i386) || defined(__x86__) || defined(__X86__) || \
+ defined(_X86_) || defined(_M_IX86) || defined(_M_X64)
+ memset(tensor->data.raw, value, tensor->bytes);
+#else
+ char* raw_ptr = tensor->data.raw;
+ for (size_t i = 0; i < tensor->bytes; ++i) {
+ *raw_ptr = value;
+ raw_ptr++;
+ }
+#endif
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/core/api/tensor_utils.h b/tensorflow/lite/core/api/tensor_utils.h
new file mode 100644
index 0000000..9f1cf94
--- /dev/null
+++ b/tensorflow/lite/core/api/tensor_utils.h
@@ -0,0 +1,28 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_CORE_API_TENSOR_UTILS_H_
+#define TENSORFLOW_LITE_CORE_API_TENSOR_UTILS_H_
+
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+// Resets a variable tensor to the default value.
+TfLiteStatus ResetVariableTensor(TfLiteTensor* tensor);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_CORE_API_TENSOR_UTILS_H_
diff --git a/tensorflow/lite/kernels/BUILD b/tensorflow/lite/kernels/BUILD
new file mode 100644
index 0000000..fcdb732
--- /dev/null
+++ b/tensorflow/lite/kernels/BUILD
@@ -0,0 +1,45 @@
+load("//tensorflow/lite:build_def.bzl", "tflite_copts")
+load("//tensorflow/lite/micro:build_def.bzl", "micro_copts")
+
+package(
+ default_visibility = [
+ "//visibility:public",
+ ],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "op_macros",
+ hdrs = [
+ "op_macros.h",
+ ],
+ copts = tflite_copts(),
+ deps = ["//tensorflow/lite/micro:debug_log"],
+)
+
+cc_library(
+ name = "kernel_util",
+ srcs = [
+ "kernel_util.cc",
+ ],
+ hdrs = [
+ "kernel_util.h",
+ ],
+ copts = tflite_copts() + micro_copts(),
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:cppmath",
+ "//tensorflow/lite/kernels/internal:quantization_util",
+ ],
+)
+
+cc_library(
+ name = "padding",
+ srcs = [],
+ hdrs = ["padding.h"],
+ copts = tflite_copts(),
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:types",
+ ],
+)
diff --git a/tensorflow/lite/kernels/internal/BUILD b/tensorflow/lite/kernels/internal/BUILD
new file mode 100644
index 0000000..3a0a6a8
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/BUILD
@@ -0,0 +1,187 @@
+load("//tensorflow/lite:build_def.bzl", "tflite_copts")
+load("//tensorflow/lite/micro:build_def.bzl", "micro_copts")
+
+package(
+ default_visibility = [
+ "//visibility:public",
+ ],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "common",
+ srcs = [],
+ hdrs = [
+ "common.h",
+ "optimized/neon_check.h",
+ ],
+ copts = tflite_copts(),
+ deps = [
+ ":cppmath",
+ ":types",
+ "@gemmlowp//:fixedpoint",
+ ],
+)
+
+cc_library(
+ name = "compatibility",
+ hdrs = ["compatibility.h"],
+ copts = tflite_copts(),
+ deps = [
+ "//tensorflow/lite/kernels:op_macros",
+ ],
+)
+
+cc_library(
+ name = "cppmath",
+ srcs = [],
+ hdrs = [
+ "cppmath.h",
+ "max.h",
+ "min.h",
+ ],
+ copts = tflite_copts(),
+)
+
+cc_library(
+ name = "quantization_util",
+ srcs = ["quantization_util.cc"],
+ hdrs = ["quantization_util.h"],
+ copts = tflite_copts() + micro_copts(),
+ deps = [
+ ":compatibility",
+ ":cppmath",
+ ":types",
+ ],
+)
+
+cc_library(
+ name = "reference",
+ hdrs = [
+ "portable_tensor.h",
+ "tensor_ctypes.h",
+ ],
+ copts = tflite_copts(),
+ deps = [
+ ":types",
+ "//tensorflow/lite/c:common",
+ ],
+)
+
+cc_library(
+ name = "reference_base",
+ srcs = [],
+ hdrs = [
+ "reference/add.h",
+ "reference/add_n.h",
+ "reference/arg_min_max.h",
+ "reference/batch_to_space_nd.h",
+ "reference/binary_function.h",
+ "reference/ceil.h",
+ "reference/comparisons.h",
+ "reference/concatenation.h",
+ "reference/conv.h",
+ "reference/cumsum.h",
+ "reference/depthwiseconv_float.h",
+ "reference/depthwiseconv_uint8.h",
+ "reference/dequantize.h",
+ "reference/elu.h",
+ "reference/exp.h",
+ "reference/fill.h",
+ "reference/floor.h",
+ "reference/floor_div.h",
+ "reference/floor_mod.h",
+ "reference/fully_connected.h",
+ "reference/hard_swish.h",
+ "reference/integer_ops/add.h",
+ "reference/integer_ops/conv.h",
+ "reference/integer_ops/depthwise_conv.h",
+ "reference/integer_ops/fully_connected.h",
+ "reference/integer_ops/l2normalization.h",
+ "reference/integer_ops/logistic.h",
+ "reference/integer_ops/mean.h",
+ "reference/integer_ops/mul.h",
+ "reference/integer_ops/pooling.h",
+ "reference/integer_ops/tanh.h",
+ "reference/integer_ops/transpose_conv.h",
+ "reference/l2normalization.h",
+ "reference/leaky_relu.h",
+ "reference/logistic.h",
+ "reference/maximum_minimum.h",
+ "reference/mul.h",
+ "reference/neg.h",
+ "reference/pad.h",
+ "reference/pooling.h",
+ "reference/prelu.h",
+ "reference/process_broadcast_shapes.h",
+ "reference/quantize.h",
+ "reference/reduce.h",
+ "reference/requantize.h",
+ "reference/resize_nearest_neighbor.h",
+ "reference/round.h",
+ "reference/softmax.h",
+ "reference/space_to_batch_nd.h",
+ "reference/strided_slice.h",
+ "reference/sub.h",
+ "reference/tanh.h",
+ "reference/transpose_conv.h",
+ ],
+ copts = tflite_copts(),
+ # We are disabling parse_headers for this header-only target so that the
+ # external and internal builds are consistent. The primary issue here is
+ # that parse_headers is not supported with bazel and the TFLM team would
+ # really like to have all build errors be reproducible from the OSS build as
+ # well.
+ #
+ # See b/175817116 for more details.
+ features = ["-parse_headers"],
+ deps = [
+ ":common",
+ ":compatibility",
+ ":cppmath",
+ ":quantization_util",
+ ":strided_slice_logic",
+ ":tensor",
+ ":types",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels:kernel_util",
+ "//tensorflow/lite/kernels:op_macros",
+ "@gemmlowp//:fixedpoint",
+ "@ruy//ruy/profiler:instrumentation",
+ ],
+)
+
+cc_library(
+ name = "strided_slice_logic",
+ srcs = [],
+ hdrs = [
+ "strided_slice_logic.h",
+ ],
+ copts = tflite_copts(),
+ deps = [
+ ":compatibility",
+ ":types",
+ ],
+)
+
+cc_library(
+ name = "tensor",
+ hdrs = [
+ "portable_tensor.h",
+ "tensor_ctypes.h",
+ ],
+ copts = tflite_copts(),
+ deps = [
+ ":types",
+ "//tensorflow/lite/c:common",
+ ],
+)
+
+cc_library(
+ name = "types",
+ hdrs = ["types.h"],
+ copts = tflite_copts(),
+ deps = [
+ ":compatibility",
+ ],
+)
diff --git a/tensorflow/lite/kernels/internal/common.h b/tensorflow/lite/kernels/internal/common.h
new file mode 100644
index 0000000..c433fc8
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/common.h
@@ -0,0 +1,1037 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_COMMON_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_COMMON_H_
+
+#ifndef ALLOW_SLOW_GENERIC_DEPTHWISECONV_FALLBACK
+#ifdef GEMMLOWP_ALLOW_SLOW_SCALAR_FALLBACK
+#define ALLOW_SLOW_GENERIC_DEPTHWISECONV_FALLBACK
+#endif
+#endif
+
+#include <functional>
+
+#include "fixedpoint/fixedpoint.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/optimized/neon_check.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+constexpr int kReverseShift = -1;
+
+inline void GetActivationMinMax(FusedActivationFunctionType ac,
+ float* output_activation_min,
+ float* output_activation_max) {
+ switch (ac) {
+ case FusedActivationFunctionType::kNone:
+ *output_activation_min = std::numeric_limits<float>::lowest();
+ *output_activation_max = std::numeric_limits<float>::max();
+ break;
+ case FusedActivationFunctionType::kRelu:
+ *output_activation_min = 0.f;
+ *output_activation_max = std::numeric_limits<float>::max();
+ break;
+ case FusedActivationFunctionType::kRelu1:
+ *output_activation_min = -1.f;
+ *output_activation_max = 1.f;
+ break;
+ case FusedActivationFunctionType::kRelu6:
+ *output_activation_min = 0.f;
+ *output_activation_max = 6.f;
+ break;
+ }
+}
+
+template <typename T>
+inline T ActivationFunctionWithMinMax(T x, T output_activation_min,
+ T output_activation_max) {
+ using std::max;
+ using std::min;
+ return min(max(x, output_activation_min), output_activation_max);
+}
+
+// Legacy function, left for compatibility only.
+template <FusedActivationFunctionType Ac>
+float ActivationFunction(float x) {
+ float output_activation_min, output_activation_max;
+ GetActivationMinMax(Ac, &output_activation_min, &output_activation_max);
+ return ActivationFunctionWithMinMax(x, output_activation_min,
+ output_activation_max);
+}
+
+inline void BiasAndClamp(float clamp_min, float clamp_max, int bias_size,
+ const float* bias_data, int array_size,
+ float* array_data) {
+ // Note: see b/132215220: in May 2019 we thought it would be OK to replace
+ // this with the Eigen one-liner:
+ // return (array.colwise() + bias).cwiseMin(clamp_max).cwiseMin(clamp_max).
+ // This turned out to severely regress performance: +4ms (i.e. 8%) on
+ // MobileNet v2 / 1.0 / 224. So we keep custom NEON code for now.
+ TFLITE_DCHECK_EQ((array_size % bias_size), 0);
+#ifdef USE_NEON
+ float* array_ptr = array_data;
+ float* array_end_ptr = array_ptr + array_size;
+ const auto clamp_min_vec = vdupq_n_f32(clamp_min);
+ const auto clamp_max_vec = vdupq_n_f32(clamp_max);
+ for (; array_ptr != array_end_ptr; array_ptr += bias_size) {
+ int i = 0;
+ for (; i <= bias_size - 16; i += 16) {
+ auto b0 = vld1q_f32(bias_data + i);
+ auto b1 = vld1q_f32(bias_data + i + 4);
+ auto b2 = vld1q_f32(bias_data + i + 8);
+ auto b3 = vld1q_f32(bias_data + i + 12);
+ auto a0 = vld1q_f32(array_ptr + i);
+ auto a1 = vld1q_f32(array_ptr + i + 4);
+ auto a2 = vld1q_f32(array_ptr + i + 8);
+ auto a3 = vld1q_f32(array_ptr + i + 12);
+ auto x0 = vaddq_f32(a0, b0);
+ auto x1 = vaddq_f32(a1, b1);
+ auto x2 = vaddq_f32(a2, b2);
+ auto x3 = vaddq_f32(a3, b3);
+ x0 = vmaxq_f32(clamp_min_vec, x0);
+ x1 = vmaxq_f32(clamp_min_vec, x1);
+ x2 = vmaxq_f32(clamp_min_vec, x2);
+ x3 = vmaxq_f32(clamp_min_vec, x3);
+ x0 = vminq_f32(clamp_max_vec, x0);
+ x1 = vminq_f32(clamp_max_vec, x1);
+ x2 = vminq_f32(clamp_max_vec, x2);
+ x3 = vminq_f32(clamp_max_vec, x3);
+ vst1q_f32(array_ptr + i, x0);
+ vst1q_f32(array_ptr + i + 4, x1);
+ vst1q_f32(array_ptr + i + 8, x2);
+ vst1q_f32(array_ptr + i + 12, x3);
+ }
+ for (; i <= bias_size - 4; i += 4) {
+ auto b = vld1q_f32(bias_data + i);
+ auto a = vld1q_f32(array_ptr + i);
+ auto x = vaddq_f32(a, b);
+ x = vmaxq_f32(clamp_min_vec, x);
+ x = vminq_f32(clamp_max_vec, x);
+ vst1q_f32(array_ptr + i, x);
+ }
+ for (; i < bias_size; i++) {
+ array_ptr[i] = ActivationFunctionWithMinMax(array_ptr[i] + bias_data[i],
+ clamp_min, clamp_max);
+ }
+ }
+#else // not NEON
+ for (int array_offset = 0; array_offset < array_size;
+ array_offset += bias_size) {
+ for (int i = 0; i < bias_size; i++) {
+ array_data[array_offset + i] = ActivationFunctionWithMinMax(
+ array_data[array_offset + i] + bias_data[i], clamp_min, clamp_max);
+ }
+ }
+#endif
+}
+
+inline int32_t MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ int32_t x, int32_t quantized_multiplier, int left_shift) {
+ using gemmlowp::RoundingDivideByPOT;
+ using gemmlowp::SaturatingRoundingDoublingHighMul;
+ return RoundingDivideByPOT(
+ SaturatingRoundingDoublingHighMul(x, quantized_multiplier), -left_shift);
+}
+
+inline int32_t MultiplyByQuantizedMultiplierGreaterThanOne(
+ int32_t x, int32_t quantized_multiplier, int left_shift) {
+ using gemmlowp::SaturatingRoundingDoublingHighMul;
+ return SaturatingRoundingDoublingHighMul(x * (1 << left_shift),
+ quantized_multiplier);
+}
+
+inline int32_t MultiplyByQuantizedMultiplier(int32_t x,
+ int32_t quantized_multiplier,
+ int shift) {
+ using gemmlowp::RoundingDivideByPOT;
+ using gemmlowp::SaturatingRoundingDoublingHighMul;
+ int left_shift = shift > 0 ? shift : 0;
+ int right_shift = shift > 0 ? 0 : -shift;
+ return RoundingDivideByPOT(SaturatingRoundingDoublingHighMul(
+ x * (1 << left_shift), quantized_multiplier),
+ right_shift);
+}
+
+inline int32_t MultiplyByQuantizedMultiplier(int64_t x,
+ int32_t quantized_multiplier,
+ int shift) {
+ // Inputs:
+ // - quantized_multiplier has fixed point at bit 31
+ // - shift is -31 to +7 (negative for right shift)
+ //
+ // Assumptions: The following input ranges are assumed
+ // - quantize_scale>=0 (the usual range is (1<<30) to (1>>31)-1)
+ // - scaling is chosen so final scaled result fits in int32_t
+ // - input x is in the range -(1<<47) <= x < (1<<47)
+ assert(quantized_multiplier >= 0);
+ assert(shift >= -31 && shift < 8);
+ assert(x >= -(static_cast<int64_t>(1) << 47) &&
+ x < (static_cast<int64_t>(1) << 47));
+
+ int32_t reduced_multiplier = (quantized_multiplier < 0x7FFF0000)
+ ? ((quantized_multiplier + (1 << 15)) >> 16)
+ : 0x7FFF;
+ int total_shift = 15 - shift;
+ x = (x * (int64_t)reduced_multiplier) + ((int64_t)1 << (total_shift - 1));
+ int32_t result = x >> total_shift;
+ return result;
+}
+
+#ifdef USE_NEON
+// Round uses ARM's rounding shift right.
+inline int32x4x4_t MultiplyByQuantizedMultiplier4Rows(
+ int32x4x4_t input_val, int32_t quantized_multiplier, int shift) {
+ const int left_shift = std::max(shift, 0);
+ const int right_shift = std::min(shift, 0);
+ int32x4x4_t result;
+
+ int32x4_t multiplier_dup = vdupq_n_s32(quantized_multiplier);
+ int32x4_t left_shift_dup = vdupq_n_s32(left_shift);
+ int32x4_t right_shift_dup = vdupq_n_s32(right_shift);
+
+ result.val[0] =
+ vrshlq_s32(vqrdmulhq_s32(vshlq_s32(input_val.val[0], left_shift_dup),
+ multiplier_dup),
+ right_shift_dup);
+
+ result.val[1] =
+ vrshlq_s32(vqrdmulhq_s32(vshlq_s32(input_val.val[1], left_shift_dup),
+ multiplier_dup),
+ right_shift_dup);
+
+ result.val[2] =
+ vrshlq_s32(vqrdmulhq_s32(vshlq_s32(input_val.val[2], left_shift_dup),
+ multiplier_dup),
+ right_shift_dup);
+
+ result.val[3] =
+ vrshlq_s32(vqrdmulhq_s32(vshlq_s32(input_val.val[3], left_shift_dup),
+ multiplier_dup),
+ right_shift_dup);
+
+ return result;
+}
+#endif
+
+template <typename T>
+int CountLeadingZeros(T integer_input) {
+ static_assert(std::is_unsigned<T>::value,
+ "Only unsigned integer types handled.");
+#if defined(__GNUC__)
+ return integer_input ? __builtin_clz(integer_input)
+ : std::numeric_limits<T>::digits;
+#else
+ if (integer_input == 0) {
+ return std::numeric_limits<T>::digits;
+ }
+
+ const T one_in_leading_positive = static_cast<T>(1)
+ << (std::numeric_limits<T>::digits - 1);
+ int leading_zeros = 0;
+ while (integer_input < one_in_leading_positive) {
+ integer_input <<= 1;
+ ++leading_zeros;
+ }
+ return leading_zeros;
+#endif
+}
+
+template <typename T>
+inline int CountLeadingSignBits(T integer_input) {
+ static_assert(std::is_signed<T>::value, "Only signed integer types handled.");
+#if defined(__GNUC__) && !defined(__clang__)
+ return integer_input ? __builtin_clrsb(integer_input)
+ : std::numeric_limits<T>::digits;
+#else
+ using U = typename std::make_unsigned<T>::type;
+ return integer_input >= 0
+ ? CountLeadingZeros(static_cast<U>(integer_input)) - 1
+ : integer_input != std::numeric_limits<T>::min()
+ ? CountLeadingZeros(2 * static_cast<U>(-integer_input) - 1)
+ : 0;
+#endif
+}
+
+// Use "count leading zeros" helper functions to do a fast Floor(log_2(x)).
+template <typename Integer>
+inline Integer FloorLog2(Integer n) {
+ static_assert(std::is_integral<Integer>::value, "");
+ static_assert(std::is_signed<Integer>::value, "");
+ static_assert(sizeof(Integer) == 4 || sizeof(Integer) == 8, "");
+ TFLITE_CHECK_GT(n, 0);
+ if (sizeof(Integer) == 4) {
+ return 30 - CountLeadingSignBits(n);
+ } else {
+ return 62 - CountLeadingSignBits(n);
+ }
+}
+
+// generate INT16 LUT for function(), e.g., table exp(x) and 1/(1+x) used in
+// softmax
+// func - the function to build the LUT for (e.g exp(x))
+// min,max - table limits
+// table - pointer to buffer
+// num - number of elements in the LUT
+inline void gen_lut(double (*func)(double), double min, double max,
+ int16_t* table, const int num) {
+ // size of table should equal to num + 1
+ // last element only for slope calculation
+ double step = (max - min) / (num - 1);
+ double half_step = step / 2.0;
+ for (int i = 0; i < num - 1; i++) {
+ double sample_val = TfLiteRound(func(min + i * step) * 32768.0);
+ double midpoint_interp_val =
+ TfLiteRound((func(min + (i + 1) * step) * 32768.0 +
+ TfLiteRound(func(min + i * step) * 32768.0)) /
+ 2.0);
+ double midpoint_val =
+ TfLiteRound(func(min + i * step + half_step) * 32768.0);
+ double midpoint_err = midpoint_interp_val - midpoint_val;
+ double bias = TfLiteRound(midpoint_err / 2.0);
+ table[i] = std::min<double>(std::max<double>(sample_val - bias, -32768.0),
+ 32767.0);
+ }
+ table[num - 1] = std::min<double>(
+ std::max<double>(TfLiteRound(func(max) * 32768.0), -32768.0), 32767.0);
+}
+
+// generate INT16 LUT for function(), e.g., table exp(x) and 1/(1+x) used in
+// softmax
+// func - the function to build the LUT for (e.g exp(x))
+// min,max - table limits
+// table - pointer to buffer
+// num - number of elements in the LUT
+inline void gen_lut(float (*func)(float), float min, float max, int16_t* table,
+ const int num) {
+ // size of table should equal to num + 1
+ // last element only for slope calculation
+ float step = (max - min) / (num - 1);
+ float half_step = step / 2.0f;
+ for (int i = 0; i < num - 1; i++) {
+ float sample_val = TfLiteRound(func(min + i * step) * 32768.0f);
+ float midpoint_interp_val =
+ TfLiteRound((func(min + (i + 1) * step) * 32768.0f +
+ TfLiteRound(func(min + i * step) * 32768.0f)) /
+ 2.0f);
+ float midpoint_val =
+ TfLiteRound(func(min + i * step + half_step) * 32768.0f);
+ float midpoint_err = midpoint_interp_val - midpoint_val;
+ float bias = TfLiteRound(midpoint_err / 2.0f);
+ table[i] = std::min<float>(std::max<float>(sample_val - bias, -32768.0f),
+ 32767.0f);
+ }
+ table[num - 1] = std::min<float>(
+ std::max<float>(TfLiteRound(func(max) * 32768.0f), -32768.0f), 32767.0f);
+}
+
+// int16_t func table lookup, e.g., lookup exp() and 1/(1+x) used in softmax
+inline int16_t generic_int16_table_lookup(int16_t value, const int16_t* lut) {
+ // 512 base value, lut[513] only for calculate slope
+ uint16_t index = static_cast<uint16_t>(256 + (value >> 7));
+ assert(index < 512 && "LUT index out of range.");
+ int16_t offset = value & 0x7f;
+
+ // base and slope are Q0.15
+ int16_t base = lut[index];
+ int16_t slope = lut[index + 1] - lut[index];
+
+ // Q0.15 * Q0.7 = Q0.22
+ // Round and convert from Q0.22 to Q0.15
+ int32_t delta = (static_cast<int32_t>(slope) * offset + 64) >> 7;
+
+ // Q0.15 + Q0.15
+ return base + delta;
+}
+
+// Table of sigmoid(i/24) at 0.16 format - 256 elements.
+
+// We use combined sigmoid and tanh look-up table, since
+// tanh(x) = 2*sigmoid(2*x) -1.
+// Both functions are symmetric, so the LUT table is only needed
+// for the absolute value of the input.
+static const uint16_t sigmoid_table_uint16[256] = {
+ 32768, 33451, 34133, 34813, 35493, 36169, 36843, 37513, 38180, 38841, 39498,
+ 40149, 40794, 41432, 42064, 42688, 43304, 43912, 44511, 45102, 45683, 46255,
+ 46817, 47369, 47911, 48443, 48964, 49475, 49975, 50464, 50942, 51409, 51865,
+ 52311, 52745, 53169, 53581, 53983, 54374, 54755, 55125, 55485, 55834, 56174,
+ 56503, 56823, 57133, 57433, 57724, 58007, 58280, 58544, 58800, 59048, 59288,
+ 59519, 59743, 59959, 60168, 60370, 60565, 60753, 60935, 61110, 61279, 61441,
+ 61599, 61750, 61896, 62036, 62172, 62302, 62428, 62549, 62666, 62778, 62886,
+ 62990, 63090, 63186, 63279, 63368, 63454, 63536, 63615, 63691, 63765, 63835,
+ 63903, 63968, 64030, 64090, 64148, 64204, 64257, 64308, 64357, 64405, 64450,
+ 64494, 64536, 64576, 64614, 64652, 64687, 64721, 64754, 64786, 64816, 64845,
+ 64873, 64900, 64926, 64950, 64974, 64997, 65019, 65039, 65060, 65079, 65097,
+ 65115, 65132, 65149, 65164, 65179, 65194, 65208, 65221, 65234, 65246, 65258,
+ 65269, 65280, 65291, 65301, 65310, 65319, 65328, 65337, 65345, 65352, 65360,
+ 65367, 65374, 65381, 65387, 65393, 65399, 65404, 65410, 65415, 65420, 65425,
+ 65429, 65433, 65438, 65442, 65445, 65449, 65453, 65456, 65459, 65462, 65465,
+ 65468, 65471, 65474, 65476, 65479, 65481, 65483, 65485, 65488, 65489, 65491,
+ 65493, 65495, 65497, 65498, 65500, 65501, 65503, 65504, 65505, 65507, 65508,
+ 65509, 65510, 65511, 65512, 65513, 65514, 65515, 65516, 65517, 65517, 65518,
+ 65519, 65520, 65520, 65521, 65522, 65522, 65523, 65523, 65524, 65524, 65525,
+ 65525, 65526, 65526, 65526, 65527, 65527, 65528, 65528, 65528, 65529, 65529,
+ 65529, 65529, 65530, 65530, 65530, 65530, 65531, 65531, 65531, 65531, 65531,
+ 65532, 65532, 65532, 65532, 65532, 65532, 65533, 65533, 65533, 65533, 65533,
+ 65533, 65533, 65533, 65534, 65534, 65534, 65534, 65534, 65534, 65534, 65534,
+ 65534, 65534, 65535};
+
+// TODO(b/77858996): Add these to gemmlowp.
+template <typename IntegerType>
+IntegerType SaturatingAddNonGemmlowp(IntegerType a, IntegerType b) {
+ static_assert(std::is_same<IntegerType, void>::value, "unimplemented");
+ return a;
+}
+
+template <>
+inline std::int32_t SaturatingAddNonGemmlowp(std::int32_t a, std::int32_t b) {
+ std::int64_t a64 = a;
+ std::int64_t b64 = b;
+ std::int64_t sum = a64 + b64;
+ return static_cast<std::int32_t>(std::min(
+ static_cast<std::int64_t>(std::numeric_limits<std::int32_t>::max()),
+ std::max(
+ static_cast<std::int64_t>(std::numeric_limits<std::int32_t>::min()),
+ sum)));
+}
+
+template <typename tRawType, int tIntegerBits>
+gemmlowp::FixedPoint<tRawType, tIntegerBits> SaturatingAddNonGemmlowp(
+ gemmlowp::FixedPoint<tRawType, tIntegerBits> a,
+ gemmlowp::FixedPoint<tRawType, tIntegerBits> b) {
+ return gemmlowp::FixedPoint<tRawType, tIntegerBits>::FromRaw(
+ SaturatingAddNonGemmlowp(a.raw(), b.raw()));
+}
+
+template <typename IntegerType>
+IntegerType SaturatingSub(IntegerType a, IntegerType b) {
+ static_assert(std::is_same<IntegerType, void>::value, "unimplemented");
+ return a;
+}
+
+template <>
+inline std::int16_t SaturatingSub(std::int16_t a, std::int16_t b) {
+ std::int32_t a32 = a;
+ std::int32_t b32 = b;
+ std::int32_t diff = a32 - b32;
+ return static_cast<std::int16_t>(
+ std::min(static_cast<int32_t>(32767),
+ std::max(static_cast<int32_t>(-32768), diff)));
+}
+
+template <>
+inline std::int32_t SaturatingSub(std::int32_t a, std::int32_t b) {
+ std::int64_t a64 = a;
+ std::int64_t b64 = b;
+ std::int64_t diff = a64 - b64;
+ return static_cast<std::int32_t>(std::min(
+ static_cast<std::int64_t>(std::numeric_limits<std::int32_t>::max()),
+ std::max(
+ static_cast<std::int64_t>(std::numeric_limits<std::int32_t>::min()),
+ diff)));
+}
+
+template <typename tRawType, int tIntegerBits>
+gemmlowp::FixedPoint<tRawType, tIntegerBits> SaturatingSub(
+ gemmlowp::FixedPoint<tRawType, tIntegerBits> a,
+ gemmlowp::FixedPoint<tRawType, tIntegerBits> b) {
+ return gemmlowp::FixedPoint<tRawType, tIntegerBits>::FromRaw(
+ SaturatingSub(a.raw(), b.raw()));
+}
+// End section to be moved to gemmlowp.
+
+template <typename IntegerType>
+IntegerType SaturatingRoundingMultiplyByPOTParam(IntegerType x, int exponent) {
+ if (exponent == 0) {
+ return x;
+ }
+ using ScalarIntegerType =
+ typename gemmlowp::FixedPointRawTypeTraits<IntegerType>::ScalarRawType;
+ const IntegerType min =
+ gemmlowp::Dup<IntegerType>(std::numeric_limits<ScalarIntegerType>::min());
+ const IntegerType max =
+ gemmlowp::Dup<IntegerType>(std::numeric_limits<ScalarIntegerType>::max());
+ const int ScalarIntegerTypeBits = 8 * sizeof(ScalarIntegerType);
+
+ const std::int32_t threshold =
+ ((1 << (ScalarIntegerTypeBits - 1 - exponent)) - 1);
+ const IntegerType positive_mask =
+ gemmlowp::MaskIfGreaterThan(x, gemmlowp::Dup<IntegerType>(threshold));
+ const IntegerType negative_mask =
+ gemmlowp::MaskIfLessThan(x, gemmlowp::Dup<IntegerType>(-threshold));
+
+ IntegerType result = gemmlowp::ShiftLeft(x, exponent);
+ result = gemmlowp::SelectUsingMask(positive_mask, max, result);
+ result = gemmlowp::SelectUsingMask(negative_mask, min, result);
+ return result;
+}
+
+// If we want to leave IntegerBits fixed, then multiplication
+// by a power of two has to be saturating/rounding, not exact anymore.
+template <typename tRawType, int tIntegerBits>
+gemmlowp::FixedPoint<tRawType, tIntegerBits>
+SaturatingRoundingMultiplyByPOTParam(
+ gemmlowp::FixedPoint<tRawType, tIntegerBits> a, int exponent) {
+ return gemmlowp::FixedPoint<tRawType, tIntegerBits>::FromRaw(
+ SaturatingRoundingMultiplyByPOTParam(a.raw(), exponent));
+}
+
+// Convert int32_t multiplier to int16_t with rounding.
+inline void DownScaleInt32ToInt16Multiplier(int32_t multiplier_int32_t,
+ int16_t* multiplier_int16_t) {
+ TFLITE_DCHECK_GE(multiplier_int32_t, 0);
+ static constexpr int32_t kRoundingOffset = 1 << 15;
+ if (multiplier_int32_t >=
+ std::numeric_limits<int32_t>::max() - kRoundingOffset) {
+ *multiplier_int16_t = std::numeric_limits<int16_t>::max();
+ return;
+ }
+ const int32_t result = (multiplier_int32_t + kRoundingOffset) >> 16;
+ TFLITE_DCHECK_LE(result << 16, multiplier_int32_t + kRoundingOffset);
+ TFLITE_DCHECK_GT(result << 16, multiplier_int32_t - kRoundingOffset);
+ *multiplier_int16_t = result;
+ TFLITE_DCHECK_EQ(*multiplier_int16_t, result);
+}
+
+// Minimum output bits to accommodate log of maximum input range. It actually
+// does not matter if one considers, say, [-64,64] or [-64,64).
+//
+// For example, run this through Octave:
+// [0:127; ...
+// ceil(log(abs( log(2.^(0:127))+1 ))/log(2)); ...
+// ceil(log(abs( log(2.^(0:127))+1 ))/log(2))]
+constexpr int min_log_x_output_bits(int input_bits) {
+ return input_bits > 90 ? 7
+ : input_bits > 44 ? 6
+ : input_bits > 21 ? 5
+ : input_bits > 10 ? 4
+ : input_bits > 4 ? 3
+ : input_bits > 1 ? 2
+ : 1;
+}
+
+// Although currently the name of this function says that it cannot handle
+// values less than 1, in practice it can handle as low as 1/x_max, where
+// x_max is the largest representable input. In other words, the output range
+// is symmetric.
+template <int OutputIntegerBits, int InputIntegerBits>
+inline gemmlowp::FixedPoint<int32_t, OutputIntegerBits>
+log_x_for_x_greater_than_or_equal_to_1_impl(
+ gemmlowp::FixedPoint<int32_t, InputIntegerBits> input_val) {
+ // assert(__builtin_clz(0u) >= std::numeric_limits<uint32_t>::digits - 1);
+ // assert(__builtin_clz(0u) <= std::numeric_limits<uint32_t>::digits);
+ using FixedPoint0 = gemmlowp::FixedPoint<int32_t, 0>;
+ // The reason for accumulating the result with an extra bit of headroom is
+ // that z_pow_2_adj * log_2 might be saturated, and adding num_scaled *
+ // recip_denom will otherwise introduce an error.
+ static constexpr int kAccumIntegerBits = OutputIntegerBits + 1;
+ using FixedPointAccum = gemmlowp::FixedPoint<int32_t, kAccumIntegerBits>;
+
+ const FixedPoint0 log_2 = GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(
+ FixedPoint0, 1488522236, std::log(2.0));
+ const FixedPoint0 sqrt_sqrt_half = GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(
+ FixedPoint0, 1805811301, std::sqrt(std::sqrt(0.5)));
+ const FixedPoint0 sqrt_half = GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(
+ FixedPoint0, 1518500250, std::sqrt(0.5));
+ const FixedPoint0 one_quarter =
+ GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(FixedPoint0, 536870912, 1.0 / 4.0);
+
+ const FixedPoint0 alpha_n = GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(
+ FixedPoint0, 117049297, 11.0 / 240.0 * std::sqrt(std::sqrt(2.0)));
+ const FixedPoint0 alpha_d = GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(
+ FixedPoint0, 127690142, 1.0 / 20.0 * std::sqrt(std::sqrt(2.0)));
+ const FixedPoint0 alpha_i = GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(
+ FixedPoint0, 1057819769,
+ 2.0 / std::sqrt(std::sqrt(2.0)) - std::sqrt(std::sqrt(2.0)));
+ const FixedPoint0 alpha_f = GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(
+ FixedPoint0, 638450708, 1.0 / 4.0 * std::sqrt(std::sqrt(2.0)));
+
+ const FixedPointAccum shifted_quarter =
+ gemmlowp::Rescale<kAccumIntegerBits>(one_quarter);
+
+ // Reinterpret the input value as Q0.31, because we will figure out the
+ // required shift "ourselves" instead of using, say, Rescale.
+ FixedPoint0 z_a = FixedPoint0::FromRaw(input_val.raw());
+ // z_a_pow_2 = input_integer_bits - z_a_headroom;
+ int z_a_headroom_plus_1 = CountLeadingZeros(static_cast<uint32_t>(z_a.raw()));
+ FixedPoint0 r_a_tmp =
+ SaturatingRoundingMultiplyByPOTParam(z_a, (z_a_headroom_plus_1 - 1));
+ const int32_t r_a_raw =
+ SaturatingRoundingMultiplyByPOTParam((r_a_tmp * sqrt_half).raw(), 1);
+ // z_pow_2_adj = max(z_pow_2_a - 0.75, z_pow_2_b - 0.25);
+ // z_pow_2_adj = max(InputIntegerBits - z_a_headroom_plus_1 + 0.25,
+ // InputIntegerBits - z_b_headroom - 0.25);
+ const FixedPointAccum z_a_pow_2_adj = SaturatingAddNonGemmlowp(
+ FixedPointAccum::FromRaw(SaturatingRoundingMultiplyByPOTParam(
+ InputIntegerBits - z_a_headroom_plus_1, 31 - kAccumIntegerBits)),
+ shifted_quarter);
+
+ // z_b is treated like z_a, but premultiplying by sqrt(0.5).
+ FixedPoint0 z_b = z_a * sqrt_half;
+ int z_b_headroom = CountLeadingZeros(static_cast<uint32_t>(z_b.raw())) - 1;
+ const int32_t r_b_raw =
+ SaturatingRoundingMultiplyByPOTParam(z_a.raw(), z_b_headroom);
+ const FixedPointAccum z_b_pow_2_adj = SaturatingSub(
+ FixedPointAccum::FromRaw(SaturatingRoundingMultiplyByPOTParam(
+ InputIntegerBits - z_b_headroom, 31 - kAccumIntegerBits)),
+ shifted_quarter);
+
+ const FixedPoint0 r = FixedPoint0::FromRaw(std::min(r_a_raw, r_b_raw));
+ const FixedPointAccum z_pow_2_adj = FixedPointAccum::FromRaw(
+ std::max(z_a_pow_2_adj.raw(), z_b_pow_2_adj.raw()));
+
+ const FixedPoint0 p = gemmlowp::RoundingHalfSum(r, sqrt_sqrt_half);
+ FixedPoint0 q = r - sqrt_sqrt_half;
+ q = q + q;
+
+ const FixedPoint0 common_sq = q * q;
+ const FixedPoint0 num = q * r + q * common_sq * alpha_n;
+ const FixedPoint0 denom_minus_one_0 =
+ p * (alpha_i + q + alpha_d * common_sq) + alpha_f * q;
+ const FixedPoint0 recip_denom =
+ one_over_one_plus_x_for_x_in_0_1(denom_minus_one_0);
+
+ const FixedPointAccum num_scaled = gemmlowp::Rescale<kAccumIntegerBits>(num);
+ return gemmlowp::Rescale<OutputIntegerBits>(z_pow_2_adj * log_2 +
+ num_scaled * recip_denom);
+}
+
+template <int OutputIntegerBits, int InputIntegerBits>
+inline gemmlowp::FixedPoint<int32_t, OutputIntegerBits>
+log_x_for_x_greater_than_or_equal_to_1(
+ gemmlowp::FixedPoint<int32_t, InputIntegerBits> input_val) {
+ static_assert(
+ OutputIntegerBits >= min_log_x_output_bits(InputIntegerBits),
+ "Output integer bits must be sufficient to accommodate logs of inputs.");
+ return log_x_for_x_greater_than_or_equal_to_1_impl<OutputIntegerBits,
+ InputIntegerBits>(
+ input_val);
+}
+
+inline int32_t GetReciprocal(int32_t x, int x_integer_digits,
+ int* num_bits_over_unit) {
+ int headroom_plus_one = CountLeadingZeros(static_cast<uint32_t>(x));
+ // This is the number of bits to the left of the binary point above 1.0.
+ // Consider x=1.25. In that case shifted_scale=0.8 and
+ // no later adjustment will be needed.
+ *num_bits_over_unit = x_integer_digits - headroom_plus_one;
+ const int32_t shifted_sum_minus_one =
+ static_cast<int32_t>((static_cast<uint32_t>(x) << headroom_plus_one) -
+ (static_cast<uint32_t>(1) << 31));
+
+ gemmlowp::FixedPoint<int32_t, 0> shifted_scale =
+ gemmlowp::one_over_one_plus_x_for_x_in_0_1(
+ gemmlowp::FixedPoint<int32_t, 0>::FromRaw(shifted_sum_minus_one));
+ return shifted_scale.raw();
+}
+
+inline void GetInvSqrtQuantizedMultiplierExp(int32_t input, int reverse_shift,
+ int32_t* output_inv_sqrt,
+ int* output_shift) {
+ TFLITE_DCHECK_GE(input, 0);
+ if (input <= 1) {
+ // Handle the input value 1 separately to avoid overflow in that case
+ // in the general computation below (b/143972021). Also handle 0 as if it
+ // were a 1. 0 is an invalid input here (divide by zero) and 1 is a valid
+ // but rare/unrealistic input value. We can expect both to occur in some
+ // incompletely trained models, but probably not in fully trained models.
+ *output_inv_sqrt = std::numeric_limits<std::int32_t>::max();
+ *output_shift = 0;
+ return;
+ }
+ TFLITE_DCHECK_GT(input, 1);
+ *output_shift = 11;
+ while (input >= (1 << 29)) {
+ input /= 4;
+ ++*output_shift;
+ }
+ const unsigned max_left_shift_bits =
+ CountLeadingZeros(static_cast<uint32_t>(input)) - 1;
+ const unsigned max_left_shift_bit_pairs = max_left_shift_bits / 2;
+ const unsigned left_shift_bit_pairs = max_left_shift_bit_pairs - 1;
+ *output_shift -= left_shift_bit_pairs;
+ input <<= 2 * left_shift_bit_pairs;
+ TFLITE_DCHECK_GE(input, (1 << 27));
+ TFLITE_DCHECK_LT(input, (1 << 29));
+ using gemmlowp::FixedPoint;
+ using gemmlowp::Rescale;
+ using gemmlowp::SaturatingRoundingMultiplyByPOT;
+ // Using 3 integer bits gives us enough room for the internal arithmetic in
+ // this Newton-Raphson iteration.
+ using F3 = FixedPoint<int32_t, 3>;
+ using F0 = FixedPoint<int32_t, 0>;
+ const F3 fixedpoint_input = F3::FromRaw(input >> 1);
+ const F3 fixedpoint_half_input =
+ SaturatingRoundingMultiplyByPOT<-1>(fixedpoint_input);
+ const F3 fixedpoint_half_three =
+ GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(F3, (1 << 28) + (1 << 27), 1.5);
+ // Newton-Raphson iteration
+ // Naive unoptimized starting guess: x = 1
+ F3 x = F3::One();
+ // Naive unoptimized number of iterations: 5
+ for (int i = 0; i < 5; i++) {
+ const F3 x3 = Rescale<3>(x * x * x);
+ x = Rescale<3>(fixedpoint_half_three * x - fixedpoint_half_input * x3);
+ }
+ const F0 fixedpoint_half_sqrt_2 =
+ GEMMLOWP_CHECKED_FIXEDPOINT_CONSTANT(F0, 1518500250, std::sqrt(2.) / 2.);
+ x = x * fixedpoint_half_sqrt_2;
+ *output_inv_sqrt = x.raw();
+ if (*output_shift < 0) {
+ *output_inv_sqrt <<= -*output_shift;
+ *output_shift = 0;
+ }
+ // Convert right shift (right is positive) to left shift.
+ *output_shift *= reverse_shift;
+}
+
+// DO NOT USE THIS STRUCT FOR NEW FUNCTIONALITY BEYOND IMPLEMENTING
+// BROADCASTING.
+//
+// NdArrayDesc<N> describes the shape and memory layout of an N-dimensional
+// rectangular array of numbers.
+//
+// NdArrayDesc<N> is basically identical to Dims<N> defined in types.h.
+// However, as Dims<N> is to be deprecated, this class exists as an adaptor
+// to enable simple unoptimized implementations of element-wise broadcasting
+// operations.
+template <int N>
+struct NdArrayDesc {
+ // The "extent" of each dimension. Indices along dimension d must be in the
+ // half-open interval [0, extents[d]).
+ int extents[N];
+
+ // The number of *elements* (not bytes) between consecutive indices of each
+ // dimension.
+ int strides[N];
+};
+
+// DO NOT USE THIS FUNCTION FOR NEW FUNCTIONALITY BEYOND IMPLEMENTING
+// BROADCASTING.
+//
+// Same as Offset(), except takes as NdArrayDesc<N> instead of Dims<N>.
+inline int SubscriptToIndex(const NdArrayDesc<4>& desc, int i0, int i1, int i2,
+ int i3) {
+ TFLITE_DCHECK(i0 >= 0 && i0 < desc.extents[0]);
+ TFLITE_DCHECK(i1 >= 0 && i1 < desc.extents[1]);
+ TFLITE_DCHECK(i2 >= 0 && i2 < desc.extents[2]);
+ TFLITE_DCHECK(i3 >= 0 && i3 < desc.extents[3]);
+ return i0 * desc.strides[0] + i1 * desc.strides[1] + i2 * desc.strides[2] +
+ i3 * desc.strides[3];
+}
+
+inline int SubscriptToIndex(const NdArrayDesc<5>& desc, int indexes[5]) {
+ return indexes[0] * desc.strides[0] + indexes[1] * desc.strides[1] +
+ indexes[2] * desc.strides[2] + indexes[3] * desc.strides[3] +
+ indexes[4] * desc.strides[4];
+}
+
+inline int SubscriptToIndex(const NdArrayDesc<8>& desc, int indexes[8]) {
+ return indexes[0] * desc.strides[0] + indexes[1] * desc.strides[1] +
+ indexes[2] * desc.strides[2] + indexes[3] * desc.strides[3] +
+ indexes[4] * desc.strides[4] + indexes[5] * desc.strides[5] +
+ indexes[6] * desc.strides[6] + indexes[7] * desc.strides[7];
+}
+
+// Given the dimensions of the operands for an element-wise binary broadcast,
+// adjusts them so that they can be directly iterated over with simple loops.
+// Returns the adjusted dims as instances of NdArrayDesc in 'desc0_out' and
+// 'desc1_out'. 'desc0_out' and 'desc1_out' cannot be nullptr.
+//
+// This function assumes that the two input shapes are compatible up to
+// broadcasting and the shorter one has already been prepended with 1s to be the
+// same length. E.g., if shape0 is (1, 16, 16, 64) and shape1 is (1, 64),
+// shape1 must already have been prepended to be (1, 1, 1, 64). Recall that
+// Dims<N> refer to shapes in reverse order. In this case, input0_dims will be
+// (64, 16, 16, 1) and input1_dims will be (64, 1, 1, 1).
+//
+// When two shapes are compatible up to broadcasting, for each dimension d,
+// the input extents are either equal, or one of them is 1.
+//
+// This function performs the following for each dimension d:
+// - If the extents are equal, then do nothing since the loop that walks over
+// both of the input arrays is correct.
+// - Otherwise, one (and only one) of the extents must be 1. Say extent0 is 1
+// and extent1 is e1. Then set extent0 to e1 and stride0 *to 0*. This allows
+// array0 to be referenced *at any index* in dimension d and still access the
+// same slice.
+template <int N>
+inline void NdArrayDescsForElementwiseBroadcast(const Dims<N>& input0_dims,
+ const Dims<N>& input1_dims,
+ NdArrayDesc<N>* desc0_out,
+ NdArrayDesc<N>* desc1_out) {
+ TFLITE_DCHECK(desc0_out != nullptr);
+ TFLITE_DCHECK(desc1_out != nullptr);
+
+ // Copy dims to desc.
+ for (int i = 0; i < N; ++i) {
+ desc0_out->extents[i] = input0_dims.sizes[i];
+ desc0_out->strides[i] = input0_dims.strides[i];
+ desc1_out->extents[i] = input1_dims.sizes[i];
+ desc1_out->strides[i] = input1_dims.strides[i];
+ }
+
+ // Walk over each dimension. If the extents are equal do nothing.
+ // Otherwise, set the desc with extent 1 to have extent equal to the other and
+ // stride 0.
+ for (int i = 0; i < N; ++i) {
+ const int extent0 = ArraySize(input0_dims, i);
+ const int extent1 = ArraySize(input1_dims, i);
+ if (extent0 != extent1) {
+ if (extent0 == 1) {
+ desc0_out->strides[i] = 0;
+ desc0_out->extents[i] = extent1;
+ } else {
+ TFLITE_DCHECK_EQ(extent1, 1);
+ desc1_out->strides[i] = 0;
+ desc1_out->extents[i] = extent0;
+ }
+ }
+ }
+}
+
+// Copies dims to desc, calculating strides.
+template <int N>
+inline void CopyDimsToDesc(const RuntimeShape& input_shape,
+ NdArrayDesc<N>* desc_out) {
+ int desc_stride = 1;
+ for (int i = N - 1; i >= 0; --i) {
+ desc_out->extents[i] = input_shape.Dims(i);
+ desc_out->strides[i] = desc_stride;
+ desc_stride *= input_shape.Dims(i);
+ }
+}
+
+template <int N>
+inline void NdArrayDescsForElementwiseBroadcast(
+ const RuntimeShape& input0_shape, const RuntimeShape& input1_shape,
+ NdArrayDesc<N>* desc0_out, NdArrayDesc<N>* desc1_out) {
+ TFLITE_DCHECK(desc0_out != nullptr);
+ TFLITE_DCHECK(desc1_out != nullptr);
+
+ auto extended_input0_shape = RuntimeShape::ExtendedShape(N, input0_shape);
+ auto extended_input1_shape = RuntimeShape::ExtendedShape(N, input1_shape);
+
+ // Copy dims to desc, calculating strides.
+ CopyDimsToDesc<N>(extended_input0_shape, desc0_out);
+ CopyDimsToDesc<N>(extended_input1_shape, desc1_out);
+
+ // Walk over each dimension. If the extents are equal do nothing.
+ // Otherwise, set the desc with extent 1 to have extent equal to the other and
+ // stride 0.
+ for (int i = 0; i < N; ++i) {
+ const int extent0 = extended_input0_shape.Dims(i);
+ const int extent1 = extended_input1_shape.Dims(i);
+ if (extent0 != extent1) {
+ if (extent0 == 1) {
+ desc0_out->strides[i] = 0;
+ desc0_out->extents[i] = extent1;
+ } else {
+ TFLITE_DCHECK_EQ(extent1, 1);
+ desc1_out->strides[i] = 0;
+ desc1_out->extents[i] = extent0;
+ }
+ }
+ }
+}
+
+template <int N>
+inline void NdArrayDescsForElementwiseBroadcast(
+ const RuntimeShape& input0_shape, const RuntimeShape& input1_shape,
+ const RuntimeShape& input2_shape, NdArrayDesc<N>* desc0_out,
+ NdArrayDesc<N>* desc1_out, NdArrayDesc<N>* desc2_out) {
+ TFLITE_DCHECK(desc0_out != nullptr);
+ TFLITE_DCHECK(desc1_out != nullptr);
+ TFLITE_DCHECK(desc2_out != nullptr);
+
+ auto extended_input0_shape = RuntimeShape::ExtendedShape(N, input0_shape);
+ auto extended_input1_shape = RuntimeShape::ExtendedShape(N, input1_shape);
+ auto extended_input2_shape = RuntimeShape::ExtendedShape(N, input2_shape);
+
+ // Copy dims to desc, calculating strides.
+ CopyDimsToDesc<N>(extended_input0_shape, desc0_out);
+ CopyDimsToDesc<N>(extended_input1_shape, desc1_out);
+ CopyDimsToDesc<N>(extended_input2_shape, desc2_out);
+
+ // Walk over each dimension. If the extents are equal do nothing.
+ // Otherwise, set the desc with extent 1 to have extent equal to the other and
+ // stride 0.
+ for (int i = 0; i < N; ++i) {
+ const int extent0 = extended_input0_shape.Dims(i);
+ const int extent1 = extended_input1_shape.Dims(i);
+ const int extent2 = extended_input2_shape.Dims(i);
+
+ int extent = extent0;
+ if (extent1 != 1) extent = extent1;
+ if (extent2 != 1) extent = extent2;
+
+ TFLITE_DCHECK(extent0 == 1 || extent0 == extent);
+ TFLITE_DCHECK(extent1 == 1 || extent1 == extent);
+ TFLITE_DCHECK(extent2 == 1 || extent2 == extent);
+
+ if (!(extent0 == extent1 && extent1 == extent2)) {
+ if (extent0 == 1) {
+ desc0_out->strides[i] = 0;
+ desc0_out->extents[i] = extent;
+ }
+ if (extent1 == 1) {
+ desc1_out->strides[i] = 0;
+ desc1_out->extents[i] = extent;
+ }
+ if (extent2 == 1) {
+ desc2_out->strides[i] = 0;
+ desc2_out->extents[i] = extent;
+ }
+ }
+ }
+}
+
+// Detailed implementation of NDOpsHelper, the indexes must be a zero array.
+// This implementation is equivalent to N nested loops. Ex, if N=4, it can be
+// re-writen as:
+// for (int b = 0; b < output.extents[0]; ++b) {
+// for (int y = 0; y < output.extents[1]; ++y) {
+// for (int x = 0; x < output.extents[2]; ++x) {
+// for (int c = 0; c < output.extents[3]; ++c) {
+// calc({b,y,x,c});
+// }
+// }
+// }
+// }
+template <int N, int DIM, typename Calc>
+typename std::enable_if<DIM != N - 1, void>::type NDOpsHelperImpl(
+ const NdArrayDesc<N>& output, const Calc& calc, int indexes[N]) {
+ for (indexes[DIM] = 0; indexes[DIM] < output.extents[DIM]; ++indexes[DIM]) {
+ NDOpsHelperImpl<N, DIM + 1, Calc>(output, calc, indexes);
+ }
+}
+
+template <int N, int DIM, typename Calc>
+typename std::enable_if<DIM == N - 1, void>::type NDOpsHelperImpl(
+ const NdArrayDesc<N>& output, const Calc& calc, int indexes[N]) {
+ for (indexes[DIM] = 0; indexes[DIM] < output.extents[DIM]; ++indexes[DIM]) {
+ calc(indexes);
+ }
+}
+
+// Execute the calc function in the innermost iteration based on the shape of
+// the output. The calc function should take a single argument of type int[N].
+template <int N, typename Calc>
+inline void NDOpsHelper(const NdArrayDesc<N>& output, const Calc& calc) {
+ int indexes[N] = {0};
+ NDOpsHelperImpl<N, 0, Calc>(output, calc, indexes);
+}
+// Copied from gemmlowp::RoundDown when we dropped direct dependency on
+// gemmlowp.
+//
+// Returns the runtime argument rounded down to the nearest multiple of
+// the fixed Modulus.
+template <unsigned Modulus, typename Integer>
+Integer RoundDown(Integer i) {
+ return i - (i % Modulus);
+}
+
+// Copied from gemmlowp::RoundUp when we dropped direct dependency on
+// gemmlowp.
+//
+// Returns the runtime argument rounded up to the nearest multiple of
+// the fixed Modulus.
+template <unsigned Modulus, typename Integer>
+Integer RoundUp(Integer i) {
+ return RoundDown<Modulus>(i + Modulus - 1);
+}
+
+// Copied from gemmlowp::CeilQuotient when we dropped direct dependency on
+// gemmlowp.
+//
+// Returns the quotient a / b rounded up ('ceil') to the nearest integer.
+template <typename Integer>
+Integer CeilQuotient(Integer a, Integer b) {
+ return (a + b - 1) / b;
+}
+
+// This function is a copy of gemmlowp::HowManyThreads, copied when we dropped
+// the direct dependency of internal/optimized/ on gemmlowp.
+//
+// It computes a reasonable number of threads to use for a GEMM of shape
+// (rows, cols, depth).
+//
+// TODO(b/131910176): get rid of this function by switching each call site
+// to its own more sensible logic for its own workload.
+template <int KernelRows>
+inline int LegacyHowManyThreads(int max_num_threads, int rows, int cols,
+ int depth) {
+ // Early-exit in the default case where multi-threading is disabled.
+ if (max_num_threads == 1) {
+ return 1;
+ }
+
+ // Ensure that each thread has KernelRows rows to process, if at all possible.
+ int thread_count = std::min(max_num_threads, rows / KernelRows);
+
+ // Limit the number of threads according to the overall size of the problem.
+ if (thread_count > 1) {
+ // Empirically determined value.
+ static constexpr std::uint64_t min_cubic_size_per_thread = 64 * 1024;
+
+ // We can only multiply two out of three sizes without risking overflow
+ const std::uint64_t cubic_size =
+ std::uint64_t(rows) * std::uint64_t(cols) * std::uint64_t(depth);
+
+ thread_count = std::min(
+ thread_count, static_cast<int>(cubic_size / min_cubic_size_per_thread));
+ }
+
+ if (thread_count < 1) {
+ thread_count = 1;
+ }
+
+ assert(thread_count > 0 && thread_count <= max_num_threads);
+ return thread_count;
+}
+
+template <typename T>
+void optimized_ops_preload_l1_stream(const T* ptr) {
+#ifdef __GNUC__
+ // builtin offered by GCC-compatible compilers including clang
+ __builtin_prefetch(ptr, /* 0 means read */ 0, /* 0 means no locality */ 0);
+#else
+ (void)ptr;
+#endif
+}
+
+template <typename T>
+void optimized_ops_preload_l1_keep(const T* ptr) {
+#ifdef __GNUC__
+ // builtin offered by GCC-compatible compilers including clang
+ __builtin_prefetch(ptr, /* 0 means read */ 0, /* 3 means high locality */ 3);
+#else
+ (void)ptr;
+#endif
+}
+
+template <typename T>
+void optimized_ops_prefetch_write_l1_keep(const T* ptr) {
+#ifdef __GNUC__
+ // builtin offered by GCC-compatible compilers including clang
+ __builtin_prefetch(ptr, /* 1 means write */ 1, /* 3 means high locality */ 3);
+#else
+ (void)ptr;
+#endif
+}
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_COMMON_H_
diff --git a/tensorflow/lite/kernels/internal/compatibility.h b/tensorflow/lite/kernels/internal/compatibility.h
new file mode 100644
index 0000000..61becad
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/compatibility.h
@@ -0,0 +1,112 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_COMPATIBILITY_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_COMPATIBILITY_H_
+
+#include <cstdint>
+
+#include "tensorflow/lite/kernels/op_macros.h"
+
+#ifndef TFLITE_DCHECK
+#define TFLITE_DCHECK(condition) (condition) ? (void)0 : TFLITE_ASSERT_FALSE
+#endif
+
+#ifndef TFLITE_DCHECK_EQ
+#define TFLITE_DCHECK_EQ(x, y) ((x) == (y)) ? (void)0 : TFLITE_ASSERT_FALSE
+#endif
+
+#ifndef TFLITE_DCHECK_NE
+#define TFLITE_DCHECK_NE(x, y) ((x) != (y)) ? (void)0 : TFLITE_ASSERT_FALSE
+#endif
+
+#ifndef TFLITE_DCHECK_GE
+#define TFLITE_DCHECK_GE(x, y) ((x) >= (y)) ? (void)0 : TFLITE_ASSERT_FALSE
+#endif
+
+#ifndef TFLITE_DCHECK_GT
+#define TFLITE_DCHECK_GT(x, y) ((x) > (y)) ? (void)0 : TFLITE_ASSERT_FALSE
+#endif
+
+#ifndef TFLITE_DCHECK_LE
+#define TFLITE_DCHECK_LE(x, y) ((x) <= (y)) ? (void)0 : TFLITE_ASSERT_FALSE
+#endif
+
+#ifndef TFLITE_DCHECK_LT
+#define TFLITE_DCHECK_LT(x, y) ((x) < (y)) ? (void)0 : TFLITE_ASSERT_FALSE
+#endif
+
+// TODO(ahentz): Clean up: We should stick to the DCHECK versions.
+#ifndef TFLITE_CHECK
+#define TFLITE_CHECK(condition) (condition) ? (void)0 : TFLITE_ABORT
+#endif
+
+#ifndef TFLITE_CHECK_EQ
+#define TFLITE_CHECK_EQ(x, y) ((x) == (y)) ? (void)0 : TFLITE_ABORT
+#endif
+
+#ifndef TFLITE_CHECK_NE
+#define TFLITE_CHECK_NE(x, y) ((x) != (y)) ? (void)0 : TFLITE_ABORT
+#endif
+
+#ifndef TFLITE_CHECK_GE
+#define TFLITE_CHECK_GE(x, y) ((x) >= (y)) ? (void)0 : TFLITE_ABORT
+#endif
+
+#ifndef TFLITE_CHECK_GT
+#define TFLITE_CHECK_GT(x, y) ((x) > (y)) ? (void)0 : TFLITE_ABORT
+#endif
+
+#ifndef TFLITE_CHECK_LE
+#define TFLITE_CHECK_LE(x, y) ((x) <= (y)) ? (void)0 : TFLITE_ABORT
+#endif
+
+#ifndef TFLITE_CHECK_LT
+#define TFLITE_CHECK_LT(x, y) ((x) < (y)) ? (void)0 : TFLITE_ABORT
+#endif
+
+#ifndef TF_LITE_STATIC_MEMORY
+// TODO(b/162019032): Consider removing these type-aliases.
+using int8 = std::int8_t;
+using uint8 = std::uint8_t;
+using int16 = std::int16_t;
+using uint16 = std::uint16_t;
+using int32 = std::int32_t;
+using uint32 = std::uint32_t;
+#endif // !defined(TF_LITE_STATIC_MEMORY)
+
+// TFLITE_DEPRECATED()
+//
+// Duplicated from absl/base/macros.h to avoid pulling in that library.
+// Marks a deprecated class, struct, enum, function, method and variable
+// declarations. The macro argument is used as a custom diagnostic message (e.g.
+// suggestion of a better alternative).
+//
+// Example:
+//
+// class TFLITE_DEPRECATED("Use Bar instead") Foo {...};
+// TFLITE_DEPRECATED("Use Baz instead") void Bar() {...}
+//
+// Every usage of a deprecated entity will trigger a warning when compiled with
+// clang's `-Wdeprecated-declarations` option. This option is turned off by
+// default, but the warnings will be reported by clang-tidy.
+#if defined(__clang__) && __cplusplus >= 201103L
+#define TFLITE_DEPRECATED(message) __attribute__((deprecated(message)))
+#endif
+
+#ifndef TFLITE_DEPRECATED
+#define TFLITE_DEPRECATED(message)
+#endif
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_COMPATIBILITY_H_
diff --git a/tensorflow/lite/kernels/internal/cppmath.h b/tensorflow/lite/kernels/internal/cppmath.h
new file mode 100644
index 0000000..5a32774
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/cppmath.h
@@ -0,0 +1,41 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_CPPMATH_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_CPPMATH_H_
+
+#include <cmath>
+
+namespace tflite {
+
+#if defined(TF_LITE_USE_GLOBAL_CMATH_FUNCTIONS) || \
+ (defined(__ANDROID__) && !defined(__NDK_MAJOR__)) || defined(ARDUINO) || \
+ defined(__ZEPHYR__)
+#define TF_LITE_GLOBAL_STD_PREFIX
+#else
+#define TF_LITE_GLOBAL_STD_PREFIX std
+#endif
+
+#define DECLARE_STD_GLOBAL_SWITCH1(tf_name, std_name) \
+ template <class T> \
+ inline T tf_name(const T x) { \
+ return TF_LITE_GLOBAL_STD_PREFIX::std_name(x); \
+ }
+
+DECLARE_STD_GLOBAL_SWITCH1(TfLiteRound, round);
+DECLARE_STD_GLOBAL_SWITCH1(TfLiteExpm1, expm1);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_CPPMATH_H_
diff --git a/tensorflow/lite/kernels/internal/max.h b/tensorflow/lite/kernels/internal/max.h
new file mode 100644
index 0000000..c181002
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/max.h
@@ -0,0 +1,35 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_MAX_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_MAX_H_
+
+#include <cmath>
+
+namespace tflite {
+
+#if defined(TF_LITE_USE_GLOBAL_MAX) || defined(__ZEPHYR__)
+inline float TfLiteMax(const float& x, const float& y) {
+ return std::max(x, y);
+}
+#else
+template <class T>
+inline T TfLiteMax(const T& x, const T& y) {
+ return std::fmax(x, y);
+}
+#endif
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_MAX_H_
diff --git a/tensorflow/lite/kernels/internal/min.h b/tensorflow/lite/kernels/internal/min.h
new file mode 100644
index 0000000..62035dc
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/min.h
@@ -0,0 +1,35 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_MIN_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_MIN_H_
+
+#include <cmath>
+
+namespace tflite {
+
+#if defined(TF_LITE_USE_GLOBAL_MIN) || defined(__ZEPHYR__)
+inline float TfLiteMin(const float& x, const float& y) {
+ return std::min(x, y);
+}
+#else
+template <class T>
+inline T TfLiteMin(const T& x, const T& y) {
+ return std::fmin(x, y);
+}
+#endif
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_MIN_H_
diff --git a/tensorflow/lite/kernels/internal/optimized/neon_check.h b/tensorflow/lite/kernels/internal/optimized/neon_check.h
new file mode 100644
index 0000000..bbf745c
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/optimized/neon_check.h
@@ -0,0 +1,40 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_OPTIMIZED_NEON_CHECK_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_OPTIMIZED_NEON_CHECK_H_
+
+#if defined(__ARM_NEON__) || defined(__ARM_NEON)
+#define USE_NEON
+#include <arm_neon.h>
+#endif
+
+#if defined __GNUC__ && defined __SSE4_1__ && !defined TF_LITE_DISABLE_X86_NEON
+#define USE_NEON
+#include "NEON_2_SSE.h"
+#endif
+
+// NEON_OR_PORTABLE(SomeFunc, args) calls NeonSomeFunc(args) if USE_NEON is
+// defined, PortableSomeFunc(args) otherwise.
+#ifdef USE_NEON
+// Always use Neon code
+#define NEON_OR_PORTABLE(funcname, ...) Neon##funcname(__VA_ARGS__)
+
+#else
+// No NEON available: Use Portable code
+#define NEON_OR_PORTABLE(funcname, ...) Portable##funcname(__VA_ARGS__)
+
+#endif // defined(USE_NEON)
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_OPTIMIZED_NEON_CHECK_H_
diff --git a/tensorflow/lite/kernels/internal/portable_tensor.h b/tensorflow/lite/kernels/internal/portable_tensor.h
new file mode 100644
index 0000000..4d71c96
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/portable_tensor.h
@@ -0,0 +1,122 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_PORTABLE_TENSOR_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_PORTABLE_TENSOR_H_
+
+#include <vector>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+inline RuntimeShape GetTensorShape(std::vector<int32_t> data) {
+ return RuntimeShape(data.size(), data.data());
+}
+
+// A list of tensors in a format that can be used by kernels like split and
+// concatenation.
+template <typename T>
+class VectorOfTensors {
+ public:
+ // Build with the tensors in 'tensor_list'.
+ VectorOfTensors(const TfLiteContext& context,
+ const TfLiteIntArray& tensor_list) {
+ int num_tensors = tensor_list.size;
+
+ all_data_.reserve(num_tensors);
+ all_shape_.reserve(num_tensors);
+ all_shape_ptr_.reserve(num_tensors);
+
+ for (int i = 0; i < num_tensors; ++i) {
+ TfLiteTensor* t = &context.tensors[tensor_list.data[i]];
+ all_data_.push_back(GetTensorData<T>(t));
+ all_shape_.push_back(GetTensorShape(t));
+ }
+
+ // Taking the pointer from inside a std::vector is only OK if the vector is
+ // never modified, so we populate all_shape in the previous loop and then we
+ // are free to grab iterators here.
+ for (int i = 0; i < num_tensors; ++i) {
+ all_shape_ptr_.push_back(&all_shape_[i]);
+ }
+ }
+ // Return a pointer to the data pointers of all tensors in the list. For
+ // example:
+ // float* const* f = v.data();
+ // f[0][1] is the second element of the first tensor.
+ T* const* data() const { return all_data_.data(); }
+
+ // Return a pointer the shape pointers of all tensors in the list. For
+ // example:
+ // const RuntimeShape* const* d = v.dims();
+ // dims[1] are the dimensions of the second tensor in the list.
+ const RuntimeShape* const* shapes() const { return all_shape_ptr_.data(); }
+
+ private:
+ std::vector<T*> all_data_;
+ std::vector<RuntimeShape> all_shape_;
+ std::vector<RuntimeShape*> all_shape_ptr_;
+};
+
+// A list of quantized tensors in a format that can be used by kernels like
+// split and concatenation.
+class VectorOfQuantizedTensors : public VectorOfTensors<uint8_t> {
+ public:
+ // Build with the tensors in 'tensor_list'.
+ VectorOfQuantizedTensors(const TfLiteContext& context,
+ const TfLiteIntArray& tensor_list)
+ : VectorOfTensors<uint8_t>(context, tensor_list) {
+ for (int i = 0; i < tensor_list.size; ++i) {
+ TfLiteTensor* t = &context.tensors[tensor_list.data[i]];
+ zero_point_.push_back(t->params.zero_point);
+ scale_.push_back(t->params.scale);
+ }
+ }
+
+ const float* scale() const { return scale_.data(); }
+ const int32_t* zero_point() const { return zero_point_.data(); }
+
+ private:
+ std::vector<int32_t> zero_point_;
+ std::vector<float> scale_;
+};
+
+// Writes randomly accessed values from `input` sequentially into `output`.
+template <typename T>
+class SequentialTensorWriter {
+ public:
+ SequentialTensorWriter(const TfLiteTensor* input, TfLiteTensor* output) {
+ input_data_ = GetTensorData<T>(input);
+ output_ptr_ = GetTensorData<T>(output);
+ }
+ SequentialTensorWriter(const T* input_data, T* output_data)
+ : input_data_(input_data), output_ptr_(output_data) {}
+
+ void Write(int position) { *output_ptr_++ = input_data_[position]; }
+ void WriteN(int position, int len) {
+ memcpy(output_ptr_, &input_data_[position], sizeof(T) * len);
+ output_ptr_ += len;
+ }
+
+ private:
+ const T* input_data_;
+ T* output_ptr_;
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_PORTABLE_TENSOR_H_
diff --git a/tensorflow/lite/kernels/internal/quantization_util.cc b/tensorflow/lite/kernels/internal/quantization_util.cc
new file mode 100644
index 0000000..ed0fe43
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/quantization_util.cc
@@ -0,0 +1,395 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+
+#include <algorithm>
+#include <cmath>
+#include <limits>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+
+namespace tflite {
+
+namespace {
+// These constants are used to manipulate the binary representation of doubles.
+// Double-precision binary64 floating point format is:
+// Bit | 63 | 62-52 | 51-0 |
+// | Sign | Exponent | Fraction |
+// To avoid 64-bit integers as much as possible, I break this into high and
+// low 32-bit chunks. High is:
+// Bit | 31 | 30-20 | 19-0 |
+// | Sign | Exponent | High Fraction |
+// Low is:
+// Bit | 31-0 |
+// | Low Fraction |
+// We then access the components through logical bit-wise operations to
+// extract the parts needed, with the positions and masks derived from the
+// layout shown above.
+constexpr uint64_t kSignMask = 0x8000000000000000LL;
+constexpr uint64_t kExponentMask = 0x7ff0000000000000LL;
+constexpr int32_t kExponentShift = 52;
+constexpr int32_t kExponentBias = 1023;
+constexpr uint32_t kExponentIsBadNum = 0x7ff;
+constexpr uint64_t kFractionMask = 0x000fffffffc00000LL;
+constexpr uint32_t kFractionShift = 22;
+constexpr uint32_t kFractionRoundingMask = 0x003fffff;
+constexpr uint32_t kFractionRoundingThreshold = 0x00200000;
+} // namespace
+
+void QuantizeMultiplier(double double_multiplier, int32_t* quantized_multiplier,
+ int* shift) {
+ if (double_multiplier == 0.) {
+ *quantized_multiplier = 0;
+ *shift = 0;
+ return;
+ }
+#ifdef TFLITE_EMULATE_FLOAT
+ // If we're trying to avoid the use of floating-point instructions (for
+ // example on microcontrollers) then use an alternative implementation
+ // that only requires integer and bitwise operations. To enable this, you
+ // need to set the define during the build process for your platform.
+ int64_t q_fixed = IntegerFrExp(double_multiplier, shift);
+#else // TFLITE_EMULATE_FLOAT
+ const double q = std::frexp(double_multiplier, shift);
+ auto q_fixed = static_cast<int64_t>(TfLiteRound(q * (1ll << 31)));
+#endif // TFLITE_EMULATE_FLOAT
+ TFLITE_CHECK(q_fixed <= (1ll << 31));
+ if (q_fixed == (1ll << 31)) {
+ q_fixed /= 2;
+ ++*shift;
+ }
+ TFLITE_CHECK_LE(q_fixed, std::numeric_limits<int32_t>::max());
+ // A shift amount smaller than -31 would cause all bits to be shifted out
+ // and thus all results would be zero. We implement that instead with
+ // q_fixed==0, so as to avoid hitting issues with right-shift
+ // operations with shift amounts greater than 31. Note that this happens
+ // roughly when abs(double_multiplier) < 2^-31 and the present handling means
+ // that we're effectively flushing tiny double_multiplier's to zero.
+ // We could conceivably handle values in the range (roughly) [32, 63]
+ // as 'denormals' i.e. (shift==0, q_fixed < 2^30). In that point of view
+ // the present handling is just doing 'flush denormals to zero'. We could
+ // reconsider and actually generate nonzero denormals if a need arises.
+ if (*shift < -31) {
+ *shift = 0;
+ q_fixed = 0;
+ }
+ *quantized_multiplier = static_cast<int32_t>(q_fixed);
+}
+
+void QuantizeMultiplierGreaterThanOne(double double_multiplier,
+ int32_t* quantized_multiplier,
+ int* left_shift) {
+ TFLITE_CHECK_GT(double_multiplier, 1.);
+ QuantizeMultiplier(double_multiplier, quantized_multiplier, left_shift);
+ TFLITE_CHECK_GE(*left_shift, 0);
+}
+
+void QuantizeMultiplierSmallerThanOneExp(double double_multiplier,
+ int32_t* quantized_multiplier,
+ int* left_shift) {
+ TFLITE_CHECK_LT(double_multiplier, 1.);
+ TFLITE_CHECK_GT(double_multiplier, 0.);
+ int shift;
+ QuantizeMultiplier(double_multiplier, quantized_multiplier, &shift);
+ TFLITE_CHECK_LE(shift, 0);
+ *left_shift = shift;
+}
+
+int64_t IntegerFrExp(double input, int* shift) {
+ // Make sure our assumptions about the double layout hold.
+ TFLITE_CHECK_EQ(8, sizeof(double));
+
+ // We want to access the bits of the input double value directly, which is
+ // tricky to do safely, so use a union to handle the casting.
+ union {
+ double double_value;
+ uint64_t double_as_uint;
+ } cast_union;
+ cast_union.double_value = input;
+ const uint64_t u = cast_union.double_as_uint;
+
+ // If the bitfield is all zeros apart from the sign bit, this is a normalized
+ // zero value, so return standard values for this special case.
+ if ((u & ~kSignMask) == 0) {
+ *shift = 0;
+ return 0;
+ }
+
+ // Deal with NaNs and Infs, which are always indicated with a fixed pattern in
+ // the exponent, and distinguished by whether the fractions are zero or
+ // non-zero.
+ const uint32_t exponent_part = ((u & kExponentMask) >> kExponentShift);
+ if (exponent_part == kExponentIsBadNum) {
+ *shift = std::numeric_limits<int>::max();
+ if (u & kFractionMask) {
+ // NaN, so just return zero (with the exponent set to INT_MAX).
+ return 0;
+ } else {
+ // Infinity, so return +/- INT_MAX.
+ if (u & kSignMask) {
+ return std::numeric_limits<int64_t>::min();
+ } else {
+ return std::numeric_limits<int64_t>::max();
+ }
+ }
+ }
+
+ // The shift is fairly easy to extract from the high bits of the double value,
+ // just by masking it out and applying a bias. The std::frexp() implementation
+ // always returns values between 0.5 and 1.0 though, whereas the exponent
+ // assumes 1.0 to 2.0 is the standard range, so I add on one to match that
+ // interface.
+ *shift = (exponent_part - kExponentBias) + 1;
+
+ // There's an implicit high bit in the double format definition, so make sure
+ // we include that at the top, and then reconstruct the rest of the fractional
+ // value from the remaining fragments.
+ int64_t fraction = 0x40000000 + ((u & kFractionMask) >> kFractionShift);
+
+ // We're cutting off some bits at the bottom, so to exactly match the standard
+ // frexp implementation here we'll apply rounding by adding one to the least
+ // significant bit of the result if the discarded portion is over half of the
+ // maximum.
+ if ((u & kFractionRoundingMask) > kFractionRoundingThreshold) {
+ fraction += 1;
+ }
+ // Negate the fraction if the sign bit was set.
+ if (u & kSignMask) {
+ fraction *= -1;
+ }
+
+ return fraction;
+}
+
+double DoubleFromFractionAndShift(int64_t fraction, int shift) {
+ union {
+ double double_value;
+ uint64_t double_as_uint;
+ } result;
+
+ // Detect NaNs and infinities.
+ if (shift == std::numeric_limits<int>::max()) {
+ if (fraction == 0) {
+ return std::numeric_limits<double>::quiet_NaN();
+ } else if (fraction > 0) {
+ return std::numeric_limits<double>::infinity();
+ } else {
+ return -std::numeric_limits<double>::infinity();
+ }
+ }
+
+ // Return a normalized zero for a zero fraction.
+ if (fraction == 0) {
+ result.double_as_uint = 0;
+ return result.double_value;
+ }
+
+ bool is_negative = (fraction < 0);
+ int64_t encoded_fraction = is_negative ? -fraction : fraction;
+ int64_t encoded_shift = (shift - 1);
+ while (encoded_fraction < 0x40000000) {
+ encoded_fraction *= 2;
+ encoded_shift -= 1;
+ }
+ while (encoded_fraction > 0x80000000) {
+ encoded_fraction /= 2;
+ encoded_shift += 1;
+ }
+ encoded_fraction -= 0x40000000;
+ if (encoded_shift < -1022) {
+ encoded_shift = -1023;
+ } else if (encoded_shift > 1022) {
+ encoded_shift = 1023;
+ }
+ encoded_shift += kExponentBias;
+ uint64_t encoded_sign = is_negative ? kSignMask : 0;
+ result.double_as_uint = encoded_sign | (encoded_shift << kExponentShift) |
+ (encoded_fraction << kFractionShift);
+ return result.double_value;
+}
+
+double IntegerDoubleMultiply(double a, double b) {
+ int a_shift;
+ const int64_t a_fraction = IntegerFrExp(a, &a_shift);
+ int b_shift;
+ const int64_t b_fraction = IntegerFrExp(b, &b_shift);
+ // Detect NaNs and infinities.
+ if (a_shift == std::numeric_limits<int>::max() ||
+ (b_shift == std::numeric_limits<int>::max())) {
+ return std::numeric_limits<double>::quiet_NaN();
+ }
+ const int result_shift = a_shift + b_shift + 1;
+ const int64_t result_fraction = (a_fraction * b_fraction) >> 32;
+ return DoubleFromFractionAndShift(result_fraction, result_shift);
+}
+
+int IntegerDoubleCompare(double a, double b) {
+ int a_shift;
+ const int64_t a_fraction = IntegerFrExp(a, &a_shift);
+ int b_shift;
+ const int64_t b_fraction = IntegerFrExp(b, &b_shift);
+
+ // Detect NaNs and infinities.
+ if (a_shift == std::numeric_limits<int>::max() ||
+ (b_shift == std::numeric_limits<int>::max())) {
+ return 1;
+ }
+
+ if ((a_fraction == 0) && (b_fraction < 0)) {
+ return 1;
+ } else if ((a_fraction < 0) && (b_fraction == 0)) {
+ return -1;
+ } else if (a_shift < b_shift) {
+ return -1;
+ } else if (a_shift > b_shift) {
+ return 1;
+ } else if (a_fraction < b_fraction) {
+ return -1;
+ } else if (a_fraction > b_fraction) {
+ return 1;
+ } else {
+ return 0;
+ }
+}
+
+void PreprocessSoftmaxScaling(double beta, double input_scale,
+ int input_integer_bits,
+ int32_t* quantized_multiplier, int* left_shift) {
+ // If the overall multiplier (input and beta) is large, then exp() of an
+ // input difference of 1 scaled by this will be large. In other words, we
+ // can cap the multiplier and know that, when it is used, the output will be
+ // (round to) zero wherever the input is not at the maximum value.
+
+ // If the overall scale is less than one, and input_integer_bits=0, then the
+ // result is double equivalent of Q0.31 (actually with more precision). Thus
+ // this generates a Q(input_integer_bits).(31-input_integer_bits)
+ // representation.
+#ifdef TFLITE_EMULATE_FLOAT
+ const double input_beta = IntegerDoubleMultiply(beta, input_scale);
+ int shift;
+ int64_t fraction = IntegerFrExp(input_beta, &shift);
+ shift += (31 - input_integer_bits);
+ double input_beta_real_multiplier =
+ DoubleFromFractionAndShift(fraction, shift);
+ if (IntegerDoubleCompare(input_beta_real_multiplier, (1ll << 31) - 1.0) > 0) {
+ input_beta_real_multiplier = (1ll << 31) - 1.0;
+ }
+#else // TFLITE_EMULATE_FLOAT
+ const double input_beta_real_multiplier = std::min<double>(
+ beta * input_scale * (1 << (31 - input_integer_bits)), (1ll << 31) - 1.0);
+#endif // TFLITE_EMULATE_FLOAT
+
+ QuantizeMultiplierGreaterThanOne(input_beta_real_multiplier,
+ quantized_multiplier, left_shift);
+}
+
+void PreprocessLogSoftmaxScalingExp(double beta, double input_scale,
+ int input_integer_bits,
+ int32_t* quantized_multiplier,
+ int* left_shift,
+ int32_t* reverse_scaling_divisor,
+ int* reverse_scaling_left_shift) {
+ PreprocessSoftmaxScaling(beta, input_scale, input_integer_bits,
+ quantized_multiplier, left_shift);
+
+ // Also calculate what amounts to the inverse scaling factor for the input.
+ const double real_reverse_scaling_divisor =
+ (1 << (31 - *left_shift)) / static_cast<double>(*quantized_multiplier);
+ tflite::QuantizeMultiplierSmallerThanOneExp(real_reverse_scaling_divisor,
+ reverse_scaling_divisor,
+ reverse_scaling_left_shift);
+}
+
+int CalculateInputRadius(int input_integer_bits, int input_left_shift,
+ int total_signed_bits) {
+#ifdef TFLITE_EMULATE_FLOAT
+ int64_t result = (1 << input_integer_bits) - 1;
+ result <<= (total_signed_bits - input_integer_bits);
+ result >>= input_left_shift;
+ return result;
+#else // TFLITE_EMULATE_FLOAT
+ const double max_input_rescaled =
+ 1.0 * ((1 << input_integer_bits) - 1) *
+ (1ll << (total_signed_bits - input_integer_bits)) /
+ (1ll << input_left_shift);
+ // Tighten bound using floor. Suppose that we could use the exact value.
+ // After scaling the difference, the result would be at the maximum. Thus we
+ // must ensure that our value has lower magnitude.
+ return static_cast<int>(std::floor(max_input_rescaled));
+#endif // TFLITE_EMULATE_FLOAT
+}
+
+void NudgeQuantizationRange(const float min, const float max,
+ const int quant_min, const int quant_max,
+ float* nudged_min, float* nudged_max,
+ float* nudged_scale) {
+ // This code originates from tensorflow/core/kernels/fake_quant_ops_functor.h.
+ const float quant_min_float = static_cast<float>(quant_min);
+ const float quant_max_float = static_cast<float>(quant_max);
+ *nudged_scale = (max - min) / (quant_max_float - quant_min_float);
+ const float zero_point_from_min = quant_min_float - min / *nudged_scale;
+ uint16_t nudged_zero_point;
+ if (zero_point_from_min < quant_min_float) {
+ nudged_zero_point = static_cast<uint16_t>(quant_min);
+ } else if (zero_point_from_min > quant_max_float) {
+ nudged_zero_point = static_cast<uint16_t>(quant_max);
+ } else {
+ nudged_zero_point = static_cast<uint16_t>(TfLiteRound(zero_point_from_min));
+ }
+ *nudged_min = (quant_min_float - nudged_zero_point) * (*nudged_scale);
+ *nudged_max = (quant_max_float - nudged_zero_point) * (*nudged_scale);
+}
+
+void FakeQuantizeArray(const float nudged_scale, const float nudged_min,
+ const float nudged_max, const float* input_data,
+ float* output_data, const float size) {
+ // This code originates from tensorflow/core/kernels/fake_quant_ops_functor.h.
+ const float inv_nudged_scale = 1.0f / nudged_scale;
+
+ for (int i = 0; i < size; i++) {
+ const float src_val = input_data[i];
+ const float clamped = std::min(nudged_max, std::max(nudged_min, src_val));
+ const float clamped_shifted = clamped - nudged_min;
+ const float dst_val =
+ TfLiteRound(clamped_shifted * inv_nudged_scale) * nudged_scale +
+ nudged_min;
+ output_data[i] = dst_val;
+ }
+}
+
+bool CheckedLog2(const float x, int* log2_result) {
+ // Using TfLiteRound instead of std::round and std::log instead of
+ // std::log2 to work around these functions being missing in a toolchain
+ // used in some TensorFlow tests as of May 2018.
+ const float x_log2 = std::log(x) * (1.0f / std::log(2.0f));
+ const float x_log2_rounded = TfLiteRound(x_log2);
+ const float x_log2_fracpart = x_log2 - x_log2_rounded;
+
+ *log2_result = static_cast<int>(x_log2_rounded);
+ return std::abs(x_log2_fracpart) < 1e-3f;
+}
+
+void QuantizeMultiplierArray(const double* effective_scales, size_t size,
+ int32_t* effective_scale_significand,
+ int* effective_shift) {
+ for (size_t i = 0; i < size; ++i) {
+ QuantizeMultiplier(effective_scales[i], &effective_scale_significand[i],
+ &effective_shift[i]);
+ }
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/kernels/internal/quantization_util.h b/tensorflow/lite/kernels/internal/quantization_util.h
new file mode 100644
index 0000000..0ee914b
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/quantization_util.h
@@ -0,0 +1,292 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_QUANTIZATION_UTIL_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_QUANTIZATION_UTIL_H_
+
+#include <cmath>
+#include <cstdint>
+#include <limits>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+// Given the min and max values of a float array, return
+// reasonable quantization parameters to use for this array.
+template <typename T>
+QuantizationParams ChooseQuantizationParams(double rmin, double rmax,
+ bool narrow_range) {
+ const T qmin = std::numeric_limits<T>::min() + (narrow_range ? 1 : 0);
+ const T qmax = std::numeric_limits<T>::max();
+ const double qmin_double = qmin;
+ const double qmax_double = qmax;
+ // 0 should always be a representable value. Let's assume that the initial
+ // min,max range contains 0.
+ TFLITE_CHECK_LE(rmin, 0.);
+ TFLITE_CHECK_GE(rmax, 0.);
+ if (rmin == rmax) {
+ // Special case where the min,max range is a point. Should be {0}.
+ TFLITE_CHECK_EQ(rmin, 0.);
+ TFLITE_CHECK_EQ(rmax, 0.);
+ QuantizationParams quantization_params;
+ quantization_params.zero_point = 0;
+ quantization_params.scale = 0.;
+ return quantization_params;
+ }
+
+ // General case.
+ //
+ // First determine the scale.
+ const double scale = (rmax - rmin) / (qmax_double - qmin_double);
+
+ // Zero-point computation.
+ // First the initial floating-point computation. The zero-point can be
+ // determined from solving an affine equation for any known pair
+ // (real value, corresponding quantized value).
+ // We know two such pairs: (rmin, qmin) and (rmax, qmax).
+ // The arithmetic error on the zero point computed from either pair
+ // will be roughly machine_epsilon * (sum of absolute values of terms)
+ // so we want to use the variant that adds the smaller terms.
+ const double zero_point_from_min = qmin_double - rmin / scale;
+ const double zero_point_from_max = qmax_double - rmax / scale;
+ const double zero_point_from_min_error =
+ std::abs(qmin_double) + std::abs(rmin / scale);
+ const double zero_point_from_max_error =
+ std::abs(qmax_double) + std::abs(rmax / scale);
+
+ const double zero_point_double =
+ zero_point_from_min_error < zero_point_from_max_error
+ ? zero_point_from_min
+ : zero_point_from_max;
+
+ // Now we need to nudge the zero point to be an integer
+ // (our zero points are integer, and this is motivated by the requirement
+ // to be able to represent the real value "0" exactly as a quantized value,
+ // which is required in multiple places, for example in Im2col with SAME
+ // padding).
+ T nudged_zero_point = 0;
+ if (zero_point_double < qmin_double) {
+ nudged_zero_point = qmin;
+ } else if (zero_point_double > qmax_double) {
+ nudged_zero_point = qmax;
+ } else {
+ nudged_zero_point = static_cast<T>(round(zero_point_double));
+ }
+ // The zero point should always be in the range of quantized value,
+ // [qmin, qmax].
+ TFLITE_CHECK_GE(nudged_zero_point, qmin);
+ TFLITE_CHECK_LE(nudged_zero_point, qmax);
+
+ // Finally, store the result nudged quantization params.
+ QuantizationParams quantization_params;
+ quantization_params.zero_point = nudged_zero_point;
+ quantization_params.scale = scale;
+ return quantization_params;
+}
+
+template <typename T>
+QuantizationParams ChooseQuantizationParams(double rmin, double rmax) {
+ return ChooseQuantizationParams<T>(rmin, rmax, false);
+}
+
+// Converts a floating-point number to an integer. For all inputs x where
+// static_cast<IntOut>(x) is legal according to the C++ standard, the result
+// is identical to that cast (i.e. the result is x with its fractional part
+// truncated whenever that is representable as IntOut).
+//
+// static_cast would cause undefined behavior for the following cases, which
+// have well-defined behavior for this function:
+//
+// 1. If x is NaN, the result is zero.
+//
+// 2. If the truncated form of x is above the representable range of IntOut,
+// the result is std::numeric_limits<IntOut>::max().
+//
+// 3. If the truncated form of x is below the representable range of IntOut,
+// the result is std::numeric_limits<IntOut>::min().
+//
+// Note that cases #2 and #3 cover infinities as well as finite numbers.
+//
+// The range of FloatIn must include the range of IntOut, otherwise
+// the results are undefined.
+// TODO(sfeuz): Replace by absl::SafeCast once available.
+template <class IntOut, class FloatIn>
+IntOut SafeCast(FloatIn x) {
+ static_assert(!std::numeric_limits<FloatIn>::is_integer,
+ "FloatIn is integer");
+ static_assert(std::numeric_limits<IntOut>::is_integer,
+ "IntOut is not integer");
+ static_assert(std::numeric_limits<IntOut>::radix == 2, "IntOut is base 2");
+
+ // Special case NaN, for which the logic below doesn't work.
+ if (std::isnan(x)) {
+ return 0;
+ }
+
+ // Negative values all clip to zero for unsigned results.
+ if (!std::numeric_limits<IntOut>::is_signed && x < 0) {
+ return 0;
+ }
+
+ // Handle infinities.
+ if (std::isinf(x)) {
+ return x < 0 ? std::numeric_limits<IntOut>::min()
+ : std::numeric_limits<IntOut>::max();
+ }
+
+ // Set exp such that x == f * 2^exp for some f with |f| in [0.5, 1.0),
+ // unless x is zero in which case exp == 0. Note that this implies that the
+ // magnitude of x is strictly less than 2^exp.
+ int exp = 0;
+ std::frexp(x, &exp);
+
+ // Let N be the number of non-sign bits in the representation of IntOut. If
+ // the magnitude of x is strictly less than 2^N, the truncated version of x
+ // is representable as IntOut. The only representable integer for which this
+ // is not the case is kMin for signed types (i.e. -2^N), but that is covered
+ // by the fall-through below.
+ if (exp <= std::numeric_limits<IntOut>::digits) {
+ return x;
+ }
+
+ // Handle numbers with magnitude >= 2^N.
+ return x < 0 ? std::numeric_limits<IntOut>::min()
+ : std::numeric_limits<IntOut>::max();
+}
+
+// Decompose a double multiplier into a Q0.31 int32 representation of its
+// significand, and shift representation of NEGATIVE its exponent ---
+// this is intended as a RIGHT-shift.
+//
+// Restricted to the case where the multiplier < 1 (and non-negative).
+void QuantizeMultiplierSmallerThanOneExp(double double_multiplier,
+ int32_t* quantized_multiplier,
+ int* left_shift);
+
+// Decompose a double multiplier into a Q0.31 int32 representation of its
+// significand, and shift representation of its exponent.
+//
+// Restricted to the case where the multiplier > 1.
+void QuantizeMultiplierGreaterThanOne(double double_multiplier,
+ int32_t* quantized_multiplier,
+ int* left_shift);
+
+// Decompose a double multiplier into a Q0.31 int32 representation of its
+// significand, and shift representation of its exponent.
+//
+// Handles an arbitrary positive multiplier. The 'shift' output-value is
+// basically the 'floating-point exponent' of the multiplier:
+// Negative for a right-shift (when the multiplier is <1), positive for a
+// left-shift (when the multiplier is >1)
+void QuantizeMultiplier(double double_multiplier, int32_t* quantized_multiplier,
+ int* shift);
+
+// Splits a double input value into a returned fraction, and a shift value from
+// the exponent, using only bitwise and integer operations to support
+// microcontrollers and other environments without floating-point support.
+//
+// This is designed to be a replacement for how std::frexp() is used within the
+// QuantizeMultiplier() function, and so has a different signature than the
+// standard version, returning a 64-bit integer rather than a double. This
+// result has a maximum value of 1<<31, with the fraction expressed as a
+// proportion of that maximum.
+//
+// std::frexp() returns NaNs and infinities unmodified, but since we're
+// returning integers that can't represent those values, instead we return
+// a shift of std::numeric_limits<int>::max() for all bad numbers, with an int64
+// result of 0 for NaNs, std:numeric_limits<int64_t>::max() for +INFINITY, and
+// std::numeric_limits<int64_t>::min() for -INFINITY. Denormalized inputs will
+// result in return values that end up truncating some bits at the end,
+// reflecting the loss of precision inherent in denormalization.
+int64_t IntegerFrExp(double input, int* shift);
+
+// Converts an integer fraction in the format produced by IntegerFrExp (where
+// 0x40000000 is 1.0) and an exponent shift (between -1022 and +1022) into an
+// IEEE binary64 double format result. The implementation uses only integer and
+// bitwise operators, so no floating point hardware support or emulation is
+// needed. This is here so quantized operations can run non-time-critical
+// preparation calculations on microcontrollers and other platforms without
+// float support.
+double DoubleFromFractionAndShift(int64_t fraction, int shift);
+
+// Performs a multiplication of two numbers in double format, using only integer
+// and bitwise instructions. This is aimed at supporting housekeeping functions
+// for quantized operations on microcontrollers without floating-point hardware.
+double IntegerDoubleMultiply(double a, double b);
+
+// Returns -1 if a is less than b, 0 if a and b are equal, and +1 if a is
+// greater than b. It is implemented using only integer and logical instructions
+// so that it can be easily run on microcontrollers for quantized operations.
+int IntegerDoubleCompare(double a, double b);
+
+// This first creates a multiplier in a double equivalent of
+// Q(input_integer_bits).(31-input_integer_bits) representation, with extra
+// precision in the double's fractional bits. It then splits the result into
+// significand and exponent.
+void PreprocessSoftmaxScaling(double beta, double input_scale,
+ int input_integer_bits,
+ int32_t* quantized_multiplier, int* left_shift);
+// Like PreprocessSoftmaxScaling, but inverse scaling factors also calculated.
+void PreprocessLogSoftmaxScalingExp(double beta, double input_scale,
+ int input_integer_bits,
+ int32_t* quantized_multiplier,
+ int* left_shift,
+ int32_t* reverse_scaling_divisor,
+ int* reverse_scaling_left_shift);
+// Calculate the largest input that will result in a within-bounds intermediate
+// result within MultiplyByQuantizedMultiplierGreaterThanOne. In other words,
+// it must not overflow before we reduce the value by multiplication by the
+// input multiplier. The negative radius is used as the minimum difference in
+// Softmax.
+int CalculateInputRadius(int input_integer_bits, int input_left_shift,
+ int total_signed_bits = 31);
+
+// Nudges a min/max quantization range to ensure zero is zero.
+// Gymnastics with nudged zero point is to ensure that real zero maps to
+// an integer, which is required for e.g. zero-padding in convolutional layers.
+// Outputs nudged_min, nudged_max, nudged_scale.
+void NudgeQuantizationRange(const float min, const float max,
+ const int quant_min, const int quant_max,
+ float* nudged_min, float* nudged_max,
+ float* nudged_scale);
+
+// Fake quantizes (quantizes and dequantizes) input_data using the scale,
+// nudged_min, and nudged_max from NudgeQuantizationRange. This matches the code
+// in TensorFlow's FakeQuantizeWithMinMaxVarsFunctor.
+void FakeQuantizeArray(const float nudged_scale, const float nudged_min,
+ const float nudged_max, const float* input_data,
+ float* output_data, const float size);
+
+// If x is approximately a power of two (with any positive or negative
+// exponent), stores that exponent (i.e. log2(x)) in *log2_result, otherwise
+// returns false.
+bool CheckedLog2(const float x, int* log2_result);
+
+// Decomposes an array of double multipliers into a Q0.31 int32 representation
+// of its significand, and shift representation of its exponent.
+//
+// Handles an arbitrary multiplier. The 'shift' output-value is
+// basically the 'floating-point exponent' of the multiplier:
+// Negative for a right-shift (when the multiplier is <1), positive for a
+// left-shift (when the multiplier is >1)
+void QuantizeMultiplierArray(const double* effective_scales, size_t size,
+ int32_t* effective_scale_significand,
+ int* effective_shift);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_QUANTIZATION_UTIL_H_
diff --git a/tensorflow/lite/kernels/internal/reference/add.h b/tensorflow/lite/kernels/internal/reference/add.h
new file mode 100644
index 0000000..3da76d8
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/add.h
@@ -0,0 +1,446 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ADD_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ADD_H_
+
+#include "fixedpoint/fixedpoint.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+template <typename T>
+inline void Add(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const T* input1_data,
+ const RuntimeShape& input2_shape, const T* input2_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = ActivationFunctionWithMinMax(
+ input1_data[i] + input2_data[i], params.quantized_activation_min,
+ params.quantized_activation_max);
+ }
+}
+
+inline void Add(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const float* input1_data,
+ const RuntimeShape& input2_shape, const float* input2_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+ for (int i = 0; i < flat_size; i++) {
+ auto x = input1_data[i] + input2_data[i];
+ output_data[i] = ActivationFunctionWithMinMax(
+ x, params.float_activation_min, params.float_activation_max);
+ }
+}
+
+// Element-wise add that can often be used for inner loop of broadcast add as
+// well as the non-broadcast add.
+
+// This function is used for 8-bit as well as for 16-bit, but the accumulator
+// is 32-bit for both cases. The overflow does not happen due to the
+// choice of the shift (20 or 15, accordingly - see add.cc for more comments).
+template <typename T>
+inline void AddElementwise(int size, const ArithmeticParams& params,
+ const T* input1_data, const T* input2_data,
+ T* output_data) {
+ TFLITE_DCHECK_GT(params.input1_offset, -std::numeric_limits<T>::max());
+ TFLITE_DCHECK_GT(params.input2_offset, -std::numeric_limits<T>::max());
+ TFLITE_DCHECK_LT(params.input1_offset, std::numeric_limits<T>::max());
+ TFLITE_DCHECK_LT(params.input2_offset, std::numeric_limits<T>::max());
+
+ for (int i = 0; i < size; ++i) {
+ const int32_t input1_val = params.input1_offset + input1_data[i];
+ const int32_t input2_val = params.input2_offset + input2_data[i];
+ const int32_t shifted_input1_val = input1_val * (1 << params.left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier, params.input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier, params.input2_shift);
+ const int32_t raw_sum = scaled_input1_val + scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sum, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[i] = static_cast<T>(clamped_output);
+ }
+}
+
+// Scalar-broadcast add that can be used for inner loop of more general
+// broadcast add, so that, for example, scalar-broadcast with batch will still
+// be fast.
+inline void AddScalarBroadcast(int size, const ArithmeticParams& params,
+ uint8_t input1_data, const uint8_t* input2_data,
+ uint8_t* output_data) {
+ TFLITE_DCHECK_GT(params.input1_offset, -256);
+ TFLITE_DCHECK_GT(params.input2_offset, -256);
+ TFLITE_DCHECK_LT(params.input1_offset, 256);
+ TFLITE_DCHECK_LT(params.input2_offset, 256);
+
+ const int32_t input1_val = params.input1_offset + input1_data;
+ const int32_t shifted_input1_val = input1_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier, params.input1_shift);
+ for (int i = 0; i < size; ++i) {
+ const int32_t input2_val = params.input2_offset + input2_data[i];
+ const int32_t shifted_input2_val = input2_val * (1 << params.left_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier, params.input2_shift);
+ const int32_t raw_sum = scaled_input1_val + scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sum, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[i] = static_cast<uint8_t>(clamped_output);
+ }
+}
+
+inline void Add(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const uint8_t* input1_data,
+ const RuntimeShape& input2_shape, const uint8_t* input2_data,
+ const RuntimeShape& output_shape, uint8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+
+ TFLITE_DCHECK_GT(params.input1_offset, -256);
+ TFLITE_DCHECK_GT(params.input2_offset, -256);
+ TFLITE_DCHECK_LT(params.input1_offset, 256);
+ TFLITE_DCHECK_LT(params.input2_offset, 256);
+ AddElementwise(flat_size, params, input1_data, input2_data, output_data);
+}
+
+inline void AddGeneralParamScale(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int16_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int16_t* input2_data,
+ const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+
+ int max_value = std::numeric_limits<int16_t>::max();
+
+ TFLITE_DCHECK_GT(params.input1_offset, -max_value);
+ TFLITE_DCHECK_GT(params.input2_offset, -max_value);
+ TFLITE_DCHECK_LT(params.input1_offset, max_value);
+ TFLITE_DCHECK_LT(params.input2_offset, max_value);
+ AddElementwise(flat_size, params, input1_data, input2_data, output_data);
+}
+
+inline void Add(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const int16_t* input1_data,
+ const RuntimeShape& input2_shape, const int16_t* input2_data,
+ const RuntimeShape& output_shape, int16_t* output_data,
+ bool pot_scale = true) {
+ if (!pot_scale) {
+ AddGeneralParamScale(params, input1_shape, input1_data, input2_shape,
+ input2_data, output_shape, output_data);
+ return;
+ }
+
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+
+ const int input1_shift = params.input1_shift;
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+ const int16_t output_activation_min = params.quantized_activation_min;
+ const int16_t output_activation_max = params.quantized_activation_max;
+
+ TFLITE_DCHECK(input1_shift == 0 || params.input2_shift == 0);
+ TFLITE_DCHECK_LE(input1_shift, 0);
+ TFLITE_DCHECK_LE(params.input2_shift, 0);
+ const int16_t* not_shift_input =
+ input1_shift == 0 ? input1_data : input2_data;
+ const int16_t* shift_input = input1_shift == 0 ? input2_data : input1_data;
+ const int input_right_shift =
+ input1_shift == 0 ? -params.input2_shift : -input1_shift;
+
+ for (int i = 0; i < flat_size; i++) {
+ // F0 uses 0 integer bits, range [-1, 1].
+ using F0 = gemmlowp::FixedPoint<std::int16_t, 0>;
+
+ F0 input_ready_scaled = F0::FromRaw(not_shift_input[i]);
+ F0 scaled_input = F0::FromRaw(
+ gemmlowp::RoundingDivideByPOT(shift_input[i], input_right_shift));
+ F0 result = gemmlowp::SaturatingAdd(scaled_input, input_ready_scaled);
+ const int16_t raw_output = result.raw();
+ const int16_t clamped_output = std::min(
+ output_activation_max, std::max(output_activation_min, raw_output));
+ output_data[i] = clamped_output;
+ }
+}
+
+inline void BroadcastAdd4DSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const float* input1_data,
+ const RuntimeShape& input2_shape,
+ const float* input2_data,
+ const RuntimeShape& output_shape,
+ float* output_data) {
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ output_data[Offset(extended_output_shape, b, y, x, c)] =
+ ActivationFunctionWithMinMax(
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)] +
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)],
+ params.float_activation_min, params.float_activation_max);
+ }
+ }
+ }
+ }
+}
+
+inline void BroadcastAdd4DSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int32_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int32_t* input2_data,
+ const RuntimeShape& output_shape,
+ int32_t* output_data) {
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ output_data[Offset(extended_output_shape, b, y, x, c)] =
+ ActivationFunctionWithMinMax(
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)] +
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)],
+ params.quantized_activation_min,
+ params.quantized_activation_max);
+ }
+ }
+ }
+ }
+}
+
+// This function is used for 8-bit as well as for 16-bit, but the accumulator
+// is 32-bit for both cases. The overflow does not happen due to the
+// choice of the shift (20 or 15, accordingly - see add.cc for more comments).
+template <typename T>
+inline void BroadcastAdd4DSlow(
+ const ArithmeticParams& params, const RuntimeShape& input1_shape,
+ const T* input1_data, const RuntimeShape& input2_shape,
+ const T* input2_data, const RuntimeShape& output_shape, T* output_data) {
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ const int32_t input1_val =
+ params.input1_offset +
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)];
+ const int32_t input2_val =
+ params.input2_offset +
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)];
+ const int32_t shifted_input1_val =
+ input1_val * (1 << params.left_shift);
+ const int32_t shifted_input2_val =
+ input2_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier,
+ params.input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier,
+ params.input2_shift);
+ const int32_t raw_sum = scaled_input1_val + scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sum, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[Offset(extended_output_shape, b, y, x, c)] =
+ static_cast<T>(clamped_output);
+ }
+ }
+ }
+ }
+}
+
+inline void BroadcastAddFivefold(const ArithmeticParams& unswitched_params,
+ const RuntimeShape& unswitched_input1_shape,
+ const uint8_t* unswitched_input1_data,
+ const RuntimeShape& unswitched_input2_shape,
+ const uint8_t* unswitched_input2_data,
+ const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ ArithmeticParams switched_params = unswitched_params;
+ switched_params.input1_offset = unswitched_params.input2_offset;
+ switched_params.input1_multiplier = unswitched_params.input2_multiplier;
+ switched_params.input1_shift = unswitched_params.input2_shift;
+ switched_params.input2_offset = unswitched_params.input1_offset;
+ switched_params.input2_multiplier = unswitched_params.input1_multiplier;
+ switched_params.input2_shift = unswitched_params.input1_shift;
+
+ const bool use_unswitched =
+ unswitched_params.broadcast_category ==
+ tflite::BroadcastableOpCategory::kFirstInputBroadcastsFast;
+
+ const ArithmeticParams& params =
+ use_unswitched ? unswitched_params : switched_params;
+ const uint8_t* input1_data =
+ use_unswitched ? unswitched_input1_data : unswitched_input2_data;
+ const uint8_t* input2_data =
+ use_unswitched ? unswitched_input2_data : unswitched_input1_data;
+
+ // Fivefold nested loops. The second input resets its position for each
+ // iteration of the second loop. The first input resets its position at the
+ // beginning of the fourth loop. The innermost loop is an elementwise add of
+ // sections of the arrays.
+ uint8_t* output_data_ptr = output_data;
+ const uint8_t* input1_data_ptr = input1_data;
+ const uint8_t* input2_data_reset = input2_data;
+ // In the fivefold pattern, y0, y2 and y4 are not broadcast, and so shared
+ // between input shapes. y3 for input 1 is always broadcast, and so the
+ // dimension there is 1, whereas optionally y1 might be broadcast for input 2.
+ // Put another way,
+ // input1.shape.FlatSize = y0 * y1 * y2 * y4,
+ // input2.shape.FlatSize = y0 * y2 * y3 * y4.
+ int y0 = params.broadcast_shape[0];
+ int y1 = params.broadcast_shape[1];
+ int y2 = params.broadcast_shape[2];
+ int y3 = params.broadcast_shape[3];
+ int y4 = params.broadcast_shape[4];
+ if (y4 > 1) {
+ // General fivefold pattern, with y4 > 1 so there is a non-broadcast inner
+ // dimension.
+ for (int i0 = 0; i0 < y0; ++i0) {
+ const uint8_t* input2_data_ptr;
+ for (int i1 = 0; i1 < y1; ++i1) {
+ input2_data_ptr = input2_data_reset;
+ for (int i2 = 0; i2 < y2; ++i2) {
+ for (int i3 = 0; i3 < y3; ++i3) {
+ AddElementwise(y4, params, input1_data_ptr, input2_data_ptr,
+ output_data_ptr);
+ input2_data_ptr += y4;
+ output_data_ptr += y4;
+ }
+ // We have broadcast y4 of input1 data y3 times, and now move on.
+ input1_data_ptr += y4;
+ }
+ }
+ // We have broadcast y2*y3*y4 of input2 data y1 times, and now move on.
+ input2_data_reset = input2_data_ptr;
+ }
+ } else {
+ // Special case of y4 == 1, in which the innermost loop is a single element
+ // and can be combined with the next (y3) as an inner broadcast.
+ //
+ // Note that this handles the case of pure scalar broadcast when
+ // y0 == y1 == y2 == 1. With low overhead it handles cases such as scalar
+ // broadcast with batch (as y2 > 1).
+ //
+ // NOTE The process is the same as the above general case except simplified
+ // for y4 == 1 and the loop over y3 is contained within the
+ // AddScalarBroadcast function.
+ for (int i0 = 0; i0 < y0; ++i0) {
+ const uint8_t* input2_data_ptr;
+ for (int i1 = 0; i1 < y1; ++i1) {
+ input2_data_ptr = input2_data_reset;
+ for (int i2 = 0; i2 < y2; ++i2) {
+ AddScalarBroadcast(y3, params, *input1_data_ptr, input2_data_ptr,
+ output_data_ptr);
+ input2_data_ptr += y3;
+ output_data_ptr += y3;
+ input1_data_ptr += 1;
+ }
+ }
+ input2_data_reset = input2_data_ptr;
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ADD_H_
diff --git a/tensorflow/lite/kernels/internal/reference/add_n.h b/tensorflow/lite/kernels/internal/reference/add_n.h
new file mode 100644
index 0000000..b6b5882
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/add_n.h
@@ -0,0 +1,86 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ADD_N_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ADD_N_H_
+
+#include <algorithm>
+#include <limits>
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_ops {
+
+// T is expected to be either float or int.
+template <typename T>
+inline void AddN(const RuntimeShape& input_shape, const size_t num_inputs,
+ const T* const* input_data, T* output_data) {
+ // All inputs and output should have the same shape, this is checked during
+ // Prepare stage.
+ const size_t size = input_shape.FlatSize();
+ for (size_t i = 0; i < size; ++i) {
+ T x = 0;
+ for (size_t j = 0; j < num_inputs; ++j) {
+ x += input_data[j][i];
+ }
+ output_data[i] = x;
+ }
+}
+
+inline void AddN(const ArithmeticParams& params,
+ const RuntimeShape& input_shape, const size_t num_inputs,
+ const int8_t* const* input_data, int8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ // Input offset is negative input zero point. Activation tensors are
+ // asymmetric quantized so they span the full int8 range.
+ // All inputs should have same zero-point and scale, this is checked during
+ // Prepare stage.
+ TFLITE_DCHECK_GE(-params.input1_offset, std::numeric_limits<int8_t>::min());
+ TFLITE_DCHECK_LE(-params.input1_offset, std::numeric_limits<int8_t>::max());
+
+ // All inputs and output should have the same shape, this is checked during
+ // Prepare stage.
+ const size_t size = input_shape.FlatSize();
+ for (size_t i = 0; i < size; ++i) {
+ // accumulate in scaled_x before clamping to avoid overflow
+ const int32_t x = params.input1_offset; // x = 0
+ const int32_t shifted_x = x * (1 << params.left_shift);
+ int32_t scaled_x = MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_x, params.input1_multiplier, params.input1_shift);
+
+ for (size_t j = 0; j < num_inputs; ++j) {
+ const int32_t y = params.input1_offset + input_data[j][i];
+ const int32_t shifted_y = y * (1 << params.left_shift);
+ int32_t scaled_y = MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_y, params.input1_multiplier, params.input1_shift);
+ scaled_x += scaled_y;
+ }
+
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ scaled_x, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[i] = static_cast<int8_t>(clamped_output);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ADD_N_H_
diff --git a/tensorflow/lite/kernels/internal/reference/arg_min_max.h b/tensorflow/lite/kernels/internal/reference/arg_min_max.h
new file mode 100644
index 0000000..8154fbf
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/arg_min_max.h
@@ -0,0 +1,88 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ARG_MIN_MAX_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ARG_MIN_MAX_H_
+
+#include <functional>
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+template <typename T>
+std::function<bool(T, T)> GetComparefunction(bool is_arg_max) {
+ if (is_arg_max) {
+ return std::greater<T>();
+ } else {
+ return std::less<T>();
+ }
+}
+
+template <typename T1, typename T2, typename T3, typename Cmp>
+void ArgMinMax(const RuntimeShape& input1_shape, const T1* input1_data,
+ const T3* input2_data, const RuntimeShape& output_shape,
+ T2* output_data, const Cmp& cmp) {
+ TFLITE_DCHECK_GT(input1_shape.DimensionsCount(), 0);
+ TFLITE_DCHECK_EQ(input1_shape.DimensionsCount() - 1,
+ output_shape.DimensionsCount());
+ int axis = input2_data[0];
+ if (axis < 0) {
+ axis += input1_shape.DimensionsCount();
+ }
+ const int axis_size = input1_shape.Dims(axis);
+
+ int outer_size = 1;
+ for (int i = 0; i < axis; ++i) {
+ TFLITE_DCHECK_EQ(input1_shape.Dims(i), output_shape.Dims(i));
+ outer_size *= input1_shape.Dims(i);
+ }
+
+ int inner_size = 1;
+ const int dims_count = input1_shape.DimensionsCount();
+ for (int i = axis + 1; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(input1_shape.Dims(i), output_shape.Dims(i - 1));
+ inner_size *= input1_shape.Dims(i);
+ }
+ for (int outer = 0; outer < outer_size; ++outer) {
+ for (int inner = 0; inner < inner_size; ++inner) {
+ auto min_max_value = input1_data[outer * axis_size * inner_size + inner];
+ T2 min_max_index = 0;
+ for (int i = 1; i < axis_size; ++i) {
+ const auto& curr_value =
+ input1_data[(outer * axis_size + i) * inner_size + inner];
+ if (cmp(curr_value, min_max_value)) {
+ min_max_value = curr_value;
+ min_max_index = static_cast<T2>(i);
+ }
+ }
+ output_data[outer * inner_size + inner] = min_max_index;
+ }
+ }
+}
+
+template <typename T1, typename T2, typename T3>
+void ArgMinMax(const RuntimeShape& input1_shape, const T1* input1_data,
+ const T3* input2_data, const RuntimeShape& output_shape,
+ T2* output_data, const bool is_arg_max) {
+ ArgMinMax(input1_shape, input1_data, input2_data, output_shape, output_data,
+ GetComparefunction<T1>(is_arg_max));
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ARG_MIN_MAX_H_
diff --git a/tensorflow/lite/kernels/internal/reference/batch_to_space_nd.h b/tensorflow/lite/kernels/internal/reference/batch_to_space_nd.h
new file mode 100644
index 0000000..cda46a2
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/batch_to_space_nd.h
@@ -0,0 +1,101 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_BATCH_TO_SPACE_ND_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_BATCH_TO_SPACE_ND_H_
+
+#include <cmath>
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+// TODO(b/135760455): Move this method anonymous namespace in a cc file.
+inline RuntimeShape ExtendShapeBatchToSpace(const RuntimeShape& shape) {
+ if (shape.DimensionsCount() == 4) {
+ return shape;
+ }
+ RuntimeShape new_shape(4, 1);
+ new_shape.SetDim(0, shape.Dims(0));
+ new_shape.SetDim(1, shape.Dims(1));
+ new_shape.SetDim(3, shape.Dims(2));
+ return new_shape;
+}
+
+template <typename T>
+inline void BatchToSpaceND(const RuntimeShape& unextended_input1_shape,
+ const T* input1_data,
+ const RuntimeShape& unextended_input2_shape,
+ const int32_t* block_shape_data,
+ const RuntimeShape& unextended_input3_shape,
+ const int32_t* crops_data,
+ const RuntimeShape& unextended_output_shape,
+ T* output_data) {
+ ruy::profiler::ScopeLabel label("BatchToSpaceND");
+ TFLITE_DCHECK_GE(unextended_input1_shape.DimensionsCount(), 3);
+ TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(unextended_input1_shape.DimensionsCount(),
+ unextended_output_shape.DimensionsCount());
+
+ const RuntimeShape input1_shape =
+ ExtendShapeBatchToSpace(unextended_input1_shape);
+ const RuntimeShape output_shape =
+ ExtendShapeBatchToSpace(unextended_output_shape);
+
+ const int output_width = output_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_batch_size = output_shape.Dims(0);
+
+ const int depth = input1_shape.Dims(3);
+ const int input_width = input1_shape.Dims(2);
+ const int input_height = input1_shape.Dims(1);
+ const int input_batch_size = input1_shape.Dims(0);
+
+ const int block_shape_height = block_shape_data[0];
+ const int block_shape_width =
+ unextended_input1_shape.DimensionsCount() == 4 ? block_shape_data[1] : 1;
+ const int crops_top = crops_data[0];
+ const int crops_left =
+ unextended_input1_shape.DimensionsCount() == 4 ? crops_data[2] : 0;
+ for (int in_batch = 0; in_batch < input_batch_size; ++in_batch) {
+ const int out_batch = in_batch % output_batch_size;
+ const int spatial_offset = in_batch / output_batch_size;
+ for (int in_h = 0; in_h < input_height; ++in_h) {
+ const int out_h = in_h * block_shape_height +
+ spatial_offset / block_shape_width - crops_top;
+ if (out_h < 0 || out_h >= output_height) {
+ continue;
+ }
+ for (int in_w = 0; in_w < input_width; ++in_w) {
+ const int out_w = in_w * block_shape_width +
+ spatial_offset % block_shape_width - crops_left;
+
+ if (out_w < 0 || out_w >= output_width) {
+ continue;
+ }
+ T* out = output_data + Offset(output_shape, out_batch, out_h, out_w, 0);
+ const T* in =
+ input1_data + Offset(input1_shape, in_batch, in_h, in_w, 0);
+ memcpy(out, in, depth * sizeof(T));
+ }
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_BATCH_TO_SPACE_ND_H_
diff --git a/tensorflow/lite/kernels/internal/reference/binary_function.h b/tensorflow/lite/kernels/internal/reference/binary_function.h
new file mode 100644
index 0000000..1711940
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/binary_function.h
@@ -0,0 +1,80 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_BINARY_FUNCTION_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_BINARY_FUNCTION_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+// Also appears to duplicate MinimumMaximum.
+//
+// R: Result type. T1: Input 1 type. T2: Input 2 type.
+template <typename R, typename T1, typename T2>
+inline void BroadcastBinaryFunction4DSlow(
+ const RuntimeShape& unextended_input1_shape, const T1* input1_data,
+ const RuntimeShape& unextended_input2_shape, const T2* input2_data,
+ const RuntimeShape& unextended_output_shape, R* output_data,
+ R (*func)(T1, T2)) {
+ TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(4, unextended_output_shape);
+
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(unextended_input1_shape,
+ unextended_input2_shape, &desc1, &desc2);
+
+ for (int b = 0; b < output_shape.Dims(0); ++b) {
+ for (int y = 0; y < output_shape.Dims(1); ++y) {
+ for (int x = 0; x < output_shape.Dims(2); ++x) {
+ for (int c = 0; c < output_shape.Dims(3); ++c) {
+ auto out_idx = Offset(output_shape, b, y, x, c);
+ auto in1_idx = SubscriptToIndex(desc1, b, y, x, c);
+ auto in2_idx = SubscriptToIndex(desc2, b, y, x, c);
+ auto in1_val = input1_data[in1_idx];
+ auto in2_val = input2_data[in2_idx];
+ output_data[out_idx] = func(in1_val, in2_val);
+ }
+ }
+ }
+ }
+}
+
+// R: Result type. T1: Input 1 type. T2: Input 2 type.
+template <typename R, typename T1, typename T2>
+inline void BinaryFunction(const RuntimeShape& input1_shape,
+ const T1* input1_data,
+ const RuntimeShape& input2_shape,
+ const T2* input2_data,
+ const RuntimeShape& output_shape, R* output_data,
+ R (*func)(T1, T2)) {
+ const int flat_size =
+ MatchingFlatSize(input1_shape, input2_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = func(input1_data[i], input2_data[i]);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_BINARY_FUNCTION_H_
diff --git a/tensorflow/lite/kernels/internal/reference/ceil.h b/tensorflow/lite/kernels/internal/reference/ceil.h
new file mode 100644
index 0000000..66d1dc3
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/ceil.h
@@ -0,0 +1,37 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CEIL_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CEIL_H_
+
+#include <cmath>
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline void Ceil(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = std::ceil(input_data[i]);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CEIL_H_
diff --git a/tensorflow/lite/kernels/internal/reference/comparisons.h b/tensorflow/lite/kernels/internal/reference/comparisons.h
new file mode 100644
index 0000000..6344bdc
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/comparisons.h
@@ -0,0 +1,280 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_COMPARISONS_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_COMPARISONS_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+template <typename T>
+inline bool EqualFn(T lhs, T rhs) {
+ return lhs == rhs;
+}
+
+template <typename T>
+inline bool NotEqualFn(T lhs, T rhs) {
+ return lhs != rhs;
+}
+
+template <typename T>
+inline bool GreaterFn(T lhs, T rhs) {
+ return lhs > rhs;
+}
+template <typename T>
+inline bool GreaterEqualFn(T lhs, T rhs) {
+ return lhs >= rhs;
+}
+template <typename T>
+inline bool LessFn(T lhs, T rhs) {
+ return lhs < rhs;
+}
+template <typename T>
+inline bool LessEqualFn(T lhs, T rhs) {
+ return lhs <= rhs;
+}
+
+template <typename T>
+using ComparisonFn = bool (*)(T, T);
+
+template <typename T, ComparisonFn<T> F>
+inline void ComparisonImpl(
+ const ComparisonParams& op_params, const RuntimeShape& input1_shape,
+ const T* input1_data, const RuntimeShape& input2_shape,
+ const T* input2_data, const RuntimeShape& output_shape, bool* output_data) {
+ const int64_t flatsize =
+ MatchingFlatSize(input1_shape, input2_shape, output_shape);
+ for (int64_t i = 0; i < flatsize; ++i) {
+ output_data[i] = F(input1_data[i], input2_data[i]);
+ }
+}
+
+template <ComparisonFn<float> F>
+inline void Comparison(const ComparisonParams& op_params,
+ const RuntimeShape& input1_shape,
+ const float* input1_data,
+ const RuntimeShape& input2_shape,
+ const float* input2_data,
+ const RuntimeShape& output_shape, bool* output_data) {
+ ComparisonImpl<float, F>(op_params, input1_shape, input1_data, input2_shape,
+ input2_data, output_shape, output_data);
+}
+
+template <typename T, ComparisonFn<int32_t> F>
+inline void ComparisonWithScaling(
+ const ComparisonParams& op_params, const RuntimeShape& input1_shape,
+ const T* input1_data, const RuntimeShape& input2_shape,
+ const T* input2_data, const RuntimeShape& output_shape, bool* output_data) {
+ int left_shift = op_params.left_shift;
+ int32_t input1_offset = op_params.input1_offset;
+ int32_t input1_multiplier = op_params.input1_multiplier;
+ int input1_shift = op_params.input1_shift;
+ int32_t input2_offset = op_params.input2_offset;
+ int32_t input2_multiplier = op_params.input2_multiplier;
+ int input2_shift = op_params.input2_shift;
+
+ const int64_t flatsize =
+ MatchingFlatSize(input1_shape, input2_shape, output_shape);
+ for (int64_t i = 0; i < flatsize; ++i) {
+ const int32_t input1_val = input1_offset + input1_data[i];
+ const int32_t input2_val = input2_offset + input2_data[i];
+ const int32_t shifted_input1_val = input1_val * (1 << left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, input1_multiplier, input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, input2_multiplier, input2_shift);
+ output_data[i] = F(scaled_input1_val, scaled_input2_val);
+ }
+}
+
+struct BroadcastComparison4DSlowCommon {
+ const RuntimeShape output_shape;
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+};
+
+inline BroadcastComparison4DSlowCommon BroadcastComparison4DSlowPreprocess(
+ const RuntimeShape& unextended_input1_shape,
+ const RuntimeShape& unextended_input2_shape,
+ const RuntimeShape& unextended_output_shape) {
+ TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(unextended_input1_shape,
+ unextended_input2_shape, &desc1, &desc2);
+ return {RuntimeShape::ExtendedShape(4, unextended_output_shape), desc1,
+ desc2};
+}
+
+template <typename T, ComparisonFn<T> F>
+inline void BroadcastComparison4DSlowImpl(
+ const ComparisonParams& op_params,
+ const RuntimeShape& unextended_input1_shape, const T* input1_data,
+ const RuntimeShape& unextended_input2_shape, const T* input2_data,
+ const RuntimeShape& unextended_output_shape, bool* output_data) {
+ const BroadcastComparison4DSlowCommon dims =
+ BroadcastComparison4DSlowPreprocess(unextended_input1_shape,
+ unextended_input2_shape,
+ unextended_output_shape);
+
+ for (int b = 0; b < dims.output_shape.Dims(0); ++b) {
+ for (int y = 0; y < dims.output_shape.Dims(1); ++y) {
+ for (int x = 0; x < dims.output_shape.Dims(2); ++x) {
+ for (int c = 0; c < dims.output_shape.Dims(3); ++c) {
+ output_data[Offset(dims.output_shape, b, y, x, c)] =
+ F(input1_data[SubscriptToIndex(dims.desc1, b, y, x, c)],
+ input2_data[SubscriptToIndex(dims.desc2, b, y, x, c)]);
+ }
+ }
+ }
+ }
+}
+
+template <ComparisonFn<float> F>
+inline void BroadcastComparison4DSlow(const ComparisonParams& op_params,
+ const RuntimeShape& input1_shape,
+ const float* input1_data,
+ const RuntimeShape& input2_shape,
+ const float* input2_data,
+ const RuntimeShape& output_shape,
+ bool* output_data) {
+ BroadcastComparison4DSlowImpl<float, F>(op_params, input1_shape, input1_data,
+ input2_shape, input2_data,
+ output_shape, output_data);
+}
+
+template <typename T, ComparisonFn<int32_t> F>
+inline void BroadcastComparison4DSlowWithScaling(
+ const ComparisonParams& op_params,
+ const RuntimeShape& unextended_input1_shape, const T* input1_data,
+ const RuntimeShape& unextended_input2_shape, const T* input2_data,
+ const RuntimeShape& unextended_output_shape, bool* output_data) {
+ const BroadcastComparison4DSlowCommon dims =
+ BroadcastComparison4DSlowPreprocess(unextended_input1_shape,
+ unextended_input2_shape,
+ unextended_output_shape);
+
+ int left_shift = op_params.left_shift;
+ int32_t input1_offset = op_params.input1_offset;
+ int32_t input1_multiplier = op_params.input1_multiplier;
+ int input1_shift = op_params.input1_shift;
+ int32_t input2_offset = op_params.input2_offset;
+ int32_t input2_multiplier = op_params.input2_multiplier;
+ int input2_shift = op_params.input2_shift;
+
+ for (int b = 0; b < dims.output_shape.Dims(0); ++b) {
+ for (int y = 0; y < dims.output_shape.Dims(1); ++y) {
+ for (int x = 0; x < dims.output_shape.Dims(2); ++x) {
+ for (int c = 0; c < dims.output_shape.Dims(3); ++c) {
+ const int32_t input1_val =
+ input1_offset +
+ input1_data[SubscriptToIndex(dims.desc1, b, y, x, c)];
+ const int32_t input2_val =
+ input2_offset +
+ input2_data[SubscriptToIndex(dims.desc2, b, y, x, c)];
+ const int32_t shifted_input1_val = input1_val * (1 << left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, input1_multiplier, input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, input2_multiplier, input2_shift);
+ output_data[Offset(dims.output_shape, b, y, x, c)] =
+ F(scaled_input1_val, scaled_input2_val);
+ }
+ }
+ }
+ }
+}
+
+#define TFLITE_COMPARISON_OP(name) \
+ inline void name(const ComparisonParams& op_params, \
+ const RuntimeShape& input1_shape, const float* input1_data, \
+ const RuntimeShape& input2_shape, const float* input2_data, \
+ const RuntimeShape& output_shape, bool* output_data) { \
+ Comparison<name##Fn>(op_params, input1_shape, input1_data, input2_shape, \
+ input2_data, output_shape, output_data); \
+ } \
+ template <typename T> \
+ inline void name##NoScaling( \
+ const ComparisonParams& op_params, const RuntimeShape& input1_shape, \
+ const T* input1_data, const RuntimeShape& input2_shape, \
+ const T* input2_data, const RuntimeShape& output_shape, \
+ bool* output_data) { \
+ ComparisonImpl<T, name##Fn>(op_params, input1_shape, input1_data, \
+ input2_shape, input2_data, output_shape, \
+ output_data); \
+ } \
+ template <typename T> \
+ inline void name##WithScaling( \
+ const ComparisonParams& op_params, const RuntimeShape& input1_shape, \
+ const T* input1_data, const RuntimeShape& input2_shape, \
+ const T* input2_data, const RuntimeShape& output_shape, \
+ bool* output_data) { \
+ ComparisonWithScaling<T, name##Fn>(op_params, input1_shape, input1_data, \
+ input2_shape, input2_data, \
+ output_shape, output_data); \
+ } \
+ template <typename T> \
+ inline void Broadcast4DSlow##name##NoScaling( \
+ const ComparisonParams& op_params, const RuntimeShape& input1_shape, \
+ const T* input1_data, const RuntimeShape& input2_shape, \
+ const T* input2_data, const RuntimeShape& output_shape, \
+ bool* output_data) { \
+ BroadcastComparison4DSlowImpl<T, name##Fn>( \
+ op_params, input1_shape, input1_data, input2_shape, input2_data, \
+ output_shape, output_data); \
+ } \
+ inline void Broadcast4DSlow##name( \
+ const ComparisonParams& op_params, const RuntimeShape& input1_shape, \
+ const float* input1_data, const RuntimeShape& input2_shape, \
+ const float* input2_data, const RuntimeShape& output_shape, \
+ bool* output_data) { \
+ BroadcastComparison4DSlow<name##Fn>(op_params, input1_shape, input1_data, \
+ input2_shape, input2_data, \
+ output_shape, output_data); \
+ } \
+ template <typename T> \
+ inline void Broadcast4DSlow##name##WithScaling( \
+ const ComparisonParams& op_params, const RuntimeShape& input1_shape, \
+ const T* input1_data, const RuntimeShape& input2_shape, \
+ const T* input2_data, const RuntimeShape& output_shape, \
+ bool* output_data) { \
+ BroadcastComparison4DSlowWithScaling<T, name##Fn>( \
+ op_params, input1_shape, input1_data, input2_shape, input2_data, \
+ output_shape, output_data); \
+ }
+TFLITE_COMPARISON_OP(Equal);
+TFLITE_COMPARISON_OP(NotEqual);
+TFLITE_COMPARISON_OP(Greater);
+TFLITE_COMPARISON_OP(GreaterEqual);
+TFLITE_COMPARISON_OP(Less);
+TFLITE_COMPARISON_OP(LessEqual);
+#undef TFLITE_COMPARISON_OP
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_COMPARISONS_H_
diff --git a/tensorflow/lite/kernels/internal/reference/concatenation.h b/tensorflow/lite/kernels/internal/reference/concatenation.h
new file mode 100644
index 0000000..998bb09
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/concatenation.h
@@ -0,0 +1,139 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CONCATENATION_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CONCATENATION_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+template <typename Scalar>
+inline void Concatenation(const ConcatenationParams& params,
+ const RuntimeShape* const* input_shapes,
+ const Scalar* const* input_data,
+ const RuntimeShape& output_shape,
+ Scalar* output_data) {
+ int axis = params.axis;
+ int inputs_count = params.inputs_count;
+ const int concat_dimensions = output_shape.DimensionsCount();
+ TFLITE_DCHECK_LT(axis, concat_dimensions);
+
+ int64_t concat_size = 0;
+ for (int i = 0; i < inputs_count; i++) {
+ TFLITE_DCHECK_EQ(input_shapes[i]->DimensionsCount(), concat_dimensions);
+ for (int j = 0; j < concat_dimensions; j++) {
+ if (j != axis) {
+ MatchingDim(*input_shapes[i], j, output_shape, j);
+ }
+ }
+ concat_size += input_shapes[i]->Dims(axis);
+ }
+ TFLITE_DCHECK_EQ(concat_size, output_shape.Dims(axis));
+ int64_t outer_size = 1;
+ for (int i = 0; i < axis; ++i) {
+ outer_size *= output_shape.Dims(i);
+ }
+ // For all input arrays,
+ // FlatSize() = outer_size * Dims(axis) * base_inner_size;
+ int64_t base_inner_size = 1;
+ for (int i = axis + 1; i < concat_dimensions; ++i) {
+ base_inner_size *= output_shape.Dims(i);
+ }
+
+ Scalar* output_ptr = output_data;
+ for (int k = 0; k < outer_size; k++) {
+ for (int i = 0; i < inputs_count; ++i) {
+ const int copy_size = input_shapes[i]->Dims(axis) * base_inner_size;
+ const Scalar* input_ptr = input_data[i] + k * copy_size;
+ memcpy(output_ptr, input_ptr, copy_size * sizeof(Scalar));
+ output_ptr += copy_size;
+ }
+ }
+}
+
+// TODO(b/174275780): The quantized implementation of concatentation isn't fully
+// quantized as it takes scale as a floating point value. This should be fixed
+// when optimizng this routine further.
+inline void ConcatenationWithScaling(const ConcatenationParams& params,
+ const RuntimeShape* const* input_shapes,
+ const uint8_t* const* input_data,
+ const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ int axis = params.axis;
+ const int32_t* input_zeropoint = params.input_zeropoint;
+ const float* input_scale = params.input_scale;
+ int inputs_count = params.inputs_count;
+ const int32_t output_zeropoint = params.output_zeropoint;
+ const float output_scale = params.output_scale;
+
+ const int concat_dimensions = output_shape.DimensionsCount();
+ TFLITE_DCHECK_LT(axis, concat_dimensions);
+
+ int64_t concat_size = 0;
+ for (int i = 0; i < inputs_count; i++) {
+ TFLITE_DCHECK_EQ(input_shapes[i]->DimensionsCount(), concat_dimensions);
+ for (int j = 0; j < concat_dimensions; j++) {
+ if (j != axis) {
+ MatchingDim(*input_shapes[i], j, output_shape, j);
+ }
+ }
+ concat_size += input_shapes[i]->Dims(axis);
+ }
+ TFLITE_DCHECK_EQ(concat_size, output_shape.Dims(axis));
+ int64_t outer_size = 1;
+ for (int i = 0; i < axis; ++i) {
+ outer_size *= output_shape.Dims(i);
+ }
+ // For all input arrays,
+ // FlatSize() = outer_size * Dims(axis) * base_inner_size;
+ int64_t base_inner_size = 1;
+ for (int i = axis + 1; i < concat_dimensions; ++i) {
+ base_inner_size *= output_shape.Dims(i);
+ }
+
+ const float inverse_output_scale = 1.f / output_scale;
+ uint8_t* output_ptr = output_data;
+ for (int k = 0; k < outer_size; k++) {
+ for (int i = 0; i < inputs_count; ++i) {
+ const int copy_size = input_shapes[i]->Dims(axis) * base_inner_size;
+ const uint8_t* input_ptr = input_data[i] + k * copy_size;
+ if (input_zeropoint[i] == output_zeropoint &&
+ input_scale[i] == output_scale) {
+ memcpy(output_ptr, input_ptr, copy_size);
+ } else {
+ const float scale = input_scale[i] * inverse_output_scale;
+ const float bias = -input_zeropoint[i] * scale;
+ for (int j = 0; j < copy_size; ++j) {
+ const int32_t value = static_cast<int32_t>(tflite::TfLiteRound(
+ input_ptr[j] * scale + bias)) +
+ output_zeropoint;
+ output_ptr[j] = static_cast<uint8_t>(
+ std::max<int32_t>(std::min<int32_t>(255, value), 0));
+ }
+ }
+ output_ptr += copy_size;
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CONCATENATION_H_
diff --git a/tensorflow/lite/kernels/internal/reference/conv.h b/tensorflow/lite/kernels/internal/reference/conv.h
new file mode 100644
index 0000000..5a6369d
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/conv.h
@@ -0,0 +1,264 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CONV_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CONV_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline void Conv(const ConvParams& params, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& filter_shape,
+ const float* filter_data, const RuntimeShape& bias_shape,
+ const float* bias_data, const RuntimeShape& output_shape,
+ float* output_data, const RuntimeShape& im2col_shape,
+ float* im2col_data) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const float output_activation_min = params.float_activation_min;
+ const float output_activation_max = params.float_activation_max;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ (void)im2col_data; // only used in optimized code.
+ (void)im2col_shape; // only used in optimized code.
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ float total = 0.f;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+
+ if (!is_point_inside_image) {
+ continue;
+ }
+
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ float input_value = input_data[Offset(input_shape, batch, in_y,
+ in_x, in_channel)];
+ float filter_value = filter_data[Offset(
+ filter_shape, out_channel, filter_y, filter_x, in_channel)];
+ total += (input_value * filter_value);
+ }
+ }
+ }
+ float bias_value = 0.0f;
+ if (bias_data) {
+ bias_value = bias_data[out_channel];
+ }
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ ActivationFunctionWithMinMax(total + bias_value,
+ output_activation_min,
+ output_activation_max);
+ }
+ }
+ }
+ }
+}
+
+inline void Conv(const ConvParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& filter_shape,
+ const uint8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ uint8_t* output_data, const RuntimeShape& im2col_shape,
+ uint8_t* im2col_data, void* cpu_backend_context) {
+ (void)cpu_backend_context; // only used in optimized code.
+ (void)im2col_data; // only used in optimized code.
+ (void)im2col_shape; // only used in optimized code.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ int32_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+
+ if (!is_point_inside_image) {
+ continue;
+ }
+
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ int32_t input_val = input_data[Offset(input_shape, batch, in_y,
+ in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, out_channel, filter_y, filter_x, in_channel)];
+ acc +=
+ (filter_val + filter_offset) * (input_val + input_offset);
+ }
+ }
+ }
+ if (bias_data) {
+ acc += bias_data[out_channel];
+ }
+ acc = MultiplyByQuantizedMultiplier(acc, output_multiplier,
+ output_shift);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ static_cast<uint8_t>(acc);
+ }
+ }
+ }
+ }
+}
+
+inline void HybridConvPerChannel(
+ const ConvParams& params, float* scaling_factors_ptr,
+ const RuntimeShape& input_shape, const int8_t* input_data,
+ const RuntimeShape& filter_shape, const int8_t* filter_data,
+ const RuntimeShape& bias_shape, const float* bias_data,
+ const RuntimeShape& output_shape, float* output_data,
+ const RuntimeShape& im2col_shape, int8_t* im2col_data,
+ const float* per_channel_scale, int32_t* input_offset) {
+ (void)im2col_data; // only used in optimized code.
+ (void)im2col_shape; // only used in optimized code.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const float output_activation_min = params.float_activation_min;
+ const float output_activation_max = params.float_activation_max;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ int32_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ const int in_y =
+ in_y_origin + dilation_height_factor * filter_y;
+ // If the location is outside the bounds of the input image,
+ // use zero as a default value.
+ if ((in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height)) {
+ int32_t input_val = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ int32_t filter_val =
+ filter_data[Offset(filter_shape, out_channel, filter_y,
+ filter_x, in_channel)];
+ acc += filter_val * (input_val - input_offset[batch]);
+ }
+ }
+ }
+ }
+ float acc_float =
+ acc * per_channel_scale[out_channel] * scaling_factors_ptr[batch];
+ if (bias_data) {
+ acc_float += bias_data[out_channel];
+ }
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ ActivationFunctionWithMinMax(acc_float, output_activation_min,
+ output_activation_max);
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CONV_H_
diff --git a/tensorflow/lite/kernels/internal/reference/cumsum.h b/tensorflow/lite/kernels/internal/reference/cumsum.h
new file mode 100644
index 0000000..e65bf58
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/cumsum.h
@@ -0,0 +1,85 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CUMSUM_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CUMSUM_H_
+
+#include <cstdint>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+template <typename T>
+inline void CumSum(const T* input_data, const RuntimeShape& shape, int32_t axis,
+ bool exclusive, bool reverse, T* output_data) {
+ const int32_t rank = shape.DimensionsCount();
+ TFLITE_DCHECK_GE(rank, 1);
+ TFLITE_DCHECK_GE(axis, 0);
+ TFLITE_DCHECK_LT(axis, rank);
+
+ size_t inner = 1;
+ size_t outer = 1;
+ size_t depth = 1;
+ for (int32_t i = 0; i < rank; i++) {
+ if (i < axis)
+ inner *= shape.Dims(i);
+ else if (i > axis)
+ outer *= shape.Dims(i);
+ else
+ depth = shape.Dims(i);
+ }
+
+ for (size_t outer_index = 0; outer_index < outer; outer_index++) {
+ size_t outer_index_adj;
+ if (reverse)
+ outer_index_adj = (outer - 1) - outer_index;
+ else
+ outer_index_adj = outer_index;
+ for (size_t inner_index = 0; inner_index < inner; inner_index++) {
+ T accumulator = 0;
+ size_t inner_index_adj;
+ if (reverse)
+ inner_index_adj = (inner - 1) - inner_index;
+ else
+ inner_index_adj = inner_index;
+ for (size_t depth_index = 0; depth_index < depth; depth_index++) {
+ size_t depth_index_adj;
+ if (reverse)
+ depth_index_adj = (depth - 1) - depth_index;
+ else
+ depth_index_adj = depth_index;
+
+ size_t index = outer_index_adj;
+ index += inner_index_adj * depth * outer;
+ index += depth_index_adj * outer;
+
+ if (exclusive) {
+ output_data[index] = accumulator;
+ accumulator += input_data[index];
+ } else {
+ accumulator += input_data[index];
+ output_data[index] = accumulator;
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CUMSUM_H_
diff --git a/tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h b/tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h
new file mode 100644
index 0000000..0cecb16
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h
@@ -0,0 +1,100 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEPTHWISECONV_FLOAT_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEPTHWISECONV_FLOAT_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline void DepthwiseConv(
+ const DepthwiseParams& params, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& filter_shape,
+ const float* filter_data, const RuntimeShape& bias_shape,
+ const float* bias_data, const RuntimeShape& output_shape,
+ float* output_data) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const float output_activation_min = params.float_activation_min;
+ const float output_activation_max = params.float_activation_max;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ for (int b = 0; b < batches; ++b) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int ic = 0; ic < input_depth; ++ic) {
+ for (int m = 0; m < depth_multiplier; m++) {
+ const int oc = m + ic * depth_multiplier;
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ float total = 0.f;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ const int in_y =
+ in_y_origin + dilation_height_factor * filter_y;
+ // If the location is outside the bounds of the input image,
+ // use zero as a default value.
+ if ((in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height)) {
+ float input_value =
+ input_data[Offset(input_shape, b, in_y, in_x, ic)];
+ float filter_value = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, oc)];
+ total += (input_value * filter_value);
+ }
+ }
+ }
+ float bias_value = 0.0f;
+ if (bias_data) {
+ bias_value = bias_data[oc];
+ }
+ output_data[Offset(output_shape, b, out_y, out_x, oc)] =
+ ActivationFunctionWithMinMax(total + bias_value,
+ output_activation_min,
+ output_activation_max);
+ }
+ }
+ }
+ }
+ }
+}
+
+} // end namespace reference_ops
+} // end namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEPTHWISECONV_FLOAT_H_
diff --git a/tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h b/tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h
new file mode 100644
index 0000000..20bf83d
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h
@@ -0,0 +1,297 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEPTHWISECONV_UINT8_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEPTHWISECONV_UINT8_H_
+
+#include <algorithm>
+
+#include "fixedpoint/fixedpoint.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+// Used in tests and template parameters to control which version of depthwise
+// convolution is called. Primarily for reference code, and specializations
+// forced in tests.
+enum class DepthwiseConvImplementation {
+ // Run all tests against kUseStandardEntry even if also testing another
+ // kernel, since we need to be sure that the main DepthwiseConv() function in
+ // optimized_ops.h dispatches to a correctly-executing kernel.
+ kNone = 0, // The "default" option: use the normal
+ // DepthwiseConv kernel (entry) function.
+ kUseGenericKernel, // Forced use of generic kernel.
+ kUseNeon3x3, // 3x3 kernel that uses NEON when available.
+ kUseNeon3x3DotProduct, // 3x3 kernel that uses dot-product enabled NEON
+ // when available.
+ kUseCModel3x3DotProduct, // 3x3 kernel, reference C model that is intended
+ // to match overall design NEON code.
+ kUseUnwound3x3DotProduct, // 3x3 kernel, reference C model with unwound loops
+ // and some arrays.
+ kUseIntrinsics3x3DotProduct, // 3x3 kernel using NEON intrinsics.
+};
+
+// Category of depthwise convolution output rounding.
+enum class DepthwiseConvOutputRounding {
+ kNone = 0, // Invalid: specific method must be specified.
+ kAwayFromZero, // Original method: exact halves rounded away from zero.
+ kUpward, // Halves towards +infinity: adds 0.5 before truncate.
+ // This is where a future kNearestEven would be placed.
+};
+
+// Category of depthwise convolution depth multiplication.
+enum class DepthwiseConvDepthMultiplication {
+ kNoMultiplication = 0, // Depth multiplier = 1.
+ kUnitInputDepth, // Input depth = 1, output depth = depth multiplier.
+};
+
+namespace reference_ops {
+namespace depthwise_conv {
+
+template <DepthwiseConvOutputRounding output_rounding>
+inline int32_t DepthwiseConvRound(int32_t x, int32_t quantized_multiplier,
+ int shift) {
+ TFLITE_DCHECK_NE(output_rounding, DepthwiseConvOutputRounding::kNone);
+ return MultiplyByQuantizedMultiplier(x, quantized_multiplier, shift);
+}
+
+template <>
+inline int32_t DepthwiseConvRound<DepthwiseConvOutputRounding::kAwayFromZero>(
+ int32_t x, int32_t quantized_multiplier, int shift) {
+ return MultiplyByQuantizedMultiplier(x, quantized_multiplier, shift);
+}
+
+template <>
+inline int32_t DepthwiseConvRound<DepthwiseConvOutputRounding::kUpward>(
+ int32_t x, int32_t quantized_multiplier, int shift) {
+ using gemmlowp::SaturatingRoundingDoublingHighMul;
+ const int left_shift = shift > 0 ? shift : 0;
+ const int right_shift = shift > 0 ? 0 : -shift;
+ const int rounding_offset = right_shift > 0 ? 1 << (right_shift - 1) : 0;
+ return (SaturatingRoundingDoublingHighMul(x * (1 << left_shift),
+ quantized_multiplier) +
+ rounding_offset) >>
+ right_shift;
+}
+
+template <DepthwiseConvOutputRounding output_rounding>
+struct DepthwiseConvBasicKernel {
+ static inline void Run(
+ const DepthwiseParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& filter_shape,
+ const uint8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ for (int b = 0; b < batches; ++b) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int ic = 0; ic < input_depth; ++ic) {
+ for (int m = 0; m < depth_multiplier; m++) {
+ const int oc = m + ic * depth_multiplier;
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ int32_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x =
+ in_x_origin + dilation_width_factor * filter_x;
+ const int in_y =
+ in_y_origin + dilation_height_factor * filter_y;
+ // If the location is outside the bounds of the input image,
+ // use zero as a default value.
+ if ((in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height)) {
+ int32_t input_val =
+ input_data[Offset(input_shape, b, in_y, in_x, ic)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, oc)];
+ acc += (filter_val + filter_offset) *
+ (input_val + input_offset);
+ }
+ }
+ }
+ if (bias_data) {
+ acc += bias_data[oc];
+ }
+ acc = DepthwiseConvRound<output_rounding>(acc, output_multiplier,
+ output_shift);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[Offset(output_shape, b, out_y, out_x, oc)] =
+ static_cast<uint8_t>(acc);
+ }
+ }
+ }
+ }
+ }
+ }
+
+ // TODO(b/148596273): Reconcile reference versions, perhaps with common
+ // MultiplyByQuantizedMultiplier or DepthwiseConvRound function.
+ static inline void RunPerChannel(
+ const DepthwiseParams& params, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ // Get parameters.
+ // TODO(b/141565753): Re-introduce ScopedProfilingLabel on Micro.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t input_offset = params.input_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ const int32_t* output_multiplier = params.output_multiplier_per_channel;
+ const int32_t* output_shift = params.output_shift_per_channel;
+
+ // Check dimensions of the tensors.
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ for (int m = 0; m < depth_multiplier; ++m) {
+ const int output_channel = m + in_channel * depth_multiplier;
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ int32_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x =
+ in_x_origin + dilation_width_factor * filter_x;
+ const int in_y =
+ in_y_origin + dilation_height_factor * filter_y;
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+ if (is_point_inside_image) {
+ int32_t input_val = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, output_channel)];
+ // Accumulate with 32 bits accumulator.
+ // In the nudging process during model quantization, we
+ // force real value of 0.0 be represented by a quantized
+ // value. This guarantees that the input_offset is a int8_t,
+ // even though it is represented using int32_t. int32_t +=
+ // int8_t
+ // * (int8_t - int8_t) so the highest value we can get from
+ // each accumulation is [-127, 127] * ([-128, 127] -
+ // [-128, 127]), which is [-32512, 32512]. log2(32512)
+ // = 14.98, which means we can accumulate at least 2^16
+ // multiplications without overflow. The accumulator is
+ // applied to a filter so the accumulation logic will hold
+ // as long as the filter size (filter_y * filter_x *
+ // in_channel) does not exceed 2^16, which is the case in
+ // all the models we have seen so far.
+ acc += filter_val * (input_val + input_offset);
+ }
+ }
+ }
+ if (bias_data) {
+ acc += bias_data[output_channel];
+ }
+ acc = DepthwiseConvRound<output_rounding>(
+ acc, output_multiplier[output_channel],
+ output_shift[output_channel]);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ output_channel)] = static_cast<int8_t>(acc);
+ }
+ }
+ }
+ }
+ }
+ }
+};
+
+} // namespace depthwise_conv
+
+inline void DepthwiseConv(
+ const DepthwiseParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& filter_shape,
+ const uint8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ return depthwise_conv::DepthwiseConvBasicKernel<
+ DepthwiseConvOutputRounding::kAwayFromZero>::Run(params, input_shape,
+ input_data, filter_shape,
+ filter_data, bias_shape,
+ bias_data, output_shape,
+ output_data);
+}
+
+} // namespace reference_ops
+} // end namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEPTHWISECONV_UINT8_H_
diff --git a/tensorflow/lite/kernels/internal/reference/dequantize.h b/tensorflow/lite/kernels/internal/reference/dequantize.h
new file mode 100644
index 0000000..b90951f
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/dequantize.h
@@ -0,0 +1,78 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEQUANTIZE_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEQUANTIZE_H_
+
+#include <limits.h>
+
+#include <vector>
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+// Dequantizes into a float without rounding.
+template <typename InputT, typename OutputT>
+inline void Dequantize(const tflite::DequantizationParams& op_params,
+ const RuntimeShape& input_shape,
+ const InputT* input_data,
+ const RuntimeShape& output_shape, OutputT* output_data) {
+ int32_t zero_point = op_params.zero_point;
+ const double scale = op_params.scale;
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; i++) {
+ const int32_t val = input_data[i];
+ const OutputT result = static_cast<OutputT>(scale * (val - zero_point));
+ output_data[i] = result;
+ }
+}
+
+// Dequantizes per-channel quantized tensor to float.
+template <typename T>
+inline void PerChannelDequantize(
+ const tflite::PerChannelDequantizationParams& op_params,
+ const RuntimeShape& input_shape, const T* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ // Ensure flat size is same.
+ MatchingFlatSize(input_shape, output_shape);
+
+ const int32_t* zero_point = op_params.zero_point;
+ const float* scale = op_params.scale;
+ const int32_t quantized_dimension = op_params.quantized_dimension;
+ const int32_t num_dims = input_shape.DimensionsCount();
+ const int32_t* dims_data = input_shape.DimsData();
+ std::vector<int> current_dim(num_dims, 0);
+
+ do {
+ size_t offset =
+ ReducedOutputOffset(num_dims, reinterpret_cast<const int*>(dims_data),
+ current_dim.data(), 0, nullptr);
+ const int channel = current_dim[quantized_dimension];
+ const int32_t val = input_data[offset];
+ const float result =
+ static_cast<float>(scale[channel] * (val - zero_point[channel]));
+ output_data[offset] = result;
+ } while (NextIndex(num_dims, reinterpret_cast<const int*>(dims_data),
+ current_dim.data()));
+}
+
+} // namespace reference_ops
+
+} // namespace tflite
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_DEQUANTIZE_H_
diff --git a/tensorflow/lite/kernels/internal/reference/elu.h b/tensorflow/lite/kernels/internal/reference/elu.h
new file mode 100644
index 0000000..3dc9358
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/elu.h
@@ -0,0 +1,37 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ELU_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ELU_H_
+
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline void Elu(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ const float val = input_data[i];
+ output_data[i] = val < 0.0f ? TfLiteExpm1(val) : val;
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ELU_H_
diff --git a/tensorflow/lite/kernels/internal/reference/exp.h b/tensorflow/lite/kernels/internal/reference/exp.h
new file mode 100644
index 0000000..134ee13
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/exp.h
@@ -0,0 +1,38 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_EXP_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_EXP_H_
+
+#include <cmath>
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+template <typename T>
+inline void Exp(const T* input_data, const size_t num_elements,
+ T* output_data) {
+ ruy::profiler::ScopeLabel label("Exp");
+ for (size_t idx = 0; idx < num_elements; ++idx) {
+ output_data[idx] = std::exp(input_data[idx]);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_EXP_H_
diff --git a/tensorflow/lite/kernels/internal/reference/fill.h b/tensorflow/lite/kernels/internal/reference/fill.h
new file mode 100644
index 0000000..16630e6
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/fill.h
@@ -0,0 +1,38 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FILL_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FILL_H_
+
+#include <cmath>
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+template <typename T>
+void Fill(const RuntimeShape& value_shape, const T* value_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ TFLITE_DCHECK_EQ(value_shape.DimensionsCount(), 0);
+ const int flat_size = output_shape.FlatSize();
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = *value_data;
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FILL_H_
diff --git a/tensorflow/lite/kernels/internal/reference/floor.h b/tensorflow/lite/kernels/internal/reference/floor.h
new file mode 100644
index 0000000..0693fd4
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/floor.h
@@ -0,0 +1,39 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_H_
+
+#include <cmath>
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline void Floor(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; i++) {
+ int offset = i;
+ output_data[offset] = std::floor(input_data[offset]);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_H_
diff --git a/tensorflow/lite/kernels/internal/reference/floor_div.h b/tensorflow/lite/kernels/internal/reference/floor_div.h
new file mode 100644
index 0000000..e75d473
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/floor_div.h
@@ -0,0 +1,35 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_DIV_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_DIV_H_
+
+#include <cmath>
+#include <functional>
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+template <typename T>
+T FloorDiv(T input1, T input2) {
+ return std::floor(std::divides<double>()(static_cast<double>(input1),
+ static_cast<double>(input2)));
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_DIV_H_
diff --git a/tensorflow/lite/kernels/internal/reference/floor_mod.h b/tensorflow/lite/kernels/internal/reference/floor_mod.h
new file mode 100644
index 0000000..20ce18b
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/floor_mod.h
@@ -0,0 +1,44 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_MOD_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_MOD_H_
+
+#include <cmath>
+#include <functional>
+
+namespace tflite {
+
+namespace reference_ops {
+
+template <typename T>
+T FloorMod(T input1, T input2) {
+ struct FloatMod {
+ float operator()(const float lhs, const float rhs) const {
+ return std::fmod(lhs, rhs);
+ }
+ };
+ using ModFunc = typename std::conditional<std::is_integral<T>::value,
+ std::modulus<T>, FloatMod>::type;
+ ModFunc mod_func;
+ T trunc_mod = mod_func(input1, input2);
+ return (trunc_mod != 0) && ((input2 < 0) != (trunc_mod < 0))
+ ? (trunc_mod + input2)
+ : trunc_mod;
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FLOOR_MOD_H_
diff --git a/tensorflow/lite/kernels/internal/reference/fully_connected.h b/tensorflow/lite/kernels/internal/reference/fully_connected.h
new file mode 100644
index 0000000..d5ad9d6
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/fully_connected.h
@@ -0,0 +1,320 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FULLY_CONNECTED_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FULLY_CONNECTED_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline void FullyConnected(
+ const FullyConnectedParams& params, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& weights_shape,
+ const float* weights_data, const RuntimeShape& bias_shape,
+ const float* bias_data, const RuntimeShape& output_shape,
+ float* output_data) {
+ const float output_activation_min = params.float_activation_min;
+ const float output_activation_max = params.float_activation_max;
+ // TODO(b/62193649): This really should be:
+ // const int batches = ArraySize(output_dims, 1);
+ // but the current --variable_batch hack consists in overwriting the 3rd
+ // dimension with the runtime batch size, as we don't keep track for each
+ // array of which dimension is the batch dimension in it.
+ const int output_dims_count = output_shape.DimensionsCount();
+ const int weights_dims_count = weights_shape.DimensionsCount();
+ const int batches = FlatSizeSkipDim(output_shape, output_dims_count - 1);
+ const int output_depth = MatchingDim(weights_shape, weights_dims_count - 2,
+ output_shape, output_dims_count - 1);
+ const int accum_depth = weights_shape.Dims(weights_dims_count - 1);
+ for (int b = 0; b < batches; ++b) {
+ for (int out_c = 0; out_c < output_depth; ++out_c) {
+ float total = 0.f;
+ for (int d = 0; d < accum_depth; ++d) {
+ total += input_data[b * accum_depth + d] *
+ weights_data[out_c * accum_depth + d];
+ }
+ float bias_value = 0.0f;
+ if (bias_data) {
+ bias_value = bias_data[out_c];
+ }
+ output_data[out_c + output_depth * b] = ActivationFunctionWithMinMax(
+ total + bias_value, output_activation_min, output_activation_max);
+ }
+ }
+}
+
+inline void FullyConnected(
+ const FullyConnectedParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& filter_shape,
+ const uint8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ TFLITE_DCHECK_GE(filter_shape.DimensionsCount(), 2);
+ TFLITE_DCHECK_GE(output_shape.DimensionsCount(), 1);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ // TODO(b/62193649): This really should be:
+ // const int batches = ArraySize(output_dims, 1);
+ // but the current --variable_batch hack consists in overwriting the 3rd
+ // dimension with the runtime batch size, as we don't keep track for each
+ // array of which dimension is the batch dimension in it.
+ const int output_dim_count = output_shape.DimensionsCount();
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ const int batches = FlatSizeSkipDim(output_shape, output_dim_count - 1);
+ const int output_depth = MatchingDim(filter_shape, filter_dim_count - 2,
+ output_shape, output_dim_count - 1);
+ const int accum_depth = filter_shape.Dims(filter_dim_count - 1);
+ for (int b = 0; b < batches; ++b) {
+ for (int out_c = 0; out_c < output_depth; ++out_c) {
+ int32_t acc = 0;
+ for (int d = 0; d < accum_depth; ++d) {
+ int32_t input_val = input_data[b * accum_depth + d];
+ int32_t filter_val = filter_data[out_c * accum_depth + d];
+ acc += (filter_val + filter_offset) * (input_val + input_offset);
+ }
+ if (bias_data) {
+ acc += bias_data[out_c];
+ }
+ acc = MultiplyByQuantizedMultiplier(acc, output_multiplier, output_shift);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[out_c + output_depth * b] = static_cast<uint8_t>(acc);
+ }
+ }
+}
+
+inline void FullyConnected(
+ const FullyConnectedParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& filter_shape,
+ const uint8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ TFLITE_DCHECK_EQ(output_offset, 0);
+ // TODO(b/62193649): This really should be:
+ // const int batches = ArraySize(output_dims, 1);
+ // but the current --variable_batch hack consists in overwriting the 3rd
+ // dimension with the runtime batch size, as we don't keep track for each
+ // array of which dimension is the batch dimension in it.
+ const int output_dim_count = output_shape.DimensionsCount();
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ const int batches = FlatSizeSkipDim(output_shape, output_dim_count - 1);
+ const int output_depth = MatchingDim(filter_shape, filter_dim_count - 2,
+ output_shape, output_dim_count - 1);
+ const int accum_depth = filter_shape.Dims(filter_dim_count - 1);
+ for (int b = 0; b < batches; ++b) {
+ for (int out_c = 0; out_c < output_depth; ++out_c) {
+ // Internal accumulation.
+ // Initialize accumulator with the bias-value.
+ int32_t accum = bias_data[out_c];
+ // Accumulation loop.
+ for (int d = 0; d < accum_depth; ++d) {
+ int16_t input_val = input_data[b * accum_depth + d] + input_offset;
+ int16_t filter_val =
+ filter_data[out_c * accum_depth + d] + filter_offset;
+ accum += filter_val * input_val;
+ }
+ // Down-scale the final int32_t accumulator to the scale used by our
+ // (16-bit, typically 3 integer bits) fixed-point format. The quantized
+ // multiplier and shift here have been pre-computed offline
+ // (e.g. by toco).
+ accum =
+ MultiplyByQuantizedMultiplier(accum, output_multiplier, output_shift);
+ // Saturate, cast to int16_t, and store to output array.
+ accum = std::max(accum, output_activation_min - output_offset);
+ accum = std::min(accum, output_activation_max - output_offset);
+ accum += output_offset;
+ output_data[out_c + output_depth * b] = accum;
+ }
+ }
+}
+
+inline void ShuffledFullyConnected(
+ const FullyConnectedParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& weights_shape,
+ const uint8_t* shuffled_weights_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int16_t* output_data, uint8_t* shuffled_input_workspace_data) {
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+
+ TFLITE_DCHECK_GE(input_shape.DimensionsCount(), 1);
+ TFLITE_DCHECK_GE(weights_shape.DimensionsCount(), 2);
+ TFLITE_DCHECK_GE(output_shape.DimensionsCount(), 1);
+ // TODO(b/62193649): This really should be:
+ // const int batches = ArraySize(output_dims, 1);
+ // but the current --variable_batch hack consists in overwriting the 3rd
+ // dimension with the runtime batch size, as we don't keep track for each
+ // array of which dimension is the batch dimension in it.
+ const int output_dim_count = output_shape.DimensionsCount();
+ const int weights_dim_count = weights_shape.DimensionsCount();
+ const int batches = FlatSizeSkipDim(output_shape, output_dim_count - 1);
+ const int output_depth = MatchingDim(weights_shape, weights_dim_count - 2,
+ output_shape, output_dim_count - 1);
+ const int accum_depth = weights_shape.Dims(weights_dim_count - 1);
+ TFLITE_DCHECK((accum_depth % 16) == 0);
+ TFLITE_DCHECK((output_depth % 4) == 0);
+
+ // Shuffling and xoring of input activations into the workspace buffer
+ uint8_t* shuffled_input_workspace_ptr = shuffled_input_workspace_data;
+ if (batches == 1) {
+ for (int i = 0; i < accum_depth; i++) {
+ shuffled_input_workspace_data[i] = input_data[i] ^ 0x80;
+ }
+ } else if (batches == 4) {
+ for (int c = 0; c < accum_depth; c += 16) {
+ for (int b = 0; b < 4; b++) {
+ const uint8_t* src_data_ptr = input_data + b * accum_depth + c;
+ for (int j = 0; j < 16; j++) {
+ uint8_t src_val = *src_data_ptr++;
+ // Flip the sign bit, so that the kernel will only need to
+ // reinterpret these uint8_t values as int8_t, getting for free the
+ // subtraction of the zero_point value 128.
+ uint8_t dst_val = src_val ^ 0x80;
+ *shuffled_input_workspace_ptr++ = dst_val;
+ }
+ }
+ }
+ } else {
+ TFLITE_DCHECK(false);
+ return;
+ }
+
+ // Actual computation
+ if (batches == 1) {
+ int16_t* output_ptr = output_data;
+ // Shuffled weights have had their sign bit (0x80) pre-flipped (xor'd)
+ // so that just reinterpreting them as int8_t values is equivalent to
+ // subtracting 128 from them, thus implementing for free the subtraction of
+ // the zero_point value 128.
+ const int8_t* shuffled_weights_ptr =
+ reinterpret_cast<const int8_t*>(shuffled_weights_data);
+ // Likewise, we preshuffled and pre-xored the input data above.
+ const int8_t* shuffled_input_data =
+ reinterpret_cast<const int8_t*>(shuffled_input_workspace_data);
+ for (int c = 0; c < output_depth; c += 4) {
+ // Internal accumulation.
+ // Initialize accumulator with the bias-value.
+ int32_t accum[4] = {0};
+ // Accumulation loop.
+ for (int d = 0; d < accum_depth; d += 16) {
+ for (int i = 0; i < 4; i++) {
+ for (int j = 0; j < 16; j++) {
+ int8_t input_val = shuffled_input_data[d + j];
+ int8_t weights_val = *shuffled_weights_ptr++;
+ accum[i] += weights_val * input_val;
+ }
+ }
+ }
+ for (int i = 0; i < 4; i++) {
+ // Add bias value
+ int32_t acc = accum[i] + bias_data[c + i];
+ // Down-scale the final int32_t accumulator to the scale used by our
+ // (16-bit, typically 3 integer bits) fixed-point format. The quantized
+ // multiplier and shift here have been pre-computed offline
+ // (e.g. by toco).
+ acc =
+ MultiplyByQuantizedMultiplier(acc, output_multiplier, output_shift);
+ // Saturate, cast to int16_t, and store to output array.
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_ptr[c + i] = acc;
+ }
+ }
+ } else if (batches == 4) {
+ int16_t* output_ptr = output_data;
+ // Shuffled weights have had their sign bit (0x80) pre-flipped (xor'd)
+ // so that just reinterpreting them as int8_t values is equivalent to
+ // subtracting 128 from them, thus implementing for free the subtraction of
+ // the zero_point value 128.
+ const int8_t* shuffled_weights_ptr =
+ reinterpret_cast<const int8_t*>(shuffled_weights_data);
+ // Likewise, we preshuffled and pre-xored the input data above.
+ const int8_t* shuffled_input_data =
+ reinterpret_cast<const int8_t*>(shuffled_input_workspace_data);
+ for (int c = 0; c < output_depth; c += 4) {
+ const int8_t* shuffled_input_ptr = shuffled_input_data;
+ // Accumulation loop.
+ // Internal accumulation.
+ // Initialize accumulator with the bias-value.
+ int32_t accum[4][4];
+ for (int i = 0; i < 4; i++) {
+ for (int b = 0; b < 4; b++) {
+ accum[i][b] = 0;
+ }
+ }
+ for (int d = 0; d < accum_depth; d += 16) {
+ for (int i = 0; i < 4; i++) {
+ for (int b = 0; b < 4; b++) {
+ for (int j = 0; j < 16; j++) {
+ int8_t input_val = shuffled_input_ptr[16 * b + j];
+ int8_t weights_val = shuffled_weights_ptr[16 * i + j];
+ accum[i][b] += weights_val * input_val;
+ }
+ }
+ }
+ shuffled_input_ptr += 64;
+ shuffled_weights_ptr += 64;
+ }
+ for (int i = 0; i < 4; i++) {
+ for (int b = 0; b < 4; b++) {
+ // Add bias value
+ int32_t acc = accum[i][b] + bias_data[c + i];
+ // Down-scale the final int32_t accumulator to the scale used by our
+ // (16-bit, typically 3 integer bits) fixed-point format. The
+ // quantized multiplier and shift here have been pre-computed offline
+ // (e.g. by toco).
+ acc = MultiplyByQuantizedMultiplier(acc, output_multiplier,
+ output_shift);
+ // Saturate, cast to int16_t, and store to output array.
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_ptr[b * output_depth + c + i] = acc;
+ }
+ }
+ }
+ } else {
+ TFLITE_DCHECK(false);
+ return;
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_FULLY_CONNECTED_H_
diff --git a/tensorflow/lite/kernels/internal/reference/hard_swish.h b/tensorflow/lite/kernels/internal/reference/hard_swish.h
new file mode 100644
index 0000000..cda1b5c
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/hard_swish.h
@@ -0,0 +1,166 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ACTIVATIONS_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ACTIVATIONS_H_
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline int16_t SaturatingLeftShift(int16_t value, int amount) {
+ int32_t result = static_cast<int32_t>(value) * (1 << amount);
+ result = std::min<int32_t>(result, std::numeric_limits<int16_t>::max());
+ result = std::max<int32_t>(result, std::numeric_limits<int16_t>::min());
+ return result;
+}
+
+// Similar to ARM instruction SQDMULH.
+// Similar to gemmlowp::SaturatingRoundingDoublingHighMul except
+// rounding to zero instead of to nearest (SQRDMULH).
+inline std::int16_t SaturatingDoublingHighMul(std::int16_t a, std::int16_t b) {
+ bool overflow = a == b && a == std::numeric_limits<std::int16_t>::min();
+ std::int32_t a_32(a);
+ std::int32_t b_32(b);
+ std::int32_t ab_32 = a_32 * b_32;
+ std::int16_t ab_x2_high16 = static_cast<std::int16_t>((ab_32) / (1 << 15));
+ return overflow ? std::numeric_limits<std::int16_t>::max() : ab_x2_high16;
+}
+
+template <typename T>
+inline void HardSwish(const RuntimeShape& input_shape, const T* input_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ ruy::profiler::ScopeLabel label("ReferenceHardSwish/Float");
+ auto matching_size = MatchingFlatSize(input_shape, output_shape);
+ const T* in_end = input_data + matching_size;
+ for (; input_data < in_end; input_data++, output_data++) {
+ const float in = *input_data;
+ *output_data =
+ in * std::min(static_cast<T>(6), std::max(static_cast<T>(0), in + 3)) /
+ 6;
+ }
+}
+
+template <typename T>
+inline void HardSwish(const HardSwishParams& params,
+ const RuntimeShape& input_shape, const T* input_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ ruy::profiler::ScopeLabel label("ReferenceHardSwish/Quantized");
+
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; i++) {
+ const int16_t input_value = input_data[i] - params.input_zero_point;
+ // Left-shift as much as we can without overflow/saturation to put
+ // significant bits in the high bits of our 16-bit fixedpoint values, so
+ // that fixed-point approximate computations below are as accurate as
+ // possible.
+ const int16_t input_value_on_hires_input_scale = input_value * (1 << 7);
+ // Compute the input value on essentially the output scale, just not
+ // right-shifted yet. This is the value that we'll use in the (x >= +3)
+ // case, and that in the general case we'll multiply against the "relu-ish"
+ // fixed-point multiplier in [0, 1].
+ const int16_t input_value_on_preshift_output_scale =
+ gemmlowp::SaturatingRoundingDoublingHighMul(
+ input_value_on_hires_input_scale,
+ params.output_multiplier_fixedpoint_int16);
+ // Now compute the "relu-ish multiplier". In the (-3 <= x <= +3) case, that
+ // is just an affine rescaling of x from [-3, 3] to [0, 1]. In the general
+ // case, it is just that plus saturation at the boundaries of [-3, 3].
+ // First, we rescale from [-3, 3] to [-1, 1], saturating.
+ // That is done by rescaling the input value with a fixed-point multiplier
+ // (reluish_multiplier_fixedpoint) and bit-shift such that we represent
+ // that input value on the scale where the real value 3.0f is represented
+ // by the quantized value 32768. (+32768 is actually not representable as
+ // int16_t, so this saturates at +32767, and that is seen empirically to be
+ // a negligible contribution to numerical error/bias).
+ //
+ // This code is careful to correctly implement any magnitude of multiplier,
+ // involving either a right shift or a left shift, with correct saturation
+ // behavior in the left-shift case. This forces this code to be more
+ // complicated, but is necessary for real applications: a partially
+ // trained quantized MobileNet v3-small model that motivated this code
+ // exhibits some large [min, max] range boundaries, of the order of
+ // magnitude of 10 or 100 depending on layers.
+ //
+ // The next few lines are basically just an ordinary
+ // MultiplyByQuantizedMultiplier, except that we are more careful here
+ // about the fine details of saturation when left-shifting, because here
+ // overflow in left-shift is a common case, not an anomaly as
+ // MultiplyByQuantizedMultiplier assumes.
+ int16_t reluish_value = input_value_on_hires_input_scale;
+ // Shift left, saturating, as much as we can while ensuring that this
+ // saturation will not contribute to the result. That is, left shift amount
+ // reduced by 1.
+ if (params.reluish_multiplier_exponent > 0) {
+ reluish_value = SaturatingLeftShift(
+ reluish_value, params.reluish_multiplier_exponent - 1);
+ }
+ // Apply the fixed-point multiplier, dividing the value by a divisor
+ // ranging in [1, 2].
+ reluish_value = gemmlowp::SaturatingRoundingDoublingHighMul(
+ reluish_value, params.reluish_multiplier_fixedpoint_int16);
+ // Apply the last bit of left-shift. Thus, in the left-shifting case, if
+ // any saturation affects the result, it is happening here --- any
+ // saturation having occurred above is overwritten here, not affecting the
+ // result.
+ if (params.reluish_multiplier_exponent > 0) {
+ reluish_value = SaturatingLeftShift(reluish_value, 1);
+ }
+ // Shift right, in the right-shifting case.
+ if (params.reluish_multiplier_exponent < 0) {
+ reluish_value = gemmlowp::RoundingDivideByPOT(
+ reluish_value, -params.reluish_multiplier_exponent);
+ }
+ // At this point we have rescaled the value into a 16bit fixedpoint
+ // reluish_value in [-1, 1].
+ // We now convert that to a 16bit fixedpoint value in [0, 1].
+ reluish_value = (reluish_value + (1 << 15)) >> 1;
+ // Use of SaturatingDoublingHighMul here is important to cancel the biases
+ // from the above SaturatingRoundingDoublingHighMul.
+ //
+ // On a partially trained MobileNet-v3-small,
+ //
+ // | bias on | ImageNet
+ // | quantized | Top-1
+ // Operation used here | values | accuracy (50k)
+ // --------------------------------------+------------+-----------
+ // SaturatingDoublingHighMul | -0.0024 | 58.920
+ // SaturatingRoundingDoublingHighMul | -0.0067 | 58.064
+ //
+ // In activations_test, this is covered by this testcase:
+ // QuantizedActivationsOpTest.HardSwishBias
+ //
+ const int16_t preshift_output_value = SaturatingDoublingHighMul(
+ reluish_value, input_value_on_preshift_output_scale);
+ // We were so far operating on the pre-shift output scale. Now we finally
+ // apply that output shift, arriving at the final output scale.
+ int16_t output_value = gemmlowp::RoundingDivideByPOT(
+ preshift_output_value, -params.output_multiplier_exponent);
+ output_value += params.output_zero_point;
+ output_value =
+ std::min<int16_t>(output_value, std::numeric_limits<T>::max());
+ output_value =
+ std::max<int16_t>(output_value, std::numeric_limits<T>::min());
+ output_data[i] = output_value;
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_CONV_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/add.h b/tensorflow/lite/kernels/internal/reference/integer_ops/add.h
new file mode 100644
index 0000000..10bee90
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/add.h
@@ -0,0 +1,144 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_ADD_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_ADD_H_
+
+#include <limits>
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+inline void CheckArithmeticParams(const ArithmeticParams& params) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ // Input offset is negative input zero point. Activation tensors are
+ // asymmetric quantized so they span the full int8 range.
+ TFLITE_DCHECK_GE(-params.input1_offset, std::numeric_limits<int8_t>::min());
+ TFLITE_DCHECK_GE(-params.input2_offset, std::numeric_limits<int8_t>::min());
+ TFLITE_DCHECK_LE(-params.input1_offset, std::numeric_limits<int8_t>::max());
+ TFLITE_DCHECK_LE(-params.input2_offset, std::numeric_limits<int8_t>::max());
+}
+
+inline void ElementWise(
+ int size, const ArithmeticParams& params, const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ void (*check_arithmetic_params)(const ArithmeticParams&),
+ int8_t (*binary_func)(int8_t, int8_t, const ArithmeticParams&)) {
+ CheckArithmeticParams(params);
+ for (int i = 0; i < size; ++i) {
+ output_data[i] = binary_func(input1_data[i], input2_data[i], params);
+ }
+}
+
+inline void BroadcastBinaryFunction4DSlow(
+ const ArithmeticParams& params, const RuntimeShape& input1_shape,
+ const int8_t* input1_data, const RuntimeShape& input2_shape,
+ const int8_t* input2_data, const RuntimeShape& output_shape,
+ int8_t* output_data,
+ void (*check_arithmetic_params)(const ArithmeticParams&),
+ int8_t (*binary_func)(int8_t, int8_t, const ArithmeticParams&)) {
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ output_data[Offset(extended_output_shape, b, y, x, c)] = binary_func(
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)],
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)], params);
+ }
+ }
+ }
+ }
+}
+
+inline int8_t AddFunc(int8_t x, int8_t y, const ArithmeticParams& params) {
+ const int32_t input1_val = params.input1_offset + x;
+ const int32_t input2_val = params.input2_offset + y;
+ const int32_t shifted_input1_val = input1_val * (1 << params.left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier, params.input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier, params.input2_shift);
+ const int32_t raw_sum = scaled_input1_val + scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sum, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ return static_cast<int8_t>(clamped_output);
+}
+
+// Element-wise add that can often be used for inner loop of broadcast add as
+// well as the non-broadcast add.
+inline void AddElementwise(int size, const ArithmeticParams& params,
+ const int8_t* input1_data, const int8_t* input2_data,
+ int8_t* output_data) {
+ ElementWise(size, params, input1_data, input2_data, output_data,
+ CheckArithmeticParams, AddFunc);
+}
+
+inline void Add(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const int8_t* input1_data,
+ const RuntimeShape& input2_shape, const int8_t* input2_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ CheckArithmeticParams(params);
+
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+
+ AddElementwise(flat_size, params, input1_data, input2_data, output_data);
+}
+
+inline void BroadcastAdd4DSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int8_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int8_t* input2_data,
+ const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ BroadcastBinaryFunction4DSlow(params, input1_shape, input1_data, input2_shape,
+ input2_data, output_shape, output_data,
+ CheckArithmeticParams, AddFunc);
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_ADD_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/conv.h b/tensorflow/lite/kernels/internal/reference/integer_ops/conv.h
new file mode 100644
index 0000000..3a4164d
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/conv.h
@@ -0,0 +1,221 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_CONV_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_CONV_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+// Fixed-point per-channel-quantization convolution reference kernel.
+inline void ConvPerChannel(
+ const ConvParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ // Get parameters.
+ const int32_t input_offset = params.input_offset; // r = s(q - Z)
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int32_t output_offset = params.output_offset;
+
+ // Set min and max value of the output.
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ // Consistency check.
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+
+ // Check dimensions of the tensors.
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ int32_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+
+ if (!is_point_inside_image) {
+ continue;
+ }
+
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ int32_t input_val = input_data[Offset(input_shape, batch, in_y,
+ in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, out_channel, filter_y, filter_x, in_channel)];
+ // Accumulate with 32 bits accumulator.
+ // In the nudging process during model quantization, we force
+ // real value of 0.0 be represented by a quantized value. This
+ // guarantees that the input_offset is a int8_t, even though
+ // it is represented using int32_t. int32_t += int8_t *
+ // (int8_t - int8_t) so the highest value we can get from each
+ // accumulation is [-127, 127] * ([-128, 127] -
+ // [-128, 127]), which is [-32512, 32512]. log2(32512)
+ // = 14.98, which means we can accumulate at least 2^16
+ // multiplications without overflow. The accumulator is
+ // applied to a filter so the accumulation logic will hold as
+ // long as the filter size (filter_y * filter_x * in_channel)
+ // does not exceed 2^16, which is the case in all the models
+ // we have seen so far.
+ // TODO(b/174275578): Add a check to make sure the
+ // accumulator depth is smaller than 2^16.
+ acc += filter_val * (input_val + input_offset);
+ }
+ }
+ }
+
+ if (bias_data) {
+ acc += bias_data[out_channel];
+ }
+ acc = MultiplyByQuantizedMultiplier(
+ acc, output_multiplier[out_channel], output_shift[out_channel]);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ static_cast<int8_t>(acc);
+ }
+ }
+ }
+ }
+}
+
+// Fixed-point per-channel-quantization convolution reference kernel.
+// 16-bit data and 8-bit filter
+inline void ConvPerChannel(
+ const ConvParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int16_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const std::int64_t* bias_data, const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ // Get parameters.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+
+ // Set min and max value of the output.
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ // Consistency check.
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+
+ // Check dimensions of the tensors.
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ std::int64_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+
+ if (!is_point_inside_image) {
+ continue;
+ }
+
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ int32_t input_val = input_data[Offset(input_shape, batch, in_y,
+ in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, out_channel, filter_y, filter_x, in_channel)];
+ // Accumulate with 64 bits accumulator.
+ // int64_t += int8_t * int16_t so the highest value we can
+ // get from each accumulation is [-127, 127] * ([-32768,
+ // 32767] -
+ // [-32768, 32767]), which is [-8322945, 8322945].
+ // log2(8322945) = 22.99.
+ acc += filter_val * input_val;
+ }
+ }
+ }
+ if (bias_data) {
+ acc += bias_data[out_channel];
+ }
+ int32_t scaled_acc = MultiplyByQuantizedMultiplier(
+ acc, output_multiplier[out_channel], output_shift[out_channel]);
+ scaled_acc = std::max(scaled_acc, output_activation_min);
+ scaled_acc = std::min(scaled_acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ static_cast<int16_t>(scaled_acc);
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_CONV_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h b/tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h
new file mode 100644
index 0000000..f0ca09c
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h
@@ -0,0 +1,289 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_DEPTHWISE_CONV_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_DEPTHWISE_CONV_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+inline void DepthwiseConvPerChannel(
+ const DepthwiseParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ // Get parameters.
+ // TODO(b/141565753): Re-introduce ScopedProfilingLabel on Micro.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t input_offset = params.input_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ // Check dimensions of the tensors.
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ for (int m = 0; m < depth_multiplier; ++m) {
+ const int output_channel = m + in_channel * depth_multiplier;
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ int32_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ const int in_y =
+ in_y_origin + dilation_height_factor * filter_y;
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+ if (is_point_inside_image) {
+ int32_t input_val = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, output_channel)];
+ // Accumulate with 32 bits accumulator.
+ // In the nudging process during model quantization, we force
+ // real value of 0.0 be represented by a quantized value. This
+ // guarantees that the input_offset is a int8_t, even though
+ // it is represented using int32_t. int32_t += int8_t *
+ // (int8_t - int8_t) so the highest value we can get from each
+ // accumulation is [-127, 127] * ([-128, 127] -
+ // [-128, 127]), which is [-32512, 32512]. log2(32512)
+ // = 14.98, which means we can accumulate at least 2^16
+ // multiplications without overflow. The accumulator is
+ // applied to a filter so the accumulation logic will hold as
+ // long as the filter size (filter_y * filter_x * in_channel)
+ // does not exceed 2^16, which is the case in all the models
+ // we have seen so far.
+ // TODO(b/174275578): Add a check to make sure the
+ // accumulator depth is smaller than 2^16.
+ acc += filter_val * (input_val + input_offset);
+ }
+ }
+ }
+ if (bias_data) {
+ acc += bias_data[output_channel];
+ }
+ acc = MultiplyByQuantizedMultiplier(
+ acc, output_multiplier[output_channel],
+ output_shift[output_channel]);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ output_channel)] = static_cast<int8_t>(acc);
+ }
+ }
+ }
+ }
+ }
+}
+
+inline void DepthwiseConvPerChannel(
+ const DepthwiseParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int16_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const std::int64_t* bias_data, const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ // Get parameters.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ // Check dimensions of the tensors.
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ for (int m = 0; m < depth_multiplier; ++m) {
+ const int output_channel = m + in_channel * depth_multiplier;
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ std::int64_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ const int in_y =
+ in_y_origin + dilation_height_factor * filter_y;
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+ if (is_point_inside_image) {
+ int32_t input_val = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, output_channel)];
+ // Accumulate with 64 bits accumulator.
+ // We assume maximum of 2^16 accumulations as with the 8-bit
+ // case so actually the value in the accumulator should not
+ // exceed 40 bits
+ acc += static_cast<int64_t>(filter_val) *
+ static_cast<int64_t>(input_val);
+ }
+ }
+ }
+ if (bias_data) {
+ acc += bias_data[output_channel];
+ }
+ int32_t scaled_acc = MultiplyByQuantizedMultiplier(
+ acc, output_multiplier[output_channel],
+ output_shift[output_channel]);
+ scaled_acc = std::max(scaled_acc, output_activation_min);
+ scaled_acc = std::min(scaled_acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ output_channel)] =
+ static_cast<int16_t>(scaled_acc);
+ }
+ }
+ }
+ }
+ }
+}
+
+inline void DepthwiseConvHybridPerChannel(
+ const DepthwiseParams& params, float* scaling_factors_ptr,
+ const RuntimeShape& input_shape, const int8_t* input_data,
+ const RuntimeShape& filter_shape, const int8_t* filter_data,
+ const RuntimeShape& bias_shape, const float* bias_data,
+ const RuntimeShape& output_shape, float* output_data,
+ const float* per_channel_scale, int32_t* input_offset) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const float output_activation_min = params.float_activation_min;
+ const float output_activation_max = params.float_activation_max;
+ // Check dimensions of the tensors.
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int bias_depth = bias_shape.FlatSize();
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_depth, output_depth);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ for (int m = 0; m < depth_multiplier; ++m) {
+ const int output_channel = m + in_channel * depth_multiplier;
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ int32_t acc = 0;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ const int in_y =
+ in_y_origin + dilation_height_factor * filter_y;
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+ if (is_point_inside_image) {
+ int32_t input_val = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, output_channel)];
+ acc += filter_val * (input_val - input_offset[batch]);
+ }
+ }
+ }
+ float acc_float = static_cast<float>(acc);
+ acc_float *=
+ per_channel_scale[output_channel] * scaling_factors_ptr[batch];
+ if (bias_data && output_channel < bias_depth) {
+ acc_float += bias_data[output_channel];
+ }
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ output_channel)] =
+ ActivationFunctionWithMinMax(acc_float, output_activation_min,
+ output_activation_max);
+ }
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_DEPTHWISE_CONV_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h b/tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h
new file mode 100644
index 0000000..2bc3e79
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h
@@ -0,0 +1,108 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_FULLY_CONNECTED_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_FULLY_CONNECTED_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+inline void FullyConnected(
+ const FullyConnectedParams& params, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ TFLITE_DCHECK_GE(filter_shape.DimensionsCount(), 2);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 2);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ const int batches = output_shape.Dims(0);
+ const int output_depth = output_shape.Dims(1);
+ TFLITE_DCHECK_LE(output_depth, filter_shape.Dims(filter_dim_count - 2));
+ const int accum_depth = filter_shape.Dims(filter_dim_count - 1);
+ for (int b = 0; b < batches; ++b) {
+ for (int out_c = 0; out_c < output_depth; ++out_c) {
+ int32_t acc = 0;
+ for (int d = 0; d < accum_depth; ++d) {
+ int32_t input_val = input_data[b * accum_depth + d];
+ int32_t filter_val = filter_data[out_c * accum_depth + d];
+ acc += (filter_val + filter_offset) * (input_val + input_offset);
+ }
+ if (bias_data) {
+ acc += bias_data[out_c];
+ }
+ acc = MultiplyByQuantizedMultiplier(acc, output_multiplier, output_shift);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[out_c + output_depth * b] = static_cast<int8_t>(acc);
+ }
+ }
+}
+
+inline void FullyConnected(
+ const FullyConnectedParams& params, const RuntimeShape& input_shape,
+ const int16_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int64_t* bias_data, const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ TFLITE_DCHECK_GE(filter_shape.DimensionsCount(), 2);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 2);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ const int batches = output_shape.Dims(0);
+ const int output_depth = output_shape.Dims(1);
+ TFLITE_DCHECK_LE(output_depth, filter_shape.Dims(filter_dim_count - 2));
+ const int accum_depth = filter_shape.Dims(filter_dim_count - 1);
+ for (int b = 0; b < batches; ++b) {
+ for (int out_c = 0; out_c < output_depth; ++out_c) {
+ int64_t acc = 0;
+ for (int d = 0; d < accum_depth; ++d) {
+ int32_t input_val = input_data[b * accum_depth + d];
+ int32_t filter_val = filter_data[out_c * accum_depth + d];
+ acc += (filter_val + filter_offset) * input_val;
+ }
+ if (bias_data) {
+ acc += bias_data[out_c];
+ }
+ int32_t acc_scaled =
+ MultiplyByQuantizedMultiplier(acc, output_multiplier, output_shift);
+ acc_scaled = std::max(acc_scaled, output_activation_min);
+ acc_scaled = std::min(acc_scaled, output_activation_max);
+ output_data[out_c + output_depth * b] = static_cast<int16_t>(acc_scaled);
+ }
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_FULLY_CONNECTED_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/l2normalization.h b/tensorflow/lite/kernels/internal/reference/integer_ops/l2normalization.h
new file mode 100644
index 0000000..31f2de9
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/l2normalization.h
@@ -0,0 +1,65 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_L2NORMALIZATION_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_L2NORMALIZATION_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+inline void L2Normalization(int32_t input_zero_point, int32_t outer_size,
+ int32_t depth, const int8_t* input_data,
+ int8_t* output_data) {
+ static constexpr int8_t kMinInt8 = std::numeric_limits<int8_t>::min();
+ static constexpr int8_t kMaxInt8 = std::numeric_limits<int8_t>::max();
+ // The output scale must be in sync with Prepare().
+ // Output is in 1/128 scale so the actual output range is nudged from [-1, 1]
+ // to [-1, 127/128].
+ static constexpr int32_t kOutputScale = 7;
+ for (int outer_index = 0; outer_index < outer_size; ++outer_index) {
+ // int32_t = (int8_t - int8_t) ^ 2.
+ // ([-128, 127] - [-128, 127]) ^ 2 = [0, (2^8 - 1)^2] so the accumulator is
+ // safe from overflowing in at least 2^16 steps.
+ int32_t acc = 0;
+ for (int inner_index = 0; inner_index < depth; ++inner_index) {
+ int32_t input =
+ input_data[depth * outer_index + inner_index] - input_zero_point;
+ acc += input * input;
+ }
+ int32_t inv_l2norm_multiplier;
+ int inv_l2norm_shift;
+ GetInvSqrtQuantizedMultiplierExp(acc, kReverseShift, &inv_l2norm_multiplier,
+ &inv_l2norm_shift);
+
+ for (int inner_index = 0; inner_index < depth; ++inner_index) {
+ int32_t input =
+ input_data[depth * outer_index + inner_index] - input_zero_point;
+
+ // Rescale and downcast. Rescale is folded into the division.
+ int32_t output_in_q24 = MultiplyByQuantizedMultiplier(
+ input, inv_l2norm_multiplier, inv_l2norm_shift + kOutputScale);
+ output_in_q24 =
+ std::min(static_cast<int32_t>(kMaxInt8),
+ std::max(static_cast<int32_t>(kMinInt8), output_in_q24));
+ output_data[depth * outer_index + inner_index] =
+ static_cast<int8_t>(output_in_q24);
+ }
+ }
+}
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_L2NORMALIZATION_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/logistic.h b/tensorflow/lite/kernels/internal/reference/integer_ops/logistic.h
new file mode 100644
index 0000000..95697ec
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/logistic.h
@@ -0,0 +1,119 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_LOGISTIC_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_LOGISTIC_H_
+
+#include <limits>
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+inline void Logistic(int32_t input_zero_point, int32_t input_range_radius,
+ int32_t input_multiplier, int32_t input_left_shift,
+ int32_t input_size, const int8_t* input_data,
+ int8_t* output_data) {
+ // Integer bits must be in sync with Prepare() function.
+ static constexpr int32_t kInputIntegerBits = 4;
+ static constexpr int32_t kOutputIntegerBits = 8;
+ static constexpr int8_t kMinInt8 = std::numeric_limits<int8_t>::min();
+ static constexpr int8_t kMaxInt8 = std::numeric_limits<int8_t>::max();
+ static constexpr int32_t kOutputZeroPoint = -128;
+
+ for (int i = 0; i < input_size; ++i) {
+ const int32_t input =
+ static_cast<int32_t>(input_data[i]) - input_zero_point;
+ if (input <= -input_range_radius) {
+ output_data[i] = kMinInt8;
+ } else if (input >= input_range_radius) {
+ output_data[i] = kMaxInt8;
+ } else {
+ const int32_t input_in_q4 = MultiplyByQuantizedMultiplier(
+ input, input_multiplier, input_left_shift);
+ using FixedPoint4 = gemmlowp::FixedPoint<int32_t, kInputIntegerBits>;
+ const int32_t output_in_q0 =
+ gemmlowp::logistic(FixedPoint4::FromRaw(input_in_q4)).raw();
+
+ // Rescale and downcast.
+ using gemmlowp::RoundingDivideByPOT;
+ int32_t output_in_q23 =
+ RoundingDivideByPOT(output_in_q0, 31 - kOutputIntegerBits);
+ output_in_q23 = std::min(std::max(output_in_q23 + kOutputZeroPoint,
+ static_cast<int32_t>(kMinInt8)),
+ static_cast<int32_t>(kMaxInt8));
+ output_data[i] = static_cast<int8_t>(output_in_q23);
+ }
+ }
+}
+
+inline void Logistic(int32_t input_multiplier, int32_t input_left_shift,
+ int32_t input_size, const int16_t* ptr_input_data,
+ int16_t* ptr_output_data) {
+ // We use the LUT for sigmoid and take into account, that
+ // tanh(x) = 2*sigmoid(2*x) - 1
+
+ // We scale by 3/4 to expand range [-8,8]->[-10.7,10.7].
+ // In case of general parameter scale, multiplier 3 is taken into account
+ // in TanhPrepare function and it is included in
+ // input_multiplier already.
+
+ TFLITE_DCHECK_GE(input_left_shift, 0);
+ if (input_multiplier == 0) { // power of two case
+ input_multiplier = 3 << input_left_shift;
+ input_left_shift = 0;
+ }
+
+ int32_t round = (input_left_shift > 0) ? 1 << (input_left_shift - 1) : 0;
+
+ for (int i = 0; i < input_size; ++i, ptr_input_data++, ptr_output_data++) {
+ int32_t input_data =
+ ((*ptr_input_data) * input_multiplier + round) >> input_left_shift;
+
+ // We do interpolation on unsigned values.
+ uint32_t abs_input_data = abs(input_data);
+
+ // We divide by 2 power of 9, because
+ // we need to divide by 2 in power of 7 for
+ // the input conversion + 1/4 from the scale above.
+
+ // Define uh as uint32_t type not to make this function overflow.
+ uint32_t uh = abs_input_data >> 9;
+ uint32_t result;
+
+ if (uh >= 255) {
+ // Saturate to maximum.
+ result = 0x7FFF << 10;
+ } else {
+ uint32_t ua = sigmoid_table_uint16[uh];
+ uint32_t ub = sigmoid_table_uint16[uh + 1];
+ uint32_t ut = abs_input_data & 0x1ff;
+ // Interpolation is done using the fractional bit.
+ result = (ua << 9) + ut * (ub - ua);
+ }
+
+ result = (input_data >= 0) ? (result + (1 << 9))
+ : ((1 << (16 + 9)) - result + (1 << 9) - 1);
+
+ // Back to 16-bit.
+ result >>= 10;
+
+ *ptr_output_data = result;
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_LOGISTIC_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/mean.h b/tensorflow/lite/kernels/internal/reference/integer_ops/mean.h
new file mode 100644
index 0000000..bd48427
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/mean.h
@@ -0,0 +1,77 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_MEAN_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_MEAN_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+template <typename integer_type>
+inline void Mean(const tflite::MeanParams& op_params, int32_t multiplier,
+ int32_t shift, const RuntimeShape& unextended_input_shape,
+ const integer_type* input_data, int32_t input_zero_point,
+ const RuntimeShape& unextended_output_shape,
+ integer_type* output_data, int32_t output_zero_point) {
+ // Current implementation only supports dimension equals 4 and simultaneous
+ // reduction over width and height.
+ TFLITE_CHECK_EQ(unextended_input_shape.DimensionsCount(), 4);
+ TFLITE_CHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+ const RuntimeShape input_shape =
+ RuntimeShape::ExtendedShape(4, unextended_input_shape);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(4, unextended_output_shape);
+ const int output_batch = output_shape.Dims(0);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int output_depth = output_shape.Dims(3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int num_elements_in_axis = input_width * input_height;
+
+ TFLITE_CHECK_EQ(op_params.axis_count, 2);
+ TFLITE_CHECK((op_params.axis[0] == 1 && op_params.axis[1] == 2) ||
+ (op_params.axis[0] == 2 && op_params.axis[1] == 1));
+ TFLITE_CHECK_EQ(output_height, 1);
+ TFLITE_CHECK_EQ(output_width, 1);
+
+ static constexpr int32_t kMinInt = std::numeric_limits<integer_type>::min();
+ static constexpr int32_t kMaxInt = std::numeric_limits<integer_type>::max();
+
+ for (int out_b = 0; out_b < output_batch; ++out_b) {
+ for (int out_d = 0; out_d < output_depth; ++out_d) {
+ int32_t acc = 0;
+ for (int in_h = 0; in_h < input_height; ++in_h) {
+ for (int in_w = 0; in_w < input_width; ++in_w) {
+ acc += input_data[Offset(input_shape, out_b, in_h, in_w, out_d)] -
+ input_zero_point;
+ }
+ }
+ acc = MultiplyByQuantizedMultiplier(acc, multiplier, shift);
+ acc = acc > 0 ? (acc + num_elements_in_axis / 2) / num_elements_in_axis
+ : (acc - num_elements_in_axis / 2) / num_elements_in_axis;
+ acc += output_zero_point;
+ acc = std::min(std::max(acc, kMinInt), kMaxInt);
+ output_data[Offset(output_shape, out_b, 0, 0, out_d)] =
+ static_cast<integer_type>(acc);
+ }
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_MEAN_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/mul.h b/tensorflow/lite/kernels/internal/reference/integer_ops/mul.h
new file mode 100644
index 0000000..b80838a
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/mul.h
@@ -0,0 +1,131 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_MUL_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_MUL_H_
+
+#include "fixedpoint/fixedpoint.h"
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+template <typename T>
+inline void MulElementwise(int size, const ArithmeticParams& params,
+ const T* input1_data, const T* input2_data,
+ T* output_data) {
+ for (int i = 0; i < size; ++i) {
+ const int32_t input1_val = params.input1_offset + input1_data[i];
+ const int32_t input2_val = params.input2_offset + input2_data[i];
+ const int32_t unclamped_result =
+ params.output_offset +
+ MultiplyByQuantizedMultiplier(input1_val * input2_val,
+ params.output_multiplier,
+ params.output_shift);
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, unclamped_result));
+ output_data[i] = static_cast<T>(clamped_output);
+ }
+}
+
+template <typename T>
+inline void Mul(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const T* input1_data,
+ const RuntimeShape& input2_shape, const T* input2_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ ruy::profiler::ScopeLabel label("Mul/8bit");
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+
+ MulElementwise(flat_size, params, input1_data, input2_data, output_data);
+}
+
+// Mul with 16 bit inputs and int8_t outputs.
+inline void Mul(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const int16_t* input1_data,
+ const RuntimeShape& input2_shape, const int16_t* input2_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ ruy::profiler::ScopeLabel label("Mul/Int16Int8");
+ int32_t output_offset = params.output_offset;
+ int32_t output_activation_min = params.quantized_activation_min;
+ int32_t output_activation_max = params.quantized_activation_max;
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+
+ for (int i = 0; i < flat_size; i++) {
+ // F0 uses 0 integer bits, range [-1, 1].
+ using F0 = gemmlowp::FixedPoint<std::int16_t, 0>;
+
+ F0 unclamped_result =
+ F0::FromRaw(input1_data[i]) * F0::FromRaw(input2_data[i]);
+ int16_t rescaled_result =
+ gemmlowp::RoundingDivideByPOT(unclamped_result.raw(), 8);
+ int16_t clamped_result = std::min<int16_t>(
+ output_activation_max - output_offset, rescaled_result);
+ clamped_result = std::max<int16_t>(output_activation_min - output_offset,
+ clamped_result);
+ output_data[i] = output_offset + clamped_result;
+ }
+}
+
+template <typename T>
+inline void BroadcastMul4DSlow(
+ const ArithmeticParams& params, const RuntimeShape& input1_shape,
+ const T* input1_data, const RuntimeShape& input2_shape,
+ const T* input2_data, const RuntimeShape& output_shape, T* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastMul4DSlow");
+
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ // The input shapes are extended as part of NdArrayDesc initialization.
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ const int32_t input1_val =
+ params.input1_offset +
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)];
+ const int32_t input2_val =
+ params.input2_offset +
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)];
+ const int32_t unclamped_result =
+ params.output_offset +
+ MultiplyByQuantizedMultiplier(input1_val * input2_val,
+ params.output_multiplier,
+ params.output_shift);
+ const int32_t clamped_output = std::min(
+ params.quantized_activation_max,
+ std::max(params.quantized_activation_min, unclamped_result));
+ output_data[Offset(extended_output_shape, b, y, x, c)] =
+ static_cast<T>(clamped_output);
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_MUL_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/pooling.h b/tensorflow/lite/kernels/internal/reference/integer_ops/pooling.h
new file mode 100644
index 0000000..17944bc
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/pooling.h
@@ -0,0 +1,258 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_POOLING_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_POOLING_H_
+
+#include <limits>
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+inline void AveragePool(const PoolParams& params,
+ const RuntimeShape& input_shape,
+ const int8_t* input_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ int32_t acc = 0;
+ int filter_count = 0;
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ acc +=
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)];
+ filter_count++;
+ }
+ }
+ // Round to the closest integer value.
+ acc = acc > 0 ? (acc + filter_count / 2) / filter_count
+ : (acc - filter_count / 2) / filter_count;
+ acc = std::max(acc, params.quantized_activation_min);
+ acc = std::min(acc, params.quantized_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ static_cast<int8_t>(acc);
+ }
+ }
+ }
+ }
+}
+
+inline void MaxPool(const PoolParams& params, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ TFLITE_DCHECK_GE(params.quantized_activation_min,
+ std::numeric_limits<int8_t>::min());
+ TFLITE_DCHECK_LE(params.quantized_activation_max,
+ std::numeric_limits<int8_t>::max());
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ int8_t max = std::numeric_limits<int8_t>::lowest();
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ max = std::max(
+ max,
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)]);
+ }
+ }
+ max = std::max<int8_t>(max, params.quantized_activation_min);
+ max = std::min<int8_t>(max, params.quantized_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ static_cast<int8_t>(max);
+ }
+ }
+ }
+ }
+}
+
+inline void AveragePool(const PoolParams& params,
+ const RuntimeShape& input_shape,
+ const int16_t* input_data,
+ const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ int32_t acc = 0;
+ int filter_count = 0;
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ acc +=
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)];
+ filter_count++;
+ }
+ }
+ // Round to the closest integer value.
+ acc = acc > 0 ? (acc + filter_count / 2) / filter_count
+ : (acc - filter_count / 2) / filter_count;
+ acc = std::max(acc, params.quantized_activation_min);
+ acc = std::min(acc, params.quantized_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ static_cast<int16_t>(acc);
+ }
+ }
+ }
+ }
+}
+
+inline void MaxPool(const PoolParams& params, const RuntimeShape& input_shape,
+ const int16_t* input_data, const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ TFLITE_DCHECK_GE(params.quantized_activation_min,
+ std::numeric_limits<int16_t>::min());
+ TFLITE_DCHECK_LE(params.quantized_activation_max,
+ std::numeric_limits<int16_t>::max());
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ int16_t max = std::numeric_limits<int16_t>::lowest();
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ max = std::max(
+ max,
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)]);
+ }
+ }
+ max = std::max<int16_t>(max, params.quantized_activation_min);
+ max = std::min<int16_t>(max, params.quantized_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ static_cast<int16_t>(max);
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_POOLING_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/tanh.h b/tensorflow/lite/kernels/internal/reference/integer_ops/tanh.h
new file mode 100644
index 0000000..63e4093
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/tanh.h
@@ -0,0 +1,116 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_TANH_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_TANH_H_
+
+#include <limits>
+
+#include "fixedpoint/fixedpoint.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+inline void Tanh(int32_t input_zero_point, int32_t input_range_radius,
+ int32_t input_multiplier, int32_t input_shift,
+ const RuntimeShape& input_shape, const int8_t* input_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ // Integer bits must be in sync with Prepare() function.
+ static constexpr int32_t kInputIntegerBits = 4;
+ static constexpr int32_t kOutputScale = 7;
+ static constexpr int32_t kMinInt8 = std::numeric_limits<int8_t>::min();
+ static constexpr int32_t kMaxInt8 = std::numeric_limits<int8_t>::max();
+ using F4 = gemmlowp::FixedPoint<int32_t, kInputIntegerBits>;
+
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; ++i) {
+ const int32_t input =
+ static_cast<int32_t>(input_data[i]) - input_zero_point;
+ if (input <= -input_range_radius) {
+ output_data[i] = kMinInt8;
+ } else if (input >= input_range_radius) {
+ output_data[i] = kMaxInt8;
+ } else {
+ const int32_t input_in_q4 =
+ MultiplyByQuantizedMultiplier(input, input_multiplier, input_shift);
+ const int32_t output_in_q0 =
+ gemmlowp::tanh(F4::FromRaw(input_in_q4)).raw();
+
+ // Rescale and downcast.
+ using gemmlowp::RoundingDivideByPOT;
+ int32_t output_in_q24 =
+ RoundingDivideByPOT(output_in_q0, 31 - kOutputScale);
+ output_in_q24 = std::min(std::max(output_in_q24, kMinInt8), kMaxInt8);
+ output_data[i] = static_cast<int8_t>(output_in_q24);
+ }
+ }
+}
+
+inline void Tanh(int32_t input_multiplier, int32_t input_left_shift,
+ const RuntimeShape& input_shape, const int16_t* ptr_input_data,
+ const RuntimeShape& output_shape, int16_t* ptr_output_data) {
+ // We use the LUT for sigmoid and take into account, that
+ // tanh(x) = 2*sigmoid(2*x) - 1
+
+ // We scale by 3/4 to expand range [-8,8]->[-10.7,10.7].
+ // In case of general parameter scale, multiplier 3 is taken into account
+ // in TanhPrepare function and it is included in
+ // input_multiplier already.
+
+ if (input_multiplier == 0) { // power of two case
+ input_multiplier = 3 << input_left_shift;
+ input_left_shift = 0;
+ }
+
+ int32_t round = (input_left_shift > 0) ? 1 << (input_left_shift - 1) : 0;
+
+ int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; ++i, ptr_input_data++, ptr_output_data++) {
+ int32_t input_data =
+ ((*ptr_input_data) * input_multiplier + round) >> input_left_shift;
+
+ uint32_t abs_input_data = abs(input_data);
+ uint32_t uh = abs_input_data >> 8;
+ int32_t result;
+
+ if (uh >= 255) {
+ // Saturate to maximum.
+ result = 0xFFFF << 8;
+ } else {
+ uint32_t ua = sigmoid_table_uint16[uh];
+ uint32_t ub = sigmoid_table_uint16[uh + 1];
+
+ uint8_t ut = abs_input_data & 0xFF;
+
+ result = (ua << 8) + ut * (ub - ua);
+ }
+
+ result = (input_data >= 0)
+ ? (result - (1 << (14 + 9)) + (1 << (9 - 2)))
+ : (-result + (1 << (14 + 9)) + (1 << (9 - 2)) - 1);
+
+ // Convert back to 16-bit.
+ result >>= (9 - 1);
+
+ *ptr_output_data = result;
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_TANH_H_
diff --git a/tensorflow/lite/kernels/internal/reference/integer_ops/transpose_conv.h b/tensorflow/lite/kernels/internal/reference/integer_ops/transpose_conv.h
new file mode 100644
index 0000000..284c0f2
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/integer_ops/transpose_conv.h
@@ -0,0 +1,221 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_TRANSPOSE_CONV_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_TRANSPOSE_CONV_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_integer_ops {
+
+// Fixed-point per-channel-quantization transpose convolution reference kernel.
+inline void TransposeConv(
+ const ConvParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data, const RuntimeShape& im2col_shape, int8_t* im2col_data,
+ int32_t* scratch_buffer) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ (void)im2col_data; // only used in optimized code.
+ (void)im2col_shape; // only used in optimized code.
+
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int32_t input_offset = params.input_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_activation_min = std::numeric_limits<int8_t>::min();
+ const int32_t output_activation_max = std::numeric_limits<int8_t>::max();
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+
+ const int num_elements = output_shape.FlatSize();
+ // We need to initialize scratch_buffer to all 0s, as we apply the same
+ // 'scatter' based trick as in float version.
+ memset(scratch_buffer, 0, num_elements * sizeof(int32_t));
+
+ // Loop through input elements one at a time.
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int in_y = 0; in_y < input_height; ++in_y) {
+ for (int in_x = 0; in_x < input_width; ++in_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ // Loop through the output elements it will influence.
+ const int out_x_origin = (in_x * stride_width) - pad_width;
+ const int out_y_origin = (in_y * stride_height) - pad_height;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ for (int out_channel = 0; out_channel < output_depth;
+ ++out_channel) {
+ // Compute output element location.
+ const int out_x = out_x_origin + filter_x;
+ const int out_y = out_y_origin + filter_y;
+ // We cannot accumulate out of bounds.
+ if ((out_x >= 0) && (out_x < output_width) && (out_y >= 0) &&
+ (out_y < output_height)) {
+ const int8_t input_value = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ const int8_t filter_value =
+ filter_data[Offset(filter_shape, out_channel, filter_y,
+ filter_x, in_channel)];
+ scratch_buffer[Offset(output_shape, batch, out_y, out_x,
+ out_channel)] +=
+ (input_value + input_offset) * filter_value;
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ int32_t acc = scratch_buffer[Offset(output_shape, batch, out_y, out_x,
+ out_channel)];
+ if (bias_data) {
+ acc += bias_data[out_channel];
+ }
+ acc = MultiplyByQuantizedMultiplier(
+ acc, output_multiplier[out_channel], output_shift[out_channel]);
+ acc += output_offset;
+ acc = std::max(acc, output_activation_min);
+ acc = std::min(acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ static_cast<int8_t>(acc);
+ }
+ }
+ }
+ }
+}
+
+// int16_t input (zero_point=0), int8_t filter, int64 accumulator
+inline void TransposeConv(
+ const ConvParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int16_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const std::int64_t* bias_data, const RuntimeShape& output_shape,
+ int16_t* output_data, const RuntimeShape& im2col_shape, int8_t* im2col_data,
+ std::int64_t* scratch_buffer) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ (void)im2col_data; // only used in optimized code.
+ (void)im2col_shape; // only used in optimized code.
+
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int32_t output_activation_min = std::numeric_limits<int16_t>::min();
+ const int32_t output_activation_max = std::numeric_limits<int16_t>::max();
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+
+ const int num_elements = output_shape.FlatSize();
+ // We need to initialize scratch_buffer to all 0s, as we apply the same
+ // 'scatter' based trick as in float version.
+ memset(scratch_buffer, 0, num_elements * sizeof(std::int64_t));
+
+ // Loop through input elements one at a time.
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int in_y = 0; in_y < input_height; ++in_y) {
+ for (int in_x = 0; in_x < input_width; ++in_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ // Loop through the output elements it will influence.
+ const int out_x_origin = (in_x * stride_width) - pad_width;
+ const int out_y_origin = (in_y * stride_height) - pad_height;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ for (int out_channel = 0; out_channel < output_depth;
+ ++out_channel) {
+ // Compute output element location.
+ const int out_x = out_x_origin + filter_x;
+ const int out_y = out_y_origin + filter_y;
+ // We cannot accumulate out of bounds.
+ if ((out_x >= 0) && (out_x < output_width) && (out_y >= 0) &&
+ (out_y < output_height)) {
+ const int32_t input_value = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ const int32_t filter_value =
+ filter_data[Offset(filter_shape, out_channel, filter_y,
+ filter_x, in_channel)];
+ scratch_buffer[Offset(output_shape, batch, out_y, out_x,
+ out_channel)] +=
+ input_value * filter_value;
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ std::int64_t acc = scratch_buffer[Offset(output_shape, batch, out_y,
+ out_x, out_channel)];
+ if (bias_data) {
+ acc += bias_data[out_channel];
+ }
+ int32_t scaled_acc = MultiplyByQuantizedMultiplier(
+ acc, output_multiplier[out_channel], output_shift[out_channel]);
+ scaled_acc = std::max(scaled_acc, output_activation_min);
+ scaled_acc = std::min(scaled_acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ static_cast<int16_t>(scaled_acc);
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_integer_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_INTEGER_OPS_TRANSPOSE_CONV_H_
diff --git a/tensorflow/lite/kernels/internal/reference/l2normalization.h b/tensorflow/lite/kernels/internal/reference/l2normalization.h
new file mode 100644
index 0000000..7587d2b
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/l2normalization.h
@@ -0,0 +1,90 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_L2NORMALIZATION_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_L2NORMALIZATION_H_
+
+#include <algorithm>
+#include <cmath>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline void L2Normalization(const tflite::L2NormalizationParams& op_params,
+ const RuntimeShape& input_shape,
+ const float* input_data,
+ const RuntimeShape& output_shape,
+ float* output_data, float epsilon = 1e-6) {
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+ for (int i = 0; i < outer_size; ++i) {
+ float squared_l2_norm = 0;
+ for (int c = 0; c < depth; ++c) {
+ const float val = input_data[depth * i + c];
+ squared_l2_norm += val * val;
+ }
+ float l2_norm = std::sqrt(squared_l2_norm);
+ l2_norm = std::max(l2_norm, epsilon);
+ for (int c = 0; c < depth; ++c) {
+ output_data[depth * i + c] = input_data[depth * i + c] / l2_norm;
+ }
+ }
+}
+
+inline void L2Normalization(const tflite::L2NormalizationParams& op_params,
+ const RuntimeShape& input_shape,
+ const uint8_t* input_data,
+ const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int32_t input_zero_point = op_params.input_zero_point;
+
+ for (int i = 0; i < outer_size; ++i) {
+ int32_t square_l2_norm = 0;
+ for (int c = 0; c < depth; c++) {
+ int32_t diff = input_data[depth * i + c] - input_zero_point;
+ square_l2_norm += diff * diff;
+ }
+ int32_t inv_l2norm_multiplier;
+ int inv_l2norm_shift;
+ GetInvSqrtQuantizedMultiplierExp(square_l2_norm, kReverseShift,
+ &inv_l2norm_multiplier, &inv_l2norm_shift);
+ for (int c = 0; c < depth; c++) {
+ int32_t diff = input_data[depth * i + c] - input_zero_point;
+ int32_t rescaled_diff = MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ 128 * diff, inv_l2norm_multiplier, inv_l2norm_shift);
+ int32_t unclamped_output_val = 128 + rescaled_diff;
+ int32_t output_val =
+ std::min(static_cast<int32_t>(255),
+ std::max(static_cast<int32_t>(0), unclamped_output_val));
+ output_data[depth * i + c] = static_cast<uint8_t>(output_val);
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_L2NORMALIZATION_H_
diff --git a/tensorflow/lite/kernels/internal/reference/leaky_relu.h b/tensorflow/lite/kernels/internal/reference/leaky_relu.h
new file mode 100644
index 0000000..06f691a
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/leaky_relu.h
@@ -0,0 +1,69 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_LEAKY_RELU_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_LEAKY_RELU_H_
+
+#include <algorithm>
+#include <limits>
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline void LeakyRelu(const tflite::LeakyReluParams& params,
+ const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ const float val = input_data[i];
+ // Note that alpha might be > 1 or < 0, so we don't use std::max here.
+ output_data[i] = val > 0 ? val : val * params.alpha;
+ }
+}
+
+template <typename T>
+inline void QuantizeLeakyRelu(const LeakyReluParams& params,
+ const RuntimeShape& input_shape,
+ const T* input_data,
+ const RuntimeShape& output_shape,
+ T* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ static const int32_t quantized_min = std::numeric_limits<T>::min();
+ static const int32_t quantized_max = std::numeric_limits<T>::max();
+ for (int i = 0; i < flat_size; ++i) {
+ const int32_t input_value = input_data[i] - params.input_offset;
+ int32_t unclamped_output;
+ if (input_value >= 0) {
+ unclamped_output = params.output_offset +
+ MultiplyByQuantizedMultiplier(
+ input_value, params.output_multiplier_identity,
+ params.output_shift_identity);
+ } else {
+ unclamped_output = params.output_offset +
+ MultiplyByQuantizedMultiplier(
+ input_value, params.output_multiplier_alpha,
+ params.output_shift_alpha);
+ }
+ const T clamped_output =
+ std::min(quantized_max, std::max(quantized_min, unclamped_output));
+ output_data[i] = static_cast<T>(clamped_output);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_LEAKY_RELU_H_
diff --git a/tensorflow/lite/kernels/internal/reference/logistic.h b/tensorflow/lite/kernels/internal/reference/logistic.h
new file mode 100644
index 0000000..64b7133
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/logistic.h
@@ -0,0 +1,132 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_LOGISTIC_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_LOGISTIC_H_
+
+#include <cmath>
+
+#include "fixedpoint/fixedpoint.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline void Logistic(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const float cutoff_upper = 16.619047164916992188f;
+ const float cutoff_lower = -9.f;
+
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ // Rational for using approximation in reference kernel.
+ // 0. This approximation gives enough precision for float.
+ // 1. This works around an issue on an embedded chipset where exp() does not
+ // return correctly as expected - exp(x) should return inf when overflown
+ // not 1.701417 IEEE 754 defines representation for inf.
+ // 2. This will speed up calculation and is matching the behavior in the
+ // optimized kernels. (check the definition of scalar_logistic_op<float>)
+
+ for (int i = 0; i < flat_size; i++) {
+ float val = input_data[i];
+ float result;
+ if (val > cutoff_upper) {
+ result = 1.0f;
+ } else if (val < cutoff_lower) {
+ result = std::exp(val);
+ } else {
+ result = 1.f / (1.f + std::exp(-val));
+ }
+ output_data[i] = result;
+ }
+}
+
+// Convenience version that allows, for example, generated-code calls to be
+// uniform between data types.
+inline void Logistic(const LogisticParams&, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& output_shape,
+ float* output_data) {
+ // Drop params: not needed.
+ Logistic(input_shape, input_data, output_shape, output_data);
+}
+
+inline void Logistic(const LogisticParams& params,
+ const RuntimeShape& input_shape, const int16_t* input_data,
+ const RuntimeShape& output_shape, int16_t* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; i++) {
+ // F0 uses 0 integer bits, range [-1, 1].
+ // This is the return type of math functions such as tanh, logistic,
+ // whose range is in [-1, 1].
+ using F0 = gemmlowp::FixedPoint<std::int16_t, 0>;
+ // F3 uses 3 integer bits, range [-8, 8], the input range expected here.
+ using F3 = gemmlowp::FixedPoint<std::int16_t, 3>;
+
+ const F3 input = F3::FromRaw(input_data[i]);
+ F0 output = gemmlowp::logistic(input);
+ output_data[i] = output.raw();
+ }
+}
+
+// Quantized int8_t logistic activation. Cheats by dequantizing and
+// requantizing around the floating point logistic method. This implementation
+// is slow on platforms without a floating point unit.
+
+// TODO(b/141211002): Delete this int8_t implementation once we can reuse the
+// approach used in TFLite for int8_t Logistic.
+inline void Logistic(const RuntimeShape& input_shape, const int8_t* input_data,
+ float input_scale, int input_zero_point,
+ const RuntimeShape& output_shape, int8_t* output_data,
+ float output_scale, int output_zero_point) {
+ const float cutoff_upper = 16.619047164916992188f;
+ const float cutoff_lower = -9.f;
+
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ // Rational for using approximation in reference kernel.
+ // 0. This approximation gives enough precision for float.
+ // 1. This works around an issue on an embedded chipset where exp() does not
+ // return correctly as expected - exp(x) should return inf when overflown
+ // not 1.701417 IEEE 754 defines representation for inf.
+ // 2. This will speed up calculation and is matching the behavior in the
+ // optimized kernels. (check the definition of scalar_logistic_op<float>)
+
+ for (int i = 0; i < flat_size; i++) {
+ // Dequantize.
+ float val =
+ static_cast<float>((input_data[i] - input_zero_point) * input_scale);
+ float result;
+ if (val > cutoff_upper) {
+ result = 1.0f;
+ } else if (val < cutoff_lower) {
+ result = std::exp(val);
+ } else {
+ result = 1.f / (1.f + std::exp(-val));
+ }
+ // Requantize
+ int8_t output =
+ static_cast<int8_t>(result / output_scale + output_zero_point);
+ output_data[i] = output;
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_LOGISTIC_H_
diff --git a/tensorflow/lite/kernels/internal/reference/maximum_minimum.h b/tensorflow/lite/kernels/internal/reference/maximum_minimum.h
new file mode 100644
index 0000000..cd11b41
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/maximum_minimum.h
@@ -0,0 +1,64 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_MAXIMUM_MINIMUM_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_MAXIMUM_MINIMUM_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+template <typename T, typename Op, int N = 5>
+void MaximumMinimumBroadcastSlow(const RuntimeShape& unextended_input1_shape,
+ const T* input1_data,
+ const RuntimeShape& unextended_input2_shape,
+ const T* input2_data,
+ const RuntimeShape& unextended_output_shape,
+ T* output_data, Op op) {
+ // Uses element-wise calculation if broadcast is not required.
+ if (unextended_input1_shape == unextended_input2_shape) {
+ const int flat_size =
+ MatchingElementsSize(unextended_input1_shape, unextended_input2_shape,
+ unextended_output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = op(input1_data[i], input2_data[i]);
+ }
+ } else {
+ TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), N);
+
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(
+ unextended_input1_shape, unextended_input2_shape, &desc1, &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, unextended_output_shape),
+ &output_desc);
+
+ auto maxmin_func = [&](int indexes[N]) {
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ op(input1_data[SubscriptToIndex(desc1, indexes)],
+ input2_data[SubscriptToIndex(desc2, indexes)]);
+ };
+ NDOpsHelper<N>(output_desc, maxmin_func);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_MAXIMUM_MINIMUM_H_
diff --git a/tensorflow/lite/kernels/internal/reference/mul.h b/tensorflow/lite/kernels/internal/reference/mul.h
new file mode 100644
index 0000000..0578b81
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/mul.h
@@ -0,0 +1,166 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_MUL_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_MUL_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+// Element-wise mul that can often be used for inner loop of broadcast Mul as
+// well as the non-broadcast Mul.
+inline void MulElementwise(int size, const ArithmeticParams& params,
+ const uint8_t* input1_data,
+ const uint8_t* input2_data, uint8_t* output_data) {
+ for (int i = 0; i < size; ++i) {
+ const int32_t input1_val = params.input1_offset + input1_data[i];
+ const int32_t input2_val = params.input2_offset + input2_data[i];
+ const int32_t unclamped_result =
+ params.output_offset +
+ MultiplyByQuantizedMultiplier(input1_val * input2_val,
+ params.output_multiplier,
+ params.output_shift);
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, unclamped_result));
+ output_data[i] = static_cast<uint8_t>(clamped_output);
+ }
+}
+
+template <typename T>
+inline void Mul(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const T* input1_data,
+ const RuntimeShape& input2_shape, const T* input2_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ T output_activation_min;
+ T output_activation_max;
+ GetActivationParams(params, &output_activation_min, &output_activation_max);
+
+ const int flat_size =
+ MatchingFlatSize(input1_shape, input2_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = ActivationFunctionWithMinMax(
+ input1_data[i] * input2_data[i], output_activation_min,
+ output_activation_max);
+ }
+}
+
+inline void Mul(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const uint8_t* input1_data,
+ const RuntimeShape& input2_shape, const uint8_t* input2_data,
+ const RuntimeShape& output_shape, uint8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ const int flat_size =
+ MatchingFlatSize(input1_shape, input2_shape, output_shape);
+
+ MulElementwise(flat_size, params, input1_data, input2_data, output_data);
+}
+
+inline void BroadcastMul4DSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const uint8_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const uint8_t* input2_data,
+ const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ const int32_t input1_val =
+ params.input1_offset +
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)];
+ const int32_t input2_val =
+ params.input2_offset +
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)];
+ const int32_t unclamped_result =
+ params.output_offset +
+ MultiplyByQuantizedMultiplier(input1_val * input2_val,
+ params.output_multiplier,
+ params.output_shift);
+ const int32_t clamped_output = std::min(
+ params.quantized_activation_max,
+ std::max(params.quantized_activation_min, unclamped_result));
+ output_data[Offset(extended_output_shape, b, y, x, c)] =
+ static_cast<uint8_t>(clamped_output);
+ }
+ }
+ }
+ }
+}
+
+template <typename T>
+void BroadcastMul4DSlow(const ArithmeticParams& params,
+ const RuntimeShape& unextended_input1_shape,
+ const T* input1_data,
+ const RuntimeShape& unextended_input2_shape,
+ const T* input2_data,
+ const RuntimeShape& unextended_output_shape,
+ T* output_data) {
+ T output_activation_min;
+ T output_activation_max;
+ GetActivationParams(params, &output_activation_min, &output_activation_max);
+
+ TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(4, unextended_output_shape);
+
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(unextended_input1_shape,
+ unextended_input2_shape, &desc1, &desc2);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ for (int b = 0; b < output_shape.Dims(0); ++b) {
+ for (int y = 0; y < output_shape.Dims(1); ++y) {
+ for (int x = 0; x < output_shape.Dims(2); ++x) {
+ for (int c = 0; c < output_shape.Dims(3); ++c) {
+ output_data[Offset(output_shape, b, y, x, c)] =
+ ActivationFunctionWithMinMax(
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)] *
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)],
+ output_activation_min, output_activation_max);
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_MUL_H_
diff --git a/tensorflow/lite/kernels/internal/reference/neg.h b/tensorflow/lite/kernels/internal/reference/neg.h
new file mode 100644
index 0000000..e127883
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/neg.h
@@ -0,0 +1,37 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_NEG_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_NEG_H_
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+template <typename T>
+inline void Negate(const RuntimeShape& input_shape, const T* input_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = -input_data[i];
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_NEG_H_
diff --git a/tensorflow/lite/kernels/internal/reference/pad.h b/tensorflow/lite/kernels/internal/reference/pad.h
new file mode 100644
index 0000000..2758944
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/pad.h
@@ -0,0 +1,169 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PAD_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PAD_H_
+
+#include <vector>
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+// TFLite Pad supports activation tensors with up to 5 dimensions.
+constexpr int PadKernelMaxDimensionCount() { return 5; }
+
+// There are two versions of pad: Pad and PadV2. In PadV2 there is a second
+// scalar input that provides the padding value. Therefore pad_value_ptr can be
+// equivalent to a simple input1_data. For Pad, it should point to a zero
+// value.
+//
+// Note that two typenames are required, so that T=P=int32_t is considered a
+// specialization distinct from P=int32_t.
+template <typename T, typename P>
+inline void PadImpl(const tflite::PadParams& op_params,
+ const RuntimeShape& input_shape, const T* input_data,
+ const P* pad_value_ptr, const RuntimeShape& output_shape,
+ T* output_data) {
+ const RuntimeShape ext_input_shape =
+ RuntimeShape::ExtendedShape(PadKernelMaxDimensionCount(), input_shape);
+ const RuntimeShape ext_output_shape =
+ RuntimeShape::ExtendedShape(PadKernelMaxDimensionCount(), output_shape);
+ TFLITE_DCHECK_LE(op_params.left_padding_count, PadKernelMaxDimensionCount());
+ TFLITE_DCHECK_LE(op_params.right_padding_count, PadKernelMaxDimensionCount());
+
+ // Runtime calls are currently fixed at 5 dimensions. Copy inputs so we can
+ // pad them to 5 dims (yes, we are "padding the padding").
+ int left_padding_copy[PadKernelMaxDimensionCount()];
+ for (int i = 0; i < PadKernelMaxDimensionCount(); i++) {
+ left_padding_copy[i] = 0;
+ }
+ for (int i = 0; i < op_params.left_padding_count; ++i) {
+ left_padding_copy[i + PadKernelMaxDimensionCount() -
+ op_params.left_padding_count] = op_params.left_padding[i];
+ }
+ int right_padding_copy[PadKernelMaxDimensionCount()];
+ for (int i = 0; i < PadKernelMaxDimensionCount(); i++) {
+ right_padding_copy[i] = 0;
+ }
+ for (int i = 0; i < op_params.right_padding_count; ++i) {
+ right_padding_copy[i + PadKernelMaxDimensionCount() -
+ op_params.right_padding_count] =
+ op_params.right_padding[i];
+ }
+
+ const int output_batch = ext_output_shape.Dims(0);
+ const int output_plane = ext_output_shape.Dims(1);
+ const int output_height = ext_output_shape.Dims(2);
+ const int output_width = ext_output_shape.Dims(3);
+ const int output_depth = ext_output_shape.Dims(4);
+
+ const int left_b_padding = left_padding_copy[0];
+ const int left_p_padding = left_padding_copy[1];
+ const int left_h_padding = left_padding_copy[2];
+ const int left_w_padding = left_padding_copy[3];
+ const int left_d_padding = left_padding_copy[4];
+
+ const int right_b_padding = right_padding_copy[0];
+ const int right_p_padding = right_padding_copy[1];
+ const int right_h_padding = right_padding_copy[2];
+ const int right_w_padding = right_padding_copy[3];
+ const int right_d_padding = right_padding_copy[4];
+
+ const T pad_value = *pad_value_ptr;
+
+ const T* in_ptr = input_data;
+ T* out_ptr = output_data;
+ for (int out_b = 0; out_b < output_batch; ++out_b) {
+ for (int out_p = 0; out_p < output_plane; ++out_p) {
+ for (int out_h = 0; out_h < output_height; ++out_h) {
+ for (int out_w = 0; out_w < output_width; ++out_w) {
+ for (int out_d = 0; out_d < output_depth; ++out_d) {
+ if (out_b < left_b_padding ||
+ out_b >= output_batch - right_b_padding ||
+ out_p < left_p_padding ||
+ out_p >= output_plane - right_p_padding ||
+ out_h < left_h_padding ||
+ out_h >= output_height - right_h_padding ||
+ out_w < left_w_padding ||
+ out_w >= output_width - right_w_padding ||
+ out_d < left_d_padding ||
+ out_d >= output_depth - right_d_padding) {
+ *out_ptr++ = pad_value;
+ } else {
+ *out_ptr++ = *in_ptr++;
+ }
+ }
+ }
+ }
+ }
+ }
+}
+
+template <typename T, typename P>
+inline void Pad(const tflite::PadParams& op_params,
+ const RuntimeShape& input_shape, const T* input_data,
+ const P* pad_value_ptr, const RuntimeShape& output_shape,
+ T* output_data) {
+ PadImpl(op_params, input_shape, input_data, pad_value_ptr, output_shape,
+ output_data);
+}
+
+// The second (pad-value) input can be int32_t when, say, the first is uint8_t.
+template <typename T>
+inline void Pad(const tflite::PadParams& op_params,
+ const RuntimeShape& input_shape, const T* input_data,
+ const int32_t* pad_value_ptr, const RuntimeShape& output_shape,
+ T* output_data) {
+ const T converted_pad_value = static_cast<T>(*pad_value_ptr);
+ PadImpl(op_params, input_shape, input_data, &converted_pad_value,
+ output_shape, output_data);
+}
+
+// This version avoids conflicting template matching.
+template <>
+inline void Pad(const tflite::PadParams& op_params,
+ const RuntimeShape& input_shape, const int32_t* input_data,
+ const int32_t* pad_value_ptr, const RuntimeShape& output_shape,
+ int32_t* output_data) {
+ PadImpl(op_params, input_shape, input_data, pad_value_ptr, output_shape,
+ output_data);
+}
+
+template <typename T, typename P>
+inline void PadImageStyle(const tflite::PadParams& op_params,
+ const RuntimeShape& input_shape, const T* input_data,
+ const P* pad_value_ptr,
+ const RuntimeShape& output_shape, T* output_data) {
+ Pad(op_params, input_shape, input_data, pad_value_ptr, output_shape,
+ output_data);
+}
+
+template <typename P>
+inline void PadImageStyle(const tflite::PadParams& op_params,
+ const RuntimeShape& input_shape,
+ const float* input_data, const P* pad_value_ptr,
+ const RuntimeShape& output_shape,
+ float* output_data) {
+ Pad(op_params, input_shape, input_data, pad_value_ptr, output_shape,
+ output_data);
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PAD_H_
diff --git a/tensorflow/lite/kernels/internal/reference/pooling.h b/tensorflow/lite/kernels/internal/reference/pooling.h
new file mode 100644
index 0000000..0872f52
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/pooling.h
@@ -0,0 +1,297 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_POOLING_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_POOLING_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline void AveragePool(const PoolParams& params,
+ const RuntimeShape& input_shape,
+ const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ float total = 0.f;
+ float filter_count = 0;
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ total +=
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)];
+ filter_count++;
+ }
+ }
+ const float average = total / filter_count;
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ ActivationFunctionWithMinMax(average, params.float_activation_min,
+ params.float_activation_max);
+ }
+ }
+ }
+ }
+}
+
+inline void AveragePool(const PoolParams& params,
+ const RuntimeShape& input_shape,
+ const uint8_t* input_data,
+ const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ int32_t acc = 0;
+ int filter_count = 0;
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ acc +=
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)];
+ filter_count++;
+ }
+ }
+ acc = (acc + filter_count / 2) / filter_count;
+ acc = std::max(acc, params.quantized_activation_min);
+ acc = std::min(acc, params.quantized_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ static_cast<uint8_t>(acc);
+ }
+ }
+ }
+ }
+}
+
+inline void L2Pool(const PoolParams& params, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& output_shape,
+ float* output_data) {
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ float sum_squares = 0.f;
+ int filter_count = 0;
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ const float val =
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)];
+ sum_squares += val * val;
+ filter_count++;
+ }
+ }
+ const float l2pool_result = std::sqrt(sum_squares / filter_count);
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ ActivationFunctionWithMinMax(l2pool_result,
+ params.float_activation_min,
+ params.float_activation_max);
+ }
+ }
+ }
+ }
+}
+
+inline void MaxPool(const PoolParams& params, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& output_shape,
+ float* output_data) {
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ float max = std::numeric_limits<float>::lowest();
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ max = std::max(
+ max,
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)]);
+ }
+ }
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ ActivationFunctionWithMinMax(max, params.float_activation_min,
+ params.float_activation_max);
+ }
+ }
+ }
+ }
+}
+
+inline void MaxPool(const PoolParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ TFLITE_DCHECK_GE(params.quantized_activation_min, 0);
+ TFLITE_DCHECK_LE(params.quantized_activation_max, 255);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int channel = 0; channel < depth; ++channel) {
+ const int in_x_origin =
+ (out_x * stride_width) - params.padding_values.width;
+ const int in_y_origin =
+ (out_y * stride_height) - params.padding_values.height;
+ // Compute the boundaries of the filter region clamped so as to
+ // ensure that the filter window fits in the input array.
+ const int filter_x_start = std::max(0, -in_x_origin);
+ const int filter_x_end =
+ std::min(params.filter_width, input_width - in_x_origin);
+ const int filter_y_start = std::max(0, -in_y_origin);
+ const int filter_y_end =
+ std::min(params.filter_height, input_height - in_y_origin);
+ uint8_t max = 0;
+ for (int filter_y = filter_y_start; filter_y < filter_y_end;
+ ++filter_y) {
+ for (int filter_x = filter_x_start; filter_x < filter_x_end;
+ ++filter_x) {
+ const int in_x = in_x_origin + filter_x;
+ const int in_y = in_y_origin + filter_y;
+ max = std::max(
+ max,
+ input_data[Offset(input_shape, batch, in_y, in_x, channel)]);
+ }
+ }
+ max = std::max<uint8_t>(max, params.quantized_activation_min);
+ max = std::min<uint8_t>(max, params.quantized_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, channel)] =
+ static_cast<uint8_t>(max);
+ }
+ }
+ }
+ }
+}
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_POOLING_H_
diff --git a/tensorflow/lite/kernels/internal/reference/prelu.h b/tensorflow/lite/kernels/internal/reference/prelu.h
new file mode 100644
index 0000000..02db517
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/prelu.h
@@ -0,0 +1,109 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PRELU_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PRELU_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+// Broadcast prelu to output_shape for quantized uint8_t/int8_t data.
+template <typename T>
+inline void BroadcastPrelu4DSlow(
+ const PreluParams& params, const RuntimeShape& input_shape,
+ const T* input_data, const RuntimeShape& alpha_shape, const T* alpha_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ TFLITE_DCHECK_LE(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(alpha_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(output_shape.DimensionsCount(), 4);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(input_shape, alpha_shape, &desc1, &desc2);
+
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ int output_index = Offset(extended_output_shape, b, y, x, c);
+ int input_index = SubscriptToIndex(desc1, b, y, x, c);
+ const int32_t input_value =
+ params.input_offset + input_data[input_index];
+ int32_t output_value;
+ if (input_value >= 0) {
+ output_value = MultiplyByQuantizedMultiplier(
+ input_value, params.output_multiplier_1, params.output_shift_1);
+ } else {
+ auto alpha_index = SubscriptToIndex(desc2, b, y, x, c);
+ const int32_t alpha_value =
+ params.alpha_offset + alpha_data[alpha_index];
+
+ output_value = MultiplyByQuantizedMultiplier(
+ input_value * alpha_value, params.output_multiplier_2,
+ params.output_shift_2);
+ }
+ output_value += params.output_offset;
+
+ const int32_t quantized_min = std::numeric_limits<T>::min();
+ const int32_t quantized_max = std::numeric_limits<T>::max();
+ const int32_t clamped_output =
+ std::min(quantized_max, std::max(quantized_min, output_value));
+ output_data[output_index] = static_cast<T>(clamped_output);
+ }
+ }
+ }
+ }
+}
+
+template <typename T>
+inline void Prelu(const PreluParams& params, const RuntimeShape& input_shape,
+ const T* input_data, const RuntimeShape& alpha_shape,
+ const T* alpha_data, const RuntimeShape& output_shape,
+ T* output_data) {
+ const int32_t quantized_min = std::numeric_limits<T>::min();
+ const int32_t quantized_max = std::numeric_limits<T>::max();
+
+ const int flat_size =
+ MatchingElementsSize(input_shape, alpha_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ const int32_t input_value = params.input_offset + input_data[i];
+ int32_t output_value;
+ if (input_value >= 0) {
+ output_value = MultiplyByQuantizedMultiplier(
+ input_value, params.output_multiplier_1, params.output_shift_1);
+ } else {
+ const int32_t alpha_value = params.alpha_offset + alpha_data[i];
+
+ output_value = MultiplyByQuantizedMultiplier(input_value * alpha_value,
+ params.output_multiplier_2,
+ params.output_shift_2);
+ }
+ output_value += params.output_offset;
+
+ const int32_t clamped_output =
+ std::min(quantized_max, std::max(quantized_min, output_value));
+ output_data[i] = static_cast<T>(clamped_output);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PRELU_H_
diff --git a/tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h b/tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h
new file mode 100644
index 0000000..40f779c
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h
@@ -0,0 +1,138 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PROCESS_BROADCAST_SHAPES_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PROCESS_BROADCAST_SHAPES_H_
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+// Consolidates dimensions in broadcast inputs, checks for five-fold pattern.
+//
+// For example, if sequence of dimensions of one input is
+// ..., 1, 3, 1, 7, 9, 5,... and the other is ..., 2, 3, 1, 7, 1, 1, ...
+// we can consolidate these as
+// ..., 1, 3*7, 9*5, ... and 2, 3*7, 1.
+//
+// The category is updated in the less-frequent case of shapes that are
+// not suited to a fivefold-loop broadcast.
+//
+// Falls back to generic pattern when it does not know how to process properly.
+//
+// Returns true iff there is some sort of broadcast, which includes five-fold
+// patterns and falling back to generic broadcast.
+inline bool ProcessBroadcastShapes(const RuntimeShape& shape0,
+ const RuntimeShape& shape1,
+ tflite::ArithmeticParams* params) {
+ const int dims_count =
+ std::max(shape0.DimensionsCount(), shape1.DimensionsCount());
+
+ params->broadcast_category = BroadcastableOpCategory::kGenericBroadcast;
+ RuntimeShape scalar_shape(dims_count, 1);
+
+ auto extended_shape0 = RuntimeShape::ExtendedShape(dims_count, shape0);
+ auto extended_shape1 = RuntimeShape::ExtendedShape(dims_count, shape1);
+
+ // Check for "exact" match, implicitly accepting any scalar shapes.
+ if (extended_shape0 == extended_shape1) {
+ params->broadcast_category = BroadcastableOpCategory::kNonBroadcast;
+ return false;
+ }
+
+ for (int i = dims_count - 1; i >= 0; --i) {
+ if (extended_shape0.Dims(i) == extended_shape1.Dims(i)) {
+ continue;
+ } else if (extended_shape0.Dims(i) == 1) {
+ params->broadcast_category =
+ BroadcastableOpCategory::kFirstInputBroadcastsFast;
+ break;
+ } else if (extended_shape1.Dims(i) == 1) {
+ params->broadcast_category =
+ BroadcastableOpCategory::kSecondInputBroadcastsFast;
+ break;
+ } else {
+ // This case is erroneous: there is a dimension that does not match and
+ // is not a broadcast from one shape to the other.
+ params->broadcast_category = BroadcastableOpCategory::kGenericBroadcast;
+ return true;
+ }
+ }
+
+ if (params->broadcast_category !=
+ BroadcastableOpCategory::kFirstInputBroadcastsFast &&
+ params->broadcast_category !=
+ BroadcastableOpCategory::kSecondInputBroadcastsFast) {
+ // This is unreachable because at least one else clause in the above loop
+ // must be reached.
+ TFLITE_DCHECK(false);
+ params->broadcast_category = BroadcastableOpCategory::kNonBroadcast;
+ return false;
+ }
+
+ // From this point it is assumed contractually that corresponding dimensions
+ // in shape0 and shape1 are either (a) equal or (b) one or other equals 1.
+ const bool swap_inputs = params->broadcast_category ==
+ BroadcastableOpCategory::kSecondInputBroadcastsFast;
+ const RuntimeShape* shape_a =
+ swap_inputs ? &extended_shape1 : &extended_shape0;
+ const RuntimeShape* shape_b =
+ swap_inputs ? &extended_shape0 : &extended_shape1;
+
+ int i = dims_count - 1;
+ params->broadcast_shape[0] = 1;
+ params->broadcast_shape[1] = 1;
+ params->broadcast_shape[2] = 1;
+ params->broadcast_shape[3] = 1;
+ params->broadcast_shape[4] = 1;
+ // y_0 is greedy: include dims if both or neither equal 1: in other words,
+ // test for equality rather than (shape_a->Dims(i) != 1).
+ while (i >= 0 && shape_a->Dims(i) == shape_b->Dims(i)) {
+ params->broadcast_shape[4] *= shape_b->Dims(i);
+ --i;
+ }
+ // Here either input_a or input_b has dim of 1 (if i >= 0). If it is input_b
+ // that has the unit dimension, the next two loops are not entered.
+ while (i >= 0 && shape_a->Dims(i) == 1) {
+ params->broadcast_shape[3] *= shape_b->Dims(i);
+ --i;
+ }
+ while (i >= 0 && shape_a->Dims(i) == shape_b->Dims(i)) {
+ params->broadcast_shape[2] *= shape_a->Dims(i);
+ --i;
+ }
+ // Here either input_a or input_b has dim of 1 (if i >= 0).
+ while (i >= 0 && shape_b->Dims(i) == 1) {
+ params->broadcast_shape[1] *= shape_a->Dims(i);
+ --i;
+ }
+ while (i >= 0 && shape_a->Dims(i) == shape_b->Dims(i)) {
+ params->broadcast_shape[0] *= shape_b->Dims(i);
+ --i;
+ }
+
+ // Rarer case is when the broadcast dimensions cannot be handled by a fivefold
+ // loop.
+ if (i >= 0) {
+ params->broadcast_category = BroadcastableOpCategory::kGenericBroadcast;
+ }
+ return true;
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_PROCESS_BROADCAST_SHAPES_H_
diff --git a/tensorflow/lite/kernels/internal/reference/quantize.h b/tensorflow/lite/kernels/internal/reference/quantize.h
new file mode 100644
index 0000000..6f3f9ae
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/quantize.h
@@ -0,0 +1,55 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_QUANTIZE_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_QUANTIZE_H_
+
+#include <algorithm>
+#include <limits>
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+template <typename InputT, typename OutputT>
+inline void AffineQuantize(const tflite::QuantizationParams& op_params,
+ const RuntimeShape& input_shape,
+ const InputT* input_data,
+ const RuntimeShape& output_shape,
+ OutputT* output_data) {
+ const int32_t zero_point = op_params.zero_point;
+ const double scale = op_params.scale;
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ static constexpr int32_t min_val = std::numeric_limits<OutputT>::min();
+ static constexpr int32_t max_val = std::numeric_limits<OutputT>::max();
+
+ for (int i = 0; i < flat_size; i++) {
+ const InputT val = input_data[i];
+ int32_t unclamped =
+ static_cast<int32_t>(TfLiteRound(val / static_cast<float>(scale))) +
+ zero_point;
+ int32_t clamped = std::min(std::max(unclamped, min_val), max_val);
+ output_data[i] = clamped;
+ }
+}
+
+} // namespace reference_ops
+
+} // namespace tflite
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_QUANTIZE_H_
diff --git a/tensorflow/lite/kernels/internal/reference/reduce.h b/tensorflow/lite/kernels/internal/reference/reduce.h
new file mode 100644
index 0000000..a7c86dd
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/reduce.h
@@ -0,0 +1,412 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_REDUCE_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_REDUCE_H_
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/max.h"
+#include "tensorflow/lite/kernels/internal/min.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+// A generic reduce method that can be used for reduce_sum, reduce_mean, etc.
+// This method iterates through input data and reduce elements along the
+// dimensions given in axis.
+template <typename In, typename Out>
+inline bool Reduce(const In* input_data, const int* input_dims,
+ const int* output_dims, const int input_num_dims,
+ const int output_num_dims, const int* axis,
+ const int num_axis, int* input_iter,
+ Out reducer(const Out current, const In in),
+ Out* output_data) {
+ // Reset input iterator.
+ for (int idx = 0; idx < input_num_dims; ++idx) {
+ input_iter[idx] = 0;
+ }
+ // Iterate through input_data.
+ do {
+ size_t input_offset =
+ ReducedOutputOffset(input_num_dims, input_dims, input_iter, 0, nullptr);
+ size_t output_offset = ReducedOutputOffset(input_num_dims, input_dims,
+ input_iter, num_axis, axis);
+ output_data[output_offset] =
+ reducer(output_data[output_offset], input_data[input_offset]);
+ } while (NextIndex(input_num_dims, input_dims, input_iter));
+ return true;
+}
+
+// This method parses the input 'axis' to remove duplicates and handle negative
+// values, and returns a valid 'out_axis'
+inline bool ResolveAxis(const int num_dims, const int* axis,
+ const int64_t num_axis, int* out_axis,
+ int* out_num_axis) {
+ *out_num_axis = 0; // Just in case.
+ // Short-circuit axis resolution for scalars; the axis will go unused.
+ if (num_dims == 0) {
+ return true;
+ }
+ // o(n^2) is fine since out_num_axis should be really small, mostly <= 4
+ for (int64_t idx = 0; idx < num_axis; ++idx) {
+ // Handle negative index. A positive index 'p_idx' can be represented as a
+ // negative index 'n_idx' as: n_idx = p_idx-num_dims
+ // eg: For num_dims=3, [0, 1, 2] is the same as [-3, -2, -1] */
+ int current = axis[idx] < 0 ? (axis[idx] + num_dims) : axis[idx];
+ TFLITE_DCHECK(current >= 0 && current < num_dims);
+ if (current < 0 || current >= num_dims) {
+ return false;
+ }
+ bool is_dup = false;
+ for (int j = 0; j < *out_num_axis; ++j) {
+ if (out_axis[j] == current) {
+ is_dup = true;
+ break;
+ }
+ }
+ if (!is_dup) {
+ out_axis[*out_num_axis] = current;
+ *out_num_axis += 1;
+ }
+ }
+ return true;
+}
+
+// This method expects that output_data has been initialized.
+template <typename In, typename Out>
+inline bool ReduceSumImpl(const In* input_data, const int* input_dims,
+ const int* output_dims, const int input_num_dims,
+ const int output_num_dims, const int* axis,
+ const int num_axis, int* input_iter,
+ Out* output_data) {
+ auto reducer = [](const Out current, const In in) -> Out {
+ const Out actual_in = static_cast<Out>(in);
+ return current + actual_in;
+ };
+ return Reduce<In, Out>(input_data, input_dims, output_dims, input_num_dims,
+ output_num_dims, axis, num_axis, input_iter, reducer,
+ output_data);
+}
+
+template <typename T>
+inline bool InitTensorDataForReduce(const int* dims, const int num_dims,
+ const T init_value, T* data) {
+ size_t num_elements = 1;
+ for (int idx = 0; idx < num_dims; ++idx) {
+ size_t current = static_cast<size_t>(dims[idx]);
+ // Overflow prevention.
+ if (num_elements > std::numeric_limits<size_t>::max() / current) {
+ return false;
+ }
+ num_elements *= current;
+ }
+ for (size_t idx = 0; idx < num_elements; ++idx) {
+ data[idx] = init_value;
+ }
+ return true;
+}
+
+// Computes the generic value (i.e., sum/max/min/prod) of elements across
+// dimensions given in axis. It needs to pass in init_value and reducer.
+template <typename T>
+inline bool ReduceGeneric(const T* input_data, const int* input_dims,
+ const int input_num_dims, T* output_data,
+ const int* output_dims, const int output_num_dims,
+ const int* axis, const int64_t num_axis_dimensions,
+ bool keep_dims, int* temp_index, int* resolved_axis,
+ T init_value,
+ T reducer(const T current, const T in)) {
+ // Return early when input shape has zero dim.
+ for (int i = 0; i < input_num_dims; ++i) {
+ if (input_dims[i] == 0) return true;
+ }
+
+ // Reset output data.
+ if (!InitTensorDataForReduce(output_dims, output_num_dims, init_value,
+ output_data)) {
+ return false;
+ }
+
+ // Resolve axis.
+ int num_resolved_axis = 0;
+ if (!ResolveAxis(input_num_dims, axis, num_axis_dimensions, resolved_axis,
+ &num_resolved_axis)) {
+ return false;
+ }
+
+ return Reduce<T, T>(input_data, input_dims, output_dims, input_num_dims,
+ output_num_dims, resolved_axis, num_resolved_axis,
+ temp_index, reducer, output_data);
+}
+
+// Computes the mean of elements across dimensions given in axis.
+// It does so in two stages, first calculates the sum of elements along the axis
+// then divides it by the number of element in axis.
+template <typename T, typename U>
+inline bool Mean(const T* input_data, const int* input_dims,
+ const int input_num_dims, T* output_data,
+ const int* output_dims, const int output_num_dims,
+ const int* axis, const int num_axis_dimensions, bool keep_dims,
+ int* temp_index, int* resolved_axis, U* temp_sum) {
+ ruy::profiler::ScopeLabel label("Mean");
+ // Reset output data.
+ size_t num_outputs = 1;
+ for (int idx = 0; idx < output_num_dims; ++idx) {
+ size_t current = static_cast<size_t>(output_dims[idx]);
+ // Overflow prevention.
+ if (num_outputs > std::numeric_limits<size_t>::max() / current) {
+ return false;
+ }
+ num_outputs *= current;
+ }
+ for (size_t idx = 0; idx < num_outputs; ++idx) {
+ output_data[idx] = T();
+ temp_sum[idx] = U();
+ }
+
+ // Resolve axis.
+ int num_resolved_axis = 0;
+ if (!ResolveAxis(input_num_dims, axis, num_axis_dimensions, resolved_axis,
+ &num_resolved_axis)) {
+ return false;
+ }
+
+ if (!ReduceSumImpl<T, U>(input_data, input_dims, output_dims, input_num_dims,
+ output_num_dims, resolved_axis, num_resolved_axis,
+ temp_index, temp_sum)) {
+ return false;
+ }
+
+ // Calculate mean by dividing output_data by num of aggregated element.
+ size_t num_elements_in_axis = 1;
+ for (int idx = 0; idx < num_resolved_axis; ++idx) {
+ size_t current = static_cast<size_t>(input_dims[resolved_axis[idx]]);
+ // Overflow prevention.
+ if (current > (std::numeric_limits<size_t>::max() / num_elements_in_axis)) {
+ return false;
+ }
+ num_elements_in_axis *= current;
+ }
+
+ if (num_elements_in_axis > 0) {
+ for (size_t idx = 0; idx < num_outputs; ++idx) {
+ output_data[idx] =
+ static_cast<T>(temp_sum[idx] / static_cast<U>(num_elements_in_axis));
+ }
+ }
+ return true;
+}
+
+template <typename T>
+inline void Mean(const tflite::MeanParams& op_params,
+ const RuntimeShape& unextended_input_shape,
+ const T* input_data,
+ const RuntimeShape& unextended_output_shape, T* output_data) {
+ ruy::profiler::ScopeLabel label("Mean4D");
+
+ // Current implementation only supports dimension equals 4 and simultaneous
+ // reduction over width and height.
+ TFLITE_CHECK_EQ(unextended_input_shape.DimensionsCount(), 4);
+ TFLITE_CHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+ const RuntimeShape input_shape =
+ RuntimeShape::ExtendedShape(4, unextended_input_shape);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(4, unextended_output_shape);
+
+ const int output_batch = output_shape.Dims(0);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int output_depth = output_shape.Dims(3);
+
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+
+ TFLITE_CHECK_EQ(op_params.axis_count, 2);
+ TFLITE_CHECK((op_params.axis[0] == 1 && op_params.axis[1] == 2) ||
+ (op_params.axis[0] == 2 && op_params.axis[1] == 1));
+ TFLITE_CHECK_EQ(output_height, 1);
+ TFLITE_CHECK_EQ(output_width, 1);
+
+ for (int out_b = 0; out_b < output_batch; ++out_b) {
+ for (int out_d = 0; out_d < output_depth; ++out_d) {
+ float value = 0;
+ for (int in_h = 0; in_h < input_height; ++in_h) {
+ for (int in_w = 0; in_w < input_width; ++in_w) {
+ value += input_data[Offset(input_shape, out_b, in_h, in_w, out_d)];
+ }
+ }
+ output_data[Offset(output_shape, out_b, 0, 0, out_d)] =
+ value / (input_width * input_height);
+ }
+ }
+}
+
+inline void Mean(const tflite::MeanParams& op_params,
+ const RuntimeShape& unextended_input_shape,
+ const uint8_t* input_data, int32_t input_zero_point,
+ float input_scale, const RuntimeShape& unextended_output_shape,
+ uint8_t* output_data, int32_t output_zero_point,
+ float output_scale) {
+ ruy::profiler::ScopeLabel label("Mean4D/Uint8");
+
+ // Current implementation only supports dimension equals 4 and simultaneous
+ // reduction over width and height.
+ TFLITE_CHECK_EQ(unextended_input_shape.DimensionsCount(), 4);
+ TFLITE_CHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+ const RuntimeShape input_shape =
+ RuntimeShape::ExtendedShape(4, unextended_input_shape);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(4, unextended_output_shape);
+ const int output_batch = output_shape.Dims(0);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int output_depth = output_shape.Dims(3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const float num_elements_in_axis = input_width * input_height;
+
+ TFLITE_CHECK_EQ(op_params.axis_count, 2);
+ TFLITE_CHECK((op_params.axis[0] == 1 && op_params.axis[1] == 2) ||
+ (op_params.axis[0] == 2 && op_params.axis[1] == 1));
+ TFLITE_CHECK_EQ(output_height, 1);
+ TFLITE_CHECK_EQ(output_width, 1);
+
+ constexpr int32_t kMinValue = std::numeric_limits<uint8_t>::min();
+ constexpr int32_t kMaxValue = std::numeric_limits<uint8_t>::max();
+
+ int32_t bias =
+ output_zero_point -
+ static_cast<int32_t>(input_zero_point * input_scale / output_scale);
+ double real_scale =
+ static_cast<double>(input_scale / (num_elements_in_axis * output_scale));
+
+ int32_t multiplier;
+ int shift;
+ QuantizeMultiplier(real_scale, &multiplier, &shift);
+ for (int out_b = 0; out_b < output_batch; ++out_b) {
+ for (int out_d = 0; out_d < output_depth; ++out_d) {
+ int32_t acc = 0;
+ for (int in_h = 0; in_h < input_height; ++in_h) {
+ for (int in_w = 0; in_w < input_width; ++in_w) {
+ acc += input_data[Offset(input_shape, out_b, in_h, in_w, out_d)];
+ }
+ }
+ acc = MultiplyByQuantizedMultiplier(acc, multiplier, shift);
+ acc += bias;
+ acc = std::min(std::max(acc, kMinValue), kMaxValue);
+ output_data[Offset(output_shape, out_b, 0, 0, out_d)] =
+ static_cast<uint8_t>(acc);
+ }
+ }
+}
+
+// Computes the mean of elements across dimensions given in axis.
+// It does so in two stages, first calculates the sum of elements along the axis
+// then divides it by the number of element in axis for quantized values.
+template <typename T, typename U>
+inline bool QuantizedMeanOrSum(const T* input_data, int32_t input_zero_point,
+ float input_scale, const int* input_dims,
+ const int input_num_dims, T* output_data,
+ int32_t output_zero_point, float output_scale,
+ const int* output_dims,
+ const int output_num_dims, const int* axis,
+ const int num_axis_dimensions, bool keep_dims,
+ int* temp_index, int* resolved_axis, U* temp_sum,
+ bool compute_sum) {
+ const bool uint8_case = std::is_same<T, uint8_t>::value;
+ const bool int16_case = std::is_same<T, int16_t>::value;
+ if (uint8_case) {
+ ruy::profiler::ScopeLabel label(compute_sum ? "Sum/Uint8" : "Mean/Uint8");
+ } else if (int16_case) {
+ ruy::profiler::ScopeLabel label(compute_sum ? "Sum/Int16" : "Mean/Int16");
+ } else {
+ ruy::profiler::ScopeLabel label(compute_sum ? "Sum/Int8" : "Mean/Int8");
+ }
+ // Reset output data.
+ size_t num_outputs = 1;
+ for (int idx = 0; idx < output_num_dims; ++idx) {
+ size_t current = static_cast<size_t>(output_dims[idx]);
+ // Overflow prevention.
+ if (num_outputs > std::numeric_limits<size_t>::max() / current) {
+ return false;
+ }
+ num_outputs *= current;
+ }
+ for (size_t idx = 0; idx < num_outputs; ++idx) {
+ output_data[idx] = T();
+ temp_sum[idx] = U();
+ }
+
+ // Resolve axis.
+ int num_resolved_axis = 0;
+ if (!ResolveAxis(input_num_dims, axis, num_axis_dimensions, resolved_axis,
+ &num_resolved_axis)) {
+ return false;
+ }
+
+ if (!ReduceSumImpl<T, U>(input_data, input_dims, output_dims, input_num_dims,
+ output_num_dims, resolved_axis, num_resolved_axis,
+ temp_index, temp_sum)) {
+ return false;
+ }
+
+ // Calculate mean by dividing output_data by num of aggregated element.
+ size_t num_elements_in_axis = 1;
+ for (int idx = 0; idx < num_resolved_axis; ++idx) {
+ size_t current = static_cast<size_t>(input_dims[resolved_axis[idx]]);
+ // Overflow prevention.
+ if (current > (std::numeric_limits<size_t>::max() / num_elements_in_axis)) {
+ return false;
+ }
+ num_elements_in_axis *= current;
+ }
+
+ if (num_elements_in_axis > 0) {
+ const float scale = input_scale / output_scale;
+ if (compute_sum) {
+ // TODO(b/116341117): Eliminate float and do this completely in 8bit.
+ const float bias = -input_zero_point * scale * num_elements_in_axis;
+ for (size_t idx = 0; idx < num_outputs; ++idx) {
+ const U value =
+ static_cast<U>(TfLiteRound(temp_sum[idx] * scale + bias)) +
+ output_zero_point;
+ output_data[idx] = static_cast<T>(value);
+ }
+ } else {
+ const float bias = -input_zero_point * scale;
+ for (size_t idx = 0; idx < num_outputs; ++idx) {
+ float float_mean = static_cast<float>(temp_sum[idx]) /
+ static_cast<float>(num_elements_in_axis);
+ float result = TfLiteMin(
+ TfLiteRound(float_mean * scale + bias) + output_zero_point,
+ static_cast<float>(std::numeric_limits<T>::max()));
+ result = TfLiteMax(result,
+ static_cast<float>(std::numeric_limits<T>::min()));
+ output_data[idx] = static_cast<T>(result);
+ }
+ }
+ }
+ return true;
+}
+
+} // namespace reference_ops
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_REDUCE_H_
diff --git a/tensorflow/lite/kernels/internal/reference/requantize.h b/tensorflow/lite/kernels/internal/reference/requantize.h
new file mode 100644
index 0000000..d1e6778
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/requantize.h
@@ -0,0 +1,68 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_REQUANTIZE_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_REQUANTIZE_H_
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+template <typename input_type, typename output_type>
+inline void Requantize(const input_type* input_data, int32_t size,
+ int32_t effective_scale_multiplier,
+ int32_t effective_scale_shift, int32_t input_zeropoint,
+ int32_t output_zeropoint, output_type* output_data) {
+ ruy::profiler::ScopeLabel label("Requantize");
+ const bool same_scale =
+ (effective_scale_multiplier == 1 << 30 && effective_scale_shift == 1);
+ if (same_scale) {
+ const bool mixed_type_int8_uint8 =
+ std::is_same<input_type, int8_t>::value &&
+ std::is_same<output_type, uint8_t>::value;
+ const bool mixed_type_uint8_int8 =
+ std::is_same<input_type, uint8_t>::value &&
+ std::is_same<output_type, int8_t>::value;
+ const int32_t zero_point_diff = input_zeropoint - output_zeropoint;
+ // Fast path to do requantization for the case when just a shift of 128 is
+ // needed.
+ if ((mixed_type_int8_uint8 && zero_point_diff == -128) ||
+ (mixed_type_uint8_int8 && zero_point_diff == 128)) {
+ for (int i = 0; i < size; ++i) {
+ output_data[i] = input_data[i] ^ 0x80;
+ }
+ return;
+ }
+ }
+ static constexpr int32_t kMinOutput = std::numeric_limits<output_type>::min();
+ static constexpr int32_t kMaxOutput = std::numeric_limits<output_type>::max();
+ for (int i = 0; i < size; ++i) {
+ const int32_t input = input_data[i] - input_zeropoint;
+ const int32_t output =
+ MultiplyByQuantizedMultiplier(input, effective_scale_multiplier,
+ effective_scale_shift) +
+ output_zeropoint;
+ const int32_t clamped_output =
+ std::max(std::min(output, kMaxOutput), kMinOutput);
+ output_data[i] = static_cast<output_type>(clamped_output);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_REQUANTIZE_H_
diff --git a/tensorflow/lite/kernels/internal/reference/resize_nearest_neighbor.h b/tensorflow/lite/kernels/internal/reference/resize_nearest_neighbor.h
new file mode 100644
index 0000000..95550ab
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/resize_nearest_neighbor.h
@@ -0,0 +1,101 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_RESIZE_NEAREST_NEIGHBOR_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_RESIZE_NEAREST_NEIGHBOR_H_
+
+#include <cmath>
+
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline int32_t GetNearestNeighbor(const int input_value,
+ const int32_t input_size,
+ const int32_t output_size,
+ const bool align_corners,
+ const bool half_pixel_centers) {
+ const float scale =
+ (align_corners && output_size > 1)
+ ? (input_size - 1) / static_cast<float>(output_size - 1)
+ : input_size / static_cast<float>(output_size);
+ const float offset = half_pixel_centers ? 0.5f : 0.0f;
+ int32_t output_value = std::min(
+ align_corners
+ ? static_cast<int32_t>(TfLiteRound((input_value + offset) * scale))
+ : static_cast<int32_t>(std::floor((input_value + offset) * scale)),
+ input_size - 1);
+ if (half_pixel_centers) {
+ output_value = std::max(static_cast<int32_t>(0), output_value);
+ }
+ return output_value;
+}
+
+template <typename T>
+inline void ResizeNearestNeighbor(
+ const tflite::ResizeNearestNeighborParams& op_params,
+ const RuntimeShape& unextended_input_shape, const T* input_data,
+ const RuntimeShape& output_size_shape, const int32_t* output_size_data,
+ const RuntimeShape& unextended_output_shape, T* output_data) {
+ TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+
+ const RuntimeShape input_shape =
+ RuntimeShape::ExtendedShape(4, unextended_input_shape);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(4, unextended_output_shape);
+
+ int32_t batches = MatchingDim(input_shape, 0, output_shape, 0);
+ int32_t input_height = input_shape.Dims(1);
+ int32_t input_width = input_shape.Dims(2);
+ int32_t depth = MatchingDim(input_shape, 3, output_shape, 3);
+
+ // The Tensorflow version of this op allows resize on the width and height
+ // axis only.
+ TFLITE_DCHECK_EQ(output_size_shape.FlatSize(), 2);
+ int32_t output_height = output_size_data[0];
+ int32_t output_width = output_size_data[1];
+
+ const int col_offset = input_shape.Dims(3);
+ const int row_offset = input_shape.Dims(2) * col_offset;
+ const int batch_offset = input_shape.Dims(1) * row_offset;
+
+ const T* input_ptr = input_data;
+ T* output_ptr = output_data;
+ for (int b = 0; b < batches; ++b) {
+ for (int y = 0; y < output_height; ++y) {
+ int32_t in_y = GetNearestNeighbor(y, input_height, output_height,
+ op_params.align_corners,
+ op_params.half_pixel_centers);
+ const T* y_input_ptr = input_ptr + in_y * row_offset;
+ for (int x = 0; x < output_width; ++x) {
+ int32_t in_x = GetNearestNeighbor(x, input_width, output_width,
+ op_params.align_corners,
+ op_params.half_pixel_centers);
+ const T* x_input_ptr = y_input_ptr + in_x * col_offset;
+ memcpy(output_ptr, x_input_ptr, depth * sizeof(T));
+ output_ptr += depth;
+ }
+ }
+ input_ptr += batch_offset;
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_RESIZE_NEAREST_NEIGHBOR_H_
diff --git a/tensorflow/lite/kernels/internal/reference/round.h b/tensorflow/lite/kernels/internal/reference/round.h
new file mode 100644
index 0000000..9bd8f3f
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/round.h
@@ -0,0 +1,51 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ROUND_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ROUND_H_
+
+#include <cmath>
+
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline float RoundToNearest(float value) {
+ auto floor_val = std::floor(value);
+ auto diff = value - floor_val;
+ if ((diff < 0.5f) ||
+ ((diff == 0.5f) && (static_cast<int>(floor_val) % 2 == 0))) {
+ return floor_val;
+ } else {
+ return floor_val = floor_val + 1.0f;
+ }
+}
+
+inline void Round(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ // Note that this implementation matches that of tensorFlow tf.round
+ // and corresponds to the bankers rounding method.
+ // cfenv (for fesetround) is not yet supported universally on Android, so
+ // using a work around.
+ output_data[i] = RoundToNearest(input_data[i]);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_ROUND_H_
diff --git a/tensorflow/lite/kernels/internal/reference/softmax.h b/tensorflow/lite/kernels/internal/reference/softmax.h
new file mode 100644
index 0000000..1b3f118
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/softmax.h
@@ -0,0 +1,232 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SOFTMAX_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SOFTMAX_H_
+
+#include <limits>
+
+#include "fixedpoint/fixedpoint.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline void Softmax(const SoftmaxParams& params,
+ const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+
+ for (int i = 0; i < outer_size; ++i) {
+ // Find max element value which we'll use to ensure numerical stability
+ // taking advantage of the following equality:
+ // exp(x[i])/sum(exp(x[i])) == exp(x[i]+C)/sum(exp(x[i]+C))
+ float max = std::numeric_limits<float>::lowest();
+ for (int c = 0; c < depth; ++c) {
+ max = std::max(max, input_data[i * depth + c]);
+ }
+
+ // Compute sum.
+ float sum = 0.f;
+ for (int c = 0; c < depth; ++c) {
+ const float exp_c = std::exp((input_data[i * depth + c] - max) *
+ static_cast<float>(params.beta));
+ output_data[i * depth + c] = exp_c;
+ sum += exp_c;
+ }
+
+ // Compute result.
+ for (int c = 0; c < depth; ++c) {
+ output_data[i * depth + c] = output_data[i * depth + c] / sum;
+ }
+ }
+}
+
+// Quantized softmax with int8_t/uint8_t input and int8_t/uint8_t/int16_t
+// output.
+template <typename InputT, typename OutputT>
+inline void Softmax(const SoftmaxParams& params,
+ const RuntimeShape& input_shape, const InputT* input_data,
+ const RuntimeShape& output_shape, OutputT* output_data) {
+ const int32_t input_beta_multiplier = params.input_multiplier;
+ const int32_t input_beta_left_shift = params.input_left_shift;
+ const int diff_min = params.diff_min;
+ // The representation chosen for the input to the exp() function is Q5.26.
+ // We need to leave extra space since values that we skip might be as large as
+ // -32 before multiplying by input_beta_multiplier, and therefore as large as
+ // -16 afterwards. Note that exp(-8) is definitely not insignificant to
+ // accumulation, but exp(-16) definitely is.
+ static const int kScaledDiffIntegerBits = 5;
+ static const int kAccumulationIntegerBits = 12;
+ using FixedPointScaledDiff =
+ gemmlowp::FixedPoint<int32_t, kScaledDiffIntegerBits>;
+ using FixedPointAccum =
+ gemmlowp::FixedPoint<int32_t, kAccumulationIntegerBits>;
+ using FixedPoint0 = gemmlowp::FixedPoint<int32_t, 0>;
+
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+
+ for (int i = 0; i < outer_size; ++i) {
+ InputT max_in_row = std::numeric_limits<InputT>::min();
+ for (int c = 0; c < depth; ++c) {
+ max_in_row = std::max(max_in_row, input_data[i * depth + c]);
+ }
+
+ FixedPointAccum sum_of_exps = FixedPointAccum::Zero();
+ for (int c = 0; c < depth; ++c) {
+ int32_t input_diff =
+ static_cast<int32_t>(input_data[i * depth + c]) - max_in_row;
+ if (input_diff >= diff_min) {
+ const int32_t input_diff_rescaled =
+ MultiplyByQuantizedMultiplierGreaterThanOne(
+ input_diff, input_beta_multiplier, input_beta_left_shift);
+ const FixedPointScaledDiff scaled_diff_f8 =
+ FixedPointScaledDiff::FromRaw(input_diff_rescaled);
+ sum_of_exps = sum_of_exps + gemmlowp::Rescale<kAccumulationIntegerBits>(
+ exp_on_negative_values(scaled_diff_f8));
+ }
+ }
+
+ int num_bits_over_unit;
+ FixedPoint0 shifted_scale = FixedPoint0::FromRaw(GetReciprocal(
+ sum_of_exps.raw(), kAccumulationIntegerBits, &num_bits_over_unit));
+
+ for (int c = 0; c < depth; ++c) {
+ int32_t input_diff =
+ static_cast<int32_t>(input_data[i * depth + c]) - max_in_row;
+ if (input_diff >= diff_min) {
+ const int32_t input_diff_rescaled =
+ MultiplyByQuantizedMultiplierGreaterThanOne(
+ input_diff, input_beta_multiplier, input_beta_left_shift);
+ const FixedPointScaledDiff scaled_diff_f8 =
+ FixedPointScaledDiff::FromRaw(input_diff_rescaled);
+
+ FixedPoint0 exp_in_0 = exp_on_negative_values(scaled_diff_f8);
+ int32_t unsat_output = gemmlowp::RoundingDivideByPOT(
+ (shifted_scale * exp_in_0).raw(),
+ num_bits_over_unit + 31 - (sizeof(OutputT) * 8));
+
+ const int32_t shifted_output =
+ unsat_output +
+ static_cast<int32_t>(std::numeric_limits<OutputT>::min());
+
+ output_data[i * depth + c] = static_cast<OutputT>(std::max(
+ std::min(shifted_output,
+ static_cast<int32_t>(std::numeric_limits<OutputT>::max())),
+ static_cast<int32_t>(std::numeric_limits<OutputT>::min())));
+ } else {
+ output_data[i * depth + c] = std::numeric_limits<OutputT>::min();
+ }
+ }
+ }
+}
+
+// Computes exp(input - max_input)
+inline int16_t SoftMaxCalculateExp(const SoftmaxParams& params,
+ const int16_t* input_data, const int depth,
+ int16_t max_in_row, int i, int c) {
+ int32_t input_diff = input_data[i * depth + c] - max_in_row;
+ // scale the input_diff such that [-65535, 0] correspond to [-10.0, 0.0]
+ // exp lut generated with range [-10, 0], as exp(-10) is negligible.
+ int32_t scaled_diff = MultiplyByQuantizedMultiplier(
+ input_diff, params.input_multiplier, params.input_left_shift);
+ // recenter to [-32768, 32767]
+ int32_t sym_scaled_diff = scaled_diff + 32767;
+ int16_t sat_sym_scaled_diff =
+ std::min(std::max(sym_scaled_diff, static_cast<int32_t>(-32768)),
+ static_cast<int32_t>(32767));
+ // apply the exp() LUT activation function
+ return generic_int16_table_lookup(sat_sym_scaled_diff, params.exp_lut);
+}
+// Quantized softmax with int16_t input and int16_t output.
+inline void SoftmaxInt16(const SoftmaxParams& params,
+ const RuntimeShape& input_shape,
+ const int16_t* input_data,
+ const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+
+ for (int i = 0; i < outer_size; ++i) {
+ // Find the largest element
+ int16_t max_in_row = std::numeric_limits<int16_t>::min();
+ for (int c = 0; c < depth; ++c) {
+ max_in_row = std::max(max_in_row, input_data[i * depth + c]);
+ }
+
+ // This loops computes the exp values and their sum. We will need the exp
+ // values later on in the function so we cache them in the output_data
+ // buffer. This is an optimization done to avoid calculating the exp values
+ // twice making use of the output_data buffer as scratch memory.
+ int32_t sum_of_exps = 0; // Q16.15 fixed point format.
+ int16_t* exp_results_Q015 = output_data + i * depth;
+ for (int c = 0; c < depth; ++c) {
+ exp_results_Q015[c] =
+ SoftMaxCalculateExp(params, input_data, depth, max_in_row, i, c);
+ sum_of_exps += exp_results_Q015[c];
+ }
+
+ // Compute the reciprocal 1/sum_of_exps
+ uint8_t headroom_plus_one =
+ CountLeadingZeros(static_cast<uint32_t>(sum_of_exps));
+ int32_t shifted_sum =
+ ((static_cast<int64_t>(sum_of_exps) << (headroom_plus_one - 1)) +
+ (1 << 13)) >>
+ 14;
+ // since the LUT computes 1/(1 + x) we need to first compute x = (sum - 1).
+ // also, the LUT expects a symmetrical input, so we must also recenter x
+ // from [0, 65535] to [-32768, 32767].
+ int32_t sym_shifted_sum = shifted_sum + (-((1 << 15) + (1 << 16)));
+ int16_t sat_sym_shifted_sum = static_cast<int16_t>(
+ std::min(std::max(sym_shifted_sum, static_cast<int32_t>(-32768)),
+ static_cast<int32_t>(32767)));
+ // apply 1/(1 + x) LUT activation function
+ int16_t reciprocal_scale_Q015 = generic_int16_table_lookup(
+ sat_sym_shifted_sum, params.one_over_one_plus_x_lut);
+
+ // Rescale the exp_result with reciprocal
+ // range of output is [0, 32767] correspond to [0.0, 1.0]
+ for (int c = 0; c < depth; ++c) {
+ uint8_t right_shift = 31 - headroom_plus_one;
+ int64_t round = 1 << (right_shift - 1);
+ int32_t result = (static_cast<int64_t>(exp_results_Q015[c]) *
+ static_cast<int64_t>(reciprocal_scale_Q015) +
+ round) >>
+ right_shift;
+ output_data[i * depth + c] = static_cast<int16_t>(
+ std::min(std::max(result, static_cast<int32_t>(0)),
+ static_cast<int32_t>(32767)));
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SOFTMAX_H_
diff --git a/tensorflow/lite/kernels/internal/reference/space_to_batch_nd.h b/tensorflow/lite/kernels/internal/reference/space_to_batch_nd.h
new file mode 100644
index 0000000..7f84415
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/space_to_batch_nd.h
@@ -0,0 +1,109 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SPACE_TO_BATCH_ND_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SPACE_TO_BATCH_ND_H_
+
+#include <cmath>
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace reference_ops {
+
+// TODO(b/135760455): Move this method anonymous namespace in a cc file.
+inline RuntimeShape ExtendShapeSpaceToBatch(const RuntimeShape& shape) {
+ if (shape.DimensionsCount() == 4) {
+ return shape;
+ }
+ RuntimeShape new_shape(4, 1);
+ new_shape.SetDim(0, shape.Dims(0));
+ new_shape.SetDim(1, shape.Dims(1));
+ new_shape.SetDim(3, shape.Dims(2));
+ return new_shape;
+}
+
+template <typename T>
+inline void SpaceToBatchND(const SpaceToBatchParams& params,
+ const RuntimeShape& unextended_input1_shape,
+ const T* input1_data,
+ const RuntimeShape& unextended_input2_shape,
+ const int32_t* block_shape_data,
+ const RuntimeShape& unextended_input3_shape,
+ const int32_t* paddings_data,
+ const RuntimeShape& unextended_output_shape,
+ T* output_data) {
+ ruy::profiler::ScopeLabel label("SpaceToBatchND");
+ TFLITE_DCHECK_GE(unextended_input1_shape.DimensionsCount(), 3);
+ TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(unextended_input1_shape.DimensionsCount(),
+ unextended_output_shape.DimensionsCount());
+
+ // Extends the input/output shape from 3D to 4D if needed, NHC -> NH1C.
+ const RuntimeShape input1_shape =
+ ExtendShapeSpaceToBatch(unextended_input1_shape);
+ const RuntimeShape output_shape =
+ ExtendShapeSpaceToBatch(unextended_output_shape);
+
+ const int depth = input1_shape.Dims(3);
+ const int input_width = input1_shape.Dims(2);
+ const int input_height = input1_shape.Dims(1);
+ const int input_batch_size = input1_shape.Dims(0);
+
+ const int output_width = output_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_batch_size = output_shape.Dims(0);
+
+ const int block_shape_height = block_shape_data[0];
+ const int block_shape_width =
+ unextended_input1_shape.DimensionsCount() == 4 ? block_shape_data[1] : 1;
+ const int padding_top = paddings_data[0];
+ const int padding_left =
+ unextended_input1_shape.DimensionsCount() == 4 ? paddings_data[2] : 0;
+
+ // For uint8 quantized, the correct padding "zero value" is the output offset.
+ const int32_t pad_value = params.output_offset;
+ for (int out_b = 0; out_b < output_batch_size; ++out_b) {
+ int input_batch = out_b % input_batch_size;
+ int shift_w = (out_b / input_batch_size) % block_shape_width;
+ int shift_h = (out_b / input_batch_size) / block_shape_width;
+ for (int out_h = 0; out_h < output_height; ++out_h) {
+ for (int out_w = 0; out_w < output_width; ++out_w) {
+ T* out = output_data + Offset(output_shape, out_b, out_h, out_w, 0);
+ if (out_h * block_shape_height + shift_h < padding_top ||
+ out_h * block_shape_height + shift_h >=
+ padding_top + input_height ||
+ out_w * block_shape_width + shift_w < padding_left ||
+ out_w * block_shape_width + shift_w >= padding_left + input_width) {
+ // This may not execute correctly when pad_value != 0 and T != uint8.
+ memset(out, pad_value, depth * sizeof(T));
+ } else {
+ const T* in =
+ input1_data +
+ Offset(input1_shape, input_batch,
+ (out_h * block_shape_height + shift_h) - padding_top,
+ (out_w * block_shape_width + shift_w) - padding_left, 0);
+ memcpy(out, in, depth * sizeof(T));
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SPACE_TO_BATCH_ND_H_
diff --git a/tensorflow/lite/kernels/internal/reference/strided_slice.h b/tensorflow/lite/kernels/internal/reference/strided_slice.h
new file mode 100644
index 0000000..40dc2e9
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/strided_slice.h
@@ -0,0 +1,121 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_STRIDED_SLICE_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_STRIDED_SLICE_H_
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/portable_tensor.h"
+#include "tensorflow/lite/kernels/internal/strided_slice_logic.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+template <typename T>
+inline void StridedSlice(const tflite::StridedSliceParams& op_params,
+ const RuntimeShape& unextended_input_shape,
+ const RuntimeShape& unextended_output_shape,
+ SequentialTensorWriter<T>* writer) {
+ using strided_slice::LoopCondition;
+ using strided_slice::StartForAxis;
+ using strided_slice::StopForAxis;
+
+ ruy::profiler::ScopeLabel label("StridedSlice");
+
+ // Note that the output_shape is not used herein.
+ tflite::StridedSliceParams params_copy = op_params;
+
+ TFLITE_DCHECK_LE(unextended_input_shape.DimensionsCount(), 5);
+ TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 5);
+ const RuntimeShape input_shape =
+ RuntimeShape::ExtendedShape(5, unextended_input_shape);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(5, unextended_output_shape);
+
+ // Reverse and pad to 5 dimensions because that is what the runtime code
+ // requires (ie. all shapes must be 5D and are given backwards).
+ strided_slice::StridedSlicePadIndices(¶ms_copy, 5);
+
+ const int start_0 = StartForAxis(params_copy, input_shape, 0);
+ const int stop_0 = StopForAxis(params_copy, input_shape, 0, start_0);
+ const int start_1 = StartForAxis(params_copy, input_shape, 1);
+ const int stop_1 = StopForAxis(params_copy, input_shape, 1, start_1);
+ const int start_2 = StartForAxis(params_copy, input_shape, 2);
+ const int stop_2 = StopForAxis(params_copy, input_shape, 2, start_2);
+ const int start_3 = StartForAxis(params_copy, input_shape, 3);
+ const int stop_3 = StopForAxis(params_copy, input_shape, 3, start_3);
+ const int start_4 = StartForAxis(params_copy, input_shape, 4);
+ const int stop_4 = StopForAxis(params_copy, input_shape, 4, start_4);
+
+ for (int offset_0 = start_0 * input_shape.Dims(1),
+ end_0 = stop_0 * input_shape.Dims(1),
+ step_0 = params_copy.strides[0] * input_shape.Dims(1);
+ !LoopCondition(offset_0, end_0, params_copy.strides[0]);
+ offset_0 += step_0) {
+ for (int offset_1 = (offset_0 + start_1) * input_shape.Dims(2),
+ end_1 = (offset_0 + stop_1) * input_shape.Dims(2),
+ step_1 = params_copy.strides[1] * input_shape.Dims(2);
+ !LoopCondition(offset_1, end_1, params_copy.strides[1]);
+ offset_1 += step_1) {
+ for (int offset_2 = (offset_1 + start_2) * input_shape.Dims(3),
+ end_2 = (offset_1 + stop_2) * input_shape.Dims(3),
+ step_2 = params_copy.strides[2] * input_shape.Dims(3);
+ !LoopCondition(offset_2, end_2, params_copy.strides[2]);
+ offset_2 += step_2) {
+ for (int offset_3 = (offset_2 + start_3) * input_shape.Dims(4),
+ end_3 = (offset_2 + stop_3) * input_shape.Dims(4),
+ step_3 = params_copy.strides[3] * input_shape.Dims(4);
+ !LoopCondition(offset_3, end_3, params_copy.strides[3]);
+ offset_3 += step_3) {
+ for (int offset_4 = offset_3 + start_4, end_4 = offset_3 + stop_4;
+ !LoopCondition(offset_4, end_4, params_copy.strides[4]);
+ offset_4 += params_copy.strides[4]) {
+ writer->Write(offset_4);
+ }
+ }
+ }
+ }
+ }
+}
+
+template <typename T>
+inline void StridedSlice(const tflite::StridedSliceParams& op_params,
+ const RuntimeShape& unextended_input_shape,
+ const T* input_data,
+ const RuntimeShape& unextended_output_shape,
+ T* output_data) {
+ SequentialTensorWriter<T> writer(input_data, output_data);
+ StridedSlice<T>(op_params, unextended_input_shape, unextended_output_shape,
+ &writer);
+}
+
+template <typename T>
+inline void StridedSlice(const tflite::StridedSliceParams& op_params,
+ const RuntimeShape& unextended_input_shape,
+ const TfLiteTensor* input,
+ const RuntimeShape& unextended_output_shape,
+ TfLiteTensor* output) {
+ SequentialTensorWriter<T> writer(input, output);
+ StridedSlice<T>(op_params, unextended_input_shape, unextended_output_shape,
+ &writer);
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_STRIDED_SLICE_H_
diff --git a/tensorflow/lite/kernels/internal/reference/sub.h b/tensorflow/lite/kernels/internal/reference/sub.h
new file mode 100644
index 0000000..b8b8b73
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/sub.h
@@ -0,0 +1,556 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SUB_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SUB_H_
+
+#include <stdint.h>
+
+#include <algorithm>
+#include <limits>
+
+#include "ruy/profiler/instrumentation.h" // from @ruy
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline void SubNonBroadcast(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const float* input1_data,
+ const RuntimeShape& input2_shape,
+ const float* input2_data,
+ const RuntimeShape& output_shape,
+ float* output_data) {
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = ActivationFunctionWithMinMax(
+ input1_data[i] - input2_data[i], params.float_activation_min,
+ params.float_activation_max);
+ }
+}
+
+inline void SubNonBroadcast(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int32_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int32_t* input2_data,
+ const RuntimeShape& output_shape,
+ int32_t* output_data) {
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = ActivationFunctionWithMinMax(
+ input1_data[i] - input2_data[i], params.quantized_activation_min,
+ params.quantized_activation_max);
+ }
+}
+
+// TODO(b/151345304): We can implement BroadcastSub on buffers of arbitrary
+// dimensionality if the runtime code does a single loop over one dimension
+// that handles broadcasting as the base case. The code generator would then
+// generate max(D1, D2) nested for loops.
+template <int N = 5>
+inline void BroadcastSubSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const float* input1_data,
+ const RuntimeShape& input2_shape,
+ const float* input2_data,
+ const RuntimeShape& output_shape,
+ float* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastSubSlow/float");
+ TFLITE_DCHECK_LE(input1_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(input2_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(output_shape.DimensionsCount(), N);
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, output_shape), &output_desc);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ auto sub_func = [&](int indexes[N]) {
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ ActivationFunctionWithMinMax(
+ input1_data[SubscriptToIndex(desc1, indexes)] -
+ input2_data[SubscriptToIndex(desc2, indexes)],
+ params.float_activation_min, params.float_activation_max);
+ };
+ NDOpsHelper<N>(output_desc, sub_func);
+}
+
+template <int N = 5>
+inline void BroadcastSubSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const uint8_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const uint8_t* input2_data,
+ const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastSubSlow/uint8_t");
+ TFLITE_DCHECK_LE(input1_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(input2_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(output_shape.DimensionsCount(), N);
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, output_shape), &output_desc);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ auto sub_func = [&](int indexes[N]) {
+ const int32_t input1_val =
+ params.input1_offset + input1_data[SubscriptToIndex(desc1, indexes)];
+ const int32_t input2_val =
+ params.input2_offset + input2_data[SubscriptToIndex(desc2, indexes)];
+ const int32_t shifted_input1_val = input1_val * (1 << params.left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier, params.input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier, params.input2_shift);
+ const int32_t raw_sub = scaled_input1_val - scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sub, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ static_cast<uint8_t>(clamped_output);
+ };
+ NDOpsHelper<N>(output_desc, sub_func);
+}
+
+template <int N = 5>
+inline void BroadcastSubSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int32_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int32_t* input2_data,
+ const RuntimeShape& output_shape,
+ int32_t* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastSubSlow/int32_t");
+ TFLITE_DCHECK_LE(input1_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(input2_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(output_shape.DimensionsCount(), N);
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, output_shape), &output_desc);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ auto sub_func = [&](int indexes[N]) {
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ ActivationFunctionWithMinMax(
+ input1_data[SubscriptToIndex(desc1, indexes)] -
+ input2_data[SubscriptToIndex(desc2, indexes)],
+ params.quantized_activation_min, params.quantized_activation_max);
+ };
+ NDOpsHelper<N>(output_desc, sub_func);
+}
+
+template <int N = 5>
+inline void BroadcastSubSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int8_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int8_t* input2_data,
+ const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastSubSlow/int8_t");
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, output_shape), &output_desc);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ auto sub_func = [&](int indexes[N]) {
+ const int32_t input1_val =
+ params.input1_offset + input1_data[SubscriptToIndex(desc1, indexes)];
+ const int32_t input2_val =
+ params.input2_offset + input2_data[SubscriptToIndex(desc2, indexes)];
+ const int32_t shifted_input1_val = input1_val * (1 << params.left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier, params.input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier, params.input2_shift);
+ const int32_t raw_sub = scaled_input1_val - scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sub, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ static_cast<int8_t>(clamped_output);
+ };
+ NDOpsHelper<N>(output_desc, sub_func);
+}
+
+template <int N = 5>
+void BroadcastSubSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int64_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int64_t* input2_data,
+ const RuntimeShape& output_shape, int64_t* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastSubSlow/int64_t");
+ TFLITE_DCHECK_LE(input1_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(input2_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(output_shape.DimensionsCount(), N);
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, output_shape), &output_desc);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ auto sub_func = [&](int indexes[N]) {
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ ActivationFunctionWithMinMax(
+ input1_data[SubscriptToIndex(desc1, indexes)] -
+ input2_data[SubscriptToIndex(desc2, indexes)],
+ params.int64_activation_min, params.int64_activation_max);
+ };
+ NDOpsHelper<N>(output_desc, sub_func);
+}
+
+template <typename T, int N = 5>
+void BroadcastSubSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const T* input1_data,
+ const RuntimeShape& input2_shape, const T* input2_data,
+ const RuntimeShape& output_shape, T* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastSubSlow/templated");
+ TFLITE_DCHECK_LE(input1_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(input2_shape.DimensionsCount(), N);
+ TFLITE_DCHECK_LE(output_shape.DimensionsCount(), N);
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, output_shape), &output_desc);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ auto sub_func = [&](int indexes[N]) {
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ ActivationFunctionWithMinMax(
+ input1_data[SubscriptToIndex(desc1, indexes)] -
+ input2_data[SubscriptToIndex(desc2, indexes)],
+ params.quantized_activation_min, params.quantized_activation_max);
+ };
+ NDOpsHelper<N>(output_desc, sub_func);
+}
+
+template <int N = 5>
+inline void BroadcastSub16POTSlow(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape,
+ const int16_t* input1_data,
+ const RuntimeShape& input2_shape,
+ const int16_t* input2_data,
+ const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ ruy::profiler::ScopeLabel label("BroadcastSub16POTSlow/int16_t");
+ NdArrayDesc<N> desc1;
+ NdArrayDesc<N> desc2;
+ NdArrayDesc<N> output_desc;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ CopyDimsToDesc(RuntimeShape::ExtendedShape(N, output_shape), &output_desc);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ auto sub_func = [&](int indexes[N]) {
+ const int32_t input1_val = input1_data[SubscriptToIndex(desc1, indexes)];
+ const int32_t input2_val = input2_data[SubscriptToIndex(desc2, indexes)];
+ const int32_t scaled_input1_val =
+ gemmlowp::RoundingDivideByPOT(input1_val, -params.input1_shift);
+ const int32_t scaled_input2_val =
+ gemmlowp::RoundingDivideByPOT(input2_val, -params.input2_shift);
+ const int32_t raw_output = scaled_input1_val - scaled_input2_val;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[SubscriptToIndex(output_desc, indexes)] =
+ static_cast<int16_t>(clamped_output);
+ };
+ NDOpsHelper<N>(output_desc, sub_func);
+}
+
+// Element-wise Sub that can often be used for inner loop of broadcast sub as
+// well as the non-broadcast sub.
+inline void SubElementwise(int size, const ArithmeticParams& params,
+ const uint8_t* input1_data,
+ const uint8_t* input2_data, uint8_t* output_data) {
+ TFLITE_DCHECK_GT(params.input1_offset, -256);
+ TFLITE_DCHECK_GT(params.input2_offset, -256);
+ TFLITE_DCHECK_LT(params.input1_offset, 256);
+ TFLITE_DCHECK_LT(params.input2_offset, 256);
+
+ for (int i = 0; i < size; ++i) {
+ const int32_t input1_val = params.input1_offset + input1_data[i];
+ const int32_t input2_val = params.input2_offset + input2_data[i];
+ const int32_t shifted_input1_val = input1_val * (1 << params.left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier, params.input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier, params.input2_shift);
+ const int32_t raw_sub = scaled_input1_val - scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sub, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[i] = static_cast<uint8_t>(clamped_output);
+ }
+}
+
+// Element-wise add that can often be used for inner loop of broadcast add as
+// well as the non-broadcast add.
+inline void SubElementwise(int size, const ArithmeticParams& params,
+ const int8_t* input1_data, const int8_t* input2_data,
+ int8_t* output_data) {
+ const int32_t int8_max_value = std::numeric_limits<int8_t>::max();
+ TFLITE_DCHECK_GE(params.input1_offset, -1 * int8_max_value);
+ TFLITE_DCHECK_GE(params.input2_offset, -1 * int8_max_value);
+ TFLITE_DCHECK_LE(params.input1_offset, int8_max_value);
+ TFLITE_DCHECK_LE(params.input2_offset, int8_max_value);
+
+ for (int i = 0; i < size; ++i) {
+ const int32_t input1_val = params.input1_offset + input1_data[i];
+ const int32_t input2_val = params.input2_offset + input2_data[i];
+ const int32_t shifted_input1_val = input1_val * (1 << params.left_shift);
+ const int32_t shifted_input2_val = input2_val * (1 << params.left_shift);
+ const int32_t scaled_input1_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input1_val, params.input1_multiplier, params.input1_shift);
+ const int32_t scaled_input2_val =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ shifted_input2_val, params.input2_multiplier, params.input2_shift);
+ const int32_t raw_sub = scaled_input1_val - scaled_input2_val;
+ const int32_t raw_output =
+ MultiplyByQuantizedMultiplierSmallerThanOneExp(
+ raw_sub, params.output_multiplier, params.output_shift) +
+ params.output_offset;
+ const int32_t clamped_output =
+ std::min(params.quantized_activation_max,
+ std::max(params.quantized_activation_min, raw_output));
+ output_data[i] = static_cast<int8_t>(clamped_output);
+ }
+}
+
+inline void Sub(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const uint8_t* input1_data,
+ const RuntimeShape& input2_shape, const uint8_t* input2_data,
+ const RuntimeShape& output_shape, uint8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+
+ TFLITE_DCHECK_GT(params.input1_offset, -256);
+ TFLITE_DCHECK_GT(params.input2_offset, -256);
+ TFLITE_DCHECK_LT(params.input1_offset, 256);
+ TFLITE_DCHECK_LT(params.input2_offset, 256);
+ SubElementwise(flat_size, params, input1_data, input2_data, output_data);
+}
+
+inline void Sub(const ArithmeticParams& params,
+ const RuntimeShape& input1_shape, const int8_t* input1_data,
+ const RuntimeShape& input2_shape, const int8_t* input2_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ TFLITE_DCHECK_LE(params.quantized_activation_min,
+ params.quantized_activation_max);
+
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+
+ const int32_t int8_max_value = std::numeric_limits<int8_t>::max();
+ TFLITE_DCHECK_GE(params.input1_offset, -1 * int8_max_value);
+ TFLITE_DCHECK_GE(params.input2_offset, -1 * int8_max_value);
+ TFLITE_DCHECK_LE(params.input1_offset, int8_max_value);
+ TFLITE_DCHECK_LE(params.input2_offset, int8_max_value);
+ SubElementwise(flat_size, params, input1_data, input2_data, output_data);
+}
+
+template <typename T>
+void Sub(const ArithmeticParams& params, const RuntimeShape& input1_shape,
+ const T* input1_data, const RuntimeShape& input2_shape,
+ const T* input2_data, const RuntimeShape& output_shape,
+ T* output_data) {
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(input1_shape, input2_shape, &desc1,
+ &desc2);
+ const RuntimeShape extended_output_shape =
+ RuntimeShape::ExtendedShape(4, output_shape);
+
+ // In Tensorflow, the dimensions are canonically named (batch_number, row,
+ // col, channel), with extents (batches, height, width, depth), with the
+ // trailing dimension changing most rapidly (channels has the smallest stride,
+ // typically 1 element).
+ //
+ // In generated C code, we store arrays with the dimensions reversed. The
+ // first dimension has smallest stride.
+ //
+ // We name our variables by their Tensorflow convention, but generate C code
+ // nesting loops such that the innermost loop has the smallest stride for the
+ // best cache behavior.
+ for (int b = 0; b < extended_output_shape.Dims(0); ++b) {
+ for (int y = 0; y < extended_output_shape.Dims(1); ++y) {
+ for (int x = 0; x < extended_output_shape.Dims(2); ++x) {
+ for (int c = 0; c < extended_output_shape.Dims(3); ++c) {
+ output_data[Offset(extended_output_shape, b, y, x, c)] =
+ input1_data[SubscriptToIndex(desc1, b, y, x, c)] -
+ input2_data[SubscriptToIndex(desc2, b, y, x, c)];
+ }
+ }
+ }
+ }
+}
+
+inline void SetActivationMinMax(const ArithmeticParams& params,
+ int32_t* activation_min,
+ int32_t* activation_max) {
+ *activation_min = params.quantized_activation_min;
+ *activation_max = params.quantized_activation_max;
+}
+
+inline void SetActivationMinMax(const ArithmeticParams& params,
+ float* activation_min, float* activation_max) {
+ *activation_min = params.float_activation_min;
+ *activation_max = params.float_activation_max;
+}
+
+inline void SetActivationMinMax(const ArithmeticParams& params,
+ int64_t* activation_min,
+ int64_t* activation_max) {
+ *activation_min = params.int64_activation_min;
+ *activation_max = params.int64_activation_max;
+}
+
+template <typename T>
+inline void SubWithActivation(
+ const ArithmeticParams& params, const RuntimeShape& input1_shape,
+ const T* input1_data, const RuntimeShape& input2_shape,
+ const T* input2_data, const RuntimeShape& output_shape, T* output_data) {
+ ruy::profiler::ScopeLabel label("SubWithActivation");
+ const int flat_size =
+ MatchingElementsSize(input1_shape, input2_shape, output_shape);
+ T activation_min, activation_max;
+ SetActivationMinMax(params, &activation_min, &activation_max);
+
+ for (int i = 0; i < flat_size; ++i) {
+ output_data[i] = ActivationFunctionWithMinMax(
+ input1_data[i] - input2_data[i], activation_min, activation_max);
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_SUB_H_
diff --git a/tensorflow/lite/kernels/internal/reference/tanh.h b/tensorflow/lite/kernels/internal/reference/tanh.h
new file mode 100644
index 0000000..3a05c47
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/tanh.h
@@ -0,0 +1,129 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_TANH_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_TANH_H_
+
+#include <cmath>
+
+#include "fixedpoint/fixedpoint.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+
+namespace tflite {
+namespace reference_ops {
+
+inline void Tanh(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; i++) {
+ float val = input_data[i];
+ float result = std::tanh(val);
+ output_data[i] = result;
+ }
+}
+
+// Convenience version that allows, for example, generated-code calls to be
+// uniform between data types.
+inline void Tanh(const TanhParams&, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& output_shape,
+ float* output_data) {
+ // Drop params: not needed.
+ Tanh(input_shape, input_data, output_shape, output_data);
+}
+
+inline void Tanh(const TanhParams& params, const RuntimeShape& input_shape,
+ const int16_t* input_data, const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ const int input_left_shift = params.input_left_shift;
+ // Support for shifts is limited until we have a parameterized version of
+ // SaturatingRoundingMultiplyByPOT().
+ TFLITE_DCHECK_GE(input_left_shift, 0);
+ TFLITE_DCHECK_LE(input_left_shift, 1);
+
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ // F0 uses 0 integer bits, range [-1, 1].
+ // This is the return type of math functions such as tanh, logistic,
+ // whose range is in [-1, 1].
+ using F0 = gemmlowp::FixedPoint<std::int16_t, 0>;
+ // F3 uses 3 integer bits, range [-8, 8], the input range expected here.
+ using F3 = gemmlowp::FixedPoint<std::int16_t, 3>;
+
+ if (input_left_shift == 0) {
+ for (int i = 0; i < flat_size; i++) {
+ F3 input = F3::FromRaw(input_data[i]);
+ F0 output = gemmlowp::tanh(input);
+ output_data[i] = output.raw();
+ }
+ } else {
+ for (int i = 0; i < flat_size; i++) {
+ F3 input = F3::FromRaw(
+ gemmlowp::SaturatingRoundingMultiplyByPOT<1>(input_data[i]));
+ F0 output = gemmlowp::tanh(input);
+ output_data[i] = output.raw();
+ }
+ }
+}
+
+inline void Tanh(const TanhParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ const int32_t input_zero_point = params.input_zero_point;
+ const int32_t input_range_radius = params.input_range_radius;
+ const int32_t input_multiplier = params.input_multiplier;
+ const int input_left_shift = params.input_left_shift;
+ const int32_t output_zero_point = 128;
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+
+ for (int i = 0; i < flat_size; i++) {
+ const uint8_t input_val_u8 = input_data[i];
+ const int32_t input_val_centered =
+ static_cast<int32_t>(input_val_u8) - input_zero_point;
+ uint8_t output_val;
+ if (input_val_centered <= -input_range_radius) {
+ output_val = 0;
+ } else if (input_val_centered >= input_range_radius) {
+ output_val = 255;
+ } else {
+ const int32_t input_val_rescaled =
+ MultiplyByQuantizedMultiplierGreaterThanOne(
+ input_val_centered, input_multiplier, input_left_shift);
+ using FixedPoint4 = gemmlowp::FixedPoint<int32_t, 4>;
+ using FixedPoint0 = gemmlowp::FixedPoint<int32_t, 0>;
+ const FixedPoint4 input_val_f4 = FixedPoint4::FromRaw(input_val_rescaled);
+ const FixedPoint0 output_val_f0 = gemmlowp::tanh(input_val_f4);
+ // Convert from Q0.31 to Q24.7.
+ using gemmlowp::RoundingDivideByPOT;
+ int32_t output_val_s32 = RoundingDivideByPOT(output_val_f0.raw(), 24);
+ output_val_s32 += output_zero_point;
+ if (output_val_s32 == 256) {
+ output_val_s32 = 255;
+ }
+ // Reinterpret as Q0.7, encoded in uint8_t.
+ TFLITE_DCHECK_GE(output_val_s32, 0);
+ TFLITE_DCHECK_LE(output_val_s32, 255);
+ output_val = static_cast<uint8_t>(output_val_s32);
+ }
+ output_data[i] = output_val;
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_TANH_H_
diff --git a/tensorflow/lite/kernels/internal/reference/transpose_conv.h b/tensorflow/lite/kernels/internal/reference/transpose_conv.h
new file mode 100644
index 0000000..6e9cb1f
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/reference/transpose_conv.h
@@ -0,0 +1,217 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_TRANSPOSE_CONV_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_TRANSPOSE_CONV_H_
+
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+namespace reference_ops {
+
+inline void TransposeConv(
+ const ConvParams& params, const RuntimeShape& input_shape,
+ const float* input_data, const RuntimeShape& filter_shape,
+ const float* filter_data, const RuntimeShape& bias_shape,
+ const float* bias_data, const RuntimeShape& output_shape,
+ float* output_data, const RuntimeShape& im2col_shape, float* im2col_data) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ (void)im2col_data; // only used in optimized code.
+ (void)im2col_shape; // only used in optimized code.
+
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+
+ // Although transpose convolution simplifies to convolution with transposed
+ // weights for strides of 1, non-unitary striding complicates matters. To
+ // keep this reference implementation as clear as possible, we use a
+ // "scatter" access pattern, where we loop through all the input elements,
+ // computing their influence on the output, rather than looping through the
+ // output elements in the typical "gather" access pattern of a conv. We
+ // therefore must initialize the output array to zero.
+ const int num_elements = output_shape.FlatSize();
+ for (int i = 0; i < num_elements; i++) {
+ output_data[i] = 0.0f;
+ }
+
+ // Loop through input elements one at a time.
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int in_y = 0; in_y < input_height; ++in_y) {
+ for (int in_x = 0; in_x < input_width; ++in_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ // Loop through the output elements it will influence
+ const int out_x_origin = (in_x * stride_width) - pad_width;
+ const int out_y_origin = (in_y * stride_height) - pad_height;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ for (int out_channel = 0; out_channel < output_depth;
+ ++out_channel) {
+ // Compute output element location
+ const int out_x = out_x_origin + filter_x;
+ const int out_y = out_y_origin + filter_y;
+ // We cannot accumulate out of bounds
+ if ((out_x >= 0) && (out_x < output_width) && (out_y >= 0) &&
+ (out_y < output_height)) {
+ float input_value = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ float filter_value =
+ filter_data[Offset(filter_shape, out_channel, filter_y,
+ filter_x, in_channel)];
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ out_channel)] +=
+ input_value * filter_value;
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ if (bias_data) {
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ out_channel)] += bias_data[out_channel];
+ }
+ }
+ }
+ }
+ }
+}
+
+inline void TransposeConv(
+ const ConvParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& filter_shape,
+ const uint8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ uint8_t* output_data, const RuntimeShape& im2col_shape,
+ uint8_t* im2col_data, int32_t* scratch_buffer) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ (void)im2col_data; // only used in optimized code.
+ (void)im2col_shape; // only used in optimized code.
+
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ if (bias_data) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+
+ const int num_elements = output_shape.FlatSize();
+ // We need to initialize scratch_buffer to all 0s, as we apply the same
+ // 'scatter' based trick as in float version.
+ memset(scratch_buffer, 0, num_elements * sizeof(int32_t));
+
+ // Loop through input elements one at a time.
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int in_y = 0; in_y < input_height; ++in_y) {
+ for (int in_x = 0; in_x < input_width; ++in_x) {
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ // Loop through the output elements it will influence.
+ const int out_x_origin = (in_x * stride_width) - pad_width;
+ const int out_y_origin = (in_y * stride_height) - pad_height;
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ for (int out_channel = 0; out_channel < output_depth;
+ ++out_channel) {
+ // Compute output element location.
+ const int out_x = out_x_origin + filter_x;
+ const int out_y = out_y_origin + filter_y;
+ // We cannot accumulate out of bounds.
+ if ((out_x >= 0) && (out_x < output_width) && (out_y >= 0) &&
+ (out_y < output_height)) {
+ uint8_t input_value = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ uint8_t filter_value =
+ filter_data[Offset(filter_shape, out_channel, filter_y,
+ filter_x, in_channel)];
+ scratch_buffer[Offset(output_shape, batch, out_y, out_x,
+ out_channel)] +=
+ (input_value + input_offset) *
+ (filter_value + filter_offset);
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ int32_t acc = scratch_buffer[Offset(output_shape, batch, out_y, out_x,
+ out_channel)];
+ if (bias_data) {
+ acc += bias_data[out_channel];
+ }
+ int32_t scaled_acc = MultiplyByQuantizedMultiplier(
+ acc, output_multiplier, output_shift);
+ scaled_acc += output_offset;
+ scaled_acc = std::max(scaled_acc, output_activation_min);
+ scaled_acc = std::min(scaled_acc, output_activation_max);
+ output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
+ static_cast<uint8_t>(scaled_acc);
+ }
+ }
+ }
+ }
+}
+
+} // namespace reference_ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_REFERENCE_TRANSPOSE_CONV_H_
diff --git a/tensorflow/lite/kernels/internal/strided_slice_logic.h b/tensorflow/lite/kernels/internal/strided_slice_logic.h
new file mode 100644
index 0000000..bfe8405
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/strided_slice_logic.h
@@ -0,0 +1,211 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_STRIDED_SLICE_LOGIC_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_STRIDED_SLICE_LOGIC_H_
+
+#include <limits>
+#include <vector>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace strided_slice {
+
+// Use until std::clamp() is available from C++17.
+inline int Clamp(const int v, const int lo, const int hi) {
+ TFLITE_DCHECK(!(hi < lo));
+ if (hi < v) return hi;
+ if (v < lo) return lo;
+ return v;
+}
+
+inline void StridedSlicePadIndices(tflite::StridedSliceParams* p,
+ int dim_count) {
+ // Add indices and mask bits to fully include extra dimensions
+ TFLITE_CHECK_LE(dim_count, 5);
+ TFLITE_CHECK_GE(dim_count, p->start_indices_count);
+ TFLITE_CHECK_EQ(p->start_indices_count, p->stop_indices_count);
+ TFLITE_CHECK_EQ(p->stop_indices_count, p->strides_count);
+
+ const int pad_count = dim_count - p->start_indices_count;
+
+ // Pad indices at start, so move arrays by pad_count.
+ for (int i = p->start_indices_count - 1; i >= 0; --i) {
+ p->strides[i + pad_count] = p->strides[i];
+ p->start_indices[i + pad_count] = p->start_indices[i];
+ p->stop_indices[i + pad_count] = p->stop_indices[i];
+ }
+ for (int i = 0; i < pad_count; ++i) {
+ p->start_indices[i] = 0;
+ p->stop_indices[i] = 1;
+ p->strides[i] = 1;
+ }
+
+ // Pad masks with 0s or 1s as required.
+ p->shrink_axis_mask <<= pad_count;
+ p->ellipsis_mask <<= pad_count;
+ p->new_axis_mask <<= pad_count;
+ p->begin_mask <<= pad_count;
+ p->end_mask <<= pad_count;
+ p->begin_mask |= (1 << pad_count) - 1;
+ p->end_mask |= (1 << pad_count) - 1;
+
+ p->start_indices_count = dim_count;
+ p->stop_indices_count = dim_count;
+ p->strides_count = dim_count;
+}
+
+// Return the index for the first element along that axis. This index will be a
+// positive integer between [0, axis_size] (or [-1, axis_size -1] if stride < 0)
+// that can be used to index directly into the data.
+inline int StartForAxis(const tflite::StridedSliceParams& params,
+ const RuntimeShape& input_shape, int axis) {
+ const auto begin_mask = params.begin_mask;
+ const auto* start_indices = params.start_indices;
+ const auto* strides = params.strides;
+ const int axis_size = input_shape.Dims(axis);
+ if (axis_size == 0) {
+ return 0;
+ }
+ // Begin with the specified index.
+ int start = start_indices[axis];
+
+ // begin_mask override
+ if (begin_mask & 1 << axis) {
+ if (strides[axis] > 0) {
+ // Forward iteration - use the first element. These values will get
+ // clamped below (Note: We could have set them to 0 and axis_size-1, but
+ // use lowest() and max() to maintain symmetry with StopForAxis())
+ start = std::numeric_limits<int>::lowest();
+ } else {
+ // Backward iteration - use the last element.
+ start = std::numeric_limits<int>::max();
+ }
+ }
+
+ // Handle negative indices
+ if (start < 0) {
+ start += axis_size;
+ }
+
+ // Clamping
+ if (strides[axis] > 0) {
+ // Forward iteration
+ start = Clamp(start, 0, axis_size);
+ } else {
+ // Backward iteration
+ start = Clamp(start, -1, axis_size - 1);
+ }
+
+ return start;
+}
+
+// Return the "real" index for the end of iteration along that axis. This is an
+// "end" in the traditional C sense, in that it points to one past the last
+// element. ie. So if you were iterating through all elements of a 1D array of
+// size 4, this function would return 4 as the stop, because it is one past the
+// "real" indices of 0, 1, 2 & 3.
+inline int StopForAxis(const tflite::StridedSliceParams& params,
+ const RuntimeShape& input_shape, int axis,
+ int start_for_axis) {
+ const auto end_mask = params.end_mask;
+ const auto shrink_axis_mask = params.shrink_axis_mask;
+ const auto* stop_indices = params.stop_indices;
+ const auto* strides = params.strides;
+ const int axis_size = input_shape.Dims(axis);
+ if (axis_size == 0) {
+ return 0;
+ }
+
+ // Begin with the specified index
+ const bool shrink_axis = shrink_axis_mask & (1 << axis);
+ int stop = stop_indices[axis];
+
+ // When shrinking an axis, the end position does not matter (and can be
+ // incorrect when negative indexing is used, see Issue #19260). Always use
+ // start_for_axis + 1 to generate a length 1 slice, since start_for_axis has
+ // already been adjusted for negative indices.
+ if (shrink_axis) {
+ return start_for_axis + 1;
+ }
+
+ // end_mask override
+ if (end_mask & (1 << axis)) {
+ if (strides[axis] > 0) {
+ // Forward iteration - use the last element. These values will get
+ // clamped below
+ stop = std::numeric_limits<int>::max();
+ } else {
+ // Backward iteration - use the first element.
+ stop = std::numeric_limits<int>::lowest();
+ }
+ }
+
+ // Handle negative indices
+ if (stop < 0) {
+ stop += axis_size;
+ }
+
+ // Clamping
+ // Because the end index points one past the last element, we need slightly
+ // different clamping ranges depending on the direction.
+ if (strides[axis] > 0) {
+ // Forward iteration
+ stop = Clamp(stop, 0, axis_size);
+ } else {
+ // Backward iteration
+ stop = Clamp(stop, -1, axis_size - 1);
+ }
+
+ return stop;
+}
+
+inline bool LoopCondition(int index, int stop, int stride) {
+ // True when we have reached the end of an axis and should loop.
+ return stride > 0 ? index >= stop : index <= stop;
+}
+
+inline tflite::StridedSliceParams BuildStridedSliceParams(
+ int begin_mask, int end_mask, int shrink_axis_mask,
+ const std::vector<int>& start_indices, const std::vector<int>& stop_indices,
+ const std::vector<int>& strides) {
+ tflite::StridedSliceParams op_params;
+ const int dims_count = start_indices.size();
+
+ op_params.start_indices_count = dims_count;
+ op_params.stop_indices_count = dims_count;
+ op_params.strides_count = dims_count;
+ for (int i = 0; i < dims_count; ++i) {
+ op_params.start_indices[i] = start_indices[i];
+ op_params.stop_indices[i] = stop_indices[i];
+ op_params.strides[i] = strides[i];
+ }
+
+ op_params.begin_mask = begin_mask;
+ op_params.ellipsis_mask = 0;
+ op_params.end_mask = end_mask;
+ op_params.new_axis_mask = 0;
+ op_params.shrink_axis_mask = shrink_axis_mask;
+
+ return op_params;
+}
+
+} // namespace strided_slice
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_STRIDED_SLICE_LOGIC_H_
diff --git a/tensorflow/lite/kernels/internal/tensor_ctypes.h b/tensorflow/lite/kernels/internal/tensor_ctypes.h
new file mode 100644
index 0000000..f1d3e17
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/tensor_ctypes.h
@@ -0,0 +1,47 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_TENSOR_CTYPES_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_TENSOR_CTYPES_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+template <typename T>
+inline T* GetTensorData(TfLiteTensor* tensor) {
+ return tensor != nullptr ? reinterpret_cast<T*>(tensor->data.raw) : nullptr;
+}
+
+template <typename T>
+inline const T* GetTensorData(const TfLiteTensor* tensor) {
+ return tensor != nullptr ? reinterpret_cast<const T*>(tensor->data.raw)
+ : nullptr;
+}
+
+inline RuntimeShape GetTensorShape(const TfLiteTensor* tensor) {
+ if (tensor == nullptr) {
+ return RuntimeShape();
+ }
+
+ TfLiteIntArray* dims = tensor->dims;
+ const int dims_size = dims->size;
+ const int32_t* dims_data = reinterpret_cast<const int32_t*>(dims->data);
+ return RuntimeShape(dims_size, dims_data);
+}
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_TENSOR_CTYPES_H_
diff --git a/tensorflow/lite/kernels/internal/types.h b/tensorflow/lite/kernels/internal/types.h
new file mode 100644
index 0000000..9e80ffb
--- /dev/null
+++ b/tensorflow/lite/kernels/internal/types.h
@@ -0,0 +1,1201 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_INTERNAL_TYPES_H_
+#define TENSORFLOW_LITE_KERNELS_INTERNAL_TYPES_H_
+
+#include <algorithm>
+#include <cstdint>
+#include <cstring>
+#include <initializer_list>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+
+namespace tflite {
+
+enum class FusedActivationFunctionType : uint8_t {
+ kNone,
+ kRelu6,
+ kRelu1,
+ kRelu
+};
+enum class PaddingType : uint8_t { kNone, kSame, kValid };
+
+struct PaddingValues {
+ int16_t width;
+ int16_t height;
+ // offset is used for calculating "remaining" padding, for example, `width`
+ // is 1 and `width_offset` is 1, so padding_left is 1 while padding_right is
+ // 1 + 1 = 2.
+ int16_t width_offset;
+ // Same as width_offset except it's over the height dimension.
+ int16_t height_offset;
+};
+
+struct Padding3DValues {
+ int16_t width;
+ int16_t height;
+ int16_t depth;
+ // offset is used for calculating "remaining" padding, for example, `width`
+ // is 1 and `width_offset` is 1, so padding_left is 1 while padding_right is
+ // 1 + 1 = 2.
+ int16_t width_offset;
+ // Same as width_offset except it's over the height dimension.
+ int16_t height_offset;
+ // Same as width_offset except it's over the depth dimension.
+ int16_t depth_offset;
+};
+
+// This enumeration allows for non-default formats for the weights array
+// of a fully-connected operator, allowing the use of special optimized
+// runtime paths.
+enum class FullyConnectedWeightsFormat : uint8_t {
+ // Default format (flat 2D layout, the inner contiguous dimension
+ // is input_depth, the outer non-contiguous dimension is output_depth)
+ kDefault,
+ // Summary: optimized layout for fast CPU runtime implementation,
+ // aimed specifically at ARM CPUs at the moment, and specialized for
+ // 8-bit quantized layers.
+ //
+ // The use case we're concerned with here is: 8-bit quantization,
+ // large weights matrix that doesn't fit in cache (e.g. 4096x2048 in
+ // a key application that drove this), very small batch size (e.g. 1 -- 4).
+ //
+ // Even with 8-bit quantization of weights, the performance of memory
+ // accesses to the weights can become the dominant issue when
+ // the batch size is small, so each weight value is used in only a few
+ // arithmetic ops, i.e. the fully-connected node has a low arithmetic
+ // intensity. The specific issues that arise are of three kinds:
+ // (1) One may, ideally, max out DRAM bandwidth, i.e. be truly memory
+ // bound. That's the "good" issue to run into.
+ // (2) One may run into sub-optimal pre-fetching: the data hasn't been
+ // prefetched into the cache by the time we need it.
+ // (3) One may run into cache aliasing: multiple values that are
+ // pre-fetched, alias each other in the L1 cache (which typically
+ // has only 4-way set associativity in ARM CPUs) and thus evict
+ // each other before we get to using them.
+ //
+ // The point of this shuffling is to avoid issues (2) and (3) so that
+ // we get as fast as possible given only the hard constraint (1).
+ // This is achieved by turning the difficulty into a solution: the
+ // difficulty, that each value loaded from memory is used only in
+ // one kernel iteration, making this operation memory-intensive, hints at
+ // the solution, of shuffling the weights so that they are stored in the
+ // exact order as the kernel needs to load them, so that the memory
+ // accesses made by the kernel are trivial. This solves (2) because the
+ // trivial memory access pattern allows the CPU's automatic prefetching
+ // to perform very well (no need even for preload instructions), and this
+ // solves (3) because the values being loaded concurrently are now
+ // contiguous in the address space, thus don't alias each other in the cache.
+ //
+ // On ARM, we typically want our kernel to process a 4x16 block of weights
+ // at a time, because:
+ // - 16 is the number of bytes in a NEON register.
+ // - 4 is how many rows we need to handle concurrently in the kernel in
+ // order to have sufficient mutual independence of instructions to
+ // maximize arithmetic throughput.
+ //
+ // Finally, the 'Int8' part in the name refers to the fact that this
+ // weights format has each weights value encoded as a signed int8_t value,
+ // even if the data type of the weights buffer is uint8_t. This is intended
+ // to save runtime kernels the effort to have to XOR the top bit of these
+ // bytes before using them in signed arithmetic, see this file for more
+ // explanations on the 'signed int8_t trick' in matrix multiplication kernels:
+ //
+ // tensorflow/lite/toco/graph_transformations/ensure_uint8_weights_safe_for_fast_int8_kernels.cc
+ //
+ kShuffled4x16Int8,
+};
+
+// Quantization parameters, determining the mapping of quantized values
+// to real values (i.e. determining how quantized values are mathematically
+// interpreted).
+//
+// The correspondence is as follows:
+//
+// real_value = scale * (quantized_value - zero_point);
+//
+// In other words, zero_point designates which quantized value corresponds to
+// the real 0 value, and scale designates the difference between the real values
+// corresponding to consecutive quantized values differing by 1.
+struct QuantizationParams {
+ int32_t zero_point = 0;
+ double scale = 0.0;
+};
+
+inline bool operator==(const QuantizationParams& qp1,
+ const QuantizationParams& qp2) {
+ return qp1.zero_point == qp2.zero_point && qp1.scale == qp2.scale;
+}
+
+template <int N>
+struct Dims {
+ int sizes[N];
+ int strides[N];
+};
+
+class RuntimeShape {
+ public:
+ // Shapes with dimensions up to 5 are stored directly in the structure, while
+ // larger shapes are separately allocated.
+ static constexpr int kMaxSmallSize = 5;
+
+ RuntimeShape& operator=(RuntimeShape const&) = delete;
+
+ RuntimeShape() : size_(0) {}
+
+ explicit RuntimeShape(int dimensions_count) : size_(dimensions_count) {
+ if (dimensions_count > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ dims_pointer_ = new int32_t[dimensions_count];
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ }
+
+ RuntimeShape(int shape_size, int32_t value) : size_(0) {
+ Resize(shape_size);
+ for (int i = 0; i < shape_size; ++i) {
+ SetDim(i, value);
+ }
+ }
+
+ RuntimeShape(int dimensions_count, const int32_t* dims_data) : size_(0) {
+ ReplaceWith(dimensions_count, dims_data);
+ }
+
+ RuntimeShape(const std::initializer_list<int> init_list) : size_(0) {
+ BuildFrom(init_list);
+ }
+
+ // Avoid using this constructor. We should be able to delete it when C++17
+ // rolls out.
+ RuntimeShape(RuntimeShape const& other) : size_(other.DimensionsCount()) {
+ if (size_ > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else
+ dims_pointer_ = new int32_t[size_];
+#endif
+ }
+ std::memcpy(DimsData(), other.DimsData(), sizeof(int32_t) * size_);
+ }
+
+ bool operator==(const RuntimeShape& comp) const {
+ return this->size_ == comp.size_ &&
+ std::memcmp(DimsData(), comp.DimsData(), size_ * sizeof(int32_t)) ==
+ 0;
+ }
+
+ ~RuntimeShape() {
+ if (size_ > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ delete[] dims_pointer_;
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ }
+
+ inline int32_t DimensionsCount() const { return size_; }
+ inline int32_t Dims(int i) const {
+ TFLITE_DCHECK_GE(i, 0);
+ TFLITE_DCHECK_LT(i, size_);
+ return size_ > kMaxSmallSize ? dims_pointer_[i] : dims_[i];
+ }
+ inline void SetDim(int i, int32_t val) {
+ TFLITE_DCHECK_GE(i, 0);
+ TFLITE_DCHECK_LT(i, size_);
+ if (size_ > kMaxSmallSize) {
+ dims_pointer_[i] = val;
+ } else {
+ dims_[i] = val;
+ }
+ }
+
+ inline int32_t* DimsData() {
+ return size_ > kMaxSmallSize ? dims_pointer_ : dims_;
+ }
+ inline const int32_t* DimsData() const {
+ return size_ > kMaxSmallSize ? dims_pointer_ : dims_;
+ }
+ // The caller must ensure that the shape is no bigger than 5-D.
+ inline const int32_t* DimsDataUpTo5D() const { return dims_; }
+
+ inline void Resize(int dimensions_count) {
+ if (size_ > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ delete[] dims_pointer_;
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ size_ = dimensions_count;
+ if (dimensions_count > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ dims_pointer_ = new int32_t[dimensions_count];
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ }
+
+ inline void ReplaceWith(int dimensions_count, const int32_t* dims_data) {
+ Resize(dimensions_count);
+ int32_t* dst_dims = DimsData();
+ std::memcpy(dst_dims, dims_data, dimensions_count * sizeof(int32_t));
+ }
+
+ template <typename T>
+ inline void BuildFrom(const T& src_iterable) {
+ const int dimensions_count =
+ std::distance(src_iterable.begin(), src_iterable.end());
+ Resize(dimensions_count);
+ int32_t* data = DimsData();
+ for (auto it : src_iterable) {
+ *data = it;
+ ++data;
+ }
+ }
+
+ // This will probably be factored out. Old code made substantial use of 4-D
+ // shapes, and so this function is used to extend smaller shapes. Note that
+ // (a) as Dims<4>-dependent code is eliminated, the reliance on this should be
+ // reduced, and (b) some kernels are stricly 4-D, but then the shapes of their
+ // inputs should already be 4-D, so this function should not be needed.
+ inline static RuntimeShape ExtendedShape(int new_shape_size,
+ const RuntimeShape& shape) {
+ return RuntimeShape(new_shape_size, shape, 1);
+ }
+
+ inline void BuildFrom(const std::initializer_list<int> init_list) {
+ BuildFrom<const std::initializer_list<int>>(init_list);
+ }
+
+ // Returns the total count of elements, that is the size when flattened into a
+ // vector.
+ inline int FlatSize() const {
+ int buffer_size = 1;
+ const int* dims_data = reinterpret_cast<const int*>(DimsData());
+ for (int i = 0; i < size_; i++) {
+ buffer_size *= dims_data[i];
+ }
+ return buffer_size;
+ }
+
+ bool operator!=(const RuntimeShape& comp) const { return !((*this) == comp); }
+
+ private:
+ // For use only by ExtendedShape(), written to guarantee (return-value) copy
+ // elision in C++17.
+ // This creates a shape padded to the desired size with the specified value.
+ RuntimeShape(int new_shape_size, const RuntimeShape& shape, int pad_value)
+ : size_(0) {
+ // If the following check fails, it is likely because a 4D-only kernel is
+ // being used with an array of larger dimension count.
+ TFLITE_CHECK_GE(new_shape_size, shape.DimensionsCount());
+ Resize(new_shape_size);
+ const int size_increase = new_shape_size - shape.DimensionsCount();
+ for (int i = 0; i < size_increase; ++i) {
+ SetDim(i, pad_value);
+ }
+ std::memcpy(DimsData() + size_increase, shape.DimsData(),
+ sizeof(int32_t) * shape.DimensionsCount());
+ }
+
+ int32_t size_;
+ union {
+ int32_t dims_[kMaxSmallSize];
+ int32_t* dims_pointer_;
+ };
+};
+
+// Converts inference-style shape to legacy tflite::Dims<4>.
+inline tflite::Dims<4> ToRuntimeDims(const tflite::RuntimeShape& array_shape) {
+ tflite::Dims<4> result;
+ const int dimensions_count = array_shape.DimensionsCount();
+ TFLITE_CHECK_LE(dimensions_count, 4);
+ int cum_prod = 1;
+ for (int i = 0; i < 4; i++) {
+ const int new_dim =
+ (i < dimensions_count) ? array_shape.Dims(dimensions_count - 1 - i) : 1;
+ result.sizes[i] = new_dim;
+ result.strides[i] = cum_prod;
+ cum_prod *= new_dim;
+ }
+ return result;
+}
+
+// TODO(b/80418076): Move to legacy ops file, update invocations.
+inline RuntimeShape DimsToShape(const tflite::Dims<4>& dims) {
+ return RuntimeShape(
+ {dims.sizes[3], dims.sizes[2], dims.sizes[1], dims.sizes[0]});
+}
+
+// Gets next index to iterate through a multidimensional array.
+inline bool NextIndex(const int num_dims, const int* dims, int* current) {
+ if (num_dims == 0) {
+ return false;
+ }
+ TFLITE_DCHECK(dims != nullptr);
+ TFLITE_DCHECK(current != nullptr);
+ int carry = 1;
+ for (int idx = num_dims - 1; idx >= 0; --idx) {
+ int current_val = current[idx] + carry;
+ TFLITE_DCHECK_GE(dims[idx], current_val);
+ if (dims[idx] == current_val) {
+ current[idx] = 0;
+ } else {
+ current[idx] = current_val;
+ carry = 0;
+ break;
+ }
+ }
+ return (carry == 0);
+}
+
+// Gets offset of index if reducing on axis. When reducing, the flattened offset
+// will not change, if the input index changes on the given axis. For example,
+// if you have a 3D tensor and you are reducing to 2D by eliminating axis 0,
+// then index (0, 1, 2) and index (1, 1, 2) will map to the same flattened
+// offset.
+// TODO(kanlig): uses Dims to represent dimensions.
+inline size_t ReducedOutputOffset(const int num_dims, const int* dims,
+ const int* index, const int num_axis,
+ const int* axis) {
+ if (num_dims == 0) {
+ return 0;
+ }
+ TFLITE_DCHECK(dims != nullptr);
+ TFLITE_DCHECK(index != nullptr);
+ size_t offset = 0;
+ for (int idx = 0; idx < num_dims; ++idx) {
+ // if we need to skip this axis
+ bool is_axis = false;
+ if (axis != nullptr) {
+ for (int axis_idx = 0; axis_idx < num_axis; ++axis_idx) {
+ if (idx == axis[axis_idx]) {
+ is_axis = true;
+ break;
+ }
+ }
+ }
+ if (!is_axis) {
+ offset = offset * static_cast<size_t>(dims[idx]) +
+ static_cast<size_t>(index[idx]);
+ }
+ }
+ return offset;
+}
+
+inline int Offset(const RuntimeShape& shape, int i0, int i1, int i2, int i3) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), 4);
+ const int* dims_data = reinterpret_cast<const int*>(shape.DimsDataUpTo5D());
+ TFLITE_DCHECK(i0 >= 0 && i0 < dims_data[0]);
+ TFLITE_DCHECK(i1 >= 0 && i1 < dims_data[1]);
+ TFLITE_DCHECK(i2 >= 0 && i2 < dims_data[2]);
+ TFLITE_DCHECK(i3 >= 0 && i3 < dims_data[3]);
+ return ((i0 * dims_data[1] + i1) * dims_data[2] + i2) * dims_data[3] + i3;
+}
+
+inline int Offset(const RuntimeShape& shape, int i0, int i1, int i2, int i3,
+ int i4) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), 5);
+ const int* dims_data = reinterpret_cast<const int*>(shape.DimsDataUpTo5D());
+ TFLITE_DCHECK(i0 >= 0 && i0 < dims_data[0]);
+ TFLITE_DCHECK(i1 >= 0 && i1 < dims_data[1]);
+ TFLITE_DCHECK(i2 >= 0 && i2 < dims_data[2]);
+ TFLITE_DCHECK(i3 >= 0 && i3 < dims_data[3]);
+ TFLITE_DCHECK(i4 >= 0 && i4 < dims_data[4]);
+ return (((i0 * dims_data[1] + i1) * dims_data[2] + i2) * dims_data[3] + i3) *
+ dims_data[4] +
+ i4;
+}
+
+inline int Offset(const Dims<4>& dims, int i0, int i1, int i2, int i3) {
+ TFLITE_DCHECK(i0 >= 0 && i0 < dims.sizes[0]);
+ TFLITE_DCHECK(i1 >= 0 && i1 < dims.sizes[1]);
+ TFLITE_DCHECK(i2 >= 0 && i2 < dims.sizes[2]);
+ TFLITE_DCHECK(i3 >= 0 && i3 < dims.sizes[3]);
+ return i0 * dims.strides[0] + i1 * dims.strides[1] + i2 * dims.strides[2] +
+ i3 * dims.strides[3];
+}
+
+inline int Offset(const Dims<4>& dims, int* index) {
+ return Offset(dims, index[0], index[1], index[2], index[3]);
+}
+
+inline int Offset(const RuntimeShape& shape, int* index) {
+ return Offset(shape, index[0], index[1], index[2], index[3]);
+}
+
+// Get array size, DCHECKing that the dim index is in range.
+//
+// Note that this will be phased out with Dims<4>, since RuntimeShape::Dims()
+// already performs this check.
+template <int N>
+int ArraySize(const Dims<N>& array, int index) {
+ TFLITE_DCHECK(index >= 0 && index < N);
+ return array.sizes[index];
+}
+
+// Get common array size, DCHECKing that they all agree.
+template <typename ArrayType1, typename ArrayType2>
+int MatchingArraySize(const ArrayType1& array1, int index1,
+ const ArrayType2& array2, int index2) {
+ TFLITE_DCHECK_EQ(ArraySize(array1, index1), ArraySize(array2, index2));
+ return ArraySize(array1, index1);
+}
+
+template <typename ArrayType1, typename ArrayType2, typename... Args>
+int MatchingArraySize(const ArrayType1& array1, int index1,
+ const ArrayType2& array2, int index2, Args... args) {
+ TFLITE_DCHECK_EQ(ArraySize(array1, index1), ArraySize(array2, index2));
+ return MatchingArraySize(array1, index1, args...);
+}
+
+// Get common shape dim, DCHECKing that they all agree.
+inline int MatchingDim(const RuntimeShape& shape1, int index1,
+ const RuntimeShape& shape2, int index2) {
+ TFLITE_DCHECK_EQ(shape1.Dims(index1), shape2.Dims(index2));
+ return std::min(shape1.Dims(index1), shape2.Dims(index2));
+}
+
+template <typename... Args>
+int MatchingDim(const RuntimeShape& shape1, int index1,
+ const RuntimeShape& shape2, int index2, Args... args) {
+ TFLITE_DCHECK_EQ(shape1.Dims(index1), shape2.Dims(index2));
+ return MatchingDim(shape1, index1, args...);
+}
+
+// Will be phased out with Dims<4>, replaced by RuntimeShape::FlatSize().
+template <int N>
+inline int FlatSize(const Dims<N>& dims) {
+ int flat_size = 1;
+ for (int i = 0; i < N; ++i) {
+ flat_size *= dims.sizes[i];
+ }
+ return flat_size;
+}
+
+TFLITE_DEPRECATED("Prefer FlatSize.")
+inline int RequiredBufferSizeForDims(const Dims<4>& dims) {
+ return FlatSize(dims);
+}
+
+inline int MatchingElementsSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0) {
+ const int size_1 = shape.FlatSize();
+ const int size_2 = check_shape_0.FlatSize();
+ TFLITE_CHECK_EQ(size_1, size_2);
+ return size_1;
+}
+
+inline int MatchingElementsSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1) {
+ const int size_1 = shape.FlatSize();
+ const int size_2 = check_shape_0.FlatSize();
+ const int size_3 = check_shape_1.FlatSize();
+ TFLITE_CHECK_EQ(size_1, size_2);
+ TFLITE_CHECK_EQ(size_2, size_3);
+ return size_1;
+}
+
+// Flat size calculation, checking that dimensions match with one or more other
+// arrays.
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return shape.FlatSize();
+}
+
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return MatchingFlatSize(shape, check_shape_1);
+}
+
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return MatchingFlatSize(shape, check_shape_1, check_shape_2);
+}
+
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2,
+ const RuntimeShape& check_shape_3) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return MatchingFlatSize(shape, check_shape_1, check_shape_2, check_shape_3);
+}
+
+// Flat size calculation, checking that dimensions match with one or more other
+// arrays.
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return FlatSize(dims);
+}
+
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return MatchingFlatSize(dims, check_dims_1);
+}
+
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return MatchingFlatSize(dims, check_dims_1, check_dims_2);
+}
+
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2,
+ const Dims<N>& check_dims_3) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return MatchingFlatSize(dims, check_dims_1, check_dims_2, check_dims_3);
+}
+
+// Data is required to be contiguous, and so many operators can use either the
+// full array flat size or the flat size with one dimension skipped (commonly
+// the depth).
+template <int N>
+inline int FlatSizeSkipDim(const Dims<N>& dims, int skip_dim) {
+ TFLITE_DCHECK(skip_dim >= 0 && skip_dim < N);
+ int flat_size = 1;
+ for (int i = 0; i < N; ++i) {
+ flat_size *= (i == skip_dim) ? 1 : dims.sizes[i];
+ }
+ return flat_size;
+}
+
+// A combination of MatchingFlatSize() and FlatSizeSkipDim().
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return FlatSizeSkipDim(dims, skip_dim);
+}
+
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(dims, skip_dim, check_dims_1);
+}
+
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(dims, skip_dim, check_dims_1, check_dims_2);
+}
+
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2,
+ const Dims<N>& check_dims_3) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(dims, skip_dim, check_dims_1, check_dims_2,
+ check_dims_3);
+}
+
+// Data is required to be contiguous, and so many operators can use either the
+// full array flat size or the flat size with one dimension skipped (commonly
+// the depth).
+inline int FlatSizeSkipDim(const RuntimeShape& shape, int skip_dim) {
+ const int dims_count = shape.DimensionsCount();
+ TFLITE_DCHECK(skip_dim >= 0 && skip_dim < dims_count);
+ const auto* dims_data = shape.DimsData();
+ int flat_size = 1;
+ for (int i = 0; i < dims_count; ++i) {
+ flat_size *= (i == skip_dim) ? 1 : dims_data[i];
+ }
+ return flat_size;
+}
+
+// A combination of MatchingFlatSize() and FlatSizeSkipDim().
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return FlatSizeSkipDim(shape, skip_dim);
+}
+
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(shape, skip_dim, check_shape_1);
+}
+
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(shape, skip_dim, check_shape_1, check_shape_2);
+}
+
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2,
+ const RuntimeShape& check_shape_3) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(shape, skip_dim, check_shape_1, check_shape_2,
+ check_shape_3);
+}
+
+template <int N>
+bool IsPackedWithoutStrides(const Dims<N>& dims) {
+ int expected_stride = 1;
+ for (int d = 0; d < N; d++) {
+ if (dims.strides[d] != expected_stride) return false;
+ expected_stride *= dims.sizes[d];
+ }
+ return true;
+}
+
+template <int N>
+void ComputeStrides(Dims<N>* dims) {
+ dims->strides[0] = 1;
+ for (int d = 1; d < N; d++) {
+ dims->strides[d] = dims->strides[d - 1] * dims->sizes[d - 1];
+ }
+}
+
+enum class BroadcastableOpCategory : uint8_t {
+ kNone,
+ kNonBroadcast, // Matching input shapes.
+ kFirstInputBroadcastsFast, // Fivefold nested loops.
+ kSecondInputBroadcastsFast, // Fivefold nested loops.
+ kGenericBroadcast, // Fall-back.
+};
+
+struct MinMax {
+ float min;
+ float max;
+};
+static_assert(sizeof(MinMax) == 8, "");
+
+struct ActivationParams {
+ FusedActivationFunctionType activation_type;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+};
+
+struct ReluParams : public ActivationParams {
+ int32_t input_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+};
+
+// Styles of resizing op usages. For example, kImageStyle can be used with a Pad
+// op for pattern-specific optimization.
+enum class ResizingCategory : uint8_t {
+ kNone,
+ kImageStyle, // 4D, operating on inner dimensions, say {0, a, b, 0}.
+ kGenericResize,
+};
+
+// For Add, Sub, Mul ops.
+struct ArithmeticParams {
+ // Shape dependent / common to data / op types.
+ BroadcastableOpCategory broadcast_category;
+ // uint8_t inference params.
+ int32_t input1_offset;
+ int32_t input2_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // Add / Sub, not Mul, uint8_t inference params.
+ int left_shift;
+ int32_t input1_multiplier;
+ int input1_shift;
+ int32_t input2_multiplier;
+ int input2_shift;
+
+ // TODO(b/158622529): Union the following activation params.
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+ // int64_t activation params.
+ int64_t int64_activation_min;
+ int64_t int64_activation_max;
+
+ // Processed output dimensions.
+ // Let input "a" be the one that broadcasts in the faster-changing dimension.
+ // Then, after coalescing, for shapes {a0, a1, a2, a3, a4} and
+ // {b0, b1, b2, b3, b4},
+ // broadcast_shape[4] = b0 = a0.
+ // broadcast_shape[3] = b1; a1 = 1.
+ // broadcast_shape[2] = b2 = a2.
+ // broadcast_shape[1] = a3; b3 = 1.
+ // broadcast_shape[0] = b4 = a4.
+ int broadcast_shape[5];
+};
+
+struct ConcatenationParams {
+ int8_t axis;
+ const int32_t* input_zeropoint;
+ const float* input_scale;
+ uint16_t inputs_count;
+ int32_t output_zeropoint;
+ float output_scale;
+};
+
+struct ComparisonParams {
+ // uint8_t inference params.
+ int left_shift;
+ int32_t input1_offset;
+ int32_t input1_multiplier;
+ int input1_shift;
+ int32_t input2_offset;
+ int32_t input2_multiplier;
+ int input2_shift;
+ // Shape dependent / common to inference types.
+ bool is_broadcast;
+};
+
+struct ConvParams {
+ PaddingType padding_type;
+ PaddingValues padding_values;
+ // TODO(starka): This was just "stride", so check that width+height is OK.
+ int16_t stride_width;
+ int16_t stride_height;
+ int16_t dilation_width_factor;
+ int16_t dilation_height_factor;
+ // uint8_t inference params.
+ // TODO(b/65838351): Use smaller types if appropriate.
+ int32_t input_offset;
+ int32_t weights_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+};
+
+struct Conv3DParams {
+ Padding3DValues padding_values;
+ int stride_width;
+ int stride_height;
+ int stride_depth;
+ int dilation_width;
+ int dilation_height;
+ int dilation_depth;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+};
+
+struct DepthToSpaceParams {
+ int32_t block_size;
+};
+
+struct DepthwiseParams {
+ PaddingType padding_type;
+ PaddingValues padding_values;
+ int16_t stride_width;
+ int16_t stride_height;
+ int16_t dilation_width_factor;
+ int16_t dilation_height_factor;
+ int16_t depth_multiplier;
+ // uint8_t inference params.
+ // TODO(b/65838351): Use smaller types if appropriate.
+ int32_t input_offset;
+ int32_t weights_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+ const int32_t* output_multiplier_per_channel;
+ const int32_t* output_shift_per_channel;
+};
+
+struct DequantizationParams {
+ double scale;
+ int32_t zero_point;
+};
+
+struct PerChannelDequantizationParams {
+ const float* scale;
+ const int32_t* zero_point;
+ int32_t quantized_dimension;
+};
+
+struct FakeQuantParams {
+ MinMax minmax;
+ int32_t num_bits;
+};
+
+struct FullyConnectedParams {
+ // uint8_t inference params.
+ // TODO(b/65838351): Use smaller types if appropriate.
+ int32_t input_offset;
+ int32_t weights_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+ // Mark the operands as cacheable if they are unchanging, e.g. weights.
+ bool lhs_cacheable;
+ bool rhs_cacheable;
+ FullyConnectedWeightsFormat weights_format;
+};
+
+struct GatherParams {
+ int16_t axis;
+ int16_t batch_dims;
+};
+
+struct L2NormalizationParams {
+ // uint8_t inference params.
+ int32_t input_zero_point;
+};
+
+struct LocalResponseNormalizationParams {
+ int32_t range;
+ double bias;
+ double alpha;
+ double beta;
+};
+
+struct HardSwishParams {
+ // zero_point of the input activations.
+ int16_t input_zero_point;
+ // zero_point of the output activations.
+ int16_t output_zero_point;
+ // 16bit fixed-point component of the multiplier to apply to go from the
+ // "high-res input scale", which is the input scale multiplied by 2^7, to the
+ // "relu-ish scale", which 3.0/32768.
+ // See the implementation of HardSwishPrepare.
+ int16_t reluish_multiplier_fixedpoint_int16;
+ // exponent/bit-shift component of the aforementioned multiplier.
+ int reluish_multiplier_exponent;
+ // 16bit fixed-point component of the multiplier to apply to go from the
+ // "high-res input scale", which is the input scale multiplied by 2^7, to the
+ // output scale.
+ // See the implementation of HardSwishPrepare.
+ int16_t output_multiplier_fixedpoint_int16;
+ // exponent/bit-shift component of the aforementioned multiplier.
+ int output_multiplier_exponent;
+};
+
+struct LogisticParams {
+ // uint8_t inference params.
+ int32_t input_zero_point;
+ int32_t input_range_radius;
+ int32_t input_multiplier;
+ int input_left_shift;
+};
+
+struct LstmCellParams {
+ int32_t weights_zero_point;
+ int32_t accum_multiplier;
+ int accum_shift;
+ int state_integer_bits;
+};
+
+struct MeanParams {
+ int8_t axis_count;
+ int16_t axis[4];
+};
+
+struct PackParams {
+ int8_t axis;
+ const int32_t* input_zeropoint;
+ const float* input_scale;
+ uint16_t inputs_count;
+ int32_t output_zeropoint;
+ float output_scale;
+};
+
+struct PadParams {
+ int8_t left_padding_count;
+ int32_t left_padding[5];
+ int8_t right_padding_count;
+ int32_t right_padding[5];
+ ResizingCategory resizing_category;
+};
+
+struct PreluParams {
+ int32_t input_offset;
+ int32_t alpha_offset;
+ int32_t output_offset;
+ int32_t output_multiplier_1;
+ int output_shift_1;
+ int32_t output_multiplier_2;
+ int output_shift_2;
+};
+
+struct PoolParams {
+ FusedActivationFunctionType activation;
+ PaddingType padding_type;
+ PaddingValues padding_values;
+ int stride_height;
+ int stride_width;
+ int filter_height;
+ int filter_width;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+};
+
+struct ReshapeParams {
+ int8_t shape_count;
+ int32_t shape[4];
+};
+
+struct ResizeBilinearParams {
+ bool align_corners;
+ // half_pixel_centers assumes pixels are of half the actual dimensions, and
+ // yields more accurate resizes. Corresponds to the same argument for the
+ // original TensorFlow op in TF2.0.
+ bool half_pixel_centers;
+};
+
+struct ResizeNearestNeighborParams {
+ bool align_corners;
+ bool half_pixel_centers;
+};
+
+struct SliceParams {
+ int8_t begin_count;
+ int32_t begin[5];
+ int8_t size_count;
+ int32_t size[5];
+};
+
+struct SoftmaxParams {
+ // beta is not really used (not a Tensorflow parameter) and not implemented
+ // for LogSoftmax.
+ double beta;
+ // uint8_t inference params. Used even when beta defaults to 1.0.
+ int32_t input_multiplier;
+ int32_t input_left_shift;
+ // Reverse scaling is only used by LogSoftmax.
+ int32_t reverse_scaling_divisor;
+ int32_t reverse_scaling_right_shift;
+ int diff_min;
+ int32_t zero_point;
+ float scale;
+ float* table;
+ // int16 LUT for exp(x), where x uniform distributed between [-10.0 , 0.0]
+ int16_t* exp_lut;
+ // int16 LUT for 1 / (1 + x), where x uniform distributed between [0.0 , 1.0]
+ int16_t* one_over_one_plus_x_lut;
+ uint8_t* uint8_table1;
+ uint8_t* uint8_table2;
+};
+
+struct SpaceToBatchParams {
+ // "Zero" padding for uint8_t means padding with the output offset.
+ int32_t output_offset;
+};
+
+struct SpaceToDepthParams {
+ int32_t block_size;
+};
+
+struct SplitParams {
+ // Graphs that split into, say, 2000 nodes are encountered. The indices in
+ // OperatorEdges are of type uint16_t.
+ uint16_t num_split;
+ int16_t axis;
+};
+
+struct SqueezeParams {
+ int8_t squeeze_dims_count;
+ int32_t squeeze_dims[4];
+};
+
+struct StridedSliceParams {
+ int8_t start_indices_count;
+ int32_t start_indices[5];
+ int8_t stop_indices_count;
+ int32_t stop_indices[5];
+ int8_t strides_count;
+ int32_t strides[5];
+
+ int16_t begin_mask;
+ int16_t ellipsis_mask;
+ int16_t end_mask;
+ int16_t new_axis_mask;
+ int16_t shrink_axis_mask;
+};
+
+struct TanhParams {
+ int32_t input_zero_point;
+ int32_t input_range_radius;
+ int32_t input_multiplier;
+ int input_left_shift;
+};
+
+struct TransposeParams {
+ int8_t perm_count;
+ int32_t perm[5];
+};
+
+struct UnpackParams {
+ uint16_t num_split;
+ int16_t axis;
+};
+
+struct LeakyReluParams {
+ float alpha;
+ int32_t input_offset;
+ int32_t output_offset;
+ int32_t output_multiplier_alpha;
+ int32_t output_shift_alpha;
+ int32_t output_multiplier_identity;
+ int32_t output_shift_identity;
+};
+
+template <typename P>
+inline void SetActivationParams(float min, float max, P* params) {
+ params->float_activation_min = min;
+ params->float_activation_max = max;
+}
+
+template <typename P>
+inline void SetActivationParams(int32_t min, int32_t max, P* params) {
+ params->quantized_activation_min = min;
+ params->quantized_activation_max = max;
+}
+
+template <typename P>
+inline void SetActivationParams(int64_t min, int64_t max, P* params) {
+ params->int64_activation_min = min;
+ params->int64_activation_max = max;
+}
+
+template <typename P>
+inline void GetActivationParams(const P& params, int32_t* min, int32_t* max) {
+ *min = params.quantized_activation_min;
+ *max = params.quantized_activation_max;
+}
+
+template <typename P>
+inline void GetActivationParams(const P& params, float* min, float* max) {
+ *min = params.float_activation_min;
+ *max = params.float_activation_max;
+}
+
+template <typename P>
+inline void GetActivationParams(const P& params, int64_t* min, int64_t* max) {
+ *min = params.int64_activation_min;
+ *max = params.int64_activation_max;
+}
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_INTERNAL_TYPES_H_
diff --git a/tensorflow/lite/kernels/kernel_util.cc b/tensorflow/lite/kernels/kernel_util.cc
new file mode 100644
index 0000000..c8fbea6
--- /dev/null
+++ b/tensorflow/lite/kernels/kernel_util.cc
@@ -0,0 +1,529 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/kernel_util.h"
+
+#include <stdint.h>
+#include <stdlib.h>
+
+#include <algorithm>
+#include <complex>
+#include <limits>
+#include <memory>
+#ifndef TF_LITE_STATIC_MEMORY
+#include <string>
+#endif // TF_LITE_STATIC_MEMORY
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+
+#if defined(__APPLE__)
+#include "TargetConditionals.h"
+#endif
+
+namespace tflite {
+
+namespace {
+
+// Assumes tensor_index is a valid index (in bounds)
+inline TfLiteTensor* GetTensorAtIndex(const TfLiteContext* context,
+ int tensor_index) {
+ if (context->tensors != nullptr) {
+ return &context->tensors[tensor_index];
+ } else {
+ return context->GetTensor(context, tensor_index);
+ }
+}
+
+// Validate in a single place to reduce binary size
+inline TfLiteStatus ValidateTensorIndexingSafe(const TfLiteContext* context,
+ int index, int max_size,
+ const int* tensor_indices,
+ int* tensor_index) {
+ if (index < 0 || index >= max_size) {
+ TF_LITE_KERNEL_LOG(const_cast<TfLiteContext*>(context),
+ "Invalid tensor index %d (not in [0, %d))\n", index,
+ max_size);
+ return kTfLiteError;
+ }
+ if (tensor_indices[index] == kTfLiteOptionalTensor) {
+ TF_LITE_KERNEL_LOG(const_cast<TfLiteContext*>(context),
+ "Tensor at index %d was optional but was expected\n",
+ index);
+ return kTfLiteError;
+ }
+
+ *tensor_index = tensor_indices[index];
+ return kTfLiteOk;
+}
+
+// Same as above but returns -1 for invalid inputs instead of status + logging
+// error.
+inline int ValidateTensorIndexing(const TfLiteContext* context, int index,
+ int max_size, const int* tensor_indices) {
+ if (index >= 0 && index < max_size) {
+ const int tensor_index = tensor_indices[index];
+ if (tensor_index != kTfLiteOptionalTensor) {
+ return tensor_index;
+ }
+ }
+ return -1;
+}
+
+inline TfLiteTensor* GetMutableInput(const TfLiteContext* context,
+ const TfLiteNode* node, int index) {
+ const int tensor_index = ValidateTensorIndexing(
+ context, index, node->inputs->size, node->inputs->data);
+ if (tensor_index < 0) {
+ return nullptr;
+ }
+ return GetTensorAtIndex(context, tensor_index);
+}
+
+inline TfLiteStatus GetMutableInputSafe(const TfLiteContext* context,
+ const TfLiteNode* node, int index,
+ const TfLiteTensor** tensor) {
+ int tensor_index;
+ TF_LITE_ENSURE_OK(
+ context, ValidateTensorIndexingSafe(context, index, node->inputs->size,
+ node->inputs->data, &tensor_index));
+ *tensor = GetTensorAtIndex(context, tensor_index);
+ return kTfLiteOk;
+}
+
+} // anonymous namespace.
+
+const TfLiteTensor* GetInput(const TfLiteContext* context,
+ const TfLiteNode* node, int index) {
+ return GetMutableInput(context, node, index);
+}
+
+TfLiteStatus GetInputSafe(const TfLiteContext* context, const TfLiteNode* node,
+ int index, const TfLiteTensor** tensor) {
+ return GetMutableInputSafe(context, node, index, tensor);
+}
+
+TfLiteTensor* GetVariableInput(TfLiteContext* context, const TfLiteNode* node,
+ int index) {
+ TfLiteTensor* tensor = GetMutableInput(context, node, index);
+ return tensor->is_variable ? tensor : nullptr;
+}
+
+TfLiteTensor* GetOutput(TfLiteContext* context, const TfLiteNode* node,
+ int index) {
+ const int tensor_index = ValidateTensorIndexing(
+ context, index, node->outputs->size, node->outputs->data);
+ if (tensor_index < 0) {
+ return nullptr;
+ }
+ return GetTensorAtIndex(context, tensor_index);
+}
+
+TfLiteStatus GetOutputSafe(const TfLiteContext* context, const TfLiteNode* node,
+ int index, TfLiteTensor** tensor) {
+ int tensor_index;
+ TF_LITE_ENSURE_OK(
+ context, ValidateTensorIndexingSafe(context, index, node->outputs->size,
+ node->outputs->data, &tensor_index));
+ *tensor = GetTensorAtIndex(context, tensor_index);
+ return kTfLiteOk;
+}
+
+const TfLiteTensor* GetOptionalInputTensor(const TfLiteContext* context,
+ const TfLiteNode* node, int index) {
+ return GetInput(context, node, index);
+}
+
+#ifndef TF_LITE_STATIC_MEMORY
+TfLiteTensor* GetTemporary(TfLiteContext* context, const TfLiteNode* node,
+ int index) {
+ const int tensor_index = ValidateTensorIndexing(
+ context, index, node->temporaries->size, node->temporaries->data);
+ if (tensor_index < 0) {
+ return nullptr;
+ }
+ return GetTensorAtIndex(context, tensor_index);
+}
+
+TfLiteStatus GetTemporarySafe(const TfLiteContext* context,
+ const TfLiteNode* node, int index,
+ TfLiteTensor** tensor) {
+ int tensor_index;
+ TF_LITE_ENSURE_OK(context, ValidateTensorIndexingSafe(
+ context, index, node->temporaries->size,
+ node->temporaries->data, &tensor_index));
+ *tensor = GetTensorAtIndex(context, tensor_index);
+ return kTfLiteOk;
+}
+
+const TfLiteTensor* GetIntermediates(TfLiteContext* context,
+ const TfLiteNode* node, int index) {
+ const int tensor_index = ValidateTensorIndexing(
+ context, index, node->intermediates->size, node->intermediates->data);
+ if (tensor_index < 0) {
+ return nullptr;
+ }
+ return GetTensorAtIndex(context, tensor_index);
+}
+
+TfLiteStatus GetIntermediatesSafe(const TfLiteContext* context,
+ const TfLiteNode* node, int index,
+ TfLiteTensor** tensor) {
+ int tensor_index;
+ TF_LITE_ENSURE_OK(context, ValidateTensorIndexingSafe(
+ context, index, node->intermediates->size,
+ node->intermediates->data, &tensor_index));
+ *tensor = GetTensorAtIndex(context, tensor_index);
+ return kTfLiteOk;
+}
+#endif // TF_LITE_STATIC_MEMORY
+
+// Per-axis
+TfLiteStatus PopulateConvolutionQuantizationParams(
+ TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* filter, const TfLiteTensor* bias, TfLiteTensor* output,
+ const TfLiteFusedActivation& activation, int32_t* multiplier, int* shift,
+ int32_t* output_activation_min, int32_t* output_activation_max,
+ int32_t* per_channel_multiplier, int* per_channel_shift) {
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ return PopulateConvolutionQuantizationParams(
+ context, input, filter, bias, output, activation, multiplier, shift,
+ output_activation_min, output_activation_max, per_channel_multiplier,
+ per_channel_shift, affine_quantization->scale->size);
+}
+
+// Per-axis & per-tensor
+TfLiteStatus PopulateConvolutionQuantizationParams(
+ TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* filter, const TfLiteTensor* bias, TfLiteTensor* output,
+ const TfLiteFusedActivation& activation, int32_t* multiplier, int* shift,
+ int32_t* output_activation_min, int32_t* output_activation_max,
+ int32_t* per_channel_multiplier, int* per_channel_shift, int num_channels) {
+ TF_LITE_ENSURE_EQ(context, input->quantization.type,
+ kTfLiteAffineQuantization);
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+ // TODO(jianlijianli): Enable bias type check and bias scale == input scale
+ // * filter scale for each channel in affine quantization once bias
+ // quantization is properly populated.
+ // TF_LITE_ENSURE_EQ(context, bias->quantization.type,
+ // kTfLiteAffineQuantization);
+
+ // Check data type.
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ TF_LITE_ENSURE(context, affine_quantization);
+ TF_LITE_ENSURE(context, affine_quantization->scale);
+ const bool is_per_channel = affine_quantization->scale->size > 1;
+ if (is_per_channel) {
+ // Currently only Int8/Int16 is supported for per channel quantization.
+ TF_LITE_ENSURE(context,
+ input->type == kTfLiteInt8 || input->type == kTfLiteInt16);
+ TF_LITE_ENSURE_EQ(context, filter->type, kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size, num_channels);
+ TF_LITE_ENSURE_EQ(
+ context, num_channels,
+ filter->dims->data[affine_quantization->quantized_dimension]);
+ }
+
+ // Populate multiplier and shift using affine quantization.
+ const float input_scale = input->params.scale;
+ const float output_scale = output->params.scale;
+ const float* filter_scales = affine_quantization->scale->data;
+ for (int i = 0; i < num_channels; ++i) {
+ // If per-tensor quantization parameter is specified, broadcast it along the
+ // quantization dimension (channels_out).
+ const float scale = is_per_channel ? filter_scales[i] : filter_scales[0];
+ const double filter_scale = static_cast<double>(scale);
+ const double effective_output_scale = static_cast<double>(input_scale) *
+ filter_scale /
+ static_cast<double>(output_scale);
+ int32_t significand;
+ int channel_shift;
+ QuantizeMultiplier(effective_output_scale, &significand, &channel_shift);
+ per_channel_multiplier[i] = significand;
+ per_channel_shift[i] = channel_shift;
+ }
+
+ // Populate scalar quantization parameters.
+ // This check on legacy quantization parameters is kept only for backward
+ // compatibility.
+ if (input->type == kTfLiteUInt8) {
+ // Check bias scale == input scale * filter scale.
+ double real_multiplier = 0.0;
+ TF_LITE_ENSURE_STATUS(GetQuantizedConvolutionMultipler(
+ context, input, filter, bias, output, &real_multiplier));
+ int exponent;
+
+ // Populate quantization parameters with multiplier and shift.
+ QuantizeMultiplier(real_multiplier, multiplier, &exponent);
+ *shift = -exponent;
+ }
+ if (input->type == kTfLiteInt8 || input->type == kTfLiteUInt8 ||
+ input->type == kTfLiteInt16) {
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, activation, output, output_activation_min,
+ output_activation_max));
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus GetQuantizedConvolutionMultipler(TfLiteContext* context,
+ const TfLiteTensor* input,
+ const TfLiteTensor* filter,
+ const TfLiteTensor* bias,
+ TfLiteTensor* output,
+ double* multiplier) {
+ const double input_product_scale = static_cast<double>(input->params.scale) *
+ static_cast<double>(filter->params.scale);
+ // The following conditions must be guaranteed by the training pipeline.
+ if (bias) {
+ const double bias_scale = static_cast<double>(bias->params.scale);
+ // Here we're making sure the input_product_scale & bias_scale are about the
+ // same. Since we have:
+ // (output - output_zp) * output_scale =
+ // input_product_scale * input_product + bias * bias_scale ---- (0)
+ //
+ // (0) equals:
+ // (input_product + bias) * input_product_scale ----- (1)
+ // +
+ // bias * (bias_scale - input_product_scale) ------ (2)
+ //
+ // For the real kernel computation, we're doing (1), so we really need to
+ // make sure (2) has minimum impact on the output, so:
+ // bias * (bias_scale - input_product_scale) / output_scale should be
+ // a small number for an integer.
+ // Since normally bias should be within a small range.
+ // We should expect (bias_scale - input_product_scale) / output_scale to
+ // be a small number like 0.02.
+ const double scale_diff = std::abs(input_product_scale - bias_scale);
+ const double output_scale = static_cast<double>(output->params.scale);
+
+ TF_LITE_ENSURE(context, scale_diff / output_scale <= 0.02);
+ }
+ return GetQuantizedConvolutionMultipler(context, input, filter, output,
+ multiplier);
+}
+
+TfLiteStatus GetQuantizedConvolutionMultipler(TfLiteContext* context,
+ const TfLiteTensor* input,
+ const TfLiteTensor* filter,
+ TfLiteTensor* output,
+ double* multiplier) {
+ const double input_product_scale =
+ static_cast<double>(input->params.scale * filter->params.scale);
+ TF_LITE_ENSURE(context, input_product_scale >= 0);
+ *multiplier = input_product_scale / static_cast<double>(output->params.scale);
+
+ return kTfLiteOk;
+}
+
+namespace {
+void CalculateActivationRangeQuantizedImpl(TfLiteFusedActivation activation,
+ int32_t qmin, int32_t qmax,
+ TfLiteTensor* output,
+ int32_t* act_min, int32_t* act_max) {
+ const auto scale = output->params.scale;
+ const auto zero_point = output->params.zero_point;
+
+ auto quantize = [scale, zero_point](float f) {
+ return zero_point + static_cast<int32_t>(TfLiteRound(f / scale));
+ };
+
+ if (activation == kTfLiteActRelu) {
+ *act_min = std::max(qmin, quantize(0.0));
+ *act_max = qmax;
+ } else if (activation == kTfLiteActRelu6) {
+ *act_min = std::max(qmin, quantize(0.0));
+ *act_max = std::min(qmax, quantize(6.0));
+ } else if (activation == kTfLiteActReluN1To1) {
+ *act_min = std::max(qmin, quantize(-1.0));
+ *act_max = std::min(qmax, quantize(1.0));
+ } else {
+ *act_min = qmin;
+ *act_max = qmax;
+ }
+}
+} // namespace
+
+TfLiteStatus CalculateActivationRangeQuantized(TfLiteContext* context,
+ TfLiteFusedActivation activation,
+ TfLiteTensor* output,
+ int32_t* act_min,
+ int32_t* act_max) {
+ int32_t qmin = 0;
+ int32_t qmax = 0;
+ if (output->type == kTfLiteUInt8) {
+ qmin = std::numeric_limits<uint8_t>::min();
+ qmax = std::numeric_limits<uint8_t>::max();
+ } else if (output->type == kTfLiteInt8) {
+ qmin = std::numeric_limits<int8_t>::min();
+ qmax = std::numeric_limits<int8_t>::max();
+ } else if (output->type == kTfLiteInt16) {
+ qmin = std::numeric_limits<int16_t>::min();
+ qmax = std::numeric_limits<int16_t>::max();
+ } else {
+ TF_LITE_ENSURE(context, false);
+ }
+
+ CalculateActivationRangeQuantizedImpl(activation, qmin, qmax, output, act_min,
+ act_max);
+ return kTfLiteOk;
+}
+
+bool HaveSameShapes(const TfLiteTensor* input1, const TfLiteTensor* input2) {
+ return TfLiteIntArrayEqual(input1->dims, input2->dims);
+}
+
+#ifndef TF_LITE_STATIC_MEMORY
+
+// TODO(b/172067338): Having this function be part of TF_LITE_STATIC_MEMORY
+// build results in a 6KB size increase, even though the function is unsused for
+// that build. What appears to be happening is that while the linker drops the
+// unsused function, the string library that gets pulled in is not dropped,
+// resulting in the increased binary size.
+std::string GetShapeDebugString(const TfLiteIntArray* shape) {
+ std::string str;
+ for (int d = 0; d < shape->size; ++d) {
+ if (str.empty())
+ str = "[" + std::to_string(shape->data[d]);
+ else
+ str += ", " + std::to_string(shape->data[d]);
+ }
+ str += "]";
+ return str;
+}
+
+TfLiteStatus CalculateShapeForBroadcast(TfLiteContext* context,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2,
+ TfLiteIntArray** output_shape) {
+ int dims1 = NumDimensions(input1);
+ int dims2 = NumDimensions(input2);
+ int out_dims = std::max(dims1, dims2);
+ if (NumElements(input1) == 0) {
+ *output_shape = TfLiteIntArrayCopy(input1->dims);
+ return kTfLiteOk;
+ }
+ std::unique_ptr<TfLiteIntArray, void (*)(TfLiteIntArray*)> shape(
+ TfLiteIntArrayCreate(out_dims), TfLiteIntArrayFree);
+ for (int i = 0; i < out_dims; ++i) {
+ int d1 = i >= dims1 ? 1 : SizeOfDimension(input1, dims1 - i - 1);
+ int d2 = i >= dims2 ? 1 : SizeOfDimension(input2, dims2 - i - 1);
+ if (!(d1 == d2 || d1 == 1 || d2 == 1)) {
+ context->ReportError(context,
+ "Given shapes, %s and %s, are not broadcastable.",
+ GetShapeDebugString(input1->dims).c_str(),
+ GetShapeDebugString(input2->dims).c_str());
+ return kTfLiteError;
+ }
+ shape->data[out_dims - i - 1] = std::max(d1, d2);
+ }
+ *output_shape = shape.release();
+ return kTfLiteOk;
+}
+
+TfLiteStatus CalculateShapeForBroadcast(TfLiteContext* context,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2,
+ const TfLiteTensor* input3,
+ TfLiteIntArray** output_shape) {
+ int dims1 = NumDimensions(input1);
+ int dims2 = NumDimensions(input2);
+ int dims3 = NumDimensions(input3);
+ int out_dims = std::max(std::max(dims1, dims2), dims3);
+ std::unique_ptr<TfLiteIntArray, void (*)(TfLiteIntArray*)> shape(
+ TfLiteIntArrayCreate(out_dims), TfLiteIntArrayFree);
+ for (int i = 0; i < out_dims; ++i) {
+ int d1 = i >= dims1 ? 1 : SizeOfDimension(input1, dims1 - i - 1);
+ int d2 = i >= dims2 ? 1 : SizeOfDimension(input2, dims2 - i - 1);
+ int d3 = i >= dims3 ? 1 : SizeOfDimension(input3, dims3 - i - 1);
+ int max_value = std::max(std::max(d1, d2), d3);
+ if (!(d1 == 1 || d1 == max_value) || !(d2 == 1 || d2 == max_value) ||
+ !(d3 == 1 || d3 == max_value)) {
+ context->ReportError(
+ context, "Given shapes, %s, %s and %s, are not broadcastable.",
+ GetShapeDebugString(input1->dims).c_str(),
+ GetShapeDebugString(input2->dims).c_str(),
+ GetShapeDebugString(input3->dims).c_str());
+ return kTfLiteError;
+ }
+ shape->data[out_dims - i - 1] = max_value;
+ }
+ *output_shape = shape.release();
+ return kTfLiteOk;
+}
+#endif // TF_LITE_STATIC_MEMORY
+
+// Size of string is not constant, return 0 in such case.
+int TfLiteTypeGetSize(TfLiteType type) {
+ switch (type) {
+ case kTfLiteUInt8:
+ TF_LITE_ASSERT_EQ(sizeof(uint8_t), 1);
+ return 1;
+ case kTfLiteInt8:
+ TF_LITE_ASSERT_EQ(sizeof(int8_t), 1);
+ return 1;
+ case kTfLiteBool:
+ return sizeof(bool);
+ case kTfLiteInt16:
+ TF_LITE_ASSERT_EQ(sizeof(int16_t), 2);
+ return 2;
+ case kTfLiteFloat16:
+ TF_LITE_ASSERT_EQ(sizeof(int16_t), 2);
+ return 2;
+ case kTfLiteFloat32:
+ TF_LITE_ASSERT_EQ(sizeof(float), 4);
+ return 4;
+ case kTfLiteInt32:
+ TF_LITE_ASSERT_EQ(sizeof(int32_t), 4);
+ return 4;
+ case kTfLiteUInt32:
+ TF_LITE_ASSERT_EQ(sizeof(uint32_t), 4);
+ return 4;
+ case kTfLiteInt64:
+ TF_LITE_ASSERT_EQ(sizeof(int64_t), 8);
+ return 8;
+ case kTfLiteUInt64:
+ TF_LITE_ASSERT_EQ(sizeof(uint64_t), 8);
+ return 8;
+ case kTfLiteFloat64:
+ TF_LITE_ASSERT_EQ(sizeof(double), 8);
+ return 8;
+ case kTfLiteComplex64:
+ TF_LITE_ASSERT_EQ(sizeof(std::complex<float>), 8);
+ return 8;
+ case kTfLiteComplex128:
+ TF_LITE_ASSERT_EQ(sizeof(std::complex<double>), 16);
+ return 16;
+ default:
+ return 0;
+ }
+}
+
+bool IsMobilePlatform() {
+#if defined(ANDROID) || defined(__ANDROID__)
+ return true;
+#elif defined(__APPLE__)
+#if TARGET_IPHONE_SIMULATOR || TARGET_OS_IPHONE
+ return true;
+#endif
+#endif
+ return false;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/kernels/kernel_util.h b/tensorflow/lite/kernels/kernel_util.h
new file mode 100644
index 0000000..9441842
--- /dev/null
+++ b/tensorflow/lite/kernels/kernel_util.h
@@ -0,0 +1,296 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_KERNEL_UTIL_H_
+#define TENSORFLOW_LITE_KERNELS_KERNEL_UTIL_H_
+
+#include <stdint.h>
+
+#include <limits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+// A fair number of functions in this header have historically been inline.
+// It is ok to change functions to not be inline if the latency with
+// benchmark_model for MobileNet + MobileBERT is unaffected. If such a change is
+// made, move the newly non-inlined function declarations to the top of this
+// header file.
+
+// Note: You must check if result is not null:
+//
+// TfLiteTensor* my_tensor = GetInput(context, node, kMyTensorIdx);
+// TF_LITE_ENSURE(context, my_tensor != nullptr);
+//
+// This is because the index might point to the optional tensor constant
+// (kTfLiteOptionalTensor) in which case there is no tensor to return.
+const TfLiteTensor* GetInput(const TfLiteContext* context,
+ const TfLiteNode* node, int index);
+
+// Same as `GetInput` but returns boolean and uses output argument for tensor.
+//
+// TfLiteTensor* my_tensor;
+// TF_LITE_ENSURE_OK(context,
+// GetInputSafe(context, node, kMyTensorIdx, &my_tensor));
+// // can use my_tensor directly from here onwards, it is not nullptr
+//
+// Should be used in cases where the binary size is too large.
+TfLiteStatus GetInputSafe(const TfLiteContext* context, const TfLiteNode* node,
+ int index, const TfLiteTensor** tensor);
+
+// Note: You must check if result is not null:
+//
+// TfLiteTensor* my_tensor = GetVariableInput(context, node, kMyTensorIdx);
+// TF_LITE_ENSURE(context, my_tensor != nullptr);
+//
+// This is because the index might point to the optional tensor constant
+// (kTfLiteOptionalTensor) in which case there is no tensor to return.
+TfLiteTensor* GetVariableInput(TfLiteContext* context, const TfLiteNode* node,
+ int index);
+
+// Note: You must check if result is not null:
+//
+// TfLiteTensor* my_tensor = GetOutput(context, node, kMyTensorIdx);
+// TF_LITE_ENSURE(context, my_tensor != nullptr);
+//
+// This is because the index might point to the optional tensor constant
+// (kTfLiteOptionalTensor) in which case there is no tensor to return.
+TfLiteTensor* GetOutput(TfLiteContext* context, const TfLiteNode* node,
+ int index);
+
+// Same as `GetOutput` but returns boolean and uses output argument for tensor.
+//
+// TfLiteTensor* my_tensor;
+// TF_LITE_ENSURE_OK(context,
+// GetOutputSafe(context, node, kMyTensorIdx, &my_tensor));
+// // can use my_tensor directly from here onwards, it is not nullptr
+//
+// Should be used in cases where the binary size is too large.
+TfLiteStatus GetOutputSafe(const TfLiteContext* context, const TfLiteNode* node,
+ int index, TfLiteTensor** tensor);
+
+// Note: You must check if result is not null:
+//
+// TfLiteTensor* my_tensor = GetOptionalInputTensor(context, node, kIdx);
+// TF_LITE_ENSURE(context, my_tensor != nullptr);
+//
+// This is because the index might point to the optional tensor constant
+// (kTfLiteOptionalTensor) in which case there is no tensor to return.
+//
+// Deprecated. GetInput has the same functionality.
+const TfLiteTensor* GetOptionalInputTensor(const TfLiteContext* context,
+ const TfLiteNode* node, int index);
+
+#ifndef TF_LITE_STATIC_MEMORY
+// Note: You must check if result is not null:
+//
+// TfLiteTensor* my_tensor = GetTemporary(context, node, kMyTensorIdx);
+// TF_LITE_ENSURE(context, my_tensor != nullptr);
+//
+// This is because the index might point to the optional tensor constant
+// (kTfLiteOptionalTensor) in which case there is no tensor to return.
+TfLiteTensor* GetTemporary(TfLiteContext* context, const TfLiteNode* node,
+ int index);
+
+// Same as `GetTemporary` but returns boolean and uses output argument for
+// tensor.
+//
+// TfLiteTensor* my_tensor;
+// TF_LITE_ENSURE_OK(context,
+// GetTemporarySafe(context, node, kMyTensorIdx,
+// &my_tensor));
+// // can use my_tensor directly from here onwards, it is not nullptr
+//
+// Should be used in cases where the binary size is too large.
+TfLiteStatus GetTemporarySafe(const TfLiteContext* context,
+ const TfLiteNode* node, int index,
+ TfLiteTensor** tensor);
+
+// Note: You must check if result is not null:
+//
+// TfLiteTensor* my_tensor = GetIntermediates(context, node, kMyTensorIdx);
+// TF_LITE_ENSURE(context, my_tensor != nullptr);
+//
+// This is because the index might point to the optional tensor constant
+// (kTfLiteOptionalTensor) in which case there is no tensor to return.
+const TfLiteTensor* GetIntermediates(TfLiteContext* context,
+ const TfLiteNode* node, int index);
+
+// Same as `GetIntermediates` but returns boolean and uses output argument for
+// tensor.
+//
+// TfLiteTensor* my_tensor;
+// TF_LITE_ENSURE_OK(context,
+// GetIntermediatesSafe(context, node, kMyTensorIdx,
+// &my_tensor));
+// // can use my_tensor directly from here onwards, it is not nullptr
+//
+// Should be used in cases where the binary size is too large.
+TfLiteStatus GetIntermediatesSafe(const TfLiteContext* context,
+ const TfLiteNode* node, int index,
+ TfLiteTensor** tensor);
+#endif // TF_LITE_STATIC_MEMORY
+
+inline int NumDimensions(const TfLiteTensor* t) { return t->dims->size; }
+inline int SizeOfDimension(const TfLiteTensor* t, int dim) {
+ return t->dims->data[dim];
+}
+
+inline int NumInputs(const TfLiteNode* node) { return node->inputs->size; }
+inline int NumOutputs(const TfLiteNode* node) { return node->outputs->size; }
+
+#ifndef TF_LITE_STATIC_MEMORY
+inline int NumIntermediates(const TfLiteNode* node) {
+ return node->intermediates->size;
+}
+#endif // TF_LITE_STATIC_MEMORY
+
+inline int64_t NumElements(const TfLiteIntArray* dims) {
+ int64_t count = 1;
+ for (int i = 0; i < dims->size; ++i) {
+ count *= dims->data[i];
+ }
+ return count;
+}
+
+inline int64_t NumElements(const TfLiteTensor* t) {
+ return NumElements(t->dims);
+}
+
+// Determines whether tensor is constant.
+// TODO(b/138199592): Introduce new query which checks for constant OR
+// persistent-read-only, which would be useful for most tensor kernels that
+// are potentially dynamic based on the input tensor value availability at the
+// time of prepare.
+inline bool IsConstantTensor(const TfLiteTensor* tensor) {
+ return tensor->allocation_type == kTfLiteMmapRo;
+}
+
+// Determines whether tensor is dynamic. Note that a tensor can be non-const and
+// not dynamic. This function specifically checks for a dynamic tensor.
+inline bool IsDynamicTensor(const TfLiteTensor* tensor) {
+ return tensor->allocation_type == kTfLiteDynamic;
+}
+
+// Sets tensor to dynamic.
+inline void SetTensorToDynamic(TfLiteTensor* tensor) {
+ if (tensor->allocation_type != kTfLiteDynamic) {
+ tensor->allocation_type = kTfLiteDynamic;
+ tensor->data.raw = nullptr;
+ }
+}
+
+// Sets tensor to persistent and read-only.
+inline void SetTensorToPersistentRo(TfLiteTensor* tensor) {
+ if (tensor->allocation_type != kTfLitePersistentRo) {
+ tensor->allocation_type = kTfLitePersistentRo;
+ tensor->data.raw = nullptr;
+ }
+}
+
+// Determines whether it is a hybrid op - one that has float inputs and
+// quantized weights.
+inline bool IsHybridOp(const TfLiteTensor* input, const TfLiteTensor* weight) {
+ return ((weight->type == kTfLiteUInt8 || weight->type == kTfLiteInt8) &&
+ input->type == kTfLiteFloat32);
+}
+
+// Check dimensionality match and populate OpData for Conv and DepthwiseConv.
+TfLiteStatus PopulateConvolutionQuantizationParams(
+ TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* filter, const TfLiteTensor* bias, TfLiteTensor* output,
+ const TfLiteFusedActivation& activation, int32_t* multiplier, int* shift,
+ int32_t* output_activation_min, int32_t* output_activation_max,
+ int32_t* per_channel_multiplier, int* per_channel_shift);
+
+TfLiteStatus PopulateConvolutionQuantizationParams(
+ TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* filter, const TfLiteTensor* bias, TfLiteTensor* output,
+ const TfLiteFusedActivation& activation, int32_t* multiplier, int* shift,
+ int32_t* output_activation_min, int32_t* output_activation_max,
+ int32_t* per_channel_multiplier, int* per_channel_shift, int num_channels);
+
+// Calculates the multiplication factor for a quantized convolution (or
+// quantized depthwise convolution) involving the given tensors. Returns an
+// error if the scales of the tensors are not compatible.
+TfLiteStatus GetQuantizedConvolutionMultipler(TfLiteContext* context,
+ const TfLiteTensor* input,
+ const TfLiteTensor* filter,
+ const TfLiteTensor* bias,
+ TfLiteTensor* output,
+ double* multiplier);
+
+TfLiteStatus GetQuantizedConvolutionMultipler(TfLiteContext* context,
+ const TfLiteTensor* input,
+ const TfLiteTensor* filter,
+ TfLiteTensor* output,
+ double* multiplier);
+
+// Calculates the useful quantized range of an activation layer given its
+// activation tensor.
+TfLiteStatus CalculateActivationRangeQuantized(TfLiteContext* context,
+ TfLiteFusedActivation activation,
+ TfLiteTensor* output,
+ int32_t* act_min,
+ int32_t* act_max);
+
+// Calculates the useful range of an activation layer given its activation
+// tensor.a
+template <typename T>
+void CalculateActivationRange(TfLiteFusedActivation activation,
+ T* activation_min, T* activation_max) {
+ if (activation == kTfLiteActRelu) {
+ *activation_min = 0;
+ *activation_max = std::numeric_limits<T>::max();
+ } else if (activation == kTfLiteActRelu6) {
+ *activation_min = 0;
+ *activation_max = 6;
+ } else if (activation == kTfLiteActReluN1To1) {
+ *activation_min = -1;
+ *activation_max = 1;
+ } else {
+ *activation_min = std::numeric_limits<T>::lowest();
+ *activation_max = std::numeric_limits<T>::max();
+ }
+}
+
+// Return true if the given tensors have the same shape.
+bool HaveSameShapes(const TfLiteTensor* input1, const TfLiteTensor* input2);
+
+// Calculates the output_shape that is necessary for element-wise operations
+// with broadcasting involving the two input tensors.
+TfLiteStatus CalculateShapeForBroadcast(TfLiteContext* context,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2,
+ TfLiteIntArray** output_shape);
+
+// Calculates the output_shape that is necessary for element-wise operations
+// with broadcasting involving the three input tensors.
+TfLiteStatus CalculateShapeForBroadcast(TfLiteContext* context,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2,
+ const TfLiteTensor* input3,
+ TfLiteIntArray** output_shape);
+
+// Return the size of given type in bytes. Return 0 in in case of string.
+int TfLiteTypeGetSize(TfLiteType type);
+
+// Whether the current platform is mobile (Android or iOS).
+bool IsMobilePlatform();
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_KERNEL_UTIL_H_
diff --git a/tensorflow/lite/kernels/op_macros.h b/tensorflow/lite/kernels/op_macros.h
new file mode 100644
index 0000000..293dc76
--- /dev/null
+++ b/tensorflow/lite/kernels/op_macros.h
@@ -0,0 +1,83 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_OP_MACROS_H_
+#define TENSORFLOW_LITE_KERNELS_OP_MACROS_H_
+
+// If we're on a platform without standard IO functions, fall back to a
+// non-portable function.
+#ifdef TF_LITE_MCU_DEBUG_LOG
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#define DEBUG_LOG(x) \
+ do { \
+ DebugLog(x); \
+ } while (0)
+
+inline void InfiniteLoop() {
+ DEBUG_LOG("HALTED\n");
+ while (1) {
+ }
+}
+
+#define TFLITE_ABORT InfiniteLoop();
+
+#else // TF_LITE_MCU_DEBUG_LOG
+
+#include <cstdio>
+#include <cstdlib>
+
+#define DEBUG_LOG(x) \
+ do { \
+ fprintf(stderr, "%s", (x)); \
+ } while (0)
+
+// Report Error for unsupported type by op 'op_name' and returns kTfLiteError.
+#define TF_LITE_UNSUPPORTED_TYPE(context, type, op_name) \
+ do { \
+ TF_LITE_KERNEL_LOG((context), "%s:%d Type %s is unsupported by op %s.", \
+ __FILE__, __LINE__, TfLiteTypeGetName(type), \
+ (op_name)); \
+ return kTfLiteError; \
+ } while (0)
+
+#define TFLITE_ABORT abort()
+
+#endif // TF_LITE_MCU_DEBUG_LOG
+
+#if defined(NDEBUG) || defined(ARDUINO)
+#define TFLITE_ASSERT_FALSE (static_cast<void>(0))
+#else
+#define TFLITE_ASSERT_FALSE TFLITE_ABORT
+#endif
+
+#define TF_LITE_FATAL(msg) \
+ do { \
+ DEBUG_LOG(msg); \
+ DEBUG_LOG("\nFATAL\n"); \
+ TFLITE_ABORT; \
+ } while (0)
+
+#define TF_LITE_ASSERT(x) \
+ do { \
+ if (!(x)) TF_LITE_FATAL(#x); \
+ } while (0)
+
+#define TF_LITE_ASSERT_EQ(x, y) \
+ do { \
+ if ((x) != (y)) TF_LITE_FATAL(#x " didn't equal " #y); \
+ } while (0)
+
+#endif // TENSORFLOW_LITE_KERNELS_OP_MACROS_H_
diff --git a/tensorflow/lite/kernels/padding.h b/tensorflow/lite/kernels/padding.h
new file mode 100644
index 0000000..d41e471
--- /dev/null
+++ b/tensorflow/lite/kernels/padding.h
@@ -0,0 +1,111 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_KERNELS_PADDING_H_
+#define TENSORFLOW_LITE_KERNELS_PADDING_H_
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+// TODO(renjieliu): Migrate others to use ComputePaddingWithLeftover.
+inline int ComputePadding(int stride, int dilation_rate, int in_size,
+ int filter_size, int out_size) {
+ int effective_filter_size = (filter_size - 1) * dilation_rate + 1;
+ int padding = ((out_size - 1) * stride + effective_filter_size - in_size) / 2;
+ return padding > 0 ? padding : 0;
+}
+
+// It's not guaranteed that padding is symmetric. It's important to keep
+// offset for algorithms need all paddings.
+inline int ComputePaddingWithOffset(int stride, int dilation_rate, int in_size,
+ int filter_size, int out_size,
+ int* offset) {
+ int effective_filter_size = (filter_size - 1) * dilation_rate + 1;
+ int total_padding =
+ ((out_size - 1) * stride + effective_filter_size - in_size);
+ total_padding = total_padding > 0 ? total_padding : 0;
+ *offset = total_padding % 2;
+ return total_padding / 2;
+}
+
+// Matching GetWindowedOutputSize in TensorFlow.
+inline int ComputeOutSize(TfLitePadding padding, int image_size,
+ int filter_size, int stride, int dilation_rate = 1) {
+ int effective_filter_size = (filter_size - 1) * dilation_rate + 1;
+ switch (padding) {
+ case kTfLitePaddingSame:
+ return (image_size + stride - 1) / stride;
+ case kTfLitePaddingValid:
+ return (image_size + stride - effective_filter_size) / stride;
+ default:
+ return 0;
+ }
+}
+
+inline TfLitePaddingValues ComputePaddingHeightWidth(
+ int stride_height, int stride_width, int dilation_rate_height,
+ int dilation_rate_width, int in_height, int in_width, int filter_height,
+ int filter_width, TfLitePadding padding, int* out_height, int* out_width) {
+ *out_width = ComputeOutSize(padding, in_width, filter_width, stride_width,
+ dilation_rate_width);
+ *out_height = ComputeOutSize(padding, in_height, filter_height, stride_height,
+ dilation_rate_height);
+
+ TfLitePaddingValues padding_values;
+ int offset = 0;
+ padding_values.height =
+ ComputePaddingWithOffset(stride_height, dilation_rate_height, in_height,
+ filter_height, *out_height, &offset);
+ padding_values.height_offset = offset;
+ padding_values.width =
+ ComputePaddingWithOffset(stride_width, dilation_rate_width, in_width,
+ filter_width, *out_width, &offset);
+ padding_values.width_offset = offset;
+ return padding_values;
+}
+
+inline Padding3DValues ComputePadding3DValues(
+ int stride_height, int stride_width, int stride_depth,
+ int dilation_rate_height, int dilation_rate_width, int dilation_rate_depth,
+ int in_height, int in_width, int in_depth, int filter_height,
+ int filter_width, int filter_depth, TfLitePadding padding, int* out_height,
+ int* out_width, int* out_depth) {
+ *out_width = ComputeOutSize(padding, in_width, filter_width, stride_width,
+ dilation_rate_width);
+ *out_height = ComputeOutSize(padding, in_height, filter_height, stride_height,
+ dilation_rate_height);
+ *out_depth = ComputeOutSize(padding, in_depth, filter_depth, stride_depth,
+ dilation_rate_depth);
+
+ Padding3DValues padding_values;
+ int offset = 0;
+ padding_values.depth =
+ ComputePaddingWithOffset(stride_depth, dilation_rate_depth, in_depth,
+ filter_depth, *out_depth, &offset);
+ padding_values.depth_offset = offset;
+ padding_values.height =
+ ComputePaddingWithOffset(stride_height, dilation_rate_height, in_height,
+ filter_height, *out_height, &offset);
+ padding_values.height_offset = offset;
+ padding_values.width =
+ ComputePaddingWithOffset(stride_width, dilation_rate_width, in_width,
+ filter_width, *out_width, &offset);
+ padding_values.width_offset = offset;
+ return padding_values;
+}
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_KERNELS_PADDING_H_
diff --git a/tensorflow/lite/micro/BUILD b/tensorflow/lite/micro/BUILD
new file mode 100644
index 0000000..dc06fb5
--- /dev/null
+++ b/tensorflow/lite/micro/BUILD
@@ -0,0 +1,400 @@
+load("@bazel_skylib//:bzl_library.bzl", "bzl_library")
+load(
+ "//tensorflow/lite/micro:build_def.bzl",
+ "micro_copts",
+)
+
+package(
+ default_visibility = ["//visibility:public"],
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+package_group(
+ name = "micro",
+ packages = ["//tensorflow/lite/micro/..."],
+)
+
+cc_library(
+ name = "micro_compatibility",
+ hdrs = [
+ "compatibility.h",
+ ],
+ copts = micro_copts(),
+)
+
+cc_library(
+ name = "micro_framework",
+ srcs = [
+ "micro_allocator.cc",
+ "micro_interpreter.cc",
+ "simple_memory_allocator.cc",
+ ],
+ hdrs = [
+ "micro_allocator.h",
+ "micro_interpreter.h",
+ "simple_memory_allocator.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":memory_helpers",
+ ":micro_compatibility",
+ ":micro_profiler",
+ ":op_resolvers",
+ "//tensorflow/lite:type_to_tflitetype",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/core/api",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/micro/memory_planner",
+ "//tensorflow/lite/micro/memory_planner:greedy_memory_planner",
+ "//tensorflow/lite/schema:schema_fbs",
+ "//tensorflow/lite/schema:schema_utils",
+ "@flatbuffers//:runtime_cc",
+ ],
+)
+
+cc_library(
+ name = "memory_helpers",
+ srcs = ["memory_helpers.cc"],
+ hdrs = ["memory_helpers.h"],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/core/api",
+ "//tensorflow/lite/kernels/internal:reference",
+ "//tensorflow/lite/schema:schema_fbs",
+ "@flatbuffers//:runtime_cc",
+ ],
+)
+
+cc_library(
+ name = "test_helpers",
+ srcs = [
+ "test_helpers.cc",
+ ],
+ hdrs = [
+ "test_helpers.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":micro_utils",
+ ":op_resolvers",
+ "//tensorflow/lite:type_to_tflitetype",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/core/api",
+ "//tensorflow/lite/kernels:kernel_util",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/schema:schema_fbs",
+ "@flatbuffers//:runtime_cc",
+ ],
+)
+
+cc_library(
+ name = "op_resolvers",
+ srcs = [
+ "all_ops_resolver.cc",
+ ],
+ hdrs = [
+ "all_ops_resolver.h",
+ "micro_mutable_op_resolver.h",
+ "micro_op_resolver.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":micro_compatibility",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/core/api",
+ "//tensorflow/lite/kernels:op_macros",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "//tensorflow/lite/micro/kernels:conv",
+ "//tensorflow/lite/micro/kernels:depthwise_conv",
+ "//tensorflow/lite/micro/kernels:ethosu",
+ "//tensorflow/lite/micro/kernels:fully_connected",
+ "//tensorflow/lite/micro/kernels:micro_ops",
+ "//tensorflow/lite/schema:schema_fbs",
+ ],
+)
+
+cc_library(
+ name = "debug_log",
+ srcs = [
+ "debug_log.cc",
+ ],
+ hdrs = [
+ "debug_log.h",
+ ],
+ copts = micro_copts(),
+)
+
+cc_library(
+ name = "micro_error_reporter",
+ srcs = [
+ "micro_error_reporter.cc",
+ ],
+ hdrs = [
+ "micro_error_reporter.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":debug_log",
+ ":micro_compatibility",
+ ":micro_string",
+ "//tensorflow/lite/core/api",
+ ],
+)
+
+cc_library(
+ name = "micro_string",
+ srcs = [
+ "micro_string.cc",
+ ],
+ hdrs = [
+ "micro_string.h",
+ ],
+ copts = micro_copts(),
+)
+
+cc_library(
+ name = "micro_time",
+ srcs = [
+ "micro_time.cc",
+ ],
+ hdrs = [
+ "micro_time.h",
+ ],
+ copts = micro_copts() + ["-DTF_LITE_USE_CTIME"],
+ deps = ["//tensorflow/lite/c:common"],
+)
+
+cc_library(
+ name = "micro_profiler",
+ srcs = [
+ "micro_profiler.cc",
+ ],
+ hdrs = [
+ "micro_profiler.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":micro_error_reporter",
+ ":micro_time",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ ],
+)
+
+cc_library(
+ name = "micro_utils",
+ srcs = [
+ "micro_utils.cc",
+ ],
+ hdrs = [
+ "micro_utils.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels:op_macros",
+ ],
+)
+
+cc_library(
+ name = "recording_allocators",
+ srcs = [
+ "recording_micro_allocator.cc",
+ "recording_simple_memory_allocator.cc",
+ ],
+ hdrs = [
+ "recording_micro_allocator.h",
+ "recording_micro_interpreter.h",
+ "recording_simple_memory_allocator.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":micro_compatibility",
+ ":micro_framework",
+ "//tensorflow/lite/core/api",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ ],
+)
+
+cc_library(
+ name = "system_setup",
+ srcs = [
+ "system_setup.cc",
+ ],
+ hdrs = [
+ "system_setup.h",
+ ],
+ copts = micro_copts(),
+)
+
+cc_test(
+ name = "micro_error_reporter_test",
+ srcs = [
+ "micro_error_reporter_test.cc",
+ ],
+ deps = [
+ ":micro_error_reporter",
+ ],
+)
+
+cc_test(
+ name = "micro_mutable_op_resolver_test",
+ srcs = [
+ "micro_mutable_op_resolver_test.cc",
+ ],
+ deps = [
+ ":micro_framework",
+ ":op_resolvers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "micro_interpreter_test",
+ srcs = [
+ "micro_interpreter_test.cc",
+ ],
+ deps = [
+ ":micro_compatibility",
+ ":micro_framework",
+ ":micro_utils",
+ ":op_resolvers",
+ ":recording_allocators",
+ ":test_helpers",
+ "//tensorflow/lite/core/api",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "simple_memory_allocator_test",
+ srcs = [
+ "simple_memory_allocator_test.cc",
+ ],
+ deps = [
+ ":micro_framework",
+ ":test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "recording_simple_memory_allocator_test",
+ srcs = [
+ "recording_simple_memory_allocator_test.cc",
+ ],
+ deps = [
+ ":micro_framework",
+ ":recording_allocators",
+ ":test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "micro_allocator_test",
+ srcs = [
+ "micro_allocator_test.cc",
+ ],
+ deps = [
+ ":memory_helpers",
+ ":micro_framework",
+ ":test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ "//tensorflow/lite/micro/testing:test_conv_model",
+ ],
+)
+
+cc_test(
+ name = "recording_micro_allocator_test",
+ srcs = [
+ "recording_micro_allocator_test.cc",
+ ],
+ deps = [
+ ":micro_framework",
+ ":op_resolvers",
+ ":recording_allocators",
+ ":test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ "//tensorflow/lite/micro/testing:test_conv_model",
+ ],
+)
+
+cc_test(
+ name = "memory_helpers_test",
+ srcs = [
+ "memory_helpers_test.cc",
+ ],
+ deps = [
+ ":memory_helpers",
+ ":test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "testing_helpers_test",
+ srcs = [
+ "testing_helpers_test.cc",
+ ],
+ deps = [
+ ":micro_framework",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "micro_utils_test",
+ srcs = [
+ "micro_utils_test.cc",
+ ],
+ deps = [
+ ":micro_utils",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "micro_string_test",
+ srcs = [
+ "micro_string_test.cc",
+ ],
+ deps = [
+ ":micro_string",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "micro_time_test",
+ srcs = [
+ "micro_time_test.cc",
+ ],
+ deps = [
+ ":micro_time",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "memory_arena_threshold_test",
+ srcs = [
+ "memory_arena_threshold_test.cc",
+ ],
+ deps = [
+ ":op_resolvers",
+ ":recording_allocators",
+ "//tensorflow/lite/micro/benchmarks:keyword_scrambled_model_data",
+ "//tensorflow/lite/micro/testing:micro_test",
+ "//tensorflow/lite/micro/testing:test_conv_model",
+ ],
+)
+
+bzl_library(
+ name = "build_def_bzl",
+ srcs = ["build_def.bzl"],
+ visibility = [":micro"],
+)
diff --git a/tensorflow/lite/micro/CONTRIBUTING.md b/tensorflow/lite/micro/CONTRIBUTING.md
new file mode 100644
index 0000000..1e4b85f
--- /dev/null
+++ b/tensorflow/lite/micro/CONTRIBUTING.md
@@ -0,0 +1,378 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+<!--
+Semi-automated TOC generation with instructions from
+https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc
+-->
+
+<!--ts-->
+ * [Contributing Guidelines](#contributing-guidelines)
+ * [General Pull Request Guidelines](#general-pull-request-guidelines)
+ * [Guidelines for Specific Contribution Categories](#guidelines-for-specific-contribution-categories)
+ * [Bug Fixes](#bug-fixes)
+ * [Reference Kernel Implementations](#reference-kernel-implementations)
+ * [Optimized Kernel Implementations](#optimized-kernel-implementations)
+ * [New Target / Platform / IDE / Examples](#new-target--platform--ide--examples)
+ * [New Features](#new-features)
+ * [Development Workflow Notes](#development-workflow-notes)
+ * [Initial Setup](#initial-setup)
+ * [Before submitting your PR](#before-submitting-your-pr)
+ * [During the PR review](#during-the-pr-review)
+ * [Reviewer notes](#reviewer-notes)
+ * [Python notes](#python-notes)
+ * [Continuous Integration System](#continuous-integration-system)
+
+<!-- Added by: advaitjain, at: Wed 27 Jan 2021 02:25:07 PM PST -->
+
+<!--te-->
+
+# Contributing Guidelines
+
+We look forward to your contributions to the TensorFlow Lite Micro codebase and
+provide guidelines with the goal of enabling community contributions while still
+maintaining code health, maintainability, and consistency in style.
+
+Please note that while these guidelines may seem onerous to some developers,
+they are derived from Google's software engineering best practices.
+
+Before we describe project-specific guidelines, we recommend that external
+contributors read these tips from the Google Testing Blog:
+
+* [Code Health: Providing Context with Commit Messages and Bug Reports](https://testing.googleblog.com/2017/09/code-health-providing-context-with.html)
+* [Code Health: Understanding Code In Review](https://testing.googleblog.com/2018/05/code-health-understanding-code-in-review.html)
+* [Code Health: Too Many Comments on Your Code Reviews?](https://testing.googleblog.com/2017/06/code-health-too-many-comments-on-your.html)
+* [Code Health: To Comment or Not to Comment?](https://testing.googleblog.com/2017/07/code-health-to-comment-or-not-to-comment.html)
+
+We also recommend that contributors take a look at the
+[Tensorflow Contributing Guidelines](https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md).
+
+## General Pull Request Guidelines
+
+We strongly recommend that contributors:
+
+1. Initiate a conversation with the TFLM team via a
+ [TF Lite Micro Github issue](https://github.com/tensorflow/tensorflow/issues/new?labels=comp%3Amicro&template=70-tflite-micro-issue.md)
+ as early as possible.
+
+ * This enables us to give guidance on how to proceed, prevent duplicated
+ effort and also point to alternatives as well as context if we are not
+ able to accept a particular contribution at a given time.
+
+ * Ideally, you should make an issue ***before*** starting to work on a
+ pull request and provide context on both what you want to contribute and
+ why.
+
+1. Once step 1. is complete and it is determined that a PR from an external
+ contributor is the way to go, please follow these guidelines from
+ [Google's Engineering Practices documentation](https://google.github.io/eng-practices/):
+
+ * [Send Small Pull Requests](https://google.github.io/eng-practices/review/developer/small-cls.html)
+
+ * If a pull request is doing more than one thing, the reviewer will
+ request that it be broken up into two or more PRs.
+
+ * [Write Good Pull Request Descriptions](https://google.github.io/eng-practices/review/developer/cl-descriptions.html)
+
+ * We require that all PR descriptions link to the github issue created
+ in step 1.
+
+ * While github offers flexibility in linking
+ [commits and issues](https://github.blog/2011-04-09-issues-2-0-the-next-generation/#commits-issues),
+ we require that the PR description have a separate line with either
+ `Fixes #nn` (if the PR fixes the issue) or `Issue #nn` if the PR
+ addresses some aspect of an issue without fixing it.
+
+ * We will be adding internal checks that automate this requirement by
+ matching the PR description to the regexp: `(Fixes|Issue) #`
+
+1. Unit tests are critical to a healthy codebase. PRs without tests should be
+ the exception rather than the norm. And contributions to improve, simplify,
+ or make the unit tests more exhaustive are welcome! Please refer to
+ [this guideline](https://google.github.io/eng-practices/review/developer/small-cls.html#test_code)
+ on how test code and writing small PRs should be reconciled.
+
+## Guidelines for Specific Contribution Categories
+
+We provide some additional guidelines for different categories of contributions.
+
+### Bug Fixes
+
+Pull requests that fix bugs are always welcome and often uncontroversial, unless
+there is a conflict between different requirements from the platform, or if
+fixing a bug needs a bigger architectural change.
+
+1. Create a
+ [TF Lite Micro Github issue](https://github.com/tensorflow/tensorflow/issues/new?labels=comp%3Amicro&template=70-tflite-micro-issue.md)
+ to determine the scope of the bug fix.
+1. Send a PR (if that is determined to be the best path forward).
+1. Bugfix PRs should be accompanied by a test case that fails prior to the fix
+ and passes with the fix. This validates that the fix works as expected, and
+ helps prevent future regressions.
+
+### Reference Kernel Implementations
+
+Pull requests that port reference kernels from TF Lite Mobile to TF Lite Micro
+are welcome once we have enough context from the contributor on why the
+additional kernel is needed.
+
+1. Please create a
+ [TF Lite Micro Github issue](https://github.com/tensorflow/tensorflow/issues/new?labels=comp%3Amicro&template=70-tflite-micro-issue.md)
+ before starting on any such PRs with as much context as possible, such as:
+
+ * What is the model architecture?
+ * What is the application that you are targetting?
+ * What embedded target(s) are you planning to run on?
+ * Motivate your use-case and the need for adding support for this
+ additional OP.
+
+1. In the interest of having
+ [small pull requests](https://google.github.io/eng-practices/review/developer/small-cls.html),
+ limit each pull request to porting a single kernel (and the corresponding
+ test).
+
+1. TODO(b/165627437): Create and link to a guide to porting reference ops.
+
+### Optimized Kernel Implementations
+
+In order to have the TFLM codebase be a central repository of optimized kernel
+implementations, we would like to make some improvements to the current
+infrastructure to enable adding and maintaining optimized kernel implementations
+in a scalable way.
+
+Until that work is complete, we are requesting a ***pause*** on contributions that
+add new optimized kernel implementations. We plan to make these improvements by
+October 2020 and will provide additional guidelines at that time.
+
+* If you would like to have an exception to this pause, with the understanding
+ that your optimized kernels will break as we improve the underlying
+ framework, then please send an email to the [SIG Micro email
+ group](https://groups.google.com/a/tensorflow.org/g/micro) to figure out
+ a middle ground.
+
+* Every optimized kernel directory must have a README.md with the github IDs
+ of the maintainers and any other relevant documentation. PRs that add
+ maintainers to the existing optimized kernels are always welcome.
+
+### New Target / Platform / IDE / Examples
+
+As discussed in the
+[SIG-micro Aug 12, 2020 meeting](http://doc/1YHq9rmhrOUdcZnrEnVCWvd87s2wQbq4z17HbeRl-DBc),
+we are currently ***pausing*** accepting pull requests that add new targets,
+platforms, IDE integration or examples while we revisit some of the
+infrastructure to enable us to make this process easier and more scalable.
+
+In the meantime, snapshotting and/or forking the tensorflow repo could be a
+viable way to prototype platform support.
+
+Having said that, we still invite
+[TF Lite Micro Github issues](https://github.com/tensorflow/tensorflow/issues/new?labels=comp%3Amicro&template=70-tflite-micro-issue.md)
+on this topic as we would like to enable such integration in the future.
+
+### New Features
+
+As discussed in the
+[SIG-micro Aug 12, 2020 meeting](http://doc/1YHq9rmhrOUdcZnrEnVCWvd87s2wQbq4z17HbeRl-DBc),
+we are currently ***pausing*** accepting pull requests that add new features while
+we revisit some of the infrastructure to enable us to make this process easier
+and more scalable.
+
+Having said that, we still invite feature requests via
+[TF Lite Micro Github issues](https://github.com/tensorflow/tensorflow/issues/new?labels=comp%3Amicro&template=70-tflite-micro-issue.md)
+to determine if the requested feature aligns with the TFLM roadmap.
+
+# Development Workflow Notes
+
+## Initial Setup
+
+Below are some tips that might be useful and improve the development experience.
+
+* Add the [Refined GitHub](https://github.com/sindresorhus/refined-github)
+ plugin to make the github experience even better.
+
+* Code search the [TfLite Micro codebase](https://sourcegraph.com/github.com/tensorflow/tensorflow@master/-/tree/tensorflow/lite/micro)
+ on Sourcegraph. And optionally install the [plugin that enables GitHub integration](https://docs.sourcegraph.com/integration/github#github-integration-with-sourcegraph).
+
+* Install [bazel](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/ci_build/install/install_bazel.sh) and [buildifier](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/ci_build/install/install_buildifier.sh).
+
+* Install the latest clang and clang-format. For example,
+ [here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/tools/ci_build/Dockerfile.micro)
+ is the what we do for the TFLM continuous integration Docker container.
+
+* Get a copy of [cpplint](https://github.com/google/styleguide/tree/gh-pages/cpplint)
+
+* Add a git hook to check for code style etc. prior to creating a pull request:
+ ```
+ cp tensorflow/lite/micro/tools/dev_setup/pre-push.tflm .git/hooks/pre-push
+ ```
+
+## Before submitting your PR
+
+1. Run in-place clang-format on all the files that are modified in your git
+ tree with
+
+ ```
+ clang-format -i -style=google `git ls-files -m | grep "\.cc"`
+ clang-format -i -style=google `git ls-files -m | grep "\.h"`
+ ```
+
+1. Make sure your code is lint-free.
+
+ ```
+ cpplint.py `git ls-files -m`
+ ```
+
+1. Run all the tests for x86, and any other platform that you are modifying.
+
+ ```
+ tensorflow/lite/micro/tools/ci_build/test_x86.sh
+ ```
+
+ Please check the READMEs in the optimized kernel directories for specific
+ instructions.
+
+1. Sometimes, bugs are caught by the sanitizers that can go unnoticed
+ via the Makefile. To run a test with the different sanitizers, use the
+ following commands (replace `micro_interpreter_test` with the target that you
+ want to test:
+
+ ```
+ CC=clang bazel run --config=asan tensorflow/lite/micro:micro_interpreter_test
+ CC=clang bazel run --config=msan tensorflow/lite/micro:micro_interpreter_test
+ CC=clang bazel run --config=ubsan tensorflow/lite/micro:micro_interpreter_test
+ ```
+
+## During the PR review
+
+1. Do not change the git version history.
+
+ * Always merge upstream/master (***do not rebase***) and no force-pushes
+ please.
+
+ * Having an extra merge commit it ok as the github review tool handles
+ that gracefully.
+
+ Assuming that you forked tensorflow and added a remote called upstream with:
+
+ `git remote add upstream https://github.com/tensorflow/tensorflow.git`
+
+ Fetch the latest changes from upstream and merge into your local branch.
+
+ ```
+ git fetch upstream
+ git merge upstream/master
+ ```
+
+ In case of a merge conflict, resolve via:
+
+ ```
+ git mergetool
+
+ # Use your favorite diff tools (e.g. meld) to resolve the conflicts.
+
+ git add <files that were manually resolved>
+
+ git commit
+ ```
+
+1. If a force push seems to be the only path forward, please stop and let your
+ PR reviewer know ***before*** force pushing. We will attempt to do the merge
+ for you. This will also help us better understand in what conditions a
+ force-push may be unavoidable.
+
+## Reviewer notes
+
+* [GIthub CLI](https://cli.github.com) can be useful to quickly checkout a PR
+ to test locally.
+
+ `gh pr checkout <PR number>`
+
+* Google engineers on the Tensorflow team will have the permissions to push
+ edits to most PRs. This can be useful to make some small fixes as a result
+ of errors due to internal checks that are not easily reproducible via
+ github.
+
+ One example of this is
+ [this comment](https://github.com/tensorflow/tensorflow/pull/38634#issuecomment-683190474).
+
+ And a sketch of the steps:
+
+ ```
+ git remote add <remote_name> git@github.com:<PR author>/tensorflow.git
+ git fetch <remote_name>
+
+ git checkout -b <local-branch-name> <remote_name>/<PR branch name>
+
+ # make changes and commit to local branch
+
+ # push changes to remove branch
+
+ git push <remote_name> <PR branch name>
+
+ # remove the temp remote to clean up your git environment.
+
+ git remote rm <remote_name>
+ ```
+
+## Python notes
+
+Most PRs for TensorFlow Lite Micro will be C++ only. Adding some notes on Python
+that can be expanded and improved as necessary.
+
+* [TensorFlow guide](https://www.tensorflow.org/community/contribute/code_style#python_style)
+ for Python development
+
+* [yapf](https://github.com/google/yapf/) should be used for formatting.
+
+ ```
+ yapf log_parser.py -i --style='{based_on_style: pep8, indent_width: 2}'
+ ```
+
+# Continuous Integration System
+
+* As a contributor, please make sure that the TfLite Micro build is green.
+ You can click on the details link to see what the errors are:
+
+[](https://storage.googleapis.com/tensorflow-kokoro-build-badges/tflite-micro.html)
+
+* Tests that are run as part of the CI are with the
+ [micro/tools/ci_build/test_all.sh](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/tools/ci_build/test_all.sh)
+ script when run with the `GITHUB_PRESUBMIT` command line parameter:
+ ```
+ tensorflow/lite/micro/tools/ci_build/test_all.sh GITHUB_PRESUBMIT
+ ```
+
+* If an error is not reproducible on your development machine, you can
+ recreate the docker container that is used on the CI servers.
+
+ * First, create a build a TFLM docker image with:
+ ```
+ tensorflow/tools/ci_build/ci_build.sh micro bash
+ ```
+ The second parameter to the ci_build.sh script is not important. It can
+ be any command.
+
+ * Next, mount the tensorflow repo on your machine to the docker container.
+ Please be careful (or make a separate clone of tensorflow) since any
+ changes docker container will also be reflected in the directory in the
+ host machine.
+ ```
+ docker run -v `pwd`:/tensorflow -it tf_ci.micro bash
+ # cd tensorflow
+ ```
+
+ * If you would prefer to not mount your local folder on the docker image,
+ you can also simply download the branch:
+ ```
+ docker run -it tf_ci.micro bash
+ # wget https://github.com/<github-username>/tensorflow/archive/<git-branch>.zip
+ # unzip <git-branch>.zip
+ # cd tensorflow-<git-branch>
+ ```
+
+ * Within the docker container, you can now run the TFLM test script, or
+ any other command that you would like to test. For example, the following
+ commands will run all of the TFLM checks:
+ ```
+ # tensorflow/lite/micro/tools/ci_build/test_all.sh GITHUB_PRESUBMIT
+ ```
+
diff --git a/tensorflow/lite/micro/README.md b/tensorflow/lite/micro/README.md
new file mode 100644
index 0000000..a5811f0
--- /dev/null
+++ b/tensorflow/lite/micro/README.md
@@ -0,0 +1,72 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+<!--
+Semi-automated TOC generation with instructions from
+https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc
+-->
+
+<!--ts-->
+ * [TensorFlow Lite for Microcontrollers](#tensorflow-lite-for-microcontrollers)
+ * [Continuous Build Status](#continuous-build-status)
+ * [Official Builds](#official-builds)
+ * [Community Supported Builds](#community-supported-builds)
+ * [Getting Help and Involved](#getting-help-and-involved)
+ * [Additional Documentation](#additional-documentation)
+
+<!-- Added by: advaitjain, at: Mon 23 Nov 2020 03:32:57 PM PST -->
+
+<!--te-->
+
+# TensorFlow Lite for Microcontrollers
+
+TensorFlow Lite for Microcontrollers is a port of TensorFlow Lite designed to
+run machine learning models on microcontrollers and other devices with only
+kilobytes of memory.
+
+To learn how to use the framework, visit the developer documentation at
+[tensorflow.org/lite/microcontrollers](https://www.tensorflow.org/lite/microcontrollers).
+
+# Continuous Build Status
+
+## Official Builds
+Build Type | Status | Artifacts
+---------- | ----------- | ---------
+Linux | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/tflite-micro.html) |
+
+## Community Supported Builds
+Build Type | Status | Artifacts
+---------- | ----------- | ---------
+Arduino | [](https://github.com/antmicro/tensorflow-arduino-examples/actions/workflows/test_examples.yml) |
+Xtensa | [](https://github.com/advaitjain/tensorflow/tree/local-continuous-builds/tensorflow/lite/micro/docs/local_continuous_builds/xtensa.md) |
+
+
+# Getting Help and Involved
+
+A
+[TF Lite Micro Github issue](https://github.com/tensorflow/tensorflow/issues/new?labels=comp%3Amicro&template=70-tflite-micro-issue.md)
+should be the primary method of getting in touch with the TensorFlow Lite Micro
+(TFLM) team.
+
+The following resources may also be useful:
+
+1. SIG Micro [email group](https://groups.google.com/a/tensorflow.org/g/micro)
+ and
+ [monthly meetings](http://doc/1YHq9rmhrOUdcZnrEnVCWvd87s2wQbq4z17HbeRl-DBc).
+
+1. SIG Micro [gitter chat room](https://gitter.im/tensorflow/sig-micro).
+
+If you are interested in contributing code to TensorFlow Lite for
+Microcontrollers then please read our [contributions guide](CONTRIBUTING.md).
+
+# Additional Documentation
+
+For developers that are interested in more details of the internals of the
+project, we have additional documentation in the [docs](docs/) folder.
+
+* [Benchmarks](benchmarks/README.md)
+* [Profiling](docs/profiling.md)
+* [Memory Management](docs/memory_management.md)
+* [Optimized Kernel Implementations](docs/optimized_kernel_implementations.md)
+* [New Platform Support](docs/new_platform_support.md)
+* [Software Emulation with Renode](docs/renode.md)
+* [Pre-allocated tensors](docs/preallocated_tensors.md)
diff --git a/tensorflow/lite/micro/all_ops_resolver.cc b/tensorflow/lite/micro/all_ops_resolver.cc
new file mode 100644
index 0000000..a73a953
--- /dev/null
+++ b/tensorflow/lite/micro/all_ops_resolver.cc
@@ -0,0 +1,95 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+
+#include "tensorflow/lite/micro/kernels/micro_ops.h"
+
+namespace tflite {
+
+AllOpsResolver::AllOpsResolver() {
+ // Please keep this list of Builtin Operators in alphabetical order.
+ AddAbs();
+ AddAdd();
+ AddAddN();
+ AddArgMax();
+ AddArgMin();
+ AddAveragePool2D();
+ AddBatchToSpaceNd();
+ AddCeil();
+ AddConcatenation();
+ AddConv2D();
+ AddCos();
+ AddCumSum();
+ AddDepthwiseConv2D();
+ AddDequantize();
+ AddDetectionPostprocess();
+ AddElu();
+ AddEqual();
+ AddEthosU();
+ AddFloor();
+ AddFloorDiv();
+ AddFloorMod();
+ AddFullyConnected();
+ AddGreater();
+ AddGreaterEqual();
+ AddHardSwish();
+ AddL2Normalization();
+ AddL2Pool2D();
+ AddLeakyRelu();
+ AddLess();
+ AddLessEqual();
+ AddLog();
+ AddLogicalAnd();
+ AddLogicalNot();
+ AddLogicalOr();
+ AddLogistic();
+ AddMaxPool2D();
+ AddMaximum();
+ AddMean();
+ AddMinimum();
+ AddMul();
+ AddNeg();
+ AddNotEqual();
+ AddPack();
+ AddPad();
+ AddPadV2();
+ AddPrelu();
+ AddQuantize();
+ AddReduceMax();
+ AddRelu();
+ AddRelu6();
+ AddReshape();
+ AddResizeNearestNeighbor();
+ AddRound();
+ AddRsqrt();
+ AddShape();
+ AddSin();
+ AddSoftmax();
+ AddSpaceToBatchNd();
+ AddSplit();
+ AddSplitV();
+ AddSqrt();
+ AddSquare();
+ AddSqueeze();
+ AddStridedSlice();
+ AddSub();
+ AddSvdf();
+ AddTanh();
+ AddTransposeConv();
+ AddUnpack();
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/all_ops_resolver.h b/tensorflow/lite/micro/all_ops_resolver.h
new file mode 100644
index 0000000..391b4f0
--- /dev/null
+++ b/tensorflow/lite/micro/all_ops_resolver.h
@@ -0,0 +1,38 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_ALL_OPS_RESOLVER_H_
+#define TENSORFLOW_LITE_MICRO_ALL_OPS_RESOLVER_H_
+
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+
+namespace tflite {
+
+// The magic number in the template parameter is the maximum number of ops that
+// can be added to AllOpsResolver. It can be increased if needed. And most
+// applications that care about the memory footprint will want to directly use
+// MicroMutableOpResolver and have an application specific template parameter.
+// The examples directory has sample code for this.
+class AllOpsResolver : public MicroMutableOpResolver<128> {
+ public:
+ AllOpsResolver();
+
+ private:
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_ALL_OPS_RESOLVER_H_
diff --git a/tensorflow/lite/micro/apollo3evb/debug_log.cc b/tensorflow/lite/micro/apollo3evb/debug_log.cc
new file mode 100644
index 0000000..ea33a8e
--- /dev/null
+++ b/tensorflow/lite/micro/apollo3evb/debug_log.cc
@@ -0,0 +1,53 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Reference implementation of the DebugLog() function that's required for a
+// platform to support the TensorFlow Lite for Microcontrollers library. This is
+// the only function that's absolutely required to be available on a target
+// device, since it's used for communicating test results back to the host so
+// that we can verify the implementation is working correctly.
+// It's designed to be as easy as possible to supply an implementation though.
+// On platforms that have a POSIX stack or C library, it can be written as a
+// single call to `fprintf(stderr, "%s", s)` to output a string to the error
+// stream of the console, but if there's no OS or C library available, there's
+// almost always an equivalent way to write out a string to some serial
+// interface that can be used instead. For example on Arm M-series MCUs, calling
+// the `bkpt #0xAB` assembler instruction will output the string in r1 to
+// whatever debug serial connection is available. If you're running mbed, you
+// can do the same by creating `Serial pc(USBTX, USBRX)` and then calling
+// `pc.printf("%s", s)`.
+// To add an equivalent function for your own platform, create your own
+// implementation file, and place it in a subfolder with named after the OS
+// you're targeting. For example, see the Cortex M bare metal version in
+// tensorflow/lite/micro/bluepill/debug_log.cc or the mbed one on
+// tensorflow/lite/micro/mbed/debug_log.cc.
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+// These are headers from Ambiq's Apollo3 SDK.
+#include "am_bsp.h" // NOLINT
+#include "am_util.h" // NOLINT
+
+extern "C" void DebugLog(const char* s) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ am_bsp_itm_printf_enable();
+ is_initialized = true;
+ }
+
+ am_util_stdio_printf("%s", s);
+#endif
+}
diff --git a/tensorflow/lite/micro/apollo3evb/micro_time.cc b/tensorflow/lite/micro/apollo3evb/micro_time.cc
new file mode 100644
index 0000000..12c9ae5
--- /dev/null
+++ b/tensorflow/lite/micro/apollo3evb/micro_time.cc
@@ -0,0 +1,72 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Reference implementation of timer functions. Platforms are not required to
+// implement these timer methods, but they are required to enable profiling.
+
+// On platforms that have a POSIX stack or C library, it can be written using
+// methods from <sys/time.h> or clock() from <time.h>.
+
+// To add an equivalent function for your own platform, create your own
+// implementation file, and place it in a subfolder with named after the OS
+// you're targeting. For example, see the Cortex M bare metal version in
+// tensorflow/lite/micro/bluepill/micro_timer.cc or the mbed one on
+// tensorflow/lite/micro/mbed/micro_timer.cc.
+
+#include "tensorflow/lite/micro/micro_time.h"
+
+// These are headers from Ambiq's Apollo3 SDK.
+#include "am_bsp.h" // NOLINT
+#include "am_mcu_apollo.h" // NOLINT
+#include "am_util.h" // NOLINT
+
+namespace tflite {
+namespace {
+
+// Select CTIMER 1 as benchmarking timer on Sparkfun Edge. This timer must not
+// be used elsewhere.
+constexpr int kTimerNum = 1;
+
+// Clock set to operate at 12MHz.
+constexpr int kClocksPerSecond = 12e6;
+
+} // namespace
+
+int32_t ticks_per_second() { return kClocksPerSecond; }
+
+// Calling this method enables a timer that runs for eternity. The user is
+// responsible for avoiding trampling on this timer's config, otherwise timing
+// measurements may no longer be valid.
+int32_t GetCurrentTimeTicks() {
+ // TODO(b/150808076): Split out initialization, intialize in interpreter.
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ am_hal_ctimer_config_t timer_config;
+ // Operate as a 32-bit timer.
+ timer_config.ui32Link = 1;
+ // Set timer A to continuous mode at 12MHz.
+ timer_config.ui32TimerAConfig =
+ AM_HAL_CTIMER_FN_CONTINUOUS | AM_HAL_CTIMER_HFRC_12MHZ;
+
+ am_hal_ctimer_stop(kTimerNum, AM_HAL_CTIMER_BOTH);
+ am_hal_ctimer_clear(kTimerNum, AM_HAL_CTIMER_BOTH);
+ am_hal_ctimer_config(kTimerNum, &timer_config);
+ am_hal_ctimer_start(kTimerNum, AM_HAL_CTIMER_TIMERA);
+ is_initialized = true;
+ }
+ return CTIMERn(kTimerNum)->TMR0;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/arc_emsdp/debug_log.cc b/tensorflow/lite/micro/arc_emsdp/debug_log.cc
new file mode 100644
index 0000000..1b4d641
--- /dev/null
+++ b/tensorflow/lite/micro/arc_emsdp/debug_log.cc
@@ -0,0 +1,111 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include <cstdint>
+#include <cstdio>
+#include <cstring>
+
+// Print to debug console by default. One can define next to extend destinations
+// set: EMSDP_LOG_TO_MEMORY
+// : fill .debug_log memory region (data section) with passed chars.
+// EMSDP_LOG_TO_HOST
+// : Use MetaWare HostLink to print output log. Requires Synopsys MetaWare
+// debugger
+// EMSDP_LOG_TO_UART
+// : use default debug UART (out to FTDI channel 0). The same USB Port is used
+// for JTAG.
+#define EMSDP_LOG_TO_UART
+
+// Memory size for symbols dump in EMSDP_LOG_TO_MEMORY destination
+#define EMSDP_LOG_TO_MEMORY_SIZE (2 * 1024)
+
+// EMSDP Debug UART related defines (registers and bits)
+#define EMSDP_DBG_UART_BASE (0xF0004000U)
+#define DW_UART_CPR_FIFO_STAT (1 << 10)
+#define DW_UART_USR_TFNF (0x02)
+#define DW_UART_LSR_TXD_EMPTY (0x20)
+
+// EMSDP UART registers map (only necessairy fields)
+typedef volatile struct dw_uart_reg {
+ uint32_t DATA; /* data in/out and DLL */
+ uint32_t RES1[4];
+ uint32_t LSR; /* Line Status Register */
+ uint32_t RES2[25];
+ uint32_t USR; /* UART status register */
+ uint32_t RES3[29];
+ uint32_t CPR; /* Component parameter register */
+} DW_UART_REG;
+
+// For simplicity we assume U-boot has already initialized debug console during
+// application loading (or on reset). Hence, we use only status and data
+// registers to organize blocking loop for printing symbols. No input and no IRQ
+// handling. See embarc_osp repository for full EMSDP uart driver.
+// (https://github.com/foss-for-synopsys-dwc-arc-processors/embarc_osp)
+void DbgUartSendStr(const char* s) {
+ DW_UART_REG* uart_reg_ptr = (DW_UART_REG*)(EMSDP_DBG_UART_BASE);
+ const char* src = s;
+ while (*src) {
+ // Check uart status to send char
+ bool uart_is_ready = false;
+ if (uart_reg_ptr->CPR & DW_UART_CPR_FIFO_STAT)
+ uart_is_ready = ((uart_reg_ptr->USR & DW_UART_USR_TFNF) != 0);
+ else
+ uart_is_ready = ((uart_reg_ptr->LSR & DW_UART_LSR_TXD_EMPTY) != 0);
+
+ // Send char if uart is ready.
+ if (uart_is_ready) uart_reg_ptr->DATA = *src++;
+ }
+}
+
+// Simple dump of symbols to a pre-allocated memory region.
+// When total log exceeds memory region size, cursor is moved to its begining.
+// The memory region can be viewed afterward with debugger.
+// It can be viewed/read with debugger afterward.
+void LogToMem(const char* s) {
+ static int cursor = 0;
+#pragma Bss(".debug_log")
+ static volatile char debug_log_mem[EMSDP_LOG_TO_MEMORY_SIZE];
+#pragma Bss()
+
+ const char* src = s;
+ while (*src) {
+ debug_log_mem[cursor] = *src++;
+ cursor = (cursor < EMSDP_LOG_TO_MEMORY_SIZE) ? cursor + 1 : 0;
+ }
+ debug_log_mem[cursor] = '^';
+}
+
+extern "C" void DebugLog(const char* s) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+
+#if defined EMSDP_LOG_TO_UART
+ DbgUartSendStr(s);
+#endif
+
+#if defined EMSDP_LOG_TO_MEMORY
+#warning \
+ "EMSDP_LOG_TO_MEMORY is defined. View .debug_log memory region for stdout"
+ LogToMem(s);
+#endif
+
+#if defined EMSDP_LOG_TO_HOST
+#warning "EMSDP_LOG_TO_HOST is defined. Ensure hostlib is linked."
+ fprintf(stderr, "%s", s);
+#endif
+
+#endif // TF_LITE_STRIP_ERROR_STRINGS
+}
diff --git a/tensorflow/lite/micro/arduino/abi.cc b/tensorflow/lite/micro/arduino/abi.cc
new file mode 100644
index 0000000..6e58671
--- /dev/null
+++ b/tensorflow/lite/micro/arduino/abi.cc
@@ -0,0 +1,16 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+void* __dso_handle;
diff --git a/tensorflow/lite/micro/arduino/debug_log.cc b/tensorflow/lite/micro/arduino/debug_log.cc
new file mode 100644
index 0000000..f1babc1
--- /dev/null
+++ b/tensorflow/lite/micro/arduino/debug_log.cc
@@ -0,0 +1,21 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+// This file is empty to ensure that a specialized implementation of
+// debug_log.h is used (instead of the default implementation from
+// tensorflow/lite/micro/debug_log.cc).
+//
+// The actual target-specific implementation of debug_log.h is in
+// system_setup.cc since that allows us to consolidate all the target-specific
+// specializations into one source file.
diff --git a/tensorflow/lite/micro/arduino/system_setup.cc b/tensorflow/lite/micro/arduino/system_setup.cc
new file mode 100644
index 0000000..3bf21c9
--- /dev/null
+++ b/tensorflow/lite/micro/arduino/system_setup.cc
@@ -0,0 +1,36 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/system_setup.h"
+
+#include "Arduino.h"
+#include "tensorflow/lite/micro/debug_log.h"
+
+// The Arduino DUE uses a different object for the default serial port shown in
+// the monitor than most other models, so make sure we pick the right one. See
+// https://github.com/arduino/Arduino/issues/3088#issuecomment-406655244
+#if defined(__SAM3X8E__)
+#define DEBUG_SERIAL_OBJECT (SerialUSB)
+#else
+#define DEBUG_SERIAL_OBJECT (Serial)
+#endif
+
+extern "C" void DebugLog(const char* s) { DEBUG_SERIAL_OBJECT.print(s); }
+
+namespace tflite {
+
+void InitializeTarget() { DEBUG_SERIAL_OBJECT.begin(9600); }
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/benchmarks/BUILD b/tensorflow/lite/micro/benchmarks/BUILD
new file mode 100644
index 0000000..4e21d2a
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/BUILD
@@ -0,0 +1,81 @@
+load("@bazel_skylib//rules:build_test.bzl", "build_test")
+
+package(
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+package_group(
+ name = "micro_top_level",
+ packages = ["//tensorflow/lite/micro"],
+)
+
+cc_library(
+ name = "micro_benchmark",
+ hdrs = [
+ "micro_benchmark.h",
+ ],
+ visibility = [
+ "//visibility:public",
+ ],
+ deps = [
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:micro_time",
+ "//tensorflow/lite/micro:op_resolvers",
+ ],
+)
+
+cc_library(
+ name = "keyword_scrambled_model_data",
+ srcs = [
+ "keyword_scrambled_model_data.cc",
+ ],
+ hdrs = [
+ "keyword_scrambled_model_data.h",
+ ],
+ visibility = [
+ ":micro_top_level",
+ ],
+)
+
+cc_binary(
+ name = "keyword_benchmark",
+ srcs = ["keyword_benchmark.cc"],
+ deps = [
+ ":keyword_scrambled_model_data",
+ ":micro_benchmark",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:system_setup",
+ "//tensorflow/lite/micro/kernels:fully_connected",
+ ],
+)
+
+cc_binary(
+ name = "person_detection_benchmark",
+ srcs = ["person_detection_benchmark.cc"],
+ tags = [
+ "no_oss", # TODO(b/174680668): Exclude from OSS.
+ ],
+ deps = [
+ ":micro_benchmark",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:micro_utils",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:system_setup",
+ "//tensorflow/lite/micro/examples/person_detection:model_settings",
+ "//tensorflow/lite/micro/examples/person_detection:person_detect_model_data",
+ "//tensorflow/lite/micro/examples/person_detection:simple_images_test_data",
+ "//tensorflow/lite/schema:schema_fbs",
+ ],
+)
+
+build_test(
+ name = "build_test",
+ targets = [":keyword_benchmark"],
+)
diff --git a/tensorflow/lite/micro/benchmarks/Makefile.inc b/tensorflow/lite/micro/benchmarks/Makefile.inc
new file mode 100644
index 0000000..2106ae3
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/Makefile.inc
@@ -0,0 +1,27 @@
+KEYWORD_BENCHMARK_SRCS := \
+tensorflow/lite/micro/benchmarks/keyword_benchmark.cc \
+tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.cc
+
+KEYWORD_BENCHMARK_HDRS := \
+tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h \
+tensorflow/lite/micro/benchmarks/micro_benchmark.h
+
+PERSON_DETECTION_BENCHMARK_SRCS := \
+tensorflow/lite/micro/benchmarks/person_detection_benchmark.cc \
+$(MAKEFILE_DIR)/downloads/person_model_int8/no_person_image_data.cc \
+$(MAKEFILE_DIR)/downloads/person_model_int8/person_detect_model_data.cc \
+$(MAKEFILE_DIR)/downloads/person_model_int8/person_image_data.cc
+
+PERSON_DETECTION_BENCHMARK_HDRS := \
+tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h \
+tensorflow/lite/micro/examples/person_detection/no_person_image_data.h \
+tensorflow/lite/micro/examples/person_detection/person_image_data.h \
+tensorflow/lite/micro/examples/person_detection/model_settings.h \
+tensorflow/lite/micro/benchmarks/micro_benchmark.h
+
+# Builds a standalone binary.
+$(eval $(call microlite_test,keyword_benchmark,\
+$(KEYWORD_BENCHMARK_SRCS),$(KEYWORD_BENCHMARK_HDRS)))
+
+$(eval $(call microlite_test,person_detection_benchmark,\
+$(PERSON_DETECTION_BENCHMARK_SRCS),$(PERSON_DETECTION_BENCHMARK_HDRS)))
diff --git a/tensorflow/lite/micro/benchmarks/README.md b/tensorflow/lite/micro/benchmarks/README.md
new file mode 100644
index 0000000..74de759
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/README.md
@@ -0,0 +1,66 @@
+# TFLite for Microcontrollers Benchmarks
+
+These benchmarks are for measuring the performance of key models and workloads.
+They are meant to be used as part of the model optimization process for a given
+platform.
+
+## Table of contents
+
+- [Keyword Benchmark](#keyword-benchmark)
+- [Person Detection Benchmark](#person-detection-benchmark)
+- [Run on x86](#run-on-x86)
+- [Run on Xtensa XPG Simulator](#run-on-xtensa-xpg-simulator)
+- [Run on Sparkfun Edge](#run-on-sparkfun-edge)
+
+## Keyword benchmark
+
+The keyword benchmark contains a model for keyword detection with scrambled
+weights and biases. This model is meant to test performance on a platform only.
+Since the weights are scrambled, the output is meaningless. In order to validate
+the accuracy of optimized kernels, please run the kernel tests.
+
+## Person detection benchmark
+
+The keyword benchmark provides a way to evaluate the performance of the 250KB
+visual wakewords model.
+
+## Run on x86
+
+To run the keyword benchmark on x86, run
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile run_keyword_benchmark
+```
+
+To run the person detection benchmark on x86, run
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile run_person_detection_benchmark
+```
+
+## Run on Xtensa XPG Simulator
+
+To run the keyword benchmark on the Xtensa XPG simulator, you will need a valid
+Xtensa toolchain and license. With these set up, run:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=xtensa OPTIMIZED_KERNEL_DIR=xtensa TARGET_ARCH=<target architecture> XTENSA_CORE=<xtensa core> run_keyword_benchmark -j18
+```
+
+## Run on Sparkfun Edge
+The following instructions will help you build and deploy this benchmark on the
+[SparkFun Edge development board](https://sparkfun.com/products/15170).
+
+
+If you're new to using this board, we recommend walking through the
+[AI on a microcontroller with TensorFlow Lite and SparkFun Edge](https://codelabs.developers.google.com/codelabs/sparkfun-tensorflow)
+codelab to get an understanding of the workflow.
+
+Build binary using
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=sparkfun_edge person_detection_benchmark_bin
+```
+
+Refer to flashing instructions in the [Person Detection Example](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/person_detection/README.md#running-on-sparkfun-edge).
+
diff --git a/tensorflow/lite/micro/benchmarks/keyword_benchmark.cc b/tensorflow/lite/micro/benchmarks/keyword_benchmark.cc
new file mode 100644
index 0000000..f38368b
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/keyword_benchmark.cc
@@ -0,0 +1,106 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cstdint>
+#include <cstdlib>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h"
+#include "tensorflow/lite/micro/benchmarks/micro_benchmark.h"
+#include "tensorflow/lite/micro/kernels/fully_connected.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+#include "tensorflow/lite/micro/micro_profiler.h"
+#include "tensorflow/lite/micro/system_setup.h"
+
+/*
+ * Keyword Spotting Benchmark for performance optimizations. The model used in
+ * this benchmark only serves as a reference. The values assigned to the model
+ * weights and parameters are not representative of the original model.
+ */
+
+namespace tflite {
+
+using KeywordBenchmarkRunner = MicroBenchmarkRunner<int16_t>;
+using KeywordOpResolver = MicroMutableOpResolver<6>;
+
+#if defined(HEXAGON)
+// TODO(b/174781826): reduce arena usage for optimized Hexagon kernels.
+constexpr int kOptimizedKernelArenaIncrement = 21000;
+#else
+constexpr int kOptimizedKernelArenaIncrement = 0;
+#endif
+
+// Create an area of memory to use for input, output, and intermediate arrays.
+// Align arena to 16 bytes to avoid alignment warnings on certain platforms.
+constexpr int kTensorArenaSize = 21 * 1024 + kOptimizedKernelArenaIncrement;
+alignas(16) uint8_t tensor_arena[kTensorArenaSize];
+
+uint8_t benchmark_runner_buffer[sizeof(KeywordBenchmarkRunner)];
+uint8_t op_resolver_buffer[sizeof(KeywordOpResolver)];
+
+// Initialize benchmark runner instance explicitly to avoid global init order
+// issues on Sparkfun. Use new since static variables within a method
+// are automatically surrounded by locking, which breaks bluepill and stm32f4.
+KeywordBenchmarkRunner* CreateBenchmarkRunner(MicroProfiler* profiler) {
+ // We allocate the KeywordOpResolver from a global buffer because the object's
+ // lifetime must exceed that of the KeywordBenchmarkRunner object.
+ KeywordOpResolver* op_resolver = new (op_resolver_buffer) KeywordOpResolver();
+ op_resolver->AddFullyConnected(tflite::Register_FULLY_CONNECTED_INT8());
+ op_resolver->AddQuantize();
+ op_resolver->AddSoftmax();
+ op_resolver->AddSvdf();
+
+ return new (benchmark_runner_buffer)
+ KeywordBenchmarkRunner(g_keyword_scrambled_model_data, op_resolver,
+ tensor_arena, kTensorArenaSize, profiler);
+}
+
+void KeywordRunNIerations(int iterations, const char* tag,
+ KeywordBenchmarkRunner& benchmark_runner,
+ MicroProfiler& profiler) {
+ int32_t ticks = 0;
+ for (int i = 0; i < iterations; ++i) {
+ benchmark_runner.SetRandomInput(i);
+ profiler.ClearEvents();
+ benchmark_runner.RunSingleIteration();
+ ticks += profiler.GetTotalTicks();
+ }
+ MicroPrintf("%s took %d ticks (%d ms)", tag, ticks, TicksToMs(ticks));
+}
+
+} // namespace tflite
+
+int main(int argc, char** argv) {
+ tflite::InitializeTarget();
+ tflite::MicroProfiler profiler;
+
+ uint32_t event_handle = profiler.BeginEvent("InitializeKeywordRunner");
+ tflite::KeywordBenchmarkRunner* benchmark_runner =
+ CreateBenchmarkRunner(&profiler);
+ profiler.EndEvent(event_handle);
+ profiler.Log();
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+
+ tflite::KeywordRunNIerations(1, "KeywordRunNIerations(1)", *benchmark_runner,
+ profiler);
+ profiler.Log();
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+
+ tflite::KeywordRunNIerations(10, "KeywordRunNIerations(10)",
+ *benchmark_runner, profiler);
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+}
diff --git a/tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.cc b/tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.cc
new file mode 100644
index 0000000..254e194
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.cc
@@ -0,0 +1,2845 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h"
+
+// Keep model aligned to 8 bytes to guarantee aligned 64-bit accesses.
+alignas(8) const unsigned char g_keyword_scrambled_model_data[] = {
+ 0x1c, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x0e, 0x00, 0x14, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00,
+ 0x00, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xd0, 0x6e, 0x00, 0x00, 0x60, 0x83, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0xbc, 0x6e, 0x00, 0x00, 0xac, 0x56, 0x00, 0x00,
+ 0x9c, 0x52, 0x00, 0x00, 0x8c, 0x51, 0x00, 0x00, 0x7c, 0x4d, 0x00, 0x00,
+ 0x2c, 0x4d, 0x00, 0x00, 0x1c, 0x49, 0x00, 0x00, 0x0c, 0x45, 0x00, 0x00,
+ 0xfc, 0x43, 0x00, 0x00, 0xec, 0x3f, 0x00, 0x00, 0x9c, 0x3f, 0x00, 0x00,
+ 0x8c, 0x3b, 0x00, 0x00, 0x7c, 0x37, 0x00, 0x00, 0x6c, 0x36, 0x00, 0x00,
+ 0x5c, 0x32, 0x00, 0x00, 0x0c, 0x32, 0x00, 0x00, 0xfc, 0x2d, 0x00, 0x00,
+ 0xec, 0x29, 0x00, 0x00, 0xdc, 0x28, 0x00, 0x00, 0xcc, 0x24, 0x00, 0x00,
+ 0x7c, 0x24, 0x00, 0x00, 0x6c, 0x22, 0x00, 0x00, 0x5c, 0x1a, 0x00, 0x00,
+ 0xcc, 0x19, 0x00, 0x00, 0xbc, 0x15, 0x00, 0x00, 0xac, 0x0d, 0x00, 0x00,
+ 0x1c, 0x0d, 0x00, 0x00, 0x0c, 0x09, 0x00, 0x00, 0xfc, 0x00, 0x00, 0x00,
+ 0x6c, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x2a, 0x91, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x34, 0xe1, 0x4f, 0xa1, 0x63, 0xa4, 0x62, 0xbf, 0x3e, 0x91, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0xa3, 0xb2, 0x8f, 0xee,
+ 0x35, 0xe6, 0xf2, 0xcc, 0x68, 0xa0, 0x33, 0xc4, 0x7d, 0x4e, 0xbb, 0xa9,
+ 0x10, 0x32, 0x8e, 0x3d, 0x76, 0x14, 0x1c, 0x33, 0x0e, 0x77, 0xf7, 0xc8,
+ 0x7b, 0x45, 0xc7, 0xdb, 0xcf, 0x87, 0xc7, 0x70, 0xa9, 0x29, 0xfd, 0x70,
+ 0x32, 0x96, 0x35, 0x7d, 0xe9, 0xac, 0x6d, 0x9b, 0xfd, 0xe4, 0xbc, 0x4a,
+ 0x57, 0xcd, 0x43, 0xcc, 0x73, 0x72, 0xdf, 0x07, 0x68, 0xc5, 0x67, 0xbd,
+ 0x8a, 0x91, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x80, 0x00, 0x00, 0x00,
+ 0xb0, 0xfb, 0x5f, 0xdf, 0x0e, 0xb9, 0xa2, 0xfd, 0x66, 0x86, 0x13, 0x1b,
+ 0x6d, 0x1d, 0x53, 0xdb, 0x83, 0xbf, 0x44, 0x29, 0x3f, 0x93, 0xee, 0x42,
+ 0x9a, 0xf4, 0x31, 0x6e, 0xc3, 0x15, 0x7e, 0x48, 0x72, 0x50, 0xc3, 0x53,
+ 0xef, 0x35, 0x1f, 0xc2, 0x29, 0x42, 0xb4, 0xd7, 0x4b, 0xd7, 0x98, 0x60,
+ 0xb9, 0x3e, 0xbb, 0x31, 0x35, 0xc3, 0xf6, 0x15, 0x7a, 0x9a, 0x2c, 0xfd,
+ 0xff, 0x04, 0xd9, 0x04, 0x57, 0x52, 0xae, 0x99, 0xa3, 0x95, 0xae, 0x6a,
+ 0x66, 0x52, 0x5f, 0x91, 0x17, 0x83, 0x0d, 0x27, 0x16, 0x02, 0x06, 0x64,
+ 0x80, 0x05, 0x99, 0x1c, 0x6c, 0xab, 0xb1, 0xa1, 0x0e, 0x44, 0x1f, 0x63,
+ 0xe9, 0xc1, 0xab, 0x8d, 0x08, 0x79, 0x56, 0xe0, 0x90, 0xa5, 0xb8, 0x3b,
+ 0xc4, 0x1e, 0xa5, 0x1f, 0x64, 0xe4, 0x0b, 0x72, 0x62, 0x19, 0x5f, 0x66,
+ 0xc0, 0x9b, 0x7b, 0xc4, 0xe5, 0x9f, 0x82, 0xa7, 0x16, 0x92, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x3e, 0x3d, 0xf4, 0x61,
+ 0x45, 0x2a, 0x48, 0x53, 0x1f, 0x22, 0x74, 0x65, 0xea, 0x5a, 0x00, 0x83,
+ 0x68, 0xf9, 0xbb, 0xa3, 0xc2, 0x1a, 0x8f, 0xe1, 0xfb, 0x76, 0x6a, 0xe9,
+ 0x1a, 0x0e, 0x4d, 0x32, 0xc6, 0xf3, 0x8d, 0x85, 0x54, 0xa1, 0xe9, 0xb8,
+ 0x35, 0xee, 0xba, 0x53, 0x40, 0xa2, 0xea, 0x7f, 0xc3, 0x99, 0x71, 0x17,
+ 0xdd, 0xd5, 0xfe, 0xdf, 0x5e, 0x15, 0xa0, 0x73, 0xf8, 0x78, 0x49, 0x73,
+ 0xcc, 0xf0, 0x18, 0x12, 0x06, 0x81, 0xd6, 0x19, 0x2c, 0xa8, 0xd7, 0x80,
+ 0x19, 0x19, 0xbf, 0x1e, 0x50, 0xb1, 0xfb, 0xb3, 0xa6, 0x56, 0x6f, 0x52,
+ 0xa6, 0xc0, 0xdd, 0x3f, 0xbb, 0x13, 0x6e, 0x04, 0xdf, 0x79, 0xca, 0x8b,
+ 0xa5, 0x9c, 0xa1, 0x78, 0x49, 0xca, 0xe5, 0x29, 0xbb, 0x29, 0x7c, 0x96,
+ 0xc6, 0x29, 0x06, 0x99, 0xec, 0x50, 0xd1, 0xe8, 0x9b, 0xb7, 0x53, 0xd2,
+ 0x36, 0x89, 0xb1, 0x5c, 0x38, 0xf4, 0x2f, 0xa1, 0xda, 0x6f, 0xd8, 0xd1,
+ 0x62, 0xd2, 0xd4, 0x97, 0xce, 0xf1, 0xbd, 0x73, 0x2d, 0x92, 0xdb, 0x62,
+ 0x0c, 0xb0, 0x77, 0xed, 0x32, 0x3a, 0xfc, 0x59, 0x94, 0xef, 0x2b, 0x48,
+ 0x60, 0xb2, 0x82, 0xa2, 0xb6, 0x51, 0xdb, 0x51, 0x47, 0x99, 0x4c, 0x50,
+ 0x93, 0x53, 0x9d, 0xa9, 0x3c, 0x94, 0x34, 0x9f, 0xa6, 0x3e, 0x4f, 0x87,
+ 0xd4, 0xa0, 0x40, 0xeb, 0x7b, 0xfa, 0x1b, 0x7d, 0x03, 0xa8, 0xf8, 0x8b,
+ 0xa5, 0x32, 0x3a, 0xaf, 0x7e, 0x6b, 0x25, 0x08, 0x97, 0x71, 0x8d, 0x0c,
+ 0x30, 0xc9, 0xa7, 0x23, 0xe3, 0x51, 0xb3, 0xf2, 0x86, 0xad, 0x12, 0xe2,
+ 0x79, 0x94, 0x7f, 0xf3, 0xf7, 0x88, 0x67, 0x3e, 0x8e, 0x8e, 0x04, 0x5e,
+ 0x4f, 0x01, 0x6f, 0x1d, 0x78, 0x42, 0x9e, 0x47, 0x81, 0xdf, 0x03, 0x39,
+ 0x3d, 0x9b, 0xbd, 0xb6, 0x06, 0x21, 0x82, 0xfe, 0xf2, 0x50, 0xe1, 0x14,
+ 0xbc, 0xe3, 0x5e, 0xe1, 0xbd, 0x8f, 0xfa, 0x35, 0x31, 0x4e, 0x66, 0xeb,
+ 0x67, 0x49, 0x1c, 0x07, 0x88, 0xb6, 0x22, 0x0c, 0xeb, 0xd9, 0x9f, 0x9b,
+ 0x8b, 0xe0, 0x9c, 0x3c, 0xf7, 0x91, 0xab, 0x98, 0x5b, 0x0e, 0x09, 0xdd,
+ 0xe3, 0x0b, 0x14, 0x55, 0xe9, 0xe4, 0x42, 0xd8, 0xce, 0xd7, 0xfd, 0x4c,
+ 0x20, 0x9f, 0x44, 0x93, 0xa6, 0x17, 0x8a, 0x68, 0x8f, 0xec, 0x62, 0xd1,
+ 0x97, 0x9c, 0xcc, 0xc4, 0xd9, 0x42, 0xda, 0xf1, 0x34, 0x04, 0xc6, 0xb6,
+ 0x0f, 0xc7, 0xe6, 0x2d, 0x26, 0x6e, 0x6f, 0x92, 0x7e, 0xd9, 0xd4, 0x40,
+ 0xc6, 0x70, 0xfa, 0x12, 0x2a, 0x1b, 0xbc, 0x50, 0xeb, 0x3b, 0x24, 0x96,
+ 0x8d, 0x7c, 0xae, 0xbe, 0xc3, 0x27, 0xce, 0x97, 0xcf, 0xcd, 0x10, 0x13,
+ 0x01, 0xc6, 0x48, 0x6a, 0x99, 0x38, 0x79, 0xb9, 0x1c, 0xc9, 0x09, 0xac,
+ 0x96, 0x8c, 0xf7, 0x82, 0x8f, 0xb8, 0x17, 0x94, 0x2c, 0x5f, 0x40, 0xcc,
+ 0x80, 0xf4, 0x9f, 0xaa, 0xcb, 0x83, 0x13, 0x7b, 0x3a, 0x78, 0x0a, 0x9f,
+ 0x79, 0x9e, 0xfc, 0x0e, 0x8f, 0x98, 0x60, 0x39, 0x86, 0x44, 0x8e, 0x4b,
+ 0xc4, 0xad, 0xe6, 0x98, 0x92, 0x08, 0x84, 0x48, 0x8f, 0x1d, 0x78, 0x10,
+ 0x9e, 0xf7, 0xb8, 0x61, 0x65, 0x46, 0xdb, 0x4a, 0xcf, 0xc5, 0x37, 0xe3,
+ 0x77, 0x76, 0xcf, 0x0a, 0x7e, 0x72, 0x3f, 0xe4, 0x51, 0x30, 0x28, 0x57,
+ 0x13, 0xfd, 0xdb, 0x7e, 0xd6, 0xa3, 0xdd, 0x64, 0xdd, 0x00, 0xd0, 0x7f,
+ 0xbc, 0x48, 0x1d, 0xaf, 0xde, 0x0e, 0x45, 0xc4, 0xc9, 0xfa, 0xf6, 0xb2,
+ 0xb7, 0x9a, 0x42, 0x8b, 0x18, 0x08, 0xed, 0xdb, 0xa9, 0xc3, 0x32, 0xf1,
+ 0x9c, 0xcf, 0x16, 0x74, 0x57, 0xce, 0xe9, 0x44, 0x21, 0xdb, 0x8a, 0x45,
+ 0x89, 0x70, 0x41, 0x5c, 0xbf, 0x10, 0xdf, 0x83, 0x4a, 0xe4, 0x4c, 0xd8,
+ 0xc9, 0x2e, 0x5b, 0xa3, 0x05, 0xed, 0x73, 0xb1, 0xb0, 0xb7, 0xc4, 0xd7,
+ 0x0d, 0xea, 0xf6, 0xb4, 0xc1, 0x5e, 0x12, 0x54, 0x30, 0x73, 0x5c, 0x93,
+ 0xd9, 0xf7, 0xc9, 0x24, 0x43, 0x8f, 0x4f, 0x8e, 0x94, 0x95, 0xb6, 0xfd,
+ 0xa3, 0x14, 0x42, 0x50, 0xb8, 0x66, 0xfb, 0xc4, 0xed, 0x72, 0xcf, 0x7b,
+ 0xa9, 0x73, 0xeb, 0xc4, 0x4a, 0x05, 0xea, 0xb4, 0x47, 0xca, 0x21, 0x56,
+ 0x28, 0xa8, 0x87, 0xb8, 0x87, 0x0b, 0xe3, 0x8d, 0xfd, 0x70, 0xf7, 0x33,
+ 0x76, 0xf0, 0x3d, 0xa4, 0x3b, 0x83, 0xab, 0x14, 0x01, 0xe1, 0xb0, 0xa9,
+ 0x44, 0xe8, 0xd7, 0x50, 0x26, 0x0b, 0xbb, 0x2d, 0x57, 0x39, 0x82, 0x7c,
+ 0x71, 0xd8, 0x12, 0xaf, 0xf3, 0x9f, 0x46, 0xbd, 0x62, 0xd6, 0x61, 0xf5,
+ 0xb7, 0x04, 0x94, 0xbf, 0x87, 0xea, 0xc4, 0xc4, 0x33, 0xcf, 0x36, 0x3b,
+ 0x4f, 0xc7, 0x71, 0xf1, 0x98, 0xe6, 0xb0, 0x96, 0x25, 0xd7, 0xac, 0x75,
+ 0xfc, 0x92, 0xe0, 0x69, 0x72, 0x37, 0x8d, 0x40, 0x31, 0xaa, 0x2c, 0x86,
+ 0xfb, 0x95, 0x3f, 0x9c, 0x23, 0xd4, 0x39, 0x99, 0xff, 0xea, 0x95, 0x79,
+ 0xb9, 0x2e, 0xb0, 0x33, 0xf1, 0xe8, 0xd0, 0x42, 0xb5, 0x70, 0x5c, 0xca,
+ 0x69, 0x48, 0x28, 0x23, 0x58, 0xb4, 0x07, 0xfc, 0x3e, 0x15, 0x29, 0x00,
+ 0xa9, 0x22, 0x44, 0x70, 0xd0, 0xc7, 0x01, 0x0d, 0x3e, 0xfc, 0x57, 0xb7,
+ 0x54, 0x3a, 0xc3, 0x43, 0xd6, 0x2f, 0x55, 0x09, 0x52, 0x4a, 0x6b, 0x8e,
+ 0x4c, 0x82, 0xbb, 0x4e, 0x3e, 0x38, 0xe1, 0x9e, 0x72, 0x83, 0xec, 0x40,
+ 0xf5, 0xf7, 0x0e, 0x3c, 0x24, 0xed, 0xda, 0xf2, 0x39, 0x6c, 0xad, 0xeb,
+ 0xff, 0xfb, 0x4a, 0x38, 0x50, 0x49, 0x28, 0x3d, 0x05, 0xb2, 0x98, 0x44,
+ 0x2b, 0x61, 0xa2, 0x9b, 0x3a, 0x3c, 0xad, 0xd9, 0x8c, 0xef, 0x3c, 0x72,
+ 0x50, 0x74, 0x13, 0x80, 0xc4, 0x7e, 0x6e, 0xf3, 0xc9, 0xdf, 0x63, 0xf6,
+ 0x41, 0xb2, 0x08, 0x78, 0x9b, 0x7c, 0xa9, 0x13, 0xd1, 0x21, 0xe7, 0x5e,
+ 0x6a, 0x0d, 0x64, 0xf7, 0x52, 0x75, 0xf2, 0x80, 0x69, 0xbe, 0x43, 0xf8,
+ 0xd4, 0xad, 0x49, 0xfc, 0x97, 0x76, 0x1c, 0xb6, 0x43, 0x9e, 0xcb, 0x45,
+ 0x4d, 0x75, 0x07, 0xae, 0xdb, 0xbf, 0xf5, 0x8a, 0xeb, 0xb9, 0x6b, 0x12,
+ 0x06, 0xbf, 0x94, 0xad, 0x77, 0x29, 0xb1, 0xae, 0x24, 0x9b, 0x4d, 0xdc,
+ 0xe1, 0x5e, 0xd7, 0x57, 0xec, 0xd1, 0xd8, 0xad, 0xf0, 0x06, 0x08, 0x43,
+ 0x33, 0x99, 0xd2, 0x04, 0xfc, 0xc8, 0xf6, 0x53, 0x3d, 0x73, 0xd4, 0x36,
+ 0xd3, 0x8e, 0x4a, 0xcd, 0xb1, 0xe9, 0xcb, 0x3a, 0x5f, 0x54, 0xbc, 0xde,
+ 0x16, 0xa2, 0x85, 0xde, 0x35, 0x27, 0x99, 0x32, 0x4f, 0xb9, 0x2c, 0x16,
+ 0xa2, 0x6e, 0xae, 0x75, 0x60, 0x77, 0xe9, 0x08, 0x0f, 0x08, 0xc4, 0xd0,
+ 0x62, 0xc7, 0xd2, 0x1f, 0x3b, 0x29, 0xdd, 0xb7, 0xea, 0xa3, 0x58, 0xaf,
+ 0x4c, 0x05, 0xd2, 0x82, 0x6a, 0xe0, 0xc4, 0xe9, 0x70, 0x7e, 0xf2, 0xca,
+ 0x82, 0x6a, 0xae, 0xc1, 0x9a, 0x42, 0x5d, 0x46, 0x4a, 0xb7, 0x8f, 0x4d,
+ 0x33, 0xfe, 0x6f, 0x47, 0xb5, 0x49, 0xb3, 0x89, 0x51, 0x31, 0x74, 0x68,
+ 0x14, 0xda, 0x0a, 0x41, 0x3d, 0x1f, 0x8e, 0x30, 0x8c, 0x77, 0xd1, 0xa9,
+ 0x36, 0x41, 0x78, 0x34, 0xb7, 0x7e, 0x4e, 0x7a, 0x77, 0x12, 0x43, 0x97,
+ 0x43, 0xba, 0xd6, 0x28, 0x14, 0x2a, 0x9f, 0x98, 0xb4, 0x39, 0x08, 0x5c,
+ 0xb7, 0xb8, 0x03, 0x63, 0x62, 0x68, 0xc6, 0x9a, 0x4d, 0xf5, 0xdc, 0x7c,
+ 0x0f, 0x7e, 0x77, 0xdc, 0x85, 0x53, 0x31, 0x8c, 0x53, 0x8b, 0x27, 0xc4,
+ 0xb7, 0x3d, 0xd0, 0x94, 0x9b, 0x7e, 0x59, 0x59, 0x03, 0x09, 0x8c, 0x30,
+ 0x70, 0x7d, 0x9c, 0x73, 0x89, 0x6c, 0x5f, 0xbf, 0xf9, 0xc7, 0x72, 0x76,
+ 0x12, 0x98, 0xe3, 0xbe, 0xc3, 0x67, 0xdf, 0xa1, 0x76, 0xa3, 0xec, 0x44,
+ 0x30, 0x70, 0x2f, 0x6a, 0x86, 0x28, 0xb9, 0x9d, 0x7f, 0x93, 0xf2, 0x4a,
+ 0x34, 0x48, 0x1f, 0x2e, 0x2e, 0x95, 0x88, 0xdb, 0x1f, 0x2c, 0x19, 0x46,
+ 0x2e, 0x91, 0x5f, 0x81, 0x0d, 0x08, 0x9d, 0x03, 0x0b, 0xaf, 0x59, 0x0a,
+ 0x41, 0xad, 0x4d, 0x6c, 0x09, 0x0e, 0x9f, 0xd1, 0xc4, 0xdb, 0xac, 0x59,
+ 0x27, 0x04, 0x1c, 0x73, 0xe9, 0xf3, 0xe8, 0x54, 0xd9, 0x11, 0x31, 0xb2,
+ 0xed, 0x2d, 0x8c, 0xeb, 0x99, 0x26, 0x48, 0x9e, 0xac, 0x88, 0x96, 0xcb,
+ 0x19, 0x49, 0xfa, 0x4a, 0x82, 0xd5, 0x5d, 0xb8, 0x0f, 0x22, 0x3f, 0xb6,
+ 0x5c, 0x02, 0x2a, 0xb9, 0xd9, 0xfe, 0x4d, 0x9d, 0xdb, 0x85, 0x90, 0x19,
+ 0x7f, 0x1a, 0x44, 0xa3, 0x74, 0x68, 0xbf, 0xa2, 0x3b, 0xb4, 0x3b, 0xeb,
+ 0xab, 0x99, 0xc2, 0x46, 0x50, 0x7e, 0xec, 0xa9, 0xb4, 0x86, 0xfa, 0x50,
+ 0xcb, 0x71, 0x7e, 0x75, 0xa5, 0xca, 0xa6, 0x2f, 0x40, 0x1d, 0xa1, 0x4a,
+ 0x5c, 0x91, 0xd7, 0x2a, 0xa6, 0x17, 0x11, 0x4d, 0x19, 0x2b, 0xb3, 0x0f,
+ 0xf0, 0xb3, 0x06, 0x70, 0x51, 0x5c, 0x52, 0x8c, 0xdf, 0xe3, 0x19, 0x92,
+ 0x08, 0x40, 0xa2, 0xb4, 0xc0, 0xf2, 0xe8, 0x44, 0xcc, 0x36, 0xaa, 0xf9,
+ 0xf8, 0xfc, 0x2d, 0x83, 0x79, 0xc6, 0x58, 0xc1, 0xdf, 0x32, 0xb7, 0xde,
+ 0x0f, 0x3e, 0xc0, 0xa8, 0x7e, 0xeb, 0xf2, 0x30, 0x16, 0xdf, 0x38, 0xcb,
+ 0x69, 0xd9, 0x44, 0x0d, 0x44, 0xf4, 0x45, 0x9c, 0x81, 0xc8, 0xe7, 0x06,
+ 0xae, 0x95, 0xaf, 0xff, 0x17, 0x3b, 0x1c, 0x3f, 0xda, 0xa5, 0xf8, 0xfd,
+ 0x9c, 0xf1, 0x0a, 0xca, 0xda, 0xc0, 0xfa, 0x02, 0xc4, 0xce, 0x78, 0xfb,
+ 0x35, 0x8c, 0xfe, 0x55, 0xad, 0x0d, 0x9b, 0xeb, 0x10, 0xf1, 0x7b, 0xb1,
+ 0x09, 0xf8, 0xef, 0xfc, 0xde, 0x7a, 0x69, 0x74, 0x76, 0xef, 0x91, 0x64,
+ 0x33, 0xc4, 0x08, 0x15, 0x73, 0x85, 0x56, 0xae, 0x9c, 0xf6, 0xdd, 0x55,
+ 0x19, 0x96, 0xe6, 0x41, 0x12, 0xc9, 0x87, 0x91, 0x9e, 0xc6, 0x18, 0xe8,
+ 0xbf, 0xa0, 0x59, 0xfd, 0x20, 0xab, 0xb5, 0xcf, 0x0f, 0x6e, 0x30, 0xd3,
+ 0xc5, 0x70, 0xf2, 0x50, 0xa4, 0x2a, 0xdf, 0xb0, 0x45, 0xfc, 0x82, 0x1a,
+ 0x3b, 0xfe, 0x0c, 0xad, 0x41, 0x95, 0xf1, 0xd6, 0x85, 0xa2, 0xc9, 0xff,
+ 0xbe, 0x3a, 0x64, 0x70, 0x43, 0xc0, 0xc5, 0xc8, 0x80, 0x11, 0x0d, 0x20,
+ 0xcd, 0xf2, 0xa2, 0xbb, 0x43, 0x68, 0x0e, 0xf4, 0x01, 0xb3, 0x73, 0x79,
+ 0x9f, 0x68, 0x41, 0x63, 0x3e, 0xda, 0xf9, 0xf4, 0x23, 0x57, 0x97, 0x84,
+ 0x99, 0xe8, 0x5e, 0xdb, 0xaa, 0x24, 0xab, 0x9c, 0x40, 0x83, 0xf9, 0x3f,
+ 0x4f, 0x5a, 0x53, 0xa6, 0xf1, 0xe8, 0x95, 0xcf, 0xcb, 0x50, 0x13, 0x51,
+ 0xa7, 0x8c, 0x71, 0x1d, 0xff, 0xcc, 0x66, 0xab, 0xff, 0xca, 0xc5, 0xc3,
+ 0x73, 0x45, 0xb7, 0x21, 0x1d, 0x65, 0x7a, 0xe5, 0x1f, 0x3f, 0x1a, 0x58,
+ 0x23, 0x28, 0xc8, 0xf3, 0xbf, 0x98, 0x25, 0xc0, 0x83, 0x68, 0xf0, 0x62,
+ 0x63, 0x90, 0xcf, 0x1f, 0x20, 0xb8, 0x04, 0x5c, 0xc4, 0x80, 0x5b, 0xf4,
+ 0x6d, 0xdc, 0xe9, 0xac, 0xd8, 0x13, 0x3b, 0x42, 0xf8, 0x4e, 0xa2, 0x1c,
+ 0xce, 0x3f, 0x8d, 0x15, 0xd3, 0x87, 0x1b, 0x44, 0x79, 0x52, 0x34, 0x4b,
+ 0x63, 0x4d, 0xbf, 0x95, 0xec, 0xae, 0xf9, 0xc6, 0x7b, 0x7b, 0x85, 0x8c,
+ 0x4f, 0x20, 0x58, 0x9d, 0x48, 0x03, 0x2f, 0x77, 0x2e, 0x8b, 0x6f, 0x66,
+ 0x76, 0xb9, 0xb8, 0xb7, 0x34, 0x5a, 0x63, 0x06, 0x85, 0x82, 0x5f, 0x23,
+ 0x8f, 0x8d, 0x0c, 0x92, 0x3b, 0xd2, 0x8a, 0x1b, 0x39, 0xee, 0x6a, 0xbc,
+ 0xf6, 0x94, 0x2a, 0xc6, 0x73, 0xa6, 0x99, 0x98, 0xdc, 0x96, 0xd7, 0xc1,
+ 0xfe, 0x9b, 0xc8, 0xfb, 0x86, 0x5a, 0xad, 0xce, 0xf8, 0xd5, 0x32, 0x62,
+ 0x96, 0x63, 0xaf, 0x4c, 0x4a, 0xae, 0xec, 0x26, 0x3d, 0x84, 0x69, 0x50,
+ 0x5f, 0x37, 0x9b, 0x29, 0xac, 0x15, 0x76, 0x3d, 0x33, 0x96, 0x06, 0xde,
+ 0xc1, 0x6d, 0xa2, 0xc7, 0xc3, 0x8a, 0x20, 0x2e, 0xf7, 0x08, 0x55, 0x83,
+ 0x23, 0x9c, 0x23, 0x2d, 0x3a, 0xa1, 0x32, 0xbc, 0x47, 0x48, 0xd5, 0x6a,
+ 0x71, 0xb9, 0xcc, 0x2d, 0x99, 0xa0, 0x37, 0x07, 0x46, 0x45, 0xbe, 0xf0,
+ 0x27, 0x5a, 0x25, 0x72, 0x58, 0x47, 0x6d, 0xbf, 0x23, 0xdc, 0x48, 0x44,
+ 0x45, 0x95, 0xb1, 0x62, 0xf1, 0x7e, 0x4c, 0x95, 0x1c, 0xb4, 0x17, 0x8b,
+ 0x59, 0x2e, 0xf3, 0x4f, 0x45, 0x3b, 0x5d, 0x67, 0x92, 0x52, 0xd8, 0xc1,
+ 0x91, 0xfa, 0x53, 0xaa, 0x87, 0xc0, 0xa7, 0xb0, 0x9f, 0x10, 0xe8, 0xac,
+ 0x45, 0x52, 0xbb, 0x17, 0xee, 0xf6, 0x18, 0xbe, 0x02, 0x70, 0xce, 0x79,
+ 0x66, 0x72, 0xf9, 0xf6, 0xca, 0x66, 0xff, 0xa4, 0x9a, 0xd9, 0xb7, 0x07,
+ 0xa9, 0xc1, 0x23, 0x7e, 0x7b, 0x9c, 0xe3, 0x02, 0x7a, 0xcc, 0xa3, 0x67,
+ 0xb7, 0xb0, 0x37, 0xba, 0xae, 0x12, 0xda, 0x48, 0x6e, 0x7f, 0xde, 0x5f,
+ 0x75, 0x15, 0xca, 0xd2, 0x46, 0xdd, 0xb0, 0x82, 0xbf, 0x6d, 0xe9, 0x51,
+ 0x66, 0xa5, 0x9e, 0x0c, 0xd5, 0x03, 0xbd, 0x97, 0x0e, 0x1b, 0x88, 0xf6,
+ 0x61, 0x5a, 0x8b, 0xe0, 0xdd, 0x3e, 0x59, 0x4c, 0x35, 0xfd, 0xb0, 0x3b,
+ 0x79, 0x8c, 0x1c, 0x96, 0x97, 0x35, 0x62, 0x36, 0x62, 0x4c, 0x4b, 0x46,
+ 0xb1, 0x21, 0xf7, 0xf0, 0x34, 0xdc, 0xd9, 0x9f, 0xf8, 0x53, 0x7d, 0xca,
+ 0xbc, 0x4d, 0xaf, 0xf4, 0xb7, 0x2f, 0xa7, 0x5d, 0x18, 0xf9, 0x3b, 0xa9,
+ 0xb0, 0xbb, 0xdf, 0xfa, 0x28, 0x2b, 0x58, 0xce, 0x46, 0x01, 0x3f, 0x76,
+ 0xf2, 0x39, 0x45, 0x8b, 0x3c, 0xda, 0x62, 0x2b, 0x6b, 0xe1, 0x5f, 0x14,
+ 0xfc, 0x79, 0x17, 0x2d, 0xe2, 0xe5, 0x8c, 0xc5, 0xde, 0x91, 0xfd, 0xf5,
+ 0x6d, 0x9b, 0x6b, 0xbb, 0xb0, 0x13, 0xae, 0xbe, 0x1e, 0xa8, 0x8f, 0x3c,
+ 0xfd, 0x24, 0xbe, 0xb8, 0x39, 0x80, 0x03, 0x06, 0x8b, 0xff, 0xca, 0x90,
+ 0x88, 0x0f, 0x45, 0xc4, 0xeb, 0x50, 0x52, 0xf5, 0x00, 0x8c, 0x16, 0x9d,
+ 0x26, 0xaa, 0xec, 0xb1, 0x44, 0xd6, 0xfe, 0x67, 0xa3, 0xc1, 0xec, 0x4a,
+ 0x12, 0xa6, 0x7c, 0x7c, 0xc3, 0x46, 0x1c, 0x64, 0x61, 0x67, 0xec, 0xce,
+ 0x1e, 0xa2, 0xb4, 0xdd, 0x6e, 0x7f, 0x02, 0x14, 0xf4, 0x1c, 0x17, 0xa7,
+ 0x31, 0x9f, 0xc2, 0xc6, 0xc0, 0x21, 0x41, 0x88, 0x61, 0xd8, 0xca, 0x06,
+ 0xa5, 0xe4, 0xef, 0xa4, 0xaa, 0x4d, 0xa3, 0xad, 0x5f, 0xd4, 0x0c, 0x6b,
+ 0x14, 0x38, 0x2e, 0xe8, 0x87, 0x5a, 0x68, 0x10, 0x51, 0xd8, 0xbb, 0xa6,
+ 0xd9, 0xdc, 0xd3, 0x7f, 0x1f, 0xea, 0xa8, 0xcc, 0x3f, 0x43, 0xa4, 0x04,
+ 0x95, 0xb4, 0xde, 0x2f, 0x07, 0x5d, 0x91, 0x1c, 0x8e, 0xc3, 0xbc, 0xaa,
+ 0x46, 0x8a, 0xa8, 0x42, 0xa7, 0x2c, 0x0f, 0x1f, 0xb3, 0xe2, 0x8a, 0x0b,
+ 0xa0, 0x3f, 0xfb, 0x87, 0x9e, 0x42, 0xa5, 0x60, 0xce, 0x5a, 0x54, 0x91,
+ 0x26, 0x51, 0xea, 0x81, 0x6f, 0xf1, 0x54, 0x93, 0xe7, 0xa0, 0xf8, 0x64,
+ 0xab, 0x1d, 0x0d, 0x9d, 0x64, 0x6a, 0xd5, 0x19, 0x03, 0xbb, 0x94, 0x7f,
+ 0x0a, 0xb8, 0x6b, 0x87, 0xc3, 0x1a, 0x38, 0xe5, 0xe8, 0xba, 0x13, 0x17,
+ 0xeb, 0x13, 0xcc, 0xac, 0xcb, 0x1f, 0x96, 0x4c, 0x3b, 0x18, 0xfb, 0xe8,
+ 0x5c, 0x54, 0xce, 0x1a, 0x91, 0x44, 0xf5, 0x49, 0x6c, 0x38, 0x2a, 0x92,
+ 0x8a, 0x0d, 0x3d, 0x08, 0xc2, 0x5f, 0x6c, 0xac, 0x48, 0xb3, 0xdc, 0x2e,
+ 0xa6, 0x5a, 0xa8, 0xee, 0x22, 0x9a, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x04, 0x00, 0x00, 0x96, 0xc5, 0x3a, 0x4e, 0x42, 0x7d, 0x27, 0xce,
+ 0x44, 0x84, 0xf1, 0x67, 0x8c, 0xc5, 0xdd, 0x75, 0x3b, 0x8a, 0xed, 0x2e,
+ 0x29, 0x62, 0x7b, 0xb0, 0xe6, 0xa3, 0xb4, 0x61, 0x73, 0x10, 0xff, 0x0e,
+ 0x0c, 0x98, 0x74, 0xef, 0xbb, 0xc4, 0xca, 0x03, 0x88, 0xa4, 0x96, 0x61,
+ 0xef, 0x36, 0x6d, 0xa2, 0xb1, 0xc8, 0xf0, 0xac, 0xf1, 0xb2, 0x08, 0x56,
+ 0xc7, 0x99, 0xcf, 0xae, 0x0a, 0x37, 0x85, 0x60, 0x78, 0x2d, 0x14, 0xda,
+ 0xb1, 0xa7, 0x00, 0xb6, 0x00, 0x04, 0x76, 0x80, 0x0e, 0x9f, 0x2a, 0x30,
+ 0x8b, 0x85, 0xd9, 0xc1, 0xaf, 0xee, 0x27, 0x80, 0x20, 0xed, 0xef, 0x25,
+ 0x5c, 0x98, 0x6b, 0xcc, 0xf8, 0x72, 0xfb, 0x3f, 0x13, 0xe6, 0x9b, 0x47,
+ 0xee, 0xa1, 0x18, 0x55, 0xa0, 0x68, 0xbe, 0xd4, 0x21, 0x59, 0x72, 0xa8,
+ 0xa4, 0xd2, 0x33, 0x57, 0x50, 0xfc, 0x6b, 0xa8, 0x49, 0x1b, 0x74, 0xdb,
+ 0x5a, 0x16, 0xb8, 0x52, 0x0c, 0xda, 0xa0, 0xa3, 0xff, 0x33, 0x56, 0x82,
+ 0x0f, 0x0a, 0x90, 0x82, 0xee, 0xf1, 0x1b, 0xb3, 0x05, 0x44, 0x39, 0x01,
+ 0xf7, 0x1e, 0xff, 0xcb, 0xea, 0xd0, 0xb6, 0x20, 0xbc, 0x84, 0xb1, 0xf9,
+ 0xa2, 0xc1, 0x56, 0xe6, 0xfa, 0x47, 0xc9, 0xfd, 0x45, 0x77, 0x51, 0x8e,
+ 0x01, 0xe4, 0x17, 0x20, 0x6f, 0x99, 0xe3, 0x90, 0x2f, 0xcc, 0xaf, 0xd9,
+ 0x61, 0x32, 0x91, 0x62, 0x58, 0xf4, 0x98, 0xf5, 0xf4, 0xeb, 0x13, 0xeb,
+ 0xdc, 0x8a, 0xac, 0xb2, 0x9e, 0xcf, 0xe7, 0xa7, 0xd4, 0x97, 0x22, 0x12,
+ 0x08, 0x10, 0x6d, 0x40, 0xea, 0x26, 0xea, 0x42, 0x29, 0x6e, 0x75, 0x62,
+ 0x47, 0x08, 0x17, 0xa8, 0x69, 0x0f, 0xf7, 0x35, 0x59, 0x23, 0x86, 0x83,
+ 0xfd, 0xb5, 0x61, 0x98, 0x9c, 0x4d, 0x37, 0xda, 0x9f, 0xfc, 0xfb, 0x16,
+ 0xb7, 0x6c, 0x52, 0xee, 0xa8, 0x9c, 0x3e, 0x93, 0x43, 0xc5, 0x2b, 0xd4,
+ 0xd0, 0x9f, 0x69, 0x2c, 0xc9, 0x1f, 0x2e, 0xdf, 0x5b, 0xe6, 0xc6, 0x5f,
+ 0x71, 0xd1, 0xd7, 0xb2, 0x8f, 0x3a, 0xba, 0x60, 0x75, 0x3d, 0x34, 0x41,
+ 0x43, 0x9b, 0x13, 0xc0, 0x3b, 0x30, 0xc5, 0xe9, 0x84, 0x81, 0xde, 0x85,
+ 0x4e, 0x65, 0x7b, 0x21, 0x37, 0xb8, 0xef, 0x24, 0x19, 0xaa, 0x26, 0x0c,
+ 0x27, 0xa7, 0xd9, 0x29, 0x47, 0x1a, 0x15, 0x42, 0x1e, 0x30, 0x79, 0x79,
+ 0x96, 0x09, 0x62, 0x26, 0xad, 0x98, 0x8b, 0xcb, 0x3d, 0xeb, 0x66, 0x83,
+ 0x77, 0xd9, 0x79, 0x4d, 0x05, 0x81, 0x72, 0xe9, 0xe0, 0x6f, 0x13, 0x00,
+ 0x7e, 0xa3, 0x92, 0x82, 0x1c, 0x90, 0x83, 0x4b, 0x15, 0x97, 0x0f, 0x92,
+ 0xe2, 0xd3, 0x3d, 0xd7, 0x6c, 0xb9, 0x60, 0x9a, 0x23, 0x52, 0xbe, 0x59,
+ 0xc9, 0x36, 0x9e, 0xf7, 0x77, 0x09, 0x79, 0x01, 0xcc, 0xec, 0x17, 0xd1,
+ 0x74, 0xbc, 0x58, 0x65, 0x45, 0x3c, 0x86, 0xf1, 0xbc, 0xbd, 0x95, 0x54,
+ 0x46, 0x45, 0x7b, 0x4c, 0xa2, 0xea, 0x2a, 0x6e, 0xa8, 0xd1, 0x66, 0x03,
+ 0xb2, 0x6a, 0xe0, 0xd3, 0x07, 0x8d, 0xe0, 0x09, 0x81, 0x42, 0xe3, 0x97,
+ 0xc4, 0xe7, 0x37, 0xc5, 0x82, 0xcf, 0xb1, 0xec, 0xba, 0xbd, 0xf4, 0xb6,
+ 0x41, 0xb2, 0xb8, 0xa6, 0x3a, 0x85, 0x4b, 0x4f, 0x46, 0x48, 0xe9, 0x9b,
+ 0x72, 0xf5, 0xb0, 0x64, 0x66, 0x75, 0x42, 0xb4, 0x00, 0xbe, 0x11, 0x6d,
+ 0x86, 0x93, 0x07, 0x50, 0xa7, 0xef, 0x55, 0x42, 0xcf, 0xe8, 0x61, 0xd0,
+ 0x9b, 0x11, 0x84, 0x8c, 0x74, 0xe4, 0xb8, 0x3f, 0x48, 0xb3, 0x61, 0xe3,
+ 0xea, 0x66, 0x86, 0x94, 0x95, 0x12, 0x77, 0x26, 0x75, 0x30, 0xb5, 0xd3,
+ 0x7a, 0xad, 0x2d, 0x58, 0x46, 0x1b, 0x4b, 0xd9, 0x2d, 0x1e, 0x0b, 0xff,
+ 0xd7, 0x03, 0x56, 0x3b, 0xbd, 0x65, 0xb0, 0xf9, 0xfe, 0x43, 0x1c, 0x9c,
+ 0x18, 0x82, 0x78, 0x5e, 0x06, 0x02, 0x21, 0x70, 0xb2, 0x7f, 0xb5, 0x63,
+ 0x71, 0x85, 0x95, 0x79, 0xae, 0x1e, 0xc6, 0x62, 0x7a, 0x7c, 0x63, 0x46,
+ 0x70, 0x1c, 0x58, 0x72, 0x1d, 0xde, 0xca, 0xb4, 0xfc, 0xc8, 0x56, 0x38,
+ 0x32, 0xf4, 0x0b, 0x56, 0x87, 0x6b, 0x5b, 0x53, 0xd2, 0x2c, 0x35, 0xef,
+ 0x5b, 0x33, 0x59, 0x13, 0x76, 0x82, 0x30, 0x80, 0x23, 0x10, 0x07, 0x4c,
+ 0x3f, 0xac, 0x9c, 0x58, 0x2d, 0x04, 0xe6, 0x6a, 0xd3, 0x5c, 0xf9, 0xb6,
+ 0x59, 0x4e, 0x85, 0xfe, 0x01, 0x71, 0xf0, 0xf7, 0xf2, 0x1f, 0x46, 0xd5,
+ 0x20, 0x3c, 0x9b, 0xc2, 0x1e, 0x73, 0x1c, 0x56, 0x9c, 0x76, 0x8c, 0x12,
+ 0x95, 0x51, 0xd4, 0x6f, 0x5b, 0x3a, 0xa7, 0x5f, 0xa7, 0xe4, 0xfa, 0xb7,
+ 0x1a, 0xdd, 0xb6, 0x4c, 0x01, 0x02, 0xae, 0x9c, 0x02, 0x0d, 0x66, 0x2f,
+ 0x40, 0x87, 0xa1, 0xbc, 0xf3, 0xde, 0xf4, 0xdb, 0x65, 0xee, 0xcc, 0xca,
+ 0xe1, 0x7a, 0xa2, 0xf4, 0xf7, 0xf5, 0x7c, 0x2a, 0x3f, 0xa4, 0x67, 0xbb,
+ 0x07, 0x50, 0x7a, 0x29, 0x8a, 0xcf, 0x2c, 0x7a, 0x0e, 0x0d, 0xc7, 0x95,
+ 0x8b, 0xf4, 0xe2, 0x50, 0xe1, 0xc1, 0x40, 0x16, 0x99, 0x5c, 0x72, 0xe7,
+ 0xe4, 0x01, 0xeb, 0x29, 0x6a, 0x99, 0xf2, 0x67, 0x23, 0x46, 0x1f, 0xaa,
+ 0xea, 0xc1, 0x51, 0x30, 0xeb, 0x7d, 0x34, 0x52, 0x91, 0x37, 0x2d, 0xc6,
+ 0x5c, 0x3a, 0x7c, 0x54, 0xc0, 0x79, 0xdc, 0xf9, 0xbf, 0x08, 0x2a, 0xf6,
+ 0xe1, 0x1e, 0xee, 0xc6, 0xd2, 0xe9, 0x30, 0x27, 0x60, 0x0c, 0xa2, 0x63,
+ 0x16, 0x06, 0x3d, 0xe2, 0xf5, 0x6f, 0xea, 0xe4, 0x4d, 0x9f, 0x2d, 0x36,
+ 0x62, 0x95, 0x47, 0x5d, 0x00, 0x22, 0x9f, 0x0c, 0xbb, 0x71, 0xad, 0xea,
+ 0xe7, 0x62, 0x59, 0x21, 0xd1, 0xaf, 0x04, 0x5a, 0xfc, 0x1f, 0x28, 0x6b,
+ 0x6f, 0x71, 0xec, 0xd4, 0xbd, 0x9c, 0x88, 0xfb, 0x3f, 0x04, 0xea, 0xd6,
+ 0xb2, 0x24, 0xe5, 0x28, 0xfe, 0xc5, 0x3e, 0x15, 0x00, 0x8c, 0xa2, 0xdf,
+ 0x18, 0x3d, 0x10, 0x9a, 0xb1, 0xcd, 0x64, 0xda, 0x87, 0x41, 0xc8, 0xa1,
+ 0x1c, 0x97, 0xd5, 0x44, 0xd9, 0x51, 0xd2, 0x96, 0xed, 0xad, 0x28, 0x1f,
+ 0x03, 0x89, 0x21, 0xbd, 0x79, 0x91, 0x48, 0x9c, 0x8e, 0x17, 0xfd, 0x36,
+ 0x72, 0xf6, 0x69, 0x4f, 0x3f, 0x02, 0x57, 0xcc, 0x3f, 0x1c, 0x49, 0x82,
+ 0x00, 0x45, 0x9e, 0x29, 0x83, 0x14, 0x12, 0xbb, 0xd2, 0xd0, 0x1a, 0x66,
+ 0x0f, 0x57, 0x24, 0xd4, 0x9f, 0x46, 0x0c, 0xf4, 0xb8, 0x28, 0x85, 0x52,
+ 0xe2, 0xa1, 0xc2, 0x3a, 0x8c, 0x34, 0x4a, 0x81, 0xe3, 0xbc, 0xa2, 0x67,
+ 0x67, 0x12, 0x13, 0xc4, 0xe7, 0xd7, 0x2c, 0x4e, 0xa9, 0xf5, 0xed, 0x63,
+ 0xf2, 0x18, 0x9c, 0x0c, 0xe2, 0x4d, 0x25, 0x23, 0x30, 0x3e, 0x49, 0x29,
+ 0xa6, 0x37, 0xdf, 0xc2, 0xdc, 0xf6, 0x5e, 0xae, 0x45, 0xd7, 0x8d, 0x56,
+ 0xba, 0x29, 0x4f, 0xee, 0xc9, 0x26, 0xd7, 0xbf, 0x10, 0x4d, 0x0a, 0x3b,
+ 0x3d, 0x1f, 0xd5, 0x72, 0xe1, 0xe6, 0xf5, 0x23, 0x4a, 0x17, 0x2d, 0xe4,
+ 0x40, 0x55, 0x9b, 0x39, 0x66, 0x36, 0xe4, 0x6d, 0x6d, 0xb6, 0x8d, 0x2a,
+ 0x7e, 0x76, 0x73, 0xa5, 0x86, 0x20, 0x3d, 0x18, 0xa0, 0x6c, 0x35, 0x59,
+ 0xc8, 0x1c, 0xef, 0x0f, 0x36, 0x1d, 0x6f, 0xba, 0x89, 0xb9, 0x9e, 0x7a,
+ 0x58, 0x1d, 0x43, 0xad, 0x85, 0x8b, 0x6b, 0xcc, 0x25, 0xb8, 0xe4, 0xdd,
+ 0xa1, 0x35, 0xd9, 0xef, 0xc4, 0xb1, 0xf6, 0x99, 0x27, 0x17, 0xb7, 0xbe,
+ 0xd1, 0x4f, 0xa1, 0x81, 0x4e, 0xb6, 0x19, 0xcd, 0xa0, 0x92, 0xeb, 0x56,
+ 0x41, 0x4f, 0x37, 0xca, 0x3b, 0x43, 0x85, 0x86, 0xdf, 0x5d, 0x5a, 0x8c,
+ 0xd4, 0x5b, 0xc4, 0x28, 0xdb, 0x16, 0xea, 0x3a, 0x2e, 0x9e, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x80, 0x00, 0x00, 0x00, 0xea, 0x59, 0x40, 0xc4,
+ 0x40, 0x8b, 0x6a, 0x8a, 0xb8, 0x7f, 0x1e, 0x0b, 0xfe, 0xab, 0xa4, 0xac,
+ 0x42, 0x91, 0xc5, 0xfa, 0x2c, 0x7e, 0xb4, 0xf9, 0x5c, 0xd5, 0x4c, 0x6a,
+ 0x74, 0x82, 0x90, 0x81, 0x96, 0xb0, 0xf4, 0xd4, 0xba, 0xc9, 0xa3, 0x2e,
+ 0x26, 0x0a, 0xc9, 0x55, 0x65, 0xac, 0xde, 0x83, 0x37, 0xec, 0x0e, 0xf6,
+ 0xdc, 0x8c, 0x34, 0xe6, 0x57, 0xde, 0x32, 0x0a, 0x02, 0x62, 0x4f, 0x6a,
+ 0x92, 0xa5, 0xb4, 0x40, 0xde, 0x57, 0xf4, 0xd1, 0xa3, 0x1c, 0xd3, 0xf7,
+ 0x4a, 0x15, 0xcc, 0x27, 0x26, 0x00, 0xba, 0xf3, 0xfa, 0x4e, 0xc6, 0xe9,
+ 0xc3, 0x05, 0x3d, 0x3a, 0x89, 0x96, 0x7d, 0x41, 0xac, 0xca, 0x28, 0x7f,
+ 0x69, 0x02, 0x40, 0x03, 0x93, 0x86, 0x85, 0x85, 0x73, 0x00, 0x09, 0x5a,
+ 0xcf, 0x5f, 0x1d, 0xaa, 0x46, 0x41, 0x9d, 0x08, 0xbf, 0xea, 0x45, 0x9b,
+ 0x93, 0xda, 0x9e, 0x81, 0xba, 0x9e, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x08, 0x00, 0x00, 0x6a, 0x1f, 0x9b, 0x03, 0xdd, 0xe4, 0x16, 0x07,
+ 0x7f, 0x5b, 0xb0, 0xee, 0xac, 0x55, 0xc4, 0x50, 0xe6, 0x2b, 0x17, 0xed,
+ 0x7f, 0x50, 0x4d, 0x71, 0x73, 0xae, 0xe0, 0x4d, 0xce, 0x08, 0xd9, 0x8b,
+ 0x83, 0x2c, 0x01, 0x48, 0x02, 0xd3, 0xbb, 0xca, 0x86, 0xd7, 0xca, 0x5f,
+ 0xc7, 0xce, 0x59, 0xdf, 0xc1, 0xcc, 0xf7, 0x7b, 0x54, 0xf8, 0x0d, 0x4f,
+ 0x81, 0x9e, 0x50, 0x6a, 0x65, 0x66, 0x4a, 0xec, 0x7a, 0x1b, 0x92, 0xb2,
+ 0x39, 0x8f, 0x5d, 0x41, 0x33, 0xcf, 0xe6, 0x1b, 0x34, 0x5d, 0xe1, 0xf6,
+ 0xef, 0xcb, 0xa0, 0x55, 0x7e, 0x1f, 0x45, 0x38, 0xb9, 0x56, 0x15, 0x3b,
+ 0x70, 0xab, 0xc8, 0x2f, 0x1c, 0xb9, 0x7d, 0x37, 0xe1, 0xb4, 0x03, 0x44,
+ 0x5a, 0xf6, 0x57, 0x97, 0x03, 0x54, 0x4c, 0x22, 0x88, 0xc3, 0x82, 0xfd,
+ 0x91, 0xc1, 0xf1, 0x63, 0xb4, 0x50, 0x46, 0x11, 0x64, 0x07, 0xfd, 0x85,
+ 0xe5, 0x78, 0x57, 0xdd, 0x19, 0x2a, 0x6b, 0x64, 0x3e, 0xec, 0xb8, 0xf3,
+ 0xb5, 0x95, 0x29, 0x72, 0xf1, 0x9d, 0xdd, 0xb9, 0xad, 0xd0, 0x78, 0x26,
+ 0x86, 0x10, 0x10, 0x19, 0xe4, 0x79, 0xae, 0xdc, 0x56, 0xb7, 0x54, 0x4f,
+ 0x94, 0xc6, 0x26, 0x9a, 0x93, 0xa8, 0x2e, 0x1b, 0x1c, 0xda, 0x87, 0x3a,
+ 0xa2, 0x44, 0xb9, 0x0b, 0x0f, 0xab, 0x70, 0x3b, 0xb7, 0x6c, 0xbf, 0x58,
+ 0x67, 0x32, 0x7d, 0xa3, 0x2a, 0xcb, 0x4e, 0x02, 0x92, 0xa1, 0x26, 0x0e,
+ 0x20, 0x5e, 0xb3, 0xec, 0xc4, 0x04, 0x5b, 0x7f, 0xe5, 0xbd, 0x30, 0xeb,
+ 0xc8, 0xdd, 0xf1, 0x72, 0x5a, 0x7e, 0xcb, 0x93, 0x22, 0xa0, 0x01, 0x9f,
+ 0xbb, 0x24, 0x9f, 0x50, 0x01, 0x1f, 0x24, 0x02, 0x85, 0x6d, 0xe6, 0x4d,
+ 0x55, 0xc4, 0x07, 0xe9, 0x87, 0x38, 0xbf, 0x1a, 0x3b, 0x05, 0x82, 0xc4,
+ 0x73, 0x4b, 0x87, 0x3c, 0xb4, 0x0a, 0x48, 0x8c, 0x06, 0x67, 0xe7, 0xbf,
+ 0xcc, 0xe7, 0xe5, 0xc3, 0xb2, 0x81, 0x60, 0xe2, 0xd1, 0xb1, 0x8f, 0x98,
+ 0xbd, 0x7d, 0xbd, 0x4e, 0x9a, 0xca, 0xbe, 0xcb, 0x81, 0x47, 0x25, 0xaa,
+ 0xfa, 0x91, 0xcf, 0x78, 0xce, 0xcb, 0x1a, 0x11, 0x79, 0xcf, 0x97, 0xa3,
+ 0x95, 0x95, 0x6f, 0xd7, 0xae, 0x80, 0xc9, 0xd5, 0x95, 0xb7, 0xcf, 0xe2,
+ 0x9d, 0x98, 0x65, 0x80, 0xfd, 0x2e, 0xee, 0x46, 0x5e, 0x46, 0x8c, 0xde,
+ 0x52, 0xb4, 0xdc, 0xce, 0xa8, 0xab, 0x4e, 0x0c, 0x12, 0x9f, 0x89, 0x9c,
+ 0x84, 0x80, 0xfe, 0x08, 0x64, 0x12, 0x12, 0x95, 0x62, 0xea, 0x65, 0xcc,
+ 0x34, 0x80, 0xcf, 0x92, 0x5f, 0xc2, 0xae, 0x76, 0xe7, 0x2f, 0xbb, 0xa8,
+ 0xdb, 0x6a, 0x66, 0x60, 0xaf, 0x88, 0xba, 0x65, 0x32, 0xcf, 0xf7, 0x6e,
+ 0xd8, 0xd0, 0x69, 0xb0, 0x12, 0x23, 0xd6, 0xc2, 0x32, 0xe5, 0x8e, 0x51,
+ 0xc5, 0x61, 0x28, 0x45, 0xf7, 0xf9, 0xea, 0x73, 0xce, 0x04, 0x2d, 0x56,
+ 0x43, 0x10, 0x8b, 0x4f, 0x6b, 0xfa, 0x32, 0xa8, 0x92, 0x8f, 0xd9, 0xb4,
+ 0xfd, 0xa4, 0x74, 0xa8, 0xea, 0xca, 0xd3, 0x84, 0xbb, 0x5a, 0x34, 0x57,
+ 0xf9, 0xda, 0x25, 0x40, 0x1f, 0x5e, 0xc2, 0x66, 0x43, 0x05, 0xdd, 0x13,
+ 0x88, 0x91, 0x60, 0xa1, 0x75, 0xd3, 0xc4, 0x27, 0xff, 0xda, 0x24, 0x3d,
+ 0xd9, 0xd7, 0x47, 0x46, 0x30, 0xd0, 0x76, 0xc4, 0x9e, 0x97, 0xe3, 0x43,
+ 0xd7, 0x45, 0xaf, 0x49, 0x36, 0xf2, 0x18, 0xdd, 0x3f, 0x86, 0x9a, 0xec,
+ 0x9a, 0x70, 0xeb, 0x5a, 0xe2, 0xa0, 0x4b, 0x45, 0x21, 0xb3, 0x32, 0x3d,
+ 0x0c, 0x8c, 0x03, 0x13, 0xae, 0x46, 0xb5, 0x1a, 0x0a, 0x03, 0x36, 0xfe,
+ 0xfe, 0xfa, 0xc9, 0x4d, 0x46, 0xf8, 0xfe, 0x6f, 0x99, 0x8c, 0xe4, 0x77,
+ 0x0c, 0x27, 0x59, 0xf7, 0xc3, 0xfc, 0x32, 0xb3, 0xa5, 0xae, 0xdc, 0x49,
+ 0xac, 0x31, 0x27, 0xa6, 0x14, 0x92, 0xfb, 0xe3, 0x69, 0x35, 0x8d, 0xa0,
+ 0x50, 0x55, 0x09, 0x90, 0xdf, 0x67, 0x08, 0x4c, 0x0e, 0xaf, 0x71, 0xc2,
+ 0xe8, 0xb8, 0xdc, 0x45, 0xe3, 0x6d, 0x58, 0x3f, 0x19, 0x8d, 0xcd, 0xeb,
+ 0xe3, 0x02, 0x49, 0xd8, 0xc8, 0x8b, 0x29, 0xb3, 0xef, 0x2b, 0xf0, 0x39,
+ 0x5c, 0x11, 0xaa, 0x52, 0x44, 0x0d, 0x1a, 0x3a, 0x7a, 0x62, 0xda, 0x6d,
+ 0xe3, 0xdd, 0x03, 0x30, 0x6d, 0x3e, 0x18, 0x30, 0x1d, 0xc0, 0xd0, 0x05,
+ 0x67, 0x98, 0xf5, 0x2a, 0xc7, 0xa1, 0x58, 0xd7, 0xf8, 0x6f, 0x7d, 0x07,
+ 0x59, 0x27, 0x95, 0xb9, 0x8d, 0x4d, 0xd7, 0xc8, 0x5e, 0x8b, 0x89, 0x14,
+ 0xb7, 0x1b, 0x35, 0xaa, 0x72, 0x02, 0x39, 0x3c, 0x41, 0x7c, 0x91, 0x93,
+ 0x81, 0xe1, 0xad, 0xbe, 0x77, 0x28, 0x80, 0xa2, 0x9c, 0xa8, 0x00, 0x18,
+ 0xa5, 0x70, 0xec, 0xec, 0x96, 0x95, 0x37, 0xa3, 0xee, 0x15, 0xa0, 0x69,
+ 0x0e, 0x05, 0xb5, 0xb4, 0xb6, 0xa7, 0x8b, 0xb9, 0x41, 0x88, 0x4f, 0x56,
+ 0x39, 0xa7, 0xbe, 0x24, 0xce, 0x4c, 0xe0, 0x9c, 0x24, 0x5a, 0xa1, 0xab,
+ 0xcd, 0x82, 0xf1, 0x16, 0x3f, 0xc0, 0xaf, 0xe1, 0x42, 0xe0, 0x7d, 0x1b,
+ 0xd9, 0x8f, 0xb8, 0x04, 0xa1, 0x88, 0xd9, 0xc3, 0xaf, 0x4f, 0xda, 0xfd,
+ 0x0b, 0x5c, 0xc3, 0x04, 0xf3, 0xdb, 0xe6, 0x76, 0x6e, 0xe9, 0xdc, 0xea,
+ 0x6f, 0xa2, 0xa5, 0x75, 0x2c, 0xc7, 0x91, 0x7d, 0x4b, 0xd5, 0x68, 0x55,
+ 0xbb, 0x2d, 0x14, 0xdb, 0x06, 0x76, 0xf7, 0xcc, 0x0a, 0x88, 0x6c, 0x2b,
+ 0xa1, 0x57, 0xd6, 0x15, 0x9c, 0x46, 0xcf, 0x5b, 0x6f, 0x9e, 0x7e, 0xc5,
+ 0x39, 0xda, 0x97, 0x26, 0x5e, 0xf5, 0x25, 0x06, 0xed, 0x8e, 0x9b, 0x1d,
+ 0x1b, 0x91, 0x07, 0x89, 0x08, 0xce, 0xd7, 0x38, 0x43, 0x64, 0x8e, 0xf5,
+ 0x3a, 0x52, 0x4a, 0xfb, 0x3e, 0xff, 0x2c, 0xb3, 0x78, 0x40, 0xb5, 0xdd,
+ 0xb2, 0x8a, 0xd3, 0x6a, 0xc5, 0xb0, 0xa3, 0x4a, 0xb8, 0xe7, 0x27, 0xa0,
+ 0x5a, 0x8f, 0x0f, 0xda, 0x53, 0x49, 0xc9, 0x77, 0x2a, 0xef, 0x78, 0xc6,
+ 0xec, 0xaf, 0x10, 0xe5, 0x71, 0xc5, 0x7a, 0x85, 0xdf, 0xb2, 0x85, 0x02,
+ 0xe3, 0x55, 0x7a, 0x91, 0x3a, 0x68, 0xb2, 0x9d, 0x3d, 0xd9, 0x01, 0xc5,
+ 0x5f, 0x3c, 0xa8, 0x1d, 0x99, 0xc6, 0xe7, 0xad, 0x09, 0xd1, 0x39, 0x3a,
+ 0x92, 0xc5, 0x77, 0x9c, 0xdf, 0x99, 0x56, 0x9f, 0xfe, 0xf8, 0xfd, 0xc8,
+ 0x4f, 0x19, 0xa3, 0xa0, 0xdf, 0xff, 0x17, 0xac, 0xa9, 0x03, 0x32, 0x85,
+ 0x4c, 0x29, 0xca, 0x89, 0x58, 0xdc, 0x88, 0xdd, 0xeb, 0x79, 0x68, 0x5e,
+ 0x0f, 0x37, 0x1a, 0xf7, 0x05, 0xfd, 0x39, 0x91, 0x25, 0x61, 0xf3, 0x04,
+ 0xda, 0x97, 0xfc, 0x7b, 0xcc, 0x40, 0x63, 0xfd, 0x5b, 0x3b, 0x27, 0x8e,
+ 0x92, 0x6d, 0x98, 0x0f, 0xcc, 0x9c, 0x9b, 0xda, 0xb2, 0xc6, 0xca, 0x56,
+ 0xff, 0x7e, 0xcc, 0xa2, 0xc0, 0x45, 0x3e, 0xf6, 0xdf, 0xa7, 0xe8, 0x2a,
+ 0xef, 0x0c, 0xde, 0xec, 0xa4, 0x1d, 0x2c, 0x3e, 0x03, 0xfd, 0xa4, 0x44,
+ 0x60, 0x4a, 0xf5, 0x83, 0x8f, 0x09, 0x2d, 0xe8, 0xd5, 0x46, 0xf6, 0x1c,
+ 0x2d, 0x39, 0x28, 0x0c, 0xdf, 0xa1, 0x2b, 0x05, 0x6e, 0x3c, 0x36, 0xdd,
+ 0x91, 0x81, 0x52, 0xf1, 0x56, 0xdc, 0xbb, 0x79, 0x62, 0xd8, 0x2e, 0x27,
+ 0x5d, 0x9f, 0x3c, 0xce, 0x81, 0x5c, 0x70, 0xe5, 0x4d, 0x33, 0x06, 0xd5,
+ 0x14, 0x04, 0xb7, 0xbc, 0x7b, 0x7a, 0xb4, 0xf7, 0x4a, 0x48, 0x8f, 0x97,
+ 0x85, 0x96, 0x69, 0xc9, 0x40, 0x52, 0xb1, 0x1c, 0x28, 0x82, 0xb3, 0x63,
+ 0xee, 0x94, 0x2f, 0xcb, 0x40, 0xad, 0xd7, 0x78, 0xb1, 0xc4, 0x21, 0x05,
+ 0x36, 0xd9, 0x46, 0xf0, 0x83, 0xcd, 0xee, 0x52, 0x7a, 0xa6, 0xa4, 0x40,
+ 0xb0, 0x2f, 0xf0, 0x1c, 0xfa, 0x42, 0x98, 0x54, 0x5b, 0xfe, 0x5e, 0xd6,
+ 0x84, 0x73, 0xca, 0x39, 0xbe, 0x87, 0xf2, 0x92, 0xee, 0x3d, 0x21, 0xcc,
+ 0x69, 0x81, 0xe5, 0xe8, 0x8a, 0xc3, 0x23, 0x64, 0x98, 0xd5, 0x1d, 0xcd,
+ 0x5c, 0x6c, 0x37, 0xc8, 0x8b, 0x08, 0x22, 0x12, 0x9f, 0x85, 0xc9, 0xed,
+ 0xb4, 0xa6, 0x07, 0xe1, 0x62, 0x79, 0x35, 0x5d, 0x26, 0x11, 0x4a, 0x6b,
+ 0x33, 0x37, 0x91, 0x78, 0xe8, 0xe2, 0xba, 0x8b, 0x8a, 0xb7, 0xbb, 0x0f,
+ 0xd2, 0xb3, 0xa2, 0x02, 0x0c, 0x57, 0x35, 0x99, 0x88, 0x6b, 0x9b, 0x64,
+ 0x79, 0x1f, 0x4a, 0x48, 0xd4, 0x3b, 0x5c, 0xeb, 0xb4, 0x83, 0xc3, 0xad,
+ 0x9c, 0x6a, 0xb0, 0xcf, 0x7f, 0x70, 0xe8, 0x22, 0x46, 0x25, 0xfe, 0x7e,
+ 0x02, 0x44, 0x83, 0x02, 0xb3, 0x08, 0x2e, 0x34, 0x08, 0x4b, 0xff, 0xa2,
+ 0xc1, 0x60, 0xbb, 0xd8, 0x89, 0x16, 0xf8, 0xaa, 0xab, 0xea, 0xf7, 0xa0,
+ 0x10, 0x9a, 0xc9, 0xe9, 0xa4, 0x81, 0xa7, 0x87, 0x32, 0x5b, 0xc1, 0xd0,
+ 0xd9, 0x70, 0x6f, 0xb6, 0x7c, 0x65, 0xd5, 0x0e, 0x65, 0x93, 0xfe, 0x6d,
+ 0x66, 0xaa, 0xab, 0xd0, 0x03, 0x07, 0xf2, 0xbe, 0x39, 0xd6, 0xc8, 0xac,
+ 0xf2, 0x06, 0x58, 0x58, 0x46, 0xc0, 0x1a, 0xbd, 0xa4, 0x96, 0x38, 0x31,
+ 0x32, 0x89, 0x04, 0xdf, 0xcd, 0x3c, 0x2e, 0x98, 0xb8, 0x39, 0xba, 0xe2,
+ 0xca, 0x6b, 0xd0, 0x53, 0xce, 0x4a, 0xc8, 0x95, 0x81, 0x84, 0x17, 0xce,
+ 0x7f, 0x1d, 0xc1, 0x5a, 0xc4, 0xc2, 0x73, 0x30, 0x6d, 0x0b, 0x8c, 0xf8,
+ 0x66, 0x38, 0x4e, 0xa3, 0x14, 0x84, 0x15, 0x36, 0x9e, 0x0d, 0x56, 0x6b,
+ 0xa6, 0x77, 0x65, 0xa4, 0x2c, 0x77, 0x00, 0x8b, 0x43, 0x57, 0xc6, 0x25,
+ 0xc5, 0xd0, 0x17, 0x79, 0x6b, 0x5d, 0xbc, 0xcd, 0xc8, 0x25, 0x8f, 0x20,
+ 0x09, 0xcc, 0xbd, 0x80, 0x10, 0xdf, 0x35, 0xf6, 0x9c, 0x04, 0x80, 0x23,
+ 0xdc, 0x97, 0xe0, 0xba, 0x29, 0x48, 0x2e, 0x95, 0x0f, 0xb1, 0x9b, 0xc7,
+ 0xe6, 0x0b, 0x89, 0x16, 0xe2, 0x81, 0x3b, 0x32, 0x69, 0xc4, 0xde, 0xc6,
+ 0x12, 0x09, 0x47, 0xff, 0x50, 0xe4, 0x45, 0xb7, 0x35, 0xd2, 0x61, 0x9b,
+ 0x52, 0x6e, 0xbe, 0xaf, 0xd2, 0xeb, 0x0c, 0x50, 0xf1, 0x57, 0x9f, 0x59,
+ 0xe1, 0xc1, 0x4f, 0x8c, 0x79, 0x07, 0x05, 0xce, 0x8d, 0x64, 0xb2, 0xf0,
+ 0xd3, 0x4f, 0xe1, 0x7b, 0xfa, 0x30, 0x0a, 0xc2, 0x5d, 0x0c, 0x47, 0x6c,
+ 0x17, 0x77, 0x1f, 0xe5, 0xd8, 0x14, 0xfd, 0xc1, 0x01, 0x70, 0x51, 0x60,
+ 0xb2, 0x20, 0xfd, 0x86, 0xbc, 0x19, 0x5e, 0x01, 0xa6, 0x19, 0x3a, 0x21,
+ 0xa5, 0x0a, 0x1c, 0xd9, 0xa9, 0x78, 0xbb, 0xc9, 0x01, 0x65, 0xe4, 0xb3,
+ 0x48, 0xb8, 0xe1, 0xe7, 0xb5, 0xf4, 0x4e, 0xa9, 0xb6, 0xe2, 0x5b, 0xeb,
+ 0xf5, 0x76, 0x06, 0x1a, 0xd9, 0x08, 0x40, 0xff, 0x72, 0xb2, 0xe3, 0x01,
+ 0x50, 0xb1, 0xad, 0xb3, 0xa3, 0xf6, 0xef, 0x72, 0x05, 0x0c, 0xf4, 0xce,
+ 0x24, 0x2c, 0x63, 0x89, 0x63, 0x9e, 0x21, 0xb8, 0xb0, 0xbe, 0xc7, 0x45,
+ 0xae, 0x47, 0x2b, 0x9e, 0x61, 0x81, 0x4c, 0x76, 0x96, 0x7b, 0x18, 0x37,
+ 0x74, 0xcb, 0x00, 0xef, 0x38, 0x72, 0x24, 0x0a, 0x63, 0xc1, 0x64, 0xd6,
+ 0x41, 0xc8, 0x6a, 0xf1, 0xe7, 0x11, 0x20, 0x4b, 0xc2, 0x95, 0x70, 0xb8,
+ 0xf8, 0x8f, 0xd9, 0xae, 0x8c, 0x12, 0xd8, 0x6f, 0x63, 0x30, 0xca, 0x56,
+ 0x46, 0x11, 0xda, 0x49, 0x1f, 0x84, 0x3d, 0xae, 0xab, 0x78, 0x29, 0x02,
+ 0x6c, 0x43, 0xa3, 0xef, 0x9d, 0x97, 0x59, 0x15, 0x53, 0xcd, 0xc7, 0x47,
+ 0x65, 0x30, 0xc7, 0xae, 0x31, 0x4a, 0x41, 0xb4, 0x66, 0x9c, 0xbb, 0x51,
+ 0x0b, 0xbd, 0xe2, 0x7d, 0x41, 0x2c, 0xd0, 0x75, 0x57, 0x93, 0xce, 0x2e,
+ 0xeb, 0x31, 0x7f, 0x56, 0xb2, 0xa4, 0x2b, 0x9f, 0xcc, 0xef, 0x6f, 0xf0,
+ 0x77, 0x19, 0xad, 0x4d, 0x2e, 0x37, 0x00, 0x75, 0x53, 0xae, 0x22, 0x44,
+ 0x69, 0x1c, 0x8a, 0x90, 0xf2, 0xcd, 0x0f, 0x6b, 0x37, 0xdb, 0xfd, 0x71,
+ 0x64, 0x80, 0xd8, 0x57, 0x1b, 0x8f, 0xff, 0x14, 0xd4, 0x5f, 0xe1, 0xd1,
+ 0x0f, 0x06, 0x13, 0x61, 0x29, 0xa9, 0x80, 0x9d, 0xc7, 0x8a, 0xa0, 0xb5,
+ 0xaa, 0xfc, 0xe0, 0xb4, 0xb4, 0xf0, 0x31, 0xf0, 0xec, 0x78, 0x03, 0x28,
+ 0xb9, 0xf7, 0xd9, 0xa7, 0xc8, 0xad, 0x2e, 0x16, 0xb8, 0x18, 0x82, 0x43,
+ 0x66, 0x8b, 0xae, 0xb2, 0x45, 0x2b, 0x0c, 0x9d, 0x69, 0xbd, 0x1b, 0xc5,
+ 0x20, 0xc6, 0x41, 0xe7, 0x4f, 0x4b, 0x7b, 0x46, 0x3d, 0x7a, 0x6d, 0x9f,
+ 0x13, 0x2e, 0x0f, 0xf3, 0x85, 0x3e, 0x5b, 0x12, 0xe5, 0xbf, 0x1b, 0x20,
+ 0xc3, 0x5f, 0x6b, 0xf7, 0xf7, 0xa3, 0xd7, 0x33, 0xd2, 0xcb, 0x18, 0xa5,
+ 0xa4, 0xa2, 0xd3, 0x59, 0x91, 0x9a, 0x04, 0xfa, 0x9d, 0xa5, 0x55, 0xad,
+ 0x09, 0x5a, 0x1e, 0x0b, 0x10, 0xd0, 0x46, 0x18, 0xe4, 0x09, 0xe8, 0x1b,
+ 0x44, 0xd3, 0x78, 0x45, 0xc0, 0xdf, 0xa2, 0xef, 0xfc, 0x59, 0x8a, 0x1b,
+ 0x22, 0x60, 0xc9, 0x58, 0x7d, 0x65, 0x45, 0xa9, 0xac, 0xd5, 0xd4, 0xc4,
+ 0x44, 0xd3, 0x08, 0x44, 0x40, 0x4d, 0x3d, 0x7e, 0x39, 0x81, 0x72, 0x15,
+ 0x49, 0xd7, 0x2c, 0xda, 0x33, 0xaf, 0xc5, 0xb5, 0x8a, 0x3c, 0xbf, 0x81,
+ 0x88, 0x4f, 0x12, 0xe4, 0xe8, 0xe6, 0x00, 0xb6, 0xd9, 0xcd, 0xb2, 0x70,
+ 0x08, 0x15, 0x72, 0xf6, 0x46, 0xc7, 0x98, 0x7c, 0x1d, 0x54, 0xd0, 0x66,
+ 0x2d, 0xa1, 0xd8, 0xda, 0xb0, 0xe5, 0x9f, 0xa3, 0x2f, 0x2c, 0xfb, 0x34,
+ 0xb3, 0x21, 0x8b, 0x61, 0xf4, 0xce, 0x60, 0x2b, 0xb5, 0x5e, 0x3d, 0x14,
+ 0x2c, 0xbe, 0x19, 0x9d, 0x5f, 0x01, 0xe1, 0x21, 0x34, 0x11, 0x6b, 0x10,
+ 0xd4, 0x17, 0x58, 0xb3, 0x0a, 0x30, 0xe4, 0x17, 0x51, 0x0b, 0xf2, 0xbb,
+ 0xa6, 0xb7, 0x00, 0xa2, 0xe8, 0xa5, 0xa3, 0x41, 0x1d, 0x65, 0x2d, 0x26,
+ 0x93, 0x26, 0x7d, 0xdc, 0xad, 0x6f, 0x83, 0xeb, 0x66, 0x55, 0xde, 0x60,
+ 0x21, 0x56, 0x19, 0x4f, 0x9b, 0x7b, 0x26, 0x4a, 0x80, 0xf5, 0xab, 0x8b,
+ 0xbf, 0xe4, 0xb1, 0xa1, 0xd6, 0x33, 0x32, 0xbf, 0x86, 0x8c, 0x3c, 0xd0,
+ 0x12, 0x03, 0xd4, 0xb9, 0x23, 0x54, 0x1b, 0x94, 0x2f, 0xa5, 0x34, 0x4d,
+ 0x59, 0x18, 0x33, 0x8e, 0x8c, 0xf7, 0x1f, 0xc9, 0x6d, 0x75, 0xfb, 0x2a,
+ 0x22, 0x6c, 0x64, 0xb7, 0x79, 0xd8, 0x3b, 0xf6, 0x4e, 0x98, 0xd8, 0xa8,
+ 0x2c, 0x06, 0xd1, 0x92, 0x32, 0x44, 0xec, 0x38, 0x40, 0x3b, 0x53, 0x16,
+ 0x40, 0x8f, 0x92, 0x72, 0x87, 0xa8, 0xb8, 0xc0, 0x8f, 0x25, 0x4c, 0x4f,
+ 0x24, 0xfc, 0x8d, 0xc6, 0xa6, 0xeb, 0x2f, 0xdf, 0x2f, 0x0d, 0x2f, 0xd3,
+ 0x6e, 0x70, 0x71, 0xfe, 0xf0, 0x2e, 0xe9, 0x84, 0xd3, 0xc1, 0xd1, 0x70,
+ 0x4b, 0x8f, 0x7b, 0x60, 0xb0, 0xb7, 0xe3, 0x79, 0x52, 0x6a, 0x6b, 0x26,
+ 0x03, 0x8f, 0x6a, 0x0f, 0x8d, 0x85, 0xd7, 0x5f, 0xf7, 0x39, 0x31, 0x0e,
+ 0x26, 0x73, 0x84, 0x3f, 0x9b, 0x10, 0x6f, 0x29, 0x63, 0x14, 0x36, 0xa2,
+ 0xec, 0x44, 0x7d, 0x84, 0xc6, 0x4a, 0xec, 0xfe, 0xac, 0xcb, 0xe4, 0xfa,
+ 0xf6, 0x68, 0x83, 0x68, 0xe0, 0x8f, 0xd3, 0x8a, 0x60, 0x73, 0xf1, 0x5c,
+ 0x71, 0x02, 0x0c, 0xa2, 0x88, 0x2c, 0xa2, 0x35, 0x35, 0x5c, 0x3f, 0xb1,
+ 0xbe, 0xb3, 0x6b, 0x5c, 0xe1, 0x78, 0x75, 0x40, 0x20, 0x87, 0x67, 0xca,
+ 0x07, 0x1c, 0x9c, 0x02, 0xc7, 0xf2, 0x9d, 0x1c, 0xda, 0x1b, 0x86, 0x1b,
+ 0xc6, 0xa6, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00,
+ 0x93, 0xca, 0x30, 0xae, 0xea, 0x26, 0x6a, 0x1b, 0x15, 0x46, 0x0a, 0xe3,
+ 0x57, 0x23, 0x4c, 0x0c, 0x98, 0x8e, 0x3e, 0xbb, 0x43, 0x14, 0x73, 0xdf,
+ 0x17, 0x91, 0xe2, 0xee, 0x39, 0xf9, 0xc2, 0x2f, 0xdc, 0xad, 0x0e, 0x00,
+ 0xf5, 0xdd, 0xe3, 0x97, 0xba, 0x8c, 0xee, 0x53, 0xc4, 0x70, 0x37, 0x46,
+ 0xcf, 0x04, 0xc3, 0xc8, 0x56, 0x38, 0x2e, 0x39, 0x75, 0x32, 0x6d, 0x98,
+ 0xc4, 0x14, 0xae, 0xa4, 0x29, 0xa3, 0xc6, 0xb6, 0x66, 0x45, 0x48, 0xdf,
+ 0xc0, 0xa9, 0x4b, 0x4f, 0xef, 0xb9, 0xb4, 0x89, 0x0d, 0x64, 0x00, 0x5c,
+ 0xd1, 0xc8, 0x2b, 0xf7, 0xc5, 0x1a, 0x1b, 0x06, 0xb7, 0x49, 0xb1, 0xe3,
+ 0x4d, 0x87, 0xf9, 0x3f, 0xba, 0x39, 0xa3, 0x56, 0x7f, 0x43, 0xcc, 0x15,
+ 0x9c, 0x3d, 0xba, 0x71, 0x7b, 0xeb, 0x45, 0x0f, 0x15, 0x1b, 0x6c, 0x84,
+ 0x75, 0x6d, 0x43, 0x0b, 0x27, 0x12, 0x6b, 0xbc, 0x0a, 0x6d, 0xe4, 0xf6,
+ 0x4f, 0xc7, 0xbb, 0x9e, 0x91, 0xb5, 0x09, 0x5f, 0x79, 0x2a, 0xbf, 0xda,
+ 0x34, 0x91, 0x44, 0x47, 0x52, 0x64, 0x00, 0x89, 0x27, 0x17, 0x5c, 0xe9,
+ 0x90, 0x8b, 0xcb, 0xbe, 0x21, 0x47, 0x65, 0x1c, 0x54, 0x61, 0x48, 0x17,
+ 0x66, 0xb7, 0xa1, 0x60, 0x27, 0x31, 0x04, 0x42, 0x3b, 0x33, 0x3d, 0xda,
+ 0xf7, 0x61, 0x3d, 0x4b, 0x91, 0xa5, 0x74, 0x4b, 0xde, 0x16, 0xf2, 0x79,
+ 0x3e, 0xf7, 0x89, 0x87, 0xb3, 0xdd, 0xa2, 0x49, 0xd7, 0x54, 0x1b, 0x39,
+ 0xff, 0xb5, 0xec, 0x9d, 0x1d, 0x09, 0x7e, 0x5a, 0x3c, 0xd1, 0xdc, 0x0e,
+ 0x2a, 0x0e, 0x2c, 0x40, 0x4e, 0xa5, 0x8c, 0x9d, 0xc8, 0x9b, 0xa5, 0xb2,
+ 0x40, 0xa4, 0xaa, 0x3b, 0xac, 0x93, 0x19, 0xf7, 0xa1, 0x8b, 0xf8, 0x4a,
+ 0x40, 0x08, 0x5d, 0x1d, 0xb0, 0xae, 0x0f, 0x67, 0xa7, 0x21, 0xaf, 0xe3,
+ 0xb1, 0xfc, 0xff, 0xa0, 0x95, 0x66, 0x2b, 0xf7, 0x82, 0x2d, 0x8a, 0x26,
+ 0x0f, 0xc3, 0xed, 0x62, 0xb6, 0xcb, 0x4c, 0x86, 0xe9, 0x20, 0x78, 0x3f,
+ 0x08, 0x53, 0x8f, 0x41, 0xf1, 0xa1, 0x04, 0x77, 0xd9, 0xe6, 0xea, 0x26,
+ 0x6d, 0x33, 0x48, 0xb3, 0xbb, 0xed, 0xfc, 0xd7, 0xa3, 0x2b, 0xe2, 0x39,
+ 0xcf, 0x78, 0x4e, 0x11, 0x26, 0xad, 0x39, 0x83, 0x6e, 0x72, 0xbf, 0xc6,
+ 0x34, 0x23, 0x97, 0x5d, 0x7b, 0x64, 0x1e, 0x78, 0x00, 0x34, 0x92, 0x5d,
+ 0x3f, 0x23, 0x28, 0x60, 0x7f, 0x88, 0xf0, 0xca, 0x96, 0x4a, 0x15, 0xbf,
+ 0x8a, 0xb7, 0xd0, 0xd9, 0x99, 0x8b, 0xdb, 0x26, 0xdc, 0x7e, 0x8d, 0x35,
+ 0x53, 0x60, 0x07, 0x85, 0x80, 0xc4, 0x9c, 0x0d, 0x81, 0xe2, 0x93, 0x85,
+ 0x76, 0x2d, 0x85, 0x21, 0x6e, 0xda, 0x29, 0xe5, 0xb1, 0x08, 0x46, 0x09,
+ 0x1b, 0x8a, 0xd9, 0xd2, 0xd7, 0x16, 0x74, 0xee, 0x26, 0x3e, 0xc4, 0x8c,
+ 0x2e, 0x6b, 0x0c, 0xbc, 0x95, 0xea, 0x4a, 0xb2, 0xd6, 0x6f, 0x43, 0xd1,
+ 0x3a, 0x8f, 0xbd, 0x77, 0xb4, 0x67, 0x63, 0x6b, 0xd2, 0xe0, 0xf0, 0x81,
+ 0x74, 0xb7, 0xc5, 0x11, 0x60, 0x10, 0x6b, 0xc6, 0x0f, 0xfd, 0x84, 0x2e,
+ 0x5c, 0x8f, 0x3b, 0xf5, 0x68, 0xa7, 0x62, 0xc6, 0x4f, 0xa6, 0xee, 0x19,
+ 0x44, 0xea, 0xc0, 0xe4, 0x64, 0x12, 0x71, 0x2f, 0xfb, 0xa3, 0x4d, 0xb0,
+ 0x8e, 0x5e, 0xe1, 0x79, 0x65, 0xd4, 0xf3, 0xed, 0x73, 0x04, 0xf1, 0x6d,
+ 0xc6, 0x75, 0x54, 0x28, 0x13, 0xe2, 0xd6, 0xa1, 0x26, 0xf9, 0xa4, 0x29,
+ 0x20, 0x5b, 0xd0, 0x3c, 0x3d, 0xf3, 0x7a, 0x18, 0x9a, 0x3d, 0xec, 0x6a,
+ 0x4c, 0xfd, 0xa5, 0x00, 0xdf, 0xec, 0xfd, 0x64, 0x38, 0x66, 0xa7, 0xba,
+ 0x59, 0xb3, 0x9b, 0x9c, 0x44, 0xfb, 0x10, 0x08, 0xb8, 0x79, 0xea, 0x85,
+ 0xbf, 0xa4, 0x14, 0xce, 0xce, 0x85, 0x22, 0x3f, 0x16, 0x00, 0x1c, 0x57,
+ 0xc8, 0x5a, 0x1b, 0xf5, 0xff, 0xde, 0x7e, 0xa9, 0xcc, 0xf3, 0xb5, 0x1d,
+ 0x57, 0x06, 0xda, 0xbb, 0x6c, 0x0a, 0x1e, 0xd4, 0x09, 0x74, 0x84, 0x1d,
+ 0xfa, 0xdf, 0x33, 0x1e, 0xe2, 0x8f, 0x10, 0xf7, 0x73, 0xab, 0x71, 0xb8,
+ 0x64, 0xce, 0xc0, 0x49, 0xc0, 0x36, 0xd3, 0x39, 0x31, 0x4c, 0x12, 0x5b,
+ 0xf3, 0xf9, 0xb4, 0x2c, 0x88, 0xba, 0xd4, 0x1a, 0xbd, 0x0c, 0x99, 0xbd,
+ 0x0e, 0xad, 0x51, 0xe0, 0xca, 0xdb, 0x25, 0x66, 0x83, 0xe0, 0x55, 0x18,
+ 0xeb, 0xa6, 0x4e, 0x56, 0xcb, 0x2f, 0xa5, 0xf2, 0x42, 0x7a, 0xa1, 0x05,
+ 0xf0, 0x3a, 0x71, 0x5a, 0x78, 0x3a, 0x7a, 0x6d, 0x12, 0x9f, 0x43, 0xc5,
+ 0xcc, 0xb3, 0xfd, 0xf2, 0xbf, 0x05, 0x16, 0xef, 0x07, 0xf9, 0xde, 0x0d,
+ 0x51, 0xf0, 0x33, 0x86, 0x43, 0x57, 0x40, 0xbc, 0xa9, 0xbd, 0xa0, 0x23,
+ 0xff, 0xbb, 0xe6, 0x15, 0xa1, 0xeb, 0xe9, 0x78, 0x0d, 0x72, 0x76, 0xf2,
+ 0xb6, 0x6e, 0x46, 0xe2, 0x86, 0xab, 0x3c, 0x52, 0x2c, 0xc6, 0x77, 0xdd,
+ 0x57, 0xf7, 0x4d, 0x36, 0xbb, 0x41, 0x08, 0x21, 0xaa, 0xe6, 0x44, 0x50,
+ 0xed, 0xaf, 0x18, 0xb3, 0xdd, 0x6b, 0x57, 0x46, 0x9e, 0x44, 0x93, 0x20,
+ 0xe0, 0x62, 0x95, 0xcd, 0xcf, 0xe4, 0x96, 0x92, 0xc3, 0x0d, 0x16, 0xb2,
+ 0xc3, 0xf4, 0x0f, 0x3f, 0x87, 0x17, 0xb9, 0x7b, 0x60, 0x60, 0xfa, 0xfb,
+ 0x81, 0x5c, 0xb3, 0xb7, 0x89, 0x73, 0xf7, 0x35, 0xf7, 0x27, 0xf1, 0x0e,
+ 0xa4, 0xa1, 0xba, 0xea, 0x6a, 0xe3, 0x5c, 0x0f, 0xf7, 0x15, 0xbc, 0x28,
+ 0x57, 0x27, 0x8f, 0xd8, 0xca, 0x82, 0x19, 0xd0, 0xa3, 0x9d, 0xe5, 0xe0,
+ 0x44, 0xbf, 0x78, 0xa4, 0x09, 0x69, 0x27, 0xa0, 0x69, 0xb5, 0xd4, 0xbe,
+ 0x00, 0xe6, 0x03, 0x97, 0xbc, 0x8b, 0xfc, 0x25, 0x70, 0xb3, 0x49, 0x30,
+ 0xe3, 0x24, 0x19, 0x77, 0xb4, 0x93, 0x46, 0x03, 0xe6, 0x22, 0xaf, 0x76,
+ 0xd2, 0x90, 0x00, 0x05, 0x46, 0xb8, 0xa4, 0xf5, 0x4c, 0xaa, 0x04, 0x63,
+ 0xa0, 0x57, 0xe0, 0x20, 0x6e, 0x1a, 0xed, 0x21, 0x86, 0xd0, 0x38, 0x5b,
+ 0xe6, 0xa7, 0xb0, 0xe7, 0x75, 0xe3, 0x76, 0xb3, 0x15, 0x8b, 0xdc, 0x10,
+ 0x52, 0x15, 0x21, 0x7b, 0xd0, 0xc4, 0x75, 0x26, 0x1d, 0x6e, 0x0d, 0x4c,
+ 0x08, 0x5b, 0x95, 0x9a, 0xd0, 0xda, 0xbe, 0x23, 0x98, 0xde, 0x60, 0x2a,
+ 0xe9, 0xa4, 0x92, 0xf0, 0x92, 0x84, 0xdc, 0x86, 0x60, 0xf5, 0x23, 0x31,
+ 0xf5, 0xe9, 0xd6, 0x00, 0xc1, 0x78, 0xab, 0x05, 0x94, 0xd3, 0x47, 0x4d,
+ 0x32, 0x0f, 0x82, 0xa0, 0x99, 0x0b, 0xfe, 0x6b, 0x58, 0xf9, 0x24, 0xf6,
+ 0x17, 0xa0, 0x5f, 0x24, 0x6a, 0xc6, 0x01, 0xa8, 0xfa, 0xca, 0xdc, 0xb6,
+ 0x83, 0xcb, 0xd2, 0x3b, 0xb7, 0x0b, 0x04, 0x3e, 0x6a, 0xaf, 0x23, 0x17,
+ 0x3e, 0x14, 0xce, 0x52, 0x1c, 0xe3, 0x06, 0x66, 0x29, 0x17, 0x6f, 0x7e,
+ 0x66, 0x06, 0xa9, 0x68, 0x7f, 0xca, 0xad, 0xa8, 0xb7, 0x2d, 0xa4, 0x5d,
+ 0xa6, 0x16, 0xcd, 0xed, 0xee, 0x14, 0x96, 0xc8, 0x12, 0x69, 0x4e, 0x70,
+ 0x72, 0x2a, 0x75, 0x82, 0x08, 0x3f, 0x3e, 0x27, 0xa0, 0xea, 0x43, 0x84,
+ 0xa9, 0x9a, 0x91, 0x87, 0x4f, 0x20, 0x61, 0x55, 0x8d, 0x70, 0xad, 0x6c,
+ 0x59, 0x5d, 0x13, 0x80, 0xbb, 0x52, 0x55, 0x81, 0x8b, 0x59, 0x94, 0x0f,
+ 0xc2, 0x54, 0x79, 0x59, 0xe8, 0x9d, 0x58, 0xe5, 0x91, 0x10, 0xb3, 0xef,
+ 0x1c, 0xda, 0xaa, 0xdd, 0x91, 0x0b, 0xb0, 0x14, 0x3b, 0xad, 0x02, 0x98,
+ 0x40, 0x3c, 0x54, 0xc4, 0x23, 0xb9, 0x40, 0x54, 0x7e, 0x88, 0x10, 0x3e,
+ 0x24, 0xe5, 0xf6, 0xdf, 0x5c, 0x9e, 0x7a, 0x9f, 0xd0, 0xff, 0x5e, 0x9c,
+ 0xb6, 0x30, 0x17, 0x94, 0xd2, 0xaa, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x80, 0x00, 0x00, 0x00, 0x96, 0xff, 0x2f, 0x01, 0x60, 0x2c, 0x1b, 0xe3,
+ 0xc6, 0xcb, 0xa4, 0x41, 0xa1, 0x44, 0x13, 0x14, 0xe2, 0x44, 0x77, 0x1c,
+ 0x96, 0xe8, 0xe6, 0x4f, 0x70, 0x99, 0x3a, 0xef, 0xa1, 0x6f, 0x1f, 0x7f,
+ 0xb9, 0xe9, 0x1e, 0x35, 0x37, 0x5b, 0x94, 0x90, 0x78, 0xcc, 0x8d, 0xcd,
+ 0x6c, 0x9f, 0xf6, 0x73, 0xed, 0x23, 0xa2, 0x28, 0x64, 0x58, 0x50, 0x64,
+ 0x05, 0xbc, 0xc9, 0x9b, 0x5a, 0xec, 0x3f, 0x2b, 0x61, 0xcf, 0xa7, 0x35,
+ 0x56, 0x8c, 0x77, 0x68, 0xd6, 0xcf, 0x9b, 0xc5, 0x62, 0xee, 0x3a, 0xb2,
+ 0xfe, 0x78, 0xba, 0x02, 0xe7, 0x26, 0x8a, 0x89, 0x30, 0x19, 0xcc, 0xb0,
+ 0x98, 0xbf, 0x30, 0x2c, 0xae, 0x13, 0x6c, 0x93, 0x86, 0x19, 0x84, 0x13,
+ 0x01, 0x2f, 0x39, 0x4e, 0x33, 0xd1, 0x15, 0x99, 0xf7, 0x1e, 0xb8, 0x86,
+ 0xdb, 0xb6, 0xf9, 0x56, 0x42, 0x0e, 0x4a, 0xb1, 0x5e, 0xf0, 0x9a, 0x06,
+ 0x5e, 0xab, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00,
+ 0xcd, 0xde, 0xad, 0x40, 0x34, 0xcd, 0x79, 0x0a, 0x29, 0x84, 0x05, 0x3f,
+ 0xb5, 0xbe, 0x49, 0x84, 0x43, 0xcc, 0xa6, 0xe3, 0xe9, 0xdc, 0x84, 0x14,
+ 0xe7, 0xb3, 0x1b, 0x96, 0xe8, 0xda, 0x35, 0x15, 0x38, 0xf5, 0xb3, 0xb5,
+ 0x91, 0xc3, 0xc3, 0x94, 0xc6, 0x79, 0xeb, 0xf5, 0x22, 0x78, 0xf0, 0x0b,
+ 0xda, 0xb0, 0x91, 0xa7, 0x43, 0x71, 0x8e, 0xa6, 0x52, 0x0f, 0x81, 0x06,
+ 0xc8, 0xdf, 0xb5, 0x1f, 0x92, 0xb0, 0xfe, 0x93, 0x38, 0x4c, 0xf4, 0x17,
+ 0x66, 0x31, 0xea, 0x08, 0x72, 0xb9, 0xaa, 0xfd, 0x40, 0x8d, 0xbf, 0x56,
+ 0x19, 0xb1, 0xb5, 0x8e, 0x4e, 0x4e, 0x73, 0x7f, 0x4b, 0x0c, 0x70, 0x94,
+ 0x7c, 0x9f, 0xfc, 0x23, 0x35, 0xba, 0xd2, 0x23, 0x88, 0x1d, 0x83, 0x28,
+ 0x45, 0xd7, 0x1b, 0x63, 0xfb, 0x36, 0x86, 0x06, 0xf3, 0x99, 0x81, 0x6e,
+ 0xd7, 0xf1, 0xd4, 0x53, 0x6d, 0x30, 0x3c, 0x8d, 0xac, 0xc6, 0x9a, 0xd5,
+ 0xe8, 0x4f, 0x11, 0x58, 0xba, 0xfd, 0x67, 0x06, 0xe7, 0x1a, 0xb4, 0xa1,
+ 0x45, 0x13, 0xf2, 0x3b, 0xdc, 0x71, 0xf0, 0xc6, 0x53, 0xfc, 0x8b, 0x2f,
+ 0x14, 0xe4, 0xe0, 0xd6, 0x8c, 0x96, 0x4c, 0x48, 0xc0, 0x30, 0x6e, 0x00,
+ 0x0f, 0x42, 0xfe, 0xa7, 0x9d, 0x0f, 0xf2, 0x52, 0x58, 0xf9, 0x35, 0x33,
+ 0x99, 0xda, 0xd5, 0x9d, 0x61, 0x26, 0x6b, 0x80, 0xff, 0x08, 0x51, 0x54,
+ 0x26, 0xfa, 0x8d, 0xfc, 0x67, 0x60, 0x93, 0x0e, 0xcd, 0x78, 0x41, 0x5a,
+ 0x31, 0x47, 0x14, 0xb0, 0x65, 0x89, 0x30, 0xcb, 0x0c, 0xc5, 0xa0, 0x37,
+ 0xa8, 0xe0, 0xcf, 0x24, 0xa4, 0x2f, 0xad, 0xa7, 0x9c, 0xa2, 0xe8, 0x81,
+ 0x17, 0xbe, 0x2f, 0xd5, 0xd1, 0xa8, 0xff, 0x9d, 0x5e, 0x7f, 0xd9, 0x6c,
+ 0x56, 0xe6, 0xc4, 0x60, 0x8d, 0xa5, 0x47, 0x5e, 0x43, 0x1e, 0x34, 0x23,
+ 0xb3, 0x6a, 0xdf, 0x6c, 0xf8, 0xd1, 0x85, 0x11, 0xaa, 0x74, 0x85, 0x71,
+ 0x27, 0xc5, 0x80, 0x37, 0x60, 0xb4, 0x2b, 0x53, 0x5a, 0xc4, 0x35, 0xd1,
+ 0xe8, 0x4b, 0x01, 0x58, 0x1f, 0xdb, 0x73, 0xf3, 0x2c, 0x8b, 0xbb, 0x17,
+ 0x36, 0x76, 0x35, 0x6b, 0xa0, 0x82, 0x47, 0xf5, 0x16, 0x21, 0x41, 0x43,
+ 0xc9, 0x1f, 0x53, 0xf9, 0xe9, 0x47, 0xf0, 0x9c, 0x6d, 0xe3, 0x23, 0x59,
+ 0x74, 0xdc, 0x1a, 0x8f, 0x4e, 0x6c, 0x71, 0x83, 0x7e, 0xd0, 0x2b, 0x50,
+ 0x44, 0x86, 0x5f, 0xbf, 0x60, 0x92, 0xeb, 0x9a, 0x9b, 0xa2, 0xc9, 0x2b,
+ 0xa8, 0xc4, 0x77, 0x4e, 0x3f, 0xf8, 0xa6, 0x39, 0x50, 0x5c, 0x7e, 0x2a,
+ 0x70, 0xb0, 0x5d, 0x28, 0xb2, 0x81, 0xa9, 0xaf, 0x16, 0x5e, 0x27, 0xeb,
+ 0x03, 0x0e, 0x82, 0xad, 0x28, 0x51, 0x16, 0xd1, 0xf4, 0x58, 0x75, 0x1a,
+ 0xf9, 0x6a, 0xbf, 0x73, 0xd7, 0x84, 0x07, 0x7f, 0x4c, 0x4e, 0x29, 0x02,
+ 0x9b, 0x60, 0x81, 0x85, 0xa9, 0xbf, 0xc7, 0xa0, 0x8f, 0x8a, 0xdc, 0xa4,
+ 0xc5, 0x17, 0x51, 0x24, 0x15, 0x28, 0x9e, 0x5e, 0x78, 0x84, 0x21, 0x02,
+ 0xca, 0x26, 0x61, 0x4e, 0x95, 0xa6, 0x8d, 0xa6, 0x98, 0x7d, 0x1f, 0x84,
+ 0x19, 0x24, 0x8b, 0x31, 0x76, 0x89, 0x2a, 0x5f, 0xa9, 0xfb, 0xaa, 0x8a,
+ 0x8c, 0xce, 0xe4, 0x30, 0xd6, 0xec, 0x5b, 0x39, 0xb7, 0x09, 0x80, 0x23,
+ 0x4c, 0xe1, 0x6e, 0x8f, 0x7c, 0x10, 0xe8, 0x8a, 0x60, 0x35, 0xd7, 0xa3,
+ 0xe0, 0x5f, 0xcd, 0xfa, 0x3d, 0x8f, 0xd8, 0x5d, 0xec, 0xc9, 0xc5, 0xa0,
+ 0x73, 0x41, 0x89, 0xe5, 0x39, 0xf2, 0x42, 0xff, 0x08, 0xa0, 0x12, 0xb7,
+ 0x4a, 0x5e, 0x46, 0x06, 0x31, 0xbd, 0x88, 0x5e, 0x9e, 0x05, 0x17, 0x51,
+ 0xb3, 0xe7, 0x88, 0x10, 0x19, 0x32, 0xff, 0x8a, 0x1e, 0xce, 0x66, 0xbc,
+ 0x84, 0x1f, 0xed, 0x52, 0x52, 0x77, 0xe1, 0x5e, 0xa6, 0x21, 0xe4, 0xad,
+ 0x59, 0xca, 0xa3, 0x77, 0xea, 0x66, 0x28, 0x15, 0x73, 0x3a, 0xfd, 0xe4,
+ 0x75, 0x46, 0x99, 0x59, 0x5c, 0x7a, 0x9b, 0x9d, 0x11, 0xb4, 0x76, 0x45,
+ 0x06, 0x45, 0x41, 0x1e, 0x94, 0xb7, 0xd9, 0xb8, 0xcb, 0xbf, 0x71, 0xec,
+ 0xba, 0x9f, 0x4a, 0x1b, 0xbc, 0xfd, 0x5c, 0x06, 0x64, 0xfd, 0x31, 0x52,
+ 0xc0, 0xe4, 0xa7, 0x21, 0x2f, 0x22, 0x92, 0xf0, 0x51, 0x33, 0x92, 0x1d,
+ 0x40, 0x3c, 0x01, 0x81, 0x3b, 0xa8, 0x2e, 0x4e, 0xb6, 0x60, 0xcd, 0xd4,
+ 0x36, 0x3b, 0x2e, 0x1d, 0x5e, 0x43, 0xd9, 0x94, 0xf1, 0x51, 0xd3, 0x59,
+ 0x94, 0x6a, 0xd5, 0x5f, 0x1f, 0xd3, 0xa6, 0x55, 0xda, 0x15, 0xf1, 0x3e,
+ 0x2c, 0x60, 0xb8, 0xc3, 0xda, 0x0e, 0x56, 0x53, 0xea, 0xcd, 0x39, 0x27,
+ 0x94, 0x86, 0x94, 0xb2, 0x5b, 0xd8, 0x9a, 0x12, 0x94, 0xb0, 0xb6, 0x77,
+ 0x28, 0xba, 0xde, 0xb6, 0x60, 0x4d, 0x2b, 0x6e, 0x3d, 0xf6, 0xf1, 0x48,
+ 0xf7, 0x77, 0xa1, 0x49, 0xe0, 0x9f, 0x1e, 0xc9, 0xe6, 0xcb, 0x95, 0x26,
+ 0x61, 0x5a, 0xc9, 0xed, 0x49, 0x40, 0x17, 0x57, 0x15, 0xfc, 0x3c, 0xb8,
+ 0x28, 0x79, 0xb8, 0x42, 0x2a, 0xf9, 0xd4, 0x19, 0xb9, 0x5f, 0x41, 0xc2,
+ 0x25, 0xd7, 0x88, 0x34, 0xb3, 0x25, 0x4e, 0xca, 0xff, 0x9e, 0x59, 0x9a,
+ 0x33, 0xc8, 0x12, 0xf9, 0xd5, 0x70, 0xc0, 0x8b, 0x43, 0x13, 0xc4, 0x8d,
+ 0x45, 0x99, 0xaa, 0xd7, 0xeb, 0xb1, 0xe9, 0xb7, 0x5b, 0xab, 0x48, 0xd1,
+ 0x26, 0x60, 0x8c, 0x13, 0x55, 0x8a, 0x41, 0xd3, 0x68, 0x58, 0xd4, 0xa6,
+ 0x30, 0x6e, 0x88, 0x3e, 0x81, 0x6e, 0x61, 0x06, 0x13, 0x66, 0xd5, 0x8e,
+ 0x5d, 0x87, 0x4f, 0xd9, 0xb1, 0x66, 0xb3, 0xc5, 0x88, 0xa9, 0xc0, 0x73,
+ 0xcb, 0x7f, 0x42, 0xec, 0x96, 0x64, 0xad, 0x72, 0x85, 0x72, 0xaf, 0xeb,
+ 0xa9, 0xc4, 0x17, 0x86, 0xab, 0xe7, 0x23, 0xd7, 0x96, 0xf7, 0xb2, 0xb3,
+ 0x51, 0xe1, 0x9a, 0x3b, 0x0e, 0xaf, 0x89, 0xca, 0x7b, 0xf1, 0x70, 0x7b,
+ 0xc7, 0x82, 0xfc, 0xc7, 0x6c, 0x37, 0xd9, 0x7b, 0x82, 0x0f, 0x94, 0xcf,
+ 0xd1, 0xa9, 0x33, 0xc2, 0xa4, 0xab, 0xed, 0xad, 0xee, 0x64, 0x5d, 0x04,
+ 0xf2, 0xcb, 0x8e, 0x99, 0x22, 0x33, 0x69, 0x85, 0x85, 0xb6, 0x1a, 0x9b,
+ 0x09, 0x18, 0xbe, 0xcd, 0x63, 0xf6, 0x5d, 0x52, 0xbc, 0x26, 0x99, 0x3e,
+ 0x52, 0xe5, 0x0c, 0xc5, 0xee, 0xdd, 0xbb, 0x07, 0xbc, 0x38, 0xc1, 0x67,
+ 0x96, 0x8c, 0xe6, 0xe4, 0x18, 0xfa, 0x07, 0x91, 0x48, 0xef, 0x9c, 0x70,
+ 0x9d, 0x5b, 0x1c, 0x0e, 0xd5, 0xd3, 0x59, 0xee, 0x44, 0x13, 0xf7, 0x00,
+ 0xa6, 0x20, 0xad, 0x65, 0x1d, 0xb7, 0x96, 0x2f, 0x79, 0x7b, 0x04, 0xa3,
+ 0x10, 0x90, 0x29, 0x8c, 0xa3, 0x2e, 0x14, 0x39, 0xd3, 0xe4, 0x6e, 0x46,
+ 0xf7, 0x6e, 0x96, 0x68, 0xd9, 0xef, 0x45, 0xf7, 0x3c, 0xcd, 0xc7, 0xca,
+ 0x33, 0x64, 0x8e, 0x31, 0x80, 0x48, 0x7b, 0x7c, 0x81, 0x9a, 0x48, 0xff,
+ 0xd5, 0x0d, 0x74, 0xe7, 0x77, 0x46, 0x61, 0x9b, 0xde, 0xed, 0x83, 0xe9,
+ 0x4f, 0x92, 0xc1, 0x16, 0xad, 0x44, 0x40, 0x23, 0xce, 0x04, 0x31, 0xbf,
+ 0xcf, 0xe2, 0x5a, 0x68, 0x5a, 0xf4, 0x0f, 0xe1, 0x87, 0x79, 0xb0, 0x32,
+ 0x0b, 0x09, 0x6b, 0x72, 0x2b, 0x16, 0x06, 0x67, 0x82, 0x0b, 0x92, 0x35,
+ 0xdb, 0x4c, 0xe2, 0x4a, 0x60, 0x99, 0xaf, 0x52, 0x10, 0x4b, 0xa5, 0xcf,
+ 0xac, 0x66, 0x49, 0x56, 0x04, 0xc0, 0xd6, 0x6f, 0x62, 0x53, 0x6f, 0xcb,
+ 0x62, 0xe9, 0xa5, 0xca, 0x18, 0x8e, 0x86, 0x3f, 0x36, 0xfd, 0xea, 0x55,
+ 0x16, 0x6d, 0x6c, 0x6a, 0x8f, 0xa7, 0x9c, 0x70, 0x15, 0xd7, 0xf4, 0x57,
+ 0x68, 0x04, 0x84, 0x60, 0x3b, 0xb0, 0x32, 0xc4, 0xea, 0x9d, 0x70, 0xb9,
+ 0xa6, 0x34, 0xe5, 0xfa, 0xa1, 0x24, 0x54, 0x7f, 0xef, 0xac, 0xb4, 0x5f,
+ 0xa0, 0xc0, 0x40, 0x3f, 0x73, 0xdf, 0x56, 0xa6, 0xd9, 0x17, 0xf4, 0xff,
+ 0x50, 0xae, 0x21, 0x0d, 0x5a, 0xe0, 0xb0, 0xf9, 0x5b, 0x7a, 0x61, 0x6e,
+ 0xa6, 0x85, 0x85, 0xbf, 0x19, 0x03, 0xe2, 0x74, 0x1f, 0x03, 0x70, 0x76,
+ 0x3c, 0xed, 0x02, 0x7d, 0xfa, 0xf9, 0x1e, 0x17, 0xdd, 0x42, 0x30, 0xf0,
+ 0x32, 0x47, 0x46, 0xae, 0xf5, 0x64, 0xe6, 0x5e, 0x2b, 0x40, 0x86, 0x97,
+ 0xb1, 0x24, 0x52, 0x69, 0x67, 0x79, 0x8e, 0x0d, 0xcc, 0x07, 0xcb, 0x72,
+ 0x29, 0xe9, 0xba, 0x2d, 0xf7, 0xcb, 0xe3, 0x86, 0x06, 0xaa, 0x6d, 0x79,
+ 0xf8, 0xb6, 0x93, 0x0a, 0x9c, 0x97, 0xef, 0x47, 0x37, 0x13, 0x2e, 0x6b,
+ 0xfd, 0x59, 0x0c, 0xc9, 0x5e, 0x5e, 0xcd, 0x71, 0x6f, 0x99, 0x0d, 0x88,
+ 0x9d, 0xbb, 0x7c, 0x2b, 0x22, 0xd5, 0xbe, 0xee, 0x26, 0x1c, 0xe1, 0xad,
+ 0xc8, 0x4d, 0x5f, 0x6b, 0xd1, 0xf4, 0x30, 0x4d, 0x46, 0x1d, 0x54, 0x11,
+ 0x4b, 0xa0, 0x7f, 0x94, 0x71, 0xc0, 0x44, 0x4a, 0x42, 0x11, 0xf5, 0x89,
+ 0xec, 0xb5, 0x24, 0x45, 0xf1, 0xf0, 0x30, 0x54, 0xf8, 0x62, 0xdb, 0x58,
+ 0x3d, 0x7c, 0x2a, 0x82, 0xe5, 0xbe, 0x13, 0xcf, 0xdc, 0x88, 0xfb, 0xd3,
+ 0x1e, 0x4d, 0xa5, 0x3e, 0xad, 0x95, 0xa2, 0xe6, 0x48, 0x73, 0xb2, 0xbe,
+ 0x96, 0xef, 0x8e, 0x0b, 0x28, 0xf9, 0xbe, 0x2a, 0xd6, 0x68, 0x9e, 0x9c,
+ 0x7b, 0x5a, 0xaf, 0x20, 0xf6, 0xa5, 0x3f, 0x99, 0x61, 0x57, 0xe8, 0x1c,
+ 0xb2, 0xc3, 0xd0, 0x7f, 0x2c, 0xb5, 0xe9, 0x66, 0x8e, 0x88, 0xec, 0x13,
+ 0x51, 0xbc, 0x8e, 0xb6, 0xe2, 0x91, 0xbf, 0x5e, 0x8c, 0x1c, 0xdd, 0x0e,
+ 0x0a, 0x13, 0x06, 0xc6, 0x62, 0x1c, 0x41, 0x8d, 0xa1, 0xc0, 0xf2, 0xfa,
+ 0x76, 0x35, 0xaa, 0x77, 0x06, 0x3f, 0x76, 0x50, 0xf6, 0x43, 0xf2, 0x25,
+ 0x00, 0x79, 0xde, 0xca, 0xa1, 0x06, 0x6f, 0xb4, 0x17, 0x4b, 0x99, 0x5a,
+ 0x00, 0x32, 0xd6, 0xb0, 0x1f, 0x80, 0x53, 0x16, 0xaa, 0x87, 0x72, 0xa2,
+ 0x34, 0xaf, 0x90, 0x3d, 0x60, 0xde, 0x0e, 0x6d, 0x83, 0xda, 0xb2, 0x11,
+ 0x2f, 0x39, 0xdc, 0x1a, 0xfe, 0x51, 0x74, 0x10, 0x3c, 0x41, 0xd5, 0x41,
+ 0x65, 0x4a, 0xa0, 0x11, 0xde, 0x95, 0x34, 0xef, 0xa0, 0xc9, 0xa8, 0xd3,
+ 0xcb, 0xb9, 0x7d, 0x51, 0x7d, 0xff, 0x26, 0x88, 0xd8, 0x29, 0x0e, 0xa0,
+ 0xd4, 0xa7, 0x07, 0x33, 0xe7, 0x7d, 0x59, 0x9f, 0x35, 0xc1, 0xb5, 0xf7,
+ 0x78, 0x78, 0x84, 0xf0, 0x20, 0x41, 0x3f, 0x02, 0x7d, 0x41, 0x90, 0x01,
+ 0x8d, 0xa4, 0xd8, 0xd7, 0xeb, 0x56, 0x7f, 0x38, 0xbc, 0x1e, 0x15, 0xdf,
+ 0xfc, 0x34, 0xe7, 0x99, 0xd4, 0x92, 0xd5, 0xf3, 0x9e, 0x16, 0x0b, 0x5c,
+ 0xeb, 0xb6, 0x78, 0xac, 0x84, 0x06, 0x8e, 0xfe, 0xd0, 0x7c, 0xce, 0x4a,
+ 0x43, 0x49, 0x3b, 0xe1, 0xab, 0x57, 0xc0, 0x12, 0xd6, 0x9d, 0xa4, 0xee,
+ 0x91, 0x10, 0x81, 0xe2, 0xfc, 0x02, 0x26, 0x7a, 0xca, 0x81, 0x5b, 0x2f,
+ 0x34, 0x51, 0xdd, 0x25, 0x4d, 0xc8, 0xf9, 0x3e, 0x59, 0x0f, 0x3d, 0x64,
+ 0x51, 0xbf, 0x42, 0xc4, 0x92, 0x9d, 0x8f, 0x39, 0x8a, 0x31, 0x09, 0x24,
+ 0x19, 0x44, 0xc0, 0xf4, 0xea, 0xca, 0x59, 0xcb, 0x86, 0x6c, 0x02, 0x7a,
+ 0xe5, 0x30, 0x79, 0xe2, 0x2c, 0x76, 0x08, 0x8f, 0x98, 0x0d, 0x4d, 0x12,
+ 0xc3, 0x98, 0xb4, 0x24, 0x04, 0x4f, 0x51, 0xec, 0x4e, 0xec, 0xbd, 0x8c,
+ 0xc4, 0x79, 0x51, 0x7f, 0xe1, 0xce, 0x76, 0x28, 0x0b, 0x7b, 0xc5, 0x3f,
+ 0x5b, 0x48, 0x19, 0x76, 0x68, 0x31, 0x8e, 0x28, 0xff, 0x18, 0x24, 0xe3,
+ 0x91, 0xe7, 0x49, 0x0d, 0x10, 0xbd, 0x00, 0xc6, 0x58, 0xfd, 0xb6, 0x88,
+ 0x63, 0xbd, 0xb4, 0x4b, 0xb8, 0xed, 0xdd, 0xb7, 0x53, 0xce, 0x89, 0xdb,
+ 0x7f, 0xf4, 0xc3, 0x21, 0x31, 0xad, 0x20, 0x78, 0x06, 0x71, 0xaf, 0xc0,
+ 0xe3, 0xdc, 0xb8, 0xf4, 0x80, 0xc8, 0x33, 0x1d, 0x8b, 0xff, 0x5a, 0x92,
+ 0x68, 0x4d, 0xc1, 0x5b, 0x58, 0x3e, 0xf6, 0x7f, 0xba, 0x42, 0xa5, 0x6d,
+ 0xec, 0x03, 0x36, 0xc9, 0x3f, 0x83, 0x1f, 0x0c, 0x33, 0x57, 0x6a, 0x43,
+ 0x5f, 0x11, 0x72, 0x19, 0x2c, 0xda, 0x71, 0x58, 0xf2, 0x50, 0x50, 0x06,
+ 0x97, 0xd0, 0xdf, 0xd1, 0x4f, 0x0b, 0x00, 0x1a, 0xea, 0x85, 0x3b, 0x37,
+ 0x2f, 0xf0, 0x40, 0x52, 0xd9, 0x2a, 0xe8, 0x54, 0xa5, 0xee, 0x0f, 0x49,
+ 0x74, 0x39, 0x96, 0x5d, 0x60, 0x8f, 0x14, 0x59, 0x86, 0x59, 0x86, 0xfb,
+ 0x67, 0x71, 0x5c, 0x26, 0x5f, 0xe9, 0xab, 0x32, 0x77, 0x83, 0xdf, 0x02,
+ 0x19, 0x85, 0xae, 0x4d, 0x7d, 0x9c, 0x8d, 0x4f, 0x61, 0x05, 0x3c, 0x0c,
+ 0xc6, 0x74, 0x9e, 0x36, 0x33, 0xb8, 0x14, 0x85, 0xab, 0xa2, 0x0b, 0x5d,
+ 0x22, 0xf2, 0x50, 0x3e, 0xa4, 0x88, 0xac, 0x67, 0xf9, 0x06, 0xe5, 0x30,
+ 0x8e, 0xf9, 0x67, 0x34, 0xd5, 0x94, 0x5b, 0x35, 0xb7, 0x3d, 0x39, 0x5f,
+ 0x4e, 0xae, 0xfe, 0xf7, 0x57, 0xd3, 0x95, 0x7b, 0x0a, 0xd9, 0x92, 0x4a,
+ 0x66, 0x29, 0xa0, 0x18, 0x35, 0x54, 0x14, 0x44, 0x79, 0x72, 0xc3, 0xbc,
+ 0xa8, 0x1a, 0xd3, 0xa3, 0xbe, 0x6f, 0x9e, 0xcc, 0x68, 0xb6, 0x5f, 0xd4,
+ 0x42, 0xab, 0xe8, 0x09, 0x60, 0x57, 0x2e, 0xb2, 0x9a, 0x5b, 0x62, 0x38,
+ 0xfb, 0x0a, 0x35, 0x9c, 0x4f, 0xf7, 0xe0, 0xd2, 0x06, 0x04, 0x1f, 0x79,
+ 0x7f, 0xa7, 0x7b, 0xd3, 0x63, 0xc9, 0xbd, 0x16, 0x58, 0x38, 0x7b, 0xaa,
+ 0x08, 0xf3, 0x14, 0x6c, 0x25, 0xf8, 0xa5, 0xe9, 0x4b, 0x45, 0x34, 0x89,
+ 0x76, 0x74, 0xcb, 0x41, 0x9c, 0x2a, 0xd9, 0xca, 0xb3, 0x12, 0x46, 0x6d,
+ 0x85, 0x4d, 0x63, 0x2d, 0x24, 0x1b, 0x19, 0x6b, 0x3f, 0x61, 0x6b, 0x4b,
+ 0x15, 0x83, 0x2d, 0x8f, 0x61, 0xab, 0xd1, 0x55, 0x93, 0x4e, 0x26, 0xd6,
+ 0x7a, 0x0a, 0x8a, 0xff, 0x58, 0x44, 0xf7, 0x39, 0x31, 0x1a, 0xab, 0xa6,
+ 0x98, 0x31, 0x41, 0x03, 0xb6, 0xc9, 0xf5, 0x50, 0xe3, 0x7b, 0xc0, 0x59,
+ 0x74, 0x60, 0x91, 0xb4, 0x79, 0x02, 0x25, 0xc1, 0xb5, 0xbd, 0xcb, 0x6e,
+ 0x40, 0x61, 0xfe, 0x68, 0x29, 0x83, 0x1b, 0xd2, 0x49, 0xe1, 0x31, 0xde,
+ 0xdd, 0x53, 0xb0, 0xb8, 0x96, 0xa2, 0xce, 0xea, 0x8b, 0x66, 0x2c, 0x5a,
+ 0x80, 0x51, 0x0b, 0xc1, 0x2d, 0x9a, 0xfa, 0x9d, 0xc6, 0xcc, 0x2b, 0xbb,
+ 0xaa, 0xce, 0x98, 0xaa, 0x26, 0x15, 0x8f, 0x4a, 0xe7, 0xdb, 0x17, 0x6c,
+ 0xe5, 0x58, 0xc9, 0xae, 0xe4, 0x9c, 0x1d, 0xab, 0x59, 0x84, 0x3e, 0x27,
+ 0x76, 0x03, 0xe3, 0x82, 0x64, 0x6f, 0x6e, 0x6f, 0x63, 0xd2, 0x12, 0x84,
+ 0xe3, 0x9b, 0x9d, 0x7e, 0x53, 0x1a, 0x54, 0x8d, 0xc1, 0xf0, 0x94, 0xae,
+ 0xad, 0x8f, 0x6a, 0x12, 0x4e, 0xa7, 0x30, 0xdb, 0x55, 0xbe, 0x09, 0xe2,
+ 0x56, 0x08, 0xc4, 0x3a, 0xb0, 0x55, 0xb0, 0x24, 0x96, 0xa6, 0x3e, 0x28,
+ 0xd0, 0x35, 0xfb, 0x58, 0x47, 0xba, 0x2d, 0x51, 0xbb, 0x72, 0x20, 0x59,
+ 0xd2, 0xdd, 0x9c, 0xe2, 0xb5, 0x31, 0x90, 0xac, 0x74, 0x5d, 0x9f, 0x3d,
+ 0x8c, 0x1c, 0x96, 0xc0, 0x60, 0x61, 0xa8, 0xbb, 0x3c, 0xb3, 0x6d, 0x6d,
+ 0x92, 0x4a, 0xca, 0xbb, 0x60, 0x5e, 0x82, 0x0d, 0x7f, 0xab, 0x4b, 0x36,
+ 0x4c, 0x93, 0x0d, 0x88, 0x71, 0xaf, 0xb6, 0x53, 0xb0, 0x38, 0xb4, 0x1c,
+ 0xb4, 0x7b, 0xd4, 0x13, 0x32, 0x6c, 0xe4, 0xee, 0x6a, 0xb3, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x88, 0x83, 0x91, 0x4c,
+ 0x2e, 0x1e, 0xbe, 0xa4, 0xb5, 0x96, 0xff, 0x67, 0x50, 0xe9, 0x81, 0x0e,
+ 0x5d, 0x0e, 0xad, 0xc4, 0x1f, 0xeb, 0x98, 0x38, 0xcc, 0x54, 0x9d, 0x27,
+ 0xa6, 0xf1, 0x37, 0x23, 0xce, 0xb4, 0x5b, 0xff, 0x12, 0xb1, 0xb8, 0x35,
+ 0x5e, 0x03, 0x02, 0x04, 0xad, 0xa6, 0x6f, 0x43, 0xfc, 0xe4, 0xbe, 0x0c,
+ 0xe0, 0x93, 0xd5, 0xef, 0x09, 0xfa, 0x04, 0xe9, 0x5a, 0x22, 0xd4, 0x81,
+ 0xc1, 0x27, 0x4f, 0x5f, 0x6e, 0x83, 0x5a, 0x8a, 0x2d, 0xbb, 0x8f, 0xa4,
+ 0x91, 0xcc, 0x82, 0x37, 0x3b, 0x14, 0x98, 0x58, 0x86, 0x44, 0xb7, 0xa9,
+ 0x58, 0xf3, 0x3d, 0x49, 0x71, 0x7a, 0x37, 0xcd, 0xc5, 0xb9, 0xc9, 0x46,
+ 0xd5, 0xd4, 0x17, 0x60, 0x1a, 0xbf, 0x93, 0xa9, 0xe9, 0x08, 0x25, 0x40,
+ 0xd1, 0x65, 0xae, 0xdd, 0x85, 0xa6, 0xcc, 0x06, 0xca, 0x91, 0xe1, 0x63,
+ 0xf9, 0x6b, 0x15, 0xa8, 0x04, 0x61, 0xd2, 0xa6, 0x59, 0x21, 0x1a, 0x1c,
+ 0xc9, 0xa9, 0xa9, 0xc8, 0x54, 0x86, 0xac, 0xa5, 0xd6, 0x95, 0x39, 0x83,
+ 0x4b, 0x6b, 0x69, 0xa6, 0x94, 0xd8, 0xc0, 0xfb, 0x66, 0x0f, 0x3a, 0xbe,
+ 0xc7, 0xf3, 0xcc, 0xd5, 0xb7, 0x1b, 0x60, 0x02, 0x95, 0x45, 0x4a, 0x12,
+ 0xc9, 0xfe, 0x75, 0x7c, 0x1b, 0xb2, 0x86, 0x96, 0x28, 0x07, 0xa2, 0x18,
+ 0x7a, 0x6c, 0x90, 0x6f, 0x32, 0x0c, 0xc8, 0x34, 0xbc, 0x75, 0x4d, 0x96,
+ 0x03, 0xa6, 0x0f, 0x3d, 0x35, 0x1b, 0x64, 0x76, 0x95, 0x55, 0xff, 0x25,
+ 0xd4, 0x71, 0xcf, 0x8a, 0x73, 0x6d, 0x9b, 0x74, 0xfe, 0xff, 0x9e, 0x31,
+ 0x9e, 0x5e, 0x89, 0x5a, 0x1a, 0xeb, 0x8d, 0x06, 0x3b, 0xf2, 0xf6, 0x06,
+ 0x5d, 0xc3, 0xba, 0x04, 0xca, 0x0f, 0x07, 0x2c, 0xbd, 0x54, 0x52, 0xd9,
+ 0x1c, 0x2f, 0x0e, 0x13, 0x5e, 0x25, 0x13, 0xe5, 0xd7, 0x8e, 0x19, 0x42,
+ 0x1b, 0x52, 0x2e, 0xd2, 0x8f, 0xc5, 0x8e, 0x1c, 0x34, 0x2e, 0x4d, 0xd5,
+ 0x51, 0x7d, 0x91, 0x64, 0xbc, 0xb4, 0x0d, 0xc9, 0xe7, 0x1c, 0x6c, 0x47,
+ 0xe9, 0xbb, 0x67, 0x9a, 0x96, 0xde, 0xad, 0xff, 0xba, 0x35, 0x25, 0x6d,
+ 0x57, 0xa1, 0x93, 0xfe, 0xe2, 0x8d, 0x02, 0xeb, 0xf0, 0x2f, 0x54, 0xfd,
+ 0x46, 0xc0, 0x8f, 0xea, 0x32, 0x7b, 0x57, 0xda, 0xe0, 0x29, 0x1c, 0x19,
+ 0xba, 0xa4, 0xa6, 0x1c, 0x6e, 0xeb, 0x7a, 0xa8, 0x8a, 0xe1, 0xc6, 0x12,
+ 0xf5, 0xa3, 0x24, 0x1a, 0x96, 0xe1, 0x02, 0xc0, 0xf4, 0x7d, 0x14, 0x72,
+ 0xd6, 0x12, 0x8e, 0x6c, 0x8c, 0xd2, 0xfd, 0x88, 0x78, 0x48, 0xf3, 0x74,
+ 0x38, 0x86, 0x04, 0x68, 0x6d, 0x7c, 0xf4, 0x4c, 0x40, 0x17, 0xf6, 0x8f,
+ 0xb2, 0x6c, 0xd7, 0x66, 0x66, 0x3b, 0x38, 0xa1, 0xbb, 0x1e, 0xff, 0x72,
+ 0x1f, 0x64, 0x56, 0xc2, 0x53, 0x1c, 0x6f, 0x84, 0x2b, 0xbd, 0x23, 0xd9,
+ 0xb4, 0x6b, 0x87, 0x79, 0x99, 0xec, 0x81, 0x8d, 0x1a, 0x58, 0x00, 0xf0,
+ 0x2c, 0xc1, 0xc4, 0x57, 0x74, 0x0f, 0xce, 0x32, 0xe2, 0x5e, 0xae, 0x02,
+ 0x1c, 0xe8, 0x94, 0xc6, 0x44, 0xaa, 0x7b, 0x9a, 0x32, 0xb5, 0x33, 0xac,
+ 0xfc, 0x41, 0x65, 0xf2, 0xca, 0xcc, 0xc6, 0x74, 0x36, 0xb2, 0xc9, 0x0e,
+ 0x26, 0x73, 0xae, 0x68, 0x98, 0xa4, 0x36, 0xe8, 0x98, 0x39, 0xad, 0x05,
+ 0x3f, 0xca, 0x12, 0xcc, 0x86, 0xfd, 0xc6, 0x57, 0xf0, 0x02, 0x4e, 0x45,
+ 0xcb, 0x54, 0x34, 0xdd, 0x66, 0x26, 0xab, 0xda, 0x95, 0xa5, 0x85, 0xec,
+ 0x02, 0x03, 0xb6, 0x29, 0x30, 0x11, 0x40, 0x54, 0x9a, 0x6a, 0x87, 0x2e,
+ 0x97, 0xa1, 0x7e, 0xeb, 0x34, 0x39, 0x78, 0x3b, 0xbc, 0x5f, 0x8e, 0xc5,
+ 0x0e, 0x21, 0x29, 0x4b, 0xb7, 0x1b, 0xe7, 0x14, 0x08, 0x34, 0xb7, 0x9a,
+ 0x0a, 0xb2, 0x6c, 0x25, 0x76, 0xb5, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0xe2, 0x7d, 0x48, 0xdd, 0x1a, 0xcb, 0xb6, 0x5c,
+ 0x6f, 0xbe, 0x32, 0x9d, 0xd2, 0x2b, 0x9e, 0x10, 0x65, 0xd7, 0x1e, 0xec,
+ 0xc8, 0xb5, 0x10, 0x64, 0x8f, 0x5d, 0xef, 0xfe, 0x9b, 0x6c, 0x9b, 0x02,
+ 0x6a, 0x6d, 0xf7, 0x98, 0x7b, 0xf7, 0x17, 0xfd, 0x49, 0x1b, 0x6a, 0xc5,
+ 0x3c, 0xa0, 0xfc, 0xa8, 0x94, 0x95, 0xed, 0x48, 0x81, 0x04, 0x53, 0x8c,
+ 0xbe, 0xe4, 0x4e, 0xaf, 0xc1, 0x9d, 0xc3, 0xdf, 0xc2, 0xb5, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0xae, 0xb0, 0x67, 0x5b,
+ 0x99, 0x26, 0x07, 0xfb, 0x6c, 0x98, 0xfe, 0xbb, 0x35, 0xf1, 0x5b, 0x02,
+ 0xc6, 0x03, 0xfc, 0x97, 0x21, 0x16, 0x8d, 0x48, 0xd4, 0x4f, 0x03, 0xd9,
+ 0x7c, 0x9f, 0xa6, 0x1e, 0x6f, 0x5a, 0x58, 0x17, 0x6d, 0x26, 0xb4, 0xc5,
+ 0x4c, 0xe5, 0x93, 0x0a, 0x9c, 0xb2, 0x40, 0xbc, 0x60, 0xc7, 0x2b, 0xdb,
+ 0x3b, 0xc0, 0x3c, 0x5c, 0x44, 0x4b, 0xdd, 0x58, 0xbe, 0xdc, 0xc5, 0xb5,
+ 0x6a, 0xf9, 0x5e, 0x73, 0x07, 0x58, 0x8f, 0x45, 0x7b, 0xac, 0xba, 0x82,
+ 0x96, 0x49, 0x4d, 0x22, 0x70, 0x7a, 0x3d, 0x69, 0x26, 0x8b, 0x88, 0x13,
+ 0xf1, 0x8d, 0xfc, 0xdf, 0x73, 0xd5, 0x20, 0x3c, 0x52, 0x92, 0x16, 0xb1,
+ 0x6e, 0xb7, 0x41, 0xbe, 0x23, 0x9b, 0x51, 0xf7, 0xc9, 0x38, 0x8a, 0xc7,
+ 0x6e, 0x68, 0x82, 0xd1, 0x59, 0x50, 0x09, 0x4b, 0x44, 0x3b, 0x28, 0x06,
+ 0x60, 0x75, 0x7a, 0xe5, 0xa1, 0x36, 0xbb, 0x62, 0x44, 0xe3, 0xd0, 0x68,
+ 0x14, 0xea, 0xad, 0xf9, 0x18, 0xcc, 0xd5, 0x42, 0x5d, 0x18, 0x53, 0xe6,
+ 0x4a, 0xfe, 0xde, 0x32, 0xe1, 0xe7, 0xf8, 0x8c, 0x9d, 0x35, 0xf4, 0x4a,
+ 0xcb, 0x23, 0x2f, 0x91, 0xb5, 0xb0, 0xb2, 0x01, 0x5c, 0x22, 0x8c, 0x42,
+ 0x42, 0xd5, 0xf0, 0x82, 0x6f, 0x9f, 0x64, 0xe5, 0x99, 0x4d, 0x36, 0x0b,
+ 0xfc, 0x78, 0x38, 0x30, 0x47, 0x8f, 0x0b, 0x57, 0x86, 0x4f, 0x1b, 0xc9,
+ 0x05, 0x0e, 0x08, 0xc4, 0xf4, 0xab, 0x9e, 0x90, 0xb4, 0x4f, 0x36, 0x54,
+ 0xe8, 0xa1, 0x3f, 0x90, 0xd2, 0xf3, 0xb4, 0xb4, 0xdd, 0xf3, 0x43, 0x2f,
+ 0xc4, 0x43, 0xbb, 0x99, 0x8e, 0xb8, 0x61, 0x59, 0x5e, 0xfa, 0x1b, 0x3c,
+ 0xc1, 0xeb, 0x9d, 0x35, 0x62, 0x34, 0x82, 0x45, 0xef, 0x41, 0xe9, 0xfc,
+ 0x35, 0xae, 0xb4, 0x0b, 0xce, 0x52, 0x5b, 0x40, 0x7d, 0xdd, 0x86, 0x83,
+ 0x52, 0x74, 0x77, 0x11, 0xc2, 0x9b, 0x8c, 0xa3, 0x63, 0xc2, 0x2d, 0xdd,
+ 0x8c, 0x76, 0x13, 0xc5, 0xc0, 0xde, 0x3e, 0x6b, 0xe1, 0x0f, 0xeb, 0x0f,
+ 0x0a, 0x25, 0x41, 0x2f, 0x8b, 0x4a, 0x98, 0x30, 0xcb, 0x1a, 0x43, 0xa3,
+ 0xc1, 0xcc, 0x44, 0x9a, 0x6c, 0xdc, 0x92, 0x40, 0xc4, 0x7a, 0x1f, 0x8a,
+ 0x6f, 0x74, 0xf3, 0xf5, 0x52, 0x72, 0xf7, 0x81, 0x6e, 0x74, 0x75, 0xe6,
+ 0xea, 0xd9, 0x57, 0x91, 0xae, 0xf2, 0x3f, 0x35, 0x4b, 0x99, 0xd9, 0x3f,
+ 0x85, 0xe0, 0x92, 0xaa, 0x35, 0xac, 0x28, 0xbf, 0x43, 0xb8, 0xad, 0xc7,
+ 0xc5, 0xf6, 0x15, 0x2f, 0x7c, 0xfb, 0x34, 0x48, 0xf3, 0x04, 0x12, 0xf4,
+ 0x2f, 0x92, 0x74, 0xc8, 0xea, 0xbc, 0x24, 0x6e, 0x3b, 0x0e, 0x9e, 0xf0,
+ 0xaf, 0x02, 0x97, 0x95, 0xbc, 0x90, 0x7f, 0xc4, 0xf8, 0xe2, 0x04, 0x9a,
+ 0x8f, 0xfc, 0xbc, 0x50, 0xfe, 0xf7, 0x89, 0x17, 0x2c, 0xdb, 0xd6, 0x5e,
+ 0xbf, 0xd9, 0x8e, 0x89, 0x8b, 0x06, 0x1d, 0x0b, 0x81, 0x2a, 0x55, 0x5c,
+ 0x5f, 0xb6, 0xa6, 0xa5, 0xd2, 0xaa, 0x79, 0x9c, 0x39, 0x31, 0x76, 0x03,
+ 0x98, 0x42, 0xd6, 0xb7, 0x37, 0x1f, 0xc8, 0x51, 0x8a, 0x1c, 0x5d, 0xcd,
+ 0x9c, 0x78, 0xa4, 0x22, 0x6e, 0x12, 0x10, 0x0a, 0x33, 0xc9, 0xe0, 0xfe,
+ 0xfc, 0xe8, 0x15, 0xe7, 0xef, 0xd8, 0x6d, 0xc7, 0xc9, 0xc2, 0x8e, 0x18,
+ 0x82, 0x2f, 0xa6, 0x09, 0x8a, 0xdc, 0x41, 0x6b, 0x89, 0xea, 0xd9, 0xd6,
+ 0x96, 0xfd, 0xba, 0x6e, 0xae, 0x2d, 0x0c, 0xf9, 0x3c, 0x4c, 0x1a, 0xfa,
+ 0x98, 0x83, 0x51, 0x45, 0x9d, 0x1e, 0xa5, 0xc1, 0x81, 0x54, 0x37, 0x5d,
+ 0x28, 0xca, 0xa6, 0xfe, 0x48, 0xf4, 0x77, 0x17, 0x92, 0x1d, 0x0c, 0xb3,
+ 0x39, 0x77, 0x22, 0xd9, 0xc7, 0xc2, 0xaf, 0x70, 0x0a, 0xd3, 0xa6, 0x57,
+ 0x69, 0xfb, 0xb9, 0xe0, 0xc4, 0x73, 0x7a, 0x68, 0xee, 0x27, 0x6e, 0x3a,
+ 0x6e, 0xae, 0x32, 0xf6, 0x09, 0xb3, 0x0b, 0x40, 0x72, 0xc6, 0x26, 0x6e,
+ 0xc5, 0x88, 0x6b, 0xce, 0x99, 0x88, 0x60, 0x6f, 0x6e, 0xa9, 0xe6, 0xd7,
+ 0x35, 0x5e, 0x3b, 0x36, 0x0d, 0x14, 0xb8, 0x2f, 0xde, 0x67, 0xc8, 0x2e,
+ 0x52, 0xc1, 0xf1, 0x58, 0x87, 0x32, 0x2a, 0x52, 0x21, 0x27, 0x1e, 0x04,
+ 0xed, 0xc4, 0x82, 0xd7, 0xeb, 0x85, 0x12, 0x3e, 0xea, 0xd0, 0x07, 0xa0,
+ 0x80, 0x48, 0xe9, 0xbd, 0x9b, 0x3a, 0x8e, 0x8b, 0xa0, 0xfc, 0x07, 0xf0,
+ 0x69, 0x4e, 0xc7, 0x1d, 0xd9, 0x9a, 0x73, 0x18, 0x63, 0xb8, 0xe6, 0x4a,
+ 0xa0, 0x81, 0xf0, 0xdb, 0xb9, 0x88, 0xf4, 0x2b, 0x1f, 0x0d, 0xda, 0x31,
+ 0xc0, 0xb0, 0x55, 0x79, 0x56, 0x48, 0x22, 0xbb, 0x49, 0x7f, 0xb1, 0xf1,
+ 0xf6, 0x6f, 0x42, 0xd3, 0xba, 0x68, 0x3a, 0x8f, 0xe7, 0xac, 0x53, 0x30,
+ 0x96, 0xec, 0x51, 0x7d, 0xfc, 0xc0, 0x35, 0xe9, 0x59, 0xe7, 0x0e, 0xed,
+ 0x29, 0x46, 0x50, 0x3c, 0x4b, 0x36, 0xc6, 0x2a, 0xaa, 0x3b, 0xbe, 0xce,
+ 0xd3, 0xda, 0x4d, 0x65, 0xb0, 0xe8, 0x52, 0x68, 0xf0, 0x23, 0xde, 0x02,
+ 0x77, 0xb3, 0xcc, 0xce, 0x78, 0xdd, 0x8c, 0xf8, 0xbe, 0x5d, 0x0d, 0xa9,
+ 0xb6, 0x96, 0x85, 0xbf, 0x92, 0x2a, 0x6b, 0x1b, 0xe8, 0x76, 0x05, 0x13,
+ 0x30, 0xd8, 0x3d, 0x80, 0xaa, 0xa2, 0xa3, 0xbc, 0x07, 0xba, 0x9c, 0x75,
+ 0x5b, 0x42, 0x03, 0xd8, 0xde, 0x42, 0x44, 0xf7, 0x29, 0x43, 0x29, 0x0d,
+ 0x48, 0x2b, 0x02, 0xd0, 0xcc, 0xe9, 0x17, 0x47, 0x23, 0x73, 0x6d, 0xc5,
+ 0x91, 0x6d, 0x4e, 0xc5, 0xcf, 0xc3, 0x58, 0xaf, 0x6e, 0xa2, 0x9e, 0xe7,
+ 0xe1, 0x88, 0xac, 0x62, 0xff, 0xbc, 0x69, 0x57, 0xad, 0x0f, 0x08, 0xf8,
+ 0x32, 0xfd, 0x79, 0xcb, 0x30, 0xbc, 0xd2, 0xe5, 0x20, 0xd9, 0x0f, 0xd1,
+ 0x33, 0xbf, 0xe4, 0x49, 0x7a, 0x2b, 0x5c, 0xb3, 0x63, 0x13, 0x4d, 0xed,
+ 0x17, 0xe7, 0x5b, 0xf4, 0x36, 0x9d, 0x3c, 0x4e, 0x51, 0xb2, 0xf7, 0xf2,
+ 0xcd, 0xfb, 0xec, 0x42, 0x79, 0x46, 0xae, 0x18, 0x50, 0xdf, 0xbf, 0x5b,
+ 0xb1, 0x9a, 0x49, 0x22, 0xae, 0xe9, 0xf3, 0x86, 0x3f, 0xe0, 0xb4, 0xc6,
+ 0x9c, 0x08, 0xd6, 0xd9, 0xf4, 0x68, 0xbb, 0x33, 0x0e, 0x59, 0x3d, 0x76,
+ 0xf0, 0xd7, 0x54, 0x04, 0x19, 0x66, 0xee, 0x61, 0x11, 0x0d, 0x48, 0x10,
+ 0x21, 0x16, 0x7c, 0xac, 0x49, 0xab, 0xe0, 0x19, 0x85, 0x93, 0x48, 0x65,
+ 0x7c, 0x5e, 0x6c, 0x1a, 0xf5, 0xb0, 0xc6, 0x80, 0xa1, 0x2a, 0xd5, 0x71,
+ 0x42, 0xec, 0x2f, 0x25, 0xf7, 0xb8, 0x84, 0xcd, 0xf0, 0x5c, 0xcd, 0xee,
+ 0x44, 0xcb, 0xeb, 0x74, 0x96, 0x3c, 0xb0, 0x56, 0xcb, 0xaf, 0x7e, 0x9e,
+ 0x4a, 0x12, 0x06, 0xae, 0x57, 0x43, 0x2d, 0xb2, 0x11, 0x96, 0x05, 0xdb,
+ 0xb3, 0x1a, 0x01, 0xa7, 0x1d, 0x02, 0x81, 0x1c, 0x36, 0x41, 0x65, 0xf0,
+ 0x67, 0xd6, 0xd0, 0x0f, 0xec, 0x34, 0x7d, 0xd3, 0x89, 0xac, 0x60, 0x67,
+ 0x95, 0x81, 0x84, 0xe7, 0xbb, 0x9a, 0x59, 0x36, 0x3b, 0xde, 0xa4, 0x88,
+ 0xda, 0xf2, 0xd2, 0xa2, 0x0c, 0xba, 0xfb, 0x93, 0xbf, 0xc8, 0xad, 0xe8,
+ 0x57, 0xa0, 0x2b, 0xbb, 0x4e, 0xa9, 0x38, 0xe7, 0x86, 0x6b, 0x95, 0x34,
+ 0x24, 0x96, 0xc0, 0x09, 0xd9, 0xfd, 0x5f, 0x1c, 0x93, 0xd9, 0x72, 0xfa,
+ 0xc4, 0x14, 0x72, 0x9c, 0x19, 0x6f, 0xee, 0x12, 0x17, 0xee, 0x65, 0xb4,
+ 0x8c, 0x83, 0x39, 0x3c, 0x0f, 0xbf, 0x25, 0xcf, 0xee, 0x05, 0x8c, 0x6a,
+ 0x56, 0x18, 0xf0, 0x20, 0x72, 0xc1, 0xbf, 0xe4, 0xce, 0x37, 0xbf, 0x2b,
+ 0xba, 0x70, 0x1e, 0xc2, 0xc8, 0xcd, 0x58, 0xb9, 0x60, 0xc7, 0xfb, 0xd0,
+ 0xce, 0xb9, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00,
+ 0x7c, 0x63, 0x50, 0x90, 0xcb, 0x9c, 0xce, 0x59, 0xb1, 0x47, 0xb0, 0x49,
+ 0x9b, 0xfc, 0xfb, 0x3d, 0x3d, 0x62, 0xcf, 0x58, 0x4c, 0x2a, 0x79, 0xf0,
+ 0x72, 0x7f, 0x81, 0x41, 0xac, 0x82, 0x2d, 0xa9, 0xf0, 0x0e, 0x4d, 0xd2,
+ 0xe0, 0xbd, 0xca, 0x17, 0xb7, 0x59, 0x9f, 0xdb, 0xfe, 0x51, 0x90, 0x88,
+ 0xb9, 0xeb, 0x4e, 0xac, 0x80, 0x30, 0x64, 0xc4, 0x49, 0xd1, 0xb6, 0x65,
+ 0x67, 0xef, 0x9d, 0x5c, 0x04, 0xe0, 0x9d, 0xbe, 0x47, 0x75, 0x9b, 0x6e,
+ 0x30, 0x76, 0xad, 0x37, 0x9a, 0x56, 0xff, 0xcd, 0x40, 0x26, 0x3e, 0xe2,
+ 0x7d, 0x30, 0x55, 0x09, 0x92, 0x25, 0x36, 0x2f, 0xf8, 0x55, 0xb8, 0x9b,
+ 0x66, 0x49, 0x41, 0x9d, 0x78, 0x6d, 0x3f, 0x54, 0x41, 0x01, 0x93, 0x9c,
+ 0x5e, 0x0c, 0x4a, 0x38, 0x79, 0x76, 0xb4, 0x98, 0xae, 0xf9, 0x99, 0x21,
+ 0x05, 0x6a, 0xfb, 0xbc, 0x44, 0xf7, 0xdc, 0x85, 0x5e, 0x5f, 0x18, 0x49,
+ 0x22, 0x11, 0x6d, 0xa5, 0x9e, 0x6b, 0x59, 0x60, 0xf8, 0x73, 0x8b, 0xcb,
+ 0x38, 0xbb, 0xc9, 0xbf, 0x49, 0x0e, 0x57, 0x65, 0x48, 0x41, 0x41, 0xa2,
+ 0x40, 0x67, 0x91, 0x1d, 0x54, 0xac, 0xa7, 0xef, 0x16, 0x8b, 0xc7, 0xd1,
+ 0xe6, 0xdb, 0xc5, 0x9c, 0xd4, 0x04, 0x67, 0xd8, 0x75, 0x21, 0x2b, 0x1d,
+ 0x11, 0xc1, 0x79, 0x45, 0xb4, 0x91, 0x7a, 0x97, 0x00, 0xde, 0xc6, 0xc5,
+ 0x8a, 0xd1, 0xd7, 0xea, 0xc1, 0x22, 0xe1, 0x58, 0x61, 0xf2, 0x89, 0x3d,
+ 0xdb, 0x04, 0x3d, 0xe4, 0xe9, 0xe7, 0xbf, 0x4b, 0x99, 0x8a, 0xc6, 0xf2,
+ 0x09, 0xc4, 0xe2, 0x6d, 0x0b, 0xda, 0x13, 0xfb, 0xff, 0xbf, 0x0b, 0xfc,
+ 0x78, 0x33, 0xb8, 0x7b, 0x3e, 0xd8, 0xba, 0x27, 0xba, 0xae, 0xdf, 0xce,
+ 0xea, 0x80, 0x08, 0x38, 0xd8, 0x33, 0x00, 0xa9, 0xb6, 0x88, 0x48, 0xa9,
+ 0x3b, 0x54, 0xf0, 0x95, 0xda, 0xba, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x04, 0x00, 0x00, 0xb1, 0xd7, 0x8d, 0x6c, 0xb9, 0x96, 0xdc, 0x64,
+ 0x9b, 0x0c, 0x74, 0x54, 0x59, 0x82, 0xf6, 0x6e, 0x7c, 0x4e, 0x23, 0x83,
+ 0x04, 0x2e, 0x49, 0xfb, 0x56, 0x4b, 0xcd, 0x0d, 0x76, 0x29, 0xb1, 0xce,
+ 0x40, 0xa3, 0xd0, 0x02, 0x16, 0x8e, 0x1c, 0x0a, 0x00, 0x5b, 0x8c, 0x06,
+ 0xf9, 0x07, 0x97, 0x12, 0x0c, 0x33, 0xd5, 0x48, 0x6d, 0xae, 0x7d, 0x2c,
+ 0x8f, 0x74, 0x32, 0x24, 0xcf, 0x91, 0xd7, 0xbe, 0xb2, 0x05, 0xcf, 0x2f,
+ 0x93, 0xd5, 0x43, 0x90, 0xce, 0x02, 0x97, 0xf8, 0x51, 0xb3, 0xba, 0x56,
+ 0x5d, 0x94, 0x41, 0xa4, 0x11, 0xf3, 0x21, 0xc0, 0xcc, 0x28, 0xf8, 0x5a,
+ 0x00, 0x0a, 0xd4, 0x53, 0xdd, 0xac, 0xfe, 0x25, 0x03, 0xea, 0x2b, 0x6b,
+ 0x9d, 0x7e, 0x1a, 0xe1, 0x5f, 0x5c, 0xa7, 0x47, 0xa2, 0x72, 0x4f, 0x92,
+ 0x60, 0x25, 0x7c, 0x1c, 0xa5, 0x34, 0xa6, 0x86, 0x0e, 0xda, 0x8f, 0x3f,
+ 0xec, 0xe2, 0xe4, 0xad, 0xa9, 0x41, 0xcc, 0x3d, 0x94, 0x43, 0xfd, 0x28,
+ 0xd8, 0xb0, 0x0f, 0x05, 0x9e, 0x2b, 0x27, 0x3f, 0xe0, 0x84, 0xbc, 0x9e,
+ 0x7a, 0xa5, 0x83, 0x3d, 0x3b, 0xac, 0x83, 0xd3, 0x16, 0x92, 0x8c, 0xd2,
+ 0x4a, 0x81, 0xdd, 0xba, 0x0a, 0xb7, 0xc5, 0x9f, 0x83, 0x0f, 0x78, 0xb8,
+ 0xab, 0x2d, 0xca, 0xf8, 0x6c, 0x06, 0xd7, 0x82, 0xb8, 0x61, 0x7d, 0x2a,
+ 0x31, 0x3a, 0x39, 0x97, 0x5f, 0xc7, 0x00, 0x6e, 0x46, 0xf2, 0xc5, 0x12,
+ 0x71, 0x55, 0x5b, 0x10, 0xaf, 0xbb, 0x07, 0x4c, 0x2f, 0xa3, 0x51, 0x53,
+ 0x22, 0x20, 0xab, 0xed, 0x02, 0x95, 0xc6, 0x5f, 0xaa, 0xb8, 0xc0, 0xcb,
+ 0xe5, 0xe0, 0x25, 0x97, 0xf7, 0xda, 0x1d, 0xd8, 0x5a, 0xff, 0x76, 0x0c,
+ 0x3e, 0x33, 0x1b, 0x7a, 0x15, 0xb8, 0x34, 0x75, 0xcf, 0xe9, 0xf3, 0x53,
+ 0x61, 0x03, 0x2d, 0x52, 0x29, 0x69, 0x3a, 0xc3, 0xd9, 0x22, 0xc0, 0x2d,
+ 0x80, 0xed, 0x66, 0xc4, 0xf4, 0x89, 0x60, 0x14, 0xdb, 0xec, 0x7d, 0xcc,
+ 0x99, 0x5c, 0x94, 0x27, 0xab, 0xed, 0xd2, 0x17, 0xf4, 0x36, 0xfc, 0x7e,
+ 0x99, 0x98, 0xb6, 0x86, 0xb6, 0x7c, 0x54, 0xd6, 0xec, 0xb5, 0xad, 0x62,
+ 0xcc, 0xb0, 0xf7, 0x8c, 0x52, 0x99, 0xf2, 0x44, 0x27, 0x3a, 0xb0, 0xff,
+ 0x8f, 0x09, 0xae, 0xe1, 0x61, 0xd8, 0x9f, 0xdd, 0x2f, 0x6b, 0xea, 0xd0,
+ 0x12, 0x70, 0x8c, 0x9d, 0x8f, 0x4c, 0x36, 0x98, 0x1e, 0x2e, 0xb5, 0x50,
+ 0x63, 0x33, 0x9c, 0x4b, 0xc3, 0xd4, 0xa0, 0xe6, 0x96, 0x96, 0x75, 0xfd,
+ 0x8a, 0xc4, 0x0c, 0xa7, 0xea, 0x9d, 0xf1, 0x23, 0x9e, 0x38, 0xff, 0x1a,
+ 0x67, 0x36, 0x5f, 0x5f, 0x17, 0x88, 0x1a, 0x43, 0x25, 0xea, 0x76, 0xb5,
+ 0xcd, 0xce, 0x43, 0xf8, 0x71, 0x2b, 0xdb, 0xf0, 0xcd, 0x76, 0xbd, 0x94,
+ 0x57, 0xdb, 0x77, 0xcd, 0xb2, 0x8f, 0xd1, 0xc0, 0xeb, 0x00, 0x61, 0x7f,
+ 0x66, 0xb0, 0x43, 0x6e, 0xe0, 0x9f, 0x11, 0x0e, 0x65, 0xf7, 0x4e, 0x00,
+ 0x74, 0xc3, 0xeb, 0xb1, 0xeb, 0x0c, 0x24, 0x5d, 0x15, 0x56, 0x16, 0x47,
+ 0x87, 0xcf, 0x34, 0xbe, 0x2a, 0xdd, 0x77, 0x55, 0xa4, 0x09, 0x15, 0x79,
+ 0x8c, 0xaa, 0xce, 0x32, 0x90, 0x9b, 0x16, 0x40, 0x94, 0x7f, 0x19, 0x27,
+ 0xbc, 0xbf, 0x45, 0x4b, 0xa5, 0xf0, 0xd0, 0x9e, 0x5b, 0xb9, 0x46, 0x6e,
+ 0x72, 0x8f, 0x49, 0x3b, 0x7a, 0xc1, 0x92, 0xb0, 0xd5, 0x25, 0x1b, 0x0b,
+ 0xf3, 0xd0, 0x8a, 0x47, 0x8b, 0xbe, 0xa4, 0xf9, 0x6a, 0x09, 0x84, 0x9a,
+ 0x5b, 0x5b, 0xea, 0xbb, 0x6f, 0xd8, 0xaf, 0xcd, 0x67, 0x9b, 0x79, 0x7c,
+ 0x8f, 0xcc, 0xd7, 0x5f, 0x3a, 0xc3, 0xd0, 0xb7, 0xba, 0x28, 0x83, 0x81,
+ 0x4a, 0x05, 0x51, 0xaf, 0xa0, 0x52, 0x34, 0xe3, 0x4f, 0xec, 0x82, 0xdc,
+ 0x97, 0xd8, 0x69, 0xb2, 0x0d, 0x68, 0x35, 0x87, 0x58, 0xc0, 0xcf, 0x58,
+ 0x0d, 0xf6, 0x6b, 0x6d, 0x2a, 0xc0, 0x72, 0xe4, 0x90, 0x8c, 0x7b, 0x45,
+ 0xba, 0xf1, 0x13, 0x6f, 0x8c, 0xd2, 0xdd, 0xc5, 0x8e, 0xc8, 0xec, 0xf9,
+ 0xfb, 0xde, 0xe5, 0xaa, 0xcb, 0xc0, 0xff, 0x77, 0x2d, 0x99, 0xb1, 0x69,
+ 0x7f, 0xe3, 0x38, 0x61, 0x35, 0xb6, 0x45, 0xdd, 0x73, 0x45, 0x84, 0x89,
+ 0x1b, 0x96, 0x7e, 0x6a, 0x1d, 0xd9, 0xe6, 0x76, 0xa8, 0x16, 0x0f, 0x42,
+ 0xc9, 0x41, 0xec, 0x5d, 0x25, 0x01, 0xb0, 0x45, 0xa6, 0xaa, 0x69, 0x87,
+ 0x11, 0xa1, 0xb8, 0x9e, 0x68, 0x48, 0x68, 0xe9, 0xb5, 0xc2, 0xff, 0x83,
+ 0x8f, 0x71, 0xb9, 0xd7, 0xbb, 0xae, 0x59, 0x8b, 0x1b, 0x4c, 0x44, 0xd8,
+ 0xe3, 0xce, 0xab, 0x88, 0xfb, 0x64, 0xd9, 0x61, 0x5a, 0x7d, 0xce, 0x3a,
+ 0x27, 0xb5, 0xa3, 0xfd, 0x5d, 0xa3, 0xb8, 0xa1, 0x15, 0x63, 0x0b, 0x75,
+ 0x39, 0xc3, 0xa4, 0xfb, 0x60, 0x53, 0xfd, 0x11, 0x21, 0x35, 0x0f, 0x19,
+ 0x28, 0x14, 0xcd, 0x8a, 0xcf, 0x33, 0xaa, 0x4f, 0x6a, 0x1e, 0x56, 0x87,
+ 0xd5, 0x6e, 0x43, 0x9b, 0xa3, 0x72, 0x95, 0x8c, 0x34, 0xa2, 0xac, 0x11,
+ 0x76, 0x95, 0xd7, 0xdd, 0xbf, 0x10, 0xf4, 0x0f, 0x2a, 0x64, 0xd2, 0x4d,
+ 0x7b, 0xc6, 0x9b, 0x7d, 0xf7, 0xa5, 0xb3, 0x84, 0x9a, 0x9a, 0x5e, 0xcf,
+ 0x7f, 0x95, 0x6d, 0x44, 0xd1, 0xb2, 0x19, 0xbb, 0xed, 0x37, 0x42, 0x4b,
+ 0x4b, 0x6d, 0xb7, 0x10, 0x02, 0x5f, 0x00, 0x1f, 0x24, 0xce, 0xb2, 0x8b,
+ 0x3e, 0x7d, 0xc6, 0x6e, 0x6c, 0x90, 0x75, 0xad, 0x3f, 0x9d, 0x63, 0x04,
+ 0x76, 0x20, 0x7a, 0x56, 0x48, 0xa1, 0x6a, 0x37, 0x74, 0xd2, 0xb7, 0x4f,
+ 0xa3, 0x64, 0x62, 0xaa, 0xce, 0x75, 0x8c, 0x15, 0x75, 0x79, 0xa0, 0xbd,
+ 0xdd, 0x01, 0x46, 0xca, 0xa0, 0x31, 0x1a, 0x16, 0x1f, 0xef, 0x8b, 0xc6,
+ 0x54, 0x57, 0xfa, 0x6e, 0x43, 0xdf, 0xb0, 0x99, 0xed, 0xa4, 0xcb, 0xeb,
+ 0x91, 0x35, 0x14, 0x0c, 0xa9, 0x1d, 0xb5, 0xa9, 0x32, 0x99, 0xe3, 0x89,
+ 0x74, 0xaa, 0xa4, 0x65, 0x1e, 0x82, 0x47, 0xfa, 0x37, 0x23, 0xe5, 0x86,
+ 0xb6, 0xc0, 0xb6, 0x89, 0x9a, 0xd9, 0xae, 0x29, 0x39, 0x7b, 0x66, 0xc7,
+ 0x5b, 0x02, 0x08, 0x86, 0xd4, 0xf0, 0x75, 0xc2, 0x05, 0x86, 0xc3, 0x75,
+ 0xd2, 0x2a, 0x1e, 0xec, 0x6e, 0x75, 0x29, 0x58, 0x8c, 0x25, 0x3b, 0x95,
+ 0x21, 0xde, 0x42, 0xd5, 0xb7, 0x15, 0x30, 0x09, 0x49, 0x78, 0x55, 0xd5,
+ 0xf2, 0x30, 0x80, 0x93, 0x8a, 0xce, 0x84, 0x27, 0xdb, 0x4a, 0x09, 0x30,
+ 0x0c, 0x7f, 0x4d, 0xd1, 0x0f, 0xda, 0x66, 0x58, 0xe1, 0x01, 0xfd, 0x75,
+ 0x83, 0xf5, 0x39, 0x2e, 0xe2, 0x6b, 0xde, 0xff, 0x20, 0x8a, 0xf7, 0xcc,
+ 0x81, 0x8e, 0x99, 0xb4, 0xeb, 0x76, 0x74, 0x38, 0x2b, 0xe0, 0x6d, 0x61,
+ 0x8f, 0x39, 0x59, 0x10, 0x7d, 0xb5, 0xd3, 0x14, 0x96, 0x04, 0x1d, 0x22,
+ 0x89, 0xef, 0x15, 0x7c, 0x28, 0x5a, 0xd6, 0x8d, 0xf3, 0xb7, 0x6a, 0x9a,
+ 0xce, 0x21, 0x77, 0xfd, 0x4f, 0x22, 0x26, 0x28, 0xb8, 0xb5, 0xb3, 0x73,
+ 0xfd, 0x2a, 0x7b, 0x42, 0x26, 0x77, 0x41, 0x93, 0xed, 0xf9, 0x8f, 0xa9,
+ 0x92, 0xd5, 0x9f, 0x2e, 0x60, 0xec, 0x60, 0x98, 0xf1, 0xd5, 0x11, 0xe2,
+ 0xe0, 0xd7, 0x45, 0xa7, 0xe4, 0xf2, 0x82, 0x61, 0x2f, 0x41, 0x1b, 0xd9,
+ 0x8e, 0x78, 0xd5, 0x6b, 0x68, 0x74, 0xf0, 0xc3, 0x83, 0x01, 0x16, 0x60,
+ 0x6e, 0x34, 0x88, 0x45, 0x8a, 0x86, 0x44, 0x5b, 0xa5, 0xa8, 0x55, 0xbc,
+ 0xfa, 0x8f, 0xbd, 0x93, 0x95, 0x3f, 0xab, 0x19, 0x54, 0x8f, 0x06, 0x8e,
+ 0xca, 0x0b, 0x4a, 0x18, 0x3f, 0x7a, 0x9c, 0x3f, 0xe6, 0xbe, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x81, 0x32, 0x41, 0x46,
+ 0x59, 0x26, 0xf4, 0xef, 0x93, 0x9f, 0x04, 0xc2, 0x67, 0x13, 0x32, 0x45,
+ 0xc0, 0x79, 0x70, 0x27, 0x21, 0x2b, 0xaf, 0x35, 0xf3, 0xc4, 0x88, 0x52,
+ 0x28, 0xea, 0xca, 0x8a, 0x08, 0x01, 0x6f, 0x61, 0xab, 0x10, 0xa3, 0xf0,
+ 0x6b, 0x3b, 0x54, 0x64, 0xf1, 0x63, 0x83, 0x38, 0x2b, 0x26, 0x18, 0x5a,
+ 0x67, 0xc4, 0x67, 0x38, 0x3f, 0x2c, 0x9a, 0xc9, 0x48, 0x33, 0x77, 0xb4,
+ 0xb2, 0xc2, 0xc7, 0x08, 0x21, 0x5e, 0xc4, 0x19, 0x59, 0xe1, 0xfa, 0x32,
+ 0xa4, 0x4c, 0x3e, 0xba, 0x65, 0x92, 0x98, 0x39, 0x71, 0x2f, 0x99, 0x08,
+ 0xf8, 0xb3, 0x7a, 0x03, 0x53, 0xd7, 0x68, 0xb2, 0x5e, 0xb0, 0xef, 0xe0,
+ 0x1e, 0x7d, 0xb2, 0x23, 0x5d, 0x2b, 0xd7, 0x09, 0xa6, 0x78, 0xa4, 0x7c,
+ 0x08, 0xed, 0x8a, 0xf6, 0x96, 0xa0, 0x10, 0x17, 0x62, 0x8b, 0x8a, 0xa0,
+ 0xac, 0x22, 0x67, 0x02, 0xa8, 0x66, 0x1a, 0xb5, 0x02, 0xde, 0xa5, 0xfa,
+ 0x69, 0x29, 0x5f, 0x24, 0x89, 0x46, 0x68, 0xd6, 0x51, 0x2a, 0xfe, 0x88,
+ 0xf0, 0x40, 0xde, 0xd1, 0x12, 0x2e, 0xed, 0x13, 0x7b, 0x49, 0xf6, 0xe1,
+ 0x7a, 0xcf, 0x61, 0xcb, 0x70, 0x9d, 0xaa, 0x51, 0x07, 0xc2, 0x54, 0x76,
+ 0x89, 0x29, 0x94, 0x29, 0x8b, 0x0e, 0xf5, 0xe8, 0x81, 0xc7, 0xdb, 0x59,
+ 0x1e, 0x75, 0xda, 0x6a, 0x94, 0x18, 0x16, 0xae, 0xbb, 0x43, 0x87, 0x56,
+ 0x66, 0x8b, 0x84, 0xe9, 0xa9, 0xd0, 0xd2, 0x8f, 0x5b, 0xbf, 0x1d, 0x24,
+ 0x3a, 0xb7, 0x64, 0xff, 0xe9, 0x22, 0x21, 0x65, 0xaf, 0x2b, 0x45, 0x8d,
+ 0x28, 0xea, 0xbc, 0x07, 0x10, 0x6e, 0xfb, 0x4d, 0x6f, 0x35, 0xe5, 0xeb,
+ 0x5d, 0x29, 0x72, 0xe1, 0x94, 0xad, 0xed, 0x25, 0xd7, 0x39, 0x63, 0x32,
+ 0x37, 0x0b, 0xb2, 0xd7, 0x54, 0x1f, 0xe4, 0x0d, 0xe7, 0xb3, 0xd1, 0xa6,
+ 0x2a, 0xcf, 0x8e, 0x97, 0xf1, 0xa8, 0xfc, 0xb1, 0x61, 0xdc, 0xb4, 0x8f,
+ 0x29, 0xa2, 0x68, 0x4a, 0xe6, 0x2f, 0x8a, 0x69, 0x2c, 0xa1, 0x1d, 0xe2,
+ 0x9e, 0x65, 0x71, 0xb7, 0x83, 0xef, 0x63, 0xf5, 0x36, 0xdc, 0xa0, 0x94,
+ 0x5a, 0x45, 0x8a, 0x85, 0x5e, 0x28, 0x86, 0x21, 0xd2, 0xbf, 0x7a, 0x2f,
+ 0x76, 0x1c, 0x2a, 0x15, 0xb2, 0xe8, 0xaf, 0x63, 0x37, 0xbe, 0xd8, 0x0a,
+ 0xef, 0x54, 0xee, 0xe6, 0xd9, 0xb3, 0xdb, 0x41, 0x55, 0xba, 0xd8, 0x14,
+ 0x7c, 0x10, 0x61, 0x06, 0x40, 0x45, 0x69, 0x37, 0x60, 0xf7, 0x6a, 0x7a,
+ 0x23, 0x70, 0x30, 0x57, 0x3e, 0xe5, 0x12, 0x24, 0xbc, 0x5e, 0x82, 0x89,
+ 0xd8, 0x37, 0xc9, 0x33, 0xb9, 0x38, 0xa5, 0xba, 0xed, 0xdd, 0x93, 0x58,
+ 0x81, 0x15, 0xec, 0x15, 0x70, 0x2f, 0x30, 0xfa, 0xaf, 0xf7, 0xf5, 0xcb,
+ 0x41, 0x74, 0xea, 0xc0, 0x91, 0xbe, 0x53, 0x4c, 0xc2, 0x74, 0x1b, 0x5b,
+ 0x8c, 0x74, 0xd8, 0xc3, 0x4a, 0x12, 0xaa, 0x57, 0xd6, 0x61, 0xb1, 0xb8,
+ 0x81, 0x5d, 0x81, 0x37, 0x1e, 0x5b, 0x3d, 0x5a, 0xbc, 0xa6, 0xb2, 0x27,
+ 0xe3, 0x01, 0x4c, 0xf0, 0xad, 0x7b, 0xdf, 0x50, 0xf9, 0xd7, 0xb7, 0xcc,
+ 0xa8, 0x5c, 0x3d, 0x9a, 0xb7, 0x60, 0x3e, 0x63, 0x3f, 0x6a, 0x08, 0x0b,
+ 0x82, 0xdc, 0x3e, 0xfa, 0x24, 0x33, 0xd3, 0x01, 0xbf, 0xef, 0xeb, 0x52,
+ 0x3f, 0x91, 0x61, 0xda, 0xe2, 0x26, 0x10, 0xdf, 0xe4, 0x9b, 0x77, 0x91,
+ 0x22, 0xc5, 0x4e, 0x9c, 0x0b, 0x32, 0xff, 0x27, 0x85, 0x85, 0x0c, 0x99,
+ 0x50, 0x8f, 0xad, 0x5d, 0x06, 0x18, 0x52, 0xb4, 0x64, 0x09, 0xc4, 0xa4,
+ 0x84, 0xd4, 0x81, 0x07, 0x0a, 0x97, 0x55, 0xf8, 0x96, 0x52, 0xb2, 0x9a,
+ 0xf4, 0x06, 0x2c, 0x9a, 0x3b, 0x8b, 0xaa, 0x67, 0x18, 0x3a, 0xee, 0xbc,
+ 0xca, 0x8f, 0x46, 0xf6, 0x4a, 0x33, 0x5b, 0x56, 0x09, 0xb2, 0x72, 0x87,
+ 0xdb, 0xbb, 0x57, 0x67, 0x53, 0x82, 0x77, 0x31, 0x66, 0xbb, 0xf1, 0x33,
+ 0x6d, 0x55, 0x82, 0xaa, 0x80, 0xd4, 0x4d, 0xb8, 0xab, 0xbd, 0x2a, 0xda,
+ 0x10, 0x3a, 0xc8, 0xf0, 0x14, 0x1e, 0xcb, 0x8e, 0x76, 0x6c, 0xc8, 0x74,
+ 0x05, 0xb3, 0x51, 0xbd, 0x63, 0x06, 0x69, 0x05, 0x2a, 0x21, 0xd6, 0x2f,
+ 0xe4, 0x38, 0xae, 0xf8, 0xd4, 0xe9, 0xa7, 0xe8, 0xc8, 0x5a, 0x65, 0x7d,
+ 0x54, 0x34, 0x33, 0x0d, 0xf6, 0x07, 0xd6, 0x8c, 0xe5, 0x72, 0x9b, 0xfb,
+ 0x60, 0x49, 0xd2, 0xaf, 0xb4, 0x17, 0xc4, 0x74, 0x8d, 0xe5, 0x54, 0xda,
+ 0x96, 0x56, 0x7d, 0x97, 0x62, 0xe8, 0xec, 0x0d, 0x2b, 0x02, 0x2e, 0x59,
+ 0xf8, 0xa1, 0x06, 0x6a, 0xb6, 0x3e, 0x15, 0xeb, 0x64, 0x1a, 0x48, 0x3d,
+ 0x53, 0x2c, 0x42, 0x3b, 0x97, 0xa1, 0x3f, 0x47, 0x8b, 0x74, 0x87, 0x8b,
+ 0x96, 0x63, 0x08, 0x4c, 0x99, 0x38, 0x5a, 0xb6, 0x93, 0xa8, 0xcc, 0xee,
+ 0x62, 0x3a, 0x00, 0x6d, 0x5c, 0xab, 0x77, 0x3c, 0x46, 0xae, 0x6e, 0xeb,
+ 0xf1, 0xf9, 0x63, 0xf1, 0xa2, 0x31, 0x21, 0x38, 0xc3, 0x4f, 0xe2, 0x3a,
+ 0x33, 0x7f, 0xe7, 0xc6, 0x69, 0xd5, 0x1c, 0x7e, 0x5b, 0x4f, 0xb1, 0x50,
+ 0x3b, 0xbe, 0x31, 0xa7, 0x42, 0xa3, 0x97, 0x7b, 0xe3, 0x90, 0xd0, 0x07,
+ 0xfd, 0x05, 0xb9, 0xf2, 0x47, 0xc4, 0xc8, 0xdd, 0x1c, 0x3c, 0xa4, 0x22,
+ 0x96, 0x04, 0xca, 0x28, 0x17, 0xcc, 0x5c, 0x49, 0x7e, 0xc6, 0x93, 0x98,
+ 0xd3, 0x8b, 0xd2, 0xf6, 0x4a, 0xb6, 0xbe, 0x8d, 0xa2, 0xdd, 0xb6, 0x7c,
+ 0x66, 0x0c, 0x29, 0xcb, 0x1d, 0x98, 0xf6, 0xe4, 0xe5, 0x30, 0x4c, 0x84,
+ 0xbf, 0x6f, 0x71, 0x4e, 0xc2, 0x12, 0x9f, 0x35, 0xd6, 0xf8, 0xc6, 0x30,
+ 0xe9, 0x9e, 0x1a, 0x8a, 0x2f, 0xd1, 0x96, 0xb3, 0x3c, 0x0f, 0xf5, 0x78,
+ 0xa7, 0xe0, 0xbd, 0x4b, 0xe0, 0xd8, 0x3d, 0x57, 0xa5, 0x44, 0xa0, 0xd9,
+ 0x10, 0x79, 0xd2, 0x10, 0x50, 0xc7, 0x77, 0x73, 0x09, 0xf8, 0xb4, 0xcf,
+ 0x66, 0xe3, 0x0c, 0xfb, 0x96, 0xf8, 0x52, 0xb3, 0x7e, 0x44, 0xf0, 0x03,
+ 0x54, 0xd4, 0xa2, 0x57, 0x38, 0x8a, 0x96, 0xfc, 0x7c, 0x4c, 0x9f, 0x3a,
+ 0xf2, 0xa2, 0x48, 0xbb, 0x3e, 0xd1, 0x11, 0x2c, 0xab, 0xdf, 0x53, 0x96,
+ 0xac, 0x58, 0x33, 0xb9, 0xdd, 0xd2, 0x4f, 0x8a, 0x0a, 0x89, 0x0e, 0xd3,
+ 0x6f, 0x58, 0x8c, 0xa1, 0x0a, 0x0b, 0xa7, 0xd7, 0x1f, 0x0a, 0x70, 0xe3,
+ 0x43, 0x12, 0x56, 0xb8, 0x6c, 0xf8, 0x75, 0x4e, 0x2b, 0xb0, 0x17, 0x29,
+ 0xe4, 0x95, 0x85, 0xd8, 0x85, 0x95, 0x63, 0x55, 0xa8, 0x82, 0xf0, 0xe7,
+ 0x7d, 0xf3, 0xf1, 0x78, 0x66, 0xd1, 0x92, 0x71, 0x99, 0xad, 0x30, 0x94,
+ 0xe9, 0x54, 0x2c, 0xe1, 0x57, 0xf3, 0x6a, 0xe6, 0x0c, 0x5e, 0xc7, 0x58,
+ 0xba, 0xb7, 0x61, 0xd3, 0x74, 0x72, 0x96, 0x06, 0x0b, 0x01, 0x3d, 0xc2,
+ 0xa1, 0xb4, 0x38, 0x81, 0x19, 0x44, 0xbc, 0x84, 0x52, 0x22, 0xc9, 0x67,
+ 0x81, 0x99, 0xfb, 0x0a, 0xc2, 0xff, 0x50, 0x67, 0xbe, 0x38, 0x5e, 0x13,
+ 0x16, 0x60, 0x83, 0x35, 0xb9, 0x2f, 0xa9, 0x55, 0xbb, 0x30, 0x6b, 0x19,
+ 0xfc, 0x2a, 0x40, 0x24, 0x74, 0x20, 0x57, 0x78, 0xb9, 0x55, 0xb7, 0x70,
+ 0x86, 0x65, 0x43, 0x1c, 0x76, 0x2e, 0x91, 0x83, 0x5e, 0x33, 0xc2, 0xd4,
+ 0xcc, 0xb5, 0x1c, 0x45, 0xaf, 0xa3, 0x87, 0x95, 0x9b, 0x77, 0x50, 0x44,
+ 0x7e, 0xdd, 0xca, 0x3f, 0x51, 0x21, 0xae, 0xf2, 0x15, 0xa9, 0x32, 0x94,
+ 0xca, 0xde, 0x3b, 0x97, 0x13, 0x6b, 0xff, 0xe0, 0x79, 0x39, 0x40, 0xf0,
+ 0x66, 0x7d, 0x5e, 0xef, 0xec, 0x0a, 0x35, 0xd2, 0x0d, 0x09, 0x19, 0x13,
+ 0xf2, 0xc2, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0xdc, 0x07, 0x2e, 0x46, 0xab, 0x4d, 0x6d, 0xf7, 0x24, 0xba, 0x02, 0xe3,
+ 0xc5, 0xe3, 0xed, 0x64, 0xc6, 0x77, 0x5a, 0x14, 0xae, 0x38, 0x52, 0x8c,
+ 0x16, 0x2c, 0x52, 0x0e, 0xf6, 0x65, 0x99, 0xcc, 0xf6, 0x9f, 0x77, 0xcc,
+ 0x2e, 0xaf, 0x14, 0xd1, 0xf0, 0x0f, 0xa7, 0x3e, 0x5b, 0x74, 0xff, 0xb9,
+ 0xd3, 0x30, 0x02, 0x5e, 0x52, 0xc8, 0x6f, 0x57, 0xef, 0x28, 0xf5, 0xfa,
+ 0x9e, 0x70, 0x00, 0xfc, 0x3e, 0xc3, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x04, 0x00, 0x00, 0xaa, 0x9f, 0x86, 0xb0, 0x6d, 0xa1, 0x0c, 0xfa,
+ 0xef, 0xb3, 0x6a, 0x50, 0xa6, 0xfe, 0xff, 0xa9, 0x61, 0x0b, 0x18, 0x72,
+ 0xee, 0xc6, 0xcd, 0x3a, 0x34, 0x5e, 0xa8, 0x81, 0x31, 0x54, 0x25, 0x05,
+ 0xc1, 0xd9, 0x66, 0x3d, 0x17, 0xbb, 0x03, 0x21, 0x07, 0x69, 0x3a, 0x37,
+ 0xe8, 0xd4, 0x6a, 0x68, 0xe1, 0xa3, 0x19, 0x5a, 0x8d, 0x14, 0x11, 0x09,
+ 0xef, 0xae, 0xfe, 0x94, 0x19, 0x8a, 0xe4, 0xb9, 0x6e, 0xe8, 0xfa, 0x12,
+ 0x2a, 0x5d, 0x00, 0x29, 0x27, 0x6d, 0x5a, 0xa5, 0x09, 0x34, 0x79, 0x2b,
+ 0xa8, 0xcc, 0x42, 0xb4, 0xde, 0xe0, 0x91, 0xb9, 0x06, 0x0c, 0x11, 0x17,
+ 0x25, 0x7a, 0x35, 0x57, 0x51, 0x40, 0xf3, 0xc7, 0xc6, 0x4a, 0x69, 0x98,
+ 0x2b, 0x2b, 0x3e, 0x5d, 0x32, 0xd8, 0x8f, 0xb0, 0x1d, 0xee, 0x77, 0xe3,
+ 0xaf, 0x4f, 0x71, 0x05, 0x04, 0xd2, 0xff, 0x51, 0xed, 0xa4, 0x69, 0x50,
+ 0x24, 0x2a, 0xe5, 0xaa, 0xbb, 0xc6, 0x7a, 0x7f, 0xb2, 0xdf, 0x1d, 0xc2,
+ 0x02, 0x2e, 0x52, 0xd1, 0xd9, 0x5b, 0xe7, 0x6c, 0x50, 0x31, 0x4e, 0xdf,
+ 0x8e, 0x3f, 0x37, 0xfc, 0xf5, 0x34, 0x0e, 0xdb, 0x4c, 0x5d, 0x7d, 0xc8,
+ 0xe4, 0x72, 0x40, 0xcb, 0x95, 0xa5, 0x41, 0xeb, 0x78, 0x5f, 0x64, 0x20,
+ 0x55, 0x19, 0xc7, 0xf9, 0x9c, 0x71, 0x40, 0x8f, 0xcc, 0x2d, 0x86, 0xc0,
+ 0xf4, 0x36, 0x2b, 0x0e, 0x28, 0xb4, 0xad, 0x1b, 0xde, 0x60, 0x67, 0x03,
+ 0x0f, 0x7c, 0x18, 0xd9, 0xc3, 0x73, 0x67, 0x0d, 0x44, 0x3d, 0xbe, 0x7c,
+ 0xcf, 0x96, 0x22, 0x0b, 0x0e, 0x3a, 0x0b, 0xcf, 0x04, 0x95, 0x92, 0x7d,
+ 0x4b, 0xa2, 0x6a, 0x0b, 0x47, 0x72, 0x73, 0xa8, 0x9b, 0x96, 0x3d, 0xc6,
+ 0x03, 0x34, 0xb1, 0x69, 0xc2, 0x50, 0x60, 0x89, 0x8c, 0x55, 0x8f, 0x8e,
+ 0x74, 0xa8, 0x9e, 0x25, 0xe4, 0x0e, 0x73, 0xef, 0x4f, 0x51, 0xbe, 0xed,
+ 0x5c, 0x14, 0xd3, 0xfa, 0x94, 0x58, 0x8d, 0x5c, 0xa0, 0xb1, 0xfc, 0x37,
+ 0x6e, 0x9c, 0x9e, 0x61, 0xe5, 0x12, 0x13, 0xb2, 0x88, 0xc6, 0xcf, 0x60,
+ 0x3f, 0x0d, 0x51, 0x33, 0x22, 0xfa, 0xfb, 0x2d, 0x2b, 0x8d, 0x43, 0x9b,
+ 0x3d, 0x1e, 0x88, 0x24, 0x50, 0x78, 0xf7, 0x7e, 0x45, 0xb1, 0x0f, 0xa9,
+ 0xe6, 0x77, 0xf8, 0x78, 0xff, 0x57, 0x6a, 0x05, 0x06, 0x0c, 0x7e, 0x1e,
+ 0x7f, 0xe9, 0x90, 0xe8, 0x61, 0x68, 0xbc, 0x9e, 0xc4, 0xe5, 0x06, 0x04,
+ 0x76, 0xcc, 0x01, 0x57, 0x1a, 0x55, 0x9e, 0x45, 0x26, 0xd6, 0xd8, 0xc2,
+ 0x50, 0x25, 0xfc, 0x72, 0x4e, 0x18, 0xbe, 0xf2, 0x2f, 0xc0, 0x1b, 0xc8,
+ 0x14, 0xeb, 0x24, 0xda, 0x15, 0x0a, 0x83, 0x38, 0xc5, 0xdd, 0xc9, 0xd7,
+ 0x12, 0x35, 0x55, 0xdf, 0x2c, 0x23, 0xea, 0x17, 0xca, 0xbf, 0x18, 0xc9,
+ 0x80, 0x63, 0x4b, 0x77, 0x8b, 0x17, 0x01, 0x05, 0x1b, 0xa3, 0x0b, 0x0f,
+ 0xdd, 0xc6, 0xe0, 0xdf, 0xc9, 0xa6, 0x8c, 0x50, 0x95, 0x8d, 0x6c, 0x96,
+ 0x67, 0xff, 0x88, 0x38, 0x3b, 0x76, 0x72, 0x11, 0x35, 0xa0, 0x1c, 0xc8,
+ 0x96, 0x9c, 0xe5, 0x90, 0x79, 0x0e, 0x62, 0x57, 0x00, 0xd9, 0x57, 0xf8,
+ 0xa4, 0xc2, 0xc2, 0x0a, 0x17, 0x8e, 0xd7, 0x03, 0x6d, 0x4d, 0x14, 0xb6,
+ 0x96, 0x8a, 0x76, 0x67, 0x58, 0xce, 0x9c, 0xb3, 0x10, 0x49, 0x06, 0xeb,
+ 0x56, 0x43, 0x40, 0xcb, 0xd4, 0xd7, 0x59, 0x42, 0xa4, 0xd7, 0x21, 0x6a,
+ 0x51, 0x3d, 0x1c, 0x54, 0xd7, 0xd6, 0xa2, 0xcf, 0xf8, 0xf6, 0x72, 0x35,
+ 0x04, 0xa6, 0xe3, 0x53, 0xca, 0xc5, 0x62, 0xee, 0xa9, 0xc3, 0x6d, 0x1b,
+ 0xc4, 0xc5, 0xd9, 0xa7, 0x37, 0xc2, 0x04, 0x01, 0xc9, 0x4a, 0x2e, 0x26,
+ 0xdd, 0x12, 0x6e, 0x41, 0x64, 0xb4, 0xe8, 0xe8, 0xc7, 0xf8, 0xab, 0x8a,
+ 0xab, 0x1d, 0x7f, 0x2d, 0x58, 0xc2, 0xc4, 0xf0, 0x5d, 0x11, 0x35, 0x52,
+ 0x88, 0xbc, 0x0f, 0x44, 0x6e, 0x91, 0x1e, 0x87, 0xb4, 0xb1, 0x91, 0x52,
+ 0x32, 0xe4, 0x38, 0x6d, 0x5e, 0x8d, 0x30, 0xf0, 0xbc, 0xc3, 0x15, 0x80,
+ 0x47, 0x36, 0x35, 0xb0, 0x93, 0xf3, 0xc4, 0x82, 0xc7, 0x73, 0xc1, 0x67,
+ 0x0c, 0x7a, 0x31, 0x36, 0xbc, 0x73, 0x67, 0x66, 0xae, 0x48, 0x82, 0x27,
+ 0x6e, 0x14, 0xd0, 0xd5, 0x12, 0x10, 0xce, 0x5e, 0x37, 0xcd, 0x7e, 0xa5,
+ 0xcb, 0xff, 0x91, 0xf0, 0x62, 0xdb, 0x95, 0x74, 0x0c, 0x8c, 0x1e, 0x78,
+ 0x11, 0x02, 0xb3, 0x02, 0x0b, 0x31, 0xe7, 0x4e, 0x8b, 0x58, 0x6a, 0xde,
+ 0x20, 0x93, 0x8b, 0x8e, 0x62, 0x03, 0x24, 0xc9, 0xca, 0xf8, 0x44, 0x1d,
+ 0x0c, 0x1b, 0xd8, 0x5d, 0xcc, 0xe2, 0x8e, 0x02, 0xc6, 0x5c, 0x06, 0x45,
+ 0xe6, 0x94, 0x8f, 0xa2, 0x3e, 0xf5, 0xe9, 0xf5, 0x88, 0x87, 0xb2, 0x84,
+ 0x1e, 0xb6, 0xb6, 0xfc, 0x9f, 0x8e, 0x79, 0xf5, 0x4b, 0x24, 0x81, 0x3e,
+ 0x5d, 0xf4, 0x10, 0x6e, 0xdd, 0x8c, 0x8c, 0xae, 0xc6, 0x2c, 0x26, 0xb2,
+ 0xfc, 0xf3, 0x99, 0xe8, 0x8c, 0x65, 0x5d, 0x6c, 0xa8, 0x1d, 0x6f, 0x1e,
+ 0x32, 0x0a, 0xee, 0x87, 0xf6, 0xe1, 0xdd, 0x5e, 0x7f, 0x7a, 0x90, 0x8c,
+ 0x3f, 0xe8, 0x47, 0x95, 0x9b, 0xc8, 0x2c, 0x49, 0xc9, 0xe4, 0x2d, 0xea,
+ 0x58, 0xfc, 0x29, 0x1a, 0xb7, 0xa1, 0xf9, 0xb8, 0x84, 0x41, 0xa0, 0xf1,
+ 0x77, 0x83, 0x56, 0x73, 0x86, 0xea, 0xf4, 0xf5, 0x2a, 0xa6, 0x6b, 0x00,
+ 0x64, 0x39, 0x08, 0x8f, 0xf0, 0x22, 0x1a, 0x4c, 0xf2, 0x5a, 0xd0, 0xaa,
+ 0x39, 0xae, 0x8a, 0xbc, 0x03, 0x99, 0xf7, 0xcc, 0x80, 0xdf, 0x2b, 0x85,
+ 0xbe, 0x1a, 0x97, 0x28, 0x63, 0x04, 0x72, 0x75, 0x75, 0xb4, 0x9c, 0xd3,
+ 0x17, 0xcc, 0x1e, 0xa1, 0xd2, 0x47, 0x18, 0x45, 0xad, 0xb4, 0x0a, 0x32,
+ 0x31, 0x36, 0x64, 0x48, 0x3f, 0x7b, 0x4b, 0xc0, 0xd6, 0x78, 0x46, 0xaa,
+ 0x90, 0x89, 0xf9, 0x36, 0x3d, 0xb4, 0xb3, 0x50, 0x51, 0xd9, 0x55, 0x6f,
+ 0xa9, 0xe7, 0x25, 0xaf, 0xa0, 0xca, 0x9d, 0x45, 0x83, 0xc3, 0x0b, 0x2a,
+ 0x0c, 0xf9, 0x3f, 0xe4, 0x08, 0xf4, 0xbd, 0x23, 0x45, 0x85, 0xcf, 0x41,
+ 0x93, 0xd3, 0x21, 0x5f, 0x53, 0xa2, 0x5b, 0xa9, 0xf5, 0xe9, 0x8f, 0x2a,
+ 0x2d, 0x53, 0x3c, 0x36, 0x17, 0xce, 0x37, 0x35, 0x3e, 0x9e, 0x6b, 0xbc,
+ 0xba, 0xaa, 0xa5, 0x61, 0x79, 0x98, 0x8e, 0xbd, 0x19, 0xf4, 0x5f, 0xa9,
+ 0xb8, 0x96, 0xa2, 0xce, 0x32, 0x00, 0xab, 0x51, 0xcb, 0xfa, 0x30, 0x3a,
+ 0x83, 0x92, 0x91, 0xad, 0x08, 0x61, 0x62, 0x51, 0x7f, 0x19, 0xa9, 0x2a,
+ 0x84, 0xf2, 0xab, 0x7e, 0x5e, 0xa7, 0x5a, 0x54, 0x7f, 0x68, 0x2a, 0x7b,
+ 0x4f, 0xde, 0x45, 0x1d, 0xef, 0x73, 0x5f, 0xc0, 0x40, 0x6e, 0xec, 0x6c,
+ 0xe9, 0xa5, 0x6b, 0x46, 0x54, 0x7c, 0x24, 0x8b, 0xa4, 0xe5, 0xb4, 0x82,
+ 0x31, 0x1f, 0x3e, 0x79, 0x2e, 0x21, 0x8c, 0xf1, 0xbd, 0xad, 0x7c, 0x28,
+ 0xcc, 0xbd, 0x58, 0x72, 0xe9, 0x6a, 0x04, 0x56, 0x67, 0x0f, 0x62, 0x98,
+ 0x5a, 0x97, 0x4b, 0xe2, 0x67, 0x70, 0xbb, 0x17, 0xb1, 0x84, 0x5b, 0xd4,
+ 0x6e, 0xab, 0x90, 0x29, 0x20, 0x93, 0x34, 0xa8, 0x03, 0x0f, 0xed, 0x1a,
+ 0xf0, 0x1b, 0x92, 0x87, 0x43, 0xa5, 0x6a, 0x1c, 0xdc, 0xd7, 0x22, 0x68,
+ 0x83, 0x98, 0x74, 0x2a, 0x4c, 0x51, 0xef, 0x71, 0x19, 0xd5, 0x3d, 0x05,
+ 0x19, 0x61, 0xb2, 0x52, 0xa8, 0x6e, 0xda, 0x72, 0x51, 0x66, 0x9f, 0xf0,
+ 0x12, 0xf6, 0x18, 0x60, 0xcc, 0xd7, 0x2f, 0x2e, 0x83, 0x14, 0x09, 0xdb,
+ 0x55, 0x1c, 0xf2, 0xaf, 0xfd, 0xa4, 0x40, 0xf1, 0x4a, 0xc7, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x9c, 0x52, 0xff, 0x48,
+ 0x06, 0x61, 0x76, 0x6d, 0xd7, 0x44, 0xb1, 0x0c, 0x32, 0x62, 0x15, 0xa1,
+ 0xc3, 0x97, 0x03, 0xdd, 0xed, 0x20, 0x3c, 0x3a, 0x09, 0x16, 0xe5, 0x7d,
+ 0x8c, 0xf9, 0x7b, 0x22, 0x5e, 0x3a, 0xdd, 0xf0, 0xc6, 0xf0, 0x3a, 0xd4,
+ 0x94, 0x85, 0x1c, 0x60, 0x74, 0x91, 0xa3, 0xe2, 0x8a, 0xe5, 0x3e, 0xd4,
+ 0x95, 0x28, 0x8b, 0x1a, 0x7b, 0xbe, 0x07, 0xc0, 0xe3, 0x6b, 0xb9, 0x85,
+ 0x82, 0x0b, 0x24, 0xba, 0x1c, 0xfc, 0xc0, 0x0a, 0x21, 0x33, 0xad, 0x00,
+ 0x19, 0xce, 0xb5, 0x8f, 0x73, 0x05, 0xf1, 0xac, 0x03, 0xbe, 0x1f, 0x22,
+ 0xd5, 0x32, 0x5e, 0x50, 0xe3, 0xe0, 0x62, 0x26, 0xf4, 0xb0, 0x85, 0xd8,
+ 0xf7, 0xa7, 0xf4, 0xa7, 0xff, 0x10, 0xb8, 0xbc, 0xe0, 0x3e, 0x4d, 0xcb,
+ 0x37, 0x74, 0xcc, 0x85, 0xed, 0xa0, 0x34, 0x6c, 0xfa, 0x37, 0x84, 0x6a,
+ 0x94, 0x55, 0x3b, 0x1e, 0x14, 0xab, 0x26, 0x7b, 0x3e, 0xac, 0xc3, 0x79,
+ 0xcd, 0x1b, 0x00, 0x02, 0xb3, 0x01, 0xc3, 0x10, 0xdd, 0x56, 0x7d, 0x0e,
+ 0x69, 0x39, 0x3c, 0x17, 0xa3, 0xae, 0x9c, 0x2d, 0xc7, 0x5a, 0x0b, 0x7c,
+ 0xd0, 0xac, 0xa1, 0x91, 0x6a, 0x6d, 0xc0, 0x3f, 0x98, 0xf1, 0x21, 0xf5,
+ 0xa5, 0x7c, 0xbc, 0x70, 0x0d, 0x7b, 0x2f, 0x0d, 0x5a, 0xa5, 0x4a, 0x5a,
+ 0xff, 0x51, 0xbf, 0x7f, 0xb5, 0x4f, 0x2c, 0xba, 0xa9, 0x46, 0x81, 0x6b,
+ 0xac, 0xc6, 0x62, 0x2d, 0xd7, 0xb5, 0x04, 0x5f, 0xd4, 0x5f, 0x1f, 0x6b,
+ 0x11, 0x7d, 0xe3, 0x58, 0x1f, 0xb5, 0xbf, 0x16, 0x43, 0x88, 0x05, 0xf5,
+ 0xa4, 0x7b, 0xb5, 0x0e, 0xf4, 0x01, 0xb6, 0x90, 0x69, 0x52, 0x0a, 0x5e,
+ 0x9b, 0x87, 0x51, 0x5e, 0xd5, 0xed, 0x2c, 0xcc, 0x58, 0xad, 0xe6, 0x77,
+ 0xa2, 0xc5, 0x7c, 0x1e, 0xc5, 0x92, 0xbe, 0xed, 0x3a, 0x9a, 0x97, 0xed,
+ 0x56, 0xc8, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00,
+ 0x16, 0xe8, 0x24, 0xe3, 0x82, 0x36, 0x8e, 0x50, 0x45, 0xbe, 0xc6, 0x10,
+ 0x02, 0xb9, 0x6d, 0xf9, 0xed, 0x8f, 0x64, 0x35, 0x4d, 0x2c, 0x9f, 0x99,
+ 0xdc, 0xee, 0xfa, 0x63, 0x99, 0xc4, 0xb8, 0x3d, 0x77, 0xea, 0xda, 0xd5,
+ 0x95, 0x8b, 0x8e, 0x76, 0x02, 0x9c, 0x62, 0xa0, 0xad, 0xfe, 0x80, 0x61,
+ 0x72, 0x59, 0xd6, 0x9f, 0x16, 0x2e, 0x09, 0x71, 0xb8, 0xd7, 0x65, 0x25,
+ 0xc2, 0x5b, 0x40, 0x67, 0x8e, 0xd6, 0xf8, 0xdf, 0x67, 0x29, 0x19, 0xa2,
+ 0xa6, 0x07, 0xf3, 0xc8, 0x91, 0x7d, 0xf2, 0x50, 0x71, 0xba, 0x5c, 0x2d,
+ 0xa7, 0xae, 0xc4, 0xd5, 0xeb, 0xb9, 0x0d, 0x2d, 0x23, 0xe5, 0x8c, 0x65,
+ 0xf5, 0xf8, 0x97, 0x69, 0xde, 0x25, 0x6f, 0xea, 0x12, 0x72, 0x3e, 0xb9,
+ 0xa7, 0x8d, 0xcf, 0xa5, 0x66, 0xee, 0x4e, 0x2e, 0x66, 0x6b, 0xec, 0x77,
+ 0x7f, 0x53, 0xdc, 0x29, 0x73, 0x5e, 0xe9, 0x2f, 0x79, 0xac, 0x8d, 0x0f,
+ 0x44, 0x09, 0x5d, 0x25, 0x1d, 0x78, 0xb6, 0xe9, 0xd0, 0xfa, 0x8f, 0x5f,
+ 0x9c, 0xf0, 0xe0, 0xfc, 0x62, 0x9f, 0x52, 0x6b, 0x5b, 0x8e, 0x3f, 0xdf,
+ 0xb4, 0xf1, 0xdf, 0x35, 0xd0, 0x8f, 0x5a, 0xc9, 0x1f, 0x08, 0x86, 0xaa,
+ 0x5a, 0x9e, 0xe8, 0xb0, 0xaa, 0xd4, 0xcd, 0x2a, 0x5b, 0x4f, 0x7f, 0x39,
+ 0x9f, 0x7f, 0x21, 0xf2, 0xfd, 0x05, 0x96, 0x53, 0x09, 0xfd, 0x36, 0x4c,
+ 0xcd, 0x98, 0x74, 0xf5, 0xbd, 0xcd, 0x9e, 0x14, 0x15, 0x05, 0xb9, 0x3d,
+ 0x5f, 0x8a, 0x02, 0x86, 0x10, 0xd7, 0xd4, 0x01, 0x20, 0xd9, 0x8c, 0x65,
+ 0x7d, 0x9d, 0x39, 0x25, 0xbc, 0xce, 0x1a, 0xb1, 0x76, 0x92, 0xc3, 0x03,
+ 0xed, 0xa2, 0x41, 0x31, 0x0d, 0xc0, 0x40, 0x94, 0x01, 0xbc, 0x9b, 0xe9,
+ 0x5e, 0x3e, 0x8c, 0x49, 0xf6, 0x98, 0x0c, 0x39, 0x79, 0xdc, 0xd1, 0x1b,
+ 0xc5, 0xb2, 0x20, 0xb4, 0x6c, 0xb4, 0x4f, 0xce, 0xf4, 0x6c, 0x0b, 0xef,
+ 0x85, 0xf2, 0x7d, 0x9a, 0x90, 0x58, 0x1b, 0x51, 0x56, 0x52, 0xac, 0x75,
+ 0x9f, 0x17, 0xe6, 0x48, 0xaf, 0x18, 0x4c, 0xd8, 0x67, 0xe8, 0xd2, 0x61,
+ 0xbc, 0xa0, 0x95, 0xc9, 0x78, 0xd8, 0xa2, 0x1d, 0x47, 0x59, 0x30, 0xcf,
+ 0xf3, 0x79, 0x06, 0xd4, 0x25, 0xf8, 0x9c, 0x5c, 0x28, 0xee, 0xb0, 0xd2,
+ 0xb6, 0xaf, 0x34, 0x0e, 0xe5, 0xe4, 0x16, 0x2e, 0x05, 0x45, 0x23, 0xc1,
+ 0x88, 0x90, 0x4a, 0x8f, 0xff, 0xfb, 0xe2, 0xc0, 0xb7, 0xae, 0xb5, 0x50,
+ 0xc9, 0x26, 0xf0, 0xa2, 0xf5, 0x21, 0x23, 0x79, 0x23, 0xb6, 0x8f, 0x57,
+ 0x64, 0xd1, 0x27, 0xc2, 0x07, 0x63, 0xa6, 0x54, 0x1f, 0x2f, 0xca, 0x16,
+ 0xb8, 0x28, 0x51, 0x2a, 0x92, 0xe0, 0x06, 0x36, 0x55, 0x00, 0x6c, 0x99,
+ 0x31, 0xa7, 0x56, 0xb3, 0x7b, 0x15, 0xcd, 0xc1, 0x32, 0x3a, 0xc0, 0x37,
+ 0x1f, 0xea, 0x29, 0xb6, 0x75, 0xdf, 0x8a, 0x17, 0x09, 0x45, 0xc2, 0x6e,
+ 0xe2, 0x4c, 0xa5, 0x93, 0x9b, 0x17, 0x08, 0x27, 0x75, 0x33, 0xdb, 0x1f,
+ 0xab, 0x37, 0xad, 0x8e, 0xaa, 0xef, 0x0b, 0x82, 0xaa, 0xa7, 0xae, 0x2c,
+ 0x43, 0x4d, 0x8f, 0xa0, 0x43, 0xd7, 0xa1, 0x34, 0xeb, 0xc0, 0x4e, 0xbd,
+ 0x64, 0xfc, 0xc8, 0x6a, 0x56, 0xa8, 0xfc, 0x9e, 0x2d, 0x5f, 0x7a, 0xa3,
+ 0x72, 0x06, 0x79, 0x38, 0x33, 0x05, 0xa7, 0xf0, 0x09, 0x48, 0x55, 0xfe,
+ 0x3f, 0xab, 0x25, 0x8e, 0x76, 0x1d, 0x12, 0x5a, 0x20, 0x68, 0xfb, 0x51,
+ 0x51, 0x33, 0x40, 0x37, 0x0c, 0x90, 0x98, 0x6f, 0x66, 0x3f, 0x40, 0xa2,
+ 0x2e, 0x3c, 0xd1, 0x22, 0x51, 0x54, 0x25, 0x7e, 0x4c, 0x5d, 0x96, 0xb2,
+ 0x65, 0x0f, 0xa3, 0xdf, 0x8e, 0x97, 0xfe, 0xeb, 0xe7, 0xc6, 0x22, 0x2a,
+ 0x47, 0x3a, 0x78, 0x1b, 0x39, 0x2e, 0xd6, 0xbc, 0x35, 0xb4, 0xf4, 0xc3,
+ 0xf2, 0x6a, 0x12, 0xc9, 0xe7, 0x6c, 0x9a, 0xfc, 0xed, 0xbc, 0x11, 0xc7,
+ 0x71, 0x09, 0x8f, 0x56, 0xc1, 0xd8, 0xb6, 0x92, 0x35, 0x97, 0x8e, 0x71,
+ 0xd2, 0xbb, 0xb4, 0xed, 0xf0, 0x7e, 0xff, 0x58, 0xd9, 0x95, 0x26, 0xea,
+ 0xa9, 0x4d, 0x38, 0x8d, 0x4e, 0x8e, 0x53, 0xae, 0x7e, 0xe6, 0xe6, 0x82,
+ 0x35, 0x96, 0xab, 0x0f, 0x04, 0x0f, 0xf2, 0xac, 0x1b, 0xcd, 0x07, 0x17,
+ 0x1b, 0x25, 0x2f, 0x92, 0xaf, 0x19, 0xa2, 0x1b, 0xa0, 0x7a, 0xc7, 0x4f,
+ 0xb8, 0x1b, 0x89, 0x21, 0xb5, 0xe2, 0x24, 0xe9, 0x78, 0xae, 0x7d, 0xd7,
+ 0xcc, 0x8e, 0x3f, 0xa7, 0xe9, 0xbe, 0xe6, 0x79, 0x0f, 0xdf, 0x86, 0xe9,
+ 0xb9, 0xcd, 0x82, 0x7b, 0xf5, 0x04, 0x89, 0xa0, 0x73, 0x5d, 0xa2, 0x4e,
+ 0xd6, 0xa0, 0x60, 0x21, 0xe2, 0xfe, 0xd3, 0xf4, 0x19, 0x8b, 0x6a, 0x03,
+ 0x12, 0x9c, 0x51, 0x9a, 0x41, 0x4e, 0xf6, 0xb4, 0x6e, 0x0c, 0x43, 0xf5,
+ 0x00, 0x00, 0x78, 0x12, 0xdd, 0x21, 0xa8, 0xc7, 0x21, 0xa1, 0x4e, 0x44,
+ 0x10, 0xd0, 0xdb, 0x6f, 0x0b, 0x4c, 0xe7, 0x7a, 0x8c, 0x0c, 0xaa, 0xb6,
+ 0x9a, 0x7d, 0xa9, 0xff, 0x5a, 0x2e, 0x15, 0x9e, 0x6f, 0xea, 0xe1, 0x42,
+ 0x0c, 0x9c, 0x5a, 0x3b, 0xd5, 0xe6, 0xde, 0x23, 0x3f, 0x9c, 0x45, 0x20,
+ 0x67, 0x96, 0x50, 0x16, 0x80, 0x42, 0xe7, 0x67, 0x7d, 0x24, 0xdc, 0x00,
+ 0xaa, 0x01, 0x8a, 0xa3, 0x61, 0xfe, 0x9a, 0xce, 0xc1, 0xe5, 0x2e, 0x19,
+ 0x85, 0x04, 0xe6, 0x7b, 0xe8, 0x7a, 0xbc, 0x9d, 0xfe, 0x71, 0x29, 0x1d,
+ 0x17, 0xae, 0x6b, 0x1a, 0x64, 0xd7, 0xfe, 0x18, 0x29, 0x07, 0x9b, 0x49,
+ 0x43, 0xba, 0x29, 0x37, 0xa8, 0xb0, 0x26, 0x27, 0x6b, 0x7d, 0xde, 0x49,
+ 0x12, 0x90, 0x05, 0xe2, 0x2c, 0xd8, 0x08, 0xd0, 0x5d, 0x74, 0xa7, 0x15,
+ 0xbe, 0x34, 0x34, 0x6d, 0xad, 0xfb, 0xa8, 0x01, 0x4a, 0x6c, 0x98, 0xba,
+ 0x84, 0x38, 0xbd, 0x05, 0xe8, 0x87, 0x27, 0x91, 0x3f, 0xb8, 0xe9, 0x06,
+ 0x27, 0xda, 0x56, 0x07, 0xaa, 0xea, 0xf4, 0x80, 0x5c, 0x12, 0x44, 0xbe,
+ 0x23, 0xb3, 0x63, 0x9f, 0x5f, 0x37, 0xa7, 0x53, 0x4c, 0xfc, 0x4d, 0x87,
+ 0xeb, 0x91, 0xe8, 0xd7, 0x5a, 0xd6, 0xca, 0x67, 0x2d, 0x2f, 0x5a, 0x0e,
+ 0xc7, 0x82, 0x78, 0xa4, 0xf3, 0x56, 0x07, 0xa5, 0xab, 0x6d, 0x09, 0xd2,
+ 0x0d, 0x08, 0x6b, 0x6e, 0x1f, 0xc1, 0xf2, 0x91, 0x1a, 0x39, 0xfe, 0x14,
+ 0x56, 0x3f, 0xeb, 0x9f, 0x14, 0xc2, 0xb3, 0xb2, 0xc2, 0x8d, 0xc2, 0xee,
+ 0x7e, 0xf0, 0x7d, 0x92, 0xd2, 0xc3, 0x57, 0x3e, 0x2c, 0x07, 0x1b, 0x6a,
+ 0x9b, 0x3b, 0x79, 0x59, 0xc9, 0x22, 0x96, 0x6c, 0x3e, 0x37, 0xd3, 0x0e,
+ 0x5c, 0xf6, 0x8f, 0xa9, 0xaa, 0xc9, 0xa4, 0x4b, 0xaf, 0x5d, 0x1a, 0xb6,
+ 0xf3, 0x91, 0x32, 0x4f, 0xca, 0x72, 0xa0, 0x42, 0x01, 0x51, 0xaf, 0x19,
+ 0x89, 0xc4, 0xcc, 0x9b, 0xf3, 0x52, 0xe9, 0xa6, 0xf2, 0x71, 0x6f, 0x5a,
+ 0x38, 0x02, 0xb8, 0x75, 0x88, 0x5f, 0x8d, 0x12, 0xc5, 0x55, 0x4f, 0xd1,
+ 0xba, 0xf2, 0x24, 0xdc, 0x63, 0x5f, 0x93, 0xc7, 0xf3, 0xe7, 0x59, 0xac,
+ 0xc3, 0xed, 0xbc, 0x02, 0xe3, 0xad, 0xb2, 0x8e, 0x2c, 0x2d, 0x47, 0xb4,
+ 0x34, 0x8d, 0xae, 0x44, 0xc8, 0x5f, 0x14, 0xe8, 0x8e, 0x7b, 0xc3, 0x60,
+ 0x53, 0x9a, 0x51, 0xea, 0x7f, 0x2f, 0xb6, 0x62, 0x61, 0xf7, 0xc0, 0x18,
+ 0x0f, 0x20, 0x79, 0x13, 0x5c, 0xe8, 0xca, 0x04, 0x29, 0x5f, 0x70, 0x4d,
+ 0x88, 0xa2, 0x43, 0x20, 0x57, 0x33, 0x04, 0x74, 0x8e, 0x7c, 0x89, 0xd4,
+ 0x56, 0x8f, 0x93, 0x86, 0x81, 0x6c, 0x11, 0xfc, 0x32, 0x0e, 0xb0, 0x3e,
+ 0xe5, 0x13, 0xbf, 0x76, 0x62, 0xcc, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x04, 0x00, 0x00, 0x0e, 0xf8, 0x8f, 0xde, 0xfd, 0xfd, 0xcf, 0xd1,
+ 0x6f, 0x9f, 0xf2, 0xb6, 0xb6, 0x59, 0xb2, 0x73, 0x1c, 0x3c, 0x0d, 0xb0,
+ 0x4d, 0xb8, 0x96, 0xc6, 0xeb, 0xe5, 0xf8, 0x0d, 0x3e, 0xd7, 0x0c, 0xbd,
+ 0x9c, 0xaa, 0xd5, 0x1c, 0x19, 0x9a, 0x4c, 0x8e, 0xfa, 0xac, 0x68, 0x74,
+ 0x16, 0x06, 0xb5, 0x49, 0xe7, 0xd5, 0x6f, 0x4f, 0xcc, 0xd9, 0x02, 0x74,
+ 0xd6, 0x08, 0x73, 0x7c, 0xa9, 0xfa, 0x3e, 0x50, 0x87, 0xf7, 0xfb, 0xa6,
+ 0x94, 0xdc, 0xb1, 0x40, 0xec, 0xa7, 0xa9, 0x39, 0xff, 0x40, 0x4a, 0x97,
+ 0x9b, 0xcc, 0x57, 0x66, 0x68, 0xd6, 0xa8, 0x4d, 0x13, 0x06, 0x0e, 0x03,
+ 0xc4, 0xdf, 0x7a, 0xe4, 0x2f, 0x0e, 0xd7, 0x54, 0xe0, 0xbd, 0x93, 0xeb,
+ 0x82, 0xd8, 0x05, 0x2d, 0xa2, 0xf0, 0x4e, 0xd0, 0xf9, 0x3e, 0x3e, 0x6b,
+ 0x3d, 0x08, 0x39, 0x4e, 0x35, 0x13, 0x7b, 0x3b, 0x39, 0x2c, 0x47, 0x2c,
+ 0x61, 0x9f, 0xfd, 0x59, 0x88, 0x5f, 0x65, 0x08, 0xa9, 0x66, 0xec, 0xb5,
+ 0x21, 0xf3, 0xe9, 0xba, 0x11, 0x63, 0x24, 0x6c, 0xf4, 0x50, 0x3a, 0xe5,
+ 0x0c, 0x06, 0x39, 0x69, 0x2f, 0xca, 0x0f, 0x48, 0xbe, 0x95, 0x7d, 0x13,
+ 0x3d, 0xa5, 0x75, 0x69, 0x85, 0xc8, 0xb3, 0x72, 0x72, 0x3c, 0x4f, 0x96,
+ 0xe7, 0xb7, 0xbd, 0xe7, 0x76, 0xba, 0xac, 0xc0, 0x07, 0x4d, 0xc1, 0xed,
+ 0xb9, 0xf0, 0x91, 0x2e, 0x36, 0xb7, 0x5b, 0x1c, 0xb7, 0xd6, 0xb3, 0x45,
+ 0x7d, 0x0a, 0xf5, 0x43, 0xdd, 0x7a, 0x8b, 0x4e, 0x18, 0xf2, 0xf3, 0x19,
+ 0xcd, 0x4a, 0xda, 0x3c, 0x1b, 0x05, 0x27, 0x67, 0x43, 0xa9, 0x8e, 0xe7,
+ 0x4a, 0x95, 0xa9, 0xad, 0x6c, 0x8c, 0xb2, 0x2e, 0x12, 0xcb, 0xf3, 0xeb,
+ 0x65, 0x26, 0xf4, 0x3e, 0x86, 0xee, 0x7e, 0xd9, 0xba, 0xce, 0x8d, 0x15,
+ 0x3e, 0xa8, 0x40, 0x59, 0x1d, 0x27, 0x78, 0x75, 0xf0, 0xf9, 0x33, 0xb5,
+ 0x32, 0xa9, 0x66, 0xe6, 0x2e, 0x2e, 0x3d, 0xf5, 0x4a, 0xf0, 0x97, 0x2d,
+ 0xe7, 0x43, 0x85, 0x43, 0x61, 0x25, 0x15, 0x13, 0x9e, 0x8e, 0xf6, 0x78,
+ 0xe8, 0x67, 0xba, 0xc2, 0x6d, 0xda, 0x46, 0x25, 0x76, 0xd9, 0x9b, 0x69,
+ 0x95, 0x4b, 0x50, 0x8c, 0xb7, 0x36, 0x49, 0xbc, 0xd7, 0x39, 0x69, 0xb9,
+ 0xc1, 0x5f, 0x5f, 0xcc, 0x83, 0x4c, 0x16, 0xb8, 0x0c, 0x85, 0xf1, 0xa4,
+ 0x57, 0x6c, 0x22, 0x1f, 0x60, 0x0c, 0xff, 0xb6, 0xc9, 0xf7, 0x21, 0x2d,
+ 0x35, 0x78, 0x31, 0x79, 0xd0, 0x6d, 0x61, 0xec, 0x61, 0x04, 0x75, 0x5c,
+ 0x06, 0xc3, 0x53, 0x1b, 0xb5, 0xdc, 0x23, 0xb9, 0xd9, 0x07, 0xd1, 0xd0,
+ 0xb3, 0xa5, 0xab, 0xd9, 0xbe, 0xb7, 0xdc, 0xae, 0x3f, 0x3e, 0xd7, 0x2a,
+ 0x79, 0x3f, 0x9c, 0x27, 0x81, 0x8d, 0x61, 0xe8, 0x46, 0x8f, 0x05, 0xf4,
+ 0x9c, 0x30, 0x35, 0x9a, 0x2f, 0x62, 0x84, 0x7c, 0xa5, 0x95, 0x68, 0x34,
+ 0xe6, 0xf0, 0xb9, 0x42, 0xd4, 0x37, 0xc6, 0xd2, 0x35, 0x1f, 0x7b, 0xe0,
+ 0xa6, 0x92, 0xcf, 0xf7, 0x0f, 0x08, 0x10, 0x79, 0xbd, 0xa8, 0x7c, 0x4e,
+ 0xef, 0xf1, 0x01, 0x8d, 0x1b, 0x0c, 0x98, 0x46, 0x28, 0xdc, 0xd5, 0xa8,
+ 0xcf, 0x67, 0x7d, 0x87, 0x2a, 0x8f, 0xdd, 0x52, 0x43, 0x5a, 0x55, 0x80,
+ 0x88, 0xa6, 0xcd, 0x9c, 0x5d, 0x36, 0xae, 0xef, 0x61, 0x43, 0xec, 0xf0,
+ 0x7f, 0x92, 0x21, 0x1f, 0xa2, 0xa3, 0x76, 0x0e, 0x5d, 0xf3, 0xa7, 0xe7,
+ 0x7d, 0xb0, 0x2c, 0x94, 0x36, 0x95, 0x34, 0x4e, 0x04, 0xfb, 0x51, 0xf9,
+ 0xe6, 0x7e, 0x56, 0x7a, 0x59, 0xce, 0x0a, 0x45, 0x7e, 0xeb, 0xc4, 0xbc,
+ 0xfd, 0x20, 0xaa, 0x34, 0x6b, 0xee, 0x3b, 0x09, 0xe8, 0x00, 0x4b, 0xfc,
+ 0x68, 0x24, 0x43, 0xdb, 0x09, 0x58, 0xd0, 0xb6, 0xbf, 0xaf, 0x1d, 0x7f,
+ 0x8a, 0x4c, 0x9e, 0x51, 0x97, 0x97, 0xe1, 0x0c, 0x0d, 0xaf, 0xd1, 0x1e,
+ 0x62, 0xad, 0x70, 0xa5, 0x8a, 0x24, 0x2f, 0x4a, 0xa6, 0x55, 0xb1, 0x44,
+ 0x09, 0x88, 0xab, 0xa5, 0x45, 0x28, 0xa0, 0x34, 0x9e, 0x14, 0x2c, 0xf9,
+ 0x0f, 0xb8, 0x33, 0x8f, 0xcc, 0xba, 0x50, 0x34, 0x4c, 0x96, 0x89, 0x09,
+ 0xb9, 0xa8, 0xfb, 0xac, 0x59, 0x73, 0xea, 0x61, 0xbc, 0x0d, 0x24, 0x3a,
+ 0x20, 0xc2, 0x76, 0xfc, 0x2e, 0xce, 0xfb, 0x75, 0x00, 0xca, 0x58, 0xbd,
+ 0xab, 0x61, 0x9b, 0x13, 0x2b, 0xa3, 0xf6, 0x15, 0x55, 0x83, 0x23, 0xc4,
+ 0xf3, 0x4c, 0x89, 0xc5, 0x4a, 0x18, 0x5c, 0x8d, 0x41, 0xcc, 0x06, 0x7b,
+ 0xe3, 0x2a, 0x1f, 0x6a, 0x57, 0xbc, 0x54, 0x61, 0x0c, 0xf2, 0xec, 0xbf,
+ 0xb0, 0xf0, 0x21, 0xde, 0xfc, 0xe4, 0xef, 0xce, 0x47, 0xc8, 0xdc, 0x11,
+ 0xc7, 0x8a, 0x12, 0x97, 0x68, 0x1d, 0x9e, 0x9a, 0xbf, 0xad, 0x62, 0x7e,
+ 0x4b, 0x88, 0xd7, 0x20, 0x22, 0xce, 0x5e, 0xe3, 0x87, 0x12, 0xa3, 0x05,
+ 0xef, 0x1f, 0x05, 0xb1, 0xbd, 0x1b, 0x80, 0x43, 0x84, 0x33, 0x8b, 0x87,
+ 0xa5, 0xc2, 0xe1, 0x49, 0xa8, 0x75, 0x49, 0x9b, 0x1b, 0x64, 0x8a, 0xd0,
+ 0x86, 0x10, 0xa8, 0x72, 0xeb, 0x2e, 0xe7, 0x3f, 0xaa, 0x6b, 0x4a, 0x22,
+ 0xae, 0x17, 0x8f, 0x10, 0x22, 0x03, 0x66, 0x67, 0x35, 0x40, 0x29, 0x1e,
+ 0xf2, 0x05, 0x36, 0xd5, 0xed, 0xe2, 0x2a, 0xcc, 0x77, 0xe2, 0x16, 0xef,
+ 0xa7, 0x9b, 0xe1, 0x1b, 0xba, 0xf3, 0xf5, 0x74, 0x6c, 0x2a, 0x98, 0x8a,
+ 0x14, 0xaf, 0x2c, 0xab, 0xfb, 0x51, 0x53, 0x75, 0x17, 0xcb, 0x5c, 0x86,
+ 0xb5, 0x60, 0x70, 0x29, 0x65, 0x69, 0x49, 0x42, 0x4f, 0x42, 0x6b, 0xc7,
+ 0xdb, 0x98, 0x7d, 0x1e, 0xf8, 0x45, 0xb2, 0x33, 0xd6, 0x34, 0x26, 0xa6,
+ 0x7f, 0x76, 0x31, 0x13, 0x13, 0x9d, 0xd2, 0xb0, 0x30, 0x0b, 0x0b, 0x3e,
+ 0x1a, 0x84, 0xb0, 0xbd, 0x81, 0x34, 0x25, 0x73, 0x99, 0x87, 0x1a, 0xc8,
+ 0x44, 0x34, 0x9d, 0x1a, 0x3d, 0x76, 0x44, 0x1d, 0xe2, 0x22, 0xad, 0x3d,
+ 0xb2, 0xa3, 0x1c, 0xd5, 0x27, 0x8c, 0xc6, 0x84, 0xdf, 0x33, 0xbe, 0xb2,
+ 0xa7, 0xb9, 0xc5, 0x6e, 0x48, 0xdc, 0xe9, 0xf8, 0xef, 0xfc, 0xaa, 0x1f,
+ 0x5e, 0x41, 0x48, 0x1e, 0xe0, 0xb9, 0xd6, 0x6e, 0x7a, 0x9c, 0xa3, 0x98,
+ 0x4b, 0xfa, 0x90, 0xa4, 0x58, 0x33, 0x85, 0x3b, 0x11, 0x44, 0x83, 0x4b,
+ 0x1e, 0x0e, 0x5d, 0x11, 0x36, 0x15, 0xe1, 0xbf, 0x15, 0x04, 0x8e, 0x88,
+ 0xc6, 0x18, 0x53, 0xc3, 0x8d, 0x28, 0x86, 0x25, 0xef, 0x55, 0x7b, 0xf6,
+ 0x85, 0xf8, 0xed, 0x3b, 0xcf, 0x5d, 0xa6, 0xc7, 0x66, 0xb7, 0xbe, 0x14,
+ 0xf0, 0x62, 0x89, 0x1f, 0x32, 0x1e, 0x86, 0x2a, 0x93, 0xd5, 0xca, 0x37,
+ 0x03, 0x0b, 0xf8, 0x0f, 0xca, 0x50, 0x6c, 0x16, 0x2b, 0xf0, 0x77, 0xca,
+ 0xbb, 0x8e, 0x95, 0x11, 0xef, 0x5b, 0xbe, 0x2f, 0x62, 0x50, 0xb8, 0x3d,
+ 0xff, 0xfa, 0x30, 0x21, 0xb2, 0x86, 0x3f, 0x50, 0x57, 0x98, 0x79, 0x15,
+ 0xce, 0x3e, 0xbf, 0x49, 0x58, 0xb0, 0xb5, 0xd7, 0xbe, 0x01, 0x55, 0xee,
+ 0x60, 0x14, 0x9d, 0x5b, 0x57, 0x48, 0x05, 0x72, 0x6a, 0x23, 0x29, 0xeb,
+ 0xf3, 0x36, 0x2a, 0xc1, 0xda, 0x5e, 0x4a, 0x63, 0xc4, 0x6b, 0x04, 0xe8,
+ 0xe8, 0xc1, 0xb5, 0xc4, 0x2d, 0x60, 0x1f, 0xa0, 0x2b, 0x33, 0xa5, 0xb7,
+ 0x82, 0x59, 0x21, 0xba, 0x13, 0xda, 0x79, 0xda, 0x5a, 0xb1, 0x82, 0x5b,
+ 0x52, 0x7f, 0x0c, 0x70, 0x75, 0x65, 0xe0, 0x44, 0xb3, 0xca, 0xd0, 0x09,
+ 0x38, 0x24, 0x83, 0x8e, 0x0c, 0x4c, 0xef, 0x96, 0xe4, 0x04, 0x30, 0x46,
+ 0x23, 0x6a, 0x28, 0x13, 0x1d, 0x37, 0x14, 0x75, 0x6e, 0xd0, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x21, 0xa2, 0xf0, 0x7d,
+ 0x29, 0x8f, 0x62, 0x2e, 0xf4, 0x0e, 0x14, 0x9b, 0x60, 0x38, 0xc0, 0x95,
+ 0xfb, 0x3c, 0x90, 0x5a, 0xa0, 0x1f, 0x30, 0x09, 0xfc, 0x6d, 0xa9, 0xd1,
+ 0x7b, 0x0b, 0x7c, 0x78, 0xf9, 0xf6, 0xa8, 0x5e, 0xa6, 0x7a, 0xf6, 0x1c,
+ 0xab, 0x1b, 0x0e, 0xa9, 0x08, 0xfd, 0xd9, 0x97, 0x08, 0x24, 0x2b, 0xda,
+ 0x08, 0x8b, 0x0c, 0x07, 0x70, 0x15, 0xa8, 0x0c, 0x86, 0xfc, 0xd1, 0x84,
+ 0xba, 0xd0, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00,
+ 0x35, 0x7a, 0xab, 0xaa, 0xbe, 0xd7, 0xad, 0x22, 0x99, 0x46, 0xbb, 0x78,
+ 0xfd, 0x47, 0x8f, 0x2a, 0x4a, 0xa6, 0x2f, 0x8d, 0x15, 0x07, 0xed, 0x26,
+ 0x1d, 0xb3, 0x12, 0xd3, 0x88, 0x0f, 0xf1, 0x75, 0x2a, 0x07, 0x62, 0xac,
+ 0xbf, 0x52, 0x4a, 0xc3, 0x12, 0xe5, 0x3c, 0xea, 0xa6, 0x1e, 0x57, 0x90,
+ 0x56, 0x60, 0x7d, 0xcf, 0x4b, 0x65, 0xaf, 0xee, 0x17, 0x56, 0xbe, 0xd2,
+ 0x38, 0x3f, 0xd6, 0xbc, 0xef, 0xa7, 0x32, 0xb7, 0x10, 0xe9, 0xbd, 0x97,
+ 0x45, 0x92, 0x3c, 0xd3, 0x35, 0x2e, 0x59, 0x37, 0x65, 0x5c, 0x7f, 0xd0,
+ 0x99, 0x9c, 0x01, 0xe9, 0x1f, 0x65, 0xe9, 0xec, 0x0f, 0x2d, 0x46, 0xbc,
+ 0xd4, 0x8f, 0x51, 0x1c, 0xa0, 0xa4, 0x9b, 0x4f, 0x95, 0x54, 0xb0, 0x50,
+ 0x74, 0xfa, 0x0f, 0xe6, 0x55, 0x81, 0xce, 0x0f, 0xd1, 0x25, 0x56, 0xc8,
+ 0x2f, 0x3a, 0x65, 0xd4, 0x86, 0x4a, 0x8e, 0xff, 0x5a, 0xcc, 0x67, 0x96,
+ 0xcc, 0x65, 0x0d, 0x20, 0xee, 0xba, 0x6b, 0xcb, 0xde, 0x10, 0x2f, 0xbf,
+ 0x67, 0x6d, 0xbe, 0xef, 0x72, 0xfc, 0x25, 0x62, 0xbf, 0xbb, 0xc5, 0xe0,
+ 0x7b, 0x4c, 0x32, 0xc5, 0xdb, 0x9f, 0xb5, 0xe2, 0x75, 0x8a, 0xba, 0xbb,
+ 0x69, 0x28, 0xb6, 0x41, 0x25, 0x83, 0x67, 0x35, 0x1b, 0xd7, 0xb3, 0xd7,
+ 0x58, 0x54, 0x8a, 0x0b, 0x7c, 0xf3, 0x05, 0xcf, 0x2c, 0x78, 0x70, 0xc6,
+ 0xed, 0x7e, 0x56, 0xb6, 0x4e, 0x48, 0xaa, 0x57, 0xc4, 0xb0, 0xb2, 0xa0,
+ 0xca, 0x50, 0xe1, 0xc7, 0x41, 0xea, 0xac, 0x5f, 0x18, 0x13, 0xe5, 0x85,
+ 0x78, 0x3f, 0x05, 0xf3, 0xfd, 0x74, 0x7a, 0x42, 0x61, 0x91, 0x19, 0xc6,
+ 0x19, 0xe9, 0xd2, 0x78, 0x2c, 0xb1, 0xa3, 0x7f, 0x62, 0xea, 0x2a, 0x35,
+ 0x1c, 0x55, 0xa3, 0xf7, 0xdc, 0xec, 0x48, 0x23, 0x99, 0x8d, 0xe1, 0x4d,
+ 0x45, 0xad, 0x92, 0xc6, 0xf4, 0xa2, 0xe5, 0xe6, 0x58, 0xe4, 0xd5, 0x37,
+ 0xd0, 0x47, 0x0b, 0x64, 0x68, 0x48, 0x7e, 0xeb, 0xbe, 0x5e, 0x74, 0xd1,
+ 0xc4, 0xa5, 0x60, 0xd0, 0x30, 0x62, 0xbc, 0x81, 0xc4, 0x01, 0x68, 0x18,
+ 0xf3, 0xac, 0x9d, 0xb1, 0x4d, 0xdd, 0x8b, 0xd2, 0x54, 0x5d, 0xd1, 0x1c,
+ 0xee, 0x75, 0x9e, 0x99, 0x42, 0x69, 0x38, 0xcc, 0x66, 0x24, 0xd9, 0x8f,
+ 0x70, 0x98, 0xc3, 0x5e, 0x08, 0xf0, 0xd8, 0x2d, 0xe6, 0x52, 0x48, 0xdf,
+ 0xd0, 0x03, 0x04, 0x92, 0xab, 0xa1, 0xa1, 0x2f, 0x7d, 0x84, 0xb2, 0x82,
+ 0x51, 0x56, 0x74, 0x4a, 0x94, 0xff, 0xd2, 0xe4, 0x4e, 0x1a, 0xbd, 0x18,
+ 0xab, 0x33, 0x68, 0x0e, 0x4f, 0x99, 0x1d, 0x7e, 0x02, 0x3f, 0x1f, 0x50,
+ 0x05, 0xf8, 0x59, 0x47, 0x97, 0x98, 0x60, 0xb1, 0x30, 0xb1, 0x14, 0xac,
+ 0x2c, 0x0a, 0xa8, 0x97, 0x83, 0xf5, 0x5a, 0x5c, 0x87, 0xe5, 0x36, 0x26,
+ 0xec, 0xb4, 0x94, 0x46, 0x9a, 0xad, 0x2b, 0x9a, 0xb7, 0xac, 0xc4, 0x1a,
+ 0x55, 0x53, 0xc0, 0x16, 0x91, 0x1c, 0xd6, 0xaa, 0x6b, 0xdd, 0x85, 0x6a,
+ 0x54, 0xec, 0x7c, 0xa1, 0xd5, 0x18, 0x00, 0x74, 0xd2, 0xf1, 0x7e, 0xad,
+ 0x7c, 0xa8, 0x85, 0x9b, 0xc0, 0x9f, 0x4f, 0x3b, 0xd9, 0x08, 0xc8, 0x9d,
+ 0x31, 0x22, 0x7a, 0x53, 0xa8, 0xbd, 0x00, 0xdf, 0xe8, 0x39, 0x52, 0xe9,
+ 0x14, 0x74, 0x7b, 0x53, 0xf9, 0xbd, 0x29, 0x8e, 0x5d, 0xf2, 0x35, 0x3b,
+ 0xe3, 0x48, 0xbf, 0xa0, 0xc4, 0x3d, 0x40, 0xb4, 0xf2, 0x7c, 0xd0, 0xe3,
+ 0x17, 0x11, 0x5b, 0xd6, 0x55, 0xd2, 0x54, 0xcf, 0x20, 0x8d, 0x74, 0x4a,
+ 0x6b, 0xe9, 0x5d, 0xfe, 0x72, 0x14, 0x6a, 0x11, 0x8b, 0x14, 0x19, 0xba,
+ 0x63, 0xe4, 0x6b, 0x39, 0xb4, 0x90, 0x67, 0x79, 0x56, 0x31, 0xd3, 0xb5,
+ 0xeb, 0x9e, 0x95, 0x4b, 0x1e, 0x04, 0x20, 0xd8, 0xbe, 0xe8, 0x1c, 0xd7,
+ 0x95, 0xcb, 0x57, 0x60, 0xe6, 0x11, 0x35, 0x42, 0x90, 0xfd, 0xb2, 0xe4,
+ 0x9b, 0x24, 0x70, 0xc0, 0xc3, 0xa9, 0x8a, 0xc9, 0x46, 0xd0, 0xea, 0xc9,
+ 0x93, 0x7d, 0x9f, 0x64, 0x12, 0x54, 0x09, 0xb7, 0xc2, 0x4d, 0x6e, 0xcc,
+ 0x60, 0x07, 0x36, 0x31, 0x64, 0x3d, 0x1e, 0xd3, 0x86, 0x47, 0x47, 0x42,
+ 0x76, 0xb6, 0xf0, 0xe5, 0xb4, 0xe7, 0xbe, 0x47, 0x91, 0x78, 0xbe, 0x06,
+ 0xf1, 0x6e, 0x58, 0xce, 0x32, 0x13, 0x26, 0x34, 0x92, 0xae, 0xb2, 0x29,
+ 0xd0, 0x30, 0x55, 0xfd, 0x89, 0x6a, 0xbf, 0x3e, 0xdf, 0x11, 0x39, 0xe4,
+ 0xfd, 0x56, 0xd7, 0x2f, 0x89, 0x96, 0x08, 0x54, 0xaa, 0xab, 0x8b, 0xfa,
+ 0x65, 0xe5, 0x64, 0xff, 0x24, 0x25, 0x8f, 0x7d, 0xf6, 0xb1, 0x7f, 0x2f,
+ 0xa6, 0xf6, 0x46, 0xab, 0x61, 0xfd, 0x47, 0xad, 0x6d, 0x38, 0x6d, 0xc1,
+ 0xe9, 0x4a, 0xf1, 0x85, 0x05, 0x0e, 0x69, 0x48, 0x7c, 0xa6, 0x76, 0x61,
+ 0xe3, 0x94, 0xf2, 0xd6, 0x7a, 0x9c, 0x79, 0xc0, 0x2a, 0x51, 0x23, 0xc6,
+ 0xaf, 0x29, 0x04, 0x0f, 0x47, 0xc2, 0x93, 0xd7, 0x64, 0xe5, 0x37, 0x2e,
+ 0x53, 0x3b, 0xb7, 0x7c, 0x9c, 0xb4, 0x63, 0x13, 0xc7, 0x56, 0x90, 0xe9,
+ 0x53, 0xd5, 0x86, 0x2b, 0x96, 0x41, 0x42, 0x56, 0xc5, 0x16, 0xd7, 0x9e,
+ 0x30, 0xce, 0xa1, 0x0d, 0x93, 0x5d, 0x11, 0x07, 0xb2, 0x95, 0xfd, 0xf6,
+ 0x0b, 0x28, 0x95, 0x1a, 0x8f, 0xfa, 0xe1, 0x57, 0x7e, 0x06, 0xff, 0x18,
+ 0xaf, 0xe3, 0x4f, 0x3c, 0x34, 0x5b, 0xd4, 0x46, 0x1a, 0xd1, 0xd1, 0x7e,
+ 0x55, 0xba, 0x5d, 0x2a, 0x1f, 0x42, 0x49, 0x95, 0x75, 0x5f, 0x80, 0x60,
+ 0x02, 0x01, 0xdb, 0x36, 0xad, 0x68, 0x69, 0x1e, 0x0b, 0x90, 0x3f, 0xa6,
+ 0xb6, 0x2f, 0x66, 0xa6, 0x7d, 0x81, 0x8c, 0xa0, 0xee, 0x05, 0x95, 0xbc,
+ 0xb3, 0x7c, 0x18, 0xd4, 0x1b, 0x40, 0x96, 0xf5, 0x05, 0x9d, 0x27, 0x3b,
+ 0x78, 0xfc, 0x19, 0x18, 0xc0, 0x61, 0xa0, 0xd6, 0xf9, 0xc0, 0x3f, 0xe5,
+ 0x48, 0x35, 0x0f, 0x8b, 0x0d, 0xfb, 0x31, 0xb7, 0x32, 0x40, 0x1d, 0x69,
+ 0x12, 0x5a, 0x23, 0xf0, 0xce, 0xe9, 0x5e, 0xa6, 0x68, 0x6b, 0xe1, 0xe2,
+ 0x68, 0x07, 0x02, 0x0d, 0x7a, 0xc2, 0x0a, 0x40, 0x10, 0x5e, 0x94, 0xba,
+ 0x77, 0x1d, 0xf7, 0xac, 0xec, 0x79, 0xa9, 0xa1, 0x8a, 0xb8, 0x49, 0x32,
+ 0x08, 0xe0, 0x18, 0xa8, 0x3d, 0x69, 0x41, 0x5d, 0x30, 0x3b, 0xb6, 0x91,
+ 0x46, 0x8d, 0x81, 0x10, 0xb0, 0xc2, 0xed, 0xa0, 0x4e, 0x59, 0x48, 0xd8,
+ 0x64, 0x7d, 0x2d, 0x46, 0xf2, 0x8a, 0x2e, 0x5d, 0x0c, 0x4d, 0x9f, 0xfe,
+ 0x7b, 0x5e, 0xbf, 0x1a, 0x78, 0xdf, 0xfc, 0x0f, 0x04, 0x37, 0x72, 0x1a,
+ 0x09, 0xb8, 0x6e, 0x1b, 0xf1, 0x18, 0x7d, 0x83, 0x44, 0xaa, 0x9b, 0x71,
+ 0xe1, 0x03, 0x04, 0x83, 0xe5, 0xaa, 0xc0, 0xd4, 0xa7, 0x80, 0x10, 0x35,
+ 0x09, 0xae, 0xf7, 0xe1, 0x5e, 0x7c, 0x31, 0x20, 0x43, 0x82, 0xda, 0x07,
+ 0x39, 0xfe, 0x8f, 0x9d, 0x70, 0x3c, 0x57, 0x43, 0x01, 0x51, 0x37, 0x2e,
+ 0x97, 0xef, 0xcf, 0x05, 0x44, 0x75, 0x69, 0xf7, 0xdb, 0xda, 0x80, 0x78,
+ 0x0c, 0xcc, 0xc1, 0x49, 0xac, 0x3b, 0x7e, 0x27, 0x6a, 0xbb, 0xdf, 0x45,
+ 0x5b, 0x3b, 0x29, 0xf6, 0x1b, 0xa9, 0x25, 0xf9, 0x2f, 0xcf, 0x37, 0x71,
+ 0x33, 0xb4, 0x90, 0xd7, 0x9b, 0x87, 0x41, 0x15, 0xd1, 0xa6, 0x39, 0xa7,
+ 0xa9, 0xcd, 0x66, 0x29, 0x59, 0xb4, 0x53, 0x12, 0xa1, 0x20, 0xd5, 0x04,
+ 0xca, 0x40, 0x31, 0xfa, 0x6f, 0xbb, 0x92, 0x04, 0xf3, 0xc2, 0x10, 0x0d,
+ 0xc1, 0x19, 0x78, 0x8c, 0x82, 0xed, 0x92, 0x3a, 0x6b, 0xd1, 0x3d, 0xe8,
+ 0xac, 0x55, 0xe4, 0x8c, 0xc6, 0xd4, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x01, 0x00, 0x00, 0xc2, 0x1d, 0x86, 0xe4, 0xf6, 0xa1, 0xbe, 0xf5,
+ 0xf3, 0x36, 0x9d, 0x32, 0x80, 0x17, 0x3b, 0x1f, 0x18, 0x21, 0xed, 0xa7,
+ 0xf5, 0xaf, 0xf1, 0x94, 0xe2, 0xa7, 0x08, 0xd5, 0xca, 0x18, 0x45, 0xf5,
+ 0x68, 0x94, 0x82, 0x61, 0xf7, 0xb7, 0xb2, 0xfa, 0xd4, 0x5e, 0x32, 0xd0,
+ 0xf0, 0x20, 0x66, 0x83, 0xd1, 0x6b, 0x3c, 0xdf, 0x73, 0xeb, 0x73, 0x82,
+ 0x09, 0x9b, 0xd0, 0xc5, 0xb0, 0x9f, 0x01, 0x77, 0x85, 0xcc, 0x6e, 0x23,
+ 0xb7, 0x00, 0x45, 0xe0, 0xa6, 0x01, 0x29, 0x1d, 0x8b, 0xc4, 0xe0, 0xc2,
+ 0xe0, 0x4f, 0x3b, 0x07, 0xd5, 0xac, 0x6b, 0x88, 0xb8, 0xa4, 0xe2, 0x5c,
+ 0x19, 0xe9, 0x98, 0x72, 0xa5, 0x6b, 0xf5, 0xa4, 0xf7, 0x15, 0xaf, 0xfb,
+ 0xb4, 0x80, 0x9a, 0xe3, 0xa5, 0x35, 0x2f, 0x45, 0x81, 0xf1, 0x8b, 0x2d,
+ 0x26, 0x5c, 0x65, 0xa9, 0x5b, 0x6e, 0x83, 0xc3, 0x62, 0x2f, 0x84, 0xef,
+ 0x11, 0xa5, 0x58, 0x48, 0xe9, 0x67, 0x7e, 0xd3, 0x0b, 0x5d, 0x51, 0x80,
+ 0x39, 0x08, 0x8e, 0xc1, 0x0d, 0x04, 0x11, 0x5f, 0x72, 0x64, 0x1f, 0x83,
+ 0xf8, 0xd3, 0x09, 0x38, 0xb6, 0x7f, 0x50, 0x78, 0x27, 0x20, 0xe5, 0xbd,
+ 0x16, 0xbf, 0x51, 0xd8, 0x4f, 0x67, 0x60, 0xf6, 0x9e, 0xff, 0x08, 0xfe,
+ 0xc6, 0x96, 0xd6, 0x64, 0x94, 0x28, 0xc6, 0x9a, 0x09, 0x1a, 0x34, 0x08,
+ 0x31, 0x4b, 0x0b, 0x97, 0x5a, 0x18, 0x72, 0x49, 0xe9, 0x1d, 0xbb, 0x9c,
+ 0xed, 0x7e, 0xb5, 0xc5, 0xa7, 0xf4, 0x25, 0x7a, 0x26, 0xe9, 0x15, 0x61,
+ 0x85, 0x32, 0xc9, 0xb3, 0xcf, 0x95, 0xbf, 0x35, 0x10, 0x2d, 0x71, 0xfe,
+ 0x03, 0xd6, 0x69, 0x75, 0x8d, 0xb7, 0x16, 0xa7, 0x3d, 0x0e, 0xb7, 0x55,
+ 0x6d, 0xa7, 0x9f, 0x10, 0x7e, 0x7e, 0xff, 0x39, 0xee, 0x8e, 0xa7, 0x81,
+ 0x7d, 0x11, 0xea, 0xa9, 0xd6, 0xed, 0x54, 0xf8, 0xd2, 0xd5, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0xf9, 0xde, 0x41, 0xe7,
+ 0xa6, 0x88, 0x53, 0x76, 0x5a, 0x26, 0xc3, 0x5c, 0xf2, 0x58, 0x68, 0x9c,
+ 0xc7, 0x4e, 0x53, 0x18, 0x53, 0x67, 0x39, 0x23, 0x96, 0xb0, 0xef, 0x58,
+ 0x29, 0xe1, 0x68, 0xd8, 0xce, 0xc0, 0x41, 0xc2, 0x35, 0x5f, 0x74, 0xfa,
+ 0xdf, 0xc7, 0x0f, 0x80, 0x50, 0xd1, 0xf6, 0x5a, 0x3a, 0x81, 0xe0, 0xd9,
+ 0x9b, 0x47, 0x96, 0xcd, 0xc5, 0x0f, 0x91, 0x12, 0x81, 0x77, 0x1e, 0xef,
+ 0x2e, 0xba, 0x16, 0x51, 0x70, 0x78, 0xdc, 0xa3, 0x84, 0x12, 0x7c, 0x9e,
+ 0x21, 0x7d, 0xa3, 0x5f, 0xce, 0xa1, 0x25, 0x84, 0x99, 0xa4, 0x2d, 0xa6,
+ 0x0f, 0x95, 0xef, 0xef, 0x31, 0xe6, 0xf2, 0x18, 0x08, 0x47, 0xd2, 0x5a,
+ 0x39, 0x01, 0x7a, 0xca, 0xd3, 0x03, 0xb1, 0xc2, 0x48, 0xf4, 0x1f, 0x6d,
+ 0xc2, 0x8c, 0x5c, 0xda, 0xf5, 0x10, 0xed, 0xfc, 0x2e, 0x0c, 0xb3, 0x52,
+ 0xaa, 0xa9, 0xed, 0xbc, 0x41, 0xcc, 0xd4, 0x4b, 0x1c, 0xd0, 0xa3, 0x1d,
+ 0xf4, 0xe7, 0x48, 0x34, 0x4e, 0xcf, 0x3b, 0xb3, 0x71, 0x06, 0xbe, 0x0c,
+ 0x35, 0xbb, 0xb4, 0x17, 0xd8, 0x8b, 0xba, 0xdd, 0x32, 0x30, 0x51, 0xb1,
+ 0xb1, 0xd6, 0x3a, 0xdc, 0x3b, 0x25, 0x9a, 0x57, 0xc7, 0x4d, 0xd3, 0x75,
+ 0x93, 0x59, 0x3e, 0x9b, 0x10, 0xcf, 0xdb, 0x38, 0x75, 0x51, 0xb2, 0x2a,
+ 0x48, 0x78, 0xfc, 0xaa, 0xe3, 0x91, 0xe7, 0x93, 0xe7, 0x0a, 0x07, 0x2c,
+ 0xf8, 0x88, 0x93, 0xde, 0x2f, 0xba, 0x7b, 0x72, 0xcd, 0x92, 0xdd, 0xb1,
+ 0xac, 0x1e, 0xe4, 0xe3, 0x5d, 0xa4, 0x7f, 0x86, 0xa7, 0xcb, 0xb5, 0x81,
+ 0x86, 0xf1, 0xf5, 0xad, 0xd6, 0x36, 0x08, 0x09, 0x9f, 0x75, 0x6f, 0x4a,
+ 0x5b, 0x30, 0xf8, 0xaf, 0xd2, 0xbc, 0xb5, 0xbe, 0xf2, 0xeb, 0x9b, 0xbc,
+ 0x11, 0xd4, 0x0c, 0x14, 0xa6, 0x6f, 0x43, 0xd3, 0xc9, 0x4e, 0xca, 0x9b,
+ 0x4e, 0x46, 0x60, 0x4c, 0x63, 0xcc, 0x07, 0x36, 0x8c, 0xf2, 0xd1, 0x93,
+ 0x7a, 0x51, 0x49, 0x15, 0xbf, 0xbf, 0x9e, 0x82, 0x21, 0x06, 0xa0, 0x39,
+ 0x11, 0x1d, 0x6c, 0x41, 0x72, 0xcd, 0x2a, 0x8a, 0x4a, 0xd0, 0x13, 0x6c,
+ 0x56, 0xf4, 0x00, 0x48, 0xaf, 0xab, 0xdf, 0xa9, 0xe9, 0xa6, 0xaa, 0x06,
+ 0x61, 0x79, 0xc4, 0x57, 0x42, 0xca, 0x12, 0x18, 0xcf, 0x81, 0xec, 0x79,
+ 0x19, 0xd2, 0xd2, 0xe3, 0x1d, 0xc6, 0x6c, 0xd0, 0xd6, 0x0a, 0xfb, 0x70,
+ 0x42, 0x28, 0x25, 0x23, 0xb6, 0x23, 0x15, 0x28, 0x5e, 0x9f, 0x49, 0xf2,
+ 0x7b, 0x69, 0x74, 0xa5, 0xb9, 0x26, 0x81, 0xfe, 0x39, 0x3e, 0x3f, 0xc8,
+ 0x7e, 0x9e, 0x5e, 0x8e, 0xf2, 0xdb, 0x6b, 0xfd, 0xe1, 0xc3, 0x01, 0x4a,
+ 0xba, 0x8f, 0x33, 0x71, 0x09, 0x80, 0x5d, 0x9c, 0x58, 0x64, 0xb7, 0x90,
+ 0x13, 0x2a, 0xe9, 0x1d, 0x07, 0x2c, 0x06, 0x70, 0x43, 0x0d, 0xb6, 0x57,
+ 0x02, 0x3c, 0xbe, 0x3c, 0x42, 0xab, 0x77, 0x15, 0x0e, 0x98, 0xfb, 0xf2,
+ 0x1d, 0x14, 0xd9, 0xb8, 0xd1, 0x59, 0x2a, 0x67, 0x6f, 0xfc, 0x59, 0x39,
+ 0x33, 0xe0, 0x49, 0x0b, 0x4e, 0x65, 0x81, 0x9f, 0x71, 0xf2, 0xa5, 0x90,
+ 0x4f, 0x24, 0xc7, 0x05, 0xfb, 0x77, 0x1e, 0x14, 0xca, 0x2f, 0xfc, 0xac,
+ 0xec, 0xbf, 0xa2, 0x69, 0x15, 0x0a, 0x6b, 0xa9, 0xa0, 0x74, 0xee, 0xad,
+ 0xa9, 0x50, 0x4d, 0x4d, 0xab, 0x6e, 0xc1, 0xb3, 0xda, 0xbb, 0xbd, 0xab,
+ 0x00, 0x05, 0x14, 0xc1, 0xc4, 0x53, 0x7b, 0x78, 0x97, 0x68, 0x3c, 0x05,
+ 0xf2, 0xed, 0x87, 0xca, 0x86, 0xd1, 0xdf, 0xda, 0xb3, 0x2f, 0x17, 0x87,
+ 0x87, 0x2f, 0xd8, 0xe9, 0xb2, 0x96, 0xdc, 0x7f, 0x22, 0xf1, 0x2a, 0x9f,
+ 0xfe, 0x54, 0x55, 0xa1, 0x96, 0xab, 0x9f, 0x61, 0x74, 0xcd, 0x4d, 0x77,
+ 0x38, 0x02, 0x23, 0x29, 0x28, 0x5b, 0xfc, 0x86, 0x17, 0x40, 0xd4, 0x42,
+ 0x2a, 0x9b, 0x84, 0xf7, 0x67, 0x2b, 0x3a, 0xc1, 0x31, 0x89, 0x4b, 0x67,
+ 0xd1, 0x7d, 0x6b, 0x36, 0xec, 0x69, 0x6b, 0x24, 0xca, 0xd6, 0x2d, 0xbb,
+ 0x21, 0xc8, 0x0c, 0x53, 0x41, 0x29, 0x0b, 0xc1, 0xfe, 0xd5, 0xa3, 0x4c,
+ 0x66, 0x2f, 0xc7, 0xf1, 0xa8, 0xc0, 0x3d, 0x9a, 0xb9, 0x09, 0x50, 0x3f,
+ 0x09, 0x87, 0xa4, 0x3f, 0x7a, 0x33, 0xef, 0xf0, 0xfb, 0x77, 0x02, 0x7d,
+ 0x92, 0xaf, 0x73, 0xaa, 0xcc, 0x3f, 0x66, 0x56, 0xd0, 0x21, 0xd1, 0xe8,
+ 0x0e, 0x47, 0x03, 0x5e, 0x3b, 0xe9, 0xa2, 0xe3, 0x83, 0x0b, 0x73, 0xd3,
+ 0xaa, 0x94, 0x80, 0xef, 0x7c, 0xdf, 0xde, 0x86, 0xc3, 0xa9, 0x62, 0x34,
+ 0x76, 0xee, 0x4d, 0x15, 0x73, 0x7b, 0xd7, 0x6d, 0xd4, 0x21, 0x05, 0xd4,
+ 0xcf, 0xf3, 0x54, 0xdc, 0x49, 0x5f, 0x5a, 0x2a, 0x37, 0x19, 0x89, 0x61,
+ 0x1d, 0x95, 0x17, 0x8b, 0x09, 0x95, 0x5d, 0x9f, 0xde, 0x86, 0x03, 0x93,
+ 0x76, 0xec, 0x54, 0xec, 0x13, 0xc3, 0xf9, 0x38, 0x8f, 0xa9, 0x11, 0xf0,
+ 0x9a, 0x0e, 0x5e, 0x38, 0x69, 0xeb, 0x62, 0x41, 0x9e, 0xd0, 0x1b, 0x59,
+ 0x8c, 0xfd, 0x16, 0xfa, 0xd8, 0x99, 0x0d, 0x83, 0x7e, 0xba, 0x5b, 0xc6,
+ 0x59, 0xe1, 0xae, 0xba, 0xb9, 0xb8, 0xba, 0xa5, 0x4d, 0x20, 0x00, 0xc9,
+ 0x0c, 0xe1, 0x77, 0xdf, 0xc4, 0x95, 0xca, 0x7c, 0xa5, 0xef, 0x0a, 0xed,
+ 0x9b, 0x31, 0x06, 0xe1, 0xc9, 0xa3, 0x88, 0x0a, 0xcc, 0x3d, 0xc8, 0xb6,
+ 0x01, 0xe2, 0xa9, 0x29, 0x03, 0x8a, 0x28, 0xf8, 0x0d, 0x70, 0x77, 0xb9,
+ 0xe1, 0x1b, 0x06, 0x19, 0x86, 0xc1, 0xd3, 0xcf, 0x6b, 0x9c, 0x09, 0x70,
+ 0x50, 0xed, 0xb5, 0xf6, 0x69, 0xcc, 0xac, 0x30, 0x6a, 0x1f, 0x1d, 0xe6,
+ 0x75, 0x33, 0xab, 0x55, 0x48, 0xfa, 0x81, 0xb8, 0x06, 0x3a, 0x78, 0xee,
+ 0xde, 0xef, 0xe2, 0x17, 0xc4, 0x3e, 0xe5, 0x22, 0xa7, 0xd1, 0x45, 0x5b,
+ 0x57, 0xb0, 0xde, 0x69, 0x30, 0xd1, 0x9a, 0xd7, 0x6b, 0x0e, 0x7a, 0x30,
+ 0x0d, 0xb5, 0xec, 0x60, 0xa7, 0x05, 0x87, 0x42, 0x4b, 0x92, 0x1f, 0x68,
+ 0x8e, 0x1a, 0x90, 0x84, 0x27, 0x2a, 0xc0, 0xd2, 0xff, 0xbc, 0x8e, 0x34,
+ 0x53, 0x9d, 0x04, 0x50, 0xcb, 0x79, 0xd9, 0x55, 0xd5, 0x4d, 0x3c, 0xe2,
+ 0xb4, 0x9b, 0x57, 0x07, 0x1f, 0xce, 0xd0, 0xa7, 0x84, 0xe1, 0xb7, 0x3a,
+ 0xaf, 0xc5, 0x67, 0x64, 0xbc, 0x02, 0xbe, 0xb0, 0x65, 0x7e, 0xb0, 0x4c,
+ 0xc2, 0x2d, 0xcd, 0xf8, 0x60, 0xcb, 0xfe, 0xd1, 0x8d, 0x14, 0x5a, 0xd3,
+ 0x38, 0xd4, 0x71, 0x5a, 0xca, 0xbb, 0xfe, 0x0e, 0x54, 0xf9, 0xb4, 0x25,
+ 0xa5, 0x71, 0x13, 0x95, 0x14, 0xdc, 0x86, 0xb8, 0x21, 0xa7, 0x2e, 0x13,
+ 0xc6, 0x2f, 0xce, 0xe7, 0x6c, 0xb8, 0x0d, 0xc9, 0xe4, 0xc4, 0x64, 0x12,
+ 0x78, 0x1c, 0x95, 0x92, 0xc2, 0xec, 0xaa, 0xd3, 0xc3, 0x3a, 0xd2, 0xe8,
+ 0x95, 0xf0, 0x6b, 0x03, 0x8c, 0xcf, 0x6b, 0xdb, 0x21, 0xa0, 0xcf, 0xf4,
+ 0x05, 0xc8, 0xe7, 0x77, 0x05, 0x55, 0x7b, 0x6b, 0xfa, 0x96, 0xf1, 0x7c,
+ 0x30, 0x62, 0x75, 0xbe, 0x6e, 0xea, 0xba, 0x9f, 0x40, 0x2e, 0x9a, 0x86,
+ 0x93, 0xcc, 0x38, 0xf7, 0xee, 0xd8, 0xbb, 0x24, 0xcd, 0x85, 0x3e, 0x85,
+ 0x16, 0x8c, 0x33, 0x23, 0x73, 0xe6, 0x43, 0xc4, 0x67, 0xbf, 0xef, 0x85,
+ 0xb1, 0x44, 0xf9, 0x55, 0x93, 0x4d, 0x0b, 0x8e, 0xc1, 0x42, 0x13, 0xc6,
+ 0xc8, 0x09, 0x63, 0xab, 0xb3, 0xc7, 0xc4, 0xa4, 0x8b, 0x72, 0xfb, 0xa5,
+ 0x99, 0xa1, 0x5d, 0x07, 0x02, 0x82, 0x56, 0x11, 0x3c, 0xc2, 0x5a, 0x55,
+ 0xf9, 0x3a, 0x93, 0x61, 0x89, 0x46, 0xb7, 0x6a, 0x42, 0x76, 0x1e, 0x70,
+ 0xde, 0xd9, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00,
+ 0x32, 0xc1, 0x61, 0xaa, 0xdb, 0xe9, 0xae, 0x88, 0xcb, 0xf7, 0x28, 0xdd,
+ 0x82, 0x62, 0x61, 0x41, 0x4e, 0xbb, 0xf9, 0xb7, 0xe8, 0x81, 0x99, 0x18,
+ 0xe2, 0xa7, 0xb4, 0x7c, 0xb7, 0x08, 0x44, 0x6f, 0x24, 0xb3, 0xda, 0x57,
+ 0x62, 0x29, 0xc7, 0xa6, 0x84, 0xb1, 0x5d, 0xc5, 0x00, 0x4c, 0x30, 0x16,
+ 0xf0, 0x0a, 0x74, 0x73, 0xec, 0xaf, 0xb5, 0xde, 0xb0, 0xa7, 0x75, 0x22,
+ 0x8f, 0x9e, 0x43, 0x01, 0x68, 0xae, 0x91, 0xeb, 0x46, 0x52, 0x3f, 0x2c,
+ 0x4e, 0xc5, 0xd0, 0xc8, 0x15, 0xea, 0x99, 0xc2, 0x37, 0x5b, 0x68, 0xb5,
+ 0xce, 0x41, 0x92, 0xbf, 0xd6, 0xdb, 0x85, 0xad, 0x08, 0xd1, 0x11, 0x93,
+ 0xe8, 0xd4, 0x78, 0x43, 0x3b, 0x7d, 0xcb, 0x42, 0x84, 0xf3, 0x61, 0x88,
+ 0x9e, 0x6a, 0x73, 0xb9, 0x78, 0x17, 0x9a, 0x9f, 0xfb, 0x97, 0xcb, 0xd6,
+ 0xb5, 0x3f, 0x00, 0x41, 0xb0, 0x30, 0x2f, 0x6f, 0x89, 0xdd, 0xfa, 0x13,
+ 0xd1, 0x07, 0xbe, 0x2f, 0xea, 0x91, 0x62, 0xaa, 0xed, 0xcb, 0xfd, 0x07,
+ 0x82, 0xbb, 0x3f, 0xf4, 0xa6, 0x94, 0x66, 0x71, 0x20, 0x61, 0xac, 0x84,
+ 0x04, 0x70, 0xf2, 0xd3, 0xdf, 0xac, 0x44, 0xfd, 0x47, 0x26, 0x81, 0x64,
+ 0xb3, 0xa6, 0x90, 0x2b, 0xd2, 0x2c, 0xd0, 0x77, 0x81, 0x53, 0x45, 0x78,
+ 0x5f, 0x30, 0x77, 0x91, 0x83, 0x13, 0x33, 0xd1, 0x91, 0xa6, 0x35, 0x21,
+ 0xcb, 0x26, 0x54, 0x0a, 0xf7, 0x70, 0x5e, 0xdb, 0xd8, 0x92, 0xc7, 0xdf,
+ 0xf9, 0x2a, 0x46, 0x91, 0x22, 0x3b, 0xe6, 0xe1, 0x91, 0xeb, 0xa6, 0x78,
+ 0x81, 0x57, 0xf3, 0x04, 0xdf, 0x34, 0x55, 0x74, 0x0a, 0xfe, 0xf2, 0xbd,
+ 0xb3, 0xeb, 0xa3, 0x8e, 0x71, 0x15, 0xa9, 0x2f, 0x53, 0xe2, 0xa1, 0x45,
+ 0xdf, 0xe8, 0x29, 0x40, 0xf1, 0x4b, 0x23, 0xdb, 0x8e, 0xee, 0x19, 0xa8,
+ 0xd4, 0x15, 0x90, 0x8c, 0x04, 0x46, 0x81, 0x49, 0x92, 0xe5, 0xe1, 0xfe,
+ 0x99, 0x06, 0xfc, 0x3e, 0x43, 0x58, 0x3b, 0x19, 0x7f, 0xd2, 0x13, 0x65,
+ 0xc2, 0x64, 0x27, 0x6d, 0x93, 0x6a, 0xcf, 0x48, 0x2a, 0x3d, 0xdd, 0x79,
+ 0x9f, 0x05, 0x32, 0xeb, 0xfd, 0xb4, 0xd2, 0x1d, 0x16, 0x61, 0x3d, 0x17,
+ 0x4c, 0xb8, 0xad, 0x63, 0x0e, 0x6b, 0x8a, 0x4a, 0x34, 0x4c, 0xb5, 0x3c,
+ 0x0f, 0x05, 0x28, 0x8c, 0x8b, 0xdf, 0xf4, 0xa0, 0x49, 0xbf, 0x34, 0x6c,
+ 0x6a, 0x5f, 0x40, 0x95, 0x48, 0x4b, 0x93, 0x1e, 0x61, 0x6d, 0x58, 0xc3,
+ 0x86, 0x98, 0x70, 0x11, 0x4e, 0x44, 0x65, 0xc1, 0x0d, 0xea, 0x2f, 0xda,
+ 0x38, 0x16, 0xbd, 0xd4, 0x7b, 0x3e, 0x31, 0xee, 0x42, 0x4c, 0xdc, 0xe9,
+ 0x8b, 0x1f, 0xa9, 0xcf, 0xab, 0x60, 0xb5, 0xb1, 0xd2, 0xf2, 0x6a, 0xe9,
+ 0xbc, 0xcc, 0xcb, 0x60, 0x4a, 0xca, 0x70, 0x79, 0x64, 0x9d, 0x07, 0x1e,
+ 0xdb, 0xef, 0x34, 0xaf, 0x17, 0x93, 0x6b, 0x60, 0x73, 0x2d, 0x8c, 0x08,
+ 0x27, 0x1e, 0x46, 0x9f, 0xcb, 0x33, 0xdd, 0x76, 0xef, 0x17, 0x58, 0x9a,
+ 0x5f, 0x82, 0x78, 0x0f, 0xbf, 0xe7, 0x0f, 0x3a, 0x1e, 0xa8, 0x30, 0xbf,
+ 0xff, 0xc7, 0xc7, 0x82, 0x8b, 0xc3, 0x65, 0x04, 0xfd, 0x45, 0xc9, 0x88,
+ 0x99, 0x8e, 0x44, 0xc5, 0x23, 0x1e, 0xbf, 0xf1, 0x95, 0x70, 0x35, 0xe6,
+ 0x56, 0x4a, 0x53, 0xb2, 0xac, 0x0c, 0xfd, 0xf5, 0x61, 0x26, 0x5b, 0x70,
+ 0xd6, 0x4c, 0xfc, 0x0f, 0xcc, 0x53, 0x6e, 0x25, 0xca, 0x1d, 0x0c, 0x56,
+ 0xf7, 0x9c, 0x95, 0xf6, 0x3c, 0x08, 0x0c, 0x64, 0xb1, 0x1c, 0x5c, 0xe6,
+ 0x25, 0xa4, 0xa3, 0xb7, 0xaf, 0x8b, 0xbc, 0xe1, 0x68, 0xdf, 0x10, 0xab,
+ 0xbb, 0xd5, 0x30, 0x64, 0x42, 0xf6, 0xe6, 0x9a, 0xb5, 0x59, 0x12, 0x76,
+ 0x92, 0xac, 0x29, 0xe9, 0x45, 0xdb, 0x2e, 0x62, 0x22, 0x58, 0x24, 0x89,
+ 0xc8, 0x6a, 0x2a, 0xa7, 0x3f, 0x04, 0x53, 0x4e, 0x07, 0x41, 0x4e, 0x5f,
+ 0x95, 0x5f, 0x6e, 0x14, 0x5b, 0xa7, 0xa7, 0xd3, 0x5a, 0xa2, 0x95, 0x4a,
+ 0xc8, 0xe9, 0x3c, 0x5a, 0x84, 0x50, 0xbc, 0xe1, 0x9c, 0x7a, 0x16, 0xe5,
+ 0xc7, 0x04, 0x9d, 0x60, 0x2e, 0x7d, 0xb3, 0x77, 0x5d, 0x86, 0x2e, 0xac,
+ 0x57, 0x2a, 0x31, 0x26, 0x23, 0x6e, 0xcc, 0x7f, 0xb8, 0x36, 0x29, 0xa9,
+ 0xa8, 0xd9, 0xc6, 0x75, 0xee, 0x16, 0x23, 0x27, 0x0f, 0xe1, 0xb0, 0x3d,
+ 0x91, 0x3a, 0x26, 0x4a, 0x60, 0x72, 0x14, 0xf9, 0x3c, 0x66, 0x66, 0xe8,
+ 0x7d, 0x4a, 0x6f, 0x7e, 0x63, 0x58, 0x6a, 0x28, 0x78, 0x50, 0xef, 0x3b,
+ 0x9d, 0xeb, 0xb6, 0x4b, 0x5d, 0x55, 0x80, 0x84, 0x97, 0x9b, 0x74, 0x4b,
+ 0x5c, 0x09, 0x1d, 0xe7, 0x57, 0xfc, 0x40, 0x3f, 0xa9, 0xbd, 0xdf, 0x61,
+ 0x2a, 0x89, 0x62, 0x51, 0xfc, 0x24, 0xee, 0xee, 0x97, 0x10, 0xca, 0xb6,
+ 0x0e, 0x8e, 0x71, 0x67, 0x2a, 0x79, 0x4f, 0xc4, 0xe6, 0x3e, 0x27, 0xc2,
+ 0x9b, 0x85, 0xfd, 0xde, 0xfb, 0x58, 0x75, 0xf3, 0x1c, 0x31, 0xa2, 0x56,
+ 0x3e, 0xdc, 0x24, 0xf4, 0x4f, 0xcb, 0x5a, 0x1a, 0x77, 0x5c, 0x28, 0xd1,
+ 0x5a, 0x55, 0xa9, 0x8c, 0xb5, 0xdd, 0x77, 0x93, 0x58, 0xd8, 0x2f, 0x7d,
+ 0x5a, 0x67, 0xa1, 0x95, 0x0a, 0xd2, 0x6a, 0x93, 0xa6, 0xf0, 0x5f, 0x7f,
+ 0x0a, 0x29, 0xdb, 0x1d, 0x8c, 0xa7, 0x12, 0x0a, 0xf4, 0xc9, 0xcd, 0x70,
+ 0xd1, 0xbd, 0x48, 0xd4, 0x9a, 0xbb, 0xbb, 0x24, 0xbf, 0x52, 0x25, 0xb9,
+ 0x75, 0xc2, 0x17, 0x36, 0x6f, 0x4a, 0xc0, 0x53, 0x6d, 0x38, 0xfb, 0x7a,
+ 0x60, 0xc8, 0x5d, 0x03, 0xc1, 0x1c, 0x0c, 0x31, 0xf0, 0x59, 0xed, 0x0a,
+ 0x5f, 0x84, 0xf2, 0x89, 0x6c, 0xb4, 0xd5, 0x24, 0x2d, 0x2a, 0xda, 0xbe,
+ 0x74, 0x1d, 0x22, 0xe2, 0xc6, 0xf0, 0x9b, 0x98, 0x5a, 0x41, 0x11, 0x4c,
+ 0x51, 0x97, 0x16, 0xa7, 0xc9, 0xd8, 0x53, 0x12, 0x53, 0xdd, 0x22, 0xa9,
+ 0xf2, 0xae, 0x52, 0x49, 0x02, 0xf9, 0x5c, 0x78, 0x00, 0xa2, 0x64, 0xff,
+ 0x91, 0x62, 0x20, 0x6a, 0x87, 0x6a, 0x40, 0x01, 0x85, 0x30, 0xf5, 0xdd,
+ 0xa7, 0x64, 0x0a, 0x85, 0x8d, 0x37, 0x99, 0xcb, 0x03, 0xc8, 0x29, 0x56,
+ 0x7e, 0x75, 0x4f, 0xa1, 0xc3, 0x76, 0xce, 0xdb, 0xa3, 0xb4, 0x7e, 0x91,
+ 0x95, 0xbe, 0x53, 0x0e, 0x20, 0xc9, 0xe7, 0x71, 0x78, 0xad, 0x3d, 0x4c,
+ 0xbb, 0x59, 0xb9, 0x77, 0xcf, 0x7d, 0x7b, 0xff, 0x15, 0xdb, 0x1d, 0xae,
+ 0x1f, 0xbe, 0x33, 0x88, 0x01, 0x04, 0x95, 0xe5, 0xe9, 0x6a, 0x1c, 0xbf,
+ 0xc8, 0xc3, 0x33, 0x3b, 0xd8, 0x2f, 0x75, 0x4a, 0xc3, 0x6f, 0x09, 0x88,
+ 0x26, 0x46, 0x90, 0x89, 0x53, 0x12, 0x27, 0xc2, 0x7d, 0x23, 0x6b, 0xc4,
+ 0xe3, 0x0a, 0x0f, 0xc2, 0x86, 0x6d, 0x20, 0x35, 0x82, 0x33, 0xec, 0xdd,
+ 0xa7, 0x6a, 0xc3, 0xa8, 0x11, 0xdc, 0x02, 0xd9, 0x05, 0x1b, 0x04, 0x75,
+ 0x92, 0x6c, 0x08, 0x9e, 0x38, 0x72, 0xd9, 0x7d, 0x9b, 0xbc, 0xfd, 0xca,
+ 0xb8, 0x06, 0x0e, 0x24, 0x89, 0x90, 0xde, 0x52, 0xe4, 0xd1, 0xcc, 0x99,
+ 0x87, 0x0b, 0x87, 0xbb, 0x5c, 0xa9, 0xab, 0xec, 0xb5, 0xe4, 0xdd, 0x5d,
+ 0xfa, 0xb1, 0x97, 0x5f, 0x61, 0xf7, 0x58, 0xd6, 0x08, 0x02, 0xf2, 0x51,
+ 0x7c, 0x7a, 0xe6, 0xf1, 0xcb, 0x43, 0xd0, 0x21, 0x09, 0xb8, 0x82, 0xa9,
+ 0x52, 0xd9, 0xa8, 0x7f, 0x2b, 0xe1, 0x0f, 0x31, 0xbc, 0x16, 0xa2, 0xce,
+ 0x35, 0x55, 0x2e, 0xd6, 0xda, 0x38, 0xd9, 0xc2, 0x5e, 0xca, 0x27, 0xd9,
+ 0xa6, 0xd6, 0x4b, 0xa2, 0x73, 0xc4, 0xce, 0x66, 0x30, 0x60, 0xa2, 0x01,
+ 0xfa, 0xc1, 0xd6, 0xc8, 0xea, 0xdd, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x70, 0xe2, 0x62, 0x68, 0xff, 0x60, 0x67, 0x64,
+ 0x88, 0xdd, 0x81, 0x79, 0x82, 0xf5, 0x46, 0xf9, 0x7e, 0x0e, 0xa9, 0x26,
+ 0xf6, 0xcf, 0x5d, 0xef, 0x10, 0x11, 0xe1, 0x71, 0x72, 0x77, 0xcf, 0x02,
+ 0x7b, 0xf1, 0x6e, 0xc4, 0xb4, 0xfa, 0x2a, 0x12, 0xfe, 0x7e, 0x3c, 0x66,
+ 0xef, 0x41, 0x98, 0x3a, 0x1f, 0xa9, 0x14, 0x8f, 0x46, 0x22, 0xa0, 0xc2,
+ 0xee, 0x93, 0x25, 0x34, 0xf2, 0xb7, 0x6d, 0x0a, 0x36, 0xde, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0xd4, 0x17, 0x62, 0x25,
+ 0xfd, 0x5b, 0x75, 0xeb, 0xec, 0x06, 0xc9, 0x39, 0x86, 0x6d, 0xc5, 0x60,
+ 0x2d, 0x33, 0x3d, 0xce, 0x6a, 0x9f, 0x07, 0x3b, 0xb9, 0x70, 0x0f, 0xc7,
+ 0x13, 0x46, 0x35, 0x46, 0x26, 0xe4, 0xbc, 0x6e, 0x54, 0x89, 0x29, 0xd5,
+ 0xa4, 0x94, 0xa0, 0x3a, 0x7a, 0x61, 0xcf, 0xd1, 0x48, 0x27, 0x7a, 0x72,
+ 0x95, 0xde, 0x93, 0xd1, 0x19, 0x1f, 0xc9, 0xc8, 0x8f, 0x0d, 0xce, 0x34,
+ 0x03, 0x39, 0x0a, 0x92, 0x16, 0x09, 0xc4, 0x49, 0xf9, 0x30, 0x2e, 0x19,
+ 0xd1, 0x69, 0x7e, 0x78, 0x00, 0x25, 0x30, 0x6f, 0x6b, 0xe1, 0xbe, 0xad,
+ 0xb2, 0x05, 0xde, 0xc7, 0xc2, 0xf7, 0xd5, 0xa7, 0x4d, 0x03, 0x6f, 0x6b,
+ 0xcd, 0xcb, 0x42, 0xfa, 0x88, 0x16, 0xd5, 0xa6, 0x60, 0x08, 0xd4, 0xa5,
+ 0x5b, 0x3b, 0x7b, 0xa2, 0xca, 0xa3, 0xa2, 0x5d, 0x63, 0x7f, 0xc0, 0x37,
+ 0xc5, 0x7e, 0x99, 0x04, 0x5d, 0x9a, 0xb9, 0xa5, 0xac, 0xd1, 0xe2, 0x5d,
+ 0xb2, 0x2b, 0x7e, 0xbb, 0xb9, 0x66, 0x13, 0xa7, 0x30, 0xbf, 0x80, 0x0c,
+ 0x2b, 0x8d, 0x45, 0xe1, 0x8d, 0x96, 0x25, 0x27, 0x47, 0x3d, 0x21, 0x7d,
+ 0x1c, 0x42, 0xac, 0x31, 0x26, 0x47, 0x59, 0xb3, 0x44, 0x85, 0xf2, 0x8e,
+ 0x7d, 0x01, 0x96, 0x6d, 0xb2, 0x64, 0xc3, 0xfc, 0xa7, 0x82, 0x06, 0x4a,
+ 0x87, 0x75, 0x9b, 0x99, 0x47, 0x7e, 0xa6, 0x4d, 0x2c, 0x36, 0xff, 0xac,
+ 0x2b, 0x77, 0x96, 0x52, 0x14, 0x8d, 0x07, 0x0d, 0x28, 0x9d, 0x84, 0xa2,
+ 0xda, 0xd6, 0x45, 0x3a, 0xd4, 0xe6, 0xb7, 0x9a, 0xf3, 0x34, 0xe3, 0xda,
+ 0x39, 0xdf, 0x35, 0x9c, 0xe4, 0x87, 0x55, 0xc8, 0x43, 0xd0, 0x61, 0x46,
+ 0x52, 0x2f, 0x75, 0x63, 0xbb, 0x98, 0x97, 0xeb, 0xfb, 0x15, 0xaf, 0x8e,
+ 0x96, 0xdc, 0xff, 0x0a, 0x90, 0xda, 0x09, 0x63, 0x28, 0x7b, 0x92, 0x73,
+ 0x0b, 0xd4, 0x2b, 0x72, 0x2a, 0x86, 0x32, 0xc3, 0xc1, 0x3e, 0xe4, 0x2c,
+ 0x07, 0x89, 0x53, 0xb7, 0xfe, 0x78, 0x6c, 0x95, 0xb4, 0x62, 0x4d, 0x4b,
+ 0xfe, 0x6c, 0xfc, 0x5e, 0x4e, 0xa7, 0x8c, 0x07, 0x4f, 0x85, 0x27, 0xe0,
+ 0x7b, 0xd9, 0x7a, 0xe5, 0x1d, 0xbc, 0x36, 0xda, 0x8e, 0x21, 0xff, 0xb3,
+ 0x60, 0x2c, 0x5e, 0x23, 0x0f, 0xde, 0x3f, 0xae, 0xa5, 0x3a, 0x50, 0xa9,
+ 0x99, 0x39, 0x45, 0xaf, 0xd3, 0x5f, 0x4a, 0x15, 0xad, 0x9c, 0x66, 0x7f,
+ 0x92, 0xe0, 0x02, 0x81, 0x3e, 0x06, 0x6a, 0x5e, 0xd0, 0x0c, 0x42, 0xe7,
+ 0xcf, 0xe2, 0xeb, 0xa3, 0xe0, 0xf7, 0x2d, 0x8a, 0x21, 0xdb, 0x64, 0x28,
+ 0x2a, 0xb3, 0x2b, 0xc4, 0xc9, 0xd5, 0x60, 0xaf, 0xfc, 0x15, 0xa1, 0x44,
+ 0x9c, 0x96, 0x04, 0x42, 0x1c, 0x55, 0x8c, 0xa5, 0xce, 0x80, 0xce, 0x75,
+ 0x64, 0xa9, 0xf6, 0xa5, 0x5a, 0x0f, 0x8a, 0x4b, 0x8b, 0x72, 0xcf, 0x3e,
+ 0xd7, 0xeb, 0xe1, 0xd0, 0xd3, 0x2d, 0x04, 0x6c, 0x9e, 0x02, 0x75, 0x43,
+ 0x5c, 0xc1, 0x57, 0x66, 0xd9, 0x14, 0x5b, 0x08, 0x10, 0x44, 0x8d, 0x8e,
+ 0x89, 0xd1, 0x65, 0x27, 0x2a, 0x0b, 0x99, 0x6f, 0x09, 0xa6, 0x20, 0xa5,
+ 0x75, 0x24, 0xe4, 0xf7, 0xf5, 0xe0, 0xed, 0x79, 0x37, 0x18, 0x13, 0x1c,
+ 0xd9, 0xd1, 0xf5, 0x69, 0x0c, 0xa5, 0x02, 0xdf, 0x6a, 0xfd, 0x2e, 0x35,
+ 0x8e, 0xd0, 0x41, 0x91, 0x61, 0x0f, 0x5c, 0xdd, 0x70, 0xbf, 0x1c, 0x49,
+ 0xcb, 0xe9, 0xc9, 0x33, 0xc4, 0x99, 0x1e, 0x8b, 0x75, 0x48, 0xc2, 0x58,
+ 0xa4, 0x70, 0x1f, 0xbb, 0xcd, 0xd3, 0x0e, 0x79, 0x25, 0xbe, 0x53, 0xfa,
+ 0x32, 0x32, 0xf6, 0xb9, 0xf0, 0x0a, 0x52, 0x5b, 0xe0, 0x69, 0xff, 0x43,
+ 0xda, 0x98, 0x1f, 0xee, 0x54, 0x60, 0xf8, 0x24, 0x43, 0xc5, 0x37, 0x72,
+ 0xd1, 0xfc, 0x99, 0x9a, 0x3e, 0x24, 0xe0, 0xd9, 0xc2, 0x61, 0x47, 0xb3,
+ 0x26, 0x09, 0x85, 0x74, 0xa1, 0x2b, 0x4a, 0x70, 0xd0, 0x1b, 0x90, 0x03,
+ 0x25, 0xd9, 0x22, 0xc2, 0x16, 0x22, 0x3a, 0x62, 0x20, 0xd4, 0x13, 0xce,
+ 0xa2, 0xc7, 0x02, 0xfb, 0x9a, 0xbf, 0xf1, 0x1c, 0x80, 0x01, 0x97, 0x90,
+ 0x7f, 0x5a, 0x98, 0x70, 0x30, 0x61, 0x77, 0xe5, 0xd4, 0x3b, 0x03, 0x42,
+ 0x57, 0x31, 0x5e, 0xc6, 0x64, 0xe1, 0xf4, 0x64, 0x77, 0x21, 0x9b, 0x44,
+ 0x1c, 0xd9, 0x8c, 0x95, 0x8a, 0xf1, 0xcb, 0x82, 0xac, 0xc1, 0x26, 0x31,
+ 0xf2, 0x22, 0x41, 0xab, 0xbb, 0x23, 0xd3, 0x8d, 0xcc, 0x5c, 0x9d, 0x9b,
+ 0x1d, 0x9c, 0x4d, 0xf3, 0x62, 0xde, 0x15, 0x6a, 0x94, 0x8d, 0x24, 0xe7,
+ 0x52, 0x8d, 0x2a, 0xa4, 0x1d, 0x54, 0x5a, 0xda, 0xaf, 0xab, 0x05, 0x27,
+ 0x4b, 0xbb, 0xb4, 0xda, 0x0c, 0xb9, 0x20, 0xb3, 0xaf, 0x4a, 0xeb, 0x37,
+ 0xe5, 0x43, 0xe4, 0xc1, 0xf6, 0x9e, 0xf8, 0x6c, 0xd8, 0xa1, 0x0c, 0xf9,
+ 0xd1, 0x4b, 0x96, 0xa0, 0x6d, 0x38, 0x64, 0x41, 0xd3, 0x14, 0xfb, 0xad,
+ 0x89, 0xa9, 0xf7, 0x36, 0x01, 0x0f, 0xbe, 0x8e, 0xd7, 0x76, 0xc6, 0x70,
+ 0x22, 0x32, 0x8b, 0x08, 0xca, 0x95, 0xbf, 0xcf, 0x5e, 0xb8, 0xc0, 0x3f,
+ 0xd9, 0xaa, 0x84, 0xab, 0x30, 0x5b, 0xe3, 0x7a, 0x61, 0x32, 0xe5, 0x54,
+ 0x01, 0x5e, 0xb6, 0x1c, 0x9c, 0x78, 0x52, 0x2a, 0xa7, 0xf5, 0x29, 0xa6,
+ 0x0f, 0x14, 0xa5, 0x3a, 0x34, 0xd4, 0xf5, 0xc2, 0xb2, 0x8d, 0x12, 0x7b,
+ 0x8a, 0x64, 0x00, 0xfd, 0x02, 0x0e, 0x02, 0x26, 0x5a, 0xb9, 0xeb, 0xfd,
+ 0x30, 0xce, 0x51, 0xec, 0x5f, 0xbc, 0xee, 0x53, 0x21, 0xec, 0x0e, 0xee,
+ 0xc4, 0x28, 0x1a, 0xec, 0x2a, 0x39, 0x4e, 0xe1, 0x50, 0x11, 0x3f, 0x16,
+ 0xdd, 0xbf, 0xaf, 0x3e, 0xbe, 0xd4, 0xfe, 0x34, 0x1e, 0x62, 0x3f, 0x5a,
+ 0xea, 0x05, 0xfc, 0xd5, 0x45, 0x08, 0x47, 0xce, 0x38, 0x3f, 0x75, 0x7e,
+ 0x0c, 0x3a, 0x2a, 0x14, 0xa7, 0x61, 0xba, 0x3a, 0xa1, 0x41, 0xa2, 0x72,
+ 0x19, 0xfa, 0x33, 0x43, 0xa7, 0xf4, 0x4e, 0x5b, 0xf9, 0xb1, 0x45, 0x16,
+ 0x57, 0x8e, 0xb1, 0xad, 0x7d, 0x88, 0xd3, 0x93, 0xa2, 0x08, 0xf3, 0x96,
+ 0x4d, 0x84, 0x63, 0x08, 0xfa, 0x9d, 0xf3, 0x04, 0x33, 0xbd, 0x7e, 0x7a,
+ 0xc7, 0x63, 0xc5, 0x31, 0x5a, 0x82, 0x33, 0x90, 0x56, 0x44, 0xe9, 0xd3,
+ 0xc4, 0xd4, 0x76, 0x29, 0x2f, 0xdb, 0xa3, 0x9d, 0xff, 0xd4, 0xd2, 0xb1,
+ 0xce, 0xf1, 0xcb, 0x7f, 0x10, 0x3b, 0x90, 0xa4, 0x1b, 0xa0, 0x9b, 0xa7,
+ 0xfa, 0x27, 0x40, 0x11, 0x35, 0xc9, 0x7f, 0x01, 0x97, 0x76, 0x9f, 0x33,
+ 0xc5, 0xd6, 0x8d, 0x20, 0x07, 0x73, 0x93, 0x0b, 0x24, 0x88, 0x4e, 0x73,
+ 0x68, 0x79, 0x92, 0x20, 0x2a, 0x71, 0xed, 0x22, 0x0b, 0xfb, 0x42, 0xb5,
+ 0xd9, 0xc3, 0xaa, 0xed, 0x45, 0x03, 0x64, 0xde, 0x6f, 0x25, 0x8e, 0x3b,
+ 0x9a, 0xef, 0xc5, 0x63, 0xc2, 0x7f, 0x34, 0xd0, 0x1b, 0x20, 0xa3, 0xab,
+ 0x9d, 0x54, 0x41, 0x0e, 0x7b, 0x2e, 0x96, 0x12, 0x75, 0x58, 0xdf, 0xd5,
+ 0xaa, 0x3c, 0xf2, 0x26, 0xc1, 0xf1, 0x18, 0x37, 0x56, 0xf2, 0xd2, 0x86,
+ 0x6f, 0xd4, 0x9f, 0x57, 0x2b, 0x32, 0xe9, 0x08, 0x94, 0x53, 0x40, 0xc5,
+ 0x4d, 0x77, 0x39, 0xc6, 0x4c, 0x63, 0x53, 0xf9, 0xbf, 0x35, 0x08, 0xc5,
+ 0x0d, 0xd0, 0x89, 0x82, 0xa7, 0x2d, 0x6a, 0xb4, 0x22, 0xb1, 0x10, 0x7f,
+ 0xcf, 0x2e, 0x21, 0x27, 0x9c, 0x12, 0xc6, 0x0e, 0xca, 0xd2, 0x32, 0xb1,
+ 0x6d, 0xfd, 0x59, 0x12, 0x23, 0x60, 0x46, 0x89, 0xe0, 0x75, 0x5e, 0xc9,
+ 0xf4, 0x3d, 0x8a, 0x89, 0xd4, 0x23, 0xc2, 0xbe, 0x30, 0x32, 0x4a, 0x95,
+ 0x42, 0xe2, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00,
+ 0xa7, 0x0b, 0x48, 0xe2, 0xeb, 0xd7, 0x12, 0x42, 0x4c, 0x71, 0xfb, 0x25,
+ 0x17, 0x23, 0x0e, 0x01, 0xa6, 0x21, 0xb9, 0x17, 0x6e, 0xf0, 0x24, 0x66,
+ 0x9e, 0x9d, 0x0f, 0x71, 0xf8, 0x5b, 0x79, 0xb0, 0x1b, 0x1f, 0xe7, 0xa2,
+ 0xc0, 0x17, 0x16, 0x08, 0x5e, 0x24, 0x7b, 0xf9, 0x7a, 0x1e, 0x70, 0xe2,
+ 0x05, 0x40, 0x16, 0x56, 0xe7, 0x79, 0xf2, 0x30, 0xa3, 0xdc, 0xe3, 0x7a,
+ 0x7e, 0x22, 0x88, 0xc0, 0xf7, 0xc8, 0x5c, 0x93, 0x95, 0x86, 0x02, 0x6c,
+ 0x73, 0x76, 0xef, 0x03, 0x2d, 0xcb, 0xa5, 0x22, 0xfe, 0x05, 0xbb, 0xe6,
+ 0xfd, 0x19, 0x8c, 0x8b, 0x67, 0x58, 0x81, 0x81, 0x2d, 0x36, 0xd0, 0xc1,
+ 0x20, 0xb2, 0x87, 0x87, 0xdb, 0xe4, 0xe5, 0xd1, 0xd1, 0xd5, 0x81, 0x34,
+ 0x4c, 0xd6, 0x09, 0xa2, 0x5d, 0xcc, 0x99, 0x12, 0xa5, 0x06, 0x0f, 0x06,
+ 0x7e, 0xbb, 0x67, 0x26, 0x69, 0x15, 0x6e, 0x5f, 0xb1, 0x8e, 0xd6, 0x34,
+ 0xfc, 0x4d, 0xd9, 0x03, 0xb7, 0x5a, 0xf4, 0xaa, 0x03, 0x00, 0x88, 0x6b,
+ 0x5a, 0xc9, 0xf2, 0xfb, 0x67, 0x72, 0xbc, 0xf7, 0xb9, 0xdc, 0x97, 0xdf,
+ 0x80, 0x91, 0xfa, 0x30, 0x18, 0x02, 0x89, 0xc7, 0xc9, 0x62, 0x1d, 0xc0,
+ 0x0b, 0xa6, 0xfe, 0x7e, 0xb9, 0xa9, 0x1f, 0x11, 0x71, 0xe1, 0xd1, 0xfe,
+ 0x8d, 0x90, 0x2c, 0x09, 0x82, 0x2e, 0x36, 0x79, 0xa5, 0x75, 0x54, 0xfb,
+ 0xd3, 0x3c, 0xb4, 0x18, 0x2f, 0x4e, 0x3f, 0x37, 0xc4, 0xf8, 0xc5, 0x59,
+ 0xa3, 0xfd, 0x0c, 0x62, 0x9e, 0xa8, 0x7a, 0x56, 0xc5, 0x97, 0x89, 0x35,
+ 0xc7, 0xb0, 0x29, 0x87, 0xbf, 0x6a, 0xdc, 0xb1, 0x2f, 0x01, 0xf4, 0x0d,
+ 0x7c, 0x25, 0x95, 0x39, 0x81, 0xdd, 0x1a, 0x81, 0x36, 0xc0, 0x6b, 0xbf,
+ 0x6b, 0x4d, 0xea, 0x23, 0xc0, 0x3e, 0x5c, 0x39, 0xe5, 0x6b, 0x59, 0xa0,
+ 0x50, 0x02, 0x99, 0xdf, 0x4e, 0xe3, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x04, 0x00, 0x00, 0x17, 0x88, 0xf8, 0xda, 0x3d, 0x57, 0x83, 0x63,
+ 0x76, 0xa0, 0x5c, 0x13, 0x1a, 0x00, 0x64, 0x30, 0x19, 0xfd, 0x2e, 0x9c,
+ 0x64, 0xb6, 0xda, 0x51, 0x7b, 0x55, 0xe8, 0xc4, 0x67, 0x1b, 0xda, 0xfc,
+ 0x4c, 0xd0, 0x27, 0x58, 0x56, 0xa1, 0x52, 0xd2, 0xb8, 0xd8, 0xd5, 0x94,
+ 0x69, 0xcf, 0xd0, 0xd5, 0x72, 0xeb, 0x2b, 0x05, 0xf3, 0x12, 0xa6, 0xac,
+ 0xa6, 0xf7, 0x90, 0x24, 0x1f, 0x22, 0x97, 0x5e, 0x8b, 0x7c, 0x2c, 0x30,
+ 0x61, 0x11, 0x9b, 0xdf, 0x83, 0x2b, 0x10, 0x09, 0x42, 0x77, 0x2b, 0xd9,
+ 0x43, 0xb3, 0x27, 0x69, 0x75, 0xf2, 0x2e, 0x72, 0xed, 0x50, 0xea, 0xbf,
+ 0x7f, 0x47, 0x39, 0x9c, 0xf8, 0x1e, 0xce, 0x6f, 0xdd, 0xe8, 0x40, 0xc5,
+ 0x14, 0x01, 0x7e, 0xbb, 0x0f, 0x43, 0x2d, 0x36, 0x70, 0x54, 0xc6, 0xbe,
+ 0x69, 0x24, 0xd1, 0x65, 0x49, 0x77, 0xf0, 0xd2, 0x99, 0xb4, 0x50, 0x8d,
+ 0x98, 0xcb, 0xbf, 0x7a, 0x7c, 0x65, 0xd3, 0x46, 0xcf, 0x90, 0x69, 0x56,
+ 0x15, 0xa2, 0xae, 0x11, 0x94, 0x60, 0xf9, 0x45, 0x17, 0x54, 0x6b, 0xbd,
+ 0xeb, 0xd8, 0x74, 0x41, 0x5c, 0xf6, 0x49, 0x0a, 0x14, 0xce, 0x43, 0x1f,
+ 0x67, 0xc3, 0x6c, 0xf4, 0x01, 0xce, 0x3f, 0x85, 0xed, 0x19, 0xa1, 0xf7,
+ 0x1b, 0xf8, 0x46, 0x45, 0xb4, 0xe9, 0xa7, 0x1f, 0x2a, 0x65, 0x00, 0x2a,
+ 0xd3, 0x8b, 0x6a, 0x3b, 0xac, 0x78, 0xab, 0xf4, 0xc8, 0x62, 0x76, 0xc8,
+ 0x24, 0xf8, 0xf8, 0x08, 0xe0, 0x64, 0x00, 0x64, 0x74, 0x9e, 0x55, 0x2e,
+ 0xf8, 0xc9, 0xc8, 0x58, 0x0e, 0x1f, 0x27, 0x32, 0xfd, 0x30, 0x24, 0x68,
+ 0xc8, 0xa4, 0x8c, 0x1c, 0xf3, 0xa7, 0x32, 0xae, 0x84, 0x0a, 0x8a, 0x1e,
+ 0x11, 0xce, 0xb2, 0x02, 0xf1, 0xb3, 0x5f, 0x7d, 0x5e, 0x54, 0x8c, 0xe0,
+ 0xeb, 0x46, 0x6e, 0x8a, 0x5f, 0x3f, 0x71, 0x47, 0x2a, 0x8a, 0xe6, 0xf0,
+ 0xb0, 0x04, 0x49, 0x64, 0xb3, 0x7e, 0x16, 0x09, 0x83, 0x5f, 0x12, 0xe0,
+ 0x85, 0xb7, 0x36, 0xc0, 0x8a, 0xa5, 0xcd, 0xae, 0xc0, 0xb4, 0xa2, 0x62,
+ 0x9b, 0xfa, 0x64, 0x18, 0x16, 0x8e, 0xb6, 0x50, 0xf2, 0x9b, 0xc4, 0x7d,
+ 0x0c, 0x4c, 0x8b, 0x58, 0xcf, 0x9b, 0x87, 0x09, 0xb1, 0x37, 0xbb, 0xaf,
+ 0xa7, 0x72, 0x79, 0x81, 0x09, 0x55, 0xa1, 0x6a, 0x87, 0xb0, 0x7d, 0xc8,
+ 0xb0, 0xc1, 0xa4, 0xa9, 0xdf, 0xcf, 0x95, 0x77, 0x36, 0x8e, 0x2b, 0xae,
+ 0xeb, 0x4b, 0xf9, 0x2a, 0x83, 0x6c, 0x53, 0x3c, 0x89, 0xa6, 0x08, 0xae,
+ 0x00, 0x4e, 0xb8, 0xf6, 0x34, 0x7c, 0xc6, 0x76, 0x87, 0x1a, 0x02, 0xb0,
+ 0x89, 0xa3, 0x0f, 0x00, 0xc6, 0x7b, 0xeb, 0xf7, 0x95, 0x40, 0xc5, 0x0d,
+ 0x6f, 0x74, 0xd8, 0x21, 0x2f, 0x9f, 0x24, 0xac, 0x43, 0xdb, 0x3a, 0x39,
+ 0x6c, 0x34, 0x59, 0x62, 0x66, 0xbc, 0x28, 0x7f, 0x8c, 0x64, 0x62, 0x8c,
+ 0x28, 0x6c, 0xf5, 0x79, 0x24, 0xb1, 0x00, 0x9c, 0x58, 0x6b, 0x09, 0xef,
+ 0xb0, 0x73, 0xcd, 0x47, 0xbb, 0x52, 0xfd, 0x26, 0x6a, 0xff, 0xb9, 0xf1,
+ 0xd5, 0x82, 0x59, 0x01, 0xfa, 0x87, 0x14, 0x24, 0x10, 0xb0, 0xf7, 0xdf,
+ 0xf9, 0x3f, 0x67, 0x19, 0xbd, 0xc7, 0x85, 0xb0, 0xad, 0x47, 0xa8, 0x4c,
+ 0x3e, 0xb6, 0x2e, 0x8a, 0xb3, 0xcc, 0x35, 0xa0, 0x48, 0xc7, 0x90, 0x81,
+ 0xb7, 0x53, 0x1c, 0x38, 0x63, 0xf2, 0x2f, 0xa0, 0x71, 0x82, 0xe2, 0x56,
+ 0xdb, 0x68, 0xe8, 0x5f, 0xf8, 0x42, 0xf2, 0xf6, 0xb8, 0x10, 0x6b, 0x54,
+ 0x21, 0xa0, 0xc1, 0xfe, 0xcb, 0xce, 0x12, 0xa2, 0x49, 0x51, 0x86, 0x53,
+ 0x56, 0xec, 0x33, 0xb3, 0x72, 0xce, 0xa4, 0x46, 0xe3, 0x37, 0xcb, 0xc0,
+ 0x95, 0xaa, 0xe2, 0xa3, 0xc5, 0xe9, 0x36, 0x40, 0xfe, 0xf7, 0xe2, 0x5a,
+ 0x6d, 0x58, 0x39, 0xb2, 0x41, 0x5d, 0xe2, 0x71, 0x72, 0xd0, 0xf0, 0x5c,
+ 0x16, 0x88, 0x95, 0x30, 0x0a, 0xfb, 0x8d, 0xda, 0x14, 0x80, 0xf4, 0x15,
+ 0xf2, 0xf6, 0xac, 0xf3, 0xd8, 0x8d, 0x13, 0x24, 0x2c, 0x74, 0x60, 0x6e,
+ 0x8c, 0xa1, 0x59, 0xcf, 0x74, 0x7c, 0x2d, 0x0b, 0xbb, 0x06, 0x5c, 0x9d,
+ 0xcd, 0xf3, 0x1e, 0x4a, 0xba, 0x3f, 0x9c, 0x4a, 0xc4, 0xd7, 0xf9, 0xf0,
+ 0xa5, 0x56, 0x7f, 0xb0, 0xa2, 0x57, 0xd0, 0xc3, 0xaa, 0xa7, 0xd0, 0x49,
+ 0xe2, 0x28, 0x9b, 0xc4, 0x64, 0x0c, 0xe0, 0x71, 0x9c, 0x05, 0x04, 0x95,
+ 0x00, 0x1f, 0x7b, 0xa9, 0xb9, 0xb3, 0x2b, 0x8f, 0x0b, 0x45, 0x1e, 0x23,
+ 0xaa, 0x27, 0x89, 0x4a, 0xb0, 0x7d, 0x03, 0xdf, 0xae, 0xdb, 0xcb, 0xc4,
+ 0xec, 0x3b, 0x02, 0xe2, 0x85, 0x3a, 0xb7, 0x25, 0xfb, 0xab, 0xca, 0xc1,
+ 0x33, 0x00, 0x5b, 0xd2, 0xcf, 0xb0, 0x11, 0x1d, 0x51, 0xb5, 0x5b, 0xea,
+ 0x94, 0xf7, 0xa0, 0x98, 0x33, 0xba, 0x58, 0xfc, 0x12, 0xea, 0xdd, 0x89,
+ 0xbd, 0x63, 0x03, 0xbe, 0x7e, 0x3b, 0x69, 0xc4, 0x9d, 0x57, 0x0f, 0xd6,
+ 0xbe, 0xea, 0x5b, 0xd0, 0x97, 0x63, 0x89, 0xb0, 0xa0, 0xc0, 0xd6, 0x39,
+ 0xc1, 0x69, 0x12, 0x6a, 0xfb, 0xac, 0x74, 0x7f, 0xfb, 0xf4, 0x7f, 0x38,
+ 0x44, 0x4c, 0x8a, 0xa2, 0x41, 0x15, 0xc0, 0x54, 0xc0, 0xed, 0x14, 0x83,
+ 0xef, 0xbc, 0x9c, 0xc7, 0xdd, 0x21, 0xd6, 0xf0, 0x9b, 0x7f, 0x09, 0xd5,
+ 0x96, 0xe5, 0xf7, 0xc5, 0xa9, 0xb3, 0x41, 0xb0, 0x9d, 0xeb, 0x49, 0x68,
+ 0x9d, 0x2b, 0xea, 0x47, 0x80, 0x3b, 0x54, 0xb8, 0xf4, 0x14, 0x5e, 0xd6,
+ 0x66, 0x89, 0x04, 0xb3, 0x00, 0xa3, 0xa8, 0x32, 0x62, 0x2e, 0xc3, 0x15,
+ 0xc6, 0x93, 0x7d, 0x40, 0x32, 0xb1, 0x6b, 0x60, 0xd3, 0x52, 0xdf, 0x09,
+ 0x8c, 0x80, 0x2b, 0x01, 0xe7, 0x97, 0x8d, 0xbb, 0x14, 0xd6, 0x10, 0x15,
+ 0x64, 0x00, 0x4a, 0x2c, 0x67, 0xca, 0xd0, 0xa1, 0x37, 0x33, 0x7b, 0xa1,
+ 0x2a, 0x5b, 0x5b, 0x78, 0xf8, 0x2f, 0xdd, 0x76, 0xab, 0x8a, 0xc3, 0xe3,
+ 0x37, 0x00, 0xd1, 0x29, 0xb0, 0x96, 0x1d, 0x18, 0xbe, 0x5d, 0x32, 0x7e,
+ 0xb7, 0x11, 0xa9, 0x78, 0x72, 0xa2, 0x2d, 0x29, 0x1c, 0x32, 0xa4, 0xff,
+ 0xc7, 0xce, 0xfe, 0xaf, 0xb7, 0x17, 0x43, 0xe5, 0x2f, 0xae, 0x45, 0xd3,
+ 0xaf, 0x10, 0xe3, 0xd0, 0x58, 0xb6, 0xee, 0xee, 0x7a, 0xb5, 0x06, 0x70,
+ 0x26, 0x7e, 0x2d, 0x5b, 0xd5, 0xe1, 0x7b, 0x9a, 0x37, 0x02, 0xfc, 0x1d,
+ 0x08, 0x4f, 0x1a, 0xf5, 0x44, 0x63, 0xde, 0x4b, 0x14, 0x68, 0x54, 0x0b,
+ 0x6a, 0x22, 0x4e, 0x02, 0x65, 0xcd, 0xf4, 0x04, 0xec, 0xcc, 0x8a, 0x0b,
+ 0xe0, 0x59, 0xf8, 0x65, 0x25, 0x63, 0xed, 0x0f, 0xa6, 0xc5, 0x3c, 0xcb,
+ 0x5d, 0xc5, 0xd8, 0x9f, 0x5a, 0xd3, 0x88, 0x3d, 0xd4, 0x2c, 0xb3, 0x04,
+ 0xf6, 0x97, 0xc7, 0xe2, 0xfd, 0xb6, 0xf4, 0x7d, 0x0d, 0xb9, 0x75, 0x7e,
+ 0x9d, 0x81, 0xdc, 0xdf, 0x8e, 0x90, 0x40, 0x0c, 0x7b, 0x45, 0xfe, 0x68,
+ 0xfd, 0xff, 0x1c, 0xf1, 0x16, 0x09, 0x33, 0x74, 0x27, 0x7b, 0x4d, 0xd9,
+ 0x9b, 0x48, 0x6d, 0x84, 0xeb, 0x96, 0x8f, 0x4b, 0x82, 0x73, 0xd5, 0x69,
+ 0x7d, 0x14, 0x45, 0x8c, 0xb8, 0x71, 0x87, 0x70, 0x09, 0x26, 0xfc, 0x89,
+ 0x6f, 0x0f, 0xb6, 0xc1, 0xd6, 0xe1, 0xbf, 0xdb, 0x85, 0x8f, 0x94, 0xad,
+ 0x94, 0x01, 0x01, 0xbb, 0x3f, 0xc0, 0xb5, 0xff, 0xf5, 0xbb, 0x4f, 0x50,
+ 0x09, 0xca, 0x7d, 0x36, 0x47, 0x66, 0x9a, 0x8c, 0xee, 0x84, 0x73, 0x9a,
+ 0x1f, 0x49, 0x75, 0xb4, 0xab, 0x66, 0xf7, 0x3b, 0xfe, 0x81, 0x67, 0xc9,
+ 0xd1, 0x16, 0xde, 0x1f, 0xc2, 0x24, 0xed, 0x6a, 0x5a, 0xe7, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0xc5, 0xd7, 0x14, 0x84,
+ 0xf8, 0xcf, 0x9b, 0xf4, 0xb7, 0x6f, 0x47, 0x90, 0x47, 0x30, 0x80, 0x4b,
+ 0x9e, 0x32, 0x25, 0xa9, 0xf1, 0x33, 0xb5, 0xde, 0xa1, 0x68, 0xf4, 0xe2,
+ 0x85, 0x1f, 0x07, 0x2f, 0xcc, 0x00, 0xfc, 0xaa, 0x7c, 0xa6, 0x20, 0x61,
+ 0x71, 0x7a, 0x48, 0xe5, 0x2e, 0x29, 0xa3, 0xfa, 0x37, 0x9a, 0x95, 0x3f,
+ 0xaa, 0x68, 0x93, 0xe3, 0x2e, 0xc5, 0xa2, 0x7b, 0x94, 0x5e, 0x60, 0x5f,
+ 0x10, 0x85, 0xf3, 0x23, 0x2d, 0x42, 0x4c, 0x13, 0x29, 0xc8, 0x8d, 0x78,
+ 0x6e, 0xd6, 0x8c, 0xe6, 0xfc, 0xb6, 0x2a, 0xa6, 0x3b, 0xf9, 0xab, 0x61,
+ 0x7c, 0x08, 0x8a, 0x3b, 0x70, 0xbe, 0x57, 0xaa, 0xda, 0x1f, 0x33, 0x4a,
+ 0x70, 0x17, 0x25, 0x0d, 0x3f, 0x60, 0x3d, 0xc8, 0x2e, 0xbd, 0x3b, 0x12,
+ 0x0b, 0x63, 0x5e, 0x3f, 0xf5, 0x6b, 0x1f, 0x0b, 0xd9, 0x33, 0x85, 0x23,
+ 0x71, 0x24, 0x9a, 0xb3, 0xdf, 0x5c, 0x1f, 0xef, 0x14, 0x33, 0xc8, 0x66,
+ 0x85, 0xb7, 0xf0, 0x56, 0x68, 0x1d, 0x51, 0x52, 0xaf, 0x80, 0x3c, 0xe2,
+ 0x59, 0x06, 0xf1, 0xd1, 0x9f, 0xb6, 0xc6, 0x80, 0x4e, 0x06, 0xea, 0x28,
+ 0xab, 0x17, 0x8f, 0x45, 0x7a, 0xf6, 0xb4, 0x93, 0xb7, 0x43, 0x9e, 0xc6,
+ 0xd4, 0x29, 0x00, 0x62, 0xab, 0x51, 0x7a, 0x72, 0xe5, 0xc1, 0xd4, 0x10,
+ 0xcd, 0xd6, 0x17, 0x54, 0xe4, 0x20, 0x84, 0x50, 0xe4, 0xf9, 0x00, 0x13,
+ 0xfd, 0xa6, 0x9f, 0xef, 0x19, 0xd4, 0x60, 0x2a, 0x42, 0x07, 0xcd, 0xd5,
+ 0xa1, 0x01, 0x6d, 0x07, 0x01, 0x32, 0x61, 0x3c, 0x65, 0x9a, 0x8f, 0x5d,
+ 0x33, 0xf3, 0xcb, 0x29, 0x0b, 0x8c, 0xe7, 0x3b, 0x83, 0x44, 0xb1, 0x3a,
+ 0x4f, 0x8e, 0x09, 0x15, 0x14, 0x69, 0x84, 0xa1, 0xbb, 0x15, 0xfd, 0xea,
+ 0xde, 0xbe, 0x5b, 0x6a, 0xc0, 0x95, 0x04, 0x46, 0x4d, 0x8a, 0xaa, 0xac,
+ 0xbc, 0x2f, 0xad, 0x12, 0x15, 0x8a, 0x53, 0x4c, 0x94, 0xb8, 0xca, 0x42,
+ 0x96, 0x3a, 0xf4, 0x7a, 0x18, 0x9d, 0x5b, 0x24, 0x9a, 0xce, 0xa8, 0x99,
+ 0xd4, 0x37, 0x32, 0xf6, 0xf2, 0xac, 0xaf, 0x3f, 0xf5, 0x3b, 0xfe, 0xda,
+ 0x13, 0x9a, 0xab, 0x4f, 0x55, 0xc0, 0x2c, 0x21, 0x2b, 0x65, 0x71, 0x1f,
+ 0xc5, 0x04, 0x32, 0xc9, 0x94, 0xe5, 0xfa, 0x6f, 0xd8, 0x2a, 0xbc, 0x70,
+ 0x85, 0x55, 0xdc, 0x62, 0xb7, 0x3a, 0x20, 0x0e, 0xe7, 0x67, 0x3c, 0xfe,
+ 0xcb, 0x83, 0x6a, 0x15, 0x6e, 0x4a, 0x35, 0x65, 0xea, 0xc1, 0xb9, 0x4d,
+ 0x35, 0xf9, 0x4b, 0xcf, 0xd8, 0xfd, 0xa5, 0xff, 0xff, 0x67, 0x70, 0x04,
+ 0xae, 0xa2, 0xa4, 0x12, 0x4b, 0x83, 0x4f, 0xc2, 0x96, 0xf0, 0x21, 0x2b,
+ 0x14, 0x21, 0x73, 0x42, 0x14, 0x99, 0x07, 0xe5, 0xa9, 0x52, 0x4c, 0xeb,
+ 0xbe, 0xc3, 0x11, 0x2e, 0x27, 0xda, 0x69, 0x94, 0xd5, 0xf6, 0xc6, 0x77,
+ 0x0a, 0x00, 0x5d, 0x9a, 0x82, 0xaa, 0x21, 0xfc, 0x86, 0x9b, 0xd0, 0xc4,
+ 0xc4, 0x1f, 0x53, 0x41, 0x7a, 0x92, 0xab, 0x1c, 0x12, 0xf6, 0xd5, 0x48,
+ 0xfb, 0x29, 0x4d, 0xb4, 0xd2, 0x12, 0xee, 0xc5, 0xea, 0x18, 0x33, 0xf1,
+ 0x4d, 0x0a, 0x10, 0x43, 0xa5, 0x35, 0xb1, 0x63, 0xc4, 0xfb, 0x38, 0x1e,
+ 0xef, 0xac, 0x3f, 0x97, 0x41, 0xc6, 0x96, 0x3e, 0x60, 0x13, 0xc8, 0xe3,
+ 0xbe, 0x61, 0xe9, 0xb6, 0x26, 0x16, 0x14, 0xf8, 0x82, 0x0d, 0x6e, 0x75,
+ 0x2f, 0xd7, 0x9c, 0x3a, 0x4a, 0xda, 0xd8, 0x2b, 0x35, 0xd4, 0x20, 0x32,
+ 0xd4, 0x4f, 0x0f, 0xe4, 0xdc, 0xd5, 0x0f, 0xfe, 0xa6, 0x81, 0x28, 0xb4,
+ 0x24, 0x3e, 0xb7, 0x0f, 0xb0, 0xb2, 0x5b, 0x05, 0x76, 0xbb, 0x24, 0x49,
+ 0x6a, 0x01, 0x68, 0x3f, 0x03, 0x96, 0xbc, 0x0c, 0x77, 0x48, 0x5f, 0xe8,
+ 0x39, 0xf4, 0xb0, 0x84, 0x42, 0x0e, 0x6a, 0xb9, 0xab, 0xf2, 0x95, 0x97,
+ 0xa7, 0x5e, 0x29, 0x34, 0x9d, 0x50, 0xc0, 0x4b, 0x40, 0x72, 0xa1, 0x7c,
+ 0x79, 0x5e, 0x95, 0xbe, 0xd6, 0x17, 0x43, 0x0a, 0xc9, 0x27, 0x25, 0x43,
+ 0xd7, 0x99, 0xd5, 0x48, 0xd8, 0x98, 0xb5, 0x2b, 0x7f, 0xe3, 0xbd, 0x1d,
+ 0xc0, 0xd1, 0x04, 0xd5, 0xa4, 0xe1, 0x68, 0xbe, 0x96, 0xf1, 0x2e, 0x5e,
+ 0x37, 0x8d, 0x39, 0x4e, 0xe4, 0xcc, 0x5e, 0xd7, 0xdd, 0x59, 0x7e, 0xe8,
+ 0xae, 0x48, 0xb5, 0xec, 0x2c, 0xf7, 0x68, 0x96, 0x00, 0xe5, 0xec, 0x03,
+ 0x6f, 0x98, 0x3a, 0x9a, 0x4f, 0xd9, 0xf1, 0x2f, 0xfe, 0x76, 0xcf, 0x8f,
+ 0x0b, 0x3d, 0x8a, 0x14, 0x00, 0x83, 0xcb, 0xca, 0xe3, 0x34, 0x81, 0xb5,
+ 0x91, 0x64, 0x2b, 0x12, 0x24, 0x86, 0x9c, 0xae, 0x3c, 0x7f, 0x53, 0x22,
+ 0xd4, 0x94, 0x90, 0x44, 0x6b, 0x35, 0xd2, 0xce, 0x8e, 0x95, 0xe2, 0xbe,
+ 0x46, 0x50, 0x3f, 0x3d, 0xc3, 0xcd, 0xef, 0x47, 0x99, 0xb5, 0xf2, 0xd4,
+ 0x6f, 0xf4, 0xfa, 0xa2, 0xfc, 0x1e, 0xe3, 0x99, 0x49, 0xfd, 0x1a, 0x6e,
+ 0x0d, 0xb5, 0xf1, 0xc8, 0x05, 0x22, 0x29, 0xca, 0x03, 0xb8, 0x15, 0x3b,
+ 0x01, 0x8a, 0x95, 0x74, 0x48, 0x93, 0x61, 0x35, 0xde, 0xeb, 0xa9, 0xc4,
+ 0x56, 0xa9, 0xd7, 0xde, 0x4b, 0xe5, 0x4b, 0xa1, 0x42, 0x6a, 0x5f, 0xe3,
+ 0xb2, 0xc7, 0xda, 0xfb, 0xc7, 0x70, 0x64, 0xe0, 0x68, 0x19, 0xc6, 0x11,
+ 0x77, 0x2b, 0x5f, 0xba, 0x1d, 0x58, 0x77, 0x98, 0x2c, 0x91, 0xb4, 0xd2,
+ 0xea, 0x1b, 0xdc, 0xe8, 0xfa, 0x82, 0xf3, 0x6e, 0xac, 0x88, 0x15, 0x16,
+ 0x1a, 0x53, 0xb3, 0x01, 0x94, 0x03, 0x47, 0x20, 0xdb, 0x71, 0xcb, 0x71,
+ 0xe8, 0x62, 0xad, 0x34, 0x2b, 0xa3, 0xa5, 0xe9, 0xa6, 0x82, 0x0e, 0x16,
+ 0x61, 0xbc, 0x29, 0x6b, 0xb1, 0x60, 0x67, 0x80, 0x9a, 0x9f, 0xc4, 0x82,
+ 0xf6, 0xb0, 0x7a, 0x16, 0x9c, 0x25, 0x04, 0xeb, 0xfd, 0xe0, 0x18, 0xd3,
+ 0xfc, 0xeb, 0xe1, 0x3c, 0x2b, 0x29, 0x7b, 0x32, 0x4e, 0xd3, 0x6d, 0xe1,
+ 0x27, 0xda, 0xc9, 0x14, 0x5c, 0x7f, 0xfa, 0x70, 0x41, 0x8e, 0xb4, 0xa3,
+ 0xde, 0x36, 0x92, 0x67, 0x97, 0xe2, 0xec, 0x85, 0x8b, 0x76, 0x08, 0x3c,
+ 0x32, 0x58, 0xd4, 0x7f, 0x6f, 0x91, 0x03, 0xdb, 0x19, 0x3e, 0xc4, 0x8b,
+ 0x3c, 0xb7, 0x75, 0x90, 0x71, 0x7a, 0x21, 0x9d, 0xa7, 0x77, 0xbf, 0xf5,
+ 0x92, 0x57, 0x46, 0x07, 0xa7, 0xbb, 0x0c, 0x42, 0xca, 0x4f, 0x5a, 0x27,
+ 0x45, 0x69, 0xfe, 0x6d, 0x78, 0x43, 0x77, 0xc4, 0xb4, 0x43, 0xff, 0x37,
+ 0x0d, 0xb7, 0xfa, 0xe9, 0x9e, 0x06, 0x70, 0x53, 0xfd, 0xf6, 0xa0, 0x28,
+ 0x84, 0x46, 0xcd, 0x61, 0xa2, 0x95, 0xc4, 0x1e, 0x6a, 0x13, 0xa1, 0x7f,
+ 0xaf, 0xe1, 0x73, 0x85, 0xb0, 0x53, 0x9c, 0x08, 0xb6, 0x1d, 0x4d, 0xb4,
+ 0x0b, 0xfb, 0x1f, 0x0c, 0x7b, 0x17, 0x06, 0x73, 0xa7, 0x22, 0x1f, 0xb0,
+ 0xd8, 0x45, 0x6e, 0xe5, 0xde, 0x48, 0xb7, 0x9f, 0x5a, 0xa8, 0xd1, 0xc3,
+ 0x04, 0xd1, 0x87, 0xec, 0x15, 0x3e, 0xd1, 0xc7, 0x57, 0x01, 0x46, 0x4b,
+ 0x28, 0xa8, 0x79, 0x5a, 0x7e, 0x0b, 0x56, 0x56, 0x28, 0xda, 0x35, 0xea,
+ 0x4c, 0x14, 0x81, 0xae, 0xc0, 0x0d, 0x12, 0xfe, 0x2d, 0xb7, 0x95, 0x4d,
+ 0xea, 0x78, 0xb6, 0x53, 0xcf, 0xac, 0x8a, 0xfc, 0xc9, 0x07, 0x9f, 0x93,
+ 0xf0, 0x11, 0x86, 0x13, 0xe9, 0xca, 0x3d, 0xce, 0xb1, 0xfd, 0x1a, 0x0a,
+ 0x8b, 0x11, 0x82, 0x94, 0x6a, 0xae, 0xc5, 0x80, 0x6a, 0x3b, 0xa8, 0x7c,
+ 0xb4, 0x53, 0x4e, 0xa9, 0x04, 0x1a, 0x4f, 0xb0, 0xb9, 0x95, 0x96, 0xa5,
+ 0xfd, 0xce, 0xdc, 0x57, 0x00, 0x48, 0x16, 0xe2, 0x40, 0xae, 0x04, 0xf5,
+ 0x83, 0x60, 0x23, 0xd9, 0x8e, 0x59, 0x56, 0x20, 0x50, 0x38, 0xc4, 0xde,
+ 0x88, 0x9f, 0x91, 0x06, 0xdb, 0x8f, 0x84, 0xa2, 0xaf, 0x61, 0xdd, 0x48,
+ 0x03, 0x4f, 0xc4, 0xb8, 0xed, 0x12, 0xd2, 0x74, 0x08, 0xb9, 0x51, 0x63,
+ 0xb5, 0xfe, 0x09, 0x7f, 0x7b, 0x8c, 0x5e, 0xd7, 0x27, 0xe5, 0x79, 0xe6,
+ 0x33, 0x60, 0x54, 0xe1, 0x21, 0xda, 0xca, 0x8b, 0x81, 0xdf, 0xb6, 0xa7,
+ 0x2e, 0x9d, 0x0f, 0xfc, 0x05, 0x80, 0x67, 0xcb, 0xc5, 0xdf, 0xc7, 0x13,
+ 0xee, 0xb5, 0x40, 0x8e, 0xa7, 0x0c, 0xcb, 0xf2, 0x45, 0x15, 0x29, 0xb1,
+ 0xb8, 0x02, 0x23, 0x61, 0x38, 0xf1, 0x16, 0xa1, 0x0c, 0xa1, 0xc9, 0x40,
+ 0x8c, 0xd0, 0x48, 0x4b, 0xce, 0x9c, 0x1e, 0x53, 0x40, 0x44, 0xf6, 0x17,
+ 0x16, 0xc6, 0x5c, 0xb0, 0x2a, 0x29, 0x59, 0x87, 0x67, 0x85, 0xa7, 0x81,
+ 0x84, 0xe9, 0x4f, 0xe5, 0x4e, 0x13, 0x5a, 0x11, 0xa1, 0x24, 0x62, 0xe9,
+ 0x7a, 0xea, 0x51, 0xaa, 0x45, 0xf3, 0x1d, 0x2a, 0xaf, 0x01, 0x28, 0x35,
+ 0xda, 0xb4, 0xe7, 0xab, 0xc1, 0xb9, 0x3c, 0x45, 0xa2, 0x0b, 0x5d, 0x40,
+ 0x09, 0xac, 0x62, 0x16, 0xd3, 0x1f, 0x9f, 0xc7, 0x1a, 0x56, 0xb7, 0x27,
+ 0xd1, 0x1b, 0xe1, 0xb5, 0x82, 0x9e, 0xe8, 0xd3, 0x5c, 0x0f, 0xe8, 0x87,
+ 0x61, 0xc6, 0x20, 0xb7, 0x31, 0x3f, 0x0d, 0xb3, 0x0a, 0x5a, 0xce, 0x06,
+ 0xa5, 0xe9, 0xfd, 0xf3, 0x29, 0x1a, 0xcd, 0x86, 0x0e, 0x31, 0x29, 0xaa,
+ 0xb7, 0x32, 0xf1, 0x10, 0x4e, 0x92, 0x12, 0x00, 0xc0, 0xac, 0x50, 0x4b,
+ 0x52, 0x59, 0x51, 0x7c, 0xa8, 0x0c, 0xf7, 0xcb, 0x16, 0x73, 0x7b, 0x90,
+ 0xa8, 0x57, 0x79, 0xb4, 0x73, 0x53, 0xd7, 0xed, 0xba, 0x46, 0xc5, 0x06,
+ 0x53, 0x02, 0xc7, 0x58, 0x4c, 0x09, 0x0c, 0xa5, 0x01, 0x13, 0x18, 0x39,
+ 0x4b, 0x4e, 0xc2, 0x0d, 0xd6, 0xdf, 0xaa, 0x7e, 0x46, 0xba, 0x6e, 0xcc,
+ 0x25, 0x42, 0xd0, 0xb3, 0x31, 0xdc, 0xdf, 0x7d, 0xf1, 0xc3, 0x73, 0xca,
+ 0x7a, 0xf6, 0xcb, 0x23, 0x81, 0x8d, 0xbe, 0x0b, 0xf2, 0x79, 0x8d, 0x14,
+ 0xa4, 0xc8, 0x36, 0x18, 0x49, 0xc8, 0x0d, 0xd7, 0xc9, 0xdd, 0x35, 0xeb,
+ 0xec, 0x52, 0x56, 0xae, 0xf2, 0xd2, 0x51, 0x91, 0x39, 0xbc, 0xb0, 0x49,
+ 0xb7, 0xf2, 0x1b, 0x64, 0x83, 0x5a, 0xa6, 0x97, 0xc2, 0x15, 0x95, 0xdc,
+ 0x11, 0xd2, 0x89, 0xc0, 0x6a, 0xb1, 0x44, 0x43, 0x38, 0xb6, 0x54, 0x0f,
+ 0xdc, 0xcb, 0xed, 0x26, 0x27, 0xd9, 0x46, 0x56, 0x4e, 0x6a, 0x54, 0x74,
+ 0x0f, 0x45, 0xfc, 0xb6, 0x93, 0xab, 0x3c, 0xd1, 0x86, 0x51, 0xaf, 0xa9,
+ 0x4a, 0xc0, 0x9c, 0x78, 0xc1, 0xb1, 0xc7, 0xf1, 0x9c, 0xd1, 0xd0, 0x32,
+ 0x4e, 0x4b, 0x02, 0x36, 0x68, 0x38, 0x88, 0x56, 0xc0, 0x2b, 0x12, 0x05,
+ 0x3b, 0xb9, 0xf6, 0xa2, 0x37, 0xe7, 0xbc, 0x81, 0xf9, 0x75, 0x51, 0x27,
+ 0x56, 0x0d, 0x55, 0xd1, 0x6a, 0xe0, 0xcf, 0x87, 0x0a, 0x44, 0xc6, 0x57,
+ 0xe1, 0x1b, 0xc0, 0x2c, 0xcf, 0xab, 0x77, 0xe9, 0x14, 0xf5, 0x34, 0x89,
+ 0xfb, 0xc9, 0xf2, 0x87, 0x5c, 0x75, 0xba, 0x51, 0x9a, 0x49, 0xe9, 0x23,
+ 0x23, 0xf4, 0xc9, 0xd1, 0x2f, 0x87, 0xf6, 0x75, 0x38, 0x97, 0x48, 0xb8,
+ 0x30, 0x46, 0x1d, 0x46, 0x65, 0x03, 0x10, 0xcf, 0xfb, 0x36, 0xf2, 0xb1,
+ 0xaf, 0x31, 0x02, 0x7b, 0x74, 0xfe, 0x9f, 0x8c, 0x73, 0x04, 0xfd, 0xb5,
+ 0xae, 0x2e, 0x27, 0x9c, 0xd8, 0x73, 0xbc, 0xc3, 0x4a, 0x76, 0x93, 0x66,
+ 0xf6, 0xb7, 0x90, 0xc4, 0x42, 0x3d, 0xcd, 0xb5, 0xf1, 0x75, 0xbf, 0xb7,
+ 0xdd, 0x8e, 0xb7, 0xcd, 0x90, 0x35, 0xf5, 0x95, 0x3d, 0xe4, 0x4e, 0xb0,
+ 0x7c, 0x5f, 0xad, 0xff, 0x75, 0x38, 0xc4, 0xc7, 0xed, 0xec, 0x70, 0xcc,
+ 0x9f, 0xf9, 0x77, 0xa1, 0x00, 0x2f, 0xf1, 0xa2, 0xc9, 0x74, 0xdc, 0x18,
+ 0x14, 0xd0, 0x2f, 0x86, 0x66, 0xa7, 0x5b, 0x39, 0x5c, 0xba, 0x0e, 0x77,
+ 0x16, 0x04, 0xc3, 0x02, 0x42, 0x3b, 0x66, 0x29, 0xee, 0x65, 0x00, 0xd4,
+ 0x22, 0x5a, 0x77, 0x74, 0xd4, 0xc3, 0xf3, 0x00, 0xdf, 0x6b, 0xc3, 0x15,
+ 0x89, 0x0e, 0xb1, 0xbc, 0xac, 0xe8, 0x44, 0x2f, 0x80, 0x34, 0x34, 0x8b,
+ 0x0c, 0x48, 0x45, 0xc2, 0x6a, 0xa3, 0x67, 0xd7, 0x3d, 0x36, 0xf3, 0x3f,
+ 0xe5, 0xf0, 0x5b, 0xe8, 0xad, 0x41, 0xd5, 0x82, 0xc1, 0x28, 0xab, 0x77,
+ 0xe8, 0x7f, 0xb3, 0xf6, 0xd2, 0x0c, 0xe4, 0x03, 0xcf, 0xe4, 0x72, 0xdb,
+ 0x7b, 0x81, 0xf4, 0xf3, 0x48, 0x74, 0xe1, 0x91, 0xb8, 0xf8, 0x4c, 0x2c,
+ 0x60, 0x99, 0x3e, 0x1e, 0x4f, 0xaf, 0x12, 0xab, 0x52, 0xef, 0xc7, 0x60,
+ 0xd2, 0xfe, 0x62, 0x55, 0xc8, 0x18, 0xad, 0x60, 0xa7, 0x5d, 0xde, 0x4d,
+ 0xfc, 0x6d, 0xe1, 0x10, 0x7c, 0xf9, 0xa2, 0x64, 0x00, 0x16, 0x1f, 0x44,
+ 0x7c, 0xe2, 0x72, 0x37, 0xd9, 0x92, 0xad, 0xfc, 0x62, 0x53, 0xbe, 0xb6,
+ 0xe0, 0xc8, 0xe0, 0xa2, 0xef, 0x22, 0x4b, 0x70, 0x3a, 0x4f, 0xc9, 0xed,
+ 0x6b, 0xbc, 0x17, 0x0a, 0xcf, 0x6a, 0x2c, 0xd3, 0xd2, 0x6b, 0x02, 0x45,
+ 0xfa, 0x9e, 0xc2, 0x21, 0x28, 0xfc, 0x07, 0x68, 0xd6, 0xb8, 0x9f, 0x2a,
+ 0x0b, 0x7a, 0x0e, 0xbc, 0x4e, 0xee, 0x84, 0x38, 0xe4, 0x8e, 0x70, 0xc3,
+ 0xc4, 0xad, 0x74, 0x87, 0x2d, 0x16, 0x4f, 0xa1, 0xf8, 0x20, 0xf5, 0xde,
+ 0xa3, 0xc5, 0x0c, 0x3b, 0xde, 0x44, 0x48, 0x0f, 0x3c, 0xdc, 0x7e, 0x10,
+ 0x8b, 0x87, 0xc4, 0x3b, 0xb0, 0x95, 0xbf, 0x61, 0x1e, 0xad, 0x07, 0x52,
+ 0xfd, 0x0b, 0x84, 0xa9, 0x46, 0xb0, 0x32, 0xd5, 0x22, 0x80, 0x35, 0x26,
+ 0x41, 0xf8, 0x11, 0x72, 0xb1, 0x31, 0x6f, 0x5a, 0x75, 0xcc, 0x67, 0xe0,
+ 0xb2, 0x50, 0x89, 0xb2, 0x66, 0x6e, 0xee, 0xa0, 0x41, 0x8d, 0x00, 0x2a,
+ 0xa7, 0x9d, 0xa5, 0x11, 0x2b, 0x07, 0x95, 0x3a, 0x55, 0x8c, 0x67, 0xb1,
+ 0xe5, 0x2d, 0xd4, 0xd1, 0x3e, 0x29, 0xed, 0xa5, 0x59, 0x97, 0x7b, 0xdf,
+ 0x92, 0x10, 0x0b, 0x04, 0x89, 0x27, 0xa0, 0xa2, 0x93, 0x18, 0x7f, 0x47,
+ 0x84, 0x1c, 0xc6, 0xd6, 0x8f, 0x73, 0x81, 0xa0, 0xfa, 0xe5, 0x3e, 0xd8,
+ 0xbf, 0x56, 0x1a, 0x76, 0xf4, 0xc4, 0x0f, 0x7a, 0x29, 0x9d, 0x32, 0x5d,
+ 0x41, 0xe0, 0x07, 0xb9, 0xd3, 0x3f, 0x7e, 0xff, 0x90, 0x89, 0xce, 0xdc,
+ 0xf1, 0x1d, 0x54, 0xb6, 0x67, 0x7f, 0x4d, 0x71, 0x9a, 0x4a, 0x5f, 0x80,
+ 0x0d, 0x5c, 0x77, 0xd5, 0x50, 0x7c, 0x41, 0x56, 0x7e, 0x99, 0x0a, 0xeb,
+ 0x66, 0x1f, 0xd2, 0x55, 0xc3, 0xc6, 0x6c, 0xc5, 0xfc, 0x34, 0x40, 0x2c,
+ 0x05, 0x29, 0x05, 0x7c, 0xca, 0xe6, 0x8d, 0xd3, 0xb0, 0xca, 0x84, 0x27,
+ 0x50, 0x7c, 0x6b, 0x17, 0x1b, 0x22, 0xe4, 0x7f, 0xe6, 0x44, 0x94, 0x06,
+ 0x4b, 0xb3, 0xb7, 0xbb, 0x98, 0x81, 0x44, 0x0b, 0xf5, 0x66, 0xcb, 0xad,
+ 0xf2, 0x9a, 0xe1, 0x47, 0xf3, 0x97, 0xa9, 0xb2, 0xc2, 0xca, 0xcd, 0x98,
+ 0x78, 0x60, 0xdc, 0x6e, 0x87, 0x55, 0x47, 0xf3, 0xae, 0x84, 0xdd, 0x9a,
+ 0xe9, 0x1a, 0x63, 0x83, 0xea, 0x23, 0x09, 0x67, 0x34, 0x83, 0x00, 0x6e,
+ 0x5e, 0x58, 0xb8, 0x89, 0x04, 0x08, 0x0a, 0x55, 0x9e, 0x78, 0xc9, 0xff,
+ 0xb9, 0xb5, 0x2c, 0xdd, 0x3b, 0x0c, 0x58, 0x07, 0x8b, 0xb4, 0x6a, 0xc4,
+ 0x64, 0xa3, 0x5e, 0x5b, 0xfe, 0x4d, 0xd0, 0x74, 0x01, 0x1b, 0xdf, 0x10,
+ 0x45, 0x2b, 0xd6, 0x9e, 0xa9, 0x60, 0x1f, 0xad, 0x46, 0xa1, 0x8c, 0xf8,
+ 0xf6, 0xa9, 0x8a, 0x27, 0xea, 0x51, 0x37, 0x84, 0xcf, 0xe5, 0xd7, 0x51,
+ 0xd6, 0x40, 0x39, 0x39, 0x5f, 0xf6, 0x96, 0x33, 0xd9, 0x86, 0x8d, 0x38,
+ 0xb6, 0x26, 0x04, 0x14, 0x07, 0x46, 0x3e, 0xd0, 0xc5, 0xf6, 0x0d, 0xa0,
+ 0x47, 0x2b, 0xc8, 0x73, 0x18, 0x6b, 0xd3, 0x0e, 0x18, 0xcc, 0x43, 0x98,
+ 0xd0, 0xcf, 0x1c, 0xe4, 0x4a, 0x41, 0x6a, 0x56, 0x2d, 0xf0, 0x93, 0x89,
+ 0x81, 0x6c, 0xce, 0x04, 0x1a, 0x23, 0x05, 0x91, 0x4f, 0x48, 0x44, 0x3a,
+ 0xaa, 0x03, 0xa5, 0x4a, 0xa9, 0x20, 0x2c, 0xbe, 0x6a, 0x81, 0xe6, 0xa9,
+ 0xf8, 0xf0, 0x2b, 0x29, 0xa1, 0xe0, 0xc4, 0xce, 0xf5, 0xda, 0x25, 0x70,
+ 0x49, 0xcc, 0xa0, 0x4b, 0x24, 0x49, 0x4f, 0x11, 0xc4, 0x3b, 0x22, 0x89,
+ 0x9a, 0xb4, 0xf4, 0xcd, 0xa3, 0xee, 0xb0, 0x76, 0x13, 0xc4, 0xbb, 0xaf,
+ 0x03, 0x7f, 0x27, 0xf3, 0x38, 0xbc, 0xde, 0x7c, 0x0c, 0x39, 0x14, 0xb7,
+ 0x14, 0xbb, 0x5c, 0xae, 0x89, 0xf8, 0xf7, 0xd6, 0x00, 0x78, 0xf4, 0xb0,
+ 0x52, 0x16, 0xf5, 0x54, 0xc5, 0x93, 0xf7, 0x6d, 0x0d, 0xe8, 0x58, 0xe2,
+ 0xa1, 0xa7, 0xdc, 0x49, 0xdb, 0xc8, 0x79, 0xbc, 0xc3, 0x97, 0x7b, 0x6c,
+ 0x82, 0x7b, 0xbe, 0xe9, 0x79, 0xac, 0x4a, 0xa4, 0x7c, 0x49, 0x83, 0x58,
+ 0x3a, 0xe4, 0xf5, 0x68, 0x5c, 0xb7, 0x7f, 0x2d, 0xfe, 0x6b, 0x96, 0xc7,
+ 0x8b, 0x67, 0xb5, 0xd0, 0xa1, 0x0a, 0x16, 0x62, 0x64, 0x53, 0xea, 0x29,
+ 0x80, 0x93, 0xf9, 0xd6, 0xa0, 0xc5, 0x1b, 0x3a, 0x1e, 0xab, 0x51, 0x88,
+ 0xe0, 0x9e, 0xd4, 0xf6, 0xbf, 0x70, 0x2d, 0x29, 0x2e, 0x08, 0xa9, 0x31,
+ 0x78, 0x0a, 0x15, 0x30, 0x9f, 0x2e, 0xc8, 0x41, 0x65, 0x8e, 0x97, 0x51,
+ 0x5e, 0x73, 0x46, 0x42, 0x74, 0x84, 0xfd, 0x9b, 0x4a, 0x8a, 0x68, 0x28,
+ 0x45, 0xd0, 0x5d, 0x65, 0x08, 0xb3, 0xf5, 0x40, 0x8a, 0x29, 0x8e, 0x70,
+ 0x02, 0x49, 0x6a, 0x01, 0xd6, 0x41, 0x4a, 0xf8, 0x15, 0xa3, 0x70, 0x59,
+ 0xe9, 0xa2, 0xe2, 0x76, 0x8c, 0x60, 0x33, 0xb3, 0xfa, 0x8b, 0xb4, 0x90,
+ 0x6f, 0x92, 0xc8, 0x21, 0x59, 0xc0, 0x3a, 0x30, 0x46, 0xeb, 0x49, 0xd8,
+ 0x85, 0x63, 0x5a, 0x23, 0x87, 0xe1, 0xa7, 0xc0, 0x1a, 0xb0, 0xc7, 0xc4,
+ 0x40, 0x4d, 0x11, 0x9c, 0xe3, 0xd4, 0x6b, 0xef, 0x68, 0xc8, 0x2c, 0x31,
+ 0xcd, 0x3e, 0xee, 0x55, 0x10, 0x67, 0x77, 0x7b, 0x30, 0xc1, 0xd0, 0x23,
+ 0x6c, 0x65, 0x6f, 0xfb, 0x2e, 0x62, 0x33, 0x42, 0x63, 0xdc, 0xca, 0x86,
+ 0xf1, 0x0e, 0xb3, 0xb0, 0x69, 0x11, 0x65, 0xe1, 0x6e, 0x6c, 0x03, 0x49,
+ 0x79, 0xe8, 0xf1, 0x2e, 0x8d, 0x94, 0xc8, 0xa8, 0x98, 0x2d, 0x3f, 0xfe,
+ 0xbd, 0x2d, 0x75, 0x45, 0xd1, 0x7a, 0x09, 0xf8, 0x90, 0x49, 0xbd, 0x4a,
+ 0x3b, 0xa4, 0xa3, 0x26, 0xb8, 0x62, 0x66, 0x97, 0xd9, 0xc1, 0xca, 0x12,
+ 0x49, 0xe1, 0x27, 0x93, 0x4f, 0x60, 0xfa, 0xb3, 0x4f, 0x4c, 0xdb, 0x87,
+ 0x6c, 0x3b, 0x50, 0x47, 0xe2, 0xd8, 0x5b, 0x13, 0x99, 0xf0, 0x2b, 0xbb,
+ 0x32, 0x33, 0xfd, 0x7d, 0x15, 0x0f, 0x2c, 0xee, 0x85, 0x83, 0xc0, 0x53,
+ 0x79, 0x3e, 0x51, 0xfe, 0x7c, 0x06, 0x73, 0x49, 0x49, 0x4f, 0x5a, 0x22,
+ 0x36, 0x8f, 0x30, 0x8a, 0xef, 0x84, 0xd6, 0x15, 0x26, 0x48, 0xe7, 0x1e,
+ 0xb1, 0xaa, 0x82, 0xd0, 0xc7, 0x0b, 0x97, 0x7b, 0x6c, 0x2d, 0x49, 0x7e,
+ 0x6d, 0xe7, 0xa3, 0x05, 0x80, 0xd7, 0x42, 0xa9, 0xc6, 0x66, 0x98, 0x30,
+ 0xe3, 0x8a, 0x79, 0x86, 0x9c, 0x2b, 0xbc, 0x4a, 0xe6, 0x0d, 0xc5, 0xe5,
+ 0x1a, 0x92, 0xd9, 0xef, 0x63, 0x52, 0x03, 0x88, 0x36, 0xc5, 0x83, 0x65,
+ 0xf8, 0xf1, 0x87, 0xce, 0x43, 0xfe, 0x89, 0x58, 0x07, 0x6a, 0xad, 0x85,
+ 0x37, 0x0f, 0xdf, 0x9e, 0xa5, 0x62, 0xa9, 0xd2, 0x41, 0x3f, 0x7f, 0xb7,
+ 0xf1, 0xe2, 0x58, 0xb5, 0xda, 0xdf, 0xd1, 0xba, 0x36, 0x2c, 0xe7, 0x43,
+ 0x31, 0x07, 0xc5, 0xf5, 0x79, 0xc9, 0x31, 0xd7, 0x1d, 0x97, 0x57, 0x9a,
+ 0x8e, 0x3f, 0xac, 0x00, 0x49, 0x00, 0x2f, 0xad, 0xac, 0xe7, 0x65, 0x7c,
+ 0xbf, 0xec, 0x85, 0x57, 0xe6, 0xcc, 0x07, 0x34, 0x02, 0x36, 0xa8, 0x6a,
+ 0x9f, 0x3a, 0x9a, 0x2f, 0x34, 0x93, 0x1f, 0x7d, 0x38, 0x54, 0xe3, 0x54,
+ 0x54, 0xee, 0x84, 0x55, 0xe1, 0x0d, 0xc1, 0x08, 0x3e, 0x33, 0x9e, 0x2a,
+ 0xc3, 0x6a, 0x83, 0xc4, 0x75, 0xed, 0xbc, 0x5f, 0xd9, 0x04, 0xd7, 0x77,
+ 0x91, 0xb1, 0xa0, 0xf2, 0xef, 0x81, 0xb0, 0x8b, 0x53, 0x5f, 0x71, 0xec,
+ 0xa5, 0x0b, 0xbe, 0xf2, 0x92, 0x7e, 0x0a, 0x34, 0xeb, 0x5d, 0x65, 0xc7,
+ 0xa9, 0x44, 0x10, 0xfb, 0xd3, 0xef, 0xe1, 0xbc, 0x06, 0x65, 0x68, 0x22,
+ 0xfb, 0x43, 0x2c, 0xcf, 0x8e, 0x6a, 0x28, 0xdb, 0x0b, 0xf4, 0xaf, 0x01,
+ 0x65, 0x97, 0xd6, 0xe5, 0x91, 0x20, 0x13, 0x2c, 0xb1, 0xc2, 0xd3, 0xc3,
+ 0x76, 0x90, 0xf8, 0xcd, 0x00, 0xde, 0x93, 0xf8, 0x4e, 0xcc, 0xdc, 0xca,
+ 0x9a, 0xf0, 0xbd, 0x9b, 0xd6, 0x57, 0xb1, 0x13, 0xd9, 0xe0, 0xe1, 0x9e,
+ 0x21, 0x74, 0xa9, 0x76, 0xc0, 0x0c, 0xad, 0x4f, 0x5d, 0xfe, 0x23, 0x32,
+ 0x5a, 0x10, 0x75, 0x5b, 0x05, 0xdf, 0xdc, 0x5b, 0x94, 0xcb, 0xe1, 0x9f,
+ 0x13, 0x51, 0xf5, 0x50, 0x36, 0x3b, 0xf2, 0x90, 0x9c, 0x9a, 0xc8, 0x10,
+ 0x88, 0xa9, 0xec, 0x22, 0x1e, 0x96, 0x70, 0xe8, 0x9e, 0x69, 0xc1, 0x22,
+ 0xd9, 0x14, 0x15, 0x2e, 0xbc, 0x03, 0x96, 0x9e, 0x1d, 0x00, 0x10, 0x16,
+ 0x4f, 0x56, 0xf0, 0x29, 0x47, 0x0a, 0x45, 0x34, 0x27, 0x21, 0x3b, 0x67,
+ 0x33, 0xf9, 0xdd, 0x29, 0x3a, 0xf2, 0xe4, 0x56, 0x34, 0x46, 0xbe, 0xd8,
+ 0x42, 0x29, 0x11, 0x7f, 0x30, 0xc1, 0xbe, 0xa5, 0xc8, 0x9d, 0x7b, 0x2e,
+ 0x4e, 0xcf, 0xba, 0x91, 0xb4, 0xbf, 0x0a, 0x04, 0x00, 0x49, 0x83, 0x6b,
+ 0x46, 0x5f, 0x3b, 0xfa, 0xf7, 0x40, 0x8d, 0x85, 0x47, 0x14, 0x58, 0xb3,
+ 0xa5, 0x66, 0x30, 0xfd, 0x4a, 0x80, 0xa4, 0x61, 0x3b, 0x7c, 0xb4, 0xcc,
+ 0x34, 0x8c, 0xc6, 0xb6, 0x10, 0xa9, 0x76, 0xc9, 0x11, 0xd7, 0x8a, 0x51,
+ 0x86, 0x17, 0x89, 0x28, 0xab, 0xd5, 0x03, 0x88, 0x74, 0x5b, 0x81, 0xbd,
+ 0x3a, 0x57, 0xfe, 0x66, 0x25, 0xd0, 0x92, 0x15, 0x84, 0x02, 0x0f, 0x51,
+ 0xa8, 0x58, 0xcf, 0x77, 0x65, 0x10, 0x61, 0xe8, 0xe6, 0xab, 0xb1, 0xba,
+ 0x3b, 0x08, 0xd6, 0xba, 0x5f, 0xf5, 0x74, 0xc5, 0x07, 0x60, 0xfd, 0xd3,
+ 0xc8, 0x52, 0x4e, 0xdb, 0xc3, 0xe3, 0x6d, 0x81, 0x20, 0x51, 0x01, 0x9a,
+ 0x5e, 0x32, 0x4e, 0x80, 0x5a, 0xcb, 0x83, 0xd7, 0xa4, 0xd9, 0xfb, 0xed,
+ 0x3d, 0x80, 0xa1, 0x83, 0x81, 0x91, 0xc0, 0x0b, 0xff, 0x67, 0xd8, 0x8b,
+ 0xd0, 0x12, 0x0b, 0xd4, 0x2b, 0x8e, 0x0d, 0x0f, 0xfc, 0xc7, 0xb3, 0xf1,
+ 0xe3, 0xf3, 0x5e, 0x0c, 0xb6, 0x6b, 0x9d, 0xdc, 0x22, 0x70, 0x31, 0x54,
+ 0xe8, 0x41, 0xfe, 0xa1, 0xe1, 0x4f, 0xfa, 0x81, 0xfb, 0xae, 0x72, 0x16,
+ 0xb8, 0x87, 0xc9, 0x31, 0x9d, 0x42, 0x47, 0x4a, 0x20, 0xae, 0x63, 0x16,
+ 0x0d, 0xfa, 0xf1, 0x27, 0x19, 0x47, 0xee, 0x45, 0x84, 0x29, 0x9a, 0xb6,
+ 0x42, 0xef, 0xbd, 0x15, 0xa8, 0x34, 0x33, 0x38, 0x9c, 0x9d, 0xbb, 0x5c,
+ 0x03, 0xf3, 0xcf, 0xcf, 0x6d, 0x2e, 0xd5, 0x88, 0xf8, 0xdd, 0xfc, 0xc0,
+ 0x4a, 0xdb, 0x69, 0xd9, 0x62, 0x89, 0x24, 0x46, 0xee, 0xa4, 0xb9, 0x95,
+ 0xe6, 0xaf, 0x7d, 0x53, 0xec, 0x41, 0xae, 0x70, 0xfe, 0x4f, 0x31, 0xe3,
+ 0xa2, 0x59, 0x2c, 0xa1, 0x53, 0x8b, 0xb6, 0x3b, 0x39, 0xc1, 0xa4, 0xa7,
+ 0x9e, 0xaa, 0x00, 0x60, 0x9a, 0x5f, 0x56, 0x51, 0xf3, 0x7b, 0x28, 0x84,
+ 0x36, 0x1a, 0xc1, 0x2d, 0xc8, 0xed, 0xf8, 0x48, 0x48, 0x1d, 0x39, 0x4d,
+ 0x3d, 0xce, 0x30, 0x90, 0x29, 0x33, 0x6f, 0x9a, 0xce, 0x58, 0xe7, 0x88,
+ 0xac, 0x59, 0xce, 0x85, 0x5a, 0x52, 0x2b, 0x6c, 0xb7, 0xe9, 0x2e, 0xa9,
+ 0xd9, 0x9a, 0xea, 0x1c, 0x47, 0xb2, 0x59, 0xff, 0x73, 0x76, 0x21, 0x40,
+ 0xe1, 0xde, 0x32, 0xb8, 0x73, 0x3d, 0xa5, 0x44, 0x66, 0x79, 0xa1, 0xfe,
+ 0xaf, 0xf6, 0x8a, 0x97, 0x09, 0x5c, 0x8b, 0x64, 0x38, 0x9f, 0xe1, 0x59,
+ 0x38, 0x18, 0xe9, 0xc0, 0xd6, 0xa2, 0xac, 0x74, 0xa9, 0xfd, 0x4a, 0x0d,
+ 0xf6, 0x47, 0x00, 0x2b, 0x09, 0x46, 0x38, 0x1c, 0xa4, 0x9f, 0x63, 0x20,
+ 0x18, 0x75, 0x5a, 0xb8, 0xc4, 0xbc, 0xd6, 0x6b, 0xc8, 0x14, 0x72, 0x03,
+ 0xe4, 0x05, 0xd4, 0x4e, 0x66, 0x20, 0x42, 0xa2, 0x8f, 0x96, 0xe7, 0xaf,
+ 0xd3, 0xfb, 0xa8, 0x88, 0x9b, 0xe3, 0xaa, 0xcd, 0xab, 0xce, 0x8f, 0x07,
+ 0x6d, 0xef, 0x98, 0xce, 0xdb, 0x42, 0x5b, 0xf4, 0x61, 0x57, 0x62, 0x27,
+ 0x8a, 0x53, 0x5e, 0xf8, 0x3e, 0xf6, 0x7f, 0xde, 0x5e, 0x3b, 0x1b, 0x13,
+ 0x2e, 0x30, 0x46, 0x4b, 0x6b, 0xb7, 0xbb, 0x33, 0x31, 0xc0, 0xfa, 0x40,
+ 0xab, 0x68, 0x72, 0xe3, 0x92, 0x30, 0x47, 0xd6, 0x30, 0x60, 0x42, 0x5b,
+ 0x88, 0x8d, 0xa6, 0x56, 0xe4, 0xac, 0x33, 0x2e, 0xca, 0x05, 0x1f, 0x60,
+ 0xaf, 0xde, 0x7f, 0xa9, 0xda, 0x3f, 0xa8, 0x21, 0xf6, 0xfc, 0x98, 0x7d,
+ 0xc4, 0x1e, 0xb0, 0xa9, 0x56, 0x2d, 0x8d, 0xea, 0x03, 0x51, 0x48, 0xac,
+ 0xe8, 0x22, 0xc7, 0x8b, 0xef, 0x91, 0x0e, 0xcf, 0x0c, 0xe9, 0x38, 0x43,
+ 0x99, 0xa8, 0x98, 0x4f, 0xfa, 0xe3, 0x03, 0xa6, 0x4f, 0xd4, 0x0d, 0x98,
+ 0x5b, 0x50, 0x28, 0xd7, 0xe7, 0x46, 0xd7, 0xad, 0x43, 0xb8, 0x56, 0x2a,
+ 0x2f, 0x7c, 0x39, 0x67, 0xf4, 0x62, 0x0e, 0xc0, 0xa8, 0x87, 0xb5, 0x81,
+ 0xe2, 0x13, 0x9f, 0xe4, 0xdd, 0x72, 0xf2, 0x07, 0xca, 0xac, 0x6d, 0xb2,
+ 0x96, 0x53, 0x5a, 0x8f, 0x66, 0x3c, 0xb4, 0xc1, 0x4f, 0x9a, 0x82, 0x55,
+ 0xcf, 0x0e, 0x27, 0x5f, 0xc7, 0xd2, 0x28, 0x27, 0x7f, 0x22, 0x6e, 0xa5,
+ 0xe7, 0x32, 0x56, 0x51, 0x18, 0xe0, 0x85, 0x6d, 0x1f, 0xfc, 0x25, 0x08,
+ 0x18, 0x60, 0x57, 0xfc, 0x66, 0x94, 0x2c, 0x4c, 0xbe, 0x00, 0xab, 0x9e,
+ 0x73, 0x9b, 0x06, 0xd3, 0xb5, 0x24, 0xa8, 0x8f, 0xb1, 0x33, 0x99, 0x4c,
+ 0xb4, 0x13, 0x07, 0xcd, 0x04, 0xdd, 0x77, 0xdc, 0xee, 0x96, 0x02, 0x59,
+ 0xe8, 0x22, 0x07, 0x16, 0x2e, 0x41, 0xc9, 0xc4, 0x59, 0x70, 0x37, 0x0f,
+ 0x14, 0xc9, 0xcf, 0x90, 0x57, 0xc2, 0x0d, 0xa3, 0xd7, 0x66, 0xb6, 0x7d,
+ 0x10, 0xd4, 0xfc, 0x18, 0x66, 0xad, 0xea, 0x5e, 0x64, 0x6c, 0x12, 0x66,
+ 0x3d, 0x96, 0xa5, 0xa8, 0x9c, 0x49, 0x5c, 0xd4, 0x8d, 0x1c, 0xc3, 0x38,
+ 0xfe, 0x53, 0xc2, 0x71, 0xd1, 0xc6, 0x41, 0xe2, 0xb9, 0x17, 0x74, 0x6e,
+ 0xcc, 0xf8, 0x72, 0x28, 0x38, 0x4e, 0x54, 0x9b, 0x0e, 0xa3, 0x3a, 0x43,
+ 0x5c, 0xd5, 0x83, 0x06, 0xbb, 0x46, 0x16, 0x6e, 0xe3, 0x8a, 0xd5, 0x1e,
+ 0x7f, 0x88, 0x62, 0xac, 0x35, 0x89, 0xfb, 0xbe, 0x96, 0x1d, 0x87, 0x37,
+ 0xb7, 0x91, 0x63, 0xae, 0x77, 0x7b, 0x66, 0x60, 0xc1, 0x3e, 0x80, 0x56,
+ 0xb1, 0xc8, 0x0d, 0x16, 0xde, 0x38, 0x82, 0x66, 0x99, 0x2b, 0x35, 0xd8,
+ 0xb4, 0x5b, 0x4b, 0x3e, 0x93, 0x96, 0x59, 0xf8, 0x96, 0x7e, 0x7b, 0x27,
+ 0xf4, 0x62, 0xb7, 0xda, 0x89, 0xa7, 0x34, 0x47, 0xed, 0xb3, 0x42, 0x20,
+ 0xeb, 0xcd, 0xf6, 0xa3, 0x9f, 0xf7, 0x48, 0x91, 0x17, 0xd2, 0x21, 0xed,
+ 0x5a, 0x22, 0x39, 0xc9, 0x76, 0x95, 0x36, 0xd9, 0x97, 0x0f, 0x19, 0xce,
+ 0xd3, 0xbc, 0x74, 0x7d, 0x53, 0x37, 0x3b, 0x4a, 0x97, 0xb7, 0xf8, 0x7e,
+ 0xdd, 0x4c, 0x5f, 0xae, 0x5c, 0x0b, 0xab, 0x4c, 0x34, 0xa1, 0x7e, 0x34,
+ 0x35, 0xf4, 0xfc, 0x92, 0xab, 0x2e, 0x6a, 0x15, 0xce, 0x84, 0xae, 0x70,
+ 0xae, 0x85, 0x21, 0xe6, 0x41, 0x13, 0x31, 0xe0, 0x8f, 0xab, 0x82, 0xe3,
+ 0x09, 0xaf, 0xa4, 0x7c, 0xb4, 0xb9, 0xb7, 0xc0, 0x67, 0x08, 0xc9, 0x9d,
+ 0xcd, 0x0b, 0x3c, 0xa0, 0x0c, 0xde, 0x49, 0x2f, 0x40, 0x19, 0x95, 0x64,
+ 0xb9, 0x7c, 0x2a, 0x72, 0xdd, 0xa2, 0x92, 0x0a, 0x21, 0xeb, 0x8c, 0xc3,
+ 0x6d, 0x52, 0xe7, 0x05, 0x50, 0x01, 0x55, 0x19, 0x2f, 0xbd, 0x1b, 0x72,
+ 0x73, 0xfe, 0x82, 0x9f, 0xbf, 0xa0, 0xfe, 0x19, 0x7c, 0x42, 0x6d, 0x76,
+ 0x32, 0x47, 0x36, 0x15, 0x2e, 0xde, 0xe8, 0xe6, 0xca, 0x07, 0xa3, 0x6b,
+ 0x40, 0x99, 0x96, 0xcd, 0x19, 0xea, 0x7e, 0xc9, 0x87, 0x9d, 0x3d, 0xa0,
+ 0x82, 0x88, 0xe7, 0xe4, 0x34, 0x9f, 0xa5, 0x27, 0xdf, 0xae, 0x03, 0x37,
+ 0xa8, 0x35, 0x64, 0x02, 0x09, 0x09, 0x9e, 0xec, 0x38, 0x0a, 0xff, 0x79,
+ 0x8c, 0x9a, 0x87, 0x66, 0xcd, 0xe4, 0xf4, 0x9d, 0xa9, 0x07, 0x96, 0x36,
+ 0xae, 0x2e, 0x4e, 0xc5, 0xe9, 0x86, 0xb2, 0x8e, 0x71, 0x5d, 0xe8, 0xee,
+ 0x84, 0xf3, 0x30, 0x2a, 0x58, 0x1a, 0x80, 0xb8, 0xaa, 0xb8, 0x1d, 0xc4,
+ 0xae, 0x59, 0x91, 0xf3, 0x16, 0x9b, 0xa3, 0x8a, 0xa3, 0x26, 0xb2, 0x0a,
+ 0xe5, 0x58, 0xb7, 0x96, 0x87, 0xfb, 0x00, 0xe4, 0x50, 0x7c, 0xb1, 0x77,
+ 0x3a, 0x18, 0xc2, 0xe3, 0xc1, 0x12, 0xa6, 0x0d, 0x06, 0xeb, 0x80, 0x6c,
+ 0x5a, 0xee, 0x34, 0xcc, 0x1c, 0x87, 0x35, 0x46, 0x1d, 0x05, 0x83, 0xd8,
+ 0x91, 0x22, 0xaa, 0xf6, 0xad, 0x87, 0xab, 0x76, 0x18, 0x79, 0xe2, 0x09,
+ 0xc3, 0xa3, 0x15, 0x67, 0x3a, 0x7c, 0x0f, 0xa0, 0x4c, 0x7b, 0xfc, 0xfc,
+ 0xdd, 0x5c, 0xe4, 0x86, 0x58, 0x13, 0xb8, 0x97, 0xae, 0x8c, 0x75, 0xc8,
+ 0x02, 0x1e, 0x33, 0x45, 0xa9, 0x54, 0x09, 0x15, 0x53, 0x4f, 0x28, 0x47,
+ 0x4d, 0x5f, 0xd0, 0xc7, 0x09, 0xbd, 0x93, 0xb0, 0x08, 0x79, 0x05, 0xbc,
+ 0xbc, 0xaf, 0x2c, 0xbd, 0xbb, 0x21, 0xd1, 0x60, 0xb8, 0x81, 0x4c, 0x6c,
+ 0x5e, 0x45, 0x39, 0xa3, 0x31, 0x54, 0xb7, 0x82, 0xef, 0x86, 0xe4, 0x5e,
+ 0xca, 0xd6, 0xb8, 0x31, 0xa2, 0x4c, 0x84, 0x5b, 0xac, 0xe5, 0x29, 0xbf,
+ 0xbf, 0x89, 0xb4, 0x4c, 0xd3, 0x69, 0x66, 0x50, 0xeb, 0xda, 0x7d, 0x00,
+ 0xbb, 0x45, 0x0f, 0xe1, 0xd1, 0x30, 0x1a, 0xc6, 0x94, 0x66, 0xdc, 0x01,
+ 0x75, 0xce, 0xf8, 0xfc, 0xd9, 0xce, 0xcf, 0x1f, 0x9e, 0x5a, 0x55, 0xa4,
+ 0x3e, 0xe6, 0x51, 0xc7, 0x74, 0x40, 0x82, 0x09, 0xea, 0xa0, 0xf5, 0xb2,
+ 0x70, 0x9f, 0x0e, 0xfb, 0x46, 0x8a, 0x69, 0xbf, 0x07, 0x92, 0xdc, 0x74,
+ 0x03, 0x70, 0xc6, 0x44, 0x81, 0x66, 0x40, 0xc7, 0xf5, 0xb8, 0xf0, 0x45,
+ 0x0f, 0xca, 0xd8, 0xb0, 0x9e, 0x48, 0x94, 0xff, 0x85, 0xcb, 0x7b, 0xec,
+ 0x67, 0x5d, 0xfe, 0xe9, 0x13, 0xd1, 0x67, 0x95, 0xd9, 0x35, 0x9e, 0x8a,
+ 0x53, 0x4d, 0x6b, 0x9d, 0x42, 0x53, 0xb1, 0x6b, 0x51, 0x1e, 0x35, 0x40,
+ 0x81, 0x92, 0x91, 0x5f, 0x1f, 0x8e, 0xbe, 0x37, 0xd3, 0x85, 0xab, 0x85,
+ 0x37, 0x1c, 0x0f, 0xae, 0xd9, 0xf7, 0xa2, 0x75, 0x3d, 0xd9, 0xd7, 0x2a,
+ 0x80, 0xb0, 0x4c, 0x14, 0x04, 0x40, 0xc5, 0xba, 0x0e, 0xbe, 0xab, 0xcc,
+ 0x38, 0x35, 0x62, 0x6c, 0xa5, 0xce, 0x49, 0x15, 0x2a, 0x10, 0xb5, 0x6a,
+ 0xd2, 0x3b, 0xd2, 0x6a, 0xad, 0x2e, 0x34, 0x46, 0x8b, 0x78, 0x57, 0x6e,
+ 0xc4, 0xde, 0x65, 0x68, 0x05, 0x8f, 0xd6, 0x6e, 0x34, 0xb9, 0xaa, 0x80,
+ 0x77, 0xff, 0x6c, 0x1a, 0x37, 0x87, 0xdd, 0x33, 0x13, 0x33, 0xa7, 0xa9,
+ 0x3a, 0x90, 0x32, 0x7b, 0x9b, 0x21, 0x31, 0xc8, 0xf5, 0x4c, 0xa6, 0x73,
+ 0x42, 0x79, 0x46, 0x14, 0x1b, 0xef, 0xf4, 0x78, 0xd9, 0x7e, 0x6f, 0x31,
+ 0xaa, 0x59, 0x97, 0x34, 0xe5, 0xe6, 0x67, 0xf3, 0x86, 0xf5, 0x61, 0xe7,
+ 0x51, 0x6d, 0xce, 0xb3, 0xdc, 0x86, 0xc7, 0x55, 0x43, 0xfa, 0x38, 0x78,
+ 0xb0, 0x8d, 0x03, 0x9c, 0xe4, 0x6c, 0xca, 0x73, 0x94, 0xa1, 0x0c, 0xb8,
+ 0x11, 0xda, 0x0c, 0x0b, 0x18, 0x1b, 0xd0, 0x99, 0xe7, 0xa9, 0x0d, 0xc3,
+ 0x36, 0xd7, 0x8c, 0x16, 0xad, 0x16, 0x1f, 0xb2, 0x3c, 0x07, 0x32, 0x11,
+ 0x6c, 0xd2, 0x8f, 0x33, 0x37, 0x5c, 0x3e, 0x4f, 0x7a, 0x76, 0xf7, 0x85,
+ 0xcc, 0x68, 0x1a, 0xf9, 0x26, 0x74, 0x42, 0xc9, 0xea, 0x21, 0x7e, 0x74,
+ 0x3c, 0x4f, 0xde, 0xfb, 0xd7, 0x83, 0x62, 0x12, 0xc7, 0x4f, 0xfc, 0x47,
+ 0x18, 0x9d, 0xc5, 0xf5, 0xe9, 0xd7, 0xaa, 0x76, 0x20, 0x99, 0x79, 0xae,
+ 0x9b, 0x7a, 0xde, 0x8b, 0x95, 0xc2, 0xa5, 0xa3, 0x6a, 0x30, 0x9b, 0x99,
+ 0x63, 0x34, 0x7c, 0xd1, 0x53, 0xa1, 0x6c, 0xd6, 0xed, 0x7d, 0x8c, 0xba,
+ 0xc8, 0x21, 0xf3, 0xe1, 0x31, 0x55, 0x3d, 0x88, 0x87, 0x04, 0xc7, 0xc9,
+ 0x65, 0x0c, 0x53, 0x1e, 0xd4, 0xd9, 0xaa, 0xda, 0xc2, 0x14, 0x88, 0xf2,
+ 0x07, 0x2c, 0x12, 0x4d, 0x79, 0x54, 0xaa, 0xd9, 0x47, 0x95, 0xf9, 0x7e,
+ 0x26, 0x89, 0x4b, 0x63, 0x7e, 0x44, 0x06, 0x0e, 0xe2, 0x8d, 0x9a, 0x0a,
+ 0xc3, 0xee, 0x55, 0x13, 0x55, 0x04, 0xcc, 0xb5, 0x2e, 0xa0, 0x0d, 0xec,
+ 0x76, 0x84, 0xc1, 0x1e, 0xdd, 0xe6, 0xfa, 0x54, 0x6e, 0x38, 0x30, 0x6f,
+ 0xcc, 0xa4, 0x8d, 0x76, 0x1e, 0xa3, 0x8e, 0x2c, 0x5e, 0x37, 0xeb, 0x0b,
+ 0xf4, 0xb5, 0x80, 0xde, 0x58, 0x13, 0x5a, 0x52, 0xdc, 0x65, 0x99, 0x1a,
+ 0x1b, 0x75, 0x0c, 0xbd, 0x83, 0xe8, 0x90, 0x8e, 0xa9, 0xbf, 0x42, 0x22,
+ 0xe1, 0x3a, 0x31, 0x4e, 0x54, 0xad, 0xd4, 0x6f, 0x80, 0xb4, 0xb5, 0x82,
+ 0x05, 0x20, 0xd7, 0x38, 0xd7, 0xeb, 0x25, 0x33, 0xe9, 0x4b, 0xc3, 0x5e,
+ 0xd1, 0x11, 0xb0, 0xd9, 0x8e, 0x90, 0x48, 0x2a, 0xe3, 0xa0, 0x60, 0x16,
+ 0x70, 0xe3, 0xd1, 0x45, 0x11, 0x64, 0x91, 0x69, 0x87, 0x1c, 0xbb, 0x91,
+ 0xc4, 0x43, 0x12, 0x62, 0x99, 0x69, 0xe5, 0x96, 0x01, 0x15, 0xdb, 0xdf,
+ 0x05, 0x55, 0x34, 0xbb, 0xd6, 0x76, 0x89, 0xcd, 0xb5, 0x4f, 0x2e, 0xa7,
+ 0x6e, 0x15, 0xc9, 0xc0, 0x8e, 0xa8, 0x63, 0x79, 0x12, 0xfb, 0x7e, 0x69,
+ 0x8f, 0x52, 0x5e, 0xe7, 0x76, 0x16, 0x28, 0x76, 0xca, 0xcb, 0xd8, 0x0e,
+ 0x4a, 0x93, 0x9d, 0x16, 0x68, 0x98, 0xf8, 0xc3, 0x39, 0xb2, 0x2d, 0xea,
+ 0xba, 0x72, 0x16, 0x33, 0xb7, 0xec, 0x61, 0x9e, 0x94, 0x32, 0x01, 0x22,
+ 0xde, 0x66, 0xfd, 0x68, 0xfa, 0xcf, 0xf2, 0x52, 0x4f, 0x02, 0xe8, 0x25,
+ 0xd3, 0xa3, 0x5b, 0x29, 0xae, 0xe9, 0x62, 0xfa, 0xd6, 0x1a, 0x50, 0x80,
+ 0x95, 0x96, 0xdf, 0x00, 0xfc, 0x23, 0xf1, 0x95, 0xef, 0xbb, 0xf5, 0x23,
+ 0x9d, 0x6b, 0xd6, 0xed, 0xb4, 0xe2, 0x4a, 0xf6, 0xb8, 0x20, 0x83, 0x6b,
+ 0x45, 0x92, 0x29, 0x5a, 0x02, 0xe9, 0xf7, 0x8e, 0x5c, 0x02, 0xde, 0xb4,
+ 0x9a, 0xdf, 0x18, 0x10, 0x17, 0x7f, 0xd8, 0x2e, 0x17, 0xc0, 0xf0, 0x6b,
+ 0x3b, 0x88, 0x09, 0x58, 0xf2, 0x18, 0x22, 0x09, 0x80, 0x4a, 0xe0, 0x51,
+ 0x6f, 0x7a, 0x70, 0x09, 0x1f, 0xe5, 0xfa, 0xa9, 0x4d, 0x24, 0x1f, 0x18,
+ 0x1c, 0x74, 0xcd, 0x87, 0x04, 0xfd, 0x85, 0x33, 0x4c, 0x28, 0xbd, 0xa3,
+ 0x66, 0x6c, 0x99, 0x7e, 0x50, 0x5e, 0xb5, 0x22, 0x33, 0x92, 0xd4, 0xd8,
+ 0x82, 0x4e, 0x38, 0xbe, 0xcb, 0x3d, 0x5f, 0x19, 0xd1, 0x0f, 0x8b, 0xa1,
+ 0x78, 0x08, 0x1c, 0x10, 0x0b, 0x77, 0xa7, 0x39, 0x2e, 0x91, 0x83, 0xee,
+ 0x1d, 0x36, 0xd8, 0x77, 0x87, 0x8a, 0x38, 0x45, 0x3c, 0xbd, 0xb9, 0x88,
+ 0xbb, 0x1b, 0x20, 0xd1, 0x95, 0xb9, 0x8f, 0x03, 0x46, 0xfa, 0xab, 0x70,
+ 0x68, 0x26, 0xd9, 0xb1, 0x25, 0x52, 0x5a, 0x77, 0x2d, 0x92, 0xc2, 0x1d,
+ 0xb6, 0x6e, 0xec, 0x67, 0xef, 0x34, 0xe2, 0x64, 0xb3, 0xa0, 0xae, 0x0c,
+ 0xd9, 0x36, 0xa1, 0xc7, 0xd8, 0xbf, 0x7a, 0x43, 0xbf, 0xc0, 0xc6, 0x90,
+ 0x60, 0x6a, 0x23, 0xc0, 0x6a, 0x5d, 0x62, 0x18, 0xac, 0xc1, 0x20, 0x35,
+ 0x17, 0xba, 0x4e, 0x54, 0xb7, 0xec, 0xd4, 0xad, 0x99, 0x94, 0xa4, 0xda,
+ 0x57, 0xe7, 0x46, 0xed, 0x47, 0xd1, 0xb4, 0xa2, 0x3e, 0x0f, 0x4a, 0xb6,
+ 0xa6, 0x68, 0x3e, 0x94, 0xb9, 0x18, 0x30, 0xe0, 0x75, 0x08, 0xe8, 0xf3,
+ 0x21, 0x79, 0x26, 0x68, 0x6a, 0x65, 0xb6, 0xbe, 0x03, 0x98, 0x8f, 0x04,
+ 0xad, 0x1e, 0xb0, 0x54, 0xd2, 0x28, 0xdd, 0x4a, 0xe9, 0xf3, 0xa0, 0x06,
+ 0xbf, 0x0b, 0x2a, 0xee, 0xf8, 0x03, 0x7e, 0x1d, 0x37, 0xc1, 0x32, 0xd1,
+ 0x41, 0xf4, 0x9b, 0xc5, 0x02, 0x10, 0x6f, 0x55, 0x5a, 0xec, 0x5b, 0xe7,
+ 0x61, 0x05, 0x17, 0xf0, 0xf8, 0xc6, 0x89, 0xe8, 0xad, 0x32, 0x57, 0x14,
+ 0xe5, 0xf8, 0xf5, 0x88, 0xd9, 0x73, 0x17, 0x10, 0xa7, 0xc3, 0xf8, 0x78,
+ 0x0b, 0x66, 0xab, 0x63, 0x4f, 0x96, 0x5d, 0xdf, 0x36, 0x83, 0xc4, 0x6f,
+ 0x20, 0xbd, 0xcb, 0x4c, 0xd2, 0xfa, 0x35, 0x87, 0xd8, 0xb6, 0xbb, 0xcc,
+ 0xb6, 0xd2, 0x85, 0x03, 0x6a, 0xea, 0xbb, 0x6d, 0x2f, 0xa2, 0x06, 0xc0,
+ 0xd6, 0x68, 0xd9, 0x7f, 0xd6, 0xa2, 0x3b, 0x08, 0x6a, 0x98, 0x26, 0x6d,
+ 0x9a, 0x2b, 0x68, 0x51, 0x78, 0xde, 0xa6, 0x96, 0x50, 0x7b, 0xfc, 0x03,
+ 0x43, 0xf8, 0x21, 0x01, 0x9d, 0xe2, 0x89, 0x65, 0x47, 0xae, 0x9c, 0x45,
+ 0x5e, 0xa5, 0xce, 0x97, 0xb3, 0xe6, 0xf6, 0xd4, 0x5a, 0xe8, 0x6b, 0x87,
+ 0xd6, 0xdf, 0xfb, 0x1f, 0xaf, 0xfb, 0xaf, 0x19, 0xa5, 0xfd, 0xba, 0xe0,
+ 0x22, 0x2f, 0x91, 0x97, 0xdf, 0xae, 0xe9, 0x39, 0xb1, 0xe4, 0xd3, 0x10,
+ 0xcb, 0xb3, 0x03, 0xb5, 0x0b, 0xf0, 0xd9, 0x70, 0x1e, 0x9c, 0x63, 0x6f,
+ 0x3a, 0xcf, 0x3c, 0x1b, 0x86, 0xa3, 0xad, 0x1a, 0xe7, 0x4c, 0x09, 0xd0,
+ 0x80, 0xf6, 0x8b, 0x72, 0x96, 0x53, 0x7e, 0x66, 0xfb, 0x7c, 0x7c, 0x8a,
+ 0xb0, 0x60, 0xa6, 0x4c, 0x20, 0xc4, 0x63, 0x69, 0x6a, 0xc3, 0x53, 0xf8,
+ 0x9a, 0x28, 0x30, 0x9d, 0x6f, 0x0e, 0x1b, 0xb2, 0x2c, 0xe6, 0x94, 0x9f,
+ 0xfc, 0xc0, 0x8d, 0x71, 0xbe, 0x37, 0xa6, 0xc9, 0xbd, 0x3c, 0x4a, 0xf3,
+ 0xc4, 0xb3, 0x88, 0x4c, 0x45, 0x26, 0x4e, 0x2f, 0x83, 0x16, 0x70, 0xb6,
+ 0xc7, 0xb2, 0x36, 0xf0, 0x0c, 0x67, 0xd2, 0x0a, 0xd3, 0xd9, 0x7c, 0x35,
+ 0x29, 0xac, 0xd4, 0x9c, 0x6d, 0xfc, 0xec, 0x58, 0x92, 0xf0, 0xba, 0x32,
+ 0x00, 0xae, 0xb1, 0xeb, 0x4d, 0x8c, 0x1a, 0x20, 0xe7, 0x5c, 0xfc, 0x9a,
+ 0x4d, 0x51, 0x24, 0x7b, 0x52, 0xeb, 0x13, 0x3d, 0xb4, 0xab, 0xda, 0xb3,
+ 0x74, 0x39, 0xd2, 0xf8, 0x2d, 0xef, 0x9b, 0x0f, 0xae, 0xf5, 0x3c, 0x99,
+ 0x34, 0xbe, 0x15, 0x5c, 0x9f, 0x5d, 0xae, 0xf4, 0x72, 0xc2, 0xac, 0x06,
+ 0xbe, 0xad, 0xe4, 0x68, 0xea, 0xd5, 0xa1, 0xdc, 0xdb, 0xf4, 0x61, 0x51,
+ 0xf5, 0x1a, 0x62, 0x15, 0xfd, 0x00, 0x51, 0x35, 0x53, 0x6c, 0x39, 0x3e,
+ 0xdb, 0x60, 0x0a, 0x52, 0xc1, 0x52, 0x3c, 0xd7, 0xab, 0x73, 0xea, 0x1e,
+ 0x38, 0x38, 0x65, 0x35, 0x35, 0x2b, 0x28, 0x04, 0x5c, 0x82, 0xea, 0x4a,
+ 0x9e, 0x96, 0x72, 0xa4, 0x8e, 0x42, 0xfd, 0x55, 0xa8, 0x66, 0x7a, 0x40,
+ 0xc9, 0xf2, 0xc2, 0x1e, 0x5d, 0x09, 0x90, 0x32, 0x18, 0xdb, 0x11, 0x4c,
+ 0x6c, 0x9c, 0x27, 0x62, 0x0a, 0xe6, 0xc1, 0xdf, 0xf2, 0x6a, 0x8c, 0x26,
+ 0xb4, 0xfb, 0xda, 0xa9, 0x08, 0x10, 0x3a, 0xf0, 0xe1, 0x64, 0xe5, 0x03,
+ 0x81, 0x7d, 0x15, 0x74, 0xa1, 0x8d, 0x10, 0xc8, 0xbb, 0x6a, 0x7c, 0x60,
+ 0xa1, 0x09, 0x35, 0x19, 0x2d, 0x70, 0xb5, 0x36, 0xc8, 0x8b, 0x66, 0x5f,
+ 0xe0, 0xe7, 0xea, 0x70, 0x2f, 0x5d, 0x3f, 0xae, 0x5e, 0x25, 0x84, 0xdd,
+ 0x9b, 0x69, 0x44, 0x37, 0x7c, 0x6b, 0x9e, 0x81, 0x18, 0x36, 0x4b, 0xff,
+ 0x86, 0x44, 0x2a, 0x39, 0x66, 0x7f, 0x71, 0x43, 0xe7, 0x65, 0xfe, 0xfd,
+ 0x34, 0xb9, 0xd9, 0x5a, 0x00, 0xd1, 0x41, 0x43, 0xc7, 0xbc, 0x65, 0x68,
+ 0xb7, 0x73, 0xff, 0x19, 0xd3, 0xed, 0x15, 0xa4, 0x67, 0xa1, 0x53, 0x0e,
+ 0xa6, 0xfb, 0x25, 0xce, 0x9d, 0x5b, 0x73, 0x08, 0xf3, 0x3b, 0x69, 0xe4,
+ 0x94, 0x9b, 0x94, 0x03, 0xb3, 0x8a, 0x2e, 0x07, 0x0c, 0xef, 0x18, 0x4c,
+ 0x2b, 0x1c, 0x83, 0x9f, 0x25, 0x20, 0x29, 0x72, 0x11, 0xa0, 0xaa, 0xed,
+ 0x0c, 0xf9, 0xce, 0x94, 0x0d, 0x7a, 0xb6, 0xb3, 0xa4, 0x57, 0xd6, 0x61,
+ 0xca, 0x1a, 0x0e, 0x89, 0x6d, 0x99, 0x4d, 0x06, 0xcd, 0x83, 0x7e, 0x09,
+ 0x14, 0x5b, 0xe7, 0x4c, 0x72, 0xa8, 0x98, 0xc8, 0x27, 0xf3, 0x70, 0x89,
+ 0x87, 0x11, 0xbb, 0x98, 0x82, 0x77, 0x9d, 0xaa, 0x95, 0x8c, 0xc1, 0xf8,
+ 0x39, 0x27, 0xd5, 0x64, 0x59, 0x6a, 0x8c, 0xbe, 0xe2, 0xe1, 0xd1, 0x6b,
+ 0xe3, 0xaf, 0x30, 0x6f, 0xf4, 0x9e, 0x35, 0x0b, 0x10, 0x24, 0x77, 0xd8,
+ 0xa4, 0x30, 0x2e, 0xf7, 0x97, 0xfd, 0xef, 0x1e, 0x9e, 0xf2, 0xbd, 0xf2,
+ 0x41, 0x73, 0x19, 0xe6, 0x7b, 0x7f, 0x74, 0x11, 0x91, 0x38, 0xc5, 0xac,
+ 0xd5, 0xb0, 0x48, 0xc4, 0xe9, 0x41, 0xd4, 0x50, 0x76, 0x13, 0xbf, 0xec,
+ 0xe8, 0x3a, 0xa8, 0x84, 0x42, 0x98, 0x12, 0x64, 0x95, 0x85, 0x79, 0x29,
+ 0xea, 0x3a, 0xf9, 0xa4, 0x5c, 0x9c, 0x35, 0x01, 0x68, 0x71, 0xb9, 0x5b,
+ 0xbe, 0xaa, 0x76, 0x9e, 0x63, 0x1c, 0xc1, 0x83, 0x94, 0xc6, 0x89, 0x2b,
+ 0x1d, 0x00, 0x43, 0x74, 0x00, 0x41, 0x93, 0x58, 0x52, 0xf9, 0x13, 0xfe,
+ 0x9f, 0x7a, 0xb7, 0x3d, 0x6b, 0x70, 0x4e, 0x4f, 0x8f, 0xf4, 0x9c, 0xe4,
+ 0x97, 0x62, 0xaf, 0x69, 0x45, 0xec, 0xf4, 0x53, 0x71, 0xdc, 0xc7, 0x8d,
+ 0x6f, 0xb2, 0x9d, 0xec, 0x43, 0xdd, 0xc0, 0xe5, 0xd1, 0x6c, 0x1a, 0x82,
+ 0x19, 0xf6, 0x18, 0xd3, 0x59, 0x0e, 0x07, 0x81, 0x5a, 0x23, 0x10, 0x8b,
+ 0xaa, 0x0b, 0x99, 0xc8, 0x34, 0xc2, 0xd0, 0xa9, 0x69, 0x7f, 0x54, 0xe3,
+ 0xc4, 0xa0, 0xe7, 0x4b, 0x31, 0x90, 0xe7, 0x3b, 0x45, 0x9b, 0x7f, 0xae,
+ 0xd2, 0xab, 0x22, 0xb9, 0xfc, 0x07, 0x39, 0x4b, 0x45, 0x83, 0x8d, 0x41,
+ 0x7a, 0x52, 0xb2, 0xae, 0x71, 0x78, 0x17, 0x63, 0xfa, 0xbe, 0x59, 0xca,
+ 0xf0, 0xfd, 0x68, 0xe5, 0xc4, 0x9a, 0x74, 0x3d, 0xec, 0xd4, 0x8b, 0xa1,
+ 0x2c, 0x31, 0x4d, 0x73, 0xfd, 0x5c, 0x1e, 0xeb, 0x5f, 0xf6, 0x42, 0x0d,
+ 0x79, 0x5f, 0x64, 0x10, 0xae, 0xb2, 0xf6, 0x9e, 0xa8, 0xab, 0xa5, 0x2b,
+ 0x9a, 0xcf, 0x25, 0xfa, 0xa2, 0xb3, 0xdc, 0x30, 0x3d, 0x08, 0x4e, 0xbb,
+ 0x7b, 0x0c, 0x28, 0x34, 0x9d, 0xda, 0xc4, 0x94, 0xa4, 0xf4, 0x1e, 0x78,
+ 0x8b, 0xa9, 0xd3, 0xa7, 0x1c, 0x2a, 0x27, 0x14, 0xa0, 0x44, 0x1a, 0x9a,
+ 0x87, 0x72, 0xa5, 0x6d, 0x69, 0x46, 0xe5, 0xc1, 0x4f, 0x29, 0x87, 0xc0,
+ 0xa7, 0xa8, 0x96, 0xde, 0xa9, 0x63, 0x08, 0xd8, 0x4a, 0xa1, 0x25, 0x43,
+ 0x76, 0x41, 0xf7, 0x9f, 0x17, 0xe3, 0xe1, 0x4b, 0xc6, 0x2b, 0x79, 0xea,
+ 0xd5, 0xa7, 0x72, 0x16, 0x0a, 0x8c, 0xcd, 0x49, 0x70, 0x75, 0xd4, 0x59,
+ 0x4a, 0x19, 0x7b, 0x31, 0x02, 0x7a, 0x3a, 0x20, 0x15, 0x62, 0x7e, 0x4e,
+ 0x6f, 0xac, 0xd0, 0xd1, 0x29, 0xbd, 0x2d, 0xa1, 0xc6, 0x3e, 0xa6, 0x1a,
+ 0x26, 0x18, 0x96, 0x98, 0x12, 0x56, 0x37, 0xbf, 0xb4, 0x91, 0x57, 0xe8,
+ 0xda, 0x61, 0x7c, 0x2f, 0x3e, 0xd4, 0x51, 0xfe, 0xe8, 0x5b, 0x00, 0x30,
+ 0x08, 0xf6, 0x4e, 0x69, 0xa8, 0x1a, 0x2b, 0x82, 0x41, 0x85, 0xa9, 0xd9,
+ 0x3c, 0xc8, 0x02, 0x91, 0x99, 0xd4, 0xa2, 0xfd, 0x9d, 0x1b, 0x08, 0xfc,
+ 0x41, 0x3e, 0x10, 0x6b, 0x80, 0x74, 0x3d, 0x72, 0x61, 0x97, 0xdd, 0x96,
+ 0xec, 0xf4, 0xd6, 0x6d, 0x68, 0x02, 0x6e, 0xbb, 0x55, 0x9d, 0x6f, 0x11,
+ 0xde, 0xd1, 0xad, 0x6d, 0x42, 0x96, 0x2c, 0x42, 0x1e, 0xa9, 0x19, 0x42,
+ 0x22, 0x38, 0x38, 0x18, 0x3c, 0x4b, 0xc1, 0x9c, 0x0f, 0xe1, 0x34, 0x61,
+ 0x06, 0x77, 0x54, 0x04, 0xe0, 0x87, 0x94, 0x5c, 0xc9, 0xa1, 0x35, 0x55,
+ 0x3d, 0x4a, 0xf2, 0x4f, 0x05, 0x11, 0x98, 0x6f, 0x3c, 0x85, 0x84, 0xe6,
+ 0xf8, 0x71, 0x8a, 0xdf, 0xe9, 0x9a, 0xe3, 0x70, 0xd6, 0x36, 0xd6, 0xc8,
+ 0x66, 0x3e, 0xba, 0x7c, 0x0a, 0x23, 0x0a, 0xd0, 0xb6, 0x66, 0x68, 0xa8,
+ 0xdf, 0x37, 0x17, 0xfb, 0xdd, 0x9c, 0x8b, 0xc7, 0x8e, 0xc4, 0x4f, 0x40,
+ 0x08, 0x23, 0x58, 0x15, 0xa2, 0xba, 0xef, 0xdf, 0x67, 0xcd, 0x1f, 0xb6,
+ 0xc4, 0xea, 0xce, 0x81, 0x38, 0x58, 0x92, 0x57, 0xcf, 0x83, 0x47, 0x29,
+ 0x9f, 0xde, 0x9b, 0xde, 0x01, 0xfe, 0x68, 0x91, 0x67, 0x06, 0x9d, 0x31,
+ 0xd0, 0xb9, 0xc3, 0xbb, 0xc3, 0x6b, 0xa0, 0x04, 0x1e, 0x34, 0xd5, 0x38,
+ 0xd4, 0xac, 0x70, 0xae, 0xab, 0xb2, 0xbd, 0x4b, 0xa0, 0xad, 0x2b, 0x82,
+ 0xaf, 0x8c, 0x90, 0x4d, 0xd3, 0xca, 0x71, 0x35, 0x75, 0x89, 0xe5, 0x42,
+ 0x91, 0x46, 0x8d, 0x18, 0x04, 0x7a, 0xb9, 0xaa, 0x3b, 0xe7, 0x1e, 0x8c,
+ 0x4e, 0xf9, 0x6e, 0x74, 0xaa, 0x2e, 0x36, 0x86, 0xfb, 0xef, 0x9c, 0xd7,
+ 0xba, 0x5e, 0x2e, 0x3c, 0x40, 0xce, 0x8b, 0x2b, 0x94, 0x55, 0xf2, 0xd4,
+ 0x7d, 0xbf, 0x8c, 0x8a, 0xa8, 0x59, 0x84, 0x6f, 0x32, 0x95, 0xc5, 0xcc,
+ 0xad, 0xee, 0x30, 0x23, 0x7c, 0x54, 0xea, 0x60, 0xb8, 0x88, 0x12, 0x45,
+ 0x03, 0xbc, 0xe3, 0x92, 0x9f, 0xa8, 0x5b, 0x07, 0x97, 0x53, 0x0d, 0xe1,
+ 0xe3, 0x3d, 0xdf, 0xf2, 0x2a, 0x12, 0xee, 0xdf, 0x73, 0x8d, 0x41, 0xf4,
+ 0xe4, 0x2c, 0xb4, 0xd4, 0x9e, 0xfe, 0xf2, 0xe6, 0xa0, 0x9e, 0x2a, 0x3a,
+ 0x36, 0x26, 0x7e, 0xd9, 0xe1, 0x22, 0xee, 0x0b, 0x5b, 0x48, 0xd2, 0xa9,
+ 0x55, 0xab, 0x50, 0x7c, 0xf6, 0xc8, 0x56, 0x31, 0xbb, 0x51, 0xe9, 0x31,
+ 0x4d, 0xaa, 0x13, 0x3a, 0x99, 0x9f, 0x8c, 0x59, 0x6a, 0xc9, 0xf1, 0x0a,
+ 0x89, 0xcc, 0x39, 0x98, 0xbd, 0xc3, 0x93, 0x97, 0x28, 0xe5, 0x73, 0x94,
+ 0xf2, 0x0a, 0x7a, 0x09, 0x38, 0x0b, 0xab, 0xd8, 0x49, 0x98, 0x14, 0x34,
+ 0x32, 0x9d, 0xef, 0x9d, 0x47, 0xdb, 0x82, 0xb9, 0x84, 0xd6, 0xd7, 0x9f,
+ 0xf7, 0xdf, 0x79, 0x5b, 0xe8, 0x92, 0x44, 0x31, 0x5d, 0x42, 0x80, 0x90,
+ 0x8d, 0x36, 0xa2, 0x39, 0x02, 0x64, 0x21, 0xa2, 0xb8, 0xfc, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xc8, 0xeb, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0xd8, 0x03, 0x00, 0x00, 0xdc, 0x03, 0x00, 0x00,
+ 0xe0, 0x03, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0xa8, 0x03, 0x00, 0x00,
+ 0x50, 0x03, 0x00, 0x00, 0x04, 0x03, 0x00, 0x00, 0xac, 0x02, 0x00, 0x00,
+ 0x74, 0x02, 0x00, 0x00, 0x2c, 0x02, 0x00, 0x00, 0xf4, 0x01, 0x00, 0x00,
+ 0xac, 0x01, 0x00, 0x00, 0x74, 0x01, 0x00, 0x00, 0x2c, 0x01, 0x00, 0x00,
+ 0xe4, 0x00, 0x00, 0x00, 0x9c, 0x00, 0x00, 0x00, 0x64, 0x00, 0x00, 0x00,
+ 0x28, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x9e, 0xfc, 0xff, 0xff,
+ 0x0c, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x0d, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x35, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x33, 0x00, 0x00, 0x00, 0x5e, 0xfd, 0xff, 0xff, 0x1c, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x04, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x80, 0x3f, 0x01, 0x00, 0x00, 0x00,
+ 0x33, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x32, 0x00, 0x00, 0x00,
+ 0x96, 0xfd, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08,
+ 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00,
+ 0x88, 0xfd, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00, 0x32, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x2f, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x31, 0x00, 0x00, 0x00, 0xca, 0xfd, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x06, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x0a, 0x00, 0x00, 0x00, 0x78, 0xfd, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01,
+ 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x2f, 0x00, 0x00, 0x00,
+ 0x05, 0x00, 0x00, 0x00, 0x2a, 0x00, 0x00, 0x00, 0x2b, 0x00, 0x00, 0x00,
+ 0x2c, 0x00, 0x00, 0x00, 0x2d, 0x00, 0x00, 0x00, 0x2e, 0x00, 0x00, 0x00,
+ 0x0e, 0xfe, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00,
+ 0xbc, 0xfd, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x2a, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
+ 0x25, 0x00, 0x00, 0x00, 0x26, 0x00, 0x00, 0x00, 0x27, 0x00, 0x00, 0x00,
+ 0x28, 0x00, 0x00, 0x00, 0x29, 0x00, 0x00, 0x00, 0x52, 0xfe, 0xff, 0xff,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x00, 0xfe, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x25, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x21, 0x00, 0x00, 0x00, 0x22, 0x00, 0x00, 0x00, 0x23, 0x00, 0x00, 0x00,
+ 0x24, 0x00, 0x00, 0x00, 0x96, 0xfe, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x08, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x07, 0x00, 0x00, 0x00, 0x88, 0xfe, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x1d, 0x00, 0x00, 0x00,
+ 0x1e, 0x00, 0x00, 0x00, 0x1f, 0x00, 0x00, 0x00, 0xca, 0xfe, 0xff, 0xff,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00, 0x78, 0xfe, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x1d, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x19, 0x00, 0x00, 0x00, 0x1a, 0x00, 0x00, 0x00, 0x1b, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x0e, 0xff, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x08, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x05, 0x00, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x15, 0x00, 0x00, 0x00,
+ 0x16, 0x00, 0x00, 0x00, 0x17, 0x00, 0x00, 0x00, 0x42, 0xff, 0xff, 0xff,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xf0, 0xfe, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x15, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x11, 0x00, 0x00, 0x00, 0x12, 0x00, 0x00, 0x00, 0x13, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x86, 0xff, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x08, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x78, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x0d, 0x00, 0x00, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0xba, 0xff, 0xff, 0xff,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x68, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0d, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x09, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x14, 0x00,
+ 0x10, 0x00, 0x0c, 0x00, 0x0b, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08, 0x14, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x04, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00,
+ 0x07, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x0c, 0x00, 0x0b, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x07, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00,
+ 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00, 0x0a, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x0d, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x34, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x35, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00, 0x36, 0x00, 0x00, 0x00,
+ 0x34, 0x10, 0x00, 0x00, 0xd4, 0x0f, 0x00, 0x00, 0x7c, 0x0f, 0x00, 0x00,
+ 0x38, 0x0f, 0x00, 0x00, 0xdc, 0x0e, 0x00, 0x00, 0x74, 0x0e, 0x00, 0x00,
+ 0x2c, 0x0e, 0x00, 0x00, 0xe8, 0x0d, 0x00, 0x00, 0x90, 0x0d, 0x00, 0x00,
+ 0x48, 0x0d, 0x00, 0x00, 0x04, 0x0d, 0x00, 0x00, 0xc0, 0x0c, 0x00, 0x00,
+ 0x64, 0x0c, 0x00, 0x00, 0x0c, 0x0c, 0x00, 0x00, 0xc4, 0x0b, 0x00, 0x00,
+ 0x80, 0x0b, 0x00, 0x00, 0x28, 0x0b, 0x00, 0x00, 0xe0, 0x0a, 0x00, 0x00,
+ 0x9c, 0x0a, 0x00, 0x00, 0x58, 0x0a, 0x00, 0x00, 0xfc, 0x09, 0x00, 0x00,
+ 0xa4, 0x09, 0x00, 0x00, 0x5c, 0x09, 0x00, 0x00, 0x18, 0x09, 0x00, 0x00,
+ 0xc0, 0x08, 0x00, 0x00, 0x78, 0x08, 0x00, 0x00, 0x34, 0x08, 0x00, 0x00,
+ 0xf0, 0x07, 0x00, 0x00, 0x94, 0x07, 0x00, 0x00, 0x3c, 0x07, 0x00, 0x00,
+ 0xf4, 0x06, 0x00, 0x00, 0xb0, 0x06, 0x00, 0x00, 0x58, 0x06, 0x00, 0x00,
+ 0x10, 0x06, 0x00, 0x00, 0xcc, 0x05, 0x00, 0x00, 0x88, 0x05, 0x00, 0x00,
+ 0x2c, 0x05, 0x00, 0x00, 0xd4, 0x04, 0x00, 0x00, 0x8c, 0x04, 0x00, 0x00,
+ 0x48, 0x04, 0x00, 0x00, 0x04, 0x04, 0x00, 0x00, 0xa8, 0x03, 0x00, 0x00,
+ 0x50, 0x03, 0x00, 0x00, 0x08, 0x03, 0x00, 0x00, 0xc4, 0x02, 0x00, 0x00,
+ 0x80, 0x02, 0x00, 0x00, 0x24, 0x02, 0x00, 0x00, 0xcc, 0x01, 0x00, 0x00,
+ 0x84, 0x01, 0x00, 0x00, 0x40, 0x01, 0x00, 0x00, 0xe8, 0x00, 0x00, 0x00,
+ 0x8c, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0xb2, 0xf0, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,
+ 0x28, 0x00, 0x00, 0x00, 0xfc, 0xf0, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x01, 0x00, 0x38, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0xf2, 0xf0, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x07, 0x28, 0x00, 0x00, 0x00, 0x3c, 0xf1, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0a, 0xd7, 0x23, 0x3a, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x60, 0x00, 0x00, 0x00, 0x32, 0xf1, 0xff, 0xff,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07, 0x40, 0x00, 0x00, 0x00,
+ 0x24, 0xf1, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0x00, 0x80, 0x37, 0x01, 0x00, 0x00, 0x00,
+ 0xc2, 0xff, 0x7f, 0x3f, 0x01, 0x00, 0x00, 0x00, 0xd2, 0x6f, 0x75, 0x36,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x8a, 0xf1, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x3c, 0x00, 0x00, 0x00, 0x7c, 0xf1, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x06, 0x16, 0x49, 0x3d, 0x01, 0x00, 0x00, 0x00,
+ 0x87, 0x19, 0xb1, 0x40, 0x01, 0x00, 0x00, 0x00, 0x58, 0x80, 0xdf, 0xc0,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x3a, 0xf2, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x1f, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00, 0x2c, 0xf2, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x5d, 0xd1, 0xce, 0x39, 0x01, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x7a, 0xf2, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x1e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00,
+ 0x6c, 0xf2, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x23, 0x20, 0xb6, 0x3b,
+ 0x02, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x62, 0xf2, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x3c, 0x00, 0x00, 0x00, 0x54, 0xf2, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0xa2, 0x5a, 0x91, 0x3d, 0x01, 0x00, 0x00, 0x00,
+ 0x47, 0xc9, 0x90, 0x41, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x00, 0xf4, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01, 0x0c, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x07, 0x3c, 0x00, 0x00, 0x00, 0xac, 0xf2, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x81, 0xb7, 0xf1, 0x39,
+ 0x01, 0x00, 0x00, 0x00, 0x9e, 0xb5, 0x71, 0x41, 0x01, 0x00, 0x00, 0x00,
+ 0x33, 0x20, 0x70, 0xc1, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x04, 0x00, 0x00, 0x6a, 0xf3, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x1d, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00,
+ 0x5c, 0xf3, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x7a, 0x08, 0x97, 0x35,
+ 0x01, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0xaa, 0xf3, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07,
+ 0x24, 0x00, 0x00, 0x00, 0x9c, 0xf3, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x2f, 0xf5, 0x1f, 0x3b,
+ 0x02, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0xea, 0xf3, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x1b, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00, 0xdc, 0xf3, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xc7, 0xea, 0x1a, 0x3c, 0x02, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0xd2, 0xf3, 0xff, 0xff,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x3c, 0x00, 0x00, 0x00,
+ 0xc4, 0xf3, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00,
+ 0xb2, 0x78, 0x3f, 0x3d, 0x01, 0x00, 0x00, 0x00, 0x39, 0xb9, 0x3e, 0x41,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x70, 0xf5, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x01, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07,
+ 0x3c, 0x00, 0x00, 0x00, 0x1c, 0xf4, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x89, 0x25, 0xf2, 0x39, 0x01, 0x00, 0x00, 0x00,
+ 0xde, 0xdc, 0x1d, 0x41, 0x01, 0x00, 0x00, 0x00, 0xa5, 0x23, 0x72, 0xc1,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00,
+ 0xda, 0xf4, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x1a, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00, 0xcc, 0xf4, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x42, 0xe0, 0x90, 0x35, 0x01, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x1a, 0xf5, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x19, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07, 0x24, 0x00, 0x00, 0x00,
+ 0x0c, 0xf5, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x1a, 0x2a, 0x19, 0x3b, 0x02, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x5a, 0xf5, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x28, 0x00, 0x00, 0x00, 0x4c, 0xf5, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xe9, 0x36, 0xdd, 0x3b, 0x02, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x42, 0xf5, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x3c, 0x00, 0x00, 0x00, 0x34, 0xf5, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff,
+ 0xff, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00, 0xdd, 0x43, 0x7e, 0x3d,
+ 0x01, 0x00, 0x00, 0x00, 0x99, 0x45, 0x7d, 0x41, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0xe0, 0xf6, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07, 0x3c, 0x00, 0x00, 0x00,
+ 0x8c, 0xf5, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x5c, 0xfd, 0xa9, 0x39, 0x01, 0x00, 0x00, 0x00, 0x1e, 0xaa, 0x87, 0x40,
+ 0x01, 0x00, 0x00, 0x00, 0x08, 0xfc, 0x29, 0xc1, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x4a, 0xf6, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x17, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,
+ 0x28, 0x00, 0x00, 0x00, 0x3c, 0xf6, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x55, 0xf7, 0x52, 0x35, 0x01, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x8a, 0xf6, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x16, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x07, 0x24, 0x00, 0x00, 0x00, 0x7c, 0xf6, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xd0, 0xda, 0x1e, 0x3b, 0x02, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0xca, 0xf6, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x15, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00,
+ 0xbc, 0xf6, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x8e, 0x0b, 0xa8, 0x3b,
+ 0x02, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xb2, 0xf6, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x3c, 0x00, 0x00, 0x00, 0xa4, 0xf6, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xf5, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0x12, 0x1c, 0x6e, 0x3d, 0x01, 0x00, 0x00, 0x00,
+ 0xdd, 0x4a, 0x00, 0x41, 0x01, 0x00, 0x00, 0x00, 0x31, 0xc6, 0xd9, 0xc0,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x62, 0xf7, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00, 0x54, 0xf7, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0x9d, 0x16, 0x39, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0xa2, 0xf7, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x13, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00,
+ 0x94, 0xf7, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xa4, 0x34, 0xab, 0x3b,
+ 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x8a, 0xf7, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x3c, 0x00, 0x00, 0x00, 0x7c, 0xf7, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0x2e, 0x36, 0xe1, 0x3c, 0x01, 0x00, 0x00, 0x00,
+ 0xf8, 0x54, 0xe0, 0x40, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x28, 0xf9, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01, 0x0c, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x07, 0x3c, 0x00, 0x00, 0x00, 0xd4, 0xf7, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xe1, 0xd0, 0xa2, 0x39,
+ 0x01, 0x00, 0x00, 0x00, 0x9b, 0xcf, 0x22, 0x41, 0x01, 0x00, 0x00, 0x00,
+ 0xea, 0x23, 0x12, 0xc1, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x02, 0x00, 0x00, 0x92, 0xf8, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x12, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00,
+ 0x84, 0xf8, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x99, 0xd3, 0xf7, 0x34,
+ 0x01, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0xd2, 0xf8, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x11, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07,
+ 0x24, 0x00, 0x00, 0x00, 0xc4, 0xf8, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0xd5, 0xc2, 0x3a,
+ 0x02, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x12, 0xf9, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00, 0x04, 0xf9, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x8f, 0x84, 0xa2, 0x3b, 0x02, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0xfa, 0xf8, 0xff, 0xff,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x3c, 0x00, 0x00, 0x00,
+ 0xec, 0xf8, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xf7, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00,
+ 0x64, 0xeb, 0x8e, 0x3d, 0x01, 0x00, 0x00, 0x00, 0x3b, 0xf3, 0x17, 0x41,
+ 0x01, 0x00, 0x00, 0x00, 0xb7, 0xc5, 0x04, 0xc1, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0xaa, 0xf9, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,
+ 0x28, 0x00, 0x00, 0x00, 0x9c, 0xf9, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x92, 0xa8, 0x98, 0x39, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xea, 0xf9, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00, 0xdc, 0xf9, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x58, 0x76, 0xb9, 0x3b, 0x02, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0xd2, 0xf9, 0xff, 0xff,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x3c, 0x00, 0x00, 0x00,
+ 0xc4, 0xf9, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00,
+ 0x43, 0xb8, 0x52, 0x3d, 0x01, 0x00, 0x00, 0x00, 0x8b, 0xe5, 0x51, 0x41,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x70, 0xfb, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x01, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07,
+ 0x3c, 0x00, 0x00, 0x00, 0x1c, 0xfa, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xe3, 0xa1, 0xf0, 0x39, 0x01, 0x00, 0x00, 0x00,
+ 0x02, 0xa0, 0x70, 0x41, 0x01, 0x00, 0x00, 0x00, 0x87, 0x08, 0x65, 0xc1,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00,
+ 0xda, 0xfa, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x0d, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00, 0xcc, 0xfa, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xcc, 0x98, 0x41, 0x35, 0x01, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x1a, 0xfb, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07, 0x24, 0x00, 0x00, 0x00,
+ 0x0c, 0xfb, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xed, 0xf5, 0xcd, 0x3a, 0x02, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x5a, 0xfb, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x28, 0x00, 0x00, 0x00, 0x4c, 0xfb, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x9d, 0xca, 0xd4, 0x3b, 0x02, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x42, 0xfb, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x3c, 0x00, 0x00, 0x00, 0x34, 0xfb, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x58, 0x58, 0xce, 0x3d,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x49, 0x41, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x06, 0x52, 0xc1, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0xf2, 0xfb, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00,
+ 0xe4, 0xfb, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x9b, 0x9c, 0xe1, 0x39,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x32, 0xfc, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x28, 0x00, 0x00, 0x00, 0x24, 0xfc, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xf8, 0xb6, 0xc3, 0x3b, 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x1a, 0xfc, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x3c, 0x00, 0x00, 0x00, 0x0c, 0xfc, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff,
+ 0xff, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00, 0x94, 0x8d, 0x93, 0x3d,
+ 0x01, 0x00, 0x00, 0x00, 0x06, 0xfa, 0x92, 0x41, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0xb8, 0xfd, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07, 0x3c, 0x00, 0x00, 0x00,
+ 0x64, 0xfc, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x7a, 0xf6, 0x5f, 0x3a, 0x01, 0x00, 0x00, 0x00, 0xba, 0xf4, 0xdf, 0x41,
+ 0x01, 0x00, 0x00, 0x00, 0xf4, 0x7c, 0xcf, 0xc1, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x22, 0xfd, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,
+ 0x28, 0x00, 0x00, 0x00, 0x14, 0xfd, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x46, 0x2f, 0xc4, 0x35, 0x01, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x62, 0xfd, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x07, 0x24, 0x00, 0x00, 0x00, 0x54, 0xfd, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x8f, 0x3f, 0xe0, 0x3a, 0x02, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0xa2, 0xfd, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00,
+ 0x94, 0xfd, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x25, 0xd7, 0xa9, 0x3b,
+ 0x02, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x8a, 0xfd, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x3c, 0x00, 0x00, 0x00, 0x7c, 0xfd, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xe3, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0xc4, 0xf4, 0x39, 0x3e, 0x01, 0x00, 0x00, 0x00,
+ 0xf4, 0x1f, 0xe3, 0x41, 0x01, 0x00, 0x00, 0x00, 0xaa, 0x55, 0x8f, 0xc1,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x3a, 0xfe, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x02, 0x28, 0x00, 0x00, 0x00, 0x2c, 0xfe, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x8b, 0x00, 0x4b, 0x3a, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x7a, 0xfe, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x28, 0x00, 0x00, 0x00,
+ 0x6c, 0xfe, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xd7, 0xdf, 0xc3, 0x3b,
+ 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x62, 0xfe, 0xff, 0xff, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x3c, 0x00, 0x00, 0x00, 0x54, 0xfe, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0x68, 0xa8, 0x04, 0x3e, 0x01, 0x00, 0x00, 0x00,
+ 0xc0, 0x23, 0x04, 0x42, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x14, 0x00, 0x10, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x07, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07, 0x3c, 0x00, 0x00, 0x00,
+ 0xbc, 0xfe, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x3b, 0xda, 0x75, 0x3b, 0x01, 0x00, 0x00, 0x00, 0x4f, 0xd8, 0xf5, 0x42,
+ 0x01, 0x00, 0x00, 0x00, 0xa8, 0x2a, 0x61, 0xc2, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x7a, 0xff, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,
+ 0x28, 0x00, 0x00, 0x00, 0x6c, 0xff, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xcf, 0x37, 0x69, 0x37, 0x01, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0xba, 0xff, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x07, 0x28, 0x00, 0x00, 0x00, 0xac, 0xff, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x14, 0xd8, 0x72, 0x3b, 0x02, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00,
+ 0x14, 0x00, 0x10, 0x00, 0x0f, 0x00, 0x08, 0x00, 0x00, 0x00, 0x04, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x30, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x0c, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x08, 0x00, 0x04, 0x00, 0x0c, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xd4, 0x42, 0x16, 0x3c, 0x02, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x60, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x10, 0x00, 0x0c, 0x00,
+ 0x0b, 0x00, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x4c, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x14, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xa8, 0x41, 0x5b, 0x3d, 0x01, 0x00, 0x00, 0x00,
+ 0x66, 0x66, 0x5a, 0x41, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x60, 0x00, 0x00, 0x00,
+ 0x0f, 0x00, 0x00, 0x00, 0xc4, 0x00, 0x00, 0x00, 0xb4, 0x00, 0x00, 0x00,
+ 0xa4, 0x00, 0x00, 0x00, 0x98, 0x00, 0x00, 0x00, 0x8c, 0x00, 0x00, 0x00,
+ 0x80, 0x00, 0x00, 0x00, 0x74, 0x00, 0x00, 0x00, 0x68, 0x00, 0x00, 0x00,
+ 0x5c, 0x00, 0x00, 0x00, 0x50, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00,
+ 0x38, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x0c, 0x00, 0x0b, 0x00,
+ 0x00, 0x00, 0x04, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x06, 0x96, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x72,
+ 0x9e, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x19, 0xa6, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x09, 0xae, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x1b,
+ 0xb6, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x1b, 0xbe, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x1b, 0xc6, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09,
+ 0xce, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x1b, 0xd6, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x09, 0xde, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x1b,
+ 0xe6, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0xfa, 0xff, 0xff, 0xff,
+ 0x00, 0x1b, 0x06, 0x00, 0x06, 0x00, 0x05, 0x00, 0x06, 0x00, 0x00, 0x00,
+ 0x00, 0x09, 0x06, 0x00, 0x08, 0x00, 0x07, 0x00, 0x06, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x1b};
+
+const unsigned int g_keyword_scrambled_model_data_length = 34520;
diff --git a/tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h b/tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h
new file mode 100644
index 0000000..ce34426
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h
@@ -0,0 +1,22 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_BENCHMARKS_KEYWORD_SCRAMBLED_MODEL_DATA_H_
+#define TENSORFLOW_LITE_MICRO_BENCHMARKS_KEYWORD_SCRAMBLED_MODEL_DATA_H_
+
+extern const unsigned char g_keyword_scrambled_model_data[];
+extern const unsigned int g_keyword_scrambled_model_data_length;
+
+#endif // TENSORFLOW_LITE_MICRO_BENCHMARKS_KEYWORD_SCRAMBLED_MODEL_DATA_H_
diff --git a/tensorflow/lite/micro/benchmarks/micro_benchmark.h b/tensorflow/lite/micro/benchmarks/micro_benchmark.h
new file mode 100644
index 0000000..272c720
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/micro_benchmark.h
@@ -0,0 +1,82 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_BENCHMARKS_MICRO_BENCHMARK_H_
+#define TENSORFLOW_LITE_MICRO_BENCHMARKS_MICRO_BENCHMARK_H_
+
+#include <climits>
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_op_resolver.h"
+#include "tensorflow/lite/micro/micro_profiler.h"
+#include "tensorflow/lite/micro/micro_time.h"
+
+namespace tflite {
+
+template <typename inputT>
+class MicroBenchmarkRunner {
+ public:
+ // The lifetimes of model, op_resolver, tensor_arena, profiler must exceed
+ // that of the created MicroBenchmarkRunner object.
+ MicroBenchmarkRunner(const uint8_t* model,
+ const tflite::MicroOpResolver* op_resolver,
+ uint8_t* tensor_arena, int tensor_arena_size,
+ MicroProfiler* profiler)
+ : interpreter_(GetModel(model), *op_resolver, tensor_arena,
+ tensor_arena_size, GetMicroErrorReporter(), profiler) {
+ interpreter_.AllocateTensors();
+ }
+
+ void RunSingleIteration() {
+ // Run the model on this input and make sure it succeeds.
+ TfLiteStatus invoke_status = interpreter_.Invoke();
+ if (invoke_status == kTfLiteError) {
+ MicroPrintf("Invoke failed.");
+ }
+ }
+
+ void SetRandomInput(const int random_seed) {
+ // The pseudo-random number generator is initialized to a constant seed
+ std::srand(random_seed);
+ TfLiteTensor* input = interpreter_.input(0);
+
+ // Pre-populate input tensor with random values.
+ int input_length = input->bytes / sizeof(inputT);
+ inputT* input_values = tflite::GetTensorData<inputT>(input);
+ for (int i = 0; i < input_length; i++) {
+ // Pre-populate input tensor with a random value based on a constant seed.
+ input_values[i] = static_cast<inputT>(
+ std::rand() % (std::numeric_limits<inputT>::max() -
+ std::numeric_limits<inputT>::min() + 1));
+ }
+ }
+
+ void SetInput(const inputT* custom_input) {
+ TfLiteTensor* input = interpreter_.input(0);
+ inputT* input_buffer = tflite::GetTensorData<inputT>(input);
+ int input_length = input->bytes / sizeof(inputT);
+ for (int i = 0; i < input_length; i++) {
+ input_buffer[i] = custom_input[i];
+ }
+ }
+
+ private:
+ tflite::MicroInterpreter interpreter_;
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_BENCHMARKS_MICRO_BENCHMARK_H_
diff --git a/tensorflow/lite/micro/benchmarks/person_detection_benchmark.cc b/tensorflow/lite/micro/benchmarks/person_detection_benchmark.cc
new file mode 100644
index 0000000..1e98bbd
--- /dev/null
+++ b/tensorflow/lite/micro/benchmarks/person_detection_benchmark.cc
@@ -0,0 +1,110 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/benchmarks/micro_benchmark.h"
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+#include "tensorflow/lite/micro/examples/person_detection/no_person_image_data.h"
+#include "tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h"
+#include "tensorflow/lite/micro/examples/person_detection/person_image_data.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/system_setup.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+/*
+ * Person Detection benchmark. Evaluates runtime performance of the visual
+ * wakewords person detection model. This is the same model found in
+ * exmaples/person_detection.
+ */
+
+namespace tflite {
+
+using PersonDetectionOpResolver = tflite::AllOpsResolver;
+using PersonDetectionBenchmarkRunner = MicroBenchmarkRunner<int8_t>;
+
+// Create an area of memory to use for input, output, and intermediate arrays.
+// Align arena to 16 bytes to avoid alignment warnings on certain platforms.
+constexpr int kTensorArenaSize = 135 * 1024;
+alignas(16) uint8_t tensor_arena[kTensorArenaSize];
+
+uint8_t op_resolver_buffer[sizeof(PersonDetectionOpResolver)];
+uint8_t benchmark_runner_buffer[sizeof(PersonDetectionBenchmarkRunner)];
+
+// Initialize benchmark runner instance explicitly to avoid global init order
+// issues on Sparkfun. Use new since static variables within a method
+// are automatically surrounded by locking, which breaks bluepill and stm32f4.
+PersonDetectionBenchmarkRunner* CreateBenchmarkRunner(MicroProfiler* profiler) {
+ // We allocate PersonDetectionOpResolver from a global buffer
+ // because the object's lifetime must exceed that of the
+ // PersonDetectionBenchmarkRunner object.
+ return new (benchmark_runner_buffer) PersonDetectionBenchmarkRunner(
+ g_person_detect_model_data,
+ new (op_resolver_buffer) PersonDetectionOpResolver(), tensor_arena,
+ kTensorArenaSize, profiler);
+}
+
+void PersonDetectionNIerations(const int8_t* input, int iterations,
+ const char* tag,
+ PersonDetectionBenchmarkRunner& benchmark_runner,
+ MicroProfiler& profiler) {
+ benchmark_runner.SetInput(input);
+ int32_t ticks = 0;
+ for (int i = 0; i < iterations; ++i) {
+ profiler.ClearEvents();
+ benchmark_runner.RunSingleIteration();
+ ticks += profiler.GetTotalTicks();
+ }
+ MicroPrintf("%s took %d ticks (%d ms)", tag, ticks, TicksToMs(ticks));
+}
+
+} // namespace tflite
+
+int main(int argc, char** argv) {
+ tflite::InitializeTarget();
+
+ tflite::MicroProfiler profiler;
+
+ uint32_t event_handle = profiler.BeginEvent("InitializeBenchmarkRunner");
+ tflite::PersonDetectionBenchmarkRunner* benchmark_runner =
+ CreateBenchmarkRunner(&profiler);
+ profiler.EndEvent(event_handle);
+ profiler.Log();
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+
+ tflite::PersonDetectionNIerations(
+ reinterpret_cast<const int8_t*>(g_person_data), 1,
+ "WithPersonDataIterations(1)", *benchmark_runner, profiler);
+ profiler.Log();
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+
+ tflite::PersonDetectionNIerations(
+ reinterpret_cast<const int8_t*>(g_no_person_data), 1,
+ "NoPersonDataIterations(1)", *benchmark_runner, profiler);
+ profiler.Log();
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+
+ tflite::PersonDetectionNIerations(
+ reinterpret_cast<const int8_t*>(g_person_data), 10,
+ "WithPersonDataIterations(10)", *benchmark_runner, profiler);
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+
+ tflite::PersonDetectionNIerations(
+ reinterpret_cast<const int8_t*>(g_no_person_data), 10,
+ "NoPersonDataIterations(10)", *benchmark_runner, profiler);
+ MicroPrintf(""); // null MicroPrintf serves as a newline.
+}
diff --git a/tensorflow/lite/micro/bluepill/debug_log.cc b/tensorflow/lite/micro/bluepill/debug_log.cc
new file mode 100644
index 0000000..3fd2d52
--- /dev/null
+++ b/tensorflow/lite/micro/bluepill/debug_log.cc
@@ -0,0 +1,27 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+// For Arm Cortex-M devices, calling SYS_WRITE0 will output the zero-terminated
+// string pointed to by R1 to any debug console that's attached to the system.
+extern "C" void DebugLog(const char* s) {
+ asm("mov r0, #0x04\n" // SYS_WRITE0
+ "mov r1, %[str]\n"
+ "bkpt #0xAB\n"
+ :
+ : [str] "r"(s)
+ : "r0", "r1");
+}
diff --git a/tensorflow/lite/micro/build_def.bzl b/tensorflow/lite/micro/build_def.bzl
new file mode 100644
index 0000000..edca4cb
--- /dev/null
+++ b/tensorflow/lite/micro/build_def.bzl
@@ -0,0 +1,2 @@
+def micro_copts():
+ return []
diff --git a/tensorflow/lite/micro/ceva/micro_time.cc b/tensorflow/lite/micro/ceva/micro_time.cc
new file mode 100644
index 0000000..15bb872
--- /dev/null
+++ b/tensorflow/lite/micro/ceva/micro_time.cc
@@ -0,0 +1,14 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
diff --git a/tensorflow/lite/micro/ceva/system_setup.cc b/tensorflow/lite/micro/ceva/system_setup.cc
new file mode 100644
index 0000000..09cc1e7
--- /dev/null
+++ b/tensorflow/lite/micro/ceva/system_setup.cc
@@ -0,0 +1,34 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/system_setup.h"
+
+#include <ceva-time.h>
+
+#include "tensorflow/lite/micro/micro_time.h"
+
+namespace tflite {
+
+int32_t ticks_per_second() { return 100e6; }
+
+int32_t GetCurrentTimeTicks() { return clock(); }
+
+void InitializeTarget() {
+ // start clock for profiler
+ reset_clock();
+ start_clock();
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/chre/debug_log.cc b/tensorflow/lite/micro/chre/debug_log.cc
new file mode 100644
index 0000000..23bb82e
--- /dev/null
+++ b/tensorflow/lite/micro/chre/debug_log.cc
@@ -0,0 +1,22 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include <chre.h>
+
+extern "C" void DebugLog(const char* s) {
+ chreLog(CHRE_LOG_DEBUG, "[TFL_MICRO] %s", s);
+}
diff --git a/tensorflow/lite/micro/compatibility.h b/tensorflow/lite/micro/compatibility.h
new file mode 100644
index 0000000..49acb28
--- /dev/null
+++ b/tensorflow/lite/micro/compatibility.h
@@ -0,0 +1,32 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_COMPATIBILITY_H_
+#define TENSORFLOW_LITE_MICRO_COMPATIBILITY_H_
+
+// C++ will automatically create class-specific delete operators for virtual
+// objects, which by default call the global delete function. For embedded
+// applications we want to avoid this, and won't be calling new/delete on these
+// objects, so we need to override the default implementation with one that does
+// nothing to avoid linking in ::delete().
+// This macro needs to be included in all subclasses of a virtual base class in
+// the private section.
+#ifdef TF_LITE_STATIC_MEMORY
+#define TF_LITE_REMOVE_VIRTUAL_DELETE \
+ void operator delete(void* p) {}
+#else
+#define TF_LITE_REMOVE_VIRTUAL_DELETE
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_COMPATIBILITY_H_
diff --git a/tensorflow/lite/micro/cortex_m_corstone_300/README.md b/tensorflow/lite/micro/cortex_m_corstone_300/README.md
new file mode 100644
index 0000000..b4ff9a1
--- /dev/null
+++ b/tensorflow/lite/micro/cortex_m_corstone_300/README.md
@@ -0,0 +1,47 @@
+ <!-- mdformat off(b/169948621#comment2) -->
+
+# Running a fixed virtual platform based on Corstone-300 software
+
+This target makes use of a fixed virtual platform (FVP) based on Arm Cortex-300
+based software. More info about Arm Corstone-300 software:
+https://developer.arm.com/ip-products/subsystem/corstone/corstone-300. More info
+about FVPs:
+https://developer.arm.com/tools-and-software/simulation-models/fixed-virtual-platforms.
+
+To fullfill the needed requirements it is depending the following projects:
+
+- Arm Ethos-U Core Platform:
+ https://review.mlplatform.org/admin/repos/ml/ethos-u/ethos-u-core-platform.
+ - Arm Ethos-U Core Platform provides the linker file as well as UART and
+ retarget functions.
+- CMSIS: https://github.com/ARM-software/CMSIS_5.
+ - CMSIS provides startup functionality, e.g. for setting up interrupt
+ handlers and clock speed.
+
+# General build info
+
+This target is based on the cortex_m_generic target and except that for now the
+only supported toolchain is GCC, the same general build info applies:
+tensorflow/lite/micro/cortex_m_generic/README.md.
+
+Required parameters:
+
+- TARGET: cortex_m_corstone_300
+- TARGET_ARCH: cortex-mXX (For all options see:
+ tensorflow/lite/micro/tools/make/targets/cortex_m_corstone_300_makefile.inc)
+
+# How to run
+
+Note that Corstone-300 is targetted for Cortex-M55 but it is backwards
+compatible. This means one could potentially run it for example with a
+Cortex-M7. Note that the clock speed would be that of an Cortex-M55. This may
+not matter when running unit tests or for debugging.
+
+Some examples:
+
+```
+make -j -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=cmsis_nn TARGET=cortex_m_corstone_300 TARGET_ARCH=cortex-m55 test_kernel_fully_connected_test
+make -j -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_corstone_300 TARGET_ARCH=cortex-m55 test_kernel_fully_connected_test
+make -j -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=cmsis_nn TARGET=cortex_m_corstone_300 TARGET_ARCH=cortex-m7+fp test_kernel_fully_connected_test
+make -j -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_corstone_300 TARGET_ARCH=cortex-m3 test_kernel_fully_connected_test
+```
diff --git a/tensorflow/lite/micro/cortex_m_corstone_300/system_setup.cc b/tensorflow/lite/micro/cortex_m_corstone_300/system_setup.cc
new file mode 100644
index 0000000..a2438e8
--- /dev/null
+++ b/tensorflow/lite/micro/cortex_m_corstone_300/system_setup.cc
@@ -0,0 +1,26 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/system_setup.h"
+
+namespace tflite {
+
+extern "C" {
+void uart_init(void);
+}
+
+void InitializeTarget() { uart_init(); }
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/cortex_m_generic/README.md b/tensorflow/lite/micro/cortex_m_generic/README.md
new file mode 100644
index 0000000..80fb6c8
--- /dev/null
+++ b/tensorflow/lite/micro/cortex_m_generic/README.md
@@ -0,0 +1,65 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+# Generic Cortex-Mx customizations
+
+The customization requires a definition where the debug log goes to. The purpose
+of the generic Cortex-Mx target is to generate a TFLM library file for use in
+application projects outside of this repo. As the chip HAL and the board
+specific layer are only defined in the application project, the TFLM library
+cannot write the debug log anywhere. Instead, we allow the application layer to
+register a callback function for writing the TFLM kernel debug log.
+
+# Usage
+
+See debug_log_callback.h
+
+# How to build
+
+Required parameters:
+
+ - TARGET: cortex_m_generic
+ - TARGET_ARCH: cortex-mXX (For all options see: tensorflow/lite/micro/tools/make/targets/cortex_m_generic_makefile.inc)
+
+Optional parameters:
+
+ - TOOLCHAIN: gcc (default) or armmclang
+ - For Cortex-M55, ARM Compiler 6.14 or later is required.
+
+Some examples:
+
+Building with arm-gcc
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_generic TARGET_ARCH=cortex-m7 microlite
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_generic TARGET_ARCH=cortex-m7 OPTIMIZED_KERNEL_DIR=cmsis_nn microlite
+
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_generic TARGET_ARCH=cortex-m4 OPTIMIZED_KERNEL_DIR=cmsis_nn microlite
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_generic TARGET_ARCH=cortex-m4+fp OPTIMIZED_KERNEL_DIR=cmsis_nn microlite
+```
+
+Building with armclang
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TOOLCHAIN=armclang TARGET=cortex_m_generic TARGET_ARCH=cortex-m55 microlite
+make -f tensorflow/lite/micro/tools/make/Makefile TOOLCHAIN=armclang TARGET=cortex_m_generic TARGET_ARCH=cortex-m55 OPTIMIZED_KERNEL_DIR=cmsis_nn microlite
+make -f tensorflow/lite/micro/tools/make/Makefile TOOLCHAIN=armclang TARGET=cortex_m_generic TARGET_ARCH=cortex-m55+nofp OPTIMIZED_KERNEL_DIR=cmsis_nn microlite
+```
+
+The Tensorflow Lite Micro makefiles download a specific version of the arm-gcc
+compiler to tensorflow/lite/micro/tools/make/downloads/gcc_embedded.
+
+If desired, a different version can be used by providing `TARGET_TOOLCHAIN_ROOT`
+option to the Makefile:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_generic TARGET_ARCH=cortex-m4+fp TARGET_TOOLCHAIN_ROOT=/path/to/arm-gcc/ microlite
+```
+
+Similarly, `OPTIMIZED_KERNEL_DIR=cmsis_nn` downloads a specific version of CMSIS to
+tensorflow/lite/micro/tools/make/downloads/cmsis. While this is the only version
+that is regularly tested, you can use your own version of CMSIS as well by
+providing `CMSIS_PATH` to the Makefile:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=cortex_m_generic TARGET_ARCH=cortex-m4+fp OPTIMIZED_KERNEL_DIR=cmsis_nn CMSIS_PATH=/path/to/own/cmsis microlite
+```
diff --git a/tensorflow/lite/micro/cortex_m_generic/debug_log.cc b/tensorflow/lite/micro/cortex_m_generic/debug_log.cc
new file mode 100644
index 0000000..bc79d43
--- /dev/null
+++ b/tensorflow/lite/micro/cortex_m_generic/debug_log.cc
@@ -0,0 +1,43 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Implementation for the DebugLog() function that prints to the debug logger on
+// an generic Cortex-M device.
+
+#ifdef __cplusplus
+extern "C" {
+#endif // __cplusplus
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include "tensorflow/lite/micro/cortex_m_generic/debug_log_callback.h"
+
+static DebugLogCallback debug_log_callback = nullptr;
+
+void RegisterDebugLogCallback(void (*cb)(const char* s)) {
+ debug_log_callback = cb;
+}
+
+void DebugLog(const char* s) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ if (debug_log_callback != nullptr) {
+ debug_log_callback(s);
+ }
+#endif
+}
+
+#ifdef __cplusplus
+} // extern "C"
+#endif // __cplusplus
diff --git a/tensorflow/lite/micro/cortex_m_generic/debug_log_callback.h b/tensorflow/lite/micro/cortex_m_generic/debug_log_callback.h
new file mode 100644
index 0000000..c1afd19
--- /dev/null
+++ b/tensorflow/lite/micro/cortex_m_generic/debug_log_callback.h
@@ -0,0 +1,49 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_CORTEX_M_GENERIC_DEBUG_LOG_CALLBACK_H_
+#define TENSORFLOW_LITE_MICRO_CORTEX_M_GENERIC_DEBUG_LOG_CALLBACK_H_
+
+// The application layer must implement and register a callback before calling
+// the network in a way similar to
+//
+// void debug_log_printf(const char* s)
+// {
+// printf(s);
+// }
+//
+// int main(void)
+// {
+// // Register callback for printing debug log
+// RegisterDebugLogCallback(debug_log_printf);
+//
+// // now call the network
+// TfLiteStatus invoke_status = interpreter->Invoke();
+// }
+
+#ifdef __cplusplus
+extern "C" {
+#endif // __cplusplus
+
+typedef void (*DebugLogCallback)(const char* s);
+
+// Registers and application-specific callback for debug logging. It must be
+// called before the first call to DebugLog().
+void RegisterDebugLogCallback(DebugLogCallback callback);
+
+#ifdef __cplusplus
+} // extern "C"
+#endif // __cplusplus
+
+#endif // TENSORFLOW_LITE_MICRO_CORTEX_M_GENERIC_DEBUG_LOG_CALLBACK_H_
diff --git a/tensorflow/lite/micro/debug_log.cc b/tensorflow/lite/micro/debug_log.cc
new file mode 100644
index 0000000..46ca253
--- /dev/null
+++ b/tensorflow/lite/micro/debug_log.cc
@@ -0,0 +1,50 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Reference implementation of the DebugLog() function that's required for a
+// platform to support the TensorFlow Lite for Microcontrollers library. This is
+// the only function that's absolutely required to be available on a target
+// device, since it's used for communicating test results back to the host so
+// that we can verify the implementation is working correctly.
+// It's designed to be as easy as possible to supply an implementation though.
+// On platforms that have a POSIX stack or C library, it can be written as a
+// single call to `fprintf(stderr, "%s", s)` to output a string to the error
+// stream of the console, but if there's no OS or C library available, there's
+// almost always an equivalent way to write out a string to some serial
+// interface that can be used instead. For example on Arm M-series MCUs, calling
+// the `bkpt #0xAB` assembler instruction will output the string in r1 to
+// whatever debug serial connection is available. If you're running mbed, you
+// can do the same by creating `Serial pc(USBTX, USBRX)` and then calling
+// `pc.printf("%s", s)`.
+// To add an equivalent function for your own platform, create your own
+// implementation file, and place it in a subfolder with named after the OS
+// you're targeting. For example, see the Cortex M bare metal version in
+// tensorflow/lite/micro/bluepill/debug_log.cc or the mbed one on
+// tensorflow/lite/micro/mbed/debug_log.cc.
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+#include <cstdio>
+#endif
+
+extern "C" void DebugLog(const char* s) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ // Reusing TF_LITE_STRIP_ERROR_STRINGS to disable DebugLog completely to get
+ // maximum reduction in binary size. This is because we have DebugLog calls
+ // via TF_LITE_CHECK that are not stubbed out by TF_LITE_REPORT_ERROR.
+ fprintf(stderr, "%s", s);
+#endif
+}
diff --git a/tensorflow/lite/micro/debug_log.h b/tensorflow/lite/micro/debug_log.h
new file mode 100644
index 0000000..c2840d0
--- /dev/null
+++ b/tensorflow/lite/micro/debug_log.h
@@ -0,0 +1,31 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_DEBUG_LOG_H_
+#define TENSORFLOW_LITE_MICRO_DEBUG_LOG_H_
+
+#ifdef __cplusplus
+extern "C" {
+#endif // __cplusplus
+
+// This function should be implemented by each target platform, and provide a
+// way for strings to be output to some text stream. For more information, see
+// tensorflow/lite/micro/debug_log.cc.
+void DebugLog(const char* s);
+
+#ifdef __cplusplus
+} // extern "C"
+#endif // __cplusplus
+
+#endif // TENSORFLOW_LITE_MICRO_DEBUG_LOG_H_
diff --git a/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_bg_1.png b/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_bg_1.png
new file mode 100644
index 0000000..0bc0dbe
--- /dev/null
+++ b/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_bg_1.png
Binary files differ
diff --git a/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_bg_2.png b/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_bg_2.png
new file mode 100644
index 0000000..25deaf4
--- /dev/null
+++ b/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_bg_2.png
Binary files differ
diff --git a/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_impl1.png b/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_impl1.png
new file mode 100644
index 0000000..d88b912
--- /dev/null
+++ b/tensorflow/lite/micro/docs/images/preallocated_tensors/preallocated_tensors_impl1.png
Binary files differ
diff --git a/tensorflow/lite/micro/docs/images/tflm_continuous_integration_1.png b/tensorflow/lite/micro/docs/images/tflm_continuous_integration_1.png
new file mode 100644
index 0000000..acecc0e
--- /dev/null
+++ b/tensorflow/lite/micro/docs/images/tflm_continuous_integration_1.png
Binary files differ
diff --git a/tensorflow/lite/micro/docs/memory_management.md b/tensorflow/lite/micro/docs/memory_management.md
new file mode 100644
index 0000000..ab77e28
--- /dev/null
+++ b/tensorflow/lite/micro/docs/memory_management.md
@@ -0,0 +1,213 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+<!--
+Semi-automated TOC generation with instructions from
+https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc
+-->
+
+<!--ts-->
+ * [Memory Management in TensorFlow Lite Micro](#memory-management-in-tensorflow-lite-micro)
+ * [Tensor Arena](#tensor-arena)
+ * [Head Section](#head-section)
+ * [Offline planned tensor allocations](#offline-planned-tensor-allocations)
+ * [Temporary Section](#temporary-section)
+ * [Tail Section](#tail-section)
+ * [Recording Memory APIs](#recording-memory-apis)
+ * [Allocation Section Details](#allocation-section-details)
+
+<!-- Added by: freddan80, at: Mon 29 Mar 2021 01:47:42 PM CEST -->
+
+<!--te-->
+
+# Memory Management in TensorFlow Lite Micro
+
+This document outlines how memory is managed internally by TensorFlow Lite Micro
+(TFLM) today. It outlines the "online" allocation strategy used by the default
+TFLM APIs for loading a model into a shared tensor arena.
+
+## Tensor Arena
+
+The main "working" space for TFLM allocations is inside a single `char` or
+`int8_t` buffer. This buffer can be managed by passing it directly into a
+`tflite::MicroInterpreter` constructor or through a `tflite::MicroAllocator`
+instance that can be passed into a `tflite::MicroInterpreter` constructor.
+Internally, the `tflite::MicroAllocator` classifies allocations into 3 different
+sections:
+
+* **Head** - non-persistent allocations.
+* **Temporary** - short term "scoped" allocations.
+* **Tail** - persistent allocations.
+
+The illustration below represents typical allocations in TFLM:
+
+```
+--------------------------------------------------------------------------------
+| | | |
+| HEAD |<-- TEMPORARY -->| TAIL |
+| | | |
+--------------------------------------------------------------------------------
+* Lowest Address Highest Address *
+```
+
+### Head Section
+
+This non-persistent section typically holds shared Tensor buffers. This section
+does not allocate small iterative chunks, it can only be set by a specific
+length for the entire section.
+
+This allocation length of this section is managed by the
+`tflite::GreedyMemoryPlanner`. That memory planner looks at the entire graph of
+a model and tries to reuse as many buffers as possible to create the smallest
+length for the head. The Tensor buffers for this section can be accessed via a
+`TfLiteEvalTensor` or `TfLiteTensor` instance on the `tflite::MicroInterpreter`.
+
+#### Offline planned tensor allocations
+
+All, or a subset of, tensors can be allocated using an offline planner. An
+offline planner performs tensor allocation on e.g. a host PC. The offline tensor
+allocation plan is added to model metadata. See format below.
+
+For each non-constant tensor in the `tensors:[Tensor]` list of the subgraph, a
+byte offset to the start of the head section of the memory arena is given. -1
+indicates that the tensor will be allocated at runtime by the
+`tflite::GreedyMemoryPlanner`. The offline plan is permitted to overlap buffers
+if it knows that the data will not be used at the same time.
+
+The offline tensor allocation plan will be encoded in the `metadata:[Metadata]`
+field of the model, using the following encoding:
+
+| Metadata component | Value |
+|-|-|
+| name:string | “OfflineMemoryAllocation” |
+| buffer:unit | Index of buffer containing offline tensor allocation data |
+
+The buffer contents for the offline tensor allocation is a list of 32-bit
+integers of the following format:
+
+| Offset | Value |
+|-|-|
+| 0 | Offline allocation format version |
+| 1 | Subgraph index to which this allocation applies |
+| 2 | Number offsets following: n |
+| 3 | Byte offset of tensor #0 or -1 to allocate at runtime |
+| 4 | Byte offset of tensor #1 or -1 to allocate at runtime |
+| ... | ... |
+| 3+(n-1) | Byte offset of tensor #(n-1) or -1 to allocate at runtime |
+
+The `tflite::GreedyMemoryPlanner` treats the provided offline tensor allocation
+plan as constant fixed offset to the start of the head section and will attempt
+to fit any other tensors (such as scratch tensors added a runtime using the
+`RequestScratchBufferInArena` API of `TfLiteContext`) around those fixed
+offsets.
+
+### Temporary Section
+
+This section is used to allocate "scoped" or short-term, non-guaranteed buffers.
+Allocations from this section start from the current end address of the head
+section and grow towards the tail section. An allocation chain can be reset (and
+must be reset before adjusting the head) and moves the current allocation start
+address back to the end of the head section.
+
+TFLM currently uses these allocations for a scope allocation of large C structs
+or scratch memory that is expected to be valid for at least the lifetime of a
+method call. This section.
+
+### Tail Section
+
+This section holds all persistent allocations used by TFLM. This section
+contains many random sized allocations and grows towards the end of the head
+section. Allocations in this section come from a variety of areas inside of
+TFLM. TFLM provides a [recording API](#Recording-Memory-APIs) to assist with
+auditing the contents of this section.
+
+## Recording Memory APIs
+
+TFLM provides simple APIs for auditing memory usage in the shared tensor arena.
+These APIs are opt-in and require some additional memory overhead and a working
+debug logging implementation
+[(reference implementation)](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/debug_log.cc).
+
+A typical bare-bones TFLM interpreter setup looks as such:
+
+```c++
+// Buffer for the tensor arena:
+size_t tensor_arena_size = 2048;
+uint8_t tensor_arena[tensor_arena_size];
+
+// Interpreter using the shared tensor arena above:
+tflite::MicroInterpreter interpreter(
+ tflite::GetModel(my_model_data), ops_resolver,
+ tensor_arena, tensor_arena_size, error_reporter);
+
+// Invoke one time which will allocate internals:
+if (interpreter.Invoke() != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Exception during invoke()!");
+}
+```
+
+Recording API can simply be used by including the `RecordingMicroInterpreter`
+class (`recording_micro_interpreter.h`) and replace `tflite::MicroInterpreter`
+with `tflite::RecordingMicroInterpreter`. The same call to `invoke()` is
+performed, but another call is made to `PrintAllocations()` which will output
+detailed allocation logging:
+
+```c++
+// Add an include to the recording API:
+#include "recording_micro_interpreter.h"
+
+// Simply change the class name from 'MicroInterpreter' to 'RecordingMicroInterpreter':
+tflite::RecordingMicroInterpreter interpreter(
+ tflite::GetModel(my_model_data), ops_resolver,
+ tensor_arena, tensor_arena_size, error_reporter);
+
+// Invoke one time which will allocate internals:
+if (interpreter.Invoke() != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Exception during invoke()!");
+}
+
+// Print out detailed allocation information:
+interpreter.PrintAllocations();
+```
+
+The output of this call will look something similar to this (output from the
+[memory_arena_threshold_test](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/memory_arena_threshold_test.cc#L205)):
+
+```bash
+[RecordingMicroAllocator] Arena allocation total 9568 bytes
+[RecordingMicroAllocator] Arena allocation head 7744 bytes
+[RecordingMicroAllocator] Arena allocation tail 1824 bytes
+[RecordingMicroAllocator] 'TfLiteEvalTensor data' used 360 bytes with alignment overhead (requested 360 bytes for 15 allocations)
+[RecordingMicroAllocator] 'Persistent TfLiteTensor data' used 0 bytes with alignment overhead (requested 0 bytes for 0 tensors)
+[RecordingMicroAllocator] 'Persistent TfLiteTensor quantization data' used 0 bytes with alignment overhead (requested 0 bytes for 0 allocations)
+[RecordingMicroAllocator] 'TfLiteTensor variable buffer data' used 0 bytes with alignment overhead (requested 0 bytes for 0 allocations)
+[RecordingMicroAllocator] 'NodeAndRegistration struct' used 392 bytes with alignment overhead (requested 392 bytes for 7 NodeAndRegistration structs)
+[RecordingMicroAllocator] 'Operator runtime data' used 136 bytes with alignment overhead (requested 136 bytes for 5 OpData structs)
+```
+
+### Allocation Section Details
+
+More information about each recorded allocation section:
+
+* 'TfLiteEvalTensor data'
+ * C struct that holds the data type, dimension, and a pointer to the
+ buffer representing the Tensor.
+* 'Persistent TfLiteTensor data'
+ * C struct that holds more information than a `TfLiteEvalTensor` struct in
+ the graph.
+ * Allocations in this bucket will only show up when accessing tensors from
+ the accessors on `tflite::MicroInterpreter`.
+* 'Persistent TfLiteTensor quantization data'
+ * Length of persistent quantization data assigned to persistent
+ `TfLiteTensor` structs.
+ * Allocations in this bucket will only show up when accessing tensors from
+ the accessors on `tflite::MicroInterpreter`.
+* 'TfLiteTensor variable buffer data'
+ * Length of buffer data from a variable tensor (retains data throughout
+ calls to `invoke()`).
+* 'NodeAndRegistration struct'
+ * C struct that holds a `TfLiteRegistration` and `TfLiteNode` struct
+ instance.
+ * Each operator in a model will contain one `NodeAndRegistration` struct.
+* 'Operator runtime data'
+ * Persistent allocations of data cached by TFLM kernels (e.g. quantization
+ params, multipliers, etc).
diff --git a/tensorflow/lite/micro/docs/new_platform_support.md b/tensorflow/lite/micro/docs/new_platform_support.md
new file mode 100644
index 0000000..0e1287a
--- /dev/null
+++ b/tensorflow/lite/micro/docs/new_platform_support.md
@@ -0,0 +1,306 @@
+<!--
+Semi-automated TOC generation with instructions from
+https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc
+-->
+
+<!--ts-->
+
+* [Porting to a new platform](#porting-to-a-new-platform)
+ * [Requirements](#requirements)
+ * [Getting started](#getting-started)
+ * [Troubleshooting](#troubleshooting)
+ * [Optimizing for your platform](#optimizing-for-your-platform)
+ * [Code module organization](#code-module-organization)
+ * [Implementing more optimizations](#implementing-more-optimizations)
+
+<!-- Added by: advaitjain, at: Mon 05 Oct 2020 02:36:46 PM PDT -->
+
+<!--te-->
+
+***Please note that we are currently pausing accepting new platforms***. Please
+see our [contributions guide](../CONTRIBUTING.md) for more details and context.
+
+Parts of the documentation below will likely change as we start accepting new
+platform support again.
+
+# Porting to a new platform
+
+The remainder of this document provides guidance on porting TensorFlow Lite for
+Microcontrollers to new platforms. You should read the
+[developer documentation](https://www.tensorflow.org/lite/microcontrollers)
+first.
+
+## Requirements
+
+Since the core neural network operations are pure arithmetic, and don't require
+any I/O or other system-specific functionality, the code doesn't have to have
+many dependencies. We've tried to enforce this, so that it's as easy as possible
+to get TensorFlow Lite Micro running even on 'bare metal' systems without an OS.
+Here are the core requirements that a platform needs to run the framework:
+
+- C/C++ compiler capable of C++11 compatibility. This is probably the most
+ restrictive of the requirements, since C++11 is not as widely adopted in the
+ embedded world as it is elsewhere. We made the decision to require it since
+ one of the main goals of TFL Micro is to share as much code as possible with
+ the wider TensorFlow codebase, and since that relies on C++11 features, we
+ need compatibility to achieve it. We only use a small subset of C++ though,
+ so don't worry about having to deal with template metaprogramming or
+ similar challenges!
+
+- Debug logging. The core network operations don't need any I/O functions, but
+ to be able to run tests and tell if they've worked as expected, the
+ framework needs some way to write out a string to some kind of debug
+ console. This will vary from system to system, for example on Linux it could
+ just be `fprintf(stderr, debug_string)` whereas an embedded device might
+ write the string out to a specified UART. As long as there's some mechanism
+ for outputting debug strings, you should be able to use TFL Micro on that
+ platform.
+
+- Math library. The C standard `libm.a` library is needed to handle some of
+ the mathematical operations used to calculate neural network results.
+
+- Global variable initialization. We do use a pattern of relying on global
+ variables being set before `main()` is run in some places, so you'll need to
+ make sure your compiler toolchain supports this.
+
+And that's it! You may be wondering about some other common requirements that
+are needed by a lot of non-embedded software, so here's a brief list of things
+that aren't necessary to get started with TFL Micro on a new platform:
+
+- Operating system. Since the only platform-specific function we need is
+ `DebugLog()`, there's no requirement for any kind of Posix or similar
+ functionality around files, processes, or threads.
+
+- C or C++ standard libraries. The framework tries to avoid relying on any
+ standard library functions that require linker-time support. This includes
+ things like string functions, but still allows us to use headers like
+ `stdtypes.h` which typically just define constants and typedefs.
+ Unfortunately this distinction isn't officially defined by any standard, so
+ it's possible that different toolchains may decide to require linked code
+ even for the subset we use, but in practice we've found it's usually a
+ pretty obvious decision and stable over platforms and toolchains.
+
+- Dynamic memory allocation. All the TFL Micro code avoids dynamic memory
+ allocation, instead relying on local variables on the stack in most cases,
+ or global variables for a few situations. These are all fixed-size, which
+ can mean some compile-time configuration to ensure there's enough space for
+ particular networks, but does avoid any need for a heap and the
+ implementation of `malloc\new` on a platform.
+
+- Floating point. Eight-bit integer arithmetic is enough for inference on many
+ networks, so if a model sticks to these kind of quantized operations, no
+ floating point instructions should be required or executed by the framework.
+
+## Getting started
+
+We recommend that you start trying to compile and run one of the simplest tests
+in the framework as your first step. The full TensorFlow codebase can seem
+overwhelming to work with at first, so instead you can begin with a collection
+of self-contained project folders that only include the source files needed for
+a particular test or executable. You can find a set of pre-generated projects
+[here](https://drive.google.com/open?id=1cawEQAkqquK_SO4crReDYqf_v7yAwOY8).
+
+As mentioned above, the one function you will need to implement for a completely
+new platform is debug logging. If your device is just a variation on an existing
+platform you may be able to reuse code that's already been written. To
+understand what's available, begin with the default reference implementation at
+[tensorflow/lite/micro/debug_log.cc](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/debug_log.cc),
+which uses fprintf and stderr. If your platform has this level of support for
+the C standard library in its toolchain, then you can just reuse this.
+Otherwise, you'll need to do some research into how your platform and device can
+communicate logging statements to the outside world. As another example, take a
+look at
+[the Mbed version of `DebugLog()`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/mbed/debug_log.cc),
+which creates a UART object and uses it to output strings to the host's console
+if it's connected.
+
+Begin by navigating to the micro_error_reporter_test folder in the pregenerated
+projects you downloaded. Inside here, you'll see a set of folders containing all
+the source code you need. If you look through them, you should find a total of
+around 60 C or C++ files that compiled together will create the test executable.
+There's an example makefile in the directory that lists all of the source files
+and include paths for the headers. If you're building on a Linux or MacOS host
+system, you may just be able to reuse that same makefile to cross-compile for
+your system, as long as you swap out the `CC` and `CXX` variables from their
+defaults, to point to your cross compiler instead (for example
+`arm-none-eabi-gcc` or `riscv64-unknown-elf-gcc`). Otherwise, set up a project
+in the build system you are using. It should hopefully be fairly
+straightforward, since all of the source files in the folder need to be
+compiled, so on many IDEs you can just drag the whole lot in. Then you need to
+make sure that C++11 compatibility is turned on, and that the right include
+paths (as mentioned in the makefile) have been added.
+
+You'll see the default `DebugLog()` implementation in
+'tensorflow/lite/micro/debug_log.cc' inside the micro_error_reporter_test
+folder. Modify that file to add the right implementation for your platform, and
+then you should be able to build the set of files into an executable. Transfer
+that executable to your target device (for example by flashing it), and then try
+running it. You should see output that looks something like this:
+
+```
+Number: 42
+Badly-formed format string
+Another badly-formed format string
+~~ALL TESTS PASSED~~~
+```
+
+If not, you'll need to debug what went wrong, but hopefully with this small
+starting project it should be manageable.
+
+## Troubleshooting
+
+When we've been porting to new platforms, it's often been hard to figure out
+some of the fundamentals like linker settings and other toolchain setup flags.
+If you are having trouble, see if you can find a simple example program for your
+platform, like one that just blinks an LED. If you're able to build and run that
+successfully, then start to swap in parts of the TF Lite Micro codebase to that
+working project, taking it a step at a time and ensuring it's still working
+after every change. For example, a first step might be to paste in your
+`DebugLog()` implementation and call `DebugLog("Hello World!")` from the main
+function.
+
+Another common problem on embedded platforms is the stack size being too small.
+Mbed defaults to 4KB for the main thread's stack, which is too small for most
+models since TensorFlow Lite allocates buffers and other data structures that
+require more memory. The exact size will depend on which model you're running,
+but try increasing it if you are running into strange corruption issues that
+might be related to stack overwriting.
+
+## Optimizing for your platform
+
+The default reference implementations in TensorFlow Lite Micro are written to be
+portable and easy to understand, not fast, so you'll want to replace performance
+critical parts of the code with versions specifically tailored to your
+architecture. The framework has been designed with this in mind, and we hope the
+combination of small modules and many tests makes it as straightforward as
+possible to swap in your own code a piece at a time, ensuring you have a working
+version at every step. To write specialized implementations for a platform, it's
+useful to understand how optional components are handled inside the build
+system.
+
+## Code module organization
+
+We have adopted a system of small modules with platform-specific implementations
+to help with portability. Every module is just a standard `.h` header file
+containing the interface (either functions or a class), with an accompanying
+reference implementation in a `.cc` with the same name. The source file
+implements all of the code that's declared in the header. If you have a
+specialized implementation, you can create a folder in the same directory as the
+header and reference source, name it after your platform, and put your
+implementation in a `.cc` file inside that folder. We've already seen one
+example of this, where the Mbed and Bluepill versions of `DebugLog()` are inside
+[mbed](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/mbed)
+and
+[bluepill](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/bluepill)
+folders, children of the
+[same directory](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite//micro)
+where the stdio-based
+[`debug_log.cc`](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/debug_log.cc)
+reference implementation is found.
+
+The advantage of this approach is that we can automatically pick specialized
+implementations based on the current build target, without having to manually
+edit build files for every new platform. It allows incremental optimizations
+from a always-working foundation, without cluttering the reference
+implementations with a lot of variants.
+
+To see why we're doing this, it's worth looking at the alternatives. TensorFlow
+Lite has traditionally used preprocessor macros to separate out some
+platform-specific code within particular files, for example:
+
+```
+#ifndef USE_NEON
+#if defined(__ARM_NEON__) || defined(__ARM_NEON)
+#define USE_NEON
+#include <arm_neon.h>
+#endif
+```
+
+There’s also a tradition in gemmlowp of using file suffixes to indicate
+platform-specific versions of particular headers, with kernel_neon.h being
+included by kernel.h if `USE_NEON` is defined. As a third variation, kernels are
+separated out using a directory structure, with
+tensorflow/lite/kernels/internal/reference containing portable implementations,
+and tensorflow/lite/kernels/internal/optimized holding versions optimized for
+NEON on Arm platforms.
+
+These approaches are hard to extend to multiple platforms. Using macros means
+that platform-specific code is scattered throughout files in a hard-to-find way,
+and can make following the control flow difficult since you need to understand
+the macro state to trace it. For example, I temporarily introduced a bug that
+disabled NEON optimizations for some kernels when I removed
+tensorflow/lite/kernels/internal/common.h from their includes, without realizing
+it was where USE_NEON was defined!
+
+It’s also tough to port to different build systems, since figuring out the right
+combination of macros to use can be hard, especially since some of them are
+automatically defined by the compiler, and others are only set by build scripts,
+often across multiple rules.
+
+The approach we are using extends the file system approach that we use for
+kernel implementations, but with some specific conventions:
+
+- For each module in TensorFlow Lite, there will be a parent directory that
+ contains tests, interface headers used by other modules, and portable
+ implementations of each part.
+- Portable means that the code doesn’t include code from any libraries except
+ flatbuffers, or other TF Lite modules. You can include a limited subset of
+ standard C or C++ headers, but you can’t use any functions that require
+ linking against those libraries, including fprintf, etc. You can link
+ against functions in the standard math library, in <math.h>.
+- Specialized implementations are held inside subfolders of the parent
+ directory, named after the platform or library that they depend on. So, for
+ example if you had my_module/foo.cc, a version that used RISC-V extensions
+ would live in my_module/riscv/foo.cc. If you had a version that used the
+ CMSIS library, it should be in my_module/cmsis/foo.cc.
+- These specialized implementations should completely replace the top-level
+ implementations. If this involves too much code duplication, the top-level
+ implementation should be split into smaller files, so only the
+ platform-specific code needs to be replaced.
+- There is a convention about how build systems pick the right implementation
+ file. There will be an ordered list of 'tags' defining the preferred
+ implementations, and to generate the right list of source files, each module
+ will be examined in turn. If a subfolder with a tag’s name contains a .cc
+ file with the same base name as one in the parent folder, then it will
+ replace the parent folder’s version in the list of build files. If there are
+ multiple subfolders with matching tags and file names, then the tag that’s
+ latest in the ordered list will be chosen. This allows us to express “I’d
+ like generically-optimized fixed point if it’s available, but I’d prefer
+ something using the CMSIS library” using the list 'fixed_point cmsis'. These
+ tags are passed in as `TAGS="<foo>"` on the command line when you use the
+ main Makefile to build.
+- There is an implicit “reference” tag at the start of every list, so that
+ it’s possible to support directory structures like the current
+ tensorflow/kernels/internal where portable implementations are held in a
+ “reference” folder that’s a sibling to the NEON-optimized folder.
+- The headers for each unit in a module should remain platform-agnostic, and
+ be the same for all implementations. Private headers inside a sub-folder can
+ be used as needed, but shouldn’t be referred to by any portable code at the
+ top level.
+- Tests should be at the parent level, with no platform-specific code.
+- No platform-specific macros or #ifdef’s should be used in any portable code.
+
+The implementation of these rules is handled inside the Makefile, with a
+[`specialize` function](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/tools/make/helper_functions.inc#L42)
+that takes a list of reference source file paths as an input, and returns the
+equivalent list with specialized versions of those files swapped in if they
+exist.
+
+## Implementing more optimizations
+
+Clearly, getting debug logging support is only the beginning of the work you'll
+need to do on a particular platform. It's very likely that you'll want to
+optimize the core deep learning operations that take up the most time when
+running models you care about. The good news is that the process for providing
+optimized implementations is the same as the one you just went through to
+provide your own logging. You'll need to identify parts of the code that are
+bottlenecks, and then add specialized implementations in their own folders.
+These don't need to be platform specific, they can also be broken out by which
+library they rely on for example. [Here's where we do that for the CMSIS
+implementation of integer fast-fourier
+transforms](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/micro_speech/simple_features/simple_features_generator.cc).
+This more complex case shows that you can also add helper source files alongside
+the main implementation, as long as you
+[mention them in the platform-specific makefile](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/micro_speech/CMSIS/Makefile.inc).
+You can also do things like update the list of libraries that need to be linked
+in, or add include paths to required headers.
diff --git a/tensorflow/lite/micro/docs/optimized_kernel_implementations.md b/tensorflow/lite/micro/docs/optimized_kernel_implementations.md
new file mode 100644
index 0000000..5d5d214
--- /dev/null
+++ b/tensorflow/lite/micro/docs/optimized_kernel_implementations.md
@@ -0,0 +1,200 @@
+<!-- mdformateoff(b/169948621#comment2) -->
+
+<!--
+Semi-automated TOC generation with instructions from
+https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc
+-->
+
+<!--ts-->
+
+* [Summary](#summary)
+* [High-Level Steps](#high-level-steps)
+ * [Why not Optimize the Reference Kernels](#why-not-optimize-the-reference-kernels)
+* [Software Architecture](#software-architecture)
+ * [Hardware-specific NN library](#hardware-specific-nn-library)
+ * [Optimized Kernels](#optimized-kernels)
+ * [Build System Integration](#build-system-integration)
+ * [Testing and Continuous Integration](#testing-and-continuous-integration)
+
+<!-- Added by: advaitjain, at: Wed 17 Feb 2021 02:14:16 PM PST -->
+
+<!--te-->
+
+# Summary
+
+This guide describes the recommended high-level architecture and steps to add
+hardware-specific optimized kernels to TfLite Micro.
+
+The goal with these optimizations and the process that we recommend to getting
+them merged into the TfLite Micro codebase is to have a measurable and
+documented performance improvement on a benchmark of interest.
+
+Once the optimizations are merged, they will indeed be used for more than the
+benchmark but the context for why the optimizations were added is still very
+important.
+
+# High-Level Steps
+
+1. Pick a benchmark that you would like to measure the performance for.
+
+ * Existing benchmarks are in the [benchmarks directory](../benchmarks).
+ * If none of the existing benchmarks capture your use-case, then please
+ create a github issue or start a thread on micro@tensorflow.org to
+ figure out how to add in a new benchmark.
+ * If adding a publicly-available benchmark to the TFLM codebase is
+ determined to be infeasible, then a fall-back would be to have an
+ internal benchmark that can be used to document the benefits of adding
+ in the optimizations via PR descriptions.
+ * Adding optimized code without any associated benchmarks will need very
+ strong justification and will most likely not be permitted.
+
+1. Do the groundwork and architecture needed to be able to add in optimizations
+ for your target (more details in the
+ [software architecture](#software-architecture) section).
+
+1. Create one pull request for each optimized kernel with the PR description
+ clearly stating the commands that were used to measure the performance
+ improvement.
+
+ * This context is important even if the toolchain is proprietary and there
+ are currently a small number of users.
+ * See [this PR](https://github.com/tensorflow/tensorflow/pull/47098)
+ as an example.
+ * At minimum the latency with and without the particular optimized
+ kernel should be documented.
+ [Additional context](https://github.com/tensorflow/tensorflow/pull/46746)
+ may also be desirable.
+ * Here is some
+ [general guidance](https://testing.googleblog.com/2017/09/code-health-providing-context-with.html)
+ on writing
+ [good PR descriptions](https://google.github.io/eng-practices/review/developer/cl-descriptions.html)
+
+## Why Not Optimize the Portable Reference Kernels?
+
+We would like to explicitly point out (as have others) that the reference kernel
+implementations are not performant and there are plenty of opportunities to
+speed them up. This is by design and the reference kernels are meant to be a
+shared starting point to then be optimized in a target specific optimized kernel
+implementation.
+
+Two previous discussions on this topic are on
+[PR #42477](https://github.com/tensorflow/tensorflow/pull/42477) and
+[PR #45227](https://github.com/tensorflow/tensorflow/pull/45227)
+
+Our current point of view on this topic is that while optimizing shared
+reference code in a portable manner is attractive, we are making an explicit
+choice to not go down that path and instead rely on target-specific optimized
+implementations. The TFLM codebase has a growing list of optimized kernel
+implementations, and we are investing in making the process of adding new
+implementations smoother.
+
+# Software Architecture
+
+The optimized kernel architecture is composed of the following three modules:
+
+1. Hardware-specific NN library
+1. Optimized Kernels
+1. Build System Integration
+
+## Hardware-specific NN library
+
+This library uses knowledge of the hardware and compiler to implement the
+underlying operations. Examples of this are
+[CMSIS-NN](https://github.com/ARM-software/CMSIS_5/tree/develop/CMSIS/NN) from
+ARM and [NNLib](https://github.com/foss-xtensa/nnlib-hifi4) from Cadence.
+
+The benefits of having this API separation are:
+
+1. The NN library does not need to follow the style guide of the rest of the
+ TFLM code.
+1. Releases of the NN library can be made independent of TFLM
+1. The same NN library can be used and tested independent of TFLM.
+1. The maintainers of the NN library have full control over the development
+ process that they would like to follow.
+
+## Optimized Kernels
+
+These will be (hopefully thin) wrappers that act as the glue between TFLM and
+the NN library.
+
+The goal here is to delegate as much work as possible to the NN library while
+still allowing the two APIs (TFLM and NN library) to be independent of each
+other. If there is a performance degradation due to this (for example,
+unnecessary memory copies) then we can evaluate those on a case-by-case basis.
+
+This code will be reviewed and merged in the TFLM github repository and must
+follow the development style of the TFLM codebase.
+
+Some amount of refactoring of the existing code may be needed to ensure that
+code is suitably shared between the reference and optimized kernels. There is
+currently no fixed recipe for this refactor and we will evaluate on a
+case-by-case basis during the PR review.
+
+For example, to add an optimized implementation for `fully_conntected` for the
+Xtensa Fusion F1 the steps were: *
+[PR 1](https://github.com/tensorflow/tensorflow/pull/45464): refactor for
+reference fallbacks and a baseline latency. *
+[PR 2](https://github.com/tensorflow/tensorflow/pull/46242): refactor to share
+code between reference and optimized kernels. *
+[PR 3](https://github.com/tensorflow/tensorflow/pull/46411): add the code needed
+to use the optimized NN lib and document the latency improvement.
+
+## Build System Integration
+
+This module is the least defined but we strongly recommend the following: 1. A
+single target makefile.inc for all the architectures that you would like to
+support along with optional target-specific
+[system_setup.cc](../arduino/system_setup.cc). See
+[cortex_m_generic_makefile.inc](../tools/make/targets/cortex_m_generic_makefile.inc)
+and [xtensa_makefile.inc](../tools/make/targets/xtensa_makefile.inc) as
+examples.
+
+1. A single `ext_libs.inc` (and associated scripts) that downloads any external
+ dependencies (including the NN library). For example:
+
+ * [cmsis_nn.inc](../tools/make/ext_libs/cmsis_nn.inc) and
+ [cmsis_download.sh](../tools/make/ext_libs/cmsis_download.sh)
+ * [xtensa.inc](../tools/make/ext_libs/xtensa.inc) and
+ [xtensa_download.sh](../tools/make/ext_libs/xtensa_download.sh)
+
+1. The optimized kernels will then live in a kernels subdirectory (e.g.
+ [kernels/cmsis_nn](../kernels/cmsis_nn) and
+ [kernels/xtensa](../kernels/xtensa))
+
+Two development workflows that the TFLM team would like to encourage and
+support:
+
+1. Export static library + headers into target-specific development environment
+
+ * Build a static libtensorflow-microlite.a using the TFLM makefile with:
+ `make -f tensorflow/lite/micro/tools/make/Makefile TARGET=<target>
+ OPTIMIZED_KERNEL_DIR=<optimize_dir> microlite`
+ * Use the static library and any TFLM headers as part of the overall
+ application (with its own build system).
+
+1. Integrate TFLM with IDE:
+
+ * This has historically been done using the TFLM Makefile’s support for
+ project generation.
+
+ * However, given the learning curve and high-maintenance overhead, we are
+ moving away from supporting project generation via the Makefile and are
+ encouraging future IDE integrations to be done outside of the TFLM
+ Makefiles.
+
+ * The TFLM team is currently working through the details on this topic.
+
+## Testing and Continuous Integration
+
+The kernel tests are the primary method of ensuring that the optimized kernel
+implementations are accurate.
+
+Currently, most of the tests require the optimizations to be bit-exact to the
+quantized reference implementation. We can revisit this requirement if it ends
+up having a high associated cost on the latency.
+
+We strongly encourage optimized kernel implementations to have an associated
+continuous build that runs through all the unit tests and publishes a build
+badge to the
+[TFLM community supported builds](../README.md#community-supported-builds)
+table. Running the units tests once a day is often a good place to start.
diff --git a/tensorflow/lite/micro/docs/profiling.md b/tensorflow/lite/micro/docs/profiling.md
new file mode 100644
index 0000000..95f18e2
--- /dev/null
+++ b/tensorflow/lite/micro/docs/profiling.md
@@ -0,0 +1,44 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+<!--
+Semi-automated TOC generation with instructions from
+https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc
+-->
+
+<!--ts-->
+ * [Profiling](#profiling)
+ * [API](#api)
+ * [Per-Op Profiling](#per-op-profiling)
+ * [Subroutine Profiling](#subroutine-profiling)
+
+<!-- Added by: njeff, at: Wed 04 Nov 2020 04:35:07 PM PST -->
+
+<!--te-->
+
+# Profiling
+
+This doc outlines how to use the TFLite Micro profiler to gather information
+about per-op invoke duration and to use the profiler to identify bottlenecks
+from within operator kernels and other TFLite Micro routines.
+
+## API
+
+The MicroInterpreter class constructor contains and optional profiler argument.
+This profiler must be an instance of the tflite::Profiler class, and should
+implement the BeginEvent and EndEvent methods. There is a default implementation
+in tensorflow/lite/micro/micro_profiler.cc which can be used for most purposes.
+
+## Per-Op Profiling
+
+There is a feature in the MicroInterpreter to enable per-op profiling. To enable
+this, provide a MicroProfiler to the MicroInterpreter's constructor then build
+with a non-release build to disable the NDEBUG define surrounding the
+ScopedOperatorProfile within the MicroInterpreter.
+
+## Subroutine Profiling
+
+In order to further dig into performance of specific routines, the MicroProfiler
+can be used directly from the TFLiteContext or a new MicroProfiler can be
+created if the TFLiteContext is not available where the profiling needs to
+happen. The MicroProfiler's BeginEvent and EndEvent can be called directly, or
+wrapped using a [ScopedProfile](../../lite/core/api/profiler.h).
diff --git a/tensorflow/lite/micro/docs/renode.md b/tensorflow/lite/micro/docs/renode.md
new file mode 100644
index 0000000..7bbf906
--- /dev/null
+++ b/tensorflow/lite/micro/docs/renode.md
@@ -0,0 +1,139 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+<!--
+Semi-automated TOC generation with instructions from
+https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc
+-->
+
+<!--ts-->
+ * [Software Emulation with Renode](#software-emulation-with-renode)
+ * [Installation](#installation)
+ * [Running Unit Tests](#running-unit-tests)
+ * [Under the hood of the Testing Infrastructure](#under-the-hood-of-the-testing-infrastructure)
+ * [Running a non-test Binary with Renode](#running-a-non-test-binary-with-renode)
+ * [Useful External Links for Renode and Robot Documentation](#useful-external-links-for-renode-and-robot-documentation)
+
+<!-- Added by: advaitjain, at: Tue 10 Nov 2020 09:43:05 AM PST -->
+
+<!--te-->
+
+# Software Emulation with Renode
+
+TensorFlow Lite Micro makes use of [Renode](https://github.com/renode/renode) to
+for software emulation.
+
+Here, we document how Renode is used as part of the TFLM project. For more
+general use of Renode, please refer to the [Renode
+documentation](https://renode.readthedocs.io/en/latest/).
+
+You can also read more about Renode from a [publicly available slide deck](https://docs.google.com/presentation/d/1j0gjI4pVkgF9CWvxaxr5XuCKakEB25YX2n-iFxlYKnE/edit).
+
+# Installation
+
+Renode can be installed and used in a variety of ways, as documented in the
+[Renode README](https://github.com/renode/renode/blob/master/README.rst#installation/). For the purpose of Tensorflow
+Lite Micro, we make use of the portable version for Linux.
+
+Portable renode will be automatically installed when using the TfLite Micro
+Makefile to `tensorflow/lite/micro/tools/make/downloads/renode`.
+
+The Makefile internally calls the `renode_download.sh` script:
+
+```
+tensorflow/lite/micro/testing/renode_download.sh tensorflow/lite/micro/tools/make/downloads
+```
+
+# Running Unit Tests
+
+All the tests for a specific platform (e.g. bluepill) can be run with:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=bluepill test
+```
+
+ * This makes use of the robot framework from Renode.
+ * Note that the tests can currently not be run in parallel.
+ * It takes about 25 second to complete all tests, including around 3 seconds for suite startup/teardown and average 0.38 second per test.
+
+## Under the hood of the Testing Infrastructure
+
+Describe how we wait for a particular string on the UART. Some pointers into the
+robot files as well as any relevant documentation from Renode.
+
+A test failure is the absence of a specific string on the UART so the test will
+wait for a specific timeout period (configured in the .robot) file before
+failing.
+
+ * What this means in practice is that a failing test will take longer to finish
+ than a test that passes.
+
+ * If needed, an optimization on this would be to have a specific failure
+ message as well so that both success and failure can be detected quickly.
+
+# Running a non-test Binary with Renode
+
+Renode can also be used to run and debug binaries interactively. For example,
+to debug `kernel_addr_test` on Bluepill platform, run Renode:
+
+```
+tensorflow/lite/micro/tools/make/downloads/renode/renode
+```
+and issue following commands:
+```
+# Create platform
+include @tensorflow/lite/micro/testing/bluepill_nontest.resc
+# Load ELF file
+sysbus LoadELF @tensorflow/lite/micro/tools/make/gen/bluepill_cortex-m3_default/bin/keyword_benchmark
+# Start simulation
+start
+
+# To run again:
+Clear
+include @tensorflow/lite/micro/testing/bluepill_nontest.resc
+sysbus LoadELF @tensorflow/lite/micro/tools/make/gen/bluepill_cortex-m3_default/bin/keyword_benchmark
+start
+
+```
+
+To make repeat runs a bit easier, you can put all the commands into a
+single line (up arrow will show the last command in the Renode terminal):
+```
+Clear; include @tensorflow/lite/micro/testing/bluepill_nontest.resc; sysbus LoadELF @tensorflow/lite/micro/tools/make/gen/bluepill_cortex-m3_default/bin/keyword_benchmark; start
+```
+
+You can also connect GDB to the simulation.
+To do that, start the GDB server in Renode before issuing the `start` command:
+```
+machine StartGdbServer 3333
+```
+Than you can connect from GDB with:
+```
+target remote localhost:3333
+```
+
+For further reference please see the [Renode documentation](https://renode.readthedocs.io/en/latest/).
+
+# Useful External Links for Renode and Robot Documentation
+
+ * [Testing with Renode](https://renode.readthedocs.io/en/latest/introduction/testing.html?highlight=robot#running-the-robot-test-script)
+
+ * [Robot Testing Framework on Github](https://github.com/robotframework/robotframework). For someone new to
+ the Robot Framework, the documentation can be a bit hard to navigate, so
+ here are some links that are relevant to the use of the Robot Framework with
+ Renode for TFLM:
+
+ * [Creating Test Data](http://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#creating-test-data)
+ section of the user guide.
+
+ * Renode-specific additions to the Robot test description format are in the
+ [RobotFrameworkEngine directory](https://github.com/renode/renode/tree/master/src/Renode/RobotFrameworkEngine). For example,
+
+ * [Start Emulation](https://github.com/renode/renode/blob/master/src/Renode/RobotFrameworkEngine/RenodeKeywords.cs#L41-L42)
+ * [Wait For Line On Uart](https://github.com/renode/renode/blob/master/src/Renode/RobotFrameworkEngine/UartKeywords.cs#L62-L63)
+ is where `Wait For Line On Uart` is defined.
+
+ * Some documentation for all the [Standard Libraries](http://robotframework.org/robotframework/#standard-libraries)
+ that define commands such as:
+
+ * [Remove File](http://robotframework.org/robotframework/latest/libraries/OperatingSystem.html#Remove%20File)
+ * [List Files In Directory](https://robotframework.org/robotframework/latest/libraries/OperatingSystem.html#List%20Files%20In%20Directory)
diff --git a/tensorflow/lite/micro/docs/rfc/preallocated_tensors.md b/tensorflow/lite/micro/docs/rfc/preallocated_tensors.md
new file mode 100644
index 0000000..caf932a
--- /dev/null
+++ b/tensorflow/lite/micro/docs/rfc/preallocated_tensors.md
@@ -0,0 +1,151 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+<!--ts-->
+
+* [Pre-allocated tensors](#pre-allocated-tensors)
+ * [Background](#background)
+ * [Current status](#current-status)
+ * [Proposed implementation](#proposed-implementation)
+ * [Performance overview](#performance-overview)
+ * [Cycle aspect](#cycle-aspect)
+ * [Memory aspect](#memory-aspect)
+ <!-- Semi-automated TOC generation with instructions from https://github.com/ekalinin/github-markdown-toc#auto-insert-and-update-toc -->
+
+<!--te-->
+
+# Pre-allocated tensors
+
+## Background
+
+Tensors are allocated differently depending on the type of tensor. Weight
+tensors are located in the flatbuffer, which is allocated by the application
+that calls TensorFlow Lite Micro. EvalTensors are allocated in the tensor arena,
+either offline planned as specified in the flatbuffers metadata (described in
+this
+[RFC](https://docs.google.com/document/d/16aTSHL5wxsq99t6adVbBz1U3K8Y5tBDAvs16iroZDEU)),
+or allocated during runtime by the
+[memory planner](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/memory_planner)
+(online planned), see
+[RFC](https://docs.google.com/document/d/1akpqu0uiPQshmCrnV6dOEFgYM4tCCnI8Zce85PnjHMI).
+The tensor arena is allocated by MicroAllocator in TensorFlow Lite Micro, and
+the model buffer (represented by a .tflite-file) is allocated by the application
+using TensorFlow Lite Micro. An illustration of this can be seen in the image
+below.
+
+
+
+Is some use cases it could be advantageous to place some of the EvalTensors
+outside of the tensor arena, for example: * When sensor output data is stored in
+its own defined buffer, outside the tensor arena, and therefore needs to be
+copied into the tensor arena before inference. * When the tensor is to be
+consumed from a memory location outside the tensor arena, e.g. a separate memory
+bank DSP. \
+Details regarding the impact on the number of clock cycles and memory
+consumption can be found under “Performance overview”. In this RFC we present an
+option to allow an application to provide pre-allocated buffers to TensorFlow
+Lite Micro for selected tensors. An illustration of the resulting memory layout
+with pre-allocated tensors can be seen in the figure below.
+
+
+
+## Current status
+
+The purpose of pre-allocating tensors is to reduce the number of clock cycles,
+and our initial motivation for this feature was that avoiding the copying of the
+buffer described in the Background section would reduce the number of cycles
+consumed by the application.
+
+Our second motivation was that by using a buffer outside of the memory arena,
+there was an opportunity to significantly reduce the required size of the memory
+arena.
+
+An initial investigation into these matters, using the person detection model as
+an example, indicates that the performance gain might not be very significant in
+many use cases. The reduction in the number of clock cycles looks to be ~1%.
+Details regarding this can be found in the Performance overview section.
+
+The reduction in the size of the memory arena is not straightforward to
+estimate. As described in the Performance overview section, it depends on the
+size of other tensors in the network. In the worst case scenario it might not
+reduce the memory arena size at all. If the pre allocated buffer is much larger
+than the second largest buffer, then the reduction in size may be significant.
+
+Therefore, our current position is that the performance gain expected from pre
+allocating the tensors does not motivate the increased complexity that this
+feature would introduce to the TensorFlow Lite Micro framework.
+
+## Proposed implementation
+
+MicroAllocator initializes all tensors to nullptr, and during the allocation
+process only allocates the tensors whose data field is nullptr. The application
+tells the MicroInterpreter which tensor is preallocated, and supplies a memory
+buffer using the RegisterPreallocatedTensor() function. The MicroInterpreter
+then assigns the pre-allocated buffer to the tensor data-field. If the tensor in
+question is marked as offline planned, as described in this
+[RFC](https://docs.google.com/document/d/16aTSHL5wxsq99t6adVbBz1U3K8Y5tBDAvs16iroZDEU),
+the MicroInterpreter should not pre-allocated it, and instead return an error.
+If multiple tensors are to be pre-allocated, multiple calls to
+RegisterPreallocatedTensor() are required. An example can be seen in the MSC
+below.
+
+
+
+## Performance overview
+
+### Cycle aspect
+
+In this section we try to estimate the number of clock cycles one memcpy() takes
+in relation to the total inference time for the person_detection model. The
+reason for looking closer at this model is that it has a relatively large input
+data size, which should make the cycle consumption of a memcpy() relatively
+large. Please note that these numbers are approximate and based on calculations,
+not actual benchmarking numbers. A word aligned memcpy() consumes somewhere
+between 1 - 4 bytes per cycle depending on which CPU is used. The input size for
+the person_detection model is 96x96 = 9216 bytes. On a reference system without
+accelerators one memcpy() of 9216 bytes corresponds to, in order of magnitudes,
+~0.01% of the total amount of clock cycles for one inference. The ratio will
+differ depending on the input size and the number of inferences/second. When
+using an accelerator, the total inference time will be significantly less which
+means that the memcpy()-call will consume a larger part of the total inference
+time. Approximations show that one memcpy() of 9216 bytes will consume ~1% of
+the total execution time for a reference system utilizing an ML HW accelerator.
+
+### Memory aspect
+
+In this section we'll look at memory savings aspects of pre-allocating tensors
+outside the tensor arena. The default memory planner in TFLu is
+[GreedyPlanner](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/memory_planner/greedy_memory_planner.h)
+(see
+[RFC](https://docs.google.com/document/d/1akpqu0uiPQshmCrnV6dOEFgYM4tCCnI8Zce85PnjHMI)).
+One good tool for understanding tensor layout in the tensor arena is using
+[PrintMemoryPlan API](https://github.com/tensorflow/tensorflow/blob/6f89198ee3206431ec6836e1e3df54455b89ebcf/tensorflow/lite/micro/memory_planner/greedy_memory_planner.h#L84).
+If we print the calculated memory layout for the
+[person detection model](https://storage.googleapis.com/download.tensorflow.org/data/tf_lite_micro_person_data_int8_grayscale_2020_06_23.zip),
+the tensor arena looks like this at each layer: `Layer 1:
+00000000000000000000000000tttttttttttttt........................................
+Layer 2:
+00000000000000000000000000...........................999999999999999999999999999
+Layer 3:
+aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa999999999999999999999999999
+Layer 4:
+aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbb..............
+Layer 5:
+cccccccccccccccccccccccccc...........................bbbbbbbbbbbbb..............
+Layer 6:
+ccccccccccccccccccccccccccddddddddddddddddddddddddddd...........................`
+The horizontal axis shows offset from the start of the tensor arena. The
+vertical axis shows execution order. The dots are "unused" memory for that
+specific layer. The letters and numbers represent the EvalTensor index, mapped
+to 0-9, then a-z. 't' is the input tensor of layer 1 (equivalent to the input
+data to the model) and '0' is the output tensor of layer 1. Hence, '0' is also
+the input tensor to layer 2, and '9' is the output tensor of layer 2. And so on.
+The reason for showing this illustration is that it becomes obvious that it is
+**the largest combination of simultaneously used tensors, of your model, that
+defines how large the tensor arena needs to be.** In this example, it's Layer 3.
+The combined size of tensors 'a' and '9' defines the size needed for the tensors
+arena. As a consequence, to save tensor arena memory by pre-allocation, we must
+start by pre-allocating tensor 'a' or '9' outside the arena. This will make the
+total size of the tensor arena smaller, which will reduce the total memory
+footprint of TensorFlow Lite Micro if the pre-allocated tensor is already
+allocated outside of the memory arena, like in the examples given in the
+Background section.
diff --git a/tensorflow/lite/micro/ecm3531/debug_log.cc b/tensorflow/lite/micro/ecm3531/debug_log.cc
new file mode 100644
index 0000000..17e810e
--- /dev/null
+++ b/tensorflow/lite/micro/ecm3531/debug_log.cc
@@ -0,0 +1,20 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include "eta_csp_io.h"
+
+extern "C" void DebugLog(const char* s) { EtaCspIoPrintf("%s", s); }
diff --git a/tensorflow/lite/micro/examples/hello_world/BUILD b/tensorflow/lite/micro/examples/hello_world/BUILD
new file mode 100644
index 0000000..a526aad
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/BUILD
@@ -0,0 +1,94 @@
+# Description:
+# TensorFlow Lite for Microcontrollers "hello world" example.
+load(
+ "//tensorflow/lite/micro:build_def.bzl",
+ "micro_copts",
+)
+
+package(
+ default_visibility = ["//visibility:public"],
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "model",
+ srcs = [
+ "model.cc",
+ ],
+ hdrs = [
+ "model.h",
+ ],
+ copts = micro_copts(),
+)
+
+cc_test(
+ name = "hello_world_test",
+ srcs = [
+ "hello_world_test.cc",
+ ],
+ deps = [
+ ":model",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ "//tensorflow/lite/schema:schema_fbs",
+ ],
+)
+
+cc_library(
+ name = "output_handler",
+ srcs = [
+ "output_handler.cc",
+ ],
+ hdrs = [
+ "output_handler.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ ],
+)
+
+cc_library(
+ name = "constants",
+ srcs = [
+ "constants.cc",
+ ],
+ hdrs = [
+ "constants.h",
+ ],
+ copts = micro_copts(),
+)
+
+cc_binary(
+ name = "hello_world",
+ srcs = [
+ "main.cc",
+ "main_functions.cc",
+ "main_functions.h",
+ ],
+ copts = [
+ "-Werror",
+ "-Wdouble-promotion",
+ "-Wsign-compare",
+ ],
+ deps = [
+ ":constants",
+ ":model",
+ ":output_handler",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:system_setup",
+ "//tensorflow/lite/schema:schema_fbs",
+ ],
+)
+
+sh_test(
+ name = "hello_world_binary_test",
+ srcs = ["hello_world_binary_test.sh"],
+ data = [":hello_world"],
+)
diff --git a/tensorflow/lite/micro/examples/hello_world/Makefile.inc b/tensorflow/lite/micro/examples/hello_world/Makefile.inc
new file mode 100644
index 0000000..102ca36
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/Makefile.inc
@@ -0,0 +1,50 @@
+EXAMPLE_NAME:=hello_world
+
+HELLO_WORLD_TEST_SRCS := \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/$(EXAMPLE_NAME)_test.cc \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/model.cc
+
+HELLO_WORLD_TEST_HDRS := \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/model.h
+
+OUTPUT_HANDLER_TEST_SRCS := \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/output_handler_test.cc \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/output_handler.cc
+
+OUTPUT_HANDLER_TEST_HDRS := \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/output_handler.h \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/constants.h
+
+HELLO_WORLD_SRCS := \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/main.cc \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/main_functions.cc \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/model.cc \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/output_handler.cc \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/constants.cc
+
+HELLO_WORLD_HDRS := \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/model.h \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/output_handler.h \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/constants.h \
+tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/main_functions.h
+
+#Find any platform - specific rules for this example.
+include $(wildcard tensorflow/lite/micro/examples/$(EXAMPLE_NAME)/*/Makefile.inc)
+
+# Tests loading and running the sine model.
+$(eval $(call microlite_test,$(EXAMPLE_NAME)_test,\
+$(HELLO_WORLD_TEST_SRCS),$(HELLO_WORLD_TEST_HDRS)))
+
+# Tests producing an output.
+$(eval $(call microlite_test,output_handler_test,\
+$(OUTPUT_HANDLER_TEST_SRCS),$(OUTPUT_HANDLER_TEST_HDRS)))
+
+# Builds a standalone binary.
+$(eval $(call microlite_test,$(EXAMPLE_NAME),\
+$(HELLO_WORLD_SRCS),$(HELLO_WORLD_HDRS)))
+
+list_$(EXAMPLE_NAME)_example_sources:
+ @echo $(HELLO_WORLD_SRCS)
+
+list_$(EXAMPLE_NAME)_example_headers:
+ @echo $(HELLO_WORLD_HDRS)
diff --git a/tensorflow/lite/micro/examples/hello_world/README.md b/tensorflow/lite/micro/examples/hello_world/README.md
new file mode 100644
index 0000000..7dcc891
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/README.md
@@ -0,0 +1,589 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+# Hello World Example
+
+This example is designed to demonstrate the absolute basics of using [TensorFlow
+Lite for Microcontrollers](https://www.tensorflow.org/lite/microcontrollers).
+It includes the full end-to-end workflow of training a model, converting it for
+use with TensorFlow Lite for Microcontrollers for running inference on a
+microcontroller.
+
+The model is trained to replicate a `sine` function and generates a pattern of
+data to either blink LEDs or control an animation, depending on the capabilities
+of the device.
+
+
+
+## Table of contents
+
+- [Deploy to ARC EM SDP](#deploy-to-arc-em-sdp)
+- [Deploy to Arduino](#deploy-to-arduino)
+- [Deploy to ESP32](#deploy-to-esp32)
+- [Deploy to Himax WE1 EVB](#deploy-to-himax-we1-evb)
+- [Deploy to SparkFun Edge](#deploy-to-sparkfun-edge)
+- [Deploy to STM32F746](#deploy-to-STM32F746)
+- [Run the tests on a development machine](#run-the-tests-on-a-development-machine)
+- [Train your own model](#train-your-own-model)
+
+## Deploy to ARC EM SDP
+
+The following instructions will help you to build and deploy this example to
+[ARC EM SDP](https://www.synopsys.com/dw/ipdir.php?ds=arc-em-software-development-platform)
+board. General information and instructions on using the board with TensorFlow
+Lite Micro can be found in the common
+[ARC targets description](/tensorflow/lite/micro/tools/make/targets/arc/README.md).
+
+### Initial Setup
+
+Follow the instructions on the
+[ARC EM SDP Initial Setup](/tensorflow/lite/micro/tools/make/targets/arc/README.md#ARC-EM-Software-Development-Platform-ARC-EM-SDP)
+to get and install all required tools for work with ARC EM SDP.
+
+### Generate Example Project
+
+The example project for ARC EM SDP platform can be generated with the following
+command:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=arc_emsdp OPTIMIZED_KERNEL_DIR=arc_mli ARC_TAGS=no_arc_mli generate_hello_world_make_project
+```
+
+### Build and Run Example
+
+For more detailed information on building and running examples see the
+appropriate sections of general descriptions of the
+[ARC EM SDP usage with TFLM](/tensorflow/lite/micro/tools/make/targets/arc/README.md#ARC-EM-Software-Development-Platform-ARC-EM-SDP).
+In the directory with generated project you can also find a
+*README_ARC_EMSDP.md* file with instructions and options on building and
+running. Here we only briefly mention main steps which are typically enough to
+get it started.
+
+1. You need to
+ [connect the board](/tensorflow/lite/micro/tools/make/targets/arc/README.md#connect-the-board)
+ and open an serial connection.
+
+2. Go to the generated example project director
+
+ ```
+ cd tensorflow/lite/micro/tools/make/gen/arc_emsdp_arc/prj/hello_world/make
+ ```
+
+3. Build the example using
+
+ ```
+ make app
+ ```
+
+4. To generate artefacts for self-boot of example from the board use
+
+ ```
+ make flash
+ ```
+
+5. To run application from the board using microSD card:
+
+ * Copy the content of the created /bin folder into the root of microSD
+ card. Note that the card must be formatted as FAT32 with default cluster
+ size (but less than 32 Kbytes)
+ * Plug in the microSD card into the J11 connector.
+ * Push the RST button. If a red LED is lit beside RST button, push the CFG
+ button.
+ * Type or copy next commands one-by-another into serial terminal: `setenv
+ loadaddr 0x10800000 setenv bootfile app.elf setenv bootdelay 1 setenv
+ bootcmd fatload mmc 0 \$\{loadaddr\} \$\{bootfile\} \&\& bootelf
+ saveenv`
+ * Push the RST button.
+
+6. If you have the MetaWare Debugger installed in your environment:
+
+ * To run application from the console using it type `make run`.
+ * To stop the execution type `Ctrl+C` in the console several times.
+
+In both cases (step 5 and 6) you will see the application output in the serial
+terminal.
+
+## Deploy to Arduino
+
+The following instructions will help you build and deploy this sample
+to [Arduino](https://www.arduino.cc/) devices.
+
+
+
+The sample has been tested with the following devices:
+
+- [Arduino Nano 33 BLE Sense](https://store.arduino.cc/usa/nano-33-ble-sense-with-headers)
+- [Arduino MKRZERO](https://store.arduino.cc/usa/arduino-mkrzero)
+
+The sample will use PWM to fade an LED on and off according to the model's
+output. In the code, the `LED_BUILTIN` constant is used to specify the board's
+built-in LED as the one being controlled. However, on some boards, this built-in
+LED is not attached to a pin with PWM capabilities. In this case, the LED will
+blink instead of fading.
+
+### Install the Arduino_TensorFlowLite library
+
+This example application is included as part of the official TensorFlow Lite
+Arduino library. To install it, open the Arduino library manager in
+`Tools -> Manage Libraries...` and search for `Arduino_TensorFlowLite`.
+
+### Load and run the example
+
+Once the library has been added, go to `File -> Examples`. You should see an
+example near the bottom of the list named `TensorFlowLite:hello_world`. Select
+it and click `hello_world` to load the example.
+
+Use the Arduino IDE to build and upload the example. Once it is running,
+you should see the built-in LED on your device flashing.
+
+The Arduino Desktop IDE includes a plotter that we can use to display the sine
+wave graphically. To view it, go to `Tools -> Serial Plotter`. You will see one
+datapoint being logged for each inference cycle, expressed as a number between 0
+and 255.
+
+## Deploy to ESP32
+
+The following instructions will help you build and deploy this sample
+to [ESP32](https://www.espressif.com/en/products/hardware/esp32/overview)
+devices using the [ESP IDF](https://github.com/espressif/esp-idf).
+
+The sample has been tested on ESP-IDF version 4.0 with the following devices:
+- [ESP32-DevKitC](http://esp-idf.readthedocs.io/en/latest/get-started/get-started-devkitc.html)
+- [ESP-EYE](https://github.com/espressif/esp-who/blob/master/docs/en/get-started/ESP-EYE_Getting_Started_Guide.md)
+
+### Install the ESP IDF
+
+Follow the instructions of the
+[ESP-IDF get started guide](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html)
+to setup the toolchain and the ESP-IDF itself.
+
+The next steps assume that the
+[IDF environment variables are set](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html#step-4-set-up-the-environment-variables) :
+
+ * The `IDF_PATH` environment variable is set
+ * `idf.py` and Xtensa-esp32 tools (e.g. `xtensa-esp32-elf-gcc`) are in `$PATH`
+
+### Generate the examples
+The example project can be generated with the following command:
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=esp generate_hello_world_esp_project
+```
+
+### Building the example
+
+Go to the example project directory `cd
+tensorflow/lite/micro/tools/make/gen/esp_xtensa-esp32/prj/hello_world/esp-idf`
+
+Then build with `idf.py`
+```
+idf.py build
+```
+
+### Load and run the example
+
+To flash (replace `/dev/ttyUSB0` with the device serial port):
+```
+idf.py --port /dev/ttyUSB0 flash
+```
+
+Monitor the serial output:
+```
+idf.py --port /dev/ttyUSB0 monitor
+```
+
+Use `Ctrl+]` to exit.
+
+The previous two commands can be combined:
+```
+idf.py --port /dev/ttyUSB0 flash monitor
+```
+
+## Deploy to Himax WE1 EVB
+
+The following instructions will help you build and deploy this example to
+[HIMAX WE1 EVB](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_board_brief)
+board. To understand more about using this board, please check
+[HIMAX WE1 EVB user guide](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_user_guide).
+
+### Initial Setup
+
+To use the HIMAX WE1 EVB, please make sure following software are installed:
+
+#### MetaWare Development Toolkit
+
+See
+[Install the Synopsys DesignWare ARC MetaWare Development Toolkit](/tensorflow/lite/micro/tools/make/targets/arc/README.md#install-the-synopsys-designware-arc-metaware-development-toolkit)
+section for instructions on toolchain installation.
+
+#### Make Tool version
+
+A `'make'` tool is required for deploying Tensorflow Lite Micro applications on
+HIMAX WE1 EVB, See
+[Check make tool version](/tensorflow/lite/micro/tools/make/targets/arc/README.md#make-tool)
+section for proper environment.
+
+#### Serial Terminal Emulation Application
+
+There are 2 main purposes for HIMAX WE1 EVB Debug UART port
+
+- print application output
+- burn application to flash by using xmodem send application binary
+
+You can use any terminal emulation program (like [PuTTY](https://www.putty.org/)
+or [minicom](https://linux.die.net/man/1/minicom)).
+
+### Generate Example Project
+
+The example project for HIMAX WE1 EVB platform can be generated with the
+following command:
+
+Download related third party data
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=himax_we1_evb third_party_downloads
+```
+
+Generate hello world project
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile generate_hello_world_make_project TARGET=himax_we1_evb ARC_TAGS=no_arc_mli
+```
+
+### Build and Burn Example
+
+Following the Steps to run hello world example at HIMAX WE1 EVB platform.
+
+1. Go to the generated example project directory.
+
+ ```
+ cd tensorflow/lite/micro/tools/make/gen/himax_we1_evb_arc/prj/hello_world/make
+ ```
+
+2. Build the example using
+
+ ```
+ make app
+ ```
+
+3. After example build finish, copy ELF file and map file to image generate
+ tool directory. \
+ image generate tool directory located at
+ `'tensorflow/lite/micro/tools/make/downloads/himax_we1_sdk/image_gen_linux_v3/'`
+
+ ```
+ cp hello_world.elf himax_we1_evb.map ../../../../../downloads/himax_we1_sdk/image_gen_linux_v3/
+ ```
+
+4. Go to flash image generate tool directory.
+
+ ```
+ cd ../../../../../downloads/himax_we1_sdk/image_gen_linux_v3/
+ ```
+
+ make sure this tool directory is in $PATH. You can permanently set it to
+ PATH by
+
+ ```
+ export PATH=$PATH:$(pwd)
+ ```
+
+5. run image generate tool, generate flash image file.
+
+ * Before running image generate tool, by typing `sudo chmod +x image_gen`
+ and `sudo chmod +x sign_tool` to make sure it is executable.
+
+ ```
+ image_gen -e hello_world.elf -m himax_we1_evb.map -o out.img
+ ```
+
+6. Download flash image file to HIMAX WE1 EVB by UART:
+
+ * more detail about download image through UART can be found at
+ [HIMAX WE1 EVB update Flash image](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_user_guide#flash-image-update)
+
+After these steps, press reset button on the HIMAX WE1 EVB, you will see
+application output in the serial terminal.
+
+## Deploy to SparkFun Edge
+
+The following instructions will help you build and deploy this sample on the
+[SparkFun Edge development board](https://sparkfun.com/products/15170).
+
+
+
+If you're new to using this board, we recommend walking through the
+[AI on a microcontroller with TensorFlow Lite and SparkFun Edge](https://codelabs.developers.google.com/codelabs/sparkfun-tensorflow)
+codelab to get an understanding of the workflow.
+
+### Compile the binary
+
+The following command will download the required dependencies and then compile a
+binary for the SparkFun Edge:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=sparkfun_edge hello_world_bin
+```
+
+The binary will be created in the following location:
+
+```
+tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4/bin/hello_world.bin
+```
+
+### Sign the binary
+
+The binary must be signed with cryptographic keys to be deployed to the device.
+We'll now run some commands that will sign our binary so it can be flashed to
+the SparkFun Edge. The scripts we are using come from the Ambiq SDK, which is
+downloaded when the `Makefile` is run.
+
+Enter the following command to set up some dummy cryptographic keys we can use
+for development:
+
+```
+cp tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/keys_info0.py \
+tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/keys_info.py
+```
+
+Next, run the following command to create a signed binary:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/create_cust_image_blob.py \
+--bin tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4/bin/hello_world.bin \
+--load-address 0xC000 \
+--magic-num 0xCB \
+-o main_nonsecure_ota \
+--version 0x0
+```
+
+This will create the file `main_nonsecure_ota.bin`. We'll now run another
+command to create a final version of the file that can be used to flash our
+device with the bootloader script we will use in the next step:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/create_cust_wireupdate_blob.py \
+--load-address 0x20000 \
+--bin main_nonsecure_ota.bin \
+-i 6 \
+-o main_nonsecure_wire \
+--options 0x1
+```
+
+You should now have a file called `main_nonsecure_wire.bin` in the directory
+where you ran the commands. This is the file we'll be flashing to the device.
+
+### Flash the binary
+
+Next, attach the board to your computer via a USB-to-serial adapter.
+
+**Note:** If you're using the [SparkFun Serial Basic Breakout](https://www.sparkfun.com/products/15096),
+you should [install the latest drivers](https://learn.sparkfun.com/tutorials/sparkfun-serial-basic-ch340c-hookup-guide#drivers-if-you-need-them)
+before you continue.
+
+Once connected, assign the USB device name to an environment variable:
+
+```
+export DEVICENAME=put your device name here
+```
+
+Set another variable with the baud rate:
+
+```
+export BAUD_RATE=921600
+```
+
+Now, hold the button marked `14` on the device. While still holding the button,
+hit the button marked `RST`. Continue holding the button marked `14` while
+running the following command:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/uart_wired_update.py \
+-b ${BAUD_RATE} ${DEVICENAME} \
+-r 1 \
+-f main_nonsecure_wire.bin \
+-i 6
+```
+
+You should see a long stream of output as the binary is flashed to the device.
+Once you see the following lines, flashing is complete:
+
+```
+Sending Reset Command.
+Done.
+```
+
+If you don't see these lines, flashing may have failed. Try running through the
+steps in [Flash the binary](#flash-the-binary) again (you can skip over setting
+the environment variables). If you continue to run into problems, follow the
+[AI on a microcontroller with TensorFlow Lite and SparkFun Edge](https://codelabs.developers.google.com/codelabs/sparkfun-tensorflow)
+codelab, which includes more comprehensive instructions for the flashing
+process.
+
+The binary should now be deployed to the device. Hit the button marked `RST` to
+reboot the board. You should see the device's four LEDs flashing in sequence.
+
+Debug information is logged by the board while the program is running. To view
+it, establish a serial connection to the board using a baud rate of `115200`.
+On OSX and Linux, the following command should work:
+
+```
+screen ${DEVICENAME} 115200
+```
+
+You will see a lot of output flying past! To stop the scrolling, hit `Ctrl+A`,
+immediately followed by `Esc`. You can then use the arrow keys to explore the
+output, which will contain the results of running inference on various `x`
+values:
+
+```
+x_value: 1.1843798*2^2, y_value: -1.9542645*2^-1
+```
+
+To stop viewing the debug output with `screen`, hit `Ctrl+A`, immediately
+followed by the `K` key, then hit the `Y` key.
+
+
+## Deploy to STM32F746
+
+The following instructions will help you build and deploy the sample to the
+[STM32F7 discovery kit](https://os.mbed.com/platforms/ST-Discovery-F746NG/)
+using [ARM Mbed](https://github.com/ARMmbed/mbed-cli).
+
+
+
+Before we begin, you'll need the following:
+
+- STM32F7 discovery kit board
+- Mini-USB cable
+- ARM Mbed CLI ([installation instructions](https://os.mbed.com/docs/mbed-os/v5.12/tools/installation-and-setup.html). Check it out for MacOS Catalina - [mbed-cli is broken on MacOS Catalina #930](https://github.com/ARMmbed/mbed-cli/issues/930#issuecomment-660550734))
+- Python 2.7 and pip
+
+Since Mbed requires a special folder structure for projects, we'll first run a
+command to generate a subfolder containing the required source files in this
+structure:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=mbed TAGS="CMSIS disco_f746ng" generate_hello_world_mbed_project
+```
+
+This will result in the creation of a new folder:
+
+```
+tensorflow/lite/micro/tools/make/gen/mbed_cortex-m4/prj/hello_world/mbed
+```
+
+This folder contains all of the example's dependencies structured in the correct
+way for Mbed to be able to build it.
+
+Change into the directory and run the following commands, making sure you are
+using Python 2.7.15.
+
+First, tell Mbed that the current directory is the root of an Mbed project:
+
+```
+mbed config root .
+```
+
+Next, tell Mbed to download the dependencies and prepare to build:
+
+```
+mbed deploy
+```
+
+By default, Mbed will build the project using C++98. However, TensorFlow Lite
+requires C++11. Run the following Python snippet to modify the Mbed
+configuration files so that it uses C++11:
+
+```
+python -c 'import fileinput, glob;
+for filename in glob.glob("mbed-os/tools/profiles/*.json"):
+ for line in fileinput.input(filename, inplace=True):
+ print line.replace("\"-std=gnu++98\"","\"-std=c++11\", \"-fpermissive\"")'
+
+```
+
+Finally, run the following command to compile:
+
+```
+mbed compile -m DISCO_F746NG -t GCC_ARM
+```
+
+This should result in a binary at the following path:
+
+```
+./BUILD/DISCO_F746NG/GCC_ARM/mbed.bin
+```
+
+To deploy, plug in your STM board and copy the file to it. On MacOS, you can do
+this with the following command:
+
+```
+cp ./BUILD/DISCO_F746NG/GCC_ARM/mbed.bin /Volumes/DIS_F746NG/
+```
+
+Copying the file will initiate the flashing process. Once this is complete, you
+should see an animation on the device's screen.
+
+
+```
+screen /dev/tty.usbmodem14403 9600
+```
+
+In addition to this animation, debug information is logged by the board while
+the program is running. To view it, establish a serial connection to the board
+using a baud rate of `9600`. On OSX and Linux, the following command should
+work, replacing `/dev/tty.devicename` with the name of your device as it appears
+in `/dev`:
+
+```
+screen /dev/tty.devicename 9600
+```
+
+You will see a lot of output flying past! To stop the scrolling, hit `Ctrl+A`,
+immediately followed by `Esc`. You can then use the arrow keys to explore the
+output, which will contain the results of running inference on various `x`
+values:
+
+```
+x_value: 1.1843798*2^2, y_value: -1.9542645*2^-1
+```
+
+To stop viewing the debug output with `screen`, hit `Ctrl+A`, immediately
+followed by the `K` key, then hit the `Y` key.
+
+## Run the tests on a development machine
+
+To compile and test this example on a desktop Linux or macOS machine, first
+clone the TensorFlow repository from GitHub to a convenient place:
+
+```bash
+git clone --depth 1 https://github.com/tensorflow/tensorflow.git
+```
+
+Next, `cd` into the source directory from a terminal, and then run the following
+command:
+
+```bash
+make -f tensorflow/lite/micro/tools/make/Makefile test_hello_world_test
+```
+
+This will take a few minutes, and downloads frameworks the code uses. Once the
+process has finished, you should see a series of files get compiled, followed by
+some logging output from a test, which should conclude with
+`~~~ALL TESTS PASSED~~~`.
+
+If you see this, it means that a small program has been built and run that loads
+the trained TensorFlow model, runs some example inputs through it, and got the
+expected outputs.
+
+To understand how TensorFlow Lite does this, you can look at the source in
+[hello_world_test.cc](hello_world_test.cc).
+It's a fairly small amount of code that creates an interpreter, gets a handle to
+a model that's been compiled into the program, and then invokes the interpreter
+with the model and sample inputs.
+
+## Train your own model
+
+So far you have used an existing trained model to run inference on
+microcontrollers. If you wish to train your own model, follow the instructions
+given in the [train/](train/) directory.
+
diff --git a/tensorflow/lite/micro/examples/hello_world/arduino/constants.cc b/tensorflow/lite/micro/examples/hello_world/arduino/constants.cc
new file mode 100644
index 0000000..e516b6c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/arduino/constants.cc
@@ -0,0 +1,19 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/constants.h"
+
+// This is tuned so that a full cycle takes ~4 seconds on an Arduino MKRZERO.
+const int kInferencesPerCycle = 1000;
diff --git a/tensorflow/lite/micro/examples/hello_world/arduino/main.cc b/tensorflow/lite/micro/examples/hello_world/arduino/main.cc
new file mode 100644
index 0000000..e34e8bb
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/arduino/main.cc
@@ -0,0 +1,20 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/main_functions.h"
+
+// Arduino automatically calls the setup() and loop() functions in a sketch, so
+// where other systems need their own main routine in this file, it can be left
+// empty.
diff --git a/tensorflow/lite/micro/examples/hello_world/arduino/output_handler.cc b/tensorflow/lite/micro/examples/hello_world/arduino/output_handler.cc
new file mode 100644
index 0000000..097a6ca
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/arduino/output_handler.cc
@@ -0,0 +1,47 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/output_handler.h"
+
+#include "Arduino.h"
+#include "tensorflow/lite/micro/examples/hello_world/constants.h"
+
+// The pin of the Arduino's built-in LED
+int led = LED_BUILTIN;
+
+// Track whether the function has run at least once
+bool initialized = false;
+
+// Animates a dot across the screen to represent the current x and y values
+void HandleOutput(tflite::ErrorReporter* error_reporter, float x_value,
+ float y_value) {
+ // Do this only once
+ if (!initialized) {
+ // Set the LED pin to output
+ pinMode(led, OUTPUT);
+ initialized = true;
+ }
+
+ // Calculate the brightness of the LED such that y=-1 is fully off
+ // and y=1 is fully on. The LED's brightness can range from 0-255.
+ int brightness = (int)(127.5f * (y_value + 1));
+
+ // Set the brightness of the LED. If the specified pin does not support PWM,
+ // this will result in the LED being on when y > 127, off otherwise.
+ analogWrite(led, brightness);
+
+ // Log the current brightness value for display in the Arduino plotter
+ TF_LITE_REPORT_ERROR(error_reporter, "%d\n", brightness);
+}
diff --git a/tensorflow/lite/micro/examples/hello_world/constants.cc b/tensorflow/lite/micro/examples/hello_world/constants.cc
new file mode 100644
index 0000000..3eccb72
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/constants.cc
@@ -0,0 +1,19 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/constants.h"
+
+// This is a small number so that it's easy to read the logs
+const int kInferencesPerCycle = 20;
diff --git a/tensorflow/lite/micro/examples/hello_world/constants.h b/tensorflow/lite/micro/examples/hello_world/constants.h
new file mode 100644
index 0000000..f452893
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/constants.h
@@ -0,0 +1,32 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_CONSTANTS_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_CONSTANTS_H_
+
+// This constant represents the range of x values our model was trained on,
+// which is from 0 to (2 * Pi). We approximate Pi to avoid requiring additional
+// libraries.
+const float kXrange = 2.f * 3.14159265359f;
+
+// This constant determines the number of inferences to perform across the range
+// of x values defined above. Since each inference takes time, the higher this
+// number, the more time it will take to run through the entire range. The value
+// of this constant can be tuned so that one full cycle takes a desired amount
+// of time. Since different devices take different amounts of time to perform
+// inference, this value should be defined per-device.
+extern const int kInferencesPerCycle;
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_CONSTANTS_H_
diff --git a/tensorflow/lite/micro/examples/hello_world/create_sine_model.ipynb b/tensorflow/lite/micro/examples/hello_world/create_sine_model.ipynb
new file mode 100644
index 0000000..b34c0bb
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/create_sine_model.ipynb
@@ -0,0 +1 @@
+{"nbformat":4,"nbformat_minor":0,"metadata":{"colab":{"name":"Redirect","provenance":[],"collapsed_sections":[],"authorship_tag":"ABX9TyO1u6oks1qPVEQNnHFD3Cyo"},"kernelspec":{"name":"python3","display_name":"Python 3"}},"cells":[{"cell_type":"markdown","metadata":{"id":"86C-FMxpdZxv","colab_type":"text"},"source":["This Colab notebook has been moved to [https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb)\n"]}]}
\ No newline at end of file
diff --git a/tensorflow/lite/micro/examples/hello_world/disco_f746ng/Makefile.inc b/tensorflow/lite/micro/examples/hello_world/disco_f746ng/Makefile.inc
new file mode 100644
index 0000000..6d18e48
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/disco_f746ng/Makefile.inc
@@ -0,0 +1,6 @@
+# Settings for the Discovery STM32F746NG board.
+ifneq ($(filter disco_f746ng,$(ALL_TAGS)),)
+ hello_world_MBED_PROJECT_FILES += \
+ BSP_DISCO_F746NG.lib \
+ LCD_DISCO_F746NG.lib
+endif
diff --git a/tensorflow/lite/micro/examples/hello_world/disco_f746ng/constants.cc b/tensorflow/lite/micro/examples/hello_world/disco_f746ng/constants.cc
new file mode 100644
index 0000000..8d6d07c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/disco_f746ng/constants.cc
@@ -0,0 +1,19 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/constants.h"
+
+// A larger number than the default to make the animation smoother
+const int kInferencesPerCycle = 70;
diff --git a/tensorflow/lite/micro/examples/hello_world/disco_f746ng/output_handler.cc b/tensorflow/lite/micro/examples/hello_world/disco_f746ng/output_handler.cc
new file mode 100644
index 0000000..4e99209
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/disco_f746ng/output_handler.cc
@@ -0,0 +1,81 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/output_handler.h"
+
+#include "LCD_DISCO_F746NG.h"
+#include "tensorflow/lite/micro/examples/hello_world/constants.h"
+
+// The LCD driver
+LCD_DISCO_F746NG lcd;
+
+// The colors we'll draw
+const uint32_t background_color = 0xFFF4B400; // Yellow
+const uint32_t foreground_color = 0xFFDB4437; // Red
+// The size of the dot we'll draw
+const int dot_radius = 10;
+// Track whether the function has run at least once
+bool initialized = false;
+// Size of the drawable area
+int width;
+int height;
+// Midpoint of the y axis
+int midpoint;
+// Pixels per unit of x_value
+int x_increment;
+
+// Animates a dot across the screen to represent the current x and y values
+void HandleOutput(tflite::ErrorReporter* error_reporter, float x_value,
+ float y_value) {
+ // Do this only once
+ if (!initialized) {
+ // Set the background and foreground colors
+ lcd.Clear(background_color);
+ lcd.SetTextColor(foreground_color);
+ // Calculate the drawable area to avoid drawing off the edges
+ width = lcd.GetXSize() - (dot_radius * 2);
+ height = lcd.GetYSize() - (dot_radius * 2);
+ // Calculate the y axis midpoint
+ midpoint = height / 2;
+ // Calculate fractional pixels per unit of x_value
+ x_increment = static_cast<float>(width) / kXrange;
+ initialized = true;
+ }
+
+ // Log the current X and Y values
+ TF_LITE_REPORT_ERROR(error_reporter, "x_value: %f, y_value: %f\n", x_value,
+ y_value);
+
+ // Clear the previous drawing
+ lcd.Clear(background_color);
+
+ // Calculate x position, ensuring the dot is not partially offscreen,
+ // which causes artifacts and crashes
+ int x_pos = dot_radius + static_cast<int>(x_value * x_increment);
+
+ // Calculate y position, ensuring the dot is not partially offscreen
+ int y_pos;
+ if (y_value >= 0) {
+ // Since the display's y runs from the top down, invert y_value
+ y_pos = dot_radius + static_cast<int>(midpoint * (1.f - y_value));
+ } else {
+ // For any negative y_value, start drawing from the midpoint
+ y_pos =
+ dot_radius + midpoint + static_cast<int>(midpoint * (0.f - y_value));
+ }
+
+ // Draw the dot
+ lcd.FillCircle(x_pos, y_pos, dot_radius);
+}
diff --git a/tensorflow/lite/micro/examples/hello_world/esp/main.cc b/tensorflow/lite/micro/examples/hello_world/esp/main.cc
new file mode 100644
index 0000000..b68b189
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/esp/main.cc
@@ -0,0 +1,23 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/main_functions.h"
+
+extern "C" void app_main(void) {
+ setup();
+ while (true) {
+ loop();
+ }
+}
diff --git a/tensorflow/lite/micro/examples/hello_world/hello_world_binary_test.sh b/tensorflow/lite/micro/examples/hello_world/hello_world_binary_test.sh
new file mode 100755
index 0000000..fe7683e
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/hello_world_binary_test.sh
@@ -0,0 +1,33 @@
+#!/bin/bash
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Bash unit tests for the example binary.
+
+set -e
+
+OUTPUT_LOG_FILE=${TEST_TMPDIR}/output_log.txt
+
+# Needed for copybara compatibility.
+SCRIPT_BASE_DIR=/org_"tensor"flow
+${TEST_SRCDIR}${SCRIPT_BASE_DIR}/tensorflow/lite/micro/examples/hello_world/hello_world 2>&1 | head > ${OUTPUT_LOG_FILE}
+
+if ! grep -q 'x_value:.*y_value:' ${OUTPUT_LOG_FILE}; then
+ echo "ERROR: Expected logs not found in output '${OUTPUT_LOG_FILE}'"
+ exit 1
+fi
+
+echo
+echo "SUCCESS: hello_world_binary_test PASSED"
diff --git a/tensorflow/lite/micro/examples/hello_world/hello_world_test.cc b/tensorflow/lite/micro/examples/hello_world/hello_world_test.cc
new file mode 100644
index 0000000..f726057
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/hello_world_test.cc
@@ -0,0 +1,131 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <math.h>
+
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/examples/hello_world/model.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(LoadModelAndPerformInference) {
+ // Define the input and the expected output
+ float x = 0.0f;
+ float y_true = sin(x);
+
+ // Set up logging
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ // Map the model into a usable data structure. This doesn't involve any
+ // copying or parsing, it's a very lightweight operation.
+ const tflite::Model* model = ::tflite::GetModel(g_model);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.\n",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ }
+
+ // This pulls in all the operation implementations we need
+ tflite::AllOpsResolver resolver;
+
+ constexpr int kTensorArenaSize = 2000;
+ uint8_t tensor_arena[kTensorArenaSize];
+
+ // Build an interpreter to run the model with
+ tflite::MicroInterpreter interpreter(model, resolver, tensor_arena,
+ kTensorArenaSize, µ_error_reporter);
+ // Allocate memory from the tensor_arena for the model's tensors
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);
+
+ // Obtain a pointer to the model's input tensor
+ TfLiteTensor* input = interpreter.input(0);
+
+ // Make sure the input has the properties we expect
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input);
+ // The property "dims" tells us the tensor's shape. It has one element for
+ // each dimension. Our input is a 2D tensor containing 1 element, so "dims"
+ // should have size 2.
+ TF_LITE_MICRO_EXPECT_EQ(2, input->dims->size);
+ // The value of each element gives the length of the corresponding tensor.
+ // We should expect two single element tensors (one is contained within the
+ // other).
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[1]);
+ // The input is an 8 bit integer value
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt8, input->type);
+
+ // Get the input quantization parameters
+ float input_scale = input->params.scale;
+ int input_zero_point = input->params.zero_point;
+
+ // Quantize the input from floating-point to integer
+ int8_t x_quantized = x / input_scale + input_zero_point;
+ // Place the quantized input in the model's input tensor
+ input->data.int8[0] = x_quantized;
+
+ // Run the model and check that it succeeds
+ TfLiteStatus invoke_status = interpreter.Invoke();
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
+
+ // Obtain a pointer to the output tensor and make sure it has the
+ // properties we expect. It should be the same as the input tensor.
+ TfLiteTensor* output = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt8, output->type);
+
+ // Get the output quantization parameters
+ float output_scale = output->params.scale;
+ int output_zero_point = output->params.zero_point;
+
+ // Obtain the quantized output from model's output tensor
+ int8_t y_pred_quantized = output->data.int8[0];
+ // Dequantize the output from integer to floating-point
+ float y_pred = (y_pred_quantized - output_zero_point) * output_scale;
+
+ // Check if the output is within a small range of the expected output
+ float epsilon = 0.05f;
+ TF_LITE_MICRO_EXPECT_NEAR(y_true, y_pred, epsilon);
+
+ // Run inference on several more values and confirm the expected outputs
+ x = 1.f;
+ y_true = sin(x);
+ input->data.int8[0] = x / input_scale + input_zero_point;
+ interpreter.Invoke();
+ y_pred = (output->data.int8[0] - output_zero_point) * output_scale;
+ TF_LITE_MICRO_EXPECT_NEAR(y_true, y_pred, epsilon);
+
+ x = 3.f;
+ y_true = sin(x);
+ input->data.int8[0] = x / input_scale + input_zero_point;
+ interpreter.Invoke();
+ y_pred = (output->data.int8[0] - output_zero_point) * output_scale;
+ TF_LITE_MICRO_EXPECT_NEAR(y_true, y_pred, epsilon);
+
+ x = 5.f;
+ y_true = sin(x);
+ input->data.int8[0] = x / input_scale + input_zero_point;
+ interpreter.Invoke();
+ y_pred = (output->data.int8[0] - output_zero_point) * output_scale;
+ TF_LITE_MICRO_EXPECT_NEAR(y_true, y_pred, epsilon);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/hello_world/images/animation_on_STM32F746.gif b/tensorflow/lite/micro/examples/hello_world/images/animation_on_STM32F746.gif
new file mode 100644
index 0000000..e427bc8
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/images/animation_on_STM32F746.gif
Binary files differ
diff --git a/tensorflow/lite/micro/examples/hello_world/images/animation_on_arduino_mkrzero.gif b/tensorflow/lite/micro/examples/hello_world/images/animation_on_arduino_mkrzero.gif
new file mode 100644
index 0000000..d896534
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/images/animation_on_arduino_mkrzero.gif
Binary files differ
diff --git a/tensorflow/lite/micro/examples/hello_world/images/animation_on_sparkfun_edge.gif b/tensorflow/lite/micro/examples/hello_world/images/animation_on_sparkfun_edge.gif
new file mode 100644
index 0000000..057a52d
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/images/animation_on_sparkfun_edge.gif
Binary files differ
diff --git a/tensorflow/lite/micro/examples/hello_world/images/model_architecture.png b/tensorflow/lite/micro/examples/hello_world/images/model_architecture.png
new file mode 100644
index 0000000..792d18f
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/images/model_architecture.png
Binary files differ
diff --git a/tensorflow/lite/micro/examples/hello_world/main.cc b/tensorflow/lite/micro/examples/hello_world/main.cc
new file mode 100644
index 0000000..bdf7942
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/main.cc
@@ -0,0 +1,27 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/main_functions.h"
+
+// This is the default main used on systems that have the standard C entry
+// point. Other devices (for example FreeRTOS or ESP32) that have different
+// requirements for entry code (like an app_main function) should specialize
+// this main.cc file in a target-specific subfolder.
+int main(int argc, char* argv[]) {
+ setup();
+ while (true) {
+ loop();
+ }
+}
diff --git a/tensorflow/lite/micro/examples/hello_world/main_functions.cc b/tensorflow/lite/micro/examples/hello_world/main_functions.cc
new file mode 100644
index 0000000..b8c630c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/main_functions.cc
@@ -0,0 +1,121 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/main_functions.h"
+
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/examples/hello_world/constants.h"
+#include "tensorflow/lite/micro/examples/hello_world/model.h"
+#include "tensorflow/lite/micro/examples/hello_world/output_handler.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/system_setup.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+// Globals, used for compatibility with Arduino-style sketches.
+namespace {
+tflite::ErrorReporter* error_reporter = nullptr;
+const tflite::Model* model = nullptr;
+tflite::MicroInterpreter* interpreter = nullptr;
+TfLiteTensor* input = nullptr;
+TfLiteTensor* output = nullptr;
+int inference_count = 0;
+
+constexpr int kTensorArenaSize = 2000;
+uint8_t tensor_arena[kTensorArenaSize];
+} // namespace
+
+// The name of this function is important for Arduino compatibility.
+void setup() {
+ tflite::InitializeTarget();
+
+ // Set up logging. Google style is to avoid globals or statics because of
+ // lifetime uncertainty, but since this has a trivial destructor it's okay.
+ // NOLINTNEXTLINE(runtime-global-variables)
+ static tflite::MicroErrorReporter micro_error_reporter;
+ error_reporter = µ_error_reporter;
+
+ // Map the model into a usable data structure. This doesn't involve any
+ // copying or parsing, it's a very lightweight operation.
+ model = tflite::GetModel(g_model);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ return;
+ }
+
+ // This pulls in all the operation implementations we need.
+ // NOLINTNEXTLINE(runtime-global-variables)
+ static tflite::AllOpsResolver resolver;
+
+ // Build an interpreter to run the model with.
+ static tflite::MicroInterpreter static_interpreter(
+ model, resolver, tensor_arena, kTensorArenaSize, error_reporter);
+ interpreter = &static_interpreter;
+
+ // Allocate memory from the tensor_arena for the model's tensors.
+ TfLiteStatus allocate_status = interpreter->AllocateTensors();
+ if (allocate_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
+ return;
+ }
+
+ // Obtain pointers to the model's input and output tensors.
+ input = interpreter->input(0);
+ output = interpreter->output(0);
+
+ // Keep track of how many inferences we have performed.
+ inference_count = 0;
+}
+
+// The name of this function is important for Arduino compatibility.
+void loop() {
+ // Calculate an x value to feed into the model. We compare the current
+ // inference_count to the number of inferences per cycle to determine
+ // our position within the range of possible x values the model was
+ // trained on, and use this to calculate a value.
+ float position = static_cast<float>(inference_count) /
+ static_cast<float>(kInferencesPerCycle);
+ float x = position * kXrange;
+
+ // Quantize the input from floating-point to integer
+ int8_t x_quantized = x / input->params.scale + input->params.zero_point;
+ // Place the quantized input in the model's input tensor
+ input->data.int8[0] = x_quantized;
+
+ // Run inference, and report any error
+ TfLiteStatus invoke_status = interpreter->Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed on x: %f\n",
+ static_cast<double>(x));
+ return;
+ }
+
+ // Obtain the quantized output from model's output tensor
+ int8_t y_quantized = output->data.int8[0];
+ // Dequantize the output from integer to floating-point
+ float y = (y_quantized - output->params.zero_point) * output->params.scale;
+
+ // Output the results. A custom HandleOutput function can be implemented
+ // for each supported hardware target.
+ HandleOutput(error_reporter, x, y);
+
+ // Increment the inference_counter, and reset it if we have reached
+ // the total number per cycle
+ inference_count += 1;
+ if (inference_count >= kInferencesPerCycle) inference_count = 0;
+}
diff --git a/tensorflow/lite/micro/examples/hello_world/main_functions.h b/tensorflow/lite/micro/examples/hello_world/main_functions.h
new file mode 100644
index 0000000..a1ea715
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/main_functions.h
@@ -0,0 +1,37 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_MAIN_FUNCTIONS_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_MAIN_FUNCTIONS_H_
+
+// Expose a C friendly interface for main functions.
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+// Initializes all data needed for the example. The name is important, and needs
+// to be setup() for Arduino compatibility.
+void setup();
+
+// Runs one iteration of data gathering and inference. This should be called
+// repeatedly from the application code. The name needs to be loop() for Arduino
+// compatibility.
+void loop();
+
+#ifdef __cplusplus
+}
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_MAIN_FUNCTIONS_H_
diff --git a/tensorflow/lite/micro/examples/hello_world/model.cc b/tensorflow/lite/micro/examples/hello_world/model.cc
new file mode 100644
index 0000000..08d639b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/model.cc
@@ -0,0 +1,237 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Automatically created from a TensorFlow Lite flatbuffer using the command:
+// xxd -i model.tflite > model.cc
+
+// This is a standard TensorFlow Lite model file that has been converted into a
+// C data array, so it can be easily compiled into a binary for devices that
+// don't have a file system.
+
+// See train/README.md for a full description of the creation process.
+
+#include "tensorflow/lite/micro/examples/hello_world/model.h"
+
+// Keep model aligned to 8 bytes to guarantee aligned 64-bit accesses.
+alignas(8) const unsigned char g_model[] = {
+ 0x1c, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x14, 0x00, 0x20, 0x00,
+ 0x1c, 0x00, 0x18, 0x00, 0x14, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x04, 0x00, 0x14, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x98, 0x00, 0x00, 0x00, 0xc8, 0x00, 0x00, 0x00, 0x1c, 0x03, 0x00, 0x00,
+ 0x2c, 0x03, 0x00, 0x00, 0x30, 0x09, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x60, 0xf7, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00,
+ 0x44, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x73, 0x65, 0x72, 0x76,
+ 0x65, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x73, 0x65, 0x72, 0x76,
+ 0x69, 0x6e, 0x67, 0x5f, 0x64, 0x65, 0x66, 0x61, 0x75, 0x6c, 0x74, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xbc, 0xff, 0xff, 0xff,
+ 0x09, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,
+ 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x34, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x76, 0xfd, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x0d, 0x00, 0x00, 0x00, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x5f,
+ 0x69, 0x6e, 0x70, 0x75, 0x74, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x13, 0x00, 0x00, 0x00, 0x6d, 0x69, 0x6e, 0x5f, 0x72, 0x75, 0x6e, 0x74,
+ 0x69, 0x6d, 0x65, 0x5f, 0x76, 0x65, 0x72, 0x73, 0x69, 0x6f, 0x6e, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x50, 0x02, 0x00, 0x00, 0x48, 0x02, 0x00, 0x00,
+ 0x34, 0x02, 0x00, 0x00, 0xdc, 0x01, 0x00, 0x00, 0x8c, 0x01, 0x00, 0x00,
+ 0x6c, 0x01, 0x00, 0x00, 0x5c, 0x00, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00,
+ 0x34, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0xfa, 0xfd, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x31, 0x2e, 0x35, 0x2e, 0x30, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x84, 0xfd, 0xff, 0xff,
+ 0x88, 0xfd, 0xff, 0xff, 0x8c, 0xfd, 0xff, 0xff, 0x22, 0xfe, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x21, 0xa5, 0x8b, 0xca,
+ 0x5e, 0x1d, 0xce, 0x42, 0x9d, 0xce, 0x1f, 0xb0, 0xdf, 0x54, 0x2f, 0x81,
+ 0x3e, 0xfe, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00,
+ 0xee, 0xfc, 0x00, 0xec, 0x05, 0x17, 0xef, 0xec, 0xe6, 0xf8, 0x03, 0x01,
+ 0x00, 0xfa, 0xf8, 0xf5, 0xdc, 0xeb, 0x27, 0x14, 0xf1, 0xde, 0xe2, 0xdb,
+ 0xf0, 0xde, 0x31, 0x06, 0x02, 0xe6, 0xee, 0xf9, 0x00, 0x16, 0x07, 0xe0,
+ 0xfe, 0xff, 0xe9, 0x06, 0xe7, 0xef, 0x81, 0x1b, 0x18, 0xea, 0xc9, 0x01,
+ 0x0f, 0x00, 0xda, 0xf7, 0x0e, 0xec, 0x13, 0x1f, 0x04, 0x13, 0xb4, 0xe6,
+ 0xfd, 0x06, 0xb9, 0xe0, 0x0d, 0xec, 0xf0, 0xde, 0xeb, 0xf7, 0x05, 0x26,
+ 0x1a, 0xe4, 0x6f, 0x1a, 0xea, 0x1e, 0x35, 0xdf, 0x1a, 0xf3, 0xf1, 0x19,
+ 0x0f, 0x03, 0x1b, 0xe1, 0xde, 0x13, 0xf6, 0x19, 0xff, 0xf6, 0x1b, 0x18,
+ 0xf0, 0x1c, 0xda, 0x1b, 0x1b, 0x20, 0xe5, 0x1a, 0xf5, 0xff, 0x96, 0x0b,
+ 0x00, 0x01, 0xcd, 0xde, 0x0d, 0xf6, 0x16, 0xe3, 0xed, 0xfc, 0x0e, 0xe9,
+ 0xfa, 0xeb, 0x5c, 0xfc, 0x1d, 0x02, 0x5b, 0xe2, 0xe1, 0xf5, 0x15, 0xec,
+ 0xf4, 0x00, 0x13, 0x05, 0xec, 0x0c, 0x1d, 0x14, 0x0e, 0xe7, 0x0b, 0xf4,
+ 0x19, 0x00, 0xd7, 0x05, 0x27, 0x02, 0x15, 0xea, 0xea, 0x02, 0x9b, 0x00,
+ 0x0c, 0xfa, 0xe8, 0xea, 0xfd, 0x00, 0x14, 0xfd, 0x0b, 0x02, 0xef, 0xee,
+ 0x06, 0xee, 0x01, 0x0d, 0x06, 0xe6, 0xf7, 0x11, 0xf7, 0x09, 0xf8, 0xf1,
+ 0x21, 0xff, 0x0e, 0xf3, 0xec, 0x12, 0x26, 0x1d, 0xf2, 0xe9, 0x28, 0x18,
+ 0xe0, 0xfb, 0xf3, 0xf4, 0x05, 0x1d, 0x1d, 0xfb, 0xfd, 0x1e, 0xfc, 0x11,
+ 0xe8, 0x07, 0x09, 0x03, 0x12, 0xf2, 0x36, 0xfb, 0xdc, 0x1c, 0xf9, 0xef,
+ 0xf3, 0xe7, 0x6f, 0x0c, 0x1d, 0x00, 0x45, 0xfd, 0x0e, 0xf0, 0x0b, 0x19,
+ 0x1a, 0xfa, 0xe0, 0x19, 0x1f, 0x13, 0x36, 0x1c, 0x12, 0xeb, 0x3b, 0x0c,
+ 0xb4, 0xcb, 0xe6, 0x13, 0xfa, 0xeb, 0xf1, 0x06, 0x1c, 0xfa, 0x18, 0xe5,
+ 0xeb, 0xcb, 0x0c, 0xf4, 0x4a, 0xff, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x75, 0x1c, 0x11, 0xe1, 0x0c, 0x81, 0xa5, 0x42,
+ 0xfe, 0xd5, 0xd4, 0xb2, 0x61, 0x78, 0x19, 0xdf, 0x66, 0xff, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x77, 0x0b, 0x00, 0x00, 0x53, 0xf6, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x77, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0xd3, 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x72, 0x21, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x2f, 0x07, 0x00, 0x00,
+ 0x67, 0xf5, 0xff, 0xff, 0x34, 0xf0, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0xb2, 0xff, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0xb5, 0x04, 0x00, 0x00, 0x78, 0x0a, 0x00, 0x00,
+ 0x2d, 0x06, 0x00, 0x00, 0x71, 0xf8, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x9a, 0x0a, 0x00, 0x00, 0xfe, 0xf7, 0xff, 0xff, 0x0e, 0x05, 0x00, 0x00,
+ 0xd4, 0x09, 0x00, 0x00, 0x47, 0xfe, 0xff, 0xff, 0xb6, 0x04, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0xac, 0xf7, 0xff, 0xff, 0x4b, 0xf9, 0xff, 0xff,
+ 0x4a, 0x05, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x04, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x8c, 0xef, 0xff, 0xff, 0x84, 0xff, 0xff, 0xff, 0x88, 0xff, 0xff, 0xff,
+ 0x0f, 0x00, 0x00, 0x00, 0x4d, 0x4c, 0x49, 0x52, 0x20, 0x43, 0x6f, 0x6e,
+ 0x76, 0x65, 0x72, 0x74, 0x65, 0x64, 0x2e, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x14, 0x00,
+ 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0xdc, 0x00, 0x00, 0x00,
+ 0xe0, 0x00, 0x00, 0x00, 0xe4, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x6d, 0x61, 0x69, 0x6e, 0x00, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x84, 0x00, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x96, 0xff, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08,
+ 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x04, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xca, 0xff, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x08, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0xba, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,
+ 0x05, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00,
+ 0x16, 0x00, 0x00, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x0b, 0x00, 0x04, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00,
+ 0x08, 0x00, 0x07, 0x00, 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01,
+ 0x01, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x4c, 0x04, 0x00, 0x00,
+ 0xd0, 0x03, 0x00, 0x00, 0x68, 0x03, 0x00, 0x00, 0x0c, 0x03, 0x00, 0x00,
+ 0x98, 0x02, 0x00, 0x00, 0x24, 0x02, 0x00, 0x00, 0xb0, 0x01, 0x00, 0x00,
+ 0x24, 0x01, 0x00, 0x00, 0x98, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0xf0, 0xfb, 0xff, 0xff, 0x18, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x54, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x6c, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0xdc, 0xfb, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x4a, 0xce, 0x0a, 0x3c, 0x01, 0x00, 0x00, 0x00,
+ 0x34, 0x84, 0x85, 0x3f, 0x01, 0x00, 0x00, 0x00, 0xc5, 0x02, 0x8f, 0xbf,
+ 0x1e, 0x00, 0x00, 0x00, 0x53, 0x74, 0x61, 0x74, 0x65, 0x66, 0x75, 0x6c,
+ 0x50, 0x61, 0x72, 0x74, 0x69, 0x74, 0x69, 0x6f, 0x6e, 0x65, 0x64, 0x43,
+ 0x61, 0x6c, 0x6c, 0x3a, 0x30, 0x5f, 0x69, 0x6e, 0x74, 0x38, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0xfc, 0xff, 0xff, 0x18, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x54, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x64, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x6c, 0xfc, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0x93, 0xd0, 0xc0, 0x3b, 0x01, 0x00, 0x00, 0x00,
+ 0xc2, 0x0f, 0xc0, 0x3f, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x74, 0x66, 0x6c, 0x2e, 0x66, 0x75, 0x6c, 0x6c,
+ 0x79, 0x5f, 0x63, 0x6f, 0x6e, 0x6e, 0x65, 0x63, 0x74, 0x65, 0x64, 0x31,
+ 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x08, 0xfd, 0xff, 0xff, 0x18, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x58, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x64, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0xff, 0xff, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0xf4, 0xfc, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x24, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff,
+ 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xe0, 0xdb, 0x47, 0x3c, 0x01, 0x00, 0x00, 0x00, 0x04, 0x14, 0x47, 0x40,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x13, 0x00, 0x00, 0x00,
+ 0x74, 0x66, 0x6c, 0x2e, 0x66, 0x75, 0x6c, 0x6c, 0x79, 0x5f, 0x63, 0x6f,
+ 0x6e, 0x6e, 0x65, 0x63, 0x74, 0x65, 0x64, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x02, 0xfe, 0xff, 0xff,
+ 0x14, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x50, 0x00, 0x00, 0x00, 0x6c, 0xfd, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xfb, 0x4b, 0x0b, 0x3c,
+ 0x01, 0x00, 0x00, 0x00, 0x40, 0x84, 0x4b, 0x3f, 0x01, 0x00, 0x00, 0x00,
+ 0x63, 0x35, 0x8a, 0xbf, 0x0d, 0x00, 0x00, 0x00, 0x73, 0x74, 0x64, 0x2e,
+ 0x63, 0x6f, 0x6e, 0x73, 0x74, 0x61, 0x6e, 0x74, 0x32, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x72, 0xfe, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x50, 0x00, 0x00, 0x00,
+ 0xdc, 0xfd, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x60, 0x01, 0x4f, 0x3c, 0x01, 0x00, 0x00, 0x00, 0x47, 0x6d, 0xb3, 0x3f,
+ 0x01, 0x00, 0x00, 0x00, 0x5d, 0x63, 0xcd, 0xbf, 0x0d, 0x00, 0x00, 0x00,
+ 0x73, 0x74, 0x64, 0x2e, 0x63, 0x6f, 0x6e, 0x73, 0x74, 0x61, 0x6e, 0x74,
+ 0x31, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0xe2, 0xfe, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,
+ 0x48, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x50, 0x00, 0x00, 0x00, 0x4c, 0xfe, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xd5, 0x6b, 0x8a, 0x3b, 0x01, 0x00, 0x00, 0x00,
+ 0xab, 0x49, 0x01, 0x3f, 0x01, 0x00, 0x00, 0x00, 0xfd, 0x56, 0x09, 0xbf,
+ 0x0c, 0x00, 0x00, 0x00, 0x73, 0x74, 0x64, 0x2e, 0x63, 0x6f, 0x6e, 0x73,
+ 0x74, 0x61, 0x6e, 0x74, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x52, 0xff, 0xff, 0xff,
+ 0x14, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x02, 0x3c, 0x00, 0x00, 0x00, 0x44, 0xff, 0xff, 0xff,
+ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x28, 0xb3, 0xd9, 0x38, 0x0c, 0x00, 0x00, 0x00,
+ 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x2f, 0x62, 0x69, 0x61, 0x73,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xaa, 0xff, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x38, 0x00, 0x00, 0x00,
+ 0x9c, 0xff, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xdd, 0x9b, 0x21, 0x39, 0x0c, 0x00, 0x00, 0x00,
+ 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x33, 0x2f, 0x62, 0x69, 0x61, 0x73,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x14, 0x00, 0x13, 0x00, 0x0c, 0x00,
+ 0x08, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,
+ 0x48, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x04, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xf4, 0xd4, 0x51, 0x38, 0x0c, 0x00, 0x00, 0x00, 0x64, 0x65, 0x6e, 0x73,
+ 0x65, 0x5f, 0x34, 0x2f, 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x14, 0x00, 0x1c, 0x00,
+ 0x18, 0x00, 0x17, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x04, 0x00, 0x14, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x2c, 0x00, 0x00, 0x00, 0x64, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09, 0x84, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0xff, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x14, 0x00,
+ 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00, 0x0c, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x24, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff,
+ 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x5d, 0x4f, 0xc9, 0x3c, 0x01, 0x00, 0x00, 0x00, 0x0e, 0x86, 0xc8, 0x40,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x72, 0x76, 0x69, 0x6e, 0x67, 0x5f, 0x64, 0x65, 0x66, 0x61,
+ 0x75, 0x6c, 0x74, 0x5f, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x5f,
+ 0x69, 0x6e, 0x70, 0x75, 0x74, 0x3a, 0x30, 0x5f, 0x69, 0x6e, 0x74, 0x38,
+ 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x24, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xd8, 0xff, 0xff, 0xff,
+ 0x06, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06,
+ 0x0c, 0x00, 0x0c, 0x00, 0x0b, 0x00, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x72, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x72,
+ 0x0c, 0x00, 0x10, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x08, 0x00, 0x04, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x09};
+const int g_model_len = 2488;
diff --git a/tensorflow/lite/micro/examples/hello_world/model.h b/tensorflow/lite/micro/examples/hello_world/model.h
new file mode 100644
index 0000000..488f47b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/model.h
@@ -0,0 +1,31 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Automatically created from a TensorFlow Lite flatbuffer using the command:
+// xxd -i model.tflite > model.cc
+
+// This is a standard TensorFlow Lite model file that has been converted into a
+// C data array, so it can be easily compiled into a binary for devices that
+// don't have a file system.
+
+// See train/README.md for a full description of the creation process.
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_MODEL_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_MODEL_H_
+
+extern const unsigned char g_model[];
+extern const int g_model_len;
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_MODEL_H_
diff --git a/tensorflow/lite/micro/examples/hello_world/output_handler.cc b/tensorflow/lite/micro/examples/hello_world/output_handler.cc
new file mode 100644
index 0000000..4cae034
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/output_handler.cc
@@ -0,0 +1,24 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/output_handler.h"
+
+void HandleOutput(tflite::ErrorReporter* error_reporter, float x_value,
+ float y_value) {
+ // Log the current X and Y values
+ TF_LITE_REPORT_ERROR(error_reporter, "x_value: %f, y_value: %f\n",
+ static_cast<double>(x_value),
+ static_cast<double>(y_value));
+}
diff --git a/tensorflow/lite/micro/examples/hello_world/output_handler.h b/tensorflow/lite/micro/examples/hello_world/output_handler.h
new file mode 100644
index 0000000..14e9d70
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/output_handler.h
@@ -0,0 +1,26 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_OUTPUT_HANDLER_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_OUTPUT_HANDLER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+// Called by the main loop to produce some output based on the x and y values
+void HandleOutput(tflite::ErrorReporter* error_reporter, float x_value,
+ float y_value);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_HELLO_WORLD_OUTPUT_HANDLER_H_
diff --git a/tensorflow/lite/micro/examples/hello_world/output_handler_test.cc b/tensorflow/lite/micro/examples/hello_world/output_handler_test.cc
new file mode 100644
index 0000000..db52983
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/output_handler_test.cc
@@ -0,0 +1,31 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/output_handler.h"
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestCallability) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ // This will have external side-effects (like printing to the debug console
+ // or lighting an LED) that are hard to observe, so the most we can do is
+ // make sure the call doesn't crash.
+ HandleOutput(µ_error_reporter, 0, 0);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/hello_world/riscv32_mcu/Makefile.inc b/tensorflow/lite/micro/examples/hello_world/riscv32_mcu/Makefile.inc
new file mode 100644
index 0000000..f24610a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/riscv32_mcu/Makefile.inc
@@ -0,0 +1,26 @@
+ifeq ($(TARGET), riscv32_mcu)
+ # Wrap functions
+ MICRO_FE310_LIBWRAP_SRCS := \
+ $(wildcard $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/sys/*.c) \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/misc/write_hex.c \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/stdlib/malloc.c
+
+ MICRO_FE310_BSP_ENV_SRCS := \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/start.S \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/entry.S \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/freedom-e300-hifive1/init.c
+
+ HELLO_WORLD_TEST_SRCS += $(MICRO_FE310_LIBWRAP_SRCS) $(MICRO_FE310_BSP_ENV_SRCS)
+ HELLO_WORLD_SRCS += $(MICRO_FE310_LIBWRAP_SRCS) $(MICRO_FE310_BSP_ENV_SRCS) \
+ tensorflow/lite/micro/arduino/abi.cc
+
+ LIBWRAP_SYMS := malloc free \
+ open lseek read write fstat stat close link unlink \
+ execve fork getpid kill wait \
+ isatty times sbrk _exit puts
+
+ LDFLAGS += $(foreach s,$(LIBWRAP_SYMS),-Wl,--wrap=$(s))
+ LDFLAGS += $(foreach s,$(LIBWRAP_SYMS),-Wl,--wrap=_$(s))
+ LDFLAGS += -L. -Wl,--start-group -lc -Wl,--end-group
+endif
+
diff --git a/tensorflow/lite/micro/examples/hello_world/sparkfun_edge/constants.cc b/tensorflow/lite/micro/examples/hello_world/sparkfun_edge/constants.cc
new file mode 100644
index 0000000..1816a2f
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/sparkfun_edge/constants.cc
@@ -0,0 +1,19 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/constants.h"
+
+// This is tuned so that a full cycle takes ~4 seconds on a SparkFun Edge.
+const int kInferencesPerCycle = 1000;
diff --git a/tensorflow/lite/micro/examples/hello_world/sparkfun_edge/output_handler.cc b/tensorflow/lite/micro/examples/hello_world/sparkfun_edge/output_handler.cc
new file mode 100644
index 0000000..87f2cdf
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/sparkfun_edge/output_handler.cc
@@ -0,0 +1,81 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/output_handler.h"
+
+#include "am_bsp.h" // NOLINT
+
+/*
+This function uses the device's LEDs to visually indicate the current y value.
+The y value is in the range -1 <= y <= 1. The LEDs (red, green, blue,
+and yellow) are physically lined up in the following order:
+
+ [ R B G Y ]
+
+The following table represents how we will light the LEDs for different values:
+
+| Range | LEDs lit |
+| 0.75 <= y <= 1 | [ 0 0 1 1 ] |
+| 0 < y < 0.75 | [ 0 0 1 0 ] |
+| y = 0 | [ 0 0 0 0 ] |
+| -0.75 < y < 0 | [ 0 1 0 0 ] |
+| -1 <= y <= 0.75 | [ 1 1 0 0 ] |
+
+*/
+void HandleOutput(tflite::ErrorReporter* error_reporter, float x_value,
+ float y_value) {
+ // The first time this method runs, set up our LEDs correctly
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ // Setup LED's as outputs
+#ifdef AM_BSP_NUM_LEDS
+ am_devices_led_array_init(am_bsp_psLEDs, AM_BSP_NUM_LEDS);
+ am_devices_led_array_out(am_bsp_psLEDs, AM_BSP_NUM_LEDS, 0x00000000);
+#endif
+ is_initialized = true;
+ }
+
+ // Set the LEDs to represent negative values
+ if (y_value < 0) {
+ // Clear unnecessary LEDs
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_GREEN);
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
+ // The blue LED is lit for all negative values
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_BLUE);
+ // The red LED is lit in only some cases
+ if (y_value <= -0.75f) {
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_RED);
+ } else {
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_RED);
+ }
+ // Set the LEDs to represent positive values
+ } else if (y_value > 0) {
+ // Clear unnecessary LEDs
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_RED);
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_BLUE);
+ // The green LED is lit for all positive values
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_GREEN);
+ // The yellow LED is lit in only some cases
+ if (y_value >= 0.75f) {
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
+ } else {
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
+ }
+ }
+ // Log the current X and Y values
+ TF_LITE_REPORT_ERROR(error_reporter, "x_value: %f, y_value: %f\n",
+ static_cast<double>(x_value),
+ static_cast<double>(y_value));
+}
diff --git a/tensorflow/lite/micro/examples/hello_world/spresense/Makefile.inc b/tensorflow/lite/micro/examples/hello_world/spresense/Makefile.inc
new file mode 100644
index 0000000..d66091c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/spresense/Makefile.inc
@@ -0,0 +1,18 @@
+# Settings for Spresense platform for Hello World example
+# This should be read when the EXTERNALS_TENSORFLOW_EXAMPLE_HELLOWORLD option is selected
+# in Spresense configuration.
+
+ifeq ($(TARGET), spresense)
+ifeq ($(CONFIG_EXTERNALS_TENSORFLOW_EXAMPLE_HELLOWORLD),y)
+
+SPRESENSE_HELLO_WORLD_EXCLUDED_SRCS = \
+ tensorflow/lite/micro/examples/hello_world/main.cc
+
+SPRESENSE_HELLO_WORLD_SRCS = \
+ $(filter-out $(SPRESENSE_HELLO_WORLD_EXCLUDED_SRCS),$(HELLO_WORLD_SRCS))
+
+# In spresence case, those file should be included into libtensorflow-microlite.
+THIRD_PARTY_CC_SRCS += $(SPRESENSE_HELLO_WORLD_SRCS)
+
+endif
+endif
diff --git a/tensorflow/lite/micro/examples/hello_world/spresense/README.md b/tensorflow/lite/micro/examples/hello_world/spresense/README.md
new file mode 100644
index 0000000..db46ba1
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/spresense/README.md
@@ -0,0 +1,84 @@
+# Hello World Example for Spresense
+
+Here explaines how to build and execute this Hello World Example for Spresense.
+To try this on the Spresense, below hardware is required.
+
+Spresense Main board, which is a microcontroller board.
+
+## Table of contents
+
+- [How to build](#how-to-build)
+- [How to run](#how-to-run)
+
+## How to build
+
+The tensorflow.git will be downloaded in build system of Spresense.
+
+### Initial setup
+
+The Spresense SDK build system is required to build this example. The following
+instructions will help you to make it on your PC.
+[Spresense SDK Getting Started Guide:EN](https://developer.sony.com/develop/spresense/docs/sdk_set_up_en.html)
+[Spresense SDK Getting Started Guide:JA](https://developer.sony.com/develop/spresense/docs/sdk_set_up_ja.html)
+[Spresense SDK Getting Started Guide:CN](https://developer.sony.com/develop/spresense/docs/sdk_set_up_zh.html)
+
+And after setup the build system, download
+[Spresense repository](https://github.com/sonydevworld/spresense).
+
+```
+git clone --recursive https://github.com/sonydevworld/spresense.git
+```
+
+### Configure Spresense for this example
+
+The Spresense SDK uses Kconfig mechanism for configuration of software
+components. So at first, you need to configure it for this example. Spresense
+SDK provides some default configurations, and there is a default config to build
+this Hello World example.
+
+1. Go to sdk/ directory in the repository.
+
+ ```
+ cd spresense/sdk
+ ```
+
+2. Execute config.py to configure for this example.
+
+ ```
+ ./tools/config.py examples/tf_example_hello_world
+ ```
+
+This command creates .config file in spesense/nuttx directory.
+
+### Build and Flash the binary into Spresense Main board
+
+After configured, execute make and then flash built image.
+
+1. Execute "make" command in the same directory you configured.
+
+ ```
+ make
+ ```
+
+2. Flash built image into Spresense main board. If the build is successful, a
+ file named nuttx.spk will be created in the current directory, and flash it
+ into Spresense Main board. Make sure USB cable is connected between the
+ board and your PC. The USB will be recognized as USB/serial device like
+ /dev/ttyUSB0 in your PC. In this explanation, we will assume that the device
+ is recognized as /dev/ttyUSB0.
+
+ ```
+ ./tools/flash.sh -c /dev/ttyUSB0 nuttx.spk
+ ```
+
+## How to run
+
+To run the example, connect to the device with a terminal soft like "minicom".
+Then you can see a "nsh>" prompt on it. (If you can't see the prompt, try to
+press enter.)
+
+1. Execute tf_example command on the prompt.
+
+ ```
+ nsh> tf_example
+ ```
diff --git a/tensorflow/lite/micro/examples/hello_world/train/README.md b/tensorflow/lite/micro/examples/hello_world/train/README.md
new file mode 100644
index 0000000..ed59b2a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/train/README.md
@@ -0,0 +1,63 @@
+# Hello World Training
+
+This example shows how to train a 2.5 kB model to generate a `sine` wave.
+
+## Table of contents
+
+- [Overview](#overview)
+- [Training](#training)
+- [Trained Models](#trained-models)
+- [Model Architecture](#model-architecture)
+
+## Overview
+
+1. Dataset: Data is generated locally in the Jupyter Notebook.
+2. Dataset Type: **Structured Data**
+3. Deep Learning Framework: **TensorFlow 2**
+4. Language: **Python 3.7**
+5. Model Size: **2.5 kB**
+6. Model Category: **Regression**
+
+## Training
+
+Train the model in the cloud using Google Colaboratory or locally using a
+Jupyter Notebook.
+
+<table class="tfo-notebook-buttons" align="left">
+ <td>
+ <a target="_blank" href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Google Colaboratory</a>
+ </td>
+ <td>
+ <a target="_blank" href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />Jupyter Notebook</a>
+ </td>
+</table>
+
+*Estimated Training Time: 10 minutes.*
+
+
+## Trained Models
+
+Download Link | [hello_world.zip](https://storage.googleapis.com/download.tensorflow.org/models/tflite/micro/hello_world_2020_12_28.zip)
+------------- | ------------------------------------------------------------------------------------------------------------------------
+
+The `models` directory in the above zip file can be generated by following the
+instructions in the [Training](#training) section above. It
+includes the following 3 model files:
+
+| Name | Format | Target Framework | Target Device |
+| :------------- |:-------------|:-------------|-----|
+| `model.pb` | Keras SavedModel | TensorFlow | Large-Scale/Cloud/Servers |
+| `model.tflite` *(2.5 kB)* | Integer Only Quantized TFLite Model | TensorFlow Lite | Mobile Devices|
+| `model.cc` | C Source File | TensorFlow Lite for Microcontrollers | Microcontrollers |
+
+
+## Model Architecture
+
+The final model used to simulate a sine wave is displayed below. It is a
+simple feed forward deep neural network with 2 fully connected layers with
+ReLu activations and a final fully connected output layer with as shown below.
+
+
+
+*This image was derived from visualizing the 'model.tflite' file in [Netron](https://github.com/lutzroeder/netron)*
+
diff --git a/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb b/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb
new file mode 100644
index 0000000..54f8fcb
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb
@@ -0,0 +1,3691 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "train_hello_world_model.ipynb",
+ "provenance": [],
+ "collapsed_sections": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ }
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aCZBFzjClURz"
+ },
+ "source": [
+ "# Train a Simple TensorFlow Lite for Microcontrollers model\n",
+ "\n",
+ "This notebook demonstrates the process of training a 2.5 kB model using TensorFlow and converting it for use with TensorFlow Lite for Microcontrollers. \n",
+ "\n",
+ "Deep learning networks learn to model patterns in underlying data. Here, we're going to train a network to model data generated by a [sine](https://en.wikipedia.org/wiki/Sine) function. This will result in a model that can take a value, `x`, and predict its sine, `y`.\n",
+ "\n",
+ "The model created in this notebook is used in the [hello_world](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/hello_world) example for [TensorFlow Lite for MicroControllers](https://www.tensorflow.org/lite/microcontrollers/overview).\n",
+ "\n",
+ "<table class=\"tfo-notebook-buttons\" align=\"left\">\n",
+ " <td>\n",
+ " <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n",
+ " </td>\n",
+ " <td>\n",
+ " <a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n",
+ " </td>\n",
+ "</table>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "_UQblnrLd_ET"
+ },
+ "source": [
+ "## Configure Defaults"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "5PYwRFppd-WB"
+ },
+ "source": [
+ "# Define paths to model files\n",
+ "import os\n",
+ "MODELS_DIR = 'models/'\n",
+ "if not os.path.exists(MODELS_DIR):\n",
+ " os.mkdir(MODELS_DIR)\n",
+ "MODEL_TF = MODELS_DIR + 'model'\n",
+ "MODEL_NO_QUANT_TFLITE = MODELS_DIR + 'model_no_quant.tflite'\n",
+ "MODEL_TFLITE = MODELS_DIR + 'model.tflite'\n",
+ "MODEL_TFLITE_MICRO = MODELS_DIR + 'model.cc'"
+ ],
+ "execution_count": 1,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dh4AXGuHWeu1"
+ },
+ "source": [
+ "## Setup Environment\n",
+ "\n",
+ "Install Dependencies"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "cr1VLfotanf6",
+ "outputId": "510567d6-300e-40e2-f5b8-c3520a3f3a8b",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "! pip install tensorflow==2.4.0"
+ ],
+ "execution_count": 2,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "Requirement already satisfied: tensorflow==2.4.0rc0 in /usr/local/lib/python3.6/dist-packages (2.4.0rc0)\n",
+ "Requirement already satisfied: termcolor~=1.1.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.1.0)\n",
+ "Requirement already satisfied: gast==0.3.3 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (0.3.3)\n",
+ "Requirement already satisfied: astunparse~=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.6.3)\n",
+ "Requirement already satisfied: absl-py~=0.10 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (0.10.0)\n",
+ "Requirement already satisfied: keras-preprocessing~=1.1.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.1.2)\n",
+ "Requirement already satisfied: six~=1.15.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.15.0)\n",
+ "Requirement already satisfied: tensorboard~=2.3 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (2.3.0)\n",
+ "Requirement already satisfied: tensorflow-estimator~=2.3.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (2.3.0)\n",
+ "Requirement already satisfied: flatbuffers~=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.12)\n",
+ "Requirement already satisfied: google-pasta~=0.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (0.2.0)\n",
+ "Requirement already satisfied: protobuf~=3.13.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (3.13.0)\n",
+ "Requirement already satisfied: grpcio~=1.32.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.32.0)\n",
+ "Requirement already satisfied: h5py~=2.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (2.10.0)\n",
+ "Requirement already satisfied: wrapt~=1.12.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.12.1)\n",
+ "Requirement already satisfied: opt-einsum~=3.3.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (3.3.0)\n",
+ "Requirement already satisfied: numpy~=1.19.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (1.19.4)\n",
+ "Requirement already satisfied: typing-extensions~=3.7.4 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (3.7.4.3)\n",
+ "Requirement already satisfied: wheel~=0.35 in /usr/local/lib/python3.6/dist-packages (from tensorflow==2.4.0rc0) (0.35.1)\n",
+ "Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tensorboard~=2.3->tensorflow==2.4.0rc0) (1.0.1)\n",
+ "Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tensorboard~=2.3->tensorflow==2.4.0rc0) (3.3.3)\n",
+ "Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.6/dist-packages (from tensorboard~=2.3->tensorflow==2.4.0rc0) (0.4.2)\n",
+ "Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard~=2.3->tensorflow==2.4.0rc0) (1.7.0)\n",
+ "Requirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard~=2.3->tensorflow==2.4.0rc0) (2.23.0)\n",
+ "Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard~=2.3->tensorflow==2.4.0rc0) (50.3.2)\n",
+ "Requirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorboard~=2.3->tensorflow==2.4.0rc0) (1.17.2)\n",
+ "Requirement already satisfied: importlib-metadata; python_version < \"3.8\" in /usr/local/lib/python3.6/dist-packages (from markdown>=2.6.8->tensorboard~=2.3->tensorflow==2.4.0rc0) (2.0.0)\n",
+ "Requirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.3->tensorflow==2.4.0rc0) (1.3.0)\n",
+ "Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard~=2.3->tensorflow==2.4.0rc0) (2020.6.20)\n",
+ "Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard~=2.3->tensorflow==2.4.0rc0) (1.24.3)\n",
+ "Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard~=2.3->tensorflow==2.4.0rc0) (3.0.4)\n",
+ "Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard~=2.3->tensorflow==2.4.0rc0) (2.10)\n",
+ "Requirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tensorboard~=2.3->tensorflow==2.4.0rc0) (4.1.1)\n",
+ "Requirement already satisfied: rsa<5,>=3.1.4; python_version >= \"3\" in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tensorboard~=2.3->tensorflow==2.4.0rc0) (4.6)\n",
+ "Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tensorboard~=2.3->tensorflow==2.4.0rc0) (0.2.8)\n",
+ "Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.6/dist-packages (from importlib-metadata; python_version < \"3.8\"->markdown>=2.6.8->tensorboard~=2.3->tensorflow==2.4.0rc0) (3.4.0)\n",
+ "Requirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.3->tensorflow==2.4.0rc0) (3.1.0)\n",
+ "Requirement already satisfied: pyasn1>=0.1.3 in /usr/local/lib/python3.6/dist-packages (from rsa<5,>=3.1.4; python_version >= \"3\"->google-auth<2,>=1.6.3->tensorboard~=2.3->tensorflow==2.4.0rc0) (0.4.8)\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "tx9lOPWh9grN"
+ },
+ "source": [
+ "Import Dependencies"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "53PBJBv1jEtJ"
+ },
+ "source": [
+ "# TensorFlow is an open source machine learning library\n",
+ "import tensorflow as tf\n",
+ "\n",
+ "# Keras is TensorFlow's high-level API for deep learning\n",
+ "from tensorflow import keras\n",
+ "# Numpy is a math library\n",
+ "import numpy as np\n",
+ "# Pandas is a data manipulation library \n",
+ "import pandas as pd\n",
+ "# Matplotlib is a graphing library\n",
+ "import matplotlib.pyplot as plt\n",
+ "# Math is Python's math library\n",
+ "import math\n",
+ "\n",
+ "# Set seed for experiment reproducibility\n",
+ "seed = 1\n",
+ "np.random.seed(seed)\n",
+ "tf.random.set_seed(seed)"
+ ],
+ "execution_count": 3,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "p-PuBEb6CMeo"
+ },
+ "source": [
+ "## Dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7gB0-dlNmLT-"
+ },
+ "source": [
+ "### 1. Generate Data\n",
+ "\n",
+ "The code in the following cell will generate a set of random `x` values, calculate their sine values, and display them on a graph."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "uKjg7QeMDsDx",
+ "outputId": "2ded7790-62a2-40df-a4f9-429f2dd5357f",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 265
+ }
+ },
+ "source": [
+ "# Number of sample datapoints\n",
+ "SAMPLES = 1000\n",
+ "\n",
+ "# Generate a uniformly distributed set of random numbers in the range from\n",
+ "# 0 to 2π, which covers a complete sine wave oscillation\n",
+ "x_values = np.random.uniform(\n",
+ " low=0, high=2*math.pi, size=SAMPLES).astype(np.float32)\n",
+ "\n",
+ "# Shuffle the values to guarantee they're not in order\n",
+ "np.random.shuffle(x_values)\n",
+ "\n",
+ "# Calculate the corresponding sine values\n",
+ "y_values = np.sin(x_values).astype(np.float32)\n",
+ "\n",
+ "# Plot our data. The 'b.' argument tells the library to print blue dots.\n",
+ "plt.plot(x_values, y_values, 'b.')\n",
+ "plt.show()"
+ ],
+ "execution_count": 4,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYIAAAD4CAYAAADhNOGaAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO3df5hcdX0v8Pd7syRBuJgQthDZNBtLlER7G9pp0gFNqWAWei2JVbxA9hIVn+GHVq2P7oT2eS5WrWaD1qAlkJGoyd0oBhCIt7QbREJAhoRNCUqyhexNQ9k0gYUENfxIzOZz//ieaWbmnM3u7MycM2fm/XqeeXbPZ87sflbMfOb7m2YGERFpXE1RJyAiItFSIRARaXAqBCIiDU6FQESkwakQiIg0uOaoExiLM844w9ra2qJOQ0QkVrZt2/aymbUUx2NZCNra2tDb2xt1GiIisULy+aC4uoZERBqcCoGISINTIRARaXAqBCIiDU6FQESkwVWkEJD8LsmXSD4zzPMk+S2S/SR/QfIP855bQnKX91hSiXxERGT0KtUi+D6AS07w/KUAZnqPFIDbAIDk6QBuAjAPwFwAN5GcXKGcZAzSaWDaNOAd7wCmTAGamgASaG4GZswAMpmoMxSRSqtIITCzzQAOnOCWhQDWmvMEgEkkpwJoB/CgmR0ws4MAHsSJC4pUWEcHMGECMG6ce9NfvhwYGAB27QIOHAByu5QPDQF79gDXXnu8MMyeDbS3qziIxF1YYwRnA3gh73rAiw0X9yGZItlLsndwcLBqiTaCTMZ9um9qAtatA44cAY4dO/6mPxpDQ0BfH7BxoysO06YB118PZLPVy1tEqiM2g8VmljGzhJklWlp8K6RlFDIZ4K1vdW/ce/aU9sY/koEB4PbbgfPPB047zXUxiUg8hFUI9gKYlnfd6sWGi0sFpdPAqae6AvDrX4/uNZMmAaef7rqBSvWb37guptmzS3+tiIQvrEKwAcDV3uyhPwHwKzPbB6AHwAKSk71B4gVeTCogm3VdNsuXA6+9NvL9J53kCkBnJ3DwIPDKK8e7jMyAxYuB8ePdvePGuUJxIn19bvxBrQOR2lap6aM/BJAF8E6SAySvIXkdyeu8Wx4AsBtAP4DvALgBAMzsAIAvA3jSe3zJi0mZ0mnXTTMwMPw9JDBxonuDN3NjBQcPAl1dwfd3dwOHD7t7jx51haKz07U2hnPkiCtEHR3l/T0iUj2M4+H1iUTCtPvo8ObNA7ZuPfE9CxYAPRVse6XTwMqVwKFDw9+zaJErHMlk5X6viIweyW1mliiOx2awWEanre3ERWD+fODxxytbBADXivjNb9zPbm0Nvue++1wrZd68yv5uESmPCkGdyGaBlhbg+cDdxoGZM92b9COPVPcTeTIJvPCC++Q/nK1bNZAsUktUCOpAJuM+ab/8cvDzCxYAzz0XbpdMV5crPIsWBT/f1+daLyISPRWCmJs3z00LDTJunPtkXuluoNFKJoF773WFKMjzz7tZRVqZLBKtWB5VKc6JBoVnzQJ27gw3n+H09LitKDZu9D935MjxQpZKhZuXiDhqEcRUJjN8EViwoHaKQE5Pj+sqmjQp+PmvfS3cfETkOBWCGMpk3L4+QRYvjq4raCTJpFuncNZZ/uf27FEXkUhUVAhipqPDdaUcO+Z/bvFit+ir1u3b53It9uUva+M6kSioEMRIR4fbLTRIZ2c8ikBOd7d/imn+xnXalkIkPCoEMZHNBheBRYtc3/tw20LUsq4uYNUq4Jxz/M8tX66uIpGwaIuJGMhmgSuv9C8W+4M/ALZvjyanSspmgQsu8G+LPWEC8Oab0eQkUo+0xURM5d4ki4sACdx2WzQ5VVoyCXzhC/744cNu2qmIVJcKQY1buDD4AJnbb6+vzdu6uoKnlm7cqL2JRKpNhaCGTZ0KBJ3K2dlZn4uvHnggOL51q7axFqkmFYIaNW8esH+/P75gQTwHhkcjmXSDx0Gnoq1bp2mlItWiQlCDstngVcOzZtXuYrFKSaWAn//cDRQXW7o0/HxEGkGlTii7hOSzJPtJ+v65kvwmye3e4zmSr+Y9N5T33IZK5BN3CxcGx2tt24hqSSaBb33LH9+9O/xcRBpB2YWA5DgAtwK4FMBsAFeSLNht3sz+2szmmNkcAN8G8OO8p9/IPWdml5WbT9y1tQWPCwy3g2e9SqX8f/Pb367uIZFqqESLYC6AfjPbbWZHANwJYJjPtACAKwH8sAK/t+60twcfLNMIXUJBenrcwHhrq9tS+9FHgfe8R6uORSqtEoXgbAAv5F0PeDEfktMBzADws7zwRJK9JJ8gOcwxJgDJlHdf72DQR+aYy2SCt2mupe2ko9DVBdxwg9tbycx9Xb5c6wtEKinsweIrANxtZkN5seneSrerAKwg+XtBLzSzjJklzCzR0tISRq6hCtqGefr0xi4CORde6J9JtHGjppSKVEolCsFeANPyrlu9WJArUNQtZGZ7va+7AWwCcF4FcoqVdNptw5zv5JP9sUaVTAKf/7w/vm6d9iMSqYRKFIInAcwkOYPkeLg3e9/sH5LnApgMIJsXm0xygvf9GQAuANBQn4HTadfVUeyv/ir8XGpZVxcwc6Y/fu21GkAWKVfZhcDMjgL4FIAeAH0A1pvZDpJfIpk/C+gKAHda4S53swD0knwawMMAlplZQxWClSv9sba2+l00Vo41a4Ljl18ebh4i9aYiZxab2QMAHiiK/e+i6y8GvO5xAL9fiRziKJ0GDh3yx2+8Mfxc4iCZdLOIiltQe/e6/y1VPEXGRiuLI5LNAl//uj++eHF97iNUKV1dwNy5/vjy5eoiEhkrFYKILF3qP24yLkdNRm3LFuC00/zxoLEWERmZCkEE0mlg8+bCWNyOmozazTf7Yxs2qFUgMhYqBCHLZoFbby2Mtbaqf7tUqZT/zOPcYjMRKY0KQYiyWbdFwmuvFcavuiqafOKuq8ud2ZzvJz9Rq0CkVCoEIbr+ev+4wPTpag2Uo7PT7UOUc+wYcPXVWmgmUgoVghD19fljf/M34edRT5JJtxbjpJPcNhRmQH+/W2imYiAyOioEIenoAI4cKYy1tmqqaCWkUsAjjwDFW1AF7d8kIn4qBCHIZNy+OMXWrw8/l3qVTAJNRf9v3rNH4wUio6FCEIJbbvHHOjvdm5dUzuTJ/thHPhJ+HiJxo0JQZZmMfyvpxYs1QFwNn/2sPzYwoO2qRUaiQlBlK1YUXs+apYVj1ZJKuSJb7J57ws9FJE5UCKoonfbPFAr61CqV093t337izTd1vKXIiagQVEnQpnKzZ2uWUBiCtp9YvlzTSUWGo0JQJWvX+hePfeYz0eTSaFIpYP58f3z16vBzEYkDFYIqyGaB7373+DXpZgmpNRCeZcv8sf/8z/DzEImDihQCkpeQfJZkP8mlAc9/lOQgye3e4xN5zy0huct7LKlEPlFbuxb47W/d96Rb5apZQuFKJv37EGkGkUiwsgsByXEAbgVwKYDZAK4kOTvg1h+Z2RzvcYf32tMB3ARgHoC5AG4iGTAbPD4yGeA733FbHQBu64Orr442p0ZVvDspoAPvRYJUokUwF0C/me02syMA7gSwcJSvbQfwoJkdMLODAB4EcEkFcopEJgNcdx0wNHQ89vGPa+FYVJLJ4OmkOvBepFAlCsHZAF7Iux7wYsU+RPIXJO8mOa3E14JkimQvyd7BwcEKpF1Z2awrArmWAOC2PFBrIFrd3cCpp/rjS30dmCKNK6zB4p8AaDOz/w73qX9NqT/AzDJmljCzREvx7mI1YPnywiIAAOeeq9ZALbjhBn9s82a1CkRyKlEI9gKYlnfd6sX+i5m9YmaHvcs7APzRaF8bF0884Y9pumht6OoCZs70x3WamYhTiULwJICZJGeQHA/gCgAb8m8gOTXv8jIAufW2PQAWkJzsDRIv8GKxkskA+/cXxubM0XTRWrJmjZvBle+++9QqEAEqUAjM7CiAT8G9gfcBWG9mO0h+ieRl3m2fJrmD5NMAPg3go95rDwD4MlwxeRLAl7xYrBTve0+6w1KkdiSTwO23++MXXhh6KiI1h1bcsR0DiUTCent7o04DANDeDmzcWBjr7NS6gVo1fvzxNR45c+cCW7ZEk49ImEhuM7NEcVwri8uQyfiLQEuLikAt+7M/88dq5DOFSGRUCMrw13/tj33sY+HnIaPX0+NaBfmOHdNYgTQ2FYIxam8HXn+9MDZliloDcbBpkz+mk8ykkakQjNHDD/tjX/1q+HlI6ZJJt/VHvoEBtQqkcakQjNHJJxden3KKpovGSdBYQVBLQaQRqBCMQSYDHDpUGPuHf4gmFxmbnh43Wyinudl17Yk0IhWCEqXTbtOy/ENnFi1SayCOtmwBVq1y3URDQ8AnP6mdSaUxqRCUIJPxb0vQ1BS83bHEwyuvuCJgBhw9Clx/vYqBNB4VghLccos/9s53amO5OLvwQlfMc44dc8VAA8fSSFQIRimbBXbu9Mc/+9nwc5HKSSaBW28t3IcoVwxEGoUKwSgF7VSpc4jrQyoF/O7vFsaeflpdRNI4VAhG6dlnC69nz9bisXpy3nn+2E03hZ+HSBRUCEYhmwV27SqM6ayB+hI04L9/v8YKpDGoEIzC2rVuRknO/PnqEqo3yaQ7Q6KYxgqkEagQjCCbBf75nwtjs2dHk4tUV9AZErt3h5+HSNgqUghIXkLyWZL9JH3HgpP8HMmd3uH1D5GcnvfcEMnt3mND8WujlM26T//PP388Nm6cDqSvV8kksGBBYYzUoLHUv7ILAclxAG4FcCmA2QCuJFn8mfkpAAnv8Pq7AeTPwXnDzOZ4j8tQQzZtKuwSAoA/+iOtG6hnxVtP/PrXbiW5ioHUs0q0COYC6Dez3WZ2BMCdABbm32BmD5tZbtPmJ+AOqa95r77qP+f2mmuiyUXCM2mSP7ZiRfh5iISlEoXgbAAv5F0PeLHhXAMgv9d9Islekk+QXDTci0imvPt6BwcHy8t4FNJpt3Ygd5JnW5vbl0aDxPXvQx/yx954I/w8RMIS6mAxyQ4ACQA354Wne2doXgVgBcnfC3qtmWXMLGFmiZaWlqrmmc0CX/96Yewd71ARaBSpFLB4cWHsP/5D3UNSvypRCPYCmJZ33erFCpC8GMDfArjMzA7n4ma21/u6G8AmAAFLe8K1aVPh7qJA8KdEqV/d3W5X2RztQST1rBKF4EkAM0nOIDkewBUACmb/kDwPwCq4IvBSXnwyyQne92cAuABAwI4+4dqxo/B68WK1BhpRZ6d/Q7obboguH5FqKbsQmNlRAJ8C0AOgD8B6M9tB8kskc7OAbgZwKoC7iqaJzgLQS/JpAA8DWGZmkRaC9nZg3brC2LveFU0uEq1kEjj33MLY9u3qIpL6Q8uNhsZIIpGw3t7eiv/c3ABxvqYm4LHHNGW0UWUybvpovrPOAvbtiyYfkXKQ3OaNyRbQyuI83/62P/b5z6sINLJUCjj11MKY9iCSeqNC4Ono8E8RbG3VDqMSPC4QtC25SFypEHjuussf+8AHws9Dak9Xl3866X33aaxA6ocKgWdoyB/TnkKS091duPUEANx4YzS5iFSaCgHcJ7viQrBggcYGpFDx9iIHDrhZZiJxp1lDAN72tsJZIFOmAC+/XLEfL3WkubnwQ8OECcCbb0aXj0gpNGtoGOm0fyrge98bTS5S+97+9sLr4rOOReKo4QvBN77hjwUdWygCAGvWFO5Ie9FFmkoq8dfQhWDePP/YwPjxGhuQ4SWTwM9/Dlx3nesmWrUKuPBCFQOJt4YtBJkMsHWrP3755eHnIvGS+6Bw9KjbpvzIEXeutUhcNWwhCJr6N2mSmyYoMpL9+wuvn3gimjxEKqEhC0E266b+FXvggfBzkXg666zC6+3b3cQDkThqyEKwdKk/pnUDUoqrr/YfY7p8ucYKJJ4arhBks8CjjxbGTjvNHVouMlrJZPA04yVLws9FpFwNVwg2bTp+DnHO+94XSSoSc8uW+WO7dmkPIomfhisE991XeN3UpHUDMjbJpH8zOgD42tfCz0WkHBUpBCQvIfksyX6Svh54khNI/sh7fgvJtrznbvTiz5Ks6s4tHR3+KaOplMYGZOy6u4GZMwtje/aoVSDxUnYhIDkOwK0ALgUwG8CVJGcX3XYNgINmdg6AbwLo8l47G+6M43cBuATASu/nVcW99/pj2mFUyrVmjT92yy3h5yEyVpVoEcwF0G9mu83sCIA7ASwsumchgNw/l7sBXESSXvxOMztsZv8OoN/7eRWXyQCvv14Y00whqYRkEpgzpzDW16cZRBIflSgEZwN4Ie96wIsF3uMddv8rAFNG+VoAAMkUyV6SvYODgyUnec89hddTp2qmkFTOn/xJ4bWZVhtLZWUybtvzanQ7xmaw2MwyZpYws0RLS0vJr//Qhwqvv/jFyuQlArguxpNOKox95ztqFUhlZDLAtdcCGze6r5UuBpUoBHsBTMu7bvVigfeQbAbwVgCvjPK1FZFKuQ3CFixwX1OpavwWaVTJJPDII0Bb2/HY0FDw4kWRUhXPRFu9urI/vxKF4EkAM0nOIDkebvB3Q9E9GwDkltp8GMDPzJ2IswHAFd6sohkAZgII2AquMlIp1x2kIiDVEDTetHmzWgVSnkzGzUTL97a3VfZ3lF0IvD7/TwHoAdAHYL2Z7SD5JZKXebetBjCFZD+AzwFY6r12B4D1AHYC+BcAnzSzgNODReLh5JP9MbUKpBxB3diVXvukoypFKijXl5uPdGcYaIaalCqddntY5Zs/33VDjoWOqhQJQSrlX22sGUQyVt/+tj8WtLVJuVQIRCqsu9u/rkDnFUipMhngjTcKY6ecUp2WpQqBSBUUryvYvt1tcSIyWkGr0z/5yer8LhUCkSoIOq9g3TrtQSSjk80CO3cWxmbOBLq6qvP7VAhEqmC48wq0M6mMxg03+GNBe1pVigqBSJUEDert2aN1BXJi2azrSszX0lLdWWcqBCJVkkwCkyb545s2hZ6KxEjxdFEA+NjHqvs7VQhEqihoFfuOHeHnIfGQzfoPz5ozp3pjAzkqBCJV1NXlFgDlW7fOLRQSKbaweAN/ACtXVv/3qhCIVNmyZf4ZRMuXa6xACqXTQPEO+xMnhrMiXYVApMqSSWD6dH98yRJ/TBrXD37gj517bji/W4VAJAQ33uiP7d4dfh5SuyZO9MfC6BYCVAhEQpFKuSmA+Y4dU/eQOOk00N9fGFu1KryNClUIREJy//2F12bBUwWlsWSzwM03F8ZmzQr33BQVApGQJJPuU15T3r+6++7TDKJGt3y5+1CQ753vDDcHFQKREKVSQKJoN/ivf11dRI0qm/W3FMnKHzwzkrIKAcnTST5Icpf3dXLAPXNIZknuIPkLkv8z77nvk/x3ktu9x5zi14vUm2uuKbw+dkznFTSqtWv9rYGFC8M/xKjcFsFSAA+Z2UwAD3nXxV4HcLWZvQvAJQBWkMxfeP8FM5vjPbYHvF6krqRSrg843+23q1XQiPbvL7xuagq/NQCUXwgWAsjtibcGwKLiG8zsOTPb5X3/nwBeAtBSfJ9II3nxRX9MA8eNJZMBfvKT49dNTcBtt0VzpGm5heBMM9vnfb8fwJknupnkXADjAfy/vPDfe11G3yQ54QSvTZHsJdk7WLz8TiRmLr3UH3v00fDzkGhks+6QmaEhd026lmKYM4XyjVgISP6U5DMBj4JdMczMANgwPwYkpwL4PwA+ZmbHvPCNAM4F8McATgcw7PwJM8uYWcLMEi3FE7JFYqa7G2htLYy98grQ3h5NPhKuTZvc2FBOc7M7zCgqIxYCM7vYzN4d8LgfwIveG3zujf6loJ9B8jQA/wTgb83sibyfvc+cwwC+B2BuJf4okThYv94f27hRp5g1ggsvBCZMcN1Bzc3AP/5jNF1COeV2DW0AkNsxZQmA+4tvIDkewL0A1prZ3UXP5YoI4cYXnikzH5HYSCaBxYv98RUrws9FwpNOu0//f/mXwFe+AmzeHF2XUE65hWAZgPeT3AXgYu8aJBMk7/Du+QiA+QA+GjBNdB3JXwL4JYAzAHylzHxEYqW7GzjnnMJYX59mENWrdNpNCujvd9uRv/pqtC2BHFrxJNYYSCQS1tvbG3UaIhWRzQIXXFA4n3zOHOCpp6LLSaqjufn4ADEAnHwy8Prr4f1+ktvMLFEc18pikYglk/51Bdu3a6yg3qTThUUAAI4ciSaXYioEIjXgM5/xx266Kfw8pHqCCvtFF4WfRxAVApEakEoBZ51VGNu/X62CepHNuvGAfBMmAD090eRTTIVApEb83d/5Y0EH2kj8BK0a/9a3ws9jOCoEIjUilQJOP70wduCAtqmOu0zGv8Po/PnRTxnNp0IgUkPmz/fHvve98POQyshmgeuuK5wR1tQELFsWXU5BVAhEakjQzpPNzeHnIZURdOjMZZfVxtqBfCoEIjUkmfQXgxdf1KBxXD37rD8WxTbTI1EhEKkxXV3AorwN3Y8dA264QauN4yaddqvE83V21l5rAFAhEKlJnZ3AuHHHr4eGXDGQeMhk/DOF5s93Rb4WqRCI1KBkEviLvyiMbd+uGURxccst/tjs2eHnMVoqBCI1Kqgv+RvfCD8PKU02C+zcWRhraor2vIGRqBCI1KhkEjj11MLY0JAOr6l1QV14UR1BOVoqBCI1LOhN5aGHws9DRieTcV14+WbPrq3FY0FUCERqWFeX25Mm39AQ0NERTT5yYl/7mj8WtKFgrSmrEJA8neSDJHd5XycPc99Q3qE0G/LiM0huIdlP8kfeaWYikidoT5p16zRwXGvSaWDPnsLYWWfVfmsAKL9FsBTAQ2Y2E8BD3nWQN8xsjve4LC/eBeCbZnYOgIMArikzH5G6k0oFbz2xcmX4uUiwoOmiQPBGgrWo3EKwEMAa7/s1cOcOj4p3TvH7AOTOMS7p9SKNJGhvmkOHtOK4VgSdHVFrG8udSLmF4Ewz2+d9vx/AmcPcN5FkL8knSObe7KcAeNXMjnrXAwDOHu4XkUx5P6N3cHCwzLRF4iVo6wkA+OIXQ09FimQy7uyIYrW2sdyJjFgISP6U5DMBj4X595k7/Hi4A5Cne+dkXgVgBcnfKzVRM8uYWcLMEi0tLaW+XCT2urqAxYsLY/v2aeA4aqtX+2NtbbU9XbTYiPsamtnFwz1H8kWSU81sH8mpAF4a5mfs9b7uJrkJwHkA7gEwiWSz1ypoBbB3DH+DSMPo7gbuvbfwwPMNG4a/X6pv925/LG4HCpXbNbQBwBLv+yUA7i++geRkkhO8788AcAGAnV4L4mEAHz7R60Wk0Ac/WHitsYLotLUBL79cGOvsjM/YQA6teLPsUl5MTgGwHsDvAngewEfM7ADJBIDrzOwTJM8HsArAMbjCs8LMVnuvfzuAOwGcDuApAB1mdnik35tIJKy3t3fMeYvE3Zw5wNNPH79uagIeeyxe3RFxN28esHVrYWzCBODNN6PJZzRIbvO66QuUdeSFmb0C4KKAeC+AT3jfPw7g94d5/W4Ac8vJQaQR3XYb8J73uC2qAff1+uv9q1qlOtJpfxEAgD/90/BzqQStLBaJoWTSf77x00/rzIKwrFjhj02fDvT0hJ9LJagQiMTUxz/ujy0dbkmnVEw2Cxw5Uhgj/auK40SFQCSmurrcWEG+zZs1cFxtQSuI3//+8POoJBUCkRhbudJ9Gs0X1G0hlZFOA/fdVxhrbY1vl1COCoFIjCWTwHvfWxjr69Mis2oI2k+oqQlYvz6afCpJhUAk5pYtc29I+bQ7aeUFtbQuu6w+puyqEIjEXDLpppMW0+6klZPNAi+84I8H7f8URyoEInUglXJ73+c7dEitgkrIZt36gEOHCuPz59dHawBQIRCpG0F73998s9YWlGvpUuC3vy2MNTXFa3fRkagQiNSJVMq/O6kZcPnl0eRTDzIZNyU3H1n7h9GXSoVApI50dwNvfWthbO9ezSIaq6AB4ttvj9+mciNRIRCpM9de64+tW6cuolJls+68h3xtbfVXBAAVApG609UFzA3YynHBgvBziatMBjj/fODVVwvjcTtnYLRUCETq0JYtwbOI2toiSSdWstngVtWiRfXZGgBUCETqVtAsouef15TSkVx9dXC8XtYMBFEhEKlTQWsLALdNgjamC5bNAv39/viCBfU1S6hYWYWA5OkkHyS5y/s6OeCePyO5Pe/xJslF3nPfJ/nvec/N8f8WERmrffuAiRP98Xrt6y7X2rX+WJzPGRitclsESwE8ZGYzATzkXRcws4fNbI6ZzQHwPgCvA9iYd8sXcs+bmc5XEqmwW27xxw4c0JTSYtks8MgjhbFzzon3OQOjVW4hWAhgjff9GgCLRrj/wwD+2cxeL/P3isgopVLB/dt33RV+LrUqnXazhPr6jsdOOim4hVCPyi0EZ5pZbqbtfgBnjnD/FQB+WBT7e5K/IPlNkhOGeyHJFMlekr2Dg4NlpCzSeLq6gClTCmNHjgDt7dHkU0s6OoIPm7nmmvoeF8g3YiEg+VOSzwQ8FubfZ2YGwE7wc6bCHWKf39t2I4BzAfwxgNMBDDufwcwyZpYws0RLS8tIaYtIka9+1R/buLGxu4gyGbfYrti4ccPPHqpHzSPdYGYXD/ccyRdJTjWzfd4b/Usn+FEfAXCvmf3X9k15rYnDJL8H4POjzFtESpRKuX1zit/41q0DBgfrf0A0yKc/HRxfubJxWgNA+V1DGwAs8b5fAuD+E9x7JYq6hbziAZKEG194psx8ROQEuruDVxhv3AjMmxd+PlFqbwcOH/bHFy+u34Vjwym3ECwD8H6SuwBc7F2DZILkHbmbSLYBmAagaEwe60j+EsAvAZwB4Ctl5iMiI+jp8e9SCgBbtzbO+oJMxhW/YrNmuWLZaOi69uMlkUhYb29v1GmIxFp7u//NcPr0+p8umckA113ntujON2kScPBgNDmFheQ2M0sUx7WyWKRB9fQAZ59dGHv++foePM7tI1RcBJqagAceiCanWqBCINLA7rrLHbSSr54Pvv/zP/fHZs0CHnussQaHi6kQiDSwZBL4whf88Ztvrr/xgnTav600AKxe3dhFAFAhEGl4XV3BR1xee239dBO1twcvGps1S6Z0iREAAAeQSURBVEUAUCEQEbiZMp2dwd1Es2dHk1OldHQEzxCaPh3YuTP8fGqRCoGIAHAtg9tv98f7+vzbU8RFRwfwgx/4452d9T87qhQqBCLyX1Kp4DUGBw7Erxi0tbkWTfEMoQULXNGT41QIRKRAd7frOy924EB8uona291U2HykK3KNuJXGSFQIRMRn587gA236+oDzznPz8WtRJgO8613BYwJXXdWYq4ZHQ4VARAL97GfB8e3b3d79tbbWoKPDzXQKGgCePl1F4ERUCEQkUDIJPP44cMYZwc8vX147XUXz5gVvJw24MQENDJ+YCoGIDCuZdFtUBw0gA66r6JRTolt8lk4Dzc1uw7xiTU3AqlUaExgNFQIRGVF3t3tTDfL6665LJuxtrKdMca2SoSH/c2ed5baNaLTtpMdKhUBERmW4s49ztm51A8zVHjvIZl0r4MCB4OdJ4Mc/1orhUqgQiMioBW1Hke/wYfcp/Xd+p/Izizo6gFNPdQPVQa0AwG0l/fOfqwiUSoVAREqS6yY67bTh7xkcdG/Yra3A9dePvSik066onHSSGwx+7bXh7507150noCJQurIKAcnLSe4geYyk77CDvPsuIfksyX6SS/PiM0hu8eI/Ijm+nHxEJBypFPCrX7nWwbhxw9+3d6/btuL8812XzVveMnLXUXu76/ohXeticBA4enT4+0lXmLZsGdvfIuW3CJ4B8JcANg93A8lxAG4FcCmA2QCuJJmbdNYF4Jtmdg6AgwCuKTMfEQlRd7d7kz7R2EG+N95wb+7TprlP+eTxx8SJbgbSxo3Dd/0UmzULOHZMg8LlKqsQmFmfmT07wm1zAfSb2W4zOwLgTgALvQPr3wfgbu++NXAH2ItIzHR1uTUHc+acuIWQMzDg/5R/+LCbgTSSSZPcUZOPP67dQysljDGCswG8kHc94MWmAHjVzI4WxQORTJHsJdk7ODhYtWRFZGySSeCpp9wb/OLFbgzhlFMq9/MnT3Ytj4MHgdtu01hAJY1YCEj+lOQzAY+FYSSYY2YZM0uYWaKlpSXMXy0iJerudmMIhw65opDr8x8/3i30GknuXISmJmDmTPfp/8AB7RpaLSP+JzGzi83s3QGP+0f5O/YCmJZ33erFXgEwiWRzUVxE6kh3N/Db37q+/MOH3UKv+fNdccg3YYLbsmLVKnevmRsreO45ffqvtuaRbynbkwBmkpwB90Z/BYCrzMxIPgzgw3DjBksAjLa4iEhMJZPAI49EnYXkK3f66AdJDgBIAvgnkj1e/G0kHwAAbwzgUwB6APQBWG9mO7wfkQbwOZL9cGMGq8vJR0RESkcrPr4nBhKJhPX29kadhohIrJDcZma+NV9aWSwi0uBUCEREGpwKgYhIg1MhEBFpcLEcLCY5COD5Mb78DAAvVzCdKMT9b4h7/kD8/4a45w/E/2+IIv/pZuZbkRvLQlAOkr1Bo+ZxEve/Ie75A/H/G+KePxD/v6GW8lfXkIhIg1MhEBFpcI1YCDJRJ1ABcf8b4p4/EP+/Ie75A/H/G2om/4YbIxARkUKN2CIQEZE8KgQiIg2uoQoByUtIPkuyn+TSqPMpFcnvknyJ5DNR5zIWJKeRfJjkTpI7SH4m6pxKQXIiya0kn/by/7uocxorkuNIPkXy/0ady1iQ3EPylyS3k4zdDpQkJ5G8m+S/kewjGemJCw0zRkByHIDnALwf7ljMJwFcaWaxOfWU5HwAhwCsNbN3R51PqUhOBTDVzP6V5H8DsA3Aorj8N/DO2T7FzA6RPAnAYwA+Y2ZPRJxayUh+DkACwGlm9oGo8ykVyT0AEmYWywVlJNcAeNTM7iA5HsBbzOzVqPJppBbBXAD9ZrbbzI7AHYYT6nGb5TKzzQAORJ3HWJnZPjP7V+/738CdTzHsOdW1xpxD3uVJ3iN2n6RItgL4HwDuiDqXRkTyrQDmwzt/xcyORFkEgMYqBGcDeCHvegAxehOqNyTbAJwHYEu0mZTG61LZDuAlAA+aWazy96wA0AngWNSJlMEAbCS5jWQq6mRKNAPAIIDved1zd5A8JcqEGqkQSI0geSqAewB81sx+HXU+pTCzITObA3fG9lySseqiI/kBAC+Z2baocynTe8zsDwFcCuCTXrdpXDQD+EMAt5nZeQBeAxDpmGUjFYK9AKblXbd6MQmR17d+D4B1ZvbjqPMZK68p/zCAS6LOpUQXALjM62O/E8D7SHZHm1LpzGyv9/UlAPfCdf3GxQCAgbzW5N1whSEyjVQIngQwk+QMb3DmCgAbIs6poXiDrasB9JnZP0SdT6lItpCc5H1/MtzEg3+LNqvSmNmNZtZqZm1w/wZ+ZmYdEadVEpKneJMN4HWpLAAQm5l0ZrYfwAsk3+mFLgIQ6YSJ5ih/eZjM7CjJTwHoATAOwHfNbEfEaZWE5A8BXAjgDJIDAG4ys9XRZlWSCwD8LwC/9PrZAeBvzOyBCHMqxVQAa7wZaE0A1ptZLKdfxtyZAO51nyvQDOAHZvYv0aZUsr8CsM77ULobwMeiTKZhpo+KiEiwRuoaEhGRACoEIiINToVARKTBqRCIiDQ4FQIRkQanQiAi0uBUCEREGtz/B3TdSrfISH+TAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "iWOlC7W_FYvA"
+ },
+ "source": [
+ "### 2. Add Noise\n",
+ "Since it was generated directly by the sine function, our data fits a nice, smooth curve.\n",
+ "\n",
+ "However, machine learning models are good at extracting underlying meaning from messy, real world data. To demonstrate this, we can add some noise to our data to approximate something more life-like.\n",
+ "\n",
+ "In the following cell, we'll add some random noise to each value, then draw a new graph:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "i0FJe3Y-Gkac",
+ "outputId": "10d4d994-3b78-4512-a029-5ef0e444d75c",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 265
+ }
+ },
+ "source": [
+ "# Add a small random number to each y value\n",
+ "y_values += 0.1 * np.random.randn(*y_values.shape)\n",
+ "\n",
+ "# Plot our data\n",
+ "plt.plot(x_values, y_values, 'b.')\n",
+ "plt.show()"
+ ],
+ "execution_count": 5,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAXwAAAD4CAYAAADvsV2wAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO2de5RcdZXvv7se6aAzTO4UrAkPYxxBFCdLGkOckjE2AwoBA9HccSlzpzMhpAMkIOMjmjtyzYhDnOCSCImYJo+bvpfxsYzkMSaCPMoEKEg6dJweCTgJgyHBXGI7GcYx9KPqd//Yvf39zq/Oqa5OV3W99metXt116pyqU1Vd+7fPfnw3GWOgKIqiND6xap+AoiiKMj6owVcURWkS1OAriqI0CWrwFUVRmgQ1+IqiKE1CotonEMUZZ5xhpk6dWu3TUBRFqSv27dv3K2PMmWH31azBnzp1Krq7u6t9GoqiKHUFEf0i6j4N6SiKojQJavAVRVGaBDX4iqIoTYIafEVRlCZBDb6iKEqToAZfURSlSVCDrwAAsllgxQr+rShKY1KzdfjK+JHNApdfDgwMABMmAI89BqTT1T4rRVHKjXr4CjIZNva5HP/OZKp9RoqiVAI1+Ara2tizj8f5d1tbtc9IUZRKoCEdBek0h3EyGTb2Gs5RlMZEDb4CgI28b+izWV0EFKWRUIOvhKKJXEVpPDSGr4SiiVxFaTzU4CuhaCJXURoPDekooWgiV1EaDzX4SiRhiVxFUeoXDek0CCqNoCjKSKiH3wCUu6ImrBxTSzQVpf5Rg98AuBU1b7wBdHWVbpR9Qx62eAClLSi6KChKbaMGvwFoa+NqmlwOMAbYuBFobx/Z6IYZ96hyTH9bWJOW1u0rSm2jMfwGIJ0GbrgBIOLbQ0Ol1c37xr2rCzh8mBcPtxyzlBJNrdtXlNpHPfw6YaRwSXs7sGkTG9t4nA13NlvcyxZDLsds3MiLRSIBLFwYvEoYqUTTfSyt21eU2oSMMdU+h1CmT59uuru7q30aNUFUXD0ssbpyJbB9O4d2Egn2/IuFd2QhOXwYeOAB9tDjceDOO/mxS43JZ7N8hQCUFk5SFKUyENE+Y8z0sPvUw68DwkIv4s378fIf/pD3A/j+tWt5Xz+mLoY+leLbra1BDz2VKj0m7y9I7e2VeicURRkLavDrAD9cAoQnUTMZa+wFYwoTrZ2dwJIlHL4xBojFgGQSmDWL7588GejpiU7U+uGlsPi9eviKUnuowa8DfJkDIOjhy7a2NqClBejv5wRuLAbk8xzakZg+ACxezMZeyOf5mC1b+LYsAPE433afo7OTj8/n+bkee0zj94pSL6jBrxN8mQNZAFIpWxETtjB0dQEbNnB8ftMmYN48NtbFyOd5QVi4EJgyJVijL1cGAC8SmQywbJnq7ihKPaAGv04RoxoVZxfjO2UKh1ok3ALYq4BYDPj0p3nfPXuCj59IFCZfM5nglQGRXVhUd0dRah81+HVMVO27uwisWhUMt7S384/fXfuBDwTj/0NDQG9v0IinUhzzj8JNBPf08Laoih3tylWU8UcNfh0QZRzDYuf+ItDXx56/lEz29vI297F6ewuTvbkccMstwLRpdr++Pvbqxejn8zZBK5U6/f3BkNG6dcCNNwYNv3blKkp1KIvBJ6INAD4C4DVjzJ+E3E8AvgHgagC/BfDXxpjnyvHcjYhr4AFrSGMxYM0aoKODt6fT7MFv3gzMncu3e3ttwtZNoG7aZI2xJGXnz2dDvHlz+HnkckFdHllg+vv5djxuH18WGj8/MDRUWBqqVT2KUh3K5eH/bwCrAXRF3D8LwPnDP+8DcP/wb8XD937nzbOGOp/npCnA3nYqBdx+O++7ezdvv/123i8e58UAAJYvZ1E11zPv77eG+NZbgUceCT+f55+359XVBbzvfcCTT/JjGMOVPRLGkcXAN/p+aai7cBDZXgBFUSpLWQy+MWYXEU0tsst1ALoMt/U+Q0STiOgsY8wvy/H8jYTv/QJWIwfg7YsX2/r5XI4N7MAAsH69NexEHEdfsgQYHAx/LmPY6E6aBMycCezaVbjPk08CH/0oN3T5j5PLcWdvLMaJ4FWreCE6cYK7fU+eBI4e5f1isaBhv/JK3ief50XKDR0pilIZxiuGfw6AV5zbR4a3BQw+EXUA6ACAKVOmjNOpVRc/Pu/H5VtbrWEH2JCLty+GXX56eqwXn0iwdx5l7F22bAEmTgy/L5+39flRyIIjuYG2NrtYJRJ8brkcG3aAf7tXHBrWUZTxoaaStsaYTgCdAGvpVPl0Ko4bvkkkbEzdrWnPZIIhkksvBZ591gqeAbbsUiDirtmnngp/3pijkZrP25LMRMJq6RhTmMiNws0XZDLBRWZoyCZ6BwY4XzAwYI295Bs0rKMolWe8DP5RAG9xbp87vK2pccM3uVwwublsmd1PDDHARlxCPOLpA9aAxmJssLdvDzfYySSwejV741u2BOvvL74YmDOHDXdvL1fpRBn9CRNYmK21NVj109sbvCJJJPjcjOFj5s7lfMPAgO0EFu9fwzqKUlnGSw9/G4B2Yv4UwH9o/J6NZMJZciWmnsnYGbWA1bgB7OIgRtSN78diwDvfWejxA7zfnDnAggVsWJct479dFizg7ek0G3H3WNHIb2kBbrqJz7G9PWjss1lOAEsl0MyZ/NsYm0Tu6OAFbeFCXiyMsSEh1dBXlMpSrrLMbwNoA3AGER0B8CUASQAwxnwLwA5wSeZBcFnm/HI8b73hx+vTaQ7jrF0b9NB9pcorryx8rFiMDfG0aexVG8Pe+4svhksnGANs28Z/y1WElHdKWWdHh63GOXYsqKUjCdlUCti5E7j+etbnAWyJ57FjNnZvDMfpJalMxMe7Es6Sh/BLSBVFqQzlqtL55Aj3GwCLy/Fc9YpfbikG9PTTbWhD6uz7+oKVOpMn2xGGgPXsczlg/34+7tpreb/OzuhzkIXg5Ek2ug89xAtGTw//dHayhy5GO5kMDkLJZtlrd+UVAFviGfOuFydOtK+NiKt33IQuwPdfcQWXjmo4R1EqS00lbRsZN17f328VJ11vXCptXG168bLf8Q7gwAG7r3tcPs8e8+zZ1sACwUXCZ8sW4POfB77xDdtIJeEXYWiItXhcfR7f2AsSYorHrULnM8/YBO7QEHDPPYXHE6mxV5TxQg3+OOGWW7r18y7SlTpxIl8B7NzJhryz0xr+KHI5YOtWG+oRA3zhhXz/iy8WGv9166yxB+xVhhh9P8wiOQdfQC2R4GMnTOArhP37gTe9yYaQ3NfnJnQBfi5fs0dRlMqgBn+ccKWLpUO2WFdqTw/wT/8UNI4zZ9ou1zDEyEtVTz4PvPACh2Z8QwsAv/514WNIaAiwk6tWrLB5h127OBz085/zVcfSpWywN28GLroIuO8+20HrC63FYsA3v8mLmVyt5POFmj2KolQGNfjjiCshPG2alSXeujVYly5TrVzDHo+zt/7kk4WPe/75wEsv8WNIx+vmzcCjj9oKGN/4ikGWKh8pm1y61MbrRUtfavNlPu5DD/Ex/j6PP24riMKYPZtf98GDwe3SsSuPqyhKZVCDXyXE8B8+bMMkiQSXRopnvWkTV7oQAR//OG8LM6Yvv1xY+jhtGte7u962LCB+GEYSyG555eWXB7thpU9g40auyGltBW67LRgScsNJPskkLyZdXeHdv9u38/Oql68olUMN/jjT2VkY/nA9eVdGeNUqO2HqwQfDjalU67ilj4BV0lyyxHrocryrexOmR5/J8Hn5zyV9AlKR44eIWlqAj32Mz9U/xwUL+HlEptnHmKDUsmrlK0r5UYM/jnR2AosW8d+PPFJowAcHrRxxNssLgxsiCTP2118PfO97fNtPsvb12UogosKRhVGkUsFF6KKLOOYuoaEw2QUiXkRk8ImLDF4B+Pf69fxaJREti1Bbm2rlK0olUYM/jkTpzvv4w0TcWna3QeuTnwR+8AOrRrlqVfEBKf4Qkigv2h908rOfsRxDT4+N18diwdCMe3XhE1aKKT/vfz9w/Dhw5pnW+3d7ELq67Pao6VmKopSGGvxxZO7coO6877HH4xwbd9UkpTFp7lw2uA88YEM43/52MC7vG1x/qHmpE6fa2vhcxFDncvzY999vxyMePhzsEHaHocg5CpKUnTGDj5OrlqEhK8l84AD/nUxa8Tb/sTZsUFVNRRkTxpia/Hnve99rGpGlS42JxSQwEvz58IeNiceD2yZMMObpp/nYu+4yhij8WHe/kbjrLvs88Tjf9lm71phkks/1tNMKH/vpp3l7LGZMIsH7u8f65xmP809LC59r1OsgMmbmzPD3iCj8XBVFsQDoNhF2VT38MlMsVJLNclNSVB192NSpG24IjhhMJoPSBMLb3176OYbNwvWRSp+o1xJ19dDZyTH697wH+Od/tlcpUiVkDDB9OjeXhfUUJBKsCBr2HrlXEYqijB4yUUXTVWb69Ommu7u72qcxKoqFSqKGfBejpQV44gn+W+LYra0c2tm1y44fBDikM3Gifc6RKl0qUQnjJqUBNtCiiuk2mrk9ALEYa/wDHMY6+2zu0A17j266icNKiqJEQ0T7jDHTw+5TD7+MFBvO7Q75dpudojjrLOC667iL1RU0k0WgvR247DJbBy8duiIxPFKli9sEVi78pHQux1VBcrWwfLltBpNzBrihbNMm22HsSj67tLaW93wVpdkYLz38pkBCJfF4uA6N1MInk8DnPse/o4zba69xwtKfSesuJE88wV6v/5xhC894MHdu8HYiwSWeouu/fDm/ZhcpzZTzHRy0lUn+exNW8qkoSumoh19GouLaAHvqQ0M2Bfn66zam7SNVKq5evFSquAuJeOlSOeM+50gx+kog+vrr13NoZtYsDuW4Vxrz5wPf+pY9RuQapKvYTdP6bNigpZmKMhbU4JcZGfO3fHlwqMgtt9hQxuAgDwtxRxcKF14IfOpTQUPpNjSFGTw/PFNs4ak0HR3W8K9YUXil4YdlWlv5/Zo2jXMQMq83zODncpzLkNcFaEeuoowGNfhlxu+mPXQImDSpMAn56qvsAW/ZEtw+c+bIFTJRhE3UqiZh1UCZTHDgy86dwfdg6VK++vFr+QHef+NGXjAl4StNYGvW2IVGUZRw1OCXmfXrg7fvvpuTr4lEMBa/Z48dOC6GLZm0EgSjNdi1KEkQdaXR0mLP89VXg8fs3w88/DBPAlu5MnhfPm/DYoB93/J54Oab+W81+ooSjRr8MpLNFiYWjWH542SSh4i/+GJQC16Gi0+ePLb4dLEKoWoyUript5cXP0ESv6+/XvhYUsoZFu7J53mK2KFDvGhIOE1RFIsa/DKSyUQPEM/lWFpg8uTgqEJj2MsVHfpTpZRmqlrBXQTktz9Ifd264DGxGF8ZXHKJlWMAgguASDgAtolNjb6iWLQss4yI0fXLCWWoSSplb7vs2cPhmGz21J9bPOc776yNcM5o6OjgMI4Y566uoOCa5DXmzQP+8i/Z8BPx7899jsNlYWWcpYrVKUqzoB5+GRGj29XFyUUZaiIDQ269leP4rtSA0N8/9jBMLSRqTxU34exz/Lh9PydMAO6912r5Azb848f9/b4ARWl21OCPkpEkCdzaeJFDOP104Mtftt2yuRzw1rcCv/iFPY6otsMw5cY38G7C+dZbg8nsF16wYRvpxgXYuO/YwftJ+eqcORwiW7BAwzmK4qMGfxS4ejillAK6zUQ+b35z8Pbs2fXrnY8Wv6Jo3jybcO7vB77+9aDomrx/MppRBqi49PdzV7KMbZw2bfxfl6LUOhrDHwVdXcDJk7Y88JZbouPuUjUTZuxbWri5SuL9Mjy8WfArigArDxGP2yldABt4kY1YtIjDY/5AFWFoaPzlJBSlnlAPv0SyWY4ju0jnJ1AY5pEEru/hz5ljK3JOpbmqEQibxCXyEKlUYZexP2Dd9/DdKwGi0mWUdXau0myowS+RTCbcszx2zIYn4nGrDQNwqALgGP7+/TwbdtIke2w9J1nHgl+LDwQN70g6/AsW2GlbUpbpzv3N5bh715WU9ge212KjmqJUGjX4JZDN8mi+RMJW14jq5eTJNjyRy7Eh2rDBhn2SSeAnP2HPXg2MRRa7KMNb7L0RsTVZZI0JevxuPb4gdfzy+LXaqKYolURj+CMgBumBB9iwdHSwUf/7v2cj0d4erL0XXXq5GhgcZONTLcniWqeU9yWbZSE2yZek01zJM3ky8K53lfY8+Xzw8YtJWStKo1IWD5+IrgLwDQBxAOuMMV/17v9rAHcDODq8abUxxuulrD2yWVa9dKdUyUAPF7f2XvTcXV59tb46YceTkd4X9wpAQmZuvf3Ro/4jRuM/voTcVHJZaRbGbPCJKA5gDYAPATgCYC8RbTPGPO/t+l1jzJKxPt944Y8kjMX4R7plXdza+9tvD2rDABxzrqZkcS0z0vviXgFIyCxqaAxgBene/W7OmwhEfFUQFkaSnIuiNDrl8PBnADhojHkJAIjoOwCuA+Ab/LoibCRhLscGfdq06LmxrpGJxYDPftZeETRrknYkir0v/gIridowkkleXMWAf+ADtnnLGOCeeziX0tVlq6c0fq80E+WI4Z8D4BXn9pHhbT5zieifiej7RPSWMjxvRXFHEsaG3yU3Dixe4h13WB2cri6bPCQCrr2Wq3LGopHTzGSzwG23BXXxJfm6dCnH713jLzN0Af6MPvGJ4ONJGe2GDbaqJ5HQ8JrSPIxXlc52AN82xvQT0SIAmwD8ub8TEXUA6ACAKfLNrQJivMUoiDCXtPC3tQW9xP5+9vyfey54zI4dwPbtWpVzqshVlkAEXHEF51UAvpp64YXg/amUDdf4uFdqcnv+fP1clOahHAb/KADXYz8XNjkLADDG9Dk31wHwiuZ+t18ngE4AmD59ekiPauURz91tmMrngYUL2XsUDXep2pH79+4NNlgZw5U67lWBGpbRIQnd/n6+nUxaYy/5Ffc9J+IJWlFyFkRck+83fSlKs1AOg78XwPlE9Dawof8EgOvdHYjoLGPML4dvXgvgAGoUXxJBpA+kkqOzk6cruZU4UUM55MpAq3JOjXQaeOIJ20Aln4HMyvWrofJ5vqIK+ywA3t7Xp8lzpXkZs8E3xgwR0RIAD4PLMjcYY35GRF8G0G2M2QbgNiK6FsAQgF8D+OuxPm+lSKVs3D6R4DLA1lY2OitXAtu2FRr7RMJW8uTzbFhaWgplAZTRE5bQlfyKG9uXcE3YABq5Xxbe3l4r46Cfi9JMkIlyh6rM9OnTTXd397g+pxvOIeIKmzlzgMsus2EFH9FuufhirhBpVn2c8ebmm4PyCr7Egs955/GwlEOHgl24S5dyYl0/L6VRIKJ9xpjpofepwbesWAF88YvWS4zHOXYvhqUYRMDEiZqcHS+yWV6IBwaCA2Wiwmvi4fsKpm7YTT87pREoZvBVWsGhra2wzO/YMQ7ZjIRb062MD26eJZnkBVrklP1affl8/MVAxNb0s1OaATX4w0gT1aWXBre//HIwVhyG6Lhrcnb8yGT4c5Ewzvz5fDUmHr7kYFwSicKZw7KvfnZKM9C0apn+iL22Nm6akpi8GHm3cxYALrwQ+Nd/tQ1WLS3BGasaEhgfwjT1ZRGQBPpZZwFHjvD+RLYLd/ly4NFH7X5ubf+KFfo5Ko1LUxp8X0vlyitto44bJgiLBc+cCaxbV1gqqIwvURo8iYQ1+q6wmjEsupZOs3Hfvdt+/m5tv8pXK41MUxp8X5L31VcL9/FH7QFsTMTAqzGoPmGfg9/85iJaOuk0l8xu3gzMnRus7Vd9fKWRaUqD74cDFiwAenpsmGbCBOC++zhMk0rxfYB687WOhHSiyOXYm587l5UzBwf5mGnTbG1/Pl/6iERFqTeaxuD7ypaiYQ/wF371ap6VevbZduas0NnJ9x07VnifUju4C7k0wbm6Ofk8x+4fe8xuHxjgBf+CC4LhPEVpRJqiDj9sjB5gt8noQhFHk/szGeDEiWCjTiIB7NqlRr9WkYX98GFeqKU2/+1vB156KboT1yUeB+68E1i2rOKnqyhlp1gdflN4+FFj9GSbGAGp1e7qsjNTfQMxNKTx3VpGPpeVK4Of68c+xmE6d3pZGKp9pDQyTVGHHza/1N8mjTsTJvAx/f22ztslFlNjUMvI1dzWrXZbLMbyCY89xiWYMt/AnXUA8Od/ySWc0AWCc3QVpRFoCg8/qoTP3QbYv3t7g16g1OXHYsD996t3X8v4aqcAf5YilDZ3LvD447w9mQRmzbL77dwJ7NsH/PSnhSE+/cyVRqApDP5IbNnCDVZSopfJ2KRfLBbUwtcvfm0jV26uJn4sxhVX2SwPqpG4fi5nB9RIL4YYeqG/X0N4SuPQ8AZfpletW8df5ESCv7zHjwMHD3JMXgzDI4/w77Y29v4GBvi3lmPWD24F1oYN/JnH45zE7eoqnFMsE8uidPTl6kBRGoGGNvgSzz150m4bHOQqmyg2b+YyTfny12gRk1IEachqb2cjv3EjTygTcTXAVmYNDfHtqESuXB0oSiPQ0ElbfyZqKcydGxTmyuVURbFeSac5FDc0xJ9jLscia3feyZO07rvPSiuLrj5gE7kyMF1yPNmsJnKV+qahPfxUKjiFqhixGA886ejgL7TbiZtKqahWvRImsiafYSZjjb2IqJ15JvDss8D73ge8+932Mw/r5dD/BaXeaFiDn80Ct91m5RIAvox/29tY7dKHiEv3gKDWykUXcaJPv+j1SViFljRnpVJ2SHosxsb+wQf5uIMHefCNuzio1o5S7zSswe/qKhxLKElb8foFXw9dqjkGBvjSX5qz9Iten7gia66nnkiwJ//UU/wZ/+M/Bo+7+27O56TTwVnH8r/iy3UoSq3TsAY/DGOAAwfsWDv3Un758nBvTvbRDszGwP1sc7niCfxDh3hxWLXKlnPG47YxS0M8Sr3RsEnb9nY73cgXw5KyPEnKucYeCHbhtrQAa9Zwok+/1PWPfLbFBNJOO41/i9TG+vVc1y9y2X190XIdilLLNKyHLw1UK1dyY5WPNFWtWlVoxKM6c5X6x63TX7fOlmW6uGW8sRjLY0vS35VOlmSw1Plns/q/otQ2DevhA/zl++1vo+/P57mdPurYZcv0C9yISI3+xRcHSzHPO6/Q8x8asosCEXDDDTYn8Nhjdo7uAw9wiEdLNpWxUsny34Y2+Nks8KY3Fd8nbNqV0thI4ra72+ZoWlqAz32OvXUXt2wzkQBaW1l2+corWXPJrfPX0I4yVuR/8447KuNANGxIp7MTWLIk/JLdZcGC8TkfpXaQ+Ls/xDyd5kStO//AJZcDFi+2/1OPPMIDcdw6f03qK2Oh0uW/DWnws9ngFzOKOXO40UppLvxmLDdpP2lSYdkuYD19f/v+/ZrvUcqH/79ZbgeiIQ1+JjPyZKNkEpg8WRNtzUhUUj6b5eSrCOe5Iw8TiWATnyAKq9LQpR3ZyliodMFIQ444lDiYNF6FGX/RUEkmtZlKCTZkxePA1VcDO3ZYTfyPfcx24QrnncdJXPHCtC5fqQWabsRhOg3ceivwgx/wUPLduwu1dGQRkJGG+uVsbtzYKQDMmMHx+a4uHl7/7W8XHvNv/wZ88YvsPHzkIyq9oIwet1sbqHxosCENfmenTbwdPFjdc1Hqg6jY6aZNwWEqLrI45POspy8VPpq8VUrBvaqUvJF0c69ZU5n8YlnKMonoKiJ6kYgOEtEXQu5vIaLvDt//LBFNLcfzRrF5c+n7yoATpbmR2KnbUZ3JcFgwzNifc07wdi7HQnsLF2o4RykN96pycNBKuQwNcYVhTdbhE1EcwBoAswBcCOCTRHSht9sCAP9ujDkPwD0A/mGsz1uMiy6Kvs+VWiDiskz9cipAYbNdW1twyLlLmDTDnj08ZUtRSqGtzQ7k8anUHI5yePgzABw0xrxkjBkA8B0A13n7XAdg0/Df3wdwOVExNZOxMWlStFYKEV8yxePAxInq3TczI3U0ptN8aZ1MWsMvInrXXx9+jOSEFGUk0mkeyBNmq1wJj3JSjhj+OQBecW4fAfC+qH2MMUNE9B8AUgB+5e5ERB0AOgBgypQpp3xCbW1szPv7C2WQW1pYP6evT8vnmplSB5p0dLBEsujny/8NADzzDPDkkyOXACvNR6nS2e3tnCdybRVRkyRtjTGdADoBLss81cdxa1nlS+p+WdXIK6PpaHT19IFg2S8RMHMmbxsaslO1lOZlNNPRwsT8jGHZ7ssu43kctdZpexTAW5zb5w5vC9vnCBElAPwBgIqOhva/pIriMpaORknmikeWzQKrVwe9f23Aal6inIkorz+dZoPvKwPUqrTCXgDnE9HbwIb9EwD8COc2APMAZAH8dwCPm1rt+FKagrF0NEoyVwx+LsfGftkynX2rhDsTxf4vsln27n1qUlphOCa/BMDDAOIANhhjfkZEXwbQbYzZBmA9gP9DRAcB/Bq8KIwLOoZOiWI0V4H+/9GaNVw6l8txXki+1MuXW+/fVc/U/8HmIcyZWLEiOoSYydieDoEIuPfe8v+/lCWGb4zZAWCHt+1/OX+/AeAvyvFco0G9LaUchP0fSTJXKnJ6e7m7e2CAb8vs21RK/webEd+Z8L3+Eyd4nvLZZwOzZln9JoGIrxrLTU0lbctNpaVGleag2P/Rpk32i+p6aWecAbz//TwtS4594w2V8Wgm/KtC8fpPnAhKcG/dymW+//Vf3LFtjL1qLDcNafCzWauBIo0N4m1pMk0ZLVEJXl9/x+W113i0Zixm66yNATZu5Coe/f9rbKKiC+k0e/YuxrAw39q1rN9UyfBfwxn8bJbLmUQpM5HgdvfWVuD22/XSWhk9UQleWQj8fg8XGbIiDA3plWYzUKxSp6cn/JhVq4C/+qvKOqQNN+JQ3mghl+MxdH19hR+AopRK2IxjWQiuuCK6s1tIJLh7UoXVmgNxBuJx/uxlyH2xWR0HDrD6aiVnIzecwZc3WkgmeZv7AeiXTikX6TRX5rj/c/5c3GSSq3pcYTalsXGH3Btjh9ynUsH/D1+rya/uKjcNF9JJp7k7Taon3HipjqJTKoH/P/f889wpKcyapaM0mxFRXM3lbGShr4+H5l33Ox0AAB1tSURBVKxda1VYEwkrjSzVXZVySBvO4APR9dXafatUCnfM4Z/9WfC+yZPDj9EekcZFPttUKpjwT6VYVVWMfT4PfPKTwPHjrPI7aZIOQBk1+kVSKon//yVVYQBXhvmCfa2thdVh2iPSuPifrYg1plJcOHLyZHB/mab2+OMc+qvk/0HDGXz9IimVJOzL7Ddcubz97cHqMPnyHz4cLCLo6lInpVHwK3REduPmm7kXw0cchHyeu7enTVMPv2S02UqpJP7/1+bNPK1I8CswDh2y2/v7+Qudz9uqHYB/b9xo1TbVSalfsllezP1xl9ksD8cZSUFMBp+owS+RsaggKspI+P9fc+cWlgK7GMNffpm0lsvZRWHhQi4ZPnyYqzjUSalv3Ku/RAKYPdvmbzKZQjVMosIFoFKDT4SGM/hjUUFUlJEI+/+aNo3DNnv2FO5vDPDpTwOvv87VO089ZSsxpIIsm7USDeqk1C/u1Z8xLJlgDHv2990XVFgF+D7f6Fd6mA7Vqkrx9OnTTXd3d7VPQ1FKorMTWLQo/L6pU4Ff/MJ+seNx4JvftJO0XKkG/291WOoHdzCOb7hvuomT9zffXHifa/RjMeArX+GY/6lCRPuMMdPD7mu4xitFqQZ9fdHdti+/XOjF9fSwcbjjDv4N8Je8txf44Acr33GplJ90mpPyUT50Rwdw//3RM2xlBKuGdBSlxmlrK5S4jUIqecKkPhYvtrHe/n6N59cbPT2FBl8MfDZrG/BuusnuR2TzOZW+qlODryhlQLoqRaUVAH74w2AFj/CZz3C5JlGws9LXWal0Ak8pL9ksV1u5xGL8OT7wAOdpZJYCwIt7Ps9e/XgpqKrBV5Qy4Xdyd3YGPTnhnntsK30iwWEAOa6lhT37WIzn5Kp3Xz90dQWv8GbMAC6+2FZg9fez7tLy5XaAznjnatTgK0qFkLi+b/Bdr39w0E420gqz+sLtuAaCdfYtLbyQA+zZSyL30UeB3buD+vjjiRp8RakQbW3WY5fwTViI50c/sgZe9Z7qA7/jet684CCc97yHf8sivnw5G3tXDbMan7NW6ShKhZAv+1e+wl7d6tXAuecW7rdrV7AiJ5tl7R2t0Kld/I5rgA2/JOS7u+1nKhLaiQQv/NXMzajBV5QKIoNTAG7OOno0fD+pyOnstGWZl13Gddtq+GsPf75Ge7sdhiMNVhKzl89PqnVGGpZTSdTgK8o4kMmwAYiq0c7nebj14sUc9hGDsXat1uPXInL1duedHKuXstrlyzmMJ0b/0Uf58+vq4nJbY+yYy2qgMXxFGQdSqeJt80TAD35QqLdijOrr1AJhkuvyW2L58TgPN1m1Cli/nqU2JGYP1IbGlxp8RSkDI81giKrYEYyxypouRKqvU22iJNezWfbopQInl+MrsmQy+DknEhzyaW+vfgWWGnxFGSOlzGBoa2MPUDz4MOMvYlpurPfSS4ELL4x+3mobkGYgTHIdCNfNMSZYiUUEzJ9feFVQLTSGryhjJMoguKTTPM0ombTdtaKZnkjY2xMn8sg7gB9v1y5O5PoJXFlkRItHY/yVw0/QSlf0wAAbeyJelFtaeJ9kMvh5trdX+QU4qIevKGOklBkM2SyHdVavthOvHniA7zOGY78AyzJ85ztBr1ESuN/6lm3P10E/44eIom3ezPMP0mkWuROMAQ4eZAnkvj77+cvYy1pCDb6ijJGROmTDQj6A1cCPx9nQ79zJhr0YUr6pg37Gj2zWjqn8yU9Y8fKnPw2G5HI5O8pQjpHPVxbpWliQ1eArShko1iHre+Pi+V1yCfCrXwEvvghs2VL6cx0+zL9VhmF8cD+/XA7Yvz94f1hivVavwMZk8InoDwF8F8BUAC8D+Lgx5t9D9ssBkIugw8aYa8fyvIpST7jeeCLBJXthEgtRuAnefJ5DOxs2sBEZy6AMJRo3IZ5KRe9HxINvWltt7iadrt0rsLF6+F8A8Jgx5qtE9IXh258P2e+kMeaiMT6XotQlbsjn8GEu3RsNYaWcAwMcZliwwMaNa8GDbAT82bRSchnGhz7Exn7xYt4nkeA8TUdHbV6BjWnEIRG9CKDNGPNLIjoLQMYYc0HIfr8xxvzeaB5bRxwqjUg2yxU3xWL1orfiN2FFIZOSaiVOXO+sWMHVT7lc8d4JwGrnuEn2RIKrq6r1WVRyxOEfGWN+Ofz3MQB/FLHfRCLqJqJniGhOkRPtGN6v+/jx42M8NUWpDVwxtHQaeOIJ1smfM4d/r10LfPjDwfr7G29kPXWXqVOtgXFxFRiVseOWYYrgWRQy18DfVqufxYghHSJ6FMDkkLv+1r1hjDFEFLUWvtUYc5SI/hjA40TUa4wp6Cs0xnQC6ATYwx/x7BWlxolqyvK9v0OHgEce4b/zeeD003l4Rk8Pe/qJBPDqq3y/zD/N5Xhfd2qWMjqimtfmzePKqR07Rv+YLS0c91+xorbCOUAJBt8Yc0XUfUT0/4joLCek81rEYxwd/v0SEWUAtAIIaSRXlMailGqNbBb4+teD2772Nf6dTHJSEOC6/XyeDf6CBTwDNZXSGP6pIuE1WYyfeIK3ywJNxJ/bSCEdIvu53Hgjx/SljDOq87pajDWksw3AvOG/5wHY6u9ARP+NiFqG/z4DwKUAnh/j8ypKXRDWpemTyRQmBSVUMDjIhr29vVCOt62tNGOv+vrhdHVZBdP+fr7tl2C6xv788wvDO8bw1deiRRy3v/9+vip7443indfVYqxVOl8F8D0iWgDgFwA+DgBENB3ATcaYGwG8C8BaIsqDF5ivGmPU4CtNQSljC9vabIjGR4Zl+N2egNVyicdtZQhQOHpvJJ2fRiebtb0PMiw8mwWeey6437Fj7J2LnpHv2R86FK5/NDTEi7I8rjvqMJGosVCbMaYmf9773vcaRWkWZs40hs2E/YnHjVm7lu9/+mljTjuNt512mjE33WRMLGb3TSR4H9kvFjMmmTRmzhw+Rh7vrruq+zrHm6efNqalxb5PsRi/1xMmBN8/uY/I/u1/HrGYfS/dbaedxs9jDL+/sg8Rf07jDYBuE2FXVTxNUapMNgs8+6y9TcQVPLt3W6+9qysYJgCs+BpgK0Nk0IqEg7Zu5asHCQVJMrFZwjsSohHyeQ69iPCZSz4fbHBzIWJv/TOf4feSiPMr117LCV7BDeHVmnAaoNIKilJ1MpmgbPKiRRwLlth7KhUME0hp5t/8DSd783muDGlrC4p6AXxMPg8sXFjbycRKIQZ4JI2iYrjlsq+/zn8bw4vv9u38/m7cyEnfUkJ41UQNvqJUGb8Nv709WM7px/fzea7YmTCBJZddhcbbby/0To3hGLMkE5tpipb0PXzhC3zFJItmMgmcdx5w4MDIjyHHyKIhnxVgP5f+fmDlSu6daGurXckLNfiKUmXCvMIVK2y1iDG2/M8tFXzjDTbiMklpzx7e5hOP81XC3/2dNV6SDG4WnnkmeIW0ejX/fcstvEAmk8Cf/imHe4px+un2s9qzJyh6t307/9Ty1ZMafEWpAfxmLN/rX7WKPfkTJ9iTBNiArVvHP2EyDCLRIBr8btjohhtq0yCNhc5OFqY7+2xg1ix75ZPJBMXqjOGFctMmu5hefTUfs3cvcPJk9HPs3w/8wz/YipwdO/ixYzEbPqvlqyc1+IpSg0TFglesCJYMRuntzJwJXHWVPTabLQwbNQrZLC+Crre9ZYvVGFq1ij14d5g4EEzcbt0KPPww79vTw4toWNOVlMQC/L5KojyVCuZHavXqSQ2+otQoYRIMbW1B4xUl7vWHfxiMI/sLCGBb/4HChaVe5uVKriPMKxdvu6+PX4tbiw+why85Dclr9PVxwlzCZKkUD6b5+c+BM87gxUA0kYDgZzRtWu2/Z2rwFaWOSKfZk7z77uIt/5ND1K/EOPnyv1JxIqGjnh6uCpJttRqPBgrLLl1cjaHeXuCll+yIQoBfV1cXV9hIWEa0731DftllwPPPc4xfZhH470mxITi1ghp8RakjRHdHjH2U0W9tjX4MVz5AQhoiL7BkCYeJ5HFrOR4NBHMdsRhX3lxwQTCG39tr9YhEoK6jwxpoV8/+9tvZwLuv119UBgdr+z0phhp8RakjwnR3wujr499hoRl/Apd4+L5YGFHQ660mUSGmUurely8P3r777qBR7+srnnD1a/mTydqN0Y+EGnxFqSPa2kobjnLiRHFpZj+e7yceYzE76SnM6x1Pol6HEBZKcReIuXOtZw+wJs7ll9vH8SuifGnjdBq4915bAbR0aX1694AafEWpK9JpbrZasoSNcTIJ/PEfFzYQ3XMPd4VK6Ka/nz3duXNtqMNP6gI28Xj4sJVjrnZYJ0xiWraHefVhC8TSpTwL+PXXwxvPRB5BupH7+3nRW7OG3xNZCHt7+bHqFTX4ilJndHQEK0IA4IMfDNaaS9hHQhH5PPDjH7OnW2wkopvY3bSp/GWGo63+yWZ58Ukk7OtJpYp7/P4C0dXFiVY3Di8qltks/x4Y4Cun2bPt+5XP88K6YMHIMw3qBTX4ilIH+IbSDWNks8A113B1zSuv8LaWFi4tbG9nz/7HPw4Kg7mGK0w+GLBer7ttrK9hNFLN7v7xOOsBSblkmAGW9yiVsgtdLMayx+5iCADz5/MxH/1oUCZh27ag5r27cNZ6jX0pqMFXlBqnmKH0h6InEsBHPsJ/d3WxgTzzzGA1D5E1XK6HC3CcevXqYBNRuZq0Spn+FbU/YDXngUID7L9Ht97K1Uy5HNfRu3kPWQyzWZZCcDGGFTB/+EM+1l04a73GvhTU4CtKjVPMUPolg0ND3DUqBn7t2sLSzQ99yFauLF9eWHK4fn1hSKQcxs5Pjo7kKbe18QImpaNujbwknVMpm3Nwz3n/flt5MzTEVwcAe/uAvaLx35sJEzhGv3Rp4WuuZ0MvqMFXlBqnmKEMk/91jZhv0GIxa+xlYpbP2WdzclLKNsvVhHUq0sGiUZ/Lca28VAvJsW4DmcwHmDCBk9O7dxdepbhXM8kkHzc0xFc9s2cHK3AawcD7qMFXlBqnmKEU+d+uLg5PHD1a/LE++9mgGmc+H4xZJ5NBD1eqdcqVsBxNN6ovejY0xK/Tv7qRkM/ChRz2kQXxyiuBV1/lpCtgw1Tu4y1aZI9pRAPvowZfUeqAYobS7RiVjtIw5sxhpUcgXI2zp6fwMUdbrdPZaefuyrSukYhKGsusX1/fXwibIwDwY8kiBfDrktmzLnLMSInjRojd/46o2YfV/tGZtooyetauNea88+xsVpmtetppfN9dd9n5q08/zbfXrg3O1G1psfvIY374w/xbjnHvd/dz572683ijjnn6aZ4vG/bcTz/Nc3nlvmSy8DHcx5Z5vu5rj/qZMSP8fPzHducIj7R/rYAiM23Vw1eUBkJq9N3Y9vz57P3fdpv1hmUcH8BSyq73299vPe6VK7lU0Rg+RuQXXI1+8X43bw6ey+bNwXOJqpl3wzZu2KirK6jhf801tukqTK1SwlR+3kIGx8iVgkgmj+Sxj7aqqB5Qg68oDUZYzP/mm22CVgy6b1Rdjh0LJjiBoGHu7+ckqjHWkPsSBnPnBoeq9/eH69S4cs+i3ZPNBuf4GsMLz7ZtwaYxt/b+8GFO3Ep1jjxePM5GOxbjeP1FF5X2Po62qqgeUIOvKA1IKcnRbBZ47rnC7fE4yyv7zUo+IrQm3q+UUQ4N8e9p07jaR4xvPl8oxCZDRFau5KSzMZxcnTevcCGSx5GFA7CVRpJ8TiT4Kqe1la8+XIkIAHj5Zf7ZsWNkiYZaH0h+KqjBV5QGICq5KNtbW9lLHRxko3jsWKEcAxHwgQ8AX/0q33YTn2H483G7uuz+xliD6g5p2bkzmMyV8xP9fukCBoonbLds4Zmy7tQqY+zrEekJed0y6EQYHOTzdRPSxaQmGgU1+IpS50R14vrb77vPDjdxm7MA4NxzgTvusMa4szPa2AL2PpmPC/AgEX8R6O0NPs+WLSxnIAJkrnSCq5fT3s7G+pZbgouOxOL37LHP43PsGHcfy+u+915+3evX2wUhmeTfjRajHwk1+IpS54SJhYV1n/b1cQw7bFbrkSMsFHboECtKPvBA8YlagjFsmDOZ8CHp4uW7bNnC82PnzQsOYrnuOmDGDNs929YGfPObbKgnTuSxjU89BRw/bh/rrLP43AVZANx8xc6dwEMP8Xm6EsdAZQTiahk1+IpS57jJxXicPW2Jo7vdp2LQXAVNl8FBjqVHzckV3FBLLGYrdVzBMpm45cb1XcQgS0LVGDbMs2bZBilJwMprCaul/+AHge9+lx8jHmc5Y7efAOCrmc9/nq9wXInjRozRjwSZUpbxKjB9+nTT3d1d7dNQlLpAYuFuZ6woTPqdpG5lS0/PyLH6YkyYYEMhnZ1Wp9+vpFm5kvVtXn7ZHrt2LT+/6P0QAZdcAuzbZydwFTNPM2cCe/fy4uFKIwCci3BfUyzGv/N5fl/uvDM4D6CRIKJ9xpjpYffFxvtkFEUpP+k0G7D2djbC8biNhS9bVijHsGwZJzanTAE+8xn2oEVigYiPf897ij+nG79fsYKNt+jIu4NKenuB3/6WyyHF8MqVQWur3WYMG3u535V88EkmOcTzxht2MtfWrZwTADgUFPOsm9TjixZ+MzKmkA4R/QWA5QDeBWCGMSbUJSeiqwB8A0AcwDpjzFfH8ryKooRTapjCT+h++tPsgZ95JodI8nng5z9nj3n79uBELQm1xGLAf/4ne9r5PBtSN/Ha1sZevyv3EI/bxejECeBLXwp64uLZj+Tdp9NcWukLxclCI967OxnMrSBqVsYaw/8XAB8DsDZqByKKA1gD4EMAjgDYS0TbjDHPj/G5FUUJoZRSQjfR+8YbPNjbmGDj0sAAMGkSx8lfeMEa+dmzWS9+cBB48EH7mENDXOXjhpD8AeLG2Dr5xYvDm75EAKEYx4/bihsZtg4EcxXuZDAJdYnyZjNU5IQxJoNvjDkAAFTs2guYAeCgMeal4X2/A+A6AGrwFaWCFBP+cpOsbvJWYv+uF+5W7BCxAmWYoY7FCsXILroo2H0rz9XXV5g3iPLqYzHgne8EXnzRXkkcPGj3TSY5IevKPAiVHtlYb4xHlc45AF5xbh8B8L6wHYmoA0AHAEyZMqXyZ6YoDcpI4wQl9LN8edAgA+zBS3nk4sWFIZe9e8P1atasKWz6uu++wnPbsIErcfzHiDL2sRgbe0lCA7wIyfNefXW4sXdpxoqcMEY0+ET0KIDJIXf9rTFmazlPxhjTCaAT4Cqdcj62ojQTpQh/ScjlJz+xZZKihy+a+WHNV2GG+brrbNOWWzHkavEIQ0Ph9flhXHAB5xLcMYdtbdZbTyQ4lr99+8gDWvxQV8NJH5fAiAbfGHPFGJ/jKIC3OLfPHd6mKEqFKFX4yx2gAhTq0be0ACdPFh6XTNp4uCwSQOHgcamfdxeOfN5W44yEVAzJIvOjH/FCIkqdUQNaRjLmox2o3iiMR0hnL4DziehtYEP/CQDXj8PzKkrTMpoQhuv5ZrPs2csxq1ZxpYuvuXPNNVb/xl0k/ClUs2cD3d3BbliguGyDywsv2Nh+Pg/s2sU/Uv8PFMbmSzHmjSh9XApjLcv8KID7AJwJ4IdEtN8YcyURnQ0uv7zaGDNEREsAPAwuy9xgjPnZmM9cUZSijFb4Swxlfz971atXc229m6AlYo9+507e7k6aAgq7fnfuDJ+bG4vZRcFN1hJxgvb3f58XiqiFYXDQll/6C5vo4hcz5o0ofVwKY63SeQjAQyHbXwVwtXN7B4AdY3kuRVEqi6tdn8+zcFksFqyGkfmwUXNu3SsLCbeE8Y532FJPCdvI877wAhvhRIINe1jOIJm0Rtpf2Eox5s2axFVpBUVRALCHHyaZLEZ50SLg/vvDQyZAofGU/cJyAHPmsICaPMattwJf+1pQhfOSS1jobOdOPici4NJLgQsvbMJZtKOgmLSCGnxFUX5HZyeXYkq9O5EN3bjaOG6SF2DDOjjInrfr8WezwI03As87XTexGPDkk/y3GOVMBvjiF4MhnFjMjiMUQbSRDL1S3OCrWqaiKL/D7U6VUIjrKfvefXs7G38pvxwYYAO/bp099h3vCBr8a68NhoCElhYb73e7fXt6WAF0YIDljRcsUMN/qqiHryhKyaxYwYNSZEbsFVcAb3oTa9y7JJP26gCwcgktLcEB6u7VgowlTKWsRPKECcCVVwYfn4j18ZullHK0qIevKEpZ8CUZHn3Uhn78EYL+tliM9e6Fzs7gRCtXatm9ypAFQXBF0tTgjw6VR1YUpWSkuuWKK+wglFwOeNe7gvuJJIJLPm8ljF3tfEFKLeV5RNZZJJ/dx26mUspyoh6+oiijQiQZdu+2YZdPfco2aMViXM0DADffHEzEine+eXOheJpbauk/XyZjh7aMpJujRKMGX1GUUSEljyJvIEbaHTAybRpvSybt2ENptkokgLlzecHwp1WVqoOjnBpq8BVFKZko2YIVK+xsWtGbB4JJW3cAybRpzdn4VG3U4CuKUjJRGjRR3a1hmvuilumPXlQqjyZtFUUpGTHsMiDFlTd47DEeDi5ev5vgdWckxeOacK0WWoevKMqoGK1sgSvKFovxoBRfO1/DOuVD6/AVRSkbo02gRgmVNasmfTVRg68oSsUJWySaVZO+mmgMX1GUqhCVD1Aqh3r4iqJUhWbVpK8mavAVRaka2lA1vmhIR1EUpUlQg68oitIkqMFXFEVpEtTgK4qiNAlq8BVFUZoENfiKoihNQs1q6RDRcQC/GMNDnAHgV2U6nWpQ7+cP1P9rqPfzB/Q11ALjff5vNcacGXZHzRr8sUJE3VECQvVAvZ8/UP+vod7PH9DXUAvU0vlrSEdRFKVJUIOvKIrSJDSywe+s9gmMkXo/f6D+X0O9nz+gr6EWqJnzb9gYvqIoihKkkT18RVEUxUENvqIoSpPQcAafiK4ioheJ6CARfaHa5zNaiGgDEb1GRP9S7XM5FYjoLUT0BBE9T0Q/I6JPVfucRgsRTSSiPUT00+HX8HfVPqdTgYjiRNRDRP9U7XM5FYjoZSLqJaL9RFSXA66JaBIRfZ+IXiCiA0RUVTHohorhE1EcwM8BfAjAEQB7AXzSGPN8VU9sFBDRTAC/AdBljPmTap/PaCGiswCcZYx5joh+H8A+AHPq7DMgAG82xvyGiJIAngTwKWPMM1U+tVFBRJ8GMB3A6caYj1T7fEYLEb0MYLoxpm6brohoE4Ddxph1RDQBwJuMMSeqdT6N5uHPAHDQGPOSMWYAwHcAXFflcxoVxphdAH5d7fM4VYwxvzTGPDf8938COADgnOqe1egwzG+GbyaHf+rKMyKicwFcA2Bdtc+lWSGiPwAwE8B6ADDGDFTT2AONZ/DPAfCKc/sI6szYNBJENBVAK4Bnq3smo2c4HLIfwGsAfmyMqbfXsArAUgD5ap/IGDAAHiGifUTUUe2TOQXeBuA4gI3DobV1RPTmap5Qoxl8pUYgot8DsBnA7caY16t9PqPFGJMzxlwE4FwAM4iobsJrRPQRAK8ZY/ZV+1zGyJ8ZYy4GMAvA4uFwZz2RAHAxgPuNMa0A/gtAVfOKjWbwjwJ4i3P73OFtyjgyHPfeDOBBY8wPqn0+Y2H4EvwJAFdV+1xGwaUArh2OgX8HwJ8T0f+t7imNHmPM0eHfrwF4CByyrSeOADjiXB1+H7wAVI1GM/h7AZxPRG8bTpB8AsC2Kp9TUzGc8FwP4IAx5uvVPp9TgYjOJKJJw3+fBi4CeKG6Z1U6xphlxphzjTFTwd+Bx40x/6PKpzUqiOjNw0l/DIdBPgygrirXjDHHALxCRBcMb7ocQFWLFxLVfPJyY4wZIqIlAB4GEAewwRjzsyqf1qggom8DaANwBhEdAfAlY8z66p7VqLgUwF8B6B2OgQPA/zTG7KjiOY2WswBsGq76igH4njGmLksb65g/AvAQ+w9IAPhHY8yPqntKp8StAB4cdkBfAjC/mifTUGWZiqIoSjSNFtJRFEVRIlCDryiK0iSowVcURWkS1OAriqI0CWrwFUVRmgQ1+IqiKE2CGnxFUZQm4f8DVAgRlRU5GYAAAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Up8Xk_pMH4Rt"
+ },
+ "source": [
+ "### 3. Split the Data\n",
+ "We now have a noisy dataset that approximates real world data. We'll be using this to train our model.\n",
+ "\n",
+ "To evaluate the accuracy of the model we train, we'll need to compare its predictions to real data and check how well they match up. This evaluation happens during training (where it is referred to as validation) and after training (referred to as testing) It's important in both cases that we use fresh data that was not already used to train the model.\n",
+ "\n",
+ "The data is split as follows:\n",
+ " 1. Training: 60%\n",
+ " 2. Validation: 20%\n",
+ " 3. Testing: 20% \n",
+ "\n",
+ "The following code will split our data and then plots each set as a different color:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "nNYko5L1keqZ",
+ "outputId": "e1e6915d-5cfe-4086-d20f-8e3aebd80292",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 265
+ }
+ },
+ "source": [
+ "# We'll use 60% of our data for training and 20% for testing. The remaining 20%\n",
+ "# will be used for validation. Calculate the indices of each section.\n",
+ "TRAIN_SPLIT = int(0.6 * SAMPLES)\n",
+ "TEST_SPLIT = int(0.2 * SAMPLES + TRAIN_SPLIT)\n",
+ "\n",
+ "# Use np.split to chop our data into three parts.\n",
+ "# The second argument to np.split is an array of indices where the data will be\n",
+ "# split. We provide two indices, so the data will be divided into three chunks.\n",
+ "x_train, x_test, x_validate = np.split(x_values, [TRAIN_SPLIT, TEST_SPLIT])\n",
+ "y_train, y_test, y_validate = np.split(y_values, [TRAIN_SPLIT, TEST_SPLIT])\n",
+ "\n",
+ "# Double check that our splits add up correctly\n",
+ "assert (x_train.size + x_validate.size + x_test.size) == SAMPLES\n",
+ "\n",
+ "# Plot the data in each partition in different colors:\n",
+ "plt.plot(x_train, y_train, 'b.', label=\"Train\")\n",
+ "plt.plot(x_test, y_test, 'r.', label=\"Test\")\n",
+ "plt.plot(x_validate, y_validate, 'y.', label=\"Validate\")\n",
+ "plt.legend()\n",
+ "plt.show()\n"
+ ],
+ "execution_count": 6,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAXwAAAD4CAYAAADvsV2wAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nOyde3wU1d3/32dmd4MKJhr15wVBioAEc+HiZYrgYKz0Uaq0aEWrQfEBRUVRlBYvT3kerLQoGi9UAYWSp1pqyyNKvdbFUZBR5BISWECgCFJF7WoCVLOzO3N+f5xsbgQBSbgk5/165ZXs7GXObmY/c+Z7vt/PV0gp0Wg0Gk3LxzjYA9BoNBrNgUELvkaj0bQStOBrNBpNK0ELvkaj0bQStOBrNBpNKyF0sAewO4477jh52mmnHexhaDQazWHFsmXL/iWlPL6x+w5ZwT/ttNNYunTpwR6GRqPRHFYIITbv7j4d0tFoNJpWghZ8jUajaSVowddoNJpWwiEbw9doNK2PZDLJ1q1bqaqqOthDOeRp06YN7du3JxwO7/VztOBrNJpDhq1bt9KuXTtOO+00hBAHeziHLFJK4vE4W7dupVOnTnv9PB3S0Wg0hwxVVVVkZ2drsd8DQgiys7P3+UpIC74GANeFSZPUb43mYKLFfu/4Pp+TDulocF0oLATPg0gEolGwrIM9Ko1G09ToGb4Gx1Fi7/vqt+Mc7BFpNAeHeDxOQUEBBQUFnHjiiZxyyik1tz3P+87nLl26lNtuu+0AjfT7oWf4GmxbzezTM3zbPtgj0mgODtnZ2ZSWlgIwYcIE2rZty1133VVzfyqVIhRqXDb79OlDnz59Dsg4vy96hq/BslQYZ+JEHc7RHH409/rTddddx0033cQ555zDuHHjWLJkCZZl0bNnT374wx+ybt06ABzHYdCgQYA6WQwfPhzbtvnBD37A448/3jyD20f0DF8DKJFvKPSVlS4VFQ5ZWTaZmfosoDn0OFDrT1u3bmXx4sWYpsn27dtZuHAhoVCIt956i3vuuYe5c+fu8py1a9fy9ttvs2PHDrp168aoUaP2KWe+OdCCr2mUykqXlSsLCQIPw4iQnx/Voq855Ghs/ak5BP+KK67ANE0AKisrGTZsGOvXr0cIQTKZbPQ5l1xyCRkZGWRkZHDCCSfw+eef0759+6Yf3D6gQzqaRqmocAgCD/AJAo+KCudgD0mj2YX0+pNpNu/601FHHVXz9/3338+AAQNYtWoV8+fP320ufEZGRs3fpmmSSqWaZ3D7gJ7haxolK8vGMCI1M/ysLPtgD0mj2YX0+pPjKLE/EOtPlZWVnHLKKQD84Q9/aP4dNiFa8DWNkplpkZ8f1TF8zSFPY+tPzcm4ceMYNmwYDzzwAJdccsmB23ETIKSUB3sMjdKnTx+pG6BoNK2LNWvW0L1794M9jMOGxj4vIcQyKWWj+aE6ht9C0NYIGo1mT+iQTgugqVPTXHfXmGhj2zQazeGFFvwWQN3UtKoqKCnZe1FuKOSNnTxg704oOm9fozm00YLfArBtlZbm+yAlzJoFRUV7Fv3GxH13vjp7ynXWefsazaGPjuG3ACwLhg+HtFtqKrV3BmgNxb2kBLZsUSePunnNe5PrrPP2NZpDHz3DP0zYU7ikqAhmz1bCbZpKuF33u2f5dU3TTFNdGaRSEArBiBH1rxL2lOus8/Y1mkMfLfiHAY2FS2Ixq54ApwtQXnnF5ZNPHBYtslkzE2YPd+hYZDeq0nWLVrZsgRkz1GwfoEMH9XvSpPr72B2xmMXKlVEKChzy8nQMX3N4Eo/HKSwsBGDbtm2Ypsnxxx8PwJIlS4hEIt/5fMdxiEQi/PCHP2z2sX4ftOAfBjQMl5SVOQwcaO2yiJqT4/LNN4WAxy+uCpE/VnL8NB9m77rSml6szc5Wt3v2rG+RnJ2995k/tWsBFpGIpR03NYcte7JH3hOO49C2bdtDVvB1DP8wIB0uARPDiFBaaje6sFpR4WCaHqbpEwp5fFOQxJC7djWZPh3OPx/uvRduvBHuuw9uuw0GDoRf/crljTcmkUi4u22K0jDnXzdQ0RxUmrkIZdmyZZx//vn07t2bgQMH8tlnnwHw+OOPk5OTQ15eHkOHDuXjjz/m6aef5tFHH6WgoICFCxc2y3j2Bz3DPwxoaHMQDluNNiypG0eHEFkxCaaPH4rw3BabLtXfh1tuUbH6NEEAPRMu535UQq8bZ+H7KXJzI+TlRSkrs+rtY/p09fwggIwMNfPXDVQ0B41m9keWUjJ69Gheeukljj/+eP785z9z7733MnPmTH7729+yadMmMjIyqKioICsri5tuummfrwoOJFrwDxMyM62auHjd2Ht2du2M2rIa+N/8HjaXOAybabNohkVkNgwbpsS6LufiEqWQzwuq2BxOW214PPaYw6JFVr0c/VtvrT1ZJBJq3+PHH3gDK40GaHZ/5EQiwapVq/jRj34EgO/7nHTSSQDk5eXxi1/8gsGDBzN48OAm22dzogX/MCV9TO86ubGIxSyef16Jr9PBYpFf+30ANTNPJMAw4M47wXIcIks8ji2VfJKEADDMEHl5Nv361e7TcaBbN5dL8krIKoVX1hVh27UnIS30mgNOM19eSinp0aMHbiPholdeeYV3332X+fPn85vf/Iby8vIm3XdzoAX/MGZ3sfO6J4Hi4vrfh6Ii9VNvNu7afH2ToPJM6Pwk7OwKmCkIl0PfWhXv39+lT88BhMMJjCSM/OVMjsUB6vsvlGfb/H6F2ra7AjBt1aBpEprZHzkjI4Mvv/wS13WxLItkMslHH31E9+7d+eSTTxgwYADnnXcec+bMYefOnbRr147t27c36RiaEi34hwG7E8fGJjcNTwLxuPo+LF3qUlDgkBNkk/luHKvOi1UG5ZT/LkUQBpECBEjT5/Nvbya/MrcmlNS+vcOmjR4YEEjYkZfk2PQldHUsVSY8OgcRSonyPhbPPAP/+Z/1hf9AtaXTtBKa8fLSMAz++te/ctttt1FZWUkqlWLMmDF07dqVa665hsrKSqSU3HbbbWRlZfGTn/yEyy+/nJdeeoknnniCfnUvkQ8BmkTwhRAzgUHAF1LKMxu5XwCPARcD3wDXSSmXN8W+WyJ1BR6UOPZKuHxrOLSdapM7sjaMUlwMc+fCkCHqdhC4XHONw7JlNhs3qvh7To5LMlmI7ydY+e+A/OcNMv87DNdfD0VFVGyYS9AeMEECCJSop3wqykrI7Kf2V7Mo7CcQQHinWTvI6jONCHzCeNg4vI9FKgXTpqmisLSwH6i2dBrN/jBhwoSav999991d7l+0aNEu27p27UpZWVlzDmu/aKoZ/h+AJ4GS3dz/H0CX6p9zgKeqf2sa0HD2O2yYEvs3g0IigYe8NUI5Uf4Wt8jOhjFj1GMXLoQePVx8v5DrrvO49toIbdpEsYDN8yYQnFoFhiQIQUVewNGrEjBtGmL2bLKeHo2RfJMgvV4bqB8jBf7cbdBPjWt9CfT8wX/wVe+XkSJg7S0mb62HfzowKNsmNxJBJjySQQQHu+Y9SVlf2NNXJomEsoNI1wJoNJrmpUkEX0r5rhDitO94yGVAiVTdVt4XQmQJIU6SUn7WFPtvSTSc/QIM7lHC57lVHFsqabfW4y+3ODwoLQxDPS4I1GOXLXPIzfUQwsc0PdoHJQQDZpHZJYExBYKQEvFMVVeCkBKZ8Mj8ZxZffj6OY3o+DEJiBpITX4X/9yYctfY1Jm9zeeUVeC1ZyOdXVxHvJcGEIEjxxhsOc+ZYTMyw+KA4Sm7c4bOKbO75RwmfdSvhqVeKKCtTY60r7AMHwvz5auxjxkBurp7lazTNzYEqvDoF+KTO7a3V2+ohhBgphFgqhFj65ZdfHqChHVwqK102b55EZaXKAmhoVHbNNS59imexebhk5RT4+kyTBYGNX515I0Ttz6xZNolEhFTKBCIEz29DJBNkxSBvLHSaBWeOFayNnU2CCElMPCKMmWfzr6OzkEJgmJLAEGR8AVkxIEhRMc/hh0mHCCqTx0hCkBKkUqoILH3C+VtcTd+P+/toMm94mq4DnuaRhwdUX3koYZ8+XV3BvPRS/ZOVLtbSaJqfQ2rRVko5HZgOqsXhQR5Os1PXIwcilJdH6dPHqpd0cPLJDps2qcT3ANhy88Usvd1CVBueAZxxhkvPng6lpTZjx0bp1cuhY0ebnnNLOK16X5kxaBeDBG24yygG4HwcFgQ27y+xyNkJjz8eQUoPRIh2qyQpfJJEeLs6POMR4ciYR7exJo8WDGd+aRGxmJq912TEOQ4VPZIEYcAE4Xvk5zuUlysriLlzlcCnO2sKwS6zf41G0zwcKMH/J3Bqndvtq7e1aup65KRSHh984PDLXyrBHz9ePaay0sYgRJDyMVLQ8fevcrbvsgiLIIDu3V0eeqiQcNgjmYxw991RVq2yEcJh/fE9ueTLCGGSpAgxkxuYEy6i6EmLeBzmzbNYskTtJxazeO65KL/+tSra2nILPHqzQ9S3eb867bKQKDYO78Rslm2wGD4cbr9dZQKlk37Ky21OLgtjJD0CCVJEWLnSrjkpDBmi1hs8Twl9EFAz+9dhHY2meTlQgv8ycKsQYg5qsbZSx++pthCOkEp5pFIRVqywa6pXc3Jq7ZD/31vXE9k0jWNLJUfGfM4TDgulhZTQs6dDOKz8cwzD4/bbS+jQYTam6ZG8OsJ/jx3D+bFSXhRD+OKykeScWCus2dnUCD7AuedadOyoFPdvcfgtFj61s/APsVgRsrj+ephSBBb180VdF255Gn6cO5xTf7+N0y45kXunFbF6tYVpqoyikSPV/pcudZHSYcYMm1WrLJ2to9EcAJoqLfNPgA0cJ4TYCvwaCANIKZ8GXkWlZG5ApWVe3xT7PdxomE+fmWlRXh7lgw8cVqywicUsQiFV4FTXDvlTirn0+TZ8m5Ng89WCTWXZnIkK43TokI2UEcBDiAjr1kGnTuoEgExwQ8EjnBaT9JcLuejlXF7GqkmRHDlSjSud1jlypBrj0qUup5+ubI7TXjrFxWomn50NFa+5VFxdQnLLLEKkCMIRnrs+ykfZ8OCDtVcbL7ygvHiCQJ004nH1+q+84mLbhZimx0MPqauSdAqpRnMwGTBgAL/61a8YOHBgzbbi4mLWrVvHU089tcvjbdvm4Ycfpk+fPlx88cU8//zzZGVl1XvM3rhuzps3j65du5KTk9N0b6YRmipL56o93C+BW5piX4crDdMt0wJaUWGxeQ5cFjgca8K1Uy1V4LSp1g75lIFxRswvZvjvboWwz3Wp0ZimQIgUyWSExx8v5tpr42zbZvP663DhhTOBAALBsaUBIQIkHv0Ch/ew+PZbmDwZXnwRrrzSZWB3ZZVQPr2IW56uFe2HH46werVaV0jXVv2yv8vrqUIyqMJAIoAg4bFumsPWa6m52pDS45xzHP74x1rBr6hQJ7vLL3cYMEBlE2VkeNx1l0PXrpae3WsOOldddRVz5sypJ/hz5sxh8uTJe3zuq6+++r33O2/ePAYNGtTsgq/tkQ8QddMtEwnlOHnfffDuZJc3/EL+R95PVBTSZoXL1q21dshCmJxwwhYGjF4B4QDTDAiFkhhGrQ1yu3ZxrrpqPAsWqNCJEEKFYUyDJCGSmCSpnxs/bx6UlLisXDGATd7TrOzyNCc/YfPjnJIa0RbC49JLnRohdhw4L6WydUxVooWPIEmEBdJm+XIbKSNIqWycp02z6drV5aqrJtGtm8ujj0IyCaWlNsmkyiby/QiDB9ta7DXfm4aZbvvD5ZdfziuvvIJXnRP98ccf8+mnn/KnP/2JPn360KNHD3796183+tzTTjuNf/3rXwD85je/oWvXrpx33nmsW7eu5jEzZszgrLPOIj8/nyFDhvDNN9+wePFiXn75Ze6++24KCgrYuHEjGzdu5Mc//jG9e/emX79+rF27dr/fGxxiWTotmbo2CHXz520cqnISfFkQ0LY0wbppDjfNHs/f/x4FSkilZvHZZzM4/fQQiYSp0lt8gS8MAiOoSY30fZXqeO21DqFQCsOQQMCbV4+A5zswfZ3N+36tqubkuKRSE9SisamsErbnJTlmJSSTKlsnFKrfqtC24ZchGy8VQeLhYzJbDOf5UBEfBhaRjXDsp8Vky7m464eQTMIjjwwgFFJrFGPHvs2aNcrcbezYKBddVIJhwBFHQN++B/gfomkRNNYNbn+6rR177LGcffbZvPbaa1x22WXMmTOHn//859xzzz0ce+yx+L5PYWEhZWVl5OXlNfoay5YtY86cOZSWlpJKpejVqxe9e/cG4Gc/+xkjRowA4L777uPZZ59l9OjRXHrppQwaNIjLL78cgMLCQp5++mm6dOnCBx98wM0338yCBQu+9/tKowX/ANHQ0njMGDXT/8cZ2ayaEhCEwUgGbBibjbcO/vhHi2+/dbj22hSg+g4e/e1POPH//kboK5/tXWA+P+F/3xxHLKYOcClh+XKboiIV06+qijB5ThHrN1oEBpzru9g4/CMnm+unjCEjI4FEInxVkHVkaRjZtYj164tqWhU2bKX4u3ctnpwc5aSPHD7ratNvnIUohzZzYVSBS6+bxiATHieJhWy5fSDhcAIhIBxO8OMflzB6tEWxygpl4MDZhMMe3347m8rK/fuialonDbvBVVQ4+30cpcM6acF/9tlneeGFF5g+fTqpVIrPPvuMWCy2W8FfuHAhP/3pTznyyCMBuPTSS2vuW7VqFffddx8VFRXs3LmzXugozc6dO1m8eDFXXHFFzbZEIrFf7ymNFvwDSF2Pp9xcJf6nnx7HjxgIIyApDSK94kQ2qccsW2YzdKiabQsRIeeTE2FFQOkUiQz5nJWaz/++OY6iLi4d/uHwtrRZvtGiTZsoGzY4PPywyoARAs6VLm9RSASPjwsEn0QChAgAgw0r+vDVH3rxXxuKmPSMiqVXVkJZmcPtt0NZmcV5psvs4Q5WkY31ogWooP7mkkmMn2mzyLc4Z4HDpb6HIX0EHifLT+u9/5/8BMJhOH6Dyy+umEA4nMA0A1IpjzffdLjiCi34mn2jbtMfw6h/Rfp9ueyyy7jjjjtYvnw533zzDcceeywPP/wwH374IccccwzXXXcdVVVV3+u1r7vuOubNm0d+fj5/+MMfcBqpOAyCgKysrJpWi02JjuEfJNKeMtu22QgjDAjMUJizz7aJRpW75MaNFrPvLmbz7EK+WVLMS7EiNl8JMgwYYIR9igZO5pmP1RrA22YhHxS79O1r0bXreDZutOhruNxrTGKYUUIEjxA+x5UFmNJEtUzMoLtVjP+Lp5jkpMVeXSanUvfz4IOFDOk2nVe9Qk6ddj/+gEJKRrmUT3fxBxTS/un7edUr5CzfZUFg44kI8RyDzVcLlnxk43kRfF8gRIT8/CLWl7i8lizk8tK3CCcD/JRBKhVh4kS7uTrUaVow6W5wnTpN3O9wTpq2bdsyYMAAhg8fzlVXXcX27ds56qijyMzM5PPPP+e11177zuf379+fefPm8e2337Jjxw7mz59fc9+OHTs46aSTSCaTPPfcczXb27Vrx44dOwA4+uij6dSpE3/5y18A5cm/cuXK/X5foGf4B5z33nPZsMFBCJubbrLo3BkeflgSDoNhSIqKIDNTPfaDYpczbh2DudqjSi7khjOLOaUYzDqvd4r4lJBf7VIpPHLjDqCEWz2/kJDvEZgmUoSQErI2RshvU0xF+7jqjJVp1Yuhq8vkBEIEhEMJLiyYSySmZu7J6oycjwyY4KsTSAZVDKOEOzOe4u/3F3NkT5VNdHHyCZ544gmOOSbO2Wfb2LbF+UwigseRsYAeYw3mFlzIY6UTWLvWqsnD1175mn2hbje4puKqq67ipz/9KXPmzOGMM86gZ8+enHHGGZx66qn03cOCU69evbjyyivJz8/nhBNO4Kyzzqq5b+LEiZxzzjkcf/zxnHPOOTUiP3ToUEaMGMHjjz/OX//6V5577jlGjRrFAw88QDKZZOjQoeTn5+/3+9KCfwB57z2XHTsKad9e5al37hwlL88hFPIxDEkq5VNW5tCvnypiSsx1lJhLZTk8IG+ueiGhfklpknncDaTMckJ4iAYdf3LjDgQeBD6mAEaMgA4dwLbJtCwydzPOrK3ZGFUBQQjCqYDuHI/IiOB7HkmpMnKED/cRwsTHQHK9mEnf4iIqusfxPJVNJKVHZmacv/xlPDffrF67Y5FN6tkIqaRH23UR/nfdBNZKi4wMNXTtla85FBg8eDBS1rq7/OEPf2j0cXVDMh9//HHN3/feey/33nvvLo8fNWoUo0aN2mV73759icVi9ba9/vrr+zbovUAL/gFkwwaH9u1r89Tz81XBVTorJpWKsGaNTSiU9sC3eTOI0MZQlsNvlw2hU/IdTJFAYND2i7EMmjiSXn4uFxgOVxTb5H5Xh5SGXUh2M43OfDdO/vOCijxJVilkrn8BnnySzSviDJtp86Gv/HNmJa9nJNMwkYSFT27c4YlSmy5d1PsJUiFyS7ewJeWS7orlYjFeROkrHBYKG+OHFt2+hOOPh5Jqc+26bqElJbXbd9c9S6PR7B2i7lnsUKJPnz5y6dKlB3sYTUp6hh8KJQCB6/6EOXPGAVBQ4LBqlc0tt1i8/76L56mTwTFr4YELHbKH2KxYAT9Z3J/tZ6bIKoUj12ZwfvA2Lir/fuLEWg+eGhoT9j1No10X+vev7VZuGPDAAzB+fM3LbdkCZdNc/i4LCeNBOEL4nSguFjfe6HJxbgl3lM4kO+bjEeHle4uxRsR5+WWbO+6w8P3GP6NwWBVpnZVyGSAcHNSCMKihavuFls2aNWvo3r37wR7GYUNjn5cQYpmUsk+jT5BSHpI/vXv3li2Rd9+dJqNRUy5YgFywAPn66xF5ySXT5NVXPyifvWOafCj3JvnGaxnyrbdM+dprR8iePRfLxYurn/zgg1IKIaXKwJRf5SCnXX2RzMlZLCMRWfu4PfHgg1Kapnod01S3GzJtmpThsJSGIeURR+zy4osXq819jcXy/tCDsmza4npPvUc8KJOoffwrx5DO38Py7bdN+fbb6j3VeRv1foSQ8pf9F8tvjSNkClP+myPkuSyuua+xoWpaDrFYTAZBcLCHcVgQBIGMxWK7bAeWyt3oqg7pNDHfteDouvCPf8Tp0CFAVMfhQ6EkY8bciiFShJKSEyRsq7YWBo/HHnOw0i9k22oK7HlU5ED5FOgcfospyYU8+2yUmmbie6KxZrgNSbuc7ebN1NYVWNi2RW713ZXvTeecqrlkXVWAPyeCkB47+ghkyEcZPCd49NEJzJkzgenTle1CXUIhCL3nEAo8TOq3SzTNxoeqaTm0adOGeDxOdnY2Iv0l0eyClJJ4PE6bNm326Xla8JuQ74qUpO/r3NlmypQI4bAqpJDSwBAp1XgE+HcXED74UmCGIuTl2TWGZgUFDnkLniDzjyv4Z/vlpMJLaxZHMzIcCgutmn1WVta6be6SwVC3Cuy7UmH20By64d2V701n5Y4bCXrAiV3f5IHycfxn3yyOuSabLf4YgiABBEj5FpddtpBFi6KsWVObIVRVBSefDM7LNh6qmverHBNZsIWcUpf+/bXfTkunffv2bN26ldbSAGl/aNOmDe3bt9+n52jBb0K+qzl3+r5VqyzGjn2biy4q4fhgG23XQ49bXwYkGLCjG4gUbF1+GZVHjOOjjyyeftrlwQcL8TyPFWaEnr+N0p4ivlxRiO/XWiun95mTsxfl5nsQ8+9D3WbogYQOuaU83+ENxveF/MpcPv54Al9//RYQEAp55OU5rFljkZOjmpx7HrRZ4WILhzEU84OcFfSaMosfhWdgJ2fTrt0+XMVoDkvC4TCdOnU62MNosWjBb0K+K1Ji23Ce6dI3cHjvI5t+FxdxyaOFmKkE2zcFbB4GX/cGTPClQXT12Tz3nMqG+fnPnXoulBUVDh07jqdnzyhlZQ53322zbp1Vs8/mKDffG7JOH4KxQzVDN1Lwzuoh9D8fJk0C27bIyZnA118vrPH/Ly21a7p2eR6c5bu85heSITwqzjR5cVgBZjiJaQaYoor2QQla8DWa748W/CbkuyIlOcF0Zl15C1nLAv57fQah7cNUjrwMyIzBabOhMg8CBAEZLF+uDNGkhLIyu1FDs8xMi379LKZOrb/PysqmLzffGzL7jiT/Pfh42VzWfDGE/jePZMyYuiEu5f//8cclNZbJw4erdMvZs+GCKoeI9NjZ3Wf1Qz6nR5aomoMUGClJ1l0zYarOzdRovi9a8JsYy4K25S7xCQ7lQ2xyR1pUVrqUfnsrcliKT66GHmMTeNvghFAE6ScwCTgqZtBtbIg3rx7OD+wiNm60ahqZ33qrxfr10RpDs4az9YbRmXS5+W5j+M1IZt+R5PcdST5qZt8wxNW/P3TpokzTBg5UYZrycovcXPDb2IgPIlT0qiIIqxAXPhyzXJ0QM9f5VC4toeJk9b4aGrtpNJrvRgt+E1M+3aXzjYV0x8N7M8K8jVF63uwQGD7CULHtrwsMntxQxMn/UUTFPIcvyeY44jgxm4KtFtf2bexKodqw7DuonyHU9OXm+0pjIS7VlF2Fm0zT49NPHW68UY1zCRbnjosyoH0JhpxR28d3NrSLCb4uMCnPnUWwKUUqpTplHVUG3xoObaeqk6tGo9k9WvCbmI3POnSvNimTeHz4kMPSsM0FF2QQpBKQMrm39EleiKn4vDBri5DCYXikSP29r2uqh6IlQWMhrobhptdes+s956lSi8G/s8gvOZqKNyaTWQqZMZjHZSzLPZFCOQMhfAyqGJYzmZGlbxAJEohRJvBkbd9GjUazC1rwmxDXhUdX2FxUnVKY7gT1wYMWr74aZfx4hxdesPlrzCInR6VZlpXZnH66xYkn7p91wHdlCB1M9hRuOvdci1mzau8fMkT9rnCzOPV5A4OAFAZLOJu/rbCxr5lFyPAJpSTXls4ngwATiQwCuOUWNm6ET0rjZA/RM36NpiFa8JsQx4H3AotCotgoW4D3sUAqT/kNGyyOO06lTU6ZovrG+skQkReux95Po5i9qaU6VKjrbri7RupT3WwmXG1wTCkcEctgoWGzcaPFUS9ez4nbp3FsqeSomEQIgZSqt670fWQshY4AACAASURBVE6dfAsdkXhvRignqkVfo6mDFvwmJC26H1RZvC9rhUYItT07W3nQ9OpVm2ZpSp/TEtOgcPZ+xWH2tpbqUGTkyPqRmKVLXa757Rg2hwM2J03WvVTMlTkwqWASOUZP2ha2UWe2jAjG7aPhkUcgCAgwMaRf07Q9PtcBLfgaTQ1a8JuQtOiWlMCsWcp7LBSC66+Hnj3h+dEufZMO23OzCYIIQlYRSkmOKZXIhIfYzzhMM9RSHTjqrDgXFDh4nqe6YUlBpPcKTj99DL7vsVJGyI8Wk/luHGwbF4v12wdzPg6po7M5afKYmnBa9hD7YL8rjeaQQgv+PrKn5hxp0S0qqrX1Pfpo+Pv/uLzqqRaDXlmE/y4uRmSt4I7SmRwZ80maESKHchymian3OVJ/xfmop4tJnKwWdlOpCLEYdOqkroiCwKNMxHl+y3i2TYZXXwXft4hEVK/cisG5dP3UofMNOoav0TREC/4+UOuH47JunUMQ2PTtu3tRmT1b+cNICb/CqWkxKPE48+M4RbGneIcibByO+YnNuMN2er5vNMwoWjPMoWP1irNMeMy7Ic6LZ6i6g9JSmyCAiy6ajWGo3r633WbTsN1nIgG33gpBoMQ/mntw3ptGcyijBX8fWLrUZdSoEgYOnIVppvj22wiVlY330UxnzaTbDTgoQzDwMDIiFNxuExkNHyQtloctnHEH9K0cVBpmFL2DTVH1inPKiLDAV83XYzFVfBYEcM89UR57TJ0AVq5s/MSYSqnP+1DKUtJoDiW04O8llZUuubmF9OhRhRASISCV8igrcwiFdq34TC/gpmf476Oydx4b7HD2ONWZytm9+3CLpmFGUZciC4rUivPabJvlYyzM6vuKiyEeV148lmUp++QQJJO1r2cY6jM+R6qmKYtN1T93T+jeuZrWhu54tZds3jyJTZvuB/x0qw48rw2LFkV55BELz4O8PJfHHlP2BwBlZWpGunWrRWkpFBRAVpYWGKgvtlBfePckxKNGwbRpSuTTlunnSJcohSRyElT2MfiqcCrvVeZSUOBgGDbvvmvtU9MvjeZw5bs6XukZ/t7gumQt3YKRGyIAPM/kjTeG4zhFnHOOEvtu3ZSFcSrlUVpq4vvK9atHjwhFRVFiMUsLTB3Si9u7E97v+mzSZmueB6YJ50qXe5IT+OqSb9l4O0gjwE/dTLcTQ3heimQywvPPR5k4sbZfwKFaqKbRNCfGwR7AIU+1ImXeMYP8OyWdzBG0betw/PFPMXWqRVGREqp0br0QPoGfRJDAMFRWyZtvOo0KjKZx4W2I6yojNtdVty0LRo+GwkKXkgdGMa+HzTk5f2fjGJAhwAQR8gmFVGZP2nu/7uunw0ppg7pWlCClacU0yQxfCPFj4DFUY75npJS/bXD/dcBDwD+rNz0ppXymKfbdnLguJCY4nJ/wEIFPZhlkLupAx/G1XZpAzUqXLrUxzQiQwEgGIEAaEKRCvPaazYgRh08l7IFkTxXCda8ATFPZKR99NPztb6paORKuojxX8v/eAClQdsoSAmkS+CEMI1XjvV/39S1c1gxzeAebLkW6k5amdbDfgi+EMIGpwI+ArcCHQoiXpZSxBg/9s5Ty1v3d34EiLTS9EjZvBhHaGB6+EWFttk3DjD8VgrCorIxSMXsMmdOWIICvCgR/Lr2ec2+3DutK2OZkT59L3SsA31exeyFg6FB1RWWYkqB6GcpIQmAaCMPEiT7Jiy+qGH5lZTY9ezr88pfq/5T+53b0PJUdVKQ7aWlaB00xwz8b2CCl/AeAEGIOcBnQUPAPK9JC815g8SOhvHHe8VUGSTS38cXFzBhk3l0KHkjgiLURzririMHVtgGHdSVsM/Jdn8ugbJd/4xCt9iVKL9SWlqqmMMgqQlLSbgOc6ISpePwGsvKKiEQsflt9nZn2LQKVRltR4nBqlYchdQBf07poihj+KcAndW5vrd7WkCFCiDIhxF+FEKc2wX6bFdtWWTfXXDOJnbnwW8bzXmDV6EP6CuD++9Vv14XNJQ5BUnkdCyGIX3o9a7KsmtizZh9xXXJuK2SCfz9RCjkXF8OAjAwYNMhiwYJiTCGQBmy4BUj5dFzUoaYxytChUFBQ61tkGCqNdthMmyoZIYmJH9LxNU3r4UBl6cwH/iSlTAghbgRmAxc0fJAQYiQwEqBDhw4HaGi74rqqyOrhhwsRwkPKCHfdFaWsrLZv7PoSlzuqHBZIm52d4cMPHZa42UzpbvJNQUDmqjBXvVrEovk6K+d74zgIz8Osrk4eIByOvtBiwgR190cfxdWURVQ3lullsCXbron55+S4XHjhFlIps7oALsKqVTaLfFUTcYFw6Ha9TZH+x2haCU0h+P8E6s7Y21O7OAuAlDJe5+YzwOTGXkhKOR2YDioPvwnGts+kZ+5Dhjjk5HgYho8QHo895rBokcrlblvuMnRGIYb0uC3HpOwhgRlJ0e13JmVCqupQXxAfC/4qHTX43tg2MhIhmVBmaIvDNpMmqLuUxYXNQw9lEA6pxjL3rXySf2+3qKqC7t1dJk+utqD2Q7zyygjefruIm29WJ+0PPYuVEYto0UF9hxrNAaUpBP9DoIsQohNK6IcCV9d9gBDiJCnlZ9U3LwXWNMF+m4V07H75cptf/CKCYXiYZoS8PJt+/eC991yWLJzAKd0SHBsL+LYgIBwBDEkoFCAEGIZEGCl693ZYs8bSWTnfF8vCfDvK1hKVTTOpOpsm3Su37SpYOXYYFQXwcmkRa9daiFWqIKtuKEdK+OKLDqxaZRGP68VzTetlvwVfSpkSQtwKvIFKy5wppVwthPgfYKmU8mXgNiHEpUAK+Aq4bn/321z07+9yzTUOy5bZNf4thmHzq19ZZGe7nH9+Iaddl2DVLwJ6jDU4qiyEygVMYZomQZD+O8KIETbdumlh2S8si46WRd2JuG3DeabLq34hkZiHF4vwlejJYOHgBDaLsWoWdaVUjptlZbVpmeXlSvCzs/X/RdO60NYKdaisdFm5shDfVyLx2WdRunSxGDBAuTFeffUkhg+/H9P08VMGG2ddyOw/TeDfeTB8uEPv3jZnnklN+76D3US8JbN51CROnXY/hvSRwiAQJkIGVMkIhUR5n9o2ktu3Z9O7d5wf/cjmy5fhg8m13cheHOcyOMvRZ2VNi0FbK+wlFRUOQaCqZU2zivLyElxXZeYA9WaNQRBizQk/oKI7xFZajBlj0aZNenFWC0dz07HIxp8Vwfc8hCEwpQ8yIEN4DJAO76PcNkGlZWZkqHaSfV+VDMLHI8LtFPPjh8eA0H4XmtaBtlaoQ1aWTRCEqnO9JRdeOJPsbJdQ9WkxFrMYOzbKK6+MQErJoEEzmDKlkJwct54tr6b5cbEolFH+i4ncKqbihzPANJGhCAtNu8ZULR3LF8InkB7/zksSwieMxxDmEpba70LTetCCX43rwu9/b1FZeT1SCoQA0/Tp0qWEoUMnkZOjkuljMYsvvuhAKORjmj7hsEefPo72ZDnAOA4s8i0elOOZLkfy3PVRNo+YyIUiymJpYRjKRjl9VZZKmSAjHLMmjC9MkkT4P4aQkBGkof95mtZBq43hN7TnHW+7/DDp8HGPbIY/Ogbw8H0TIQSmqRwXx45VJfiRiMukSYWEQh6hUIRwOLqL/a6meWnMZdNxVCGc78OZZ7pcfLHDK6/YSAk9ezqcc47N6D7gTHC47y2b9wKLvobLAxc62BNUf1ydvaM53NEx/AY0FIsJA+v0m10VYfiYYkIFcY4/fguDBs2oTu3zKChwOPpoi6Iii6VLVQu+vDy1OFvXTE3T/OzOgycUgjPOcHnooUIiEY8BA9SJ+rnnxnPKKcBoyJhgsXwhmB4sj1hkTLBw0f74mpZPqxT8hpa8XT+t32/2B6vjPLRuPGec4TJw4Oya1L7Vq22eeqrWLE0bbh1cGvPgkRLy86uN1QxljVxQ4BCLWTz6KAwerJ5TXAxz58KQIdTL7df++JqWTKsU/IaWvJ1vsGFFhGSyuqIzYjP1CYjHLdq1ixIEDmvW2Dz1lLbRPZRxHCXY6bi9EF6NNTKo+yZMUCL//GiXvkmH5x2b3FyrxjupRw+H1av3rkWiRnO40Wpi+A2dLV0XSkrUfUVFyi5h47MOH51s029cfWGfPh2efRZOPhnGjdMzv0OVuqG63FyX3FyH5cttVq+2EELN/g0Dfihc3vBVCC9FiLLL/4PM0fBZ8BpSphAiQs+ejTen12gOdVp9DL+xBT6obZM3axZIaeH7FpFyiI6rPUFUVMC7k10uQBXr9P+bxbvvatE/FKkb19+yxaJ8OvwkcMgU8EVni3/8A4IA+lEbwtuZ41N1wzy+SQFGukeuR0WFowVf0+JoFYK/uzZ66W1BoG6nc+lLSmpPBucEqjl2BA+PCIWpKI6jQzuHKpalulltm1xCVjCTED6ejPDmz6Jc/YRFIgFvBzYeEQRVVBZIgjAqQVkCQmAYEbKy7IP7RjSaZqBVCP7u2uilt4VCSux9X20D6NzZJS/PIa90C5FY7YLuBYaj47uHMtWXcydWVSGRCMAwPAZnOUSjylr5rbcsCoMow0QJPy97BiOZUl2zQibt2vXmpJNuqPHU1ymampZEqxD83aXw1d0GtX8Hgctllylr3SAZonKcSWY5BEaEoU/Z5GoBOHRJX85Vr035CBJBhI3ZNpYF//VfLiedpMzxxqx/iu2nF3HZohK4aBvb5Gvs2LGMHTvKufPO3Jr+BzpFU9NSaDWVthYu45mEyriuz/r1Lh99NIn+/V0sC9q3d2jTRlnrhtuk2Dl1OKEHJ5KxKEruSP3NP6SpvpzzhUmCDKZzIxcZUf4Wt6isdPH9Qq677n4efbSQM85wuWe+Rc9HnqLs87MJghTgI2UVV9qTudufRK+Eqx0XNC2Glj/Dr07HqXSfoSLX5+gXwvzuaIeXv7TYsAG6dVNFOuGwx44dEd57L8qZZ9qAMkkTIkJWXhH000J/WFB9Obe1RLUyXORbmCbkboGyMmWOBz6m6ZGb67BypYrrT5xo89BDJpGID0jO/fE8ct94mftjGWzM1k3ONS2Dlj3Dr47nVi58mpW/TbHpOkn5JI+sf5WwZg0kk5CXV9soIxTy2LBBFenceWeUmTMncued0RrXRc1hgmXR8anxTHIsRoxQmTczZsDtt9tABDARQhXSGdXfgFWrLF5/fXiNj5I0YEdBwBGGR27cOXjvRaNpQlq24FfHcyvyUZkYJgQhqCiofUhlZTZSGvi+QSoV4fTTbRwHysos/vjH8ZSVWfqS/jDFsqBDB0il1IJ8WZlFeXmUTp0m0rNnlJtuUiZrUqqft94qwvPagDQwUpBVZiAyalf5XVdV5Oqm9JrDlRYd0inPtjnDiJBZlsBIBgQIvFSE+aWqf1JOjsvo0WOqvXIMjjqqmL59lQjUzeoZlO3CJEenbByGNMzQ6tPHomNH9T+Mx2vF3jDg5JMtkiuKaZOYy3EZBWRenVXzP2+slkMfCprDjRYr+K4LA26z6JWMcv4qh013ZdOmT5yKCrsmRFNQ4BAKeQgRIISgQwfVa92y4O9/d9mwwSFXZJN70xj9TT9MaSxDK11Ul51dba3R2aV3b4ch3bIpvGdMdc3FQsqnRcmt/l83VsuhDwPN4UaLFfySEtWW0MXCxYLVIGJwxhlqNhcEtZ4rpunVK7ZJZ3N07Oix0zeo7OyTuSrQ3/TDlLoma3Vn6qEQXH+9y5AhhZimh0waVOX4HBkLgARHPTQBcieAZTEo2+Vb4bDAsFkeUd47De06NJpDnRYr+I0hJaxZowRfCNXM5O67o9x1l8PgwbU9aNOtDsEnMCUVvQ0y1wjdJKMFUHem7vuwfbuDENUdsQzJVwUGR8fAJKDTxregcCEUF5M7ZgxnBh73mxHWFkfZiaVDPJrDjha7aFtUpL6IQlDT7i5NEKhthgEbN1p07Tq+nm9KVpaNYahsDsPIIGvEVJg4UX+rWwDpmH76mEiVZkPSwE8ZJFMZ3LdyKouPuBCJgZDVV3XPPgtVVYjAJxyorJ3d2XVoNIcyLXaGb1nqSzh5MsybV/++nByXggKHsjKb0aN39cXJzLTIz49SUeGQlVU989cNTloE6Zh+SQmsfsZlVmwMVWN9viowuG9lMX9ePZKjAYsoAhCGAStW1FTuYppg29jULgabJmzZokI8ej6gOZRpsYIP6sv3zTf1t+XkuEyZogqtkskIixY1XlSTmWlpt8QWSlqUP1/ukPGhx5GxgGPWCi76QZxPhMvj8jZC+AD4KR8DEKAuC4YPB8vCovbEMWuWyvOfPVtfBGr2n+ZcG2rRgu+6cOSR6u9zcbFxkAVbagqtpPQ44QQHXUXZukgv3PZK2FwkIxxheIiMCGfdbfPxLQ7fdk3weQFklULbWECSMCFD4JsR1vYswp1e2y2rbp6/XtPX7C/Nnf7bYgV/+nS49Vb1Zfx5znR+U3ALx5YGJEtDrEyGkBJSqQi9e9sHe6iaA0w6/v5eYHGREa1pYp5rWSTblFN+girUM5LQfWyIe2NPcjxx3vFtPrjFIpVSr/Pmm6ohTmNOrBrN96G5039bpOC7LtxyixL7nByXkVNuZWs4xadJ6DE2xfKxIykv6ECnTjYPPKCnY62NusVY6Sbm6Yu87PPjbN9kAAG+FEwp+E9mxEYiqgu0zg3UlaKDzftYlJY27sSq0Xwfdmfl3lS0SMF3nNqmJgUFDoR9Zasg4esCg5eeLyKyHh68wQEX/S1tZezOLtt1YelSm9zcDKT0SFRXZQuhcvb7JF3eqtsMhyhDhlg1ef5p6wUt/Jrvy+6OzaaiRQq+bUNGhiq8KiuzSSYzQCYgZXJv6ZMI4P+62ezcmaTyljCZUx39DW1l1C3GgrqxU4u8vCjjxztMmmSzbp1Fmzbws5/Bqc/VtkaUeIw43eHzuFXjraPz8jVNQcNjsylpkYJvWfD8aJev/s/ho2NtZt9dzIC8uURLh/BCbCSTckax+iGvOk7rkb+0hEz97WzV1I2dlpVZbNhgMXWqysLZtg3+9Cc4G9UaUeKRJMKsTTaL71P1HIMGaesFzb5TWenWpH8fiC5rLVLwy6e7XDRZXXr7GwxMAlgluYaFbCGXyoI67plSuWdmHuxBaw4qu4udzp4NVVUqfv8+FoVEa2P4vvpWBgHMn6/y8UEv3mr2jspKl5UrCwkCjyCIcMcdUYIA1q1zCAKbvn2bXvWbRPCFED8GHgNM4Bkp5W8b3J8BlAC9gThwpZTy46bYd2PE5zp0J0GIALM6n1oVViYYgMNLpUUMSM4iJKs9dPKKmmsomsOExmKnkyapsGC65gqU6L+PxSmnAP+sTfeN+9lc3DvO9l42XYp0k3vNnqln4RJ4XHBBCQMHziYc9qiqilBZGW3yWqD9FnwhhAlMBX4EbAU+FEK8LKWM1XnYDcDXUsrThRBDgd8BV+7vvnfHqQXZmG8GpL+nApBAgMk7wmbNGos7xr5Nr14OZ59tY1+gv52aXWOntl1rtNcQIZTYRykkQoKdOQGVpwuyPgiTWeSgazs0e0KZNUZIpTxSqQhAvRqhigrn0BN84Gxgg5TyHwBCiDnAZUBdwb8MmFD991+BJ4UQQsq6c6emo3NWHCmUF4pENbL2MbmFJ3lfWJgGrFtnsWmTxc03N8cINIcDe6potCyYOlXVc/h+rQdTOAxXXw3GZLWI+++cgLIpEISlXhPS7DWZmaohzwcfOKxYYQMwcODs2taq1e69TUlTCP4pwCd1bm8FztndY6SUKSFEJZAN/Kvug4QQI4GRAB06dPj+I7JtRJsMZMIjEYSYxfWUUMQSwyIjA4qLVfMLnT7XetnbisaRIyE3t9Y/P33cALz0vk1qUYSvC6oIwlKvCWlq2Ft7hD59LH75S9VX+ezAZeXYYbTpuY2z251I5pE0+YXiIbVoK6WcDkwH6NOnz/ef/VcHZIXjsD7bpiJucX02XKpFXlPNvlQ07i6Fs3NnCP1iGFfmbsMQrxDIFEZIrwm1dvbFHiG9drS+xGXoM4UYsQRmLCDAwJ81G/Ptps3vbQrB/ydwap3b7au3NfaYrUKIEGoCFG+Cfe+e6m9pLpDbrDvSHI7sT0Wj46guWQ89pEz4viBC9zOeJJmM11yGb948qdZpVdOq2N1kom4KZt3jwrLg5BIHI+URQoWhTQL8ZsjvbQrB/xDoIoTohBL2ocDVDR7zMjAMVdd6ObCgueL3Gs3esD8VjbatUufSC2zgkUzG6dhxfL1UO8OIkJ/f9JkWmkObxiYT33VcuC788hmb14kACUwCUhiIZsjv3W/Br47J3wq8gUrLnCmlXC2E+B9gqZTyZeBZ4H+FEBuAr1AnhQOCbkOn2R37UtHY8DgKApuqqghQ2x7TdeGjjxw6dqxNtauocA5IQY3m0KGxycTmzfVTMOtm4DgOLPJrazz+RTYniDhDH7dreio3FU0Sw5dSvgq82mDbf9X5uwq4oin2tS80t9WopnXQ2HHUt69FZWWUirISskphy1oYP9rl4i5bOPnhEOE2YBgRtm61+dGP9DHY2mg4mUh30UvP8LdsyWbFS6Po/gUM6lDEhLDF+56q8QAwBLSNN304+pBatG1qmttqVNM62N1xlBmDzIGzwfPozkxe9wWh1Sm+HitYfVFvPj3qBt6JW3genOW7XFDlsL7ExtIHYaug/lVhbRe9LVuyqfr3bWT1SPB5V+h+90weucLhrX9bzJ+vCv0yMpqnWrtFCr7r1nqghKrfYSSi0uq0m6FmX9ntAm+dM8HOHj4V+XBMKRwXg36xD/lXTimreq/gypyezCgfQ0R6iFkRKNLT/JZO49EF1UVvxUujyOyRqEnj3ZmXZOtzDv8xzWLcuOYNQbc4wXddGDBAlcSDEvwRI6BnTxgzRl9aa/ad3S7wVp8JKjsnKHsoIAjDliTkjQWBZN0UjwvC0xDXhPDu9DlydQApfanZGthtdMF1OX/WTMonKbE3UtC2NEQHtvBN8XSsa+NYzTgjbXGCn/6g0/i+akMXj+vwjub70+gCb/WZoOKjCfiRtxCGapoSLzAwCFTlrSnB8KnsY5C1VmhntVZC3avCUKhOk3vH4Zhyn/yx8HUBfF16Gu1inzKC6ZhrArjPUPGcZpqRGk3+igeZ9AedJhxW29LbTVN/5zRNiGWRNXgCwsgglTJJpNrwX6t+z19W3oiXVNsQGWSNmAoTJ+pLy1ZC+qpwxAgVk58xQ4V4yrNtME0yY3Da85C/9hPCpAgRKIPHIKidkTYDLW6Gb1nw9tsqhg9QVFT7/dKt6DTNQWamRc+eUcrKHNassdmaZfH8u5AztoiCAodOnWzsByzoe7BHqjmQWJbSG9+vjSz8LW6RO3w4cto0hJQIJEbIgAAl9obRrDPSFif4sPv86ubsJKNp3WRmWvTrZxEKqbUigFjMIhazuOmm3TxJF4m0WNL/2uzs+gv+g7Jdti0Bs7vJzgKfI0tDxK8Zw1Enl5IlCsj8Z1azHg8tUvB3V8Ks0TQFuxxfrkvl0hIqCuCVN4oIgtpjzjDg5p4uTHJ2baCri0RaJA3/tWmzxkHZLrljCqn4QYKyKQF+WJBKSYzQY5hmEiEW0OXCqZx8cvMdBy1O8HVpu6Y52eX4Moth9GhWPugReDDg/Fm8+OLbABQUOPzg39nk1kkPq/x7MRXt42Qt3UJmnSyCyqUlVJysJyktgYYZOvE4jB8Pm0c5BFUelfkqo0uYEoMUQiiXGSkD1q+/laOOym22Y6DFCX7DLjLN0URA03rZ5fjaNBd6JGtaZhp4XHRRbeciwzeo3OiTuSqgsnOClVW3EmwKMHJD5OeZZJZBZZ7JytxZBJtSepJymFNZ6XLeeQ55eTZlZVZNON51YfxMm9elydGlPkYSktIg5YcwTR8hfIQAKf1m1awWJ/gNS5ibo4mApvWyy/F1+hB4zMFIegQSkjWdixKYZgCGpKK3QeYaQUVvQWD6QEAAVDw2gsxFHag4bwuBPwM9STm8qXv198gjEd56K0o8XuuXk0oBCI6OCU6bavDm+b156Z0bkBLuuONmhAgwjHCzalaLE/zMzNoSZn15rGlqGj2+puYSzChhZWIbmaXQ94fvYxjVfRFFQPiGu9h8RBavkE3X1BhCoTq9lPtZZFW6GCtn60nKYU7dqz9IkJU1gXnzJjBzpsUTT8AFhkMoSLEzR7JptE/n0BJuy1/J448/TiplEg4H+H7zmgiLQ9WluE+fPnLp0qUHexgazV5RPt2ly402VTkeKx8DaaKaKQdQuWAwSx48mwXSZnsO9OnjMHKkjWHUumjm5NQuBAN6wnIYUjvDTyBlgJSQTEa4806H/v0tbu7p0mVUIZtuq+LzSyUIlaO/du3ZdO26rNpq26RTp4l07Dj+e49DCLFMStmnsfta3AxfozkY5MYdpEjyeQFIgRJ7CcKH81+cxyXyZe4lg8JYlP9dM54jj4TZs+sm6VhYlkXle9NVnN/0MYwMHc8/jMjMtDDNKLHYGLp1W1KdUq/WdKqqLHJHWpQTZeW6MZzCElVoBcTjJyNlOXWttpuLFldpq9EcFGwbEQ6TVQpGEvCV2Hd5TLlqhggI42HjYFR/6xpafeC6VMy4hYAkEBAECSoqnIP2ljT7zh//aPHRR73qbUv/v10Xcv9/e+ceJUV17/vPru6uwRc9OjGiRtAgICMDw0O0RLDIKD5jzOGcxGDuuHyhAkbiKCcky4RzzJVEwaAGDRDgMPfqiUlQ8HlFG0p5lA9gZhhtREGQ+CB6RmfQRLq6q/b9Y/drhuHlAD2P/VmL1dPd1VW7uhff2vXbv9/3N97itH+Zhe+b+L7A80wef3wKGzfGOO20uw/5BV7P8DWag0G6rDJaXc2gVTtoHATd73mOY2pTkO5glMTkZWyqqlQ/XCFaFFY6DsXrAoyr0sZaIqTj+R0I14WFC6F370ouvngh4bBHEJgsX15Jfb26F/kfRgAAIABJREFUo8v0Uli92mHePId162y2bLEYNgx69Tr0d3Ja8DWag0W6lDuKatpc/7nLn252+ESW8A0acLB5FYu1v1NV9EGgjLVmzcrUXNlE7y5i0J0JGocaFN/4ex3O6UBUV6u7tXjc4vbbVzB+vIMQNvX1Fr6vHHynTVP/Roywmq3hHK6aOy34Gs0h4pkGi98Ii6BFXsTQpMv3SlVl7jN1ldnUvYzjVtRxiGq7hXZPfsV1PG6xYIFahAXYvNnirLPU72eaSuyDAF56CVauzBVWH+6fWAu+RnOIsG3ldJtI5MI3w5IuT5babJrpEUTgO8mFPLl0Ba5rqf/82vCpQ9Cy4rquLobvq9/tzDNdxo93KC1VWVaxmJrVv/RSczPMQvzMWvA1mkNEy8YpR9e7GHdP45/lucrcsPTYudOhosLKzvq0p1r7p2XFdXm5g2la9O7tct99FXTr5lFXp6qmLcti2jRIOC4jkg6rQza2XZgfVgu+RnMIyU7YXRcmVyB3JWiqlfwtqRZmg1SYstrtvJ9wcRyL+nqYNEll70QicO21zS2+Ne2DlhXXAwfaxGLwzjsO3bplLgQJtm2bxqmnTsMCYqICgYcUJiFiwOH/UXVapkZzOHAcZMJDyICj4wZfVQ2nduGVlFUJ7ojPY1lQQf9Gl4kToU8fl6uumk7v3i5z5ijnRdct9Alo8slUXJ922t2EQjEefliJ95VXqguBktaAzz9/ibq6CprWVhNKeRjSJ5Q6dA1O9oWe4Ws0h4H6EpvegUkEjyQm0+KzsOMOJTxNGB8hPD57wqFfP5gxo4JIxCOZNKmqirFpk6VbchaY1izXo1HV7+DCC1VcPhSC666z+PGPY0TlZD4PXgcRKH+kcojmG+MXqOWeFnyN5iCwrx4MzzRYPCNijJJONj0TwMNE4pGUJvO32Az6kUMk4hEK+UjpMWSIw9atlm7JWUD2aLnuuiSmOQxJ2KwOVOrlnDmwcQE8WVpL03QIwmCEw8o3KVZZ8MUZLfgaTRvZnx4Mtg2/DFmsSanXhYBXpUUFMWwcXsbGlRY7N0AQmBiGB5hYR5fw62um0wub3WK+enX3sNCq5XocqKjg/ITHssDkAmK4WEgJI5IO0TrVqLxxiKB4+LVEbUv9fAX+nbTgazRtZH96MFgWzJ7dfEE2lYJXfYu1YQvDgJAPW7ZYrF0bY+NGB299CQvemswRhoe/0OTRa2P0qbRyi8C6Y9ZhoVXL9ccc8DxE4FMkPG7p77B+i0UqBatDNlKYRDd5RLeaMKGywGeQQwu+RtNG9qcHQ1OTy0UXOaxYYfPKKxbbt8O8eeo9KeG665RjZo8eDnffbeP7NreVT2OXTJAk4LPyXexYWc3Ni9Lpmy3bKukg/yEjY4q2davD6aerkF19CfTDRGTCcZttHnxIdbeybYsQMd6vVndufbAKkI/TOlrwNZo2sq8eDC1DPhMmxIjHraxbZigEJSUuZWVqmxkzwkgpCYdT1PsBSJBhSXlyIb3vrMRxLCzbbt4dWwf5DxmuCxdeaOF5qkn9/f3n0qduMc/KW2miGAebN3yLi9KtDNVnLCoWWernWdR+bsC04Gs0B4Fo1Nqj703LkM+OHdWkUg4zrinhmFcamLvJZutWB99Xi7XhsGqeYhiSwAAhAQMMmaK83GH7dgsXCyu/qqs9qEknJf9m6s5+/85lpfcS9eCC+DLGM4fXhEW3Ftfc9noD1ibBF0IcBzwOnApsA34gpfy8le18oD79dLuU8oq2HFej6Ujkh3yECPPxxwsI/BQDvhcw4BWDsX4R19bOIpk0kdJDSoNwOImUanEX38APIJUyWb/eJh6HBQtQM/2p7UBFOiH5WVclJeo7Li11GTNzBlsjygJ7YBX8YONiwjeNZ/DgXGq9ZSnxb483YG2d4f8MiEkpfyOE+Fn6+b+3st1XUsryNh5Lo+mQ5Id8du3azkcfzcMIBQQSvigPOCbu8e14A1VVMcrLHb75ze1cfvlc1RM3Bce8E9Dt3RD/uWwW8bgSn9NPd3njDYcgUGsCepJ/8MgPwYHJI48on5zycgciEkIQAO9fA6fuOJ4JZ7j8ZaJDzLf5Vdji97+H8eOb22q0l9+mrZW23wMWpf9eBFzZxv1pNJ2SaNSiV6+p9OhRiRAmfsrASMHRtTmf/Hjc4rHHpvLSS5VAEUggBF/0g4aLfIZQA6iZ5syZFQwYcBdffFHBY4+5uhr3IJIfgpPSo7TUASBVW4JICtWy1oDPh8JHl/yJkx6y+WXqLl6UFQxNqmpp11UiP3Vq+xF7aLvgnyCl/Dj99w7ghD1s100IsVYI8aoQYo8XBSHE+PR2az/99NM2Dk2jaR+4Lkyfrh6jUYvBg2OYRb/mo1Vz+HLUr9kyJ8YxYyzOFS4/YzrROMTjMY41hqupZEgV8Bz7feW4WV6uirMMwycc9hg40Ml1zdK0mUwIDkIIGaZ8w3ZuYC6L4j+hvCrg2HXkfhcRsHNgkjB+tqNZELTf32KfIR0hxEtAj1be+kX+EymlFELsqSN6Lynlh0KIbwPLhRD1UsotLTeSUs4F5oJqYr7P0Ws07ZzW0+UtRo60YGRuu1u2uIxZVoGJhxeYvB2dRbceQxAf1yBlCgyTPzyn8rnr622EMAGPVMpkwwa7XcWJOxKt1a7F4xZ1dTHO7lFNv+kLGPnWPHwMQiTpFgexCJoGgi8FyZTJkbWSJD5JTBxsioqgpERd5NtTOAf2Q/CllBfs6T0hxN+FECdKKT8WQpwIfLKHfXyYfnxPCOEAg4HdBF+j6WzsT7aG68L6+x0uxyOMzxelu/iixy3s/BiEiHDiiTexbFklGzZYBIESpLfeinHFFQ4ffGAzbpyO4X8dXBdGj85djFesUK+rC7TFz4XDMN/HkD4SSUAIA5/ucehfFeb+8ht4ZkMlxZtglHBYGbIpv8Hi2sEweXL7rIlr66LtU8A1wG/Sj0tbbiCEOBb4p5QyIYT4BjACuLeNx9VoOgT7k63hOBDzbX6GCSTYWR4gQ+oGV8ok3br1ZNgwq9l+hg2zKC4GcJgwgb22QtQODK1TXa2a04B6rK6Gnj1zF+iYsPmZzBneze4zi+6bawgkVMcreTVuIYT6PQZca/HbtI31LbfArl2qoK49pWRC2wX/N8CfhRDXA+8DPwAQQgwDbpZS3gD0B+YIIQLUmsFvpJTxNh5Xo+kQtGyC0tp/fNuGuwyLCj/Gr5jG8NoXMZKyWSPzXr1U79vFi2HsWLVwm8kk8X2Tbt1ijBihdp4v8KAdGJqaXDZscKittRk2LGdNcdF6h9o8I7sdO2DwYJUKKwSsyfM6crB5fcvu7SqlVBYZPXvmmtfktzoMh9tXqK1Ngi+lbAAqWnl9LXBD+u81QFlbjqPRdGT21bXQsmDECHjlFYv/YBqx+ErOrErwxTCDY8erRuaumwsTrFwJ/fs3zySZN8/BMNRBKirUjDUUgssua58FQIeLpiaXmpoKfN+jb98Qy5dfCjug9O7n+F6dz8WEWci1VFPJp0/B+0sdzpI2rxnKCO1VrOwFwUB9p76f279hNL9zc5zc+0KoBjbt6fvWlbYaTYFxXXjtNfX3q1hcKGL8rq/D8JvtrFpUVzcPE9TW2pSWqkKtVMpk3To7mxmSaZg9PHApXerwWdhmNSok1F4XEw8VjY0OUqoKZsPwOffcJSSA2ulQfjt0j/uMZw7XshACSRifX2BSEcSyQn8OLqOFw5qwzdmTLWbOVN9vOKwuqD3yUlpahvAq249vGqAFX6MpOI6jwgKgZoUDb7IY/oia1TvTlUjnhwlGGC5XxB0aorN4cHkD69bZbNmiFm7r0/XsNzCX2UzCkD5BUMSfboyxa7DVbhcTDxXFxSqjyfd3YRhSVS4DMgyN5dA9DiEk4AHqb4lHJdXYOPwPJTwoJmPigTB5dKdqTSilmsk//bQS/4UL1aLv/oTwCokWfI2mwLQ2K8xP5zSMXJjAwuXFoAJznkevRSZVs2I80y/XIGXyZDg7cJnNRCKkEICUCSp7OlTXwE93OSyXNm94XaOLVqbuYfnyao45Zj6hUFLF6EMR/u5dxgk8RwgfnzAgCfDxCXEtCwmTIsDgy/5JPimHaN0uzkc1K/fU9SH7uyQScO+9MHy4+j0zJmrtDS34Gk2BaW1WOH16LvYupRJ9IeAC4fDPMxJsvSAAsYueiWpsW4n366+rsM/5OBgESuwBoew4ufo/KpDS4xeYXBqKYdudXO3TxOMWV11lcfrplYwZU00oBN//fiW1F1pUPekyMnBYE7E55xwwXnE4he3cyDzC+HxeGvDmTAgiYCQlgz5pzDauev11WLIkd5ynn1b/2vPdkxZ8jaYd0HJht+Wsf9Ys5bV+0ckl1J0QIE0AycdyPpNvqaSuzqK01OVHP3J4r7YEL15ESCQQIQN+/3toaFDNs9P9cxdd59CrPSpSG5g7F+LzXcad5HDEJTbPNKg7H8eBZFIJfzydSvmPf8CiRZCQFhgw81L1mbPfmEr5Vy7XsAiJx+flkiDjnyOhUdZmfyvXheeeU/s2DHVhDoL2vTiuBV+jaYfsKRb8/vsN7NyambuDJMWZZzokkzBzZq75+X8tncWEng25D7tu9goSMk16VdqFObFDgOuqcMqOJS4x0tXKS0yeNWLcXWQxa5bqMJYJw5imevQ8tbD9AhV0W+phvGDy2qwYD9dYXPzHGOf5DrK2kUuS96oU2RQUnz42e1zLUr+P46h1lvz1kfaUipmPFnyNpp3SWjqnWoSMIKUHEgI/TG2tnfXXyTQ/P/47DfBvU5vvLP8KAtl0HRdrtwtLRynWyqx1fPUV/AwHM12tLPEYGTi86lk0NKhzqa5Wn8lkzixaBN/Z5WBKD0OqvNWyBodHHrFwKy0cx6KkBD5a1ZsBR8znqA9OYill9DFy30n+b1RW1v6/My34Gk0HIhq1OOb9hziybgJCBpS8KOgeh1rsrJ9+KmWyY4e9+4fzYxHpFWE/bDJVxljlq7TN12a5dK9xmLrAzr7WXuPRkLOuAHCw8TCR6crYlUbOY6i+Ht57TxWtZc4lFoN3q23EQhOSCRWXKSkBWlxs3TL80fXIxDr+lRe4dEGM6Y6123eyr3qL9kBb3TI1Gs1hxHVhyfUNfPP/Sbr9XSKCFDYO8bhFVVWMhQvvpqoqRlHRXpSnhcHPiKSD78OQhMsZkyo4Zc5dPOdVcJbvtnsXzsxaRygE6yIWt/aPUXPl3WyZE+OyX6v+v/X1cNNNsGyZepw7V33WsqDyEYvQg7NyqVCTJ+/uM+04CM/LOmKOSDrt+jvZG3qGr9F0IBwH3j2jhDfvC9KZIwHvVZVwTtylMl4NcXgPtcALtB6byV8RDpusljYhH74jHMK+h5BK2EYLh3WGlZn0FpQ9hZh2X+uwIF0wlSnvnzYtt/05uITvc6Asb0cNDXtfcbVtpGmSTKg7h9URm+n2oTjLQ48WfI2mA2HbsGlTA8mIQSgUkJQG3y6vYVH8VorwaCqFMeXzaDr5YXDLWjfSyVPJkG0zPR3Dv7zERkxWFwJhmKwM7Oykt6yscOGK1i2mc++3GkrJu0KMHWuxbJkS+xgVdNviQUXejlqkRNWX2DyTX41sWcQfjLFlvsM7J9lMn7J7OKejoAVfo+lAWBYEgc2uXUWARyhscq4HEZLsLIUNMyGI+BhMomnt9UTToRuZ8Hh5msM7Y9Uipm3n+uGmNU39VaYuBI9tt3HnWe0izbA1i+nM660ukLa4QoyPxdgyxaL4Dw7mztwCbeakXCzevSbG+TjsHKzsExLpkP7s2epiVzHZwvMszHqITTmcZ39w0YKv0XQwRoywaGqKZZtsR28Hf+kCGss9ggjpnqs+jeUQNU1kwuOrwOQXL9qsWaaErKhoD4ux6elyHxfMRQc/zTC/OfjeLJ0zuC5s3658a4CsH9BeHUBbXCHer3aYtcBiiGdzW3pR1wibhGwb14WptsulfaqZNwTYnvMiCgKYNAmuv77zGNBpwddoOgAtY9jRqJUVzKZSl02PXof/chwRrEaGJIZRRPHASohV8vI0R4m9VNu3nLU3Nbns2KFyFnv0qMzu95pr1LErKw+OwOU3BzcMk0GDYvv08c8IeygEN96oxrKnpjKZ7+jyEpuy9IUuZZg8vsMmmVTGdBXEGI3DGdfaVFoWK7/v8vjpNptmqIulHyzkqadWUF+vxpWxTthXT4OOghZ8jaads7cYdtb+9ziP5OUmcx5+mKnjaojWwdL/hj6VFq4Np37DobGWbKVpRriamlxqa22k9JASPv54IZHICi680Drojo/5zcGDwKOx0dmr4OcLO+Q852F3Ac7/ju42LR67Ncb6+x2W+zZrn7cIhZRB3atY1BRZrEj7Fe182uGfP0xm74xCwuOuuxyuvtrC99WdUGVl7kLTnnPs9wct+BpNO2dvbRLz7X+l9DjntOcpWfoMx9YE/CC+gD+vupSh9z3P8OEpkkmTO+6IcfLJVjZzZckSh549k9mmH0HgsW6dg+dZ2eNVVx8cscs0B8/M8IuL7b1ub9sqlBME6nkmWyg/M2fUKJeTTnJ46im72ZgfqbWISQs/gFBK3R2AanJy5pkuqZRqiOJIm1trIxhJT1XThk3GjLF5+eXdz7kjC30GLfgaTTtnb20SM/a/qZRHEIQZdtHT/C3s8+GPYWCVx6iBS9iWnr1K6TFkiMMtt+QapfTubTNjRgTTVNVLqZTJJ5/YuazNsLJm9v22m4JFoxaDBsUOKIYfBGStiCdOzGULWVau69fWrR5lZSYDB8bYsEEVi40dqxrFtLxLmTjR5aabKvA8jzPPNPnnoBhj6xyunFLNqLug3xgV0uoIRVRfBy34Gk07Z28e6xn73w0bHN54YzuDBs3NGn29fw0c/woYSUhJQSplcsEFdjM3zjfftLjjDocxY6qREhynktmzLS67TB1v+3aYN+/gLVjmrz3si4zpWYZUSt1t5N/dZEJE4PHAAw6rVqUbuuNy/u3VbPwmHD+0ElC9APr3b25BoT4zlRG2xfBOKPAt0YKv0XQA9jbjjEYtRo60MAyXL75YBHIXRkjy+VBoGgin/D7M3OgNhE6r5Ne/VjvJv2vYssWiXz+Lmho4++zmx3Nd5TmzvwuWc+fm+u6OH79/5+a68G61y/k4ytTNyo3RMHIhnZa0DBENHGgTDqt99Vtj8/ffehRHIJlYyOTbV1BXZ/HllzkLinBYfWbkyL2PrTPE7rNIKdvlv6FDh0qNRnNgrFq1Rj7xxBi5YoUhV6xAxl4UcurVN8sjjpByw5w1Ut5zj5Rr1kgp1cM996jPrP/DlfLFM4fLG5kji4qym2T3+V//dY9ctWpN9jP572eYM0dKFYBR/+bMkc2O09pn1qyR8nxzjfwHR8gkIZkqOqLZ+CKR3P4ikd330di4Rm7bdo9sbFRjO+IIKaeKe+R744Rc8RJyxQrk8peEHDfunux+SkvXyAceUJ/ZG5n9hULqsbXxt0eAtXIPuqpn+BpNJ0Ll6E+jrm6lmvmGTU48u5LXRrmU/qSCwPOQpkloRQzLUh76tetG0dQnReR+uPenryPjUF2tpufPPuty/vkVnHKKRyKhFn0zcfKMR39m9rt4cfOxLF6cLlraS86848CIZM7l0s+LG1VXN2/9mAkzQW4f+SGizOL2CmlzW95CbECYE0/cTmmpSzxusWWLxVlnWUSje/8u97ZY3lHR5mkaTScjszh62ml3M3hwjFtvtehe4yATqso0SKhiJIAdO6qRIgUGyAj8fQyMZTE7digh37rVwTASGIYPMsEt/adxlu+SSKhF1LvuUoLuuiqMk8/YsUokEwklmonE7kZstg2rI8rlMoWBSDtWuq5aLO7f32XcuOlcdtlcjjlmOo895maPB+px+nRYvdrlvPOmM3Cgy+uGxZVxB/eOm3nj+SsJhQ0uv3weD84azZ8uu4X/vKSFOdoeyDdm6+j59xn0DF+j6YS0XBx9GZt/zbMOfhmbPi5s2wYn9mj+2aWhsfTooRZMjzyyEcMI0m0WAy5uepGrWckYYqzxVTPvzOw3k0aZSqnHsjLlVJmJwQcBuxmxWRZMdyyce2dx8dMTle3B5Mm8e00ZffvCffdVEIkkMIyAIDAYN66IO++M4Tj5mUYuQ4bYFBUluf/+CPX1DkVFFg0NFueeNx3ffxrwCQmf4dE5fPexRVz6nLI4hj3H6Nt7Q/KvgxZ8jaYTsKfFxczrJYMtLjVjjEg6rArbHLfD4tnzoW/fSmbOXEBRJAk+bN11J5UrVThn5+q5/OiHMwAVUiEFQVQSweN8HFanK3dDIXXctWtdrrrKYf16m02brOxs/lzhUiXv5WQ+ouH565ut5mbGN65HAwY5x8rzcVg+lHRGjbrgqEePyjH3Muaof7Lx2bF43nguuKA6m1YKHmPGVNOjh8riiURK2LzZJPB3YaQkx9XKrMVxdbXVbEG6tZTTzpaeqQVfo+ng7KkSt+Xrsx6yqKmxeHUBJJeqJcy33rK4/XaHyy93uOIKG/uRtLrNncuJg25hmwhApBupSzi61iCJyYrABtSF4LrrVE58IlFBaanH1Veb/Pznqkn60fUut8tRmKhgfNM7r/P+X56neMwU4nErO74XQjaxsEkINdhelTY3BvDVVya+r2b4qZSBwGD4RUv4PAQn9V3GD8/c/ftIJndQU6Matgth0rfvLJJbauh++wKOjPtZi+P+dL4Y/b7Qgq/RdHBaLi5mKmO3b2/+ekODsifwfSXgGTLNvX/3O/jpT+HMnS4/njeRY/sFbL8aAgBpsOLPP2JT+acsF2Nx31LKKCUMHqxm06Dy2w1D5bdb6aavkhQCaMq4eZpLMOpeoK4uhudZ9OvncsoQh7/0msVVRzUoe2JH5dOfdcQstq1bzOZEOcGpxXTfvITQ8NeztQY/vngxdz47jUsuWUg47AEmn33WA99XYwmCXWzeXMOoUY/ALYP5fP5i3JPGMn2KGv+BpJx2BrTgazQdnPyc+lAIFi7MxdFDIbVNvqCZZs4RMp9kUjUDnyocAhkQjcPAKmgqB5oEyUl/JRRJcVqwkvrJZcTjFoahLiS5nPgEhiHo3bskOziRDuw3lqM8awxl4VBe7jBwINxzT0U6dGOyOhLL+vicF3J5SU6mLOVxZngl35ExTuxbwsTBr2ebiqeKx7Jpk0VV1QqGDnW48Uab9euhX7+FGIaPEJJUah4frezOSZMf4ljP49L6lTBFlex2thj9vtCCr9F0cPIXF/MrY0F5yPTs2VzQMtuWlEBNTfPtQaU1ehRh8BXROBTHYeu4gHDEwwhJpFRiHY9bhMNq39Goxemnz+Lddychpc/mzZM56qgyopYFr7wC996L2bSJVHIzyIBUyuSYY2weeMAhlfIQQlW+5vv4nBs4ID2+KPX5rHwXl9ZWMzX+CFTBBeWLSXYfyx2LxhMEsHGjxemnqwvQsGHwxBPXcsklczAMiRA+7yZncFRviL7Z3Cq0s8Xo94UWfI2mE7CnytjWrI0z2zY1uVx0kYNl2Vx/vZUN9bwmLC4yYtw7oJrBdQsI4XN0rYCkxJeSVMqkttbOxu9BpUaed14DUgZA0MwNc269xeJ/PsmRR8LmO10GDnTYsMFm3DiLUaPA901ANV9fvryEq6+ezvr1NtsoYdMF8D+XgAxJhiXnM70KlsYrmfjueC67DHbtyoWnli6FF15QF7Qrr6wkkfgjpNcOpAGNQwTRtwTZq1QXpE2CL4T4N2Aa0B8YLqVcu4ftLgYeAELAH6WUv2nLcTUaTevsbyphvjf9qaeazJ8f49FHLY4/Hh5/HNYEFhXvWDw2pZJjn67m7PhCyquSfFZu8Kv6Wbz9trIc/uILGDVKhYcGDbK5/34l3hk3zLlzVePw0lKX8nIHw7B5/PGpmCY0NsLo0RZ9+8YYNMihqamESZMmY5oelZVhpJT83QiyTp5hmeSH5XP4SXwR/2nF+N1zVrO1iPwU0alTLT76aHb2jsMgQnGdn9uwi9LWGf6bwL8Ac/a0gRAiBMwGLgQ+AN4QQjwlpYy38dgajaYV9idM0dybPsEnn0zjww+nEYtZzfp5byy2GHe+Q+TtFMfFA459W3DbFQ385W3o29dFSoe+fW3icYu6Oov6+hhXXJFzw1y8WIn9zJkqTu/7Jps2xSgqspg4Ua01ZPS3b98aIhEPw/AJAiX0hiHV+4GK2WfSKi/5tJpQ0mE5Nq8JFcqB5msVJ500nqOOKlPunE9tJ/rmvJz1ZldIyWmFNgm+lHIjgBBib5sNBzZLKd9Lb/sn4HuAFnyN5hCyN+Ov/EVWKQMGD36JAQNWUlUVY9MmK1td2tgIP55n84I0ieDxxYAQH43ezkWpudw68SeEIx6ppMlPq1bwzjsWw4ZZ9OqVO9gt5S6ffGMakUiCUCjAMHYxZkw1TzxhccYZLhdcUM3FFy8gHPaRMoTvh5UoB4JAGgShAAjx1bZLGfHQcxy90YdIiJGbFzJCpvgFJpdGYox7yGpm85AhW4A27BD1bOxgHI4Y/snA3/KefwCc3dqGQojxwHiAnj17HvqRaTSdlL11yYKc/cK2bdNoaHgpW9RUXu7Qt6/F8OFqUXfiREj5qjXg90qrGfLbhUSL5jG5FELChxCYMsGVQ6rpdZvV/MLiulz5UAWN305Q5wcEBggh2bFjAeedN5jBgydjmrsQQiIEyECy89l+lH+yiWNrfVIIHhh6I89sqOTNNy3OC7ksusmhF2pl2sBHCI97L3WINVh7z7TpjGWzX4N9Cr4Q4iWgRytv/UJKufRgDkZKOReYCzBs2LCuG2jTaNrI/hh/RaMWp546jc8/X0kqpRZN43Gbhx8m65mfSd18FYtvlzucFUkhhE/IEIj0Iq+Rgspe0C9dQJutnt3u0MvzKH4r4LjXoOE89b6UPkGwmCIzgTAkSMCHUDJg9LKNFMdBAJIUF0r4zTtqQXkVFo8Vw0ZcAAAKgklEQVT1tJhq561Mh02mPGez6un9aNDSItbV6ayP94N9Cr6U8oI2HuND4JS8599Kv6bRaA4Re+uSlU9+A5WNG20efjg3S7dt1dP1q6/U89raPC95I0yfh32SR/sUvxUhOlu1lMq/s8hUz37ZP8FnwwMkgIRkMszDD4/l1ptXEAoHiABOeB5OWAbHxpX+ZxGqlkDK9MLvcdU0rYVo2qrz0e02q+ZZu1/Y9qHm+7oD6qwcjpDOG0AfIcRpKKG/Chh3GI6r0XRZDiSCkWmgMnKkyt55/3216GpZFrNmwaRJqigrHreoqooxZIiDbZdw2u01FNdCdEIu9zP/zmIVFjO/G2Nk38nI8OvKj8eH9c9fwlNPjaf/u1u4sXwGxbWSI+MRQJAiSYgAiSCByS/ersQXSuxn3DsaM5KgLgmDfm4Sne3QB2v30Px+qHlntD7eH9qalvl94CHgeOBZIUStlPIiIcRJqPTLS6WUKSHEJOAFVFrmAinlW20euUaj2SsHWlSUn6rp+ybdusVIJOCHP1SGaPG4xcaNFkVFcP31FWz1PYxBJoNKK8lYy7es+v3l8xZ/eOckvj2abHVs6bLPGGG43BV/CDMOiBATeIh6yhgtHL55RgmnHtPAjLU2qwN1AgMHOoQjXtZSofHMJFHHwZraSrXsdGefar6/d0CdjbZm6TwJPNnK6x8Bl+Y9fw54ri3H0mg0h5b8VE0pPZYsqeaSSxZlDdGmTo1xzjkW48Y5+H4mpTNXYAWtV/1+Fe+RtWiI1sJR8dVE+1fT7W0PQwZIIegRamB+YPFqYCHeViIswyCSKpxTW2uTSpqYMoGRguK3IjDBzh6zmZ7vh5p31TVcXWmr0WgAlarp+ypGn0qZBAEIofLiDcPjwQcdRo60aGqyqavL9ZItLrZ3C5nnV/3+n68quSE+j2jcR7ksS/r1A2ObEmVhmgy51QblxIyUMNRzufMsh3dOsvnl8xZvv21xx5QV/HZiNed6qDWDPan0fqp5V7NVAC34Go0mTTRq0a1bjHnzHNats4lE4LvfXYRywVQNvzOccMI1APToUUk8rlIik0mIRHIRlIzu3nCDxYT4w8xmEgY+KaOIHlMqYUplVpQ3OjnlPQeXF2UFR6z1EEUmlzwY4+EaC7AoHmgR3R+R7opqvh9owddoNFlGjLAwDCs7OS4tjalK1XTlbH6c3zBMevSopLpaRU8ATj/dZflyh9JSm2gcLMfhmr42/x4fz5uUYeNw7BU2UzJinH60URlBiQR8B4du0kMEKgbfvcZh4ULloBmf71J9vUOvSlsL+tdAC75Go2lG88lx81aJzS0ZPJYscdixQ73/g9K5jJ85CSI+NesiDL5D0r3O56eEiYprWSQr+V3RVFZMyR3LdZV/P+Saol9eYmNMzsXgH99hk0iomf/zyQqK5niwqAvlUh5EtOBrNJr9JmfJ4LFrl8mMGTbvvKPaGP7v8ol8EEmpXDzfo7EUojWSMD43MId/HbCALb+8jn6llYDF3LkwYULOmtk0VYSnzLKgLBeD31qduQtwMPEIyS6WS3kQ0YKv0Wj2m4wlw5IlDjNm2Lz5pvLdubm/w3G1AR8lVdqkkAZH14fwSWIg+bJU8tZ9HkHRHOrqFhEKxZg0yWrmw59M5ml43m1GJbBgAbzs2XiYhAy10NtlcikPIlrwNRrNARGNWvTta7FlC1mTtfLbbLpPKmJAVYKmoQbH3TSb7RPL+Ost1VwTLOCz8iRBRIKQBIHH1q0Ovt98dh6JtK7h6U6JOI7FlpIYZQ1O18qlPIgI2U69oYcNGybXrm3VXl+j0RSQpiaXxkaHDz6weeUVKyvSU22XEUmH1RGb6emsm9GjYUjC5fsDqjnrgflgpBDCJBxewYUXWiQSyuv+u9+FKVO0hh8MhBDrpJTDWntPz/A1Gs1+0zJLZ8KEGNGoxfTpsMq3eFlahNJ286D87l0selHPWUEABoBkwICuWfhUaLTgazSa/aZllk6mynZPxa2mqWb4dw+cyAdCBeylTNHY6GBZlhb6w4wWfI1Gs9/kZ+lkqmxhz8WtsRgkpjl8Y0NuQdcQoeznNIcXHcPXaDQHRCaGnynG2idp98qm3gkahxoU3zib6Ijx2bd0WOfgomP4Go3moJFtG7i/pKf/UcchmqfsXdWTvpBowddoNIeeVrxtuqonfSExCj0AjUbTNcks9GZy+XUd1aFHz/A1Gk1B6Kqe9IVEC75GoykY2sX48KJDOhqNRtNF0IKv0Wg0XQQt+BqNRtNF0IKv0Wg0XQQt+BqNRtNF0IKv0Wg0XYR266UjhPgUeL8Nu/gG8D8HaTiFoKOPHzr+OXT08YM+h/bA4R5/Lynl8a290W4Fv60IIdbuyUCoI9DRxw8d/xw6+vhBn0N7oD2NX4d0NBqNpougBV+j0Wi6CJ1Z8OcWegBtpKOPHzr+OXT08YM+h/ZAuxl/p43hazQajaY5nXmGr9FoNJo8tOBrNBpNF6HTCb4Q4mIhxCYhxGYhxM8KPZ4DRQixQAjxiRDizUKP5esghDhFCLFCCBEXQrwlhLit0GM6UIQQ3YQQrwsh6tLn8B+FHtPXQQgREkLUCCGeKfRYvg5CiG1CiHohRK0QokM2uBZCFAsh/iqEeFsIsVEIUVAz6E4VwxdChIB3gAuBD4A3gB9JKeMFHdgBIIQYBXwJVEspBxR6PAeKEOJE4EQp5XohxDHAOuDKDvYbCOAoKeWXQogIsAq4TUr5aoGHdkAIIW4HhgHdpZSXF3o8B4oQYhswTErZYYuuhBCLgJVSyj8KIUzgSCllY6HG09lm+MOBzVLK96SUHvAn4HsFHtMBIaV8Bfis0OP4ukgpP5ZSrk///QWwETi5sKM6MKTiy/TTSPpfh5oZCSG+BVwG/LHQY+mqCCGiwChgPoCU0iuk2EPnE/yTgb/lPf+ADiY2nQkhxKnAYOC1wo7kwEmHQ2qBT4AXpZQd7RxmAVOAoNADaQMSWCaEWCeEGF/owXwNTgM+BRamQ2t/FEIcVcgBdTbB17QThBBHA4uByVLKnYUez4EipfSllOXAt4DhQogOE14TQlwOfCKlXFfosbSR86SUQ4BLgInpcGdHIgwMAR6RUg4G/gEUdF2xswn+h8Apec+/lX5NcxhJx70XA49KKZ8o9HjaQvoWfAVwcaHHcgCMAK5Ix8D/BHxHCPF/CzukA0dK+WH68RPgSVTItiPxAfBB3t3hX1EXgILR2QT/DaCPEOK09ALJVcBTBR5TlyK94Dkf2CilvL/Q4/k6CCGOF0IUp/8+ApUE8HZhR7X/SCmnSim/JaU8FfV/YLmU8scFHtYBIYQ4Kr3oTzoMMgboUJlrUsodwN+EEP3SL1UABU1eCBfy4AcbKWVKCDEJeAEIAQuklG8VeFgHhBDivwEb+IYQ4gPgV1LK+YUd1QExAvhfQH06Bg7wcynlcwUc04FyIrAonfVlAH+WUnbI1MYOzAnAk2r+QBh4TEr5/wo7pK/FrcCj6Qnoe8C1hRxMp0rL1Gg0Gs2e6WwhHY1Go9HsAS34Go1G00XQgq/RaDRdBC34Go1G00XQgq/RaDRdBC34Go1G00XQgq/RaDRdhP8PTbAQXVY+FCEAAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Wfdelu1TmgPk"
+ },
+ "source": [
+ "## Training"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "t5McVnHmNiDw"
+ },
+ "source": [
+ "### 1. Design the Model\n",
+ "We're going to build a simple neural network model that will take an input value (in this case, `x`) and use it to predict a numeric output value (the sine of `x`). This type of problem is called a _regression_. It will use _layers_ of _neurons_ to attempt to learn any patterns underlying the training data, so it can make predictions.\n",
+ "\n",
+ "To begin with, we'll define two layers. The first layer takes a single input (our `x` value) and runs it through 8 neurons. Based on this input, each neuron will become _activated_ to a certain degree based on its internal state (its _weight_ and _bias_ values). A neuron's degree of activation is expressed as a number.\n",
+ "\n",
+ "The activation numbers from our first layer will be fed as inputs to our second layer, which is a single neuron. It will apply its own weights and bias to these inputs and calculate its own activation, which will be output as our `y` value.\n",
+ "\n",
+ "**Note:** To learn more about how neural networks function, you can explore the [Learn TensorFlow](https://codelabs.developers.google.com/codelabs/tensorflow-lab1-helloworld) codelabs.\n",
+ "\n",
+ "The code in the following cell defines our model using [Keras](https://www.tensorflow.org/guide/keras), TensorFlow's high-level API for creating deep learning networks. Once the network is defined, we _compile_ it, specifying parameters that determine how it will be trained:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "gD60bE8cXQId"
+ },
+ "source": [
+ "# We'll use Keras to create a simple model architecture\n",
+ "model_1 = tf.keras.Sequential()\n",
+ "\n",
+ "# First layer takes a scalar input and feeds it through 8 \"neurons\". The\n",
+ "# neurons decide whether to activate based on the 'relu' activation function.\n",
+ "model_1.add(keras.layers.Dense(8, activation='relu', input_shape=(1,)))\n",
+ "\n",
+ "# Final layer is a single neuron, since we want to output a single value\n",
+ "model_1.add(keras.layers.Dense(1))\n",
+ "\n",
+ "# Compile the model using the standard 'adam' optimizer and the mean squared error or 'mse' loss function for regression.\n",
+ "model_1.compile(optimizer='adam', loss='mse', metrics=['mae'])"
+ ],
+ "execution_count": 7,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "O0idLyRLQeGj"
+ },
+ "source": [
+ "### 2. Train the Model\n",
+ "Once we've defined the model, we can use our data to _train_ it. Training involves passing an `x` value into the neural network, checking how far the network's output deviates from the expected `y` value, and adjusting the neurons' weights and biases so that the output is more likely to be correct the next time.\n",
+ "\n",
+ "Training runs this process on the full dataset multiple times, and each full run-through is known as an _epoch_. The number of epochs to run during training is a parameter we can set.\n",
+ "\n",
+ "During each epoch, data is run through the network in multiple _batches_. Each batch, several pieces of data are passed into the network, producing output values. These outputs' correctness is measured in aggregate and the network's weights and biases are adjusted accordingly, once per batch. The _batch size_ is also a parameter we can set.\n",
+ "\n",
+ "The code in the following cell uses the `x` and `y` values from our training data to train the model. It runs for 500 _epochs_, with 64 pieces of data in each _batch_. We also pass in some data for _validation_. As you will see when you run the cell, training can take a while to complete:\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "p8hQKr4cVOdE",
+ "outputId": "e275e119-9fea-451e-89ae-6b3746cbf96d",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "# Train the model on our training data while validating on our validation set\n",
+ "history_1 = model_1.fit(x_train, y_train, epochs=500, batch_size=64,\n",
+ " validation_data=(x_validate, y_validate))"
+ ],
+ "execution_count": 8,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "Epoch 1/500\n",
+ "10/10 [==============================] - 1s 47ms/step - loss: 0.7289 - mae: 0.7120 - val_loss: 0.6401 - val_mae: 0.6504\n",
+ "Epoch 2/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.6329 - mae: 0.6488 - val_loss: 0.5587 - val_mae: 0.6031\n",
+ "Epoch 3/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.5201 - mae: 0.5735 - val_loss: 0.5014 - val_mae: 0.5763\n",
+ "Epoch 4/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.5057 - mae: 0.5760 - val_loss: 0.4632 - val_mae: 0.5615\n",
+ "Epoch 5/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.4502 - mae: 0.5459 - val_loss: 0.4386 - val_mae: 0.5536\n",
+ "Epoch 6/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.4168 - mae: 0.5332 - val_loss: 0.4227 - val_mae: 0.5490\n",
+ "Epoch 7/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.4211 - mae: 0.5341 - val_loss: 0.4125 - val_mae: 0.5464\n",
+ "Epoch 8/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3988 - mae: 0.5287 - val_loss: 0.4060 - val_mae: 0.5452\n",
+ "Epoch 9/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3901 - mae: 0.5230 - val_loss: 0.4014 - val_mae: 0.5440\n",
+ "Epoch 10/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3804 - mae: 0.5179 - val_loss: 0.3979 - val_mae: 0.5426\n",
+ "Epoch 11/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3695 - mae: 0.5150 - val_loss: 0.3950 - val_mae: 0.5412\n",
+ "Epoch 12/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3856 - mae: 0.5245 - val_loss: 0.3921 - val_mae: 0.5399\n",
+ "Epoch 13/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3744 - mae: 0.5184 - val_loss: 0.3893 - val_mae: 0.5386\n",
+ "Epoch 14/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3749 - mae: 0.5175 - val_loss: 0.3865 - val_mae: 0.5371\n",
+ "Epoch 15/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3467 - mae: 0.4993 - val_loss: 0.3837 - val_mae: 0.5354\n",
+ "Epoch 16/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3736 - mae: 0.5234 - val_loss: 0.3808 - val_mae: 0.5336\n",
+ "Epoch 17/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3655 - mae: 0.5148 - val_loss: 0.3778 - val_mae: 0.5318\n",
+ "Epoch 18/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3558 - mae: 0.5067 - val_loss: 0.3747 - val_mae: 0.5297\n",
+ "Epoch 19/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3343 - mae: 0.4908 - val_loss: 0.3716 - val_mae: 0.5275\n",
+ "Epoch 20/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3742 - mae: 0.5257 - val_loss: 0.3686 - val_mae: 0.5258\n",
+ "Epoch 21/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3296 - mae: 0.4831 - val_loss: 0.3654 - val_mae: 0.5235\n",
+ "Epoch 22/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3432 - mae: 0.4962 - val_loss: 0.3622 - val_mae: 0.5214\n",
+ "Epoch 23/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3397 - mae: 0.4951 - val_loss: 0.3589 - val_mae: 0.5191\n",
+ "Epoch 24/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3229 - mae: 0.4803 - val_loss: 0.3558 - val_mae: 0.5172\n",
+ "Epoch 25/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3562 - mae: 0.5105 - val_loss: 0.3524 - val_mae: 0.5150\n",
+ "Epoch 26/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3458 - mae: 0.5042 - val_loss: 0.3492 - val_mae: 0.5128\n",
+ "Epoch 27/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3163 - mae: 0.4764 - val_loss: 0.3459 - val_mae: 0.5106\n",
+ "Epoch 28/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3441 - mae: 0.5018 - val_loss: 0.3427 - val_mae: 0.5086\n",
+ "Epoch 29/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3062 - mae: 0.4705 - val_loss: 0.3395 - val_mae: 0.5065\n",
+ "Epoch 30/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3202 - mae: 0.4808 - val_loss: 0.3362 - val_mae: 0.5043\n",
+ "Epoch 31/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.3313 - mae: 0.4919 - val_loss: 0.3330 - val_mae: 0.5022\n",
+ "Epoch 32/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.3028 - mae: 0.4682 - val_loss: 0.3297 - val_mae: 0.4996\n",
+ "Epoch 33/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3056 - mae: 0.4670 - val_loss: 0.3264 - val_mae: 0.4972\n",
+ "Epoch 34/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3203 - mae: 0.4781 - val_loss: 0.3233 - val_mae: 0.4954\n",
+ "Epoch 35/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3256 - mae: 0.4912 - val_loss: 0.3201 - val_mae: 0.4929\n",
+ "Epoch 36/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3079 - mae: 0.4728 - val_loss: 0.3170 - val_mae: 0.4905\n",
+ "Epoch 37/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2969 - mae: 0.4641 - val_loss: 0.3139 - val_mae: 0.4885\n",
+ "Epoch 38/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3043 - mae: 0.4693 - val_loss: 0.3108 - val_mae: 0.4863\n",
+ "Epoch 39/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2902 - mae: 0.4549 - val_loss: 0.3078 - val_mae: 0.4843\n",
+ "Epoch 40/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3003 - mae: 0.4720 - val_loss: 0.3047 - val_mae: 0.4823\n",
+ "Epoch 41/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2970 - mae: 0.4678 - val_loss: 0.3017 - val_mae: 0.4804\n",
+ "Epoch 42/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2903 - mae: 0.4582 - val_loss: 0.2988 - val_mae: 0.4787\n",
+ "Epoch 43/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2853 - mae: 0.4553 - val_loss: 0.2960 - val_mae: 0.4769\n",
+ "Epoch 44/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2910 - mae: 0.4603 - val_loss: 0.2931 - val_mae: 0.4748\n",
+ "Epoch 45/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2819 - mae: 0.4533 - val_loss: 0.2902 - val_mae: 0.4727\n",
+ "Epoch 46/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2744 - mae: 0.4525 - val_loss: 0.2872 - val_mae: 0.4697\n",
+ "Epoch 47/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2707 - mae: 0.4411 - val_loss: 0.2845 - val_mae: 0.4680\n",
+ "Epoch 48/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2641 - mae: 0.4414 - val_loss: 0.2818 - val_mae: 0.4661\n",
+ "Epoch 49/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2642 - mae: 0.4378 - val_loss: 0.2793 - val_mae: 0.4647\n",
+ "Epoch 50/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2603 - mae: 0.4385 - val_loss: 0.2767 - val_mae: 0.4628\n",
+ "Epoch 51/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2684 - mae: 0.4473 - val_loss: 0.2740 - val_mae: 0.4604\n",
+ "Epoch 52/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2539 - mae: 0.4312 - val_loss: 0.2714 - val_mae: 0.4583\n",
+ "Epoch 53/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2621 - mae: 0.4417 - val_loss: 0.2690 - val_mae: 0.4568\n",
+ "Epoch 54/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2556 - mae: 0.4366 - val_loss: 0.2664 - val_mae: 0.4545\n",
+ "Epoch 55/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2524 - mae: 0.4309 - val_loss: 0.2639 - val_mae: 0.4525\n",
+ "Epoch 56/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2555 - mae: 0.4364 - val_loss: 0.2614 - val_mae: 0.4507\n",
+ "Epoch 57/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2483 - mae: 0.4264 - val_loss: 0.2589 - val_mae: 0.4485\n",
+ "Epoch 58/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.2403 - mae: 0.4212 - val_loss: 0.2564 - val_mae: 0.4460\n",
+ "Epoch 59/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2462 - mae: 0.4274 - val_loss: 0.2542 - val_mae: 0.4446\n",
+ "Epoch 60/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2364 - mae: 0.4178 - val_loss: 0.2522 - val_mae: 0.4437\n",
+ "Epoch 61/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2409 - mae: 0.4254 - val_loss: 0.2500 - val_mae: 0.4418\n",
+ "Epoch 62/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2338 - mae: 0.4172 - val_loss: 0.2478 - val_mae: 0.4400\n",
+ "Epoch 63/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2283 - mae: 0.4132 - val_loss: 0.2456 - val_mae: 0.4381\n",
+ "Epoch 64/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2438 - mae: 0.4330 - val_loss: 0.2433 - val_mae: 0.4360\n",
+ "Epoch 65/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2169 - mae: 0.4049 - val_loss: 0.2415 - val_mae: 0.4348\n",
+ "Epoch 66/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2208 - mae: 0.4087 - val_loss: 0.2393 - val_mae: 0.4329\n",
+ "Epoch 67/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2440 - mae: 0.4321 - val_loss: 0.2373 - val_mae: 0.4312\n",
+ "Epoch 68/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2250 - mae: 0.4131 - val_loss: 0.2353 - val_mae: 0.4295\n",
+ "Epoch 69/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2222 - mae: 0.4081 - val_loss: 0.2334 - val_mae: 0.4277\n",
+ "Epoch 70/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2245 - mae: 0.4138 - val_loss: 0.2316 - val_mae: 0.4261\n",
+ "Epoch 71/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2132 - mae: 0.3983 - val_loss: 0.2298 - val_mae: 0.4244\n",
+ "Epoch 72/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.2232 - mae: 0.4144 - val_loss: 0.2280 - val_mae: 0.4227\n",
+ "Epoch 73/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.2077 - mae: 0.3941 - val_loss: 0.2265 - val_mae: 0.4219\n",
+ "Epoch 74/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2116 - mae: 0.3993 - val_loss: 0.2249 - val_mae: 0.4205\n",
+ "Epoch 75/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.2227 - mae: 0.4148 - val_loss: 0.2235 - val_mae: 0.4198\n",
+ "Epoch 76/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2026 - mae: 0.3917 - val_loss: 0.2216 - val_mae: 0.4175\n",
+ "Epoch 77/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2083 - mae: 0.3966 - val_loss: 0.2200 - val_mae: 0.4157\n",
+ "Epoch 78/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2055 - mae: 0.3947 - val_loss: 0.2186 - val_mae: 0.4144\n",
+ "Epoch 79/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2069 - mae: 0.3965 - val_loss: 0.2171 - val_mae: 0.4128\n",
+ "Epoch 80/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1983 - mae: 0.3871 - val_loss: 0.2158 - val_mae: 0.4117\n",
+ "Epoch 81/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1994 - mae: 0.3876 - val_loss: 0.2146 - val_mae: 0.4109\n",
+ "Epoch 82/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1971 - mae: 0.3824 - val_loss: 0.2135 - val_mae: 0.4104\n",
+ "Epoch 83/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1965 - mae: 0.3879 - val_loss: 0.2120 - val_mae: 0.4085\n",
+ "Epoch 84/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2006 - mae: 0.3906 - val_loss: 0.2109 - val_mae: 0.4074\n",
+ "Epoch 85/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2048 - mae: 0.3979 - val_loss: 0.2096 - val_mae: 0.4057\n",
+ "Epoch 86/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1932 - mae: 0.3864 - val_loss: 0.2083 - val_mae: 0.4042\n",
+ "Epoch 87/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1916 - mae: 0.3830 - val_loss: 0.2073 - val_mae: 0.4036\n",
+ "Epoch 88/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1984 - mae: 0.3905 - val_loss: 0.2062 - val_mae: 0.4023\n",
+ "Epoch 89/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1939 - mae: 0.3874 - val_loss: 0.2052 - val_mae: 0.4010\n",
+ "Epoch 90/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1902 - mae: 0.3827 - val_loss: 0.2042 - val_mae: 0.4001\n",
+ "Epoch 91/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1888 - mae: 0.3784 - val_loss: 0.2038 - val_mae: 0.4009\n",
+ "Epoch 92/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1927 - mae: 0.3843 - val_loss: 0.2030 - val_mae: 0.4003\n",
+ "Epoch 93/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1851 - mae: 0.3730 - val_loss: 0.2018 - val_mae: 0.3981\n",
+ "Epoch 94/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1984 - mae: 0.3916 - val_loss: 0.2008 - val_mae: 0.3963\n",
+ "Epoch 95/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1851 - mae: 0.3733 - val_loss: 0.2001 - val_mae: 0.3960\n",
+ "Epoch 96/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1881 - mae: 0.3796 - val_loss: 0.1994 - val_mae: 0.3953\n",
+ "Epoch 97/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1859 - mae: 0.3765 - val_loss: 0.1987 - val_mae: 0.3949\n",
+ "Epoch 98/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1822 - mae: 0.3711 - val_loss: 0.1979 - val_mae: 0.3935\n",
+ "Epoch 99/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1886 - mae: 0.3764 - val_loss: 0.1970 - val_mae: 0.3915\n",
+ "Epoch 100/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1878 - mae: 0.3758 - val_loss: 0.1964 - val_mae: 0.3908\n",
+ "Epoch 101/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1769 - mae: 0.3670 - val_loss: 0.1958 - val_mae: 0.3897\n",
+ "Epoch 102/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1832 - mae: 0.3731 - val_loss: 0.1953 - val_mae: 0.3897\n",
+ "Epoch 103/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1827 - mae: 0.3728 - val_loss: 0.1952 - val_mae: 0.3910\n",
+ "Epoch 104/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1867 - mae: 0.3783 - val_loss: 0.1945 - val_mae: 0.3898\n",
+ "Epoch 105/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1813 - mae: 0.3691 - val_loss: 0.1937 - val_mae: 0.3869\n",
+ "Epoch 106/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1715 - mae: 0.3605 - val_loss: 0.1932 - val_mae: 0.3869\n",
+ "Epoch 107/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1800 - mae: 0.3692 - val_loss: 0.1928 - val_mae: 0.3859\n",
+ "Epoch 108/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1884 - mae: 0.3725 - val_loss: 0.1925 - val_mae: 0.3863\n",
+ "Epoch 109/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1777 - mae: 0.3686 - val_loss: 0.1922 - val_mae: 0.3862\n",
+ "Epoch 110/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1801 - mae: 0.3715 - val_loss: 0.1917 - val_mae: 0.3853\n",
+ "Epoch 111/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1794 - mae: 0.3665 - val_loss: 0.1913 - val_mae: 0.3846\n",
+ "Epoch 112/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1811 - mae: 0.3664 - val_loss: 0.1908 - val_mae: 0.3831\n",
+ "Epoch 113/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1821 - mae: 0.3655 - val_loss: 0.1904 - val_mae: 0.3823\n",
+ "Epoch 114/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1755 - mae: 0.3621 - val_loss: 0.1901 - val_mae: 0.3818\n",
+ "Epoch 115/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1718 - mae: 0.3584 - val_loss: 0.1899 - val_mae: 0.3820\n",
+ "Epoch 116/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1684 - mae: 0.3516 - val_loss: 0.1896 - val_mae: 0.3815\n",
+ "Epoch 117/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1760 - mae: 0.3618 - val_loss: 0.1894 - val_mae: 0.3816\n",
+ "Epoch 118/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1748 - mae: 0.3587 - val_loss: 0.1890 - val_mae: 0.3804\n",
+ "Epoch 119/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1749 - mae: 0.3626 - val_loss: 0.1887 - val_mae: 0.3792\n",
+ "Epoch 120/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1620 - mae: 0.3493 - val_loss: 0.1884 - val_mae: 0.3779\n",
+ "Epoch 121/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1720 - mae: 0.3573 - val_loss: 0.1883 - val_mae: 0.3789\n",
+ "Epoch 122/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.1767 - mae: 0.3623 - val_loss: 0.1881 - val_mae: 0.3787\n",
+ "Epoch 123/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1835 - mae: 0.3729 - val_loss: 0.1881 - val_mae: 0.3794\n",
+ "Epoch 124/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1782 - mae: 0.3691 - val_loss: 0.1876 - val_mae: 0.3775\n",
+ "Epoch 125/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1669 - mae: 0.3548 - val_loss: 0.1877 - val_mae: 0.3784\n",
+ "Epoch 126/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1819 - mae: 0.3693 - val_loss: 0.1878 - val_mae: 0.3791\n",
+ "Epoch 127/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1731 - mae: 0.3626 - val_loss: 0.1877 - val_mae: 0.3789\n",
+ "Epoch 128/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1696 - mae: 0.3556 - val_loss: 0.1872 - val_mae: 0.3773\n",
+ "Epoch 129/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1764 - mae: 0.3649 - val_loss: 0.1869 - val_mae: 0.3758\n",
+ "Epoch 130/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1770 - mae: 0.3649 - val_loss: 0.1867 - val_mae: 0.3750\n",
+ "Epoch 131/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1857 - mae: 0.3696 - val_loss: 0.1867 - val_mae: 0.3760\n",
+ "Epoch 132/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1715 - mae: 0.3566 - val_loss: 0.1865 - val_mae: 0.3754\n",
+ "Epoch 133/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1717 - mae: 0.3536 - val_loss: 0.1869 - val_mae: 0.3772\n",
+ "Epoch 134/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1692 - mae: 0.3558 - val_loss: 0.1863 - val_mae: 0.3751\n",
+ "Epoch 135/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1844 - mae: 0.3690 - val_loss: 0.1862 - val_mae: 0.3744\n",
+ "Epoch 136/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1608 - mae: 0.3431 - val_loss: 0.1861 - val_mae: 0.3737\n",
+ "Epoch 137/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1626 - mae: 0.3457 - val_loss: 0.1860 - val_mae: 0.3739\n",
+ "Epoch 138/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1705 - mae: 0.3598 - val_loss: 0.1861 - val_mae: 0.3748\n",
+ "Epoch 139/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1797 - mae: 0.3651 - val_loss: 0.1863 - val_mae: 0.3759\n",
+ "Epoch 140/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1692 - mae: 0.3543 - val_loss: 0.1858 - val_mae: 0.3739\n",
+ "Epoch 141/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1696 - mae: 0.3572 - val_loss: 0.1859 - val_mae: 0.3743\n",
+ "Epoch 142/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1652 - mae: 0.3503 - val_loss: 0.1861 - val_mae: 0.3754\n",
+ "Epoch 143/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1644 - mae: 0.3504 - val_loss: 0.1857 - val_mae: 0.3734\n",
+ "Epoch 144/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1721 - mae: 0.3567 - val_loss: 0.1855 - val_mae: 0.3728\n",
+ "Epoch 145/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1772 - mae: 0.3612 - val_loss: 0.1856 - val_mae: 0.3737\n",
+ "Epoch 146/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1654 - mae: 0.3502 - val_loss: 0.1856 - val_mae: 0.3736\n",
+ "Epoch 147/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1761 - mae: 0.3575 - val_loss: 0.1856 - val_mae: 0.3738\n",
+ "Epoch 148/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1693 - mae: 0.3542 - val_loss: 0.1853 - val_mae: 0.3719\n",
+ "Epoch 149/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1634 - mae: 0.3450 - val_loss: 0.1854 - val_mae: 0.3727\n",
+ "Epoch 150/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1642 - mae: 0.3457 - val_loss: 0.1853 - val_mae: 0.3723\n",
+ "Epoch 151/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1868 - mae: 0.3703 - val_loss: 0.1854 - val_mae: 0.3731\n",
+ "Epoch 152/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1797 - mae: 0.3615 - val_loss: 0.1852 - val_mae: 0.3716\n",
+ "Epoch 153/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1739 - mae: 0.3548 - val_loss: 0.1851 - val_mae: 0.3716\n",
+ "Epoch 154/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1779 - mae: 0.3633 - val_loss: 0.1851 - val_mae: 0.3711\n",
+ "Epoch 155/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1606 - mae: 0.3401 - val_loss: 0.1850 - val_mae: 0.3709\n",
+ "Epoch 156/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1834 - mae: 0.3646 - val_loss: 0.1853 - val_mae: 0.3728\n",
+ "Epoch 157/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1704 - mae: 0.3552 - val_loss: 0.1850 - val_mae: 0.3712\n",
+ "Epoch 158/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1741 - mae: 0.3575 - val_loss: 0.1850 - val_mae: 0.3714\n",
+ "Epoch 159/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1624 - mae: 0.3450 - val_loss: 0.1849 - val_mae: 0.3705\n",
+ "Epoch 160/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1691 - mae: 0.3547 - val_loss: 0.1850 - val_mae: 0.3712\n",
+ "Epoch 161/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1604 - mae: 0.3414 - val_loss: 0.1849 - val_mae: 0.3703\n",
+ "Epoch 162/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.1600 - mae: 0.3412 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 163/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1564 - mae: 0.3413 - val_loss: 0.1848 - val_mae: 0.3694\n",
+ "Epoch 164/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1664 - mae: 0.3461 - val_loss: 0.1851 - val_mae: 0.3719\n",
+ "Epoch 165/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1672 - mae: 0.3500 - val_loss: 0.1848 - val_mae: 0.3698\n",
+ "Epoch 166/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1717 - mae: 0.3600 - val_loss: 0.1847 - val_mae: 0.3694\n",
+ "Epoch 167/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1645 - mae: 0.3450 - val_loss: 0.1849 - val_mae: 0.3707\n",
+ "Epoch 168/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1697 - mae: 0.3467 - val_loss: 0.1853 - val_mae: 0.3724\n",
+ "Epoch 169/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1742 - mae: 0.3566 - val_loss: 0.1850 - val_mae: 0.3712\n",
+ "Epoch 170/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1650 - mae: 0.3455 - val_loss: 0.1847 - val_mae: 0.3693\n",
+ "Epoch 171/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1667 - mae: 0.3511 - val_loss: 0.1847 - val_mae: 0.3693\n",
+ "Epoch 172/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1689 - mae: 0.3476 - val_loss: 0.1849 - val_mae: 0.3710\n",
+ "Epoch 173/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1709 - mae: 0.3538 - val_loss: 0.1848 - val_mae: 0.3706\n",
+ "Epoch 174/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1794 - mae: 0.3588 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 175/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1753 - mae: 0.3539 - val_loss: 0.1846 - val_mae: 0.3680\n",
+ "Epoch 176/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1704 - mae: 0.3511 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 177/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1635 - mae: 0.3465 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 178/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1669 - mae: 0.3508 - val_loss: 0.1850 - val_mae: 0.3712\n",
+ "Epoch 179/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1661 - mae: 0.3434 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 180/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1668 - mae: 0.3500 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 181/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1600 - mae: 0.3416 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 182/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1672 - mae: 0.3500 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 183/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1663 - mae: 0.3461 - val_loss: 0.1847 - val_mae: 0.3698\n",
+ "Epoch 184/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1690 - mae: 0.3494 - val_loss: 0.1847 - val_mae: 0.3695\n",
+ "Epoch 185/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1716 - mae: 0.3513 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 186/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1748 - mae: 0.3588 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 187/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1588 - mae: 0.3364 - val_loss: 0.1849 - val_mae: 0.3705\n",
+ "Epoch 188/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1739 - mae: 0.3539 - val_loss: 0.1849 - val_mae: 0.3704\n",
+ "Epoch 189/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1711 - mae: 0.3497 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 190/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1706 - mae: 0.3525 - val_loss: 0.1845 - val_mae: 0.3678\n",
+ "Epoch 191/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1621 - mae: 0.3447 - val_loss: 0.1846 - val_mae: 0.3688\n",
+ "Epoch 192/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1669 - mae: 0.3485 - val_loss: 0.1847 - val_mae: 0.3699\n",
+ "Epoch 193/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1694 - mae: 0.3498 - val_loss: 0.1847 - val_mae: 0.3697\n",
+ "Epoch 194/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1708 - mae: 0.3520 - val_loss: 0.1846 - val_mae: 0.3694\n",
+ "Epoch 195/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1796 - mae: 0.3623 - val_loss: 0.1849 - val_mae: 0.3708\n",
+ "Epoch 196/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1624 - mae: 0.3417 - val_loss: 0.1849 - val_mae: 0.3706\n",
+ "Epoch 197/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1671 - mae: 0.3529 - val_loss: 0.1848 - val_mae: 0.3703\n",
+ "Epoch 198/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1680 - mae: 0.3479 - val_loss: 0.1845 - val_mae: 0.3690\n",
+ "Epoch 199/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1750 - mae: 0.3587 - val_loss: 0.1844 - val_mae: 0.3677\n",
+ "Epoch 200/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1613 - mae: 0.3419 - val_loss: 0.1845 - val_mae: 0.3684\n",
+ "Epoch 201/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1625 - mae: 0.3434 - val_loss: 0.1845 - val_mae: 0.3684\n",
+ "Epoch 202/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1780 - mae: 0.3576 - val_loss: 0.1845 - val_mae: 0.3688\n",
+ "Epoch 203/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1567 - mae: 0.3381 - val_loss: 0.1845 - val_mae: 0.3677\n",
+ "Epoch 204/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1675 - mae: 0.3489 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 205/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1766 - mae: 0.3609 - val_loss: 0.1847 - val_mae: 0.3694\n",
+ "Epoch 206/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1649 - mae: 0.3489 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 207/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1723 - mae: 0.3526 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 208/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1788 - mae: 0.3573 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 209/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1659 - mae: 0.3427 - val_loss: 0.1847 - val_mae: 0.3694\n",
+ "Epoch 210/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1737 - mae: 0.3549 - val_loss: 0.1845 - val_mae: 0.3684\n",
+ "Epoch 211/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1616 - mae: 0.3437 - val_loss: 0.1845 - val_mae: 0.3686\n",
+ "Epoch 212/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.1665 - mae: 0.3466 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 213/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1726 - mae: 0.3560 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 214/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1716 - mae: 0.3516 - val_loss: 0.1844 - val_mae: 0.3673\n",
+ "Epoch 215/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1662 - mae: 0.3398 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 216/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1773 - mae: 0.3588 - val_loss: 0.1845 - val_mae: 0.3686\n",
+ "Epoch 217/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1645 - mae: 0.3485 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 218/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1664 - mae: 0.3514 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 219/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1775 - mae: 0.3572 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 220/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1650 - mae: 0.3451 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 221/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1607 - mae: 0.3393 - val_loss: 0.1845 - val_mae: 0.3686\n",
+ "Epoch 222/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1796 - mae: 0.3623 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 223/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1759 - mae: 0.3592 - val_loss: 0.1845 - val_mae: 0.3682\n",
+ "Epoch 224/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1702 - mae: 0.3513 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 225/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1823 - mae: 0.3648 - val_loss: 0.1852 - val_mae: 0.3715\n",
+ "Epoch 226/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1698 - mae: 0.3515 - val_loss: 0.1848 - val_mae: 0.3701\n",
+ "Epoch 227/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1658 - mae: 0.3447 - val_loss: 0.1847 - val_mae: 0.3699\n",
+ "Epoch 228/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1756 - mae: 0.3553 - val_loss: 0.1846 - val_mae: 0.3694\n",
+ "Epoch 229/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1670 - mae: 0.3549 - val_loss: 0.1844 - val_mae: 0.3671\n",
+ "Epoch 230/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1685 - mae: 0.3480 - val_loss: 0.1845 - val_mae: 0.3682\n",
+ "Epoch 231/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1740 - mae: 0.3578 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 232/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1774 - mae: 0.3602 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 233/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1566 - mae: 0.3383 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 234/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1714 - mae: 0.3518 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 235/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1650 - mae: 0.3435 - val_loss: 0.1847 - val_mae: 0.3697\n",
+ "Epoch 236/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1721 - mae: 0.3513 - val_loss: 0.1846 - val_mae: 0.3694\n",
+ "Epoch 237/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1710 - mae: 0.3535 - val_loss: 0.1845 - val_mae: 0.3683\n",
+ "Epoch 238/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1638 - mae: 0.3453 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 239/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1687 - mae: 0.3518 - val_loss: 0.1845 - val_mae: 0.3687\n",
+ "Epoch 240/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1701 - mae: 0.3519 - val_loss: 0.1847 - val_mae: 0.3697\n",
+ "Epoch 241/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1721 - mae: 0.3530 - val_loss: 0.1849 - val_mae: 0.3703\n",
+ "Epoch 242/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1610 - mae: 0.3413 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 243/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1556 - mae: 0.3387 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 244/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1663 - mae: 0.3485 - val_loss: 0.1845 - val_mae: 0.3688\n",
+ "Epoch 245/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1761 - mae: 0.3585 - val_loss: 0.1848 - val_mae: 0.3703\n",
+ "Epoch 246/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1592 - mae: 0.3394 - val_loss: 0.1849 - val_mae: 0.3706\n",
+ "Epoch 247/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1724 - mae: 0.3568 - val_loss: 0.1845 - val_mae: 0.3682\n",
+ "Epoch 248/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1668 - mae: 0.3516 - val_loss: 0.1844 - val_mae: 0.3671\n",
+ "Epoch 249/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1676 - mae: 0.3474 - val_loss: 0.1845 - val_mae: 0.3688\n",
+ "Epoch 250/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1747 - mae: 0.3563 - val_loss: 0.1844 - val_mae: 0.3680\n",
+ "Epoch 251/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1766 - mae: 0.3607 - val_loss: 0.1844 - val_mae: 0.3676\n",
+ "Epoch 252/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1693 - mae: 0.3522 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 253/500\n",
+ "10/10 [==============================] - 0s 19ms/step - loss: 0.1632 - mae: 0.3429 - val_loss: 0.1844 - val_mae: 0.3675\n",
+ "Epoch 254/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1747 - mae: 0.3537 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 255/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1731 - mae: 0.3574 - val_loss: 0.1847 - val_mae: 0.3695\n",
+ "Epoch 256/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1696 - mae: 0.3525 - val_loss: 0.1845 - val_mae: 0.3676\n",
+ "Epoch 257/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1572 - mae: 0.3387 - val_loss: 0.1845 - val_mae: 0.3681\n",
+ "Epoch 258/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1617 - mae: 0.3409 - val_loss: 0.1849 - val_mae: 0.3702\n",
+ "Epoch 259/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1809 - mae: 0.3600 - val_loss: 0.1850 - val_mae: 0.3707\n",
+ "Epoch 260/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1633 - mae: 0.3435 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 261/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1684 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 262/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1710 - mae: 0.3512 - val_loss: 0.1848 - val_mae: 0.3703\n",
+ "Epoch 263/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1657 - mae: 0.3471 - val_loss: 0.1850 - val_mae: 0.3709\n",
+ "Epoch 264/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1764 - mae: 0.3611 - val_loss: 0.1849 - val_mae: 0.3704\n",
+ "Epoch 265/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1710 - mae: 0.3487 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 266/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1759 - mae: 0.3565 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 267/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1680 - mae: 0.3505 - val_loss: 0.1844 - val_mae: 0.3669\n",
+ "Epoch 268/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1764 - mae: 0.3597 - val_loss: 0.1844 - val_mae: 0.3671\n",
+ "Epoch 269/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1676 - mae: 0.3494 - val_loss: 0.1847 - val_mae: 0.3693\n",
+ "Epoch 270/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1641 - mae: 0.3478 - val_loss: 0.1846 - val_mae: 0.3687\n",
+ "Epoch 271/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1784 - mae: 0.3615 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 272/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1767 - mae: 0.3571 - val_loss: 0.1846 - val_mae: 0.3687\n",
+ "Epoch 273/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1714 - mae: 0.3521 - val_loss: 0.1845 - val_mae: 0.3676\n",
+ "Epoch 274/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1710 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3678\n",
+ "Epoch 275/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1729 - mae: 0.3507 - val_loss: 0.1845 - val_mae: 0.3683\n",
+ "Epoch 276/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1754 - mae: 0.3579 - val_loss: 0.1845 - val_mae: 0.3677\n",
+ "Epoch 277/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1705 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3672\n",
+ "Epoch 278/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1721 - mae: 0.3553 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 279/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1664 - mae: 0.3476 - val_loss: 0.1847 - val_mae: 0.3692\n",
+ "Epoch 280/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1655 - mae: 0.3467 - val_loss: 0.1847 - val_mae: 0.3692\n",
+ "Epoch 281/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1693 - mae: 0.3534 - val_loss: 0.1846 - val_mae: 0.3687\n",
+ "Epoch 282/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1732 - mae: 0.3580 - val_loss: 0.1847 - val_mae: 0.3692\n",
+ "Epoch 283/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1779 - mae: 0.3598 - val_loss: 0.1847 - val_mae: 0.3694\n",
+ "Epoch 284/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1763 - mae: 0.3570 - val_loss: 0.1849 - val_mae: 0.3705\n",
+ "Epoch 285/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1636 - mae: 0.3474 - val_loss: 0.1845 - val_mae: 0.3674\n",
+ "Epoch 286/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1716 - mae: 0.3496 - val_loss: 0.1845 - val_mae: 0.3680\n",
+ "Epoch 287/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1769 - mae: 0.3579 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 288/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1771 - mae: 0.3565 - val_loss: 0.1856 - val_mae: 0.3726\n",
+ "Epoch 289/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1709 - mae: 0.3516 - val_loss: 0.1848 - val_mae: 0.3703\n",
+ "Epoch 290/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1719 - mae: 0.3584 - val_loss: 0.1844 - val_mae: 0.3675\n",
+ "Epoch 291/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1730 - mae: 0.3544 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 292/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1751 - mae: 0.3558 - val_loss: 0.1846 - val_mae: 0.3694\n",
+ "Epoch 293/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1658 - mae: 0.3511 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 294/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1713 - mae: 0.3536 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 295/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1725 - mae: 0.3565 - val_loss: 0.1844 - val_mae: 0.3678\n",
+ "Epoch 296/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1724 - mae: 0.3513 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 297/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1680 - mae: 0.3520 - val_loss: 0.1845 - val_mae: 0.3683\n",
+ "Epoch 298/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1734 - mae: 0.3523 - val_loss: 0.1848 - val_mae: 0.3704\n",
+ "Epoch 299/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1756 - mae: 0.3561 - val_loss: 0.1846 - val_mae: 0.3695\n",
+ "Epoch 300/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1650 - mae: 0.3467 - val_loss: 0.1844 - val_mae: 0.3675\n",
+ "Epoch 301/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1690 - mae: 0.3495 - val_loss: 0.1844 - val_mae: 0.3669\n",
+ "Epoch 302/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1642 - mae: 0.3458 - val_loss: 0.1846 - val_mae: 0.3655\n",
+ "Epoch 303/500\n",
+ "10/10 [==============================] - 0s 19ms/step - loss: 0.1732 - mae: 0.3490 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 304/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1686 - mae: 0.3514 - val_loss: 0.1847 - val_mae: 0.3698\n",
+ "Epoch 305/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1757 - mae: 0.3568 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 306/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1650 - mae: 0.3475 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 307/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1544 - mae: 0.3364 - val_loss: 0.1845 - val_mae: 0.3673\n",
+ "Epoch 308/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1714 - mae: 0.3512 - val_loss: 0.1849 - val_mae: 0.3703\n",
+ "Epoch 309/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1729 - mae: 0.3549 - val_loss: 0.1853 - val_mae: 0.3718\n",
+ "Epoch 310/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1677 - mae: 0.3540 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 311/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1731 - mae: 0.3513 - val_loss: 0.1845 - val_mae: 0.3678\n",
+ "Epoch 312/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1717 - mae: 0.3521 - val_loss: 0.1845 - val_mae: 0.3687\n",
+ "Epoch 313/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1656 - mae: 0.3425 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 314/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1632 - mae: 0.3439 - val_loss: 0.1847 - val_mae: 0.3694\n",
+ "Epoch 315/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1694 - mae: 0.3512 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 316/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1679 - mae: 0.3496 - val_loss: 0.1851 - val_mae: 0.3712\n",
+ "Epoch 317/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1754 - mae: 0.3533 - val_loss: 0.1851 - val_mae: 0.3712\n",
+ "Epoch 318/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1757 - mae: 0.3582 - val_loss: 0.1847 - val_mae: 0.3694\n",
+ "Epoch 319/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1705 - mae: 0.3522 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 320/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1539 - mae: 0.3368 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 321/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1691 - mae: 0.3523 - val_loss: 0.1849 - val_mae: 0.3704\n",
+ "Epoch 322/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1695 - mae: 0.3494 - val_loss: 0.1854 - val_mae: 0.3720\n",
+ "Epoch 323/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1648 - mae: 0.3469 - val_loss: 0.1845 - val_mae: 0.3680\n",
+ "Epoch 324/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1781 - mae: 0.3610 - val_loss: 0.1845 - val_mae: 0.3684\n",
+ "Epoch 325/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1565 - mae: 0.3364 - val_loss: 0.1850 - val_mae: 0.3707\n",
+ "Epoch 326/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1680 - mae: 0.3496 - val_loss: 0.1849 - val_mae: 0.3706\n",
+ "Epoch 327/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1680 - mae: 0.3463 - val_loss: 0.1849 - val_mae: 0.3704\n",
+ "Epoch 328/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1699 - mae: 0.3538 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 329/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1782 - mae: 0.3604 - val_loss: 0.1848 - val_mae: 0.3704\n",
+ "Epoch 330/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1746 - mae: 0.3527 - val_loss: 0.1848 - val_mae: 0.3704\n",
+ "Epoch 331/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1695 - mae: 0.3496 - val_loss: 0.1846 - val_mae: 0.3695\n",
+ "Epoch 332/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1635 - mae: 0.3445 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 333/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1611 - mae: 0.3453 - val_loss: 0.1845 - val_mae: 0.3678\n",
+ "Epoch 334/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1595 - mae: 0.3416 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 335/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1733 - mae: 0.3562 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 336/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1668 - mae: 0.3458 - val_loss: 0.1845 - val_mae: 0.3676\n",
+ "Epoch 337/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1678 - mae: 0.3455 - val_loss: 0.1846 - val_mae: 0.3685\n",
+ "Epoch 338/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1768 - mae: 0.3578 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 339/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1674 - mae: 0.3485 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 340/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1736 - mae: 0.3536 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 341/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1655 - mae: 0.3474 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 342/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1727 - mae: 0.3539 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 343/500\n",
+ "10/10 [==============================] - 0s 19ms/step - loss: 0.1721 - mae: 0.3489 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 344/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1620 - mae: 0.3464 - val_loss: 0.1845 - val_mae: 0.3675\n",
+ "Epoch 345/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1757 - mae: 0.3548 - val_loss: 0.1845 - val_mae: 0.3681\n",
+ "Epoch 346/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1753 - mae: 0.3576 - val_loss: 0.1846 - val_mae: 0.3685\n",
+ "Epoch 347/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1698 - mae: 0.3471 - val_loss: 0.1845 - val_mae: 0.3678\n",
+ "Epoch 348/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1793 - mae: 0.3578 - val_loss: 0.1845 - val_mae: 0.3676\n",
+ "Epoch 349/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1677 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3683\n",
+ "Epoch 350/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1683 - mae: 0.3502 - val_loss: 0.1847 - val_mae: 0.3686\n",
+ "Epoch 351/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1813 - mae: 0.3624 - val_loss: 0.1846 - val_mae: 0.3678\n",
+ "Epoch 352/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1656 - mae: 0.3440 - val_loss: 0.1846 - val_mae: 0.3674\n",
+ "Epoch 353/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1705 - mae: 0.3515 - val_loss: 0.1848 - val_mae: 0.3692\n",
+ "Epoch 354/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1786 - mae: 0.3562 - val_loss: 0.1850 - val_mae: 0.3703\n",
+ "Epoch 355/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1719 - mae: 0.3518 - val_loss: 0.1847 - val_mae: 0.3683\n",
+ "Epoch 356/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1698 - mae: 0.3528 - val_loss: 0.1846 - val_mae: 0.3679\n",
+ "Epoch 357/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1682 - mae: 0.3499 - val_loss: 0.1846 - val_mae: 0.3678\n",
+ "Epoch 358/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1627 - mae: 0.3442 - val_loss: 0.1848 - val_mae: 0.3694\n",
+ "Epoch 359/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1634 - mae: 0.3428 - val_loss: 0.1855 - val_mae: 0.3718\n",
+ "Epoch 360/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1671 - mae: 0.3486 - val_loss: 0.1848 - val_mae: 0.3694\n",
+ "Epoch 361/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1748 - mae: 0.3609 - val_loss: 0.1846 - val_mae: 0.3681\n",
+ "Epoch 362/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1655 - mae: 0.3470 - val_loss: 0.1846 - val_mae: 0.3673\n",
+ "Epoch 363/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1610 - mae: 0.3395 - val_loss: 0.1848 - val_mae: 0.3693\n",
+ "Epoch 364/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1713 - mae: 0.3539 - val_loss: 0.1847 - val_mae: 0.3688\n",
+ "Epoch 365/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1664 - mae: 0.3484 - val_loss: 0.1847 - val_mae: 0.3691\n",
+ "Epoch 366/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1554 - mae: 0.3350 - val_loss: 0.1847 - val_mae: 0.3691\n",
+ "Epoch 367/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1701 - mae: 0.3511 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 368/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1720 - mae: 0.3546 - val_loss: 0.1847 - val_mae: 0.3691\n",
+ "Epoch 369/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1675 - mae: 0.3495 - val_loss: 0.1847 - val_mae: 0.3695\n",
+ "Epoch 370/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1645 - mae: 0.3449 - val_loss: 0.1846 - val_mae: 0.3684\n",
+ "Epoch 371/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1790 - mae: 0.3588 - val_loss: 0.1846 - val_mae: 0.3687\n",
+ "Epoch 372/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1662 - mae: 0.3466 - val_loss: 0.1847 - val_mae: 0.3689\n",
+ "Epoch 373/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1693 - mae: 0.3557 - val_loss: 0.1850 - val_mae: 0.3707\n",
+ "Epoch 374/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1682 - mae: 0.3493 - val_loss: 0.1851 - val_mae: 0.3711\n",
+ "Epoch 375/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1777 - mae: 0.3612 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 376/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1682 - mae: 0.3517 - val_loss: 0.1846 - val_mae: 0.3687\n",
+ "Epoch 377/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1623 - mae: 0.3432 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 378/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1790 - mae: 0.3576 - val_loss: 0.1850 - val_mae: 0.3709\n",
+ "Epoch 379/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1795 - mae: 0.3594 - val_loss: 0.1846 - val_mae: 0.3685\n",
+ "Epoch 380/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1635 - mae: 0.3440 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 381/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1727 - mae: 0.3509 - val_loss: 0.1847 - val_mae: 0.3697\n",
+ "Epoch 382/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1671 - mae: 0.3511 - val_loss: 0.1848 - val_mae: 0.3703\n",
+ "Epoch 383/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1748 - mae: 0.3557 - val_loss: 0.1848 - val_mae: 0.3701\n",
+ "Epoch 384/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1745 - mae: 0.3581 - val_loss: 0.1848 - val_mae: 0.3703\n",
+ "Epoch 385/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1728 - mae: 0.3566 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 386/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1679 - mae: 0.3499 - val_loss: 0.1847 - val_mae: 0.3696\n",
+ "Epoch 387/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1647 - mae: 0.3420 - val_loss: 0.1849 - val_mae: 0.3704\n",
+ "Epoch 388/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1685 - mae: 0.3485 - val_loss: 0.1846 - val_mae: 0.3684\n",
+ "Epoch 389/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1622 - mae: 0.3443 - val_loss: 0.1847 - val_mae: 0.3692\n",
+ "Epoch 390/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1656 - mae: 0.3495 - val_loss: 0.1847 - val_mae: 0.3692\n",
+ "Epoch 391/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1680 - mae: 0.3484 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 392/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1779 - mae: 0.3601 - val_loss: 0.1846 - val_mae: 0.3688\n",
+ "Epoch 393/500\n",
+ "10/10 [==============================] - 0s 19ms/step - loss: 0.1667 - mae: 0.3450 - val_loss: 0.1847 - val_mae: 0.3695\n",
+ "Epoch 394/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1668 - mae: 0.3466 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 395/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1751 - mae: 0.3564 - val_loss: 0.1845 - val_mae: 0.3683\n",
+ "Epoch 396/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1742 - mae: 0.3558 - val_loss: 0.1845 - val_mae: 0.3686\n",
+ "Epoch 397/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1800 - mae: 0.3653 - val_loss: 0.1845 - val_mae: 0.3676\n",
+ "Epoch 398/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1663 - mae: 0.3425 - val_loss: 0.1845 - val_mae: 0.3678\n",
+ "Epoch 399/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1731 - mae: 0.3566 - val_loss: 0.1845 - val_mae: 0.3683\n",
+ "Epoch 400/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1656 - mae: 0.3431 - val_loss: 0.1846 - val_mae: 0.3691\n",
+ "Epoch 401/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1603 - mae: 0.3438 - val_loss: 0.1846 - val_mae: 0.3688\n",
+ "Epoch 402/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1670 - mae: 0.3487 - val_loss: 0.1848 - val_mae: 0.3701\n",
+ "Epoch 403/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1762 - mae: 0.3544 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 404/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1714 - mae: 0.3497 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 405/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1652 - mae: 0.3454 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 406/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1663 - mae: 0.3471 - val_loss: 0.1851 - val_mae: 0.3710\n",
+ "Epoch 407/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1604 - mae: 0.3435 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 408/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1710 - mae: 0.3495 - val_loss: 0.1845 - val_mae: 0.3671\n",
+ "Epoch 409/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1716 - mae: 0.3498 - val_loss: 0.1846 - val_mae: 0.3689\n",
+ "Epoch 410/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1906 - mae: 0.3736 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 411/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1804 - mae: 0.3610 - val_loss: 0.1848 - val_mae: 0.3703\n",
+ "Epoch 412/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1685 - mae: 0.3505 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 413/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1598 - mae: 0.3406 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 414/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1619 - mae: 0.3453 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 415/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1786 - mae: 0.3603 - val_loss: 0.1849 - val_mae: 0.3704\n",
+ "Epoch 416/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1803 - mae: 0.3594 - val_loss: 0.1847 - val_mae: 0.3698\n",
+ "Epoch 417/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1714 - mae: 0.3564 - val_loss: 0.1845 - val_mae: 0.3681\n",
+ "Epoch 418/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1673 - mae: 0.3479 - val_loss: 0.1845 - val_mae: 0.3674\n",
+ "Epoch 419/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1648 - mae: 0.3469 - val_loss: 0.1847 - val_mae: 0.3695\n",
+ "Epoch 420/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1642 - mae: 0.3439 - val_loss: 0.1847 - val_mae: 0.3698\n",
+ "Epoch 421/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1738 - mae: 0.3554 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 422/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1662 - mae: 0.3466 - val_loss: 0.1845 - val_mae: 0.3681\n",
+ "Epoch 423/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1678 - mae: 0.3476 - val_loss: 0.1845 - val_mae: 0.3686\n",
+ "Epoch 424/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1762 - mae: 0.3599 - val_loss: 0.1845 - val_mae: 0.3684\n",
+ "Epoch 425/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1688 - mae: 0.3467 - val_loss: 0.1846 - val_mae: 0.3693\n",
+ "Epoch 426/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1708 - mae: 0.3483 - val_loss: 0.1846 - val_mae: 0.3687\n",
+ "Epoch 427/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1641 - mae: 0.3435 - val_loss: 0.1845 - val_mae: 0.3680\n",
+ "Epoch 428/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1683 - mae: 0.3438 - val_loss: 0.1845 - val_mae: 0.3683\n",
+ "Epoch 429/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1659 - mae: 0.3468 - val_loss: 0.1845 - val_mae: 0.3667\n",
+ "Epoch 430/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1630 - mae: 0.3462 - val_loss: 0.1845 - val_mae: 0.3670\n",
+ "Epoch 431/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1713 - mae: 0.3480 - val_loss: 0.1849 - val_mae: 0.3703\n",
+ "Epoch 432/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1818 - mae: 0.3676 - val_loss: 0.1851 - val_mae: 0.3712\n",
+ "Epoch 433/500\n",
+ "10/10 [==============================] - 0s 19ms/step - loss: 0.1833 - mae: 0.3606 - val_loss: 0.1847 - val_mae: 0.3697\n",
+ "Epoch 434/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1676 - mae: 0.3489 - val_loss: 0.1845 - val_mae: 0.3669\n",
+ "Epoch 435/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1651 - mae: 0.3451 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 436/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1736 - mae: 0.3534 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 437/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1700 - mae: 0.3531 - val_loss: 0.1847 - val_mae: 0.3697\n",
+ "Epoch 438/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1799 - mae: 0.3615 - val_loss: 0.1845 - val_mae: 0.3685\n",
+ "Epoch 439/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1684 - mae: 0.3535 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 440/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1644 - mae: 0.3445 - val_loss: 0.1848 - val_mae: 0.3699\n",
+ "Epoch 441/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1702 - mae: 0.3541 - val_loss: 0.1845 - val_mae: 0.3682\n",
+ "Epoch 442/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1621 - mae: 0.3424 - val_loss: 0.1845 - val_mae: 0.3666\n",
+ "Epoch 443/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1757 - mae: 0.3551 - val_loss: 0.1845 - val_mae: 0.3670\n",
+ "Epoch 444/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1639 - mae: 0.3403 - val_loss: 0.1845 - val_mae: 0.3682\n",
+ "Epoch 445/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1739 - mae: 0.3512 - val_loss: 0.1848 - val_mae: 0.3695\n",
+ "Epoch 446/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1712 - mae: 0.3530 - val_loss: 0.1848 - val_mae: 0.3700\n",
+ "Epoch 447/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1630 - mae: 0.3460 - val_loss: 0.1848 - val_mae: 0.3698\n",
+ "Epoch 448/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1670 - mae: 0.3458 - val_loss: 0.1846 - val_mae: 0.3687\n",
+ "Epoch 449/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1576 - mae: 0.3345 - val_loss: 0.1846 - val_mae: 0.3685\n",
+ "Epoch 450/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1603 - mae: 0.3429 - val_loss: 0.1847 - val_mae: 0.3694\n",
+ "Epoch 451/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1689 - mae: 0.3507 - val_loss: 0.1848 - val_mae: 0.3697\n",
+ "Epoch 452/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1692 - mae: 0.3490 - val_loss: 0.1848 - val_mae: 0.3699\n",
+ "Epoch 453/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1685 - mae: 0.3514 - val_loss: 0.1845 - val_mae: 0.3679\n",
+ "Epoch 454/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1774 - mae: 0.3588 - val_loss: 0.1846 - val_mae: 0.3692\n",
+ "Epoch 455/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1672 - mae: 0.3472 - val_loss: 0.1846 - val_mae: 0.3690\n",
+ "Epoch 456/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1731 - mae: 0.3566 - val_loss: 0.1846 - val_mae: 0.3688\n",
+ "Epoch 457/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1658 - mae: 0.3454 - val_loss: 0.1847 - val_mae: 0.3693\n",
+ "Epoch 458/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1702 - mae: 0.3520 - val_loss: 0.1845 - val_mae: 0.3683\n",
+ "Epoch 459/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1739 - mae: 0.3532 - val_loss: 0.1846 - val_mae: 0.3684\n",
+ "Epoch 460/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1699 - mae: 0.3490 - val_loss: 0.1846 - val_mae: 0.3688\n",
+ "Epoch 461/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1703 - mae: 0.3547 - val_loss: 0.1845 - val_mae: 0.3671\n",
+ "Epoch 462/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1694 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3682\n",
+ "Epoch 463/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1728 - mae: 0.3542 - val_loss: 0.1848 - val_mae: 0.3698\n",
+ "Epoch 464/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1638 - mae: 0.3433 - val_loss: 0.1847 - val_mae: 0.3691\n",
+ "Epoch 465/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1648 - mae: 0.3382 - val_loss: 0.1845 - val_mae: 0.3676\n",
+ "Epoch 466/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1713 - mae: 0.3515 - val_loss: 0.1845 - val_mae: 0.3670\n",
+ "Epoch 467/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1660 - mae: 0.3467 - val_loss: 0.1846 - val_mae: 0.3684\n",
+ "Epoch 468/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1815 - mae: 0.3630 - val_loss: 0.1852 - val_mae: 0.3714\n",
+ "Epoch 469/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1685 - mae: 0.3455 - val_loss: 0.1852 - val_mae: 0.3712\n",
+ "Epoch 470/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1791 - mae: 0.3612 - val_loss: 0.1846 - val_mae: 0.3686\n",
+ "Epoch 471/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1707 - mae: 0.3523 - val_loss: 0.1846 - val_mae: 0.3685\n",
+ "Epoch 472/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1703 - mae: 0.3525 - val_loss: 0.1846 - val_mae: 0.3683\n",
+ "Epoch 473/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1608 - mae: 0.3447 - val_loss: 0.1846 - val_mae: 0.3671\n",
+ "Epoch 474/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1675 - mae: 0.3465 - val_loss: 0.1848 - val_mae: 0.3693\n",
+ "Epoch 475/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1689 - mae: 0.3513 - val_loss: 0.1846 - val_mae: 0.3683\n",
+ "Epoch 476/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1632 - mae: 0.3431 - val_loss: 0.1847 - val_mae: 0.3692\n",
+ "Epoch 477/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1642 - mae: 0.3464 - val_loss: 0.1846 - val_mae: 0.3674\n",
+ "Epoch 478/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1734 - mae: 0.3511 - val_loss: 0.1851 - val_mae: 0.3707\n",
+ "Epoch 479/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1803 - mae: 0.3612 - val_loss: 0.1847 - val_mae: 0.3687\n",
+ "Epoch 480/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1679 - mae: 0.3531 - val_loss: 0.1846 - val_mae: 0.3677\n",
+ "Epoch 481/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1597 - mae: 0.3406 - val_loss: 0.1846 - val_mae: 0.3677\n",
+ "Epoch 482/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1761 - mae: 0.3575 - val_loss: 0.1850 - val_mae: 0.3701\n",
+ "Epoch 483/500\n",
+ "10/10 [==============================] - 0s 20ms/step - loss: 0.1707 - mae: 0.3541 - val_loss: 0.1847 - val_mae: 0.3692\n",
+ "Epoch 484/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1746 - mae: 0.3534 - val_loss: 0.1847 - val_mae: 0.3686\n",
+ "Epoch 485/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1644 - mae: 0.3457 - val_loss: 0.1846 - val_mae: 0.3675\n",
+ "Epoch 486/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1724 - mae: 0.3497 - val_loss: 0.1849 - val_mae: 0.3699\n",
+ "Epoch 487/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1743 - mae: 0.3552 - val_loss: 0.1849 - val_mae: 0.3699\n",
+ "Epoch 488/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.1662 - mae: 0.3468 - val_loss: 0.1846 - val_mae: 0.3678\n",
+ "Epoch 489/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1742 - mae: 0.3513 - val_loss: 0.1847 - val_mae: 0.3686\n",
+ "Epoch 490/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1695 - mae: 0.3481 - val_loss: 0.1846 - val_mae: 0.3674\n",
+ "Epoch 491/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1736 - mae: 0.3521 - val_loss: 0.1847 - val_mae: 0.3689\n",
+ "Epoch 492/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1554 - mae: 0.3364 - val_loss: 0.1846 - val_mae: 0.3664\n",
+ "Epoch 493/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1760 - mae: 0.3597 - val_loss: 0.1847 - val_mae: 0.3685\n",
+ "Epoch 494/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1666 - mae: 0.3457 - val_loss: 0.1849 - val_mae: 0.3697\n",
+ "Epoch 495/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1673 - mae: 0.3484 - val_loss: 0.1848 - val_mae: 0.3695\n",
+ "Epoch 496/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1754 - mae: 0.3581 - val_loss: 0.1848 - val_mae: 0.3695\n",
+ "Epoch 497/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1729 - mae: 0.3563 - val_loss: 0.1847 - val_mae: 0.3687\n",
+ "Epoch 498/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1727 - mae: 0.3584 - val_loss: 0.1847 - val_mae: 0.3688\n",
+ "Epoch 499/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1713 - mae: 0.3522 - val_loss: 0.1847 - val_mae: 0.3685\n",
+ "Epoch 500/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1634 - mae: 0.3428 - val_loss: 0.1846 - val_mae: 0.3680\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "cRE8KpEqVfaS"
+ },
+ "source": [
+ "### 3. Plot Metrics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SDsjqfjFm7Fz"
+ },
+ "source": [
+ "**1. Loss (or Mean Squared Error)**\n",
+ "\n",
+ "During training, the model's performance is constantly being measured against both our training data and the validation data that we set aside earlier. Training produces a log of data that tells us how the model's performance changed over the course of the training process.\n",
+ "\n",
+ "The following cells will display some of that data in a graphical form:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "CmvA-ksoln8r",
+ "outputId": "220ea767-6ffd-4eab-c327-c82a016c10eb",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 295
+ }
+ },
+ "source": [
+ "# Draw a graph of the loss, which is the distance between\n",
+ "# the predicted and actual values during training and validation.\n",
+ "train_loss = history_1.history['loss']\n",
+ "val_loss = history_1.history['val_loss']\n",
+ "\n",
+ "epochs = range(1, len(train_loss) + 1)\n",
+ "\n",
+ "plt.plot(epochs, train_loss, 'g.', label='Training loss')\n",
+ "plt.plot(epochs, val_loss, 'b', label='Validation loss')\n",
+ "plt.title('Training and validation loss')\n",
+ "plt.xlabel('Epochs')\n",
+ "plt.ylabel('Loss')\n",
+ "plt.legend()\n",
+ "plt.show()"
+ ],
+ "execution_count": 9,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYIAAAEWCAYAAABrDZDcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO3deXxU5b3H8c8vIQsQZHeBRIMWUCwCEsCISxR7q2LRurRSW6AqKK21aiuitUq1Xot6q5dW26JWa8WLbb1ycatWBFGJCioqIAhqKLhC2Ncs/O4f50yYbCRATibJfN+v17zmnDNn+T0zk/nleZ5znmPujoiIJK+URAcgIiKJpUQgIpLklAhERJKcEoGISJJTIhARSXJKBCIiSU6JQBqUmT1nZqMbet1EMrMiMzstgv26mX0tnP6jmf2yPuvuw3EuMrMX9jXOPey3wMxWN/R+pfG1SnQAknhmtiVutg2wEygP5y9z92n13Ze7nxHFui2du1/eEPsxs1zgEyDN3cvCfU8D6v0ZSvJRIhDcPSs2bWZFwKXu/mLV9cysVezHRURaDjUNSa1iVX8zu87MvgAeMrOOZva0ma0xs/XhdHbcNnPM7NJweoyZvWpmd4XrfmJmZ+zjuj3MbK6ZbTazF83sXjN7tJa46xPjrWb2Wri/F8ysS9zrPzCzlWZWbGa/2MP7M8TMvjCz1Lhl3zaz98LpwWZWaGYbzOxzM/u9maXXsq+HzezXcfPXhtt8ZmYXV1l3uJm9Y2abzGyVmU2Ke3lu+LzBzLaYWX7svY3b/ngzm29mG8Pn4+v73uyJmR0Vbr/BzBab2Yi41840syXhPj81s5+Hy7uEn88GM1tnZq+YmX6XGpnecKnLwUAn4DBgHMF35qFw/lBgO/D7PWw/BFgGdAHuAB40M9uHdR8D3gQ6A5OAH+zhmPWJ8XvAD4EDgXQg9sPUB/hDuP9u4fGyqYG7vwFsBU6tst/Hwuly4OqwPPnAMOBHe4ibMIbTw3i+AfQEqvZPbAVGAR2A4cB4MzsnfO2k8LmDu2e5e2GVfXcCngGmhGX7LfCMmXWuUoZq700dMacBTwEvhNv9BJhmZr3DVR4kaGZsB3wdeClc/jNgNdAVOAi4AdC4N41MiUDqsgu42d13uvt2dy929yfcfZu7bwZuA07ew/Yr3f1+dy8H/gIcQvAHX+91zexQYBBwk7uXuPurwMzaDljPGB9y9w/dfTvwN6B/uPx84Gl3n+vuO4Ffhu9Bbf4HGAlgZu2AM8NluPtb7v66u5e5exHwpxriqMl3wvgWuftWgsQXX7457v6+u+9y9/fC49VnvxAkjuXu/tcwrv8BlgLfiluntvdmT44DsoDfhJ/RS8DThO8NUAr0MbMD3H29u78dt/wQ4DB3L3X3V1wDoDU6JQKpyxp33xGbMbM2ZvansOlkE0FTRIf45pEqvohNuPu2cDJrL9ftBqyLWwawqraA6xnjF3HT2+Ji6ha/7/CHuLi2YxH893+umWUA5wJvu/vKMI5eYbPHF2Ec/0lQO6hLpRiAlVXKN8TMZodNXxuBy+u539i+V1ZZthLoHjdf23tTZ8zuHp804/d7HkGSXGlmL5tZfrj8TmAF8IKZfWxmE+tXDGlISgRSl6r/nf0M6A0McfcD2N0UUVtzT0P4HOhkZm3iluXsYf39ifHz+H2Hx+xc28ruvoTgB+8MKjcLQdDEtBToGcZxw77EQNC8Fe8xghpRjru3B/4Yt9+6/pv+jKDJLN6hwKf1iKuu/eZUad+v2K+7z3f3swmajWYQ1DRw983u/jN3PxwYAVxjZsP2MxbZS0oEsrfaEbS5bwjbm2+O+oDhf9gLgElmlh7+N/mtPWyyPzH+AzjLzE4IO3Zvoe6/k8eAnxIknL9XiWMTsMXMjgTG1zOGvwFjzKxPmIiqxt+OoIa0w8wGEySgmDUETVmH17LvZ4FeZvY9M2tlZt8F+hA04+yPNwhqDxPMLM3MCgg+o+nhZ3aRmbV391KC92QXgJmdZWZfC/uCNhL0q+ypKU4ioEQge+seoDWwFngd+GcjHfcigg7XYuDXwOME1zvUZJ9jdPfFwI8Jftw/B9YTdGbuSayN/iV3Xxu3/OcEP9KbgfvDmOsTw3NhGV4iaDZ5qcoqPwJuMbPNwE2E/12H224j6BN5LTwT57gq+y4GziKoNRUDE4CzqsS919y9hOCH/wyC9/0+YJS7Lw1X+QFQFDaRXU7weULQGf4isAUoBO5z99n7E4vsPVO/jDRHZvY4sNTdI6+RiLR0qhFIs2Bmg8zsCDNLCU+vPJugrVlE9pOuLJbm4mDgfwk6blcD4939ncSGJNIyqGlIRCTJqWlIRCTJNbumoS5dunhubm6iwxARaVbeeuutte7etabXml0iyM3NZcGCBYkOQ0SkWTGzqleUV1DTkIhIklMiEBFJcpEmAjM73cyWmdmKmgaTMrO7zWxh+PjQzDZEGY+IiFQXWR9BONLjvQRjqq8G5pvZzHCQLgDc/eq49X8CDIgqHhHZd6WlpaxevZodO3bUvbIkVGZmJtnZ2aSlpdV7myg7iwcDK9z9YwAzm05wNeiSWtYfSSMMYCYie2/16tW0a9eO3Nxcar+vkCSau1NcXMzq1avp0aNHvbeLsmmoO5XHVF9N5THPK5jZYUAPqg+uFXt9nJktMLMFa9asafBARWTPduzYQefOnZUEmjgzo3Pnzntdc2sqncUXAv8I70xVjbtPdfc8d8/r2rXG02DrVLiqkNtfuZ3CVYV1rywi1SgJNA/78jlF2TT0KZVvrpFN7Te/uJBg6N9IFK4qZNgjwygpLyE9NZ1Zo2aRn5Nf94YiIkkgyhrBfKCnmfUIb/BxITXcZza8YUdHgrHIIzGnaA4l5SWUezkl5SXMKZoT1aFEJALFxcX079+f/v37c/DBB9O9e/eK+ZKSkj1uu2DBAq688so6j3H88cc3SKxz5szhrLPOapB9NZbIagTuXmZmVwDPA6nAn919sZndAixw91hSuBCYHuUNqwtyC0hPTa+oERTkFkR1KBGJQOfOnVm4cCEAkyZNIisri5///OcVr5eVldGqVc0/Z3l5eeTl5dV5jHnz5jVMsM1QpH0E7v6su/dy9yPc/bZw2U1xSQB3n+Tukd6wOj8nn1mjZnHrKbeqWUikkUTdLzdmzBguv/xyhgwZwoQJE3jzzTfJz89nwIABHH/88Sxbtgyo/B/6pEmTuPjiiykoKODwww9nypQpFfvLysqqWL+goIDzzz+fI488kosuuojY/6nPPvssRx55JAMHDuTKK6+s8z//devWcc4553DMMcdw3HHH8d577wHw8ssvV9RoBgwYwObNm/n888856aST6N+/P1//+td55ZVXGvw9q02zG2toX+Xn5CsBiDSSxuqXW716NfPmzSM1NZVNmzbxyiuv0KpVK1588UVuuOEGnnjiiWrbLF26lNmzZ7N582Z69+7N+PHjq51z/84777B48WK6devG0KFDee2118jLy+Oyyy5j7ty59OjRg5EjR9YZ380338yAAQOYMWMGL730EqNGjWLhwoXcdddd3HvvvQwdOpQtW7aQmZnJ1KlT+eY3v8kvfvELysvL2bZtW4O9T3VJmkQgIo2npn65KBLBBRdcQGpqKgAbN25k9OjRLF++HDOjtLS0xm2GDx9ORkYGGRkZHHjggXz55ZdkZ2dXWmfw4MEVy/r3709RURFZWVkcfvjhFefnjxw5kqlTp+4xvldffbUiGZ166qkUFxezadMmhg4dyjXXXMNFF13EueeeS3Z2NoMGDeLiiy+mtLSUc845h/79++/Xe7M3msrpoyLSgsT65VItNdJ+ubZt21ZM//KXv+SUU05h0aJFPPXUU7WeS5+RkVExnZqaSllZ2T6tsz8mTpzIAw88wPbt2xk6dChLly7lpJNOYu7cuXTv3p0xY8bwyCOPNOgx90Q1AhFpcLF+uTlFcyjILWiUZtmNGzfSvXtwzerDDz/c4Pvv3bs3H3/8MUVFReTm5vL444/Xuc2JJ57ItGnT+OUvf8mcOXPo0qULBxxwAB999BF9+/alb9++zJ8/n6VLl9K6dWuys7MZO3YsO3fu5O2332bUqFENXo6aKBGISCQau19uwoQJjB49ml//+tcMHz68wfffunVr7rvvPk4//XTatm3LoEGD6twm1jl9zDHH0KZNG/7yl78AcM899zB79mxSUlI4+uijOeOMM5g+fTp33nknaWlpZGVlNWqNoNndszgvL891YxqRxvXBBx9w1FFHJTqMhNuyZQtZWVm4Oz/+8Y/p2bMnV199dd0bNrKaPi8ze8vdazyPVn0EIiL1dP/999O/f3+OPvpoNm7cyGWXXZbokBqEmoZEROrp6quvbpI1gP2lGoGISJJTIhARSXJKBCIiSU6JQEQkySkRiEiTd8opp/D8889XWnbPPfcwfvz4WrcpKCggdqr5mWeeyYYNG6qtM2nSJO666649HnvGjBksWbL7Drs33XQTL7744t6EX6OmNFy1EoGINHkjR45k+vTplZZNnz69XgO/QTBqaIcOHfbp2FUTwS233MJpp522T/tqqpQIRKTJO//883nmmWcqbkJTVFTEZ599xoknnsj48ePJy8vj6KOP5uabb65x+9zcXNauXQvAbbfdRq9evTjhhBMqhqqG4BqBQYMG0a9fP8477zy2bdvGvHnzmDlzJtdeey39+/fno48+YsyYMfzjH/8AYNasWQwYMIC+ffty8cUXs3Pnzorj3XzzzRx77LH07duXpUuX7rF8iR6uWtcRiMheueoqCO8R02D694d77qn99U6dOjF48GCee+45zj77bKZPn853vvMdzIzbbruNTp06UV5ezrBhw3jvvfc45phjatzPW2+9xfTp01m4cCFlZWUce+yxDBw4EIBzzz2XsWPHAnDjjTfy4IMP8pOf/IQRI0Zw1llncf7551fa144dOxgzZgyzZs2iV69ejBo1ij/84Q9cddVVAHTp0oW3336b++67j7vuuosHHnig1vIlerjqpKkR/PnPcPTRUMuAhCLSxMU3D8U3C/3tb3/j2GOPZcCAASxevLhSM05Vr7zyCt/+9rdp06YNBxxwACNGjKh4bdGiRZx44on07duXadOmsXjx4j3Gs2zZMnr06EGvXr0AGD16NHPnzq14/dxzzwVg4MCBFBUV7XFfr776Kj/4wQ+AmoernjJlChs2bKBVq1YMGjSIhx56iEmTJvH+++/Trl27Pe67PpKmRrB+PSxZAiUlkJmZ6GhEmq89/ecepbPPPpurr76at99+m23btjFw4EA++eQT7rrrLubPn0/Hjh0ZM2ZMrcNP12XMmDHMmDGDfv368fDDDzNnzpz9ijc2lPX+DGM9ceJEhg8fzrPPPsvQoUN5/vnnK4arfuaZZxgzZgzXXHPNfo9SmjQ1gtgNiGq5V4WINHFZWVmccsopXHzxxRW1gU2bNtG2bVvat2/Pl19+yXPPPbfHfZx00knMmDGD7du3s3nzZp566qmK1zZv3swhhxxCaWkp06ZNq1jerl07Nm/eXG1fvXv3pqioiBUrVgDw17/+lZNPPnmfyhYbrhqocbjq6667jkGDBrF06VJWrlzJQQcdxNixY7n00kt5++239+mY8ZKmRqBEINL8jRw5km9/+9sVTUT9+vVjwIABHHnkkeTk5DB06NA9bn/sscfy3e9+l379+nHggQdWGkr61ltvZciQIXTt2pUhQ4ZU/PhfeOGFjB07lilTplR0EgNkZmby0EMPccEFF1BWVsagQYO4/PLL96lciR6uOmmGoX7gARg7Fv79b8jJiSAwkRZMw1A3LxqGuhaqEYiI1EyJQEQkySkRiEi9NLdm5GS1L5+TEoGI1CkzM5Pi4mIlgybO3SkuLiZzL8+R11lDIlKn7OxsVq9ezZo1axIditQhMzOT7OzsvdpGiUBE6pSWlkaPHj0SHYZEJOmahsIxq0REJJQ0iSA9PXhWjUBEpLJIE4GZnW5my8xshZlNrGWd75jZEjNbbGaPRRWLmoZERGoWWR+BmaUC9wLfAFYD881sprsviVunJ3A9MNTd15vZgVHFo0QgIlKzKGsEg4EV7v6xu5cA04Gzq6wzFrjX3dcDuPtXUQWjRCAiUrMoE0F3YFXc/OpwWbxeQC8ze83MXjez02vakZmNM7MFZrZgX09fiyWCf7z/fxSuKtynfYiItESJ7ixuBfQECoCRwP1mVu3Gou4+1d3z3D2va9eu+3Sg99cEQ7X+fdEMhj0yTMlARCQUZSL4FIgf5zM7XBZvNTDT3Uvd/RPgQ4LE0ODmfzEPAC9LpaS8hDlFc6I4jIhIsxNlIpgP9DSzHmaWDlwIzKyyzgyC2gBm1oWgqejjKII5scdxANiuDNJT0ynILYjiMCIizU5kicDdy4ArgOeBD4C/uftiM7vFzGI3Cn0eKDazJcBs4Fp3L44invzcYBju4Uecw6xRs8jPyY/iMCIizU6kQ0y4+7PAs1WW3RQ37cA14SNSsc7igkO/Qb5uTCMiUiHRncWNRqePiojUTIlARCTJJU0iSE0NnpUIREQqS5pEYBbUCjT6qIhIZUmTCCAYgVQ1AhGRypIqEaSlKRGIiFSlRCAikuSUCEREkpwSgYhIklMiEBFJckmVCDIyYOfOREchItK0KBGIiCQ5JQIRkSSnRCAikuSSLhHs2JHoKEREmpakSgSZmaoRiIhUlVSJQE1DIiLVKRGIiCQ5JQIRkSSXdIlAncUiIpUlVSJQZ7GISHVJlQiCpiHn9ldup3BVYaLDERFpEpIqEXy1YxXl5caNs25m2CPDlAxEREiyRLBq6woAdpW2oqS8hDlFcxIbkIhIE5BUieDIg3IBSClvS3pqOgW5BQmNR0SkKWiV6AAa05GH9ABgwpBfMiJvEPk5+QmOSEQk8ZIqEWRkBM+XDbiS3JzExiIi0lQkVdNQLBHoFFIRkd2UCEREklykicDMTjezZWa2wswm1vD6GDNbY2YLw8elUcYTSwS6ulhEZLfI+gjMLBW4F/gGsBqYb2Yz3X1JlVUfd/crooojXmZm8KwagYjIblHWCAYDK9z9Y3cvAaYDZ0d4vDrFEoFqBCIiu0WZCLoDq+LmV4fLqjrPzN4zs3+YWY3n8pjZODNbYGYL1qxZs88BtWkTPG/bts+7EBFpcRLdWfwUkOvuxwD/Av5S00ruPtXd89w9r2vXrvt8sLZtg+etW/d5FyIiLU6UieBTIP4//OxwWQV3L3b3WIv9A8DACONRIhARqUGUiWA+0NPMephZOnAhMDN+BTM7JG52BPBBhPEoEYiI1CCys4bcvczMrgCeB1KBP7v7YjO7BVjg7jOBK81sBFAGrAPGRBUPKBGIiNQk0iEm3P1Z4Nkqy26Km74euD7KGOKlpUFqqhKBiEi8RHcWNyqzoFags4ZERHZLqkQAQSJQjUBEZLekSwSpGdt5s2ix7k4mIhJKqkRQuKqQT3cs571VH+lWlSIioaRKBHOK5uBpW6CkjW5VKSISSqpEUJBbQEr6NijTrSpFRGKS6g5l+Tn5DD1iHcs/KuV/R83SrSpFREiyRACQ06UTn30E+TkHJToUEZEmIamahgDat4eNGxMdhYhI05F0iaBjR1i/HtwTHYmISNOQdImgQwcoL4ctWxIdiYhI05B0iaBjx+B5w4bExiEi0lTUKxGYWVszSwmne5nZCDNLiza0aMQSwfr1iY1DRKSpqG+NYC6QaWbdgReAHwAPRxVUlDp0CJ6VCEREAvVNBObu24Bzgfvc/QLg6OjCio5qBCIildU7EZhZPnAR8Ey4LDWakKIVSwSPvvG0xhoSEaH+ieAqghvIPBneZexwYHZ0YUVn+dY3Afjfd2Zr4DkREeqZCNz9ZXcf4e6Tw07jte5+ZcSxRWJ+8SxIKcW3dtHAcyIi1P+socfM7AAzawssApaY2bXRhhaNUw8vwLK+xLZ008BzIiLUv2moj7tvAs4BngN6EJw51Ozk5+Rz1OHtOaLVSczSwHMiIvVOBGnhdQPnADPdvRRotoM09MptR8b2HkoCIiLUPxH8CSgC2gJzzewwYFNUQUWtWzf47LNERyEi0jTUt7N4irt3d/czPbASOCXi2CLTrVtwHcGOHYmOREQk8erbWdzezH5rZgvCx38R1A6apZKs5QA8OW9hgiMREUm8+jYN/RnYDHwnfGwCHooqqCgVripk8rIfAjDmwd/oOgIRSXr1TQRHuPvN7v5x+PgVcHiUgUVlTtEcSju+D0Dpl1/TdQQikvTqmwi2m9kJsRkzGwpsjyakaBXkFpDRphQOWEXK2j66jkBEkl5971l8OfCImbUP59cDo6MJKVr5OfnMGjWLS57bzpbPvk1+TutEhyQiklD1PWvoXXfvBxwDHOPuA4BTI40sQvk5+Qw7JZ1Vn7TmqQULEh2OiEhC7dUdytx9U3iFMcA1da1vZqeb2TIzW2FmE/ew3nlm5maWtzfx7KvCVYXcv+57AJx3+1R1GItIUtufW1XaHl80SwXuBc4A+gAjzaxPDeu1A34KvLEfseyVOUVzKD3wTejwMaXvXqAOYxFJavuTCOoaYmIwsCI8y6gEmA6cXcN6twKTgUa7vKsgt4CMVulY/7/CR98gZ8eZjXVoEZEmZ4+JwMw2m9mmGh6bgW517Ls7sCpufnW4LH7/xwI57v4Me2Bm42IXs61Zs6aOw9Yt1mE8etwm0tts58G7s/d7nyIizdUeE4G7t3P3A2p4tHP3+p5xVKPwvga/BX5W17ruPtXd89w9r2vXrvtz2Eoe//gPlA76L+Y815mHn32vwfYrItKc7E/TUF0+BXLi5rPDZTHtgK8Dc8ysCDgOmNlYHcZziuaws2wnnn8ntFnDLTe2x5vteKoiIvsuykQwH+hpZj3MLB24EJgZe9HdN7p7F3fPdfdc4HVghLs3yvmcndt0Zhe7IHMTFEzik3cO46mnGuPIIiJNS2SJwN3LgCuA54EPgL+F9zu+xcxGRHXc+ireVkyKhcUfeD8dun/BtddCaWli4xIRaWxR1ghw92fdvZe7H+Hut4XLbnL3mTWsW9BYtQEIzhxqlRJ2c6SWsvnk8Xz4IfzpT40VgYhI0xBpImjK8nPyOfNru08bLe85gy593mfSJNiwIXFxiYg0tqRNBAAHZx28e8Zg3Uk/ZN065/bbExeTiEhjS+pEMKrfKFIttWLeD36bnqe8zj33QFFR4uISEWlMSZ0I8nPyuW/4fRXJwHE+HvA9sF386lcJDk5EpJEkdSIAGDdwHN/q9a2K+bJ2ReQMe5pHHoHlyxMYmIhII0n6RABV+gqAj/tcRlp6ObfemqCAREQakRIBQV9BStxb4VlfkHPaU0ybBkuXJjAwEZFGoERA0Fcw4sjK17itOGocaRml3HJLgoISEWkkSgShCcdPqHQGEW3XUDLwbqZPd5YsSVxcIiJRUyIIxc4gsrj77Xj+HaRm7NAZRCLSoikRxBk3cBxnHxl375y2xZQNupu//915//3ExSUiEiUlgiomHD+hUscx+XfRKlO1AhFpuZQIqqjWcdxmPYef8RRPPAHvvpu4uEREoqJEUIMJx08gLSWtYn55rx/ROmunagUi0iIpEdQgPyefSwZcUjG/K7OYHXmTefJJWLgwgYGJiERAiaAW1QakG/JbWrXZyqRJiYtJRCQKSgS1yM/J51u9d49BROuNlA2+g//7P3j77cTFJSLS0JQI9qDaRWbH3QOZ6/npdesSF5SISANTItiDaheZZW6C/P/i1Rc7saDRbqopIhItJYI6VLvIbMgU0rI2q69ARFoMJYJ6qHQ6aeZmyofcwTPPwJtvJjYuEZGGoERQD/k5+QzvObxiftfge1QrEJEWQ4mgnirdvCZjC6VDbue55+D11xMXk4hIQ1AiqKeq1xUw+HfQZi1XTdyQuKBERBqAEkE9VTuDKGMLHH8nb7zcgcLCxMYmIrI/lAj2QrUziAbdS3q7jeorEJFmTYlgL1U6gyhjK2X5t/PCCzBvXmLjEhHZV0oEe6naGUR5vyPjgA3ccAO4JzAwEZF9FGkiMLPTzWyZma0ws4k1vH65mb1vZgvN7FUz6xNlPA2l0hlE6dvYecIvePlleOaZxMUkIrKvIksEZpYK3AucAfQBRtbwQ/+Yu/d19/7AHcBvo4qnIVU7g2jgVOj8IVdes42yssTFJSKyL6KsEQwGVrj7x+5eAkwHzo5fwd03xc22BZpF40q1M4hSy2DYRD5Z3oaHH05oaCIiey3KRNAdWBU3vzpcVomZ/djMPiKoEVwZYTwNqtoZREc9CdnzuP4XJWzdmri4RET2VsI7i939Xnc/ArgOuLGmdcxsnJktMLMFa9asadwA96DSje4N+I9rWftVOnffndCwRET2SpSJ4FMgJ24+O1xWm+nAOTW94O5T3T3P3fO6du3agCHun2o3uj90HocMep3Jk+HLLxMXl4jI3ogyEcwHeppZDzNLBy4EZsavYGY942aHA8sjjCcSVW90/+VxF7Nt+y5uuimBQYmI7IXIEoG7lwFXAM8DHwB/c/fFZnaLmcX+jb7CzBab2ULgGmB0VPFEpdqN7jt/gA/6HQ884Lz7bgIDExGpJ/NmdhVUXl6eL2hitwcrXFXIiQ+dSLmXBwu2dyDt3n9zwqB2zJoFZomNT0TEzN5y97yaXkt4Z3FLUP1G9xsoPel6Zs+GGTMSF5eISH0oETSQaje6H/hHOHAR43+yky1bEheXiEhdlAgaSPWLzMrhrMv48rM0bqzxpFgRkaZBiaABVbvI7NB5kPcHpkxx3clMRJosJYIGVukiM4Bh15PZsZhLL4WSksTFJSJSGyWCBlbtIrPMzWz/5g9ZvBgmT05cXCIitVEiiEC1juPeT2Nfn86tv97FBx8kLi4RkZooEUSgWscx4KdfCelbufRS2LUrgcGJiFShRBCRah3HWWsoO+1K5s2DP/4xcXGJiFSlRBChqh3H3u9huvZdyHXXwapVe9hQRKQRKRFEqFrHscGaU8+lpKyUH/1I9zgWkaZBiSBi1TqOO35C6cnX8/TT8OijiYtLRCRGiSBiNXYcD7mbzkcu5vLLYcmSBAYnIoISQaOo1nGcsot1Z36TjDYlnENQq6QAAA88SURBVHcebN6cuNhERJQIGkm1juMDPqXP5bfy4Ycwdqz6C0QkcZQIGkm1jmPgtVa/5oQfPsfjj8Pvf5+gwEQk6SkRNKJqHcfA3O7DOeK4JVxzDRQWJigwEUlqSgSNqKaOY1Kcj04+gQO77eCCC2DNmsTFJyLJSYmgkY0bOI5rh15beWHr9fS6/AbWroULL4TS0sTEJiLJSYkgASafNpmTDjup0rKXS+5h5PWzeekluOwydR6LSONRIkiQ3wz7TaX+Asf5C8MYPvYtHnoIbr01gcGJSFJRIkiQGi80w3mm2yDyz1rGzTfDf/93AgMUkaShRJBA1S40AzDnjQH9KTijmKuugptuUjORiERLiSDBJhw/gbSUtErLdqXuoPzcC7jkkqCJ6Fe/SlBwIpIUlAgSLD8nn5fHvEyfLn0qLX/l09l0+u51/PCHQSK45RbVDEQkGkoETUB+Tj4PjHig8vUFwJ3z7qDzd69n9Gi4+WYYNw5KShIUpIi0WEoETUR+Tn716wuAu17/DaXf+j433ggPPAAnnAAffZSAAEWkxVIiaEImnzaZCUMnVFv+2KJplJx8HU88AcuXw4ABMG1aAgIUkRZJiaCJqS0Z3PHaHbxxwHW8+y706wff/z6MHq0hrEVk/0WaCMzsdDNbZmYrzGxiDa9fY2ZLzOw9M5tlZodFGU9zMfm0yVzU96Jqy+947Q5uWPB9Zs8O+gwefRQGDoT58xMQpIi0GJElAjNLBe4FzgD6ACPNrE+V1d4B8tz9GOAfwB1RxdPcPHruozXWDKa9P41hj57MNy8pZPZs2L4dhgyB00+H115LQKAi0uxFWSMYDKxw94/dvQSYDlS6esrdZ7v7tnD2dSA7wniandqaieaunMsJD53A0rZTWbQoqB28/z6ceCKMH6/OZBHZO1Emgu7Aqrj51eGy2lwCPFfTC2Y2zswWmNmCNUk2TnNtzUS7fBeXPX0ZI548mf+4uJBly+BHP4IHH4ReveC88+CNNxIQsIg0O02is9jMvg/kAXfW9Lq7T3X3PHfP69q1a+MG1wTU1kwEQe1g6J+H8tiyqfz+91BUBNddBy+9BMcdB/37Bwnin/+E8vLGjVtEmocoE8GnQE7cfHa4rBIzOw34BTDC3XdGGE+zNvm0yfzprD9Vuu9xjONc9vRlnPzwyawsL+Q//xP+/W/43e+gTZugU/mMM+Cww+CKK+Cvfw1OQ9WVyiICYB7Rr4GZtQI+BIYRJID5wPfcfXHcOgMIOolPd/fl9dlvXl6eL1iwIIKIm4fCVYVMfHEic/89t9Z1zjnyHCYcP4H8nHwguBr5qafgoYfg5Zdhy5ZgvQMPhOOPh0GD4Jhjgkd2NqQ0iXqiiDQkM3vL3fNqfC2qRBAe+EzgHiAV+LO732ZmtwAL3H2mmb0I9AU+Dzf5t7uPqGV3gBJBzHUvXsedr92JU/vnd9JhJ/GbYb+pSAgQNA998AHMmxecZTRvHqxYsXsbM2jfHjp2hA4dglrEkCFw8MFQVgbdugXJIj09SCi9ewe1jtTUGgIQkSYjYYkgCkoEu9WndgDQ/+D+HNf9OEb1G1UpKcRs2gSLFsF778Fnn8GGDbB+ffBYurR+ZyGZBckgM3P3IyOj8nz8so0b4YADgmSycSP07Bkkl5SU4FFaGhy/U6dg3ykpwXP89K5dQW1n/fogSaWnQ1ra7kcsOcV/xVNSoF072LYtOHZ5eZD4WreGTz4JjtuhQ/V91ObLL4PE2Lp1cJxNm4Iy7tgRbLt6dZBE164NXuvSBTp3DrYtLd19nF27YOfO4FFSsvv5kEOC9+edd2DYsGDfO3dWfy+qTi9ZEmz/9a8H782OHcE/AB07whFHBJ91q1ZBrXDt2mA6LS14rjodi7Vt25rfgx074NNP4aCDgtgWLQpOWDj44GC7HTt2ly2+jD16BNtv2xbEUVoaLC8pCaa7dAnWTU2FrKzd3zOz4L0uKQk+v7KyoAzduwfvcWlp8B3btSvYpnPnIIYdO4J9WuUhvVi5MvjO9+4dlHfXruC07J07g+9CeXmw//LyIJZWrYLnqtO7dgXrlJcHn9O6dbBsWfAZZGXt/ny2bw++N9267X7v27SB4uLgfYjtJyUlWDc1NdhfejpcdBGcfHLdf481USJo4epTO4ipKynUZNOm4AtbVhYkirVrgz+SVq2Cvojt24PXysqC5bE/utgPQE3zGRnBdq1bBz/MRUXB9u7BH4JZsHzr1mBZbHn8c0pK8IPVvn2wv9LS3T8mpaXBH1Psjz72XFYWlCcrK3ikpgbz27YFialDhyC+2L7i9xEvFlOnTsGPYHl5MN+mTTDdunWw/cEHw5o1wQ9Q+/bBH3txcbBufMypqcEfekbG7kerVsGPVOwHe1V4Dl5GRvBc9f2In87ODt7fjRt3/7B/7WtBWYuKIDc3SKCxdWOfX1lZEE/8tHsQ29atld/LmLS0IL5164If4I4dgzJu3Bi8Fkv+8WVLSQlqomlpwfSWLcExYo/UVPjqq+D9LC0NyhIro3sQQ3r67h/u9PTgM2zfPpiOrZ+aGsTSunVwrPXrq3+OBx0UxByrGaekBPto3TooQ0pK8PmlpQXvSSz5xH70Y9MpKUE8KSnB9zwtDY46KkjA8d/tlJTgeJs3B985s2C6a9fguxLbx65dQQzl5bv/OZg8GUaNqtefbTVKBEmgcFUhd7x2BzOWzaj3Nj079aRVSit6d+ldqU9BRFoeJYIkEksIr69+nS+2frFX2x6cdTCZrTLpkNmB9JR0Ljn2EsYNHBdRpCLSmJQIktTUt6Zyz+v38MHaD/Z5H51ad+KAjAPokNmB9dvXY2bVpneW7SSjVUa119umt+WnQ35K3wP7MqdoDgW5Bap1NCGFqwr1uSQRJYIkF6slvPPFO6zcuDJhcRjGQVkHVdQ6aksge5Ns9nfdZD3GzvKdfLnlSxyv9rm01DI31WPUd91D2x9Kny599qp/r9LfnxKBxMSSwrLiZZTtKmP5unpdviEiTURGagazR8/e62Swp0TQqkEik2YjPyefJy98smK+cFUhj7z7CEvWLGHlxpWYGWkpaUoQIk1USXkJc4rmNGhznhJBksvPya/xCxXfnLQvVdsvNn+x153VIlK39NR0CnILGnSfSgRSo6o1h30R3wzVtW1XcCpqHU2hzTXZj3Fo+0PplNmJddvXVfpcWnKZm+IxGquPYE+UCCQyDZFMRCR6Gl5MRCTJKRGIiCQ5JQIRkSSnRCAikuSUCEREkpwSgYhIkmt2Q0yY2RpgXwfM6QKsbcBwmgOVOTmozMlhf8p8mLt3remFZpcI9oeZLahtrI2WSmVODipzcoiqzGoaEhFJckoEIiJJLtkSwdREB5AAKnNyUJmTQyRlTqo+AhERqS7ZagQiIlKFEoGISJJLikRgZqeb2TIzW2FmExMdT0Mxsz+b2VdmtihuWScz+5eZLQ+fO4bLzcymhO/Be2Z2bOIi33dmlmNms81siZktNrOfhstbbLnNLNPM3jSzd8My/ypc3sPM3gjL9riZpYfLM8L5FeHruYmMf3+YWaqZvWNmT4fzLbrMZlZkZu+b2UIzWxAui/y73eITgZmlAvcCZwB9gJFm1iexUTWYh4HTqyybCMxy957ArHAegvL3DB/jgD80UowNrQz4mbv3AY4Dfhx+ni253DuBU929H9AfON3MjgMmA3e7+9eA9cAl4fqXAOvD5XeH6zVXPwU+iJtPhjKf4u79464XiP677e4t+gHkA8/HzV8PXJ/ouBqwfLnAorj5ZcAh4fQhwLJw+k/AyJrWa84P4P+AbyRLuYE2wNvAEIIrTFuFyyu+58DzQH443SpczxId+z6UNTv84TsVeBqwJChzEdClyrLIv9stvkYAdAdWxc2vDpe1VAe5++fh9BfAQeF0i3sfwur/AOANWni5wyaShcBXwL+Aj4AN7l4WrhJfrooyh69vBDo3bsQN4h5gArArnO9Myy+zAy+Y2VtmNi5cFvl3W7eqbMHc3c2sRZ4fbGZZwBPAVe6+ycwqXmuJ5Xb3cqC/mXUAngSOTHBIkTKzs4Cv3P0tMytIdDyN6AR3/9TMDgT+ZWZL41+M6rudDDWCT4GcuPnscFlL9aWZHQIQPn8VLm8x74OZpREkgWnu/r/h4hZfbgB33wDMJmgW6WBmsX/m4stVUebw9fZAcSOHur+GAiPMrAiYTtA89N+07DLj7p+Gz18RJPzBNMJ3OxkSwXygZ3i2QTpwITAzwTFFaSYwOpweTdCGHls+KjzT4DhgY1x1s9mw4F//B4EP3P23cS+12HKbWdewJoCZtSboE/mAICGcH65Wtcyx9+J84CUPG5GbC3e/3t2z3T2X4G/2JXe/iBZcZjNra2btYtPAfwCLaIzvdqI7RxqpA+ZM4EOCdtVfJDqeBizX/wCfA6UE7YOXELSLzgKWAy8CncJ1jeDsqY+A94G8RMe/j2U+gaAd9T1gYfg4syWXGzgGeCcs8yLgpnD54cCbwArg70BGuDwznF8Rvn54osuwn+UvAJ5u6WUOy/Zu+Fgc+61qjO+2hpgQEUlyydA0JCIie6BEICKS5JQIRESSnBKBiEiSUyIQEUlySgQiITMrD0d9jD0abKRaM8u1uFFiRZoSDTEhstt2d++f6CBEGptqBCJ1CMeIvyMcJ/5NM/tauDzXzF4Kx4KfZWaHhssPMrMnw/sHvGtmx4e7SjWz+8N7CrwQXiWMmV1pwf0V3jOz6QkqpiQxJQKR3VpXaRr6btxrG929L/B7glExAX4H/MXdjwGmAVPC5VOAlz24f8CxBFeJQjBu/L3ufjSwATgvXD4RGBDu5/KoCidSG11ZLBIysy3unlXD8iKCG8N8HA5494W7dzaztQTjv5eGyz939y5mtgbIdvedcfvIBf7lwc1FMLPrgDR3/7WZ/RPYAswAZrj7loiLKlKJagQi9eO1TO+NnXHT5ezuoxtOMGbMscD8uNE1RRqFEoFI/Xw37rkwnJ5HMDImwEXAK+H0LGA8VNxQpn1tOzWzFCDH3WcD1xEMn1ytViISJf3nIbJb6/AuYDH/dPfYKaQdzew9gv/qR4bLfgI8ZGbXAmuAH4bLfwpMNbNLCP7zH08wSmxNUoFHw2RhwBQP7jkg0mjURyBSh7CPIM/d1yY6FpEoqGlIRCTJqUYgIpLkVCMQEUlySgQiIklOiUBEJMkpEYiIJDklAhGRJPf/XLyidzr6ZFEAAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "iOFBSbPcYCN4"
+ },
+ "source": [
+ "The graph shows the _loss_ (or the difference between the model's predictions and the actual data) for each epoch. There are several ways to calculate loss, and the method we have used is _mean squared error_. There is a distinct loss value given for the training and the validation data.\n",
+ "\n",
+ "As we can see, the amount of loss rapidly decreases over the first 25 epochs, before flattening out. This means that the model is improving and producing more accurate predictions!\n",
+ "\n",
+ "Our goal is to stop training when either the model is no longer improving, or when the _training loss_ is less than the _validation loss_, which would mean that the model has learned to predict the training data so well that it can no longer generalize to new data.\n",
+ "\n",
+ "To make the flatter part of the graph more readable, let's skip the first 50 epochs:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Zo0RYroFZYIV",
+ "outputId": "8dc7544d-9504-4ec8-e362-d8dab905a474",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 295
+ }
+ },
+ "source": [
+ "# Exclude the first few epochs so the graph is easier to read\n",
+ "SKIP = 50\n",
+ "\n",
+ "plt.plot(epochs[SKIP:], train_loss[SKIP:], 'g.', label='Training loss')\n",
+ "plt.plot(epochs[SKIP:], val_loss[SKIP:], 'b.', label='Validation loss')\n",
+ "plt.title('Training and validation loss')\n",
+ "plt.xlabel('Epochs')\n",
+ "plt.ylabel('Loss')\n",
+ "plt.legend()\n",
+ "plt.show()"
+ ],
+ "execution_count": 10,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYgAAAEWCAYAAAB8LwAVAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO3de3xV1Zn/8c+TQECNiAQUBSSoeMEiRIN4QDEWf1O8jPe2UtvAYAWxTofaiv7qy+poL7+iM5NxqlbUWujooNUZa73U1kgENVbuIIgD2iBYUAwiUC4hyfP7Y+8TTg4nyUlyTm7n++bFK+fs69r7JHmy1rPW2ubuiIiIxMtq7wKIiEjHpAAhIiIJKUCIiEhCChAiIpKQAoSIiCSkACEiIgkpQEibMLOXzWxSqrdtT2ZWYWYXpOG4bmYnhq9/aWZ3JLNtC85zrZn9saXlbOS4RWa2KdXHlbbXrb0LIB2Xme2KeXsosA+oCd9Pc/cnkj2Wu1+Yjm27One/IRXHMbN84C9Ad3evDo/9BJD0ZyiZRwFCGuTuudHXZlYBfNvdX43fzsy6RX/piEjXoSYmabZoE4KZ3WpmW4DHzexIM3vBzLaa2efh64Ex+5SZ2bfD15PN7A0zuy/c9i9mdmELtx1iZgvMbKeZvWpmD5jZfzZQ7mTKeI+ZvRke749m1jdm/bfMbIOZVZrZ7Y3cn9FmtsXMsmOWXWFmK8PXZ5lZuZltN7PNZvYLM8tp4Fi/NrMfx7y/Jdznr2Y2JW7bi81smZntMLONZnZXzOoF4dftZrbLzCLRexuz/xgzW2RmX4RfxyR7bxpjZqeG+283s9VmdmnMuovMbE14zI/N7Afh8r7h57PdzLaZ2UIz0++rNqYbLi3VH+gDDAamEnwvPR6+Pw7YA/yikf1HA+8DfYFZwGNmZi3Y9kngHSAPuAv4ViPnTKaM3wD+ATgKyAGiv7CGAQ+Fxz82PN9AEnD3PwN/A74cd9wnw9c1wPfC64kA44EbGyk3YRkmhOX5P8BQID7/8TegGOgNXAxMN7PLw3Xjwq+93T3X3cvjjt0HeBG4P7y2fwVeNLO8uGs46N40UebuwO+BP4b7/SPwhJmdHG7yGEFz5eHAl4DXwuXfBzYB/YCjgR8CmheojSlASEvVAne6+z533+Pule7+rLvvdvedwE+A8xrZf4O7P+LuNcAc4BiCXwRJb2tmxwGjgB+5e5W7vwE839AJkyzj4+7+v+6+B3gaGBkuvxp4wd0XuPs+4I7wHjTkv4CJAGZ2OHBRuAx3X+Lub7t7tbtXAA8nKEciXwvL9667/40gIMZeX5m7r3L3WndfGZ4vmeNCEFDWuftvwnL9F7AW+PuYbRq6N405G8gF/l/4Gb0GvEB4b4D9wDAz6+Xun7v70pjlxwCD3X2/uy90TRzX5hQgpKW2uvve6BszO9TMHg6bYHYQNGn0jm1mibMl+sLdd4cvc5u57bHAtphlABsbKnCSZdwS83p3TJmOjT12+Au6sqFzEdQWrjSzHsCVwFJ33xCW46Sw+WRLWI6fEtQmmlKvDMCGuOsbbWbzwya0L4Abkjxu9Ngb4pZtAAbEvG/o3jRZZnePDaaxx72KIHhuMLPXzSwSLr8XWA/80cw+NLPbkrsMSSUFCGmp+L/mvg+cDIx2914caNJoqNkoFTYDfczs0JhlgxrZvjVl3Bx77PCceQ1t7O5rCH4RXkj95iUImqrWAkPDcvywJWUgaCaL9SRBDWqQux8B/DLmuE399f1Xgqa3WMcBHydRrqaOOyguf1B3XHdf5O6XETQ/PUdQM8Hdd7r79939eOBS4GYzG9/KskgzKUBIqhxO0Ka/PWzPvjPdJwz/Il8M3GVmOeFfn3/fyC6tKeMzwCVmdk6YUL6bpn9+ngT+iSAQ/TauHDuAXWZ2CjA9yTI8DUw2s2FhgIov/+EENaq9ZnYWQWCK2krQJHZ8A8d+CTjJzL5hZt3M7OvAMILmoNb4M0FtY6aZdTezIoLPaF74mV1rZke4+36Ce1ILYGaXmNmJYa7pC4K8TWNNepIGChCSKiXAIcBnwNvAH9rovNcSJHorgR8DTxGM10ikxWV099XAdwh+6W8GPidIojYmmgN4zd0/i1n+A4Jf3juBR8IyJ1OGl8NreI2g+eW1uE1uBO42s53Ajwj/Gg/33U2Qc3kz7Bl0dtyxK4FLCGpZlcBM4JK4cjebu1cRBIQLCe77g0Cxu68NN/kWUBE2td1A8HlCkIR/FdgFlAMPuvv81pRFms+U95GuxMyeAta6e9prMCJdnWoQ0qmZ2SgzO8HMssJuoJcRtGWLSCtpJLV0dv2B/yZIGG8Cprv7svYtkkjXoCYmERFJSE1MIiKSUJdpYurbt6/n5+e3dzFERDqVJUuWfObu/RKt6zIBIj8/n8WLF7d3MUREOhUzix9BX0dNTCIikpAChIiIJKQAISIiCXWZHISItL39+/ezadMm9u7d2/TG0q569uzJwIED6d69e9L7KECISItt2rSJww8/nPz8fBp+3pO0N3ensrKSTZs2MWTIkKT3UxOTiLTY3r17ycvLU3Do4MyMvLy8Ztf0FCCA8nL42c+CryLSPAoOnUNLPqeMb2IqL4fx46GqCnJyoLQUIpGm9xMR6eoyvgZRVhYEh5qa4GtZWXuXSESSVVlZyciRIxk5ciT9+/dnwIABde+rqqoa3Xfx4sV897vfbfIcY8aMSUlZy8rKuOSSS1JyrLaS8TWIoqKg5hCtQRQVtXeJRCRZeXl5LF++HIC77rqL3NxcfvCDH9Str66uplu3xL/mCgsLKSwsbPIcb731VmoK2wllfA0iEgmale65R81LIm2hfGM5P1v4M8o3pifpN3nyZG644QZGjx7NzJkzeeedd4hEIhQUFDBmzBjef/99oP5f9HfddRdTpkyhqKiI448/nvvvv7/ueLm5uXXbFxUVcfXVV3PKKadw7bXXEp0N+6WXXuKUU07hzDPP5Lvf/W6TNYVt27Zx+eWXc/rpp3P22WezcuVKAF5//fW6GlBBQQE7d+5k8+bNjBs3jpEjR/KlL32JhQsXpvyeNSTjaxAi0nbKN5Yzfu54qmqqyMnOobS4lMig1P9VtmnTJt566y2ys7PZsWMHCxcupFu3brz66qv88Ic/5Nlnnz1on7Vr1zJ//nx27tzJySefzPTp0w8aM7Bs2TJWr17Nsccey9ixY3nzzTcpLCxk2rRpLFiwgCFDhjBx4sQmy3fnnXdSUFDAc889x2uvvUZxcTHLly/nvvvu44EHHmDs2LHs2rWLnj17Mnv2bL7yla9w++23U1NTw+7du1N2n5qS8QFCSWqRtlNWUUZVTRU1XkNVTRVlFWVpCRBf/epXyc7OBuCLL75g0qRJrFu3DjNj//79Cfe5+OKL6dGjBz169OCoo47ik08+YeDAgfW2Oeuss+qWjRw5koqKCnJzczn++OPrxhdMnDiR2bNnN1q+N954oy5IffnLX6ayspIdO3YwduxYbr75Zq699lquvPJKBg4cyKhRo5gyZQr79+/n8ssvZ+TIka26N82R8U1MSlKLtJ2i/CJysnPItmxysnMoyi9Ky3kOO+ywutd33HEH559/Pu+++y6///3vGxwL0KNHj7rX2dnZVFdXt2ib1rjtttt49NFH2bNnD2PHjmXt2rWMGzeOBQsWMGDAACZPnszcuXNTes7GZHwNQklqkbYTGRShtLiUsooyivKL0lJ7iPfFF18wYMAAAH7961+n/Pgnn3wyH374IRUVFeTn5/PUU081uc+5557LE088wR133EFZWRl9+/alV69efPDBBwwfPpzhw4ezaNEi1q5dyyGHHMLAgQO5/vrr2bdvH0uXLqW4uDjl15FIxgeIaJK6rCwIDmpeEkmvyKBImwSGqJkzZzJp0iR+/OMfc/HFF6f8+IcccggPPvggEyZM4LDDDmPUqFFN7hNNip9++ukceuihzJkzB4CSkhLmz59PVlYWp512GhdeeCHz5s3j3nvvpXv37uTm5rZpDaLLPJO6sLDQW/PAoPJyBQmR5nrvvfc49dRT27sY7W7Xrl3k5ubi7nznO99h6NChfO9732vvYh0k0edlZkvcPWF/34yvQYAS1SLSOo888ghz5syhqqqKgoICpk2b1t5FSgkFCBInqhUgRCRZ3/ve9zpkjaG1Mr4XExxIVGdnK1EtIhKlGgRKVIuIJKIAEYoGheg4CAUJEcl0ChAhJapFROpTDiKkEdUinc/555/PK6+8Um9ZSUkJ06dPb3CfoqIiol3iL7roIrZv337QNnfddRf33Xdfo+d+7rnnWLNmTd37H/3oR7z66qvNKX5CHWlacAWIkBLVIp3PxIkTmTdvXr1l8+bNS2rCPAhmYe3du3eLzh0fIO6++24uuOCCFh2ro1KACEUiUFISNDOVlKh5SSRdUvmI36uvvpoXX3yx7uFAFRUV/PWvf+Xcc89l+vTpFBYWctppp3HnnXcm3D8/P5/PPvsMgJ/85CecdNJJnHPOOXVTgkMwxmHUqFGMGDGCq666it27d/PWW2/x/PPPc8sttzBy5Eg++OADJk+ezDPPPANAaWkpBQUFDB8+nClTprBv37668915552cccYZDB8+nLVr1zZ6fe09LbgCRKi8HGbMCHIPM2bo+dQi6RDN9d1xR/C1tT9nffr04ayzzuLll18GgtrD1772NcyMn/zkJyxevJiVK1fy+uuv1/1yTWTJkiXMmzeP5cuX89JLL7Fo0aK6dVdeeSWLFi1ixYoVnHrqqTz22GOMGTOGSy+9lHvvvZfly5dzwgkn1G2/d+9eJk+ezFNPPcWqVauorq7moYceqlvft29fli5dyvTp05tsxopOC75y5Up++tOf1s3BFJ0WfPny5SxcuJBDDjmEJ598kq985SssX76cFStWpGTWVwWIkHIQIumXjp+z2Gam2Oalp59+mjPOOIOCggJWr15drzko3sKFC7niiis49NBD6dWrF5deemndunfffZdzzz2X4cOH88QTT7B69epGy/P+++8zZMgQTjrpJAAmTZrEggUL6tZfeeWVAJx55plUVFQ0eqw33niDb33rW0DiacHvv/9+tm/fTrdu3Rg1ahSPP/44d911F6tWreLwww9v9NjJUIAIKQchkn7p+Dm77LLLKC0tZenSpezevZszzzyTv/zlL9x3332UlpaycuVKLr744gan+W7K5MmT+cUvfsGqVau48847W3ycqOiU4a2ZLrytpgVXgAjp0aMi6ZeOn7Pc3FzOP/98pkyZUld72LFjB4cddhhHHHEEn3zySV0TVEPGjRvHc889x549e9i5cye///3v69bt3LmTY445hv379/PEE0/ULT/88MPZuXPnQcc6+eSTqaioYP369QD85je/4bzzzmvRtUWnBQcSTgt+6623MmrUKNauXcuGDRs4+uijuf766/n2t7/N0qVLW3TOWBoHQfAYxOj89EVFEQ2WE0mjSCT1P1sTJ07kiiuuqGtqGjFiBAUFBZxyyikMGjSIsWPHNrr/GWecwde//nVGjBjBUUcdVW/K7nvuuYfRo0fTr18/Ro8eXRcUrrnmGq6//nruv//+uuQ0QM+ePXn88cf56le/SnV1NaNGjeKGG25o0XW197TgaZ3u28wmAP8OZAOPuvv/i1t/M/BtoBrYCkxx9w3huuOAR4FBgAMXuXtFQ+dq6XTfsc/Izf74HGxuKdX7szVYTiQJmu67c2nudN9pa2Iys2zgAeBCYBgw0cyGxW22DCh099OBZ4BZMevmAve6+6nAWcCn6Shn7DNy938wlqoqU6JaRIT05iDOAta7+4fuXgXMAy6L3cDd57v77vDt28BAgDCQdHP3P4Xb7YrZLqVin5Hb/YQ3yclxJapFREhvDmIAsDHm/SZgdCPbXwdEM0knAdvN7L+BIcCrwG3uXpPqQsY/I5fJ2ZrVVaQZ3B0za+9iSBNakk7oEElqM/smUAhEU/3dgHOBAuAj4ClgMvBY3H5TgakAxx13XErKolldRZLXs2dPKisrycvLU5DowNydyspKevbs2az90hkgPiZIMEcNDJfVY2YXALcD57n7vnDxJmC5u38YbvMccDZxAcLdZwOzIUhSt6SQsUnqnOwcSk77MzO+MVyzuookYeDAgWzatImtW7e2d1GkCT179mTgwIHN2iedAWIRMNTMhhAEhmuAb8RuYGYFwMPABHf/NG7f3mbWz923Al8Gmt9FKQmxSeqqmiqefblSjx8VSVL37t0ZMmRIexdD0iRtSWp3rwZuAl4B3gOedvfVZna3mUXHsd8L5AK/NbPlZvZ8uG8N8AOg1MxWAQY8ko5yxiapc7JzuOrCPI2oFhEhzeMg2lJLx0FA/YFykUERZs+GZ5+Fq66CqVNTXFARkQ6ksXEQHSJJ3d4ig4I2pLKKMlYtyWXGjCAHsXAhDB+uJiYRyUwKENRPVNsbe6it+hK1NaYchIhkNE3WR/1Ede3g18juVq0chIhkPNUgOJCorqqpIid/KSXz1lL53nANlhORjKYAwcGjqSODhlN+tAbLiUhmU4AIHZSo1mA5EclwChAhJapFROpTkjqUKFGdlQVmkJfX3qUTEWl7ChCh2BHVPfKX8r27PiI7G2prYcYMKC9v7xKKiLQtBYhQNFF9z/n3UFpcSm8/gdraIEDo4UEikokUIBpQVITmZBKRjKYkdSh+2u/S4lJKSyN6eJCIZCzVIELx036XVZS1d5FERNqVahCheqOps3PIq7yE8d9AYyFEJGMpQISiSeq5K+YCsGxhLz04SEQymgJEnDkr5lBVU0X29vfo1r0UyFaSWkQykgJEjNg8BAPe4Pp/fQJWFrd3sURE2oWS1DHiHz9acEwBc+bAI4/A+PEaLCcimUU1iBjxs7qW/edw5SFEJGMpQMSJndU179RccnIOzOqqPISIZBIFiDj1B8zdQ8mTf2bZK8Pbu1giIm1OOYg48QPmlm1epjyEiGQkBYg48YlqKs47KA8hIpIJFCDiRAZFKJlQwvgh4ymZUELx5YM1aZ+IZCTlIOKUbyxnxh9mUFVTxcKPFlJaPJySkgjPPgtXXaVeTCKSORQg4sTnIOa+sI45349QVQULF8Lw4QoSIpIZ1MQURzkIEZGAahBx4iftK6jeQU4OGgshIhlHAaIB0Un7crLnaCyEiGSktDYxmdkEM3vfzNab2W0J1t9sZmvMbKWZlZrZ4Lj1vcxsk5n9Ip3ljKexECIiaQwQZpYNPABcCAwDJprZsLjNlgGF7n468AwwK279PcCCdJWxIcpDiIikt4npLGC9u38IYGbzgMuANdEN3H1+zPZvA9+MvjGzM4GjgT8AhWks50GUhxARSW+AGABsjHm/CRjdyPbXAS8DmFkW8C8EAeOChnYws6nAVIDjjjuulcU9mPIQIpLJOkQ3VzP7JkEt4d5w0Y3AS+6+qbH93H22uxe6e2G/fv1SWiblIUQk06WzBvExMCjm/cBwWT1mdgFwO3Ceu+8LF0eAc83sRiAXyDGzXe5+UKI7XaJ5iKAGkTgPoQFzItKVpTNALAKGmtkQgsBwDfCN2A3MrAB4GJjg7p9Gl7v7tTHbTCZIZLdZcICDHx7EpsHM+Q/lIUQkc6QtQLh7tZndBLwCZAO/cvfVZnY3sNjdnydoUsoFfmtmAB+5+6XpKlNrRCJQWgpz57Z3SURE2oa5e3uXISUKCwt98eLFKTte/QcH5VBaXAqbIowff6AWUVqqZiYR6dzMbIm7J+wp2iGS1B1RfJK6rKKMsjI0HkJEMoam2mhAfJK6KL8IugXPhaitDb4qDyEiXZkCRAPiB8tFBamSA19FRLoqBYgmRAfLzVkxh0k73qO6ejDuUF2trq4i0rUpB9GI+DwE+a/r8aMikjFUg2hEfB6i+JKhFI9UV1cRyQwKEI1oKA8xZ07Qi2nOHHV1FZGuSwEiCfF5iKqqwZpyQ0S6POUgmtBQHiIrK+jJlJfX3iUUEUkPBYgmxD88qPiSoZSUHBgPMWOGZnYVka5JAaIJkUERSiaUMH7IeEomlBAZFKGyMggOtbUaUS0iXZdyEE0o31jOjD/MoKqmioUfLWT4UcMpKoroCXMi0uWpBtGERHMyRSJQUhI8OKikRElqEemaVINoQqI5mcrLg9xDVRUsXAjDhytIiEjXowDRhERjIRLN6qoAISJdjQJEkmLHQpSc9mdycoazb5+6uopI16UcRBLi8xCVeS+oq6uIdHkKEEmIHwtRlF+krq4i0uWpiSkJifIQRUVBF1c1M4lIV6UaRDPMWTGHR5Y+wvi542FguZqZRKRLU4BIUqLxEGpmEpGuLKkmJjM7DNjj7rVmdhJwCvCyu+9Pa+k6ED2jWkQyTbI5iAXAuWZ2JPBHYBHwdeDadBWso9EzqkUk0yQbIMzdd5vZdcCD7j7LzJans2AdlZ5RLSKZItkchJlZhKDG8GK4LDs9Req49GwIEckkyQaIGcD/Bf7H3Veb2fHA/PQVq2Mqyi8iOysbw8jOytazIUSkS0uqicndXwdeBzCzLOAzd/9uOgvWURlW72uinkxqZhKRriCpGoSZPWlmvcLeTO8Ca8zslvQWreMpqyijurYax6muraasoqxuwJyamUSkq0m2iWmYu+8ALgdeBoYA30pbqTqoRFNuRJ8NoWYmEelqkg0Q3c2sO0GAeD4c/+BN7WRmE8zsfTNbb2a3JVh/s5mtMbOVZlZqZoPD5SPNrNzMVofrvt6ci0qXaFfX68+4nkkjJtUt14A5EemKkg0QDwMVwGHAgvAX+Y7GdjCzbOAB4EJgGDDRzIbFbbYMKHT304FngFnh8t1AsbufBkwASsysd5JlTbvYKTfKN5ZTVBTUIMw0YE5Euo6kAoS73+/uA9z9Ig9sAM5vYrezgPXu/qG7VwHzgMvijjvf3XeHb98GBobL/9fd14Wv/wp8CvRL+qrSKNGUG6ABcyLS9SSbpD7CzP7VzBaH//+FoDbRmAHAxpj3m8JlDbmOIL8Rf+6zgBzggwTrpkbLtHXr1iavIxWieYgssjAz8g7No6wsGCgXO2BORKSzS7aJ6VfATuBr4f8dwOOpKoSZfRMoBO6NW34M8BvgH9y9Nn4/d5/t7oXuXtivX9tUMCKDIpRMKCE7K5tar2XGH2aQd+oq9WQSkS4n2QBxgrvfGTYXfeju/wwc38Q+HwODYt4PDJfVY2YXALcDl7r7vpjlvQhGbd/u7m8nWc42Ubm7klqvpdZr9YQ5Eemykg0Qe8zsnOgbMxsL7Glin0XAUDMbYmY5wDXA87EbmFkBQQL8Unf/NGZ5DvA/wFx3fybJMrYZPWFORDJBspP13QDMNbMjwvefA5Ma2R53rzazm4BXCOZt+lU4TcfdwGJ3f56gSSkX+K0F2d2P3P1SgmascUCemU0ODznZ3TvEBIHRZqZn1zzLVcOuIjIoAkV6wpyIdC3m3uRwhgMbB80+uPsOM5vh7iVpK1kzFRYW+uLFi9vkXOUbyxk/d3zdsyFKi0uJDIowezbcdBPU1ECPHlBaqmk3RKRjM7Ml7l6YaF2znijn7jvCEdUAN7e6ZJ1UQ11dKyuD4FBbG9Qk1MwkIp1Zax45mrE9/hN1dYWgWak27GtVW6tmJhHp3FoTIJJvm+piEnV1Ld9YTmVl0NUVgq+Vle1bThGR1mg0SW1mO0kcCAw4JC0l6iTiu7oGM7tG6NEjaF7KylINQkQ6t0ZrEO5+uLv3SvD/cHdPtgdUl5SomUkzu4pIV9KaJqaM1lgzU3Q8xN69MHdue5dURKRlFCBaIXEzU1CDgGBupscfVy1CRDonBYhWiH9GdfQBQlOmHNhm/351dxWRzkkBopXin1ENUFBwYL26u4pIZ6UA0QqJnlENqLuriHQJChCt0NCAuaKiYKqNrCx1dxWRzksBohUa6smk7q4i0hUoQLRSop5MgLq7ikinpwDRSo01M6m7q4h0ZgoQrdRYM5O6u4pIZ6YAkQINNTOpu6uIdGYKECmQaMAc1O/uagbLlrVfGUVEmksBIkUSDZgrKoJu4ZSGykOISGejAJECDQ2Yi+YhLIwZVVXqzSQinYcCRAo01JMJoLgYuncPXqsWISKdiQJECjTUkwlQbyYR6bQUIFKkoZ5MoN5MItI5KUCkSGPNTOrNJCKdkQJEijTWzBTfm+mRR2D27PYrq4hIMhQgUqihZqb4PERNDdx4o5LVItKxKUCkUEMD5iDozRSdmwmCIKEuryLSkSlApFiiAXMQ1CL+/u/bo0QiIi2jAJFCsQPmqmqqmLuifhVh5szgQUIQ1CZiezeJiHQ0ChApFG1iAnCcx5c/XpeohqAWcf/9wcA5dz1ISEQ6trQGCDObYGbvm9l6M7stwfqbzWyNma00s1IzGxyzbpKZrQv/T0pnOVMlMijClJFT6pqXEtUi9CAhEeks0hYgzCwbeAC4EBgGTDSzYXGbLQMK3f104BlgVrhvH+BOYDRwFnCnmR2ZrrKmUvGIYrpnB3NrJKpFxD9I6LHHVIsQkY4pnTWIs4D17v6hu1cB84DLYjdw9/nuvjt8+zYwMHz9FeBP7r7N3T8H/gRMSGNZUya+FhE7eR8EzUwXXXRg+/37YdasNi6kiEgS0hkgBgAbY95vCpc15Drg5ebsa2ZTzWyxmS3eunVrK4ubOtFaRKLurgD9+9ff/ne/08A5Eel4OkSS2sy+CRQC9zZnP3ef7e6F7l7Yr1+/9BSuhRrq7goHj4lwh5tuUlOTiHQs6QwQHwODYt4PDJfVY2YXALcDl7r7vubs21E11d01EoEHHzwwPxNAdbUS1iLSsaQzQCwChprZEDPLAa4Bno/dwMwKgIcJgsOnMateAf7OzI4Mk9N/Fy7rFJrq7gowdSo89FD9hLWeFSEiHUnaAoS7VwM3Efxifw942t1Xm9ndZnZpuNm9QC7wWzNbbmbPh/tuA+4hCDKLgLvDZZ1CU4nqqKlT4frrD7zXsyJEpCPpls6Du/tLwEtxy34U8/qCRvb9FfCr9JUuvYpHFDNnxRz2Ve87aPrvWPHPiti+vY0KKCLShA6RpO6KGpv+O1Zl5YFnVgPcd596NIlIx6AAkUaVuyupqa2h1mvZV70vYTNT7MA5CGoRN9ygICEi7bPY+HQAABHESURBVE8BIo3yDs2jlloAaqlN2MwUicADD9SvRbgrSIhI+1OASKPK3ZVkWXCLDWPZ5sTPGp06FS67rP4yjY0QkfamAJFGRflFdMsK+gE01N01aubMYJbXWNXV6tUkIu1HASKNkpndtW7bCLz+Oowbd2CZu3o1iUj7UYBIs6Zmd40VicCECfXzEffeC7fe2hYlFRGpTwEizaK1iKj9NfsT9maKiu/V5B7M9qogISJtTQGiDRQcc2A0XEO9maIS9WoCBQkRaXsKEG0g2d5MUVOnwi23HLxcQUJE2pICRBuI7830yNJHmL2k8UEOP/950LMp3r33anyEiLQNBYg2EJ+HqPEabnrppgaT1VGJgoQG0YlIW1GAaCPFI4rrahHQ8Ayv8RoKEtOmqblJRNJLAaKNRAZFuDlyc917xxtNVsf6+c/h8ssPXj5rFpx3nkZbi0h6KEC0od49ejcrWR0r0UhrgAUL4Jxz1OQkIqmnANGGWpKsjko00jqqtjZociooCGoUo0crYIhI6ylAtKGWJqvr9g+DRKLeTQDLlwc1infeUY5CRFpPAaKNtTRZHevnP4eHH4asJj69WbOCWsX06cpTiEjzKUC0sUTJ6u37mj8j39Sp8MYbiZucYi1fDr/8JYwZA0OGBAFj9OigdvGznylwiEjD0vpMakmsd4/eGIbjAPxb+b9x+cmXExkUadZxok1Os2fDY49Bz56wY0cQFBKpqDjw+p13gq9mMHgwHHccDBsGxcXBcaXtlJcH07oXFeneS8di7t7eZUiJwsJCX7x4cXsXIynlG8sZ9+txVNdWA0GPpmlnTuOhSx5KyfFvvTVoXmqp/Hzo3Rv27YN+/YJle/cGv8B694a8vOBZ2kVFwbq54Qzm8cGlvX/xpfP80WPH3ouWnKO8HMaPh6oqyMmB0tLmHSf+GsvL638ekJpyNnbe6DmaOnZs2QoKUleeVH3O6f5+jf9sGvpZgbb9uTGzJe5emHCdAkT7mL1kNje+eCM1XgNAtmXz4MUPMvXMqak5/mwoKYH33kvJ4ZIWDS6ffw4ffRQM6outpQBs3Qo9egQBqLVfowEs/piJzh8Nei09ZqJjRzV0jqaO9fHHwbqofv1gwIDkyrdhQ/1rPPpo+OSTg8vVWDmbKl+ir9XV8MEHQe+52HM09jlXV8P69fXL0th9a87nvHFjUJbWHCv2mszgxBOhW7fWfx829j0zdGhwjvj7mZXV/HKcfHLQeaUlAUUBooOa/sJ0frnkl3Xvu2d15/XJrze7qakx0b9a1qwJvnkb+kEVkc6te/egybm5QaKxAKEcRDsqHlHMo8serWtqivZoSmWAiEQO/oaJBo0tW2Dbtvp/iYpI57R/f9A0lcpmKQWIdhTt0TTrzSBh0NIeTc0+byNBI1rTiK0679gBK1YogIh0ZN27H8hhpIoCRDuL79F031v3ccKRJ6QsF5GsREEjVmytI2rbtgPJ6x07EgeXPn2C7bZubVl7d2vafuPPn6r25Nhjx96LhsqQ7LGSLWfsMRPd42HDoFev4K/Jnj0bL2dLP5OcnKANfd26A+do6nPOyTnwvRL9PmrJNafy/jV0TVVVqfs+jN0m9rOJPUfsuY89Fk466eBt0pWDaIwCRDsryi8iOyu7rpmp1mu58cUbGX7U8JQ2NbVWUwFERLoeDZRrZ5FBER646AGMA88YrfGaumYnEZH2ogDRAUw9cyqXnXJZvWW/e/93SU/kJyKSDmkNEGY2wczeN7P1ZnZbgvXjzGypmVWb2dVx62aZ2Woze8/M7jczi9+/K5k5ZibZll333nFufPHGpCfyExFJtbQFCDPLBh4ALgSGARPNbFjcZh8Bk4En4/YdA4wFTge+BIwCzktXWTuCyKAID178oJqaRKTDSGcN4ixgvbt/6O5VwDygXjuKu1e4+0qgNm5fB3oCOUAPoDvwSRrL2iGoqUlEOpJ0BogBwMaY95vCZU1y93JgPrA5/P+Kux80aYSZTTWzxWa2eGvsfAWdmJqaRKSj6JBJajM7ETgVGEgQVL5sZufGb+fus9290N0L+0U7IndyamoSkY4inQHiY2BQzPuB4bJkXAG87e673H0X8DKQMb3w1dQkIh1BOgPEImComQ0xsxzgGuD5JPf9CDjPzLqZWXeCBHUbz0vavtTUJCLtLW0Bwt2rgZuAVwh+uT/t7qvN7G4zuxTAzEaZ2Sbgq8DDZrY63P0Z4ANgFbACWOHuv09XWTuihpqavv38txUkRKRNaLrvDu6Kp67gubXP1VuWjmnBRSQzNTbdd4dMUssB8U1NAPtr93P5vMuVkxCRtFKA6OASNTUBfLr7U6a9ME1BQkTSRgGiE5h65lR+eckvDwoSALf88RYFCRFJCwWITiIaJLLiPrIdVTuY9sI0hvz7EAUKEUkpBYhOZOqZU3ljyhsM6xs/pRVUbK9g2gvTuPXVW9uhZCLSFSlAdDKRQREevfRRumUlftbTrDdncdqDp6k2ISKtpgDRCUUGRVgweQHjjhuXcP2arWuY9sI0jvmXY7jiqSs0bkJEWkQBopOKDIrw+j+8zltT3mLcceMSJrC37NrCc2ufY8yvxnDer89ToBCRZtFAuS5i9pLZTH9hOrUHzZxe39A+Q+mW1Y2T+57MhSdeSOXuSoryizToTiRDNTZQTgGiCynfWM5tr97Ggo8WNGs/wxjRfwRnDzib4hHFChZdTPnGcsoqyvSHgCSkAJFhyjeWM+vNWby96W22/G1Ls/fP751P75692Ve9j36H9QOHrbu30qNbD3KychiaN5Stf9vKyGNGsmPvDoB2Cyxd4Zdf9BryDs1rtEaX6Fqbuv7yjeWMnzueqpoqcrJzKC0u7bT3KZ3a+/somfOnq4wKEBls9pLZ/HThT9nwxYa0nyvafNWjWw/2Ve876Gt8sEm0TXO+fr7nczbu2Ii7k2VZDD96ODlZORQNKWLH3h2s2bqm3rn6HdaPYX2H0atnL8r+UkbP7j3p07MP2/ZsY+vurfQ7rB99evZJeG3RbWKD5LrKdXXH6J/bn+IRxaz6dBWPLX2Mnt17MqzvMAqOKeDldS/zfuX7nNz3ZGaOmVm3TVVtVd011PqBpsFuWd24OXIz//vZ//J+5ft11/rRFx8BkJ2VzSVDLwHgxXUvsr92P4Zxar9TKehfwLrKdVTVVrGveh97qvewYfsGnODnfPARgzm0+6F11xG9V1t2bWnyGgH65/an4JgClm1eBlD3Orr/3uq9XHfGdQB11xg9T+8evdm+b3vdvY/9LKLlbegziD3vll1b6n0m8Z9r9FiNfR/GnmPbnm28ufFNar0Wwziu93F1fyAls29sGeLvR+z3X7RZN/5+Dc0bytOrn6a6tposy2LscWPrzhHdpnfP3rz6l1ep9VqyLIsLhlzA9r3bD/r+a0ngUIAQZi+ZXfcDu2XnlhbVLESk4+qR3YP5k+Y3O0g0FiASd6aXLmfqmVOZeubUuvezl8zm2TXP0u+wfizdvJS1n62t+ytTRDqfqpoqyirKUtr8pACRoeIDRvnGcuaumJuwWSbaLFRdW80H2z5osqeUiLS9LMuiKL8opcdUgBAgGFeRzF8esQnVaDt0c9p+U5mDiB6zfGM5+2v3JyxvNOH++Z7PD8rDGIbjGMbRuUfz6d8+rWuHBurVqAxjcO/BdM/qXi9IRo/RGMM48pAj2bZnW73lQ/sMpaqm6qAcRKz+uf3pn9u/7ppXfbKKGq+pt00WWZzQ54S6chnGiX1OpKqmio+++Cip62jtNTZk4OED+Xjnx03uH70X8eVtTPRzi+YkYo/VWC6sR7cerNyy8qA/dCz811AOIpoHauh+rtu27qDjDe49mN49ezerWdcwzKzueyJ6/7Msi8JjClm8efFB67ItmwcvfjDlCXYFCGmWZANJW4rt3QEwd8Vc4OCeVdFaUnQdUK9XSPxxGupZlGi7aPL12F7HMnPMzITliOaBotvEHy96ru37trN883KuGnZVvVpe/LbRAB09fmO9nBq7jmSvMXrOLbu20D+3P7169mL55uWMPGYkvXv0bvD+R+97dL/ovU/0OcWXKfZrbGI8trzxn2tz/9CJPU9TPYQau2fRZtvY+xF7rETrY+9D7HVF73n864a+T9PV+0pJahGRDKYnyomISLMpQIiISEIKECIikpAChIiIJKQAISIiCSlAiIhIQl2mm6uZbQXSPyNdevUFPmvvQnQguh8H6F7Up/tRX2vux2B375doRZcJEF2BmS1uqD9yJtL9OED3oj7dj/rSdT/UxCQiIgkpQIiISEIKEB3L7PYuQAej+3GA7kV9uh/1peV+KAchIiIJqQYhIiIJKUCIiEhCChBtyMx+ZWafmtm7Mcv6mNmfzGxd+PXIcLmZ2f1mtt7MVprZGe1X8tQzs0FmNt/M1pjZajP7p3B5pt6Pnmb2jpmtCO/HP4fLh5jZn8PrfsrMcsLlPcL368P1+e1Z/nQws2wzW2ZmL4TvM/leVJjZKjNbbmaLw2Vp/1lRgGhbvwYmxC27DSh196FAafge4EJgaPh/KvBQG5WxrVQD33f3YcDZwHfMbBiZez/2AV929xHASGCCmZ0N/Bz4N3c/EfgcuC7c/jrg83D5v4XbdTX/BLwX8z6T7wXA+e4+Mma8Q/p/Vtxd/9vwP5APvBvz/n3gmPD1McD74euHgYmJtuuK/4HfAf9H98MBDgWWAqMJRsd2C5dHgFfC168AkfB1t3A7a++yp/AeDAx/6X0ZeAGwTL0X4XVVAH3jlqX9Z0U1iPZ3tLtvDl9vAY4OXw8ANsZstylc1uWETQIFwJ/J4PsRNqksBz4F/gR8AGx39+pwk9hrrrsf4fovgLy2LXFalQAzoe7B0Xlk7r0AcOCPZrbEzKLPoU37z4qeSd2BuLubWUb1OzazXOBZYIa77zCzunWZdj/cvQYYaWa9gf8BTmnnIrULM7sE+NTdl5hZUXuXp4M4x90/NrOjgD+Z2drYlen6WVENov19YmbHAIRfPw2XfwwMitluYLisyzCz7gTB4Ql3/+9wccbejyh33w7MJ2hG6W1m0T/kYq+57n6E648AKtu4qOkyFrjUzCqAeQTNTP9OZt4LANz94/DrpwR/PJxFG/ysKEC0v+eBSeHrSQRt8dHlxWGPhLOBL2Kqk52eBVWFx4D33P1fY1Zl6v3oF9YcMLNDCPIx7xEEiqvDzeLvR/Q+XQ285mGDc2fn7v/X3Qe6ez5wDcG1XUsG3gsAMzvMzA6Pvgb+DniXtvhZae/kSyb9B/4L2AzsJ2gXvI6grbQUWAe8CvQJtzXgAYJ26FVAYXuXP8X34hyCdtWVwPLw/0UZfD9OB5aF9+Nd4Efh8uOBd4D1wG+BHuHynuH79eH649v7GtJ0X4qAFzL5XoTXvSL8vxq4PVye9p8VTbUhIiIJqYlJREQSUoAQEZGEFCBERCQhBQgREUlIAUJERBJSgBBpgpnVhLNoRv/f1vReSR8732Jm9xXpSDTVhkjT9rj7yPYuhEhbUw1CpIXCOfpnhfP0v2NmJ4bL883stXAu/lIzOy5cfrSZ/U/4zIcVZjYmPFS2mT0SPgfij+FIaszsuxY8L2Olmc1rp8uUDKYAIdK0Q+KamL4es+4Ldx8O/IJgBlKA/wDmuPvpwBPA/eHy+4HXPXjmwxkEo2IhmLf/AXc/DdgOXBUuvw0oCI9zQ7ouTqQhGkkt0gQz2+XuuQmWVxA85OfDcOLBLe6eZ2afEcy/vz9cvtnd+5rZVmCgu++LOUY+8CcPHvqCmd0KdHf3H5vZH4BdwHPAc+6+K82XKlKPahAireMNvG6OfTGvaziQG7yYYE6dM4BFMTOZirQJBQiR1vl6zNfy8PVbBLOQAlwLLAxflwLToe7hQEc0dFAzywIGuft84FaCKawPqsWIpJP+IhFp2iHhk96i/uDu0a6uR5rZSoJawMRw2T8Cj5vZLcBW4B/C5f8EzDaz6whqCtMJZvdNJBv4zzCIGHC/B8+JEGkzykGItFCYgyh098/auywi6aAmJhERSUg1CBERSUg1CBERSUgBQkREElKAEBGRhBQgREQkIQUIERFJ6P8DuY1bQtxc3zoAAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "W4EQD-Bb8hLM"
+ },
+ "source": [
+ "From the plot, we can see that loss continues to reduce until around 200 epochs, at which point it is mostly stable. This means that there's no need to train our network beyond 200 epochs.\n",
+ "\n",
+ "However, we can also see that the lowest loss value is still around 0.155. This means that our network's predictions are off by an average of ~15%. In addition, the validation loss values jump around a lot, and is sometimes even higher.\n",
+ "\n",
+ "**2. Mean Absolute Error**\n",
+ "\n",
+ "To gain more insight into our model's performance we can plot some more data. This time, we'll plot the _mean absolute error_, which is another way of measuring how far the network's predictions are from the actual numbers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Md9E_azmpkZU",
+ "outputId": "e47fe879-5e16-4e3c-9e98-279059955384",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 295
+ }
+ },
+ "source": [
+ "plt.clf()\n",
+ "\n",
+ "# Draw a graph of mean absolute error, which is another way of\n",
+ "# measuring the amount of error in the prediction.\n",
+ "train_mae = history_1.history['mae']\n",
+ "val_mae = history_1.history['val_mae']\n",
+ "\n",
+ "plt.plot(epochs[SKIP:], train_mae[SKIP:], 'g.', label='Training MAE')\n",
+ "plt.plot(epochs[SKIP:], val_mae[SKIP:], 'b.', label='Validation MAE')\n",
+ "plt.title('Training and validation mean absolute error')\n",
+ "plt.xlabel('Epochs')\n",
+ "plt.ylabel('MAE')\n",
+ "plt.legend()\n",
+ "plt.show()"
+ ],
+ "execution_count": 11,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYgAAAEWCAYAAAB8LwAVAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO2de5wU1ZX4v6ebmQEEJQ6YUUGGKKAoy1O0UXEM0fURFUUTDbvIYuShGDGJaB4a4zOSbGRVVDAGYWNAXX+yqKir6CjKRAVBEJVIdBRUEEcBDTLDzJzfH7eqp7qnu6d76J7n+c6nP1N161bVqVvddeqec+65oqoYhmEYRjyh5hbAMAzDaJmYgjAMwzASYgrCMAzDSIgpCMMwDCMhpiAMwzCMhJiCMAzDMBJiCqKFIyJPichF2a7bnIhIuYh8LwfHVRE5zFu+V0SuTaduI84zTkT+r7FytjVE5AERuSnLx5wgIi9n85hG5nRobgHaIiLydWC1M1AJ1Hjrk1X1wXSPpaqn5aJuW0dVp2TjOCJSDHwA5KlqtXfsB4G076GRW0RkAvBjVT2+uWVpa5iCyAGq2sVfFpFy3Jf3ufh6ItLBf+gYhtHySfSbzfR33Jp+92ZiakJEpERENovI1SKyBZgnIt8SkSdEZJuIfOkt9wzsUyoiP/aWJ4jIyyLyB6/uByJyWiPr9hGRl0TkKxF5TkRmi8hfksidjow3isgr3vH+T0S6B7b/u4h8KCIVIvKrFO1zjIhsEZFwoOwcEVnrLY8QkTIR2S4in4rIXSKSn+RYMWYPEbnK2+cTEZkYV/cMEVktIjtFZJOIXB/Y/JL3f7uIfC0ikXjzh4iMFJHXRWSH939kum0TJ4f//ZghIp958o4RkdNF5O8i8oWI/DJQPyQi14jIP7y2fVhE9g9sf8Rrzx3evT4yrn1mi8iTnlyvisihKe5N0mN5dBeRZ71jvSgivb39RERu965np4isE5GjvG37icgC73v1oYj8WkTqPZNEpFicSbBDoKxURH4sIkcA9wIR7/5s97YXeN/9j0RkqziTY6cU1zdRRN7xvt/P+PJ721RELhOR94D3JPHvuEBEZnnfr0+85YK4+xqtn0yOloYpiKanCNgf6A1Mwt2Ded76IcA3wF0p9j8G2AB0B2YC94uINKLuX4HXgELgeuDfU5wzHRl/BPwHcACQD/wcQEQGAPd4xz/IO19PEqCqrwL/BL4bd9y/ess1wJXe9USA0cClKeTGk+FUT56Tgb5AvP/jn8B4oBtwBjBVRMZ420Z5/7upahdVLYs79v7Ak8Ad3rX9EXhSRArjrqFe2yShCOgIHAxcB9wH/BswDDgBuFZE+nh1LwfGACfi2vZLYHbgWE9513sA8Ab1zWIXAL8FvgVsBG5OIVdDxxoH3Ii7N2sC20/BtWE/YD/gB0CFt+1Or+w73jWMx7VT2qjqO8AUoMy7P928Tb/zzjkYOIy69qyHiJwN/BI4F+gBLAcWxlUbg/s9DfDW43/HvwKO9c43CBgB/Dqwf3z91oGq2ieHH6Ac+J63XAJUAR1T1B8MfBlYL8WZqAAmABsD2zoDChRlUhf3kK8GOge2/wX4S5rXlEjGXwfWLwWe9pavAxYFtu3jtcH3khz7JuDP3nJX3MO7d5K604HHAusKHOYtPwDc5C3/GfhdoF6/YN0Ex50F3O4tF3t1OwS2TwBe9pb/HXgtbv8yYEJDbZPgvCU45RsOXL8CxwTqrALGeMvvAKMD2w4E9gRlDWzr5h1rv0D7/Cmw/XTg3TTvf6JjBe9xF5wy74VT9n/HPTxDgTph73swIFA2GShN0MaJ7kEpsd/1lwPbxPveHBooiwAfJLmep4CLA+shYJf/vfPO/d24+xTzOwb+AZweWP9XoDzd331L/VgPounZpqq7/RUR6Swic7wu9k6cSaObBMwscWzxF1R1l7fYJcO6BwFfBMoANiUTOE0ZtwSWdwVkOih4bFX9J3VvkIn4K3Cu1z0/F3hDVT/05Ognzry1xZPjFtwba0PEyAB8GHd9x4jIC56pYwfujTSd4/rH/jCu7EPcG6tPsrZJRIWq+gEN33j/twa2fxPYvzfwmDiT23acwqgBvi0iYRH5nWd+2ol7UYHY60pLrjSPFbzHXwNfAAep6vO43uZs4DMRmSsi+3r75hHbdvHt1lh64F6IVgXa5mmvPBG9gf8K1P0Cp2SCssT/PmJ+x9T/HnzolSWr3yowBdH0xKfP/RnQH/eWuC91Jo1kZqNs8Cmwv4h0DpT1SlF/b2T8NHhs75yFySqr6tu4H9dpxJqXwJmq3gX6enL8sjEy4HpQQf4KLAF6qep+OJu2f9yG0h1/gnvABDkE+DgNufaWTcBpqtot8Omoqh/j2u5snDltP9xbODTue5XOsYL3uAvOnPIJgKreoarDcOaZfsBVwOe43k6w7ZK12z+9/8Hva1FgOf4efY5TpEcG2mU/DQSPxLEJF10YbMdOqroixTni1+O/B4d4ZcnqtwpMQTQ/XXFf5u2ePfs3uT6h90a+ErheRPJFJAKcmSMZ/wf4vogcL86hfAMNf+/+ClyBU0SPxMmxE/haRA4HpqYpw8PABBEZ4CmoePm74npUu0VkBO6B6LMNqMXZyROxFOgnIj8SkQ4i8kPcg/CJNGXbG+4Fbg44hHt49nRw11SJ6611xvW2Gks6xzo9cI9vBP6mqptE5Givh5aHe9DvBmq9XtLDnvxdvWv4Kc7UGYOqbsMpjn/zejMTgaBDfSvQ0zs3qlqL893cLiIHAIjIwSLyr0mu717gF+I53j3n+fkZtA84n8WvvXvQHWdaTRj00ZowBdH8zAI64d56/obrCjcF43B22Qqc3f8h3EMgEY2WUVXXA5fhHvqf4hypmxvYbSHOafm8qn4eKP857uH9Fe4B8FCaMjzlXcPzOGfs83FVLgVuEJGvcD/shwP77sI5b1/xTBDHxh27Avg+rpdVAcwAvh8nd674L1zP5/882f+Gc6QCLMD1xD4G3va2NZZ0jvVXnOL9AudQ/zevfF/cvfrSO0YF8Htv2+U4pfE+8LJ3jD8nkeESXM+jAjgSCL7dPw+sB7aIiN/uV+Pu9d88s9hzuF5wPVT1MeA2YJFX9y1cDzYTbsK9dK0F1uEc+VkdPNgciOdEMdo5IvIQzkmZ8x6MYRitA+tBtFO8rv+h4mLpT8XZmBc3t1yGYbQcbCR1+6UI+H84h/FmYKqqrm5ekQzDaEmYickwDMNIiJmYDMMwjIS0GRNT9+7dtbi4uLnFMAzDaFWsWrXqc1VNOIiwzSiI4uJiVq5c2dxiGIZhtCpEJD4TQBQzMRmGYRgJMQVhGIZhJMQUhGEYhpGQNuODMAyj6dizZw+bN29m9+5Wl6C03dKxY0d69uxJXl5e2vuYgjAMI2M2b95M165dKS4uJvl8VUZLQVWpqKhg8+bN9OnTp+EdPMzEZBhGxuzevZvCwkJTDq0EEaGwsDDjHl9OFYSInCoiG0Rko4hck6LeWG/e1+GBsn8RN//wenHz2HbMlZxlZXDrre6/YRjpYcqhddGY+5UzE5M329hs3DzAm4HXRWSJNyFMsF5XXO7/VwNlHXC51P9dVd/05vfdkws5y8pg9GioqoL8fFi2DCKRXJzJMAyjdZHLHsQI3JzI76tqFbAIlzE0nhtxudiDfZ9TgLWq+ia4nPuBaRizSmmpUw41Ne5/aWkuzmIYRjapqKhg8ODBDB48mKKiIg4++ODoelVVVcp9V65cyU9+8pMGzzFy5MisyFpaWoqI8Kc//SlatmbNGkSEP/zhD9Gy6upqevTowTXXxBpbSkpK6N+/f/T6zjvvvKzIlQ65VBAHEzuP62bi5psVkaG4aR6fjNu3H6Ai8oyIvCEiMxKdQEQmichKEVm5bdu2RglZUuJ6DuGw+19S0qjDGIbRhBQWFrJmzRrWrFnDlClTuPLKK6Pr+fn5VFdXJ913+PDh3HHHHQ2eY8WKFQ3WSZejjjqKhx+OzkPFwoULGTRoUEydZ599ln79+vHII48Qn0T1wQcfjF7f//zP/2RNroZoNie1iISAP+Jm4oqnA3A8btaz44FzRGR0fCVVnauqw1V1eI8eyeYjT00kArNmOTPTrFlmXjKMXFG2qYxbl99K2abcOPsmTJjAlClTOOaYY5gxYwavvfYakUiEIUOGMHLkSDZs2AC4N/rvf//7AFx//fVMnDiRkpISvvOd78Qoji5dukTrl5SUcN5553H44Yczbty46AN86dKlHH744QwbNoyf/OQn0ePG07t3b3bv3s3WrVtRVZ5++mlOOy120rqFCxdyxRVXcMghh1DWQhyiuQxz/ZjYieJ7EjsheVfgKKDUc54UAUtE5Cxcb+Mlf9pGEVkKDAWWZVvIsjKYPt2Zl5Yvh4EDTUkYRrYp21TG6AWjqaqpIj+cz7Lxy4j0yv4PbfPmzaxYsYJwOMzOnTtZvnw5HTp04LnnnuOXv/wljz76aL193n33XV544QW++uor+vfvz9SpU+uNFVi9ejXr16/noIMO4rjjjuOVV15h+PDhTJ48mZdeeok+ffpw4YUXppTtvPPO45FHHmHIkCEMHTqUgoKC6Lbdu3fz3HPPMWfOHLZv387ChQtjTFzjxo2jU6dOAJx88sn8/ve/r3f8XJDLHsTrQF8R6eNNJn4Bbv5cAFR1h6p2V9ViVS3GzXN7lqquBJ4BBopIZ89hfSJuLtysYz4Iw8g9peWlVNVUUaM1VNVUUVpempPznH/++YTDYQB27NjB+eefz1FHHcWVV17J+vXrE+5zxhlnUFBQQPfu3TnggAPYunVrvTojRoygZ8+ehEIhBg8eTHl5Oe+++y7f+c53ouMKGlIQP/jBD3jkkUdYuHBhvbpPPPEEJ510Ep06dWLs2LEsXryYmpo6t2vQxNRUygFyqCBUtRqYhnvYvwM8rKrrReQGr5eQat8vcean14E1wBsJ/BRZwfdBhEIgAoWFuTiLYbRvSopLyA/nE5Yw+eF8SopLcnKeffbZJ7p87bXXctJJJ/HWW2/x+OOPJx0DEHyTD4fDCf0X6dRpiKKiIvLy8nj22WcZPTrWYr5w4UKee+45iouLGTZsGBUVFTz//PMZnyPb5HQktaouBZbGlV2XpG5J3PpfcKGuOcX3QUyb5noR06ebmckwsk2kV4Rl45dRWl5KSXFJTsxL8ezYsYODD3ZxMQ888EDWj9+/f3/ef/99ysvLKS4u5qGHHmpwnxtuuIHPPvss2ssBoqawTZs2RRXRvHnzWLhwISeffHLW5c4ES7UBVFRAba37+GYmUxCGkV0ivSJNohh8ZsyYwUUXXcRNN93EGWeckfXjd+rUibvvvptTTz2VffbZh6OPPrrBfRKFzj722GN897vfjemlnH322cyYMYPKykog1gfRvXt3nnvuuSxdRWrazJzUw4cP18ZOGGSD5QwjM9555x2OOOKI5haj2fn666/p0qULqspll11G3759ufLKK5tbrKQkum8iskpVhyeqbz0InDJYtgwWLGhuSQzDaE3cd999zJ8/n6qqKoYMGcLkyZObW6SsYgoiwPz5rhcxf771IgzDaJgrr7yyRfcY9hbL5uph4a6GYRixmILwKClx6TZE3H9LuWEYRnvHFEQAPxuuZTE2DMMwBRGltBSqq0HV/TcTk2EY7R1TEB6W1dUwWg8nnXQSzzzzTEzZrFmzmDp1atJ9SkpK8EPhTz/9dLZv316vzvXXXx+TgjsRixcv5u236zL/XHfddVkZl9AS04KbgvDwQ10vuQQuuqi5pTEMIxUXXnghixYtiilbtGhRg/mQfJYuXUq3bt0ade54BXHDDTfwve99r1HHiqelpQU3BRHH/Plw331u4FwLybhrGG2CbE7te9555/Hkk09GJwcqLy/nk08+4YQTTmDq1KkMHz6cI488kt/85jcJ9y8uLubzzz8H4Oabb6Zfv34cf/zx0ZTg4MY4HH300QwaNIixY8eya9cuVqxYwZIlS7jqqqsYPHgw//jHP5gwYUL0Ybxs2TKGDBnCwIEDmThxYnQkdHFxMb/5zW8YOnQoAwcO5N13300oV0tLC24KIoCFuhpGbvCzFVx7bXZevvbff39GjBjBU089Bbjeww9+8ANEhJtvvpmVK1eydu1aXnzxRdauXZv0OKtWrWLRokWsWbOGpUuX8vrrr0e3nXvuubz++uu8+eabHHHEEdx///2MHDmSs846i9///vesWbOGQw89NFp/9+7dTJgwgYceeoh169ZRXV3NPffcE93evXt33njjDaZOnZrSjOWnBV+xYkXStOBnnnkmF154IQsXLozZd9y4cVET01VXXZV+gybBFEQAy+xqGLkhFy9fQTNT0Lz08MMPM3ToUIYMGcL69etjzEHxLF++nHPOOYfOnTuz7777ctZZdYmm33rrLU444QQGDhzIgw8+mDRduM+GDRvo06cP/fr1A+Ciiy7ipZdeim4/99xzARg2bBjl5eVJj9OS0oKbggjgZ3YNh13ivunTzcxkGNkgF0EgZ599NsuWLeONN95g165dDBs2jA8++IA//OEPLFu2jLVr13LGGWckTfPdEBMmTOCuu+5i3bp1/OY3v2n0cXz8nkBD6cJbUlpwUxBxJMrsahjG3uEHgdx4Y/bS2HTp0oWTTjqJiRMnRt+0d+7cyT777MN+++3H1q1boyaoZIwaNYrFixfzzTff8NVXX/H4449Ht3311VcceOCB7NmzhwcffDBa3rVrV7766qt6x+rfvz/l5eVs3LgRgP/+7//mxBNPbNS13XDDDdx2220J04J/9NFHlJeXU15ezuzZs+uZmbKJ5WKKw3/T8TO7WrirYWSHSCT7+c0uvPBCzjnnnKipadCgQQwZMoTDDz+cXr16cdxxx6Xcf+jQofzwhz9k0KBBHHDAATEpu2+88UaOOeYYevTowTHHHBNVChdccAGXXHIJd9xxR0ykUMeOHZk3bx7nn38+1dXVHH300UyZMqVR19VS0oJbuu8ElJW5nkNJiSXsM4xEWLrv1kmm6b7NxGQYhmEkxExMcdjkQYZhGA7rQcQRDMfbvdsmETKMZLQV83R7oTH3yxREHH7ab3CJ++bNs1BXw4inY8eOVFRUmJJoJagqFRUVdOzYMaP9zMQURyQCEyfCnDlOQVRVuV6EmZkMo46ePXuyefNmtm3b1tyiGGnSsWNHevbsmdE+FsWUgLIy15Pw0rxQUAAvvGBKwjCMtodFMWWI34vwJw6y+SEMw2iPmIJIwvjx0LGjzQ9hGEb7xXwQSfDzMj36KIwda+YlwzDaH6YgklBW5pL1VVXB8uUwcKApCcMw2hc5NTGJyKkiskFENorINSnqjRURFZHhceWHiMjXIvLzXMqZCJsbwjCM9k7OFISIhIHZwGnAAOBCERmQoF5X4Arg1QSH+SOQOh1jjrC5IQzDaO/ksgcxAtioqu+rahWwCDg7Qb0bgduAmGTrIjIG+ABIPUtHjrC5IQzDaO/kUkEcDGwKrG/2yqKIyFCgl6o+GVfeBbga+G2qE4jIJBFZKSIr92bATtmmMm5dfitlm2I1gM0NYRhGe6bZnNQiEsKZkCYk2Hw9cLuqfi3+YIQEqOpcYC64gXKNkaNsUxmjF4ymqqaK/HA+y8YvI9LLeaN9M1NlpZmZDMNof+SyB/Ex0Cuw3tMr8+kKHAWUikg5cCywxHNUHwPM9MqnA78UkWm5ELK0vJSqmipqtIaqmipKy0uj28zMZBhGeyaXPYjXgb4i0genGC4AfuRvVNUdQHd/XURKgZ+r6krghED59cDXqnpXLoQsKS4hP5wf7UGUFJfEbE9kZrJwV8Mw2gM5UxCqWu299T8DhIE/q+p6EbkBWKmqS3J17kyI9Iow69RZPPr2o4wdMDZqXvKxKUgNw2ivtPtkfal8ED5z59aNqJ40KVsSG4ZhND+WrC8FqXwQUDeietky80EYhtG+aPcKwvdBhAghIhR2jg1VshnmDMNor7R7BeH7IMKhMLVay/Snp8eMh7AZ5gzDaK+0ewUBULGrglqtpVZrE4a62twQhmG0R0xB0LCZyZ8bwvIyGYbRnjAFQcNmJhswZxhGe8QUhEcqMxNYXibDMNofpiA8fDNTWMIJR1T7zmoR998GzBmG0daxGeU8GhpRDXWO6hT5Aw3DMNoMpiA8yjaVMf3p6VTVVLH8o+UMPGBgjJIoLXURTKp1kUyWk8kwjLaMmZg8GhpRbTPMGYbR3jAF4dFQqKtFMhmG0d4wBeHRUKgrWCSTYRjtC1MQARoKdfXNTOGwpf42DKPtY07qAL6ZqbK6MqmZadkyS9hnGEb7wHoQAdIxMwHMnw/33QejR5sfwjCMtospiDgaMjOVlkJlpUv/XVlpfgjDMNoupiDiKCkuIRwKIwjhULjeiOrCQuekBvffwl0Nw2irmIJIgCAx/4NUVLixEOD+V1Q0pWSGYRhNhymIOErLS6murUZRqmurE0YyFRS4SKaCAotkMgyj7WJRTHH4kUxVNVUJk/ZZJJNhGO0FUxBxRHpFWDZ+GQveTK0B5s93g+Xmz3cKw/IyGYbR1jATUxLmvzmf+964j9ELRtcLdS0tdcqhpsZGVBuG0XYxBZGAYOK+3dW76/UmLHGfYRjtAVMQCfBDXQEUZd6aeQmnIBVxvYjLL7cBc4ZhtD1MQSQg0ivCxMETo2GuiaKZVq92ykHVmZnMaW0YRlsjpwpCRE4VkQ0islFErklRb6yIqIgM99ZPFpFVIrLO+//dXMqZiPGDxpMXzks6YM4wDKOtkzMFISJhYDZwGjAAuFBEBiSo1xW4Ang1UPw5cKaqDgQuAv47V3KmItWAufHj3TgIcGMihgxpSskMwzByTy57ECOAjar6vqpWAYuAsxPUuxG4DdjtF6jqalX9xFtdD3QSkYIcylqPhgbMRSJwxx2Ql+dSblx2Gcyd25QSGoZh5JZcKoiDgU2B9c1eWRQRGQr0UtUnUxxnLPCGqlbGbxCRSSKyUkRWbtu2LRsyR2lohjlwaTZ8P0R1NUybZs5qwzDaDs3mpBaREPBH4Gcp6hyJ611MTrRdVeeq6nBVHd6jR4+sypdO6u+Skrq8TOCUhY2JMAyjrZBLBfEx0Cuw3tMr8+kKHAWUikg5cCywJOCo7gk8BoxX1X/kUM6kNJT6OxKB2bOdmSkUstxMhmG0LXKZauN1oK+I9MEphguAH/kbVXUH0N1fF5FS4OequlJEugFPAteo6is5lDElDc0wBzBpkvv/6KMwdqyl3DAMo+2Qsx6EqlYD04BngHeAh1V1vYjcICJnNbD7NOAw4DoRWeN9DsiVrMlIx8xUVgbTp7t8TNOnmw/CMIy2Q06T9anqUmBpXNl1SeqWBJZvAm7KpWzpksjMFOlV101IlJfJehGGYbQFbCR1AzQ0w5zlZTIMo61iCiINUg2Y8/MyhcNuPISZmQzDaCuYgmiAhgbMgRsPUVvrPrt3W14mwzDaBqYgGiCdAXMlJa4HAW7Q3Lx51oswDKP1YwqiAdKJZIpEYOJE54MAN6raBswZhtHaMQWRBg0NmAOXvK9jR3NWG4bRdjAFkQbpmJnMWW0YRlvDFEQapGNmgrrkfbW1UFlpZibDMFo3piDSJB0zU2GhUw7g/puZyTCM1owpiDRpaMAcuB6En91VxE1LahiG0VoxBZEBqQbMgQt37eAlL1GF++6zSYQMw2i9mIJIk3QGzPnhrj41NTaJkGEYrRdTEGmSTiQTuHDXDoEUiDaJkGEYrZWUCkJE9k2x7ZDsi9NySTeSyZ9EKBx2fogOHWwSIcMwWicN9SBK/QURWRa3bXHWpWnhpBPJBDBwYF0vQhK7KwzDMFo8DSmI4ONt/xTb2gXpmplKS126DVU3R4Ql7zMMozXSkILQJMuJ1ts86ZqZLHmfYRhtgYYUxAEi8lMR+Vlg2V/v0QTytTgqdlVQU1tDrdZSWV2ZMprJkvcZhtGaaUhB3Ad0BboElv31P+VWtJZJYedCanHDpWupTRnNZMn7DMNozaSck1pVf5tsm4gcnX1xWj4VuyoISYharSUkISp2VSSs5yfvmzbNhbpOn+6c1zZftWEYrYWMxkGIyAARuVFENgL35EimFk1JcQkF4QJChAhJKGkPAmJnmquqMjOTYRitiwYVhIgUi8gvRGQt8N/AVOB7qjo859K1QNJ1VEOds1rE/bfxEIZhtCYaGihXBjyJM0WNVdVhwFeqWt4EsrVYguMhdlfvZsGbyeNYRVwkU00NrFvXhEIahmHsJQ31ILbinNLfpi5qqd2Ft8bjZ3YFUJR5a+Yl7EWUlsKePW7Z8jIZhtHaSKkgVHUMMBBYBVwvIh8A3xKREU0hXEsl0ivCxMETo1ldkyXvKympS/8NLtzVBs0ZhtFaaNAHoao7VHWeqp4CHAtcB9wuIptyLl0LZvyg8eSF81LODxHMywQ2aM4wjNZFRlFMqrpVVe9U1eOA43MkU6uhofkhACZNgksuqVvfs8eimQzDaB005KRekuwD3NnQwUXkVBHZICIbReSaFPXGioiKyPBA2S+8/TaIyL9mdFVNQHB+iKqaqpSO6iFD6pZra+G116wXYRhGyyflQDkgAmwCFgKvkkGCPhEJA7OBk4HNwOsiskRV346r1xW4wju+XzYAuAA4EjgIeE5E+qlqTbrnzzW+o7qmpibqqB4/aDyRXvVHwvlTkfrzVS9eDEuXup6EDZwzDKOl0pCJqQj4JXAU8F+4h/3nqvqiqr7YwL4jgI2q+r6qVgGLgLMT1LsRuA3YHSg7G1ikqpWq+gGw0TteiyHeUZ2qFxGcitTHsrwahtHSaSiKqUZVn1bVi3AO6o1AqYhMS+PYB+N6Hz6bvbIoIjIU6KWqT2a6r7f/JBFZKSIrt23bloZI2cV3VEPqcNf4qUgNwzBaA+mMpC4QkXOBvwCXAXcAj+3tiUUkBPwR+Fljj6Gqc1V1uKoO79Gj6ZPL+r0Inz01e5JOIjR+POTn163n5bkywzCMlkpKH4SILMCZl5YCv1XVtzI49sdAr8B6T6/Mp6t37FJxebGLgCUiclYa+7YYhhxY54FOld01EnE+hwULYMsWKCpqIgENwzAaSUNO6n8D/olzIv9E6ubPFEBVNUdT+BAAACAASURBVOmc1cDrQF8R6YN7uF8A/MjfqKo7gO7RA4qUAj9X1ZUi8g3wVxH5I85J3Rd4LYPrajLSze4KdQ7p0aOdD2L+fFi2zBzVhmG0TBpK953ROIm4fas9X8UzQBj4s6quF5EbgJWquiTFvutF5GHgbaAauKwlRTAF8bO7VlZXNpjdFVwvoqrKpd7wM7yagjAMoyXSaAWQDqq6VFX7qeqhqnqzV3ZdIuWgqiWqujKwfrO3X39VfSqXcu4NmWR3BRfRlJ9fl8Rv+/amk9UwDCMTcqog2gvB7K5VNVVJHdXgeguXX+6UQ20tzJwJc+c2nayGYRjpYgoiC5QUl5AfzidECBFp0My0Zk3s+o032shqwzBaHqYgskCmZqaxY2PXN2+Gk04yJWEYRsvCFESWyGQSoUmTYMyY2DKbktQwjJaGKYgske4kQj4zZsQOnOvQwaYkNQyjZWEKIktkMqoanLP6zjvr5qwO2Z0wDKOFYY+lLJLuqGqfCm9Mnaqbbc5MTIZhtCRMQWQRf1Q1uEmEVn+6OmV9f0xEKOR6EYWp9YlhGEaTYgoii5QUl9Ah5Aanp+OHiERg1ixnZqqthenT3ZiIW2+1iCbDMJofUxBZJJM5InwqKpxyqK2Fb76BSy+Fa691+ZpMSRiG0ZyYgsgy6c4R4VNS4noQPjU17lNZaT4JwzCaF1MQWaYx0UyJJhOqrTWfhGEYzYspiByQaTTTkCH1y0KhuignwzCM5sAURA7INJqposJFMQUJh23gnGEYzYspiByQaTRTSYmbgtQnHIa77rJ5IgzDaF5MQeSA+Gim6trqBv0QpaUwZYr7LF/u8jUZhmE0J6YgcsT4QePp2KFj2inAIxG45x73AZg61X0s1NUwjObCFESOyDQFuE9ZmTM53Xuv+4wcCSeeaIrCMIymxxREDqnYVUFNbQ21WktldWVKM5NPaSns2RNb9tJLcPzxNvOcYRhNiymIHFLYuZBaaoH0wl2hvsPap7YWpk2znoRhGE2HKYgckmm4K9Q5rEeNqr/NMr4ahtGUmILIIZmGu/pEIvDiizBnDvTuXVeuaqOrDcNoOkxB5JDGJO8LMmkSTJ5cN5mQCKxuuBNiGIaRFUxB5JhMk/fFU1LipiMF14OYN8/8EIZhNA2mIHJMpsn76u3vJfPzU3FUVrp5I0xJGIaRa0xBNAHxyfu2V27PaP/x42Mjm157DY47Dq6+OlsSGoZh1McURBNQsasi6ocAuL3s9ozMTJEInH56bJkqzJxpYyMMw8gdOVUQInKqiGwQkY0ick2C7VNEZJ2IrBGRl0VkgFeeJyLzvW3viMgvcilnrikpLiEcqpsVqLq2OiNnNUBRUeLy++/fG8kMwzCSkzMFISJhYDZwGjAAuNBXAAH+qqoDVXUwMBP4o1d+PlCgqgOBYcBkESnOlay5JtIrwuzTZxMWpyQU5f7V92fUixg/HgoK6pevXm3+CMMwckMuexAjgI2q+r6qVgGLgLODFVR1Z2B1H0D9TcA+ItIB6ARUAcG6rY5JwyZxZr8zo+t7avdk1IuIROCFF+CWW2IH0VVXO1PTrbc6c9Ott5rCMAwjO3TI4bEPBjYF1jcDx8RXEpHLgJ8C+cB3veL/wSmTT4HOwJWq+kWCfScBkwAOOeSQbMqeE4q6xNqJtny9JaP9IxH3KSlxn6oq54tYvNh9wEU7hcMwe7alDDcMY+9odie1qs5W1UOBq4Ffe8UjgBrgIKAP8DMR+U6Cfeeq6nBVHd6jR48mk7mxjB80nrxQXTjSUxufysjM5JNsHmtwCqO62vI2GYax9+RSQXwM9Aqs9/TKkrEIGOMt/wh4WlX3qOpnwCvA8JxI2YREekW4eMjFjR5ZHWT8eNdTSEZNjeVtMgxj78ilgngd6CsifUQkH7gAWBKsICJ9A6tnAO95yx/hmZtEZB/gWODdHMraZMSPrM7UWR0k1MDdKyx0vQjzSxiG0RhypiBUtRqYBjwDvAM8rKrrReQGETnLqzZNRNaLyBqcH+Iir3w20EVE1uMUzTxVXZsrWZuSSK8Ipx9WN6hhT+0eZr4yM+PjlJa6FODJUIXLL4eTToJrr4XRo01JGIaRGbl0UqOqS4GlcWXXBZavSLLf17hQ1zZJvLP68b8/TtmmMiK9Imkfo6QE8vOdozocds5pf6Kh2lqnIKqq6upXVdWZnEpL3f6R9E9nGEY7JKcKwkjM+EHjue+N+6jRGgBqtZYFby7ISEFEIrBsWd3DHtzy9u0u7DWeDh2cyWn06DqlMnGi82WYojAMIxHNHsXUHon0inD3GXfHDJzLNMsruAf7L35RF/76i19At26JfROHHuoG1VVWOgd2VZWbb8JMT4ZhJMMURDMxadgkLhl6SXQ90yyvyQimBw/y9ttw332xfgtVpzAs2skwjESYgmhG9jbLayJSjZGoqalfVlsLTz8N55wDU6dab8IwjDpMQTQje5vlNRnjx0OnTs7UJNJw/ZdeciOx770XTjzRFIVhGA5TEM1INrK8JsJ3YN90k3vopxpQF8+ePbG+CRtHkXusjY2Wiqhqw7VaAcOHD9eVK1c2txgZM3fVXC598tJoRFNeKI8XJ7yYUURTg+eYC5demtjElIxQyOVymj/fObTz853SiUTcgyw+esrCZhtHWVldZFmwjbN5fLs/RipEZJWqJsxUYWGuzcykYZN46r2nWLzBZdvzs7xmU0FMmgQDB8ICr3MyZIiLaLrvvuRKw/dNVFa65d276/YPhsqKuNxPuXi47Q2t5cFYWura0o8sKy1NX96GrjHXyiddOQxHa2wnUxAtgPiBcy99+FLGA+cawg+FDTJkiEvqV13tIpriKS+vW1Z1CmXLlroHmh8RpeoUyMyZMGJE3Q8gkx9ENn88TfVg9M+1N3IHBzzm59f1ytI5b6JrLCurU+RQd68qK+H6690n2z2UdNs6Vz3PbH13cvkA99upstL1zltLtmVTEC2A8YPGc//q+9lT64ZCv/3525z4wIlZNzXFE+xZzJtXlz48GTU1zpntz48tUjdq2087/r//67bfeSdMn574wTF3Ljz6KIwd62QI/nhE4MwzYcaMxv9IM30rj39w+Q/YZIMI/Yfwli3w5JPObxMOw913p/+jD55z2bLYh3qyekFZSkvrenfBUGU/DTy4+xAK1SnzZ5915zruONh/fzdLYWMHSvpyffRRem1dVubSvlRVuTDsUKiu5zlrluvRgntpqahI/yGdSEH57VNYmP6x5s51L0s1NW5irmy/VATvV22tO9fAgXXnaLG9C1VtE59hw4Zpa2bK41OU64n5THl8SpOdf8UK1VtuUZ0xQ1XEf+Qn/wwerBoOJ98+YIBqKOSWRVTHjKk7frDejBmqI0bU37+gwMmULnPmqJ5yivu/YoVqp07u/OGwO3fwWPF1CwqcjHl57pNKhhUrVPPzE19zOJyezL584bD7P2dO7Lp/jPh6K1bE3qfguefMceXx9y7VPUp0jf7xU11HUK78fHeMeNnjmTIl9ry+nCL1ZQ6F6tolmSy+nFOm1F2jf6+D1yyi2qGDO1bwvscfq0OH2H2mTHHHj5dhxQq3bcoUt5zsmPFyzpkTe45QyJUn+z74+wTPlck9ygRgpSZ5rpqTuoVQtqmME+adEHVWA4zpP4bHLnisyWWZO9eFuqZKBpgtRBL3WkTg5pvdG1XwjR7qUoqsWeN6IQCTJ9ftO2OGGzkedMyHw3DBBfDyy/Dhh3V1DzwQPv00uWy+DP4b6aOPujfxZD+bMWNizWxB/J7HSy+5gYvg3qSHD4fXX687Zu/e8O1vQ8eOsHy5KxeBs8+GZ55xb6JQd39CIRexVlgYe81+iHNDP/FTTnGmp3Xr0nuLnjrVRbqpunY980z45BM46CA47TTXG9gSmAurqMit+5Na+TI39P3yvxsdOsSaZPy3/epqdxz/WOGwK0t03Pjv2YwZLuuAf29/9avY7Xl5dT2vUMi1x6xZ7rx+zrP4axgzxl2/32uBWLPSD38IDz9c176zZrm6r73met6qdaHp8b7BggI3o6R/zN27Xb2f/xxuuy11OzZEKid1s7/5Z+vT2nsQqqpzVs7R0PWhaA8i/NuwzlmZ5NUkx/hvSmPG1H8ra4pPXp57S45/G/R7JcFPt271ywYNyo4MY8bU9TDS3c+Xc8CAujfLOXOSt2G6bZvo2kMh9xY/alTscUKhOplDIff2muoagvX9T8+esW/G/nci2MuK73WlapNUvYZ0PmPG1H8T92UfMcK1QSb3yO9dzJhRvweRqFeTqKeb7Nj5+a5+8Dh5eXW9Av97leieprr+RDKMGrV3vQlS9CASFrbGT1tQEKr1TU15N+Tpio+y1JfcC1ascA+8vX3opvvDTfTAaspPcXH2lGL8wzubnyOOaPgBfcQR7uHS2Ps3apTbP9F59t23ae9LLr4TIqrjxrnr85VponqHHbb35xkxIj2FmuknFEpu5mqIVArCTEwtjLJNZYx6YBTVtdXRsuYyNcXjOxp9E4dIXd4nv9udzGSUDuGw2zfbpq29kamlM2BAnbkqXVpie4jUBT00B36QgW/yCZrDWgvhsDNJZurkTmVispHULYxIrwizT59NKHBrFm9YzNXPXd2MUjkiEWcHveUWZ4O++WZ48UX3mTLFfc4+O3afUaNcdEkQ324cZMwY9wNNlGhwb8jLgxNOiC0bMMCdL5vnyMtruF4Q/4EYpKEZAv39gvXfTTDPYkPpVU4+2dngMxlhnyv8l4x773X+oREj0ksPk4pQKPP7UVPjfCeFhfD445nt2xztmOi7Ulubg8SbyboWre3TVkxMPiPmjogxNcn10mz+iEzwo3x8O2ww8iYYERKMaglGdMRHuyTrqofD9W3uc+Y4e7JvnvLty8GoIz9qJxjplKheOp8jjoiNZknHjBQK1UWmBO3PoVBs1Feq/X1zSKJ6Y8a4qJpkxwhGLU2ZUr+ebwYpLs7czBH8BKPY/E847NrZv/5EUUqJInrGjEl8PUcckdg/FLT1x5vVUtn8479ToNq7d/19CgrcdZxySuKoqWybjxK1rf+dC8qWaeSfD+aDaH3MWTmnXthr+LfhFuGPaIhMQyUThXYGnYh+OGXwoRIMb/TDEhOd/5Zb0qsXXE/2QPIdskHl55NuiKmvDBMpqPjQUT9MN16RnHJK4mOnUn7JwiX9ev6xg+G0/n1Ipaz8T9AJ7ivB4PXEnzvT70+8As7Li335CN6zcDg2hNRXIgUFsaGjc+ak9sv45xgzJrZ8zJjk3+M5c+o7p+OXfWdzqrbNy0vuxA4qgviw28aQSkGYD6IFc/VzV9ebr3rKsCnc8/17mkmi7JJscFA6I27THcHbmFHVwX3CYTj99LpBZankCQ5SKyiAO+5wZou334ZXXnE/72D4aPz1J7tuP/y0utrJ89OfuoGIieTLdOCVXy/RoLLgtuBANn852B6FhfUHRiZrq8YSHCUeP8Av1X1O1RZTpzrzlo/vBwuOdo6vM2UK3BP4CSa6j0FZLr8cbr89NnwY6s/umKpt77+/LhQ6HIYbb3QThGWDVD4IUxAtnHMeOofF79Z5zFqKw7olkOlDMJMHVWP3SfUA25uHZfxIXz+GviWNvG3u0cCNvWclJS7Iws8AkEhRBuukky8rlfJvzOjpXKaPMQXRiinbVMaJD5wYTcMRljB3n3E3k4a1gkQuRta49Va49lqnILL9BtneSedB3dzKL5cymIJo5Ux9Yir3rqrr44YlzPL/WJ7TPE1Gy6IpExAa7QsLc23ljB80nrDUxdLVaA1jFo1h7qq5zSiV0ZT4k0DdeKMpB6PpsGyurYBIrwhn9j8zxhfx2a7PmPyES0Bk5qb2QaKU7YaRS6wH0UqYMXJGTC/C5/437m8GaQzDaA+YgmglRHpFuPuMu2NGWAOs/HSlmZoMw8gJOVUQInKqiGwQkY0ick2C7VNEZJ2IrBGRl0VkQGDbv4hImYis9+p0zKWsrYFJwybx8sSXGdA92kzUai1TnphiSsIwjKyTMwUhImFgNnAaMAC4MKgAPP6qqgNVdTAwE/ijt28H4C/AFFU9EigB9uRK1tZEpFeEP531pxhzk6JMfmJyi8jXZBhG2yGXPYgRwEZVfV9Vq4BFQEwqN1XdGVjdB/Bjbk8B1qrqm169ClWNm0Kj/eI7reOZ+cpMUxKGYWSNXCqIg4FNgfXNXlkMInKZiPwD14P4iVfcD1AReUZE3hCRGTmUs1UyY+QM8kL1U1bOfGUmJz5wImWbyppBKsMw2hLN7qRW1dmqeihwNfBrr7gDcDwwzvt/joiMjt9XRCaJyEoRWblt27Ymk7klEOkV4cUJLzLqkFH1tr304UscP+9480sYhrFX5FJBfAz0Cqz39MqSsQjws/RvBl5S1c9VdRewFBgav4OqzlXV4ao6vEePHlkSu/UQ6RXhxf94kRnH1e9g1Wot05ZOs56EYRiNJpcK4nWgr4j0EZF84AJgSbCCiPQNrJ4BvOctPwMMFJHOnsP6RCDDebPaD7d977aESmJP7R5mvjKTW5ffaorCMIyMydlIalWtFpFpuId9GPizqq4XkRtw+ceXANNE5Hu4CKUvgYu8fb8UkT/ilIwCS1X1yVzJ2ha47Xu3cei3DuWW5bfw4Y4Po+WLNyxm8YbFdAh1YPbps23UtWEYaWPJ+toYty6/lV89/yuU+vfVkvwZhhGPJetrR5QUl5AXTjwhb43WcO5D5zJg9gDOeegcMzsZhpESUxBtjEivCKUXlSaMbgLY8s8tvPP5Oyx+dzEj/zzSQmINw0iKKYg2iB/dNOf7cxhx0AhCkvw2W0isYRjJMAXRhpk0bBKvXvIq95xxT8JMsD61WsvkJyZz5N1HmqIwDCOKOanbCWWbyljw5gLe3vY2f6/4O1v+uSVp3aIuRRzb81hmjHShs6XlpZQUl5hz2zDaIDblqFGPuavm8uvnf822XalHoAuCojYXtmG0UUxBGAkp21TGiQ+cyJ7a9BPljuo9inEDx1Gxq4KS4hIAFry5AHBTo1ovwzBaF6YgjKT4pqe/bf4ba7auyXh/v4cBECJE/+796d+9PzNGzmDdZ+t49O1HGTtgrPU8UuDfA8hMyZZtKmvQ/NfYY7dH0mnP1nCOTDEFYaRF2aYyZr4yk79t/ltKH0VjmHHcDMb0H0NpeSnbK7ez5tM1MYoj6CPZXb2bi4denJFSif/h+cfb8rW7jqIuRWk/INN98JaWl1LYuZDVn64GGvdwL+xcyOVPXU5VTRUABeECXrjohehxEj3g/bJ5a+axp2YPoVAoOko+/rqffO/JaA8xL5THGX3PAOCLb75oVDsnaiNIrxcZvJYhBw6J6YXOfGUmGyo20GOfHgzoPoDxg8YD6fm/4mWZ+cpMPvnqE0r6lLBz986oXKmOV7apjJL5Jeyp2UNeOI/Si0qz/gAv21TG6AWjqaqpIj+cz7Lxy2Luc3MpDlMQRsbMXTWX+9+4n455Hdm5e2ejehfxBHsbPkVdiuia35WNX2yst21w0WCOPfhYhhw4hNWfrmbL11v44psv2LZrGwUdCsgP5VPSp4S/f/53lvx9CbVaiyD07tabTTs2URM3hYj/gPSP0WOfHuzfcf/oev/u/elX2I//XPGf1Gpt9EEBRB/mFbsq2F65nf9c8Z/1ji8IVx13FWP6j4k+pOIfwL4SXvL3JagqIQlRq7Ux1957v950zutMQYcC1m5ZSy21gFMeVxx7RcJzhyXMcb2OY/lHyxOOok9FsJ2feu+peg/qRA/T0QtGU1ldiYgAROXxZSz9oJSOeR3Zv+P+0f0e//vj9eROhf99EYTD9j+Mb3X8FhcPvZiBBwyMKpSCDgWs27qOWq0lJCFUNdpeQUKECIVCVNdWEyLE8b2PZ/+O+0dfHBa8uYB7V90brT/qkFEM6DGg3gsGEKOAg9/HyurKeu0WVIpb/rmF/333f6PXNHnYZO75/j0x7RkKhfjhkT9k2z+3MfjAwUkV3LrP1nH/G/dz0L4HMWPkjL1SKqYgjL1m7qq59fI8tQe6FXRjR+WOjB+6QYq6FNGvsB8ojXqANyeCMKhoEJXVldGH4Pbd2/n060+bW7SsIQhFXYoavKawhOsp81QUdSli69dbU9Yv7lZMZXVlWu3pj2cSpJ6iHdV7FL8b/btGKQpTEEbWmLtqLo++/Sg99unBexXvcdC+B9GvsB+3l92ekbPbMIzskhfK48UJL2asJFIpiJxlczXaJpOGTUpos/b9C4WdC5m2dFpUWYQIJezyJ6Nn155s/mpz1uQ1Wg/7d3LmPqNx7KndQ2l5dn0npiCMrBDpFYl+MQceMDDGaenbS32bdFGXohh7t+9P8O31c1fN5dInL01or/Z9DHmhvBi/hSCc0PsEdu7eyZtb34yW+9OyxvduiroU8dk/P4v6Lb7V6VsZP5wGFw2meL9iiroU8VXVVzy47sGM9k/kk/HLv93l21H5MpXp2IOPZd+O+9bzVQhCOBTmx0N+HL0vido5Ww/qRNcXIkQ4FKamtgYRYeC3B8bc+/hghb6FfXmv4j2+3P0l733xXsyxiroUUdSliHVb19W7hnEDx/Hw+oeprq2OkUFwPpNkZh/x/tJ9qfG/j906duPLb77kox0fNZsJMS+UF3XUZwszMRktEj+qw494GnzgYLoVdIuJ8kgWwhlfDnWOxWA0U3zkiG8+G3zgYO589U52V+8GYFDRoKgi2LfjvvUisHx8xeY7uO887U6eeu8pVm9ZHX1whAhx1uFnRUepB+UKRvYE5Yt3iueF8rjr9Lui0VPJZEoWNRR8w4xvZ/8YwWioeEdsMEBg5+6dUfn37bgvpR+URh2nQMJIL78804gd38Ef7/xPdQ2pzl/YuZCn3nuKJRuWUEttdDBo8AXHf5FZvGFxVI74sUDx7ekruPjAh+D9CwZL+O3Zt7AvD69/mBqtoUOoA6cfdnq0XR/f8Djvfv5uVPn4sgJ77aw2H4RhZEhjww6T7be3YYw2niF3pHNv/JeHxo7pSff+pZIlV98BUxCGYRhGQmzCIMMwDCNjTEEYhmEYCTEFYRiGYSTEFIRhGIaREFMQhmEYRkJMQRiGYRgJaTNhriKyDWjtmeS6A583txAtCGuPOqwtYrH2iGVv2qO3qvZItKHNKIi2gIisTBaP3B6x9qjD2iIWa49YctUeZmIyDMMwEmIKwjAMw0iIKYiWxdzmFqCFYe1Rh7VFLNYeseSkPcwHYRiGYSTEehCGYRhGQkxBGIZhGAkxBdFEiMifReQzEXkrULa/iDwrIu95/7/llYuI3CEiG0VkrYgMbT7Jc4OI9BKRF0TkbRFZLyJXeOXtsk1EpKOIvCYib3rt8VuvvI+IvOpd90Miku+VF3jrG73txc0pfy4QkbCIrBaRJ7z19twW5SKyTkTWiMhKryznvxVTEE3HA8CpcWXXAMtUtS+wzFsHOA3o630mAfc0kYxNSTXwM1UdABwLXCYiA2i/bVIJfFdVBwGDgVNF5FjgNuB2VT0M+BK42Kt/MfClV367V6+tcQXwTmC9PbcFwEmqOjgw3iH3vxVVtU8TfYBi4K3A+gbgQG/5QGCDtzwHuDBRvbb6Af4XONnaRAE6A28Ax+BGx3bwyiPAM97yM0DEW+7g1ZPmlj2LbdDTe+h9F3gCkPbaFt51lQPd48py/luxHkTz8m1V/dRb3gJ821s+GNgUqLfZK2uTeCaBIcCrtOM28Uwqa4DPgGeBfwDbVbXaqxK85mh7eNt3AIVNK3FOmQXMAGq99ULab1sAKPB/IrJKRPw5T3P+W+nQmJ2M7KOqKiLtLuZYRLoAjwLTVXWniES3tbc2UdUaYLCIdAMeAw5vZpGaBRH5PvCZqq4SkZLmlqeFcLyqfiwiBwDPisi7wY25+q1YD6J52SoiBwJ4/z/zyj8GegXq9fTK2hQikodTDg+q6v/zitt1mwCo6nbgBZwZpZuI+C9ywWuOtoe3fT+goolFzRXHAWeJSDmwCGdm+i/aZ1sAoKofe/8/w708jKAJfiumIJqXJcBF3vJFODu8Xz7ei0Y4FtgR6Eq2CcR1Fe4H3lHVPwY2tcs2EZEeXs8BEemE88e8g1MU53nV4tvDb6fzgOfVMzi3dlT1F6raU1WLgQtw1zaOdtgWACKyj4h09ZeBU4C3aIrfSnM7X9rLB1gIfArswdkEL8bZSZcB7wHPAft7dQWYjbNBrwOGN7f8OWiP43F21bXAGu9zenttE+BfgNVee7wFXOeVfwd4DdgIPAIUeOUdvfWN3vbvNPc15KhdSoAn2nNbeNf9pvdZD/zKK8/5b8VSbRiGYRgJMROTYRiGkRBTEIZhGEZCTEEYhmEYCTEFYRiGYSTEFIRhGIaREFMQhtEAIlLjZdH0P9c0vFfaxy6WQIZfw2hJWKoNw2iYb1R1cHMLYRhNjfUgDKOReDn6Z3p5+l8TkcO88mIRed7Lxb9MRA7xyr8tIo95cz68KSIjvUOFReQ+bx6I//NGUiMiPxE3X8ZaEVnUTJdptGNMQRhGw3SKMzH9MLBth6oOBO7CZSAFuBOYr6r/AjwI3OGV3wG8qG7Oh6G4UbHg8vbPVtUjge3AWK/8GmCId5wpubo4w0iGjaQ2jAYQka9VtUuC8nLcJD/ve4kHt6hqoYh8jsu/v8cr/1RVu4vINqCnqlYGjlEMPKtu0hdE5GogT1VvEpGnga+BxcBiVf06x5dqGDFYD8Iw9g5NspwJlYHlGup8g2fgcuoMBV4PZDI1jCbBFIRh7B0/DPwv85ZX4LKQAowDlnvLy4CpEJ0caL9kBxWRENBLVV8ArsalsK7XizGMXGJvJIbRMJ28md58nlZVP9T1WyKyFtcLuNAruxyYJyJXAduA//DKrwDmisjFuJ7CVFyG30SEgb94SkSAO9TNE2EYTYb5IAyjkXg+iOGq+nlzy2IYucBMTIZhGEZCrAdhGIZhJMR6oBY/ZwAAAClJREFUEIZhGEZCTEEYhmEYCTEFYRiGYSTEFIRhGIaREFMQhmEYRkL+P94K4Phwv1s2AAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ctawd0CXAVEw"
+ },
+ "source": [
+ "This graph of _mean absolute error_ tells another story. We can see that training data shows consistently lower error than validation data, which means that the network may have _overfit_, or learned the training data so rigidly that it can't make effective predictions about new data.\n",
+ "\n",
+ "In addition, the mean absolute error values are quite high, ~0.305 at best, which means some of the model's predictions are at least 30% off. A 30% error means we are very far from accurately modelling the sine wave function.\n",
+ "\n",
+ "**3. Actual vs Predicted Outputs**\n",
+ "\n",
+ "To get more insight into what is happening, let's check its predictions against the test dataset we set aside earlier:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "i13eVIT3B9Mj",
+ "outputId": "6004cf7f-77d3-4cb9-fa0d-49bdc591301e",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 299
+ }
+ },
+ "source": [
+ "# Calculate and print the loss on our test dataset\n",
+ "test_loss, test_mae = model_1.evaluate(x_test, y_test)\n",
+ "\n",
+ "# Make predictions based on our test dataset\n",
+ "y_test_pred = model_1.predict(x_test)\n",
+ "\n",
+ "# Graph the predictions against the actual values\n",
+ "plt.clf()\n",
+ "plt.title('Comparison of predictions and actual values')\n",
+ "plt.plot(x_test, y_test, 'b.', label='Actual values')\n",
+ "plt.plot(x_test, y_test_pred, 'r.', label='TF predictions')\n",
+ "plt.legend()\n",
+ "plt.show()"
+ ],
+ "execution_count": 12,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "7/7 [==============================] - 0s 2ms/step - loss: 0.1627 - mae: 0.3434\n"
+ ],
+ "name": "stdout"
+ },
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAXwAAAEICAYAAABcVE8dAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO2deZgU1dXwf6d7hs0lxnFFJKjBfBrZImL6E3AIBjUuoCQxUYNrBqL4xtcFJdFITCJLFnndmQjqBEQTEdQ3JvJhGAHpaEBBEzCKBmXAhYxLXGCAmfv9cavomp7qvXu6uvv8nqef7lr61qmq7nNPnXPuuWKMQVEURSl/QsUWQFEURekcVOEriqJUCKrwFUVRKgRV+IqiKBWCKnxFUZQKQRW+oihKhaAKv4wRkfNEZHGx5XARke4i8oSIfCQifyjC8aeIyFznc28R+UREwlm08yMRuTf/EnYOInK/iPy82HIkw3uv8txu4M+9kKjCTwMROVdEVjkK4m0R+ZOIDC22XKkwxswzxowqthwevgkcCNQYY75VTEGMMW8ZY/Y0xrQm209EakWkKe67txhjLi2shKWFiFwoIiuKLYeSHFX4KRCRq4CZwC1YZdUbuAsYXUy5UiEiVcWWwYcvAK8aY3bl2lBAz09Rgo0xRl8JXsDngE+AbyXZpyu2Q9jivGYCXZ1ttUATMAl4D3gbGAN8A3gVeB/4kaetKcAjwMPAx8ALwADP9uuB151t64CzPNsuBJ4FbgWagZ8761Y428XZ9h7wH+Bl4BjPeTYAW4E3gRuAkKfdFcCvgA+AfwGnJrkeRwGNwIfAP4AznfU/BXYAO51reonPd1Od/0bgOuAloAWoAr4KrHSOtxao9ex/GPCM09b/A+4A5jrb+gAGqHKW9wXuc+7hB8AiYA9gG9DmyPwJ0NORc67nOGc65/qhc+5Hxcl8jSPzR865dXO27Qf8r/O994Hl7nX3uTb/A2xy7t1qYFjcdfu9cw8/dmQZ7Nk+yLmWHzvHfwj4eYLjHAH8Bfsb+jcwD9jHs/1Q4FHnt9LsXNOjgO1Aq3ONPnT2bQQujfuNrsjgnOYmkHE9cLpnucqR5yvO8h+Ad5zrvQz4smff+91zj5fHWWeAL3r+278C3gLeBe4Bumd674L0Ugs/ORGgG7AwyT4/xiqdgcAAYAhWYboc5LRxCPAT4LfA+cCxwDDgRhE5zLP/aOwPdl/gQWCRiFQ72153vvM5rAKdKyIHe757PPAG9knkF3FyjgKGA0c63/829g8LcLuz7nDgRGAccFFcu//E/shnALNFROIvhCPnE8Bi4ADgCmCeiHzJGHMT9inpYWNdKbPjv5/G+QN8FzgN2Mc5zz9iO7d9sYp1gYjs7+z7IFaR7Af8DLggwTEBfgf0AL7syH6rMeZT4FRgiyPznsaYLXHnfCQwH7gS2B94EnhCRLp4dvs2cAq2A+qPVTQAV2MNgv2dc/kRVuH48Tfsb8y9Ln8QkW6e7WdiFfk+wONYRYwjxyLn/PbFXtuxSa6DAFOxHdtRWAU/xWkrjFVyb2I7zEOAh4wx64EJQNS5RvskaT+Tc0rEfOzvwOVk4N/GmBec5T8BfbH38QVsp5UN07D/l4HAF4n9hyGzexccit3jBPkFnAe8k2Kf14FveJZPBjY6n2uxFmLYWd4L+6M43rP/amCM83kK8FfPthD2qWBYgmOvAUY7ny8E3orbfiExC/9r2KeKr+KxRIAw1vI+2rNuPNDoaWODZ1sP5xwO8pFnGNay8rY/H5jiOT9fqy2d88dayxd7tl8H/C6ujaewir03sAvYw7PtQXwsfOBgrBX/eR+ZaoEmHznddm4Efh8n82acJw1H5vM922cA9zifbwYew7EoM/xtfoDz9OPIs8Sz7Whgm/N5OPapRTzbV5LAwvc5zhjgRedzBGtJV/nst/u35lnXSBILP41zSmThfxH7tNLDWZ4H/CTBvvs49/lzzvL9pGHhYzu+T4EjPNsiwL9yvXfFfKmFn5xmYL8U/uKeWIvH5U1n3e42TCwwuM15f9ezfRuwp2d5k/vBGNOGtSJ6AojIOBFZIyIfisiHwDFY67XDd+MxxvwFa/XdCbwnIvUisrfz/WqfczjEs/yOp53PnI9emV16ApscuRO1lYqE5x+/HRsT+JZ7PZxrMhSrwHsCHxhrpXtl8eNQ4H1jzAcZyOnS7v47Mm8iwfUDPiN27X4JbAAWi8gbInJ9ooOIyDUist7JcPoQ+0Tmvffxx+jm/G57ApuNo6UcEl0HRORAEXlIRDaLyH+AuZ7jHAq8afIQg0nznHwxxmzAunXOEJEe2KebB502wyIyTURed+Tf6HwtZbtx7I81blZ7flt/dtZDBvcuSKjCT04U6ysek2SfLVjF49LbWZcth7ofRCQE9AK2iMgXsO6gidgsl32Av2MtEZekj5TGmNuMMcdiLcAjgWuxftqdPuewOQvZtwCHOnJn25bv+Xu2e89xE9bC38fz2sMYMw37ZPB5EdkjThY/NgH7ioifKyLVY3q7+++4ug4ljXM2xnxsjLnaGHM4VmldJSIj4/cTkWHYONC3sU8h+2D90x3caj68DRwS54JLdB3Aut0M0M8YszfW/eh+dxPQO4EB5HedPsUqTZeD3A85nhPE3DqjgXVOJwBwrrPuJGwH0sc9ZCr5ROQgz7Z/Y42xL3t+W58zxuwJ6d+7oKEKPwnGmI+wPrs7RWSMiPQQkWoROVVEZji7zQduEJH9RWQ/Z/9c8oePFZGznT/VldgO56/YAKLBPlIjIhdhLfy0EJHjROR4xx/+KTbI1uY8ffwe+IWI7OV0LFdleQ7PYa3LSc51qgXOwPqW0yXR+fsxF2vlnexYdt2cNMpexpg3gVXAT0Wki5NGe4ZfI8aYt7F+37tE5POO7MOdze8CNSLyuQQy/B44TURGOtf2akfmlalOVEROF5EvOsr4I2zQs81n172w7qmtQJWI/ATYO1X7DlHnu//lnNfZ2DhTIvbCBl4/EpFDsEaBy/PYDmSaiOzhXO8TnG3vAr3iYhdrgLOd/80XgUvydE5gf1OjgB/gWPeedluwT+c9sB1YItYCXxaRgU7sYIq7wXlS+y1wq4gcACAih4jIyc7ndO9doFCFnwJjzK+xCvAG7I9zE9bKXuTs8nOsYnkJm/nygrMuWx4DzsH6M78HnG2M2WmMWQf8GvsHfhfoh83KSZe9sT/gD7CP9M3Yx1KwwdVPsQHfFdg/0JxMBTfG7MAq1VOxFtJdwDhjzCsZNON7/gmOtwlrzf2I2L25ltjv+lxswPl94CZsFksivod90nkFm8l0pXOMV7Cd+hvOo73XvYQx5p9YK/h255zPAM5wrkUq+gJLsAo2CtxljFnqs99TWHfCq9h7t50k7rs4+XYAZ2P91e9jr+2jSb7yU+ArWCX2R+++jnFwBtbH/RbW3XaOs/kv2Oygd0Tk3866W7HxoXeBB2gfPM36nBxZ3sZes/+LzTxyaXDa24zNZEtkLGCMeRXri18CvIb97Xu5Duu2+avjHloCfMnZlu69CxTS3rWnFBMRmYINAp1fbFmKQaWfv6IUGrXwFUVRKgRV+IqiKBWCunQURVEqBLXwFUVRKoTAFqDab7/9TJ8+fYothqIoSkmxevXqfxtj9vfbFliF36dPH1atWlVsMRRFUUoKEUk4klpdOoqiKBWCKnxFUZQKQRW+oihKhRBYH76iKMVj586dNDU1sX379mKLoiSgW7du9OrVi+rq6tQ7O6jCVxSlA01NTey111706dMHn7lulCJjjKG5uZmmpiYOO+yw1F9wUJeOoigd2L59OzU1NarsA4qIUFNTk/ETmCr8MiUahalT7buiZIMq+2CTzf1Rl04ZEo3CyJGwYwd06QJPPw2RSLGlUhSl2KiFX4Y0Nlpl39pq3xsbiy2RomTHokWLEBFeeSX1lAozZ87ks88+S7lfIu6//34mTpyY9ffz3U4hUIVfhtTWWss+HLbvtbXFlkhRsmP+/PkMHTqU+fPnp9w3V4VfCajCL0MiEevG+dnP0nPnqL9fyQf5/h198sknrFixgtmzZ/PQQ7FZMltbW7nmmms45phj6N+/P7fffju33XYbW7ZsYcSIEYwYMQKAPffcc/d3HnnkES688EIAnnjiCY4//ngGDRrESSedxLvvvptQhra2Nvr06cOHH364e13fvn15991302rnwgsv5JFHHtm97JXpl7/8Jccddxz9+/fnpptuAuDTTz/ltNNOY8CAARxzzDE8/PDDHdrMBfXhlymRSHp++2z8/dGodRPV1mpsQLEUIm702GOPccopp3DkkUdSU1PD6tWrOfbYY6mvr2fjxo2sWbOGqqoq3n//ffbdd19+85vfsHTpUvbbb7+k7Q4dOpS//vWviAj33nsvM2bM4Ne//rXvvqFQiNGjR7Nw4UIuuuginnvuOb7whS9w4IEHZtROPIsXL+a1117j+eefxxjDmWeeybJly9i6dSs9e/bkj3/8IwAfffRRZhctBarwK5x4f39DQ3JlrgFhxQ+/uFGuv4v58+fzwx/+EIDvfOc7zJ8/n2OPPZYlS5YwYcIEqqqs+tp3330zarepqYlzzjmHt99+mx07dqTMYz/nnHO4+eabueiii3jooYc455xzsmrHy+LFi1m8eDGDBg0C7NPMa6+9xrBhw7j66qu57rrrOP300xk2bFhG55YKdelUOLW11tcvAqEQzJkDN95olbrfo3mygLC6hiqXfMeN3n//ff7yl79w6aWX0qdPH375y1/y+9//nkwmbPKmLXrz1a+44gomTpzIyy+/zKxZs1LmskciETZs2MDWrVtZtGgRZ599dtrtVFVV0dbWBlj30I4ddm57YwyTJ09mzZo1rFmzhg0bNnDJJZdw5JFH8sILL9CvXz9uuOEGbr755rTPNx1U4VcQiRSy+79oa4Ndu6wy377dWvvxJPpju5Z/ss5CKV8yjRul4pFHHuF73/seb775Jhs3bmTTpk0cdthhLF++nK9//evMmjWLXbt2AbZzANhrr734+OOPd7dx4IEHsn79etra2li4cOHu9R999BGHHHIIAA888EBKWUSEs846i6uuuoqjjjqKmpqatNvp06cPq1evBuDxxx9n586dAJx88snMmTOHTz75BIDNmzfz3nvvsWXLFnr06MH555/PtddeywsvvJD+RUsDdemUCLn6zb2umKoquOgiGDfOtrlrFxhjX67yNwbuu8/u4z2e+8eOl6UQj/RKaZFu3Cgd5s+fz3XXXddu3dixY5k/fz633347r776Kv3796e6uprvf//7TJw4kbq6Ok455RR69uzJ0qVLmTZtGqeffjr7778/gwcP3q1cp0yZwre+9S0+//nP87WvfY1//etfKeU555xzOO6447j//vt3r0unne9///uMHj2aAQMGcMopp7DHHnsAMGrUKNavX0/EuWB77rknc+fOZcOGDVx77bWEQiGqq6u5++67s72E/hhjcn4Bc4D3gL8n2C7AbcAG4CXgK6naPPbYY41iWbnSmO7djQmH7fvKlZl995ZbjBkzxhgRV63bz927GzNrVvu2x4yJ7RMK2e/Gt+V3/FxkVILHunXrii2CkgZ+9wlYZRLo1XxZ+PcDdwA+TgAATgX6Oq/jgbuddyUNsrWe6+th4sSYBe/FGNtWc3N7i/3ll2HRIrtPWxs4T68pg7WJLH9FUYJDXhS+MWaZiPRJsstooMHpff4qIvuIyMHGmLfzcfxyx/Wbu8o2nYBYNAqXX26VvRc3OAuxtryP4o2Ndntbm31vbo6tT9XpeNvwLiuKEgw6y4d/CLDJs9zkrGun8EWkDqgD6N27dyeJVhpccIF9j/epJ6Kx0SptL6EQdO0KM2daRe5nidfW2n3iO5d0Oh1N2VSUYBOooK0xph6oBxg8eHD6+VdlTLwSHTcuve+5irulxSr6q66CffZJ7W5J5JpJx2WjgVtFCTadpfA3A4d6lns565QUZKtEc/GpJ8q2SJWFkY3rSVGUzqOzFP7jwEQReQgbrP1I/ffpkYsSLaRP3S9NVAO3ihJs8qLwRWQ+UAvsJyJNwE1ANYAx5h7gSeAb2LTMz4CL8nHcSiAXJVoon7qb/dPaat1G3nbzmYutVC7Nzc2MHDkSgHfeeYdwOMz+++8PwNq1axkwYMDufRctWkSfPn0KJsv999/PqlWruOOOO7jnnnvo0aMH4xL4Vjdu3MjKlSs599xzAVi1ahUNDQ3cdtttBZMvE/KVpfPdFNsNcHk+jlVupDOgKlslmo47KNMBXfHZPy0t6qtX8k9NTQ1r1qwB7ACnPffck2uuuQawg5TcbbnQ2tpKOBzO6DsTJkxIun3jxo08+OCDuxX+4MGDGTx4cNYy5hstrVBECl2OIFV9k2yOH5/9Ew6rr15xCEgxpcbGRoYPH85pp53Gl770JSZMmLC7ns2ee+7J1VdfzYABA4hGo8ydO5chQ4YwcOBAxo8fT2trKwD33XcfRx55JEOGDOHZZ5/d3faUKVP41a9+BcCGDRs46aSTGDBgAF/5yld4/fXXuf7661m+fDkDBw7k1ltvpbGxkdNPPx2wJSDGjBlD//79+epXv8pLL720u82LL76Y2tpaDj/88N1PA4UolawKv4hkOjNVpv+nVPVNspkZy83+CYVsiYY77lDrXqFTiylt27aNgQMHMnDgQM466yzffZ5//nluv/121q1bx+uvv86jjz4KWCV6/PHHs3btWmpqanj44Yd59tlnWbNmDeFwmHnz5vH2229z00038eyzz7JixQrWrVvne4zzzjuPyy+/nLVr17Jy5UoOPvhgpk2bxrBhw1izZg3//d//3W7/m266iUGDBvHSSy9xyy23tHMLvfLKKzz11FM8//zz/PSnP2Xnzp38+c9/pmfPnqxdu5a///3vnHLKKTlfu0ClZVYamQRks/XHu+4gt7Pwum6yCQgniylonfwKphNzcrt3757SpTNkyBAOP/xwAL773e+yYsUKvvnNbxIOhxk7diwATz/9NKtXr+a4444DbEdywAEH8Nxzz1FbW7s7ZnDOOefw6quvtmv/448/ZvPmzbs7nG7duqWUe8WKFSxYsACAr33tazQ3N/Of//wHgNNOO42uXbvStWtXDjjgAN5991369euX91LJqvCLSCYB2Vz+T4k6i2wDwn4xBR10VeEELCfXWxrZu9ytW7fdfntjDBdccAFTp05tt+8it7ZIJ9K1a9fdn8PhMLt27dpdKvnJJ5/khhtuYOTIkfzkJz/J6Tjq0ikykQhMnpxaOSbzx6dy9SRz3aRz/ETte9dn4h4KiKtXySf5ro+cI88//zz/+te/aGtr4+GHH2bo0KEd9hk5ciSPPPII7733HmB97G+++SbHH388zzzzDM3NzezcuZM//OEPHb6711570atXr92dQ0tLC5999lmHEs1ehg0bxrx58wAbZ9hvv/3Ye++9E55DIUolq4UfcLxuEj9rPJll7X63piZ74ytR+/HrZ85M7xj6JFDGBCgn97jjjmPixIls2LCBESNG+Pr6jz76aH7+858zatQo2traqK6u5s477+SrX/0qU6ZMIRKJsM8++zBw4EDfY/zud79j/Pjx/OQnP6G6upo//OEP9O/fn3A4zIABA7jwwgt3z2gFseBs//796dGjR8pa/C+//HL+SyUnKqNZ7JeWR06v5PAtt9jtYN/dcsbx3501K3FpY7/juvsmat+7XsSYCROSl09OJa8SLEq5PPLSpUvNaaedVmwxOoVilUdWCkA6fvtErtP47zY3W9dNKlwL3FuDx6/92lqbpdPaakstz5lj6/ykOkbAXL2KUlGowg8w8cqxpgZ+8AO7za2amSjwmkqxJsqoaWy0yr6tzb5uvdWmXsZX14xE7KxZs2ZZhd/a2rFD0vILSjGora2lVi0JX1ThBxivcqypgSuusAoc7PSDS5fGlL5fbfpk6ZOJ/Oi1tbF6+GAVeaKng3Hj4IEH/DuVZMdI5erV9M5gYIzpkO2iBAeTwYTuLpqlExASZa64WTTNzeDMfwykN1AqUQZOqqydO++E6upY/fxExlKyxIxsBnWBToYeFLp160Zzc3NWSkUpPMYYmpub08r/96IWfgCIRmHEiJg17FruXmprrRJ2Lfxc/N+p3D11ddCvX3pWdiJrPVtfvdbUDwa9evWiqamJrVu3FlsUJQHdunWjV69eGX1HFX4AaGiwfnOw7w0N/i6axka7DdKf+cqPdPzo2WTYxbtisvHVa1A3GFRXV3PYYYcVWwwlz6jCLxJe5Zgu+UxzznfKdLLRvJnKpUFdRSkMqvA7iXgF7yrHqio49VTrrtm1y76nO41hkMiHK8Z7jdwgsQZwFSV/qMLvBOKt3wsuiCnH1lZ47DGr6MePz81VU0xydcX4PSGAjspVlHyiCr8TiLd+wSqw7dttDrubx967d+kqtFxdMX5PCG+9FbtGGsBVlNzRtMwCEJ9iGV/4bNw4qxzHj08+QUmpkW4hOD/ir1FNjR1r4GYF6kQripI7auHnmUTBSz/rNxKxyl991B2vUWNjbNyBCFx8sf/1UR+/oqSPKvw8kyh4mShjJUAFBouO91q8/HJstK8x4Ck62K4K6JVX2lTWcNiWgKir63SxFaVkUIWfZzSPPD80N8dKPIRCdhnaP0GJxIq3tbXZydX79dMOVFESoT78PJPJPBA6EUhi3Llzw+H25R28T1BtbVbpu7S2wpQpej0VJRES1FoZgwcPNqtWrSq2GAVDJwJJjZ9/Pv66XXEF/OY3MUvfrf+j11OpVERktTFmsN+28nTp1NfDggUwcCC8+iq8+CLssQf88IfWyZtIk/hF/+rrYfZs6NkTJk2KTfeUqAxlQwO88w4cdFD7pHpXprFjoa6O1xqi/GZ7A//HrKP7tu10v6wvHLB193bfNt9/H/79bzjyyJgsiWSPRmHGjNi5DxoEr71mz+PUU+16sOv/9CfYsgUuucT6RK6/Ht54A849F6ZPz++98SHR5Uy3CuiYMdayX7LEWv2awqkoCUg0M0qxX1nPeDVrlpva7v+aNKnjNFKJppaKb6uqyq7z23flSmO6dGm/f5cudv2sWaYNdr/MpEmmtbpru3Vt3u/NmpW4TfdVXZ1Y9pUr7fZk1yHRS6T98nnnZXcf0iSdWb06sx1FKXWoqBmvFixIvv3RR/3r9vql1sS3tWuXXee3rzeP0GXnTmhs5INFjewDCGCAbQ8+SvddO5KfQ12df5txbfvK7m7PhngX34MPwvDhHWdAyRP5qo6pNXgUJTXlF7QdOzb59rPP7jjaKX7UjxshjG+rqsqu89vXrV/spboaamuJ9rTtuKr0xcMdGVKdg1+bcW37yp7se6nwm/Di8sttgfoRI+yUW3mMiia69NmQy8AvRakEyjNoGzAffjQKvxtez+hdC3isaizfW1ZHBGffdets/YC+fWFrQHz4l10Ga9fa7e7EtW5SvAh065bXqKgOnlKU/JEsaFueCj+AlJxSix/d5Ba1Aav0jzgCrr02MCOdSu76KkqBUIWv5Ib7lDFnjo0NeH8zw4fDtGlF1bKa4qooMZIp/PLz4Sv5JxKBu++2JvQRR7TftmwZDBtmXV9FoqHBPoBkOn+uolQaqvBToKNhPUQi1o0TT2urDewW4SJFo/bBw33oqKrSchaKkghV+ElwXQU33mjf09FnZd9B1NXZgHEo7qfT1mYHbPXtC9dd12niNDba/gZsaOGii9Jz55T9fVIUH/Ki8EXkFBH5p4hsEJHrfbZfKCJbRWSN87o0H8ctNH454smor4cTT4Qbbki/gyhJpk+HFSvsENdw2Cp/Eeve2bDBZgedf36niOJN6+zWLb3pIbPpyBWlHMhZ4YtIGLgTOBU4GviuiBzts+vDxpiBzuveXI/bGWSSIx6NWq/Gzp3W2G1pKXNfciQCCxfC8uXw85/DwQe33/7gg7YHzMGMTscKj0Rg5kyruGfOTM+6z7QjV5RyIR8jbYcAG4wxbwCIyEPAaGBdHtouKpmM3mxsjKWqQwXN0OQWvPnwQ2vZuxhje0BjskqdSTfzJhq1WaM7dti+J53yyFrCWqlU8uHSOQTY5FluctbFM1ZEXhKRR0TkUL+GRKRORFaJyKqtW7fmQbTcSXf0plvONxSygcM77qiw1MDp0+G886xrR8SO9G1ry9qMTtcKz8Zaz6SEtaKUE51VS+cJYL4xpkVExgMPAF+L38kYUw/Ug83D7yTZMsZvkI/WcgHmzrVWvXfAVpZmdLpWeLbWus40plQiOQ+8EpEIMMUYc7KzPBnAGDM1wf5h4H1jzOeStRvUgVc6yCcDkpWgSKNnTHf0rI6yVZQYha6H/zegr4gcBmwGvgOcGyfAwcaYt53FM4H1eThuUchXdceKwM+MzqDHTGWFexX95Ml5k1pRypacFb4xZpeITASeAsLAHGPMP0TkZmxd5seB/xKRM4FdwPvAhbket1howC9H8tRjxvcbM2cWrIKzopQNWksnC9SFkAN+Fj5kfEGnTrV59K2tNlAeDtsYcaZuNr2XSrlReVMcFhgN+OVAfHQbsgqKeJ+0RGIVnFM9NHgVfJaHVpSSRRW+0vl4e8ypU2MunpYWOzntlCkpNa+330g3ISj+4eKCCzQeo1QWqvCV4uKa6i0t1kRfsgSeecYWxfFOAu+Dt9/o1y+1ayY+fAAaj1EqC/XhO6gvt4hEo9aqX7Kk/cxaoZAt2XDuuXZgVx4Ok4fwgaIEGp0AJQWaWx8A3JvgnVnLy3nn2YFdeTiMKnilnNEJUFKgxbQCgOuUHz/ef4L3Bx/MS1lLnehcqWRU4ZNZVUylgHhn1ho+vP02Y7QnVpQcUYWPFtMKHJGIDdy6xdgAuneP9cR5mL1EJ0BRKhH14SvBJt7pnoeAi8ZslHJGffg5oJZgkYl3unsDLi0tNgH/Bz/wvUGJ7l18E1Om6P1VKgO18JOglmAAcW+Km7fvZcAAGwOIRJLeu/gmQiE7l4HeX6UcUAs/SzR7J4C4AZeTTor5913WrsX83xN48qx6GhoS3ztvE6FQ+5IMilLOqMJPgmbvBJRIxPphqqt9NhpGLZqA/LaecDjxvXOb6NpV769SOahLJwU6UCfARK4ZkRYAABxJSURBVKNw2WWwZk271QbYSRUzxyyjdUgk6b3LcY4WRQkcFT/SVv+8Zc7558O8ebi/ZAF2EeLfY+o4aEjvjG+8xm6UUqZiffjRqE3gqK21tdNHjtRsjLJk7lxYuRIZMwYTCtNKiFB1NQc9OSerG6+xG6VcKdtqmX6lWbQEbhkTicDChYTcx7m33oLf/jar2sc6q5lSrpStwnetNFfZi+iftyJwayZHo/DAAx21dhr+vfg5WtRAUMqFslX4Xiutqiqt8uoJ0RhACeKntb3O+VAIBg2CSy6Bujqg433We62UG2Wr8PNlpWkAr4SJ19pe53xrKzz/vH0B0X51ep+VsqdsFT7kx0rzC+CpIihR3Me+bdvar7/ySsxxr7Njx/Td97mhoePDgT7lKaVOWSv8fKABvDLCfeybMQMWLYqt37aNyLIZTA3D5PB0qqpgzhzbyXfpAjNntp8zV61/pVQp67TMfKClk8sMJ5uHWbOge3e8o1D+a995LBk5lZtPje72+uzYAbNn22wvTdNUSp2KGHilKH40nX8dh8ybsXvZhKsIYWgLVXFv60Xc3zaOVdW2h9+50+7TpYu69ZRgU7EDrxQlGb/78nRmMInX+CLLGA5tBlpbkZ0tXNp2Dys4gdk7z6e11e4vAhdfrMpeKV0qQuFrTXvFj9pa+Gn36Rwdfo2bukzDdOmCcSpwhgDBcD7zuMVcRzgM3brZ1F5FKVXKPmiraZVKItqn7kYI8zQvXNnAwOfvAWxNHgNc9rkH+fqR/+HgnnAw4wD9ASmlSdkrfE2rVJLRPnU3QsvMCPOHfsy5bbFibHt9/DZfcToBnpyjPyKlZCl7l47WtFcyIRKBw1fMJTp8Ett7fREZPrzdzFpmxw7eGDeFl+vVP6iUHhWRpeM3D7YOolHSIhqFESOgpWW3xd9KiB105fVZT9OvTn9ASrBIlqVT9i4daP/Yrj59JSMiEVi6FBoa2PK/L3Bg0yqqaMOwg52zG+DFBrtftoWaFKUTKUuXTrKsHK11rmRMJAJ33837N85kB13ZSZhWqhiw+l645x77GjoU6uuLLamiJKXsLPx4C/6KK+wMeGPH2qKIWipByZZ+dRFe5mmaFzTypR5vcfBjs2Ib29pgwgT4059g0iS19pVAkhcfvoicAvwPEAbuNcZMi9veFWgAjgWagXOMMRuTtZmtD3/qVDvJUWurHSjjPb1Zs6zSVx++kjPRKAwbxu5RWdgUTgGbIXDXXbvLLitKZ1LQkbYiEgbuBE4Fjga+KyJHx+12CfCBMeaLwK3A9FyPm4jaWvt/c8bPtGPBAvseicDkyarslRyIRHj96rtoJYTBo+zBdgI/+IG6eJTAkQ8f/hBggzHmDWPMDuAhYHTcPqOBB5zPjwAjRfxUcn5wWw6H268fO7ZQR1QqjWgU+t1exzBWsJAx7RQ/YF08l11mFb8O8VYCQj4U/iHAJs9yk7POdx9jzC7gI6AmD8fuQGMj7NplXTnGwJgxMGpUzJ2jKPnADf5HiTCWhQxnBY+HxuwuzQBYS3/WLBg+HI4/Xi1+pegEKmgrInVAHUDv3r2zaiM+KKvxM6UQxE+hOeCiCAeMW0jo5XqYOLG91bFrV2x2rWXLYO7cYouvBBA3tlhTA83NhYkx5kPhbwYO9Sz3ctb57dMkIlXA57DB23YYY+qBerBB22yE0Qmolc4g4e8sUgf9+tkps+bMsT2Cl3nzrMWvj5uKBze7sKXFegNDIejaNf/jhPKh8P8G9BWRw7CK/TvAuXH7PA5cAESBbwJ/MQUc4qsTUCudQcLfmbth3LiOs2uBnVGlUCacUpK4LkK3ikdbW2Fqf+Xsw3d88hOBp4D1wO+NMf8QkZtF5Exnt9lAjYhsAK4Crs/1uIoSeNzZtc47r/36F1+0ucMjRmhQVwFiLsKQo5FDocKME6qIWjqKUnTq621ecI8e8MQT7fL3qaqyvn219iuafPnwk+Xhq8JXlBzI+E/qOmu3bWu/fswY+zSgKDlS8cXTFKUQJAq0zZzZUfnHRndHiDz9NHz729DUFGtsy5bYU4BbB0Qpa4ox4l8VvqJkiV+graXFZmW2tcWqsUJ8hdYIkRtvhPHjY4317RtbXrxYa/KUOcWq2qsKX1GyxA20eS38UMi6571ZFuAz69pkx4J3LXq37ofLokXw1FNav7sMiUZhypTY78b7Oym0xa8KX1GyxJuL7/rwa2rgyis7VmP1rdBaV9fedbN4cfsDbN9uUzuvvVZdPGWCnxuwSxf48EM48URrFBQi/95FFb6i5IBfLn6/fh0ttZSDAV2FPnu2Tdt0R+pu2BBz9ajSL3ni3YCDB8Mll8Dll9tbDrYzKNS0yZqloyhBIxq1lv2GDbF1o0ZZF49S0kSjttN3B2B37QoXXWTj9W4nUF0NzzyTvcIvaHlkRVHyTCRi3ThetNRrWRCJwMUXxyr6ulZ9167WvVNVBXfcoT58Raks6uKCul53jqZvlizuoOrqauuv79LFPsyNG9c5KZrq0lGUHEgnlzrRPlnlYdfXt0/nHDNG0zdLBG8qZlWVdeWMG5f/W6cDrxSlAKSTS51on6zzsDV9s2RxA7ZuVY3evTv/lqkPX1GyxPsH9uZSp7NPOt/1xc+Xv2OHrcp58sk6yUqAccdthMOFKYyWDmrhK0qWxE+24/cHTrRPOt/1xZu++cILNnVTJFaC2c3lV99+4IhEbNkNN/xSjAcy9eErSg50ug/fr+FFi+xsWi5HHw29emlQN2B0VjkF9eErSoHwDryKRu1EV9A+GJdoopScJ+pxG6ipaa/w162zL63JEyj83HidfVtU4StKHogfUHPffXDbbbFyCwWd4MqbwrlpE6xfH9u2aJGtv3/XXWrtF5ms3Xh5RF06ipIHpk6FH//YutTButXDYTt6Mt05SvNSLjc+bdMlHIbly9XSLzKdURJZXTqKUmBqa+1gGtfCD4Viyh5Sz1GaN/+ua8X/7Gft6+23tdlMns8+U99+ESn2fNuq8BUlD0QiVpm7PvxBg2zVzPiqiIke4/Pq362rsxXcTjwRdu6060IhzeRRVOErSr6It97cqpnp+PDz7t+NRGwFLrcHeuGF9oHd2bMLHFhQgoj68BWlkylYmmYy4n371dXtp+VSpV82qA9fUQJCMl99Qf273kyeHj1s5o7rP2po6PzJVZWioKUVFKUTybqkQj6oq7N1dyZNio3xr6qCOXPghhusz19LM5Q1auErSifgumtqaoqfi91ubsa33orNvtHWBpddZmfcKkQZxwqnM1IyU6E+fEUpMPFunJkzO2lAVrrCebN5wA4i6NKlcPV7K5DOKqsAOuOVohSVeDeOq+SvvBJuvNEqAndijE4nErFTLFV5HvaNsfmk99wDQ4fCddcVSbjyoaiuPA+q8BWlwPiVxQ2KAgCsb3/ZMpgwwQ4Hduffg9iALfXtZ0w0akdgu2U3il0aGdSloyidQrz/tjMf8TPCrQA3a1asTgRoBU4fkvnk/e4vdNI0hpqWqSjFJT7l0hs3TaQAUgX5ChIEdAXde29r2bt4K3BCxSv9VB223xPc5MnF79RV4StKkUiWd59KoRT8CWH6dDjiCP8KnAsWVLzCT1UKIwiVMf1QH76iBJBUPv5OiQG4eftXXtl+vd80ixVGKp+8+wT3s58FyF2HWviKEkhSWYidakF6R+l6ffhBSCwvIhdcYN8TZa4WuzKmHxq0VZSAUhQffroENupceOrr4fLLbQJTqjkOioEGbRUlgOSqsItqQSbyKZW5xR+N2sHIra12uaWlOFMVZktOCl9E9gUeBvoAG4FvG2M+8NmvFXjZWXzLGHNmLsdVlFKn6EHZXIn3KdXUBFzg/NDQEFP2YIcs1NTYfPtS6OdyDdpeDzxtjOkLPO0s+7HNGDPQeamyVyqeQARlcyE+Ktnc3F7ghobYqKMy5oQTAjJiOk1ydemMBmqdzw8AjYCOw1aUFAQqKJst8T4lV+Bw2M7ivmtXWVn70Si8846dPMwYO6XA0UfDs8/maaayTiCnoK2IfGiM2cf5LMAH7nLcfruANcAuYJoxZlGC9uqAOoDevXsf++abb2Ytm6IEHb/Rt8mWA48r8FtvwW9/a7VgKAS9e8Onn8JRR8G0aSVyMjHcwcezZ8dqzIXDcNdddlazoHmykgVtUyp8EVkCHOSz6cfAA14FLyIfGGM+79PGIcaYzSJyOPAXYKQx5vVkx9UsHaWSCLzPPhPck3En9PUiYouylcjALfdUtm9vX2lCBH7xCzt6Nmgdc07VMo0xJxljjvF5PQa8KyIHOwc5GHgvQRubnfc3sG6fQVmei6KUJV6ffUsLTJkSfH9wQlz//kknddxmjC3SViIn596XeLu4ujrmZotEglE2IR1yDdo+DjjDD7gAeCx+BxH5vIh0dT7vB5wArMvxuIpSVrg++1DIGsVLlpRGEDAhkYjttcLhjtuMCWAU2h/viNquXWHMGNtfBd1Xn4hcFf404Osi8hpwkrOMiAwWkXudfY4CVonIWmAp1oevCl9RPHiNYlfpBzI7JxMiEVi+3FbZ9BIOW03qrR8cULzJSEuXwsKFcPfdpansQUfaKkqgKCtfvpfrroMHH4TDD7eBW4j5+UMhuPPOTvXrB83vnk9yCtoWC1X4SqVSzspoN1On2onT3aBuOAxnnAEHHVTwaRW9nWpVVWwmRyiP664KX1EqkEB3HNEoDB9uc/Xjqa6GZ54pmNBTp9qBUu6IWXcKX2Psuvgnq0BfRx+0lo6ilBHpFFVraAj42KdIxLpxJk60QnoNz5074dvftlq5AG4eNxDrploaY619iH1uaLDXuKbGjqQtFxebKnxFKSHSrcHjzRsPbG2zujo7cqmhwZag9ObsNzXB+PHw+ut2MpY84gZiGxpgzhxr1VdVxSx870DhUCjWH5VaoTQ/VOErSgmRaqal+Lxx110R2NpmbnmGQYPal6F0+eUv4T//ybtf3z3suHGxThA6DhR2nwDA9kc1NXkToSjojFeKUkKkmmkpfvv48f61zQKX7llXZ1M4x4xpv94YO6F6moMSMs30jETsNXOvx+TJthNwr2E4bDtNsNZ+c3PaZxRI1MJXlBIi1eTnybaXRDG2hQttCuevfhVz8cQ71hP4pLJJaU30HfcaxvvwA3ndMkAVvqKUGKkmPvHbHt8RQIBruE+fbi19b+S5qso63N3qZcOGdSjElsrd5Uei73ivoRtmKAc0LVNRSoxc0wSTWcKBS0H0VuCcNat9Nk8oZIe9Opk8+bTwM90nSGhapqKUCflQPoms2kAqNtfUjkZtJo9X4be12bTOfv0gEknp7krUvJuxk4hsnhyCigZtFaWESDQTVn09nHyyfffiF8RMFPgN9CxbkQhcc03H9a2t7QTNtnLlAw/YzBy/2HCqQHkpoRa+opQQfjNh1dfbbByAxYvte11dYos9kSUc+Fm2pk+HI46AmTPhn/+067p29RU0mWsqflsqCz6bJ4fAYowJ5OvYY481iqJ0ZOVKY265xb4bY8yoUW62uH2NGmXX33KLMeGwXRcO2+VM2w4siQRdudJsnHCLObHLShMOG9O9e/tdVq6067zb/NaVMsAqk0CvqoWvKCVGfBbO2LExy95dhuws9lQZQIHBT1DnkebQ7Tt40nRhJE/ztx2Rdha7nzU/eXIZWfApUIWvKCWOW25mwQKr7N3lsnJFpIOjzUOmlS5s43FO534uZWhtrDSDXycYuMykAqJpmYqilAdu0GLbNrxaTSZNalePx6vgIYCZSTmS05y2iqKUFiUwkVRhcB9p9t0Xgd0vHn3UbncuTITo7kyeQGcmFQB16ShKGeHNzAmH4eKLCz6fSLCIRODSS2HGjNi6s8+2F+bEE+1IXU+9/cBnJuUZVfiKUkZ4LdbWVjs49YEHysNVkTau++bRR62ynz4dzjorVpZh50645BKYPZtIJFJRcQ5V+IpSRiSa3KOUR4dmxfTp7evob9nSfvv69XbGrTvvJFJXVzHXRn34ilJGuG7s8ePtmKRSGR2a77hDh/YuuaTjTrt22Rr8P/hBxQQ8NEtHUcqUUkk3zHcNn4Tt1dfD7NmwalX72bXAFmK75pq8z65VDDRLR1EqkPi6Moms6GjUGrnFMnTznSmTsL26OnjuOVths7o6NrMJ2A5gxgwb2C1ja199+IpSASSyeqNRGDHCztcKtuR8Z/v7850pk7I971y68SWXly2LTYEV5MeiLFGFrygVQKICYe56l507/XVdId1D6ZQozqa9eHnbn4NTmmHvvduncIK9CClm1ypZEhXZKfZLi6cpSv5IVCBs5UpjunaNFV7r0sW3HlnBi4sV+hhJ2580yRiR2EWoqrIXpUSrqZGkeJr68BWlAnCt3p/9rH1QNBKBpUthwgT78rPuc/WxR6M2Df744zvW68/mGNlk9CRtf/p0ePbZ2EW49FKbwePufP310LevnWu31EnUExT7pRa+ohSPlSuNmTDBvmbNyt76XrnSGsze8s2zZvnvl84xsn0SyOh73p3d+tLua+DAwFv8aHlkRVHSJRq1rmvXt19dDXfcAc3Nmbu0GxutsexlwYJYRU+X9Pzu2U83GInYeVPciqJJv+MV5q67oKkptm3NGjuB+l13dTyJEkAVvqIo7WhsjFUhAPv5xRdtNmOm1NZCVVV7pe/W648nvsS9X2ZRthk90ShceaX93vLlu6fBTYwrzIcfdgzqtrbakW3z5sG0aSUV1FUfvqIo7aitteOQ8kEkYjMdx4yBIUNsFmS6hnEia94vFpFNW2kxfTqcd57/tmXLYOjQxIGJAKIjbRVF6UB9va060NZmXTrFSEvP5whcd7yB29bSpRm2FY1aS3/Roo7bqqqs8g+Ipa8jbRVFyYi6Ouv6+MUvYtZwZ9fYj7fmc5XBtW2zsnEjEVi4ECZN6rittRWmTCmNEbqJornpvIBvAf8A2oDBSfY7BfgnsAG4Pp22NUtHUYJBECb5zlWGbCZ0T8isWcYcfbQxoVAsfz8UCkzOPgXMw/87cDawLNEOIhIG7gROBY4GvisiR+d4XEVROokgzAoVL0NDQ2bWvhvszUv10Lo6+Mc/YMUK+PrXbcCjra0kpszKKUvHGLMeQLxFiDoyBNhgjHnD2fchYDSwLpdjK4rSOSTKjEmn3EI2JRn8vuOVIRyG++6zmT/p+vYLMqF7JGJdOcuX+6cNBbBcaWekZR4CbPIsNwHH++0oInVAHUDv3r0LL5miKCnxU5bpBFTT3Seddr0yvPUW/Pa32eXi513vJhtAEMDZ0VMqfBFZAhzks+nHxpjH8imMMaYeqAebpZPPthVFyZ54ZZnOAKhU+8TrRHdglDtbV0tL+++4MkSjdtrGwMxD69eTZDtCrMCkVPjGmJNyPMZm4FDPci9nnaIoJUo6A6Di3TBvvWWVtav3vDqxpQUmTrRuGjeLpq0Namo6tpuOe6bo3hS/C1R0oTrHpfM3oK+IHIZV9N8Bzu2E4yqKUiDSUbruPjNmwBNP2Nx+74TqXp0oYhW/N2UyFLLlHLx4debkyf6yBcKbEn+BwAq1fbv9PGxYUUbp5qTwReQs4HZgf+CPIrLGGHOyiPQE7jXGfMMYs0tEJgJPAWFgjjHmHzlLrihKUUnXJ/7HP1plDh3dNBdcYN8HDbKlD1parGUfCtk5eeNjoOko8sB4U7wXaOrUmK8K7ECtE06A0aNtbn8nCZhrls5CYKHP+i3ANzzLTwJP5nIsRVFKj8bGmLJ3qanpqLzHjYsZxDU1/oXa0lXk+Z5BKy/U1trHGO8jjDF25O6f/pTF0N/s0OJpiqIUjNpaa6m7xq0x1pK/4IKOyts7/26ittJR5AVJwcyVSMROkh5fiA1iAws6QWBV+IqiFAxX+U6ZAkuWxMYnQXLl7RffzESRFyQFM1emT4cjjoD/+R9Yvz5m7VdV2cmEd+2yvqw77yxY6WUtnqYoSsHx87+Dv/IORNC10ESj7Sfxra+3vSHYlKbly7M+6WTF09TCVxQl78Rb6Ims80yDrgHIbMwP3keQaNSOJHNpbbV+r5kz836SqvAVRckLrjKuqYlNNuIOqHKDsIlSKb0kK+VQlpZ/JAJnnNG+9PLf/mZPNs8nqQpfUZSc8SpjEeudaGuzaZaXX27d1bnWvQlMumUhmDTJZuu0tNhlYwpykloPX1GUnPEq47Y264Z2X21tmVfajEQ6Zu3kteJl0IhEbGrmhAk2ralAJ6kWvqIoORPvhnHdOPHunVz0VyDTLfOJ69cfN65gJ6lZOoqi5IVEAdWyCbSWCMmydFThK4qilBE6p62iKEUlGu38OXGVjqgPX1GUglK26ZQliFr4iqIUlCDMiatYVOErilJQyjqdssRQl46iKAWl7NMpSwhV+IqiFJxAVq+sQNSloyiKUiGowlcURakQVOEriqJUCKrwFUVRKgRV+IqiKBWCKnxFUZQKIbDF00RkK/Bmll/fD/h3HsUpBqV+DqUuP+g5BIFSlx86/xy+YIzZ329DYBV+LojIqkTV4kqFUj+HUpcf9ByCQKnLD8E6B3XpKIqiVAiq8BVFUSqEclX49cUWIA+U+jmUuvyg5xAESl1+CNA5lKUPX1EURelIuVr4iqIoShyq8BVFUSqEslL4InKKiPxTRDaIyPXFlidTRGSOiLwnIn8vtizZIiKHishSEVknIv8QkR8WW6ZMEZFuIvK8iKx1zuGnxZYpG0QkLCIvisj/FluWbBCRjSLysoisEZFVxZYnG0RkHxF5REReEZH1IlLUItFl48MXkTDwKvB1oAn4G/BdY8y6ogqWASIyHPgEaDDGHFNsebJBRA4GDjbGvCAiewGrgTEldh8E2MMY84mIVAMrgB8aY/5aZNEyQkSuAgYDextjTi+2PJkiIhuBwcaYkh14JSIPAMuNMfeKSBeghzHmw2LJU04W/hBggzHmDWPMDuAhYHSRZcoIY8wy4P1iy5ELxpi3jTEvOJ8/BtYDhxRXqswwlk+cxWrnVVKWkYj0Ak4D7i22LJWKiHwOGA7MBjDG7CimsofyUviHAJs8y02UmKIpN0SkDzAIeK64kmSO4w5ZA7wH/D9jTKmdw0xgEtBWbEFywACLRWS1iNQVW5gsOAzYCtznuNbuFZE9iilQOSl8JUCIyJ7AAuBKY8x/ii1PphhjWo0xA4FewBARKRkXm4icDrxnjFldbFlyZKgx5ivAqcDljsuzlKgCvgLcbYwZBHwKFDW2WE4KfzNwqGe5l7NO6WQcv/cCYJ4x5tFiy5MLziP4UuCUYsuSAScAZzo+8IeAr4nI3OKKlDnGmM3O+3vAQqzbtpRoApo8T4ePYDuAolFOCv9vQF8ROcwJjnwHeLzIMlUcTsBzNrDeGPObYsuTDSKyv4js43zujk0EeKW4UqWPMWayMaaXMaYP9n/wF2PM+UUWKyNEZA8n6I/jBhkFlFT2mjHmHWCTiHzJWTUSKGryQlUxD55PjDG7RGQi8BQQBuYYY/5RZLEyQkTmA7XAfiLSBNxkjJldXKky5gTge8DLjg8c4EfGmCeLKFOmHAw84GR+hYDfG2NKMrWxhDkQWGjtB6qAB40xfy6uSFlxBTDPMULfAC4qpjBlk5apKIqiJKecXDqKoihKElThK4qiVAiq8BVFUSoEVfiKoigVgip8RVGUCkEVvqIoSoWgCl9RFKVC+P+IeD9lpzo2HAAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Wokallj1D21L"
+ },
+ "source": [
+ "Oh dear! The graph makes it clear that our network has learned to approximate the sine function in a very limited way.\n",
+ "\n",
+ "The rigidity of this fit suggests that the model does not have enough capacity to learn the full complexity of the sine wave function, so it's only able to approximate it in an overly simplistic way. By making our model bigger, we should be able to improve its performance."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "T7sL-hWtoAZC"
+ },
+ "source": [
+ "## Training a Larger Model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aQd0JSdOoAbw"
+ },
+ "source": [
+ "### 1. Design the Model\n",
+ "To make our model bigger, let's add an additional layer of neurons. The following cell redefines our model in the same way as earlier, but with 16 neurons in the first layer and an additional layer of 16 neurons in the middle:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "oW0xus6AF-4o"
+ },
+ "source": [
+ "model = tf.keras.Sequential()\n",
+ "\n",
+ "# First layer takes a scalar input and feeds it through 16 \"neurons\". The\n",
+ "# neurons decide whether to activate based on the 'relu' activation function.\n",
+ "model.add(keras.layers.Dense(16, activation='relu', input_shape=(1,)))\n",
+ "\n",
+ "# The new second and third layer will help the network learn more complex representations\n",
+ "model.add(keras.layers.Dense(16, activation='relu'))\n",
+ "\n",
+ "# Final layer is a single neuron, since we want to output a single value\n",
+ "model.add(keras.layers.Dense(1))\n",
+ "\n",
+ "# Compile the model using the standard 'adam' optimizer and the mean squared error or 'mse' loss function for regression.\n",
+ "model.compile(optimizer='adam', loss=\"mse\", metrics=[\"mae\"])"
+ ],
+ "execution_count": 13,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Dv2SC409Grap"
+ },
+ "source": [
+ "### 2. Train the Model ###\n",
+ "\n",
+ "We'll now train and save the new model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "DPAUrdkmGq1M",
+ "outputId": "b0b50b8b-f5fc-4433-db0e-703697443b76",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "# Train the model\n",
+ "history = model.fit(x_train, y_train, epochs=500, batch_size=64,\n",
+ " validation_data=(x_validate, y_validate))\n",
+ "\n",
+ "# Save the model to disk\n",
+ "model.save(MODEL_TF)"
+ ],
+ "execution_count": 14,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "Epoch 1/500\n",
+ "10/10 [==============================] - 1s 20ms/step - loss: 0.4355 - mae: 0.5542 - val_loss: 0.4315 - val_mae: 0.5685\n",
+ "Epoch 2/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.4183 - mae: 0.5548 - val_loss: 0.4157 - val_mae: 0.5581\n",
+ "Epoch 3/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3871 - mae: 0.5322 - val_loss: 0.3988 - val_mae: 0.5444\n",
+ "Epoch 4/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3954 - mae: 0.5348 - val_loss: 0.3834 - val_mae: 0.5350\n",
+ "Epoch 5/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3670 - mae: 0.5163 - val_loss: 0.3684 - val_mae: 0.5257\n",
+ "Epoch 6/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3426 - mae: 0.4999 - val_loss: 0.3532 - val_mae: 0.5166\n",
+ "Epoch 7/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3453 - mae: 0.5006 - val_loss: 0.3369 - val_mae: 0.5055\n",
+ "Epoch 8/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.3182 - mae: 0.4830 - val_loss: 0.3203 - val_mae: 0.4940\n",
+ "Epoch 9/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.3013 - mae: 0.4691 - val_loss: 0.3041 - val_mae: 0.4833\n",
+ "Epoch 10/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2795 - mae: 0.4523 - val_loss: 0.2867 - val_mae: 0.4699\n",
+ "Epoch 11/500\n",
+ "10/10 [==============================] - 0s 20ms/step - loss: 0.2632 - mae: 0.4395 - val_loss: 0.2698 - val_mae: 0.4558\n",
+ "Epoch 12/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.2581 - mae: 0.4331 - val_loss: 0.2534 - val_mae: 0.4436\n",
+ "Epoch 13/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2363 - mae: 0.4185 - val_loss: 0.2381 - val_mae: 0.4318\n",
+ "Epoch 14/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.2171 - mae: 0.3972 - val_loss: 0.2220 - val_mae: 0.4151\n",
+ "Epoch 15/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1944 - mae: 0.3783 - val_loss: 0.2095 - val_mae: 0.4041\n",
+ "Epoch 16/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1948 - mae: 0.3796 - val_loss: 0.1969 - val_mae: 0.3902\n",
+ "Epoch 17/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1842 - mae: 0.3642 - val_loss: 0.1868 - val_mae: 0.3790\n",
+ "Epoch 18/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1706 - mae: 0.3480 - val_loss: 0.1781 - val_mae: 0.3677\n",
+ "Epoch 19/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1599 - mae: 0.3348 - val_loss: 0.1713 - val_mae: 0.3576\n",
+ "Epoch 20/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1563 - mae: 0.3340 - val_loss: 0.1653 - val_mae: 0.3468\n",
+ "Epoch 21/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1487 - mae: 0.3161 - val_loss: 0.1613 - val_mae: 0.3391\n",
+ "Epoch 22/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1425 - mae: 0.3061 - val_loss: 0.1577 - val_mae: 0.3306\n",
+ "Epoch 23/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1347 - mae: 0.3005 - val_loss: 0.1552 - val_mae: 0.3235\n",
+ "Epoch 24/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1411 - mae: 0.2995 - val_loss: 0.1533 - val_mae: 0.3185\n",
+ "Epoch 25/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1414 - mae: 0.2992 - val_loss: 0.1517 - val_mae: 0.3122\n",
+ "Epoch 26/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1397 - mae: 0.3011 - val_loss: 0.1517 - val_mae: 0.3129\n",
+ "Epoch 27/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1335 - mae: 0.2879 - val_loss: 0.1494 - val_mae: 0.3057\n",
+ "Epoch 28/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1335 - mae: 0.2897 - val_loss: 0.1490 - val_mae: 0.3049\n",
+ "Epoch 29/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1287 - mae: 0.2792 - val_loss: 0.1478 - val_mae: 0.3010\n",
+ "Epoch 30/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1291 - mae: 0.2774 - val_loss: 0.1472 - val_mae: 0.2992\n",
+ "Epoch 31/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1245 - mae: 0.2756 - val_loss: 0.1467 - val_mae: 0.2991\n",
+ "Epoch 32/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1327 - mae: 0.2775 - val_loss: 0.1460 - val_mae: 0.2977\n",
+ "Epoch 33/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1163 - mae: 0.2613 - val_loss: 0.1453 - val_mae: 0.2955\n",
+ "Epoch 34/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1251 - mae: 0.2731 - val_loss: 0.1443 - val_mae: 0.2922\n",
+ "Epoch 35/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1365 - mae: 0.2829 - val_loss: 0.1441 - val_mae: 0.2951\n",
+ "Epoch 36/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1283 - mae: 0.2757 - val_loss: 0.1427 - val_mae: 0.2905\n",
+ "Epoch 37/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1146 - mae: 0.2567 - val_loss: 0.1432 - val_mae: 0.2930\n",
+ "Epoch 38/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1231 - mae: 0.2655 - val_loss: 0.1412 - val_mae: 0.2869\n",
+ "Epoch 39/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1263 - mae: 0.2739 - val_loss: 0.1407 - val_mae: 0.2890\n",
+ "Epoch 40/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1396 - mae: 0.2878 - val_loss: 0.1398 - val_mae: 0.2867\n",
+ "Epoch 41/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1194 - mae: 0.2651 - val_loss: 0.1390 - val_mae: 0.2835\n",
+ "Epoch 42/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1206 - mae: 0.2607 - val_loss: 0.1379 - val_mae: 0.2831\n",
+ "Epoch 43/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1296 - mae: 0.2716 - val_loss: 0.1373 - val_mae: 0.2850\n",
+ "Epoch 44/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1155 - mae: 0.2545 - val_loss: 0.1362 - val_mae: 0.2814\n",
+ "Epoch 45/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1237 - mae: 0.2610 - val_loss: 0.1353 - val_mae: 0.2806\n",
+ "Epoch 46/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1163 - mae: 0.2529 - val_loss: 0.1350 - val_mae: 0.2815\n",
+ "Epoch 47/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1123 - mae: 0.2527 - val_loss: 0.1339 - val_mae: 0.2814\n",
+ "Epoch 48/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1136 - mae: 0.2541 - val_loss: 0.1325 - val_mae: 0.2775\n",
+ "Epoch 49/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1154 - mae: 0.2535 - val_loss: 0.1318 - val_mae: 0.2783\n",
+ "Epoch 50/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1249 - mae: 0.2632 - val_loss: 0.1312 - val_mae: 0.2715\n",
+ "Epoch 51/500\n",
+ "10/10 [==============================] - 0s 17ms/step - loss: 0.1117 - mae: 0.2534 - val_loss: 0.1319 - val_mae: 0.2801\n",
+ "Epoch 52/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1088 - mae: 0.2529 - val_loss: 0.1289 - val_mae: 0.2727\n",
+ "Epoch 53/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1166 - mae: 0.2611 - val_loss: 0.1290 - val_mae: 0.2760\n",
+ "Epoch 54/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1137 - mae: 0.2537 - val_loss: 0.1270 - val_mae: 0.2696\n",
+ "Epoch 55/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1063 - mae: 0.2480 - val_loss: 0.1268 - val_mae: 0.2726\n",
+ "Epoch 56/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1083 - mae: 0.2461 - val_loss: 0.1253 - val_mae: 0.2655\n",
+ "Epoch 57/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0997 - mae: 0.2326 - val_loss: 0.1245 - val_mae: 0.2668\n",
+ "Epoch 58/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1066 - mae: 0.2470 - val_loss: 0.1235 - val_mae: 0.2644\n",
+ "Epoch 59/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.1068 - mae: 0.2399 - val_loss: 0.1231 - val_mae: 0.2662\n",
+ "Epoch 60/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1055 - mae: 0.2396 - val_loss: 0.1217 - val_mae: 0.2618\n",
+ "Epoch 61/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1034 - mae: 0.2338 - val_loss: 0.1207 - val_mae: 0.2606\n",
+ "Epoch 62/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1057 - mae: 0.2456 - val_loss: 0.1217 - val_mae: 0.2662\n",
+ "Epoch 63/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1067 - mae: 0.2439 - val_loss: 0.1189 - val_mae: 0.2564\n",
+ "Epoch 64/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0984 - mae: 0.2338 - val_loss: 0.1185 - val_mae: 0.2593\n",
+ "Epoch 65/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0974 - mae: 0.2356 - val_loss: 0.1175 - val_mae: 0.2598\n",
+ "Epoch 66/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0982 - mae: 0.2355 - val_loss: 0.1161 - val_mae: 0.2540\n",
+ "Epoch 67/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.1027 - mae: 0.2385 - val_loss: 0.1159 - val_mae: 0.2556\n",
+ "Epoch 68/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1017 - mae: 0.2356 - val_loss: 0.1144 - val_mae: 0.2511\n",
+ "Epoch 69/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0948 - mae: 0.2266 - val_loss: 0.1136 - val_mae: 0.2529\n",
+ "Epoch 70/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0969 - mae: 0.2316 - val_loss: 0.1127 - val_mae: 0.2516\n",
+ "Epoch 71/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0959 - mae: 0.2247 - val_loss: 0.1116 - val_mae: 0.2473\n",
+ "Epoch 72/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0988 - mae: 0.2279 - val_loss: 0.1107 - val_mae: 0.2468\n",
+ "Epoch 73/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.1069 - mae: 0.2367 - val_loss: 0.1097 - val_mae: 0.2461\n",
+ "Epoch 74/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0924 - mae: 0.2292 - val_loss: 0.1090 - val_mae: 0.2463\n",
+ "Epoch 75/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0967 - mae: 0.2268 - val_loss: 0.1080 - val_mae: 0.2454\n",
+ "Epoch 76/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0892 - mae: 0.2194 - val_loss: 0.1070 - val_mae: 0.2415\n",
+ "Epoch 77/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0939 - mae: 0.2265 - val_loss: 0.1064 - val_mae: 0.2431\n",
+ "Epoch 78/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0874 - mae: 0.2146 - val_loss: 0.1056 - val_mae: 0.2370\n",
+ "Epoch 79/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0895 - mae: 0.2188 - val_loss: 0.1050 - val_mae: 0.2413\n",
+ "Epoch 80/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0820 - mae: 0.2127 - val_loss: 0.1036 - val_mae: 0.2366\n",
+ "Epoch 81/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0890 - mae: 0.2167 - val_loss: 0.1027 - val_mae: 0.2380\n",
+ "Epoch 82/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0905 - mae: 0.2191 - val_loss: 0.1018 - val_mae: 0.2359\n",
+ "Epoch 83/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0822 - mae: 0.2072 - val_loss: 0.1012 - val_mae: 0.2346\n",
+ "Epoch 84/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0870 - mae: 0.2135 - val_loss: 0.1001 - val_mae: 0.2334\n",
+ "Epoch 85/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0936 - mae: 0.2228 - val_loss: 0.0993 - val_mae: 0.2310\n",
+ "Epoch 86/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0762 - mae: 0.2036 - val_loss: 0.0990 - val_mae: 0.2330\n",
+ "Epoch 87/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0781 - mae: 0.2018 - val_loss: 0.0978 - val_mae: 0.2314\n",
+ "Epoch 88/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0835 - mae: 0.2111 - val_loss: 0.0969 - val_mae: 0.2289\n",
+ "Epoch 89/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0814 - mae: 0.2084 - val_loss: 0.0961 - val_mae: 0.2279\n",
+ "Epoch 90/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0791 - mae: 0.2048 - val_loss: 0.0953 - val_mae: 0.2268\n",
+ "Epoch 91/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0816 - mae: 0.2088 - val_loss: 0.0948 - val_mae: 0.2288\n",
+ "Epoch 92/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0818 - mae: 0.2083 - val_loss: 0.0939 - val_mae: 0.2217\n",
+ "Epoch 93/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0735 - mae: 0.1931 - val_loss: 0.0934 - val_mae: 0.2255\n",
+ "Epoch 94/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0812 - mae: 0.2072 - val_loss: 0.0921 - val_mae: 0.2217\n",
+ "Epoch 95/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0815 - mae: 0.2055 - val_loss: 0.0913 - val_mae: 0.2205\n",
+ "Epoch 96/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0766 - mae: 0.2003 - val_loss: 0.0905 - val_mae: 0.2187\n",
+ "Epoch 97/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0803 - mae: 0.2053 - val_loss: 0.0898 - val_mae: 0.2202\n",
+ "Epoch 98/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0748 - mae: 0.1963 - val_loss: 0.0890 - val_mae: 0.2184\n",
+ "Epoch 99/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0754 - mae: 0.1959 - val_loss: 0.0885 - val_mae: 0.2134\n",
+ "Epoch 100/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0785 - mae: 0.2020 - val_loss: 0.0876 - val_mae: 0.2138\n",
+ "Epoch 101/500\n",
+ "10/10 [==============================] - 0s 19ms/step - loss: 0.0724 - mae: 0.1939 - val_loss: 0.0868 - val_mae: 0.2148\n",
+ "Epoch 102/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0742 - mae: 0.1977 - val_loss: 0.0861 - val_mae: 0.2130\n",
+ "Epoch 103/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0714 - mae: 0.1943 - val_loss: 0.0855 - val_mae: 0.2151\n",
+ "Epoch 104/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0777 - mae: 0.2017 - val_loss: 0.0845 - val_mae: 0.2110\n",
+ "Epoch 105/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0689 - mae: 0.1883 - val_loss: 0.0845 - val_mae: 0.2105\n",
+ "Epoch 106/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0660 - mae: 0.1848 - val_loss: 0.0832 - val_mae: 0.2100\n",
+ "Epoch 107/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0721 - mae: 0.1913 - val_loss: 0.0825 - val_mae: 0.2089\n",
+ "Epoch 108/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0819 - mae: 0.2055 - val_loss: 0.0819 - val_mae: 0.2077\n",
+ "Epoch 109/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0731 - mae: 0.1940 - val_loss: 0.0812 - val_mae: 0.2072\n",
+ "Epoch 110/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0678 - mae: 0.1863 - val_loss: 0.0805 - val_mae: 0.2051\n",
+ "Epoch 111/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0688 - mae: 0.1840 - val_loss: 0.0799 - val_mae: 0.2031\n",
+ "Epoch 112/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0739 - mae: 0.1874 - val_loss: 0.0792 - val_mae: 0.2031\n",
+ "Epoch 113/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0745 - mae: 0.1944 - val_loss: 0.0788 - val_mae: 0.2023\n",
+ "Epoch 114/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0704 - mae: 0.1902 - val_loss: 0.0780 - val_mae: 0.2016\n",
+ "Epoch 115/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0664 - mae: 0.1864 - val_loss: 0.0774 - val_mae: 0.2016\n",
+ "Epoch 116/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0624 - mae: 0.1774 - val_loss: 0.0769 - val_mae: 0.1986\n",
+ "Epoch 117/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0688 - mae: 0.1869 - val_loss: 0.0761 - val_mae: 0.1991\n",
+ "Epoch 118/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0671 - mae: 0.1801 - val_loss: 0.0756 - val_mae: 0.1975\n",
+ "Epoch 119/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0656 - mae: 0.1839 - val_loss: 0.0750 - val_mae: 0.1986\n",
+ "Epoch 120/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0554 - mae: 0.1686 - val_loss: 0.0742 - val_mae: 0.1973\n",
+ "Epoch 121/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0627 - mae: 0.1815 - val_loss: 0.0737 - val_mae: 0.1971\n",
+ "Epoch 122/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0668 - mae: 0.1842 - val_loss: 0.0733 - val_mae: 0.1955\n",
+ "Epoch 123/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0683 - mae: 0.1886 - val_loss: 0.0726 - val_mae: 0.1935\n",
+ "Epoch 124/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0601 - mae: 0.1734 - val_loss: 0.0726 - val_mae: 0.1966\n",
+ "Epoch 125/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0608 - mae: 0.1845 - val_loss: 0.0715 - val_mae: 0.1950\n",
+ "Epoch 126/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0644 - mae: 0.1833 - val_loss: 0.0709 - val_mae: 0.1940\n",
+ "Epoch 127/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0572 - mae: 0.1708 - val_loss: 0.0703 - val_mae: 0.1916\n",
+ "Epoch 128/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0571 - mae: 0.1712 - val_loss: 0.0698 - val_mae: 0.1901\n",
+ "Epoch 129/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0593 - mae: 0.1732 - val_loss: 0.0692 - val_mae: 0.1899\n",
+ "Epoch 130/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0583 - mae: 0.1718 - val_loss: 0.0688 - val_mae: 0.1914\n",
+ "Epoch 131/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0659 - mae: 0.1828 - val_loss: 0.0681 - val_mae: 0.1880\n",
+ "Epoch 132/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0601 - mae: 0.1734 - val_loss: 0.0686 - val_mae: 0.1927\n",
+ "Epoch 133/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0614 - mae: 0.1796 - val_loss: 0.0675 - val_mae: 0.1877\n",
+ "Epoch 134/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0575 - mae: 0.1725 - val_loss: 0.0670 - val_mae: 0.1899\n",
+ "Epoch 135/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0638 - mae: 0.1833 - val_loss: 0.0663 - val_mae: 0.1832\n",
+ "Epoch 136/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0519 - mae: 0.1603 - val_loss: 0.0661 - val_mae: 0.1886\n",
+ "Epoch 137/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0523 - mae: 0.1655 - val_loss: 0.0650 - val_mae: 0.1851\n",
+ "Epoch 138/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0499 - mae: 0.1625 - val_loss: 0.0645 - val_mae: 0.1841\n",
+ "Epoch 139/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0582 - mae: 0.1712 - val_loss: 0.0640 - val_mae: 0.1838\n",
+ "Epoch 140/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0520 - mae: 0.1618 - val_loss: 0.0640 - val_mae: 0.1853\n",
+ "Epoch 141/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0509 - mae: 0.1662 - val_loss: 0.0630 - val_mae: 0.1824\n",
+ "Epoch 142/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.0508 - mae: 0.1620 - val_loss: 0.0625 - val_mae: 0.1832\n",
+ "Epoch 143/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0484 - mae: 0.1564 - val_loss: 0.0624 - val_mae: 0.1823\n",
+ "Epoch 144/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0526 - mae: 0.1651 - val_loss: 0.0615 - val_mae: 0.1791\n",
+ "Epoch 145/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0536 - mae: 0.1649 - val_loss: 0.0611 - val_mae: 0.1809\n",
+ "Epoch 146/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0484 - mae: 0.1590 - val_loss: 0.0606 - val_mae: 0.1786\n",
+ "Epoch 147/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0555 - mae: 0.1652 - val_loss: 0.0601 - val_mae: 0.1770\n",
+ "Epoch 148/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0493 - mae: 0.1578 - val_loss: 0.0597 - val_mae: 0.1778\n",
+ "Epoch 149/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0475 - mae: 0.1538 - val_loss: 0.0591 - val_mae: 0.1779\n",
+ "Epoch 150/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0484 - mae: 0.1541 - val_loss: 0.0589 - val_mae: 0.1765\n",
+ "Epoch 151/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0580 - mae: 0.1705 - val_loss: 0.0584 - val_mae: 0.1741\n",
+ "Epoch 152/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0556 - mae: 0.1653 - val_loss: 0.0579 - val_mae: 0.1759\n",
+ "Epoch 153/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0491 - mae: 0.1562 - val_loss: 0.0576 - val_mae: 0.1714\n",
+ "Epoch 154/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0526 - mae: 0.1610 - val_loss: 0.0569 - val_mae: 0.1756\n",
+ "Epoch 155/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0460 - mae: 0.1538 - val_loss: 0.0563 - val_mae: 0.1722\n",
+ "Epoch 156/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0530 - mae: 0.1634 - val_loss: 0.0558 - val_mae: 0.1721\n",
+ "Epoch 157/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0464 - mae: 0.1522 - val_loss: 0.0556 - val_mae: 0.1710\n",
+ "Epoch 158/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0477 - mae: 0.1548 - val_loss: 0.0550 - val_mae: 0.1701\n",
+ "Epoch 159/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0447 - mae: 0.1499 - val_loss: 0.0546 - val_mae: 0.1706\n",
+ "Epoch 160/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0428 - mae: 0.1500 - val_loss: 0.0541 - val_mae: 0.1686\n",
+ "Epoch 161/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0436 - mae: 0.1471 - val_loss: 0.0540 - val_mae: 0.1717\n",
+ "Epoch 162/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0400 - mae: 0.1434 - val_loss: 0.0534 - val_mae: 0.1664\n",
+ "Epoch 163/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0361 - mae: 0.1362 - val_loss: 0.0540 - val_mae: 0.1735\n",
+ "Epoch 164/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0431 - mae: 0.1522 - val_loss: 0.0536 - val_mae: 0.1694\n",
+ "Epoch 165/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0444 - mae: 0.1504 - val_loss: 0.0531 - val_mae: 0.1711\n",
+ "Epoch 166/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0448 - mae: 0.1549 - val_loss: 0.0516 - val_mae: 0.1643\n",
+ "Epoch 167/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0417 - mae: 0.1455 - val_loss: 0.0511 - val_mae: 0.1664\n",
+ "Epoch 168/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0454 - mae: 0.1517 - val_loss: 0.0510 - val_mae: 0.1636\n",
+ "Epoch 169/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0439 - mae: 0.1469 - val_loss: 0.0506 - val_mae: 0.1663\n",
+ "Epoch 170/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0410 - mae: 0.1447 - val_loss: 0.0501 - val_mae: 0.1610\n",
+ "Epoch 171/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0404 - mae: 0.1449 - val_loss: 0.0495 - val_mae: 0.1643\n",
+ "Epoch 172/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0427 - mae: 0.1489 - val_loss: 0.0491 - val_mae: 0.1626\n",
+ "Epoch 173/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0421 - mae: 0.1473 - val_loss: 0.0490 - val_mae: 0.1632\n",
+ "Epoch 174/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0460 - mae: 0.1511 - val_loss: 0.0486 - val_mae: 0.1590\n",
+ "Epoch 175/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0431 - mae: 0.1461 - val_loss: 0.0480 - val_mae: 0.1602\n",
+ "Epoch 176/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0426 - mae: 0.1484 - val_loss: 0.0473 - val_mae: 0.1597\n",
+ "Epoch 177/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0380 - mae: 0.1396 - val_loss: 0.0473 - val_mae: 0.1617\n",
+ "Epoch 178/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0367 - mae: 0.1401 - val_loss: 0.0467 - val_mae: 0.1582\n",
+ "Epoch 179/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0406 - mae: 0.1438 - val_loss: 0.0462 - val_mae: 0.1578\n",
+ "Epoch 180/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0378 - mae: 0.1410 - val_loss: 0.0461 - val_mae: 0.1566\n",
+ "Epoch 181/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0353 - mae: 0.1352 - val_loss: 0.0457 - val_mae: 0.1591\n",
+ "Epoch 182/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0381 - mae: 0.1427 - val_loss: 0.0451 - val_mae: 0.1558\n",
+ "Epoch 183/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0372 - mae: 0.1353 - val_loss: 0.0448 - val_mae: 0.1562\n",
+ "Epoch 184/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0400 - mae: 0.1428 - val_loss: 0.0442 - val_mae: 0.1548\n",
+ "Epoch 185/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0378 - mae: 0.1393 - val_loss: 0.0438 - val_mae: 0.1541\n",
+ "Epoch 186/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0379 - mae: 0.1409 - val_loss: 0.0434 - val_mae: 0.1540\n",
+ "Epoch 187/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0357 - mae: 0.1355 - val_loss: 0.0431 - val_mae: 0.1535\n",
+ "Epoch 188/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0405 - mae: 0.1478 - val_loss: 0.0427 - val_mae: 0.1514\n",
+ "Epoch 189/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0375 - mae: 0.1384 - val_loss: 0.0423 - val_mae: 0.1512\n",
+ "Epoch 190/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0387 - mae: 0.1432 - val_loss: 0.0425 - val_mae: 0.1541\n",
+ "Epoch 191/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0347 - mae: 0.1374 - val_loss: 0.0418 - val_mae: 0.1500\n",
+ "Epoch 192/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0336 - mae: 0.1321 - val_loss: 0.0413 - val_mae: 0.1518\n",
+ "Epoch 193/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0369 - mae: 0.1356 - val_loss: 0.0409 - val_mae: 0.1506\n",
+ "Epoch 194/500\n",
+ "10/10 [==============================] - 0s 19ms/step - loss: 0.0355 - mae: 0.1353 - val_loss: 0.0405 - val_mae: 0.1480\n",
+ "Epoch 195/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0396 - mae: 0.1430 - val_loss: 0.0401 - val_mae: 0.1487\n",
+ "Epoch 196/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0348 - mae: 0.1352 - val_loss: 0.0403 - val_mae: 0.1510\n",
+ "Epoch 197/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0320 - mae: 0.1299 - val_loss: 0.0396 - val_mae: 0.1464\n",
+ "Epoch 198/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0349 - mae: 0.1328 - val_loss: 0.0393 - val_mae: 0.1484\n",
+ "Epoch 199/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0362 - mae: 0.1389 - val_loss: 0.0387 - val_mae: 0.1446\n",
+ "Epoch 200/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0303 - mae: 0.1235 - val_loss: 0.0384 - val_mae: 0.1446\n",
+ "Epoch 201/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0326 - mae: 0.1310 - val_loss: 0.0394 - val_mae: 0.1510\n",
+ "Epoch 202/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0345 - mae: 0.1359 - val_loss: 0.0389 - val_mae: 0.1460\n",
+ "Epoch 203/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0294 - mae: 0.1263 - val_loss: 0.0388 - val_mae: 0.1494\n",
+ "Epoch 204/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0336 - mae: 0.1355 - val_loss: 0.0373 - val_mae: 0.1438\n",
+ "Epoch 205/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0323 - mae: 0.1316 - val_loss: 0.0368 - val_mae: 0.1418\n",
+ "Epoch 206/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0294 - mae: 0.1234 - val_loss: 0.0366 - val_mae: 0.1427\n",
+ "Epoch 207/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0330 - mae: 0.1294 - val_loss: 0.0360 - val_mae: 0.1410\n",
+ "Epoch 208/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0333 - mae: 0.1314 - val_loss: 0.0357 - val_mae: 0.1417\n",
+ "Epoch 209/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0295 - mae: 0.1240 - val_loss: 0.0360 - val_mae: 0.1401\n",
+ "Epoch 210/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0313 - mae: 0.1265 - val_loss: 0.0356 - val_mae: 0.1434\n",
+ "Epoch 211/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0301 - mae: 0.1257 - val_loss: 0.0348 - val_mae: 0.1396\n",
+ "Epoch 212/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0295 - mae: 0.1253 - val_loss: 0.0349 - val_mae: 0.1390\n",
+ "Epoch 213/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0314 - mae: 0.1312 - val_loss: 0.0341 - val_mae: 0.1387\n",
+ "Epoch 214/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0332 - mae: 0.1322 - val_loss: 0.0341 - val_mae: 0.1381\n",
+ "Epoch 215/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0310 - mae: 0.1268 - val_loss: 0.0344 - val_mae: 0.1396\n",
+ "Epoch 216/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0310 - mae: 0.1300 - val_loss: 0.0331 - val_mae: 0.1369\n",
+ "Epoch 217/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0273 - mae: 0.1208 - val_loss: 0.0329 - val_mae: 0.1352\n",
+ "Epoch 218/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0278 - mae: 0.1210 - val_loss: 0.0326 - val_mae: 0.1368\n",
+ "Epoch 219/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0308 - mae: 0.1274 - val_loss: 0.0327 - val_mae: 0.1341\n",
+ "Epoch 220/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0267 - mae: 0.1191 - val_loss: 0.0319 - val_mae: 0.1340\n",
+ "Epoch 221/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0258 - mae: 0.1150 - val_loss: 0.0318 - val_mae: 0.1359\n",
+ "Epoch 222/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0307 - mae: 0.1293 - val_loss: 0.0326 - val_mae: 0.1346\n",
+ "Epoch 223/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0305 - mae: 0.1271 - val_loss: 0.0320 - val_mae: 0.1380\n",
+ "Epoch 224/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0284 - mae: 0.1225 - val_loss: 0.0306 - val_mae: 0.1320\n",
+ "Epoch 225/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0305 - mae: 0.1289 - val_loss: 0.0313 - val_mae: 0.1332\n",
+ "Epoch 226/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0281 - mae: 0.1235 - val_loss: 0.0309 - val_mae: 0.1355\n",
+ "Epoch 227/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0266 - mae: 0.1183 - val_loss: 0.0320 - val_mae: 0.1343\n",
+ "Epoch 228/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0306 - mae: 0.1269 - val_loss: 0.0294 - val_mae: 0.1294\n",
+ "Epoch 229/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0257 - mae: 0.1170 - val_loss: 0.0316 - val_mae: 0.1385\n",
+ "Epoch 230/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0275 - mae: 0.1260 - val_loss: 0.0293 - val_mae: 0.1300\n",
+ "Epoch 231/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0268 - mae: 0.1226 - val_loss: 0.0286 - val_mae: 0.1288\n",
+ "Epoch 232/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0270 - mae: 0.1187 - val_loss: 0.0291 - val_mae: 0.1270\n",
+ "Epoch 233/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0236 - mae: 0.1130 - val_loss: 0.0281 - val_mae: 0.1288\n",
+ "Epoch 234/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0263 - mae: 0.1200 - val_loss: 0.0276 - val_mae: 0.1266\n",
+ "Epoch 235/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0249 - mae: 0.1160 - val_loss: 0.0282 - val_mae: 0.1251\n",
+ "Epoch 236/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.0265 - mae: 0.1175 - val_loss: 0.0272 - val_mae: 0.1249\n",
+ "Epoch 237/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0263 - mae: 0.1169 - val_loss: 0.0273 - val_mae: 0.1278\n",
+ "Epoch 238/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0232 - mae: 0.1113 - val_loss: 0.0269 - val_mae: 0.1241\n",
+ "Epoch 239/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0234 - mae: 0.1135 - val_loss: 0.0263 - val_mae: 0.1240\n",
+ "Epoch 240/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0234 - mae: 0.1114 - val_loss: 0.0261 - val_mae: 0.1247\n",
+ "Epoch 241/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0241 - mae: 0.1151 - val_loss: 0.0263 - val_mae: 0.1229\n",
+ "Epoch 242/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0225 - mae: 0.1123 - val_loss: 0.0257 - val_mae: 0.1235\n",
+ "Epoch 243/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0217 - mae: 0.1099 - val_loss: 0.0253 - val_mae: 0.1234\n",
+ "Epoch 244/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0247 - mae: 0.1167 - val_loss: 0.0249 - val_mae: 0.1222\n",
+ "Epoch 245/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0243 - mae: 0.1174 - val_loss: 0.0247 - val_mae: 0.1216\n",
+ "Epoch 246/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0207 - mae: 0.1061 - val_loss: 0.0245 - val_mae: 0.1210\n",
+ "Epoch 247/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0224 - mae: 0.1101 - val_loss: 0.0244 - val_mae: 0.1203\n",
+ "Epoch 248/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0212 - mae: 0.1060 - val_loss: 0.0240 - val_mae: 0.1203\n",
+ "Epoch 249/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0200 - mae: 0.1066 - val_loss: 0.0237 - val_mae: 0.1199\n",
+ "Epoch 250/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0221 - mae: 0.1084 - val_loss: 0.0241 - val_mae: 0.1182\n",
+ "Epoch 251/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0230 - mae: 0.1124 - val_loss: 0.0235 - val_mae: 0.1195\n",
+ "Epoch 252/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0206 - mae: 0.1072 - val_loss: 0.0237 - val_mae: 0.1199\n",
+ "Epoch 253/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0205 - mae: 0.1058 - val_loss: 0.0235 - val_mae: 0.1192\n",
+ "Epoch 254/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0221 - mae: 0.1101 - val_loss: 0.0230 - val_mae: 0.1177\n",
+ "Epoch 255/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0215 - mae: 0.1077 - val_loss: 0.0225 - val_mae: 0.1171\n",
+ "Epoch 256/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0202 - mae: 0.1054 - val_loss: 0.0235 - val_mae: 0.1206\n",
+ "Epoch 257/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0205 - mae: 0.1071 - val_loss: 0.0220 - val_mae: 0.1163\n",
+ "Epoch 258/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0208 - mae: 0.1110 - val_loss: 0.0218 - val_mae: 0.1163\n",
+ "Epoch 259/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0224 - mae: 0.1096 - val_loss: 0.0219 - val_mae: 0.1151\n",
+ "Epoch 260/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0206 - mae: 0.1071 - val_loss: 0.0222 - val_mae: 0.1178\n",
+ "Epoch 261/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0209 - mae: 0.1093 - val_loss: 0.0214 - val_mae: 0.1157\n",
+ "Epoch 262/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0211 - mae: 0.1089 - val_loss: 0.0226 - val_mae: 0.1142\n",
+ "Epoch 263/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0201 - mae: 0.1063 - val_loss: 0.0208 - val_mae: 0.1141\n",
+ "Epoch 264/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0186 - mae: 0.1007 - val_loss: 0.0207 - val_mae: 0.1134\n",
+ "Epoch 265/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0195 - mae: 0.1037 - val_loss: 0.0209 - val_mae: 0.1129\n",
+ "Epoch 266/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0208 - mae: 0.1072 - val_loss: 0.0207 - val_mae: 0.1124\n",
+ "Epoch 267/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0186 - mae: 0.1016 - val_loss: 0.0216 - val_mae: 0.1167\n",
+ "Epoch 268/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0193 - mae: 0.1050 - val_loss: 0.0206 - val_mae: 0.1119\n",
+ "Epoch 269/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0193 - mae: 0.1063 - val_loss: 0.0198 - val_mae: 0.1116\n",
+ "Epoch 270/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0175 - mae: 0.0996 - val_loss: 0.0197 - val_mae: 0.1114\n",
+ "Epoch 271/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0194 - mae: 0.1037 - val_loss: 0.0196 - val_mae: 0.1107\n",
+ "Epoch 272/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0191 - mae: 0.1032 - val_loss: 0.0194 - val_mae: 0.1106\n",
+ "Epoch 273/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0182 - mae: 0.1026 - val_loss: 0.0193 - val_mae: 0.1106\n",
+ "Epoch 274/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0189 - mae: 0.1042 - val_loss: 0.0197 - val_mae: 0.1105\n",
+ "Epoch 275/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0192 - mae: 0.1077 - val_loss: 0.0189 - val_mae: 0.1098\n",
+ "Epoch 276/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0199 - mae: 0.1072 - val_loss: 0.0204 - val_mae: 0.1141\n",
+ "Epoch 277/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0197 - mae: 0.1104 - val_loss: 0.0195 - val_mae: 0.1116\n",
+ "Epoch 278/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0194 - mae: 0.1074 - val_loss: 0.0192 - val_mae: 0.1091\n",
+ "Epoch 279/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0179 - mae: 0.1027 - val_loss: 0.0183 - val_mae: 0.1081\n",
+ "Epoch 280/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0177 - mae: 0.1019 - val_loss: 0.0182 - val_mae: 0.1076\n",
+ "Epoch 281/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0170 - mae: 0.0987 - val_loss: 0.0181 - val_mae: 0.1079\n",
+ "Epoch 282/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0167 - mae: 0.0997 - val_loss: 0.0182 - val_mae: 0.1069\n",
+ "Epoch 283/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0182 - mae: 0.1022 - val_loss: 0.0177 - val_mae: 0.1069\n",
+ "Epoch 284/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0199 - mae: 0.1073 - val_loss: 0.0192 - val_mae: 0.1088\n",
+ "Epoch 285/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0179 - mae: 0.1033 - val_loss: 0.0177 - val_mae: 0.1061\n",
+ "Epoch 286/500\n",
+ "10/10 [==============================] - 0s 21ms/step - loss: 0.0171 - mae: 0.1013 - val_loss: 0.0173 - val_mae: 0.1060\n",
+ "Epoch 287/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0179 - mae: 0.1022 - val_loss: 0.0174 - val_mae: 0.1053\n",
+ "Epoch 288/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0185 - mae: 0.1055 - val_loss: 0.0182 - val_mae: 0.1070\n",
+ "Epoch 289/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0182 - mae: 0.1038 - val_loss: 0.0176 - val_mae: 0.1047\n",
+ "Epoch 290/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0173 - mae: 0.1032 - val_loss: 0.0177 - val_mae: 0.1069\n",
+ "Epoch 291/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0176 - mae: 0.1015 - val_loss: 0.0169 - val_mae: 0.1044\n",
+ "Epoch 292/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0173 - mae: 0.1022 - val_loss: 0.0171 - val_mae: 0.1044\n",
+ "Epoch 293/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0152 - mae: 0.0967 - val_loss: 0.0166 - val_mae: 0.1037\n",
+ "Epoch 294/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0165 - mae: 0.0998 - val_loss: 0.0164 - val_mae: 0.1027\n",
+ "Epoch 295/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0165 - mae: 0.0986 - val_loss: 0.0163 - val_mae: 0.1024\n",
+ "Epoch 296/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0165 - mae: 0.0979 - val_loss: 0.0163 - val_mae: 0.1026\n",
+ "Epoch 297/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0162 - mae: 0.0987 - val_loss: 0.0162 - val_mae: 0.1020\n",
+ "Epoch 298/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0173 - mae: 0.1011 - val_loss: 0.0160 - val_mae: 0.1021\n",
+ "Epoch 299/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0170 - mae: 0.1019 - val_loss: 0.0165 - val_mae: 0.1029\n",
+ "Epoch 300/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0164 - mae: 0.0996 - val_loss: 0.0155 - val_mae: 0.1005\n",
+ "Epoch 301/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0161 - mae: 0.0987 - val_loss: 0.0156 - val_mae: 0.1005\n",
+ "Epoch 302/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0147 - mae: 0.0952 - val_loss: 0.0162 - val_mae: 0.1029\n",
+ "Epoch 303/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0161 - mae: 0.0999 - val_loss: 0.0171 - val_mae: 0.1027\n",
+ "Epoch 304/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0164 - mae: 0.0990 - val_loss: 0.0161 - val_mae: 0.1007\n",
+ "Epoch 305/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0161 - mae: 0.0975 - val_loss: 0.0156 - val_mae: 0.1001\n",
+ "Epoch 306/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0159 - mae: 0.0982 - val_loss: 0.0167 - val_mae: 0.1039\n",
+ "Epoch 307/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0150 - mae: 0.0951 - val_loss: 0.0162 - val_mae: 0.1023\n",
+ "Epoch 308/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0175 - mae: 0.1035 - val_loss: 0.0148 - val_mae: 0.0985\n",
+ "Epoch 309/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0152 - mae: 0.0970 - val_loss: 0.0187 - val_mae: 0.1059\n",
+ "Epoch 310/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0172 - mae: 0.1025 - val_loss: 0.0154 - val_mae: 0.1006\n",
+ "Epoch 311/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0162 - mae: 0.0999 - val_loss: 0.0180 - val_mae: 0.1055\n",
+ "Epoch 312/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0162 - mae: 0.1019 - val_loss: 0.0149 - val_mae: 0.0978\n",
+ "Epoch 313/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0151 - mae: 0.0991 - val_loss: 0.0157 - val_mae: 0.0996\n",
+ "Epoch 314/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0150 - mae: 0.0951 - val_loss: 0.0148 - val_mae: 0.0983\n",
+ "Epoch 315/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0151 - mae: 0.0974 - val_loss: 0.0150 - val_mae: 0.0988\n",
+ "Epoch 316/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0156 - mae: 0.0987 - val_loss: 0.0146 - val_mae: 0.0977\n",
+ "Epoch 317/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0160 - mae: 0.0987 - val_loss: 0.0151 - val_mae: 0.0971\n",
+ "Epoch 318/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0154 - mae: 0.0973 - val_loss: 0.0141 - val_mae: 0.0960\n",
+ "Epoch 319/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0143 - mae: 0.0940 - val_loss: 0.0141 - val_mae: 0.0963\n",
+ "Epoch 320/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0131 - mae: 0.0904 - val_loss: 0.0143 - val_mae: 0.0965\n",
+ "Epoch 321/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0142 - mae: 0.0952 - val_loss: 0.0144 - val_mae: 0.0972\n",
+ "Epoch 322/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0146 - mae: 0.0954 - val_loss: 0.0147 - val_mae: 0.0964\n",
+ "Epoch 323/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0143 - mae: 0.0941 - val_loss: 0.0147 - val_mae: 0.0973\n",
+ "Epoch 324/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0149 - mae: 0.0952 - val_loss: 0.0150 - val_mae: 0.0984\n",
+ "Epoch 325/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0154 - mae: 0.0975 - val_loss: 0.0137 - val_mae: 0.0945\n",
+ "Epoch 326/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.0135 - mae: 0.0925 - val_loss: 0.0137 - val_mae: 0.0944\n",
+ "Epoch 327/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0134 - mae: 0.0913 - val_loss: 0.0142 - val_mae: 0.0962\n",
+ "Epoch 328/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0143 - mae: 0.0955 - val_loss: 0.0135 - val_mae: 0.0937\n",
+ "Epoch 329/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0142 - mae: 0.0938 - val_loss: 0.0145 - val_mae: 0.0957\n",
+ "Epoch 330/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0150 - mae: 0.0955 - val_loss: 0.0160 - val_mae: 0.1011\n",
+ "Epoch 331/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0162 - mae: 0.0996 - val_loss: 0.0136 - val_mae: 0.0940\n",
+ "Epoch 332/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0135 - mae: 0.0913 - val_loss: 0.0134 - val_mae: 0.0933\n",
+ "Epoch 333/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0133 - mae: 0.0900 - val_loss: 0.0141 - val_mae: 0.0953\n",
+ "Epoch 334/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0144 - mae: 0.0954 - val_loss: 0.0132 - val_mae: 0.0929\n",
+ "Epoch 335/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0134 - mae: 0.0895 - val_loss: 0.0144 - val_mae: 0.0956\n",
+ "Epoch 336/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0142 - mae: 0.0930 - val_loss: 0.0136 - val_mae: 0.0939\n",
+ "Epoch 337/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0135 - mae: 0.0924 - val_loss: 0.0130 - val_mae: 0.0922\n",
+ "Epoch 338/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0133 - mae: 0.0918 - val_loss: 0.0130 - val_mae: 0.0920\n",
+ "Epoch 339/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0132 - mae: 0.0921 - val_loss: 0.0131 - val_mae: 0.0920\n",
+ "Epoch 340/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0890 - val_loss: 0.0134 - val_mae: 0.0928\n",
+ "Epoch 341/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0139 - mae: 0.0937 - val_loss: 0.0135 - val_mae: 0.0929\n",
+ "Epoch 342/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0141 - mae: 0.0948 - val_loss: 0.0131 - val_mae: 0.0919\n",
+ "Epoch 343/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0154 - mae: 0.0979 - val_loss: 0.0143 - val_mae: 0.0955\n",
+ "Epoch 344/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0139 - mae: 0.0927 - val_loss: 0.0136 - val_mae: 0.0932\n",
+ "Epoch 345/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0136 - mae: 0.0914 - val_loss: 0.0127 - val_mae: 0.0906\n",
+ "Epoch 346/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0139 - mae: 0.0944 - val_loss: 0.0142 - val_mae: 0.0951\n",
+ "Epoch 347/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0129 - mae: 0.0892 - val_loss: 0.0129 - val_mae: 0.0910\n",
+ "Epoch 348/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0148 - mae: 0.0956 - val_loss: 0.0134 - val_mae: 0.0925\n",
+ "Epoch 349/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0127 - mae: 0.0886 - val_loss: 0.0141 - val_mae: 0.0943\n",
+ "Epoch 350/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0130 - mae: 0.0918 - val_loss: 0.0130 - val_mae: 0.0915\n",
+ "Epoch 351/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0144 - mae: 0.0945 - val_loss: 0.0131 - val_mae: 0.0920\n",
+ "Epoch 352/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0128 - mae: 0.0893 - val_loss: 0.0127 - val_mae: 0.0907\n",
+ "Epoch 353/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0132 - mae: 0.0926 - val_loss: 0.0135 - val_mae: 0.0927\n",
+ "Epoch 354/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0136 - mae: 0.0945 - val_loss: 0.0127 - val_mae: 0.0904\n",
+ "Epoch 355/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0127 - mae: 0.0893 - val_loss: 0.0136 - val_mae: 0.0937\n",
+ "Epoch 356/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0137 - mae: 0.0936 - val_loss: 0.0135 - val_mae: 0.0937\n",
+ "Epoch 357/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0144 - mae: 0.0973 - val_loss: 0.0128 - val_mae: 0.0906\n",
+ "Epoch 358/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0130 - mae: 0.0906 - val_loss: 0.0125 - val_mae: 0.0893\n",
+ "Epoch 359/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0896 - val_loss: 0.0125 - val_mae: 0.0899\n",
+ "Epoch 360/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0136 - mae: 0.0931 - val_loss: 0.0134 - val_mae: 0.0935\n",
+ "Epoch 361/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0139 - mae: 0.0942 - val_loss: 0.0124 - val_mae: 0.0892\n",
+ "Epoch 362/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0133 - mae: 0.0922 - val_loss: 0.0125 - val_mae: 0.0894\n",
+ "Epoch 363/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0127 - mae: 0.0894 - val_loss: 0.0126 - val_mae: 0.0904\n",
+ "Epoch 364/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0126 - mae: 0.0910 - val_loss: 0.0124 - val_mae: 0.0895\n",
+ "Epoch 365/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0121 - mae: 0.0883 - val_loss: 0.0123 - val_mae: 0.0892\n",
+ "Epoch 366/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0118 - mae: 0.0867 - val_loss: 0.0124 - val_mae: 0.0896\n",
+ "Epoch 367/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0122 - mae: 0.0872 - val_loss: 0.0121 - val_mae: 0.0881\n",
+ "Epoch 368/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0118 - mae: 0.0865 - val_loss: 0.0125 - val_mae: 0.0903\n",
+ "Epoch 369/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0131 - mae: 0.0908 - val_loss: 0.0121 - val_mae: 0.0885\n",
+ "Epoch 370/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0131 - mae: 0.0910 - val_loss: 0.0120 - val_mae: 0.0879\n",
+ "Epoch 371/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0127 - mae: 0.0897 - val_loss: 0.0129 - val_mae: 0.0906\n",
+ "Epoch 372/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0137 - mae: 0.0928 - val_loss: 0.0129 - val_mae: 0.0904\n",
+ "Epoch 373/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0128 - mae: 0.0900 - val_loss: 0.0123 - val_mae: 0.0886\n",
+ "Epoch 374/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0125 - mae: 0.0898 - val_loss: 0.0125 - val_mae: 0.0901\n",
+ "Epoch 375/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0131 - mae: 0.0911 - val_loss: 0.0120 - val_mae: 0.0877\n",
+ "Epoch 376/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.0121 - mae: 0.0889 - val_loss: 0.0121 - val_mae: 0.0878\n",
+ "Epoch 377/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0112 - mae: 0.0845 - val_loss: 0.0125 - val_mae: 0.0889\n",
+ "Epoch 378/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0123 - mae: 0.0869 - val_loss: 0.0122 - val_mae: 0.0880\n",
+ "Epoch 379/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0123 - mae: 0.0886 - val_loss: 0.0128 - val_mae: 0.0911\n",
+ "Epoch 380/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0904 - val_loss: 0.0119 - val_mae: 0.0878\n",
+ "Epoch 381/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0125 - mae: 0.0897 - val_loss: 0.0124 - val_mae: 0.0897\n",
+ "Epoch 382/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0127 - mae: 0.0904 - val_loss: 0.0119 - val_mae: 0.0872\n",
+ "Epoch 383/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0896 - val_loss: 0.0118 - val_mae: 0.0872\n",
+ "Epoch 384/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0127 - mae: 0.0895 - val_loss: 0.0120 - val_mae: 0.0881\n",
+ "Epoch 385/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0127 - mae: 0.0897 - val_loss: 0.0120 - val_mae: 0.0884\n",
+ "Epoch 386/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0120 - mae: 0.0875 - val_loss: 0.0120 - val_mae: 0.0882\n",
+ "Epoch 387/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0124 - mae: 0.0889 - val_loss: 0.0118 - val_mae: 0.0874\n",
+ "Epoch 388/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0135 - mae: 0.0933 - val_loss: 0.0132 - val_mae: 0.0915\n",
+ "Epoch 389/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0133 - mae: 0.0926 - val_loss: 0.0125 - val_mae: 0.0892\n",
+ "Epoch 390/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0130 - mae: 0.0903 - val_loss: 0.0130 - val_mae: 0.0909\n",
+ "Epoch 391/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0899 - val_loss: 0.0126 - val_mae: 0.0896\n",
+ "Epoch 392/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0132 - mae: 0.0906 - val_loss: 0.0121 - val_mae: 0.0878\n",
+ "Epoch 393/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0129 - mae: 0.0902 - val_loss: 0.0122 - val_mae: 0.0887\n",
+ "Epoch 394/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0123 - mae: 0.0901 - val_loss: 0.0117 - val_mae: 0.0870\n",
+ "Epoch 395/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0909 - val_loss: 0.0120 - val_mae: 0.0882\n",
+ "Epoch 396/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0125 - mae: 0.0885 - val_loss: 0.0117 - val_mae: 0.0869\n",
+ "Epoch 397/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0123 - mae: 0.0885 - val_loss: 0.0120 - val_mae: 0.0883\n",
+ "Epoch 398/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0130 - mae: 0.0907 - val_loss: 0.0120 - val_mae: 0.0882\n",
+ "Epoch 399/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0128 - mae: 0.0918 - val_loss: 0.0122 - val_mae: 0.0889\n",
+ "Epoch 400/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0124 - mae: 0.0901 - val_loss: 0.0119 - val_mae: 0.0878\n",
+ "Epoch 401/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0116 - mae: 0.0862 - val_loss: 0.0117 - val_mae: 0.0868\n",
+ "Epoch 402/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0900 - val_loss: 0.0119 - val_mae: 0.0878\n",
+ "Epoch 403/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0118 - mae: 0.0861 - val_loss: 0.0124 - val_mae: 0.0896\n",
+ "Epoch 404/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0893 - val_loss: 0.0118 - val_mae: 0.0875\n",
+ "Epoch 405/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0119 - mae: 0.0881 - val_loss: 0.0121 - val_mae: 0.0879\n",
+ "Epoch 406/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0122 - mae: 0.0884 - val_loss: 0.0115 - val_mae: 0.0862\n",
+ "Epoch 407/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0115 - mae: 0.0864 - val_loss: 0.0121 - val_mae: 0.0880\n",
+ "Epoch 408/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0127 - mae: 0.0901 - val_loss: 0.0121 - val_mae: 0.0886\n",
+ "Epoch 409/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0123 - mae: 0.0882 - val_loss: 0.0127 - val_mae: 0.0906\n",
+ "Epoch 410/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0130 - mae: 0.0898 - val_loss: 0.0119 - val_mae: 0.0875\n",
+ "Epoch 411/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0127 - mae: 0.0903 - val_loss: 0.0126 - val_mae: 0.0896\n",
+ "Epoch 412/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0119 - mae: 0.0872 - val_loss: 0.0115 - val_mae: 0.0864\n",
+ "Epoch 413/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0117 - mae: 0.0867 - val_loss: 0.0127 - val_mae: 0.0896\n",
+ "Epoch 414/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0117 - mae: 0.0874 - val_loss: 0.0127 - val_mae: 0.0898\n",
+ "Epoch 415/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0134 - mae: 0.0921 - val_loss: 0.0120 - val_mae: 0.0876\n",
+ "Epoch 416/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0139 - mae: 0.0941 - val_loss: 0.0117 - val_mae: 0.0869\n",
+ "Epoch 417/500\n",
+ "10/10 [==============================] - 0s 18ms/step - loss: 0.0122 - mae: 0.0889 - val_loss: 0.0120 - val_mae: 0.0879\n",
+ "Epoch 418/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0120 - mae: 0.0868 - val_loss: 0.0120 - val_mae: 0.0882\n",
+ "Epoch 419/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0122 - mae: 0.0884 - val_loss: 0.0119 - val_mae: 0.0877\n",
+ "Epoch 420/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0123 - mae: 0.0895 - val_loss: 0.0127 - val_mae: 0.0902\n",
+ "Epoch 421/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0901 - val_loss: 0.0128 - val_mae: 0.0911\n",
+ "Epoch 422/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0134 - mae: 0.0921 - val_loss: 0.0117 - val_mae: 0.0868\n",
+ "Epoch 423/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0119 - mae: 0.0880 - val_loss: 0.0118 - val_mae: 0.0871\n",
+ "Epoch 424/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0127 - mae: 0.0910 - val_loss: 0.0117 - val_mae: 0.0868\n",
+ "Epoch 425/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0120 - mae: 0.0881 - val_loss: 0.0117 - val_mae: 0.0869\n",
+ "Epoch 426/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0127 - mae: 0.0896 - val_loss: 0.0118 - val_mae: 0.0870\n",
+ "Epoch 427/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0117 - mae: 0.0870 - val_loss: 0.0116 - val_mae: 0.0865\n",
+ "Epoch 428/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0126 - mae: 0.0909 - val_loss: 0.0119 - val_mae: 0.0874\n",
+ "Epoch 429/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0115 - mae: 0.0848 - val_loss: 0.0119 - val_mae: 0.0877\n",
+ "Epoch 430/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0118 - mae: 0.0878 - val_loss: 0.0122 - val_mae: 0.0883\n",
+ "Epoch 431/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0123 - mae: 0.0889 - val_loss: 0.0118 - val_mae: 0.0871\n",
+ "Epoch 432/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0124 - mae: 0.0885 - val_loss: 0.0120 - val_mae: 0.0878\n",
+ "Epoch 433/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0124 - mae: 0.0891 - val_loss: 0.0116 - val_mae: 0.0863\n",
+ "Epoch 434/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0117 - mae: 0.0879 - val_loss: 0.0119 - val_mae: 0.0877\n",
+ "Epoch 435/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0124 - mae: 0.0891 - val_loss: 0.0126 - val_mae: 0.0901\n",
+ "Epoch 436/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0125 - mae: 0.0887 - val_loss: 0.0126 - val_mae: 0.0901\n",
+ "Epoch 437/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0129 - mae: 0.0913 - val_loss: 0.0123 - val_mae: 0.0886\n",
+ "Epoch 438/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0120 - mae: 0.0868 - val_loss: 0.0116 - val_mae: 0.0868\n",
+ "Epoch 439/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0128 - mae: 0.0894 - val_loss: 0.0132 - val_mae: 0.0911\n",
+ "Epoch 440/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0111 - mae: 0.0849 - val_loss: 0.0115 - val_mae: 0.0865\n",
+ "Epoch 441/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0121 - mae: 0.0866 - val_loss: 0.0118 - val_mae: 0.0875\n",
+ "Epoch 442/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0116 - mae: 0.0868 - val_loss: 0.0119 - val_mae: 0.0875\n",
+ "Epoch 443/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0118 - mae: 0.0861 - val_loss: 0.0124 - val_mae: 0.0891\n",
+ "Epoch 444/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0883 - val_loss: 0.0121 - val_mae: 0.0883\n",
+ "Epoch 445/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0114 - mae: 0.0854 - val_loss: 0.0122 - val_mae: 0.0884\n",
+ "Epoch 446/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0893 - val_loss: 0.0116 - val_mae: 0.0866\n",
+ "Epoch 447/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0879 - val_loss: 0.0122 - val_mae: 0.0885\n",
+ "Epoch 448/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0121 - mae: 0.0878 - val_loss: 0.0117 - val_mae: 0.0868\n",
+ "Epoch 449/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0113 - mae: 0.0865 - val_loss: 0.0117 - val_mae: 0.0866\n",
+ "Epoch 450/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0112 - mae: 0.0855 - val_loss: 0.0133 - val_mae: 0.0930\n",
+ "Epoch 451/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0137 - mae: 0.0931 - val_loss: 0.0121 - val_mae: 0.0883\n",
+ "Epoch 452/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0117 - mae: 0.0861 - val_loss: 0.0114 - val_mae: 0.0862\n",
+ "Epoch 453/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0113 - mae: 0.0855 - val_loss: 0.0117 - val_mae: 0.0870\n",
+ "Epoch 454/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0135 - mae: 0.0928 - val_loss: 0.0118 - val_mae: 0.0870\n",
+ "Epoch 455/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0884 - val_loss: 0.0114 - val_mae: 0.0860\n",
+ "Epoch 456/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0125 - mae: 0.0904 - val_loss: 0.0117 - val_mae: 0.0869\n",
+ "Epoch 457/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0124 - mae: 0.0883 - val_loss: 0.0114 - val_mae: 0.0862\n",
+ "Epoch 458/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0122 - mae: 0.0873 - val_loss: 0.0117 - val_mae: 0.0869\n",
+ "Epoch 459/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0122 - mae: 0.0887 - val_loss: 0.0116 - val_mae: 0.0865\n",
+ "Epoch 460/500\n",
+ "10/10 [==============================] - 0s 5ms/step - loss: 0.0125 - mae: 0.0894 - val_loss: 0.0118 - val_mae: 0.0874\n",
+ "Epoch 461/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0115 - mae: 0.0857 - val_loss: 0.0115 - val_mae: 0.0863\n",
+ "Epoch 462/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0115 - mae: 0.0862 - val_loss: 0.0117 - val_mae: 0.0874\n",
+ "Epoch 463/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0118 - mae: 0.0880 - val_loss: 0.0119 - val_mae: 0.0876\n",
+ "Epoch 464/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0132 - mae: 0.0928 - val_loss: 0.0116 - val_mae: 0.0865\n",
+ "Epoch 465/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0135 - mae: 0.0922 - val_loss: 0.0116 - val_mae: 0.0865\n",
+ "Epoch 466/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0121 - mae: 0.0885 - val_loss: 0.0115 - val_mae: 0.0863\n",
+ "Epoch 467/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0117 - mae: 0.0868 - val_loss: 0.0116 - val_mae: 0.0871\n",
+ "Epoch 468/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0117 - mae: 0.0861 - val_loss: 0.0117 - val_mae: 0.0872\n",
+ "Epoch 469/500\n",
+ "10/10 [==============================] - 0s 17ms/step - loss: 0.0121 - mae: 0.0896 - val_loss: 0.0115 - val_mae: 0.0863\n",
+ "Epoch 470/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0123 - mae: 0.0896 - val_loss: 0.0125 - val_mae: 0.0895\n",
+ "Epoch 471/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0916 - val_loss: 0.0114 - val_mae: 0.0862\n",
+ "Epoch 472/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0113 - mae: 0.0854 - val_loss: 0.0114 - val_mae: 0.0861\n",
+ "Epoch 473/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0116 - mae: 0.0862 - val_loss: 0.0129 - val_mae: 0.0904\n",
+ "Epoch 474/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0138 - mae: 0.0954 - val_loss: 0.0127 - val_mae: 0.0901\n",
+ "Epoch 475/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0134 - mae: 0.0923 - val_loss: 0.0118 - val_mae: 0.0877\n",
+ "Epoch 476/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0121 - mae: 0.0877 - val_loss: 0.0115 - val_mae: 0.0862\n",
+ "Epoch 477/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0117 - mae: 0.0865 - val_loss: 0.0117 - val_mae: 0.0874\n",
+ "Epoch 478/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0130 - mae: 0.0899 - val_loss: 0.0113 - val_mae: 0.0859\n",
+ "Epoch 479/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0131 - mae: 0.0907 - val_loss: 0.0115 - val_mae: 0.0864\n",
+ "Epoch 480/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0122 - mae: 0.0877 - val_loss: 0.0118 - val_mae: 0.0877\n",
+ "Epoch 481/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0119 - mae: 0.0866 - val_loss: 0.0115 - val_mae: 0.0864\n",
+ "Epoch 482/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0118 - mae: 0.0874 - val_loss: 0.0115 - val_mae: 0.0866\n",
+ "Epoch 483/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0121 - mae: 0.0873 - val_loss: 0.0123 - val_mae: 0.0890\n",
+ "Epoch 484/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0127 - mae: 0.0898 - val_loss: 0.0116 - val_mae: 0.0868\n",
+ "Epoch 485/500\n",
+ "10/10 [==============================] - 0s 9ms/step - loss: 0.0112 - mae: 0.0845 - val_loss: 0.0123 - val_mae: 0.0890\n",
+ "Epoch 486/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0123 - mae: 0.0876 - val_loss: 0.0114 - val_mae: 0.0860\n",
+ "Epoch 487/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0116 - mae: 0.0852 - val_loss: 0.0118 - val_mae: 0.0873\n",
+ "Epoch 488/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0114 - mae: 0.0859 - val_loss: 0.0114 - val_mae: 0.0859\n",
+ "Epoch 489/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0117 - mae: 0.0871 - val_loss: 0.0130 - val_mae: 0.0917\n",
+ "Epoch 490/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0135 - mae: 0.0933 - val_loss: 0.0131 - val_mae: 0.0920\n",
+ "Epoch 491/500\n",
+ "10/10 [==============================] - 0s 8ms/step - loss: 0.0120 - mae: 0.0879 - val_loss: 0.0119 - val_mae: 0.0881\n",
+ "Epoch 492/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0115 - mae: 0.0859 - val_loss: 0.0115 - val_mae: 0.0863\n",
+ "Epoch 493/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0113 - mae: 0.0854 - val_loss: 0.0114 - val_mae: 0.0862\n",
+ "Epoch 494/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0114 - mae: 0.0866 - val_loss: 0.0116 - val_mae: 0.0868\n",
+ "Epoch 495/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0119 - mae: 0.0875 - val_loss: 0.0113 - val_mae: 0.0860\n",
+ "Epoch 496/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0118 - mae: 0.0861 - val_loss: 0.0114 - val_mae: 0.0863\n",
+ "Epoch 497/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0107 - mae: 0.0818 - val_loss: 0.0115 - val_mae: 0.0864\n",
+ "Epoch 498/500\n",
+ "10/10 [==============================] - 0s 7ms/step - loss: 0.0123 - mae: 0.0894 - val_loss: 0.0114 - val_mae: 0.0862\n",
+ "Epoch 499/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0126 - mae: 0.0895 - val_loss: 0.0113 - val_mae: 0.0857\n",
+ "Epoch 500/500\n",
+ "10/10 [==============================] - 0s 6ms/step - loss: 0.0121 - mae: 0.0882 - val_loss: 0.0115 - val_mae: 0.0865\n"
+ ],
+ "name": "stdout"
+ },
+ {
+ "output_type": "stream",
+ "text": [
+ "/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.\n",
+ " warnings.warn('`Model.state_updates` will be removed in a future version. '\n",
+ "/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/base_layer.py:1397: UserWarning: `layer.updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.\n",
+ " warnings.warn('`layer.updates` will be removed in a future version. '\n"
+ ],
+ "name": "stderr"
+ },
+ {
+ "output_type": "stream",
+ "text": [
+ "WARNING:tensorflow:FOR KERAS USERS: The object that you are saving contains one or more Keras models or layers. If you are loading the SavedModel with `tf.keras.models.load_model`, continue reading (otherwise, you may ignore the following instructions). Please change your code to save with `tf.keras.models.save_model` or `model.save`, and confirm that the file \"keras.metadata\" exists in the export directory. In the future, Keras will only load the SavedModels that have this file. In other words, `tf.saved_model.save` will no longer write SavedModels that can be recovered as Keras models (this will apply in TF 2.5).\n",
+ "\n",
+ "FOR DEVS: If you are overwriting _tracking_metadata in your class, this property has been used to save metadata in the SavedModel. The metadta field will be deprecated soon, so please move the metadata to a different file.\n",
+ "INFO:tensorflow:Assets written to: models/model/assets\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Mc_CQu2_IvOP"
+ },
+ "source": [
+ "### 3. Plot Metrics\n",
+ "Each training epoch, the model prints out its loss and mean absolute error for training and validation. You can read this in the output above (note that your exact numbers may differ): \n",
+ "\n",
+ "```\n",
+ "Epoch 500/500\n",
+ "10/10 [==============================] - 0s 10ms/step - loss: 0.0121 - mae: 0.0882 - val_loss: 0.0115 - val_mae: 0.0865\n",
+ "```\n",
+ "\n",
+ "You can see that we've already got a huge improvement - validation loss has dropped from 0.15 to 0.01, and validation MAE has dropped from 0.33 to 0.08.\n",
+ "\n",
+ "The following cell will print the same graphs we used to evaluate our original model, but showing our new training history:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "SYHGswAJJgrC",
+ "outputId": "0b4baed5-9565-45c7-9fcc-2fd59a86d438",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 297
+ }
+ },
+ "source": [
+ "# Draw a graph of the loss, which is the distance between\n",
+ "# the predicted and actual values during training and validation.\n",
+ "train_loss = history.history['loss']\n",
+ "val_loss = history.history['val_loss']\n",
+ "\n",
+ "epochs = range(1, len(train_loss) + 1)\n",
+ "\n",
+ "# Exclude the first few epochs so the graph is easier to read\n",
+ "SKIP = 100\n",
+ "\n",
+ "plt.figure(figsize=(10, 4))\n",
+ "plt.subplot(1, 2, 1)\n",
+ "\n",
+ "plt.plot(epochs[SKIP:], train_loss[SKIP:], 'g.', label='Training loss')\n",
+ "plt.plot(epochs[SKIP:], val_loss[SKIP:], 'b.', label='Validation loss')\n",
+ "plt.title('Training and validation loss')\n",
+ "plt.xlabel('Epochs')\n",
+ "plt.ylabel('Loss')\n",
+ "plt.legend()\n",
+ "\n",
+ "plt.subplot(1, 2, 2)\n",
+ "\n",
+ "# Draw a graph of mean absolute error, which is another way of\n",
+ "# measuring the amount of error in the prediction.\n",
+ "train_mae = history.history['mae']\n",
+ "val_mae = history.history['val_mae']\n",
+ "\n",
+ "plt.plot(epochs[SKIP:], train_mae[SKIP:], 'g.', label='Training MAE')\n",
+ "plt.plot(epochs[SKIP:], val_mae[SKIP:], 'b.', label='Validation MAE')\n",
+ "plt.title('Training and validation mean absolute error')\n",
+ "plt.xlabel('Epochs')\n",
+ "plt.ylabel('MAE')\n",
+ "plt.legend()\n",
+ "\n",
+ "plt.tight_layout()"
+ ],
+ "execution_count": 15,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAsMAAAEYCAYAAAC5nfszAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nOzdfXxU1bXw8d+aSUJQVFrEWjEYrOIrkvBmj1QYxLbiG1jRq481IuoAiq1ai9pq5Yper8BTuVZUQERpFdT6SFFRK0gANS0CRikKt2ojoGI1FsEKJJlZzx/7TDIzmSRDyOR1ffnkkzn7vMyemWSzs8/aa4uqYowxxhhjTEcUaOkKGGOMMcYY01KsM2yMMcYYYzos6wwbY4wxxpgOyzrDxhhjjDGmw7LOsDHGGGOM6bCsM2yMMcYYYzos6wybeonIiyJyWVMf25JEpExETs/AdVVEjvIfPyQit6VzbCOe5xIR+XNj61nPdUMisrWpr2tMc7N2a6+u26bbrbZKRB4VkTub+JpjROS1prxmR5HV0hUwTU9Evo7b3A/YA0T87XGq+ni611LVEZk4tr1T1fFNcR0RyQf+AWSrapV/7ceBtD9DY9oCa7danrVbHYeIjAGuVNUftHRdWgPrDLdDqtol9lhEynA/8EuTjxORrFhDZYwxLcnaLWPap1S/s3v7e5zp33sLk+hAYrfBReQmEdkGzBORb4nI8yLyuYj8y398eNw5xSJypf94jIi8JiLT/WP/ISIjGnlsLxFZKSI7RWSpiMwUkT/UUe906jhFRF73r/dnETk4bv+lIvKRiJSLyK/reX9OFpFtIhKMKztPRN7xHw8SkRIR2S4in4rI/SKSU8e1Em6Bicgv/XM+EZGxSceeJSJvicgOEdkiIpPjdq/0v28Xka9FxEu+FSYip4jImyLylf/9lHTfm/qIyHH++dtFZIOInBu370wRede/5scicqNffrD/+WwXkS9FZJWIWDtjGs3aLWu36mu34n4+JonIP/36jvLbqP/126FfxR0fEJGbReQD/719SkS+Hbf/af/9/Mr/rE9Ien9misgLfr3+KiLfq+ezqfNavoNF5BX/WitE5Aj/PBGRe/3Xs0NE1ovIif6+g0Rkvv9z9ZGI3Cop2lgRyRcX1pIVV1YsIleKyHHAQ4Dnfz7b/f2d/J/9zSLymbiwmc71vL6xIvKe//P9cqz+/j4VkWtE5O/A3yX173EnEZnh/3x94j/ulPS5Vh9fVz2agv0n1fEcCnwbOAII434G5vnbPYFdwP31nH8ysAk4GJgKzBURacSxTwCrgW7AZODSep4znTr+H+By4BAgB4h1zo4HHvSvf5j/fIeTgqr+Ffg3cFrSdZ/wH0eA6/3X4wHDgavrqTd+Hc7w6/ND4GggOe7v30AR0BU4C5ggIqP8fUP8711VtYuqliRd+9vAC8B9/mv7LfCCiHRLeg213psG6pwNPAf82T/vWuBxETnGP2Qu7tb1AcCJwKt++S+ArUB34DvArwBb893sK2u3rN2qr906FMgFegC/AeYAPwX6A6cCt4lIL//Ya4FRwFDce/svYGbctV70X+8hwDpqh3ZcBPwn8C3gfeCueurV0LUuAabgPpvSuP0/wr2HvYGDgAuBcn/f7/yyI/3XUIR7n9Kmqu8B44ES//Pp6u/6b/85C4CjqHk/axGRkbj2/Se49n4VsCDpsFG436fj/e3k3+NfA9/3n68vMAi4Ne785OMzR1Xtqx1/AWXA6f7jEFAB5NZzfAHwr7jtYtztSoAxwPtx+/bDdXQO3Ztjcf8xVAH7xe3/A/CHNF9TqjreGrd9NfCS//g3wMK4ffv778HpdVz7TuAR//EBuAb/iDqOvQ54Nm5bgaP8x48Cd/qPHwH+O+643vHHprjuDOBe/3G+f2xW3P4xwGv+40uB1UnnlwBjGnpvUjxvCNjqPz4V2AYE4vYvACb7jzcD44ADk65xB/Cnul6bfdlXOl/Wblm7tZft1i4gGPf6FTg57pi1wCj/8XvA8Lh93wUq4+sat6+rf62D4t6fh+P2nwlsTPPzT3Wt+M+4C+4PlzzcHzb/i+soxrfBQf/n4Pi4snFAcYr3ONVnUEziz/prcfvE/7n5XlyZB/yjjtfzInBF3HYA+Cb2c+c/92lJn1PC7zHwAXBm3PaPgbJ0f++b8stGhjuez1V1d2xDRPYTkVn+7ZYduNtbXSXulluSbbEHqvqN/7DLXh57GPBlXBnAlroqnGYdt8U9/iauTofFX1tV/03NX9ipPAH8xL9V8xNgnap+5Nejt7hbndv8evwX7i/6hiTUAfgo6fWdLCLL/dteX+H+Yk8rlMG/9kdJZR/h/qKPqeu9abDOqhqt47rn4/4j+Mi/vef55dNwoyV/FpEPReTm9F6GMfWydsvarfrarXJVjU223OV//yxu/664848AnhUXNrId1zmOAN8RkaCI/Le4EIoduD/KIPF1pVWvNK8V/xl/DXwJHKaqr+LuIswE/ikis0XkQP/cbBLfu+T3rbG64/74Wxv33rzkl6dyBPA/ccd+ietQx9cl+fcj4feY2j8HH/lldR2fMdYZ7niSb1n/AjgG91f0gdTc3qrrFmJT+BT4tojsF1eWV8/x+1LHT+Ov7T9nt7oOVtV3cb+QI0i81QjutuVG4Gi/Hr9qTB1wI0zxngAWA3mqehAulit23YZCDD7BNUrxegIfp1Gvhq6blxSLVn1dVX1TVUfibv8tAp7yy3eq6i9U9UjgXOAGERm+j3Uxxtota7eayhZghKp2jfvKVdWPce/dSFxIyEG40VVo3M9VOteK/4y74EICPgFQ1ftUtT8uxKA38EvgC9wodvx7V9f79m//e/zP66Fxj5M/oy9wfzScEPe+HKRxE1uTbMGFysW/j51V9Y16niN5O/nnoKdfVtfxGWOdYXMA7hdgux/HdXumn9AfsVgDTBaRHH9U8ZwM1fGPwNki8gNxk0buoOGf+yeAn+P+83o6qR47gK9F5FhgQpp1eAoYIyLH+/+pJdf/ANyI024RGYRrRGM+B6K4+LBUlgC9ReT/iEiWiPwHrvF8Ps261eWvuFGPSSKSLSIh3Ge00P/MLhGRg1S1EveeRAFE5GwROcqPsfwKN+ISTf0UxjSatVu1WbuVnoeAu6Rmslp3P/4V3GvagxuF3w83it5Y6VzrzLjPeArwF1XdIiID/ZH3bFyndjcQ9Ue/n/Lrf4D/Gm7AheskUNXPcZ3kn/qj1GOB+Ml+nwGH+8+NfxdwDnCviBwCICI9ROTHdby+h4BbxJ8UKG5i3wV78f6AC7271f8MDsaFB6WckJpp1hk2M4DOuL8K/4K7LdIcLsHFI5Xj4t2exDUcqTS6jqq6AbgG9x/Fp7jJEg0tLLEANzHhVVX9Iq78RlyDvxPXaDyZZh1e9F/Dq7gQgleTDrkauENEduIag6fizv0GN0Hjdf921PeTrl0OnI0bhSoHJgFnJ9V7r6lqBe4/+hG49/0BoEhVN/qHXAqU+bf/xuM+T3CTRZYCX+NiAB9Q1eX7UhdjUrB2q7YO326l6X9wI9p/9uv+F9wkL4D5uBH2j4F3/X2Nlc61nsD9kfElbrLfT/3yA3Gf1b/8a5TjQtDATQD8N/Ah8Jp/jUfqqMNVuBHlcuAEIH7U9lVgA7BNRGLv+024z/ovftu+FHd3oxZVfRa4BzdAsgP4G+7/i71xJ+4PzHeA9bhJhk26EEm6xA9UNqZFiciTuIkIGR/hMcaYpmDtljHtg40Mmxbh3wb6nricj2fgYqsWtXS9jDGmLtZuGdM+2Qp0pqUcCvw/3KSQrcAEVX2rZatkjDH1snbLmHbIwiSMMcYYY0yHldEwCRE5Q0Q2icj7qfKNiluK70l//19FJN8vzxGReeKWIHzbn8lujDHGGGNMk8pYmISfWHwmbinHrcCbIrLYz4cYcwVuRZ6jROQi3MzE/8DNgERV+/gpPl4UkYFJCwAkOPjggzU/Pz9Dr8YYY/bd2rVrv1DVupLYNyk/pvV/cKtWPayq/520/wbgStyqap8DY1X1IxEpwOWmPRCXGu8uVa03A4G1v8aY1q6+9jeTMcODcMtafgggIgtxkw3iO8Mjceu7g8ureL+fn/R4/DQuqvpPf3WTAbg14VPKz89nzZo1Tf0ajDGmyYhI8qpbmXqedAYj3gIGqOo3IjIBmIobjPgGl0bv7yJyGG5FqpdVdXtdz2ftrzGmtauv/c1kmEQPEpfi20rtJQOrj1HVKlyS/m7A28C5fjLuXrj8e7VW+hGRsIisEZE1n3/+eQZegjHGtEnVgxF+zujYYEQ1VV0et7TwX4DD/fL/VdW/+48/Af5J3UuyGmNMm9daU6s9gus8r8El/X4Dd7sugarOVtUBqjqge3drq40xxpfOYES8K4AXkwv9lcVygA9S7LPBCGNMu5DJMImPSRzNPZza62fHjtkqIlm49bvL1aW4uD52kIi8AfxvButqjDEdkoj8FBeGNjSp/LvA74HLUs3XUNXZwGyAAQMGWFoiY0yblcnO8JvA0X6Yw8fARSSuXQ5uScTLcMu2jsYtI6n+Ouiiqv8WkR8CVUmxbsZ0OJWVlWzdupXdu3e3dFVMA3Jzczn88MPJzs5uqSqkMxiBiJwO/BoYqqp74soPBF4Afq2q+7IkrTFtmrW7bU9j2t+MdYZVtUpEJgIv42YzP6KqG0TkDmCNqi4G5gK/F5H3cWtzX+SffgjwsohEcQ34pZmqpzFtxdatWznggAPIz8/HzTM1rZGqUl5eztatW+nVq1dLVaPBwQgRKQRmAWeo6j/jynOAZ4H5qvrH5quyMa2PtbttS2Pb34yuQKeqS4AlSWW/iXu8G7ggxXllwDGZrJsxbc3u3butQW4DRIRu3brRknG0aQ5GTAO6AE/7P1ObVfVc4EJgCNBNRMb4lxyjqqXN/TqMaWnW7rYtjW1/O/RyzCUlUFwMoRB4XkvXxpiGWYPcNrSGzymNwYjT6zjvD8AfMls7x9pg0xa0ht9nk77GfF4dtjNcUgLDh0NFBeTkwLJl1hgbY0xzmT0bJk6ESAQ6dbI22BjTclprarWMKy52HeFIBHbvhvnzW7pGxrRu5eXlFBQUUFBQwKGHHkqPHj2qtysqKuo9d82aNfzsZz9r8DlOOeWUJqlrcXExZ599dpNcyzS9khK45hqorIRoFPbscW2yMSZRW2t3RYSHH364uqy0tBQRYfr06dVlVVVVdO/enZtvvjnh/FAoxDHHHFP9+kaPHt0k9UpHhx0ZDoUgGHSdYVWYNw+Kimxkwpi6dOvWjdJSFzY6efJkunTpwo033li9v6qqiqys1E3KgAEDGDBgQIPP8cYbbzRNZU2rVlzsOsExwaBrk40xidpau3viiSfy1FNPceWVVwKwYMEC+vbtm3DMK6+8Qu/evXn66ae5++67E8IaHn/88bTq3NQ67Miw58HYsTXblZU2MmHan5ItJdy96m5KtpRk5Ppjxoxh/PjxnHzyyUyaNInVq1fjeR6FhYWccsopbNq0CUgcqZ08eTJjx44lFApx5JFHct9991Vfr0uXLtXHh0IhRo8ezbHHHssll1yCSz8OS5Ys4dhjj6V///787Gc/a3AE+Msvv2TUqFGcdNJJfP/73+edd94BYMWKFdUjEIWFhezcuZNPP/2UIUOGUFBQwIknnsiqVaua/D0zruMb+/87GIT777eBCNN+dOR294gjjmD37t189tlnqCovvfQSI0aMSDhmwYIF/PznP6dnz56UlGTmPdpbHXZkGKCwsOZxNArdurVcXYxpaiVbShg+fzgVkQpygjksK1qGl9f0PY6tW7fyxhtvEAwG2bFjB6tWrSIrK4ulS5fyq1/9imeeeabWORs3bmT58uXs3LmTY445hgkTJtTKCfnWW2+xYcMGDjvsMAYPHszrr7/OgAEDGDduHCtXrqRXr15cfPHFDdbv9ttvp7CwkEWLFvHqq69SVFREaWkp06dPZ+bMmQwePJivv/6a3NxcZs+ezY9//GN+/etfE4lE+Oabbxq8vmkcEfeVlQV9+rR0bYxpGtbuwujRo3n66acpLCykX79+dOrUqXrf7t27Wbp0KbNmzWL79u0sWLAgIUzjkksuoXPnzgD88Ic/ZNq0afvyNqWtw44MA5SXQ8B/B0Tgrbdatj7GNKXismIqIhVENEJFpILisuKMPM8FF1xAMBgE4KuvvuKCCy7gxBNP5Prrr2fDhg0pzznrrLPo1KkTBx98MIcccgifffZZrWMGDRrE4YcfTiAQoKCggLKyMjZu3MiRRx5ZnT8ync7wa6+9xqWXulTlp512GuXl5ezYsYPBgwdzww03cN9997F9+3aysrIYOHAg8+bNY/Lkyaxfv54DDjigsW+LqUdxMVRVuRC1qiq7K2faD2t34cILL+Tpp59mwYIFtY59/vnnGTZsGJ07d+b8889n0aJFRCKR6v2PP/44paWllJaWNltHGDp4Zzj+Vp0qzJnjZjgb0x6E8kPkBHMISpCcYA6h/FBGnmf//fevfnzbbbcxbNgw/va3v/Hcc8/VuWpT/EhBMBikqqqqUcfsi5tvvpmHH36YXbt2MXjwYDZu3MiQIUNYuXIlPXr0YMyYMcy3mbUZEQq5LD7BoBuIWLTI2l7TPli7C4ceeijZ2dm88sorDB8+PGHfggULWLp0Kfn5+fTv35/y8nJeffXVvX6OptahO8PJccORiEv100pCWIzZJ16ex7KiZUwZNiVjt+qSffXVV/To0QOARx99tMmvf8wxx/Dhhx9SVlYGwJNPPtngOaeeeiqPP/444GLiDj74YA488EA++OAD+vTpw0033cTAgQPZuHEjH330Ed/5zne46qqruPLKK1m3bl2Tvwbj2t5ly+Ccc9zI8OrVMG4c3HRTS9fMmH1j7a5zxx13cM8991SPXgPV4RybN2+mrKyMsrIyZs6cyYIFC5q8znurQ8cMg8sg8fDDrkEG1yEuLrbJHKZ98PK8ZmmMYyZNmsRll13GnXfeyVlnndXk1+/cuTMPPPAAZ5xxBvvvvz8DBw5s8JzYxJGTTjqJ/fbbj8ceewyAGTNmsHz5cgKBACeccAIjRoxg4cKFTJs2jezsbLp06WIjwxnkeZAckj19OowaZe2vadus3U2dru3ZZ5/ltNNOSxh9HjlyJJMmTWLPnj1AYszwwQcfzNKlS5voVdRPYjMF27oBAwbomjVrGnXu7Nlw9dVuEl12tnWGTev03nvvcdxxx7V0NVrc119/TZcuXVBVrrnmGo4++miuv/76lq5WLak+LxFZq6rNnzcowxrb/s6e7UaEY0Tc9oMPNmHljNkH1u46baXdjdnb9rdDh0nE9OlTEztsqy4a07rNmTOHgoICTjjhBL766ivGxfemTJsSDsOkSTXtbiznu4WqGdO6tPd2t8OHSUDizOaKCrcanY0MG9M6XX/99a16RMLsnXvugR07YNYsa4ONaa3ae7trI8PUrEYHllXCGGOaW1GRC1ED1wbPnWujw8aY5mOdYSyrhDHGtCTPgzPPrNmurHSjw8YY0xysM+wrKqqJGwZLBG+MMc3p0ENbugbGmI7KOsM+z4MbbqjZVrXlmY0xprkUFUEs41IwCIWFLVsfY0zHkdHOsIicISKbROR9Ebk5xf5OIvKkv/+vIpLvl2eLyGMisl5E3hORWzJZz5iuXW15ZmPqMmzYMF5++eWEshkzZjBhwoQ6zwmFQsRSbp155pls37691jGTJ09m+vTp9T73okWLePfdd6u3f/Ob3zRJ/sni4mLOPvvsfb6O2XeeB/fd52KHVeG66yxUzZj22u6KCA8//HB1WWlpKSKSUKeqqiq6d+/OzTcndh9DoRDHHHMMBQUFFBQUMHr06H2uU8Y6wyISBGYCI4DjgYtF5Pikw64A/qWqRwH3Avf45RcAnVS1D9AfGBfrKGdS8vLMluLHmBoXX3wxCxcuTChbuHBhg+vUxyxZsoSuXbs26rmTG+U77riD008/vVHXMq1XebnL9x6NuqwSFqpmOrr22u6eeOKJPPXUU9XbCxYsoG/fvgnHvPLKK/Tu3Zunn36a5DUxHn/8cUpLSyktLeWPf/zjPtcnkyPDg4D3VfVDVa0AFgIjk44ZCTzmP/4jMFxEBFBgfxHJAjoDFcCODNYVqJlIF8t5GUvxY0xbVVICd9/dNH/UjR49mhdeeIGKigoAysrK+OSTTzj11FOZMGECAwYM4IQTTuD2229PeX5+fj5ffPEFAHfddRe9e/fmBz/4AZs2bao+Zs6cOQwcOJC+ffty/vnn88033/DGG2+wePFifvnLX1JQUMAHH3zAmDFjqhvAZcuWUVhYSJ8+fRg7dmz1Skb5+fncfvvt9OvXjz59+rBx48Z6X9+XX37JqFGjOOmkk/j+97/PO++8A8CKFSuqRyAKCwvZuXMnn376KUOGDKGgoIATTzyRVatW7dubawA3IJGT49pgVUgxoGVMq2ftbsPt7hFHHMHu3bv57LPPUFVeeuklRowYkXDMggUL+PnPf07Pnj0pyfDIZCY7wz2ALXHbW/2ylMeoahXwFdAN1zH+N/ApsBmYrqpfJj+BiIRFZI2IrPn888+bpNKW4se0FyUlMHw43Hab+76vP8ff/va3GTRoEC+++CLgRicuvPBCRIS77rqLNWvW8M4777BixYrqjmQqa9euZeHChZSWlrJkyRLefPPN6n0/+clPePPNN3n77bc57rjjmDt3Lqeccgrnnnsu06ZNo7S0lO9973vVx+/evZsxY8bw5JNPsn79eqqqqngwbvmygw8+mHXr1jFhwoQGbwnefvvtFBYW8s477/Bf//VfFBUVATB9+nRmzpxJaWkpq1atonPnzjzxxBP8+Mc/prS0lLfffpuCgoJGvacmkefBtde6tjcahalT4aabWrpWxqTP2t30293Ro0fz9NNP88Ybb9CvX7+EZZp3797N0qVLOeecc7j44otZsGBBwrmXXHJJ9SDFL3/5y/Tf0Dq01gl0g4AIcBjQC/iFiByZfJCqzlbVAao6oHv37k3yxJbix7QXxcXu7kYk0nS3nONv2cXfqnvqqafo168fhYWFbNiwIeHWWrJVq1Zx3nnnsd9++3HggQdy7rnnVu/729/+xqmnnkqfPn14/PHH2bBhQ7312bRpE7169aJ3794AXHbZZaxcubJ6/09+8hMA+vfvT1lZWb3Xeu2117j00ksBOO200ygvL2fHjh0MHjyYG264gfvuu4/t27eTlZXFwIEDmTdvHpMnT2b9+vUccMAB9V7bpK+0NHHbOsSmLbF2N/1298ILL+Tpp59mwYIFtcI+nn/+eYYNG0bnzp05//zzWbRoEZFIpHp/fJjEtGnT6q1vOjLZGf4YyIvbPtwvS3mMHxJxEFAO/B/gJVWtVNV/Aq8DKdeTzoTkFD/btjXXMxvTdGK3nINB9z0U2vdrjhw5kmXLlrFu3Tq++eYb+vfvzz/+8Q+mT5/OsmXLeOeddzjrrLPYvXt3o64/ZswY7r//ftavX8/tt9/e6OvExEYagsEgVVVVjbrGzTffzMMPP8yuXbsYPHgwGzduZMiQIaxcuZIePXowZswY5rfCv5jTmMB8g4i8KyLviMgyETkibt9lIvJ3/+uy5qz3+efXLps61RZCMm2Dtbvpt7uHHnoo2dnZvPLKKwwfPjxh34IFC1i6dCn5+fn079+f8vJyXn311X2qV30y2Rl+EzhaRHqJSA5wEbA46ZjFQKyhHQ28qi5KejNwGoCI7A98H6g/4K8JxYdKALz4ooVKmLbH82DZMpgyxX1viuVtu3TpwrBhwxg7dmz1X/I7duxg//3356CDDuKzzz6rvp1XlyFDhrBo0SJ27drFzp07ee6556r37dy5k+9+97tUVlby+OOPV5cfcMAB7Ny5s9a1jjnmGMrKynj//fcB+P3vf8/QoUMb9dpOPfXU6ucsLi7m4IMP5sADD+SDDz6gT58+3HTTTQwcOJCNGzfy0Ucf8Z3vfIerrrqKK6+8knXr1jXqOTMlzQnMbwEDVPUkXGjaVP/cbwO3Ayfj7tLdLiLfaq66h8MwaVLt8meeaa4aGNN41u7unTvuuIN77rmHYGwZYP+1rVq1is2bN1NWVkZZWRkzZ86sFSrRlLIaPqRxVLVKRCYCLwNB4BFV3SAidwBrVHUxMBf4vYi8D3yJ6zCDa8TnicgGQIB5qlp3MEwT8zy44gqYNcvFrsUm0jXFD7Uxzcnzmv7n9uKLL+a8886rvm3Xt29fCgsLOfbYY8nLy2Pw4MH1nt+vXz/+4z/+g759+3LIIYcwcODA6n1Tpkzh5JNPpnv37px88snVDfFFF13EVVddxX333Zcwczg3N5d58+ZxwQUXUFVVxcCBAxk/fnyjXtfkyZMZO3YsJ510Evvttx+PPebm9s6YMYPly5cTCAQ44YQTGDFiBAsXLmTatGlkZ2fTpUuX1jgyXD2BGUBEYhOYq++jquryuOP/AvzUf/xj4JXYPA0ReQU4A8jc/0RJ7vHzCk2dWlOWasTYmNbI2t30nXLKKbXKnn32WU477bSEGOKRI0cyadKk6ol6l1xyCZ07dwZcjPK+pnyT5HQVbdWAAQM0llevKZSUuNsb/gROsrNhxQrrEJuW895773Hccce1dDVMmlJ9XiKyVlUzHvIlIqOBM1T1Sn/7UuBkVZ1Yx/H3A9tU9U4RuRHIVdU7/X23AbtUtc6ZME3d/sbMnu1GhAsKXB74UMjaYNO8rN1tm/a2/c3YyHBbF5tIt2iR245NpLOG2BjTnojIT3FzMvbqPqeIhIEwQM+ePTNQMxcyATBxIlRVuTjMmTNryo0xpim01mwSrYJNpDPGtFHpTGBGRE4Hfg2cq6p79ubcTGTzSVZSAtdc4wYjVF2HeOJEm8NhjGla1hmuh02kM61Newlrau9awefU4ARmESkEZuE6wv+M2/Uy8CMR+ZY/ce5HflmTK9lSwt2r7qZkS+qGtbjYpaiKV1mZGEtsTKa1gt9nsxca83lZZ7gesYl0tiKdaQ1yc3MpLy+3hrmVU1XKy8vJzc1tyTpUAbEJzO8BT8UmMItILMHoNKAL8LSIlIrIYv/cL4EpuA71m8AdqRY92lclW0oYPn84t+yDkiUAACAASURBVC2/jeHzh6fsEIdCLjQi2aJFcN55NjhhMs/a3balse2vTaBrgE2kM61FZWUlW7du3ecckCbzcnNzOfzww8mOv7VE802ga26NaX8nPD+BWWtnoShBCTJl2BRuOfWWWsfNnu1CIyora1+jc+emS19lTCrW7rY9jWl/bQJdA2winWktsrOz6dWrV0tXw5h9VrKlhEdKH0FxgzFZgSxC+aGUx4bD0KePC42ItcMxu3dbe2wyy9rdjsHCJNJgE+mMMabpFJcVE4m6YGBBuLzgcrw8r84YYs+DZ591i3HEwtbATaqbN8/CJYwx+8Y6w2mwiXTGGNN0QvkhsgJZCEJWIIttX2/jvIXnMeyxYfXGEHftCoGk/7VsLocxZl91+M5wQ7OZwSbSGWNMU1P/X2W0kkWbFrFo0yL2RPYQ0QgVkQqKy4prnRMKQU6OjQ4bY5pWh+4Mz147m6GPDuXW5bfWORIREz86rApz51rja4wxjREfJpFMEHKCOSljiD0PZsyArKTZLlVVLg1bSQncfbe1zcaYvdNhO8MlW0q4Zsk1VEYriWqU3VW7U45ExMQm0sVYrktjjGmcUH6InGAOgaT/grID2YzrP45lRcvw8lLPiisvh2i0ZlvEjRZ36wbDh8Ntt7nv1iE2xqSrw2aTSB6ZUJRu+3Wr95zkiXTPPecaXJvJbIwx6fPyPJYVLaO4rJhu+3XjrU/fAqCob1GdneCYWKhERYXrCPfr58qeeQb27HEd5YoKN1JsbbMxJh0dtjMcyg8RDASpilYB7tZcrEGuS1ERzJlTsyJSJOJGh599NtO1NcaY9sXL8xrs+KY8z3O5hefPd7HCa9bA6tWuY6zqJtjl5LgOsjHGpKPDhkl4eR4zz5xJUNzyRooyZ90cZq+dXfc5HjzwQOJs5kWLXFJ4Y4wxey+dSczJPA969nSxwrGQCVXXIR4wAC67LEOVNca0Sx22MwwQ7h/mqn5XVW9HNMLEJRPrbZTDYdfYxnvmmUzV0Bhj2q/4JZlDj4WY8PyEtDvFqZZqVoW33nJ38Cxu2BiTrg7dGQYXo5YVqIkWqYxWMrl4cr0N8hVXJG4XFGSqdsYY034VlxVTEamoTqc2a+2stDvFngdjx9Yur6pyIWx79sDkydYhNsY0rMN3hr08jxu8GxLKXvnwlXpTrYXDbiWkWLjEb39roRLGGLO3YlklBJc4WNHqTnFD6S7BzePIyanZDgRc2rVAwIVPLF1qI8TGmIZ1+M4wQNdOXQlIzVsRa5DrS7XWtWvN46oqmDjRGlxjjNkbsawS4/qPIztQs8ynouyJ7Km3DQY3OlxcDKNGuZAJVdcJPvbYmg5xLLOEMcbUJaOdYRE5Q0Q2icj7InJziv2dRORJf/9fRSTfL79ERErjvqIikrFghNjSoPGyAlkpk75XnxNKnEhXVWWr0hljzN7y8jwePPtBrihMjD8LSrDeNrj6fA8GDXIdYVUXIrFpk1skKRi0zBLGmIZlrDMsIkFgJjACOB64WESOTzrsCuBfqnoUcC9wD4CqPq6qBapaAFwK/ENVSzNVVy/PY2zB2OpbdYJwecHl9ab98TyYObNmAoetSmeMMY1X1LeIzlmdCRAgKEHO6n1W9b6GMk4kD06owuWXw5QpLg2b5Rs2xtQnkyPDg4D3VfVDVa0AFgIjk44ZCTzmP/4jMFwkftV5AC72z82oor5F5GbluoY4EKTwu4UNnhMOwznn1GxXVtrosDHGNEYsZCLcP0xWIIvFGxcz5NEh3LT0puqME3XFEccGJ7KzXae4UycXT3zLLW6/LdFsjKlPJjvDPYAtcdtb/bKUx6hqFfAVkLwM3H8AC1I9gYiERWSNiKz5/PPP96myXp7HjDNmEAwEiWqU6166Lq0UP8mr0m3btk/VMMaYDsvL8+h5UE8qIhVEiVIVrWLa69PYXbW7OuNEXXHE4TCsWAF33ulGgwEmTIBhw2yJZmNM/Vr1BDoRORn4RlX/lmq/qs5W1QGqOqB79+77/Hzl35QT1ShRjTY4gS6mqMiNRsQsXgznnWeNrjHGNEa3/bqhaPW2+v8CEiAnmFNvHLHn1YwGDx8Os2a5FGuRiE2kM8bULZOd4Y+BvLjtw/2ylMeISBZwEFAet/8i6hgVzoRYmp8AAUSEbvslD1LX5nmJeYejUbcq3bBh1iE2xpi9Vf5NefX8jRhBOL3X6SwrWpbWEs7z58OuXS52OCYQsIl0xpjUMtkZfhM4WkR6iUgOrmO7OOmYxUBs4czRwKuqrvkSkQBwIc0QLxzT2FCJoiKX2zKejUIYY8zeC+WHyM3Kre4QBwiQm5XL5NDk6o5wfRPqSkrgkUdqXzcScZ1kG6QwxiTLaviQxlHVKhGZCLwMBIFHVHWDiNwBrFHVxcBc4Pci8j7wJa7DHDME2KKqH2aqjqnEh0rsrtrN/LfnNzgS4Xlwww0wdWpNmQh0a3hg2RhjTJzYRLrismK279lO8T+KOezAw6r3x5Zw3lO1h0AgwMwzZxLuH67eX1zsOr7JolF46CHXUS4utgwTxpgaGesMA6jqEmBJUtlv4h7vBi6o49xi4PuZrF8qofwQwUCQSCSCosx9ay5FfYsa7BB37VqT5B3c7bnrroM+fazRNcaYvRFrb0OPhaiIVMAn8OLfX2T5ZcspLitmT9UeokSJRqNMXDKRPof0qTkn5HILV1S4QYlotKZdBlc+f761y8aYGq16Al1L8PI8zjzqzOrtymglU1+fWs8ZTijk0vnEEsOpuokbFiphjGkJaSx6NERE1olIlYiMTto3VUQ2iMh7InJfipSXGVdcVkxlpLJ6uyJSwfy357P5q83EVyeikYTJzp7nsklMmQIrV7osE8nWrbNwCWNMjYyODLdVh3ZJzJf2p01/4qalN9G1U1dC+aGUo8SxBnjqVDeBDtxoxPbtzVFjY4ypEbfo0Q9xaS3fFJHFqvpu3GGbgTHAjUnnngIMBk7yi14DhgLFma11olB+iOxgthsZ9s1eNxuAgAQIEkRROgU71cow4XmJI7+PPOJGhGPWrHHZJmxBDmMM2MhwSkV9iwhKsHpbUaa+PpVbl99aZ9J3qFkWNH4MZfp0mD070zU2xpgEDS56pKplqvoOEE06V4FcIAfoBGQDn2W+yom8PI/iy4oZdcwoAgRQtHo+R1SjXNXvKu4cdmeDGSY8z92hGz/etc+xcDab5GyMibHOcApenscDZz1AQBLfnnTyD4dCNUs0g2t0J060W3LGmGaVzqJHKalqCbAc+NT/ellV30s+rikXPaqLl+cxqMeghLzD4FKtFfUt4pZTb0kr1ZrnwYMPujSYwaDrEOfkWKo1Y4xjneE6hPuHufGUhLuHBEgv6fvMma6xjYlEbATCGNM2iMhRwHG43PA9gNNE5NTk45p60aO6xMIl4iUPVKSjpMRNaq6qctvXXmshEsYYxzrD9ejaqWtCozvgsAFpJX0Ph90oRDDoQiaysmwEwhjTrNJZ9Kgu5wF/UdWvVfVr4EWgxbqNsXCJQYcNqs49HNVoyjt09eUfLi52k5pV3R276dPh5JMtjM0YY53heoXyQ2QFauYYrv10Lev/uT6tc/v0cZ1gVTcyvD6904wxpimks+hRXTYDQ0UkS0SycZPnaoVJNKfYgki5Wbl1rhAayz982/LbUs7tCIUS79hFo7B6NYwbZx1iYzo66wzXw8vzGFswtno7ohEmLpmY1qp0xcVQ6WcFikQsbtgY03xUtQqILXr0HvBUbNEjETkXQEQGishWXK73WSKywT/9j8AHwHrgbeBtVX2u2V9EkvgVQiPRCNcsuYbZa2t6scVlxVREKohoJOXcjlgIW/ycjpi5czNceWNMq2ad4QYU9S1KGB2ujFamtUxz8ihEZWXiCnXGGJNJqrpEVXur6vdU9S6/7Df+6p+o6puqeriq7q+q3VT1BL88oqrjVPU4VT1eVW9oydcRr/ybciJRtyBSVbSKCc9P4OQ5JzN77WxC+SFygjkEJVjn3I5wGK66qvZ116yBm26Cu++2QQtjOiLrDDfAy/OYeebMhFRrqz9ZzdBHhzLh+Qn1pllLnki3aJHdjjPGmMYK5YcIxDWqUaKs/mQ1454fx/p/rmdZ0TKmDJtS79yOoiLo3DmxLBp1gxW33uryD1uH2JiOxTrDaQj3D3NVv8ThhMpoJQ+tfYhhjw2rs0McDsOAAYlldjvOGGMaJzY4kR3IrrXvmXefwcvzGky3Flsgafz42iETln/YmI7JOsNpKupbRE4wp1b5nsge5r89v87zrrgicfutt2zUwRhjGivcP8yKMSsYdcyohPKC7xZUZ5KoL6sE1OQdfuCBxA5xqvzDJSUWPmFMe2fLMafJy/P43YjfMf758bUSwNcnHIYXX6xZojkWO/zssxmqqDHGtHNensezFz3L7LWzeebdZ+i+f3fuLbmXiEbICmQhCFXRKnKCOfWGTPTp4zrD0aj7fuWVLowiln+4pMSFTVRUuE6yLd9sTPtkI8N7ofyb8uo8lzEBCVD43cJ6z5s0yaVZi7HYYWOM2Xfh/mHOP/58FvxtAZXRyupVQvdE9tSZVSJecbHL9hPLPfzhh7X3V1S4Yyx8wpj2yzrDeyGUH6JTVicCsX/+ghwNZZfwPOjXL7HMYoeNMWbflGwp4Zol1xDVaMr9WYGselcMDYXciG8g4DrDr7wCQ4a4wYqSEti82Q1kBIO2fLMx7Zl1hveCl+exrGgZd552J+H+YQSpHomob/QBascOr1ljo8PGGLMvisuKiUYTO8Kxu3eCcHnB5WlNpotNdFZ1yzWPHw9Dh8KcOa7snHPgsssy9jKMMS3MOsN7KTZbOTahrr6clvHCYRgVN98jGrWFOIwxZl+E8kNkBWti0GJ37AISIDcrl6K+RWldp7Q0cVvVze+IRFzn+IUXXMfY0q4Z0z5ltDMsImeIyCYReV9Ebk6xv5OIPOnv/6uI5MftO0lESkRkg4isF5HcTNZ1b8VGia/qdxWX9U1vyCA5driqymLQjDGmsWKrhMZGg6NEiWiEgASYccaMekeFY2Jxw3URcfstbtiY9itjnWERCQIzgRHA8cDFInJ80mFXAP9S1aOAe4F7/HOzgD8A4/1VkUJAZabqui8ee/sx5qybw/D5wxtclc7z4Ia4tZxUYfv2DFfQGGPasaK+ReRm5SZMblZV3vr0rXrTq8XE4oaDwdp5h0VciER2tnuclWVxw8a0R5kcGR4EvK+qH6pqBbAQGJl0zEjgMf/xH4HhIiLAj4B3VPVtAFUtV9V6/nZvGcVlxVREKohohF1Vu5j6esPrLXft6hrVmOnTLXbYGGMaK3aXblz/cXQKdiIoQYKBIPNK53Hb8tsaHKiIxQ1PmeKWao5vn0Wgd283cAE1340x7UsmO8M9gC1x21v9spTHqGoV8BXQDegNqIi8LCLrRGRSqicQkbCIrBGRNZ9//nmTv4CGhPJDSFzLuWjTIm5aehMTnp9Q51LNoVDi6IPFDhtjzL7x8jwePPtBll+2nCnDpjC2YCyV0UoiGmF31W4mF09usEN8yy0ux3Bubk2HWBV++1sX0qbqQiUsTMKY9qe1TqDLAn4AXOJ/P09EhicfpKqzVXWAqg7o3r17c9cRL8+j36GJOdOmvT6Nh9Y+xENrH2Loo0NrNcCeBzNnulQ+MZWVML/uReyMMcakITbBufC7hdXp1hTlzx/+mSGPDmH22vpvw8VGiX/4Q9dGx/IPx0IoLL2aMe1TJjvDHwN5cduH+2Upj/HjhA8CynGjyCtV9QtV/QZYAiRl6m0druiXmDMtfnW6ymhlyqWaw2G48cbEstmzLVzCGGOaQvk35QSS/nurilYxccnEtOZ2TJ4MnTq5DnEgANdf78IobAU6Y9qnTHaG3wSOFpFeIpIDXAQsTjpmMRBLxTAaeFVVFXgZ6CMi+/md5KHAuxmsa6OF+4cZdeyohg9Mkhw7bOESxhjTNJJTrsVENNJgTnhwHd4ZM2qWav7d72pGhCdMcF/WVhvTfmSsM+zHAE/EdWzfA55S1Q0icoeInOsfNhfoJiLvAzcAN/vn/gv4La5DXQqsU9UXMlXXfTXplEkEJVirvFOwU515LkMhN0M5nqVaM8aYfZecci0mIAG67dctrWuUl7uOcDTqUqrNn+/a7Ycecl/DhlmH2Jj2IqMxw6q6RFV7q+r3VPUuv+w3qrrYf7xbVS9Q1aNUdZCqfhh37h9U9QRVPVFVU06gay28PI9zjjknoey4g4/j8oLL6z7Hcx3fIUNqyizVmjHGNI2ivkVkBxNHHCLRCNe9dF2DoRKQmHItJ8eVVcYl+LScw8a0H611Al2bM+mUSXQKdkIQsgPZfPivD5m9dna9kzY8D844w1KtGWNMU0s1OqwoFZGKtEMlYinXli2DwsLEic+BAHRLb5DZGNPKWWe4iXh5HssvW85dp93FFYVXUBmpJEq0wUkblmrNGGMyI7YgR2wynSCISNqhErGUawDXXefaZ6jJNHHttRY/bEx7YJ3hJhRL61PUt4hA3BBCfZM2UqVaq6qyVGvGGLOvYgty3HnanVzS5xJEZK9CJWKKi2HPnppFN+JjiWfNguHDrUNsTFtmneEM8PI8Zp45k+xANgEJ0CnYiVB+qM7jw2F48MGaEWJVmDvXGldjjNlXXp5HKD/EkxueJKpRFGV31e6UaS/rEgolDljEU3UdZYsfNqbtss5whoT7h7n/zPs5vdfpzDhjBl5e/ckpw2E4J24OXmUlTG14dWdjjDENKC4rJhqLccDFDs9ZN6fOlUKTxe7gZWe7TnEwKXmQCGzebAMYxrRV1hnOkJItJVz30nUs+8eytG/JHXpo4vaf/mST6YwxjSMiZ4jIJhF5X0RuTrF/iL/cfZWIjE7a11NE/iwi74nIuyKS31z1zoRQfohOWZ0SyiIaYdbaWQyfPzyt9jkchhUr4M474Re/cB1jEdcxDgRgzhwLlzCmrbLOcIYUlxVTEakgohF2Ve1Kq0NcVJQ44qAKV19tjasxZu+ISBCYCYwAjgcuFpHjkw7bDIwBnkhxifnANFU9DhgE/DNztc28WOzwoMMGJZQryp6qPUwunpz2CHEo5BbhiERcez14sJvnEYlYujVj2irrDGdIKD9EMFDTs139yWp+MO8HdaZZA9fQPvBAYqq1SMQm0xlj9tog4H1V/VBVK4CFwMj4A1S1TFXfAaLx5X6nOUtVX/GP+1pVv2mmemeMl+cx44wZZAcScw9HibL0H0vTHiEuLnad3tgkutdfr5lYFwjUrFRnjGk7rDOcIbEcl/GiGuXqF66ut8ENh2HkyMSyl16y9D3GmL3SA9gSt73VL0tHb2C7iPw/EXlLRKb5I80JRCQsImtEZM3nn3/eBFXOPC/P44rCK2qtTBfVaNr5h+MX4xBxAxbV14nC+vVw993WXhvTllhnOIOK+hbVWqY5qtEGG9xJkxKXai4rc8t/nnqqxRAbYzIuCzgVuBEYCByJC6dIoKqzVXWAqg7o3r1789ZwH6RamQ4gK5BVb9afmNhiHFddVTvDRCTiQttuu83ih41pS6wznEFenscDZz1QnfA9Zvue+tdc9jy44ora5ZGILchhjEnLx0Be3Pbhflk6tgKlfohFFbAI6NfE9Wsxqe7aAfT9Tl/W/3M9d6+6u8FwCc+Dnj1rFuGIF4lY/LAxbY11hjMs3D/Ma2NfY0jPIYCbsDH19an1xg6Dm0yXlVW7vKrKGlhjTIPeBI4WkV4ikgNcBCzei3O7ikhsuPc04N0M1LHFFPUtIieYk1C2+pPVjHt+HL9+9ddpxQ/Hh0skp1oD135b/LAxbYN1hpuBl+eRm5WbUDZ33dz6z/HgyisTJ9OBm6jRLb2VRI0xHZQ/ojsReBl4D3hKVTeIyB0ici6AiAwUka3ABcAsEdngnxvBhUgsE5H1gABzWuJ1ZIqX51F8WTGjjhlVK35YUfZE9jQYzhYLl5gyxU18Th686Nu3iSttjMkY6ww3k/OPPz9h+61tb6WVai03N7FDHAhAeXkmamiMaU9UdYmq9lbV76nqXX7Zb1R1sf/4TVU9XFX3V9VuqnpC3LmvqOpJqtpHVcf4GSnaFS/PY1CPQbU6wzHd9qsZdSjZUpIyfMLz4JZb3MTnG25IPH/1ahg2zMLajGkLrDPcTML9w4w6dlT1dlW0qsHlQGMjD+PGQadOriMcCNjIsDHGNIVUi3EAqGp1bviSLSWEHgvx61d/TeixUJ2DGF271p5Qt2ePrSRqTFuQVmdYRPYXkYD/uLeInCsitafjmnpNOmVSdZyaosx9a25aEzUefBDuu8/FpUWjcN11NtpgTHsnIgfWs69nc9alvYotxvGjI3+UMEKsaHWqtflvz6ciUlFdVtcgRijkBi2SxVYSLSmxlGvGtFbpjgyvBHJFpAfwZ+BS4NFMVaq98vI8zjzqzOrtymhlg6PDMeXlNUned+2y0QZjOoDi2AMRWZa0b1HzVqX98vI8Jocmk5uVW535RxACEmDzV5vZ9u9t6V3Hv5M3fnziCLGqu7s3dKilXDOmtUq3Myz+CkQ/AR5Q1QuAExo4BxE5Q0Q2icj7InJziv2dRORJf/9fRSTfL88XkV0iUup/PZT+S2rdDu1yaML2yo9WprXqUSiUGDu8aBHcdFMTV84Y05rEB7N+u559Zh/FRojD/cNkB7JRlMpoJbPXzWbJ35eQHchGEDoFO1HUt6ju6/h38h58sPbk58pKS7lmTGuVdmdYRDzgEuAFvyxFMpmEE4LATGAEcDxwsb/MZ7wrgH+p6lHAvcA9cfs+UNUC/2t8mvVs9Yr6FiUsB/ruF+8y9NGhaYVL9EvK9Dltmi3CYUw7pnU8TrVt9pGX59HzoJ5EtSZ5cFSjRKIRrii8grtOu4vlly3Hy/MavFaqlUTBdZBzcizlmjGtTbqd4euAW4Bn/fQ8RwLLGzhnEPC+n7i9AlgIJDcPI4HH/Md/BIaLJP893b7ElgONVxmt5MrFVzbYIU5eiEPVFuEwph07RERuEJFfxD2ObbedJd/akFB+iGAgcZxHUQq/W0goP0RxWXFad/Kg9kqi2dkuXGLGDDcybO22Ma1HimUdalPVFcAKAH8i3Req+rMGTusBbInb3gqcXNcxqlolIl8BsVwJvUTkLWAHcKuqrkqnrm1BUd8i5qybQ0RrFrWPjRCvGLOizpGHcBg++MCNCKs/LhRbhMNreLDCGNO2zAEOSPEY4OHmr077F1ud7qG1NZF5UY0ycclEAhKgKlpFTjCHZUXLGhwh9jxYsQLmz4dtftjxtm3ws5+5djsYhLFjXQpNz3Od4+JiN2ps7bkxzSutzrCIPAGMByK41YkOFJH/UdVpGarXp0BPVS0Xkf7AIhE5QVV3JNUrDIQBevZsO5OrY8s0j39+PBp3tzM2oa6+RvYeP5AkNoFOFV56yRpQY9obVf3PuvaJyMDmrEtHUtS3iIffepiqaFV1WWW0EkESskykEy4Ra5NDIRcrHC8SgVmz4LHH3Gjxdde5Y3Jy3EQ8a8+NaT7phkkc73dERwEvAr1wGSXq8zGQF7d9uF+W8hgRyQIOAspVdY+qlgOo6lrgA6B38hOo6mxVHaCqA7p3b1t3DcP9wzx09kO1Er5v+7rhmctduyZOzli50s1UtttuxrRfInK8iEwRkfeBB1u6Pu2Vl+cx88yZBKV2uIQgiEjCghwNKS52k+dSUXUd4Geecd9tgp0xLSPdznC2n1d4FLBYVStpeALHm8DRItJLRHKAi4DFSccsBi7zH48GXlVVFZHu/gQ8/Pjko4EP06xrmxHrEAfiPobFmxZz3pPn1RuXFgq5W2zxKivd7ThjTPvhZ9a5RUTeAX4PTABOV9UBLVy1di3cP8yqy1cx6LCaFerE/xeJRvjZiz9LO3Y4FEqMHY4Xm1B3/vnueyDgymxhJWOaV7qd4VlAGbA/sFJEjsDF8tZJVauAicDLwHvAU/7kuztE5Fz/sLlAN3+k4wYgln5tCPCOiJTiJtaNV9Uv039ZbUe4f5hw/3D1dpQoizYuqjfDhOfBzJm1U/dsSy8dpjGmDRCRElz2nizgfFXtD+xU1bIWrVgH4eV5zDhjBrlZuQQlSEACRImiKHsie9LOEe95bqR30KDE8kAABg6Ea691eeSvvdYWVjKmpYhq4zL0iEiW3+FtFQYMGKBr1qxp6Wo0SsmWEoY8OiQhRg1gfP/xPHh23XdDZ8+GCRNc4wlu9aPlyy3WzJjWSkTWpjuqKyKLgH64O2hPqOobIvKhqh6Z0Uo2QltufxtSsqWE4rJiVn+8mkWbatY6GXTYIGacMSOt2GFwndvhw90SzTGq7isQcF+xhZWCQZgyBW65palfjTEdV33tb7rLMR8kIr8VkTX+1//FjRKbJhCLUUuOH25oQY5w2H3FRoj37LGV6YxpL1R1FNAHWAtMFpF/AN8SkUH1n2makpfnccuptzBp8CRygjnV5as/Wc2QR4cwe216yd5jK9TF2uxotCYrUHwnOBi0XMTGNLd0wyQeAXYCF/pfO4B5mapUR5QqfvjdL95l2GPD6u0QFxUlxg/bynTGtB+q+pWqzlPVHwHfB34D3CsiWxo41TQxL8/jdyN+R0Bq2uiqaBUTl0xMO37Y86Bnz5pOcEwg4O7s3X+/GxG2bBLGNK90O8PfU9Xb/QU0PvRT/rS6W3VtXXL8MMCeyJ7qRO93r7q7VqObamW66dMt3syY9kZVP1PV36nqYOAHLV2fjqj8m3KSQwsro5VMfT39W3KhkOv4xs/5CARqYoctTaYxzS/dzvAuEalufEVkMLArM1Xq2Ir6FpEVSEz//NS7TzHssWHctvw2hs8fXqtDnLwyXTRq4RLGtHUisriuL+B3LV2/jijVCnUAizYt2utwiR/+0HWCwbXZ994Lt93m4optMMOY5pVuZ3g8MFNEykSkDLgfGJexWnVgXp7HlYVXJpSVHgM/tAAAIABJREFUbitlT2QPEY1UJ3yPFw67pT/jWbiEMW2eh8vPvgqYDvzfpC/TzGLzO7IDtXOlPfPuM+lfx4PJk90IcSDgwiYqKy3PsDEtJa3OsKq+rap9gZOAk1S1EDgtozXrwFKNDscEJEAoP1Sr/J57aqfusXAJY9q0Q4FfAScC/wP8EPhCVVeo6ooWrVkHFu4fZsWYFYw6ZlRCeff9u6cMZauL57mV50QSY4gDAdi82dpuY5pTuiPDAKjqjrglkW/IQH0MNaMPgRQfT1SjdZ6XKlzC8lUa0zapakRVX1LVy3CT594HikVkYgtXrcPz8jyevehZJg2eVD2h7vH1j/OrV3+1VxkmystrUmPGRKMwZ05NuERJCdx9t7XjxmTSXnWGk0jDh5jGSjWZDlxnuK5k77FwifiJGatXw7Bh1pAa0xaJSCcR+QnwB+Aa4D7g2ZatlYnp2qlrrQl1VdEqrn7haiY8P6HBUeLk1emCQTdKHInA7t1u7sfw4RZLbEym7UtnuHGrdZi0FfUtonNW54T8w4oyr3RenY3sPffAuKRo7j17LAbNmLZGROYDJbiFN/5TVQeq6hRV/biFq2Z8ofwQkrwUKBDRCLPWzko54TlebHW68ePd1wMP1EyqU4XnnnPtt8USG5NZ9XaGRWSniOxI8bUTOKyZ6thheXkey4qWcddpdzHq2FHVneKqaFWtSXTxioogKynkePv2DFbUGJMJPwWOBn4OvBHf/orIjgbONc3Ay/O48ZQbU+5TNOWE51rX8ODBB91Xnz6J8cORiLvTZwtxGJNZ9XaGVfUAVT0wxdcBqpp6hpdpUtWrH50yidysXARBUbbvqbt363lwZWJCCqZPd8s3G2PaBlUN+G1tcjt8gKoe2ND5InKGiGwSkfdF5OYU+4eIyDoRqRKR0Sn2HygiW0Xk/qZ6Te3RPaffw6yzZ3HUt45KKBeEnGBOygnPdSkurr0gB8BVV9lCHMZk0r6ESZhm5OV5XHvytShKVKNMfX0qNy2tO3da8uhwNApXX20xZ8Z0BCISBGYCI4DjgYtF5PikwzYDY4An6rjMFGBlpurYnoT7h5l/3vyE5ZoBrj35Wry89HuwsQU54kUisG2bdYSNySTrDLchpZ+WJmxPe31anbOWPQ9mzkycTBeJuBFj6xAb0+4NAt73VwytABYCI+MPUNUyVX0HqJWiRkT6A98B/twclW0PvDyPsQVjq7cVZerrUznhgROq2+m6VhKtvoa/IEdymsw//cnd2bPMEsZkhnWG25Dzjz8/YVtRrn7h6job1nAYRo5MLHv3XRg61BpTY9q5HsCWuO2tflmDRCSAW9QjdTBszXFhEVkjIms+//zzRle0PUmVI/7dz99l3PPjGPro0HpXEo2J5R8Oxi10p+omRv/gB3DrrQ1nlrBOszF7xzrDbUi4f5hJgxOXmotohKmv17328qRJiY0quJWObLlmY0wdrgaWqOrW+g5S1dmqOkBVB3Tv3r2Zqta6VeeIl9r/ta78aGW9K4kmXMdLzCwRE426r+QMQfGd35ISS8dmzN6yznAbc8/p9zDq2MSVj/606U/1hks88EBiuAS4lD3WSBrTbn0M5MVtH+6XpcMDJopIGW4Z6CIR+e+mrV77Fe4f5sGzHky5aBKkP7EuHHYZJpI7xODa81hmif/f3pmHSVFdDf93umfBJYoMKCoD40JQEgICQVsFh2AUFRWjSUzyZcCtBSQJb76EJS4h0aiM+SJZkMUFmcQk5tUwEsUVGUDSguwIioAZBATRQVQis3TX/f64VT3VywyDTA+znN/z9NNVt25VnS6G06fPPUuy8VtSYsuwaTk2RWk4agy3QMafP56g1Lp7GxIuMWNGokHsOFZpKorSKnkD6C4ip4lIDnA9MK8hJxpjfmCM6WqMKcCGSpQYY1KqUSh1E+4X5rUbX6Nnx+ScRRARpg6dCnDQ9s2eQZzszMjPt/o7ErHGrt/4BVuGTcuxKUrDUWO4BRLKD/HQFQ8lNOM4WLiEZxB7IRPGwKOPqndYUVojxpgoMBZ4EXgL+IcxZoOI/FpErgIQka+LyA7g28BMEdlw5CRufYTyQzxy1SMclXVUwrhjHJ5Y9wQXPX4Rdyy846CNOZJ1N0B5uR0bPBjy8hKN36Iim4R3991ajk1RGkpGjeEG1LnMFZEn3ePLRKQg6XhXEdkvIvUmcrRFwv3CXH1WYnZc6abSesuthcNw5ZW1+zU1Wl1CUVorxpj5xpgvG2POMMb8xh27yxgzz91+wxjTxRhzjDEmzxjzlTTXeNwYM7apZW8teI2TBpySWB5iyXtLqHFqcIxDVawqIX44XcWJcBiWLIFLLkn0EldVwdNP24S7u++2715YxKRJaggrSkPJmDHcwDqXNwEfG2POBB4EpiQd/x3wfKZkbOkkh0sAFC8trjN+GKBz58R9rS6hKIqSOUL5IaYOnUpusLaAsCGxs0be0XmANYSHlAxJW3EiFILJk1MTol96CW67zXYZHTdOE+cU5YuQSc/wQetcuvtz3O2ngCHiNnoXkeHAfwBduquDdOESAD9/6ed1GsRFRVpdQlEUpSkJ5YdYOGJhiocYwBjDuBfGEdkeoay8jOpYdZ0VJ9J1FwWIRm2X0cpKGzucXG1CUZT6yaQx3JA6l/E5bozbJ0CeiBwLTAB+Vd8NtM6lDZf4+QU/Txj7tPpTbn321rQGcV3VJZ55BiZM0NqUiqIomSCUH6LvyX1Txg2GymglJWtLKCwoJCeYQ1CCdVacKCqyscHJOE5tK2fHsbHEiqI0jOaaQDcZeNAYs7++SVrn0pKu3BrA3YvuTpuYka66hDHWO/yLX8DAgbbbkaIoitJ4FPUuSgiX8DAYHl71MCVrS5g6dCp3D76bBUUL0rZyDoXgxhtThhP0eSAAFRWNKbmitG4yaQw3pM5lfI6IZAHHAxXAuUCxW+dyHPALEdEkjnoYf/74lM5HOz7bwcDZA9N6iNMZxB6xGIwZox5iRVGUxsQLlxjVb1SKURwzMWasnMG4F8ZRWFCY1hD2SPYOBwKJ9Yizs7WkmqIcCpk0hhtS53IeMMLdvg541VgGGmMK3DqXU4F7jTF/yqCsLZ5QfojFIxen1LWMmRhj54+t00Oc3K7Zw3E05kxRFKWxCeWHmD5sep0xxF7IRL3XCFn9PGqUfV11ldXZYB0cN9yglSQU5VDImDHckDqXwKPYGOEtwE8BLex+GHh1LXOCiQFlNU5Nnco1Xbtm0GLtiqIomcSrMpFcEcgLmaivKhBYY3f6dOslnj+/Nl7YqzWsKErDyWjMcAPqXFYaY75tjDnTGDPAGPNummtMNsb8NpNytiZC+SHKRpQxqOughPFZq2bVm1CXnW09CsEgDBpkPQuKoihK5vAqAiUbxPWt6CVTVmZD20C9woryRWmuCXTKYRDKDzH0zKEJJdcc4zDq2VFMeGVC2oLuixbBb35jDePXX4eZM61nWOOGFUVRMke4X5hb+t6SMh4zsZTSaukoLKztQNeunfUKRyJaGUhRDoWsg09RWiKFBYVkB7OpjlXHxwyG4qXFCEK7rHYJ2cqhkH2NHl3b37662laYmDv3SHwCRVGUtkFR7yLmrJ1DZbQSg0EQAhIg7+g8Itsj8TC3ot5FKYl1oZBtu1xWZg3j9eth7FhbezgQsF1Hx49Xb7Gi1IcYYw4+qwXQv39/s2LFiiMtRrMisj3CzfNuZuNHG1OOBQhwzzfuYdLASQnjo0fbKhPxeQHrOS4qUmWqKIeLiKw0xvQ/0nI0Nqp/Dx+v6ca+qn08GHmQmIkRkACO4+Bgs+Nyg7ksHLGwzkoTkYgNc4tGE8dzc2HhQtXhStumPv2rYRKtGC+hLjuQnXpQqLOguz+hznGscaztPRVFUTJHKD/EpIGTaJ/bHsc4OMYh6kTjhjCQtiudn7Ky2qoSfqqroaREQycUpS7UGG7lhPJDLBq5KCWh7sRjTqT438UpCRpeQl0g6S+jstIqU0VRFCVzFBYUIukKwANZgSze++S9OhPrCgutFzj59EAAZs+GO+9Ux4aipEON4TZAKD/EohsWMXPYTM7ueDYAu/fvpvTtUi6cfWFKlYlwGPonLSQYY5WpKlFFUZTMEcoP0bdzattmsEl1M1fOZNDjg+qsDrRggU2G9pfNdBzrHY7F7LvWkFeURNQYbkOE+4XJPy4/YcwxDmOeG8PoZ0cneBtuuin1/Koqm1CnKIqiZI6b+qZRwFh9bTBEnWidpddCIZg0Cdq3r609bIx9BQJaQ15R0qHGcBvj2p7Xpox53oYhJUPiyjUctuXVBgxIDJkoLYVrrlEPsaIoSqYI9wszc9hMBpwygOxAdkKZTI+DlV4rLEwNdzvrLOs51kQ6RUlEjeE2hqdkux3fLWHcYKiMVjK5bHKCQbxsWWrIRGkpDB6sBrGiKEqmCPcLs+yWZSwauYire1ydcEwQsgJZLN+5PGVVzyMUgmnTEg3ijRut/tZEOkVJRI3hNki4X5hb+92a4m0wGF5+92UK5xQmKNi6QiY0oU5RFCWzhPJDDDh1AAGxX9eCcFbHs4jGopRuKmXGyhkMnjM4rUGcLv+juBhuv10T6RTFjxrDbRSvKUcyBkN1rDohbCIchuHDU6+xe3cTCKooitLGKSwoJDeYS1CCZAez2VSxKaHkWlWsinEvjEvrJU7nzDAGDhyAm29Wg1hRQI3hNksoP0TZiDKG9xieNh7NM4q9mLTx423ihZ958zR+WFEUJdOE8kMsKFrA3YPv5vLul+OY1GLCy99fzoyVM7jo8Yu45u/XxA1jL/+jQ4fU627cCBddpDpcUdQYbsOE8kPMvX4uM4bNICjBlOMBCcQbc4RCthzPgAG1xx3Hxp9ddJHtXKcKVVEUJTN4TTk6H9O53nk1Tk1K+EQ4bOOE086v0ZA3RVFjWCHcL8wtfW9JGY86UdbvWQ+4rUKj93HTpPUJHerAKtMZM2wb0AkTNDlDURQlUxT1LiInmHPwiSR2rPM8xGefnTpv5kyruxWlraLGsAKkV7AGw+jnRjPhlQkMKRnCnQvvZNyGc7ng4oq014hGbXLGHXfYsj7qLVaUI4eIDBWRTSKyRUQmpjk+SERWiUhURK7zjfcRkYiIbBCRdSLy3aaVXKkPL8Tt3m/cy/gLxscT69JhMOQdnRffD4dtaMTMmdCli2+esbo72SCORNS5obQNso60AErzwFOwxUuLeWbTMxhstXbHOBQvLUaQeBxxz6ufY1lZEVVV6a/ldTuaORPmzNG6lorS1IhIEJgGfBPYAbwhIvOMMRt9094DRgI/Szr9c6DIGLNZRE4BVorIi8aYfU0gutIAQvkhQvlWqZ5xwhmMnT+WGqcmZV6AABWfpzovwmHo1QsuvNDqa4/iYti5E77yFcjLg3HjrC7PyVE9rrRu1DOsxPHHEKcruyYIwUCQomHdWbgwMX44HcZo609FOUIMALYYY941xlQDfwcSitUaY8qNMesAJ2n8HWPMZnf7fWAP0KlpxFYOlXC/MItGLmJUv1FkB2orBAUkQG5WbjzvI5lQCH6W/DMIeOIJ+MUvYNQoqKzUFs5K2yCjxnADlulyReRJ9/gyESlwxweIyBr3tVZErsmknEoi4X5hrj7r6pRxg6EmVkPxv4uhS4SpUyE3F0TsKxlt/akoR4xTge2+/R3u2CEhIgOAHGBrmmNhEVkhIis+/PDDLyyocviE8kNMHzadRSMXce837mXmsJncM/geFhQtiHuQ0zFliq0UlA5t4ay0JTJmDPuW6S4DegLfE5GeSdNuAj42xpwJPAhMccffBPobY/oAQ4GZIqIhHU3I+PPHJ3gZPAyG0rdLuejxi6BLhIUL4dZbISvpX0cELr5Yl9YUpaUiIicDfwZuMCa1lpcxZpYxpr8xpn+nTuo4bg54FSfC/cIUFhRSVl7GrJWzuG/JfWmbckD9BjHU6nHQ+GGl9ZJJAzO+TAcgIt4ynT9m7Wpgsrv9FPAnERFjzOe+Oe3ADWBVmoxQfohFIxdRvLSYeZvmJRR4B1u+p3hpMXOvn0tZWWLcmQi0aweTJ6shrChHiJ1Avm+/izvWIETkOOA54HZjzOuNLJuSYSLbIwwpGUJltDIe4tYuq12dnuIprhvqgQesN9hDBPr0sdtDhmj8sNJ6yWSYREOW6eJzjDFR4BMgD0BEzhWRDcB6YJR7PAFdpsssXgzxaze+xvAeqS3ontn0DLNWzqKw0CrIYNC+X301XHqprV2pXgRFOSK8AXQXkdNEJAe4HpjXkBPd+XOBEmPMUxmUUckQZeVlVEWr4onQBsOB6AGKlxbXeU779jYkwo9XZaK42BrC/vhhrTShtCaabQKdMWaZMeYrwNeBSSLSLs0cXaZrAjyjeOawmQmJdQbDmOfGUFIxmh9NK2XITWWM+9VW5s+3zThmzNCGHIpyJHCdB2OBF4G3gH8YYzaIyK9F5CoAEfm6iOwAvo0NRdvgnv4dYBAw0pe70ecIfAzlC1JYUIikSeQo3VTKrJWz0p9TWOvUSDaKFyywY57DIy/PeorvvNO+q35XWjqZDJNoyDKdN2eHGxN8PJBQB8YY85aI7Ae+CqzInLjKwQj3CwMw+rnR8XagMRNjxsoZwAwCpwZ49dXbidZMxvudVVOjJdYU5UhgjJkPzE8au8u3/QZWLyef9xfgLxkXUMkYofwQV/a4ktK3S1OO3b3obgAqPq+gsKAwHjYRClkdXVYG+/ZZb7DHZ5/Z95494Sc/gYqKVE+x6nalJZNJz3BDlunmASPc7euAV40xxj0nC0BEugFnAeUZlFVpIOF+YX52fpp6PNiaxLGuCyBQjQ3zti9j4MABG0OsHgRFUZTMM/788eQGc1PGd3y2g1ufvZU7Ft7BkJIhCYl1oRBMmmRjiGfOhA4dEs/duNHWHs7LSwyN00oTSksnY8ZwQ5bpgEeBPBHZAvwU8MqvXQisFZE12Ni1McaYjzIlq3JotM9tn1KHOE5+BEYOhlOXYY1hwct/fPllXVJTFEVpCkL5IRaOWMi937iXQd0GpRx3jJPQrjmZcNjGBCdz4AA8+ihMnQp3351+xU/jiZWWRkbLlTVgma4SG6+WfN6fsSV9lGZIYUEh2cFsqmPVKccMBvJfh6H/A7MXgZMNruHsb8KhS2qKoiiZxetUV1hQyMDZA4mZWMLxrEBWnU05wBrEzz9vc0D8LF8Oq1fDokXpDWGtPKG0NJptAp3SfPFaN4/qN4qeHZNLR7vkvw6XjwWJ4q+MZ4xdYlMURVGahlB+iIeueChlRe/cU8+lrLyszhrEYGsQH3VUamOlmprEuGKPsrLUeGJFae6oMax8IbyOR49c9Qg5wZz0k/o/TKD/7IQhx4ExY2BW+oRmRVEUJQOE+4WZMWwGQQnGxxa/t5hfvPoLBj0+qM4qE15i3a23plaZKC2Fa65JDIdILrWp8cRKS0CNYeWw8HuJC44vSJ3Qu4RAMLFhRyxm+94nK1FFURQlc4T7hbml7y0p41Enytj5Y+v0EIdCMH26fSV7iEtL4YILYMKE2rlTp9pQialTNURCaRmoMawcNp6X+K/X/jUhe1kQAl2X8b0JrxEMJp5jjFWigwerQawoitJUFPUuIiuQmi4UM7E6k+k8wmFbP76u5hwTJlh9Pm6c9SaPG6f6XWkZqDGsNBr+7OXxF4wnK5BF1Iny15zB9Jo4hkGXpBYEqaqyneoURVGUzBPKDzHt8mlkB7ITDxhY/v7yeuOHwRrE06eT4uAAaxAPHw6VlRozrLQs1BhWGpVQfohJAyfRPrc9Ucd20DYY1mRPZ/H5ncjruxh/Qh3YMj3qPVAURWkawv3CLBq5iFH9RsVjiB0cSt8u5fzHzue035/GNU9eQ2R7hMj2CPctuS/BSA6HYckSGJRasY09e6ynWERjhpWWQ0ZLqyltF68dqDGJhm/FORNg7UKI5eKVXPOykufOPQKCKoqitEFC+SHKysvi3UT9lO8rp3xfOc+8/QxZgSwc4xAMBLn8zMvpfGxninoXEQqFWLTIhkY88IA1gP0YA5deWrsfiVgvcWGhxhErzQ/1DCsZIZQfSt+pLv91GDmYYwo24PcQl5bCRReph1hRFKWp8GrG14XBUOPUEDMxqmPVlG4qZcbKGQyeMzjuKZ4yJX0cMVi9PmiQNZiHDIE779TGS0rzRI1hJWNMuXgKM4fNpNvx3RIP5L/Of4fcklKDePFim5WsVSYURVEyj1cNaHiP4XV3FU1Dcue6cBhee80avtYoNni6PRq1K38aR6w0Z9QYVjJKuF+Y8nHlzBw2ky5f6lJ7IP91uGIM4JDclKO0FAYO1FrEiqIomSaUH2Lu9XNZeuNSRvUbxaCug2if277ec3KCOSmd60Ih25Fu+tPrCX79ESBGsm734ojz8mD0aPtSx4fSHNCYYaVJCPcL0+vEXoktQfs/Ah+fDksnUqs0rXfCq0W8dSu0b69xZoqiKJnEa90MENkeYdDjg+JJ0H4GnDKAqUOnAnDfkvsoLCiMnwewOushYlfMgM/y4O1rEs41Bnr0gLFjba4IwOzZsHCh6nflyKKeYaXJ8FqCBvx/dt/8BQwLw9EfpMz3alfefrvGmSmKojQVofwQi0cujnuKgxJEELICWRSeVkjJ2hIGzxnMnQvvZEjJkHj8cGR7hMfWPGYvcsEDEKjGHzIBsGZNrSEMhxY2EYmoR1nJDOoZVpoUz0N887yb2fjRRjvY/xE46U14fCHEckj+jWaMrUfsKUzNSFYURcksfk/xrJWzGDt/LFEnSvHS4oR5B6IHGPfCOKYOnUpZeRnRmOtNzn8dbiiEV+6HbWlqsLk0tPxaJGLnVVfbffUoK42JeoaVJieUH+KRqx5JLPruVpmg/0wIeIl1td4EEdi3z1acuOMO9RQriqI0FRWfV+AYB5NUI95j+fvLGTxnMHlH5xHwlZWQ/GWM+tPfmTlT6NIl9bzu3aF3b1i//uAylJV9cY+yohwMNYaVI0IoP8SikYsYcMqA2sH812HYGLhhIHTa4JttCOZU8sADhpoacJxET7GiKIqSOQoLCskJ5tRbcaIqVkXF5xXx7nYBCdAuqx1FvYsIh+Ef/0jtWrd5MyxfDrfeasuv1UUkAss37EICtRWItKGH0phIclOElkr//v3NihUrjrQYyiES2R6hcE4h1bHqxAPbz3PDJrJJ/M1mlXF2ts1cBg2bUFoOIrLSGNP/SMvR2Kj+bf1EtkcoWVvCw6serk2CTqJP5z6cd+p5nHPyOVR8XpGQXBfZHqH4Dx/zzO+GYhzB6nKDp9MDAVueDaxOz8uDigr7/uOfxKiqMhCIEvjyC1zV7zzGj+msOl85JOrTv2oMK0ecyPYIE1+ZyOL3Fice2H4ezJ0De7tD3CNh/17HjxeGD7fhEtXV1kuwYIEaxErzRo1hpaXjGcW79+/mnYp3anM/fGQHslk00norysrL2Fe1jwcjD9rqFCtvwTz3R3ACgOcqtvq9oAB27SK+AihiX45xwASAGPR/mHt/9zGTBk5qks+rtB7UGFZaBBNemcADSx9IjEtbcTM86y84LECME078nOOP/hLl5XY0EIB77oFJqh+VZowaw0pror4SbMN7DGf+lvmpq35gHR3lhbCnJ6z/AQeP2PR9JwSrmPnUZsLDex2O6EobpD79m9GYYREZKiKbRGSLiExMczxXRJ50jy8TkQJ3/JsislJE1rvv38iknErzYMrFU1h641KG9xheW36t/yO29FrHDSAxIAoE+HjPsZSX1ypIx7HLaR6RCNx3nybZKYqiZIpQfohpl08jKMGUY5sqNqU3hMHmhwy8n+xv38SJXy6HOhLzapH4e4Acnn6+Il7OrSHo94FyMDJmDItIEJgGXAb0BL4nIj2Tpt0EfGyMORN4EJjijn8EXGmM6QWMAP6cKTmV5oXXDem1G19jVL9R9OzY0xrEY3vBjQOhw7vuTC/mzMOwerXdikRs+MQddxouGlzDrNIGpCorSiujAc6IQSKySkSiInJd0rERIrLZfY1oOqmVlka4X5glNyyJOzEEISeYQ4+OPQ56bo1Tw54v3+/uJRrExx5b29pZAjGysg2BoMGhmpdWvcWFv/45s1YevE2p931w551ahUipm0zWGR4AbDHGvAsgIn8Hrgb8AUZXA5Pd7aeAP4mIGGNW++ZsAI4SkVxjTFUG5VWaEV6Ny4QEu/zX4fwH3LCJVE/CzJkOn30W4MMP4cABBwjgxITbHvpfevXbn9AlSVFaMz5nxDeBHcAbIjLPGOPXv+8BI4GfJZ3bAfgl0B/7H22le+7HTSG70vLwnBiR7RHKysvirZr/telfdSbbxen/MGA4dvm97N/TyR007N9fO8U4QpQaOvddze7VfWDlLThrRjCaS+h1V696dXtZmc0ricVqy7FpbomSTCbDJE4Ftvv2d7hjaecYY6LAJ0Be0pxrgVXpDGERCYvIChFZ8eGHHzaa4ErzIZQfomxEGcN7DLdLcV7YxKnLoNsitwSbzUg2RnjiCcNLL3kZygYIEv38aMrKy3SpTGlLxJ0RxphqwHNGxDHGlBtj1gFO0rmXAi8bY/a6BvDLwNCmEFpp2YTyQ0waOCnuzHjoiocSQigCUofJ0f8ROk4aQPeiB8jq+C61VSa81b8AODns+/AocLLAZEE0B2fhnZQ8u7lemQoLbYJ1MKjl2JS6adYd6ETkK9jQiUvSHTfGzAJmgU3gaELRlCbE73UoXlpMKY9YoxhsIsZjS8Akl+rxvUd+yr6l2xny68OvPBGJaCk3pUWQzhlx7mGcm+zIQETCQBiga9euX0xKpVXjdRwtWVsCwDknn8O4F8ZRGa1MaeBR/kk5nD4erv6nW1YzN+V6lf8N2qZMMYAgbL2YmWNh97vzGf/jE2rLuCXp6QULVG8r9ZNJY3gnkO/b7+KOpZuzQ0SygOOBCgAR6QLMBYqMMVszKKfSQvCM4gn4BwB4AAAgAElEQVSvTOC3//6tLbfjhU4snYi/ZqXF3XeyKJt7xmEvlXmxZ1rKTVHUGaE0DH9bZyBuHM9eM5vqWHVqVzuvG+naIth/ErwzDJwgEICKs6wx3P492HcaEMQ4htLfXsqzm3/E4j8CO0Jp9bTqaqU+MmkMvwF0F5HTsEbv9cD3k+bMwybIRYDrgFeNMUZE2gPPARONMUszKKPSAply8RSG9xger1/5ALdbdbp0PLWRP5532BrEy5fHkICAGLKyIS8vyH33HZqnwB97VlkJJSWqYJVmS0OcEfWdW5h0blmjSKW0eTzjuKh3ESVrS5i1apZ1bPjJf92+wK7+lf0S3r3YhkfEgH3dfJMFCBCd93uKu7/M+4utfjZGY4SVhpMxY9gYExWRscCL2MrajxljNojIr4EVxph5wKPAn0VkC7AXazADjAXOBO4SkbvcsUuMMXsyJa/SsvB7G8444QxGMxrnrHmw9Oew6UpA3By7IJ6ytPrWoeqk1xg15kJMLEAgCNMfChAOH/yeeWevh8DZEAtijDB7NhQVqaJVmiUNcUbUxYvAvSJygrt/CaAVvJVGxdPh55x8DmOeG0PMxBCEbu270b5de9bsXmMn5r8Ohb+CbYMgZkCM27DDc3hgt00Wpb+9LOEeWVkaI6w0jIzGDBtj5gPzk8bu8m1XAt9Oc949wD2ZlE1pPXhxaRNfmcji/GvjBd2P/XAI+9cNcWd54RNB2DYI4yZnODHDqNExOHFjvUXcI9sjjNswBKf372DFLUCQaFS9DkrzpCHOCBH5OjYU7QTgShH5lTHmK8aYvSJyN9agBvi1MWbvEfkgSqvH099eFYpQfoj7ltzHug/W4RgHQfjmRcfR54KXKCuDdl/az9KHv0OsOorn6EiP4dxzhbIyKF20lbK31nNKr3cY/92BB60s5K+K0ZKqELVUuZsD2oFOaVXMWjmLpzc+zbU9r2XruhMpvvkycHLco+kS7AAc5Kx5LH3ppNoEDFep5FUMo+KtXizfO59nVi/FHLUHXvg94uTSLjeoccPKIaEd6BTl4ES2RxhSMoTqWDU5wRwWFC1IMO4mzC6l+IllcNRHMP9Pdep4CdgSm8bBNm0KRAn0LeFn3xpCe3NGQpicl3S3T7byu1fn4HR7ldyCVSn3bq4c7Jkp9evfZl1NQlEOlXC/MOF+bsxDP9j52TSemH4ybLrK7W1f28nIv8Rm3r6awsJlXD66mM9rPuflBdWYoz6CF8+AqAPmMpBLIFhN4LKfckrW1/j+lacQCg1v+g+pKIrSignlh1hQtKBOL2f7M99CBk6xyXe7+8KKMHYBxNPpDoiD8YdTmCyIBXHeuIniNwIEApCbaxPswCZHV1WB45wOchcEJ1I18hLKystahFFZVl5GdayamIlRHatuMXI3F9QYVlo1f/nxbdx2TYTiJ3/HplfP5e0XL8A4Xt1Lfy1LQ/W751L6868TN5jFcQ3oAHFlGhWcXb3ZMWwMxe8Br4xnysVTUm+chJZkUxRFaTjJVSj8FBYU0i6rnS3R1rsE1oyAaI5V3V/9K+T+F1beRKKBHMPqcjvmONb4LSuzR6uqDY7j6n6TBVEwC39J3hWdE+7dXEMRCgsKyQnmUBWtQkTIOzq5ZcORp7k+O1BjWGkDhPJDzP1ZCH5mjdLiabtYuv3ffBh7J01JNl81CuONGd97AFbfAL1t3cwH7g9yxv719ccba0k2RVGURsPvOd5XtY9iLobyi6CgzCbcPfsQmGziXuFjd8J+z6it1feOA3l5wInrceQMIAdrLMeAIObdwfz4e0KvV+2ZxdN28a931mN6P0dW4EVubD+HouHd0urzpjb8Qvkhpg6dytj5Y4mZGONeGEevE+vvzteUNPcwDjWGlTZFKARzQycT2X4KQ0p+yAHEVqBIKMnmJ02ccSwLXngQdvfBOFmMWeKwemoJRcO6p/3Pre1AFUVRGpfEikKzGPPcGBzjkB3MoWuH7mzxT95/Cv5VQE+XS8Dh108+x4GaA3BqBbx3AZgY/tCK6uoYEyd/xJJXTsA4nYFbYOUIqsUw0+Qw54+pDo7I9giFcwqpidWQHcymbETThCxUfF6BYxwc42QkVOJwVjibexiHGsNKmyTuWRhUxr4t/+KR4jPY+/ZXIbkAfBxfLBpB2Pl1rAEtxKpjzPjNl3lk9XgW3zmFUH6ICbNL+efze/nWZR0YXjicnJxaz7CW+lEURWk8kitSlORtZsuCKojlUFtxotYI9raN47Dz1StIdIL480kMxhgWv9w+MefEybbHCKR1cJSsLaE6Vg1AdayakrUl9Rp+jeVF9kIlPO9rYUHhF75WiowRGPyNGNXVQk6OYeGrwUMyiA9VtqYOLVRjWGmzxD0LA2HKDTDh/q3Mni0c2Pcl9u/pSEodywRD2YtFc0Mndp5L9NFXuDR4Je0+7s+H/5gMJkjxP6vZ+btpTP3rIB6du5VTer0DXQYCWtpHURSlsUiIMR4GD6/6JrE137dhbU7Q2sMxLwfE0+de/og/JM4hwYts/HPc74BADYFgACdmMMEYeWe/A9QdKgd1G3eR7REK75lEzdYLyD5jEn8Mf5+Kzyu+kA49WOKh/57Jcw6mu0tKt1FVdSqYIFVVNZSU7iAU6pYy73BlA5g1C8aOtaupXpJjpg1iNYYVxWXKxDOYMrE2xreyymCIEQiAiQWxVQjTeRhqvQWfPfYPPqs+lrjCjeXyRHE/njjnj3AgD7LLeH7OXfzhq29Q8VavBMU4q3Q9Tz9fQaeOwpNvLCDW7gOClc8zbcyx9cYkNxeae0yYoihtg1B+iIdG/ZCx88cS7fMXgtuG0L3vTt7aEID502rbOycYwe720XugMs+d4w+tcGx5tq5LodNbOJ1XwYGOOAVljF63HPKnE+4XJrI9wu63TyPw2u043RYQ7PoGx314KUO+kz5vpOTZzVQ/Nh+iOVQvdLj1/bFI/0dol9XuoDo0nYHt/1GQ7ng6PQ0wpGQIVeV9CWw7kP47p2ARBK+zjU+CNazKfZDI9u8eko735paVlyXsJ3+m226DaNT+m1RVGcrKRI1hRWlqQiGrrMrKhMJC+1+kpARmz4aaqAFiOE7AdRIkGcTVx7lX8S277RwAO8+N17ms6j6fMVvPBqdWMa7/YD23fucMqDkb6624AAgSlRhjFjn0Kjv0X8ZN7aX1x4RVRisPujSoKIqSKZJDJ9bvWc+tR90KJ70Ja4tstQmT7TvD9Qh/3pHEKhQ+vvo3eOs62HYhBBy4/DZ75uLx3Pre40zvvIZ1L/bBWf1jm1sivyTW41/8vy/twVQbnJhQWRWjpHQHdHmfsvIydm8YYithkAWOgfl/wpy0nqr85fXG1R4sMXvC/Vv57R0FGBOgXa7EjyfH7pY8u5lVL36VA5uegM2X4ThZjF1s6LUw8XpFw7rz2JrLqdl6PqZgISuyljOkZFaDnR5e8vq8d9bhfO1f5BRMThtLXVYGMafW2eRQQ97ZmziY5/1wUWNYUdIQCiUqglDItl72DOT162H0bTGcKNR6i/1xZ35F6ivNFgvC29cQc48cqIxy+c+f4r/vdYeadr5rZcXPidXUUDxtF0yDNVt3wzEf0GfoOi4787IU77LHkUjgKCwoJBgIEovFMBhmr5lNUe+iZmUQaxiHorQd/F5S7/3pjU/T6fKlrFq+go8X3Ey7A6fTtfdWPno3n43LTrF62gt/S1gFBN78vqvaXcP12enunazhtkZwqxC5XmdjrL4PVEOgGiSAkRgzXp3Pw3v/CvkRgjUvQuAVez3EeqTXFmHyl5F3dF6CzmJHKO7p9SdmH6h0+NYtm+madyI3/eAEOHE9xbf3iLetrqxyKCndTln0r+QdnReP3Q3uvJBHf/MDaqoDwDnxzxKLmpQ46FB+iLI77mNy2WRe+c/yBifpRSLWmfToo1BT0xkIw6oRVI8cnNZhUlgIgawaYtWB+A+O1VlZwPR0l2801BhWlAbiN5BDIejVK2g7Fu2DB37r2C5HcTxjOODbTo4/tvFo+5Z+h8TluqR3I5Q+caJ7LVseqHzhYErFgBMlkB1j+pPvJCxrFS8tTkjgKF5azNzr59b52WaVrmfqrL0IMOzbH9P+zLcO2WAM5Ye4sc+NzFw5E4Mh6kQPOWP4YEkTXijJtZflHXLoyKGEcXgKHOyPIK3+oSgtn4SmTN/yHzkpniBWVRUDY5tyIDGcmN+4hVqvsZAYc2ySVgv9IXRZcPIb8KX3YfPlsPIWYmtGwIghxKiyNe3j1w3AypsxnVcxRsZgtp+H859ByNGPIy/2hVgOuTnCj34Ejlc72Qi7N3yZ3cDyxYZO/T6NG8I20S/KzL3fRxa+Tm4wl6lDp7J612pWbb2U5TVC4vePITdHyMuD++5LDcGYXDiZJe8tOWgiXGR7hJJnNzP7pz+gusoLM3TvE8uG8kJW7XqVyPYI7Agl6NsrfzOV0hc+ri2Vx6iG/yN/QbQds6I0ApEIFBfDpk3QowdcdhmMHhPDidURl5YQc0wd48lJe37Ps2d5B0Bq4Bt30f3qp8kKZBF1omxem2eXAgF6lxDIX85VPa5i7zs9+GjjV/hy/11cNrg9FZ9XsG/L2RTfMhRiue5tonDFbRx13l/i8WR1eVP9RuNxx0HZ6x+z6oTbMX1nITvOp/uOu+mR14PxYzqnJI34r+klL1a82xVMkNwcSVn2m1XqhpJEcyBYzfD7/sT47w5ssLE9enoJMx773D7T3iUMv7hz2h8IkYj9Aqiuts8+kB1l+j/ebpS4bW3HrCjNF+/HeF4eVFRYPTDt2UU8cX/IVpMQx40l9hvEyXhJeIGk8Zir0j0jOgod37ahdZ+emnRNY8PqTnsJ/nOpayNbI916rmMgruc5ISHQfT/6A5ujYqQ2nKP/IwAIwlkHbuCdlafgHLUHM//3tbofkIDDz38W5Pd/iFFVaS/Z6dxX6NRtDx07Cj2PGcg5oU9ZnfUQAOecfA6rd62Ob1d8XkHe0XmMe2EclQv/B/Pqr3zedpdgFYwcjOQvI/v9QZjHF7jeacjOMfzpyQ3cNv82ou9eQOC0JUwfVRSPxz6clb369K8aw4qSIWbNglFjYphYslKElFjjtMavfy51HHMVb/ttcPx2OGqvHX7nCnBy3NNjcP4DUNXeZlbHshIV5JKJsOAear0criK+YjQdLvwn+yr34eAgCGd+/kOyt11sjekzL+NH3+0VNxr9dLj4EfYu/GFcyUpWDQPvvIuefT/huHbH8WDkQaJOlGAgyDf2/o2Xpl6b8HkDQYfwLQE4bhu7Oz3J3s/3subJ4Xz6Vn+rWN0fAFkX/ZZpl0+r9fb48BRnXsUwVr/Yi4cfjhKLuZ/RVcbDv9mZ8eePhx0hiqft4v3PdnHKcafwzBMnYeJNV2IELv4lrz12xWGHVqgxrCgtD29Fqs9p+fz+VwXWSEwxdtMhpFSnANIby/6xdI4Qh9rwDZLm1WWYO3BBMXzzF7VDL98L/x5fa2B/5e+wrRA+7YLnXMntvI2qXaeTuLLpyicxsnNARlxMzSmLbUvs7edBeSFUHge7z4Gz/4n0fwSz/VyYs8B6ggMx6D6/VuZjP4DOq+Cta2HrJb7PFePY0zbx3+1n2u/OYDWBkZfwtf7/Zf0H63GMQ0ACXNnjSsafP/6QdLIaw4pyhPB7Ts85B6b/7T+sWZwPjrf0lo50nuE0zT/qrInsvw6+eYntpyEGndfBgePhk9NT7y8x29p075chq9Ieeu+CWm9Dpzfhgz6+z+GTK3s/1ByDX8Ex5A4YeD+suBlW32SXDM98HhbfCZ/mJ34mqQEJ+Bzgxn1mQcCBYA2MHOwuoUGfzn3gvRA713cn97jPqPr0S+w96Z/ETNQq42guidnjrjwFZbB2BKy+0Sps794EaksqSRSuGMMJFzxNtxO6URWtotMxnejZsechx0SrMawoLRu/93j1atj4nwrWbaxi3/bOJOaP1OXY8BuvieEJiJOmlFu6ayXpdonCaS/Du0PTXDdmPdBZ1Um63n9d23EvXjEjIbEw3XdPFDq8C2c/DRU9YNOVPo+3ywX3WwfM/pOs4et2beXxhQme6Np7+/F+GLj3OuMVKPxVXN975AZzWThiYYN1sBrDitKM8CvT55+H99+3y3GffmorVlTXGIwDgYBdsorFcBWN5x3wG3V1UV/4BdStYOs7nm5eQ3GgwxaoOgb+e2o987zP6G3XJVMMOr0NX/6XVbgfnm0zvBMK7DvQ7hOo7JBGZleej0+3S48pZZYcUu7b7TXrefc8Ggc6kn36v1l05/2NooxbMqp/lbZMPN447jG2uuTEE2HPnobqXscNfTjYCiFJx33G6d7TiSdf13kv/3jyu/cK1HNuOq92umv6iVn9GW3nNqzyrUImzE922Hj3crc7r4NgNRQshHafQsEi7h1xJZMGTkojTxoJ1RhWlJZBupg1sAXPdzsbYNc5/OvvJxGL1WUM1xdvnC4sA99+XddIvlc6JZou/jndtUmakyzToXyWdBzMc55Okdfz5ZRikCddK6uKUX94iumji+qQJ+mqagwrSqvE09379sGaNXCtG/l16621c+JhvgkYEEN2tiEgQaqrk+fUpYc8Ped5Vv26tC4PNNSvSw8lVC/dd0pDzktHXXrb7/xJvoaBrEpm/u/WBudz1Kd/tZqEojQjkku61Y53A7oBELnNhl7s3m2P7d0L27bB9u3gOOBXiN27w+bNnlKEtAoF7xyHQBA3exrfeENCNZK9C+mUbF339fY9pZ9srKYz3Osy6v3XTPeDIZDmWF0ekuTnkCxT0LZ7Lb8ozX0URWlL1KW7AZ5+utY4HjPGlkMD213tD38QKiqk1vERL0Nm97Ozrc6qqQEJGDp1rWDPtjy7oiUxOpzyKR/vOgHjBBCxBjdAMMvhlLN2sG1dV1J1sT/+uFb3Gwdf1QcHui0h+P4FxGrqCt2oy6mRbAQfTN8mH4PEHwHprhEg4BxFxVu9YDiHTUaNYREZCvwe+7PlEWPM/UnHc4ESoB9QAXzXGFMuInnAU8DXgceNMWMzKaeitCTqUrrpPBPhMMyaJTz9NPTpY0Mxdu+G557zlK3EFWhuboCpU20c3MMPS1xhe3NqvRWeknJADJ2+uoa9b52D4xiMRBGThXEECRhOOv0Ddm/pTFoj3H9RcejzrZdZP+9iYjV+peeWDkohnTHdEPzGbrrz6zKMSRq328FggKLh3Rp4b0VR2hrhsH159OpVf9lGr6a9fw54JScDQCdfs40g993VgXHjaptvTJ3qrSoGCYW6MWuWNa7f3/M5O7e1A6BduwDfGrGDvz18MphAgu73mksFs2L8aWoHep2UxcTJH/HaKx1wjHHDODy9XJfe9Y2nOHXTGbeOzUMx4oatAYEagoFsYtG6Pc7BYO2PiMMlY2ESIhIE3gG+CewA3gC+Z4zZ6JszBviaMWaUiFwPXGOM+a6IHIOtAP1V4KsNMYZ1mU5RGo6/ni+kadkZSa+MvfANfxhHKFT/9TxlXF0NVVW29Nz48XZe8peCd9+N/6mgMncbN92QTa+TetV6wo/dDZ1XsWFBHzav7oxnmIrAwIHQoYO93t4DFWzbtR850JGuJx8DwNKl1vYOBODUU+G998Aa5THO/toBuhQc4JV/5eE4Nm4vEICsLOG88+C11zyvey3BIDz0UOIX3cHQMAlFUQ6X5HrsB6vPfijn1XWt5BA+L4EQbHK4f/uJpz/i3e1VfL+okuEXnRHX350718599FGIRq0evfnm2u8Zr6pPiu4Hysth3Tqrx4NBmDat8fRvJo3hEDDZGHOpuz8JwBhzn2/Oi+6ciIhkAbuBTsYVSkRGAv3VGFYUJZlDbYxxKF8EdRn7/i+AL9KMQ41hRVGUhhvwjXUeHDlj+DpgqDHmZnf/h8C5fsNWRN505+xw97e6cz5y90dSjzEsImEgDNC1a9d+27Zty8hnURRFaQzUGFYURTky1Kd/G1I1utlijJlljOlvjOnfqVOnIy2OoiiKoiiK0sLIpDG8E8j37Xdxx9LOccMkjscm0imKoiiHgYgMFZFNIrJFRCamOZ4rIk+6x5eJSIE7ni0ic0RkvYi85YW4KYqitFYyaQy/AXQXkdNEJAe4HpiXNGceMMLdvg541WQqbkNRFKWN4CYwTwMuA3oC3xORnknTbgI+NsacCTwITHHHvw3kGmN6YSv93OoZyoqiKK2RjBnDxpgoMBZ4EXgL+IcxZoOI/FpErnKnPQrkicgW4KdA3HshIuXA74CRIrIjjSJXFEVR0jMA2GKMedcYUw38Hbg6ac7VwBx3+ylgiIh4hZCOcVfrjgKqgU+bRmxFUZSmJ6N1ho0x84H5SWN3+bYrsV6IdOcWZFI2RVGUVsypwHbf/g7g3LrmGGOiIvIJ4NV4vxrYBRwN/I8xZm/GJVYURTlCtOgEOkVRFKXRGYCtqn8KcBrwf0Xk9ORJIhIWkRUisuLDDz9sahkVRVEajVbTjnnlypUficih1lbrCHyUCXkOEZUjEZUjEZUjkZYsR1O1qzuUBOYdSQnM3wdeMMbUAHtEZCnQH3jXf7IxZhYwC0BEPlT9e9ioHImoHImoHIk0qv5tNcawMeaQa6uJyIrmUPNT5VA5VA6Vo5GJJzBjjd7rsUauHy+BOYIvgVlE3gO+AfzZ7QZ6HjC1vpup/lU5VA6VoyXLoWESiqIorYzDTGCeBhwrIhuwRvVsY8y6pv0EiqIoTUer8QwriqIotXzRBGZjzP5044qiKK2Vtu4ZnnWkBXBRORJRORJRORJROVoHzeX5qRyJqByJqByJtEo5RHtcKIqiKIqiKG2Vtu4ZVhRFURRFUdowagwriqIoiqIobZZWbQyLyGMiskdE3vSNdRCRl0Vks/t+gjsuIvIHEdkiIutEpG+G5ZgsIjtFZI37utx3bJIrxyYRubSRZMgXkYUislFENojIT9zxJn0e9cjR1M+jnYgsF5G1rhy/csdPE5Fl7v2eFJEcdzzX3d/iHi/IsByPi8h/fM+jjzuesb9T9/pBEVktIs+6+036POqRo8mfh4iUi8h6934r3LEm1x8tlTr0nupf1b+qf+uWR/VvrQxNq3+NMa32BQwC+gJv+saKgYnu9kRgirt9OfA8INi6mssyLMdk4Gdp5vYE1gK52O5PW4FgI8hwMtDX3f4S8I57ryZ9HvXI0dTPQ4Bj3e1sYJn7Of8BXO+OzwBGu9tjgBnu9vXAk430POqS43HgujTzM/Z36l7/p8BfgWfd/SZ9HvXI0eTPAygHOiaNNbn+aKkvVP/6r6v6N/G6qn/Ty6P6t/ba5TSh/m3VnmFjzGJgb9Lw1cAcd3sOMNw3XmIsrwPtReTkDMpRF1cDfzfGVBlj/gNswbZHPVwZdhljVrnbn2Frj55KEz+PeuSoi0w9D2NsCSmwSjAbMNhmA0+548nPw3tOTwFDREQyKEddZOzvVES6AFcAj7j7QhM/j3RyHISMPY967tek+qOlovo3QQbVv4lyqP5NQvVvg8jY/5dWbQzXwUnGmF3u9m7gJHf7VGC7b94O6lcSjcFY16X/mOfubwo53CWVc7C/go/Y80iSA5r4ebhLQWuAPcDLWK/HPmMbFiTfKy6He/wTIC8TchhjvOfxG/d5PCgiuclypJHxcJkKjAccdz+PI/A80sjh0dTPwwAvichKEQm7Y81Jf7REmtPzU/2r+lf178Hl8GjV+rctGsNxjPWvH6nactOBM4A+wC7g/zXFTUXkWOBpYJwx5lP/saZ8HmnkaPLnYYyJGWP6AF2w3o6zMn3PhsghIl8FJrnyfB3oAEzIpAwiMgzYY4xZmcn7HIYcTfo8XC40xvQFLgNuE5FB/oNHWH+0eFT/qv5V/WtR/ZuWJtW/bdEY/sBzn7vve9zxnUC+b14XdywjGGM+cP8TOsDD1C49ZUwOEcnGKsAnjDH/dIeb/Hmkk+NIPA8PY8w+YCEQwi6veJ0Z/feKy+EePx6oyJAcQ93lTGOMqQJmk/nncQFwlYiUA3/HLs/9nqZ/HilyiMhfjsDzwBiz033fA8x179ks9EcLplk8P9W/qn/rkUP1bxvUv23RGJ4HjHC3RwDP+MaL3KzE84BPfO74RicpnuUawMt0ngdcLzZb9DSgO7C8Ee4nwKPAW8aY3/kONenzqEuOI/A8OolIe3f7KOCb2Pi5hcB17rTk5+E9p+uAV91fppmQ423ff3jBxkX5n0ej/7sYYyYZY7oYYwqwCRmvGmN+QBM/jzrk+D9N/TxE5BgR+ZK3DVzi3rNZ6I8WTLN4fqp/Vf/WI4fq37aof00jZiA2txfwN+ySTw02huQmbFzNAmAz8ArQwZ0rwDRs3NJ6oH+G5fize5917j/kyb75t7tybAIuayQZLsQuKawD1rivy5v6edQjR1M/j68Bq937vQnc5Y6fjlX2W4D/BXLd8Xbu/hb3+OkZluNV93m8CfyF2oznjP2d+mQqpDaLuEmfRz1yNOnzcD/3Wve1AbjdHW9y/dFSX6j+9cug+jdRDtW/dctUiOrfJte/2o5ZURRFURRFabO0xTAJRVEURVEURQHUGFYURVEURVHaMGoMK4qiKIqiKG0WNYYVRVEURVGUNosaw4qiKIqiKEqbRY1hpVUiIjERWeN7TWzEaxeIyJsHn6koitL2UP2rtDSyDj5FUVokB4xtsakoiqI0Lap/lRaFeoaVNoWIlItIsYisF5HlInKmO14gIq+KyDoRWSAiXd3xk0RkroisdV/nu5cKisjDIrJBRF5yuxchIj8WkY3udf5+hD6moihKs0P1r9JcUWNYaa0clbRM913fsU+MMb2APwFT3bE/AnOMMV8DngD+4I7/AVhkjOkN9MV2wwHblnSaMeYrwD7gWnd8InCOe51RmfpwiqIozRjVv0qLQjvQKa0SEdlvjDk2zXg58A1jzLsikg3sNsbkichH2BakNe74LmNMRxH5EOhijPObAikAAAE/SURBVKnyXaMAeNkY093dnwBkG2PuEZEXgP1AKVBqjNmf4Y+qKIrSrFD9q7Q01DOstEVMHduHQpVvO0Zt/P0V2B7pfYE3RETj8hVFUWpR/as0O9QYVtoi3/W9R9ztfwPXu9s/AJa42wuA0QAiEhSR4+u6qIgEgHxjzEJgAnA8kOIdURRFacOo/lWaHfqrSWmtHCUia3z7LxhjvPI+J4jIOqx34Xvu2I+A2SLyc+BD4AZ3/CfALBG5CeuBGA3squOeQeAvrsIW4A/GmH2N9okURVFaBqp/lRaFxgwrbQo3Zq2/MeajIy2LoihKW0L1r9Jc0TAJRVEURVEUpc2inmFFURRFURSlzaKeYUVRFEVRFKXNosawoiiKoiiK0mZRY1hRFEVRFEVps6gxrCiKoiiKorRZ1BhWFEVRFEVR2iz/H9GjIHEHN3R4AAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "<Figure size 720x288 with 2 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "f86dWOyZKmN9"
+ },
+ "source": [
+ "Great results! From these graphs, we can see several exciting things:\n",
+ "\n",
+ "* The overall loss and MAE are much better than our previous network\n",
+ "* Metrics are better for validation than training, which means the network is not overfitting\n",
+ "\n",
+ "The reason the metrics for validation are better than those for training is that validation metrics are calculated at the end of each epoch, while training metrics are calculated throughout the epoch, so validation happens on a model that has been trained slightly longer.\n",
+ "\n",
+ "This all means our network seems to be performing well! To confirm, let's check its predictions against the test dataset we set aside earlier:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "lZfztKKyhLxX",
+ "outputId": "f48f33ad-aba0-4c62-ba15-cc742bd23805",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 299
+ }
+ },
+ "source": [
+ "# Calculate and print the loss on our test dataset\n",
+ "test_loss, test_mae = model.evaluate(x_test, y_test)\n",
+ "\n",
+ "# Make predictions based on our test dataset\n",
+ "y_test_pred = model.predict(x_test)\n",
+ "\n",
+ "# Graph the predictions against the actual values\n",
+ "plt.clf()\n",
+ "plt.title('Comparison of predictions and actual values')\n",
+ "plt.plot(x_test, y_test, 'b.', label='Actual values')\n",
+ "plt.plot(x_test, y_test_pred, 'r.', label='TF predicted')\n",
+ "plt.legend()\n",
+ "plt.show()"
+ ],
+ "execution_count": 16,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "7/7 [==============================] - 0s 2ms/step - loss: 0.0102 - mae: 0.0815\n"
+ ],
+ "name": "stdout"
+ },
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAXwAAAEICAYAAABcVE8dAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nO2de3hU1dX/P2smCVFR0UBVRESp+mqNgCJ6fgKOYkHrDaXWqjVilYAFX2kVkL61ptoKRFtpUZQIKBFErQiK2reUyMhtvABieQutgqKCqDRe6gVymdm/P/aZZDLM5DrJ3NbneeaZmXP22Wefc2a+Z521115bjDEoiqIomY8n2Q1QFEVROgYVfEVRlCxBBV9RFCVLUMFXFEXJElTwFUVRsgQVfEVRlCxBBT+DEZFrRGRZstsRRkT2E5GlIvKliPw5CfsvEZH57ueeIvK1iHhbUc8vRWR24lvYMYjIYyLy22S3ozEir1WC6035Y29PVPCbgYhcLSLrXIHYJSJ/EZGByW5XUxhjFhhjhia7HRH8EDgMKDDGXJHMhhhjPjDGdDbGBBsrJyI+EdkRte09xpgb27eF6YWIjBSR1cluh9I4KvhNICK/AKYD92DFqicwE7g0me1qChHJSXYbYnA08LYxpratFaXo8SlKamOM0VecF3Aw8DVwRSNlOmFvCB+5r+lAJ3edD9gBTAQ+BXYBw4EfAG8DnwG/jKirBHgGeAr4CtgA9IlYfzuwzV23GbgsYt1IYA1wP1AJ/NZdttpdL+66T4H/AJuAkyOOsxzYDbwP/ArwRNS7GrgP+Bx4D7igkfNxIuAHvgD+AVziLv8NUA3UuOf0hhjbNnX824FJwN+BKiAHOBNY6+7vLcAXUf4Y4BW3rr8BDwDz3XW9AAPkuN8PBR51r+HnwBLgAGAPEHLb/DXQ3W3n/Ij9XOIe6xfusZ8Y1ebb3DZ/6R5bvruuK/CCu91nwKrweY9xbv4IfOheu/XAoKjz9rR7Db9y29I/Yn0/91x+5e7/SeC3cfbTG3gZ+xv6N7AA6BKx/ijgWfe3Uume0xOBvUDQPUdfuGX9wI1Rv9HVLTim+XHauAW4KOJ7jtueU93vfwY+ds/3SuB7EWUfCx97dHvcZQb4bsR/+z7gA+AT4GFgv5Zeu1R6qYXfOA6QDyxupMz/YEWnL9AHGIAVzDCHu3UcCfwaeAT4CXAaMAi4Q0SOiSh/KfYHeyjwBLBERHLdddvcbQ7GCuh8ETkiYtszgHexTyK/i2rnUGAwcLy7/Y+wf1iAGe6yY4GzgSLg+qh6/4X9kZcCc0REok+E286lwDLgO8DNwAIROcEYcyf2KekpY10pc6K3b8bxA1wFXAh0cY/zRezN7VCssC4SkW5u2SewQtIVuBu4Ls4+AR4H9ge+57b9fmPMN8AFwEdumzsbYz6KOubjgYXAeKAb8BKwVETyIor9CDgfewM6BSs0ALdiDYJu7rH8Eis4sXgD+xsLn5c/i0h+xPpLsELeBXgeK8S47VjiHt+h2HM7opHzIMAU7I3tRKzAl7h1ebEi9z72hnkk8KQxZgswBgi456hLI/W35JjisRD7OwgzDPi3MWaD+/0vwHHY67gBe9NqDVOx/5e+wHep/w9Dy65d6pDsO04qv4BrgI+bKLMN+EHE92HAdvezD2shet3vB2J/FGdElF8PDHc/lwCvRqzzYJ8KBsXZ90bgUvfzSOCDqPUjqbfwz8U+VZxJhCUCeLGW90kRy0YD/og6tkas2989hsNjtGcQ1rKKrH8hUBJxfDGttuYcP9Za/mnE+knA41F1/BUr7D2BWuCAiHVPEMPCB47AWvGHxGiTD9gRo53heu4Ano5q807cJw23zT+JWF8KPOx+vgt4DteibOFv83Pcpx+3Pcsj1p0E7HE/D8Y+tUjE+rXEsfBj7Gc48Kb72cFa0jkxytX91iKW+WnEwm/GMcWz8L+LfVrZ3/2+APh1nLJd3Ot8sPv9MZph4WNvfN8AvSPWOcB7bb12yXyphd84lUDXJvzF3bEWT5j33WV1dZj6jsE97vsnEev3AJ0jvn8Y/mCMCWGtiO4AIlIkIhtF5AsR+QI4GWu97rNtNMaYl7FW34PApyJSJiIHudvnxjiGIyO+fxxRz7fux8g2h+kOfOi2O15dTRH3+KPXY/sErgifD/ecDMQKeHfgc2Ot9Mi2xOIo4DNjzOctaGeYBtffbfOHxDl/wLfUn7t7ga3AMhF5V0Ruj7cTEblNRLa4EU5fYJ/IIq999D7y3d9td2CncVXKJd55QEQOE5EnRWSniPwHmB+xn6OA900C+mCaeUwxMcZsxbp1LhaR/bFPN0+4dXpFZKqIbHPbv93drMl6o+iGNW7WR/y2/tddDi24dqmECn7jBLC+4uGNlPkIKzxherrLWstR4Q8i4gF6AB+JyNFYd9A4bJRLF+D/sJZImEYfKY0xfzLGnIa1AI8HJmD9tDUxjmFnK9r+EXCU2+7W1hXz+CPWRx7jh1gLv0vE6wBjzFTsk8EhInJAVFti8SFwqIjEckU09Zje4Pq7rq6jaMYxG2O+Msbcaow5FitavxCRIdHlRGQQth/oR9inkC5Y//Q+brUY7AKOjHLBxTsPYN1uBig0xhyEdT+Gt/0Q6BnHAIp1nr7BimaYw8Mf2nhMUO/WuRTY7N4EAK52l52HvYH0Cu+yqfaJyOER6/6NNca+F/HbOtgY0xmaf+1SDRX8RjDGfIn12T0oIsNFZH8RyRWRC0Sk1C22EPiViHQTka5u+bbED58mIpe7f6rx2BvOq9gORIN9pEZErsda+M1CRE4XkTNcf/g32E62kPv08TTwOxE50L2x/KKVx/Aa1rqc6J4nH3Ax1rfcXOIdfyzmY628Ya5ll++GUfYwxrwPrAN+IyJ5bhjtxbEqMcbswvp9Z4rIIW7bB7urPwEKROTgOG14GrhQRIa45/ZWt81rmzpQEblIRL7rivGX2E7PUIyiB2LdU7uBHBH5NXBQU/W7BNxt/9s9rsux/UzxOBDb8fqliByJNQrCvI69gUwVkQPc832Wu+4ToEdU38VG4HL3f/Nd4IYEHRPY39RQ4CZc6z6i3irs0/n+2BtYPN4Cvicifd2+g5LwCvdJ7RHgfhH5DoCIHCkiw9zPzb12KYUKfhMYY36PFcBfYX+cH2Kt7CVukd9iheXv2MiXDe6y1vIccCXWn3ktcLkxpsYYsxn4PfYP/AlQiI3KaS4HYX/An2Mf6Suxj6VgO1e/wXb4rsb+gea2tOHGmGqsqF6AtZBmAkXGmH+2oJqYxx9nfx9irblfUn9tJlD/u74a2+H8GXAnNoolHtdin3T+iY1kGu/u45/Ym/q77qN9pHsJY8y/sFbwDPeYLwYuds9FUxwHLMcKbACYaYxZEaPcX7HuhLex124vjbjvotpXDVyO9Vd/hj23zzayyW+AU7Ei9mJkWdc4uBjr4/4A62670l39MjY66GMR+be77H5s/9AnwDwadp62+pjctuzCnrP/h408ClPu1rcTG8kWz1jAGPM21he/HHgH+9uPZBLWbfOq6x5aDpzgrmvutUsppKFrT0kmIlKC7QT6SbLbkgyy/fgVpb1RC19RFCVLUMFXFEXJEtSloyiKkiWoha8oipIlpGwCqq5du5pevXoluxmKoihpxfr16/9tjOkWa13KCn6vXr1Yt25dspuhKIqSVohI3JHU6tJRFEXJElTwFUVRsgQVfEVRlCwhZX34iqKkBjU1NezYsYO9e/cmuylKBPn5+fTo0YPc3NymC7uo4CuK0ig7duzgwAMPpFevXsSY90ZJAsYYKisr2bFjB8ccc0zTG7ioS0dRlEbZu3cvBQUFKvYphIhQUFDQ4qcuFfwMJRCAKVPsu6K0FRX71KM110RdOhlIIABDhkB1NeTlQUUFOE6yW6UoSrJRCz8D8fut2AeD9t3vT3aLFKXtLFmyBBHhn/9senqF6dOn8+233zZZLh6PPfYY48aNa/X2ia4nUajgZyA+n7XsvV777vMlu0WK0nYWLlzIwIEDWbhwYZNl2yr4mYoKfgbiONaNc/fdzXPnqL9fSTSJ/k19/fXXrF69mjlz5vDkk/UzZgaDQW677TZOPvlkTjnlFGbMmMGf/vQnPvroI8455xzOOeccADp37ly3zTPPPMPIkSMBWLp0KWeccQb9+vXjvPPO45NPPonbhlAoRK9evfjiiy/qlh133HF88sknzapn5MiRPPPMM3XfI9t07733cvrpp3PKKadw5513AvDNN99w4YUX0qdPH04++WSeeuqpfepsKerDz1Acp3l++9b4+wMB6yby+bRvQNmX9uhDeu655zj//PM5/vjjKSgoYP369Zx22mmUlZWxfft2Nm7cSE5ODp999hmHHnoof/jDH1ixYgVdu3ZttN6BAwfy6quvIiLMnj2b0tJSfv/738cs6/F4uPTSS1m8eDHXX389r732GkcffTSHHXZYi+qJZtmyZbzzzju8/vrrGGO45JJLWLlyJbt376Z79+68+OKLAHz55ZctO2kxUMHPcqL9/eXljYu5dggrTRGrD6mtv5GFCxdyyy23APDjH/+YhQsXctppp7F8+XLGjBlDTo6VskMPPbRF9e7YsYMrr7ySXbt2UV1d3WRM+5VXXsldd93F9ddfz5NPPsmVV17ZqnoiWbZsGcuWLaNfv36AfZp55513GDRoELfeeiuTJk3ioosuYtCgQS06tlioSyfL8flgFGX8L8O40ZQxdy7ccYcV9ViP4411CKtrSIHE9yF99tlnvPzyy9x444306tWLe++9l6effpqWTN4UGcIYGbt+8803M27cODZt2sSsWbOajGt3HIetW7eye/dulixZwuWXX97senJycgiFQoB1D1VX23nujTFMnjyZjRs3snHjRrZu3coNN9zA8ccfz4YNGygsLORXv/oVd911V7OPNx4q+FlELEE+6sFJzAyOZijLeCg0mt9UT2JCcAp99wQoL9+3jnh/5rDl39jNQskOWtqH1BTPPPMM1157Le+//z7bt2/nww8/5JhjjmHVqlV8//vfZ9asWdTW1gL25gBw4IEH8tVXX9XVcdhhh7FlyxZCoRCLFy+uW/7ll19y5JFHAjBv3rwm2yIiXHbZZfziF7/gxBNPpKCgoNn19OrVi/Xr1wPw/PPPU1NTA8CwYcOYO3cuX3/9NQA7d+7k008/5aOPPmL//ffnJz/5CRMmTGDDhg3NP2lxUJdOmtBWv3mkK+YsT4C7jivn5K4f033lcwAIYIDbuA8IIQhPzrqaQNH8BvsL/5mj29Iej/FK+tLcPqTmsHDhQiZNmtRg2YgRI1i4cCEzZszg7bff5pRTTiE3N5dRo0Yxbtw4iouLOf/88+nevTsrVqxg6tSpXHTRRXTr1o3+/fvXiWtJSQlXXHEFhxxyCOeeey7vvfdek+258sorOf3003nsscfqljWnnlGjRnHppZfSp08fzj//fA444AAAhg4dypYtW3DcE9a5c2fmz5/P1q1bmTBhAh6Ph9zcXB566KHWnsI6EjKnrYjMBS4CPjXGnBxjvQB/BH4AfAuMNMY0ervq37+/0QlQLG3xm4dvFAc/XcapG+ewl3wcAuRRU1cmLPYAIcAb8X1T32s45c35DeqKddNR337msmXLFk488cRkN0OJQaxrIyLrjTH9Y5VPlIX/GPAAEMMJAMAFwHHu6wzgIfddaQattZ5f+UkZXRdMp4gv6M6uBuvCHk0TfomHf3//KrouewKDqbsJFG58AsoG8/6blUye62N10Ikp6PEsf0VRUoeECL4xZqWI9GqkyKVAubGPE6+KSBcROcIYs6uRbRSXsN88bD03pxNsx08mMXhBaYNl0SIPYLy5eEbdgBQV8R3H4e/9oHDjAgwRlv/YsRwVNPyvyeFRrmdBVRF+v7OPqEe6dyK/K4qSGnSUD/9I4MOI7zvcZQ0EX0SKgWKAnj17dlDT0oPrrrPvRUXNENJAgO5P3AfEEXlPDu+ccBEHnXA4R0xsWOE3M+fzxEC4KvQEIUC8OUgoiMeE6ESQYmbx09BsquefCgU3QHFx5G7VraMoKUxKddoaY8qAMrA+/CQ3JyWIFtGiojiFIn0pfj8S4ZYJ80WXowmd0o+CqRM5IY4SOw6wej7zy8dyNn6O7lcA48fD3r1gDF4MHmrptPl1GP06bNsG06YB2nGrKKlORwn+TuCoiO893GVKEzQporHMap8Pyc/H7K3CGEP1EUeTXzKZQyKs8cawERYO4O6osBDKy5G5c6G6mgZJWe+9F95+GyZOxOdzWux6UhSl4+ioOPzngSKxnAl8qf775tHkIJZ4d4SKCuR3v+Ufs9Zw/83vEShsntjHxHHgoYds3cOHAxHuIWNgyRLw+XAIJDT+WlGUxJIQC19EFgI+oKuI7ADuBHIBjDEPAy9hQzK3YsMyr0/EfrOBfaJfCMAUf737Jl6PruMQwEmsT91xYPFi3hw2iT7L7gXXbQRATQ3cfjvORx/hXH45ONPasCNFqaeyspIhQ4YA8PHHH+P1eunWrRsAb731Fn369Kkru2TJEnr16tVubXnsscdYt24dDzzwAA8//DD7778/RTH9rLB9+3bWrl3L1Vdf3aJ9jBw5kosuuogf/vCHiWhyAxIVpXNVE+sNMDYR+8o0mjOgqm4Qy6RJcN99YAzk59creJx4yOb41Fs6oCsQgMEvT2MkvZnJz8ghCLhD11eutIVKS2HnTpg/vwVnQlFiU1BQwMaNGwE7wKlz587cdtttgB2kFF7XFoLBIF6vt0XbjBkzptH127dv54knnmix4LcnmlohiTQ7HUEgAGefbYU0FLKCv3dvw/jHyZP3Ueym3EGtSYfg99smzKaYwayiTMbw8fAx0L17w4JPPAFlZZpcJ1tJkcRKfr+fwYMHc+GFF3LCCScwZsyYunw2nTt35tZbb6VPnz4EAgHmz5/PgAED6Nu3L6NHjyYYtMbMo48+yvHHH8+AAQNYs2ZNXd0lJSXcd5+Nhtu6dSvnnXceffr04dRTT2Xbtm3cfvvtrFq1ir59+3L//fcTDAaZMGFCXRrkWbNmAdYtOm7cOE444QTOO+88Pv3003Y7Hyr4SaRZM1MFAnDOObByZb3fHECkyV7RpnKatGZmLJ8POnUCjwfW5TjIww9xxOKHINqKMQbGjtXkOtlIByZW2rNnD3379qVv375cdtllMcu8/vrrzJgxg82bN7Nt2zaeffZZwOabP+OMM3jrrbcoKCjgqaeeYs2aNWzcuBGv18uCBQvYtWsXd955J2vWrGH16tVs3rw55j6uueYaxo4dy1tvvcXatWs54ogjmDp1KoMGDWLjxo38/Oc/Z86cORx88MG88cYbvPHGGzzyyCO89957LF68mH/9619s3ryZ8vJy1q5d227nK6XCMrONZg2oKi+HqiqgYQqEHVfdRo9m+GDC7qCwwRXpumnNgK64HqRp0/h04066LnsCASQ3x95JQiGN0cw2OjA+d7/99mvSpTNgwACOPfZYAK666ipWr17ND3/4Q7xeLyNGjACgoqKC9evXc/rppwP2RvKd73yH1157DZ/PV9dncOWVV/L22283qP+rr75i586ddTec/Pz8mO1YtmwZf//73+smQfnyyy955513WLlyJVdddRVer5fu3btz7rnntvJsNI0KfhJpMh1BIABz5wL1Qh9E+D0TCH1vGpObuZ94A6Jamw4hVmKsQACGrJrPqZ6xnOvxc93PC+g9Y7zGaGYjrbEk2pHI1MiR3/Pz8+v89sYYrrvuOqZMmdKg7JIlSxLWDmMMM2bMYNiwYQ2Wv/TSSwnbR1OoSyfJxHG/W/x+ayUBiPCGDMDnWcNv9pvW4D/UlLu0MddNo/tvov7I5eF9rAk53GMm83SX4rj+pE1lAfzDprCpTN08GUmi8yO3kddff5333nuPUCjEU089xcCBA/cpM2TIEJ555pk6//lnn33G+++/zxlnnMErr7xCZWUlNTU1/PnPf95n2wMPPJAePXrU3Ryqqqr49ttv90nRPGzYMB566KG6tMhvv/0233zzDYMHD+app54iGAyya9cuVqxY0R6nAVALP7Xx+Qjm5EHIWkr7/Wk6F1Y63Our/w81ls4gLMQFBa03uOLVH718+vQY+4jxKLCpLEDv0UM4kWqql+WxiQoKi9XVk3EkMj9yGzn99NMZN24cW7du5Zxzzonp6z/ppJP47W9/y9ChQwmFQuTm5vLggw9y5plnUlJSguM4dOnShb59+8bcx+OPP87o0aP59a9/TW5uLn/+85855ZRT8Hq99OnTh5EjR3LLLbewfft2Tj31VIwxdOvWjSVLlnDZZZfx8ssvc9JJJ9GzZ8+6NMntgjEmJV+nnXaaySpmzTJm6FD77rJ2rTFn5601v5R7zNl5a83atftuds89xni9xoB9v+ee+m33288u228/W+0995iYdUSzdm192Xj1Ry4XMWbMmIbbxWPF0HtMDXbDarxmxdB7WnCSlGSwefPmZDeh1axYscJceOGFyW5GuxHr2gDrTBxdVQs/FSgrg9Gj7edly+x7cTF+P6wOOrxiHLzB2H1f8dyl0W6cykrrummKsOVeVWUjcX7xi9j1+3yQ4/bLGmO7GoqKmt5HwQgf1cvyMFRTQx4FI3xNN0pRlISggp9sysr2VclFi6C4eB8xLyiAm26yRcJZM+N1vDbVbxZvwJXfb8U+FLKv+++HBx6wN4zIso4D118Ps2ZZwQ/GuCHF2kdhscMmKqhc5KdghE/dOUq74vP58GnAQD3xTP9kv7LCpTNxovWJRL+i3Dr33GMX5eXVF+nUqWn3TDwXS7S7J3L92rXG5OTU78fjqXfjxKq/sXrirWuqoc1xDSkdx+bNm00oFEp2M5QoQqFQi106SRf2eK+MF/y1a62ausoaAvPNfoearRNnxSx+zz3WVx4WYpH4QtwU8fzyYWbNMiY31zavKbGOJ85N7aNBBRF3hr/PWtv8G4XSIbz77rtm9+7dKvopRCgUMrt37zbvvvvuPusaE3x16SSL8nLrM6E+xn78nimU/7GYFcNj++pzc62LBtoW3tyUu6e42GZEbk58frxgjGaHYkd2NlRVccC9JZxaVcKakKPjtVKEHj16sGPHDnbv3p3spigR5Ofn06NHjxZtk5BJzNuDjJ7EPJwuwR1BG0QoZQK/xGaYHDPGZiOOtVm5O2tws2a+aqIJiZ5/NrrOZu0jspc4FMKIhz2mE0M9FWzo5KRCGLeipBUdMYm50hL8fkxNrU2VIMLqE0fzy81NpxNOZGhzosOkGxvN22RDKiqgpASWL0dCIfbzVFF+bAnfTCihUNVeURKGjrTtICJHpW4q8LEnlEcNXvaYfP7StYjcXJsPLe40hilOaxKx1eE4UFJCMLcTIfFAKMSx7y6ncPwQNpUFUiHpoqJkBGrhdwDR1u911zls8lQwKOTHj4/XVjnk5tpQ/La6apJFW9OnBHCYbCqYbEoYwnJyQiHMnr3kjyliOxMYkl+s7h1FaSMq+B1AtPULsKGTw9q9DsYAbhx7z57pK2itTcQWJjzIrIQSBrEKYS8eDN81W3mY0bAX/P7itD0/ipIKqEunHYhONubzwUBvgF/KFAZ6AxQVWXEcPbqJ+WrTjOYkYotH+AnhDa/DD/Iq+PYQO6FKOM/hT82ctD8/ipJs1MJPMDE7LwnwsjkHMdUYk4eHFeA4OI514SQ6WiYdafiE4PDRjadz/Oc769YfckQ+x8c4P+0RbaQomYoKfoKJOffDB+V4atxJTGqqbGylq04plFQw6USeiyUXTeTYzS+QQy0Ax376qlV3x2mQBXT8eBvR6fXaFBDFxclrv6KkOir4CSZm52V5khuVhmzp4rCLGylmFl4MErLJegI4dU9QIvXJ20IhO6NiYaHeQBUlHurDTzAx534oKrLqHxV3mSLzPKckPh88lVdEFfnUUN/JEfkEFQrZUxomGLTh/Ho+FSU2OtK2o4hyNjc2cYliCQTgnfIAZ+Pn6CJfzPN2883whz/UW/oej51kXc+nkq3oSNtUIMpZ34HzPKc88Tpe7SlzAKfBsujwz+HD6wbq6pzpitIIKvgdRLSopdg8z0mjNU860R3d7kBdVq3S86kojaGC3wHEE7W2DFTKFFr1pBPjkUDPp6I0jQp+exAlSPFETUMyW/Gk08gjgZ5PRWkcFfxEU1Zm4wNDobreQ5/PUfdNHFpsmWvnh6K0GhX8RBIIwLhxUGsHC1FVBX4/zmRH3Q2N0CLLPPKRICcHPvgAAgECOHp+FaUJVPATSXl5vdiDjRF0zXl1NySI8CNBeTnMnQtlZYQemc3j8iBlplhDXBWlEXTgVaIIBKwAhcc1eL3w4IOqPO2B49jUorW1EAohwVqm147j9GCg5bn4FSWLUMFvgmaPhvX7rV8Z7PDPUaM0sUt74vOBx4PBZtTMpYYJlJKTo30kihIPFfxGCAeE3HGHfW9U9F3fsvF4qcnJZ1O/NJy2Kp1wHHjwQYx46iaBv4wlzD6jrFkPVZrWQslGEiL4InK+iPxLRLaKyO0x1o8Ukd0istF93ZiI/bY3LZq2z3FYcnMFd3A3vtoKzhjvqJi0N8XF7Ol5AlCfN/+y96c3uVmLbuSKkkG0WfBFxAs8CFwAnARcJSInxSj6lDGmr/ua3db9dgThgJDmTFASCMAVf3D4XWgya40TDtBR2kBzrPAD+p3Q8PsH/2xSwds0/66ipDGJsPAHAFuNMe8aY6qBJ4FLE1Bv0omZ+TIOfr8NvQ/j9aovuS001wrfdMFEgkidL98YA6Wljdbdkhu5omQSiRD8I4EPI77vcJdFM0JE/i4iz4jIUbEqEpFiEVknIut2796dgKa1neZO2+fz2XFWHo8ND3/gAQ3QaQvNtcJfqHRYGm1fLF3aqJXfkhu5omQSHdVpuxToZYw5BfgbMC9WIWNMmTGmvzGmf7du3TqoaS1nU1kA/7ApbCqrF5WwiPz2t7BypQbotJXmWuE+H/wxbyK1eOusfIJBG6ffCG2Zf1dR0pU258MXEQcoMcYMc79PBjDGTIlT3gt8Zow5uLF6UzUf/qayAL1HDyGPaqrJY9usCgqLVTXag+bOVxsIwOelZZz//M/whNzQ2HZ5oBIAACAASURBVLw8TbugZCWN5cNPhIX/BnCciBwjInnAj4HnoxpwRMTXS4AtCdhvUqhc5CePanIIkks1lYv8yW5SxtKUFR7u1AX4weJiPMWj6qfACga1N1ZRomhzagVjTK2IjAP+CniBucaYf4jIXcA6Y8zzwH+LyCVALfAZMLKt+00WBSN8VC/Lw1BNDXkUjPAlu0lZSXTSzOnTIZ8irsmbh7dWs9QpSix0isOmCATq/cFFReA4bCoLULnIT8EIn7pzksSUKTaCJxi0HeVer42SGugNMO+n7pSI0KRPqLluI0VJF3SKw9YSCMDZZ0NNjf0+dy74/VbkVeiTSmTSTJH6Sc1X4/BET4fJxM6bHynwoPMKK9mFCn5jlJfXiz1o/vUUIjKPfkEBjB8fNd9AjLjOAE4Dgb/uOk2tr2QXKvgtQUdTpRSRKacLC6NdM759ptKKvgeAziusZBfqw3eJ6csNBOCcc6wieDwwc6YG2KcTURc11uyIoD58JbNozIevgk+j06Rqr16GoZdTyXS007YJGp0mVaeqyij0cirZjAo+1tob6A1wVsjPGq8Pn08VQVGUzEMFH3AIUCFDEKoxkoeXCkBFPyNxfTqbCny8UOmoa0fJKlTwAfx+OzrTBKFW4/MyFrezxlRV0zuUx4ueCu7u5Gj8vZI16BSH0GhqRp0KL33Z59q5nTUSsnmQBoX8VFVBSYleXyU7UAsfGo7iiXjGbzR6R0lpYl678LzDVdWYkIdLWcK/QwXMXV7MqlV6fZXMRwU/TIzwjUajd5SUJBx2+cEHMa7dZHtjl9JScpcs4Qxe5wxehxA8Wl2s11fJeFTwGyEyX4uOxEx9Iq36nBzroYOoa+c48O23dZOeG+CHLGJBXrFeXyXjUcFvhDieHiVFiXwiAxg1Cnr2jHHtRoyAZcvqvp76nR1sGllGb6d+FLUO0FIykawQ/Lb8eXWgTvoQ/UTmZrPel3B6jOnTkS1b6PbpZrqVjobedp323SiZSkZH6QQCcNNNVgjuuMP+iTUaI3Np0eTkxcVw4IENl82ZAzR/AnVFSTcy1sIPW2l790I4XVBd5x36vJ6ptOiJrHv3mN+170bJVDJW8MNWWljsReyf96ICfV5XXCZOhBdegNpa28s7cSKgfTdK5pKxgh9ppeXkwPXXW59uYStiLbUDL0NxHFi5su7iBnDwT6m/znqtlUwjYwU/vpXma9HzunbgZTiusgcCMNkX4KwaP5NzfUzxO3qdlYwjYwUf4lhpLXxe18FX2cE75QFeqh5CHtVUV+fxQGkF/gH1ydX0KU/JBDJa8OPSgud17cDLDs7GTx7V5BDEUM1/lvqZutQhLw+mT284Z64+5SnpSkaHZSaCFoX6KWlHOMHaf/r5kE55BMULnhx6BD/g9GCA6mobrbl3r4ZpKumPTnGoZC3R/TOvTQ9Q+GY5wTlzMTU1gPB7uY07cqZRU2O3yctTt56S2jQ2xWF2WPhlZTBsmH1XFJfo/pkXKh3o2ROpqSEHg5cQE00pI2vs70YEfvpTFXslfcl8wS8rw4wejVm2DDN6tIq+UkesaRA2Ffgw2KRq4QRrNzAHrxfy821or6KkKxkv+J/PWQTU/3nD3xUlVv/MC5UOqxnUoFy3vt21D0fJCDI+SmdLfl8clhHuqQh0H8EPktoiJZWIDtjy+WBy3lT+Wn02udQQ8uZy7MyJTFahVzKAzBb8QIAzA38kBIDwB+8EBk4sbmIjJZtxHJjid3iq/BXOxs/RRT67YsqU+tG4fo3HV9KTzBb80lI8NVUAGAzXXvwfDtdBNEoTWKvfAZz6UJ6qKkLi5XF5gDJTrPH4SlqSuYIfCMDSpXVfBTj8cE2VoLQQvx+qqiAUQggxnbG8SSFvVDsanqmkHRnZaRsIgL/EjwlFjDHweqGoSHOdKy3D56ubK1EADyHOFb+OulbSkowT/LAF/6vlPvaYToTEQ63k8sqPZ4LjxAzFU5S4OA488IBNuerxIJ06ccJonz4ZKmlJQlw6InI+8EfAC8w2xkyNWt8JKAdOAyqBK40x2xOx72jCFvyakMN5VHC28ePHx6sLHGYNthMdaa5zpUUUF0NhIfj9eAsKKKr0uyvsj0f7hJR0oc2CLyJe4EHg+8AO4A0Red4Yszmi2A3A58aY74rIj4FpwJVt3XcsfD4YRRnDWcQiRjCVyXXrFi2y/13Nda60mPAPJqIDaNP0Cma+6TB3rnURap+QkuokwsIfAGw1xrwLICJPApcCkYJ/KVDifn4GeEBExLRDIp/vLCljZnA0AEPd+PvZ2FDMESMSvTclq4joADJV1fx5rJ9ZQWffKTRV8JUUJRE+/COBDyO+73CXxSxjjKkFvgQKErDvfZBnG46s/dl3FjF0KMyaZa17RWk1ER1Atd48Xg759plCU/uElFQmpcIyRaQYrDnes2fPVtVhLh8BpfUjaw8aOYK/TktQA5XsJmLynH8W+Ngw3sEbNYWmWvdKawn3BRUUQGVl+/QJJULwdwJHRXzv4S6LVWaHiOQAB2M7bxtgjCkDysCmR25NY3pPK2Yb1tI3l4+g9zQ165UE4nYAFQIVhdpZqySGiPF9hELg8UCnTonvE0qE4L8BHCcix2CF/cfA1VFlngeuAwLAD4GX28N/H6b3tGJQoVfaGYcAzgflNv4MNe+V1hPuHgrZPDCEQu3TJ9RmwTfG1IrIOOCv2LDMucaYf4jIXcA6Y8zzwBzgcRHZCnyGvSkoSvoSCFjTvrrafp8zB155RUVfaRXh7qFIC789+oQS4sM3xrwEvBS17NcRn/cCVyRiX4qSEvj91E2DBfZzebkKvtIqIrqHUt6HryjZh88HHg8mGESwE6a8/crHfBZQzVdaR0eMD8q41AqK0iE4DttunUkQT11E2LFblvL44DLKymw25UCgvnh4svTIZUp2k4zfhFr4itJKnu5SzCG8ySgexgvkEGRG7U2MvQlmS30KZdAMrUpDkpW1Vy18RWklPh88mVdEkJy6OXA9hPhTaCynBwN1URaaoVWJJBCAkhLbQRv5m+gIi18tfEVpJeHZsZaXPsj5z90EJoQAXmq5jnLeynPqoizy8uqtOR2Nm73EirfPy4MvvoCzz7Y3gEE5Aeb91J1tLcFmvwq+orQBxwEWF9vhgj/7GQSDeIBR8gjfv7kfvR07HkQztCqwb7x9//5www0wdizU1sKZBHipegj5s6phXuJ9PerSUZREUFwMo0YB1rXjNUF63z+u7vnccWDyZBX7bCdiPh0A3noL3nzT3gDOJMCdlJBHFR7TPv4/FXxFSRRFRTaxTphgUB32SgMcB376U5tsD6xVD9aNs4Jz+D7L8NJ+I69U8BUlUTgOPPgg5ObWJ0NRh70SQbhDNje3fta9oiJYdGYpnajCi5vpt3//dgndUR++orSBfWa7ipgdi4IC8PvZtAleqHT28d/rTFnZRWQoZk6O9QAWFdmcTKxZ2rDwqae2y49CBV9RWkncWOqI2bFMVTW9Q3m86Kng7k5OXZlkxWErySMyPBegZ0/3mk/xQ2QuSa/X3gnaAXXpKEoraTS+3l0poSC5VDMo5G9QRmPzs4+I+XMauud9Puv+83is6T9zZrvd/dXCV5RWEv4Dx4yvd1eaqmpCIWE4S/hSCvD5ipveVslIHAemT7dza9/UN4BT7qbWLirqsLhdace09G2if//+Zt26dcluhqI0SqN++EAASksxS5bULZKIuTbVh59dhN14p1YFWB7y0Ylq20HbqROsWJGwH4GIrDfG9I+1Ti18RWkDkRkOAwGbIRnC0x068O23dfMrA9bEcwW/I7IjKqlD2I13TaicvLDYQ/vMdBIHFXxFSQDR86E8+ij86U/QY/8RXMCyunKyZQuUldWJvpI9+HwwhUkUM6supbZAh/r0tNNWURJA9Hwo1dV2uPzFzxfzD04CqPuTs2hRzDo0hXJm4yyZxG3BUjwYBFfsBwxIqDunKdTCV5QE4PPZwTRhC9/jscPlQyH4I7dQxui6vPmMGLHP9hqmmeEEAnDffQ3dex6PdfF14IVWwVeUBOA41soP+/D79YPx421WxNmhYgS4wrOIY28bQe/CQmvKR/TWxgrTVMHPIPz+hrH2ALfd1uEXWQVfURJEdCds5IDbyspiOvuK6U1sU17DNDMcnw/y82HvXptI57bbYNq0Dm+GCr6itBMxo3Cm+DFVdkCWqapGXFM+chJrDdPMQFLkAqvgK0oHsqnAR+9QHrlUUxPKY1uBj0J3nYZpZhjRAy1S4AKr4CtKB/JCpcOLngoGhfx04QuuuLcEGKFhmplGivbCq+ArSgcQNvYKCmBDJ4fv7d3EPeaXsBUY7cbpq+hnDjF64QM4yfboqOArSnsTbexNnw4X3jUHdtbH5sucOSr4mURUL/ymAl9KGPw68EpR2ploY6+yEvJ7d29QpjK/e+yNlfQk3El7991QUcELlU5KZEdVwVeUdiZWWtwXT5pIDbmEgBpyefGkiUlupZJoAjhMYTIBnPipkTsYdekoSjsTOyLPYejcVzirxs+aXB9TipLfoae0jHC/zEUFAQor/Q2c87H6bFMgKlMFX1E6guiIPMeBKX4Hv99his9dFxXG11T6ZE2vnDwiUx3fEhqC8VQjneqd87FGTk+enPzrpIKvKEmiwU0gEIBzzqnv5PvTCoaMd+J28qVo1F/WEBb0QSG/TXUcapgTI1VHTqsPX1FSgfJym3jHGKiqomZOeaOdfDpFYnLx+WCgN8DRfEAtORhPQ+d8VJ9tytyM1cJXlBTku19tYKA3wGqcmBZiqlqQ2ULnTQGWBYfglWrI8SI3jArPelNXJgUG1u6DWviKkgoUFVnlFptA96B/raNChjB3VCCmhZiqFmQ2sGRSgG9Gj8cb3IvXBPEEg9CzZ1pcBLXwFSVJNOx0dfMrl5TA8uUQCuGpqabnu34gtpCkogWZ6WybVMZFpTfhJQTYQXNB8ZKTJo9YbRJ8ETkUeAroBWwHfmSM+TxGuSCwyf36gTHmkrbsV1HSndidro4V/FWrMFXV7Anl8avlPjasUis+JQgEOPren+ElVDeRSQj411k/5Xm/g4/Uv0ZtdencDlQYY44DKtzvsdhjjOnrvlTslawnbqer66t55by7mcHN/CpUwrV7y7RTNhUoL8djgnVib4AQXsa+WsQdd9gbeKpPT9lWwb8UmOd+ngcMb2N9ipIVNDry0nE4qm8BEyllGMt42IzmR1+UJamlCgBlZZiyR+pyHxkgiIcnB89kddBJm2iptvrwDzPG7HI/fwwcFqdcvoisA2qBqcaYJbEKiUgxUAzQs2fPNjZNUVKXWKNvG/j0Ny6ySdWw4tJ74yLcv4bSwez4ySS6L7gXcScfDwFvMIBdE6fTe7hD3pD0iZZqUvBFZDlweIxV/xP5xRhjRMTEKAdwtDFmp4gcC7wsIpuMMduiCxljyoAygP79+8erS1EygshO12if/qabR9B7mU2bLBBz4nOl/dk2qYxjF5QC9TffWnL5OdO5uIvD8NSYyKrZNCn4xpjz4q0TkU9E5AhjzC4ROQL4NE4dO933d0XED/QD9hF8RclWIn36VVXws43FzJzoWvYjdIKUZJG/YA5AA1fOWB5gfZ7D7322TDpFS7XVpfM8cB0w1X1/LrqAiBwCfGuMqRKRrsBZQGkb96soGUXYp19VBaGQjcwsXFVMRUVx2ohJRuH61zp3zYed9Ys3Fwwm54pi/EXpI/KRtFXwpwJPi8gNwPvAjwBEpD8wxhhzI3AiMEtEQthO4qnGmM1t3K+iZBRhn35EGH5kahalI4nwrx3s9RLy5kCwFpOTy8lLp/JQGl+PNgm+MaYSGBJj+TrgRvfzWqibp1lRlDhEhOGnTSdgutJoptFI/xrgGTUKevZE0sFJ3wQ60lZRUojYufOj0LzIbSKygzwnB66/3ma2gHB+ex+FkYmKitLUfxMDMSY1g2H69+9v1q1bl+xmKEpqEZVGmRUr4oqR3hdiM2UK3HFHnQGPiD2VA4IBBgXthDQzZlA3qUkqTD7eEkRkvTGmf6x1auErSjpRXo6pqrJRI1VVSHn5PioUCNhsy48+CrW1mi8/mnAH+d69Nhu1MVBUVcYDjMVDiOrqTjzwlwpeGDCZgk0wfnzmzDuggq8oacSujxsOivnPKxs4KBDYZ2q9sJhBwxGg6WSpthdht1l5OcydC6fXBnggNI5cat20CVV8tdTPlKUOHo+9abrTFKR9J7qmR1aUNOJvhxdRRR7hjC6dt6xrkMQl3N8YFvuwu6KgwBZLl5wv7Y3jwEMPwboZARYX3EAuNXWx9oiHFcZHMGjdPuFzGQrZ85jOqOArShpxXJHD+Xl+lvN9gnjwEGpgwkfn6Bk92lqzlZXZMUNWIGB99M26oQUCFI47m667twBW7MXj4f0JD7Khk4PXa8+jO0UBHo89j+mMunQUJY0IT37+TnkJ8ugqqK2OObVeLNdNps+Q1eJ5fv1+TE1Ng+yXX/1Xf3pPK6ZiuD2HBQUNffjpft5U8BUlzbBD+R0oilB2sKatz4fjOHFnyIpRPK190pHESjkd99gCAfjgA4LixWuCdYtXHX8DP6BhuoTCQuvvzwRU8BUlzagPt3RwJrtpNn0+qKmB3Ny4ShcWscYs4XQO5Wz2PL8RJ8CTk8PK2rPIN3uZl3MD106MnbNo3jxb77x56R2po4KvKGlETLEuL7cLwL7HCNWMJJ4l3GKXSIrRrEFrYM+PG8bkAXqNPp+pTI5bb4ueHFIcFXxFSSNiig80yJ0vEeVjWezxLOFMELZGM1eGByjMmVMfepOTw3/6+Zg3Pr4F3+wnhzRABV9R0ohY4rNkSRHn8yi5VFNDHlvePYh+w4axre8Ihswo3sdij2cJZ5Kw7XOjCwRg8GCora2/OYog11/PC5VOoze6Zj85pAGaWkFR0oxoMRs2DP6zLIAPPwfxBbdTWmftb+YkpnMLj3qLuftumBzfcxGz7nQkpmuq9DJYYifas3PRQhX7sW1WBV8XOmntyopGUysoSgYR7bYYMQJGL3N4FYe/MKxB2ZPYTBmjOZ5tDPRNa3Hd6UhM19RHHzUos5MeXO15mgsrHSZnkAXfFDrwSlHSnOJimDULhg6F/a4ZUefDF+r9+beG7sMhO4bXxpwg/oYbAHckLfA7uYMNnRx8vsx4qmku6tJRlEyjrAymT4ctW+qXidhhtz17ZoWyxRTxsjJYtIhtfUfwdJfiuj6KTHLnQOMuHRV8RckwwmJ37T8m0WPhfTYiJS/PJoMJp89sJK1yRjBpEjz7LFx+OUyL78qKTJXs9dKsfo5UR334ipIlRHZYlnincfclw7nycD9Hf/x6XaclVVVNxuqnNZMmQak7bXb4PY7oZ1JkUnNQH76iZBDRHZa3P+dw4rzJ7GqQVBn4+OMWZBlLIwIBmD274bJnn41bPBxyeffdmeHOaQq18BUlg4g1uUd1tU2rXJQ316Zf8HrhL3+BpUszx3EN9Y83e/Y0XH755Y1ulgmRSc1FLXxFySDCFuvo0dCpU32kynFFjjX/f/c7uPFG68tPoVzJLUprHI/w4w02Gufb/Q5lxzUTG/XhZxvaaasoGUrccMPokUnTp8Obb9p1SZiwO2E5fNyKTFU1e0J5DPVUsKGTkzEPMM1FO20VJQuJdlU0yLIZHmlUUEBo3H8jNVUAhB6ZjXfUjR0q/AnL4eM+3rxS4udXy32sCTl40zQnUHuhLh1FyQLCVnTdFIc4MHky779Ziamprhuk5QnWYmbN6tB5EGMOlGotjkOnksl1M1ZlQ+RNS1DBV5QsIJYVDfAKPmrIw1A/ClXCM3aXlNSJfkJ87HEI9zuMGgXXXZe4+qIjb9rzGNIGY0xKvk477TSjKEpiWLvWmP32M8brte9r19YvH5y71sxkjFnEcLOHTibk8YQDfIzxeMyH10yMuW1HtC9d6k8lgHUmjq6qha8oWUA8q9dxYOorDn8f8xB/G7OYd2atQM47r37DUIgjF5Ry7d6yVgf1BAJw2WVwxhk2u0Es4j2BxKuv/KYA79/UfHO9JfVnNPHuBMl+qYWvKEli7VoTFI8JuVZ+CMwyz9BWWcdr1xqTk1P/wADGzJoVu1xzLPC1a425KWeWqSLX1OIxtZ2a1yC18NXCVxQlBgEc7pPbgHq/fs/+3Xj7mGFsurmsRREvfr8N+Y9k0aJ9yzXX725un8QDtWPIpQYvIaS6qlnmuuPY6NMhQ+x7tkbtaFimoigN8Pvhf8w03qE3I1jEp3Tj2tcX2FTLpcugNzYnczPw+SAnp6HojxgRu2ysMNLI+Py3L5+Es9LmxglP8ILH26wwnEAAxrvTGK5aBYWF2Sn6auEritIAnw88HphNMRfwV77D7oYFYpnocXAcWLkShg+HAQNs3v5m3isa+N1PrQrQ/Yn76sJHDYAInpkPNEu51YdvUcFXFKUBjgMzZ9q4eBF4zhtlkscz0Rupb/FieO215os9NIzPP9fjt+GiLgLIhAktftIQse/ZGpuvLh1FUfahuNi6PezI3GLeXQLy7CLM5SPoHRbZdp4qKnLy8IsKfIT+Ox+q9iIieCbc1uIcOeH7RYpmk+kQ2iT4InIFUAKcCAwwxsRMfiMi5wN/BLzAbGPM1LbsV1GU9ifsUw8EoHBGMdXVxeTNgIrh2OkSO2CqKIcADn424WOIqeAs8bMm18eU4Q4t2Zvfb905xtj3bE230FYL//+Ay4FZ8QqIiBd4EPg+sAN4Q0SeN8ZsbuO+FUXpAGLmuiHWwgQraESv7X958qgNVnCPmYw3aOdvacnDRbZNdBKPNgm+MWYLgIg0VmwAsNUY865b9kngUkAFX1HSgNhi6SOYkwehasjJwxtnNvDWeH0CAXinPMDFG0o4pKoKQiFyTDXnevy8KjZHzqOP1s/W2JyHi0j3UBZM6RuXjvDhHwl8GPF9B3BGrIIiUgwUA/Ts2bP9W6YoSpPEEstAwGGyqeAs/KwxPmZsgsLxDV08AZwmvT7RN4RAAB4fXMb02rF4CGIwiMeDdMrjiuk+9quEDz6ARx5p+cNFNk10Eo8mBV9ElkP0/GgA/I8x5rlENsYYUwaUgc2Hn8i6FUVpPdFi6ffD6qDDK8bBG4TKRVP2cfH4cRr1+sRKy795ToA/1v6MHIIIEETwnncelJRQ6DgUutvNm6fumdbQpOAbY85rqkwT7ASOivjew12mKEqaEu3mKRjhg1WRCwq4+s0p/NXrYzXWDfPBB1asw6If2TdQVQWP/yzAvcHxdWJvY+09NmtnxJ2iOe6Zdg4gSls6wqXzBnCciByDFfofA1d3wH4VRWknokW30HGgsH5SFcaP5+jqal725PBatwt465PDeXxWEUPm1c9AFXnTcAjwt6CPPKob7Gfrf13MCRGKHSnkkyfHblvCZtDKQNoalnkZMAPoBrwoIhuNMcNEpDs2/PIHxphaERkH/BUbljnXGPOPNrdcUZSkso9PPLxgSr17R4JBzvx4CWcCxTzM/D3X4PfPr9sunP9+4quldNpYXWfZh4Bq8qgeP7Gu+uYKecJm0MpA2hqlsxhYHGP5R8APIr6/BLzUln0pipImhE33vXvBGCJj+K5lAW8vgYBvfp14D/QGOLp2aYMqdvUYwGd3TKewuF6pmyvkGoIZH02toChKYgn7e0aPbjiTlvt+3OsLWFUaqBPvs2r8EKq/MYjXy5FPNxR7aP5UiPEybyqaWkFRlPbAde94DjoIU1qKgbrEZyHg+I/8DPTCj4PlHCEfY3JyIFhrs7Y9+KAdXzulYadrS2LpNQQzNir4iqK0H9OmWZEvLa1bVEMnCn0FVLzpw0M1hEC8uTaBT1FRo/H7KuRtQ106iqIknAYTl0ybhmftWj4ePoY3B4zhnVkr6N2lEm9tTZ3VT20t9OwJjtNoKmOdiLxtqIWvKEpCCIdMulGZDQZUVVY6+CY69dZ5AMjNtYWggVM+Xqerhlu2HRV8RVHaTKQYi0AoZF9VVTB2rM1S2UCkHcfeHcrLbQVFRXXqHc9Xr+GWbUcFX1GUNhMpxh5P/eQpHo9dFgrFEOlGHPKxVmm4ZdtRwVcUpc1Ei7F14+zr3mmLSGvGy7ajgq8oSptpTIzrZ85qu0hrlE7bEJOi833179/frFsXcwItRVEUJQ4ist4Y0z/WOg3LVBSl3dFwytRAXTqKorQrGk6ZOqiFryhKu9LYQCqlY1HBVxSlXWlu0jOl/VGXjqIo7YqGU6YOKviKorQ7Gk6ZGqhLR1EUJUtQwVcURckSVPAVRVGyBBV8RVGULEEFX1EUJUtQwVcURckSUjZ5mojsBt5v5eZdgX8nsDnJIN2PId3bD3oMqUC6tx86/hiONsZ0i7UiZQW/LYjIunjZ4tKFdD+GdG8/6DGkAunefkitY1CXjqIoSpaggq8oipIlZKrglyW7AQkg3Y8h3dsPegypQLq3H1LoGDLSh68oiqLsS6Za+IqiKEoUKviKoihZQkYJvoicLyL/EpGtInJ7stvTUkRkroh8KiL/l+y2tBYROUpEVojIZhH5h4jckuw2tRQRyReR10XkLfcYfpPsNrUGEfGKyJsi8kKy29IaRGS7iGwSkY0isi7Z7WkNItJFRJ4RkX+KyBYRSWqS6Izx4YuIF3gb+D6wA3gDuMoYszmpDWsBIjIY+BooN8acnOz2tAYROQI4whizQUQOBNYDw9PsOghwgDHmaxHJBVYDtxhjXk1y01qEiPwC6A8cZIy5KNntaSkish3ob4xJ24FXIjIPWGWMmS0iecD+xpgvktWeTLLwBwBbjTHvGmOqgSeBS5PcphZhjFkJfJbsdrQFY8wuY8wG9/NXwBbgyOS2qmUYy9fu11z3lVaWkYj0AC4EZie7LdmKiBwMDAbmABhjqpMp9pBZgn8k8GHE9x2kmdBkGiLSC+gHvJbclrQc1x2yEfgU+JsxJt2OYTowEQgluyFtwADLRGS9d5iqDAAAAbZJREFUiBQnuzGt4BhgN/Co61qbLSIHJLNBmST4SgohIp2BRcB4Y8x/kt2elmKMCRpj+gI9gAEikjYuNhG5CPjUGLM+2W1pIwONMacCFwBjXZdnOpEDnAo8ZIzpB3wDJLVvMZMEfydwVMT3Hu4ypYNx/d6LgAXGmGeT3Z624D6CrwDOT3ZbWsBZwCWuD/xJ4FwRmZ/cJrUcY8xO9/1TYDHWbZtO7AB2RDwdPoO9ASSNTBL8N4DjROQYt3Pkx8DzSW5T1uF2eM4Bthhj/pDs9rQGEekmIl3cz/thAwH+mdxWNR9jzGRjTA9jTC/s/+BlY8xPktysFiEiB7id/rhukKFAWkWvGWM+Bj4UkRPcRUOApAYv5CRz54nEGFMrIuOAvwJeYK4x5h9JblaLEJGFgA/oKiI7gDuNMXOS26oWcxZwLbDJ9YED/NIY81IS29RSjgDmuZFfHuBpY0xahjamMYcBi639QA7whDHmf5PbpFZxM7DANULfBa5PZmMyJixTURRFaZxMcukoiqIojaCCryiKkiWo4CuKomQJKviKoihZggq+oihKlqCCryiKkiWo4CuKomQJ/x8XT+v5zgF9agAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3h7IcvuOOS4J"
+ },
+ "source": [
+ "Much better! The evaluation metrics we printed show that the model has a low loss and MAE on the test data, and the predictions line up visually with our data fairly well.\n",
+ "\n",
+ "The model isn't perfect; its predictions don't form a smooth sine curve. For instance, the line is almost straight when `x` is between 4.2 and 5.2. If we wanted to go further, we could try further increasing the capacity of the model, perhaps using some techniques to defend from overfitting.\n",
+ "\n",
+ "However, an important part of machine learning is *knowing when to stop*. This model is good enough for our use case - which is to make some LEDs blink in a pleasing pattern.\n",
+ "\n",
+ "## Generate a TensorFlow Lite Model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "sHe-Wv47rhm8"
+ },
+ "source": [
+ "### 1. Generate Models with or without Quantization\n",
+ "We now have an acceptably accurate model. We'll use the [TensorFlow Lite Converter](https://www.tensorflow.org/lite/convert) to convert the model into a special, space-efficient format for use on memory-constrained devices.\n",
+ "\n",
+ "Since this model is going to be deployed on a microcontroller, we want it to be as tiny as possible! One technique for reducing the size of a model is called [quantization](https://www.tensorflow.org/lite/performance/post_training_quantization). It reduces the precision of the model's weights, and possibly the activations (output of each layer) as well, which saves memory, often without much impact on accuracy. Quantized models also run faster, since the calculations required are simpler.\n",
+ "\n",
+ "In the following cell, we'll convert the model twice: once with quantization, once without."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "1muAoUm8lSXL",
+ "outputId": "aad8259e-df57-4f03-da77-d490e5609d9f",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "# Convert the model to the TensorFlow Lite format without quantization\n",
+ "converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_TF)\n",
+ "model_no_quant_tflite = converter.convert()\n",
+ "\n",
+ "# Save the model to disk\n",
+ "open(MODEL_NO_QUANT_TFLITE, \"wb\").write(model_no_quant_tflite)\n",
+ "\n",
+ "# Convert the model to the TensorFlow Lite format with quantization\n",
+ "def representative_dataset():\n",
+ " for i in range(500):\n",
+ " yield([x_train[i].reshape(1, 1)])\n",
+ "# Set the optimization flag.\n",
+ "converter.optimizations = [tf.lite.Optimize.DEFAULT]\n",
+ "# Enforce integer only quantization\n",
+ "converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]\n",
+ "converter.inference_input_type = tf.int8\n",
+ "converter.inference_output_type = tf.int8\n",
+ "# Provide a representative dataset to ensure we quantize correctly.\n",
+ "converter.representative_dataset = representative_dataset\n",
+ "model_tflite = converter.convert()\n",
+ "\n",
+ "# Save the model to disk\n",
+ "open(MODEL_TFLITE, \"wb\").write(model_tflite)"
+ ],
+ "execution_count": 17,
+ "outputs": [
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/plain": [
+ "2488"
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "execution_count": 17
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "L_vE-ZDkHVxe"
+ },
+ "source": [
+ "### 2. Compare Model Performance\n",
+ "\n",
+ "To prove these models are accurate even after conversion and quantization, we'll compare their predictions and loss on our test dataset.\n",
+ "\n",
+ "**Helper functions**\n",
+ "\n",
+ "We define the `predict` (for predictions) and `evaluate` (for loss) functions for TFLite models. *Note: These are already included in a TF model, but not in a TFLite model.*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "NKtmxEhko1S1",
+ "cellView": "code"
+ },
+ "source": [
+ "def predict_tflite(tflite_model, x_test):\n",
+ " # Prepare the test data\n",
+ " x_test_ = x_test.copy()\n",
+ " x_test_ = x_test_.reshape((x_test.size, 1))\n",
+ " x_test_ = x_test_.astype(np.float32)\n",
+ "\n",
+ " # Initialize the TFLite interpreter\n",
+ " interpreter = tf.lite.Interpreter(model_content=tflite_model)\n",
+ " interpreter.allocate_tensors()\n",
+ "\n",
+ " input_details = interpreter.get_input_details()[0]\n",
+ " output_details = interpreter.get_output_details()[0]\n",
+ "\n",
+ " # If required, quantize the input layer (from float to integer)\n",
+ " input_scale, input_zero_point = input_details[\"quantization\"]\n",
+ " if (input_scale, input_zero_point) != (0.0, 0):\n",
+ " x_test_ = x_test_ / input_scale + input_zero_point\n",
+ " x_test_ = x_test_.astype(input_details[\"dtype\"])\n",
+ " \n",
+ " # Invoke the interpreter\n",
+ " y_pred = np.empty(x_test_.size, dtype=output_details[\"dtype\"])\n",
+ " for i in range(len(x_test_)):\n",
+ " interpreter.set_tensor(input_details[\"index\"], [x_test_[i]])\n",
+ " interpreter.invoke()\n",
+ " y_pred[i] = interpreter.get_tensor(output_details[\"index\"])[0]\n",
+ " \n",
+ " # If required, dequantized the output layer (from integer to float)\n",
+ " output_scale, output_zero_point = output_details[\"quantization\"]\n",
+ " if (output_scale, output_zero_point) != (0.0, 0):\n",
+ " y_pred = y_pred.astype(np.float32)\n",
+ " y_pred = (y_pred - output_zero_point) * output_scale\n",
+ "\n",
+ " return y_pred\n",
+ "\n",
+ "def evaluate_tflite(tflite_model, x_test, y_true):\n",
+ " global model\n",
+ " y_pred = predict_tflite(tflite_model, x_test)\n",
+ " loss_function = tf.keras.losses.get(model.loss)\n",
+ " loss = loss_function(y_true, y_pred).numpy()\n",
+ " return loss"
+ ],
+ "execution_count": 27,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pLZLY0D4gl6U"
+ },
+ "source": [
+ "**1. Predictions**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "0RS3zni1gkrt"
+ },
+ "source": [
+ "# Calculate predictions\n",
+ "y_test_pred_tf = model.predict(x_test)\n",
+ "y_test_pred_no_quant_tflite = predict_tflite(model_no_quant_tflite, x_test)\n",
+ "y_test_pred_tflite = predict_tflite(model_tflite, x_test)"
+ ],
+ "execution_count": 28,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "-J7IKlXiYVPz",
+ "outputId": "24017e5e-7672-460c-8b76-c0ed71f3ec27",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 281
+ }
+ },
+ "source": [
+ "# Compare predictions\n",
+ "plt.clf()\n",
+ "plt.title('Comparison of various models against actual values')\n",
+ "plt.plot(x_test, y_test, 'bo', label='Actual values')\n",
+ "plt.plot(x_test, y_test_pred_tf, 'ro', label='TF predictions')\n",
+ "plt.plot(x_test, y_test_pred_no_quant_tflite, 'bx', label='TFLite predictions')\n",
+ "plt.plot(x_test, y_test_pred_tflite, 'gx', label='TFLite quantized predictions')\n",
+ "plt.legend()\n",
+ "plt.show()"
+ ],
+ "execution_count": 29,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAXwAAAEICAYAAABcVE8dAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nOydeXxMV/vAv2cmC1GERO3JpC1FIgkSoqQyGqWo0jaoULQob1X7tnZVqtZYWlpVulgqlkRraX9tbRkqNG1CRRWvIhP7vhRBljm/P+5kTJKZLIRs9/v53M/Mvffcc88999znnvs8z3mOkFKioqKiolL60RR1AVRUVFRUHg6qwFdRUVEpI6gCX0VFRaWMoAp8FRUVlTKCKvBVVFRUygiqwFdRUVEpI6gCv4gRQoQLITYVdTkyEUKUF0L8IIS4JoSIfgjn+1sIEfKgz/MwEELohBBSCOGQj7T9hBCxD6Nc+UEI4SGEuCGE0BZ1WR4GQogQIcTJB5Bvsbqv2Sk1Al8I0UsIkWButGeEED8LIVoXdbnyQkoZKaV8tqjLYcXLQHXATUoZ9qBPJqX0llJue9DnUckdKeVxKeUjUsqM+8lHCLFNCDGgsMpllW++X6Yq9ikVAl8I8S7wCTAVRVh5AJ8DLxRlufKimDZeT+CwlDL9QZ6kmF67ikrpRkpZohegMnADCMsljTPKC+G0efkEcDbvCwFOAiOB88AZoCvQETgMXAbGWuU1EVgDrAauA3sAP6v9o4Gj5n0HgG5W+/oBO4GPgUvAZPO2WPN+Yd53HvgX+AvwsbrOZcAFIBl4H9BY5RsLzAKuAEnAc7nUR0NgG3AV+BvoYt7+IZAKpJnr9PVsx9UCbgFVrbY1AS4CjsDjQIz52i4CkYCrVVojMArYB9wBHMzbQvNxnyz1ZJWfBJ4w/+9oru/rwClguJ1rt74HV4FjwFPm7SfMdd83W/uyV+9ac51fNOfzprlMDlbHfo3Spk6Z77c2+/Xkdt9tlL8/cNB8nceAN7LtH2k+32lgQLY66gT8aT7HCWCi1XG6bGXfBnxkrqvrwCbA3byvHLDcfJ+vAvEoHa0pQAZwG6X9fGbnGqKBs8A14FfA22pfeWC2ua6vobTr8sBxc/lumJeWKM/i8lyuwW5dYX7u7ZRvATAr27b1wLv5fMZjbZXHql4HWK2/Zi7jFWAj4FnQNlEgefkghPDDXIAOQLp1pdpIMwmIAx4FqgG7gI+sbnw68AGK0BqI8nCvACoC3ihCzsucfiKKQHzZnH44ioB1NO8PQxGMGqAHcBOoadUY0oG3UIRd+WwNpD2wG3A13/CGVscuMze6iuaGdBizQDbnkWYuuxYYgvLACxt14QgcAcYCTkBbc8N90ur6ludSlzHAQKv1mcAX5v9PAO1QBHc1lIf5E6u0RmAvUBcob7UtNB/3yVJPVvlZC7MzQLD5fxWgqZ3yZ96D/ua6mowiTOaby/2suT4eyUe9DwYOma+nKmAgq8BZCywEKpiv6Q/MQie/991G+TuhvFgF0AZIybxWlGfhLEqbdUERytZ1FAI0RmmbvsA5oKst4YQimI4C9VHa6TZgunnfG8AP5nNogWZAJVsCzc41vGauz8wX/F6rffPNedQ25/2UOV2W8tlqqzauIbe6CsG+wH8a5YUorNrTLaBWPp/xfAl8FA3EEfP9dkDpTOwqaJsokLx8WIL5QS1AOHA2jzRHgY5W6+0Bo9WNv8XdnldF801qYZV+t9WDMRGIs9qnwUrY2Dj3XuAFq8ZwPNt+6wbSFkWgBGHuRZq3a1F63o2str0BbLPK44jVPhfzNdSwUZ5gFKFgnf9KzL098hb4A4AY839hfjCetpO2K/Cn1boReC1bGiN3BX5u98lST1b7rYXZcXOdVMqjLfQD/rFab2zOp7rVtkuAfz7qPQYYbLXvWXNeDig93juYX2zm/a8Ahvze93y2/3XA2+b/3wDTrPY9YV1HNo79BPjY/F9HToH/vlXa/wC/mP+/hvIy9rWR5zbyEPjZ0ruaz1sZ5Vm6hdUXs1W6LOWz1VZtpcmlrkKwL/CFuT09bV4fiLnN20mf/RnPr8D/GauvaPP1p6CoVe+5TeS2lAYd/iXAPQ+dcC2UT8RMks3bLHnIu8aqW+bfc1b7bwGPWK2fyPwjpTShqIRqAQghXhVC7BVCXBVCXAV8AHdbx2ZHShkDfIbSyzkvhFgkhKhkPt7RxjXUtlo/a5VPivmvdZkzqQWcMJfbXl658R3QUghRE6UnZAJ2AAghqgshVgkhTgkh/kXpYbpnO97u9ZP3fcqNl1DUOslCiO1CiJa5pM1+b5FS2rrfedV7LbJej3U6T/OxZ6zawkKUnn4WcrnvORBCPCeEiBNCXDbn2ZG7dZy9PCeyHdtCCGEQQlwQQlxD+ULJfn+sOWv1P4W77elbFPXDKiHEaSFEhBDCMZd8rMugFUJMF0IcNbcRo3mXu3kph/Liv2/yqCu7SEX6rkJ5QQP0QlFPZuab1zOeXzyBuVb5XEZ52dQuSJsoCKVB4P+G0pPqmkua0yiVm4mHedu9UjfzjxBCA9QBTgshPIEvgaEoXi6uwH6Um5iJzC1jKeU8KWUzoBHK5/QIFB1xmo1rOHUPZT8N1DWXu8B5SSmvoOhze6A8CKvMDwgoRnMJNJZSVgJ6k/XaIffrz+0+3UT5cgFACFEjW7nipZQvoAjUdUBUfq4nD/Kq9zNYtQXzvkxOoLRLdymlq3mpJKX0tnUiO/c9C0IIZ5QX7iyULxJX4Cfu1vEZlLaYSd2sObAC2ADUlVJWBr4g5/3JEyllmpTyQyllIxSVS2fg1czdeRzeC0WVEYrSq9eZtwuU+r6NoobJcVob27K0CcDSJvJRV3mxEnjZ/Ey3MOdFPp9x6/Jhr4wobeQNq/bhKqUsL6XcBflrEwWlxAt8KeU1FP37fCFEVyGEixDC0fx2jzAnWwm8L4SoJoRwN6dffh+nbSaEeNH8VfEOyoMdh6KrlSg2AIQQ/VHe/vlCCBFo7oU5ojSW24DJ/PURBUwRQlQ0N7p37/EafkfprY0011MI8DxKjya/rEB5wF82/8+kIopB7ZoQojYFb6C53adEwFsI4S+EKIfyOQ+AEMLJPJ6hspQyDcXIZeI+yUe9RwHDhBB1hBBVUIx5mceeQXkxzhZCVBJCaIQQjwsh2mQ/j737bqNITij67AtAuhDiORQ1UiZRQH8hREMhhAswPtvxFYHLUsrbQojmKMK3wAgh9EKIxmaf/X9RXoqZ5T0HPJbL4RVRnpdLKIJwauYO81fnN8AcIUQt89dAS7PwvmA+h3Xee4GnzWMIKgNjrPblVVe5IqX8E+UF9BWwUUp51bwr38+4lPICSuegt/laXiPry+wLYIwQwtucV2UhRJj5f37bRIEo8QIfQEo5G+VBfB/lRpxAeQOvMyeZDCSgeIf8heJZM/k+TrkepYd7BegDvGju9RxA8TD4DaXhN0bxcsgvlVB6D1dQ1AOXUIyioBh6b6J4G8SiCNpvClpwKWUqioB/DqVBfw68KqU8VIBsNgD1UGwniVbbPwSaonhX/B/wfQGLZ/c+SSkPoxh1twD/oNSBNX0Ao1lNMBjFtlMY5FbvX6KoNhLNZc1+va+iCJ4DKPd0DVDTxjlyu+8WpJTXgWEogv0KisDeYLX/Z2AeivH4CEonBBQBC4oefpIQ4jrKy/Rev4JqmK/lXxQPk+0oah6AuSg94ytCiHk2jl1mvsZTKPUSl23/cJR7H4+i4piBosNOQfEC2mlWgQRJKTejeMvtQ7Gz/ZiZSV51lU9WoHyJWDo19/CMD0Tp+FxCMabvssprrfn6Vpnb7X6U5xLy2SYKSqYVWiWfCCEmohjBehd1WVRUckMI0RBFiDjLBzyuQqVkUCp6+CoqKgpCiG5CCGezimkG8IMq7FUyUQW+ikrp4g2UwTpHUQZBDSna4qgUJ1SVjoqKikoZQe3hq6ioqJQRim0AK3d3d6nT6Yq6GCoqKiolit27d1+UUlazta/YCnydTkdCQkJRF0NFRUWlRCGESLa3T1XpqKioqJQRVIGvoqKiUkZQBb6KiopKGaHY6vBVVB40aWlpnDx5ktu3bxd1UVRUCky5cuWoU6cOjo75ClQKqAJfpQxz8uRJKlasiE6nQ4gCB41UUSkypJRcunSJkydP4uXlle/jVJVOKSQyEnQ60GiU38jIvI4om9y+fRs3NzdV2KuUOIQQuLm5FfjrVO3hlzIiI2HQIEgxT4GSnKysA4QXVvzIUoQq7FVKKvfSdtUefilj3Li7wj6TlBRlu4qKStlGFfiljOPHC7ZdpehZt24dQggOHcp7SoJPPvmElOxv9AKwZMkShg4des/HF3Y+Kg8XVeCXMjw8CrZd1ffnnwdVVytXrqR169asXLkyz7T3K/BVyjaqwC9lTJkCLi5Zt7m4KNuzk6nvT04GKe/q+3MTZGX1BXEvdZUfbty4QWxsLF9//TWrVt2dZTIjI4Phw4fj4+ODr68vn376KfPmzeP06dPo9Xr0ej0Ajzxyd576NWvW0K9fPwB++OEHWrRoQZMmTQgNDeXcuXPYw2QyodPpuHr1qmVbvXr1OHfuXL7y6devH2vWrLGsW5dp5syZBAYG4uvry4QJEwC4efMmnTp1ws/PDx8fH1avXl3AWlO5V1SBX8oID4dFi8DTE4RQfhctsm2wtafv793btjB/UEKvJPCgbCPr16+nQ4cO1K9fHzc3N3bv3g3AokWLMBqN7N27l3379hEeHs6wYcOoVasWBoMBg8GQa76tW7cmLi6OP//8k549exIREWE3rUaj4YUXXmDt2rUA/P7773h6elK9evUC5ZOdTZs28c8///DHH3+wd+9edu/eza+//sovv/xCrVq1SExMZP/+/XTo0CHfearcH6qXTikkPNy2gI/YGcHRy0fp6dOT+NPxJLf7Dt1pV0I1mzlVSdL2mGCWVxPOieokr/iJ1ycb+PFKPCuHjgTyFnrjxim2Ag8P5YuiNHkFPSjbyMqVK3n77bcB6NmzJytXrqRZs2Zs2bKFwYMH4+CgPKJVq1YtUL4nT56kR48enDlzhtTU1Dx9tXv06MGkSZPo378/q1atokePHveUjzWbNm1i06ZNNGnSBFC+Zv755x+Cg4N57733GDVqFJ07dyY4OLhA16Zy76g9/DJCZCTMeS+QRbtW88xXXVkZ6YB49E+MgZtY7Cu4ctWPEe0l5+rvoeXVk6zQ1cD0fDfWzg/EkGQgYmeEXeGW2dMvzT3/gtpG8sPly5eJiYlhwIAB6HQ6Zs6cSVRUFAWZlMjaNc/aJ/utt95i6NCh/PXXXyxcuDBPf+2WLVty5MgRLly4wLp163jxxRfznY+DgwMmkwlQ1EOpqamAMjhozJgx7N27l71793LkyBFef/116tevz549e2jcuDHvv/8+kyZNyvf1qtwfqsAvAdyv3jxTFXPudz21Vn1KeVMKB6uMQGoUYZHhaCKu2d9K4nQHEv3/YmCPi5SPXkxt1yie+fp5AmsF2hVuWm3pdwUtiG0kv6xZs4Y+ffqQnJyM0WjkxIkTeHl5sWPHDtq1a8fChQtJT1emo718+TIAFStW5Pr165Y8qlevzsGDBzGZTBaVDMC1a9eoXbs2AEuXLs2zLEIIunXrxrvvvkvDhg1xc3PLdz46nc6iitqwYQNpaWkAtG/fnm+++YYbN24AcOrUKc6fP8/p06dxcXGhd+/ejBgxgj179uS/0lTuC1WlU8y5l4FUHSM7knQliaYMZNUfW3BJv0HbkKMk6q5w5morMk4+jXwiBkiF5NbgGQvadLjzCDjcIUULpDpRx38ux/y243CzMh9NBvNzq6AzQO14XP4cmUPYZ1KaXEEz67ow1VYrV65k1KhRWba99NJLrFy5kk8//ZTDhw/j6+uLo6MjAwcOZOjQoQwaNIgOHTpYdPnTp0+nc+fOVKtWjYCAAItwnThxImFhYVSpUoW2bduSlJSUZ3l69OhBYGAgS5YssWzLTz4DBw7khRdewM/Pjw4dOlChQgUAnn32WQ4ePEjLli0BxZi7fPlyjhw5wogRI9BoNDg6OrJgwYJ7rUKVAlIoc9oKIb4BOgPnpZQ+NvYLYC7QEUgB+kkpc32tBwQESHUCFKVHn2xjOgNPTzAac26P2BnBZ8uNnKiuPESNDnlxoMHdh9TxeBPSPP5UVkyOoEkz/9eCJuPudqTyEpDgHN+Pct6RLIiuylfG5cTotBDWnUobo/h8pJ5x4wpWxuLCwYMHadiwYVEXQ0XlnrHVhoUQu6WUAbbSF5ZKZwmQm6n9OaCeeRkEqK/0fJKbsTBiZwSGpKzeGju2OXC66jcQPxggi7BHirvCPn4IZCi3X6Q54ry7z910mjSLsCfDiSYHnuCD6EYMCbtMbLeFOPdqR5PoUWiO6wkPt63uEAI6dryfK1dRUSlsCkXgSyl/BS7nkuQFYJlUiANchRA1C+PcpR17zhkeHhBYK5Dua7pbhL4hycCOtEk4x4ylnPdyuFYXBMpypxJoJAjQJPZCe602nPdDxA+i4z53vFy3wcZZaM8/fvckUgNI4npGMIapXEt3J9VvDU8fdOeEsS/RV5/hhVf68k58R/r2VYS85VAJS5eWLsOtikpJ52EZbWsDJ6zWT5q3ZUEIMUgIkSCESLhw4cJDKlrxJTISrOxzFhwdlV51fLSeMddG0X1RKB+0FcrvGm96x1Un/UwzcD2h9NIl4PwvmDQgwdRoPYGnYPZXT1Hppxns+PEAT383kfpny5PhpnxSOCS3AGECqUVo0kh9djxUOgMSNje4zhhdOz4NSmPDk99S/2B1Vq5UhLw1pc1wq6JS0ilWXjpSykVSygApZUC1ajYnXS9TjBsHZg83aBWhGEqBSpUUY6HDv7MYv+1fnvu9Lh+1ged+r8u0v9dxtuMk0h/fblbJWE2OIEy4HmoFjjeJ6zUVqTOwulw/euov8PikvhhDfgZtGi4bP2TT4vLM3gg43Ebeqgq19qBN7AkbZ4PTLd57dR8b2u/gqY1dObwpghbeetyCxijlzERnILlO/gfqqKioPFgelsA/BdS1Wq9j3qaSC1n096cCIaw76Axcvqyob6ZljKJvxgqWB9wgeHsblgfcICyoJT82PQdX68LGWXDWHzIc4NDzcKEBNbSn6LxJT4VrT7J1QC/a31rHwph6jBwJz4Rm4H9+Nu0PPIUXSfjHheAc3w9R8TT19rbAVG8zWvf9cONRRT0kBYln+xOmG8LmJ29wqf10nsg4ppRXZ4Cw7lRPDyySulNRUcnJw3LL3AAMFUKsAloA16SUZx7SuUssHh4oPeSG38H+HjSJHkVyWCgd/zHRfjHUuF6eZcGn6R3dg2+Ni+mT1J/FvZbBlmnUjevOO8ylSVwFuuqiaFh7KcbVMTj71eSHvbbP91P4TxAOfA5gZNo0A+XudGPqmpZM+3sds3TtGBH+LTikKwZfjYmbvcJY4JAKQtIlvha7ghfyfvmFTH3KEdPNGsx+S/8Qa0xFRSU3CqWHL4RYCfwGPCmEOCmEeF0IMVgIMdic5CfgGHAE+BL4T2Gct6ST14CqKVPA+VIgVNsP7d/jfzVSaPZPNZb7Q5oGTl4O4dXojvxsjGA8k/jZGEHoircZ4LKUXdoQ3mEuXiQRYKzI7zvXcY6aWMXHyvP8jz8dz9q+a0l/dSdRYxMx1KyKySGd6id0kPYImBzA8Y7S2wf20ZghCTC5DZgc0qh71J9T6necXS5duoS/vz/+/v7UqFGD2rVrW9aFEJb//v7+GB+wf6t1uOMvvviCZcuW2U1rNBpZsWKFZT0hIYFhw4Y90PKpFBJSymK5NGvWTJZmli+X0sVFSsXUqSwuLsr2TJ6bPEO2bLNMdtb9VzLGRTKBu8vYCvIp3STpznkZQ4iUIGMIUdbHbpZCZM07cxEi/+fPjqbPc7JhUD/pznnZTt9CMhFlGVlFMtZZKdcHQvl930FW0n2vlM3TU84eN1M+N3nGg63UAnLgwIGCHbB8uZSenkolenrmXlkFZMKECXLmzJmW9QoVKhRKvunp6flKt3jxYvnmm2/mK63BYJCdOnW6n2KpFBK22jCQIO3I1WJltC1L5BWILGJnBLrbx4hr/l9i0FP/kPddF8tzjam/YiaJYdMYo2uH3jMJhEDvmUTU2ETiK4fmGfvlXqI/yuU/cTBuMQ1089nc8i+Q4JguKCduotn7qpJII+FmNUhzIbVnT9BtY45wZXjqdEJvleDmVsxChW7bto2nn36aTp068eSTTzJ48GBLPJtHHnmE9957Dz8/P3777TeWL19O8+bN8ff354033iAjQxlgt3jxYurXr0/z5s3ZuXOnJe+JEycya9YsAI4cOUJoaCh+fn40bdqUo0ePMnr0aHbs2IG/vz8ff/wx27Zto3PnzoASAqJr1674+voSFBTEvn37LHm+9tprhISE8NhjjzFv3jxADZX8sCnBT2DJJq/oi0d/DWRF6mIG73AlpWdvDjdOMHvdCKi+n5M1LjApuj7p3snKcFaTCYxG9FNCGTnS9mAoUMIjREbeW/RHDw9AZyC25ycg0um30ZtflkucRSqmZl8piW5VhgoXcDE247Ysx2tPezE87CSzouvw7vLP8lk7xZCHPHfkrVu3LOqcbt262Uzzxx9/8Omnn3LgwAGOHj3K999/DyhCtEWLFiQmJuLm5sbq1avZuXMne/fuRavVEhkZyZkzZ5gwYQI7d+4kNjaWAwcO2DxHeHg4b775JomJiezatYuaNWsyffp0goOD2bt3L//973+zpJ8wYQJNmjRh3759TJ06lVdffdWy79ChQ2zcuJE//viDDz/8kLS0NDVU8kNGFfhFRF498J43MpBRq1gWYgSnf5We8+lmVPh2LaSWJ6X9BMbXeJFAv2ib+WTGxTfHwLJw6ZLSMc1tQJc9pkwBR1087O8Bkb+wJG4/ocmS8skBoJFUOVEf9xn/4B7/IikNDDhdrovxsSRaJ/jwrjGxZAfXechzR5YvX94SZdI6KJo1zZs357HHHkOr1fLKK68QGxsLgFar5aWXXgJg69at7N69m8DAQPz9/dm6dSvHjh3j999/JyQkhGrVquHk5GQJh2zN9evXOXXqlOWFU65cOVxs9SKsiI2NpU8fZdR227ZtuXTpEv/++y8AnTp1wtnZGXd3dx599FHOnTtH48aN2bx5M6NGjWLHjh1Urlz53ipMJV+oAr+IyCv6oj5yAOuM87h12Vu5S5e9wDUZiYYuKwfA4U5UeGw9i46F2jW8hoeD1eRDFjI7qvmJ/mht2B03DgY0HInnXwvBqEerVbQbZ6tep2b882i/iSWK7lz46XuqHGpFao2DNN7+ArEB+5mj86Nj2/a8FT6Lkw46TELDSQcdb4XPouOUEuCr/yDiI98n1qGRrdfLlSuHVqsFFBtd3759LS+P//3vf0ycOPFhFxUAZ2dny3+tVkt6eroaKvkhowr8IiLPmamOHyc66ASmmn9BYh8cnK8wZEdlboX1ZwuhdF45gKvRu9mwwbZaOVNQ2wpqBnD5ct4zY9lSWy9dqsTIcXEBsyoY5h/izE8b8CURL5KYrfPjqschhnzbjd6G+syKrsPwsJPcLv8o82tPJ6quKxokUXVdmV97Oo8fKAHN8EHER75P/vjjD5KSkjCZTKxevZrWrVvnSPPMM8+wZs0azp8/Dyg69uTkZFq0aMH27du5dOkSaWlpREfn/FKsWLEiderUYd26dQDcuXOHlJSUHCGarQkODibS3OvYtm0b7u7uVKpUye41qKGSHy5qeOQiIGJnBN8d+I4ePj242XULz5+rxjt/LGfO/5mI/BkcM15l24AnSal2DO3GafSKq8l6XTdWhPVg0A4PomvvYOOpCCpVUlQ01qSkwNtvw61bOVXO1nh42J4ZKzLybghgjcZKqFvlv2hRzu0AMYTihRFqR9AkWsPYE59RR3wP0gOcRvPjla0W4b8uoQ2xAfuZFV2H7ic+g8jh91SXD40HER/5PgkMDGTo0KEcOXIEvV5vU9ffqFEjJk+ezLPPPovJZMLR0ZH58+cTFBTExIkTadmyJa6urvj7+9s8x7fffssbb7zBBx98gKOjI9HR0fj6+qLVavHz86Nfv36WGa3grnHW19cXFxeXPGPx//XXX2qo5IeJPfedol5Ks1tmzLEYWWFKBSkmCuk9JEAyQUjN+0KKCUjvHl6SCUJWf6XZXbdGs8tlJd338vFWAywegfZcL/Na7Llf2nLVvNfF1jkyUAocrG8jmaj8SlC2FwEFdsssRqiukSpSqm6ZJQK9lx7vfT/gkO7E348mgEli0ko0V+rwdwMjXTa25p2VoQQYK+JFEiaEZQDV0Z1fkpys9OILOM0poKhu+vZVOqrZ9f62HFFsYVYPF/gcp7UezNH5ERuwn+DtbSy6/dPaotODq6iUKey9CYp6Ka09/BmxM+SgqTFySK21Ev37dwcvjXOSTEQ69w+UEqQJ8uxFa7VSOjnl7Fm7udlOn/llYG/AVX6+GFxcpBwyxP5+Ieyfo0e7mVKMcJOzdX5Sguys+68UI9zkjPpPWQYzze2yWbq6PpCxTTkoyT18FRUp1R5+sSewViCr73Rjqcc+HFrOuBu+2CEVzeW63PFI4IWgYKRGa9OP3pqMDKhYMafhde5c+/bF3NzJ83I4ycz/889zuntm4uFh/xzrTSbePDWa7ieuYkIwIPkY5aMX81216iAlhmQvJm3wo+nVLciiH9ukolL6sPcmKOql1PbwZ0g5JMT7boiE9x0tv9Y6fH3nVy0j+XPrcQs76m97UQByC7mQWy/f0zNn/gX9UshRVk9PGUOIdGw1SbbTjbaEiUhDK5voZkpazbB57sJC7eGrlHTUHn4xJ/DaFpamvYjbdSclTMI1T9g4E5b/TIPDOjy0Sfhs7MO2yhcID1cG0Xp62s/PXq8881jzAFyLM0lu7uTh4TB4cNaZq8C292F2t1I3NyhfHvr0UfT2+SlrRJ1k0G0j5FQKm8O+ooluDui20bXzo+wNm06TU0pGJXm8lopKscLem6Col9Law5eennK2zk8ywl3R4Y9wly66DXIIn0lBhuxGtKVHnMny5VI6OubsMTs5FVzHnZ+gadcYUm8AACAASURBVAWNEZYf7x5bXjsxLarLyiMcZSXd97KdbrRkVCWpGessGecshwQ9LtPQyrYoOv2YYzFyRmzhBl9Te/gqJZ2C9vCLXLDbW0qTwLcWoFt0yMojHKXQbZYgZR9dP4vQ68zaLEIyex7Wxlg3t3s3aBZ20Ed7aietNvdzxIzdLCvpvpeVRzjK8XoUYT8R6fTfqrLCWORsnZ9047xsopspxbgK8vFpze+voNkoaoF/8eJF6efnJ/38/GT16tVlrVq1LOuA5b+fn59MSkqy64r5+uuvy7///ltKKeWUKVMe9mXkIDPS56lTp+RLL72Ua9qPP/5Y3rx507L+3HPPyStXrjzQ8pUmVIFfzMje+x3VylV21v1XVuaKHM+H0p3zcrbOT/Zp1SiLsHRzK+qS55986+yzMWOGIvTfbysUT6Wx5aWXvtfdUNBjXWQfvaesMNZs72g5u1C9dgoi8GfMkDImJuu2mBhle2GQn/DI+fG9L6ywytlJS0vLd9qClMHT01NeuHDhXoqkIlUdfrFjgKEjKb5zLOvxO6OJqeHKk70eZxITiKI7U42bObVzriWNo6PiaVNSuNcwMyNHAgO0TG/hAqnlcRJ3GHprBe4rv4FUF3BM4ds2ydx0BDbOwvu30CKbFD0wELp3B4NBWTcYlPXAYjCDY0hICAkJCYwePdoSZTPcbLSxFxrZGp1Ox8iRI2ncuDHNmzfnyJEjAPTr14/BgwfTokULRo4cydGjR+nQoQPNmjUjODiYQ4cOAZCUlETLli0t8XAyMRqN+Pj4AJCRkcHw4cPx8fHB19eXTz/9lHnz5nH69Gn0ej16vd5SlosXLwIwZ84cfHx88PHx4ZNPPrHk2bBhQwYOHIi3tzfPPvsst27dAmDevHk0atQIX19fevbs+SCquuRj701Q1EtJ7eFnV5cQNFsyQchxQVVkBkLqg55TvHCCnpMZCJmEp2zL5iw94wfpe/4guJfJVKRU9PLuEe6SzoNkE91MOTNIGW3sHDRZiqAIZTKViUg+0Mpyuv+Tm9Hn+dVQEAqq0omJkdLdXcrx45Xf7D3++yF7D1+j0VjUOV27dpVS2u/ht2nTRsbHx0sps/auDxw4IDt37ixTU1OllFIOGTJELl26NMfxnp6ecvLkyVJKKZcuXWo5R9++fWWnTp0sk6i0bdtWHj58WEopZVxcnNTr9VJKKZ9//nlLvp999pmlDElJSdLb21tKKeXnn38uX3rpJcuXwqVLlyzntu7hZ64nJCRIHx8feePGDXn9+nXZqFEjuWfPHpmUlCS1Wq38888/pZRShoWFyW+//VZKKWXNmjXl7du3pZSyzKiFCtrDV2PpFCKZwcYyfdCTk+Hx5Oc5xS2mtn+fXxtCrMfPlNs4meNx3dFSL0cenp5FGp7lnrjXMDPxp+OJejmK/vP1/JkMVYz+lGcXac+MR2g0SCHhbGOo/hf0ep7EFY2pnG2KxocZ2kavhyFD4KOPYPx4Zf1BkRke+X6wDo0MSoz9Rx991GbaV155xfJrHeM+LCwMrVbLjRs32LVrF2FhYZZ9d+7cAWDnzp189913APTp04dRo0blyH/Lli0MHjwYBwdF5FTNY5h4bGws3bp1o0KFCgC8+OKL7Nixgy5duuDl5WWJ/dOsWTPL9I++vr6Eh4fTtWtXunbtmnvllFFUlU4hYmvA0UxG4BT3JprjLdnhCZrjLXGKe5NZjMhxfBEHX7wv7LmB5sbIViPRe+ktgShjCCUo7ik8r0lM2gw43RS+2AcbZ3Hb0cSotg74thuITqe4gvbpkzWSZ58+8J8HOFuywQALFijCfsGCu+qd4oqU+Q+NbB1q2fp/psA1mUy4urpa8tq7dy8HDx60ecyDxlaYZYD/+7//480332TPnj0EBgZatqvcRRX4hYgtf/GurCc8KIAMjzhIDibDI47woAC6sp7ly3MPT1xWsPbpj/HScsxVA6eaQq0/cQiahmPcWxA/GFlrL0MSfrCEfJYyaz5SwhdfPJiRuZk6+6gomDRJ+bXW6RcXHB0dSUtLA+yHRrZF5tSCq1evpmXLljn2V6pUCS8vL0sYZSkliYmJALRq1YpVq1YBWEIjZ6ddu3YsXLjQIoQvX74MYDfUcnBwMOvWrSMlJYWbN2+ydu1agoOD7V63yWTixIkT6PV6ZsyYwbVr17hx44bd9GUVVeAXIraMlHOC4Iv2R3HcOAUW/4rjxil80f4os4OKVaTdIic8HBYbDLgP6U6F5Wuo8OV2hmx8jPT2Y0nrOgC811B/+Vy6J53PNR8plcBthS304+MVIZ+pxtHrlfX4+MI9T15s3bqVOnXqWJbffvsty/5BgwZZVBvWoZF9fX1p164dZ86csZnvlStX8PX1Ze7cuXz88cc200RGRvL111/j5+eHt7c369evB2Du3LnMnz+fxo0bc+rUKZvHDhgwAA8PD3x9ffHz82PFihWW8nbo0MFitM2kadOm9OvXj+bNm9OiRQsGDBiQJQxzdjIyMujduzeNGzemSZMmDBs2DFdXV7vpyyz2lPtFvZREo60t42XTXo/KckGTZSWzG2YlrshyQZNl016PFtjIWdqZETtDxhyLka6uUn7PCzKGEOnUNUzxzdePkIP4QibhmesAr4LUZ1H74RcXVNfIkovqllmE2JrFqs6fsTjFvck6ujGJCayjG05xb3JtRWyWYx/gfNjFGuspFD8PH8npXXo++wwWaofSVTeM8vXWMX47lA/4hFW6R3mdr/KVb1mtTxWV3FAFfiGT3XjZql89PuqSQD2tEte+njaJABI4asNDp6zFjLE1heKgQcq+1L5abnfvz4Loqkw0CFZsrMqtPr3Y1mpf1kx0Bmhle07cslaf94rRaMTd3b2oi6HyEFAFfiERsTOCN354A0PSXSueIcnALw5vMPzfPdTNMKLFRN0MIwYRajOPIpwPu0jILVRzh9fi+WXwWl5JOotGmuiYeJb2zlNwaDuO1Y/VIAMNqx+rQflXusFp26Ofylp9qqjkheqHXwhE7IzAQePAsj2ridwdyQ+/PMKfmnOMewbS0yuQbvwhS3opFZWPtZdJSXbJvFfs9cCPH1dcNrPzboovv65YwaCwHuxPkMwLuIzjytVM981gzLmsL4+yWJ8qKnmh9vALgcBagXywaRrPHnqBlDta2oee571nISPDAe2qKNoacw5nl1J1ySxoSAZ95ADWGeeRmvAWH7WB1IS3WGecx7DEATlsJ2WxPlVU8kIV+IWA3kvPpLRR/FD3/9Cdq0iaowQBaXGjmWrczNcMyHGMp2fBByqVNjIHXFmTa8/8+HHQbSM94GvYPh4R8AXotiGTk/nuP1tITlZdXFVUckMV+IVARAQ0+TSW0CMOJHmeggwtpLqgaf4xTXSf4EFW3YWqblCw5dWUW8/c0PxRuoU54hT9LQ6G90lJq0KHcA0f6/zY8a8f3VhDsvd/6PN7gxIxLeKlS5fw9/fH39+fGjVqULt2bcu6EMLy39/fH6PRyLZt2+jcuXOOfAYMGMCBAwcAmDp16sO+jHyxbt06SxkBPvjgA7Zs2XLf+T7yyCP3nUdeWNf7hg0bmD59ut20V69e5fPPP7esnz59mpdffvmBlzHf2PPXLOqlJPnhx4zdLF2CPpRMQGrGOUhGV5YiaIZkdCVZYZRW/p9v9UKNP19WGfT+AFlJ972MIUTO5h1Jx8FKnb8WIGfzjnTu2E8Jo9xxSL6mRSxQeGTzGAFrCnNSluIeHvl+6du3r4yOji70fO/nejODwuVFfuo9E+uAcQ8D1Q+/ELH2Edfpchm9ubU3prYfojncHlPkRhxXrYbgCLps8yP9716s7/J8mVffFAaPV/ySdb0qEt9qG//r/AluB/QQPwRT3QTeG76cO4FLqHuiJvz0eaG7ZAbWCqT7mu4WLyxDkoHua7oTWKvo4yPfb3jkX375hQYNGtC0aVOGDRtm6c1OnDiRWbNmWdL5+PhYApV17dqVZs2a4e3tzaJFiyxpHnnkEcaNG4efnx9BQUGcO3eOXbt2sWHDBkaMGIG/vz9Hjx6lX79+rFmzhoSEBMtXTOPGjS0xeQoaitkao9FIgwYNCA8Pp2HDhrz88sukmC36Op2OUaNG0bRpU6Kjo9m0aRMtW7akadOmhIWFWcIxWNfJ999/b8l7yZIlDB06FIBz587RrVs3/Pz88PPzY9euXYwePZqjR4/i7+/PiBEjsoSIvn37Nv3797eMBjaY43IsWbKEF198kQ4dOlCvXj1GjlQcFjIyMujXrx8+Pj40btzY7gjoAmHvTVDUS1H38AsS8ndGK2V2JkfuSJByPB/K2To/6dJqvJz9VHShTZKhohDTorqsMEorGV1ZotsqGV5NCaM8AYlui/QmMdcefmYI659/PiATE6W8eDGf5zWHcx4fM166R7jn6PHfD0UVHvnWrVuyTp068vDhw9JkMsmwsDDLObKXydvbWyYlJUkp74Y3TklJkd7e3vKiuRIBuWHDBimllCNGjJAfffSRlDJnD99Wj3/48OFy+PDhUsqCh2K2JikpSQIyNjZWSill//79Ldfh6ekpZ5gfyAsXLsjg4GB548YNKaWU06dPlx9++GGudbJ48WL55ptvSiml7N69u/z444+llMrXwtWrV3P08K3XZ82aJfv37y+llPLgwYOybt268tatW3Lx4sXSy8tLXr16Vd66dUt6eHjI48ePy4SEBBkaGmrJy1bIZ7WHX0jk5iOenZEnPfmfcQjlSWE8k1jAEJoYqxC5cx/xHi8zMqeHocr98MxytKujcZR3oE97qHABpNIz1DZaSX8WYyP+F5B1sBdAaqry/9KlvE+r99IzJGAIH/36EUMChqD3enDxkTPDI+/du5e1a9feUx7W4ZH9/f3ZunUrx44dy5Lm0KFDeHl5Ua9ePYQQ9O7dO195z5s3z9KLP3HiBP/88w8ATk5Oli8E69DFebF69Wr27NnD9OnTs4RizvwyyYwBtHPnTkso5z59+tjNr27durRq1QqA3r17Ext7d2R7jx49AIiLi+PAgQO0atUKf39/li5dSnJycr7rJCYmhiFDhgBK1M7KlSvneo2xsbGWvBo0aICnpyeHDx8GlEB3lStXply5cjRq1Ijk5GQee+wxjh07xltvvcUvv/xCpUqV8qzHvCgUgS+E6CCE+J8Q4ogQYrSN/f2EEBeEEHvNS063lWJGbj7i2Znn9xXf8aIlfEIU3Qkjik8ZSrbYVir5JDd1WnzlUCbUysB0+UnQpoMAEntD/GAyAr9mTMd/uXHnWyJ25hyBa+tFbjKBnZhfWTAkGViQsIDxT49nQcKCLIPsiiNS5j88si0cHBwwmUyW9du3bwOKEXPLli389ttvJCYm0qRJE8s+R0dHi1rGOnRxbuzfv5+JEyeyatUqtFptoYRizp7GVshnKSXt2rWznOPAgQN8/fXXeeb9ILAV8rlKlSokJiYSEhLCF198wYAB9y8271vgCyG0wHzgOaAR8IoQopGNpKullP7mJX8BUYoQm77grSJ4tHnWh9yQZGDUzT34kYgXSvgEL5LwI5EYQtXh/feAvZALmUJ/5Ej4X2c3TDUTERkaSHcGv+Vw+QmIH0R6/V8wPPEGR3/NqV+3dz9SU3MvU6bOPurlKCbpJxH1clQWnX5xoaDhkRs0aIDRaOTo0aMArFy50rJPp9OxZ88eAPbs2UNSUhIA165do0qVKri4uHDo0CHi4uLyLJe9MMhXr17llVdeYdmyZVSrVg24/1DMAMePH7dEEl2xYgWtW7fOkSYoKIidO3dapnS8efMmhw8fzrVOrHnmmWdYsGABoOjbr127Zvc6QQn5nFnmw4cPc/z4cZ588km713Dx4kVMJhMvvfQSkydPttyL+6EwevjNgSNSymNSylRgFfBCIeRbpNjyEXe+FEhKp5yGu9vHAokhFC+U8AleGIlBCZ+gDu8vOHmp0wxJBlaJrjinOiPPBCD29IU0F2g/ApxTEOUvcftKQ3reyGmgtHc/nJxyL1Pm7FyZahy9l56ol6OIP/1w4yMXdnjkcuXKsWjRIjp16kTTpk2zzIj10ksvcfnyZby9vfnss8+oX78+AB06dCA9PZ2GDRsyevRogoKC8ix3z549mTlzJk2aNLEIUoD169eTnJzMwIEDLcZbuL9QzABPPvkk8+fPp2HDhly5csWierGmWrVqLFmyhFdeeQVfX19atmzJoUOHcq0Ta+bOnYvBYKBx48Y0a9aMAwcO4ObmRqtWrfDx8WHEiKyTHP3nP//BZDLRuHFjevTowZIlS7L07LNz6tQpQkJC8Pf3p3fv3kybNs1+BecXe8r9/C7Ay8BXVut9gM+ypekHnAH2AWuAunbyGgQkAAkeHh45jBEPm+zz0/bsKeXQXjNl1REa+b4eWXWERg7tNVO6umY17mYuQqgumPeCEPbrU0rFRXLQhkGyou576Rg01eyKOUgyqInFeDsk6HEZU+mFHAZza2P8zz8fkPHxUu7enX/DbWmnIC6IxZWH7RpZlBRXo+0PgE5K6QtsBpbaSiSlXCSlDJBSBmR+3hUl2SNftkzZwsoVfemUUJfJbaBTQl1WrujLQK8tOb4GhIDBg1UXzHshr5ALI1uNZOHzC9Fe7cbEuGs4b5wMgV8qc99KINUFzvrT/d8vCbyWdXCP9WAvUHr2np7g5vbgrkdFpbhQGAL/FFDXar2OeZsFKeUlKeUd8+pXQLNCOO8DxVb0yxr7e/PEKw34tuUFgre3YXnADcbq2jFsX85YLt9+C1YD7lQKQH5CLkRGglYL3/A6Dmd90ZhQDLjHn4K/wlnQcwtjdO3QRyqGLkOSwWLEzXyRe3qCr68q7K0JCQnhxx9/LOpi3Bc6nY79+/cXdTGKJYUh8OOBekIILyGEE9AT2GCdQAhR02q1C3CQYs7Ry0eJ/CuSrqu7YkgyYEgy0PeVc/xe/zLtYoLZYdhG7+jnmRaWyP/qJt/TJN4qtskr5EKmUffSJThKPR5pORGTBhonVwaPXWByACmJ8TkPx4/nOkhK+QJWUSl53Evbve/wyFLKdCHEUGAjoAW+kVL+LYSYhKJL2gAME0J0AdKByyg6/eLN/p6k3VpJhukGnb5qi0nAHQfwiH+OXXFRir+9MYIx0X8SUyeZZ4q6vKWM8HD7L80sRt2gOZyr/yfNDj9Kr99qML7Gi6S0n4g2/jU2NY4ktKokcVEoY7QziI/Wo7caE3HpUjn27LmElG44OQlq11Z7+yolAyklly5doly5cgU6ThTXHk5AQIBMSEgosvO/0fYfliX9w+1eL4PTLQA0ia9gWruc2bzHu3yCgRDCiOKDLokMW297UhOVwkejsZpLoFdHOBZKk7Mm9oZNZ1Z0HY7UuMFCH1dMjx4Ap1v02e7Jz4Z4xndJZE6i4ipbtSo4OKQxduxJnnjiNhqN8jXh5gZmN20VlWJNuXLlqFOnDo6Ojlm2CyF2SykDbB2jToBih567RxBZ9XXQmF37Mhww1f8/uuj+yzDjfMt0hR90SuR2K1XYP0w8PO6OlGXFTwD8CTSJhilho/hPgony7lpuZlRAt/1Flgf8wqykdnT94SpvSyOQObLWkbff9sqSd2bYahWV0ojaw7eDwUvQsZeG245SGcXZYANazS0qZKSyLgr0x4pnvZUFMnX42X31AdB/AG0+onwqvLyiH98aF9NH15+fw5awKhpCjbnfNyEUO4yKSkkltx5+mY+lE7EzgnFfGrIM4x/3pYHRoWASoN04HdYtQ7MqigxTORoer0p8I9eiLnaZJrtrpWXUvM4AAQtodcwZjUnLerownkn8bIxgTLQfm2vnfd/UgXIqpZkyL/CvHQhk6pHuJAuDMoxfGJh6pDtuFzzRRP6AKW44fVhGRWNzyq1ayd7jwwj0iy7qYpd5Mr2ipFRcYKu3MEBYd6r/GkX3qz+iXRWNCOuBXqfENppm3Ez8ztzvmzoxjUppp8zr8COn6EFEQVh3SBgCAQsgKorjZ+rAnTrMsjLQdjOuJdhUh/jKvjy4OIkqBSU8HE7p4gmsFYU+Qk9EBKzz2QJbqxJf+xwjZRLj/RIZ/nMopN09ztERKlWCy5fVqRFVygZlXocvBLRlC976l/m0zTXe2l6Zvw1riCGUmLFblIE7x4+DhweG8K+IrxyqhjsuoURGKi6d5tupCniVUomqw8+FbpW2kKC7zrKAFMZvh2UBKSTortOt0hb0U0KzjKbST1GFfUklIgJqHdiCER0ZUkPsSR2Le2+hSpVcZjJTUSlllHmVzgBdb2LaX0ZGrwbjX8ikxoiwHgzYWBU4W9TFUykkAq9toftUP6LwQk8y/2R4sRc/ml7dwqBBilut2ttXKe2U+R7+/ornWBudxtvGv/iID3jb+Bdro9PYX/Fc/ue0VSl2ZL93sfFhjNG1oztRfMCHdCeKsbp2BLYKIyUF+vZV769KGcBeGM2iXh7anLaenjKGEOnOeTmeD6U752UMIfK6m2e+57RVKV7Ymo94iw7pPgJZS7dMgpR9dP2k+wjkVh2yG9Hq/VUpNZBLeOQiF+z2locl8GPGbrYIeQkW4d+t0mabMdlzmxxbpWjJnL/A1n1LwlPO1vlJRrhJ9O9LRrjJ2To/OZt3pCDDIvTV+6tS0slN4Jd5lU585VCixiai90wCIdB7JhE1NpG1/9oOl6BOWVg8yT45eXZe5yumGjfTJ+ERaDMZEoYwyvgH7zGbWbxHFD0B9f6qlG7KvMAfORKb3jiZozizo47ELJ7YmhbRmhhCaei9lJ8Dkhm/HUTAAtJ1O9Fh5F0+QUsG3ViDs3PuE6irqJRkSr3At354q3RWwihYYz0xhjX5mYRDpfiQV8/cuYGBxB4zeOwKJN4KRqa5QHhHjLokXggKplEvHWs7boWBXrlOoK6iUpIptQI/MhLc3aF377sP79W/lTAKmUI/t4kx8pqEQ6V4kduXl6cndHsznvW9o6hx41U2tI+l+jUtONyGLv3Z0D6WQ841IfALQo+m5jqBuopKSaZUjrTNLZpiE90sksNG8WaCiQUtNIzRziC90nB1QFUJx9Y9d3HJ+ZLu2BEcK/flhyeX4XrdkSsV0+C2K5S7Spf4Wqz76TQacj4TahRNlZJCmRtpa0+f25YtHDcqk5B/1Aae+70u06b0zTHRtUrJI79fZD/9BOtXLqX1cbhSKQ0ynKD8VbhWlzY/dbebv2q7USkNlEqBb0+f+zUDGKtrx/KAG5ZJyK0nuraFasArOeR3XuE5v81hhwfwbw3QpuJ8yxkqn+C9jreZxqi74ZbNqLYbldJCqRT49npjR3XJTAtLpHf081kmITdobPvyWbv6qQa80sGc3+YwfNNwKpwPgIpn8T5eiTvl7lD9XBUI/IJPOh7mmNTRRDcLWkWothuVUkWpFPi2PGwAttZxZUy0Hz8bI7JMjGFvQhNbqiHVgFey2XJsC7OenUX5GtfpYurM/pgqPB9fi3PuN/A+5IX02sb3Olf2hk2nySnl8di5U/3KUykdlEqjLSgP5QBDR24fCMXz9LtMmaJES+wcswufx+by+4rLGAihO1HKwKspOQdaZZks2wrVgFe6MAod3+tcGR52ktYJPsQG7GdWdB1eNF7FC2OO9LaMwSoqxYUyZ7QF5WGc8nooov1whq2cQ3g4zHHZx632E+lxRWYZVRtf2faoWnuqIdWAVzrItM94cJx3jYl4JnRgR5vttE7wUdZJpi05DfrqV55KSaVUh0d+t+W7AAzfNJx1h9YRmx7LrPazeHfiu5Y0evNiiylTbLv6qQa8ko+1G+dxPPhe50pywC+wfRw7AhYyJ8mPJsYq7MOPzqzjR7pmOV4NwaBSEim1PXxQfK4Z7kHrZMmO4ztonSxhuIeyPR+og69KL9b2mRd1QxkedpJOB51w9PsSjrfkvbBTdNa9y1O6yfz42nSc3vTKcrz6ladSEim1PfyOkR1xrFyN9674ggcEJ8MOD9hRfjyz9wK8nK98wsNVAV8ase6h/1nbRJPo0fyXEWz0E9DgBzjUhTSf79jgtxocbvNsfC1+tDpe/cpTKYmUSqNtxM4IjFeNLIhfoGzYOIsaVXdwNnA9ALM2Cd7bpVpdyzI6Xc7Imkkoxtv3wg+Bwx2QAoTMMQLXzQ0uXnz4ZVZRyQ9lzmgbWCuQZQnRVLvmBICL/+ecDVxPlfgwOm8MYatX8XzJqTw8bLnuvs5XTDNuptkuPQhAI+FaXWr/NNaSxsUF5s59uGVVUSksSqXA13vp0SfO4aJjRR65VoWUGsdwPlePKz+t5mLcFDas0BZ1EVWKGFv2mTiXUJrrprL7qW0gAZOAyidY0HE/c3iH4xodetMWevdW/fFVSialUuBHRID+x7/hjB83XK/gfLUad6ofQQTN4neC6M4qdRCNSo5QDO98YuCn8AXgcJsu8bXotKcGmDQQ+AUzOiZzxOTFjhrX0XVuR3KdCHXUtUqJo1QK/MBrWxjb7hzy8Rg48gx3HCXEv4FsP5LOQSGs5WU1VIJKDio3iqc8j6JL7Mzcnxx5d/8ZnDI0YNJwpf4uuuqGkdqzJ0bvP2hySqP646uUOEqd0TYyEhw/qEF4r/OIPf2RPykzGxHWnS5/O5HmepqfV2S9Zk9PpYenopIFjQaDp6R9z/KkaUCDCVOGM7NXe1lG4aqjrlWKG2XGaJs5mCap5jlmLPdF89N80nEi2KjFJfobNl0bxMAVL+Q4Th1Eo2ITDw8whuDw+xBwuoXJ6Q6N/9DzrjERD45bkqiolBRKlcAfYOhIiu8ceuz0xGD8iFScaBbUi7hek/jIGIPTzrcZwcwcx6kPrYotDOFf0VU3DNniM0gtjybVmb+aG/iP7iVMaGiv3ULNmmpgNZWSQ6EIfCFEByHE/4QQR4QQo23sdxZCrDbv/10IoSuM82bn9t+h0H4404McMaDn+aAQdrdfSY1j3kxjLM+whaPUy3KMGipBxR6rHtGSSUqragAAIABJREFUGt6b27IcQfsep1zMWJxEKgt6bGaYriu/1b3OBe1ANXy2SonhvgW+EEILzAeeAxoBrwghGmVL9jpwRUr5BPAxMON+z2uLsD88YONMFrY/ymP967Ch/Q7YOIvBceXxJZG15tG1aqgElfzw+NPx+Dr3ZrbDeKYeOIBj8GQcto3B7ZI7C1veRIT14KNTPyiJdQZoFaEaclWKNfdttBVCtAQmSinbm9fHAEgpp1ml2WhO85sQwgE4C1STuZz8Xoy26cKBebzFe/0TwDMWklsze3EAw/gUR9IB0GohPb2gV6lS5jEbcDuHuZDyz0vg9y2zN8I7cQKtbiuEdYfoKDDqVUOuSpHyoI22tYETVusnzdtsppFSpgPXALdCOHcWtGRA0CfgsROSg5XfoE+U7WYGDSrss6qUCcwGXJkwGPy/xSkxjEnBjryjr5RF2GcmVVEpCJmhuoUABwfl90HYhIpV8DQhxCBgEIDHPTw1s4MEI9pL2DiT4LhAdgTF81774ZgQaOMVYf/554VdapWygCH8K7quuI5TQA+Gb4d5Aeu4deQFPm2zBraPtwh71SakUlCsQ3UDZJj7p5k2ISg8tXNh9PBPAXWt1uuYt9lMY1bpVAYuZc9ISrlIShkgpQyoVq1agQuyoLE/bJzF7LiT/EobZsedhI2zWNDYn/R0Vdir3DurHtEi+vZn7a9VqWAYSb0dL5Hqu4YmiY1wD/iID3WtaKD9hy5dVJuQSsGwNZVqJoVtEyoMgR8P1BNCeAkhnICewIZsaTYAfc3/XwZictPf3ytPntzDqIueDONTJDCMTxl10ZMnT+4p7FOplDEefzqetX3Xoo87i+O4aiSEfgfn61Mr7Qpjov2YGPY//mk/g621/P6/vTuPi7raHz/+OjMMImqu5Q6DWllqZIqiZgrCRcmNEkXR/FpmUd2619QylzZpIfXXdrO6ltcUN0pNja5BjEsoNlRabjdTRhRzyV0UGGbO748PIOiAIuAww3k+HvOAGWY+8x7Q95w55/15H+JS45wdruJCrnUeUGWeJ1ThKR0pZb4Q4hlgPaAHPpdS7hJCvAakSynXAJ8Bi4QQfwCn0N4UKl1iImjvJ9qqrAfwVlU8kVLjTOk1pej7/O2x9JTt2RKwk28a1CZp53x0u1ZiC/iM81YdAS0CnBip4mp8fK5u1X3lzyuL27VWUJQqV7C7favAf5IV9i7Y9aDLxytPx6ylnUgP3M7Spc4OUnEVV87hF+ftXf7S8RrTWkFRbgofH0z05Uzaa5DZC/T5IKB3WgBvWZLIXfZliSqLwgoMdTauUqj4v4lp02DsWO28INBKx6FqzhNSI3xFKSfTtGSGvtGVS4HzsIZNKxrhk+fN4KXj2WKZTm82sopheHpqZ+FarZcffyOjNsV9OBrRV+a/CTXCV5RKZK4fQu3AWVjDpuGVJ+iyKBbWzwHPi6wZ9QmRxhg204dgkslrYcLareQirjobt+aKj9dG81dO31y8CGM+jkO0MZX4FGjKMFVqEYBK+IpSTlOmwMk7d9Pl99vo91tTdnbcSe0mP8PewaDPZ36Pc3Qf6M/ZkaNh1CDIunoRV3VorXkKR/Y2m+Ofy8MBGIZF8KZoxsjROhL9mxGxMIL9myqvCKBanXilKK7iP6GJLBqbzObW5xFRUVwSHiAN8NMErAHz+K8NbHpBx/Vj2FlwUlZx6mzcmqesenuAYIuN9IQFxESOYE+65P2up5ALlxM1qpR3iBugRviKcgOio6FhZAjhWTY8ly3DS+aD/hIEzAO7DpsHdNlxJ0fTZhMikks8Vp2NWzOV9akumGTW05/VlvfJS/87r/eBi+kTWW15n6D48ZUWg0r4inKDli6FzrOG8XILG2LbM2DIAwHo7XDwfn6+/QRTjaGsajRedWhVSv1UV3tUH7YEbmMzvcG4AXvXf8MfoeT3mgPGDZU6/6cSvqJUwJQp8L+BjdEFvo8+H5CATUDzX/C8WI+Zo3ZgvuUgC0wm3tocx7NL5xJPuLPDVpwg3NGfvVccnc6cIydsBmHhbRgQWY/czL7QNgmPnx8hItKAqdttlRaDSviKcoPi46FZoIlPz0VwSXhgk7Xoae4EttpgyCa3YRbZBpgaBGHzIpg+x8Kk7yYR0iZE1ebXMPHxsHDh1bd3ztJh7nCInuaOWAM+Jze3CbRfS09zJ9YnHkAmLGdZ6KBKi0MlfEW5AYUVF8c8zLBzBPZfH+GB+Bf5PfF7YpYMwPB7KDop4WRbtrUG2/kWWO/5GI+U2fyxaCITJqB2yqpBihZse8XBwCe0DXOAlZYPeXJzA7Z0/h1y6kOjDDjWkVmJjQliA6tH1aNtvX9XWhzqxCtFuQFGo+P+JxG3JLMyuz8mW28eDLqPS33mwplW0OAwAQdrYV6Qg17vuDTP1xcslqqOXHGGgm4cWqIfMVRb0Fm2imSCGTJCT7YnoLfheeY28uqfwGv96yTuNhN0dnW5n0udeKUolay0dbTV50O07a6MG8jtugD+CIX6h+l0FNJ9cukYOLbUOmxVm+++ihZsLUG0WP4h3jIb71HBDBoF2QYBOht1/+iO1WCjp7kjOWEzeGnwXZUeh0r4inIDSqu48PEBU7fbiIg0IHY9BG2T0O0dQGY9Az3MndgZtghjeJj20f46j6m4vsIF22CSuWAZhO3Hf3LREy55Ajo7OvPjrFlcm9kJrdja4Qg9D4Vy+o4dlR6HOvFKUW5AbKzjDocHD8LjrQYhE8Lp0nM8vx66hxy/LZzbMIsteklPczxpXZJgu7HE41RtvntbkBcOI/X02XqKB8nm+W4ZYDOAzgp2Pe/s/pEgdhAkfcHzRZLb2EmdNuXaBy4nNYevKDcoPl5bjHM0lx9MMsmE8rTxYeaNSAIhqL9tDLndPyVHehH1wz/ZevgVMjO1kX1srKrNd1dxqXG88IZFOynPWgsvrFh1ApveBtZa6JHUteexajkEHah4PlZz+IpSBaKjtUXWwra2xaUQgg097SytYflK0OVxts+H5Oj0xCwPZWnaLCwWbbq/cKFWlWm6p/2bAvDsEA/mJ8GQS46HXUv2+V7olqzFa8mX9N7ZHPPdDao8FpXwFaWCSltsHc4yJjGHGOahw15wq9C+FFu5LSzxVGWa7inqgg2vhP/g1WExnG2tZV0BjbaMI9nyBnpLbzav202Af0KVx6ISvqJUUGmLrasYxhPGESyIWovdVguvAz1BwidR6zEZAaORudNnM35BnMN2uaqFsnsIih/Pasv75P95HzQ4BHYBEk4FLuQX42lWi4cZEXQCc/2QKo9FJXxFqaDYWDAYHP/svx3PkCO9iFkeSuymbJAe2D1yebqHkbmiAZPy3uKu/TqtPvuKyh1VpukmMjNJCN9AfttNkG+A3Lra9I7nRZ4fuY9fXhrAJym3M6Xy12ivoqp0FKWCChdbn3sOTp4s+TPL6VDuX96L9y2z0GODZf48P2ofe9odZpLvKWYv86OVbjYjHrZBwooSj1Vlmu7B1O02PrnvLzjUlTtSxnKUZuRFPkKO+Ulu8/2e5JZ2Jt6kWNQIX1EqQXQ0/PWXNgcvJSxeXLCYmzqFrYdewUA+EsFEyw56bw0AfT563UXO+O3g6YePUWvtCijWN1+VabquuDhtG8zCVfhldRrD4kQCP5/L/yxPsdryPp4JXxAoL9LF8juJVVB+WRqV8BWlChRW8EgJ+fna1yN6H+Ya/dncdRd+G0eRj4HX+8CT6fCP/JN4eakWyu4g4Gwyw9/wx3TQT/vDpzxLPUs33rglDoQgyDeD1aPqEdF3IYmJNzc2NaWjKFWssF6/Uetn2B75Fu0TXmYvd2PothJrXm3e7iaxZjTkwaa/ss5yj7PDVSrIvCOSqUZfhluSiGEeK3mImca+JLc6SL9UOz5A7N0wxQlv6GqEryhVqHjJ5S8t7dyb8CKETIORg7EuX4ffkvexnrwHRj3I/tD7ix5X2ZtXKzdPwO4zvBm5gwHGKbzOTAYYp/Bm5A6CD59xetmtSviKUoVK7GOaOoVfLJNom30ePC8imv1EhmU8HLkXDLnUt58HtGQ//MvhBLSovM2rlZsnyO7L1AR/FkeupXdQXxZHrmVqgj9tLZfP0HNW2a1K+IpShRyVVq5dCoPX90aGvQjjHoCAf9PT3In9jWGmaSbDvxzOimErCPK7evNzpfozRc/nTUsSo9PrsrnPRkan1+UNSxKPMb/E/ZxRdqsSvqJUIUellW/yAmvSNqDL7AG+m9Fl9mBL4nY6pffk9U2vE9M1RiX7ai4+Hho2hBCRzGEPI1JoPTFM05L55zchGNss5Juuh5i+Eb7peggf40JSKHlilTPKblXCV5QqFBurlVgWN4fnMQS+jfTZQu+DYPfZgi78STb2+JkxO2Ded7H8PXo2DRuCaGOi4cC4q+Z71RaJzjPywzgem2WicYfHMRvPs8/mxwaj5IlWeoYuOc/ZNg+S/vDbnEpIZpZJciohmV8i3y7a5QqcWHYrpayWly5dukhFcQeLF0vp6yulENpXnxFzJC8LOS2wobQh5B3hQZKXkT4j7pFNJiNjAttKMbmxbBz4omRyE4kxRXp7a8cpPJ63d2HFv3Yp/nOlajXtniKZ3EROC2wo6082SO/AV6X3ZG/pHfiqrD/ZIEcOrCsxppT4+2BMkfR6u+jfQFX+rYB0WUpeVe2RFeUmC48Pp+HpEFJnTyQzEzqPbMoOWxeE3srILa1YHLkW8WcnhHEjtsXfF52QVbgFYmnbK6otEqteXGocL4wOoDM/cShyMgP+gEX3AH/eh6H+ftYnnKWPRaAvapZ32c36+6j2yIpSjSRGJxL/zMSi9siztxynrk8y9i2TWWRZgNgXir3dBkbulARbLnfVLFzkK22xT/XeqXoBLQLwHB7BftoyIN2XRf6A3QNa/IwufQJY+nKxsc9V03jV5cxplfAVxcmCLDAz4W7skdEQ8Qh2/+WEbm/K2tsNpBvPE0wycHmRr6ztFZWqExcHr9zfitgVftiiIlnU4zjk1wJdPrdv745X13cZanwW8xPz+fRTbURf3c6cVglfUZyg+KLraobwmmUDHn/0A/9F8Oe9bNi+EGvCV4jIEYw3jkbfzkSPSdqJWI4WgqvLCNJdxcXBt3G/kn6kOa/wGvk6CZ6XwK5DrI/j+O0/M3OzFTF2HMvq6otaaxRucFMdkj2ohK8oN92VG55M4h2sxs143JXAmB2gu/U3rKMepiVHWJVgxdTxGLZhERyz7ge05FFdR5Duav/5x9kU8SjWwA/I6biSXHs9ONIZ9FbouJyZCXdz0qMBT7dcRdsHzM4Ot1QVWrQVQjQClgNGwAIMl1KednA/G/BbwdVMKeXgax1bLdoq7uqqRVejCUNkBIkJ59FbHiAkcAD2sBfA6s2YrbeypvtBsmVtxKpvyPufqs+/2eLiwOOLXkwbkkaOwQ7WOpDyGgTPBEM2XlYdnku+pKulHmneIU5/8y1r0baiCT8OOCWlfEsI8SLQUEr5goP7XZBS1i3PsVXCV9yVTqeN7Iv0ioOsAPpZbOzAn0hWMC8wBxE6Bam3o88zYFvyLRGW06yUw5wWd00UHhvH6Ywkdn//FC/zKpNG/4bU20EKEBKv9bOIPZrA9pZWFqXuApxfLVWVVTpDgIUF3y8EhlbweIri9q5aXE2dApYgUkQI/uzgXzxDzNGtSJsXADYMxDCPFUTd/GBrsDovtOe3vQmkNfmRvKgopvEG8nRbbVtinUQc64Au7Tles2wgK/W9osdV52qpiib8plLKPwu+Pwo0LeV+XkKIdCFEmhCi1DcFIcSEgvulnzhxooKhKUr15GjRFbRR//eEYDLCkqiv0NkEbJyBziZYEvUVm4y2qx+kVJkG++7hcNt0jBYfcqQXOWMGQZN9IEFnA9l0N9bAD2hFZom2CdW5WuqaCV8IkSyE2OngMqT4/QrO8Cptfsi34CPGKOBdIURbR3eSUn4qpewqpex66623lve1KIpLuHLRVa8v+fOlHQW50hP78q/pbQrBvvxrcqUnyzsJ5wRcQy1c9Rd682NY2u/UFmf1dhCg29+Xdxb542UVWMNeYldgctFjqnu11DUTvpQyRErZ0cHla+CYEKI5QMHX46UcI6vg6wFgA9C50l6Borig4mV79itOytx6Opqc5YnMsaxjE32YY1lHzvJEsuqpMpyqVnx7wn6YSErcD9m3aiWYErB54NlqC6/yMncteRtDxkC8OiS7TLVURad01gBjC74fC3x95R2EEA2FELUKvm8C9AJ2V/B5FcVtXDkFsCt1ERGW0zzLB0jgWT5gTovT2E8vckp8Ncn+848zdMl5TAf9EMDIERegzomiuQvj7+3JkV5cjBrNdl0XFvxtLZfmJ1a7evvSVDThvwWECiH2ASEF1xFCdBVCFDZ/vgtIF0LsAEzAW1JKlfAVpYCjOf1VDMNAPjokniKfianDbvr+p+6qrE6jUUlrEZEjGGp8ltbhAznWPh3sOkLXhxVN77S2GJF7RzPin+Zqn+CvpJqnKUo1EB8PY8eCzcG6bGGZX1yctkF2UPx4rRTExwdT9HzM9UOYMuWmh+ySCk96K9qFDKBXHF4nA6hzIojjJ3VsNEoGRNUiV6cHYWdO/J1MtOzARF9Cw9tiuGMjl/7fPqe9hmtRzdMUpZqLjoaFC8tumfDh4T6Ep2zDdNAPpMR00I/wlG18eLjPVcdT/fIdK7HlZKGsAGyDIvigXjMEkl/wJ1enA8+LeG75O50tDZHA7foM5npE8Wrz6pvsr0UlfEWpJq7VMmHgbyfJCZtBeGAIM3mV8MAQcsJmMPC3k0XHiI+HJk1g9OjLrRucuWl2deOoRj7CcpLaCQuIiTzF2CBfnh+RAXYDYzb6UrugIVoISbS2WZiaHELLljc/7kpTWqN8Z1/UBiiKUpIdbXMUXhaScb0lLwsZE9hW2kGmvJQko6Ku3hil+EWvlzdlA47qzNe35O8kmCTZhONyDv+QtYMmSl5B8pK3jDE+LO0glxibSsPk+iU2NPH1dfarKBtlbICiRviK4kIi01ojMnuC72ZEZk8i01qzgb4Mf8Of3MTkq6crirHZ1Ii/+AJ5I/4inG9YwXBeNT5AXtcFcKAfwqYnkq+QCEZZjmJNWAUtLzdEc7T5jKtQCV9RXMRqhhAeGIL0SaXB0VZIny30G1mbgcaJTDWGckenSO2ORpPWn6cMFy9q89nu5HrWLQqnzdr3eZzT4/szaeQ+3g20cSlyHLbN08HqBReaEz5Kx3LjbdqDLEFa+4sCV54o50pUlY6iuIhmvadyrN/bDDY3Z0uHIzTaFczvASmIfE/q5eexcjmEkAKRwyFhRdHWiKUR4uqTvlyVo+obb++SayBxqXHsP7WfqI5RMHIk4f1OaN0v7QKyukGznWDIxpDngcE0g+b6Q+xP/bfD56umaRNQVTqK4hZ0gTu447sJfJV4jKkJ/uzrsIO6+7sjdTZsQs8GP2gUGULnhBdKJHtdKf/LpXSfCh5H1TdXfooJaBHAFz8vY9DCQXDsGLEpBe92Ogmtt2mtjvN01F66grC0u0tN9o0bV9GLuAlUwlcUF3HknUT63fsx/fkvb1iSGJ1elwvttmH4YRLWbROZ1QceTG/Nfst42rEPX19YvBi++MJxszYoOZ/vyqWc17PPb5BfELHWGWTn6BkwSsdLwTqw1dK6XxZceqcF8JXlQ0wNSm9Dff68a/1uilMJX1FcRHy8Vqv/PSH4GBfyTddDjN7oi7XbPPK6f0Ltky1Y1OMENuNmPr1lMhYLHGszl3jCi8o9Hbl4EZ57ruQuXK62sHs9+/zGxUHnD35gzI8NyfW0k+tpB2HX2iYUXJICf2NWm96cPq39HhyN5vPyXHf9Q83hK4qLKNopy2gqmqd/vGMwi+7RkWOrC79FQ8A8DPmCcTskF8LmsOSvSfDdbHyPTCQ2FsaMKd/8s7M387heZc3hZ2VpZyjz4YcMbTQW24hILhr0SH0eAAar4M0UyfRgnTann+fNS37riH086OrNagpU5/UPNYevKG6gaHqipbnEoqzeLvDY+CKcNSLME7B6SL6+E5b+9Twd14+BrROLRuyNGt3gc1ZzxU9aA62SpnAOf3rW7YRuX8YvjSzYRkSSLeogT7YBmwHsevQIWhxtSs6SZPh9IJzoyEdfa2WY1/PJwZWohK8oLqIoyRTskAUwYN0Q5LJV2HrPwc9zB7LDSjjWkWP1wJjZkl1pC5jNRCL4smj066h9Q2kLka6U2KKjL9fZF/YkOngQOv9RF1vAZ0wK9qTFrt6Q0Qdu20urn8OYs6gj8tdoZrQcpP1Ol66F+ds4m6iVYTpqbFfde96XRSV8RXERjpLPZN7BYOnN6PS6ZPRZQqs/G0PTXXDwfjJ8jjAosC8CyWoeYiCrOXnScfuG995zj8TmqFonLXE7Pc2dkK3N7Gu3H9qvpZV5IDmJn9PZ0pCl685dVZFT+EZ3rXYXrkbN4SuKC4mP15JaQbNMMjPhXt/ZHIx8gfv+tJPcFrwOdSLneA+w6yDgE1j/DoOPZrK+42naXazFzu8dlxteeezYWNdLbI7m3O0INtCX4H/shwaH4ExrUt7VNt2LZAX+7CixReGV9fuupqw5fJXwFcWFDXnOxJpa2gJu/57BnDvTiS33ZKLT5WK3eWoLuZ3iwSOPOvlW1iy3ESx9eWpMf1I8M9k7w72a7BctbBeTRD/6h/thC/gMj7PNyK9/FL35Mb5L3E8s00okeyHgySfho49ubtyVSS3aKoqb6jXczODcFegPBVF7SQJbE7fTfWdr7sxopmWve/+jbc/nkYPPCW+CLfBUcw/m6T+l4e/+zg6/0uXlwUBWY0cUXYaEt8AW8Bk9zZ2wvnuUnuZO2AI+Y1j4rSWSPWifDtx5oxmV8BXFhU3pNYWv3wsiPx8O+A/jYVbSeeed7Gl1gTv23qkle70V7Ab2tD6Pzzgf5oUdoNb613ljzR5nh1/phorVrGMIT/MhAniaD7noZ6bpTw+Run43EtiYuBuj+W+c9vvV4TFcpTLpRng4OwBFUSrHmTPwJcPAMoy7No9jT9hC9Daw6UBn02E/0ZFDvjvhYE++TUsmiA1gNLrFrlmFu4GlRETQIeN+5iVu4ise5jhN6ZCxjHy/lZAvEWhJL4OC6R8Hx3KlyqTyUiN8RXETRSNTo4k9fVch8j2w6WH0r+AhrNB0JxztBD5beTdQq1s0HfRj+Bv+2olJLqxw8/E7M1qwK+AHvMLHcdy4B/2jXdkV8APBGVc/xt1KLq+HSviK4iaKRqYtzXCwNzK/NmycQcJdevI87OgOdaXduRz05kdZE/YDrUb6M9T4LFONoZh3aK2VTRkm4lLLbq1c2Sqjh0/h5uMbdn9IE/ND5AQshEf6YWv9Mx3M9/ORg3l5dyu5vB4q4SuKmygasWYFQKs0WL4aTK8hj3UAqzfvpFj5dMs+6nb4AmF+nCzvWlwYMYaZUTsJ2HUGk58g4uP+bJ7TnLiblPMLWyJUtIdP0I/HWZVg5WLko/x1qQNIATpJ3bMN2ZW4iUcarnL4uOhorXWE3a59dedkDyrhK4rbKByxet9esvVC3mc76LLsVf5qdZC+FpiZcDd0+IpmB+7BLjzIlnWY5BfOoMja5K/4kk2rBhEQOxTTtOQqT/zX09b4uvj4gKUv+elPQ5/XQUhuO1OLC/VP4xM+gKXnh1ZazK5MJXxFcSPR0ZD93RQWzwoqmqpo3Bh+PTSJN384TQhJRa2Vj/aZT+i29vDjs/zcJ5Hs9OeRliBWEwHnzt6Uuf3raWt8PUzR8xlqfBZDjzdAag3RclYvpYV5IJkB68kPe6riwboBlfAVxQ0Vn6qoWxesVu32lGKtladvhB+7b8PQbQ5snAFdPybXuIUFjGM4K1jBcILe7s/7Q5Jp2LBq+uSXVhFT3iZvy+rqEWPH0eSijifNsHDJbVyKHMeR3RPBHIOubYrL9vqvTCrhK4qbKzFaNpr4JfJtTiUkc3dGU/KlHqsw4JkRSK2Ehdgio1lkbI0vFoLYgMnWm9fX+HP/mdVV0ic/NhY8Pa++/dy58j1H2wfMrBq7ine65vPFBlli83FD0kd4fLzXZXv9VybVWkFR3FyJdgO94rRFXUsQ7Xo9zp9Zg5FAx57/R5ctQcwjBtHSjEx9gTuMH3O45Z+MTW3Kx8QwlJWsQtsJ6nr75MfHwxNPQHa2dl2n064Xb13QpAmcPHn1Y4s/R3h8ODqhY8+PLWmRfDuLdn3IV4EHWXqvgea3hmKr1YfEaVOKnrN4T6ALF659fHeieukoSg1W2uYg99wD+/RTeDYrlTpkMznyME8m9OXLkJ84Y2+ItfEhvPb0J2fn/zG42avktdnMf5dIbQOWlmbkD2WfqRUfD4884nijkJiYy0n/ejYZmbt1Ls+vfx5dvgFpq82gX+uyJuAIHvk68m11maOfwcRZkxzG4YqbmFSESviKUsOV1glz2r9NvLl/OHL5CjrzE3uiJ5On0xptepnHkrN7LEQPAI9cZq8H/6M6Hoysg/z6a/L+F1TmczpqZFZIr4f8/LLv17ixtv6QmQm1akGbe8exO+w/CLtA6iTYPcBah5hlIXwk00sdrpd2/Jo4wldz+IpSA5RWbx77eBDfP7GCJk8NZ+Dn58gVBux6aHKkNTkBX6Dv/xR45CLyDZytDUMja5GXsIqJdgdzJFcoq9KmcIMScHzGq8GgbRZeOO8ekrOaPWmf0TyzLVIvtU3H9fk03zaMjyxflflk4eHlu92dqYSvKDVckF8QMV1jeH3T60i7gZbb+/BXi8PUyfbC1mwvtY+1QW55gdf7QHb688yxrOOtjKhrHresnjR6/eXvHZ3xesstWudLgGCSSaMXPQKH8afPfq05kARsHhztnsBco3+ZT1Za90t37opZGpXwFaWGM2WYeG/be3gbvBF4kLX9Zeof8SO77iXq5MKlpgegh1bzLyOEAAAM5ElEQVS66dH1Awh8l7hA2zWPGxurzZ87MmFCyetXfgI5deryzwJ6RdIz/F62hK2C/FpgrYd+b3/Q5aPXX2BSVAZzRz9TahyVVevvDlTCV5QazJRhYviXw4nqEMW6keuYalwN0eGcbXEAsrqQVzgSN1zC79JJ8jfP4PkwgcXerkQDHEdn5UZHwxdfQJ06l2/T6Uou2Jam+IA9NOsM3953BO9DHWHHWLw2TMLmk04H8/3Io/50O9GN5Nqlr76WVtNf3lp/d6ASvqLUYOYjZlYMW8Engz4hyC+IkBAQ+nw41B3+nU7L7SGQ541Hvg59wEfU6T0D1r/DfN0jmA76gZRldtyMjtbKIqXULjZb2ck+LjUOU4aJBg/G0bXNbDIwIoB223tx8dZMPBvtIrf3uwxOGMXuxI1M+HYmD92RVFSSqZStQglfCBEphNglhLALIRyuChfcr78Q4n9CiD+EEC9W5DkVRak8U3pNIcjvcrWN+YiZ7//vOxYHp2lVLOuSuH/pZB44ZOePxvCP9Bxi007QOTWU4axgJq9ePis3fnyF4wloEcDwL4fTs9EBfnr4LeICPXgo0sDevwaD3kpem1RGp9dli2U6D7KGBaeG0rJl2ccsPj10Pbe7NSnlDV+Au4A7gQ1A11Luowf2A20AT2AHcPe1jt2lSxepKIpzCSElxhTJ5CaSoBmSyU1kslEbsM/gVQlS9iNJptBXG8QLIaWvr0x5KUlGRUnp61t0k1y8+NrPFxUl5f0d3pFNJiNDI5pKXhay0dBwyYu3yDov6OX0IGSjyTrZ2fiOLPzc4O1d9rF9faW8/Bnj8sXXt3J+R9UNkC5Ly9ml/aA8l2sk/B7A+mLXpwJTr3VMlfAVxfmadi9I9sYULVEaU2Ttl4SMCWwrm3BczuBVWZ/T0tu4Rk7o1UZKkCn0lU04LsP0SSUS7JWJefHikm8IgYFSDiNBNuG4HBPkK3kF2WBcR8krSP1LnjLFiLQhLr8BFcZ0jeS9eLH23GXF4k6cnfCHAfOLXR8DfFjKfScA6UC6j49PFf9aFEW5lqgP3pa12qeUSJbtAp+QvOQt5xj9pQQ5x+gvxeTG0tu4Rs7gVdmE4zKFvjID31JH1Y6ScFt+l/U5LWOMD0sxubFsFtFP8rKQnhPuluLFW+Qco//lYxpTJL3eLnqsEGW/jivfXNw12UtZwYQPJAM7HVyGFLtPpST84hc1wleU6uHKZAlSdja+IxtN1snpQcg6LyFjAtvKfmgj+jEslClG5Fu9kBn4ymBKjvQLjwdSS9rju8l2gU/IgFGNpCH8UckLt0iPmLaS6QbJiIHSY7r2iUJMblxiKqe06ZmalNwdKSvhX3MTcyllyHUvCDiWBbQudr1VwW2KoriA6OiSO0EZjfCLZRKkn2NWn9eJ2F6HJb0zkUfPc1/LESyydWN571v4W8JjGJCkG8/zeMu2DEjtxGTeYdy424vaNZMVgOjzCn+Emem5txHWgM/Brif/tnOQ2QPaf0O4uTlGjwM8nRXHJ0Y7WErGV3wf2iv7BhV2xix8HTXdzSjLNAO3CyH8hBCeQBSw5iY8r6IoVSA2Fmq1N0HXebBxButu98C6eToicgQdblsBYZPIO9ybdYTzvHEQFyPH0T6rHqONj3Gw1wrqWk9cPpgliEeXDAFrbba0P1mwNaENTvuBTxqD19/PlsTteDX6js9XT8K6oWT5ZePGJfehrbQdtNxURcsyI4QQh9EWZr8RQqwvuL2FECIRQEqZDzwDrAf2ACuklLsqFraiKM7SoqcJz1HDabppBWLDa3h+uwrRby6D//RkkT+M+RUMvikwajBEPUR+wkomMZuLkY+SnxXIaZrgxz5Aa5vwteV9Qrd20vrj6CTk3gKNMtBlBrIxbQ0TmcPLm0KuSuSgNVcrPnJXZ9WWrUIJX0q5SkrZSkpZS0rZVEoZVnD7ESlleLH7JUop75BStpVSxlY0aEVRnMd8xMzXo1dwNC0Iux0u/BbEaw/O5Ku7JDO212dNOwNi70DwvAS6PPDbgIwcCQnLwRKMgTxOcSvBJPMZ45lqDCWpx29afxy7Dmqdo/kpL6TPVnIC/0XaXY9x9qzjWK5M5KW11Cmrr09Nos60VRSlXK48WcuUYeLNH95k3ch1BN39JdbN07H6J+CdowNDjrapeHoMWIIh/Cmsk1rhOSqEqbzBAeNBpo36DQyXYO9gEBJsBv5smEv3vY3JDZtBZt+1153IHXXeLD7HX9OphK8oSoUUtmcI8gtiWV09hrC5PLmxA5fOtgOkNnLv+RaMGAIBH0Odvzjhu4fwgT4sb9kG/fH2YH4Cmv+E/vdQYhYPRv97KDv0HWD9bH69kEx4+PUlckedN4vP8dd0agMURVEqTVxqHGd3B/De+5Az4GFs55tD092O72z1xrBkJVYMMCKCOiKb15Z15E1LEr3ZWLSdImiJOzxcS942m9ZeecKEazdhq4nUjleKolSpwh21Dh7URtayp7Z3bh1LV7JfaA21CybhJWCtAymvYOgzE6teAJJadjvfLsulrwVCSCKFq6vBvb2v3qZRjd6vpna8UhSlyhTWvhduIyglkDoFLEFkh78AXme1RA8goHOmJwPT7sT+43PgeVFb3N32LFj6kqX3dZjs9XpVblkZrnnilaIoSlkc1b4DEP4UBMy7fN0uQEh+aXuaX0fMw2ZMpVaeNubM7f4JgzIW88Y9tfFOvnok7/D4qHLL8lIjfEVRKqTUpOuXApcaaN9b68AX30NmTwBs7b/FS5/Nt0vsfLvETh0uYh0dza5AvcNFV19fx0+hyi3LR43wFUWpEB+fy9M5JfxrL4wKB6mHrRPBEgQLUvF6dBD12m8jon0EQbGfALA2w8Syncto28hMdK8gh/PyxVsmgCq3vBFq0VZRlAq5sn8NFCzcystfC1VkobVwYTgzU3uTiY1VC7aOqEVbRVGqjKPa90WLtES/aJHW76ZQ7doVe57iG52rZF9+akpHUZQKu7KjZnGXLl3+/uRJ1b3SmdQIX1GUKqO6V1YvKuErilJlVPfK6kUlfEVRqozqXlm9qISvKEqVUd0rqxeV8BVFqTKqe2X1oqp0FEWpUmVV8Cg3lxrhK4qi1BAq4SuKotQQKuEriqLUECrhK4qi1BAq4SuKotQQ1bZbphDiBOCo6er1aAL8VYnhOIOrvwZXjx/Ua6gOXD1+uPmvwVdKeaujH1TbhF8RQoj00tqDugpXfw2uHj+o11AduHr8UL1eg5rSURRFqSFUwlcURakh3DXhf+rsACqBq78GV48f1GuoDlw9fqhGr8Et5/AVRVGUq7nrCF9RFEW5gkr4iqIoNYRbJXwhRH8hxP+EEH8IIV50djzlJYT4XAhxXAix09mx3CghRGshhEkIsVsIsUsI8ZyzYyovIYSXEOJHIcSOgtfwqrNjuhFCCL0Q4hchxDpnx3IjhBAWIcRvQojtQoh0Z8dzI4QQDYQQXwoh9goh9gghejg1HneZwxdC6IHfgVDgMGAGRkopdzs1sHIQQjwAXAC+kFJ2dHY8N0II0RxoLqX8WQhRD/gJGOpifwcB1JFSXhBCGIAfgOeklGlODq1chBATga7ALVLKgc6Op7yEEBagq5TSZU+8EkIsBDZLKecLITwBbynlGWfF404j/G7AH1LKA1LKPGAZMMTJMZWLlHITcMrZcVSElPJPKeXPBd+fB/YALZ0bVflIzYWCq4aCi0uNjIQQrYAHgfnOjqWmEkLUBx4APgOQUuY5M9mDeyX8lsChYtcP42KJxt0IIYxAZ2CbcyMpv4LpkO3AcSBJSulqr+FdYApgd3YgFSCB74QQPwkhJjg7mBvgB5wAFhRMrc0XQtRxZkDulPCVakQIURf4CviHlPKcs+MpLymlTUp5L9AK6CaEcJkpNiHEQOC4lPInZ8dSQfdLKe8DBgBPF0x5uhIP4D5gnpSyM5ANOHVt0Z0SfhbQutj1VgW3KTdZwbz3V0C8lHKls+OpiIKP4Cagv7NjKYdewOCCOfBlQLAQYrFzQyo/KWVWwdfjwCq0aVtXchg4XOzT4ZdobwBO404J3wzcLoTwK1gciQLWODmmGqdgwfMzYI+Ucq6z47kRQohbhRANCr6vjVYIsNe5UV0/KeVUKWUrKaUR7f9BipRytJPDKhchRJ2CRX8KpkH+BrhU9ZqU8ihwSAhxZ8FN/QCnFi+4zSbmUsp8IcQzwHpAD3wupdzl5LDKRQixFOgLNBFCHAZellJ+5tyoyq0XMAb4rWAOHOAlKWWiE2Mqr+bAwoLKLx2wQkrpkqWNLqwpsEobP+ABLJFS/te5Id2QvwPxBYPQA8A4ZwbjNmWZiqIoStncaUpHURRFKYNK+IqiKDWESviKoig1hEr4iqIoNYRK+IqiKDWESviKoig1hEr4iqIoNcT/B3t7QQYFDknGAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "<Figure size 432x288 with 1 Axes>"
+ ]
+ },
+ "metadata": {
+ "tags": [],
+ "needs_background": "light"
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "V7vlfJqbiZMU"
+ },
+ "source": [
+ "**2. Loss (MSE/Mean Squared Error)**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "IpHifyGZRhw8"
+ },
+ "source": [
+ "# Calculate loss\n",
+ "loss_tf, _ = model.evaluate(x_test, y_test, verbose=0)\n",
+ "loss_no_quant_tflite = evaluate_tflite(model_no_quant_tflite, x_test, y_test)\n",
+ "loss_tflite = evaluate_tflite(model_tflite, x_test, y_test)"
+ ],
+ "execution_count": 30,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "g3HLT0UOjTY_",
+ "outputId": "0c1c279a-96bd-4e8d-8a65-6a071376825b",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 171
+ }
+ },
+ "source": [
+ "# Compare loss\n",
+ "df = pd.DataFrame.from_records(\n",
+ " [[\"TensorFlow\", loss_tf],\n",
+ " [\"TensorFlow Lite\", loss_no_quant_tflite],\n",
+ " [\"TensorFlow Lite Quantized\", loss_tflite]],\n",
+ " columns = [\"Model\", \"Loss/MSE\"], index=\"Model\").round(4)\n",
+ "df"
+ ],
+ "execution_count": 31,
+ "outputs": [
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/html": [
+ "<div>\n",
+ "<style scoped>\n",
+ " .dataframe tbody tr th:only-of-type {\n",
+ " vertical-align: middle;\n",
+ " }\n",
+ "\n",
+ " .dataframe tbody tr th {\n",
+ " vertical-align: top;\n",
+ " }\n",
+ "\n",
+ " .dataframe thead th {\n",
+ " text-align: right;\n",
+ " }\n",
+ "</style>\n",
+ "<table border=\"1\" class=\"dataframe\">\n",
+ " <thead>\n",
+ " <tr style=\"text-align: right;\">\n",
+ " <th></th>\n",
+ " <th>Loss/MSE</th>\n",
+ " </tr>\n",
+ " <tr>\n",
+ " <th>Model</th>\n",
+ " <th></th>\n",
+ " </tr>\n",
+ " </thead>\n",
+ " <tbody>\n",
+ " <tr>\n",
+ " <th>TensorFlow</th>\n",
+ " <td>0.0102</td>\n",
+ " </tr>\n",
+ " <tr>\n",
+ " <th>TensorFlow Lite</th>\n",
+ " <td>0.0102</td>\n",
+ " </tr>\n",
+ " <tr>\n",
+ " <th>TensorFlow Lite Quantized</th>\n",
+ " <td>0.0108</td>\n",
+ " </tr>\n",
+ " </tbody>\n",
+ "</table>\n",
+ "</div>"
+ ],
+ "text/plain": [
+ " Loss/MSE\n",
+ "Model \n",
+ "TensorFlow 0.0102\n",
+ "TensorFlow Lite 0.0102\n",
+ "TensorFlow Lite Quantized 0.0108"
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "execution_count": 31
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "E7Vjw7VckLu1"
+ },
+ "source": [
+ "**3. Size**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wEXiJ8dFkL2R"
+ },
+ "source": [
+ "# Calculate size\n",
+ "size_tf = os.path.getsize(MODEL_TF)\n",
+ "size_no_quant_tflite = os.path.getsize(MODEL_NO_QUANT_TFLITE)\n",
+ "size_tflite = os.path.getsize(MODEL_TFLITE)"
+ ],
+ "execution_count": 32,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "8DdsCaL7kL4u",
+ "outputId": "9644f10d-0914-4939-b596-facb90e4b961",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 171
+ }
+ },
+ "source": [
+ "# Compare size\n",
+ "pd.DataFrame.from_records(\n",
+ " [[\"TensorFlow\", f\"{size_tf} bytes\", \"\"],\n",
+ " [\"TensorFlow Lite\", f\"{size_no_quant_tflite} bytes \", f\"(reduced by {size_tf - size_no_quant_tflite} bytes)\"],\n",
+ " [\"TensorFlow Lite Quantized\", f\"{size_tflite} bytes\", f\"(reduced by {size_no_quant_tflite - size_tflite} bytes)\"]],\n",
+ " columns = [\"Model\", \"Size\", \"\"], index=\"Model\")"
+ ],
+ "execution_count": 33,
+ "outputs": [
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/html": [
+ "<div>\n",
+ "<style scoped>\n",
+ " .dataframe tbody tr th:only-of-type {\n",
+ " vertical-align: middle;\n",
+ " }\n",
+ "\n",
+ " .dataframe tbody tr th {\n",
+ " vertical-align: top;\n",
+ " }\n",
+ "\n",
+ " .dataframe thead th {\n",
+ " text-align: right;\n",
+ " }\n",
+ "</style>\n",
+ "<table border=\"1\" class=\"dataframe\">\n",
+ " <thead>\n",
+ " <tr style=\"text-align: right;\">\n",
+ " <th></th>\n",
+ " <th>Size</th>\n",
+ " <th></th>\n",
+ " </tr>\n",
+ " <tr>\n",
+ " <th>Model</th>\n",
+ " <th></th>\n",
+ " <th></th>\n",
+ " </tr>\n",
+ " </thead>\n",
+ " <tbody>\n",
+ " <tr>\n",
+ " <th>TensorFlow</th>\n",
+ " <td>4096 bytes</td>\n",
+ " <td></td>\n",
+ " </tr>\n",
+ " <tr>\n",
+ " <th>TensorFlow Lite</th>\n",
+ " <td>2788 bytes</td>\n",
+ " <td>(reduced by 1308 bytes)</td>\n",
+ " </tr>\n",
+ " <tr>\n",
+ " <th>TensorFlow Lite Quantized</th>\n",
+ " <td>2488 bytes</td>\n",
+ " <td>(reduced by 300 bytes)</td>\n",
+ " </tr>\n",
+ " </tbody>\n",
+ "</table>\n",
+ "</div>"
+ ],
+ "text/plain": [
+ " Size \n",
+ "Model \n",
+ "TensorFlow 4096 bytes \n",
+ "TensorFlow Lite 2788 bytes (reduced by 1308 bytes)\n",
+ "TensorFlow Lite Quantized 2488 bytes (reduced by 300 bytes)"
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "execution_count": 33
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qXdmfo7imGMB"
+ },
+ "source": [
+ "**Summary**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "R1LVMA2nkM_l"
+ },
+ "source": [
+ "We can see from the predictions (graph) and loss (table) that the original TF model, the TFLite model, and the quantized TFLite model are all close enough to be indistinguishable - even though they differ in size (table). This implies that the quantized (smallest) model is ready to use!\n",
+ "\n",
+ "*Note: The quantized (integer) TFLite model is just 300 bytes smaller than the original (float) TFLite model - a tiny reduction in size! This is because the model is already so small that quantization has little effect. Complex models with more weights, can have upto a 4x reduction in size!*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HPSFmDL7pv2L"
+ },
+ "source": [
+ "## Generate a TensorFlow Lite for Microcontrollers Model\n",
+ "Convert the TensorFlow Lite quantized model into a C source file that can be loaded by TensorFlow Lite for Microcontrollers."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "j1FB4ieeg0lw",
+ "outputId": "c25b75c6-a28d-47b1-9b3a-b7ba821ee310",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "# Install xxd if it is not available\n",
+ "!apt-get update && apt-get -qq install xxd\n",
+ "# Convert to a C source file, i.e, a TensorFlow Lite for Microcontrollers model\n",
+ "!xxd -i {MODEL_TFLITE} > {MODEL_TFLITE_MICRO}\n",
+ "# Update variable names\n",
+ "REPLACE_TEXT = MODEL_TFLITE.replace('/', '_').replace('.', '_')\n",
+ "!sed -i 's/'{REPLACE_TEXT}'/g_model/g' {MODEL_TFLITE_MICRO}"
+ ],
+ "execution_count": 34,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "\r0% [Working]\r \rIgn:1 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease\n",
+ "\r0% [Waiting for headers] [Waiting for headers] [Waiting for headers] [Waiting f\r \rHit:2 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease\n",
+ "\r0% [Waiting for headers] [Waiting for headers] [Waiting for headers] [Waiting f\r0% [2 InRelease gpgv 3,626 B] [Waiting for headers] [Waiting for headers] [Wait\r \rIgn:3 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease\n",
+ "\r0% [2 InRelease gpgv 3,626 B] [Waiting for headers] [Waiting for headers] [Wait\r \rHit:4 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease\n",
+ "\r0% [2 InRelease gpgv 3,626 B] [Waiting for headers] [Waiting for headers] [Conn\r \rHit:5 http://archive.ubuntu.com/ubuntu bionic InRelease\n",
+ "\r0% [2 InRelease gpgv 3,626 B] [Waiting for headers] [Waiting for headers] [Conn\r \rHit:6 http://security.ubuntu.com/ubuntu bionic-security InRelease\n",
+ "Hit:7 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release\n",
+ "Hit:8 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release\n",
+ "Hit:9 http://archive.ubuntu.com/ubuntu bionic-updates InRelease\n",
+ "Hit:10 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease\n",
+ "Hit:11 http://archive.ubuntu.com/ubuntu bionic-backports InRelease\n",
+ "Reading package lists... Done\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JvRy0ZyMhQOX"
+ },
+ "source": [
+ "## Deploy to a Microcontroller\n",
+ "\n",
+ "Follow the instructions in the [hello_world](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/hello_world) README.md for [TensorFlow Lite for MicroControllers](https://www.tensorflow.org/lite/microcontrollers/overview) to deploy this model on a specific microcontroller.\n",
+ "\n",
+ "**Reference Model:** If you have not modified this notebook, you can follow the instructions as is, to deploy the model. Refer to the [`hello_world/train/models`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/models) directory to access the models generated in this notebook.\n",
+ "\n",
+ "**New Model:** If you have generated a new model, then update the values assigned to the variables defined in [`hello_world/model.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/model.cc) with values displayed after running the following cell."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "l4-WhtGpvb-E",
+ "outputId": "4c7925a5-4cf3-4f7a-fcbc-c8c2857423ea",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
+ },
+ "source": [
+ "# Print the C source file\n",
+ "!cat {MODEL_TFLITE_MICRO}"
+ ],
+ "execution_count": 35,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "unsigned char g_model[] = {\n",
+ " 0x1c, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x14, 0x00, 0x20, 0x00,\n",
+ " 0x1c, 0x00, 0x18, 0x00, 0x14, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x00, 0x00,\n",
+ " 0x08, 0x00, 0x04, 0x00, 0x14, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,\n",
+ " 0x98, 0x00, 0x00, 0x00, 0xc8, 0x00, 0x00, 0x00, 0x1c, 0x03, 0x00, 0x00,\n",
+ " 0x2c, 0x03, 0x00, 0x00, 0x30, 0x09, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x60, 0xf7, 0xff, 0xff,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00,\n",
+ " 0x44, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x73, 0x65, 0x72, 0x76,\n",
+ " 0x65, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x73, 0x65, 0x72, 0x76,\n",
+ " 0x69, 0x6e, 0x67, 0x5f, 0x64, 0x65, 0x66, 0x61, 0x75, 0x6c, 0x74, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xbc, 0xff, 0xff, 0xff,\n",
+ " 0x09, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,\n",
+ " 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x34, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x04, 0x00, 0x00, 0x00, 0x76, 0xfd, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x0d, 0x00, 0x00, 0x00, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x5f,\n",
+ " 0x69, 0x6e, 0x70, 0x75, 0x74, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x0c, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00,\n",
+ " 0x08, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x13, 0x00, 0x00, 0x00, 0x6d, 0x69, 0x6e, 0x5f, 0x72, 0x75, 0x6e, 0x74,\n",
+ " 0x69, 0x6d, 0x65, 0x5f, 0x76, 0x65, 0x72, 0x73, 0x69, 0x6f, 0x6e, 0x00,\n",
+ " 0x0c, 0x00, 0x00, 0x00, 0x50, 0x02, 0x00, 0x00, 0x48, 0x02, 0x00, 0x00,\n",
+ " 0x34, 0x02, 0x00, 0x00, 0xdc, 0x01, 0x00, 0x00, 0x8c, 0x01, 0x00, 0x00,\n",
+ " 0x6c, 0x01, 0x00, 0x00, 0x5c, 0x00, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00,\n",
+ " 0x34, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,\n",
+ " 0x04, 0x00, 0x00, 0x00, 0xfa, 0xfd, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x31, 0x2e, 0x35, 0x2e, 0x30, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x84, 0xfd, 0xff, 0xff,\n",
+ " 0x88, 0xfd, 0xff, 0xff, 0x8c, 0xfd, 0xff, 0xff, 0x22, 0xfe, 0xff, 0xff,\n",
+ " 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x21, 0xa5, 0x8b, 0xca,\n",
+ " 0x5e, 0x1d, 0xce, 0x42, 0x9d, 0xce, 0x1f, 0xb0, 0xdf, 0x54, 0x2f, 0x81,\n",
+ " 0x3e, 0xfe, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00,\n",
+ " 0xee, 0xfc, 0x00, 0xec, 0x05, 0x17, 0xef, 0xec, 0xe6, 0xf8, 0x03, 0x01,\n",
+ " 0x00, 0xfa, 0xf8, 0xf5, 0xdc, 0xeb, 0x27, 0x14, 0xf1, 0xde, 0xe2, 0xdb,\n",
+ " 0xf0, 0xde, 0x31, 0x06, 0x02, 0xe6, 0xee, 0xf9, 0x00, 0x16, 0x07, 0xe0,\n",
+ " 0xfe, 0xff, 0xe9, 0x06, 0xe7, 0xef, 0x81, 0x1b, 0x18, 0xea, 0xc9, 0x01,\n",
+ " 0x0f, 0x00, 0xda, 0xf7, 0x0e, 0xec, 0x13, 0x1f, 0x04, 0x13, 0xb4, 0xe6,\n",
+ " 0xfd, 0x06, 0xb9, 0xe0, 0x0d, 0xec, 0xf0, 0xde, 0xeb, 0xf7, 0x05, 0x26,\n",
+ " 0x1a, 0xe4, 0x6f, 0x1a, 0xea, 0x1e, 0x35, 0xdf, 0x1a, 0xf3, 0xf1, 0x19,\n",
+ " 0x0f, 0x03, 0x1b, 0xe1, 0xde, 0x13, 0xf6, 0x19, 0xff, 0xf6, 0x1b, 0x18,\n",
+ " 0xf0, 0x1c, 0xda, 0x1b, 0x1b, 0x20, 0xe5, 0x1a, 0xf5, 0xff, 0x96, 0x0b,\n",
+ " 0x00, 0x01, 0xcd, 0xde, 0x0d, 0xf6, 0x16, 0xe3, 0xed, 0xfc, 0x0e, 0xe9,\n",
+ " 0xfa, 0xeb, 0x5c, 0xfc, 0x1d, 0x02, 0x5b, 0xe2, 0xe1, 0xf5, 0x15, 0xec,\n",
+ " 0xf4, 0x00, 0x13, 0x05, 0xec, 0x0c, 0x1d, 0x14, 0x0e, 0xe7, 0x0b, 0xf4,\n",
+ " 0x19, 0x00, 0xd7, 0x05, 0x27, 0x02, 0x15, 0xea, 0xea, 0x02, 0x9b, 0x00,\n",
+ " 0x0c, 0xfa, 0xe8, 0xea, 0xfd, 0x00, 0x14, 0xfd, 0x0b, 0x02, 0xef, 0xee,\n",
+ " 0x06, 0xee, 0x01, 0x0d, 0x06, 0xe6, 0xf7, 0x11, 0xf7, 0x09, 0xf8, 0xf1,\n",
+ " 0x21, 0xff, 0x0e, 0xf3, 0xec, 0x12, 0x26, 0x1d, 0xf2, 0xe9, 0x28, 0x18,\n",
+ " 0xe0, 0xfb, 0xf3, 0xf4, 0x05, 0x1d, 0x1d, 0xfb, 0xfd, 0x1e, 0xfc, 0x11,\n",
+ " 0xe8, 0x07, 0x09, 0x03, 0x12, 0xf2, 0x36, 0xfb, 0xdc, 0x1c, 0xf9, 0xef,\n",
+ " 0xf3, 0xe7, 0x6f, 0x0c, 0x1d, 0x00, 0x45, 0xfd, 0x0e, 0xf0, 0x0b, 0x19,\n",
+ " 0x1a, 0xfa, 0xe0, 0x19, 0x1f, 0x13, 0x36, 0x1c, 0x12, 0xeb, 0x3b, 0x0c,\n",
+ " 0xb4, 0xcb, 0xe6, 0x13, 0xfa, 0xeb, 0xf1, 0x06, 0x1c, 0xfa, 0x18, 0xe5,\n",
+ " 0xeb, 0xcb, 0x0c, 0xf4, 0x4a, 0xff, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x75, 0x1c, 0x11, 0xe1, 0x0c, 0x81, 0xa5, 0x42,\n",
+ " 0xfe, 0xd5, 0xd4, 0xb2, 0x61, 0x78, 0x19, 0xdf, 0x66, 0xff, 0xff, 0xff,\n",
+ " 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x77, 0x0b, 0x00, 0x00, 0x53, 0xf6, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x77, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0xd3, 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x72, 0x21, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x2f, 0x07, 0x00, 0x00,\n",
+ " 0x67, 0xf5, 0xff, 0xff, 0x34, 0xf0, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0xb2, 0xff, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0xb5, 0x04, 0x00, 0x00, 0x78, 0x0a, 0x00, 0x00,\n",
+ " 0x2d, 0x06, 0x00, 0x00, 0x71, 0xf8, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x9a, 0x0a, 0x00, 0x00, 0xfe, 0xf7, 0xff, 0xff, 0x0e, 0x05, 0x00, 0x00,\n",
+ " 0xd4, 0x09, 0x00, 0x00, 0x47, 0xfe, 0xff, 0xff, 0xb6, 0x04, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0xac, 0xf7, 0xff, 0xff, 0x4b, 0xf9, 0xff, 0xff,\n",
+ " 0x4a, 0x05, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x04, 0x00,\n",
+ " 0x06, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x8c, 0xef, 0xff, 0xff, 0x84, 0xff, 0xff, 0xff, 0x88, 0xff, 0xff, 0xff,\n",
+ " 0x0f, 0x00, 0x00, 0x00, 0x4d, 0x4c, 0x49, 0x52, 0x20, 0x43, 0x6f, 0x6e,\n",
+ " 0x76, 0x65, 0x72, 0x74, 0x65, 0x64, 0x2e, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x14, 0x00,\n",
+ " 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00,\n",
+ " 0x14, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0xdc, 0x00, 0x00, 0x00,\n",
+ " 0xe0, 0x00, 0x00, 0x00, 0xe4, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x6d, 0x61, 0x69, 0x6e, 0x00, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,\n",
+ " 0x84, 0x00, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x96, 0xff, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x04, 0x00,\n",
+ " 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00,\n",
+ " 0x03, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0xca, 0xff, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x08, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,\n",
+ " 0xba, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x08, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,\n",
+ " 0x05, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00,\n",
+ " 0x16, 0x00, 0x00, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x0b, 0x00, 0x04, 0x00,\n",
+ " 0x0e, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08,\n",
+ " 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00,\n",
+ " 0x08, 0x00, 0x07, 0x00, 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x4c, 0x04, 0x00, 0x00,\n",
+ " 0xd0, 0x03, 0x00, 0x00, 0x68, 0x03, 0x00, 0x00, 0x0c, 0x03, 0x00, 0x00,\n",
+ " 0x98, 0x02, 0x00, 0x00, 0x24, 0x02, 0x00, 0x00, 0xb0, 0x01, 0x00, 0x00,\n",
+ " 0x24, 0x01, 0x00, 0x00, 0x98, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0xf0, 0xfb, 0xff, 0xff, 0x18, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x54, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,\n",
+ " 0x6c, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0xdc, 0xfb, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x4a, 0xce, 0x0a, 0x3c, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x34, 0x84, 0x85, 0x3f, 0x01, 0x00, 0x00, 0x00, 0xc5, 0x02, 0x8f, 0xbf,\n",
+ " 0x1e, 0x00, 0x00, 0x00, 0x53, 0x74, 0x61, 0x74, 0x65, 0x66, 0x75, 0x6c,\n",
+ " 0x50, 0x61, 0x72, 0x74, 0x69, 0x74, 0x69, 0x6f, 0x6e, 0x65, 0x64, 0x43,\n",
+ " 0x61, 0x6c, 0x6c, 0x3a, 0x30, 0x5f, 0x69, 0x6e, 0x74, 0x38, 0x00, 0x00,\n",
+ " 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x80, 0xfc, 0xff, 0xff, 0x18, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x54, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,\n",
+ " 0x64, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x6c, 0xfc, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x93, 0xd0, 0xc0, 0x3b, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0xc2, 0x0f, 0xc0, 0x3f, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x14, 0x00, 0x00, 0x00, 0x74, 0x66, 0x6c, 0x2e, 0x66, 0x75, 0x6c, 0x6c,\n",
+ " 0x79, 0x5f, 0x63, 0x6f, 0x6e, 0x6e, 0x65, 0x63, 0x74, 0x65, 0x64, 0x31,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x08, 0xfd, 0xff, 0xff, 0x18, 0x00, 0x00, 0x00,\n",
+ " 0x20, 0x00, 0x00, 0x00, 0x58, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x09, 0x64, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,\n",
+ " 0xff, 0xff, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0xf4, 0xfc, 0xff, 0xff,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x24, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff,\n",
+ " 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0xe0, 0xdb, 0x47, 0x3c, 0x01, 0x00, 0x00, 0x00, 0x04, 0x14, 0x47, 0x40,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x13, 0x00, 0x00, 0x00,\n",
+ " 0x74, 0x66, 0x6c, 0x2e, 0x66, 0x75, 0x6c, 0x6c, 0x79, 0x5f, 0x63, 0x6f,\n",
+ " 0x6e, 0x6e, 0x65, 0x63, 0x74, 0x65, 0x64, 0x00, 0x02, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x02, 0xfe, 0xff, 0xff,\n",
+ " 0x14, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x09, 0x50, 0x00, 0x00, 0x00, 0x6c, 0xfd, 0xff, 0xff,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,\n",
+ " 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xfb, 0x4b, 0x0b, 0x3c,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x40, 0x84, 0x4b, 0x3f, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x63, 0x35, 0x8a, 0xbf, 0x0d, 0x00, 0x00, 0x00, 0x73, 0x74, 0x64, 0x2e,\n",
+ " 0x63, 0x6f, 0x6e, 0x73, 0x74, 0x61, 0x6e, 0x74, 0x32, 0x00, 0x00, 0x00,\n",
+ " 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x72, 0xfe, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00,\n",
+ " 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x50, 0x00, 0x00, 0x00,\n",
+ " 0xdc, 0xfd, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,\n",
+ " 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x60, 0x01, 0x4f, 0x3c, 0x01, 0x00, 0x00, 0x00, 0x47, 0x6d, 0xb3, 0x3f,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x5d, 0x63, 0xcd, 0xbf, 0x0d, 0x00, 0x00, 0x00,\n",
+ " 0x73, 0x74, 0x64, 0x2e, 0x63, 0x6f, 0x6e, 0x73, 0x74, 0x61, 0x6e, 0x74,\n",
+ " 0x31, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0xe2, 0xfe, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,\n",
+ " 0x48, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,\n",
+ " 0x50, 0x00, 0x00, 0x00, 0x4c, 0xfe, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x18, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0xd5, 0x6b, 0x8a, 0x3b, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0xab, 0x49, 0x01, 0x3f, 0x01, 0x00, 0x00, 0x00, 0xfd, 0x56, 0x09, 0xbf,\n",
+ " 0x0c, 0x00, 0x00, 0x00, 0x73, 0x74, 0x64, 0x2e, 0x63, 0x6f, 0x6e, 0x73,\n",
+ " 0x74, 0x61, 0x6e, 0x74, 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x52, 0xff, 0xff, 0xff,\n",
+ " 0x14, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x02, 0x3c, 0x00, 0x00, 0x00, 0x44, 0xff, 0xff, 0xff,\n",
+ " 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x28, 0xb3, 0xd9, 0x38, 0x0c, 0x00, 0x00, 0x00,\n",
+ " 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x2f, 0x62, 0x69, 0x61, 0x73,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0xaa, 0xff, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,\n",
+ " 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02, 0x38, 0x00, 0x00, 0x00,\n",
+ " 0x9c, 0xff, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0xdd, 0x9b, 0x21, 0x39, 0x0c, 0x00, 0x00, 0x00,\n",
+ " 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x33, 0x2f, 0x62, 0x69, 0x61, 0x73,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x14, 0x00, 0x13, 0x00, 0x0c, 0x00,\n",
+ " 0x08, 0x00, 0x04, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x40, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,\n",
+ " 0x48, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x08, 0x00, 0x04, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,\n",
+ " 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0xf4, 0xd4, 0x51, 0x38, 0x0c, 0x00, 0x00, 0x00, 0x64, 0x65, 0x6e, 0x73,\n",
+ " 0x65, 0x5f, 0x34, 0x2f, 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x14, 0x00, 0x1c, 0x00,\n",
+ " 0x18, 0x00, 0x17, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x04, 0x00, 0x14, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,\n",
+ " 0x2c, 0x00, 0x00, 0x00, 0x64, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x09, 0x84, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,\n",
+ " 0xff, 0xff, 0xff, 0xff, 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x14, 0x00,\n",
+ " 0x10, 0x00, 0x0c, 0x00, 0x08, 0x00, 0x04, 0x00, 0x0c, 0x00, 0x00, 0x00,\n",
+ " 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,\n",
+ " 0x24, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff,\n",
+ " 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x5d, 0x4f, 0xc9, 0x3c, 0x01, 0x00, 0x00, 0x00, 0x0e, 0x86, 0xc8, 0x40,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,\n",
+ " 0x73, 0x65, 0x72, 0x76, 0x69, 0x6e, 0x67, 0x5f, 0x64, 0x65, 0x66, 0x61,\n",
+ " 0x75, 0x6c, 0x74, 0x5f, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x5f,\n",
+ " 0x69, 0x6e, 0x70, 0x75, 0x74, 0x3a, 0x30, 0x5f, 0x69, 0x6e, 0x74, 0x38,\n",
+ " 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n",
+ " 0x01, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,\n",
+ " 0x24, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xd8, 0xff, 0xff, 0xff,\n",
+ " 0x06, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06,\n",
+ " 0x0c, 0x00, 0x0c, 0x00, 0x0b, 0x00, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00,\n",
+ " 0x0c, 0x00, 0x00, 0x00, 0x72, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x72,\n",
+ " 0x0c, 0x00, 0x10, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x08, 0x00, 0x04, 0x00,\n",
+ " 0x0c, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n",
+ " 0x00, 0x00, 0x00, 0x09\n",
+ "};\n",
+ "unsigned int g_model_len = 2488;\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/Makefile.inc b/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/Makefile.inc
new file mode 100644
index 0000000..292adbb
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/Makefile.inc
@@ -0,0 +1,28 @@
+ifeq ($(TARGET), zephyr_vexriscv)
+ export ZEPHYR_TOOLCHAIN_VARIANT?=zephyr
+ export TOOLCHAIN_BASE=${ZEPHYR_SDK_INSTALL_DIR}/riscv64-zephyr-elf/riscv64-zephyr-elf
+ export TOOLCHAIN_VERSION=9.2.0
+ PROJECT_INCLUDES += ${CURDIR} ${TOOLCHAIN_BASE}/include/c++/${TOOLCHAIN_VERSION} ${TOOLCHAIN_BASE}/include ${TOOLCHAIN_BASE}/include/c++/${TOOLCHAIN_VERSION}/riscv64-zephyr-elf/rv32i/ilp32
+ ZEPHYR_HELLO_WORLD_SRCS = \
+tensorflow/lite/micro/examples/hello_world/zephyr_riscv/src/assert.cc \
+tensorflow/lite/micro/examples/hello_world/main.cc \
+tensorflow/lite/micro/examples/hello_world/main_functions.cc \
+tensorflow/lite/micro/examples/hello_world/constants.cc \
+tensorflow/lite/micro/examples/hello_world/output_handler.cc \
+tensorflow/lite/micro/examples/hello_world/model.cc \
+prj.conf
+
+$(eval $(call generate_project,cmake,zephyr_cmake_project.cmake,hello_world,$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(ZEPHYR_HELLO_WORLD_SRCS) $(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(HELLO_WORLD_HDRS),,$(LDFLAGS) $(MICROLITE_LIBS),$(CXXFLAGS),$(CCFLAGS),))
+
+$(PRJDIR)hello_world/cmake/CMakeLists.txt: $(PRJDIR)hello_world/cmake/zephyr_cmake_project.cmake
+ @sed -E 's#\%\{INCLUDE_DIRS\}\%#$(PROJECT_INCLUDES)#g' $< > $@
+
+#We are skipping here copy of `zephyr` third_party repository
+#To compile standalone project ZEPHYR_BASE enviroment variable should be set
+hello_world_bin: generate_hello_world_cmake_project $(PRJDIR)hello_world/cmake/CMakeLists.txt
+ ( \
+ . ${ZEPHYR_BASE}/venv-zephyr/bin/activate; \
+ cmake -B${GENDIR}hello_world/build -DBOARD="litex_vexriscv" -H${PRJDIR}hello_world/cmake/ -DPython_ROOT_DIR=${ZEPHYR_BASE}/venv-zephyr/bin/; \
+ make -C ${GENDIR}hello_world/build; \
+ )
+endif
diff --git a/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/prj.conf b/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/prj.conf
new file mode 100644
index 0000000..4533ed5
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/prj.conf
@@ -0,0 +1,17 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+CONFIG_CPLUSPLUS=y
+CONFIG_NEWLIB_LIBC=y
+CONFIG_NETWORKING=n
diff --git a/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/src/assert.cc b/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/src/assert.cc
new file mode 100644
index 0000000..2f709c6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/hello_world/zephyr_riscv/src/assert.cc
@@ -0,0 +1,19 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+extern "C" {
+
+void __assert_func(const char*, int, const char*, const char*) {}
+}
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/.gitignore b/tensorflow/lite/micro/examples/image_recognition_experimental/.gitignore
new file mode 100644
index 0000000..5762b70
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/.gitignore
@@ -0,0 +1 @@
+first_10_cifar_images.h
\ No newline at end of file
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/BUILD b/tensorflow/lite/micro/examples/image_recognition_experimental/BUILD
new file mode 100644
index 0000000..4946b6a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/BUILD
@@ -0,0 +1,39 @@
+# Description:
+# TensorFlow Lite for Microcontrollers image recognition example.
+package(
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "image_model_data",
+ srcs = [
+ "first_10_cifar_images.cc",
+ "image_recognition_model.cc",
+ ],
+ hdrs = [
+ "first_10_cifar_images.h",
+ "image_recognition_model.h",
+ "util.h",
+ ],
+ tags = [
+ "no_oss", # TODO(b/174680668): Exclude from OSS.
+ ],
+)
+
+cc_test(
+ name = "image_recognition_test",
+ srcs = ["image_recognition_test.cc"],
+ tags = [
+ "no_oss", # TODO(b/174680668): Exclude from OSS.
+ "notap", # TODO(#44912): Consider removing this (uint8) example.
+ ],
+ deps = [
+ ":image_model_data",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ "//tensorflow/lite/schema:schema_fbs",
+ ],
+)
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc b/tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc
new file mode 100644
index 0000000..feb6ed4
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc
@@ -0,0 +1,39 @@
+$(eval $(call add_third_party_download,$(IMAGE_RECOGNITION_MODEL_URL),$(IMAGE_RECOGNITION_MODEL_MD5),image_recognition_model,))
+$(eval $(call add_third_party_download,$(CIFAR10_DATASET_URL),$(CIFAR10_DATASET_MD5),cifar10,patch_cifar10_dataset))
+
+IMAGE_RECOGNITION_HDRS := \
+tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_model.h \
+tensorflow/lite/micro/examples/image_recognition_experimental/image_provider.h \
+tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.h \
+tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.h \
+tensorflow/lite/micro/examples/image_recognition_experimental/util.h
+
+IMAGE_RECOGNITION_SRCS := \
+$(MAKEFILE_DIR)/downloads/image_recognition_model/image_recognition_model.cc \
+tensorflow/lite/micro/examples/image_recognition_experimental/main.cc \
+tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_provider.cc \
+tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.cc \
+tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.cc
+
+IMAGE_RECOGNITION_TEST_SRCS := \
+tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_test.cc \
+$(MAKEFILE_DIR)/downloads/image_recognition_model/image_recognition_model.cc
+
+IMAGE_RECOGNITION_TEST_HDRS := \
+tensorflow/lite/micro/examples/image_recognition_experimental/first_10_cifar_images.h \
+tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_model.h \
+tensorflow/lite/micro/examples/image_recognition_experimental/util.h
+
+include $(wildcard tensorflow/lite/micro/examples/image_recognition_experimental/*/Makefile.inc)
+
+ifneq ($(filter disco_f746ng,$(ALL_TAGS)),)
+ MBED_PROJECT_FILES += \
+ BSP_DISCO_F746NG.lib \
+ LCD_DISCO_F746NG.lib
+endif
+
+$(eval $(call microlite_test,image_recognition,\
+$(IMAGE_RECOGNITION_SRCS),$(IMAGE_RECOGNITION_HDRS), exclude))
+
+$(eval $(call microlite_test,image_recognition_test,\
+$(IMAGE_RECOGNITION_TEST_SRCS),$(IMAGE_RECOGNITION_TEST_HDRS)))
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/README.md b/tensorflow/lite/micro/examples/image_recognition_experimental/README.md
new file mode 100644
index 0000000..7a29d2f
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/README.md
@@ -0,0 +1,90 @@
+# Image Recognition Example
+
+## Table of Contents
+
+- [Introduction](#introduction)
+- [Hardware](#hardware)
+- [Building](#building)
+ - [Building the testcase](#building-the-testcase)
+ - [Building the image recognition application](#building-the-image-recognition-application)
+ - [Prerequisites](#prerequisites)
+ - [Compiling and flashing](#compiling-and-flashing)
+
+## Introduction
+
+This example shows how you can use Tensorflow Lite Micro to perform image
+recognition on a
+[STM32F746 discovery kit](https://www.st.com/en/evaluation-tools/32f746gdiscovery.html)
+with a STM32F4DIS-CAM camera module attached. It classifies the captured image
+into 1 of 10 different classes, and those classes are "Plane", "Car", "Bird",
+"Cat", "Deer", "Dog", "Frog", "Horse", "Ship", "Truck".
+
+## Hardware
+
+[STM32F746G-DISCO board (Cortex-M7)](https://www.st.com/en/evaluation-tools/32f746gdiscovery.html)
+\
+[STM32F4DIS-CAM Camera module](https://www.element14.com/community/docs/DOC-67585?ICID=knode-STM32F4-cameramore)
+
+## Building
+
+These instructions have been tested on Ubuntu 16.04.
+
+### Building the test case
+
+```
+$ make -f tensorflow/lite/micro/tools/make/Makefile image_recognition_test
+```
+
+This will build and run the test case. As input, the test case uses the first 10
+images of the test batch included in the
+[CIFAR10](https://www.cs.toronto.edu/~kriz/cifar.html) dataset. Details
+surrounding the dataset can be found in
+[this paper](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf).
+
+### Building the image recognition application
+
+#### Prerequisites
+
+Install mbed-cli: `$ pip install mbed-cli`
+
+Install the arm-none-eabi-toolchain.
+
+For Ubuntu, this can be done by installing the package `gcc-arm-none-eabi`. In
+Ubuntu 16.04, the version included in the repository is 4.9.3 while the
+recommended version is 6 and up. Later versions can be downloaded from
+[here](https://developer.arm.com/tools-and-software/open-source-software/developer-tools/gnu-toolchain/gnu-rm/downloads)
+for Windows, Mac OS X and Linux.
+
+#### Compiling and flashing
+
+In order to generate the mbed project, run the following command: `$ make -f
+tensorflow/lite/micro/tools/make/Makefile TAGS=disco_f746ng
+generate_image_recognition_mbed_project` This will copy all of the necessary
+files needed to build and flash the application.
+
+Navigate to the output folder: `$ cd
+tensorflow/lite/micro/tools/make/gen/linux_x86_64/prj/image_recognition/mbed/`
+
+The following instructions for compiling and flashing can also be found in the
+file README_MBED.md in the output folder.
+
+To load the dependencies required, run: `$ mbed config root . $ mbed deploy`
+
+In order to compile, run: `mbed compile -m auto -t GCC_ARM --profile release`
+
+`-m auto`: Automatically detects the correct target if the Discovery board is
+connected to the computer. If the board is not connected, replace `auto` with
+`DISCO_F746NG`. \
+`-t GCC_ARM`: Specifies the toolchain used to compile. `GCC_ARM` indicates that
+the arm-none-eabi-toolchain will be used. \
+`--profile release`: Build the `release` profile. The different profiles can be
+found under mbed-os/tools/profiles/.
+
+This will produce a file named `mbed.bin` in
+`BUILD/DISCO_F746NG/GCC_ARM-RELEASE/`. To flash it to the board, simply copy the
+file to the volume mounted as a USB drive. Alternatively, the `-f` option can be
+appended to flash automatically after compilation.
+
+On Ubuntu 16.04 (and possibly other Linux distributions) there may be an error
+message when running `mbed compile` saying that the Python module `pywin32`
+failed to install. This message can be ignored.
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/image_provider.h b/tensorflow/lite/micro/examples/image_recognition_experimental/image_provider.h
new file mode 100644
index 0000000..b466796
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/image_provider.h
@@ -0,0 +1,41 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_IMAGE_PROVIDER_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_IMAGE_PROVIDER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+TfLiteStatus InitCamera(tflite::ErrorReporter* error_reporter);
+
+// This is an abstraction around an image source like a camera, and is
+// expected to return 8-bit sample data. The assumption is that this will be
+// called in a low duty-cycle fashion in a low-power application. In these
+// cases, the imaging sensor need not be run in a streaming mode, but rather can
+// be idled in a relatively low-power mode between calls to GetImage(). The
+// assumption is that the overhead and time of bringing the low-power sensor out
+// of this standby mode is commensurate with the expected duty cycle of the
+// application. The underlying sensor may actually be put into a streaming
+// configuration, but the image buffer provided to GetImage should not be
+// overwritten by the driver code until the next call to GetImage();
+//
+// The reference implementation can have no platform-specific dependencies, so
+// it just returns a static image. For real applications, you should
+// ensure there's a specialized implementation that accesses hardware APIs.
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int image_width,
+ int image_height, int channels, uint8_t* image_data);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_IMAGE_PROVIDER_H_
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_model.h b/tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_model.h
new file mode 100644
index 0000000..a32dcd0
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_model.h
@@ -0,0 +1,27 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This is a standard TensorFlow Lite model file that has been converted into a
+// C data array, so it can be easily compiled into a binary for devices that
+// don't have a file system. It can be created using the command:
+// xxd -i image_recognition_model.tflite > image_recognition_model.cc
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_IMAGE_RECOGNITION_MODEL_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_IMAGE_RECOGNITION_MODEL_H_
+
+extern const unsigned char image_recognition_model_data[];
+extern const unsigned int image_recognition_model_data_len;
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_IMAGE_RECOGNITION_MODEL_H_
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_test.cc b/tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_test.cc
new file mode 100644
index 0000000..76d313b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_test.cc
@@ -0,0 +1,99 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/first_10_cifar_images.h"
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_model.h"
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/util.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+#define IMAGE_BYTES 3072
+#define LABEL_BYTES 1
+#define ENTRY_BYTES (IMAGE_BYTES + LABEL_BYTES)
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestImageRecognitionInvoke) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ const tflite::Model* model = ::tflite::GetModel(image_recognition_model_data);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.\n",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ }
+
+ tflite::MicroMutableOpResolver<4> micro_op_resolver;
+
+ micro_op_resolver.AddConv2D();
+ micro_op_resolver.AddMaxPool2D();
+ micro_op_resolver.AddFullyConnected();
+ micro_op_resolver.AddSoftmax();
+
+ const int tensor_arena_size = 50 * 1024;
+ uint8_t tensor_arena[tensor_arena_size];
+
+ tflite::MicroInterpreter interpreter(model, micro_op_resolver, tensor_arena,
+ tensor_arena_size,
+ µ_error_reporter);
+ interpreter.AllocateTensors();
+
+ TfLiteTensor* input = interpreter.input(0);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input);
+ TF_LITE_MICRO_EXPECT_EQ(4, input->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(32, input->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(32, input->dims->data[2]);
+ TF_LITE_MICRO_EXPECT_EQ(3, input->dims->data[3]);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteUInt8, input->type);
+
+ int num_correct = 0;
+ int num_images = 10;
+ for (int image_num = 0; image_num < num_images; image_num++) {
+ memset(input->data.uint8, 0, input->bytes);
+
+ uint8_t correct_label = 0;
+
+ correct_label =
+ tensorflow_lite_micro_tools_make_downloads_cifar10_test_batch_bin
+ [image_num * ENTRY_BYTES];
+ memcpy(input->data.uint8,
+ &tensorflow_lite_micro_tools_make_downloads_cifar10_test_batch_bin
+ [image_num * ENTRY_BYTES + LABEL_BYTES],
+ IMAGE_BYTES);
+ reshape_cifar_image(input->data.uint8, IMAGE_BYTES);
+
+ TfLiteStatus invoke_status = interpreter.Invoke();
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Invoke failed\n");
+ }
+
+ TfLiteTensor* output = interpreter.output(0);
+ int guess = get_top_prediction(output->data.uint8, 10);
+
+ if (correct_label == guess) {
+ num_correct++;
+ }
+ }
+
+ TF_LITE_MICRO_EXPECT_EQ(6, num_correct);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/main.cc b/tensorflow/lite/micro/examples/image_recognition_experimental/main.cc
new file mode 100644
index 0000000..87d68ed
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/main.cc
@@ -0,0 +1,104 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// NOLINTNEXTLINE
+#include "mbed.h"
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/image_provider.h"
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/image_recognition_model.h"
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.h"
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.h"
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/util.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+#include "tensorflow/lite/micro/system_setup.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+#define NUM_OUT_CH 3
+#define CNN_IMG_SIZE 32
+
+uint8_t camera_buffer[NUM_IN_CH * IN_IMG_WIDTH * IN_IMG_HEIGHT]
+ __attribute__((aligned(4)));
+static const char* labels[] = {"Plane", "Car", "Bird", "Cat", "Deer",
+ "Dog", "Frog", "Horse", "Ship", "Truck"};
+
+int main(int argc, char** argv) {
+ tflite::InitializeTarget();
+ init_lcd();
+ wait_ms(100);
+
+ tflite::MicroErrorReporter micro_error_reporter;
+ tflite::ErrorReporter* error_reporter = µ_error_reporter;
+
+ if (InitCamera(error_reporter) != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to init camera.");
+ return 1;
+ }
+
+ const tflite::Model* model = ::tflite::GetModel(image_recognition_model_data);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ return 1;
+ }
+
+ tflite::MicroMutableOpResolver<4> micro_op_resolver;
+
+ micro_op_resolver.AddConv2D();
+ micro_op_resolver.AddFullyConnected();
+ micro_op_resolver.AddMaxPool2D();
+ micro_op_resolver.AddSoftmax();
+
+ constexpr int tensor_arena_size = 50 * 1024;
+ uint8_t tensor_arena[tensor_arena_size];
+ tflite::MicroInterpreter interpreter(model, micro_op_resolver, tensor_arena,
+ tensor_arena_size, error_reporter);
+ interpreter.AllocateTensors();
+
+ while (true) {
+ TfLiteTensor* input = interpreter.input(0);
+
+ GetImage(error_reporter, IN_IMG_WIDTH, IN_IMG_HEIGHT, NUM_OUT_CH,
+ camera_buffer);
+
+ ResizeConvertImage(error_reporter, IN_IMG_WIDTH, IN_IMG_HEIGHT, NUM_IN_CH,
+ CNN_IMG_SIZE, CNN_IMG_SIZE, NUM_OUT_CH, camera_buffer,
+ input->data.uint8);
+
+ if (input->type != kTfLiteUInt8) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Wrong input type.");
+ }
+
+ TfLiteStatus invoke_status = interpreter.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed.");
+ break;
+ }
+
+ display_image_rgb565(IN_IMG_WIDTH, IN_IMG_HEIGHT, camera_buffer, 40, 40);
+ display_image_rgb888(CNN_IMG_SIZE, CNN_IMG_SIZE, input->data.uint8, 300,
+ 100);
+
+ TfLiteTensor* output = interpreter.output(0);
+
+ int top_ind = get_top_prediction(output->data.uint8, 10);
+ print_prediction(labels[top_ind]);
+ print_confidence(output->data.uint8[top_ind]);
+ }
+
+ return 0;
+}
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.cc b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.cc
new file mode 100644
index 0000000..22e03c6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.cc
@@ -0,0 +1,79 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.h"
+
+#include <stdint.h>
+
+#include "LCD_DISCO_F746NG/LCD_DISCO_F746NG.h"
+
+LCD_DISCO_F746NG lcd;
+
+extern "C" {
+// defined in stm32746g_discovery_camera.c
+extern DCMI_HandleTypeDef hDcmiHandler;
+void DCMI_IRQHandler(void) { HAL_DCMI_IRQHandler(&hDcmiHandler); }
+void DMA2_Stream1_IRQHandler(void) {
+ HAL_DMA_IRQHandler(hDcmiHandler.DMA_Handle);
+}
+}
+
+static char lcd_output_string[50];
+
+void init_lcd() { lcd.Clear(LCD_COLOR_WHITE); }
+
+void display_image_rgb888(int x_dim, int y_dim, const uint8_t* image_data,
+ int x_loc, int y_loc) {
+ for (int y = 0; y < y_dim; ++y) {
+ for (int x = 0; x < x_dim; ++x, image_data += 3) {
+ uint8_t a = 0xFF;
+ auto r = image_data[0];
+ auto g = image_data[1];
+ auto b = image_data[2];
+ int pixel = a << 24 | r << 16 | g << 8 | b;
+ lcd.DrawPixel(x_loc + x, y_loc + y, pixel);
+ }
+ }
+}
+
+void display_image_rgb565(int x_dim, int y_dim, const uint8_t* image_data,
+ int x_loc, int y_loc) {
+ for (int y = 0; y < y_dim; ++y) {
+ for (int x = 0; x < x_dim; ++x, image_data += 2) {
+ uint8_t a = 0xFF;
+ uint8_t pix_lo = image_data[0];
+ uint8_t pix_hi = image_data[1];
+ uint8_t r = (0xF8 & pix_hi);
+ uint8_t g = ((0x07 & pix_hi) << 5) | ((0xE0 & pix_lo) >> 3);
+ uint8_t b = (0x1F & pix_lo) << 3;
+ int pixel = a << 24 | r << 16 | g << 8 | b;
+ // inverted image, so draw from bottom-right to top-left
+ lcd.DrawPixel(x_loc + (x_dim - x), y_loc + (y_dim - y), pixel);
+ }
+ }
+}
+
+void print_prediction(const char* prediction) {
+ // NOLINTNEXTLINE
+ sprintf(lcd_output_string, " Prediction: %s ", prediction);
+ lcd.DisplayStringAt(0, LINE(8), (uint8_t*)lcd_output_string, LEFT_MODE);
+}
+
+void print_confidence(uint8_t max_score) {
+ // NOLINTNEXTLINE
+ sprintf(lcd_output_string, " Confidence: %.1f%% ",
+ (max_score / 255.0) * 100.0);
+ lcd.DisplayStringAt(0, LINE(9), (uint8_t*)lcd_output_string, LEFT_MODE);
+}
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.h b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.h
new file mode 100644
index 0000000..b114812
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/display_util.h
@@ -0,0 +1,33 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_STM32F746_DISCOVERY_DISPLAY_UTIL_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_STM32F746_DISCOVERY_DISPLAY_UTIL_H_
+
+#include <stdint.h>
+
+void init_lcd();
+
+void display_image_rgb888(int x_dim, int y_dim, const uint8_t* image_data,
+ int x_loc, int y_loc);
+
+void display_image_rgb565(int x_dim, int y_dim, const uint8_t* image_data,
+ int x_loc, int y_loc);
+
+void print_prediction(const char* prediction);
+
+void print_confidence(uint8_t max_score);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_STM32F746_DISCOVERY_DISPLAY_UTIL_H_
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_provider.cc b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_provider.cc
new file mode 100644
index 0000000..594af5b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_provider.cc
@@ -0,0 +1,39 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/image_provider.h"
+
+#include "BSP_DISCO_F746NG/Drivers/BSP/STM32746G-Discovery/stm32746g_discovery_camera.h"
+
+TfLiteStatus InitCamera(tflite::ErrorReporter* error_reporter) {
+ if (BSP_CAMERA_Init(RESOLUTION_R160x120) != CAMERA_OK) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to init camera.\n");
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int frame_width,
+ int frame_height, int channels, uint8_t* frame) {
+ // For consistency, the signature of this function is the
+ // same as the GetImage-function in micro_vision.
+ (void)error_reporter;
+ (void)frame_width;
+ (void)frame_height;
+ (void)channels;
+ BSP_CAMERA_SnapshotStart(frame);
+ return kTfLiteOk;
+}
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.cc b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.cc
new file mode 100644
index 0000000..49544fd
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.cc
@@ -0,0 +1,49 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.h"
+
+void ResizeConvertImage(tflite::ErrorReporter* error_reporter,
+ int in_frame_width, int in_frame_height,
+ int num_in_channels, int out_frame_width,
+ int out_frame_height, int channels,
+ const uint8_t* in_image, uint8_t* out_image) {
+ // offset so that only the center part of rectangular image is selected for
+ // resizing
+ int width_offset = ((in_frame_width - in_frame_height) / 2) * num_in_channels;
+
+ int yresize_ratio = (in_frame_height / out_frame_height) * num_in_channels;
+ int xresize_ratio = (in_frame_width / out_frame_width) * num_in_channels;
+ int resize_ratio =
+ (xresize_ratio < yresize_ratio) ? xresize_ratio : yresize_ratio;
+
+ for (int y = 0; y < out_frame_height; y++) {
+ for (int x = 0; x < out_frame_width; x++) {
+ int orig_img_loc =
+ y * in_frame_width * resize_ratio + x * resize_ratio + width_offset;
+ // correcting the image inversion here
+ int out_img_loc = ((out_frame_height - 1 - y) * out_frame_width +
+ (out_frame_width - 1 - x)) *
+ channels;
+ uint8_t pix_lo = in_image[orig_img_loc];
+ uint8_t pix_hi = in_image[orig_img_loc + 1];
+ // convert RGB565 to RGB888
+ out_image[out_img_loc] = (0xF8 & pix_hi);
+ out_image[out_img_loc + 1] =
+ ((0x07 & pix_hi) << 5) | ((0xE0 & pix_lo) >> 3);
+ out_image[out_img_loc + 2] = (0x1F & pix_lo) << 3;
+ }
+ }
+}
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.h b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.h
new file mode 100644
index 0000000..5e8a7e6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/stm32f746_discovery/image_util.h
@@ -0,0 +1,32 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_STM32F746_DISCOVERY_IMAGE_UTIL_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_STM32F746_DISCOVERY_IMAGE_UTIL_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+#define NUM_IN_CH 2
+#define IN_IMG_WIDTH 160
+#define IN_IMG_HEIGHT 120
+
+void ResizeConvertImage(tflite::ErrorReporter* error_reporter,
+ int in_frame_width, int in_frame_height,
+ int num_in_channels, int out_frame_width,
+ int out_frame_height, int channels,
+ const uint8_t* in_frame, uint8_t* out_frame);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_STM32F746_DISCOVERY_IMAGE_UTIL_H_
diff --git a/tensorflow/lite/micro/examples/image_recognition_experimental/util.h b/tensorflow/lite/micro/examples/image_recognition_experimental/util.h
new file mode 100644
index 0000000..7927e1b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/image_recognition_experimental/util.h
@@ -0,0 +1,64 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_UTIL_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_UTIL_H_
+
+#include <stdint.h>
+#include <string.h>
+
+#define IMAGE_SIZE 3072
+#define CHANNEL_SIZE 1024
+#define R_CHANNEL_OFFSET 0
+#define G_CHANNEL_OFFSET CHANNEL_SIZE
+#define B_CHANNEL_OFFSET (CHANNEL_SIZE * 2)
+
+int get_top_prediction(const uint8_t* predictions, int num_categories) {
+ int max_score = predictions[0];
+ int guess = 0;
+
+ for (int category_index = 1; category_index < num_categories;
+ category_index++) {
+ const uint8_t category_score = predictions[category_index];
+ if (category_score > max_score) {
+ max_score = category_score;
+ guess = category_index;
+ }
+ }
+
+ return guess;
+}
+
+void reshape_cifar_image(uint8_t* image_data, int num_bytes) {
+ uint8_t temp_data[IMAGE_SIZE];
+
+ memcpy(temp_data, image_data, num_bytes);
+
+ int k = 0;
+ for (int i = 0; i < CHANNEL_SIZE; i++) {
+ int r_ind = R_CHANNEL_OFFSET + i;
+ int g_ind = G_CHANNEL_OFFSET + i;
+ int b_ind = B_CHANNEL_OFFSET + i;
+
+ image_data[k] = temp_data[r_ind];
+ k++;
+ image_data[k] = temp_data[g_ind];
+ k++;
+ image_data[k] = temp_data[b_ind];
+ k++;
+ }
+}
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_IMAGE_RECOGNITION_EXPERIMENTAL_UTIL_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/BUILD b/tensorflow/lite/micro/examples/magic_wand/BUILD
new file mode 100644
index 0000000..246ced3
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/BUILD
@@ -0,0 +1,160 @@
+# Description:
+# TensorFlow Lite for Microcontrollers "gesture recognition" example.
+package(
+ default_visibility = ["//visibility:public"],
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "magic_wand_model_data",
+ srcs = [
+ "magic_wand_model_data.cc",
+ ],
+ hdrs = [
+ "magic_wand_model_data.h",
+ ],
+)
+
+cc_library(
+ name = "sample_feature_data",
+ srcs = [
+ "ring_micro_features_data.cc",
+ "slope_micro_features_data.cc",
+ ],
+ hdrs = [
+ "ring_micro_features_data.h",
+ "slope_micro_features_data.h",
+ ],
+)
+
+cc_test(
+ name = "magic_wand_test",
+ srcs = [
+ "magic_wand_test.cc",
+ ],
+ deps = [
+ ":magic_wand_model_data",
+ ":sample_feature_data",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ "//tensorflow/lite/schema:schema_fbs",
+ ],
+)
+
+cc_library(
+ name = "constants",
+ hdrs = [
+ "constants.h",
+ ],
+)
+
+cc_library(
+ name = "accelerometer_handler",
+ srcs = [
+ "accelerometer_handler.cc",
+ ],
+ hdrs = [
+ "accelerometer_handler.h",
+ ],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ ],
+)
+
+cc_test(
+ name = "accelerometer_handler_test",
+ srcs = [
+ "accelerometer_handler_test.cc",
+ ],
+ deps = [
+ ":accelerometer_handler",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_library(
+ name = "gesture_predictor",
+ srcs = [
+ "gesture_predictor.cc",
+ ],
+ hdrs = [
+ "gesture_predictor.h",
+ ],
+ deps = [
+ ":constants",
+ ],
+)
+
+cc_test(
+ name = "gesture_predictor_test",
+ srcs = [
+ "gesture_predictor_test.cc",
+ ],
+ deps = [
+ ":constants",
+ ":gesture_predictor",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_library(
+ name = "output_handler",
+ srcs = [
+ "output_handler.cc",
+ ],
+ hdrs = [
+ "output_handler.h",
+ ],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ ],
+)
+
+cc_test(
+ name = "output_handler_test",
+ srcs = [
+ "output_handler_test.cc",
+ ],
+ deps = [
+ ":output_handler",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_binary(
+ name = "magic_wand",
+ srcs = [
+ "main.cc",
+ "main_functions.cc",
+ "main_functions.h",
+ ],
+ copts = [
+ "-Werror",
+ "-Wdouble-promotion",
+ "-Wsign-compare",
+ ],
+ deps = [
+ ":accelerometer_handler",
+ ":constants",
+ ":gesture_predictor",
+ ":magic_wand_model_data",
+ ":output_handler",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:system_setup",
+ "//tensorflow/lite/schema:schema_fbs",
+ ],
+)
diff --git a/tensorflow/lite/micro/examples/magic_wand/Makefile.inc b/tensorflow/lite/micro/examples/magic_wand/Makefile.inc
new file mode 100644
index 0000000..e956230
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/Makefile.inc
@@ -0,0 +1,84 @@
+ifeq ($(TARGET), sparkfun_edge)
+ INCLUDES += \
+ -I$(APOLLO3_SDK)/$(SF_BSPS_DEST)/common/third_party/lis2dh12/
+
+ THIRD_PARTY_CC_SRCS += \
+ $(APOLLO3_SDK)/$(SF_BSPS_DEST)/common/third_party/lis2dh12/lis2dh12_platform_apollo3.c \
+ $(APOLLO3_SDK)/boards_sfe/common/third_party/lis2dh12/lis2dh12_reg.c
+
+ THIRD_PARTY_CC_HDRS += \
+ $(APOLLO3_SDK)/boards_sfe/common/third_party/lis2dh12/lis2dh12_platform_apollo3.h \
+ $(APOLLO3_SDK)/boards_sfe/common/third_party/lis2dh12/lis2dh12_reg.h
+endif
+
+ACCELEROMETER_HANDLER_TEST_SRCS := \
+tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.cc \
+tensorflow/lite/micro/examples/magic_wand/accelerometer_handler_test.cc
+
+ACCELEROMETER_HANDLER_TEST_HDRS := \
+tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h
+
+OUTPUT_HANDLER_TEST_SRCS := \
+tensorflow/lite/micro/examples/magic_wand/output_handler.cc \
+tensorflow/lite/micro/examples/magic_wand/output_handler_test.cc
+
+OUTPUT_HANDLER_TEST_HDRS := \
+tensorflow/lite/micro/examples/magic_wand/output_handler.h
+
+GESTURE_PREDICTOR_TEST_SRCS := \
+tensorflow/lite/micro/examples/magic_wand/gesture_predictor.cc \
+tensorflow/lite/micro/examples/magic_wand/gesture_predictor_test.cc
+
+GESTURE_PREDICTOR_TEST_HDRS := \
+tensorflow/lite/micro/examples/magic_wand/constants.h \
+tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h \
+
+magic_wand_TEST_SRCS := \
+tensorflow/lite/micro/examples/magic_wand/magic_wand_test.cc \
+tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.cc \
+tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.cc \
+tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.cc
+
+magic_wand_TEST_HDRS := \
+tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h \
+tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.h \
+tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.h
+
+magic_wand_SRCS := \
+tensorflow/lite/micro/examples/magic_wand/main.cc \
+tensorflow/lite/micro/examples/magic_wand/main_functions.cc \
+tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.cc \
+tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.cc \
+tensorflow/lite/micro/examples/magic_wand/gesture_predictor.cc \
+tensorflow/lite/micro/examples/magic_wand/output_handler.cc
+
+magic_wand_HDRS := \
+tensorflow/lite/micro/examples/magic_wand/main_functions.h \
+tensorflow/lite/micro/examples/magic_wand/constants.h \
+tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h \
+tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h \
+tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h \
+tensorflow/lite/micro/examples/magic_wand/output_handler.h
+
+#Find any platform - specific rules for this example.
+include $(wildcard tensorflow/lite/micro/examples/magic_wand/*/Makefile.inc)
+
+# Tests the accelerometer handler
+$(eval $(call microlite_test,gesture_accelerometer_handler_test,\
+$(ACCELEROMETER_HANDLER_TEST_SRCS),$(ACCELEROMETER_HANDLER_TEST_HDRS)))
+
+# Tests the output handler
+$(eval $(call microlite_test,gesture_output_handler_test,\
+$(OUTPUT_HANDLER_TEST_SRCS),$(OUTPUT_HANDLER_TEST_HDRS)))
+
+# Tests the gesture predictor
+$(eval $(call microlite_test,gesture_predictor_test,\
+$(GESTURE_PREDICTOR_TEST_SRCS),$(GESTURE_PREDICTOR_TEST_HDRS)))
+
+# Tests loading and running the gesture recognition model
+$(eval $(call microlite_test,magic_wand_test,\
+$(magic_wand_TEST_SRCS),$(magic_wand_TEST_HDRS)))
+
+# Builds a standalone binary
+$(eval $(call microlite_test,magic_wand,\
+$(magic_wand_SRCS),$(magic_wand_HDRS)))
diff --git a/tensorflow/lite/micro/examples/magic_wand/README.md b/tensorflow/lite/micro/examples/magic_wand/README.md
new file mode 100644
index 0000000..d9f0c75
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/README.md
@@ -0,0 +1,493 @@
+# Magic wand example
+
+This example shows how you can use TensorFlow Lite to run a 20 kilobyte neural
+network model to recognize gestures with an accelerometer. It's designed to run
+on systems with very small amounts of memory, such as microcontrollers.
+
+The example application reads data from the accelerometer on an Arduino Nano 33
+BLE Sense or SparkFun Edge board and indicates when it has detected a gesture,
+then outputs the gesture to the serial port.
+
+## Table of contents
+
+- [Getting started](#getting-started)
+- [Deploy to Arduino](#deploy-to-arduino)
+- [Deploy to Himax WE1 EVB](#deploy-to-himax-we1-evb)
+- [Deploy to SparkFun Edge](#deploy-to-sparkfun-edge)
+- [Run the tests on a development machine](#run-the-tests-on-a-development-machine)
+- [Train your own model](#train-your-own-model)
+
+## Deploy to Arduino
+
+The following instructions will help you build and deploy this sample
+to [Arduino](https://www.arduino.cc/) devices.
+
+The sample has been tested with the following devices:
+
+- [Arduino Nano 33 BLE Sense](https://store.arduino.cc/usa/nano-33-ble-sense-with-headers)
+
+### Install the Arduino_TensorFlowLite library
+
+This example application is included as part of the official TensorFlow Lite
+Arduino library. To install it, open the Arduino library manager in
+`Tools -> Manage Libraries...` and search for `Arduino_TensorFlowLite`.
+
+### Install and patch the accelerometer driver
+
+This example depends on the [Arduino_LSM9DS1](https://github.com/arduino-libraries/Arduino_LSM9DS1)
+library to communicate with the device's accelerometer. However, the library
+must be patched in order to enable the accelerometer's FIFO buffer.
+
+Follow these steps to install and patch the driver:
+
+#### Install the correct version
+
+In the Arduino IDE, go to `Tools -> Manage Libraries...` and search for
+`Arduino_LSM9DS1`. **Install version 1.0.0 of the driver** to ensure the
+following instructions work.
+
+#### Patch the driver
+
+The driver will be installed to your `Arduino/libraries` directory, in the
+subdirectory `Arduino_LSM9DS1`.
+
+Open the following file:
+
+```
+Arduino_LSM9DS1/src/LSM9DS1.cpp
+```
+
+Go to the function named `LSM9DS1Class::begin()`. Insert the following lines at
+the end of the function, immediately before the `return 1` statement:
+
+```cpp
+// Enable FIFO (see docs https://www.st.com/resource/en/datasheet/DM00103319.pdf)
+writeRegister(LSM9DS1_ADDRESS, 0x23, 0x02);
+// Set continuous mode
+writeRegister(LSM9DS1_ADDRESS, 0x2E, 0xC0);
+```
+
+Next, go to the function named `LSM9DS1Class::accelerationAvailable()`. You will
+see the following lines:
+
+```cpp
+if (readRegister(LSM9DS1_ADDRESS, LSM9DS1_STATUS_REG) & 0x01) {
+ return 1;
+}
+```
+
+Comment out those lines and replace them with the following:
+
+```cpp
+// Read FIFO_SRC. If any of the rightmost 8 bits have a value, there is data
+if (readRegister(LSM9DS1_ADDRESS, 0x2F) & 63) {
+ return 1;
+}
+```
+
+Next, save the file. Patching is now complete.
+
+### Load and run the example
+
+Once the library has been added, go to `File -> Examples`. You should see an
+example near the bottom of the list named `TensorFlowLite`. Select
+it and click `magic_wand` to load the example.
+
+Use the Arduino Desktop IDE to build and upload the example. Once it is running,
+you should see the built-in LED on your device flashing.
+
+Open the Arduino Serial Monitor (`Tools -> Serial Monitor`).
+
+You will see the following message:
+
+```
+Magic starts!
+```
+
+Hold the Arduino with its components facing upwards and the USB cable to your
+left. Perform the gestures "WING", "RING"(clockwise), and "SLOPE", and you
+should see the corresponding output:
+
+```
+WING:
+* * *
+ * * * *
+ * * * *
+ * * * *
+ * * * *
+ * *
+```
+
+```
+RING:
+ *
+ * *
+ * *
+ * *
+ * *
+ * *
+ *
+```
+
+```
+SLOPE:
+ *
+ *
+ *
+ *
+ *
+ *
+ *
+ * * * * * * * *
+```
+
+## Deploy to Himax WE1 EVB
+
+The following instructions will help you build and deploy this example to
+[HIMAX WE1 EVB](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_board_brief)
+board. To understand more about using this board, please check
+[HIMAX WE1 EVB user guide](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_user_guide).
+
+### Initial Setup
+
+To use the HIMAX WE1 EVB, please make sure following software are installed:
+
+#### MetaWare Development Toolkit
+
+See
+[Install the Synopsys DesignWare ARC MetaWare Development Toolkit](/tensorflow/lite/micro/tools/make/targets/arc/README.md#install-the-synopsys-designware-arc-metaware-development-toolkit)
+section for instructions on toolchain installation.
+
+#### Make Tool version
+
+A `'make'` tool is required for deploying Tensorflow Lite Micro applications on
+HIMAX WE1 EVB, See
+[Check make tool version](/tensorflow/lite/micro/tools/make/targets/arc/README.md#make-tool)
+section for proper environment.
+
+#### Serial Terminal Emulation Application
+
+There are 2 main purposes for HIMAX WE1 EVB Debug UART port
+
+- print application output
+- burn application to flash by using xmodem send application binary
+
+You can use any terminal emulation program (like [PuTTY](https://www.putty.org/)
+or [minicom](https://linux.die.net/man/1/minicom)).
+
+### Generate Example Project
+
+The example project for HIMAX WE1 EVB platform can be generated with the
+following command:
+
+Download related third party data
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=himax_we1_evb third_party_downloads
+```
+
+Generate magic wand project
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile generate_magic_wand_make_project TARGET=himax_we1_evb
+```
+
+### Build and Burn Example
+
+Following the Steps to run magic wand example at HIMAX WE1 EVB platform.
+
+1. Go to the generated example project directory.
+
+ ```
+ cd tensorflow/lite/micro/tools/make/gen/himax_we1_evb_arc/prj/magic_wand/make
+ ```
+
+2. Build the example using
+
+ ```
+ make app
+ ```
+
+3. After example build finish, copy ELF file and map file to image generate
+ tool directory. \
+ image generate tool directory located at
+ `'tensorflow/lite/micro/tools/make/downloads/himax_we1_sdk/image_gen_linux_v3/'`
+
+ ```
+ cp magic_wand.elf himax_we1_evb.map ../../../../../downloads/himax_we1_sdk/image_gen_linux_v3/
+ ```
+
+4. Go to flash image generate tool directory.
+
+ ```
+ cd ../../../../../downloads/himax_we1_sdk/image_gen_linux_v3/
+ ```
+
+ make sure this tool directory is in $PATH. You can permanently set it to
+ PATH by
+
+ ```
+ export PATH=$PATH:$(pwd)
+ ```
+
+5. run image generate tool, generate flash image file.
+
+ * Before running image generate tool, by typing `sudo chmod +x image_gen`
+ and `sudo chmod +x sign_tool` to make sure it is executable.
+
+ ```
+ image_gen -e magic_wand.elf -m himax_we1_evb.map -o out.img
+ ```
+
+6. Download flash image file to HIMAX WE1 EVB by UART:
+
+ * more detail about download image through UART can be found at
+ [HIMAX WE1 EVB update Flash image](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_user_guide#flash-image-update)
+
+After these steps, press reset button on the HIMAX WE1 EVB, you will see
+application output in the serial terminal. Perform following gestures
+`'Wing'`,`'Ring'`,`'Slope'` and you can see the output in serial terminal.
+
+```
+WING:
+* * *
+ * * * *
+ * * * *
+ * * * *
+ * * * *
+ * *
+```
+
+```
+RING:
+ *
+ * *
+ * *
+ * *
+ * *
+ * *
+ *
+```
+
+```
+SLOPE:
+ *
+ *
+ *
+ *
+ *
+ *
+ *
+ * * * * * * * *
+```
+
+## Deploy to SparkFun Edge
+
+The following instructions will help you build and deploy this sample on the
+[SparkFun Edge development board](https://sparkfun.com/products/15170).
+
+If you're new to using this board, we recommend walking through the
+[AI on a microcontroller with TensorFlow Lite and SparkFun Edge](https://codelabs.developers.google.com/codelabs/sparkfun-tensorflow)
+codelab to get an understanding of the workflow.
+
+### Compile the binary
+
+Run the following command to build a binary for SparkFun Edge.
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=sparkfun_edge magic_wand_bin
+```
+
+The binary will be created in the following location:
+
+```
+tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4/bin/magic_wand.bin
+```
+
+### Sign the binary
+
+The binary must be signed with cryptographic keys to be deployed to the device.
+We'll now run some commands that will sign our binary so it can be flashed to
+the SparkFun Edge. The scripts we are using come from the Ambiq SDK, which is
+downloaded when the `Makefile` is run.
+
+Enter the following command to set up some dummy cryptographic keys we can use
+for development:
+
+```
+cp tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/keys_info0.py \
+tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/keys_info.py
+```
+
+Next, run the following command to create a signed binary:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/create_cust_image_blob.py \
+--bin tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4/bin/magic_wand.bin \
+--load-address 0xC000 \
+--magic-num 0xCB \
+-o main_nonsecure_ota \
+--version 0x0
+```
+
+This will create the file `main_nonsecure_ota.bin`. We'll now run another
+command to create a final version of the file that can be used to flash our
+device with the bootloader script we will use in the next step:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/create_cust_wireupdate_blob.py \
+--load-address 0x20000 \
+--bin main_nonsecure_ota.bin \
+-i 6 \
+-o main_nonsecure_wire \
+--options 0x1
+```
+
+You should now have a file called `main_nonsecure_wire.bin` in the directory
+where you ran the commands. This is the file we'll be flashing to the device.
+
+### Flash the binary
+
+Next, attach the board to your computer via a USB-to-serial adapter.
+
+**Note:** If you're using the
+[SparkFun Serial Basic Breakout](https://www.sparkfun.com/products/15096), you
+should
+[install the latest drivers](https://learn.sparkfun.com/tutorials/sparkfun-serial-basic-ch340c-hookup-guide#drivers-if-you-need-them)
+before you continue.
+
+Once connected, assign the USB device name to an environment variable:
+
+```
+export DEVICENAME=put your device name here
+```
+
+Set another variable with the baud rate:
+
+```
+export BAUD_RATE=921600
+```
+
+Now, hold the button marked `14` on the device. While still holding the button,
+hit the button marked `RST`. Continue holding the button marked `14` while
+running the following command:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/uart_wired_update.py \
+-b ${BAUD_RATE} ${DEVICENAME} \
+-r 1 \
+-f main_nonsecure_wire.bin \
+-i 6
+```
+
+You should see a long stream of output as the binary is flashed to the device.
+Once you see the following lines, flashing is complete:
+
+```
+Sending Reset Command.
+Done.
+```
+
+If you don't see these lines, flashing may have failed. Try running through the
+steps in [Flash the binary](#flash-the-binary) again (you can skip over setting
+the environment variables). If you continue to run into problems, follow the
+[AI on a microcontroller with TensorFlow Lite and SparkFun Edge](https://codelabs.developers.google.com/codelabs/sparkfun-tensorflow)
+codelab, which includes more comprehensive instructions for the flashing
+process.
+
+The binary should now be deployed to the device. Hit the button marked `RST` to
+reboot the board.
+
+Do the three magic gestures and you will see the corresponding LED light on! Red
+for "Wing", blue for "Ring" and green for "Slope".
+
+Debug information is logged by the board while the program is running. To view
+it, establish a serial connection to the board using a baud rate of `115200`. On
+OSX and Linux, the following command should work:
+
+```
+screen ${DEVICENAME} 115200
+```
+
+You will see the following message:
+
+```
+Magic starts!
+```
+
+Keep the chip face up, do magic gestures "WING", "RING"(clockwise), and "SLOPE"
+with your wand, and you will see the corresponding output like this!
+
+```
+WING:
+* * *
+ * * * *
+ * * * *
+ * * * *
+ * * * *
+ * *
+```
+
+```
+RING:
+ *
+ * *
+ * *
+ * *
+ * *
+ * *
+ *
+```
+
+```
+SLOPE:
+ *
+ *
+ *
+ *
+ *
+ *
+ *
+ * * * * * * * *
+```
+
+To stop viewing the debug output with `screen`, hit `Ctrl+A`, immediately
+followed by the `K` key, then hit the `Y` key.
+
+## Run the tests on a development machine
+
+To compile and test this example on a desktop Linux or macOS machine, first
+clone the TensorFlow repository from GitHub to a convenient place:
+
+```bash
+git clone --depth 1 https://github.com/tensorflow/tensorflow.git
+```
+
+Next, put this folder under the
+tensorflow/tensorflow/lite/micro/examples/ folder, then `cd` into
+the source directory from a terminal and run the following command:
+
+```bash
+make -f tensorflow/lite/micro/tools/make/Makefile test_magic_wand_test
+```
+
+This will take a few minutes, and downloads frameworks the code uses like
+[CMSIS](https://developer.arm.com/embedded/cmsis) and
+[flatbuffers](https://google.github.io/flatbuffers/). Once that process has
+finished, you should see a series of files get compiled, followed by some
+logging output from a test, which should conclude with `~~~ALL TESTS PASSED~~~`.
+
+If you see this, it means that a small program has been built and run that loads
+the trained TensorFlow model, runs some example inputs through it, and got the
+expected outputs.
+
+To understand how TensorFlow Lite does this, you can look at the source in
+[hello_world_test.cc](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/hello_world/hello_world_test.cc).
+It's a fairly small amount of code that creates an interpreter, gets a handle to
+a model that's been compiled into the program, and then invokes the interpreter
+with the model and sample inputs.
+
+## Train your own model
+
+To train your own model, or create a new model for a new set of gestures,
+follow the instructions in [magic_wand/train/README.md](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/magic_wand/train/README.md).
diff --git a/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.cc b/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.cc
new file mode 100644
index 0000000..33e0be4
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.cc
@@ -0,0 +1,38 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h"
+
+int begin_index = 0;
+
+TfLiteStatus SetupAccelerometer(tflite::ErrorReporter* error_reporter) {
+ return kTfLiteOk;
+}
+
+bool ReadAccelerometer(tflite::ErrorReporter* error_reporter, float* input,
+ int length) {
+ begin_index += 3;
+ // Reset begin_index to simulate behavior of loop buffer
+ if (begin_index >= 600) begin_index = 0;
+ // Only return true after the function was called 100 times, simulating the
+ // desired behavior of a real implementation (which does not return data until
+ // a sufficient amount is available)
+ if (begin_index > 300) {
+ for (int i = 0; i < length; ++i) input[i] = 0;
+ return true;
+ } else {
+ return false;
+ }
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h b/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h
new file mode 100644
index 0000000..5174cc0
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h
@@ -0,0 +1,29 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_ACCELEROMETER_HANDLER_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_ACCELEROMETER_HANDLER_H_
+
+#define kChannelNumber 3
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+extern int begin_index;
+extern TfLiteStatus SetupAccelerometer(tflite::ErrorReporter* error_reporter);
+extern bool ReadAccelerometer(tflite::ErrorReporter* error_reporter,
+ float* input, int length);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_ACCELEROMETER_HANDLER_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler_test.cc b/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler_test.cc
new file mode 100644
index 0000000..6c326d2
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/accelerometer_handler_test.cc
@@ -0,0 +1,47 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h"
+
+#include <string.h>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestSetup) {
+ tflite::MicroErrorReporter micro_error_reporter;
+ TfLiteStatus setup_status = SetupAccelerometer(µ_error_reporter);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, setup_status);
+}
+
+TF_LITE_MICRO_TEST(TestAccelerometer) {
+ float input[384] = {0.0};
+ tflite::MicroErrorReporter micro_error_reporter;
+ // Test that the function returns false before insufficient data is available
+ bool inference_flag = ReadAccelerometer(µ_error_reporter, input, 384);
+ TF_LITE_MICRO_EXPECT_EQ(inference_flag, false);
+
+ // Test that the function returns true once sufficient data is available to
+ // fill the model's input buffer (128 sets of values)
+ for (int i = 1; i <= 128; i++) {
+ inference_flag = ReadAccelerometer(µ_error_reporter, input, 384);
+ }
+ TF_LITE_MICRO_EXPECT_EQ(inference_flag, true);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/magic_wand/arduino/Makefile.inc b/tensorflow/lite/micro/examples/magic_wand/arduino/Makefile.inc
new file mode 100644
index 0000000..4ec1b38
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/arduino/Makefile.inc
@@ -0,0 +1,7 @@
+ifeq ($(TARGET),$(filter $(TARGET),arduino))
+
+magic_wand_SRCS += \
+ tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/accelerometer_handler.cc \
+ tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/output_handler.cc
+
+endif
diff --git a/tensorflow/lite/micro/examples/magic_wand/arduino/accelerometer_handler.cc b/tensorflow/lite/micro/examples/magic_wand/arduino/accelerometer_handler.cc
new file mode 100644
index 0000000..866b8d6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/arduino/accelerometer_handler.cc
@@ -0,0 +1,141 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h"
+
+#include <Arduino.h>
+#include <Arduino_LSM9DS1.h>
+
+#include "tensorflow/lite/micro/examples/magic_wand/constants.h"
+
+// A buffer holding the last 200 sets of 3-channel values
+float save_data[600] = {0.0};
+// Most recent position in the save_data buffer
+int begin_index = 0;
+// True if there is not yet enough data to run inference
+bool pending_initial_data = true;
+// How often we should save a measurement during downsampling
+int sample_every_n;
+// The number of measurements since we last saved one
+int sample_skip_counter = 1;
+
+TfLiteStatus SetupAccelerometer(tflite::ErrorReporter* error_reporter) {
+ // Switch on the IMU
+ if (!IMU.begin()) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to initialize IMU");
+ return kTfLiteError;
+ }
+
+ // Make sure we are pulling measurements into a FIFO.
+ // If you see an error on this line, make sure you have at least v1.1.0 of the
+ // Arduino_LSM9DS1 library installed.
+ IMU.setContinuousMode();
+
+ // Determine how many measurements to keep in order to
+ // meet kTargetHz
+ float sample_rate = IMU.accelerationSampleRate();
+ sample_every_n = static_cast<int>(roundf(sample_rate / kTargetHz));
+
+ TF_LITE_REPORT_ERROR(error_reporter, "Magic starts!");
+
+ return kTfLiteOk;
+}
+
+bool ReadAccelerometer(tflite::ErrorReporter* error_reporter, float* input,
+ int length) {
+ // Keep track of whether we stored any new data
+ bool new_data = false;
+ // Loop through new samples and add to buffer
+ while (IMU.accelerationAvailable()) {
+ float x, y, z;
+ // Read each sample, removing it from the device's FIFO buffer
+ if (!IMU.readAcceleration(x, y, z)) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to read data");
+ break;
+ }
+ // Throw away this sample unless it's the nth
+ if (sample_skip_counter != sample_every_n) {
+ sample_skip_counter += 1;
+ continue;
+ }
+ // Write samples to our buffer, converting to milli-Gs and rotating the axis
+ // order for compatibility with model (sensor orientation is different on
+ // Arduino Nano BLE Sense compared with SparkFun Edge).
+ // The expected orientation of the Arduino on the wand is with the USB port
+ // facing down the shaft towards the user's hand, with the reset button
+ // pointing at the user's face:
+ //
+ // ____
+ // | |<- Arduino board
+ // | |
+ // | () | <- Reset button
+ // | |
+ // -TT- <- USB port
+ // ||
+ // ||<- Wand
+ // ....
+ // ||
+ // ||
+ // ()
+ //
+ const float norm_x = -z;
+ const float norm_y = y;
+ const float norm_z = x;
+ save_data[begin_index++] = norm_x * 1000;
+ save_data[begin_index++] = norm_y * 1000;
+ save_data[begin_index++] = norm_z * 1000;
+ // Since we took a sample, reset the skip counter
+ sample_skip_counter = 1;
+ // If we reached the end of the circle buffer, reset
+ if (begin_index >= 600) {
+ begin_index = 0;
+ }
+ new_data = true;
+ }
+
+ // Skip this round if data is not ready yet
+ if (!new_data) {
+ return false;
+ }
+
+ // Check if we are ready for prediction or still pending more initial data
+ if (pending_initial_data && begin_index >= 200) {
+ pending_initial_data = false;
+ }
+
+ // Return if we don't have enough data
+ if (pending_initial_data) {
+ return false;
+ }
+
+ // Copy the requested number of bytes to the provided input tensor
+ for (int i = 0; i < length; ++i) {
+ int ring_array_index = begin_index + i - length;
+ if (ring_array_index < 0) {
+ ring_array_index += 600;
+ }
+ input[i] = save_data[ring_array_index];
+ }
+
+ return true;
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/magic_wand/arduino/main.cc b/tensorflow/lite/micro/examples/magic_wand/arduino/main.cc
new file mode 100644
index 0000000..e34e8bb
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/arduino/main.cc
@@ -0,0 +1,20 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/hello_world/main_functions.h"
+
+// Arduino automatically calls the setup() and loop() functions in a sketch, so
+// where other systems need their own main routine in this file, it can be left
+// empty.
diff --git a/tensorflow/lite/micro/examples/magic_wand/arduino/output_handler.cc b/tensorflow/lite/micro/examples/magic_wand/arduino/output_handler.cc
new file mode 100644
index 0000000..a01869e
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/arduino/output_handler.cc
@@ -0,0 +1,57 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/magic_wand/output_handler.h"
+
+#include "Arduino.h"
+
+void HandleOutput(tflite::ErrorReporter* error_reporter, int kind) {
+ // The first time this method runs, set up our LED
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ pinMode(LED_BUILTIN, OUTPUT);
+ is_initialized = true;
+ }
+
+ // Print some ASCII art for each gesture and control the LED.
+ if (kind == 0) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "WING:\n\r* * *\n\r * * * "
+ "*\n\r * * * *\n\r * * * *\n\r * * "
+ "* *\n\r * *\n\r");
+ } else if (kind == 1) {
+ digitalWrite(LED_BUILTIN, HIGH);
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "RING:\n\r *\n\r * *\n\r * *\n\r "
+ " * *\n\r * *\n\r * *\n\r "
+ " *\n\r");
+ } else if (kind == 2) {
+ digitalWrite(LED_BUILTIN, LOW);
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "SLOPE:\n\r *\n\r *\n\r *\n\r *\n\r "
+ "*\n\r *\n\r *\n\r * * * * * * * *\n\r");
+ }
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/magic_wand/constants.h b/tensorflow/lite/micro/examples/magic_wand/constants.h
new file mode 100644
index 0000000..3f0da6c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/constants.h
@@ -0,0 +1,38 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_CONSTANTS_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_CONSTANTS_H_
+
+// The expected accelerometer data sample frequency
+const float kTargetHz = 25;
+
+// What gestures are supported.
+constexpr int kGestureCount = 4;
+constexpr int kWingGesture = 0;
+constexpr int kRingGesture = 1;
+constexpr int kSlopeGesture = 2;
+constexpr int kNoGesture = 3;
+
+// These control the sensitivity of the detection algorithm. If you're seeing
+// too many false positives or not enough true positives, you can try tweaking
+// these thresholds. Often, increasing the size of the training set will give
+// more robust results though, so consider retraining if you are seeing poor
+// predictions.
+constexpr float kDetectionThreshold = 0.8f;
+constexpr int kPredictionHistoryLength = 5;
+constexpr int kPredictionSuppressionDuration = 25;
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_CONSTANTS_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/gesture_predictor.cc b/tensorflow/lite/micro/examples/magic_wand/gesture_predictor.cc
new file mode 100644
index 0000000..b09499a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/gesture_predictor.cc
@@ -0,0 +1,72 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h"
+
+#include "tensorflow/lite/micro/examples/magic_wand/constants.h"
+
+namespace {
+// State for the averaging algorithm we're using.
+float prediction_history[kGestureCount][kPredictionHistoryLength] = {};
+int prediction_history_index = 0;
+int prediction_suppression_count = 0;
+} // namespace
+
+// Return the result of the last prediction
+// 0: wing("W"), 1: ring("O"), 2: slope("angle"), 3: unknown
+int PredictGesture(float* output) {
+ // Record the latest predictions in our rolling history buffer.
+ for (int i = 0; i < kGestureCount; ++i) {
+ prediction_history[i][prediction_history_index] = output[i];
+ }
+ // Figure out which slot to put the next predictions into.
+ ++prediction_history_index;
+ if (prediction_history_index >= kPredictionHistoryLength) {
+ prediction_history_index = 0;
+ }
+
+ // Average the last n predictions for each gesture, and find which has the
+ // highest score.
+ int max_predict_index = -1;
+ float max_predict_score = 0.0f;
+ for (int i = 0; i < kGestureCount; i++) {
+ float prediction_sum = 0.0f;
+ for (int j = 0; j < kPredictionHistoryLength; ++j) {
+ prediction_sum += prediction_history[i][j];
+ }
+ const float prediction_average = prediction_sum / kPredictionHistoryLength;
+ if ((max_predict_index == -1) || (prediction_average > max_predict_score)) {
+ max_predict_index = i;
+ max_predict_score = prediction_average;
+ }
+ }
+
+ // If there's been a recent prediction, don't trigger a new one too soon.
+ if (prediction_suppression_count > 0) {
+ --prediction_suppression_count;
+ }
+ // If we're predicting no gesture, or the average score is too low, or there's
+ // been a gesture recognised too recently, return no gesture.
+ if ((max_predict_index == kNoGesture) ||
+ (max_predict_score < kDetectionThreshold) ||
+ (prediction_suppression_count > 0)) {
+ return kNoGesture;
+ } else {
+ // Reset the suppression counter so we don't come up with another prediction
+ // too soon.
+ prediction_suppression_count = kPredictionSuppressionDuration;
+ return max_predict_index;
+ }
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h b/tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h
new file mode 100644
index 0000000..713cb56
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h
@@ -0,0 +1,21 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_GESTURE_PREDICTOR_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_GESTURE_PREDICTOR_H_
+
+extern int PredictGesture(float* output);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_GESTURE_PREDICTOR_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/gesture_predictor_test.cc b/tensorflow/lite/micro/examples/magic_wand/gesture_predictor_test.cc
new file mode 100644
index 0000000..7488666
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/gesture_predictor_test.cc
@@ -0,0 +1,66 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h"
+
+#include "tensorflow/lite/micro/examples/magic_wand/constants.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SuccessfulPrediction) {
+ // Use the threshold from the 0th gesture.
+ float probabilities[kGestureCount] = {kDetectionThreshold, 0.0, 0.0, 0.0};
+ int prediction;
+ // Loop just too few times to trigger a prediction.
+ for (int i = 0; i < kPredictionHistoryLength - 1; i++) {
+ prediction = PredictGesture(probabilities);
+ TF_LITE_MICRO_EXPECT_EQ(prediction, kNoGesture);
+ }
+ // Call once more, triggering a prediction
+ // for category 0.
+ prediction = PredictGesture(probabilities);
+ TF_LITE_MICRO_EXPECT_EQ(prediction, 0);
+}
+
+TF_LITE_MICRO_TEST(FailPartWayThere) {
+ // Use the threshold from the 0th gesture.
+ float probabilities[kGestureCount] = {kDetectionThreshold, 0.0, 0.0, 0.0};
+ int prediction;
+ // Loop just too few times to trigger a prediction.
+ for (int i = 0; i <= kPredictionHistoryLength - 1; i++) {
+ prediction = PredictGesture(probabilities);
+ TF_LITE_MICRO_EXPECT_EQ(prediction, kNoGesture);
+ }
+ // Call with a different prediction, triggering a failure.
+ probabilities[0] = 0.0;
+ probabilities[2] = 1.0;
+ prediction = PredictGesture(probabilities);
+ TF_LITE_MICRO_EXPECT_EQ(prediction, kNoGesture);
+}
+
+TF_LITE_MICRO_TEST(InsufficientProbability) {
+ // Just below the detection threshold.
+ float probabilities[kGestureCount] = {kDetectionThreshold - 0.1f, 0.0, 0.0,
+ 0.0};
+ int prediction;
+ // Loop the exact right number of times
+ for (int i = 0; i <= kPredictionHistoryLength; i++) {
+ prediction = PredictGesture(probabilities);
+ TF_LITE_MICRO_EXPECT_EQ(prediction, kNoGesture);
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/magic_wand/himax_we1_evb/accelerometer_handler.cc b/tensorflow/lite/micro/examples/magic_wand/himax_we1_evb/accelerometer_handler.cc
new file mode 100644
index 0000000..9d83b01
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/himax_we1_evb/accelerometer_handler.cc
@@ -0,0 +1,89 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h"
+
+#include "hx_drv_tflm.h"
+
+int begin_index = 0;
+
+namespace {
+// Ring buffer size
+constexpr int ring_buffer_size = 600;
+// Ring buffer
+float save_data[ring_buffer_size] = {0.0};
+// Flag to start detect gesture
+bool pending_initial_data = true;
+// Available data count in accelerometer FIFO
+int available_count = 0;
+
+} // namespace
+
+TfLiteStatus SetupAccelerometer(tflite::ErrorReporter* error_reporter) {
+ if (hx_drv_accelerometer_initial() != HX_DRV_LIB_PASS) {
+ TF_LITE_REPORT_ERROR(error_reporter, "setup fail");
+ return kTfLiteError;
+ }
+
+ TF_LITE_REPORT_ERROR(error_reporter, "setup done");
+
+ return kTfLiteOk;
+}
+
+bool ReadAccelerometer(tflite::ErrorReporter* error_reporter, float* input,
+ int length) {
+ // Check how many accelerometer data
+ available_count = hx_drv_accelerometer_available_count();
+
+ if (available_count == 0) return false;
+
+ for (int i = 0; i < available_count; i++) {
+ float x, y, z;
+ hx_drv_accelerometer_receive(&x, &y, &z);
+
+ const float norm_x = -x;
+ const float norm_y = y;
+ const float norm_z = z;
+
+ // Save data in milli-g unit
+ save_data[begin_index++] = norm_x * 1000;
+ save_data[begin_index++] = norm_y * 1000;
+ save_data[begin_index++] = norm_z * 1000;
+
+ // If reach end of buffer, return to 0 position
+ if (begin_index >= ring_buffer_size) begin_index = 0;
+ }
+
+ // Check if data enough for prediction
+ if (pending_initial_data && begin_index >= 200) {
+ pending_initial_data = false;
+ }
+
+ // Return if we don't have enough data
+ if (pending_initial_data) {
+ return false;
+ }
+
+ // Copy the requested number of bytes to the provided input tensor
+ for (int i = 0; i < length; ++i) {
+ int ring_array_index = begin_index + i - length;
+ if (ring_array_index < 0) {
+ ring_array_index += ring_buffer_size;
+ }
+ input[i] = save_data[ring_array_index];
+ }
+
+ return true;
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.cc b/tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.cc
new file mode 100644
index 0000000..d56571d
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.cc
@@ -0,0 +1,1659 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Automatically created from a TensorFlow Lite flatbuffer using the command:
+// xxd -i magic_wand_model.tflite > magic_wand_model_data.cc
+// See the README for a full description of the creation process.
+
+#include "tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h"
+
+// Keep model aligned to 8 bytes to guarantee aligned 64-bit accesses.
+alignas(8) const unsigned char g_magic_wand_model_data[] = {
+ 0x1c, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x12, 0x00,
+ 0x1c, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00,
+ 0x00, 0x00, 0x18, 0x00, 0x12, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x24, 0x4c, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x2c, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x14, 0x01, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xdc, 0x00, 0x00, 0x00,
+ 0x0f, 0x00, 0x00, 0x00, 0x54, 0x4f, 0x43, 0x4f, 0x20, 0x43, 0x6f, 0x6e,
+ 0x76, 0x65, 0x72, 0x74, 0x65, 0x64, 0x2e, 0x00, 0x12, 0x00, 0x00, 0x00,
+ 0xb0, 0x00, 0x00, 0x00, 0xa4, 0x00, 0x00, 0x00, 0x98, 0x00, 0x00, 0x00,
+ 0x8c, 0x00, 0x00, 0x00, 0x80, 0x00, 0x00, 0x00, 0x74, 0x00, 0x00, 0x00,
+ 0x68, 0x00, 0x00, 0x00, 0x60, 0x00, 0x00, 0x00, 0x58, 0x00, 0x00, 0x00,
+ 0x50, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x38, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x6e, 0xb6, 0xff, 0xff, 0x68, 0x00, 0x00, 0x00, 0x30, 0xb6, 0xff, 0xff,
+ 0x34, 0xb6, 0xff, 0xff, 0x7e, 0xb6, 0xff, 0xff, 0xf0, 0x01, 0x00, 0x00,
+ 0x86, 0xb6, 0xff, 0xff, 0xc8, 0x03, 0x00, 0x00, 0x48, 0xb6, 0xff, 0xff,
+ 0x4c, 0xb6, 0xff, 0xff, 0x50, 0xb6, 0xff, 0xff, 0x54, 0xb6, 0xff, 0xff,
+ 0x58, 0xb6, 0xff, 0xff, 0x5c, 0xb6, 0xff, 0xff, 0xa6, 0xb6, 0xff, 0xff,
+ 0xc0, 0x0d, 0x00, 0x00, 0xae, 0xb6, 0xff, 0xff, 0x00, 0x46, 0x00, 0x00,
+ 0xb6, 0xb6, 0xff, 0xff, 0x60, 0x46, 0x00, 0x00, 0xbe, 0xb6, 0xff, 0xff,
+ 0xe0, 0x46, 0x00, 0x00, 0xc6, 0xb6, 0xff, 0xff, 0x48, 0x47, 0x00, 0x00,
+ 0xce, 0xb6, 0xff, 0xff, 0x98, 0x48, 0x00, 0x00, 0x90, 0xb6, 0xff, 0xff,
+ 0x05, 0x00, 0x00, 0x00, 0x31, 0x2e, 0x35, 0x2e, 0x30, 0x00, 0x00, 0x00,
+ 0x54, 0xf4, 0xff, 0xff, 0x08, 0x00, 0x00, 0x00, 0x11, 0x00, 0x00, 0x00,
+ 0x13, 0x00, 0x00, 0x00, 0x6d, 0x69, 0x6e, 0x5f, 0x72, 0x75, 0x6e, 0x74,
+ 0x69, 0x6d, 0x65, 0x5f, 0x76, 0x65, 0x72, 0x73, 0x69, 0x6f, 0x6e, 0x00,
+ 0x0c, 0x00, 0x14, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x88, 0x48, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x9c, 0x0c, 0x00, 0x00, 0x14, 0x0b, 0x00, 0x00,
+ 0xd4, 0x00, 0x00, 0x00, 0x24, 0x45, 0x00, 0x00, 0x84, 0x00, 0x00, 0x00,
+ 0xa4, 0x02, 0x00, 0x00, 0x80, 0x45, 0x00, 0x00, 0x9c, 0x0b, 0x00, 0x00,
+ 0xb0, 0x0c, 0x00, 0x00, 0xc4, 0x47, 0x00, 0x00, 0x50, 0x0b, 0x00, 0x00,
+ 0x2c, 0x0c, 0x00, 0x00, 0x48, 0x46, 0x00, 0x00, 0xec, 0x45, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0xc8, 0x0b, 0x00, 0x00, 0x66, 0xb8, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x2a, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,
+ 0x61, 0x6c, 0x2f, 0x6d, 0x61, 0x78, 0x5f, 0x70, 0x6f, 0x6f, 0x6c, 0x69,
+ 0x6e, 0x67, 0x32, 0x64, 0x2f, 0x4d, 0x61, 0x78, 0x50, 0x6f, 0x6f, 0x6c,
+ 0x00, 0x00, 0x00, 0x00, 0x88, 0xb7, 0xff, 0xff, 0xba, 0xb8, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x34, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x16, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,
+ 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f, 0x52, 0x65,
+ 0x6c, 0x75, 0x00, 0x00, 0xd0, 0xb7, 0xff, 0xff, 0x02, 0xb9, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x44, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x27, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,
+ 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f, 0x43, 0x6f,
+ 0x6e, 0x76, 0x32, 0x44, 0x2f, 0x52, 0x65, 0x61, 0x64, 0x56, 0x61, 0x72,
+ 0x69, 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x00, 0x28, 0xb8, 0xff, 0xff,
+ 0x80, 0x01, 0x00, 0x00, 0x1c, 0x6a, 0xf6, 0xbd, 0xaa, 0x16, 0xfd, 0x3c,
+ 0xf6, 0xd9, 0x20, 0x3e, 0x64, 0xf8, 0xdd, 0x3d, 0x07, 0xc0, 0x82, 0xbe,
+ 0x9e, 0xa3, 0x38, 0xbd, 0x13, 0x41, 0xa1, 0x3d, 0xb0, 0x81, 0x90, 0xbd,
+ 0xc7, 0xdd, 0xbc, 0xbb, 0x87, 0x9c, 0x24, 0xbe, 0x72, 0x08, 0x6a, 0xbd,
+ 0x10, 0x1b, 0x61, 0x3e, 0x79, 0x49, 0x18, 0xbe, 0xda, 0x09, 0x88, 0xbe,
+ 0x2d, 0x70, 0x4d, 0x3d, 0x5c, 0x4a, 0x9e, 0xbd, 0x0f, 0xf1, 0x46, 0x3e,
+ 0x1c, 0xbd, 0x02, 0xbf, 0x56, 0xbc, 0x07, 0x3e, 0x63, 0x92, 0x39, 0xbe,
+ 0x4e, 0xde, 0x84, 0x3e, 0x64, 0x38, 0x88, 0xbd, 0xa0, 0x32, 0xc3, 0xbd,
+ 0x0f, 0x94, 0xb7, 0xbe, 0xd6, 0x11, 0x27, 0xbc, 0xcc, 0x7e, 0xf3, 0x3d,
+ 0xf3, 0x4d, 0xaa, 0x3d, 0xbc, 0x8a, 0x28, 0x3e, 0xa2, 0xb5, 0xda, 0xbd,
+ 0x92, 0x1a, 0xb6, 0xbd, 0x9a, 0x49, 0xb1, 0x3d, 0xfc, 0x93, 0x1c, 0x3d,
+ 0x74, 0xa1, 0xa1, 0xbd, 0xc7, 0x48, 0x1d, 0xbe, 0x3a, 0x53, 0xb2, 0x3b,
+ 0x92, 0x51, 0xa5, 0xbd, 0x6a, 0xc4, 0x3c, 0xbd, 0xdb, 0x61, 0x6d, 0xbd,
+ 0x78, 0x9f, 0x03, 0xbe, 0x40, 0x1f, 0x30, 0xbd, 0x17, 0xde, 0xad, 0x3d,
+ 0xd7, 0xee, 0x74, 0xbd, 0xb6, 0x5c, 0xc2, 0x3d, 0x1c, 0x89, 0x65, 0xbe,
+ 0xfd, 0xc4, 0x48, 0x3e, 0xb2, 0x29, 0x13, 0x3d, 0xcc, 0x56, 0x13, 0x3d,
+ 0xf8, 0xce, 0x1b, 0xbc, 0xb5, 0x4b, 0xe8, 0xbc, 0x48, 0x05, 0x5c, 0xbe,
+ 0xaf, 0xfa, 0x0d, 0x3e, 0x74, 0x84, 0xa4, 0x3d, 0x4c, 0x84, 0x04, 0x3e,
+ 0x09, 0x7a, 0xba, 0x3c, 0xb3, 0xa6, 0x07, 0x3e, 0x7d, 0xe5, 0xe5, 0x3d,
+ 0x7e, 0xb9, 0xa5, 0x3c, 0x4e, 0x70, 0x49, 0x3e, 0x39, 0xfe, 0x12, 0xbe,
+ 0xfa, 0x8b, 0x01, 0xbe, 0xb9, 0x8e, 0xe6, 0xbc, 0xc8, 0x2f, 0xb3, 0xbd,
+ 0x1b, 0x2b, 0x9e, 0xbd, 0xe7, 0x7f, 0x0e, 0x3d, 0x3e, 0xa3, 0x2a, 0x3d,
+ 0xa1, 0x73, 0x31, 0x3d, 0xc8, 0xc7, 0x03, 0xbd, 0x07, 0x71, 0xaf, 0xbd,
+ 0xb2, 0x6b, 0x2b, 0xbe, 0x06, 0xc2, 0x1f, 0xbe, 0x3b, 0xbf, 0x30, 0xbe,
+ 0x7e, 0x51, 0x22, 0x3e, 0x5a, 0xa7, 0x92, 0x3d, 0xb8, 0x60, 0x35, 0xbe,
+ 0xa7, 0xdf, 0x8f, 0x3d, 0xbc, 0xfc, 0x42, 0x3e, 0x42, 0x86, 0x7d, 0xbc,
+ 0x3a, 0xd0, 0xd8, 0x3c, 0xea, 0x45, 0x40, 0xbc, 0x04, 0xd3, 0x9d, 0xb7,
+ 0xe3, 0xdf, 0xae, 0xbd, 0x80, 0x5e, 0x59, 0xbe, 0x88, 0x15, 0xc0, 0xbd,
+ 0xea, 0x86, 0xaa, 0xbd, 0x3b, 0x4a, 0x64, 0x3d, 0x89, 0x25, 0x42, 0xbe,
+ 0xc2, 0x29, 0x93, 0xbe, 0x62, 0x85, 0x00, 0x3e, 0xf1, 0x0e, 0xda, 0xbd,
+ 0x48, 0x09, 0xb8, 0xbe, 0xad, 0xe2, 0x4d, 0xbe, 0x69, 0x26, 0x99, 0xbe,
+ 0x86, 0x3c, 0xcd, 0xbe, 0x05, 0xe6, 0x4e, 0xbd, 0xdb, 0x8f, 0xfb, 0x3d,
+ 0xc6, 0xf5, 0x97, 0x3e, 0xde, 0xba, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x0d, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x29, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63,
+ 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x31, 0x2f, 0x43, 0x6f, 0x6e, 0x76,
+ 0x32, 0x44, 0x2f, 0x52, 0x65, 0x61, 0x64, 0x56, 0x61, 0x72, 0x69, 0x61,
+ 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x00, 0x00, 0x00, 0x08, 0xba, 0xff, 0xff,
+ 0x00, 0x08, 0x00, 0x00, 0x40, 0x7a, 0x10, 0xbf, 0x9b, 0xf1, 0xcc, 0xbe,
+ 0x78, 0x88, 0x1d, 0xbf, 0xc2, 0xb7, 0x09, 0xbf, 0xbd, 0xd6, 0xaf, 0xbe,
+ 0xf5, 0x29, 0xed, 0xbe, 0xad, 0x18, 0x70, 0xbe, 0x3d, 0x91, 0x40, 0x3b,
+ 0x2f, 0xcf, 0x55, 0xbe, 0xc6, 0x0b, 0xed, 0x3e, 0xbe, 0x7a, 0x80, 0xbe,
+ 0x3c, 0x3c, 0xb1, 0x3a, 0xab, 0xea, 0xa6, 0x3d, 0x88, 0x57, 0x55, 0xbe,
+ 0x0c, 0x62, 0xdc, 0xbe, 0x07, 0x6b, 0xbe, 0x3e, 0x9e, 0x0d, 0x28, 0x3d,
+ 0xd9, 0xd2, 0xb1, 0x3d, 0x4c, 0x45, 0xbd, 0xbd, 0x3c, 0xe0, 0x1f, 0x3d,
+ 0x76, 0xb5, 0x48, 0xbd, 0x2b, 0xe8, 0x3a, 0xbe, 0xd3, 0x21, 0x57, 0xbe,
+ 0xdc, 0x21, 0x70, 0x3e, 0x00, 0x71, 0xec, 0x3d, 0x9c, 0xeb, 0x61, 0x3d,
+ 0x0d, 0x8a, 0x9c, 0x3d, 0x2a, 0x35, 0x03, 0x3d, 0x1b, 0x1c, 0x28, 0x3b,
+ 0xa6, 0xf9, 0xa9, 0xbd, 0x20, 0xfb, 0x2f, 0xbe, 0x8c, 0xcb, 0x04, 0x3d,
+ 0x43, 0x62, 0x64, 0x3d, 0xf8, 0x65, 0xd6, 0x3d, 0xf3, 0xbe, 0x3a, 0xbd,
+ 0xaf, 0x2b, 0x53, 0x3d, 0x99, 0x58, 0xf8, 0xbd, 0x3a, 0xbe, 0x43, 0xbd,
+ 0xd0, 0xe7, 0xc0, 0xbc, 0xa4, 0x8d, 0xf3, 0x3d, 0xa2, 0xd7, 0x9c, 0xbc,
+ 0x87, 0x1b, 0xb0, 0x3e, 0x18, 0x20, 0x88, 0xbd, 0xee, 0x9e, 0xc5, 0x3e,
+ 0xc1, 0x35, 0xaf, 0x3c, 0xc0, 0x97, 0x39, 0xbd, 0xa5, 0x6f, 0x04, 0xbd,
+ 0x7b, 0x03, 0x1c, 0xbe, 0x0f, 0x75, 0xbb, 0xbd, 0xdf, 0x1b, 0x54, 0xbd,
+ 0xfb, 0xbf, 0xcc, 0xbd, 0x1b, 0x01, 0x10, 0xbd, 0x20, 0x67, 0xb4, 0xbc,
+ 0xdf, 0xa6, 0x40, 0x3c, 0x74, 0xb4, 0x28, 0x3d, 0x65, 0xe7, 0xc3, 0xbd,
+ 0x8d, 0x38, 0x91, 0xbd, 0x8f, 0xba, 0x45, 0xbc, 0x69, 0xc7, 0x49, 0xbc,
+ 0xa3, 0xcb, 0xf8, 0x3c, 0x69, 0xed, 0x2d, 0x3e, 0x0d, 0xf4, 0xc6, 0xbc,
+ 0xd6, 0xe7, 0xfe, 0xbd, 0xfa, 0xa0, 0x86, 0xbd, 0x30, 0x83, 0xf0, 0xbd,
+ 0xf5, 0xb9, 0xd1, 0xbd, 0x1c, 0x39, 0x90, 0xbe, 0x74, 0x62, 0xd8, 0xbd,
+ 0x13, 0x28, 0x07, 0xbe, 0xbf, 0xbd, 0xbf, 0xbd, 0x15, 0xcf, 0xa8, 0xbb,
+ 0x9c, 0x1a, 0x8f, 0xbd, 0x91, 0x23, 0x93, 0x3d, 0x79, 0x63, 0xc4, 0xbd,
+ 0xec, 0xdd, 0x72, 0xbe, 0xd2, 0xd8, 0xac, 0xbe, 0xbf, 0x1e, 0x21, 0xbe,
+ 0xae, 0xab, 0x20, 0xbd, 0x8f, 0xe9, 0x90, 0x3d, 0xbb, 0x47, 0xdd, 0x3d,
+ 0xb1, 0x93, 0x37, 0xbd, 0xeb, 0xcf, 0x45, 0xbc, 0x33, 0x8f, 0x15, 0xbe,
+ 0xeb, 0x19, 0x9f, 0xbe, 0x66, 0x21, 0xe3, 0xbd, 0x53, 0x82, 0x60, 0x3c,
+ 0x11, 0xdc, 0xf1, 0xbc, 0x0c, 0x01, 0x1e, 0x3d, 0xdb, 0xd5, 0x1d, 0x3f,
+ 0x58, 0xa3, 0x61, 0x3d, 0x0a, 0x2b, 0x16, 0xbe, 0x01, 0x9d, 0x50, 0xbe,
+ 0xac, 0xac, 0x63, 0x3e, 0x76, 0xdb, 0x8a, 0xbc, 0x57, 0xec, 0x8f, 0xbc,
+ 0xad, 0x20, 0xd6, 0x3d, 0xc2, 0x63, 0x89, 0x3d, 0xc3, 0x1e, 0xe9, 0x3e,
+ 0xa8, 0x41, 0x9e, 0xbd, 0xac, 0x2c, 0x2b, 0xbe, 0x98, 0x73, 0xbf, 0x3d,
+ 0x7a, 0x22, 0x54, 0xbd, 0x44, 0xaf, 0x2c, 0xbe, 0x05, 0x45, 0xd9, 0xbc,
+ 0x74, 0xaa, 0x20, 0x3e, 0x6e, 0x1e, 0x95, 0x3e, 0x54, 0x20, 0x12, 0xbc,
+ 0xbe, 0x20, 0xcf, 0x3d, 0xa6, 0x02, 0x28, 0xbe, 0xd1, 0xfe, 0xe8, 0xbd,
+ 0x1f, 0x2a, 0x83, 0xbe, 0x33, 0x44, 0xf3, 0x3d, 0xff, 0x48, 0xda, 0xbd,
+ 0x8d, 0x1e, 0x79, 0x3e, 0xdb, 0xee, 0xb2, 0x3d, 0xdb, 0xde, 0x5b, 0xbe,
+ 0x55, 0x57, 0x49, 0xbe, 0x62, 0x4b, 0x29, 0xbf, 0x93, 0xbf, 0x23, 0xbf,
+ 0xea, 0xa3, 0x71, 0x3d, 0xa5, 0x50, 0x00, 0xbe, 0xb6, 0xd1, 0xc0, 0xbf,
+ 0x1d, 0x22, 0x7d, 0xbd, 0x00, 0x09, 0x81, 0x3d, 0xde, 0x28, 0x75, 0xbe,
+ 0x03, 0x1b, 0x2e, 0xbf, 0x3c, 0x3a, 0x3b, 0xbf, 0x52, 0x1a, 0xe6, 0xbd,
+ 0x9d, 0xe9, 0xea, 0xbd, 0x49, 0x71, 0x2c, 0x3d, 0xe8, 0x8b, 0x55, 0xbb,
+ 0x6c, 0x97, 0x24, 0xbe, 0x44, 0xe8, 0xe0, 0xba, 0x6d, 0x45, 0x4b, 0x3f,
+ 0x7f, 0x26, 0x38, 0x3e, 0xab, 0x04, 0x6e, 0xbe, 0x70, 0x59, 0x0e, 0xbe,
+ 0xd6, 0xfb, 0x7a, 0x3d, 0x45, 0x72, 0xa2, 0xbd, 0xb5, 0x6f, 0x2e, 0xbe,
+ 0xda, 0xf5, 0x07, 0x3e, 0xe0, 0x2b, 0xac, 0xbd, 0xaf, 0x35, 0xf6, 0xbd,
+ 0xd0, 0x2b, 0xac, 0xbd, 0x26, 0x2d, 0x11, 0xbe, 0x7e, 0xfa, 0x87, 0x3d,
+ 0x3a, 0xb7, 0xf6, 0xbd, 0xb1, 0xd0, 0xe2, 0xbc, 0xc8, 0xa2, 0x86, 0xbd,
+ 0x19, 0xf5, 0xb1, 0xbd, 0xf6, 0x65, 0x4d, 0xbe, 0x23, 0x63, 0x47, 0x3e,
+ 0xb7, 0x26, 0xd3, 0xbd, 0x57, 0xf4, 0x12, 0xbf, 0x93, 0xd4, 0x39, 0xbe,
+ 0x77, 0xf2, 0x62, 0x3d, 0xf6, 0x3d, 0xc3, 0xbe, 0xb6, 0xf5, 0x2b, 0xbe,
+ 0xbe, 0x8a, 0x76, 0xbe, 0xb1, 0x39, 0x63, 0x3e, 0xde, 0xbe, 0x3c, 0xbe,
+ 0xd4, 0x01, 0x94, 0xbe, 0x19, 0x1a, 0x97, 0xbb, 0xcb, 0x83, 0x4e, 0xbe,
+ 0x50, 0x19, 0x94, 0xbd, 0xf8, 0x8a, 0x95, 0xbe, 0xc8, 0xab, 0x86, 0xbe,
+ 0x18, 0x57, 0x6d, 0x3e, 0x87, 0xad, 0x8b, 0x3c, 0x72, 0x7b, 0x8d, 0x3e,
+ 0x54, 0x39, 0x95, 0x3d, 0x1d, 0xfa, 0x4b, 0xbe, 0x97, 0xd2, 0x7a, 0xbe,
+ 0x68, 0x4a, 0xcb, 0xbe, 0xf0, 0x10, 0x04, 0xbf, 0x2b, 0xb5, 0x82, 0x3e,
+ 0xf8, 0x71, 0x1a, 0x3e, 0x29, 0xf0, 0x29, 0x3d, 0x74, 0x5a, 0x1a, 0x3e,
+ 0x58, 0x75, 0xd1, 0xbd, 0x38, 0x6c, 0x99, 0x3e, 0x6c, 0xd4, 0x63, 0xbe,
+ 0xc3, 0x51, 0x90, 0xbe, 0xcf, 0xff, 0xae, 0xbe, 0xfe, 0xf1, 0x00, 0x3d,
+ 0x52, 0x64, 0x90, 0xbd, 0x02, 0x1a, 0xce, 0xbd, 0x86, 0x74, 0x00, 0x3d,
+ 0x82, 0x40, 0x04, 0x3e, 0x38, 0x03, 0x82, 0x3e, 0x8f, 0x1c, 0xf4, 0x3e,
+ 0x6f, 0x04, 0x68, 0xbe, 0x00, 0x12, 0xe3, 0x3d, 0x01, 0xf6, 0xb5, 0x3d,
+ 0xd9, 0x99, 0x36, 0x3d, 0x40, 0xad, 0xde, 0x3e, 0xaf, 0x74, 0xc1, 0x3d,
+ 0xb7, 0x8e, 0x6f, 0xbe, 0xb3, 0xa6, 0x32, 0xbe, 0xff, 0xca, 0x23, 0x3e,
+ 0x0c, 0xf1, 0x42, 0x3e, 0xe3, 0x85, 0x2c, 0x3d, 0xca, 0xc8, 0xb7, 0xba,
+ 0x1a, 0x94, 0x53, 0xbd, 0x9a, 0x33, 0xaa, 0x3d, 0x9c, 0x7c, 0x79, 0xbe,
+ 0x84, 0xb2, 0x71, 0xbe, 0x48, 0xc1, 0x2b, 0xbd, 0xf4, 0x89, 0x6c, 0xbd,
+ 0x1f, 0xd2, 0xf2, 0xbd, 0xd2, 0x4f, 0x28, 0xbd, 0xb4, 0xbb, 0xb3, 0xbd,
+ 0x6f, 0x96, 0xab, 0xbc, 0x23, 0x9d, 0x82, 0xbe, 0xe6, 0x6b, 0x59, 0xbd,
+ 0x27, 0x09, 0x03, 0xbe, 0x42, 0xa6, 0xac, 0xbd, 0xb6, 0x12, 0x20, 0x3d,
+ 0x0a, 0x63, 0x24, 0xbe, 0x75, 0x27, 0x28, 0xbe, 0xa5, 0x62, 0x2b, 0xbe,
+ 0x1f, 0x48, 0x06, 0xbe, 0x7e, 0xd0, 0xb2, 0xbd, 0xa9, 0xd6, 0x80, 0x3a,
+ 0xff, 0x7a, 0x11, 0xbe, 0x76, 0x5f, 0x41, 0x3e, 0x17, 0xa9, 0xfa, 0xbd,
+ 0x5b, 0xd1, 0x71, 0xbd, 0xf3, 0x23, 0xaf, 0xbd, 0x63, 0x24, 0xe0, 0xbc,
+ 0xc6, 0x62, 0x9d, 0x3e, 0xd6, 0x19, 0x47, 0xbe, 0x92, 0x69, 0xf1, 0xbd,
+ 0x8a, 0x67, 0x82, 0x3d, 0x17, 0x33, 0x69, 0x3d, 0x1a, 0x91, 0x25, 0xbe,
+ 0xf1, 0xab, 0xae, 0x3d, 0x3a, 0x21, 0xc1, 0x3e, 0xd8, 0xc4, 0x5d, 0xbd,
+ 0xc7, 0x58, 0xa6, 0xbe, 0xc6, 0xb0, 0xed, 0x3b, 0x75, 0xd6, 0xa2, 0x3c,
+ 0x64, 0xa8, 0x1d, 0xbe, 0xe5, 0x1f, 0x3a, 0xbe, 0x7b, 0x03, 0x39, 0xbd,
+ 0x14, 0xa2, 0x81, 0x3d, 0xdb, 0xfd, 0xb2, 0xbc, 0xca, 0x96, 0x9a, 0xbe,
+ 0x7c, 0xcc, 0xc9, 0x3c, 0xb8, 0x7d, 0x88, 0x3d, 0x36, 0x39, 0x0b, 0xbd,
+ 0x5e, 0x1f, 0x3c, 0xbe, 0x27, 0x36, 0x83, 0x3c, 0x38, 0xa1, 0x23, 0xbd,
+ 0xba, 0xfa, 0xf6, 0x3b, 0x8d, 0xa9, 0xc3, 0xbe, 0x50, 0x34, 0xf0, 0xbd,
+ 0x92, 0x0f, 0xb3, 0xbd, 0xd9, 0xad, 0x5e, 0xbe, 0xc1, 0x27, 0xb2, 0x3c,
+ 0x6a, 0x29, 0x07, 0xbe, 0x0f, 0xb5, 0x26, 0xbe, 0xc8, 0xf9, 0x27, 0x3e,
+ 0x2a, 0x97, 0xa4, 0x3e, 0xe1, 0x45, 0x53, 0x3e, 0xec, 0xd7, 0xa0, 0x3d,
+ 0xfd, 0x1a, 0x8c, 0xbe, 0x1d, 0x4c, 0xd6, 0xbd, 0x4a, 0x78, 0x63, 0xbe,
+ 0x18, 0xa4, 0xd9, 0xbc, 0x5a, 0xaa, 0x37, 0x3d, 0xff, 0xe8, 0x3b, 0xbe,
+ 0x6b, 0x8c, 0x67, 0x3e, 0x13, 0xec, 0x12, 0xbc, 0xae, 0xcc, 0xab, 0xbc,
+ 0x2e, 0x9b, 0x72, 0xbd, 0x46, 0x3f, 0xb4, 0x3e, 0xdb, 0xba, 0xd3, 0xbd,
+ 0x7b, 0xdb, 0x86, 0xbe, 0x6a, 0x66, 0xd9, 0xbe, 0x8c, 0x5c, 0x80, 0x3d,
+ 0x60, 0x64, 0x4d, 0xbe, 0x4d, 0x91, 0x58, 0x3e, 0xa9, 0xfc, 0x0e, 0xbe,
+ 0x32, 0xc8, 0xce, 0x3e, 0xa8, 0xc8, 0xb3, 0xbe, 0x4d, 0x07, 0xae, 0xbe,
+ 0xbc, 0xa3, 0x2c, 0xbf, 0x57, 0x9c, 0x21, 0xbe, 0x0e, 0x6d, 0x6e, 0xbe,
+ 0x30, 0xa6, 0x15, 0xbf, 0xd6, 0x76, 0x01, 0xbf, 0x80, 0x3e, 0xab, 0xbe,
+ 0xbe, 0x98, 0x2d, 0xbe, 0xe2, 0x02, 0x48, 0xbe, 0xc8, 0x4b, 0x96, 0xbe,
+ 0x48, 0xaa, 0x2e, 0x3e, 0xa2, 0x19, 0x01, 0x3f, 0xa8, 0xec, 0x8f, 0xbe,
+ 0x15, 0xd2, 0x24, 0x3e, 0x5c, 0x80, 0xc2, 0xbc, 0xf0, 0x78, 0x29, 0xbe,
+ 0xfe, 0x1d, 0x63, 0xbe, 0x32, 0xf1, 0x22, 0xbd, 0x35, 0x8c, 0x1d, 0x3e,
+ 0xb9, 0x22, 0xc2, 0x3e, 0xde, 0x75, 0xc0, 0xbe, 0x27, 0x71, 0x73, 0xbb,
+ 0x37, 0x41, 0xde, 0x3d, 0x0a, 0x71, 0xfe, 0xbd, 0x9e, 0x66, 0xf6, 0xbd,
+ 0x2b, 0x93, 0x07, 0xbc, 0x75, 0x1e, 0x90, 0x3d, 0x01, 0x49, 0x59, 0x3e,
+ 0x0a, 0xb2, 0xbe, 0xbe, 0xd4, 0x65, 0x9f, 0xbc, 0x43, 0x20, 0xdd, 0x3d,
+ 0xef, 0x01, 0x74, 0xbd, 0xb2, 0xa4, 0xd5, 0x3b, 0xa4, 0x30, 0xf9, 0xbc,
+ 0xb8, 0x15, 0x68, 0xb8, 0x58, 0xa2, 0xa7, 0xbe, 0x5a, 0x25, 0xa5, 0x3d,
+ 0x2d, 0x86, 0xb2, 0xbe, 0xc9, 0x31, 0xc2, 0x3e, 0xd2, 0x61, 0x28, 0x3d,
+ 0xa6, 0xfe, 0xba, 0x3d, 0x4b, 0x6c, 0xf6, 0xbd, 0xaa, 0x14, 0xdc, 0xbc,
+ 0xf6, 0x7d, 0xdc, 0xbd, 0xce, 0xb6, 0x75, 0xbd, 0x0b, 0xa5, 0xa8, 0xbe,
+ 0x9b, 0xb5, 0x4a, 0x3e, 0xfc, 0xfa, 0x98, 0x3d, 0x27, 0xd6, 0x39, 0x3d,
+ 0x1a, 0xbf, 0x67, 0x3d, 0x3f, 0x04, 0x04, 0xbc, 0x07, 0x56, 0x42, 0xbd,
+ 0xd8, 0xe6, 0x52, 0xbe, 0x72, 0xff, 0xc7, 0xbd, 0xd8, 0x5b, 0xba, 0xbd,
+ 0xe9, 0xb9, 0xc8, 0xbd, 0xe2, 0x54, 0x05, 0xbe, 0xb5, 0x8f, 0xf2, 0x3e,
+ 0x74, 0xe9, 0x68, 0xbd, 0x6f, 0x16, 0xcd, 0xbe, 0x2a, 0x22, 0x40, 0x3c,
+ 0xfc, 0x03, 0xf2, 0x3d, 0x91, 0x74, 0xaa, 0x3d, 0x7d, 0xb1, 0x1f, 0xbe,
+ 0x95, 0xc1, 0x14, 0xbe, 0xbb, 0xe5, 0x89, 0xbe, 0xae, 0xff, 0x5a, 0x3d,
+ 0x31, 0x79, 0x07, 0xbe, 0x07, 0xfb, 0xba, 0x3e, 0x4e, 0xd0, 0x86, 0xbd,
+ 0x68, 0x36, 0x29, 0x3e, 0xec, 0x14, 0xc7, 0x3d, 0xef, 0xf6, 0x06, 0x3b,
+ 0x76, 0xa0, 0xe8, 0x3c, 0x97, 0x57, 0xac, 0x3c, 0xec, 0x02, 0x8d, 0xbe,
+ 0x43, 0xaf, 0x42, 0x3d, 0x13, 0x39, 0x0e, 0x3d, 0xf4, 0xed, 0x5a, 0x3e,
+ 0xbb, 0xf1, 0x18, 0xbe, 0x71, 0x1f, 0xc8, 0xbb, 0x6d, 0x8c, 0x0b, 0xbe,
+ 0xfe, 0x5d, 0xc3, 0xbd, 0x2c, 0xae, 0x87, 0xbe, 0x58, 0x74, 0x3e, 0x3d,
+ 0x14, 0x52, 0x13, 0xbe, 0x41, 0x11, 0x55, 0xbe, 0x43, 0x03, 0x0e, 0x3e,
+ 0xf8, 0x4c, 0x2e, 0x3e, 0x09, 0x6a, 0xea, 0xbd, 0xec, 0xe1, 0xc3, 0xbd,
+ 0xd5, 0xdf, 0x2a, 0xbe, 0x2e, 0xc1, 0xd9, 0xbd, 0xc1, 0x5b, 0x72, 0xbe,
+ 0x73, 0xe9, 0x0f, 0xbe, 0xab, 0xc3, 0x0c, 0x3e, 0x85, 0xd1, 0x5e, 0x3e,
+ 0x08, 0x70, 0x0d, 0xbe, 0x6f, 0xb7, 0x01, 0x3d, 0x0c, 0x0f, 0x86, 0xbd,
+ 0x0d, 0x23, 0x56, 0x3e, 0x16, 0x6f, 0x10, 0xbc, 0x4f, 0x98, 0x42, 0xbf,
+ 0x85, 0x4e, 0x44, 0xbe, 0xf0, 0x20, 0x0b, 0xbe, 0x5b, 0xa3, 0x0f, 0xbc,
+ 0xbd, 0x33, 0x45, 0xbd, 0x84, 0xfb, 0x48, 0xbd, 0x11, 0x99, 0x8c, 0x3c,
+ 0x41, 0x1e, 0x08, 0x3e, 0xe3, 0x3e, 0x6c, 0xbf, 0x97, 0x2b, 0x0c, 0xbe,
+ 0x94, 0xec, 0x23, 0xbb, 0x8f, 0x35, 0x4f, 0x3c, 0xea, 0xec, 0x0c, 0xbd,
+ 0x04, 0x13, 0x3d, 0xbe, 0x13, 0x76, 0x23, 0x3e, 0x37, 0x0d, 0x99, 0x3c,
+ 0xd4, 0xa3, 0xf4, 0xbe, 0x18, 0x6a, 0x6c, 0xbe, 0x3d, 0x3c, 0xf6, 0xbd,
+ 0xf8, 0x51, 0xaf, 0xbc, 0x1f, 0x6e, 0x8a, 0xbc, 0x55, 0xc5, 0x8c, 0xbe,
+ 0x9e, 0x9c, 0x79, 0xbd, 0x13, 0x14, 0xb7, 0xbd, 0x89, 0xcd, 0x1a, 0xbe,
+ 0x79, 0x14, 0x2e, 0x3e, 0xdd, 0xa2, 0x71, 0x3e, 0xad, 0x71, 0xbe, 0xbc,
+ 0xa3, 0xc9, 0x22, 0x3f, 0x66, 0x4b, 0x0f, 0x3d, 0x45, 0x1c, 0x29, 0xbe,
+ 0xf6, 0x79, 0x93, 0xbe, 0x71, 0x18, 0xb6, 0x3d, 0xcc, 0xcb, 0x9d, 0x3c,
+ 0xa1, 0xbb, 0xfd, 0xbc, 0xc9, 0x75, 0x05, 0x3e, 0x77, 0x4b, 0xad, 0xbd,
+ 0x81, 0x1d, 0x5c, 0x3e, 0x2d, 0xcc, 0x24, 0xbd, 0x3a, 0xce, 0x36, 0xbe,
+ 0xb8, 0x37, 0x27, 0xbe, 0xe6, 0x3e, 0x75, 0x3b, 0xb7, 0xb4, 0x2c, 0xbd,
+ 0x1f, 0x05, 0x47, 0x3c, 0x81, 0x1d, 0x33, 0x3e, 0x8a, 0xfd, 0x4f, 0x3e,
+ 0xaf, 0x7c, 0x3b, 0x3d, 0x00, 0xa0, 0xda, 0xbd, 0x39, 0xd1, 0x20, 0xbf,
+ 0xc9, 0x78, 0xf3, 0xbd, 0x9d, 0x01, 0xa3, 0xbe, 0x42, 0x44, 0xbb, 0xbc,
+ 0x5a, 0xc1, 0xd4, 0xbd, 0xfd, 0xe7, 0x3c, 0xbf, 0x46, 0x37, 0x85, 0x3d,
+ 0x79, 0x4e, 0xbc, 0x3d, 0xa4, 0xcd, 0x7f, 0xbf, 0x1d, 0xca, 0x69, 0xbf,
+ 0x97, 0xeb, 0x69, 0xbf, 0xaa, 0xc9, 0x9f, 0x3c, 0xb4, 0x82, 0x9d, 0x3e,
+ 0xf1, 0x94, 0x77, 0x3e, 0xf2, 0x74, 0x84, 0xbe, 0x88, 0x66, 0x9c, 0xbe,
+ 0xdf, 0x4e, 0xf1, 0xbd, 0xa2, 0x9e, 0x31, 0x3e, 0x8b, 0xc9, 0x49, 0x3d,
+ 0x5a, 0x63, 0x5c, 0x3e, 0xf9, 0xa5, 0x4e, 0x3d, 0x95, 0x3f, 0x8d, 0x3d,
+ 0x1c, 0xe0, 0x68, 0xbe, 0xb6, 0xe1, 0x7c, 0xbe, 0x82, 0x2b, 0x63, 0xbe,
+ 0x76, 0x6c, 0x02, 0xbe, 0xfe, 0x30, 0x36, 0xbe, 0x8f, 0x5f, 0x36, 0x3d,
+ 0x17, 0x52, 0x15, 0x3c, 0x1e, 0xc8, 0x88, 0xbf, 0x0a, 0xa1, 0x5d, 0x3d,
+ 0xe8, 0x31, 0x71, 0x3e, 0xd2, 0x45, 0x01, 0xbc, 0x41, 0x3c, 0x27, 0xbe,
+ 0xbb, 0xa9, 0x4d, 0xbc, 0x0f, 0xde, 0x9d, 0x3c, 0xbf, 0x35, 0xc3, 0xbd,
+ 0x5b, 0x0e, 0x70, 0xbf, 0xe9, 0xf4, 0xd5, 0x3b, 0x60, 0x9b, 0xec, 0x3d,
+ 0x8b, 0x75, 0x23, 0xbc, 0x17, 0x03, 0x84, 0xbe, 0x99, 0x04, 0xd0, 0x3c,
+ 0xdd, 0x01, 0x08, 0xbe, 0x82, 0xd5, 0x75, 0xbd, 0x05, 0xaa, 0xec, 0x3c,
+ 0xb9, 0x4d, 0x45, 0x3d, 0xa3, 0x11, 0x69, 0xbb, 0xa3, 0xb0, 0x50, 0x3e,
+ 0x7a, 0x5f, 0xaa, 0xbd, 0x6a, 0x73, 0xbe, 0xbd, 0x91, 0x25, 0xa9, 0xbd,
+ 0x0f, 0x8e, 0xe0, 0xbd, 0x50, 0x51, 0x8f, 0x3c, 0xf4, 0x7d, 0xb9, 0x3d,
+ 0xa2, 0x11, 0x50, 0x3d, 0x3a, 0xb5, 0x32, 0x3e, 0xe1, 0x28, 0x87, 0x3e,
+ 0x44, 0x83, 0x09, 0x3e, 0xc3, 0x5f, 0x0a, 0xbe, 0xc4, 0xb8, 0x0f, 0xbe,
+ 0xaa, 0xb2, 0xab, 0xbd, 0x93, 0x40, 0x5c, 0xbd, 0x35, 0xf0, 0x19, 0xbd,
+ 0x4a, 0xa8, 0x02, 0x3b, 0x3c, 0x51, 0x1a, 0x3c, 0xbe, 0x2d, 0xdd, 0xbb,
+ 0x55, 0x5d, 0xc3, 0x3d, 0x10, 0x6f, 0x7c, 0xbd, 0x62, 0xf7, 0x45, 0xbe,
+ 0xd5, 0xda, 0xe1, 0x3d, 0x25, 0xd5, 0x13, 0x3e, 0xf0, 0xd6, 0xea, 0xbd,
+ 0x62, 0x2b, 0x56, 0xbd, 0x80, 0x0c, 0xb1, 0x3d, 0x19, 0xbe, 0xa5, 0x3d,
+ 0x3e, 0xc3, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x63, 0x6f, 0x6e, 0x76,
+ 0x32, 0x64, 0x5f, 0x69, 0x6e, 0x70, 0x75, 0x74, 0x00, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x0c, 0x00, 0x04, 0x00, 0x08, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x7f, 0x43, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x9e, 0xc3, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x15, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64,
+ 0x65, 0x6e, 0x73, 0x65, 0x2f, 0x52, 0x65, 0x6c, 0x75, 0x00, 0x00, 0x00,
+ 0xac, 0xc2, 0xff, 0xff, 0xde, 0xc3, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x0a, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x38, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x2a, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63,
+ 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x31, 0x2f, 0x52, 0x65, 0x6c, 0x75,
+ 0x00, 0x00, 0x00, 0x00, 0xf8, 0xc2, 0xff, 0xff, 0x2a, 0xc4, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x22, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,
+ 0x61, 0x6c, 0x2f, 0x6d, 0x61, 0x78, 0x5f, 0x70, 0x6f, 0x6f, 0x6c, 0x69,
+ 0x6e, 0x67, 0x32, 0x64, 0x5f, 0x31, 0x2f, 0x4d, 0x61, 0x78, 0x50, 0x6f,
+ 0x6f, 0x6c, 0x00, 0x00, 0x4c, 0xc3, 0xff, 0xff, 0x7e, 0xc4, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x30, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x1a, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,
+ 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65,
+ 0x5f, 0x31, 0x2f, 0x42, 0x69, 0x61, 0x73, 0x41, 0x64, 0x64, 0x00, 0x00,
+ 0x90, 0xc3, 0xff, 0xff, 0xc2, 0xc4, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x07, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x49, 0x64, 0x65, 0x6e, 0x74, 0x69, 0x74, 0x79,
+ 0x00, 0x00, 0x00, 0x00, 0xc4, 0xc3, 0xff, 0xff, 0xf6, 0xc4, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x48, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xe0, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,
+ 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65,
+ 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x2f, 0x52, 0x65, 0x61, 0x64,
+ 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x2f, 0x74,
+ 0x72, 0x61, 0x6e, 0x73, 0x70, 0x6f, 0x73, 0x65, 0x00, 0x00, 0x00, 0x00,
+ 0x20, 0xc4, 0xff, 0xff, 0x00, 0x38, 0x00, 0x00, 0x91, 0x78, 0x9e, 0x3d,
+ 0x02, 0x6e, 0x72, 0x3e, 0xaf, 0x5f, 0x65, 0xbc, 0x83, 0x89, 0xa5, 0x3e,
+ 0x99, 0x1e, 0xf5, 0x3d, 0xb4, 0x02, 0x92, 0x3d, 0xaf, 0x31, 0x96, 0x3d,
+ 0x44, 0x77, 0xa2, 0xbe, 0xf0, 0x3c, 0x73, 0xbe, 0x0f, 0xec, 0x35, 0x3f,
+ 0x47, 0xd1, 0x20, 0xbc, 0xae, 0x8d, 0x48, 0xbe, 0xce, 0xcc, 0x3d, 0x3e,
+ 0xad, 0x49, 0x78, 0x3e, 0x11, 0x2e, 0x82, 0xbd, 0xa7, 0xf3, 0x7e, 0x3d,
+ 0x7b, 0xea, 0x7a, 0x3d, 0xd1, 0xe5, 0x1f, 0x3e, 0x92, 0x8c, 0x7a, 0x3d,
+ 0xe8, 0x22, 0x46, 0xbe, 0xe4, 0x5c, 0x24, 0x3e, 0xa2, 0x0d, 0x6b, 0x3c,
+ 0xfb, 0x04, 0x21, 0xbd, 0x1c, 0x6e, 0xd1, 0xbe, 0xd5, 0xc6, 0xd9, 0xbc,
+ 0xb6, 0xe8, 0xdf, 0x3d, 0xd8, 0x73, 0x09, 0x3d, 0xcb, 0x45, 0xb1, 0xbe,
+ 0xda, 0x6a, 0x0e, 0x3d, 0x40, 0xbe, 0xef, 0xbc, 0xe4, 0xbb, 0xcb, 0xbd,
+ 0xf6, 0x35, 0x30, 0x3d, 0x25, 0x3a, 0x56, 0xbe, 0x1f, 0x35, 0x0a, 0x3d,
+ 0x95, 0x31, 0x21, 0x3d, 0xde, 0xaa, 0x54, 0xbe, 0x8d, 0x0a, 0x6b, 0x3e,
+ 0xd5, 0x70, 0x02, 0xbd, 0xdc, 0x18, 0xaa, 0x3c, 0x2a, 0x0c, 0x79, 0xbe,
+ 0xee, 0xc5, 0x04, 0x3b, 0x2c, 0xb9, 0xbe, 0x3d, 0x0f, 0x55, 0x82, 0xbc,
+ 0x94, 0xf6, 0x00, 0xbf, 0x0a, 0xa2, 0x02, 0xbe, 0xa3, 0x2b, 0x58, 0xbd,
+ 0x09, 0x4f, 0xd3, 0xbd, 0x57, 0x98, 0x36, 0xbe, 0xcd, 0xed, 0x81, 0xbe,
+ 0x78, 0x4d, 0x3b, 0xbd, 0xa1, 0xf9, 0xdc, 0xbd, 0x18, 0xc4, 0x29, 0xbd,
+ 0xf5, 0x6d, 0xb2, 0x3e, 0x43, 0x7b, 0x53, 0x3e, 0x2b, 0x6a, 0x69, 0x3c,
+ 0xec, 0x2e, 0x13, 0xbf, 0x6a, 0x0d, 0x2c, 0xbe, 0x3d, 0xe3, 0x32, 0x3e,
+ 0xf4, 0x41, 0x39, 0x3d, 0x48, 0xd3, 0x49, 0xbe, 0x7f, 0x25, 0x9a, 0xbe,
+ 0xd3, 0x36, 0x0b, 0xbe, 0xa5, 0xa3, 0x89, 0xbd, 0x09, 0x30, 0xe5, 0xbd,
+ 0x13, 0x17, 0x83, 0xbe, 0x1a, 0x4c, 0xc4, 0xbc, 0x81, 0x1e, 0x67, 0xbe,
+ 0x82, 0x77, 0xdf, 0xbd, 0x02, 0x7d, 0x33, 0x3e, 0xd3, 0x35, 0x02, 0x3e,
+ 0x8a, 0xc0, 0x90, 0x3c, 0x8b, 0xd0, 0x95, 0xbe, 0x2a, 0x67, 0x6f, 0xbe,
+ 0xf3, 0xf4, 0x20, 0x3e, 0x01, 0x28, 0xba, 0x3c, 0x55, 0x65, 0xaa, 0xbd,
+ 0x76, 0x1d, 0x90, 0xbd, 0xa5, 0x37, 0xce, 0x3d, 0x8f, 0xd7, 0x80, 0xbd,
+ 0x02, 0xea, 0x7d, 0xbc, 0xd1, 0xff, 0xe6, 0xbd, 0x96, 0xb5, 0xa0, 0x3d,
+ 0xea, 0xb0, 0x90, 0xbe, 0x9e, 0xed, 0x99, 0xbd, 0x2e, 0xee, 0xd9, 0x3d,
+ 0xe9, 0xf4, 0xb5, 0x3e, 0xa2, 0xb4, 0xfe, 0x3d, 0xe5, 0x4b, 0x30, 0x3d,
+ 0x07, 0xf3, 0x58, 0xbe, 0x29, 0xa8, 0x2a, 0x3b, 0xf6, 0x0c, 0x40, 0x3e,
+ 0xb9, 0x87, 0xc0, 0xbc, 0xf3, 0x12, 0x67, 0x3d, 0xd7, 0x33, 0x82, 0xbd,
+ 0xba, 0x47, 0x15, 0xbd, 0x64, 0xca, 0x29, 0x3e, 0xca, 0x70, 0x5d, 0x3e,
+ 0x9c, 0xa8, 0xcb, 0x3d, 0xbe, 0xe3, 0xaf, 0xbd, 0xaf, 0x93, 0x2c, 0xbe,
+ 0x07, 0x36, 0xb5, 0x3e, 0xfc, 0xff, 0x34, 0x3e, 0x71, 0x9a, 0xbb, 0xbd,
+ 0xa8, 0x92, 0x4b, 0x3e, 0xb1, 0x22, 0x29, 0xbe, 0xce, 0x5d, 0x3e, 0x3e,
+ 0xda, 0xca, 0x42, 0x3e, 0x20, 0x1a, 0x58, 0x3d, 0x5c, 0x0a, 0x0c, 0x3d,
+ 0xe2, 0xff, 0xf0, 0x3d, 0x79, 0xfd, 0x0c, 0x3e, 0x69, 0x5f, 0x03, 0x3e,
+ 0x66, 0xd3, 0x2e, 0xbb, 0x3a, 0x63, 0x64, 0x3c, 0x10, 0x2f, 0x48, 0xbe,
+ 0xc5, 0xa7, 0x47, 0xbe, 0xda, 0x5a, 0x97, 0x3e, 0xc1, 0x6e, 0xcd, 0xbc,
+ 0x9a, 0x9c, 0x51, 0xbd, 0x31, 0x27, 0xdd, 0x3d, 0x0b, 0xb2, 0x80, 0xbd,
+ 0xbf, 0x75, 0xa7, 0xbc, 0xd5, 0x65, 0x2f, 0x3e, 0xc4, 0x0d, 0x1b, 0x3e,
+ 0xcf, 0x7f, 0xf2, 0x3d, 0x73, 0xc7, 0xf2, 0x3d, 0x69, 0x2e, 0x98, 0xbb,
+ 0xa8, 0x5b, 0xa8, 0x3d, 0xfd, 0xb0, 0xbf, 0xbd, 0xa3, 0x49, 0xfc, 0xbd,
+ 0xad, 0xf5, 0x02, 0xbe, 0x60, 0x1e, 0x26, 0xbe, 0x1d, 0x96, 0x3d, 0x3e,
+ 0xf7, 0x23, 0x2c, 0x3e, 0x44, 0x1b, 0x86, 0x3d, 0x88, 0x56, 0x48, 0xbd,
+ 0xad, 0xf6, 0xee, 0x3c, 0x0d, 0x81, 0x13, 0x3d, 0xd0, 0x76, 0x09, 0x3e,
+ 0x49, 0x83, 0x83, 0xbd, 0x50, 0xd6, 0x79, 0xbe, 0x8c, 0x17, 0x4f, 0x3d,
+ 0xec, 0xe5, 0x90, 0x3d, 0x1e, 0x19, 0x4f, 0x3d, 0x1f, 0x3c, 0x9f, 0xbd,
+ 0xe5, 0x47, 0x4b, 0xbe, 0x33, 0xf0, 0x14, 0xbe, 0x58, 0xbf, 0x21, 0x3d,
+ 0xd2, 0x8c, 0x42, 0x3e, 0x31, 0xe6, 0x9a, 0x3d, 0xf9, 0x4e, 0xab, 0xbd,
+ 0x6f, 0x46, 0x1f, 0xbe, 0x9e, 0xf1, 0x21, 0x3d, 0x04, 0x72, 0xfb, 0x3d,
+ 0x29, 0xca, 0x24, 0x3e, 0x32, 0x01, 0xa1, 0xbe, 0x07, 0x9b, 0x45, 0xbe,
+ 0xf9, 0x09, 0xc5, 0x3d, 0xc9, 0x84, 0x44, 0xbd, 0xde, 0xb5, 0x68, 0xbd,
+ 0x0a, 0xf6, 0x3e, 0xbe, 0x78, 0x6e, 0xbc, 0xbd, 0x03, 0xf8, 0x38, 0xbd,
+ 0xe9, 0xf6, 0x17, 0xbd, 0x1a, 0x19, 0x3b, 0x3e, 0x43, 0xb1, 0xdb, 0x3c,
+ 0xc5, 0x5b, 0x1e, 0xbb, 0xcc, 0x9b, 0x00, 0xbe, 0x01, 0xe4, 0xe4, 0xba,
+ 0xe5, 0x8d, 0x26, 0x3e, 0x4b, 0x09, 0x0a, 0xbc, 0x50, 0x4e, 0xe0, 0xbe,
+ 0xe3, 0x93, 0xf3, 0xbc, 0xe8, 0xe9, 0x20, 0x3d, 0x23, 0xa7, 0xe2, 0x3c,
+ 0xe2, 0x05, 0xa7, 0x3d, 0xd4, 0xda, 0x29, 0xbd, 0xb3, 0x43, 0xa7, 0xbc,
+ 0x28, 0x61, 0x0d, 0xbd, 0x7e, 0x55, 0xa7, 0x3d, 0x5f, 0x27, 0x3f, 0x3e,
+ 0x12, 0x19, 0xca, 0x3b, 0xc9, 0x89, 0x0b, 0xbd, 0x57, 0x99, 0x33, 0xbd,
+ 0x61, 0x8f, 0xda, 0xbc, 0x6a, 0x54, 0x5a, 0x3e, 0x31, 0xeb, 0x2b, 0x3d,
+ 0x8c, 0x95, 0x97, 0xbe, 0x5b, 0x2d, 0x85, 0x3e, 0x49, 0x3f, 0xf4, 0xbc,
+ 0x20, 0xbb, 0x62, 0x3c, 0x01, 0x69, 0xae, 0xbd, 0xe1, 0x2c, 0x43, 0xbe,
+ 0xe9, 0x5d, 0x84, 0x3d, 0xb3, 0x61, 0x17, 0x3e, 0x47, 0x07, 0x95, 0xbc,
+ 0xcd, 0x7c, 0x87, 0x3e, 0xd9, 0xb3, 0x03, 0x3d, 0x1c, 0x7e, 0x15, 0x3d,
+ 0xe1, 0x0b, 0xb0, 0xbd, 0x23, 0xfe, 0x94, 0x3c, 0xf0, 0x36, 0xd7, 0x3d,
+ 0x9e, 0x2b, 0x82, 0x3c, 0x78, 0x43, 0x9b, 0xbe, 0xf9, 0x5d, 0x0c, 0xbe,
+ 0x07, 0x45, 0xda, 0x3d, 0x79, 0x36, 0x19, 0x3d, 0x49, 0xff, 0xbc, 0x3c,
+ 0xd6, 0x6e, 0xec, 0xbe, 0x6c, 0xb2, 0xd5, 0x3c, 0x2a, 0xb0, 0x92, 0x3b,
+ 0x45, 0x87, 0x3a, 0x3e, 0xd3, 0xe5, 0xb8, 0xbd, 0x92, 0x1a, 0x2e, 0x3c,
+ 0x9b, 0x33, 0x3c, 0x3e, 0x0f, 0x3d, 0xa8, 0xbe, 0x53, 0x7c, 0xa6, 0x3d,
+ 0x3b, 0x9e, 0x98, 0xbe, 0x96, 0x91, 0xd6, 0x3c, 0x71, 0x5b, 0x99, 0xbe,
+ 0x73, 0x0b, 0x04, 0x3e, 0xfa, 0x8a, 0xc0, 0x3d, 0x7f, 0x1b, 0xdd, 0x3d,
+ 0xe4, 0x01, 0x84, 0xbd, 0xcf, 0x63, 0xdb, 0xbd, 0xda, 0x5d, 0x8d, 0xbd,
+ 0x44, 0xe1, 0x46, 0xbd, 0x65, 0x6c, 0x05, 0xbe, 0x0a, 0x83, 0xb1, 0xbd,
+ 0x97, 0x4a, 0x59, 0xbe, 0x77, 0x26, 0xa7, 0x3d, 0x0d, 0x22, 0xea, 0xbd,
+ 0x70, 0x48, 0x14, 0xbe, 0x01, 0x31, 0x04, 0x3e, 0xe0, 0x5e, 0xb8, 0xbd,
+ 0xd3, 0xe3, 0xee, 0xbd, 0x4e, 0x6f, 0xc4, 0xbc, 0x2f, 0xab, 0x53, 0x3d,
+ 0xd2, 0x79, 0x2c, 0xbe, 0xea, 0x5e, 0xdb, 0xbd, 0x02, 0x40, 0x4d, 0xbd,
+ 0xcf, 0x47, 0x5d, 0xbd, 0x1e, 0x48, 0x97, 0xbd, 0x7c, 0x3b, 0xca, 0x3d,
+ 0x75, 0x1d, 0x43, 0xbe, 0xb7, 0xab, 0x86, 0x3b, 0xfa, 0x51, 0xe2, 0x3b,
+ 0xcc, 0x0c, 0x1a, 0xbe, 0xda, 0x56, 0xc0, 0x3d, 0xd2, 0xa5, 0x6b, 0xbd,
+ 0x46, 0xe8, 0x27, 0xbe, 0x95, 0x71, 0x4e, 0xbe, 0x78, 0xda, 0xb0, 0x3d,
+ 0xec, 0xfd, 0x31, 0xbe, 0x5f, 0xb5, 0x44, 0xbe, 0x2b, 0x48, 0x06, 0xbe,
+ 0x28, 0x5c, 0xf4, 0xbd, 0x1a, 0xb1, 0xa3, 0x3c, 0x77, 0xd6, 0xef, 0xbd,
+ 0xec, 0xe1, 0x93, 0xbd, 0x85, 0xb2, 0xcd, 0xbd, 0xf8, 0x0b, 0x52, 0xbd,
+ 0x16, 0x95, 0xd7, 0x3c, 0xb2, 0x00, 0x29, 0x3c, 0x42, 0x8c, 0xb6, 0x3d,
+ 0xa8, 0x79, 0x1f, 0xbe, 0xa5, 0xfe, 0xe8, 0xbd, 0x28, 0x30, 0xb8, 0x3d,
+ 0xb8, 0x23, 0x9e, 0x3d, 0x7f, 0xe1, 0x33, 0xbe, 0x2b, 0xf8, 0x3f, 0xbe,
+ 0x05, 0x8c, 0x70, 0xbd, 0x30, 0x32, 0xe0, 0xbd, 0xff, 0xd3, 0x45, 0xbe,
+ 0x29, 0x82, 0x33, 0xbc, 0x2b, 0x86, 0x13, 0xbe, 0x0b, 0x81, 0x07, 0xbd,
+ 0xb1, 0xd4, 0xa8, 0x3c, 0x42, 0xd6, 0x2d, 0xbc, 0xfc, 0x19, 0x33, 0xba,
+ 0xd5, 0xf7, 0x29, 0xbe, 0xff, 0xb9, 0x18, 0xbe, 0x34, 0x96, 0x36, 0xbe,
+ 0x8d, 0x80, 0xcc, 0xbd, 0x55, 0x1f, 0xe9, 0xbc, 0xa1, 0xdd, 0x69, 0xbe,
+ 0xd3, 0x86, 0xb4, 0x3c, 0x3a, 0xc2, 0x0f, 0xbe, 0xc0, 0x63, 0xcd, 0xbc,
+ 0xcb, 0xf8, 0xcf, 0xbd, 0x45, 0x7f, 0x5f, 0x3d, 0x95, 0x59, 0xbd, 0x3d,
+ 0x7b, 0x9c, 0xf0, 0xbd, 0x57, 0xaf, 0xfb, 0x3c, 0xad, 0x44, 0xaf, 0xbd,
+ 0xa5, 0xf3, 0xbc, 0xbd, 0xb4, 0xe1, 0x59, 0xbd, 0xa6, 0x28, 0x29, 0x3d,
+ 0xcb, 0x8b, 0x50, 0xbe, 0x20, 0x85, 0x95, 0xbd, 0x33, 0xcf, 0xfa, 0xbb,
+ 0xde, 0xfc, 0x1c, 0x3d, 0x91, 0xb6, 0x43, 0xbe, 0x54, 0x84, 0xaf, 0xbd,
+ 0xdc, 0xde, 0x04, 0xbe, 0x69, 0xc6, 0x19, 0xbe, 0x43, 0xcf, 0x23, 0xbd,
+ 0x77, 0x3b, 0x58, 0xbe, 0x50, 0x09, 0x50, 0xbd, 0x17, 0xa2, 0x2d, 0xbd,
+ 0xe0, 0xad, 0xb5, 0xba, 0x47, 0x9d, 0xcc, 0x3d, 0x06, 0x72, 0xe3, 0x3d,
+ 0x92, 0x81, 0x9f, 0x3c, 0x55, 0x1d, 0x06, 0xbe, 0xa0, 0x79, 0x9c, 0x3c,
+ 0xe1, 0xec, 0xe6, 0xbd, 0x63, 0x0c, 0x9a, 0xbd, 0xc1, 0x82, 0x5e, 0xbe,
+ 0x01, 0x4c, 0x38, 0xbe, 0x64, 0x06, 0x52, 0xbd, 0xd1, 0x54, 0x08, 0xbe,
+ 0x0c, 0xb8, 0xc2, 0x3d, 0x5a, 0xd2, 0xb4, 0x3d, 0x84, 0xcb, 0x24, 0xbe,
+ 0x80, 0xb4, 0x8f, 0x3c, 0x84, 0x69, 0x0c, 0xbe, 0x3d, 0xda, 0x05, 0xbe,
+ 0x4c, 0x48, 0x0c, 0x3e, 0xdc, 0x35, 0xcf, 0xbc, 0x80, 0x1b, 0x0b, 0xbe,
+ 0xaa, 0x3a, 0x9c, 0xbc, 0x21, 0xd4, 0x83, 0x3d, 0x26, 0x6e, 0xe8, 0x3d,
+ 0xe4, 0x41, 0x28, 0x3d, 0x88, 0x35, 0x1d, 0xbe, 0x2c, 0xfb, 0xb2, 0x3d,
+ 0xe4, 0xbb, 0x0a, 0xbe, 0x95, 0x00, 0xfe, 0xbd, 0x3d, 0x87, 0x89, 0x3c,
+ 0x19, 0x9f, 0xa0, 0xbc, 0xac, 0xce, 0x6f, 0xbd, 0x16, 0x48, 0x21, 0xbe,
+ 0xd8, 0x21, 0x13, 0xbe, 0x15, 0x49, 0xfc, 0xbd, 0x6c, 0x10, 0x31, 0x3e,
+ 0x93, 0x04, 0xa2, 0xbd, 0xbc, 0xce, 0xbe, 0xbd, 0x59, 0xce, 0x51, 0xbd,
+ 0xd6, 0xf1, 0x60, 0x3d, 0x3a, 0x92, 0x76, 0xbd, 0xb8, 0xef, 0x66, 0x3b,
+ 0x26, 0x2c, 0x8e, 0x3d, 0xf1, 0xff, 0x1e, 0xbe, 0xc2, 0x6f, 0x26, 0x3d,
+ 0xe7, 0xb2, 0x4e, 0xbe, 0x31, 0x1e, 0xc4, 0xbd, 0x2f, 0x0a, 0x81, 0x3c,
+ 0xb9, 0x73, 0xea, 0xbd, 0x41, 0xdf, 0x4b, 0xbd, 0x9d, 0x47, 0x88, 0xbd,
+ 0xab, 0x21, 0x68, 0xbd, 0x77, 0x20, 0xf9, 0xbc, 0x40, 0x55, 0xaa, 0x3d,
+ 0x26, 0xe1, 0xf9, 0xbd, 0x97, 0xbe, 0xdd, 0x3d, 0x57, 0xe8, 0x91, 0xbd,
+ 0x00, 0xbb, 0x3e, 0xbe, 0x22, 0x51, 0x91, 0xbd, 0x6b, 0xe6, 0xa1, 0x3d,
+ 0x7d, 0xf1, 0xa6, 0x3d, 0xa9, 0x89, 0x86, 0x3d, 0x57, 0x91, 0xef, 0xbd,
+ 0xcb, 0x06, 0x01, 0xba, 0x9d, 0xc0, 0x4a, 0x3d, 0x71, 0xaf, 0x35, 0xbe,
+ 0x01, 0x3d, 0x16, 0xbc, 0x01, 0xa4, 0x81, 0xbd, 0xa4, 0xf6, 0x2e, 0xbd,
+ 0xb7, 0xe9, 0x0d, 0xbd, 0x94, 0xef, 0x26, 0xbe, 0xee, 0x31, 0x20, 0xbe,
+ 0x43, 0x8a, 0x30, 0x3d, 0x09, 0xa3, 0xb1, 0xbd, 0x20, 0xb8, 0x11, 0x3c,
+ 0x55, 0x7c, 0x1e, 0x3d, 0xbd, 0x60, 0x4f, 0xbe, 0x05, 0x06, 0xa3, 0x3c,
+ 0x92, 0x48, 0xfa, 0xbb, 0x6a, 0x53, 0x0a, 0xbe, 0xd5, 0x01, 0x19, 0xbc,
+ 0x69, 0xf6, 0x2a, 0xbe, 0xf9, 0xbe, 0x08, 0xbe, 0x4b, 0x17, 0x49, 0x3c,
+ 0xb4, 0x10, 0x79, 0x3d, 0x4f, 0xb1, 0xf2, 0xbc, 0xc4, 0x6b, 0x8a, 0x3c,
+ 0x6c, 0xa7, 0x35, 0xbe, 0xe2, 0xfb, 0xe0, 0xbd, 0xf3, 0xc0, 0x2a, 0xbd,
+ 0xe6, 0x47, 0xbd, 0xbd, 0xc3, 0x30, 0x66, 0xbe, 0xfb, 0x2d, 0x35, 0x3d,
+ 0x13, 0xd6, 0xad, 0xbd, 0x7f, 0xd2, 0x01, 0xbe, 0x9e, 0xe1, 0x57, 0xbd,
+ 0x8c, 0x02, 0xe2, 0x3c, 0x21, 0x90, 0x11, 0xbe, 0x56, 0x8f, 0xab, 0x3d,
+ 0xba, 0x5b, 0xdc, 0x3d, 0xaa, 0x5e, 0x77, 0xbe, 0x1c, 0xc9, 0x64, 0x3d,
+ 0xfa, 0xf6, 0xd4, 0x3b, 0x72, 0x3d, 0x4a, 0x3d, 0x8c, 0xd5, 0x34, 0xbe,
+ 0x32, 0x30, 0xa8, 0x3b, 0x60, 0x0c, 0x8e, 0x3c, 0x7b, 0xc7, 0x30, 0x3d,
+ 0x86, 0x51, 0xb9, 0xbb, 0xed, 0x50, 0x0e, 0x3e, 0xb3, 0x70, 0x8a, 0xbc,
+ 0xc6, 0x3a, 0x1d, 0xbe, 0x77, 0x4d, 0x09, 0xbe, 0xb7, 0x5b, 0x39, 0xbd,
+ 0x23, 0xc9, 0x94, 0x3d, 0x8c, 0x6b, 0x7d, 0xbd, 0xc7, 0x7e, 0x45, 0xbe,
+ 0xf7, 0x39, 0xb8, 0xbd, 0x22, 0x46, 0x41, 0xbe, 0x9c, 0xcc, 0x64, 0x3c,
+ 0x97, 0xae, 0x94, 0xbd, 0xf9, 0x00, 0x8e, 0xbd, 0x34, 0xd3, 0xae, 0xbd,
+ 0x95, 0x7e, 0x4c, 0x3d, 0x16, 0x3f, 0x81, 0x3d, 0x77, 0x7e, 0x9b, 0xbc,
+ 0x47, 0x7b, 0x87, 0xbc, 0xb8, 0xc1, 0x14, 0xbe, 0x48, 0x64, 0xff, 0xbd,
+ 0x41, 0x09, 0xe2, 0xbc, 0xcb, 0x02, 0x2d, 0xbd, 0x52, 0x57, 0x26, 0xba,
+ 0x2b, 0x92, 0x83, 0xbd, 0x12, 0x88, 0x81, 0xbe, 0x11, 0x87, 0xe4, 0x3d,
+ 0xf6, 0x25, 0x51, 0xbe, 0xd5, 0x2d, 0xe9, 0xbd, 0xca, 0xc7, 0x6b, 0xbe,
+ 0x20, 0x33, 0x42, 0x3c, 0xfd, 0x3b, 0x54, 0xbe, 0xcc, 0x6d, 0x18, 0xbd,
+ 0x50, 0x31, 0x1f, 0xbe, 0x15, 0x5a, 0x48, 0x3e, 0x6a, 0xa8, 0x1e, 0x3e,
+ 0x1c, 0x72, 0x9d, 0xbe, 0xc2, 0xcf, 0x19, 0x3e, 0xda, 0x99, 0x3e, 0x3d,
+ 0x33, 0x9c, 0x84, 0xbf, 0xc3, 0xf1, 0x19, 0x3d, 0x3f, 0xf7, 0x24, 0xbd,
+ 0x29, 0x2a, 0xf7, 0x3e, 0x48, 0xf5, 0x48, 0xbe, 0xf4, 0xbc, 0xf4, 0xbd,
+ 0xed, 0x44, 0x7f, 0xbd, 0x3b, 0x94, 0x8a, 0x3e, 0xcd, 0x23, 0x5d, 0xbc,
+ 0x58, 0xdb, 0x8b, 0x3e, 0xe7, 0x74, 0xac, 0xbe, 0x6e, 0x53, 0x84, 0xbd,
+ 0x18, 0x4a, 0x4a, 0x3e, 0x96, 0x8c, 0xf1, 0x3d, 0xae, 0xc0, 0x5b, 0xbc,
+ 0x92, 0x87, 0x52, 0x3e, 0x51, 0xcd, 0x55, 0xbd, 0x2d, 0x96, 0x0f, 0x3d,
+ 0xba, 0xee, 0x95, 0xbc, 0x79, 0xf2, 0x32, 0x3e, 0x9a, 0x6c, 0xd8, 0xbe,
+ 0x67, 0xfd, 0x06, 0xbe, 0x47, 0x20, 0xd5, 0xbc, 0x67, 0x20, 0xf5, 0x3d,
+ 0xb6, 0x84, 0xbb, 0x3b, 0x20, 0x91, 0x3a, 0x3e, 0x86, 0x8c, 0x2b, 0xbe,
+ 0x94, 0x2b, 0xeb, 0x3d, 0x57, 0xbd, 0x17, 0x3e, 0x8f, 0x5f, 0x18, 0xbc,
+ 0x7d, 0x8f, 0x65, 0xbd, 0x99, 0x37, 0xc3, 0x3e, 0x04, 0x8c, 0xa8, 0xbd,
+ 0x8a, 0x8d, 0xd3, 0x3d, 0xdc, 0x19, 0xa9, 0xbd, 0x92, 0x13, 0x84, 0x3d,
+ 0x91, 0xb8, 0xa3, 0xbe, 0x7b, 0x31, 0x87, 0xbd, 0x5b, 0xf4, 0x29, 0xbb,
+ 0x99, 0x9a, 0x44, 0x3e, 0x7a, 0x99, 0x26, 0xbd, 0xe1, 0xd1, 0x03, 0x3e,
+ 0x37, 0xac, 0xa1, 0x3c, 0x46, 0xe3, 0x0d, 0x3e, 0xcc, 0xad, 0x96, 0x3d,
+ 0x34, 0xab, 0xf9, 0xbd, 0xcb, 0x7e, 0x36, 0xbe, 0x75, 0xa7, 0x8c, 0x3e,
+ 0x65, 0x58, 0x41, 0xbe, 0x12, 0x45, 0xa3, 0xba, 0xd5, 0x51, 0xe2, 0xbc,
+ 0xac, 0x2c, 0xc8, 0xbc, 0x8a, 0x1d, 0x70, 0xbe, 0x58, 0xb0, 0x65, 0x3c,
+ 0x00, 0x29, 0xdc, 0x3d, 0xf7, 0x94, 0x9d, 0x3e, 0x24, 0xfa, 0x84, 0xbd,
+ 0xa0, 0x06, 0xfe, 0x3d, 0x84, 0x08, 0x10, 0xbd, 0xf0, 0x0a, 0xc5, 0x3d,
+ 0xd4, 0xf2, 0xd3, 0x3c, 0xfd, 0xa3, 0xd5, 0xbd, 0xac, 0x95, 0x4e, 0xbb,
+ 0x0a, 0x6d, 0x99, 0x3e, 0x5a, 0x84, 0x1d, 0x3c, 0x56, 0x76, 0x8c, 0xbc,
+ 0xa3, 0xff, 0xa8, 0xbc, 0xb2, 0x9d, 0x4b, 0x3c, 0xe3, 0x87, 0x8b, 0xbe,
+ 0x30, 0xe9, 0xe6, 0xbd, 0x97, 0xf3, 0xef, 0xbc, 0x67, 0x40, 0x9f, 0x3e,
+ 0x7e, 0x95, 0x9c, 0xbd, 0xa1, 0xd7, 0xf4, 0x3d, 0x14, 0x05, 0x44, 0xbd,
+ 0x32, 0x50, 0x40, 0x3e, 0x7f, 0x4f, 0x0e, 0xbe, 0x24, 0xb4, 0x35, 0xbd,
+ 0xbb, 0x01, 0x13, 0xbe, 0x75, 0x97, 0x72, 0x3e, 0x72, 0xb5, 0xc4, 0xbc,
+ 0x2d, 0x03, 0xa3, 0xbe, 0x30, 0x9c, 0x85, 0xbd, 0xe9, 0x8a, 0xdd, 0x3d,
+ 0x66, 0x85, 0xe1, 0xbd, 0x00, 0x78, 0x16, 0xbe, 0xa6, 0xe0, 0x5d, 0xbd,
+ 0x39, 0xa7, 0x61, 0x3e, 0x40, 0xe9, 0xfa, 0xbd, 0x03, 0x1a, 0x78, 0x3e,
+ 0xae, 0x8a, 0x10, 0xbe, 0xff, 0x69, 0x73, 0x3d, 0x83, 0xc1, 0xd1, 0xbd,
+ 0xe9, 0xdc, 0x01, 0xbe, 0xef, 0xa7, 0x5f, 0x3d, 0x1d, 0xe3, 0x3f, 0x3e,
+ 0xe2, 0x74, 0x36, 0x3d, 0xda, 0xb4, 0x5d, 0xbe, 0xdf, 0x67, 0x56, 0xbd,
+ 0x3b, 0xe8, 0xca, 0x3d, 0xdb, 0x14, 0x21, 0xbe, 0x26, 0x0e, 0x21, 0xbe,
+ 0x70, 0xee, 0xce, 0xbd, 0xce, 0xd1, 0x8d, 0x3e, 0xf7, 0x98, 0xdb, 0xbd,
+ 0x76, 0xd8, 0x78, 0x3d, 0xd9, 0xc5, 0x25, 0xbe, 0x7b, 0x1e, 0x97, 0x3d,
+ 0x36, 0x31, 0x11, 0xbe, 0x1b, 0x15, 0x09, 0xbe, 0x20, 0xa6, 0x0b, 0xbb,
+ 0x25, 0xa1, 0xa0, 0x3e, 0x1b, 0xb2, 0xbb, 0xbd, 0x6d, 0x78, 0x9f, 0xbe,
+ 0xdf, 0xfb, 0x6a, 0xbd, 0xae, 0xdc, 0xc3, 0xbd, 0xb2, 0xe1, 0x8a, 0xbe,
+ 0x5a, 0x86, 0x90, 0xbd, 0x36, 0x2c, 0x91, 0xbd, 0xa1, 0x4f, 0x8b, 0x3e,
+ 0xef, 0x10, 0x11, 0xbd, 0x4e, 0xcc, 0xa8, 0x3d, 0x54, 0xf0, 0x7b, 0xbe,
+ 0x28, 0x40, 0x60, 0x3d, 0xa8, 0x9b, 0x00, 0x3d, 0xcf, 0xce, 0x28, 0xbd,
+ 0x3c, 0x31, 0x48, 0x3d, 0x41, 0xa1, 0xa4, 0x3e, 0xa7, 0x2a, 0x8b, 0xbe,
+ 0xdf, 0xd5, 0xf4, 0xbd, 0xac, 0xc1, 0xa2, 0x3b, 0xc4, 0x44, 0xcf, 0xbc,
+ 0x4f, 0x37, 0x5b, 0xbe, 0x67, 0xc2, 0x4c, 0xbd, 0x8b, 0x10, 0xb2, 0x3c,
+ 0x50, 0xe3, 0x26, 0x3e, 0xf8, 0x5e, 0xc2, 0x3d, 0x03, 0x12, 0x05, 0x3e,
+ 0x62, 0xbd, 0x1f, 0xbe, 0x1c, 0xec, 0xfe, 0x3d, 0x6e, 0x47, 0x50, 0x3d,
+ 0x60, 0x32, 0x89, 0x3d, 0xac, 0x39, 0x92, 0xbd, 0x23, 0x38, 0x3c, 0x3e,
+ 0x5f, 0x1e, 0x76, 0x3c, 0x94, 0xe2, 0x19, 0xbd, 0x7a, 0xd7, 0xc8, 0xbc,
+ 0xd8, 0xe3, 0x91, 0x3b, 0x0d, 0x26, 0x99, 0xbe, 0x2a, 0xad, 0x5d, 0xbe,
+ 0x94, 0x8e, 0x89, 0x3c, 0x4f, 0x99, 0xe6, 0x3d, 0x38, 0xd7, 0x98, 0x3b,
+ 0xe2, 0x9d, 0x12, 0x3e, 0xe8, 0xb1, 0x8e, 0xbe, 0x2c, 0x89, 0x28, 0x3e,
+ 0x8f, 0xd0, 0x3e, 0x3e, 0x22, 0x07, 0x50, 0xbd, 0x01, 0x49, 0xb5, 0xbd,
+ 0x06, 0x7e, 0x76, 0x3e, 0xaa, 0x8b, 0xa0, 0xbd, 0xa5, 0x43, 0x4a, 0xbc,
+ 0xe5, 0x64, 0x84, 0xbc, 0x7c, 0xb1, 0x36, 0x3d, 0xae, 0x00, 0xc6, 0xbe,
+ 0x7f, 0x17, 0x0a, 0xbe, 0xa0, 0x53, 0x3c, 0xbd, 0xb2, 0x43, 0xab, 0x3d,
+ 0xf2, 0xff, 0xcd, 0x3d, 0x42, 0xde, 0xb6, 0x3e, 0x36, 0x05, 0x07, 0xbf,
+ 0x2d, 0x47, 0x54, 0xbd, 0x73, 0xa0, 0x21, 0x3e, 0xc1, 0x61, 0x05, 0x3e,
+ 0x27, 0x6b, 0xcb, 0xbd, 0x9a, 0xe1, 0x5b, 0x3e, 0xfe, 0xdc, 0x33, 0xbd,
+ 0x12, 0x05, 0x2f, 0x3e, 0x84, 0x79, 0x28, 0xbc, 0x3e, 0x68, 0x66, 0xbe,
+ 0x7a, 0x0f, 0xb7, 0xbe, 0xcb, 0xff, 0xa6, 0xbe, 0xe1, 0x4c, 0x6c, 0x3d,
+ 0x10, 0x0f, 0xbe, 0x3e, 0x90, 0xef, 0xd3, 0xbd, 0x20, 0x98, 0x8e, 0x3e,
+ 0x3f, 0x83, 0xbb, 0xbe, 0x22, 0x0e, 0xc8, 0xbd, 0x5b, 0x94, 0x08, 0x3e,
+ 0xf7, 0x96, 0x9b, 0x3d, 0x53, 0x44, 0x46, 0xbd, 0x31, 0x47, 0xbc, 0x3d,
+ 0x4b, 0x9a, 0xee, 0xbd, 0x38, 0xf9, 0x35, 0x3d, 0xce, 0xb3, 0x3e, 0x3d,
+ 0x9b, 0x95, 0x95, 0x3d, 0xcd, 0x6f, 0xbf, 0xbe, 0x13, 0x43, 0x6a, 0xbe,
+ 0xa7, 0x4d, 0xe2, 0x3d, 0x76, 0xb4, 0x0f, 0x3f, 0x8e, 0x98, 0xa0, 0xbc,
+ 0x26, 0x91, 0x33, 0xbe, 0xc6, 0x43, 0x7c, 0xbe, 0xbe, 0x98, 0xd5, 0xbc,
+ 0x48, 0x72, 0x43, 0x3e, 0xf7, 0x74, 0x88, 0xbc, 0xc2, 0x58, 0xec, 0x3c,
+ 0xb6, 0x16, 0xa7, 0x3d, 0x17, 0x8c, 0x39, 0x3e, 0x84, 0xf5, 0x00, 0xbe,
+ 0xc4, 0xa8, 0xe2, 0x3d, 0x56, 0xc9, 0x22, 0x3e, 0xa1, 0x57, 0x96, 0xbe,
+ 0x06, 0x1c, 0x97, 0xbd, 0xda, 0x24, 0x82, 0x3d, 0xb1, 0xaf, 0x1e, 0xbc,
+ 0x4c, 0x3d, 0x7e, 0xbe, 0xca, 0xe6, 0xbc, 0x3d, 0xec, 0xd0, 0x93, 0xbd,
+ 0x13, 0x35, 0xeb, 0xbd, 0xbb, 0x88, 0x0e, 0xbd, 0xeb, 0x2b, 0xf4, 0x3c,
+ 0x13, 0x20, 0x46, 0x3e, 0x54, 0x9f, 0x78, 0xbd, 0x3d, 0x11, 0x44, 0xbd,
+ 0xb2, 0x3d, 0xe3, 0xbd, 0x3d, 0x61, 0xa8, 0x3d, 0xa9, 0xf8, 0x10, 0xbd,
+ 0xe2, 0xdc, 0x94, 0x3d, 0x14, 0x39, 0xde, 0xbd, 0x65, 0xa4, 0xde, 0xbd,
+ 0x72, 0xdd, 0x92, 0xbd, 0xb3, 0x05, 0x53, 0xbd, 0xcf, 0x8d, 0x1d, 0x3d,
+ 0x0a, 0x84, 0xa3, 0xbe, 0x5c, 0x03, 0x86, 0xbe, 0x16, 0xb6, 0xcb, 0xbe,
+ 0x30, 0x14, 0xfd, 0xbe, 0xe8, 0xfe, 0x3f, 0x3d, 0xec, 0x02, 0xc4, 0xbd,
+ 0x55, 0x4b, 0x99, 0x3c, 0xcb, 0xa5, 0x1e, 0xbd, 0xb4, 0x06, 0x82, 0x3d,
+ 0x2a, 0xd8, 0x92, 0xbe, 0x49, 0xea, 0xa1, 0xbd, 0x25, 0x78, 0x7b, 0xbe,
+ 0x34, 0xd6, 0xe8, 0xbd, 0xf3, 0x6a, 0x95, 0xbe, 0xde, 0x0c, 0xa1, 0xbd,
+ 0x81, 0xac, 0x78, 0x3b, 0x55, 0xa5, 0xd6, 0xbe, 0xfb, 0xfa, 0x65, 0xbe,
+ 0xd2, 0xa0, 0xb2, 0xbe, 0x01, 0x33, 0x4f, 0xbe, 0xc6, 0xa4, 0x8f, 0x3d,
+ 0xb4, 0x35, 0x72, 0x3d, 0xfd, 0xfb, 0xc4, 0xbc, 0x8a, 0xc5, 0x02, 0xbc,
+ 0x2e, 0x81, 0x1b, 0x3d, 0xf1, 0x88, 0x71, 0xbe, 0x10, 0xe7, 0x23, 0xbe,
+ 0xe5, 0xd4, 0x9b, 0xbd, 0x7e, 0x92, 0x9c, 0xbd, 0x32, 0x5d, 0xa5, 0xbe,
+ 0x3f, 0x12, 0x10, 0xbd, 0x06, 0xa8, 0xa4, 0xbc, 0x81, 0xe0, 0xb0, 0xbe,
+ 0x1a, 0xef, 0x5d, 0xbe, 0x15, 0x9b, 0xca, 0xbe, 0xa3, 0xb4, 0x36, 0xbe,
+ 0x80, 0x96, 0x54, 0xbd, 0x27, 0x41, 0xd4, 0xbc, 0xe1, 0x96, 0x7a, 0x3d,
+ 0xb0, 0xf1, 0xa4, 0x3d, 0x2e, 0x9f, 0x37, 0x3d, 0x69, 0x19, 0xa0, 0xbe,
+ 0xb0, 0xd8, 0xae, 0x3d, 0x42, 0x80, 0x0e, 0xbd, 0xbe, 0xbb, 0x8d, 0x3c,
+ 0x1f, 0x71, 0x93, 0xbe, 0xe5, 0x13, 0xa0, 0xbc, 0x55, 0xb8, 0xcd, 0xbc,
+ 0x55, 0xf0, 0xc0, 0x3b, 0xba, 0xe0, 0x2c, 0xbe, 0xa5, 0x38, 0xfc, 0xbe,
+ 0x03, 0x08, 0xdc, 0xbd, 0x8c, 0x72, 0x14, 0xbd, 0xef, 0xd9, 0x67, 0x3c,
+ 0xc9, 0x03, 0xe0, 0x3d, 0x69, 0xe2, 0xa0, 0x3d, 0xe1, 0x86, 0x06, 0x3d,
+ 0xa4, 0x52, 0x90, 0xbe, 0xda, 0x56, 0x29, 0xbc, 0x2b, 0x9c, 0xbd, 0x3d,
+ 0x12, 0xf7, 0xf3, 0xbc, 0x96, 0xad, 0x41, 0xbd, 0xb6, 0x4a, 0x10, 0xbd,
+ 0x7a, 0xee, 0xb5, 0xbd, 0x88, 0x83, 0xaa, 0x3d, 0xae, 0x03, 0xbd, 0xbe,
+ 0x4d, 0xaf, 0xe1, 0xbe, 0x32, 0x22, 0x4a, 0x3c, 0x6b, 0xa2, 0x90, 0xbd,
+ 0x7e, 0x81, 0x95, 0xbd, 0xc7, 0xe1, 0xbc, 0x3d, 0x56, 0x42, 0x7e, 0xbd,
+ 0xb4, 0xdb, 0xcb, 0x3d, 0xfe, 0x8e, 0x0e, 0xbf, 0x68, 0xe9, 0x60, 0x3e,
+ 0xea, 0x83, 0xce, 0x3c, 0x04, 0x08, 0x6d, 0xbb, 0xff, 0xb2, 0x38, 0x3d,
+ 0x26, 0xe2, 0x82, 0x3c, 0x71, 0x20, 0x10, 0xbe, 0x82, 0x64, 0x13, 0x3e,
+ 0xa7, 0x1a, 0xc6, 0xbe, 0x3e, 0xe8, 0xc7, 0xbe, 0x30, 0x1e, 0xd8, 0x3d,
+ 0x66, 0x87, 0x50, 0xbe, 0x5d, 0xbf, 0x4b, 0xbe, 0xf9, 0x9e, 0xb8, 0xbd,
+ 0x22, 0x9e, 0x04, 0x3d, 0x89, 0x8f, 0x7a, 0x3d, 0x4a, 0xd9, 0x15, 0xbe,
+ 0x4f, 0x77, 0x5e, 0x3e, 0xc0, 0x19, 0x08, 0x3d, 0xe0, 0xd6, 0x47, 0xbd,
+ 0xfb, 0x2b, 0xb6, 0x3d, 0x64, 0xa3, 0xf1, 0x3c, 0x36, 0xee, 0xd1, 0xbd,
+ 0x3c, 0x60, 0x60, 0x3d, 0x23, 0xae, 0x75, 0xbe, 0xc8, 0x00, 0x89, 0xbe,
+ 0xc4, 0x9c, 0x22, 0x3e, 0xc9, 0x29, 0x88, 0xbe, 0xd5, 0x6a, 0xc2, 0xbe,
+ 0x87, 0x71, 0xca, 0xbd, 0x76, 0x80, 0xa3, 0xbc, 0x84, 0xcf, 0xbc, 0xbd,
+ 0x4c, 0xac, 0x17, 0xbe, 0xaa, 0xd8, 0x91, 0x3e, 0xa9, 0x44, 0x52, 0x3c,
+ 0xc0, 0xee, 0xfa, 0xbd, 0x2c, 0x3b, 0x24, 0x3d, 0xc8, 0x0a, 0x8c, 0x3d,
+ 0x37, 0x10, 0x07, 0x3d, 0x98, 0x78, 0xdf, 0x3d, 0x0c, 0xe2, 0xe5, 0xbd,
+ 0x2c, 0x38, 0x34, 0xbe, 0xe5, 0x49, 0xb7, 0xbd, 0xc7, 0xcf, 0xd8, 0xbe,
+ 0x54, 0xf3, 0x6e, 0xbe, 0x2d, 0xbc, 0x19, 0xbe, 0xe4, 0x0f, 0x8d, 0x3d,
+ 0xf1, 0x48, 0xdc, 0xbd, 0xa2, 0x21, 0xdc, 0x3c, 0x86, 0x4c, 0x9d, 0x3e,
+ 0x93, 0xcd, 0xe7, 0x3d, 0x30, 0x77, 0xbf, 0xbd, 0xe0, 0xd2, 0x9f, 0xbc,
+ 0x55, 0x3a, 0x8e, 0x3d, 0xf2, 0x3f, 0x6e, 0xbe, 0xfc, 0xb4, 0x96, 0x3d,
+ 0xf3, 0xfe, 0xa1, 0xbe, 0x80, 0xf7, 0xfc, 0xbd, 0x34, 0xd4, 0x6c, 0x3d,
+ 0x31, 0x5b, 0x44, 0xbe, 0xcc, 0x50, 0x45, 0xbe, 0xd0, 0x2b, 0xf4, 0xbd,
+ 0xf7, 0x13, 0x02, 0xbe, 0x60, 0x08, 0xd7, 0xbd, 0xe5, 0x7e, 0x95, 0x3e,
+ 0xed, 0x1e, 0x7e, 0x3e, 0x30, 0x5f, 0x10, 0x3d, 0xc7, 0xf2, 0x47, 0xbe,
+ 0x69, 0x3c, 0x8e, 0x3b, 0xf1, 0xee, 0x51, 0xbd, 0x8e, 0x09, 0x41, 0xbe,
+ 0x6f, 0x3e, 0xbf, 0x3d, 0x30, 0x8d, 0x09, 0xbe, 0xc1, 0xa9, 0x19, 0xbe,
+ 0xa7, 0xb8, 0x96, 0xbd, 0x6c, 0xd8, 0x82, 0x3c, 0x45, 0x45, 0x3d, 0xbd,
+ 0x81, 0xb8, 0x4f, 0xbe, 0xd5, 0xe1, 0x32, 0x3d, 0x26, 0x85, 0x51, 0xbc,
+ 0x86, 0x09, 0x8b, 0x3e, 0xa3, 0x45, 0x87, 0x3e, 0x50, 0xeb, 0x52, 0x3e,
+ 0x17, 0xe7, 0x97, 0x3c, 0xc6, 0x63, 0x18, 0xbe, 0x34, 0xff, 0xd4, 0xbc,
+ 0xf9, 0xdc, 0xe5, 0xbe, 0x4c, 0x05, 0x86, 0x3d, 0xee, 0x91, 0xf2, 0xbc,
+ 0x9f, 0x83, 0xfa, 0xbc, 0x02, 0x38, 0x9e, 0xbd, 0x7c, 0x8a, 0xfe, 0xbc,
+ 0x9a, 0x13, 0x02, 0xbe, 0xc3, 0xcf, 0x08, 0xbe, 0x49, 0xfb, 0x0d, 0x3d,
+ 0x17, 0xf6, 0x29, 0xbd, 0x88, 0x7a, 0xdd, 0x3e, 0x6f, 0x3b, 0x01, 0x3e,
+ 0x19, 0xdd, 0x5b, 0x3e, 0x47, 0xbc, 0x19, 0xbd, 0x43, 0xc4, 0x9a, 0xbd,
+ 0xdd, 0x16, 0x82, 0x3d, 0xd4, 0x08, 0x89, 0xbe, 0x1f, 0xb5, 0xd8, 0xbe,
+ 0x5a, 0x44, 0x69, 0x3d, 0x35, 0x15, 0x60, 0xbe, 0x06, 0x34, 0x9e, 0xbe,
+ 0xff, 0x5a, 0xa1, 0x3e, 0x61, 0x69, 0x86, 0xbe, 0x90, 0xee, 0x8a, 0xbd,
+ 0x4a, 0x55, 0x36, 0xbe, 0x43, 0x71, 0x57, 0x3d, 0xaa, 0xcb, 0x0e, 0xbf,
+ 0xb4, 0x91, 0x35, 0xbf, 0x6f, 0x5b, 0x0f, 0xbf, 0x40, 0x82, 0x03, 0x3e,
+ 0x07, 0x78, 0x98, 0xbe, 0xc2, 0x15, 0x90, 0xbe, 0xf9, 0x72, 0xaa, 0xbe,
+ 0xe2, 0x17, 0x9c, 0xbe, 0x08, 0x3e, 0xa9, 0x3d, 0x9f, 0xae, 0x1a, 0xbf,
+ 0xf0, 0xf7, 0x28, 0xbf, 0xe1, 0x8b, 0xfc, 0x3d, 0x5b, 0xb5, 0xec, 0xbe,
+ 0x64, 0x14, 0xa9, 0x3c, 0x5f, 0x3a, 0xdb, 0xbc, 0xc2, 0xc8, 0xd3, 0xbd,
+ 0x1d, 0xa2, 0x52, 0xbf, 0x8d, 0x06, 0x85, 0x3d, 0x59, 0xfc, 0xaf, 0xbe,
+ 0xab, 0xa1, 0xb0, 0x3c, 0x4d, 0xa0, 0x2f, 0xbe, 0x04, 0x1f, 0xd3, 0xbb,
+ 0x20, 0x49, 0xe2, 0xbc, 0x12, 0xc7, 0x02, 0x3d, 0x76, 0x89, 0x31, 0x3e,
+ 0xb6, 0x83, 0x48, 0x3d, 0x40, 0xc8, 0xcf, 0xbe, 0xa3, 0x9e, 0xdb, 0x3d,
+ 0x2f, 0x47, 0x2a, 0x3e, 0xa8, 0xf7, 0x8d, 0xbf, 0xfc, 0x3a, 0x25, 0x3d,
+ 0x82, 0x9c, 0xb3, 0xbd, 0xe4, 0x25, 0x05, 0x3e, 0x56, 0x7d, 0xc0, 0xbe,
+ 0x7c, 0xec, 0x9f, 0x3d, 0x48, 0x59, 0x8e, 0xbd, 0xcd, 0x4b, 0x91, 0x3e,
+ 0x53, 0x6e, 0x0d, 0x3e, 0x91, 0x99, 0x93, 0x3e, 0x54, 0x9c, 0x16, 0xbe,
+ 0x68, 0x8f, 0xbf, 0x3d, 0xbd, 0xef, 0xa1, 0x3d, 0xc4, 0x83, 0xcf, 0x3b,
+ 0xd6, 0xc4, 0xc1, 0xbe, 0x11, 0x47, 0x3e, 0x3e, 0x37, 0x5c, 0xf5, 0xbd,
+ 0xc2, 0x27, 0xdb, 0x3d, 0x5d, 0x79, 0x97, 0xbd, 0x98, 0xf2, 0x0c, 0x3d,
+ 0x6c, 0xa6, 0xaa, 0xbe, 0xd9, 0x30, 0xb5, 0xbd, 0x90, 0x05, 0x01, 0x3a,
+ 0xf1, 0x8f, 0x35, 0x3e, 0x82, 0x5d, 0xfd, 0xbc, 0xc7, 0xf8, 0x54, 0x3e,
+ 0x9e, 0xe1, 0xd8, 0xbc, 0xba, 0x9d, 0x23, 0x3e, 0xc5, 0x87, 0x06, 0x3e,
+ 0x6b, 0xe7, 0xee, 0x3c, 0xae, 0x75, 0x2a, 0xbe, 0x9b, 0xf5, 0x2c, 0x3e,
+ 0xc5, 0x58, 0x9d, 0xbc, 0x4b, 0x3b, 0xbb, 0x3c, 0x96, 0x33, 0x7a, 0x3c,
+ 0xd7, 0xd3, 0xab, 0xbe, 0x33, 0x03, 0x5e, 0xbe, 0x24, 0xe4, 0x2c, 0x3d,
+ 0xc6, 0x66, 0x09, 0xbc, 0x6f, 0x16, 0x8e, 0x3e, 0xd1, 0x41, 0x07, 0x3b,
+ 0x25, 0xcc, 0x40, 0x3e, 0xe2, 0x18, 0x0f, 0x3d, 0x15, 0xe8, 0x82, 0x3e,
+ 0x41, 0x69, 0xdb, 0x3d, 0xe1, 0x27, 0x37, 0xbe, 0x00, 0x5b, 0x9d, 0xbe,
+ 0xcb, 0xdb, 0x40, 0x3e, 0xe1, 0x3c, 0xea, 0xbb, 0x0e, 0x61, 0x30, 0xbc,
+ 0xba, 0x37, 0x95, 0x3d, 0xfd, 0x17, 0xf3, 0xbe, 0xc2, 0x74, 0x50, 0xbe,
+ 0x9a, 0x7a, 0x7e, 0xbd, 0x30, 0x34, 0xc3, 0x3d, 0x54, 0xe2, 0xc3, 0x3e,
+ 0x6d, 0xa6, 0x9a, 0x3d, 0xaf, 0xa2, 0x88, 0x3e, 0xd8, 0x11, 0x71, 0x3d,
+ 0x4b, 0xa8, 0x26, 0x3e, 0xb8, 0x2f, 0xeb, 0x3b, 0x65, 0x63, 0x2b, 0xbd,
+ 0x92, 0xd3, 0x37, 0x3c, 0x95, 0xf0, 0xa6, 0x3e, 0x00, 0x6a, 0x15, 0xbe,
+ 0x36, 0x55, 0x37, 0x3d, 0x1d, 0x59, 0x4d, 0x3d, 0x7c, 0xdf, 0x91, 0xbe,
+ 0xa2, 0x6b, 0x6f, 0xbe, 0x27, 0x4b, 0xe2, 0x3c, 0x1a, 0x00, 0x50, 0xbc,
+ 0xe9, 0x40, 0x9e, 0x3e, 0x99, 0xaa, 0x01, 0xbe, 0xc2, 0x58, 0x70, 0xbb,
+ 0x83, 0x8c, 0xd9, 0x3c, 0x0d, 0x3e, 0xe6, 0x3d, 0xf1, 0x6f, 0x81, 0x3d,
+ 0xcb, 0x83, 0x7b, 0x3c, 0x78, 0xff, 0x3b, 0xbd, 0xe1, 0xae, 0x79, 0x3e,
+ 0x27, 0x72, 0x85, 0xbc, 0x72, 0xb1, 0x0a, 0xbe, 0xda, 0xc6, 0x8a, 0x3b,
+ 0x6b, 0xe5, 0x14, 0xbe, 0xaf, 0x70, 0x9e, 0xbd, 0xa2, 0xba, 0xc3, 0x3d,
+ 0x3e, 0x64, 0x10, 0xbd, 0x6c, 0xe2, 0x94, 0x3e, 0x65, 0x6a, 0x08, 0xbd,
+ 0x70, 0x66, 0x9a, 0x3e, 0x9e, 0x96, 0xd4, 0xbd, 0xb3, 0xcd, 0x70, 0x3e,
+ 0x93, 0x7a, 0x0f, 0x3e, 0x8c, 0x94, 0xfa, 0xbd, 0xa4, 0x90, 0x63, 0xbd,
+ 0xcb, 0x07, 0x88, 0x3e, 0x06, 0xab, 0x48, 0x3d, 0x44, 0x5b, 0x3e, 0x3e,
+ 0x7f, 0xd6, 0x6c, 0xbb, 0x04, 0xed, 0xf0, 0xbc, 0xe4, 0xc3, 0x7c, 0xbe,
+ 0x26, 0x94, 0x2c, 0xbd, 0x4a, 0x27, 0xcc, 0x3c, 0xfc, 0xc2, 0x92, 0x3e,
+ 0x82, 0x1b, 0x27, 0xbd, 0x9a, 0xf4, 0x9b, 0x3e, 0x36, 0x53, 0x8b, 0xbe,
+ 0x0f, 0x9c, 0x8c, 0x3e, 0x2f, 0x68, 0x99, 0x3d, 0x20, 0x62, 0xaa, 0x3c,
+ 0xbb, 0x1e, 0x6f, 0xbc, 0x9d, 0x1f, 0x4b, 0x3e, 0x54, 0x7f, 0x45, 0xbe,
+ 0x9b, 0xba, 0xb5, 0x3c, 0x4b, 0x19, 0x2b, 0x3c, 0x99, 0xe6, 0xb7, 0x3c,
+ 0x0b, 0x45, 0x23, 0xbe, 0x78, 0xd6, 0x2a, 0x3d, 0x02, 0xe2, 0x07, 0x3e,
+ 0xd6, 0x26, 0x66, 0x3e, 0x3a, 0x28, 0x2b, 0xbe, 0x45, 0x77, 0x36, 0x3e,
+ 0x2e, 0xf3, 0xf6, 0xbd, 0xb9, 0x28, 0xea, 0x3d, 0x74, 0xdf, 0xdb, 0x3d,
+ 0x15, 0x69, 0x82, 0x3a, 0xe2, 0x89, 0xa1, 0x3c, 0x04, 0xfe, 0xb6, 0x3e,
+ 0xc2, 0x5b, 0x1c, 0x3e, 0x73, 0x7a, 0x08, 0xbd, 0x4d, 0x50, 0x0e, 0x3d,
+ 0xa0, 0x55, 0xb3, 0xbd, 0x18, 0x24, 0x1d, 0xbe, 0xbc, 0x5b, 0xd1, 0xbd,
+ 0xcc, 0xb0, 0xd9, 0x3d, 0xa1, 0x2c, 0x95, 0x3d, 0x79, 0x70, 0x08, 0xbe,
+ 0xeb, 0x53, 0x18, 0x3e, 0xc5, 0x8d, 0x43, 0xbd, 0x5d, 0xa3, 0x6e, 0x3d,
+ 0x66, 0x05, 0x0f, 0x3e, 0xa4, 0x01, 0x8b, 0xbd, 0x57, 0xb8, 0x47, 0xbd,
+ 0xe8, 0x97, 0x8a, 0x3e, 0x77, 0x52, 0x13, 0xbd, 0x40, 0xa2, 0xae, 0x3d,
+ 0x8f, 0xbc, 0xd4, 0x3a, 0x8b, 0x08, 0xd4, 0xbd, 0x56, 0x1a, 0x44, 0xbe,
+ 0x22, 0x87, 0x35, 0xbd, 0xb1, 0x29, 0xa9, 0xbc, 0xfe, 0x06, 0x8c, 0x3e,
+ 0xca, 0x88, 0x38, 0xbd, 0xba, 0xdd, 0x04, 0x3e, 0x66, 0x0b, 0xa9, 0xbe,
+ 0x9d, 0xa8, 0x9d, 0xbe, 0x55, 0x60, 0x32, 0x3b, 0x7d, 0x09, 0x09, 0x3e,
+ 0x4f, 0xb5, 0x3f, 0xbc, 0x71, 0x79, 0xde, 0x3e, 0x2d, 0xe9, 0x38, 0xbe,
+ 0x9a, 0x4c, 0x76, 0xbd, 0xa2, 0xe8, 0xa0, 0xbc, 0xf4, 0xc7, 0x10, 0xbd,
+ 0x71, 0x07, 0x20, 0x3c, 0x6d, 0xc8, 0x46, 0x3d, 0x44, 0x3c, 0x16, 0xbd,
+ 0xfb, 0x5a, 0x5a, 0x3e, 0x43, 0x01, 0xe0, 0xbe, 0x2e, 0xbf, 0x41, 0xbf,
+ 0x14, 0x7f, 0x1e, 0xbf, 0xcf, 0x88, 0x4d, 0xbf, 0x85, 0xb0, 0xa6, 0xbe,
+ 0x65, 0xd0, 0x9a, 0x3d, 0xad, 0xbe, 0x1c, 0xbc, 0xfa, 0xc1, 0x85, 0x3d,
+ 0xfc, 0x72, 0xae, 0xbd, 0x14, 0xf5, 0xc8, 0xbd, 0x0c, 0x20, 0x08, 0x3d,
+ 0xe8, 0x35, 0x63, 0x3e, 0xc0, 0xf5, 0x74, 0x3d, 0x8b, 0xd5, 0x0d, 0xbf,
+ 0x3d, 0x94, 0x4b, 0x3d, 0x69, 0xff, 0x33, 0xbe, 0x6f, 0xb7, 0x81, 0xbf,
+ 0x2a, 0x05, 0x5e, 0xbf, 0x21, 0x19, 0x94, 0xbe, 0x34, 0x2a, 0xed, 0xbe,
+ 0x10, 0xf1, 0x03, 0xbf, 0x40, 0xf0, 0x80, 0xbf, 0x08, 0x44, 0x1e, 0xbd,
+ 0x0d, 0x59, 0x46, 0xbf, 0x31, 0xa6, 0xb3, 0xbe, 0x58, 0x5d, 0xc4, 0xbe,
+ 0x1a, 0x05, 0x10, 0xbd, 0xa7, 0xe6, 0xe1, 0x3e, 0xf7, 0x06, 0xb9, 0xbe,
+ 0xce, 0xf0, 0xa0, 0xbf, 0xf4, 0xcf, 0x85, 0xbc, 0x3a, 0xe2, 0x82, 0xbe,
+ 0xfd, 0x85, 0x73, 0xbf, 0x24, 0x22, 0x55, 0xbf, 0x49, 0xad, 0x20, 0xbf,
+ 0x90, 0x58, 0x3f, 0xbc, 0x5d, 0xbf, 0xb4, 0xbe, 0x23, 0x4b, 0x61, 0xbf,
+ 0x4a, 0x9a, 0x4d, 0x3c, 0x7a, 0x20, 0x3d, 0xbf, 0xfd, 0x8c, 0xa1, 0x3b,
+ 0xc4, 0x15, 0x0e, 0xbe, 0x2a, 0xb8, 0x56, 0xbc, 0xb5, 0x41, 0x0c, 0x3f,
+ 0xf6, 0xfa, 0xcf, 0xbe, 0x3b, 0x1c, 0xfc, 0xbe, 0xb5, 0x8b, 0x24, 0xbd,
+ 0xca, 0xe0, 0xfd, 0x3e, 0x2a, 0xf3, 0xc9, 0x3e, 0x58, 0x8b, 0x1a, 0x3b,
+ 0x06, 0x37, 0x0f, 0x3f, 0xe5, 0x79, 0x5a, 0xbe, 0xcb, 0x6c, 0xa5, 0x3d,
+ 0x61, 0xa0, 0xc6, 0x3e, 0x86, 0x27, 0xbc, 0x3c, 0xee, 0x51, 0x4b, 0xbe,
+ 0x88, 0x4a, 0x0d, 0x3f, 0x16, 0x0e, 0x82, 0xbe, 0xca, 0xd9, 0xcd, 0xbd,
+ 0x53, 0x26, 0xec, 0x3e, 0x67, 0xa6, 0x89, 0x3e, 0x3e, 0x89, 0x21, 0x3d,
+ 0x89, 0x94, 0x8a, 0xba, 0x4e, 0xbc, 0x99, 0xbe, 0xb9, 0xf0, 0xdc, 0x3d,
+ 0x4b, 0x61, 0xa7, 0xbe, 0x5a, 0x3c, 0x2e, 0xbe, 0xa8, 0x2e, 0x82, 0x3e,
+ 0x68, 0x10, 0x85, 0xbd, 0x28, 0x23, 0x7c, 0xbe, 0x82, 0x7b, 0x01, 0x3e,
+ 0xc1, 0xc3, 0x1b, 0xbe, 0x60, 0x8b, 0xc5, 0x3e, 0xda, 0x55, 0xb1, 0xbd,
+ 0xd7, 0x46, 0x29, 0x3d, 0x8e, 0xff, 0xcd, 0x3d, 0xf1, 0xac, 0xe3, 0xbd,
+ 0x72, 0x78, 0x43, 0xbe, 0xd3, 0xed, 0x52, 0x3e, 0x6d, 0x9e, 0xe8, 0xbe,
+ 0x79, 0x9a, 0x9a, 0x3d, 0x98, 0xf6, 0x63, 0xbe, 0x0c, 0x7c, 0xbf, 0xbe,
+ 0x83, 0x45, 0x9a, 0x3e, 0x1d, 0x35, 0x0b, 0xbe, 0xc5, 0x00, 0x67, 0x3b,
+ 0x75, 0x3e, 0xf4, 0x3d, 0x77, 0x2b, 0x1b, 0xbe, 0xa5, 0xff, 0xeb, 0xbc,
+ 0xb6, 0xb3, 0x74, 0x3e, 0x52, 0xbf, 0x3d, 0xbd, 0x7a, 0xdc, 0x2d, 0xbe,
+ 0x8a, 0x5b, 0x3d, 0xbe, 0xfb, 0x30, 0x6d, 0xbe, 0x67, 0xd8, 0x35, 0x3e,
+ 0x0e, 0x72, 0xb8, 0xbe, 0xd2, 0x0a, 0x80, 0x3a, 0x43, 0x8b, 0x8d, 0x3d,
+ 0xd9, 0x8f, 0x9a, 0xbe, 0xba, 0x80, 0x8a, 0x3e, 0xc7, 0x1b, 0x02, 0xbd,
+ 0x2a, 0xae, 0x80, 0xbb, 0x31, 0x31, 0x08, 0x3e, 0x55, 0x75, 0x2f, 0xbe,
+ 0xad, 0xc6, 0x48, 0xbd, 0x43, 0x03, 0x7e, 0x3e, 0x48, 0xe4, 0xb8, 0xbd,
+ 0x75, 0xc6, 0xe8, 0xbd, 0x06, 0x3c, 0xa1, 0xbd, 0xd7, 0xa2, 0xc2, 0x3d,
+ 0xe5, 0x47, 0x07, 0x3e, 0xa6, 0x42, 0xdb, 0xbe, 0x6b, 0xbf, 0x05, 0xbe,
+ 0x84, 0x62, 0xc7, 0xbd, 0xb7, 0x2e, 0x97, 0xbe, 0xdc, 0x29, 0x9e, 0x3e,
+ 0x3b, 0xc5, 0x0a, 0x3d, 0x78, 0xd2, 0x28, 0xbd, 0x41, 0x00, 0x0b, 0xbc,
+ 0x08, 0xcc, 0xc4, 0xbc, 0xa2, 0x88, 0xe0, 0xbd, 0x23, 0x48, 0xb0, 0x3e,
+ 0x00, 0x0e, 0x2f, 0xbe, 0x69, 0xb0, 0x84, 0x3d, 0x20, 0x9d, 0x83, 0xbd,
+ 0x53, 0xe3, 0xa6, 0xbc, 0x99, 0x74, 0xd1, 0x3d, 0x36, 0x33, 0x8d, 0xbe,
+ 0x35, 0x2e, 0xfe, 0xbc, 0xd4, 0xea, 0xf6, 0xbc, 0xc2, 0xf9, 0x90, 0xbe,
+ 0x72, 0x67, 0xa7, 0x3d, 0x44, 0xae, 0x08, 0x3e, 0xed, 0x6f, 0x49, 0x3d,
+ 0xed, 0xe3, 0xa4, 0xbd, 0xc8, 0x11, 0x25, 0x3d, 0xc0, 0x7b, 0x30, 0xbd,
+ 0x80, 0x6e, 0xf7, 0x3d, 0xb9, 0xe9, 0x94, 0xbe, 0x12, 0x80, 0xba, 0x3d,
+ 0x03, 0xfb, 0xac, 0xbc, 0xbe, 0x53, 0xf4, 0xbc, 0x8c, 0x26, 0x27, 0xbd,
+ 0x71, 0x13, 0xc7, 0xbe, 0x6e, 0xc5, 0x02, 0xbe, 0x54, 0x9d, 0x23, 0x3d,
+ 0xa5, 0xba, 0x39, 0xbe, 0xf0, 0x26, 0x52, 0x3d, 0xfe, 0xf6, 0xc9, 0x3d,
+ 0x94, 0x18, 0xa8, 0x3d, 0xe6, 0xd3, 0x1c, 0xbe, 0x9a, 0xd2, 0xe6, 0xbd,
+ 0xbc, 0xb0, 0x1d, 0xbd, 0x22, 0x0a, 0xb0, 0x3d, 0x09, 0x0f, 0x74, 0xbe,
+ 0x22, 0x36, 0xde, 0x3d, 0xab, 0xc6, 0x20, 0x3d, 0x5b, 0xeb, 0xd1, 0xbd,
+ 0xaf, 0x09, 0x1a, 0xbd, 0xaa, 0x83, 0x31, 0xbe, 0x2d, 0x9d, 0xbd, 0xbc,
+ 0x8f, 0xca, 0xb6, 0xbd, 0x8c, 0xa0, 0x4a, 0xbe, 0x4b, 0x67, 0xfa, 0x3d,
+ 0x3f, 0x99, 0x01, 0x3e, 0x0e, 0x64, 0xa5, 0x3d, 0xe3, 0xe9, 0xd3, 0xba,
+ 0x9d, 0x09, 0x6a, 0xbc, 0x28, 0x4f, 0x82, 0x3e, 0xe3, 0x4c, 0x0a, 0x3e,
+ 0x44, 0xfd, 0x6e, 0xbd, 0x94, 0xfc, 0xa0, 0x3d, 0x8e, 0x35, 0x83, 0x3d,
+ 0xef, 0x14, 0xea, 0xbc, 0x4b, 0xf9, 0x10, 0xbd, 0x42, 0x43, 0x8e, 0xbd,
+ 0x0b, 0x78, 0x3b, 0xbd, 0x0d, 0xc8, 0x2f, 0xbd, 0x43, 0xc0, 0xb1, 0xbe,
+ 0xf4, 0x92, 0x85, 0x3e, 0xfd, 0x10, 0xea, 0x3d, 0x3f, 0xa1, 0x89, 0x3d,
+ 0xb9, 0xd2, 0x2a, 0xbd, 0x6c, 0xfd, 0x99, 0xbe, 0x68, 0xf0, 0x22, 0x3e,
+ 0x4e, 0x3b, 0xf8, 0xbd, 0x6a, 0xa0, 0x18, 0xbe, 0x91, 0xee, 0x1d, 0xbd,
+ 0x48, 0x14, 0x0e, 0x3d, 0x64, 0x2b, 0xb2, 0xbd, 0x47, 0x34, 0xad, 0x3c,
+ 0xb1, 0x9c, 0xe7, 0xbd, 0xd0, 0x9a, 0x8b, 0x3d, 0xc6, 0x5b, 0xe5, 0x3d,
+ 0xa5, 0x1f, 0x21, 0xbe, 0x0a, 0x26, 0x0b, 0x3e, 0xa4, 0x1a, 0x5a, 0xbd,
+ 0x3e, 0x53, 0xe8, 0xbd, 0xda, 0xb5, 0xc9, 0x3b, 0xc0, 0x68, 0x53, 0xbe,
+ 0x85, 0x31, 0x9a, 0x3e, 0xf9, 0x64, 0x1a, 0x3e, 0xe0, 0x4a, 0x35, 0xbd,
+ 0xe8, 0xaa, 0xa0, 0xbd, 0xac, 0xf7, 0xbd, 0x3d, 0xbf, 0xbd, 0x1a, 0xbe,
+ 0x71, 0x3e, 0x41, 0x3d, 0x5c, 0x55, 0xfb, 0xbd, 0x4b, 0x79, 0xe0, 0x3d,
+ 0xc1, 0x0e, 0x87, 0x3d, 0xac, 0xfa, 0x83, 0xbd, 0x1c, 0x1b, 0x1e, 0x3e,
+ 0xcd, 0xe6, 0xa7, 0x3d, 0xdd, 0x2a, 0xa3, 0xbd, 0xd2, 0x48, 0xc0, 0x3c,
+ 0x4e, 0x4a, 0xd5, 0xbe, 0x61, 0xa2, 0x16, 0x3e, 0x97, 0xe6, 0x82, 0xbc,
+ 0x79, 0x7e, 0xaf, 0xbd, 0x3b, 0x1a, 0xfb, 0x3d, 0xc9, 0x30, 0x3d, 0x3e,
+ 0x3d, 0x27, 0x86, 0xbe, 0xd1, 0x31, 0x5f, 0x3e, 0x42, 0xfc, 0x99, 0xbe,
+ 0xe0, 0x82, 0xc3, 0x3d, 0x91, 0x85, 0xd1, 0x3d, 0x95, 0xbf, 0xea, 0x3c,
+ 0x39, 0x19, 0xe4, 0x3d, 0x4f, 0x40, 0x17, 0xbe, 0x5b, 0x8f, 0xd8, 0xbd,
+ 0x16, 0x8b, 0x63, 0xbd, 0xd5, 0x12, 0xa1, 0x3b, 0xc0, 0xd5, 0x68, 0x3c,
+ 0x55, 0x96, 0xb8, 0xbd, 0xbc, 0xf3, 0x9d, 0xbe, 0xf8, 0x79, 0xd5, 0x3d,
+ 0xac, 0x1a, 0xd5, 0x3d, 0xd0, 0x00, 0x14, 0xbd, 0xca, 0x1d, 0xad, 0xba,
+ 0x79, 0xed, 0x2c, 0xbe, 0xc4, 0x05, 0xc6, 0xbc, 0x0d, 0x1c, 0xf7, 0x3d,
+ 0xd8, 0xd0, 0x8f, 0xbd, 0x79, 0x0e, 0xba, 0x3d, 0x3c, 0x33, 0x30, 0x3d,
+ 0x2c, 0x08, 0xbf, 0xbd, 0x4a, 0x7a, 0x71, 0xbd, 0xc2, 0x3b, 0x45, 0xbc,
+ 0x7a, 0xac, 0x8e, 0xbe, 0x13, 0x06, 0xa9, 0xbd, 0x0e, 0xd4, 0x3b, 0xbe,
+ 0xc5, 0x4b, 0x47, 0x3d, 0x90, 0xb5, 0x85, 0xbd, 0xe5, 0xce, 0x0f, 0xbe,
+ 0x02, 0xae, 0xc7, 0x3c, 0xc1, 0x9c, 0x4d, 0xbe, 0x60, 0x07, 0x8f, 0x3d,
+ 0xa0, 0x57, 0x78, 0xbd, 0x48, 0x93, 0x86, 0x3e, 0xe4, 0xed, 0xfb, 0xbd,
+ 0x6e, 0x57, 0x74, 0x3d, 0x85, 0x53, 0x01, 0xbd, 0x56, 0xaf, 0xff, 0xbd,
+ 0xfe, 0xe2, 0x07, 0x3e, 0x13, 0xb4, 0xdb, 0xbd, 0xfb, 0x89, 0x9f, 0xbe,
+ 0x74, 0xb9, 0xe2, 0xbd, 0x4b, 0xac, 0x8c, 0x3e, 0xf8, 0x2a, 0x8d, 0xbd,
+ 0x76, 0x7d, 0x08, 0xbe, 0x39, 0xc8, 0x84, 0x3d, 0x62, 0x02, 0xe9, 0xbd,
+ 0xb0, 0x1c, 0xfc, 0x3a, 0x52, 0x7e, 0x06, 0xbd, 0xec, 0xf1, 0xce, 0xbc,
+ 0x00, 0x3b, 0xc3, 0x3c, 0x08, 0x4e, 0x3e, 0x3d, 0x5c, 0x19, 0x45, 0xbe,
+ 0xbb, 0x06, 0xbd, 0xbd, 0x9d, 0xbb, 0xf7, 0xba, 0x9c, 0xa5, 0x87, 0x3b,
+ 0x1a, 0x83, 0x85, 0xbd, 0xa3, 0x38, 0xeb, 0xbc, 0x83, 0x65, 0xdc, 0x3d,
+ 0x5c, 0x8d, 0x0e, 0x3e, 0xcf, 0x7f, 0xe6, 0x3b, 0x7d, 0x2c, 0xaf, 0xbd,
+ 0x9c, 0xc5, 0xaf, 0x3c, 0xd7, 0x6a, 0xc7, 0xbc, 0x7a, 0xc2, 0x48, 0xbe,
+ 0xfc, 0x1a, 0x0e, 0x3d, 0x9e, 0x97, 0x3e, 0x3d, 0xf1, 0x34, 0xd0, 0xba,
+ 0xbb, 0x60, 0xee, 0xbd, 0x85, 0x2f, 0xec, 0xbd, 0x8e, 0x6f, 0x7b, 0x3c,
+ 0xb9, 0x28, 0xfc, 0xbd, 0x4d, 0x84, 0x6b, 0xbe, 0x26, 0x35, 0x4c, 0xbd,
+ 0x8a, 0xe9, 0x2f, 0xbd, 0x2a, 0x11, 0x1c, 0xbe, 0xbb, 0x7e, 0x08, 0xbe,
+ 0xf6, 0x73, 0x81, 0xbe, 0x36, 0xfd, 0x11, 0xbd, 0x6a, 0x85, 0xcf, 0xbd,
+ 0x64, 0x9f, 0x93, 0xbd, 0xb8, 0xfe, 0xff, 0xbd, 0x4f, 0xa5, 0x19, 0xbe,
+ 0xd9, 0x9b, 0x34, 0xbe, 0x17, 0xac, 0xdb, 0x3a, 0x2d, 0x1c, 0xa1, 0xbd,
+ 0x22, 0x94, 0x90, 0x3c, 0xcb, 0xa9, 0x6d, 0xbb, 0x84, 0xad, 0x9e, 0x3d,
+ 0xfd, 0x9a, 0x11, 0xbe, 0x93, 0xaa, 0x13, 0x3d, 0x42, 0x61, 0x8b, 0xbd,
+ 0x5d, 0x21, 0x28, 0xbe, 0x15, 0x7b, 0xd2, 0xbd, 0xf5, 0x7e, 0x54, 0x3d,
+ 0xc1, 0x76, 0x81, 0x3d, 0x45, 0x13, 0xe7, 0xbd, 0xac, 0x4f, 0x12, 0x3d,
+ 0x8f, 0x1c, 0x0e, 0x3c, 0xb3, 0x6d, 0x70, 0x3c, 0x6b, 0xfa, 0xdc, 0xbb,
+ 0xd6, 0xab, 0xf9, 0xbc, 0x49, 0x49, 0xf7, 0xbc, 0x4b, 0x50, 0x59, 0xbd,
+ 0x10, 0x1e, 0xb0, 0xbd, 0x43, 0x71, 0x39, 0xbd, 0xd5, 0xe0, 0xc1, 0xbd,
+ 0x33, 0xc2, 0x5f, 0x3d, 0x48, 0xa7, 0x4a, 0xbe, 0xef, 0x8d, 0x35, 0xbe,
+ 0xa1, 0x9e, 0x3c, 0xbd, 0xb0, 0x3a, 0xa5, 0xbd, 0xa8, 0x9d, 0xa1, 0x3d,
+ 0x61, 0xb0, 0x73, 0x3d, 0xdb, 0x36, 0xbd, 0x3d, 0xa1, 0xc1, 0x03, 0xbd,
+ 0xde, 0x98, 0xac, 0xbd, 0xe1, 0x5a, 0xd4, 0x3d, 0x87, 0x04, 0xa1, 0xbd,
+ 0x22, 0xcf, 0x2f, 0x3d, 0xae, 0xf3, 0xc2, 0xbd, 0x7d, 0xe0, 0x30, 0xbe,
+ 0x1d, 0x36, 0x03, 0xbe, 0xc3, 0x86, 0xb1, 0x3d, 0x00, 0xf1, 0xbb, 0xbd,
+ 0x5f, 0x98, 0x56, 0xbd, 0xdd, 0xcd, 0x06, 0xbe, 0xcf, 0x6e, 0xa5, 0x3b,
+ 0xaa, 0xa0, 0x88, 0xbd, 0x99, 0x87, 0x56, 0xbe, 0x59, 0xce, 0x37, 0x3d,
+ 0xc6, 0x1e, 0x9c, 0xbb, 0xf9, 0x24, 0x1f, 0xbe, 0x6e, 0xee, 0x89, 0x3d,
+ 0xa5, 0xd5, 0xe8, 0xbb, 0xde, 0x47, 0x7d, 0xbd, 0xe3, 0x46, 0x26, 0xbe,
+ 0x8b, 0x42, 0xc7, 0x3d, 0xb5, 0xc8, 0xc6, 0xbd, 0x58, 0xc1, 0xc3, 0xbd,
+ 0x4d, 0x67, 0x4f, 0x3d, 0x9f, 0xdd, 0x2b, 0xbe, 0x13, 0x24, 0x02, 0xbd,
+ 0x8c, 0x30, 0x2a, 0xbd, 0x99, 0x30, 0x54, 0x3c, 0x86, 0xce, 0xa4, 0x3c,
+ 0x3c, 0xea, 0x1b, 0x3c, 0x18, 0x20, 0x00, 0x3d, 0xf5, 0x1d, 0x0a, 0xbc,
+ 0x3f, 0xc0, 0x74, 0x3d, 0x5a, 0x4f, 0xf4, 0xbb, 0x1e, 0x77, 0xc5, 0xbd,
+ 0xee, 0x16, 0xe4, 0xbd, 0xb5, 0xb4, 0x60, 0x3d, 0x25, 0xa2, 0xed, 0xbd,
+ 0x97, 0x7d, 0x9e, 0xbd, 0xc9, 0xd4, 0x36, 0xbd, 0xbf, 0x1b, 0xa6, 0x3c,
+ 0x6e, 0xb9, 0x27, 0x3d, 0xe8, 0x11, 0x2e, 0x3d, 0xa5, 0xae, 0xbd, 0xbd,
+ 0xdd, 0xfa, 0x04, 0xbd, 0xe6, 0x01, 0xe5, 0xbd, 0x03, 0x43, 0x65, 0x3d,
+ 0x36, 0xf4, 0x34, 0xbd, 0xc8, 0x33, 0xd1, 0xbd, 0x06, 0x06, 0x1c, 0xbe,
+ 0x17, 0x94, 0xb7, 0x3b, 0x64, 0x11, 0x01, 0xbe, 0xdf, 0xb1, 0xe6, 0xbd,
+ 0xa5, 0x78, 0x3b, 0xbe, 0x0d, 0x16, 0x58, 0xbd, 0x4b, 0xbc, 0xd4, 0x3c,
+ 0x92, 0x23, 0x52, 0xbe, 0x0d, 0x3f, 0x15, 0xbe, 0x8c, 0xd3, 0x52, 0xbe,
+ 0x00, 0xa4, 0x35, 0x3b, 0x37, 0x84, 0xa5, 0x3d, 0xdf, 0xe3, 0x02, 0xbe,
+ 0xbd, 0x99, 0x0f, 0xbe, 0x9d, 0x37, 0x33, 0xbe, 0x87, 0xd1, 0xfd, 0x3d,
+ 0xcb, 0x26, 0x39, 0xbe, 0x5d, 0x3f, 0x0e, 0xbe, 0xe6, 0xb1, 0x2d, 0xbe,
+ 0x4c, 0x00, 0x7d, 0xbd, 0xf7, 0x32, 0xd8, 0x3b, 0xc5, 0xcf, 0x86, 0x3d,
+ 0x60, 0x62, 0xa8, 0xbd, 0x44, 0x0d, 0x2f, 0xbe, 0xed, 0x1e, 0xf9, 0x3d,
+ 0x4d, 0x79, 0x51, 0xbe, 0x22, 0xdd, 0x50, 0xbe, 0x74, 0x3b, 0x1e, 0xbe,
+ 0xe1, 0x4f, 0x77, 0xbd, 0x00, 0x02, 0x1d, 0xbe, 0x07, 0x5f, 0x44, 0xbd,
+ 0x44, 0x3f, 0xb8, 0x3c, 0x9d, 0x95, 0xa9, 0xbb, 0x4a, 0xe8, 0x55, 0x3d,
+ 0xfd, 0x6e, 0x5d, 0x3d, 0xcd, 0x7c, 0x20, 0xbe, 0xb5, 0x23, 0xa2, 0x3d,
+ 0x92, 0xc8, 0x84, 0x3d, 0xa4, 0x4a, 0x3f, 0xbe, 0xae, 0xd7, 0x75, 0xbd,
+ 0x46, 0x5e, 0xc4, 0xbd, 0xb9, 0xe0, 0x24, 0xbd, 0x2a, 0xba, 0x83, 0xbd,
+ 0xdd, 0xfe, 0xd9, 0x3d, 0x98, 0x72, 0x94, 0x3d, 0x6b, 0x91, 0x09, 0x3d,
+ 0x51, 0xae, 0x88, 0x3b, 0x65, 0x6a, 0xd8, 0xbb, 0x44, 0x15, 0x17, 0xbe,
+ 0xcf, 0xbb, 0xb3, 0x3d, 0xfe, 0xa1, 0x3f, 0xbe, 0x57, 0xbf, 0xd8, 0xbd,
+ 0xcf, 0xc5, 0x9d, 0x3d, 0xce, 0x80, 0x59, 0xbc, 0x14, 0x38, 0xdd, 0xbd,
+ 0x49, 0xb5, 0x56, 0xbe, 0xc5, 0xb0, 0xa5, 0x3d, 0xa9, 0x99, 0x10, 0xbd,
+ 0x39, 0xea, 0x95, 0xbc, 0x73, 0x55, 0x3f, 0xbe, 0xfd, 0x57, 0x85, 0xbd,
+ 0x1d, 0xf1, 0x65, 0x3d, 0xab, 0xe9, 0x06, 0xbd, 0x77, 0x53, 0xf8, 0xbc,
+ 0xfa, 0xbc, 0x75, 0xbd, 0x32, 0xc8, 0x6c, 0x3d, 0xec, 0xfb, 0x42, 0xbe,
+ 0x4f, 0xe3, 0x8a, 0xbd, 0xc9, 0xd4, 0x32, 0xbc, 0xe0, 0x14, 0xbe, 0x3d,
+ 0xdd, 0xd2, 0x2a, 0xbe, 0x2d, 0xf3, 0x42, 0xbe, 0x8a, 0x61, 0x6e, 0x3d,
+ 0x34, 0xed, 0x85, 0xbb, 0xcc, 0x83, 0x3c, 0xbd, 0xf4, 0xe4, 0x8f, 0xbc,
+ 0x6a, 0x4e, 0x2a, 0xbd, 0x32, 0xb8, 0x1b, 0xbe, 0x45, 0xd2, 0x73, 0x3d,
+ 0xa9, 0x63, 0x64, 0xbd, 0x34, 0x23, 0xb5, 0xbd, 0xe3, 0x16, 0x00, 0x3e,
+ 0xa5, 0xac, 0xf0, 0xbd, 0x1c, 0xef, 0x3d, 0x3d, 0xfc, 0xba, 0xff, 0x3c,
+ 0xbc, 0xfa, 0x0b, 0x3d, 0xfc, 0xd7, 0x60, 0xbd, 0x91, 0x10, 0xdd, 0xbb,
+ 0xe4, 0x68, 0xbe, 0x3d, 0xa5, 0x92, 0x50, 0xbe, 0x98, 0x7b, 0x27, 0xbe,
+ 0x78, 0xe3, 0xa2, 0xbe, 0xa6, 0x63, 0x21, 0xbd, 0x6d, 0xe4, 0xc0, 0x3d,
+ 0x68, 0x9c, 0xd2, 0xbd, 0x5b, 0xb4, 0x11, 0x3e, 0xa7, 0xef, 0xa9, 0xbd,
+ 0xf9, 0xfb, 0x83, 0x3d, 0xd8, 0x6d, 0xe5, 0x3c, 0xc2, 0x59, 0x3d, 0xbd,
+ 0x6f, 0x02, 0xe3, 0xbc, 0xdd, 0x52, 0xcf, 0xbb, 0x58, 0x34, 0xbc, 0xbd,
+ 0xa9, 0x43, 0x45, 0xbd, 0x1e, 0xf0, 0x9a, 0xbd, 0x80, 0x43, 0x61, 0x3d,
+ 0x77, 0xa4, 0x72, 0xbe, 0xa1, 0x17, 0xb0, 0x3e, 0x36, 0x5f, 0xd1, 0x3e,
+ 0x12, 0x20, 0xfe, 0xbd, 0x5d, 0x4d, 0x7c, 0xbc, 0xfe, 0x0a, 0x3d, 0x3e,
+ 0xd5, 0xcf, 0x22, 0x3b, 0xdc, 0x2e, 0x0f, 0x3c, 0x79, 0x3c, 0x90, 0x3d,
+ 0xac, 0x83, 0x2e, 0x3d, 0x75, 0xce, 0x22, 0xbf, 0x23, 0x4e, 0x35, 0xbe,
+ 0x92, 0x0b, 0x61, 0x3c, 0xcf, 0xdc, 0x70, 0x3e, 0x3f, 0xe4, 0xa2, 0xbe,
+ 0x63, 0x01, 0x9e, 0x3d, 0x61, 0x05, 0xa8, 0xbe, 0x1b, 0x7d, 0xe0, 0x3d,
+ 0xb5, 0x3b, 0xcc, 0x3e, 0xdc, 0x97, 0x9d, 0xbe, 0x13, 0xf1, 0x60, 0x3d,
+ 0xfc, 0x5b, 0x95, 0xbd, 0xd8, 0x27, 0x06, 0x3e, 0x27, 0x3e, 0x65, 0xbd,
+ 0x3a, 0xc3, 0x7b, 0xbd, 0x77, 0xa5, 0x37, 0x3d, 0x30, 0x67, 0x14, 0xbe,
+ 0xf9, 0x10, 0xbe, 0xbe, 0x4f, 0xec, 0x53, 0x3e, 0xf5, 0x26, 0xd9, 0x3d,
+ 0x48, 0x3b, 0x2d, 0xbf, 0xd1, 0x9b, 0x35, 0xbc, 0x7e, 0x60, 0xae, 0x3d,
+ 0xdf, 0x08, 0x5b, 0x3d, 0x58, 0xe9, 0x9b, 0xbe, 0xb6, 0xc6, 0xf6, 0xbe,
+ 0x57, 0xa3, 0x45, 0x3e, 0xa1, 0x11, 0x19, 0xbd, 0xaf, 0xb8, 0x2d, 0x3e,
+ 0xb8, 0x9b, 0x06, 0x3e, 0xbc, 0x03, 0x31, 0xbe, 0x49, 0xe0, 0xa4, 0x3c,
+ 0x67, 0x3d, 0x16, 0xbd, 0x5d, 0xa2, 0x54, 0xbe, 0xc7, 0x85, 0x1b, 0x3d,
+ 0xfb, 0x76, 0x05, 0xbb, 0x20, 0x1f, 0xd5, 0xbb, 0xc3, 0x12, 0x65, 0xbe,
+ 0x1e, 0x60, 0x9d, 0x3e, 0x74, 0x8d, 0x03, 0xbd, 0xe6, 0x87, 0x01, 0xbf,
+ 0x4e, 0x58, 0xc3, 0xbe, 0x0b, 0x3e, 0x09, 0x3e, 0xae, 0x0f, 0x17, 0xbd,
+ 0xab, 0xeb, 0x5b, 0x3d, 0x33, 0x41, 0x89, 0x3e, 0xfe, 0x66, 0x14, 0xbe,
+ 0x82, 0xfd, 0x63, 0xbc, 0x07, 0x1d, 0xbb, 0xbe, 0x80, 0x13, 0x7e, 0x3d,
+ 0x51, 0x53, 0xdf, 0xbe, 0xb3, 0x78, 0x91, 0x3d, 0x7e, 0x79, 0xac, 0xbd,
+ 0x2e, 0xe2, 0x3f, 0xbe, 0x46, 0x85, 0x01, 0x3d, 0xec, 0xf8, 0x64, 0x3e,
+ 0x06, 0x8e, 0xed, 0xbe, 0xf7, 0x7b, 0x1c, 0xbf, 0x09, 0x5b, 0x42, 0x3d,
+ 0x5b, 0xfd, 0x82, 0x3b, 0xde, 0xa5, 0xe4, 0xbd, 0xcb, 0x7c, 0x82, 0x3e,
+ 0xd6, 0xe7, 0x77, 0xbe, 0x28, 0x8e, 0xe3, 0xba, 0xf5, 0x19, 0x16, 0xbf,
+ 0x47, 0xf9, 0x0c, 0x3e, 0x93, 0xa4, 0xa7, 0xbe, 0xa1, 0xfd, 0x0b, 0xbd,
+ 0x34, 0x25, 0x2a, 0xbe, 0x79, 0xa6, 0x3e, 0xbe, 0x72, 0x46, 0x7a, 0x3e,
+ 0xdd, 0xb1, 0xd4, 0x3e, 0xa6, 0xae, 0xd7, 0x3d, 0xcd, 0xa3, 0xb8, 0xbe,
+ 0x83, 0xf2, 0xea, 0xbd, 0xda, 0x19, 0xfc, 0xbc, 0x8d, 0x76, 0xa2, 0xbc,
+ 0x17, 0x56, 0xa2, 0x3c, 0xf4, 0xa9, 0x00, 0xbe, 0x5b, 0xde, 0x36, 0x3d,
+ 0x0f, 0x78, 0x2d, 0xbf, 0x7f, 0xdc, 0x7e, 0xbd, 0x8b, 0x23, 0x93, 0xbd,
+ 0x0b, 0x44, 0x0e, 0x3d, 0xd1, 0xda, 0x73, 0xbe, 0xcf, 0x9f, 0x5b, 0xbe,
+ 0x50, 0xe9, 0x25, 0x3e, 0x83, 0x6c, 0x95, 0x3e, 0x72, 0x08, 0x76, 0x3d,
+ 0xae, 0xe5, 0x51, 0xbe, 0xd4, 0xf0, 0xa4, 0xbd, 0xf9, 0x06, 0xce, 0xbd,
+ 0x90, 0x98, 0x14, 0x3e, 0x24, 0x29, 0x20, 0x3c, 0x11, 0x75, 0x1c, 0xbe,
+ 0x99, 0x76, 0x2b, 0x3c, 0x9b, 0x64, 0xc1, 0xbe, 0x58, 0x5d, 0x08, 0xbe,
+ 0xcc, 0x09, 0x0f, 0x3e, 0x6e, 0x15, 0x1e, 0xbd, 0x17, 0x45, 0xed, 0xbd,
+ 0x15, 0xb4, 0x00, 0xbe, 0x71, 0x06, 0x83, 0x3d, 0xe5, 0x7e, 0xb2, 0x3e,
+ 0x72, 0x95, 0x57, 0x3e, 0x10, 0x2b, 0x78, 0xbe, 0x8f, 0x8b, 0x17, 0xbe,
+ 0x7a, 0xcb, 0x69, 0xbd, 0x93, 0xe9, 0x35, 0xbd, 0x70, 0x4a, 0x13, 0x3e,
+ 0x29, 0x2f, 0xde, 0xbd, 0x49, 0x2c, 0x0f, 0x3d, 0xb4, 0xd1, 0x7b, 0x3e,
+ 0x15, 0xff, 0x1a, 0xbd, 0x09, 0xeb, 0x16, 0x3d, 0x16, 0x20, 0x94, 0x3d,
+ 0x62, 0x81, 0x37, 0xbe, 0xf4, 0xb4, 0xa9, 0xbc, 0xa1, 0xe9, 0xfb, 0xbc,
+ 0x6a, 0xe0, 0xfc, 0x3d, 0x34, 0x3e, 0x4f, 0x3e, 0xc3, 0x45, 0x37, 0xbe,
+ 0xbd, 0x7c, 0x13, 0x3d, 0x80, 0xc5, 0xa1, 0x3c, 0x95, 0x2d, 0x94, 0xbd,
+ 0x37, 0xf2, 0xc3, 0x3d, 0xea, 0x4c, 0xb5, 0xbc, 0x3c, 0x6c, 0x0e, 0x3d,
+ 0x95, 0x03, 0xea, 0x3d, 0x00, 0xcb, 0xa5, 0xbd, 0xc6, 0xdb, 0x94, 0x3d,
+ 0xe0, 0x75, 0x9f, 0x3d, 0x35, 0x2b, 0xcd, 0xbc, 0x4b, 0xd6, 0x9d, 0xbc,
+ 0x19, 0xe6, 0x34, 0x3e, 0x95, 0xc7, 0xa8, 0x3d, 0x39, 0xa8, 0x4d, 0x3e,
+ 0x1a, 0xfe, 0x2e, 0xbe, 0x63, 0x46, 0x8c, 0x3d, 0xb2, 0x63, 0x0c, 0xbe,
+ 0xcb, 0x53, 0x82, 0xbc, 0x0d, 0xcc, 0x23, 0x3d, 0x93, 0xee, 0xff, 0x3c,
+ 0xa1, 0xba, 0x10, 0xbd, 0xf4, 0x9f, 0xfd, 0xbb, 0xe4, 0x63, 0x52, 0xbe,
+ 0xa0, 0x3f, 0xdb, 0x3d, 0xe3, 0x8c, 0xa1, 0xbd, 0x75, 0x4f, 0x75, 0xbd,
+ 0x64, 0xc3, 0xe6, 0x3c, 0x91, 0x6a, 0x96, 0x3e, 0x5b, 0x8f, 0x41, 0x3e,
+ 0x0b, 0xed, 0x8d, 0x3e, 0xe1, 0xfa, 0x47, 0xbd, 0xe8, 0x79, 0xa6, 0x3d,
+ 0x7f, 0x4e, 0x77, 0x3c, 0x3d, 0xbf, 0xf1, 0xba, 0x83, 0x2e, 0x92, 0x3d,
+ 0x14, 0xc8, 0xc3, 0xbd, 0x42, 0x69, 0x00, 0x3d, 0x86, 0x93, 0x8b, 0x3d,
+ 0xc6, 0xb3, 0x37, 0xbe, 0x5d, 0x8c, 0x27, 0xbc, 0xee, 0x70, 0xc9, 0xbc,
+ 0xf7, 0xf5, 0x96, 0xbe, 0x3f, 0x20, 0xe1, 0x3d, 0x07, 0x7a, 0x8b, 0x3e,
+ 0xc1, 0x46, 0x17, 0x3d, 0x39, 0xcc, 0x3c, 0x3e, 0xd4, 0xa0, 0x11, 0xbe,
+ 0x24, 0x8b, 0xe3, 0x3d, 0x9b, 0x32, 0x49, 0x3d, 0xc1, 0x6f, 0x08, 0xbe,
+ 0x5f, 0x21, 0x0e, 0x3d, 0xc0, 0xc1, 0x1a, 0x3d, 0x4d, 0x30, 0x8e, 0x3d,
+ 0x0d, 0xdf, 0x2e, 0x3e, 0x58, 0x84, 0x4b, 0xbe, 0x96, 0x08, 0x85, 0x3d,
+ 0x9a, 0x2e, 0x4f, 0x3c, 0x26, 0x4d, 0xc2, 0xbe, 0x78, 0x76, 0xea, 0x3d,
+ 0xd6, 0x01, 0x0a, 0x3d, 0xf5, 0xef, 0x78, 0xbe, 0x66, 0x9b, 0x82, 0x3e,
+ 0x90, 0x6b, 0x5f, 0xbe, 0x8c, 0xdf, 0xf9, 0x3d, 0x84, 0x98, 0xe9, 0xbe,
+ 0x38, 0x4e, 0x73, 0x3c, 0xce, 0xac, 0x2a, 0x3e, 0x1d, 0x29, 0x80, 0x3d,
+ 0x04, 0xd4, 0x94, 0xbe, 0x5d, 0x8b, 0x2f, 0xbe, 0x02, 0xde, 0xc5, 0xbe,
+ 0xbc, 0x6b, 0x0e, 0xbd, 0x0e, 0x34, 0xb2, 0xbd, 0xfc, 0xc1, 0x71, 0xbe,
+ 0xb3, 0x9a, 0xa4, 0xbc, 0xd2, 0x28, 0x55, 0x3e, 0x99, 0x4b, 0x15, 0x3e,
+ 0x6b, 0x9e, 0x8b, 0xbe, 0x0f, 0xa7, 0xa6, 0xbe, 0x9f, 0x1c, 0x7f, 0x3d,
+ 0x03, 0x97, 0xd6, 0xbe, 0xec, 0x2d, 0x7e, 0xbd, 0x5a, 0xa2, 0x2a, 0x3e,
+ 0x96, 0x01, 0xf9, 0x3c, 0x02, 0xaa, 0xd3, 0xbe, 0xb1, 0x3a, 0x1e, 0xbf,
+ 0x4b, 0xee, 0x50, 0x3e, 0x33, 0x84, 0x4a, 0xbe, 0xae, 0x5e, 0xca, 0xbe,
+ 0x6d, 0xad, 0x3d, 0xbe, 0x35, 0xdc, 0x8b, 0xbd, 0x7f, 0x3b, 0x19, 0xbe,
+ 0xf7, 0x3f, 0xe9, 0xbd, 0x39, 0x0d, 0xa9, 0xbe, 0x62, 0xaf, 0x2f, 0xbe,
+ 0x50, 0x42, 0xf2, 0xbd, 0x0b, 0xa2, 0xec, 0x3d, 0x87, 0x39, 0x6e, 0xbe,
+ 0xa0, 0xe2, 0x18, 0xbd, 0xd0, 0xf9, 0x9d, 0xbd, 0x44, 0xca, 0x1c, 0x3c,
+ 0x22, 0x53, 0xc3, 0x3e, 0x8b, 0x89, 0x93, 0xbe, 0x5b, 0xc0, 0x2a, 0xbe,
+ 0xc5, 0x08, 0xe9, 0xbc, 0x55, 0x7a, 0xbb, 0xbd, 0xa6, 0x59, 0x44, 0xbe,
+ 0x92, 0x5a, 0x9e, 0xbe, 0x44, 0x21, 0x92, 0xbe, 0x97, 0x4f, 0x57, 0xbe,
+ 0xe6, 0x26, 0x19, 0xbe, 0x7c, 0x1a, 0xf9, 0xbe, 0xa7, 0x2d, 0x9a, 0x3c,
+ 0xa1, 0x6c, 0xb9, 0xbe, 0x17, 0x1f, 0xf0, 0xbe, 0x36, 0x41, 0x63, 0xbe,
+ 0xe1, 0xfb, 0x72, 0xbd, 0x77, 0x52, 0xe0, 0x3e, 0xa8, 0x23, 0x01, 0xbf,
+ 0x34, 0x23, 0x34, 0xbe, 0x86, 0x7c, 0xbe, 0xbd, 0x95, 0x31, 0xde, 0xbe,
+ 0xea, 0x79, 0x04, 0xbe, 0x23, 0x82, 0xcc, 0xbe, 0xf6, 0xc9, 0x1c, 0xbf,
+ 0x1a, 0x7d, 0x41, 0x3c, 0xcb, 0xc1, 0x6b, 0xbe, 0xf7, 0x47, 0x2d, 0xbf,
+ 0xfe, 0x87, 0x32, 0xbd, 0xad, 0x73, 0x82, 0xbe, 0xa2, 0xd1, 0x3e, 0xbe,
+ 0x4c, 0xfa, 0x08, 0xbd, 0xef, 0xe1, 0x3d, 0xbd, 0xaf, 0x4c, 0x72, 0x3e,
+ 0x79, 0x46, 0xa1, 0xbe, 0x5a, 0x73, 0xe1, 0xbe, 0x0d, 0x0b, 0xc8, 0xbd,
+ 0x2d, 0x22, 0x91, 0x3e, 0x3f, 0x09, 0x7d, 0xbe, 0x18, 0xe7, 0x25, 0xbe,
+ 0x20, 0x50, 0x49, 0xbd, 0x08, 0x29, 0x4b, 0xbc, 0xce, 0xd6, 0x82, 0xbe,
+ 0x98, 0xe0, 0xec, 0xbe, 0xcd, 0x3d, 0x2d, 0x3d, 0xf4, 0xf8, 0xb0, 0xbd,
+ 0x7a, 0xee, 0xf3, 0xbd, 0x21, 0xd4, 0xd8, 0xb8, 0xf1, 0xf3, 0x81, 0xbd,
+ 0x2f, 0x08, 0x0c, 0x3d, 0x80, 0x46, 0x19, 0x3e, 0x80, 0x3c, 0x9c, 0xbe,
+ 0xc1, 0x46, 0xf2, 0xbd, 0x1d, 0x89, 0x3a, 0x3e, 0xa9, 0x64, 0x0a, 0xbe,
+ 0xb5, 0xe3, 0x2f, 0xbd, 0x99, 0x8d, 0x55, 0xbe, 0x19, 0x11, 0xcf, 0xbd,
+ 0x00, 0x5d, 0x3a, 0xbd, 0xef, 0x70, 0xb8, 0xbe, 0x2f, 0xe7, 0x4e, 0xbc,
+ 0x57, 0xbc, 0xa1, 0x3e, 0xbc, 0xcd, 0xd9, 0xbc, 0x7d, 0x6a, 0xbe, 0xbd,
+ 0x23, 0x6e, 0x3a, 0xbd, 0xc8, 0x65, 0x77, 0xbd, 0xb2, 0xe9, 0x1a, 0xbe,
+ 0x4f, 0xb3, 0x7a, 0xbe, 0x92, 0x29, 0x3d, 0xbd, 0xc2, 0xf1, 0xac, 0x3e,
+ 0x60, 0x35, 0x39, 0xbd, 0x49, 0xa6, 0xe8, 0x3c, 0x35, 0xf4, 0x04, 0x3e,
+ 0x41, 0x26, 0x09, 0xbc, 0x51, 0x4e, 0xa3, 0x3e, 0x56, 0x74, 0x9a, 0xbd,
+ 0xae, 0x10, 0x94, 0x3d, 0x01, 0xe9, 0x51, 0x3d, 0xc0, 0x1d, 0x45, 0x3d,
+ 0x80, 0xb1, 0xb4, 0xbc, 0x9b, 0x51, 0xcb, 0xbd, 0xa8, 0xca, 0x2d, 0xbd,
+ 0xa3, 0x12, 0x52, 0xbc, 0x22, 0xee, 0x05, 0xbe, 0xf0, 0x4c, 0x66, 0xbd,
+ 0x12, 0x0a, 0xa3, 0x3e, 0xae, 0xe7, 0x8d, 0xbc, 0xa2, 0x32, 0x48, 0x3e,
+ 0xd9, 0x25, 0xc6, 0xbd, 0x9f, 0xe7, 0x0e, 0x3e, 0x83, 0xd4, 0x20, 0x3e,
+ 0xf5, 0x11, 0xf0, 0xbc, 0xd8, 0xb1, 0x8c, 0x3d, 0xad, 0x03, 0xd5, 0x3b,
+ 0x87, 0x4f, 0xc0, 0x3d, 0xb5, 0x17, 0x36, 0x3d, 0x13, 0xdc, 0x08, 0xbd,
+ 0x6d, 0x28, 0x23, 0x3d, 0x24, 0x48, 0x94, 0xbe, 0xd9, 0xbe, 0x4f, 0xbd,
+ 0x0b, 0x18, 0x90, 0xbd, 0x04, 0xee, 0x91, 0x3e, 0x60, 0x12, 0x20, 0x3e,
+ 0xa4, 0x50, 0x31, 0x3e, 0x79, 0xb4, 0x91, 0xbd, 0xb6, 0x3b, 0xfd, 0x3d,
+ 0x87, 0x3a, 0xce, 0x3d, 0xab, 0x25, 0x3c, 0x3d, 0x2e, 0xba, 0xf6, 0x3b,
+ 0x22, 0xbe, 0x88, 0x3e, 0x41, 0x1d, 0x91, 0x3d, 0x40, 0x2e, 0x92, 0x3d,
+ 0x02, 0xd8, 0x90, 0x3d, 0x68, 0x3f, 0x58, 0xbe, 0x9b, 0xac, 0xd7, 0xbd,
+ 0x18, 0x6d, 0x8a, 0xbb, 0x1f, 0xf4, 0x7d, 0xbc, 0xe9, 0x45, 0x09, 0x3e,
+ 0x9f, 0xfe, 0x95, 0x3d, 0x9d, 0xf8, 0x2a, 0x3e, 0x55, 0x59, 0x18, 0xbe,
+ 0xb1, 0xfd, 0x36, 0x3e, 0x2a, 0xaa, 0x3b, 0x3e, 0xa6, 0xf6, 0x39, 0xba,
+ 0xa1, 0x4d, 0x74, 0xbd, 0xd9, 0xe6, 0x8d, 0x3e, 0x80, 0xa5, 0x8c, 0xbc,
+ 0x61, 0x74, 0x25, 0x3d, 0x34, 0xfe, 0x71, 0x3d, 0xbc, 0xb5, 0x8f, 0xbe,
+ 0x46, 0x41, 0xf4, 0xbe, 0x17, 0xf2, 0x9e, 0x3a, 0x80, 0x45, 0xce, 0x3c,
+ 0xa4, 0xd1, 0x8f, 0x3e, 0xe3, 0x2e, 0x43, 0xbc, 0x3d, 0x24, 0xb4, 0x3e,
+ 0xb1, 0x1e, 0x30, 0xbd, 0x98, 0x36, 0xcd, 0x3d, 0x0c, 0x48, 0x55, 0x3d,
+ 0x39, 0x6f, 0x16, 0xbe, 0x1d, 0x82, 0x34, 0xbe, 0xc0, 0x7d, 0x81, 0x3e,
+ 0x73, 0xe1, 0x0a, 0xbe, 0x1d, 0x95, 0x13, 0x3d, 0x52, 0x6b, 0xf5, 0xbb,
+ 0x42, 0x7e, 0xbc, 0xbe, 0x0c, 0x5a, 0xcc, 0xbe, 0x6b, 0xc1, 0xc3, 0xbc,
+ 0x85, 0xa2, 0xf7, 0x3c, 0x11, 0xef, 0x4b, 0x3e, 0xa4, 0xb9, 0x85, 0x3d,
+ 0x1b, 0x76, 0xbe, 0x3e, 0x9f, 0x20, 0xd4, 0xbd, 0x65, 0x15, 0x2a, 0x3e,
+ 0x6e, 0xdd, 0xfe, 0x3d, 0x72, 0x35, 0x21, 0xbd, 0x54, 0x0f, 0x48, 0xbe,
+ 0xfe, 0xe7, 0x46, 0x3e, 0x6f, 0x80, 0x80, 0xbd, 0xf4, 0x2c, 0xc8, 0x3d,
+ 0x45, 0x0b, 0x8e, 0xbd, 0xb3, 0xd3, 0x99, 0xbe, 0x12, 0x64, 0x19, 0xbe,
+ 0x8e, 0x98, 0x34, 0x3c, 0x3f, 0x82, 0x5c, 0x3d, 0x05, 0x5c, 0x8d, 0x3e,
+ 0x66, 0x6d, 0x1d, 0x3d, 0xe8, 0xe4, 0x79, 0x3e, 0x09, 0x06, 0x0c, 0xbd,
+ 0xfc, 0x25, 0x90, 0x3d, 0xd8, 0xda, 0xf1, 0x3d, 0xbb, 0x7e, 0x18, 0x3e,
+ 0xa7, 0x79, 0xe1, 0x3c, 0x68, 0x65, 0x31, 0x3d, 0x80, 0x16, 0x0f, 0xbe,
+ 0xa6, 0x2a, 0x79, 0x3c, 0x4f, 0x6a, 0xf5, 0x3d, 0x2d, 0x8e, 0x83, 0xbe,
+ 0xef, 0x1a, 0x86, 0xbd, 0xd7, 0x98, 0xd3, 0xbc, 0xdc, 0x99, 0xfb, 0x3d,
+ 0xe8, 0x2d, 0xd0, 0x3e, 0x93, 0x99, 0x23, 0xbe, 0x36, 0xdd, 0x84, 0x3e,
+ 0x41, 0x0f, 0x0a, 0x3e, 0x90, 0x4b, 0xd5, 0xbc, 0xd3, 0x40, 0xac, 0x3d,
+ 0x8e, 0x08, 0x95, 0x3c, 0xcc, 0x5b, 0x6f, 0xbe, 0x02, 0x7b, 0x89, 0x3e,
+ 0x6f, 0x2a, 0x55, 0xbe, 0x64, 0x57, 0xcd, 0xbd, 0x8d, 0xa2, 0xa8, 0x3d,
+ 0xaa, 0x1f, 0x42, 0xbd, 0x12, 0x22, 0x5c, 0xbe, 0x9a, 0xfa, 0x43, 0xbd,
+ 0xe0, 0x93, 0x81, 0xbd, 0xa6, 0x78, 0x74, 0xbd, 0x78, 0x8d, 0xd4, 0xbe,
+ 0x7e, 0xc7, 0x32, 0xbf, 0x01, 0xc0, 0x06, 0xbf, 0xd8, 0xad, 0x7f, 0xbd,
+ 0xd2, 0xc7, 0xa7, 0xbe, 0xbe, 0xc5, 0xff, 0xbe, 0x1e, 0xf5, 0x03, 0x3c,
+ 0x96, 0xae, 0x07, 0xbf, 0x43, 0xf6, 0x60, 0xbe, 0x1c, 0x7e, 0x8c, 0xbe,
+ 0xd4, 0x05, 0x51, 0xbd, 0x21, 0x90, 0x8c, 0x3e, 0x13, 0xcb, 0x85, 0xbe,
+ 0xdf, 0xb4, 0x05, 0xbf, 0xc3, 0x79, 0xa7, 0x3b, 0x60, 0x54, 0x39, 0x3c,
+ 0x12, 0x9a, 0x91, 0x3d, 0xe2, 0x53, 0x8d, 0x3d, 0xe8, 0x49, 0x5b, 0xbb,
+ 0x28, 0xcc, 0x95, 0xbe, 0x00, 0x79, 0xd7, 0xbc, 0x2a, 0x7e, 0x80, 0x3c,
+ 0xc9, 0x5f, 0x15, 0xbe, 0x4f, 0x7e, 0x4c, 0x3d, 0x4a, 0x6d, 0x58, 0xbc,
+ 0x6d, 0xa2, 0x17, 0xbe, 0x1c, 0x64, 0x11, 0xbe, 0x05, 0xf2, 0x7d, 0x3e,
+ 0x0f, 0x16, 0xb4, 0x3b, 0x98, 0x36, 0x88, 0x3d, 0x87, 0x91, 0xc0, 0xbe,
+ 0x3a, 0xbb, 0xcd, 0x3c, 0x89, 0x5d, 0xa8, 0xbe, 0x67, 0xdb, 0xe2, 0x3d,
+ 0xd0, 0xe3, 0x5f, 0xbd, 0x2b, 0xad, 0x0e, 0xbe, 0x4c, 0x1e, 0x24, 0xbe,
+ 0xe7, 0x6f, 0x8f, 0xbe, 0x0a, 0xa3, 0xb5, 0x3c, 0xfe, 0xf3, 0x8b, 0xbd,
+ 0x42, 0xfb, 0xc2, 0x3d, 0x7b, 0x30, 0x30, 0xbd, 0xbd, 0xbf, 0x49, 0xbe,
+ 0xb6, 0x92, 0x14, 0x3e, 0x97, 0x15, 0x3d, 0xbd, 0xfa, 0x58, 0x8b, 0xbd,
+ 0x88, 0x5d, 0x89, 0xbe, 0x8d, 0x80, 0x64, 0xbe, 0x3b, 0xb3, 0x6c, 0xbe,
+ 0x87, 0xd4, 0xda, 0xbb, 0x92, 0x31, 0x64, 0xbe, 0x8a, 0x85, 0xf4, 0xbd,
+ 0x9e, 0x89, 0xa4, 0xbd, 0x5e, 0xd7, 0x5d, 0xbe, 0xbf, 0x73, 0x45, 0xbe,
+ 0x77, 0xa5, 0x52, 0x3c, 0x3a, 0x4a, 0xa7, 0xbd, 0x37, 0xfb, 0x3e, 0xbc,
+ 0x24, 0x9c, 0x8e, 0xbd, 0x1e, 0x54, 0x91, 0xbc, 0x48, 0xaf, 0x45, 0xbd,
+ 0x25, 0x8c, 0x1e, 0x3d, 0xf2, 0x1a, 0x92, 0xbd, 0x7b, 0xb7, 0x3a, 0x3e,
+ 0x0c, 0xe9, 0x98, 0xbe, 0x70, 0x74, 0xb1, 0x3d, 0x43, 0xa9, 0x59, 0xbe,
+ 0xe1, 0xe3, 0x18, 0x3d, 0xc3, 0x81, 0x90, 0xbe, 0x53, 0x0c, 0x08, 0xbe,
+ 0x06, 0x59, 0xa5, 0xbd, 0x09, 0x71, 0xa2, 0x3c, 0x7c, 0x30, 0xa6, 0x3d,
+ 0xd7, 0x3a, 0xab, 0x3b, 0x00, 0xf9, 0x68, 0xbd, 0x79, 0x2a, 0x19, 0xbe,
+ 0x6d, 0x83, 0xb1, 0xbd, 0x20, 0xc3, 0x15, 0xbd, 0x70, 0x6e, 0x95, 0xbd,
+ 0xda, 0x24, 0x53, 0xbd, 0x6c, 0x88, 0xb6, 0xbe, 0x14, 0x65, 0x5f, 0x3d,
+ 0x80, 0xd5, 0x41, 0xbe, 0xaf, 0x31, 0x37, 0x3e, 0xa3, 0xad, 0x1c, 0xbd,
+ 0x2f, 0xfa, 0x0b, 0xbe, 0xed, 0x59, 0x2e, 0xbe, 0x6a, 0x9d, 0x5b, 0x3e,
+ 0x37, 0xde, 0x8f, 0xbd, 0x39, 0x9b, 0xb0, 0x3d, 0xaf, 0xc0, 0x03, 0xbd,
+ 0x85, 0xc3, 0x04, 0x3e, 0x0f, 0x4f, 0x38, 0xbc, 0x0f, 0xb3, 0x06, 0xbe,
+ 0x64, 0x20, 0x2b, 0xbe, 0x81, 0xb0, 0x1d, 0x3e, 0x57, 0x08, 0x8c, 0xbe,
+ 0x62, 0xbc, 0xe7, 0x3d, 0x45, 0xdf, 0x4e, 0x3d, 0xa0, 0x7d, 0x29, 0x3d,
+ 0x87, 0xd4, 0xc4, 0xbd, 0xb2, 0xa7, 0x54, 0xbd, 0x87, 0xfa, 0x8f, 0x3d,
+ 0x4b, 0x05, 0x34, 0x3e, 0xef, 0x5a, 0xa9, 0x3d, 0xd5, 0xd2, 0xc9, 0xbd,
+ 0x66, 0xbd, 0x16, 0xbd, 0x54, 0xcf, 0x08, 0x3e, 0x54, 0x8a, 0xf4, 0x3c,
+ 0xc6, 0xcd, 0x31, 0x3e, 0xf6, 0x6d, 0x7c, 0xbc, 0x7e, 0x1e, 0x10, 0xbd,
+ 0x30, 0x46, 0x1d, 0xbe, 0x5d, 0x65, 0x9c, 0xbc, 0xea, 0xbe, 0x4d, 0xbe,
+ 0x76, 0xc0, 0x91, 0xbc, 0x6d, 0x84, 0x33, 0x3d, 0x63, 0xc5, 0x1a, 0xbe,
+ 0x48, 0xa0, 0xaa, 0x3d, 0x2c, 0x55, 0x27, 0x3e, 0xee, 0x41, 0x94, 0x3d,
+ 0x3a, 0x2b, 0xa2, 0x3c, 0x14, 0xa0, 0x15, 0xbe, 0x33, 0x75, 0xdb, 0x3b,
+ 0xe2, 0x0e, 0x5d, 0xbd, 0x8d, 0x94, 0xc3, 0x3c, 0x76, 0x8e, 0xc3, 0xbe,
+ 0x26, 0xd0, 0x05, 0xbe, 0xb3, 0x7c, 0xc3, 0xbd, 0x95, 0xbd, 0xa3, 0x3d,
+ 0x98, 0x07, 0xc7, 0xbc, 0xbb, 0xc0, 0x77, 0xbd, 0x0b, 0x87, 0x80, 0x3c,
+ 0x3b, 0xda, 0x88, 0xbd, 0xc3, 0x53, 0x03, 0x3e, 0xe3, 0x7d, 0x00, 0xbe,
+ 0x57, 0xf1, 0x40, 0x3c, 0xd3, 0xf2, 0x23, 0xbd, 0xcf, 0x47, 0xcf, 0xbd,
+ 0x55, 0x35, 0x0c, 0xbd, 0x3a, 0x41, 0x60, 0xbd, 0xb3, 0xc1, 0x21, 0x3e,
+ 0x17, 0x79, 0x79, 0xbe, 0x4f, 0x9e, 0x0e, 0xbe, 0x81, 0x91, 0x00, 0xbe,
+ 0xaf, 0x5b, 0xbc, 0xbc, 0xe2, 0xbc, 0xd0, 0xbc, 0xa5, 0xfe, 0x9d, 0x3d,
+ 0x03, 0xbd, 0x93, 0xbe, 0x1e, 0x59, 0xa9, 0xbd, 0x1f, 0xea, 0xd0, 0xbd,
+ 0xc9, 0x61, 0x03, 0x3e, 0xe8, 0x4c, 0x16, 0x3e, 0xe5, 0x83, 0x41, 0xbb,
+ 0xd3, 0x77, 0xd2, 0xbd, 0x9e, 0x9e, 0x8d, 0xbc, 0x75, 0x41, 0x37, 0xbc,
+ 0x61, 0x40, 0x70, 0xbd, 0xbf, 0xec, 0xde, 0xbd, 0x8c, 0x63, 0xee, 0xbc,
+ 0xc1, 0x06, 0xe8, 0xbd, 0x15, 0x17, 0x4e, 0x3c, 0xee, 0xaa, 0xf0, 0xbd,
+ 0x17, 0x12, 0x02, 0xbd, 0xbb, 0xbf, 0x67, 0xbe, 0x35, 0xcb, 0x44, 0xbe,
+ 0x40, 0xaf, 0xa2, 0x3d, 0xc1, 0xe9, 0x9d, 0xbc, 0x84, 0x51, 0x61, 0x3e,
+ 0xea, 0xad, 0x7f, 0x3d, 0x5f, 0x13, 0x82, 0x3c, 0x87, 0x1c, 0xf5, 0xbc,
+ 0x5c, 0xc4, 0xe8, 0x3c, 0xc1, 0xa3, 0x68, 0xbd, 0x2c, 0xbf, 0x98, 0xbe,
+ 0xf7, 0xa1, 0xd2, 0x3b, 0x70, 0x4c, 0x24, 0x3c, 0xe2, 0x19, 0x8b, 0xbd,
+ 0xd0, 0x95, 0x17, 0xbe, 0xa4, 0x5e, 0x2b, 0xbe, 0x55, 0x11, 0x53, 0xbe,
+ 0x33, 0xdc, 0x7c, 0xbe, 0xa3, 0x5f, 0x00, 0x3e, 0x41, 0x5c, 0xf2, 0x3d,
+ 0x0d, 0xab, 0xe8, 0xbd, 0xdd, 0xf9, 0x24, 0x3d, 0x7f, 0x07, 0x06, 0x3e,
+ 0x62, 0xd0, 0x26, 0x3d, 0x72, 0x32, 0xf9, 0xbd, 0x80, 0x7a, 0xce, 0xbd,
+ 0xa8, 0x00, 0x1c, 0xbe, 0x28, 0x3a, 0x33, 0xbe, 0xef, 0xfc, 0xe6, 0xbc,
+ 0x69, 0xd4, 0xe4, 0x3d, 0x9a, 0x5d, 0x33, 0xbe, 0xb1, 0x1f, 0xd9, 0x3c,
+ 0xa8, 0xe8, 0x5c, 0xbd, 0xdb, 0x5e, 0x9d, 0xbe, 0x17, 0xac, 0xb8, 0xbc,
+ 0x5a, 0x52, 0x4d, 0x3d, 0x3d, 0x00, 0x97, 0xbc, 0x9a, 0xaa, 0x53, 0xbe,
+ 0xc0, 0x8c, 0x18, 0xbe, 0xdd, 0x93, 0x28, 0xbd, 0xa5, 0x6a, 0x97, 0x3d,
+ 0xe1, 0x09, 0x55, 0xbd, 0xea, 0xdb, 0xaa, 0xbe, 0xb1, 0x0d, 0xa0, 0xbd,
+ 0x33, 0xb7, 0x0c, 0xbe, 0xf3, 0x7c, 0xe5, 0x3d, 0x9e, 0x05, 0x9c, 0xbe,
+ 0x52, 0x7b, 0x0e, 0xbe, 0x7d, 0x50, 0x0b, 0xbe, 0x8a, 0x99, 0x1a, 0xbe,
+ 0x70, 0x90, 0xde, 0x3c, 0x73, 0x98, 0x7f, 0xbc, 0xf2, 0x72, 0x1b, 0x3e,
+ 0x64, 0x71, 0x72, 0xbd, 0xd5, 0xdb, 0x7c, 0xbe, 0xb0, 0xb4, 0xc6, 0xbc,
+ 0x80, 0x0a, 0x43, 0xbc, 0x7c, 0x3e, 0xa8, 0x3d, 0x9a, 0xd9, 0xda, 0xbe,
+ 0xe6, 0x9d, 0x21, 0xbe, 0x5e, 0x36, 0x30, 0xbe, 0xc5, 0x14, 0x38, 0x3e,
+ 0xd1, 0xa1, 0xa3, 0x3d, 0x22, 0xdd, 0x3d, 0xbe, 0xd6, 0x71, 0x99, 0xbd,
+ 0xe8, 0xab, 0x8d, 0x3e, 0x02, 0x68, 0x38, 0x3a, 0x4c, 0x4f, 0xc6, 0xbd,
+ 0x32, 0xb3, 0x38, 0x3e, 0x29, 0x0d, 0x23, 0xbe, 0x84, 0x39, 0xd8, 0xbd,
+ 0x82, 0x93, 0xaf, 0x3d, 0x5b, 0xbb, 0x98, 0x3c, 0x33, 0x97, 0xa7, 0x3d,
+ 0x25, 0x92, 0x96, 0xbe, 0x51, 0x1f, 0x79, 0xbe, 0x24, 0x78, 0x0b, 0xbe,
+ 0x2b, 0x85, 0x78, 0xbe, 0xf7, 0xd1, 0x40, 0x3f, 0xa2, 0xd5, 0x9a, 0x3e,
+ 0x9b, 0xff, 0x63, 0xbe, 0x0c, 0xcb, 0x08, 0xbe, 0xb8, 0x8a, 0x99, 0x3d,
+ 0xd1, 0xb9, 0x25, 0x3d, 0xd0, 0x91, 0x31, 0xbd, 0x3d, 0x06, 0x88, 0x3d,
+ 0x47, 0x65, 0xed, 0x3d, 0xaa, 0xc4, 0xd2, 0xbe, 0xd9, 0x6c, 0xc4, 0xbe,
+ 0xa1, 0xee, 0xc2, 0x3d, 0x56, 0xbc, 0x62, 0x3e, 0x76, 0x7d, 0x41, 0xbe,
+ 0x35, 0x60, 0x56, 0x3d, 0x6c, 0x50, 0x1d, 0xbe, 0xcf, 0xf4, 0x84, 0x3d,
+ 0x61, 0x1d, 0x4e, 0x3e, 0xea, 0xcd, 0x36, 0xbe, 0xc4, 0xc2, 0x77, 0x3c,
+ 0xa1, 0x6a, 0x14, 0xbd, 0xf2, 0x01, 0xcb, 0x3d, 0x73, 0xe6, 0x0d, 0x3e,
+ 0xf7, 0x54, 0x4d, 0xbd, 0x1b, 0x0b, 0xf0, 0x3d, 0xd8, 0x6b, 0x4c, 0x3e,
+ 0x05, 0xd9, 0xbf, 0xbe, 0x29, 0x5a, 0x0a, 0x3e, 0x54, 0x15, 0xaa, 0x3d,
+ 0x6a, 0xd0, 0xad, 0xbe, 0xb5, 0xa9, 0x7e, 0x3d, 0x5b, 0x9b, 0xa2, 0xbd,
+ 0x66, 0xeb, 0x1e, 0x3e, 0xdf, 0xfa, 0xb3, 0x3d, 0x01, 0xb9, 0xeb, 0xbd,
+ 0xed, 0x60, 0x7b, 0x3d, 0xdd, 0xc3, 0xab, 0xbc, 0x9c, 0xf9, 0xa7, 0x3d,
+ 0x7c, 0x05, 0xd7, 0x3d, 0xf3, 0x62, 0xb7, 0xbe, 0x9d, 0x89, 0x7b, 0x3d,
+ 0x2e, 0x25, 0x20, 0x3c, 0xdb, 0xe4, 0x3d, 0xbe, 0x0e, 0xee, 0x3d, 0x3d,
+ 0x9c, 0xd3, 0xdc, 0x3c, 0x00, 0x4d, 0x38, 0xbe, 0xd6, 0x3c, 0x1e, 0xbd,
+ 0x8b, 0x41, 0x14, 0x3e, 0x56, 0x6b, 0x21, 0x3e, 0xfc, 0x0b, 0xb4, 0xbe,
+ 0x8c, 0xee, 0x24, 0xbe, 0x92, 0xf6, 0x48, 0x3e, 0x01, 0xa4, 0x4e, 0x3c,
+ 0x86, 0xf3, 0x0b, 0x3d, 0xde, 0x84, 0x1d, 0x3e, 0xe1, 0xa9, 0x00, 0xbf,
+ 0xa5, 0x03, 0xa7, 0x3d, 0x2b, 0xf4, 0x32, 0xbd, 0x7b, 0xed, 0x30, 0xbd,
+ 0xd7, 0xb6, 0x2a, 0xbe, 0xa4, 0xa7, 0xaa, 0xbd, 0x76, 0xa8, 0x59, 0x3e,
+ 0x63, 0x2b, 0x3f, 0xbd, 0x6a, 0xb1, 0x8d, 0x3c, 0x1c, 0xf7, 0x90, 0x3e,
+ 0xad, 0xa8, 0xb2, 0xbd, 0x5e, 0xe2, 0x80, 0xbe, 0xb1, 0x3b, 0x67, 0xbd,
+ 0xaa, 0x58, 0x88, 0xbc, 0xce, 0x93, 0x66, 0xbe, 0x3d, 0xe4, 0x85, 0x3d,
+ 0xfc, 0x7d, 0xd8, 0xbe, 0x73, 0x8d, 0xeb, 0xbc, 0xf7, 0x65, 0x6c, 0xbe,
+ 0xc5, 0xd4, 0x51, 0x3d, 0x62, 0x0d, 0x4b, 0xbe, 0xb0, 0xc3, 0x1f, 0xbd,
+ 0x87, 0x98, 0x69, 0x3d, 0x4d, 0x80, 0xd2, 0xbc, 0x9c, 0x0c, 0x38, 0x3e,
+ 0x89, 0x8b, 0x81, 0x3e, 0x55, 0x79, 0xea, 0x3d, 0xd0, 0xf2, 0xc8, 0xbd,
+ 0xb4, 0x9c, 0xa9, 0x3d, 0x7f, 0x05, 0x83, 0xbd, 0x05, 0x77, 0xb0, 0x3b,
+ 0x62, 0xbd, 0x4c, 0x3d, 0x49, 0x44, 0xc9, 0xbd, 0xdc, 0x3f, 0xb9, 0x3d,
+ 0x56, 0xc5, 0xe3, 0xbe, 0x5e, 0x61, 0x26, 0x3d, 0x31, 0x0e, 0x12, 0xbc,
+ 0x2b, 0xe8, 0x93, 0x3b, 0xc0, 0x15, 0x10, 0xbe, 0xdb, 0x6b, 0xd4, 0xbd,
+ 0xa7, 0xf7, 0x97, 0x3d, 0x61, 0xa0, 0x08, 0x3e, 0x54, 0x8a, 0x65, 0x3e,
+ 0x58, 0xcc, 0x1d, 0xbe, 0x33, 0x44, 0x63, 0x3c, 0x69, 0x14, 0xf6, 0xbd,
+ 0xff, 0x62, 0xd4, 0x3d, 0x05, 0x2b, 0x8b, 0x3d, 0x22, 0x2c, 0x13, 0xbe,
+ 0x52, 0x0c, 0x0f, 0x3d, 0x48, 0x96, 0xc7, 0xbd, 0x4d, 0x35, 0xab, 0x3d,
+ 0x20, 0xbe, 0xeb, 0x3d, 0x64, 0xf0, 0x86, 0xbd, 0xcb, 0x71, 0xa5, 0xbd,
+ 0xd5, 0x2a, 0x95, 0x3c, 0x57, 0xaa, 0x06, 0x3e, 0x5e, 0x14, 0x3c, 0x3e,
+ 0xcb, 0xf8, 0x11, 0x3e, 0x34, 0x34, 0x6d, 0x3d, 0xa4, 0x66, 0x0b, 0x3c,
+ 0x52, 0x5b, 0x9d, 0xbb, 0x7a, 0x84, 0x90, 0xbd, 0x11, 0xc8, 0x4a, 0x3e,
+ 0x75, 0xf9, 0x8a, 0xbd, 0x83, 0x65, 0x22, 0xbd, 0x64, 0x5d, 0x15, 0xbd,
+ 0x91, 0x22, 0x5e, 0xbc, 0xbd, 0x09, 0x12, 0x3d, 0xfe, 0x19, 0xeb, 0x3c,
+ 0xa3, 0x78, 0x2e, 0xbd, 0x62, 0xf3, 0x7f, 0x3c, 0x05, 0x5e, 0x03, 0x3e,
+ 0x6c, 0x9e, 0xb7, 0x3d, 0xb1, 0x03, 0x4d, 0x3e, 0x66, 0x72, 0xfd, 0xbd,
+ 0xc5, 0x12, 0x11, 0x3d, 0x99, 0x39, 0xab, 0x3c, 0xc8, 0xf5, 0x5a, 0xbd,
+ 0x33, 0x84, 0x98, 0x3c, 0x0a, 0xd6, 0x99, 0x3d, 0x4f, 0xcb, 0xb5, 0xbb,
+ 0x00, 0x39, 0x41, 0x3e, 0xdc, 0x20, 0x27, 0xbc, 0x34, 0xdb, 0xbb, 0x3d,
+ 0x33, 0x3c, 0x26, 0x3d, 0x3a, 0x99, 0x2b, 0x3d, 0xa4, 0x31, 0x76, 0x3d,
+ 0x50, 0x79, 0x91, 0x3d, 0x80, 0x50, 0xc3, 0x3d, 0x5c, 0x3d, 0x39, 0x3e,
+ 0xc9, 0x7b, 0xed, 0xbc, 0xf2, 0xbb, 0x88, 0x3d, 0x76, 0xb2, 0x5e, 0xbe,
+ 0x0c, 0x80, 0xb9, 0xbd, 0x10, 0x91, 0x12, 0x3d, 0xca, 0xfb, 0x47, 0x3d,
+ 0xc4, 0x43, 0xc4, 0xbd, 0xd3, 0x36, 0x82, 0xbd, 0x03, 0x96, 0xda, 0xbd,
+ 0xac, 0x46, 0xbf, 0x3d, 0x26, 0x6b, 0x26, 0x3d, 0x02, 0xa1, 0x0f, 0xbe,
+ 0x68, 0x09, 0x42, 0x3e, 0x32, 0xf7, 0x5d, 0x3e, 0xad, 0xa5, 0xec, 0x3d,
+ 0x97, 0x8a, 0xb1, 0x3e, 0xc7, 0x0e, 0xee, 0xbd, 0x12, 0x2d, 0xf0, 0x3d,
+ 0x05, 0x02, 0xae, 0xbe, 0x63, 0x2c, 0xe3, 0x3c, 0x1c, 0x86, 0x47, 0x3e,
+ 0xe5, 0xa6, 0x46, 0x3e, 0x6b, 0x88, 0x8c, 0xbd, 0x6b, 0x84, 0x28, 0x3e,
+ 0xad, 0xc4, 0x79, 0xbe, 0x77, 0x46, 0xfc, 0xbc, 0x40, 0x27, 0x28, 0x3e,
+ 0x2c, 0x30, 0xe0, 0xbd, 0xe5, 0xb6, 0xd8, 0x3c, 0x68, 0xac, 0x90, 0x3e,
+ 0x14, 0x75, 0x1c, 0xbe, 0x0d, 0xc9, 0x9e, 0xbe, 0x4b, 0xec, 0x4f, 0xbe,
+ 0x1b, 0x78, 0xcb, 0x3d, 0xf6, 0xeb, 0xd3, 0xbe, 0x38, 0xab, 0xed, 0xbd,
+ 0x86, 0x1a, 0xf4, 0x3d, 0x43, 0x3f, 0xd2, 0x3c, 0xbf, 0x91, 0xc3, 0xbe,
+ 0x76, 0x19, 0x6a, 0x3d, 0xd9, 0x29, 0x35, 0xbe, 0x3b, 0x83, 0xe7, 0xba,
+ 0x6e, 0xcd, 0x2e, 0xbf, 0xec, 0x5f, 0x25, 0x3e, 0xb6, 0x01, 0x9f, 0x3d,
+ 0xd6, 0x6e, 0x37, 0x3e, 0x09, 0x82, 0x49, 0xbe, 0x31, 0x65, 0x67, 0xbf,
+ 0x1a, 0xf7, 0xfc, 0xbe, 0xa9, 0x80, 0x7a, 0xbc, 0x09, 0x7e, 0xa0, 0xbe,
+ 0x62, 0x1c, 0x38, 0xbd, 0xce, 0x50, 0x9e, 0x3d, 0x69, 0x4b, 0x47, 0xbe,
+ 0x53, 0x6d, 0x8f, 0xbe, 0xee, 0x17, 0xa4, 0xbe, 0x42, 0x75, 0x52, 0x3c,
+ 0xe5, 0x67, 0x1a, 0xbe, 0x34, 0xb7, 0x53, 0xbf, 0xc7, 0xdf, 0xb3, 0xbd,
+ 0x6a, 0x60, 0x00, 0xbe, 0x32, 0xd9, 0xc0, 0x3d, 0x15, 0x83, 0x9c, 0x3b,
+ 0x79, 0x94, 0x9a, 0xbe, 0xac, 0x0b, 0xf1, 0xbe, 0x13, 0xd8, 0x11, 0xbe,
+ 0x25, 0x26, 0xb3, 0xbe, 0x13, 0xce, 0xc7, 0x3d, 0x3a, 0xb6, 0x17, 0x3e,
+ 0xb7, 0xd8, 0x6f, 0x3d, 0x1f, 0xc1, 0xe2, 0xbe, 0x5a, 0x21, 0x26, 0xbe,
+ 0xbd, 0x0b, 0x39, 0x3e, 0xf3, 0xb2, 0x87, 0x3d, 0x47, 0x17, 0xf0, 0xbe,
+ 0x09, 0xb9, 0xd8, 0x3d, 0x3c, 0x61, 0x81, 0x3e, 0x21, 0xe5, 0xba, 0xbd,
+ 0x26, 0x80, 0x0c, 0x3e, 0x95, 0x3e, 0x9a, 0xbd, 0x45, 0xc1, 0x31, 0xbe,
+ 0x3d, 0xa0, 0x14, 0xbd, 0x02, 0x58, 0x32, 0xbd, 0x59, 0xc7, 0xff, 0x3c,
+ 0x15, 0x05, 0xe2, 0x3e, 0x86, 0x1d, 0x0f, 0xbe, 0xa0, 0x40, 0xbc, 0xbe,
+ 0x68, 0x5e, 0x44, 0x3e, 0x99, 0x1f, 0xfb, 0x3d, 0xfe, 0x0e, 0x21, 0xbe,
+ 0x13, 0xf4, 0x67, 0xbe, 0x39, 0x82, 0xe1, 0xbc, 0xf4, 0x0d, 0xdb, 0x3d,
+ 0xd6, 0x05, 0x98, 0xbe, 0xd5, 0x96, 0x43, 0xbe, 0x0d, 0x8b, 0x04, 0xbe,
+ 0xdb, 0x1b, 0x9b, 0xbd, 0xa7, 0xb8, 0x86, 0xbe, 0x93, 0xa7, 0x48, 0x3e,
+ 0xff, 0x83, 0x70, 0xbe, 0x81, 0x92, 0xb6, 0x3e, 0x00, 0xde, 0x2d, 0xbe,
+ 0xcb, 0xea, 0xd1, 0xbe, 0x26, 0x5f, 0x89, 0x3d, 0xa9, 0x78, 0x94, 0xbc,
+ 0x46, 0xe4, 0xc0, 0xbc, 0xf8, 0x7a, 0x7f, 0xbe, 0x7f, 0x6c, 0xda, 0xbd,
+ 0xf0, 0x26, 0x7a, 0x3d, 0xc8, 0xe1, 0x68, 0xbe, 0xf9, 0x78, 0x22, 0xbd,
+ 0xc6, 0xe1, 0x7e, 0xbe, 0x48, 0xa7, 0xa1, 0xbd, 0x79, 0xdc, 0x63, 0xbc,
+ 0x3b, 0x33, 0x25, 0x3e, 0xe9, 0x5d, 0x8a, 0xbe, 0x68, 0x6a, 0x42, 0xbe,
+ 0xb6, 0x15, 0x24, 0xbd, 0x8a, 0xab, 0xec, 0xbe, 0x57, 0x0d, 0xf0, 0x3d,
+ 0xea, 0x0e, 0xd0, 0xbd, 0x6e, 0xe6, 0xd4, 0xbd, 0xc1, 0x3c, 0x84, 0xbe,
+ 0xfe, 0xc7, 0x0f, 0xbe, 0xe0, 0x6e, 0x3b, 0xbd, 0xb5, 0x5b, 0x75, 0xbe,
+ 0x57, 0xb2, 0x70, 0xbe, 0x9a, 0xb9, 0x45, 0x3c, 0xc0, 0xe1, 0xd2, 0xbc,
+ 0x71, 0xc3, 0xbc, 0xbd, 0xc1, 0x3a, 0x0b, 0x3d, 0x0d, 0x92, 0xd4, 0xbc,
+ 0x90, 0x72, 0x14, 0xbd, 0x19, 0x0f, 0x79, 0x3c, 0x8d, 0xb0, 0xc9, 0xbe,
+ 0xec, 0x8b, 0xe0, 0x3d, 0x61, 0xeb, 0x92, 0xbd, 0xcc, 0x90, 0xf1, 0xbd,
+ 0xc4, 0x38, 0x92, 0xbd, 0x89, 0xa0, 0x33, 0xbc, 0x4e, 0xe5, 0x4d, 0xbd,
+ 0x7a, 0xd2, 0x83, 0xbd, 0x61, 0x9a, 0xd0, 0x3d, 0x33, 0xca, 0x94, 0xbd,
+ 0x8c, 0x1a, 0xb3, 0x3d, 0x4e, 0x06, 0x51, 0x3e, 0xd5, 0x7a, 0xb3, 0x3d,
+ 0x6a, 0x1d, 0x01, 0xbe, 0x3a, 0xc0, 0xc4, 0x3e, 0xe6, 0xf7, 0xee, 0xbd,
+ 0xe2, 0x8e, 0x1f, 0xbe, 0xc2, 0xfd, 0x96, 0x3e, 0x6c, 0xe1, 0x62, 0xbe,
+ 0xff, 0xd8, 0x13, 0xbe, 0xbd, 0xb6, 0x81, 0xbd, 0xd8, 0xdc, 0x4a, 0x3b,
+ 0xe5, 0xe2, 0xcb, 0x3a, 0x49, 0x4c, 0xc3, 0xbd, 0xfb, 0x38, 0xa1, 0x3d,
+ 0x96, 0x5e, 0xa7, 0xbc, 0xcb, 0xde, 0x23, 0x3d, 0x0f, 0x0d, 0x8f, 0x3e,
+ 0x9b, 0x54, 0x04, 0x3e, 0x7d, 0x1b, 0x78, 0xbd, 0x06, 0x2f, 0x2a, 0x3e,
+ 0x3e, 0x9a, 0xce, 0xbe, 0xa2, 0xa0, 0xa7, 0xbe, 0x58, 0x1f, 0x5e, 0x3e,
+ 0x23, 0xe4, 0xc5, 0x3c, 0x25, 0xc4, 0x1f, 0xbe, 0x9a, 0x80, 0x56, 0x3b,
+ 0x69, 0xb9, 0x17, 0x3e, 0x4d, 0xd6, 0xf1, 0x3d, 0xf3, 0x63, 0x4a, 0xbe,
+ 0x2b, 0xa0, 0xcd, 0x3d, 0x14, 0xc3, 0x28, 0xbe, 0x61, 0x71, 0x05, 0x3e,
+ 0x6a, 0xb8, 0x07, 0x3d, 0x55, 0xf9, 0x2b, 0x3e, 0x39, 0x86, 0x0f, 0xbd,
+ 0x38, 0xd5, 0x61, 0x3e, 0xdb, 0x24, 0xa6, 0xbe, 0x20, 0xde, 0x2c, 0xbe,
+ 0x15, 0x3f, 0xc8, 0x3d, 0x9e, 0x9b, 0x45, 0x3d, 0xed, 0x09, 0x22, 0xbe,
+ 0x2a, 0x2c, 0x33, 0xbe, 0x37, 0x8a, 0x54, 0xbd, 0x48, 0x0c, 0x84, 0xba,
+ 0x2f, 0x23, 0x12, 0xbe, 0xc4, 0x7c, 0x48, 0x3e, 0x82, 0xd5, 0x95, 0xbe,
+ 0x79, 0xda, 0x06, 0x3c, 0x2d, 0xf1, 0x33, 0x3d, 0x55, 0x60, 0x77, 0xbd,
+ 0x1d, 0x61, 0x05, 0xbe, 0x81, 0xcb, 0x8d, 0x3e, 0x06, 0x08, 0x01, 0xbe,
+ 0x95, 0xc7, 0x51, 0xbd, 0xf0, 0x72, 0x99, 0xbd, 0x06, 0xb2, 0xc6, 0x3d,
+ 0xfb, 0x0f, 0xca, 0x3d, 0x8e, 0x73, 0x7e, 0x3b, 0xfd, 0x34, 0x67, 0xbd,
+ 0x70, 0x32, 0xdd, 0xbc, 0x2d, 0x99, 0xea, 0xbe, 0xc2, 0x73, 0x64, 0xbd,
+ 0x00, 0x94, 0x0f, 0xbe, 0x75, 0x7a, 0xba, 0xbd, 0x85, 0xc4, 0x2a, 0x3d,
+ 0x76, 0x88, 0x30, 0x3d, 0x53, 0x72, 0x9d, 0xbd, 0x30, 0x57, 0x81, 0x3e,
+ 0x6e, 0x96, 0x95, 0xbd, 0x3c, 0x35, 0x38, 0x3d, 0x9b, 0x98, 0x6f, 0xbb,
+ 0xf0, 0x78, 0x27, 0x3d, 0xdc, 0xa7, 0x13, 0x3d, 0x6d, 0x26, 0x01, 0x3e,
+ 0x0c, 0x56, 0x0d, 0x3c, 0x34, 0x73, 0x26, 0x3d, 0x9c, 0xd1, 0xe5, 0xbe,
+ 0x3a, 0x3d, 0x80, 0xbd, 0x12, 0x3e, 0xf8, 0xbd, 0xaf, 0x15, 0x82, 0xbd,
+ 0x50, 0x20, 0x49, 0xbe, 0x69, 0x45, 0x3e, 0x3e, 0xaa, 0xf1, 0x2d, 0xbe,
+ 0x46, 0x98, 0x5a, 0xbe, 0x3a, 0x09, 0xb8, 0xbe, 0x10, 0xa7, 0x6b, 0xbe,
+ 0xf4, 0x2a, 0x71, 0x3e, 0x34, 0xde, 0x1a, 0xbd, 0x14, 0x25, 0xc5, 0x3d,
+ 0xac, 0x10, 0x0e, 0xbd, 0xdd, 0xd6, 0x6c, 0x3e, 0x4a, 0x10, 0x6d, 0x3d,
+ 0x8a, 0x02, 0x45, 0xbe, 0x79, 0x00, 0x82, 0x3d, 0xa0, 0x2d, 0x6d, 0x3e,
+ 0xcf, 0x3b, 0xaa, 0xbd, 0x62, 0xbc, 0x3b, 0x3d, 0x1d, 0x84, 0x85, 0x3e,
+ 0x74, 0x75, 0x49, 0xbe, 0x72, 0x3d, 0x81, 0xbe, 0xd5, 0xb1, 0x13, 0xbe,
+ 0x15, 0x6e, 0x95, 0xbe, 0x6f, 0x24, 0x95, 0x3e, 0x07, 0xc3, 0x22, 0x3e,
+ 0x71, 0x27, 0x1c, 0xbd, 0xf8, 0x56, 0x55, 0xbe, 0x4d, 0x4b, 0x50, 0xbe,
+ 0x4e, 0x36, 0x61, 0xbd, 0xb4, 0x21, 0x08, 0xbf, 0x18, 0x79, 0xe1, 0xbc,
+ 0x05, 0x0e, 0x58, 0x3e, 0xaf, 0xa3, 0xff, 0xbd, 0x20, 0x4e, 0x78, 0xbd,
+ 0xce, 0x7a, 0xfe, 0xbc, 0x8d, 0xca, 0x02, 0xbe, 0x0c, 0x26, 0xb8, 0xbe,
+ 0x64, 0x00, 0xab, 0xbe, 0xd2, 0x25, 0x2b, 0xbe, 0x1f, 0x46, 0x4e, 0xbd,
+ 0x30, 0x12, 0xa0, 0xbd, 0xea, 0xae, 0x29, 0x3e, 0x7f, 0xe0, 0x8f, 0xbe,
+ 0x9e, 0x18, 0x2b, 0x3d, 0xe2, 0xa8, 0x14, 0xbe, 0x23, 0xe3, 0x17, 0x3c,
+ 0xee, 0xc3, 0x21, 0x3e, 0x43, 0xdf, 0xce, 0x3d, 0x12, 0x1c, 0xd2, 0xbb,
+ 0x7f, 0xd5, 0xca, 0x3d, 0x3c, 0x5c, 0xf1, 0x3d, 0x95, 0x71, 0x44, 0x3d,
+ 0x93, 0xf3, 0xba, 0xbe, 0x68, 0x93, 0x5c, 0xbe, 0x10, 0x67, 0xf1, 0xbe,
+ 0x2a, 0x15, 0x18, 0x3d, 0x73, 0xe2, 0x82, 0x3b, 0xd6, 0x91, 0xbc, 0x3d,
+ 0x52, 0xcb, 0xb9, 0xbe, 0xcb, 0x4a, 0xd7, 0x3c, 0x6c, 0x72, 0xa3, 0xbe,
+ 0xf7, 0xb6, 0xed, 0xbc, 0xf2, 0x4b, 0x78, 0x3a, 0x22, 0x3b, 0x92, 0xbe,
+ 0x93, 0xd9, 0x90, 0x3e, 0x45, 0x47, 0x15, 0xbe, 0x15, 0xb5, 0x29, 0xbc,
+ 0x12, 0x00, 0xe3, 0xbd, 0xfb, 0xb2, 0xa7, 0xbe, 0x88, 0x19, 0x9b, 0xbe,
+ 0x18, 0x47, 0x29, 0xbe, 0x65, 0xe8, 0xec, 0xbb, 0xd7, 0x95, 0x5e, 0xbe,
+ 0x44, 0xf0, 0xae, 0xbd, 0x5e, 0xb2, 0x63, 0xbe, 0x8f, 0x8c, 0xda, 0xbd,
+ 0x21, 0xec, 0xce, 0x3c, 0x61, 0xec, 0xc9, 0xbd, 0xc4, 0xbc, 0xae, 0xbe,
+ 0x55, 0x77, 0xa7, 0xbe, 0x5b, 0x6f, 0x43, 0xbe, 0x09, 0x7c, 0x72, 0x3d,
+ 0x07, 0x9c, 0x9d, 0xbe, 0xa3, 0x3f, 0x50, 0x3c, 0x1c, 0xa9, 0x0c, 0xbe,
+ 0x67, 0x2d, 0x3b, 0xbd, 0xc4, 0xed, 0x10, 0x3d, 0x50, 0xa2, 0xd4, 0xbe,
+ 0x47, 0x29, 0x0c, 0xbe, 0x9d, 0x91, 0x12, 0x3d, 0x88, 0xdd, 0x67, 0xb8,
+ 0x38, 0x07, 0x2f, 0xbe, 0x1a, 0x06, 0x37, 0xbc, 0x62, 0x98, 0xa3, 0xbe,
+ 0x98, 0xcc, 0x81, 0x3e, 0x6e, 0x97, 0xd6, 0xbd, 0x95, 0x8b, 0xdd, 0xbd,
+ 0x79, 0xa4, 0xf3, 0x3c, 0xb5, 0xc2, 0x11, 0xbe, 0xd3, 0xec, 0x66, 0xbe,
+ 0xa3, 0x56, 0x80, 0xbc, 0x01, 0x00, 0x63, 0x3c, 0x56, 0x89, 0x87, 0x3b,
+ 0xe2, 0x59, 0x39, 0xbe, 0x4d, 0x6d, 0xfb, 0x3d, 0xa0, 0x39, 0xcc, 0x3d,
+ 0x69, 0x45, 0x8e, 0xbd, 0x5f, 0x84, 0xd6, 0x3d, 0xa1, 0x84, 0xbd, 0x3d,
+ 0x10, 0x07, 0x38, 0xbe, 0x9e, 0xfa, 0x10, 0x3e, 0xb7, 0xa7, 0x29, 0xbe,
+ 0x97, 0x88, 0x6a, 0xbd, 0xbe, 0x44, 0x49, 0xbc, 0x6d, 0xaf, 0x52, 0xbe,
+ 0x1b, 0x47, 0x60, 0xbd, 0x2d, 0x4d, 0x09, 0x3e, 0xaf, 0x9b, 0x4d, 0x3d,
+ 0x0e, 0x61, 0x8d, 0x3b, 0x79, 0xf0, 0x43, 0x3e, 0xf1, 0xe4, 0x6e, 0x3e,
+ 0x30, 0x82, 0xb4, 0x3d, 0xb1, 0x9a, 0x1f, 0xbe, 0xf0, 0x6d, 0xe7, 0x3d,
+ 0xa4, 0x03, 0x72, 0x3d, 0xf6, 0x2b, 0xa5, 0x3b, 0xd0, 0x1c, 0xd9, 0x3d,
+ 0x46, 0x22, 0xaa, 0xbe, 0xd3, 0x08, 0x54, 0xbd, 0xcd, 0xb1, 0xc2, 0xba,
+ 0x07, 0xf2, 0xb6, 0xbd, 0xfe, 0x75, 0x73, 0x3c, 0xe4, 0x9b, 0x0a, 0xbd,
+ 0xc7, 0x90, 0x9e, 0xbd, 0xf1, 0xea, 0xa7, 0x3c, 0xc8, 0x26, 0x52, 0x3e,
+ 0xfc, 0x27, 0xc7, 0x3e, 0x97, 0x6f, 0xa9, 0x3d, 0x7f, 0xcb, 0x24, 0xbe,
+ 0x7d, 0x06, 0xb8, 0xbd, 0xa3, 0x40, 0x5e, 0x3d, 0x27, 0x47, 0x2b, 0xbe,
+ 0x44, 0x61, 0x8d, 0x3e, 0x04, 0x26, 0x8c, 0xbe, 0x5c, 0x59, 0xfa, 0xbd,
+ 0xcf, 0xf0, 0xa6, 0xbd, 0xc6, 0xdd, 0x9c, 0x3d, 0x44, 0xe8, 0x70, 0xbe,
+ 0xda, 0x14, 0x31, 0xbe, 0x38, 0xdb, 0xd2, 0xbd, 0x50, 0xa7, 0x19, 0x3d,
+ 0xf0, 0x2d, 0x3b, 0x3e, 0xfd, 0x9c, 0xe7, 0x3e, 0xb3, 0x62, 0xbb, 0x3d,
+ 0xe6, 0xe4, 0x95, 0x3c, 0xa4, 0x26, 0x10, 0x3e, 0xf6, 0x96, 0x4d, 0x3d,
+ 0xd8, 0x93, 0x34, 0xbd, 0x87, 0x9d, 0x81, 0xbd, 0x4f, 0xb4, 0x85, 0xbd,
+ 0x7a, 0xb6, 0x55, 0xbe, 0xbd, 0xfd, 0x84, 0x3d, 0x53, 0xa2, 0x15, 0x3e,
+ 0x10, 0x1e, 0x93, 0xbe, 0x4e, 0xab, 0xc5, 0xbd, 0x55, 0xd9, 0xdf, 0x3d,
+ 0xca, 0xf4, 0x6d, 0x3d, 0xdb, 0xfe, 0x84, 0x3e, 0x95, 0x98, 0x36, 0x3e,
+ 0x93, 0x3e, 0xfd, 0x3c, 0x61, 0x70, 0x04, 0xbd, 0x46, 0x72, 0xe4, 0x3c,
+ 0xa9, 0x0e, 0x58, 0xbe, 0xe5, 0x86, 0x33, 0x3d, 0x2d, 0x46, 0x03, 0xbe,
+ 0x94, 0xdc, 0xf0, 0xbd, 0xaa, 0x48, 0x27, 0xbe, 0x34, 0xb0, 0x63, 0xbd,
+ 0x56, 0x1f, 0xb7, 0xbb, 0xcd, 0xce, 0xde, 0xbd, 0xc7, 0xb0, 0x4d, 0x3d,
+ 0x65, 0x11, 0x01, 0x3e, 0xf5, 0xab, 0x8a, 0x3d, 0x34, 0xe1, 0x10, 0xbe,
+ 0x49, 0x06, 0xff, 0xbd, 0xb6, 0xe4, 0x69, 0xbe, 0xc8, 0x48, 0x78, 0xbd,
+ 0x1a, 0x63, 0x2b, 0x3d, 0x7f, 0x73, 0x35, 0xbe, 0x1e, 0x01, 0xf5, 0xbd,
+ 0x89, 0xad, 0x6b, 0xbe, 0x6a, 0x85, 0x09, 0x3d, 0x74, 0x69, 0xf6, 0xbd,
+ 0x62, 0x39, 0xc9, 0xbe, 0x72, 0x00, 0x8e, 0x3d, 0xfc, 0xa5, 0x9c, 0xbe,
+ 0x53, 0x4e, 0x95, 0xbd, 0xc7, 0x7d, 0xae, 0xbb, 0xa7, 0x61, 0xb9, 0xba,
+ 0xb8, 0x9a, 0xce, 0xbe, 0x80, 0xcc, 0xd2, 0xbe, 0xcf, 0xeb, 0x5c, 0xbe,
+ 0x69, 0xa4, 0x0e, 0xbd, 0x12, 0xa9, 0x1e, 0xbe, 0xc9, 0x6d, 0x50, 0xbe,
+ 0xfc, 0xd5, 0xe6, 0xbd, 0x9f, 0x5c, 0xd0, 0xbe, 0x33, 0xcf, 0xbb, 0xbd,
+ 0x70, 0x66, 0xa5, 0xbe, 0x6b, 0x92, 0xfa, 0xbe, 0x27, 0xa0, 0x4b, 0x3d,
+ 0x5d, 0x26, 0x75, 0xbe, 0x46, 0x63, 0x8c, 0xbe, 0x57, 0x65, 0xaf, 0xbd,
+ 0xea, 0xd8, 0x1c, 0x3d, 0xcd, 0x4f, 0xc2, 0xbe, 0x87, 0xf0, 0x0b, 0xbf,
+ 0x25, 0xdf, 0xd9, 0xbe, 0x5d, 0x6a, 0x4e, 0x3d, 0xaa, 0x06, 0xf1, 0xbd,
+ 0x31, 0xe2, 0x60, 0xbe, 0x72, 0x6f, 0xf2, 0xbc, 0xb9, 0x4a, 0x9e, 0xbe,
+ 0xfb, 0xb0, 0xd7, 0xbd, 0x9f, 0xfa, 0x96, 0xbe, 0xc8, 0x14, 0x13, 0xbf,
+ 0xaa, 0x6a, 0x39, 0xbc, 0x7f, 0x24, 0x5a, 0xbd, 0x12, 0x36, 0xa9, 0x3d,
+ 0x9e, 0x86, 0x60, 0x3d, 0xbc, 0x33, 0x85, 0x3c, 0x4c, 0x72, 0xf2, 0xbe,
+ 0x39, 0x9f, 0xba, 0xbe, 0xc2, 0xa5, 0x68, 0xbe, 0x35, 0x06, 0xa1, 0x3c,
+ 0xb5, 0xad, 0x53, 0x3d, 0x3e, 0xd0, 0xa2, 0xbd, 0xfd, 0x9b, 0xaa, 0x3c,
+ 0x0a, 0x8f, 0xa8, 0x3e, 0x24, 0xca, 0x09, 0xbd, 0x14, 0x2c, 0x4c, 0xbe,
+ 0x56, 0x1b, 0xae, 0xbd, 0x9d, 0x45, 0x60, 0xbc, 0xb7, 0x16, 0x5f, 0xbe,
+ 0x57, 0x8f, 0x8d, 0x3e, 0x5d, 0xab, 0x50, 0xbd, 0xcc, 0x11, 0xb0, 0x3c,
+ 0x52, 0x21, 0xd1, 0xbe, 0xfb, 0xff, 0xb2, 0xbc, 0x9b, 0xd1, 0x14, 0xbe,
+ 0xfc, 0x2c, 0x7e, 0xbd, 0x39, 0x94, 0xfb, 0xb9, 0xca, 0x93, 0xca, 0xbd,
+ 0x0a, 0xa7, 0xfc, 0xbd, 0xf6, 0xd3, 0x7f, 0x3e, 0xd3, 0xda, 0x0b, 0xbe,
+ 0x8e, 0xf9, 0x99, 0xbd, 0xc5, 0xe4, 0x73, 0xbd, 0xba, 0x7d, 0xae, 0xbd,
+ 0x5b, 0x0e, 0x24, 0x3d, 0xcf, 0x46, 0x90, 0x3d, 0x42, 0x80, 0x88, 0xbc,
+ 0x93, 0x44, 0xa0, 0x3c, 0x02, 0x2c, 0x53, 0xbb, 0xb3, 0x0d, 0xdf, 0x3e,
+ 0xf3, 0x46, 0xc8, 0x3c, 0xc5, 0x84, 0xa4, 0xbd, 0xf8, 0x13, 0xad, 0x3b,
+ 0x6d, 0x41, 0xb5, 0x3c, 0xeb, 0x74, 0x5f, 0xbe, 0x67, 0x82, 0xd0, 0x3e,
+ 0x3c, 0xd0, 0x9c, 0xbd, 0xa0, 0x97, 0x48, 0x3e, 0x1f, 0x0a, 0x36, 0xbe,
+ 0xf6, 0x51, 0x4a, 0xbd, 0x4f, 0xe5, 0x20, 0xbe, 0xa1, 0x8e, 0x0d, 0xbd,
+ 0x70, 0x13, 0x9c, 0xbd, 0xe8, 0x43, 0xb1, 0xbb, 0xc3, 0x59, 0xa4, 0x3e,
+ 0x06, 0xd6, 0x10, 0x3e, 0x8e, 0x8e, 0x88, 0x3e, 0xe8, 0xa8, 0xe1, 0xbd,
+ 0xb3, 0x6e, 0x6b, 0xbe, 0x28, 0x96, 0x7f, 0xbe, 0xde, 0xcc, 0xab, 0xbe,
+ 0xb0, 0xc9, 0xa6, 0xbe, 0x60, 0x75, 0xc5, 0x3d, 0x39, 0x36, 0xea, 0x3d,
+ 0x53, 0x43, 0xea, 0xbe, 0xb0, 0x9d, 0x9e, 0x3d, 0x06, 0x01, 0x7c, 0xbe,
+ 0xb8, 0x49, 0x51, 0xbe, 0x7c, 0xad, 0xe8, 0x3c, 0xe2, 0x4e, 0xc6, 0x3c,
+ 0x9f, 0x1f, 0x56, 0xbe, 0x5a, 0xd7, 0x79, 0x3d, 0x62, 0x73, 0x81, 0xbe,
+ 0xe6, 0xc1, 0xd1, 0x3c, 0x4e, 0x1c, 0x18, 0x3f, 0x2a, 0xe7, 0xa4, 0x3e,
+ 0xf6, 0x80, 0x24, 0x3e, 0x06, 0xf7, 0x00, 0x3f, 0x34, 0x8e, 0x91, 0xbe,
+ 0x17, 0x9f, 0xf3, 0x3c, 0xc5, 0x69, 0x15, 0x3f, 0x18, 0xd8, 0xab, 0x3d,
+ 0x98, 0xd2, 0x55, 0x3d, 0xf1, 0x5f, 0xdb, 0x3e, 0x21, 0x48, 0x05, 0xbf,
+ 0xf7, 0x44, 0x65, 0xbd, 0xbd, 0x27, 0xf6, 0x3e, 0x4e, 0x58, 0xaa, 0x3e,
+ 0x1f, 0x87, 0xd5, 0x3b, 0x4e, 0x6f, 0xa8, 0xbd, 0x1f, 0x08, 0xd0, 0xbe,
+ 0x06, 0xd5, 0x76, 0x3d, 0x15, 0xf8, 0x48, 0x3e, 0x38, 0xe0, 0x0e, 0xbf,
+ 0xaa, 0x5c, 0xaf, 0xbd, 0xfd, 0xe2, 0xbd, 0xbe, 0x54, 0x5b, 0x2f, 0xbf,
+ 0x37, 0xe6, 0xd9, 0x3d, 0xd4, 0x6d, 0x89, 0xbe, 0xe4, 0xa0, 0xc4, 0x3c,
+ 0x76, 0x37, 0xe2, 0xbe, 0xd2, 0xf0, 0x98, 0x3c, 0xe7, 0x7a, 0xcc, 0x3e,
+ 0xaa, 0x3f, 0x11, 0xbf, 0x86, 0x4a, 0x3e, 0xbf, 0xae, 0xa4, 0xe5, 0x3b,
+ 0x62, 0x98, 0x31, 0xbe, 0xff, 0x4e, 0x80, 0x3d, 0x79, 0xe7, 0xba, 0xbd,
+ 0x93, 0x5b, 0xca, 0xbe, 0x3c, 0x97, 0x97, 0x3d, 0xf1, 0x41, 0x2d, 0xbf,
+ 0xc9, 0xa4, 0x4b, 0xbf, 0x9e, 0x2a, 0xde, 0x3d, 0xad, 0x4e, 0x84, 0xbe,
+ 0x01, 0x2f, 0x5c, 0x3b, 0xab, 0x1c, 0x45, 0xbe, 0x32, 0x41, 0x2b, 0x3c,
+ 0x73, 0x53, 0x50, 0x3e, 0xe2, 0xc4, 0x06, 0xbf, 0x62, 0xef, 0x13, 0xbf,
+ 0x6e, 0x3d, 0x86, 0x3c, 0x6d, 0x9a, 0xee, 0xbd, 0x49, 0xbc, 0xa8, 0x3d,
+ 0x68, 0xfe, 0x11, 0x3e, 0xde, 0x38, 0xfa, 0xbe, 0xbc, 0x06, 0x81, 0xbc,
+ 0xb7, 0x85, 0xc3, 0xbe, 0x26, 0x4f, 0x24, 0xbf, 0xe8, 0x94, 0xbb, 0xbb,
+ 0x16, 0x0e, 0x9b, 0xbe, 0xca, 0xe8, 0x52, 0xbe, 0xa2, 0xb7, 0x53, 0xbd,
+ 0x04, 0xef, 0x52, 0x3b, 0x08, 0xad, 0x1e, 0xbd, 0x72, 0xba, 0x01, 0xbf,
+ 0xd7, 0x49, 0x87, 0xbe, 0xf3, 0x7b, 0xf2, 0x3c, 0xfc, 0x8e, 0x84, 0x3d,
+ 0xcf, 0xcc, 0x3a, 0x3d, 0x35, 0xe0, 0xe4, 0xbc, 0x88, 0x88, 0x05, 0x3d,
+ 0x8d, 0x2f, 0xab, 0x3d, 0x33, 0x4f, 0x49, 0xbe, 0xc6, 0x68, 0xfc, 0xbe,
+ 0xfc, 0x90, 0x2f, 0xbb, 0x20, 0x38, 0xc1, 0xbd, 0x19, 0x53, 0x27, 0xbd,
+ 0xa2, 0xee, 0x09, 0xbe, 0x5e, 0x6f, 0x6b, 0x3d, 0x1e, 0xf9, 0x0d, 0x3d,
+ 0x76, 0xd5, 0xdd, 0xbe, 0xe3, 0xa8, 0xac, 0xbe, 0xaa, 0xad, 0x0d, 0x3d,
+ 0x91, 0x62, 0xce, 0xbd, 0x83, 0x52, 0xbb, 0xbc, 0xfd, 0x4e, 0x18, 0x3e,
+ 0x98, 0x73, 0x8f, 0xbd, 0x55, 0x1f, 0x55, 0x39, 0xb9, 0x85, 0x67, 0xbe,
+ 0x1a, 0xcf, 0xd3, 0xbe, 0x97, 0x08, 0x14, 0xbd, 0xca, 0xf1, 0x11, 0xbe,
+ 0x8b, 0x4b, 0x39, 0xbe, 0xe8, 0xe0, 0xd8, 0xbc, 0x0a, 0xf4, 0x26, 0xbc,
+ 0x0d, 0xda, 0x20, 0xbd, 0x52, 0xe7, 0xb1, 0xbe, 0xfc, 0x69, 0xd3, 0xbe,
+ 0x6f, 0x10, 0xc8, 0x3c, 0xb8, 0xb5, 0x20, 0xbe, 0xcd, 0xd6, 0x72, 0x3d,
+ 0xb4, 0x1b, 0xca, 0xbd, 0x1c, 0xa7, 0xfb, 0xbd, 0xf4, 0x0c, 0x91, 0xbd,
+ 0x95, 0xec, 0xda, 0xbc, 0x00, 0xff, 0x2b, 0xbe, 0x17, 0x4b, 0x45, 0xbd,
+ 0x45, 0x0c, 0x85, 0xbe, 0x97, 0x38, 0x88, 0xbd, 0x76, 0xfb, 0x0a, 0xbe,
+ 0xe3, 0xb5, 0xdf, 0x3c, 0x80, 0x2c, 0xd5, 0x3d, 0xc7, 0xb8, 0xb5, 0xbe,
+ 0x94, 0x5d, 0xba, 0xbe, 0x1e, 0x73, 0xba, 0x3c, 0xe6, 0x81, 0x25, 0xbe,
+ 0xff, 0x3d, 0x49, 0x3d, 0xc1, 0x10, 0x7d, 0x3e, 0x62, 0x4f, 0x55, 0xbe,
+ 0x3e, 0x29, 0x2f, 0xbe, 0x8c, 0x31, 0x6c, 0xbe, 0xb3, 0x0f, 0xdf, 0xbe,
+ 0x63, 0x87, 0xb2, 0xbc, 0xf0, 0x8a, 0x3f, 0xbe, 0x24, 0xe6, 0x92, 0x3c,
+ 0xb3, 0x20, 0xa7, 0xbd, 0x89, 0xa6, 0xb4, 0x3b, 0x73, 0xe7, 0xfc, 0x3d,
+ 0xe7, 0x9d, 0xbc, 0xbe, 0x09, 0x19, 0x97, 0xbe, 0x7c, 0xfc, 0x78, 0x3d,
+ 0xae, 0x7b, 0x23, 0xbe, 0xe5, 0x86, 0x3a, 0x3d, 0x07, 0x56, 0x87, 0xbd,
+ 0x8e, 0x90, 0x87, 0xbe, 0xc4, 0x20, 0x4e, 0xbe, 0x22, 0x0e, 0x38, 0xbc,
+ 0xe7, 0x44, 0xae, 0xbe, 0xa8, 0xd5, 0x1a, 0x3d, 0x93, 0x4e, 0x93, 0xbe,
+ 0x00, 0xb9, 0x2f, 0xbc, 0x30, 0xcf, 0xb5, 0xbe, 0xfb, 0x54, 0x8b, 0xbb,
+ 0x65, 0xd0, 0x00, 0x3e, 0xd5, 0x24, 0xda, 0xbe, 0xcf, 0xc4, 0xd8, 0xbe,
+ 0x34, 0x93, 0xb9, 0x3c, 0x02, 0x97, 0x8a, 0xbe, 0x8f, 0xd4, 0x22, 0x3d,
+ 0x9a, 0xfc, 0xa8, 0xbe, 0x3c, 0x29, 0x5c, 0xbd, 0xab, 0x08, 0xf5, 0x3c,
+ 0x45, 0x1e, 0x42, 0xbe, 0xc4, 0x6e, 0xc9, 0xbe, 0x0a, 0xb0, 0xce, 0x3c,
+ 0x7c, 0xf9, 0x94, 0xbe, 0x09, 0xeb, 0x1f, 0xbe, 0x82, 0x6a, 0x9e, 0xbe,
+ 0x29, 0x1f, 0x9e, 0x3c, 0x00, 0x19, 0x0d, 0x3d, 0x47, 0x54, 0x77, 0xbe,
+ 0x31, 0x68, 0x44, 0xbf, 0x0a, 0x4c, 0x14, 0x3d, 0xdd, 0x90, 0xe0, 0x3d,
+ 0xd4, 0xc2, 0x8e, 0x3d, 0x64, 0xfb, 0xa7, 0xbe, 0x76, 0x35, 0x63, 0xbe,
+ 0xdf, 0xe6, 0x18, 0xbe, 0x82, 0x50, 0x08, 0xbf, 0xd5, 0x97, 0x1b, 0xbf,
+ 0x28, 0x8d, 0xce, 0xbc, 0x09, 0xa0, 0xaa, 0xbe, 0xbc, 0x7f, 0xce, 0xbd,
+ 0xae, 0x93, 0x7a, 0xbe, 0x6c, 0x9f, 0xec, 0x3b, 0xf2, 0x7c, 0x89, 0x3d,
+ 0xa7, 0x8e, 0x9b, 0xbe, 0x7d, 0x7e, 0x01, 0xbf, 0x0d, 0xae, 0x7e, 0x3d,
+ 0xfc, 0xe0, 0x09, 0xbd, 0xf4, 0x70, 0x5a, 0x3d, 0xd3, 0x33, 0xf9, 0xbd,
+ 0xc5, 0xf8, 0xbb, 0xbe, 0xd5, 0xc6, 0x8d, 0xbe, 0xc9, 0xb1, 0x5e, 0xbe,
+ 0x93, 0x6e, 0xd6, 0xbe, 0xae, 0x9a, 0xca, 0x3c, 0x59, 0x9d, 0x62, 0xbe,
+ 0x95, 0x6f, 0x62, 0xbe, 0xa8, 0x20, 0xac, 0xbe, 0x40, 0xb2, 0xb0, 0x3c,
+ 0x08, 0xf4, 0xed, 0x3d, 0x39, 0x3c, 0x42, 0xbe, 0x31, 0x1c, 0xe3, 0xbe,
+ 0x1a, 0x1a, 0x0e, 0x3c, 0x59, 0x79, 0xe9, 0x3b, 0xa2, 0x22, 0x10, 0xbe,
+ 0x30, 0xaa, 0xa5, 0x3d, 0x71, 0x8f, 0x06, 0xbf, 0x16, 0x24, 0xa0, 0xbe,
+ 0x67, 0xb2, 0xc9, 0xbe, 0x52, 0x7b, 0x0f, 0xbf, 0xf9, 0xe9, 0x4f, 0x3d,
+ 0xac, 0x49, 0x17, 0xbe, 0xae, 0x48, 0x68, 0xbd, 0x7b, 0x00, 0xb6, 0xbe,
+ 0xeb, 0xb6, 0x68, 0x3c, 0xc9, 0xc1, 0xe9, 0x3d, 0xed, 0x2d, 0xc3, 0xbe,
+ 0xa0, 0x62, 0x41, 0xbf, 0x62, 0x09, 0x25, 0x3d, 0x9b, 0x06, 0x56, 0xbe,
+ 0x9f, 0x8b, 0x17, 0x3e, 0x34, 0xe7, 0x3c, 0x3c, 0x8a, 0xbb, 0x17, 0x3e,
+ 0x9d, 0xe9, 0x15, 0x3c, 0x24, 0x65, 0x04, 0xbf, 0x3e, 0x1f, 0x0c, 0xbe,
+ 0xd7, 0x33, 0x83, 0x3c, 0xc7, 0x55, 0xa0, 0xbc, 0xb4, 0xc6, 0xbf, 0xbd,
+ 0x5a, 0xb1, 0xfb, 0xbd, 0x64, 0x9e, 0x0b, 0x3d, 0x1a, 0xbc, 0x5f, 0x3e,
+ 0x3b, 0x78, 0xc8, 0x3d, 0x60, 0x10, 0xd6, 0xbd, 0x2d, 0xe4, 0x7d, 0x3d,
+ 0x9d, 0x40, 0x9b, 0xbe, 0xeb, 0x0c, 0xd1, 0xbc, 0x58, 0x00, 0x2e, 0xbe,
+ 0xb9, 0x75, 0xff, 0x3e, 0x4d, 0x20, 0xab, 0x3e, 0x26, 0x60, 0xed, 0xbd,
+ 0xc3, 0xb9, 0xdd, 0xbe, 0xb5, 0xda, 0xa8, 0x3e, 0x33, 0x68, 0xa2, 0x3d,
+ 0x43, 0xd0, 0xa9, 0x3c, 0xf1, 0x7f, 0x8b, 0x3b, 0x3f, 0x6b, 0xbf, 0x3e,
+ 0x6c, 0x69, 0x34, 0xbe, 0x79, 0x58, 0xf3, 0xbe, 0xf1, 0x2e, 0xdb, 0xbd,
+ 0x62, 0x48, 0x98, 0x3e, 0x59, 0x6d, 0x75, 0xbd, 0x37, 0x2c, 0x5a, 0x3c,
+ 0x13, 0xe7, 0x30, 0xbd, 0xa1, 0xac, 0xfc, 0x3c, 0xb2, 0xd8, 0x2a, 0x3e,
+ 0x22, 0x4b, 0xb6, 0xbd, 0xd1, 0xa3, 0x81, 0xbe, 0x73, 0x91, 0x15, 0xbd,
+ 0xe7, 0xfa, 0x76, 0x3d, 0x60, 0xf1, 0xdb, 0x3c, 0x07, 0xcf, 0xc2, 0x3c,
+ 0x7d, 0xaa, 0x8a, 0x3c, 0xa2, 0x13, 0xb1, 0x3e, 0xfa, 0x90, 0xa3, 0xbe,
+ 0x83, 0x37, 0x1f, 0x3e, 0xd3, 0xe8, 0xb0, 0x3d, 0xda, 0x49, 0x68, 0xbe,
+ 0x9d, 0x3c, 0x6b, 0x3e, 0xbc, 0x5a, 0x1d, 0xbc, 0xc9, 0x02, 0x25, 0x3d,
+ 0x9e, 0x16, 0x15, 0x3e, 0xb5, 0x40, 0x17, 0xbe, 0x19, 0x17, 0x1a, 0x3e,
+ 0x17, 0x95, 0x8c, 0xbd, 0xe5, 0x42, 0x0a, 0xbd, 0x61, 0x6f, 0xc9, 0x3d,
+ 0x16, 0x3c, 0x58, 0xbe, 0x19, 0x15, 0x7a, 0xbe, 0x2a, 0xb1, 0xa2, 0x3e,
+ 0x52, 0xa2, 0x5c, 0xbd, 0x92, 0x5f, 0x11, 0x3e, 0xb5, 0x1f, 0x2c, 0xbd,
+ 0xa5, 0xf8, 0x20, 0xbe, 0x0b, 0x75, 0xc9, 0x3d, 0x1e, 0x00, 0x82, 0x3e,
+ 0xfe, 0xa1, 0x61, 0x3d, 0xd5, 0x3f, 0x41, 0x3e, 0x09, 0x65, 0xcb, 0x3d,
+ 0xc5, 0x75, 0x1e, 0x3c, 0xbb, 0x0f, 0x76, 0xbe, 0xbf, 0xb6, 0xa0, 0x3d,
+ 0xdf, 0x04, 0xae, 0x3d, 0x9b, 0xda, 0x06, 0xbf, 0x38, 0x8c, 0x84, 0xbe,
+ 0x92, 0x5c, 0x0c, 0x3e, 0xb8, 0x67, 0xfc, 0xbd, 0xb7, 0xec, 0x95, 0xbd,
+ 0x13, 0x50, 0x15, 0xbe, 0x75, 0xb1, 0x8d, 0xbd, 0x0a, 0x71, 0x1e, 0x3e,
+ 0x7d, 0x79, 0xf8, 0x3d, 0x40, 0x97, 0x77, 0x3d, 0x3b, 0xe7, 0x9d, 0xbe,
+ 0xb2, 0x88, 0xaa, 0x3c, 0x79, 0x16, 0x44, 0x3d, 0xb9, 0xdc, 0x02, 0xbe,
+ 0xe1, 0xcb, 0xa3, 0xbc, 0x29, 0xda, 0xff, 0xbb, 0xb2, 0x4a, 0xb8, 0xbe,
+ 0xd9, 0x15, 0xfb, 0xbe, 0xf4, 0x0b, 0x43, 0xbd, 0x3e, 0xc0, 0x17, 0xbd,
+ 0x04, 0xa3, 0xae, 0xbc, 0xd0, 0xff, 0xdf, 0xbe, 0x72, 0xcb, 0x0f, 0x3e,
+ 0x03, 0x79, 0xff, 0x3d, 0x91, 0x65, 0x40, 0x3e, 0xb6, 0x77, 0xbb, 0xbd,
+ 0xa5, 0x8f, 0x15, 0xbf, 0x30, 0x61, 0x1e, 0xbe, 0x8b, 0xa9, 0xc2, 0x3d,
+ 0x6e, 0xdf, 0x06, 0xbe, 0x1e, 0x89, 0xdf, 0x3d, 0x8a, 0x8f, 0xf2, 0x3c,
+ 0xfd, 0xcd, 0x43, 0xbc, 0x9c, 0x4c, 0xa2, 0xbe, 0x30, 0xb4, 0x19, 0xbe,
+ 0xb3, 0x94, 0x45, 0x3d, 0x6c, 0xaf, 0xc1, 0xbd, 0xd4, 0x46, 0x12, 0xbf,
+ 0xbb, 0xde, 0x5b, 0x3e, 0x30, 0xb4, 0xb0, 0x3d, 0xce, 0x2e, 0x84, 0x3d,
+ 0x3e, 0x76, 0xce, 0xbd, 0x82, 0x5a, 0x93, 0xbe, 0x2d, 0x20, 0xc8, 0x3d,
+ 0x00, 0x41, 0x07, 0xbd, 0xb1, 0x5a, 0x36, 0xbe, 0x40, 0x9e, 0xce, 0xbc,
+ 0x04, 0x6a, 0x0a, 0x3e, 0x1d, 0xc6, 0x05, 0xbe, 0x48, 0xb8, 0x22, 0xbd,
+ 0xf7, 0x49, 0x95, 0xbe, 0xfb, 0xbd, 0xca, 0xbd, 0x25, 0x34, 0x31, 0xbe,
+ 0xc3, 0xe3, 0x0f, 0xbf, 0xcf, 0xb1, 0x32, 0x3d, 0x73, 0x0d, 0x86, 0x3d,
+ 0x05, 0xbb, 0xcf, 0xbc, 0x4a, 0xd5, 0x8d, 0xbd, 0xb3, 0x6e, 0x0d, 0xbf,
+ 0x64, 0xec, 0x2f, 0xbe, 0x52, 0xf8, 0x15, 0xbe, 0xd3, 0xa2, 0x80, 0x3d,
+ 0xac, 0x9f, 0x6a, 0xbd, 0x5e, 0xc7, 0xf9, 0xbd, 0xc8, 0x90, 0x81, 0xbd,
+ 0xe7, 0x9d, 0x49, 0x3d, 0xd4, 0x4a, 0x06, 0xbe, 0x43, 0x04, 0x00, 0x3d,
+ 0x27, 0xa5, 0xc2, 0xbe, 0x90, 0x68, 0xfa, 0xbe, 0xe9, 0xb1, 0x1c, 0x3e,
+ 0x6c, 0x40, 0x94, 0xbd, 0xee, 0xe3, 0x39, 0x3c, 0x40, 0xd9, 0xd7, 0xbd,
+ 0xe8, 0x19, 0x46, 0xbe, 0x72, 0x04, 0xaa, 0xbe, 0x80, 0xd8, 0xd3, 0xbd,
+ 0xe6, 0x8e, 0x04, 0xbe, 0x80, 0xea, 0xf8, 0xbc, 0xa2, 0x17, 0x51, 0x3e,
+ 0xd9, 0x2b, 0x59, 0x3d, 0x0c, 0x8f, 0x75, 0xbb, 0xdd, 0x53, 0x82, 0xbd,
+ 0x06, 0xc3, 0x50, 0x3d, 0xf2, 0x35, 0x54, 0xbe, 0xce, 0xf5, 0xea, 0xbe,
+ 0x22, 0x31, 0x61, 0xbc, 0x03, 0x0f, 0x4b, 0xbe, 0x1a, 0x66, 0x1e, 0x3d,
+ 0xb2, 0x6b, 0x22, 0xbe, 0xd7, 0x96, 0xe0, 0xbe, 0x08, 0x6f, 0xb3, 0xbe,
+ 0x30, 0x04, 0xf9, 0xbd, 0xea, 0x57, 0x23, 0xbe, 0x79, 0x3f, 0x8b, 0xbd,
+ 0xea, 0xa2, 0x62, 0x3d, 0xdc, 0x5b, 0xfb, 0x3c, 0x91, 0x51, 0x17, 0x3d,
+ 0xe7, 0x8d, 0x58, 0xbe, 0xab, 0x9a, 0x4f, 0xbd, 0x7c, 0xab, 0xad, 0xbe,
+ 0xa8, 0x66, 0x06, 0xbf, 0xbf, 0xfb, 0x9e, 0x3c, 0x48, 0xf1, 0x1e, 0xbd,
+ 0xad, 0xaf, 0x94, 0x3c, 0xf7, 0xdc, 0x81, 0xbe, 0xaa, 0x56, 0xda, 0xbe,
+ 0x41, 0xca, 0x1a, 0xbe, 0xaf, 0x06, 0xab, 0xbe, 0x9e, 0xb7, 0xa3, 0xbd,
+ 0x08, 0x79, 0xb6, 0x3d, 0x19, 0x31, 0x04, 0xbd, 0x90, 0xb5, 0xed, 0xbc,
+ 0x5d, 0xf7, 0x8a, 0x3c, 0x16, 0x86, 0x37, 0xbe, 0xa6, 0x12, 0xcd, 0x3d,
+ 0x82, 0x94, 0x42, 0xbe, 0xd7, 0x01, 0xad, 0xbe, 0xd1, 0xec, 0xb4, 0x3d,
+ 0x43, 0xf6, 0x2d, 0x3c, 0xeb, 0x80, 0xcc, 0x3d, 0x65, 0x14, 0x85, 0xbe,
+ 0x83, 0xc6, 0xdb, 0xbe, 0xf4, 0xd0, 0x8b, 0xbe, 0x97, 0x01, 0xfd, 0xbc,
+ 0x99, 0xdc, 0x9e, 0xbe, 0xf9, 0xc5, 0x09, 0x3e, 0x12, 0x1a, 0xc0, 0x3d,
+ 0x95, 0x7d, 0x2c, 0x3e, 0x40, 0x16, 0x88, 0xbd, 0xd0, 0x85, 0x3b, 0xbe,
+ 0xea, 0xef, 0x51, 0x3d, 0x63, 0xb3, 0x5b, 0xbe, 0x50, 0x49, 0xc5, 0xbe,
+ 0xc3, 0xa6, 0x2c, 0x3e, 0x3e, 0x64, 0x47, 0x3b, 0xfd, 0xe2, 0x22, 0x3d,
+ 0x1e, 0xf2, 0x52, 0xbe, 0x9d, 0x8f, 0xd6, 0xbe, 0x39, 0xf8, 0x0e, 0xbe,
+ 0x60, 0x67, 0x72, 0xbd, 0x05, 0x60, 0x0a, 0xbe, 0x43, 0x19, 0x8f, 0x3c,
+ 0x84, 0xe1, 0x3d, 0x3e, 0x7d, 0x8b, 0x24, 0x3d, 0x17, 0xf5, 0x3e, 0xbd,
+ 0xab, 0xf2, 0xe3, 0xbd, 0x8c, 0xc2, 0x9c, 0x3d, 0xf6, 0x55, 0x21, 0xbd,
+ 0x64, 0x77, 0x8a, 0xbe, 0xca, 0x5e, 0x97, 0xbb, 0x57, 0x52, 0x08, 0x3e,
+ 0x82, 0xb2, 0xd1, 0x3d, 0x7c, 0x53, 0x0b, 0xbd, 0x9b, 0x78, 0x9e, 0x3c,
+ 0xe5, 0xe2, 0xa5, 0xbd, 0x1a, 0x31, 0xbe, 0xbd, 0x37, 0x59, 0x8a, 0xbd,
+ 0xb5, 0x48, 0x5e, 0x3e, 0x6f, 0xd3, 0xe2, 0x3d, 0x7f, 0x74, 0x26, 0xbd,
+ 0x8d, 0xfe, 0x8c, 0xbe, 0x35, 0xbc, 0x75, 0xbe, 0xdf, 0xa9, 0x07, 0x3d,
+ 0x2c, 0x90, 0xf4, 0x3d, 0x63, 0xb0, 0x9e, 0x3d, 0x38, 0x84, 0x78, 0x3e,
+ 0xa4, 0x5c, 0xd1, 0x3e, 0x0c, 0x9d, 0xa8, 0xbd, 0x08, 0x4f, 0x8e, 0x3e,
+ 0x12, 0xc1, 0x96, 0xbe, 0x9a, 0x4c, 0xee, 0xbb, 0xe2, 0x69, 0x9a, 0x3e,
+ 0x71, 0x14, 0xc7, 0xbe, 0xc8, 0xaa, 0xe9, 0xbc, 0x1a, 0x81, 0xae, 0x3e,
+ 0x0d, 0x0f, 0x0b, 0xbf, 0x9f, 0x40, 0x15, 0xbf, 0x99, 0xec, 0x9f, 0x3e,
+ 0xfe, 0x81, 0x42, 0x3e, 0x74, 0xb0, 0x42, 0xbe, 0x25, 0x93, 0x96, 0xbe,
+ 0xee, 0x36, 0x36, 0x3d, 0xa5, 0x9f, 0xa2, 0x3d, 0x07, 0x8e, 0x3e, 0x3e,
+ 0x89, 0x2a, 0x9f, 0x3d, 0xe5, 0x83, 0x58, 0xbd, 0x72, 0xf7, 0x01, 0xbe,
+ 0x9c, 0x8b, 0x67, 0xbc, 0x28, 0xc1, 0xf7, 0xbd, 0x3b, 0x5d, 0x86, 0xbd,
+ 0x8c, 0x2d, 0x34, 0xbd, 0x6f, 0x8f, 0xde, 0xbe, 0x8a, 0xf3, 0xf2, 0xbe,
+ 0x3b, 0x49, 0xb9, 0x3e, 0xfb, 0x63, 0x83, 0xbd, 0xda, 0x2f, 0x93, 0xbe,
+ 0xd6, 0x44, 0xa8, 0xbe, 0x3d, 0xec, 0xff, 0x3b, 0xb5, 0xd6, 0x04, 0xbd,
+ 0xe3, 0xc9, 0x19, 0x3d, 0x6c, 0xdb, 0x87, 0x3d, 0x70, 0xbc, 0x9e, 0xbc,
+ 0x76, 0x16, 0x24, 0x3e, 0x63, 0xb6, 0x6e, 0x3d, 0xb7, 0x58, 0x9a, 0xbe,
+ 0x79, 0xd0, 0x21, 0x3e, 0x16, 0xe7, 0x22, 0x3b, 0x4c, 0x44, 0x4a, 0xbd,
+ 0x78, 0x34, 0xcc, 0xbe, 0xfd, 0x92, 0x82, 0x3d, 0x3d, 0x22, 0x9b, 0xbd,
+ 0x01, 0xba, 0xcb, 0xbd, 0xf0, 0xac, 0xed, 0xbc, 0x92, 0x5f, 0x09, 0x3e,
+ 0x76, 0x6e, 0x97, 0xbd, 0x6e, 0x7d, 0x18, 0x3d, 0xed, 0x55, 0xf8, 0x3c,
+ 0x01, 0xaa, 0x4a, 0x3e, 0x49, 0xf7, 0x77, 0x3e, 0xa9, 0xd2, 0xd4, 0x3d,
+ 0x6b, 0x7a, 0xac, 0xbd, 0xb1, 0x67, 0x90, 0xbd, 0x30, 0xf5, 0x94, 0xbd,
+ 0xdd, 0xb9, 0xd7, 0x3d, 0xc3, 0x2e, 0x04, 0xbe, 0xfd, 0xc1, 0xa8, 0x3d,
+ 0x80, 0xf0, 0x41, 0xbe, 0xae, 0x23, 0x8e, 0x3c, 0x03, 0x8a, 0x05, 0xbc,
+ 0x50, 0x33, 0x26, 0x3e, 0xdd, 0x04, 0xca, 0x3d, 0x11, 0xd9, 0x82, 0xbe,
+ 0xc9, 0x2b, 0x42, 0x3e, 0xbb, 0x94, 0x72, 0x3e, 0xdb, 0x8f, 0xa5, 0x3c,
+ 0xde, 0x89, 0xd0, 0x3d, 0x24, 0xb6, 0x86, 0xbe, 0x1b, 0xa7, 0x54, 0xbe,
+ 0x48, 0x2e, 0xd1, 0xbd, 0x5d, 0x47, 0x00, 0x3e, 0x8c, 0xd7, 0xa9, 0x3d,
+ 0xc9, 0x22, 0x9b, 0xbd, 0x9c, 0xa0, 0xe8, 0x3d, 0xc0, 0x7b, 0x1c, 0xbd,
+ 0x27, 0xd2, 0xdd, 0x3d, 0x24, 0x8e, 0xa0, 0x3d, 0x62, 0xf4, 0x53, 0xbc,
+ 0x16, 0x38, 0xba, 0xbe, 0x7c, 0x6e, 0xe3, 0x3d, 0x7b, 0x0d, 0x44, 0x3e,
+ 0xae, 0x3c, 0x8d, 0x3d, 0x1b, 0x4e, 0x4f, 0x3d, 0x73, 0x75, 0x4d, 0xbe,
+ 0x98, 0x9b, 0x44, 0xbe, 0xd2, 0xe8, 0x74, 0xbe, 0x8f, 0xd9, 0x56, 0x3e,
+ 0x74, 0x2a, 0x4e, 0x3e, 0xda, 0xb1, 0xd8, 0x3d, 0x38, 0xd7, 0x85, 0x3d,
+ 0x09, 0xbe, 0x3c, 0x3d, 0x24, 0x28, 0x6d, 0x3c, 0xbb, 0xcd, 0x1f, 0x3d,
+ 0xfb, 0x77, 0x3f, 0xbe, 0x33, 0xde, 0xbe, 0xbc, 0x5c, 0xa1, 0xb3, 0x3c,
+ 0x6b, 0xd1, 0x9d, 0x3d, 0xf1, 0x7b, 0x3b, 0x3e, 0x4c, 0x2c, 0x75, 0x3d,
+ 0x70, 0xef, 0xb2, 0xbe, 0xb5, 0x17, 0xe0, 0xbd, 0x61, 0x87, 0x65, 0xbd,
+ 0x3a, 0x09, 0x3e, 0x3e, 0x48, 0x49, 0xbf, 0xbb, 0x2f, 0x30, 0xaa, 0x3d,
+ 0x65, 0x75, 0x07, 0x3d, 0xbd, 0xc2, 0x1f, 0x3e, 0xe9, 0x8c, 0xf8, 0xbd,
+ 0x7c, 0x97, 0xe8, 0x3c, 0x9d, 0xc7, 0x51, 0xbb, 0x40, 0x8d, 0x89, 0xbd,
+ 0xd5, 0x27, 0x87, 0x3c, 0x92, 0xa1, 0x65, 0xbd, 0xf7, 0x7a, 0xa6, 0xbc,
+ 0xec, 0x7c, 0xd6, 0x3c, 0xf7, 0x47, 0x14, 0xbe, 0xd5, 0x0d, 0x92, 0x3c,
+ 0x3a, 0x11, 0x01, 0xbb, 0x9a, 0x3b, 0x03, 0x3e, 0xe0, 0xde, 0x22, 0xbe,
+ 0x37, 0xad, 0xe4, 0xbc, 0x4e, 0xb3, 0x03, 0xbb, 0x3f, 0xe8, 0xf6, 0xbd,
+ 0x87, 0x10, 0xf7, 0xbb, 0xe2, 0xc3, 0x9a, 0xbd, 0x0e, 0x42, 0x0b, 0x3e,
+ 0x92, 0x26, 0x9d, 0xbe, 0x4f, 0xe3, 0x32, 0xbc, 0x26, 0x0a, 0x03, 0x3e,
+ 0xf3, 0x60, 0xa7, 0x3c, 0x0c, 0x24, 0x05, 0x3d, 0x3e, 0xc8, 0x94, 0xbe,
+ 0x50, 0x31, 0x02, 0xbe, 0xff, 0xd4, 0x69, 0xbd, 0x1d, 0x42, 0x72, 0x3d,
+ 0xe7, 0x8c, 0x7f, 0xbe, 0x33, 0x87, 0x16, 0x3d, 0x93, 0x2c, 0xa2, 0xbd,
+ 0x88, 0xf0, 0xe3, 0xbb, 0xa8, 0x96, 0x84, 0x3d, 0xda, 0xc0, 0x40, 0x3e,
+ 0x8a, 0x68, 0x58, 0x3d, 0xad, 0xb0, 0x19, 0xbe, 0x97, 0x4e, 0x26, 0xbc,
+ 0x1c, 0x26, 0xe6, 0x3d, 0x48, 0x68, 0x55, 0x3d, 0xc6, 0xe3, 0xc3, 0x3d,
+ 0xa7, 0xe6, 0xc8, 0xbb, 0xf3, 0x00, 0x99, 0xbd, 0x2d, 0x63, 0xda, 0x3c,
+ 0xb4, 0xbd, 0x81, 0x3e, 0xdf, 0xb9, 0x92, 0xbe, 0x48, 0x3a, 0xb2, 0xbd,
+ 0x9f, 0xcb, 0xd2, 0x3d, 0x0b, 0x38, 0x97, 0x3c, 0xe2, 0x95, 0xb7, 0xbc,
+ 0xf6, 0x82, 0x13, 0x39, 0xc0, 0x98, 0x1a, 0x3d, 0xc2, 0xf4, 0x51, 0x3d,
+ 0x0d, 0xeb, 0xf5, 0x3c, 0x1d, 0xda, 0x52, 0x3d, 0xad, 0xb0, 0x77, 0x3d,
+ 0xca, 0x58, 0x51, 0x3d, 0x5a, 0x2d, 0xb0, 0x3c, 0xf0, 0x8b, 0xeb, 0xbd,
+ 0x0d, 0xd8, 0x50, 0x3e, 0x65, 0x25, 0x18, 0xbe, 0xb0, 0x18, 0xfd, 0xbe,
+ 0xc4, 0x02, 0x3b, 0xbd, 0xfa, 0x7b, 0x82, 0x3d, 0xce, 0xa0, 0x4d, 0xbe,
+ 0x0b, 0xc6, 0x32, 0xbd, 0x84, 0x62, 0xc0, 0x3d, 0x60, 0x6e, 0x1e, 0x3d,
+ 0x31, 0x01, 0x28, 0x3e, 0x31, 0x76, 0x04, 0x3e, 0x91, 0x6b, 0x60, 0xbd,
+ 0x14, 0xf5, 0x20, 0x3e, 0x5c, 0x38, 0x67, 0xbd, 0x36, 0x21, 0xc2, 0x3d,
+ 0x13, 0x10, 0x7e, 0xbe, 0x19, 0xd1, 0x9f, 0x3e, 0xd0, 0x1a, 0x16, 0xbe,
+ 0x34, 0xb5, 0xaf, 0xbe, 0x86, 0x67, 0x16, 0x3d, 0x11, 0x05, 0x58, 0xbe,
+ 0xfb, 0x0d, 0xd0, 0x3c, 0x90, 0x88, 0x20, 0xbd, 0xdc, 0xcc, 0x9a, 0x3d,
+ 0x11, 0x29, 0x7a, 0x3e, 0x05, 0x44, 0xbf, 0xbe, 0x54, 0x1a, 0x0a, 0x3e,
+ 0xff, 0x6f, 0xb4, 0xbd, 0xeb, 0xa4, 0x86, 0x3d, 0x5e, 0x43, 0x00, 0x3e,
+ 0xfa, 0x4f, 0xd9, 0xbc, 0xad, 0x7b, 0xa2, 0xbd, 0x0e, 0xf6, 0x01, 0x3e,
+ 0x90, 0xf0, 0xb4, 0xbd, 0xd0, 0x21, 0x9a, 0xbe, 0x74, 0x43, 0x14, 0x3e,
+ 0x4d, 0xe8, 0x0b, 0xbe, 0x80, 0x2b, 0x93, 0xbd, 0x87, 0x39, 0x35, 0x3e,
+ 0x90, 0x63, 0xb8, 0x3d, 0xcf, 0x2c, 0x83, 0x3e, 0xbd, 0xe5, 0x0b, 0xbf,
+ 0x5f, 0xf7, 0x90, 0x3c, 0xa0, 0x61, 0x52, 0xbc, 0x8f, 0x88, 0xac, 0xbc,
+ 0x0c, 0x64, 0xd3, 0x3d, 0x9c, 0xd9, 0x8b, 0x3d, 0x80, 0xb7, 0x39, 0xbe,
+ 0x4e, 0x30, 0x95, 0x3e, 0x73, 0x3e, 0xda, 0xbe, 0x51, 0x56, 0x84, 0x3d,
+ 0xe6, 0x28, 0x85, 0x3d, 0xb9, 0xe9, 0x87, 0xbe, 0x46, 0x01, 0x6c, 0xbd,
+ 0x4b, 0x64, 0xd5, 0x3d, 0x56, 0xfd, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x05, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x1d, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63,
+ 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f, 0x43, 0x6f, 0x6e, 0x76, 0x32, 0x44,
+ 0x5f, 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x00, 0x68, 0xfc, 0xff, 0xff,
+ 0x20, 0x00, 0x00, 0x00, 0xe4, 0xe5, 0x3e, 0xc0, 0x22, 0xe7, 0x92, 0x3f,
+ 0x57, 0x04, 0xde, 0xbf, 0xda, 0x8f, 0x1c, 0x3e, 0x47, 0xbf, 0x05, 0xc0,
+ 0x53, 0xab, 0xcb, 0xbf, 0x68, 0x6a, 0x6a, 0xbf, 0xd2, 0x0b, 0xe4, 0xbf,
+ 0xbe, 0xfd, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x1f, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,
+ 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32,
+ 0x64, 0x5f, 0x31, 0x2f, 0x43, 0x6f, 0x6e, 0x76, 0x32, 0x44, 0x5f, 0x62,
+ 0x69, 0x61, 0x73, 0x00, 0xd0, 0xfc, 0xff, 0xff, 0x40, 0x00, 0x00, 0x00,
+ 0xa3, 0x15, 0xb7, 0x3e, 0x29, 0x67, 0x95, 0x3f, 0x4b, 0x96, 0x62, 0xbe,
+ 0x61, 0x5f, 0xfc, 0x3e, 0xa2, 0xd4, 0x3e, 0xbf, 0x45, 0x1c, 0x0d, 0xbf,
+ 0x29, 0xdd, 0x70, 0xbe, 0x9a, 0x75, 0x97, 0xbf, 0xfc, 0x0a, 0x6f, 0xbe,
+ 0xcc, 0x56, 0x25, 0x3f, 0xdf, 0xac, 0x98, 0xbf, 0x0e, 0x1c, 0x8b, 0xbf,
+ 0xa5, 0xd8, 0x8c, 0x3f, 0xa5, 0x42, 0xd5, 0x3c, 0xa9, 0x8e, 0x7a, 0xbf,
+ 0x9e, 0xdb, 0x71, 0xbe, 0x46, 0xfe, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x1e, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64,
+ 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x31, 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75,
+ 0x6c, 0x5f, 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x58, 0xfd, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0xc3, 0x99, 0xb6, 0xbf, 0xe9, 0x87, 0x8b, 0x3f,
+ 0xac, 0x83, 0x9a, 0xbf, 0x4c, 0x49, 0x3d, 0xbe, 0x9e, 0xfe, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x48, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x32, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,
+ 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65,
+ 0x5f, 0x31, 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x2f, 0x52, 0x65,
+ 0x61, 0x64, 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70,
+ 0x2f, 0x74, 0x72, 0x61, 0x6e, 0x73, 0x70, 0x6f, 0x73, 0x65, 0x00, 0x00,
+ 0xc8, 0xfd, 0xff, 0xff, 0x00, 0x01, 0x00, 0x00, 0x40, 0x5c, 0x8a, 0xbe,
+ 0xc5, 0x88, 0xaa, 0x3e, 0xb0, 0x76, 0x1f, 0xbe, 0x35, 0x3a, 0x58, 0x3e,
+ 0x84, 0xa5, 0xa3, 0x3e, 0x38, 0xd9, 0x49, 0x3d, 0x58, 0x63, 0x78, 0xbc,
+ 0x82, 0x94, 0x2e, 0xbe, 0x97, 0xde, 0x6e, 0xbe, 0xea, 0x27, 0x9f, 0xbe,
+ 0x1d, 0x24, 0xc0, 0x3d, 0x21, 0x31, 0x66, 0x3c, 0x80, 0xf8, 0x88, 0xbe,
+ 0xdd, 0x06, 0x19, 0xbe, 0x3f, 0x4b, 0xb3, 0xbe, 0x70, 0xdc, 0x8d, 0x3e,
+ 0x20, 0xee, 0x93, 0xbe, 0xde, 0x7c, 0xbf, 0xbe, 0xda, 0x3a, 0x50, 0xbe,
+ 0x0e, 0x91, 0x6e, 0x3e, 0x18, 0xbc, 0x81, 0x3e, 0x18, 0x9c, 0xfe, 0xb9,
+ 0x11, 0x2d, 0x9b, 0xbe, 0xa2, 0x73, 0x3f, 0xbe, 0x0c, 0x6c, 0xa3, 0xbe,
+ 0x37, 0x4b, 0x8c, 0xbe, 0x91, 0x26, 0xa0, 0x3d, 0xb3, 0x04, 0xbd, 0x3e,
+ 0x01, 0x3e, 0x70, 0xbe, 0xd1, 0xdb, 0x69, 0xbe, 0xb4, 0xc0, 0x98, 0xbe,
+ 0xd4, 0xd9, 0x80, 0x3e, 0x62, 0xa9, 0x74, 0xbe, 0x8a, 0xe9, 0x83, 0xbe,
+ 0x7a, 0x92, 0x54, 0xbe, 0x92, 0x5d, 0x43, 0x3e, 0xe3, 0x35, 0x7b, 0x3e,
+ 0xee, 0x81, 0x2e, 0x3d, 0xbb, 0x68, 0xec, 0x3d, 0x70, 0x72, 0x1b, 0xbe,
+ 0x64, 0x20, 0xa4, 0xbe, 0x4f, 0x1f, 0x8d, 0xbd, 0xee, 0xd6, 0xf8, 0x3d,
+ 0xdb, 0x83, 0xb0, 0x3e, 0xd1, 0x99, 0x8c, 0xbe, 0x99, 0x21, 0x45, 0xbe,
+ 0x97, 0x04, 0x82, 0xbe, 0x25, 0xdf, 0x88, 0x3e, 0xe2, 0xe6, 0x5b, 0xbe,
+ 0xe5, 0x53, 0x68, 0x3d, 0x0b, 0xcd, 0x40, 0xbe, 0x4e, 0xea, 0x55, 0x3e,
+ 0x54, 0xd8, 0x85, 0x3e, 0x3c, 0xba, 0x82, 0x3d, 0x58, 0xc0, 0xe9, 0x3e,
+ 0x0c, 0xcc, 0x29, 0xbe, 0x3a, 0x6e, 0xa2, 0xbe, 0x84, 0x4a, 0x12, 0x3e,
+ 0x32, 0xd9, 0xcb, 0x3d, 0xad, 0x16, 0xd4, 0x3e, 0xf5, 0xa8, 0x85, 0xbe,
+ 0x5c, 0x34, 0xc8, 0xbd, 0x31, 0x02, 0xac, 0xbe, 0x3e, 0x15, 0x9e, 0x3e,
+ 0x00, 0x00, 0x0e, 0x00, 0x14, 0x00, 0x04, 0x00, 0x00, 0x00, 0x08, 0x00,
+ 0x0c, 0x00, 0x10, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64,
+ 0x65, 0x6e, 0x73, 0x65, 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x5f,
+ 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x00, 0x00, 0x20, 0xff, 0xff, 0xff,
+ 0x40, 0x00, 0x00, 0x00, 0xa9, 0xa9, 0x93, 0x3f, 0x3c, 0xda, 0x21, 0xbe,
+ 0x33, 0xe3, 0x3d, 0x3d, 0xd8, 0xed, 0x33, 0xbf, 0x4c, 0x9d, 0x3e, 0xbf,
+ 0xba, 0x40, 0xa6, 0x3f, 0x6e, 0x4e, 0x25, 0xbe, 0x6e, 0x5e, 0x93, 0x3f,
+ 0x48, 0xa2, 0xc5, 0xbe, 0x67, 0xaa, 0x33, 0x3e, 0xc0, 0x66, 0x20, 0x3f,
+ 0xb3, 0x25, 0x7e, 0xbe, 0x8a, 0x2f, 0xd9, 0xbe, 0xda, 0x64, 0xc8, 0x3f,
+ 0x1a, 0x14, 0x89, 0xbd, 0xea, 0x48, 0x89, 0x3e, 0x07, 0x00, 0x00, 0x00,
+ 0x00, 0x02, 0x00, 0x00, 0x90, 0x01, 0x00, 0x00, 0x3c, 0x01, 0x00, 0x00,
+ 0xd0, 0x00, 0x00, 0x00, 0x8c, 0x00, 0x00, 0x00, 0x48, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x30, 0xfe, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09,
+ 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x24, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0b, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x04, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x80, 0x3f, 0x70, 0xfe, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x08, 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00,
+ 0x0d, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x04, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0xb0, 0xfe, 0xff, 0xff, 0x00, 0x00, 0x00, 0x08, 0x02, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x2e, 0xfe, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x01, 0xf0, 0xfe, 0xff, 0xff, 0x00, 0x00, 0x00, 0x05,
+ 0x03, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x2c, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x07, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x14, 0x00, 0x18, 0x00, 0x00, 0x00, 0x08, 0x00,
+ 0x0c, 0x00, 0x07, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x14, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x10, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x00, 0x00, 0x08, 0x00,
+ 0x0c, 0x00, 0x07, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01,
+ 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xa8, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x05, 0x03, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00,
+ 0x18, 0x00, 0x07, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x03, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x1c, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x07, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x18, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x02, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x1c, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x07, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00,
+ 0x48, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0xce, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x19,
+ 0xd6, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0xde, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x09, 0xe6, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x11,
+ 0xfa, 0xff, 0xff, 0xff, 0x00, 0x03, 0x06, 0x00, 0x06, 0x00, 0x05, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x00, 0x11, 0x06, 0x00, 0x08, 0x00, 0x07, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x04};
+unsigned int model_tflite_len = 19616;
diff --git a/tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h b/tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h
new file mode 100644
index 0000000..40a0b4d
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h
@@ -0,0 +1,27 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This is a standard TensorFlow Lite model file that has been converted into a
+// C data array, so it can be easily compiled into a binary for devices that
+// don't have a file system. It was created using the command:
+// xxd -i magic_wand_model.tflite > magic_wand_model_data.cc
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_MAGIC_WAND_MODEL_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_MAGIC_WAND_MODEL_DATA_H_
+
+extern const unsigned char g_magic_wand_model_data[];
+extern const int g_magic_wand_model_data_len;
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_MAGIC_WAND_MODEL_DATA_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/magic_wand_test.cc b/tensorflow/lite/micro/examples/magic_wand/magic_wand_test.cc
new file mode 100644
index 0000000..bf561e1
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/magic_wand_test.cc
@@ -0,0 +1,149 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h"
+#include "tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.h"
+#include "tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(LoadModelAndPerformInference) {
+ // Set up logging
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ // Map the model into a usable data structure. This doesn't involve any
+ // copying or parsing, it's a very lightweight operation.
+ const tflite::Model* model = ::tflite::GetModel(g_magic_wand_model_data);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.\n",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ }
+
+ // Pull in only the operation implementations we need.
+ // This relies on a complete list of all the ops needed by this graph.
+ // An easier approach is to just use the AllOpsResolver, but this will
+ // incur some penalty in code space for op implementations that are not
+ // needed by this graph.
+ static tflite::MicroMutableOpResolver<5> micro_op_resolver; // NOLINT
+ micro_op_resolver.AddConv2D();
+ micro_op_resolver.AddDepthwiseConv2D();
+ micro_op_resolver.AddFullyConnected();
+ micro_op_resolver.AddMaxPool2D();
+ micro_op_resolver.AddSoftmax();
+
+ // Create an area of memory to use for input, output, and intermediate arrays.
+ // Finding the minimum value for your model may require some trial and error.
+ const int tensor_arena_size = 60 * 1024;
+ uint8_t tensor_arena[tensor_arena_size];
+
+ // Build an interpreter to run the model with
+ tflite::MicroInterpreter interpreter(model, micro_op_resolver, tensor_arena,
+ tensor_arena_size,
+ µ_error_reporter);
+
+ // Allocate memory from the tensor_arena for the model's tensors
+ interpreter.AllocateTensors();
+
+ // Obtain a pointer to the model's input tensor
+ TfLiteTensor* input = interpreter.input(0);
+
+ // Make sure the input has the properties we expect
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input);
+ TF_LITE_MICRO_EXPECT_EQ(4, input->dims->size);
+ // The value of each element gives the length of the corresponding tensor.
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(128, input->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(3, input->dims->data[2]);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[3]);
+ // The input is a 32 bit floating point value
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, input->type);
+
+ // Provide an input value
+ const float* ring_features_data = g_ring_micro_f9643d42_nohash_4_data;
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "%d", input->bytes);
+ for (size_t i = 0; i < (input->bytes / sizeof(float)); ++i) {
+ input->data.f[i] = ring_features_data[i];
+ }
+
+ // Run the model on this input and check that it succeeds
+ TfLiteStatus invoke_status = interpreter.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Invoke failed\n");
+ }
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
+
+ // Obtain a pointer to the output tensor and make sure it has the
+ // properties we expect.
+ TfLiteTensor* output = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(4, output->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, output->type);
+
+ // There are four possible classes in the output, each with a score.
+ const int kWingIndex = 0;
+ const int kRingIndex = 1;
+ const int kSlopeIndex = 2;
+ const int kNegativeIndex = 3;
+
+ // Make sure that the expected "Ring" score is higher than the other
+ // classes.
+ float wing_score = output->data.f[kWingIndex];
+ float ring_score = output->data.f[kRingIndex];
+ float slope_score = output->data.f[kSlopeIndex];
+ float negative_score = output->data.f[kNegativeIndex];
+ TF_LITE_MICRO_EXPECT_GT(ring_score, wing_score);
+ TF_LITE_MICRO_EXPECT_GT(ring_score, slope_score);
+ TF_LITE_MICRO_EXPECT_GT(ring_score, negative_score);
+
+ // Now test with a different input, from a recording of "Slope".
+ const float* slope_features_data = g_slope_micro_f2e59fea_nohash_1_data;
+ for (size_t i = 0; i < (input->bytes / sizeof(float)); ++i) {
+ input->data.f[i] = slope_features_data[i];
+ }
+
+ // Run the model on this "Slope" input.
+ invoke_status = interpreter.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Invoke failed\n");
+ }
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
+
+ // Get the output from the model, and make sure it's the expected size and
+ // type.
+ output = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(4, output->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, output->type);
+
+ // Make sure that the expected "Slope" score is higher than the other classes.
+ wing_score = output->data.f[kWingIndex];
+ ring_score = output->data.f[kRingIndex];
+ slope_score = output->data.f[kSlopeIndex];
+ negative_score = output->data.f[kNegativeIndex];
+ TF_LITE_MICRO_EXPECT_GT(slope_score, wing_score);
+ TF_LITE_MICRO_EXPECT_GT(slope_score, ring_score);
+ TF_LITE_MICRO_EXPECT_GT(slope_score, negative_score);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/magic_wand/main.cc b/tensorflow/lite/micro/examples/magic_wand/main.cc
new file mode 100644
index 0000000..7dab1cd
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/main.cc
@@ -0,0 +1,27 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/main_functions.h"
+
+// This is the default main used on systems that have the standard C entry
+// point. Other devices (for example FreeRTOS or ESP32) that have different
+// requirements for entry code (like an app_main function) should specialize
+// this main.cc file in a target-specific subfolder.
+int main(int argc, char* argv[]) {
+ setup();
+ while (true) {
+ loop();
+ }
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/main_functions.cc b/tensorflow/lite/micro/examples/magic_wand/main_functions.cc
new file mode 100644
index 0000000..583cee8
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/main_functions.cc
@@ -0,0 +1,122 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/main_functions.h"
+
+#include "tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h"
+#include "tensorflow/lite/micro/examples/magic_wand/constants.h"
+#include "tensorflow/lite/micro/examples/magic_wand/gesture_predictor.h"
+#include "tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.h"
+#include "tensorflow/lite/micro/examples/magic_wand/output_handler.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+#include "tensorflow/lite/micro/system_setup.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+// Globals, used for compatibility with Arduino-style sketches.
+namespace {
+tflite::ErrorReporter* error_reporter = nullptr;
+const tflite::Model* model = nullptr;
+tflite::MicroInterpreter* interpreter = nullptr;
+TfLiteTensor* model_input = nullptr;
+int input_length;
+
+// Create an area of memory to use for input, output, and intermediate arrays.
+// The size of this will depend on the model you're using, and may need to be
+// determined by experimentation.
+constexpr int kTensorArenaSize = 60 * 1024;
+uint8_t tensor_arena[kTensorArenaSize];
+} // namespace
+
+// The name of this function is important for Arduino compatibility.
+void setup() {
+ tflite::InitializeTarget();
+
+ // Set up logging. Google style is to avoid globals or statics because of
+ // lifetime uncertainty, but since this has a trivial destructor it's okay.
+ static tflite::MicroErrorReporter micro_error_reporter; // NOLINT
+ error_reporter = µ_error_reporter;
+
+ // Map the model into a usable data structure. This doesn't involve any
+ // copying or parsing, it's a very lightweight operation.
+ model = tflite::GetModel(g_magic_wand_model_data);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ return;
+ }
+
+ // Pull in only the operation implementations we need.
+ // This relies on a complete list of all the ops needed by this graph.
+ // An easier approach is to just use the AllOpsResolver, but this will
+ // incur some penalty in code space for op implementations that are not
+ // needed by this graph.
+ static tflite::MicroMutableOpResolver<5> micro_op_resolver; // NOLINT
+ micro_op_resolver.AddConv2D();
+ micro_op_resolver.AddDepthwiseConv2D();
+ micro_op_resolver.AddFullyConnected();
+ micro_op_resolver.AddMaxPool2D();
+ micro_op_resolver.AddSoftmax();
+
+ // Build an interpreter to run the model with.
+ static tflite::MicroInterpreter static_interpreter(
+ model, micro_op_resolver, tensor_arena, kTensorArenaSize, error_reporter);
+ interpreter = &static_interpreter;
+
+ // Allocate memory from the tensor_arena for the model's tensors.
+ interpreter->AllocateTensors();
+
+ // Obtain pointer to the model's input tensor.
+ model_input = interpreter->input(0);
+ if ((model_input->dims->size != 4) || (model_input->dims->data[0] != 1) ||
+ (model_input->dims->data[1] != 128) ||
+ (model_input->dims->data[2] != kChannelNumber) ||
+ (model_input->type != kTfLiteFloat32)) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Bad input tensor parameters in model");
+ return;
+ }
+
+ input_length = model_input->bytes / sizeof(float);
+
+ TfLiteStatus setup_status = SetupAccelerometer(error_reporter);
+ if (setup_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Set up failed\n");
+ }
+}
+
+void loop() {
+ // Attempt to read new data from the accelerometer.
+ bool got_data =
+ ReadAccelerometer(error_reporter, model_input->data.f, input_length);
+ // If there was no new data, wait until next time.
+ if (!got_data) return;
+
+ // Run inference, and report any error.
+ TfLiteStatus invoke_status = interpreter->Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed on index: %d\n",
+ begin_index);
+ return;
+ }
+ // Analyze the results to obtain a prediction
+ int gesture_index = PredictGesture(interpreter->output(0)->data.f);
+
+ // Produce an output
+ HandleOutput(error_reporter, gesture_index);
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/main_functions.h b/tensorflow/lite/micro/examples/magic_wand/main_functions.h
new file mode 100644
index 0000000..d69755b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/main_functions.h
@@ -0,0 +1,37 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_MAIN_FUNCTIONS_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_MAIN_FUNCTIONS_H_
+
+// Expose a C friendly interface for main functions.
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+// Initializes all data needed for the example. The name is important, and needs
+// to be setup() for Arduino compatibility.
+void setup();
+
+// Runs one iteration of data gathering and inference. This should be called
+// repeatedly from the application code. The name needs to be loop() for Arduino
+// compatibility.
+void loop();
+
+#ifdef __cplusplus
+}
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_MAIN_FUNCTIONS_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/output_handler.cc b/tensorflow/lite/micro/examples/magic_wand/output_handler.cc
new file mode 100644
index 0000000..417a7b6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/output_handler.cc
@@ -0,0 +1,38 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/output_handler.h"
+
+void HandleOutput(tflite::ErrorReporter* error_reporter, int kind) {
+ // light (red: wing, blue: ring, green: slope)
+ if (kind == 0) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "WING:\n\r* * *\n\r * * * "
+ "*\n\r * * * *\n\r * * * *\n\r * * "
+ "* *\n\r * *\n\r");
+ } else if (kind == 1) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "RING:\n\r *\n\r * *\n\r * *\n\r "
+ " * *\n\r * *\n\r * *\n\r "
+ " *\n\r");
+ } else if (kind == 2) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "SLOPE:\n\r *\n\r *\n\r *\n\r *\n\r "
+ "*\n\r *\n\r *\n\r * * * * * * * *\n\r");
+ }
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/output_handler.h b/tensorflow/lite/micro/examples/magic_wand/output_handler.h
new file mode 100644
index 0000000..7b85254
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/output_handler.h
@@ -0,0 +1,24 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_OUTPUT_HANDLER_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_OUTPUT_HANDLER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+void HandleOutput(tflite::ErrorReporter* error_reporter, int kind);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_OUTPUT_HANDLER_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/output_handler_test.cc b/tensorflow/lite/micro/examples/magic_wand/output_handler_test.cc
new file mode 100644
index 0000000..2c34dfc
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/output_handler_test.cc
@@ -0,0 +1,30 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/output_handler.h"
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestCallability) {
+ tflite::MicroErrorReporter micro_error_reporter;
+ HandleOutput(µ_error_reporter, 0);
+ HandleOutput(µ_error_reporter, 1);
+ HandleOutput(µ_error_reporter, 2);
+ HandleOutput(µ_error_reporter, 3);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.cc b/tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.cc
new file mode 100644
index 0000000..49f7d54
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.cc
@@ -0,0 +1,65 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.h"
+
+const int g_ring_micro_f9643d42_nohash_4_length = 128;
+const int g_ring_micro_f9643d42_nohash_4_dim = 3;
+// Raw accelerometer data with a sample rate of 25Hz
+const float g_ring_micro_f9643d42_nohash_4_data[] = {
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, -665.0, 228.0, 827.0, -680.0, 339.0, 716.0,
+ -680.0, 564.0, 812.0, -679.0, 552.0, 818.0, -665.0, 528.0, 751.0,
+ -658.0, 432.0, 618.0, -655.0, 445.0, 592.0, -667.0, 484.0, 556.0,
+ -684.0, 590.0, 510.0, -674.0, 672.0, 475.0, -660.0, 786.0, 390.0,
+ -562.0, 1124.0, 128.0, -526.0, 1140.0, 111.0, -486.0, 1044.0, 33.0,
+ -416.0, 652.0, -134.0, -390.0, 534.0, -143.0, -365.0, 381.0, -117.0,
+ -314.0, 60.0, 94.0, -322.0, 7.0, 190.0, -338.0, -95.0, 342.0,
+ -360.0, -106.0, 842.0, -351.0, -41.0, 965.0, -352.0, 12.0, 960.0,
+ -366.0, 42.0, 1124.0, -322.0, 56.0, 1178.0, -312.0, 15.0, 1338.0,
+ -254.0, 10.0, 1532.0, -241.0, 5.0, 1590.0, -227.0, 60.0, 1565.0,
+ -204.0, 282.0, 1560.0, -180.0, 262.0, 1524.0, -138.0, 385.0, 1522.0,
+ -84.0, 596.0, 1626.0, -55.0, 639.0, 1604.0, -19.0, 771.0, 1511.0,
+ 16.0, 932.0, 1132.0, 15.0, 924.0, 1013.0, 1.0, 849.0, 812.0,
+ -88.0, 628.0, 500.0, -114.0, 609.0, 463.0, -155.0, 559.0, 382.0,
+ -234.0, 420.0, 278.0, -254.0, 390.0, 272.0, -327.0, 200.0, 336.0,
+ -558.0, -556.0, 630.0, -640.0, -607.0, 740.0, -706.0, -430.0, 868.0,
+ -778.0, 42.0, 1042.0, -763.0, 84.0, 973.0, -735.0, 185.0, 931.0,
+ -682.0, 252.0, 766.0, -673.0, 230.0, 757.0, -671.0, 218.0, 757.0,
+ -656.0, 222.0, 714.0, -659.0, 238.0, 746.0, -640.0, 276.0, 731.0,
+ -634.0, 214.0, 754.0, -637.0, 207.0, 735.0, -637.0, 194.0, 742.0,
+ -634.0, 248.0, 716.0, -631.0, 265.0, 697.0, -628.0, 252.0, 797.0,
+ -592.0, 204.0, 816.0, -618.0, 218.0, 812.0, -633.0, 231.0, 828.0,
+ -640.0, 222.0, 736.0, -634.0, 221.0, 787.0,
+};
diff --git a/tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.h b/tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.h
new file mode 100644
index 0000000..9cd02cd
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/ring_micro_features_data.h
@@ -0,0 +1,23 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_RING_MICRO_FEATURES_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_RING_MICRO_FEATURES_DATA_H_
+
+extern const int g_ring_micro_f9643d42_nohash_4_length;
+extern const int g_ring_micro_f9643d42_nohash_4_dim;
+extern const float g_ring_micro_f9643d42_nohash_4_data[];
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_RING_MICRO_FEATURES_DATA_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/riscv32_mcu/Makefile.inc b/tensorflow/lite/micro/examples/magic_wand/riscv32_mcu/Makefile.inc
new file mode 100644
index 0000000..545ed1a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/riscv32_mcu/Makefile.inc
@@ -0,0 +1,27 @@
+ifeq ($(TARGET), riscv32_mcu)
+ # Wrap functions
+ MICRO_FE310_LIBWRAP_SRCS := \
+ $(wildcard $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/sys/*.c) \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/misc/write_hex.c \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/stdlib/malloc.c
+
+ MICRO_FE310_BSP_ENV_SRCS := \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/start.S \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/entry.S \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/freedom-e300-hifive1/init.c
+
+ magic_wand_TEST_SRCS += $(MICRO_FE310_LIBWRAP_SRCS) $(MICRO_FE310_BSP_ENV_SRCS) \
+ tensorflow/lite/micro/arduino/abi.cc
+ magic_wand_SRCS += $(MICRO_FE310_LIBWRAP_SRCS) $(MICRO_FE310_BSP_ENV_SRCS) \
+ tensorflow/lite/micro/arduino/abi.cc
+
+ LIBWRAP_SYMS := malloc free \
+ open lseek read write fstat stat close link unlink \
+ execve fork getpid kill wait \
+ isatty times sbrk _exit puts
+
+ LDFLAGS += $(foreach s,$(LIBWRAP_SYMS),-Wl,--wrap=$(s))
+ LDFLAGS += $(foreach s,$(LIBWRAP_SYMS),-Wl,--wrap=_$(s))
+ LDFLAGS += -L. -Wl,--start-group -lc -Wl,--end-group
+endif
+
diff --git a/tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.cc b/tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.cc
new file mode 100644
index 0000000..3790b93
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.cc
@@ -0,0 +1,65 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.h"
+
+const int g_slope_micro_f2e59fea_nohash_1_length = 128;
+const int g_slope_micro_f2e59fea_nohash_1_dim = 3;
+// Raw accelerometer data with a sample rate of 25Hz
+const float g_slope_micro_f2e59fea_nohash_1_data[] = {
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ 0.0, 0.0, 0.0, -766.0, 132.0, 709.0, -751.0, 249.0, 659.0,
+ -714.0, 314.0, 630.0, -709.0, 244.0, 623.0, -707.0, 230.0, 659.0,
+ -704.0, 202.0, 748.0, -714.0, 219.0, 728.0, -722.0, 239.0, 710.0,
+ -744.0, 116.0, 612.0, -753.0, -49.0, 570.0, -748.0, -279.0, 527.0,
+ -668.0, -664.0, 592.0, -601.0, -635.0, 609.0, -509.0, -559.0, 606.0,
+ -286.0, -162.0, 536.0, -255.0, -144.0, 495.0, -209.0, -85.0, 495.0,
+ 6.0, 416.0, 698.0, -33.0, 304.0, 1117.0, -82.0, 405.0, 1480.0,
+ -198.0, 1008.0, 1908.0, -229.0, 990.0, 1743.0, -234.0, 934.0, 1453.0,
+ -126.0, 838.0, 896.0, -78.0, 792.0, 911.0, -27.0, 741.0, 918.0,
+ 114.0, 734.0, 960.0, 135.0, 613.0, 959.0, 152.0, 426.0, 1015.0,
+ 106.0, -116.0, 1110.0, 63.0, -314.0, 1129.0, -12.0, -486.0, 1179.0,
+ -118.0, -656.0, 1510.0, -116.0, -558.0, 1553.0, -126.0, -361.0, 1367.0,
+ -222.0, -76.0, 922.0, -210.0, -26.0, 971.0, -194.0, 50.0, 1053.0,
+ -178.0, 72.0, 1082.0, -169.0, 100.0, 1073.0, -162.0, 133.0, 1050.0,
+ -156.0, 226.0, 976.0, -154.0, 323.0, 886.0, -130.0, 240.0, 1154.0,
+ -116.0, 124.0, 916.0, -132.0, 124.0, 937.0, -153.0, 115.0, 981.0,
+ -184.0, 94.0, 962.0, -177.0, 85.0, 1017.0, -173.0, 92.0, 1027.0,
+ -168.0, 158.0, 1110.0, -181.0, 101.0, 1030.0, -180.0, 139.0, 1054.0,
+ -152.0, 10.0, 1044.0, -169.0, 74.0, 1007.0,
+};
diff --git a/tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.h b/tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.h
new file mode 100644
index 0000000..6ed0c3c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/slope_micro_features_data.h
@@ -0,0 +1,23 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_SLOPE_MICRO_FEATURES_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_SLOPE_MICRO_FEATURES_DATA_H_
+
+extern const int g_slope_micro_f2e59fea_nohash_1_length;
+extern const int g_slope_micro_f2e59fea_nohash_1_dim;
+extern const float g_slope_micro_f2e59fea_nohash_1_data[];
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_SLOPE_MICRO_FEATURES_DATA_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/accelerometer_handler.cc b/tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/accelerometer_handler.cc
new file mode 100644
index 0000000..ae2d127
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/accelerometer_handler.cc
@@ -0,0 +1,220 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h"
+
+// These are headers from Ambiq's Apollo3 SDK.
+#include <string.h>
+
+#include "am_bsp.h" // NOLINT
+#include "am_mcu_apollo.h" // NOLINT
+#include "am_util.h" // NOLINT
+#include "lis2dh12_platform_apollo3.h"
+
+lis2dh12_platform_apollo3_if_t dev_if; // accelerometer device interface
+lis2dh12_ctx_t dev_ctx; // accelerometer device control
+
+// A union representing either int16_t[3] or uint8_t[6],
+// storing the most recent data
+axis3bit16_t data_raw_acceleration;
+// A buffer holding the last 200 sets of 3-channel values
+float save_data[600] = {0.0};
+// Most recent position in the save_data buffer
+int begin_index = 0;
+// True if there is not yet enough data to run inference
+bool pending_initial_data = true;
+
+int initAccelerometer(void) {
+ uint32_t retVal32 = 0;
+ static uint8_t whoamI = 0;
+
+ am_hal_iom_config_t i2cConfig;
+ memset((void*)(&i2cConfig), 0x00, sizeof(am_hal_iom_config_t));
+ i2cConfig.eInterfaceMode = AM_HAL_IOM_I2C_MODE;
+ i2cConfig.ui32ClockFreq = AM_HAL_IOM_100KHZ;
+
+ // Initialize the IOM.
+ retVal32 = am_hal_iom_initialize(
+ AM_BSP_ACCELEROMETER_I2C_IOM,
+ &(dev_if.iomHandle)); // set the iomHandle of the device interface
+ if (retVal32 != AM_HAL_STATUS_SUCCESS) {
+ return (int)retVal32;
+ }
+
+ retVal32 =
+ am_hal_iom_power_ctrl((dev_if.iomHandle), AM_HAL_SYSCTRL_WAKE, false);
+ if (retVal32 != AM_HAL_STATUS_SUCCESS) {
+ return (int)retVal32;
+ }
+
+ retVal32 = am_hal_iom_configure((dev_if.iomHandle), &i2cConfig);
+ if (retVal32 != AM_HAL_STATUS_SUCCESS) {
+ return (int)retVal32;
+ }
+
+ // Configure the IOM pins.
+ am_hal_gpio_pinconfig(AM_BSP_ACCELEROMETER_I2C_SDA_PIN,
+ g_AM_BSP_ACCELEROMETER_I2C_SDA_PIN);
+ am_hal_gpio_pinconfig(AM_BSP_ACCELEROMETER_I2C_SCL_PIN,
+ g_AM_BSP_ACCELEROMETER_I2C_SDA_PIN);
+
+ // Enable the IOM.
+ retVal32 = am_hal_iom_enable((dev_if.iomHandle));
+ if (retVal32 != AM_HAL_STATUS_SUCCESS) {
+ return (int)retVal32;
+ }
+
+ //
+ // Apply accelerometer configuration
+ lis2dh12_device_id_get(&dev_ctx, &whoamI);
+ if (whoamI != LIS2DH12_ID) {
+ return AM_HAL_STATUS_FAIL;
+ }
+
+ lis2dh12_block_data_update_set(&dev_ctx, PROPERTY_ENABLE);
+ lis2dh12_temperature_meas_set(&dev_ctx, LIS2DH12_TEMP_ENABLE);
+ lis2dh12_data_rate_set(&dev_ctx, LIS2DH12_ODR_25Hz);
+ lis2dh12_full_scale_set(&dev_ctx, LIS2DH12_2g);
+ lis2dh12_temperature_meas_set(&dev_ctx, LIS2DH12_TEMP_ENABLE);
+ lis2dh12_operating_mode_set(&dev_ctx, LIS2DH12_HR_12bit);
+
+ return (int)AM_HAL_STATUS_SUCCESS;
+}
+
+TfLiteStatus SetupAccelerometer(tflite::ErrorReporter* error_reporter) {
+ // Set the clock frequency.
+ am_hal_clkgen_control(AM_HAL_CLKGEN_CONTROL_SYSCLK_MAX, 0);
+
+ // Set the default cache configuration
+ am_hal_cachectrl_config(&am_hal_cachectrl_defaults);
+ am_hal_cachectrl_enable();
+
+ // Configure the board for low power operation.
+ am_bsp_low_power_init();
+
+ // Initialize the device interface and control structures
+ dev_if.iomHandle =
+ NULL; // Gets initialized once iomHandle is known (in initAccel())
+ dev_if.addCS = AM_BSP_ACCELEROMETER_I2C_ADDRESS; // Gets the accelerometer
+ // I2C address for the board
+ dev_if.useSPI = false; // Using I2C
+
+ dev_ctx.write_reg = lis2dh12_write_platform_apollo3; // write bytes function
+ dev_ctx.read_reg = lis2dh12_read_platform_apollo3; // read bytes function
+ dev_ctx.handle = (void*)&dev_if; // Apollo3-specific interface information
+
+ // Collecting data at 25Hz.
+ int accInitRes = initAccelerometer();
+ if (accInitRes != (int)AM_HAL_STATUS_SUCCESS) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to initialize the accelerometer. (code %d)",
+ accInitRes);
+ }
+
+ // Enable the accelerometer's FIFO buffer.
+ // Note: LIS2DH12 has a FIFO buffer which holds up to 32 data entries. It
+ // accumulates data while the CPU is busy. Old data will be overwritten if
+ // it's not fetched in time, so we need to make sure that model inference is
+ // faster than 1/25Hz * 32 = 1.28s
+ if (lis2dh12_fifo_set(&dev_ctx, 1)) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to enable FIFO buffer.");
+ }
+
+ if (lis2dh12_fifo_mode_set(&dev_ctx, LIS2DH12_BYPASS_MODE)) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to clear FIFO buffer.");
+ return kTfLiteError;
+ }
+
+ if (lis2dh12_fifo_mode_set(&dev_ctx, LIS2DH12_DYNAMIC_STREAM_MODE)) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to set streaming mode.");
+ return kTfLiteError;
+ }
+
+ TF_LITE_REPORT_ERROR(error_reporter, "Magic starts!");
+
+ return kTfLiteOk;
+}
+
+bool ReadAccelerometer(tflite::ErrorReporter* error_reporter, float* input,
+ int length) {
+ // Check FIFO buffer for new samples
+ lis2dh12_fifo_src_reg_t status;
+ if (lis2dh12_fifo_status_get(&dev_ctx, &status)) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to get FIFO status.");
+ return false;
+ }
+
+ int samples = status.fss;
+ if (status.ovrn_fifo) {
+ samples++;
+ }
+
+ // Skip this round if data is not ready yet
+ if (samples == 0) {
+ return false;
+ }
+
+ // Load data from FIFO buffer
+ axis3bit16_t data_raw_acceleration_local;
+ for (int i = 0; i < samples; i++) {
+ // Zero out the struct that holds raw accelerometer data
+ memset(data_raw_acceleration_local.u8bit, 0x00, 3 * sizeof(int16_t));
+ // If the return value is non-zero, sensor data was successfully read
+ if (lis2dh12_acceleration_raw_get(&dev_ctx,
+ data_raw_acceleration_local.u8bit)) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Failed to get raw data.");
+ } else {
+ // Convert each raw 16-bit value into floating point values representing
+ // milli-Gs, a unit of acceleration, and store in the current position of
+ // our buffer
+ save_data[begin_index++] =
+ lis2dh12_from_fs2_hr_to_mg(data_raw_acceleration_local.i16bit[0]);
+ save_data[begin_index++] =
+ lis2dh12_from_fs2_hr_to_mg(data_raw_acceleration_local.i16bit[1]);
+ save_data[begin_index++] =
+ lis2dh12_from_fs2_hr_to_mg(data_raw_acceleration_local.i16bit[2]);
+ // Start from beginning, imitating loop array.
+ if (begin_index >= 600) begin_index = 0;
+ }
+ }
+
+ // Check if we are ready for prediction or still pending more initial data
+ if (pending_initial_data && begin_index >= 200) {
+ pending_initial_data = false;
+ }
+
+ // Return if we don't have enough data
+ if (pending_initial_data) {
+ return false;
+ }
+
+ // Copy the requested number of bytes to the provided input tensor
+ for (int i = 0; i < length; ++i) {
+ int ring_array_index = begin_index + i - length;
+ if (ring_array_index < 0) {
+ ring_array_index += 600;
+ }
+ input[i] = save_data[ring_array_index];
+ }
+ return true;
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/output_handler.cc b/tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/output_handler.cc
new file mode 100644
index 0000000..4c3cb42
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/sparkfun_edge/output_handler.cc
@@ -0,0 +1,73 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/magic_wand/output_handler.h"
+
+#include "am_bsp.h" // NOLINT
+#include "am_mcu_apollo.h" // NOLINT
+#include "am_util.h" // NOLINT
+
+void HandleOutput(tflite::ErrorReporter* error_reporter, int kind) {
+ // The first time this method runs, set up our LEDs correctly
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ // Setup LED's as outputs
+#ifdef AM_BSP_NUM_LEDS
+ am_devices_led_array_init(am_bsp_psLEDs, AM_BSP_NUM_LEDS);
+ am_devices_led_array_out(am_bsp_psLEDs, AM_BSP_NUM_LEDS, 0x00000000);
+#endif
+ is_initialized = true;
+ }
+
+ // Toggle the yellow LED every time an inference is performed
+ am_devices_led_toggle(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
+
+ // Set the LED color and print a symbol (red: wing, blue: ring, green: slope)
+ if (kind == 0) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "WING:\n\r* * *\n\r * * * "
+ "*\n\r * * * *\n\r * * * *\n\r * * "
+ "* *\n\r * *\n\r");
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_RED);
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_BLUE);
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_GREEN);
+ } else if (kind == 1) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "RING:\n\r *\n\r * *\n\r * *\n\r "
+ " * *\n\r * *\n\r * *\n\r "
+ " *\n\r");
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_RED);
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_BLUE);
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_GREEN);
+ } else if (kind == 2) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "SLOPE:\n\r *\n\r *\n\r *\n\r *\n\r "
+ "*\n\r *\n\r *\n\r * * * * * * * *\n\r");
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_RED);
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_BLUE);
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_GREEN);
+ }
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/README.md b/tensorflow/lite/micro/examples/magic_wand/train/README.md
new file mode 100644
index 0000000..115fd35
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/README.md
@@ -0,0 +1,191 @@
+# Gesture Recognition Magic Wand Training Scripts
+
+## Introduction
+
+The scripts in this directory can be used to train a TensorFlow model that
+classifies gestures based on accelerometer data. The code uses Python 3.7 and
+TensorFlow 2.0. The resulting model is less than 20KB in size.
+
+The following document contains instructions on using the scripts to train a
+model, and capturing your own training data.
+
+This project was inspired by the [Gesture Recognition Magic Wand](https://github.com/jewang/gesture-demo)
+project by Jennifer Wang.
+
+## Training
+
+### Dataset
+
+Three magic gestures were chosen, and data were collected from 7
+different people. Some random long movement sequences were collected and divided
+into shorter pieces, which made up "negative" data along with some other
+automatically generated random data.
+
+The dataset can be downloaded from the following URL:
+
+[download.tensorflow.org/models/tflite/magic_wand/data.tar.gz](http://download.tensorflow.org/models/tflite/magic_wand/data.tar.gz)
+
+### Training in Colab
+
+The following [Google Colaboratory](https://colab.research.google.com)
+notebook demonstrates how to train the model. It's the easiest way to get
+started:
+
+<table class="tfo-notebook-buttons" align="left">
+ <td>
+ <a target="_blank" href="https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/magic_wand/train/train_magic_wand_model.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
+ </td>
+ <td>
+ <a target="_blank" href="https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/magic_wand/train/train_magic_wand_model.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
+ </td>
+</table>
+
+If you'd prefer to run the scripts locally, use the following instructions.
+
+### Running the scripts
+
+Use the following command to install the required dependencies:
+
+```shell
+pip install -r requirements.txt
+```
+
+There are two ways to train the model:
+
+- Random data split, which mixes different people's data together and randomly
+ splits them into training, validation, and test sets
+- Person data split, which splits the data by person
+
+#### Random data split
+
+Using a random split results in higher training accuracy than a person split,
+but inferior performance on new data.
+
+```shell
+$ python data_prepare.py
+
+$ python data_split.py
+
+$ python train.py --model CNN --person false
+```
+
+#### Person data split
+
+Using a person data split results in lower training accuracy but better
+performance on new data.
+
+```shell
+$ python data_prepare.py
+
+$ python data_split_person.py
+
+$ python train.py --model CNN --person true
+```
+
+#### Model type
+
+In the `--model` argument, you can provide `CNN` or `LSTM`. The CNN model has a
+smaller size and lower latency.
+
+## Collecting new data
+
+To obtain new training data using the
+[SparkFun Edge development board](https://sparkfun.com/products/15170), you can
+modify one of the examples in the [SparkFun Edge BSP](https://github.com/sparkfun/SparkFun_Edge_BSP)
+and deploy it using the Ambiq SDK.
+
+### Install the Ambiq SDK and SparkFun Edge BSP
+
+Follow SparkFun's
+[Using SparkFun Edge Board with Ambiq Apollo3 SDK](https://learn.sparkfun.com/tutorials/using-sparkfun-edge-board-with-ambiq-apollo3-sdk/all)
+guide to set up the Ambiq SDK and SparkFun Edge BSP.
+
+#### Modify the example code
+
+First, `cd` into
+`AmbiqSuite-Rel2.2.0/boards/SparkFun_Edge_BSP/examples/example1_edge_test`.
+
+##### Modify `src/tf_adc/tf_adc.c`
+
+Add `true` in line 62 as the second parameter of function
+`am_hal_adc_samples_read`.
+
+##### Modify `src/main.c`
+
+Add the line below in `int main(void)`, just before the line `while(1)`:
+
+```cc
+am_util_stdio_printf("-,-,-\r\n");
+```
+
+Change the following lines in `while(1){...}`
+
+```cc
+am_util_stdio_printf("Acc [mg] %04.2f x, %04.2f y, %04.2f z, Temp [deg C] %04.2f, MIC0 [counts / 2^14] %d\r\n", acceleration_mg[0], acceleration_mg[1], acceleration_mg[2], temperature_degC, (audioSample) );
+```
+
+to:
+
+```cc
+am_util_stdio_printf("%04.2f,%04.2f,%04.2f\r\n", acceleration_mg[0], acceleration_mg[1], acceleration_mg[2]);
+```
+
+#### Flash the binary
+
+Follow the instructions in
+[SparkFun's guide](https://learn.sparkfun.com/tutorials/using-sparkfun-edge-board-with-ambiq-apollo3-sdk/all#example-applications)
+to flash the binary to the device.
+
+#### Collect accelerometer data
+
+First, in a new terminal window, run the following command to begin logging
+output to `output.txt`:
+
+```shell
+$ script output.txt
+```
+
+Next, in the same window, use `screen` to connect to the device:
+
+```shell
+$ screen ${DEVICENAME} 115200
+```
+
+Output information collected from accelerometer sensor will be shown on the
+screen and saved in `output.txt`, in the format of "x,y,z" per line.
+
+Press the `RST` button to start capturing a new gesture, then press Button 14
+when it ends. New data will begin with a line "-,-,-".
+
+To exit `screen`, hit +Ctrl\\+A+, immediately followed by the +K+ key,
+then hit the +Y+ key. Then run
+
+```shell
+$ exit
+```
+
+to stop logging data. Data will be saved in `output.txt`. For compatibility
+with the training scripts, change the file name to include person's name and
+the gesture name, in the following format:
+
+```
+output_{gesture_name}_{person_name}.txt
+```
+
+#### Edit and run the scripts
+
+Edit the following files to include your new gesture names (replacing
+"wing", "ring", and "slope")
+
+- `data_load.py`
+- `data_prepare.py`
+- `data_split.py`
+
+Edit the following files to include your new person names (replacing "hyw",
+"shiyun", "tangsy", "dengyl", "jiangyh", "xunkai", "lsj", "pengxl", "liucx",
+and "zhangxy"):
+
+- `data_prepare.py`
+- `data_split_person.py`
+
+Finally, run the commands described earlier to train a new model.
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_augmentation.py b/tensorflow/lite/micro/examples/magic_wand/train/data_augmentation.py
new file mode 100644
index 0000000..8d30fa1
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_augmentation.py
@@ -0,0 +1,74 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint: disable=g-bad-import-order
+
+"""Data augmentation that will be used in data_load.py."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import random
+
+import numpy as np
+
+
+def time_wrapping(molecule, denominator, data):
+ """Generate (molecule/denominator)x speed data."""
+ tmp_data = [[0
+ for i in range(len(data[0]))]
+ for j in range((int(len(data) / molecule) - 1) * denominator)]
+ for i in range(int(len(data) / molecule) - 1):
+ for j in range(len(data[i])):
+ for k in range(denominator):
+ tmp_data[denominator * i +
+ k][j] = (data[molecule * i + k][j] * (denominator - k) +
+ data[molecule * i + k + 1][j] * k) / denominator
+ return tmp_data
+
+
+def augment_data(original_data, original_label):
+ """Perform data augmentation."""
+ new_data = []
+ new_label = []
+ for idx, (data, label) in enumerate(zip(original_data, original_label)): # pylint: disable=unused-variable
+ # Original data
+ new_data.append(data)
+ new_label.append(label)
+ # Sequence shift
+ for num in range(5): # pylint: disable=unused-variable
+ new_data.append((np.array(data, dtype=np.float32) +
+ (random.random() - 0.5) * 200).tolist())
+ new_label.append(label)
+ # Random noise
+ tmp_data = [[0 for i in range(len(data[0]))] for j in range(len(data))]
+ for num in range(5):
+ for i in range(len(tmp_data)):
+ for j in range(len(tmp_data[i])):
+ tmp_data[i][j] = data[i][j] + 5 * random.random()
+ new_data.append(tmp_data)
+ new_label.append(label)
+ # Time warping
+ fractions = [(3, 2), (5, 3), (2, 3), (3, 4), (9, 5), (6, 5), (4, 5)]
+ for molecule, denominator in fractions:
+ new_data.append(time_wrapping(molecule, denominator, data))
+ new_label.append(label)
+ # Movement amplification
+ for molecule, denominator in fractions:
+ new_data.append(
+ (np.array(data, dtype=np.float32) * molecule / denominator).tolist())
+ new_label.append(label)
+ return new_data, new_label
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_augmentation_test.py b/tensorflow/lite/micro/examples/magic_wand/train/data_augmentation_test.py
new file mode 100644
index 0000000..76bac65
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_augmentation_test.py
@@ -0,0 +1,58 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint: disable=g-bad-import-order
+
+"""Test for data_augmentation.py."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import unittest
+
+import numpy as np
+
+from data_augmentation import augment_data
+from data_augmentation import time_wrapping
+
+
+class TestAugmentation(unittest.TestCase):
+
+ def test_time_wrapping(self):
+ original_data = np.random.rand(10, 3).tolist()
+ wrapped_data = time_wrapping(4, 5, original_data)
+ self.assertEqual(len(wrapped_data), int(len(original_data) / 4 - 1) * 5)
+ self.assertEqual(len(wrapped_data[0]), len(original_data[0]))
+
+ def test_augment_data(self):
+ original_data = [
+ np.random.rand(128, 3).tolist(),
+ np.random.rand(66, 2).tolist(),
+ np.random.rand(9, 1).tolist()
+ ]
+ original_label = ["data", "augmentation", "test"]
+ augmented_data, augmented_label = augment_data(original_data,
+ original_label)
+ self.assertEqual(25 * len(original_data), len(augmented_data))
+ self.assertIsInstance(augmented_data, list)
+ self.assertEqual(25 * len(original_label), len(augmented_label))
+ self.assertIsInstance(augmented_label, list)
+ for i in range(len(original_label)):
+ self.assertEqual(augmented_label[25 * i], original_label[i])
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_load.py b/tensorflow/lite/micro/examples/magic_wand/train/data_load.py
new file mode 100644
index 0000000..fc9ba71
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_load.py
@@ -0,0 +1,106 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint: disable=g-bad-import-order
+
+"""Load data from the specified paths and format them for training."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import json
+
+import numpy as np
+import tensorflow as tf
+
+from data_augmentation import augment_data
+
+LABEL_NAME = "gesture"
+DATA_NAME = "accel_ms2_xyz"
+
+
+class DataLoader(object):
+ """Loads data and prepares for training."""
+
+ def __init__(self, train_data_path, valid_data_path, test_data_path,
+ seq_length):
+ self.dim = 3
+ self.seq_length = seq_length
+ self.label2id = {"wing": 0, "ring": 1, "slope": 2, "negative": 3}
+ self.train_data, self.train_label, self.train_len = self.get_data_file(
+ train_data_path, "train")
+ self.valid_data, self.valid_label, self.valid_len = self.get_data_file(
+ valid_data_path, "valid")
+ self.test_data, self.test_label, self.test_len = self.get_data_file(
+ test_data_path, "test")
+
+ def get_data_file(self, data_path, data_type):
+ """Get train, valid and test data from files."""
+ data = []
+ label = []
+ with open(data_path, "r") as f:
+ lines = f.readlines()
+ for idx, line in enumerate(lines): # pylint: disable=unused-variable
+ dic = json.loads(line)
+ data.append(dic[DATA_NAME])
+ label.append(dic[LABEL_NAME])
+ if data_type == "train":
+ data, label = augment_data(data, label)
+ length = len(label)
+ print(data_type + "_data_length:" + str(length))
+ return data, label, length
+
+ def pad(self, data, seq_length, dim):
+ """Get neighbour padding."""
+ noise_level = 20
+ padded_data = []
+ # Before- Neighbour padding
+ tmp_data = (np.random.rand(seq_length, dim) - 0.5) * noise_level + data[0]
+ tmp_data[(seq_length -
+ min(len(data), seq_length)):] = data[:min(len(data), seq_length)]
+ padded_data.append(tmp_data)
+ # After- Neighbour padding
+ tmp_data = (np.random.rand(seq_length, dim) - 0.5) * noise_level + data[-1]
+ tmp_data[:min(len(data), seq_length)] = data[:min(len(data), seq_length)]
+ padded_data.append(tmp_data)
+ return padded_data
+
+ def format_support_func(self, padded_num, length, data, label):
+ """Support function for format.(Helps format train, valid and test.)"""
+ # Add 2 padding, initialize data and label
+ length *= padded_num
+ features = np.zeros((length, self.seq_length, self.dim))
+ labels = np.zeros(length)
+ # Get padding for train, valid and test
+ for idx, (data, label) in enumerate(zip(data, label)):
+ padded_data = self.pad(data, self.seq_length, self.dim)
+ for num in range(padded_num):
+ features[padded_num * idx + num] = padded_data[num]
+ labels[padded_num * idx + num] = self.label2id[label]
+ # Turn into tf.data.Dataset
+ dataset = tf.data.Dataset.from_tensor_slices(
+ (features, labels.astype("int32")))
+ return length, dataset
+
+ def format(self):
+ """Format data(including padding, etc.) and get the dataset for the model."""
+ padded_num = 2
+ self.train_len, self.train_data = self.format_support_func(
+ padded_num, self.train_len, self.train_data, self.train_label)
+ self.valid_len, self.valid_data = self.format_support_func(
+ padded_num, self.valid_len, self.valid_data, self.valid_label)
+ self.test_len, self.test_data = self.format_support_func(
+ padded_num, self.test_len, self.test_data, self.test_label)
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_load_test.py b/tensorflow/lite/micro/examples/magic_wand/train/data_load_test.py
new file mode 100644
index 0000000..8a4ef45
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_load_test.py
@@ -0,0 +1,95 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint: disable=g-bad-import-order
+
+"""Test for data_load.py."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import unittest
+from data_load import DataLoader
+
+import tensorflow as tf
+
+
+class TestLoad(unittest.TestCase):
+
+ def setUp(self): # pylint: disable=g-missing-super-call
+ self.loader = DataLoader(
+ "./data/train", "./data/valid", "./data/test", seq_length=512)
+
+ def test_get_data(self):
+ self.assertIsInstance(self.loader.train_data, list)
+ self.assertIsInstance(self.loader.train_label, list)
+ self.assertIsInstance(self.loader.valid_data, list)
+ self.assertIsInstance(self.loader.valid_label, list)
+ self.assertIsInstance(self.loader.test_data, list)
+ self.assertIsInstance(self.loader.test_label, list)
+ self.assertEqual(self.loader.train_len, len(self.loader.train_data))
+ self.assertEqual(self.loader.train_len, len(self.loader.train_label))
+ self.assertEqual(self.loader.valid_len, len(self.loader.valid_data))
+ self.assertEqual(self.loader.valid_len, len(self.loader.valid_label))
+ self.assertEqual(self.loader.test_len, len(self.loader.test_data))
+ self.assertEqual(self.loader.test_len, len(self.loader.test_label))
+
+ def test_pad(self):
+ original_data1 = [[2, 3], [1, 1]]
+ expected_data1_0 = [[2, 3], [2, 3], [2, 3], [2, 3], [1, 1]]
+ expected_data1_1 = [[2, 3], [1, 1], [1, 1], [1, 1], [1, 1]]
+ original_data2 = [[-2, 3], [-77, -681], [5, 6], [9, -7], [22, 3333],
+ [9, 99], [-100, 0]]
+ expected_data2 = [[-2, 3], [-77, -681], [5, 6], [9, -7], [22, 3333]]
+ padding_data1 = self.loader.pad(original_data1, seq_length=5, dim=2)
+ padding_data2 = self.loader.pad(original_data2, seq_length=5, dim=2)
+ for i in range(len(padding_data1[0])):
+ for j in range(len(padding_data1[0].tolist()[0])):
+ self.assertLess(
+ abs(padding_data1[0].tolist()[i][j] - expected_data1_0[i][j]),
+ 10.001)
+ for i in range(len(padding_data1[1])):
+ for j in range(len(padding_data1[1].tolist()[0])):
+ self.assertLess(
+ abs(padding_data1[1].tolist()[i][j] - expected_data1_1[i][j]),
+ 10.001)
+ self.assertEqual(padding_data2[0].tolist(), expected_data2)
+ self.assertEqual(padding_data2[1].tolist(), expected_data2)
+
+ def test_format(self):
+ self.loader.format()
+ expected_train_label = int(self.loader.label2id[self.loader.train_label[0]])
+ expected_valid_label = int(self.loader.label2id[self.loader.valid_label[0]])
+ expected_test_label = int(self.loader.label2id[self.loader.test_label[0]])
+ for feature, label in self.loader.train_data: # pylint: disable=unused-variable
+ format_train_label = label.numpy()
+ break
+ for feature, label in self.loader.valid_data:
+ format_valid_label = label.numpy()
+ break
+ for feature, label in self.loader.test_data:
+ format_test_label = label.numpy()
+ break
+ self.assertEqual(expected_train_label, format_train_label)
+ self.assertEqual(expected_valid_label, format_valid_label)
+ self.assertEqual(expected_test_label, format_test_label)
+ self.assertIsInstance(self.loader.train_data, tf.data.Dataset)
+ self.assertIsInstance(self.loader.valid_data, tf.data.Dataset)
+ self.assertIsInstance(self.loader.test_data, tf.data.Dataset)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_prepare.py b/tensorflow/lite/micro/examples/magic_wand/train/data_prepare.py
new file mode 100644
index 0000000..b5f1fcf
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_prepare.py
@@ -0,0 +1,164 @@
+# Lint as: python3
+# coding=utf-8
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Prepare data for further process.
+
+Read data from "/slope", "/ring", "/wing", "/negative" and save them
+in "/data/complete_data" in python dict format.
+
+It will generate a new file with the following structure:
+├── data
+│ └── complete_data
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import csv
+import json
+import os
+import random
+
+LABEL_NAME = "gesture"
+DATA_NAME = "accel_ms2_xyz"
+folders = ["wing", "ring", "slope"]
+names = [
+ "hyw", "shiyun", "tangsy", "dengyl", "zhangxy", "pengxl", "liucx",
+ "jiangyh", "xunkai"
+]
+
+
+def prepare_original_data(folder, name, data, file_to_read): # pylint: disable=redefined-outer-name
+ """Read collected data from files."""
+ if folder != "negative":
+ with open(file_to_read, "r") as f:
+ lines = csv.reader(f)
+ data_new = {}
+ data_new[LABEL_NAME] = folder
+ data_new[DATA_NAME] = []
+ data_new["name"] = name
+ for idx, line in enumerate(lines): # pylint: disable=unused-variable,redefined-outer-name
+ if len(line) == 3:
+ if line[2] == "-" and data_new[DATA_NAME]:
+ data.append(data_new)
+ data_new = {}
+ data_new[LABEL_NAME] = folder
+ data_new[DATA_NAME] = []
+ data_new["name"] = name
+ elif line[2] != "-":
+ data_new[DATA_NAME].append([float(i) for i in line[0:3]])
+ data.append(data_new)
+ else:
+ with open(file_to_read, "r") as f:
+ lines = csv.reader(f)
+ data_new = {}
+ data_new[LABEL_NAME] = folder
+ data_new[DATA_NAME] = []
+ data_new["name"] = name
+ for idx, line in enumerate(lines):
+ if len(line) == 3 and line[2] != "-":
+ if len(data_new[DATA_NAME]) == 120:
+ data.append(data_new)
+ data_new = {}
+ data_new[LABEL_NAME] = folder
+ data_new[DATA_NAME] = []
+ data_new["name"] = name
+ else:
+ data_new[DATA_NAME].append([float(i) for i in line[0:3]])
+ data.append(data_new)
+
+
+def generate_negative_data(data): # pylint: disable=redefined-outer-name
+ """Generate negative data labeled as 'negative6~8'."""
+ # Big movement -> around straight line
+ for i in range(100):
+ if i > 80:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative8"}
+ elif i > 60:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative7"}
+ else:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative6"}
+ start_x = (random.random() - 0.5) * 2000
+ start_y = (random.random() - 0.5) * 2000
+ start_z = (random.random() - 0.5) * 2000
+ x_increase = (random.random() - 0.5) * 10
+ y_increase = (random.random() - 0.5) * 10
+ z_increase = (random.random() - 0.5) * 10
+ for j in range(128):
+ dic[DATA_NAME].append([
+ start_x + j * x_increase + (random.random() - 0.5) * 6,
+ start_y + j * y_increase + (random.random() - 0.5) * 6,
+ start_z + j * z_increase + (random.random() - 0.5) * 6
+ ])
+ data.append(dic)
+ # Random
+ for i in range(100):
+ if i > 80:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative8"}
+ elif i > 60:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative7"}
+ else:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative6"}
+ for j in range(128):
+ dic[DATA_NAME].append([(random.random() - 0.5) * 1000,
+ (random.random() - 0.5) * 1000,
+ (random.random() - 0.5) * 1000])
+ data.append(dic)
+ # Stay still
+ for i in range(100):
+ if i > 80:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative8"}
+ elif i > 60:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative7"}
+ else:
+ dic = {DATA_NAME: [], LABEL_NAME: "negative", "name": "negative6"}
+ start_x = (random.random() - 0.5) * 2000
+ start_y = (random.random() - 0.5) * 2000
+ start_z = (random.random() - 0.5) * 2000
+ for j in range(128):
+ dic[DATA_NAME].append([
+ start_x + (random.random() - 0.5) * 40,
+ start_y + (random.random() - 0.5) * 40,
+ start_z + (random.random() - 0.5) * 40
+ ])
+ data.append(dic)
+
+
+# Write data to file
+def write_data(data_to_write, path):
+ with open(path, "w") as f:
+ for idx, item in enumerate(data_to_write): # pylint: disable=unused-variable,redefined-outer-name
+ dic = json.dumps(item, ensure_ascii=False)
+ f.write(dic)
+ f.write("\n")
+
+
+if __name__ == "__main__":
+ data = [] # pylint: disable=redefined-outer-name
+ for idx1, folder in enumerate(folders):
+ for idx2, name in enumerate(names):
+ prepare_original_data(folder, name, data,
+ "./%s/output_%s_%s.txt" % (folder, folder, name))
+ for idx in range(5):
+ prepare_original_data("negative", "negative%d" % (idx + 1), data,
+ "./negative/output_negative_%d.txt" % (idx + 1))
+ generate_negative_data(data)
+ print("data_length: " + str(len(data)))
+ if not os.path.exists("./data"):
+ os.makedirs("./data")
+ write_data(data, "./data/complete_data")
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_prepare_test.py b/tensorflow/lite/micro/examples/magic_wand/train/data_prepare_test.py
new file mode 100644
index 0000000..a2af099
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_prepare_test.py
@@ -0,0 +1,75 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Test for data_prepare.py."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import csv
+import json
+import os
+import unittest
+from data_prepare import generate_negative_data
+from data_prepare import prepare_original_data
+from data_prepare import write_data
+
+
+class TestPrepare(unittest.TestCase):
+
+ def setUp(self): # pylint: disable=g-missing-super-call
+ self.file = "./%s/output_%s_%s.txt" % (folders[0], folders[0], names[0]) # pylint: disable=undefined-variable
+ self.data = []
+ prepare_original_data(folders[0], names[0], self.data, self.file) # pylint: disable=undefined-variable
+
+ def test_prepare_data(self):
+ num = 0
+ with open(self.file, "r") as f:
+ lines = csv.reader(f)
+ for idx, line in enumerate(lines): # pylint: disable=unused-variable
+ if len(line) == 3 and line[2] == "-":
+ num += 1
+ self.assertEqual(len(self.data), num)
+ self.assertIsInstance(self.data, list)
+ self.assertIsInstance(self.data[0], dict)
+ self.assertEqual(list(self.data[-1]), ["gesture", "accel_ms2_xyz", "name"])
+ self.assertEqual(self.data[0]["name"], names[0]) # pylint: disable=undefined-variable
+
+ def test_generate_negative(self):
+ original_len = len(self.data)
+ generate_negative_data(self.data)
+ self.assertEqual(original_len + 300, len(self.data))
+ generated_num = 0
+ for idx, data in enumerate(self.data): # pylint: disable=undefined-variable, unused-variable
+ if data["name"] == "negative6" or data["name"] == "negative7" or data[
+ "name"] == "negative8":
+ generated_num += 1
+ self.assertEqual(generated_num, 300)
+
+ def test_write_data(self):
+ data_path_test = "./data/data0"
+ write_data(self.data, data_path_test)
+ with open(data_path_test, "r") as f:
+ lines = f.readlines()
+ self.assertEqual(len(lines), len(self.data))
+ self.assertEqual(json.loads(lines[0]), self.data[0])
+ self.assertEqual(json.loads(lines[-1]), self.data[-1])
+ os.remove(data_path_test)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_split.py b/tensorflow/lite/micro/examples/magic_wand/train/data_split.py
new file mode 100644
index 0000000..3bf4747
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_split.py
@@ -0,0 +1,90 @@
+# Lint as: python3
+# coding=utf-8
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Mix and split data.
+
+Mix different people's data together and randomly split them into train,
+validation and test. These data would be saved separately under "/data".
+It will generate new files with the following structure:
+
+├── data
+│ ├── complete_data
+│ ├── test
+│ ├── train
+│ └── valid
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import json
+import random
+from data_prepare import write_data
+
+
+# Read data
+def read_data(path):
+ data = [] # pylint: disable=redefined-outer-name
+ with open(path, "r") as f:
+ lines = f.readlines()
+ for idx, line in enumerate(lines): # pylint: disable=unused-variable
+ dic = json.loads(line)
+ data.append(dic)
+ print("data_length:" + str(len(data)))
+ return data
+
+
+def split_data(data, train_ratio, valid_ratio): # pylint: disable=redefined-outer-name
+ """Splits data into train, validation and test according to ratio."""
+ train_data = [] # pylint: disable=redefined-outer-name
+ valid_data = [] # pylint: disable=redefined-outer-name
+ test_data = [] # pylint: disable=redefined-outer-name
+ num_dic = {"wing": 0, "ring": 0, "slope": 0, "negative": 0}
+ for idx, item in enumerate(data): # pylint: disable=unused-variable
+ for i in num_dic:
+ if item["gesture"] == i:
+ num_dic[i] += 1
+ print(num_dic)
+ train_num_dic = {}
+ valid_num_dic = {}
+ for i in num_dic:
+ train_num_dic[i] = int(train_ratio * num_dic[i])
+ valid_num_dic[i] = int(valid_ratio * num_dic[i])
+ random.seed(30)
+ random.shuffle(data)
+ for idx, item in enumerate(data):
+ for i in num_dic:
+ if item["gesture"] == i:
+ if train_num_dic[i] > 0:
+ train_data.append(item)
+ train_num_dic[i] -= 1
+ elif valid_num_dic[i] > 0:
+ valid_data.append(item)
+ valid_num_dic[i] -= 1
+ else:
+ test_data.append(item)
+ print("train_length:" + str(len(train_data)))
+ print("test_length:" + str(len(test_data)))
+ return train_data, valid_data, test_data
+
+
+if __name__ == "__main__":
+ data = read_data("./data/complete_data")
+ train_data, valid_data, test_data = split_data(data, 0.6, 0.2)
+ write_data(train_data, "./data/train")
+ write_data(valid_data, "./data/valid")
+ write_data(test_data, "./data/test")
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_split_person.py b/tensorflow/lite/micro/examples/magic_wand/train/data_split_person.py
new file mode 100644
index 0000000..be05213
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_split_person.py
@@ -0,0 +1,75 @@
+# Lint as: python3
+# coding=utf-8
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Split data into train, validation and test dataset according to person.
+
+That is, use some people's data as train, some other people's data as
+validation, and the rest ones' data as test. These data would be saved
+separately under "/person_split".
+
+It will generate new files with the following structure:
+├──person_split
+│ ├── test
+│ ├── train
+│ └──valid
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+import random
+from data_split import read_data
+from data_split import write_data
+
+
+def person_split(whole_data, train_names, valid_names, test_names): # pylint: disable=redefined-outer-name
+ """Split data by person."""
+ random.seed(30)
+ random.shuffle(whole_data)
+ train_data = [] # pylint: disable=redefined-outer-name
+ valid_data = [] # pylint: disable=redefined-outer-name
+ test_data = [] # pylint: disable=redefined-outer-name
+ for idx, data in enumerate(whole_data): # pylint: disable=redefined-outer-name,unused-variable
+ if data["name"] in train_names:
+ train_data.append(data)
+ elif data["name"] in valid_names:
+ valid_data.append(data)
+ elif data["name"] in test_names:
+ test_data.append(data)
+ print("train_length:" + str(len(train_data)))
+ print("valid_length:" + str(len(valid_data)))
+ print("test_length:" + str(len(test_data)))
+ return train_data, valid_data, test_data
+
+
+if __name__ == "__main__":
+ data = read_data("./data/complete_data")
+ train_names = [
+ "hyw", "shiyun", "tangsy", "dengyl", "jiangyh", "xunkai", "negative3",
+ "negative4", "negative5", "negative6"
+ ]
+ valid_names = ["lsj", "pengxl", "negative2", "negative7"]
+ test_names = ["liucx", "zhangxy", "negative1", "negative8"]
+ train_data, valid_data, test_data = person_split(data, train_names,
+ valid_names, test_names)
+ if not os.path.exists("./person_split"):
+ os.makedirs("./person_split")
+ write_data(train_data, "./person_split/train")
+ write_data(valid_data, "./person_split/valid")
+ write_data(test_data, "./person_split/test")
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_split_person_test.py b/tensorflow/lite/micro/examples/magic_wand/train/data_split_person_test.py
new file mode 100644
index 0000000..3a91ce4
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_split_person_test.py
@@ -0,0 +1,54 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Test for data_split_person.py."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import unittest
+from data_split_person import person_split
+from data_split_person import read_data
+
+
+class TestSplitPerson(unittest.TestCase):
+
+ def setUp(self): # pylint: disable=g-missing-super-call
+ self.data = read_data("./data/complete_data")
+
+ def test_person_split(self):
+ train_names = ["dengyl"]
+ valid_names = ["liucx"]
+ test_names = ["tangsy"]
+ dengyl_num = 63
+ liucx_num = 63
+ tangsy_num = 30
+ train_data, valid_data, test_data = person_split(self.data, train_names,
+ valid_names, test_names)
+ self.assertEqual(len(train_data), dengyl_num)
+ self.assertEqual(len(valid_data), liucx_num)
+ self.assertEqual(len(test_data), tangsy_num)
+ self.assertIsInstance(train_data, list)
+ self.assertIsInstance(valid_data, list)
+ self.assertIsInstance(test_data, list)
+ self.assertIsInstance(train_data[0], dict)
+ self.assertIsInstance(valid_data[0], dict)
+ self.assertIsInstance(test_data[0], dict)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/data_split_test.py b/tensorflow/lite/micro/examples/magic_wand/train/data_split_test.py
new file mode 100644
index 0000000..9a8f151
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/data_split_test.py
@@ -0,0 +1,77 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Test for data_split.py."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import json
+import unittest
+from data_split import read_data
+from data_split import split_data
+
+
+class TestSplit(unittest.TestCase):
+
+ def setUp(self): # pylint: disable=g-missing-super-call
+ self.data = read_data("./data/complete_data")
+ self.num_dic = {"wing": 0, "ring": 0, "slope": 0, "negative": 0}
+ with open("./data/complete_data", "r") as f:
+ lines = f.readlines()
+ self.num = len(lines)
+
+ def test_read_data(self):
+ self.assertEqual(len(self.data), self.num)
+ self.assertIsInstance(self.data, list)
+ self.assertIsInstance(self.data[0], dict)
+ self.assertEqual(
+ set(list(self.data[-1])), set(["gesture", "accel_ms2_xyz", "name"]))
+
+ def test_split_data(self):
+ with open("./data/complete_data", "r") as f:
+ lines = f.readlines()
+ for idx, line in enumerate(lines): # pylint: disable=unused-variable
+ dic = json.loads(line)
+ for ges in self.num_dic:
+ if dic["gesture"] == ges:
+ self.num_dic[ges] += 1
+ train_data_0, valid_data_0, test_data_100 = split_data(self.data, 0, 0)
+ train_data_50, valid_data_50, test_data_0 = split_data(self.data, 0.5, 0.5)
+ train_data_60, valid_data_20, test_data_20 = split_data(self.data, 0.6, 0.2)
+ len_60 = int(self.num_dic["wing"] * 0.6) + int(
+ self.num_dic["ring"] * 0.6) + int(self.num_dic["slope"] * 0.6) + int(
+ self.num_dic["negative"] * 0.6)
+ len_50 = int(self.num_dic["wing"] * 0.5) + int(
+ self.num_dic["ring"] * 0.5) + int(self.num_dic["slope"] * 0.5) + int(
+ self.num_dic["negative"] * 0.5)
+ len_20 = int(self.num_dic["wing"] * 0.2) + int(
+ self.num_dic["ring"] * 0.2) + int(self.num_dic["slope"] * 0.2) + int(
+ self.num_dic["negative"] * 0.2)
+ self.assertEqual(len(train_data_0), 0)
+ self.assertEqual(len(train_data_50), len_50)
+ self.assertEqual(len(train_data_60), len_60)
+ self.assertEqual(len(valid_data_0), 0)
+ self.assertEqual(len(valid_data_50), len_50)
+ self.assertEqual(len(valid_data_20), len_20)
+ self.assertEqual(len(test_data_100), self.num)
+ self.assertEqual(len(test_data_0), (self.num - 2 * len_50))
+ self.assertEqual(len(test_data_20), (self.num - len_60 - len_20))
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/netmodels/CNN/weights.h5 b/tensorflow/lite/micro/examples/magic_wand/train/netmodels/CNN/weights.h5
new file mode 100644
index 0000000..1d825b3
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/netmodels/CNN/weights.h5
Binary files differ
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/requirements.txt b/tensorflow/lite/micro/examples/magic_wand/train/requirements.txt
new file mode 100644
index 0000000..93f2ed4
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/requirements.txt
@@ -0,0 +1,2 @@
+numpy==1.16.2
+tensorflow==2.4.0
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/train.py b/tensorflow/lite/micro/examples/magic_wand/train/train.py
new file mode 100644
index 0000000..6ccaa8c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/train.py
@@ -0,0 +1,203 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint: disable=redefined-outer-name
+# pylint: disable=g-bad-import-order
+
+"""Build and train neural networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import datetime
+import os
+from data_load import DataLoader
+
+import numpy as np
+import tensorflow as tf
+
+logdir = "logs/scalars/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
+tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir)
+
+
+def reshape_function(data, label):
+ reshaped_data = tf.reshape(data, [-1, 3, 1])
+ return reshaped_data, label
+
+
+def calculate_model_size(model):
+ print(model.summary())
+ var_sizes = [
+ np.product(list(map(int, v.shape))) * v.dtype.size
+ for v in model.trainable_variables
+ ]
+ print("Model size:", sum(var_sizes) / 1024, "KB")
+
+
+def build_cnn(seq_length):
+ """Builds a convolutional neural network in Keras."""
+ model = tf.keras.Sequential([
+ tf.keras.layers.Conv2D(
+ 8, (4, 3),
+ padding="same",
+ activation="relu",
+ input_shape=(seq_length, 3, 1)), # output_shape=(batch, 128, 3, 8)
+ tf.keras.layers.MaxPool2D((3, 3)), # (batch, 42, 1, 8)
+ tf.keras.layers.Dropout(0.1), # (batch, 42, 1, 8)
+ tf.keras.layers.Conv2D(16, (4, 1), padding="same",
+ activation="relu"), # (batch, 42, 1, 16)
+ tf.keras.layers.MaxPool2D((3, 1), padding="same"), # (batch, 14, 1, 16)
+ tf.keras.layers.Dropout(0.1), # (batch, 14, 1, 16)
+ tf.keras.layers.Flatten(), # (batch, 224)
+ tf.keras.layers.Dense(16, activation="relu"), # (batch, 16)
+ tf.keras.layers.Dropout(0.1), # (batch, 16)
+ tf.keras.layers.Dense(4, activation="softmax") # (batch, 4)
+ ])
+ model_path = os.path.join("./netmodels", "CNN")
+ print("Built CNN.")
+ if not os.path.exists(model_path):
+ os.makedirs(model_path)
+ model.load_weights("./netmodels/CNN/weights.h5")
+ return model, model_path
+
+
+def build_lstm(seq_length):
+ """Builds an LSTM in Keras."""
+ model = tf.keras.Sequential([
+ tf.keras.layers.Bidirectional(
+ tf.keras.layers.LSTM(22),
+ input_shape=(seq_length, 3)), # output_shape=(batch, 44)
+ tf.keras.layers.Dense(4, activation="sigmoid") # (batch, 4)
+ ])
+ model_path = os.path.join("./netmodels", "LSTM")
+ print("Built LSTM.")
+ if not os.path.exists(model_path):
+ os.makedirs(model_path)
+ return model, model_path
+
+
+def load_data(train_data_path, valid_data_path, test_data_path, seq_length):
+ data_loader = DataLoader(
+ train_data_path, valid_data_path, test_data_path, seq_length=seq_length)
+ data_loader.format()
+ return data_loader.train_len, data_loader.train_data, data_loader.valid_len, \
+ data_loader.valid_data, data_loader.test_len, data_loader.test_data
+
+
+def build_net(args, seq_length):
+ if args.model == "CNN":
+ model, model_path = build_cnn(seq_length)
+ elif args.model == "LSTM":
+ model, model_path = build_lstm(seq_length)
+ else:
+ print("Please input correct model name.(CNN LSTM)")
+ return model, model_path
+
+
+def train_net(
+ model,
+ model_path, # pylint: disable=unused-argument
+ train_len, # pylint: disable=unused-argument
+ train_data,
+ valid_len,
+ valid_data, # pylint: disable=unused-argument
+ test_len,
+ test_data,
+ kind):
+ """Trains the model."""
+ calculate_model_size(model)
+ epochs = 50
+ batch_size = 64
+ model.compile(
+ optimizer="adam",
+ loss="sparse_categorical_crossentropy",
+ metrics=["accuracy"])
+ if kind == "CNN":
+ train_data = train_data.map(reshape_function)
+ test_data = test_data.map(reshape_function)
+ valid_data = valid_data.map(reshape_function)
+ test_labels = np.zeros(test_len)
+ idx = 0
+ for data, label in test_data: # pylint: disable=unused-variable
+ test_labels[idx] = label.numpy()
+ idx += 1
+ train_data = train_data.batch(batch_size).repeat()
+ valid_data = valid_data.batch(batch_size)
+ test_data = test_data.batch(batch_size)
+ model.fit(
+ train_data,
+ epochs=epochs,
+ validation_data=valid_data,
+ steps_per_epoch=1000,
+ validation_steps=int((valid_len - 1) / batch_size + 1),
+ callbacks=[tensorboard_callback])
+ loss, acc = model.evaluate(test_data)
+ pred = np.argmax(model.predict(test_data), axis=1)
+ confusion = tf.math.confusion_matrix(
+ labels=tf.constant(test_labels),
+ predictions=tf.constant(pred),
+ num_classes=4)
+ print(confusion)
+ print("Loss {}, Accuracy {}".format(loss, acc))
+ # Convert the model to the TensorFlow Lite format without quantization
+ converter = tf.lite.TFLiteConverter.from_keras_model(model)
+ tflite_model = converter.convert()
+
+ # Save the model to disk
+ open("model.tflite", "wb").write(tflite_model)
+
+ # Convert the model to the TensorFlow Lite format with quantization
+ converter = tf.lite.TFLiteConverter.from_keras_model(model)
+ converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
+ tflite_model = converter.convert()
+
+ # Save the model to disk
+ open("model_quantized.tflite", "wb").write(tflite_model)
+
+ basic_model_size = os.path.getsize("model.tflite")
+ print("Basic model is %d bytes" % basic_model_size)
+ quantized_model_size = os.path.getsize("model_quantized.tflite")
+ print("Quantized model is %d bytes" % quantized_model_size)
+ difference = basic_model_size - quantized_model_size
+ print("Difference is %d bytes" % difference)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model", "-m")
+ parser.add_argument("--person", "-p")
+ args = parser.parse_args()
+
+ seq_length = 128
+
+ print("Start to load data...")
+ if args.person == "true":
+ train_len, train_data, valid_len, valid_data, test_len, test_data = \
+ load_data("./person_split/train", "./person_split/valid",
+ "./person_split/test", seq_length)
+ else:
+ train_len, train_data, valid_len, valid_data, test_len, test_data = \
+ load_data("./data/train", "./data/valid", "./data/test", seq_length)
+
+ print("Start to build net...")
+ model, model_path = build_net(args, seq_length)
+
+ print("Start training...")
+ train_net(model, model_path, train_len, train_data, valid_len, valid_data,
+ test_len, test_data, args.model)
+
+ print("Training finished!")
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/train_magic_wand_model.ipynb b/tensorflow/lite/micro/examples/magic_wand/train/train_magic_wand_model.ipynb
new file mode 100644
index 0000000..0f33efb
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/train_magic_wand_model.ipynb
@@ -0,0 +1,238 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "1BtkMGSYQOTQ"
+ },
+ "source": [
+ "# Train a gesture recognition model for microcontroller use"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "BaFfr7DHRmGF"
+ },
+ "source": [
+ "This notebook demonstrates how to train a 20kb gesture recognition model for [TensorFlow Lite for Microcontrollers](https://tensorflow.org/lite/microcontrollers/overview). It will produce the same model used in the [magic_wand](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/magic_wand) example application.\n",
+ "\n",
+ "The model is designed to be used with [Google Colaboratory](https://colab.research.google.com).\n",
+ "\n",
+ "\u003ctable class=\"tfo-notebook-buttons\" align=\"left\"\u003e\n",
+ " \u003ctd\u003e\n",
+ " \u003ca target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/magic_wand/train/train_magic_wand_model.ipynb\"\u003e\u003cimg src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /\u003eRun in Google Colab\u003c/a\u003e\n",
+ " \u003c/td\u003e\n",
+ " \u003ctd\u003e\n",
+ " \u003ca target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/magic_wand/train/train_magic_wand_model.ipynb\"\u003e\u003cimg src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /\u003eView source on GitHub\u003c/a\u003e\n",
+ " \u003c/td\u003e\n",
+ "\u003c/table\u003e\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "xXgS6rxyT7Qk"
+ },
+ "source": [
+ "Training is much faster using GPU acceleration. Before you proceed, ensure you are using a GPU runtime by going to **Runtime -\u003e Change runtime type** and selecting **GPU**. Training will take around 5 minutes on a GPU runtime."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "LG6ErX5FRIaV"
+ },
+ "source": [
+ "## Configure dependencies\n",
+ "\n",
+ "Run the following cell to ensure the correct version of TensorFlow is used."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "STNft9TrfoVh"
+ },
+ "source": [
+ "We'll also clone the TensorFlow repository, which contains the training scripts, and copy them into our workspace."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab": {},
+ "colab_type": "code",
+ "id": "ygkWw73dRNda"
+ },
+ "outputs": [],
+ "source": [
+ "# Clone the repository from GitHub\n",
+ "!git clone --depth 1 -q https://github.com/tensorflow/tensorflow\n",
+ "# Copy the training scripts into our workspace\n",
+ "!cp -r tensorflow/tensorflow/lite/micro/examples/magic_wand/train train"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "pXI7R4RehFdU"
+ },
+ "source": [
+ "## Prepare the data\n",
+ "\n",
+ "Next, we'll download the data and extract it into the expected location within the training scripts' directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab": {},
+ "colab_type": "code",
+ "id": "W2Sg2AKzVr2L"
+ },
+ "outputs": [],
+ "source": [
+ "# Download the data we will use to train the model\n",
+ "!wget http://download.tensorflow.org/models/tflite/magic_wand/data.tar.gz\n",
+ "# Extract the data into the train directory\n",
+ "!tar xvzf data.tar.gz -C train 1\u003e/dev/null"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "DNjukI1Sgl2C"
+ },
+ "source": [
+ "We'll then run the scripts that split the data into training, validation, and test sets."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab": {},
+ "colab_type": "code",
+ "id": "XBqSVpi6Vxss"
+ },
+ "outputs": [],
+ "source": [
+ "# The scripts must be run from within the train directory\n",
+ "%cd train\n",
+ "# Prepare the data\n",
+ "!python data_prepare.py\n",
+ "# Split the data by person\n",
+ "!python data_split_person.py"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "5-cmVbFvhTvy"
+ },
+ "source": [
+ "## Load TensorBoard\n",
+ "\n",
+ "Now, we set up TensorBoard so that we can graph our accuracy and loss as training proceeds."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab": {},
+ "colab_type": "code",
+ "id": "CCx6SN9NWRPw"
+ },
+ "outputs": [],
+ "source": [
+ "# Load TensorBoard\n",
+ "%load_ext tensorboard\n",
+ "%tensorboard --logdir logs/scalars"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "ERC2Cr4PhaOl"
+ },
+ "source": [
+ "## Begin training\n",
+ "\n",
+ "The following cell will begin the training process. Training will take around 5 minutes on a GPU runtime. You'll see the metrics in TensorBoard after a few epochs."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab": {},
+ "colab_type": "code",
+ "id": "DXmQZgbuWQFO"
+ },
+ "outputs": [],
+ "source": [
+ "!python train.py --model CNN --person true"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "colab_type": "text",
+ "id": "4gXbVzcXhvGD"
+ },
+ "source": [
+ "## Create a C source file\n",
+ "\n",
+ "The `train.py` script writes a model, `model.tflite`, to the training scripts' directory.\n",
+ "\n",
+ "In the following cell, we convert this model into a C++ source file we can use with TensorFlow Lite for Microcontrollers."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 0,
+ "metadata": {
+ "colab": {},
+ "colab_type": "code",
+ "id": "8wgei4OGe3Nz"
+ },
+ "outputs": [],
+ "source": [
+ "# Install xxd if it is not available\n",
+ "!apt-get -qq install xxd\n",
+ "# Save the file as a C source file\n",
+ "!xxd -i model.tflite \u003e /content/model.cc\n",
+ "# Print the source file\n",
+ "!cat /content/model.cc"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [],
+ "name": "Train a gesture recognition model for microcontroller use",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/train/train_test.py b/tensorflow/lite/micro/examples/magic_wand/train/train_test.py
new file mode 100644
index 0000000..4790eb2
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/train/train_test.py
@@ -0,0 +1,78 @@
+# Lint as: python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Test for train.py."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import unittest
+
+import numpy as np
+import tensorflow as tf
+from train import build_cnn
+from train import build_lstm
+from train import load_data
+from train import reshape_function
+
+
+class TestTrain(unittest.TestCase):
+
+ def setUp(self): # pylint: disable=g-missing-super-call
+ self.seq_length = 128
+ self.train_len, self.train_data, self.valid_len, self.valid_data, \
+ self.test_len, self.test_data = \
+ load_data("./data/train", "./data/valid", "./data/test",
+ self.seq_length)
+
+ def test_load_data(self):
+ self.assertIsInstance(self.train_data, tf.data.Dataset)
+ self.assertIsInstance(self.valid_data, tf.data.Dataset)
+ self.assertIsInstance(self.test_data, tf.data.Dataset)
+
+ def test_build_net(self):
+ cnn, cnn_path = build_cnn(self.seq_length)
+ lstm, lstm_path = build_lstm(self.seq_length)
+ cnn_data = np.random.rand(60, 128, 3, 1)
+ lstm_data = np.random.rand(60, 128, 3)
+ cnn_prob = cnn(tf.constant(cnn_data, dtype="float32")).numpy()
+ lstm_prob = lstm(tf.constant(lstm_data, dtype="float32")).numpy()
+ self.assertIsInstance(cnn, tf.keras.Sequential)
+ self.assertIsInstance(lstm, tf.keras.Sequential)
+ self.assertEqual(cnn_path, "./netmodels/CNN")
+ self.assertEqual(lstm_path, "./netmodels/LSTM")
+ self.assertEqual(cnn_prob.shape, (60, 4))
+ self.assertEqual(lstm_prob.shape, (60, 4))
+
+ def test_reshape_function(self):
+ for data, label in self.train_data:
+ original_data_shape = data.numpy().shape
+ original_label_shape = label.numpy().shape
+ break
+ self.train_data = self.train_data.map(reshape_function)
+ for data, label in self.train_data:
+ reshaped_data_shape = data.numpy().shape
+ reshaped_label_shape = label.numpy().shape
+ break
+ self.assertEqual(
+ reshaped_data_shape,
+ (int(original_data_shape[0] * original_data_shape[1] / 3), 3, 1))
+ self.assertEqual(reshaped_label_shape, original_label_shape)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/Makefile.inc b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/Makefile.inc
new file mode 100644
index 0000000..e257e66
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/Makefile.inc
@@ -0,0 +1,31 @@
+ifeq ($(TARGET), zephyr_vexriscv)
+ export ZEPHYR_TOOLCHAIN_VARIANT?=zephyr
+ export TOOLCHAIN_BASE=${ZEPHYR_SDK_INSTALL_DIR}/riscv64-zephyr-elf/riscv64-zephyr-elf
+ export TOOLCHAIN_VERSION=9.2.0
+ PROJECT_INCLUDES += ${CURDIR} ${TOOLCHAIN_BASE}/include/c++/${TOOLCHAIN_VERSION} ${TOOLCHAIN_BASE}/include ${TOOLCHAIN_BASE}/include/c++/${TOOLCHAIN_VERSION}/riscv64-zephyr-elf/rv32i/ilp32
+ ZEPHYR_MAGIC_WAND_SRCS = \
+tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/assert.cc \
+tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.cc \
+tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.h \
+tensorflow/lite/micro/examples/magic_wand/main.cc \
+tensorflow/lite/micro/examples/magic_wand/main_functions.cc \
+tensorflow/lite/micro/examples/magic_wand/magic_wand_model_data.cc \
+tensorflow/lite/micro/examples/magic_wand/gesture_predictor.cc \
+tensorflow/lite/micro/examples/magic_wand/output_handler.cc \
+boards/litex_vexriscv.overlay \
+prj.conf
+
+$(eval $(call generate_project,cmake,zephyr_cmake_project.cmake,magic_wand,$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(ZEPHYR_MAGIC_WAND_SRCS) $(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(magic_wand_HDRS),,$(LDFLAGS) $(MICROLITE_LIBS),$(CXXFLAGS),$(CCFLAGS),))
+
+$(PRJDIR)magic_wand/cmake/CMakeLists.txt: $(PRJDIR)magic_wand/cmake/zephyr_cmake_project.cmake
+ @sed -E 's#\%\{INCLUDE_DIRS\}\%#$(PROJECT_INCLUDES)#g' $< > $@
+
+#We are skipping here copy of `zephyr` third_party repository
+#To compile standalone project ZEPHYR_BASE enviroment variable should be set
+magic_wand_bin: generate_magic_wand_cmake_project $(PRJDIR)magic_wand/cmake/CMakeLists.txt
+ ( \
+ . ${ZEPHYR_BASE}/venv-zephyr/bin/activate; \
+ cmake -B${GENDIR}magic_wand/build -DBOARD="litex_vexriscv" -H${PRJDIR}magic_wand/cmake/ -DPython_ROOT_DIR=${ZEPHYR_BASE}/venv-zephyr/bin/; \
+ make -C ${GENDIR}magic_wand/build; \
+ )
+endif
diff --git a/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/boards/litex_vexriscv.overlay b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/boards/litex_vexriscv.overlay
new file mode 100644
index 0000000..a75435b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/boards/litex_vexriscv.overlay
@@ -0,0 +1,38 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+&i2c0 {
+ label = "I2C0";
+ reg = <0xe0003000 0x4 0xe0003004 0x4>;
+
+ adxl@1d {
+ compatible = "adi,adxl345";
+ label = "accel-0";
+ reg = <0x1d>;
+ };
+
+};
+
+&pwm0 {
+ status = "disabled";
+};
+
+ð0 {
+ status = "disabled";
+};
+
+&prbs0 {
+ status = "disabled";
+};
diff --git a/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/prj.conf b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/prj.conf
new file mode 100644
index 0000000..449a721
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/prj.conf
@@ -0,0 +1,22 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+CONFIG_CPLUSPLUS=y
+CONFIG_NEWLIB_LIBC=y
+CONFIG_SENSOR=y
+CONFIG_ADXL345=y
+CONFIG_PWM=n
+CONFIG_PWM_LITEX=n
+CONFIG_NETWORKING=n
+CONFIG_MAIN_STACK_SIZE=4096
diff --git a/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.cc b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.cc
new file mode 100644
index 0000000..f7f019d
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.cc
@@ -0,0 +1,98 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/magic_wand/accelerometer_handler.h"
+
+#include <device.h>
+#include <drivers/sensor.h>
+#include <stdio.h>
+#include <string.h>
+#include <zephyr.h>
+
+#define BUFLEN 300
+int begin_index = 0;
+struct device* sensor = NULL;
+int current_index = 0;
+
+float bufx[BUFLEN] = {0.0f};
+float bufy[BUFLEN] = {0.0f};
+float bufz[BUFLEN] = {0.0f};
+
+bool initial = true;
+
+TfLiteStatus SetupAccelerometer(tflite::ErrorReporter* error_reporter) {
+ sensor = device_get_binding(DT_INST_0_ADI_ADXL345_LABEL);
+ if (sensor == NULL) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to get accelerometer, label: %s\n",
+ DT_INST_0_ADI_ADXL345_LABEL);
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter, "Got accelerometer, label: %s\n",
+ DT_INST_0_ADI_ADXL345_LABEL);
+ }
+ return kTfLiteOk;
+}
+
+bool ReadAccelerometer(tflite::ErrorReporter* error_reporter, float* input,
+ int length) {
+ int rc;
+ struct sensor_value accel[3];
+ int samples_count;
+
+ rc = sensor_sample_fetch(sensor);
+ if (rc < 0) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Fetch failed\n");
+ return false;
+ }
+ // skip if there is no data
+ if (!rc) {
+ return false;
+ }
+
+ samples_count = rc;
+ for (int i = 0; i < samples_count; i++) {
+ rc = sensor_channel_get(sensor, SENSOR_CHAN_ACCEL_XYZ, accel);
+ if (rc < 0) {
+ TF_LITE_REPORT_ERROR(error_reporter, "ERROR: Update failed: %d\n", rc);
+ return false;
+ }
+ bufx[begin_index] = (float)sensor_value_to_double(&accel[0]);
+ bufy[begin_index] = (float)sensor_value_to_double(&accel[1]);
+ bufz[begin_index] = (float)sensor_value_to_double(&accel[2]);
+ begin_index++;
+ if (begin_index >= BUFLEN) begin_index = 0;
+ }
+
+ if (initial && begin_index >= 100) {
+ initial = false;
+ }
+
+ if (initial) {
+ return false;
+ }
+
+ int sample = 0;
+ for (int i = 0; i < (length - 3); i += 3) {
+ int ring_index = begin_index + sample - length / 3;
+ if (ring_index < 0) {
+ ring_index += BUFLEN;
+ }
+ input[i] = bufx[ring_index];
+ input[i + 1] = bufy[ring_index];
+ input[i + 2] = bufz[ring_index];
+ sample++;
+ }
+ return true;
+}
diff --git a/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.h b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.h
new file mode 100644
index 0000000..5b3fb54
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/accelerometer_handler.h
@@ -0,0 +1,29 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_ACCELEROMETER_HANDLER_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_ACCELEROMETER_HANDLER_H_
+
+#define kChannelNumber 3
+
+#include "tensorflow/lite/c/c_api_internal.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+extern int begin_index;
+extern TfLiteStatus SetupAccelerometer(tflite::ErrorReporter* error_reporter);
+extern bool ReadAccelerometer(tflite::ErrorReporter* error_reporter,
+ float* input, int length, bool reset_buffer);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_MAGIC_WAND_ACCELEROMETER_HANDLER_H_
diff --git a/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/assert.cc b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/assert.cc
new file mode 100644
index 0000000..2f709c6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/magic_wand/zephyr_riscv/src/assert.cc
@@ -0,0 +1,19 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+extern "C" {
+
+void __assert_func(const char*, int, const char*, const char*) {}
+}
diff --git a/tensorflow/lite/micro/examples/network_tester/.gitignore b/tensorflow/lite/micro/examples/network_tester/.gitignore
new file mode 100644
index 0000000..f266b9b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/network_tester/.gitignore
@@ -0,0 +1,3 @@
+input_data.h
+expected_output_data.h
+network_model.h
diff --git a/tensorflow/lite/micro/examples/network_tester/Makefile.inc b/tensorflow/lite/micro/examples/network_tester/Makefile.inc
new file mode 100644
index 0000000..a5c9112
--- /dev/null
+++ b/tensorflow/lite/micro/examples/network_tester/Makefile.inc
@@ -0,0 +1,42 @@
+NETWORK_TESTER_TEST_SRCS := \
+tensorflow/lite/micro/examples/network_tester/network_tester_test.cc
+
+NETWORK_TESTER_TEST_HDRS := \
+tensorflow/lite/micro/examples/network_tester/network_model.h \
+tensorflow/lite/micro/examples/network_tester/input_data.h \
+tensorflow/lite/micro/examples/network_tester/expected_output_data.h
+
+#Find any platform - specific rules for this example.
+include $(wildcard tensorflow/lite/micro/examples/network_tester/*/Makefile.inc)
+
+ifdef NETWORK_MODEL
+ INCLUDES += -include $(NETWORK_MODEL)
+endif
+
+ifdef OUTPUT_DATA
+ INCLUDES += -include $(OUTPUT_DATA)
+endif
+
+ifdef INPUT_DATA
+ INCLUDES += -include $(INPUT_DATA)
+endif
+
+ifdef ARENA_SIZE
+ CXXFLAGS += -DTENSOR_ARENA_SIZE=$(ARENA_SIZE)
+endif
+
+ifdef NUM_BYTES_TO_PRINT
+ CXXFLAGS += -DNUM_BYTES_TO_PRINT=$(NUM_BYTES_TO_PRINT)
+endif
+
+ifeq ($(COMPARE_OUTPUT_DATA),no)
+ CXXFLAGS += -DNO_COMPARE_OUTPUT_DATA
+endif
+
+ifdef NUM_INFERENCES
+ CXXFLAGS += -DNUM_INFERENCES=$(NUM_INFERENCES)
+endif
+
+# Builds a standalone object recognition binary.
+$(eval $(call microlite_test,network_tester_test,\
+$(NETWORK_TESTER_TEST_SRCS),$(NETWORK_TESTER_TEST_HDRS)))
diff --git a/tensorflow/lite/micro/examples/network_tester/README.md b/tensorflow/lite/micro/examples/network_tester/README.md
new file mode 100644
index 0000000..f441522
--- /dev/null
+++ b/tensorflow/lite/micro/examples/network_tester/README.md
@@ -0,0 +1,51 @@
+The aim of this application is to provide a quick way to test different
+networks.
+
+It contains one testcase and a default network model (network_model.h), default
+input data (input_data.h) and default expected output data
+(expected_output_data.h). The header files were created using the `xxd` command.
+
+The default model is a single MaxPool2D operator, with an input shape of {1, 4,
+4, 1} and an output shape of {1, 2, 2, 1}.
+
+In order to use another model, input data, or expected output data, simply
+specify the path to the new header files when running make as seen below.
+
+The variables in the specified header files (array and array length) needs to
+have the same name and type as the ones in the default header files. The include
+guards also needs to be the same. When swapping out the network model, it is
+likely that the memory allocated by the interpreter needs to be increased to fit
+the new model. This is done by using the `ARENA_SIZE` option when running
+`make`.
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile network_tester_test \
+ NETWORK_MODEL=path/to/network_model.h \
+ INPUT_DATA=path/to/input_data.h \
+ OUTPUT_DATA=path/to/expected_output_data.h \
+ ARENA_SIZE=<tensor arena size in bytes> \
+ NUM_BYTES_TO_PRINT=<number of bytes to print> \
+ COMPARE_OUTPUT_DATA=no
+```
+
+`NETWORK_MODEL`: The path to the network model header. \
+`INPUT_DATA`: The path to the input data. \
+`OUTPUT_DATA`: The path to the expected output data. \
+`ARENA_SIZE`: The size of the memory to be allocated (in bytes) by the
+interpreter. \
+`NUM_BYTES_TO_PRINT`: The number of bytes of the output data to print. \
+If set to 0, all bytes of the output are printed. \
+`COMPARE_OUTPUT_DATA`: If set to "no" the output data is not compared to the
+expected output data. This could be useful e.g. if the execution time needs to
+be minimized, or there is no expected output data. If omitted, the output data
+is compared to the expected output. `NUM_INFERENCES`: Define how many inferences
+that are made. Defaults to 1. \
+
+The output is printed in JSON format using printf: `num_of_outputs: 1
+output_begin [ { "dims": [4,1,2,2,1], "data_address": "0x000000",
+"data":"0x06,0x08,0x0e,0x10" }] output_end`
+
+If there are multiple output tensors, the output will look like this:
+`num_of_outputs: 2 output_begin [ { "dims": [4,1,2,2,1], "data_address":
+"0x000000", "data":"0x06,0x08,0x0e,0x10" }, { "dims": [4,1,2,2,1],
+"data_address": "0x111111", "data":"0x06,0x08,0x0e,0x10" }] output_end`
diff --git a/tensorflow/lite/micro/examples/network_tester/expected_output_data.h b/tensorflow/lite/micro/examples/network_tester/expected_output_data.h
new file mode 100644
index 0000000..37f2d5c
--- /dev/null
+++ b/tensorflow/lite/micro/examples/network_tester/expected_output_data.h
@@ -0,0 +1,21 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_EXPECTED_OUTPUT_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_EXPECTED_OUTPUT_DATA_H_
+
+static unsigned char expected_output_data[1][4] = {{6, 8, 14, 16}};
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_EXPECTED_OUTPUT_DATA_H_
diff --git a/tensorflow/lite/micro/examples/network_tester/input_data.h b/tensorflow/lite/micro/examples/network_tester/input_data.h
new file mode 100644
index 0000000..a94f6f9
--- /dev/null
+++ b/tensorflow/lite/micro/examples/network_tester/input_data.h
@@ -0,0 +1,23 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_INPUT_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_INPUT_DATA_H_
+
+static const int input_data_len = 16;
+static const unsigned char input_data[1][16] = {
+ {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}};
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_INPUT_DATA_H_
diff --git a/tensorflow/lite/micro/examples/network_tester/network_model.h b/tensorflow/lite/micro/examples/network_tester/network_model.h
new file mode 100644
index 0000000..5b4b4cf
--- /dev/null
+++ b/tensorflow/lite/micro/examples/network_tester/network_model.h
@@ -0,0 +1,70 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_NETWORK_MODEL_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_NETWORK_MODEL_H_
+
+const unsigned char network_model[] = {
+ 0x18, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x0e, 0x00,
+ 0x18, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x08, 0x02, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x38, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00,
+ 0x54, 0x4f, 0x43, 0x4f, 0x20, 0x43, 0x6f, 0x6e, 0x76, 0x65, 0x72, 0x74,
+ 0x65, 0x64, 0x2e, 0x00, 0x03, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xf8, 0xff, 0xff, 0xff,
+ 0xfc, 0xff, 0xff, 0xff, 0x04, 0x00, 0x04, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0xf8, 0xfe, 0xff, 0xff, 0x20, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x3c, 0x01, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x94, 0x00, 0x00, 0x00,
+ 0x7e, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x03, 0x10, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x64, 0x61, 0x74, 0x61, 0x2f, 0x50, 0x6c, 0x61, 0x63, 0x65, 0x68, 0x6f,
+ 0x6c, 0x64, 0x65, 0x72, 0x00, 0x00, 0x00, 0x00, 0x6c, 0xff, 0xff, 0xff,
+ 0x30, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x80, 0x3f, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7f, 0x43,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00,
+ 0x18, 0x00, 0x08, 0x00, 0x07, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0x10, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x17, 0x00, 0x00, 0x00,
+ 0x70, 0x6f, 0x6f, 0x6c, 0x31, 0x2f, 0x4d, 0x61, 0x78, 0x50, 0x6f, 0x6f,
+ 0x6c, 0x32, 0x44, 0x2f, 0x4d, 0x61, 0x78, 0x50, 0x6f, 0x6f, 0x6c, 0x00,
+ 0x0c, 0x00, 0x14, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x80, 0x3f, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7f, 0x43,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x14, 0x00, 0x18, 0x00, 0x00, 0x00, 0x08, 0x00,
+ 0x0c, 0x00, 0x07, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x14, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05, 0x10, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x2c, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00,
+ 0x18, 0x00, 0x07, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x02, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00,
+ 0x08, 0x00, 0x07, 0x00, 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x11};
+const unsigned int network_model_len = 576;
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_NETWORK_TESTER_NETWORK_MODEL_H_
diff --git a/tensorflow/lite/micro/examples/network_tester/network_tester_test.cc b/tensorflow/lite/micro/examples/network_tester/network_tester_test.cc
new file mode 100644
index 0000000..73d942a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/network_tester/network_tester_test.cc
@@ -0,0 +1,137 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/examples/network_tester/expected_output_data.h"
+#include "tensorflow/lite/micro/examples/network_tester/input_data.h"
+#include "tensorflow/lite/micro/examples/network_tester/network_model.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+#ifndef TENSOR_ARENA_SIZE
+#define TENSOR_ARENA_SIZE (1024)
+#endif
+
+#ifndef NUM_INFERENCES
+#define NUM_INFERENCES 1
+#endif
+
+uint8_t tensor_arena[TENSOR_ARENA_SIZE];
+
+#ifdef NUM_BYTES_TO_PRINT
+inline void print_output_data(TfLiteTensor* output) {
+ int num_bytes_to_print =
+ ((output->bytes < NUM_BYTES_TO_PRINT) || NUM_BYTES_TO_PRINT == 0)
+ ? output->bytes
+ : NUM_BYTES_TO_PRINT;
+
+ int dims_size = output->dims->size;
+ printf("{\n");
+ printf("\"dims\": [%d,", dims_size);
+ for (int i = 0; i < output->dims->size - 1; ++i) {
+ printf("%d,", output->dims->data[i]);
+ }
+ printf("%d],\n", output->dims->data[dims_size - 1]);
+
+ printf("\"data_address\": \"%p\",\n", output->data.raw);
+ printf("\"data\":\"");
+ for (int i = 0; i < num_bytes_to_print - 1; ++i) {
+ if (i % 16 == 0 && i != 0) {
+ printf("\n");
+ }
+ printf("0x%02x,", output->data.uint8[i]);
+ }
+ printf("0x%02x\"\n", output->data.uint8[num_bytes_to_print - 1]);
+ printf("}");
+}
+#endif
+
+template <typename T>
+void check_output_elem(TfLiteTensor* output, const T* expected_output,
+ const int index) {
+ TF_LITE_MICRO_EXPECT_EQ(tflite::GetTensorData<T>(output)[index],
+ expected_output[index]);
+}
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestInvoke) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ const tflite::Model* model = ::tflite::GetModel(network_model);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.\n",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ return kTfLiteError;
+ }
+
+ tflite::AllOpsResolver resolver;
+
+ tflite::MicroInterpreter interpreter(
+ model, resolver, tensor_arena, TENSOR_ARENA_SIZE, µ_error_reporter);
+
+ TfLiteStatus allocate_status = interpreter.AllocateTensors();
+ if (allocate_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Tensor allocation failed\n");
+ return kTfLiteError;
+ }
+
+ for (int n = 0; n < NUM_INFERENCES; n++) {
+ for (size_t i = 0; i < interpreter.inputs_size(); ++i) {
+ TfLiteTensor* input = interpreter.input(i);
+ memcpy(input->data.data, input_data[i], input->bytes);
+ }
+ TfLiteStatus invoke_status = interpreter.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Invoke failed\n");
+ return kTfLiteError;
+ }
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
+
+#ifdef NUM_BYTES_TO_PRINT
+ // Print all of the output data, or the first NUM_BYTES_TO_PRINT bytes,
+ // whichever comes first as well as the output shape.
+ printf("num_of_outputs: %d\n", interpreter.outputs_size());
+ printf("output_begin\n");
+ printf("[\n");
+ for (int i = 0; i < interpreter.outputs_size(); i++) {
+ TfLiteTensor* output = interpreter.output(i);
+ print_output_data(output);
+ if (i != interpreter.outputs_size() - 1) {
+ printf(",\n");
+ }
+ }
+ printf("]\n");
+ printf("output_end\n");
+#endif
+
+#ifndef NO_COMPARE_OUTPUT_DATA
+ for (size_t i = 0; i < interpreter.outputs_size(); i++) {
+ TfLiteTensor* output = interpreter.output(i);
+ for (int j = 0; j < tflite::ElementCount(*(output->dims)); ++j) {
+ check_output_elem(output, expected_output_data[i], j);
+ }
+ }
+#endif
+ }
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Ran successfully\n");
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/person_detection/Makefile.inc b/tensorflow/lite/micro/examples/person_detection/Makefile.inc
new file mode 100644
index 0000000..1b7ba8b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/Makefile.inc
@@ -0,0 +1,81 @@
+person_detection_MODEL_SRCS := \
+tensorflow/lite/micro/examples/person_detection/model_settings.cc \
+$(MAKEFILE_DIR)/downloads/person_model_int8/person_detect_model_data.cc
+
+person_detection_MODEL_HDRS := \
+tensorflow/lite/micro/examples/person_detection/model_settings.h \
+tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h
+
+person_detection_TEST_SRCS := \
+tensorflow/lite/micro/examples/person_detection/person_detection_test.cc \
+$(MAKEFILE_DIR)/downloads/person_model_int8/no_person_image_data.cc \
+$(MAKEFILE_DIR)/downloads/person_model_int8/person_image_data.cc \
+$(person_detection_MODEL_SRCS)
+
+person_detection_TEST_HDRS := \
+tensorflow/lite/micro/examples/person_detection/no_person_image_data.h \
+tensorflow/lite/micro/examples/person_detection/person_image_data.h \
+$(person_detection_MODEL_HDRS)
+
+IMAGE_PROVIDER_TEST_SRCS := \
+tensorflow/lite/micro/examples/person_detection/image_provider.cc \
+tensorflow/lite/micro/examples/person_detection/image_provider_test.cc \
+tensorflow/lite/micro/examples/person_detection/model_settings.cc
+
+IMAGE_PROVIDER_TEST_HDRS := \
+tensorflow/lite/micro/examples/person_detection/image_provider.h \
+tensorflow/lite/micro/examples/person_detection/model_settings.h
+
+DETECTION_RESPONDER_TEST_SRCS := \
+tensorflow/lite/micro/examples/person_detection/detection_responder.cc \
+tensorflow/lite/micro/examples/person_detection/detection_responder_test.cc
+
+DETECTION_RESPONDER_TEST_HDRS := \
+tensorflow/lite/micro/examples/person_detection/detection_responder.h
+
+person_detection_SRCS := \
+tensorflow/lite/micro/examples/person_detection/detection_responder.cc \
+tensorflow/lite/micro/examples/person_detection/image_provider.cc \
+tensorflow/lite/micro/examples/person_detection/main.cc \
+tensorflow/lite/micro/examples/person_detection/main_functions.cc \
+$(person_detection_MODEL_SRCS)
+
+person_detection_HDRS := \
+tensorflow/lite/micro/examples/person_detection/detection_responder.h \
+tensorflow/lite/micro/examples/person_detection/image_provider.h \
+tensorflow/lite/micro/examples/person_detection/main_functions.h \
+$(person_detection_MODEL_HDRS)
+
+#Find any platform - specific rules for this example.
+include $(wildcard tensorflow/lite/micro/examples/person_detection/*/Makefile.inc)
+
+# Tests loading and running a vision model.
+$(eval $(call microlite_test,person_detection_test_int8,\
+$(person_detection_TEST_SRCS),$(person_detection_TEST_HDRS)))
+
+# Three conflicting issues here:
+# 1. The image_provider_test fails on Sparkfun Edge we do not have a way to
+# filter out individual tests within and example.
+# 2. We do not want to completely remove person_detection from the sparkfun_edge
+# build.
+# 3. We do want to keep as many targets as possible be part of the sparkfun_edge
+# CI build to avoid getting into similar situations where some parts of the
+# code are supported on a platform while other parts are not.
+#
+# The current nasty workaround is to explicitly exclude the offending test for
+# the sparkfun_edge target. Note that we are not exluding it for
+# TARGET=apollo3evb becuase that is not part of our CI builds (and the two are
+# basically equivalent).
+ifneq ($(TARGET),sparkfun_edge)
+# Tests the image provider module.
+$(eval $(call microlite_test,image_provider_test_int8,\
+$(IMAGE_PROVIDER_TEST_SRCS),$(IMAGE_PROVIDER_TEST_HDRS)))
+endif
+
+# Tests the detection responder module.
+$(eval $(call microlite_test,detection_responder_test_int8,\
+$(DETECTION_RESPONDER_TEST_SRCS),$(DETECTION_RESPONDER_TEST_HDRS)))
+
+# Builds a standalone object recognition binary.
+$(eval $(call microlite_test,person_detection_int8,\
+$(person_detection_SRCS),$(person_detection_HDRS)))
diff --git a/tensorflow/lite/micro/examples/person_detection/README.md b/tensorflow/lite/micro/examples/person_detection/README.md
new file mode 100644
index 0000000..5fe66b3
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/README.md
@@ -0,0 +1,646 @@
+# Person detection example
+
+This example shows how you can use Tensorflow Lite to run a 250 kilobyte neural
+network to recognize people in images captured by a camera. It is designed to
+run on systems with small amounts of memory such as microcontrollers and DSPs.
+This uses the experimental int8 quantized version of the person detection model.
+
+## Table of contents
+
+- [Getting started](#getting-started)
+- [Running on ARC EM SDP](#running-on-arc-em-sdp)
+- [Running on Arduino](#running-on-arduino)
+- [Running on ESP32](#running-on-esp32)
+- [Running on HIMAX WE1 EVB](#running-on-himax-we1-evb)
+- [Running on SparkFun Edge](#running-on-sparkfun-edge)
+- [Run the tests on a development machine](#run-the-tests-on-a-development-machine)
+- [Debugging image capture](#debugging-image-capture)
+- [Training your own model](#training-your-own-model)
+
+## Running on ARC EM SDP
+
+The following instructions will help you to build and deploy this example to
+[ARC EM SDP](https://www.synopsys.com/dw/ipdir.php?ds=arc-em-software-development-platform)
+board. General information and instructions on using the board with TensorFlow
+Lite Micro can be found in the common
+[ARC targets description](/tensorflow/lite/micro/tools/make/targets/arc/README.md).
+
+This example uses asymmetric int8 quantization and can therefore leverage
+optimized int8 kernels from the embARC MLI library
+
+The ARC EM SDP board contains a rich set of extension interfaces. You can choose
+any compatible camera and modify
+[image_provider.cc](/tensorflow/lite/micro/examples/person_detection/image_provider.cc)
+file accordingly to use input from your specific camera. By default, results of
+running this example are printed to the console. If you would like to instead
+implement some target-specific actions, you need to modify
+[detection_responder.cc](/tensorflow/lite/micro/examples/person_detection/detection_responder.cc)
+accordingly.
+
+The reference implementations of these files are used by default on the EM SDP.
+
+### Initial setup
+
+Follow the instructions on the
+[ARC EM SDP Initial Setup](/tensorflow/lite/micro/tools/make/targets/arc/README.md#ARC-EM-Software-Development-Platform-ARC-EM-SDP)
+to get and install all required tools for work with ARC EM SDP.
+
+### Generate Example Project
+
+The example project for ARC EM SDP platform can be generated with the following
+command:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile \
+TARGET=arc_emsdp ARC_TAGS=reduce_codesize \
+OPTIMIZED_KERNEL_DIR=arc_mli \
+generate_person_detection_int8_make_project
+```
+
+Note that `ARC_TAGS=reduce_codesize` applies example specific changes of code to
+reduce total size of application. It can be omitted.
+
+### Build and Run Example
+
+For more detailed information on building and running examples see the
+appropriate sections of general descriptions of the
+[ARC EM SDP usage with TFLM](/tensorflow/lite/micro/tools/make/targets/arc/README.md#ARC-EM-Software-Development-Platform-ARC-EM-SDP).
+In the directory with generated project you can also find a
+*README_ARC_EMSDP.md* file with instructions and options on building and
+running. Here we only briefly mention main steps which are typically enough to
+get it started.
+
+1. You need to
+ [connect the board](/tensorflow/lite/micro/tools/make/targets/arc/README.md#connect-the-board)
+ and open an serial connection.
+
+2. Go to the generated example project director
+
+ ```
+ cd tensorflow/lite/micro/tools/make/gen/arc_emsdp_arc/prj/person_detection_int8/make
+ ```
+
+3. Build the example using
+
+ ```
+ make app
+ ```
+
+4. To generate artefacts for self-boot of example from the board use
+
+ ```
+ make flash
+ ```
+
+5. To run application from the board using microSD card:
+
+ * Copy the content of the created /bin folder into the root of microSD
+ card. Note that the card must be formatted as FAT32 with default cluster
+ size (but less than 32 Kbytes)
+ * Plug in the microSD card into the J11 connector.
+ * Push the RST button. If a red LED is lit beside RST button, push the CFG
+ button.
+ * Type or copy next commands one-by-another into serial terminal: `setenv
+ loadaddr 0x10800000 setenv bootfile app.elf setenv bootdelay 1 setenv
+ bootcmd fatload mmc 0 \$\{loadaddr\} \$\{bootfile\} \&\& bootelf
+ saveenv`
+ * Push the RST button.
+
+6. If you have the MetaWare Debugger installed in your environment:
+
+ * To run application from the console using it type `make run`.
+ * To stop the execution type `Ctrl+C` in the console several times.
+
+In both cases (step 5 and 6) you will see the application output in the serial
+terminal.
+
+## Running on Arduino
+
+The following instructions will help you build and deploy this sample
+to [Arduino](https://www.arduino.cc/) devices.
+
+The sample has been tested with the following device:
+
+- [Arduino Nano 33 BLE Sense](https://store.arduino.cc/usa/nano-33-ble-sense-with-headers)
+
+You will also need the following camera module:
+
+- [Arducam Mini 2MP Plus](https://www.amazon.com/Arducam-Module-Megapixels-Arduino-Mega2560/dp/B012UXNDOY)
+
+### Hardware
+
+Connect the Arducam pins as follows:
+
+|Arducam pin name|Arduino pin name|
+|----------------|----------------|
+|CS|D7 (unlabelled, immediately to the right of D6)|
+|MOSI|D11|
+|MISO|D12|
+|SCK|D13|
+|GND|GND (either pin marked GND is fine)|
+|VCC|3.3 V|
+|SDA|A4|
+|SCL|A5|
+
+### Install the Arduino_TensorFlowLite library
+
+Download the current nightly build of the library:
+[person_detection.zip](https://storage.googleapis.com/download.tensorflow.org/data/tf_lite_micro_person_data_int8_grayscale_2020_01_13.zip)
+
+This example application is included as part of the official TensorFlow Lite
+Arduino library. To install it, open the Arduino library manager in
+`Tools -> Manage Libraries...` and search for `Arduino_TensorFlowLite`.
+
+### Install other libraries
+
+In addition to the TensorFlow library, you'll also need to install two
+libraries:
+
+* The Arducam library, so our code can interface with the hardware
+* The JPEGDecoder library, so we can decode JPEG-encoded images
+
+The Arducam Arduino library is available from GitHub at
+[https://github.com/ArduCAM/Arduino](https://github.com/ArduCAM/Arduino).
+To install it, download or clone the repository. Next, copy its `ArduCAM`
+subdirectory into your `Arduino/libraries` directory. To find this directory on
+your machine, check the *Sketchbook location* in the Arduino IDE's
+*Preferences* window.
+
+After downloading the library, you'll need to edit one of its files to make sure
+it is configured for the Arducam Mini 2MP Plus. To do so, open the following
+file:
+
+```
+Arduino/libraries/ArduCAM/memorysaver.h
+```
+
+You'll see a bunch of `#define` statements listed. Make sure that they are all
+commented out, except for `#define OV2640_MINI_2MP_PLUS`, as so:
+
+```
+//Step 1: select the hardware platform, only one at a time
+//#define OV2640_MINI_2MP
+//#define OV3640_MINI_3MP
+//#define OV5642_MINI_5MP
+//#define OV5642_MINI_5MP_BIT_ROTATION_FIXED
+#define OV2640_MINI_2MP_PLUS
+//#define OV5642_MINI_5MP_PLUS
+//#define OV5640_MINI_5MP_PLUS
+```
+
+Once you save the file, we're done configuring the Arducam library.
+
+Our next step is to install the JPEGDecoder library. We can do this from within
+the Arduino IDE. First, go to the *Manage Libraries...* option in the *Tools*
+menu and search for `JPEGDecoder`. You should install version _1.8.0_ of the
+library.
+
+Once the library has installed, we'll need to configure it to disable some
+optional components that are not compatible with the Arduino Nano 33 BLE Sense.
+Open the following file:
+
+```
+Arduino/libraries/JPEGDecoder/src/User_Config.h
+```
+
+Make sure that both `#define LOAD_SD_LIBRARY` and `#define LOAD_SDFAT_LIBRARY`
+are commented out, as shown in this excerpt from the file:
+
+```c++
+// Comment out the next #defines if you are not using an SD Card to store the JPEGs
+// Commenting out the line is NOT essential but will save some FLASH space if
+// SD Card access is not needed. Note: use of SdFat is currently untested!
+
+//#define LOAD_SD_LIBRARY // Default SD Card library
+//#define LOAD_SDFAT_LIBRARY // Use SdFat library instead, so SD Card SPI can be bit bashed
+```
+
+Once you've saved the file, you are done installing libraries.
+
+### Load and run the example
+
+Go to `File -> Examples`. You should see an
+example near the bottom of the list named `TensorFlowLite`. Select
+it and click `person_detection` to load the example. Connect your device, then
+build and upload the example.
+
+To test the camera, start by pointing the device's camera at something that is
+definitely not a person, or just covering it up. The next time the blue LED
+flashes, the device will capture a frame from the camera and begin to run
+inference. The vision model we are using for person detection is relatively
+large, but with cmsis-nn optimizations it only takes around 800ms to run the
+model.
+
+After a moment, the inference result will be translated into another LED being
+lit. Since you pointed the camera at something that isn't a person, the red LED
+should light up.
+
+Now, try pointing the device's camera at yourself! The next time the blue LED
+flashes, the device will capture another image and begin to run inference. After
+a brief puase, the green LED should light up!
+
+Remember, image data is captured as a snapshot before each inference, whenever
+the blue LED flashes. Whatever the camera is pointed at during that moment is
+what will be fed into the model. It doesn't matter where the camera is pointed
+until the next time an image is captured, when the blue LED will flash again.
+
+If you're getting seemingly incorrect results, make sure you are in an
+environment with good lighting. You should also make sure that the camera is
+oriented correctly, with the pins pointing downwards, so that the images it
+captures are the right way up—the model was not trained to recognize upside-down
+people! In addition, it's good to remember that this is a tiny model, which
+trades accuracy for small size. It works very well, but it isn't accurate 100%
+of the time.
+
+We can also see the results of inference via the Arduino Serial Monitor. To do
+this, open the *Serial Monitor* from the *Tools* menu. You'll see a detailed
+log of what is happening while our application runs. It's also interesting to
+check the *Show timestamp* box, so you can see how long each part of the process
+takes:
+
+```
+14:17:50.714 -> Starting capture
+14:17:50.714 -> Image captured
+14:17:50.784 -> Reading 3080 bytes from ArduCAM
+14:17:50.887 -> Finished reading
+14:17:50.887 -> Decoding JPEG and converting to greyscale
+14:17:51.074 -> Image decoded and processed
+14:18:09.710 -> Person score: 246 No person score: 66
+```
+
+From the log, we can see that it took around 170 ms to capture and read the
+image data from the camera module, 180 ms to decode the JPEG and convert it to
+greyscale, and 18.6 seconds to run inference.
+
+## Running on ESP32
+
+The following instructions will help you build and deploy this sample to
+[ESP32](https://www.espressif.com/en/products/hardware/esp32/overview) devices
+using the [ESP IDF](https://github.com/espressif/esp-idf).
+
+The sample has been tested on ESP-IDF version 4.0 with the following devices: -
+[ESP32-DevKitC](http://esp-idf.readthedocs.io/en/latest/get-started/get-started-devkitc.html) -
+[ESP-EYE](https://github.com/espressif/esp-who/blob/master/docs/en/get-started/ESP-EYE_Getting_Started_Guide.md)
+
+ESP-EYE is a board which has a built-in camera which can be used to run this
+example , if you want to use other esp boards you will have to connect camera
+externally and write your own
+[image_provider.cc](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/person_detection/esp/image_provider.cc).
+and
+[app_camera_esp.c](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.c).
+You can also write you own
+[detection_responder.cc](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/person_detection/detection_responder.cc).
+
+### Install the ESP IDF
+
+Follow the instructions of the
+[ESP-IDF get started guide](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html)
+to setup the toolchain and the ESP-IDF itself.
+
+The next steps assume that the
+[IDF environment variables are set](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html#step-4-set-up-the-environment-variables) :
+
+* The `IDF_PATH` environment variable is set
+* `idf.py` and Xtensa-esp32 tools (e.g. `xtensa-esp32-elf-gcc`) are in `$PATH`
+* `esp32-camera` should be downloaded in `components/` dir of example as
+ explained in `Building the example`(below)
+
+### Generate the examples
+
+The example project can be generated with the following command:
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=esp generate_person_detection_esp_project
+```
+
+### Building the example
+
+Go to the example project directory
+```
+cd tensorflow/lite/micro/tools/make/gen/esp_xtensa-esp32/prj/person_detection/esp-idf
+```
+
+As the `person_detection` example requires an external component `esp32-camera`
+for functioning hence we will have to manually clone it in `components/`
+directory of the example with following command.
+```
+git clone https://github.com/espressif/esp32-camera.git components/esp32-camera
+```
+
+Then build with `idf.py` `idf.py build`
+
+### Load and run the example
+
+To flash (replace `/dev/ttyUSB0` with the device serial port):
+```
+idf.py --port /dev/ttyUSB0 flash
+```
+
+Monitor the serial output:
+```
+idf.py --port /dev/ttyUSB0 monitor
+```
+
+Use `Ctrl+]` to exit.
+
+The previous two commands can be combined:
+```
+idf.py --port /dev/ttyUSB0 flash monitor
+```
+
+## Running on HIMAX WE1 EVB
+
+The following instructions will help you build and deploy this example to
+[HIMAX WE1 EVB](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_board_brief)
+board. To understand more about using this board, please check
+[HIMAX WE1 EVB user guide](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_user_guide).
+
+### Initial Setup
+
+To use the HIMAX WE1 EVB, please make sure following software are installed:
+
+#### MetaWare Development Toolkit
+
+See
+[Install the Synopsys DesignWare ARC MetaWare Development Toolkit](/tensorflow/lite/micro/tools/make/targets/arc/README.md#install-the-synopsys-designware-arc-metaware-development-toolkit)
+section for instructions on toolchain installation.
+
+#### Make Tool version
+
+A `'make'` tool is required for deploying Tensorflow Lite Micro applications on
+HIMAX WE1 EVB, See
+[Check make tool version](/tensorflow/lite/micro/tools/make/targets/arc/README.md#make-tool)
+section for proper environment.
+
+#### Serial Terminal Emulation Application
+
+There are 2 main purposes for HIMAX WE1 EVB Debug UART port
+
+- print application output
+- burn application to flash by using xmodem send application binary
+
+You can use any terminal emulation program (like [PuTTY](https://www.putty.org/)
+or [minicom](https://linux.die.net/man/1/minicom)).
+
+### Generate Example Project
+
+The example project for HIMAX WE1 EVB platform can be generated with the
+following command:
+
+Download related third party data
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=himax_we1_evb third_party_downloads
+```
+
+Generate person detection project
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile generate_person_detection_int8_make_project TARGET=himax_we1_evb
+```
+
+### Build and Burn Example
+
+Following the Steps to run person detection example at HIMAX WE1 EVB platform.
+
+1. Go to the generated example project directory.
+
+ ```
+ cd tensorflow/lite/micro/tools/make/gen/himax_we1_evb_arc/prj/person_detection_int8/make
+ ```
+
+2. Build the example using
+
+ ```
+ make app
+ ```
+
+3. After example build finish, copy ELF file and map file to image generate
+ tool directory. \
+ image generate tool directory located at
+ `'tensorflow/lite/micro/tools/make/downloads/himax_we1_sdk/image_gen_linux_v3/'`
+
+ ```
+ cp person_detection_int8.elf himax_we1_evb.map ../../../../../downloads/himax_we1_sdk/image_gen_linux_v3/
+ ```
+
+4. Go to flash image generate tool directory.
+
+ ```
+ cd ../../../../../downloads/himax_we1_sdk/image_gen_linux_v3/
+ ```
+
+ make sure this tool directory is in $PATH. You can permanently set it to
+ PATH by
+
+ ```
+ export PATH=$PATH:$(pwd)
+ ```
+
+5. run image generate tool, generate flash image file.
+
+ * Before running image generate tool, by typing `sudo chmod +x image_gen`
+ and `sudo chmod +x sign_tool` to make sure it is executable.
+
+ ```
+ image_gen -e person_detection_int8.elf -m himax_we1_evb.map -o out.img
+ ```
+
+6. Download flash image file to HIMAX WE1 EVB by UART:
+
+ * more detail about download image through UART can be found at
+ [HIMAX WE1 EVB update Flash image](https://github.com/HimaxWiseEyePlus/bsp_tflu/tree/master/HIMAX_WE1_EVB_user_guide#flash-image-update)
+
+After these steps, press reset button on the HIMAX WE1 EVB, you will see
+application output in the serial terminal.
+
+## Running on SparkFun Edge
+
+The following instructions will help you build and deploy this sample on the
+[SparkFun Edge development board](https://sparkfun.com/products/15170). This
+sample requires the Sparkfun Himax camera for the Sparkfun Edge board. It is
+not available for purchase yet.
+
+If you're new to using this board, we recommend walking through the
+[AI on a microcontroller with TensorFlow Lite and SparkFun Edge](https://codelabs.developers.google.com/codelabs/sparkfun-tensorflow)
+codelab to get an understanding of the workflow.
+
+### Compile the binary
+
+The following command will download the required dependencies and then compile a
+binary for the SparkFun Edge:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=sparkfun_edge person_detection_int8_bin
+```
+
+The binary will be created in the following location:
+
+```
+tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4/bin/person_detection_int8.bin
+```
+
+### Sign the binary
+
+The binary must be signed with cryptographic keys to be deployed to the device.
+We'll now run some commands that will sign our binary so it can be flashed to
+the SparkFun Edge. The scripts we are using come from the Ambiq SDK, which is
+downloaded when the `Makefile` is run.
+
+Enter the following command to set up some dummy cryptographic keys we can use
+for development:
+
+```
+cp tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/tools/apollo3_scripts/keys_info0.py \
+tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/tools/apollo3_scripts/keys_info.py
+```
+
+Next, run the following command to create a signed binary:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/tools/apollo3_scripts/create_cust_image_blob.py \
+--bin tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4/bin/person_detection_int8.bin \
+--load-address 0xC000 \
+--magic-num 0xCB \
+-o main_nonsecure_ota \
+--version 0x0
+```
+
+This will create the file `main_nonsecure_ota.bin`. We'll now run another
+command to create a final version of the file that can be used to flash our
+device with the bootloader script we will use in the next step:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/tools/apollo3_scripts/create_cust_wireupdate_blob.py \
+--load-address 0x20000 \
+--bin main_nonsecure_ota.bin \
+-i 6 \
+-o main_nonsecure_wire \
+--options 0x1
+```
+
+You should now have a file called `main_nonsecure_wire.bin` in the directory
+where you ran the commands. This is the file we'll be flashing to the device.
+
+### Flash the binary
+
+Next, attach the board to your computer via a USB-to-serial adapter.
+
+**Note:** If you're using the [SparkFun Serial Basic Breakout](https://www.sparkfun.com/products/15096),
+you should [install the latest drivers](https://learn.sparkfun.com/tutorials/sparkfun-serial-basic-ch340c-hookup-guide#drivers-if-you-need-them)
+before you continue.
+
+Once connected, assign the USB device name to an environment variable:
+
+```
+export DEVICENAME=put your device name here
+```
+
+Set another variable with the baud rate:
+
+```
+export BAUD_RATE=921600
+```
+
+Now, hold the button marked `14` on the device. While still holding the button,
+hit the button marked `RST`. Continue holding the button marked `14` while
+running the following command:
+
+```
+python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.0.0/tools/apollo3_scripts/uart_wired_update.py \
+-b ${BAUD_RATE} ${DEVICENAME} \
+-r 1 \
+-f main_nonsecure_wire.bin \
+-i 6
+```
+
+You should see a long stream of output as the binary is flashed to the device.
+Once you see the following lines, flashing is complete:
+
+```
+Sending Reset Command.
+Done.
+```
+
+If you don't see these lines, flashing may have failed. Try running through the
+steps in [Flash the binary](#flash-the-binary) again (you can skip over setting
+the environment variables). If you continue to run into problems, follow the
+[AI on a microcontroller with TensorFlow Lite and SparkFun Edge](https://codelabs.developers.google.com/codelabs/sparkfun-tensorflow)
+codelab, which includes more comprehensive instructions for the flashing
+process.
+
+The binary should now be deployed to the device. Hit the button marked `RST` to
+reboot the board. You should see the device's four LEDs flashing in sequence.
+
+Debug information is logged by the board while the program is running. To view
+it, establish a serial connection to the board using a baud rate of `115200`.
+On OSX and Linux, the following command should work:
+
+```
+screen ${DEVICENAME} 115200
+```
+
+To stop viewing the debug output with `screen`, hit `Ctrl+A`, immediately
+followed by the `K` key, then hit the `Y` key.
+
+## Run the tests on a development machine
+
+To compile and test this example on a desktop Linux or MacOS machine, download
+[the TensorFlow source code](https://github.com/tensorflow/tensorflow), `cd`
+into the source directory from a terminal, and then run the following command:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile
+```
+
+This will take a few minutes, and downloads frameworks the code uses like
+[CMSIS](https://developer.arm.com/embedded/cmsis) and
+[flatbuffers](https://google.github.io/flatbuffers/). Once that process has
+finished, run:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile test_person_detection_test
+```
+
+You should see a series of files get compiled, followed by some logging output
+from a test, which should conclude with `~~~ALL TESTS PASSED~~~`. If you see
+this, it means that a small program has been built and run that loads a trained
+TensorFlow model, runs some example images through it, and got the expected
+outputs. This particular test runs images with a and without a person in them,
+and checks that the network correctly identifies them.
+
+To understand how TensorFlow Lite does this, you can look at the `TestInvoke()`
+function in
+[person_detection_test.cc](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/person_detection/person_detection_test.cc).
+It's a fairly small amount of code, creating an interpreter, getting a handle to
+a model that's been compiled into the program, and then invoking the interpreter
+with the model and sample inputs.
+
+## Debugging image capture
+When the sample is running, check the LEDs to determine whether the inference is
+running correctly. If the red light is stuck on, it means there was an error
+communicating with the camera. This is likely due to an incorrectly connected
+or broken camera.
+
+During inference, the blue LED will toggle every time inference is complete. The
+orange LED indicates that no person was found, and the green LED indicates a
+person was found. The red LED should never turn on, since it indicates an error.
+
+In order to view the captured image, set the DUMP_IMAGE define in main.cc. This
+causes the board to log raw image info to the console. After the board has been
+flashed and reset, dump the log to a text file:
+
+
+```
+screen -L -Logfile <dump file> ${DEVICENAME} 115200
+```
+
+Next, run the raw to bitmap converter to view captured images:
+
+```
+python3 raw_to_bitmap.py -r GRAY -i <dump file>
+```
+
+## Training your own model
+
+You can train your own model with some easy-to-use scripts. See
+[training_a_model.md](training_a_model.md) for instructions.
diff --git a/tensorflow/lite/micro/examples/person_detection/apollo3evb/image_provider.cc b/tensorflow/lite/micro/examples/person_detection/apollo3evb/image_provider.cc
new file mode 100644
index 0000000..1dd53e4
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/apollo3evb/image_provider.cc
@@ -0,0 +1,198 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.h"
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_RAW8_QVGA_8bits_lsb_5fps.h"
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.h"
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.h"
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/platform_Sparkfun_Edge.h"
+
+// These are headers from Ambiq's Apollo3 SDK.
+#include "am_bsp.h" // NOLINT
+#include "am_mcu_apollo.h" // NOLINT
+#include "am_util.h" // NOLINT
+
+// #define DEMO_HM01B0_FRAMEBUFFER_DUMP_ENABLE
+
+// Enabling logging increases power consumption by preventing low power mode
+// from being enabled.
+#define ENABLE_LOGGING
+
+namespace {
+
+//*****************************************************************************
+//
+// HM01B0 Configuration
+//
+//*****************************************************************************
+static hm01b0_cfg_t s_HM01B0Cfg = {
+ // i2c settings
+ ui16SlvAddr : HM01B0_DEFAULT_ADDRESS,
+ eIOMMode : HM01B0_IOM_MODE,
+ ui32IOMModule : HM01B0_IOM_MODULE,
+ sIOMCfg : {
+ eInterfaceMode : HM01B0_IOM_MODE,
+ ui32ClockFreq : HM01B0_I2C_CLOCK_FREQ,
+ },
+ pIOMHandle : NULL,
+
+ // MCLK settings
+ ui32CTimerModule : HM01B0_MCLK_GENERATOR_MOD,
+ ui32CTimerSegment : HM01B0_MCLK_GENERATOR_SEG,
+ ui32CTimerOutputPin : HM01B0_PIN_MCLK,
+
+ // data interface
+ ui8PinSCL : HM01B0_PIN_SCL,
+ ui8PinSDA : HM01B0_PIN_SDA,
+ ui8PinD0 : HM01B0_PIN_D0,
+ ui8PinD1 : HM01B0_PIN_D1,
+ ui8PinD2 : HM01B0_PIN_D2,
+ ui8PinD3 : HM01B0_PIN_D3,
+ ui8PinD4 : HM01B0_PIN_D4,
+ ui8PinD5 : HM01B0_PIN_D5,
+ ui8PinD6 : HM01B0_PIN_D6,
+ ui8PinD7 : HM01B0_PIN_D7,
+ ui8PinVSYNC : HM01B0_PIN_VSYNC,
+ ui8PinHSYNC : HM01B0_PIN_HSYNC,
+ ui8PinPCLK : HM01B0_PIN_PCLK,
+
+ ui8PinTrig : HM01B0_PIN_TRIG,
+ ui8PinInt : HM01B0_PIN_INT,
+ pfnGpioIsr : NULL,
+};
+
+static constexpr int kFramesToInitialize = 4;
+
+bool g_is_camera_initialized = false;
+
+void boost_mode_enable(tflite::ErrorReporter* error_reporter, bool bEnable) {
+ am_hal_burst_avail_e eBurstModeAvailable;
+ am_hal_burst_mode_e eBurstMode;
+
+ // Check that the Burst Feature is available.
+ if (AM_HAL_STATUS_SUCCESS ==
+ am_hal_burst_mode_initialize(&eBurstModeAvailable)) {
+ if (AM_HAL_BURST_AVAIL == eBurstModeAvailable) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Apollo3 Burst Mode is Available\n");
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Apollo3 Burst Mode is Not Available\n");
+ return;
+ }
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to Initialize for Burst Mode operation\n");
+ }
+
+ // Make sure we are in "Normal" mode.
+ if (AM_HAL_STATUS_SUCCESS == am_hal_burst_mode_disable(&eBurstMode)) {
+ if (AM_HAL_NORMAL_MODE == eBurstMode) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Apollo3 operating in Normal Mode (48MHz)\n");
+ }
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to Disable Burst Mode operation\n");
+ }
+
+ // Put the MCU into "Burst" mode.
+ if (bEnable) {
+ if (AM_HAL_STATUS_SUCCESS == am_hal_burst_mode_enable(&eBurstMode)) {
+ if (AM_HAL_BURST_MODE == eBurstMode) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Apollo3 operating in Burst Mode (96MHz)\n");
+ }
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to Enable Burst Mode operation\n");
+ }
+ }
+}
+
+} // namespace
+
+TfLiteStatus InitCamera(tflite::ErrorReporter* error_reporter) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Initializing HM01B0...\n");
+
+ am_hal_clkgen_control(AM_HAL_CLKGEN_CONTROL_SYSCLK_MAX, 0);
+
+ // Set the default cache configuration
+ am_hal_cachectrl_config(&am_hal_cachectrl_defaults);
+ am_hal_cachectrl_enable();
+
+ // Configure the board for low power operation. This breaks logging by
+ // turning off the itm and uart interfaces.
+#ifndef ENABLE_LOGGING
+ am_bsp_low_power_init();
+#endif
+
+ // Enable interrupts so we can receive messages from the boot host.
+ am_hal_interrupt_master_enable();
+
+ boost_mode_enable(error_reporter, true);
+
+ hm01b0_power_up(&s_HM01B0Cfg);
+
+ am_util_delay_ms(1);
+
+ hm01b0_mclk_enable(&s_HM01B0Cfg);
+
+ am_util_delay_ms(1);
+
+ hm01b0_init_if(&s_HM01B0Cfg);
+
+ hm01b0_init_system(&s_HM01B0Cfg, (hm_script_t*)sHM01B0InitScript,
+ sizeof(sHM01B0InitScript) / sizeof(hm_script_t));
+
+ // Put camera into streaming mode - this makes it so that the camera
+ // constantly captures images. It is still OK to read and image since the
+ // camera uses a double-buffered input. This means there is always one valid
+ // image to read while the other buffer fills. Streaming mode allows the
+ // camera to perform auto exposure constantly.
+ hm01b0_set_mode(&s_HM01B0Cfg, HM01B0_REG_MODE_SELECT_STREAMING, 0);
+
+ return kTfLiteOk;
+}
+
+// Capture single frame. Frame pointer passed in to reduce memory usage. This
+// allows the input tensor to be used instead of requiring an extra copy.
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int frame_width,
+ int frame_height, int channels, uint8_t* frame) {
+ if (!g_is_camera_initialized) {
+ TfLiteStatus init_status = InitCamera(error_reporter);
+ if (init_status != kTfLiteOk) {
+ return init_status;
+ }
+ // Drop a few frames until auto exposure is calibrated.
+ for (int i = 0; i < kFramesToInitialize; ++i) {
+ hm01b0_blocking_read_oneframe_scaled(frame, frame_width, frame_height,
+ channels);
+ }
+ g_is_camera_initialized = true;
+ }
+
+ hm01b0_blocking_read_oneframe_scaled(frame, frame_width, frame_height,
+ channels);
+
+#ifdef DEMO_HM01B0_FRAMEBUFFER_DUMP_ENABLE
+ // Allow some time to see result of previous inference before dumping image.
+ am_util_delay_ms(2000);
+ hm01b0_framebuffer_dump(frame, frame_width * frame_height * channels);
+#endif
+
+ return kTfLiteOk;
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/arc_emsdp/Makefile.inc b/tensorflow/lite/micro/examples/person_detection/arc_emsdp/Makefile.inc
new file mode 100644
index 0000000..85a0846
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/arc_emsdp/Makefile.inc
@@ -0,0 +1,43 @@
+ifeq ($(TARGET), arc_emsdp)
+
+#Patch of arc make project to adjust it specifically
+#for experimental person detection example.In particular:
+# - Use Linker command file with better usage of fast memory
+#- Stripout TFLM reference code by default.
+#- Optional : replace mli switchers with specialized kernels
+#for smaller code size
+
+ person_detection_HDRS += \
+ person_detection_int8_patch.txt
+
+ person_detection_TEST_HDRS += \
+ person_detection_int8_patch.txt
+
+ ARC_MLI_BACKEND_PATH = /tensorflow/lite/micro/kernels/arc_mli
+
+#Apply changes in generated project files.
+#See related comment echoed(@echo <comment>) after each change
+#to get understanding on it's purpose.
+%/person_detection_int8_patch.txt: %/emsdp.lcf %/Makefile %$(ARC_MLI_BACKEND_PATH)/conv.cc %$(ARC_MLI_BACKEND_PATH)/depthwise_conv.cc %$(ARC_MLI_BACKEND_PATH)/pooling.cc
+ @cp tensorflow/lite/micro/examples/person_detection/arc_emsdp/emsdp.lcf $<
+ @echo emsdp.lcf: Replace with example specific memory map > $@
+
+ @sed -E -i 's#MLI_ONLY *\?= *false#MLI_ONLY \?= true#' $(word 2, $^)
+ @echo Makefile: No Reference fallback for MLI supported functions >> $@
+
+ifneq ($(filter $(ARC_TAGS), reduce_codesize),)
+#In case 'reduce_codesize' tag is present, we replace common MLI functions with
+#specializations appropriate for this particular graph.But such changes of code
+#with high probability may not be acceptable for other graphs and will need
+#to be adjusted by the user
+
+ @sed -E -i 's#mli_krn_conv2d_nhwc_sa8_sa8_sa32#mli_krn_conv2d_nhwc_sa8_sa8_sa32_k1x1_nopad#' $(word 3, $^)
+ @sed -E -i 's#mli_krn_depthwise_conv2d_hwcn_sa8_sa8_sa32#mli_krn_depthwise_conv2d_hwcn_sa8_sa8_sa32_k3x3_krnpad#' $(word 4, $^)
+ @sed -E -i 's#mli_krn_avepool_hwc_sa8#mli_krn_avepool_hwc_sa8_k3x3_nopad#' $(word 5, $^)
+ @sed -E -i 's#mli_krn_maxpool_hwc_sa8\(in_ptr, \&cfg, out_ptr\);#return kTfLiteError;#' $(word 5, $^)
+ @echo $(word 3, $^): Use specialization >> $@
+ @echo $(word 4, $^): Use specialization >> $@
+ @echo $(word 5, $^): Use specialization and remove max pooling >> $@
+endif
+
+endif
diff --git a/tensorflow/lite/micro/examples/person_detection/arc_emsdp/emsdp.lcf b/tensorflow/lite/micro/examples/person_detection/arc_emsdp/emsdp.lcf
new file mode 100644
index 0000000..9486ac6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/arc_emsdp/emsdp.lcf
@@ -0,0 +1,77 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Difference with common EMSDP LCF file (to reduce data access time):
+# - move data from external PSRAM to on-chip memory
+# - move text from SRAM to ICCM
+#
+# CCMWRAP memory regions indicate unusable portions of the address space
+# due to CCM memory wrapping into upper addresses beyond its size
+
+MEMORY {
+ PSRAM : ORIGIN = 0x10000400, LENGTH = (0x01000000 >> 1) - 0x400
+ SRAM : ORIGIN = 0x20000000, LENGTH = 0x00040000
+ IVT : ORIGIN = 0x60000000, LENGTH = 0x400
+ ICCM0 : ORIGIN = 0x60000400, LENGTH = (0x00020000 - 0x400)
+# CCMWRAP0: ORIGIN = 0x60020000, LENGTH = 0x0ffe0000
+ DCCM : ORIGIN = 0x80000000, LENGTH = 0x00020000
+# CCMWRAP1: ORIGIN = 0x80020000, LENGTH = 0x0ffe0000
+ XCCM : ORIGIN = 0x90000000, LENGTH = 0x00004000
+# CCMWRAP2: ORIGIN = 0x90004000, LENGTH = 0x0fffc000
+ YCCM : ORIGIN = 0xa0000000, LENGTH = 0x00004000
+# CCMWRAP3: ORIGIN = 0xa0004000, LENGTH = 0x0fffc000
+ }
+
+SECTIONS {
+
+ GROUP BLOCK(4) : {
+ .vectors (TEXT) SIZE(DEFINED _IVTSIZE?_IVTSIZE:756): {} = FILL(0xa5a5a5a5,4)
+ } > IVT
+
+ GROUP BLOCK(4): {
+ .text? : { *('.text$crt*') }
+ * (TEXT): {}
+ * (LIT): {}
+ } > ICCM0
+
+ GROUP BLOCK(4): {
+ .rodata_in_data? : {}
+ } > PSRAM
+
+ GROUP BLOCK(4): {
+ /* _SDA_BASE_ computed implicitly */
+ .sdata?: {}
+ .sbss?: {}
+ * (DATA): {}
+ * (BSS): {}
+ .debug_log? : {}
+ } > SRAM
+
+ GROUP BLOCK(4): {
+ .Zdata? : {}
+ .heap? ALIGN(4) SIZE(DEFINED _HEAPSIZE?_HEAPSIZE:8K): {}
+ .stack ALIGN(4) SIZE(DEFINED _STACKSIZE?_STACKSIZE:8K): {}
+ } > DCCM
+
+ GROUP BLOCK(4): {
+ .Xdata? : {}
+ } > XCCM
+
+ GROUP BLOCK(4): {
+ .Ydata? : {}
+ } > YCCM
+}
+
+
diff --git a/tensorflow/lite/micro/examples/person_detection/arduino/HM01B0_platform.h b/tensorflow/lite/micro/examples/person_detection/arduino/HM01B0_platform.h
new file mode 100644
index 0000000..50835f9
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/arduino/HM01B0_platform.h
@@ -0,0 +1,25 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_ARDUINO_HM01B0_PLATFORM_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_ARDUINO_HM01B0_PLATFORM_H_
+
+#if defined(ARDUINO) && defined(ARDUINO_SFE_EDGE)
+#include "hm01b0_platform_edge.h"
+#define HM01B0_PIN_TRIG 0 // unused
+#define HM01B0_PIN_INT 0 // unused
+#endif // defined(ARDUINO) && defined(ARDUINO_SFE_EDGE)
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_ARDUINO_HM01B0_PLATFORM_H_
\ No newline at end of file
diff --git a/tensorflow/lite/micro/examples/person_detection/arduino/Makefile.inc b/tensorflow/lite/micro/examples/person_detection/arduino/Makefile.inc
new file mode 100644
index 0000000..3181b36
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/arduino/Makefile.inc
@@ -0,0 +1,18 @@
+ifeq ($(TARGET),$(filter $(TARGET),arduino))
+
+person_detection_SRCS += \
+ tensorflow/lite/micro/examples/person_detection/sparkfun_edge/image_provider.cc \
+ tensorflow/lite/micro/examples/person_detection/sparkfun_edge/detection_responder.cc \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.c \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.c \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.c
+
+person_detection_HDRS += \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_RAW8_QVGA_8bits_lsb_5fps.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.h \
+ tensorflow/lite/micro/examples/person_detection/arduino/HM01B0_platform.h
+
+endif
diff --git a/tensorflow/lite/micro/examples/person_detection/arduino/detection_responder.cc b/tensorflow/lite/micro/examples/person_detection/arduino/detection_responder.cc
new file mode 100644
index 0000000..672ab90
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/arduino/detection_responder.cc
@@ -0,0 +1,64 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/person_detection/detection_responder.h"
+
+#include "Arduino.h"
+
+// Flash the blue LED after each inference
+void RespondToDetection(tflite::ErrorReporter* error_reporter,
+ int8_t person_score, int8_t no_person_score) {
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ // Pins for the built-in RGB LEDs on the Arduino Nano 33 BLE Sense
+ pinMode(LEDR, OUTPUT);
+ pinMode(LEDG, OUTPUT);
+ pinMode(LEDB, OUTPUT);
+ is_initialized = true;
+ }
+
+ // Note: The RGB LEDs on the Arduino Nano 33 BLE
+ // Sense are on when the pin is LOW, off when HIGH.
+
+ // Switch the person/not person LEDs off
+ digitalWrite(LEDG, HIGH);
+ digitalWrite(LEDR, HIGH);
+
+ // Flash the blue LED after every inference.
+ digitalWrite(LEDB, LOW);
+ delay(100);
+ digitalWrite(LEDB, HIGH);
+
+ // Switch on the green LED when a person is detected,
+ // the red when no person is detected
+ if (person_score > no_person_score) {
+ digitalWrite(LEDG, LOW);
+ digitalWrite(LEDR, HIGH);
+ } else {
+ digitalWrite(LEDG, HIGH);
+ digitalWrite(LEDR, LOW);
+ }
+
+ TF_LITE_REPORT_ERROR(error_reporter, "Person score: %d No person score: %d",
+ person_score, no_person_score);
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/arduino/image_provider.cc b/tensorflow/lite/micro/examples/person_detection/arduino/image_provider.cc
new file mode 100644
index 0000000..f1a3956
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/arduino/image_provider.cc
@@ -0,0 +1,274 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+
+/*
+ * The sample requires the following third-party libraries to be installed and
+ * configured:
+ *
+ * Arducam
+ * -------
+ * 1. Download https://github.com/ArduCAM/Arduino and copy its `ArduCAM`
+ * subdirectory into `Arduino/libraries`. Commit #e216049 has been tested
+ * with this code.
+ * 2. Edit `Arduino/libraries/ArduCAM/memorysaver.h` and ensure that
+ * "#define OV2640_MINI_2MP_PLUS" is not commented out. Ensure all other
+ * defines in the same section are commented out.
+ *
+ * JPEGDecoder
+ * -----------
+ * 1. Install "JPEGDecoder" 1.8.0 from the Arduino library manager.
+ * 2. Edit "Arduino/Libraries/JPEGDecoder/src/User_Config.h" and comment out
+ * "#define LOAD_SD_LIBRARY" and "#define LOAD_SDFAT_LIBRARY".
+ */
+
+#if defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_ARDUINO_NANO33BLE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+// Required by Arducam library
+#include <SPI.h>
+#include <Wire.h>
+#include <memorysaver.h>
+// Arducam library
+#include <ArduCAM.h>
+// JPEGDecoder library
+#include <JPEGDecoder.h>
+
+// Checks that the Arducam library has been correctly configured
+#if !(defined OV2640_MINI_2MP_PLUS)
+#error Please select the hardware platform and camera module in the Arduino/libraries/ArduCAM/memorysaver.h
+#endif
+
+// The size of our temporary buffer for holding
+// JPEG data received from the Arducam module
+#define MAX_JPEG_BYTES 4096
+// The pin connected to the Arducam Chip Select
+#define CS 7
+
+// Camera library instance
+ArduCAM myCAM(OV2640, CS);
+// Temporary buffer for holding JPEG data from camera
+uint8_t jpeg_buffer[MAX_JPEG_BYTES] = {0};
+// Length of the JPEG data currently in the buffer
+uint32_t jpeg_length = 0;
+
+// Get the camera module ready
+TfLiteStatus InitCamera(tflite::ErrorReporter* error_reporter) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Attempting to start Arducam");
+ // Enable the Wire library
+ Wire.begin();
+ // Configure the CS pin
+ pinMode(CS, OUTPUT);
+ digitalWrite(CS, HIGH);
+ // initialize SPI
+ SPI.begin();
+ // Reset the CPLD
+ myCAM.write_reg(0x07, 0x80);
+ delay(100);
+ myCAM.write_reg(0x07, 0x00);
+ delay(100);
+ // Test whether we can communicate with Arducam via SPI
+ myCAM.write_reg(ARDUCHIP_TEST1, 0x55);
+ uint8_t test;
+ test = myCAM.read_reg(ARDUCHIP_TEST1);
+ if (test != 0x55) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Can't communicate with Arducam");
+ delay(1000);
+ return kTfLiteError;
+ }
+ // Use JPEG capture mode, since it allows us to specify
+ // a resolution smaller than the full sensor frame
+ myCAM.set_format(JPEG);
+ myCAM.InitCAM();
+ // Specify the smallest possible resolution
+ myCAM.OV2640_set_JPEG_size(OV2640_160x120);
+ delay(100);
+ return kTfLiteOk;
+}
+
+// Begin the capture and wait for it to finish
+TfLiteStatus PerformCapture(tflite::ErrorReporter* error_reporter) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Starting capture");
+ // Make sure the buffer is emptied before each capture
+ myCAM.flush_fifo();
+ myCAM.clear_fifo_flag();
+ // Start capture
+ myCAM.start_capture();
+ // Wait for indication that it is done
+ while (!myCAM.get_bit(ARDUCHIP_TRIG, CAP_DONE_MASK)) {
+ }
+ TF_LITE_REPORT_ERROR(error_reporter, "Image captured");
+ delay(50);
+ // Clear the capture done flag
+ myCAM.clear_fifo_flag();
+ return kTfLiteOk;
+}
+
+// Read data from the camera module into a local buffer
+TfLiteStatus ReadData(tflite::ErrorReporter* error_reporter) {
+ // This represents the total length of the JPEG data
+ jpeg_length = myCAM.read_fifo_length();
+ TF_LITE_REPORT_ERROR(error_reporter, "Reading %d bytes from Arducam",
+ jpeg_length);
+ // Ensure there's not too much data for our buffer
+ if (jpeg_length > MAX_JPEG_BYTES) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Too many bytes in FIFO buffer (%d)",
+ MAX_JPEG_BYTES);
+ return kTfLiteError;
+ }
+ if (jpeg_length == 0) {
+ TF_LITE_REPORT_ERROR(error_reporter, "No data in Arducam FIFO buffer");
+ return kTfLiteError;
+ }
+ myCAM.CS_LOW();
+ myCAM.set_fifo_burst();
+ for (int index = 0; index < jpeg_length; index++) {
+ jpeg_buffer[index] = SPI.transfer(0x00);
+ }
+ delayMicroseconds(15);
+ TF_LITE_REPORT_ERROR(error_reporter, "Finished reading");
+ myCAM.CS_HIGH();
+ return kTfLiteOk;
+}
+
+// Decode the JPEG image, crop it, and convert it to greyscale
+TfLiteStatus DecodeAndProcessImage(tflite::ErrorReporter* error_reporter,
+ int image_width, int image_height,
+ int8_t* image_data) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Decoding JPEG and converting to greyscale");
+ // Parse the JPEG headers. The image will be decoded as a sequence of Minimum
+ // Coded Units (MCUs), which are 16x8 blocks of pixels.
+ JpegDec.decodeArray(jpeg_buffer, jpeg_length);
+
+ // Crop the image by keeping a certain number of MCUs in each dimension
+ const int keep_x_mcus = image_width / JpegDec.MCUWidth;
+ const int keep_y_mcus = image_height / JpegDec.MCUHeight;
+
+ // Calculate how many MCUs we will throw away on the x axis
+ const int skip_x_mcus = JpegDec.MCUSPerRow - keep_x_mcus;
+ // Roughly center the crop by skipping half the throwaway MCUs at the
+ // beginning of each row
+ const int skip_start_x_mcus = skip_x_mcus / 2;
+ // Index where we will start throwing away MCUs after the data
+ const int skip_end_x_mcu_index = skip_start_x_mcus + keep_x_mcus;
+ // Same approach for the columns
+ const int skip_y_mcus = JpegDec.MCUSPerCol - keep_y_mcus;
+ const int skip_start_y_mcus = skip_y_mcus / 2;
+ const int skip_end_y_mcu_index = skip_start_y_mcus + keep_y_mcus;
+
+ // Pointer to the current pixel
+ uint16_t* pImg;
+ // Color of the current pixel
+ uint16_t color;
+
+ // Loop over the MCUs
+ while (JpegDec.read()) {
+ // Skip over the initial set of rows
+ if (JpegDec.MCUy < skip_start_y_mcus) {
+ continue;
+ }
+ // Skip if we're on a column that we don't want
+ if (JpegDec.MCUx < skip_start_x_mcus ||
+ JpegDec.MCUx >= skip_end_x_mcu_index) {
+ continue;
+ }
+ // Skip if we've got all the rows we want
+ if (JpegDec.MCUy >= skip_end_y_mcu_index) {
+ continue;
+ }
+ // Pointer to the current pixel
+ pImg = JpegDec.pImage;
+
+ // The x and y indexes of the current MCU, ignoring the MCUs we skip
+ int relative_mcu_x = JpegDec.MCUx - skip_start_x_mcus;
+ int relative_mcu_y = JpegDec.MCUy - skip_start_y_mcus;
+
+ // The coordinates of the top left of this MCU when applied to the output
+ // image
+ int x_origin = relative_mcu_x * JpegDec.MCUWidth;
+ int y_origin = relative_mcu_y * JpegDec.MCUHeight;
+
+ // Loop through the MCU's rows and columns
+ for (int mcu_row = 0; mcu_row < JpegDec.MCUHeight; mcu_row++) {
+ // The y coordinate of this pixel in the output index
+ int current_y = y_origin + mcu_row;
+ for (int mcu_col = 0; mcu_col < JpegDec.MCUWidth; mcu_col++) {
+ // Read the color of the pixel as 16-bit integer
+ color = *pImg++;
+ // Extract the color values (5 red bits, 6 green, 5 blue)
+ uint8_t r, g, b;
+ r = ((color & 0xF800) >> 11) * 8;
+ g = ((color & 0x07E0) >> 5) * 4;
+ b = ((color & 0x001F) >> 0) * 8;
+ // Convert to grayscale by calculating luminance
+ // See https://en.wikipedia.org/wiki/Grayscale for magic numbers
+ float gray_value = (0.2126 * r) + (0.7152 * g) + (0.0722 * b);
+
+ // Convert to signed 8-bit integer by subtracting 128.
+ gray_value -= 128;
+
+ // The x coordinate of this pixel in the output image
+ int current_x = x_origin + mcu_col;
+ // The index of this pixel in our flat output buffer
+ int index = (current_y * image_width) + current_x;
+ image_data[index] = static_cast<int8_t>(gray_value);
+ }
+ }
+ }
+ TF_LITE_REPORT_ERROR(error_reporter, "Image decoded and processed");
+ return kTfLiteOk;
+}
+
+// Get an image from the camera module
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int image_width,
+ int image_height, int channels, int8_t* image_data) {
+ static bool g_is_camera_initialized = false;
+ if (!g_is_camera_initialized) {
+ TfLiteStatus init_status = InitCamera(error_reporter);
+ if (init_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "InitCamera failed");
+ return init_status;
+ }
+ g_is_camera_initialized = true;
+ }
+
+ TfLiteStatus capture_status = PerformCapture(error_reporter);
+ if (capture_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "PerformCapture failed");
+ return capture_status;
+ }
+
+ TfLiteStatus read_data_status = ReadData(error_reporter);
+ if (read_data_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "ReadData failed");
+ return read_data_status;
+ }
+
+ TfLiteStatus decode_status = DecodeAndProcessImage(
+ error_reporter, image_width, image_height, image_data);
+ if (decode_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "DecodeAndProcessImage failed");
+ return decode_status;
+ }
+
+ return kTfLiteOk;
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/arduino/main.cc b/tensorflow/lite/micro/examples/person_detection/arduino/main.cc
new file mode 100644
index 0000000..feaf350
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/arduino/main.cc
@@ -0,0 +1,20 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/main_functions.h"
+
+// Arduino automatically calls the setup() and loop() functions in a sketch, so
+// where other systems need their own main routine in this file, it can be left
+// empty.
diff --git a/tensorflow/lite/micro/examples/person_detection/detection_responder.cc b/tensorflow/lite/micro/examples/person_detection/detection_responder.cc
new file mode 100644
index 0000000..2e3f99b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/detection_responder.cc
@@ -0,0 +1,25 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/detection_responder.h"
+
+// This dummy implementation writes person and no person scores to the error
+// console. Real applications will want to take some custom action instead, and
+// should implement their own versions of this function.
+void RespondToDetection(tflite::ErrorReporter* error_reporter,
+ int8_t person_score, int8_t no_person_score) {
+ TF_LITE_REPORT_ERROR(error_reporter, "person score:%d no person score %d",
+ person_score, no_person_score);
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/detection_responder.h b/tensorflow/lite/micro/examples/person_detection/detection_responder.h
new file mode 100644
index 0000000..8887c58
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/detection_responder.h
@@ -0,0 +1,34 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Provides an interface to take an action based on the output from the person
+// detection model.
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_DETECTION_RESPONDER_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_DETECTION_RESPONDER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+// Called every time the results of a person detection run are available. The
+// `person_score` has the numerical confidence that the captured image contains
+// a person, and `no_person_score` has the numerical confidence that the image
+// does not contain a person. Typically if person_score > no person score, the
+// image is considered to contain a person. This threshold may be adjusted for
+// particular applications.
+void RespondToDetection(tflite::ErrorReporter* error_reporter,
+ int8_t person_score, int8_t no_person_score);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_DETECTION_RESPONDER_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/detection_responder_test.cc b/tensorflow/lite/micro/examples/person_detection/detection_responder_test.cc
new file mode 100644
index 0000000..6a2198b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/detection_responder_test.cc
@@ -0,0 +1,32 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/detection_responder.h"
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestCallability) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ // This will have external side-effects (like printing to the debug console
+ // or lighting an LED) that are hard to observe, so the most we can do is
+ // make sure the call doesn't crash.
+ RespondToDetection(µ_error_reporter, -100, 100);
+ RespondToDetection(µ_error_reporter, 100, 50);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/Makefile.inc b/tensorflow/lite/micro/examples/person_detection/esp/Makefile.inc
new file mode 100644
index 0000000..e3c07e5
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/Makefile.inc
@@ -0,0 +1,49 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+ifeq ($(TARGET), esp)
+
+# Adding some esp specific files in the main CMakeLists.txt
+ESP_PERSON_DETECTION_SRCS := \
+tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.c
+
+ESP_PERSON_DETECTION_HDRS := \
+tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.h
+
+person_detection_SRCS += $(ESP_PERSON_DETECTION_SRCS)
+person_detection_HDRS += $(ESP_PERSON_DETECTION_HDRS)
+MAIN_SRCS += $(ESP_PERSON_DETECTION_SRCS)
+
+# ESP specific flags and files
+CCFLAGS += -Wno-nonnull
+CXXFLAGS += -Wno-return-type -Wno-strict-aliasing
+person_detection_ESP_PROJECT_FILES := \
+ sdkconfig.defaults \
+ main/Kconfig.projbuild
+
+# Remap downloaded model files as if they were in tensorflow/lite/micro/examples/..
+MODEL_DOWNLOADS_DIR := tensorflow/lite/micro/tools/make/downloads/person_model_grayscale
+MODEL_EXAMPLES_DIR := tensorflow/lite/micro/examples/person_detection/person_model_grayscale
+person_detection_SRCS := $(patsubst $(MODEL_DOWNLOADS_DIR)/%,$(MODEL_EXAMPLES_DIR)/%,$(person_detection_SRCS))
+
+# Custom rule to transform downloaded model files
+$(PRJDIR)person_detection/esp-idf/main/person_model_grayscale/%: $(MODEL_DOWNLOADS_DIR)/%
+ @mkdir -p $(dir $@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=esp \
+ --is_example_source \
+ --source_path="$(patsubst $(MODEL_DOWNLOADS_DIR)/%,$(MODEL_EXAMPLES_DIR)/%,$<)" \
+ < $< > $@
+
+endif
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/README_ESP.md b/tensorflow/lite/micro/examples/person_detection/esp/README_ESP.md
new file mode 100644
index 0000000..6075e1b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/README_ESP.md
@@ -0,0 +1,73 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+# TensorFlow Lite Micro ESP-IDF Project
+
+This folder has been autogenerated by TensorFlow, and contains source, header,
+and project files needed to build a single TensorFlow Lite Micro target using
+Espressif's [ESP-IDF](https://docs.espressif.com/projects/esp-idf/en/latest/).
+
+## Usage
+
+### Install the ESP IDF
+
+Follow the instructions of the
+[ESP-IDF get started guide](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html)
+to setup the toolchain and the ESP-IDF itself.
+
+The next steps assume that the
+[IDF environment variables are set](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html#step-4-set-up-the-environment-variables) :
+* The `IDF_PATH` environment variable is set. * `idf.py` and Xtensa-esp32 tools
+(e.g., `xtensa-esp32-elf-gcc`) are in `$PATH`. * `esp32-camera` should be
+downloaded in `components/` dir of example as explained in `Build the
+example`(below)
+
+## Build the example
+
+As the `person_detection` example requires an external component `esp32-camera`
+for functioning hence we will have to manually clone it in `components/`
+directory of the example with following commands.
+
+```
+ git clone https://github.com/espressif/esp32-camera.git components/esp32-camera
+ cd components/esp32-camera/
+ git checkout eacd640b8d379883bff1251a1005ebf3cf1ed95c
+ cd ../../
+```
+
+To build this, run:
+
+```
+idf.py build
+```
+
+### Load and run the example
+
+To flash (replace `/dev/ttyUSB0` with the device serial port):
+```
+idf.py --port /dev/ttyUSB0 flash
+```
+
+Monitor the serial output:
+```
+idf.py --port /dev/ttyUSB0 monitor
+```
+
+Use `Ctrl+]` to exit.
+
+The previous two commands can be combined:
+```
+idf.py --port /dev/ttyUSB0 flash monitor
+```
+
+## Project Generation
+
+See
+[tensorflow/lite/micro](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro)
+for details on how projects like this can be generated from the main source
+tree.
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository,
+and third party dependencies are covered by their respective licenses, in the
+third_party folder of this package.
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.c b/tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.c
new file mode 100644
index 0000000..420f74b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.c
@@ -0,0 +1,67 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "app_camera_esp.h"
+
+static const char* TAG = "app_camera";
+
+int app_camera_init() {
+#if CONFIG_CAMERA_MODEL_ESP_EYE
+ /* IO13, IO14 is designed for JTAG by default,
+ * to use it as generalized input,
+ * firstly declair it as pullup input */
+ gpio_config_t conf;
+ conf.mode = GPIO_MODE_INPUT;
+ conf.pull_up_en = GPIO_PULLUP_ENABLE;
+ conf.pull_down_en = GPIO_PULLDOWN_DISABLE;
+ conf.intr_type = GPIO_INTR_DISABLE;
+ conf.pin_bit_mask = 1LL << 13;
+ gpio_config(&conf);
+ conf.pin_bit_mask = 1LL << 14;
+ gpio_config(&conf);
+#endif
+ camera_config_t config;
+ config.ledc_channel = LEDC_CHANNEL_0;
+ config.ledc_timer = LEDC_TIMER_0;
+ config.pin_d0 = Y2_GPIO_NUM;
+ config.pin_d1 = Y3_GPIO_NUM;
+ config.pin_d2 = Y4_GPIO_NUM;
+ config.pin_d3 = Y5_GPIO_NUM;
+ config.pin_d4 = Y6_GPIO_NUM;
+ config.pin_d5 = Y7_GPIO_NUM;
+ config.pin_d6 = Y8_GPIO_NUM;
+ config.pin_d7 = Y9_GPIO_NUM;
+ config.pin_xclk = XCLK_GPIO_NUM;
+ config.pin_pclk = PCLK_GPIO_NUM;
+ config.pin_vsync = VSYNC_GPIO_NUM;
+ config.pin_href = HREF_GPIO_NUM;
+ config.pin_sscb_sda = SIOD_GPIO_NUM;
+ config.pin_sscb_scl = SIOC_GPIO_NUM;
+ config.pin_pwdn = PWDN_GPIO_NUM;
+ config.pin_reset = -1; // RESET_GPIO_NUM;
+ config.xclk_freq_hz = XCLK_FREQ;
+ config.pixel_format = CAMERA_PIXEL_FORMAT;
+ config.frame_size = CAMERA_FRAME_SIZE;
+ config.jpeg_quality = 10;
+ config.fb_count = 1;
+
+ // camera init
+ esp_err_t err = esp_camera_init(&config);
+ if (err != ESP_OK) {
+ ESP_LOGE(TAG, "Camera init failed with error 0x%x", err);
+ return -1;
+ }
+ return 0;
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.h b/tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.h
new file mode 100644
index 0000000..83a7fdb
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/app_camera_esp.h
@@ -0,0 +1,178 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_ESP_APP_CAMERA_ESP_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_ESP_APP_CAMERA_ESP_H_
+
+#include "esp_camera.h"
+#include "esp_log.h"
+#include "esp_system.h"
+#include "sensor.h"
+
+/**
+ * PIXFORMAT_RGB565, // 2BPP/RGB565
+ * PIXFORMAT_YUV422, // 2BPP/YUV422
+ * PIXFORMAT_GRAYSCALE, // 1BPP/GRAYSCALE
+ * PIXFORMAT_JPEG, // JPEG/COMPRESSED
+ * PIXFORMAT_RGB888, // 3BPP/RGB888
+ */
+#define CAMERA_PIXEL_FORMAT PIXFORMAT_GRAYSCALE
+
+/*
+ * FRAMESIZE_96X96, // 96x96
+ * FRAMESIZE_QQVGA, // 160x120
+ * FRAMESIZE_QQVGA2, // 128x160
+ * FRAMESIZE_QCIF, // 176x144
+ * FRAMESIZE_HQVGA, // 240x176
+ * FRAMESIZE_QVGA, // 320x240
+ * FRAMESIZE_CIF, // 400x296
+ * FRAMESIZE_VGA, // 640x480
+ * FRAMESIZE_SVGA, // 800x600
+ * FRAMESIZE_XGA, // 1024x768
+ * FRAMESIZE_SXGA, // 1280x1024
+ * FRAMESIZE_UXGA, // 1600x1200
+ */
+#define CAMERA_FRAME_SIZE FRAMESIZE_96X96
+
+#if CONFIG_CAMERA_MODEL_WROVER_KIT
+#define PWDN_GPIO_NUM -1
+#define RESET_GPIO_NUM -1
+#define XCLK_GPIO_NUM 21
+#define SIOD_GPIO_NUM 26
+#define SIOC_GPIO_NUM 27
+
+#define Y9_GPIO_NUM 35
+#define Y8_GPIO_NUM 34
+#define Y7_GPIO_NUM 39
+#define Y6_GPIO_NUM 36
+#define Y5_GPIO_NUM 19
+#define Y4_GPIO_NUM 18
+#define Y3_GPIO_NUM 5
+#define Y2_GPIO_NUM 4
+#define VSYNC_GPIO_NUM 25
+#define HREF_GPIO_NUM 23
+#define PCLK_GPIO_NUM 22
+
+#elif CONFIG_CAMERA_MODEL_ESP_EYE
+#define PWDN_GPIO_NUM -1
+#define RESET_GPIO_NUM -1
+#define XCLK_GPIO_NUM 4
+#define SIOD_GPIO_NUM 18
+#define SIOC_GPIO_NUM 23
+
+#define Y9_GPIO_NUM 36
+#define Y8_GPIO_NUM 37
+#define Y7_GPIO_NUM 38
+#define Y6_GPIO_NUM 39
+#define Y5_GPIO_NUM 35
+#define Y4_GPIO_NUM 14
+#define Y3_GPIO_NUM 13
+#define Y2_GPIO_NUM 34
+#define VSYNC_GPIO_NUM 5
+#define HREF_GPIO_NUM 27
+#define PCLK_GPIO_NUM 25
+
+#elif CONFIG_CAMERA_MODEL_M5STACK_PSRAM
+#define PWDN_GPIO_NUM -1
+#define RESET_GPIO_NUM 15
+#define XCLK_GPIO_NUM 27
+#define SIOD_GPIO_NUM 25
+#define SIOC_GPIO_NUM 23
+
+#define Y9_GPIO_NUM 19
+#define Y8_GPIO_NUM 36
+#define Y7_GPIO_NUM 18
+#define Y6_GPIO_NUM 39
+#define Y5_GPIO_NUM 5
+#define Y4_GPIO_NUM 34
+#define Y3_GPIO_NUM 35
+#define Y2_GPIO_NUM 32
+#define VSYNC_GPIO_NUM 22
+#define HREF_GPIO_NUM 26
+#define PCLK_GPIO_NUM 21
+
+#elif CONFIG_CAMERA_MODEL_M5STACK_WIDE
+#define PWDN_GPIO_NUM -1
+#define RESET_GPIO_NUM 15
+#define XCLK_GPIO_NUM 27
+#define SIOD_GPIO_NUM 22
+#define SIOC_GPIO_NUM 23
+
+#define Y9_GPIO_NUM 19
+#define Y8_GPIO_NUM 36
+#define Y7_GPIO_NUM 18
+#define Y6_GPIO_NUM 39
+#define Y5_GPIO_NUM 5
+#define Y4_GPIO_NUM 34
+#define Y3_GPIO_NUM 35
+#define Y2_GPIO_NUM 32
+#define VSYNC_GPIO_NUM 25
+#define HREF_GPIO_NUM 26
+#define PCLK_GPIO_NUM 21
+
+#elif CONFIG_CAMERA_MODEL_AI_THINKER
+#define PWDN_GPIO_NUM 32
+#define RESET_GPIO_NUM -1
+#define XCLK_GPIO_NUM 0
+#define SIOD_GPIO_NUM 26
+#define SIOC_GPIO_NUM 27
+
+#define Y9_GPIO_NUM 35
+#define Y8_GPIO_NUM 34
+#define Y7_GPIO_NUM 39
+#define Y6_GPIO_NUM 36
+#define Y5_GPIO_NUM 21
+#define Y4_GPIO_NUM 19
+#define Y3_GPIO_NUM 18
+#define Y2_GPIO_NUM 5
+#define VSYNC_GPIO_NUM 25
+#define HREF_GPIO_NUM 23
+#define PCLK_GPIO_NUM 22
+
+#elif CONFIG_CAMERA_MODEL_CUSTOM
+#define PWDN_GPIO_NUM CONFIG_CAMERA_PIN_PWDN
+#define RESET_GPIO_NUM CONFIG_CAMERA_PIN_RESET
+#define XCLK_GPIO_NUM CONFIG_CAMERA_PIN_XCLK
+#define SIOD_GPIO_NUM CONFIG_CAMERA_PIN_SIOD
+#define SIOC_GPIO_NUM CONFIG_CAMERA_PIN_SIOC
+
+#define Y9_GPIO_NUM CONFIG_CAMERA_PIN_Y9
+#define Y8_GPIO_NUM CONFIG_CAMERA_PIN_Y8
+#define Y7_GPIO_NUM CONFIG_CAMERA_PIN_Y7
+#define Y6_GPIO_NUM CONFIG_CAMERA_PIN_Y6
+#define Y5_GPIO_NUM CONFIG_CAMERA_PIN_Y5
+#define Y4_GPIO_NUM CONFIG_CAMERA_PIN_Y4
+#define Y3_GPIO_NUM CONFIG_CAMERA_PIN_Y3
+#define Y2_GPIO_NUM CONFIG_CAMERA_PIN_Y2
+#define VSYNC_GPIO_NUM CONFIG_CAMERA_PIN_VSYNC
+#define HREF_GPIO_NUM CONFIG_CAMERA_PIN_HREF
+#define PCLK_GPIO_NUM CONFIG_CAMERA_PIN_PCLK
+
+#else
+#error "No camera module configured, please configure in menuconfig"
+#endif
+
+#define XCLK_FREQ 20000000
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+int app_camera_init();
+
+#ifdef __cplusplus
+}
+#endif
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_ESP_APP_CAMERA_ESP_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/image_provider.cc b/tensorflow/lite/micro/examples/person_detection/esp/image_provider.cc
new file mode 100644
index 0000000..02ed467
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/image_provider.cc
@@ -0,0 +1,88 @@
+
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "../image_provider.h"
+
+#include <cstdlib>
+#include <cstring>
+#include <iostream>
+
+#include "app_camera_esp.h"
+#include "esp_camera.h"
+#include "esp_log.h"
+#include "esp_spi_flash.h"
+#include "esp_system.h"
+#include "esp_timer.h"
+#include "freertos/FreeRTOS.h"
+#include "freertos/task.h"
+
+camera_fb_t* fb = NULL;
+static const char* TAG = "app_camera";
+
+// Get the camera module ready
+TfLiteStatus InitCamera(tflite::ErrorReporter* error_reporter) {
+ int ret = app_camera_init();
+ if (ret != 0) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Camera init failed\n");
+ return kTfLiteError;
+ }
+ TF_LITE_REPORT_ERROR(error_reporter, "Camera Initialized\n");
+ return kTfLiteOk;
+}
+
+extern "C" int capture_image() {
+ fb = esp_camera_fb_get();
+ if (!fb) {
+ ESP_LOGE(TAG, "Camera capture failed");
+ return -1;
+ }
+ return 0;
+}
+// Begin the capture and wait for it to finish
+TfLiteStatus PerformCapture(tflite::ErrorReporter* error_reporter,
+ uint8_t* image_data) {
+ /* 2. Get one image with camera */
+ int ret = capture_image();
+ if (ret != 0) {
+ return kTfLiteError;
+ }
+ TF_LITE_REPORT_ERROR(error_reporter, "Image Captured\n");
+ memcpy(image_data, fb->buf, fb->len);
+ esp_camera_fb_return(fb);
+ /* here the esp camera can give you grayscale image directly */
+ return kTfLiteOk;
+}
+
+// Get an image from the camera module
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int image_width,
+ int image_height, int channels, uint8_t* image_data) {
+ static bool g_is_camera_initialized = false;
+ if (!g_is_camera_initialized) {
+ TfLiteStatus init_status = InitCamera(error_reporter);
+ if (init_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "InitCamera failed\n");
+ return init_status;
+ }
+ g_is_camera_initialized = true;
+ }
+ /* Camera Captures Image of size 96 x 96 which is of the format grayscale
+ * thus, no need to crop or process further , directly send it to tf */
+ TfLiteStatus capture_status = PerformCapture(error_reporter, image_data);
+ if (capture_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "PerformCapture failed\n");
+ return capture_status;
+ }
+ return kTfLiteOk;
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/main.cc b/tensorflow/lite/micro/examples/person_detection/esp/main.cc
new file mode 100644
index 0000000..45a01c4
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/main.cc
@@ -0,0 +1,32 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "../main_functions.h"
+#include "esp_log.h"
+#include "esp_system.h"
+#include "freertos/FreeRTOS.h"
+#include "freertos/task.h"
+
+void tf_main(void) {
+ setup();
+ while (true) {
+ loop();
+ }
+}
+
+extern "C" void app_main() {
+ xTaskCreate((TaskFunction_t)&tf_main, "tensorflow", 32 * 1024, NULL, 8, NULL);
+ vTaskDelete(NULL);
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/main/Kconfig.projbuild b/tensorflow/lite/micro/examples/person_detection/esp/main/Kconfig.projbuild
new file mode 100755
index 0000000..c338ead
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/main/Kconfig.projbuild
@@ -0,0 +1,164 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+menu "Camera Pins"
+choice CAMERA_MODEL
+ bool "Select Camera Pinout"
+ default CAMERA_MODEL_WROVER_KIT
+ help
+ Select Camera Pinout.
+
+config CAMERA_MODEL_WROVER_KIT
+ bool "WROVER-KIT With OV2640 Module"
+config CAMERA_MODEL_ESP_EYE
+ bool "ESP_EYE DevKit"
+config CAMERA_MODEL_M5STACK_PSRAM
+ bool "M5Stack Camera With PSRAM"
+config CAMERA_MODEL_M5STACK_WIDE
+ bool "M5Stack Camera F (Wide)"
+config CAMERA_MODEL_AI_THINKER
+ bool "ESP32-CAM by AI-Thinker"
+config CAMERA_MODEL_CUSTOM
+ bool "Custom Camera Pinout"
+endchoice
+
+config CAMERA_PIN_PWDN
+ depends on CAMERA_MODEL_CUSTOM
+ int "Power Down pin"
+ range -1 33
+ default -1
+ help
+ Select Power Down pin or -1 for unmanaged.
+
+config CAMERA_PIN_RESET
+ depends on CAMERA_MODEL_CUSTOM
+ int "Reset pin"
+ range -1 33
+ default -1
+ help
+ Select Camera Reset pin or -1 for software reset.
+
+config CAMERA_PIN_XCLK
+ depends on CAMERA_MODEL_CUSTOM
+ int "XCLK pin"
+ range 0 33
+ default 21
+ help
+ Select Camera XCLK pin.
+
+config CAMERA_PIN_SIOD
+ depends on CAMERA_MODEL_CUSTOM
+ int "SIOD pin"
+ range 0 33
+ default 26
+ help
+ Select Camera SIOD pin.
+
+config CAMERA_PIN_SIOC
+ depends on CAMERA_MODEL_CUSTOM
+ int "SIOC pin"
+ range 0 33
+ default 27
+ help
+ Select Camera SIOC pin.
+
+config CAMERA_PIN_VSYNC
+ depends on CAMERA_MODEL_CUSTOM
+ int "VSYNC pin"
+ range 0 39
+ default 25
+ help
+ Select Camera VSYNC pin.
+
+config CAMERA_PIN_HREF
+ depends on CAMERA_MODEL_CUSTOM
+ int "HREF pin"
+ range 0 39
+ default 23
+ help
+ Select Camera HREF pin.
+
+config CAMERA_PIN_PCLK
+ depends on CAMERA_MODEL_CUSTOM
+ int "PCLK pin"
+ range 0 39
+ default 25
+ help
+ Select Camera PCLK pin.
+
+config CAMERA_PIN_Y2
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y2 pin"
+ range 0 39
+ default 4
+ help
+ Select Camera Y2 pin.
+
+config CAMERA_PIN_Y3
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y3 pin"
+ range 0 39
+ default 5
+ help
+ Select Camera Y3 pin.
+
+config CAMERA_PIN_Y4
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y4 pin"
+ range 0 39
+ default 18
+ help
+ Select Camera Y4 pin.
+
+config CAMERA_PIN_Y5
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y5 pin"
+ range 0 39
+ default 19
+ help
+ Select Camera Y5 pin.
+
+config CAMERA_PIN_Y6
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y6 pin"
+ range 0 39
+ default 36
+ help
+ Select Camera Y6 pin.
+
+config CAMERA_PIN_Y7
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y7 pin"
+ range 0 39
+ default 39
+ help
+ Select Camera Y7 pin.
+
+config CAMERA_PIN_Y8
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y8 pin"
+ range 0 39
+ default 34
+ help
+ Select Camera Y8 pin.
+
+config CAMERA_PIN_Y9
+ depends on CAMERA_MODEL_CUSTOM
+ int "Y9 pin"
+ range 0 39
+ default 35
+ help
+ Select Camera Y9 pin.
+
+endmenu
diff --git a/tensorflow/lite/micro/examples/person_detection/esp/sdkconfig.defaults b/tensorflow/lite/micro/examples/person_detection/esp/sdkconfig.defaults
new file mode 100644
index 0000000..021ea58
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/esp/sdkconfig.defaults
@@ -0,0 +1,96 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+CONFIG_ESPTOOLPY_BAUD_115200B=
+CONFIG_ESPTOOLPY_BAUD_230400B=
+CONFIG_ESPTOOLPY_BAUD_921600B=y
+CONFIG_ESPTOOLPY_BAUD_2MB=
+CONFIG_ESPTOOLPY_BAUD_OTHER=
+CONFIG_ESPTOOLPY_BAUD_OTHER_VAL=115200
+CONFIG_ESPTOOLPY_BAUD=921600
+CONFIG_ESPTOOLPY_COMPRESSED=y
+CONFIG_FLASHMODE_QIO=y
+CONFIG_FLASHMODE_QOUT=
+CONFIG_FLASHMODE_DIO=
+CONFIG_FLASHMODE_DOUT=
+CONFIG_ESPTOOLPY_FLASHMODE="dio"
+CONFIG_ESPTOOLPY_FLASHFREQ_80M=y
+CONFIG_ESPTOOLPY_FLASHFREQ_40M=
+CONFIG_ESPTOOLPY_FLASHFREQ_26M=
+CONFIG_ESPTOOLPY_FLASHFREQ_20M=
+CONFIG_ESPTOOLPY_FLASHFREQ="80m"
+CONFIG_ESPTOOLPY_FLASHSIZE_1MB=
+CONFIG_ESPTOOLPY_FLASHSIZE_2MB=
+CONFIG_ESPTOOLPY_FLASHSIZE_4MB=y
+CONFIG_ESPTOOLPY_FLASHSIZE_8MB=
+CONFIG_ESPTOOLPY_FLASHSIZE_16MB=
+CONFIG_ESPTOOLPY_FLASHSIZE="4MB"
+CONFIG_ESPTOOLPY_FLASHSIZE_DETECT=y
+CONFIG_ESPTOOLPY_BEFORE_RESET=y
+CONFIG_ESPTOOLPY_BEFORE_NORESET=
+CONFIG_ESPTOOLPY_BEFORE="default_reset"
+CONFIG_ESPTOOLPY_AFTER_RESET=y
+CONFIG_ESPTOOLPY_AFTER_NORESET=
+CONFIG_ESPTOOLPY_AFTER="hard_reset"
+CONFIG_MONITOR_BAUD_9600B=
+CONFIG_MONITOR_BAUD_57600B=
+CONFIG_MONITOR_BAUD_115200B=y
+CONFIG_MONITOR_BAUD_230400B=
+CONFIG_MONITOR_BAUD_921600B=
+CONFIG_MONITOR_BAUD_2MB=
+CONFIG_MONITOR_BAUD_OTHER=
+CONFIG_MONITOR_BAUD_OTHER_VAL=115200
+CONFIG_MONITOR_BAUD=115200
+CONFIG_COMPILER_OPTIMIZATION_PERF=y
+
+# Camera configuration
+#
+CONFIG_ENABLE_TEST_PATTERN=
+CONFIG_OV2640_SUPPORT=y
+CONFIG_OV7725_SUPPORT=
+
+#
+# ESP32-specific
+#
+CONFIG_ESP32_DEFAULT_CPU_FREQ_80=
+CONFIG_ESP32_DEFAULT_CPU_FREQ_160=
+CONFIG_ESP32_DEFAULT_CPU_FREQ_240=y
+CONFIG_ESP32_DEFAULT_CPU_FREQ_MHZ=240
+
+#
+# SPI RAM config
+#
+CONFIG_SPIRAM_BOOT_INIT=y
+CONFIG_SPIRAM_IGNORE_NOTFOUND=
+CONFIG_SPIRAM_USE_MEMMAP=
+CONFIG_SPIRAM_USE_CAPS_ALLOC=y
+CONFIG_SPIRAM_USE_MALLOC=
+CONFIG_SPIRAM_TYPE_AUTO=y
+CONFIG_SPIRAM_TYPE_ESPPSRAM32=
+CONFIG_SPIRAM_TYPE_ESPPSRAM64=
+CONFIG_SPIRAM_SIZE=-1
+CONFIG_SPIRAM_SPEED_40M=
+CONFIG_SPIRAM_SPEED_80M=y
+CONFIG_SPIRAM_MEMTEST=y
+CONFIG_SPIRAM_CACHE_WORKAROUND=y
+CONFIG_SPIRAM_BANKSWITCH_ENABLE=y
+CONFIG_SPIRAM_BANKSWITCH_RESERVE=8
+CONFIG_WIFI_LWIP_ALLOCATION_FROM_SPIRAM_FIRST=
+CONFIG_SPIRAM_ALLOW_BSS_SEG_EXTERNAL_MEMORY=
+
+CONFIG_TASK_WDT=
+
+#For no set the camera module as ESP-EYE
+CONFIG_CAMERA_MODEL_ESP_EYE=y
+CONFIG_RTCIO_SUPPORT_RTC_GPIO_DESC=y
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.c b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.c
new file mode 100644
index 0000000..70adf66
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.c
@@ -0,0 +1,732 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "HM01B0.h"
+
+#include "HM01B0_Walking1s_01.h"
+#include "am_bsp.h"
+#include "am_mcu_apollo.h"
+#include "am_util.h"
+#include "platform.h" // TARGET specific implementation
+
+//#define ENABLE_ASYNC
+
+const am_hal_gpio_pincfg_t g_HM01B0_pin_vsync = {
+ .uFuncSel = 3,
+ .eGPOutcfg = AM_HAL_GPIO_PIN_OUTCFG_DISABLE,
+#ifdef ENABLE_ASYNC
+ .eIntDir = AM_HAL_GPIO_PIN_INTDIR_BOTH,
+#endif
+ .eGPInput = AM_HAL_GPIO_PIN_INPUT_ENABLE,
+ .eGPRdZero = AM_HAL_GPIO_PIN_RDZERO_READPIN};
+
+const am_hal_gpio_pincfg_t g_HM01B0_pin_int = {
+ .uFuncSel = 3,
+ .eGPOutcfg = AM_HAL_GPIO_PIN_OUTCFG_DISABLE,
+ .eIntDir = AM_HAL_GPIO_PIN_INTDIR_LO2HI,
+ .eGPInput = AM_HAL_GPIO_PIN_INPUT_ENABLE,
+ .eGPRdZero = AM_HAL_GPIO_PIN_RDZERO_READPIN};
+
+#ifdef ENABLE_ASYNC
+static bool s_bVsyncAsserted = false;
+
+//*****************************************************************************
+//
+// GPIO ISR
+//
+//*****************************************************************************
+static void hm01b0_gpio_isr(void) {
+ //
+ // Clear the GPIO Interrupt (write to clear).
+ //
+ am_hal_gpio_interrupt_clear(1 << HM01B0_PIN_VSYNC);
+
+ if (read_vsync()) {
+ s_bVsyncAsserted = true;
+ } else {
+ s_bVsyncAsserted = false;
+ }
+}
+#endif
+
+//*****************************************************************************
+//
+//! @brief Write HM01B0 registers
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param ui16Reg - Register address.
+//! @param pui8Value - Pointer to the data to be written.
+//! @param ui32NumBytes - Length of the data in bytes to be written.
+//!
+//! This function writes value to HM01B0 registers.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+static uint32_t hm01b0_write_reg(hm01b0_cfg_t* psCfg, uint16_t ui16Reg,
+ uint8_t* pui8Value, uint32_t ui32NumBytes) {
+ am_hal_iom_transfer_t Transaction;
+
+ //
+ // Create the transaction.
+ //
+ Transaction.ui32InstrLen = sizeof(uint16_t);
+ Transaction.ui32Instr = (ui16Reg & 0x0000FFFF);
+ Transaction.eDirection = AM_HAL_IOM_TX;
+ Transaction.ui32NumBytes = ui32NumBytes;
+ Transaction.pui32TxBuffer = (uint32_t*)pui8Value;
+ Transaction.uPeerInfo.ui32I2CDevAddr = (uint32_t)psCfg->ui16SlvAddr;
+ Transaction.bContinue = false;
+ Transaction.ui8RepeatCount = 0;
+ Transaction.ui32PauseCondition = 0;
+ Transaction.ui32StatusSetClr = 0;
+
+ //
+ // Execute the transaction over IOM.
+ //
+ if (am_hal_iom_blocking_transfer(psCfg->pIOMHandle, &Transaction)) {
+ return HM01B0_ERR_I2C;
+ }
+
+ return HM01B0_ERR_OK;
+}
+
+//*****************************************************************************
+//
+//! @brief Read HM01B0 registers
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param ui16Reg - Register address.
+//! @param pui8Value - Pointer to the buffer for read data to be put
+//! into.
+//! @param ui32NumBytes - Length of the data to be read.
+//!
+//! This function reads value from HM01B0 registers.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+static uint32_t hm01b0_read_reg(hm01b0_cfg_t* psCfg, uint16_t ui16Reg,
+ uint8_t* pui8Value, uint32_t ui32NumBytes) {
+ am_hal_iom_transfer_t Transaction;
+
+ //
+ // Create the transaction.
+ //
+ Transaction.ui32InstrLen = sizeof(uint16_t);
+ Transaction.ui32Instr = (ui16Reg & 0x0000FFFF);
+ Transaction.eDirection = AM_HAL_IOM_RX;
+ Transaction.ui32NumBytes = ui32NumBytes;
+ Transaction.pui32RxBuffer = (uint32_t*)pui8Value;
+ ;
+ Transaction.uPeerInfo.ui32I2CDevAddr = (uint32_t)psCfg->ui16SlvAddr;
+ Transaction.bContinue = false;
+ Transaction.ui8RepeatCount = 0;
+ Transaction.ui32PauseCondition = 0;
+ Transaction.ui32StatusSetClr = 0;
+
+ //
+ // Execute the transaction over IOM.
+ //
+ if (am_hal_iom_blocking_transfer(psCfg->pIOMHandle, &Transaction)) {
+ return HM01B0_ERR_I2C;
+ }
+
+ return HM01B0_ERR_OK;
+}
+
+//*****************************************************************************
+//
+//! @brief Load HM01B0 a given script
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param psScrip - Pointer to the script to be loaded.
+//! @param ui32ScriptCmdNum - Number of entries in a given script.
+//!
+//! This function loads HM01B0 a given script.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+static uint32_t hm01b0_load_script(hm01b0_cfg_t* psCfg, hm_script_t* psScript,
+ uint32_t ui32ScriptCmdNum) {
+ uint32_t ui32Err = HM01B0_ERR_OK;
+ for (uint32_t idx = 0; idx < ui32ScriptCmdNum; idx++) {
+ ui32Err = hm01b0_write_reg(psCfg, (psScript + idx)->ui16Reg,
+ &((psScript + idx)->ui8Val), sizeof(uint8_t));
+ if (ui32Err != HM01B0_ERR_OK) {
+ break;
+ }
+ }
+
+ return ui32Err;
+}
+
+//*****************************************************************************
+//
+//! @brief Power up HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function powers up HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_power_up(hm01b0_cfg_t* psCfg) {
+ // place holder
+}
+
+//*****************************************************************************
+//
+//! @brief Power down HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function powers up HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_power_down(hm01b0_cfg_t* psCfg) {
+ // place holder
+}
+
+//*****************************************************************************
+//
+//! @brief Enable MCLK
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function utilizes CTimer to generate MCLK for HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_mclk_enable(hm01b0_cfg_t* psCfg) {
+#define MCLK_UI64PATTERN 0x55555555
+#define MCLK_UI64PATTERNLEN 31
+
+ am_hal_clkgen_control(AM_HAL_CLKGEN_CONTROL_SYSCLK_MAX, 0);
+
+ //
+ // Set up timer.
+ //
+ am_hal_ctimer_clear(psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment);
+
+ am_hal_ctimer_config_single(
+ psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment,
+ (AM_HAL_CTIMER_FN_PTN_REPEAT | AM_HAL_CTIMER_HFRC_12MHZ));
+
+ //
+ // Set the pattern in the CMPR registers.
+ //
+ am_hal_ctimer_compare_set(psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment,
+ 0, (uint32_t)(MCLK_UI64PATTERN & 0xFFFF));
+ am_hal_ctimer_compare_set(psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment,
+ 1, (uint32_t)((MCLK_UI64PATTERN >> 16) & 0xFFFF));
+
+ //
+ // Set the timer trigger and pattern length.
+ //
+ am_hal_ctimer_config_trigger(
+ psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment,
+ ((MCLK_UI64PATTERNLEN << CTIMER_AUX0_TMRA0LMT_Pos) |
+ (CTIMER_AUX0_TMRB0TRIG_DIS << CTIMER_AUX0_TMRA0TRIG_Pos)));
+
+ //
+ // Configure timer output pin.
+ //
+ am_hal_ctimer_output_config(psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment,
+ psCfg->ui32CTimerOutputPin,
+ AM_HAL_CTIMER_OUTPUT_NORMAL,
+ AM_HAL_GPIO_PIN_DRIVESTRENGTH_12MA);
+
+ //
+ // Start the timer.
+ //
+ am_hal_ctimer_start(psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment);
+}
+
+//*****************************************************************************
+//
+//! @brief Disable MCLK
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function disable CTimer to stop MCLK for HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_mclk_disable(hm01b0_cfg_t* psCfg) {
+ //
+ // Stop the timer.
+ //
+ am_hal_ctimer_stop(psCfg->ui32CTimerModule, psCfg->ui32CTimerSegment);
+ am_hal_gpio_pinconfig(psCfg->ui32CTimerOutputPin, g_AM_HAL_GPIO_DISABLE);
+}
+
+//*****************************************************************************
+//
+//! @brief Initialize interfaces
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function initializes interfaces.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_init_if(hm01b0_cfg_t* psCfg) {
+ void* pIOMHandle = NULL;
+
+ if (psCfg->ui32IOMModule > AM_REG_IOM_NUM_MODULES) {
+ return HM01B0_ERR_I2C;
+ }
+
+ //
+ // Enable fault detection.
+ //
+#if AM_APOLLO3_MCUCTRL
+ am_hal_mcuctrl_control(AM_HAL_MCUCTRL_CONTROL_FAULT_CAPTURE_ENABLE, 0);
+#else // AM_APOLLO3_MCUCTRL
+ am_hal_mcuctrl_fault_capture_enable();
+#endif // AM_APOLLO3_MCUCTRL
+
+ //
+ // Initialize the IOM instance.
+ // Enable power to the IOM instance.
+ // Configure the IOM for Serial operation during initialization.
+ // Enable the IOM.
+ //
+ if (am_hal_iom_initialize(psCfg->ui32IOMModule, &pIOMHandle) ||
+ am_hal_iom_power_ctrl(pIOMHandle, AM_HAL_SYSCTRL_WAKE, false) ||
+ am_hal_iom_configure(pIOMHandle, &(psCfg->sIOMCfg)) ||
+ am_hal_iom_enable(pIOMHandle)) {
+ return HM01B0_ERR_I2C;
+ } else {
+ //
+ // Configure the IOM pins.
+ //
+ am_bsp_iom_pins_enable(psCfg->ui32IOMModule, psCfg->eIOMMode);
+
+ psCfg->pIOMHandle = pIOMHandle;
+ }
+
+ // initialize pins for camera parallel interface.
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD0);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD1);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD2);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD3);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD4);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD5);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD6);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD7);
+
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD0);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD1);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD2);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD3);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD4);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD5);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD6);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD7);
+
+ am_hal_gpio_fast_pinconfig(
+ (uint64_t)0x1 << psCfg->ui8PinD0 | (uint64_t)0x1 << psCfg->ui8PinD1 |
+ (uint64_t)0x1 << psCfg->ui8PinD2 | (uint64_t)0x1 << psCfg->ui8PinD3 |
+ (uint64_t)0x1 << psCfg->ui8PinD4 | (uint64_t)0x1 << psCfg->ui8PinD5 |
+ (uint64_t)0x1 << psCfg->ui8PinD6 | (uint64_t)0x1 << psCfg->ui8PinD7,
+ g_AM_HAL_GPIO_INPUT, 0);
+
+ am_hal_gpio_pinconfig(psCfg->ui8PinVSYNC, g_HM01B0_pin_vsync);
+#ifdef ENABLE_ASYNC
+ psCfg->pfnGpioIsr = hm01b0_gpio_isr;
+ am_hal_gpio_interrupt_clear(AM_HAL_GPIO_BIT(psCfg->ui8PinVSYNC));
+ am_hal_gpio_interrupt_enable(AM_HAL_GPIO_BIT(psCfg->ui8PinVSYNC));
+ NVIC_EnableIRQ(GPIO_IRQn);
+#endif
+ am_hal_gpio_pinconfig(psCfg->ui8PinHSYNC, g_AM_HAL_GPIO_INPUT);
+ am_hal_gpio_pinconfig(psCfg->ui8PinPCLK, g_AM_HAL_GPIO_INPUT);
+
+ am_hal_gpio_pinconfig(psCfg->ui8PinTrig, g_AM_HAL_GPIO_OUTPUT);
+
+ am_hal_gpio_pinconfig(psCfg->ui8PinInt, g_AM_HAL_GPIO_DISABLE);
+ // am_hal_gpio_pinconfig(psCfg->ui8PinInt, g_HM01B0_pin_int);
+ // am_hal_gpio_interrupt_clear(AM_HAL_GPIO_BIT(psCfg->ui8PinInt));
+ // am_hal_gpio_interrupt_enable(AM_HAL_GPIO_BIT(psCfg->ui8PinInt));
+ // NVIC_EnableIRQ(GPIO_IRQn);
+
+ return HM01B0_ERR_OK;
+}
+
+//*****************************************************************************
+//
+//! @brief Deinitialize interfaces
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function deinitializes interfaces.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_deinit_if(hm01b0_cfg_t* psCfg) {
+ am_hal_iom_disable(psCfg->pIOMHandle);
+ am_hal_iom_uninitialize(psCfg->pIOMHandle);
+
+ am_hal_gpio_pinconfig(psCfg->ui8PinSCL, g_AM_HAL_GPIO_DISABLE);
+ am_hal_gpio_pinconfig(psCfg->ui8PinSDA, g_AM_HAL_GPIO_DISABLE);
+
+ // initialize pins for camera parallel interface.
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD0);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD1);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD2);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD3);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD4);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD5);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD6);
+ am_hal_gpio_fastgpio_disable(psCfg->ui8PinD7);
+
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD0);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD1);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD2);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD3);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD4);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD5);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD6);
+ am_hal_gpio_fastgpio_clr(psCfg->ui8PinD7);
+
+ am_hal_gpio_pinconfig(psCfg->ui8PinVSYNC, g_AM_HAL_GPIO_DISABLE);
+#ifdef ENABLE_ASYNC
+ NVIC_DisableIRQ(GPIO_IRQn);
+ am_hal_gpio_interrupt_disable(AM_HAL_GPIO_BIT(psCfg->ui8PinVSYNC));
+ am_hal_gpio_interrupt_clear(AM_HAL_GPIO_BIT(psCfg->ui8PinVSYNC));
+ psCfg->pfnGpioIsr = NULL;
+#endif
+ am_hal_gpio_pinconfig(psCfg->ui8PinHSYNC, g_AM_HAL_GPIO_DISABLE);
+ am_hal_gpio_pinconfig(psCfg->ui8PinPCLK, g_AM_HAL_GPIO_DISABLE);
+
+ am_hal_gpio_pinconfig(psCfg->ui8PinTrig, g_AM_HAL_GPIO_DISABLE);
+ am_hal_gpio_pinconfig(psCfg->ui8PinInt, g_AM_HAL_GPIO_DISABLE);
+
+ return HM01B0_ERR_OK;
+}
+
+//*****************************************************************************
+//
+//! @brief Get HM01B0 Model ID
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param pui16MID - Pointer to buffer for the read back model ID.
+//!
+//! This function reads back HM01B0 model ID.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_get_modelid(hm01b0_cfg_t* psCfg, uint16_t* pui16MID) {
+ uint8_t ui8Data[1];
+ uint32_t ui32Err;
+
+ *pui16MID = 0x0000;
+
+ ui32Err =
+ hm01b0_read_reg(psCfg, HM01B0_REG_MODEL_ID_H, ui8Data, sizeof(ui8Data));
+ if (ui32Err == HM01B0_ERR_OK) {
+ *pui16MID |= (ui8Data[0] << 8);
+ }
+
+ ui32Err =
+ hm01b0_read_reg(psCfg, HM01B0_REG_MODEL_ID_L, ui8Data, sizeof(ui8Data));
+ if (ui32Err == HM01B0_ERR_OK) {
+ *pui16MID |= ui8Data[0];
+ }
+
+ return ui32Err;
+}
+
+//*****************************************************************************
+//
+//! @brief Initialize HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param psScript - Pointer to HM01B0 initialization script.
+//! @param ui32ScriptCmdNum - No. of commands in HM01B0 initialization
+//! script.
+//!
+//! This function initializes HM01B0 with a given script.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_init_system(hm01b0_cfg_t* psCfg, hm_script_t* psScript,
+ uint32_t ui32ScriptCmdNum) {
+ return hm01b0_load_script(psCfg, psScript, ui32ScriptCmdNum);
+}
+
+//*****************************************************************************
+//
+//! @brief Set HM01B0 in the walking 1s test mode
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function sets HM01B0 in the walking 1s test mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_test_walking1s(hm01b0_cfg_t* psCfg) {
+ uint32_t ui32ScriptCmdNum =
+ sizeof(sHM01b0TestModeScript_Walking1s) / sizeof(hm_script_t);
+ hm_script_t* psScript = (hm_script_t*)sHM01b0TestModeScript_Walking1s;
+
+ return hm01b0_load_script(psCfg, psScript, ui32ScriptCmdNum);
+}
+
+//*****************************************************************************
+//
+//! @brief Software reset HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function resets HM01B0 by issuing a reset command.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_reset_sw(hm01b0_cfg_t* psCfg) {
+ uint8_t ui8Data[1] = {0x00};
+ return hm01b0_write_reg(psCfg, HM01B0_REG_SW_RESET, ui8Data, sizeof(ui8Data));
+}
+
+//*****************************************************************************
+//
+//! @brief Get current HM01B0 operation mode.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param pui8Mode - Pointer to buffer
+//! - for the read back operation mode to be put into
+//!
+//! This function get HM01B0 operation mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_get_mode(hm01b0_cfg_t* psCfg, uint8_t* pui8Mode) {
+ uint8_t ui8Data[1] = {0x01};
+ uint32_t ui32Err;
+
+ ui32Err =
+ hm01b0_read_reg(psCfg, HM01B0_REG_MODE_SELECT, ui8Data, sizeof(ui8Data));
+
+ *pui8Mode = ui8Data[0];
+
+ return ui32Err;
+}
+
+//*****************************************************************************
+//
+//! @brief Set HM01B0 operation mode.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param ui8Mode - Operation mode. One of:
+//! HM01B0_REG_MODE_SELECT_STANDBY
+//! HM01B0_REG_MODE_SELECT_STREAMING
+//! HM01B0_REG_MODE_SELECT_STREAMING_NFRAMES
+//! HM01B0_REG_MODE_SELECT_STREAMING_HW_TRIGGER
+//! @param ui8FrameCnt - Frame count for
+//! HM01B0_REG_MODE_SELECT_STREAMING_NFRAMES.
+//! - Discarded if other modes.
+//!
+//! This function set HM01B0 operation mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_set_mode(hm01b0_cfg_t* psCfg, uint8_t ui8Mode,
+ uint8_t ui8FrameCnt) {
+ uint32_t ui32Err = HM01B0_ERR_OK;
+
+ if (ui8Mode == HM01B0_REG_MODE_SELECT_STREAMING_NFRAMES) {
+ ui32Err = hm01b0_write_reg(psCfg, HM01B0_REG_PMU_PROGRAMMABLE_FRAMECNT,
+ &ui8FrameCnt, sizeof(ui8FrameCnt));
+ }
+
+ if (ui32Err == HM01B0_ERR_OK) {
+ ui32Err = hm01b0_write_reg(psCfg, HM01B0_REG_MODE_SELECT, &ui8Mode,
+ sizeof(ui8Mode));
+ }
+
+ return ui32Err;
+}
+
+//*****************************************************************************
+//
+//! @brief Hardware trigger HM01B0 to stream.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param bTrigger - True to start streaming
+//! - False to stop streaming
+//!
+//! This function triggers HM01B0 to stream by toggling the TRIG pin.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_hardware_trigger_streaming(hm01b0_cfg_t* psCfg, bool bTrigger) {
+ uint32_t ui32Err = HM01B0_ERR_OK;
+ uint8_t ui8Mode;
+
+ ui32Err = hm01b0_get_mode(psCfg, &ui8Mode);
+
+ if (ui32Err != HM01B0_ERR_OK) goto end;
+
+ if (ui8Mode != HM01B0_REG_MODE_SELECT_STREAMING_HW_TRIGGER) {
+ ui32Err = HM01B0_ERR_MODE;
+ goto end;
+ }
+
+ if (bTrigger) {
+ am_hal_gpio_output_set(psCfg->ui8PinTrig);
+ } else {
+ am_hal_gpio_output_clear(psCfg->ui8PinTrig);
+ }
+
+end:
+ return ui32Err;
+}
+
+//*****************************************************************************
+//
+//! @brief Set HM01B0 mirror mode.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param bHmirror - Horizontal mirror
+//! @param bVmirror - Vertical mirror
+//!
+//! This function set HM01B0 mirror mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_set_mirror(hm01b0_cfg_t* psCfg, bool bHmirror, bool bVmirror) {
+ uint8_t ui8Data = 0x00;
+ uint32_t ui32Err = HM01B0_ERR_OK;
+
+ if (bHmirror) {
+ ui8Data |= HM01B0_REG_IMAGE_ORIENTATION_HMIRROR;
+ }
+
+ if (bVmirror) {
+ ui8Data |= HM01B0_REG_IMAGE_ORIENTATION_VMIRROR;
+ }
+
+ ui32Err = hm01b0_write_reg(psCfg, HM01B0_REG_IMAGE_ORIENTATION, &ui8Data,
+ sizeof(ui8Data));
+
+ if (ui32Err == HM01B0_ERR_OK) {
+ ui8Data = HM01B0_REG_GRP_PARAM_HOLD_HOLD;
+ ui32Err = hm01b0_write_reg(psCfg, HM01B0_REG_GRP_PARAM_HOLD, &ui8Data,
+ sizeof(ui8Data));
+ }
+
+ return ui32Err;
+}
+
+//*****************************************************************************
+//
+//! @brief Read data of one frame from HM01B0.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param pui8Buffer - Pointer to the frame buffer.
+//! @param ui32BufferLen - Framebuffer size.
+//!
+//! This function read data of one frame from HM01B0.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_blocking_read_oneframe(hm01b0_cfg_t* psCfg, uint8_t* pui8Buffer,
+ uint32_t ui32BufferLen) {
+ uint32_t ui32Err = HM01B0_ERR_OK;
+ uint32_t ui32Idx = 0x00;
+
+ am_util_stdio_printf("[%s] +\n", __func__);
+#ifdef ENABLE_ASYNC
+ while (!s_bVsyncAsserted)
+ ;
+
+ while (s_bVsyncAsserted) {
+ // we don't check HSYNC here on the basis of assuming HM01B0 in the gated
+ // PCLK mode which PCLK toggles only when HSYNC is asserted. And also to
+ // minimize the overhead of polling.
+
+ if (read_pclk()) {
+ *(pui8Buffer + ui32Idx++) = read_byte();
+
+ if (ui32Idx == ui32BufferLen) {
+ goto end;
+ }
+
+ while (read_pclk())
+ ;
+ }
+ }
+#else
+ uint32_t ui32HsyncCnt = 0x00;
+
+ while ((ui32HsyncCnt < HM01B0_PIXEL_Y_NUM)) {
+ while (0x00 == read_hsync())
+ ;
+
+ // read one row
+ while (read_hsync()) {
+ while (0x00 == read_pclk())
+ ;
+
+ *(pui8Buffer + ui32Idx++) = read_byte();
+
+ if (ui32Idx == ui32BufferLen) {
+ goto end;
+ }
+
+ while (read_pclk())
+ ;
+ }
+
+ ui32HsyncCnt++;
+ }
+#endif
+end:
+ am_util_stdio_printf("[%s] - Byte Counts %d\n", __func__, ui32Idx);
+ return ui32Err;
+}
+
+uint32_t hm01b0_single_frame_capture(hm01b0_cfg_t* psCfg) {
+ hm01b0_write_reg(psCfg, HM01B0_REG_PMU_PROGRAMMABLE_FRAMECNT, 0x01, 1);
+ hm01b0_write_reg(psCfg, HM01B0_REG_MODE_SELECT,
+ HM01B0_REG_MODE_SELECT_STREAMING_NFRAMES, 1);
+ hm01b0_write_reg(psCfg, HM01B0_REG_GRP_PARAM_HOLD, 0x01, 1);
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.h b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.h
new file mode 100644
index 0000000..8984d65
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.h
@@ -0,0 +1,413 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_H_
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+#ifndef ARDUINO_EXCLUDE_CODE
+#include "am_bsp.h" // NOLINT
+#include "am_mcu_apollo.h" // NOLINT
+#include "am_util.h" // NOLINT
+#endif // ARDUINO_EXCLUDE_CODE
+
+#if defined(ARDUINO)
+#include "tensorflow/lite/micro/examples/person_detection/arduino/HM01B0_platform.h"
+#endif // defined(ARDUINO)
+
+#define HM01B0_DRV_VERSION (0)
+#define HM01B0_DRV_SUBVERSION (3)
+
+#define HM01B0_DEFAULT_ADDRESS (0x24)
+
+#define HM01B0_PIXEL_X_NUM (324)
+#define HM01B0_PIXEL_Y_NUM (244)
+
+#define HM01B0_REG_MODEL_ID_H (0x0000)
+#define HM01B0_REG_MODEL_ID_L (0x0001)
+#define HM01B0_REG_SILICON_REV (0x0002)
+#define HM01B0_REG_FRAME_COUNT (0x0005)
+#define HM01B0_REG_PIXEL_ORDER (0x0006)
+
+#define HM01B0_REG_MODE_SELECT (0x0100)
+#define HM01B0_REG_IMAGE_ORIENTATION (0x0101)
+#define HM01B0_REG_SW_RESET (0x0103)
+#define HM01B0_REG_GRP_PARAM_HOLD (0x0104)
+
+#define HM01B0_REG_I2C_ID_SEL (0x3400)
+#define HM01B0_REG_I2C_ID_REG (0x3401)
+
+#define HM01B0_REG_PMU_PROGRAMMABLE_FRAMECNT (0x3020)
+
+// #define HM01B0_REG_MODE_SELECT (0x0100)
+#define HM01B0_REG_MODE_SELECT_STANDBY (0x00)
+#define HM01B0_REG_MODE_SELECT_STREAMING (0x01)
+#define HM01B0_REG_MODE_SELECT_STREAMING_NFRAMES (0x03)
+#define HM01B0_REG_MODE_SELECT_STREAMING_HW_TRIGGER (0x05)
+
+// #define HM01B0_REG_IMAGE_ORIENTATION (0x0101)
+#define HM01B0_REG_IMAGE_ORIENTATION_DEFAULT (0x00)
+#define HM01B0_REG_IMAGE_ORIENTATION_HMIRROR (0x01)
+#define HM01B0_REG_IMAGE_ORIENTATION_VMIRROR (0x02)
+#define HM01B0_REG_IMAGE_ORIENTATION_HVMIRROR \
+ (HM01B0_REG_IMAGE_ORIENTATION_HMIRROR | HM01B0_REG_IMAGE_ORIENTATION_HVMIRROR)
+
+// #define HM01B0_REG_GRP_PARAM_HOLD (0x0104)
+#define HM01B0_REG_GRP_PARAM_HOLD_CONSUME (0x00)
+#define HM01B0_REG_GRP_PARAM_HOLD_HOLD (0x01)
+
+// Helpers for reading raw values from the camera.
+#define read_vsync() \
+ (AM_REGVAL(AM_REGADDR(GPIO, RDA)) & (1 << HM01B0_PIN_VSYNC))
+#define read_hsync() \
+ (AM_REGVAL(AM_REGADDR(GPIO, RDA)) & (1 << HM01B0_PIN_HSYNC))
+#define read_pclk() (AM_REGVAL(AM_REGADDR(GPIO, RDA)) & (1 << HM01B0_PIN_PCLK))
+#define read_byte() (APBDMA->BBINPUT)
+
+enum {
+ HM01B0_ERR_OK = 0x00,
+ HM01B0_ERR_I2C,
+ HM01B0_ERR_MODE,
+};
+
+typedef struct {
+ uint16_t ui16Reg;
+ uint8_t ui8Val;
+} hm_script_t;
+
+typedef struct {
+ uint16_t ui16SlvAddr;
+ am_hal_iom_mode_e eIOMMode;
+ uint32_t ui32IOMModule;
+ am_hal_iom_config_t sIOMCfg;
+ void* pIOMHandle;
+
+ uint32_t ui32CTimerModule;
+ uint32_t ui32CTimerSegment;
+ uint32_t ui32CTimerOutputPin;
+
+ uint8_t ui8PinSCL;
+ uint8_t ui8PinSDA;
+ uint8_t ui8PinD0;
+ uint8_t ui8PinD1;
+ uint8_t ui8PinD2;
+ uint8_t ui8PinD3;
+ uint8_t ui8PinD4;
+ uint8_t ui8PinD5;
+ uint8_t ui8PinD6;
+ uint8_t ui8PinD7;
+ uint8_t ui8PinVSYNC;
+ uint8_t ui8PinHSYNC;
+ uint8_t ui8PinPCLK;
+
+ uint8_t ui8PinTrig;
+ uint8_t ui8PinInt;
+ void (*pfnGpioIsr)(void);
+} hm01b0_cfg_t;
+
+//*****************************************************************************
+//
+//! @brief Write HM01B0 registers
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param ui16Reg - Register address.
+//! @param pui8Value - Pointer to the data to be written.
+//! @param ui32NumBytes - Length of the data in bytes to be written.
+//!
+//! This function writes value to HM01B0 registers.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+static uint32_t hm01b0_write_reg(hm01b0_cfg_t* psCfg, uint16_t ui16Reg,
+ uint8_t* pui8Value, uint32_t ui32NumBytes);
+
+//*****************************************************************************
+//
+//! @brief Read HM01B0 registers
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param ui16Reg - Register address.
+//! @param pui8Value - Pointer to the buffer for read data to be put
+//! into.
+//! @param ui32NumBytes - Length of the data to be read.
+//!
+//! This function reads value from HM01B0 registers.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+static uint32_t hm01b0_read_reg(hm01b0_cfg_t* psCfg, uint16_t ui16Reg,
+ uint8_t* pui8Value, uint32_t ui32NumBytes);
+
+//*****************************************************************************
+//
+//! @brief Load HM01B0 a given script
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param psScrip - Pointer to the script to be loaded.
+//! @param ui32ScriptCmdNum - Number of entries in a given script.
+//!
+//! This function loads HM01B0 a given script.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+static uint32_t hm01b0_load_script(hm01b0_cfg_t* psCfg, hm_script_t* psScript,
+ uint32_t ui32ScriptCmdNum);
+
+//*****************************************************************************
+//
+//! @brief Power up HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function powers up HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_power_up(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Power down HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function powers up HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_power_down(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Enable MCLK
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function utilizes CTimer to generate MCLK for HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_mclk_enable(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Disable MCLK
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function disable CTimer to stop MCLK for HM01B0.
+//!
+//! @return none.
+//
+//*****************************************************************************
+void hm01b0_mclk_disable(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Initialize interfaces
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function initializes interfaces.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_init_if(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Deinitialize interfaces
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function deinitializes interfaces.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_deinit_if(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Get HM01B0 Model ID
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param pui16MID - Pointer to buffer for the read back model ID.
+//!
+//! This function reads back HM01B0 model ID.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_get_modelid(hm01b0_cfg_t* psCfg, uint16_t* pui16MID);
+
+//*****************************************************************************
+//
+//! @brief Initialize HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param psScript - Pointer to HM01B0 initialization script.
+//! @param ui32ScriptCmdNum - No. of commands in HM01B0 initialization
+//! script.
+//!
+//! This function initializes HM01B0 with a given script.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_init_system(hm01b0_cfg_t* psCfg, hm_script_t* psScript,
+ uint32_t ui32ScriptCmdNum);
+
+//*****************************************************************************
+//
+//! @brief Set HM01B0 in the walking 1s test mode
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function sets HM01B0 in the walking 1s test mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_test_walking1s(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Software reset HM01B0
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function resets HM01B0 by issuing a reset command.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_reset_sw(hm01b0_cfg_t* psCfg);
+
+//*****************************************************************************
+//
+//! @brief Get current HM01B0 operation mode.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param pui8Mode - Pointer to buffer
+//! - for the read back operation mode to be put into
+//!
+//! This function get HM01B0 operation mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_get_mode(hm01b0_cfg_t* psCfg, uint8_t* pui8Mode);
+
+//*****************************************************************************
+//
+//! @brief Set HM01B0 operation mode.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param ui8Mode - Operation mode. One of:
+//! HM01B0_REG_MODE_SELECT_STANDBY
+//! HM01B0_REG_MODE_SELECT_STREAMING
+//! HM01B0_REG_MODE_SELECT_STREAMING_NFRAMES
+//! HM01B0_REG_MODE_SELECT_STREAMING_HW_TRIGGER
+//! @param framecnt - Frame count for
+//! HM01B0_REG_MODE_SELECT_STREAMING_NFRAMES.
+//! - Discarded if other modes.
+//!
+//! This function set HM01B0 operation mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_set_mode(hm01b0_cfg_t* psCfg, uint8_t ui8Mode,
+ uint8_t framecnt);
+
+//*****************************************************************************
+//
+//! @brief Hardware trigger HM01B0 to stream.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param bTrigger - True to start streaming
+//! - False to stop streaming
+//!
+//! This function triggers HM01B0 to stream by toggling the TRIG pin.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_hardware_trigger_streaming(hm01b0_cfg_t* psCfg, bool bTrigger);
+
+//*****************************************************************************
+//
+//! @brief Set HM01B0 mirror mode.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param bHmirror - Horizontal mirror
+//! @param bVmirror - Vertical mirror
+//!
+//! This function set HM01B0 mirror mode.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_set_mirror(hm01b0_cfg_t* psCfg, bool bHmirror, bool bVmirror);
+
+//*****************************************************************************
+//
+//! @brief Read data of one frame from HM01B0.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//! @param pui8Buffer - Pointer to the frame buffer.
+//! @param ui32BufferLen - Framebuffer size.
+//!
+//! This function read data of one frame from HM01B0.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_blocking_read_oneframe(hm01b0_cfg_t* psCfg, uint8_t* pui8Buffer,
+ uint32_t ui32BufferLen);
+
+//*****************************************************************************
+//
+//! @brief Read data of one frame from HM01B0.
+//!
+//! @param psCfg - Pointer to HM01B0 configuration structure.
+//!
+//! This function wakes up the camera and captures a single frame.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_single_frame_capture(hm01b0_cfg_t* psCfg);
+
+#ifdef __cplusplus
+}
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_RAW8_QVGA_8bits_lsb_5fps.h b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_RAW8_QVGA_8bits_lsb_5fps.h
new file mode 100644
index 0000000..32897ca
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_RAW8_QVGA_8bits_lsb_5fps.h
@@ -0,0 +1,510 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_RAW8_QVGA_8BITS_LSB_5FPS_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_RAW8_QVGA_8BITS_LSB_5FPS_H_
+
+#include "HM01B0.h"
+
+const hm_script_t sHM01B0InitScript[] = {
+ // ;*************************************************************************
+ // ; Sensor: HM01B0
+ // ; I2C ID: 24
+ // ; Resolution: 324x244
+ // ; Lens:
+ // ; Flicker:
+ // ; Frequency:
+ // ; Description: AE control enable
+ // ; 8-bit mode, LSB first
+ // ;
+ // ;
+ // ; Note:
+ // ;
+ // ; $Revision: 1338 $
+ // ; $Date:: 2017-04-11 15:43:45 +0800#$
+ // ;*************************************************************************
+ //
+ // // ---------------------------------------------------
+ // // HUB system initial
+ // // ---------------------------------------------------
+ // W 20 8A04 01 2 1
+ // W 20 8A00 22 2 1
+ // W 20 8A01 00 2 1
+ // W 20 8A02 01 2 1
+ // W 20 0035 93 2 1 ; [3]&[1] hub616 20bits in, [5:4]=1 mclk=48/2=24mhz
+ // W 20 0036 00 2 1
+ // W 20 0011 09 2 1
+ // W 20 0012 B6 2 1
+ // W 20 0014 08 2 1
+ // W 20 0015 98 2 1
+ // ;W 20 0130 16 2 1 ; 3m soc, signal buffer control
+ // ;W 20 0100 44 2 1 ; [6] hub616 20bits in
+ // W 20 0100 04 2 1 ; [6] hub616 20bits in
+ // W 20 0121 01 2 1 ; [0] Q1 Intf enable, [1]:4bit mode, [2] msb first, [3]
+ // serial mode
+ // W 20 0150 00 2 1 ;
+ // W 20 0150 04 2 1 ;
+ //
+ //
+ // //---------------------------------------------------
+ // // Initial
+ // //---------------------------------------------------
+ // W 24 0103 00 2 1 ; software reset-> was 0x22
+ {
+ 0x0103,
+ 0x00,
+ },
+ // W 24 0100 00 2 1; power up
+ {
+ 0x0100,
+ 0x00,
+ },
+ //
+ //
+ //
+ // //---------------------------------------------------
+ // // Analog
+ // //---------------------------------------------------
+ // L HM01B0_analog_setting.txt
+ {
+ 0x1003,
+ 0x08,
+ },
+ {
+ 0x1007,
+ 0x08,
+ },
+ {
+ 0x3044,
+ 0x0A,
+ },
+ {
+ 0x3045,
+ 0x00,
+ },
+ {
+ 0x3047,
+ 0x0A,
+ },
+ {
+ 0x3050,
+ 0xC0,
+ },
+ {
+ 0x3051,
+ 0x42,
+ },
+ {
+ 0x3052,
+ 0x50,
+ },
+ {
+ 0x3053,
+ 0x00,
+ },
+ {
+ 0x3054,
+ 0x03,
+ },
+ {
+ 0x3055,
+ 0xF7,
+ },
+ {
+ 0x3056,
+ 0xF8,
+ },
+ {
+ 0x3057,
+ 0x29,
+ },
+ {
+ 0x3058,
+ 0x1F,
+ },
+ {
+ 0x3059,
+ 0x1E,
+ },
+ {
+ 0x3064,
+ 0x00,
+ },
+ {
+ 0x3065,
+ 0x04,
+ },
+ //
+ //
+ // //---------------------------------------------------
+ // // Digital function
+ // //---------------------------------------------------
+ //
+ // // BLC
+ // W 24 1000 43 2 1 ; BLC_on, IIR
+ {
+ 0x1000,
+ 0x43,
+ },
+ // W 24 1001 40 2 1 ; [6] : BLC dithering en
+ {
+ 0x1001,
+ 0x40,
+ },
+ // W 24 1002 32 2 1 ; // blc_darkpixel_thd
+ {
+ 0x1002,
+ 0x32,
+ },
+ //
+ // // Dgain
+ // W 24 0350 7F 2 1 ; Dgain Control
+ {
+ 0x0350,
+ 0x7F,
+ },
+ //
+ // // BLI
+ // W 24 1006 01 2 1 ; [0] : bli enable
+ {
+ 0x1006,
+ 0x01,
+ },
+ //
+ // // DPC
+ // W 24 1008 00 2 1 ; [2:0] : DPC option 0: DPC off 1 : mono 3 : bayer1 5 :
+ // bayer2
+ {
+ 0x1008,
+ 0x00,
+ },
+ // W 24 1009 A0 2 1 ; cluster hot pixel th
+ {
+ 0x1009,
+ 0xA0,
+ },
+ // W 24 100A 60 2 1 ; cluster cold pixel th
+ {
+ 0x100A,
+ 0x60,
+ },
+ // W 24 100B 90 2 1 ; single hot pixel th
+ {
+ 0x100B,
+ 0x90,
+ },
+ // W 24 100C 40 2 1 ; single cold pixel th
+ {
+ 0x100C,
+ 0x40,
+ },
+ // //
+ // advance VSYNC by 1 row
+ {
+ 0x3022,
+ 0x01,
+ },
+ // W 24 1012 00 2 1 ; Sync. enable VSYNC shift
+ {
+ 0x1012,
+ 0x01,
+ },
+
+ //
+ // // ROI Statistic
+ // W 24 2000 07 2 1 ; [0] : AE stat en [1] : MD LROI stat en [2] : MD GROI
+ // stat en [3] : RGB stat ratio en [4] : IIR selection (1 -> 16, 0 -> 8)
+ {
+ 0x2000,
+ 0x07,
+ },
+ // W 24 2003 00 2 1 ; MD GROI 0 y start HB
+ {
+ 0x2003,
+ 0x00,
+ },
+ // W 24 2004 1C 2 1 ; MD GROI 0 y start LB
+ {
+ 0x2004,
+ 0x1C,
+ },
+ // W 24 2007 00 2 1 ; MD GROI 1 y start HB
+ {
+ 0x2007,
+ 0x00,
+ },
+ // W 24 2008 58 2 1 ; MD GROI 1 y start LB
+ {
+ 0x2008,
+ 0x58,
+ },
+ // W 24 200B 00 2 1 ; MD GROI 2 y start HB
+ {
+ 0x200B,
+ 0x00,
+ },
+ // W 24 200C 7A 2 1 ; MD GROI 2 y start LB
+ {
+ 0x200C,
+ 0x7A,
+ },
+ // W 24 200F 00 2 1 ; MD GROI 3 y start HB
+ {
+ 0x200F,
+ 0x00,
+ },
+ // W 24 2010 B8 2 1 ; MD GROI 3 y start LB
+ {
+ 0x2010,
+ 0xB8,
+ },
+ //
+ // W 24 2013 00 2 1 ; MD LRIO y start HB
+ {
+ 0x2013,
+ 0x00,
+ },
+ // W 24 2014 58 2 1 ; MD LROI y start LB
+ {
+ 0x2014,
+ 0x58,
+ },
+ // W 24 2017 00 2 1 ; MD LROI y end HB
+ {
+ 0x2017,
+ 0x00,
+ },
+ // W 24 2018 9B 2 1 ; MD LROI y end LB
+ {
+ 0x2018,
+ 0x9B,
+ },
+ //
+ // // AE
+ // W 24 2100 01 2 1 ; [0]: AE control enable
+ {
+ 0x2100,
+ 0x01,
+ },
+ // W 24 2101 07 2 1 ; AE target mean
+ {
+ 0x2101,
+ 0x5F,
+ },
+ // W 24 2102 0A 2 1 ; AE min mean
+ {
+ 0x2102,
+ 0x0A,
+ },
+ // W 24 2104 03 2 1 ; AE Threshold
+ {
+ 0x2103,
+ 0x03,
+ },
+ // W 24 2104 05 2 1 ; AE Threshold
+ {
+ 0x2104,
+ 0x05,
+ },
+ // W 24 2105 01 2 1 ; max INTG Hb
+ {
+ 0x2105,
+ 0x02,
+ },
+ // W 24 2106 54 2 1 ; max INTG Lb
+ {
+ 0x2106,
+ 0x14,
+ },
+ // W 24 2108 02 2 1 ; max AGain in full
+ {
+ 0x2107,
+ 0x02,
+ },
+ // W 24 2108 03 2 1 ; max AGain in full
+ {
+ 0x2108,
+ 0x03,
+ },
+ // W 24 2109 04 2 1 ; max AGain in bin2
+ {
+ 0x2109,
+ 0x03,
+ },
+ // W 24 210A 00 2 1 ; min AGAIN
+ {
+ 0x210A,
+ 0x00,
+ },
+ // W 24 210B C0 2 1 ; max DGain
+ {
+ 0x210B,
+ 0x80,
+ },
+ // W 24 210C 40 2 1 ; min DGain
+ {
+ 0x210C,
+ 0x40,
+ },
+ // W 24 210D 20 2 1 ; damping factor
+ {
+ 0x210D,
+ 0x20,
+ },
+ // W 24 210E 03 2 1 ; FS ctrl
+ {
+ 0x210E,
+ 0x03,
+ },
+ // W 24 210F 00 2 1 ; FS 60Hz Hb
+ {
+ 0x210F,
+ 0x00,
+ },
+ // W 24 2110 85 2 1 ; FS 60Hz Lb
+ {
+ 0x2110,
+ 0x85,
+ },
+ // W 24 2111 00 2 1 ; Fs 50Hz Hb
+ {
+ 0x2111,
+ 0x00,
+ },
+ // W 24 2112 A0 2 1 ; FS 50Hz Lb
+ {
+ 0x2112,
+ 0xA0,
+ },
+
+ //
+ //
+ // // MD
+ // W 24 2150 03 2 1 ; [0] : MD LROI en [1] : MD GROI en
+ {
+ 0x2150,
+ 0x03,
+ },
+ //
+ //
+ // //---------------------------------------------------
+ // // frame rate : 5 FPS
+ // //---------------------------------------------------
+ // W 24 0340 0C 2 1 ; smia frame length Hb
+ {
+ 0x0340,
+ 0x0C,
+ },
+ // W 24 0341 7A 2 1 ; smia frame length Lb 3192
+ {
+ 0x0341,
+ 0x7A,
+ },
+ //
+ // W 24 0342 01 2 1 ; smia line length Hb
+ {
+ 0x0342,
+ 0x01,
+ },
+ // W 24 0343 77 2 1 ; smia line length Lb 375
+ {
+ 0x0343,
+ 0x77,
+ },
+ //
+ // //---------------------------------------------------
+ // // Resolution : QVGA 324x244
+ // //---------------------------------------------------
+ // W 24 3010 01 2 1 ; [0] : window mode 0 : full frame 324x324 1 : QVGA
+ {
+ 0x3010,
+ 0x01,
+ },
+ //
+ //
+ // W 24 0383 01 2 1 ;
+ {
+ 0x0383,
+ 0x01,
+ },
+ // W 24 0387 01 2 1 ;
+ {
+ 0x0387,
+ 0x01,
+ },
+ // W 24 0390 00 2 1 ;
+ {
+ 0x0390,
+ 0x00,
+ },
+ //
+ // //---------------------------------------------------
+ // // bit width Selection
+ // //---------------------------------------------------
+ // W 24 3011 70 2 1 ; [0] : 6 bit mode enable
+ {
+ 0x3011,
+ 0x70,
+ },
+ //
+ //
+ // W 24 3059 02 2 1 ; [7]: Self OSC En, [6]: 4bit mode, [5]: serial mode,
+ // [4:0]: keep value as 0x02
+ {
+ 0x3059,
+ 0x02,
+ },
+ // W 24 3060 01 2 1 ; [5]: gated_clock, [4]: msb first,
+ {
+ 0x3060,
+ 0x20,
+ },
+ // ; [3:2]: vt_reg_div -> div by 4/8/1/2
+ // ; [1;0]: vt_sys_div -> div by 8/4/2/1
+ //
+ //
+ {
+ 0x0101,
+ 0x01,
+ },
+ // //---------------------------------------------------
+ // // CMU update
+ // //---------------------------------------------------
+ //
+ // W 24 0104 01 2 1 ; was 0100
+ {
+ 0x0104,
+ 0x01,
+ },
+ //
+ //
+ //
+ // //---------------------------------------------------
+ // // Turn on rolling shutter
+ // //---------------------------------------------------
+ // W 24 0100 01 2 1 ; was 0005 ; mode_select 00 : standby - wait fir I2C SW
+ // trigger 01 : streaming 03 : output "N" frame, then enter standby 04 :
+ // standby - wait for HW trigger (level), then continuous video out til HW
+ // TRIG goes off 06 : standby - wait for HW trigger (edge), then output "N"
+ // frames then enter standby
+ {
+ 0x0100,
+ 0x01,
+ },
+ //
+ // ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
+};
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_RAW8_QVGA_8BITS_LSB_5FPS_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.h b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.h
new file mode 100644
index 0000000..712b232
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.h
@@ -0,0 +1,56 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_WALKING1S_01_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_WALKING1S_01_H_
+
+#include "HM01B0.h"
+
+const hm_script_t sHM01b0TestModeScript_Walking1s[] = {
+ {
+ 0x2100,
+ 0x00,
+ }, // W 24 2100 00 2 1 ; AE
+ {
+ 0x1000,
+ 0x00,
+ }, // W 24 1000 00 2 1 ; BLC
+ {
+ 0x1008,
+ 0x00,
+ }, // W 24 1008 00 2 1 ; DPC
+ {
+ 0x0205,
+ 0x00,
+ }, // W 24 0205 00 2 1 ; AGain
+ {
+ 0x020E,
+ 0x01,
+ }, // W 24 020E 01 2 1 ; DGain
+ {
+ 0x020F,
+ 0x00,
+ }, // W 24 020F 00 2 1 ; DGain
+ {
+ 0x0601,
+ 0x11,
+ }, // W 24 0601 11 2 1 ; Test pattern
+ {
+ 0x0104,
+ 0x01,
+ }, // W 24 0104 01 2 1 ;
+};
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_WALKING1S_01_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.txt b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.txt
new file mode 100644
index 0000000..1244cad
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.txt
@@ -0,0 +1,8 @@
+W 24 2100 00 2 1 ; AE
+W 24 1000 00 2 1 ; BLC
+W 24 1008 00 2 1 ; DPC
+W 24 0205 00 2 1 ; AGain
+W 24 020E 01 2 1 ; DGain
+W 24 020F 00 2 1 ; DGain
+W 24 0601 11 2 1 ; Test pattern
+W 24 0104 01 2 1 ;
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.c b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.c
new file mode 100644
index 0000000..9e83315
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.c
@@ -0,0 +1,43 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "HM01B0_debug.h"
+
+#include "am_util.h" // NOLINT
+
+void hm01b0_framebuffer_dump(uint8_t* frame, uint32_t length) {
+ am_util_stdio_printf("+++ frame +++");
+
+ for (uint32_t i = 0; i < length; i++) {
+ if ((i & 0xF) == 0x00) {
+ am_util_stdio_printf("\n0x%08LX ", i);
+ // this delay is to let itm have time to flush out data.
+ am_util_delay_ms(1);
+ }
+
+ am_util_stdio_printf("%02X ", frame[i]);
+ }
+
+ am_util_stdio_printf("\n--- frame ---\n");
+ am_util_delay_ms(1);
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.h b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.h
new file mode 100644
index 0000000..61b3699
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.h
@@ -0,0 +1,49 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_DEBUG_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_DEBUG_H_
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+#include "HM01B0.h"
+
+//*****************************************************************************
+//
+//! @brief Read one frame of data from HM01B0 scaled to 96x96 RGB.
+//!
+//! @param buffer - Pointer to the frame buffer.
+//! @param w - Image width.
+//! @param h - Image height.
+//! @param channels - Number of channels per pixel.
+//!
+//! This function reads data of one frame from HM01B0. It trims the image to an
+//! even power of two multiple of the requested width and height. It down
+//! samples the original image and duplicates the greyscale value for each color
+//! channel.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+
+void hm01b0_framebuffer_dump(uint8_t* frame, uint32_t len);
+
+#ifdef __cplusplus
+}
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_DEBUG_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.c b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.c
new file mode 100644
index 0000000..e60d874
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.c
@@ -0,0 +1,98 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "HM01B0.h"
+#include "am_bsp.h" //NOLINT
+#include "am_mcu_apollo.h" //NOLINT
+#include "platform.h" // TARGET specific implementation
+
+// Image is down-sampled by applying a stride of 2 pixels in both the x and y
+// directions.
+static const int kStrideShift = 1;
+
+//*****************************************************************************
+//
+//! @brief Read one frame of data from HM01B0 scaled to 96x96 RGB.
+//!
+//! @param buffer - Pointer to the frame buffer.
+//! @param w - Image width.
+//! @param h - Image height.
+//! @param channels - Number of channels per pixel.
+//!
+//! This function reads data of one frame from HM01B0. It trims the image to an
+//! even power of two mulitple of the requested width and height. It down
+//! samples the original image and duplicates the greyscale value for each color
+//! channel.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_blocking_read_oneframe_scaled(hm01b0_cfg_t* psCfg,
+ int8_t* buffer, int w, int h,
+ int channels) {
+ hm01b0_single_frame_capture(psCfg);
+
+ // Calculate the number of pixels to crop to get a centered image.
+ const int offset_x = (HM01B0_PIXEL_X_NUM - (w * (1 << kStrideShift))) / 2;
+ const int offset_y = (HM01B0_PIXEL_Y_NUM - (h * (1 << kStrideShift))) / 2;
+
+ uint32_t hsync_count = 0;
+
+ while ((hsync_count < HM01B0_PIXEL_Y_NUM)) {
+ // Wait for horizontal sync.
+ while (!read_hsync())
+ ;
+
+ // Get resulting image position. When hsync_count < offset_y, this will
+ // underflow resulting in an index out of bounds which we check later,
+ // avoiding an unnecessary conditional.
+ const uint32_t output_y = (hsync_count - offset_y) >> kStrideShift;
+ uint32_t rowidx = 0;
+
+ // Read one row. Hsync is held high for the duration of a row read.
+ while (read_hsync()) {
+ // Wait for pixel value to be ready.
+ while (!read_pclk())
+ ;
+
+ // Read 8-bit value from camera.
+ const uint8_t value = read_byte();
+ const uint32_t output_x = (rowidx++ - offset_x) >> kStrideShift;
+ if (output_x < w && output_y < h) {
+ const int output_idx = (output_y * w + output_x) * channels;
+ for (int i = 0; i < channels; i++) {
+ // See the top of main_functions.cc for an explanation of and
+ // rationale for our unsigned to signed input conversion.
+ buffer[output_idx + i] = value - 128;
+ }
+ }
+
+ // Wait for next pixel clock.
+ while (read_pclk())
+ ;
+ }
+
+ hsync_count++;
+ }
+ return HM01B0_ERR_OK;
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.h b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.h
new file mode 100644
index 0000000..d40d4e6
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.h
@@ -0,0 +1,50 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_OPTIMIZED_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_OPTIMIZED_H_
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+#include "HM01B0.h"
+
+//*****************************************************************************
+//
+//! @brief Read one frame of data from HM01B0 scaled to 96x96 RGB.
+//!
+//! @param buffer - Pointer to the frame buffer.
+//! @param w - Image width.
+//! @param h - Image height.
+//! @param channels - Number of channels per pixel.
+//!
+//! This function reads data of one frame from HM01B0. It trims the image to an
+//! even power of two multiple of the requested width and height. It down
+//! samples the original image and duplicates the greyscale value for each color
+//! channel.
+//!
+//! @return Error code.
+//
+//*****************************************************************************
+uint32_t hm01b0_blocking_read_oneframe_scaled(hm01b0_cfg_t* psCfg,
+ int8_t* buffer, int w, int h,
+ int channels);
+
+#ifdef __cplusplus
+}
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_HIMAX_DRIVER_HM01B0_OPTIMIZED_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_driver/Makefile.inc b/tensorflow/lite/micro/examples/person_detection/himax_driver/Makefile.inc
new file mode 100644
index 0000000..43ebaf4
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_driver/Makefile.inc
@@ -0,0 +1,13 @@
+ifeq ($(TARGET),$(filter $(TARGET),apollo3evb sparkfun_edge))
+ person_detection_SRCS += \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.c \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.c \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.c
+
+ person_detection_HDRS += \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_RAW8_QVGA_8bits_lsb_5fps.h \
+ tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_Walking1s_01.h
+endif
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_we1_evb/detection_responder.cc b/tensorflow/lite/micro/examples/person_detection/himax_we1_evb/detection_responder.cc
new file mode 100644
index 0000000..707a2b9
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_we1_evb/detection_responder.cc
@@ -0,0 +1,41 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/person_detection/detection_responder.h"
+
+#include "hx_drv_tflm.h" // NOLINT
+
+// This dummy implementation writes person and no person scores to the error
+// console. Real applications will want to take some custom action instead, and
+// should implement their own versions of this function.
+void RespondToDetection(tflite::ErrorReporter* error_reporter,
+ int8_t person_score, int8_t no_person_score) {
+ if (person_score > no_person_score) {
+ hx_drv_led_on(HX_DRV_LED_GREEN);
+ } else {
+ hx_drv_led_off(HX_DRV_LED_GREEN);
+ }
+
+ TF_LITE_REPORT_ERROR(error_reporter, "person score:%d no person score %d",
+ person_score, no_person_score);
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/himax_we1_evb/image_provider.cc b/tensorflow/lite/micro/examples/person_detection/himax_we1_evb/image_provider.cc
new file mode 100644
index 0000000..55cb651
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/himax_we1_evb/image_provider.cc
@@ -0,0 +1,49 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+
+#include "hx_drv_tflm.h" // NOLINT
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+
+hx_drv_sensor_image_config_t g_pimg_config;
+
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int image_width,
+ int image_height, int channels, int8_t* image_data) {
+ static bool is_initialized = false;
+
+ if (!is_initialized) {
+ if (hx_drv_sensor_initial(&g_pimg_config) != HX_DRV_LIB_PASS) {
+ return kTfLiteError;
+ }
+ is_initialized = true;
+ }
+
+ hx_drv_sensor_capture(&g_pimg_config);
+
+ hx_drv_image_rescale((uint8_t*)g_pimg_config.raw_address,
+ g_pimg_config.img_width, g_pimg_config.img_height,
+ image_data, image_width, image_height);
+
+ return kTfLiteOk;
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/image_provider.cc b/tensorflow/lite/micro/examples/person_detection/image_provider.cc
new file mode 100644
index 0000000..a44158f
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/image_provider.cc
@@ -0,0 +1,26 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int image_width,
+ int image_height, int channels, int8_t* image_data) {
+ for (int i = 0; i < image_width * image_height * channels; ++i) {
+ image_data[i] = 0;
+ }
+ return kTfLiteOk;
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/image_provider.h b/tensorflow/lite/micro/examples/person_detection/image_provider.h
new file mode 100644
index 0000000..15a3c12
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/image_provider.h
@@ -0,0 +1,39 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_IMAGE_PROVIDER_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_IMAGE_PROVIDER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+// This is an abstraction around an image source like a camera, and is
+// expected to return 8-bit sample data. The assumption is that this will be
+// called in a low duty-cycle fashion in a low-power application. In these
+// cases, the imaging sensor need not be run in a streaming mode, but rather can
+// be idled in a relatively low-power mode between calls to GetImage(). The
+// assumption is that the overhead and time of bringing the low-power sensor out
+// of this standby mode is commensurate with the expected duty cycle of the
+// application. The underlying sensor may actually be put into a streaming
+// configuration, but the image buffer provided to GetImage should not be
+// overwritten by the driver code until the next call to GetImage();
+//
+// The reference implementation can have no platform-specific dependencies, so
+// it just returns a static image. For real applications, you should
+// ensure there's a specialized implementation that accesses hardware APIs.
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int image_width,
+ int image_height, int channels, int8_t* image_data);
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_IMAGE_PROVIDER_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/image_provider_test.cc b/tensorflow/lite/micro/examples/person_detection/image_provider_test.cc
new file mode 100644
index 0000000..ec2748b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/image_provider_test.cc
@@ -0,0 +1,43 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+
+#include <limits>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestImageProvider) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ int8_t image_data[kMaxImageSize];
+ TfLiteStatus get_status = GetImage(µ_error_reporter, kNumCols, kNumRows,
+ kNumChannels, image_data);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, get_status);
+ TF_LITE_MICRO_EXPECT_NE(image_data, nullptr);
+
+ // Make sure we can read all of the returned memory locations.
+ uint32_t total = 0;
+ for (int i = 0; i < kMaxImageSize; ++i) {
+ total += image_data[i];
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/person_detection/main.cc b/tensorflow/lite/micro/examples/person_detection/main.cc
new file mode 100644
index 0000000..b53d366
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/main.cc
@@ -0,0 +1,27 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/main_functions.h"
+
+// This is the default main used on systems that have the standard C entry
+// point. Other devices (for example FreeRTOS or ESP32) that have different
+// requirements for entry code (like an app_main function) should specialize
+// this main.cc file in a target-specific subfolder.
+int main(int argc, char* argv[]) {
+ setup();
+ while (true) {
+ loop();
+ }
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/main_functions.cc b/tensorflow/lite/micro/examples/person_detection/main_functions.cc
new file mode 100644
index 0000000..7e6e40d
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/main_functions.cc
@@ -0,0 +1,119 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/main_functions.h"
+
+#include "tensorflow/lite/micro/examples/person_detection/detection_responder.h"
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+#include "tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+#include "tensorflow/lite/micro/system_setup.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+// Globals, used for compatibility with Arduino-style sketches.
+namespace {
+tflite::ErrorReporter* error_reporter = nullptr;
+const tflite::Model* model = nullptr;
+tflite::MicroInterpreter* interpreter = nullptr;
+TfLiteTensor* input = nullptr;
+
+// In order to use optimized tensorflow lite kernels, a signed int8_t quantized
+// model is preferred over the legacy unsigned model format. This means that
+// throughout this project, input images must be converted from unisgned to
+// signed format. The easiest and quickest way to convert from unsigned to
+// signed 8-bit integers is to subtract 128 from the unsigned value to get a
+// signed value.
+
+// An area of memory to use for input, output, and intermediate arrays.
+constexpr int kTensorArenaSize = 136 * 1024;
+static uint8_t tensor_arena[kTensorArenaSize];
+} // namespace
+
+// The name of this function is important for Arduino compatibility.
+void setup() {
+ tflite::InitializeTarget();
+
+ // Set up logging. Google style is to avoid globals or statics because of
+ // lifetime uncertainty, but since this has a trivial destructor it's okay.
+ // NOLINTNEXTLINE(runtime-global-variables)
+ static tflite::MicroErrorReporter micro_error_reporter;
+ error_reporter = µ_error_reporter;
+
+ // Map the model into a usable data structure. This doesn't involve any
+ // copying or parsing, it's a very lightweight operation.
+ model = tflite::GetModel(g_person_detect_model_data);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ return;
+ }
+
+ // Pull in only the operation implementations we need.
+ // This relies on a complete list of all the ops needed by this graph.
+ // An easier approach is to just use the AllOpsResolver, but this will
+ // incur some penalty in code space for op implementations that are not
+ // needed by this graph.
+ //
+ // tflite::AllOpsResolver resolver;
+ // NOLINTNEXTLINE(runtime-global-variables)
+ static tflite::MicroMutableOpResolver<5> micro_op_resolver;
+ micro_op_resolver.AddAveragePool2D();
+ micro_op_resolver.AddConv2D();
+ micro_op_resolver.AddDepthwiseConv2D();
+ micro_op_resolver.AddReshape();
+ micro_op_resolver.AddSoftmax();
+
+ // Build an interpreter to run the model with.
+ // NOLINTNEXTLINE(runtime-global-variables)
+ static tflite::MicroInterpreter static_interpreter(
+ model, micro_op_resolver, tensor_arena, kTensorArenaSize, error_reporter);
+ interpreter = &static_interpreter;
+
+ // Allocate memory from the tensor_arena for the model's tensors.
+ TfLiteStatus allocate_status = interpreter->AllocateTensors();
+ if (allocate_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
+ return;
+ }
+
+ // Get information about the memory area to use for the model's input.
+ input = interpreter->input(0);
+}
+
+// The name of this function is important for Arduino compatibility.
+void loop() {
+ // Get image from provider.
+ if (kTfLiteOk != GetImage(error_reporter, kNumCols, kNumRows, kNumChannels,
+ input->data.int8)) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Image capture failed.");
+ }
+
+ // Run the model on this input and make sure it succeeds.
+ if (kTfLiteOk != interpreter->Invoke()) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed.");
+ }
+
+ TfLiteTensor* output = interpreter->output(0);
+
+ // Process the inference results.
+ int8_t person_score = output->data.uint8[kPersonIndex];
+ int8_t no_person_score = output->data.uint8[kNotAPersonIndex];
+ RespondToDetection(error_reporter, person_score, no_person_score);
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/main_functions.h b/tensorflow/lite/micro/examples/person_detection/main_functions.h
new file mode 100644
index 0000000..2620097
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/main_functions.h
@@ -0,0 +1,37 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_MAIN_FUNCTIONS_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_MAIN_FUNCTIONS_H_
+
+// Expose a C friendly interface for main functions.
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+// Initializes all data needed for the example. The name is important, and needs
+// to be setup() for Arduino compatibility.
+void setup();
+
+// Runs one iteration of data gathering and inference. This should be called
+// repeatedly from the application code. The name needs to be loop() for Arduino
+// compatibility.
+void loop();
+
+#ifdef __cplusplus
+}
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_MAIN_FUNCTIONS_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/model_settings.cc b/tensorflow/lite/micro/examples/person_detection/model_settings.cc
new file mode 100644
index 0000000..f11d48a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/model_settings.cc
@@ -0,0 +1,21 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+
+const char* kCategoryLabels[kCategoryCount] = {
+ "notperson",
+ "person",
+};
diff --git a/tensorflow/lite/micro/examples/person_detection/model_settings.h b/tensorflow/lite/micro/examples/person_detection/model_settings.h
new file mode 100644
index 0000000..f94d58e
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/model_settings.h
@@ -0,0 +1,35 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_MODEL_SETTINGS_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_MODEL_SETTINGS_H_
+
+// Keeping these as constant expressions allow us to allocate fixed-sized arrays
+// on the stack for our working memory.
+
+// All of these values are derived from the values used during model training,
+// if you change your model you'll need to update these constants.
+constexpr int kNumCols = 96;
+constexpr int kNumRows = 96;
+constexpr int kNumChannels = 1;
+
+constexpr int kMaxImageSize = kNumCols * kNumRows * kNumChannels;
+
+constexpr int kCategoryCount = 2;
+constexpr int kPersonIndex = 1;
+constexpr int kNotAPersonIndex = 0;
+extern const char* kCategoryLabels[kCategoryCount];
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_MODEL_SETTINGS_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/no_person_image_data.h b/tensorflow/lite/micro/examples/person_detection/no_person_image_data.h
new file mode 100644
index 0000000..4e026af
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/no_person_image_data.h
@@ -0,0 +1,30 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This data was created from a sample image from without a person in it.
+// Convert original image to simpler format:
+// convert -resize 96x96\! noperson.PNG noperson.bmp3
+// Skip the 54 byte bmp3 header and add the reset of the bytes to a C array:
+// xxd -s 54 -i /tmp/noperson.bmp3 > /tmp/noperson.cc
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_NO_PERSON_IMAGE_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_NO_PERSON_IMAGE_DATA_H_
+
+#include <cstdint>
+
+extern const int g_no_person_data_size;
+extern const uint8_t g_no_person_data[];
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_NO_PERSON_IMAGE_DATA_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h b/tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h
new file mode 100644
index 0000000..86471b3
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h
@@ -0,0 +1,27 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This is a standard TensorFlow Lite model file that has been converted into a
+// C data array, so it can be easily compiled into a binary for devices that
+// don't have a file system. It was created using the command:
+// xxd -i person_detect.tflite > person_detect_model_data.cc
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_PERSON_DETECT_MODEL_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_PERSON_DETECT_MODEL_DATA_H_
+
+extern const unsigned char g_person_detect_model_data[];
+extern const int g_person_detect_model_data_len;
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_PERSON_DETECT_MODEL_DATA_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/person_detection_binary_test.sh b/tensorflow/lite/micro/examples/person_detection/person_detection_binary_test.sh
new file mode 100755
index 0000000..00d985d
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/person_detection_binary_test.sh
@@ -0,0 +1,33 @@
+#!/bin/bash
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Bash unit tests for the example binary.
+
+set -e
+
+OUTPUT_LOG_FILE=${TEST_TMPDIR}/output_log.txt
+
+# Needed for copybara compatibility.
+SCRIPT_BASE_DIR=/org_"tensor"flow
+${TEST_SRCDIR}${SCRIPT_BASE_DIR}/tensorflow/lite/micro/examples/person_detection/person_detection 2>&1 | head > ${OUTPUT_LOG_FILE}
+
+if ! grep -q 'person score' ${OUTPUT_LOG_FILE}; then
+ echo "ERROR: Expected logs not found in output '${OUTPUT_LOG_FILE}'"
+ exit 1
+fi
+
+echo
+echo "SUCCESS: person_detection_binary_test PASSED"
diff --git a/tensorflow/lite/micro/examples/person_detection/person_detection_test.cc b/tensorflow/lite/micro/examples/person_detection/person_detection_test.cc
new file mode 100644
index 0000000..3d9d1cf
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/person_detection_test.cc
@@ -0,0 +1,134 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+#include "tensorflow/lite/micro/examples/person_detection/no_person_image_data.h"
+#include "tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h"
+#include "tensorflow/lite/micro/examples/person_detection/person_image_data.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+// Create an area of memory to use for input, output, and intermediate arrays.
+constexpr int tensor_arena_size = 136 * 1024;
+uint8_t tensor_arena[tensor_arena_size];
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestInvoke) {
+ // Set up logging.
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ // Map the model into a usable data structure. This doesn't involve any
+ // copying or parsing, it's a very lightweight operation.
+ const tflite::Model* model = ::tflite::GetModel(g_person_detect_model_data);
+ if (model->version() != TFLITE_SCHEMA_VERSION) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter,
+ "Model provided is schema version %d not equal "
+ "to supported version %d.\n",
+ model->version(), TFLITE_SCHEMA_VERSION);
+ }
+
+ // Pull in only the operation implementations we need.
+ // This relies on a complete list of all the ops needed by this graph.
+ // An easier approach is to just use the AllOpsResolver, but this will
+ // incur some penalty in code space for op implementations that are not
+ // needed by this graph.
+ tflite::MicroMutableOpResolver<5> micro_op_resolver;
+ micro_op_resolver.AddAveragePool2D();
+ micro_op_resolver.AddConv2D();
+ micro_op_resolver.AddDepthwiseConv2D();
+ micro_op_resolver.AddReshape();
+ micro_op_resolver.AddSoftmax();
+
+ // Build an interpreter to run the model with.
+ tflite::MicroInterpreter interpreter(model, micro_op_resolver, tensor_arena,
+ tensor_arena_size,
+ µ_error_reporter);
+ interpreter.AllocateTensors();
+
+ // Get information about the memory area to use for the model's input.
+ TfLiteTensor* input = interpreter.input(0);
+
+ // Make sure the input has the properties we expect.
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input);
+ TF_LITE_MICRO_EXPECT_EQ(4, input->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(kNumRows, input->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(kNumCols, input->dims->data[2]);
+ TF_LITE_MICRO_EXPECT_EQ(kNumChannels, input->dims->data[3]);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt8, input->type);
+
+ // Copy an image with a person into the memory area used for the input.
+ TFLITE_DCHECK_EQ(input->bytes, static_cast<size_t>(g_person_data_size));
+ memcpy(input->data.int8, g_person_data, input->bytes);
+
+ // Run the model on this input and make sure it succeeds.
+ TfLiteStatus invoke_status = interpreter.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Invoke failed\n");
+ }
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
+
+ // Get the output from the model, and make sure it's the expected size and
+ // type.
+ TfLiteTensor* output = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(kCategoryCount, output->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt8, output->type);
+
+ // Make sure that the expected "Person" score is higher than the other class.
+ int8_t person_score = output->data.int8[kPersonIndex];
+ int8_t no_person_score = output->data.int8[kNotAPersonIndex];
+ TF_LITE_REPORT_ERROR(µ_error_reporter,
+ "person data. person score: %d, no person score: %d\n",
+ person_score, no_person_score);
+ TF_LITE_MICRO_EXPECT_GT(person_score, no_person_score);
+
+ // TODO(b/161461076): Update model to make this work on real negative inputs.
+ memset(input->data.int8, 0, input->bytes);
+
+ // Run the model on this "No Person" input.
+ invoke_status = interpreter.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Invoke failed\n");
+ }
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
+
+ // Get the output from the model, and make sure it's the expected size and
+ // type.
+ output = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(kCategoryCount, output->dims->data[1]);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt8, output->type);
+
+ // Make sure that the expected "No Person" score is higher.
+ person_score = output->data.int8[kPersonIndex];
+ no_person_score = output->data.int8[kNotAPersonIndex];
+ TF_LITE_REPORT_ERROR(
+ µ_error_reporter,
+ "no person data. person score: %d, no person score: %d\n", person_score,
+ no_person_score);
+ TF_LITE_MICRO_EXPECT_GT(no_person_score, person_score);
+
+ TF_LITE_REPORT_ERROR(µ_error_reporter, "Ran successfully\n");
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/examples/person_detection/person_image_data.h b/tensorflow/lite/micro/examples/person_detection/person_image_data.h
new file mode 100644
index 0000000..1e677ed
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/person_image_data.h
@@ -0,0 +1,30 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This data was created from a sample image from with a person in it.
+// Convert original image to simpler format:
+// convert -resize 96x96\! person.PNG person.bmp3
+// Skip the 54 byte bmp3 header and add the reset of the bytes to a C array:
+// xxd -s 54 -i /tmp/person.bmp3 > /tmp/person.cc
+
+#ifndef TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_PERSON_IMAGE_DATA_H_
+#define TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_PERSON_IMAGE_DATA_H_
+
+#include <cstdint>
+
+extern const int g_person_data_size;
+extern const uint8_t g_person_data[];
+
+#endif // TENSORFLOW_LITE_MICRO_EXAMPLES_PERSON_DETECTION_PERSON_IMAGE_DATA_H_
diff --git a/tensorflow/lite/micro/examples/person_detection/riscv32_mcu/Makefile.inc b/tensorflow/lite/micro/examples/person_detection/riscv32_mcu/Makefile.inc
new file mode 100644
index 0000000..e138efd
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/riscv32_mcu/Makefile.inc
@@ -0,0 +1,26 @@
+ifeq ($(TARGET), riscv32_mcu)
+ # Wrap functions
+ MICRO_FE310_LIBWRAP_SRCS := \
+ $(wildcard $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/sys/*.c) \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/misc/write_hex.c \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/libwrap/stdlib/malloc.c
+
+ MICRO_FE310_BSP_ENV_SRCS := \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/start.S \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/entry.S \
+ $(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/freedom-e300-hifive1/init.c
+
+ person_detection_TEST_HDRS += $(MICRO_FE310_LIBWRAP_SRCS) $(MICRO_FE310_BSP_ENV_SRCS) \
+ tensorflow/lite/micro/arduino/abi.cc
+ person_detection_SRCS += $(MICRO_FE310_LIBWRAP_SRCS) $(MICRO_FE310_BSP_ENV_SRCS) \
+ tensorflow/lite/micro/arduino/abi.cc
+
+ LIBWRAP_SYMS := malloc free \
+ open lseek read write fstat stat close link unlink \
+ execve fork getpid kill wait \
+ isatty times sbrk _exit puts
+
+ LDFLAGS += $(foreach s,$(LIBWRAP_SYMS),-Wl,--wrap=$(s))
+ LDFLAGS += $(foreach s,$(LIBWRAP_SYMS),-Wl,--wrap=_$(s))
+ LDFLAGS += -L. -Wl,--start-group -lc -Wl,--end-group
+endif
diff --git a/tensorflow/lite/micro/examples/person_detection/sparkfun_edge/detection_responder.cc b/tensorflow/lite/micro/examples/person_detection/sparkfun_edge/detection_responder.cc
new file mode 100644
index 0000000..0ab9a3b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/sparkfun_edge/detection_responder.cc
@@ -0,0 +1,57 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/person_detection/detection_responder.h"
+
+#include "am_bsp.h" // NOLINT
+
+// This implementation will light up LEDs on the board in response to the
+// inference results.
+void RespondToDetection(tflite::ErrorReporter* error_reporter,
+ int8_t person_score, int8_t no_person_score) {
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ // Setup LED's as outputs. Leave red LED alone since that's an error
+ // indicator for sparkfun_edge in image_provider.
+ am_devices_led_init((am_bsp_psLEDs + AM_BSP_LED_BLUE));
+ am_devices_led_init((am_bsp_psLEDs + AM_BSP_LED_GREEN));
+ am_devices_led_init((am_bsp_psLEDs + AM_BSP_LED_YELLOW));
+ is_initialized = true;
+ }
+
+ // Toggle the blue LED every time an inference is performed.
+ am_devices_led_toggle(am_bsp_psLEDs, AM_BSP_LED_BLUE);
+
+ // Turn on the green LED if a person was detected. Turn on the yellow LED
+ // otherwise.
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_GREEN);
+ if (person_score > no_person_score) {
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_GREEN);
+ } else {
+ am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
+ }
+
+ TF_LITE_REPORT_ERROR(error_reporter, "Person score: %d No person score: %d",
+ person_score, no_person_score);
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/sparkfun_edge/image_provider.cc b/tensorflow/lite/micro/examples/person_detection/sparkfun_edge/image_provider.cc
new file mode 100644
index 0000000..05db2c2
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/sparkfun_edge/image_provider.cc
@@ -0,0 +1,217 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#if defined(ARDUINO)
+#include "tensorflow/lite/micro/examples/person_detection/arduino/HM01B0_platform.h"
+#endif // defined(ARDUINO)
+
+#if defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+#define ARDUINO_EXCLUDE_CODE
+#endif // defined(ARDUINO) && !defined(ARDUINO_SFE_EDGE)
+
+#ifndef ARDUINO_EXCLUDE_CODE
+
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0.h"
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_RAW8_QVGA_8bits_lsb_5fps.h"
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_debug.h"
+#include "tensorflow/lite/micro/examples/person_detection/himax_driver/HM01B0_optimized.h"
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+
+// These are headers from Ambiq's Apollo3 SDK.
+#include "am_bsp.h" // NOLINT
+#include "am_mcu_apollo.h" // NOLINT
+#include "am_util.h" // NOLINT
+#include "platform.h" // TARGET specific implementation
+
+// #define DEMO_HM01B0_FRAMEBUFFER_DUMP_ENABLE
+
+// Enabling logging increases power consumption by preventing low power mode
+// from being enabled.
+#define ENABLE_LOGGING
+
+namespace {
+
+//*****************************************************************************
+//
+// HM01B0 Configuration
+//
+//*****************************************************************************
+static hm01b0_cfg_t s_HM01B0Cfg = {
+ // i2c settings
+ ui16SlvAddr : HM01B0_DEFAULT_ADDRESS,
+ eIOMMode : HM01B0_IOM_MODE,
+ ui32IOMModule : HM01B0_IOM_MODULE,
+ sIOMCfg : {
+ eInterfaceMode : HM01B0_IOM_MODE,
+ ui32ClockFreq : HM01B0_I2C_CLOCK_FREQ,
+ },
+ pIOMHandle : NULL,
+
+ // MCLK settings
+ ui32CTimerModule : HM01B0_MCLK_GENERATOR_MOD,
+ ui32CTimerSegment : HM01B0_MCLK_GENERATOR_SEG,
+ ui32CTimerOutputPin : HM01B0_PIN_MCLK,
+
+ // data interface
+ ui8PinSCL : HM01B0_PIN_SCL,
+ ui8PinSDA : HM01B0_PIN_SDA,
+ ui8PinD0 : HM01B0_PIN_D0,
+ ui8PinD1 : HM01B0_PIN_D1,
+ ui8PinD2 : HM01B0_PIN_D2,
+ ui8PinD3 : HM01B0_PIN_D3,
+ ui8PinD4 : HM01B0_PIN_D4,
+ ui8PinD5 : HM01B0_PIN_D5,
+ ui8PinD6 : HM01B0_PIN_D6,
+ ui8PinD7 : HM01B0_PIN_D7,
+ ui8PinVSYNC : HM01B0_PIN_VSYNC,
+ ui8PinHSYNC : HM01B0_PIN_HSYNC,
+ ui8PinPCLK : HM01B0_PIN_PCLK,
+
+ ui8PinTrig : HM01B0_PIN_TRIG,
+ ui8PinInt : HM01B0_PIN_INT,
+ pfnGpioIsr : NULL,
+};
+
+static constexpr int kFramesToInitialize = 4;
+
+bool g_is_camera_initialized = false;
+
+void burst_mode_enable(tflite::ErrorReporter* error_reporter, bool bEnable) {
+ am_hal_burst_avail_e eBurstModeAvailable;
+ am_hal_burst_mode_e eBurstMode;
+
+ // Check that the Burst Feature is available.
+ if (AM_HAL_STATUS_SUCCESS ==
+ am_hal_burst_mode_initialize(&eBurstModeAvailable)) {
+ if (AM_HAL_BURST_AVAIL == eBurstModeAvailable) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Apollo3 Burst Mode is Available\n");
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Apollo3 Burst Mode is Not Available\n");
+ return;
+ }
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to Initialize for Burst Mode operation\n");
+ }
+
+ // Make sure we are in "Normal" mode.
+ if (AM_HAL_STATUS_SUCCESS == am_hal_burst_mode_disable(&eBurstMode)) {
+ if (AM_HAL_NORMAL_MODE == eBurstMode) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Apollo3 operating in Normal Mode (48MHz)\n");
+ }
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to Disable Burst Mode operation\n");
+ }
+
+ // Put the MCU into "Burst" mode.
+ if (bEnable) {
+ if (AM_HAL_STATUS_SUCCESS == am_hal_burst_mode_enable(&eBurstMode)) {
+ if (AM_HAL_BURST_MODE == eBurstMode) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Apollo3 operating in Burst Mode (96MHz)\n");
+ }
+ } else {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Failed to Enable Burst Mode operation\n");
+ }
+ }
+}
+
+} // namespace
+
+TfLiteStatus InitCamera(tflite::ErrorReporter* error_reporter) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Initializing HM01B0...\n");
+
+ am_hal_clkgen_control(AM_HAL_CLKGEN_CONTROL_SYSCLK_MAX, 0);
+
+ // Set the default cache configuration
+ am_hal_cachectrl_config(&am_hal_cachectrl_defaults);
+ am_hal_cachectrl_enable();
+
+ // Configure the board for low power operation. This breaks logging by
+ // turning off the itm and uart interfaces.
+#ifndef ENABLE_LOGGING
+ am_bsp_low_power_init();
+#endif
+
+ // Enable interrupts so we can receive messages from the boot host.
+ am_hal_interrupt_master_enable();
+
+ burst_mode_enable(error_reporter, true);
+
+ // Turn on the 1.8V regulator for DVDD on the camera.
+ am_hal_gpio_pinconfig(AM_BSP_GPIO_CAMERA_HM01B0_DVDDEN,
+ g_AM_HAL_GPIO_OUTPUT_12);
+ am_hal_gpio_output_set(AM_BSP_GPIO_CAMERA_HM01B0_DVDDEN);
+
+ // Configure Red LED for debugging.
+ am_devices_led_init((am_bsp_psLEDs + AM_BSP_LED_RED));
+ am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_RED);
+
+ hm01b0_power_up(&s_HM01B0Cfg);
+
+ // TODO(njeff): check the delay time to just fit the spec.
+ am_util_delay_ms(1);
+
+ hm01b0_mclk_enable(&s_HM01B0Cfg);
+
+ // TODO(njeff): check the delay time to just fit the spec.
+ am_util_delay_ms(1);
+
+ if (HM01B0_ERR_OK != hm01b0_init_if(&s_HM01B0Cfg)) {
+ return kTfLiteError;
+ }
+
+ if (HM01B0_ERR_OK !=
+ hm01b0_init_system(&s_HM01B0Cfg, (hm_script_t*)sHM01B0InitScript,
+ sizeof(sHM01B0InitScript) / sizeof(hm_script_t))) {
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+// Capture single frame. Frame pointer passed in to reduce memory usage. This
+// allows the input tensor to be used instead of requiring an extra copy.
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int frame_width,
+ int frame_height, int channels, int8_t* frame) {
+ if (!g_is_camera_initialized) {
+ TfLiteStatus init_status = InitCamera(error_reporter);
+ if (init_status != kTfLiteOk) {
+ am_hal_gpio_output_set(AM_BSP_GPIO_LED_RED);
+ return init_status;
+ }
+ // Drop a few frames until auto exposure is calibrated.
+ for (int i = 0; i < kFramesToInitialize; ++i) {
+ hm01b0_blocking_read_oneframe_scaled(&s_HM01B0Cfg, frame, frame_width,
+ frame_height, channels);
+ }
+ g_is_camera_initialized = true;
+ }
+
+ hm01b0_blocking_read_oneframe_scaled(&s_HM01B0Cfg, frame, frame_width,
+ frame_height, channels);
+
+#ifdef DEMO_HM01B0_FRAMEBUFFER_DUMP_ENABLE
+ hm01b0_framebuffer_dump(frame, frame_width * frame_height * channels);
+#endif
+
+ return kTfLiteOk;
+}
+
+#endif // ARDUINO_EXCLUDE_CODE
diff --git a/tensorflow/lite/micro/examples/person_detection/spresense/Makefile.inc b/tensorflow/lite/micro/examples/person_detection/spresense/Makefile.inc
new file mode 100644
index 0000000..a0d0acf
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/spresense/Makefile.inc
@@ -0,0 +1,20 @@
+# Settings for Spresense platform for Person detection example
+# This should be read when the EXTERNALS_TENSORFLOW_EXAMPLE_PERSONDETECTION option is selected
+# in Spresense configuration.
+
+ifeq ($(TARGET), spresense)
+ifeq ($(CONFIG_EXTERNALS_TENSORFLOW_EXAMPLE_PERSONDETECTION),y)
+
+SPRESENSE_PERSON_DETECTION_EXCLUDED_SRCS = \
+ tensorflow/lite/micro/examples/person_detection/main.cc \
+ tensorflow/lite/micro/examples/person_detection/image_provider.cc
+
+SPRESENSE_PERSON_DETECTION_SRCS = \
+ tensorflow/lite/micro/examples/person_detection/spresense/src/spresense_image_provider.cc \
+ $(filter-out $(SPRESENSE_PERSON_DETECTION_EXCLUDED_SRCS),$(person_detection_SRCS))
+
+# In spresence case, those file should be included into libtensorflow-microlite.
+THIRD_PARTY_CC_SRCS += $(SPRESENSE_PERSON_DETECTION_SRCS)
+
+endif
+endif
diff --git a/tensorflow/lite/micro/examples/person_detection/spresense/README.md b/tensorflow/lite/micro/examples/person_detection/spresense/README.md
new file mode 100644
index 0000000..c00de7a
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/spresense/README.md
@@ -0,0 +1,89 @@
+# Person detection example for Spresense
+
+Here explaines how to build and execute this Person detection example for
+Spresense. To try this on the Spresense, below hardware is required.
+
+Spresense Main board, which is a microcontroller board. Spresense Extention
+board, which is for connecting a mic like MEMS mic. Spresense Camera board,
+which is for sensing image
+
+## Table of contents
+
+- [How to build](#how-to-build)
+- [How to run](#how-to-run)
+
+## How to build
+
+The tensorflow.git will be downloaded in build system of Spresense.
+
+### Initial setup
+
+The Spresense SDK build system is required to build this example. The following
+instructions will help you to make it on your PC.
+[Spresense SDK Getting Started Guide:EN](https://developer.sony.com/develop/spresense/docs/sdk_set_up_en.html)
+[Spresense SDK Getting Started Guide:JA](https://developer.sony.com/develop/spresense/docs/sdk_set_up_ja.html)
+[Spresense SDK Getting Started Guide:CN](https://developer.sony.com/develop/spresense/docs/sdk_set_up_zh.html)
+
+And after setup the build system, download
+[Spresense repository](https://github.com/sonydevworld/spresense).
+
+```
+git clone --recursive https://github.com/sonydevworld/spresense.git
+```
+
+### Configure Spresense for this example
+
+The Spresense SDK uses Kconfig mechanism for configuration of software
+components. So at first, you need to configure it for this example. Spresense
+SDK provides some default configurations, and there is a default config to build
+this Person detection example.
+
+1. Go to sdk/ directory in the repository.
+
+ ```
+ cd spresense/sdk
+ ```
+
+2. Execute config.py to configure for this example.
+
+ ```
+ ./tools/config.py examples/tf_example_persondetection
+ ```
+
+This command creates .config file in spesense/nuttx directory.
+
+### Build and Flash the binary into Spresense Main board
+
+After configured, execute make and then flash built image.
+
+1. Execute "make" command in the same directory you configured.
+
+ ```
+ make
+ ```
+
+2. Flash built image into Spresense main board. If the build is successful, a
+ file named nuttx.spk will be created in the current directory, and flash it
+ into Spresense Main board. Make sure USB cable is connected between the
+ board and your PC. The USB will be recognized as USB/serial device like
+ /dev/ttyUSB0 in your PC. In this explanation, we will assume that the device
+ is recognized as /dev/ttyUSB0.
+
+ ```
+ ./tools/flash.sh -c /dev/ttyUSB0 nuttx.spk
+ ```
+
+## How to run
+
+To run the example, connect to the device with a terminal soft like "minicom".
+Then you can see a "nsh>" prompt on it. (If you can't see the prompt, try to
+press enter.)
+
+1. Execute tf_example command on the prompt.
+
+ ```
+ nsh> tf_example
+ ```
+
+2. Put a person's face in the camera image. Rate which is a face or not will
+ print on the terminal as a result of the detection.
diff --git a/tensorflow/lite/micro/examples/person_detection/spresense/src/spresense_image_provider.cc b/tensorflow/lite/micro/examples/person_detection/spresense/src/spresense_image_provider.cc
new file mode 100644
index 0000000..ba7aa40
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/spresense/src/spresense_image_provider.cc
@@ -0,0 +1,32 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// The SPRESENSE_CONFIG_H is defined on compiler option.
+// It contains "nuttx/config.h" from Spresense SDK to see the configurated
+// parameters.
+#include SPRESENSE_CONFIG_H
+#include "spresense_image_provider.h"
+
+#include "tensorflow/lite/micro/examples/person_detection/image_provider.h"
+#include "tensorflow/lite/micro/examples/person_detection/model_settings.h"
+
+TfLiteStatus GetImage(tflite::ErrorReporter* error_reporter, int image_width,
+ int image_height, int channels, int8_t* image_data) {
+ if (spresense_getimage((unsigned char*)image_data) == 0) {
+ return kTfLiteOk;
+ } else {
+ return kTfLiteError;
+ }
+}
diff --git a/tensorflow/lite/micro/examples/person_detection/training_a_model.md b/tensorflow/lite/micro/examples/person_detection/training_a_model.md
new file mode 100644
index 0000000..81ac39b
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/training_a_model.md
@@ -0,0 +1,455 @@
+## Training a model
+
+The following document will walk you through the process of training your own
+250 KB embedded vision model using scripts that are easy to run. You can use
+either the [Visual Wake Words dataset](https://arxiv.org/abs/1906.05721) for
+person detection, or choose one of the [80
+categories from the MSCOCO dataset](http://cocodataset.org/#explore).
+
+This model will take several days to train on a powerful machine with GPUs. We
+recommend using a [Google Cloud Deep
+Learning VM](https://cloud.google.com/deep-learning-vm/).
+
+### Training framework choice
+
+Keras is the recommended interface for building models in TensorFlow, but when
+the person detector model was being created it didn't yet support all the
+features we needed. For that reason, we'll be showing you how to train a model
+using tf.slim, an older interface. It is still widely used but deprecated, so
+future versions of TensorFlow may not support this approach. We hope to publish
+Keras instructions in the future.
+
+The model definitions for Slim are part of the
+[TensorFlow models repository](https://github.com/tensorflow/models), so to get
+started you'll need to download it from GitHub using a command like this:
+
+```
+! cd ~
+! git clone https://github.com/tensorflow/models.git
+```
+
+The following guide is going to assume that you've done this from your home
+directory, so the model repository code is at ~/models, and that all commands
+are run from the home directory too unless otherwise noted. You can place the
+repository somewhere else, but you'll need to update all references to it.
+
+To use Slim, you'll need to make sure its modules can be found by Python, and
+install one dependency. Here's how to do this in an iPython notebook:
+
+```
+! pip install contextlib2
+import os
+new_python_path = (os.environ.get("PYTHONPATH") or '') + ":models/research/slim"
+%env PYTHONPATH=$new_python_path
+```
+
+Updating `PYTHONPATH` through an `EXPORT` statement like this only works for the
+current Jupyter session, so if you're using bash directly, you should add it to
+a persistent startup script, running something like this:
+
+```
+echo 'export PYTHONPATH=$PYTHONPATH:models/research/slim' >> ~/.bashrc
+source ~/.bashrc
+```
+
+If you see import errors running the slim scripts, you should make sure the
+`PYTHONPATH` is set up correctly, and that contextlib2 has been installed. You
+can find more general information on tf.slim in the
+[repository's
+README](https://github.com/tensorflow/models/tree/master/research/slim).
+
+### Building the dataset
+
+In order to train a person detector model, we need a large collection of images
+that are labeled depending on whether or not they have people in them. The
+ImageNet one-thousand class data that's widely used for training image
+classifiers doesn't include labels for people, but luckily the
+[COCO dataset](http://cocodataset.org/#home) does. You can also download this
+data without manually registering too, and Slim provides a convenient script to
+grab it automatically:
+
+```
+! chmod +x models/research/slim/datasets/download_mscoco.sh
+! bash models/research/slim/datasets/download_mscoco.sh coco
+```
+
+This is a large download, about 40GB, so it will take a while and you'll need
+to make sure you have at least 100GB free on your drive to allow space for
+unpacking and further processing. The argument to the script is the path that
+the data will be downloaded to. If you change this, you'll also need to update
+the commands below that use it.
+
+The dataset is designed to be used for training models for localization, so the
+images aren't labeled with the "contains a person", "doesn't contain a person"
+categories that we want to train for. Instead each image comes with a list of
+bounding boxes for all of the objects it contains. "Person" is one of these
+object categories, so to get to the classification labels we want, we have to
+look for images with bounding boxes for people. To make sure that they aren't
+too tiny to be recognizable we also need to exclude very small bounding boxes.
+Slim contains a script to convert the bounding box into labels:
+
+```
+! python models/research/slim/datasets/build_visualwakewords_data.py
+--logtostderr \
+--train_image_dir=coco/raw-data/train2014 \
+--val_image_dir=coco/raw-data/val2014 \
+--train_annotations_file=coco/raw-data/annotations/instances_train2014.json \
+--val_annotations_file=coco/raw-data/annotations/instances_val2014.json \
+--output_dir=coco/processed \
+--small_object_area_threshold=0.005 \
+--foreground_class_of_interest='person'
+```
+
+Don't be surprised if this takes up to twenty minutes to complete. When it's
+done, you'll have a set of TFRecords in `coco/processed` holding the labeled
+image information. This data was created by Aakanksha Chowdhery and is known as
+the [Visual Wake Words dataset](https://arxiv.org/abs/1906.05721). It's designed
+to be useful for benchmarking and testing embedded computer vision, since it
+represents a very common task that we need to accomplish with tight resource
+constraints. We're hoping to see it drive even better models for this and
+similar tasks.
+
+### Training the model
+
+One of the nice things about using tf.slim to handle the training is that the
+parameters you commonly need to modify are available as command line arguments,
+so we can just call the standard `train_image_classifier.py` script to train
+our model. You can use this command to build the model we use in the example:
+
+```
+! python models/research/slim/train_image_classifier.py \
+ --train_dir=vww_96_grayscale \
+ --dataset_name=visualwakewords \
+ --dataset_split_name=train \
+ --dataset_dir=coco/processed \
+ --model_name=mobilenet_v1_025 \
+ --preprocessing_name=mobilenet_v1 \
+ --train_image_size=96 \
+ --input_grayscale=True \
+ --save_summaries_secs=300 \
+ --learning_rate=0.045 \
+ --label_smoothing=0.1 \
+ --learning_rate_decay_factor=0.98 \
+ --num_epochs_per_decay=2.5 \
+ --moving_average_decay=0.9999 \
+ --batch_size=96 \
+ --max_number_of_steps=1000000
+```
+
+This will take a couple of days on a single-GPU v100 instance to complete all
+one-million steps, but you should be able to get a fairly accurate model after
+a few hours if you want to experiment early.
+
+- The checkpoints and summaries will the saved in the folder given in the
+ `--train_dir` argument, so that's where you'll have to look for the results.
+- The `--dataset_dir` parameter should match the one where you saved the
+ TFRecords from the Visual Wake Words build script.
+- The architecture we'll be using is defined by the `--model_name` argument.
+ The 'mobilenet_v1' prefix tells the script to use the first version of
+ MobileNet. We did experiment with later versions, but these used more RAM
+ for their intermediate activation buffers, so for now we kept with the
+ original. The '025' is the depth multiplier to use, which mostly affects the
+ number of weight parameters, this low setting ensures the model fits within
+ 250KB of Flash.
+- `--preprocessing_name` controls how input images are modified before they're
+ fed into the model. The 'mobilenet_v1' version shrinks the width and height
+ of the images to the size given in `--train_image_size` (in our case 96
+ pixels since we want to reduce the compute requirements). It also scales the
+ pixel values from 0 to 255 integers into -1.0 to +1.0 floating point numbers
+ (though we'll be quantizing those after training).
+- The
+ [HM01B0](https://himax.com.tw/products/cmos-image-sensor/image-sensors/hm01b0/)
+ camera we're using on the SparkFun Edge board is monochrome, so to get the
+ best results we have to train our model on black and white images too, so we
+ pass in the `--input_grayscale` flag to enable that preprocessing.
+- The `--learning_rate`, `--label_smoothing`, `--learning_rate_decay_factor`,
+ `--num_epochs_per_decay`, `--moving_average_decay` and `--batch_size` are
+ all parameters that control how weights are updated during the training
+ process. Training deep networks is still a bit of a dark art, so these exact
+ values we found through experimentation for this particular model. You can
+ try tweaking them to speed up training or gain a small boost in accuracy,
+ but we can't give much guidance for how to make those changes, and it's easy
+ to get combinations where the training accuracy never converges.
+- The `--max_number_of_steps` defines how long the training should continue.
+ There's no good way to figure out this threshold in advance, you have to
+ experiment to tell when the accuracy of the model is no longer improving to
+ tell when to cut it off. In our case we default to a million steps, since
+ with this particular model we know that's a good point to stop.
+
+Once you start the script, you should see output that looks something like this:
+
+```
+INFO:tensorflow:global step 4670: loss = 0.7112 (0.251 sec/step)
+I0928 00:16:21.774756 140518023943616 learning.py:507] global step 4670: loss =
+0.7112 (0.251 sec/step)
+INFO:tensorflow:global step 4680: loss = 0.6596 (0.227 sec/step)
+I0928 00:16:24.365901 140518023943616 learning.py:507] global step 4680: loss =
+0.6596 (0.227 sec/step)
+```
+
+Don't worry about the line duplication, this is just a side-effect of the way
+TensorFlow log printing interacts with Python. Each line has two key bits of
+information about the training process. The global step is a count of how far
+through the training we are. Since we've set the limit as a million steps, in
+this case we're nearly five percent complete. The steps per second estimate is
+also useful, since you can use it to estimate a rough duration for the whole
+training process. In this case, we're completing about four steps a second, so
+a million steps will take about 70 hours, or three days. The other crucial
+piece of information is the loss. This is a measure of how close the
+partially-trained model's predictions are to the correct values, and lower
+values are better. This will show a lot of variation but should on average
+decrease during training if the model is learning. Because it's so noisy, the
+amounts will bounce around a lot over short time periods, but if things are
+working well you should see a noticeable drop if you wait an hour or so and
+check back. This kind of variation is a lot easier to see in a graph, which is
+one of the main reasons to try TensorBoard.
+
+### TensorBoard
+
+TensorBoard is a web application that lets you view data visualizations from
+TensorFlow training sessions, and it's included by default in most cloud
+instances. If you're using Google Cloud's AI Platform, you can start up a new
+TensorBoard session by open the command palette from the left tabs on the
+notebook interface, and scrolling down to select "Create a new tensorboard".
+You'll be prompted for the location of the summary logs, enter the path you
+used for `--train_dir` in the training script, in our example
+'vww_96_grayscale'. One common error to watch out for is adding a slash to the
+end of the path, which will cause tensorboard to fail to find the directory. If
+you're starting tensorboard from the command line in a different environment
+you'll have to pass in this path as the `--logdir` argument to the tensorboard
+command line tool, and point your browser to http://localhost:6006 (or the
+address of the machine you're running it on).
+
+It may take a little while for the graphs to have anything useful in them, since
+the script only saves summaries every five minutes. The most important graph is
+called 'clone_loss', and this shows the progression of the same loss value
+that's displayed on the logging output. It fluctuates a lot, but the
+overall trend is downwards over time. If you don't see this sort of progression
+after a few hours of training, it's a good sign that your model isn't
+converging to a good solution, and you may need to debug what's going wrong
+either with your dataset or the training parameters.
+
+Tensorboard defaults to the 'Scalars' tab when it opens, but the other section
+that can be useful during training is 'Images'. This shows a
+random selection of the pictures the model is currently being trained on,
+including any distortions and other preprocessing. This information isn't as
+essential as the loss graphs, but it can be useful to ensure the dataset is what
+you expect, and it is interesting to see the examples updating as training
+progresses.
+
+### Evaluating the model
+
+The loss function correlates with how well your model is training, but it isn't
+a direct, understandable metric. What we really care about is how many people
+our model detects correctly, but to get calculate this we need to run a
+separate script. You don't need to wait until the model is fully trained, you
+can check the accuracy of any checkpoints in the `--train_dir` folder.
+
+```
+! python models/research/slim/eval_image_classifier.py \
+ --alsologtostderr \
+ --checkpoint_path=vww_96_grayscale/model.ckpt-698580 \
+ --dataset_dir=coco/processed/ \
+ --dataset_name=visualwakewords \
+ --dataset_split_name=val \
+ --model_name=mobilenet_v1_025 \
+ --preprocessing_name=mobilenet_v1 \
+ --input_grayscale=True \
+ --train_image_size=96
+```
+
+You'll need to make sure that `--checkpoint_path` is pointing to a valid set of
+checkpoint data. Checkpoints are stored in three separate files, so the value
+should be their common prefix. For example if you have a checkpoint file called
+'model.ckpt-5179.data-00000-of-00001', the prefix would be 'model.ckpt-5179'.
+The script should produce output that looks something like this:
+
+```
+INFO:tensorflow:Evaluation [406/406]
+I0929 22:52:59.936022 140225887045056 evaluation.py:167] Evaluation [406/406]
+eval/Accuracy[0.717438412]eval/Recall_5[1]
+```
+
+The important number here is the accuracy. It shows the proportion of the
+images that were classified correctly, which is 72% in this case, after
+converting to a percentage. If you follow the example script, you should expect
+a fully-trained model to achieve an accuracy of around 84% after one million
+steps, and show a loss of around 0.4.
+
+### Exporting the model to TensorFlow Lite
+
+When the model has trained to an accuracy you're happy with, you'll need to
+convert the results from the TensorFlow training environment into a form you
+can run on an embedded device. As we've seen in previous chapters, this can be
+a complex process, and tf.slim adds a few of its own wrinkles too.
+
+#### Exporting to a GraphDef protobuf file
+
+Slim generates the architecture from the model_name every time one of its
+scripts is run, so for a model to be used outside of Slim it needs to be saved
+in a common format. We're going to use the GraphDef protobuf serialization
+format, since that's understood by both Slim and the rest of TensorFlow.
+
+```
+! python models/research/slim/export_inference_graph.py \
+ --alsologtostderr \
+ --dataset_name=visualwakewords \
+ --model_name=mobilenet_v1_025 \
+ --image_size=96 \
+ --input_grayscale=True \
+ --output_file=vww_96_grayscale_graph.pb
+```
+
+If this succeeds, you should have a new 'vww_96_grayscale_graph.pb' file in
+your home folder. This contains the layout of the operations in the model, but
+doesn't yet have any of the weight data.
+
+#### Freezing the weights
+
+The process of storing the trained weights together with the operation graph is
+known as freezing. This converts all of the variables in the graph to
+constants, after loading their values from a checkpoint file. The command below
+uses a checkpoint from the millionth training step, but you can supply any
+valid checkpoint path. The graph freezing script is stored inside the main
+tensorflow repository, so we have to download this from GitHub before running
+this command.
+
+```
+! git clone https://github.com/tensorflow/tensorflow
+! python tensorflow/tensorflow/python/tools/freeze_graph.py \
+--input_graph=vww_96_grayscale_graph.pb \
+--input_checkpoint=vww_96_grayscale/model.ckpt-1000000 \
+--input_binary=true --output_graph=vww_96_grayscale_frozen.pb \
+--output_node_names=MobilenetV1/Predictions/Reshape_1
+```
+
+After this, you should see a file called 'vww_96_grayscale_frozen.pb'.
+
+#### Quantizing and converting to TensorFlow Lite
+
+Quantization is a tricky and involved process, and it's still very much an
+active area of research, so taking the float graph that we've trained so far
+and converting it down to eight bit takes quite a bit of code. You can find
+more of an explanation of what quantization is and how it works in the chapter
+on latency optimization, but here we'll show you how to use it with the model
+we've trained. The majority of the code is preparing example images to feed
+into the trained network, so that the ranges of the activation layers in
+typical use can be measured. We rely on the TFLiteConverter class to handle the
+quantization and conversion into the TensorFlow Lite flatbuffer file that we
+need for the inference engine.
+
+```
+import tensorflow as tf
+import io
+import PIL
+import numpy as np
+
+def representative_dataset_gen():
+
+ record_iterator =
+tf.python_io.tf_record_iterator(path='coco/processed/val.record-00000-of-00010')
+
+ count = 0
+ for string_record in record_iterator:
+ example = tf.train.Example()
+ example.ParseFromString(string_record)
+ image_stream =
+io.BytesIO(example.features.feature['image/encoded'].bytes_list.value[0])
+ image = PIL.Image.open(image_stream)
+ image = image.resize((96, 96))
+ image = image.convert('L')
+ array = np.array(image)
+ array = np.expand_dims(array, axis=2)
+ array = np.expand_dims(array, axis=0)
+ array = ((array / 127.5) - 1.0).astype(np.float32)
+ yield([array])
+ count += 1
+ if count > 300:
+ break
+
+converter =
+tf.lite.TFLiteConverter.from_frozen_graph('vww_96_grayscale_frozen.pb',
+['input'], ['MobilenetV1/Predictions/Reshape_1'])
+converter.optimizations = [tf.lite.Optimize.DEFAULT]
+converter.representative_dataset = representative_dataset_gen
+converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
+converter.inference_input_type = tf.int8
+converter.inference_output_type = tf.int8
+
+tflite_quant_model = converter.convert()
+open("vww_96_grayscale_quantized.tflite", "wb").write(tflite_quant_model)
+```
+
+#### Converting into a C source file
+
+The converter writes out a file, but most embedded devices don't have a file
+system. To access the serialized data from our program, we have to compile it
+into the executable and store it in Flash. The easiest way to do that is to
+convert the file into a C data array.
+
+```
+# Install xxd if it is not available
+!apt-get -qq install xxd
+# Save the file as a C source file
+!xxd -i vww_96_grayscale_quantized.tflite > person_detect_model_data.cc
+```
+
+You can now replace the existing person_detect_model_data.cc file with the
+version you've trained, and be able to run your own model on embedded devices.
+
+### Training for other categories
+
+There are over 60 different object types in the MS-COCO dataset, so an easy way
+to customize your model would be to choose one of those instead of 'person'
+when you build the training dataset. Here's an example that looks for cars:
+
+```
+! python models/research/slim/datasets/build_visualwakewords_data.py
+--logtostderr \
+--train_image_dir=coco/raw-data/train2014 \
+--val_image_dir=coco/raw-data/val2014 \
+--train_annotations_file=coco/raw-data/annotations/instances_train2014.json \
+--val_annotations_file=coco/raw-data/annotations/instances_val2014.json \
+--output_dir=coco/processed_cars \
+--small_object_area_threshold=0.005 \
+--foreground_class_of_interest='car'
+```
+
+You should be able to follow the same steps you did for the person detector,
+but substitute the new 'coco/processed_cars' path wherever 'coco/processed'
+used to be.
+
+If the kind of object you're interested in isn't present in MS-COCO, you may be
+able to use transfer learning to help you train on a custom dataset you've
+gathered, even if it's much smaller. We don't have an example of this
+yet, but we hope to share one soon.
+
+### Understanding the architecture
+
+[MobileNets](https://arxiv.org/abs/1704.04861) are a family of architectures
+designed to provide good accuracy for as few weight parameters and arithmetic
+operations as possible. There are now multiple versions, but in our case we're
+using the original v1 since it required the smallest amount of RAM at runtime.
+The core concept behind the architecture is depthwise separable convolution.
+This is a variant of classical two-dimensional convolutions that works in a
+much more efficient way, without sacrificing very much accuracy. Regular
+convolution calculates an output value based on applying a filter of a
+particular size across all channels of the input. This means the number of
+calculations involved in each output is width of the filter multiplied by
+height, multiplied by the number of input channels. Depthwise convolution
+breaks this large calculation into separate parts. First each input channel is
+filtered by one or more rectangular filters to produce intermediate values.
+These values are then combined using pointwise convolutions. This dramatically
+reduces the number of calculations needed, and in practice produces similar
+results to regular convolution.
+
+MobileNet v1 is a stack of 14 of these depthwise separable convolution layers
+with an average pool, then a fully-connected layer followed by a softmax at the
+end. We've specified a 'width multiplier' of 0.25, which has the effect of
+reducing the number of computations down to around 60 million per inference, by
+shrinking the number of channels in each activation layer by 75% compared to
+the standard model. In essence it's very similar to a normal convolutional
+neural network in operation, with each layer learning patterns in the input.
+Earlier layers act more like edge recognition filters, spotting low-level
+structure in the image, and later layers synthesize that information into more
+abstract patterns that help with the final object classification.
diff --git a/tensorflow/lite/micro/examples/person_detection/utils/raw_to_bitmap.py b/tensorflow/lite/micro/examples/person_detection/utils/raw_to_bitmap.py
new file mode 100644
index 0000000..4ebb849
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/utils/raw_to_bitmap.py
@@ -0,0 +1,200 @@
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Convert raw bytes to a bitmap.
+
+Converts a raw image dumped to a file into a bitmap. The file must contain
+complete bitmap images in 324 x 244 resolution, formatted as follows:
+
++++ frame +++
+<byte number> <16 one-byte values separated by spaces>
+--- frame ---
+
+For example, the first line might look like:
+0x00000000 C5 C3 CE D1 D9 DA D6 E3 E2 EB E9 EB DB E4 F5 FF
+
+The bitmaps are automatically saved to the same directory as the log file, and
+are displayed by the script.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import os
+import os.path
+import re
+
+import numpy as np
+
+_DICT_RESOLUTIONS = {
+ 'QVGA': (324, 244, 1),
+ 'GRAY': (96, 96, 1),
+ 'RGB': (96, 96, 3),
+}
+
+_VERSION = 0
+_SUBVERSION = 1
+
+
+def check_file_existence(x):
+ if not os.path.isfile(x):
+ # Argparse uses the ArgumentTypeError to give a rejection message like:
+ # error: argument input: x does not exist
+ raise argparse.ArgumentTypeError('{0} does not exist'.format(x))
+ return x
+
+
+def show_and_save_bitmaps(input_file, bitmap_list, channels):
+ """Display and save a list of bitmaps.
+
+ Args:
+ input_file: input file name
+ bitmap_list: list of numpy arrays to represent bitmap images
+ channels: color channel count
+ """
+ try:
+ from PIL import Image # pylint: disable=g-import-not-at-top
+ except ImportError:
+ raise NotImplementedError('Image display and save not implemented.')
+
+ for idx, bitmap in enumerate(bitmap_list):
+ path = os.path.dirname(os.path.abspath(input_file))
+ basename = os.path.split(os.path.splitext(input_file)[0])[-1]
+ outputfile = os.path.join(path, basename + '_' + str(idx) + '.bmp')
+
+ if channels == 3:
+ img = Image.fromarray(bitmap, 'RGB')
+ else:
+ img = Image.fromarray(bitmap, 'L')
+
+ img.save(outputfile)
+ img.show()
+
+
+def reshape_bitmaps(frame_list, width, height, channels):
+ """Reshape flat integer arrays.
+
+ Args:
+ frame_list: list of 1-D arrays to represent raw image data
+ width: image width in pixels
+ height: image height in pixels
+ channels: color channel count
+
+ Returns:
+ list of numpy arrays to represent bitmap images
+ """
+
+ bitmap_list = []
+ for frame in frame_list:
+ shape = (height, width, channels) if channels > 1 else (height, width)
+ bitmap = np.reshape(frame, shape)
+ bitmap = np.flip(bitmap, 0)
+ bitmap_list.append(bitmap)
+ return bitmap_list
+
+
+def parse_file(inputfile, width, height, channels):
+ """Convert log file to array of pixels.
+
+ Args:
+ inputfile: log file to parse
+ width: image width in pixels
+ height: image height in pixels
+ channels: color channel count
+
+ Returns:
+ list 1-D arrays to represent raw image data.
+ """
+
+ data = None
+ bytes_written = 0
+ frame_start = False
+ frame_stop = False
+ frame_list = list()
+
+ # collect all pixel data into an int array
+ for line in inputfile:
+ if line == '+++ frame +++\n':
+ frame_start = True
+ data = np.zeros(height * width * channels, dtype=np.uint8)
+ bytes_written = 0
+ continue
+ elif line == '--- frame ---\n':
+ frame_stop = True
+
+ if frame_start and not frame_stop:
+ linelist = re.findall(r"[\w']+", line)
+
+ if len(linelist) != 17:
+ # drop this frame
+ frame_start = False
+ continue
+
+ for item in linelist[1:]:
+ data[bytes_written] = int(item, base=16)
+ bytes_written += 1
+
+ elif frame_start and frame_stop:
+ if bytes_written == height * width * channels:
+ frame_list.append(data)
+ frame_start = False
+ frame_stop = False
+
+ return frame_list
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='This program converts raw data from HM01B0 to a bmp file.')
+
+ parser.add_argument(
+ '-i',
+ '--input',
+ dest='inputfile',
+ required=True,
+ help='input file',
+ metavar='FILE',
+ type=check_file_existence)
+
+ parser.add_argument(
+ '-r',
+ '--resolution',
+ dest='resolution',
+ required=False,
+ help='Resolution',
+ choices=['QVGA', 'RGB', 'GRAY'],
+ default='QVGA',
+ )
+
+ parser.add_argument(
+ '-v',
+ '--version',
+ help='Program version',
+ action='version',
+ version='%(prog)s {ver}'.format(ver='v%d.%d' % (_VERSION, _SUBVERSION)))
+
+ args = parser.parse_args()
+
+ (width, height,
+ channels) = _DICT_RESOLUTIONS.get(args.resolution,
+ ('Resolution not supported', 0, 0, 0))
+ frame_list = parse_file(open(args.inputfile), width, height, channels)
+ bitmap_list = reshape_bitmaps(frame_list, width, height, channels)
+ show_and_save_bitmaps(args.inputfile, bitmap_list, channels)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tensorflow/lite/micro/examples/person_detection/utils/raw_to_bitmap_test.py b/tensorflow/lite/micro/examples/person_detection/utils/raw_to_bitmap_test.py
new file mode 100644
index 0000000..ade895d
--- /dev/null
+++ b/tensorflow/lite/micro/examples/person_detection/utils/raw_to_bitmap_test.py
@@ -0,0 +1,120 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for raw to bitmap converter utility."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import io
+
+import numpy as np
+
+from tensorflow.lite.micro.examples.person_detection.utils.raw_to_bitmap import parse_file
+from tensorflow.lite.micro.examples.person_detection.utils.raw_to_bitmap import reshape_bitmaps
+from tensorflow.python.platform import googletest
+
+_RGB_RAW = u"""
++++ frame +++
+0x0000 0x00 0x00 0x00 0x01 0x01 0x01 0x02 0x02 0x02 0x03 0x03 0x03 0x04 0x04 0x04 0x05
+0x0010 0x05 0x05 0x06 0x06 0x06 0x07 0x07 0x07 0x08 0x08 0x08 0x09 0x09 0x09 0x0a 0x0a
+0x0020 0x0a 0x0b 0x0b 0x0b 0x0c 0x0c 0x0c 0x0d 0x0d 0x0d 0x0e 0x0e 0x0e 0x0f 0x0f 0x0f
+--- frame ---
+"""
+
+_RGB_FLAT = np.array([[
+ 0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6, 7, 7, 7, 8,
+ 8, 8, 9, 9, 9, 10, 10, 10, 11, 11, 11, 12, 12, 12, 13, 13, 13, 14, 14, 14,
+ 15, 15, 15
+]])
+
+_RGB_RESHAPED = np.array([[[[12, 12, 12], [13, 13, 13], [14, 14, 14],
+ [15, 15, 15]],
+ [[8, 8, 8], [9, 9, 9], [10, 10, 10], [11, 11, 11]],
+ [[4, 4, 4], [5, 5, 5], [6, 6, 6], [7, 7, 7]],
+ [[0, 0, 0], [1, 1, 1], [2, 2, 2], [3, 3, 3]]]])
+
+_GRAYSCALE_RAW = u"""
++++ frame +++
+0x0000 0x00 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08 0x09 0x0a 0x0b 0x0c 0x0d 0x0e 0x0f
+--- frame ---
+"""
+
+_GRAYSCALE_FLAT = np.array(
+ [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]])
+
+_GRAYSCALE_RESHAPED = np.array([[[12, 13, 14, 15], [8, 9, 10, 11], [4, 5, 6, 7],
+ [0, 1, 2, 3]]])
+
+_GRAYSCALE_RAW_MULTI = u"""
++++ frame +++
+0x0000 0x00 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08 0x09 0x0a 0x0b 0x0c 0x0d 0x0e 0x0f
+--- frame ---
++++ frame +++
+0x0000 0x10 0x11 0x12 0x13 0x14 0x15 0x16 0x17 0x18 0x19 0x1a 0x1b 0x1c 0x1d 0x1e 0x1f
+--- frame ---
++++ frame +++
+0x0000 0x20 0x21 0x22 0x23 0x24 0x25 0x26 0x27 0x28 0x29 0x2a 0x2b 0x2c 0x2d 0x2e 0x2f
+--- frame ---
++++ frame +++
+0x0000 0x30 0x31 0x32 0x33 0x34 0x35 0x36 0x37 0x38 0x39 0x3a 0x3b 0x3c 0x3d 0x3e 0x3f
+--- frame ---
+"""
+
+_GRAYSCALE_FLAT_MULTI = [
+ np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]),
+ np.array([16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]),
+ np.array([32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]),
+ np.array([48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63])
+]
+
+_GRAYSCALE_RESHAPED_MULTI = [
+ np.array([[12, 13, 14, 15], [8, 9, 10, 11], [4, 5, 6, 7], [0, 1, 2, 3]]),
+ np.array([[28, 29, 30, 31], [24, 25, 26, 27], [20, 21, 22, 23],
+ [16, 17, 18, 19]]),
+ np.array([[44, 45, 46, 47], [40, 41, 42, 43], [36, 37, 38, 39],
+ [32, 33, 34, 35]]),
+ np.array([[60, 61, 62, 63], [56, 57, 58, 59], [52, 53, 54, 55],
+ [48, 49, 50, 51]])
+]
+
+
+class RawToBitmapTest(googletest.TestCase):
+
+ def test_parse_rgb(self):
+ frame_list = parse_file(io.StringIO(_RGB_RAW), 4, 4, 3)
+ self.assertTrue(np.array_equal(_RGB_FLAT, frame_list))
+
+ def test_parse_grayscale(self):
+ frame_list = parse_file(io.StringIO(_GRAYSCALE_RAW), 4, 4, 1)
+ self.assertTrue(np.array_equal(_GRAYSCALE_FLAT, frame_list))
+
+ def test_reshape_rgb(self):
+ reshaped = reshape_bitmaps(_RGB_FLAT, 4, 4, 3)
+ self.assertTrue(np.array_equal(_RGB_RESHAPED, reshaped))
+
+ def test_reshape_grayscale(self):
+ reshaped = reshape_bitmaps(_GRAYSCALE_FLAT, 4, 4, 1)
+ self.assertTrue(np.array_equal(_GRAYSCALE_RESHAPED, reshaped))
+
+ def test_multiple_grayscale(self):
+ frame_list = parse_file(io.StringIO(_GRAYSCALE_RAW_MULTI), 4, 4, 1)
+ self.assertTrue(np.array_equal(_GRAYSCALE_FLAT_MULTI, frame_list))
+ reshaped = reshape_bitmaps(frame_list, 4, 4, 1)
+ self.assertTrue(np.array_equal(_GRAYSCALE_RESHAPED_MULTI, reshaped))
+
+
+if __name__ == '__main__':
+ googletest.main()
diff --git a/tensorflow/lite/micro/himax_we1_evb/debug_log.cc b/tensorflow/lite/micro/himax_we1_evb/debug_log.cc
new file mode 100644
index 0000000..3431b8d
--- /dev/null
+++ b/tensorflow/lite/micro/himax_we1_evb/debug_log.cc
@@ -0,0 +1,28 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include "hx_drv_tflm.h"
+
+extern "C" void DebugLog(const char* s) {
+ static bool is_initialized = false;
+ if (!is_initialized) {
+ hx_drv_uart_initial();
+ is_initialized = true;
+ }
+
+ hx_drv_uart_print("%s", s);
+}
diff --git a/tensorflow/lite/micro/kernels/BUILD b/tensorflow/lite/micro/kernels/BUILD
new file mode 100644
index 0000000..e00b622
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/BUILD
@@ -0,0 +1,1163 @@
+load(
+ "//tensorflow/lite/micro:build_def.bzl",
+ "micro_copts",
+)
+
+package(
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+config_setting(
+ name = "xtensa_hifimini",
+ define_values = {"tflm_build": "xtensa_hifimini"},
+)
+
+package_group(
+ name = "micro",
+ packages = ["//tensorflow/lite/micro/..."],
+)
+
+package_group(
+ name = "micro_top_level",
+ packages = ["//tensorflow/lite/micro"],
+)
+
+####################################
+# C++ libraries
+####################################
+
+cc_library(
+ name = "activation_utils",
+ hdrs = ["activation_utils.h"],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:cppmath",
+ ],
+)
+
+cc_library(
+ name = "circular_buffer_flexbuffers_generated_data",
+ srcs = [
+ "circular_buffer_flexbuffers_generated_data.cc",
+ ],
+ hdrs = [
+ "circular_buffer_flexbuffers_generated_data.h",
+ ],
+)
+
+cc_library(
+ name = "conv",
+ srcs = [
+ "conv_common.cc",
+ ] + select({
+ "//conditions:default": [
+ "conv.cc",
+ ],
+ ":xtensa_hifimini": [
+ "xtensa/conv.cc",
+ ],
+ }),
+ hdrs = ["conv.h"],
+ copts = micro_copts(),
+ visibility = [
+ # Kernel variants need to be visible to the examples and benchmarks.
+ ":micro",
+ ],
+ deps = [
+ ":fixedpoint_utils",
+ ":kernel_util",
+ ":xtensa",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:common",
+ "//tensorflow/lite/kernels/internal:quantization_util",
+ "//tensorflow/lite/kernels/internal:reference_base",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/kernels:kernel_util",
+ "//tensorflow/lite/kernels:padding",
+ ] + select({
+ "//conditions:default": [],
+ ":xtensa_hifimini": [
+ #"//third_party/xtensa/cstub64s:hifi_mini",
+ ],
+ }),
+)
+
+cc_library(
+ name = "conv_test_common",
+ srcs = [
+ "conv_test_common.cc",
+ ],
+ hdrs = [
+ "conv_test.h",
+ ],
+ deps = [
+ ":kernel_runner",
+ ":micro_ops",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_library(
+ name = "depthwise_conv",
+ srcs = [
+ "depthwise_conv_common.cc",
+ ] + select({
+ "//conditions:default": [
+ "depthwise_conv.cc",
+ ],
+ ":xtensa_hifimini": [
+ "xtensa/depthwise_conv.cc",
+ ],
+ }),
+ hdrs = ["depthwise_conv.h"],
+ copts = micro_copts(),
+ visibility = [
+ # Kernel variants need to be visible to the examples and benchmarks.
+ ":micro",
+ ],
+ deps = [
+ ":conv",
+ ":fixedpoint_utils",
+ ":kernel_util",
+ ":xtensa",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:common",
+ "//tensorflow/lite/kernels/internal:quantization_util",
+ "//tensorflow/lite/kernels/internal:reference_base",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/kernels:kernel_util",
+ "//tensorflow/lite/kernels:padding",
+ ] + select({
+ "//conditions:default": [],
+ ":xtensa_hifimini": [
+ #"//third_party/xtensa/cstub64s:hifi_mini",
+ ],
+ }),
+)
+
+cc_library(
+ name = "ethosu",
+ srcs = [
+ "ethosu.cc",
+ ],
+ hdrs = ["ethosu.h"],
+ copts = micro_copts(),
+ visibility = [
+ # Kernel variants need to be visible to the examples and benchmarks.
+ ":micro",
+ ],
+ deps = [
+ "//tensorflow/lite/c:common",
+ ],
+)
+
+cc_library(
+ name = "fixedpoint_utils",
+ hdrs = select({
+ "//conditions:default": [
+ ],
+ ":xtensa_hifimini": [
+ "xtensa/fixedpoint_utils.h",
+ ],
+ }),
+ copts = micro_copts(),
+ deps = [
+ ":xtensa",
+ ] + select({
+ "//conditions:default": [],
+ ":xtensa_hifimini": [
+ #"//third_party/xtensa/cstub64s:hifi_mini",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ ],
+ }),
+)
+
+cc_library(
+ name = "detection_postprocess_flexbuffers_generated_data",
+ srcs = [
+ "detection_postprocess_flexbuffers_generated_data.cc",
+ ],
+ hdrs = [
+ "detection_postprocess_flexbuffers_generated_data.h",
+ ],
+)
+
+cc_library(
+ name = "fully_connected",
+ srcs = [
+ "fully_connected_common.cc",
+ ] + select({
+ "//conditions:default": [
+ "fully_connected.cc",
+ ],
+ ":xtensa_hifimini": [
+ "xtensa/fully_connected.cc",
+ ],
+ }),
+ hdrs = ["fully_connected.h"],
+ copts = micro_copts(),
+ visibility = [
+ # Kernel variants need to be visible to the examples and benchmarks.
+ ":micro",
+ ],
+ deps = [
+ ":fixedpoint_utils",
+ ":kernel_util",
+ ":xtensa",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels:kernel_util",
+ "//tensorflow/lite/kernels/internal:common",
+ "//tensorflow/lite/kernels/internal:quantization_util",
+ "//tensorflow/lite/kernels/internal:reference_base",
+ "//tensorflow/lite/kernels/internal:tensor",
+ ] + select({
+ "//conditions:default": [],
+ ":xtensa_hifimini": [
+ #"//third_party/xtensa/cstub64s:hifi_mini",
+ ],
+ }),
+)
+
+cc_library(
+ name = "kernel_runner",
+ srcs = [
+ "kernel_runner.cc",
+ ],
+ hdrs = ["kernel_runner.h"],
+ visibility = [
+ "//visibility:public",
+ ],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ ],
+)
+
+cc_library(
+ name = "kernel_util",
+ srcs = [
+ "kernel_util.cc",
+ ],
+ hdrs = ["kernel_util.h"],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "//tensorflow/lite/kernels/internal:types",
+ "//tensorflow/lite/micro:debug_log",
+ ],
+)
+
+cc_library(
+ name = "micro_ops",
+ srcs = [
+ "activations.cc",
+ "hard_swish.cc",
+ "add.cc",
+ "add_n.cc",
+ "arg_min_max.cc",
+ "batch_to_space_nd.cc",
+ "cast.cc",
+ "ceil.cc",
+ "circular_buffer.cc",
+ "comparisons.cc",
+ "concatenation.cc",
+ "cumsum.cc",
+ "dequantize.cc",
+ "detection_postprocess.cc",
+ "elementwise.cc",
+ "elu.cc",
+ "exp.cc",
+ "expand_dims.cc",
+ "fill.cc",
+ "floor.cc",
+ "floor_div.cc",
+ "floor_mod.cc",
+ "l2norm.cc",
+ "l2_pool_2d.cc",
+ "leaky_relu.cc",
+ "logical.cc",
+ "logistic.cc",
+ "maximum_minimum.cc",
+ "mul.cc",
+ "neg.cc",
+ "pack.cc",
+ "pad.cc",
+ "pooling.cc",
+ "prelu.cc",
+ "quantize_common.cc",
+ "reduce.cc",
+ "reshape.cc",
+ "resize_nearest_neighbor.cc",
+ "round.cc",
+ "shape.cc",
+ "softmax_common.cc",
+ "space_to_batch_nd.cc",
+ "split.cc",
+ "split_v.cc",
+ "squeeze.cc",
+ "strided_slice.cc",
+ "sub.cc",
+ "svdf_common.cc",
+ "tanh.cc",
+ "transpose_conv.cc",
+ "unpack.cc",
+ "zeros_like.cc",
+ ] + select({
+ "//conditions:default": [
+ "quantize.cc",
+ "softmax.cc",
+ "svdf.cc",
+ ],
+ ":xtensa_hifimini": [
+ "xtensa/quantize.cc",
+ "xtensa/softmax.cc",
+ "xtensa/svdf.cc",
+ ],
+ }),
+ hdrs = [
+ "micro_ops.h",
+ "quantize.h",
+ "softmax.h",
+ "svdf.h",
+ ],
+ copts = micro_copts(),
+ visibility = [
+ # Needed for micro:op_resolvers but visibility can not be finer-grained
+ # than a package.
+ ":micro_top_level",
+ ],
+ deps = [
+ ":activation_utils",
+ ":fixedpoint_utils",
+ ":kernel_util",
+ ":micro_utils",
+ ":xtensa",
+ "@flatbuffers",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels:kernel_util",
+ "//tensorflow/lite/kernels:op_macros",
+ "//tensorflow/lite/kernels:padding",
+ "//tensorflow/lite/kernels/internal:common",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "//tensorflow/lite/kernels/internal:quantization_util",
+ "//tensorflow/lite/kernels/internal:reference_base",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/kernels/internal:types",
+ "//tensorflow/lite/micro:memory_helpers",
+ "//tensorflow/lite/micro:micro_utils",
+ ] + select({
+ "//conditions:default": [],
+ ":xtensa_hifimini": [
+ #"//third_party/xtensa/cstub64s:hifi_mini",
+ ],
+ }),
+)
+
+cc_library(
+ name = "micro_utils",
+ hdrs = ["micro_utils.h"],
+)
+
+cc_library(
+ name = "xtensa",
+ hdrs = select({
+ "//conditions:default": [
+ ],
+ ":xtensa_hifimini": [
+ "xtensa/xtensa.h",
+ ],
+ }),
+ copts = micro_copts(),
+ deps = select({
+ "//conditions:default": [],
+ ":xtensa_hifimini": [
+ #"//third_party/xtensa/cstub64s:hifi_mini",
+ ],
+ }),
+)
+
+####################################
+# C++ tests
+####################################
+
+cc_test(
+ name = "activations_test",
+ srcs = [
+ "activations_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "add_n_test",
+ srcs = [
+ "add_n_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "add_test",
+ srcs = [
+ "add_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "arg_min_max_test",
+ srcs = [
+ "arg_min_max_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "batch_to_space_nd_test",
+ srcs = [
+ "batch_to_space_nd_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "cast_test",
+ srcs = ["cast_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "ceil_test",
+ srcs = [
+ "ceil_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "circular_buffer_test",
+ srcs = [
+ "circular_buffer_test.cc",
+ ],
+ deps = [
+ "circular_buffer_flexbuffers_generated_data",
+ ":kernel_runner",
+ ":micro_ops",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "comparisons_test",
+ srcs = [
+ "comparisons_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "concatenation_test",
+ srcs = [
+ "concatenation_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "conv_test",
+ srcs = [
+ "conv_test.cc",
+ ],
+ deps = [
+ ":conv_test_common",
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_utils",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "cumsum_test",
+ srcs = [
+ "cumsum_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "depthwise_conv_test",
+ srcs = [
+ "depthwise_conv_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "dequantize_test",
+ srcs = [
+ "dequantize_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "detection_postprocess_test",
+ srcs = [
+ "detection_postprocess_test.cc",
+ ],
+ deps = [
+ ":detection_postprocess_flexbuffers_generated_data",
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ "@flatbuffers",
+ ],
+)
+
+cc_test(
+ name = "elementwise_test",
+ srcs = ["elementwise_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "elu_test",
+ srcs = [
+ "elu_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "exp_test",
+ srcs = ["exp_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "expand_dims_test",
+ srcs = ["expand_dims_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "fill_test",
+ srcs = [
+ "fill_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "floor_div_test",
+ srcs = ["floor_div_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "floor_mod_test",
+ srcs = ["floor_mod_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "floor_test",
+ srcs = [
+ "floor_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "fully_connected_test",
+ srcs = [
+ "fully_connected_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_utils",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "hard_swish_test",
+ srcs = ["hard_swish_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "l2norm_test",
+ srcs = [
+ "l2norm_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "l2_pool_2d_test",
+ srcs = [
+ "l2_pool_2d_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "leaky_relu_test",
+ srcs = [
+ "leaky_relu_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "logical_test",
+ srcs = [
+ "logical_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "logistic_test",
+ srcs = [
+ "logistic_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "maximum_minimum_test",
+ srcs = [
+ "maximum_minimum_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "mul_test",
+ srcs = [
+ "mul_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "neg_test",
+ srcs = [
+ "neg_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "pack_test",
+ srcs = [
+ "pack_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "pad_test",
+ srcs = [
+ "pad_test.cc",
+ ],
+ tags = [
+ "noasan",
+ "nomsan", # TODO(b/175133159): currently failing with asan and msan
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "pooling_test",
+ srcs = [
+ "pooling_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "prelu_test",
+ srcs = [
+ "prelu_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "quantization_util_test",
+ srcs = [
+ "quantization_util_test.cc",
+ ],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:quantization_util",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "quantize_test",
+ srcs = [
+ "quantize_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "reduce_test",
+ srcs = [
+ "reduce_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "reshape_test",
+ srcs = [
+ "reshape_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/kernels/internal:tensor",
+ "//tensorflow/lite/micro:micro_utils",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "resize_nearest_neighbor_test",
+ srcs = [
+ "resize_nearest_neighbor_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "round_test",
+ srcs = [
+ "round_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "shape_test",
+ srcs = ["shape_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "softmax_test",
+ srcs = [
+ "softmax_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "space_to_batch_nd_test",
+ srcs = [
+ "space_to_batch_nd_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_utils",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "split_test",
+ srcs = [
+ "split_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "split_v_test",
+ srcs = [
+ "split_v_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "squeeze_test",
+ srcs = ["squeeze_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "strided_slice_test",
+ srcs = [
+ "strided_slice_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "sub_test",
+ srcs = [
+ "sub_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "svdf_test",
+ srcs = [
+ "svdf_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "tanh_test",
+ srcs = ["tanh_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "transpose_conv_test",
+ srcs = [
+ "transpose_conv_test.cc",
+ ],
+ deps = [
+ ":conv_test_common",
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_utils",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "unpack_test",
+ srcs = [
+ "unpack_test.cc",
+ ],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "zeros_like_test",
+ srcs = ["zeros_like_test.cc"],
+ deps = [
+ ":kernel_runner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:debug_log",
+ "//tensorflow/lite/micro:op_resolvers",
+ "//tensorflow/lite/micro:test_helpers",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
diff --git a/tensorflow/lite/micro/kernels/activation_utils.h b/tensorflow/lite/micro/kernels/activation_utils.h
new file mode 100644
index 0000000..95ecc26
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/activation_utils.h
@@ -0,0 +1,57 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_ACTIVATION_UTILS_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_ACTIVATION_UTILS_H_
+
+#include <algorithm>
+#include <cmath>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/max.h"
+#include "tensorflow/lite/kernels/internal/min.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+
+// Returns the floating point value for a fused activation:
+inline float ActivationValFloat(TfLiteFusedActivation act, float a) {
+ switch (act) {
+ case kTfLiteActNone:
+ return a;
+ case kTfLiteActRelu:
+ return TfLiteMax(0.0f, a);
+ case kTfLiteActReluN1To1:
+ return TfLiteMax(-1.0f, TfLiteMin(a, 1.0f));
+ case kTfLiteActRelu6:
+ return TfLiteMax(0.0f, TfLiteMin(a, 6.0f));
+ case kTfLiteActTanh:
+ return std::tanh(a);
+ case kTfLiteActSignBit:
+ return std::signbit(a);
+ case kTfLiteActSigmoid:
+ return 1.0f / (1.0f + std::exp(-a));
+ }
+ return 0.0f; // To indicate an unsupported activation (i.e. when a new fused
+ // activation is added to the enum and not handled here).
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_ACTIVATION_UTILS_H_
diff --git a/tensorflow/lite/micro/kernels/activations.cc b/tensorflow/lite/micro/kernels/activations.cc
new file mode 100644
index 0000000..a92d5c7
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/activations.cc
@@ -0,0 +1,288 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace activations {
+namespace {
+
+struct ReluOpData {
+ ReluParams params;
+};
+
+struct Relu6OpData {
+ int8_t six_int8;
+ int8_t zero_int8;
+ uint8_t six_uint8;
+ uint8_t zero_uint8;
+};
+
+} // namespace
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+template <typename T>
+inline void ReluQuantized(const ReluOpData& data,
+ const RuntimeShape& input_shape,
+ const RuntimeShape& output_shape, const T* input_data,
+ T* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ const int32_t val = static_cast<int32_t>(input_data[i]);
+ int32_t clamped =
+ data.params.output_offset +
+ MultiplyByQuantizedMultiplier(val - data.params.input_offset,
+ data.params.output_multiplier,
+ data.params.output_shift);
+ clamped = std::max(data.params.quantized_activation_min, clamped);
+ clamped = std::min(data.params.quantized_activation_max, clamped);
+ output_data[i] = static_cast<T>(clamped);
+ }
+}
+
+template <typename T>
+inline void CalculateReluOpData(const TfLiteTensor* input, TfLiteTensor* output,
+ ReluOpData* data) {
+ float act_min = 0.0;
+ float act_max = std::numeric_limits<float>::infinity();
+ double real_multiplier =
+ static_cast<double>(input->params.scale / output->params.scale);
+
+ const RuntimeShape input_shape = GetTensorShape(input);
+ const RuntimeShape output_shape = GetTensorShape(output);
+
+ QuantizeMultiplier(real_multiplier, &data->params.output_multiplier,
+ &data->params.output_shift);
+
+ data->params.quantized_activation_min = std::max(
+ static_cast<int32_t>(std::numeric_limits<T>::min()),
+ output->params.zero_point +
+ static_cast<int32_t>(roundf(act_min / output->params.scale)));
+ data->params.quantized_activation_max =
+ act_max == std::numeric_limits<float>::infinity()
+ ? static_cast<int32_t>(std::numeric_limits<T>::max())
+ : std::min(static_cast<int32_t>(std::numeric_limits<T>::max()),
+ output->params.zero_point +
+ static_cast<int32_t>(
+ roundf(act_max / output->params.scale)));
+ data->params.input_offset = input->params.zero_point;
+ data->params.output_offset = output->params.zero_point;
+}
+
+inline void ReluFloat(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ const float val = input_data[i];
+ const float lower = 0.0f;
+ const float clamped = val < lower ? lower : val;
+ output_data[i] = clamped;
+ }
+}
+
+inline void Relu6Float(const RuntimeShape& input_shape, const float* input_data,
+ const RuntimeShape& output_shape, float* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ const float val = input_data[i];
+ const float upper = 6.0f;
+ const float lower = 0.0f;
+ const float clamped = val > upper ? upper : val < lower ? lower : val;
+ output_data[i] = clamped;
+ }
+}
+
+template <typename Q>
+inline void Relu6Quantized(Q lower, Q upper, const RuntimeShape& input_shape,
+ const Q* input_data,
+ const RuntimeShape& output_shape, Q* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ for (int i = 0; i < flat_size; ++i) {
+ const Q val = input_data[i];
+ const Q clamped = val > upper ? upper : val < lower ? lower : val;
+ output_data[i] = clamped;
+ }
+}
+
+void* ReluInit(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(ReluOpData));
+}
+
+TfLiteStatus ReluPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ ReluOpData* data = static_cast<ReluOpData*>(node->user_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ if (input->type == kTfLiteInt8) {
+ CalculateReluOpData<int8_t>(input, output, data);
+ } else if (input->type == kTfLiteUInt8) {
+ CalculateReluOpData<uint8_t>(input, output, data);
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus ReluEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const ReluOpData& data = *(static_cast<const ReluOpData*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ ReluFloat(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+
+ return kTfLiteOk;
+ }
+ case kTfLiteInt8: {
+ ReluQuantized<int8_t>(data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+ }
+ case kTfLiteUInt8: {
+ ReluQuantized<uint8_t>(data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ return kTfLiteOk;
+ }
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Only float32 is supported currently, got %s",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ }
+}
+
+void* Relu6Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(Relu6OpData));
+}
+
+TfLiteStatus Relu6Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ Relu6OpData* data = static_cast<Relu6OpData*>(node->user_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+
+ if (input->type == kTfLiteInt8) {
+ data->six_int8 = FloatToQuantizedType<int8_t>(6.0f, input->params.scale,
+ input->params.zero_point);
+ data->zero_int8 = input->params.zero_point;
+ } else if (input->type == kTfLiteUInt8) {
+ data->six_uint8 = FloatToQuantizedType<uint8_t>(6.0f, input->params.scale,
+ input->params.zero_point);
+ data->zero_uint8 = input->params.zero_point;
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Relu6Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const Relu6OpData& data = *(static_cast<const Relu6OpData*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ Relu6Float(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+
+ return kTfLiteOk;
+ }
+ case kTfLiteInt8: {
+ Relu6Quantized<int8_t>(data.zero_int8, data.six_int8,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+ }
+ case kTfLiteUInt8: {
+ Relu6Quantized<uint8_t>(data.zero_uint8, data.six_uint8,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ return kTfLiteOk;
+ }
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Only float32 is supported currently, got %s",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ }
+}
+
+} // namespace activations
+
+TfLiteRegistration Register_RELU() {
+ return {/*init=*/activations::ReluInit,
+ /*free=*/nullptr,
+ /*prepare=*/activations::ReluPrepare,
+ /*invoke=*/activations::ReluEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_RELU6() {
+ return {/*init=*/activations::Relu6Init,
+ /*free=*/nullptr,
+ /*prepare=*/activations::Relu6Prepare,
+ /*invoke=*/activations::Relu6Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/activations_test.cc b/tensorflow/lite/micro/kernels/activations_test.cc
new file mode 100644
index 0000000..8e6dec4
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/activations_test.cc
@@ -0,0 +1,377 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestReluFloat(const int* input_dims_data, const float* input_data,
+ const int* output_dims_data, const float* golden,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_RELU();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestRelu6Float(const int* input_dims_data, const float* input_data,
+ const int* output_dims_data, const float* golden,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_RELU6();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestReluUint8(const int* input_dims_data, const float* input_data,
+ uint8_t* input_data_quantized, const float input_scale,
+ const int input_zero_point, const float* golden,
+ uint8_t* golden_quantized, const int* output_dims_data,
+ const float output_scale, const int output_zero_point,
+ uint8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_data_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_RELU();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ Quantize(golden, golden_quantized, output_elements_count, output_scale,
+ output_zero_point);
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden_quantized[i], output_data[i]);
+ }
+}
+
+void TestRelu6Uint8(const int* input_dims_data, const float* input_data,
+ uint8_t* input_data_quantized, const float input_scale,
+ const int input_zero_point, const float* golden,
+ uint8_t* golden_quantized, const int* output_dims_data,
+ const float output_scale, const int output_zero_point,
+ uint8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_data_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_RELU6();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ Quantize(golden, golden_quantized, output_elements_count, output_scale,
+ output_zero_point);
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden_quantized[i], output_data[i]);
+ }
+}
+
+void TestReluInt8(const int* input_dims_data, const float* input_data,
+ int8_t* input_data_quantized, const float input_scale,
+ const int input_zero_point, const float* golden,
+ int8_t* golden_quantized, const int* output_dims_data,
+ const float output_scale, const int output_zero_point,
+ int8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_data_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_RELU();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ Quantize(golden, golden_quantized, output_elements_count, output_scale,
+ output_zero_point);
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden_quantized[i], output_data[i]);
+ }
+}
+
+void TestRelu6Int8(const int* input_dims_data, const float* input_data,
+ int8_t* input_data_quantized, const float input_scale,
+ const int input_zero_point, const float* golden,
+ int8_t* golden_quantized, const int* output_dims_data,
+ const float output_scale, const int output_zero_point,
+ int8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_data_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_RELU6();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ Quantize(golden, golden_quantized, output_elements_count, output_scale,
+ output_zero_point);
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden_quantized[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SimpleReluTestFloat) {
+ const int output_elements_count = 10;
+ const int input_shape[] = {2, 1, 5};
+ const float input_data[] = {
+ 1.0, 2.0, 3.0, 4.0, 5.0, -1.0, -2.0, -3.0, -4.0, -5.0,
+ };
+ const float golden[] = {1.0, 2.0, 3.0, 4.0, 5.0, 0, 0, 0, 0, 0};
+ const int output_shape[] = {2, 1, 5};
+ float output_data[output_elements_count];
+ tflite::testing::TestReluFloat(input_shape, input_data, output_shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleRelu6TestFloat) {
+ const int output_elements_count = 10;
+ float output_data[output_elements_count];
+ const int input_shape[] = {2, 1, 5};
+ const float input_data[] = {4.0, 5.0, 6.0, 7.0, 8.0,
+ -4.0, -5.0, -6.0, -7.0, -8.0};
+ const int output_shape[] = {2, 1, 5};
+ const float golden[] = {
+ 4.0, 5.0, 6.0, 6.0, 6.0, 0.0, 0.0, 0.0, 0.0, 0.0,
+ };
+
+ tflite::testing::TestRelu6Float(input_shape, input_data, output_shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleReluTestUint8) {
+ const int elements_count = 10;
+
+ const int input_shape[] = {2, 1, 5};
+ const float input_data[] = {1, 2, 3, 4, 5, -1, -2, -3, -4, -5};
+ uint8_t input_quantized[elements_count];
+ const int output_shape[] = {2, 1, 5};
+ const float golden[] = {1, 2, 3, 4, 5, 0, 0, 0, 0, 0};
+ uint8_t golden_quantized[elements_count];
+ uint8_t output_data[elements_count];
+
+ const float input_scale = 0.5f;
+ const int input_zero_point = 127;
+ const float output_scale = 0.5f;
+ const int output_zero_point = 127;
+
+ tflite::testing::TestReluUint8(input_shape, input_data, input_quantized,
+ input_scale, input_zero_point, golden,
+ golden_quantized, output_shape, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleRelu6TestUint8) {
+ const int elements_count = 10;
+
+ const int input_shape[] = {2, 1, 5};
+ const float input_data[] = {4, 5, 6, 7, 8, -1, -2, -3, -4, -5};
+ uint8_t input_quantized[elements_count];
+ const int output_shape[] = {2, 1, 5};
+ const float golden[] = {4, 5, 6, 6, 6, 0, 0, 0, 0, 0};
+ uint8_t golden_quantized[elements_count];
+ uint8_t output_data[elements_count];
+
+ const float input_scale = 0.5f;
+ const int input_zero_point = 127;
+ const float output_scale = 0.5f;
+ const int output_zero_point = 127;
+
+ tflite::testing::TestRelu6Uint8(input_shape, input_data, input_quantized,
+ input_scale, input_zero_point, golden,
+ golden_quantized, output_shape, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleReluTestInt8) {
+ const int elements_count = 10;
+
+ const int input_shape[] = {2, 1, 5};
+ const float input_data[] = {1, 2, 3, 4, 5, -1, -2, -3, -4, -5};
+ int8_t input_quantized[elements_count];
+ const int output_shape[] = {2, 1, 5};
+ const float golden[] = {1, 2, 3, 4, 5, 0, 0, 0, 0, 0};
+ int8_t golden_quantized[elements_count];
+ int8_t output_data[elements_count];
+
+ const float input_scale = 0.5f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5f;
+ const int output_zero_point = 0;
+
+ tflite::testing::TestReluInt8(input_shape, input_data, input_quantized,
+ input_scale, input_zero_point, golden,
+ golden_quantized, output_shape, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleRelu6TestInt8) {
+ const int elements_count = 10;
+
+ const int input_shape[] = {2, 1, 5};
+ const float input_data[] = {4, 5, 6, 7, 8, -1, -2, -3, -4, -5};
+ int8_t input_quantized[elements_count];
+ const int output_shape[] = {2, 1, 5};
+ const float golden[] = {4, 5, 6, 6, 6, 0, 0, 0, 0, 0};
+ int8_t golden_quantized[elements_count];
+ int8_t output_data[elements_count];
+
+ const float input_scale = 0.5f;
+ const int input_zero_point = 127;
+ const float output_scale = 0.5f;
+ const int output_zero_point = 127;
+
+ tflite::testing::TestRelu6Int8(input_shape, input_data, input_quantized,
+ input_scale, input_zero_point, golden,
+ golden_quantized, output_shape, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/add.cc b/tensorflow/lite/micro/kernels/add.cc
new file mode 100644
index 0000000..e50d22c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/add.cc
@@ -0,0 +1,261 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/add.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/add.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace add {
+
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ bool requires_broadcast;
+
+ // These fields are used in both the general 8-bit -> 8bit quantized path,
+ // and the special 16-bit -> 16bit quantized path
+ int input1_shift;
+ int input2_shift;
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+
+ // These fields are used only in the general 8-bit -> 8bit quantized path
+ int32_t input1_multiplier;
+ int32_t input2_multiplier;
+ int32_t output_multiplier;
+ int output_shift;
+ int left_shift;
+ int32_t input1_offset;
+ int32_t input2_offset;
+ int32_t output_offset;
+
+ // Used only for float evals:
+ float output_activation_min_f32;
+ float output_activation_max_f32;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteAddParams* params,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2, TfLiteTensor* output,
+ OpData* data) {
+ data->requires_broadcast = !HaveSameShapes(input1, input2);
+
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ // 8bit -> 8bit general quantized path, with general rescalings
+ data->input1_offset = -input1->params.zero_point;
+ data->input2_offset = -input2->params.zero_point;
+ data->output_offset = output->params.zero_point;
+ data->left_shift = 20;
+ const double twice_max_input_scale =
+ 2 * static_cast<double>(
+ std::max(input1->params.scale, input2->params.scale));
+ const double real_input1_multiplier =
+ static_cast<double>(input1->params.scale) / twice_max_input_scale;
+ const double real_input2_multiplier =
+ static_cast<double>(input2->params.scale) / twice_max_input_scale;
+ const double real_output_multiplier =
+ twice_max_input_scale /
+ ((1 << data->left_shift) * static_cast<double>(output->params.scale));
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_input1_multiplier, &data->input1_multiplier, &data->input1_shift);
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_input2_multiplier, &data->input2_multiplier, &data->input2_shift);
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_output_multiplier, &data->output_multiplier, &data->output_shift);
+
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, params->activation, output, &data->output_activation_min,
+ &data->output_activation_max));
+ } else if (output->type == kTfLiteFloat32) {
+ CalculateActivationRange(params->activation,
+ &data->output_activation_min_f32,
+ &data->output_activation_max_f32);
+ }
+
+ return kTfLiteOk;
+}
+
+void EvalAdd(TfLiteContext* context, TfLiteNode* node, TfLiteAddParams* params,
+ const OpData* data, const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2, TfLiteEvalTensor* output) {
+ tflite::ArithmeticParams op_params;
+ SetActivationParams(data->output_activation_min_f32,
+ data->output_activation_max_f32, &op_params);
+ if (data->requires_broadcast) {
+ reference_ops::BroadcastAdd4DSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<float>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<float>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ } else {
+ reference_ops::Add(op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<float>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<float>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ }
+}
+
+TfLiteStatus EvalAddQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLiteAddParams* params, const OpData* data,
+ const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2,
+ TfLiteEvalTensor* output) {
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ tflite::ArithmeticParams op_params;
+ op_params.left_shift = data->left_shift;
+ op_params.input1_offset = data->input1_offset;
+ op_params.input1_multiplier = data->input1_multiplier;
+ op_params.input1_shift = data->input1_shift;
+ op_params.input2_offset = data->input2_offset;
+ op_params.input2_multiplier = data->input2_multiplier;
+ op_params.input2_shift = data->input2_shift;
+ op_params.output_offset = data->output_offset;
+ op_params.output_multiplier = data->output_multiplier;
+ op_params.output_shift = data->output_shift;
+ SetActivationParams(data->output_activation_min,
+ data->output_activation_max, &op_params);
+ bool need_broadcast = reference_ops::ProcessBroadcastShapes(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2), &op_params);
+ if (output->type == kTfLiteInt8) {
+ if (need_broadcast) {
+ reference_integer_ops::BroadcastAdd4DSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<int8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ } else {
+ reference_integer_ops::Add(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<int8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+ } else {
+ if (need_broadcast) {
+ reference_ops::BroadcastAdd4DSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<uint8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<uint8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ reference_ops::Add(op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<uint8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<uint8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ }
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ const TfLiteTensor* input1 = GetInput(context, node, kInputTensor1);
+ TF_LITE_ENSURE(context, input1 != nullptr);
+ const TfLiteTensor* input2 = GetInput(context, node, kInputTensor2);
+ TF_LITE_ENSURE(context, input2 != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ auto* params = reinterpret_cast<TfLiteAddParams*>(node->builtin_data);
+
+ TF_LITE_ENSURE_STATUS(
+ CalculateOpData(context, params, input1, input2, output, data));
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = reinterpret_cast<TfLiteAddParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ if (output->type == kTfLiteFloat32) {
+ EvalAdd(context, node, params, data, input1, input2, output);
+ } else if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_OK(context, EvalAddQuantized(context, node, params, data,
+ input1, input2, output));
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(output->type), output->type);
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace add
+
+TfLiteRegistration Register_ADD() {
+ return {/*init=*/add::Init,
+ /*free=*/nullptr,
+ /*prepare=*/add::Prepare,
+ /*invoke=*/add::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/add_n.cc b/tensorflow/lite/micro/kernels/add_n.cc
new file mode 100644
index 0000000..b57a2ae
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/add_n.cc
@@ -0,0 +1,215 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/add_n.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+constexpr int kInputTensor0 = 0;
+constexpr int kOutputTensor = 0;
+
+constexpr int kAddNIntegerShift = 20;
+
+// only used with INT8 tensors
+struct OpData {
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+ int32_t input_offset;
+ int32_t output_offset;
+ int32_t input_multiplier;
+ int32_t output_multiplier;
+ int input_shift;
+ int output_shift;
+ int left_shift;
+ int scratch_index;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node) {
+ int num_inputs = NumInputs(node);
+ TF_LITE_ENSURE(context, num_inputs >= 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input_tensor_first;
+ TF_LITE_ENSURE_OK(
+ context, GetInputSafe(context, node, kInputTensor0, &input_tensor_first));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ // Check that all tensors have the same shape and type.
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, input_tensor_first->type);
+ for (int i = kInputTensor0 + 1; i < num_inputs; ++i) {
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, i, &input));
+ TF_LITE_ENSURE(context, HaveSameShapes(input_tensor_first, input));
+ TF_LITE_ENSURE_TYPES_EQ(context, input_tensor_first->type, input->type);
+
+ // Check that all INT8 input tensors have the same zero-point and scale.
+ if (input_tensor_first->type == kTfLiteInt8) {
+ TF_LITE_ENSURE(context, input_tensor_first->params.zero_point ==
+ input->params.zero_point);
+ TF_LITE_ENSURE(context,
+ input_tensor_first->params.scale == input->params.scale);
+ }
+ }
+
+ if (output->type == kTfLiteFloat32) {
+ // Allocate scratch buffer space for pointer to each tensor's data
+ // and store the scratch buffer index in the node's user_data
+ int scratch_index;
+ size_t scratch_size = sizeof(float*) * num_inputs;
+ TF_LITE_ENSURE_OK(context, context->RequestScratchBufferInArena(
+ context, scratch_size, &scratch_index));
+ node->user_data =
+ reinterpret_cast<decltype(node->user_data)>(scratch_index);
+ } else if (output->type == kTfLiteInt8) {
+ node->user_data =
+ context->AllocatePersistentBuffer(context, sizeof(OpData));
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ // Allocate scratch buffer space for pointer to each tensor's data
+ // and store the scratch buffer index in OpData
+ size_t scratch_size = sizeof(int8_t*) * num_inputs;
+ TF_LITE_ENSURE_OK(
+ context, context->RequestScratchBufferInArena(context, scratch_size,
+ &data->scratch_index));
+
+ // 8bit -> 8bit general quantized path, with general rescalings
+ data->input_offset = -input_tensor_first->params.zero_point;
+ data->output_offset = output->params.zero_point;
+ data->left_shift = kAddNIntegerShift;
+ const double twice_max_input_scale =
+ 2 * static_cast<double>(input_tensor_first->params.scale);
+ const double real_input_multiplier =
+ static_cast<double>(input_tensor_first->params.scale) /
+ twice_max_input_scale;
+ const double real_output_multiplier =
+ twice_max_input_scale /
+ ((1 << data->left_shift) * static_cast<double>(output->params.scale));
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_input_multiplier, &data->input_multiplier, &data->input_shift);
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_output_multiplier, &data->output_multiplier, &data->output_shift);
+
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, kTfLiteActNone, output, &data->output_activation_min,
+ &data->output_activation_max));
+ } else {
+ TF_LITE_KERNEL_LOG(context, "ADD_N only supports FLOAT32 and INT8, got %s.",
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ return CalculateOpData(context, node);
+}
+
+template <typename T>
+inline const T** CopyInputsToScratchBuffer(TfLiteContext* context,
+ TfLiteNode* node,
+ const int scratch_index) {
+ int num_inputs = NumInputs(node);
+ void* scratch_buffer = context->GetScratchBuffer(context, scratch_index);
+ const T** all_inputs = static_cast<decltype(all_inputs)>(scratch_buffer);
+ for (int i = 0; i < num_inputs; i++) {
+ const TfLiteEvalTensor* next_input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor0 + i);
+ all_inputs[i] = tflite::micro::GetTensorData<T>(next_input);
+ }
+
+ return all_inputs;
+}
+
+template <typename T>
+void EvalAddN(TfLiteContext* context, TfLiteNode* node,
+ TfLiteEvalTensor* output) {
+ int num_inputs = NumInputs(node);
+
+ int scratch_index =
+ static_cast<int>(reinterpret_cast<intptr_t>(node->user_data));
+ const T** all_inputs =
+ CopyInputsToScratchBuffer<T>(context, node, scratch_index);
+
+ reference_ops::AddN<T>(tflite::micro::GetTensorShape(output), num_inputs,
+ all_inputs, tflite::micro::GetTensorData<T>(output));
+}
+
+template <typename T>
+void EvalAddNQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLiteEvalTensor* output) {
+ int num_inputs = NumInputs(node);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const T** all_inputs =
+ CopyInputsToScratchBuffer<T>(context, node, data->scratch_index);
+
+ ArithmeticParams params;
+ params.left_shift = data->left_shift;
+ params.input1_offset = data->input_offset;
+ params.input1_multiplier = data->input_multiplier;
+ params.input1_shift = data->input_shift;
+ params.output_offset = data->output_offset;
+ params.output_multiplier = data->output_multiplier;
+ params.output_shift = data->output_shift;
+ SetActivationParams(data->output_activation_min, data->output_activation_max,
+ ¶ms);
+
+ reference_ops::AddN(params, tflite::micro::GetTensorShape(output), num_inputs,
+ all_inputs, tflite::micro::GetTensorData<T>(output));
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ if (output->type == kTfLiteFloat32) {
+ EvalAddN<float>(context, node, output);
+ } else if (output->type == kTfLiteInt8) {
+ EvalAddNQuantized<int8_t>(context, node, output);
+ } else {
+ TF_LITE_KERNEL_LOG(context, "ADD_N only supports FLOAT32 and INT8, got %s.",
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_ADD_N() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/add_n_test.cc b/tensorflow/lite/micro/kernels/add_n_test.cc
new file mode 100644
index 0000000..4ea7817
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/add_n_test.cc
@@ -0,0 +1,170 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <type_traits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int kMaxInputTensors = 3;
+constexpr int kMaxOutputTensors = 1;
+
+void ExecuteAddN(TfLiteTensor* tensors, int tensors_count) {
+ int input_array_data[kMaxInputTensors + kMaxOutputTensors] = {tensors_count -
+ 1};
+ for (int i = 1; i < tensors_count; i++) {
+ input_array_data[i] = i - 1;
+ }
+ TfLiteIntArray* inputs_array = IntArrayFromInts(input_array_data);
+ const int kOutputArrayData[] = {1, tensors_count - 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(kOutputArrayData);
+
+ const TfLiteRegistration registration = tflite::Register_ADD_N();
+ micro::KernelRunner runner(registration, tensors, tensors_count, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+}
+
+template <typename T>
+void TestAddN(const int* input_dims_data, const T* const* input_data,
+ int input_data_count, const int* expected_dims,
+ const T* expected_data, T* output_data) {
+ TF_LITE_MICRO_EXPECT_LE(input_data_count, kMaxInputTensors);
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ TfLiteTensor tensors[kMaxInputTensors + kMaxOutputTensors] = {};
+ for (int i = 0; i < input_data_count; i++) {
+ tensors[i] = CreateTensor(input_data[i], input_dims);
+ }
+ tensors[input_data_count] = CreateTensor(output_data, output_dims);
+
+ ExecuteAddN(tensors, input_data_count + 1);
+
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_data[i], output_data[i]);
+ }
+}
+
+// min/max are used to compute scale, zero-point, compare tolerance
+template <typename T, int kNumInputs, int kOutputSize>
+struct TestQuantParams {
+ float data_min; // input and output data minimum value
+ float data_max; // input and output data maximum value
+ T input_data[kNumInputs][kOutputSize]; // quantized input storage
+ T output_data[kOutputSize]; // quantized output storage
+};
+
+// for quantized Add, the error shouldn't exceed step
+template <typename T>
+float GetTolerance(float min, float max) {
+ float kQuantizedStep =
+ 2.0f * (max - min) /
+ (std::numeric_limits<T>::max() - std::numeric_limits<T>::min());
+ return kQuantizedStep;
+}
+
+template <typename T, int kNumInputs, int kOutputSize>
+void TestAddNQuantized(TestQuantParams<T, kNumInputs, kOutputSize>* params,
+ const int* input_dims_data,
+ const float* const* input_data, const int* expected_dims,
+ const float* expected_data, float* output_data) {
+ TF_LITE_MICRO_EXPECT_LE(kNumInputs, kMaxInputTensors);
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+
+ const float scale = ScaleFromMinMax<T>(params->data_min, params->data_max);
+ const int zero_point =
+ ZeroPointFromMinMax<T>(params->data_min, params->data_max);
+
+ TfLiteTensor tensors[kMaxInputTensors + kMaxOutputTensors] = {};
+ for (int i = 0; i < kNumInputs; i++) {
+ tensors[i] = CreateQuantizedTensor(input_data[i], params->input_data[i],
+ input_dims, scale, zero_point);
+ }
+ tensors[kNumInputs] = CreateQuantizedTensor(params->output_data, output_dims,
+ scale, zero_point);
+
+ ExecuteAddN(tensors, kNumInputs + 1);
+
+ Dequantize(params->output_data, kOutputSize, scale, zero_point, output_data);
+ const float kTolerance = GetTolerance<T>(params->data_min, params->data_max);
+ for (int i = 0; i < kOutputSize; i++) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_data[i], output_data[i], kTolerance);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatAddNOpAddMultipleTensors) {
+ constexpr int kDims[] = {4, 1, 2, 2, 1};
+ constexpr float kInput1[] = {-2.0, 0.2, 0.7, 0.8};
+ constexpr float kInput2[] = {0.1, 0.2, 0.3, 0.5};
+ constexpr float kInput3[] = {0.5, 0.1, 0.1, 0.2};
+ constexpr float kExpect[] = {-1.4, 0.5, 1.1, 1.5};
+ const float* kInputs[tflite::testing::kMaxInputTensors] = {
+ kInput1,
+ kInput2,
+ kInput3,
+ };
+ constexpr int kInputCount = std::extent<decltype(kInputs)>::value;
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestAddN(kDims, kInputs, kInputCount, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Int8AddNOpAddMultipleTensors) {
+ constexpr int kDims[] = {4, 1, 2, 2, 1};
+ constexpr float kInput1[] = {-2.0, 0.2, 0.7, 0.8};
+ constexpr float kInput2[] = {0.1, 0.2, 0.3, 0.5};
+ constexpr float kInput3[] = {0.5, 0.1, 0.1, 0.2};
+ constexpr float kExpect[] = {-1.4, 0.5, 1.1, 1.5};
+ const float* kInputs[tflite::testing::kMaxInputTensors] = {
+ kInput1,
+ kInput2,
+ kInput3,
+ };
+ constexpr int kInputCount = std::extent<decltype(kInputs)>::value;
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestQuantParams<int8_t, kInputCount, kOutputCount> params =
+ {};
+ params.data_min = -3.0;
+ params.data_max = 3.0;
+
+ tflite::testing::TestAddNQuantized<int8_t, kInputCount, kOutputCount>(
+ ¶ms, kDims, kInputs, kDims, kExpect, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/add_test.cc b/tensorflow/lite/micro/kernels/add_test.cc
new file mode 100644
index 0000000..66645a0
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/add_test.cc
@@ -0,0 +1,494 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Shapes and values for mixed broadcast tests.
+const int broadcast_output_dims_count = 36;
+const int broadcast_num_shapes = 4;
+
+const int broadcast_input1_shape[] = {4, 2, 3, 1, 2};
+const float broadcast_input1_values[] = {-0.3, 2.3, 0.9, 0.5, 0.8, -1.1,
+ 1.2, 2.8, -1.6, 0.0, 0.7, -2.2};
+const float broadcast_input2_values[] = {0.2, 0.3, -0.4, 0.5, 1.0, 0.9};
+const float
+ broadcast_goldens[broadcast_num_shapes][broadcast_output_dims_count] = {
+ {-0.1, 2.6, -0.7, 2.8, 0.7, 3.2, 1.1, 0.8, 0.5, 1.0, 1.9, 1.4,
+ 1.0, -0.8, 0.4, -0.6, 1.8, -0.2, 1.4, 3.1, 0.8, 3.3, 2.2, 3.7,
+ -1.4, 0.3, -2.0, 0.5, -0.6, 0.9, 0.9, -1.9, 0.3, -1.7, 1.7, -1.3},
+ {-0.1, 2.6, 0.5, 1.0, 1.8, -0.2, 1.4, 3.1, -2.0, 0.5, 1.7, -1.3},
+ {-0.1, 2.5, 0.0, 2.6, -0.7, 1.9, 1.1, 0.7, 1.2, 0.8, 0.5, 0.1,
+ 1.0, -0.9, 1.1, -0.8, 0.4, -1.5, 1.7, 3.3, 2.2, 3.8, 2.1, 3.7,
+ -1.1, 0.5, -0.6, 1.0, -0.7, 0.9, 1.2, -1.7, 1.7, -1.2, 1.6, -1.3},
+ {-0.1, 2.5, 1.2, 0.8, 0.4, -1.5, 1.7, 3.3, -0.6, 1.0, 1.6, -1.3},
+};
+
+const int broadcast_max_shape_size = 5;
+const int broadcast_input2_shapes[broadcast_num_shapes]
+ [broadcast_max_shape_size] = {
+ {4, 1, 1, 3, 2},
+ {4, 1, 3, 1, 2},
+ {4, 2, 1, 3, 1},
+ {4, 2, 3, 1, 1},
+};
+const int broadcast_output_shapes[broadcast_num_shapes]
+ [broadcast_max_shape_size] = {
+ {4, 2, 3, 3, 2},
+ {4, 2, 3, 1, 2},
+ {4, 2, 3, 3, 2},
+ {4, 2, 3, 1, 2},
+};
+
+template <typename T>
+void ValidateAddGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* golden, T* output, int output_size,
+ TfLiteFusedActivation activation,
+ float tolerance = 1e-5) {
+ TfLiteAddParams builtin_data;
+ builtin_data.activation = activation;
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_ADD();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, &builtin_data);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_size; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output[i], tolerance);
+ }
+}
+
+void TestAddFloat(const int* input1_dims_data, const float* input1_data,
+ const int* input2_dims_data, const float* input2_data,
+ const int* output_dims_data, const float* expected_output,
+ TfLiteFusedActivation activation, float* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateAddGoldens(tensors, tensors_size, expected_output, output_data,
+ ElementCount(*output_dims), activation);
+}
+
+template <typename T>
+void TestAddQuantized(const int* input1_dims_data, const float* input1_data,
+ T* input1_quantized, float input1_scale,
+ int input1_zero_point, const int* input2_dims_data,
+ const float* input2_data, T* input2_quantized,
+ float input2_scale, int input2_zero_point,
+ const int* output_dims_data, const float* golden,
+ T* golden_quantized, float output_scale,
+ int output_zero_point, TfLiteFusedActivation activation,
+ T* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ tflite::testing::CreateQuantizedTensor(input1_data, input1_quantized,
+ input1_dims, input1_scale,
+ input1_zero_point),
+ tflite::testing::CreateQuantizedTensor(input2_data, input2_quantized,
+ input2_dims, input2_scale,
+ input2_zero_point),
+ tflite::testing::CreateQuantizedTensor(output_data, output_dims,
+ output_scale, output_zero_point),
+ };
+ tflite::Quantize(golden, golden_quantized, ElementCount(*output_dims),
+ output_scale, output_zero_point);
+
+ ValidateAddGoldens(tensors, tensors_size, golden_quantized, output_data,
+ ElementCount(*output_dims), activation);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatAddNoActivation) {
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8};
+ const float input2_values[] = {0.1, 0.2, 0.3, 0.5};
+ const float golden_values[] = {-1.9, 0.4, 1.0, 1.3};
+ float output_data[output_dims_count];
+ tflite::testing::TestAddFloat(inout_shape, input1_values, inout_shape,
+ input2_values, inout_shape, golden_values,
+ kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatAddActivationRelu1) {
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8};
+ const float input2_values[] = {0.1, 0.2, 0.3, 0.5};
+ const float golden_values[] = {-1.0, 0.4, 1.0, 1.0};
+
+ float output_data[output_dims_count];
+ tflite::testing::TestAddFloat(inout_shape, input1_values, inout_shape,
+ input2_values, inout_shape, golden_values,
+ kTfLiteActReluN1To1, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatAddVariousInputShapes) {
+ const int output_dims_count = 6;
+ float output_data[output_dims_count];
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const float input2_values[] = {0.1, 0.2, 0.3, 0.5, 1.1, 0.1};
+ const float expected_output[] = {-1.9, 0.4, 1.0, 1.3, 2.2, 2.1};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestAddFloat(test_shapes[i], input1_values, test_shapes[i],
+ input2_values, test_shapes[i],
+ expected_output, kTfLiteActNone, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(FloatAddWithScalarBroadcast) {
+ const int output_dims_count = 6;
+ float output_data[output_dims_count];
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const int input2_shape[] = {0};
+ const float input2_values[] = {0.1};
+ const float expected_output[] = {-1.9, 0.3, 0.8, 0.9, 1.2, 2.1};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestAddFloat(test_shapes[i], input1_values, input2_shape,
+ input2_values, test_shapes[i],
+ expected_output, kTfLiteActNone, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddNoActivationUint8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {125, 129, 135};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {1.01, 1.99, 2.99, 4.02};
+ const float golden_values[] = {-1, 1, 3, 5};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ tflite::testing::TestAddQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActNone, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddNoActivationInt8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {-10, 4, 13};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {1.01, 1.99, 2.99, 4.02};
+ const float golden_values[] = {-1, 1, 3, 5};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ tflite::testing::TestAddQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActNone, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddActivationRelu1Uint8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {125, 129, 135};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {1.01, 1.99, 2.99, 4.02};
+ const float golden_values[] = {-1, 1, 1, 1};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ tflite::testing::TestAddQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActReluN1To1, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddActivationRelu1Int8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {-10, 4, 13};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {1.01, 1.99, 2.99, 4.02};
+ const float golden_values[] = {-1, 1, 1, 1};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ tflite::testing::TestAddQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActReluN1To1, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddVariousInputShapesUint8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {120, 130, 139};
+ const int output_dims_count = 6;
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const float input2_values[] = {0.1, 0.2, 0.3, 0.5, 1.1, 0.1};
+ const float golden_values[] = {-1.9, 0.4, 1.0, 1.3, 2.2, 2.1};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; i++) {
+ tflite::testing::TestAddQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], test_shapes[i], input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden_values,
+ golden_quantized, scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddVariousInputShapesInt8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {-9, 5, 14};
+ const int output_dims_count = 6;
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const float input2_values[] = {0.1, 0.2, 0.3, 0.5, 1.1, 0.1};
+ const float golden_values[] = {-1.9, 0.4, 1.0, 1.3, 2.2, 2.1};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; i++) {
+ tflite::testing::TestAddQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], test_shapes[i], input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden_values,
+ golden_quantized, scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddWithScalarBroadcastUint8) {
+ const int output_dims_count = 6;
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const int input2_shape[] = {0};
+ const float input2_values[] = {0.1};
+ const float golden[] = {-1.9, 0.3, 0.8, 0.9, 1.2, 2.1};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float scales[] = {0.1, 0.1, 0.1};
+ const int zero_points[] = {120, 131, 139};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestAddQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], input2_shape, input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden, golden_quantized,
+ scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+TF_LITE_MICRO_TEST(QuantizedAddWithScalarBroadcastFloat) {
+ float output_float[tflite::testing::broadcast_output_dims_count];
+
+ for (int i = 0; i < tflite::testing::broadcast_num_shapes; ++i) {
+ tflite::testing::TestAddFloat(tflite::testing::broadcast_input1_shape,
+ tflite::testing::broadcast_input1_values,
+ tflite::testing::broadcast_input2_shapes[i],
+ tflite::testing::broadcast_input2_values,
+ tflite::testing::broadcast_output_shapes[i],
+ tflite::testing::broadcast_goldens[i],
+ kTfLiteActNone, output_float);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddWithScalarBroadcastInt8) {
+ const int output_dims_count = 6;
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const int input2_shape[] = {0};
+ const float input2_values[] = {0.1};
+ const float golden[] = {-1.9, 0.3, 0.8, 0.9, 1.2, 2.1};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float scales[] = {0.1, 0.05, 0.05};
+ const int zero_points[] = {-8, 4, 12};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestAddQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], input2_shape, input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden, golden_quantized,
+ scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddWithMixedBroadcastUint8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {127, 131, 139};
+ uint8_t input1_quantized[tflite::testing::broadcast_output_dims_count];
+ uint8_t input2_quantized[tflite::testing::broadcast_output_dims_count];
+ uint8_t golden_quantized[tflite::testing::broadcast_output_dims_count];
+ uint8_t output[tflite::testing::broadcast_output_dims_count];
+
+ for (int i = 0; i < tflite::testing::broadcast_num_shapes; ++i) {
+ tflite::testing::TestAddQuantized(
+ tflite::testing::broadcast_input1_shape,
+ tflite::testing::broadcast_input1_values, input1_quantized, scales[0],
+ zero_points[0], tflite::testing::broadcast_input2_shapes[i],
+ tflite::testing::broadcast_input2_values, input2_quantized, scales[1],
+ zero_points[1], tflite::testing::broadcast_output_shapes[i],
+ tflite::testing::broadcast_goldens[i], golden_quantized, scales[2],
+ zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedAddWithMixedBroadcastInt8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {-10, -5, 7};
+ int8_t input1_quantized[tflite::testing::broadcast_output_dims_count];
+ int8_t input2_quantized[tflite::testing::broadcast_output_dims_count];
+ int8_t golden_quantized[tflite::testing::broadcast_output_dims_count];
+ int8_t output[tflite::testing::broadcast_output_dims_count];
+
+ for (int i = 0; i < tflite::testing::broadcast_num_shapes; ++i) {
+ tflite::testing::TestAddQuantized(
+ tflite::testing::broadcast_input1_shape,
+ tflite::testing::broadcast_input1_values, input1_quantized, scales[0],
+ zero_points[0], tflite::testing::broadcast_input2_shapes[i],
+ tflite::testing::broadcast_input2_values, input2_quantized, scales[1],
+ zero_points[1], tflite::testing::broadcast_output_shapes[i],
+ tflite::testing::broadcast_goldens[i], golden_quantized, scales[2],
+ zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/arc_mli/README.md b/tensorflow/lite/micro/kernels/arc_mli/README.md
new file mode 100644
index 0000000..3d6ddc0
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/README.md
@@ -0,0 +1,103 @@
+# EmbARC MLI Library Based Optimizations of TensorFlow Lite Micro Kernels for ARC Platforms.
+
+## Maintainers
+
+* [dzakhar](https://github.com/dzakhar)
+* [JaccovG](https://github.com/JaccovG)
+
+## Introduction
+
+This folder contains kernel implementations which use optimized
+[embARC MLI Library](https://github.com/foss-for-synopsys-dwc-arc-processors/embarc_mli).
+It allows acceleration of inference operations which use int8 (asymmetric
+quantization).
+
+## Usage
+
+embARC MLI Library is used by default to speed up execution of some kernels for
+asymmetrically quantized layers. This means that usual project generation for
+ARC specific target implies usage of embARC MLI.
+
+For example:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=arc_emsdp OPTIMIZED_KERNEL_DIR=arc_mli generate_person_detection_int8_make_project
+```
+
+In case MLI implementation can’t be used, kernels in this folder fallback to
+TFLM reference implementations. For applications which may not benefit from MLI
+library, projects can be generated without these implementations by adding
+`ARC_TAGS=no_arc_mli` in the command line, which can reduce overall code size:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=arc_emsdp OPTIMIZED_KERNEL_DIR=arc_mli ARC_TAGS=no_arc_mli generate_person_detection_int8_make_project
+```
+
+For ARC EM SDP board, a pre-compiled MLI library is downloaded and used in the
+application. For a custom target ARC-based platform, MLI sources are downloaded
+and compiled during project generation phase. To build library from sources for
+ARC EM SDP platform, add `BUILD_ARC_MLI=true` option to make command:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile TARGET=arc_emsdp OPTIMIZED_KERNEL_DIR=arc_mli BUILD_ARC_MLI=true generate_person_detection_int8_make_project
+```
+
+If an application exclusively uses accelerated MLI kernel implementations, one
+can strip out TFLM reference kernel implementations to reduce code size of
+application. Build application with `MLI_ONLY=true` option in generated project
+(after the project was built):
+
+```
+cd tensorflow/lite/micro/tools/make/gen/arc_emsdp_arc/prj/person_detection_int8/make
+
+make app MLI_ONLY=true
+```
+
+if you try this and application execution fails, then most probably MLI can’t be
+used for some nodes and you need to revert to using TFLM reference kernels.
+
+## Limitations
+
+Currently, the MLI Library provides optimized implementation only for int8
+(asymmetric) versions of the following kernels: 1. Convolution 2D – Per axis
+quantization only, `dilation_ratio==1` 2. Depthwise Convolution 2D – Per axis
+quantization only, `dilation_ratio==1` 3. Average Pooling 4. Max Pooling 5.
+Fully Connected
+
+Currently only
+[/tensorflow/lite/micro/examples/person_detection](/tensorflow/lite/micro/examples/person_detection)
+is quantized using this specification. Other examples can be executed on
+ARC-based targets, but will only use reference kernels.
+
+## Scratch Buffers and Slicing
+
+The following information applies only for ARC EM SDP and other targets with XY
+memory. embARC MLI uses specific optimizations which assumes node operands are
+in XY memory and/or DCCM (Data Closely Coupled Memory). As operands might be
+quite big and may not fit in available XY memory, special slicing logic is
+applied which allows kernel calculations to be split into multiple parts. For
+this reason, internal static buffers are allocated in these X, Y and DCCM memory
+banks and used to execute sub-calculations.
+
+All this is performed automatically and invisible to the user. Half of the DCCM
+memory bank and the full XY banks are occupied for MLI specific needs. If the
+user needs space in XY memory for other tasks, these arrays can be reduced by
+setting specific sizes. For this, add the following option to build command
+replacing **<size[a|b|c]>** with required values:
+
+```
+EXT_CFLAGS=”-DSCRATCH_MEM_Z_SIZE=<size_a> -DSCRATCH_MEM_X_SIZE=<size_b> -DSCRATCH_MEM_Y_SIZE=<size_c>”
+```
+
+For example, to reduce sizes of arrays placed in DCCM and XCCM to 32k and 8k
+respectively, use next command:
+
+```
+make app EXT_CFLAGS=”-DSCRATCH_MEM_Z_SIZE=32*1024 -DSCRATCH_MEM_X_SIZE=8*1024”
+```
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository,
+and third party dependencies are covered by their respective licenses, in the
+third_party folder of this package.
diff --git a/tensorflow/lite/micro/kernels/arc_mli/conv.cc b/tensorflow/lite/micro/kernels/arc_mli/conv.cc
new file mode 100644
index 0000000..bf5f024
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/conv.cc
@@ -0,0 +1,565 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/conv.h"
+
+#include "mli_api.h" // NOLINT
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kFilterTensor = 1;
+constexpr int kBiasTensor = 2;
+constexpr int kOutputTensor = 0;
+
+// Conv is quantized along dimension 0:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+constexpr int kConvQuantizedDimension = 0;
+
+// This file has 2 implementation of Conv.
+
+struct OpData {
+ TfLitePaddingValues padding;
+
+ // Cached tensor zero point values for quantized operations.
+ int32_t input_zero_point;
+ int32_t filter_zero_point;
+ int32_t output_zero_point;
+
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t output_multiplier;
+ int output_shift;
+
+ // Per channel output multiplier and shift.
+ int32_t* per_channel_output_multiplier;
+ int32_t* per_channel_output_shift;
+
+ // The range of the fused activation layer. For example for kNone and
+ // uint8_t these would be 0 and 255.
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+
+ // The result of checking if MLI optimized version of tensors can be used.
+ bool is_mli_applicable;
+
+ // Tensors in MLI format.
+ mli_tensor* mli_in;
+ mli_tensor* mli_weights;
+ mli_tensor* mli_bias;
+ mli_tensor* mli_out;
+ mli_conv2d_cfg* cfg;
+};
+
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+inline PaddingType RuntimePaddingType(TfLitePadding padding) {
+ switch (padding) {
+ case TfLitePadding::kTfLitePaddingSame:
+ return PaddingType::kSame;
+ case TfLitePadding::kTfLitePaddingValid:
+ return PaddingType::kValid;
+ case TfLitePadding::kTfLitePaddingUnknown:
+ default:
+ return PaddingType::kNone;
+ }
+}
+#endif
+
+bool IsMliApplicable(TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* filter, const TfLiteTensor* bias,
+ const TfLiteConvParams* params) {
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ // MLI optimized version only supports int8_t datatype, dilation factor of 1
+ // and per-axis quantization of weights (no broadcasting/per-tensor)
+ bool ret_val = (filter->type == kTfLiteInt8) &&
+ (input->type == kTfLiteInt8) && (bias->type == kTfLiteInt32) &&
+ (params->dilation_width_factor == 1) &&
+ (params->dilation_height_factor == 1) &&
+ (affine_quantization->scale->size ==
+ filter->dims->data[kConvQuantizedDimension]);
+ return ret_val;
+}
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteConvParams* params, int width,
+ int height, int filter_width, int filter_height,
+ int out_width, int out_height,
+ const TfLiteType data_type, OpData* data) {
+ bool has_bias = node->inputs->size == 3;
+ // Check number of inputs/outputs
+ TF_LITE_ENSURE(context, has_bias || node->inputs->size == 2);
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+
+ // Matching GetWindowedOutputSize in TensorFlow.
+ auto padding = params->padding;
+ data->padding = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width,
+ params->dilation_height_factor, params->dilation_width_factor, height,
+ width, filter_height, filter_width, padding, &out_height, &out_width);
+ // Note that quantized inference requires that all tensors have their
+ // parameters set. This is usually done during quantized training.
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+ const TfLiteTensor* bias = GetOptionalInputTensor(context, node, kBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+
+ if (data_type != kTfLiteFloat32 && !data->is_mli_applicable) {
+ int output_channels = filter->dims->data[kConvQuantizedDimension];
+
+ TF_LITE_ENSURE_STATUS(tflite::PopulateConvolutionQuantizationParams(
+ context, input, filter, bias, output, params->activation,
+ &data->output_multiplier, &data->output_shift,
+ &data->output_activation_min, &data->output_activation_max,
+ data->per_channel_output_multiplier,
+ reinterpret_cast<int*>(data->per_channel_output_shift),
+ output_channels));
+ }
+#endif
+ return kTfLiteOk;
+}
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const auto params = static_cast<const TfLiteConvParams*>(node->builtin_data);
+
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+ const TfLiteTensor* bias = GetOptionalInputTensor(context, node, kBiasTensor);
+
+ int input_width = input->dims->data[2];
+ int input_height = input->dims->data[1];
+ int filter_width = filter->dims->data[2];
+ int filter_height = filter->dims->data[1];
+ int output_width = output->dims->data[2];
+ int output_height = output->dims->data[1];
+
+ // Dynamically allocate per-channel quantization parameters.
+ const int num_channels = filter->dims->data[kConvQuantizedDimension];
+ data->per_channel_output_multiplier =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->per_channel_output_shift =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ data->is_mli_applicable =
+ IsMliApplicable(context, input, filter, bias, params);
+
+ // All per-channel quantized tensors need valid zero point and scale arrays.
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+
+ const auto* affine_quantization =
+ static_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ TF_LITE_ENSURE(context, affine_quantization);
+ TF_LITE_ENSURE(context, affine_quantization->scale);
+ TF_LITE_ENSURE(context, affine_quantization->zero_point);
+
+ TF_LITE_ENSURE(context,
+ affine_quantization->scale->size == 1 ||
+ affine_quantization->scale->size ==
+ filter->dims->data[kConvQuantizedDimension]);
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size,
+ affine_quantization->zero_point->size);
+ }
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(
+ context, node, params, input_width, input_height, filter_width,
+ filter_height, output_width, output_height, input->type, data));
+
+ data->input_zero_point = input->params.zero_point;
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ if (data->is_mli_applicable) {
+ data->mli_in = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_weights = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_bias = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_out = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->cfg = static_cast<mli_conv2d_cfg*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_conv2d_cfg)));
+
+ // reuse space allocated for OpData parameters
+ data->mli_weights->el_params.asym.scale.pi32 =
+ static_cast<int32_t*>(data->per_channel_output_multiplier);
+ data->mli_bias->el_params.asym.scale.pi32 =
+ static_cast<int32_t*>(data->per_channel_output_shift);
+
+ data->mli_weights->el_params.asym.zero_point.pi16 =
+ reinterpret_cast<int16_t*>(&data->filter_zero_point);
+ data->mli_bias->el_params.asym.zero_point.pi16 =
+ reinterpret_cast<int16_t*>(&data->filter_zero_point) + sizeof(int16_t);
+
+ ops::micro::ConvertToMliTensor(input, data->mli_in);
+ ops::micro::ConvertToMliTensorPerChannel(filter, data->mli_weights);
+ ops::micro::ConvertToMliTensorPerChannel(bias, data->mli_bias);
+ ops::micro::ConvertToMliTensor(output, data->mli_out);
+
+ if (params->activation == kTfLiteActRelu) {
+ data->cfg->relu.type = MLI_RELU_GEN;
+ } else if (params->activation == kTfLiteActRelu6) {
+ data->cfg->relu.type = MLI_RELU_6;
+ } else if (params->activation == kTfLiteActReluN1To1) {
+ data->cfg->relu.type = MLI_RELU_1;
+ } else {
+ data->cfg->relu.type = MLI_RELU_NONE;
+ }
+ data->cfg->stride_width = params->stride_width;
+ data->cfg->stride_height = params->stride_height;
+ if (params->padding == kTfLitePaddingValid) {
+ data->cfg->padding_left = 0;
+ data->cfg->padding_right = 0;
+ data->cfg->padding_top = 0;
+ data->cfg->padding_bottom = 0;
+ } else {
+ data->cfg->padding_left = data->padding.width;
+ data->cfg->padding_right =
+ data->padding.width + data->padding.width_offset;
+ data->cfg->padding_top = data->padding.height;
+ data->cfg->padding_bottom =
+ data->padding.height + data->padding.height_offset;
+ }
+ }
+ return kTfLiteOk;
+}
+
+void EvalQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLiteConvParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter, const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* im2col, TfLiteEvalTensor* hwcn_weights,
+ TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ const int32_t input_offset = -data.input_zero_point;
+ const int32_t filter_offset = -data.filter_zero_point;
+ const int32_t output_offset = data.output_zero_point;
+
+ ConvParams op_params;
+ op_params.padding_type = RuntimePaddingType(params->padding);
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params->stride_width;
+ op_params.stride_height = params->stride_height;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.input_offset = input_offset;
+ op_params.weights_offset = filter_offset;
+ op_params.output_offset = output_offset;
+ op_params.output_multiplier = data.output_multiplier;
+ op_params.output_shift = -data.output_shift;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+ reference_ops::Conv(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<uint8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output),
+ tflite::micro::GetTensorShape(im2col),
+ tflite::micro::GetTensorData<uint8_t>(im2col), nullptr);
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+
+TfLiteStatus EvalMliQuantizedPerChannel(
+ TfLiteContext* context, TfLiteNode* node, TfLiteConvParams* params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter, const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ // Run Conv MLI kernel
+ // MLI optimized version only supports int8_t dataype and dilation factor of 1
+ if (data.is_mli_applicable) {
+ // Copy configuration data from external to local memory
+ mli_conv2d_cfg cfg_local = *data.cfg;
+
+ ops::micro::MliTensorAttachBuffer<int8_t>(input, data.mli_in);
+ ops::micro::MliTensorAttachBuffer<int8_t>(filter, data.mli_weights);
+ ops::micro::MliTensorAttachBuffer<int32_t>(bias, data.mli_bias);
+ ops::micro::MliTensorAttachBuffer<int8_t>(output, data.mli_out);
+
+ // for height slicing
+ const int height_dimension = 1;
+ int in_slice_height = 0;
+ int out_slice_height = 0;
+ const int kernel_height =
+ static_cast<int>(data.mli_weights->shape[KRNL_H_DIM_HWC]);
+ const int overlap = kernel_height - cfg_local.stride_height;
+
+ // for weight slicing (on output channels)
+ // NHWC layout for weights, output channel dimension is the first dimension.
+ const int weight_out_ch_dimension = 0;
+ int slice_channels =
+ static_cast<int>(data.mli_weights->shape[weight_out_ch_dimension]);
+ // Batch-Height-Width-Channel layout means last dimension is output
+ // channels.
+ const int out_tensor_ch_dimension = 3;
+
+ // Tensors for data in fast (local) memory and config to copy data from
+ // external to local memory
+ mli_tensor weights_local = *data.mli_weights;
+ mli_tensor bias_local = *data.mli_bias;
+ mli_tensor in_local = *data.mli_in;
+ mli_tensor out_local = *data.mli_out;
+ mli_mov_cfg_t copy_config;
+ mli_mov_cfg_for_copy(©_config);
+ TF_LITE_ENSURE_STATUS(ops::micro::get_arc_scratch_buffer_for_conv_tensors(
+ context, &in_local, &weights_local, &bias_local, &out_local));
+ TF_LITE_ENSURE_STATUS(ops::micro::arc_scratch_buffer_calc_slice_size_io(
+ &in_local, &out_local, kernel_height, cfg_local.stride_height,
+ cfg_local.padding_top, cfg_local.padding_bottom, &in_slice_height,
+ &out_slice_height));
+ TF_LITE_ENSURE_STATUS(
+ ops::micro::arc_scratch_buffer_calc_slice_size_weights(
+ &weights_local, &bias_local, weight_out_ch_dimension,
+ &slice_channels));
+
+ /* is_local indicates that the tensor is already in local memory,
+ so in that case the original tensor can be used,
+ and there is no need to copy it to the local tensor*/
+ const bool in_is_local = in_local.data == data.mli_in->data;
+ const bool out_is_local = out_local.data == data.mli_out->data;
+ const bool w_is_local = weights_local.data == data.mli_weights->data;
+ const bool b_is_local = bias_local.data == data.mli_bias->data;
+
+ ops::micro::TensorSlicer w_slice(data.mli_weights, weight_out_ch_dimension,
+ slice_channels);
+ ops::micro::TensorSlicer b_slice(data.mli_bias, weight_out_ch_dimension,
+ slice_channels);
+ ops::micro::TensorSlicer out_ch_slice(data.mli_out, out_tensor_ch_dimension,
+ slice_channels, 0, 0, 0, true);
+
+ mli_tensor* w_ptr = w_is_local ? w_slice.Sub() : &weights_local;
+ mli_tensor* b_ptr = b_is_local ? b_slice.Sub() : &bias_local;
+
+ void* input_buffer_ptr = NULL;
+ uint32_t input_buffer_size = 0;
+
+ while (!w_slice.Done()) {
+ mli_mov_tensor_sync(w_slice.Sub(), ©_config, w_ptr);
+ mli_mov_tensor_sync(b_slice.Sub(), ©_config, b_ptr);
+
+ /* mli_in tensor contains batches of HWC tensors. so it is a 4 dimensional
+ tensor. because the mli kernel will process one HWC tensor at a time, the
+ 4 dimensional tensor needs to be sliced into nBatch 3 dimensional tensors.
+ on top of that there could be a need to also slice in the Height
+ dimension. for that the sliceHeight has been calculated. The tensor slicer
+ is configured that it will completely slice the nBatch dimension (0) and
+ slice the height dimension (1) in chunks of 'sliceHeight' */
+ ops::micro::TensorSlicer in_slice(data.mli_in, height_dimension,
+ in_slice_height, cfg_local.padding_top,
+ cfg_local.padding_bottom, overlap);
+
+ /* output tensor is already sliced in the output channel dimension.
+ out_ch_slice.Sub() is the tensor for the amount of output channels of this
+ iteration of the weight slice loop. This tensor needs to be further
+ sliced over the batch and height dimension. */
+ ops::micro::TensorSlicer out_slice(out_ch_slice.Sub(), height_dimension,
+ out_slice_height);
+
+ /* setup the pointers to the local or remote tensor to make the code
+ * inside the loop easier. */
+ mli_tensor* in_ptr = in_is_local ? in_slice.Sub() : &in_local;
+ mli_tensor* out_ptr = out_is_local ? out_slice.Sub() : &out_local;
+
+ while (!out_slice.Done()) {
+ TF_LITE_ENSURE(context, !in_slice.Done());
+ cfg_local.padding_top = in_slice.GetPaddingPre();
+ cfg_local.padding_bottom = in_slice.GetPaddingPost();
+
+ // if same input copy as previous iteration, skip the copy of input
+ if ((in_slice.Sub()->data != input_buffer_ptr) ||
+ (mli_hlp_count_elem_num(in_slice.Sub(), 0) != input_buffer_size)) {
+ mli_mov_tensor_sync(in_slice.Sub(), ©_config, in_ptr);
+ input_buffer_ptr = in_slice.Sub()->data;
+ input_buffer_size = mli_hlp_count_elem_num(in_slice.Sub(), 0);
+ }
+ mli_krn_conv2d_nhwc_sa8_sa8_sa32(in_ptr, w_ptr, b_ptr, &cfg_local,
+ out_ptr);
+ mli_mov_tensor_sync(out_ptr, ©_config, out_slice.Sub());
+
+ in_slice.Next();
+ out_slice.Next();
+ }
+ w_slice.Next();
+ b_slice.Next();
+ out_ch_slice.Next();
+ TF_LITE_ENSURE(context, in_slice.Done());
+ }
+ }
+ return kTfLiteOk;
+}
+
+void EvalQuantizedPerChannel(TfLiteContext* context, TfLiteNode* node,
+ TfLiteConvParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output,
+ TfLiteEvalTensor* im2col) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ ConvParams op_params;
+ op_params.input_offset = -data.input_zero_point;
+ op_params.output_offset = data.output_zero_point;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+
+ reference_integer_ops::ConvPerChannel(
+ op_params, data.per_channel_output_multiplier,
+ data.per_channel_output_shift, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Node configuration is not supported by ARC MLI Library.");
+#endif
+}
+
+void EvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLiteConvParams* params, const OpData& data,
+ const TfLiteEvalTensor* input, const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias, TfLiteEvalTensor* im2col,
+ TfLiteEvalTensor* hwcn_weights, TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ float output_activation_min, output_activation_max;
+ CalculateActivationRange(params->activation, &output_activation_min,
+ &output_activation_max);
+ ConvParams op_params;
+ op_params.padding_type = RuntimePaddingType(params->padding);
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params->stride_width;
+ op_params.stride_height = params->stride_height;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.float_activation_min = output_activation_min;
+ op_params.float_activation_max = output_activation_max;
+
+ reference_ops::Conv(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output),
+ tflite::micro::GetTensorShape(im2col),
+ tflite::micro::GetTensorData<float>(im2col));
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = reinterpret_cast<TfLiteConvParams*>(node->builtin_data);
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFilterTensor);
+ const TfLiteEvalTensor* bias =
+ tflite::micro::GetEvalInput(context, node, kBiasTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32:
+ EvalFloat(context, node, params, data, input, filter, bias, nullptr,
+ nullptr, output);
+ break;
+ case kTfLiteInt8:
+ if (data.is_mli_applicable) {
+ EvalMliQuantizedPerChannel(context, node, params, data, input, filter,
+ bias, output);
+ } else {
+ EvalQuantizedPerChannel(context, node, params, data, input, filter,
+ bias, output, nullptr);
+ }
+ break;
+ case kTfLiteUInt8:
+ EvalQuantized(context, node, params, data, input, filter, bias, nullptr,
+ nullptr, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arc_mli/conv_slicing_test.cc b/tensorflow/lite/micro/kernels/arc_mli/conv_slicing_test.cc
new file mode 100644
index 0000000..8a44e02
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/conv_slicing_test.cc
@@ -0,0 +1,506 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This test checks that slicing logic doesn`t affect result of convolution
+// kernel
+//
+// This test doesn`t replace default convolution test
+// (tensorflow/lite/micro/kernels/conv_test.cc). It is added to the whole
+// testset only in case MLI for ARC platform is used during generation (which is
+// handled in arc_mli.inc). So such tests won`t be generated for other
+// platforms.
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/micro/testing/test_utils.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Common inputs and outputs 1.
+static const int kInput1Elements = 20;
+static const int kInput1Shape[] = {4, 1, 5, 2, 2};
+static const float kInput1Data[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+static const int kFilter1Elements = 36;
+static const int kFilter1Shape[] = {4, 2, 3, 3, 2};
+static const float kFilter1Data[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+static const int kBias1Elements = 2;
+static const int kBias1Shape[] = {1, 2};
+static const float kBias1Data[] = {2, 2};
+static const int kOutput1Elements = 20;
+static const int kOutput1Shape[] = {4, 1, 5, 2, 2};
+static const float kGolden1Data[] = {34, 34, 34, 34, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 34, 34, 34, 34};
+
+// Common inputs and outputs 2.
+static const int kInput2Elements = 80;
+static const int kInput2Shape[] = {4, 1, 20, 2, 2};
+static const float kInput2Data[] = {
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+static const int kFilter2Elements = 36;
+static const int kFilter2Shape[] = {4, 2, 3, 3, 2};
+static const float kFilter2Data[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+static const int kBias2Elements = 2;
+static const int kBias2Shape[] = {1, 2};
+static const float kBias2Data[] = {2, 2};
+static const int kOutput2Elements = 80;
+static const int kOutput2Shape[] = {4, 1, 20, 2, 2};
+static const float kGolden2Data[] = {
+ 34, 34, 34, 34, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 34, 34, 34, 34};
+
+// Common inputs and outputs 3.
+static const int kInput3Elements = 40;
+static const int kInput3Shape[] = {4, 1, 2, 2, 10};
+static const float kInput3Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+static const int kFilter3Elements = 90;
+static const int kFilter3Shape[] = {4, 1, 3, 3, 10}; // 1 3 3 10
+static const float kFilter3Data[] = {
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+static const int kBias3Elements = 1;
+static const int kBias3Shape[] = {1, 1};
+static const float kBias3Data[] = {1};
+static const int kOutput3Elements = 4;
+static const int kOutput3Shape[] = {4, 1, 2, 2, 1}; // 2 2 1
+static const float kGolden3Data[] = {41, 41, 41, 41};
+
+// Common inputs and outputs 4.
+static const int kInput4Elements = 80;
+static const int kInput4Shape[] = {4, 1, 4, 2, 10};
+static const float kInput4Data[] = {
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+static const int kFilter4Elements = 90;
+static const int kFilter4Shape[] = {4, 1, 3, 3, 10};
+static const float kFilter4Data[] = {
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+static const int kBias4Elements = 1;
+static const int kBias4Shape[] = {1, 1};
+static const float kBias4Data[] = {1};
+static const int kOutput4Elements = 8;
+static const int kOutput4Shape[] = {4, 1, 4, 2, 1};
+static const float kGolden4Data[] = {41, 41, 61, 61, 61, 61, 41, 41};
+
+static TfLiteConvParams common_conv_params = {
+ kTfLitePaddingSame, // padding
+ 1, // stride_width
+ 1, // stride_height
+ kTfLiteActNone, // activation
+ 1, // dilation_width_factor
+ 1, // dilation_height_factor
+};
+
+template <typename T>
+TfLiteStatus ValidateConvGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* expected_output_data, T* output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ float tolerance = 1e-5) {
+ TfLiteContext context;
+ PopulateContext(tensors, tensors_size, &context);
+
+ ::tflite::AllOpsResolver resolver;
+
+ const TfLiteRegistration* registration =
+ resolver.FindOp(tflite::BuiltinOperator_CONV_2D);
+
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration);
+
+ const char* init_data = reinterpret_cast<const char*>(conv_params);
+ size_t init_data_size = 0;
+ void* user_data = nullptr;
+
+ if (registration->init) {
+ user_data = registration->init(&context, init_data, init_data_size);
+ }
+
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+ int temporaries_array_data[] = {0};
+ TfLiteIntArray* temporaries_array = IntArrayFromInts(temporaries_array_data);
+
+ TfLiteNode node;
+ node.inputs = inputs_array;
+ node.outputs = outputs_array;
+ node.temporaries = temporaries_array;
+ node.user_data = user_data;
+ node.builtin_data = reinterpret_cast<void*>(conv_params);
+ node.custom_initial_data = nullptr;
+ node.custom_initial_data_size = 0;
+ node.delegate = nullptr;
+
+ if (registration->prepare) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->prepare(&context, &node));
+ }
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration->invoke);
+ TfLiteStatus return_val = registration->invoke(&context, &node);
+ if (return_val != kTfLiteOk) {
+ return return_val;
+ }
+
+ if (registration->free) {
+ registration->free(&context, user_data);
+ }
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i],
+ tolerance);
+ }
+ return kTfLiteOk;
+}
+
+void TestConvQuantizedPerChannel(
+ const int* input_dims_data, const float* input_data,
+ int8_t* input_quantized, float input_scale, int input_zero_point,
+ const int* filter_dims_data, const float* filter_data,
+ int8_t* filter_data_quantized, const int* bias_dims_data,
+ const float* bias_data, int32_t* bias_data_quantized, float* bias_scales,
+ int* bias_zero_points, const int* output_dims_data,
+ const float* expected_output_data, int8_t* expected_output_data_quantized,
+ int8_t* output_data, float output_scale, int output_zero_point,
+ TfLiteConvParams* conv_params) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ int filter_zero_points[5];
+ float filter_scales[5];
+ TfLiteAffineQuantization filter_quant;
+ TfLiteAffineQuantization bias_quant;
+ TfLiteTensor input_tensor =
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point, "input_tensor");
+ TfLiteTensor filter_tensor = CreateSymmetricPerChannelQuantizedTensor(
+ filter_data, filter_data_quantized, filter_dims, filter_scales,
+ filter_zero_points, &filter_quant, 0 /* quantized dimension */,
+ "filter_tensor");
+
+ // DN: to replace scales and quantized data to avoid second quantization
+ int channel_count = filter_dims->data[0];
+ float true_filter_scales[5] = {1.0, 1.0, 1.0, 1.0, 1.0};
+ true_filter_scales[0] = static_cast<float>(channel_count);
+ TfLiteAffineQuantization* to_change =
+ (TfLiteAffineQuantization*)filter_tensor.quantization.params;
+ to_change->scale = FloatArrayFromFloats(true_filter_scales);
+
+ int filter_size = filter_tensor.bytes;
+ for (int i = 0; i < filter_size; ++i) {
+ filter_tensor.data.int8[i] = filter_data[i];
+ }
+
+ TfLiteTensor bias_tensor = CreatePerChannelQuantizedBiasTensor(
+ bias_data, bias_data_quantized, bias_dims, input_scale, &filter_scales[1],
+ bias_scales, bias_zero_points, &bias_quant, 0 /* quantized dimension */,
+ "bias_tensor");
+ TfLiteTensor output_tensor =
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point, "output_tensor");
+
+ float input_scales[] = {1, input_scale};
+ int input_zero_points[] = {1, input_zero_point};
+ TfLiteAffineQuantization input_quant = {FloatArrayFromFloats(input_scales),
+ IntArrayFromInts(input_zero_points)};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ float output_scales[] = {1, output_scale};
+ int output_zero_points[] = {1, output_zero_point};
+ TfLiteAffineQuantization output_quant = {
+ FloatArrayFromFloats(output_scales),
+ IntArrayFromInts(output_zero_points)};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ tflite::AsymmetricQuantize(expected_output_data,
+ expected_output_data_quantized, output_dims_count,
+ output_scale, output_zero_point);
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ ValidateConvGoldens(tensors, tensors_size, expected_output_data_quantized,
+ output_data, output_dims_count, conv_params,
+ 1.0 /* tolerance */));
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+// Test group 1
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel1) {
+ const int output_dims_count = 20;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::kInput1Elements];
+ int8_t filter_quantized[tflite::testing::kFilter1Elements];
+ int32_t bias_quantized[tflite::testing::kBias1Elements];
+ int8_t golden_quantized[tflite::testing::kOutput1Elements];
+ int8_t output_data[output_dims_count];
+
+ int zero_points[tflite::testing::kBias1Elements + 1];
+ float scales[tflite::testing::kBias1Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput1Shape, tflite::testing::kInput1Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter1Shape, tflite::testing::kFilter1Data,
+ filter_quantized, tflite::testing::kBias1Shape,
+ tflite::testing::kBias1Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput1Shape, tflite::testing::kGolden1Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel1) {
+ const int output_dims_count = 20;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+#pragma Bss(".Xdata")
+ static int8_t input_quantized[tflite::testing::kInput1Elements];
+ static int8_t filter_quantized[tflite::testing::kFilter1Elements];
+ static int32_t bias_quantized[tflite::testing::kBias1Elements];
+ static int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ int8_t golden_quantized[tflite::testing::kOutput1Elements];
+ int zero_points[tflite::testing::kBias1Elements + 1];
+ float scales[tflite::testing::kBias1Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput1Shape, tflite::testing::kInput1Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter1Shape, tflite::testing::kFilter1Data,
+ filter_quantized, tflite::testing::kBias1Shape,
+ tflite::testing::kBias1Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput1Shape, tflite::testing::kGolden1Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+
+// Test group 2
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel2) {
+ const int output_dims_count = 80;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::kInput2Elements];
+ int8_t filter_quantized[tflite::testing::kFilter2Elements];
+ int32_t bias_quantized[tflite::testing::kBias2Elements];
+ int8_t golden_quantized[tflite::testing::kOutput2Elements];
+ int8_t output_data[output_dims_count];
+
+ int zero_points[tflite::testing::kBias2Elements + 1];
+ float scales[tflite::testing::kBias2Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput2Shape, tflite::testing::kInput2Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter2Shape, tflite::testing::kFilter2Data,
+ filter_quantized, tflite::testing::kBias2Shape,
+ tflite::testing::kBias2Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput2Shape, tflite::testing::kGolden2Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel2) {
+ const int output_dims_count = 80;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+#pragma Bss(".Xdata")
+ static int8_t input_quantized[tflite::testing::kInput2Elements];
+ static int8_t filter_quantized[tflite::testing::kFilter2Elements];
+ static int32_t bias_quantized[tflite::testing::kBias2Elements];
+ static int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ int8_t golden_quantized[tflite::testing::kOutput2Elements];
+ int zero_points[tflite::testing::kBias2Elements + 1];
+ float scales[tflite::testing::kBias2Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput2Shape, tflite::testing::kInput2Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter2Shape, tflite::testing::kFilter2Data,
+ filter_quantized, tflite::testing::kBias2Shape,
+ tflite::testing::kBias2Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput2Shape, tflite::testing::kGolden2Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+
+// Test group 3
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel3) {
+ const int output_dims_count = 4;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::kInput3Elements];
+ int8_t filter_quantized[tflite::testing::kFilter3Elements];
+ int32_t bias_quantized[tflite::testing::kBias3Elements];
+ int8_t golden_quantized[tflite::testing::kOutput3Elements];
+ int8_t output_data[output_dims_count];
+
+ int zero_points[tflite::testing::kBias3Elements + 1];
+ float scales[tflite::testing::kBias3Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput3Shape, tflite::testing::kInput3Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter3Shape, tflite::testing::kFilter3Data,
+ filter_quantized, tflite::testing::kBias3Shape,
+ tflite::testing::kBias3Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput3Shape, tflite::testing::kGolden3Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel3) {
+ const int output_dims_count = 4;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+#pragma Bss(".Xdata")
+ static int8_t input_quantized[tflite::testing::kInput3Elements];
+ static int8_t filter_quantized[tflite::testing::kFilter3Elements];
+ static int32_t bias_quantized[tflite::testing::kBias3Elements];
+ static int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ int8_t golden_quantized[tflite::testing::kOutput3Elements];
+ int zero_points[tflite::testing::kBias3Elements + 1];
+ float scales[tflite::testing::kBias3Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput3Shape, tflite::testing::kInput3Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter3Shape, tflite::testing::kFilter3Data,
+ filter_quantized, tflite::testing::kBias3Shape,
+ tflite::testing::kBias3Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput3Shape, tflite::testing::kGolden3Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+
+// Test group 4
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel4) {
+ const int output_dims_count = 8;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::kInput4Elements];
+ int8_t filter_quantized[tflite::testing::kFilter4Elements];
+ int32_t bias_quantized[tflite::testing::kBias4Elements];
+ int8_t golden_quantized[tflite::testing::kOutput4Elements];
+ int8_t output_data[output_dims_count];
+
+ int zero_points[tflite::testing::kBias4Elements + 1];
+ float scales[tflite::testing::kBias4Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput4Shape, tflite::testing::kInput4Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter4Shape, tflite::testing::kFilter4Data,
+ filter_quantized, tflite::testing::kBias4Shape,
+ tflite::testing::kBias4Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput4Shape, tflite::testing::kGolden4Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel4) {
+ const int output_dims_count = 8;
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+#pragma Bss(".Xdata")
+ static int8_t input_quantized[tflite::testing::kInput4Elements];
+ static int8_t filter_quantized[tflite::testing::kFilter4Elements];
+ static int32_t bias_quantized[tflite::testing::kBias4Elements];
+ static int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ int8_t golden_quantized[tflite::testing::kOutput4Elements];
+ int zero_points[tflite::testing::kBias4Elements + 1];
+ float scales[tflite::testing::kBias4Elements + 1];
+
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInput4Shape, tflite::testing::kInput4Data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilter4Shape, tflite::testing::kFilter4Data,
+ filter_quantized, tflite::testing::kBias4Shape,
+ tflite::testing::kBias4Data, bias_quantized, scales, zero_points,
+ tflite::testing::kOutput4Shape, tflite::testing::kGolden4Data,
+ golden_quantized, output_data, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params);
+}
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/arc_mli/depthwise_conv.cc b/tensorflow/lite/micro/kernels/arc_mli/depthwise_conv.cc
new file mode 100644
index 0000000..1c973a4
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/depthwise_conv.cc
@@ -0,0 +1,587 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h"
+
+#include "mli_api.h" // NOLINT
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kFilterTensor = 1;
+constexpr int kBiasTensor = 2;
+constexpr int kOutputTensor = 0;
+
+// Depthwise conv is quantized along dimension 3:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+constexpr int kDepthwiseConvQuantizedDimension = 3;
+
+struct OpData {
+ TfLitePaddingValues padding;
+
+ // Cached tensor zero point values for quantized operations.
+ int32_t input_zero_point;
+ int32_t filter_zero_point;
+ int32_t output_zero_point;
+
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t output_multiplier;
+ int output_shift;
+
+ // Per channel output multiplier and shift.
+ int32_t* per_channel_output_multiplier;
+ int32_t* per_channel_output_shift;
+
+ // The range of the fused activation layer. For example for kNone and
+ // uint8_t these would be 0 and 255.
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+
+ // The result of checking if MLI optimized version of tensors can be used.
+ bool is_mli_applicable;
+
+ // Tensors in MLI format.
+ mli_tensor* mli_in;
+ mli_tensor* mli_weights;
+ mli_tensor* mli_bias;
+ mli_tensor* mli_out;
+ mli_conv2d_cfg* cfg;
+};
+
+bool IsMliApplicable(TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* filter, const TfLiteTensor* bias,
+ const TfLiteDepthwiseConvParams* params) {
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ const int in_ch = SizeOfDimension(input, 3);
+ const int filters_num = SizeOfDimension(filter, 3);
+
+ // MLI optimized version only supports int8_t datatype, dilation factor of 1
+ // and per-axis quantization of weights (no broadcasting/per-tensor) (in_ch ==
+ // filters_num) || (in_ch == 1)) is a forbidding of channel multiplier logic
+ // for multichannel input.
+ bool ret_val = (filter->type == kTfLiteInt8) &&
+ (input->type == kTfLiteInt8) && (bias->type == kTfLiteInt32) &&
+ (params->dilation_width_factor == 1) &&
+ (params->dilation_height_factor == 1) &&
+ (affine_quantization->scale->size ==
+ filter->dims->data[kDepthwiseConvQuantizedDimension]) &&
+ ((in_ch == filters_num) || (in_ch == 1));
+ return ret_val;
+}
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node,
+ TfLiteDepthwiseConvParams* params, int width,
+ int height, int filter_width, int filter_height,
+ const TfLiteType data_type, OpData* data) {
+ bool has_bias = node->inputs->size == 3;
+ // Check number of inputs/outputs
+ TF_LITE_ENSURE(context, has_bias || node->inputs->size == 2);
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+
+ int unused_output_height, unused_output_width;
+ data->padding = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width, 1, 1, height, width,
+ filter_height, filter_width, params->padding, &unused_output_height,
+ &unused_output_width);
+
+ // Note that quantized inference requires that all tensors have their
+ // parameters set. This is usually done during quantized training.
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+ const TfLiteTensor* bias = GetOptionalInputTensor(context, node, kBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+
+ if (data_type != kTfLiteFloat32 && !data->is_mli_applicable) {
+ int num_channels = filter->dims->data[kDepthwiseConvQuantizedDimension];
+
+ return tflite::PopulateConvolutionQuantizationParams(
+ context, input, filter, bias, output, params->activation,
+ &data->output_multiplier, &data->output_shift,
+ &data->output_activation_min, &data->output_activation_max,
+ data->per_channel_output_multiplier,
+ reinterpret_cast<int*>(data->per_channel_output_shift), num_channels);
+ }
+#endif
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* params =
+ reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+ const TfLiteTensor* bias = GetOptionalInputTensor(context, node, kBiasTensor);
+
+ const TfLiteType data_type = input->type;
+ int width = SizeOfDimension(input, 2);
+ int height = SizeOfDimension(input, 1);
+ int filter_width = SizeOfDimension(filter, 2);
+ int filter_height = SizeOfDimension(filter, 1);
+
+ // Per channel quantization is only needed for int8 inference. For other
+ // quantized types, only a single scale and zero point is needed.
+ const int num_channels = filter->dims->data[kDepthwiseConvQuantizedDimension];
+ // Dynamically allocate per-channel quantization parameters.
+ data->per_channel_output_multiplier =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->per_channel_output_shift =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ data->is_mli_applicable =
+ IsMliApplicable(context, input, filter, bias, params);
+
+ // All per-channel quantized tensors need valid zero point and scale arrays.
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(
+ filter->quantization.params);
+ TF_LITE_ENSURE(context, affine_quantization);
+ TF_LITE_ENSURE(context, affine_quantization->scale);
+ TF_LITE_ENSURE(context, affine_quantization->zero_point);
+ TF_LITE_ENSURE(
+ context, affine_quantization->scale->size == 1 ||
+ affine_quantization->scale->size ==
+ filter->dims->data[kDepthwiseConvQuantizedDimension]);
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size,
+ affine_quantization->zero_point->size);
+ }
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(context, node, params, width, height,
+ filter_width, filter_height, data_type,
+ data));
+
+ data->input_zero_point = input->params.zero_point;
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ if (data->is_mli_applicable) {
+ data->mli_in = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_weights = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_bias = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_out = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->cfg = static_cast<mli_conv2d_cfg*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_conv2d_cfg)));
+
+ // reuse space allocated for OpData parameters
+ data->mli_weights->el_params.asym.scale.pi32 =
+ static_cast<int32_t*>(data->per_channel_output_multiplier);
+ data->mli_bias->el_params.asym.scale.pi32 =
+ static_cast<int32_t*>(data->per_channel_output_shift);
+
+ data->mli_weights->el_params.asym.zero_point.pi16 =
+ reinterpret_cast<int16_t*>(&data->filter_zero_point);
+ data->mli_bias->el_params.asym.zero_point.pi16 =
+ reinterpret_cast<int16_t*>(&data->filter_zero_point) + sizeof(int16_t);
+
+ ops::micro::ConvertToMliTensor(input, data->mli_in);
+ ops::micro::ConvertToMliTensorPerChannel(filter, data->mli_weights);
+ ops::micro::ConvertToMliTensorPerChannel(bias, data->mli_bias);
+ ops::micro::ConvertToMliTensor(output, data->mli_out);
+
+ if (params->activation == kTfLiteActRelu) {
+ data->cfg->relu.type = MLI_RELU_GEN;
+ } else if (params->activation == kTfLiteActRelu6) {
+ data->cfg->relu.type = MLI_RELU_6;
+ } else if (params->activation == kTfLiteActReluN1To1) {
+ data->cfg->relu.type = MLI_RELU_1;
+ } else {
+ data->cfg->relu.type = MLI_RELU_NONE;
+ }
+
+ data->cfg->stride_width = params->stride_width;
+ data->cfg->stride_height = params->stride_height;
+ if (params->padding == kTfLitePaddingValid) {
+ data->cfg->padding_left = 0;
+ data->cfg->padding_right = 0;
+ data->cfg->padding_top = 0;
+ data->cfg->padding_bottom = 0;
+ } else {
+ data->cfg->padding_left = data->padding.width;
+ data->cfg->padding_right =
+ data->padding.width + data->padding.width_offset;
+ data->cfg->padding_top = data->padding.height;
+ data->cfg->padding_bottom =
+ data->padding.height + data->padding.height_offset;
+ }
+ }
+ return kTfLiteOk;
+}
+
+void EvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLiteDepthwiseConvParams* params, const OpData& data,
+ const TfLiteEvalTensor* input, const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias, TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ float output_activation_min, output_activation_max;
+ CalculateActivationRange(params->activation, &output_activation_min,
+ &output_activation_max);
+
+ tflite::DepthwiseParams op_params;
+ // Padding type is ignored, but still set.
+ op_params.padding_type = PaddingType::kSame;
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params->stride_width;
+ op_params.stride_height = params->stride_height;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.depth_multiplier = params->depth_multiplier;
+ op_params.float_activation_min = output_activation_min;
+ op_params.float_activation_max = output_activation_max;
+
+ tflite::reference_ops::DepthwiseConv(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+TfLiteStatus EvalMliQuantizedPerChannel(
+ TfLiteContext* context, TfLiteNode* node, TfLiteDepthwiseConvParams* params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter, const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ // Run Depthwise Conv MLI kernel
+ // MLI optimized version only supports int8_t dataype and dilation factor of 1
+ if (data.is_mli_applicable) {
+ // Copy configuration data from external to local memory
+ mli_conv2d_cfg cfg_local = *data.cfg;
+
+ ops::micro::MliTensorAttachBuffer<int8_t>(input, data.mli_in);
+ ops::micro::MliTensorAttachBuffer<int8_t>(filter, data.mli_weights);
+ ops::micro::MliTensorAttachBuffer<int32_t>(bias, data.mli_bias);
+ ops::micro::MliTensorAttachBuffer<int8_t>(output, data.mli_out);
+
+ // for height slicing
+ const int heightDimension = 1;
+ int inSliceHeight = 0;
+ int outSliceHeight = 0;
+ const int kernelHeight =
+ static_cast<int>(data.mli_weights->shape[KRNL_DW_H_DIM_HWC]);
+ const int overlap = kernelHeight - cfg_local.stride_height;
+
+ // for weight slicing (on output channels)
+ // HWCN layout for weights, output channel dimension is the first dimension.
+ const int weight_out_ch_dimension = 3;
+ // bias has only 1 dimension
+ const int bias_out_ch_dimension = 0;
+ // Batch-Height-Width-Channel layout means last dimension is output
+ // channels.
+ const int out_tensor_ch_dimension = 3;
+ const int32_t in_channels = data.mli_in->shape[out_tensor_ch_dimension];
+ const int32_t out_channels = data.mli_out->shape[out_tensor_ch_dimension];
+ int slice_channels =
+ static_cast<int>(data.mli_weights->shape[weight_out_ch_dimension]);
+
+ // Tensors for data in fast (local) memory
+ // and config to copy data from external to local memory
+ mli_tensor weights_local = *data.mli_weights;
+ mli_tensor bias_local = *data.mli_bias;
+ mli_tensor in_local = *data.mli_in;
+ mli_tensor out_local =
+ *data.mli_out; // this assumes that output shape
+ // is already filled in the tensor struct.
+ mli_mov_cfg_t copy_config;
+ mli_mov_cfg_for_copy(©_config);
+
+ TF_LITE_ENSURE_STATUS(ops::micro::get_arc_scratch_buffer_for_conv_tensors(
+ context, &in_local, &weights_local, &bias_local, &out_local));
+ /* is_local indicates that the tensor is already in local memory,
+ so in that case the original tensor can be used,
+ and there is no need to copy it to the local tensor*/
+ const bool in_is_local = in_local.data == data.mli_in->data;
+ const bool out_is_local = out_local.data == data.mli_out->data;
+ const bool w_is_local = weights_local.data == data.mli_weights->data;
+ const bool b_is_local = bias_local.data == data.mli_bias->data;
+
+ TF_LITE_ENSURE_STATUS(ops::micro::arc_scratch_buffer_calc_slice_size_io(
+ &in_local, &out_local, kernelHeight, cfg_local.stride_height,
+ cfg_local.padding_top, cfg_local.padding_bottom, &inSliceHeight,
+ &outSliceHeight));
+ TF_LITE_ENSURE_STATUS(
+ ops::micro::arc_scratch_buffer_calc_slice_size_weights(
+ &weights_local, &bias_local, weight_out_ch_dimension,
+ &slice_channels));
+
+ /* if input channels is not equal to output channels, a channel multiplier
+ is used. in this case the slice channels needs to be rounded down to a
+ multiple of the input channels */
+ if (in_channels != out_channels) {
+ slice_channels = (slice_channels / in_channels) * in_channels;
+ }
+
+ ops::micro::TensorSlicer b_slice(data.mli_bias, bias_out_ch_dimension,
+ slice_channels);
+ ops::micro::TensorSlicer w_slice(data.mli_weights, weight_out_ch_dimension,
+ slice_channels, 0, 0, 0, true);
+ ops::micro::TensorSlicer out_ch_slice(data.mli_out, out_tensor_ch_dimension,
+ slice_channels, 0, 0, 0, true);
+ ops::micro::TensorSlicer in_ch_slice(data.mli_in, out_tensor_ch_dimension,
+ slice_channels, 0, 0, 0, true);
+
+ mli_tensor* w_ptr = w_is_local ? w_slice.Sub() : &weights_local;
+ mli_tensor* b_ptr = b_is_local ? b_slice.Sub() : &bias_local;
+
+ void* input_buffer_ptr = NULL;
+ uint32_t input_buffer_size = 0;
+ int padding_top = cfg_local.padding_top;
+ int padding_bottom = cfg_local.padding_bottom;
+
+ while (!w_slice.Done()) {
+ mli_mov_tensor_sync(w_slice.Sub(), ©_config, w_ptr);
+ mli_mov_tensor_sync(b_slice.Sub(), ©_config, b_ptr);
+
+ /* input tensor is already sliced in the channel dimension.
+ out_ch_slice.Sub() is the tensor for the amount of channels of this
+ iteration of the weight slice loop. This tensor needs to be further
+ sliced over the batch and height dimension. in_ch_slice.Sub() tensor
+ contains batches of HWC tensors. so it is a 4 dimensional tensor. because
+ the mli kernel will process one HWC tensor at a time, the 4 dimensional
+ tensor needs to be sliced into nBatch 3 dimensional tensors. on top of
+ that there could be a need to also slice in the Height dimension. for that
+ the sliceHeight has been calculated. The tensor slicer is configured that
+ it will completely slice the nBatch dimension (0) and slice the height
+ dimension (1) in chunks of 'sliceHeight' */
+ ops::micro::TensorSlicer in_slice(in_ch_slice.Sub(), heightDimension,
+ inSliceHeight, padding_top,
+ padding_bottom, overlap);
+
+ /* output tensor is already sliced in the output channel dimension.
+ out_ch_slice.Sub() is the tensor for the amount of output channels of this
+ iteration of the weight slice loop. This tensor needs to be further
+ sliced over the batch and height dimension. */
+ ops::micro::TensorSlicer out_slice(out_ch_slice.Sub(), heightDimension,
+ outSliceHeight);
+
+ /* setup the pointers to the local or remote tensor to make the code
+ * inside the loop easier. */
+ mli_tensor* in_ptr = in_is_local ? in_slice.Sub() : &in_local;
+ mli_tensor* out_ptr = out_is_local ? out_slice.Sub() : &out_local;
+
+ while (!out_slice.Done()) {
+ TF_LITE_ENSURE(context, !in_slice.Done());
+ cfg_local.padding_top = in_slice.GetPaddingPre();
+ cfg_local.padding_bottom = in_slice.GetPaddingPost();
+
+ // if same input copy as previous iteration, skip the copy of input
+ if ((in_slice.Sub()->data != input_buffer_ptr) ||
+ (mli_hlp_count_elem_num(in_slice.Sub(), 0) != input_buffer_size)) {
+ mli_mov_tensor_sync(in_slice.Sub(), ©_config, in_ptr);
+ input_buffer_ptr = in_slice.Sub()->data;
+ input_buffer_size = mli_hlp_count_elem_num(in_slice.Sub(), 0);
+ }
+ mli_krn_depthwise_conv2d_hwcn_sa8_sa8_sa32(in_ptr, w_ptr, b_ptr,
+ &cfg_local, out_ptr);
+ mli_mov_tensor_sync(out_ptr, ©_config, out_slice.Sub());
+
+ in_slice.Next();
+ out_slice.Next();
+ }
+ w_slice.Next();
+ b_slice.Next();
+ out_ch_slice.Next();
+ in_ch_slice.Next();
+ TF_LITE_ENSURE(context, in_slice.Done());
+ }
+ }
+ return kTfLiteOk;
+}
+
+void EvalQuantizedPerChannel(TfLiteContext* context, TfLiteNode* node,
+ TfLiteDepthwiseConvParams* params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ DepthwiseParams op_params;
+ op_params.padding_type = PaddingType::kSame;
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params->stride_width;
+ op_params.stride_height = params->stride_height;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.depth_multiplier = params->depth_multiplier;
+ op_params.input_offset = -data.input_zero_point;
+ op_params.weights_offset = 0;
+ op_params.output_offset = data.output_zero_point;
+ op_params.quantized_activation_min = std::numeric_limits<int8_t>::min();
+ op_params.quantized_activation_max = std::numeric_limits<int8_t>::max();
+
+ reference_integer_ops::DepthwiseConvPerChannel(
+ op_params, data.per_channel_output_multiplier,
+ data.per_channel_output_shift, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Node configuration is not supported by ARC MLI Library.");
+#endif
+}
+
+void EvalQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLiteDepthwiseConvParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter, const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ const int32_t input_offset = -data.input_zero_point;
+ const int32_t filter_offset = -data.filter_zero_point;
+ const int32_t output_offset = data.output_zero_point;
+
+ tflite::DepthwiseParams op_params;
+ // Padding type is ignored, but still set.
+ op_params.padding_type = PaddingType::kSame;
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params->stride_width;
+ op_params.stride_height = params->stride_height;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.depth_multiplier = params->depth_multiplier;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+ op_params.input_offset = input_offset;
+ op_params.weights_offset = filter_offset;
+ op_params.output_offset = output_offset;
+ op_params.output_multiplier = data.output_multiplier;
+ // Legacy ops used mixed left and right shifts. Now all are +ve-means-left.
+ op_params.output_shift = -data.output_shift;
+
+ tflite::reference_ops::DepthwiseConv(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<uint8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* params =
+ reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFilterTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kBiasTensor)
+ : nullptr;
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32:
+ EvalFloat(context, node, params, data, input, filter, bias, output);
+ break;
+ case kTfLiteInt8:
+ if (data.is_mli_applicable) {
+ EvalMliQuantizedPerChannel(context, node, params, data, input, filter,
+ bias, output);
+ } else {
+ EvalQuantizedPerChannel(context, node, params, data, input, filter,
+ bias, output);
+ }
+ break;
+ case kTfLiteUInt8:
+ EvalQuantized(context, node, params, data, input, filter, bias, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_DEPTHWISE_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arc_mli/depthwise_conv_slicing_test.cc b/tensorflow/lite/micro/kernels/arc_mli/depthwise_conv_slicing_test.cc
new file mode 100644
index 0000000..3d39bc5
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/depthwise_conv_slicing_test.cc
@@ -0,0 +1,550 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This test checks that slicing logic doesn`t affect result of depthwise
+// convolution kernel
+//
+// This test doesn`t replace default depthwise convolution test
+// (tensorflow/lite/micro/kernels/depthwise_conv_test.cc). It is added to the
+// whole testset only in case MLI for ARC platform is used during generation
+// (which is handled in arc_mli.inc). So such tests won`t be generated for other
+// platforms.
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/micro/testing/test_utils.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int kMaxFilterChannels = 64;
+constexpr int kMaxBiasChannels = 64;
+
+// Index of the output tensor in context->tensors, specific to
+// DepthwiseConv.
+constexpr int kOutputTensorIndex = 3;
+
+// Creates a DepthwiseConv opeerator, calls it with the provided input tensors
+// and some defaults parameters, and compares the output with
+// expected_output_data.
+//
+// The tensors parameter contains both the input tensors as well as a
+// preallocated output tensor into which the output is stored.
+template <typename T>
+TfLiteStatus ValidateDepthwiseConvGoldens(const T* expected_output_data,
+ int output_length,
+ TfLiteFusedActivation activation,
+ float tolerance, int tensors_size,
+ TfLiteTensor* tensors) {
+ TfLiteContext context;
+ PopulateContext(tensors, tensors_size, &context);
+
+ ::tflite::AllOpsResolver resolver;
+ const TfLiteRegistration* registration =
+ resolver.FindOp(tflite::BuiltinOperator_DEPTHWISE_CONV_2D);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration);
+
+ int input_depth = tensors[0].dims->data[3];
+ int output_depth = tensors[1].dims->data[3];
+ int depth_mul = output_depth / input_depth;
+ TfLiteDepthwiseConvParams builtin_data;
+ builtin_data.padding = kTfLitePaddingValid;
+ builtin_data.activation = activation;
+ builtin_data.stride_height = 1;
+ builtin_data.stride_width = 1;
+ builtin_data.dilation_height_factor = 1;
+ builtin_data.dilation_width_factor = 1;
+ builtin_data.depth_multiplier = depth_mul;
+
+ const char* init_data = reinterpret_cast<const char*>(&builtin_data);
+ size_t init_data_size = 0;
+ void* user_data = nullptr;
+ if (registration->init) {
+ user_data = registration->init(&context, init_data, init_data_size);
+ }
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+ int temporaries_array_data[] = {0};
+ TfLiteIntArray* temporaries_array = IntArrayFromInts(temporaries_array_data);
+
+ TfLiteNode node;
+ node.inputs = inputs_array;
+ node.outputs = outputs_array;
+ node.temporaries = temporaries_array;
+ node.user_data = user_data;
+ node.builtin_data = reinterpret_cast<void*>(&builtin_data);
+ node.custom_initial_data = nullptr;
+ node.custom_initial_data_size = 0;
+ node.delegate = nullptr;
+ if (registration->prepare) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->prepare(&context, &node));
+ }
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration->invoke);
+ TfLiteStatus invoke_status = registration->invoke(&context, &node);
+ if (invoke_status != kTfLiteOk) {
+ return invoke_status;
+ }
+
+ if (registration->free) {
+ registration->free(&context, user_data);
+ }
+
+ const T* output_data = tflite::GetTensorData<T>(&tensors[kOutputTensorIndex]);
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i],
+ tolerance);
+ }
+ return kTfLiteOk;
+}
+
+void TestDepthwiseConvQuantizedPerChannel(
+ const int* input_dims_data, const float* input_data,
+ int8_t* input_quantized, float input_scale, int input_zero_point,
+ const int* filter_dims_data, const float* filter_data,
+ int8_t* filter_data_quantized, const int* bias_dims_data,
+ const float* bias_data, int32_t* bias_data_quantized,
+ const int* output_dims_data, const float* expected_output_data,
+ int8_t* expected_output_data_quantized, int8_t* output_data,
+ float output_scale, int output_zero_point,
+ TfLiteFusedActivation activation) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ int filter_zero_points[kMaxFilterChannels];
+ float filter_scales[kMaxFilterChannels];
+ int bias_zero_points[kMaxBiasChannels];
+ float bias_scales[kMaxBiasChannels];
+ TfLiteAffineQuantization filter_quant;
+ TfLiteAffineQuantization bias_quant;
+ TfLiteTensor input_tensor =
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point, "input_tensor");
+ TfLiteTensor filter_tensor = CreateSymmetricPerChannelQuantizedTensor(
+ filter_data, filter_data_quantized, filter_dims, filter_scales,
+ filter_zero_points, &filter_quant, 3 /* quantized dimension */,
+ "filter_tensor");
+ TfLiteTensor bias_tensor = CreatePerChannelQuantizedBiasTensor(
+ bias_data, bias_data_quantized, bias_dims, input_scale, &filter_scales[1],
+ bias_scales, bias_zero_points, &bias_quant, 3 /* quantized dimension */,
+ "bias_tensor");
+ TfLiteTensor output_tensor =
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ input_zero_point, "output_tensor");
+
+ float input_scales[] = {1, input_scale};
+ int input_zero_points[] = {1, input_zero_point};
+ TfLiteAffineQuantization input_quant = {FloatArrayFromFloats(input_scales),
+ IntArrayFromInts(input_zero_points)};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ float output_scales[] = {1, output_scale};
+ int output_zero_points[] = {1, output_zero_point};
+ TfLiteAffineQuantization output_quant = {
+ FloatArrayFromFloats(output_scales),
+ IntArrayFromInts(output_zero_points)};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ AsymmetricQuantize(expected_output_data, expected_output_data_quantized,
+ output_dims_count, output_scale, output_zero_point);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, ValidateDepthwiseConvGoldens(expected_output_data_quantized,
+ output_dims_count, activation,
+ 1.0, tensors_size, tensors));
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+// Test group 1
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel1) {
+ const int input_elements = 20;
+ const int input_shape[] = {4, 1, 5, 2, 2};
+ const float input_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int filter_elements = 36;
+ const int filter_shape[] = {4, 2, 3, 3, 2};
+ const float filter_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int bias_elements = 2;
+ const int bias_shape[] = {4, 1, 1, 1, 2};
+ const int output_elements = 20;
+ const float bias_values[] = {2, 2};
+ const float golden[] = {34, 34, 34, 34, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 34, 34, 34, 34};
+ const int output_shape[] = {4, 1, 5, 2, 2};
+ const int output_dims_count = 20;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel1) {
+ const int input_elements = 20;
+ const int input_shape[] = {4, 1, 5, 2, 2};
+ const int filter_elements = 36;
+ const int filter_shape[] = {4, 2, 3, 3, 2};
+ const int bias_elements = 2;
+ const int bias_shape[] = {4, 1, 1, 1, 2};
+ const int output_elements = 20;
+ const int output_shape[] = {4, 1, 5, 2, 2};
+ const int output_dims_count = 20;
+
+#pragma Bss(".Zdata")
+ const float input_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const float filter_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const float bias_values[] = {2, 2};
+ int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ const float golden[] = {34, 34, 34, 34, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 34, 34, 34, 34};
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+
+// Test group 2
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel2) {
+ const int input_elements = 80;
+ const int input_shape[] = {4, 1, 20, 2, 2};
+ const float input_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int filter_elements = 36;
+ const int filter_shape[] = {4, 2, 3, 3, 2};
+ const float filter_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int bias_elements = 2;
+ const int bias_shape[] = {4, 1, 1, 1, 2};
+ const int output_elements = 80;
+ const float bias_values[] = {2, 2};
+ const float golden[] = {
+ 34, 34, 34, 34, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 34, 34, 34, 34};
+ const int output_shape[] = {4, 1, 20, 2, 2};
+ const int output_dims_count = 80;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel2) {
+ const int input_elements = 80;
+ const int input_shape[] = {4, 1, 20, 2, 2};
+ const int filter_elements = 36;
+ const int filter_shape[] = {4, 2, 3, 3, 2};
+ const int bias_elements = 2;
+ const int bias_shape[] = {4, 1, 1, 1, 2};
+ const int output_elements = 80;
+ const int output_shape[] = {4, 1, 20, 2, 2};
+ const int output_dims_count = 80;
+
+#pragma Bss(".Zdata")
+ float input_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ float filter_values[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ float bias_values[] = {2, 2};
+ int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ const float golden[] = {
+ 34, 34, 34, 34, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
+ 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 34, 34, 34, 34};
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+
+// Test group 3
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel3) {
+ const int input_elements = 40;
+ const int input_shape[] = {4, 1, 2, 2, 10};
+ const float input_values[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int filter_elements = 90;
+ const int filter_shape[] = {4, 1, 3, 3, 10};
+ const float filter_values[] = {
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int bias_elements = 1;
+ const int bias_shape[] = {4, 1, 1, 1, 1};
+ const int output_elements = 4;
+ const float bias_values[] = {1};
+ const float golden[] = {41, 41, 41, 41};
+ const int output_shape[] = {4, 1, 2, 2, 1};
+ const int output_dims_count = 4;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel3) {
+ const int input_elements = 40;
+ const int input_shape[] = {4, 1, 2, 2, 10};
+ const int filter_elements = 90;
+ const int filter_shape[] = {4, 1, 3, 3, 10};
+ const int bias_elements = 1;
+ const int bias_shape[] = {4, 1, 1, 1, 1};
+ const int output_elements = 4;
+ const int output_shape[] = {4, 1, 2, 2, 1};
+ const int output_dims_count = 4;
+
+#pragma Bss(".Zdata")
+ float input_values[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ float filter_values[] = {
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ float bias_values[] = {1};
+ int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ const float golden[] = {41, 41, 41, 41};
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+
+// Test group 4
+TF_LITE_MICRO_TEST(SystemTestQuantizedPerChannel4) {
+ const int input_elements = 80;
+ const int input_shape[] = {4, 1, 4, 2, 10};
+ const float input_values[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int filter_elements = 90;
+ const int filter_shape[] = {4, 1, 3, 3, 10};
+ const float filter_values[] = {
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int bias_elements = 1;
+ const int bias_shape[] = {4, 1, 1, 1, 1};
+ const int output_elements = 8;
+ const float bias_values[] = {1};
+ const float golden[] = {41, 41, 61, 61, 61, 61, 41, 41};
+ const int output_shape[] = {4, 1, 4, 2, 1};
+ const int output_dims_count = 8;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(LocalTestQuantizedPerChannel4) {
+ const int input_elements = 80;
+ const int input_shape[] = {4, 1, 4, 2, 10};
+ const int filter_elements = 90;
+ const int filter_shape[] = {4, 1, 3, 3, 10};
+ const int bias_elements = 1;
+ const int bias_shape[] = {4, 1, 1, 1, 1};
+ const int output_elements = 8;
+ const int output_shape[] = {4, 1, 4, 2, 1};
+ const int output_dims_count = 8;
+
+#pragma Bss(".Zdata")
+ float input_values[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ float filter_values[] = {
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ float bias_values[] = {1};
+ int8_t output_data[output_dims_count];
+#pragma Bss()
+
+ const float golden[] = {41, 41, 61, 61, 61, 61, 41, 41};
+
+ const float input_scale = 1.0;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, kTfLiteActNone);
+}
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/arc_mli/fully_connected.cc b/tensorflow/lite/micro/kernels/arc_mli/fully_connected.cc
new file mode 100644
index 0000000..82e233f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/fully_connected.cc
@@ -0,0 +1,425 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/fully_connected.h"
+
+#include "mli_api.h" // NOLINT
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+struct OpData {
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t output_multiplier;
+ int output_shift;
+ // The range of the fused activation layer. For example for kNone and
+ // uint8_t these would be 0 and 255.
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+ // The index of the temporary tensor where the quantized inputs are cached.
+ int input_quantized_index;
+ // Cached tensor zero point values for quantized operations.
+ int32_t input_zero_point;
+ int32_t filter_zero_point;
+ int32_t output_zero_point;
+
+ // The result of checking if MLI optimized version of tensors can be used.
+ bool is_mli_applicable;
+
+ // Tensors in MLI format.
+ mli_tensor* mli_in;
+ mli_tensor* mli_weights;
+ mli_tensor* mli_bias;
+ mli_tensor* mli_out;
+};
+
+constexpr int kInputTensor = 0;
+constexpr int kWeightsTensor = 1;
+constexpr int kBiasTensor = 2;
+constexpr int kOutputTensor = 0;
+
+bool IsMliApplicable(TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* filter, const TfLiteTensor* bias,
+ const TfLiteFullyConnectedParams* params) {
+ // MLI optimized version only supports int8_t datatype and no fused Relu and
+ // symmetric per-tensor quantization of weights (not per-axis)
+ bool ret_val = (filter->type == kTfLiteInt8) &&
+ (input->type == kTfLiteInt8) && (bias->type == kTfLiteInt32) &&
+ (params->activation == kTfLiteActNone) &&
+ (filter->params.zero_point == 0);
+ return ret_val;
+}
+
+TfLiteStatus CalculateOpData(TfLiteContext* context,
+ const TfLiteFullyConnectedParams* params,
+ TfLiteType data_type, const TfLiteTensor* input,
+ const TfLiteTensor* filter,
+ const TfLiteTensor* bias, TfLiteTensor* output,
+ OpData* data) {
+ TfLiteStatus status = kTfLiteOk;
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ if (data_type != kTfLiteFloat32 && !data->is_mli_applicable) {
+ double real_multiplier = 0.0;
+ TF_LITE_ENSURE_STATUS(GetQuantizedConvolutionMultipler(
+ context, input, filter, bias, output, &real_multiplier));
+ int exponent;
+ QuantizeMultiplier(real_multiplier, &data->output_multiplier, &exponent);
+ data->output_shift = -exponent;
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, params->activation, output, &data->output_activation_min,
+ &data->output_activation_max));
+ }
+#endif
+ return status;
+}
+
+} // namespace
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const auto params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* filter = GetInput(context, node, kWeightsTensor);
+ const TfLiteTensor* bias = GetOptionalInputTensor(context, node, kBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_MSG(context, input->type == filter->type,
+ "Hybrid models are not supported on TFLite Micro.");
+
+ data->input_zero_point = input->params.zero_point;
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ data->is_mli_applicable =
+ IsMliApplicable(context, input, filter, bias, params);
+
+ if (input->type == kTfLiteInt8 && data->is_mli_applicable) {
+ data->mli_in = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_weights = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_bias = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_out = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+
+ ops::micro::ConvertToMliTensor(input, data->mli_in);
+ ops::micro::ConvertToMliTensor(filter, data->mli_weights);
+ ops::micro::ConvertToMliTensor(bias, data->mli_bias);
+ ops::micro::ConvertToMliTensor(output, data->mli_out);
+
+ /* The input tensor can have more than 2 dimensions. for the compute this
+ doesn't make any difference because all the inputs or a batch entry will
+ be used anyway. because the MLI kernel doesn't recognize the multiple
+ dimensions, the tensor shape is casted to a {batchnum, inputsize} shape. */
+ data->mli_in->shape[0] = data->mli_out->shape[0];
+ data->mli_in->shape[1] = data->mli_weights->shape[1];
+ data->mli_in->shape[2] = 0;
+ data->mli_in->shape[3] = 0;
+ data->mli_in->rank = 2;
+ }
+
+ return (CalculateOpData(context, params, input->type, input, filter, bias,
+ output, data));
+}
+
+TfLiteStatus EvalMliQuantizedInt8(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteFullyConnectedParams* params,
+ const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ ops::micro::MliTensorAttachBuffer<int8_t>(input, data.mli_in);
+ ops::micro::MliTensorAttachBuffer<int8_t>(filter, data.mli_weights);
+ ops::micro::MliTensorAttachBuffer<int32_t>(bias, data.mli_bias);
+ ops::micro::MliTensorAttachBuffer<int8_t>(output, data.mli_out);
+
+ // Tensors for data in fast (local) memory and config to copy data from
+ // external to local memory
+ mli_tensor weights_local = *data.mli_weights;
+ mli_tensor bias_local = *data.mli_bias;
+ mli_tensor in_local = *data.mli_in;
+ mli_tensor out_local = *data.mli_out;
+ mli_mov_cfg_t copy_config;
+ mli_mov_cfg_for_copy(©_config);
+ const int weight_out_dimension = 0;
+ const int out_tensor_dimension = 1;
+ const int input_size_dimension = 1;
+ int slice_size = data.mli_weights->shape[weight_out_dimension];
+
+ /* allocate the local buffers, and compute the slice size */
+ TF_LITE_ENSURE_STATUS(
+ ops::micro::get_arc_scratch_buffer_for_fully_connect_tensors(
+ context, &in_local, &weights_local, &bias_local, &out_local));
+ TF_LITE_ENSURE_STATUS(ops::micro::arc_scratch_buffer_calc_slice_size_weights(
+ &weights_local, &bias_local, weight_out_dimension, &slice_size));
+ int max_out_slice_size =
+ out_local.capacity / mli_hlp_tensor_element_size(&out_local);
+ if (slice_size > max_out_slice_size) slice_size = max_out_slice_size;
+
+ /* is_local indicates that the tensor is already in local memory,
+ so in that case the original tensor can be used,
+ and there is no need to copy it to the local tensor*/
+ const bool in_is_local = in_local.data == data.mli_in->data;
+ const bool out_is_local = out_local.data == data.mli_out->data;
+ const bool w_is_local = weights_local.data == data.mli_weights->data;
+ const bool b_is_local = bias_local.data == data.mli_bias->data;
+
+ ops::micro::TensorSlicer w_slice(data.mli_weights, weight_out_dimension,
+ slice_size);
+ ops::micro::TensorSlicer b_slice(data.mli_bias, weight_out_dimension,
+ slice_size);
+ ops::micro::TensorSlicer out_ch_slice(data.mli_out, out_tensor_dimension,
+ slice_size, 0, 0, 0, true);
+
+ mli_tensor* w_ptr = w_is_local ? w_slice.Sub() : &weights_local;
+ mli_tensor* b_ptr = b_is_local ? b_slice.Sub() : &bias_local;
+
+ void* input_buffer_ptr = NULL;
+
+ while (!w_slice.Done()) {
+ mli_mov_tensor_sync(w_slice.Sub(), ©_config, w_ptr);
+ mli_mov_tensor_sync(b_slice.Sub(), ©_config, b_ptr);
+
+ // Slice the input over the batches (one at a time with the size of a
+ // complete input)
+ ops::micro::TensorSlicer in_slice(data.mli_in, input_size_dimension,
+ data.mli_in->shape[input_size_dimension]);
+
+ /* output tensor is already sliced in the output size dimension.
+ out_ch_slice.Sub() is the tensor for the amount of output size of this
+ iteration of the weight slice loop. This tensor needs to be further
+ sliced over the batch */
+ ops::micro::TensorSlicer out_slice(out_ch_slice.Sub(), out_tensor_dimension,
+ slice_size);
+
+ /* setup the pointers to the local or remote tensor to make the code
+ * inside the loop easier. */
+ mli_tensor* in_ptr = in_is_local ? in_slice.Sub() : &in_local;
+ mli_tensor* out_ptr = out_is_local ? out_slice.Sub() : &out_local;
+
+ while (!out_slice.Done()) {
+ // if same input copy as previous iteration, skip the copy of input
+ if (in_slice.Sub()->data != input_buffer_ptr) {
+ mli_mov_tensor_sync(in_slice.Sub(), ©_config, in_ptr);
+ input_buffer_ptr = in_slice.Sub()->data;
+ }
+ mli_krn_fully_connected_sa8_sa8_sa32(in_ptr, w_ptr, b_ptr, out_ptr);
+ mli_mov_tensor_sync(out_ptr, ©_config, out_slice.Sub());
+
+ in_slice.Next();
+ out_slice.Next();
+ }
+ w_slice.Next();
+ b_slice.Next();
+ out_ch_slice.Next();
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalQuantizedInt8(TfLiteContext* context, TfLiteNode* node,
+ const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ tflite::FullyConnectedParams op_params;
+ op_params.input_offset = -data.input_zero_point;
+ op_params.weights_offset = -data.filter_zero_point;
+ op_params.output_offset = data.output_zero_point;
+ op_params.output_multiplier = data.output_multiplier;
+ op_params.output_shift = -data.output_shift;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+
+ reference_integer_ops::FullyConnected(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Node configuration is not supported by ARC MLI Library.");
+ return kTfLiteError;
+#endif
+}
+
+TfLiteStatus EvalQuantized(TfLiteContext* context, TfLiteNode* node,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ const int32_t input_offset = -data.input_zero_point;
+ const int32_t filter_offset = -data.filter_zero_point;
+ const int32_t output_offset = data.output_zero_point;
+
+ tflite::FullyConnectedParams op_params;
+ op_params.input_offset = input_offset;
+ op_params.weights_offset = filter_offset;
+ op_params.output_offset = output_offset;
+ op_params.output_multiplier = data.output_multiplier;
+ // Legacy ops used mixed left and right shifts. Now all are +ve-means-left.
+ op_params.output_shift = -data.output_shift;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+
+#define TF_LITE_FULLY_CONNECTED(output_data_type) \
+ reference_ops::FullyConnected( \
+ op_params, tflite::micro::GetTensorShape(input), \
+ tflite::micro::GetTensorData<uint8_t>(input), \
+ tflite::micro::GetTensorShape(filter), \
+ tflite::micro::GetTensorData<uint8_t>(filter), \
+ tflite::micro::GetTensorShape(bias), \
+ tflite::micro::GetTensorData<int32_t>(bias), \
+ tflite::micro::GetTensorShape(output), \
+ tflite::micro::GetTensorData<output_data_type>(output))
+ switch (output->type) {
+ case kTfLiteUInt8:
+ TF_LITE_FULLY_CONNECTED(uint8_t);
+ break;
+ case kTfLiteInt16:
+ TF_LITE_FULLY_CONNECTED(int16_t);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(output->type), output->type);
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+#endif
+}
+
+TfLiteStatus EvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLiteFusedActivation activation,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias, TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ float output_activation_min, output_activation_max;
+ CalculateActivationRange(activation, &output_activation_min,
+ &output_activation_max);
+ tflite::FullyConnectedParams op_params;
+ op_params.float_activation_min = output_activation_min;
+ op_params.float_activation_max = output_activation_max;
+ tflite::reference_ops::FullyConnected(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+#endif
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto* params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ tflite::micro::GetEvalInput(context, node, kBiasTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ // Checks in Prepare ensure input, output and filter types are all the same.
+ switch (input->type) {
+ case kTfLiteFloat32:
+ return EvalFloat(context, node, params->activation, input, filter, bias,
+ output);
+ case kTfLiteInt8:
+ if (data.is_mli_applicable) {
+ return EvalMliQuantizedInt8(context, node, params, data, input, filter,
+ bias, output);
+ } else {
+ return EvalQuantizedInt8(context, node, data, input, filter, bias,
+ output);
+ }
+
+ case kTfLiteUInt8:
+ return EvalQuantized(context, node, data, input, filter, bias, output);
+
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteRegistration Register_FULLY_CONNECTED() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arc_mli/fully_connected_slicing_test.cc b/tensorflow/lite/micro/kernels/arc_mli/fully_connected_slicing_test.cc
new file mode 100644
index 0000000..8a6749f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/fully_connected_slicing_test.cc
@@ -0,0 +1,425 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This test checks that slicing logic doesn`t affect result of fully
+// connected kernel
+//
+// This test doesn`t replace default fully connected test
+// (tensorflow/lite/micro/kernels/fully_connected_test.cc). It is added to the
+// whole testset only in case MLI for ARC platform is used during generation
+// (which is handled in arc_mli.inc). So such tests won`t be generated for other
+// platforms.
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/micro/testing/test_utils.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void TestFullyConnectedQuantized(
+ const int* input_dims_data, const T* input_data, const float input_min,
+ const float input_max, const int* weights_dims_data, const T* weights_data,
+ const float weights_min, const float weights_max, const int* bias_dims_data,
+ const int32_t* bias_data, const float bias_scale,
+ const T* expected_output_data, const int* output_dims_data,
+ const float output_min, const float output_max,
+ TfLiteFusedActivation activation, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* weights_dims = IntArrayFromInts(weights_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_dims, "input_tensor", input_min,
+ input_max),
+ CreateQuantizedTensor(weights_data, weights_dims, "weights_tensor",
+ weights_min, weights_max),
+ CreateQuantized32Tensor(bias_data, bias_dims, "bias_tensor", bias_scale),
+ CreateQuantizedTensor(output_data, output_dims, "output_tensor",
+ output_min, output_max),
+ };
+
+ tensors[0].params.zero_point = 0;
+ tensors[1].params.zero_point = 0;
+ tensors[3].params.zero_point = 0;
+
+ TfLiteContext context;
+ PopulateContext(tensors, tensors_size, &context);
+
+ ::tflite::AllOpsResolver resolver;
+ const TfLiteRegistration* registration =
+ resolver.FindOp(tflite::BuiltinOperator_FULLY_CONNECTED, 4);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration);
+
+ TfLiteFullyConnectedParams builtin_data = {
+ activation,
+ kTfLiteFullyConnectedWeightsFormatDefault,
+ };
+ const char* init_data = reinterpret_cast<const char*>(&builtin_data);
+ size_t init_data_size = 0;
+ void* user_data = nullptr;
+ if (registration->init) {
+ user_data = registration->init(&context, init_data, init_data_size);
+ }
+
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+ int temporaries_array_data[] = {0};
+ TfLiteIntArray* temporaries_array = IntArrayFromInts(temporaries_array_data);
+
+ TfLiteNode node;
+ node.inputs = inputs_array;
+ node.outputs = outputs_array;
+ node.temporaries = temporaries_array;
+ node.user_data = user_data;
+ node.builtin_data = reinterpret_cast<void*>(&builtin_data);
+ node.custom_initial_data = nullptr;
+ node.custom_initial_data_size = 0;
+ node.delegate = nullptr;
+
+ if (registration->prepare) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->prepare(&context, &node));
+ }
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration->invoke);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->invoke(&context, &node));
+ if (registration->free) {
+ registration->free(&context, user_data);
+ }
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+// Test group 1
+TF_LITE_MICRO_TEST(SystemSimpleTestQuantized1) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data[] = {2, 2, 10};
+ const int8_t input_data[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int weights_dims_data[] = {2, 3, 10};
+ const int8_t weights_data[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int bias_dims_data[] = {1, 3};
+ const int32_t bias_data[] = {1, 1, 1};
+ const int8_t expected_output_data[] = {41, 41, 41, 41, 41, 41};
+ const int output_dims_data[] = {2, 2, 3};
+
+ const int output_dims_count = 6;
+ int8_t output_data[output_dims_count];
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data, input_data, input_min, input_max, weights_dims_data,
+ weights_data, weights_min, weights_max, bias_dims_data, bias_data,
+ bias_scale, expected_output_data, output_dims_data, output_min,
+ output_max, kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(LocalSimpleTestQuantized1) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data_local[] = {2, 2, 10};
+ const int weights_dims_data_local[] = {2, 3, 10};
+ const int bias_dims_data_local[] = {1, 3};
+ const int output_dims_data_local[] = {2, 2, 3};
+
+ const int output_dims_count = 6;
+
+#pragma Bss(".Zdata")
+ const int8_t input_data_local[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int8_t weights_data_local[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int32_t bias_data_local[] = {1, 1, 1};
+ int8_t output_data_local[output_dims_count];
+#pragma Bss()
+
+ const int8_t expected_output_data[] = {41, 41, 41, 41, 41, 41};
+
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data_local, input_data_local, input_min, input_max,
+ weights_dims_data_local, weights_data_local, weights_min, weights_max,
+ bias_dims_data_local, bias_data_local, bias_scale, expected_output_data,
+ output_dims_data_local, output_min, output_max, kTfLiteActNone,
+ output_data_local);
+}
+
+// Test group 2
+TF_LITE_MICRO_TEST(SystemSimpleTestQuantized2) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data_2[] = {2, 10, 4};
+ const int8_t input_data_2[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int weights_dims_data_2[] = {2, 6, 4};
+ const int8_t weights_data_2[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int bias_dims_data_2[] = {1, 6};
+ const int32_t bias_data_2[] = {1, 1, 1, 1, 1, 1};
+ const int8_t expected_output_data_2[] = {
+ 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17,
+ 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17,
+ 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17,
+ 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17};
+ const int output_dims_data_2[] = {2, 10, 6};
+
+ const int output_dims_count_2 = 60;
+ int8_t output_data_2[output_dims_count_2];
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data_2, input_data_2, input_min, input_max,
+ weights_dims_data_2, weights_data_2, weights_min, weights_max,
+ bias_dims_data_2, bias_data_2, bias_scale, expected_output_data_2,
+ output_dims_data_2, output_min, output_max, kTfLiteActNone,
+ output_data_2);
+}
+
+TF_LITE_MICRO_TEST(LocalSimpleTestQuantized2) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data_local_2[] = {2, 10, 4};
+ const int weights_dims_data_local_2[] = {2, 6, 4};
+ const int bias_dims_data_local_2[] = {1, 6};
+ const int output_dims_data_local_2[] = {2, 10, 6};
+
+ const int output_dims_count_local_2 = 60;
+
+#pragma Bss(".Zdata")
+ const int8_t input_data_local_2[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int8_t weights_data_local_2[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int32_t bias_data_local_2[] = {1, 1, 1, 1, 1, 1};
+ int8_t output_data_local_2[output_dims_count_local_2];
+#pragma Bss()
+
+ const int8_t expected_output_data_local_2[] = {41, 41, 41, 41, 41, 41};
+
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data_local_2, input_data_local_2, input_min, input_max,
+ weights_dims_data_local_2, weights_data_local_2, weights_min, weights_max,
+ bias_dims_data_local_2, bias_data_local_2, bias_scale,
+ expected_output_data_local_2, output_dims_data_local_2, output_min,
+ output_max, kTfLiteActNone, output_data_local_2);
+}
+
+// Test group 3
+TF_LITE_MICRO_TEST(SystemSimpleTestQuantized3) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data_3[] = {2, 2, 5};
+ const int8_t input_data_3[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int weights_dims_data_3[] = {2, 10, 5};
+ const int8_t weights_data_3[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int bias_dims_data_3[] = {1, 10};
+ const int32_t bias_data_3[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int8_t expected_output_data_3[] = {21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21};
+ const int output_dims_data_3[] = {2, 2, 10};
+
+ const int output_dims_count_3 = 20;
+ int8_t output_data_3[output_dims_count_3];
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data_3, input_data_3, input_min, input_max,
+ weights_dims_data_3, weights_data_3, weights_min, weights_max,
+ bias_dims_data_3, bias_data_3, bias_scale, expected_output_data_3,
+ output_dims_data_3, output_min, output_max, kTfLiteActNone,
+ output_data_3);
+}
+
+TF_LITE_MICRO_TEST(LocalSimpleTestQuantized3) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data_local_3[] = {2, 2, 5};
+ const int weights_dims_data_local_3[] = {2, 10, 5};
+ const int bias_dims_data_local_3[] = {1, 10};
+ const int output_dims_data_local_3[] = {2, 2, 10};
+
+ const int output_dims_count_local_3 = 20;
+
+#pragma Bss(".Zdata")
+ static int8_t input_data_local_3[10];
+ static int8_t weights_data_local_3[50];
+ static int32_t bias_data_local_3[10];
+ static int8_t output_data_local_3[output_dims_count_local_3];
+#pragma Bss()
+
+ for (int i = 0; i < 10; ++i) {
+ input_data_local_3[i] = 2;
+ }
+
+ for (int i = 0; i < 50; ++i) {
+ weights_data_local_3[i] = 2;
+ }
+
+ for (int i = 0; i < 10; ++i) {
+ bias_data_local_3[i] = 1;
+ }
+
+ for (int i = 0; i < 20; ++i) {
+ output_data_local_3[i] = 0;
+ }
+
+ const int8_t expected_output_data_local_3[] = {21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21};
+
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data_local_3, input_data_local_3, input_min, input_max,
+ weights_dims_data_local_3, weights_data_local_3, weights_min, weights_max,
+ bias_dims_data_local_3, bias_data_local_3, bias_scale,
+ expected_output_data_local_3, output_dims_data_local_3, output_min,
+ output_max, kTfLiteActNone, output_data_local_3);
+}
+
+// Test group 4
+TF_LITE_MICRO_TEST(SystemSimpleTestQuantized4) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data_4[] = {2, 5, 10};
+ const int8_t input_data_4[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int weights_dims_data_4[] = {2, 5, 10};
+ const int8_t weights_data_4[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int bias_dims_data_4[] = {1, 5};
+ const int32_t bias_data_4[] = {1, 1, 1, 1, 1};
+ const int8_t expected_output_data_4[] = {41, 41, 41, 41, 41, 41, 41, 41, 41,
+ 41, 41, 41, 41, 41, 41, 41, 41, 41,
+ 41, 41, 41, 41, 41, 41, 41};
+ const int output_dims_data_4[] = {2, 5, 5};
+
+ const int output_dims_count_4 = 25;
+ int8_t output_data_4[output_dims_count_4];
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data_4, input_data_4, input_min, input_max,
+ weights_dims_data_4, weights_data_4, weights_min, weights_max,
+ bias_dims_data_4, bias_data_4, bias_scale, expected_output_data_4,
+ output_dims_data_4, output_min, output_max, kTfLiteActNone,
+ output_data_4);
+}
+
+TF_LITE_MICRO_TEST(LocalSimpleTestQuantized4) {
+ const float input_min = -128.0f;
+ const float input_max = 127.0f;
+ const float weights_min = -128.0f;
+ const float weights_max = 127.0f;
+ const float bias_scale = 1.0f;
+ const float output_min = -128.0f;
+ const float output_max = 127.0f;
+
+ const int input_dims_data_local_4[] = {2, 5, 10};
+ const int weights_dims_data_local_4[] = {2, 5, 10};
+ const int bias_dims_data_local_4[] = {1, 5};
+ const int output_dims_data_local_4[] = {2, 5, 5};
+
+ const int output_dims_count_local_4 = 25;
+
+#pragma Bss(".Zdata")
+ const int8_t input_data_local_4[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int8_t weights_data_local_4[] = {2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2};
+ const int32_t bias_data_local_4[] = {1, 1, 1, 1, 1};
+ int8_t output_data_local_4[output_dims_count_local_4];
+#pragma Bss()
+
+ const int8_t expected_output_data_local_4[] = {
+ 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41,
+ 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41};
+
+ tflite::testing::TestFullyConnectedQuantized<int8_t>(
+ input_dims_data_local_4, input_data_local_4, input_min, input_max,
+ weights_dims_data_local_4, weights_data_local_4, weights_min, weights_max,
+ bias_dims_data_local_4, bias_data_local_4, bias_scale,
+ expected_output_data_local_4, output_dims_data_local_4, output_min,
+ output_max, kTfLiteActNone, output_data_local_4);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/arc_mli/mli_slicers.cc b/tensorflow/lite/micro/kernels/arc_mli/mli_slicers.cc
new file mode 100644
index 0000000..905c6fe
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/mli_slicers.cc
@@ -0,0 +1,126 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "mli_slicers.h" // NOLINT
+
+#include <algorithm>
+
+namespace tflite {
+namespace ops {
+namespace micro {
+
+TensorSlicer::TensorSlicer(const mli_tensor* full_tensor, int slice_dim,
+ int slice_size, int padding_pre, int padding_post,
+ int overlap, bool interleave_mode)
+ : full_tensor_(full_tensor),
+ sub_tensor_{},
+ sub_cfg_{},
+ done_(false),
+ sliceDim_(slice_dim),
+ pad_pre_(padding_pre),
+ pad_post_(padding_post),
+ overlap_(overlap) {
+ /* In the interleave mode, the slicing happens from the deepest dimension up
+ to the slice_dim for example in an HWC layout this can mode can be used to
+ slice in the C dimenstion. in this mode the data is not contiguous in memory
+ anymore */
+ if (interleave_mode) {
+ for (int i = 0; i < static_cast<int>(full_tensor->rank); i++) {
+ if (i > slice_dim) {
+ sub_cfg_.size[i] = 1;
+ } else if (i == slice_dim) {
+ sub_cfg_.size[i] = slice_size;
+ } else {
+ sub_cfg_.size[i] = full_tensor->shape[i];
+ }
+ }
+ sub_cfg_.sub_tensor_rank = full_tensor->rank;
+
+ } else {
+ /* In the not interleaved mode, the slicing happens from the outer most
+ dimension up to the slice_dim for example in an HWC layout this mode can be
+ used to slice in the H dimension. in this mode the data of the slice is
+ still contiguous in memory (if that was the case in the input tensor */
+ for (int i = 0; i < static_cast<int>(full_tensor->rank); i++) {
+ if (i < slice_dim) {
+ sub_cfg_.size[i] = 1;
+ } else if (i == slice_dim) {
+ sub_cfg_.size[i] = slice_size;
+ } else {
+ sub_cfg_.size[i] = full_tensor->shape[i];
+ }
+ }
+ sub_cfg_.sub_tensor_rank = full_tensor->rank - slice_dim;
+ }
+
+ ComputeSubTensor();
+}
+
+void TensorSlicer::ComputeSubTensor(void) {
+ // subtsr_cfg_ is used to keep track of the iteration.
+ // A copy is created to update it with the correct clipping and padding for
+ // the current slice
+ mli_sub_tensor_cfg cfg_new = sub_cfg_;
+
+ // begin and end spans the complete input region including padding areas.
+ const int begin = (int)sub_cfg_.offset[sliceDim_] - pad_pre_;
+ // end is clipped to the end of the full input region. this is needed for
+ // cases where the last slice is smaller than the rest.
+ const int end = std::min(begin + sub_cfg_.size[sliceDim_] + overlap_,
+ full_tensor_->shape[sliceDim_] + pad_post_);
+ // The start coordinate of the subtensor is clipped to zero
+ cfg_new.offset[sliceDim_] = std::max(begin, 0);
+ // and the stop coordinate is clipped to the size of the full tensor
+ const int stop_coord =
+ std::min(end, static_cast<int>(full_tensor_->shape[sliceDim_]));
+ // compute the size of the subtensor
+ cfg_new.size[sliceDim_] = stop_coord - cfg_new.offset[sliceDim_];
+
+ // compute the padding configuration for the current slice.
+ actual_padding_pre = cfg_new.offset[sliceDim_] - begin;
+ actual_padding_post = end - stop_coord;
+
+ mli_hlp_create_subtensor(full_tensor_, &cfg_new, &sub_tensor_);
+}
+
+void TensorSlicer::Next(void) {
+ for (int i = full_tensor_->rank - 1; i >= 0; i--) {
+ sub_cfg_.offset[i] += sub_cfg_.size[i];
+ if (sub_cfg_.offset[i] >= full_tensor_->shape[i]) {
+ // wrap
+ sub_cfg_.offset[i] = 0;
+ // and continue to the next dimension, if no next dimension we are done.
+ if (i == 0) done_ = true;
+ continue;
+ } else {
+ // carry is false, so break from the loop
+ break;
+ }
+ }
+
+ if (!done_) ComputeSubTensor();
+}
+
+bool TensorSlicer::Done(void) { return done_; }
+
+int TensorSlicer::GetPaddingPre(void) { return actual_padding_pre; }
+
+int TensorSlicer::GetPaddingPost(void) { return actual_padding_post; }
+
+mli_tensor* TensorSlicer::Sub(void) { return &sub_tensor_; }
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h b/tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h
new file mode 100644
index 0000000..b21a5b6
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h
@@ -0,0 +1,56 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_ARC_MLI_SLICERS_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_ARC_MLI_SLICERS_H_
+
+#include "mli_api.h" // NOLINT
+namespace tflite {
+namespace ops {
+namespace micro {
+
+class TensorSlicer {
+ public:
+ TensorSlicer(const mli_tensor* full_tensor, int slice_dim, int slice_size,
+ int padding_pre = 0, int padding_post = 0, int overlap = 0,
+ bool interleave_mode = false);
+ ~TensorSlicer() = default;
+
+ void Next();
+ bool Done();
+ int GetPaddingPre();
+ int GetPaddingPost();
+
+ mli_tensor* Sub();
+
+ // Default constructor is deleted
+ TensorSlicer() = delete;
+
+ private:
+ const mli_tensor* full_tensor_;
+ mli_tensor sub_tensor_;
+ mli_sub_tensor_cfg sub_cfg_;
+ bool done_;
+ int sliceDim_;
+ int pad_pre_, pad_post_, overlap_;
+ int actual_padding_pre, actual_padding_post;
+
+ void ComputeSubTensor();
+};
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_ARC_MLI_SLICERS_H_
diff --git a/tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h b/tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h
new file mode 100644
index 0000000..799ce97
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h
@@ -0,0 +1,120 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_ARC_MLI_TF_UTILS_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_ARC_MLI_TF_UTILS_H_
+
+#include "mli_api.h" // NOLINT
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+constexpr int kFracBitsQ15 = 15;
+constexpr int kFracBitsQ31 = 31;
+
+namespace tflite {
+namespace ops {
+namespace micro {
+
+inline void ConvertToMliTensorData(const TfLiteTensor* tfT, mli_tensor* mliT) {
+ // Data is NULL until MliTensorAttachBuffer is called.
+ mliT->data = NULL;
+ if (tfT->type == kTfLiteInt8) {
+ mliT->el_type = MLI_EL_ASYM_I8;
+ } else if (tfT->type == kTfLiteInt32) {
+ mliT->el_type = MLI_EL_ASYM_I32;
+ } else {
+ TF_LITE_FATAL("Wrong data type. Expected int8_t or int32_t.");
+ }
+
+ mliT->capacity = tfT->bytes;
+ mliT->rank = GetTensorShape(tfT).DimensionsCount();
+ for (int i = 0; i < GetTensorShape(tfT).DimensionsCount(); i++) {
+ mliT->shape[i] = GetTensorShape(tfT).Dims(i);
+ }
+}
+
+inline void ConvertToMliQuantParams(const TfLiteTensor* tfT, mli_tensor* mliT) {
+ mliT->el_params.asym.dim = -1;
+ mliT->el_params.asym.zero_point.i16 = tfT->params.zero_point;
+ float fscale = tfT->params.scale;
+ int exp;
+ frexpf(fscale, &exp);
+ int frac_bits = kFracBitsQ31 - exp;
+ int32_t iscale = (int32_t)((1ll << frac_bits) * fscale + 0.5f);
+ mliT->el_params.asym.scale_frac_bits = frac_bits;
+ mliT->el_params.asym.scale.i32 = (int32_t)iscale;
+}
+
+inline void ConvertToMliQuantParamsPerChannel(const TfLiteTensor* tfT,
+ mli_tensor* mliT) {
+ // mli tensor scale and zero_point arrays should be allocated at this point
+ TFLITE_DCHECK_NE(mliT->el_params.asym.scale.pi16, 0);
+ TFLITE_DCHECK_NE(mliT->el_params.asym.zero_point.pi16, 0);
+
+ // get per channel quantization parameters
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(tfT->quantization.params);
+ mliT->el_params.asym.dim = affine_quantization->quantized_dimension;
+
+ // find frac_bits
+ const int num_channels =
+ mliT->shape[affine_quantization->quantized_dimension];
+ int min_frac_bits;
+ float* fscale = affine_quantization->scale->data;
+ for (int i = 0; i < num_channels; i++) {
+ int exp;
+ frexpf(fscale[i], &exp);
+ int cur_frac_bits = kFracBitsQ31 - exp;
+ if (i == 0) {
+ min_frac_bits = cur_frac_bits;
+ } else {
+ min_frac_bits =
+ min_frac_bits < cur_frac_bits ? min_frac_bits : cur_frac_bits;
+ }
+ }
+ mliT->el_params.asym.scale_frac_bits = min_frac_bits;
+
+ for (int i = 0; i < num_channels; i++) {
+ int32_t iscale = (int32_t)((1ll << min_frac_bits) * fscale[i] + 0.5f);
+ mliT->el_params.asym.scale.pi32[i] = iscale;
+ }
+}
+
+template <typename datatype>
+inline void MliTensorAttachBuffer(const TfLiteEvalTensor* tfT,
+ mli_tensor* mliT) {
+ // "const_cast" here used to attach const data buffer to the initially
+ // non-const mli_tensor. This is required by current implementation of MLI
+ // backend and planned for redesign due to this and some other aspects.
+ mliT->data = const_cast<void*>(
+ static_cast<const void*>(tflite::micro::GetTensorData<datatype>(tfT)));
+}
+
+inline void ConvertToMliTensor(const TfLiteTensor* tfT, mli_tensor* mliT) {
+ ConvertToMliTensorData(tfT, mliT);
+ ConvertToMliQuantParams(tfT, mliT);
+}
+
+inline void ConvertToMliTensorPerChannel(const TfLiteTensor* tfT,
+ mli_tensor* mliT) {
+ ConvertToMliTensorData(tfT, mliT);
+ ConvertToMliQuantParamsPerChannel(tfT, mliT);
+}
+} // namespace micro
+} // namespace ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_ARC_MLI_TF_UTILS_H_
diff --git a/tensorflow/lite/micro/kernels/arc_mli/pooling.cc b/tensorflow/lite/micro/kernels/arc_mli/pooling.cc
new file mode 100644
index 0000000..d1cd56f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/pooling.cc
@@ -0,0 +1,423 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/pooling.h"
+
+#include "mli_api.h" // NOLINT
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/pooling.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h"
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace pooling {
+
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ TfLitePaddingValues padding;
+ int32_t activation_min;
+ int32_t activation_max;
+ float activation_min_f32;
+ float activation_max_f32;
+
+ // The result of checking if MLI optimized version of tensors can be used.
+ bool is_mli_applicable;
+
+ // Tensors in MLI format.
+ mli_tensor* mli_in;
+ mli_tensor* mli_out;
+ mli_pool_cfg* cfg;
+};
+
+enum MliPoolingType { AveragePooling = 0, MaxPooling = 1 };
+
+bool IsMliApplicable(TfLiteContext* context, const TfLiteTensor* input,
+ const TfLitePoolParams* params) {
+ // MLI optimized version only supports int8_t datatype and no fused Relu
+ return (input->type == kTfLiteInt8 && params->activation == kTfLiteActNone);
+}
+
+TfLiteStatus CalculateOpData(TfLiteContext* context,
+ const TfLitePoolParams* params,
+ const TfLiteTensor* input,
+ const TfLiteTensor* output, OpData* data) {
+ // input: batch, height, width, channel
+ int height = SizeOfDimension(input, 1);
+ int width = SizeOfDimension(input, 2);
+
+ int out_height, out_width;
+
+ data->padding = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width,
+ /*dilation_rate_height=*/1,
+ /*dilation_rate_width=*/1, height, width, params->filter_height,
+ params->filter_width, params->padding, &out_height, &out_width);
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ data->is_mli_applicable = IsMliApplicable(context, input, params);
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(context, params, input, output, data));
+
+ if (input->type == kTfLiteFloat32) {
+ CalculateActivationRange(params->activation, &data->activation_min_f32,
+ &data->activation_max_f32);
+ } else if (input->type == kTfLiteInt8 || input->type == kTfLiteUInt8) {
+ CalculateActivationRangeQuantized(context, params->activation, output,
+ &data->activation_min,
+ &data->activation_max);
+ }
+
+ if (data->is_mli_applicable) {
+ data->mli_in = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->mli_out = static_cast<mli_tensor*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_tensor)));
+ data->cfg = static_cast<mli_pool_cfg*>(
+ context->AllocatePersistentBuffer(context, sizeof(mli_pool_cfg)));
+
+ ops::micro::ConvertToMliTensor(input, data->mli_in);
+ ops::micro::ConvertToMliTensor(output, data->mli_out);
+
+ data->cfg->kernel_width = params->filter_width;
+ data->cfg->kernel_height = params->filter_height;
+ data->cfg->stride_width = params->stride_width;
+ data->cfg->stride_height = params->stride_height;
+
+ if (params->padding == kTfLitePaddingValid) {
+ data->cfg->padding_left = 0;
+ data->cfg->padding_right = 0;
+ data->cfg->padding_top = 0;
+ data->cfg->padding_bottom = 0;
+ } else {
+ data->cfg->padding_left = data->padding.width;
+ data->cfg->padding_right =
+ data->padding.width + data->padding.width_offset;
+ data->cfg->padding_top = data->padding.height;
+ data->cfg->padding_bottom =
+ data->padding.height + data->padding.height_offset;
+ }
+ }
+ return kTfLiteOk;
+}
+
+void AverageEvalFloat(TfLiteContext* context, const TfLiteNode* node,
+ const TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ float activation_min, activation_max;
+ CalculateActivationRange(params->activation, &activation_min,
+ &activation_max);
+
+ PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.float_activation_min = activation_min;
+ op_params.float_activation_max = activation_max;
+ reference_ops::AveragePool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+
+// Prepare MLI tensors and run Average or Max Pooling
+TfLiteStatus EvalMli(TfLiteContext* context, const TfLitePoolParams* params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output,
+ const MliPoolingType pooling_type) {
+ mli_pool_cfg cfg_local = *data.cfg;
+
+ ops::micro::MliTensorAttachBuffer<int8_t>(input, data.mli_in);
+ ops::micro::MliTensorAttachBuffer<int8_t>(output, data.mli_out);
+
+ const int height_dimension = 1;
+ int in_slice_height = 0;
+ int out_slice_height = 0;
+ const int overlap = cfg_local.kernel_height - cfg_local.stride_height;
+
+ // Tensors for data in fast (local) memory and config to copy data from
+ // external to local memory
+ mli_tensor in_local = *data.mli_in;
+ mli_tensor out_local = *data.mli_out;
+ mli_mov_cfg_t copy_config;
+ mli_mov_cfg_for_copy(©_config);
+ TF_LITE_ENSURE_STATUS(get_arc_scratch_buffer_for_pooling_tensors(
+ context, &in_local, &out_local));
+ bool in_is_local = in_local.data == data.mli_in->data;
+ bool out_is_local = out_local.data == data.mli_out->data;
+ TF_LITE_ENSURE_STATUS(arc_scratch_buffer_calc_slice_size_io(
+ &in_local, &out_local, cfg_local.kernel_height, cfg_local.stride_height,
+ cfg_local.padding_top, cfg_local.padding_bottom, &in_slice_height,
+ &out_slice_height));
+
+ /* mli_in tensor contains batches of HWC tensors. so it is a 4 dimensional
+ tensor. because the mli kernel will process one HWC tensor at a time, the 4
+ dimensional tensor needs to be sliced into nBatch 3 dimensional tensors. on
+ top of that there could be a need to also slice in the Height dimension.
+ for that the sliceHeight has been calculated. The tensor slicer is
+ configured that it will completely slice the nBatch dimension (0) and slice
+ the height dimension (1) in chunks of 'sliceHeight' */
+ TensorSlicer in_slice(data.mli_in, height_dimension, in_slice_height,
+ cfg_local.padding_top, cfg_local.padding_bottom,
+ overlap);
+ TensorSlicer out_slice(data.mli_out, height_dimension, out_slice_height);
+
+ /* is_local indicates that the tensor is already in local memory,
+ so in that case the original tensor can be used,
+ and there is no need to copy it to the local tensor*/
+ mli_tensor* in_ptr = in_is_local ? in_slice.Sub() : &in_local;
+ mli_tensor* out_ptr = out_is_local ? out_slice.Sub() : &out_local;
+
+ while (!out_slice.Done()) {
+ cfg_local.padding_top = in_slice.GetPaddingPre();
+ cfg_local.padding_bottom = in_slice.GetPaddingPost();
+
+ mli_mov_tensor_sync(in_slice.Sub(), ©_config, in_ptr);
+ if (pooling_type == AveragePooling)
+ mli_krn_avepool_hwc_sa8(in_ptr, &cfg_local, out_ptr);
+ else if (pooling_type == MaxPooling)
+ mli_krn_maxpool_hwc_sa8(in_ptr, &cfg_local, out_ptr);
+ mli_mov_tensor_sync(out_ptr, ©_config, out_slice.Sub());
+
+ in_slice.Next();
+ out_slice.Next();
+ }
+ return kTfLiteOk;
+}
+
+void AverageEvalQuantized(TfLiteContext* context, const TfLiteNode* node,
+ const TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ TFLITE_DCHECK(input->type == kTfLiteUInt8 || input->type == kTfLiteInt8);
+
+ PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.quantized_activation_min = data.activation_min;
+ op_params.quantized_activation_max = data.activation_max;
+
+ if (input->type == kTfLiteUInt8) {
+ reference_ops::AveragePool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ reference_integer_ops::AveragePool(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+#else
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+
+void MaxEvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ tflite::PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.float_activation_min = data.activation_min_f32;
+ op_params.float_activation_max = data.activation_max_f32;
+ reference_ops::MaxPool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+#else
+ TF_LITE_KERNEL_LOG(
+ context,
+ "Node configuration or type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+
+void MaxEvalQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+#if !defined(TF_LITE_STRIP_REFERENCE_IMPL)
+ tflite::PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.quantized_activation_min = data.activation_min;
+ op_params.quantized_activation_max = data.activation_max;
+
+ if (input->type == kTfLiteUInt8) {
+ reference_ops::MaxPool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ reference_integer_ops::MaxPool(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+#else
+ TF_LITE_KERNEL_LOG(
+ context,
+ "Node configuration or type %s (%d) is not supported by ARC MLI Library.",
+ TfLiteTypeGetName(input->type), input->type);
+#endif
+}
+} // namespace
+
+TfLiteStatus AverageEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ // Inputs and outputs share the same type, guaranteed by the converter.
+ switch (input->type) {
+ case kTfLiteFloat32:
+ AverageEvalFloat(context, node, params, data, input, output);
+ break;
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ if (data.is_mli_applicable) {
+ EvalMli(context, params, data, input, output, AveragePooling);
+ } else {
+ AverageEvalQuantized(context, node, params, data, input, output);
+ }
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input type %s is not currently supported",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus MaxEval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ switch (input->type) {
+ case kTfLiteFloat32:
+ MaxEvalFloat(context, node, params, data, input, output);
+ break;
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ if (data.is_mli_applicable) {
+ EvalMli(context, params, data, input, output, MaxPooling);
+ } else {
+ MaxEvalQuantized(context, node, params, data, input, output);
+ }
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s not currently supported.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace pooling
+
+TfLiteRegistration Register_AVERAGE_POOL_2D() {
+ return {/*init=*/pooling::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pooling::Prepare,
+ /*invoke=*/pooling::AverageEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_MAX_POOL_2D() {
+ return {/*init=*/pooling::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pooling::Prepare,
+ /*invoke=*/pooling::MaxEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arc_mli/pooling_slicing_test.cc b/tensorflow/lite/micro/kernels/arc_mli/pooling_slicing_test.cc
new file mode 100644
index 0000000..e367bb2
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/pooling_slicing_test.cc
@@ -0,0 +1,422 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This test checks that slicing logic doesn`t affect result of pooling kernels
+//
+// This test doesn`t replace default pooling test
+// (tensorflow/lite/micro/kernels/pooling.cc). It is added to the
+// whole testset only in case MLI for ARC platform is used during generation
+// (which is handled in arc_mli.inc). So such tests won`t be generated for other
+// platforms.
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/micro/testing/test_utils.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void TestAveragePoolingQuantized(
+ const int* input_dims_data, const T* input_data, const float input_min,
+ const float input_max, const int filter_height, const int filter_width,
+ const int stride_height, const int stride_width,
+ const T* expected_output_data, const int* output_dims_data,
+ float output_min, float output_max, TfLitePadding padding,
+ TfLiteFusedActivation activation, T* output_data) {
+ static_assert(sizeof(T) == 1, "Only int8_t/uint8_t data types allowed.");
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_dims, "input_tensor", input_min,
+ input_max),
+ CreateQuantizedTensor(output_data, output_dims, "output_tensor",
+ output_min, output_max),
+ };
+
+ TfLiteContext context;
+ PopulateContext(tensors, tensors_size, &context);
+
+ ::tflite::AllOpsResolver resolver;
+ const TfLiteRegistration* registration =
+ resolver.FindOp(tflite::BuiltinOperator_AVERAGE_POOL_2D);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration);
+
+ TfLitePoolParams builtin_data = {padding, stride_width, stride_height,
+ filter_width, filter_height, activation};
+ const char* init_data = reinterpret_cast<const char*>(&builtin_data);
+ size_t init_data_size = 0;
+ void* user_data = nullptr;
+ if (registration->init) {
+ user_data = registration->init(&context, init_data, init_data_size);
+ }
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+ int temporaries_array_data[] = {0};
+ TfLiteIntArray* temporaries_array = IntArrayFromInts(temporaries_array_data);
+
+ TfLiteNode node;
+ node.inputs = inputs_array;
+ node.outputs = outputs_array;
+ node.temporaries = temporaries_array;
+ node.user_data = user_data;
+ node.builtin_data = reinterpret_cast<void*>(&builtin_data);
+ node.custom_initial_data = nullptr;
+ node.custom_initial_data_size = 0;
+ node.delegate = nullptr;
+
+ if (registration->prepare) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->prepare(&context, &node));
+ }
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration->invoke);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->invoke(&context, &node));
+ if (registration->free) {
+ registration->free(&context, user_data);
+ }
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+template <typename T>
+void TestMaxPoolQuantized(const int* input_dims_data, const T* input_data,
+ float input_min, float input_max, int filter_width,
+ int filter_height, int stride_width,
+ int stride_height, const T* expected_output_data,
+ float output_min, float output_max,
+ const int* output_dims_data, TfLitePadding padding,
+ TfLiteFusedActivation activation, T* output_data) {
+ static_assert(sizeof(T) == 1, "Only int8_t/uint8_t data types allowed.");
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_dims, "input_tensor", input_min,
+ input_max),
+ CreateQuantizedTensor(output_data, output_dims, "output_tensor",
+ output_min, output_max),
+ };
+
+ TfLiteContext context;
+ PopulateContext(tensors, tensors_size, &context);
+
+ ::tflite::AllOpsResolver resolver;
+ const TfLiteRegistration* registration =
+ resolver.FindOp(tflite::BuiltinOperator_MAX_POOL_2D);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration);
+
+ TfLitePoolParams builtin_data = {
+ padding, stride_width, stride_height,
+ filter_width, filter_height, activation,
+ };
+
+ const char* init_data = reinterpret_cast<const char*>(&builtin_data);
+ size_t init_data_size = 0;
+ void* user_data = nullptr;
+ if (registration->init) {
+ user_data = registration->init(&context, init_data, init_data_size);
+ }
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+ int temporaries_array_data[] = {0};
+ TfLiteIntArray* temporaries_array = IntArrayFromInts(temporaries_array_data);
+
+ TfLiteNode node;
+ node.inputs = inputs_array;
+ node.outputs = outputs_array;
+ node.temporaries = temporaries_array;
+ node.user_data = user_data;
+ node.builtin_data = reinterpret_cast<void*>(&builtin_data);
+ node.custom_initial_data = nullptr;
+ node.custom_initial_data_size = 0;
+ node.delegate = nullptr;
+ if (registration->prepare) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->prepare(&context, &node));
+ }
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration->invoke);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->invoke(&context, &node));
+ if (registration->free) {
+ registration->free(&context, user_data);
+ }
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SystemAveragePoolTestInt1) {
+ using tflite::testing::F2QS;
+
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int8_t output_data[3];
+
+ const int kInput1Shape[] = {4, 1, 2, 4, 1};
+ const int8_t kInput1Data[] = {1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput1Shape[] = {4, 1, 1, 3, 1};
+ const int8_t kGolden1Data[] = {1, 1, 1};
+
+ tflite::testing::TestAveragePoolingQuantized(
+ kInput1Shape, // Input shape
+ kInput1Data, input_min, input_max, // input quantization range
+ 2, 2, // filter height, filter width
+ 1, 1, // stride height, stride width
+ kGolden1Data,
+ kOutput1Shape, // Output shape
+ output_min, output_max, // output quantization range
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(LocalAveragePoolTestInt1) {
+ using tflite::testing::F2QS;
+
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int8_t output_data[3];
+
+#pragma Bss(".Zdata")
+ const int kInput1Shape[] = {4, 1, 2, 4, 1};
+ const int8_t kInput1Data[] = {1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput1Shape[] = {4, 1, 1, 3, 1};
+ const int8_t kGolden1Data[] = {1, 1, 1};
+#pragma Bss()
+
+ tflite::testing::TestAveragePoolingQuantized(
+ kInput1Shape, // Input shape
+ kInput1Data, input_min, input_max, // input quantization range
+ 2, 2, // filter height, filter width
+ 1, 1, // stride height, stride width
+ kGolden1Data,
+ kOutput1Shape, // Output shape
+ output_min, output_max, // output quantization range
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+// Test group AVG 2
+TF_LITE_MICRO_TEST(SystemAveragePoolTestInt2) {
+ using tflite::testing::F2QS;
+
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int8_t output_data[45];
+
+ const int kInput2Shape[] = {4, 1, 6, 10, 1};
+ const int8_t kInput2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput2Shape[] = {4, 1, 5, 9, 1};
+ const int8_t kGolden2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+
+ tflite::testing::TestAveragePoolingQuantized(
+ kInput2Shape, // Input shape
+ kInput2Data, input_min, input_max, // input quantization range
+ 2, 2, // filter height, filter width
+ 1, 1, // stride height, stride width
+ kGolden2Data,
+ kOutput2Shape, // Output shape
+ output_min, output_max, // output quantization range
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(LocalAveragePoolTestInt2) {
+ using tflite::testing::F2QS;
+
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int8_t output_data[45];
+
+#pragma Bss(".Zdata")
+ const int kInput2Shape[] = {4, 1, 6, 10, 1};
+ const int8_t kInput2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput2Shape[] = {4, 1, 5, 9, 1};
+ const int8_t kGolden2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+#pragma Bss()
+
+ tflite::testing::TestAveragePoolingQuantized(
+ kInput2Shape, // Input shape
+ kInput2Data, input_min, input_max, // input quantization range
+ 2, 2, // filter height, filter width
+ 1, 1, // stride height, stride width
+ kGolden2Data,
+ kOutput2Shape, // Output shape
+ output_min, output_max, // output quantization range
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+// Test group MAX 1
+TF_LITE_MICRO_TEST(SystemMaxPoolTestInt1) {
+ using tflite::testing::F2QS;
+
+ int8_t output_data[3];
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int filter_width = 2;
+ int filter_height = 2;
+ int stride_width = 1;
+ int stride_height = 1;
+
+ const int kInput1Shape[] = {4, 1, 2, 4, 1};
+ const int8_t kInput1Data[] = {1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput1Shape[] = {4, 1, 1, 3, 1};
+ const int8_t kGolden1Data[] = {1, 1, 1};
+
+ tflite::testing::TestMaxPoolQuantized(
+ kInput1Shape, // Input shape
+ kInput1Data, input_min, input_max, filter_width, filter_height,
+ stride_width, stride_height, kGolden1Data, output_min, output_max,
+ kOutput1Shape, // Output shape
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(LocalMaxPoolTestInt1) {
+ using tflite::testing::F2QS;
+
+ int8_t output_data[3];
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int filter_width = 2;
+ int filter_height = 2;
+ int stride_width = 1;
+ int stride_height = 1;
+
+#pragma Bss(".Zdata")
+ const int kInput1Shape[] = {4, 1, 2, 4, 1};
+ const int8_t kInput1Data[] = {1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput1Shape[] = {4, 1, 1, 3, 1};
+ const int8_t kGolden1Data[] = {1, 1, 1};
+#pragma Bss()
+
+ tflite::testing::TestMaxPoolQuantized(
+ kInput1Shape, // Input shape
+ kInput1Data, input_min, input_max, filter_width, filter_height,
+ stride_width, stride_height, kGolden1Data, output_min, output_max,
+ kOutput1Shape, // Output shape
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+// Test group MAX 2
+TF_LITE_MICRO_TEST(SystemMaxPoolTestInt2) {
+ using tflite::testing::F2QS;
+
+ int8_t output_data[45];
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int filter_width = 2;
+ int filter_height = 2;
+ int stride_width = 1;
+ int stride_height = 1;
+
+ const int kInput2Shape[] = {4, 1, 6, 10, 1};
+ const int8_t kInput2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput2Shape[] = {4, 1, 5, 9, 1};
+ const int8_t kGolden2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+
+ tflite::testing::TestMaxPoolQuantized(
+ kInput2Shape, // Input shape
+ kInput2Data, input_min, input_max, filter_width, filter_height,
+ stride_width, stride_height, kGolden2Data, output_min, output_max,
+ kOutput2Shape, // Output shape
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(LocalMaxPoolTestInt2) {
+ using tflite::testing::F2QS;
+
+ int8_t output_data[45];
+ const float input_min = -128;
+ const float input_max = 127;
+ const float output_min = -128;
+ const float output_max = 127;
+ int filter_width = 2;
+ int filter_height = 2;
+ int stride_width = 1;
+ int stride_height = 1;
+
+#pragma Bss(".Zdata")
+ const int kInput2Shape[] = {4, 1, 6, 10, 1};
+ const int8_t kInput2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int kOutput2Shape[] = {4, 1, 5, 9, 1};
+ const int8_t kGolden2Data[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+#pragma Bss()
+
+ tflite::testing::TestMaxPoolQuantized(
+ kInput2Shape, // Input shape
+ kInput2Data, input_min, input_max, filter_width, filter_height,
+ stride_width, stride_height, kGolden2Data, output_min, output_max,
+ kOutput2Shape, // Output shape
+ kTfLitePaddingValid, kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.cc b/tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.cc
new file mode 100644
index 0000000..a047552
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.cc
@@ -0,0 +1,342 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h"
+
+#include <limits.h>
+
+#include <algorithm>
+
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+
+#ifdef __Xxy
+static void get_arc_two_buffer_sizes(int request_size_1, int request_size_2,
+ int* grant_size_1, int* grant_size_2) {
+ int maxrequest = 0;
+ int secondrequest = 0;
+ int maxavailable = 0;
+ int secondavail = 0;
+
+ // determine the largest requested buffer.
+ if (request_size_1 > request_size_2) {
+ maxrequest = request_size_1;
+ secondrequest = request_size_2;
+ } else {
+ maxrequest = request_size_2;
+ secondrequest = request_size_1;
+ }
+
+ // find the two largest available buffers.
+ get_arc_scratch_buffer_two_max_sizes(&maxavailable, &secondavail);
+
+ // in case two buffers are available, the largest buffer can go to the largest
+ // request.
+ if (secondavail > 0) { // this condition can be enhanced to prevent cases
+ // where the second buffer is so small that it is
+ // better to use one buffer and split it.
+ if (request_size_1 > request_size_2) {
+ *grant_size_1 = maxavailable;
+ *grant_size_2 = secondavail;
+ } else {
+ *grant_size_1 = secondavail;
+ *grant_size_2 = maxavailable;
+ }
+ } else {
+ // In case only one buffer is available,
+ // use only the max buffer, and split it.
+ *grant_size_1 = maxavailable / 2;
+ *grant_size_2 = maxavailable / 2;
+ }
+}
+
+static TfLiteStatus get_arc_scratch_buffer_for_io_tensors(
+ TfLiteContext* context, mli_tensor* in, mli_tensor* out) {
+ int request_size_in = 0;
+ int request_size_out = 0;
+ int grant_size_in = 0;
+ int grant_size_out = 0;
+ if (!inside_arc_ccm(in->data)) {
+ // In case the input tensor contains multiple batches, it has rank 4
+ // because the mli kernel cannot operate on batches, we need to have the
+ // size of a single HWC tensor. that is why the start_rank is 1 in case of
+ // input rank 4
+ int start_rank = in->rank - 3;
+ request_size_in = mli_hlp_count_elem_num(in, start_rank) *
+ mli_hlp_tensor_element_size(in);
+ }
+ if (!inside_arc_ccm(out->data)) {
+ // In case the input tensor contains multiple batches, it has rank 4
+ // because the mli kernel cannot operate on batches, we need to have the
+ // size of a single batch. that is why the start_rank is 1 in case of input
+ // rank 4
+ int start_rank = out->rank - 3;
+ request_size_out = mli_hlp_count_elem_num(out, start_rank) *
+ mli_hlp_tensor_element_size(out);
+ }
+
+ get_arc_two_buffer_sizes(request_size_in, request_size_out, &grant_size_in,
+ &grant_size_out);
+
+ if (!inside_arc_ccm(in->data)) {
+ in->data = get_arc_scratch_buffer(grant_size_in);
+ in->capacity = grant_size_in;
+ if (in->data == NULL) return kTfLiteError;
+ }
+ if (!inside_arc_ccm(out->data)) {
+ out->data = get_arc_scratch_buffer(grant_size_out);
+ out->capacity = grant_size_out;
+ if (out->data == NULL) return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+#endif
+
+TfLiteStatus get_arc_scratch_buffer_for_conv_tensors(TfLiteContext* context,
+ mli_tensor* in,
+ mli_tensor* weights,
+ mli_tensor* bias,
+ mli_tensor* out) {
+ TfLiteStatus ret_val = kTfLiteOk;
+#ifdef __Xxy
+ init_arc_scratch_buffers();
+ if (!inside_arc_ccm(weights->data)) {
+ int weights_size = mli_hlp_count_elem_num(weights, 0) *
+ mli_hlp_tensor_element_size(weights);
+ int max_weights_size = 0;
+ weights->data = get_arc_scratch_buffer(weights_size);
+ weights->capacity = weights_size;
+ if (weights->data == NULL) {
+ get_arc_scratch_buffer_max_size(&max_weights_size);
+ weights->data = get_arc_scratch_buffer(max_weights_size);
+ weights->capacity = max_weights_size;
+ if (max_weights_size == 0) ret_val = kTfLiteError;
+ }
+ if (weights->data == NULL) ret_val = kTfLiteError;
+ }
+
+ if (!inside_arc_ccm(bias->data)) {
+ uint32_t bias_mem_requirements =
+ mli_hlp_count_elem_num(bias, 0) * mli_hlp_tensor_element_size(bias);
+ bias->data = get_arc_scratch_buffer(bias_mem_requirements);
+ bias->capacity = bias_mem_requirements;
+ }
+
+ if (ret_val == kTfLiteOk) {
+ ret_val = get_arc_scratch_buffer_for_io_tensors(context, in, out);
+ }
+
+ if (bias->data == NULL) {
+ int max_bias_size = 0;
+ get_arc_scratch_buffer_max_size(&max_bias_size);
+ bias->data = get_arc_scratch_buffer(max_bias_size);
+ bias->capacity = max_bias_size;
+ if (max_bias_size == 0) ret_val = kTfLiteError;
+ }
+ if (bias->data == NULL) ret_val = kTfLiteError;
+
+#endif
+ return ret_val;
+}
+
+TfLiteStatus get_arc_scratch_buffer_for_fully_connect_tensors(
+ TfLiteContext* context, mli_tensor* in, mli_tensor* weights,
+ mli_tensor* bias, mli_tensor* out) {
+ TfLiteStatus ret_val = kTfLiteOk;
+#ifdef __Xxy
+ init_arc_scratch_buffers();
+ /* strategy for FC kernels:
+ first allocate input, because this cannot be sliced. (in case of batch
+ processing, only a single input needs to be allocated) then weights & bias
+ because if fully loaded, they can be reused over batches. then output.
+ The number of output channels (for weights slicing) depends on size of
+ output and size of weights&bias */
+
+ if (!inside_arc_ccm(in->data)) {
+ /* In case the input tensor contains multiple batches,
+ only count the size if the inner most dimension */
+ int size_in = mli_hlp_count_elem_num(in, in->rank - 1) *
+ mli_hlp_tensor_element_size(in);
+ in->data = get_arc_scratch_buffer(size_in);
+ in->capacity = size_in;
+ if (in->data == NULL) {
+ in->capacity = 0;
+ ret_val = kTfLiteError;
+ }
+ }
+
+ if (!inside_arc_ccm(weights->data)) {
+ int weights_size = mli_hlp_count_elem_num(weights, 0) *
+ mli_hlp_tensor_element_size(weights);
+ int max_weights_size = 0;
+ weights->data = get_arc_scratch_buffer(weights_size);
+ weights->capacity = weights_size;
+ if (weights->data == NULL) {
+ get_arc_scratch_buffer_max_size(&max_weights_size);
+ weights->data = get_arc_scratch_buffer(max_weights_size);
+ weights->capacity = max_weights_size;
+ if (max_weights_size == 0) ret_val = kTfLiteError;
+ }
+ if (weights->data == NULL) ret_val = kTfLiteError;
+ }
+
+ if (!inside_arc_ccm(bias->data)) {
+ int bias_mem_requirements =
+ mli_hlp_count_elem_num(bias, 0) * mli_hlp_tensor_element_size(bias);
+ bias->data = get_arc_scratch_buffer(bias_mem_requirements);
+ bias->capacity = bias_mem_requirements;
+ }
+
+ if (!inside_arc_ccm(out->data)) {
+ /* In case the input tensor contains multiple batches,
+ only count the size if the inner most dimension */
+ int out_size = mli_hlp_count_elem_num(out, out->rank - 1) *
+ mli_hlp_tensor_element_size(out);
+ int max_out_size = 0;
+ out->data = get_arc_scratch_buffer(out_size);
+ out->capacity = out_size;
+ if (out->data == NULL) {
+ get_arc_scratch_buffer_max_size(&max_out_size);
+ out->data = get_arc_scratch_buffer(max_out_size);
+ out->capacity = max_out_size;
+ if (max_out_size == 0) ret_val = kTfLiteError;
+ }
+ if (out->data == NULL) ret_val = kTfLiteError;
+ }
+
+ if (bias->data == NULL) {
+ int max_bias_size = 0;
+ get_arc_scratch_buffer_max_size(&max_bias_size);
+ bias->data = get_arc_scratch_buffer(max_bias_size);
+ bias->capacity = max_bias_size;
+ if (max_bias_size == 0) ret_val = kTfLiteError;
+ }
+ if (bias->data == NULL) ret_val = kTfLiteError;
+
+#endif
+ return ret_val;
+}
+
+TfLiteStatus arc_scratch_buffer_calc_slice_size_io(
+ const mli_tensor* in, const mli_tensor* out, const int kernel_height,
+ const int stride_height, const int padding_top, const int padding_bot,
+ int* in_slice_height, int* out_slice_height) {
+ const int height_dimension = 1;
+ const int in_height = in->shape[height_dimension];
+ const int out_height = out->shape[height_dimension];
+ const int line_size_in = mli_hlp_count_elem_num(in, height_dimension + 1) *
+ mli_hlp_tensor_element_size(in);
+ const int line_size_out = mli_hlp_count_elem_num(out, height_dimension + 1) *
+ mli_hlp_tensor_element_size(out);
+ int max_lines_in = 0;
+ int max_lines_out = 0;
+ int max_out_lines_for_input = 0;
+ bool fit = (static_cast<int>(in->capacity) >= in_height * line_size_in) &&
+ (static_cast<int>(out->capacity) >= out_height * line_size_out);
+ if (fit) {
+ // in case both tensors completely fit in the capacity, there is no need for
+ // slicing. As padding can affect effective input region, we also derive it
+ // from output height, and rely on a clipping logic which intend to reduce
+ // last smaller slice. I.e the only slice is a kind of
+ // "smaller last slice that need to be corrected"
+ *in_slice_height = std::max(in_height, out_height * stride_height);
+ *out_slice_height = out_height;
+ } else {
+ // First compute how many lines fit into the input tensor, and compute how
+ // many output lines can be computed with that.
+ max_lines_in =
+ std::min(in_height, static_cast<int>(in->capacity) / line_size_in);
+ if (max_lines_in >= in_height) {
+ max_out_lines_for_input = out_height;
+ } else if (2 * max_lines_in >= in_height) {
+ // in this case only two slices are needed, so both could benefit from
+ // padding. take the MIN to get the worst case.
+ max_out_lines_for_input =
+ (max_lines_in + std::min(padding_top, padding_bot) - kernel_height +
+ 1) /
+ stride_height;
+ } else {
+ max_out_lines_for_input =
+ (max_lines_in - kernel_height + 1) / stride_height;
+ }
+ // Then compute how many output lines fit into the output tensor.
+ max_lines_out =
+ std::min(out_height, static_cast<int>(out->capacity) / line_size_out);
+ // the smallest of the two determines the slice height for the output, and
+ // the derived sliceheight for the input.
+ *out_slice_height = std::min(max_out_lines_for_input, max_lines_out);
+ *in_slice_height = *out_slice_height * stride_height;
+ }
+
+ if ((*in_slice_height > 0) && (*out_slice_height > 0)) {
+ return kTfLiteOk;
+ } else {
+ return kTfLiteError;
+ }
+}
+
+TfLiteStatus arc_scratch_buffer_calc_slice_size_weights(
+ const mli_tensor* weights, const mli_tensor* bias,
+ const int weight_out_ch_dimension, int* slice_channels) {
+ const int channels = weights->shape[weight_out_ch_dimension];
+ const int ch_size_w = (mli_hlp_count_elem_num(weights, 0) / channels) *
+ mli_hlp_tensor_element_size(weights);
+ const int ch_size_b = (mli_hlp_count_elem_num(bias, 0) / channels) *
+ mli_hlp_tensor_element_size(bias);
+ int max_ch_weigths = 0;
+ int max_ch_bias = 0;
+
+ bool fit = (static_cast<int>(weights->capacity) >= channels * ch_size_w) &&
+ (static_cast<int>(bias->capacity) >= channels * ch_size_b);
+ if (fit) {
+ // in case both tensors completely fit in the capacity, there is no need for
+ // slicing
+ *slice_channels = channels;
+ } else {
+ // First compute how many channels fit into the weights tensor
+ max_ch_weigths =
+ std::min(channels, static_cast<int>(weights->capacity) / ch_size_w);
+ // Ten compute how many channels fit into the bias tensor.
+ max_ch_bias =
+ std::min(channels, static_cast<int>(bias->capacity) / ch_size_b);
+ // the smallest of the two determines the slice size
+ *slice_channels = std::min(max_ch_weigths, max_ch_bias);
+ }
+
+ if (*slice_channels > 0) {
+ return kTfLiteOk;
+ } else {
+ return kTfLiteError;
+ }
+}
+
+TfLiteStatus get_arc_scratch_buffer_for_pooling_tensors(TfLiteContext* context,
+ mli_tensor* in,
+ mli_tensor* out) {
+#ifdef __Xxy
+ init_arc_scratch_buffers();
+ return get_arc_scratch_buffer_for_io_tensors(context, in, out);
+#else
+ return kTfLiteOk;
+#endif
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h b/tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h
new file mode 100644
index 0000000..0db2db5
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h
@@ -0,0 +1,129 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_ARC_SCRATCH_BUF_MGR_H_
+#define TENSORFLOW_LITE_MICRO_ARC_SCRATCH_BUF_MGR_H_
+
+#include "mli_api.h" // NOLINT
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+
+/**
+ * @brief Function to allocate scratch buffers for the convolution tensors
+ *
+ * @detail This function will update the data pointers in the 4 tensors with
+ * pointers to scratch buffers in fast local memory.
+ *
+ * @param context [I] pointer to TfLite context (needed for error handling)
+ * @param in [IO] pointer to the input tensor
+ * @param weights [IO] pointer to the weights tensor
+ * @param bias [IO] pointer to the bias tensor
+ * @param output [IO] pointer to the output tensor
+ *
+ * @return Tf Lite status code
+ */
+TfLiteStatus get_arc_scratch_buffer_for_conv_tensors(TfLiteContext* context,
+ mli_tensor* in,
+ mli_tensor* weights,
+ mli_tensor* bias,
+ mli_tensor* out);
+
+/**
+ * @brief Function to allocate scratch buffers for pooling kernels with only
+ * input and output buffers
+ *
+ * @detail This function will update the data pointers in the 2 tensors with
+ * pointers to scratch buffers in fast local memory.
+ *
+ * @param context [I] pointer to TfLite context (needed for error handling)
+ * @param in [IO] pointer to the input tensor
+ * @param output [IO] pointer to the output tensor
+ *
+ * @return Tf Lite status code
+ */
+TfLiteStatus get_arc_scratch_buffer_for_pooling_tensors(TfLiteContext* context,
+ mli_tensor* in,
+ mli_tensor* out);
+
+/**
+ * @brief Function to allocate scratch buffers for the fully connect tensors
+ *
+ * @detail This function will update the data pointers in the 4 tensors with
+ * pointers to scratch buffers in fast local memory.
+ *
+ * @param context [I] pointer to TfLite context (needed for error handling)
+ * @param in [IO] pointer to the input tensor
+ * @param weights [IO] pointer to the weights tensor
+ * @param bias [IO] pointer to the bias tensor
+ * @param output [IO] pointer to the output tensor
+ *
+ * @return Tf Lite status code
+ */
+TfLiteStatus get_arc_scratch_buffer_for_fully_connect_tensors(
+ TfLiteContext* context, mli_tensor* in, mli_tensor* weights,
+ mli_tensor* bias, mli_tensor* out);
+
+/**
+ * @brief Function to calculate slice size for io tensors
+ *
+ * @detail This function will calculate the slice size in the height dimension
+ * for input and output tensors. it takes into account the kernel size and the
+ * padding. the function will look at the capacity filed in the in and out
+ * tensor to determine the available buffersize.
+ *
+ * @param in [I] pointer to the input tensor
+ * @param out [I] pointer to the output tensor
+ * @param kernelHeight [I] size of the kernel in height dimension
+ * @param strideHeight [I] input stride in height dimension
+ * @param padding_top [I] number of lines with zeros at the top
+ * @param padding_bot [I] number of lines with zeros at the bottom
+ * @param inSliceHeight [O] slice size in height dimension for the input tensor
+ * @param outSliceHeight [O] slice size in height dimension for the output
+ * tensor
+ *
+ * @return Tf Lite status code
+ */
+TfLiteStatus arc_scratch_buffer_calc_slice_size_io(
+ const mli_tensor* in, const mli_tensor* out, const int kernelHeight,
+ const int strideHeight, const int padding_top, const int padding_bot,
+ int* in_slice_height, int* out_slice_height);
+
+/**
+ * @brief Function to calculate slice size for weight slicing
+ *
+ * @detail This function will calculate the slice size in the output channel
+ * dimension for weight and bias tensors. the function will look at the capacity
+ * filed in the weights and bias tensor to determine the available buffersize.
+ *
+ * @param weights [I] pointer to the input tensor
+ * @param bias [I] pointer to the output tensor
+ * @param weightOutChDimension [I] dimension of the output channels in the
+ * weights tensor
+ * @param sliceChannels [O] slice size in output channel dimension
+ *
+ * @return Tf Lite status code
+ */
+TfLiteStatus arc_scratch_buffer_calc_slice_size_weights(
+ const mli_tensor* weights, const mli_tensor* bias,
+ const int weight_out_ch_dimension, int* slice_channels);
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_ARC_SCRATCH_BUF_MGR_H_
diff --git a/tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.cc b/tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.cc
new file mode 100644
index 0000000..296b9b6
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.cc
@@ -0,0 +1,135 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h"
+
+#include <limits.h>
+
+namespace tflite {
+namespace ops {
+namespace micro {
+
+/* by default use all the XY memory, and half of the DCCM because DCCM is also
+ * used for the data section and the stack. the values can be overruled by
+ * adding a -D option to the makefile of the application
+ */
+#ifndef SCRATCH_MEM_X_SIZE
+#ifdef core_config_xy_size
+#define SCRATCH_MEM_X_SIZE (core_config_xy_size)
+#else
+#define SCRATCH_MEM_X_SIZE (0)
+#endif
+#endif
+
+#ifndef SCRATCH_MEM_Y_SIZE
+#ifdef core_config_xy_size
+#define SCRATCH_MEM_Y_SIZE (core_config_xy_size)
+#else
+#define SCRATCH_MEM_Y_SIZE (0)
+#endif
+#endif
+
+#ifndef SCRATCH_MEM_Z_SIZE
+#ifdef core_config_dccm_size
+#define SCRATCH_MEM_Z_SIZE ((core_config_dccm_size) / 2)
+#else
+#define SCRATCH_MEM_Z_SIZE (0)
+#endif
+#endif
+
+namespace {
+#pragma Bss(".Xdata")
+static int8_t scratch_mem_x[SCRATCH_MEM_X_SIZE];
+#pragma Bss()
+
+#pragma Bss(".Ydata")
+static int8_t scratch_mem_y[SCRATCH_MEM_Y_SIZE];
+#pragma Bss()
+
+#pragma Bss(".Zdata")
+static int8_t scratch_mem_z[SCRATCH_MEM_Z_SIZE];
+#pragma Bss()
+} // namespace
+
+static int8_t* scratch_mem[] = {scratch_mem_x, scratch_mem_y, scratch_mem_z};
+static uint32_t scratch_sizes[] = {SCRATCH_MEM_X_SIZE, SCRATCH_MEM_Y_SIZE,
+ SCRATCH_MEM_Z_SIZE};
+
+void* get_arc_scratch_buffer(int size) {
+ // Function to asign fast memory from one of 3 scratch buffers.
+ // Best Fit strategy - memory is allocated from that memory bank that leaves
+ // the least unused memory.
+ void* buf = NULL;
+ int best_mem_idx = -1;
+ int best_mem_delta = INT_MAX;
+ const int num_mem = sizeof(scratch_mem) / sizeof(scratch_mem[0]);
+ // find a local memory that fits the data size.
+ for (int mem_idx = 0; mem_idx < num_mem; ++mem_idx) {
+ // Best Fit
+ if ((size <= static_cast<int>(scratch_sizes[mem_idx])) &&
+ (static_cast<int>(scratch_sizes[mem_idx]) - size < best_mem_delta)) {
+ best_mem_idx = mem_idx;
+ best_mem_delta = scratch_sizes[mem_idx] - size;
+ }
+ }
+ if (best_mem_idx >= 0) {
+ buf = static_cast<void*>(scratch_mem[best_mem_idx]);
+ scratch_mem[best_mem_idx] += size;
+ scratch_sizes[best_mem_idx] -= size;
+ }
+ return buf;
+}
+
+void get_arc_scratch_buffer_max_size(int* size) {
+ int maxavailable = 0;
+ const int num_mem = sizeof(scratch_mem) / sizeof(scratch_mem[0]);
+ // find the largest available buffer.
+ for (int i = 0; i < num_mem; i++) {
+ if (static_cast<int>(scratch_sizes[i]) > maxavailable) {
+ maxavailable = scratch_sizes[i];
+ }
+ }
+ *size = maxavailable;
+}
+
+void get_arc_scratch_buffer_two_max_sizes(int* size1, int* size2) {
+ int maxavailable = 0;
+ int secondavail = 0;
+ const int num_mem = sizeof(scratch_mem) / sizeof(scratch_mem[0]);
+ // find the two largest available buffers.
+ for (int i = 0; i < num_mem; i++) {
+ if (static_cast<int>(scratch_sizes[i]) > maxavailable) {
+ secondavail = maxavailable;
+ maxavailable = scratch_sizes[i];
+ } else if (static_cast<int>(scratch_sizes[i]) > secondavail) {
+ secondavail = scratch_sizes[i];
+ }
+ }
+ *size1 = maxavailable;
+ *size2 = secondavail;
+}
+
+void init_arc_scratch_buffers(void) {
+ scratch_mem[0] = scratch_mem_x;
+ scratch_mem[1] = scratch_mem_y;
+ scratch_mem[2] = scratch_mem_z;
+ scratch_sizes[0] = SCRATCH_MEM_X_SIZE;
+ scratch_sizes[1] = SCRATCH_MEM_Y_SIZE;
+ scratch_sizes[2] = SCRATCH_MEM_Z_SIZE;
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h b/tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h
new file mode 100644
index 0000000..6e3feb3
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h
@@ -0,0 +1,68 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_ARC_SCRATCH_BUFFERS_H_
+#define TENSORFLOW_LITE_MICRO_ARC_SCRATCH_BUFFERS_H_
+
+#include "mli_api.h" // NOLINT
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+
+void init_arc_scratch_buffers(void);
+void* get_arc_scratch_buffer(int size); // Function to assign fast memory
+ // from one of 3 scratch buffers.
+
+void get_arc_scratch_buffer_max_size(int* size);
+void get_arc_scratch_buffer_two_max_sizes(int* size1, int* size2);
+
+static inline bool inside_arc_dccm(void* p) {
+#if core_config_dccm_present
+ return ((unsigned)p >= core_config_dccm_base) &&
+ ((unsigned)p < core_config_dccm_base + core_config_dccm_size);
+#else
+ return false;
+#endif
+}
+
+static inline bool inside_arc_xccm(void* p) {
+#if core_config_xy
+ return ((unsigned)p >= core_config_xy_x_base) &&
+ ((unsigned)p < core_config_xy_x_base + core_config_xy_size);
+#else
+ return false;
+#endif
+}
+
+static inline bool inside_arc_yccm(void* p) {
+#if core_config_xy
+ return ((unsigned)p >= core_config_xy_y_base) &&
+ ((unsigned)p < core_config_xy_y_base + core_config_xy_size);
+#else
+ return false;
+#endif
+}
+
+static inline bool inside_arc_ccm(void* p) {
+ return inside_arc_dccm(p) || inside_arc_xccm(p) || inside_arc_yccm(p);
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_ARC_SCRATCH_BUFFERS_H_
diff --git a/tensorflow/lite/micro/kernels/arg_min_max.cc b/tensorflow/lite/micro/kernels/arg_min_max.cc
new file mode 100644
index 0000000..12ac001
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arg_min_max.cc
@@ -0,0 +1,133 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/arg_min_max.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/micro_utils.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace arg_min_max {
+
+constexpr int kInputTensor = 0;
+constexpr int kAxis = 1;
+constexpr int kOutputTensor = 0;
+
+template <typename T1, typename T2, typename T3>
+inline void ArgMinMaxHelper(const RuntimeShape& input1_shape,
+ const T1* input1_data, const T3* input2_data,
+ const RuntimeShape& output_shape, T2* output_data,
+ bool is_arg_max) {
+ if (is_arg_max) {
+ reference_ops::ArgMinMax(input1_shape, input1_data, input2_data,
+ output_shape, output_data, micro::Greater());
+ } else {
+ reference_ops::ArgMinMax(input1_shape, input1_data, input2_data,
+ output_shape, output_data, micro::Less());
+ }
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node, bool is_arg_max) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* axis =
+ tflite::micro::GetEvalInput(context, node, kAxis);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+#define TF_LITE_ARG_MIN_MAX(data_type, axis_type, output_type) \
+ ArgMinMaxHelper(tflite::micro::GetTensorShape(input), \
+ tflite::micro::GetTensorData<data_type>(input), \
+ tflite::micro::GetTensorData<axis_type>(axis), \
+ tflite::micro::GetTensorShape(output), \
+ tflite::micro::GetTensorData<output_type>(output), \
+ is_arg_max)
+ if (axis->type == kTfLiteInt32) {
+ if (output->type == kTfLiteInt32) {
+ switch (input->type) {
+ case kTfLiteFloat32:
+ TF_LITE_ARG_MIN_MAX(float, int32_t, int32_t);
+ break;
+ case kTfLiteUInt8:
+ TF_LITE_ARG_MIN_MAX(uint8_t, int32_t, int32_t);
+ break;
+ case kTfLiteInt8:
+ TF_LITE_ARG_MIN_MAX(int8_t, int32_t, int32_t);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "Only float32, uint8_t and int8_t are "
+ "supported currently, got %s.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ } else {
+ TF_LITE_KERNEL_LOG(context,
+ "Only int32_t are supported currently, got %s.",
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Only int32_t are supported currently, got %s.",
+ TfLiteTypeGetName(axis->type));
+ return kTfLiteError;
+ }
+
+#undef TF_LITE_ARG_MIN_MAX
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus ArgMinEval(TfLiteContext* context, TfLiteNode* node) {
+ return Eval(context, node, false);
+}
+
+TfLiteStatus ArgMaxEval(TfLiteContext* context, TfLiteNode* node) {
+ return Eval(context, node, true);
+}
+
+} // namespace arg_min_max
+
+TfLiteRegistration Register_ARG_MAX() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/arg_min_max::ArgMaxEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_ARG_MIN() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/arg_min_max::ArgMinEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/arg_min_max_test.cc b/tensorflow/lite/micro/kernels/arg_min_max_test.cc
new file mode 100644
index 0000000..0b9e7f1
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/arg_min_max_test.cc
@@ -0,0 +1,267 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void ValidateArgMinMaxGoldens(TfLiteTensor* tensors, int tensors_size,
+ const int32_t* golden, int32_t* output,
+ int output_size, bool using_min) {
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = using_min
+ ? ops::micro::Register_ARG_MIN()
+ : ops::micro::Register_ARG_MAX();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_size; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden[i], output[i]);
+ }
+}
+
+void TestArgMinMaxFloat(const int* input_dims_data, const float* input_values,
+ const int* axis_dims_data, const int32_t* axis_values,
+ const int* output_dims_data, int32_t* output,
+ const int32_t* goldens, bool using_min) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_values, input_dims),
+ CreateTensor(axis_values, axis_dims),
+ CreateTensor(output, output_dims),
+ };
+
+ ValidateArgMinMaxGoldens(tensors, tensors_size, goldens, output,
+ output_dims_count, using_min);
+}
+
+template <typename T>
+void TestArgMinMaxQuantized(const int* input_dims_data,
+ const float* input_values, T* input_quantized,
+ float input_scale, int input_zero_point,
+ const int* axis_dims_data,
+ const int32_t* axis_values,
+ const int* output_dims_data, int32_t* output,
+ const int32_t* goldens, bool using_min) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_values, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateTensor(axis_values, axis_dims),
+ CreateTensor(output, output_dims),
+ };
+
+ ValidateArgMinMaxGoldens(tensors, tensors_size, goldens, output,
+ output_dims_count, using_min);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(GetMaxArgFloat) {
+ int32_t output_data[1];
+ const int input_dims[] = {4, 1, 1, 1, 4};
+ const float input_values[] = {0.1, 0.9, 0.7, 0.3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 1};
+ const int32_t goldens[] = {1};
+
+ tflite::testing::TestArgMinMaxFloat(input_dims, input_values, axis_dims,
+ axis_values, output_dims, output_data,
+ goldens, false);
+}
+
+TF_LITE_MICRO_TEST(GetMinArgFloat) {
+ int32_t output_data[1];
+ const int input_dims[] = {4, 1, 1, 1, 4};
+ const float input_values[] = {0.1, 0.9, 0.7, 0.3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 1};
+ const int32_t goldens[] = {0};
+
+ tflite::testing::TestArgMinMaxFloat(input_dims, input_values, axis_dims,
+ axis_values, output_dims, output_data,
+ goldens, true);
+}
+
+TF_LITE_MICRO_TEST(GetMaxArgUInt8) {
+ int32_t output_data[1];
+ const int input_size = 4;
+ const int input_dims[] = {4, 1, 1, 1, input_size};
+ const float input_values[] = {1, 9, 7, 3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 1};
+ const int32_t goldens[] = {1};
+
+ float input_scale = 0.5;
+ int input_zero_point = 124;
+ uint8_t input_quantized[input_size];
+
+ tflite::testing::TestArgMinMaxQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ axis_dims, axis_values, output_dims, output_data, goldens, false);
+}
+
+TF_LITE_MICRO_TEST(GetMinArgUInt8) {
+ int32_t output_data[1];
+ const int input_size = 4;
+ const int input_dims[] = {4, 1, 1, 1, input_size};
+ const float input_values[] = {1, 9, 7, 3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 1};
+ const int32_t goldens[] = {0};
+
+ float input_scale = 0.5;
+ int input_zero_point = 124;
+ uint8_t input_quantized[input_size];
+
+ tflite::testing::TestArgMinMaxQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ axis_dims, axis_values, output_dims, output_data, goldens, true);
+}
+
+TF_LITE_MICRO_TEST(GetMaxArgInt8) {
+ int32_t output_data[1];
+ const int input_size = 4;
+ const int input_dims[] = {4, 1, 1, 1, input_size};
+ const float input_values[] = {1, 9, 7, 3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 1};
+ const int32_t goldens[] = {1};
+
+ float input_scale = 0.5;
+ int input_zero_point = -9;
+ int8_t input_quantized[input_size];
+
+ tflite::testing::TestArgMinMaxQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ axis_dims, axis_values, output_dims, output_data, goldens, false);
+}
+
+TF_LITE_MICRO_TEST(GetMinArgInt8) {
+ int32_t output_data[1];
+ const int input_size = 4;
+ const int input_dims[] = {4, 1, 1, 1, input_size};
+ const float input_values[] = {1, 9, 7, 3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 1};
+ const int32_t goldens[] = {0};
+
+ float input_scale = 0.5;
+ int input_zero_point = -9;
+ int8_t input_quantized[input_size];
+
+ tflite::testing::TestArgMinMaxQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ axis_dims, axis_values, output_dims, output_data, goldens, true);
+}
+
+TF_LITE_MICRO_TEST(GetMaxArgMulDimensions) {
+ int32_t output_data[2];
+ const int input_size = 8;
+ const int input_dims[] = {4, 1, 1, 2, 4};
+ const float input_values[] = {1, 2, 7, 8, 1, 9, 7, 3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 2};
+ const int32_t goldens[] = {3, 1};
+
+ float input_scale = 0.5;
+ int input_zero_point = -9;
+ int8_t input_quantized[input_size];
+
+ tflite::testing::TestArgMinMaxQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ axis_dims, axis_values, output_dims, output_data, goldens, false);
+}
+
+TF_LITE_MICRO_TEST(GetMinArgMulDimensions) {
+ int32_t output_data[2];
+ const int input_size = 8;
+ const int input_dims[] = {4, 1, 1, 2, 4};
+ const float input_values[] = {1, 2, 7, 8, 1, 9, 7, 3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {3};
+ const int output_dims[] = {3, 1, 1, 2};
+ const int32_t goldens[] = {0, 0};
+
+ float input_scale = 0.5;
+ int input_zero_point = -9;
+ int8_t input_quantized[input_size];
+
+ tflite::testing::TestArgMinMaxQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ axis_dims, axis_values, output_dims, output_data, goldens, true);
+}
+
+TF_LITE_MICRO_TEST(GetMaxArgNegativeAxis) {
+ const int input_size = 8;
+ const int output_size = 4;
+ const int input_dims[] = {4, 1, 1, 2, 4};
+ const float input_values[] = {1, 2, 7, 8, 1, 9, 7, 3};
+ const int axis_dims[] = {3, 1, 1, 1};
+ const int32_t axis_values[] = {-2};
+ const int output_dims[] = {3, 1, 1, 4};
+ const int32_t goldens[] = {0, 1, 0, 0};
+
+ float input_scale = 0.5;
+ int input_zero_point = -9;
+ int32_t output_data[output_size];
+ int8_t input_quantized[input_size];
+
+ tflite::testing::TestArgMinMaxQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ axis_dims, axis_values, output_dims, output_data, goldens, false);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/batch_to_space_nd.cc b/tensorflow/lite/micro/kernels/batch_to_space_nd.cc
new file mode 100644
index 0000000..a6fa046
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/batch_to_space_nd.cc
@@ -0,0 +1,111 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/batch_to_space_nd.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kBlockShapeTensor = 1;
+constexpr int kCropsTensor = 2;
+constexpr int kOutputTensor = 0;
+
+// Currently, only 3D NHC and 4D NHWC input/output op_context are supported.
+// In case of 3D input, it will be extended to 3D NHWC by adding W=1.
+// The 4D array need to have exactly 2 spatial dimensions.
+// TODO(b/149952582): Support arbitrary dimension in SpaceToBatchND.
+const int kInputOutputMinDimensionNum = 3;
+const int kInputOutputMaxDimensionNum = 4;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 3);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, input != nullptr && output != nullptr);
+
+ TF_LITE_ENSURE(context, NumDimensions(input) >= kInputOutputMinDimensionNum);
+ TF_LITE_ENSURE(context, NumDimensions(output) >= kInputOutputMinDimensionNum);
+ TF_LITE_ENSURE(context, NumDimensions(input) <= kInputOutputMaxDimensionNum);
+ TF_LITE_ENSURE(context, NumDimensions(output) <= kInputOutputMaxDimensionNum);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* block_shape =
+ tflite::micro::GetEvalInput(context, node, kBlockShapeTensor);
+ const TfLiteEvalTensor* crops =
+ tflite::micro::GetEvalInput(context, node, kCropsTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32:
+ reference_ops::BatchToSpaceND(
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(block_shape),
+ tflite::micro::GetTensorData<int32_t>(block_shape),
+ tflite::micro::GetTensorShape(crops),
+ tflite::micro::GetTensorData<int32_t>(crops),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ case kTfLiteInt8:
+ reference_ops::BatchToSpaceND(
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(block_shape),
+ tflite::micro::GetTensorData<int32_t>(block_shape),
+ tflite::micro::GetTensorShape(crops),
+ tflite::micro::GetTensorData<int32_t>(crops),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace.
+
+TfLiteRegistration Register_BATCH_TO_SPACE_ND() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/batch_to_space_nd_test.cc b/tensorflow/lite/micro/kernels/batch_to_space_nd_test.cc
new file mode 100644
index 0000000..2d195dd
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/batch_to_space_nd_test.cc
@@ -0,0 +1,154 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int kBasicInputOutputSize = 16;
+const int basic_input_dims[] = {4, 4, 2, 2, 1};
+const float basic_input[kBasicInputOutputSize] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
+const int basic_block_shape_dims[] = {1, 2};
+const int32_t basic_block_shape[] = {2, 2};
+const int basic_crops_dims[] = {1, 4};
+const int32_t basic_crops[] = {0, 0, 0, 0};
+const int basic_output_dims[] = {4, 1, 4, 4, 1};
+const float basic_golden[kBasicInputOutputSize] = {1, 5, 2, 6, 9, 13, 10, 14,
+ 3, 7, 4, 8, 11, 15, 12, 16};
+
+template <typename T>
+TfLiteStatus ValidateBatchToSpaceNdGoldens(TfLiteTensor* tensors,
+ int tensors_size, const T* golden,
+ T* output, int output_size) {
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_BATCH_TO_SPACE_ND();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_ENSURE_STATUS(runner.InitAndPrepare());
+ TF_LITE_ENSURE_STATUS(runner.Invoke());
+
+ for (int i = 0; i < output_size; ++i) {
+ // TODO(b/158102673): workaround for not having fatal test assertions.
+ TF_LITE_MICRO_EXPECT_EQ(golden[i], output[i]);
+ if (golden[i] != output[i]) {
+ return kTfLiteError;
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus TestBatchToSpaceNdFloat(
+ const int* input_dims_data, const float* input_data,
+ const int* block_shape_dims_data, const int32_t* block_shape_data,
+ const int* crops_dims_data, const int32_t* crops_data,
+ const int* output_dims_data, const float* golden, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* block_shape_dims = IntArrayFromInts(block_shape_dims_data);
+ TfLiteIntArray* crops_dims = IntArrayFromInts(crops_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(block_shape_data, block_shape_dims),
+ CreateTensor(crops_data, crops_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ return ValidateBatchToSpaceNdGoldens(tensors, tensors_size, golden,
+ output_data, ElementCount(*output_dims));
+}
+
+template <typename T>
+TfLiteStatus TestBatchToSpaceNdQuantized(
+ const int* input_dims_data, const float* input_data, T* input_quantized,
+ float input_scale, int input_zero_point, const int* block_shape_dims_data,
+ const int32_t* block_shape_data, const int* crops_dims_data,
+ const int32_t* crops_data, const int* output_dims_data, const float* golden,
+ T* golden_quantized, float output_scale, int output_zero_point,
+ T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* block_shape_dims = IntArrayFromInts(block_shape_dims_data);
+ TfLiteIntArray* crops_dims = IntArrayFromInts(crops_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ tflite::testing::CreateQuantizedTensor(input_data, input_quantized,
+ input_dims, input_scale,
+ input_zero_point),
+ tflite::testing::CreateTensor(block_shape_data, block_shape_dims),
+ tflite::testing::CreateTensor(crops_data, crops_dims),
+ tflite::testing::CreateQuantizedTensor(output_data, output_dims,
+ output_scale, output_zero_point),
+ };
+ tflite::Quantize(golden, golden_quantized, ElementCount(*output_dims),
+ output_scale, output_zero_point);
+
+ return ValidateBatchToSpaceNdGoldens(tensors, tensors_size, golden_quantized,
+ output_data, ElementCount(*output_dims));
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(BatchToSpaceBasicFloat) {
+ float output[tflite::testing::kBasicInputOutputSize];
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestBatchToSpaceNdFloat(
+ tflite::testing::basic_input_dims, tflite::testing::basic_input,
+ tflite::testing::basic_block_shape_dims,
+ tflite::testing::basic_block_shape, tflite::testing::basic_crops_dims,
+ tflite::testing::basic_crops, tflite::testing::basic_output_dims,
+ tflite::testing::basic_golden, output));
+}
+
+TF_LITE_MICRO_TEST(BatchToSpaceBasicInt8) {
+ int8_t output[tflite::testing::kBasicInputOutputSize];
+ int8_t input_quantized[tflite::testing::kBasicInputOutputSize];
+ int8_t golden_quantized[tflite::testing::kBasicInputOutputSize];
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestBatchToSpaceNdQuantized(
+ tflite::testing::basic_input_dims, tflite::testing::basic_input,
+ input_quantized, 1.0f, 0, tflite::testing::basic_block_shape_dims,
+ tflite::testing::basic_block_shape, tflite::testing::basic_crops_dims,
+ tflite::testing::basic_crops, tflite::testing::basic_output_dims,
+ tflite::testing::basic_golden, golden_quantized, 1.0f, 0, output));
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/cast.cc b/tensorflow/lite/micro/kernels/cast.cc
new file mode 100644
index 0000000..b0462ed
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cast.cc
@@ -0,0 +1,96 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ return kTfLiteOk;
+}
+
+template <typename FromT, typename ToT>
+void copyCast(const FromT* in, ToT* out, int num_elements) {
+ std::transform(in, in + num_elements, out,
+ [](FromT a) { return static_cast<ToT>(a); });
+}
+
+template <typename FromT>
+TfLiteStatus copyToTensor(TfLiteContext* context, const FromT* in,
+ TfLiteEvalTensor* out, int num_elements) {
+ switch (out->type) {
+ case kTfLiteInt8:
+ copyCast(in, out->data.int8, num_elements);
+ break;
+ case kTfLiteFloat32:
+ copyCast(in, tflite::micro::GetTensorData<float>(out), num_elements);
+ break;
+ default:
+ // Unsupported type.
+ TF_LITE_KERNEL_LOG(context, "Output type %s (%d) not supported.",
+ TfLiteTypeGetName(out->type), out->type);
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ int num_elements = MatchingFlatSize(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorShape(output));
+
+ switch (input->type) {
+ case kTfLiteInt8:
+ return copyToTensor(context, input->data.int8, output, num_elements);
+ case kTfLiteFloat32:
+ return copyToTensor(context, tflite::micro::GetTensorData<float>(input),
+ output, num_elements);
+ default:
+ // Unsupported type.
+ TF_LITE_KERNEL_LOG(context, "Input type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ }
+ return kTfLiteOk;
+}
+} // namespace
+
+TfLiteRegistration Register_CAST() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cast_test.cc b/tensorflow/lite/micro/kernels/cast_test.cc
new file mode 100644
index 0000000..3633a61
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cast_test.cc
@@ -0,0 +1,117 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestCastFloatToInt8(const int* input_dims_data, const float* input_data,
+ const int8_t* expected_output_data,
+ int8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(input_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_CAST();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+void TestCastInt8ToFloat(const int* input_dims_data, const int8_t* input_data,
+ const float* expected_output_data,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(input_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_CAST();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(CastFloatToInt8) {
+ int8_t output_data[6];
+ const int input_dims[] = {2, 3, 2};
+
+ // TODO(b/178391195): Test negative and out-of-range numbers.
+ const float input_values[] = {100.f, 1.0f, 0.f, 0.4f, 1.999f, 1.1f};
+ const int8_t golden[] = {100, 1, 0, 0, 1, 1};
+ tflite::testing::TestCastFloatToInt8(input_dims, input_values, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(CastInt8ToFloat) {
+ float output_data[6];
+ const int input_dims[] = {2, 3, 2};
+ const int8_t input_values[] = {123, 0, 1, 2, 3, 4};
+ const float golden[] = {123.f, 0.f, 1.f, 2.f, 3.f, 4.f};
+ tflite::testing::TestCastInt8ToFloat(input_dims, input_values, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/ceil.cc b/tensorflow/lite/micro/kernels/ceil.cc
new file mode 100644
index 0000000..f929ce6
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceil.cc
@@ -0,0 +1,76 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/ceil.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace ceil {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, input->type);
+ TF_LITE_ENSURE_EQ(context, output->bytes, input->bytes);
+ TF_LITE_ENSURE_EQ(context, output->dims->size, input->dims->size);
+ for (int i = 0; i < output->dims->size; ++i) {
+ TF_LITE_ENSURE_EQ(context, output->dims->data[i], input->dims->data[i]);
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ reference_ops::Ceil(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+
+ return kTfLiteOk;
+}
+} // namespace ceil
+
+TfLiteRegistration Register_CEIL() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/ceil::Prepare,
+ /*invoke=*/ceil::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/ceil_test.cc b/tensorflow/lite/micro/kernels/ceil_test.cc
new file mode 100644
index 0000000..52c39a2
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceil_test.cc
@@ -0,0 +1,83 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestCeil(const int* input_dims_data, const float* input_data,
+ const float* expected_output_data, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(input_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = ops::micro::Register_CEIL();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SingleDim) {
+ float output_data[2];
+ const int input_dims[] = {1, 2};
+ const float input_values[] = {8.5, 0.0};
+ const float golden[] = {9, 0};
+ tflite::testing::TestCeil(input_dims, input_values, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(MultiDims) {
+ float output_data[10];
+ const int input_dims[] = {4, 2, 1, 1, 5};
+ const float input_values[] = {
+ 0.0001, 8.0001, 0.9999, 9.9999, 0.5,
+ -0.0001, -8.0001, -0.9999, -9.9999, -0.5,
+ };
+ const float golden[] = {1, 9, 1, 10, 1, 0, -8, 0, -9, 0};
+ tflite::testing::TestCeil(input_dims, input_values, golden, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/ceva/ceva_common.cc b/tensorflow/lite/micro/kernels/ceva/ceva_common.cc
new file mode 100644
index 0000000..c776290
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/ceva_common.cc
@@ -0,0 +1,23 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h"
+#define CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL_DEF 32768
+int32_t CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL =
+ CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL_DEF;
+#ifndef WIN32
+__attribute__((section(".MODEL_DATA")))
+#endif
+int32_t CEVA_TFLM_KERNELS_SCRATCH[CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL_DEF];
diff --git a/tensorflow/lite/micro/kernels/ceva/ceva_common.h b/tensorflow/lite/micro/kernels/ceva/ceva_common.h
new file mode 100755
index 0000000..e99e797
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/ceva_common.h
@@ -0,0 +1,24 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_CEVA_CEVA_COMMON_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_CEVA_CEVA_COMMON_H_
+
+#if defined(CEVA_BX1) || defined(CEVA_SP500)
+extern int32_t* CEVA_TFLM_KERNELS_SCRATCH;
+extern int32_t CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL;
+#endif
+
+#endif
\ No newline at end of file
diff --git a/tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h b/tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h
new file mode 100644
index 0000000..49134c2
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h
@@ -0,0 +1,613 @@
+
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// API header for CEVA TFLM optimized kernel library
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_CEVA_CEVA_TFLM_LIB_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_CEVA_CEVA_TFLM_LIB_H_
+
+#include "tensorflow/lite/micro/kernels/ceva/types.h"
+
+#if defined(__cplusplus)
+extern "C" {
+#endif /* __cplusplus */
+
+void CEVA_TFLM_ResizeNearestNeighbor_float32(
+ const bool align_corners, int32_t output_height, int32_t output_width,
+ int32_t row_offset, int32_t input_height, int32_t input_width,
+ int32_t col_offset, int32_t depth, const int32_t* input_ptr,
+ int32_t* output_ptr, const bool half_pixel_centers, int32_t* scratch);
+void CEVA_TFLM_ResizeNearestNeighbor_int8(
+ const bool align_corners, int32_t output_height, int32_t output_width,
+ int32_t row_offset, int32_t input_height, int32_t input_width,
+ int32_t col_offset, int32_t depth, const int8_t* input_ptr,
+ int8_t* output_ptr, const bool half_pixel_centers, int32_t* scratch);
+
+void CEVA_TFLM_Abs_Float32(const float* input_data, float* output_data,
+ int flat_size);
+void CEVA_TFLM_Sqrt_Float32(const float* input_data, float* output_data,
+ int flat_size);
+void CEVA_TFLM_Rsqrt_Float32(const float* input_data, float* output_data,
+ int flat_size);
+void CEVA_TFLM_Square_Float32(const float* input_data, float* output_data,
+ int flat_size);
+
+void CEVA_TFLM_Cos_Float32(const float* input_data, float* output_data,
+ int flat_size);
+void CEVA_TFLM_Sin_Float32(const float* input_data, float* output_data,
+ int flat_size);
+void CEVA_TFLM_Tanh_Float32(const float* input_data, float* output_data,
+ int flat_size);
+
+void CEVA_TFLM_Sigmoid_Float32(const float* input_data, float* output_data,
+ int flat_size);
+void CEVA_TFLM_Log_Float32(const float* input_data, float* output_data,
+ int flat_size);
+
+void CEVA_TFLM_LogicalNot(const bool* input_data, bool* output_data,
+ int flat_size);
+
+void CEVA_TFLM_AffineQuantize_Int8(const float_32* input_data,
+ int8_t* output_data, int flat_size,
+ float_32 scale, int zero_point);
+
+void CEVA_TFLM_Softmax_Float32(const float* input_data, float* output_data,
+ const float beta, const int depth);
+
+void CEVA_TFLM_Neg_Float32(const float_32* input_data, float_32* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_RoundToNearest_asm(const float* input_arr, float* output_arr,
+ const int size);
+float RoundToNearest(float value);
+
+void CEVA_TFLM_Round_float32(const float* input_data, float* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_Softmax_Int8(const int8_t* input_data, int8_t* output_data,
+ const int32_t input_beta_multiplier,
+ const int32_t input_beta_left_shift,
+ const int32_t depth, void* scratch);
+
+void CEVA_TFLM_Min_Max_Float32(const float* input_data,
+ const float float_activation_min,
+ const float float_activation_max,
+ const int flat_size, float* output_data);
+
+void CEVA_TFLM_Add_Float32(const void* params_inp, const float* input1_data,
+ const float* input2_data, float* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_BroadcastAdd4DSlow_Float32(const void* params_inp,
+ const float* input1_data,
+ const float* input2_data,
+ float* output_data, const int* Dims,
+ const int* desc1, const int* desc2);
+
+void CEVA_TFLM_BroadcastSubSlow_Float32(
+ const void* params_inp, const float* input1_data, const float* input2_data,
+ float* output_data, const int* strides1, const int* strides2,
+ const int* output_strides, const int* output_extents);
+
+void CEVA_TFLM_BroadcastSubSlow_Float32_loop(
+ const void* params_inp, const float* input1_data, const float* input2_data,
+ float* output_data, const int* output_extents, const int* strides1,
+ const int* strides2, const int* output_strides);
+
+void CEVA_TFLM_SubWithActivation_Float32(const void* params_inp,
+ const float* input1_data,
+ const float* input2_data,
+ float* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_MaximumBroadcastSlow_Float32(
+ const float* input1_data, const float* input2_data, float* output_data,
+ const int* strides1, const int* strides2, const int* output_strides,
+ const int* output_extents);
+void CEVA_TFLM_MinimumBroadcastSlow_Float32(
+ const float* input1_data, const float* input2_data, float* output_data,
+ const int* strides1, const int* strides2, const int* output_strides,
+ const int* output_extents);
+
+void CEVA_TFLM_Maximum_Float32(const float* input1_data,
+ const float* input2_data, float* output_data,
+ const int flat_size);
+void CEVA_TFLM_Minimum_Float32(const float* input1_data,
+ const float* input2_data, float* output_data,
+ const int flat_size);
+void CEVA_TFLM_Maximum_Float32_asm(const float* input1_data,
+ const float* input2_data, float* output_data,
+ const int flat_size);
+void CEVA_TFLM_Minimum_Float32_asm(const float* input1_data,
+ const float* input2_data, float* output_data,
+ const int flat_size);
+void CEVA_TFLM_DepthwiseConv_Float32(
+ // const DepthwiseParams& params,
+ // const int batches, // always 1
+ const int stride_width, const int stride_height, const int pad_width,
+ const int pad_height, const int depth_multiplier, const int input_height,
+ const int input_width, const int input_depth, const float* input_data,
+ const int filter_height, const int filter_width, const int filter_depth,
+ const float* filter_data, const float* bias_data, const int output_height,
+ const int output_width, const int output_depth, float* output_data,
+ const int dilation_width_factor, const int dilation_height_factor,
+ const float output_activation_min, const float output_activation_max
+
+);
+void CEVA_TFLM_DepthwiseConvPerChannel_int8(
+ const int stride_width, const int stride_height, const int pad_width,
+ const int pad_height, const int depth_multiplier_,
+ const int32_t input_offset_, const int32_t output_offset,
+ const int32_t* output_multiplier, const int32_t* output_shift,
+ const int input_height, const int input_width_, const int input_depth_,
+ const int8_t* input_data, const int filter_height, const int filter_width,
+ const int filter_depth_, const int8_t* filter_data,
+ const int32_t* bias_data, const int output_height, const int output_width,
+ const int output_depth,
+
+ int8_t* output_data, int32_t* scratch_
+
+ ,
+ const int dilation_width_factor_, const int dilation_height_factor,
+ const int32_t output_activation_min, const int32_t output_activation_max);
+
+void CEVA_TFLM_ConvPerChannel_Int8(
+ const int stride_width, const int stride_height, const int pad_width,
+ const int pad_height, // const int depth_multiplier,
+ const int32_t input_offset, const int32_t output_offset,
+ const int32_t* output_multiplier, const int32_t* output_shift,
+ const int input_height, const int input_width, const int input_depth_Dims3,
+ const int input_depth, const int8_t* input_data, const int filter_height,
+ const int filter_width, const int filter_depth, const int8_t* filter_data,
+ const int32_t* bias_data, const int output_height, const int output_width,
+ const int output_depth_Dims3, const int output_depth, int8_t* output_data,
+ int32_t* scratch, const int dilation_width_factor,
+ const int dilation_height_factor, const int32_t output_activation_min,
+ const int32_t output_activation_max);
+
+void CEVA_TFLM_Conv_Float32(
+ // const int batches,
+ const int stride_width, const int stride_height, const int pad_width,
+ const int pad_height, // const int depth_multiplier,
+ const int input_height, const int input_width, const int input_depth_Dims3,
+ const int input_depth, const float* input_data, const int filter_height,
+ const int filter_width, const int filter_depth, const float* filter_data,
+ const float* bias_data, const int output_height, const int output_width,
+ const int output_depth_Dims3, const int output_depth, float* output_data,
+ const int dilation_width_factor, const int dilation_height_factor,
+ const float output_activation_min, const float output_activation_max
+
+);
+
+///////////////////
+void CEVA_TFLM_MaximumBroadcastSlow_Int8(
+ const int8_t* input1_data, const int8_t* input2_data, int8_t* output_data,
+ const int* strides1, const int* strides2, const int* output_strides,
+ const int* output_extents);
+void CEVA_TFLM_MinimumBroadcastSlow_Int8(
+ const int8_t* input1_data, const int8_t* input2_data, int8_t* output_data,
+ const int* strides1, const int* strides2, const int* output_strides,
+ const int* output_extents);
+
+void CEVA_TFLM_Maximum_Int8(const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ const int flat_size);
+void CEVA_TFLM_Minimum_Int8(const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_BroadcastSubSlow_Int8(
+ const void* params_inp, const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data, const int* strides1,
+ const int* strides2, const int* output_strides, const int* output_extents);
+
+void CEVA_TFLM_BroadcastSubSlow_Int8_loop(
+ const void* params_inp, const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data, const int* output_extents,
+ const int* strides1, const int* strides2, const int* output_strides);
+
+void CEVA_TFLM_BroadcastAddSlow_Int8(const void* params_inp,
+ const int8_t* input1_data,
+ const int8_t* input2_data,
+ int8_t* output_data, const int* strides1,
+ const int* strides2,
+ const int* output_extents);
+
+void CEVA_TFLM_BroadcastAddSlow_Int8_loop(
+ const void* params_inp, const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data, const int* output_extents,
+ const int* strides1, const int* strides2);
+
+void CEVA_TFLM_Sub_Int8(const void* params_inp, const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_Sub_Uint8(const void* params_inp, const uint8_t* input1_data,
+ const uint8_t* input2_data, uint8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_Add_Uint8(const void* params, const uint8_t* input1_data,
+ const uint8_t* input2_data, uint8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_Add_Int8(const void* params_inp, const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_BroadcastAdd4DSlow_Uint8(const void* params,
+ const uint8_t* input1_data,
+ const uint8_t* input2_data,
+ uint8_t* output_data, const int* Dims,
+ const int* desc1, const int* desc2,
+ const int* dims_data);
+void CEVA_TFLM_svdf_Float32(float_32* vector1_ptr, float_32* vector2_ptr,
+ int32_t num_units, int32_t memory_size_rank,
+ float_32* output_ptr_batch);
+void CEVA_TFLM_svdf_Int8(int n_memory, const int8_t* matrix_ptr,
+ const int8_t* vector_in_batch_t,
+ int16_t* result_in_batch, int input_zp, int n_input,
+ int effective_scale_1_a, int effective_scale_1_b,
+ int n_filter, int* scratch);
+void CEVA_TFLM_AffineQuantize_Int8(const float_32* input_data,
+ int8_t* output_data, int flat_size,
+ float_32 scale, int zero_point);
+
+// int32_t MultiplyByQuantizedMultiplier_t(int32_t x, int32_t
+// quantized_multiplier, int shift); int32_t
+// MultiplyByQuantizedMultiplier_t1(int32_t x, int32_t quantized_multiplier, int
+// shift);
+
+void CEVA_TFLM_L2Normalization_Float32(const float* input_data,
+ float* output_data, float epsilon,
+ const int outer_size, const int depth);
+void CEVA_TFLM_L2Normalization_Int8(int32_t input_zero_point,
+ int32_t outer_size, int32_t depth,
+ const int8_t* input_data,
+ int8_t* output_data);
+
+void CEVA_TFLM_prelu_Float32(const float* in1_data, const int32_t* in1_strides,
+ const float* in2_data, const int32_t* in2_strides,
+ float* out_data, const int32_t* out_strides,
+ const int32_t* dims);
+
+void CEVA_TFLM_prelu_Int8(const int8_t* in1_data, const int32_t* in1_strides,
+ const int8_t* alpha_data,
+ const int32_t* alpha_strides, int8_t* out_data,
+ const int32_t* out_strides, const int32_t* dims,
+ const int32_t* params);
+void CEVA_TFLM_FullyConnected_Float32(
+ const void* params_inp, const int input_shape, const float* input_data,
+ const int weights_shape_DimensionsCount, const int* weights_shape_DimsData,
+ const float* weights_data, const int bias_shape, const float* bias_data,
+ const int output_shape_DimensionsCount, const int* output_shape_DimsData,
+ float* output_data);
+void CEVA_TFLM_FullyConnected_int8(
+ const void* params_inp, const int input_shape, const int8_t* input_data,
+ const int filter_shape_DimensionsCount, const int* filter_shape_DimsData,
+ const int8_t* filter_data, const int bias_shape, const int32_t* bias_data,
+ const int output_shape_DimensionsCount, const int* output_shape_DimsData,
+ int8_t* output_data, int* scratch);
+
+void CEVA_TFLM_tanh_Int8(int32_t input_zero_point, int32_t input_range_radius,
+ int32_t input_multiplier, int32_t input_shift,
+ int32_t input_size, const int8_t* input_data,
+ int8_t* output_data);
+
+void CEVA_TFLM_Logistic_Int8(int32_t input_zero_point,
+ int32_t input_range_radius,
+ int32_t input_multiplier, int32_t input_left_shift,
+ int32_t input_size, const int8_t* input_data,
+ int8_t* output_data);
+
+void CEVA_TFLM_Tanh_float32(const float_32* input_data, float_32* output_data,
+ const int flat_size);
+void CEVA_TFLM_Logistic_float32(const float_32* input_data,
+ float_32* output_data, const int flat_size);
+
+void CEVA_TFLM_PackImplLoop_float(const float* input_ptr, float* output_ptr,
+ int outer_size, int copy_size,
+ int step_vcount_copy_size);
+void CEVA_TFLM_PackUnpackImplLoopInitSizes(int* const copy_size,
+ int* const outer_size,
+ const int* const outputDimsData,
+ const int dimensions, int axis);
+void CEVA_TFLM_PackImplLoop_Int8(const int8_t* input_ptr, int8_t* output_ptr,
+ int outer_size, int copy_size,
+ int step_vcount_copy_size);
+void CEVA_TFLM_UnpackImplLoop_float(const float* input_ptr, float* output_ptr,
+ int outer_size, int copy_size,
+ int step_vcount_copy_size);
+void CEVA_TFLM_UnpackImplLoop_Int8(const int8_t* input_ptr, int8_t* output_ptr,
+ int outer_size, int copy_size,
+ int step_vcount_copy_size);
+
+void CEVA_TFLM_ComparisonEqual_Float32(const float* input1, const float* input2,
+ bool* output, const int32_t size);
+void CEVA_TFLM_ComparisonNotEqual_Float32(const float* input1,
+ const float* input2, bool* output,
+ const int32_t size);
+void CEVA_TFLM_ComparisonGreater_Float32(const float* input1,
+ const float* input2, bool* output,
+ const int32_t size);
+void CEVA_TFLM_ComparisonGreaterEqual_Float32(const float* input1,
+ const float* input2, bool* output,
+ const int32_t size);
+void CEVA_TFLM_ComparisonLess_Float32(const float* input1, const float* input2,
+ bool* output, const int32_t size);
+void CEVA_TFLM_ComparisonLessEqual_Float32(const float* input1,
+ const float* input2, bool* output,
+ const int32_t size);
+
+void CEVA_TFLM_ComparisonEqual_Float32_Broadcast(const float* input1,
+ const float* input2,
+ bool* output,
+ const int32_t* dims,
+ const int32_t** op_param);
+
+void CEVA_TFLM_ComparisonNotEqual_Float32_Broadcast(const float* input1,
+ const float* input2,
+ bool* output,
+ const int32_t* dims,
+ const int32_t** op_param);
+
+void CEVA_TFLM_ComparisonGreater_Float32_Broadcast(const float* input1,
+ const float* input2,
+ bool* output,
+ const int32_t* dims,
+ const int32_t** op_param);
+void CEVA_TFLM_ComparisonGreaterEqual_Float32_Broadcast(
+ const float* input1, const float* input2, bool* output, const int32_t* dims,
+ const int32_t** op_param);
+
+void CEVA_TFLM_ComparisonLess_Float32_Broadcast(const float* input1,
+ const float* input2,
+ bool* output,
+ const int32_t* dims,
+ const int32_t** op_param);
+
+void CEVA_TFLM_ComparisonLessEqual_Float32_Broadcast(const float* input1,
+ const float* input2,
+ bool* output,
+ const int32_t* dims,
+ const int32_t** op_param);
+
+void CEVA_TFLM_ComparisonEqual_Int8(const int8_t* input1, const int8_t* input2,
+ bool* output, const int32_t flatsize,
+ void* op_params);
+void CEVA_TFLM_ComparisonNotEqual_Int8(const int8_t* input1,
+ const int8_t* input2, bool* output,
+ const int32_t flatsize, void* op_params);
+void CEVA_TFLM_ComparisonGreater_Int8(const int8_t* input1,
+ const int8_t* input2, bool* output,
+ const int32_t flatsize, void* op_params);
+void CEVA_TFLM_ComparisonGreaterEqual_Int8(const int8_t* input1,
+ const int8_t* input2, bool* output,
+ const int32_t flatsize,
+ void* op_params);
+void CEVA_TFLM_ComparisonLess_Int8(const int8_t* input1, const int8_t* input2,
+ bool* output, const int32_t flatsize,
+ void* op_params);
+void CEVA_TFLM_ComparisonLessEqual_Int8(const int8_t* input1,
+ const int8_t* input2, bool* output,
+ const int32_t flatsize,
+ void* op_params);
+
+void CEVA_TFLM_ComparisonEqual_Int8_Broadcast(const int8_t* input1,
+ const int8_t* input2,
+ bool* output, const int32_t* dims,
+ void* op_params);
+void CEVA_TFLM_ComparisonNotEqual_Int8_Broadcast(const int8_t* input1,
+ const int8_t* input2,
+ bool* output,
+ const int32_t* dims,
+ void* op_params);
+void CEVA_TFLM_ComparisonGreater_Int8_Broadcast(const int8_t* input1,
+ const int8_t* input2,
+ bool* output,
+ const int32_t* dims,
+ void* op_params);
+void CEVA_TFLM_ComparisonGreaterEqual_Int8_Broadcast(const int8_t* input1,
+ const int8_t* input2,
+ bool* output,
+ const int32_t* dims,
+ void* op_params);
+void CEVA_TFLM_ComparisonLess_Int8_Broadcast(const int8_t* input1,
+ const int8_t* input2, bool* output,
+ const int32_t* dims,
+ void* op_params);
+void CEVA_TFLM_ComparisonLessEqual_Int8_Broadcast(const int8_t* input1,
+ const int8_t* input2,
+ bool* output,
+ const int32_t* dims,
+ void* op_params);
+
+void CEVA_TFLM_Mul_Float32(const void* params_inp, const float* input1_data,
+ const float* input2_data, float* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_BroadcastMul4DSlow_Float32(const void* params_inp,
+ const float* input1_data,
+ const float* input2_data,
+ float* output_data, const int* Dims,
+ const int* desc1, const int* desc2);
+
+void CEVA_TFLM_AveragePool_Float32(const void* params, const int* input_shape,
+ const float* input_data,
+ const int* output_shape, float* output_data);
+
+void CEVA_TFLM_AveragePool_Int8(const void* params_inp, const int* input_shape,
+ const int8_t* input_data,
+ const int* output_shape, int8_t* output_data);
+
+void CEVA_TFLM_AveragePool_Int8_Loop(
+ const int* input_shape, const int8_t* input_data, int8_t* output_data,
+ const int depth, int batch, int in_y, const int filter_y_start,
+ const int filter_y_end, const int in_x_origin, const int filter_x_start,
+ const int filter_x_end, int filter_count, int32_t quantized_activation_min,
+ int32_t quantized_activation_max, int indx_out);
+
+void CEVA_TFLM_MaxPool_Float32(const void* params_inp, const int* input_shape,
+ const float* input_data, const int* output_shape,
+ float* output_data);
+
+void CEVA_TFLM_MaxPool_Int8(const void* params_inp, const int* input_shape,
+ const int8_t* input_data, const int* output_shape,
+ int8_t* output_data);
+
+void CEVA_TFLM_MaxPool_Int8_Loop(
+ const int* input_shape, const int8_t* input_data, int8_t* output_data,
+ const int depth, int batch, int in_y, const int filter_y_start,
+ const int filter_y_end, const int in_x_origin, const int filter_x_start,
+ const int filter_x_end, int32_t quantized_activation_min,
+ int32_t quantized_activation_max, int indx_out);
+
+void CEVA_TFLM_Mul_Int8(const void* params_inp, const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_BroadcastMul4DSlow_Int8(const void* params_inp,
+ const int8_t* input1_data,
+ const int8_t* input2_data,
+ int8_t* output_data, const int* Dims,
+ const int* desc1, const int* desc2);
+
+void CEVA_TFLM_Dequantize_Float32(const int8_t* input_data,
+ float_32* output_data, int flat_size,
+ float_32 scale, int zero_point);
+
+void CEVA_TFLM_Ceil_Float32(const float* input_data, float* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_Logical_And_Int8(const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_BroadcastLogicalAnd4DSlow_Int8(const int8_t* input1_data,
+ const int8_t* input2_data,
+ int8_t* output_data,
+ const int* Dims, const int* desc1,
+ const int* desc2);
+
+void CEVA_TFLM_Logical_Or_Int8(const int8_t* input1_data,
+ const int8_t* input2_data, int8_t* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_BroadcastLogicalOr4DSlow_Int8(const int8_t* input1_data,
+ const int8_t* input2_data,
+ int8_t* output_data,
+ const int* Dims, const int* desc1,
+ const int* desc2);
+
+void CEVA_TFLM_SplitLoops_Float32(float** out_ptrs, const int* dataIndex,
+ const float* input_ptr, int outer_size,
+ int output_count, int copy_size);
+void CEVA_TFLM_SplitLoops_int8(int8_t** out_ptrs, const int* dataIndex,
+ const int8_t* input_ptr, int outer_size,
+ int output_count, int copy_size);
+
+void CEVA_TFLM_Relu_Float32(const float* input_data, float* output_data,
+ const int flat_size);
+void CEVA_TFLM_Relu6_Float32(const float* input_data, float* output_data,
+ const int flat_size);
+void CEVA_TFLM_Relu_int8(const void* params, const int8_t* input_data,
+ int8_t* output_data, const int flat_size);
+void CEVA_TFLM_Relu6_int8(const int8_t lower, const int8_t upper,
+ const int8_t* input_data, int8_t* output_data,
+ const int flat_size);
+void CEVA_TFLM_Floor_float32(const float* input_data, float* output_data,
+ const int flat_size);
+
+void CEVA_TFLM_Concatenation_Float32(const void* params_inp,
+ const int** input_shape,
+ const float** input_data,
+ const int output_shape_DimensionsCount,
+ const int* output_shape_DimsData,
+ float* output_data);
+
+void CEVA_TFLM_Concatenation_int8(const void* params_inp,
+ const int** input_shape,
+ const int8_t** input_data,
+ const int output_shape_DimensionsCount,
+ const int* output_shape_DimsData,
+ int8_t* output_data);
+
+void CEVA_TFLM_Mean4D_Float32(const float* input_data, float* output_data,
+ const int* Dims, const int* Dims_inp,
+ const int* dims_data, const int* dims_data_inp);
+bool CEVA_TFLM_Mean_Float32(const float* input_data, const int* input_dims,
+ const int input_num_dims, float* output_data,
+ const int* output_dims, const int output_num_dims,
+ const int* axis, const int num_axis_dimensions,
+ bool keep_dims, int* temp_index, int* resolved_axis,
+ float* temp_sum);
+void CEVA_TFLM_Mean_Float32_loop(float* temp_sum, float* output_data,
+ int num_elements_in_axis, size_t num_outputs);
+void CEVA_TFLM_Mean4D_Int8(int32_t multiplier, int32_t shift,
+ const int8_t* input_data, int32_t input_zero_point,
+ int8_t* output_data, int32_t output_zero_point,
+ int* input_shape, int* output_shape);
+bool CEVA_TFLM_Mean_Int8(const int8_t* input_data, const int* input_dims,
+ const int input_num_dims, int8_t* output_data,
+ const int* output_dims, const int output_num_dims,
+ const int* axis, const int num_axis_dimensions,
+ bool keep_dims, int* temp_index, int* resolved_axis,
+ int32_t* temp_sum);
+void CEVA_TFLM_Mean_Int8_loop(int32_t* temp_sum, int8_t* output_data,
+ int num_elements_in_axis, size_t num_outputs);
+void CEVA_TFLM_StridedSlice_Float32(void* op_params,
+ int unextended_input_shape_DimensionsCount,
+ int* unextended_input_shape_DimsData,
+ float* input_data,
+
+ float* output_data);
+
+void CEVA_TFLM_StridedSlice_Float32(void* op_params,
+ int unextended_input_shape_DimensionsCount,
+ int* unextended_input_shape_DimsData,
+ float* input_data, float* output_data);
+
+void CEVA_TFLM_StridedSlice_loop_Float32(float* input_data, float* output_data,
+ void* params);
+
+void CEVA_TFLM_StridedSlice_int8(void* op_params,
+ int unextended_input_shape_DimensionsCount,
+ int* unextended_input_shape_DimsData,
+ int8_t* input_data, int8_t* output_data);
+
+void CEVA_TFLM_StridedSlice_loop_int8(int8_t* input_data, int8_t* output_data,
+ void* params);
+
+void CEVA_TFLM_Pad_Float32(void* op_params, int input_shape, int* output_shape,
+ const float* input_data, const float* pad_value_ptr,
+ float* output_data);
+
+void CEVA_TFLM_Pad_Int8(void* op_params, int input_shape, int* output_shape,
+ const int8_t* input_data, const int8_t* pad_value_ptr,
+ int8_t* output_data);
+
+int CEVA_TFLM_ReshapeOutput(int input_type, const int input_size,
+ const int* input_data, int output_type,
+ int* output_size, int* output_data,
+ int node_in_size);
+
+int CEVA_TFLM_EvalRashape(const int8_t* input, int8_t* output,
+ unsigned int N_cnt);
+
+#if defined(__cplusplus)
+}
+#endif /* __cplusplus */
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_CEVA_CEVA_TFLM_LIB_H_
diff --git a/tensorflow/lite/micro/kernels/ceva/fully_connected.cc b/tensorflow/lite/micro/kernels/ceva/fully_connected.cc
new file mode 100644
index 0000000..66677a2
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/fully_connected.cc
@@ -0,0 +1,257 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/fully_connected.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+//#define MCPS_MEASUREMENT
+#ifdef MCPS_MEASUREMENT
+#include "tensorflow/lite/micro/kernels/ceva/mcps_macros.h"
+#endif
+
+#if defined(CEVA_BX1) || defined(CEVA_SP500)
+extern int32_t* CEVA_TFLM_KERNELS_SCRATCH;
+extern int32_t CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL;
+#endif // CEVA platform
+
+namespace tflite {
+namespace {
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+
+ return context->AllocatePersistentBuffer(context,
+ sizeof(OpDataFullyConnected));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* data = static_cast<OpDataFullyConnected*>(node->user_data);
+
+ const auto params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteTensor* input =
+ GetInput(context, node, kFullyConnectedInputTensor);
+ const TfLiteTensor* filter =
+ GetInput(context, node, kFullyConnectedWeightsTensor);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kFullyConnectedBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kFullyConnectedOutputTensor);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_MSG(context, input->type == filter->type,
+ "Hybrid models are not supported on TFLite Micro.");
+
+ return CalculateOpDataFullyConnected(context, params->activation, input->type,
+ input, filter, bias, output, data);
+}
+
+TfLiteStatus EvalQuantizedInt8CEVA(TfLiteContext* context, TfLiteNode* node,
+ const OpDataFullyConnected& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ tflite::FullyConnectedParams op_params = FullyConnectedParamsQuantized(data);
+
+ int input_shape_dimensions_count =
+ tflite::micro::GetTensorShape(input).DimensionsCount();
+ int weights_shape_dimensions_count =
+ tflite::micro::GetTensorShape(filter).DimensionsCount();
+ int* weights_shape_dims_data =
+ const_cast<int*>(tflite::micro::GetTensorShape(filter).DimsData());
+ int bias_shape_dimensions_count =
+ tflite::micro::GetTensorShape(bias).DimensionsCount();
+ int output_shape_dimensions_count =
+ tflite::micro::GetTensorShape(output).DimensionsCount();
+ int* output_shape_dims_data =
+ const_cast<int*>(tflite::micro::GetTensorShape(output).DimsData());
+
+ void* params = (void*)&op_params;
+ int8_t* inputp =
+ const_cast<int8_t*>(tflite::micro::GetTensorData<int8_t>(input));
+ int8_t* filterp =
+ const_cast<int8_t*>(tflite::micro::GetTensorData<int8_t>(filter));
+ int32_t* biasp =
+ const_cast<int32_t*>(tflite::micro::GetTensorData<int32_t>(bias));
+ int8_t* outputp =
+ const_cast<int8_t*>(tflite::micro::GetTensorData<int8_t>(output));
+
+#ifdef MCPS_MEASUREMENT
+ int batches = output_shape_dims_data[0];
+ int output_depth =
+ weights_shape_dims_data[weights_shape_dimensions_count - 2];
+ int accum_depth = weights_shape_dims_data[weights_shape_dimensions_count - 1];
+ MCPS_START_ONE;
+#endif
+
+ int sizeof_scratch_required = output_shape_dims_data[1];
+
+ if (sizeof_scratch_required > CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL) {
+ TF_LITE_KERNEL_LOG(context, "Scratch size (%d) less that required (%d)",
+ CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL,
+ sizeof_scratch_required);
+ return kTfLiteError;
+ }
+
+ CEVA_TFLM_FullyConnected_int8(
+ params, input_shape_dimensions_count, inputp,
+ weights_shape_dimensions_count, weights_shape_dims_data, filterp,
+ bias_shape_dimensions_count, biasp, output_shape_dimensions_count,
+ output_shape_dims_data, outputp, CEVA_TFLM_KERNELS_SCRATCH);
+#ifdef MCPS_MEASUREMENT
+ MCPS_STOP_ONE(
+ "Test params:Call CEVA_TFLM_FullyConnected_int8 inetrnal loop = %dx%dx%d",
+ batches, output_depth, accum_depth);
+#endif
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalFloatCEVA(TfLiteContext* context, TfLiteNode* node,
+ TfLiteFusedActivation activation,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ // float output_activation_min, output_activation_max;
+ tflite::FullyConnectedParams op_params;
+ CalculateActivationRange(activation, &op_params.float_activation_min,
+ &op_params.float_activation_max);
+
+ // op_params.float_activation_min = output_activation_min;
+ // op_params.float_activation_max = output_activation_max;
+
+ int input_shape_dimensions_count =
+ tflite::micro::GetTensorShape(input).DimensionsCount();
+ int weights_shape_dimensions_count =
+ tflite::micro::GetTensorShape(filter).DimensionsCount();
+ int* weights_shape_dims_data =
+ const_cast<int*>(tflite::micro::GetTensorShape(filter).DimsData());
+ int bias_shape_dimensions_count =
+ tflite::micro::GetTensorShape(bias).DimensionsCount();
+ int output_shape_dimensions_count =
+ tflite::micro::GetTensorShape(output).DimensionsCount();
+ int* output_shape_dims_data =
+ const_cast<int*>(tflite::micro::GetTensorShape(output).DimsData());
+
+ void* params = (void*)&op_params;
+ float* inputp =
+ const_cast<float*>(tflite::micro::GetTensorData<float>(input));
+ float* filterp =
+ const_cast<float*>(tflite::micro::GetTensorData<float>(filter));
+ float* biasp = const_cast<float*>(tflite::micro::GetTensorData<float>(bias));
+ float* outputp =
+ const_cast<float*>(tflite::micro::GetTensorData<float>(output));
+
+#ifdef MCPS_MEASUREMENT
+ int batches = 1;
+ int i;
+ for (i = 0; i < (output_shape_dimensions_count - 1); i++)
+ batches *= output_shape_dims_data[i];
+
+ int output_depth =
+ weights_shape_dims_data[weights_shape_dimensions_count - 2];
+ int accum_depth = weights_shape_dims_data[weights_shape_dimensions_count - 1];
+ MCPS_START_ONE;
+#endif
+ CEVA_TFLM_FullyConnected_Float32(
+ params,
+ input_shape_dimensions_count, // GetTensorShape(input),
+ inputp,
+ weights_shape_dimensions_count, // GetTensorShape(filter),
+ weights_shape_dims_data, filterp,
+ bias_shape_dimensions_count, // GetTensorShape(bias),
+ biasp,
+ output_shape_dimensions_count, // GetTensorShape(output),
+ output_shape_dims_data, outputp);
+#ifdef MCPS_MEASUREMENT
+ MCPS_STOP_ONE(
+ "Test params:Call CEVA_TFLM_FullyConnected_Float32 inetrnal loop = "
+ "%dx%dx%d",
+ batches, output_depth, accum_depth);
+#endif
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalCEVA(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto* params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedBiasTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kFullyConnectedOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpDataFullyConnected& data =
+ *(static_cast<const OpDataFullyConnected*>(node->user_data));
+
+ // Checks in Prepare ensure input, output and filter types are all the same.
+ switch (input->type) {
+ case kTfLiteFloat32:
+ return EvalFloatCEVA(context, node, params->activation, input, filter,
+ bias, output);
+ case kTfLiteInt8:
+ return EvalQuantizedInt8CEVA(context, node, data, input, filter, bias,
+ output);
+
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+#if defined(CEVA_BX1) || defined(CEVA_SP500)
+ return EvalCEVA(context, node);
+#else
+ return EvalQuantizeReference(context, node);
+#endif
+}
+
+} // namespace
+
+TfLiteRegistration Register_FULLY_CONNECTED() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/ceva/mcps_macros.h b/tensorflow/lite/micro/kernels/ceva/mcps_macros.h
new file mode 100644
index 0000000..0d51e5a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/mcps_macros.h
@@ -0,0 +1,115 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// MCPS measurement macros for CEVA optimized kernels
+
+#ifndef MCPS_MACROS_
+#define MCPS_MACROS_
+
+#ifndef WIN32
+#include <ceva-time.h>
+#endif
+
+#ifdef MCPS_MEASUREMENT
+
+#ifdef STACK_MEASUREMENT
+#if defined(__cplusplus)
+extern "C" {
+#endif /* __cplusplus */
+void CEVA_BX_Stack_Marking(const int32_t _count);
+int32_t CEVA_BX_Stack_Measurement(const int32_t count);
+#if defined(__cplusplus)
+}
+#endif /* __cplusplus */
+#endif
+
+#define MCPS_CALL_RET_VALUE 4
+
+#ifdef STACK_MEASUREMENT
+#define MCPS_VARIBLES \
+ clock_t c1, c2; \
+ int ClockCEVA, Constant_cycles; \
+ int StackSize; \
+ FILE* f_mcps_report;
+#else
+#define MCPS_VARIBLES \
+ clock_t c1, c2; \
+ int ClockCEVA, Constant_cycles; \
+ FILE* f_mcps_report;
+#endif
+#define MCPS_OPEN_FILE f_mcps_report = fopen("mcps_report.txt", "at");
+
+#define MCPS_CLOSE_FILE fclose(f_mcps_report);
+
+#ifdef STACK_MEASUREMENT
+#define MCPS_START_CLOCK \
+ CEVA_BX_Stack_Marking(0x800); \
+ reset_clock(); \
+ start_clock(); \
+ c1 = clock(); \
+ c2 = clock(); \
+ Constant_cycles = c2 - c1; \
+ c1 = clock();
+
+#define MCPS_STOP_AND_LOG(...) \
+ c2 = clock(); \
+ ClockCEVA = c2 - c1 - Constant_cycles - MCPS_CALL_RET_VALUE; \
+ StackSize = CEVA_BX_Stack_Measurement(0x800) * 4; \
+ fprintf(f_mcps_report, __VA_ARGS__); \
+ fprintf(f_mcps_report, ":cycles:%d:Stack:%d\r\n", ClockCEVA, StackSize);
+
+#else // STACK_MEASUREMENT
+#define MCPS_START_CLOCK \
+ reset_clock(); \
+ start_clock(); \
+ c1 = clock(); \
+ c2 = clock(); \
+ Constant_cycles = c2 - c1; \
+ c1 = clock();
+
+#define MCPS_STOP_AND_LOG(...) \
+ c2 = clock(); \
+ ClockCEVA = c2 - c1 - Constant_cycles - MCPS_CALL_RET_VALUE; \
+ fprintf(f_mcps_report, __VA_ARGS__); \
+ fprintf(f_mcps_report, ":cycles:%d\r\n", ClockCEVA);
+#endif // STACK_MEASUREMENT
+
+#define MCPS_STOP_AND_PRINT(...) \
+ c2 = clock(); \
+ ClockCEVA = c2 - c1 - Constant_cycles - MCPS_CALL_RET_VALUE; \
+ fprintf(stdout, __VA_ARGS__); \
+ fprintf(stdout, ":cycles=%d\n", ClockCEVA);
+
+#define MCPS_START_ONE \
+ MCPS_VARIBLES; \
+ MCPS_OPEN_FILE; \
+ MCPS_START_CLOCK;
+#define MCPS_STOP_ONE(...) \
+ MCPS_STOP_AND_LOG(__VA_ARGS__); \
+ MCPS_CLOSE_FILE;
+
+#else
+#define MCPS_VARIBLES
+#define MCPS_OPEN_FILE
+#define MCPS_START_CLOCK
+#define MCPS_STOP_AND_LOG(...)
+#define MCPS_STOP_AND_PRINT(...)
+#define MCPS_CLOSE_FILE
+
+#define MCPS_START_ONE
+#define MCPS_STOP_ONE(...)
+#endif
+
+#endif
diff --git a/tensorflow/lite/micro/kernels/ceva/quantize.cc b/tensorflow/lite/micro/kernels/ceva/quantize.cc
new file mode 100644
index 0000000..c267b61
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/quantize.cc
@@ -0,0 +1,93 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/quantize.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/requantize.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/quantize.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#ifdef MCPS_MEASUREMENT
+#include "tensorflow/lite/micro/kernels/ceva/mcps_macros.h "
+#endif
+
+namespace tflite {
+namespace {
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context,
+ sizeof(OpDataQuantizeReference));
+}
+
+TfLiteStatus EvalCEVA(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+
+ auto* data = static_cast<OpDataQuantizeReference*>(node->user_data);
+
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ if (input->type == kTfLiteFloat32 && output->type == kTfLiteInt8) {
+ const float* input_data = tflite::micro::GetTensorData<float>(input);
+ int8_t* output_data = tflite::micro::GetTensorData<int8_t>(output);
+ const int flat_size =
+ MatchingFlatSize(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorShape(output));
+
+#ifdef MCPS_MEASUREMENT
+ MCPS_START_ONE;
+#endif
+ CEVA_TFLM_AffineQuantize_Int8(input_data, output_data, flat_size,
+ data->quantization_params.scale,
+ data->quantization_params.zero_point);
+#ifdef MCPS_MEASUREMENT
+ MCPS_STOP_ONE("Test params:CEVA_TFLM_AffineQuantize_Int8 loop = %d",
+ flat_size);
+#endif
+ } else
+ return EvalQuantizeReference(context, node);
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+#if defined(CEVA_BX1) || defined(CEVA_SP500)
+ return EvalCEVA(context, node);
+#else
+ return EvalQuantizeReference(context, node);
+#endif
+}
+
+} // namespace
+
+// This Op (QUANTIZE) quantizes the input and produces quantized output.
+// AffineQuantize takes scale and zero point and quantizes the float value to
+// quantized output, in int8_t or uint8_t format.
+TfLiteRegistration Register_QUANTIZE() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/PrepareQuantizeReference,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/ceva/softmax.cc b/tensorflow/lite/micro/kernels/ceva/softmax.cc
new file mode 100644
index 0000000..3f1dedb
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/softmax.cc
@@ -0,0 +1,172 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/softmax.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/ceva/ceva_common.h"
+#include "tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/softmax.h"
+#ifdef MCPS_MEASUREMENT
+#include "tensorflow/lite/micro/kernels/ceva/mcps_macros.h"
+#endif
+
+namespace tflite {
+namespace {
+
+// Takes a tensor and performs softmax along the last dimension.
+void SoftmaxFloatCEVA(const TfLiteEvalTensor* input, TfLiteEvalTensor* output,
+ const SoftmaxParams& op_data) {
+ const RuntimeShape& input_shape = tflite::micro::GetTensorShape(input);
+ const float* input_data = tflite::micro::GetTensorData<float>(input);
+ const RuntimeShape& output_shape = tflite::micro::GetTensorShape(output);
+ float* output_data = tflite::micro::GetTensorData<float>(output);
+
+ const float beta = static_cast<float>(op_data.beta);
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+ int outer_size_mcps = outer_size;
+ int depth_mcps = depth;
+
+#ifdef MCPS_MEASUREMENT
+ MCPS_START_ONE;
+#endif
+ for (int i = 0; i < outer_size; ++i) {
+ CEVA_TFLM_Softmax_Float32(&input_data[i * depth], &output_data[i * depth],
+ beta, depth);
+ }
+#ifdef MCPS_MEASUREMENT
+ MCPS_STOP_ONE(
+ "Test params:Call CEVA_TFLM_Softmax_Float32 %d times, inetrnal loop = %d",
+ outer_size_mcps, depth_mcps);
+#endif
+}
+
+TfLiteStatus SoftmaxQuantizedCEVA(TfLiteContext* context,
+ const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output,
+ const SoftmaxParams& op_data) {
+ if (input->type == kTfLiteInt8) {
+ if (output->type == kTfLiteInt16) {
+ tflite::reference_ops::Softmax(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ } else {
+ const RuntimeShape& input_shape = tflite::micro::GetTensorShape(input);
+ const int8_t* input_data = tflite::micro::GetTensorData<int8_t>(input);
+
+ const RuntimeShape& output_shape = tflite::micro::GetTensorShape(output);
+ int8_t* output_data = tflite::micro::GetTensorData<int8_t>(output);
+
+ const int32_t input_beta_multiplier =
+ static_cast<int32_t>(op_data.input_multiplier);
+ const int32_t input_beta_left_shift =
+ static_cast<int32_t>(op_data.input_left_shift);
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+ int outer_size_mcps = outer_size;
+ int depth_mcps = depth;
+
+ if (depth > CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL) {
+ TF_LITE_KERNEL_LOG(context, "Scratch size (%d) less that required (%d)",
+ CEVA_TFLM_KERNELS_SCRATCH_SIZE_VAL, depth);
+ return kTfLiteError;
+ }
+
+#ifdef MCPS_MEASUREMENT
+ MCPS_START_ONE;
+#endif
+ for (int i = 0; i < outer_size; ++i) {
+ CEVA_TFLM_Softmax_Int8(&input_data[i * depth], &output_data[i * depth],
+ input_beta_multiplier, input_beta_left_shift,
+ depth, CEVA_TFLM_KERNELS_SCRATCH);
+ }
+#ifdef MCPS_MEASUREMENT
+ MCPS_STOP_ONE(
+ "Test params:Call CEVA_TFLM_Softmax_Int8 %d times, inetrnal loop = "
+ "%d",
+ outer_size_mcps, depth_mcps);
+#endif
+ }
+ } else {
+ tflite::reference_ops::SoftmaxInt16(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int16_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus SoftmaxEvalCEVA(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ SoftmaxParams op_data = *static_cast<SoftmaxParams*>(node->user_data);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ SoftmaxFloatCEVA(input, output, op_data);
+ return kTfLiteOk;
+ }
+ case kTfLiteInt8:
+ case kTfLiteInt16: {
+ return SoftmaxQuantizedCEVA(context, input, output, op_data);
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+#if defined(CEVA_BX1) || defined(CEVA_SP500)
+ return SoftmaxEvalCEVA(context, node);
+#else
+ return SoftmaxEval(context, node); // reference fallback
+#endif
+}
+} // namespace
+
+TfLiteRegistration Register_SOFTMAX() {
+ return {/*init=*/SoftmaxInit,
+ /*free=*/nullptr,
+ /*prepare=*/SoftmaxPrepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/ceva/types.h b/tensorflow/lite/micro/kernels/ceva/types.h
new file mode 100644
index 0000000..d9d9294
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ceva/types.h
@@ -0,0 +1,1286 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef CEVA_TYPES_H_
+#define CEVA_TYPES_H_
+
+#include <stdbool.h>
+#include <stddef.h>
+#include <stdint.h>
+
+// typedef int8_t int8_t;
+// typedef int16_t int16;
+// typedef int32_t int32_t;
+// typedef uint8_t uint8;
+// typedef uint16_t uint16;
+// typedef uint32_t uint32;
+
+typedef float float_32;
+typedef unsigned long long uint64;
+typedef long long int64;
+
+#if 1
+enum BroadcastableOpCategory {
+ kNone,
+ kNonBroadcast, // Matching input shapes.
+ kFirstInputBroadcastsFast, // Fivefold nested loops.
+ kSecondInputBroadcastsFast, // Fivefold nested loops.
+ kGenericBroadcast, // Fall-back.
+};
+
+#else
+enum class BroadcastableOpCategory : uint8_t {
+ kNone,
+ kNonBroadcast, // Matching input shapes.
+ kFirstInputBroadcastsFast, // Fivefold nested loops.
+ kSecondInputBroadcastsFast, // Fivefold nested loops.
+ kGenericBroadcast, // Fall-back.
+};
+#endif
+
+typedef struct {
+ // Shape dependent / common to data / op types.
+ uint8_t broadcast_category; // BroadcastableOpCategory broadcast_category;
+ // uint8_t inference params.
+ int32_t input1_offset;
+ int32_t input2_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // Add / Sub, not Mul, uint8_t inference params.
+ int left_shift;
+ int32_t input1_multiplier;
+ int input1_shift;
+ int32_t input2_multiplier;
+ int input2_shift;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+
+ // Processed output dimensions.
+ // Let input "a" be the one that broadcasts in the faster-changing dimension.
+ // Then, after coalescing, for shapes {a0, a1, a2, a3, a4} and
+ // {b0, b1, b2, b3, b4},
+ // broadcast_shape[4] = b0 = a0.
+ // broadcast_shape[3] = b1; a1 = 1.
+ // broadcast_shape[2] = b2 = a2.
+ // broadcast_shape[1] = a3; b3 = 1.
+ // broadcast_shape[0] = b4 = a4.
+ int broadcast_shape[5];
+} ArithmeticParams_ceva;
+
+struct SoftmaxParams_ceva {
+ // beta is not really used (not a Tensorflow parameter) and not implemented
+ // for LogSoftmax.
+ double beta;
+ // uint8_t inference params. Used even when beta defaults to 1.0.
+ int32_t input_multiplier;
+ int32_t input_left_shift;
+ // Reverse scaling is only used by LogSoftmax.
+ int32_t reverse_scaling_divisor;
+ int32_t reverse_scaling_right_shift;
+ int diff_min;
+ int32_t zero_point;
+ float scale;
+ float* table;
+ int16_t* exp_lut;
+ int16_t* one_over_one_plus_x_lut;
+ uint8_t* uint8_table1;
+ uint8_t* uint8_table2;
+};
+
+enum class FusedActivationFunctionType_ceva : uint8_t {
+ kNone,
+ kRelu6,
+ kRelu1,
+ kRelu
+};
+enum class PaddingType_ceva : uint8_t { kNone, kSame, kValid };
+
+struct PaddingValues_ceva {
+ int16_t width;
+ int16_t height;
+ // offset is used for calculating "remaining" padding, for example, `width`
+ // is 1 and `width_offset` is 1, so padding_left is 1 while padding_right is
+ // 1 + 1 = 2.
+ int16_t width_offset;
+ // Same as width_offset except it's over the height dimension.
+ int16_t height_offset;
+};
+
+typedef struct {
+ int8_t start_indices_count;
+ int32_t start_indices[5];
+ int8_t stop_indices_count;
+ int32_t stop_indices[5];
+ int8_t strides_count;
+ int32_t strides[5];
+
+ int16_t begin_mask;
+ int16_t ellipsis_mask;
+ int16_t end_mask;
+ int16_t new_axis_mask;
+ int16_t shrink_axis_mask;
+} StridedSliceParams_ceva;
+
+struct PoolParams_ceva {
+ FusedActivationFunctionType_ceva activation;
+ PaddingType_ceva padding_type;
+ PaddingValues_ceva padding_values;
+ int stride_height;
+ int stride_width;
+ int filter_height;
+ int filter_width;
+ // uint8, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+};
+
+inline size_t ReducedOutputOffset(const int num_dims, const int* dims,
+ const int* index, const int num_axis,
+ const int* axis) {
+ if (num_dims == 0) {
+ return 0;
+ }
+ // TFLITE_DCHECK(dims != nullptr);
+ // TFLITE_DCHECK(index != nullptr);
+ size_t offset = 0;
+ for (int idx = 0; idx < num_dims; ++idx) {
+ // if we need to skip this axis
+ bool is_axis = false;
+ if (axis != nullptr) {
+ for (int axis_idx = 0; axis_idx < num_axis; ++axis_idx) {
+ if (idx == axis[axis_idx]) {
+ is_axis = true;
+ break;
+ }
+ }
+ }
+ if (!is_axis) {
+ offset = offset * static_cast<size_t>(dims[idx]) +
+ static_cast<size_t>(index[idx]);
+ }
+ }
+ return offset;
+}
+inline bool NextIndex(const int num_dims, const int* dims, int* current) {
+ if (num_dims == 0) {
+ return false;
+ }
+ // TFLITE_DCHECK(dims != nullptr);
+ // TFLITE_DCHECK(current != nullptr);
+ int carry = 1;
+ for (int idx = num_dims - 1; idx >= 0; --idx) {
+ int current_val = current[idx] + carry;
+ // TFLITE_DCHECK_GE(dims[idx], current_val);
+ if (dims[idx] == current_val) {
+ current[idx] = 0;
+ } else {
+ current[idx] = current_val;
+ carry = 0;
+ break;
+ }
+ }
+ return (carry == 0);
+}
+
+#if 0
+#include <algorithm>
+#include <cstdint>
+#include <cstring>
+#include <initializer_list>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+
+namespace tflite {
+
+enum class FusedActivationFunctionType : uint8_t { kNone, kRelu6, kRelu1, kRelu };
+enum class PaddingType : uint8_t { kNone, kSame, kValid };
+
+struct PaddingValues {
+ int16 width;
+ int16 height;
+ // offset is used for calculating "remaining" padding, for example, `width`
+ // is 1 and `width_offset` is 1, so padding_left is 1 while padding_right is
+ // 1 + 1 = 2.
+ int16 width_offset;
+ // Same as width_offset except it's over the height dimension.
+ int16 height_offset;
+};
+
+// This enumeration allows for non-default formats for the weights array
+// of a fully-connected operator, allowing the use of special optimized
+// runtime paths.
+enum class FullyConnectedWeightsFormat : uint8_t {
+ // Default format (flat 2D layout, the inner contiguous dimension
+ // is input_depth, the outer non-contiguous dimension is output_depth)
+ kDefault,
+ // Summary: optimized layout for fast CPU runtime implementation,
+ // aimed specifically at ARM CPUs at the moment, and specialized for
+ // 8-bit quantized layers.
+ //
+ // The use case we're concerned with here is: 8-bit quantization,
+ // large weights matrix that doesn't fit in cache (e.g. 4096x2048 in
+ // a key application that drove this), very small batch size (e.g. 1 -- 4).
+ //
+ // Even with 8-bit quantization of weights, the performance of memory
+ // accesses to the weights can become the dominant issue when
+ // the batch size is small, so each weight value is used in only a few
+ // arithmetic ops, i.e. the fully-connected node has a low arithmetic
+ // intensity. The specific issues that arise are of three kinds:
+ // (1) One may, ideally, max out DRAM bandwidth, i.e. be truly memory
+ // bound. That's the "good" issue to run into.
+ // (2) One may run into sub-optimal pre-fetching: the data hasn't been
+ // prefetched into the cache by the time we need it.
+ // (3) One may run into cache aliasing: multiple values that are
+ // pre-fetched, alias each other in the L1 cache (which typically
+ // has only 4-way set associativity in ARM CPUs) and thus evict
+ // each other before we get to using them.
+ //
+ // The point of this shuffling is to avoid issues (2) and (3) so that
+ // we get as fast as possible given only the hard constraint (1).
+ // This is achieved by turning the difficulty into a solution: the
+ // difficulty, that each value loaded from memory is used only in
+ // one kernel iteration, making this operation memory-intensive, hints at
+ // the solution, of shuffling the weights so that they are stored in the
+ // exact order as the kernel needs to load them, so that the memory
+ // accesses made by the kernel are trivial. This solves (2) because the
+ // trivial memory access pattern allows the CPU's automatic prefetching
+ // to perform very well (no need even for preload instructions), and this
+ // solves (3) because the values being loaded concurrently are now
+ // contiguous in the address space, thus don't alias each other in the cache.
+ //
+ // On ARM, we typically want our kernel to process a 4x16 block of weights
+ // at a time, because:
+ // - 16 is the number of bytes in a NEON register.
+ // - 4 is how many rows we need to handle concurrently in the kernel in
+ // order to have sufficient mutual independence of instructions to
+ // maximize arithmetic throughput.
+ //
+ // Finally, the 'int8_t' part in the name refers to the fact that this
+ // weights format has each weights value encoded as a signed int8_t value,
+ // even if the data type of the weights buffer is uint8_t. This is intended
+ // to save runtime kernels the effort to have to XOR the top bit of these
+ // bytes before using them in signed arithmetic, see this file for more
+ // explanations on the 'signed int8_t trick' in matrix multiplication kernels:
+ //
+ // tensorflow/lite/toco/graph_transformations/ensure_uint8_weights_safe_for_fast_int8_kernels.cc
+ //
+ kShuffled4x16Int8,
+};
+
+// Quantization parameters, determining the mapping of quantized values
+// to real values (i.e. determining how quantized values are mathematically
+// interpreted).
+//
+// The correspondence is as follows:
+//
+// real_value = scale * (quantized_value - zero_point);
+//
+// In other words, zero_point designates which quantized value corresponds to
+// the real 0 value, and scale designates the difference between the real values
+// corresponding to consecutive quantized values differing by 1.
+struct QuantizationParams {
+ int32_t zero_point = 0;
+ double scale = 0.0;
+};
+
+inline bool operator==(const QuantizationParams& qp1,
+ const QuantizationParams& qp2) {
+ return qp1.zero_point == qp2.zero_point && qp1.scale == qp2.scale;
+}
+
+template <int N>
+struct Dims {
+ int sizes[N];
+ int strides[N];
+};
+
+class RuntimeShape {
+ public:
+ // Shapes with dimensions up to 5 are stored directly in the structure, while
+ // larger shapes are separately allocated.
+ static constexpr int kMaxSmallSize = 5;
+
+ RuntimeShape& operator=(RuntimeShape const&) = delete;
+
+ RuntimeShape() : size_(0) {}
+
+ explicit RuntimeShape(int dimensions_count) : size_(dimensions_count) {
+ if (dimensions_count > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ dims_pointer_ = new int32_t[dimensions_count];
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ }
+
+ RuntimeShape(int shape_size, int32_t value) : size_(0) {
+ Resize(shape_size);
+ for (int i = 0; i < shape_size; ++i) {
+ SetDim(i, value);
+ }
+ }
+
+ RuntimeShape(int dimensions_count, const int32_t* dims_data) : size_(0) {
+ ReplaceWith(dimensions_count, dims_data);
+ }
+
+ RuntimeShape(const std::initializer_list<int> init_list) : size_(0) {
+ BuildFrom(init_list);
+ }
+
+ // Avoid using this constructor. We should be able to delete it when C++17
+ // rolls out.
+ RuntimeShape(RuntimeShape const& other) : size_(other.DimensionsCount()) {
+ if (size_ > kMaxSmallSize) {
+ dims_pointer_ = new int32_t[size_];
+ }
+ std::memcpy(DimsData(), other.DimsData(), sizeof(int32_t) * size_);
+ }
+
+ bool operator==(const RuntimeShape& comp) const {
+ return this->size_ == comp.size_ &&
+ std::memcmp(DimsData(), comp.DimsData(), size_ * sizeof(int32_t)) == 0;
+ }
+
+ ~RuntimeShape() {
+ if (size_ > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ delete[] dims_pointer_;
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ }
+
+ inline int32_t DimensionsCount() const { return size_; }
+ inline int32_t Dims(int i) const {
+ TFLITE_DCHECK_GE(i, 0);
+ TFLITE_DCHECK_LT(i, size_);
+ return size_ > kMaxSmallSize ? dims_pointer_[i] : dims_[i];
+ }
+ inline void SetDim(int i, int32_t val) {
+ TFLITE_DCHECK_GE(i, 0);
+ TFLITE_DCHECK_LT(i, size_);
+ if (size_ > kMaxSmallSize) {
+ dims_pointer_[i] = val;
+ } else {
+ dims_[i] = val;
+ }
+ }
+
+ inline int32_t* DimsData() {
+ return size_ > kMaxSmallSize ? dims_pointer_ : dims_;
+ }
+ inline const int32_t* DimsData() const {
+ return size_ > kMaxSmallSize ? dims_pointer_ : dims_;
+ }
+ // The caller must ensure that the shape is no bigger than 5-D.
+ inline const int32_t* DimsDataUpTo5D() const { return dims_; }
+
+ inline void Resize(int dimensions_count) {
+ if (size_ > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ delete[] dims_pointer_;
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ size_ = dimensions_count;
+ if (dimensions_count > kMaxSmallSize) {
+#ifdef TF_LITE_STATIC_MEMORY
+ TFLITE_CHECK(false && "No shape resizing supported on this platform");
+#else // TF_LITE_STATIC_MEMORY
+ dims_pointer_ = new int32_t[dimensions_count];
+#endif // TF_LITE_STATIC_MEMORY
+ }
+ }
+
+ inline void ReplaceWith(int dimensions_count, const int32_t* dims_data) {
+ Resize(dimensions_count);
+ int32_t* dst_dims = DimsData();
+ std::memcpy(dst_dims, dims_data, dimensions_count * sizeof(int32_t));
+ }
+
+ template <typename T>
+ inline void BuildFrom(const T& src_iterable) {
+ const int dimensions_count =
+ std::distance(src_iterable.begin(), src_iterable.end());
+ Resize(dimensions_count);
+ int32_t* data = DimsData();
+ for (auto it : src_iterable) {
+ *data = it;
+ ++data;
+ }
+ }
+
+ // This will probably be factored out. Old code made substantial use of 4-D
+ // shapes, and so this function is used to extend smaller shapes. Note that
+ // (a) as Dims<4>-dependent code is eliminated, the reliance on this should be
+ // reduced, and (b) some kernels are stricly 4-D, but then the shapes of their
+ // inputs should already be 4-D, so this function should not be needed.
+ inline static RuntimeShape ExtendedShape(int new_shape_size,
+ const RuntimeShape& shape) {
+ return RuntimeShape(new_shape_size, shape, 1);
+ }
+
+ inline void BuildFrom(const std::initializer_list<int> init_list) {
+ BuildFrom<const std::initializer_list<int>>(init_list);
+ }
+
+ // Returns the total count of elements, that is the size when flattened into a
+ // vector.
+ inline int FlatSize() const {
+ int buffer_size = 1;
+ const int* dims_data = reinterpret_cast<const int*>(DimsData());
+ for (int i = 0; i < size_; i++) {
+ buffer_size *= dims_data[i];
+ }
+ return buffer_size;
+ }
+
+ bool operator!=(const RuntimeShape& comp) const { return !((*this) == comp); }
+
+ private:
+ // For use only by ExtendedShape(), written to guarantee (return-value) copy
+ // elision in C++17.
+ // This creates a shape padded to the desired size with the specified value.
+ RuntimeShape(int new_shape_size, const RuntimeShape& shape, int pad_value)
+ : size_(0) {
+ // If the following check fails, it is likely because a 4D-only kernel is
+ // being used with an array of larger dimension count.
+ TFLITE_CHECK_GE(new_shape_size, shape.DimensionsCount());
+ Resize(new_shape_size);
+ const int size_increase = new_shape_size - shape.DimensionsCount();
+ for (int i = 0; i < size_increase; ++i) {
+ SetDim(i, pad_value);
+ }
+ std::memcpy(DimsData() + size_increase, shape.DimsData(),
+ sizeof(int32_t) * shape.DimensionsCount());
+ }
+
+ int32_t size_;
+ union {
+ int32_t dims_[kMaxSmallSize];
+ int32_t* dims_pointer_;
+ };
+};
+
+// Converts inference-style shape to legacy tflite::Dims<4>.
+inline tflite::Dims<4> ToRuntimeDims(const tflite::RuntimeShape& array_shape) {
+ tflite::Dims<4> result;
+ const int dimensions_count = array_shape.DimensionsCount();
+ TFLITE_CHECK_LE(dimensions_count, 4);
+ int cum_prod = 1;
+ for (int i = 0; i < 4; i++) {
+ const int new_dim =
+ (i < dimensions_count) ? array_shape.Dims(dimensions_count - 1 - i) : 1;
+ result.sizes[i] = new_dim;
+ result.strides[i] = cum_prod;
+ cum_prod *= new_dim;
+ }
+ return result;
+}
+
+// TODO(b/80418076): Move to legacy ops file, update invocations.
+inline RuntimeShape DimsToShape(const tflite::Dims<4>& dims) {
+ return RuntimeShape(
+ {dims.sizes[3], dims.sizes[2], dims.sizes[1], dims.sizes[0]});
+}
+
+// Gets next index to iterate through a multidimensional array.
+inline bool NextIndex(const int num_dims, const int* dims, int* current) {
+ if (num_dims == 0) {
+ return false;
+ }
+ TFLITE_DCHECK(dims != nullptr);
+ TFLITE_DCHECK(current != nullptr);
+ int carry = 1;
+ for (int idx = num_dims - 1; idx >= 0; --idx) {
+ int current_val = current[idx] + carry;
+ TFLITE_DCHECK_GE(dims[idx], current_val);
+ if (dims[idx] == current_val) {
+ current[idx] = 0;
+ } else {
+ current[idx] = current_val;
+ carry = 0;
+ break;
+ }
+ }
+ return (carry == 0);
+}
+
+// Gets offset of index if reducing on axis. When reducing, the flattened offset
+// will not change, if the input index changes on the given axis. For example,
+// if you have a 3D tensor and you are reducing to 2D by eliminating axis 0,
+// then index (0, 1, 2) and index (1, 1, 2) will map to the same flattened
+// offset.
+// TODO(kanlig): uses Dims to represent dimensions.
+inline size_t ReducedOutputOffset(const int num_dims, const int* dims,
+ const int* index, const int num_axis,
+ const int* axis) {
+ if (num_dims == 0) {
+ return 0;
+ }
+ TFLITE_DCHECK(dims != nullptr);
+ TFLITE_DCHECK(index != nullptr);
+ size_t offset = 0;
+ for (int idx = 0; idx < num_dims; ++idx) {
+ // if we need to skip this axis
+ bool is_axis = false;
+ if (axis != nullptr) {
+ for (int axis_idx = 0; axis_idx < num_axis; ++axis_idx) {
+ if (idx == axis[axis_idx]) {
+ is_axis = true;
+ break;
+ }
+ }
+ }
+ if (!is_axis) {
+ offset = offset * static_cast<size_t>(dims[idx]) +
+ static_cast<size_t>(index[idx]);
+ }
+ }
+ return offset;
+}
+
+inline int Offset(const RuntimeShape& shape, int i0, int i1, int i2, int i3) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), 4);
+ const int* dims_data = reinterpret_cast<const int*>(shape.DimsDataUpTo5D());
+ TFLITE_DCHECK(i0 >= 0 && i0 < dims_data[0]);
+ TFLITE_DCHECK(i1 >= 0 && i1 < dims_data[1]);
+ TFLITE_DCHECK(i2 >= 0 && i2 < dims_data[2]);
+ TFLITE_DCHECK(i3 >= 0 && i3 < dims_data[3]);
+ return ((i0 * dims_data[1] + i1) * dims_data[2] + i2) * dims_data[3] + i3;
+}
+
+inline int Offset(const Dims<4>& dims, int i0, int i1, int i2, int i3) {
+ TFLITE_DCHECK(i0 >= 0 && i0 < dims.sizes[0]);
+ TFLITE_DCHECK(i1 >= 0 && i1 < dims.sizes[1]);
+ TFLITE_DCHECK(i2 >= 0 && i2 < dims.sizes[2]);
+ TFLITE_DCHECK(i3 >= 0 && i3 < dims.sizes[3]);
+ return i0 * dims.strides[0] + i1 * dims.strides[1] + i2 * dims.strides[2] +
+ i3 * dims.strides[3];
+}
+
+inline int Offset(const Dims<4>& dims, int* index) {
+ return Offset(dims, index[0], index[1], index[2], index[3]);
+}
+
+inline int Offset(const RuntimeShape& shape, int* index) {
+ return Offset(shape, index[0], index[1], index[2], index[3]);
+}
+
+// Get array size, DCHECKing that the dim index is in range.
+//
+// Note that this will be phased out with Dims<4>, since RuntimeShape::Dims()
+// already performs this check.
+template <int N>
+int ArraySize(const Dims<N>& array, int index) {
+ TFLITE_DCHECK(index >= 0 && index < N);
+ return array.sizes[index];
+}
+
+// Get common array size, DCHECKing that they all agree.
+template <typename ArrayType1, typename ArrayType2>
+int MatchingArraySize(const ArrayType1& array1, int index1,
+ const ArrayType2& array2, int index2) {
+ TFLITE_DCHECK_EQ(ArraySize(array1, index1), ArraySize(array2, index2));
+ return ArraySize(array1, index1);
+}
+
+template <typename ArrayType1, typename ArrayType2, typename... Args>
+int MatchingArraySize(const ArrayType1& array1, int index1,
+ const ArrayType2& array2, int index2, Args... args) {
+ TFLITE_DCHECK_EQ(ArraySize(array1, index1), ArraySize(array2, index2));
+ return MatchingArraySize(array1, index1, args...);
+}
+
+// Get common shape dim, DCHECKing that they all agree.
+inline int MatchingDim(const RuntimeShape& shape1, int index1,
+ const RuntimeShape& shape2, int index2) {
+ TFLITE_DCHECK_EQ(shape1.Dims(index1), shape2.Dims(index2));
+ return shape1.Dims(index1);
+}
+
+template <typename... Args>
+int MatchingDim(const RuntimeShape& shape1, int index1,
+ const RuntimeShape& shape2, int index2, Args... args) {
+ TFLITE_DCHECK_EQ(shape1.Dims(index1), shape2.Dims(index2));
+ return MatchingDim(shape1, index1, args...);
+}
+
+// Will be phased out with Dims<4>, replaced by RuntimeShape::FlatSize().
+template <int N>
+inline int FlatSize(const Dims<N>& dims) {
+ int flat_size = 1;
+ for (int i = 0; i < N; ++i) {
+ flat_size *= dims.sizes[i];
+ }
+ return flat_size;
+}
+
+TFLITE_DEPRECATED("Prefer FlatSize.")
+inline int RequiredBufferSizeForDims(const Dims<4>& dims) {
+ return FlatSize(dims);
+}
+
+inline int MatchingElementsSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0) {
+ const int size_1 = shape.FlatSize();
+ const int size_2 = check_shape_0.FlatSize();
+ TFLITE_CHECK_EQ(size_1, size_2);
+ return size_1;
+}
+
+inline int MatchingElementsSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1) {
+ const int size_1 = shape.FlatSize();
+ const int size_2 = check_shape_0.FlatSize();
+ const int size_3 = check_shape_1.FlatSize();
+ TFLITE_CHECK_EQ(size_1, size_2);
+ TFLITE_CHECK_EQ(size_2, size_3);
+ return size_1;
+}
+
+// Flat size calculation, checking that dimensions match with one or more other
+// arrays.
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return shape.FlatSize();
+}
+
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return MatchingFlatSize(shape, check_shape_1);
+}
+
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return MatchingFlatSize(shape, check_shape_1, check_shape_2);
+}
+
+inline int MatchingFlatSize(const RuntimeShape& shape,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2,
+ const RuntimeShape& check_shape_3) {
+ TFLITE_DCHECK_EQ(shape.DimensionsCount(), check_shape_0.DimensionsCount());
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ return MatchingFlatSize(shape, check_shape_1, check_shape_2, check_shape_3);
+}
+
+// Flat size calculation, checking that dimensions match with one or more other
+// arrays.
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return FlatSize(dims);
+}
+
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return MatchingFlatSize(dims, check_dims_1);
+}
+
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return MatchingFlatSize(dims, check_dims_1, check_dims_2);
+}
+
+template <int N>
+inline int MatchingFlatSize(const Dims<N>& dims, const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2,
+ const Dims<N>& check_dims_3) {
+ for (int i = 0; i < N; ++i) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ return MatchingFlatSize(dims, check_dims_1, check_dims_2, check_dims_3);
+}
+
+// Data is required to be contiguous, and so many operators can use either the
+// full array flat size or the flat size with one dimension skipped (commonly
+// the depth).
+template <int N>
+inline int FlatSizeSkipDim(const Dims<N>& dims, int skip_dim) {
+ TFLITE_DCHECK(skip_dim >= 0 && skip_dim < N);
+ int flat_size = 1;
+ for (int i = 0; i < N; ++i) {
+ flat_size *= (i == skip_dim) ? 1 : dims.sizes[i];
+ }
+ return flat_size;
+}
+
+// A combination of MatchingFlatSize() and FlatSizeSkipDim().
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return FlatSizeSkipDim(dims, skip_dim);
+}
+
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(dims, skip_dim, check_dims_1);
+}
+
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(dims, skip_dim, check_dims_1, check_dims_2);
+}
+
+template <int N>
+inline int MatchingFlatSizeSkipDim(const Dims<N>& dims, int skip_dim,
+ const Dims<N>& check_dims_0,
+ const Dims<N>& check_dims_1,
+ const Dims<N>& check_dims_2,
+ const Dims<N>& check_dims_3) {
+ for (int i = 0; i < N; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(ArraySize(dims, i), ArraySize(check_dims_0, i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(dims, skip_dim, check_dims_1, check_dims_2,
+ check_dims_3);
+}
+
+// Data is required to be contiguous, and so many operators can use either the
+// full array flat size or the flat size with one dimension skipped (commonly
+// the depth).
+inline int FlatSizeSkipDim(const RuntimeShape& shape, int skip_dim) {
+ const int dims_count = shape.DimensionsCount();
+ TFLITE_DCHECK(skip_dim >= 0 && skip_dim < dims_count);
+ const auto* dims_data = shape.DimsData();
+ int flat_size = 1;
+ for (int i = 0; i < dims_count; ++i) {
+ flat_size *= (i == skip_dim) ? 1 : dims_data[i];
+ }
+ return flat_size;
+}
+
+// A combination of MatchingFlatSize() and FlatSizeSkipDim().
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return FlatSizeSkipDim(shape, skip_dim);
+}
+
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(shape, skip_dim, check_shape_1);
+}
+
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(shape, skip_dim, check_shape_1, check_shape_2);
+}
+
+inline int MatchingFlatSizeSkipDim(const RuntimeShape& shape, int skip_dim,
+ const RuntimeShape& check_shape_0,
+ const RuntimeShape& check_shape_1,
+ const RuntimeShape& check_shape_2,
+ const RuntimeShape& check_shape_3) {
+ const int dims_count = shape.DimensionsCount();
+ for (int i = 0; i < dims_count; ++i) {
+ if (i != skip_dim) {
+ TFLITE_DCHECK_EQ(shape.Dims(i), check_shape_0.Dims(i));
+ }
+ }
+ return MatchingFlatSizeSkipDim(shape, skip_dim, check_shape_1, check_shape_2,
+ check_shape_3);
+}
+
+template <int N>
+bool IsPackedWithoutStrides(const Dims<N>& dims) {
+ int expected_stride = 1;
+ for (int d = 0; d < N; d++) {
+ if (dims.strides[d] != expected_stride) return false;
+ expected_stride *= dims.sizes[d];
+ }
+ return true;
+}
+
+template <int N>
+void ComputeStrides(Dims<N>* dims) {
+ dims->strides[0] = 1;
+ for (int d = 1; d < N; d++) {
+ dims->strides[d] = dims->strides[d - 1] * dims->sizes[d - 1];
+ }
+}
+
+enum class BroadcastableOpCategory : uint8_t {
+ kNone,
+ kNonBroadcast, // Matching input shapes.
+ kFirstInputBroadcastsFast, // Fivefold nested loops.
+ kSecondInputBroadcastsFast, // Fivefold nested loops.
+ kGenericBroadcast, // Fall-back.
+};
+
+struct MinMax {
+ float min;
+ float max;
+};
+static_assert(sizeof(MinMax) == 8, "");
+
+struct ActivationParams {
+ FusedActivationFunctionType activation_type;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+};
+
+struct ReluParams : public ActivationParams {
+ int32_t input_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int32_t output_shift;
+};
+
+// Styles of resizing op usages. For example, kImageStyle can be used with a Pad
+// op for pattern-specific optimization.
+enum class ResizingCategory : uint8_t {
+ kNone,
+ kImageStyle, // 4D, operating on inner dimensions, say {0, a, b, 0}.
+ kGenericResize,
+};
+
+// For Add, Sub, Mul ops.
+
+
+struct ConcatenationParams {
+ int8_t axis;
+ const int32_t* input_zeropoint;
+ const float* input_scale;
+ uint16 inputs_count;
+ int32_t output_zeropoint;
+ float output_scale;
+};
+
+struct ComparisonParams {
+ // uint8_t inference params.
+ int left_shift;
+ int32_t input1_offset;
+ int32_t input1_multiplier;
+ int input1_shift;
+ int32_t input2_offset;
+ int32_t input2_multiplier;
+ int input2_shift;
+ // Shape dependent / common to inference types.
+ bool is_broadcast;
+};
+
+struct ConvParams {
+ PaddingType padding_type;
+ PaddingValues padding_values;
+ // TODO(starka): This was just "stride", so check that width+height is OK.
+ int16 stride_width;
+ int16 stride_height;
+ int16 dilation_width_factor;
+ int16 dilation_height_factor;
+ // uint8_t inference params.
+ // TODO(b/65838351): Use smaller types if appropriate.
+ int32_t input_offset;
+ int32_t weights_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+};
+
+struct DepthToSpaceParams {
+ int32_t block_size;
+};
+
+struct DepthwiseParams {
+ PaddingType padding_type;
+ PaddingValues padding_values;
+ int16 stride_width;
+ int16 stride_height;
+ int16 dilation_width_factor;
+ int16 dilation_height_factor;
+ int16 depth_multiplier;
+ // uint8_t inference params.
+ // TODO(b/65838351): Use smaller types if appropriate.
+ int32_t input_offset;
+ int32_t weights_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+ const int32_t* output_multiplier_per_channel;
+ const int32_t* output_shift_per_channel;
+};
+
+struct DequantizationParams {
+ double scale;
+ int32_t zero_point;
+};
+
+struct PerChannelDequantizationParams {
+ const float* scale;
+ const int32_t* zero_point;
+ int32_t quantized_dimension;
+};
+
+struct FakeQuantParams {
+ MinMax minmax;
+ int32_t num_bits;
+};
+
+struct FullyConnectedParams {
+ // uint8_t inference params.
+ // TODO(b/65838351): Use smaller types if appropriate.
+ int32_t input_offset;
+ int32_t weights_offset;
+ int32_t output_offset;
+ int32_t output_multiplier;
+ int output_shift;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+ // Mark the operands as cacheable if they are unchanging, e.g. weights.
+ bool lhs_cacheable;
+ bool rhs_cacheable;
+ FullyConnectedWeightsFormat weights_format;
+};
+
+struct GatherParams {
+ int16 axis;
+};
+
+struct L2NormalizationParams {
+ // uint8_t inference params.
+ int32_t input_zero_point;
+};
+
+struct LocalResponseNormalizationParams {
+ int32_t range;
+ double bias;
+ double alpha;
+ double beta;
+};
+
+struct HardSwishParams {
+ // zero_point of the input activations.
+ int16_t input_zero_point;
+ // zero_point of the output activations.
+ int16_t output_zero_point;
+ // 16bit fixed-point component of the multiplier to apply to go from the
+ // "high-res input scale", which is the input scale multiplied by 2^7, to the
+ // "relu-ish scale", which 3.0/32768.
+ // See the implementation of HardSwishPrepare.
+ int16_t reluish_multiplier_fixedpoint_int16;
+ // exponent/bit-shift component of the aforementioned multiplier.
+ int reluish_multiplier_exponent;
+ // 16bit fixed-point component of the multiplier to apply to go from the
+ // "high-res input scale", which is the input scale multiplied by 2^7, to the
+ // output scale.
+ // See the implementation of HardSwishPrepare.
+ int16_t output_multiplier_fixedpoint_int16;
+ // exponent/bit-shift component of the aforementioned multiplier.
+ int output_multiplier_exponent;
+};
+
+struct LogisticParams {
+ // uint8_t inference params.
+ int32_t input_zero_point;
+ int32_t input_range_radius;
+ int32_t input_multiplier;
+ int input_left_shift;
+};
+
+struct LstmCellParams {
+ int32_t weights_zero_point;
+ int32_t accum_multiplier;
+ int accum_shift;
+ int state_integer_bits;
+};
+
+struct MeanParams {
+ int8_t axis_count;
+ int16 axis[4];
+};
+
+struct PackParams {
+ int8_t axis;
+ const int32_t* input_zeropoint;
+ const float* input_scale;
+ uint16 inputs_count;
+ int32_t output_zeropoint;
+ float output_scale;
+};
+
+struct PadParams {
+ int8_t left_padding_count;
+ int32_t left_padding[4];
+ int8_t right_padding_count;
+ int32_t right_padding[4];
+ ResizingCategory resizing_category;
+};
+
+struct PreluParams {
+ int32_t input_offset;
+ int32_t alpha_offset;
+ int32_t output_offset;
+ int32_t output_multiplier_1;
+ int32_t output_shift_1;
+ int32_t output_multiplier_2;
+ int32_t output_shift_2;
+};
+
+struct PoolParams {
+ FusedActivationFunctionType activation;
+ PaddingType padding_type;
+ PaddingValues padding_values;
+ int stride_height;
+ int stride_width;
+ int filter_height;
+ int filter_width;
+ // uint8_t, etc, activation params.
+ int32_t quantized_activation_min;
+ int32_t quantized_activation_max;
+ // float activation params.
+ float float_activation_min;
+ float float_activation_max;
+};
+
+struct ReshapeParams {
+ int8_t shape_count;
+ int32_t shape[4];
+};
+
+struct ResizeBilinearParams {
+ bool align_corners;
+ // half_pixel_centers assumes pixels are of half the actual dimensions, and
+ // yields more accurate resizes. Corresponds to the same argument for the
+ // original TensorFlow op in TF2.0.
+ bool half_pixel_centers;
+};
+
+struct ResizeNearestNeighborParams {
+ bool align_corners;
+ bool half_pixel_centers;
+};
+
+struct SliceParams {
+ int8_t begin_count;
+ int32_t begin[4];
+ int8_t size_count;
+ int32_t size[4];
+};
+
+struct SoftmaxParams {
+ // beta is not really used (not a Tensorflow parameter) and not implemented
+ // for LogSoftmax.
+ double beta;
+ // uint8_t inference params. Used even when beta defaults to 1.0.
+ int32_t input_multiplier;
+ int32_t input_left_shift;
+ // Reverse scaling is only used by LogSoftmax.
+ int32_t reverse_scaling_divisor;
+ int32_t reverse_scaling_right_shift;
+ int diff_min;
+ int32_t zero_point;
+ float scale;
+ float* table;
+ int16_t* exp_lut;
+ int16_t* one_over_one_plus_x_lut;
+ uint8_t* uint8_table1;
+ uint8_t* uint8_table2;
+};
+
+struct SpaceToBatchParams {
+ // "Zero" padding for uint8_t means padding with the output offset.
+ int32_t output_offset;
+};
+
+struct SpaceToDepthParams {
+ int32_t block_size;
+};
+
+struct SplitParams {
+ // Graphs that split into, say, 2000 nodes are encountered. The indices in
+ // OperatorEdges are of type uint16.
+ uint16 num_split;
+ int16 axis;
+};
+
+struct SqueezeParams {
+ int8_t squeeze_dims_count;
+ int32_t squeeze_dims[4];
+};
+
+struct StridedSliceParams {
+ int8_t start_indices_count;
+ int32_t start_indices[5];
+ int8_t stop_indices_count;
+ int32_t stop_indices[5];
+ int8_t strides_count;
+ int32_t strides[5];
+
+ int16 begin_mask;
+ int16 ellipsis_mask;
+ int16 end_mask;
+ int16 new_axis_mask;
+ int16 shrink_axis_mask;
+};
+
+struct TanhParams {
+ int32_t input_zero_point;
+ int32_t input_range_radius;
+ int32_t input_multiplier;
+ int input_left_shift;
+};
+
+struct TransposeParams {
+ int8_t perm_count;
+ int32_t perm[5];
+};
+
+struct UnpackParams {
+ uint16 num_split;
+ int16 axis;
+};
+
+struct LeakyReluParams {
+ float alpha;
+ int32_t input_offset;
+ int32_t output_offset;
+ int32_t output_multiplier_alpha;
+ int32_t output_shift_alpha;
+ int32_t output_multiplier_identity;
+ int32_t output_shift_identity;
+};
+
+template <typename P>
+inline void SetActivationParams(float min, float max, P* params) {
+ params->float_activation_min = min;
+ params->float_activation_max = max;
+}
+
+template <typename P>
+inline void SetActivationParams(int32_t min, int32_t max, P* params) {
+ params->quantized_activation_min = min;
+ params->quantized_activation_max = max;
+}
+
+template <typename P>
+inline void GetActivationParams(const P& params, int32_t* min, int32_t* max) {
+ *min = params.quantized_activation_min;
+ *max = params.quantized_activation_max;
+}
+
+template <typename P>
+inline void GetActivationParams(const P& params, float* min, float* max) {
+ *min = params.float_activation_min;
+ *max = params.float_activation_max;
+}
+
+} // namespace tflite
+#endif
+#endif // CEVA_TYPES_H_
diff --git a/tensorflow/lite/micro/kernels/circular_buffer.cc b/tensorflow/lite/micro/kernels/circular_buffer.cc
new file mode 100644
index 0000000..d9c898b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/circular_buffer.cc
@@ -0,0 +1,192 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#define FLATBUFFERS_LOCALE_INDEPENDENT 0
+#include "flatbuffers/flexbuffers.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+/*
+ * The circular buffer custom operator is used to implement strided streaming
+ * convolutions on TFLite Micro. Each time this operator is invoked, it checks
+ * whether or not to run, based on a predetermined stride in time. If the op
+ * runs, it inserts the input into the end of the output buffer and shifts the
+ * output values towards the start of the buffer. It discards the oldest value
+ * in the output buffer.
+ *
+ * Input: [<input N+1]
+ * Before shifting:
+ * Output: [<input 1>, <input 2>, <input ...>, <input N>]
+ *
+ * After shifting:
+ * Output: [<input 2>, <input 3>, <input ...>, <input N+1>]
+ *
+ * We make some assumptions in this custom operator:
+ * - Input shape must be [1, 1, 1, depth]
+ * - Output shape must be [1, num_slots, 1, depth]
+ * - Input and output types must match.
+ * - Input and output quantization params must be identical.
+ */
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace circular_buffer {
+
+namespace {
+
+// The CircularBuffer op has one input and one output tensor.
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+// TODO(b/149795762): Add this to TfLiteStatus enum.
+constexpr TfLiteStatus kTfLiteAbort = static_cast<TfLiteStatus>(-9);
+
+// These fields control the stride period of a strided streaming model. This op
+// returns kTfLiteAbort until cycles_until_run-- is zero. At this time,
+// cycles_until_run is reset to cycles_max.
+struct OpData {
+ int cycles_until_run;
+ int cycles_max;
+};
+
+} // namespace
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ OpData* op_data = static_cast<OpData*>(
+ context->AllocatePersistentBuffer(context, sizeof(OpData)));
+
+ if (buffer != nullptr && length > 0) {
+ const uint8_t* buffer_t = reinterpret_cast<const uint8_t*>(buffer);
+ const flexbuffers::Map& m = flexbuffers::GetRoot(buffer_t, length).AsMap();
+ op_data->cycles_max = m["cycles_max"].AsInt32();
+ } else {
+ op_data->cycles_max = 0;
+ }
+
+ return op_data;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* op_data = static_cast<OpData*>(node->user_data);
+
+ TF_LITE_ENSURE(context, input != nullptr);
+ TF_LITE_ENSURE(context, output != nullptr);
+ TF_LITE_ENSURE_EQ(context, input->dims->data[0], output->dims->data[0]);
+ TF_LITE_ENSURE_EQ(context, 1, input->dims->data[1]);
+ TF_LITE_ENSURE_EQ(context, input->dims->data[2], output->dims->data[2]);
+ TF_LITE_ENSURE_EQ(context, output->dims->data[3], input->dims->data[3]);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ // The circular buffer custom operator currently only supports int8.
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteInt8);
+
+ if (op_data->cycles_max <= 0) {
+ // The last circular buffer layer simply accumulates outputs, and does not
+ // run periodically.
+ // TODO(b/150001379): Move this special case logic to the tflite flatbuffer.
+ static int cb_prepare_count = 0;
+ cb_prepare_count++;
+ // These checks specifically work for the only two streaming models
+ // supported on TFLM. They use the shape of the output tensor along with the
+ // layer number to determine if the circular buffer period should be 1 or 2.
+
+ // These models are outlined int the following documents:
+ // https://docs.google.com/document/d/1lc_G2ZFhjiKFo02UHjBaljye1xsL0EkfybkaVELEE3Q/edit?usp=sharing
+ // https://docs.google.com/document/d/1pGc42PuWyrk-Jy1-9qeqtggvsmHr1ifz8Lmqfpr2rKA/edit?usp=sharing
+ if (output->dims->data[1] == 5 || output->dims->data[1] == 13 ||
+ (cb_prepare_count == 5 && output->dims->data[2] == 2 &&
+ output->dims->data[3] == 96)) {
+ op_data->cycles_max = 1;
+ cb_prepare_count = 0;
+ } else {
+ op_data->cycles_max = 2;
+ }
+ }
+ op_data->cycles_until_run = op_data->cycles_max;
+ node->user_data = op_data;
+
+ return kTfLiteOk;
+}
+
+// Shifts buffer over by the output depth, and write new input to end of buffer.
+// num_slots is the number of samples stored in the output buffer.
+// depth is the size of each sample.
+void EvalInt8(const int8_t* input, int num_slots, int depth, int8_t* output) {
+ memmove(output, &output[depth], (num_slots - 1) * depth);
+ memcpy(&output[(num_slots - 1) * depth], input, depth);
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = reinterpret_cast<OpData*>(node->user_data);
+
+ int num_slots = output->dims->data[1];
+ int depth = output->dims->data[2] * output->dims->data[3];
+
+ if (input->type == kTfLiteInt8) {
+ EvalInt8(tflite::micro::GetTensorData<int8_t>(input), num_slots, depth,
+ tflite::micro::GetTensorData<int8_t>(output));
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+
+ if (--data->cycles_until_run != 0) {
+ // Signal the interpreter to end current run if the delay before op invoke
+ // has not been reached.
+ // TODO(b/149795762): Add kTfLiteAbort to TfLiteStatus enum.
+ return static_cast<TfLiteStatus>(kTfLiteAbort);
+ }
+
+ data->cycles_until_run = data->cycles_max;
+
+ return kTfLiteOk;
+}
+
+} // namespace circular_buffer
+
+TfLiteRegistration* Register_CIRCULAR_BUFFER() {
+ static TfLiteRegistration r = {/*init=*/circular_buffer::Init,
+ /*free=*/nullptr,
+ /*prepare=*/circular_buffer::Prepare,
+ /*invoke=*/circular_buffer::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+ return &r;
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.cc b/tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.cc
new file mode 100644
index 0000000..e292198
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.cc
@@ -0,0 +1,25 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This file is generated. See:
+// third_party/tensorflow/lite/micro/kernels/test_data_generation/README.md
+
+#include "tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.h"
+
+const int g_gen_data_size_circular_buffer_config = 21;
+const unsigned char g_gen_data_circular_buffer_config[] = {
+ 0x63, 0x79, 0x63, 0x6c, 0x65, 0x73, 0x5f, 0x6d, 0x61, 0x78, 0x00,
+ 0x01, 0x0c, 0x01, 0x01, 0x01, 0x01, 0x04, 0x02, 0x24, 0x01,
+};
diff --git a/tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.h b/tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.h
new file mode 100644
index 0000000..2fbf4fe
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.h
@@ -0,0 +1,22 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_FLEXBUFFERS_GENERATED_DATA_H
+#define TENSORFLOW_LITE_MICRO_KERNELS_FLEXBUFFERS_GENERATED_DATA_H
+
+extern const int g_gen_data_size_circular_buffer_config;
+extern const unsigned char g_gen_data_circular_buffer_config[];
+
+#endif
diff --git a/tensorflow/lite/micro/kernels/circular_buffer_test.cc b/tensorflow/lite/micro/kernels/circular_buffer_test.cc
new file mode 100644
index 0000000..0d5ab08
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/circular_buffer_test.cc
@@ -0,0 +1,246 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/kernels/micro_ops.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int kRunPeriod = 2;
+
+// TODO(b/149795762): Add this to TfLiteStatus enum.
+constexpr TfLiteStatus kTfLiteAbort = static_cast<TfLiteStatus>(-9);
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(OutputTensorLength4) {
+ constexpr int depth = 3;
+ constexpr int num_slots = 4;
+ int8_t input_data[depth];
+ int8_t output_data[depth * num_slots];
+
+ memset(output_data, 0, sizeof(output_data));
+
+ // There are four input dimensions - [1, 1, 1, depth].
+ const int input_dims[] = {4, 1, 1, 1, depth};
+ // There are four output dimensions - [1, num_slots, 1, depth].
+ const int output_dims[] = {4, 1, num_slots, 1, depth};
+
+ TfLiteIntArray* input_tensor_dims =
+ tflite::testing::IntArrayFromInts(input_dims);
+ TfLiteIntArray* output_tensor_dims =
+ tflite::testing::IntArrayFromInts(output_dims);
+
+ const int output_dims_count = tflite::ElementCount(*output_tensor_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ tflite::testing::CreateQuantizedTensor(input_data, input_tensor_dims, 1,
+ 0),
+ tflite::testing::CreateQuantizedTensor(output_data, output_tensor_dims, 1,
+ 0),
+ };
+
+ // There is one input - tensor 0.
+ const int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array =
+ tflite::testing::IntArrayFromInts(inputs_array_data);
+ // There is one output - tensor 1.
+ const int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array =
+ tflite::testing::IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration* registration =
+ tflite::ops::micro::Register_CIRCULAR_BUFFER();
+ tflite::micro::KernelRunner runner = tflite::micro::KernelRunner(
+ *registration, tensors, tensors_size, inputs_array, outputs_array,
+ /*builtin_data=*/nullptr);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+
+ const int8_t goldens[5][16] = {{0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3},
+ {0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6},
+ {0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9},
+ {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12},
+ {4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}};
+
+ // Expect the circular buffer to run every other invoke for 4xN output.
+ for (int i = 0; i < 5; i++) {
+ for (int j = 0; j < depth; j++) {
+ input_data[j] = i * depth + j + 1;
+ }
+ TfLiteStatus status = runner.Invoke();
+
+ for (int j = 0; j < output_dims_count; ++j) {
+ TF_LITE_MICRO_EXPECT_EQ(goldens[i][j], output_data[j]);
+ }
+
+ // Every kRunPeriod iterations, the circular buffer should return kTfLiteOk.
+ if (i % tflite::testing::kRunPeriod == tflite::testing::kRunPeriod - 1) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, status);
+ } else {
+ TF_LITE_MICRO_EXPECT_EQ(tflite::testing::kTfLiteAbort, status);
+ }
+ }
+}
+
+TF_LITE_MICRO_TEST(OutputTensorOnEveryIterationLength4) {
+ constexpr int depth = 3;
+ constexpr int num_slots = 4;
+ int8_t input_data[depth];
+ int8_t output_data[depth * num_slots];
+
+ memset(output_data, 0, sizeof(output_data));
+
+ // There are four input dimensions - [1, 1, 1, depth].
+ const int input_dims[] = {4, 1, 1, 1, depth};
+ // There are four output dimensions - [1, num_slots, 1, depth].
+ const int output_dims[] = {4, 1, num_slots, 1, depth};
+
+ TfLiteIntArray* input_tensor_dims =
+ tflite::testing::IntArrayFromInts(input_dims);
+ TfLiteIntArray* output_tensor_dims =
+ tflite::testing::IntArrayFromInts(output_dims);
+
+ const int output_dims_count = tflite::ElementCount(*output_tensor_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ tflite::testing::CreateQuantizedTensor(input_data, input_tensor_dims, 1,
+ 0),
+ tflite::testing::CreateQuantizedTensor(output_data, output_tensor_dims, 1,
+ 0),
+ };
+
+ // There is one input - tensor 0.
+ const int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array =
+ tflite::testing::IntArrayFromInts(inputs_array_data);
+ // There is one output - tensor 1.
+ const int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array =
+ tflite::testing::IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration* registration =
+ tflite::ops::micro::Register_CIRCULAR_BUFFER();
+ tflite::micro::KernelRunner runner = tflite::micro::KernelRunner(
+ *registration, tensors, tensors_size, inputs_array, outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, runner.InitAndPrepare(reinterpret_cast<const char*>(
+ g_gen_data_circular_buffer_config),
+ g_gen_data_size_circular_buffer_config));
+
+ const int8_t goldens[5][16] = {{0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3},
+ {0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6},
+ {0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9},
+ {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12},
+ {4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}};
+
+ // Expect the circular buffer to run every other invoke for 4xN output.
+ for (int i = 0; i < 5; i++) {
+ for (int j = 0; j < depth; j++) {
+ input_data[j] = i * depth + j + 1;
+ }
+ TfLiteStatus status = runner.Invoke();
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, status);
+
+ for (int j = 0; j < output_dims_count; ++j) {
+ TF_LITE_MICRO_EXPECT_EQ(goldens[i][j], output_data[j]);
+ }
+ }
+}
+
+TF_LITE_MICRO_TEST(OutputTensorLength5) {
+ constexpr int depth = 4;
+ constexpr int num_slots = 5;
+ int8_t input_data[depth];
+ int8_t output_data[depth * num_slots];
+
+ memset(output_data, 0, sizeof(output_data));
+ const int input_dims[] = {4, 1, 1, 1, depth};
+ const int output_dims[] = {4, 1, num_slots, 1, depth};
+ TfLiteIntArray* input_tensor_dims =
+ tflite::testing::IntArrayFromInts(input_dims);
+ TfLiteIntArray* output_tensor_dims =
+ tflite::testing::IntArrayFromInts(output_dims);
+
+ const int output_dims_count = tflite::ElementCount(*output_tensor_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ tflite::testing::CreateQuantizedTensor(input_data, input_tensor_dims, 1,
+ 0),
+ tflite::testing::CreateQuantizedTensor(output_data, output_tensor_dims, 1,
+ 0),
+ };
+
+ // There is one input - tensor 0.
+ const int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array =
+ tflite::testing::IntArrayFromInts(inputs_array_data);
+ // There is one output - tensor 1.
+ const int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array =
+ tflite::testing::IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration* registration =
+ tflite::ops::micro::Register_CIRCULAR_BUFFER();
+ tflite::micro::KernelRunner runner = tflite::micro::KernelRunner(
+ *registration, tensors, tensors_size, inputs_array, outputs_array,
+ /*builtin_data=*/nullptr);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+
+ const int8_t goldens[6][20] = {
+ {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4},
+ {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8},
+ {0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12},
+ {0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16},
+ {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20},
+ {5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
+ 15, 16, 17, 18, 19, 20, 21, 22, 23, 24}};
+
+ // Expect circular buffer to run every cycle for 5xN output.
+ for (int i = 0; i < 6; i++) {
+ for (int j = 0; j < depth; j++) {
+ input_data[j] = i * depth + j + 1;
+ }
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int j = 0; j < output_dims_count; ++j) {
+ TF_LITE_MICRO_EXPECT_EQ(goldens[i][j], output_data[j]);
+ }
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/README.md b/tensorflow/lite/micro/kernels/cmsis_nn/README.md
new file mode 100644
index 0000000..7d88541
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/README.md
@@ -0,0 +1,67 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+# Info
+CMSIS-NN is a library containing kernel optimizations for Arm(R) Cortex(TM)-M
+processors. To use CMSIS-NN optimized kernels instead of reference kernels, add
+`OPTIMIZED_KERNEL_DIR=cmsis_nn` to the make command line. See examples below.
+
+For more information about the optimizations, check out
+[CMSIS-NN documentation](https://github.com/ARM-software/CMSIS_5/blob/develop/CMSIS/NN/README.md)
+
+# Example 1
+
+A simple way to compile a binary with CMSIS-NN optimizations.
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=cmsis_nn \
+TARGET=sparkfun_edge person_detection_int8_bin
+```
+
+# Example 2 - MBED
+
+Using mbed you'll be able to compile for the many different targets supported by
+mbed. Here's an example on how to do that. Start by generating an mbed project.
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=cmsis_nn \
+generate_person_detection_mbed_project
+```
+
+Go into the generated mbed project folder, currently:
+
+```
+tensorflow/lite/micro/tools/make/gen/linux_x86_64/prj/person_detection_int8/mbed
+```
+
+and setup mbed.
+
+```
+mbed new .
+```
+
+Note: Mbed has a dependency to an old version of arm_math.h. Therefore you need
+to copy the newer version as follows:
+
+```
+cp tensorflow/lite/micro/tools/make/downloads/cmsis/CMSIS/DSP/Include/\
+arm_math.h mbed-os/cmsis/TARGET_CORTEX_M/arm_math.h
+```
+
+There's also a dependency to an old cmsis_gcc.h, which you can fix with the
+following:
+
+```
+tensorflow/lite/micro/tools/make/downloads/cmsis/CMSIS/Core/Include/\
+cmsis_gcc.h mbed-os/cmsis/TARGET_CORTEX_M/cmsis_gcc.h
+```
+
+This issue will be resolved soon.
+
+Now type:
+
+```
+mbed compile -m DISCO_F746NG -t GCC_ARM
+```
+
+and that gives you a binary for the DISCO_F746NG with CMSIS-NN optimized
+kernels.
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/add.cc b/tensorflow/lite/micro/kernels/cmsis_nn/add.cc
new file mode 100644
index 0000000..4f92d21
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/add.cc
@@ -0,0 +1,255 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/add.h"
+
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/add.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace add {
+
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ bool requires_broadcast;
+
+ // These fields are used in both the general 8-bit -> 8bit quantized path,
+ // and the special 16-bit -> 16bit quantized path
+ int input1_shift;
+ int input2_shift;
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+
+ // These fields are used only in the general 8-bit -> 8bit quantized path
+ int32_t input1_multiplier;
+ int32_t input2_multiplier;
+ int32_t output_multiplier;
+ int output_shift;
+ int left_shift;
+ int32_t input1_offset;
+ int32_t input2_offset;
+ int32_t output_offset;
+
+ // Used only for float evals:
+ float output_activation_min_f32;
+ float output_activation_max_f32;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteAddParams* params,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2, TfLiteTensor* output,
+ OpData* data) {
+ data->requires_broadcast = !HaveSameShapes(input1, input2);
+
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ // 8bit -> 8bit general quantized path, with general rescalings
+ data->input1_offset = -input1->params.zero_point;
+ data->input2_offset = -input2->params.zero_point;
+ data->output_offset = output->params.zero_point;
+ data->left_shift = 20;
+ const double twice_max_input_scale =
+ 2 * static_cast<double>(
+ std::max(input1->params.scale, input2->params.scale));
+ const double real_input1_multiplier =
+ static_cast<double>(input1->params.scale) / twice_max_input_scale;
+ const double real_input2_multiplier =
+ static_cast<double>(input2->params.scale) / twice_max_input_scale;
+ const double real_output_multiplier =
+ twice_max_input_scale /
+ ((1 << data->left_shift) * static_cast<double>(output->params.scale));
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_input1_multiplier, &data->input1_multiplier, &data->input1_shift);
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_input2_multiplier, &data->input2_multiplier, &data->input2_shift);
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_output_multiplier, &data->output_multiplier, &data->output_shift);
+
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, params->activation, output, &data->output_activation_min,
+ &data->output_activation_max));
+ } else if (output->type == kTfLiteFloat32) {
+ CalculateActivationRange(params->activation,
+ &data->output_activation_min_f32,
+ &data->output_activation_max_f32);
+ }
+
+ return kTfLiteOk;
+}
+
+void EvalAdd(TfLiteContext* context, TfLiteNode* node, TfLiteAddParams* params,
+ const OpData* data, const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2, TfLiteEvalTensor* output) {
+ tflite::ArithmeticParams op_params;
+ SetActivationParams(data->output_activation_min_f32,
+ data->output_activation_max_f32, &op_params);
+#define TF_LITE_ADD(opname) \
+ reference_ops::opname(op_params, tflite::micro::GetTensorShape(input1), \
+ tflite::micro::GetTensorData<float>(input1), \
+ tflite::micro::GetTensorShape(input2), \
+ tflite::micro::GetTensorData<float>(input2), \
+ tflite::micro::GetTensorShape(output), \
+ tflite::micro::GetTensorData<float>(output))
+ if (data->requires_broadcast) {
+ TF_LITE_ADD(BroadcastAdd4DSlow);
+ } else {
+ TF_LITE_ADD(Add);
+ }
+#undef TF_LITE_ADD
+}
+
+TfLiteStatus EvalAddQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLiteAddParams* params, const OpData* data,
+ const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2,
+ TfLiteEvalTensor* output) {
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ tflite::ArithmeticParams op_params;
+ op_params.left_shift = data->left_shift;
+ op_params.input1_offset = data->input1_offset;
+ op_params.input1_multiplier = data->input1_multiplier;
+ op_params.input1_shift = data->input1_shift;
+ op_params.input2_offset = data->input2_offset;
+ op_params.input2_multiplier = data->input2_multiplier;
+ op_params.input2_shift = data->input2_shift;
+ op_params.output_offset = data->output_offset;
+ op_params.output_multiplier = data->output_multiplier;
+ op_params.output_shift = data->output_shift;
+ SetActivationParams(data->output_activation_min,
+ data->output_activation_max, &op_params);
+ bool need_broadcast = reference_ops::ProcessBroadcastShapes(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2), &op_params);
+#define TF_LITE_ADD(type, opname, dtype) \
+ type::opname(op_params, tflite::micro::GetTensorShape(input1), \
+ tflite::micro::GetTensorData<dtype>(input1), \
+ tflite::micro::GetTensorShape(input2), \
+ tflite::micro::GetTensorData<dtype>(input2), \
+ tflite::micro::GetTensorShape(output), \
+ tflite::micro::GetTensorData<dtype>(output));
+ if (output->type == kTfLiteInt8) {
+ if (need_broadcast) {
+ TF_LITE_ADD(reference_integer_ops, BroadcastAdd4DSlow, int8_t);
+ } else {
+ arm_elementwise_add_s8(
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorData<int8_t>(input2),
+ op_params.input1_offset, op_params.input1_multiplier,
+ op_params.input1_shift, op_params.input2_offset,
+ op_params.input2_multiplier, op_params.input2_shift,
+ op_params.left_shift, tflite::micro::GetTensorData<int8_t>(output),
+ op_params.output_offset, op_params.output_multiplier,
+ op_params.output_shift, op_params.quantized_activation_min,
+ op_params.quantized_activation_max,
+ MatchingElementsSize(tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorShape(output)));
+ }
+ } else {
+ if (need_broadcast) {
+ TF_LITE_ADD(reference_ops, BroadcastAdd4DSlow, uint8_t);
+ } else {
+ TF_LITE_ADD(reference_ops, Add, uint8_t);
+ }
+ }
+#undef TF_LITE_ADD
+ }
+
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ const TfLiteTensor* input1 = GetInput(context, node, kInputTensor1);
+ TF_LITE_ENSURE(context, input1 != nullptr);
+ const TfLiteTensor* input2 = GetInput(context, node, kInputTensor2);
+ TF_LITE_ENSURE(context, input2 != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ auto* params = reinterpret_cast<TfLiteAddParams*>(node->builtin_data);
+
+ TF_LITE_ENSURE_STATUS(
+ CalculateOpData(context, params, input1, input2, output, data));
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = reinterpret_cast<TfLiteAddParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ if (output->type == kTfLiteFloat32) {
+ EvalAdd(context, node, params, data, input1, input2, output);
+ } else if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_OK(context, EvalAddQuantized(context, node, params, data,
+ input1, input2, output));
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(output->type), output->type);
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace add
+
+TfLiteRegistration Register_ADD() {
+ return {/*init=*/add::Init,
+ /*free=*/nullptr,
+ /*prepare=*/add::Prepare,
+ /*invoke=*/add::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/conv.cc b/tensorflow/lite/micro/kernels/cmsis_nn/conv.cc
new file mode 100644
index 0000000..517284d
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/conv.cc
@@ -0,0 +1,307 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/conv.h"
+
+#include "CMSIS/NN/Include/arm_nn_types.h"
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/conv.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+struct OpData {
+ OpDataConv reference_op_data;
+
+ // Index to buffer for optimizations if applicable.
+ int buffer_idx;
+};
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ int32_t buf_size = 0;
+ const auto& params =
+ *(static_cast<const TfLiteConvParams*>(node->builtin_data));
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+ const TfLiteTensor* output = GetOutput(context, node, kConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ RuntimeShape input_shape = GetTensorShape(input);
+ RuntimeShape output_shape = GetTensorShape(output);
+
+ // Initialize cmsis_nn input dimensions
+ cmsis_nn_dims input_dims;
+ input_dims.n = MatchingDim(input_shape, 0, output_shape, 0);
+ input_dims.h = input->dims->data[1];
+ input_dims.w = input->dims->data[2];
+ input_dims.c = input_shape.Dims(3);
+
+ // Initialize cmsis_nn filter dimensions
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = output_shape.Dims(3);
+ filter_dims.h = filter->dims->data[1];
+ filter_dims.w = filter->dims->data[2];
+ filter_dims.c = input_dims.c;
+
+ // Initialize cmsis_nn output dimensions
+ cmsis_nn_dims output_dims;
+ output_dims.n = input_dims.n;
+ output_dims.h = output->dims->data[1];
+ output_dims.w = output->dims->data[2];
+ output_dims.c = output_shape.Dims(3);
+
+ // Dynamically allocate per-channel quantization parameters.
+ // TODO(#42883): This allocation is done even for non-int8 cases to get around
+ // a bug in kernel_util.cc which incorrectly uses per_channel_output_shift in
+ // non-int8 cases. Protect this section with a if (input->type == kTfLiteInt8)
+ // when the issue is fixed.
+ const int num_channels = filter->dims->data[kConvQuantizedDimension];
+ data->reference_op_data.per_channel_output_multiplier =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->reference_op_data.per_channel_output_shift =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ TF_LITE_ENSURE_STATUS(CalculateOpDataConv(
+ context, node, params, input_dims.w, input_dims.h, filter_dims.w,
+ filter_dims.h, output_dims.w, output_dims.h, input->type,
+ &data->reference_op_data));
+
+ if (input->type == kTfLiteInt8) {
+ // Initialize cmsis_nn convolution parameters
+ cmsis_nn_conv_params conv_params;
+ conv_params.input_offset = -input->params.zero_point;
+ conv_params.output_offset = output->params.zero_point;
+ conv_params.stride.h = params.stride_height;
+ conv_params.stride.w = params.stride_width;
+ conv_params.dilation.h = params.dilation_height_factor;
+ conv_params.dilation.w = params.dilation_width_factor;
+ conv_params.padding.h = data->reference_op_data.padding.height;
+ conv_params.padding.w = data->reference_op_data.padding.width;
+ conv_params.activation.min = data->reference_op_data.output_activation_min;
+ conv_params.activation.max = data->reference_op_data.output_activation_max;
+
+ buf_size = arm_convolve_wrapper_s8_get_buffer_size(
+ &conv_params, &input_dims, &filter_dims, &output_dims);
+ }
+
+ if (buf_size > 0) {
+ TF_LITE_ENSURE_STATUS(context->RequestScratchBufferInArena(
+ context, buf_size, &data->buffer_idx));
+ } else {
+ data->buffer_idx = -1;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalQuantizedPerChannel(
+ TfLiteContext* context, TfLiteNode* node, const TfLiteConvParams& params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter, const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output, TfLiteEvalTensor* im2col) {
+ cmsis_nn_conv_params conv_params;
+ conv_params.dilation.h = params.dilation_height_factor;
+ conv_params.dilation.w = params.dilation_width_factor;
+ // TODO(#43557) Remove checks for dilation and call to reference
+ // implementation when dilation is supported in the optimized implementation
+ // by CMSIS-NN.
+ if (conv_params.dilation.h == 1 && conv_params.dilation.w == 1) {
+ // Initialize cmsis_nn convolution parameters
+ conv_params.input_offset = -data.reference_op_data.input_zero_point;
+ conv_params.output_offset = data.reference_op_data.output_zero_point;
+ conv_params.stride.h = params.stride_height;
+ conv_params.stride.w = params.stride_width;
+ conv_params.padding.h = data.reference_op_data.padding.height;
+ conv_params.padding.w = data.reference_op_data.padding.width;
+ conv_params.activation.min = data.reference_op_data.output_activation_min;
+ conv_params.activation.max = data.reference_op_data.output_activation_max;
+
+ // Initialize cmsis_nn per channel quantization parameters
+ cmsis_nn_per_channel_quant_params quant_params;
+ quant_params.multiplier = const_cast<int32_t*>(
+ data.reference_op_data.per_channel_output_multiplier);
+ quant_params.shift =
+ const_cast<int32_t*>(data.reference_op_data.per_channel_output_shift);
+
+ RuntimeShape filter_shape = tflite::micro::GetTensorShape(filter);
+ RuntimeShape input_shape = tflite::micro::GetTensorShape(input);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ RuntimeShape bias_shape = tflite::micro::GetTensorShape(bias);
+
+ // Consistency check.
+ TFLITE_DCHECK_LE(conv_params.activation.min, conv_params.activation.max);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+ const int batch_size = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ if (tflite::micro::GetTensorData<int8_t>(bias)) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+
+ // Initialize cmsis_nn dimensions
+ // Input
+ cmsis_nn_dims input_dims;
+ input_dims.n = batch_size;
+ input_dims.h = input_shape.Dims(1);
+ input_dims.w = input_shape.Dims(2);
+ input_dims.c = input_depth;
+
+ // Filter
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = output_depth;
+ filter_dims.h = filter_shape.Dims(1);
+ filter_dims.w = filter_shape.Dims(2);
+ filter_dims.c = input_depth;
+
+ // Bias
+ cmsis_nn_dims bias_dims;
+ bias_dims.n = 1;
+ bias_dims.h = 1;
+ bias_dims.w = 1;
+ bias_dims.c = output_depth;
+
+ // Output
+ cmsis_nn_dims output_dims;
+ output_dims.n = batch_size;
+ output_dims.h = output_shape.Dims(1);
+ output_dims.w = output_shape.Dims(2);
+ output_dims.c = output_depth;
+
+ // Initialize cmsis_nn context
+ cmsis_nn_context ctx;
+ ctx.buf = nullptr;
+ ctx.size = 0;
+
+ if (data.buffer_idx > -1) {
+ ctx.buf = context->GetScratchBuffer(context, data.buffer_idx);
+ // Note: ctx.size is currently not used in cmsis_nn.
+ // The buffer should be allocated in the Prepare function through
+ // arm_convolve_wrapper_s8_get_buffer_size
+ }
+
+ // arm_convolve_wrapper_s8 dispatches the optimized kernel accordingly with
+ // the parameters passed
+ TFLITE_DCHECK_EQ(
+ arm_convolve_wrapper_s8(
+ &ctx, &conv_params, &quant_params, &input_dims,
+ tflite::micro::GetTensorData<int8_t>(input), &filter_dims,
+ tflite::micro::GetTensorData<int8_t>(filter), &bias_dims,
+ tflite::micro::GetTensorData<int32_t>(bias), &output_dims,
+ tflite::micro::GetTensorData<int8_t>(output)),
+ ARM_MATH_SUCCESS);
+ } else {
+ reference_integer_ops::ConvPerChannel(
+ ConvParamsQuantized(params, data.reference_op_data),
+ data.reference_op_data.per_channel_output_multiplier,
+ data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kConvInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kConvWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kConvBiasTensor)
+ : nullptr;
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kConvOutputTensor);
+
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto& params =
+ *(reinterpret_cast<TfLiteConvParams*>(node->builtin_data));
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ TF_LITE_ENSURE_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_MSG(context, input->type == filter->type,
+ "Hybrid models are not supported on TFLite Micro.");
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32: {
+ tflite::reference_ops::Conv(
+ ConvParamsFloat(params, data.reference_op_data),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output),
+ tflite::micro::GetTensorShape(nullptr), nullptr);
+ break;
+ }
+ case kTfLiteInt8:
+ return EvalQuantizedPerChannel(context, node, params, data, input, filter,
+ bias, output, nullptr);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/depthwise_conv.cc b/tensorflow/lite/micro/kernels/cmsis_nn/depthwise_conv.cc
new file mode 100644
index 0000000..81ecb9b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/depthwise_conv.cc
@@ -0,0 +1,311 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/depthwise_conv.h"
+
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/conv.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+struct OpData {
+ OpDataConv reference_op_data;
+
+ // Index to buffer for optimizations if applicable.
+ int buffer_idx;
+};
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const auto& params =
+ *(reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data));
+
+ const TfLiteTensor* input =
+ GetInput(context, node, kDepthwiseConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter =
+ GetInput(context, node, kDepthwiseConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kDepthwiseConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ const TfLiteType data_type = input->type;
+ int input_width = SizeOfDimension(input, 2);
+ int input_height = SizeOfDimension(input, 1);
+ int filter_width = SizeOfDimension(filter, 2);
+ int filter_height = SizeOfDimension(filter, 1);
+ int output_width = SizeOfDimension(output, 2);
+ int output_height = SizeOfDimension(output, 1);
+
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+
+ // All per-channel quantized tensors need valid zero point and scale arrays.
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(
+ filter->quantization.params);
+ TF_LITE_ENSURE(context, affine_quantization);
+ TF_LITE_ENSURE(context, affine_quantization->scale);
+ TF_LITE_ENSURE(context, affine_quantization->zero_point);
+ TF_LITE_ENSURE(
+ context, affine_quantization->scale->size == 1 ||
+ affine_quantization->scale->size ==
+ filter->dims->data[kDepthwiseConvQuantizedDimension]);
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size,
+ affine_quantization->zero_point->size);
+ }
+
+ // Allocate memory for per-channel quantization parameters
+ const int num_channels = filter->dims->data[kDepthwiseConvQuantizedDimension];
+
+ data->reference_op_data.per_channel_output_multiplier =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->reference_op_data.per_channel_output_shift =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ TF_LITE_ENSURE_STATUS(CalculateOpDataDepthwiseConv(
+ context, node, params, input_width, input_height, filter_width,
+ filter_height, output_width, output_height, data_type,
+ &data->reference_op_data));
+
+ if (input->type == kTfLiteInt8) {
+ RuntimeShape input_shape = GetTensorShape(input);
+ RuntimeShape output_shape = GetTensorShape(output);
+ RuntimeShape filter_shape = GetTensorShape(filter);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ const int batch_size = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(output_shape, 3, filter_shape, 3);
+ TFLITE_DCHECK_EQ(batch_size, 1); /* Only batch = 1 is supported */
+
+ cmsis_nn_dims input_dims;
+ input_dims.n = batch_size;
+ input_dims.h = input_height;
+ input_dims.w = input_width;
+ input_dims.c = input_shape.Dims(3);
+
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = 1;
+ filter_dims.h = filter_height;
+ filter_dims.w = filter_width;
+ filter_dims.c = output_depth;
+
+ cmsis_nn_dims output_dims;
+ output_dims.n = batch_size;
+ output_dims.h = output_height;
+ output_dims.w = output_width;
+ output_dims.c = output_depth;
+
+ cmsis_nn_dw_conv_params dw_conv_params;
+ dw_conv_params.padding.h = data->reference_op_data.padding.height;
+ dw_conv_params.padding.w = data->reference_op_data.padding.width;
+
+ const int32_t buf_size = arm_depthwise_conv_wrapper_s8_get_buffer_size(
+ &dw_conv_params, &input_dims, &filter_dims, &output_dims);
+
+ if (buf_size > 0) {
+ TF_LITE_ENSURE_STATUS(context->RequestScratchBufferInArena(
+ context, buf_size, &data->buffer_idx));
+ } else {
+ data->buffer_idx = -1;
+ }
+ }
+ return kTfLiteOk;
+}
+
+void EvalQuantizedPerChannel(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteDepthwiseConvParams& params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ cmsis_nn_dw_conv_params dw_conv_params;
+ dw_conv_params.dilation.h = params.dilation_height_factor;
+ dw_conv_params.dilation.w = params.dilation_width_factor;
+ // Call to reference implementation can be removed when dilation is supported
+ // in the optimized implementations.
+ if (1 == dw_conv_params.dilation.h && 1 == dw_conv_params.dilation.w) {
+ dw_conv_params.input_offset = -data.reference_op_data.input_zero_point;
+ dw_conv_params.output_offset = data.reference_op_data.output_zero_point;
+ dw_conv_params.stride.h = params.stride_height;
+ dw_conv_params.stride.w = params.stride_width;
+ dw_conv_params.padding.h = data.reference_op_data.padding.height;
+ dw_conv_params.padding.w = data.reference_op_data.padding.width;
+ // TODO(b/130439627): Use calculated value for clamping.
+ dw_conv_params.activation.min = std::numeric_limits<int8_t>::min();
+ dw_conv_params.activation.max = std::numeric_limits<int8_t>::max();
+ dw_conv_params.ch_mult = params.depth_multiplier;
+
+ cmsis_nn_per_channel_quant_params quant_params;
+ quant_params.multiplier =
+ data.reference_op_data.per_channel_output_multiplier;
+ quant_params.shift = data.reference_op_data.per_channel_output_shift;
+
+ RuntimeShape filter_shape = tflite::micro::GetTensorShape(filter);
+ RuntimeShape input_shape = tflite::micro::GetTensorShape(input);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ RuntimeShape bias_shape = tflite::micro::GetTensorShape(bias);
+
+ TFLITE_DCHECK_LE(dw_conv_params.activation.min,
+ dw_conv_params.activation.max);
+
+ const int batch_size = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+
+ if (tflite::micro::GetTensorData<int8_t>(bias)) {
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+ }
+
+ cmsis_nn_dims input_dims;
+ input_dims.n = batch_size;
+ input_dims.h = input_shape.Dims(1);
+ input_dims.w = input_shape.Dims(2);
+ input_dims.c = input_shape.Dims(3);
+
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = filter_shape.Dims(0);
+ filter_dims.h = filter_shape.Dims(1);
+ filter_dims.w = filter_shape.Dims(2);
+ filter_dims.c = output_depth;
+
+ cmsis_nn_dims bias_dims;
+ bias_dims.n = 1;
+ bias_dims.h = 1;
+ bias_dims.w = 1;
+ bias_dims.c = output_depth;
+
+ cmsis_nn_dims output_dims;
+ output_dims.n = batch_size;
+ output_dims.h = output_shape.Dims(1);
+ output_dims.w = output_shape.Dims(2);
+ output_dims.c = output_depth;
+
+ cmsis_nn_context ctx;
+ ctx.buf = nullptr;
+ /* 'size' is unused */
+ ctx.size = 0;
+
+ if (data.buffer_idx > -1) {
+ ctx.buf = context->GetScratchBuffer(context, data.buffer_idx);
+ }
+
+ TFLITE_DCHECK_EQ(
+ arm_depthwise_conv_wrapper_s8(
+ &ctx, &dw_conv_params, &quant_params, &input_dims,
+ tflite::micro::GetTensorData<int8_t>(input), &filter_dims,
+ tflite::micro::GetTensorData<int8_t>(filter), &bias_dims,
+ tflite::micro::GetTensorData<int32_t>(bias), &output_dims,
+ tflite::micro::GetTensorData<int8_t>(output)),
+ ARM_MATH_SUCCESS);
+ } else {
+ reference_integer_ops::DepthwiseConvPerChannel(
+ DepthwiseConvParamsQuantized(params, data.reference_op_data),
+ data.reference_op_data.per_channel_output_multiplier,
+ data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ const auto& params =
+ *(reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data));
+ const OpData& data = *(static_cast<OpData*>(node->user_data));
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kDepthwiseConvOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kDepthwiseConvInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kDepthwiseConvWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kDepthwiseConvBiasTensor)
+ : nullptr;
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32: {
+ tflite::reference_ops::DepthwiseConv(
+ DepthwiseConvParamsFloat(params, data.reference_op_data),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ }
+ case kTfLiteInt8:
+ EvalQuantizedPerChannel(context, node, params, data, input, filter, bias,
+ output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_DEPTHWISE_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/fully_connected.cc b/tensorflow/lite/micro/kernels/cmsis_nn/fully_connected.cc
new file mode 100644
index 0000000..8f5e683
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/fully_connected.cc
@@ -0,0 +1,274 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/fully_connected.h"
+
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+struct OpData {
+ OpDataFullyConnected reference_op_data;
+
+ // Index to buffer for optimizations if applicable.
+ int buffer_idx;
+};
+
+// TODO(b/169801227): This global struct is needed for the linker to drop unused
+// code (for example, by using Register_FULLY_CONNECTED_INT8 instead of
+// Register_FULLY_CONNECTED).
+TfLiteRegistration fully_connected_registration;
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const auto params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteTensor* input =
+ GetInput(context, node, kFullyConnectedInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter =
+ GetInput(context, node, kFullyConnectedWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kFullyConnectedBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kFullyConnectedOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_MSG(context, input->type == filter->type,
+ "Hybrid models are not supported on TFLite Micro.");
+
+ // Set buffer index to a reset value
+ data->buffer_idx = -1;
+ TF_LITE_ENSURE_STATUS(CalculateOpDataFullyConnected(
+ context, params->activation, input->type, input, filter, bias, output,
+ &(data->reference_op_data)));
+
+ if (input->type == kTfLiteInt8) {
+ RuntimeShape filter_shape = GetTensorShape(filter);
+ RuntimeShape output_shape = GetTensorShape(output);
+
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 2);
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = filter_shape.Dims(filter_dim_count - 1);
+ filter_dims.h = 1;
+ filter_dims.w = 1;
+ filter_dims.c = output_shape.Dims(1);
+
+ const int32_t buf_size =
+ arm_fully_connected_s8_get_buffer_size(&filter_dims);
+
+ if (buf_size > 0) {
+ TF_LITE_ENSURE_STATUS(context->RequestScratchBufferInArena(
+ context, buf_size, &data->buffer_idx));
+ } else {
+ data->buffer_idx = -1;
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalQuantizedInt8(TfLiteContext* context, TfLiteNode* node,
+ const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ const RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 2);
+ const int batches = output_shape.Dims(0);
+ const int output_depth = output_shape.Dims(1);
+ const RuntimeShape filter_shape = tflite::micro::GetTensorShape(filter);
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ const int accum_depth = filter_shape.Dims(filter_dim_count - 1);
+ const RuntimeShape input_shape = tflite::micro::GetTensorShape(input);
+
+ cmsis_nn_fc_params fc_params;
+ fc_params.input_offset = -data.reference_op_data.input_zero_point;
+ fc_params.output_offset = data.reference_op_data.output_zero_point;
+ fc_params.filter_offset = -data.reference_op_data.filter_zero_point;
+ fc_params.activation.min = data.reference_op_data.output_activation_min;
+ fc_params.activation.max = data.reference_op_data.output_activation_max;
+
+ cmsis_nn_per_tensor_quant_params quant_params;
+ quant_params.multiplier = data.reference_op_data.output_multiplier;
+ quant_params.shift = data.reference_op_data.output_shift;
+
+ cmsis_nn_dims input_dims;
+ input_dims.n = batches;
+ input_dims.h = 1;
+ input_dims.w = 1;
+ input_dims.c = accum_depth;
+
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = accum_depth;
+ filter_dims.h = 1;
+ filter_dims.w = 1;
+ filter_dims.c = output_depth;
+
+ cmsis_nn_dims bias_dims;
+ bias_dims.n = 1;
+ bias_dims.h = 1;
+ bias_dims.w = 1;
+ bias_dims.c = output_depth;
+
+ cmsis_nn_dims output_dims;
+ output_dims.n = batches;
+ output_dims.h = 1;
+ output_dims.w = 1;
+ output_dims.c = output_depth;
+
+ cmsis_nn_context ctx;
+ ctx.buf = nullptr;
+ ctx.size = 0;
+
+ if (data.buffer_idx > -1) {
+ ctx.buf = context->GetScratchBuffer(context, data.buffer_idx);
+ }
+
+ TF_LITE_ENSURE_EQ(
+ context,
+ arm_fully_connected_s8(
+ &ctx, &fc_params, &quant_params, &input_dims,
+ tflite::micro::GetTensorData<int8_t>(input), &filter_dims,
+ tflite::micro::GetTensorData<int8_t>(filter), &bias_dims,
+ tflite::micro::GetTensorData<int32_t>(bias), &output_dims,
+ tflite::micro::GetTensorData<int8_t>(output)),
+ ARM_MATH_SUCCESS);
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto* params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedBiasTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kFullyConnectedOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ // Checks in Prepare ensure input, output and filter types are all the same.
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ tflite::reference_ops::FullyConnected(
+ FullyConnectedParamsFloat(params->activation),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ }
+ case kTfLiteInt8: {
+ return EvalQuantizedInt8(context, node, data, input, filter, bias,
+ output);
+ }
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ }
+ return kTfLiteOk;
+}
+
+// Note that the current function names are not ideal at all (this EvalInt8
+// function internally calls EvalQuantizedInt8, and there is similar name
+// aliasing in the Eval function too). We will be attempting to have a more
+// descriptive naming convention but holding off on that for now, since the
+// renaming might be coupled with reducing code duplication and some additional
+// refactoring.
+TfLiteStatus EvalInt8(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedBiasTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kFullyConnectedOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ // Checks in Prepare ensure input, output and filter types are all the same.
+ if (input->type != kTfLiteInt8) {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+
+ return EvalQuantizedInt8(context, node, data, input, filter, bias, output);
+}
+
+} // namespace
+
+TfLiteRegistration Register_FULLY_CONNECTED() {
+ fully_connected_registration.init = Init;
+ fully_connected_registration.free = nullptr;
+ fully_connected_registration.prepare = Prepare;
+ fully_connected_registration.invoke = Eval;
+ fully_connected_registration.profiling_string = nullptr;
+ fully_connected_registration.builtin_code = 0;
+ fully_connected_registration.custom_name = nullptr;
+ fully_connected_registration.version = 0;
+ return fully_connected_registration;
+}
+
+TfLiteRegistration Register_FULLY_CONNECTED_INT8() {
+ fully_connected_registration.init = Init;
+ fully_connected_registration.free = nullptr;
+ fully_connected_registration.prepare = Prepare;
+ fully_connected_registration.invoke = EvalInt8;
+ fully_connected_registration.profiling_string = nullptr;
+ fully_connected_registration.builtin_code = 0;
+ fully_connected_registration.custom_name = nullptr;
+ fully_connected_registration.version = 0;
+ return fully_connected_registration;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/mul.cc b/tensorflow/lite/micro/kernels/cmsis_nn/mul.cc
new file mode 100644
index 0000000..9612368
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/mul.cc
@@ -0,0 +1,225 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/mul.h"
+
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/mul.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace mul {
+
+constexpr int kInput1Tensor = 0;
+constexpr int kInput2Tensor = 1;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+
+ int32_t output_multiplier;
+ int output_shift;
+
+ // Cached tensor zero point values for quantized operations.
+ int32_t input1_zero_point;
+ int32_t input2_zero_point;
+ int32_t output_zero_point;
+
+ float output_activation_min_f32;
+ float output_activation_max_f32;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node,
+ TfLiteMulParams* params, OpData* data) {
+ const TfLiteTensor* input1 = GetInput(context, node, kInput1Tensor);
+ TF_LITE_ENSURE(context, input1 != nullptr);
+ const TfLiteTensor* input2 = GetInput(context, node, kInput2Tensor);
+ TF_LITE_ENSURE(context, input2 != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input1->type, input2->type);
+
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, params->activation, output, &data->output_activation_min,
+ &data->output_activation_max));
+
+ double real_multiplier = static_cast<double>(input1->params.scale) *
+ static_cast<double>(input2->params.scale) /
+ static_cast<double>(output->params.scale);
+ QuantizeMultiplier(real_multiplier, &data->output_multiplier,
+ &data->output_shift);
+
+ data->input1_zero_point = input1->params.zero_point;
+ data->input2_zero_point = input2->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+ } else {
+ CalculateActivationRange(params->activation,
+ &data->output_activation_min_f32,
+ &data->output_activation_max_f32);
+ }
+
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLiteMulParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ return CalculateOpData(context, node, params, data);
+}
+
+void EvalQuantized(TfLiteContext* context, TfLiteNode* node, const OpData& data,
+ const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2, TfLiteEvalTensor* output) {
+ tflite::ArithmeticParams op_params;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+ op_params.input1_offset = -data.input1_zero_point;
+ op_params.input2_offset = -data.input2_zero_point;
+ op_params.output_offset = data.output_zero_point;
+ op_params.output_multiplier = data.output_multiplier;
+ op_params.output_shift = data.output_shift;
+
+ bool need_broadcast = reference_ops::ProcessBroadcastShapes(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2), &op_params);
+
+#define TF_LITE_MUL(type, opname, dtype) \
+ type::opname(op_params, tflite::micro::GetTensorShape(input1), \
+ tflite::micro::GetTensorData<dtype>(input1), \
+ tflite::micro::GetTensorShape(input2), \
+ tflite::micro::GetTensorData<dtype>(input2), \
+ tflite::micro::GetTensorShape(output), \
+ tflite::micro::GetTensorData<dtype>(output));
+
+ if (output->type == kTfLiteInt8) {
+ if (need_broadcast) {
+ TF_LITE_MUL(reference_integer_ops, BroadcastMul4DSlow, int8_t);
+ } else {
+ arm_elementwise_mul_s8(
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorData<int8_t>(input2), op_params.input1_offset,
+ op_params.input2_offset, tflite::micro::GetTensorData<int8_t>(output),
+ op_params.output_offset, op_params.output_multiplier,
+ op_params.output_shift, op_params.quantized_activation_min,
+ op_params.quantized_activation_max,
+ MatchingElementsSize(tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorShape(output)));
+ }
+ } else if (output->type == kTfLiteUInt8) {
+ if (need_broadcast) {
+ TF_LITE_MUL(reference_integer_ops, BroadcastMul4DSlow, uint8_t);
+ } else {
+ TF_LITE_MUL(reference_integer_ops, Mul, uint8_t);
+ }
+ }
+#undef TF_LITE_MUL
+}
+
+void EvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLiteMulParams* params, const OpData& data,
+ const TfLiteEvalTensor* input1, const TfLiteEvalTensor* input2,
+ TfLiteEvalTensor* output) {
+ tflite::ArithmeticParams op_params;
+ op_params.float_activation_min = data.output_activation_min_f32;
+ op_params.float_activation_max = data.output_activation_max_f32;
+
+ bool need_broadcast = reference_ops::ProcessBroadcastShapes(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2), &op_params);
+#define TF_LITE_MUL(opname) \
+ reference_ops::opname(op_params, tflite::micro::GetTensorShape(input1), \
+ tflite::micro::GetTensorData<float>(input1), \
+ tflite::micro::GetTensorShape(input2), \
+ tflite::micro::GetTensorData<float>(input2), \
+ tflite::micro::GetTensorShape(output), \
+ tflite::micro::GetTensorData<float>(output));
+
+ if (need_broadcast) {
+ TF_LITE_MUL(BroadcastMul4DSlow);
+ } else {
+ TF_LITE_MUL(Mul);
+ }
+#undef TF_LITE_MUL
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLiteMulParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInput1Tensor);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInput2Tensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ switch (input1->type) {
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ EvalQuantized(context, node, data, input1, input2, output);
+ break;
+ case kTfLiteFloat32:
+ EvalFloat(context, node, params, data, input1, input2, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+} // namespace mul
+
+TfLiteRegistration Register_MUL() {
+ return {/* Init=*/mul::Init,
+ /* Free=*/nullptr,
+ /* Prepare=*/mul::Prepare,
+ /*invoke=*/mul::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/pooling.cc b/tensorflow/lite/micro/kernels/cmsis_nn/pooling.cc
new file mode 100644
index 0000000..7336ff8
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/pooling.cc
@@ -0,0 +1,408 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/pooling.h"
+
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "flatbuffers/base.h" // from @flatbuffers
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/pooling.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace pooling {
+
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ TfLitePaddingValues padding;
+ // Index to buffer for optimizations if applicable.
+ int buffer_idx;
+
+ int32_t activation_min;
+ int32_t activation_max;
+ float activation_min_f32;
+ float activation_max_f32;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context,
+ const TfLitePoolParams* params,
+ const TfLiteTensor* input, TfLiteTensor* output,
+ OpData* data) {
+ // input: batch, height, width, channel
+ int height = SizeOfDimension(input, 1);
+ int width = SizeOfDimension(input, 2);
+
+ int out_height, out_width;
+
+ data->padding = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width,
+ /*dilation_rate_height=*/1,
+ /*dilation_rate_width=*/1, height, width, params->filter_height,
+ params->filter_width, params->padding, &out_height, &out_width);
+
+ if (input->type == kTfLiteFloat32) {
+ CalculateActivationRange(params->activation, &data->activation_min_f32,
+ &data->activation_max_f32);
+ } else {
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, params->activation, output, &data->activation_min,
+ &data->activation_max));
+ TFLITE_DCHECK_LE(data->activation_min, data->activation_max);
+ }
+
+ // Set buffer index to a reset value
+ data->buffer_idx = -1;
+
+ return kTfLiteOk;
+}
+
+void AverageEvalFloat(const TfLiteContext* context, const TfLiteNode* node,
+ const TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+ float activation_min, activation_max;
+ CalculateActivationRange(params->activation, &activation_min,
+ &activation_max);
+
+ PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.float_activation_min = activation_min;
+ op_params.float_activation_max = activation_max;
+ reference_ops::AveragePool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+}
+
+void AverageEvalQuantized(TfLiteContext* context, const TfLiteNode* node,
+ const TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output) {
+ TFLITE_DCHECK(input->type == kTfLiteUInt8 || input->type == kTfLiteInt8);
+
+ if (input->type == kTfLiteUInt8) {
+ PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.quantized_activation_min = data.activation_min;
+ op_params.quantized_activation_max = data.activation_max;
+
+ reference_ops::AveragePool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ RuntimeShape input_shape = tflite::micro::GetTensorShape(input);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+
+ cmsis_nn_dims input_dims;
+ input_dims.n = 1;
+ input_dims.h = input_shape.Dims(1);
+ input_dims.w = input_shape.Dims(2);
+ input_dims.c = depth;
+
+ cmsis_nn_dims output_dims;
+ output_dims.n = 1;
+ output_dims.h = output_shape.Dims(1);
+ output_dims.w = output_shape.Dims(2);
+ output_dims.c = depth;
+
+ cmsis_nn_pool_params pool_params;
+ pool_params.stride.h = params->stride_height;
+ pool_params.stride.w = params->stride_width;
+ pool_params.padding.h = data.padding.height;
+ pool_params.padding.w = data.padding.width;
+ pool_params.activation.min = data.activation_min;
+ pool_params.activation.max = data.activation_max;
+
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = 1;
+ filter_dims.h = params->filter_height;
+ filter_dims.w = params->filter_width;
+ filter_dims.c = 1;
+
+ cmsis_nn_context ctx;
+ ctx.buf = nullptr;
+ ctx.size = 0;
+ if (data.buffer_idx > -1) {
+ ctx.buf = context->GetScratchBuffer(context, data.buffer_idx);
+ }
+
+ TFLITE_DCHECK_EQ(
+ arm_avgpool_s8(&ctx, &pool_params, &input_dims,
+ tflite::micro::GetTensorData<int8_t>(input),
+ &filter_dims, &output_dims,
+ tflite::micro::GetTensorData<int8_t>(output)),
+ ARM_MATH_SUCCESS);
+ }
+}
+
+void MaxEvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+ float activation_min, activation_max;
+ CalculateActivationRange(params->activation, &activation_min,
+ &activation_max);
+ tflite::PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.float_activation_min = data.activation_min_f32;
+ op_params.float_activation_max = data.activation_max_f32;
+ reference_ops::MaxPool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+}
+
+void MaxEvalQuantizedUInt8(TfLiteContext* context, TfLiteNode* node,
+ TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output) {
+ tflite::PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.quantized_activation_min = data.activation_min;
+ op_params.quantized_activation_max = data.activation_max;
+ reference_ops::MaxPool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+}
+
+TfLiteStatus MaxEvalInt8(TfLiteContext* context, const TfLiteNode* node,
+ const TfLitePoolParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output) {
+ RuntimeShape input_shape = tflite::micro::GetTensorShape(input);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+
+ cmsis_nn_dims input_dims;
+ input_dims.n = 1;
+ input_dims.h = input_shape.Dims(1);
+ input_dims.w = input_shape.Dims(2);
+ input_dims.c = depth;
+
+ cmsis_nn_dims output_dims;
+ output_dims.n = 1;
+ output_dims.h = output_shape.Dims(1);
+ output_dims.w = output_shape.Dims(2);
+ output_dims.c = depth;
+
+ cmsis_nn_pool_params pool_params;
+ pool_params.stride.h = params->stride_height;
+ pool_params.stride.w = params->stride_width;
+ pool_params.padding.h = data.padding.height;
+ pool_params.padding.w = data.padding.width;
+ pool_params.activation.min = data.activation_min;
+ pool_params.activation.max = data.activation_max;
+
+ cmsis_nn_dims filter_dims;
+ filter_dims.n = 1;
+ filter_dims.h = params->filter_height;
+ filter_dims.w = params->filter_width;
+ filter_dims.c = 1;
+
+ cmsis_nn_context ctx;
+ ctx.buf = nullptr;
+ ctx.size = 0;
+ if (data.buffer_idx > -1) {
+ ctx.buf = context->GetScratchBuffer(context, data.buffer_idx);
+ }
+
+ TFLITE_DCHECK_EQ(
+ arm_max_pool_s8(&ctx, &pool_params, &input_dims,
+ tflite::micro::GetTensorData<int8_t>(input), &filter_dims,
+ &output_dims,
+ tflite::micro::GetTensorData<int8_t>(output)),
+ ARM_MATH_SUCCESS);
+
+ return kTfLiteOk;
+}
+
+} // namespace
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus MaxPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(context, params, input, output, data));
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus AveragePrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(context, params, input, output, data));
+
+ if (input->type == kTfLiteInt8) {
+ RuntimeShape input_shape = GetTensorShape(input);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+
+ RuntimeShape output_shape = GetTensorShape(output);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ const int depth = MatchingDim(input_shape, 3, output_shape, 3);
+ const int output_width = output_shape.Dims(2);
+
+ const int32_t buffer_size =
+ arm_avgpool_s8_get_buffer_size(output_width, depth);
+
+ if (buffer_size > 0) {
+ TF_LITE_ENSURE_STATUS(context->RequestScratchBufferInArena(
+ context, buffer_size, &data->buffer_idx));
+ } else {
+ data->buffer_idx = -1;
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus AverageEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ // Inputs and outputs share the same type, guaranteed by the converter.
+ switch (input->type) {
+ case kTfLiteFloat32:
+ AverageEvalFloat(context, node, params, data, input, output);
+ break;
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ AverageEvalQuantized(context, node, params, data, input, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input type %s is not currently supported",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus MaxEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input->type) {
+ case kTfLiteFloat32:
+ MaxEvalFloat(context, node, params, data, input, output);
+ break;
+ case kTfLiteUInt8:
+ MaxEvalQuantizedUInt8(context, node, params, data, input, output);
+ break;
+ case kTfLiteInt8:
+ MaxEvalInt8(context, node, params, data, input, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s not currently supported.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace pooling
+
+TfLiteRegistration Register_AVERAGE_POOL_2D() {
+ return {/*init=*/pooling::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pooling::AveragePrepare,
+ /*invoke=*/pooling::AverageEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_MAX_POOL_2D() {
+ return {/*init=*/pooling::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pooling::MaxPrepare,
+ /*invoke=*/pooling::MaxEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/softmax.cc b/tensorflow/lite/micro/kernels/cmsis_nn/softmax.cc
new file mode 100644
index 0000000..8df4edf
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/softmax.cc
@@ -0,0 +1,112 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/softmax.h"
+
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/softmax.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+void SoftmaxQuantized(const TfLiteEvalTensor* input, TfLiteEvalTensor* output,
+ const SoftmaxParams& op_data) {
+ if (input->type == kTfLiteUInt8) {
+ tflite::reference_ops::Softmax(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else if (input->type == kTfLiteInt8) {
+ if (output->type == kTfLiteInt16) {
+ tflite::reference_ops::Softmax(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ } else {
+ const auto input_shape = tflite::micro::GetTensorShape(input);
+ const auto output_shape = tflite::micro::GetTensorShape(output);
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+
+ arm_softmax_s8(tflite::micro::GetTensorData<int8_t>(input), outer_size,
+ depth, op_data.input_multiplier, op_data.input_left_shift,
+ op_data.diff_min,
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+ } else {
+ tflite::reference_ops::SoftmaxInt16(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int16_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ }
+}
+
+TfLiteStatus SoftmaxEval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const SoftmaxParams data =
+ *static_cast<const SoftmaxParams*>(node->user_data);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ tflite::reference_ops::Softmax(
+ data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ }
+ case kTfLiteInt8:
+ case kTfLiteUInt8:
+ case kTfLiteInt16: {
+ SoftmaxQuantized(input, output, data);
+ return kTfLiteOk;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+}
+
+} // namespace
+
+TfLiteRegistration Register_SOFTMAX() {
+ return {/*init=*/SoftmaxInit,
+ /*free=*/nullptr,
+ /*prepare=*/SoftmaxPrepare,
+ /*invoke=*/SoftmaxEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cmsis_nn/svdf.cc b/tensorflow/lite/micro/kernels/cmsis_nn/svdf.cc
new file mode 100644
index 0000000..63a4731
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cmsis_nn/svdf.cc
@@ -0,0 +1,480 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cmath>
+#include <cstdint>
+
+#include "CMSIS/NN/Include/arm_nn_types.h"
+#include "CMSIS/NN/Include/arm_nnfunctions.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/activation_utils.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace {
+
+struct OpData {
+ int32_t effective_scale_1_a;
+ int32_t effective_scale_2_a;
+ // b versions of each scale are kept at int since the numbers are just the
+ // shift value - typically between [-32, 32].
+ int effective_scale_1_b;
+ int effective_scale_2_b;
+ int scratch_tensor_index;
+ int scratch_output_tensor_index;
+
+ // Cached tensor zero point values for quantized operations.
+ int input_zero_point;
+ int output_zero_point;
+};
+
+// Input tensors.
+constexpr int kInputTensor = 0;
+constexpr int kWeightsFeatureTensor = 1;
+constexpr int kWeightsTimeTensor = 2;
+constexpr int kBiasTensor = 3;
+// This is a variable tensor, and will be modified by this op.
+constexpr int kInputActivationStateTensor = 4;
+
+// Output tensor.
+constexpr int kOutputTensor = 0;
+
+/**
+ * This version of SVDF is specific to TFLite Micro. It contains the following
+ * differences between the TFLite version:
+ *
+ * 1.) Scratch tensor allocation - scratch tensors must be known ahead of time
+ * for the Micro interpreter.
+ * 2.) Output dimensions - the TFLite version determines output size and runtime
+ * and resizes the output tensor. Micro runtime does not support tensor
+ * resizing.
+ */
+static inline void ApplyTimeWeightsBiasAndActivation(
+ int batch_size, int memory_size, int num_filters, int num_units, int rank,
+ const float* const __restrict__ weights_time_ptr,
+ const float* const __restrict__ bias_ptr, TfLiteFusedActivation activation,
+ float* const __restrict__ state_ptr, float* const __restrict__ scratch_ptr,
+ float* const __restrict__ output_ptr) {
+ // Compute matmul(activation_state, weights_time).
+ for (int b = 0; b < batch_size; ++b) {
+ // Perform batched vector dot product:
+ float* scratch_ptr_batch = scratch_ptr + b * num_filters;
+ const float* vector1_ptr = weights_time_ptr;
+ const float* vector2_ptr = state_ptr + b * memory_size * num_filters;
+ for (int i = 0; i < num_filters; ++i) {
+ *scratch_ptr_batch = 0.f;
+ for (int j = 0; j < memory_size; ++j) {
+ *scratch_ptr_batch += *vector1_ptr++ * *vector2_ptr++;
+ }
+ scratch_ptr_batch++;
+ }
+ }
+
+ // Initialize output with bias if provided.
+ if (bias_ptr) {
+ // VectorBatchVectorAssign
+ for (int i = 0; i < batch_size; ++i) {
+ float* output_data = output_ptr + i * num_units;
+ const float* bias_data = bias_ptr;
+ for (int j = 0; j < num_units; ++j) {
+ *output_data++ = *bias_data++;
+ }
+ }
+ } else {
+ float* output_data = output_ptr;
+ for (int i = 0; i < batch_size * num_units; ++i) {
+ *output_data++ = 0.0f;
+ }
+ }
+
+ // Reduction sum.
+ for (int b = 0; b < batch_size; ++b) {
+ float* output_ptr_batch = output_ptr + b * num_units;
+ float* scratch_ptr_batch = scratch_ptr + b * num_filters;
+
+ // Reduction sum vector
+ for (int i = 0; i < num_units; ++i) {
+ for (int j = 0; j < rank; j++) {
+ output_ptr_batch[i] += *scratch_ptr_batch++;
+ }
+ }
+ }
+
+ // Apply activation.
+ for (int b = 0; b < batch_size; ++b) {
+ float* output_ptr_batch = output_ptr + b * num_units;
+ for (int i = 0; i < num_units; ++i) {
+ *output_ptr_batch =
+ tflite::ops::micro::ActivationValFloat(activation, *output_ptr_batch);
+ ++output_ptr_batch;
+ }
+ }
+}
+
+inline void EvalFloatSVDF(
+ TfLiteContext* context, TfLiteNode* node, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* weights_feature,
+ const TfLiteEvalTensor* weights_time, const TfLiteEvalTensor* bias,
+ const TfLiteSVDFParams* params, int scratch_tensor_index,
+ TfLiteEvalTensor* activation_state, TfLiteEvalTensor* output) {
+ const int rank = params->rank;
+ const int batch_size = input->dims->data[0];
+ const int input_size = input->dims->data[1];
+ const int num_filters = weights_feature->dims->data[0];
+ const int num_units = num_filters / rank;
+ const int memory_size = weights_time->dims->data[1];
+
+ const float* weights_feature_ptr =
+ tflite::micro::GetTensorData<float>(weights_feature);
+ const float* weights_time_ptr =
+ tflite::micro::GetTensorData<float>(weights_time);
+ const float* bias_ptr = tflite::micro::GetTensorData<float>(bias);
+ const float* input_ptr = tflite::micro::GetTensorData<float>(input);
+
+ float* state_ptr = tflite::micro::GetTensorData<float>(activation_state);
+
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer != nullptr);
+
+ float* scratch_ptr = static_cast<float*>(
+ context->GetScratchBuffer(context, scratch_tensor_index));
+
+ float* output_ptr = tflite::micro::GetTensorData<float>(output);
+
+ // Left shift the activation_state.
+ {
+ float* new_state_start = state_ptr;
+ const float* old_state_start = state_ptr + 1;
+ const float* old_state_end =
+ state_ptr + batch_size * num_filters * memory_size;
+ while (old_state_start != old_state_end) {
+ *new_state_start++ = *old_state_start++;
+ }
+ }
+
+ // Note: no need to clear the latest activation, matmul is not accumulative.
+
+ // Compute conv1d(inputs, weights_feature).
+ // The activation_state's rightmost column is used to save current cycle
+ // activation. This is achieved by starting at state_ptr[memory_size - 1] and
+ // having the stride equal to memory_size.
+
+ // Perform batched matrix vector multiply operation:
+ {
+ const float* matrix = weights_feature_ptr;
+ const float* vector = input_ptr;
+ float* result = &state_ptr[memory_size - 1];
+ float* result_in_batch = result;
+ for (int i = 0; i < batch_size; ++i) {
+ const float* matrix_ptr = matrix;
+ for (int j = 0; j < num_filters; ++j) {
+ float dot_prod = 0.0f;
+ const float* vector_in_batch = vector + i * input_size;
+ for (int k = 0; k < input_size; ++k) {
+ dot_prod += *matrix_ptr++ * *vector_in_batch++;
+ }
+ *result_in_batch = dot_prod;
+ result_in_batch += memory_size;
+ }
+ }
+ }
+
+ ApplyTimeWeightsBiasAndActivation(
+ batch_size, memory_size, num_filters, num_units, rank, weights_time_ptr,
+ bias_ptr, params->activation, state_ptr, scratch_ptr, output_ptr);
+}
+
+void EvalIntegerSVDF(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input_tensor,
+ const TfLiteEvalTensor* weights_feature_tensor,
+ const TfLiteEvalTensor* weights_time_tensor,
+ const TfLiteEvalTensor* bias_tensor,
+ const TfLiteSVDFParams* params,
+ TfLiteEvalTensor* activation_state_tensor,
+ TfLiteEvalTensor* output_tensor, const OpData& data) {
+ cmsis_nn_dims input_dims;
+ input_dims.n = input_tensor->dims->data[0];
+ input_dims.h = input_tensor->dims->data[1];
+
+ cmsis_nn_dims weights_feature_dims;
+ weights_feature_dims.n = weights_feature_tensor->dims->data[0];
+ weights_feature_dims.h = weights_feature_tensor->dims->data[1];
+
+ cmsis_nn_dims weights_time_dims;
+ weights_time_dims.n = weights_time_tensor->dims->data[0];
+ weights_time_dims.h = weights_time_tensor->dims->data[1];
+
+ cmsis_nn_dims bias_dims;
+ bias_dims.n = bias_tensor->dims->data[0];
+
+ cmsis_nn_dims state_dims;
+ state_dims.n = bias_tensor->dims->data[0];
+ state_dims.h = bias_tensor->dims->data[1];
+
+ cmsis_nn_dims output_dims;
+ output_dims.n = output_tensor->dims->data[0];
+ output_dims.h = output_tensor->dims->data[1];
+
+ cmsis_nn_svdf_params svdf_params;
+ svdf_params.rank = params->rank;
+ svdf_params.input_offset = data.input_zero_point;
+ svdf_params.output_offset = data.output_zero_point;
+
+ svdf_params.input_activation.min = INT16_MIN;
+ svdf_params.input_activation.max = INT16_MAX;
+
+ svdf_params.output_activation.min = INT8_MIN;
+ svdf_params.output_activation.max = INT8_MAX;
+
+ cmsis_nn_per_tensor_quant_params in_quant_params;
+ in_quant_params.multiplier = data.effective_scale_1_a;
+ in_quant_params.shift = data.effective_scale_1_b;
+
+ cmsis_nn_per_tensor_quant_params out_quant_params;
+ out_quant_params.multiplier = data.effective_scale_2_a;
+ out_quant_params.shift = data.effective_scale_2_b;
+
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer != nullptr);
+
+ cmsis_nn_context scratch_ctx;
+ scratch_ctx.buf = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, data.scratch_tensor_index));
+
+ cmsis_nn_context scratch_output_ctx;
+ scratch_output_ctx.buf = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, data.scratch_output_tensor_index));
+
+ int8_t* output_data = tflite::micro::GetTensorData<int8_t>(output_tensor);
+ arm_svdf_s8(
+ &scratch_ctx, &scratch_output_ctx, &svdf_params, &in_quant_params,
+ &out_quant_params, &input_dims,
+ (int8_t*)tflite::micro::GetTensorData<int8_t>(input_tensor), &state_dims,
+ (int16_t*)tflite::micro::GetTensorData<int16_t>(activation_state_tensor),
+ &weights_feature_dims,
+ (int8_t*)tflite::micro::GetTensorData<int8_t>(weights_feature_tensor),
+ &weights_time_dims,
+ (int16_t*)tflite::micro::GetTensorData<int16_t>(weights_time_tensor),
+ &bias_dims, (int32_t*)tflite::micro::GetTensorData<int32_t>(bias_tensor),
+ &output_dims, output_data);
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ const auto* params = static_cast<const TfLiteSVDFParams*>(node->builtin_data);
+
+ // Validate Tensor Inputs (dtype depends on quantization):
+ // [0] = Input, {2, batch_size, input_size}
+ // [1] = Weights Feature, {2, num_filters, input_size}
+ // [2] = Weights Time, {2, num_filters, memory_size}
+ // [3] = Bias (optional), {1, num_units}
+ // [4] = Activation State (variable),
+ // {2, batch_size, memory_size * num_filters}
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* weights_feature =
+ GetInput(context, node, kWeightsFeatureTensor);
+ TF_LITE_ENSURE(context, weights_feature != nullptr);
+ const TfLiteTensor* weights_time =
+ GetInput(context, node, kWeightsTimeTensor);
+ TF_LITE_ENSURE(context, weights_time != nullptr);
+ const TfLiteTensor* bias = GetOptionalInputTensor(context, node, kBiasTensor);
+ const TfLiteTensor* activation_state =
+ GetInput(context, node, kInputActivationStateTensor);
+ TF_LITE_ENSURE(context, activation_state != nullptr);
+
+ // Define input constants based on input tensor definition above:
+ const int rank = params->rank;
+ const int input_size = input->dims->data[1];
+ const int batch_size = input->dims->data[0];
+ const int num_filters = weights_feature->dims->data[0];
+ TF_LITE_ENSURE_EQ(context, num_filters % rank, 0);
+ const int num_units = num_filters / rank;
+ const int memory_size = weights_time->dims->data[1];
+
+ // Validate Input Tensor:
+ TF_LITE_ENSURE(context,
+ input->type == kTfLiteFloat32 || input->type == kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), 2);
+
+ // Validate Tensor Output:
+ // [0] = float/int8, {2, batch_size, num_units}
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(output), 2);
+ TF_LITE_ENSURE_EQ(context, output->dims->data[0], batch_size);
+ TF_LITE_ENSURE_EQ(context, output->dims->data[1], num_units);
+
+ // Validate Weights Feature Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(weights_feature), 2);
+ TF_LITE_ENSURE_EQ(context, weights_feature->dims->data[1], input_size);
+
+ // Validate Weights Time Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(weights_time), 2);
+ TF_LITE_ENSURE_EQ(context, weights_time->dims->data[0], num_filters);
+ TF_LITE_ENSURE_EQ(context, weights_time->dims->data[1], memory_size);
+
+ // Validate Optional Bias Input Tensor:
+ if (bias != nullptr) {
+ TF_LITE_ENSURE_EQ(context, bias->dims->data[0], num_units);
+ }
+
+ // Validate Activation State Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(activation_state), 2);
+ TF_LITE_ENSURE_EQ(context, activation_state->dims->data[0], batch_size);
+ TF_LITE_ENSURE_EQ(context, activation_state->dims->data[1],
+ memory_size * num_filters);
+ // Since is_variable is not part of TFLiteEvalTensor, check is_variable here.
+ TF_LITE_ENSURE_EQ(context, activation_state->is_variable, true);
+
+ TF_LITE_ENSURE_EQ(context, node->inputs->size, 5);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, weights_feature->type, kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, weights_time->type, kTfLiteInt16);
+ TF_LITE_ENSURE_EQ(context, activation_state->type, kTfLiteInt16);
+ if (bias != nullptr) {
+ TF_LITE_ENSURE_EQ(context, bias->type, kTfLiteInt32);
+ }
+
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, kTfLiteInt8);
+
+ const double effective_scale_1 = static_cast<double>(
+ input->params.scale * weights_feature->params.scale /
+ activation_state->params.scale);
+ const double effective_scale_2 =
+ static_cast<double>(activation_state->params.scale *
+ weights_time->params.scale / output->params.scale);
+
+ // TODO(b/162018098): Use TF_LITE_ENSURE_NEAR when it is ready.
+ TF_LITE_ENSURE(
+ context,
+ std::abs(static_cast<double>(bias->params.scale) -
+ static_cast<double>(activation_state->params.scale *
+ weights_time->params.scale)) < 1e-5);
+
+ QuantizeMultiplier(effective_scale_1, &(data->effective_scale_1_a),
+ &(data->effective_scale_1_b));
+ QuantizeMultiplier(effective_scale_2, &(data->effective_scale_2_a),
+ &(data->effective_scale_2_b));
+
+ data->input_zero_point = input->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ TFLITE_DCHECK(context->RequestScratchBufferInArena != nullptr);
+
+ const TfLiteStatus scratch_status = context->RequestScratchBufferInArena(
+ context, batch_size * num_filters * sizeof(int32_t),
+ &(data->scratch_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_status);
+
+ const TfLiteStatus scratch_output_status =
+ context->RequestScratchBufferInArena(
+ context, batch_size * num_units * sizeof(int32_t),
+ &(data->scratch_output_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_output_status);
+ } else {
+ TF_LITE_ENSURE_EQ(context, weights_feature->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_EQ(context, weights_time->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_EQ(context, activation_state->type, kTfLiteFloat32);
+ if (bias != nullptr) {
+ TF_LITE_ENSURE_EQ(context, bias->type, kTfLiteFloat32);
+ }
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, kTfLiteFloat32);
+
+ TFLITE_DCHECK(context->RequestScratchBufferInArena != nullptr);
+ const TfLiteStatus scratch_status = context->RequestScratchBufferInArena(
+ context, batch_size * num_filters * sizeof(float),
+ &(data->scratch_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_status);
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = reinterpret_cast<TfLiteSVDFParams*>(node->builtin_data);
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* weights_feature =
+ tflite::micro::GetEvalInput(context, node, kWeightsFeatureTensor);
+ const TfLiteEvalTensor* weights_time =
+ tflite::micro::GetEvalInput(context, node, kWeightsTimeTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 5)
+ ? tflite::micro::GetEvalInput(context, node, kBiasTensor)
+ : nullptr;
+ TfLiteEvalTensor* activation_state = tflite::micro::GetMutableEvalInput(
+ context, node, kInputActivationStateTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (weights_feature->type) {
+ case kTfLiteFloat32: {
+ EvalFloatSVDF(context, node, input, weights_feature, weights_time, bias,
+ params, data.scratch_tensor_index, activation_state,
+ output);
+ return kTfLiteOk;
+ break;
+ }
+
+ case kTfLiteInt8: {
+ EvalIntegerSVDF(context, node, input, weights_feature, weights_time, bias,
+ params, activation_state, output, data);
+ return kTfLiteOk;
+ break;
+ }
+
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s not currently supported.",
+ TfLiteTypeGetName(weights_feature->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_SVDF() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/comparisons.cc b/tensorflow/lite/micro/kernels/comparisons.cc
new file mode 100644
index 0000000..3500764
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/comparisons.cc
@@ -0,0 +1,724 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/comparisons.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace comparisons {
+namespace {
+
+struct OpData {
+ ComparisonParams params;
+};
+
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus EqualEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ RuntimeShape input1_shape = tflite::micro::GetTensorShape(input1);
+ RuntimeShape input2_shape = tflite::micro::GetTensorShape(input2);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ bool* output_data = tflite::micro::GetTensorData<bool>(output);
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+ switch (input1->type) {
+ case kTfLiteBool:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<bool>(input1), input2_shape,
+ tflite::micro::GetTensorData<bool>(input2), output_shape,
+ output_data)
+ : reference_ops::EqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<bool>(input1), input2_shape,
+ tflite::micro::GetTensorData<bool>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteFloat32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data)
+ : reference_ops::EqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data)
+ : reference_ops::EqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt64:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data)
+ : reference_ops::EqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteUInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::EqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::EqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+// TODO(renjieliu): Refactor the logic to avoid duplications.
+TfLiteStatus NotEqualEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ RuntimeShape input1_shape = tflite::micro::GetTensorShape(input1);
+ RuntimeShape input2_shape = tflite::micro::GetTensorShape(input2);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ bool* output_data = tflite::micro::GetTensorData<bool>(output);
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+ switch (input1->type) {
+ case kTfLiteBool:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowNotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<bool>(input1), input2_shape,
+ tflite::micro::GetTensorData<bool>(input2), output_shape,
+ output_data)
+ : reference_ops::NotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<bool>(input1), input2_shape,
+ tflite::micro::GetTensorData<bool>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteFloat32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowNotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data)
+ : reference_ops::NotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowNotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data)
+ : reference_ops::NotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt64:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowNotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data)
+ : reference_ops::NotEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteUInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowNotEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::NotEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowNotEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::NotEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus GreaterEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ RuntimeShape input1_shape = tflite::micro::GetTensorShape(input1);
+ RuntimeShape input2_shape = tflite::micro::GetTensorShape(input2);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ bool* output_data = tflite::micro::GetTensorData<bool>(output);
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+ switch (input1->type) {
+ case kTfLiteFloat32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt64:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteUInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus GreaterEqualEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ RuntimeShape input1_shape = tflite::micro::GetTensorShape(input1);
+ RuntimeShape input2_shape = tflite::micro::GetTensorShape(input2);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ bool* output_data = tflite::micro::GetTensorData<bool>(output);
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+ switch (input1->type) {
+ case kTfLiteFloat32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt64:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteUInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowGreaterEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::GreaterEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus LessEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ RuntimeShape input1_shape = tflite::micro::GetTensorShape(input1);
+ RuntimeShape input2_shape = tflite::micro::GetTensorShape(input2);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ bool* output_data = tflite::micro::GetTensorData<bool>(output);
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+ switch (input1->type) {
+ case kTfLiteFloat32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data)
+ : reference_ops::LessNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt64:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteUInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus LessEqualEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ RuntimeShape input1_shape = tflite::micro::GetTensorShape(input1);
+ RuntimeShape input2_shape = tflite::micro::GetTensorShape(input2);
+ RuntimeShape output_shape = tflite::micro::GetTensorShape(output);
+ bool* output_data = tflite::micro::GetTensorData<bool>(output);
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+ switch (input1->type) {
+ case kTfLiteFloat32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data)
+ : reference_ops::LessEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<float>(input1), input2_shape,
+ tflite::micro::GetTensorData<float>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt32:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int32_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int32_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt64:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessEqualNoScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int64_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int64_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteUInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<uint8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<uint8_t>(input2), output_shape,
+ output_data);
+ break;
+ case kTfLiteInt8:
+ requires_broadcast
+ ? reference_ops::Broadcast4DSlowLessEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data)
+ : reference_ops::LessEqualWithScaling(
+ data->params, input1_shape,
+ tflite::micro::GetTensorData<int8_t>(input1), input2_shape,
+ tflite::micro::GetTensorData<int8_t>(input2), output_shape,
+ output_data);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ const TfLiteTensor* input1 = GetInput(context, node, kInputTensor1);
+ TF_LITE_ENSURE(context, input1 != nullptr);
+ const TfLiteTensor* input2 = GetInput(context, node, kInputTensor2);
+ TF_LITE_ENSURE(context, input2 != nullptr);
+
+ if (input1->type == kTfLiteUInt8 || input1->type == kTfLiteInt8) {
+ auto input1_offset = -input1->params.zero_point;
+ auto input2_offset = -input2->params.zero_point;
+ const int kLeftShift = 8;
+
+ int32_t input1_multiplier;
+ int input1_shift;
+ QuantizeMultiplierSmallerThanOneExp(
+ static_cast<double>(input1->params.scale), &input1_multiplier,
+ &input1_shift);
+ int32_t input2_multiplier;
+ int input2_shift;
+ QuantizeMultiplierSmallerThanOneExp(
+ static_cast<double>(input2->params.scale), &input2_multiplier,
+ &input2_shift);
+
+ data->params.left_shift = kLeftShift;
+ data->params.input1_offset = input1_offset;
+ data->params.input1_multiplier = input1_multiplier;
+ data->params.input1_shift = input1_shift;
+ data->params.input2_offset = input2_offset;
+ data->params.input2_multiplier = input2_multiplier;
+ data->params.input2_shift = input2_shift;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace comparisons
+
+TfLiteRegistration Register_EQUAL() {
+ return {/*init=*/comparisons::Init,
+ /*free=*/nullptr,
+ /*prepare=*/comparisons::Prepare,
+ /*invoke=*/comparisons::EqualEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_NOT_EQUAL() {
+ return {/*init=*/comparisons::Init,
+ /*free=*/nullptr,
+ /*prepare=*/comparisons::Prepare,
+ /*invoke=*/comparisons::NotEqualEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_GREATER() {
+ return {/*init=*/comparisons::Init,
+ /*free=*/nullptr,
+ /*prepare=*/comparisons::Prepare,
+ /*invoke=*/comparisons::GreaterEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_GREATER_EQUAL() {
+ return {/*init=*/comparisons::Init,
+ /*free=*/nullptr,
+ /*prepare=*/comparisons::Prepare,
+ /*invoke=*/comparisons::GreaterEqualEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_LESS() {
+ return {/*init=*/comparisons::Init,
+ /*free=*/nullptr,
+ /*prepare=*/comparisons::Prepare,
+ /*invoke=*/comparisons::LessEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_LESS_EQUAL() {
+ return {/*init=*/comparisons::Init,
+ /*free=*/nullptr,
+ /*prepare=*/comparisons::Prepare,
+ /*invoke=*/comparisons::LessEqualEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/comparisons_test.cc b/tensorflow/lite/micro/kernels/comparisons_test.cc
new file mode 100644
index 0000000..fe55a23
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/comparisons_test.cc
@@ -0,0 +1,1109 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <cstdint>
+#include <initializer_list>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int inputs_size = 2;
+constexpr int outputs_size = 1;
+constexpr int tensors_size = inputs_size + outputs_size;
+
+void TestComparison(const TfLiteRegistration& registration,
+ TfLiteTensor* tensors, bool* expected_output_data,
+ bool* output_data) {
+ const int output_dims_count = ElementCount(*tensors[inputs_size].dims);
+
+ const int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ const int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+void TestComparisonFloat(const TfLiteRegistration& registration,
+ int* input1_dims_data, float* input1_data,
+ int* input2_dims_data, float* input2_data,
+ bool* expected_output_data, int* output_dims_data,
+ bool* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TestComparison(registration, tensors, expected_output_data, output_data);
+}
+
+void TestComparisonBool(const TfLiteRegistration& registration,
+ int* input1_dims_data, bool* input1_data,
+ int* input2_dims_data, bool* input2_data,
+ bool* expected_output_data, int* output_dims_data,
+ bool* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TestComparison(registration, tensors, expected_output_data, output_data);
+}
+
+void TestComparisonInt(const TfLiteRegistration& registration,
+ int* input1_dims_data, int32_t* input1_data,
+ int* input2_dims_data, int32_t* input2_data,
+ bool* expected_output_data, int* output_dims_data,
+ bool* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TestComparison(registration, tensors, expected_output_data, output_data);
+}
+
+void TestComparisonQuantizedUInt8(const TfLiteRegistration& registration,
+ int* input1_dims_data, float* input1_data,
+ uint8_t* input1_quantized, float input1_scale,
+ int input1_zero_point, int* input2_dims_data,
+ float* input2_data, uint8_t* input2_quantized,
+ float input2_scale, int input2_zero_point,
+ bool* expected_output_data,
+ int* output_dims_data, bool* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input1_data, input1_quantized, input1_dims,
+ input1_scale, input1_zero_point),
+ CreateQuantizedTensor(input2_data, input2_quantized, input2_dims,
+ input2_scale, input2_zero_point),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TestComparison(registration, tensors, expected_output_data, output_data);
+}
+
+void TestComparisonQuantizedInt8(const TfLiteRegistration& registration,
+ int* input1_dims_data, float* input1_data,
+ int8_t* input1_quantized, float input1_scale,
+ int input1_zero_point, int* input2_dims_data,
+ float* input2_data, int8_t* input2_quantized,
+ float input2_scale, int input2_zero_point,
+ bool* expected_output_data,
+ int* output_dims_data, bool* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input1_data, input1_quantized, input1_dims,
+ input1_scale, input1_zero_point),
+ CreateQuantizedTensor(input2_data, input2_quantized, input2_dims,
+ input2_scale, input2_zero_point),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TestComparison(registration, tensors, expected_output_data, output_data);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(EqualBool) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ bool input1_data[] = {true, false, true, false};
+ bool input2_data[] = {true, true, false, false};
+
+ bool expected_data[] = {true, false, false, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonBool(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(EqualFloat) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ float input1_data[] = {0.1, 0.9, 0.7, 0.3};
+ float input2_data[] = {0.1, 0.2, 0.6, 0.5};
+
+ bool expected_data[] = {true, false, false, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonFloat(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(EqualInt) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {1, 2, 7, 5};
+
+ bool expected_data[] = {false, false, true, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(EqualBroadcast) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 1};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {7};
+
+ bool expected_data[] = {false, false, true, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(EqualBroadcastTwoD) {
+ int input1_dim[] = {4, 1, 1, 2, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3, 2, 4, 2, 8};
+ int32_t input2_data[] = {7, 1, 2, 4};
+
+ bool expected_data[] = {false, false, false, false,
+ false, false, true, false};
+ int expected_dim[] = {4, 1, 1, 2, 4};
+
+ bool output_data[8];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(NotEqualBool) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ bool input1_data[] = {true, false, true, false};
+ bool input2_data[] = {true, true, false, false};
+
+ bool expected_data[] = {false, true, true, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonBool(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(NotEqualFloat) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ float input1_data[] = {0.1, 0.9, 0.7, 0.3};
+ float input2_data[] = {0.1, 0.2, 0.6, 0.5};
+
+ bool expected_data[] = {false, true, true, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonFloat(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(NotEqualInt) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {1, 2, 7, 5};
+
+ bool expected_data[] = {true, true, false, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(NotEqualBroadcast) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 1};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {7};
+
+ bool expected_data[] = {true, true, false, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(NotEqualBroadcastTwoD) {
+ int input1_dim[] = {4, 1, 1, 2, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3, 2, 4, 2, 8};
+ int32_t input2_data[] = {7, 1, 2, 4};
+
+ bool expected_data[] = {true, true, true, true, true, true, false, true};
+ int expected_dim[] = {4, 1, 1, 2, 4};
+
+ bool output_data[8];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterFloat) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ float input1_data[] = {0.1, 0.9, 0.7, 0.3};
+ float input2_data[] = {0.1, 0.2, 0.6, 0.5};
+
+ bool expected_data[] = {false, true, true, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonFloat(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterInt) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {1, 2, 7, 5};
+
+ bool expected_data[] = {false, true, false, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterBroadcast) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 1};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {7};
+
+ bool expected_data[] = {false, true, false, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterBroadcastTwoD) {
+ int input1_dim[] = {4, 1, 1, 2, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3, 2, 4, 2, 8};
+ int32_t input2_data[] = {7, 1, 2, 4};
+
+ bool expected_data[] = {false, true, true, false, false, true, false, true};
+ int expected_dim[] = {4, 1, 1, 2, 4};
+
+ bool output_data[8];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterEqualFloat) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ float input1_data[] = {0.1, 0.9, 0.7, 0.3};
+ float input2_data[] = {0.1, 0.2, 0.6, 0.5};
+
+ bool expected_data[] = {true, true, true, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonFloat(
+ tflite::ops::micro::Register_GREATER_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterEqualInt) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {1, 2, 7, 5};
+
+ bool expected_data[] = {false, true, true, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_GREATER_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterEqualBroadcast) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 1};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {7};
+
+ bool expected_data[] = {false, true, true, false};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_GREATER_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterEqualBroadcastTwoD) {
+ int input1_dim[] = {4, 1, 1, 2, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3, 2, 4, 2, 8};
+ int32_t input2_data[] = {7, 1, 2, 4};
+
+ bool expected_data[] = {false, true, true, false, false, true, true, true};
+ int expected_dim[] = {4, 1, 1, 2, 4};
+
+ bool output_data[8];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_GREATER_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessFloat) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ float input1_data[] = {0.1, 0.9, 0.7, 0.3};
+ float input2_data[] = {0.1, 0.2, 0.6, 0.5};
+
+ bool expected_data[] = {false, false, false, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonFloat(
+ tflite::ops::micro::Register_LESS(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessInt) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {1, 2, 6, 5};
+
+ bool expected_data[] = {true, false, false, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_LESS(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessBroadcast) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 1};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {7};
+
+ bool expected_data[] = {true, false, false, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_LESS(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessBroadcastTwoD) {
+ int input1_dim[] = {4, 1, 1, 2, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3, 2, 4, 6, 8};
+ int32_t input2_data[] = {7, 1, 2, 4};
+
+ bool expected_data[] = {true, false, false, true, true, false, false, false};
+ int expected_dim[] = {4, 1, 1, 2, 4};
+
+ bool output_data[8];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_LESS(), input1_dim, input1_data, input2_dim,
+ input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessEqualFloat) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ float input1_data[] = {0.1, 0.9, 0.7, 0.3};
+ float input2_data[] = {0.1, 0.2, 0.6, 0.5};
+
+ bool expected_data[] = {true, false, false, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonFloat(
+ tflite::ops::micro::Register_LESS_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessEqualInt) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {1, 2, 7, 5};
+
+ bool expected_data[] = {true, false, true, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_LESS_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessEqualBroadcast) {
+ int input1_dim[] = {4, 1, 1, 1, 4};
+ int input2_dim[] = {4, 1, 1, 1, 1};
+
+ int32_t input1_data[] = {-1, 9, 7, 3};
+ int32_t input2_data[] = {7};
+
+ bool expected_data[] = {true, false, true, true};
+ int expected_dim[] = {4, 1, 1, 1, 4};
+
+ bool output_data[4];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_LESS_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessEqualBroadcastTwoD) {
+ int input1_dim[] = {4, 1, 1, 2, 4};
+ int input2_dim[] = {4, 1, 1, 1, 4};
+
+ int32_t input1_data[] = {-1, 9, 7, 3, 2, 4, 2, 8};
+ int32_t input2_data[] = {7, 1, 2, 4};
+
+ bool expected_data[] = {true, false, false, true, true, false, true, false};
+ int expected_dim[] = {4, 1, 1, 2, 4};
+
+ bool output_data[8];
+ tflite::testing::TestComparisonInt(
+ tflite::ops::micro::Register_LESS_EQUAL(), input1_dim, input1_data,
+ input2_dim, input2_data, expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(EqualQuantizedUInt8) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+ float input1_data[] = {1, 9, 7, 3};
+ float input2_data[] = {1, 2, 7, 5};
+
+ bool expected_data[] = {true, false, true, false};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ const float input2_scale = 0.25;
+ const int input2_zero_point = 125;
+ uint8_t input1_quantized[4];
+ uint8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input2_scale, input2_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(EqualQuantizedInt8) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+
+ float input1_data[] = {1, -9, 7, 3};
+ float input2_data[] = {-1, 2, 7, 5};
+
+ bool expected_data[] = {false, false, true, false};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = -5;
+ const float input2_scale = 0.25;
+ const int input2_zero_point = 5;
+ int8_t input1_quantized[4];
+ int8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedInt8(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input2_scale, input2_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(NotEqualQuantizedUInt8) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+ float input1_data[] = {1, 9, 7, 3};
+ float input2_data[] = {1, 2, 7, 0};
+
+ bool expected_data[] = {false, true, false, true};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ const float input2_scale = 0.25;
+ const int input2_zero_point = 125;
+ uint8_t input1_quantized[4];
+ uint8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input2_scale, input2_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(NotEqualQuantizedInt8) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+
+ float input1_data[] = {1, -9, 7, 3};
+ float input2_data[] = {1, 2, 7, 5};
+
+ bool expected_data[] = {false, true, false, true};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = -5;
+ const float input2_scale = 0.25;
+ const int input2_zero_point = 5;
+ int8_t input1_quantized[4];
+ int8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedInt8(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input2_scale, input2_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterQuantizedUInt8) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+ float input1_data[] = {1, 9, 7, 3};
+ float input2_data[] = {1, 2, 6, 5};
+
+ bool expected_data[] = {false, true, true, false};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ const float input2_scale = 0.25;
+ const int input2_zero_point = 125;
+ uint8_t input1_quantized[4];
+ uint8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input2_scale, input2_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterQuantizedUInt8SmallRange) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+ float input1_data[] = {1, 0.5, 0.35, 0.1};
+ float input2_data[] = {1.01, 0.25, 0.3, 0.4};
+
+ bool expected_data[] = {false, true, true, false};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ const float input2_scale = 0.25;
+ const int input2_zero_point = 125;
+ uint8_t input1_quantized[4];
+ uint8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input2_scale, input2_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(GreaterUInt8EqualQuantized) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+
+ float input1_data[] = {1, 9, 7, 3};
+ float input2_data[] = {1, 2, 6, 5};
+
+ bool expected_data[] = {true, true, true, false};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[4];
+ uint8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_GREATER_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessQuantizedUInt8) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+
+ float input1_data[] = {1, 9, 7, 3};
+ float input2_data[] = {1, 2, 6, 5};
+
+ bool expected_data[] = {false, false, false, true};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[4];
+ uint8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_LESS(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(LessEqualQuantizedUInt8) {
+ int input1_dim[] = {4, 1, 2, 2, 1};
+ int input2_dim[] = {4, 1, 2, 2, 1};
+
+ float input1_data[] = {1, 9, 7, 3};
+ float input2_data[] = {1, 2, 6, 5};
+
+ bool expected_data[] = {true, false, false, true};
+ int expected_dim[] = {4, 1, 2, 2, 1};
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[4];
+ uint8_t input2_quantized[4];
+
+ bool output_data[4];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_LESS_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+}
+
+TF_LITE_MICRO_TEST(EqualQuantizedUInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, 2, 7, 8, 11, 20, 2};
+ float input2_data[] = {2};
+
+ bool expected_data[] = {false, true, false, false, false, false};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[6];
+ uint8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(NotEqualQuantizedUInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, 2, 7, 8, 11, 20};
+ float input2_data[] = {2};
+
+ bool expected_data[] = {true, false, true, true, true, true};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[6];
+ uint8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(NotEqualQuantizedInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, -2, -71, 8, 11, 20};
+ float input2_data[] = {8};
+
+ bool expected_data[] = {true, true, true, false, true, true};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = -9;
+ int8_t input1_quantized[6];
+ int8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedInt8(
+ tflite::ops::micro::Register_NOT_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(GreaterQuantizedUInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, 2, 7, 8, 11, 20};
+ float input2_data[] = {2};
+
+ bool expected_data[] = {true, false, true, true, true, true};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[6];
+ uint8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(GreaterQuantizedInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, -2, -71, 8, 11, 20};
+ float input2_data[] = {8};
+
+ bool expected_data[] = {true, false, false, false, true, true};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = -9;
+ int8_t input1_quantized[6];
+ int8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedInt8(
+ tflite::ops::micro::Register_GREATER(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(GreaterEqualQuantizedUInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, 2, 7, 8, 11, 20};
+ float input2_data[] = {2};
+
+ bool expected_data[] = {true, true, true, true, true, true};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[6];
+ uint8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_GREATER_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(GreaterEqualQuantizedInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, -2, -71, 8, 11, 20};
+ float input2_data[] = {8};
+
+ bool expected_data[] = {true, false, false, true, true, true};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = -9;
+ int8_t input1_quantized[6];
+ int8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedInt8(
+ tflite::ops::micro::Register_GREATER_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(LessQuantizedUInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, 2, -1, 8, 11, 20};
+ float input2_data[] = {2};
+
+ bool expected_data[] = {false, false, true, false, false, false};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[6];
+ uint8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_LESS(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(LessQuantizedInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, -2, -71, 8, 11, 20};
+ float input2_data[] = {8};
+
+ bool expected_data[] = {false, true, true, false, false, false};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = -9;
+ int8_t input1_quantized[6];
+ int8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedInt8(
+ tflite::ops::micro::Register_LESS(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(LessEqualQuantizedUInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, 2, -1, 8, 11, 20};
+ float input2_data[] = {2};
+
+ bool expected_data[] = {false, true, true, false, false, false};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = 128;
+ uint8_t input1_quantized[6];
+ uint8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedUInt8(
+ tflite::ops::micro::Register_LESS_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(LessEqualQuantizedInt8WithBroadcast) {
+ const int num_shapes = 4;
+ const int max_shape_size = 5;
+ int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6}, {2, 2, 3}, {3, 2, 1, 3}, {4, 1, 3, 1, 2}};
+
+ for (int i = 0; i < num_shapes; ++i) {
+ int* input1_dim = test_shapes[i];
+ int input2_dim[] = {1, 1};
+ float input1_data[] = {20, -2, -71, 8, 11, 20};
+ float input2_data[] = {8};
+
+ bool expected_data[] = {false, true, true, true, false, false};
+ int* expected_dim = input1_dim;
+
+ const float input1_scale = 0.5;
+ const int input1_zero_point = -9;
+ int8_t input1_quantized[6];
+ int8_t input2_quantized[6];
+
+ bool output_data[6];
+ tflite::testing::TestComparisonQuantizedInt8(
+ tflite::ops::micro::Register_LESS_EQUAL(), input1_dim, input1_data,
+ input1_quantized, input1_scale, input1_zero_point, input2_dim,
+ input2_data, input2_quantized, input1_scale, input1_zero_point,
+ expected_data, expected_dim, output_data);
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/concatenation.cc b/tensorflow/lite/micro/kernels/concatenation.cc
new file mode 100644
index 0000000..8127cc3
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/concatenation.cc
@@ -0,0 +1,276 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/concatenation.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/portable_tensor.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace concatenation {
+
+constexpr int kMaxInputNum = 10; // Maximum number of input tensors
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ ConcatenationParams params;
+};
+
+// Handles negative axis index, coerces to positive index value.
+inline int CalculatePositiveAxis(int axis, const TfLiteTensor* output_tensor) {
+ if (axis >= 0) {
+ return axis;
+ } else {
+ return NumDimensions(output_tensor) + axis;
+ }
+}
+
+// The following functions are helpers to get tensor data in the format that the
+// reference op implementation expects. They provide the same functionality as
+// class VectorOfTensors and class VectorOfQuantizedTensors in TFLite.
+
+// Gets shapes from a list of tensors.
+inline void GetAllInputTensorShapes(const TfLiteContext* context,
+ const TfLiteNode* node,
+ RuntimeShape all_shapes[kMaxInputNum]) {
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(node != nullptr);
+ for (int i = 0; i < node->inputs->size; ++i) {
+ const TfLiteEvalTensor* t = tflite::micro::GetEvalInput(context, node, i);
+ RuntimeShape shape = tflite::micro::GetTensorShape(t);
+ all_shapes[i].ReplaceWith(shape.DimensionsCount(), shape.DimsData());
+ }
+}
+
+// Get shape pointers from a list of shapes.
+inline void GetShapesPointers(const RuntimeShape* shapes, size_t num,
+ const RuntimeShape* pointers[]) {
+ for (size_t i = 0; i < num; ++i) {
+ pointers[i] = &shapes[i];
+ }
+}
+
+// Gets data pointers from a list of tensors.
+template <typename T>
+inline void GetAllInputTensorData(const TfLiteContext* context,
+ const TfLiteNode* node,
+ T* all_data[kMaxInputNum]) {
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(node != nullptr);
+ for (int i = 0; i < node->inputs->size; ++i) {
+ const TfLiteEvalTensor* t = tflite::micro::GetEvalInput(context, node, i);
+ all_data[i] = tflite::micro::GetTensorData<T>(t);
+ }
+}
+
+template <typename data_type>
+void EvalUnquantized(TfLiteContext* context, TfLiteNode* node) {
+ // Collect the shapes and data pointer of input tensors
+ RuntimeShape inputs_shape[kMaxInputNum];
+ const RuntimeShape* inputs_shape_ptr[kMaxInputNum];
+ const data_type* inputs_data[kMaxInputNum];
+ GetAllInputTensorShapes(context, node, inputs_shape);
+ GetShapesPointers(inputs_shape, node->inputs->size, inputs_shape_ptr);
+ GetAllInputTensorData(context, node, inputs_data);
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ reference_ops::Concatenation(data->params, inputs_shape_ptr, inputs_data,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<data_type>(output));
+}
+
+void EvalQuantizedUInt8(TfLiteContext* context, TfLiteNode* node) {
+ // Collect the shapes and data pointer of input tensors
+ RuntimeShape inputs_shape[kMaxInputNum];
+ const RuntimeShape* inputs_shape_ptr[kMaxInputNum];
+ const uint8_t* inputs_data[kMaxInputNum];
+ GetAllInputTensorShapes(context, node, inputs_shape);
+ GetShapesPointers(inputs_shape, node->inputs->size, inputs_shape_ptr);
+ GetAllInputTensorData(context, node, inputs_data);
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ reference_ops::ConcatenationWithScaling(
+ data->params, inputs_shape_ptr, inputs_data,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ // This function only checks the types. Additional shape validations are
+ // performed in the reference implementation called during Eval().
+ const TfLiteConcatenationParams* params =
+ reinterpret_cast<TfLiteConcatenationParams*>(node->builtin_data);
+
+ const TfLiteTensor* input_tensor = GetInput(context, node, 0);
+ TF_LITE_ENSURE(context, input_tensor != nullptr);
+ TfLiteType input_type = input_tensor->type;
+ const TfLiteTensor* output_tensor = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output_tensor != nullptr);
+ TfLiteType output_type = output_tensor->type;
+
+ // Check activation and input type
+ TF_LITE_ENSURE_EQ(context, params->activation, kTfLiteActNone);
+ TF_LITE_ENSURE(context,
+ input_type == kTfLiteFloat32 || input_type == kTfLiteUInt8 ||
+ input_type == kTfLiteInt8 || input_type == kTfLiteInt32 ||
+ input_type == kTfLiteInt64);
+
+ // Output type must match input type
+ TF_LITE_ENSURE_EQ(context, output_type, input_type);
+
+ // This implementation does not support large number of input tensors
+ const int num_inputs = NumInputs(node);
+ TF_LITE_ENSURE(context, num_inputs <= kMaxInputNum);
+
+ // Shapes with dimensions >4 are not yet supported with static allocation.
+ for (int i = 0; i < num_inputs; ++i) {
+ const TfLiteTensor* input = GetInput(context, node, i);
+ TF_LITE_ENSURE(context, input != nullptr);
+ int num_dimensions = NumDimensions(input);
+
+ if (num_dimensions > 4) {
+ TF_LITE_KERNEL_LOG(
+ context,
+ "Op Concatenation does not currently support num dimensions >4 "
+ "Tensor has %d dimensions.",
+ num_dimensions);
+ return kTfLiteError;
+ }
+ }
+
+ // Calculate OpData.
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ switch (output_type) { // Already know in/outtypes are same.
+ case kTfLiteFloat32:
+ case kTfLiteInt32:
+ case kTfLiteInt64: {
+ data->params.axis = CalculatePositiveAxis(params->axis, output);
+ data->params.inputs_count = node->inputs->size;
+ break;
+ }
+ case kTfLiteUInt8:
+ case kTfLiteInt8: {
+ data->params.axis = CalculatePositiveAxis(params->axis, output);
+ data->params.inputs_count = node->inputs->size;
+
+ float* input_scales =
+ reinterpret_cast<float*>(context->AllocatePersistentBuffer(
+ context, node->inputs->size * sizeof(float)));
+
+ int32_t* input_zero_points =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, node->inputs->size * sizeof(int32_t)));
+
+ // Allocate persistent scale and zeropoint buffers.
+ // Store input scale and zero point values in OpParams:
+ for (int i = 0; i < node->inputs->size; ++i) {
+ const TfLiteTensor* t = GetInput(context, node, i);
+ TF_LITE_ENSURE(context, t != nullptr);
+ input_scales[i] = t->params.scale;
+ input_zero_points[i] = t->params.zero_point;
+ }
+
+ data->params.input_scale = input_scales;
+ data->params.input_zeropoint = input_zero_points;
+ data->params.output_zeropoint = output->params.zero_point;
+ data->params.output_scale = output->params.scale;
+ break;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(
+ context, "Op Concatenation does not currently support Type '%s'.",
+ TfLiteTypeGetName(output_type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* output_tensor = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output_tensor != nullptr);
+ TfLiteType output_type = output_tensor->type;
+
+ switch (output_type) { // Already know in/outtypes are same.
+ case kTfLiteFloat32:
+ EvalUnquantized<float>(context, node);
+ break;
+ case kTfLiteInt32:
+ EvalUnquantized<int32_t>(context, node);
+ break;
+ case kTfLiteUInt8:
+ EvalQuantizedUInt8(context, node);
+ break;
+ case kTfLiteInt8:
+ EvalUnquantized<int8_t>(context, node);
+ break;
+ case kTfLiteInt64:
+ EvalUnquantized<int64_t>(context, node);
+ break;
+
+ default:
+ TF_LITE_KERNEL_LOG(
+ context, "Op Concatenation does not currently support Type '%s'.",
+ TfLiteTypeGetName(output_type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace concatenation
+
+TfLiteRegistration Register_CONCATENATION() {
+ return {/*init=*/concatenation::Init,
+ /*free=*/nullptr,
+ /*prepare=*/concatenation::Prepare,
+ /*invoke=*/concatenation::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/concatenation_test.cc b/tensorflow/lite/micro/kernels/concatenation_test.cc
new file mode 100644
index 0000000..0fd2466
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/concatenation_test.cc
@@ -0,0 +1,208 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <initializer_list>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestConcatenateTwoInputs(const int* input1_dims_data,
+ const float* input1_data,
+ const int* input2_dims_data,
+ const float* input2_data, int axis,
+ const int* output_dims_data,
+ const float* expected_output_data,
+ float* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int input_size = 2;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims)};
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ TfLiteConcatenationParams builtin_data = {
+ .axis = axis,
+ .activation = kTfLiteActNone // Only activation supported in this impl
+ };
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_CONCATENATION();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ const int output_dims_count = ElementCount(*output_dims);
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestConcatenateQuantizedTwoInputs(
+ const int* input1_dims_data, const uint8_t* input1_data,
+ const int* input2_dims_data, const uint8_t* input2_data,
+ const float input_scale, const int input_zero_point, int axis,
+ const int* output_dims_data, const uint8_t* expected_output_data,
+ const float output_scale, const int output_zero_point,
+ uint8_t* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int input_size = 2;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input1_data, input1_dims, input_scale,
+ input_zero_point),
+ CreateQuantizedTensor(input2_data, input2_dims, input_scale,
+ input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point)};
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ TfLiteConcatenationParams builtin_data = {
+ .axis = axis,
+ .activation = kTfLiteActNone // Only activation supported in this impl
+ };
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_CONCATENATION();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ const int output_dims_count = ElementCount(*output_dims);
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TwoInputsAllAxesCombinations) {
+ // Concatenate the same two input tensors along all possible axes.
+
+ const int input_shape[] = {2, 2, 3};
+ const float input1_value[] = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f};
+ const float input2_value[] = {7.0f, 8.0f, 9.0f, 10.0f, 11.0f, 12.0f};
+
+ // expected output when concatenating on axis 0
+ const int output_shape_axis0[] = {2, 4, 3};
+ const float output_value_axis0[] = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f,
+ 7.0f, 8.0f, 9.0f, 10.0f, 11.0f, 12.0f};
+
+ // expected output when concatenating on axis 1
+ const int output_shape_axis1[] = {2, 2, 6};
+ const float output_value_axis1[] = {1.0f, 2.0f, 3.0f, 7.0f, 8.0f, 9.0f,
+ 4.0f, 5.0f, 6.0f, 10.0f, 11.0f, 12.0f};
+
+ float output_data[12];
+
+ // Axis = 0
+ tflite::testing::TestConcatenateTwoInputs(
+ input_shape, input1_value, input_shape, input2_value, /* axis */ 0,
+ output_shape_axis0, output_value_axis0, output_data);
+
+ // Axis = -2 (equivalent to axis = 0)
+ tflite::testing::TestConcatenateTwoInputs(
+ input_shape, input1_value, input_shape, input2_value, /* axis */ -2,
+ output_shape_axis0, output_value_axis0, output_data);
+
+ // Axis = 1
+ tflite::testing::TestConcatenateTwoInputs(
+ input_shape, input1_value, input_shape, input2_value, /* axis */ 1,
+ output_shape_axis1, output_value_axis1, output_data);
+
+ // Axis = -1 (equivalent to axis = 1)
+ tflite::testing::TestConcatenateTwoInputs(
+ input_shape, input1_value, input_shape, input2_value, /* axis */ -1,
+ output_shape_axis1, output_value_axis1, output_data);
+}
+
+TF_LITE_MICRO_TEST(TwoInputsQuantizedUint8) {
+ const int axis = 2;
+ const int input_shape[] = {3, 2, 1, 2};
+ const int output_shape[] = {3, 2, 1, 4};
+
+ const float input_scale = 0.1f;
+ const int input_zero_point = 127;
+ const float output_scale = 0.1f;
+ const int output_zero_point = 127;
+
+ const uint8_t input1_values[] = {137, 157, 167, 197};
+
+ const uint8_t input2_values[] = {138, 158, 168, 198};
+
+ const uint8_t output_value[] = {
+ 137, 157, 138, 158, 167, 197, 168, 198,
+ };
+
+ uint8_t output_data[8];
+ tflite::testing::TestConcatenateQuantizedTwoInputs(
+ input_shape, input1_values, input_shape, input2_values, input_scale,
+ input_zero_point, axis, output_shape, output_value, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TEST(ThreeDimensionalTwoInputsDifferentShapes) {
+ const int axis = 1;
+
+ const int input1_shape[] = {3, 2, 1, 2};
+ const int input2_shape[] = {3, 2, 3, 2};
+ const int output_shape[] = {3, 2, 4, 2};
+
+ const float input1_values[] = {1.0f, 3.0f, 4.0f, 7.0f};
+ const float input2_values[] = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f,
+ 7.0f, 8.0f, 9.0f, 10.0f, 11.0f, 12.0f};
+ const float output_values[] = {1.0f, 3.0f, 1.0f, 2.0f, 3.0f, 4.0f,
+ 5.0f, 6.0f, 4.0f, 7.0f, 7.0f, 8.0f,
+ 9.0f, 10.0f, 11.0f, 12.0f};
+
+ float output_data[16];
+ tflite::testing::TestConcatenateTwoInputs(
+ input1_shape, input1_values, input2_shape, input2_values, axis,
+ output_shape, output_values, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/conv.cc b/tensorflow/lite/micro/kernels/conv.cc
new file mode 100644
index 0000000..e9cbdf1
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/conv.cc
@@ -0,0 +1,107 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/conv.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/conv.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpDataConv));
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kConvInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kConvWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kConvBiasTensor)
+ : nullptr;
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kConvOutputTensor);
+
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto& params =
+ *(reinterpret_cast<TfLiteConvParams*>(node->builtin_data));
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const auto& data = *(static_cast<const OpDataConv*>(node->user_data));
+
+ TF_LITE_ENSURE_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_MSG(context, input->type == filter->type,
+ "Hybrid models are not supported on TFLite Micro.");
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32: {
+ tflite::reference_ops::Conv(
+ ConvParamsFloat(params, data), tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output),
+ tflite::micro::GetTensorShape(nullptr), nullptr);
+ break;
+ }
+ case kTfLiteInt8: {
+ reference_integer_ops::ConvPerChannel(
+ ConvParamsQuantized(params, data), data.per_channel_output_multiplier,
+ data.per_channel_output_shift, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/ConvPrepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/conv.h b/tensorflow/lite/micro/kernels/conv.h
new file mode 100644
index 0000000..46bc731
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/conv.h
@@ -0,0 +1,77 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_CONV_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_CONV_H_
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+struct OpDataConv {
+ TfLitePaddingValues padding;
+
+ // Cached tensor zero point values for quantized operations.
+ int32_t input_zero_point;
+ int32_t filter_zero_point;
+ int32_t output_zero_point;
+
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t output_multiplier;
+ int output_shift;
+
+ // Per channel output multiplier and shift.
+ int32_t* per_channel_output_multiplier;
+ int32_t* per_channel_output_shift;
+
+ // The range of the fused activation layer. For example for kNone and
+ // uint8_t these would be 0 and 255.
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+};
+
+extern const int kConvInputTensor;
+extern const int kConvWeightsTensor;
+extern const int kConvBiasTensor;
+extern const int kConvOutputTensor;
+extern const int kConvQuantizedDimension;
+
+// Returns a ConvParams struct with all the parameters needed for a
+// float computation.
+ConvParams ConvParamsFloat(const TfLiteConvParams& params,
+ const OpDataConv& data);
+
+// Returns a ConvParams struct with all the parameters needed for a
+// quantized computation.
+ConvParams ConvParamsQuantized(const TfLiteConvParams& params,
+ const OpDataConv& data);
+
+TfLiteStatus CalculateOpDataConv(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteConvParams& params, int width,
+ int height, int filter_width,
+ int filter_height, int out_width,
+ int out_height, const TfLiteType data_type,
+ OpDataConv* data);
+
+TfLiteStatus ConvPrepare(TfLiteContext* context, TfLiteNode* node);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_CONV_H_
diff --git a/tensorflow/lite/micro/kernels/conv_common.cc b/tensorflow/lite/micro/kernels/conv_common.cc
new file mode 100644
index 0000000..a4a36ae
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/conv_common.cc
@@ -0,0 +1,182 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/conv.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/conv.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+
+const int kConvInputTensor = 0;
+const int kConvWeightsTensor = 1;
+const int kConvBiasTensor = 2;
+const int kConvOutputTensor = 0;
+
+// Conv is quantized along dimension 0:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+const int kConvQuantizedDimension = 0;
+
+// Returns a ConvParams struct with all the parameters needed for a
+// float computation.
+ConvParams ConvParamsFloat(const TfLiteConvParams& params,
+ const OpDataConv& data) {
+ ConvParams op_params;
+ CalculateActivationRange(params.activation, &op_params.float_activation_min,
+ &op_params.float_activation_max);
+ op_params.padding_type = tflite::micro::RuntimePaddingType(params.padding);
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params.stride_width;
+ op_params.stride_height = params.stride_height;
+ op_params.dilation_width_factor = params.dilation_width_factor;
+ op_params.dilation_height_factor = params.dilation_height_factor;
+ return op_params;
+}
+
+// Returns a ConvParams struct with all the parameters needed for a
+// quantized computation.
+ConvParams ConvParamsQuantized(const TfLiteConvParams& params,
+ const OpDataConv& data) {
+ ConvParams op_params;
+ op_params.input_offset = -data.input_zero_point;
+ op_params.weights_offset = -data.filter_zero_point;
+ op_params.output_offset = data.output_zero_point;
+ op_params.output_multiplier = data.output_multiplier;
+ op_params.output_shift = -data.output_shift;
+ op_params.padding_type = tflite::micro::RuntimePaddingType(params.padding);
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.stride_height = params.stride_height;
+ op_params.stride_width = params.stride_width;
+ op_params.dilation_height_factor = params.dilation_height_factor;
+ op_params.dilation_width_factor = params.dilation_width_factor;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+ return op_params;
+}
+
+TfLiteStatus CalculateOpDataConv(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteConvParams& params, int width,
+ int height, int filter_width,
+ int filter_height, int out_width,
+ int out_height, const TfLiteType data_type,
+ OpDataConv* data) {
+ bool has_bias = node->inputs->size == 3;
+ // Check number of inputs/outputs
+ TF_LITE_ENSURE(context, has_bias || node->inputs->size == 2);
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+
+ // Matching GetWindowedOutputSize in TensorFlow.
+ auto padding = params.padding;
+ data->padding = ComputePaddingHeightWidth(
+ params.stride_height, params.stride_width, params.dilation_height_factor,
+ params.dilation_width_factor, height, width, filter_height, filter_width,
+ padding, &out_height, &out_width);
+
+ const TfLiteTensor* input = GetInput(context, node, kConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kConvBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ // Note that quantized inference requires that all tensors have their
+ // parameters set. This is usually done during quantized training.
+ if (data_type != kTfLiteFloat32) {
+ int output_channels = filter->dims->data[kConvQuantizedDimension];
+
+ TF_LITE_ENSURE_STATUS(tflite::PopulateConvolutionQuantizationParams(
+ context, input, filter, bias, output, params.activation,
+ &data->output_multiplier, &data->output_shift,
+ &data->output_activation_min, &data->output_activation_max,
+ data->per_channel_output_multiplier,
+ reinterpret_cast<int*>(data->per_channel_output_shift),
+ output_channels));
+ }
+
+ data->input_zero_point = input->params.zero_point;
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus ConvPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpDataConv* data = static_cast<OpDataConv*>(node->user_data);
+ const auto& params =
+ *(static_cast<const TfLiteConvParams*>(node->builtin_data));
+
+ TfLiteTensor* output = GetOutput(context, node, kConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ const TfLiteTensor* input = GetInput(context, node, kConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+
+ const int input_width = input->dims->data[2];
+ const int input_height = input->dims->data[1];
+ const int filter_width = filter->dims->data[2];
+ const int filter_height = filter->dims->data[1];
+ const int output_width = output->dims->data[2];
+ const int output_height = output->dims->data[1];
+
+ // Dynamically allocate per-channel quantization parameters.
+ const int num_channels = filter->dims->data[kConvQuantizedDimension];
+ data->per_channel_output_multiplier =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->per_channel_output_shift =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ // All per-channel quantized tensors need valid zero point and scale arrays.
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+
+ const auto* affine_quantization =
+ static_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ TFLITE_DCHECK(affine_quantization != nullptr);
+ TFLITE_DCHECK(affine_quantization->scale != nullptr);
+ TFLITE_DCHECK(affine_quantization->zero_point != nullptr);
+
+ TF_LITE_ENSURE(context,
+ affine_quantization->scale->size == 1 ||
+ affine_quantization->scale->size ==
+ filter->dims->data[kConvQuantizedDimension]);
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size,
+ affine_quantization->zero_point->size);
+ }
+
+ TF_LITE_ENSURE_STATUS(CalculateOpDataConv(
+ context, node, params, input_width, input_height, filter_width,
+ filter_height, output_width, output_height, input->type, data));
+
+ return kTfLiteOk;
+}
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/conv_test.cc b/tensorflow/lite/micro/kernels/conv_test.cc
new file mode 100644
index 0000000..9c9a713
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/conv_test.cc
@@ -0,0 +1,678 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/conv_test.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Common inputs and outputs.
+constexpr int kInputElements = 16;
+static const int kInputShape[] = {4, 2, 2, 4, 1};
+static const float kInputData[kInputElements] = {1, 1, 1, 1, 2, 2, 2, 2,
+ 1, 2, 3, 4, 1, 2, 3, 4};
+
+constexpr int kFilterElements = 12;
+static const int kFilterShape[] = {4, 3, 2, 2, 1};
+static const float kFilterData[kFilterElements] = {1, 2, 3, 4, -1, 1,
+ -1, 1, -1, -1, 1, 1};
+
+constexpr int kBiasElements = 3;
+static const int kBiasShape[] = {1, 3};
+static const float kBiasData[kBiasElements] = {1, 2, 3};
+
+constexpr int kOutputElements = 12;
+static const int kOutputShape[] = {4, 2, 1, 2, 3};
+static const float kGoldenData[kOutputElements] = {18, 2, 5, 18, 2, 5,
+ 17, 4, 3, 37, 4, 3};
+
+static TfLiteConvParams common_conv_params = {
+ kTfLitePaddingValid, // padding
+ 2, // stride_width
+ 2, // stride_height
+ kTfLiteActNone, // activation
+ 1, // dilation_width_factor
+ 1, // dilation_height_factor
+};
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+#if !defined(XTENSA) // TODO(b/170321206): xtensa kernels are less general than
+ // reference kernels and we ifdef out test cases that are
+ // currently known to fail.
+TF_LITE_MICRO_TEST(SimpleTestFloat) {
+ float output_data[tflite::testing::kOutputElements];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestConvFloat(
+ tflite::testing::kInputShape, tflite::testing::kInputData,
+ tflite::testing::kFilterShape, tflite::testing::kFilterData,
+ tflite::testing::kBiasShape, tflite::testing::kBiasData,
+ tflite::testing::kOutputShape, tflite::testing::kGoldenData,
+ &tflite::testing::common_conv_params, tflite::Register_CONV_2D(),
+ output_data));
+}
+
+TF_LITE_MICRO_TEST(InputAndFilterSameWidthHeight) {
+ const int output_dims_count = 2;
+ float output_data[output_dims_count];
+
+ const int kFilterShape[] = {4, 1, 2, 4, 1};
+ const float filter_values[] = {1, 2, 3, 4, -1, -1, 1, 1};
+ const int kBiasShape[] = {1, 1};
+ const float bias_values[] = {0};
+ const int kOutputShape[] = {4, 2, 1, 1, 1};
+ const float expected_output[] = {10, 34};
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestConvFloat(
+ tflite::testing::kInputShape, tflite::testing::kInputData,
+ kFilterShape, filter_values, kBiasShape, bias_values, kOutputShape,
+ expected_output, &tflite::testing::common_conv_params,
+ tflite::Register_CONV_2D(), output_data));
+}
+
+TF_LITE_MICRO_TEST(InputOutputDifferentTypeIsError) {
+ using tflite::testing::CreateQuantizedTensor;
+ using tflite::testing::CreateTensor;
+ using tflite::testing::IntArrayFromInts;
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(tflite::testing::kInputShape);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(tflite::testing::kFilterShape);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(tflite::testing::kBiasShape);
+ TfLiteIntArray* output_dims = IntArrayFromInts(tflite::testing::kOutputShape);
+ const int output_dims_count = tflite::ElementCount(*output_dims);
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+
+ int8_t output_data[tflite::testing::kOutputElements];
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(tflite::testing::kInputData, input_dims),
+ CreateTensor(tflite::testing::kFilterData, filter_dims),
+ CreateTensor(tflite::testing::kBiasData, bias_dims),
+ CreateQuantizedTensor(output_data, output_dims, /*scale=*/0.0f,
+ /*zero_point=*/0),
+ };
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError,
+ tflite::testing::InvokeConv(tensors, tensors_size, output_dims_count,
+ &tflite::testing::common_conv_params,
+ tflite::Register_CONV_2D(), output_data));
+}
+
+TF_LITE_MICRO_TEST(HybridModeIsError) {
+ using tflite::testing::CreateQuantizedTensor;
+ using tflite::testing::CreateTensor;
+ using tflite::testing::IntArrayFromInts;
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(tflite::testing::kInputShape);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(tflite::testing::kFilterShape);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(tflite::testing::kBiasShape);
+ TfLiteIntArray* output_dims = IntArrayFromInts(tflite::testing::kOutputShape);
+ const int output_dims_count = tflite::ElementCount(*output_dims);
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+
+ int8_t filter_data[tflite::testing::kFilterElements] = {};
+ float output_data[tflite::testing::kOutputElements];
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(tflite::testing::kInputData, input_dims),
+ CreateQuantizedTensor(filter_data, filter_dims,
+ /*scale=*/0.0f,
+ /*zero_point=*/0),
+ CreateTensor(tflite::testing::kBiasData, bias_dims),
+ CreateTensor(output_data, output_dims),
+ };
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError,
+ tflite::testing::InvokeConv(tensors, tensors_size, output_dims_count,
+ &tflite::testing::common_conv_params,
+ tflite::Register_CONV_2D(), output_data));
+}
+
+TF_LITE_MICRO_TEST(SimpleTestQuantizedPerChannel) {
+ const int output_dims_count = 12;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 0.5f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::kInputElements];
+ int8_t filter_quantized[tflite::testing::kFilterElements];
+ int32_t bias_quantized[tflite::testing::kBiasElements];
+ int8_t golden_quantized[tflite::testing::kOutputElements];
+ int zero_points[tflite::testing::kBiasElements + 1];
+ float scales[tflite::testing::kBiasElements + 1];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInputShape, tflite::testing::kInputData,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilterShape, tflite::testing::kFilterData,
+ filter_quantized, tflite::testing::kBiasShape,
+ tflite::testing::kBiasData, bias_quantized, scales, zero_points,
+ tflite::testing::kOutputShape, tflite::testing::kGoldenData,
+ golden_quantized, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params, tflite::Register_CONV_2D(),
+ output_data));
+}
+
+TF_LITE_MICRO_TEST(SimpleTestDilatedQuantizedPerChannel) {
+ const int output_dims_count = 24;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 0.5f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ const int input_elements = 48;
+ const int input_shape[] = {4, 2, 4, 6, 1};
+ const float input_data[] = {
+ // b = 0
+ 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4,
+ // b = 1
+ 1, 2, 3, 4, 5, 6, 2, 6, 2, 4, 4, 2, 3, 2, 6, 5, 1, 4, 1, 2, 1, 4, 6, 3};
+ const int output_elements = 24;
+ const int output_shape[] = {4, 2, 2, 2, 3};
+ const float golden_data[] = {25, 2, 7, 25, 2, 7, 10, 2, -3, 10, 2, -3,
+ 39, 7, 6, 50, 3, 4, 14, 4, -5, 15, 0, -7};
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[tflite::testing::kFilterElements];
+ int32_t bias_quantized[tflite::testing::kBiasElements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[tflite::testing::kBiasElements + 1];
+ float scales[tflite::testing::kBiasElements + 1];
+
+ TfLiteConvParams conv_params{tflite::testing::common_conv_params};
+ conv_params.dilation_width_factor = 3;
+ conv_params.dilation_height_factor = 2;
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestConvQuantizedPerChannel(
+ input_shape, input_data, input_quantized, input_scale,
+ input_zero_point, tflite::testing::kFilterShape,
+ tflite::testing::kFilterData, filter_quantized,
+ tflite::testing::kBiasShape, tflite::testing::kBiasData,
+ bias_quantized, scales, zero_points, output_shape, golden_data,
+ golden_quantized, output_scale, output_zero_point, &conv_params,
+ tflite::Register_CONV_2D(), output_data));
+}
+
+TF_LITE_MICRO_TEST(SimpleTestQuantizedPerChannelRelu6) {
+ const int output_dims_count = 12;
+ int8_t output_data[output_dims_count];
+
+ const float bias_values[] = {1, 2, -3};
+ const float golden_data[] = {6, 2, 0, 6, 2, 0, 6, 4, 0, 6, 4, 0};
+
+ const float input_scale = 0.023529f;
+ const float output_scale = 0.023529f;
+ const int input_zero_point = -128;
+ const int output_zero_point = -128;
+
+ int8_t input_quantized[tflite::testing::kInputElements];
+ int8_t filter_quantized[tflite::testing::kFilterElements];
+ int32_t bias_quantized[tflite::testing::kBiasElements];
+ int8_t golden_quantized[tflite::testing::kOutputElements];
+ int zero_points[tflite::testing::kBiasElements + 1];
+ float scales[tflite::testing::kBiasElements + 1];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestConvQuantizedPerChannel(
+ tflite::testing::kInputShape, tflite::testing::kInputData,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilterShape, tflite::testing::kFilterData,
+ filter_quantized, tflite::testing::kBiasShape, bias_values,
+ bias_quantized, scales, zero_points, tflite::testing::kOutputShape,
+ golden_data, golden_quantized, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params, tflite::Register_CONV_2D(),
+ output_data));
+}
+
+TF_LITE_MICRO_TEST(Kernel1x1QuantizedPerChannel) {
+ // conv params:
+ // padding, stride_<width,height>, activation, dilation_<width, height>
+ TfLiteConvParams conv_params = {kTfLitePaddingValid, 1, 1,
+ kTfLiteActNone, 1, 1};
+
+ constexpr int input_shape[] = {4, 1, 2, 2, 4}; // [len,N,H,W,C]
+ constexpr int input_elements =
+ input_shape[1] * input_shape[2] * input_shape[3] * input_shape[4];
+ constexpr float input_data[input_elements] = {1, 1, 1, 1, 2, 2, 2, 2,
+ 1, 2, 3, 4, 1, 2, 3, 4};
+
+ constexpr int filter_shape[] = {4, 3, 1, 1, 4};
+ constexpr int filter_elements =
+ filter_shape[1] * filter_shape[2] * filter_shape[3] * filter_shape[4];
+ const float filter_data[filter_elements] = {1, 2, 3, 4, -1, 1,
+ -1, 1, -1, -1, 1, 1};
+
+ constexpr int bias_elements = filter_shape[1];
+ constexpr int bias_shape[] = {1, bias_elements};
+ constexpr float bias_data[bias_elements] = {1, 2, 3};
+
+ constexpr int output_shape[] = {4, 1, 2, 2, bias_elements};
+ constexpr int output_elements = 4 * 3;
+ int8_t output_data[output_elements];
+
+ const float golden_data[output_elements] = {11, 2, 3, 21, 2, 3,
+ 31, 4, 7, 31, 4, 7};
+
+ const float input_scale = 0.5f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::testing::TestConvQuantizedPerChannel(
+ input_shape, input_data, input_quantized, input_scale,
+ input_zero_point, filter_shape, filter_data,
+ filter_quantized, bias_shape, bias_data, bias_quantized,
+ scales, zero_points, output_shape, golden_data,
+ golden_quantized, output_scale, output_zero_point,
+ &conv_params, tflite::Register_CONV_2D(), output_data));
+}
+
+TF_LITE_MICRO_TEST(Kernel1x1QuantizedPerChannelRelu6) {
+ // conv params:
+ // padding, stride_<width,height>, activation, dilation_<width, height>
+ TfLiteConvParams conv_params = {kTfLitePaddingValid, 1, 1,
+ kTfLiteActRelu6, 1, 1};
+
+ constexpr int input_shape[] = {4, 1, 2, 2, 4}; // [len,N,H,W,C]
+ constexpr int input_elements =
+ input_shape[1] * input_shape[2] * input_shape[3] * input_shape[4];
+ constexpr float input_data[input_elements] = {1, 1, 1, 1, 2, 2, 2, 2,
+ 1, 2, 3, 4, 1, 2, 3, 4};
+
+ constexpr int filter_shape[] = {4, 3, 1, 1, 4};
+ constexpr int filter_elements =
+ filter_shape[1] * filter_shape[2] * filter_shape[3] * filter_shape[4];
+ const float filter_data[filter_elements] = {1, 2, 3, 4, -1, 1,
+ -1, 1, -1, -1, 1, 1};
+
+ constexpr int bias_elements = filter_shape[1];
+ constexpr int bias_shape[] = {1, bias_elements};
+ constexpr float bias_data[bias_elements] = {1, 2, -3};
+
+ constexpr int output_shape[] = {4, 1, 2, 2, bias_elements};
+ constexpr int output_elements = 4 * 3;
+ int8_t output_data[output_elements];
+
+ const float golden_data[output_elements] = {6, 2, 0, 6, 2, 0,
+ 6, 4, 1, 6, 4, 1};
+
+ const float input_scale = 0.023529f;
+ const float output_scale = 0.023529f;
+ const int input_zero_point = -128;
+ const int output_zero_point = -128;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+ int zero_points[bias_elements + 1];
+ float scales[bias_elements + 1];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::testing::TestConvQuantizedPerChannel(
+ input_shape, input_data, input_quantized, input_scale,
+ input_zero_point, filter_shape, filter_data,
+ filter_quantized, bias_shape, bias_data, bias_quantized,
+ scales, zero_points, output_shape, golden_data,
+ golden_quantized, output_scale, output_zero_point,
+ &conv_params, tflite::Register_CONV_2D(), output_data));
+}
+
+TF_LITE_MICRO_TEST(BroadcastPerLayerQuantizationToPerChannelShouldMatchGolden) {
+ const int output_dims_count = 12;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 1.0f;
+ const float filter_scale = 1.0f;
+ const float output_scale = 1.0f;
+
+ int8_t input_quantized[tflite::testing::kInputElements];
+ int8_t filter_quantized[tflite::testing::kFilterElements];
+ int32_t bias_quantized[tflite::testing::kBiasElements];
+ int8_t golden_quantized[tflite::testing::kOutputElements];
+
+ TfLiteIntArray* input_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kInputShape);
+ TfLiteIntArray* filter_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kFilterShape);
+ TfLiteIntArray* bias_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kBiasShape);
+ TfLiteIntArray* output_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kOutputShape);
+
+ // Create per-layer quantized int8_t input tensor.
+ TfLiteTensor input_tensor = tflite::testing::CreateQuantizedTensor(
+ tflite::testing::kInputData, input_quantized, input_dims, input_scale, 0);
+ int input_zero_points[2] = {1, 0};
+ float input_scales[2] = {1, input_scale};
+ TfLiteAffineQuantization input_quant = {
+ tflite::testing::FloatArrayFromFloats(input_scales),
+ tflite::testing::IntArrayFromInts(input_zero_points), 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ // Create per-layer quantized int8_t filter tensor.
+ TfLiteTensor filter_tensor = tflite::testing::CreateQuantizedTensor(
+ tflite::testing::kFilterData, filter_quantized, filter_dims, filter_scale,
+ 0);
+ int filter_zero_points[2] = {1, 0};
+ float filter_scales[2] = {1, filter_scale};
+ TfLiteAffineQuantization filter_quant = {
+ tflite::testing::FloatArrayFromFloats(filter_scales),
+ tflite::testing::IntArrayFromInts(filter_zero_points), 0};
+ filter_tensor.quantization = {kTfLiteAffineQuantization, &filter_quant};
+
+ // Create per-layer quantized int32_t bias tensor.
+ tflite::SymmetricQuantize(tflite::testing::kBiasData, bias_quantized,
+ tflite::testing::kBiasElements,
+ input_scale * output_scale);
+ TfLiteTensor bias_tensor =
+ tflite::testing::CreateTensor(bias_quantized, bias_dims);
+
+ int bias_zero_points[2] = {1, 0};
+ float bias_scales[2] = {1, input_scale * filter_scale};
+ TfLiteAffineQuantization bias_quant = {
+ tflite::testing::FloatArrayFromFloats(bias_scales),
+ tflite::testing::IntArrayFromInts(bias_zero_points), 0};
+ bias_tensor.quantization = {kTfLiteAffineQuantization, &bias_quant};
+
+ // Create per-layer quantized int8_t output tensor.
+ TfLiteTensor output_tensor = tflite::testing::CreateQuantizedTensor(
+ output_data, output_dims, output_scale, 0 /* quantized dimension */);
+ int output_zero_points[2] = {1, 0};
+ float output_scales[2] = {1, output_scale};
+ TfLiteAffineQuantization output_quant = {
+ tflite::testing::FloatArrayFromFloats(output_scales),
+ tflite::testing::IntArrayFromInts(output_zero_points), 0};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ tflite::Quantize(tflite::testing::kGoldenData, golden_quantized,
+ output_dims_count, output_scale, 0);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::testing::ValidateConvGoldens(
+ tensors, tensors_size, golden_quantized, output_dims_count,
+ &tflite::testing::common_conv_params,
+ tflite::Register_CONV_2D(), output_data));
+}
+
+#endif // !defined(XTENSA)
+
+TF_LITE_MICRO_TEST(FilterDimsNotMatchingAffineQuantization) {
+ const int output_dims_count = 12;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 0.5f;
+ const float output_scale = 1.0f;
+
+ int8_t input_quantized[tflite::testing::kInputElements];
+ int8_t filter_quantized[tflite::testing::kFilterElements];
+ int32_t bias_quantized[tflite::testing::kBiasElements];
+ int8_t golden_quantized[tflite::testing::kOutputElements];
+ int zero_points[tflite::testing::kBiasElements + 1];
+ float scales[tflite::testing::kBiasElements + 1];
+
+ TfLiteIntArray* input_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kInputShape);
+ TfLiteIntArray* filter_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kFilterShape);
+ TfLiteIntArray* bias_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kBiasShape);
+ TfLiteIntArray* output_dims =
+ tflite::testing::IntArrayFromInts(tflite::testing::kOutputShape);
+
+ int filter_zero_points[5];
+ float filter_scales[5];
+ TfLiteAffineQuantization filter_quant;
+ TfLiteAffineQuantization bias_quant;
+ TfLiteTensor input_tensor = tflite::testing::CreateQuantizedTensor(
+ tflite::testing::kInputData, input_quantized, input_dims, input_scale, 0);
+ TfLiteTensor filter_tensor =
+ tflite::testing::CreateSymmetricPerChannelQuantizedTensor(
+ tflite::testing::kFilterData, filter_quantized, filter_dims,
+ filter_scales, filter_zero_points, &filter_quant,
+ 0 /* quantized dimension */);
+ TfLiteTensor bias_tensor =
+ tflite::testing::CreatePerChannelQuantizedBiasTensor(
+ tflite::testing::kBiasData, bias_quantized, bias_dims, input_scale,
+ &filter_scales[1], scales, zero_points, &bias_quant, 0);
+ TfLiteTensor output_tensor = tflite::testing::CreateQuantizedTensor(
+ output_data, output_dims, output_scale, 0 /* quantized dimension */);
+
+ float input_scales[] = {1, input_scale};
+ int input_zero_points[] = {1, 128};
+ TfLiteAffineQuantization input_quant = {
+ tflite::testing::FloatArrayFromFloats(input_scales),
+ tflite::testing::IntArrayFromInts(input_zero_points), 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ tflite::Quantize(tflite::testing::kGoldenData, golden_quantized,
+ output_dims_count, output_scale, 0);
+
+ // Set filter quant to mismatched dimension.
+ TfLiteAffineQuantization* quant = reinterpret_cast<TfLiteAffineQuantization*>(
+ filter_tensor.quantization.params);
+
+ // Choose arbitrary incorrect scale and zero point sizes which are neither 1
+ // (for broadcast case) nor the quantized dimension size.
+ quant->scale->size = 2;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError, tflite::testing::ValidateConvGoldens(
+ tensors, tensors_size, golden_quantized,
+ output_dims_count, &tflite::testing::common_conv_params,
+ tflite::Register_CONV_2D(), output_data));
+
+ // Set scale back to correct dimension, and make zero point array too short.
+ quant->scale->size = tflite::testing::kFilterShape[0];
+ quant->zero_point->size = 2;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError, tflite::testing::ValidateConvGoldens(
+ tensors, tensors_size, golden_quantized,
+ output_dims_count, &tflite::testing::common_conv_params,
+ tflite::Register_CONV_2D(), output_data));
+}
+
+TF_LITE_MICRO_TEST(Int8Input32x1Filter32x32ShouldMatchGolden) {
+ constexpr int kSampleSize = 32;
+ constexpr int kNumFilters = 32;
+ const int input_shape[] = {4, 1, 1, 1, kSampleSize};
+ const int filter_shape[] = {4, kNumFilters, 1, 1, kSampleSize};
+ const int bias_shape[] = {1, kSampleSize};
+ const int output_shape[] = {4, 1, 1, 1, kSampleSize};
+ float filter_values[kNumFilters * kSampleSize];
+ float input_values[kSampleSize];
+ float bias_values[kSampleSize];
+
+ // Generated these outputs using the floating point reference conv kernel.
+ // TODO(b/149942509): Do this comparison automatically on random inputs.
+ float expected_output[kSampleSize] = {
+ 5168.000000, 3377.000000, 306.000000, -4045.000000, -4556.000000,
+ -1227.000000, 822.000000, 1591.000000, 5176.000000, 3385.000000,
+ 314.000000, -4037.000000, -4548.000000, -1219.000000, 830.000000,
+ 1599.000000, 5184.000000, 3393.000000, 322.000000, -4029.000000,
+ -4540.000000, -1211.000000, 838.000000, 1607.000000, 5192.000000,
+ 3401.000000, 330.000000, -4021.000000, -4532.000000, -1203.000000,
+ 846.000000, 1615.000000};
+
+ for (int i = 0; i < kSampleSize; i++) {
+ bias_values[i] = i;
+ // Generate inputs from -16 to 15.
+ input_values[i] = i - 16;
+ }
+
+ // Generate samples of varying values between -128 and 127.
+ for (int i = 0; i < kNumFilters * kSampleSize; i++) {
+ filter_values[i] = (i * 25) % 256 - 128;
+ }
+
+ TfLiteConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_height_factor = 1;
+ conv_params.dilation_width_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+ conv_params.padding = kTfLitePaddingValid;
+
+ TfLiteIntArray* input_dims = tflite::testing::IntArrayFromInts(input_shape);
+ TfLiteIntArray* filter_dims = tflite::testing::IntArrayFromInts(filter_shape);
+ TfLiteIntArray* bias_dims = tflite::testing::IntArrayFromInts(bias_shape);
+ TfLiteIntArray* output_dims = tflite::testing::IntArrayFromInts(output_shape);
+ const int output_dims_count = tflite::ElementCount(*output_dims);
+
+ // Quantization Parameters. All scales except output are 1.0, and all zero
+ // points are 0. This direct-maps the values to floating point and makes it
+ // easy to reson about them.
+ int input_zero_point = 0;
+ float input_scale = 1.0f;
+ int filter_zero_point = 0;
+ float filter_scale = 1.0f;
+ int output_zero_point = 0;
+ // Output scale of 50 is needed to accomodate a float range of [-6400, 6350]
+ float output_scale = 50.0f;
+
+ // Create per-tensor quantized int8_t input tensor.
+ int8_t input_quantized[kSampleSize];
+ TfLiteTensor input_tensor = tflite::testing::CreateQuantizedTensor(
+ input_values, input_quantized, input_dims, input_scale, input_zero_point);
+ // Set zero point and scale arrays with a single element for each.
+ int input_zero_points[] = {1, input_zero_point};
+ float input_scales[] = {1, input_scale};
+ TfLiteAffineQuantization input_quant = {
+ tflite::testing::FloatArrayFromFloats(input_scales),
+ tflite::testing::IntArrayFromInts(input_zero_points), 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ // Create per-tensor quantized int8_t filter tensor.
+ int8_t filter_quantized[kNumFilters * kSampleSize];
+ TfLiteTensor filter_tensor = tflite::testing::CreateQuantizedTensor(
+ filter_values, filter_quantized, filter_dims, filter_scale,
+ filter_zero_point);
+ // Set zero point and scale arrays with a single element for each.
+ int filter_zero_points[] = {1, filter_zero_point};
+ float filter_scales[] = {1, filter_scale};
+ TfLiteAffineQuantization filter_quant = {
+ tflite::testing::FloatArrayFromFloats(filter_scales),
+ tflite::testing::IntArrayFromInts(filter_zero_points), 0};
+ filter_tensor.quantization = {kTfLiteAffineQuantization, &filter_quant};
+
+ // Create per-tensor quantized int32_t bias tensor.
+ int32_t bias_quantized[kSampleSize];
+ tflite::SymmetricQuantize(bias_values, bias_quantized, kSampleSize,
+ input_scale * output_scale);
+ TfLiteTensor bias_tensor =
+ tflite::testing::CreateTensor(bias_quantized, bias_dims);
+
+ // There is a single zero point of 0, and a single scale of
+ // input_scale * filter_scale.
+ int bias_zero_points[] = {1, 0};
+ float bias_scales[] = {1, input_scale * filter_scale};
+ TfLiteAffineQuantization bias_quant = {
+ tflite::testing::FloatArrayFromFloats(bias_scales),
+ tflite::testing::IntArrayFromInts(bias_zero_points), 0};
+ bias_tensor.quantization = {kTfLiteAffineQuantization, &bias_quant};
+
+ // Create per-tensor quantized int8_t output tensor.
+ int8_t output_quantized[kSampleSize];
+ TfLiteTensor output_tensor = tflite::testing::CreateQuantizedTensor(
+ output_quantized, output_dims, output_scale, output_zero_point);
+ // Set zero point and scale arrays with a single element for each.
+ int output_zero_points[] = {1, output_zero_point};
+ float output_scales[] = {1, output_scale};
+ TfLiteAffineQuantization output_quant = {
+ tflite::testing::FloatArrayFromFloats(output_scales),
+ tflite::testing::IntArrayFromInts(output_zero_points), 0};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ // The 3 inputs include the input, filter and bias tensors.
+ constexpr int kInputsSize = 3;
+ constexpr int kOutputsSize = 1;
+ constexpr int kTensorsSize = kInputsSize + kOutputsSize;
+ TfLiteTensor tensors[kTensorsSize] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ int8_t golden_quantized[kSampleSize];
+ tflite::Quantize(expected_output, golden_quantized, output_dims_count,
+ output_scale, output_zero_point);
+
+ // Rounding errors due to quantization should not exceed 1.
+ constexpr int kQuantizationTolerance = 1;
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::testing::ValidateConvGoldens(
+ tensors, kTensorsSize, golden_quantized, output_dims_count,
+ &conv_params, tflite::Register_CONV_2D(), output_quantized,
+ kQuantizationTolerance));
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/conv_test.h b/tensorflow/lite/micro/kernels/conv_test.h
new file mode 100644
index 0000000..a821a88
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/conv_test.h
@@ -0,0 +1,94 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_CONV_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_CONV_H_
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/kernels/micro_ops.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+
+TfLiteStatus InvokeConv(TfLiteTensor* tensors, int tensors_size,
+ int output_length, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, float* output_data);
+
+TfLiteStatus InvokeConv(TfLiteTensor* tensors, int tensors_size,
+ int output_length, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, int8_t* output_data);
+
+TfLiteStatus InvokeConv(TfLiteTensor* tensors, int tensors_size,
+ int output_length, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, uint8_t* output_data);
+
+TfLiteStatus ValidateConvGoldens(TfLiteTensor* tensors, int tensors_size,
+ const float* expected_output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration,
+ float* output_data, float tolerance = 1e-5);
+
+TfLiteStatus ValidateConvGoldens(TfLiteTensor* tensors, int tensors_size,
+ const int8_t* expected_output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration,
+ int8_t* output_data, float tolerance = 1e-5);
+
+TfLiteStatus ValidateConvGoldens(TfLiteTensor* tensors, int tensors_size,
+ const uint8_t* expected_output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration,
+ uint8_t* output_data, float tolerance = 1e-5);
+
+TfLiteStatus TestConvFloat(const int* input_dims_data, const float* input_data,
+ const int* filter_dims_data,
+ const float* filter_data, const int* bias_dims_data,
+ const float* bias_data, const int* output_dims_data,
+ const float* expected_output_data,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, float* output_data);
+
+TfLiteStatus TestConvQuantizedPerLayer(
+ const int* input_dims_data, const float* input_data,
+ uint8_t* input_quantized, float input_scale, const int* filter_dims_data,
+ const float* filter_data, uint8_t* filter_quantized, float filter_scale,
+ const int* bias_dims_data, const float* bias_data, int32_t* bias_quantized,
+ const int* output_dims_data, const float* expected_output_data,
+ uint8_t* expected_output_quantized, float output_scale,
+ TfLiteConvParams* conv_params, TfLiteRegistration registration,
+ uint8_t* output_data);
+
+TfLiteStatus TestConvQuantizedPerChannel(
+ const int* input_dims_data, const float* input_data,
+ int8_t* input_quantized, float input_scale, int input_zero_point,
+ const int* filter_dims_data, const float* filter_data,
+ int8_t* filter_data_quantized, const int* bias_dims_data,
+ const float* bias_data, int32_t* bias_data_quantized, float* bias_scales,
+ int* bias_zero_points, const int* output_dims_data,
+ const float* expected_output_data, int8_t* expected_output_data_quantized,
+ float output_scale, int output_zero_point, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, int8_t* output_data);
+
+} // namespace testing
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_CONV_H_
diff --git a/tensorflow/lite/micro/kernels/conv_test_common.cc b/tensorflow/lite/micro/kernels/conv_test_common.cc
new file mode 100644
index 0000000..f7e0a63
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/conv_test_common.cc
@@ -0,0 +1,187 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/conv_test.h"
+
+namespace tflite {
+namespace testing {
+
+template <typename T>
+TfLiteStatus InvokeConv(TfLiteTensor* tensors, int tensors_size,
+ int output_length, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, T* output_data) {
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, conv_params);
+
+ const char* init_data = reinterpret_cast<const char*>(conv_params);
+ TfLiteStatus status = runner.InitAndPrepare(init_data);
+ if (status != kTfLiteOk) {
+ return status;
+ }
+ return runner.Invoke();
+}
+
+template <typename T>
+TfLiteStatus ValidateConvGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* expected_output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration,
+ T* output_data, float tolerance) {
+ TfLiteStatus status = InvokeConv(tensors, tensors_size, output_length,
+ conv_params, registration, output_data);
+ if (status != kTfLiteOk) {
+ return status;
+ }
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i],
+ tolerance);
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus InvokeConv(TfLiteTensor* tensors, int tensors_size,
+ int output_length, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, float* output_data) {
+ return InvokeConv<float>(tensors, tensors_size, output_length, conv_params,
+ registration, output_data);
+}
+
+TfLiteStatus InvokeConv(TfLiteTensor* tensors, int tensors_size,
+ int output_length, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, int8_t* output_data) {
+ return InvokeConv<int8_t>(tensors, tensors_size, output_length, conv_params,
+ registration, output_data);
+}
+
+TfLiteStatus ValidateConvGoldens(TfLiteTensor* tensors, int tensors_size,
+ const float* expected_output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration,
+ float* output_data, float tolerance) {
+ return ValidateConvGoldens<float>(tensors, tensors_size, expected_output_data,
+ output_length, conv_params, registration,
+ output_data, tolerance);
+}
+
+TfLiteStatus ValidateConvGoldens(TfLiteTensor* tensors, int tensors_size,
+ const int8_t* expected_output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration,
+ int8_t* output_data, float tolerance) {
+ return ValidateConvGoldens<int8_t>(
+ tensors, tensors_size, expected_output_data, output_length, conv_params,
+ registration, output_data, tolerance);
+}
+
+TfLiteStatus TestConvFloat(const int* input_dims_data, const float* input_data,
+ const int* filter_dims_data,
+ const float* filter_data, const int* bias_dims_data,
+ const float* bias_data, const int* output_dims_data,
+ const float* expected_output_data,
+ TfLiteConvParams* conv_params,
+ TfLiteRegistration registration,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(filter_data, filter_dims),
+ CreateTensor(bias_data, bias_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ return ValidateConvGoldens(tensors, tensors_size, expected_output_data,
+ output_dims_count, conv_params, registration,
+ output_data);
+}
+
+TfLiteStatus TestConvQuantizedPerChannel(
+ const int* input_dims_data, const float* input_data,
+ int8_t* input_quantized, float input_scale, int input_zero_point,
+ const int* filter_dims_data, const float* filter_data,
+ int8_t* filter_data_quantized, const int* bias_dims_data,
+ const float* bias_data, int32_t* bias_data_quantized, float* bias_scales,
+ int* bias_zero_points, const int* output_dims_data,
+ const float* expected_output_data, int8_t* expected_output_data_quantized,
+ float output_scale, int output_zero_point, TfLiteConvParams* conv_params,
+ TfLiteRegistration registration, int8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ int filter_zero_points[5];
+ float filter_scales[5];
+ TfLiteAffineQuantization filter_quant;
+ TfLiteAffineQuantization bias_quant;
+ TfLiteTensor input_tensor = CreateQuantizedTensor(
+ input_data, input_quantized, input_dims, input_scale, input_zero_point);
+ TfLiteTensor filter_tensor = CreateSymmetricPerChannelQuantizedTensor(
+ filter_data, filter_data_quantized, filter_dims, filter_scales,
+ filter_zero_points, &filter_quant, 0 /* quantized dimension */);
+ TfLiteTensor bias_tensor = CreatePerChannelQuantizedBiasTensor(
+ bias_data, bias_data_quantized, bias_dims, input_scale, &filter_scales[1],
+ bias_scales, bias_zero_points, &bias_quant, 0 /* quantized dimension */);
+ TfLiteTensor output_tensor = CreateQuantizedTensor(
+ output_data, output_dims, output_scale, output_zero_point);
+
+ float input_scales[] = {1, input_scale};
+ int input_zero_points[] = {1, input_zero_point};
+ TfLiteAffineQuantization input_quant = {FloatArrayFromFloats(input_scales),
+ IntArrayFromInts(input_zero_points),
+ 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ float output_scales[] = {1, output_scale};
+ int output_zero_points[] = {1, output_zero_point};
+ TfLiteAffineQuantization output_quant = {FloatArrayFromFloats(output_scales),
+ IntArrayFromInts(output_zero_points),
+ 0};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ tflite::Quantize(expected_output_data, expected_output_data_quantized,
+ output_dims_count, output_scale, output_zero_point);
+ return ValidateConvGoldens(
+ tensors, tensors_size, expected_output_data_quantized, output_dims_count,
+ conv_params, registration, output_data, 1.0 /* tolerance */);
+}
+
+} // namespace testing
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cumsum.cc b/tensorflow/lite/micro/kernels/cumsum.cc
new file mode 100644
index 0000000..6df80ab
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cumsum.cc
@@ -0,0 +1,107 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/cumsum.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+static const int kInputTensor = 0;
+static const int kAxisTensor = 1;
+static const int kOutputTensor = 0;
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* axis = GetInput(context, node, kAxisTensor);
+
+ TF_LITE_ENSURE(context, input->type == kTfLiteFloat32);
+ TF_LITE_ENSURE_EQ(context, axis->type, kTfLiteInt32);
+
+ TF_LITE_ENSURE_EQ(context, NumElements(axis), 1);
+
+ TF_LITE_ENSURE(context, NumDimensions(input) >= 1);
+
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+
+ TF_LITE_ENSURE_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE(context, HaveSameShapes(input, output));
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ return CalculateOpData(context, node);
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* axis_tensor =
+ tflite::micro::GetEvalInput(context, node, kAxisTensor);
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ auto* params = static_cast<TfLiteCumsumParams*>(node->builtin_data);
+ auto input_shape = tflite::micro::GetTensorShape(input);
+
+ int32_t axis = *tflite::micro::GetTensorData<int32_t>(axis_tensor);
+ if (axis < 0) axis += input_shape.DimensionsCount();
+
+ if (axis < 0 || axis >= input_shape.DimensionsCount()) {
+ TF_LITE_KERNEL_LOG(context, "CUMSUM Invalid axis: %d", axis);
+ return kTfLiteError;
+ }
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ reference_ops::CumSum(tflite::micro::GetTensorData<float>(input),
+ input_shape, axis, params->exclusive,
+ params->reverse,
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ } break;
+ default: {
+ TF_LITE_KERNEL_LOG(
+ context, "Unsupported input type, CUMSUM only supports FLOAT32.");
+ return kTfLiteError;
+ }
+ }
+
+ return kTfLiteError;
+}
+
+} // namespace
+
+TfLiteRegistration Register_CUMSUM() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/cumsum_test.cc b/tensorflow/lite/micro/kernels/cumsum_test.cc
new file mode 100644
index 0000000..6dcc0c7
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/cumsum_test.cc
@@ -0,0 +1,180 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <limits>
+#include <type_traits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+struct CumSumTestParams {
+ bool exclusive = false;
+ bool reverse = false;
+ int32_t axis = std::numeric_limits<int32_t>::max();
+};
+
+void ExecuteCumSumTest(const CumSumTestParams& test_params,
+ TfLiteTensor* tensors, int tensors_count) {
+ constexpr int kInputArrayData[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(kInputArrayData);
+ constexpr int kOutputArrayData[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(kOutputArrayData);
+
+ TfLiteCumsumParams params;
+ params.exclusive = test_params.exclusive;
+ params.reverse = test_params.reverse;
+
+ const TfLiteRegistration registration = tflite::Register_CUMSUM();
+ micro::KernelRunner runner(registration, tensors, tensors_count, inputs_array,
+ outputs_array, static_cast<void*>(¶ms));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+}
+
+template <typename T>
+void TestCumSum(const CumSumTestParams& test_params, const int* input_dims_data,
+ const T* input_data, const int* expected_dims,
+ const T* expected_data, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ constexpr int axis_dims_data[] = {1, 1};
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ const int32_t axis_data[] = {test_params.axis};
+
+ TfLiteTensor tensors[] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(axis_data, axis_dims),
+ CreateTensor(output_data, output_dims),
+ };
+ constexpr int tensors_count = std::extent<decltype(tensors)>::value;
+ ExecuteCumSumTest(test_params, tensors, tensors_count);
+
+ constexpr float kTolerance = 1e-5;
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_data[i], output_data[i], kTolerance);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(CumSumOpTestSimpleTest) {
+ constexpr int kDims[] = {2, 2, 4};
+ constexpr float kInput[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ constexpr float kExpect[] = {1, 3, 6, 10, 5, 11, 18, 26};
+
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::CumSumTestParams test_params;
+ test_params.axis = 1;
+
+ tflite::testing::TestCumSum(test_params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(CumSumOpTestSimpleAxis0Test) {
+ constexpr int kDims[] = {2, 2, 4};
+ constexpr float kInput[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ constexpr float kExpect[] = {1, 2, 3, 4, 6, 8, 10, 12};
+
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::CumSumTestParams test_params;
+ test_params.axis = 0;
+
+ tflite::testing::TestCumSum(test_params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(CumSumOpTestSimple1DTest) {
+ constexpr int kDims[] = {1, 8};
+ constexpr float kInput[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ constexpr float kExpect[] = {1, 3, 6, 10, 15, 21, 28, 36};
+
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::CumSumTestParams test_params;
+ test_params.axis = 0;
+
+ tflite::testing::TestCumSum(test_params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(CumSumOpTestSimpleReverseTest) {
+ constexpr int kDims[] = {2, 2, 4};
+ constexpr float kInput[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ constexpr float kExpect[] = {10, 9, 7, 4, 26, 21, 15, 8};
+
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::CumSumTestParams test_params;
+ test_params.axis = 1;
+ test_params.reverse = true;
+
+ tflite::testing::TestCumSum(test_params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(CumSumOpTestSimpleExclusiveTest) {
+ constexpr int kDims[] = {2, 2, 4};
+ constexpr float kInput[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ constexpr float kExpect[] = {0, 1, 3, 6, 0, 5, 11, 18};
+
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::CumSumTestParams test_params;
+ test_params.axis = 1;
+ test_params.exclusive = true;
+
+ tflite::testing::TestCumSum(test_params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(CumSumOpTestSimpleReverseExclusiveTest) {
+ constexpr int kDims[] = {2, 2, 4};
+ constexpr float kInput[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ constexpr float kExpect[] = {9, 7, 4, 0, 21, 15, 8, 0};
+
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::CumSumTestParams test_params;
+ test_params.axis = -1;
+ test_params.exclusive = true;
+ test_params.reverse = true;
+
+ tflite::testing::TestCumSum(test_params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/depth_to_space.cc b/tensorflow/lite/micro/kernels/depth_to_space.cc
new file mode 100644
index 0000000..68696b2
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/depth_to_space.cc
@@ -0,0 +1,170 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <stdint.h>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/optimized/optimized_ops.h"
+#include "tensorflow/lite/kernels/internal/reference/reference_ops.h"
+#include "tensorflow/lite/kernels/internal/tensor.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace builtin {
+namespace depth_to_space {
+
+// This file has two implementation of DepthToSpace. Note that DepthToSpace only
+// works on 4D tensors.
+enum KernelType {
+ kReference,
+ kGenericOptimized,
+};
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ auto* params =
+ reinterpret_cast<TfLiteDepthToSpaceParams*>(node->builtin_data);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), 4);
+
+ auto data_type = output->type;
+ TF_LITE_ENSURE(context,
+ data_type == kTfLiteFloat32 || data_type == kTfLiteUInt8 ||
+ data_type == kTfLiteInt8 || data_type == kTfLiteInt32 ||
+ data_type == kTfLiteInt64);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ const int block_size = params->block_size;
+ const int input_height = input->dims->data[1];
+ const int input_width = input->dims->data[2];
+ const int input_channels = input->dims->data[3];
+ int output_height = input_height * block_size;
+ int output_width = input_width * block_size;
+ int output_channels = input_channels / block_size / block_size;
+
+ TF_LITE_ENSURE_EQ(context, input_height, output_height / block_size);
+ TF_LITE_ENSURE_EQ(context, input_width, output_width / block_size);
+ TF_LITE_ENSURE_EQ(context, input_channels,
+ output_channels * block_size * block_size);
+
+ TfLiteIntArray* output_size = TfLiteIntArrayCreate(4);
+ output_size->data[0] = input->dims->data[0];
+ output_size->data[1] = output_height;
+ output_size->data[2] = output_width;
+ output_size->data[3] = output_channels;
+
+ return context->ResizeTensor(context, output, output_size);
+}
+
+template <KernelType kernel_type>
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params =
+ reinterpret_cast<TfLiteDepthToSpaceParams*>(node->builtin_data);
+
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+#define TF_LITE_DEPTH_TO_SPACE(type, scalar) \
+ tflite::DepthToSpaceParams op_params; \
+ op_params.block_size = params->block_size; \
+ type::DepthToSpace(op_params, GetTensorShape(input), \
+ GetTensorData<scalar>(input), GetTensorShape(output), \
+ GetTensorData<scalar>(output))
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32:
+ if (kernel_type == kReference) {
+ TF_LITE_DEPTH_TO_SPACE(reference_ops, float);
+ } else {
+ TF_LITE_DEPTH_TO_SPACE(optimized_ops, float);
+ }
+ break;
+ case kTfLiteUInt8:
+ if (kernel_type == kReference) {
+ TF_LITE_DEPTH_TO_SPACE(reference_ops, uint8_t);
+ } else {
+ TF_LITE_DEPTH_TO_SPACE(optimized_ops, uint8_t);
+ }
+ break;
+ case kTfLiteInt8:
+ if (kernel_type == kReference) {
+ TF_LITE_DEPTH_TO_SPACE(reference_ops, int8_t);
+ } else {
+ TF_LITE_DEPTH_TO_SPACE(optimized_ops, int8_t);
+ }
+ break;
+ case kTfLiteInt32:
+ if (kernel_type == kReference) {
+ TF_LITE_DEPTH_TO_SPACE(reference_ops, int32_t);
+ } else {
+ TF_LITE_DEPTH_TO_SPACE(optimized_ops, int32_t);
+ }
+ break;
+ case kTfLiteInt64:
+ if (kernel_type == kReference) {
+ TF_LITE_DEPTH_TO_SPACE(reference_ops, int64_t);
+ } else {
+ TF_LITE_DEPTH_TO_SPACE(optimized_ops, int64_t);
+ }
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type '%s' not currently supported.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+#undef TF_LITE_DEPTH_TO_SPACE
+
+ return kTfLiteOk;
+}
+
+} // namespace depth_to_space
+
+TfLiteRegistration* Register_DEPTH_TO_SPACE_REF() {
+ static TfLiteRegistration r = {
+ nullptr, nullptr, depth_to_space::Prepare,
+ depth_to_space::Eval<depth_to_space::kReference>};
+ return &r;
+}
+
+TfLiteRegistration* Register_DEPTH_TO_SPACE_GENERIC_OPT() {
+ static TfLiteRegistration r = {
+ nullptr, nullptr, depth_to_space::Prepare,
+ depth_to_space::Eval<depth_to_space::kGenericOptimized>};
+ return &r;
+}
+
+TfLiteRegistration* Register_DEPTH_TO_SPACE() {
+ return Register_DEPTH_TO_SPACE_GENERIC_OPT();
+}
+
+} // namespace builtin
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/depth_to_space_test.cc b/tensorflow/lite/micro/kernels/depth_to_space_test.cc
new file mode 100644
index 0000000..3810864
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/depth_to_space_test.cc
@@ -0,0 +1,108 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <stdint.h>
+
+#include <initializer_list>
+#include <vector>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/kernels/test_util.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+namespace {
+
+using ::testing::ElementsAre;
+using ::testing::ElementsAreArray;
+
+class DepthToSpaceOpModel : public SingleOpModel {
+ public:
+ DepthToSpaceOpModel(const TensorData& tensor_data, int block_size) {
+ input_ = AddInput(tensor_data);
+ output_ = AddOutput(tensor_data);
+ SetBuiltinOp(BuiltinOperator_DEPTH_TO_SPACE,
+ BuiltinOptions_DepthToSpaceOptions,
+ CreateDepthToSpaceOptions(builder_, block_size).Union());
+ BuildInterpreter({GetShape(input_)});
+ }
+
+ template <typename T>
+ void SetInput(std::initializer_list<T> data) {
+ PopulateTensor<T>(input_, data);
+ }
+ template <typename T>
+ std::vector<T> GetOutput() {
+ return ExtractVector<T>(output_);
+ }
+ std::vector<int> GetOutputShape() { return GetTensorShape(output_); }
+
+ private:
+ int input_;
+ int output_;
+};
+
+#ifdef GTEST_HAS_DEATH_TEST
+TEST(DepthToSpaceOpModel, BadBlockSize) {
+ EXPECT_DEATH(DepthToSpaceOpModel({TensorType_FLOAT32, {1, 1, 1, 4}}, 4),
+ "Cannot allocate tensors");
+}
+#endif
+
+TEST(DepthToSpaceOpModel, Float32) {
+ DepthToSpaceOpModel m({TensorType_FLOAT32, {1, 1, 1, 4}}, 2);
+ m.SetInput<float>({1.4, 2.3, 3.2, 4.1});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<float>(), ElementsAreArray({1.4, 2.3, 3.2, 4.1}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 2, 2, 1));
+}
+
+TEST(DepthToSpaceOpModel, Uint8) {
+ DepthToSpaceOpModel m({TensorType_UINT8, {1, 1, 2, 4}}, 2);
+ m.SetInput<uint8_t>({1, 2, 3, 4, 5, 6, 7, 8});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<uint8_t>(),
+ ElementsAreArray({1, 2, 5, 6, 3, 4, 7, 8}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 2, 4, 1));
+}
+
+TEST(DepthToSpaceOpModel, int8) {
+ DepthToSpaceOpModel m({TensorType_INT8, {1, 2, 1, 4}}, 2);
+ m.SetInput<int8_t>({1, 2, 3, 4, 5, 6, 7, 8});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<int8_t>(),
+ ElementsAreArray({1, 2, 3, 4, 5, 6, 7, 8}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 4, 2, 1));
+}
+
+TEST(DepthToSpaceOpModel, Int32) {
+ DepthToSpaceOpModel m({TensorType_INT32, {1, 2, 2, 4}}, 2);
+ m.SetInput<int32_t>({1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<int32_t>(),
+ ElementsAreArray(
+ {1, 2, 5, 6, 3, 4, 7, 8, 9, 10, 13, 14, 11, 12, 15, 16}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 4, 4, 1));
+}
+
+TEST(DepthToSpaceOpModel, Int64) {
+ DepthToSpaceOpModel m({TensorType_INT64, {1, 1, 1, 1}}, 1);
+ m.SetInput<int64_t>({4});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<int64_t>(), ElementsAreArray({4}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 1, 1, 1));
+}
+
+} // namespace
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/depthwise_conv.cc b/tensorflow/lite/micro/kernels/depthwise_conv.cc
new file mode 100644
index 0000000..4f67158
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/depthwise_conv.cc
@@ -0,0 +1,106 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/depthwise_conv.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpDataConv));
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto& params =
+ *(reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data));
+ const OpDataConv& data = *(static_cast<const OpDataConv*>(node->user_data));
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kDepthwiseConvOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kDepthwiseConvInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kDepthwiseConvWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kDepthwiseConvBiasTensor)
+ : nullptr;
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32: {
+ tflite::reference_ops::DepthwiseConv(
+ DepthwiseConvParamsFloat(params, data),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ }
+ case kTfLiteInt8: {
+ reference_integer_ops::DepthwiseConvPerChannel(
+ DepthwiseConvParamsQuantized(params, data),
+ data.per_channel_output_multiplier, data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_DEPTHWISE_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/DepthwiseConvPrepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/depthwise_conv.h b/tensorflow/lite/micro/kernels/depthwise_conv.h
new file mode 100644
index 0000000..7a7eb0b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/depthwise_conv.h
@@ -0,0 +1,54 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_DEPTHWISE_CONV_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_DEPTHWISE_CONV_H_
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/micro/kernels/conv.h"
+
+namespace tflite {
+
+extern const int kDepthwiseConvInputTensor;
+extern const int kDepthwiseConvWeightsTensor;
+extern const int kDepthwiseConvBiasTensor;
+extern const int kDepthwiseConvOutputTensor;
+extern const int kDepthwiseConvQuantizedDimension;
+
+// Returns a DepthwiseParams struct with all the parameters needed for a
+// float computation.
+DepthwiseParams DepthwiseConvParamsFloat(
+ const TfLiteDepthwiseConvParams& params, const OpDataConv& data);
+
+// Returns a DepthwiseParams struct with all the parameters needed for a
+// quantized computation.
+DepthwiseParams DepthwiseConvParamsQuantized(
+ const TfLiteDepthwiseConvParams& params, const OpDataConv& data);
+
+TfLiteStatus CalculateOpDataDepthwiseConv(
+ TfLiteContext* context, TfLiteNode* node,
+ const TfLiteDepthwiseConvParams& params, int width, int height,
+ int filter_width, int filter_height, int out_width, int out_height,
+ const TfLiteType data_type, OpDataConv* data);
+
+TfLiteStatus DepthwiseConvPrepare(TfLiteContext* context, TfLiteNode* node);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_DEPTHWISE_CONV_H_
diff --git a/tensorflow/lite/micro/kernels/depthwise_conv_common.cc b/tensorflow/lite/micro/kernels/depthwise_conv_common.cc
new file mode 100644
index 0000000..6e6693a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/depthwise_conv_common.cc
@@ -0,0 +1,188 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/depthwise_conv.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+
+const int kDepthwiseConvInputTensor = 0;
+const int kDepthwiseConvWeightsTensor = 1;
+const int kDepthwiseConvBiasTensor = 2;
+const int kDepthwiseConvOutputTensor = 0;
+
+// DepthwiseConv is quantized along dimension 3:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+const int kDepthwiseConvQuantizedDimension = 3;
+
+// Returns a DepthwiseParams struct with all the parameters needed for a
+// float computation.
+DepthwiseParams DepthwiseConvParamsFloat(
+ const TfLiteDepthwiseConvParams& params, const OpDataConv& data) {
+ DepthwiseParams op_params;
+ CalculateActivationRange(params.activation, &op_params.float_activation_min,
+ &op_params.float_activation_max);
+ op_params.padding_type = tflite::micro::RuntimePaddingType(params.padding);
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params.stride_width;
+ op_params.stride_height = params.stride_height;
+ op_params.dilation_width_factor = params.dilation_width_factor;
+ op_params.dilation_height_factor = params.dilation_height_factor;
+ op_params.depth_multiplier = params.depth_multiplier;
+ return op_params;
+}
+
+// Returns a DepthwiseParams struct with all the parameters needed for a
+// quantized computation.
+DepthwiseParams DepthwiseConvParamsQuantized(
+ const TfLiteDepthwiseConvParams& params, const OpDataConv& data) {
+ DepthwiseParams op_params;
+ op_params.input_offset = -data.input_zero_point;
+ op_params.weights_offset = -data.filter_zero_point;
+ op_params.output_offset = data.output_zero_point;
+ op_params.output_multiplier = data.output_multiplier;
+ op_params.output_shift = -data.output_shift;
+ op_params.padding_type = tflite::micro::RuntimePaddingType(params.padding);
+ op_params.padding_values.height = data.padding.height;
+ op_params.padding_values.width = data.padding.width;
+ op_params.stride_height = params.stride_height;
+ op_params.stride_width = params.stride_width;
+ op_params.dilation_height_factor = params.dilation_height_factor;
+ op_params.dilation_width_factor = params.dilation_width_factor;
+ op_params.depth_multiplier = params.depth_multiplier;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+ return op_params;
+}
+
+TfLiteStatus CalculateOpDataDepthwiseConv(
+ TfLiteContext* context, TfLiteNode* node,
+ const TfLiteDepthwiseConvParams& params, int width, int height,
+ int filter_width, int filter_height, int out_width, int out_height,
+ const TfLiteType data_type, OpDataConv* data) {
+ bool has_bias = node->inputs->size == 3;
+ // Check number of inputs/outputs
+ TF_LITE_ENSURE(context, has_bias || node->inputs->size == 2);
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+
+ // Matching GetWindowedOutputSize in TensorFlow.
+ auto padding = params.padding;
+ data->padding = ComputePaddingHeightWidth(
+ params.stride_height, params.stride_width, params.dilation_height_factor,
+ params.dilation_width_factor, height, width, filter_height, filter_width,
+ padding, &out_height, &out_width);
+
+ const TfLiteTensor* input = GetInput(context, node, kConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kConvBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ // Note that quantized inference requires that all tensors have their
+ // parameters set. This is usually done during quantized training.
+ if (data_type != kTfLiteFloat32) {
+ int output_channels = filter->dims->data[kDepthwiseConvQuantizedDimension];
+
+ TF_LITE_ENSURE_STATUS(tflite::PopulateConvolutionQuantizationParams(
+ context, input, filter, bias, output, params.activation,
+ &data->output_multiplier, &data->output_shift,
+ &data->output_activation_min, &data->output_activation_max,
+ data->per_channel_output_multiplier,
+ reinterpret_cast<int*>(data->per_channel_output_shift),
+ output_channels));
+ }
+
+ data->input_zero_point = input->params.zero_point;
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus DepthwiseConvPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpDataConv* data = static_cast<OpDataConv*>(node->user_data);
+ const auto& params =
+ *(static_cast<const TfLiteDepthwiseConvParams*>(node->builtin_data));
+
+ TfLiteTensor* output = GetOutput(context, node, kDepthwiseConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ const TfLiteTensor* input =
+ GetInput(context, node, kDepthwiseConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter =
+ GetInput(context, node, kDepthwiseConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+
+ const int input_width = input->dims->data[2];
+ const int input_height = input->dims->data[1];
+ const int filter_width = filter->dims->data[2];
+ const int filter_height = filter->dims->data[1];
+ const int output_width = output->dims->data[2];
+ const int output_height = output->dims->data[1];
+
+ // Dynamically allocate per-channel quantization parameters.
+ const int num_channels = filter->dims->data[kDepthwiseConvQuantizedDimension];
+ data->per_channel_output_multiplier =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->per_channel_output_shift =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ // All per-channel quantized tensors need valid zero point and scale arrays.
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+
+ const auto* affine_quantization =
+ static_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ TFLITE_DCHECK(affine_quantization != nullptr);
+ TFLITE_DCHECK(affine_quantization->scale != nullptr);
+ TFLITE_DCHECK(affine_quantization->zero_point != nullptr);
+
+ TF_LITE_ENSURE(
+ context, affine_quantization->scale->size == 1 ||
+ affine_quantization->scale->size ==
+ filter->dims->data[kDepthwiseConvQuantizedDimension]);
+
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size,
+ affine_quantization->zero_point->size);
+ }
+
+ TF_LITE_ENSURE_STATUS(CalculateOpDataDepthwiseConv(
+ context, node, params, input_width, input_height, filter_width,
+ filter_height, output_width, output_height, input->type, data));
+
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/depthwise_conv_test.cc b/tensorflow/lite/micro/kernels/depthwise_conv_test.cc
new file mode 100644
index 0000000..8e73382
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/depthwise_conv_test.cc
@@ -0,0 +1,943 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+#if !defined(XTENSA) // Needed to avoid build errors from unused variables.
+constexpr int kMaxFilterChannels = 64;
+constexpr int kMaxBiasChannels = 64;
+#endif // !defined(XTENSA)
+
+// Index of the output tensor in context->tensors, specific to
+// DepthwiseConv.
+constexpr int kOutputTensorIndex = 3;
+
+// Creates a DepthwiseConv opeerator, calls it with the provided input tensors
+// and some defaults parameters, and compares the output with
+// expected_output_data.
+//
+// The tensors parameter contains both the input tensors as well as a
+// preallocated output tensor into which the output is stored.
+template <typename T>
+TfLiteStatus ValidateDepthwiseConvGoldens(
+ const T* expected_output_data, int output_length,
+ TfLiteDepthwiseConvParams* conv_params, float tolerance, int tensors_size,
+ TfLiteTensor* tensors) {
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_DEPTHWISE_CONV_2D();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(conv_params));
+
+ int input_depth = tensors[0].dims->data[3];
+ int output_depth = tensors[1].dims->data[3];
+ int depth_mul = output_depth / input_depth;
+
+ conv_params->padding = kTfLitePaddingValid;
+ conv_params->depth_multiplier = depth_mul;
+
+ const char* init_data = reinterpret_cast<const char*>(conv_params);
+
+ // TODO(b/154240825): Use a test macro here which fails and returns.
+ TfLiteStatus status = runner.InitAndPrepare(init_data);
+ if (status != kTfLiteOk) {
+ return status;
+ }
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ const T* output_data = tflite::GetTensorData<T>(&tensors[kOutputTensorIndex]);
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i],
+ tolerance);
+ }
+ return kTfLiteOk;
+}
+
+#if !defined(XTENSA) // Needed to avoid build errors from unsused functions.
+void TestDepthwiseConvFloat(const int* input_dims_data, const float* input_data,
+ const int* filter_dims_data,
+ const float* filter_data, const int* bias_dims_data,
+ const float* bias_data,
+ const float* expected_output_data,
+ const int* output_dims_data,
+ TfLiteDepthwiseConvParams* conv_params,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(filter_data, filter_dims),
+ CreateTensor(bias_data, bias_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateDepthwiseConvGoldens(expected_output_data, output_dims_count,
+ conv_params, 1e-5, tensors_size, tensors);
+}
+
+void TestDepthwiseConvQuantizedPerChannel(
+ const int* input_dims_data, const float* input_data,
+ int8_t* input_quantized, float input_scale, int input_zero_point,
+ const int* filter_dims_data, const float* filter_data,
+ int8_t* filter_data_quantized, const int* bias_dims_data,
+ const float* bias_data, int32_t* bias_data_quantized,
+ const int* output_dims_data, const float* expected_output_data,
+ int8_t* expected_output_data_quantized, int8_t* output_data,
+ float output_scale, int output_zero_point,
+ TfLiteDepthwiseConvParams* conv_params) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ int filter_zero_points[kMaxFilterChannels];
+ float filter_scales[kMaxFilterChannels];
+ int bias_zero_points[kMaxBiasChannels];
+ float bias_scales[kMaxBiasChannels];
+ TfLiteAffineQuantization filter_quant;
+ TfLiteAffineQuantization bias_quant;
+ TfLiteTensor input_tensor = CreateQuantizedTensor(
+ input_data, input_quantized, input_dims, input_scale, input_zero_point);
+ TfLiteTensor filter_tensor = CreateSymmetricPerChannelQuantizedTensor(
+ filter_data, filter_data_quantized, filter_dims, filter_scales,
+ filter_zero_points, &filter_quant, 3 /* quantized dimension */
+ );
+ TfLiteTensor bias_tensor = CreatePerChannelQuantizedBiasTensor(
+ bias_data, bias_data_quantized, bias_dims, input_scale, &filter_scales[1],
+ bias_scales, bias_zero_points, &bias_quant, 3 /* quantized dimension */
+ );
+ TfLiteTensor output_tensor = CreateQuantizedTensor(
+ output_data, output_dims, output_scale, input_zero_point);
+
+ // TODO(njeff): Affine Quantization Params should be set on tensor creation.
+ float input_scales[] = {1, input_scale};
+ int input_zero_points[] = {1, input_zero_point};
+ TfLiteAffineQuantization input_quant = {FloatArrayFromFloats(input_scales),
+ IntArrayFromInts(input_zero_points),
+ 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ float output_scales[] = {1, output_scale};
+ int output_zero_points[] = {1, output_zero_point};
+ TfLiteAffineQuantization output_quant = {FloatArrayFromFloats(output_scales),
+ IntArrayFromInts(output_zero_points),
+ 0};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ Quantize(expected_output_data, expected_output_data_quantized,
+ output_dims_count, output_scale, output_zero_point);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, ValidateDepthwiseConvGoldens(expected_output_data_quantized,
+ output_dims_count, conv_params,
+ 1.0, tensors_size, tensors));
+}
+
+#endif // !defined(XTENSA)
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+#if !defined(XTENSA) // TODO(b/170322965): xtensa kernels are less general than
+ // reference kernels and we ifdef out test cases that are
+ // currently known to fail.
+TF_LITE_MICRO_TEST(SimpleTest) {
+ const int input_shape[] = {4, 1, 3, 2, 2};
+ const float input_values[] = {1, 2, 7, 8, 3, 4, 9, 10, 5, 6, 11, 12};
+ const int filter_shape[] = {4, 1, 2, 2, 4};
+ const float filter_values[] = {1, 2, 3, 4, -9, 10, -11, 12,
+ 5, 6, 7, 8, 13, -14, 15, -16};
+ const int bias_shape[] = {4, 1, 1, 1, 4};
+ const float bias_values[] = {1, 2, 3, 4};
+ const float golden[] = {
+ 71, -34, 99, -20, 91, -26, 127, -4,
+ };
+ const int output_shape[] = {4, 1, 2, 1, 4};
+ const int output_dims_count = 8;
+ float output_data[output_dims_count];
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ tflite::testing::TestDepthwiseConvFloat(
+ input_shape, input_values, filter_shape, filter_values, bias_shape,
+ bias_values, golden, output_shape, &conv_params, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleTestRelu) {
+ const int input_shape[] = {4, 1, 3, 2, 2};
+ const float input_values[] = {1, 2, 7, 8, 3, 4, 9, 10, 5, 6, 11, 12};
+ const int filter_shape[] = {4, 1, 2, 2, 4};
+ const float filter_values[] = {1, 2, 3, 4, -9, 10, -11, 12,
+ 5, 6, 7, 8, 13, -14, 15, -16};
+ const int bias_shape[] = {4, 1, 1, 1, 4};
+ const float bias_values[] = {1, 2, 3, 4};
+ const int output_shape[] = {4, 1, 2, 1, 4};
+ const int output_dims_count = 8;
+ const float golden_relu[] = {71, 0, 99, 0, 91, 0, 127, 0};
+ float output_data[output_dims_count];
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActRelu;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ tflite::testing::TestDepthwiseConvFloat(
+ input_shape, input_values, filter_shape, filter_values, bias_shape,
+ bias_values, golden_relu, output_shape, &conv_params, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleTestQuantizedPerChannel) {
+ const int input_elements = 12;
+ const int input_shape[] = {4, 1, 3, 2, 2};
+ const float input_values[] = {1, 2, 7, 8, 3, 4, 9, 10, 5, 6, 11, 12};
+ const int filter_elements = 16;
+ const int filter_shape[] = {4, 1, 2, 2, 4};
+ const float filter_values[] = {1, 2, 3, 4, -9, 10, -11, 12,
+ 5, 6, 7, 8, 13, -14, 15, -16};
+ const int bias_elements = 4;
+ const int bias_shape[] = {4, 1, 1, 1, 4};
+ const int output_elements = 8;
+ const float bias_values[] = {1, 2, 3, 4};
+ const float golden[] = {
+ 71, -34, 99, -20, 91, -26, 127, -4,
+ };
+ const int output_shape[] = {4, 1, 2, 1, 4};
+ const int output_dims_count = 8;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 0.5;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, &conv_params);
+}
+
+TF_LITE_MICRO_TEST(SimpleTestQuantizedPerChannelDepthMultiplier1) {
+ const int input_elements = 12;
+ const int input_shape[] = {4, 1, 3, 2, 2};
+ const float input_values[] = {1, 2, 7, 8, 3, 4, 9, 10, 5, 6, 11, 12};
+ const int filter_elements = 8;
+ const int filter_shape[] = {4, 1, 2, 2, 2};
+ const float filter_values[] = {1, 2, 3, 4, -9, 10, -11, 12};
+ const int bias_elements = 2;
+ const int bias_shape[] = {4, 1, 1, 1, 2};
+ const int output_elements = 4;
+ const float bias_values[] = {1, 2};
+ const float golden[] = {
+ -103,
+ 127,
+ -128,
+ 127,
+ };
+ const int output_shape[] = {4, 1, 2, 1, 2};
+ const int output_dims_count = 4;
+ int8_t output_data[output_dims_count];
+
+ const float input_scale = 1.0f;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, &conv_params);
+}
+
+TF_LITE_MICRO_TEST(TestQuantizedPerChannelDepthMultiplier1Relu6) {
+ const int input_elements = 24;
+ const int input_shape[] = {4, 1, 3, 2, 4};
+ const float input_values[] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int filter_elements = 16;
+ const int filter_shape[] = {4, 1, 2, 2, 4};
+ const float filter_values[] = {0, 1, 8, -2, -1, 2, -10, 0,
+ -1, 3, -18, 0, 0, 4, 20, -3};
+ const int bias_elements = 4;
+ const int bias_shape[] = {4, 1, 1, 1, 4};
+ const int output_elements = 8;
+ const float bias_values[] = {1, 2, 3, 4};
+ const float golden[] = {
+ 0, 6, 3, 0, 0, 6, 3, 0,
+ };
+ const int output_shape[] = {4, 1, 2, 1, 4};
+ int8_t output_data[output_elements];
+
+ const float input_scale = 0.023529f;
+ const float output_scale = 0.023529f;
+ const int input_zero_point = -128;
+ const int output_zero_point = -128;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActRelu6;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, &conv_params);
+}
+
+TF_LITE_MICRO_TEST(SimpleTestDilatedQuantizedPerChannel) {
+ const int input_elements = 48;
+ const int input_shape[] = {4, 1, 4, 6, 2};
+ const float input_values[] = {1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, // h = 0
+ 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, // h = 1
+ 1, 2, 3, 4, 5, 6, 2, 6, 2, 4, 4, 2, // h = 2
+ 3, 2, 6, 5, 1, 4, 1, 2, 1, 4, 6, 3}; // h = 3
+ const int filter_elements = 16;
+ const int filter_shape[] = {4, 1, 2, 2, 4};
+ const float filter_values[] = {1, 2, 3, 4, -9, 10, -11, 12,
+ 5, 6, 7, 8, 13, -14, 15, -16};
+ const int bias_elements = 4;
+ const int bias_shape[] = {4, 1, 1, 1, 4};
+ const int output_elements = 24;
+ const float bias_values[] = {1, 2, 3, 4};
+ const float golden[] = {
+ 15, 2, 88, -48, 25, 14, 72, 0, 61, -2, 56, 48, // h = 0
+ -4, 52, 12, 48, 11, 70, 63, 40, 51, -30, 41, 48 // h = 1
+ };
+ const int output_shape[] = {4, 1, 2, 3, 4};
+ int8_t output_data[output_elements];
+
+ const float input_scale = 0.5;
+ const float output_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 3;
+ conv_params.dilation_height_factor = 2;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_shape, input_values, input_quantized, input_scale, input_zero_point,
+ filter_shape, filter_values, filter_quantized, bias_shape, bias_values,
+ bias_quantized, output_shape, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, &conv_params);
+}
+
+TF_LITE_MICRO_TEST(TestQuantizedPerChannelCompareWithFloat) {
+ const int input_dims[] = {4, 1, 2, 3, 2};
+ const float input_data[] = {3, 2, 1, -1, -2, -3, 4, 3, 2, -2, -3, -4};
+ const int filter_dims[] = {4, 1, 2, 2, 4};
+ const float filter_data[] = {1, 2, 3, 4, 3, 4, 5, 6, 7, 8, 5, 6, 3, 4, 1, 2};
+ const int bias_dims[] = {4, 1, 1, 1, 4};
+ const float bias_data[] = {3, -2, 4, 6};
+ const int output_dims[] = {4, 1, 1, 2, 4};
+ const float golden[] = {43, 48, 18, 22, 3, -4, -28, -36};
+
+ const int input_size = 12;
+ const int filter_size = 16;
+ const int output_size = 8;
+ const int bias_size = 4;
+ int8_t input_quantized[input_size];
+ int8_t filter_quantized[filter_size];
+ int32_t bias_quantized[bias_size];
+ int8_t golden_quantized[output_size];
+ int8_t output_data[output_size];
+ float output_float[output_size];
+
+ const float input_scale = 0.5;
+ const float output_scale = 1.0;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ tflite::testing::TestDepthwiseConvQuantizedPerChannel(
+ input_dims, input_data, input_quantized, input_scale, input_zero_point,
+ filter_dims, filter_data, filter_quantized, bias_dims, bias_data,
+ bias_quantized, output_dims, golden, golden_quantized, output_data,
+ output_scale, output_zero_point, &conv_params);
+
+ tflite::testing::TestDepthwiseConvFloat(
+ input_dims, input_data, filter_dims, filter_data, bias_dims, bias_data,
+ golden, output_dims, &conv_params, output_float);
+}
+
+TF_LITE_MICRO_TEST(PerChannelBroadcastQuantizationParams) {
+ const float input_scale = 1.0f;
+ const float filter_scale = 1.0f;
+ const float output_scale = 1.0f;
+
+ const int input_elements = 12;
+ const int input_shape[] = {4, 1, 3, 2, 2};
+ const float input_values[] = {1, 2, 7, 8, 3, 4, 9, 10, 5, 6, 11, 12};
+ const int filter_elements = 16;
+ const int filter_shape[] = {4, 1, 2, 2, 4};
+ const float filter_values[] = {1, 2, 3, 4, -9, 10, -11, 12,
+ 5, 6, 7, 8, 13, -14, 15, -16};
+ const int bias_elements = 4;
+ const int bias_shape[] = {4, 1, 1, 1, 4};
+ const int output_elements = 8;
+ const float bias_values[] = {1, 2, 3, 4};
+ const float golden[] = {
+ 71, -34, 99, -20, 91, -26, 127, -4,
+ };
+ const int output_shape[] = {4, 1, 2, 1, 4};
+ const int output_dims_count = 8;
+ int8_t output_data[output_dims_count];
+
+ int8_t input_quantized[input_elements];
+ int8_t filter_quantized[filter_elements];
+ int32_t bias_quantized[bias_elements];
+ int8_t golden_quantized[output_elements];
+
+ TfLiteIntArray* input_dims = tflite::testing::IntArrayFromInts(input_shape);
+ TfLiteIntArray* filter_dims = tflite::testing::IntArrayFromInts(filter_shape);
+ TfLiteIntArray* bias_dims = tflite::testing::IntArrayFromInts(bias_shape);
+ TfLiteIntArray* output_dims = tflite::testing::IntArrayFromInts(output_shape);
+
+ // Create per-layer quantized int8_t input tensor.
+ TfLiteTensor input_tensor = tflite::testing::CreateQuantizedTensor(
+ input_values, input_quantized, input_dims, input_scale, 0);
+ int input_zero_points[2] = {1, 0};
+ float input_scales[2] = {1, input_scale};
+ TfLiteAffineQuantization input_quant = {
+ tflite::testing::FloatArrayFromFloats(input_scales),
+ tflite::testing::IntArrayFromInts(input_zero_points), 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ // Create per-layer quantized int8_t filter tensor.
+ TfLiteTensor filter_tensor = tflite::testing::CreateQuantizedTensor(
+ filter_values, filter_quantized, filter_dims, filter_scale, 0);
+ int filter_zero_points[2] = {1, 0};
+ float filter_scales[2] = {1, filter_scale};
+ TfLiteAffineQuantization filter_quant = {
+ tflite::testing::FloatArrayFromFloats(filter_scales),
+ tflite::testing::IntArrayFromInts(filter_zero_points), 0};
+ filter_tensor.quantization = {kTfLiteAffineQuantization, &filter_quant};
+
+ // Create per-layer quantized int32_t bias tensor.
+ tflite::SymmetricQuantize(bias_values, bias_quantized, bias_elements,
+ input_scale * output_scale);
+ TfLiteTensor bias_tensor =
+ tflite::testing::CreateTensor(bias_quantized, bias_dims);
+
+ int bias_zero_points[2] = {1, 0};
+ float bias_scales[2] = {1, input_scale * filter_scale};
+ TfLiteAffineQuantization bias_quant = {
+ tflite::testing::FloatArrayFromFloats(bias_scales),
+ tflite::testing::IntArrayFromInts(bias_zero_points), 0};
+ bias_tensor.quantization = {kTfLiteAffineQuantization, &bias_quant};
+
+ // Create per-layer quantized int8_t output tensor.
+ TfLiteTensor output_tensor = tflite::testing::CreateQuantizedTensor(
+ output_data, output_dims, output_scale, 0);
+ int output_zero_points[2] = {1, 0};
+ float output_scales[2] = {1, output_scale};
+ TfLiteAffineQuantization output_quant = {
+ tflite::testing::FloatArrayFromFloats(output_scales),
+ tflite::testing::IntArrayFromInts(output_zero_points), 0};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ tflite::Quantize(golden, golden_quantized, output_dims_count, output_scale,
+ 0);
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::testing::ValidateDepthwiseConvGoldens(
+ golden_quantized, output_dims_count, &conv_params, 1e-5,
+ tensors_size, tensors));
+}
+
+#endif // !defined(XTENSA)
+
+TF_LITE_MICRO_TEST(FilterDimsNotMatchingAffineQuantization) {
+ const int input_shape[] = {4, 1, 2, 3, 2};
+ const float input_data[] = {3, 2, 1, -1, -2, -3, 4, 3, 2, -2, -3, -4};
+ const int filter_shape[] = {4, 1, 2, 2, 4};
+ const float filter_data[] = {1, 2, 3, 4, 3, 4, 5, 6, 7, 8, 5, 6, 3, 4, 1, 2};
+ const int bias_shape[] = {4, 1, 1, 1, 4};
+ const float bias_data[] = {3, -2, 4, 6};
+ const int output_shape[] = {4, 1, 1, 2, 4};
+
+ const int input_size = 12;
+ const int filter_size = 16;
+ const int output_size = 8;
+ const int bias_size = 4;
+ int8_t input_quantized[input_size];
+ int8_t filter_quantized[filter_size];
+ int32_t bias_quantized[bias_size];
+ int8_t golden_quantized[output_size];
+ int zero_points[bias_size + 1];
+ float scales[bias_size + 1];
+ int8_t output_data[output_size];
+
+ const float input_scale = 0.5;
+ const float output_scale = 1.0;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ TfLiteIntArray* input_dims = tflite::testing::IntArrayFromInts(input_shape);
+ TfLiteIntArray* filter_dims = tflite::testing::IntArrayFromInts(filter_shape);
+ TfLiteIntArray* bias_dims = tflite::testing::IntArrayFromInts(bias_shape);
+ TfLiteIntArray* output_dims = tflite::testing::IntArrayFromInts(output_shape);
+
+ int filter_zero_points[5];
+ float filter_scales[5];
+ TfLiteAffineQuantization filter_quant;
+ TfLiteAffineQuantization bias_quant;
+ TfLiteTensor input_tensor = tflite::testing::CreateQuantizedTensor(
+ input_data, input_quantized, input_dims, input_scale, input_zero_point);
+ TfLiteTensor filter_tensor =
+ tflite::testing::CreateSymmetricPerChannelQuantizedTensor(
+ filter_data, filter_quantized, filter_dims, filter_scales,
+ filter_zero_points, &filter_quant, 0 /* quantized dimension */);
+ TfLiteTensor bias_tensor =
+ tflite::testing::CreatePerChannelQuantizedBiasTensor(
+ bias_data, bias_quantized, bias_dims, input_scale, &filter_scales[1],
+ scales, zero_points, &bias_quant, 0);
+ TfLiteTensor output_tensor = tflite::testing::CreateQuantizedTensor(
+ output_data, output_dims, output_scale, output_zero_point);
+
+ float input_scales[] = {1, input_scale};
+ int input_zero_points[] = {1, input_zero_point};
+ TfLiteAffineQuantization input_quant = {
+ tflite::testing::FloatArrayFromFloats(input_scales),
+ tflite::testing::IntArrayFromInts(input_zero_points), 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+
+ // Set filter quant to mismatched dimension.
+ TfLiteAffineQuantization* quant = reinterpret_cast<TfLiteAffineQuantization*>(
+ filter_tensor.quantization.params);
+ quant->scale->size = 2;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError,
+ tflite::testing::ValidateDepthwiseConvGoldens(
+ golden_quantized, output_size, &conv_params, 1e-5,
+ tensors_size, tensors));
+
+ // Set scale back to correct dimension, and make zero point array too short.
+ quant->scale->size = filter_shape[0];
+ quant->zero_point->size = 2;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError,
+ tflite::testing::ValidateDepthwiseConvGoldens(
+ golden_quantized, output_size, &conv_params, 1e-5,
+ tensors_size, tensors));
+}
+
+TF_LITE_MICRO_TEST(Int8Input32x4Filter32x4ShouldMatchGolden) {
+ const int input_elements = 32 * 4;
+ const int filter_elements = 32 * 4;
+ const int bias_elements = 32;
+ const int output_elements = 32;
+ const int input_shape[] = {4, 1, 4, 1, 32};
+ const int filter_shape[] = {4, 1, 4, 1, 32};
+ const int bias_shape[] = {1, 32};
+ const int output_shape[] = {4, 1, 1, 1, 32};
+ const float input_values[] = {
+ 11.0589, 10.8824, 11.1766, 11.5295, 10.8236, 9.5295, 9.5295, 10.0001,
+ 11.2354, 10.8824, 9.1765, 9.0589, 9.6471, 8.9412, 7.9412, 9.0001,
+ 9.3530, 7.5295, 9.2354, 9.5883, 7.5883, 8.1765, 7.5883, 9.2942,
+ 9.1177, 8.5883, 8.2354, 8.6471, 8.0589, 8.0001, 7.4118, 7.3530,
+ 11.0001, 11.1177, 11.0589, 11.2354, 10.5883, 9.2942, 9.2942, 10.1177,
+ 11.2354, 10.8824, 8.9412, 8.8236, 9.2354, 8.8824, 7.0001, 9.1177,
+ 9.5883, 8.2354, 9.1765, 9.5295, 7.4118, 8.5883, 8.1177, 9.1765,
+ 9.0001, 9.0589, 8.9412, 8.2942, 7.8824, 8.4118, 7.2942, 7.2354,
+ 10.4118, 10.8824, 11.1177, 11.0001, 10.0001, 9.7060, 9.7648, 10.1766,
+ 11.1766, 10.6471, 8.6471, 8.5295, 9.5295, 9.0001, 7.0001, 9.4118,
+ 9.8236, 8.0001, 9.2354, 9.5883, 7.5295, 9.0001, 8.5295, 9.0589,
+ 8.9412, 9.1177, 8.9412, 8.0001, 8.0589, 8.8824, 7.0589, 7.3530,
+ 11.3530, 11.0589, 10.7060, 10.7648, 9.9413, 9.1177, 9.1177, 9.7648,
+ 10.7060, 10.2354, 8.5883, 8.8236, 9.7648, 9.2942, 7.5295, 9.2354,
+ 9.7060, 8.1177, 9.2942, 9.5883, 7.7648, 9.6471, 9.1177, 9.4707,
+ 9.3530, 8.8236, 8.5295, 8.0589, 8.6471, 9.5883, 7.4118, 7.5883};
+ const float filter_values[] = {
+ -0.1617, -0.1948, 0.1419, -0.2311, -0.0891, 0.1551, 0.0033, 0.3037,
+ -0.1683, 0.1353, 0.1518, -0.1683, -0.1386, 0.1452, 0.1816, 0.1716,
+ -0.1948, 0.2080, 0.2245, -0.1981, -0.2410, 0.1849, 0.1981, 0.1584,
+ 0.2509, 0.1783, -0.2146, -0.1518, 0.2080, -0.2872, 0.2014, 0.2476,
+ -0.4126, -0.0561, -0.3235, -0.0594, -0.0957, 0.2014, -0.1056, 0.1386,
+ -0.2542, -0.1617, 0.1287, -0.1816, -0.0363, 0.1419, -0.0594, 0.2344,
+ -0.0099, 0.4192, 0.1287, -0.2311, -0.2212, -0.0528, -0.2080, 0.1816,
+ -0.1452, 0.1221, 0.1254, -0.1056, -0.0759, 0.1221, 0.1023, 0.1485,
+ 0.2707, 0.1716, -0.1882, -0.1783, 0.1650, -0.2740, 0.1915, 0.2080,
+ -0.2971, -0.2575, -0.3169, 0.0198, -0.0231, 0.2410, -0.0429, 0.0660,
+ -0.1816, 0.1981, 0.2014, -0.1386, -0.1915, 0.1716, 0.1320, 0.1419,
+ 0.1320, 0.1353, -0.1386, -0.1716, 0.1320, -0.1650, 0.1386, 0.0825,
+ -0.1419, -0.1023, 0.1783, 0.0462, 0.2047, -0.2179, -0.1518, -0.1551,
+ 0.1518, 0.3334, 0.3103, -0.2047, -0.2047, -0.0957, -0.1650, 0.1221,
+ 0.0990, 0.1353, -0.1617, -0.1485, 0.1650, -0.1816, 0.1518, 0.1254,
+ -0.0363, -0.1254, 0.1386, 0.0429, 0.2113, -0.2839, -0.1056, -0.2278};
+ const float bias_values[] = {
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000};
+ const float golden[] = {
+ -5.1194, -2.0075, -2.1751, -4.7958, 1.7073, -1.2963, -0.4641, 5.0416,
+ -6.4424, 0.3836, 2.4684, -4.7643, -3.8913, 3.8382, -0.5164, 5.4304,
+ -2.7400, 7.7016, 3.6115, -6.8545, -3.6290, 0.8509, 2.3247, 5.6117,
+ 1.8215, 2.7645, -0.7032, -3.2156, 3.9689, -5.4583, 2.4346, 1.7731};
+
+ // Quantization Parameters. All scales except output are 1.0, and all zero
+ // points are 0. This direct-maps the values to floating point and makes it
+ // easy to reson about them.
+ const float input_scale = 0.058824;
+ const float filter_scale = 0.003301;
+ const float output_scale = 0.092596;
+ const int input_zero_point = -128;
+ const int output_zero_point = 0;
+
+ TfLiteIntArray* input_dims = tflite::testing::IntArrayFromInts(input_shape);
+ TfLiteIntArray* filter_dims = tflite::testing::IntArrayFromInts(filter_shape);
+ TfLiteIntArray* bias_dims = tflite::testing::IntArrayFromInts(bias_shape);
+ TfLiteIntArray* output_dims = tflite::testing::IntArrayFromInts(output_shape);
+
+ // Create per-tensor quantized int8_t input tensor.
+ int8_t input_quantized[input_elements];
+ TfLiteTensor input_tensor = tflite::testing::CreateQuantizedTensor(
+ input_values, input_quantized, input_dims, input_scale, input_zero_point);
+
+ // Set zero point and scale arrays with a single element for each.
+ int input_zero_points[] = {1, input_zero_point};
+ float input_scales[] = {1, input_scale};
+ TfLiteAffineQuantization input_quant = {
+ tflite::testing::FloatArrayFromFloats(input_scales),
+ tflite::testing::IntArrayFromInts(input_zero_points), 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ // Create per-tensor quantized int8_t filter tensor.
+ int8_t filter_quantized[filter_elements];
+ TfLiteTensor filter_tensor = tflite::testing::CreateQuantizedTensor(
+ filter_values, filter_quantized, filter_dims, filter_scale, 0);
+
+ // Set zero point and scale arrays with a single element for each.
+ int filter_zero_points[] = {1, 0};
+ float filter_scales[] = {1, filter_scale};
+ TfLiteAffineQuantization filter_quant = {
+ tflite::testing::FloatArrayFromFloats(filter_scales),
+ tflite::testing::IntArrayFromInts(filter_zero_points), 0};
+ filter_tensor.quantization = {kTfLiteAffineQuantization, &filter_quant};
+
+ // Create per-tensor quantized int32_t bias tensor.
+ int32_t bias_quantized[bias_elements];
+ // See https://www.tensorflow.org/lite/performance/quantization_spec for a
+ // detailed explanation of why bias scale is input_scale * filter_scale.
+ tflite::SymmetricQuantize(bias_values, bias_quantized, bias_elements,
+ input_scale * output_scale);
+ TfLiteTensor bias_tensor =
+ tflite::testing::CreateTensor(bias_quantized, bias_dims);
+
+ // Set zero point and scale arrays with a single element for each.
+ int bias_zero_points[] = {1, 0};
+ float bias_scales[] = {1, input_scale * filter_scale};
+ TfLiteAffineQuantization bias_quant = {
+ tflite::testing::FloatArrayFromFloats(bias_scales),
+ tflite::testing::IntArrayFromInts(bias_zero_points), 0};
+ bias_tensor.quantization = {kTfLiteAffineQuantization, &bias_quant};
+
+ // Create per-tensor quantized int8_t output tensor.
+ int8_t output_quantized[output_elements];
+ TfLiteTensor output_tensor = tflite::testing::CreateQuantizedTensor(
+ output_quantized, output_dims, output_scale, output_zero_point);
+
+ // Set zero point and scale arrays with a single element for each.
+ int output_zero_points[] = {1, output_zero_point};
+ float output_scales[] = {1, output_scale};
+ TfLiteAffineQuantization output_quant = {
+ tflite::testing::FloatArrayFromFloats(output_scales),
+ tflite::testing::IntArrayFromInts(output_zero_points), 0};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ // The 3 inputs include the input, filter and bias tensors.
+ constexpr int kInputsSize = 3;
+ constexpr int kOutputsSize = 1;
+ constexpr int kTensorsSize = kInputsSize + kOutputsSize;
+ TfLiteTensor tensors[kTensorsSize] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ int8_t golden_quantized[output_elements];
+ tflite::Quantize(golden, golden_quantized, output_elements, output_scale, 0);
+
+ // Errors due to quantization should not exceed 1.
+ constexpr int kQuantizationTolerance = 1;
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 1;
+ conv_params.stride_width = 1;
+ tflite::testing::ValidateDepthwiseConvGoldens(
+ golden_quantized, output_elements, &conv_params, kQuantizationTolerance,
+ kTensorsSize, tensors);
+}
+
+#if !defined(HIFIMINI)
+// TODO(b/184087246): Remove this ifdef once the hifimini implementation is
+// updated to be more general.
+TF_LITE_MICRO_TEST(Int8Input32x1Filter32x1ShouldMatchGolden) {
+ const int input_elements = 32 * 1;
+ const int filter_elements = 32 * 1;
+ const int bias_elements = 32;
+ const int output_elements = 32;
+ const int input_shape[] = {4, 1, 1, 1, 32};
+ const int filter_shape[] = {4, 1, 1, 1, 32};
+ const int bias_shape[] = {1, 32};
+ const int output_shape[] = {4, 1, 1, 1, 32};
+ const float input_values[] = {
+ 11.0589, 10.8824, 11.1766, 11.5295, 10.8236, 9.5295, 9.5295, 10.0001,
+ 11.2354, 10.8824, 9.1765, 9.0589, 9.6471, 8.9412, 7.9412, 9.0001,
+ 9.3530, 7.5295, 9.2354, 9.5883, 7.5883, 8.1765, 7.5883, 9.2942,
+ 9.3530, 8.8236, 8.5295, 8.0589, 8.6471, 9.5883, 7.4118, 7.5883};
+ const float filter_values[] = {
+ -0.1419, -0.1023, 0.1783, 0.0462, 0.2047, -0.2179, -0.1518, -0.1551,
+ 0.1518, 0.3334, 0.3103, -0.2047, -0.2047, -0.0957, -0.1650, 0.1221,
+ 0.0990, 0.1353, -0.1617, -0.1485, 0.1650, -0.1816, 0.1518, 0.1254,
+ -0.0363, -0.1254, 0.1386, 0.0429, 0.2113, -0.2839, -0.1056, -0.2278};
+ const float bias_values[] = {
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000};
+ const float golden[] = {
+ -1.5741, -1.1112, 2.0371, 0.5556, 2.2223, -2.0371, -1.4815, -1.5741,
+ 1.6667, 3.6112, 2.8705, -1.8519, -1.9445, -0.8334, -1.2963, 1.1112,
+ 0.9260, 1.0186, -1.4815, -1.3889, 1.2963, -1.4815, 1.1112, 1.2037,
+ -0.3704, -1.1112, 1.2037, 0.3704, 1.8519, -2.6853, -0.7408, -1.7593};
+
+ // Quantization Parameters. All scales except output are 1.0, and all zero
+ // points are 0. This direct-maps the values to floating point and makes it
+ // easy to reson about them.
+ const float input_scale = 0.058824;
+ const float filter_scale = 0.003301;
+ const float output_scale = 0.092596;
+ const int input_zero_point = -128;
+ const int output_zero_point = 0;
+
+ TfLiteIntArray* input_dims = tflite::testing::IntArrayFromInts(input_shape);
+ TfLiteIntArray* filter_dims = tflite::testing::IntArrayFromInts(filter_shape);
+ TfLiteIntArray* bias_dims = tflite::testing::IntArrayFromInts(bias_shape);
+ TfLiteIntArray* output_dims = tflite::testing::IntArrayFromInts(output_shape);
+
+ // Create per-tensor quantized int8_t input tensor.
+ int8_t input_quantized[input_elements];
+ TfLiteTensor input_tensor = tflite::testing::CreateQuantizedTensor(
+ input_values, input_quantized, input_dims, input_scale, input_zero_point);
+
+ // Set zero point and scale arrays with a single element for each.
+ int input_zero_points[] = {1, input_zero_point};
+ float input_scales[] = {1, input_scale};
+ TfLiteAffineQuantization input_quant = {
+ tflite::testing::FloatArrayFromFloats(input_scales),
+ tflite::testing::IntArrayFromInts(input_zero_points), 0};
+ input_tensor.quantization = {kTfLiteAffineQuantization, &input_quant};
+
+ // Create per-tensor quantized int8_t filter tensor.
+ int8_t filter_quantized[filter_elements];
+ TfLiteTensor filter_tensor = tflite::testing::CreateQuantizedTensor(
+ filter_values, filter_quantized, filter_dims, filter_scale, 0);
+
+ // Set zero point and scale arrays with a single element for each.
+ int filter_zero_points[] = {1, 0};
+ float filter_scales[] = {1, filter_scale};
+ TfLiteAffineQuantization filter_quant = {
+ tflite::testing::FloatArrayFromFloats(filter_scales),
+ tflite::testing::IntArrayFromInts(filter_zero_points), 0};
+ filter_tensor.quantization = {kTfLiteAffineQuantization, &filter_quant};
+
+ // Create per-tensor quantized int32_t bias tensor.
+ int32_t bias_quantized[bias_elements];
+ // See https://www.tensorflow.org/lite/performance/quantization_spec for a
+ // detailed explanation of why bias scale is input_scale * filter_scale.
+ tflite::SymmetricQuantize(bias_values, bias_quantized, bias_elements,
+ input_scale * output_scale);
+ TfLiteTensor bias_tensor =
+ tflite::testing::CreateTensor(bias_quantized, bias_dims);
+
+ // Set zero point and scale arrays with a single element for each.
+ int bias_zero_points[] = {1, 0};
+ float bias_scales[] = {1, input_scale * filter_scale};
+ TfLiteAffineQuantization bias_quant = {
+ tflite::testing::FloatArrayFromFloats(bias_scales),
+ tflite::testing::IntArrayFromInts(bias_zero_points), 0};
+ bias_tensor.quantization = {kTfLiteAffineQuantization, &bias_quant};
+
+ // Create per-tensor quantized int8_t output tensor.
+ int8_t output_quantized[output_elements];
+ TfLiteTensor output_tensor = tflite::testing::CreateQuantizedTensor(
+ output_quantized, output_dims, output_scale, output_zero_point);
+
+ // Set zero point and scale arrays with a single element for each.
+ int output_zero_points[] = {1, output_zero_point};
+ float output_scales[] = {1, output_scale};
+ TfLiteAffineQuantization output_quant = {
+ tflite::testing::FloatArrayFromFloats(output_scales),
+ tflite::testing::IntArrayFromInts(output_zero_points), 0};
+ output_tensor.quantization = {kTfLiteAffineQuantization, &output_quant};
+
+ // The 3 inputs include the input, filter and bias tensors.
+ constexpr int kInputsSize = 3;
+ constexpr int kOutputsSize = 1;
+ constexpr int kTensorsSize = kInputsSize + kOutputsSize;
+ TfLiteTensor tensors[kTensorsSize] = {
+ input_tensor,
+ filter_tensor,
+ bias_tensor,
+ output_tensor,
+ };
+
+ int8_t golden_quantized[output_elements];
+ tflite::Quantize(golden, golden_quantized, output_elements, output_scale, 0);
+
+ // Errors due to quantization should not exceed 1.
+ constexpr int kQuantizationTolerance = 1;
+
+ TfLiteDepthwiseConvParams conv_params;
+ conv_params.activation = kTfLiteActNone;
+ conv_params.dilation_width_factor = 1;
+ conv_params.dilation_height_factor = 1;
+ conv_params.stride_height = 2;
+ conv_params.stride_width = 2;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::testing::ValidateDepthwiseConvGoldens(
+ golden_quantized, output_elements, &conv_params,
+ kQuantizationTolerance, kTensorsSize, tensors));
+}
+#endif // !defined(HIFIMINI)
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/dequantize.cc b/tensorflow/lite/micro/kernels/dequantize.cc
new file mode 100644
index 0000000..b488c41
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/dequantize.cc
@@ -0,0 +1,139 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/dequantize.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/quantize.h"
+#include "tensorflow/lite/kernels/internal/reference/requantize.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace dequantize {
+
+struct OpData {
+ tflite::DequantizationParams quantization_params;
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t output_multiplier;
+ int output_shift;
+ int32_t output_zero_point;
+};
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ // TODO(b/140515557): Add cached dequant to improve hybrid model performance.
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, 0);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE(context, input->type == kTfLiteUInt8 ||
+ input->type == kTfLiteInt8 ||
+ input->type == kTfLiteInt16);
+ TF_LITE_ENSURE(context, output->type == kTfLiteFloat32);
+
+ if (output->type == kTfLiteInt32) {
+ const double effective_output_scale =
+ static_cast<double>(input->params.scale) /
+ static_cast<double>(output->params.scale);
+ QuantizeMultiplier(effective_output_scale, &data->output_multiplier,
+ &data->output_shift);
+ }
+
+ data->quantization_params.zero_point = input->params.zero_point;
+ data->quantization_params.scale = static_cast<double>(input->params.scale);
+ data->output_zero_point = output->params.zero_point;
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ if (output->type == kTfLiteFloat32) {
+ switch (input->type) {
+ case kTfLiteUInt8:
+ reference_ops::Dequantize(data->quantization_params,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ case kTfLiteInt8:
+ reference_ops::Dequantize(data->quantization_params,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ case kTfLiteInt16:
+ reference_ops::Dequantize(data->quantization_params,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int16_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace dequantize
+
+TfLiteRegistration Register_DEQUANTIZE() {
+ return {/*init=*/dequantize::Init,
+ /*free=*/nullptr,
+ /*prepare=*/dequantize::Prepare,
+ /*invoke=*/dequantize::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/dequantize_test.cc b/tensorflow/lite/micro/kernels/dequantize_test.cc
new file mode 100644
index 0000000..5bee09f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/dequantize_test.cc
@@ -0,0 +1,142 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void ValidateDequantizeGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* expected_output_data, T* output_data,
+ int output_length, float tolerance = 1e-5) {
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_DEQUANTIZE();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 0.001f);
+ }
+}
+
+template <typename T>
+void TestDequantizeToFloat(const int* input_dims_data, const float* input_data,
+ T* input_data_quantized, float scale, int zero_point,
+ const int* output_dims_data,
+ const float* expected_output_data,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_length = ElementCount(*output_dims);
+
+ // 1 input, 1 output.
+ const int tensors_size = 2;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_data_quantized, input_dims, scale,
+ zero_point),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateDequantizeGoldens(tensors, tensors_size, expected_output_data,
+ output_data, output_length);
+}
+
+template <typename T>
+void TestDequantizeToInt32(const int* input_dims_data, const float* input_data,
+ T* input_data_quantized, float input_scale,
+ int input_zero_point, const int* output_dims_data,
+ const int32_t* expected_output_data,
+ float output_scale, int output_zero_point,
+ int32_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_length = ElementCount(*output_dims);
+
+ // 1 input, 1 output.
+ const int tensors_size = 2;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_data_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateTensor(output_data, output_dims),
+ };
+
+ tensors[1].params.scale = output_scale;
+ tensors[1].params.zero_point = output_zero_point;
+
+ ValidateDequantizeGoldens(tensors, tensors_size, expected_output_data,
+ output_data, output_length);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(DequantizeOpTestUint8) {
+ const int length = 10;
+ const int dims[] = {2, 5, 2};
+ const float values[] = {-63.5, -63, -62.5, -62, -61.5,
+ 62, 62.5, 63, 63.5, 64};
+ const float scale = 0.5;
+ const int zero_point = 127;
+ uint8_t input_quantized[length];
+ float output[length];
+ tflite::testing::TestDequantizeToFloat(dims, values, input_quantized, scale,
+ zero_point, dims, values, output);
+}
+
+TF_LITE_MICRO_TEST(DequantizeOpTestInt8) {
+ const int length = 10;
+ const int dims[] = {2, 5, 2};
+ const float values[] = {-63.5, -63, -62.5, -62, -61.5,
+ 62, 62.5, 63, 63.5, 64};
+ const float scale = 0.5;
+ const int zero_point = -1;
+ int8_t input_quantized[length];
+ float output[length];
+ tflite::testing::TestDequantizeToFloat(dims, values, input_quantized, scale,
+ zero_point, dims, values, output);
+}
+
+TF_LITE_MICRO_TEST(DequantizeOpTestInt16) {
+ const int length = 10;
+ const int dims[] = {2, 5, 2};
+ const float values[] = {-63.5, -63, -62.5, -62, -61.5,
+ 62, 62.5, 63, 63.5, 64};
+ const float scale = 0.5;
+ const int zero_point = -1;
+ int16_t input_quantized[length];
+ float output[length];
+ tflite::testing::TestDequantizeToFloat(dims, values, input_quantized, scale,
+ zero_point, dims, values, output);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/detection_postprocess.cc b/tensorflow/lite/micro/kernels/detection_postprocess.cc
new file mode 100644
index 0000000..532a7e8
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/detection_postprocess.cc
@@ -0,0 +1,805 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <numeric>
+
+#define FLATBUFFERS_LOCALE_INDEPENDENT 0
+#include "flatbuffers/flexbuffers.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace {
+
+/**
+ * This version of detection_postprocess is specific to TFLite Micro. It
+ * contains the following differences between the TFLite version:
+ *
+ * 1.) Temporaries (temporary tensors) - Micro use instead scratch buffer API.
+ * 2.) Output dimensions - the TFLite version does not support undefined out
+ * dimensions. So model must have static out dimensions.
+ */
+
+// Input tensors
+constexpr int kInputTensorBoxEncodings = 0;
+constexpr int kInputTensorClassPredictions = 1;
+constexpr int kInputTensorAnchors = 2;
+
+// Output tensors
+constexpr int kOutputTensorDetectionBoxes = 0;
+constexpr int kOutputTensorDetectionClasses = 1;
+constexpr int kOutputTensorDetectionScores = 2;
+constexpr int kOutputTensorNumDetections = 3;
+
+constexpr int kNumCoordBox = 4;
+constexpr int kBatchSize = 1;
+
+constexpr int kNumDetectionsPerClass = 100;
+
+// Object Detection model produces axis-aligned boxes in two formats:
+// BoxCorner represents the lower left corner (xmin, ymin) and
+// the upper right corner (xmax, ymax).
+// CenterSize represents the center (xcenter, ycenter), height and width.
+// BoxCornerEncoding and CenterSizeEncoding are related as follows:
+// ycenter = y / y_scale * anchor.h + anchor.y;
+// xcenter = x / x_scale * anchor.w + anchor.x;
+// half_h = 0.5*exp(h/ h_scale)) * anchor.h;
+// half_w = 0.5*exp(w / w_scale)) * anchor.w;
+// ymin = ycenter - half_h
+// ymax = ycenter + half_h
+// xmin = xcenter - half_w
+// xmax = xcenter + half_w
+struct BoxCornerEncoding {
+ float ymin;
+ float xmin;
+ float ymax;
+ float xmax;
+};
+
+struct CenterSizeEncoding {
+ float y;
+ float x;
+ float h;
+ float w;
+};
+// We make sure that the memory allocations are contiguous with static_assert.
+static_assert(sizeof(BoxCornerEncoding) == sizeof(float) * kNumCoordBox,
+ "Size of BoxCornerEncoding is 4 float values");
+static_assert(sizeof(CenterSizeEncoding) == sizeof(float) * kNumCoordBox,
+ "Size of CenterSizeEncoding is 4 float values");
+
+struct OpData {
+ int max_detections;
+ int max_classes_per_detection; // Fast Non-Max-Suppression
+ int detections_per_class; // Regular Non-Max-Suppression
+ float non_max_suppression_score_threshold;
+ float intersection_over_union_threshold;
+ int num_classes;
+ bool use_regular_non_max_suppression;
+ CenterSizeEncoding scale_values;
+
+ // Scratch buffers indexes
+ int active_candidate_idx;
+ int decoded_boxes_idx;
+ int scores_idx;
+ int score_buffer_idx;
+ int keep_scores_idx;
+ int scores_after_regular_non_max_suppression_idx;
+ int sorted_values_idx;
+ int keep_indices_idx;
+ int sorted_indices_idx;
+ int buffer_idx;
+ int selected_idx;
+
+ // Cached tensor scale and zero point values for quantized operations
+ TfLiteQuantizationParams input_box_encodings;
+ TfLiteQuantizationParams input_class_predictions;
+ TfLiteQuantizationParams input_anchors;
+};
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ OpData* op_data = nullptr;
+
+ const uint8_t* buffer_t = reinterpret_cast<const uint8_t*>(buffer);
+ const flexbuffers::Map& m = flexbuffers::GetRoot(buffer_t, length).AsMap();
+
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ op_data = reinterpret_cast<OpData*>(
+ context->AllocatePersistentBuffer(context, sizeof(OpData)));
+
+ op_data->max_detections = m["max_detections"].AsInt32();
+ op_data->max_classes_per_detection = m["max_classes_per_detection"].AsInt32();
+ if (m["detections_per_class"].IsNull())
+ op_data->detections_per_class = kNumDetectionsPerClass;
+ else
+ op_data->detections_per_class = m["detections_per_class"].AsInt32();
+ if (m["use_regular_nms"].IsNull())
+ op_data->use_regular_non_max_suppression = false;
+ else
+ op_data->use_regular_non_max_suppression = m["use_regular_nms"].AsBool();
+
+ op_data->non_max_suppression_score_threshold =
+ m["nms_score_threshold"].AsFloat();
+ op_data->intersection_over_union_threshold = m["nms_iou_threshold"].AsFloat();
+ op_data->num_classes = m["num_classes"].AsInt32();
+ op_data->scale_values.y = m["y_scale"].AsFloat();
+ op_data->scale_values.x = m["x_scale"].AsFloat();
+ op_data->scale_values.h = m["h_scale"].AsFloat();
+ op_data->scale_values.w = m["w_scale"].AsFloat();
+
+ return op_data;
+}
+
+void Free(TfLiteContext* context, void* buffer) {}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ auto* op_data = static_cast<OpData*>(node->user_data);
+
+ // Inputs: box_encodings, scores, anchors
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 3);
+ const TfLiteTensor* input_box_encodings =
+ GetInput(context, node, kInputTensorBoxEncodings);
+ const TfLiteTensor* input_class_predictions =
+ GetInput(context, node, kInputTensorClassPredictions);
+ const TfLiteTensor* input_anchors =
+ GetInput(context, node, kInputTensorAnchors);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input_box_encodings), 3);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input_class_predictions), 3);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input_anchors), 2);
+
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 4);
+ const int num_boxes = input_box_encodings->dims->data[1];
+ const int num_classes = op_data->num_classes;
+
+ op_data->input_box_encodings.scale = input_box_encodings->params.scale;
+ op_data->input_box_encodings.zero_point =
+ input_box_encodings->params.zero_point;
+ op_data->input_class_predictions.scale =
+ input_class_predictions->params.scale;
+ op_data->input_class_predictions.zero_point =
+ input_class_predictions->params.zero_point;
+ op_data->input_anchors.scale = input_anchors->params.scale;
+ op_data->input_anchors.zero_point = input_anchors->params.zero_point;
+
+ // Scratch tensors
+ context->RequestScratchBufferInArena(context, num_boxes,
+ &op_data->active_candidate_idx);
+ context->RequestScratchBufferInArena(context,
+ num_boxes * kNumCoordBox * sizeof(float),
+ &op_data->decoded_boxes_idx);
+ context->RequestScratchBufferInArena(
+ context,
+ input_class_predictions->dims->data[1] *
+ input_class_predictions->dims->data[2] * sizeof(float),
+ &op_data->scores_idx);
+
+ // Additional buffers
+ context->RequestScratchBufferInArena(context, num_boxes * sizeof(float),
+ &op_data->score_buffer_idx);
+ context->RequestScratchBufferInArena(context, num_boxes * sizeof(float),
+ &op_data->keep_scores_idx);
+ context->RequestScratchBufferInArena(
+ context, op_data->max_detections * num_boxes * sizeof(float),
+ &op_data->scores_after_regular_non_max_suppression_idx);
+ context->RequestScratchBufferInArena(
+ context, op_data->max_detections * num_boxes * sizeof(float),
+ &op_data->sorted_values_idx);
+ context->RequestScratchBufferInArena(context, num_boxes * sizeof(int),
+ &op_data->keep_indices_idx);
+ context->RequestScratchBufferInArena(
+ context, op_data->max_detections * num_boxes * sizeof(int),
+ &op_data->sorted_indices_idx);
+ int buffer_size = std::max(num_classes, op_data->max_detections);
+ context->RequestScratchBufferInArena(
+ context, buffer_size * num_boxes * sizeof(int), &op_data->buffer_idx);
+ buffer_size = std::min(num_boxes, op_data->max_detections);
+ context->RequestScratchBufferInArena(
+ context, buffer_size * num_boxes * sizeof(int), &op_data->selected_idx);
+
+ // Outputs: detection_boxes, detection_scores, detection_classes,
+ // num_detections
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 4);
+
+ return kTfLiteOk;
+}
+
+class Dequantizer {
+ public:
+ Dequantizer(int zero_point, float scale)
+ : zero_point_(zero_point), scale_(scale) {}
+ float operator()(uint8_t x) {
+ return (static_cast<float>(x) - zero_point_) * scale_;
+ }
+
+ private:
+ int zero_point_;
+ float scale_;
+};
+
+void DequantizeBoxEncodings(const TfLiteEvalTensor* input_box_encodings,
+ int idx, float quant_zero_point, float quant_scale,
+ int length_box_encoding,
+ CenterSizeEncoding* box_centersize) {
+ const uint8_t* boxes =
+ tflite::micro::GetTensorData<uint8_t>(input_box_encodings) +
+ length_box_encoding * idx;
+ Dequantizer dequantize(quant_zero_point, quant_scale);
+ // See definition of the KeyPointBoxCoder at
+ // https://github.com/tensorflow/models/blob/master/research/object_detection/box_coders/keypoint_box_coder.py
+ // The first four elements are the box coordinates, which is the same as the
+ // FastRnnBoxCoder at
+ // https://github.com/tensorflow/models/blob/master/research/object_detection/box_coders/faster_rcnn_box_coder.py
+ box_centersize->y = dequantize(boxes[0]);
+ box_centersize->x = dequantize(boxes[1]);
+ box_centersize->h = dequantize(boxes[2]);
+ box_centersize->w = dequantize(boxes[3]);
+}
+
+template <class T>
+T ReInterpretTensor(const TfLiteEvalTensor* tensor) {
+ const float* tensor_base = tflite::micro::GetTensorData<float>(tensor);
+ return reinterpret_cast<T>(tensor_base);
+}
+
+template <class T>
+T ReInterpretTensor(TfLiteEvalTensor* tensor) {
+ float* tensor_base = tflite::micro::GetTensorData<float>(tensor);
+ return reinterpret_cast<T>(tensor_base);
+}
+
+TfLiteStatus DecodeCenterSizeBoxes(TfLiteContext* context, TfLiteNode* node,
+ OpData* op_data) {
+ // Parse input tensor boxencodings
+ const TfLiteEvalTensor* input_box_encodings =
+ tflite::micro::GetEvalInput(context, node, kInputTensorBoxEncodings);
+ TF_LITE_ENSURE_EQ(context, input_box_encodings->dims->data[0], kBatchSize);
+ const int num_boxes = input_box_encodings->dims->data[1];
+ TF_LITE_ENSURE(context, input_box_encodings->dims->data[2] >= kNumCoordBox);
+ const TfLiteEvalTensor* input_anchors =
+ tflite::micro::GetEvalInput(context, node, kInputTensorAnchors);
+
+ // Decode the boxes to get (ymin, xmin, ymax, xmax) based on the anchors
+ CenterSizeEncoding box_centersize;
+ CenterSizeEncoding scale_values = op_data->scale_values;
+ CenterSizeEncoding anchor;
+ for (int idx = 0; idx < num_boxes; ++idx) {
+ switch (input_box_encodings->type) {
+ // Quantized
+ case kTfLiteUInt8:
+ DequantizeBoxEncodings(
+ input_box_encodings, idx,
+ static_cast<float>(op_data->input_box_encodings.zero_point),
+ static_cast<float>(op_data->input_box_encodings.scale),
+ input_box_encodings->dims->data[2], &box_centersize);
+ DequantizeBoxEncodings(
+ input_anchors, idx,
+ static_cast<float>(op_data->input_anchors.zero_point),
+ static_cast<float>(op_data->input_anchors.scale), kNumCoordBox,
+ &anchor);
+ break;
+ // Float
+ case kTfLiteFloat32: {
+ // Please see DequantizeBoxEncodings function for the support detail.
+ const int box_encoding_idx = idx * input_box_encodings->dims->data[2];
+ const float* boxes = &(tflite::micro::GetTensorData<float>(
+ input_box_encodings)[box_encoding_idx]);
+ box_centersize = *reinterpret_cast<const CenterSizeEncoding*>(boxes);
+ anchor =
+ ReInterpretTensor<const CenterSizeEncoding*>(input_anchors)[idx];
+ break;
+ }
+ default:
+ // Unsupported type.
+ return kTfLiteError;
+ }
+
+ float ycenter = static_cast<float>(static_cast<double>(box_centersize.y) /
+ static_cast<double>(scale_values.y) *
+ static_cast<double>(anchor.h) +
+ static_cast<double>(anchor.y));
+
+ float xcenter = static_cast<float>(static_cast<double>(box_centersize.x) /
+ static_cast<double>(scale_values.x) *
+ static_cast<double>(anchor.w) +
+ static_cast<double>(anchor.x));
+
+ float half_h =
+ static_cast<float>(0.5 *
+ (std::exp(static_cast<double>(box_centersize.h) /
+ static_cast<double>(scale_values.h))) *
+ static_cast<double>(anchor.h));
+ float half_w =
+ static_cast<float>(0.5 *
+ (std::exp(static_cast<double>(box_centersize.w) /
+ static_cast<double>(scale_values.w))) *
+ static_cast<double>(anchor.w));
+
+ float* decoded_boxes = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->decoded_boxes_idx));
+ auto& box = reinterpret_cast<BoxCornerEncoding*>(decoded_boxes)[idx];
+ box.ymin = ycenter - half_h;
+ box.xmin = xcenter - half_w;
+ box.ymax = ycenter + half_h;
+ box.xmax = xcenter + half_w;
+ }
+ return kTfLiteOk;
+}
+
+void DecreasingPartialArgSort(const float* values, int num_values,
+ int num_to_sort, int* indices) {
+ std::iota(indices, indices + num_values, 0);
+ std::partial_sort(
+ indices, indices + num_to_sort, indices + num_values,
+ [&values](const int i, const int j) { return values[i] > values[j]; });
+}
+
+int SelectDetectionsAboveScoreThreshold(const float* values, int size,
+ const float threshold,
+ float* keep_values, int* keep_indices) {
+ int counter = 0;
+ for (int i = 0; i < size; i++) {
+ if (values[i] >= threshold) {
+ keep_values[counter] = values[i];
+ keep_indices[counter] = i;
+ counter++;
+ }
+ }
+ return counter;
+}
+
+bool ValidateBoxes(const float* decoded_boxes, const int num_boxes) {
+ for (int i = 0; i < num_boxes; ++i) {
+ // ymax>=ymin, xmax>=xmin
+ auto& box = reinterpret_cast<const BoxCornerEncoding*>(decoded_boxes)[i];
+ if (box.ymin >= box.ymax || box.xmin >= box.xmax) {
+ return false;
+ }
+ }
+ return true;
+}
+
+float ComputeIntersectionOverUnion(const float* decoded_boxes, const int i,
+ const int j) {
+ auto& box_i = reinterpret_cast<const BoxCornerEncoding*>(decoded_boxes)[i];
+ auto& box_j = reinterpret_cast<const BoxCornerEncoding*>(decoded_boxes)[j];
+ const float area_i = (box_i.ymax - box_i.ymin) * (box_i.xmax - box_i.xmin);
+ const float area_j = (box_j.ymax - box_j.ymin) * (box_j.xmax - box_j.xmin);
+ if (area_i <= 0 || area_j <= 0) return 0.0;
+ const float intersection_ymin = std::max<float>(box_i.ymin, box_j.ymin);
+ const float intersection_xmin = std::max<float>(box_i.xmin, box_j.xmin);
+ const float intersection_ymax = std::min<float>(box_i.ymax, box_j.ymax);
+ const float intersection_xmax = std::min<float>(box_i.xmax, box_j.xmax);
+ const float intersection_area =
+ std::max<float>(intersection_ymax - intersection_ymin, 0.0) *
+ std::max<float>(intersection_xmax - intersection_xmin, 0.0);
+ return intersection_area / (area_i + area_j - intersection_area);
+}
+
+// NonMaxSuppressionSingleClass() prunes out the box locations with high overlap
+// before selecting the highest scoring boxes (max_detections in number)
+// It assumes all boxes are good in beginning and sorts based on the scores.
+// If lower-scoring box has too much overlap with a higher-scoring box,
+// we get rid of the lower-scoring box.
+// Complexity is O(N^2) pairwise comparison between boxes
+TfLiteStatus NonMaxSuppressionSingleClassHelper(
+ TfLiteContext* context, TfLiteNode* node, OpData* op_data,
+ const float* scores, int* selected, int* selected_size,
+ int max_detections) {
+ const TfLiteEvalTensor* input_box_encodings =
+ tflite::micro::GetEvalInput(context, node, kInputTensorBoxEncodings);
+ const int num_boxes = input_box_encodings->dims->data[1];
+ const float non_max_suppression_score_threshold =
+ op_data->non_max_suppression_score_threshold;
+ const float intersection_over_union_threshold =
+ op_data->intersection_over_union_threshold;
+ // Maximum detections should be positive.
+ TF_LITE_ENSURE(context, (max_detections >= 0));
+ // intersection_over_union_threshold should be positive
+ // and should be less than 1.
+ TF_LITE_ENSURE(context, (intersection_over_union_threshold > 0.0f) &&
+ (intersection_over_union_threshold <= 1.0f));
+ // Validate boxes
+ float* decoded_boxes = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->decoded_boxes_idx));
+
+ TF_LITE_ENSURE(context, ValidateBoxes(decoded_boxes, num_boxes));
+
+ // threshold scores
+ int* keep_indices = reinterpret_cast<int*>(
+ context->GetScratchBuffer(context, op_data->keep_indices_idx));
+ float* keep_scores = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->keep_scores_idx));
+ int num_scores_kept = SelectDetectionsAboveScoreThreshold(
+ scores, num_boxes, non_max_suppression_score_threshold, keep_scores,
+ keep_indices);
+ int* sorted_indices = reinterpret_cast<int*>(
+ context->GetScratchBuffer(context, op_data->sorted_indices_idx));
+
+ DecreasingPartialArgSort(keep_scores, num_scores_kept, num_scores_kept,
+ sorted_indices);
+
+ const int num_boxes_kept = num_scores_kept;
+ const int output_size = std::min(num_boxes_kept, max_detections);
+ *selected_size = 0;
+
+ int num_active_candidate = num_boxes_kept;
+ uint8_t* active_box_candidate = reinterpret_cast<uint8_t*>(
+ context->GetScratchBuffer(context, op_data->active_candidate_idx));
+
+ for (int row = 0; row < num_boxes_kept; row++) {
+ active_box_candidate[row] = 1;
+ }
+ for (int i = 0; i < num_boxes_kept; ++i) {
+ if (num_active_candidate == 0 || *selected_size >= output_size) break;
+ if (active_box_candidate[i] == 1) {
+ selected[(*selected_size)++] = keep_indices[sorted_indices[i]];
+ active_box_candidate[i] = 0;
+ num_active_candidate--;
+ } else {
+ continue;
+ }
+ for (int j = i + 1; j < num_boxes_kept; ++j) {
+ if (active_box_candidate[j] == 1) {
+ float intersection_over_union = ComputeIntersectionOverUnion(
+ decoded_boxes, keep_indices[sorted_indices[i]],
+ keep_indices[sorted_indices[j]]);
+
+ if (intersection_over_union > intersection_over_union_threshold) {
+ active_box_candidate[j] = 0;
+ num_active_candidate--;
+ }
+ }
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+// This function implements a regular version of Non Maximal Suppression (NMS)
+// for multiple classes where
+// 1) we do NMS separately for each class across all anchors and
+// 2) keep only the highest anchor scores across all classes
+// 3) The worst runtime of the regular NMS is O(K*N^2)
+// where N is the number of anchors and K the number of
+// classes.
+TfLiteStatus NonMaxSuppressionMultiClassRegularHelper(TfLiteContext* context,
+ TfLiteNode* node,
+ OpData* op_data,
+ const float* scores) {
+ const TfLiteEvalTensor* input_box_encodings =
+ tflite::micro::GetEvalInput(context, node, kInputTensorBoxEncodings);
+ const TfLiteEvalTensor* input_class_predictions =
+ tflite::micro::GetEvalInput(context, node, kInputTensorClassPredictions);
+ TfLiteEvalTensor* detection_boxes =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensorDetectionBoxes);
+ TfLiteEvalTensor* detection_classes = tflite::micro::GetEvalOutput(
+ context, node, kOutputTensorDetectionClasses);
+ TfLiteEvalTensor* detection_scores =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensorDetectionScores);
+ TfLiteEvalTensor* num_detections =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensorNumDetections);
+
+ const int num_boxes = input_box_encodings->dims->data[1];
+ const int num_classes = op_data->num_classes;
+ const int num_detections_per_class = op_data->detections_per_class;
+ const int max_detections = op_data->max_detections;
+ const int num_classes_with_background =
+ input_class_predictions->dims->data[2];
+ // The row index offset is 1 if background class is included and 0 otherwise.
+ int label_offset = num_classes_with_background - num_classes;
+ TF_LITE_ENSURE(context, num_detections_per_class > 0);
+
+ // For each class, perform non-max suppression.
+ float* class_scores = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->score_buffer_idx));
+ int* box_indices_after_regular_non_max_suppression = reinterpret_cast<int*>(
+ context->GetScratchBuffer(context, op_data->buffer_idx));
+ float* scores_after_regular_non_max_suppression =
+ reinterpret_cast<float*>(context->GetScratchBuffer(
+ context, op_data->scores_after_regular_non_max_suppression_idx));
+
+ int size_of_sorted_indices = 0;
+ int* sorted_indices = reinterpret_cast<int*>(
+ context->GetScratchBuffer(context, op_data->sorted_indices_idx));
+ float* sorted_values = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->sorted_values_idx));
+
+ for (int col = 0; col < num_classes; col++) {
+ for (int row = 0; row < num_boxes; row++) {
+ // Get scores of boxes corresponding to all anchors for single class
+ class_scores[row] =
+ *(scores + row * num_classes_with_background + col + label_offset);
+ }
+ // Perform non-maximal suppression on single class
+ int selected_size = 0;
+ int* selected = reinterpret_cast<int*>(
+ context->GetScratchBuffer(context, op_data->selected_idx));
+ TF_LITE_ENSURE_STATUS(NonMaxSuppressionSingleClassHelper(
+ context, node, op_data, class_scores, selected, &selected_size,
+ num_detections_per_class));
+ // Add selected indices from non-max suppression of boxes in this class
+ int output_index = size_of_sorted_indices;
+ for (int i = 0; i < selected_size; i++) {
+ int selected_index = selected[i];
+
+ box_indices_after_regular_non_max_suppression[output_index] =
+ (selected_index * num_classes_with_background + col + label_offset);
+ scores_after_regular_non_max_suppression[output_index] =
+ class_scores[selected_index];
+ output_index++;
+ }
+ // Sort the max scores among the selected indices
+ // Get the indices for top scores
+ int num_indices_to_sort = std::min(output_index, max_detections);
+ DecreasingPartialArgSort(scores_after_regular_non_max_suppression,
+ output_index, num_indices_to_sort, sorted_indices);
+
+ // Copy values to temporary vectors
+ for (int row = 0; row < num_indices_to_sort; row++) {
+ int temp = sorted_indices[row];
+ sorted_indices[row] = box_indices_after_regular_non_max_suppression[temp];
+ sorted_values[row] = scores_after_regular_non_max_suppression[temp];
+ }
+ // Copy scores and indices from temporary vectors
+ for (int row = 0; row < num_indices_to_sort; row++) {
+ box_indices_after_regular_non_max_suppression[row] = sorted_indices[row];
+ scores_after_regular_non_max_suppression[row] = sorted_values[row];
+ }
+ size_of_sorted_indices = num_indices_to_sort;
+ }
+
+ // Allocate output tensors
+ for (int output_box_index = 0; output_box_index < max_detections;
+ output_box_index++) {
+ if (output_box_index < size_of_sorted_indices) {
+ const int anchor_index = floor(
+ box_indices_after_regular_non_max_suppression[output_box_index] /
+ num_classes_with_background);
+ const int class_index =
+ box_indices_after_regular_non_max_suppression[output_box_index] -
+ anchor_index * num_classes_with_background - label_offset;
+ const float selected_score =
+ scores_after_regular_non_max_suppression[output_box_index];
+ // detection_boxes
+ float* decoded_boxes = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->decoded_boxes_idx));
+ ReInterpretTensor<BoxCornerEncoding*>(detection_boxes)[output_box_index] =
+ reinterpret_cast<BoxCornerEncoding*>(decoded_boxes)[anchor_index];
+ // detection_classes
+ tflite::micro::GetTensorData<float>(detection_classes)[output_box_index] =
+ class_index;
+ // detection_scores
+ tflite::micro::GetTensorData<float>(detection_scores)[output_box_index] =
+ selected_score;
+ } else {
+ ReInterpretTensor<BoxCornerEncoding*>(
+ detection_boxes)[output_box_index] = {0.0f, 0.0f, 0.0f, 0.0f};
+ // detection_classes
+ tflite::micro::GetTensorData<float>(detection_classes)[output_box_index] =
+ 0.0f;
+ // detection_scores
+ tflite::micro::GetTensorData<float>(detection_scores)[output_box_index] =
+ 0.0f;
+ }
+ }
+ tflite::micro::GetTensorData<float>(num_detections)[0] =
+ size_of_sorted_indices;
+
+ return kTfLiteOk;
+}
+
+// This function implements a fast version of Non Maximal Suppression for
+// multiple classes where
+// 1) we keep the top-k scores for each anchor and
+// 2) during NMS, each anchor only uses the highest class score for sorting.
+// 3) Compared to standard NMS, the worst runtime of this version is O(N^2)
+// instead of O(KN^2) where N is the number of anchors and K the number of
+// classes.
+TfLiteStatus NonMaxSuppressionMultiClassFastHelper(TfLiteContext* context,
+ TfLiteNode* node,
+ OpData* op_data,
+ const float* scores) {
+ const TfLiteEvalTensor* input_box_encodings =
+ tflite::micro::GetEvalInput(context, node, kInputTensorBoxEncodings);
+ const TfLiteEvalTensor* input_class_predictions =
+ tflite::micro::GetEvalInput(context, node, kInputTensorClassPredictions);
+ TfLiteEvalTensor* detection_boxes =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensorDetectionBoxes);
+
+ TfLiteEvalTensor* detection_classes = tflite::micro::GetEvalOutput(
+ context, node, kOutputTensorDetectionClasses);
+ TfLiteEvalTensor* detection_scores =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensorDetectionScores);
+ TfLiteEvalTensor* num_detections =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensorNumDetections);
+
+ const int num_boxes = input_box_encodings->dims->data[1];
+ const int num_classes = op_data->num_classes;
+ const int max_categories_per_anchor = op_data->max_classes_per_detection;
+ const int num_classes_with_background =
+ input_class_predictions->dims->data[2];
+
+ // The row index offset is 1 if background class is included and 0 otherwise.
+ int label_offset = num_classes_with_background - num_classes;
+ TF_LITE_ENSURE(context, (max_categories_per_anchor > 0));
+ const int num_categories_per_anchor =
+ std::min(max_categories_per_anchor, num_classes);
+ float* max_scores = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->score_buffer_idx));
+ int* sorted_class_indices = reinterpret_cast<int*>(
+ context->GetScratchBuffer(context, op_data->buffer_idx));
+
+ for (int row = 0; row < num_boxes; row++) {
+ const float* box_scores =
+ scores + row * num_classes_with_background + label_offset;
+ int* class_indices = sorted_class_indices + row * num_classes;
+ DecreasingPartialArgSort(box_scores, num_classes, num_categories_per_anchor,
+ class_indices);
+ max_scores[row] = box_scores[class_indices[0]];
+ }
+
+ // Perform non-maximal suppression on max scores
+ int selected_size = 0;
+ int* selected = reinterpret_cast<int*>(
+ context->GetScratchBuffer(context, op_data->selected_idx));
+ TF_LITE_ENSURE_STATUS(NonMaxSuppressionSingleClassHelper(
+ context, node, op_data, max_scores, selected, &selected_size,
+ op_data->max_detections));
+
+ // Allocate output tensors
+ int output_box_index = 0;
+
+ for (int i = 0; i < selected_size; i++) {
+ int selected_index = selected[i];
+
+ const float* box_scores =
+ scores + selected_index * num_classes_with_background + label_offset;
+ const int* class_indices =
+ sorted_class_indices + selected_index * num_classes;
+
+ for (int col = 0; col < num_categories_per_anchor; ++col) {
+ int box_offset = num_categories_per_anchor * output_box_index + col;
+
+ // detection_boxes
+ float* decoded_boxes = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->decoded_boxes_idx));
+ ReInterpretTensor<BoxCornerEncoding*>(detection_boxes)[box_offset] =
+ reinterpret_cast<BoxCornerEncoding*>(decoded_boxes)[selected_index];
+
+ // detection_classes
+ tflite::micro::GetTensorData<float>(detection_classes)[box_offset] =
+ class_indices[col];
+
+ // detection_scores
+ tflite::micro::GetTensorData<float>(detection_scores)[box_offset] =
+ box_scores[class_indices[col]];
+
+ output_box_index++;
+ }
+ }
+
+ tflite::micro::GetTensorData<float>(num_detections)[0] = output_box_index;
+ return kTfLiteOk;
+}
+
+void DequantizeClassPredictions(const TfLiteEvalTensor* input_class_predictions,
+ const int num_boxes,
+ const int num_classes_with_background,
+ float* scores, OpData* op_data) {
+ float quant_zero_point =
+ static_cast<float>(op_data->input_class_predictions.zero_point);
+ float quant_scale =
+ static_cast<float>(op_data->input_class_predictions.scale);
+ Dequantizer dequantize(quant_zero_point, quant_scale);
+ const uint8_t* scores_quant =
+ tflite::micro::GetTensorData<uint8_t>(input_class_predictions);
+ for (int idx = 0; idx < num_boxes * num_classes_with_background; ++idx) {
+ scores[idx] = dequantize(scores_quant[idx]);
+ }
+}
+
+TfLiteStatus NonMaxSuppressionMultiClass(TfLiteContext* context,
+ TfLiteNode* node, OpData* op_data) {
+ // Get the input tensors
+ const TfLiteEvalTensor* input_box_encodings =
+ tflite::micro::GetEvalInput(context, node, kInputTensorBoxEncodings);
+ const TfLiteEvalTensor* input_class_predictions =
+ tflite::micro::GetEvalInput(context, node, kInputTensorClassPredictions);
+ const int num_boxes = input_box_encodings->dims->data[1];
+ const int num_classes = op_data->num_classes;
+
+ TF_LITE_ENSURE_EQ(context, input_class_predictions->dims->data[0],
+ kBatchSize);
+ TF_LITE_ENSURE_EQ(context, input_class_predictions->dims->data[1], num_boxes);
+ const int num_classes_with_background =
+ input_class_predictions->dims->data[2];
+
+ TF_LITE_ENSURE(context, (num_classes_with_background - num_classes <= 1));
+ TF_LITE_ENSURE(context, (num_classes_with_background >= num_classes));
+
+ const float* scores;
+ switch (input_class_predictions->type) {
+ case kTfLiteUInt8: {
+ float* temporary_scores = reinterpret_cast<float*>(
+ context->GetScratchBuffer(context, op_data->scores_idx));
+ DequantizeClassPredictions(input_class_predictions, num_boxes,
+ num_classes_with_background, temporary_scores,
+ op_data);
+ scores = temporary_scores;
+ } break;
+ case kTfLiteFloat32:
+ scores = tflite::micro::GetTensorData<float>(input_class_predictions);
+ break;
+ default:
+ // Unsupported type.
+ return kTfLiteError;
+ }
+
+ if (op_data->use_regular_non_max_suppression) {
+ TF_LITE_ENSURE_STATUS(NonMaxSuppressionMultiClassRegularHelper(
+ context, node, op_data, scores));
+ } else {
+ TF_LITE_ENSURE_STATUS(
+ NonMaxSuppressionMultiClassFastHelper(context, node, op_data, scores));
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE(context, (kBatchSize == 1));
+ auto* op_data = static_cast<OpData*>(node->user_data);
+
+ // These two functions correspond to two blocks in the Object Detection model.
+ // In future, we would like to break the custom op in two blocks, which is
+ // currently not feasible because we would like to input quantized inputs
+ // and do all calculations in float. Mixed quantized/float calculations are
+ // currently not supported in TFLite.
+
+ // This fills in temporary decoded_boxes
+ // by transforming input_box_encodings and input_anchors from
+ // CenterSizeEncodings to BoxCornerEncoding
+ TF_LITE_ENSURE_STATUS(DecodeCenterSizeBoxes(context, node, op_data));
+
+ // This fills in the output tensors
+ // by choosing effective set of decoded boxes
+ // based on Non Maximal Suppression, i.e. selecting
+ // highest scoring non-overlapping boxes.
+ TF_LITE_ENSURE_STATUS(NonMaxSuppressionMultiClass(context, node, op_data));
+
+ return kTfLiteOk;
+}
+} // namespace
+
+TfLiteRegistration* Register_DETECTION_POSTPROCESS() {
+ static TfLiteRegistration r = {/*init=*/Init,
+ /*free=*/Free,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+ return &r;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.cc b/tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.cc
new file mode 100644
index 0000000..665e01e
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.cc
@@ -0,0 +1,68 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// This file is generated. See:
+// tensorflow/lite/micro/kernels/detection_postprocess_test/README.md
+
+#include "tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.h"
+
+const int g_gen_data_size_none_regular_nms = 242;
+const unsigned char g_gen_data_none_regular_nms[] = {
+ 0x6d, 0x61, 0x78, 0x5f, 0x64, 0x65, 0x74, 0x65, 0x63, 0x74, 0x69, 0x6f,
+ 0x6e, 0x73, 0x00, 0x6d, 0x61, 0x78, 0x5f, 0x63, 0x6c, 0x61, 0x73, 0x73,
+ 0x65, 0x73, 0x5f, 0x70, 0x65, 0x72, 0x5f, 0x64, 0x65, 0x74, 0x65, 0x63,
+ 0x74, 0x69, 0x6f, 0x6e, 0x00, 0x64, 0x65, 0x74, 0x65, 0x63, 0x74, 0x69,
+ 0x6f, 0x6e, 0x73, 0x5f, 0x70, 0x65, 0x72, 0x5f, 0x63, 0x6c, 0x61, 0x73,
+ 0x73, 0x00, 0x75, 0x73, 0x65, 0x5f, 0x72, 0x65, 0x67, 0x75, 0x6c, 0x61,
+ 0x72, 0x5f, 0x6e, 0x6d, 0x73, 0x00, 0x6e, 0x6d, 0x73, 0x5f, 0x73, 0x63,
+ 0x6f, 0x72, 0x65, 0x5f, 0x74, 0x68, 0x72, 0x65, 0x73, 0x68, 0x6f, 0x6c,
+ 0x64, 0x00, 0x6e, 0x6d, 0x73, 0x5f, 0x69, 0x6f, 0x75, 0x5f, 0x74, 0x68,
+ 0x72, 0x65, 0x73, 0x68, 0x6f, 0x6c, 0x64, 0x00, 0x6e, 0x75, 0x6d, 0x5f,
+ 0x63, 0x6c, 0x61, 0x73, 0x73, 0x65, 0x73, 0x00, 0x79, 0x5f, 0x73, 0x63,
+ 0x61, 0x6c, 0x65, 0x00, 0x78, 0x5f, 0x73, 0x63, 0x61, 0x6c, 0x65, 0x00,
+ 0x68, 0x5f, 0x73, 0x63, 0x61, 0x6c, 0x65, 0x00, 0x77, 0x5f, 0x73, 0x63,
+ 0x61, 0x6c, 0x65, 0x00, 0x0b, 0x78, 0x12, 0x94, 0xa4, 0x43, 0x58, 0x33,
+ 0x6a, 0x11, 0x22, 0x2b, 0x0b, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0b, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0xa0, 0x40,
+ 0x01, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x3f,
+ 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0xa0, 0x40, 0x00, 0x00, 0x20, 0x41, 0x00, 0x00, 0x20, 0x41,
+ 0x06, 0x0e, 0x06, 0x06, 0x0e, 0x0e, 0x06, 0x6a, 0x0e, 0x0e, 0x0e, 0x37,
+ 0x26, 0x01,
+};
+const int g_gen_data_size_regular_nms = 242;
+const unsigned char g_gen_data_regular_nms[] = {
+ 0x6d, 0x61, 0x78, 0x5f, 0x64, 0x65, 0x74, 0x65, 0x63, 0x74, 0x69, 0x6f,
+ 0x6e, 0x73, 0x00, 0x6d, 0x61, 0x78, 0x5f, 0x63, 0x6c, 0x61, 0x73, 0x73,
+ 0x65, 0x73, 0x5f, 0x70, 0x65, 0x72, 0x5f, 0x64, 0x65, 0x74, 0x65, 0x63,
+ 0x74, 0x69, 0x6f, 0x6e, 0x00, 0x64, 0x65, 0x74, 0x65, 0x63, 0x74, 0x69,
+ 0x6f, 0x6e, 0x73, 0x5f, 0x70, 0x65, 0x72, 0x5f, 0x63, 0x6c, 0x61, 0x73,
+ 0x73, 0x00, 0x75, 0x73, 0x65, 0x5f, 0x72, 0x65, 0x67, 0x75, 0x6c, 0x61,
+ 0x72, 0x5f, 0x6e, 0x6d, 0x73, 0x00, 0x6e, 0x6d, 0x73, 0x5f, 0x73, 0x63,
+ 0x6f, 0x72, 0x65, 0x5f, 0x74, 0x68, 0x72, 0x65, 0x73, 0x68, 0x6f, 0x6c,
+ 0x64, 0x00, 0x6e, 0x6d, 0x73, 0x5f, 0x69, 0x6f, 0x75, 0x5f, 0x74, 0x68,
+ 0x72, 0x65, 0x73, 0x68, 0x6f, 0x6c, 0x64, 0x00, 0x6e, 0x75, 0x6d, 0x5f,
+ 0x63, 0x6c, 0x61, 0x73, 0x73, 0x65, 0x73, 0x00, 0x79, 0x5f, 0x73, 0x63,
+ 0x61, 0x6c, 0x65, 0x00, 0x78, 0x5f, 0x73, 0x63, 0x61, 0x6c, 0x65, 0x00,
+ 0x68, 0x5f, 0x73, 0x63, 0x61, 0x6c, 0x65, 0x00, 0x77, 0x5f, 0x73, 0x63,
+ 0x61, 0x6c, 0x65, 0x00, 0x0b, 0x78, 0x12, 0x94, 0xa4, 0x43, 0x58, 0x33,
+ 0x6a, 0x11, 0x22, 0x2b, 0x0b, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0b, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0xa0, 0x40,
+ 0x01, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x3f,
+ 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0xa0, 0x40, 0x00, 0x00, 0x20, 0x41, 0x00, 0x00, 0x20, 0x41,
+ 0x06, 0x0e, 0x06, 0x06, 0x0e, 0x0e, 0x06, 0x6a, 0x0e, 0x0e, 0x0e, 0x37,
+ 0x26, 0x01,
+};
diff --git a/tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.h b/tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.h
new file mode 100644
index 0000000..f5b9eae
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.h
@@ -0,0 +1,25 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_FLEXBUFFERS_GENERATED_DATA_H
+#define TENSORFLOW_LITE_MICRO_KERNELS_FLEXBUFFERS_GENERATED_DATA_H
+
+extern const int g_gen_data_size_none_regular_nms;
+extern const unsigned char g_gen_data_none_regular_nms[];
+
+extern const int g_gen_data_size_regular_nms;
+extern const unsigned char g_gen_data_regular_nms[];
+
+#endif
diff --git a/tensorflow/lite/micro/kernels/detection_postprocess_test.cc b/tensorflow/lite/micro/kernels/detection_postprocess_test.cc
new file mode 100644
index 0000000..473258d
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/detection_postprocess_test.cc
@@ -0,0 +1,479 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "flatbuffers/flexbuffers.h"
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+// See: tensorflow/lite/micro/kernels/detection_postprocess_test/README.md
+#include "tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Common inputs and outputs.
+
+static constexpr int kInputShape1[] = {3, 1, 6, 4};
+static constexpr int kInputShape2[] = {3, 1, 6, 3};
+static constexpr int kInputShape3[] = {2, 6, 4};
+static constexpr int kOutputShape1[] = {3, 1, 3, 4};
+static constexpr int kOutputShape2[] = {2, 1, 3};
+static constexpr int kOutputShape3[] = {2, 1, 3};
+static constexpr int kOutputShape4[] = {1, 1};
+
+// six boxes in center-size encoding
+static constexpr float kInputData1[] = {
+ 0.0, 0.0, 0.0, 0.0, // box #1
+ 0.0, 1.0, 0.0, 0.0, // box #2
+ 0.0, -1.0, 0.0, 0.0, // box #3
+ 0.0, 0.0, 0.0, 0.0, // box #4
+ 0.0, 1.0, 0.0, 0.0, // box #5
+ 0.0, 0.0, 0.0, 0.0 // box #6
+};
+
+// class scores - two classes with background
+static constexpr float kInputData2[] = {0., .9, .8, 0., .75, .72, 0., .6, .5,
+ 0., .93, .95, 0., .5, .4, 0., .3, .2};
+
+// six anchors in center-size encoding
+static constexpr float kInputData3[] = {
+ 0.5, 0.5, 1.0, 1.0, // anchor #1
+ 0.5, 0.5, 1.0, 1.0, // anchor #2
+ 0.5, 0.5, 1.0, 1.0, // anchor #3
+ 0.5, 10.5, 1.0, 1.0, // anchor #4
+ 0.5, 10.5, 1.0, 1.0, // anchor #5
+ 0.5, 100.5, 1.0, 1.0 // anchor #6
+};
+// Same boxes in box-corner encoding:
+// { 0.0, 0.0, 1.0, 1.0,
+// 0.0, 0.1, 1.0, 1.1,
+// 0.0, -0.1, 1.0, 0.9,
+// 0.0, 10.0, 1.0, 11.0,
+// 0.0, 10.1, 1.0, 11.1,
+// 0.0, 100.0, 1.0, 101.0}
+
+static constexpr float kGolden1[] = {0.0, 10.0, 1.0, 11.0, 0.0, 0.0,
+ 1.0, 1.0, 0.0, 100.0, 1.0, 101.0};
+static constexpr float kGolden2[] = {1, 0, 0};
+static constexpr float kGolden3[] = {0.95, 0.9, 0.3};
+static constexpr float kGolden4[] = {3.0};
+
+void TestDetectionPostprocess(
+ const int* input_dims_data1, const float* input_data1,
+ const int* input_dims_data2, const float* input_data2,
+ const int* input_dims_data3, const float* input_data3,
+ const int* output_dims_data1, float* output_data1,
+ const int* output_dims_data2, float* output_data2,
+ const int* output_dims_data3, float* output_data3,
+ const int* output_dims_data4, float* output_data4, const float* golden1,
+ const float* golden2, const float* golden3, const float* golden4,
+ const float tolerance, bool use_regular_nms,
+ uint8_t* input_data_quantized1 = nullptr,
+ uint8_t* input_data_quantized2 = nullptr,
+ uint8_t* input_data_quantized3 = nullptr, const float input_min1 = 0,
+ const float input_max1 = 0, const float input_min2 = 0,
+ const float input_max2 = 0, const float input_min3 = 0,
+ const float input_max3 = 0) {
+ TfLiteIntArray* input_dims1 = IntArrayFromInts(input_dims_data1);
+ TfLiteIntArray* input_dims2 = IntArrayFromInts(input_dims_data2);
+ TfLiteIntArray* input_dims3 = IntArrayFromInts(input_dims_data3);
+ TfLiteIntArray* output_dims1 = nullptr;
+ TfLiteIntArray* output_dims2 = nullptr;
+ TfLiteIntArray* output_dims3 = nullptr;
+ TfLiteIntArray* output_dims4 = nullptr;
+
+ const int zero_length_int_array_data[] = {0};
+ TfLiteIntArray* zero_length_int_array =
+ IntArrayFromInts(zero_length_int_array_data);
+
+ output_dims1 = output_dims_data1 == nullptr
+ ? const_cast<TfLiteIntArray*>(zero_length_int_array)
+ : IntArrayFromInts(output_dims_data1);
+ output_dims2 = output_dims_data2 == nullptr
+ ? const_cast<TfLiteIntArray*>(zero_length_int_array)
+ : IntArrayFromInts(output_dims_data2);
+ output_dims3 = output_dims_data3 == nullptr
+ ? const_cast<TfLiteIntArray*>(zero_length_int_array)
+ : IntArrayFromInts(output_dims_data3);
+ output_dims4 = output_dims_data4 == nullptr
+ ? const_cast<TfLiteIntArray*>(zero_length_int_array)
+ : IntArrayFromInts(output_dims_data4);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 4;
+ constexpr int tensors_size = inputs_size + outputs_size;
+
+ TfLiteTensor tensors[tensors_size];
+ if (input_min1 != 0 || input_max1 != 0 || input_min2 != 0 ||
+ input_max2 != 0 || input_min3 != 0 || input_max3 != 0) {
+ const float input_scale1 = ScaleFromMinMax<uint8_t>(input_min1, input_max1);
+ const int input_zero_point1 =
+ ZeroPointFromMinMax<uint8_t>(input_min1, input_max1);
+ const float input_scale2 = ScaleFromMinMax<uint8_t>(input_min2, input_max2);
+ const int input_zero_point2 =
+ ZeroPointFromMinMax<uint8_t>(input_min2, input_max2);
+ const float input_scale3 = ScaleFromMinMax<uint8_t>(input_min3, input_max3);
+ const int input_zero_point3 =
+ ZeroPointFromMinMax<uint8_t>(input_min3, input_max3);
+
+ tensors[0] =
+ CreateQuantizedTensor(input_data1, input_data_quantized1, input_dims1,
+ input_scale1, input_zero_point1);
+ tensors[1] =
+ CreateQuantizedTensor(input_data2, input_data_quantized2, input_dims2,
+ input_scale2, input_zero_point2);
+ tensors[2] =
+ CreateQuantizedTensor(input_data3, input_data_quantized3, input_dims3,
+ input_scale3, input_zero_point3);
+ } else {
+ tensors[0] = CreateTensor(input_data1, input_dims1);
+ tensors[1] = CreateTensor(input_data2, input_dims2);
+ tensors[2] = CreateTensor(input_data3, input_dims3);
+ }
+ tensors[3] = CreateTensor(output_data1, output_dims1);
+ tensors[4] = CreateTensor(output_data2, output_dims2);
+ tensors[5] = CreateTensor(output_data3, output_dims3);
+ tensors[6] = CreateTensor(output_data4, output_dims4);
+
+ ::tflite::AllOpsResolver resolver;
+ const TfLiteRegistration* registration =
+ resolver.FindOp("TFLite_Detection_PostProcess");
+ TF_LITE_MICRO_EXPECT_NE(nullptr, registration);
+
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {4, 3, 4, 5, 6};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(*registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ // Using generated data as input to operator.
+ int data_size = 0;
+ const unsigned char* init_data = nullptr;
+ if (use_regular_nms) {
+ init_data = g_gen_data_regular_nms;
+ data_size = g_gen_data_size_regular_nms;
+ } else {
+ init_data = g_gen_data_none_regular_nms;
+ data_size = g_gen_data_size_none_regular_nms;
+ }
+
+ // TfLite uses a char* for the raw bytes whereas flexbuffers use an unsigned
+ // char*. This small discrepancy results in compiler warnings unless we
+ // reinterpret_cast right before passing in the flexbuffer bytes to the
+ // KernelRunner.
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, runner.InitAndPrepare(reinterpret_cast<const char*>(init_data),
+ data_size));
+
+ // Output dimensions should not be undefined after Prepare
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensors[3].dims);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensors[4].dims);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensors[5].dims);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensors[6].dims);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ const int output_elements_count1 = tensors[3].dims->size;
+ const int output_elements_count2 = tensors[4].dims->size;
+ const int output_elements_count3 = tensors[5].dims->size;
+ const int output_elements_count4 = tensors[6].dims->size;
+
+ for (int i = 0; i < output_elements_count1; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden1[i], output_data1[i], tolerance);
+ }
+ for (int i = 0; i < output_elements_count2; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden2[i], output_data2[i], tolerance);
+ }
+ for (int i = 0; i < output_elements_count3; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden3[i], output_data3[i], tolerance);
+ }
+ for (int i = 0; i < output_elements_count4; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden4[i], output_data4[i], tolerance);
+ }
+}
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(DetectionPostprocessFloatFastNMS) {
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+
+ tflite::testing::TestDetectionPostprocess(
+ tflite::testing::kInputShape1, tflite::testing::kInputData1,
+ tflite::testing::kInputShape2, tflite::testing::kInputData2,
+ tflite::testing::kInputShape3, tflite::testing::kInputData3,
+ tflite::testing::kOutputShape1, output_data1,
+ tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, tflite::testing::kGolden1,
+ tflite::testing::kGolden2, tflite::testing::kGolden3,
+ tflite::testing::kGolden4,
+ /* tolerance */ 0, /* Use regular NMS: */ false);
+}
+
+TF_LITE_MICRO_TEST(DetectionPostprocessQuantizedFastNMS) {
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+ const int kInputElements1 = tflite::testing::kInputShape1[1] *
+ tflite::testing::kInputShape1[2] *
+ tflite::testing::kInputShape1[3];
+ const int kInputElements2 = tflite::testing::kInputShape2[1] *
+ tflite::testing::kInputShape2[2] *
+ tflite::testing::kInputShape2[3];
+ const int kInputElements3 =
+ tflite::testing::kInputShape3[1] * tflite::testing::kInputShape3[2];
+
+ uint8_t input_data_quantized1[kInputElements1 + 10];
+ uint8_t input_data_quantized2[kInputElements2 + 10];
+ uint8_t input_data_quantized3[kInputElements3 + 10];
+
+ tflite::testing::TestDetectionPostprocess(
+ tflite::testing::kInputShape1, tflite::testing::kInputData1,
+ tflite::testing::kInputShape2, tflite::testing::kInputData2,
+ tflite::testing::kInputShape3, tflite::testing::kInputData3,
+ tflite::testing::kOutputShape1, output_data1,
+ tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, tflite::testing::kGolden1,
+ tflite::testing::kGolden2, tflite::testing::kGolden3,
+ tflite::testing::kGolden4,
+ /* tolerance */ 3e-1, /* Use regular NMS: */ false, input_data_quantized1,
+ input_data_quantized2, input_data_quantized3,
+ /* input1 min/max*/ -1.0, 1.0, /* input2 min/max */ 0.0, 1.0,
+ /* input3 min/max */ 0.0, 100.5);
+}
+
+TF_LITE_MICRO_TEST(DetectionPostprocessFloatRegularNMS) {
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+ const float kGolden1[] = {0.0, 10.0, 1.0, 11.0, 0.0, 10.0,
+ 1.0, 11.0, 0.0, 0.0, 0.0, 0.0};
+ const float kGolden3[] = {0.95, 0.9, 0.0};
+ const float kGolden4[] = {2.0};
+
+ tflite::testing::TestDetectionPostprocess(
+ tflite::testing::kInputShape1, tflite::testing::kInputData1,
+ tflite::testing::kInputShape2, tflite::testing::kInputData2,
+ tflite::testing::kInputShape3, tflite::testing::kInputData3,
+ tflite::testing::kOutputShape1, output_data1,
+ tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, kGolden1,
+ tflite::testing::kGolden2, kGolden3, kGolden4,
+ /* tolerance */ 1e-1, /* Use regular NMS: */ true);
+}
+
+TF_LITE_MICRO_TEST(DetectionPostprocessQuantizedRegularNMS) {
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+ const int kInputElements1 = tflite::testing::kInputShape1[1] *
+ tflite::testing::kInputShape1[2] *
+ tflite::testing::kInputShape1[3];
+ const int kInputElements2 = tflite::testing::kInputShape2[1] *
+ tflite::testing::kInputShape2[2] *
+ tflite::testing::kInputShape2[3];
+ const int kInputElements3 =
+ tflite::testing::kInputShape3[1] * tflite::testing::kInputShape3[2];
+
+ uint8_t input_data_quantized1[kInputElements1 + 10];
+ uint8_t input_data_quantized2[kInputElements2 + 10];
+ uint8_t input_data_quantized3[kInputElements3 + 10];
+
+ const float kGolden1[] = {0.0, 10.0, 1.0, 11.0, 0.0, 10.0,
+ 1.0, 11.0, 0.0, 0.0, 0.0, 0.0};
+ const float kGolden3[] = {0.95, 0.9, 0.0};
+ const float kGolden4[] = {2.0};
+
+ tflite::testing::TestDetectionPostprocess(
+ tflite::testing::kInputShape1, tflite::testing::kInputData1,
+ tflite::testing::kInputShape2, tflite::testing::kInputData2,
+ tflite::testing::kInputShape3, tflite::testing::kInputData3,
+ tflite::testing::kOutputShape1, output_data1,
+ tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, kGolden1,
+ tflite::testing::kGolden2, kGolden3, kGolden4,
+ /* tolerance */ 3e-1, /* Use regular NMS: */ true, input_data_quantized1,
+ input_data_quantized2, input_data_quantized3,
+ /* input1 min/max*/ -1.0, 1.0, /* input2 min/max */ 0.0, 1.0,
+ /* input3 min/max */ 0.0, 100.5);
+}
+
+TF_LITE_MICRO_TEST(
+ DetectionPostprocessFloatFastNMSwithNoBackgroundClassAndKeypoints) {
+ const int kInputShape1[] = {3, 1, 6, 5};
+ const int kInputShape2[] = {3, 1, 6, 2};
+
+ // six boxes in center-size encoding
+ const float kInputData1[] = {
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #1
+ 0.0, 1.0, 0.0, 0.0, 1.0, // box #2
+ 0.0, -1.0, 0.0, 0.0, 1.0, // box #3
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #4
+ 0.0, 1.0, 0.0, 0.0, 1.0, // box #5
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #6
+ };
+
+ // class scores - two classes without background
+ const float kInputData2[] = {.9, .8, .75, .72, .6, .5,
+ .93, .95, .5, .4, .3, .2};
+
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+
+ tflite::testing::TestDetectionPostprocess(
+ kInputShape1, kInputData1, kInputShape2, kInputData2,
+ tflite::testing::kInputShape3, tflite::testing::kInputData3,
+ tflite::testing::kOutputShape1, output_data1,
+ tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, tflite::testing::kGolden1,
+ tflite::testing::kGolden2, tflite::testing::kGolden3,
+ tflite::testing::kGolden4,
+ /* tolerance */ 0, /* Use regular NMS: */ false);
+}
+
+TF_LITE_MICRO_TEST(
+ DetectionPostprocessFloatRegularNMSwithNoBackgroundClassAndKeypoints) {
+ const int kInputShape2[] = {3, 1, 6, 2};
+
+ // class scores - two classes without background
+ const float kInputData2[] = {.9, .8, .75, .72, .6, .5,
+ .93, .95, .5, .4, .3, .2};
+
+ const float kGolden1[] = {0.0, 10.0, 1.0, 11.0, 0.0, 10.0,
+ 1.0, 11.0, 0.0, 0.0, 0.0, 0.0};
+ const float kGolden3[] = {0.95, 0.9, 0.0};
+ const float kGolden4[] = {2.0};
+
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+
+ tflite::testing::TestDetectionPostprocess(
+ tflite::testing::kInputShape1, tflite::testing::kInputData1, kInputShape2,
+ kInputData2, tflite::testing::kInputShape3, tflite::testing::kInputData3,
+ tflite::testing::kOutputShape1, output_data1,
+ tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, kGolden1,
+ tflite::testing::kGolden2, kGolden3, kGolden4,
+ /* tolerance */ 1e-1, /* Use regular NMS: */ true);
+}
+
+TF_LITE_MICRO_TEST(
+ DetectionPostprocessFloatFastNMSWithBackgroundClassAndKeypoints) {
+ const int kInputShape1[] = {3, 1, 6, 5};
+
+ // six boxes in center-size encoding
+ const float kInputData1[] = {
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #1
+ 0.0, 1.0, 0.0, 0.0, 1.0, // box #2
+ 0.0, -1.0, 0.0, 0.0, 1.0, // box #3
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #4
+ 0.0, 1.0, 0.0, 0.0, 1.0, // box #5
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #6
+ };
+
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+
+ tflite::testing::TestDetectionPostprocess(
+ kInputShape1, kInputData1, tflite::testing::kInputShape2,
+ tflite::testing::kInputData2, tflite::testing::kInputShape3,
+ tflite::testing::kInputData3, tflite::testing::kOutputShape1,
+ output_data1, tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, tflite::testing::kGolden1,
+ tflite::testing::kGolden2, tflite::testing::kGolden3,
+ tflite::testing::kGolden4,
+ /* tolerance */ 0, /* Use regular NMS: */ false);
+}
+
+TF_LITE_MICRO_TEST(
+ DetectionPostprocessQuantizedFastNMSwithNoBackgroundClassAndKeypoints) {
+ const int kInputShape1[] = {3, 1, 6, 5};
+ const int kInputShape2[] = {3, 1, 6, 2};
+
+ // six boxes in center-size encoding
+ const float kInputData1[] = {
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #1
+ 0.0, 1.0, 0.0, 0.0, 1.0, // box #2
+ 0.0, -1.0, 0.0, 0.0, 1.0, // box #3
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #4
+ 0.0, 1.0, 0.0, 0.0, 1.0, // box #5
+ 0.0, 0.0, 0.0, 0.0, 1.0, // box #6
+ };
+
+ // class scores - two classes without background
+ const float kInputData2[] = {.9, .8, .75, .72, .6, .5,
+ .93, .95, .5, .4, .3, .2};
+
+ const int kInputElements1 = tflite::testing::kInputShape1[1] *
+ tflite::testing::kInputShape1[2] *
+ tflite::testing::kInputShape1[3];
+ const int kInputElements2 = tflite::testing::kInputShape2[1] *
+ tflite::testing::kInputShape2[2] *
+ tflite::testing::kInputShape2[3];
+ const int kInputElements3 =
+ tflite::testing::kInputShape3[1] * tflite::testing::kInputShape3[2];
+
+ uint8_t input_data_quantized1[kInputElements1 + 10];
+ uint8_t input_data_quantized2[kInputElements2 + 10];
+ uint8_t input_data_quantized3[kInputElements3 + 10];
+
+ float output_data1[12];
+ float output_data2[3];
+ float output_data3[3];
+ float output_data4[1];
+
+ tflite::testing::TestDetectionPostprocess(
+ kInputShape1, kInputData1, kInputShape2, kInputData2,
+ tflite::testing::kInputShape3, tflite::testing::kInputData3,
+ tflite::testing::kOutputShape1, output_data1,
+ tflite::testing::kOutputShape2, output_data2,
+ tflite::testing::kOutputShape3, output_data3,
+ tflite::testing::kOutputShape4, output_data4, tflite::testing::kGolden1,
+ tflite::testing::kGolden2, tflite::testing::kGolden3,
+ tflite::testing::kGolden4,
+ /* tolerance */ 3e-1, /* Use regular NMS: */ false, input_data_quantized1,
+ input_data_quantized2, input_data_quantized3,
+ /* input1 min/max*/ -1.0, 1.0, /* input2 min/max */ 0.0, 1.0,
+ /* input3 min/max */ 0.0, 100.5);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/elementwise.cc b/tensorflow/lite/micro/kernels/elementwise.cc
new file mode 100644
index 0000000..581e532
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/elementwise.cc
@@ -0,0 +1,214 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cmath>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace elementwise {
+namespace {
+
+bool IsNumericSupportedType(const TfLiteType type) {
+ return type == kTfLiteFloat32;
+}
+
+bool IsLogicalSupportedType(const TfLiteType type) {
+ return type == kTfLiteBool;
+}
+
+typedef bool (*IsSupportedType)(TfLiteType);
+template <IsSupportedType>
+TfLiteStatus GenericPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, 0);
+ TF_LITE_ENSURE(context, output != nullptr);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ if (!IsSupportedType(input->type)) {
+ TF_LITE_KERNEL_LOG(context, "Input data type %s (%d) is not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+template <typename T>
+inline TfLiteStatus EvalImpl(TfLiteContext* context, TfLiteNode* node,
+ T func(T), TfLiteType expected_type) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, expected_type);
+ const size_t num_elements = ElementCount(*input->dims);
+ const T* in_data = tflite::micro::GetTensorData<T>(input);
+ T* out_data = tflite::micro::GetTensorData<T>(output);
+ for (size_t i = 0; i < num_elements; ++i) {
+ out_data[i] = func(in_data[i]);
+ }
+ return kTfLiteOk;
+}
+
+inline TfLiteStatus EvalNumeric(TfLiteContext* context, TfLiteNode* node,
+ float float_func(float)) {
+ return EvalImpl<float>(context, node, float_func, kTfLiteFloat32);
+}
+
+inline TfLiteStatus EvalLogical(TfLiteContext* context, TfLiteNode* node,
+ bool bool_func(bool)) {
+ return EvalImpl<bool>(context, node, bool_func, kTfLiteBool);
+}
+
+TfLiteStatus AbsEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalNumeric(context, node, std::abs);
+}
+
+TfLiteStatus SinEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalNumeric(context, node, std::sin);
+}
+
+TfLiteStatus CosEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalNumeric(context, node, std::cos);
+}
+
+TfLiteStatus LogEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalNumeric(context, node, std::log);
+}
+
+TfLiteStatus SqrtEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalNumeric(context, node, std::sqrt);
+}
+
+TfLiteStatus RsqrtEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalNumeric(context, node, [](float f) { return 1.f / std::sqrt(f); });
+}
+
+TfLiteStatus SquareEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalNumeric(context, node, [](float f) { return f * f; });
+}
+
+TfLiteStatus LogicalNotEval(TfLiteContext* context, TfLiteNode* node) {
+ return EvalLogical(context, node, [](bool v) { return !v; });
+}
+
+} // namespace
+} // namespace elementwise
+
+TfLiteRegistration Register_ABS() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsNumericSupportedType>,
+ /*invoke=*/elementwise::AbsEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_SIN() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsNumericSupportedType>,
+ /*invoke=*/elementwise::SinEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_COS() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsNumericSupportedType>,
+ /*invoke=*/elementwise::CosEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_LOG() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsNumericSupportedType>,
+ /*invoke=*/elementwise::LogEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_SQRT() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsNumericSupportedType>,
+ /*invoke=*/elementwise::SqrtEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_RSQRT() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsNumericSupportedType>,
+ /*invoke=*/elementwise::RsqrtEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_SQUARE() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsNumericSupportedType>,
+ /*invoke=*/elementwise::SquareEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_LOGICAL_NOT() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/
+ elementwise::GenericPrepare<elementwise::IsLogicalSupportedType>,
+ /*invoke=*/elementwise::LogicalNotEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/elementwise_test.cc b/tensorflow/lite/micro/kernels/elementwise_test.cc
new file mode 100644
index 0000000..a59106c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/elementwise_test.cc
@@ -0,0 +1,192 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/debug_log.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+
+void TestElementwiseFloat(const TfLiteRegistration& registration,
+ const int* input_dims_data, const float* input_data,
+ const int* output_dims_data,
+ const float* expected_output_data,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims)};
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output_dims_count; ++i) {
+ output_data[i] = 23;
+ }
+
+ static int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ static int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestElementwiseBool(const TfLiteRegistration& registration,
+ const int* input_dims_data, const bool* input_data,
+ const int* output_dims_data,
+ const bool* expected_output_data, bool* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims)};
+
+ // Place false in the uninitialized output buffer.
+ for (int i = 0; i < output_dims_count; ++i) {
+ output_data[i] = false;
+ }
+
+ const int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ const int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(Abs) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const float input[] = {0.01, -0.01, 10, -10};
+ const float golden[] = {0.01, 0.01, 10, 10};
+ float output_data[output_dims_count];
+ tflite::testing::TestElementwiseFloat(tflite::ops::micro::Register_ABS(),
+ shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Sin) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const float input[] = {0, 3.1415926, -3.1415926, 1};
+ const float golden[] = {0, 0, 0, 0.84147};
+ float output_data[output_dims_count];
+ tflite::testing::TestElementwiseFloat(tflite::ops::micro::Register_SIN(),
+ shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Cos) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const float input[] = {0, 3.1415926, -3.1415926, 1};
+ const float golden[] = {1, -1, -1, 0.54030};
+ float output_data[output_dims_count];
+ tflite::testing::TestElementwiseFloat(tflite::ops::micro::Register_COS(),
+ shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Log) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const float input[] = {1, 2.7182818, 0.5, 2};
+ const float golden[] = {0, 1, -0.6931472, 0.6931472};
+ float output_data[output_dims_count];
+ tflite::testing::TestElementwiseFloat(tflite::ops::micro::Register_LOG(),
+ shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Sqrt) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const float input[] = {0, 1, 2, 4};
+ const float golden[] = {0, 1, 1.41421, 2};
+ float output_data[output_dims_count];
+ tflite::testing::TestElementwiseFloat(tflite::ops::micro::Register_SQRT(),
+ shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Rsqrt) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const float input[] = {1, 2, 4, 9};
+ const float golden[] = {1, 0.7071, 0.5, 0.33333};
+ float output_data[output_dims_count];
+ tflite::testing::TestElementwiseFloat(tflite::ops::micro::Register_RSQRT(),
+ shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Square) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const float input[] = {1, 2, 0.5, -3.0};
+ const float golden[] = {1, 4.0, 0.25, 9.0};
+ float output_data[output_dims_count];
+ tflite::testing::TestElementwiseFloat(tflite::ops::micro::Register_SQUARE(),
+ shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(LogicalNot) {
+ constexpr int output_dims_count = 4;
+ const int shape[] = {2, 2, 2};
+ const bool input[] = {true, false, false, true};
+ const bool golden[] = {false, true, true, false};
+ bool output_data[output_dims_count];
+ tflite::testing::TestElementwiseBool(
+ tflite::ops::micro::Register_LOGICAL_NOT(), shape, input, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/elu.cc b/tensorflow/lite/micro/kernels/elu.cc
new file mode 100644
index 0000000..a3b8107
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/elu.cc
@@ -0,0 +1,151 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/elu.h"
+
+#include <algorithm>
+#include <limits>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/cppmath.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+// Input/output tensor index.
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+// OLD-TODO(b/142762739): We should figure out a multi-threading plan for most
+// of the activation ops below.
+
+struct OpData {
+ int8_t table[256];
+};
+
+using TransformFunc = float (*)(float);
+
+template <typename T>
+void PopulateLookupTable(const TfLiteTensor* input, const TfLiteTensor* output,
+ const TransformFunc transform, OpData* data) {
+ if (sizeof(T) != 1) TF_LITE_FATAL("Lookup table valid only for 8bit");
+
+ const float inverse_scale = 1 / output->params.scale;
+ int32_t maxval = std::numeric_limits<T>::max();
+ int32_t minval = std::numeric_limits<T>::min();
+ for (int32_t val = minval; val <= maxval; ++val) {
+ const float dequantized =
+ input->params.scale * (val - input->params.zero_point);
+ const float transformed = transform(dequantized);
+ const float rescaled = TfLiteRound(transformed * inverse_scale);
+ const int32_t quantized =
+ static_cast<int32_t>(rescaled + output->params.zero_point);
+ data->table[static_cast<uint8_t>(static_cast<T>(val))] =
+ static_cast<T>(std::max(std::min(maxval, quantized), minval));
+ }
+}
+
+// OLD-TODO(b/143696793): move this to optimized_ops.
+void EvalUsingLookupTable(const OpData* data, const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output) {
+ const int size = MatchingFlatSize(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorShape(output));
+ int8_t* output_data = tflite::micro::GetTensorData<int8_t>(output);
+ const int8_t* input_data = tflite::micro::GetTensorData<int8_t>(input);
+
+ for (int i = 0; i < size; ++i) {
+ output_data[i] = data->table[static_cast<uint8_t>(input_data[i])];
+ }
+}
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ // Use LUT to handle quantized elu path.
+ if (input->type == kTfLiteInt8) {
+ OpData* data = static_cast<OpData*>(node->user_data);
+ TransformFunc transform = [](float value) {
+ return value < 0.0f ? std::exp(value) - 1.0f : value;
+ };
+ PopulateLookupTable<int8_t>(input, output, transform, data);
+ }
+
+ return kTfLiteOk;
+}
+
+void* EluInit(TfLiteContext* context, const char* buffer, size_t length) {
+ // This is a builtin op, so we don't use the contents in 'buffer', if any.
+ // Instead, we allocate a new object to carry information from Prepare() to
+ // Eval().
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus EluPrepare(TfLiteContext* context, TfLiteNode* node) {
+ return CalculateOpData(context, node);
+}
+
+TfLiteStatus EluEval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ reference_ops::Elu(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ }
+ case kTfLiteInt8: {
+ const OpData* data = static_cast<OpData*>(node->user_data);
+ EvalUsingLookupTable(data, input, output);
+ return kTfLiteOk;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(
+ context, "ELU only supports float32 and int8 currently, got %s.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+}
+
+} // namespace
+
+TfLiteRegistration Register_ELU() {
+ return {/*init=*/EluInit,
+ /*free=*/nullptr,
+ /*prepare=*/EluPrepare,
+ /*invoke=*/EluEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/elu_test.cc b/tensorflow/lite/micro/kernels/elu_test.cc
new file mode 100644
index 0000000..ef18ff5
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/elu_test.cc
@@ -0,0 +1,170 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <type_traits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// min/max are used to compute scale, zero-point
+template <typename T>
+struct TestEluParams {
+ // quantization parameters
+ float data_min; // input and output data minimum value
+ float data_max; // input and output data maximum value
+ T* input_data; // quantized input storage
+ T* output_data; // quantized output storage
+ float tolerance; // output vs expected value tolerance
+};
+
+// Our fixed-point math function implementations have roughly 12 bits of
+// accuracy, when specialized to 16-bit fixed-point arithmetic.
+// That is purely an implementation compromise, it would have been possible
+// to get closer to 16 bits of accuracy but that would be more expensive,
+// and not needed for our purposes as ultimately the output is either
+// immediately down-quantized to 8 bits, or will typically be at the output
+// of the surrounding LSTM cell.
+// So we can require roughly 2^-12 accuracy when the output is 16-bit, and
+// we can more or less expect the full 2^-8 accuracy when the output is 8-bit.
+//
+// However, the representable output interval is often [-1, 1] (it has to be
+// for tanh, and even for logistic, when we implement it in fixed-point, we
+// typically have to do so on such a symmetric interval, e.g. ARM NEON only
+// has signed fixed-point arithmetic (SQRDMULH)). As the width of [-1, 1]
+// is 2, our representable values are often diluted by a factor of 2, whence
+// the factor of 2 below.
+constexpr float kQuantizedTolerance = 2 * (1. / 256);
+
+void ExecuteEluTest(TfLiteTensor* tensors, int tensors_count) {
+ constexpr int kInputArrayData[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(kInputArrayData);
+ constexpr int kOutputArrayData[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(kOutputArrayData);
+
+ const TfLiteRegistration registration = tflite::Register_ELU();
+ micro::KernelRunner runner(registration, tensors, tensors_count, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+}
+
+template <typename T>
+void TestElu(const int* input_dims_data, const T* input_data,
+ const int* expected_dims, const T* expected_data, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ TfLiteTensor tensors[] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+ constexpr int tensors_count = std::extent<decltype(tensors)>::value;
+ ExecuteEluTest(tensors, tensors_count);
+
+ constexpr float kTolerance = 1e-5;
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_data[i], output_data[i], kTolerance);
+ }
+}
+
+template <typename T>
+void TestEluQuantized(const TestEluParams<T>& params,
+ const int* input_dims_data, const float* input_data,
+ const int* expected_dims, const float* expected_data,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ const float scale = ScaleFromMinMax<T>(params.data_min, params.data_max);
+ const int zero_point =
+ ZeroPointFromMinMax<T>(params.data_min, params.data_max);
+
+ TfLiteTensor tensors[] = {
+ CreateQuantizedTensor(input_data, params.input_data, input_dims, scale,
+ zero_point),
+ CreateQuantizedTensor(params.output_data, output_dims, scale, zero_point),
+ };
+ constexpr int kTensorsCount = std::extent<decltype(tensors)>::value;
+
+ ExecuteEluTest(tensors, kTensorsCount);
+
+ Dequantize(params.output_data, output_count, scale, zero_point, output_data);
+ const float kTolerance = params.tolerance;
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_data[i], output_data[i], kTolerance);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatActivationsOpTestElu) {
+ constexpr int kDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ 0, -6, 2, -4, //
+ 3, -2, 10, -0.1, //
+ };
+ constexpr float kExpect[] = {
+ 0.0, -0.997521, 2.0, -0.981684, //
+ 3.0, -0.864665, 10.0, -0.0951626, //
+ };
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestElu(kDims, kInput, kDims, kExpect, output_data);
+}
+
+TF_LITE_MICRO_TEST(QuantizedActivationsOpTestEluInt8) {
+ constexpr int kDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ 0, -6, 2, -4, //
+ 3, -2, 6, -0.1, //
+ };
+ constexpr float kExpect[] = {
+ 0, -1.0, 2.0, -1, //
+ 3.0, -0.875, 6.0, -0.125, //
+ };
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ // setup quantization storage and parameters
+ int8_t q_output_data[kOutputCount];
+ int8_t q_input_data[kOutputCount];
+ constexpr float kMin = -1;
+ constexpr float kMax = 127.f / 128.f;
+ tflite::testing::TestEluParams<int8_t> params = {};
+ params.data_min = 8 * kMin;
+ params.data_max = 8 * kMax;
+ params.input_data = q_input_data;
+ params.output_data = q_output_data;
+ params.tolerance = tflite::testing::kQuantizedTolerance;
+
+ tflite::testing::TestEluQuantized(params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/ethos_u/README.md b/tensorflow/lite/micro/kernels/ethos_u/README.md
new file mode 100644
index 0000000..9589efe
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ethos_u/README.md
@@ -0,0 +1,60 @@
+<!-- mdformat off(b/169948621#comment2) -->
+
+# Info
+Arm(R) Ethos(TM)-U is a new class of machine learning processors, called a
+microNPU, specifically designed to accelerate ML inference in area-constrained
+embedded and IoT devices. This readme briefly describes how to integrate Ethos-U
+related hardware and software into TFLM.
+
+To enable the Ethos-U software stack, add `CO_PROCESSOR=ethos_u` to the make
+command line. See example below.
+
+## Requirements:
+- Armclang 6.14 or later
+- GCC 10.2.1 or later
+
+## Ethos-U custom operator
+The TFLM runtime will dispatch workloads to Ethos-U when it encounters an
+Ethos-U custom op in the tflite file. The Ethos-U custom op is added by a tool
+called Vela and contains information the Ethos-U hardware need to execute
+the workload. More info in the [Vela repo](https://review.mlplatform.org/plugins/gitiles/ml/ethos-u/ethos-u-vela).
+
+```
+ | tensor0
+ |
+ v
++------------+
+| ethos-u |
+| custom op |
++------------+
+ +
+ |
+ | tensor1
+ |
+ v
++-----------+
+| transpose |
+| |
++----|------+
+ |
+ | tensor2
+ |
+ v
+```
+
+Note that the `ethousu_init()` API of the Ethos-U driver need to be called at
+startup, before calling the TFLM API. More info in the [Ethos-U driver repo](https://review.mlplatform.org/plugins/gitiles/ml/ethos-u/ethos-u-core-driver).
+
+For even more info regarding Vela and Ethos-U, checkout [Ethos-U landing page](https://review.mlplatform.org/plugins/gitiles/ml/ethos-u/ethos-u/+/refs/heads/master).
+
+# Example 1
+
+Compile a binary with Ethos-U support using the following command:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile network_tester_test CO_PROCESSOR=ethos_u \
+TARGET=<ethos_u_enabled_target> NETWORK_MODEL=<ethos_u_enabled_tflite>
+```
+
+TODO: Replace `ethos_u_enabled_target` and `ethos_u_enabled_tflite` once the
+Arm Corstone(TM)-300 example is up and running.
diff --git a/tensorflow/lite/micro/kernels/ethos_u/ethosu.cc b/tensorflow/lite/micro/kernels/ethos_u/ethosu.cc
new file mode 100644
index 0000000..45934e4
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ethos_u/ethosu.cc
@@ -0,0 +1,148 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <ethosu_driver.h>
+
+#include "flatbuffers/flexbuffers.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+constexpr uint8_t CO_TYPE_ETHOSU = 1;
+
+struct OpData {
+ int cms_data_size;
+ int base_addr_idx;
+ int base_addr_size_idx;
+};
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+void Free(TfLiteContext* context, void* buffer) {}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(context != nullptr);
+ TF_LITE_ENSURE(context, node->inputs->size > 0);
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TF_LITE_ENSURE(context, node->custom_initial_data_size > 0);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ int num_base_addr = node->inputs->size + node->outputs->size;
+
+ // Request arrays for the base address pointers and sizes
+ TF_LITE_ENSURE_STATUS(context->RequestScratchBufferInArena(
+ context, num_base_addr * sizeof(uint64_t), &data->base_addr_idx));
+ TF_LITE_ENSURE_STATUS(context->RequestScratchBufferInArena(
+ context, num_base_addr * sizeof(size_t), &data->base_addr_size_idx));
+
+ // Get command stream data size
+ TfLiteTensor* tensor = context->GetTensor(context, node->inputs->data[0]);
+ data->cms_data_size = tensor->bytes;
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer != nullptr);
+
+ // Get base addresses
+ TfLiteEvalTensor* tensor;
+ int i = 0;
+ int num_tensors = 0;
+ void* cms_data;
+ uint8_t co_type;
+ int result;
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+ uint64_t* base_addrs = static_cast<uint64_t*>(
+ context->GetScratchBuffer(context, data->base_addr_idx));
+ size_t* base_addrs_size = static_cast<size_t*>(
+ context->GetScratchBuffer(context, data->base_addr_size_idx));
+
+ const uint8_t* custom_data =
+ static_cast<uint8_t const*>(node->custom_initial_data);
+ auto root = flexbuffers::GetRoot(custom_data, node->custom_initial_data_size);
+ co_type = root.AsInt8();
+ if (co_type != CO_TYPE_ETHOSU) {
+ TF_LITE_KERNEL_LOG(context, "CO_TYPE != ETHOSU");
+ return kTfLiteError;
+ }
+
+ // Get command stream data address
+ tensor = context->GetEvalTensor(context, node->inputs->data[0]);
+ cms_data = reinterpret_cast<void*>(tensor->data.uint8);
+
+ // Get addresses to weights/scratch/input data
+ for (i = 1; i < node->inputs->size; ++i) {
+ tensor = context->GetEvalTensor(context, node->inputs->data[i]);
+ base_addrs[num_tensors] =
+ static_cast<uint64_t>(reinterpret_cast<uintptr_t>(tensor->data.uint8));
+ size_t byte_size = 1;
+ for (int k = 0; k < tensor->dims->size; k++) {
+ byte_size = byte_size * tensor->dims->data[k];
+ }
+ base_addrs_size[num_tensors] = byte_size;
+ num_tensors++;
+ }
+
+ // Get addresses to output data
+ for (i = 0; i < node->outputs->size; ++i) {
+ tensor = context->GetEvalTensor(context, node->outputs->data[i]);
+ base_addrs[num_tensors] =
+ static_cast<uint64_t>(reinterpret_cast<uintptr_t>(tensor->data.uint8));
+ size_t byte_size = 1;
+ for (int k = 0; k < tensor->dims->size; k++) {
+ byte_size = byte_size * tensor->dims->data[k];
+ }
+ base_addrs_size[num_tensors] = byte_size;
+ num_tensors++;
+ }
+
+ // Ethos-U guarantees that the tensors that require a base pointer are among
+ // the 8 first tensors
+ num_tensors = std::min(num_tensors, 8);
+
+ result = ethosu_invoke_v2(cms_data, data->cms_data_size, base_addrs,
+ base_addrs_size, num_tensors);
+ if (-1 == result) {
+ return kTfLiteError;
+ } else {
+ return kTfLiteOk;
+ }
+}
+
+} // namespace
+
+TfLiteRegistration* Register_ETHOSU() {
+ static TfLiteRegistration r = {Init,
+ Free,
+ Prepare,
+ Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+ return &r;
+}
+
+const char* GetString_ETHOSU() { return "ethos-u"; }
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/ethosu.cc b/tensorflow/lite/micro/kernels/ethosu.cc
new file mode 100644
index 0000000..c305121
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ethosu.cc
@@ -0,0 +1,27 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+//
+// This is a stub file for non-Ethos platforms
+//
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+TfLiteRegistration* Register_ETHOSU() { return nullptr; }
+
+const char* GetString_ETHOSU() { return ""; }
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/ethosu.h b/tensorflow/lite/micro/kernels/ethosu.h
new file mode 100644
index 0000000..cfbb0d3
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/ethosu.h
@@ -0,0 +1,28 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_ETHOSU_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_ETHOSU_H_
+
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+TfLiteRegistration* Register_ETHOSU();
+
+const char* GetString_ETHOSU();
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_ETHOSU_H_
diff --git a/tensorflow/lite/micro/kernels/exp.cc b/tensorflow/lite/micro/kernels/exp.cc
new file mode 100644
index 0000000..253769a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/exp.cc
@@ -0,0 +1,78 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/exp.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, input->type);
+ TF_LITE_ENSURE_EQ(context, output->bytes, input->bytes);
+ TF_LITE_ENSURE_EQ(context, output->dims->size, input->dims->size);
+ for (int i = 0; i < output->dims->size; ++i) {
+ TF_LITE_ENSURE_EQ(context, output->dims->data[i], input->dims->data[i]);
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ int flat_size = MatchingFlatSize(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorShape(output));
+
+ if (input->type == kTfLiteFloat32) {
+ reference_ops::Exp(tflite::micro::GetTensorData<float>(input),
+ static_cast<size_t>(flat_size),
+ tflite::micro::GetTensorData<float>(output));
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) currently not supported by Exp.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+} // namespace
+
+TfLiteRegistration Register_EXP() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/exp_test.cc b/tensorflow/lite/micro/kernels/exp_test.cc
new file mode 100644
index 0000000..9a77686
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/exp_test.cc
@@ -0,0 +1,77 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <limits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestExp(const int* input_dims_data, const float* input_data,
+ const float* expected_output_data, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(input_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_EXP();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SingleDim) {
+ constexpr int kInputSize = 7;
+ float output_data[kInputSize];
+ const int input_dims[] = {2, 1, kInputSize};
+ const float input_values[kInputSize] = {0.0f, 1.0f, -1.0f, 100.0f,
+ -100.0f, 0.01f, -0.01f};
+ float golden[kInputSize];
+ for (int i = 0; i < kInputSize; ++i) {
+ golden[i] = std::exp(input_values[i]);
+ }
+
+ tflite::testing::TestExp(input_dims, input_values, golden, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/expand_dims.cc b/tensorflow/lite/micro/kernels/expand_dims.cc
new file mode 100644
index 0000000..1f10521
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/expand_dims.cc
@@ -0,0 +1,152 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kAxisTensor = 1;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus ExpandTensorDim(TfLiteContext* context,
+ const TfLiteEvalTensor* input, int32_t axis,
+ TfLiteEvalTensor* output) {
+ const TfLiteIntArray* input_dims = input->dims;
+ TfLiteIntArray* output_dims = output->dims;
+ if (axis < 0) {
+ axis = input_dims->size + 1 + axis;
+ }
+ TF_LITE_ENSURE(context, (axis <= input_dims->size));
+
+ output_dims->size = input_dims->size + 1;
+ for (int i = 0; i < output_dims->size; ++i) {
+ if (i < axis) {
+ output_dims->data[i] = input_dims->data[i];
+ } else if (i == axis) {
+ output_dims->data[i] = 1;
+ } else {
+ output_dims->data[i] = input_dims->data[i - 1];
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus GetAxisValueFromTensor(TfLiteContext* context,
+ const TfLiteEvalTensor* axis,
+ int32_t* axis_value) {
+ const int axis_dims = (tflite::micro::GetTensorShape(axis)).DimensionsCount();
+ if (axis_dims > 1) {
+ TF_LITE_KERNEL_LOG(context, "Axis has only one element for Expand_Dims.",
+ axis_dims);
+ return kTfLiteError;
+ }
+
+ if (kTfLiteInt32 == (axis->type)) {
+ const int32_t* axis_ptr = tflite::micro::GetTensorData<int32_t>(axis);
+ *axis_value = axis_ptr[0];
+ return kTfLiteOk;
+ } else {
+ TF_LITE_KERNEL_LOG(context,
+ "Axis type %s (%d) not supported by Expand_Dims.",
+ TfLiteTypeGetName(axis->type), axis->type);
+ return kTfLiteError;
+ }
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ const TfLiteTensor* axis;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kAxisTensor, &axis));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+ output->type = input->type;
+ if (IsDynamicTensor(axis)) {
+ TF_LITE_KERNEL_LOG(context,
+ "DynamicTensor is not yet supported by Expand_Dims.");
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+template <typename T>
+void memCopyN(T* out, const T* in, const int num_elements) {
+ for (int i = 0; i < num_elements; ++i) {
+ out[i] = in[i];
+ }
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* axis =
+ tflite::micro::GetEvalInput(context, node, kAxisTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ const int flat_size = ElementCount(*input->dims);
+ const int input_dims = input->dims->size;
+
+ int32_t axis_value;
+ TF_LITE_ENSURE_OK(context,
+ GetAxisValueFromTensor(context, axis, &axis_value));
+ if ((axis_value > static_cast<int32_t>(input_dims)) ||
+ (axis_value < static_cast<int32_t>(-(input_dims + 1)))) {
+ TF_LITE_KERNEL_LOG(context, "Invalid Expand_Dims axis value (%d).",
+ axis_value);
+ return kTfLiteError;
+ }
+ ExpandTensorDim(context, input, axis_value, output);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ memCopyN(tflite::micro::GetTensorData<float>(output),
+ tflite::micro::GetTensorData<float>(input), flat_size);
+ } break;
+ case kTfLiteInt8: {
+ memCopyN(tflite::micro::GetTensorData<int8_t>(output),
+ tflite::micro::GetTensorData<int8_t>(input), flat_size);
+ } break;
+ default:
+ TF_LITE_KERNEL_LOG(
+ context,
+ "Expand_Dims only currently supports int8 and float32, got %d.",
+ input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+} // namespace
+
+TfLiteRegistration Register_EXPAND_DIMS() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/expand_dims_test.cc b/tensorflow/lite/micro/kernels/expand_dims_test.cc
new file mode 100644
index 0000000..ca640e3
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/expand_dims_test.cc
@@ -0,0 +1,175 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void TestExpandDims(const int* input_dims, const T* input_data,
+ const int* axis_dims, const int32_t* axis_data,
+ const int* expected_output_dims, const int* output_dims,
+ const T* expected_output_data, T* output_data) {
+ TfLiteIntArray* in_dims = IntArrayFromInts(input_dims);
+ TfLiteIntArray* ax_dims = IntArrayFromInts(axis_dims);
+ TfLiteIntArray* out_dims = IntArrayFromInts(output_dims);
+ const int in_dims_size = in_dims->size;
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, in_dims),
+ CreateTensor(axis_data, ax_dims),
+ CreateTensor(output_data, out_dims, true),
+ };
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_EXPAND_DIMS();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ // The output tensor's data and shape have been updated by the kernel.
+ TfLiteTensor* actual_out_tensor = &tensors[2];
+ TfLiteIntArray* actual_out_dims = actual_out_tensor->dims;
+ const int actual_out_dims_size = actual_out_dims->size;
+ const int output_size = ElementCount(*actual_out_dims);
+ TF_LITE_MICRO_EXPECT_EQ(actual_out_dims_size, (in_dims_size + 1));
+ for (int i = 0; i < actual_out_dims_size; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_dims[i], actual_out_dims->data[i]);
+ }
+ for (int i = 0; i < output_size; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(ExpandDimsPositiveAxisTest0) {
+ int8_t output_data[4];
+ const int input_dims[] = {2, 2, 2};
+ const int8_t input_data[] = {-1, 1, -2, 2};
+ const int8_t golden_data[] = {-1, 1, -2, 2};
+ const int axis_dims[] = {1, 1};
+ const int32_t axis_data[] = {0};
+ const int golden_dims[] = {1, 2, 2};
+ int output_dims[] = {3, 0, 0, 0};
+ tflite::testing::TestExpandDims<int8_t>(input_dims, input_data, axis_dims,
+ axis_data, golden_dims, output_dims,
+ golden_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ExpandDimsPositiveAxisTest1) {
+ float output_data[4];
+ const int input_dims[] = {2, 2, 2};
+ const float input_data[] = {-1.1, 1.2, -2.1, 2.2};
+ const float golden_data[] = {-1.1, 1.2, -2.1, 2.2};
+ const int axis_dims[] = {1, 1};
+ const int32_t axis_data[] = {1};
+ const int golden_dims[] = {2, 1, 2};
+ int output_dims[] = {3, 0, 0, 0};
+ tflite::testing::TestExpandDims<float>(input_dims, input_data, axis_dims,
+ axis_data, golden_dims, output_dims,
+ golden_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ExpandDimsPositiveAxisTest2) {
+ int8_t output_data[4];
+ const int input_dims[] = {2, 2, 2};
+ const int8_t input_data[] = {-1, 1, -2, 2};
+ const int8_t golden_data[] = {-1, 1, -2, 2};
+ const int axis_dims[] = {1, 1};
+ const int32_t axis_data[] = {2};
+ const int golden_dims[] = {2, 2, 1};
+ int output_dims[] = {3, 0, 0, 0};
+ tflite::testing::TestExpandDims<int8_t>(input_dims, input_data, axis_dims,
+ axis_data, golden_dims, output_dims,
+ golden_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ExpandDimsNegativeAxisTest4) {
+ int8_t output_data[6];
+ const int input_dims[] = {3, 3, 1, 2};
+ const int8_t input_data[] = {-1, 1, 2, -2, 0, 3};
+ const int8_t golden_data[] = {-1, 1, 2, -2, 0, 3};
+ const int axis_dims[] = {1, 1};
+ const int32_t axis_data[] = {-4};
+ const int golden_dims[] = {1, 3, 1, 2};
+ int output_dims[] = {4, 0, 0, 0, 0};
+ tflite::testing::TestExpandDims<int8_t>(input_dims, input_data, axis_dims,
+ axis_data, golden_dims, output_dims,
+ golden_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ExpandDimsNegativeAxisTest3) {
+ float output_data[6];
+ const int input_dims[] = {3, 3, 1, 2};
+ const float input_data[] = {0.1, -0.8, -1.2, -0.5, 0.9, 1.3};
+ const float golden_data[] = {0.1, -0.8, -1.2, -0.5, 0.9, 1.3};
+ const int axis_dims[] = {1, 1};
+ const int32_t axis_data[] = {-3};
+ const int golden_dims[] = {3, 1, 1, 2};
+ int output_dims[] = {4, 0, 0, 0, 0};
+ tflite::testing::TestExpandDims<float>(input_dims, input_data, axis_dims,
+ axis_data, golden_dims, output_dims,
+ golden_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ExpandDimsNegativeAxisTest2) {
+ int8_t output_data[6];
+ const int input_dims[] = {3, 1, 2, 3};
+ const int8_t input_data[] = {-1, 1, 2, -2, 0, 3};
+ const int8_t golden_data[] = {-1, 1, 2, -2, 0, 3};
+ const int axis_dims[] = {1, 1};
+ const int32_t axis_data[] = {-2};
+ const int golden_dims[] = {1, 2, 1, 3};
+ int output_dims[] = {4, 0, 0, 0, 0};
+ tflite::testing::TestExpandDims<int8_t>(input_dims, input_data, axis_dims,
+ axis_data, golden_dims, output_dims,
+ golden_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ExpandDimsNegativeAxisTest1) {
+ float output_data[6];
+ const int input_dims[] = {3, 1, 3, 2};
+ const float input_data[] = {0.1, -0.8, -1.2, -0.5, 0.9, 1.3};
+ const float golden_data[] = {0.1, -0.8, -1.2, -0.5, 0.9, 1.3};
+ const int axis_dims[] = {1, 1};
+ const int32_t axis_data[] = {-1};
+ const int golden_dims[] = {1, 3, 2, 1};
+ int output_dims[] = {4, 0, 0, 0, 0};
+ tflite::testing::TestExpandDims<float>(input_dims, input_data, axis_dims,
+ axis_data, golden_dims, output_dims,
+ golden_data, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/fill.cc b/tensorflow/lite/micro/kernels/fill.cc
new file mode 100644
index 0000000..ca3d15e
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/fill.cc
@@ -0,0 +1,131 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/fill.h"
+
+#include <stdint.h>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+
+namespace {
+
+template <typename T>
+TfLiteStatus EnsureEqImpl(TfLiteContext* context, const TfLiteIntArray* array,
+ const TfLiteTensor* tensor) {
+ for (int i = 0; i < array->size; ++i) {
+ TF_LITE_ENSURE_EQ(context, array->data[i], GetTensorData<T>(tensor)[i]);
+ }
+ return kTfLiteOk;
+}
+
+// Ensure the equality of an int array and a tensor, which must be
+// one-dimensional and of an integer type.
+TfLiteStatus EnsureEq(TfLiteContext* context, const TfLiteIntArray* array,
+ const TfLiteTensor* tensor) {
+ TF_LITE_ENSURE_EQ(context, NumDimensions(tensor), 1);
+ const auto tensor_len = tensor->dims->data[0];
+ TF_LITE_ENSURE_EQ(context, array->size, tensor_len);
+
+ switch (tensor->type) {
+ case kTfLiteInt8:
+ return EnsureEqImpl<int8_t>(context, array, tensor);
+ case kTfLiteUInt8:
+ return EnsureEqImpl<uint8_t>(context, array, tensor);
+ case kTfLiteInt16:
+ return EnsureEqImpl<int16_t>(context, array, tensor);
+ case kTfLiteInt32:
+ return EnsureEqImpl<int32_t>(context, array, tensor);
+ case kTfLiteInt64:
+ return EnsureEqImpl<int64_t>(context, array, tensor);
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "cannot compare int array to tensor of type %d.",
+ tensor->type);
+ return kTfLiteError;
+ }
+}
+
+constexpr int kDimsTensor = 0;
+constexpr int kValueTensor = 1;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ // Ensure inputs and outputs exist.
+ const TfLiteTensor* dims;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kDimsTensor, &dims));
+ const TfLiteTensor* value;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kValueTensor, &value));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ // The value tensor must be a scalar.
+ TF_LITE_ENSURE_EQ(context, NumDimensions(value), 0);
+
+ // The value type and output type must match.
+ TF_LITE_ENSURE_EQ(context, value->type, output->type);
+
+ // The dims tensor must match the output tensor shape. As a byproduct,
+ // ensures the dims tensor is of an integer type.
+ TF_LITE_ENSURE_OK(context, EnsureEq(context, output->dims, dims));
+
+ return kTfLiteOk;
+}
+
+template <typename T>
+void FillImpl(const TfLiteEvalTensor* value, TfLiteEvalTensor* output) {
+ reference_ops::Fill(
+ micro::GetTensorShape(value), micro::GetTensorData<T>(value),
+ micro::GetTensorShape(output), micro::GetTensorData<T>(output));
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* value =
+ micro::GetEvalInput(context, node, kValueTensor);
+ TfLiteEvalTensor* output = micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (value->type) {
+ case kTfLiteFloat32:
+ FillImpl<float>(value, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(
+ context, "Fill only currently supports float32 for input 1, got %d.",
+ TfLiteTypeGetName(value->type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_FILL() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/fill_test.cc b/tensorflow/lite/micro/kernels/fill_test.cc
new file mode 100644
index 0000000..8735ce5
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/fill_test.cc
@@ -0,0 +1,128 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace {
+
+template <typename DimsType, typename ValueType, typename OutputType>
+void TestFill(int* dims_shape, DimsType* dims_data, int* value_shape,
+ ValueType* value_data, int* output_shape,
+ OutputType* output_data) {
+ using tflite::testing::CreateTensor;
+ using tflite::testing::IntArrayFromInts;
+
+ TfLiteTensor tensors[] = {
+ CreateTensor(dims_data, IntArrayFromInts(dims_shape)),
+ CreateTensor(value_data, IntArrayFromInts(value_shape)),
+ CreateTensor(output_data, IntArrayFromInts(output_shape))};
+ constexpr int dims_index = 0;
+ constexpr int value_index = 1;
+ constexpr int output_index = 2;
+ constexpr int inputs[] = {2, dims_index, value_index};
+ constexpr int outputs[] = {1, output_index};
+ const auto registration = tflite::Register_FILL();
+ tflite::micro::KernelRunner runner{registration,
+ tensors,
+ sizeof(tensors) / sizeof(TfLiteTensor),
+ IntArrayFromInts(inputs),
+ IntArrayFromInts(outputs),
+ /*builtin_data=*/nullptr};
+
+ TF_LITE_MICRO_EXPECT_EQ(runner.InitAndPrepare(), kTfLiteOk);
+ TF_LITE_MICRO_EXPECT_EQ(runner.Invoke(), kTfLiteOk);
+
+ // The output shape must match the shape requested via dims.
+ const auto output_rank = output_shape[0];
+ const auto requested_rank = dims_shape[1]; // yes, 1
+ if (output_rank == requested_rank) {
+ for (int i = 0; i < requested_rank; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(output_shape[i + 1], dims_data[i]);
+ }
+ } else {
+ TF_LITE_MICRO_FAIL("output shape does not match shape requested via dims");
+ }
+
+ // The output type matches the value type.
+ TF_LITE_MICRO_EXPECT_EQ(tensors[output_index].type,
+ tensors[value_index].type);
+
+ // The output elements contain the fill value.
+ const auto elements = tflite::ElementCount(*IntArrayFromInts(output_shape));
+ for (int i = 0; i < elements; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(output_data[i], value_data[0]);
+ }
+}
+
+} // namespace
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FillFloatInt64Dims) {
+ constexpr int kDim1 = 2;
+ constexpr int kDim2 = 2;
+ constexpr int kDim3 = 2;
+
+ int dims_shape[] = {1, 3};
+ int64_t dims_data[] = {kDim1, kDim2, kDim3};
+
+ int value_shape[] = {0};
+ float value_data[] = {4.0};
+
+ int output_shape[] = {3, kDim1, kDim2, kDim3};
+ float output_data[kDim1 * kDim2 * kDim3];
+
+ TestFill(dims_shape, dims_data, value_shape, value_data, output_shape,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(FillFloatInt32Dims) {
+ constexpr int kDim1 = 2;
+ constexpr int kDim2 = 2;
+ constexpr int kDim3 = 2;
+
+ int dims_shape[] = {1, 3};
+ int32_t dims_data[] = {kDim1, kDim2, kDim3};
+
+ int value_shape[] = {0};
+ float value_data[] = {4.0};
+
+ int output_shape[] = {3, kDim1, kDim2, kDim3};
+ float output_data[kDim1 * kDim2 * kDim3];
+
+ TestFill(dims_shape, dims_data, value_shape, value_data, output_shape,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(FillScalar) {
+ int dims_shape[] = {1, 0};
+ int64_t dims_data[] = {0};
+
+ int value_shape[] = {0};
+ float value_data[] = {4.0};
+
+ int output_shape[] = {0};
+ float output_data[] = {0};
+
+ TestFill(dims_shape, dims_data, value_shape, value_data, output_shape,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/floor.cc b/tensorflow/lite/micro/kernels/floor.cc
new file mode 100644
index 0000000..b8be1cf
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/floor.cc
@@ -0,0 +1,57 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/floor.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace floor {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteFloat32);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ reference_ops::Floor(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+}
+} // namespace floor
+
+TfLiteRegistration Register_FLOOR() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/floor::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/floor_div.cc b/tensorflow/lite/micro/kernels/floor_div.cc
new file mode 100644
index 0000000..006296a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/floor_div.cc
@@ -0,0 +1,130 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/floor_div.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/reference/binary_function.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace {
+
+// Input/output tensor index.
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input1;
+ TF_LITE_ENSURE_OK(context,
+ GetInputSafe(context, node, kInputTensor1, &input1));
+ const TfLiteTensor* input2;
+ TF_LITE_ENSURE_OK(context,
+ GetInputSafe(context, node, kInputTensor2, &input2));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input1->type, input2->type);
+ TF_LITE_ENSURE_TYPES_EQ(context, input1->type, output->type);
+
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ return nullptr;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ return CalculateOpData(context, node);
+}
+
+template <typename T>
+TfLiteStatus EvalFloorDiv(TfLiteContext* context,
+ const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2,
+ TfLiteEvalTensor* output) {
+ const T* denominator_data = tflite::micro::GetTensorData<T>(input2);
+
+ // Validate the denominator.
+ for (int i = 0; i < tflite::ElementCount(*input2->dims); ++i) {
+ if (std::equal_to<T>()(denominator_data[i], 0)) {
+ TF_LITE_KERNEL_LOG(context, "Division by 0");
+ return kTfLiteError;
+ }
+ }
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+
+ if (requires_broadcast) {
+ reference_ops::BroadcastBinaryFunction4DSlow<T, T, T>(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<T>(input1),
+ tflite::micro::GetTensorShape(input2), denominator_data,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<T>(output), reference_ops::FloorDiv<T>);
+ } else {
+ reference_ops::BinaryFunction<T, T, T>(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<T>(input1),
+ tflite::micro::GetTensorShape(input2), denominator_data,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<T>(output), reference_ops::FloorDiv<T>);
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input1->type) {
+ case kTfLiteFloat32: {
+ return EvalFloorDiv<float>(context, input1, input2, output);
+ }
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Type '%s' is not supported by FLOOR_DIV.",
+ TfLiteTypeGetName(input1->type));
+ return kTfLiteError;
+ }
+ }
+}
+
+} // namespace
+
+TfLiteRegistration Register_FLOOR_DIV() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/floor_div_test.cc b/tensorflow/lite/micro/kernels/floor_div_test.cc
new file mode 100644
index 0000000..b43a271
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/floor_div_test.cc
@@ -0,0 +1,109 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <type_traits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void ExecuteFloorDivTest(TfLiteTensor* tensors, int tensors_count) {
+ constexpr int kInputArrayData[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(kInputArrayData);
+ constexpr int kOutputArrayData[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(kOutputArrayData);
+
+ const TfLiteRegistration registration = tflite::Register_FLOOR_DIV();
+ micro::KernelRunner runner(registration, tensors, tensors_count, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+}
+
+template <typename T>
+void TestFloorDiv(const int* input1_dims_data, const T* input1_data,
+ const int* input2_dims_data, const T* input2_data,
+ const int* expected_dims, const T* expected_data,
+ T* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ TfLiteTensor tensors[] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+ constexpr int tensors_count = std::extent<decltype(tensors)>::value;
+
+ ExecuteFloorDivTest(tensors, tensors_count);
+
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloorDivTestSimpleFloat) {
+ constexpr int kDims[] = {4, 1, 2, 2, 1};
+ constexpr float kInput1[] = {10.05, 9.09, 11.9, 3.01};
+ constexpr float kInput2[] = {2.05, 2.03, 3.03, 4.03};
+ constexpr float kExpect[] = {4.0, 4.0, 3.0, 0.0};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestFloorDiv(kDims, kInput1, kDims, kInput2, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(FloorDivTestNegativeValueFloat) {
+ constexpr int kDims[] = {4, 1, 2, 2, 1};
+ constexpr float kInput1[] = {10.03, -9.9, -11.0, 7.0};
+ constexpr float kInput2[] = {2.0, 2.3, -3.0, -4.1};
+ constexpr float kExpect[] = {5.0, -5.0, 3.0, -2.0};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestFloorDiv(kDims, kInput1, kDims, kInput2, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(FloorDivTestBroadcastFloat) {
+ constexpr int kDims1[] = {4, 1, 2, 2, 1};
+ constexpr int kDims2[] = {1, 1};
+ constexpr float kInput1[] = {10.03, -9.9, -11.0, 7.0};
+ constexpr float kInput2[] = {-3.3};
+ constexpr float kExpect[] = {-4.0, 2.0, 3.0, -3.0};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestFloorDiv(kDims1, kInput1, kDims2, kInput2, kDims1,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/floor_mod.cc b/tensorflow/lite/micro/kernels/floor_mod.cc
new file mode 100644
index 0000000..42f2236
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/floor_mod.cc
@@ -0,0 +1,128 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/floor_mod.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/reference/binary_function.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+// OLD-TODO(b/117523611): We should factor out a binary_op and put binary ops
+// there.
+namespace tflite {
+namespace {
+
+// Input/output tensor index.
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+// OLD-TODO(b/117912880): Support quantization.
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input1;
+ TF_LITE_ENSURE_OK(context,
+ GetInputSafe(context, node, kInputTensor1, &input1));
+ const TfLiteTensor* input2;
+ TF_LITE_ENSURE_OK(context,
+ GetInputSafe(context, node, kInputTensor2, &input2));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input1->type, input2->type);
+ TF_LITE_ENSURE_TYPES_EQ(context, input1->type, output->type);
+
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ return nullptr;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ return CalculateOpData(context, node);
+}
+
+template <typename T>
+TfLiteStatus EvalFloorMod(TfLiteContext* context, bool requires_broadcast,
+ const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2,
+ TfLiteEvalTensor* output) {
+ const T* denominator_data = tflite::micro::GetTensorData<T>(input2);
+
+ if (requires_broadcast) {
+ reference_ops::BroadcastBinaryFunction4DSlow<T, T, T>(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<T>(input1),
+ tflite::micro::GetTensorShape(input2), denominator_data,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<T>(output), reference_ops::FloorMod<T>);
+ } else {
+ reference_ops::BinaryFunction<T, T, T>(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<T>(input1),
+ tflite::micro::GetTensorShape(input2), denominator_data,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<T>(output), reference_ops::FloorMod<T>);
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ bool requires_broadcast = !tflite::micro::HaveSameShapes(input1, input2);
+
+ switch (input1->type) {
+ case kTfLiteFloat32: {
+ return EvalFloorMod<float>(context, requires_broadcast, input1, input2,
+ output);
+ }
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Type '%s' is not supported by FLOOR_MOD.",
+ TfLiteTypeGetName(input1->type));
+ return kTfLiteError;
+ }
+ }
+}
+
+} // namespace
+
+TfLiteRegistration Register_FLOOR_MOD() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/floor_mod_test.cc b/tensorflow/lite/micro/kernels/floor_mod_test.cc
new file mode 100644
index 0000000..e6e7e1f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/floor_mod_test.cc
@@ -0,0 +1,109 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <type_traits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void ExecuteFloorModTest(TfLiteTensor* tensors, int tensors_count) {
+ constexpr int kInputArrayData[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(kInputArrayData);
+ constexpr int kOutputArrayData[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(kOutputArrayData);
+
+ const TfLiteRegistration registration = tflite::Register_FLOOR_MOD();
+ micro::KernelRunner runner(registration, tensors, tensors_count, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+}
+
+template <typename T>
+void TestFloorMod(const int* input1_dims_data, const T* input1_data,
+ const int* input2_dims_data, const T* input2_data,
+ const int* expected_dims, const T* expected_data,
+ T* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ TfLiteTensor tensors[] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+ constexpr int tensors_count = std::extent<decltype(tensors)>::value;
+
+ ExecuteFloorModTest(tensors, tensors_count);
+
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloorModFloatSimple) {
+ constexpr int kDims[] = {4, 1, 2, 2, 1};
+ constexpr float kInput1[] = {10, 9, 11, 3};
+ constexpr float kInput2[] = {2, 2, 3, 4};
+ constexpr float kExpect[] = {0, 1, 2, 3};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestFloorMod(kDims, kInput1, kDims, kInput2, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(FloorModFloatNegativeValue) {
+ constexpr int kDims[] = {4, 1, 2, 2, 1};
+ constexpr float kInput1[] = {10, -9, -11, 7};
+ constexpr float kInput2[] = {2, 2, -3, -4};
+ constexpr float kExpect[] = {0, 1, -2, -1};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestFloorMod(kDims, kInput1, kDims, kInput2, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(FloorModFloatBroadcast) {
+ constexpr int kDims1[] = {4, 1, 2, 2, 1};
+ constexpr int kDims2[] = {1, 1};
+ constexpr float kInput1[] = {10, -9, -11, 7};
+ constexpr float kInput2[] = {-3};
+ constexpr float kExpect[] = {-2, 0, -2, -2};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ tflite::testing::TestFloorMod(kDims1, kInput1, kDims2, kInput2, kDims1,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/floor_test.cc b/tensorflow/lite/micro/kernels/floor_test.cc
new file mode 100644
index 0000000..5b7f8f9
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/floor_test.cc
@@ -0,0 +1,82 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestFloor(const int* input_dims_data, const float* input_data,
+ const float* expected_output_data, const int* output_dims_data,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_FLOOR();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloorOpSingleDimFloat32) {
+ const int dims[] = {1, 2};
+ const float input[] = {8.5f, 0.0f};
+ const float golden[] = {8, 0};
+ float output_data[2];
+ tflite::testing::TestFloor(dims, input, golden, dims, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloorOpMultiDimFloat32) {
+ const int dims[] = {4, 2, 1, 1, 5};
+ const float input[] = {0.0001f, 8.0001f, 0.9999f, 9.9999f, 0.5f,
+ -0.0001f, -8.0001f, -0.9999f, -9.9999f, -0.5f};
+ const float golden[] = {0.0f, 8.0f, 0.0f, 9.0f, 0.0f,
+ -1.0f, -9.0f, -1.0f, -10.0f, -1.0f};
+ float output_data[10];
+ tflite::testing::TestFloor(dims, input, golden, dims, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/fully_connected.cc b/tensorflow/lite/micro/kernels/fully_connected.cc
new file mode 100644
index 0000000..554aebb
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/fully_connected.cc
@@ -0,0 +1,134 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/fully_connected.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context,
+ sizeof(OpDataFullyConnected));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* data = static_cast<OpDataFullyConnected*>(node->user_data);
+ const auto params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteTensor* input =
+ GetInput(context, node, kFullyConnectedInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter =
+ GetInput(context, node, kFullyConnectedWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kFullyConnectedBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kFullyConnectedOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_MSG(context, input->type == filter->type,
+ "Hybrid models are not supported on TFLite Micro.");
+
+ return CalculateOpDataFullyConnected(context, params->activation, input->type,
+ input, filter, bias, output, data);
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto* params =
+ static_cast<const TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedBiasTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kFullyConnectedOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const auto& data =
+ *(static_cast<const OpDataFullyConnected*>(node->user_data));
+
+ // Checks in Prepare ensure input, output and filter types are all the same.
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ tflite::reference_ops::FullyConnected(
+ FullyConnectedParamsFloat(params->activation),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ }
+
+ case kTfLiteInt8: {
+ tflite::reference_integer_ops::FullyConnected(
+ FullyConnectedParamsQuantized(data),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ }
+
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_FULLY_CONNECTED() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/fully_connected.h b/tensorflow/lite/micro/kernels/fully_connected.h
new file mode 100644
index 0000000..4605322
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/fully_connected.h
@@ -0,0 +1,91 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_FULLY_CONNECTED_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_FULLY_CONNECTED_H_
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+struct OpDataFullyConnected {
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t output_multiplier;
+ int output_shift;
+ // The range of the fused activation layer. For example for kNone and
+ // uint8_t these would be 0 and 255.
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+ // The index of the temporary tensor where the quantized inputs are cached.
+ int input_quantized_index;
+ // Cached zero point values of tensors.
+ int32_t input_zero_point;
+ int32_t filter_zero_point;
+ int32_t output_zero_point;
+};
+
+extern const int kFullyConnectedInputTensor;
+extern const int kFullyConnectedWeightsTensor;
+extern const int kFullyConnectedBiasTensor;
+extern const int kFullyConnectedOutputTensor;
+
+// Returns a FullyConnectedParams struct with all the parameters needed for a
+// float computation.
+FullyConnectedParams FullyConnectedParamsFloat(
+ TfLiteFusedActivation activation);
+
+// Returns a FullyConnectedParams struct with all the parameters needed for a
+// quantized computation.
+FullyConnectedParams FullyConnectedParamsQuantized(
+ const OpDataFullyConnected& op_data);
+
+TfLiteStatus CalculateOpDataFullyConnected(
+ TfLiteContext* context, TfLiteFusedActivation activation,
+ TfLiteType data_type, const TfLiteTensor* input, const TfLiteTensor* filter,
+ const TfLiteTensor* bias, TfLiteTensor* output, OpDataFullyConnected* data);
+
+// This is the most generic TfLiteRegistration. The actual supported types may
+// still be target dependent. The only requirement is that every implementation
+// (reference or optimized) must define this function.
+TfLiteRegistration Register_FULLY_CONNECTED();
+
+#if defined(CMSIS_NN) || defined(ARDUINO)
+// The Arduino is a special case where we use the CMSIS kernels, but because of
+// the current approach to building for Arduino, we do not support -DCMSIS_NN as
+// part of the build. As a result, we use defined(ARDUINO) as proxy for the
+// CMSIS kernels for this one special case.
+
+// Returns a TfLiteRegistration struct for cmsis_nn kernel variant that only
+// supports int8.
+TfLiteRegistration Register_FULLY_CONNECTED_INT8();
+
+#else
+// Note that while this block gets used for both reference and optimized kernels
+// that do not have any specialized implementations, the only goal here is to
+// define fallback implementation that allow reference kernels to still be used
+// from applications that call a more specific kernel variant.
+
+inline TfLiteRegistration Register_FULLY_CONNECTED_INT8() {
+ return Register_FULLY_CONNECTED();
+}
+
+#endif
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_FULLY_CONNECTED_H_
diff --git a/tensorflow/lite/micro/kernels/fully_connected_common.cc b/tensorflow/lite/micro/kernels/fully_connected_common.cc
new file mode 100644
index 0000000..e7d0056
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/fully_connected_common.cc
@@ -0,0 +1,83 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/fully_connected.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+
+const int kFullyConnectedInputTensor = 0;
+const int kFullyConnectedWeightsTensor = 1;
+const int kFullyConnectedBiasTensor = 2;
+const int kFullyConnectedOutputTensor = 0;
+
+FullyConnectedParams FullyConnectedParamsQuantized(
+ const OpDataFullyConnected& op_data) {
+ FullyConnectedParams op_params;
+ op_params.input_offset = -op_data.input_zero_point;
+ op_params.weights_offset = -op_data.filter_zero_point;
+ op_params.output_offset = op_data.output_zero_point;
+ op_params.output_multiplier = op_data.output_multiplier;
+ op_params.output_shift = op_data.output_shift;
+ op_params.quantized_activation_min = op_data.output_activation_min;
+ op_params.quantized_activation_max = op_data.output_activation_max;
+ return op_params;
+}
+
+FullyConnectedParams FullyConnectedParamsFloat(
+ TfLiteFusedActivation activation) {
+ FullyConnectedParams op_params;
+ CalculateActivationRange(activation, &op_params.float_activation_min,
+ &op_params.float_activation_max);
+ return op_params;
+}
+
+TfLiteStatus CalculateOpDataFullyConnected(
+ TfLiteContext* context, TfLiteFusedActivation activation,
+ TfLiteType data_type, const TfLiteTensor* input, const TfLiteTensor* filter,
+ const TfLiteTensor* bias, TfLiteTensor* output,
+ OpDataFullyConnected* data) {
+ if (data_type != kTfLiteFloat32) {
+ double real_multiplier = 0.0;
+ TF_LITE_ENSURE_STATUS(GetQuantizedConvolutionMultipler(
+ context, input, filter, bias, output, &real_multiplier));
+ QuantizeMultiplier(real_multiplier, &data->output_multiplier,
+ &data->output_shift);
+
+ data->input_zero_point = input->params.zero_point;
+ // Filter weights will always be symmetric quantized since we only support
+ // int8 quantization. See
+ // https://github.com/tensorflow/tensorflow/issues/44912 for additional
+ // context.
+ TFLITE_DCHECK(filter->params.zero_point == 0);
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ return CalculateActivationRangeQuantized(context, activation, output,
+ &data->output_activation_min,
+ &data->output_activation_max);
+ }
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/fully_connected_test.cc b/tensorflow/lite/micro/kernels/fully_connected_test.cc
new file mode 100644
index 0000000..1f76b69
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/fully_connected_test.cc
@@ -0,0 +1,518 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cstddef>
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Simple test data for 2x2x10 input 2x3x10 weights.
+const int simple_input_size = 20;
+const int simple_input_dims[] = {2, 2, 10};
+const float simple_input_data[] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, -9, -10, // b = 0
+ 1, 2, 3, 4, 5, 6, 7, -8, 9, -10, // b = 1
+};
+const int simple_weights_size = 30;
+const int simple_weights_dims[] = {2, 3, 10};
+const float simple_weights_data[] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, // u = 0
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, // u = 1
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, // u = 2
+};
+const int simple_bias_dims[] = {1, 3};
+const float simple_bias_data[] = {1, 2, 3};
+const float simple_golden[] = {
+ 24, 25, 26, 58, 59, 60,
+};
+const int simple_output_size = 6;
+const int simple_output_dims[] = {2, 2, 3};
+
+// Test data for 2x2x10 input 2x3x10 weights with negative outputs to test relu.
+const int relu_input_size = 20;
+const int relu_input_dims[] = {2, 2, 10};
+const float relu_input_data[] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, -9, -10, // b = 0
+ 1, 2, 3, 4, 5, 6, 7, -8, 9, -10, // b = 1
+};
+const int relu_weights_size = 30;
+const int relu_weights_dims[] = {2, 3, 10};
+const float relu_weights_data[] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, // u = 0
+ -1, -2, -3, -4, -5, -6, -7, -8, -9, -10, // u = 1
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, // u = 2
+};
+const int relu_bias_dims[] = {1, 3};
+const float relu_bias_data[] = {1, -2, 3};
+const float relu_golden[] = {
+ 24, 0, 26, 58, 0, 60,
+};
+const int relu_output_size = 6;
+const int relu_output_dims[] = {2, 2, 3};
+
+// Input and filter similar to real model. Input shape is 1x64 and output is
+// 1x16.
+const int representative_64x16_input_size = 64;
+const int representative_64x16_input_dims[] = {2, 1, 64};
+const float representative_64x16_input_data[] = {
+ 0.0000, 0.1543, 0.0000, 0.0000, 1.8520, 0.0000, 4.7844, 1.1832,
+ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 1.5948, 0.0000,
+ 1.5948, 1.9549, 0.0000, 1.2347, 0.0000, 1.5948, 1.5948, 0.5145,
+ 0.0000, 0.0000, 0.0000, 0.0000, 2.6237, 0.0000, 0.0000, 0.0000,
+ 1.3890, 5.3503, 2.3665, 2.9838, 0.0000, 1.2861, 0.0000, 3.0867,
+ 0.9775, 0.0000, 5.9676, 0.0000, 0.0000, 1.4405, 0.5145, 2.5723,
+ 3.1896, 4.4757, 0.0000, 0.0000, 0.0000, 0.0000, 4.1671, 0.0000,
+ 2.8295, 3.0353, 0.0000, 2.7780, 0.0000, 0.0000, 0.0000, 0.0000};
+const int representative_64x16_weights_size = 64 * 16;
+const int representative_64x16_weights_dims[] = {2, 16, 64};
+const float representative_64x16_weights_data[] = {
+ -0.1075, 0.1245, 0.1811, -0.1302, -0.1868, 0.0679, 0.1245, 0.2321,
+ -0.1981, -0.2094, 0.1358, -0.1698, 0.0113, 0.0566, 0.1358, -0.2490,
+ 0.0000, -0.1189, -0.0170, -0.0396, -0.3113, 0.1641, -0.4188, 0.0566,
+ -0.4471, 0.4754, -0.0396, 0.0113, -0.0340, 0.0170, 0.0170, 0.1811,
+ -0.0792, 0.4981, 0.2490, -0.1924, 0.0792, 0.1868, -0.1075, -0.3962,
+ 0.1358, 0.2547, -0.1245, -0.0962, -0.0283, 0.4132, -0.0057, -0.5150,
+ 0.1019, 0.1585, -0.0962, -0.2207, -0.2377, 0.2830, 0.4471, 0.0170,
+ 0.0566, 0.2038, 0.1019, -0.0226, 0.2830, 0.1415, 0.0283, -0.0792,
+ 0.4301, 0.3226, -0.1132, 0.4981, -0.3849, -0.2943, -0.2547, -0.2264,
+ 0.0453, -0.0170, 0.0396, 0.1415, 0.3000, 0.2547, 0.0962, 0.2151,
+ -0.1585, -0.1302, -0.0057, -0.2773, 0.0283, -0.0906, 0.1302, -0.1075,
+ -0.0566, 0.1755, 0.2773, 0.0283, 0.0566, 0.1528, -0.0736, -0.2830,
+ 0.0792, 0.0962, -0.2321, -0.0113, 0.2660, -0.2887, -0.0566, 0.0057,
+ -0.2547, -0.0679, -0.2321, 0.0340, 0.1868, 0.2490, 0.2264, -0.3509,
+ 0.1585, -0.0849, -0.0623, 0.1132, 0.3396, -0.2490, 0.1528, 0.0679,
+ 0.1755, 0.4754, -0.0057, -0.2151, -0.1415, -0.1302, -0.2717, 0.1641,
+ 0.5037, -0.2321, 0.0170, -0.1755, -0.1075, -0.0226, 0.2038, -0.0340,
+ -0.5150, -0.3113, 0.1472, -0.0226, 0.1528, 0.1189, -0.1472, 0.0396,
+ -0.3000, -0.1924, -0.0283, 0.0283, 0.1641, 0.0736, 0.1472, -0.1755,
+ -0.1132, 0.0113, -0.1868, -0.2604, -0.3283, -0.0509, 0.0283, -0.0679,
+ 0.0623, 0.0792, -0.0283, -0.0962, 0.0396, 0.1641, 0.4584, 0.3226,
+ 0.0226, -0.1811, 0.2377, -0.1019, 0.2321, 0.1811, -0.1924, -0.0057,
+ 0.0736, 0.0113, 0.2547, -0.2264, -0.0170, -0.0396, 0.1245, -0.1415,
+ 0.1755, 0.3679, -0.2377, -0.0396, -0.1585, -0.3000, -0.1641, -0.1302,
+ -0.0396, -0.1698, 0.1189, 0.2434, 0.1132, -0.1245, -0.1415, 0.0453,
+ 0.1868, -0.0906, -0.1189, -0.0509, 0.0057, -0.1189, -0.0057, 0.0170,
+ -0.1924, 0.2207, 0.0792, -0.4641, -0.2660, 0.2943, 0.1358, -0.0340,
+ -0.3339, -0.1189, 0.0906, -0.4358, 0.0453, -0.1755, 0.1415, 0.0340,
+ 0.1924, -0.0057, 0.2321, -0.2094, -0.1132, 0.0000, 0.1924, -0.3000,
+ 0.0340, -0.3396, -0.0906, -0.0340, 0.1641, -0.0226, -0.1472, -0.1019,
+ 0.2377, -0.0962, -0.3396, -0.5433, 0.0906, 0.2151, -0.0679, 0.1755,
+ 0.1528, 0.0283, -0.4188, -0.0340, -0.0057, -0.0679, 0.0509, 0.1472,
+ -0.3849, -0.0113, 0.3962, 0.0849, 0.1472, 0.0340, -0.1358, 0.1641,
+ -0.2038, 0.2151, -0.1189, -0.3679, 0.0906, -0.0679, 0.5716, -0.0057,
+ -0.0736, 0.0113, 0.2830, -0.2887, 0.0396, 0.0849, -0.0736, -0.0736,
+ -0.3679, 0.2264, 0.0113, -0.1641, 0.0396, -0.1132, -0.0623, 0.3113,
+ 0.5999, -0.1415, 0.1472, -0.2038, -0.1132, -0.2377, 0.0566, 0.1755,
+ -0.0057, -0.0453, 0.0226, 0.1132, 0.1698, 0.0340, -0.0226, 0.0226,
+ 0.4415, -0.3792, 0.0792, 0.3736, -0.5999, -0.3056, -0.1924, -0.1132,
+ -0.0962, 0.0283, 0.0000, -0.3339, -0.3226, 0.3679, -0.0453, -0.1641,
+ 0.0170, 0.1302, -0.0170, -0.0509, 0.1755, -0.0283, -0.1302, -0.2887,
+ -0.0679, 0.0340, 0.4641, 0.2321, 0.7188, 0.3339, -0.1075, 0.4754,
+ -0.0226, 0.3226, -0.1528, -0.0849, 0.0509, -0.1981, 0.0113, 0.2321,
+ 0.2773, -0.1019, 0.4075, 0.0396, 0.0792, 0.1132, -0.0906, -0.4188,
+ 0.1924, -0.3679, -0.6396, 0.1358, 0.4981, 0.4132, -0.0283, 0.3849,
+ -0.3509, -0.0566, -0.0962, 0.3113, -0.1811, 0.4019, 0.0453, -0.0057,
+ -0.1868, -0.2490, -0.0792, -0.3622, 0.1924, -0.0453, -0.1528, -0.1811,
+ 0.5943, -0.1302, 0.3170, -0.0170, 0.0509, -0.1528, -0.1755, 0.5547,
+ 0.2490, -0.0906, 0.0000, 0.1698, 0.0000, 0.0340, -0.1132, -0.0509,
+ -0.1755, -0.2943, 0.1472, 0.0849, 0.0000, 0.1528, -0.0566, 0.1528,
+ -0.5264, -0.5320, -0.0736, 0.0566, 0.2604, -0.4075, 0.0962, -0.3453,
+ -0.1415, 0.0057, 0.3905, 0.2830, 0.3679, 0.5320, -0.2660, 0.0340,
+ 0.0736, 0.0057, 0.2207, 0.4471, 0.0849, 0.3000, -0.0057, -0.0623,
+ 0.1415, -0.0566, 0.5264, -0.0340, 0.0226, -0.0623, -0.0113, -0.5037,
+ -0.4471, 0.0170, -0.0396, -0.1358, -0.1698, 0.1924, 0.0057, -0.1585,
+ 0.0849, -0.1698, 0.0057, -0.1245, -0.0170, -0.1755, -0.0792, 0.5264,
+ 0.1358, 0.2434, 0.1585, -0.4188, -0.1472, -0.1358, -0.0849, -0.1189,
+ 0.5037, 0.0736, -0.0453, -0.2434, 0.1868, -0.0679, 0.1415, -0.2717,
+ 0.2604, 0.0057, -0.1528, -0.1811, 0.0226, -0.1641, 0.3170, -0.1981,
+ 0.1245, 0.0226, 0.0566, 0.2830, -0.1755, 0.0396, -0.2094, 0.1924,
+ 0.1698, 0.0283, 0.1641, 0.0849, 0.0000, -0.1698, -0.1415, -0.3000,
+ 0.4471, 0.3056, -0.0283, -0.4245, -0.0453, 0.0226, 0.0000, -0.1075,
+ -0.1528, -0.3226, 0.2773, -0.2264, -0.1811, 0.1755, -0.3566, -0.4188,
+ 0.1755, -0.0057, 0.2038, 0.1075, 0.3679, -0.0792, 0.2207, -0.0453,
+ 0.3736, 0.2943, -0.0113, -0.0623, 0.2264, 0.0113, -0.0396, -0.2207,
+ 0.0453, -0.2830, -0.1302, 0.0623, -0.1924, -0.1811, -0.2717, 0.2830,
+ 0.2094, 0.0170, -0.3170, -0.0283, -0.1189, -0.0509, -0.0566, -0.3622,
+ 0.1132, -0.0906, 0.1132, 0.4019, -0.4698, -0.1019, -0.1075, -0.2094,
+ -0.2207, -0.0509, 0.0057, 0.1019, -0.0509, 0.2264, -0.5716, 0.0226,
+ -0.4019, 0.1641, -0.3000, 0.3849, 0.1245, 0.0679, 0.3056, 0.2377,
+ 0.0679, -0.0170, -0.5377, -0.0170, 0.0057, 0.1358, -0.1132, -0.2038,
+ 0.0679, 0.1075, -0.2773, 0.5943, 0.0623, -0.1472, 0.3566, 0.0396,
+ -0.2377, 0.2604, 0.0849, 0.1358, -0.3792, -0.0340, -0.1415, 0.3566,
+ -0.3736, 0.1245, 0.0566, 0.3396, 0.0736, 0.4019, -0.1528, 0.1075,
+ 0.0792, -0.2547, 0.0453, -0.1755, 0.1868, -0.2547, 0.1075, 0.0623,
+ 0.1698, -0.0170, 0.1585, -0.0736, -0.4358, -0.0113, -0.6792, -0.0849,
+ -0.0396, -0.6056, 0.1358, 0.1189, 0.2547, 0.1528, 0.2887, 0.0453,
+ -0.1075, -0.3283, -0.0453, -0.0509, 0.2038, 0.2547, 0.0849, -0.0566,
+ -0.1698, 0.0509, -0.0113, -0.1585, 0.1924, -0.0792, -0.1868, 0.0509,
+ -0.1698, -0.0849, -0.0170, 0.0453, 0.3170, 0.0906, -0.5943, -0.1245,
+ 0.1585, -0.1755, -0.2151, 0.0906, 0.1924, 0.3170, -0.2490, -0.5660,
+ -0.0283, 0.0962, -0.1358, 0.1585, 0.0057, -0.2604, 0.1189, -0.0170,
+ 0.3509, 0.0623, 0.0679, -0.1302, -0.0792, 0.0906, -0.0792, 0.0849,
+ -0.1924, 0.2604, -0.1245, -0.3679, 0.0340, 0.0113, -0.1698, 0.2490,
+ 0.0283, 0.1019, -0.3736, 0.1019, -0.2207, -0.0340, 0.3170, 0.1755,
+ 0.0962, 0.3226, -0.0113, -0.1189, -0.2321, -0.0226, -0.2434, -0.0170,
+ -0.1585, -0.0283, -0.1132, 0.0679, -0.4188, -0.0453, 0.1528, -0.1302,
+ -0.3792, 0.1415, -0.1358, -0.1811, 0.1302, 0.1415, 0.5207, 0.0509,
+ -0.1358, -0.0396, -0.2434, 0.0396, 0.0792, -0.2264, -0.1415, 0.0906,
+ 0.1245, 0.0170, 0.0623, -0.1415, 0.2773, -0.3566, -0.0396, 0.2887,
+ 0.4188, 0.1698, -0.2547, 0.1132, -0.0453, -0.0113, -0.1358, 0.1075,
+ 0.0566, 0.1075, 0.2604, -0.0849, -0.2490, 0.1415, 0.0509, -0.2151,
+ 0.0340, 0.1698, 0.0509, -0.0906, 0.0566, -0.1075, -0.2151, 0.2038,
+ -0.1924, -0.0113, 0.2830, 0.1358, -0.1189, 0.0113, -0.5603, -0.2830,
+ -0.2943, 0.0453, -0.0396, 0.1358, 0.0566, 0.2038, -0.3283, -0.0509,
+ 0.0509, 0.1641, 0.2094, -0.2038, -0.1868, -0.1585, -0.2207, -0.1302,
+ 0.0396, -0.1019, -0.0679, 0.1075, -0.4584, -0.2207, 0.2434, -0.0113,
+ 0.0849, 0.1755, -0.3056, 0.1585, -0.2547, 0.0453, 0.0906, -0.1358,
+ -0.0679, -0.0509, 0.0679, -0.3509, 0.0057, 0.0453, 0.4132, -0.1981,
+ 0.2264, -0.0736, 0.1075, 0.0679, -0.0906, -0.3113, 0.0509, 0.0849,
+ 0.2604, 0.0623, -0.3113, 0.3849, 0.0000, 0.6396, -0.2038, -0.1019,
+ 0.1245, -0.0453, 0.1641, 0.1075, -0.1075, -0.2660, -0.4528, -0.0566,
+ -0.0170, 0.0453, 0.0340, 0.1189, -0.2434, -0.0283, -0.1811, 0.2547,
+ 0.0000, -0.0226, 0.4471, 0.1019, -0.1472, 0.0849, 0.1075, 0.1075,
+ 0.0283, -0.2773, 0.4415, -0.1811, 0.2717, 0.3170, 0.0509, 0.0623,
+ -0.0962, 0.1585, -0.0792, -0.1811, -0.0792, -0.3283, 0.0962, -0.1698,
+ -0.0736, 0.0453, 0.0962, -0.3566, -0.4584, 0.3396, -0.4811, 0.3056,
+ -0.1755, 0.2490, -0.1698, -0.2377, -0.3339, -0.0453, 0.1811, 0.0736,
+ 0.0340, -0.0962, -0.0113, -0.3056, -0.3339, 0.2038, 0.2038, -0.1924,
+ 0.2547, -0.4471, -0.0849, -0.2038, 0.3566, -0.4811, 0.3453, 0.0849,
+ 0.1189, 0.3170, -0.1358, 0.2717, 0.0113, -0.4754, -0.1924, 0.4245,
+ -0.2773, 0.3453, 0.2264, 0.2943, 0.5320, 0.2773, -0.2264, -0.1019,
+ -0.1132, -0.3962, 0.3679, 0.0509, -0.0623, -0.0906, -0.5603, -0.1641,
+ -0.3170, -0.2377, 0.1415, -0.0509, 0.0792, 0.0170, -0.0226, -0.0057,
+ -0.1358, -0.4245, 0.3905, 0.3113, 0.0340, -0.1189, 0.2887, -0.2943,
+ -0.3056, 0.2434, 0.1019, -0.0170, 0.3849, 0.1528, -0.0736, -0.0170,
+ 0.0792, 0.1755, 0.0509, 0.3509, 0.1472, 0.1528, 0.1472, 0.0057,
+ 0.0113, -0.0113, -0.3283, -0.3962, -0.0792, -0.1245, -0.0283, -0.1868,
+ 0.4019, 0.2943, -0.0906, -0.2321, 0.6056, 0.1189, 0.0340, -0.2207,
+ -0.0453, 0.3339, 0.2377, -0.1641, 0.3736, 0.2151, -0.2547, 0.0453,
+ 0.1924, -0.1019, -0.0340, -0.2207, 0.3962, -0.4471, -0.2547, -0.2151,
+ -0.3736, 0.0283, 0.1189, 0.0283, 0.0736, 0.0396, 0.1019, 0.0283,
+ 0.0170, 0.2321, 0.3509, -0.0226, -0.0226, 0.0736, 0.0283, 0.1641,
+ -0.0906, 0.1811, 0.0226, 0.5716, -0.0396, -0.0509, -0.1641, -0.0509,
+ 0.4132, -0.2604, 0.1019, -0.0283, -0.0340, 0.0453, 0.1472, -0.0057,
+ 0.2717, -0.2094, 0.3396, 0.0340, 0.1245, 0.2547, -0.5886, 0.2717,
+ -0.0906, 0.1641, 0.0962, -0.0792, -0.0113, 0.2264, -0.0736, 0.3170,
+ 0.0623, 0.0679, 0.0623, -0.0792, -0.2207, 0.1924, 0.1245, -0.2773};
+const int representative_64x16_bias_dims[] = {1, 16};
+const float representative_64x16_bias_data[] = {
+ -0.0084, 0.0006, 0.0000, 0.0000, -0.0087, -0.0006, -0.0003, -0.0003,
+ 0.0006, -0.0003, -0.0003, -0.0003, -0.0253, 0.0012, 0.0000, 0.0000};
+const float representative_64x16_golden[] = {
+ 3.8624, -2.9580, 4.3043, -1.2844, -1.5769, -2.7998, -0.1011, -3.4029,
+ -1.0557, -7.1931, -1.4852, -0.4163, 1.7186, -0.6965, 0.3580, 2.7378};
+const int representative_64x16_output_size = 16;
+const int representative_64x16_output_dims[] = {2, 1, 16};
+
+template <typename T>
+TfLiteStatus ValidateFullyConnectedGoldens(
+ TfLiteTensor* tensors, const int tensors_size,
+ const TfLiteFusedActivation activation, const float tolerance,
+ const int output_len, const T* golden, T* output_data) {
+ TfLiteFullyConnectedParams builtin_data = {
+ activation, kTfLiteFullyConnectedWeightsFormatDefault, false, false};
+
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_FULLY_CONNECTED();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TfLiteStatus status = runner.InitAndPrepare();
+ if (status != kTfLiteOk) {
+ return status;
+ }
+
+ status = runner.Invoke();
+ if (status != kTfLiteOk) {
+ return status;
+ }
+
+ for (int i = 0; i < output_len; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output_data[i], tolerance);
+ }
+ return kTfLiteOk;
+}
+
+#if !defined(XTENSA) // Needed to avoid build error from unused functions.
+TfLiteStatus TestFullyConnectedFloat(
+ const int* input_dims_data, const float* input_data,
+ const int* weights_dims_data, const float* weights_data,
+ const int* bias_dims_data, const float* bias_data, const float* golden,
+ const int* output_dims_data, TfLiteFusedActivation activation,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* weights_dims = IntArrayFromInts(weights_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(weights_data, weights_dims),
+ CreateTensor(bias_data, bias_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ return ValidateFullyConnectedGoldens(tensors, tensors_size, activation, 1e-4f,
+ output_dims_count, golden, output_data);
+}
+#endif
+
+template <typename T>
+TfLiteStatus TestFullyConnectedQuantized(
+ const int* input_dims_data, const float* input_data, T* input_quantized,
+ const float input_scale, const int input_zero_point,
+ const int* weights_dims_data, const float* weights_data,
+ T* weights_quantized, const float weights_scale,
+ const int weights_zero_point, const int* bias_dims_data,
+ const float* bias_data, int32_t* bias_quantized, const float* golden,
+ T* golden_quantized, const int* output_dims_data, const float output_scale,
+ const int output_zero_point, TfLiteFusedActivation activation,
+ T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* weights_dims = IntArrayFromInts(weights_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(weights_data, weights_quantized, weights_dims,
+ weights_scale, weights_zero_point),
+ CreateQuantizedBiasTensor(bias_data, bias_quantized, bias_dims,
+ input_scale, weights_scale),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ Quantize(golden, golden_quantized, output_dims_count, output_scale,
+ output_zero_point);
+
+ return ValidateFullyConnectedGoldens(tensors, tensors_size, activation, 0.0f,
+ output_dims_count, golden_quantized,
+ output_data);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+#if !defined(XTENSA) && !defined(CEVA_BX1) && !defined(CEVA_SP500)
+// TODO(b/170503075): xtensa kernels are less general
+// than reference kernels and we ifdef out test cases that are currently known
+// to fail.
+
+// CEVA's fully connected implementation assumes weights_zero_point=0 as
+// described in TFLite's quantization specification. tests which use a different
+// zero point will so ifdefed out.
+// See tflite quantization spec:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+TF_LITE_MICRO_TEST(SimpleTest) {
+ float output_data[tflite::testing::simple_output_size];
+ TF_LITE_MICRO_EXPECT_EQ(
+ tflite::testing::TestFullyConnectedFloat(
+ tflite::testing::simple_input_dims,
+ tflite::testing::simple_input_data,
+ tflite::testing::simple_weights_dims,
+ tflite::testing::simple_weights_data,
+ tflite::testing::simple_bias_dims, tflite::testing::simple_bias_data,
+ tflite::testing::simple_golden, tflite::testing::simple_output_dims,
+ kTfLiteActNone, output_data),
+ kTfLiteOk);
+}
+
+#endif
+
+TF_LITE_MICRO_TEST(SimpleTestQuantizedInt8) {
+ const float input_scale = 1.0f;
+ const int input_zero_point = -1;
+ const float weights_scale = 1.0f;
+ const int weights_zero_point = 0;
+ const float output_scale = 0.5f;
+ const int output_zero_point = -1;
+
+ int8_t input_quantized[tflite::testing::simple_input_size];
+ int8_t weights_quantized[tflite::testing::simple_weights_size];
+ int32_t bias_quantized[tflite::testing::simple_output_size];
+ int8_t golden_quantized[tflite::testing::simple_output_size];
+ int8_t output_data[tflite::testing::simple_output_size];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ tflite::testing::TestFullyConnectedQuantized(
+ tflite::testing::simple_input_dims,
+ tflite::testing::simple_input_data, input_quantized, input_scale,
+ input_zero_point, tflite::testing::simple_weights_dims,
+ tflite::testing::simple_weights_data, weights_quantized,
+ weights_scale, weights_zero_point, tflite::testing::simple_bias_dims,
+ tflite::testing::simple_bias_data, bias_quantized,
+ tflite::testing::simple_golden, golden_quantized,
+ tflite::testing::simple_output_dims, output_scale, output_zero_point,
+ kTfLiteActNone, output_data),
+ kTfLiteOk);
+}
+
+TF_LITE_MICRO_TEST(SimpleTest4DInputQuantizedInt8) {
+ const float input_scale = 1.0f;
+ const int input_zero_point = -1;
+ const float weights_scale = 1.0f;
+ const int weights_zero_point = 0;
+
+ const float output_scale = 0.5f;
+ const int output_zero_point = -1;
+
+ const int input_dims_4d[] = {4, 1, 1, 2, 10};
+
+ int8_t input_quantized[tflite::testing::simple_input_size];
+ int8_t weights_quantized[tflite::testing::simple_weights_size];
+ int32_t bias_quantized[tflite::testing::simple_output_size];
+ int8_t golden_quantized[tflite::testing::simple_output_size];
+ int8_t output_data[tflite::testing::simple_output_size];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ tflite::testing::TestFullyConnectedQuantized(
+ input_dims_4d, tflite::testing::simple_input_data, input_quantized,
+ input_scale, input_zero_point, tflite::testing::simple_weights_dims,
+ tflite::testing::simple_weights_data, weights_quantized,
+ weights_scale, weights_zero_point, tflite::testing::simple_bias_dims,
+ tflite::testing::simple_bias_data, bias_quantized,
+ tflite::testing::simple_golden, golden_quantized,
+ tflite::testing::simple_output_dims, output_scale, output_zero_point,
+ kTfLiteActNone, output_data),
+ kTfLiteOk);
+}
+
+TF_LITE_MICRO_TEST(SimpleTestQuantizedInt8Relu) {
+ const float input_scale = 1.0f;
+ const int input_zero_point = -1;
+ const float weights_scale = 1.0f;
+ const int weights_zero_point = 0;
+
+ const float output_scale = 0.5f;
+ const int output_zero_point = -128;
+
+ int8_t input_quantized[tflite::testing::relu_input_size];
+ int8_t weights_quantized[tflite::testing::relu_weights_size];
+ int32_t bias_quantized[tflite::testing::relu_output_size];
+ int8_t golden_quantized[tflite::testing::relu_output_size];
+ int8_t output_data[tflite::testing::relu_output_size];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ tflite::testing::TestFullyConnectedQuantized(
+ tflite::testing::relu_input_dims, tflite::testing::relu_input_data,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::relu_weights_dims,
+ tflite::testing::relu_weights_data, weights_quantized, weights_scale,
+ weights_zero_point, tflite::testing::relu_bias_dims,
+ tflite::testing::relu_bias_data, bias_quantized,
+ tflite::testing::relu_golden, golden_quantized,
+ tflite::testing::relu_output_dims, output_scale, output_zero_point,
+ kTfLiteActRelu, output_data),
+ kTfLiteOk);
+}
+
+#if !defined(XTENSA) // TODO(b/170503075): xtensa kernels are less general than
+ // reference kernels and we ifdef out test cases that are
+ // currently known to fail.
+TF_LITE_MICRO_TEST(SimpleTest4DInput) {
+ const int input_dims_4d[] = {4, 1, 1, 2, 10};
+
+ float output_data[tflite::testing::simple_output_size];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ tflite::testing::TestFullyConnectedFloat(
+ input_dims_4d, tflite::testing::simple_input_data,
+ tflite::testing::simple_weights_dims,
+ tflite::testing::simple_weights_data,
+ tflite::testing::simple_bias_dims, tflite::testing::simple_bias_data,
+ tflite::testing::simple_golden, tflite::testing::simple_output_dims,
+ kTfLiteActNone, output_data),
+ kTfLiteOk);
+}
+
+TF_LITE_MICRO_TEST(Representative1x64Input1x16Output) {
+ float output_data[tflite::testing::representative_64x16_output_size];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ tflite::testing::TestFullyConnectedFloat(
+ tflite::testing::representative_64x16_input_dims,
+ tflite::testing::representative_64x16_input_data,
+ tflite::testing::representative_64x16_weights_dims,
+ tflite::testing::representative_64x16_weights_data,
+ tflite::testing::representative_64x16_bias_dims,
+ tflite::testing::representative_64x16_bias_data,
+ tflite::testing::representative_64x16_golden,
+ tflite::testing::representative_64x16_output_dims, kTfLiteActNone,
+ output_data),
+ kTfLiteOk);
+}
+
+#endif
+
+TF_LITE_MICRO_TEST(Representative1x64Input1x16OutputQuantizedInt8) {
+ const float input_scale = 0.051445;
+ const int input_zero_point = -128;
+ const float weights_scale = 0.005660;
+ const int weights_zero_point = 0;
+
+ const float output_scale = 0.069785;
+ const int output_zero_point = -9;
+
+ int8_t input_quantized[tflite::testing::representative_64x16_input_size];
+ int8_t weights_quantized[tflite::testing::representative_64x16_weights_size];
+ int32_t bias_quantized[tflite::testing::representative_64x16_output_size];
+ int8_t golden_quantized[tflite::testing::representative_64x16_output_size];
+ int8_t output_data[tflite::testing::representative_64x16_output_size];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ tflite::testing::TestFullyConnectedQuantized(
+ tflite::testing::representative_64x16_input_dims,
+ tflite::testing::representative_64x16_input_data, input_quantized,
+ input_scale, input_zero_point,
+ tflite::testing::representative_64x16_weights_dims,
+ tflite::testing::representative_64x16_weights_data, weights_quantized,
+ weights_scale, weights_zero_point,
+ tflite::testing::representative_64x16_bias_dims,
+ tflite::testing::representative_64x16_bias_data, bias_quantized,
+ tflite::testing::representative_64x16_golden, golden_quantized,
+ tflite::testing::representative_64x16_output_dims, output_scale,
+ output_zero_point, kTfLiteActNone, output_data),
+ kTfLiteOk);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/gather.cc b/tensorflow/lite/micro/kernels/gather.cc
new file mode 100644
index 0000000..22020e5
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/gather.cc
@@ -0,0 +1,212 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <stdint.h>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/optimized/optimized_ops.h"
+#include "tensorflow/lite/kernels/internal/reference/reference_ops.h"
+#include "tensorflow/lite/kernels/internal/tensor.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/string_util.h"
+
+namespace tflite {
+namespace ops {
+namespace builtin {
+namespace gather {
+constexpr int kInputTensor = 0;
+constexpr int kInputPositions = 1;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const auto* params =
+ reinterpret_cast<const TfLiteGatherParams*>(node->builtin_data);
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ const TfLiteTensor* positions;
+ TF_LITE_ENSURE_OK(context,
+ GetInputSafe(context, node, kInputPositions, &positions));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ switch (positions->type) {
+ case kTfLiteInt64:
+ case kTfLiteInt32:
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "Positions of type '%s' are not supported by gather.",
+ TfLiteTypeGetName(positions->type));
+ return kTfLiteError;
+ }
+
+ // Assign to output the input type.
+ output->type = input->type;
+
+ // Check conditions for different types.
+ switch (input->type) {
+ case kTfLiteFloat32:
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ case kTfLiteInt16:
+ case kTfLiteInt64:
+ case kTfLiteInt32:
+ case kTfLiteBool:
+ break;
+ case kTfLiteString: {
+ // Only 1D input is supported.
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), 1);
+ } break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type '%s' is not supported by gather.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+
+ int axis = params->axis;
+ if (axis < 0) {
+ axis += NumDimensions(input);
+ }
+ TF_LITE_ENSURE(context, 0 <= axis && axis < NumDimensions(input));
+
+ const int num_dimensions =
+ NumDimensions(input) + NumDimensions(positions) - 1;
+ TfLiteIntArray* output_shape = TfLiteIntArrayCreate(num_dimensions);
+ int output_index = 0;
+ for (int i = 0; i < axis; ++i) {
+ output_shape->data[output_index++] = input->dims->data[i];
+ }
+ for (int i = 0; i < positions->dims->size; ++i) {
+ output_shape->data[output_index++] = positions->dims->data[i];
+ }
+ for (int i = axis + 1; i < input->dims->size; ++i) {
+ output_shape->data[output_index++] = input->dims->data[i];
+ }
+ return context->ResizeTensor(context, output, output_shape);
+}
+
+template <typename InputT, typename PositionsT>
+TfLiteStatus Gather(const TfLiteGatherParams& params, const TfLiteTensor* input,
+ const TfLiteTensor* positions, TfLiteTensor* output) {
+ tflite::GatherParams op_params;
+ op_params.axis = params.axis;
+ optimized_ops::Gather(op_params, GetTensorShape(input),
+ GetTensorData<InputT>(input), GetTensorShape(positions),
+ GetTensorData<PositionsT>(positions),
+ GetTensorShape(output), GetTensorData<InputT>(output));
+ return kTfLiteOk;
+}
+
+template <typename PositionT>
+TfLiteStatus GatherStrings(TfLiteContext* context, const TfLiteTensor* input,
+ const TfLiteTensor* positions,
+ TfLiteTensor* output) {
+ DynamicBuffer buffer;
+ const PositionT* indexes = GetTensorData<PositionT>(positions);
+ const PositionT num_strings = GetStringCount(input);
+ const int num_indexes = NumElements(positions);
+
+ for (int i = 0; i < num_indexes; ++i) {
+ const PositionT pos = indexes[i];
+ TF_LITE_ENSURE(context, pos < num_strings);
+ const auto string_ref = GetString(input, pos);
+ buffer.AddString(string_ref.str, string_ref.len);
+ }
+ buffer.WriteToTensor(output, /*new_shape=*/nullptr);
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const auto* params =
+ reinterpret_cast<const TfLiteGatherParams*>(node->builtin_data);
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ const TfLiteTensor* positions;
+ TF_LITE_ENSURE_OK(context,
+ GetInputSafe(context, node, kInputPositions, &positions));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ if (positions->type == kTfLiteInt32) {
+ switch (input->type) {
+ case kTfLiteFloat32:
+ return Gather<float, int32_t>(*params, input, positions, output);
+ case kTfLiteUInt8:
+ return Gather<uint8_t, int32_t>(*params, input, positions, output);
+ case kTfLiteInt8:
+ return Gather<int8_t, int32_t>(*params, input, positions, output);
+ case kTfLiteInt16:
+ return Gather<int16_t, int32_t>(*params, input, positions, output);
+ case kTfLiteInt32:
+ return Gather<int32_t, int32_t>(*params, input, positions, output);
+ case kTfLiteInt64:
+ return Gather<int64_t, int32_t>(*params, input, positions, output);
+ case kTfLiteBool:
+ return Gather<bool, int32_t>(*params, input, positions, output);
+ case kTfLiteString:
+ return GatherStrings<int32_t>(context, input, positions, output);
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type '%s' is not supported by gather.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ }
+ if (positions->type == kTfLiteInt64) {
+ switch (input->type) {
+ case kTfLiteFloat32:
+ return Gather<float, int64_t>(*params, input, positions, output);
+ case kTfLiteUInt8:
+ return Gather<uint8_t, int64_t>(*params, input, positions, output);
+ case kTfLiteInt8:
+ return Gather<int8_t, int64_t>(*params, input, positions, output);
+ case kTfLiteInt16:
+ return Gather<int16_t, int64_t>(*params, input, positions, output);
+ case kTfLiteInt32:
+ return Gather<int32_t, int64_t>(*params, input, positions, output);
+ case kTfLiteInt64:
+ return Gather<int64_t, int64_t>(*params, input, positions, output);
+ case kTfLiteBool:
+ return Gather<bool, int64_t>(*params, input, positions, output);
+ case kTfLiteString:
+ return GatherStrings<int64_t>(context, input, positions, output);
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type '%s' is not supported by gather.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ }
+ TF_LITE_KERNEL_LOG(context,
+ "Positions of type '%s' are not supported by gather.",
+ TfLiteTypeGetName(positions->type));
+ return kTfLiteError;
+}
+} // namespace gather
+
+TfLiteRegistration* Register_GATHER() {
+ static TfLiteRegistration r = {nullptr, nullptr, gather::Prepare,
+ gather::Eval};
+ return &r;
+}
+
+} // namespace builtin
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/hard_swish.cc b/tensorflow/lite/micro/kernels/hard_swish.cc
new file mode 100644
index 0000000..a0a245f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/hard_swish.cc
@@ -0,0 +1,142 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/hard_swish.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace hard_swish {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+void* HardSwishInit(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(HardSwishParams));
+}
+
+TfLiteStatus HardSwishPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ if (input->type == kTfLiteUInt8 || input->type == kTfLiteInt8) {
+ HardSwishParams* params = static_cast<HardSwishParams*>(node->user_data);
+
+ params->input_zero_point = input->params.zero_point;
+ params->output_zero_point = output->params.zero_point;
+
+ const float input_scale = input->params.scale;
+ const float hires_input_scale = (1.0f / 128.0f) * input_scale;
+ const float reluish_scale = 3.0f / 32768.0f;
+ const float output_scale = output->params.scale;
+
+ const double output_multiplier =
+ static_cast<double>(hires_input_scale / output_scale);
+ int32_t output_multiplier_fixedpoint_int32;
+ QuantizeMultiplier(output_multiplier, &output_multiplier_fixedpoint_int32,
+ ¶ms->output_multiplier_exponent);
+ DownScaleInt32ToInt16Multiplier(
+ output_multiplier_fixedpoint_int32,
+ ¶ms->output_multiplier_fixedpoint_int16);
+
+ TF_LITE_ENSURE(context, params->output_multiplier_exponent <= 0);
+
+ const double reluish_multiplier =
+ static_cast<double>(hires_input_scale / reluish_scale);
+ int32_t reluish_multiplier_fixedpoint_int32;
+ QuantizeMultiplier(reluish_multiplier, &reluish_multiplier_fixedpoint_int32,
+ ¶ms->reluish_multiplier_exponent);
+ DownScaleInt32ToInt16Multiplier(
+ reluish_multiplier_fixedpoint_int32,
+ ¶ms->reluish_multiplier_fixedpoint_int16);
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus HardSwishEval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ HardSwishParams* params = static_cast<HardSwishParams*>(node->user_data);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ tflite::reference_ops::HardSwish<float>(
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ } break;
+ case kTfLiteUInt8: {
+ tflite::reference_ops::HardSwish<uint8_t>(
+ *params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } break;
+ case kTfLiteInt8: {
+ tflite::reference_ops::HardSwish<int8_t>(
+ *params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ } break;
+ default: {
+ TF_LITE_KERNEL_LOG(
+ context,
+ "Only float32/int8_t/uint8_t are supported currently, got %s",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ }
+ return kTfLiteOk;
+}
+
+} // namespace hard_swish
+
+TfLiteRegistration Register_HARD_SWISH() {
+ return {/*init=*/hard_swish::HardSwishInit,
+ /*free=*/nullptr,
+ /*prepare=*/hard_swish::HardSwishPrepare,
+ /*invoke=*/hard_swish::HardSwishEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/hard_swish_test.cc b/tensorflow/lite/micro/kernels/hard_swish_test.cc
new file mode 100644
index 0000000..a877ff0
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/hard_swish_test.cc
@@ -0,0 +1,342 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <random>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void GenerateUniformRandomVector(int size, float min, float max,
+ std::minstd_rand* random_engine,
+ float* result) {
+ // Never use std::uniform_*_distribution in tests, it's
+ // implementation-defined. Likewise, don't use std::default_random_engine,
+ // implementation-defined. Implementation-defined is bad because it means that
+ // any toolchain update or new platform may run into test failures.
+ // std::minstd_rand is a standard instantiation of
+ // std::linear_congruential_engine, the cheapest generator in c++11 stdlib,
+ // it's good enough here.
+ for (int i = 0; i < size; i++) {
+ // We don't care whether the `max` value may ever be produced exactly.
+ // It may actually be thanks to rounding, as std::minstd_rand::modulus
+ // is 2^31 - 1 is greater than the inverse float epsilon.
+ float random_value_scaled_0_1 =
+ (*random_engine)() *
+ (1.0f / static_cast<float>(std::minstd_rand::modulus));
+ result[i] = min + (max - min) * random_value_scaled_0_1;
+ }
+}
+
+void EvalTestReferenceHardSwish(int size, float* input, float* result) {
+ for (int i = 0; i < size; i++) {
+ const float in = input[i];
+ result[i] = in * std::min(6.0f, std::max(0.0f, in + 3)) * (1.0f / 6.0f);
+ }
+}
+
+template <typename T>
+void TestHardSwishQuantized(int size, const T* output_data,
+ T* input_data_quantized, float* dequantized_output,
+ float input_min, float input_max, float output_min,
+ float output_max, std::minstd_rand* random_engine,
+ float* float_input_values,
+ float* float_ref_output_values) {
+ const int input_dims_data[] = {2, 1, size};
+ const int output_dims_data[] = {2, 1, size};
+ const float input_scale = ScaleFromMinMax<T>(input_min, input_max);
+ const int input_zero_point = ZeroPointFromMinMax<T>(input_min, input_max);
+ const float output_scale = ScaleFromMinMax<T>(output_min, output_max);
+ const int output_zero_point = ZeroPointFromMinMax<T>(output_min, output_max);
+
+ // The numerical error for any 8bit quantized function is at least one half
+ // times the quantization step: 0.5 * (kOutMax - kOutMin) / 256.
+ // To that we add again the quantization step (kOutMax - kOutMin) / 256
+ // to allow for an off-by-one rounding error.
+ const float kTolerance =
+ std::max(input_max - input_min, output_max - output_min) * (1.5f / 256.f);
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ TF_LITE_MICRO_EXPECT_EQ(output_elements_count, size);
+
+ GenerateUniformRandomVector(size, input_min, input_max, random_engine,
+ float_input_values);
+ EvalTestReferenceHardSwish(size, float_input_values, float_ref_output_values);
+ for (int i = 0; i < size; i++) {
+ float val = float_ref_output_values[i];
+ float_ref_output_values[i] =
+ std::min(output_max, std::max(output_min, val));
+ }
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(float_input_values, input_data_quantized,
+ input_dims, input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_HARD_SWISH();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ Dequantize<T>(output_data, output_elements_count, output_scale,
+ output_zero_point, dequantized_output);
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(float_ref_output_values[i], dequantized_output[i],
+ kTolerance);
+ }
+}
+
+template <typename T>
+void TestHardSwishQuantizedBias(const int size, const T* output_data,
+ T* input_data_quantized,
+ float* dequantized_output, float input_min,
+ float input_max, float output_min,
+ float output_max, float tolerated_bias,
+ float* float_input_values,
+ float* float_ref_output_values) {
+ const float input_scale = ScaleFromMinMax<T>(input_min, input_max);
+ const float output_scale = ScaleFromMinMax<T>(output_min, output_max);
+
+ const int input_zero_point = ZeroPointFromMinMax<T>(input_min, input_max);
+ const int output_zero_point = ZeroPointFromMinMax<T>(output_min, output_max);
+
+ const float max_scale = std::max(output_scale, input_scale);
+
+ // In this bias-focused test case, no need for randomly generated input
+ // values.
+ TF_LITE_MICRO_EXPECT_LE(input_min, -3.0f);
+ TF_LITE_MICRO_EXPECT_GE(input_max, 3.0f);
+ const int quantized_input_negative_three = std::round(
+ std::numeric_limits<T>::min() + (-3.0f - input_min) / input_scale);
+ const int quantized_input_positive_three = std::round(
+ std::numeric_limits<T>::min() + (3.0f - input_min) / input_scale);
+
+ for (int i = quantized_input_negative_three;
+ i < size && i <= quantized_input_positive_three; i++) {
+ float_input_values[i] =
+ input_min + (i - std::numeric_limits<T>::min()) * input_scale;
+ }
+
+ EvalTestReferenceHardSwish(size, float_input_values, float_ref_output_values);
+ for (int i = 0; i < size; i++) {
+ float val = float_ref_output_values[i];
+ float_ref_output_values[i] =
+ std::min(output_max, std::max(output_min, val));
+ }
+
+ const int input_dims_data[] = {2, 1, size};
+ const int output_dims_data[] = {2, 1, size};
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ TF_LITE_MICRO_EXPECT_EQ(output_elements_count, size);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(float_input_values, input_data_quantized,
+ input_dims, input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_HARD_SWISH();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ Dequantize<T>(output_data, output_elements_count, output_scale,
+ output_zero_point, dequantized_output);
+
+ float sum_diff = 0;
+ for (int i = 0; i < size; i++) {
+ sum_diff += dequantized_output[i] - float_ref_output_values[i];
+ }
+ const float bias = sum_diff / (size * max_scale);
+ TF_LITE_MICRO_EXPECT_LE(std::abs(bias), tolerated_bias);
+}
+
+void TestHardSwishFloat(const int size, float* output_data,
+ std::minstd_rand* random_engine,
+ float* float_input_values,
+ float* float_ref_output_values) {
+ const float kMin = -10.0f;
+ const float kMax = 10.0f;
+ GenerateUniformRandomVector(size, kMin, kMax, random_engine,
+ float_input_values);
+
+ EvalTestReferenceHardSwish(size, float_input_values, float_ref_output_values);
+
+ const int input_dims_data[] = {1, size};
+ const int output_dims_data[] = {1, size};
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ TF_LITE_MICRO_EXPECT_EQ(output_elements_count, size);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(float_input_values, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_HARD_SWISH();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(float_ref_output_values[i], output_data[i],
+ 1e-5f);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SimpleHardSwishTestFloat) {
+ std::minstd_rand random_engine;
+ constexpr int size = 100;
+ float output_data[size] = {0.f};
+ float input_values[size] = {0.f};
+ float output_values[size] = {0.f};
+
+ tflite::testing::TestHardSwishFloat(size, output_data, &random_engine,
+ input_values, output_values);
+}
+
+TF_LITE_MICRO_TEST(SimpleHardSwishTestInt8) {
+ std::minstd_rand random_engine;
+ constexpr int pairs = 4, one_pair = 2;
+ constexpr int size = 101;
+ constexpr float minmax_pairs[pairs][one_pair] = {
+ {0.f, 1.f}, {-2.f, 1.f}, {-5.f, 10.f}, {-40.f, 60.f}};
+ int8_t output_data[size] = {0};
+ int8_t input_data_quantized[size] = {0};
+ float dequantized_output[size] = {0.f};
+ float input_values[size] = {0.f};
+ float output_values[size] = {0.f};
+
+ for (int x = 0; x < pairs; x++) {
+ for (int y = 0; y < pairs; y++) {
+ float input_min = minmax_pairs[x][0];
+ float input_max = minmax_pairs[x][1];
+ float output_min = minmax_pairs[y][0];
+ float output_max = minmax_pairs[y][1];
+
+ tflite::testing::TestHardSwishQuantized<int8_t>(
+ size, output_data, input_data_quantized, dequantized_output,
+ input_min, input_max, output_min, output_max, &random_engine,
+ input_values, output_values);
+ }
+ }
+}
+
+TF_LITE_MICRO_TEST(SimpleHardSwishTestUint8) {
+ std::minstd_rand random_engine;
+ constexpr int size = 99;
+ constexpr int pairs = 4, one_pair = 2;
+ constexpr float minmax_pairs[pairs][one_pair] = {
+ {0.f, 1.f}, {-2.f, 1.f}, {-5.f, 10.f}, {-40.f, 60.f}};
+ uint8_t output_data[size] = {0};
+ uint8_t input_data_quantized[size] = {0};
+ float dequantized_output[size] = {0.f};
+ float input_values[size] = {0.f};
+ float output_values[size] = {0.f};
+
+ for (int x = 0; x < pairs; x++) {
+ for (int y = 0; y < pairs; y++) {
+ float input_min = minmax_pairs[x][0];
+ float input_max = minmax_pairs[x][1];
+ float output_min = minmax_pairs[y][0];
+ float output_max = minmax_pairs[y][1];
+
+ tflite::testing::TestHardSwishQuantized<uint8_t>(
+ size, output_data, input_data_quantized, dequantized_output,
+ input_min, input_max, output_min, output_max, &random_engine,
+ input_values, output_values);
+ }
+ }
+}
+
+// See the comment in the reference implementation of quantized HardSwish:
+// A numerical issue significantly affecting ImageNet classification accuracy
+// with MobileNet v3 is only observable at the scale of HardSwish unit tests
+// if we monitor specifically bias. This testcase is extracted from one of the
+// HardSwish nodes in that MobileNet v3 that exhibited this issue.
+TF_LITE_MICRO_TEST(SimpleHardSwishTestQuantizedBias) {
+ constexpr int size = 43;
+ uint8_t output_data[size] = {0};
+ uint8_t input_data_quantized[size] = {0};
+ float dequantized_output[size] = {0.f};
+ float input_values[size] = {0.f};
+ float output_values[size] = {0.f};
+
+ tflite::testing::TestHardSwishQuantizedBias<uint8_t>(
+ size, output_data, input_data_quantized, dequantized_output, -11.654928f,
+ 25.036512f, -0.3905796f, 24.50887f, 0.035, input_values, output_values);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/kernel_runner.cc b/tensorflow/lite/micro/kernels/kernel_runner.cc
new file mode 100644
index 0000000..dd0ba8b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/kernel_runner.cc
@@ -0,0 +1,161 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+namespace tflite {
+namespace micro {
+
+namespace {
+constexpr size_t kBufferAlignment = 16;
+} // namespace
+
+// TODO(b/161841696): Consider moving away from global arena buffers:
+constexpr int KernelRunner::kNumScratchBuffers_;
+constexpr int KernelRunner::kKernelRunnerBufferSize_;
+uint8_t KernelRunner::kKernelRunnerBuffer_[];
+
+KernelRunner::KernelRunner(const TfLiteRegistration& registration,
+ TfLiteTensor* tensors, int tensors_size,
+ TfLiteIntArray* inputs, TfLiteIntArray* outputs,
+ void* builtin_data)
+ : allocator_(SimpleMemoryAllocator::Create(GetMicroErrorReporter(),
+ kKernelRunnerBuffer_,
+ kKernelRunnerBufferSize_)),
+ registration_(registration),
+ tensors_(tensors) {
+ // Prepare TfLiteContext:
+ context_.impl_ = static_cast<void*>(this);
+ context_.ReportError = ReportOpError;
+ context_.recommended_num_threads = 1;
+ context_.GetTensor = GetTensor;
+ context_.GetEvalTensor = GetEvalTensor;
+ context_.AllocatePersistentBuffer = AllocatePersistentBuffer;
+ context_.RequestScratchBufferInArena = RequestScratchBufferInArena;
+ context_.GetScratchBuffer = GetScratchBuffer;
+
+ // Prepare TfLiteNode:
+ node_.inputs = inputs;
+ node_.outputs = outputs;
+ node_.builtin_data = builtin_data;
+}
+
+TfLiteStatus KernelRunner::InitAndPrepare(const char* init_data,
+ size_t length) {
+ if (registration_.init) {
+ node_.user_data = registration_.init(&context_, init_data, length);
+ }
+ if (registration_.prepare) {
+ TF_LITE_ENSURE_STATUS(registration_.prepare(&context_, &node_));
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus KernelRunner::Invoke() {
+ if (registration_.invoke == nullptr) {
+ MicroPrintf("TfLiteRegistration missing invoke function pointer!");
+ return kTfLiteError;
+ }
+ return registration_.invoke(&context_, &node_);
+}
+
+TfLiteTensor* KernelRunner::GetTensor(const struct TfLiteContext* context,
+ int tensor_index) {
+ TFLITE_DCHECK(context != nullptr);
+ KernelRunner* runner = reinterpret_cast<KernelRunner*>(context->impl_);
+ TFLITE_DCHECK(runner != nullptr);
+
+ return &runner->tensors_[tensor_index];
+}
+
+TfLiteEvalTensor* KernelRunner::GetEvalTensor(
+ const struct TfLiteContext* context, int tensor_index) {
+ TFLITE_DCHECK(context != nullptr);
+ KernelRunner* runner = reinterpret_cast<KernelRunner*>(context->impl_);
+ TFLITE_DCHECK(runner != nullptr);
+
+ TfLiteEvalTensor* eval_tensor =
+ reinterpret_cast<TfLiteEvalTensor*>(runner->allocator_->AllocateTemp(
+ sizeof(TfLiteEvalTensor), alignof(TfLiteEvalTensor)));
+ TFLITE_DCHECK(eval_tensor != nullptr);
+
+ // In unit tests, the TfLiteTensor pointer contains the source of truth for
+ // buffers and values:
+ eval_tensor->data = runner->tensors_[tensor_index].data;
+ eval_tensor->dims = runner->tensors_[tensor_index].dims;
+ eval_tensor->type = runner->tensors_[tensor_index].type;
+ return eval_tensor;
+}
+
+void* KernelRunner::AllocatePersistentBuffer(TfLiteContext* context,
+ size_t bytes) {
+ TFLITE_DCHECK(context != nullptr);
+ KernelRunner* runner = reinterpret_cast<KernelRunner*>(context->impl_);
+ TFLITE_DCHECK(runner != nullptr);
+
+ return runner->allocator_->AllocateFromTail(bytes, kBufferAlignment);
+}
+
+TfLiteStatus KernelRunner::RequestScratchBufferInArena(TfLiteContext* context,
+ size_t bytes,
+ int* buffer_index) {
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(buffer_index != nullptr);
+
+ KernelRunner* runner = reinterpret_cast<KernelRunner*>(context->impl_);
+ TFLITE_DCHECK(runner != nullptr);
+
+ if (runner->scratch_buffer_count_ == kNumScratchBuffers_) {
+ MicroPrintf("Exceeded the maximum number of scratch tensors allowed (%d).",
+ kNumScratchBuffers_);
+ return kTfLiteError;
+ }
+
+ // For tests, we allocate scratch buffers from the tail and keep them around
+ // for the lifetime of model. This means that the arena size in the tests will
+ // be more than what we would have if the scratch buffers could share memory.
+ runner->scratch_buffers_[runner->scratch_buffer_count_] =
+ runner->allocator_->AllocateFromTail(bytes, kBufferAlignment);
+ TFLITE_DCHECK(runner->scratch_buffers_[runner->scratch_buffer_count_] !=
+ nullptr);
+
+ *buffer_index = runner->scratch_buffer_count_++;
+ return kTfLiteOk;
+}
+
+void* KernelRunner::GetScratchBuffer(TfLiteContext* context, int buffer_index) {
+ TFLITE_DCHECK(context != nullptr);
+ KernelRunner* runner = reinterpret_cast<KernelRunner*>(context->impl_);
+ TFLITE_DCHECK(runner != nullptr);
+
+ TFLITE_DCHECK(runner->scratch_buffer_count_ <= kNumScratchBuffers_);
+ if (buffer_index >= runner->scratch_buffer_count_) {
+ return nullptr;
+ }
+ return runner->scratch_buffers_[buffer_index];
+}
+
+void KernelRunner::ReportOpError(struct TfLiteContext* context,
+ const char* format, ...) {
+ va_list args;
+ va_start(args, format);
+ GetMicroErrorReporter()->Report(format, args);
+ va_end(args);
+}
+
+} // namespace micro
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/kernel_runner.h b/tensorflow/lite/micro/kernels/kernel_runner.h
new file mode 100644
index 0000000..b145097
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/kernel_runner.h
@@ -0,0 +1,81 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_KERNEL_RUNNER_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_KERNEL_RUNNER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/micro/simple_memory_allocator.h"
+
+namespace tflite {
+namespace micro {
+
+// Helper class to perform a simulated kernel (i.e. TfLiteRegistration)
+// lifecycle (init, prepare, invoke). All internal allocations are handled by
+// this class. Simply pass in the registration, list of required tensors, inputs
+// array, outputs array, and any pre-builtin data. Calling Invoke() will
+// automatically walk the kernel and outputs will be ready on the TfLiteTensor
+// output provided during construction.
+class KernelRunner {
+ public:
+ KernelRunner(const TfLiteRegistration& registration, TfLiteTensor* tensors,
+ int tensors_size, TfLiteIntArray* inputs,
+ TfLiteIntArray* outputs, void* builtin_data);
+
+ // Calls init and prepare on the kernel (i.e. TfLiteRegistration) struct. Any
+ // exceptions will be DebugLog'd and returned as a status code.
+ TfLiteStatus InitAndPrepare(const char* init_data = nullptr,
+ size_t length = 0);
+
+ // Calls init, prepare, and invoke on a given TfLiteRegistration pointer.
+ // After successful invoke, results will be available in the output tensor as
+ // passed into the constructor of this class.
+ TfLiteStatus Invoke();
+
+ protected:
+ static TfLiteTensor* GetTensor(const struct TfLiteContext* context,
+ int tensor_index);
+ static TfLiteEvalTensor* GetEvalTensor(const struct TfLiteContext* context,
+ int tensor_index);
+ static void* AllocatePersistentBuffer(TfLiteContext* context, size_t bytes);
+ static TfLiteStatus RequestScratchBufferInArena(TfLiteContext* context,
+ size_t bytes,
+ int* buffer_index);
+ static void* GetScratchBuffer(TfLiteContext* context, int buffer_index);
+ static void ReportOpError(struct TfLiteContext* context, const char* format,
+ ...);
+
+ private:
+ static constexpr int kNumScratchBuffers_ = 12;
+
+ static constexpr int kKernelRunnerBufferSize_ = 10000;
+ static uint8_t kKernelRunnerBuffer_[kKernelRunnerBufferSize_];
+
+ SimpleMemoryAllocator* allocator_ = nullptr;
+ const TfLiteRegistration& registration_;
+ TfLiteTensor* tensors_ = nullptr;
+
+ TfLiteContext context_ = {};
+ TfLiteNode node_ = {};
+
+ int scratch_buffer_count_ = 0;
+ uint8_t* scratch_buffers_[kNumScratchBuffers_];
+};
+
+} // namespace micro
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_KERNEL_RUNNER_H_
diff --git a/tensorflow/lite/micro/kernels/kernel_util.cc b/tensorflow/lite/micro/kernels/kernel_util.cc
new file mode 100644
index 0000000..123d171
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/kernel_util.cc
@@ -0,0 +1,77 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+namespace micro {
+
+bool HaveSameShapes(const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2) {
+ TFLITE_DCHECK(input1 != nullptr);
+ TFLITE_DCHECK(input2 != nullptr);
+ return TfLiteIntArrayEqual(input1->dims, input2->dims);
+}
+
+const RuntimeShape GetTensorShape(const TfLiteEvalTensor* tensor) {
+ if (tensor == nullptr || tensor->dims == nullptr) {
+ return RuntimeShape();
+ }
+ TfLiteIntArray* dims = tensor->dims;
+ const int dims_size = dims->size;
+ const int32_t* dims_data = reinterpret_cast<const int32_t*>(dims->data);
+ return RuntimeShape(dims_size, dims_data);
+}
+
+PaddingType RuntimePaddingType(TfLitePadding padding) {
+ switch (padding) {
+ case TfLitePadding::kTfLitePaddingSame:
+ return PaddingType::kSame;
+ case TfLitePadding::kTfLitePaddingValid:
+ return PaddingType::kValid;
+ case TfLitePadding::kTfLitePaddingUnknown:
+ default:
+ return PaddingType::kNone;
+ }
+}
+
+// Relocate tensor dims from FlatBuffer to the persistent storage arena.
+// The old dims data is copied to the new storage area.
+// The tensor and eval_tensor must be the same tensor.
+// Only use during Prepare phase.
+TfLiteStatus CreateWritableTensorDimsWithCopy(TfLiteContext* context,
+ TfLiteTensor* tensor,
+ TfLiteEvalTensor* eval_tensor) {
+ TF_LITE_ENSURE(context, tensor != nullptr);
+ TF_LITE_ENSURE(context, eval_tensor != nullptr);
+ int ranks = tensor->dims->size;
+ size_t alloc_size = TfLiteIntArrayGetSizeInBytes(ranks);
+ TfLiteIntArray* new_dims = static_cast<TfLiteIntArray*>(
+ context->AllocatePersistentBuffer(context, alloc_size));
+ TfLiteIntArray* old_dims = tensor->dims;
+ new_dims->size = ranks;
+ tensor->dims = new_dims;
+ eval_tensor->dims = new_dims;
+ for (int i = 0; i < ranks; i++) {
+ new_dims->data[i] = old_dims->data[i];
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace micro
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/kernel_util.h b/tensorflow/lite/micro/kernels/kernel_util.h
new file mode 100644
index 0000000..63ce653
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/kernel_util.h
@@ -0,0 +1,86 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_KERNEL_UTIL_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_KERNEL_UTIL_H_
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+namespace micro {
+
+// Returns a mutable tensor for a given input index. is_variable must be checked
+// during prepare when the full TfLiteTensor is available.
+inline TfLiteEvalTensor* GetMutableEvalInput(const TfLiteContext* context,
+ const TfLiteNode* node,
+ int index) {
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(node != nullptr);
+ return context->GetEvalTensor(context, node->inputs->data[index]);
+}
+
+// Returns the TfLiteEvalTensor struct for a given input index in a node.
+inline const TfLiteEvalTensor* GetEvalInput(const TfLiteContext* context,
+ const TfLiteNode* node, int index) {
+ return GetMutableEvalInput(context, node, index);
+}
+
+// Returns the TfLiteEvalTensor struct for a given output index in a node.
+inline TfLiteEvalTensor* GetEvalOutput(const TfLiteContext* context,
+ const TfLiteNode* node, int index) {
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(node != nullptr);
+ return context->GetEvalTensor(context, node->outputs->data[index]);
+}
+
+// Returns data for a TfLiteEvalTensor struct.
+template <typename T>
+T* GetTensorData(TfLiteEvalTensor* tensor) {
+ return tensor != nullptr ? reinterpret_cast<T*>(tensor->data.raw) : nullptr;
+}
+
+// Returns const data for a TfLiteEvalTensor struct.
+template <typename T>
+const T* GetTensorData(const TfLiteEvalTensor* tensor) {
+ TFLITE_DCHECK(tensor != nullptr);
+ return reinterpret_cast<const T*>(tensor->data.raw);
+}
+
+// Returns the shape of a TfLiteEvalTensor struct.
+const RuntimeShape GetTensorShape(const TfLiteEvalTensor* tensor);
+
+// Return true if the given tensors have the same shape.
+bool HaveSameShapes(const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2);
+
+PaddingType RuntimePaddingType(TfLitePadding padding);
+
+// Relocate tensor dims from FlatBuffer to the persistent storage arena.
+// The old dims data is copied to the new storage area.
+// The tensor and eval_tensor must be the same tensor.
+// Only use during Prepare phase.
+TfLiteStatus CreateWritableTensorDimsWithCopy(TfLiteContext* context,
+ TfLiteTensor* tensor,
+ TfLiteEvalTensor* eval_tensor);
+
+} // namespace micro
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_KERNEL_UTIL_H_
diff --git a/tensorflow/lite/micro/kernels/l2_pool_2d.cc b/tensorflow/lite/micro/kernels/l2_pool_2d.cc
new file mode 100644
index 0000000..926f1ff
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/l2_pool_2d.cc
@@ -0,0 +1,143 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <stddef.h>
+#include <stdint.h>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/reference/pooling.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+// Input/output tensor index.
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+// required rank for input/output tensor shape
+constexpr int kTensorShapeRank = 4;
+
+// input/output tensor shape rank associations
+enum { kBatchRank = 0, kHeightRank, kWidthRank, kChannelRank };
+
+TfLiteStatus L2Prepare(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = static_cast<TfLitePoolParams*>(node->builtin_data);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), kTensorShapeRank);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(output), kTensorShapeRank);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ int batches = SizeOfDimension(input, kBatchRank);
+ int height = SizeOfDimension(input, kHeightRank);
+ int width = SizeOfDimension(input, kWidthRank);
+ int channels_out = SizeOfDimension(input, kChannelRank);
+
+ // Matching GetWindowedOutputSize in TensorFlow.
+ auto padding = params->padding;
+ int out_width, out_height;
+
+ params->computed.padding = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width, 1, 1, height, width,
+ params->filter_height, params->filter_width, padding, &out_height,
+ &out_width);
+
+ // We currently don't have a quantized implementation of L2Pool
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteFloat32);
+
+ // We must update the output tensor dimensions.
+ // The dims storage is expected to be the same area in memory
+ // for both TfLiteTensor and TfLiteEvalTensor. This is important
+ // because TfLiteTensor in the MicroInterpreter is a temporary
+ // allocation. For the KernelRunner interpreter, TfLiteEvalTensor
+ // is a temporary allocation. We must therefore relocate the dims
+ // from the FlatBuffer to the persistant storage arena.
+ TfLiteEvalTensor* output_eval =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE_OK(context, tflite::micro::CreateWritableTensorDimsWithCopy(
+ context, output, output_eval));
+ output->dims->data[kBatchRank] = batches;
+ output->dims->data[kHeightRank] = out_height;
+ output->dims->data[kWidthRank] = out_width;
+ output->dims->data[kChannelRank] = channels_out;
+
+ return kTfLiteOk;
+}
+
+void L2EvalFloat(const TfLitePoolParams& params, const TfLiteEvalTensor& input,
+ tflite::PoolParams* op_params, TfLiteEvalTensor* output) {
+ float activation_min, activation_max;
+ CalculateActivationRange(params.activation, &activation_min, &activation_max);
+
+ op_params->float_activation_min = activation_min;
+ op_params->float_activation_max = activation_max;
+ reference_ops::L2Pool(*op_params, tflite::micro::GetTensorShape(&input),
+ tflite::micro::GetTensorData<float>(&input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+}
+
+TfLiteStatus L2Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = static_cast<const TfLitePoolParams*>(node->builtin_data);
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+
+ tflite::PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = params->computed.padding.height;
+ op_params.padding_values.width = params->computed.padding.width;
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32:
+ L2EvalFloat(*params, *input, &op_params, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "L2_POOL_2D only supports float32 currently, got %s.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_L2_POOL_2D() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/L2Prepare,
+ /*invoke=*/L2Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/l2_pool_2d_test.cc b/tensorflow/lite/micro/kernels/l2_pool_2d_test.cc
new file mode 100644
index 0000000..37e8762
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/l2_pool_2d_test.cc
@@ -0,0 +1,222 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <type_traits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr float kTolerance = 1e-5;
+
+constexpr int kOutputDimsCount = 4;
+
+struct L2Pool2DTestParams {
+ TfLitePadding padding = kTfLitePaddingValid;
+ int stride_width = 2;
+ int stride_height = 2;
+ int filter_width = 2;
+ int filter_height = 2;
+ TfLiteFusedActivation activation = kTfLiteActNone;
+ float compare_tolerance = kTolerance;
+ // output_dims_data is a TfLiteIntArray
+ int output_dims_data[kOutputDimsCount + 1] = {kOutputDimsCount, 0, 0, 0, 0};
+};
+
+void ExecuteL2Pool2DTest(const L2Pool2DTestParams& params,
+ TfLiteTensor* tensors, int tensors_count) {
+ constexpr int kInputArrayData[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(kInputArrayData);
+ constexpr int kOutputArrayData[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(kOutputArrayData);
+
+ TfLitePoolParams op_params = {};
+ op_params.activation = params.activation;
+ op_params.filter_height = params.filter_height;
+ op_params.filter_width = params.filter_width;
+ op_params.padding = params.padding;
+ op_params.stride_height = params.stride_height;
+ op_params.stride_width = params.stride_width;
+
+ const TfLiteRegistration registration = tflite::Register_L2_POOL_2D();
+ micro::KernelRunner runner(registration, tensors, tensors_count, inputs_array,
+ outputs_array, static_cast<void*>(&op_params));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+}
+
+template <typename T>
+void TestL2Pool2D(const L2Pool2DTestParams& params, const int* input_dims_data,
+ const T* input_data, const int* expected_dims_data,
+ const T* expected_data, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* expected_dims = IntArrayFromInts(expected_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(params.output_dims_data);
+ const int expected_count = ElementCount(*expected_dims);
+
+ TfLiteTensor tensors[] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+ constexpr int tensors_count = std::extent<decltype(tensors)>::value;
+ ExecuteL2Pool2DTest(params, tensors, tensors_count);
+
+ for (int i = 0; i < expected_count; i++) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_data[i], output_data[i],
+ params.compare_tolerance);
+ }
+ for (int i = 0; i < expected_dims->size; i++) {
+ // output dims will have been relocated during prepare phase,
+ // so use the tensor dims pointer.
+ TF_LITE_MICRO_EXPECT_EQ(expected_dims->data[i], tensors[1].dims->data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatPoolingOpTestL2Pool) {
+ constexpr int kInputDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ 0, 6, 2, 4, //
+ 3, 2, 10, 7, //
+ };
+ constexpr int kExpectDims[] = {4, 1, 1, 2, 1};
+ constexpr float kExpect[] = {3.5, 6.5};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::L2Pool2DTestParams params;
+
+ tflite::testing::TestL2Pool2D(params, kInputDims, kInput, kExpectDims,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatPoolingOpTestL2PoolActivationRelu) {
+ constexpr int kInputDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ -1, -6, 2, 4, //
+ -3, -2, 10, 7, //
+ };
+ constexpr int kExpectDims[] = {4, 1, 1, 2, 1};
+ constexpr float kExpect[] = {3.53553, 6.5};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::L2Pool2DTestParams params;
+ params.activation = kTfLiteActRelu;
+
+ tflite::testing::TestL2Pool2D(params, kInputDims, kInput, kExpectDims,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatPoolingOpTestL2PoolActivationRelu1) {
+ constexpr int kInputDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ -0.1, -0.6, 2, 4, //
+ -0.3, -0.2, 10, 7, //
+ };
+ constexpr int kExpectDims[] = {4, 1, 1, 2, 1};
+ constexpr float kExpect[] = {0.353553, 1.0};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::L2Pool2DTestParams params;
+ params.activation = kTfLiteActReluN1To1;
+
+ tflite::testing::TestL2Pool2D(params, kInputDims, kInput, kExpectDims,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatPoolingOpTestL2PoolActivationRelu6) {
+ constexpr int kInputDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ -0.1, -0.6, 2, 4, //
+ -0.3, -0.2, 10, 7, //
+ };
+ constexpr int kExpectDims[] = {4, 1, 1, 2, 1};
+ constexpr float kExpect[] = {0.353553, 6.0};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::L2Pool2DTestParams params;
+ params.activation = kTfLiteActRelu6;
+
+ tflite::testing::TestL2Pool2D(params, kInputDims, kInput, kExpectDims,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatPoolingOpTestL2PoolPaddingSame) {
+ constexpr int kInputDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ 0, 6, 2, 4, //
+ 3, 2, 10, 7, //
+ };
+ constexpr int kExpectDims[] = {4, 1, 1, 2, 1};
+ constexpr float kExpect[] = {3.5, 6.5};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::L2Pool2DTestParams params;
+ params.padding = kTfLitePaddingSame;
+
+ tflite::testing::TestL2Pool2D(params, kInputDims, kInput, kExpectDims,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatPoolingOpTestL2PoolPaddingSameStride1) {
+ constexpr int kInputDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ 0, 6, 2, 4, //
+ 3, 2, 10, 7, //
+ };
+ constexpr int kExpectDims[] = {4, 1, 2, 4, 1};
+ constexpr float kExpect[] = {3.5, 6.0, 6.5, 5.70088,
+ 2.54951, 7.2111, 8.63134, 7.0};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::L2Pool2DTestParams params;
+ params.padding = kTfLitePaddingSame;
+ params.compare_tolerance = 1e-4;
+ params.stride_width = 1;
+ params.stride_height = 1;
+
+ tflite::testing::TestL2Pool2D(params, kInputDims, kInput, kExpectDims,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatPoolingOpTestL2PoolPaddingValidStride1) {
+ constexpr int kInputDims[] = {4, 1, 2, 4, 1};
+ constexpr float kInput[] = {
+ 0, 6, 2, 4, //
+ 3, 2, 10, 7, //
+ };
+ constexpr int kExpectDims[] = {4, 1, 1, 3, 1};
+ constexpr float kExpect[] = {3.5, 6.0, 6.5};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::L2Pool2DTestParams params;
+ params.stride_width = 1;
+ params.stride_height = 1;
+
+ tflite::testing::TestL2Pool2D(params, kInputDims, kInput, kExpectDims,
+ kExpect, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/l2norm.cc b/tensorflow/lite/micro/kernels/l2norm.cc
new file mode 100644
index 0000000..401741a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/l2norm.cc
@@ -0,0 +1,157 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/portable_tensor.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/l2normalization.h"
+#include "tensorflow/lite/kernels/internal/reference/l2normalization.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace l2norm {
+
+namespace {
+
+// This file has two implementation of L2Norm.
+enum KernelType {
+ kReference,
+ kGenericOptimized,
+};
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+} // namespace
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* params = reinterpret_cast<TfLiteL2NormParams*>(node->builtin_data);
+ L2NormalizationParams* data =
+ static_cast<L2NormalizationParams*>(node->user_data);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE(context, NumDimensions(input) <= 4);
+
+ TF_LITE_ENSURE(context, output->type == kTfLiteFloat32 ||
+ output->type == kTfLiteUInt8 ||
+ output->type == kTfLiteInt8);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ data->input_zero_point = input->params.zero_point;
+ } else if (output->type == kTfLiteFloat32) {
+ data->input_zero_point = 0;
+ }
+
+ // TODO(ahentz): For some reason our implementations don't support
+ // activations.
+ TF_LITE_ENSURE_EQ(context, params->activation, kTfLiteActNone);
+
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context,
+ sizeof(L2NormalizationParams));
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const L2NormalizationParams& data =
+ *(static_cast<const L2NormalizationParams*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ // TODO(b/143912164): instead of hardcode the epsilon here, we should read it
+ // from tensorflow, i.e., adding a params.
+ // We don't compute epsilon for quantized kernel:
+ //
+ // epsilon_float = (epsilon_quant - zp) * scale
+ // so
+ // espsilon_quant = epsilon_float / scale + zp
+ // We know epsilon_float is just a very small number to avoid division by
+ // zero error, and scale is > 1, so the integer value of epsilon for quant
+ // is just dominated by the zero point.
+ // Also, GetInvSqrtQuantizedMultiplierExp handles the scenario where the sum
+ // of input value squared is zero case well.
+ // So we don't even need to do handle the epsilon for quantized kernel case.
+ const float epsilon = 1e-6f;
+ if (output->type == kTfLiteFloat32) {
+ reference_ops::L2Normalization(data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output),
+ epsilon);
+ } else if (output->type == kTfLiteUInt8) {
+ reference_ops::L2Normalization(
+ data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else if (output->type == kTfLiteInt8) {
+ const auto input_shape = tflite::micro::GetTensorShape(input);
+ const auto output_shape = tflite::micro::GetTensorShape(output);
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ reference_integer_ops::L2Normalization(
+ data.input_zero_point, outer_size, depth,
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorData<int8_t>(output));
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Output type is %s, requires float.",
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace l2norm
+
+TfLiteRegistration Register_L2NORM_REF() {
+ return {/*init=*/l2norm::Init,
+ /*free=*/nullptr,
+ /*prepare=*/l2norm::Prepare,
+ /*invoke=*/l2norm::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_L2_NORMALIZATION() { return Register_L2NORM_REF(); }
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/l2norm_test.cc b/tensorflow/lite/micro/kernels/l2norm_test.cc
new file mode 100644
index 0000000..9e2a48e
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/l2norm_test.cc
@@ -0,0 +1,236 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// used to set the quantization parameters for the int8_t and uint8_t tests
+constexpr float kInputMin = -2.0;
+constexpr float kInputMax = 2.0;
+constexpr float kOutputMin = -1.0;
+constexpr float kOutputMax = 127.0 / 128.0;
+
+TfLiteTensor CreateL2NormTensor(const float* data, TfLiteIntArray* dims,
+ bool is_input) {
+ return CreateTensor(data, dims);
+}
+
+template <typename T>
+TfLiteTensor CreateL2NormTensor(const T* data, TfLiteIntArray* dims,
+ bool is_input) {
+ float kInputScale = ScaleFromMinMax<T>(kInputMin, kInputMax);
+ int kInputZeroPoint = ZeroPointFromMinMax<T>(kInputMin, kInputMax);
+ float kOutputScale = ScaleFromMinMax<T>(kOutputMin, kOutputMax);
+ int kOutputZeroPoint = ZeroPointFromMinMax<T>(kOutputMin, kOutputMax);
+ TfLiteTensor tensor;
+ if (is_input) {
+ tensor = CreateQuantizedTensor(data, dims, kInputScale, kInputZeroPoint);
+ } else {
+ tensor = CreateQuantizedTensor(data, dims, kOutputScale, kOutputZeroPoint);
+ }
+
+ tensor.quantization.type = kTfLiteAffineQuantization;
+ return tensor;
+}
+
+template <typename T>
+void TestL2Normalization(const int* input_dims_data, const T* input_data,
+ const T* expected_output_data, T* output_data) {
+ TfLiteIntArray* dims = IntArrayFromInts(input_dims_data);
+
+ const int output_dims_count = ElementCount(*dims);
+
+ constexpr int tensors_size = 2;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateL2NormTensor(input_data, dims, true),
+ CreateL2NormTensor(output_data, dims, false),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ TfLiteL2NormParams builtin_data = {
+ .activation = kTfLiteActNone,
+ };
+
+ const TfLiteRegistration registration =
+ ops::micro::Register_L2_NORMALIZATION();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SimpleFloatTest) {
+ const int input_dims[] = {4, 1, 1, 1, 6};
+ constexpr int data_length = 6;
+ const float input_data[data_length] = {-1.1, 0.6, 0.7, 1.2, -0.7, 0.1};
+ const float expected_output_data[data_length] = {-0.55, 0.3, 0.35,
+ 0.6, -0.35, 0.05};
+ float output_data[data_length];
+
+ tflite::testing::TestL2Normalization<float>(
+ input_dims, input_data, expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ZerosVectorFloatTest) {
+ const int input_dims[] = {4, 1, 1, 1, 6};
+ constexpr int data_length = 6;
+ const float input_data[data_length] = {0, 0, 0, 0, 0, 0};
+ const float expected_output_data[data_length] = {0, 0, 0, 0, 0, 0};
+ float output_data[data_length];
+
+ tflite::testing::TestL2Normalization<float>(
+ input_dims, input_data, expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleFloatWithRankLessThanFourTest) {
+ const int input_dims[] = {4, 1, 1, 1, 6};
+ constexpr int data_length = 6;
+ const float input_data[data_length] = {-1.1, 0.6, 0.7, 1.2, -0.7, 0.1};
+ const float expected_output_data[data_length] = {-0.55, 0.3, 0.35,
+ 0.6, -0.35, 0.05};
+ float output_data[data_length];
+
+ tflite::testing::TestL2Normalization<float>(
+ input_dims, input_data, expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(MultipleBatchFloatTest) {
+ const int input_dims[] = {4, 3, 1, 1, 6};
+ constexpr int data_length = 18;
+ const float input_data[data_length] = {
+ -1.1, 0.6, 0.7, 1.2, -0.7, 0.1, // batch 1
+ -1.1, 0.6, 0.7, 1.2, -0.7, 0.1, // batch 2
+ -1.1, 0.6, 0.7, 1.2, -0.7, 0.1, // batch 3
+ };
+ const float expected_output_data[data_length] = {
+ -0.55, 0.3, 0.35, 0.6, -0.35, 0.05, // batch 1
+ -0.55, 0.3, 0.35, 0.6, -0.35, 0.05, // batch 2
+ -0.55, 0.3, 0.35, 0.6, -0.35, 0.05, // batch 3
+ };
+ float output_data[data_length];
+
+ tflite::testing::TestL2Normalization<float>(
+ input_dims, input_data, expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(ZerosVectorUint8Test) {
+ const int input_dims[] = {4, 1, 1, 1, 6};
+ constexpr int data_length = 6;
+ const uint8_t input_data[data_length] = {127, 127, 127, 127, 127, 127};
+ const uint8_t expected_output[data_length] = {128, 128, 128, 128, 128, 128};
+ uint8_t output_data[data_length];
+
+ tflite::testing::TestL2Normalization<uint8_t>(input_dims, input_data,
+ expected_output, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleUint8Test) {
+ const int input_dims[] = {4, 1, 1, 1, 6};
+ constexpr int data_length = 6;
+ const uint8_t input_data[data_length] = {57, 165, 172, 204, 82, 133};
+ const uint8_t expected_output[data_length] = {
+ 58, 166, 173, 205, 83, 134,
+ };
+ uint8_t output_data[data_length];
+
+ tflite::testing::TestL2Normalization<uint8_t>(input_dims, input_data,
+ expected_output, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleInt8Test) {
+ const int input_dims[] = {4, 1, 1, 1, 6};
+ constexpr int data_length = 6;
+ const int8_t input_data[data_length] = {-71, 37, 44, 76, -46, 5};
+ const int8_t expected_output[data_length] = {-70, 38, 45, 77, -45, 6};
+ int8_t output_data[data_length];
+
+ tflite::testing::TestL2Normalization<int8_t>(input_dims, input_data,
+ expected_output, output_data);
+}
+
+TF_LITE_MICRO_TEST(ZerosVectorInt8Test) {
+ const int input_dims[] = {4, 1, 1, 1, 6};
+ constexpr int data_length = 6;
+ const int8_t input_data[data_length] = {-1, -1, -1, -1, -1, -1};
+ const int8_t expected_output[data_length] = {0, 0, 0, 0, 0, 0};
+ int8_t output_data[data_length];
+
+ tflite::testing::TestL2Normalization<int8_t>(input_dims, input_data,
+ expected_output, output_data);
+}
+
+TF_LITE_MICRO_TEST(MultipleBatchUint8Test) {
+ const int input_dims[] = {2, 3, 6};
+ constexpr int data_length = 18;
+ const uint8_t input_data[data_length] = {
+ 57, 165, 172, 204, 82, 133, // batch 1
+ 57, 165, 172, 204, 82, 133, // batch 2
+ 57, 165, 172, 204, 82, 133, // batch 3
+ };
+ const uint8_t expected_output[data_length] = {
+ 58, 166, 173, 205, 83, 134, // batch 1
+ 58, 166, 173, 205, 83, 134, // batch 2
+ 58, 166, 173, 205, 83, 134, // batch 3
+ };
+ uint8_t output_data[data_length];
+
+ tflite::testing::TestL2Normalization<uint8_t>(input_dims, input_data,
+ expected_output, output_data);
+}
+
+TF_LITE_MICRO_TEST(MultipleBatchInt8Test) {
+ const int input_dims[] = {2, 3, 6};
+ constexpr int data_length = 18;
+ const int8_t input_data[data_length] = {
+ -71, 37, 44, 76, -46, 5, // batch 1
+ -71, 37, 44, 76, -46, 5, // batch 2
+ -71, 37, 44, 76, -46, 5, // batch 3
+ };
+ const int8_t expected_output[data_length] = {
+ -70, 38, 45, 77, -45, 6, // batch 1
+ -70, 38, 45, 77, -45, 6, // batch 2
+ -70, 38, 45, 77, -45, 6, // batch 3
+ };
+ int8_t output_data[data_length];
+
+ tflite::testing::TestL2Normalization<int8_t>(input_dims, input_data,
+ expected_output, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/leaky_relu.cc b/tensorflow/lite/micro/kernels/leaky_relu.cc
new file mode 100644
index 0000000..0a7521f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/leaky_relu.cc
@@ -0,0 +1,153 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/leaky_relu.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+// Input/output tensor index.
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+struct LeakyReluOpData {
+ // quantization parameters
+ int32_t output_multiplier_alpha;
+ int32_t output_shift_alpha;
+ int32_t output_multiplier_identity;
+ int32_t output_shift_identity;
+ int32_t input_zero_point;
+ int32_t output_zero_point;
+};
+
+template <typename T>
+void QuantizeLeakyRelu(const LeakyReluOpData& data,
+ const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output) {
+ LeakyReluParams op_params = {};
+
+ op_params.input_offset = data.input_zero_point;
+ op_params.output_offset = data.output_zero_point;
+ op_params.output_multiplier_alpha = data.output_multiplier_alpha;
+ op_params.output_shift_alpha = data.output_shift_alpha;
+ op_params.output_multiplier_identity = data.output_multiplier_identity;
+ op_params.output_shift_identity = data.output_shift_identity;
+ reference_ops::QuantizeLeakyRelu(op_params,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<T>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<T>(output));
+}
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ if (output->type == kTfLiteInt8) {
+ LeakyReluOpData* data = static_cast<LeakyReluOpData*>(node->user_data);
+ const auto* params =
+ static_cast<TfLiteLeakyReluParams*>(node->builtin_data);
+
+ data->input_zero_point = input->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ int output_shift_alpha;
+ double alpha_multiplier = static_cast<double>(
+ input->params.scale * params->alpha / output->params.scale);
+ QuantizeMultiplier(alpha_multiplier, &data->output_multiplier_alpha,
+ &output_shift_alpha);
+ data->output_shift_alpha = static_cast<int32_t>(output_shift_alpha);
+
+ int output_shift_identity;
+ double identity_multiplier =
+ static_cast<double>(input->params.scale / output->params.scale);
+ QuantizeMultiplier(identity_multiplier, &data->output_multiplier_identity,
+ &output_shift_identity);
+ data->output_shift_identity = static_cast<int32_t>(output_shift_identity);
+ }
+
+ return kTfLiteOk;
+}
+
+void* LeakyReluInit(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(LeakyReluOpData));
+}
+
+TfLiteStatus LeakyReluPrepare(TfLiteContext* context, TfLiteNode* node) {
+ return CalculateOpData(context, node);
+}
+
+TfLiteStatus LeakyReluEval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ const LeakyReluOpData& data = *static_cast<LeakyReluOpData*>(node->user_data);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ LeakyReluParams op_params = {};
+ const auto* params =
+ static_cast<TfLiteLeakyReluParams*>(node->builtin_data);
+
+ op_params.alpha = params->alpha;
+ reference_ops::LeakyRelu(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ } break;
+ case kTfLiteInt8: {
+ QuantizeLeakyRelu<int8_t>(data, input, output);
+ return kTfLiteOk;
+ } break;
+ default:
+ TF_LITE_KERNEL_LOG(
+ context, "Only float32, int8 are supported by LEAKY_RELU, got %s.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteError;
+}
+
+} // namespace
+
+TfLiteRegistration Register_LEAKY_RELU() {
+ return {/*init=*/LeakyReluInit,
+ /*free=*/nullptr,
+ /*prepare=*/LeakyReluPrepare,
+ /*invoke=*/LeakyReluEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/leaky_relu_test.cc b/tensorflow/lite/micro/kernels/leaky_relu_test.cc
new file mode 100644
index 0000000..2c5a8c8
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/leaky_relu_test.cc
@@ -0,0 +1,214 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <limits>
+#include <type_traits>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// min/max are used to compute scale, zero-point, compare tolerance
+template <typename T>
+struct TestLeakyReluParams {
+ // general parameters
+ float alpha; // alpha multiplier
+
+ // quantization parameters
+ float data_min; // input and output data minimum value
+ float data_max; // input and output data maximum value
+ T* input_data; // quantized input storage
+ T* output_data; // quantized output storage
+ float tolerance; // output vs expected value tolerance
+};
+
+void ExecuteLeakyReluTest(const float alpha, const int tensors_count,
+ TfLiteTensor* tensors) {
+ TfLiteLeakyReluParams builtin_data = {};
+ builtin_data.alpha = alpha;
+
+ constexpr int kInputArrayData[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(kInputArrayData);
+ constexpr int kOutputArrayData[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(kOutputArrayData);
+
+ const TfLiteRegistration registration = tflite::Register_LEAKY_RELU();
+ micro::KernelRunner runner(registration, tensors, tensors_count, inputs_array,
+ outputs_array, static_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+}
+
+template <typename T>
+void TestLeakyRelu(const TestLeakyReluParams<T>& params,
+ const int* input_dims_data, const T* input_data,
+ const int* expected_dims, const T* expected_data,
+ T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ TfLiteTensor tensors[] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+ constexpr int tensors_count = std::extent<decltype(tensors)>::value;
+ ExecuteLeakyReluTest(params.alpha, tensors_count, tensors);
+
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_data[i], output_data[i]);
+ }
+}
+
+template <typename T>
+void TestLeakyReluQuantized(const TestLeakyReluParams<T>& params,
+ const int* input_dims_data, const float* input_data,
+ const int* expected_dims,
+ const float* expected_data, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(expected_dims);
+ const int output_count = ElementCount(*output_dims);
+
+ const float scale = ScaleFromMinMax<T>(params.data_min, params.data_max);
+ const int zero_point =
+ ZeroPointFromMinMax<T>(params.data_min, params.data_max);
+
+ TfLiteTensor tensors[] = {
+ CreateQuantizedTensor(input_data, params.input_data, input_dims, scale,
+ zero_point),
+ CreateQuantizedTensor(params.output_data, output_dims, scale, zero_point),
+ };
+ constexpr int kTensorsCount = std::extent<decltype(tensors)>::value;
+
+ ExecuteLeakyReluTest(params.alpha, kTensorsCount, tensors);
+
+ Dequantize(params.output_data, output_count, scale, zero_point, output_data);
+ const float kTolerance = params.tolerance;
+ for (int i = 0; i < output_count; i++) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_data[i], output_data[i], kTolerance);
+ }
+}
+
+// Our fixed-point math function implementations have roughly 12 bits of
+// accuracy, when specialized to 16-bit fixed-point arithmetic.
+// That is purely an implementation compromise, it would have been possible
+// to get closer to 16 bits of accuracy but that would be more expensive,
+// and not needed for our purposes as ultimately the output is either
+// immediately down-quantized to 8 bits, or will typically be at the output
+// of the surrounding LSTM cell.
+// So we can require roughly 2^-12 accuracy when the output is 16-bit, and
+// we can more or less expect the full 2^-8 accuracy when the output is 8-bit.
+//
+// However, the representable output interval is often [-1, 1] (it has to be
+// for tanh, and even for logistic, when we implement it in fixed-point, we
+// typically have to do so on such a symmetric interval, e.g. ARM NEON only
+// has signed fixed-point arithmetic (SQRDMULH)). As the width of [-1, 1]
+// is 2, our representable values are often diluted by a factor of 2, whence
+// the factor of 2 below.
+const float kQuantizedTolerance = 2 * (1. / 256);
+
+template <typename integer_dtype>
+void QuantizedActivationsOpTestLeakyRelu() {
+ constexpr int kDims[] = {2, 5, 5};
+ constexpr float kInput[] = {
+ -5.0f, -4.6f, -4.2f, -3.8f, -3.4f, // Row 1
+ -3.0f, -2.6f, -2.2f, -1.8f, -1.4f, // Row 2
+ -1.0f, -0.6f, -0.2f, 0.2f, 0.6f, // Row 3
+ 1.0f, 1.4f, 1.8f, 2.2f, 2.6f, // Row 4
+ 3.0f, 3.4f, 3.8f, 4.2f, 4.6f, // Row 5
+ };
+ constexpr float kExpect[] = {
+ -0.50f, -0.46f, -0.42f, -0.38f, -0.34f, // Row 1
+ -0.30f, -0.26f, -0.22f, -0.18f, -0.14f, // Row 2
+ -0.10f, -0.06f, -0.02f, 0.20f, 0.60f, // Row 3
+ 1.00f, 1.40f, 1.80f, 2.20f, 2.60f, // Row 4
+ 3.00f, 3.40f, 3.80f, 4.20f, 4.60f, // Row 5
+ };
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ // setup quantization storage and parameters
+ integer_dtype q_output_data[kOutputCount];
+ integer_dtype q_input_data[kOutputCount];
+ constexpr float kMin = -1;
+ constexpr float kMax =
+ std::numeric_limits<integer_dtype>::max() /
+ static_cast<float>(std::numeric_limits<integer_dtype>::max() + 1);
+ TestLeakyReluParams<integer_dtype> params = {};
+ params.alpha = 0.1f;
+ params.data_min = 5 * kMin;
+ params.data_max = 5 * kMax;
+ params.input_data = q_input_data;
+ params.output_data = q_output_data;
+ params.tolerance = kQuantizedTolerance * 5;
+
+ TestLeakyReluQuantized(params, kDims, kInput, kDims, kExpect, output_data);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(QuantizedActivationsOpTestLeakyReluInt8_1) {
+ constexpr int kDims[] = {2, 2, 3};
+ constexpr float kInput[] = {0.0f, 1.0f, 3.0f, 1.0f, -1.0f, -2.0f};
+ constexpr float kExpect[] = {0.0f, 1.0f, 3.0f, 1.0f, -0.5f, -1.0f};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+
+ // setup quantization storage and parameters
+ int8_t q_output_data[kOutputCount];
+ int8_t q_input_data[kOutputCount];
+ constexpr float kMin = -1;
+ constexpr float kMax = 127.f / 128.f;
+ tflite::testing::TestLeakyReluParams<int8_t> params = {};
+ params.alpha = 0.5f;
+ params.data_min = 8 * kMin;
+ params.data_max = 8 * kMax;
+ params.input_data = q_input_data;
+ params.output_data = q_output_data;
+ params.tolerance = tflite::testing::kQuantizedTolerance * 8;
+
+ tflite::testing::TestLeakyReluQuantized(params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(QuantizedActivationsOpTestLeakyReluInt8_2) {
+ tflite::testing::QuantizedActivationsOpTestLeakyRelu<int8_t>();
+}
+
+TF_LITE_MICRO_TEST(FloatActivationsOpTestLeakyRelu) {
+ constexpr int kDims[] = {2, 2, 3};
+ constexpr float kInput[] = {0.0f, 1.0f, 3.0f, 1.0f, -1.0f, -2.0f};
+ constexpr float kExpect[] = {0.0f, 1.0f, 3.0f, 1.0f, -0.5f, -1.0f};
+ constexpr int kOutputCount = std::extent<decltype(kExpect)>::value;
+ float output_data[kOutputCount];
+ tflite::testing::TestLeakyReluParams<float> params = {};
+ params.alpha = 0.5f;
+
+ tflite::testing::TestLeakyRelu(params, kDims, kInput, kDims, kExpect,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/logical.cc b/tensorflow/lite/micro/kernels/logical.cc
new file mode 100644
index 0000000..f4033ba
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/logical.cc
@@ -0,0 +1,105 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/reference/binary_function.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace logical {
+namespace {
+
+// Input/output tensor index.
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus LogicalImpl(TfLiteContext* context, TfLiteNode* node,
+ bool (*func)(bool, bool)) {
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ if (tflite::micro::HaveSameShapes(input1, input2)) {
+ reference_ops::BinaryFunction<bool, bool, bool>(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<bool>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<bool>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<bool>(output), func);
+ } else {
+ reference_ops::BroadcastBinaryFunction4DSlow<bool, bool, bool>(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<bool>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<bool>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<bool>(output), func);
+ }
+
+ return kTfLiteOk;
+}
+
+bool LogicalOr(bool x, bool y) { return x || y; }
+
+TfLiteStatus LogicalOrEval(TfLiteContext* context, TfLiteNode* node) {
+ return LogicalImpl(context, node, LogicalOr);
+}
+
+bool LogicalAnd(bool x, bool y) { return x && y; }
+
+TfLiteStatus LogicalAndEval(TfLiteContext* context, TfLiteNode* node) {
+ return LogicalImpl(context, node, LogicalAnd);
+}
+
+} // namespace
+} // namespace logical
+
+TfLiteRegistration Register_LOGICAL_OR() {
+ // Init, Free, Prepare, Eval are satisfying the Interface required by
+ // TfLiteRegistration.
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/logical::LogicalOrEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_LOGICAL_AND() {
+ // Init, Free, Prepare, Eval are satisfying the Interface required by
+ // TfLiteRegistration.
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/logical::LogicalAndEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/logical_test.cc b/tensorflow/lite/micro/kernels/logical_test.cc
new file mode 100644
index 0000000..a1e4eb5
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/logical_test.cc
@@ -0,0 +1,116 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestLogicalOp(const TfLiteRegistration& registration,
+ const int* input1_dims_data, const bool* input1_data,
+ const int* input2_dims_data, const bool* input2_data,
+ const int* output_dims_data,
+ const bool* expected_output_data, bool* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ TF_LITE_MICRO_EXPECT_EQ(output_dims_count, 4);
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(LogicalOr) {
+ const int shape[] = {4, 1, 1, 1, 4};
+ const bool input1[] = {true, false, false, true};
+ const bool input2[] = {true, false, true, false};
+ const bool golden[] = {true, false, true, true};
+ bool output_data[4];
+ tflite::testing::TestLogicalOp(tflite::ops::micro::Register_LOGICAL_OR(),
+ shape, input1, shape, input2, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(BroadcastLogicalOr) {
+ const int input1_shape[] = {4, 1, 1, 1, 4};
+ const bool input1[] = {true, false, false, true};
+ const int input2_shape[] = {4, 1, 1, 1, 1};
+ const bool input2[] = {false};
+ const bool golden[] = {true, false, false, true};
+ bool output_data[4];
+ tflite::testing::TestLogicalOp(tflite::ops::micro::Register_LOGICAL_OR(),
+ input1_shape, input1, input2_shape, input2,
+ input1_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(LogicalAnd) {
+ const int shape[] = {4, 1, 1, 1, 4};
+ const bool input1[] = {true, false, false, true};
+ const bool input2[] = {true, false, true, false};
+ const bool golden[] = {true, false, false, false};
+ bool output_data[4];
+ tflite::testing::TestLogicalOp(tflite::ops::micro::Register_LOGICAL_AND(),
+ shape, input1, shape, input2, shape, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(BroadcastLogicalAnd) {
+ const int input1_shape[] = {4, 1, 1, 1, 4};
+ const bool input1[] = {true, false, false, true};
+ const int input2_shape[] = {4, 1, 1, 1, 1};
+ const bool input2[] = {true};
+ const bool golden[] = {true, false, false, true};
+ bool output_data[4];
+ tflite::testing::TestLogicalOp(tflite::ops::micro::Register_LOGICAL_AND(),
+ input1_shape, input1, input2_shape, input2,
+ input1_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/logistic.cc b/tensorflow/lite/micro/kernels/logistic.cc
new file mode 100644
index 0000000..3fa81ba
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/logistic.cc
@@ -0,0 +1,150 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/logistic.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/logistic.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace activations {
+namespace {
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ int32_t input_zero_point;
+ int32_t input_range_radius;
+ int32_t input_multiplier;
+ int input_left_shift;
+};
+
+TfLiteStatus CalculateArithmeticOpData(TfLiteContext* context, TfLiteNode* node,
+ OpData* data) {
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point,
+ std::numeric_limits<int8_t>::min());
+
+ static constexpr int kInputIntegerBits = 4;
+ const double input_real_multiplier =
+ static_cast<double>(input->params.scale) *
+ static_cast<double>(1 << (31 - kInputIntegerBits));
+
+ data->input_zero_point = input->params.zero_point;
+
+ const double q = std::frexp(input_real_multiplier, &data->input_left_shift);
+ data->input_multiplier = static_cast<int32_t>(TfLiteRound(q * (1ll << 31)));
+
+ data->input_range_radius =
+ CalculateInputRadius(kInputIntegerBits, data->input_left_shift, 31);
+ }
+ return kTfLiteOk;
+}
+} // namespace
+
+void* LogisticInit(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus LogisticPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ return CalculateArithmeticOpData(context, node, data);
+}
+
+TfLiteStatus LogisticEval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ if (input->type == kTfLiteFloat32) {
+ switch (output->type) {
+ case kTfLiteFloat32: {
+ reference_ops::Logistic(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ } else if (input->type == kTfLiteInt8) {
+ switch (output->type) {
+ case kTfLiteInt8: {
+ reference_integer_ops::Logistic(
+ data->input_zero_point, data->input_range_radius,
+ data->input_multiplier, data->input_left_shift,
+ NumElements(input->dims),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ } else {
+ // TODO(b/141211002): Also support other data types once we have supported
+ // temporary tensors in TFLM.
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace activations
+
+TfLiteRegistration Register_LOGISTIC() {
+ return {/*init=*/activations::LogisticInit,
+ /*free=*/nullptr,
+ /*prepare=*/activations::LogisticPrepare,
+ /*invoke=*/activations::LogisticEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/logistic_test.cc b/tensorflow/lite/micro/kernels/logistic_test.cc
new file mode 100644
index 0000000..868af2c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/logistic_test.cc
@@ -0,0 +1,169 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// The Logistic kernel assumes an output in the range [0, 1.0], leading to these
+// quantization parameters.
+const float quantized_output_scale = 1.0 / 255.0;
+const int quantized_output_zero_point_int8 = -128;
+
+const int flat_size_basic = 10;
+const int shape_basic[] = {2, 2, 5};
+const float input_data_basic[] = {1, 2, 3, 4, 5, -1, -2, -3, -4, -5};
+const float golden_basic[] = {0.73105858, 0.88079708, 0.95257413, 0.98201379,
+ 0.99330715, 0.26894142, 0.11920292, 0.04742587,
+ 0.01798621, 0.00669285};
+
+const int flat_size_wide_range = 10;
+const int shape_wide_range[] = {2, 1, 5};
+const float input_data_wide_range[]{
+ 1.0, 2.0, 3.0, 4.0, 93.0, -1.0, -2.0, -3.0, -4.0, -93.0,
+};
+const float golden_wide_range[] = {
+ 0.73105858, 0.88079708, 0.95257413, 0.98201379, 1.0,
+ 0.26894142, 0.11920292, 0.04742587, 0.01798621, 0.0,
+};
+
+template <typename T>
+void ValidateLogisticGoldens(TfLiteTensor* tensors, const int tensor_count,
+ T* output_data, const T* golden,
+ int output_dims_count, float tolerance) {
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_LOGISTIC();
+ micro::KernelRunner runner(registration, tensors, tensor_count, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output_data[i], tolerance);
+ }
+}
+
+void TestLogisticFloat(const int* input_dims_data, const float* input_data,
+ const float* golden, const int* output_dims_data,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateLogisticGoldens(tensors, tensors_size, output_data, golden,
+ output_elements_count, 1e-5);
+}
+
+template <typename T>
+void TestLogisticQuantized(const int* input_dims_data, const float* input_data,
+ T* input_quantized, const float input_scale,
+ const int input_zero_point, const float* golden,
+ T* golden_quantized, const int* output_dims_data,
+ const float output_scale,
+ const int output_zero_point, int8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ tflite::Quantize(golden, golden_quantized, output_elements_count,
+ output_scale, output_zero_point);
+ ValidateLogisticGoldens(tensors, tensors_size, output_data, golden_quantized,
+ output_elements_count, 1.0);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(LogisticFloatBasicShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_basic];
+ tflite::testing::TestLogisticFloat(
+ tflite::testing::shape_basic, tflite::testing::input_data_basic,
+ tflite::testing::golden_basic, tflite::testing::shape_basic, output_data);
+}
+
+TF_LITE_MICRO_TEST(LogisticQuantizedInt8BasicShouldMatchGolden) {
+ const float input_scale = 0.1;
+ const int input_zero_point = 0;
+ int8_t input_quantized[tflite::testing::flat_size_basic];
+ int8_t golden_quantized[tflite::testing::flat_size_basic];
+ int8_t output_data[tflite::testing::flat_size_basic];
+
+ tflite::testing::TestLogisticQuantized(
+ tflite::testing::shape_basic, tflite::testing::input_data_basic,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::golden_basic, golden_quantized,
+ tflite::testing::shape_basic, tflite::testing::quantized_output_scale,
+ tflite::testing::quantized_output_zero_point_int8, output_data);
+}
+
+TF_LITE_MICRO_TEST(LogisticFloatWideRangeShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_wide_range];
+ tflite::testing::TestLogisticFloat(
+ tflite::testing::shape_wide_range, tflite::testing::input_data_wide_range,
+ tflite::testing::golden_wide_range, tflite::testing::shape_wide_range,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(LogisticQuantizedInt8WideRangeShouldMatchGolden) {
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ int8_t input_quantized[tflite::testing::flat_size_wide_range];
+ int8_t golden_quantized[tflite::testing::flat_size_wide_range];
+ int8_t output_data[tflite::testing::flat_size_wide_range];
+
+ tflite::testing::TestLogisticQuantized(
+ tflite::testing::shape_wide_range, tflite::testing::input_data_wide_range,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::golden_wide_range, golden_quantized,
+ tflite::testing::shape_wide_range,
+ tflite::testing::quantized_output_scale,
+ tflite::testing::quantized_output_zero_point_int8, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/maximum_minimum.cc b/tensorflow/lite/micro/kernels/maximum_minimum.cc
new file mode 100644
index 0000000..a7c343b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/maximum_minimum.cc
@@ -0,0 +1,148 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/maximum_minimum.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace maximum_minimum {
+namespace {
+
+// This file has a reference implementation of TFMaximum/TFMinimum.
+enum KernelType {
+ kReference,
+};
+
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+struct OpContext {
+ OpContext(TfLiteContext* context, TfLiteNode* node) {
+ input1 = tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ input2 = tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ output = tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ }
+ const TfLiteEvalTensor* input1;
+ const TfLiteEvalTensor* input2;
+ TfLiteEvalTensor* output;
+};
+
+struct MaximumOp {
+ template <typename data_type>
+ static data_type op(data_type el1, data_type el2) {
+ return el1 > el2 ? el1 : el2;
+ }
+};
+
+struct MinimumOp {
+ template <typename data_type>
+ static data_type op(data_type el1, data_type el2) {
+ return el1 < el2 ? el1 : el2;
+ }
+};
+
+} // namespace
+
+template <typename data_type, typename op_type>
+void TFLiteOperation(TfLiteContext* context, TfLiteNode* node,
+ const OpContext& op_context) {
+ reference_ops::MaximumMinimumBroadcastSlow(
+ tflite::micro::GetTensorShape(op_context.input1),
+ tflite::micro::GetTensorData<data_type>(op_context.input1),
+ tflite::micro::GetTensorShape(op_context.input2),
+ tflite::micro::GetTensorData<data_type>(op_context.input2),
+ tflite::micro::GetTensorShape(op_context.output),
+ tflite::micro::GetTensorData<data_type>(op_context.output),
+ op_type::template op<data_type>);
+}
+
+template <KernelType kernel_type, typename OpType>
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ OpContext op_context(context, node);
+
+ if (kernel_type == kReference) {
+ switch (op_context.output->type) {
+ case kTfLiteFloat32:
+ TFLiteOperation<float, OpType>(context, node, op_context);
+ break;
+ case kTfLiteUInt8:
+ TFLiteOperation<uint8_t, OpType>(context, node, op_context);
+ break;
+ case kTfLiteInt8:
+ TFLiteOperation<int8_t, OpType>(context, node, op_context);
+ break;
+ case kTfLiteInt32:
+ TFLiteOperation<int32_t, OpType>(context, node, op_context);
+ break;
+ case kTfLiteInt64:
+ TFLiteOperation<int64_t, OpType>(context, node, op_context);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s (%d) is not supported by Maximum/Minimum.",
+ TfLiteTypeGetName(op_context.output->type),
+ op_context.output->type);
+ return kTfLiteError;
+ }
+ } else {
+ TF_LITE_KERNEL_LOG(context,
+ "Kernel type not supported by Maximum/Minimum.");
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace maximum_minimum
+
+TfLiteRegistration Register_MAXIMUM() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/
+ maximum_minimum::Eval<maximum_minimum::kReference,
+ maximum_minimum::MaximumOp>,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_MINIMUM() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/
+ maximum_minimum::Eval<maximum_minimum::kReference,
+ maximum_minimum::MinimumOp>,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/maximum_minimum_test.cc b/tensorflow/lite/micro/kernels/maximum_minimum_test.cc
new file mode 100644
index 0000000..76a6a98
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/maximum_minimum_test.cc
@@ -0,0 +1,227 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestMaxMinFloat(const TfLiteRegistration& registration,
+ const int* input1_dims_data, const float* input1_data,
+ const int* input2_dims_data, const float* input2_data,
+ const float* expected_output_data,
+ const int* output_dims_data, float* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestMaxMinQuantized(const TfLiteRegistration& registration,
+ const int* input1_dims_data,
+ const uint8_t* input1_data, float const input1_scale,
+ const int input1_zero_point,
+ const int* input2_dims_data,
+ const uint8_t* input2_data, const float input2_scale,
+ const int input2_zero_point,
+ const uint8_t* expected_output_data,
+ const float output_scale, const int output_zero_point,
+ const int* output_dims_data, uint8_t* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input1_data, input1_dims, input1_scale,
+ input1_zero_point),
+ CreateQuantizedTensor(input2_data, input2_dims, input2_scale,
+ input2_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+void TestMaxMinQuantizedInt32(
+ const TfLiteRegistration& registration, const int* input1_dims_data,
+ const int32_t* input1_data, const int* input2_dims_data,
+ const int32_t* input2_data, const int32_t* expected_output_data,
+ const int* output_dims_data, int32_t* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatTest) {
+ const int dims[] = {3, 3, 1, 2};
+ const float data1[] = {1.0, 0.0, -1.0, 11.0, -2.0, -1.44};
+ const float data2[] = {-1.0, 0.0, 1.0, 12.0, -3.0, -1.43};
+ const float golden_max[] = {1.0, 0.0, 1.0, 12.0, -2.0, -1.43};
+ const float golden_min[] = {-1.0, 0.0, -1.0, 11.0, -3.0, -1.44};
+ float output_data[6];
+
+ tflite::testing::TestMaxMinFloat(tflite::ops::micro::Register_MAXIMUM(), dims,
+ data1, dims, data2, golden_max, dims,
+ output_data);
+
+ tflite::testing::TestMaxMinFloat(tflite::ops::micro::Register_MINIMUM(), dims,
+ data1, dims, data2, golden_min, dims,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Uint8Test) {
+ const int dims[] = {3, 3, 1, 2};
+ const uint8_t data1[] = {1, 0, 2, 11, 2, 23};
+ const uint8_t data2[] = {0, 0, 1, 12, 255, 1};
+ const uint8_t golden_max[] = {1, 0, 2, 12, 255, 23};
+ const uint8_t golden_min[] = {0, 0, 1, 11, 2, 1};
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+
+ uint8_t output_data[6];
+
+ tflite::testing::TestMaxMinQuantized(
+ tflite::ops::micro::Register_MAXIMUM(), dims, data1, input_scale,
+ input_zero_point, dims, data2, input_scale, input_zero_point, golden_max,
+ output_scale, output_zero_point, dims, output_data);
+
+ tflite::testing::TestMaxMinQuantized(
+ tflite::ops::micro::Register_MINIMUM(), dims, data1, input_scale,
+ input_zero_point, dims, data2, input_scale, input_zero_point, golden_min,
+ output_scale, output_zero_point, dims, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatWithBroadcastTest) {
+ const int dims[] = {3, 3, 1, 2};
+ const int dims_scalar[] = {1, 2};
+ const float data1[] = {1.0, 0.0, -1.0, -2.0, -1.44, 11.0};
+ const float data2[] = {0.5, 2.0};
+ const float golden_max[] = {1.0, 2.0, 0.5, 2.0, 0.5, 11.0};
+ const float golden_min[] = {0.5, 0.0, -1.0, -2.0, -1.44, 2.0};
+ float output_data[6];
+
+ tflite::testing::TestMaxMinFloat(tflite::ops::micro::Register_MAXIMUM(), dims,
+ data1, dims_scalar, data2, golden_max, dims,
+ output_data);
+
+ tflite::testing::TestMaxMinFloat(tflite::ops::micro::Register_MINIMUM(), dims,
+ data1, dims_scalar, data2, golden_min, dims,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Int32WithBroadcastTest) {
+ const int dims[] = {3, 3, 1, 2};
+ const int dims_scalar[] = {1, 1};
+ const int32_t data1[] = {1, 0, -1, -2, 3, 11};
+ const int32_t data2[] = {2};
+ const int32_t golden_max[] = {2, 2, 2, 2, 3, 11};
+ const int32_t golden_min[] = {1, 0, -1, -2, 2, 2};
+ int32_t output_data[6];
+
+ tflite::testing::TestMaxMinQuantizedInt32(
+ tflite::ops::micro::Register_MAXIMUM(), dims, data1, dims_scalar, data2,
+ golden_max, dims, output_data);
+
+ tflite::testing::TestMaxMinQuantizedInt32(
+ tflite::ops::micro::Register_MINIMUM(), dims, data1, dims_scalar, data2,
+ golden_min, dims, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/micro_ops.h b/tensorflow/lite/micro/kernels/micro_ops.h
new file mode 100644
index 0000000..942b880
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/micro_ops.h
@@ -0,0 +1,117 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_MICRO_OPS_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_MICRO_OPS_H_
+
+#include "tensorflow/lite/c/common.h"
+
+// Forward declaration of all micro op kernel registration methods. These
+// registrations are included with the standard `BuiltinOpResolver`.
+//
+// This header is particularly useful in cases where only a subset of ops are
+// needed. In such cases, the client can selectively add only the registrations
+// their model requires, using a custom `(Micro)MutableOpResolver`. Selective
+// registration in turn allows the linker to strip unused kernels.
+
+namespace tflite {
+
+// TFLM is incrementally moving towards a flat tflite namespace
+// (https://abseil.io/tips/130). Any new ops (or cleanup of existing ops should
+// have their Register function declarations in the tflite namespace.
+
+TfLiteRegistration Register_ADD_N();
+TfLiteRegistration Register_BATCH_TO_SPACE_ND();
+TfLiteRegistration Register_CAST();
+TfLiteRegistration Register_CONV_2D();
+TfLiteRegistration Register_CUMSUM();
+TfLiteRegistration Register_DEPTHWISE_CONV_2D();
+TfLiteRegistration Register_DIV();
+TfLiteRegistration Register_ELU();
+TfLiteRegistration Register_EXP();
+TfLiteRegistration Register_EXPAND_DIMS();
+TfLiteRegistration Register_FILL();
+TfLiteRegistration Register_FLOOR_DIV();
+TfLiteRegistration Register_FLOOR_MOD();
+TfLiteRegistration Register_L2_POOL_2D();
+TfLiteRegistration Register_LEAKY_RELU();
+TfLiteRegistration Register_QUANTIZE();
+TfLiteRegistration Register_SHAPE();
+TfLiteRegistration Register_SOFTMAX();
+TfLiteRegistration Register_SPACE_TO_BATCH_ND();
+TfLiteRegistration Register_SQUEEZE();
+TfLiteRegistration Register_SVDF();
+TfLiteRegistration Register_TRANSPOSE_CONV();
+TfLiteRegistration Register_ZEROS_LIKE();
+
+namespace ops {
+namespace micro {
+
+TfLiteRegistration Register_ABS();
+TfLiteRegistration Register_ADD();
+TfLiteRegistration Register_ARG_MAX();
+TfLiteRegistration Register_ARG_MIN();
+TfLiteRegistration Register_AVERAGE_POOL_2D();
+TfLiteRegistration Register_CEIL();
+// TODO(b/160234179): Change custom OPs to also return by value.
+TfLiteRegistration* Register_CIRCULAR_BUFFER();
+TfLiteRegistration Register_CONCATENATION();
+TfLiteRegistration Register_COS();
+TfLiteRegistration Register_DEQUANTIZE();
+TfLiteRegistration Register_EQUAL();
+TfLiteRegistration Register_FLOOR();
+TfLiteRegistration Register_GREATER();
+TfLiteRegistration Register_GREATER_EQUAL();
+TfLiteRegistration Register_HARD_SWISH();
+TfLiteRegistration Register_LESS();
+TfLiteRegistration Register_LESS_EQUAL();
+TfLiteRegistration Register_LOG();
+TfLiteRegistration Register_LOGICAL_AND();
+TfLiteRegistration Register_LOGICAL_NOT();
+TfLiteRegistration Register_LOGICAL_OR();
+TfLiteRegistration Register_LOGISTIC();
+TfLiteRegistration Register_MAXIMUM();
+TfLiteRegistration Register_MAX_POOL_2D();
+TfLiteRegistration Register_MEAN();
+TfLiteRegistration Register_MINIMUM();
+TfLiteRegistration Register_MUL();
+TfLiteRegistration Register_NEG();
+TfLiteRegistration Register_NOT_EQUAL();
+TfLiteRegistration Register_PACK();
+TfLiteRegistration Register_PAD();
+TfLiteRegistration Register_PADV2();
+TfLiteRegistration Register_PRELU();
+TfLiteRegistration Register_REDUCE_MAX();
+TfLiteRegistration Register_RELU();
+TfLiteRegistration Register_RELU6();
+TfLiteRegistration Register_RESHAPE();
+TfLiteRegistration Register_RESIZE_NEAREST_NEIGHBOR();
+TfLiteRegistration Register_ROUND();
+TfLiteRegistration Register_RSQRT();
+TfLiteRegistration Register_SIN();
+TfLiteRegistration Register_SPLIT();
+TfLiteRegistration Register_SPLIT_V();
+TfLiteRegistration Register_SQRT();
+TfLiteRegistration Register_SQUARE();
+TfLiteRegistration Register_STRIDED_SLICE();
+TfLiteRegistration Register_SUB();
+TfLiteRegistration Register_UNPACK();
+TfLiteRegistration Register_L2_NORMALIZATION();
+TfLiteRegistration Register_TANH();
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_MICRO_OPS_H_
diff --git a/tensorflow/lite/micro/kernels/micro_utils.h b/tensorflow/lite/micro/kernels/micro_utils.h
new file mode 100644
index 0000000..e406ac1
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/micro_utils.h
@@ -0,0 +1,40 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_MICRO_UTILS_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_MICRO_UTILS_H_
+namespace tflite {
+namespace ops {
+namespace micro {
+
+// Same as gtl::Greater but defined here to reduce dependencies and
+// binary size for micro environment.
+struct Greater {
+ template <typename T>
+ bool operator()(const T& x, const T& y) const {
+ return x > y;
+ }
+};
+
+struct Less {
+ template <typename T>
+ bool operator()(const T& x, const T& y) const {
+ return x < y;
+ }
+};
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_MICRO_UTILS_H_
diff --git a/tensorflow/lite/micro/kernels/mul.cc b/tensorflow/lite/micro/kernels/mul.cc
new file mode 100644
index 0000000..b3f3bd4
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/mul.cc
@@ -0,0 +1,236 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/mul.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/mul.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace mul {
+namespace {
+
+constexpr int kInput1Tensor = 0;
+constexpr int kInput2Tensor = 1;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ int32_t input1_zero_point;
+ int32_t input2_zero_point;
+
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+ int32_t output_zero_point;
+ int32_t output_multiplier;
+ int output_shift;
+
+ float output_activation_min_f32;
+ float output_activation_max_f32;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node,
+ TfLiteMulParams* params, OpData* data) {
+ const TfLiteTensor* input1 = GetInput(context, node, kInput1Tensor);
+ TF_LITE_ENSURE(context, input1 != nullptr);
+ const TfLiteTensor* input2 = GetInput(context, node, kInput2Tensor);
+ TF_LITE_ENSURE(context, input2 != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input1->type, input2->type);
+
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, params->activation, output, &data->output_activation_min,
+ &data->output_activation_max));
+
+ double real_multiplier = static_cast<double>(input1->params.scale) *
+ static_cast<double>(input2->params.scale) /
+ static_cast<double>(output->params.scale);
+ QuantizeMultiplier(real_multiplier, &data->output_multiplier,
+ &data->output_shift);
+
+ data->input1_zero_point = input1->params.zero_point;
+ data->input2_zero_point = input2->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+ } else {
+ CalculateActivationRange(params->activation,
+ &data->output_activation_min_f32,
+ &data->output_activation_max_f32);
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace
+
+void EvalQuantized(TfLiteContext* context, TfLiteNode* node, const OpData* data,
+ const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2, TfLiteEvalTensor* output) {
+ tflite::ArithmeticParams op_params = {};
+ op_params.quantized_activation_min = data->output_activation_min;
+ op_params.quantized_activation_max = data->output_activation_max;
+ op_params.float_activation_max = data->output_activation_max_f32;
+ op_params.input1_offset = -data->input1_zero_point;
+ op_params.input2_offset = -data->input2_zero_point;
+ op_params.output_offset = data->output_zero_point;
+ op_params.output_multiplier = data->output_multiplier;
+ op_params.output_shift = data->output_shift;
+
+ bool need_broadcast = reference_ops::ProcessBroadcastShapes(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2), &op_params);
+
+ if (output->type == kTfLiteInt8) {
+ if (need_broadcast) {
+ reference_integer_ops::BroadcastMul4DSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<int8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ } else {
+ reference_integer_ops::Mul(op_params,
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<int8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+ } else if (output->type == kTfLiteUInt8) {
+ if (need_broadcast) {
+ reference_integer_ops::BroadcastMul4DSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<uint8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<uint8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ reference_integer_ops::Mul(op_params,
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<uint8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<uint8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ }
+ }
+}
+
+void EvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLiteMulParams* params, const OpData* data,
+ const TfLiteEvalTensor* input1, const TfLiteEvalTensor* input2,
+ TfLiteEvalTensor* output) {
+ tflite::ArithmeticParams op_params = {};
+ op_params.float_activation_min = data->output_activation_min_f32;
+ op_params.float_activation_max = data->output_activation_max_f32;
+
+ bool need_broadcast = reference_ops::ProcessBroadcastShapes(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2), &op_params);
+
+ if (need_broadcast) {
+ reference_ops::BroadcastMul4DSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<float>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<float>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ } else {
+ reference_ops::Mul(op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<float>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<float>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ }
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLiteMulParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ return CalculateOpData(context, node, params, data);
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLiteMulParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInput1Tensor);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInput2Tensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input1->type) {
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ EvalQuantized(context, node, data, input1, input2, output);
+ break;
+ case kTfLiteFloat32:
+ EvalFloat(context, node, params, data, input1, input2, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input1->type), input1->type);
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+} // namespace mul
+
+TfLiteRegistration Register_MUL() {
+ return {/*init=*/mul::Init,
+ /*free=*/nullptr,
+ /*prepare=*/mul::Prepare,
+ /*invoke=*/mul::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/mul_test.cc b/tensorflow/lite/micro/kernels/mul_test.cc
new file mode 100644
index 0000000..46d7f5d
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/mul_test.cc
@@ -0,0 +1,233 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+const int flat_size_simple = 4;
+const float scale_simple = 0.01;
+const int dims_simple[] = {4, 1, 2, 2, 1};
+const float input1_simple[] = {-0.8, 0.2, 0.9, 0.7};
+const float input2_simple[] = {0.6, 0.4, 0.9, 0.8};
+const float golden_simple[] = {-0.48, 0.08, 0.81, 0.56};
+const float golden_simple_relu[] = {0.0, 0.08, 0.81, 0.56};
+
+const int flat_size_broadcast = 6;
+const float input_scale_broadcast = 0.05f;
+const float output_scale_broadcast = 0.01f;
+const int dims_broadcast[] = {4, 1, 3, 1, 2};
+const int dims_scalar_broadcast[] = {1, 1};
+const float input1_broadcast[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+const float input2_broadcast[] = {0.1};
+const float golden_broadcast[] = {-0.2, 0.02, 0.07, 0.08, 0.11, 0.2};
+const float golden_broadcast_relu[] = {0, 0.02, 0.07, 0.08, 0.11, 0.2};
+
+template <typename T>
+void ValidateMulGoldens(TfLiteTensor* tensors, int tensors_size,
+ TfLiteFusedActivation activation, const T* golden,
+ int output_len, float tolerance, T* output) {
+ TfLiteMulParams builtin_data = {
+ .activation = activation,
+ };
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_MUL();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_len; i++) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output[i], tolerance);
+ }
+}
+
+void TestMulFloat(const int* input1_dims_data, const float* input1_data,
+ const int* input2_dims_data, const float* input2_data,
+ const int* output_dims_data, const float* golden,
+ float* output_data, TfLiteFusedActivation activation) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateMulGoldens(tensors, tensors_size, activation, golden,
+ output_dims_count, 1e-5, output_data);
+}
+
+template <typename T>
+void TestMulQuantized(const int* input1_dims_data, const float* input1_data,
+ T* input1_quantized, const int* input2_dims_data,
+ const float* input2_data, T* input2_quantized,
+ const float input_scale, const int input_zero_point,
+ const int* output_dims_data, const float* golden,
+ T* golden_quantized, const float output_scale,
+ const int output_zero_point, T* output_data,
+ TfLiteFusedActivation activation) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input1_data, input1_quantized, input1_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(input2_data, input2_quantized, input2_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point)};
+
+ Quantize(golden, golden_quantized, output_dims_count, output_scale,
+ output_zero_point);
+
+ ValidateMulGoldens(tensors, tensors_size, activation, golden_quantized,
+ output_dims_count, 1.0f, output_data);
+}
+
+} // namespace
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SimpleFloatNoAcativationShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_simple];
+
+ tflite::testing::TestMulFloat(
+ tflite::testing::dims_simple, tflite::testing::input1_simple,
+ tflite::testing::dims_simple, tflite::testing::input2_simple,
+ tflite::testing::dims_simple, tflite::testing::golden_simple, output_data,
+ kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(SimpleFloatReluShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_simple];
+
+ tflite::testing::TestMulFloat(
+ tflite::testing::dims_simple, tflite::testing::input1_simple,
+ tflite::testing::dims_simple, tflite::testing::input2_simple,
+ tflite::testing::dims_simple, tflite::testing::golden_simple_relu,
+ output_data, kTfLiteActRelu);
+}
+
+TF_LITE_MICRO_TEST(SimpleInt8NoAcativationShouldMatchGolden) {
+ int8_t input1_quantized[tflite::testing::flat_size_simple];
+ int8_t input2_quantized[tflite::testing::flat_size_simple];
+ int8_t golden_quantized[tflite::testing::flat_size_simple];
+ int8_t output_data[tflite::testing::flat_size_simple];
+
+ tflite::testing::TestMulQuantized(
+ tflite::testing::dims_simple, tflite::testing::input1_simple,
+ input1_quantized, tflite::testing::dims_simple,
+ tflite::testing::input2_simple, input2_quantized,
+ tflite::testing::scale_simple, 0, tflite::testing::dims_simple,
+ tflite::testing::golden_simple, golden_quantized,
+ tflite::testing::scale_simple, 0, output_data, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(SimpleUInt8NoAcativationShouldMatchGolden) {
+ uint8_t input1_quantized[tflite::testing::flat_size_simple];
+ uint8_t input2_quantized[tflite::testing::flat_size_simple];
+ uint8_t golden_quantized[tflite::testing::flat_size_simple];
+ uint8_t output_data[tflite::testing::flat_size_simple];
+
+ tflite::testing::TestMulQuantized(
+ tflite::testing::dims_simple, tflite::testing::input1_simple,
+ input1_quantized, tflite::testing::dims_simple,
+ tflite::testing::input2_simple, input2_quantized,
+ tflite::testing::scale_simple, 128, tflite::testing::dims_simple,
+ tflite::testing::golden_simple, golden_quantized,
+ tflite::testing::scale_simple, 128, output_data, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(BroadcastFloatNoActivationShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_broadcast];
+
+ tflite::testing::TestMulFloat(
+ tflite::testing::dims_broadcast, tflite::testing::input1_broadcast,
+ tflite::testing::dims_scalar_broadcast, tflite::testing::input2_broadcast,
+ tflite::testing::dims_broadcast, tflite::testing::golden_broadcast,
+ output_data, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(BroadcastFloatReluShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_broadcast];
+
+ tflite::testing::TestMulFloat(
+ tflite::testing::dims_broadcast, tflite::testing::input1_broadcast,
+ tflite::testing::dims_scalar_broadcast, tflite::testing::input2_broadcast,
+ tflite::testing::dims_broadcast, tflite::testing::golden_broadcast_relu,
+ output_data, kTfLiteActRelu);
+}
+
+TF_LITE_MICRO_TEST(BroadcastInt8NoAcativationShouldMatchGolden) {
+ int8_t input1_quantized[tflite::testing::flat_size_broadcast];
+ int8_t input2_quantized[tflite::testing::flat_size_broadcast];
+ int8_t golden_quantized[tflite::testing::flat_size_broadcast];
+ int8_t output_data[tflite::testing::flat_size_broadcast];
+
+ tflite::testing::TestMulQuantized(
+ tflite::testing::dims_broadcast, tflite::testing::input1_broadcast,
+ input1_quantized, tflite::testing::dims_scalar_broadcast,
+ tflite::testing::input2_broadcast, input2_quantized,
+ tflite::testing::input_scale_broadcast, 0,
+ tflite::testing::dims_broadcast, tflite::testing::golden_broadcast,
+ golden_quantized, tflite::testing::output_scale_broadcast, 0, output_data,
+ kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TEST(BroadcastUInt8NoAcativationShouldMatchGolden) {
+ uint8_t input1_quantized[tflite::testing::flat_size_broadcast];
+ uint8_t input2_quantized[1];
+ uint8_t golden_quantized[tflite::testing::flat_size_broadcast];
+ uint8_t output_data[tflite::testing::flat_size_broadcast];
+
+ tflite::testing::TestMulQuantized(
+ tflite::testing::dims_broadcast, tflite::testing::input1_broadcast,
+ input1_quantized, tflite::testing::dims_scalar_broadcast,
+ tflite::testing::input2_broadcast, input2_quantized,
+ tflite::testing::input_scale_broadcast, 128,
+ tflite::testing::dims_broadcast, tflite::testing::golden_broadcast,
+ golden_quantized, tflite::testing::output_scale_broadcast, 128,
+ output_data, kTfLiteActNone);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/neg.cc b/tensorflow/lite/micro/kernels/neg.cc
new file mode 100644
index 0000000..74a95ca
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/neg.cc
@@ -0,0 +1,66 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/neg.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace neg {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ switch (input->type) {
+ // TODO(wangtz): handle for kTfLiteInt8
+ case kTfLiteFloat32:
+ reference_ops::Negate(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace neg
+
+TfLiteRegistration Register_NEG() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/neg::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/neg_test.cc b/tensorflow/lite/micro/kernels/neg_test.cc
new file mode 100644
index 0000000..4490f2a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/neg_test.cc
@@ -0,0 +1,84 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestNegFloat(const int* input_dims_data, const float* input_data,
+ const float* expected_output_data,
+ const int* output_dims_data, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_NEG();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[0], output_data[0]);
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(NegOpSingleFloat) {
+ const int dims[] = {1, 2};
+ const float input_data[] = {8.5, 0.0};
+ const float golden[] = {-8.5, 0.0};
+ float output_data[2];
+
+ tflite::testing::TestNegFloat(dims, input_data, golden, dims, output_data);
+}
+
+TF_LITE_MICRO_TEST(NegOpFloat) {
+ const int dims[] = {2, 2, 3};
+ const float input_data[] = {-2.0f, -1.0f, 0.f, 1.0f, 2.0f, 3.0f};
+ const float golden[] = {2.0f, 1.0f, -0.f, -1.0f, -2.0f, -3.0f};
+ float output_data[6];
+
+ tflite::testing::TestNegFloat(dims, input_data, golden, dims, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/pack.cc b/tensorflow/lite/micro/kernels/pack.cc
new file mode 100644
index 0000000..d332fc6
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/pack.cc
@@ -0,0 +1,127 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace pack {
+namespace {
+
+constexpr int kOutputTensor = 0;
+
+template <typename T>
+TfLiteStatus PackImpl(TfLiteContext* context, TfLiteNode* node,
+ TfLiteEvalTensor* output, int values_count, int axis) {
+ const TfLiteEvalTensor* input0 =
+ tflite::micro::GetEvalInput(context, node, 0);
+
+ const int dimensions = output->dims->size;
+ const TfLiteIntArray* input_dims = input0->dims;
+ const TfLiteIntArray* output_dims = output->dims;
+
+ if (axis < 0) {
+ axis += dimensions;
+ }
+
+ int outer_size = 1;
+ for (int i = 0; i < axis; ++i) {
+ outer_size *= output_dims->data[i];
+ }
+ int copy_size = 1;
+ for (int i = axis + 1; i < dimensions; ++i) {
+ copy_size *= output_dims->data[i];
+ }
+ int input_size = 1;
+ for (int i = 0; i < input_dims->size; ++i) {
+ input_size *= input_dims->data[i];
+ }
+ TFLITE_DCHECK_EQ(input_size, copy_size * outer_size);
+
+ T* output_data = tflite::micro::GetTensorData<T>(output);
+
+ for (int i = 0; i < values_count; ++i) {
+ const TfLiteEvalTensor* t = tflite::micro::GetEvalInput(context, node, i);
+ const T* input_data = tflite::micro::GetTensorData<T>(t);
+ for (int k = 0; k < outer_size; ++k) {
+ const T* input_ptr = input_data + copy_size * k;
+ int loc = k * values_count * copy_size + i * copy_size;
+ T* output_ptr = output_data + loc;
+ for (int j = 0; j < copy_size; ++j) output_ptr[j] = input_ptr[j];
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLitePackParams* data =
+ reinterpret_cast<TfLitePackParams*>(node->builtin_data);
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (output->type) {
+ case kTfLiteFloat32: {
+ return PackImpl<float>(context, node, output, data->values_count,
+ data->axis);
+ }
+ case kTfLiteUInt8: {
+ return PackImpl<uint8_t>(context, node, output, data->values_count,
+ data->axis);
+ }
+ case kTfLiteInt8: {
+ return PackImpl<int8_t>(context, node, output, data->values_count,
+ data->axis);
+ }
+ case kTfLiteInt32: {
+ return PackImpl<int32_t>(context, node, output, data->values_count,
+ data->axis);
+ }
+ case kTfLiteInt64: {
+ return PackImpl<int64_t>(context, node, output, data->values_count,
+ data->axis);
+ }
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Type '%s' is not supported by pack.",
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace
+} // namespace pack
+
+TfLiteRegistration Register_PACK() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/pack::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/pack_test.cc b/tensorflow/lite/micro/kernels/pack_test.cc
new file mode 100644
index 0000000..e8c6a4d
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/pack_test.cc
@@ -0,0 +1,283 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/debug_log.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+
+template <typename T>
+void ValidatePackGoldens(TfLiteTensor* tensors, int tensors_size,
+ TfLitePackParams params, TfLiteIntArray* inputs_array,
+ TfLiteIntArray* outputs_array, const T* golden,
+ int output_len, float tolerance, T* output) {
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output_len; ++i) {
+ output[i] = 23;
+ }
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_PACK();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, reinterpret_cast<void*>(¶ms));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_len; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output[i], tolerance);
+ }
+}
+
+void TestPackTwoInputsFloat(const int* input1_dims_data,
+ const float* input1_data,
+ const int* input2_dims_data,
+ const float* input2_data, int axis,
+ const int* output_dims_data,
+ const float* expected_output_data,
+ float* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int input_size = 2;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims)};
+
+ TfLitePackParams builtin_data = {
+ .values_count = 2,
+ .axis = axis,
+ };
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ ValidatePackGoldens(tensors, tensors_size, builtin_data, inputs_array,
+ outputs_array, expected_output_data, output_dims_count,
+ 1e-5f, output_data);
+}
+
+void TestPackThreeInputsFloat(
+ const int* input1_dims_data, const float* input1_data,
+ const int* input2_dims_data, const float* input2_data,
+ const int* input3_dims_data, const float* input3_data, int axis,
+ const int* output_dims_data, const float* expected_output_data,
+ float* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* input3_dims = IntArrayFromInts(input3_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int input_size = 3;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(input3_data, input3_dims),
+ CreateTensor(output_data, output_dims)};
+
+ TfLitePackParams builtin_data = {
+ .values_count = 3,
+ .axis = axis,
+ };
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ ValidatePackGoldens(tensors, tensors_size, builtin_data, inputs_array,
+ outputs_array, expected_output_data, output_dims_count,
+ 1e-5f, output_data);
+}
+
+void TestPackTwoInputsQuantized(const int* input1_dims_data,
+ const uint8_t* input1_data,
+ const int* input2_dims_data,
+ const uint8_t* input2_data, int axis,
+ const int* output_dims_data,
+ const uint8_t* expected_output_data,
+ uint8_t* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int input_size = 2;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {
+ // CreateQuantizedTensor needs scale/zero_point values as input, but these
+ // values don't matter as to the functionality of PACK, so just set as 1.0
+ // and 128.
+ CreateQuantizedTensor(input1_data, input1_dims, 1.0, 128),
+ CreateQuantizedTensor(input2_data, input2_dims, 1.0, 128),
+ CreateQuantizedTensor(output_data, output_dims, 1.0, 128)};
+
+ TfLitePackParams builtin_data = {
+ .values_count = 2,
+ .axis = axis,
+ };
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ ValidatePackGoldens(tensors, tensors_size, builtin_data, inputs_array,
+ outputs_array, expected_output_data, output_dims_count,
+ 1e-5f, output_data);
+}
+
+void TestPackTwoInputsQuantized32(const int* input1_dims_data,
+ const int32_t* input1_data,
+ const int* input2_dims_data,
+ const int32_t* input2_data, int axis,
+ const int* output_dims_data,
+ const int32_t* expected_output_data,
+ int32_t* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int input_size = 2;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims)};
+
+ TfLitePackParams builtin_data = {
+ .values_count = 2,
+ .axis = axis,
+ };
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ ValidatePackGoldens(tensors, tensors_size, builtin_data, inputs_array,
+ outputs_array, expected_output_data, output_dims_count,
+ 1e-5f, output_data);
+}
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(PackFloatThreeInputs) {
+ const int input_shape[] = {1, 2};
+ const int output_shape[] = {2, 3, 2};
+ const float input1_values[] = {1, 4};
+ const float input2_values[] = {2, 5};
+ const float input3_values[] = {3, 6};
+ const float golden[] = {1, 4, 2, 5, 3, 6};
+ const int axis = 0;
+ constexpr int output_dims_count = 6;
+ float output_data[output_dims_count];
+
+ tflite::testing::TestPackThreeInputsFloat(
+ input_shape, input1_values, input_shape, input2_values, input_shape,
+ input3_values, axis, output_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(PackFloatThreeInputsDifferentAxis) {
+ const int input_shape[] = {1, 2};
+ const int output_shape[] = {2, 2, 3};
+ const float input1_values[] = {1, 4};
+ const float input2_values[] = {2, 5};
+ const float input3_values[] = {3, 6};
+ const float golden[] = {1, 2, 3, 4, 5, 6};
+ const int axis = 1;
+ constexpr int output_dims_count = 6;
+ float output_data[output_dims_count];
+
+ tflite::testing::TestPackThreeInputsFloat(
+ input_shape, input1_values, input_shape, input2_values, input_shape,
+ input3_values, axis, output_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(PackFloatThreeInputsNegativeAxis) {
+ const int input_shape[] = {1, 2};
+ const int output_shape[] = {2, 2, 3};
+ const float input1_values[] = {1, 4};
+ const float input2_values[] = {2, 5};
+ const float input3_values[] = {3, 6};
+ const float golden[] = {1, 2, 3, 4, 5, 6};
+ const int axis = -1;
+ constexpr int output_dims_count = 6;
+ float output_data[output_dims_count];
+
+ tflite::testing::TestPackThreeInputsFloat(
+ input_shape, input1_values, input_shape, input2_values, input_shape,
+ input3_values, axis, output_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(PackFloatMultilDimensions) {
+ const int input_shape[] = {2, 2, 3};
+ const int output_shape[] = {3, 2, 2, 3};
+ const float input1_values[] = {1, 2, 3, 4, 5, 6};
+ const float input2_values[] = {7, 8, 9, 10, 11, 12};
+ const float golden[] = {1, 2, 3, 7, 8, 9, 4, 5, 6, 10, 11, 12};
+ const int axis = 1;
+ constexpr int output_dims_count = 12;
+ float output_data[output_dims_count];
+
+ tflite::testing::TestPackTwoInputsFloat(input_shape, input1_values,
+ input_shape, input2_values, axis,
+ output_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(PackQuantizedMultilDimensions) {
+ const int input_shape[] = {2, 2, 3};
+ const int output_shape[] = {3, 2, 2, 3};
+ const uint8_t input1_values[] = {1, 2, 3, 4, 5, 6};
+ const uint8_t input2_values[] = {7, 8, 9, 10, 11, 12};
+ const uint8_t golden[] = {1, 2, 3, 7, 8, 9, 4, 5, 6, 10, 11, 12};
+ const int axis = 1;
+ constexpr int output_dims_count = 12;
+ uint8_t output_data[output_dims_count];
+
+ tflite::testing::TestPackTwoInputsQuantized(
+ input_shape, input1_values, input_shape, input2_values, axis,
+ output_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(PackQuantized32MultilDimensions) {
+ const int input_shape[] = {2, 2, 3};
+ const int output_shape[] = {3, 2, 2, 3};
+ const int32_t input1_values[] = {1, 2, 3, 4, 5, 6};
+ const int32_t input2_values[] = {7, 8, 9, 10, 11, 12};
+ const int32_t golden[] = {1, 2, 3, 7, 8, 9, 4, 5, 6, 10, 11, 12};
+ const int axis = 1;
+ constexpr int output_dims_count = 12;
+ int32_t output_data[output_dims_count];
+
+ tflite::testing::TestPackTwoInputsQuantized32(
+ input_shape, input1_values, input_shape, input2_values, axis,
+ output_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/pad.cc b/tensorflow/lite/micro/kernels/pad.cc
new file mode 100644
index 0000000..5d9d436
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/pad.cc
@@ -0,0 +1,254 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/pad.h"
+
+#include <string.h>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/portable_tensor.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace pad {
+namespace {
+
+struct OpData {
+ PadParams params;
+ int32_t output_zero_point;
+};
+
+} // namespace
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ TF_LITE_ENSURE(context, NumInputs(node) == 2 || NumInputs(node) == 3);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, /*index=*/0);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* paddings = GetInput(context, node, /*index=*/1);
+ TF_LITE_ENSURE(context, paddings != nullptr);
+ const TfLiteTensor* constant_values =
+ NumInputs(node) == 3 ? GetInput(context, node, /*index=*/2) : nullptr;
+ TfLiteTensor* output = GetOutput(context, node, /*index=*/0);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_EQ(context, input->type, output->type);
+
+ // Current implementations rely on the inputs being <= 4D.
+ TF_LITE_ENSURE(context, NumDimensions(input) <=
+ reference_ops::PadKernelMaxDimensionCount());
+
+ if (constant_values != nullptr) {
+ TF_LITE_ENSURE_EQ(context, input->type, constant_values->type);
+ // Ensure that constant_values is a scalar.
+ TF_LITE_ENSURE_EQ(context, NumElements(constant_values), 1);
+ }
+
+ // There must be a pair of paddings for each output dimension.
+ TF_LITE_ENSURE_EQ(context, GetTensorShape(paddings).FlatSize(),
+ output->dims->size * 2);
+
+ // On Micro, outputs must be properly sized by the converter.
+ // NOTE: This data is only available because the paddings buffer is stored in
+ // the flatbuffer:
+ TF_LITE_ENSURE(context, IsConstantTensor(paddings));
+ const int32_t* paddings_data = GetTensorData<int32_t>(paddings);
+ for (int i = 0; i < output->dims->size; i++) {
+ int output_dim = output->dims->data[i];
+ int expected_dim =
+ input->dims->data[i] + paddings_data[i * 2] + paddings_data[i * 2 + 1];
+ TF_LITE_ENSURE_EQ(context, output_dim, expected_dim);
+ }
+
+ // Calculate OpData:
+ data->params.resizing_category = ResizingCategory::kGenericResize;
+ const int paddings_total = GetTensorShape(paddings).FlatSize();
+ if (paddings_total == 8 && (paddings_data[0] == 0 && paddings_data[1] == 0) &&
+ (paddings_data[6] == 0 && paddings_data[7] == 0)) {
+ data->params.resizing_category = ResizingCategory::kImageStyle;
+ }
+
+ const int num_input_dimensions = NumDimensions(input);
+ data->params.left_padding_count = num_input_dimensions;
+ data->params.right_padding_count = num_input_dimensions;
+
+ for (int idx = num_input_dimensions - 1; idx >= 0; --idx) {
+ data->params.left_padding[idx] = paddings_data[idx * 2];
+ data->params.right_padding[idx] = paddings_data[idx * 2 + 1];
+ }
+
+ if (input->type == kTfLiteInt8 || input->type == kTfLiteUInt8) {
+ if (constant_values == nullptr) {
+ // Quantized Pad requires that 0 is represented in the quantized
+ // range.
+ if (input->type == kTfLiteUInt8) {
+ TF_LITE_ENSURE(context, output->params.zero_point >=
+ std::numeric_limits<uint8_t>::min());
+ TF_LITE_ENSURE(context, output->params.zero_point <=
+ std::numeric_limits<uint8_t>::max());
+ } else {
+ TF_LITE_ENSURE(context, output->params.zero_point >=
+ std::numeric_limits<int8_t>::min());
+ TF_LITE_ENSURE(context, output->params.zero_point <=
+ std::numeric_limits<int8_t>::max());
+ }
+ } else {
+ // Quantized Pad requires that 'constant_values' is represented in the
+ // same quantized range as the input and output tensors.
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point,
+ constant_values->params.zero_point);
+ TF_LITE_ENSURE_EQ(context, static_cast<double>(output->params.scale),
+ static_cast<double>(constant_values->params.scale));
+ }
+ data->output_zero_point = output->params.zero_point;
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, /*index=*/0);
+ const TfLiteEvalTensor* constant_values =
+ NumInputs(node) == 3
+ ? tflite::micro::GetEvalInput(context, node, /*index=*/2)
+ : nullptr;
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, /*index=*/0);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ float pad_value =
+ constant_values == nullptr
+ ? 0.f
+ : *tflite::micro::GetTensorData<float>(constant_values);
+ if (data->params.resizing_category == ResizingCategory::kImageStyle) {
+ reference_ops::PadImageStyle(
+ data->params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input), &pad_value,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ } else {
+ reference_ops::Pad(data->params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ &pad_value, tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ }
+ } break;
+ case kTfLiteUInt8: {
+ uint8_t pad_value;
+ if (constant_values == nullptr) {
+ pad_value = static_cast<uint8_t>(data->output_zero_point);
+ } else {
+ pad_value = *tflite::micro::GetTensorData<uint8_t>(constant_values);
+ }
+ if (data->params.resizing_category == ResizingCategory::kImageStyle) {
+ reference_ops::PadImageStyle(
+ data->params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input), &pad_value,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ reference_ops::Pad(data->params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ &pad_value, tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ }
+ } break;
+ case kTfLiteInt8: {
+ int8_t pad_value;
+ if (constant_values == nullptr) {
+ pad_value = static_cast<uint8_t>(data->output_zero_point);
+ } else {
+ pad_value = *tflite::micro::GetTensorData<int8_t>(constant_values);
+ }
+ if (data->params.resizing_category == ResizingCategory::kImageStyle) {
+ reference_ops::PadImageStyle(
+ data->params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input), &pad_value,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ } else {
+ reference_ops::Pad(data->params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ &pad_value, tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+ } break;
+ case kTfLiteInt32: {
+ int32_t pad_value =
+ constant_values == nullptr
+ ? 0
+ : *tflite::micro::GetTensorData<int32_t>(constant_values);
+ reference_ops::Pad(data->params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int32_t>(input),
+ &pad_value, tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int32_t>(output));
+ } break;
+ default:
+
+ TF_LITE_KERNEL_LOG(context, "Type %s not currently supported by Pad.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+#undef TF_LITE_PAD
+ return kTfLiteOk;
+}
+
+} // namespace pad
+
+TfLiteRegistration Register_PAD() {
+ return {/*init=*/pad::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pad::Prepare,
+ /*invoke=*/pad::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+// Also register Pad as PadV2.
+TfLiteRegistration Register_PADV2() {
+ return {/*init=*/pad::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pad::Prepare,
+ /*invoke=*/pad::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/pad_test.cc b/tensorflow/lite/micro/kernels/pad_test.cc
new file mode 100644
index 0000000..eeeb785
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/pad_test.cc
@@ -0,0 +1,422 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+TfLiteStatus ValidatePadGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* golden, T* output_data,
+ int output_length) {
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_PAD();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ // Prepare should catch dimension mismatches.
+ TfLiteStatus prepare_status = runner.InitAndPrepare();
+ if (prepare_status != kTfLiteOk) {
+ return prepare_status;
+ }
+
+ // Eval should catch quantization mismatches.
+ TfLiteStatus invoke_status = runner.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ return invoke_status;
+ }
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden[i], output_data[i]);
+ }
+ return kTfLiteOk;
+}
+
+template <typename T>
+TfLiteStatus ValidatePadV2Goldens(TfLiteTensor* tensors, int tensors_size,
+ const T* golden, T* output_data,
+ int output_length) {
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_PADV2();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ // Prepare should catch dimension mismatches.
+ TfLiteStatus prepare_status = runner.InitAndPrepare();
+ if (prepare_status != kTfLiteOk) {
+ return prepare_status;
+ }
+
+ // Eval should catch quantization mismatches.
+ TfLiteStatus invoke_status = runner.Invoke();
+ if (invoke_status != kTfLiteOk) {
+ return invoke_status;
+ }
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden[i], output_data[i]);
+ }
+ return kTfLiteOk;
+}
+
+// output data and golden must be shaped correctly
+void TestPadFloat(const int* input_dims_data, const float* input_data,
+ const int* pad_dims_data, const int32_t* pad_data,
+ const int* output_dims_data, const float* golden,
+ float* output_data,
+ TfLiteStatus expected_status = kTfLiteOk) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* pad_dims = IntArrayFromInts(pad_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input_data, input_dims),
+ CreateTensor(pad_data, pad_dims),
+ CreateTensor(output_data, output_dims)};
+
+ // Pad tensor must be constant.
+ tensors[1].allocation_type = kTfLiteMmapRo;
+
+ TF_LITE_MICRO_EXPECT_EQ(expected_status,
+ ValidatePadGoldens(tensors, tensors_size, golden,
+ output_data, output_dims_count));
+}
+
+// output data and golden must be shaped correctly
+void TestPadV2Float(const int* input_dims_data, const float* input_data,
+ const int* pad_dims_data, const int32_t* pad_data,
+ const float pad_value, const int* output_dims_data,
+ const float* golden, float* output_data,
+ TfLiteStatus expected_status = kTfLiteOk) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* pad_dims = IntArrayFromInts(pad_dims_data);
+ const int pad_value_dims_data[] = {1, 1}; // Only one padding value allowed.
+ TfLiteIntArray* pad_value_dims = IntArrayFromInts(pad_value_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims), CreateTensor(pad_data, pad_dims),
+ CreateTensor(&pad_value, pad_value_dims),
+ CreateTensor(output_data, output_dims)};
+
+ // Pad tensor must be constant.
+ tensors[1].allocation_type = kTfLiteMmapRo;
+
+ TF_LITE_MICRO_EXPECT_EQ(expected_status,
+ ValidatePadV2Goldens(tensors, tensors_size, golden,
+ output_data, output_dims_count));
+}
+
+template <typename T>
+void TestPadQuantized(const int* input_dims_data, const float* input_data,
+ T* input_quantized, float input_scale,
+ int input_zero_point, const int* pad_dims_data,
+ const int32_t* pad_data, const int* output_dims_data,
+ const float* golden, T* golden_quantized,
+ float output_scale, int output_zero_point, T* output_data,
+ TfLiteStatus expected_status = kTfLiteOk) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* pad_dims = IntArrayFromInts(pad_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateTensor(pad_data, pad_dims),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point)};
+
+ // Pad tensor must be constant.
+ tensors[1].allocation_type = kTfLiteMmapRo;
+
+ tflite::Quantize(golden, golden_quantized, output_dims_count, output_scale,
+ output_zero_point);
+ TF_LITE_MICRO_EXPECT_EQ(
+ expected_status,
+ ValidatePadGoldens(tensors, tensors_size, golden_quantized, output_data,
+ output_dims_count));
+}
+
+template <typename T>
+void TestPadV2Quantized(const int* input_dims_data, const float* input_data,
+ T* input_quantized, float input_scale,
+ int input_zero_point, const int* pad_dims_data,
+ const int32_t* pad_data, const float pad_value,
+ const float pad_value_scale,
+ const int pad_value_zero_point,
+ const int* output_dims_data, const float* golden,
+ T* golden_quantized, float output_scale,
+ int output_zero_point, T* output_data,
+ TfLiteStatus expected_status = kTfLiteOk) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* pad_dims = IntArrayFromInts(pad_dims_data);
+ const int pad_value_dims_data[] = {1, 1}; // Only one padding value allowed.
+ TfLiteIntArray* pad_value_dims = IntArrayFromInts(pad_value_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ T pad_value_quantized;
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateTensor(pad_data, pad_dims),
+ CreateQuantizedTensor(&pad_value, &pad_value_quantized, pad_value_dims,
+ pad_value_scale, pad_value_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point)};
+
+ // Pad tensor must be constant.
+ tensors[1].allocation_type = kTfLiteMmapRo;
+ tensors[2].params.scale = pad_value_scale;
+ tensors[3].params.scale = output_scale;
+
+ tflite::Quantize(golden, golden_quantized, output_dims_count, output_scale,
+ output_zero_point);
+ TF_LITE_MICRO_EXPECT_EQ(
+ expected_status,
+ ValidatePadV2Goldens(tensors, tensors_size, golden_quantized, output_data,
+ output_dims_count));
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(Test2DFloat) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0,
+ 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0};
+ float output_data[24];
+
+ tflite::testing::TestPadFloat(input_dims, input_values, pad_dims, pad_values,
+ output_dims, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(Test4DFloat) {
+ const int input_dims[] = {4, 1, 1, 1, 1};
+ const float input_values[] = {42};
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 1, 1, 1, 1, 1, 1};
+ const int output_dims[] = {4, 3, 3, 3, 3};
+ const int kOutputLen = 81; // 3 * 3 * 3 * 3
+ float golden[kOutputLen];
+ for (int i = 0; i < kOutputLen; i++) {
+ golden[i] = 0;
+ }
+ golden[40] = 42;
+ float output_data[kOutputLen];
+
+ tflite::testing::TestPadFloat(input_dims, input_values, pad_dims, pad_values,
+ output_dims, const_cast<const float*>(golden),
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Test2DFloatV2) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const float pad_value = 42;
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {42, 42, 42, 42, 42, 42, 42, 42, 42, 1, 2, 42,
+ 42, 3, 4, 42, 42, 42, 42, 42, 42, 42, 42, 42};
+ float output_data[24];
+
+ tflite::testing::TestPadV2Float(input_dims, input_values, pad_dims,
+ pad_values, pad_value, output_dims, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Test2DUInt8) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const float input_scale = 1.0f;
+ const int input_zero_point = 127;
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0,
+ 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0};
+ const float output_scale = 1.0f;
+ const int output_zero_point = 127;
+ uint8_t output_data[24];
+ uint8_t input_quantized[4];
+ uint8_t golden_quantized[24];
+
+ tflite::testing::TestPadQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ pad_dims, pad_values, output_dims, golden, golden_quantized, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TEST(Test2DUInt8V2) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const float input_scale = 1.0f;
+ const int input_zero_point = 127;
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const float pad_value = 42;
+ const float pad_value_scale = 1.0;
+ const float pad_value_zero_point = 127;
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {42, 42, 42, 42, 42, 42, 42, 42, 42, 1, 2, 42,
+ 42, 3, 4, 42, 42, 42, 42, 42, 42, 42, 42, 42};
+ const float output_scale = 1.0f;
+ const int output_zero_point = 127;
+ uint8_t output_data[24];
+ uint8_t input_quantized[4];
+ uint8_t golden_quantized[24];
+
+ tflite::testing::TestPadV2Quantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ pad_dims, pad_values, pad_value, pad_value_scale, pad_value_zero_point,
+ output_dims, golden, golden_quantized, output_scale, output_zero_point,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Test2DInt8) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const float input_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0,
+ 0, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0};
+ const float output_scale = 1.0f;
+ const int output_zero_point = 0;
+ int8_t output_data[24];
+ int8_t input_quantized[4];
+ int8_t golden_quantized[24];
+
+ tflite::testing::TestPadQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ pad_dims, pad_values, output_dims, golden, golden_quantized, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TEST(Test2DInt8V2) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const float input_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const float pad_value = 42;
+ const float pad_value_scale = 1.0;
+ const float pad_value_zero_point = 0;
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {42, 42, 42, 42, 42, 42, 42, 42, 42, 1, 2, 42,
+ 42, 3, 4, 42, 42, 42, 42, 42, 42, 42, 42, 42};
+ const float output_scale = 1.0f;
+ const int output_zero_point = 0;
+ int8_t output_data[24];
+ int8_t input_quantized[4];
+ int8_t golden_quantized[24];
+
+ tflite::testing::TestPadV2Quantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ pad_dims, pad_values, pad_value, pad_value_scale, pad_value_zero_point,
+ output_dims, golden, golden_quantized, output_scale, output_zero_point,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(Test2DInt8V2ExpectFailurePadValueQuantizationMismatch) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const float input_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const float pad_value = 42;
+ // Causes failure since this is in a different quantization space than input.
+ const float pad_value_scale = .5;
+ const float pad_value_zero_point = 0;
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
+ const float output_scale = 1.0f;
+ const int output_zero_point = 0;
+ int8_t output_data[24] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
+ int8_t input_quantized[4];
+ int8_t golden_quantized[24];
+
+ tflite::testing::TestPadV2Quantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ pad_dims, pad_values, pad_value, pad_value_scale, pad_value_zero_point,
+ output_dims, golden, golden_quantized, output_scale, output_zero_point,
+ output_data, kTfLiteError);
+}
+
+TF_LITE_MICRO_TEST(Test2DInt8ExpectFailureQuantizationRangeExcludesZero) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_values[] = {1, 2, 3, 4};
+ const float input_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int pad_dims[] = {2, 4, 2};
+ const int32_t pad_values[] = {1, 1, 0, 0, 1, 1, 0, 0};
+ const int output_dims[] = {4, 3, 2, 4, 1};
+ const float golden[] = {42, 42, 42, 42, 42, 42, 42, 42, 42, 1, 2, 42,
+ 42, 3, 4, 42, 42, 42, 42, 42, 42, 42, 42, 42};
+ // Causes failure since this quantization zero point excludes zero.
+ const float output_scale = 1.0f;
+ const int output_zero_point = 129;
+ int8_t output_data[24];
+ int8_t input_quantized[4];
+ int8_t golden_quantized[24];
+
+ tflite::testing::TestPadQuantized(
+ input_dims, input_values, input_quantized, input_scale, input_zero_point,
+ pad_dims, pad_values, output_dims, golden, golden_quantized, output_scale,
+ output_zero_point, output_data, kTfLiteError);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/pooling.cc b/tensorflow/lite/micro/kernels/pooling.cc
new file mode 100644
index 0000000..64aef0e
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/pooling.cc
@@ -0,0 +1,269 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/pooling.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/pooling.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace pooling {
+
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ TfLitePaddingValues padding;
+ int32_t activation_min;
+ int32_t activation_max;
+ float activation_min_f32;
+ float activation_max_f32;
+};
+
+TfLiteStatus CalculateOpData(const TfLiteContext* context,
+ const TfLitePoolParams* params,
+ const TfLiteTensor* input,
+ const TfLiteTensor* output, OpData* data) {
+ // input: batch, height, width, channel
+ int height = SizeOfDimension(input, 1);
+ int width = SizeOfDimension(input, 2);
+
+ int out_height, out_width;
+
+ data->padding = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width,
+ /*dilation_rate_height=*/1,
+ /*dilation_rate_width=*/1, height, width, params->filter_height,
+ params->filter_width, params->padding, &out_height, &out_width);
+
+ return kTfLiteOk;
+}
+
+void AverageEvalFloat(const TfLiteContext* context, const TfLiteNode* node,
+ const TfLitePoolParams* params, const OpData* data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+ PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data->padding.height;
+ op_params.padding_values.width = data->padding.width;
+ op_params.float_activation_min = data->activation_min_f32;
+ op_params.float_activation_max = data->activation_max_f32;
+ reference_ops::AveragePool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+}
+
+void AverageEvalQuantized(TfLiteContext* context, const TfLiteNode* node,
+ const TfLitePoolParams* params, const OpData* data,
+ const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output) {
+ TFLITE_DCHECK(input->type == kTfLiteUInt8 || input->type == kTfLiteInt8);
+
+ PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data->padding.height;
+ op_params.padding_values.width = data->padding.width;
+ op_params.quantized_activation_min = data->activation_min;
+ op_params.quantized_activation_max = data->activation_max;
+
+ if (input->type == kTfLiteUInt8) {
+ reference_ops::AveragePool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ reference_integer_ops::AveragePool(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+}
+
+void MaxEvalFloat(TfLiteContext* context, TfLiteNode* node,
+ TfLitePoolParams* params, const OpData* data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+ tflite::PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data->padding.height;
+ op_params.padding_values.width = data->padding.width;
+ op_params.float_activation_min = data->activation_min_f32;
+ op_params.float_activation_max = data->activation_max_f32;
+ reference_ops::MaxPool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+}
+
+void MaxEvalQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLitePoolParams* params, const OpData* data,
+ const TfLiteEvalTensor* input, TfLiteEvalTensor* output) {
+ tflite::PoolParams op_params;
+ op_params.stride_height = params->stride_height;
+ op_params.stride_width = params->stride_width;
+ op_params.filter_height = params->filter_height;
+ op_params.filter_width = params->filter_width;
+ op_params.padding_values.height = data->padding.height;
+ op_params.padding_values.width = data->padding.width;
+ op_params.quantized_activation_min = data->activation_min;
+ op_params.quantized_activation_max = data->activation_max;
+
+ if (input->type == kTfLiteUInt8) {
+ reference_ops::MaxPool(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ reference_integer_ops::MaxPool(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+}
+} // namespace
+
+TfLiteStatus AverageEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ // Inputs and outputs share the same type, guaranteed by the converter.
+ switch (input->type) {
+ case kTfLiteFloat32:
+ AverageEvalFloat(context, node, params, data, input, output);
+ break;
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ AverageEvalQuantized(context, node, params, data, input, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input type %s is not currently supported",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus MaxEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData* data = static_cast<const OpData*>(node->user_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input->type) {
+ case kTfLiteFloat32:
+ MaxEvalFloat(context, node, params, data, input, output);
+ break;
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ MaxEvalQuantized(context, node, params, data, input, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s not currently supported.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ auto* params = reinterpret_cast<TfLitePoolParams*>(node->builtin_data);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(context, params, input, output, data));
+
+ if (input->type == kTfLiteFloat32) {
+ CalculateActivationRange(params->activation, &data->activation_min_f32,
+ &data->activation_max_f32);
+ } else if (input->type == kTfLiteInt8 || input->type == kTfLiteUInt8) {
+ CalculateActivationRangeQuantized(context, params->activation, output,
+ &data->activation_min,
+ &data->activation_max);
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace pooling
+
+TfLiteRegistration Register_AVERAGE_POOL_2D() {
+ return {/*init=*/pooling::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pooling::Prepare,
+ /*invoke=*/pooling::AverageEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_MAX_POOL_2D() {
+ return {/*init=*/pooling::Init,
+ /*free=*/nullptr,
+ /*prepare=*/pooling::Prepare,
+ /*invoke=*/pooling::MaxEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/pooling_test.cc b/tensorflow/lite/micro/kernels/pooling_test.cc
new file mode 100644
index 0000000..6f48710
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/pooling_test.cc
@@ -0,0 +1,716 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void ValidatePoolingGoldens(TfLiteTensor* tensors, int tensors_size,
+ const TfLiteRegistration registration,
+ const int filter_height, const int filter_width,
+ const int stride_height, const int stride_width,
+ const T* golden, const int output_length,
+ TfLitePadding padding,
+ TfLiteFusedActivation activation, T* output_data) {
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ TfLitePoolParams builtin_data = {padding,
+ stride_width,
+ stride_height,
+ filter_width,
+ filter_height,
+ activation,
+ {}};
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestAveragePoolFloat(const int* input_dims_data, const float* input_data,
+ const int filter_height, const int filter_width,
+ const int stride_height, const int stride_width,
+ const float* expected_output_data,
+ const int* output_dims_data, TfLitePadding padding,
+ TfLiteFusedActivation activation,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_AVERAGE_POOL_2D();
+
+ ValidatePoolingGoldens(tensors, tensors_size, registration, filter_height,
+ filter_width, stride_height, stride_width,
+ expected_output_data, output_dims_count, padding,
+ activation, output_data);
+}
+
+template <typename T>
+void TestAveragePoolQuantized(
+ const int* input_dims_data, const T* input_data, const float input_scale,
+ const int input_zero_point, const int filter_height, const int filter_width,
+ const int stride_height, const int stride_width,
+ const T* expected_output_data, const int* output_dims_data,
+ const float output_scale, const int output_zero_point,
+ TfLitePadding padding, TfLiteFusedActivation activation, T* output_data) {
+ static_assert(sizeof(T) == 1, "Only int8_t/uint8_t data types allowed.");
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_dims, input_scale,
+ input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_AVERAGE_POOL_2D();
+ ValidatePoolingGoldens(tensors, tensors_size, registration, filter_height,
+ filter_width, stride_height, stride_width,
+ expected_output_data, output_dims_count, padding,
+ activation, output_data);
+}
+
+void TestMaxPoolFloat(const int* input_dims_data, const float* input_data,
+ int filter_width, int filter_height, int stride_width,
+ int stride_height, const float* expected_output_data,
+ const int* output_dims_data, TfLitePadding padding,
+ TfLiteFusedActivation activation, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_MAX_POOL_2D();
+ ValidatePoolingGoldens(tensors, tensors_size, registration, filter_height,
+ filter_width, stride_height, stride_width,
+ expected_output_data, output_dims_count, padding,
+ activation, output_data);
+}
+
+template <typename T>
+void TestMaxPoolQuantized(const int* input_dims_data, const T* input_data,
+ const float input_scale, const int input_zero_point,
+ const int filter_height, const int filter_width,
+ const int stride_height, const int stride_width,
+ const T* expected_output_data,
+ const int* output_dims_data, const float output_scale,
+ const int output_zero_point, TfLitePadding padding,
+ TfLiteFusedActivation activation, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_dims, input_scale,
+ input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_MAX_POOL_2D();
+ ValidatePoolingGoldens(tensors, tensors_size, registration, filter_height,
+ filter_width, stride_height, stride_width,
+ expected_output_data, output_dims_count, padding,
+ activation, output_data);
+}
+
+} // namespace
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SimpleAveragePoolTestFloat) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const float input_values[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const float golden[] = {2.75, 5.75};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ float output_data[2];
+ tflite::testing::TestAveragePoolFloat(
+ input_shape, input_values, filter_height, filter_width, stride_height,
+ stride_width, golden, output_shape, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleAveragePoolTestUint8) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values[] = {0, 24, 8, 16, 12, 8, 40, 28};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const uint8_t golden[] = {11, 23};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ uint8_t output_data[2];
+
+ const float input_scale = 0.25;
+ const int input_zero_point = 0;
+ const float output_scale = .25;
+ const int output_zero_point = 0;
+ tflite::testing::TestAveragePoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleAveragePoolTestInt8PaddingValidStride2ActNone) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values[] = {0, -24, 8, 16, 12, 8, -40, 28};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const int8_t golden[] = {-1, 3};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ int8_t output_data[2];
+
+ const float input_scale = .25;
+ const int input_zero_point = 0;
+ const float output_scale = .25;
+ const int output_zero_point = 0;
+ tflite::testing::TestAveragePoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleAveragePoolTestInt8PaddingValidStride1Stride2Relu) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values[] = {0, -24, 8, 16, 12, 8, -40, 28};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 2;
+ const int8_t golden[] = {0, 0, 3};
+ const int output_shape[] = {4, 1, 1, 3, 1};
+ int8_t output_data[3];
+
+ const float input_scale = .25;
+ const int input_zero_point = 0;
+ const float output_scale = .25;
+ const int output_zero_point = 0;
+ tflite::testing::TestAveragePoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActRelu,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(
+ SimpleAveragePoolTestInt8PaddingValidStride2Stride1ReluN1To1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values[] = {0, -24, 8, 16, 12, 8, -40, 28};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 1;
+ const int8_t golden[] = {-1, 3};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ int8_t output_data[2];
+
+ const float input_scale = .25;
+ const int input_zero_point = 0;
+ const float output_scale = .25;
+ const int output_zero_point = 0;
+ tflite::testing::TestAveragePoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActReluN1To1,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleAveragePoolTestInt8PaddingValidStride2Relu6) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values[] = {12, -24, 32, 16, 12, 8, 40, 28};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const int8_t golden[] = {2, 24};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ int8_t output_data[2];
+
+ const float input_scale = .25;
+ const int input_zero_point = 0;
+ const float output_scale = .25;
+ const int output_zero_point = 0;
+ tflite::testing::TestAveragePoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActRelu6,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleAveragePoolTestInt8PaddingSameStride1ActNone) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values[] = {12, -24, 32, 16, 12, 8, 40, 28};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 1;
+ const int8_t golden[] = {2, 14, 29, 22, 10, 24, 34, 28};
+ const int output_shape[] = {4, 1, 2, 4, 1};
+ int8_t output_data[8];
+
+ const float input_scale = .25;
+ const int input_zero_point = 0;
+ const float output_scale = .25;
+ const int output_zero_point = 0;
+ tflite::testing::TestAveragePoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestFloat) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const float input_values[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const float golden[] = {6, 10};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ float output_data[2];
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values, filter_height,
+ filter_width, stride_height, stride_width,
+ golden, output_shape, kTfLitePaddingValid,
+ kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestFloatRelu) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const float input_values[] = {-1, -6, 2, 4, -3, -2, 10.5, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const float golden[] = {0, 10.5};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ float output_data[2];
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values, filter_height,
+ filter_width, stride_height, stride_width,
+ golden, output_shape, kTfLitePaddingValid,
+ kTfLiteActRelu, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestFloatReluN1To1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const float input_values1[] = {-2.75, -6, 0.2, 0.4, -3, -2, -0.3, 0.7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const float golden1[] = {-1.0, 0.7};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ float output_data[2];
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values1, filter_height,
+ filter_width, stride_height, stride_width,
+ golden1, output_shape, kTfLitePaddingValid,
+ kTfLiteActReluN1To1, output_data);
+
+ const float input_values2[] = {-2.75, -6, -2, -4, -3, -2, 10, -7};
+ const float golden2[] = {-1.0, 1.0};
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values2, filter_height,
+ filter_width, stride_height, stride_width,
+ golden2, output_shape, kTfLitePaddingValid,
+ kTfLiteActReluN1To1, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestFloatRelu6) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const float input_values1[] = {-1.5, -6, 12, 4, -3, -2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const float golden1[] = {0, 6};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ float output_data[2];
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values1, filter_height,
+ filter_width, stride_height, stride_width,
+ golden1, output_shape, kTfLitePaddingValid,
+ kTfLiteActRelu6, output_data);
+
+ const float input_values2[] = {0, 4.5, 12, 4, 3, 2, 10, 7};
+ const float golden2[] = {4.5, 6};
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values2, filter_height,
+ filter_width, stride_height, stride_width,
+ golden2, output_shape, kTfLitePaddingValid,
+ kTfLiteActRelu6, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestPaddingSameStride1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const float input_values[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 1;
+ const float golden[] = {6, 10, 10, 7, 3, 10, 10, 7};
+ const int output_shape[] = {4, 1, 2, 4, 1};
+ float output_data[8];
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values, filter_height,
+ filter_width, stride_height, stride_width,
+ golden, output_shape, kTfLitePaddingSame,
+ kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestPaddingValidStride1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const float input_values[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 1;
+ const float golden[] = {6, 10, 10};
+ const int output_shape[] = {4, 1, 1, 3, 1};
+ float output_data[8];
+ tflite::testing::TestMaxPoolFloat(input_shape, input_values, filter_height,
+ filter_width, stride_height, stride_width,
+ golden, output_shape, kTfLitePaddingValid,
+ kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestUInt8ActNone) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values[] = {0, 12, 4, 8, 6, 4, 20, 14};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const uint8_t golden[] = {12, 20};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ uint8_t output_data[2];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestUInt8ActRelu) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values[] = {0, 4, 2, 4, 3, 2, 14, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const uint8_t golden[] = {4, 14};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ uint8_t output_data[2];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 4;
+ const float output_scale = 1.0;
+ const int output_zero_point = 4;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActRelu,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestUInt8ActReluN1To1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values[] = {0, 4, 2, 4, 3, 2, 14, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const uint8_t golden[] = {3, 5};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ uint8_t output_data[2];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 4;
+ const float output_scale = 1.0;
+ const int output_zero_point = 4;
+ tflite::testing::TestAveragePoolQuantized(
+ input_shape, input_values, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActReluN1To1,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestUInt8ActRelu6) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values1[] = {12, 0, 36, 20, 6, 8, 32, 26};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const uint8_t golden1[] = {12, 24};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ uint8_t output_data[8];
+
+ const float input_scale = 0.5;
+ const int input_zero_point = 12;
+ const float output_scale = 0.5;
+ const int output_zero_point = 12;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActRelu6,
+ output_data);
+
+ const uint8_t input_values2[] = {12, 21, 36, 16, 18, 16, 32, 26};
+
+ const uint8_t golden2[] = {21, 24};
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values2, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden2, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActRelu6,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestUInt8PaddingSameStride1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values1[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 1;
+ const uint8_t golden1[] = {6, 10, 10, 7, 3, 10, 10, 7};
+ const int output_shape[] = {4, 1, 2, 4, 1};
+ uint8_t output_data[8];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestUInt8PaddingValidStride1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values1[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 1;
+ const uint8_t golden1[] = {6, 10, 10};
+ const int output_shape[] = {4, 1, 1, 3, 1};
+ uint8_t output_data[3];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(SimpleMaxPoolTestInt8ActNone) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values1[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const int8_t golden1[] = {6, 10};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ int8_t output_data[2];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestInt8ActRelu) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values1[] = {-3, -12, 4, 8, -6, -4, 20, 14};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const int8_t golden1[] = {0, 20};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ int8_t output_data[2];
+
+ const float input_scale = 0.5;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActRelu,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestInt8ActReluN1To1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values1[] = {-2, -6, -2, -4, -3, -2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const int8_t golden1[] = {-1, 1};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ int8_t output_data[2];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActReluN1To1,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestInt8ActRelu6) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const int8_t input_values1[] = {0, -6, 12, 4, -3, -2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 2;
+ const int stride_height = 2;
+ const int8_t golden1[] = {0, 6};
+ const int output_shape[] = {4, 1, 1, 2, 1};
+ int8_t output_data[2];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActRelu6,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestUInt8PaddingSameStride1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values1[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 1;
+ const uint8_t golden1[] = {6, 10, 10, 7, 3, 10, 10, 7};
+ const int output_shape[] = {4, 1, 2, 4, 1};
+ uint8_t output_data[8];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingSame, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(MaxPoolTestUInt8PaddingValidStride1) {
+ const int input_shape[] = {4, 1, 2, 4, 1};
+ const uint8_t input_values1[] = {0, 6, 2, 4, 3, 2, 10, 7};
+ const int filter_width = 2;
+ const int filter_height = 2;
+ const int stride_width = 1;
+ const int stride_height = 1;
+ const uint8_t golden1[] = {6, 10, 10};
+ const int output_shape[] = {4, 1, 1, 3, 1};
+ uint8_t output_data[3];
+
+ const float input_scale = 1.0;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0;
+ const int output_zero_point = 0;
+ tflite::testing::TestMaxPoolQuantized(
+ input_shape, input_values1, input_scale, input_zero_point, filter_height,
+ filter_width, stride_height, stride_width, golden1, output_shape,
+ output_scale, output_zero_point, kTfLitePaddingValid, kTfLiteActNone,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/prelu.cc b/tensorflow/lite/micro/kernels/prelu.cc
new file mode 100644
index 0000000..b48491d
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/prelu.cc
@@ -0,0 +1,169 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/prelu.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace activations {
+namespace {
+
+TfLiteStatus CalculatePreluParams(const TfLiteTensor* input,
+ const TfLiteTensor* alpha,
+ TfLiteTensor* output, PreluParams* params) {
+ if (output->type == kTfLiteInt8 || output->type == kTfLiteUInt8 ||
+ output->type == kTfLiteInt16) {
+ double real_multiplier_1 = static_cast<double>(input->params.scale) /
+ static_cast<double>(output->params.scale);
+ double real_multiplier_2 = static_cast<double>(input->params.scale) *
+ static_cast<double>(alpha->params.scale) /
+ static_cast<double>(output->params.scale);
+ QuantizeMultiplier(real_multiplier_1, ¶ms->output_multiplier_1,
+ ¶ms->output_shift_1);
+ QuantizeMultiplier(real_multiplier_2, ¶ms->output_multiplier_2,
+ ¶ms->output_shift_2);
+
+ params->input_offset = -input->params.zero_point;
+ params->alpha_offset = -alpha->params.zero_point;
+ params->output_offset = output->params.zero_point;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace
+
+inline void BroadcastPrelu4DSlowFloat(
+ const RuntimeShape& unextended_input1_shape, const float* input1_data,
+ const RuntimeShape& unextended_input2_shape, const float* input2_data,
+ const RuntimeShape& unextended_output_shape, float* output_data) {
+ TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4);
+ const RuntimeShape output_shape =
+ RuntimeShape::ExtendedShape(4, unextended_output_shape);
+
+ NdArrayDesc<4> desc1;
+ NdArrayDesc<4> desc2;
+ NdArrayDescsForElementwiseBroadcast(unextended_input1_shape,
+ unextended_input2_shape, &desc1, &desc2);
+
+ for (int b = 0; b < output_shape.Dims(0); ++b) {
+ for (int y = 0; y < output_shape.Dims(1); ++y) {
+ for (int x = 0; x < output_shape.Dims(2); ++x) {
+ for (int c = 0; c < output_shape.Dims(3); ++c) {
+ auto out_idx = Offset(output_shape, b, y, x, c);
+ auto in1_idx = SubscriptToIndex(desc1, b, y, x, c);
+ auto in2_idx = SubscriptToIndex(desc2, b, y, x, c);
+ auto in1_val = input1_data[in1_idx];
+ auto in2_val = input2_data[in2_idx];
+ output_data[out_idx] = in1_val >= 0.0f ? in1_val : in1_val * in2_val;
+ }
+ }
+ }
+ }
+}
+
+void* PreluInit(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(PreluParams));
+}
+
+TfLiteStatus PreluPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ PreluParams* params = static_cast<PreluParams*>(node->user_data);
+
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* alpha = GetInput(context, node, 1);
+ TF_LITE_ENSURE(context, alpha != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, 0);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ return CalculatePreluParams(input, alpha, output, params);
+}
+
+TfLiteStatus PreluEval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const PreluParams& params =
+ *(static_cast<const PreluParams*>(node->user_data));
+
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ const TfLiteEvalTensor* alpha = tflite::micro::GetEvalInput(context, node, 1);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ BroadcastPrelu4DSlowFloat(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(alpha),
+ tflite::micro::GetTensorData<float>(alpha),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ } break;
+ case kTfLiteUInt8: {
+ reference_ops::BroadcastPrelu4DSlow(
+ params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(alpha),
+ tflite::micro::GetTensorData<uint8_t>(alpha),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ return kTfLiteOk;
+ } break;
+ case kTfLiteInt8: {
+ reference_ops::BroadcastPrelu4DSlow(
+ params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(alpha),
+ tflite::micro::GetTensorData<int8_t>(alpha),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+ } break;
+ default:
+ TF_LITE_KERNEL_LOG(
+ context, "Only float32 and uint8_t are supported currently, got %d.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+}
+
+} // namespace activations
+
+TfLiteRegistration Register_PRELU() {
+ return {/*init=*/activations::PreluInit,
+ /*free=*/nullptr,
+ /*prepare=*/activations::PreluPrepare,
+ /*invoke=*/activations::PreluEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/prelu_test.cc b/tensorflow/lite/micro/kernels/prelu_test.cc
new file mode 100644
index 0000000..bbe8e2d
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/prelu_test.cc
@@ -0,0 +1,194 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void ValidatePreluGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* golden, const int output_length,
+ T* output_data) {
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_PRELU();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestPreluFloat(const int* input_dims_data, const float* input_data,
+ const int* alpha_dims_data, const float* alpha_data,
+ const float* expected_output_data,
+ const int* output_dims_data, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* alpha_dims = IntArrayFromInts(alpha_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(alpha_data, alpha_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidatePreluGoldens(tensors, tensors_size, expected_output_data,
+ output_dims_count, output_data);
+}
+
+// Template argument T can be either uint8_t or int8_t depending on which type
+// of quantization required to be tested.
+template <typename T>
+void TestPreluQuantized(const int* input_dims_data, const float* input_data,
+ T* input_quantized, const float input_scale,
+ const int input_zero_point, const int* alpha_dims_data,
+ const float* alpha_data, T* alpha_quantized,
+ const float alpha_scale, const int alpha_zero_point,
+ const float* golden, T* golden_quantized,
+ const float output_scale, const int output_zero_point,
+ const int* output_dims_data, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* alpha_dims = IntArrayFromInts(alpha_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(alpha_data, alpha_quantized, alpha_dims,
+ alpha_scale, alpha_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ Quantize(golden, golden_quantized, output_dims_count, output_scale,
+ output_zero_point);
+
+ ValidatePreluGoldens(tensors, tensors_size, golden_quantized,
+ output_dims_count, output_data);
+}
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatPreluActivationsOpTest) {
+ const int input_shape[] = {3, 2, 2, 3};
+ const float input_values[] = {
+ 0.0f, 0.0f, 0.0f, // Row 1, Column 1
+ 1.0f, 1.0f, 1.0f, // Row 1, Column 2
+ -1.0f, -1.0f, -1.0f, // Row 2, Column 1
+ -2.0f, -2.0f, -2.0f, // Row 1, Column 2
+ };
+ const int alpha_shape[] = {3, 1, 1, 3};
+ const float alpha_values[] = {0.0f, 1.0f, 2.0f};
+ const int output_shape[] = {3, 2, 2, 3};
+ const float golden[] = {
+ 0.0f, 0.0f, 0.0f, // Row 1, Column 1
+ 1.0f, 1.0f, 1.0f, // Row 1, Column 2
+ 0.0f, -1.0f, -2.0f, // Row 2, Column 1
+ 0.0f, -2.0f, -4.0f, // Row 1, Column 2
+ };
+ const int output_dims_count = 12;
+ float output_data[output_dims_count];
+ tflite::testing::TestPreluFloat(input_shape, input_values, alpha_shape,
+ alpha_values, golden, output_shape,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(QuantizedUint8PreluActivationsOpTest) {
+ const int input_shape[] = {3, 2, 2, 3};
+ const float input_values[] = {
+ 0.0f, 0.0f, 0.0f, // Row 1, Column 1
+ 0.5f, 0.5f, 0.5f, // Row 1, Column 2
+ -1.0f, -1.0f, -1.0f, // Row 2, Column 1
+ -0.25f, -0.25f, -0.25f, // Row 1, Column 2
+ };
+ const int alpha_shape[] = {3, 1, 1, 3};
+ const float alpha_values[] = {0.0f, 0.5f, -0.5f};
+ const int output_shape[] = {3, 2, 2, 3};
+ const float golden[] = {
+ 0.0f, 0.0f, 0.0f, // Row 1, Column 1
+ 0.5f, 0.5f, 0.5f, // Row 1, Column 2
+ 0.0f, -0.5f, 0.5f, // Row 2, Column 1
+ 0.0f, -0.125f, 0.125f, // Row 1, Column 2
+ };
+
+ const int dims_count = 12;
+
+ uint8_t input_quantized[dims_count];
+ uint8_t alpha_quantized[3];
+ uint8_t golden_quantized[dims_count];
+ float scale = 0.125;
+ int zero_point = 127;
+ uint8_t output_data[dims_count];
+
+ tflite::testing::TestPreluQuantized(
+ input_shape, input_values, input_quantized, scale, zero_point,
+ alpha_shape, alpha_values, alpha_quantized, scale, zero_point, golden,
+ golden_quantized, scale, zero_point, output_shape, output_data);
+}
+
+TF_LITE_MICRO_TEST(QuantizedInt8PreluActivationsOpTest) {
+ const int input_shape[] = {3, 2, 2, 3};
+ const float input_values[] = {
+ 0.0f, 0.0f, 0.0f, // Row 1, Column 1
+ 0.5f, 0.5f, 0.5f, // Row 1, Column 2
+ -1.0f, -1.0f, -1.0f, // Row 2, Column 1
+ -0.25f, -0.25f, -0.25f, // Row 1, Column 2
+ };
+ const int alpha_shape[] = {3, 1, 1, 3};
+ const float alpha_values[] = {0.0f, 0.5f, -0.5f};
+ const int output_shape[] = {3, 2, 2, 3};
+ const float golden[] = {
+ 0.0f, 0.0f, 0.0f, // Row 1, Column 1
+ 0.5f, 0.5f, 0.5f, // Row 1, Column 2
+ 0.0f, -0.5f, 0.5f, // Row 2, Column 1
+ 0.0f, -0.125f, 0.125f, // Row 1, Column 2
+ };
+ const int dims_count = 12;
+ int8_t input_quantized[dims_count];
+ int8_t alpha_quantized[3];
+ int8_t golden_quantized[dims_count];
+ float scale = 2.0 / 255.0;
+ int zero_point = 0;
+ int8_t output_data[dims_count];
+ tflite::testing::TestPreluQuantized(
+ input_shape, input_values, input_quantized, scale, zero_point,
+ alpha_shape, alpha_values, alpha_quantized, scale, zero_point, golden,
+ golden_quantized, scale, zero_point, output_shape, output_data);
+}
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/quantization_util_test.cc b/tensorflow/lite/micro/kernels/quantization_util_test.cc
new file mode 100644
index 0000000..76ee9ee
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/quantization_util_test.cc
@@ -0,0 +1,465 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace {
+
+template <class FloatIn, class IntOut>
+void RunSafeCastTests() {
+ const IntOut imax = std::numeric_limits<IntOut>::max();
+ TF_LITE_MICRO_EXPECT_GT(imax, 0);
+ const IntOut imin = std::numeric_limits<IntOut>::min();
+ const bool s = std::numeric_limits<IntOut>::is_signed;
+ if (s) {
+ TF_LITE_MICRO_EXPECT_LT(static_cast<IntOut>(imin), 0);
+ } else {
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<IntOut>(0), imin);
+ }
+
+ // Some basic tests.
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(0.0)),
+ static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(-0.0)),
+ static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(0.99)),
+ static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(1.0)),
+ static_cast<IntOut>(1));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(1.01)),
+ static_cast<IntOut>(1));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(1.99)),
+ static_cast<IntOut>(1));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(2.0)),
+ static_cast<IntOut>(2));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(2.01)),
+ static_cast<IntOut>(2));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(-0.99)),
+ static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(-1.0)),
+ s ? static_cast<IntOut>(-1) : static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(-1.01)),
+ s ? static_cast<IntOut>(-1) : static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(-1.99)),
+ s ? static_cast<IntOut>(-1) : static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(-2.0)),
+ s ? static_cast<IntOut>(-2) : static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(-2.01)),
+ s ? static_cast<IntOut>(-2) : static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(117.9)),
+ static_cast<IntOut>(117));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(118.0)),
+ static_cast<IntOut>(118));
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(118.1)),
+ static_cast<IntOut>(118));
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(-117.9)),
+ s ? static_cast<IntOut>(-117) : static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(-118.0)),
+ s ? static_cast<IntOut>(-118) : static_cast<IntOut>(0));
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(-118.1)),
+ s ? static_cast<IntOut>(-118) : static_cast<IntOut>(0));
+
+ // Some edge cases.
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(std::numeric_limits<FloatIn>::max()),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(std::numeric_limits<FloatIn>::lowest()), imin);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(std::numeric_limits<FloatIn>::infinity()), imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(-std::numeric_limits<FloatIn>::infinity()), imin);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(std::numeric_limits<FloatIn>::quiet_NaN()),
+ static_cast<IntOut>(0));
+
+ // Some larger numbers.
+ if (sizeof(IntOut) >= static_cast<size_t>(4) &&
+ sizeof(FloatIn) > static_cast<size_t>(4)) {
+ TF_LITE_MICRO_EXPECT_EQ(SafeCast<IntOut>(static_cast<FloatIn>(0x76543210)),
+ static_cast<IntOut>(0x76543210));
+ }
+
+ if (sizeof(FloatIn) > sizeof(IntOut)) {
+ // Check values near imax.
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) +
+ static_cast<FloatIn>(0.1))),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) +
+ static_cast<FloatIn>(0.99))),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) +
+ static_cast<FloatIn>(1.0))),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) +
+ static_cast<FloatIn>(1.99))),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) +
+ static_cast<FloatIn>(2.0))),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) -
+ static_cast<FloatIn>(0.1))),
+ imax - 1);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) -
+ static_cast<FloatIn>(0.99))),
+ imax - 1);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) -
+ static_cast<FloatIn>(1.0))),
+ imax - 1);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) -
+ static_cast<FloatIn>(1.01))),
+ imax - 2);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) -
+ static_cast<FloatIn>(1.99))),
+ imax - 2);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) -
+ static_cast<FloatIn>(2.0))),
+ imax - 2);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) -
+ static_cast<FloatIn>(2.01))),
+ imax - 3);
+ }
+
+ // Check values considerably larger in magnitude than imin and imax
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) * 2)),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) * 20)),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imax) * 100)),
+ imax);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imin) * 2)),
+ imin);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imin) * 20)),
+ imin);
+ TF_LITE_MICRO_EXPECT_EQ(
+ SafeCast<IntOut>(static_cast<FloatIn>(static_cast<FloatIn>(imin) * 100)),
+ imin);
+}
+
+} // namespace
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_SafeCast) {
+ tflite::RunSafeCastTests<float, int8_t>();
+ tflite::RunSafeCastTests<double, int8_t>();
+ tflite::RunSafeCastTests<float, int16_t>();
+ tflite::RunSafeCastTests<double, int16_t>();
+ tflite::RunSafeCastTests<float, int32_t>();
+ tflite::RunSafeCastTests<double, int32_t>();
+ tflite::RunSafeCastTests<float, int64_t>();
+ tflite::RunSafeCastTests<double, int64_t>();
+ tflite::RunSafeCastTests<float, uint8_t>();
+ tflite::RunSafeCastTests<double, uint8_t>();
+ tflite::RunSafeCastTests<float, uint16_t>();
+ tflite::RunSafeCastTests<double, uint16_t>();
+ tflite::RunSafeCastTests<float, uint32_t>();
+ tflite::RunSafeCastTests<double, uint32_t>();
+ tflite::RunSafeCastTests<float, uint64_t>();
+ tflite::RunSafeCastTests<double, uint64_t>();
+}
+
+// Example taken from http://www.tensorflow.org/performance/quantization
+//
+// Quantized | Float
+// --------- | -----
+// 0 | -10.0
+// 255 | 30.0
+// 128 | 10.0
+TF_LITE_MICRO_TEST(QuantizationUtilTest_ChooseQuantizationParams) {
+ tflite::QuantizationParams qp =
+ tflite::ChooseQuantizationParams<uint8_t>(-10.0, 30.0);
+ TF_LITE_MICRO_EXPECT_NEAR(qp.scale, 0.156863, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(qp.zero_point, 64);
+}
+
+TF_LITE_MICRO_TEST(
+ QuantizationUtilTest_ChooseQuantizationParamsZeroPointOnMinBoundary) {
+ tflite::QuantizationParams qp =
+ tflite::ChooseQuantizationParams<uint8_t>(0.0, 30.0);
+ TF_LITE_MICRO_EXPECT_NEAR(qp.scale, 0.117647, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(qp.zero_point, 0);
+}
+
+TF_LITE_MICRO_TEST(
+ QuantizationUtilTest_ChooseQuantizationParamsEmptyRangeZero) {
+ tflite::QuantizationParams qp =
+ tflite::ChooseQuantizationParams<uint8_t>(0.0, 0.0);
+ TF_LITE_MICRO_EXPECT_NEAR(qp.scale, 0.0, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(qp.zero_point, 0);
+}
+
+TF_LITE_MICRO_TEST(
+ QuantizationUtilTest_ChooseQuantizationParamsZeroPointOnMaxBoundary) {
+ tflite::QuantizationParams qp =
+ tflite::ChooseQuantizationParams<uint8_t>(-10.0, 0.0);
+ TF_LITE_MICRO_EXPECT_NEAR(qp.scale, 0.039216, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(qp.zero_point, 255);
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_IntegerFrExp) {
+ int shift;
+ int64_t result = tflite::IntegerFrExp(0.0, &shift);
+ TF_LITE_MICRO_EXPECT_EQ(0, result);
+ TF_LITE_MICRO_EXPECT_EQ(0, shift);
+
+ result = tflite::IntegerFrExp(1.0, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(0x40000000, result, 1ll);
+ TF_LITE_MICRO_EXPECT_EQ(1, shift);
+
+ result = tflite::IntegerFrExp(0.25, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(0x40000000, result, 1ll);
+ TF_LITE_MICRO_EXPECT_EQ(-1, shift);
+
+ result = tflite::IntegerFrExp(-1.0, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(-(1 << 30), result, 1ll);
+ TF_LITE_MICRO_EXPECT_EQ(1, shift);
+
+ result = tflite::IntegerFrExp(123.45, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(2071147315, result, 1ll);
+ TF_LITE_MICRO_EXPECT_EQ(7, shift);
+
+ result = tflite::IntegerFrExp(static_cast<double>(NAN), &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(0, result, 1);
+ TF_LITE_MICRO_EXPECT_EQ(0x7fffffff, shift);
+
+ result = tflite::IntegerFrExp(static_cast<double>(INFINITY), &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(std::numeric_limits<int64_t>::max(), result, 1);
+ TF_LITE_MICRO_EXPECT_EQ(0x7fffffff, shift);
+
+ result = tflite::IntegerFrExp(-static_cast<double>(INFINITY), &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(std::numeric_limits<int64_t>::min(), result, 1);
+ TF_LITE_MICRO_EXPECT_EQ(0x7fffffff, shift);
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_IntegerFrExpVersusDouble) {
+ int shift;
+ int32_t result = tflite::IntegerFrExp(0.0, &shift);
+ TF_LITE_MICRO_EXPECT_EQ(result, 0);
+ TF_LITE_MICRO_EXPECT_EQ(shift, 0);
+
+ int double_shift;
+ double double_result = std::frexp(0.0, &double_shift);
+ TF_LITE_MICRO_EXPECT_EQ(double_result, 0);
+ TF_LITE_MICRO_EXPECT_EQ(double_shift, 0);
+
+ result = tflite::IntegerFrExp(1.0, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(result, 0x40000000, 1);
+ TF_LITE_MICRO_EXPECT_EQ(shift, 1);
+ double_result = std::frexp(1.0, &double_shift);
+ TF_LITE_MICRO_EXPECT_NEAR(double_result, 0.5, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(double_shift, 1);
+
+ result = tflite::IntegerFrExp(0.25, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(result, 0x40000000, 1);
+ TF_LITE_MICRO_EXPECT_EQ(shift, -1);
+ double_result = std::frexp(0.25, &double_shift);
+ TF_LITE_MICRO_EXPECT_NEAR(double_result, 0.5, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(double_shift, -1);
+
+ result = tflite::IntegerFrExp(-1.0, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(result, -(1 << 30), 1);
+ TF_LITE_MICRO_EXPECT_EQ(shift, 1);
+ double_result = std::frexp(-1.0, &double_shift);
+ TF_LITE_MICRO_EXPECT_NEAR(double_result, -0.5, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(double_shift, 1);
+
+ result = tflite::IntegerFrExp(123.45, &shift);
+ TF_LITE_MICRO_EXPECT_NEAR(result, (0.964453 * (1LL << 31)), 1000);
+ TF_LITE_MICRO_EXPECT_EQ(shift, 7);
+ double_result = std::frexp(123.45, &double_shift);
+ TF_LITE_MICRO_EXPECT_NEAR(double_result, 0.964453, 1e-5);
+ TF_LITE_MICRO_EXPECT_EQ(double_shift, 7);
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_DoubleFromFractionAndShift) {
+ double result = tflite::DoubleFromFractionAndShift(0, 0);
+ TF_LITE_MICRO_EXPECT_EQ(0, result);
+
+ result = tflite::DoubleFromFractionAndShift(0x40000000, 1);
+ TF_LITE_MICRO_EXPECT_NEAR(1.0, result, 1e-5);
+
+ result = tflite::DoubleFromFractionAndShift(0x40000000, 2);
+ TF_LITE_MICRO_EXPECT_NEAR(2.0, result, 1e-5);
+
+ int shift;
+ int64_t fraction = tflite::IntegerFrExp(3.0, &shift);
+ result = tflite::DoubleFromFractionAndShift(fraction, shift);
+ TF_LITE_MICRO_EXPECT_NEAR(3.0, result, 1e-5);
+
+ fraction = tflite::IntegerFrExp(123.45, &shift);
+ result = tflite::DoubleFromFractionAndShift(fraction, shift);
+ TF_LITE_MICRO_EXPECT_NEAR(123.45, result, 1e-5);
+
+ fraction = tflite::IntegerFrExp(-23.232323, &shift);
+ result = tflite::DoubleFromFractionAndShift(fraction, shift);
+ TF_LITE_MICRO_EXPECT_NEAR(-23.232323, result, 1e-5);
+
+ fraction = tflite::IntegerFrExp(static_cast<double>(NAN), &shift);
+ result = tflite::DoubleFromFractionAndShift(fraction, shift);
+ TF_LITE_MICRO_EXPECT_TRUE(std::isnan(result));
+
+ fraction = tflite::IntegerFrExp(static_cast<double>(INFINITY), &shift);
+ result = tflite::DoubleFromFractionAndShift(fraction, shift);
+ TF_LITE_MICRO_EXPECT_FALSE(std::isfinite(result));
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_IntegerDoubleMultiply) {
+ TF_LITE_MICRO_EXPECT_NEAR(1.0, tflite::IntegerDoubleMultiply(1.0, 1.0), 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(2.0, tflite::IntegerDoubleMultiply(1.0, 2.0), 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(2.0, tflite::IntegerDoubleMultiply(2.0, 1.0), 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(4.0, tflite::IntegerDoubleMultiply(2.0, 2.0), 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(0.5, tflite::IntegerDoubleMultiply(1.0, 0.5), 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(0.25, tflite::IntegerDoubleMultiply(0.5, 0.5),
+ 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(-1.0, tflite::IntegerDoubleMultiply(1.0, -1.0),
+ 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(-1.0, tflite::IntegerDoubleMultiply(-1.0, 1.0),
+ 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(1.0, tflite::IntegerDoubleMultiply(-1.0, -1.0),
+ 1e-5);
+ TF_LITE_MICRO_EXPECT_NEAR(
+ 15000000.0, tflite::IntegerDoubleMultiply(3000.0, 5000.0), 1e-5);
+ TF_LITE_MICRO_EXPECT_TRUE(std::isnan(
+ tflite::IntegerDoubleMultiply(static_cast<double>(NAN), 5000.0)));
+ TF_LITE_MICRO_EXPECT_TRUE(std::isnan(
+ tflite::IntegerDoubleMultiply(3000.0, static_cast<double>(NAN))));
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_IntegerDoubleCompare) {
+ TF_LITE_MICRO_EXPECT_EQ(-1, tflite::IntegerDoubleCompare(0.0, 1.0));
+ TF_LITE_MICRO_EXPECT_EQ(1, tflite::IntegerDoubleCompare(1.0, 0.0));
+ TF_LITE_MICRO_EXPECT_EQ(0, tflite::IntegerDoubleCompare(1.0, 1.0));
+ TF_LITE_MICRO_EXPECT_EQ(0, tflite::IntegerDoubleCompare(0.0, 0.0));
+ TF_LITE_MICRO_EXPECT_EQ(-1, tflite::IntegerDoubleCompare(-10.0, 10.0));
+ TF_LITE_MICRO_EXPECT_EQ(1, tflite::IntegerDoubleCompare(123.45, 10.0));
+ TF_LITE_MICRO_EXPECT_EQ(
+ 1, tflite::IntegerDoubleCompare(static_cast<double>(NAN),
+ static_cast<double>(INFINITY)));
+ TF_LITE_MICRO_EXPECT_EQ(
+ 1, tflite::IntegerDoubleCompare(static_cast<double>(INFINITY),
+ static_cast<double>(NAN)));
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_PreprocessSoftmaxScaling) {
+ auto quantize = [](double beta, double scale, int integer_bits) {
+ int32_t q;
+ int s;
+ tflite::PreprocessSoftmaxScaling(beta, scale, integer_bits, &q, &s);
+ return std::pair<int32_t, int>{q, s};
+ };
+
+ // If beta * scale is greater than fits in the number of integer bits, the
+ // result is move near the maximum. Otherwise they quantize as expected.
+ // With 4 integer bits we can represent up to 16.0.
+
+ auto r = quantize(1.0, 16.0, 4);
+ TF_LITE_MICRO_EXPECT_EQ(r.first, 2147483647);
+ TF_LITE_MICRO_EXPECT_EQ(r.second, 31);
+
+ r = quantize(1.0, 8.0, 4);
+ TF_LITE_MICRO_EXPECT_EQ(r.first, 1073741824);
+ TF_LITE_MICRO_EXPECT_EQ(r.second, 31);
+
+ // But with 5 bits we can go further.
+ r = quantize(2.0, 16.0, 5);
+ TF_LITE_MICRO_EXPECT_EQ(r.first, 2147483647);
+ TF_LITE_MICRO_EXPECT_EQ(r.second, 31);
+
+ r = quantize(2.0, 8.0, 5);
+ TF_LITE_MICRO_EXPECT_EQ(r.first, 1073741824);
+ TF_LITE_MICRO_EXPECT_EQ(r.second, 31);
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_CalculateInputRadius) {
+ TF_LITE_MICRO_EXPECT_EQ(tflite::CalculateInputRadius(4, 27), 15);
+ TF_LITE_MICRO_EXPECT_EQ(tflite::CalculateInputRadius(3, 27), 14);
+ TF_LITE_MICRO_EXPECT_EQ(tflite::CalculateInputRadius(3, 28), 7);
+ TF_LITE_MICRO_EXPECT_EQ(tflite::CalculateInputRadius(4, 2), 503316480);
+}
+
+TF_LITE_MICRO_TEST(QuantizationUtilTest_QuantizeMultiplierArray) {
+ const double weights[] = {-4, -2, -1, -0.5, -0.25, -0.125, 0,
+ 0.125, 0.25, 0.5, 1, 2, 4};
+
+ const int size = 13;
+ int32_t effective_scale_significand[size];
+ int effective_scale_shift[size];
+ tflite::QuantizeMultiplierArray(weights, size, effective_scale_significand,
+ effective_scale_shift);
+ const int32_t expected_effective_scale_significand[] = {
+ -1073741824, // float scale = -4
+ -1073741824, // float scale = -2
+ -1073741824, // float scale = -1
+ -1073741824, // float scale = -0.5
+ -1073741824, // float scale = -0.25
+ -1073741824, // float scale = -0.125
+ 0, // float scale = 0
+ 1073741824, // float scale = 0.125
+ 1073741824, // float scale = 0.25
+ 1073741824, // float scale = 0.5
+ 1073741824, // float scale = 1
+ 1073741824, // float scale = 2
+ 1073741824, // float scale = 4
+ };
+
+ const int expected_effective_scale_shift[] = {
+ 3, // float scale = -4
+ 2, // float scale = -2
+ 1, // float scale = -1
+ 0, // float scale = -0.5
+ -1, // float scale = -0.25
+ -2, // float scale = -0.125
+ 0, // float scale = 0
+ -2, // float scale = 0.125
+ -1, // float scale = 0.25
+ 0, // float scale = 0.5
+ 1, // float scale = 1
+ 2, // float scale = 2
+ 3, // float scale = 4
+ };
+
+ for (int i = 0; i < size; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(effective_scale_significand[i],
+ expected_effective_scale_significand[i]);
+ TF_LITE_MICRO_EXPECT_EQ(effective_scale_shift[i],
+ expected_effective_scale_shift[i]);
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/quantize.cc b/tensorflow/lite/micro/kernels/quantize.cc
new file mode 100644
index 0000000..97f5a00
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/quantize.cc
@@ -0,0 +1,47 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/quantize.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace {
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context,
+ sizeof(OpDataQuantizeReference));
+}
+
+} // namespace
+
+TfLiteRegistration Register_QUANTIZE() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/PrepareQuantizeReference,
+ /*invoke=*/EvalQuantizeReference,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/quantize.h b/tensorflow/lite/micro/kernels/quantize.h
new file mode 100644
index 0000000..ba93809
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/quantize.h
@@ -0,0 +1,37 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_QUANTIZE_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_QUANTIZE_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+struct OpDataQuantizeReference {
+ tflite::QuantizationParams quantization_params;
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t requantize_output_multiplier;
+ int requantize_output_shift;
+
+ int32_t input_zero_point;
+};
+
+TfLiteStatus EvalQuantizeReference(TfLiteContext* context, TfLiteNode* node);
+TfLiteStatus PrepareQuantizeReference(TfLiteContext* context, TfLiteNode* node);
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_QUANTIZE_H_
diff --git a/tensorflow/lite/micro/kernels/quantize_common.cc b/tensorflow/lite/micro/kernels/quantize_common.cc
new file mode 100644
index 0000000..098854c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/quantize_common.cc
@@ -0,0 +1,171 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/quantize.h"
+#include "tensorflow/lite/kernels/internal/reference/requantize.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/quantize.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+
+TfLiteStatus PrepareQuantizeReference(TfLiteContext* context,
+ TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ auto* data = static_cast<OpDataQuantizeReference*>(node->user_data);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, 0);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ // TODO(b/128934713): Add support for fixed-point per-channel quantization.
+ // Currently this only support affine per-layer quantization.
+ TF_LITE_ENSURE_EQ(context, output->quantization.type,
+ kTfLiteAffineQuantization);
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(output->quantization.params);
+ TF_LITE_ENSURE(context, affine_quantization);
+ TF_LITE_ENSURE(context, affine_quantization->scale);
+ TF_LITE_ENSURE(context, affine_quantization->scale->size == 1);
+
+ TF_LITE_ENSURE(context, input->type == kTfLiteFloat32 ||
+ input->type == kTfLiteInt16 ||
+ input->type == kTfLiteInt8);
+ TF_LITE_ENSURE(context, output->type == kTfLiteInt8 ||
+ output->type == kTfLiteInt16 ||
+ output->type == kTfLiteInt32);
+
+ if ((input->type == kTfLiteInt16 && output->type == kTfLiteInt8) ||
+ (input->type == kTfLiteInt8 && output->type == kTfLiteInt8) ||
+ (input->type == kTfLiteInt8 && output->type == kTfLiteInt32) ||
+ (input->type == kTfLiteInt16 && output->type == kTfLiteInt16) ||
+ (input->type == kTfLiteInt16 && output->type == kTfLiteInt32)) {
+ double effective_scale = static_cast<double>(input->params.scale) /
+ static_cast<double>(output->params.scale);
+
+ QuantizeMultiplier(effective_scale, &data->requantize_output_multiplier,
+ &data->requantize_output_shift);
+ }
+
+ data->quantization_params.zero_point = output->params.zero_point;
+ data->quantization_params.scale = static_cast<double>(output->params.scale);
+
+ data->input_zero_point = input->params.zero_point;
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalQuantizeReference(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ auto* data = static_cast<OpDataQuantizeReference*>(node->user_data);
+
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ if (input->type == kTfLiteFloat32) {
+ switch (output->type) {
+ case kTfLiteInt8:
+ reference_ops::AffineQuantize(
+ data->quantization_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ case kTfLiteInt16:
+ reference_ops::AffineQuantize(
+ data->quantization_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ return kTfLiteOk;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ } else if (input->type == kTfLiteInt16) {
+ size_t size = ElementCount(*input->dims);
+ switch (output->type) {
+ case kTfLiteInt8:
+ reference_ops::Requantize(
+ tflite::micro::GetTensorData<int16_t>(input), size,
+ data->requantize_output_multiplier, data->requantize_output_shift,
+ data->input_zero_point, data->quantization_params.zero_point,
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ case kTfLiteInt16:
+ reference_ops::Requantize(
+ tflite::micro::GetTensorData<int16_t>(input), size,
+ data->requantize_output_multiplier, data->requantize_output_shift,
+ data->input_zero_point, data->quantization_params.zero_point,
+ tflite::micro::GetTensorData<int16_t>(output));
+ return kTfLiteOk;
+ case kTfLiteInt32:
+ reference_ops::Requantize(
+ tflite::micro::GetTensorData<int16_t>(input), size,
+ data->requantize_output_multiplier, data->requantize_output_shift,
+ data->input_zero_point, data->quantization_params.zero_point,
+ tflite::micro::GetTensorData<int32_t>(output));
+ return kTfLiteOk;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ } else if (input->type == kTfLiteInt8) {
+ // Int8 to Int8 requantization, required if the input and output tensors
+ // have different scales and/or zero points.
+ size_t size = ElementCount(*input->dims);
+ switch (output->type) {
+ case kTfLiteInt8:
+ reference_ops::Requantize(
+ tflite::micro::GetTensorData<int8_t>(input), size,
+ data->requantize_output_multiplier, data->requantize_output_shift,
+ data->input_zero_point, data->quantization_params.zero_point,
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ case kTfLiteInt32:
+ reference_ops::Requantize(
+ tflite::micro::GetTensorData<int8_t>(input), size,
+ data->requantize_output_multiplier, data->requantize_output_shift,
+ data->input_zero_point, data->quantization_params.zero_point,
+ tflite::micro::GetTensorData<int32_t>(output));
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/quantize_test.cc b/tensorflow/lite/micro/kernels/quantize_test.cc
new file mode 100644
index 0000000..44cfbb6
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/quantize_test.cc
@@ -0,0 +1,294 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void ValidateQuantizeGoldens(TfLiteTensor* tensors, int tensors_size,
+ const float* golden, T* golden_quantized,
+ float scale, int zero_point, int output_len,
+ T* output_data) {
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ // Version 1 of quantize supports int8_t and uint8_t quantization.
+ const TfLiteRegistration registration = Register_QUANTIZE();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ // Use reference quantization from test utils to compare against op output.
+ Quantize(golden, golden_quantized, output_len, scale, zero_point);
+ for (int i = 0; i < output_len; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden_quantized[i], output_data[i]);
+ }
+}
+
+#if !defined(XTENSA)
+template <typename T>
+void TestQuantizeFloat(const int* input_dims_data, const float* input_data,
+ const int* output_dims_data, const float* golden,
+ T* golden_quantized, const float scale,
+ const int zero_point, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ TfLiteTensor output_tensor =
+ CreateQuantizedTensor(output_data, output_dims, scale, zero_point);
+
+ TfLiteAffineQuantization quant;
+ float scales[] = {1, scale};
+ int zero_points[] = {1, zero_point};
+ quant.scale = FloatArrayFromFloats(scales);
+ quant.zero_point = IntArrayFromInts(zero_points);
+ output_tensor.quantization = {kTfLiteAffineQuantization, &quant};
+
+ // 1 input, 1 output.
+ constexpr int tensors_size = 2;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ output_tensor,
+ };
+
+ ValidateQuantizeGoldens(tensors, tensors_size, golden, golden_quantized,
+ scale, zero_point, output_dims_count, output_data);
+}
+#endif // defined(XTENSA)
+
+template <typename InputType, typename OutputType>
+void TestRequantize(const int* input_dims_data, const float* input_data,
+ InputType* input_quantized, const float input_scale,
+ const int input_zero_point, const int* output_dims_data,
+ const float* golden, OutputType* golden_quantized,
+ const float output_scale, const int output_zero_point,
+ OutputType* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ TfLiteTensor output_tensor = CreateQuantizedTensor(
+ output_data, output_dims, output_scale, output_zero_point);
+
+ TfLiteAffineQuantization quant;
+ float scales[] = {1, output_scale};
+ int zero_points[] = {1, output_zero_point};
+ quant.scale = FloatArrayFromFloats(scales);
+ quant.zero_point = IntArrayFromInts(zero_points);
+ output_tensor.quantization = {kTfLiteAffineQuantization, &quant};
+
+ // 1 input, 1 output.
+ constexpr int tensors_size = 2;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ output_tensor,
+ };
+
+ ValidateQuantizeGoldens(tensors, tensors_size, golden, golden_quantized,
+ output_scale, output_zero_point, output_dims_count,
+ output_data);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+#if !defined(XTENSA)
+TF_LITE_MICRO_TEST(QuantizeOpTestInt16) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-63.5, -63, -62.5, -62, -61.5,
+ 62, 62.5, 63, 63.5, 64};
+ const float scale = 0.5;
+ const int zero_point = -1;
+ int16_t output[length];
+ int16_t values_quantized[length];
+ tflite::testing::TestQuantizeFloat(
+ dims, values, dims, values, values_quantized, scale, zero_point, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt16NoScale) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-128, -127, -126, -125, -124,
+ 123, 124, 125, 126, 127};
+ const float scale = 1.0;
+ const int zero_point = 0;
+ int16_t output[length];
+ int16_t values_quantized[length];
+ tflite::testing::TestQuantizeFloat(
+ dims, values, dims, values, values_quantized, scale, zero_point, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt16toInt16) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-64, -62, -60, -58, -56, 54, 56, 58, 60, 62};
+ const float input_scale = 2.f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 32;
+ int16_t output_quantized[length];
+ int16_t values_quantized[length];
+ int16_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt16toInt16NoZeroPoint) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-32, -31, -30, -29, -28, 27, 28, 29, 30, 31};
+ const float input_scale = 1.f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 0;
+ int16_t output_quantized[length];
+ int16_t values_quantized[length];
+ int16_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt8toInt8) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-64, -62, -60, -58, -56, 54, 56, 58, 60, 62};
+ const float input_scale = 2.f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 32;
+ int8_t output_quantized[length];
+ int8_t values_quantized[length];
+ int8_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt8toInt8NoZeroPoint) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-32, -31, -30, -29, -28, 27, 28, 29, 30, 31};
+ const float input_scale = 1.f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 0;
+ int8_t output_quantized[length];
+ int8_t values_quantized[length];
+ int8_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+#endif // defined(XTENSA)
+
+#if !defined(XTENSA)
+// TODO(b/155682734): Hifimini optimized quantize requires input scale to be
+// smaller then output scale.
+TF_LITE_MICRO_TEST(QuantizeOpTestInt16toInt8) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-64, -62, -60, -58, -56, 54, 56, 58, 60, 62};
+ const float input_scale = 2.f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 0;
+ int8_t output_quantized[length];
+ int8_t values_quantized[length];
+ int16_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+#endif // defined(XTENSA)
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt8toInt32) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-32, -31, -30, -29, -28, 27, 28, 29, 30, 31};
+ const float input_scale = 1.f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 0;
+ int32_t output_quantized[length];
+ int32_t values_quantized[length];
+ int8_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt16toInt32) {
+ const int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-32, -31, -30, -29, -28, 27, 28, 29, 30, 31};
+ const float input_scale = 1.f;
+ const int input_zero_point = 0;
+ const float output_scale = 0.5;
+ const int output_zero_point = 0;
+ int32_t output_quantized[length];
+ int32_t values_quantized[length];
+ int16_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+
+TF_LITE_MICRO_TEST(QuantizeOpTestInt16toInt8) {
+ constexpr int length = 10;
+ const int dims[] = {2, 2, 5};
+ const float values[] = {-32, -31, -30, -29, -28, 27, 28, 29, 30, 31};
+ // TODO(b/155682734): Input scale must be smaller than output scale for
+ // xtensa.
+ const float input_scale = 0.4f;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0f;
+ const int output_zero_point = 0;
+ int8_t output_quantized[length];
+ int8_t values_quantized[length];
+ int16_t input_quantized[length];
+ tflite::testing::TestRequantize(dims, values, input_quantized, input_scale,
+ input_zero_point, dims, values,
+ values_quantized, output_scale,
+ output_zero_point, output_quantized);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/reduce.cc b/tensorflow/lite/micro/kernels/reduce.cc
new file mode 100644
index 0000000..8c60269
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/reduce.cc
@@ -0,0 +1,342 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/reduce.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/mean.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace reduce {
+
+constexpr int kMaxNumberOfAxis = 4;
+constexpr int kMaxNumberOfReducedAxis = 2;
+
+struct OpData {
+ int32_t multiplier;
+ int shift;
+ int temp_buffer_idx;
+ int resolved_axis_idx;
+ int input_zp;
+ float input_scale;
+ int output_zp;
+ float output_scale;
+ int num_output_elements;
+};
+
+void* InitReduce(TfLiteContext* context, const char* buffer, size_t length) {
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus PrepareSimple(TfLiteContext* context, TfLiteNode* node) {
+ // Inputs Tensor (dtype depends on quantization):
+ // [0] = Input
+ // [1] = Axis
+ const TfLiteTensor* input = GetInput(context, node, 0);
+
+ // Outputs Tensor (dtype depends on quantization):
+ // [0] = Output
+
+ // Validate number of inputs and outputs
+ TF_LITE_ENSURE_EQ(context, node->inputs->size, 2);
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+
+ // Validate axis type
+ const TfLiteTensor* axis = GetInput(context, node, 1);
+ TF_LITE_ENSURE(context, axis != nullptr);
+ TF_LITE_ENSURE_TYPES_EQ(context, axis->type, kTfLiteInt32);
+
+ if (input->type == kTfLiteInt8) {
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const TfLiteTensor* output = GetOutput(context, node, 0);
+ const double real_multiplier = static_cast<double>(input->params.scale) /
+ static_cast<double>(output->params.scale);
+ QuantizeMultiplier(real_multiplier, &data->multiplier, &data->shift);
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus PrepareMax(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_OK(context, PrepareSimple(context, node));
+
+ OpData* op_data = static_cast<OpData*>(node->user_data);
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ const TfLiteTensor* output = GetOutput(context, node, 0);
+ const TfLiteTensor* axis = GetInput(context, node, 1);
+
+ op_data->input_scale = input->params.scale;
+ op_data->output_scale = output->params.scale;
+ op_data->num_output_elements = NumElements(output);
+
+ context->RequestScratchBufferInArena(context, sizeof(int) * input->dims->size,
+ &op_data->temp_buffer_idx);
+ context->RequestScratchBufferInArena(
+ context, sizeof(int) * static_cast<int>(ElementCount(*axis->dims)),
+ &op_data->resolved_axis_idx);
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus PrepareMeanOrSum(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ OpData* op_data = reinterpret_cast<OpData*>(node->user_data);
+ const TfLiteTensor* output = GetOutput(context, node, 0);
+ if (input->type == kTfLiteInt8) {
+ const double real_multiplier = static_cast<double>(input->params.scale) /
+ static_cast<double>(output->params.scale);
+ QuantizeMultiplier(real_multiplier, &op_data->multiplier, &op_data->shift);
+ }
+
+ int output_size = NumElements(output);
+ if (input->type == kTfLiteInt8 || input->type == kTfLiteUInt8) {
+ context->RequestScratchBufferInArena(context, output_size * sizeof(int32_t),
+ &op_data->temp_buffer_idx);
+ op_data->input_zp = input->params.zero_point;
+ op_data->input_scale = input->params.scale;
+ op_data->output_zp = output->params.zero_point;
+ op_data->output_scale = output->params.scale;
+ }
+
+ TF_LITE_ENSURE_OK(context, PrepareSimple(context, node));
+ // TODO(b/144955155): Support uint8_t(b/144955155) and int8_t(b/144955018)
+ return kTfLiteOk;
+}
+
+void ResolveAxis(const int* axis_data, int axis_count,
+ tflite::MeanParams* op_params) {
+ int i = 0;
+ for (; i < axis_count; ++i) {
+ op_params->axis[i] = static_cast<int16_t>(axis_data[i]);
+ }
+ for (; i < 4; ++i) {
+ op_params->axis[i] = 1;
+ }
+ op_params->axis_count = axis_count;
+}
+
+TfLiteStatus EvalMean(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ const TfLiteEvalTensor* axis = tflite::micro::GetEvalInput(context, node, 1);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+ TfLiteReducerParams* params =
+ reinterpret_cast<TfLiteReducerParams*>(node->builtin_data);
+ OpData* op_data = reinterpret_cast<OpData*>(node->user_data);
+
+ int num_axis = static_cast<int>(ElementCount(*axis->dims));
+ int temp_index[kMaxNumberOfAxis];
+ int resolved_axis[kMaxNumberOfReducedAxis];
+
+ tflite::MeanParams op_params;
+ ResolveAxis(tflite::micro::GetTensorData<int>(axis), num_axis, &op_params);
+
+ // Special case mean implementation exists for 4D mean across axes 1 and 2.
+ bool special_case_4d_axes_1_and_2 =
+ input->dims->size == 4 && op_params.axis_count == 2 &&
+ ((op_params.axis[0] == 1 && op_params.axis[1] == 2) ||
+ (op_params.axis[0] == 2 && op_params.axis[1] == 1));
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ // Defer to specialized implementation for 4D Mean across axes 1 & 2.
+ if (params->keep_dims && special_case_4d_axes_1_and_2) {
+ reference_ops::Mean(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ } else {
+ TF_LITE_ENSURE(
+ context,
+ reference_ops::Mean(
+ tflite::micro::GetTensorData<float>(input), input->dims->data,
+ input->dims->size, tflite::micro::GetTensorData<float>(output),
+ output->dims->data, output->dims->size,
+ tflite::micro::GetTensorData<int>(axis), num_axis,
+ params->keep_dims, temp_index, resolved_axis,
+ tflite::micro::GetTensorData<float>(output)));
+ }
+ } break;
+ case kTfLiteInt8: {
+ // Defer to specialized implementation for 4D Mean across axes 1 & 2.
+ if (params->keep_dims && special_case_4d_axes_1_and_2) {
+ reference_integer_ops::Mean(
+ op_params, op_data->multiplier, op_data->shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input), op_data->input_zp,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output), op_data->output_zp);
+ } else if (op_data->input_zp == op_data->output_zp &&
+ op_data->input_scale == op_data->output_scale) {
+ int32_t* temp_buffer = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, op_data->temp_buffer_idx));
+ TF_LITE_ENSURE(
+ context,
+ reference_ops::Mean(
+ tflite::micro::GetTensorData<int8_t>(input), input->dims->data,
+ input->dims->size, tflite::micro::GetTensorData<int8_t>(output),
+ output->dims->data, output->dims->size,
+ tflite::micro::GetTensorData<int>(axis), num_axis,
+ params->keep_dims, temp_index, resolved_axis, temp_buffer));
+ } else {
+ int32_t* temp_buffer = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, op_data->temp_buffer_idx));
+ TF_LITE_ENSURE(
+ context,
+ reference_ops::QuantizedMeanOrSum(
+ tflite::micro::GetTensorData<int8_t>(input), op_data->input_zp,
+ op_data->input_scale, input->dims->data, input->dims->size,
+ tflite::micro::GetTensorData<int8_t>(output),
+ op_data->output_zp, op_data->output_scale, output->dims->data,
+ output->dims->size, tflite::micro::GetTensorData<int>(axis),
+ num_axis, params->keep_dims, temp_index, resolved_axis,
+ temp_buffer, false));
+ }
+ } break;
+ case kTfLiteUInt8: {
+ // Defer to specialized implementation for 4D Mean across axes 1 & 2.
+ if (params->keep_dims && special_case_4d_axes_1_and_2) {
+ reference_ops::Mean(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ op_data->input_zp, op_data->input_scale,
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output),
+ op_data->output_zp, op_data->output_scale);
+ } else if (op_data->input_zp == op_data->output_zp &&
+ op_data->input_scale == op_data->output_scale) {
+ uint32_t* temp_buffer = static_cast<uint32_t*>(
+ context->GetScratchBuffer(context, op_data->temp_buffer_idx));
+ TF_LITE_ENSURE(
+ context,
+ reference_ops::Mean(tflite::micro::GetTensorData<uint8_t>(input),
+ input->dims->data, input->dims->size,
+ tflite::micro::GetTensorData<uint8_t>(output),
+ output->dims->data, output->dims->size,
+ tflite::micro::GetTensorData<int>(axis),
+ num_axis, params->keep_dims, temp_index,
+ resolved_axis, temp_buffer));
+ } else {
+ uint32_t* temp_buffer = static_cast<uint32_t*>(
+ context->GetScratchBuffer(context, op_data->temp_buffer_idx));
+ TF_LITE_ENSURE(
+ context,
+ reference_ops::QuantizedMeanOrSum(
+ tflite::micro::GetTensorData<uint8_t>(input), op_data->input_zp,
+ op_data->input_scale, input->dims->data, input->dims->size,
+ tflite::micro::GetTensorData<uint8_t>(output),
+ op_data->output_zp, op_data->output_scale, output->dims->data,
+ output->dims->size, tflite::micro::GetTensorData<int>(axis),
+ num_axis, params->keep_dims, temp_index, resolved_axis,
+ temp_buffer, false));
+ }
+ } break;
+ default:
+ TF_LITE_ENSURE_MSG(context, false,
+ "Currently, only float32, int8 or uint8 input type "
+ "is supported.");
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalMax(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ const TfLiteEvalTensor* axis = tflite::micro::GetEvalInput(context, node, 1);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ TfLiteReducerParams* params =
+ static_cast<TfLiteReducerParams*>(node->builtin_data);
+ OpData* op_data = static_cast<OpData*>(node->user_data);
+
+ // Interpret an axis tensor with null dimensions as a scalar
+ int num_axis = static_cast<int>(ElementCount(*axis->dims));
+ int* temp_buffer = static_cast<int*>(
+ context->GetScratchBuffer(context, op_data->temp_buffer_idx));
+ int* resolved_axis = static_cast<int*>(
+ context->GetScratchBuffer(context, op_data->resolved_axis_idx));
+ switch (input->type) {
+ case kTfLiteFloat32:
+ TF_LITE_ENSURE(
+ context,
+ reference_ops::ReduceGeneric<float>(
+ tflite::micro::GetTensorData<float>(input), input->dims->data,
+ input->dims->size, tflite::micro::GetTensorData<float>(output),
+ output->dims->data, output->dims->size,
+ tflite::micro::GetTensorData<int>(axis), num_axis,
+ params->keep_dims, temp_buffer, resolved_axis,
+ std::numeric_limits<float>::lowest(),
+ [](const float current, const float in) -> float {
+ return (in > current) ? in : current;
+ }));
+ break;
+ case kTfLiteInt8:
+ TF_LITE_ENSURE_EQ(context, static_cast<double>(op_data->input_scale),
+ static_cast<double>(op_data->output_scale));
+ TF_LITE_ENSURE_EQ(context, op_data->input_zp, op_data->output_zp);
+ TF_LITE_ENSURE(
+ context,
+ reference_ops::ReduceGeneric<int8_t>(
+ tflite::micro::GetTensorData<int8_t>(input), input->dims->data,
+ input->dims->size, tflite::micro::GetTensorData<int8_t>(output),
+ output->dims->data, output->dims->size,
+ tflite::micro::GetTensorData<int>(axis), num_axis,
+ params->keep_dims, temp_buffer, resolved_axis,
+ std::numeric_limits<int8_t>::lowest(),
+ [](const int8_t current, const int8_t in) -> int8_t {
+ return (in > current) ? in : current;
+ }));
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "Only float32 and int8 types are supported.\n");
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace reduce
+
+TfLiteRegistration Register_MEAN() {
+ return {/*init=*/reduce::InitReduce,
+ /*free=*/nullptr,
+ /*prepare=*/reduce::PrepareMeanOrSum,
+ /*invoke=*/reduce::EvalMean,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+TfLiteRegistration Register_REDUCE_MAX() {
+ return {/*init=*/reduce::InitReduce,
+ /*free=*/nullptr,
+ /*prepare=*/reduce::PrepareMax,
+ /*invoke=*/reduce::EvalMax,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/reduce_test.cc b/tensorflow/lite/micro/kernels/reduce_test.cc
new file mode 100644
index 0000000..e06a111
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/reduce_test.cc
@@ -0,0 +1,617 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Common 2D inputs, outputs and axis.
+static const int kInputElements2D = 8;
+static const int kInputShape2D[] = {2, 2, 4};
+static const float kInputData2D[] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0};
+
+static const int kAxisShape2D[] = {1, 1};
+static const int32_t kAxisData2D[] = {1};
+
+static const int kOutputElements2D = 2;
+static const int kOutputShape2D[] = {2, 1, 2};
+static const float kGoldenData2D[] = {2.5, 6.5};
+
+// Common 3D inputs, outputs and axis.
+static const int kInputElements3D = 8;
+static const int kInputShape3D[] = {3, 2, 2, 2};
+static const float kInputData3D[] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0};
+
+static const int kAxisShape3D[] = {1, 2};
+static const int32_t kAxisData3D[] = {1, 2};
+
+static const int kOutputElements3D = 2;
+static const int kOutputShape3D[] = {2, 1, 2};
+static const float kGoldenData3D[] = {2.5, 6.5};
+
+// Common 4D inputs, outputs and axis.
+static const int kInputElements4D = 24;
+static const int kInputShape4D[] = {4, 2, 2, 3, 2};
+static const float kInputData4D[] = {
+ 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0,
+ 13.0, 14.0, 15.0, 16.0, 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0};
+
+static const int kAxisShape4D[] = {1, 2};
+static const int32_t kAxisData4D[] = {1, 2};
+
+static const int kOutputElements4D = 4;
+static const int kOutputShape4D[] = {4, 2, 1, 1, 2};
+static const float kGoldenData4D[] = {6, 7, 18, 19};
+
+// Axis shape and contents are independent of input / output dimensions.
+
+template <typename T>
+TfLiteStatus ValidateReduceGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* expected_output_data,
+ T* output_data, int output_length,
+ const TfLiteRegistration& registration,
+ TfLiteReducerParams* params,
+ float tolerance = 1e-5) {
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, params);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i],
+ tolerance);
+ }
+ return kTfLiteOk;
+}
+
+void TestMeanFloatInput4D(const int* input_dims_data, const float* input_data,
+ const int* axis_dims_data, const int32_t* axis_data,
+ const int* output_dims_data,
+ const float* expected_output_data, float* output_data,
+ TfLiteReducerParams* params, float tolerance = 1e-5) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_MEAN();
+
+ constexpr int num_of_inputs = 2; // input and axis
+ constexpr int num_of_outputs = 1; // output
+
+ constexpr int tensors_size = num_of_inputs + num_of_outputs;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(axis_data, axis_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, ValidateReduceGoldens(
+ tensors, tensors_size, expected_output_data, output_data,
+ output_dims_count, registration, params, tolerance));
+}
+
+void TestReduceOpFloat(const int* input_dims_data, const float* input_data,
+ const int* axis_dims_data, const int32_t* axis_data,
+ const int* output_dims_data, float* output_data,
+ const float* expected_output_data,
+ const TfLiteRegistration& registration,
+ TfLiteReducerParams* params, float tolerance = 1e-5) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int num_of_inputs = 2; // input and axis
+ constexpr int num_of_outputs = 1; // output
+
+ constexpr int tensors_size = num_of_inputs + num_of_outputs;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(axis_data, axis_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, ValidateReduceGoldens(
+ tensors, tensors_size, expected_output_data, output_data,
+ output_dims_count, registration, params, tolerance));
+}
+
+template <typename T>
+void TestReduceOpQuantized(
+ const int* input_dims_data, const float* input_data, T* input_data_quant,
+ float input_scale, int input_zero_point, const int* axis_dims_data,
+ const int32_t* axis_data, const int* output_dims_data,
+ const float* expected_output_data, T* output_data_quant,
+ T* expected_output_data_quant, float output_scale, int output_zero_point,
+ const TfLiteRegistration& registration, TfLiteReducerParams* params) {
+ // Convert dimesion arguments to TfLiteArrays
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ // Get number of elements in input and output tensors
+ const int output_dims_count = ElementCount(*output_dims);
+
+ // Initialize tensors
+ constexpr int tensors_size = 3;
+ TfLiteTensor tensors[] = {
+ CreateQuantizedTensor(input_data, input_data_quant, input_dims,
+ input_scale, input_zero_point),
+ CreateTensor(axis_data, axis_dims),
+ CreateQuantizedTensor(output_data_quant, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ // Quantize expected output
+ tflite::Quantize(expected_output_data, expected_output_data_quant,
+ output_dims_count, output_scale, output_zero_point);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ ValidateReduceGoldens(tensors, tensors_size, expected_output_data_quant,
+ output_data_quant, output_dims_count, registration,
+ params, 0.01));
+}
+
+template <typename T>
+void TestMeanOpQuantized(const int* input_dims_data, const float* input_data,
+ T* input_data_quant, float input_scale,
+ int input_zero_point, const int* axis_dims_data,
+ const int32_t* axis_data, const int* output_dims_data,
+ const float* expected_output_data,
+ T* output_data_quant, T* expected_output_data_quant,
+ float output_scale, int output_zero_point,
+ TfLiteReducerParams* params) {
+ // Convert dimesion arguments to TfLiteArrays
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ // Get number of elements in input and output tensors
+ const int output_dims_count = ElementCount(*output_dims);
+
+ // Initialize tensors
+ constexpr int tensors_size = 3;
+ TfLiteTensor tensors[] = {
+ CreateQuantizedTensor(input_data, input_data_quant, input_dims,
+ input_scale, input_zero_point),
+ CreateTensor(axis_data, axis_dims),
+ CreateQuantizedTensor(output_data_quant, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ // Quantize expected output
+ tflite::Quantize(expected_output_data, expected_output_data_quant,
+ output_dims_count, output_scale, output_zero_point);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ ValidateReduceGoldens(tensors, tensors_size, expected_output_data_quant,
+ output_data_quant, output_dims_count,
+ tflite::ops::micro::Register_MEAN(), params, 1.0));
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(MeanFloat2DKeepDims) {
+ float output_data[tflite::testing::kOutputElements2D];
+
+ TfLiteReducerParams params = {true};
+
+ tflite::testing::TestMeanFloatInput4D(
+ tflite::testing::kInputShape2D, tflite::testing::kInputData2D,
+ tflite::testing::kAxisShape2D, tflite::testing::kAxisData2D,
+ tflite::testing::kOutputShape2D, tflite::testing::kGoldenData2D,
+ output_data, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanInt82DKeepDims) {
+ int8_t expected_output_data_quant[tflite::testing::kOutputElements2D];
+ int8_t output_data_quant[tflite::testing::kOutputElements2D];
+ int8_t input_data_quant[tflite::testing::kInputElements2D];
+
+ float input_scale = 0.5f;
+ int input_zero_point = 0;
+ float output_scale = 0.5f;
+ int output_zero_point = 0;
+
+ TfLiteReducerParams params = {
+ true // keep_dims
+ };
+
+ tflite::testing::TestMeanOpQuantized<int8_t>(
+ tflite::testing::kInputShape2D, tflite::testing::kInputData2D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape2D, tflite::testing::kAxisData2D,
+ tflite::testing::kOutputShape2D, tflite::testing::kGoldenData2D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanUInt82DKeepDims) {
+ uint8_t expected_output_data_quant[tflite::testing::kOutputElements2D];
+ uint8_t output_data_quant[tflite::testing::kOutputElements2D];
+ uint8_t input_data_quant[tflite::testing::kInputElements2D];
+
+ float input_scale = 0.5f;
+ int input_zero_point = 128;
+ float output_scale = 0.5f;
+ int output_zero_point = 128;
+
+ TfLiteReducerParams params = {
+ true // keep_dims
+ };
+
+ tflite::testing::TestMeanOpQuantized<uint8_t>(
+ tflite::testing::kInputShape2D, tflite::testing::kInputData2D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape2D, tflite::testing::kAxisData2D,
+ tflite::testing::kOutputShape2D, tflite::testing::kGoldenData2D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanFloat3DKeepDims) {
+ float output_data[tflite::testing::kOutputElements3D];
+
+ TfLiteReducerParams params = {true};
+
+ tflite::testing::TestMeanFloatInput4D(
+ tflite::testing::kInputShape3D, tflite::testing::kInputData3D,
+ tflite::testing::kAxisShape3D, tflite::testing::kAxisData3D,
+ tflite::testing::kOutputShape3D, tflite::testing::kGoldenData3D,
+ output_data, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanInt83DKeepDims) {
+ int8_t expected_output_data_quant[tflite::testing::kOutputElements3D];
+ int8_t output_data_quant[tflite::testing::kOutputElements3D];
+ int8_t input_data_quant[tflite::testing::kInputElements3D];
+
+ float input_scale = 0.5f;
+ int input_zero_point = 0;
+ float output_scale = 0.5f;
+ int output_zero_point = 0;
+
+ TfLiteReducerParams params = {
+ true // keep_dims
+ };
+
+ tflite::testing::TestMeanOpQuantized<int8_t>(
+ tflite::testing::kInputShape3D, tflite::testing::kInputData3D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape3D, tflite::testing::kAxisData3D,
+ tflite::testing::kOutputShape3D, tflite::testing::kGoldenData3D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanUInt83DKeepDims) {
+ uint8_t expected_output_data_quant[tflite::testing::kOutputElements3D];
+ uint8_t output_data_quant[tflite::testing::kOutputElements3D];
+ uint8_t input_data_quant[tflite::testing::kInputElements3D];
+
+ float input_scale = 0.5f;
+ int input_zero_point = 138;
+ float output_scale = 0.5f;
+ int output_zero_point = 138;
+
+ TfLiteReducerParams params = {
+ true // keep_dims
+ };
+
+ tflite::testing::TestMeanOpQuantized<uint8_t>(
+ tflite::testing::kInputShape3D, tflite::testing::kInputData3D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape3D, tflite::testing::kAxisData3D,
+ tflite::testing::kOutputShape3D, tflite::testing::kGoldenData3D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanFloat4DKeepDims) {
+ float output_data[tflite::testing::kOutputElements4D];
+
+ TfLiteReducerParams params = {
+ true // keep_dims
+ };
+
+ tflite::testing::TestMeanFloatInput4D(
+ tflite::testing::kInputShape4D, tflite::testing::kInputData4D,
+ tflite::testing::kAxisShape4D, tflite::testing::kAxisData4D,
+ tflite::testing::kOutputShape4D, tflite::testing::kGoldenData4D,
+ output_data, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanInt84DKeepDims) {
+ int8_t expected_output_data_quant[tflite::testing::kOutputElements4D];
+ int8_t output_data_quant[tflite::testing::kOutputElements4D];
+ int8_t input_data_quant[tflite::testing::kInputElements4D];
+
+ float input_scale = 0.5f;
+ int input_zero_point = 0;
+ float output_scale = 0.5f;
+ int output_zero_point = 0;
+
+ TfLiteReducerParams params = {
+ true // keep_dims
+ };
+
+ tflite::testing::TestMeanOpQuantized<int8_t>(
+ tflite::testing::kInputShape4D, tflite::testing::kInputData4D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape4D, tflite::testing::kAxisData4D,
+ tflite::testing::kOutputShape4D, tflite::testing::kGoldenData4D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanUInt84DKeepDims) {
+ uint8_t expected_output_data_quant[tflite::testing::kOutputElements4D];
+ uint8_t output_data_quant[tflite::testing::kOutputElements4D];
+ uint8_t input_data_quant[tflite::testing::kInputElements4D];
+
+ float input_scale = 0.5f;
+ int input_zero_point = 128;
+ float output_scale = 0.5f;
+ int output_zero_point = 128;
+
+ TfLiteReducerParams params = {
+ true // keep_dims
+ };
+
+ tflite::testing::TestMeanOpQuantized<uint8_t>(
+ tflite::testing::kInputShape4D, tflite::testing::kInputData4D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape4D, tflite::testing::kAxisData4D,
+ tflite::testing::kOutputShape4D, tflite::testing::kGoldenData4D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanFloat4DWithoutKeepDims) {
+ const int kOutputShape4D[] = {2, 2, 2};
+ float output_data[tflite::testing::kOutputElements4D];
+ TfLiteReducerParams params = {
+ false // keep_dims
+ };
+
+ tflite::testing::TestMeanFloatInput4D(
+ tflite::testing::kInputShape4D, tflite::testing::kInputData4D,
+ tflite::testing::kAxisShape4D, tflite::testing::kAxisData4D,
+ kOutputShape4D, tflite::testing::kGoldenData4D, output_data, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanInt84DWithoutKeepDims) {
+ int8_t expected_output_data_quant[tflite::testing::kOutputElements4D];
+ int8_t output_data_quant[tflite::testing::kOutputElements4D];
+ int8_t input_data_quant[tflite::testing::kInputElements4D];
+
+ const int kOutputShape4D[] = {2, 2, 2};
+ TfLiteReducerParams params = {
+ false // keep_dims
+ };
+ float input_scale = 0.5f;
+ int input_zero_point = 0;
+ float output_scale = 0.5f;
+ int output_zero_point = 0;
+
+ tflite::testing::TestMeanOpQuantized<int8_t>(
+ tflite::testing::kInputShape4D, tflite::testing::kInputData4D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape4D, tflite::testing::kAxisData4D,
+ kOutputShape4D, tflite::testing::kGoldenData4D, output_data_quant,
+ expected_output_data_quant, output_scale, output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanUInt84DWithoutKeepDims) {
+ uint8_t expected_output_data_quant[tflite::testing::kOutputElements4D];
+ uint8_t output_data_quant[tflite::testing::kOutputElements4D];
+ uint8_t input_data_quant[tflite::testing::kInputElements4D];
+
+ const int kOutputShape4D[] = {2, 2, 2};
+ TfLiteReducerParams params = {
+ false // keep_dims
+ };
+ float input_scale = 0.5f;
+ int input_zero_point = 128;
+ float output_scale = 0.5f;
+ int output_zero_point = 128;
+
+ tflite::testing::TestMeanOpQuantized<uint8_t>(
+ tflite::testing::kInputShape4D, tflite::testing::kInputData4D,
+ input_data_quant, input_scale, input_zero_point,
+ tflite::testing::kAxisShape4D, tflite::testing::kAxisData4D,
+ kOutputShape4D, tflite::testing::kGoldenData4D, output_data_quant,
+ expected_output_data_quant, output_scale, output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanFloat4DWithoutKeepDimsWithPrecision) {
+ const int kInputShape4D[] = {4, 2, 2, 3, 1};
+ const float kInputData4D[] = {1.0, 24.0, 13.0, 3.0, 9.0, 17.0,
+ 11.0, 36.0, 14.0, 19.0, 17.0, 22.0};
+ const int kOutputElements4D = 2;
+ const int kOutputShape4D[] = {2, 2, 1};
+ const float kGoldenData4D[] = {11.166667, 19.833334};
+ float output_data[kOutputElements4D];
+ TfLiteReducerParams params = {
+ false // keep_dims
+ };
+
+ tflite::testing::TestMeanFloatInput4D(
+ kInputShape4D, kInputData4D, tflite::testing::kAxisShape4D,
+ tflite::testing::kAxisData4D, kOutputShape4D, kGoldenData4D, output_data,
+ ¶ms);
+}
+
+TF_LITE_MICRO_TEST(FloatMaxOpTestNotKeepDims) {
+ const int input_shape[] = {3, 4, 3, 2};
+ const float input_data[] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0,
+ 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0,
+ 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0};
+ const int axis_shape[] = {1, 4};
+ const int32_t axis_data[] = {1, 0, -3, -3};
+ const int output_shape[] = {1, 2};
+ const float expected_output_data[] = {23, 24};
+ float output_data[2];
+
+ TfLiteReducerParams params = {false};
+
+ tflite::testing::TestReduceOpFloat(
+ input_shape, input_data, axis_shape, axis_data, output_shape, output_data,
+ expected_output_data, tflite::ops::micro::Register_REDUCE_MAX(), ¶ms);
+}
+
+TF_LITE_MICRO_TEST(FloatMaxOpTestKeepDims) {
+ const int input_shape[] = {3, 4, 3, 2};
+ const float input_data[] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0,
+ 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0,
+ 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0};
+ const int axis_shape[] = {1, 2};
+ const int32_t axis_data[] = {0, 2};
+ const int output_shape[] = {1, 3};
+ const float expected_output_data[] = {20, 22, 24};
+ float output_data[3];
+
+ TfLiteReducerParams params = {true};
+
+ tflite::testing::TestReduceOpFloat(
+ input_shape, input_data, axis_shape, axis_data, output_shape, output_data,
+ expected_output_data, tflite::ops::micro::Register_REDUCE_MAX(), ¶ms);
+}
+
+TF_LITE_MICRO_TEST(Int8MaxOpTestKeepDims) {
+ const int input_shape[] = {3, 1, 3, 2};
+ const float input_data[] = {0.4, 0.2, 0.3, 0.4, 0.5, 0.6};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {1, 1};
+ const int output_shape[] = {1, 2};
+ const float expected_output_data[] = {0.5, 0.6};
+
+ float input_scale = 2 / 255.0;
+ int input_zp = 0;
+
+ TfLiteReducerParams params = {true};
+
+ int8_t input_data_quant[6];
+ int8_t output_data_quant[2];
+ int8_t expected_output_data_quant[2];
+
+ tflite::testing::TestReduceOpQuantized<int8_t>(
+ input_shape, input_data, input_data_quant, input_scale, input_zp,
+ axis_shape, axis_data, output_shape, expected_output_data,
+ output_data_quant, expected_output_data_quant, input_scale, input_zp,
+ tflite::ops::micro::Register_REDUCE_MAX(), ¶ms);
+}
+
+TF_LITE_MICRO_TEST(Int8MaxOpTestWithoutKeepDims) {
+ const int input_shape[] = {3, 1, 3, 2};
+ const float input_data[] = {0.4, 0.2, 0.3, 0.4, 0.5, 0.6};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {1, 1};
+ const int output_shape[] = {1, 2};
+ const float expected_output_data[] = {0.5, 0.6};
+
+ float input_scale = 2 / 255.0;
+ int input_zp = 0;
+ float output_scale = 2 / 255.0;
+ int output_zp = 0;
+
+ TfLiteReducerParams params = {false};
+
+ int8_t input_data_quant[6];
+ int8_t output_data_quant[2];
+ int8_t expected_output_data_quant[2];
+
+ tflite::testing::TestReduceOpQuantized<int8_t>(
+ input_shape, input_data, input_data_quant, input_scale, input_zp,
+ axis_shape, axis_data, output_shape, expected_output_data,
+ output_data_quant, expected_output_data_quant, output_scale, output_zp,
+ tflite::ops::micro::Register_REDUCE_MAX(), ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanInt84DWithoutKeepDimsWithPrecision) {
+ const int kInputShape4D[] = {4, 2, 2, 3, 1};
+ const float kInputData4D[] = {1.0, 24.0, 13.0, 3.0, 9.0, 17.0,
+ 11.0, 36.0, 14.0, 19.0, 17.0, 22.0};
+ const int kOutputShape4D[] = {2, 2, 1};
+ const float kGoldenData4D[] = {11.166667, 19.833334};
+ TfLiteReducerParams params = {
+ false // keep_dims
+ };
+ float input_scale = 0.5f;
+ int input_zero_point = 0;
+ float output_scale = 0.5f;
+ int output_zero_point = 0;
+
+ int8_t output_data_quant[2];
+ int8_t expected_output_data_quant[2];
+ int8_t input_data_quant[12];
+
+ tflite::testing::TestMeanOpQuantized<int8_t>(
+ kInputShape4D, kInputData4D, input_data_quant, input_scale,
+ input_zero_point, tflite::testing::kAxisShape4D,
+ tflite::testing::kAxisData4D, kOutputShape4D, kGoldenData4D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+
+TF_LITE_MICRO_TEST(MeanUInt84DWithoutKeepDimsWithPrecision) {
+ const int kInputShape4D[] = {4, 2, 2, 3, 1};
+ const float kInputData4D[] = {1.0, 24.0, 13.0, 3.0, 9.0, 17.0,
+ 11.0, 36.0, 14.0, 19.0, 17.0, 22.0};
+ const int kOutputShape4D[] = {2, 2, 1};
+ const float kGoldenData4D[] = {11.166667, 19.833334};
+ TfLiteReducerParams params = {
+ false // keep_dims
+ };
+
+ float input_scale = 0.5f;
+ int input_zero_point = 128;
+ float output_scale = 0.5f;
+ int output_zero_point = 128;
+
+ uint8_t output_data_quant[2];
+ uint8_t expected_output_data_quant[2];
+ uint8_t input_data_quant[12];
+
+ tflite::testing::TestMeanOpQuantized<uint8_t>(
+ kInputShape4D, kInputData4D, input_data_quant, input_scale,
+ input_zero_point, tflite::testing::kAxisShape4D,
+ tflite::testing::kAxisData4D, kOutputShape4D, kGoldenData4D,
+ output_data_quant, expected_output_data_quant, output_scale,
+ output_zero_point, ¶ms);
+}
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/reshape.cc b/tensorflow/lite/micro/kernels/reshape.cc
new file mode 100644
index 0000000..8e47e2a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/reshape.cc
@@ -0,0 +1,118 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace reshape {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus ReshapeOutput(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ // Tensorflow's Reshape allows one of the shape components to have the
+ // special -1 value, meaning it will be calculated automatically based on the
+ // input. Here we calculate what that dimension should be so that the number
+ // of output elements in the same as the number of input elements.
+ int num_input_elements = NumElements(input);
+ TfLiteIntArray* output_shape = output->dims;
+
+ if (NumInputs(node) == 1 && // Legacy scalar supported with params.
+ output_shape->size == 1 && output_shape->data[0] == 0) {
+ // Legacy tflite models use a shape parameter of [0] to indicate scalars,
+ // so adjust accordingly. TODO(b/111614235): Allow zero-sized buffers during
+ // toco conversion.
+ output_shape->size = 0;
+ }
+
+ int num_output_elements = 1;
+ int stretch_dim = -1;
+ for (int i = 0; i < output_shape->size; ++i) {
+ int value = output_shape->data[i];
+ if (value == -1) {
+ TF_LITE_ENSURE_EQ(context, stretch_dim, -1);
+ stretch_dim = i;
+ } else {
+ num_output_elements *= value;
+ }
+ }
+ if (stretch_dim != -1) {
+ output_shape->data[stretch_dim] = num_input_elements / num_output_elements;
+ num_output_elements *= output_shape->data[stretch_dim];
+ }
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_EQ(context, num_input_elements, num_output_elements);
+ return kTfLiteOk;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE(context, NumInputs(node) == 1 || NumInputs(node) == 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, ReshapeOutput(context, node), kTfLiteOk);
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ // TODO(b/162522304): storing input bytes in OpData increases some models
+ // significantly, possibly due to alignment issues.
+ size_t input_bytes;
+ TF_LITE_ENSURE_STATUS(TfLiteTypeSizeOf(input->type, &input_bytes));
+ input_bytes *= ElementCount(*input->dims);
+
+ // Do nothing for in-place reshape.
+ if (input->data.raw != output->data.raw) {
+ // Otherwise perform reshape with copy.
+ for (size_t i = 0; i < input_bytes; ++i) {
+ output->data.raw[i] = input->data.raw[i];
+ }
+ }
+ return kTfLiteOk;
+}
+
+} // namespace reshape
+
+TfLiteRegistration Register_RESHAPE() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/reshape::Prepare,
+ /*invoke=*/reshape::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/reshape_test.cc b/tensorflow/lite/micro/kernels/reshape_test.cc
new file mode 100644
index 0000000..2b7d13c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/reshape_test.cc
@@ -0,0 +1,362 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <stdint.h>
+
+#include <initializer_list>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// TODO(b/162356196): Cleanup this unit test more.
+
+template <typename T>
+void ValidateReshapeGoldens(
+ TfLiteTensor* tensors, int tensors_size, TfLiteIntArray* inputs_array,
+ TfLiteIntArray* outputs_array, const T* expected_output,
+ const size_t expected_output_len, const int* expected_dims,
+ const size_t expected_dims_len, bool expect_failure) {
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_RESHAPE();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ if (expect_failure) {
+ TF_LITE_MICRO_EXPECT_NE(kTfLiteOk, runner.InitAndPrepare());
+ return;
+ }
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ TfLiteTensor* output_tensor = &tensors[outputs_array->data[0]];
+ const T* output_data = GetTensorData<T>(output_tensor);
+ for (size_t i = 0; i < expected_output_len; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output[i], output_data[i], 1e-5f);
+ }
+ TF_LITE_MICRO_EXPECT_EQ(expected_dims_len,
+ static_cast<size_t>(output_tensor->dims->size));
+ for (size_t i = 0; i < expected_dims_len; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_dims[i], output_tensor->dims->data[i]);
+ }
+}
+template <typename T>
+void TestReshapeWithShape(TfLiteTensor* input_tensor,
+ TfLiteTensor* shape_tensor,
+ TfLiteTensor* output_tensor, const T* expected_output,
+ const size_t expected_output_len,
+ const int* expected_dims,
+ const size_t expected_dims_len, bool expect_failure) {
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size];
+ tensors[0] = *input_tensor;
+ tensors[1] = *shape_tensor;
+ tensors[2] = *output_tensor;
+
+ int inputs_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_data);
+ int outputs_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_data);
+
+ ValidateReshapeGoldens(tensors, tensors_size, inputs_array, outputs_array,
+ expected_output, expected_output_len, expected_dims,
+ expected_dims_len, expect_failure);
+}
+
+// If expected output is empty, the test is expected to fail.
+template <typename T>
+void TestReshapeWithoutShape(TfLiteTensor* input_tensor,
+ TfLiteTensor* output_tensor,
+ const T* expected_output,
+ const size_t expected_output_len,
+ const int* expected_dims,
+ const size_t expected_dims_len,
+ bool expect_failure) {
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size];
+ tensors[0] = *input_tensor;
+ tensors[1] = *output_tensor;
+
+ int inputs_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_data);
+ int outputs_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_data);
+
+ ValidateReshapeGoldens(tensors, tensors_size, inputs_array, outputs_array,
+ expected_output, expected_output_len, expected_dims,
+ expected_dims_len, expect_failure);
+}
+
+void TestReshape(const int* input_dims_data, const float* input_data,
+ const int* shape_dims_data, const int32_t* shape_data,
+ int* output_dims_data, float* output_data,
+ const float* expected_output, const size_t expected_output_len,
+ const int* expected_dims, const size_t expected_dims_len,
+ bool expect_failure = false) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* shape_dims = IntArrayFromInts(shape_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ TfLiteTensor input_tensor = CreateTensor(input_data, input_dims);
+ TfLiteTensor shape_tensor = CreateTensor(shape_data, shape_dims);
+ TfLiteTensor output_tensor = CreateTensor(output_data, output_dims);
+
+ TestReshapeWithShape(&input_tensor, &shape_tensor, &output_tensor,
+ expected_output, expected_output_len, expected_dims,
+ expected_dims_len, expect_failure);
+}
+
+template <typename T>
+void TestReshapeQuantized(const int* input_dims_data, const T* input_data,
+ const int* shape_dims_data, const int32_t* shape_data,
+ int* output_dims_data, T* output_data,
+ const T* expected_output,
+ const size_t expected_output_len,
+ const int* expected_dims,
+ const size_t expected_dims_len,
+ bool expect_failure = false) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* shape_dims = IntArrayFromInts(shape_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ TfLiteTensor input_tensor = CreateQuantizedTensor(
+ input_data, input_dims, /*scale=*/1.f, /*zero_point=*/0);
+ TfLiteTensor shape_tensor = CreateTensor(shape_data, shape_dims);
+ TfLiteTensor output_tensor = CreateQuantizedTensor(
+ output_data, output_dims, /*scale=*/1.f, /*zero_point=*/0);
+
+ TestReshapeWithShape(&input_tensor, &shape_tensor, &output_tensor,
+ expected_output, expected_output_len, expected_dims,
+ expected_dims_len, expect_failure);
+}
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(ReshapeWithMismatchedDimensionsShouldFail) {
+ float output_data[32];
+ const int input_dims[] = {4, 1, 2, 4, 1};
+ const float input_data[] = {3};
+ const int shape_dims[] = {1, 2};
+ const int32_t shape_int32[] = {2, 1};
+ int output_dims[] = {2, 2, 1};
+ const int golden_output_len = 0;
+ const float golden_output[] = {};
+ const int golden_dims_len = 0;
+ const int golden_dims[] = {};
+ tflite::testing::TestReshape(
+ input_dims, input_data, shape_dims, shape_int32, output_dims, output_data,
+ golden_output, golden_output_len, golden_dims, golden_dims_len, true);
+}
+
+TF_LITE_MICRO_TEST(ReshapeWithTooManyDimensionsShouldFail) {
+ float output_data[32];
+ const int input_dims[] = {9, 1, 1, 2, 1, 1, 1, 1, 1, 1};
+ const float input[] = {3, 2};
+ const int shape_dims[] = {1, 9};
+ const int32_t shape_int32[] = {1, 1, 1, 1, 1, 1, 1, 1, 2};
+ int output_dims[] = {9, 1, 1, 1, 1, 1, 1, 1, 1, 2};
+ const int golden_output_len = 2;
+ const float golden_output[] = {3, 2};
+ const int golden_dims_len = 9;
+ const int golden_dims[] = {1, 1, 1, 1, 1, 1, 1, 1, 2};
+ tflite::testing::TestReshape(
+ input_dims, input, shape_dims, shape_int32, output_dims, output_data,
+ golden_output, golden_output_len, golden_dims, golden_dims_len, false);
+}
+
+TF_LITE_MICRO_TEST(ReshapeWithTooManySpecialDimensionsShouldFail) {
+ float output_data[32];
+ const int input_dims[] = {4, 1, 2, 4, 11};
+ const float input[] = {3};
+ const int shape_dims[] = {1, 4};
+ const int32_t shape_int32[] = {-1, -1, 2, 4};
+ int output_dims[] = {4, -1, -1, 2, 4};
+ const int golden_output_len = 2;
+ const float golden_output[] = {};
+ const int golden_dims_len = 9;
+ const int golden_dims[] = {};
+ tflite::testing::TestReshape(
+ input_dims, input, shape_dims, shape_int32, output_dims, output_data,
+ golden_output, golden_output_len, golden_dims, golden_dims_len, true);
+}
+
+// Create the model with a 2x2 shape. Processing still works because the new
+// shape ends up being hardcoded as a flat vector.
+TF_LITE_MICRO_TEST(ReshapeWithInvalidShapeShouldFail) {
+ int input_dims_data[] = {3, 1, 2, 2};
+ TfLiteIntArray* input_dims =
+ tflite::testing::IntArrayFromInts(input_dims_data);
+ const float input_data[] = {3.0f};
+ auto input_tensor = tflite::testing::CreateTensor(input_data, input_dims);
+ float output_data[4];
+ int output_dims_data[6] = {2, 2, 1, 2, 2, 1};
+ TfLiteIntArray* output_dims =
+ tflite::testing::IntArrayFromInts(output_dims_data);
+ auto output_tensor = tflite::testing::CreateTensor(output_data, output_dims);
+ const int expected_output[] = {};
+ const int expected_output_len = 0;
+ const int expected_dims[] = {};
+ const int expected_dims_len = 0;
+ tflite::testing::TestReshapeWithoutShape(
+ &input_tensor, &output_tensor, expected_output, expected_output_len,
+ expected_dims, expected_dims_len, true);
+}
+
+TF_LITE_MICRO_TEST(ReshapeWithRegularShapesShouldSucceed) {
+ float output_data_float[32];
+ int8_t output_data_int8[32];
+ uint8_t output_data_uint8[32];
+ const int input_dims[] = {4, 1, 2, 4, 1};
+ const float input_float[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int8_t input_int8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const uint8_t input_uint8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int shape_dims[] = {1, 3};
+ const int32_t shape_int32[] = {2, 2, 2};
+ int output_dims[] = {3, 2, 2, 2};
+ const int golden_output_len = 8;
+ const float golden_output_float[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int8_t golden_output_int8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const uint8_t golden_output_uint8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int golden_dims_len = 3;
+ const int golden_dims[] = {2, 2, 2};
+ tflite::testing::TestReshape(input_dims, input_float, shape_dims, shape_int32,
+ output_dims, output_data_float,
+ golden_output_float, golden_output_len,
+ golden_dims, golden_dims_len, false);
+ tflite::testing::TestReshapeQuantized(
+ input_dims, input_int8, shape_dims, shape_int32, output_dims,
+ output_data_int8, golden_output_int8, golden_output_len, golden_dims,
+ golden_dims_len, false);
+ tflite::testing::TestReshapeQuantized(
+ input_dims, input_uint8, shape_dims, shape_int32, output_dims,
+ output_data_uint8, golden_output_uint8, golden_output_len, golden_dims,
+ golden_dims_len, false);
+}
+
+// Stretch is not supported with TF Micro
+TF_LITE_MICRO_TEST(ReshapeWithStretchDimensionShouldSucceed) {
+ float output_data_float[32];
+ int8_t output_data_int8[32];
+ uint8_t output_data_uint8[32];
+ const int input_dims[] = {4, 1, 2, 4, 1};
+ const float input_float[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int8_t input_int8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const uint8_t input_uint8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int shape_dims[] = {1, 3};
+ const int32_t shape_int32[] = {2, 1, -1};
+ int output_dims[] = {3, 2, 1, -1};
+ const int golden_output_len = 8;
+ const float golden_output_float[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int8_t golden_output_int8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const uint8_t golden_output_uint8[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int golden_dims_len = 3;
+ const int golden_dims[] = {2, 1, 4};
+ tflite::testing::TestReshape(input_dims, input_float, shape_dims, shape_int32,
+ output_dims, output_data_float,
+ golden_output_float, golden_output_len,
+ golden_dims, golden_dims_len, false);
+ tflite::testing::TestReshapeQuantized(
+ input_dims, input_int8, shape_dims, shape_int32, output_dims,
+ output_data_int8, golden_output_int8, golden_output_len, golden_dims,
+ golden_dims_len, false);
+ tflite::testing::TestReshapeQuantized(
+ input_dims, input_uint8, shape_dims, shape_int32, output_dims,
+ output_data_uint8, golden_output_uint8, golden_output_len, golden_dims,
+ golden_dims_len, false);
+}
+
+// Empty shape indicates scalar output.
+TF_LITE_MICRO_TEST(ReshapeWithScalarOutputShouldSucceed) {
+ float output_data_float[4];
+ int8_t output_data_int8[4];
+ uint8_t output_data_uint8[4];
+ const int input_dims[] = {1, 1};
+ const float input_float[] = {3};
+ const int8_t input_int8[] = {3};
+ const uint8_t input_uint8[] = {3};
+ const int shape_dims[] = {0};
+ const int32_t shape_int32[] = {};
+ int output_dims[] = {0};
+ const int golden_output_len = 1;
+ const float golden_output_float[] = {3};
+ const int8_t golden_output_int8[] = {3};
+ const uint8_t golden_output_uint8[] = {3};
+ const int golden_dims_len = 0;
+ const int golden_dims[] = {};
+ tflite::testing::TestReshape(input_dims, input_float, shape_dims, shape_int32,
+ output_dims, output_data_float,
+ golden_output_float, golden_output_len,
+ golden_dims, golden_dims_len, false);
+ tflite::testing::TestReshapeQuantized(
+ input_dims, input_int8, shape_dims, shape_int32, output_dims,
+ output_data_int8, golden_output_int8, golden_output_len, golden_dims,
+ golden_dims_len, false);
+ tflite::testing::TestReshapeQuantized(
+ input_dims, input_uint8, shape_dims, shape_int32, output_dims,
+ output_data_uint8, golden_output_uint8, golden_output_len, golden_dims,
+ golden_dims_len, false);
+}
+
+// Some old models specify '[0]' as the new shape, indicating that both input
+// and output are scalars.
+TF_LITE_MICRO_TEST(ReshapeWithLegacyScalarOutputShouldSucceed) {
+ using tflite::testing::CreateTensor;
+ using tflite::testing::IntArrayFromInts;
+
+ int input_dims_data[] = {1, 1};
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ const float input_data[] = {3.0f};
+ auto input_tensor = CreateTensor(input_data, input_dims);
+
+ float output_data[1];
+ int output_dims_data[2] = {1, 0};
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ auto output_tensor = CreateTensor(output_data, output_dims);
+
+ int shape_dims_data[] = {1, 0};
+ TfLiteIntArray* shape_dims = IntArrayFromInts(shape_dims_data);
+
+ const int32_t shape_data[] = {0};
+ auto shape_tensor = tflite::testing::CreateTensor(shape_data, shape_dims);
+ const float expected_output_with_shape[] = {};
+ const int expected_output_with_shape_len = 0;
+ const float expected_output_no_shape[] = {3};
+ const int expected_output_no_shape_len = 1;
+ const int expected_dims[] = {};
+ const int expected_dims_len = 0;
+ tflite::testing::TestReshapeWithShape<float>(
+ &input_tensor, &shape_tensor, &output_tensor, expected_output_with_shape,
+ expected_output_with_shape_len, expected_dims, expected_dims_len, true);
+
+ tflite::testing::TestReshapeWithoutShape<float>(
+ &input_tensor, &output_tensor, expected_output_no_shape,
+ expected_output_no_shape_len, expected_dims, expected_dims_len, false);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/resize_nearest_neighbor.cc b/tensorflow/lite/micro/kernels/resize_nearest_neighbor.cc
new file mode 100644
index 0000000..971de83
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/resize_nearest_neighbor.cc
@@ -0,0 +1,121 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/resize_nearest_neighbor.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace resize_nearest_neighbor {
+
+constexpr int kInputTensor = 0;
+constexpr int kSizeTensor = 1;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* size = GetInput(context, node, kSizeTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+
+ // Our current implementations rely on the input being 4D,
+ // and the size being 1D tensor with exactly 2 elements.
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), 4);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(size), 1);
+ TF_LITE_ENSURE_EQ(context, size->type, kTfLiteInt32);
+ TF_LITE_ENSURE_EQ(context, size->dims->data[0], 2);
+
+ output->type = input->type;
+
+ if (!IsConstantTensor(size)) {
+ TF_LITE_KERNEL_LOG(context, "Dynamic tensors are unsupported in tfmicro.");
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params =
+ reinterpret_cast<TfLiteResizeNearestNeighborParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* size =
+ tflite::micro::GetEvalInput(context, node, kSizeTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ tflite::ResizeNearestNeighborParams op_params;
+ op_params.align_corners = params->align_corners;
+ op_params.half_pixel_centers = false;
+
+ if (output->type == kTfLiteFloat32) {
+ reference_ops::ResizeNearestNeighbor(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int32_t>(input),
+ tflite::micro::GetTensorShape(size),
+ tflite::micro::GetTensorData<int32_t>(size),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int32_t>(output));
+ } else if (output->type == kTfLiteUInt8) {
+ reference_ops::ResizeNearestNeighbor(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(size),
+ tflite::micro::GetTensorData<int32_t>(size),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else if (output->type == kTfLiteInt8) {
+ reference_ops::ResizeNearestNeighbor(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(size),
+ tflite::micro::GetTensorData<int32_t>(size),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ } else {
+ TF_LITE_KERNEL_LOG(context,
+ "Output type is %d, requires float, uint8_t or int8_t.",
+ output->type);
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+} // namespace resize_nearest_neighbor
+
+TfLiteRegistration Register_RESIZE_NEAREST_NEIGHBOR() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/resize_nearest_neighbor::Prepare,
+ /*invoke=*/resize_nearest_neighbor::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/resize_nearest_neighbor_test.cc b/tensorflow/lite/micro/kernels/resize_nearest_neighbor_test.cc
new file mode 100644
index 0000000..0f51172
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/resize_nearest_neighbor_test.cc
@@ -0,0 +1,355 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+using uint8_t = std::uint8_t;
+using int32_t = std::int32_t;
+
+TfLiteTensor TestCreateTensor(const float* data, TfLiteIntArray* dims) {
+ return CreateTensor(data, dims);
+}
+
+TfLiteTensor TestCreateTensor(const uint8_t* data, TfLiteIntArray* dims) {
+ return CreateQuantizedTensor(data, dims, 0, 255);
+}
+
+TfLiteTensor TestCreateTensor(const int8_t* data, TfLiteIntArray* dims) {
+ return CreateQuantizedTensor(data, dims, -128, 127);
+}
+
+// Input data expects a 4-D tensor of [batch, height, width, channels]
+// Output data should match input datas batch and channels
+// Expected sizes should be a 1-D tensor with 2 elements: new_height & new_width
+template <typename T>
+void TestResizeNearestNeighbor(const int* input_dims_data, const T* input_data,
+ const int32_t* expected_size_data,
+ const T* expected_output_data,
+ const int* output_dims_data, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+
+ int expected_size_dims_data[] = {1, 2};
+ TfLiteIntArray* expected_size_dims =
+ IntArrayFromInts(expected_size_dims_data);
+
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int tensors_size = 3;
+ TfLiteTensor tensors[tensors_size] = {
+ TestCreateTensor(input_data, input_dims),
+ CreateTensor(expected_size_data, expected_size_dims),
+ TestCreateTensor(output_data, output_dims),
+ };
+
+ tensors[1].allocation_type = kTfLiteMmapRo;
+
+ TfLiteResizeNearestNeighborParams builtin_data = {false, false};
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_RESIZE_NEAREST_NEIGHBOR();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, &builtin_data);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ // compare results
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(HorizontalResize) {
+ const int input_dims[] = {4, 1, 1, 2, 1};
+ const float input_data[] = {3, 6};
+ const int32_t expected_size_data[] = {1, 3};
+ const float expected_output_data[] = {3, 3, 6};
+ const int output_dims[] = {4, 1, 1, 3, 1};
+ float output_data[3];
+
+ tflite::testing::TestResizeNearestNeighbor<float>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(HorizontalResizeUInt8) {
+ const int input_dims[] = {4, 1, 1, 2, 1};
+ const uint8_t input_data[] = {3, 6};
+ const int32_t expected_size_data[] = {1, 3};
+ const uint8_t expected_output_data[] = {3, 3, 6};
+ const int output_dims[] = {4, 1, 1, 3, 1};
+ uint8_t output_data[3];
+
+ tflite::testing::TestResizeNearestNeighbor<uint8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(HorizontalResizeInt8) {
+ const int input_dims[] = {4, 1, 1, 2, 1};
+ const int8_t input_data[] = {-3, 6};
+ const int32_t expected_size_data[] = {1, 3};
+ const int8_t expected_output_data[] = {-3, -3, 6};
+ const int output_dims[] = {4, 1, 1, 3, 1};
+ int8_t output_data[3];
+
+ tflite::testing::TestResizeNearestNeighbor<int8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(VerticalResize) {
+ const int input_dims[] = {4, 1, 2, 1, 1};
+ const float input_data[] = {3, 9};
+ const int32_t expected_size_data[] = {3, 1};
+ const float expected_output_data[] = {3, 3, 9};
+ const int output_dims[] = {4, 1, 3, 1, 1};
+ float output_data[3];
+
+ tflite::testing::TestResizeNearestNeighbor<float>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(VerticalResizeUInt8) {
+ const int input_dims[] = {4, 1, 2, 1, 1};
+ const uint8_t input_data[] = {3, 9};
+ const int32_t expected_size_data[] = {3, 1};
+ const uint8_t expected_output_data[] = {3, 3, 9};
+ const int output_dims[] = {4, 1, 3, 1, 1};
+ uint8_t output_data[3];
+
+ tflite::testing::TestResizeNearestNeighbor<uint8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(VerticalResizeInt8) {
+ const int input_dims[] = {4, 1, 2, 1, 1};
+ const int8_t input_data[] = {3, -9};
+ const int32_t expected_size_data[] = {3, 1};
+ const int8_t expected_output_data[] = {3, 3, -9};
+ const int output_dims[] = {4, 1, 3, 1, 1};
+ int8_t output_data[3];
+
+ tflite::testing::TestResizeNearestNeighbor<int8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(TwoDimensionalResize) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const float input_data[] = {
+ 3, 6, //
+ 9, 12, //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const float expected_output_data[] = {
+ 3, 3, 6, //
+ 3, 3, 6, //
+ 9, 9, 12 //
+ };
+
+ const int output_dims[] = {4, 1, 3, 3, 1};
+ float output_data[9];
+
+ tflite::testing::TestResizeNearestNeighbor<float>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(TwoDimensionalResizeUInt8) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const uint8_t input_data[] = {
+ 3, 6, //
+ 9, 12 //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const uint8_t expected_output_data[] = {
+ 3, 3, 6, //
+ 3, 3, 6, //
+ 9, 9, 12 //
+ };
+ const int output_dims[] = {4, 1, 3, 3, 1};
+ uint8_t output_data[9];
+
+ tflite::testing::TestResizeNearestNeighbor<uint8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(TwoDimensionalResizeInt8) {
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const int8_t input_data[] = {
+ 3, -6, //
+ 9, 12, //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const int8_t expected_output_data[] = {
+ 3, 3, -6, //
+ 3, 3, -6, //
+ 9, 9, 12, //
+ };
+ const int output_dims[] = {4, 1, 3, 3, 1};
+ int8_t output_data[9];
+
+ tflite::testing::TestResizeNearestNeighbor<int8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(TwoDimensionalResizeWithTwoBatches) {
+ const int input_dims[] = {4, 2, 2, 2, 1};
+ const float input_data[] = {
+ 3, 6, //
+ 9, 12, //
+ 4, 10, //
+ 10, 16 //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const float expected_output_data[] = {
+ 3, 3, 6, //
+ 3, 3, 6, //
+ 9, 9, 12, //
+ 4, 4, 10, //
+ 4, 4, 10, //
+ 10, 10, 16, //
+ };
+ const int output_dims[] = {4, 2, 3, 3, 1};
+ float output_data[18];
+
+ tflite::testing::TestResizeNearestNeighbor<float>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(TwoDimensionalResizeWithTwoBatchesUInt8) {
+ const int input_dims[] = {4, 2, 2, 2, 1};
+ const uint8_t input_data[] = {
+ 3, 6, //
+ 9, 12, //
+ 4, 10, //
+ 10, 16 //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const uint8_t expected_output_data[] = {
+ 3, 3, 6, //
+ 3, 3, 6, //
+ 9, 9, 12, //
+ 4, 4, 10, //
+ 4, 4, 10, //
+ 10, 10, 16, //
+ };
+ const int output_dims[] = {4, 2, 3, 3, 1};
+ uint8_t output_data[18];
+
+ tflite::testing::TestResizeNearestNeighbor<uint8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(TwoDimensionalResizeWithTwoBatchesInt8) {
+ const int input_dims[] = {4, 2, 2, 2, 1};
+ const int8_t input_data[] = {
+ 3, 6, //
+ 9, -12, //
+ -4, 10, //
+ 10, 16 //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const int8_t expected_output_data[] = {
+ 3, 3, 6, //
+ 3, 3, 6, //
+ 9, 9, -12, //
+ -4, -4, 10, //
+ -4, -4, 10, //
+ 10, 10, 16, //
+ };
+ const int output_dims[] = {4, 2, 3, 3, 1};
+ int8_t output_data[18];
+
+ tflite::testing::TestResizeNearestNeighbor<int8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(ThreeDimensionalResize) {
+ const int input_dims[] = {4, 1, 2, 2, 2};
+ const float input_data[] = {
+ 3, 4, 6, 10, //
+ 9, 10, 12, 16, //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const float expected_output_data[] = {
+ 3, 4, 3, 4, 6, 10, //
+ 3, 4, 3, 4, 6, 10, //
+ 9, 10, 9, 10, 12, 16, //
+ };
+ const int output_dims[] = {4, 1, 3, 3, 2};
+ float output_data[18];
+
+ tflite::testing::TestResizeNearestNeighbor<float>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(ThreeDimensionalResizeUInt8) {
+ const int input_dims[] = {4, 1, 2, 2, 2};
+ const uint8_t input_data[] = {
+ 3, 4, 6, 10, //
+ 10, 12, 14, 16, //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const uint8_t expected_output_data[] = {
+ 3, 4, 3, 4, 6, 10, //
+ 3, 4, 3, 4, 6, 10, //
+ 10, 12, 10, 12, 14, 16, //
+ };
+ const int output_dims[] = {4, 1, 3, 3, 2};
+ uint8_t output_data[18];
+
+ tflite::testing::TestResizeNearestNeighbor<uint8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+TF_LITE_MICRO_TEST(ThreeDimensionalResizeInt8) {
+ const int input_dims[] = {4, 1, 2, 2, 2};
+ const int8_t input_data[] = {
+ 3, 4, -6, 10, //
+ 10, 12, -14, 16, //
+ };
+ const int32_t expected_size_data[] = {3, 3};
+ const int8_t expected_output_data[] = {
+ 3, 4, 3, 4, -6, 10, //
+ 3, 4, 3, 4, -6, 10, //
+ 10, 12, 10, 12, -14, 16, //
+ };
+ const int output_dims[] = {4, 1, 3, 3, 2};
+ int8_t output_data[18];
+
+ tflite::testing::TestResizeNearestNeighbor<int8_t>(
+ input_dims, input_data, expected_size_data, expected_output_data,
+ output_dims, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/round.cc b/tensorflow/lite/micro/kernels/round.cc
new file mode 100644
index 0000000..5804016
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/round.cc
@@ -0,0 +1,76 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/round.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace round {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, input->type);
+ TF_LITE_ENSURE_EQ(context, output->bytes, input->bytes);
+ TF_LITE_ENSURE_EQ(context, output->dims->size, input->dims->size);
+ for (int i = 0; i < output->dims->size; ++i) {
+ TF_LITE_ENSURE_EQ(context, output->dims->data[i], input->dims->data[i]);
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ reference_ops::Round(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+
+ return kTfLiteOk;
+}
+} // namespace round
+
+TfLiteRegistration Register_ROUND() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/round::Prepare,
+ /*invoke=*/round::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/round_test.cc b/tensorflow/lite/micro/kernels/round_test.cc
new file mode 100644
index 0000000..534e3f2
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/round_test.cc
@@ -0,0 +1,80 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void TestRound(const int* input_dims_data, const float* input_data,
+ const float* expected_output_data, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(input_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_ROUND();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SingleDim) {
+ const int input_dims[] = {1, 6};
+ const float input_data[] = {8.5, 0.0, 3.5, 4.2, -3.5, -4.5};
+ const float golden[] = {8, 0, 4, 4, -4, -4};
+ float output_data[6];
+ tflite::testing::TestRound(input_dims, input_data, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(MultiDims) {
+ const int input_dims[] = {4, 2, 1, 1, 6};
+ const float input_data[] = {0.0001, 8.0001, 0.9999, 9.9999, 0.5, -0.0001,
+ -8.0001, -0.9999, -9.9999, -0.5, -2.5, 1.5};
+ const float golden[] = {0, 8, 1, 10, 0, 0, -8, -1, -10, -0, -2, 2};
+ float output_data[12];
+ tflite::testing::TestRound(input_dims, input_data, golden, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/shape.cc b/tensorflow/lite/micro/kernels/shape.cc
new file mode 100755
index 0000000..df962f6
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/shape.cc
@@ -0,0 +1,73 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+
+namespace {
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+void ExtractShape(const TfLiteEvalTensor* input, int32_t* output_data) {
+ for (int i = 0; i < input->dims->size; ++i) {
+ output_data[i] = input->dims->data[i];
+ }
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ if (output->type != kTfLiteInt32) {
+ TF_LITE_KERNEL_LOG(context, "Output type %s (%d) not supported.",
+ TfLiteTypeGetName(output->type), output->type);
+ return kTfLiteError;
+ } else {
+ ExtractShape(input, tflite::micro::GetTensorData<int32_t>(output));
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_SHAPE() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/shape_test.cc b/tensorflow/lite/micro/kernels/shape_test.cc
new file mode 100755
index 0000000..b0827ef
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/shape_test.cc
@@ -0,0 +1,138 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+void ValidateShape(TfLiteTensor* tensors, const int tensor_count,
+ int32_t* output_data, const int32_t* expected_output,
+ int output_dims_count) {
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::Register_SHAPE();
+ micro::KernelRunner runner(registration, tensors, tensor_count, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output[i], output_data[i]);
+ }
+}
+
+void TestShape(const int* input_dims_data, const float* input_data,
+ const int* output_dims_data, const int32_t* expected_output_data,
+ int32_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims, true),
+ };
+
+ ValidateShape(tensors, tensors_size, output_data, expected_output_data,
+ output_dims_count);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestShape0) {
+ int input_shape[] = {1, 5};
+ float input_values[] = {1, 3, 1, 3, 5};
+ int output_dims[] = {1, 1}; // this is actually input_shapes shape
+ int32_t expected_output_data[] = {5};
+ int32_t output_data[1];
+
+ tflite::testing::TestShape(input_shape, input_values, output_dims,
+ expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(TestShape1) {
+ int input_shape[] = {2, 4, 3};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int output_dims[] = {2, 1, 1};
+ int32_t expected_output_data[] = {4, 3};
+ int32_t output_data[2];
+
+ tflite::testing::TestShape(input_shape, input_values, output_dims,
+ expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(TestShape2) {
+ int input_shape[] = {2, 12, 1};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int output_dims[] = {2, 1, 1};
+ int32_t expected_output_data[] = {12, 1};
+ int32_t output_data[2];
+
+ tflite::testing::TestShape(input_shape, input_values, output_dims,
+ expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(TestShape3) {
+ int input_shape[] = {2, 2, 6};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int output_dims[] = {2, 1, 1};
+ int32_t expected_output_data[] = {2, 6};
+ int32_t output_data[2];
+
+ tflite::testing::TestShape(input_shape, input_values, output_dims,
+ expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(TestShape4) {
+ int input_shape[] = {2, 2, 2, 3};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int output_dims[] = {3, 1, 1, 1};
+ int32_t expected_output_data[] = {2, 2, 3};
+ int32_t output_data[3];
+
+ tflite::testing::TestShape(input_shape, input_values, output_dims,
+ expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TEST(TestShape5) {
+ int input_shape[] = {1, 1};
+ float input_values[] = {1};
+ int output_dims[] = {1, 1};
+ int32_t expected_output_data[] = {1};
+ int32_t output_data[1];
+
+ tflite::testing::TestShape(input_shape, input_values, output_dims,
+ expected_output_data, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/softmax.cc b/tensorflow/lite/micro/kernels/softmax.cc
new file mode 100644
index 0000000..f6a3001
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/softmax.cc
@@ -0,0 +1,96 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/softmax.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/softmax.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+void SoftmaxQuantized(const TfLiteEvalTensor* input, TfLiteEvalTensor* output,
+ const SoftmaxParams& op_data) {
+ if (input->type == kTfLiteInt8) {
+ if (output->type == kTfLiteInt16) {
+ tflite::reference_ops::Softmax(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ } else {
+ tflite::reference_ops::Softmax(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+ } else {
+ tflite::reference_ops::SoftmaxInt16(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int16_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ }
+}
+
+TfLiteStatus SoftmaxEval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ SoftmaxParams op_data = *static_cast<SoftmaxParams*>(node->user_data);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ tflite::reference_ops::Softmax(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ }
+ case kTfLiteInt8:
+ case kTfLiteInt16: {
+ SoftmaxQuantized(input, output, op_data);
+ return kTfLiteOk;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+}
+} // namespace
+
+TfLiteRegistration Register_SOFTMAX() {
+ return {/*init=*/SoftmaxInit,
+ /*free=*/nullptr,
+ /*prepare=*/SoftmaxPrepare,
+ /*invoke=*/SoftmaxEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/softmax.h b/tensorflow/lite/micro/kernels/softmax.h
new file mode 100644
index 0000000..3c9d0cd
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/softmax.h
@@ -0,0 +1,30 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_SOFTMAX_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_SOFTMAX_H_
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+
+namespace tflite {
+
+void* SoftmaxInit(TfLiteContext* context, const char* buffer, size_t length);
+
+TfLiteStatus SoftmaxPrepare(TfLiteContext* context, TfLiteNode* node);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_SOFTMAX_H_
diff --git a/tensorflow/lite/micro/kernels/softmax_common.cc b/tensorflow/lite/micro/kernels/softmax_common.cc
new file mode 100644
index 0000000..153f946
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/softmax_common.cc
@@ -0,0 +1,140 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/softmax.h"
+
+namespace tflite {
+
+namespace {
+// Softmax parameter data that persists in user_data
+const int kInt16LUTArraySize = 513;
+
+TfLiteStatus CalculateSoftmaxParams(TfLiteContext* context,
+ const TfLiteTensor* input,
+ TfLiteTensor* output,
+ const TfLiteSoftmaxParams* params,
+ SoftmaxParams* op_data) {
+ if (input->type == kTfLiteInt8 || input->type == kTfLiteInt16) {
+ if (input->type == kTfLiteInt16) {
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point, 0);
+ TF_LITE_ENSURE_NEAR(context, output->params.scale, 1.f / 32768,
+ (0.001f * 1.f / 32768));
+ } else { // input->type == kTfLiteInt8
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteInt8);
+ if (output->type == kTfLiteInt16) {
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point, -32768);
+ TF_LITE_ENSURE_NEAR(context, output->params.scale, 1.f / 65536,
+ (0.001f * 1.f / 65536));
+ } else { // output->type == kTfLiteint8
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point, -128);
+ TF_LITE_ENSURE(context, output->params.scale == 1.f / 256);
+ }
+ }
+
+ static const int kScaledDiffIntegerBits = 5;
+
+ // Calculate input_multiplier and input_left_shift
+ if (input->type == kTfLiteInt16) {
+ int input_left_shift;
+ double input_scale_beta_rescale =
+ static_cast<double>(input->params.scale) *
+ static_cast<double>(params->beta) /
+ (10.0 / 65535.0); // scale the input_diff such that [-65535, 0]
+ // correspond to [-10.0, 0.0]
+ QuantizeMultiplier(input_scale_beta_rescale, &op_data->input_multiplier,
+ &input_left_shift);
+ op_data->input_left_shift = input_left_shift;
+ } else {
+ int input_left_shift;
+ tflite::PreprocessSoftmaxScaling(
+ static_cast<double>(params->beta),
+ static_cast<double>(input->params.scale), kScaledDiffIntegerBits,
+ &op_data->input_multiplier, &input_left_shift);
+ op_data->input_left_shift = input_left_shift;
+ op_data->diff_min =
+ -1.0 * tflite::CalculateInputRadius(kScaledDiffIntegerBits,
+ op_data->input_left_shift);
+ }
+ } else {
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, kTfLiteFloat32);
+ op_data->beta = static_cast<double>(params->beta);
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+void* SoftmaxInit(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(SoftmaxParams));
+}
+
+TfLiteStatus SoftmaxPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TF_LITE_ENSURE(context, NumDimensions(input) >= 1);
+ TfLiteTensor* output = GetOutput(context, node, 0);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE(context, node->user_data != nullptr);
+ SoftmaxParams* op_data = static_cast<SoftmaxParams*>(node->user_data);
+ // Only allocate LUTs for KTfLiteInt16 data type
+ if (input->type == kTfLiteInt16) {
+ void* raw_exp_lut = context->AllocatePersistentBuffer(
+ context, sizeof(int16_t) * kInt16LUTArraySize);
+ TF_LITE_ENSURE(context, raw_exp_lut != nullptr);
+ op_data->exp_lut = reinterpret_cast<int16_t*>(raw_exp_lut);
+ void* one_over_one_plus_x_lut = context->AllocatePersistentBuffer(
+ context, sizeof(int16_t) * kInt16LUTArraySize);
+ TF_LITE_ENSURE(context, one_over_one_plus_x_lut != nullptr);
+ op_data->one_over_one_plus_x_lut =
+ reinterpret_cast<int16_t*>(one_over_one_plus_x_lut);
+ }
+
+ if (output->type == kTfLiteInt16) {
+ TF_LITE_ENSURE(context,
+ input->type == kTfLiteInt8 || input->type == kTfLiteInt16);
+ } else {
+ TF_LITE_ENSURE_EQ(context, input->type, output->type);
+ }
+
+ // Populate LUT if required
+ if (input->type == kTfLiteInt16) {
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point, 0);
+ // exp LUT only used on negative values
+ // we consider exp(-10.0) is insignificant to accumulation
+ gen_lut([](float value) { return std::exp(value); }, -10.0f, 0.0f,
+ op_data->exp_lut, kInt16LUTArraySize);
+ gen_lut([](float value) { return 1.0f / (1.0f + value); }, 0.0f, 1.0f,
+ op_data->one_over_one_plus_x_lut, kInt16LUTArraySize);
+ op_data->zero_point = output->params.zero_point;
+ op_data->scale = output->params.scale;
+ }
+
+ auto* params = static_cast<TfLiteSoftmaxParams*>(node->builtin_data);
+ return CalculateSoftmaxParams(context, input, output, params, op_data);
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/softmax_test.cc b/tensorflow/lite/micro/kernels/softmax_test.cc
new file mode 100644
index 0000000..b2eb5a2
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/softmax_test.cc
@@ -0,0 +1,497 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+#if !defined(XTENSA)
+// The Softmax kernel assumes an output in the range [0, 1.0], leading to these
+// quantization parameters.
+const float output_scale_int8 = 1.0f / 256.0f;
+const float output_scale_int16 = 1.0f / 32768.0f;
+const int output_zero_point_int8 = -128;
+const int output_zero_point_int16 = 0;
+
+// Empirical tolerance in quantization space
+const float tolerance_int16 = 7.0;
+
+// 1-dimensional test data.
+const int flat_size_1d = 5;
+const int shape_1d[] = {1, 5};
+const float input_data_1d[] = {1.0, 2.0, 3.0, 4.0, 5.0};
+const float golden_1d[] = {0.011656231, 0.031684921, 0.086128544, 0.234121657,
+ 0.636408647};
+
+#endif
+// 2-dimensional test data.
+const int flat_size_2d = 10;
+const int shape_2d[] = {2, 2, 5};
+const float input_data_2d[] = {1.0, 2.0, 3.0, 4.0, 5.0,
+ -1.0, -2.0, -3.0, -4.0, -5.0};
+const float golden_2d[] = {0.011656231, 0.031684921, 0.086128544, 0.234121657,
+ 0.636408647, 0.636408647, 0.234121657, 0.086128544,
+ 0.031684921, 0.011656231};
+
+#if !defined(XTENSA)
+// 3-dimensional test data.
+const int flat_size_3d = 60;
+const int shape_3d[] = {3, 3, 4, 5};
+const float input_data_3d[] = {
+ // c = 0
+ // h = 0
+ 3.00, 6.00, -5.00, 4.00, -9.00,
+ // h = 1
+ -10.00, -10.00, -8.00, 2.00, 2.00,
+ // h = 2
+ 8.00, -5.00, -8.00, 5.00, -6.00,
+ // h = 3
+ -8.00, 6.00, 1.00, -10.00, -8.00,
+
+ // c = 1
+ // h = 0
+ 7.00, 6.00, -10.00, -4.00, -5.00,
+ // h = 1
+ 2.00, 7.00, 9.00, -9.00, 7.00,
+ // h = 2
+ -4.00, -2.00, 8.00, 2.00, 2.00,
+ // h = 3
+ 3.00, 6.00, 6.00, 2.00, 4.00,
+
+ // c = 2
+ // h = 0
+ 9.00, 7.00, -7.00, 0.00, 4.00,
+ // h = 1
+ -3.00, 8.00, 8.00, -3.00, -4.00,
+ // h = 2
+ -9.00, -9.00, 4.00, -8.00, -1.00,
+ // h = 3
+ -10.00, -2.00, 6.00, -7.00, 0.00};
+
+float golden_3d[] = {
+ // c = 0
+ // h = 0
+ 0.042009463, 0.843782625, 0.000014093, 0.114193561, 0.000000258,
+ // h = 1
+ 0.000003072, 0.000003072, 0.000022699, 0.499985578, 0.499985578,
+ // h = 2
+ 0.952571219, 0.000002153, 0.000000107, 0.047425728, 0.000000792,
+ // h = 3
+ 0.000000826, 0.993305397, 0.006692839, 0.000000112, 0.000000826,
+
+ // c = 1
+ // h = 0
+ 0.731046347, 0.268936922, 0.000000030, 0.000012210, 0.000004492,
+ // h = 1
+ 0.000717124, 0.106430599, 0.786421666, 0.000000012, 0.106430599,
+ // h = 2
+ 0.000006114, 0.000045174, 0.995015917, 0.002466398, 0.002466398,
+ // h = 3
+ 0.022595176, 0.453836234, 0.453836234, 0.008312301, 0.061420055,
+
+ // c = 2
+ // h = 0
+ 0.875505904, 0.118486839, 0.000000099, 0.000108046, 0.005899112,
+ // h = 1
+ 0.000008351, 0.499990113, 0.499990113, 0.000008351, 0.000003072,
+ // h = 2
+ 0.000002245, 0.000002245, 0.993296627, 0.000006103, 0.006692780,
+ // h = 3
+ 0.000000112, 0.000334520, 0.997191323, 0.000002254, 0.002471790};
+
+// 4-dimensional test data.
+const int flat_size_4d = 120;
+const int shape_4d[] = {4, 2, 3, 4, 5};
+const float input_data_4d[] = {
+ // n = 0
+ // c = 0
+ // h = 0
+ 3.00, 6.00, -5.00, 4.00, -9.00,
+ // h = 1
+ -10.00, -10.00, -8.00, 2.00, 2.00,
+ // h = 2
+ 8.00, -5.00, -8.00, 5.00, -6.00,
+ // h = 3
+ -8.00, 6.00, 1.00, -10.00, -8.00,
+
+ // c = 1
+ // h = 0
+ 7.00, 6.00, -10.00, -4.00, -5.00,
+ // h = 1
+ 2.00, 7.00, 9.00, -9.00, 7.00,
+ // h = 2
+ -4.00, -2.00, 8.00, 2.00, 2.00,
+ // h = 3
+ 3.00, 6.00, 6.00, 2.00, 4.00,
+
+ // c = 2
+ // h = 0
+ 9.00, 7.00, -7.00, 0.00, 4.00,
+ // h = 1
+ -3.00, 8.00, 8.00, -3.00, -4.00,
+ // h = 2
+ -9.00, -9.00, 4.00, -8.00, -1.00,
+ // h = 3
+ -10.00, -2.00, 6.00, -7.00, 0.00,
+
+ // n = 1
+ // c = 0
+ // h = 0
+ -9.00, -8.00, 6.00, -1.00, -5.00,
+ // h = 1
+ -10.00, -5.00, -10.00, 7.00, -2.00,
+ // h = 2
+ -5.00, -4.00, 1.00, 2.00, 2.00,
+ // h = 3
+ -2.00, -2.00, 1.00, 1.00, -4.00,
+
+ // c = 1
+ // h = 0
+ -8.00, -3.00, 1.00, 1.00, -1.00,
+ // h = 1
+ -2.00, 6.00, -1.00, -5.00, 6.00,
+ // h = 2
+ -7.00, 8.00, 9.00, 0.00, 9.00,
+ // h = 3
+ -9.00, -5.00, -2.00, 0.00, 8.00,
+
+ // c = 2
+ // h = 0
+ 4.00, 2.00, -3.00, 5.00, 8.00,
+ // h = 1
+ -1.00, 1.00, -4.00, -9.00, 7.00,
+ // h = 2
+ 3.00, -8.00, 0.00, 9.00, -4.00,
+ // h = 3
+ 8.00, -1.00, 9.00, -9.00, 1.00};
+
+const float golden_4d[] = {
+ // n = 0
+ // c = 0
+ // h = 0
+ 0.042009463, 0.843782625, 0.000014093, 0.114193561, 0.000000258,
+ // h = 1
+ 0.000003072, 0.000003072, 0.000022699, 0.499985578, 0.499985578,
+ // h = 2
+ 0.952571219, 0.000002153, 0.000000107, 0.047425728, 0.000000792,
+ // h = 3
+ 0.000000826, 0.993305397, 0.006692839, 0.000000112, 0.000000826,
+
+ // c = 1
+ // h = 0
+ 0.731046347, 0.268936922, 0.000000030, 0.000012210, 0.000004492,
+ // h = 1
+ 0.000717124, 0.106430599, 0.786421666, 0.000000012, 0.106430599,
+ // h = 2
+ 0.000006114, 0.000045174, 0.995015917, 0.002466398, 0.002466398,
+ // h = 3
+ 0.022595176, 0.453836234, 0.453836234, 0.008312301, 0.061420055,
+
+ // c = 2
+ // h = 0
+ 0.875505904, 0.118486839, 0.000000099, 0.000108046, 0.005899112,
+ // h = 1
+ 0.000008351, 0.499990113, 0.499990113, 0.000008351, 0.000003072,
+ // h = 2
+ 0.000002245, 0.000002245, 0.993296627, 0.000006103, 0.006692780,
+ // h = 3
+ 0.000000112, 0.000334520, 0.997191323, 0.000002254, 0.002471790,
+
+ // n = 1
+ // c = 0
+ // h = 0
+ 0.000000306, 0.000000831, 0.999071142, 0.000911035, 0.000016686,
+ // h = 1
+ 0.000000041, 0.000006143, 0.000000041, 0.999870380, 0.000123394,
+ // h = 2
+ 0.000384554, 0.001045327, 0.155140254, 0.421714933, 0.421714933,
+ // h = 3
+ 0.023637081, 0.023637081, 0.474763454, 0.474763454, 0.003198931,
+
+ // c = 1
+ // h = 0
+ 0.000057299, 0.008503973, 0.464301197, 0.464301197, 0.062836334,
+ // h = 1
+ 0.000167625, 0.499684188, 0.000455653, 0.000008346, 0.499684188,
+ // h = 2
+ 0.000000048, 0.155354299, 0.422296769, 0.000052116, 0.422296769,
+ // h = 3
+ 0.000000041, 0.000002259, 0.000045383, 0.000335334, 0.999616982,
+
+ // c = 2
+ // h = 0
+ 0.017107856, 0.002315297, 0.000015600, 0.046503973, 0.934057274,
+ // h = 1
+ 0.000334516, 0.002471755, 0.000016655, 0.000000112, 0.997176963,
+ // h = 2
+ 0.002472313, 0.000000041, 0.000123089, 0.997402302, 0.000002254,
+ // h = 3
+ 0.268866557, 0.000033181, 0.730855076, 0.000000011, 0.000245175};
+
+#endif
+template <typename T>
+void ValidateSoftmaxGoldens(TfLiteTensor* tensors, const int tensor_count,
+ T* output_data, const T* expected_output,
+ int output_dims_count, float tolerance) {
+ TfLiteSoftmaxParams builtin_data = {1.0f};
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_SOFTMAX();
+ micro::KernelRunner runner(registration, tensors, tensor_count, inputs_array,
+ outputs_array, &builtin_data);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output[i], output_data[i], tolerance);
+ }
+}
+
+#if !defined(XTENSA)
+void TestSoftmaxFloat(const int* input_dims_data, const float* input_data,
+ const int* output_dims_data,
+ const float* expected_output_data, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateSoftmaxGoldens(tensors, tensors_size, output_data,
+ expected_output_data, output_dims_count, 1e-5);
+}
+#endif
+
+template <typename inputT, typename outputT>
+void TestSoftmaxQuantized(const int* input_dims_data, const float* input_data,
+ inputT* input_quantized, float input_scale,
+ int input_zero_point, const int* output_dims_data,
+ const float* golden, outputT* golden_quantized,
+ float output_scale, int output_zero_point,
+ outputT* output_data, float tolerance = 1.0) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point),
+ };
+
+ Quantize(golden, golden_quantized, output_dims_count, output_scale,
+ output_zero_point);
+
+ ValidateSoftmaxGoldens(tensors, tensors_size, output_data, golden_quantized,
+ output_dims_count, tolerance);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+#if !defined(XTENSA)
+TF_LITE_MICRO_TEST(Softmax1DFloatShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_1d];
+ tflite::testing::TestSoftmaxFloat(
+ tflite::testing ::shape_1d, tflite::testing::input_data_1d,
+ tflite::testing::shape_1d, tflite::testing::golden_1d, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax1DQuantizedInt8ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::flat_size_1d];
+ int8_t golden_quantized[tflite::testing::flat_size_1d];
+ int8_t output_data[tflite::testing::flat_size_1d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_1d, tflite::testing::input_data_1d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_1d,
+ tflite::testing::golden_1d, golden_quantized,
+ tflite::testing::output_scale_int8,
+ tflite::testing::output_zero_point_int8, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax1DQuantizedInt16ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int16_t input_quantized[tflite::testing::flat_size_1d];
+ int16_t golden_quantized[tflite::testing::flat_size_1d];
+ int16_t output_data[tflite::testing::flat_size_1d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_1d, tflite::testing::input_data_1d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_1d,
+ tflite::testing::golden_1d, golden_quantized,
+ tflite::testing::output_scale_int16,
+ tflite::testing::output_zero_point_int16, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax2DFloatShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_2d];
+ tflite::testing::TestSoftmaxFloat(
+ tflite::testing ::shape_2d, tflite::testing::input_data_2d,
+ tflite::testing::shape_2d, tflite::testing::golden_2d, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax2DQuantizedInt8ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::flat_size_2d];
+ int8_t golden_quantized[tflite::testing::flat_size_2d];
+ int8_t output_data[tflite::testing::flat_size_2d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_2d, tflite::testing::input_data_2d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_2d,
+ tflite::testing::golden_2d, golden_quantized,
+ tflite::testing::output_scale_int8,
+ tflite::testing::output_zero_point_int8, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax2DQuantizedInt16ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int16_t input_quantized[tflite::testing::flat_size_2d];
+ int16_t golden_quantized[tflite::testing::flat_size_2d];
+ int16_t output_data[tflite::testing::flat_size_2d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_2d, tflite::testing::input_data_2d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_2d,
+ tflite::testing::golden_2d, golden_quantized,
+ tflite::testing::output_scale_int16,
+ tflite::testing::output_zero_point_int16, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax3DFloatShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_3d];
+ tflite::testing::TestSoftmaxFloat(
+ tflite::testing ::shape_3d, tflite::testing::input_data_3d,
+ tflite::testing::shape_3d, tflite::testing::golden_3d, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax3DQuantizedInt8ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::flat_size_3d];
+ int8_t golden_quantized[tflite::testing::flat_size_3d];
+ int8_t output_data[tflite::testing::flat_size_3d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_3d, tflite::testing::input_data_3d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_3d,
+ tflite::testing::golden_3d, golden_quantized,
+ tflite::testing::output_scale_int8,
+ tflite::testing::output_zero_point_int8, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax3DQuantizedInt16ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int16_t input_quantized[tflite::testing::flat_size_3d];
+ int16_t golden_quantized[tflite::testing::flat_size_3d];
+ int16_t output_data[tflite::testing::flat_size_3d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_3d, tflite::testing::input_data_3d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_3d,
+ tflite::testing::golden_3d, golden_quantized,
+ tflite::testing::output_scale_int16,
+ tflite::testing::output_zero_point_int16, output_data,
+ tflite::testing::tolerance_int16);
+}
+
+TF_LITE_MICRO_TEST(Softmax4DFloatShouldMatchGolden) {
+ float output_data[tflite::testing::flat_size_4d];
+ tflite::testing::TestSoftmaxFloat(
+ tflite::testing ::shape_4d, tflite::testing::input_data_4d,
+ tflite::testing::shape_4d, tflite::testing::golden_4d, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax4DQuantizedInt8ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::flat_size_4d];
+ int8_t golden_quantized[tflite::testing::flat_size_4d];
+ int8_t output_data[tflite::testing::flat_size_4d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_4d, tflite::testing::input_data_4d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_4d,
+ tflite::testing::golden_4d, golden_quantized,
+ tflite::testing::output_scale_int8,
+ tflite::testing::output_zero_point_int8, output_data);
+}
+
+TF_LITE_MICRO_TEST(Softmax4DQuantizedInt16ShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+
+ int16_t input_quantized[tflite::testing::flat_size_4d];
+ int16_t golden_quantized[tflite::testing::flat_size_4d];
+ int16_t output_data[tflite::testing::flat_size_4d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_4d, tflite::testing::input_data_4d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_4d,
+ tflite::testing::golden_4d, golden_quantized,
+ tflite::testing::output_scale_int16,
+ tflite::testing::output_zero_point_int16, output_data,
+ tflite::testing::tolerance_int16);
+}
+#endif
+
+TF_LITE_MICRO_TEST(Softmax2DQuantizedInt8InputInt16OutputShouldMatchGolden) {
+ const float input_scale = 0.1f;
+ const int input_zero_point = 0;
+ const float output_scale = 1.0f / 65536.0f;
+ const int output_zero_point = -32768;
+
+ int8_t input_quantized[tflite::testing::flat_size_2d];
+ int16_t golden_quantized[tflite::testing::flat_size_2d];
+ int16_t output_data[tflite::testing::flat_size_2d];
+ tflite::testing::TestSoftmaxQuantized(
+ tflite::testing::shape_2d, tflite::testing::input_data_2d,
+ input_quantized, input_scale, input_zero_point, tflite::testing::shape_2d,
+ tflite::testing::golden_2d, golden_quantized, output_scale,
+ output_zero_point, output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/space_to_batch_nd.cc b/tensorflow/lite/micro/kernels/space_to_batch_nd.cc
new file mode 100644
index 0000000..fdfb81b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/space_to_batch_nd.cc
@@ -0,0 +1,121 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/space_to_batch_nd.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kBlockShapeTensor = 1;
+constexpr int kCropsTensor = 2;
+constexpr int kOutputTensor = 0;
+
+// Currently, only 3D NHC and 4D NHWC input/output op_context are supported.
+// In case of 3D input, it will be extended to 3D NHWC by adding W=1.
+// The 4D array need to have exactly 2 spatial dimensions.
+// TODO(b/149952582): Support arbitrary dimension in SpaceToBatchND.
+const int kInputOutputMinDimensionNum = 3;
+const int kInputOutputMaxDimensionNum = 4;
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(SpaceToBatchParams));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 3);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, input != nullptr && output != nullptr);
+
+ TF_LITE_ENSURE(context, NumDimensions(input) >= kInputOutputMinDimensionNum);
+ TF_LITE_ENSURE(context, NumDimensions(output) >= kInputOutputMinDimensionNum);
+ TF_LITE_ENSURE(context, NumDimensions(input) <= kInputOutputMaxDimensionNum);
+ TF_LITE_ENSURE(context, NumDimensions(output) <= kInputOutputMaxDimensionNum);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const SpaceToBatchParams& params =
+ *(static_cast<const SpaceToBatchParams*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* block_shape =
+ tflite::micro::GetEvalInput(context, node, kBlockShapeTensor);
+ const TfLiteEvalTensor* crops =
+ tflite::micro::GetEvalInput(context, node, kCropsTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32:
+ reference_ops::SpaceToBatchND(
+ params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(block_shape),
+ tflite::micro::GetTensorData<int32_t>(block_shape),
+ tflite::micro::GetTensorShape(crops),
+ tflite::micro::GetTensorData<int32_t>(crops),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ case kTfLiteInt8:
+ reference_ops::SpaceToBatchND(
+ params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(block_shape),
+ tflite::micro::GetTensorData<int32_t>(block_shape),
+ tflite::micro::GetTensorShape(crops),
+ tflite::micro::GetTensorData<int32_t>(crops),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace.
+
+TfLiteRegistration Register_SPACE_TO_BATCH_ND() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/space_to_batch_nd_test.cc b/tensorflow/lite/micro/kernels/space_to_batch_nd_test.cc
new file mode 100644
index 0000000..1d9d233
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/space_to_batch_nd_test.cc
@@ -0,0 +1,154 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int kBasicInputOutputSize = 16;
+const int basic_input_dims[] = {4, 1, 4, 4, 1};
+const float basic_input[kBasicInputOutputSize] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
+const int basic_block_shape_dims[] = {1, 2};
+const int32_t basic_block_shape[] = {2, 2};
+const int basic_crops_dims[] = {1, 4};
+const int32_t basic_crops[] = {0, 0, 0, 0};
+const int basic_output_dims[] = {4, 4, 2, 2, 1};
+const float basic_golden[kBasicInputOutputSize] = {1, 3, 9, 11, 2, 4, 10, 12,
+ 5, 7, 13, 15, 6, 8, 14, 16};
+
+template <typename T>
+TfLiteStatus ValidateSpaceToBatchNdGoldens(TfLiteTensor* tensors,
+ int tensors_size, const T* golden,
+ T* output, int output_size) {
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_SPACE_TO_BATCH_ND();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_ENSURE_STATUS(runner.InitAndPrepare());
+ TF_LITE_ENSURE_STATUS(runner.Invoke());
+
+ for (int i = 0; i < output_size; ++i) {
+ // TODO(b/158102673): workaround for not having fatal test assertions.
+ TF_LITE_MICRO_EXPECT_EQ(golden[i], output[i]);
+ if (golden[i] != output[i]) {
+ return kTfLiteError;
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus TestSpaceToBatchNdFloat(
+ const int* input_dims_data, const float* input_data,
+ const int* block_shape_dims_data, const int32_t* block_shape_data,
+ const int* crops_dims_data, const int32_t* crops_data,
+ const int* output_dims_data, const float* golden, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* block_shape_dims = IntArrayFromInts(block_shape_dims_data);
+ TfLiteIntArray* crops_dims = IntArrayFromInts(crops_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(block_shape_data, block_shape_dims),
+ CreateTensor(crops_data, crops_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ return ValidateSpaceToBatchNdGoldens(tensors, tensors_size, golden,
+ output_data, ElementCount(*output_dims));
+}
+
+template <typename T>
+TfLiteStatus TestSpaceToBatchNdQuantized(
+ const int* input_dims_data, const float* input_data, T* input_quantized,
+ float input_scale, int input_zero_point, const int* block_shape_dims_data,
+ const int32_t* block_shape_data, const int* crops_dims_data,
+ const int32_t* crops_data, const int* output_dims_data, const float* golden,
+ T* golden_quantized, float output_scale, int output_zero_point,
+ T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* block_shape_dims = IntArrayFromInts(block_shape_dims_data);
+ TfLiteIntArray* crops_dims = IntArrayFromInts(crops_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 3;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ tflite::testing::CreateQuantizedTensor(input_data, input_quantized,
+ input_dims, input_scale,
+ input_zero_point),
+ tflite::testing::CreateTensor(block_shape_data, block_shape_dims),
+ tflite::testing::CreateTensor(crops_data, crops_dims),
+ tflite::testing::CreateQuantizedTensor(output_data, output_dims,
+ output_scale, output_zero_point),
+ };
+ tflite::Quantize(golden, golden_quantized, ElementCount(*output_dims),
+ output_scale, output_zero_point);
+
+ return ValidateSpaceToBatchNdGoldens(tensors, tensors_size, golden_quantized,
+ output_data, ElementCount(*output_dims));
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SpaceToBatchBasicFloat) {
+ float output[tflite::testing::kBasicInputOutputSize];
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestSpaceToBatchNdFloat(
+ tflite::testing::basic_input_dims, tflite::testing::basic_input,
+ tflite::testing::basic_block_shape_dims,
+ tflite::testing::basic_block_shape, tflite::testing::basic_crops_dims,
+ tflite::testing::basic_crops, tflite::testing::basic_output_dims,
+ tflite::testing::basic_golden, output));
+}
+
+TF_LITE_MICRO_TEST(SpaceToBatchBasicInt8) {
+ int8_t output[tflite::testing::kBasicInputOutputSize];
+ int8_t input_quantized[tflite::testing::kBasicInputOutputSize];
+ int8_t golden_quantized[tflite::testing::kBasicInputOutputSize];
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestSpaceToBatchNdQuantized(
+ tflite::testing::basic_input_dims, tflite::testing::basic_input,
+ input_quantized, 1.0f, 0, tflite::testing::basic_block_shape_dims,
+ tflite::testing::basic_block_shape, tflite::testing::basic_crops_dims,
+ tflite::testing::basic_crops, tflite::testing::basic_output_dims,
+ tflite::testing::basic_golden, golden_quantized, 1.0f, 0, output));
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/space_to_depth.cc b/tensorflow/lite/micro/kernels/space_to_depth.cc
new file mode 100644
index 0000000..4f3f67a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/space_to_depth.cc
@@ -0,0 +1,166 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <stdint.h>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/optimized/optimized_ops.h"
+#include "tensorflow/lite/kernels/internal/reference/reference_ops.h"
+#include "tensorflow/lite/kernels/internal/tensor.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace builtin {
+namespace space_to_depth {
+
+// This file has two implementation of SpaceToDepth. Note that SpaceToDepth
+// only works on 4D tensors.
+enum KernelType {
+ kReference,
+ kGenericOptimized,
+};
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ auto* params =
+ reinterpret_cast<TfLiteSpaceToDepthParams*>(node->builtin_data);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), 4);
+
+ auto data_type = output->type;
+ TF_LITE_ENSURE(context,
+ data_type == kTfLiteFloat32 || data_type == kTfLiteUInt8 ||
+ data_type == kTfLiteInt8 || data_type == kTfLiteInt32 ||
+ data_type == kTfLiteInt64);
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ const int block_size = params->block_size;
+ const int input_height = input->dims->data[1];
+ const int input_width = input->dims->data[2];
+ int output_height = input_height / block_size;
+ int output_width = input_width / block_size;
+
+ TF_LITE_ENSURE_EQ(context, input_height, output_height * block_size);
+ TF_LITE_ENSURE_EQ(context, input_width, output_width * block_size);
+
+ TfLiteIntArray* output_size = TfLiteIntArrayCreate(4);
+ output_size->data[0] = input->dims->data[0];
+ output_size->data[1] = output_height;
+ output_size->data[2] = output_width;
+ output_size->data[3] = input->dims->data[3] * block_size * block_size;
+
+ return context->ResizeTensor(context, output, output_size);
+}
+
+template <KernelType kernel_type>
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params =
+ reinterpret_cast<TfLiteSpaceToDepthParams*>(node->builtin_data);
+
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+
+#define TF_LITE_SPACE_TO_DEPTH(type, scalar) \
+ tflite::SpaceToDepthParams op_params; \
+ op_params.block_size = params->block_size; \
+ type::SpaceToDepth(op_params, GetTensorShape(input), \
+ GetTensorData<scalar>(input), GetTensorShape(output), \
+ GetTensorData<scalar>(output))
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32:
+ if (kernel_type == kReference) {
+ TF_LITE_SPACE_TO_DEPTH(reference_ops, float);
+ } else {
+ TF_LITE_SPACE_TO_DEPTH(optimized_ops, float);
+ }
+ break;
+ case kTfLiteUInt8:
+ if (kernel_type == kReference) {
+ TF_LITE_SPACE_TO_DEPTH(reference_ops, uint8_t);
+ } else {
+ TF_LITE_SPACE_TO_DEPTH(optimized_ops, uint8_t);
+ }
+ break;
+ case kTfLiteInt8:
+ if (kernel_type == kReference) {
+ TF_LITE_SPACE_TO_DEPTH(reference_ops, int8_t);
+ } else {
+ TF_LITE_SPACE_TO_DEPTH(optimized_ops, int8_t);
+ }
+ break;
+ case kTfLiteInt32:
+ if (kernel_type == kReference) {
+ TF_LITE_SPACE_TO_DEPTH(reference_ops, int32_t);
+ } else {
+ TF_LITE_SPACE_TO_DEPTH(optimized_ops, int32_t);
+ }
+ break;
+ case kTfLiteInt64:
+ if (kernel_type == kReference) {
+ TF_LITE_SPACE_TO_DEPTH(reference_ops, int64_t);
+ } else {
+ TF_LITE_SPACE_TO_DEPTH(optimized_ops, int64_t);
+ }
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type '%s' not currently supported.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+#undef TF_LITE_SPACE_TO_DEPTH
+
+ return kTfLiteOk;
+}
+
+} // namespace space_to_depth
+
+TfLiteRegistration* Register_SPACE_TO_DEPTH_REF() {
+ static TfLiteRegistration r = {
+ nullptr, nullptr, space_to_depth::Prepare,
+ space_to_depth::Eval<space_to_depth::kReference>};
+ return &r;
+}
+
+TfLiteRegistration* Register_SPACE_TO_DEPTH_GENERIC_OPT() {
+ static TfLiteRegistration r = {
+ nullptr, nullptr, space_to_depth::Prepare,
+ space_to_depth::Eval<space_to_depth::kGenericOptimized>};
+ return &r;
+}
+
+TfLiteRegistration* Register_SPACE_TO_DEPTH() {
+ return Register_SPACE_TO_DEPTH_GENERIC_OPT();
+}
+
+} // namespace builtin
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/space_to_depth_test.cc b/tensorflow/lite/micro/kernels/space_to_depth_test.cc
new file mode 100644
index 0000000..6c6e14a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/space_to_depth_test.cc
@@ -0,0 +1,108 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <stdint.h>
+
+#include <initializer_list>
+#include <vector>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/kernels/test_util.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+namespace {
+
+using ::testing::ElementsAre;
+using ::testing::ElementsAreArray;
+
+class SpaceToDepthOpModel : public SingleOpModel {
+ public:
+ SpaceToDepthOpModel(const TensorData& tensor_data, int block_size) {
+ input_ = AddInput(tensor_data);
+ output_ = AddOutput(tensor_data);
+ SetBuiltinOp(BuiltinOperator_SPACE_TO_DEPTH,
+ BuiltinOptions_SpaceToDepthOptions,
+ CreateSpaceToDepthOptions(builder_, block_size).Union());
+ BuildInterpreter({GetShape(input_)});
+ }
+
+ template <typename T>
+ void SetInput(std::initializer_list<T> data) {
+ PopulateTensor<T>(input_, data);
+ }
+ template <typename T>
+ std::vector<T> GetOutput() {
+ return ExtractVector<T>(output_);
+ }
+ std::vector<int> GetOutputShape() { return GetTensorShape(output_); }
+
+ private:
+ int input_;
+ int output_;
+};
+
+#ifdef GTEST_HAS_DEATH_TEST
+TEST(SpaceToDepthOpModel, BadBlockSize) {
+ EXPECT_DEATH(SpaceToDepthOpModel({TensorType_FLOAT32, {1, 2, 2, 1}}, 3),
+ "Cannot allocate tensors");
+}
+#endif
+
+TEST(SpaceToDepthOpModel, Float32) {
+ SpaceToDepthOpModel m({TensorType_FLOAT32, {1, 2, 2, 2}}, 2);
+ m.SetInput<float>({1.4, 2.3, 3.2, 4.1, 5.4, 6.3, 7.2, 8.1});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<float>(),
+ ElementsAreArray({1.4, 2.3, 3.2, 4.1, 5.4, 6.3, 7.2, 8.1}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 1, 1, 8));
+}
+
+TEST(SpaceToDepthOpModel, Uint8) {
+ SpaceToDepthOpModel m({TensorType_UINT8, {1, 2, 2, 1}}, 2);
+ m.SetInput<uint8_t>({1, 2, 3, 4});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<uint8_t>(), ElementsAreArray({1, 2, 3, 4}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 1, 1, 4));
+}
+
+TEST(SpaceToDepthOpModel, int8) {
+ SpaceToDepthOpModel m({TensorType_INT8, {1, 2, 2, 1}}, 2);
+ m.SetInput<int8_t>({1, 2, 3, 4});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<int8_t>(), ElementsAreArray({1, 2, 3, 4}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 1, 1, 4));
+}
+
+TEST(SpaceToDepthOpModel, Int32) {
+ SpaceToDepthOpModel m({TensorType_INT32, {1, 2, 2, 3}}, 2);
+ m.SetInput<int32_t>({1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<int32_t>(),
+ ElementsAreArray({1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 1, 1, 12));
+}
+
+TEST(SpaceToDepthOpModel, Int64) {
+ SpaceToDepthOpModel m({TensorType_INT64, {1, 4, 4, 1}}, 2);
+ m.SetInput<int64_t>({1, 2, 5, 6, 3, 4, 7, 8, 9, 10, 13, 14, 11, 12, 15, 16});
+ m.Invoke();
+ EXPECT_THAT(m.GetOutput<int64_t>(),
+ ElementsAreArray(
+ {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}));
+ EXPECT_THAT(m.GetOutputShape(), ElementsAre(1, 2, 2, 4));
+}
+
+} // namespace
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/split.cc b/tensorflow/lite/micro/kernels/split.cc
new file mode 100644
index 0000000..a1236d7
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/split.cc
@@ -0,0 +1,135 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace split {
+
+template <typename T>
+TfLiteStatus SplitImpl(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input, int axis_value) {
+ const int output_count = NumOutputs(node);
+ const TfLiteIntArray* input_dims = input->dims;
+ const TfLiteEvalTensor* output0 =
+ tflite::micro::GetEvalOutput(context, node, 0);
+ const TfLiteIntArray* output_dims = output0->dims;
+
+ const int split_dimensions = input_dims->size;
+ int axis = axis_value < 0 ? axis_value + split_dimensions : axis_value;
+
+ TFLITE_DCHECK_LT(axis, split_dimensions);
+ TFLITE_DCHECK_EQ(output_dims->size, split_dimensions);
+
+ int64_t split_size = output_dims->data[axis] * output_count;
+
+ TFLITE_DCHECK_EQ(split_size, input_dims->data[axis]);
+ int64_t outer_size = 1;
+ for (int i = 0; i < axis; ++i) {
+ outer_size *= input_dims->data[i];
+ }
+
+ int64_t base_inner_size = 1;
+ for (int i = axis + 1; i < split_dimensions; ++i) {
+ base_inner_size *= input_dims->data[i];
+ }
+
+ const T* input_ptr = tflite::micro::GetTensorData<T>(input);
+ for (int k = 0; k < outer_size; ++k) {
+ for (int i = 0; i < output_count; ++i) {
+ TfLiteEvalTensor* t = tflite::micro::GetEvalOutput(context, node, i);
+ T* output_data = tflite::micro::GetTensorData<T>(t);
+ const int copy_size = output_dims->data[axis] * base_inner_size;
+ T* output_ptr = output_data + k * copy_size;
+ for (int j = 0; j < copy_size; ++j) output_ptr[j] = input_ptr[j];
+ input_ptr += copy_size;
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* axis = GetInput(context, node, 0);
+ TF_LITE_ENSURE(context, axis != nullptr);
+
+ // Dynamic output tensors are needed if axis tensor is not constant.
+ // But Micro doesn't support dynamic memory allocation, so we only support
+ // constant axis tensor for now.
+ TF_LITE_ENSURE_MSG(context, IsConstantTensor(axis),
+ "Non constant axis tensor not supported");
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* axis = tflite::micro::GetEvalInput(context, node, 0);
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 1);
+
+ int axis_value = tflite::micro::GetTensorData<int32_t>(axis)[0];
+ if (axis_value < 0) {
+ axis_value += input->dims->size;
+ }
+
+ TF_LITE_ENSURE(context, axis_value >= 0);
+ TF_LITE_ENSURE(context, axis_value < input->dims->size);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ return SplitImpl<float>(context, node, input, axis_value);
+ }
+ case kTfLiteUInt8: {
+ return SplitImpl<uint8_t>(context, node, input, axis_value);
+ }
+ case kTfLiteInt8: {
+ return SplitImpl<int8_t>(context, node, input, axis_value);
+ }
+ case kTfLiteInt16: {
+ return SplitImpl<int16_t>(context, node, input, axis_value);
+ }
+ case kTfLiteInt32: {
+ return SplitImpl<int32_t>(context, node, input, axis_value);
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s currently not supported.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+#undef TF_LITE_SPLIT
+
+ return kTfLiteOk;
+}
+
+} // namespace split
+
+TfLiteRegistration Register_SPLIT() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/split::Prepare,
+ /*invoke=*/split::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/split_test.cc b/tensorflow/lite/micro/kernels/split_test.cc
new file mode 100644
index 0000000..1890d8e
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/split_test.cc
@@ -0,0 +1,458 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/debug_log.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+
+void TestSplitTwoOutputsFloat(
+ const int* input_dims_data, const float* input_data,
+ const int* axis_dims_data, const int32_t* axis_data,
+ const int* output1_dims_data, const float* expected_output1_data,
+ const int* output2_dims_data, const float* expected_output2_data,
+ float* output1_data, float* output2_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output1_dims = IntArrayFromInts(output1_dims_data);
+ TfLiteIntArray* output2_dims = IntArrayFromInts(output2_dims_data);
+ const int output1_dims_count = ElementCount(*output1_dims);
+ const int output2_dims_count = ElementCount(*output2_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 2;
+ constexpr int axis_size = 1;
+ constexpr int tensors_size = input_size + output_size + axis_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(axis_data, axis_dims), CreateTensor(input_data, input_dims),
+ CreateTensor(output1_data, output1_dims),
+ CreateTensor(output2_data, output2_dims)};
+
+ // Currently only support constant axis tensor.
+ tensors[0].allocation_type = kTfLiteMmapRo;
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output1_dims_count; ++i) {
+ output1_data[i] = 23;
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ output2_data[i] = 23;
+ }
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {2, 2, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_SPLIT();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output1_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output1_data[i], output1_data[i], 1e-5f);
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output2_data[i], output2_data[i], 1e-5f);
+ }
+}
+
+void TestSplitFourOutputsFloat(
+ const int* input_dims_data, const float* input_data,
+ const int* axis_dims_data, const int32_t* axis_data,
+ const int* output1_dims_data, const float* expected_output1_data,
+ const int* output2_dims_data, const float* expected_output2_data,
+ const int* output3_dims_data, const float* expected_output3_data,
+ const int* output4_dims_data, const float* expected_output4_data,
+ float* output1_data, float* output2_data, float* output3_data,
+ float* output4_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output1_dims = IntArrayFromInts(output1_dims_data);
+ TfLiteIntArray* output2_dims = IntArrayFromInts(output2_dims_data);
+ TfLiteIntArray* output3_dims = IntArrayFromInts(output3_dims_data);
+ TfLiteIntArray* output4_dims = IntArrayFromInts(output4_dims_data);
+ const int output1_dims_count = ElementCount(*output1_dims);
+ const int output2_dims_count = ElementCount(*output2_dims);
+ const int output3_dims_count = ElementCount(*output3_dims);
+ const int output4_dims_count = ElementCount(*output4_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 4;
+ constexpr int axis_size = 1;
+ constexpr int tensors_size = input_size + output_size + axis_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(axis_data, axis_dims),
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output1_data, output1_dims),
+ CreateTensor(output2_data, output2_dims),
+ CreateTensor(output3_data, output1_dims),
+ CreateTensor(output4_data, output1_dims)};
+
+ // Currently only support constant axis tensor.
+ tensors[0].allocation_type = kTfLiteMmapRo;
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output1_dims_count; ++i) {
+ output1_data[i] = 23;
+ }
+ for (int i = 0; i < output2_dims_count; ++i) {
+ output2_data[i] = 23;
+ }
+ for (int i = 0; i < output3_dims_count; ++i) {
+ output3_data[i] = 23;
+ }
+ for (int i = 0; i < output4_dims_count; ++i) {
+ output4_data[i] = 23;
+ }
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {4, 2, 3, 4, 5};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_SPLIT();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output1_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output1_data[i], output1_data[i], 1e-5f);
+ }
+ for (int i = 0; i < output2_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output2_data[i], output2_data[i], 1e-5f);
+ }
+ for (int i = 0; i < output3_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output3_data[i], output3_data[i], 1e-5f);
+ }
+ for (int i = 0; i < output4_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output4_data[i], output4_data[i], 1e-5f);
+ }
+}
+
+void TestSplitTwoOutputsQuantized(
+ const int* input_dims_data, const uint8_t* input_data,
+ const int* axis_dims_data, const int32_t* axis_data,
+ const int* output1_dims_data, const uint8_t* expected_output1_data,
+ const int* output2_dims_data, const uint8_t* expected_output2_data,
+ uint8_t* output1_data, uint8_t* output2_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output1_dims = IntArrayFromInts(output1_dims_data);
+ TfLiteIntArray* output2_dims = IntArrayFromInts(output2_dims_data);
+ const int output1_dims_count = ElementCount(*output1_dims);
+ const int output2_dims_count = ElementCount(*output2_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 2;
+ constexpr int axis_size = 1;
+ constexpr int tensors_size = input_size + output_size + axis_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(axis_data, axis_dims),
+ CreateQuantizedTensor(input_data, input_dims, 0, 10),
+ CreateQuantizedTensor(output1_data, output1_dims, 0, 10),
+ CreateQuantizedTensor(output2_data, output2_dims, 0, 10)};
+
+ // Currently only support constant axis tensor.
+ tensors[0].allocation_type = kTfLiteMmapRo;
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output1_dims_count; ++i) {
+ output1_data[i] = 23;
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ output2_data[i] = 23;
+ }
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {2, 2, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_SPLIT();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output1_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output1_data[i], output1_data[i]);
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output2_data[i], output2_data[i]);
+ }
+}
+
+void TestSplitTwoOutputsQuantized32(
+ const int* input_dims_data, const int32_t* input_data,
+ const int* axis_dims_data, const int32_t* axis_data,
+ const int* output1_dims_data, const int32_t* expected_output1_data,
+ const int* output2_dims_data, const int32_t* expected_output2_data,
+ int32_t* output1_data, int32_t* output2_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* output1_dims = IntArrayFromInts(output1_dims_data);
+ TfLiteIntArray* output2_dims = IntArrayFromInts(output2_dims_data);
+ const int output1_dims_count = ElementCount(*output1_dims);
+ const int output2_dims_count = ElementCount(*output2_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 2;
+ constexpr int axis_size = 1;
+ constexpr int tensors_size = input_size + output_size + axis_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(axis_data, axis_dims), CreateTensor(input_data, input_dims),
+ CreateTensor(output1_data, output1_dims),
+ CreateTensor(output2_data, output2_dims)};
+
+ // Currently only support constant axis tensor.
+ tensors[0].allocation_type = kTfLiteMmapRo;
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output1_dims_count; ++i) {
+ output1_data[i] = 23;
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ output2_data[i] = 23;
+ }
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {2, 2, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_SPLIT();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output1_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output1_data[i], output1_data[i]);
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output2_data[i], output2_data[i]);
+ }
+}
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TwoSplitFourDimensionalAxisZero) {
+ const int input_shape[] = {4, 2, 2, 2, 2};
+ const float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {0};
+ const int output1_shape[] = {4, 1, 2, 2, 2};
+ const float golden1[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int output2_shape[] = {4, 1, 2, 2, 2};
+ const float golden2[] = {9, 10, 11, 12, 13, 14, 15, 16};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsFloat(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TEST(TwoSplitFourDimensionalAxisOne) {
+ const int input_shape[] = {4, 2, 2, 2, 2};
+ const float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {1};
+ const int output1_shape[] = {4, 2, 1, 2, 2};
+ const float golden1[] = {1, 2, 3, 4, 9, 10, 11, 12};
+ const int output2_shape[] = {4, 2, 1, 2, 2};
+ const float golden2[] = {5, 6, 7, 8, 13, 14, 15, 16};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsFloat(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TEST(TwoSplitFourDimensionalAxisTwo) {
+ const int input_shape[] = {4, 2, 2, 2, 2};
+ const float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {2};
+ const int output1_shape[] = {4, 2, 2, 1, 2};
+ const float golden1[] = {1, 2, 5, 6, 9, 10, 13, 14};
+ const int output2_shape[] = {4, 2, 2, 1, 2};
+ const float golden2[] = {3, 4, 7, 8, 11, 12, 15, 16};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsFloat(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TEST(TwoSplitFourDimensionalAxisThree) {
+ const int input_shape[] = {4, 2, 2, 2, 2};
+ const float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {3};
+ const int output1_shape[] = {4, 2, 2, 2, 1};
+ const float golden1[] = {1, 3, 5, 7, 9, 11, 13, 15};
+ const int output2_shape[] = {4, 2, 2, 2, 1};
+ const float golden2[] = {2, 4, 6, 8, 10, 12, 14, 16};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsFloat(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TEST(TwoSplitFourDimensionalNegativeAxis) {
+ const int input_shape[] = {4, 2, 2, 2, 2};
+ const float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {-4};
+ const int output1_shape[] = {4, 1, 2, 2, 2};
+ const float golden1[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ const int output2_shape[] = {4, 1, 2, 2, 2};
+ const float golden2[] = {9, 10, 11, 12, 13, 14, 15, 16};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsFloat(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TEST(FourSplit) {
+ const int input_shape[] = {1, 4};
+ const float input_data[] = {1, 2, 3, 4};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {0};
+ const int output1_shape[] = {1, 1};
+ const float golden1[] = {1};
+ const int output2_shape[] = {1, 1};
+ const float golden2[] = {2};
+ const int output3_shape[] = {1, 1};
+ const float golden3[] = {3};
+ const int output4_shape[] = {1, 1};
+ const float golden4[] = {4};
+
+ constexpr int output1_dims_count = 1;
+ constexpr int output2_dims_count = 1;
+ constexpr int output3_dims_count = 1;
+ constexpr int output4_dims_count = 1;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ float output3_data[output3_dims_count];
+ float output4_data[output4_dims_count];
+ tflite::testing::TestSplitFourOutputsFloat(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output3_shape, golden3, output4_shape, golden4,
+ output1_data, output2_data, output3_data, output4_data);
+}
+
+TF_LITE_MICRO_TEST(TwoSplitOneDimensional) {
+ const int input_shape[] = {1, 2};
+ const float input_data[] = {1, 2};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {0};
+ const int output1_shape[] = {1, 1};
+ const float golden1[] = {1};
+ const int output2_shape[] = {1, 1};
+ const float golden2[] = {2};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsFloat(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TEST(TwoSplitFourDimensionalQuantized) {
+ const int input_shape[] = {4, 2, 2, 2, 2};
+ const uint8_t input_data[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {1};
+ const int output1_shape[] = {4, 2, 1, 2, 2};
+ const uint8_t golden1[] = {1, 2, 3, 4, 9, 10, 11, 12};
+ const int output2_shape[] = {4, 2, 1, 2, 2};
+ const uint8_t golden2[] = {5, 6, 7, 8, 13, 14, 15, 16};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ uint8_t output1_data[output1_dims_count];
+ uint8_t output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsQuantized(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TEST(TwoSplitFourDimensionalQuantized32) {
+ const int input_shape[] = {4, 2, 2, 2, 2};
+ const int32_t input_data[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ const int axis_shape[] = {1, 1};
+ const int32_t axis_data[] = {1};
+ const int output1_shape[] = {4, 2, 1, 2, 2};
+ const int32_t golden1[] = {1, 2, 3, 4, 9, 10, 11, 12};
+ const int output2_shape[] = {4, 2, 1, 2, 2};
+ const int32_t golden2[] = {5, 6, 7, 8, 13, 14, 15, 16};
+
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ int32_t output1_data[output1_dims_count];
+ int32_t output2_data[output2_dims_count];
+ tflite::testing::TestSplitTwoOutputsQuantized32(
+ input_shape, input_data, axis_shape, axis_data, output1_shape, golden1,
+ output2_shape, golden2, output1_data, output2_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/split_v.cc b/tensorflow/lite/micro/kernels/split_v.cc
new file mode 100755
index 0000000..600523a
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/split_v.cc
@@ -0,0 +1,135 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace split_v {
+
+template <typename T>
+TfLiteStatus SplitImpl(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input, int axis_value) {
+ const TfLiteIntArray* input_dims = input->dims;
+ const TfLiteEvalTensor* output0 =
+ tflite::micro::GetEvalOutput(context, node, 0);
+
+ const int split_dimensions = input_dims->size;
+
+ TFLITE_DCHECK_LT(axis_value, split_dimensions);
+ TFLITE_DCHECK_EQ(output0->dims->size, split_dimensions);
+
+ int64_t split_size = 0;
+ const int output_count = NumOutputs(node);
+ for (int i = 0; i < output_count; i++) {
+ split_size +=
+ tflite::micro::GetEvalOutput(context, node, i)->dims->data[axis_value];
+ }
+ TFLITE_DCHECK_EQ(split_size, input_dims->data[axis_value]);
+ int64_t outer_size = 1;
+ for (int i = 0; i < axis_value; ++i) {
+ outer_size *= input_dims->data[i];
+ }
+
+ int64_t base_inner_size = 1;
+ for (int i = axis_value + 1; i < split_dimensions; ++i) {
+ base_inner_size *= input_dims->data[i];
+ }
+
+ const T* input_ptr = tflite::micro::GetTensorData<T>(input);
+ for (int k = 0; k < outer_size; ++k) {
+ for (int i = 0; i < output_count; ++i) {
+ TfLiteEvalTensor* output_tensor =
+ tflite::micro::GetEvalOutput(context, node, i);
+ T* output_data = tflite::micro::GetTensorData<T>(output_tensor);
+ const int copy_size =
+ output_tensor->dims->data[axis_value] * base_inner_size;
+ T* output_ptr = output_data + k * copy_size;
+ for (int j = 0; j < copy_size; ++j) output_ptr[j] = input_ptr[j];
+ input_ptr += copy_size;
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 3);
+
+ // Dynamic output tensors are needed if axis tensor is not constant.
+ // But Micro doesn't support dynamic memory allocation, so we only support
+ // constant axis tensor for now.
+ const TfLiteTensor* axis = GetInput(context, node, 2);
+ TF_LITE_ENSURE_MSG(context, IsConstantTensor(axis),
+ "Non constant axis tensor not supported");
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ const TfLiteEvalTensor* axis = tflite::micro::GetEvalInput(context, node, 2);
+
+ int axis_value = tflite::micro::GetTensorData<int32_t>(axis)[0];
+ if (axis_value < 0) {
+ axis_value += input->dims->size;
+ }
+
+ TF_LITE_ENSURE(context, axis_value >= 0);
+ TF_LITE_ENSURE(context, axis_value < input->dims->size);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ return SplitImpl<float>(context, node, input, axis_value);
+ }
+ case kTfLiteInt8: {
+ return SplitImpl<int8_t>(context, node, input, axis_value);
+ }
+ case kTfLiteInt16: {
+ return SplitImpl<int16_t>(context, node, input, axis_value);
+ }
+ case kTfLiteInt32: {
+ return SplitImpl<int32_t>(context, node, input, axis_value);
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s currently not supported.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace split_v
+
+TfLiteRegistration Register_SPLIT_V() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/split_v::Prepare,
+ /*invoke=*/split_v::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/split_v_test.cc b/tensorflow/lite/micro/kernels/split_v_test.cc
new file mode 100755
index 0000000..6fd3adc
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/split_v_test.cc
@@ -0,0 +1,468 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/debug_log.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+
+template <int N>
+struct OutputTensors {
+ float* data[N];
+ int* dims[N];
+ float* expected_output_data[N];
+};
+template <int N>
+void TestSplitVFloat(const int* input_dims_data, const float* input_data,
+ const int* axis_dims_data, const int32_t* axis_data,
+ const int* split_dims_data, const int32_t* split_data,
+ const OutputTensors<N>& output_tensors) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* axis_dims = IntArrayFromInts(axis_dims_data);
+ TfLiteIntArray* split_dims = IntArrayFromInts(split_dims_data);
+ TfLiteIntArray* output_dims[N];
+ for (int i = 0; i < N; i++)
+ output_dims[i] = IntArrayFromInts(output_tensors.dims[i]);
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < N; i++) {
+ int dim_count = ElementCount(*output_dims[i]);
+ for (int j = 0; j < dim_count; j++) {
+ (output_tensors.data[i])[j] = 23;
+ }
+ }
+ constexpr int input_size = 1;
+ constexpr int axis_size = 1;
+ constexpr int split_size = 1;
+ constexpr int output_size = N;
+
+ constexpr int tensors_size =
+ input_size + output_size + axis_size + split_size;
+
+ // first input tensor is data
+ // second is size_splits
+ // third is axis
+ // then come outputs
+
+ TfLiteTensor tensors[tensors_size];
+ tensors[0] = CreateTensor(input_data, input_dims);
+ tensors[1] = CreateTensor(split_data, split_dims);
+ tensors[2] = CreateTensor(axis_data, axis_dims);
+
+ // add output tensors
+ for (int i = 0; i < N; i++)
+ tensors[3 + i] = CreateTensor(output_tensors.data[i], output_dims[i]);
+
+ tensors[2].allocation_type = kTfLiteMmapRo;
+ tensors[1].allocation_type = kTfLiteMmapRo;
+
+ int inputs_array_data[] = {3, 0, 1, 2};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[N + 1];
+ outputs_array_data[0] = N;
+ for (int i = 0; i < N; i++) outputs_array_data[i + 1] = i + 3;
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_SPLIT_V();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < N; i++) {
+ int dim_count = ElementCount(*output_dims[i]);
+ for (int j = 0; j < dim_count; j++) {
+ TF_LITE_MICRO_EXPECT_NEAR((output_tensors.expected_output_data[i])[j],
+ (output_tensors.data[i])[j], 1e-5f);
+ }
+ }
+}
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SPLIT_V_ThreeOutputs) {
+ constexpr int output1_dims_count = 3;
+ constexpr int output2_dims_count = 3;
+ constexpr int output3_dims_count = 6;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ float output3_data[output3_dims_count];
+ int input_shape[] = {2, 4, 3};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int axis_shape[] = {1, 1};
+ int32_t axis_values[] = {0};
+ int split_shape[] = {1, 3};
+ int32_t split_values[] = {1, 1, 2};
+ int output1_shape[] = {2, 1, 3};
+ float output1_values[] = {1, 2, 3};
+ int output2_shape[] = {2, 1, 3};
+ float output2_values[] = {4, 5, 6};
+ int output3_shape[] = {2, 2, 3};
+ float output3_values[] = {7, 8, 9, 10, 11, 12};
+
+ tflite::testing::OutputTensors<3> output_tensors;
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+ output_tensors.data[2] = output3_data;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+ output_tensors.dims[2] = output3_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+ output_tensors.expected_output_data[2] = output3_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_values, split_shape, split_values,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TEST(SPLIT_V_FourDimensionalFloatAxis0) {
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+
+ int input_shape[] = {4, 2, 2, 2, 2};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ int axis_shape[] = {1, 1};
+ int32_t axis_values[] = {0};
+ int split_shape[] = {1, 2};
+ int32_t split_values[] = {1, 1};
+ int output1_shape[] = {4, 1, 2, 2, 2};
+ float output1_values[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ int output2_shape[] = {4, 1, 2, 2, 2};
+ float output2_values[] = {9, 10, 11, 12, 13, 14, 15, 16};
+
+ tflite::testing::OutputTensors<2> output_tensors;
+
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_values, split_shape, split_values,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TEST(SPLIT_V_FourDimensionalFloatAxis1) {
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+
+ int input_shape[] = {4, 2, 2, 2, 2};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ int axis_shape[] = {1, 1};
+ int32_t axis_values[] = {1};
+ int split_shape[] = {1, 2};
+ int32_t split_values[] = {1, 1};
+ int output1_shape[] = {4, 2, 1, 2, 2};
+ float output1_values[] = {1, 2, 3, 4, 9, 10, 11, 12};
+ int output2_shape[] = {4, 2, 1, 2, 2};
+ float output2_values[] = {5, 6, 7, 8, 13, 14, 15, 16};
+
+ tflite::testing::OutputTensors<2> output_tensors;
+
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_values, split_shape, split_values,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TEST(SPLIT_VFourDimensionalFloatAxis2) {
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+
+ int input_shape[] = {4, 2, 2, 2, 2};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ int axis_shape[] = {1, 1};
+ int32_t axis_values[] = {2};
+ int split_shape[] = {1, 2};
+ int32_t split_values[] = {1, 1};
+ int output1_shape[] = {4, 2, 2, 1, 2};
+ float output1_values[] = {1, 2, 5, 6, 9, 10, 13, 14};
+ int output2_shape[] = {4, 2, 2, 1, 2};
+ float output2_values[] = {3, 4, 7, 8, 11, 12, 15, 16};
+
+ tflite::testing::OutputTensors<2> output_tensors;
+
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_values, split_shape, split_values,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TEST(SPLIT_V_FourDimensionalFloatAxis3) {
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ int input_shape[] = {4, 2, 2, 2, 2};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ int axis_shape[] = {1, 1};
+ int32_t axis_values[] = {3};
+ int split_shape[] = {1, 2};
+ int32_t split_values[] = {1, 1};
+ int output1_shape[] = {4, 2, 2, 2, 1};
+ float output1_values[] = {1, 3, 5, 7, 9, 11, 13, 15};
+ int output2_shape[] = {4, 2, 2, 2, 1};
+ float output2_values[] = {2, 4, 6, 8, 10, 12, 14, 16};
+
+ tflite::testing::OutputTensors<2> output_tensors;
+
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_values, split_shape, split_values,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TEST(SPLIT_V_FourDimensionalFloatNegativeAxis) {
+ constexpr int output1_dims_count = 8;
+ constexpr int output2_dims_count = 8;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+
+ int input_shape[] = {4, 2, 2, 2, 2};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16};
+ int axis_shape[] = {1, 1};
+ int32_t axis_values[] = {-4};
+ int split_shape[] = {1, 2};
+ int32_t split_values[] = {1, 1};
+ int output1_shape[] = {4, 1, 2, 2, 2};
+ float output1_values[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ int output2_shape[] = {4, 1, 2, 2, 2};
+ float output2_values[] = {9, 10, 11, 12, 13, 14, 15, 16};
+
+ tflite::testing::OutputTensors<2> output_tensors;
+
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_values, split_shape, split_values,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TEST(SPLIT_V_OneDimensionalFloatAxis0) {
+ constexpr int output1_dims_count = 1;
+ constexpr int output2_dims_count = 1;
+ constexpr int output3_dims_count = 1;
+ constexpr int output4_dims_count = 1;
+ constexpr int output5_dims_count = 1;
+ constexpr int output6_dims_count = 1;
+ constexpr int output7_dims_count = 1;
+ constexpr int output8_dims_count = 1;
+
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ float output3_data[output3_dims_count];
+ float output4_data[output4_dims_count];
+ float output5_data[output5_dims_count];
+ float output6_data[output6_dims_count];
+ float output7_data[output7_dims_count];
+ float output8_data[output8_dims_count];
+ int input_shape[] = {1, 8};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ int axis_shape[] = {1, 1};
+ int32_t axis_value[] = {0};
+ int split_size_shape[] = {1, 8};
+ int32_t split[] = {1, 1, 1, 1, 1, 1, 1, 1};
+ int output1_shape[] = {1, 1};
+ float output1_values[] = {1};
+ int output2_shape[] = {1, 1};
+ float output2_values[] = {2};
+
+ int output3_shape[] = {1, 1};
+ float output3_values[] = {3};
+ int output4_shape[] = {1, 1};
+ float output4_values[] = {4};
+
+ int output5_shape[] = {1, 1};
+ float output5_values[] = {5};
+ int output6_shape[] = {1, 1};
+ float output6_values[] = {6};
+
+ int output7_shape[] = {1, 1};
+ float output7_values[] = {7};
+ int output8_shape[] = {1, 1};
+ float output8_values[] = {8};
+
+ tflite::testing::OutputTensors<8> output_tensors;
+
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+ output_tensors.data[2] = output3_data;
+ output_tensors.data[3] = output4_data;
+ output_tensors.data[4] = output5_data;
+ output_tensors.data[5] = output6_data;
+ output_tensors.data[6] = output7_data;
+ output_tensors.data[7] = output8_data;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+ output_tensors.dims[2] = output3_shape;
+ output_tensors.dims[3] = output4_shape;
+ output_tensors.dims[4] = output5_shape;
+ output_tensors.dims[5] = output6_shape;
+ output_tensors.dims[6] = output7_shape;
+ output_tensors.dims[7] = output8_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+ output_tensors.expected_output_data[2] = output3_values;
+ output_tensors.expected_output_data[3] = output4_values;
+ output_tensors.expected_output_data[4] = output5_values;
+ output_tensors.expected_output_data[5] = output6_values;
+ output_tensors.expected_output_data[6] = output7_values;
+ output_tensors.expected_output_data[7] = output8_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_value, split_size_shape, split,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TEST(SPLIT_V_OneDimensionalFloatTest2) {
+ constexpr int output1_dims_count = 1;
+ constexpr int output2_dims_count = 1;
+ constexpr int output3_dims_count = 1;
+ constexpr int output4_dims_count = 1;
+ constexpr int output5_dims_count = 1;
+ constexpr int output6_dims_count = 1;
+ constexpr int output7_dims_count = 2;
+
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ float output3_data[output3_dims_count];
+ float output4_data[output4_dims_count];
+ float output5_data[output5_dims_count];
+ float output6_data[output6_dims_count];
+ float output7_data[output7_dims_count];
+
+ int input_shape[] = {1, 8};
+ float input_values[] = {1, 2, 3, 4, 5, 6, 7, 8};
+ int axis_shape[] = {1, 1};
+ int32_t axis_value[] = {0};
+ int split_size_shape[] = {1, 8};
+ int32_t split[] = {1, 1, 1, 1, 1, 1, 2, -1};
+ int output1_shape[] = {1, 1};
+ float output1_values[] = {1};
+ int output2_shape[] = {1, 1};
+ float output2_values[] = {2};
+
+ int output3_shape[] = {1, 1};
+ float output3_values[] = {3};
+ int output4_shape[] = {1, 1};
+ float output4_values[] = {4};
+
+ int output5_shape[] = {1, 1};
+ float output5_values[] = {5};
+ int output6_shape[] = {1, 1};
+ float output6_values[] = {6};
+
+ int output7_shape[] = {1, 2};
+ float output7_values[] = {7, 8};
+ int output8_shape[] = {1, 0};
+ float output8_values[1] = {};
+
+ tflite::testing::OutputTensors<8> output_tensors;
+
+ output_tensors.data[0] = output1_data;
+ output_tensors.data[1] = output2_data;
+ output_tensors.data[2] = output3_data;
+ output_tensors.data[3] = output4_data;
+ output_tensors.data[4] = output5_data;
+ output_tensors.data[5] = output6_data;
+ output_tensors.data[6] = output7_data;
+ output_tensors.data[7] = NULL;
+
+ output_tensors.dims[0] = output1_shape;
+ output_tensors.dims[1] = output2_shape;
+ output_tensors.dims[2] = output3_shape;
+ output_tensors.dims[3] = output4_shape;
+ output_tensors.dims[4] = output5_shape;
+ output_tensors.dims[5] = output6_shape;
+ output_tensors.dims[6] = output7_shape;
+ output_tensors.dims[7] = output8_shape;
+
+ output_tensors.expected_output_data[0] = output1_values;
+ output_tensors.expected_output_data[1] = output2_values;
+ output_tensors.expected_output_data[2] = output3_values;
+ output_tensors.expected_output_data[3] = output4_values;
+ output_tensors.expected_output_data[4] = output5_values;
+ output_tensors.expected_output_data[5] = output6_values;
+ output_tensors.expected_output_data[6] = output7_values;
+ output_tensors.expected_output_data[7] = output8_values;
+
+ tflite::testing::TestSplitVFloat(input_shape, input_values, axis_shape,
+ axis_value, split_size_shape, split,
+ output_tensors);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/squeeze.cc b/tensorflow/lite/micro/kernels/squeeze.cc
new file mode 100644
index 0000000..522c2d0
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/squeeze.cc
@@ -0,0 +1,111 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+namespace tflite {
+namespace {
+
+struct SqueezeContext {
+ SqueezeContext(TfLiteContext* context, TfLiteNode* node)
+ : params(reinterpret_cast<TfLiteSqueezeParams*>(node->builtin_data)),
+ input(GetInput(context, node, 0)),
+ output(GetOutput(context, node, 0)) {}
+ TfLiteSqueezeParams* params;
+ const TfLiteTensor* const input;
+ TfLiteTensor* output;
+};
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ SqueezeContext op_context(context, node);
+ const int input_num_dims = NumDimensions(op_context.input);
+ const int num_squeeze_dims = op_context.params->num_squeeze_dims;
+
+ // Determines number of dimensions of output tensor after squeeze.
+ const TfLiteIntArray* input_dims = op_context.input->dims;
+ const TfLiteIntArray* output_dims = op_context.output->dims;
+ const int* squeeze_dims = op_context.params->squeeze_dims;
+
+ constexpr int max_squeeze_dims = 8;
+ TF_LITE_ENSURE(context, input_num_dims <= max_squeeze_dims);
+ bool should_squeeze[max_squeeze_dims] = {};
+
+ if (num_squeeze_dims == 0) {
+ for (int idx = 0; idx < input_num_dims; ++idx) {
+ if (input_dims->data[idx] == 1) {
+ should_squeeze[idx] = true;
+ }
+ }
+ } else {
+ for (int idx = 0; idx < num_squeeze_dims; ++idx) {
+ int current = squeeze_dims[idx] < 0 ? squeeze_dims[idx] + input_num_dims
+ : squeeze_dims[idx];
+ TF_LITE_ENSURE(context, current >= 0 && current < input_num_dims &&
+ input_dims->data[current] == 1);
+ should_squeeze[current] = true;
+ }
+ }
+
+ // Ensure output dimensions are big enough.
+ for (int in_idx = 0, out_idx = 0; in_idx < input_num_dims; ++in_idx) {
+ if (!should_squeeze[in_idx]) {
+ TFLITE_CHECK_GE(output_dims->data[out_idx++], input_dims->data[in_idx]);
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ SqueezeContext op_context(context, node);
+
+ if (op_context.input->type == kTfLiteString) {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(op_context.input->type),
+ op_context.input->type);
+ return kTfLiteError;
+ }
+
+ TF_LITE_ENSURE_EQ(context, op_context.input->bytes, op_context.output->bytes);
+ memcpy(op_context.output->data.raw, op_context.input->data.raw,
+ op_context.input->bytes);
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_SQUEEZE() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/squeeze_test.cc b/tensorflow/lite/micro/kernels/squeeze_test.cc
new file mode 100644
index 0000000..21229bd
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/squeeze_test.cc
@@ -0,0 +1,126 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+const int input_dims_data_common[] = {3, 1, 24, 1};
+const int output_dims_data_common[] = {1, 24};
+const int input_data_common[] = {1, 2, 3, 4, 5, 6, 7, 8,
+ 9, 10, 11, 12, 13, 14, 15, 16,
+ 17, 18, 19, 20, 21, 22, 23, 24};
+const int golden_common[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
+ 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24};
+const int expected_output_size_common = 24;
+
+void TestSqueezeOp(const int* input_dims_data, const int* input_data,
+ const int* output_dims_data, int* output_data,
+ const int* golden, int expected_output_size,
+ TfLiteSqueezeParams* squeeze_params) {
+ TfLiteIntArray* input_dims1 = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims1 = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+
+ TfLiteTensor tensors[tensors_size];
+ tensors[0] = CreateTensor(input_data, input_dims1);
+ tensors[1] = CreateTensor(output_data, output_dims1);
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_SQUEEZE();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(squeeze_params));
+
+ const char* init_data = reinterpret_cast<const char*>(squeeze_params);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare(init_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < expected_output_size; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(golden[i], output_data[i]);
+ }
+}
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SqueezeAll) {
+ int output_data[24];
+ TfLiteSqueezeParams squeeze_params = {{}, 0};
+
+ tflite::testing::TestSqueezeOp(tflite::testing::input_dims_data_common,
+ tflite::testing::input_data_common,
+ tflite::testing::output_dims_data_common,
+ output_data, tflite::testing::golden_common,
+ tflite::testing::expected_output_size_common,
+ &squeeze_params);
+}
+
+TF_LITE_MICRO_TEST(SqueezeSelectedAxis) {
+ int output_data[24];
+ TfLiteSqueezeParams squeeze_params = {{2}, 1};
+ const int output_dims_data_common[] = {2, 1, 24};
+
+ tflite::testing::TestSqueezeOp(
+ tflite::testing::input_dims_data_common,
+ tflite::testing::input_data_common, output_dims_data_common, output_data,
+ tflite::testing::golden_common,
+ tflite::testing::expected_output_size_common, &squeeze_params);
+}
+
+TF_LITE_MICRO_TEST(SqueezeNegativeAxis) {
+ int output_data[24];
+ TfLiteSqueezeParams squeeze_params = {{-1, 0}, 2};
+
+ tflite::testing::TestSqueezeOp(tflite::testing::input_dims_data_common,
+ tflite::testing::input_data_common,
+ tflite::testing::output_dims_data_common,
+ output_data, tflite::testing::golden_common,
+ tflite::testing::expected_output_size_common,
+ &squeeze_params);
+}
+
+TF_LITE_MICRO_TEST(SqueezeAllDims) {
+ const int input_dims_data[] = {7, 1, 1, 1, 1, 1, 1, 1};
+ const int output_dims_data[] = {1, 1};
+ const int input_data[] = {3};
+ const int golden[] = {3};
+ const int expected_output_size = 1;
+
+ int output_data[24];
+ TfLiteSqueezeParams squeeze_params = {{}, 0};
+
+ tflite::testing::TestSqueezeOp(input_dims_data, input_data, output_dims_data,
+ output_data, golden, expected_output_size,
+ &squeeze_params);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/strided_slice.cc b/tensorflow/lite/micro/kernels/strided_slice.cc
new file mode 100644
index 0000000..2dbe6e1
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/strided_slice.cc
@@ -0,0 +1,192 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/kernels/internal/reference/strided_slice.h"
+
+#include <cmath>
+#include <cstring>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace strided_slice {
+
+constexpr int kInputTensor = 0;
+constexpr int kBeginTensor = 1;
+constexpr int kEndTensor = 2;
+constexpr int kStridesTensor = 3;
+constexpr int kOutputTensor = 0;
+
+struct StridedSliceContext {
+ StridedSliceContext(TfLiteContext* context, TfLiteNode* node) {
+ params = reinterpret_cast<TfLiteStridedSliceParams*>(node->builtin_data);
+ input = GetInput(context, node, kInputTensor);
+ begin = GetInput(context, node, kBeginTensor);
+ end = GetInput(context, node, kEndTensor);
+ strides = GetInput(context, node, kStridesTensor);
+ output = GetOutput(context, node, kOutputTensor);
+ dims = NumDimensions(input);
+ }
+ const TfLiteStridedSliceParams* params;
+ const TfLiteTensor* input;
+ const TfLiteTensor* begin;
+ const TfLiteTensor* end;
+ const TfLiteTensor* strides;
+ TfLiteTensor* output;
+ int dims;
+};
+
+// This Op only supports 1-4D cases and since we use the reference 4D
+// implementation, the 1-3D tensors are mapped to 4D.
+const int kMaxDim = 4;
+
+tflite::StridedSliceParams BuildStridedSliceParams(
+ StridedSliceContext* op_context) {
+ tflite::StridedSliceParams op_params;
+ op_params.start_indices_count = op_context->dims;
+ op_params.stop_indices_count = op_context->dims;
+ op_params.strides_count = op_context->dims;
+
+ for (int i = 0; i < op_context->dims; ++i) {
+ op_params.start_indices[i] = GetTensorData<int32_t>(op_context->begin)[i];
+ op_params.stop_indices[i] = GetTensorData<int32_t>(op_context->end)[i];
+ op_params.strides[i] = GetTensorData<int32_t>(op_context->strides)[i];
+ }
+
+ op_params.begin_mask = op_context->params->begin_mask;
+ op_params.ellipsis_mask = 0;
+ op_params.end_mask = op_context->params->end_mask;
+ op_params.new_axis_mask = 0;
+ op_params.shrink_axis_mask = op_context->params->shrink_axis_mask;
+ return op_params;
+}
+
+// Processes the indexing tensors (begin, end and strides) to resize the
+// output tensor. This function is callable from both Prepare() and Eval() as
+// long as the caller ensures the indexing tensors are present.
+TfLiteStatus CheckOutputSize(TfLiteContext* context,
+ StridedSliceContext* op_context) {
+ using ::tflite::strided_slice::StartForAxis;
+ using ::tflite::strided_slice::StopForAxis;
+ TfLiteIntArray* output_shape = op_context->output->dims;
+ int shape_size = 0;
+ auto op_params = BuildStridedSliceParams(op_context);
+ auto input_shape = GetTensorShape(op_context->input);
+ for (int idx = 0; idx < op_context->dims; ++idx) {
+ int32_t stride = GetTensorData<int32_t>(op_context->strides)[idx];
+ TF_LITE_ENSURE_MSG(context, stride != 0, "stride value has to be non-zero");
+ int32_t begin = StartForAxis(op_params, input_shape, idx);
+ int32_t end = StopForAxis(op_params, input_shape, idx, begin);
+
+ // When shrinking an axis, the end position does not matter (and can be
+ // incorrect when negative indexing is used, see Issue #19260). Always use
+ // begin + 1 to generate a length 1 slice, since begin has
+ // already been adjusted for negative indices by StartForAxis.
+ const bool shrink_axis = op_context->params->shrink_axis_mask & (1 << idx);
+ if (shrink_axis) {
+ end = begin + 1;
+ }
+
+ // This is valid for both positive and negative strides
+ int32_t dim_shape = std::ceil((end - begin) / static_cast<float>(stride));
+ dim_shape = dim_shape < 0 ? 0 : dim_shape;
+ if (!shrink_axis) {
+ TF_LITE_ENSURE_EQ(context, output_shape->data[shape_size], dim_shape);
+ shape_size++;
+ }
+ }
+ TF_LITE_ENSURE_EQ(context, output_shape->size, shape_size);
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(StridedSliceParams));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ StridedSliceParams* op_params =
+ static_cast<StridedSliceParams*>(node->user_data);
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 4);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ StridedSliceContext op_context(context, node);
+ TF_LITE_ENSURE_MSG(context, op_context.dims <= kMaxDim,
+ "input dim should not exceed 4");
+ auto params = BuildStridedSliceParams(&op_context);
+ memcpy(op_params, ¶ms, sizeof(StridedSliceParams));
+ return CheckOutputSize(context, &op_context);
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const StridedSliceParams& op_params =
+ *(static_cast<const StridedSliceParams*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ switch (output->type) {
+ case kTfLiteFloat32:
+ reference_ops::StridedSlice(op_params,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ break;
+ case kTfLiteUInt8:
+ reference_ops::StridedSlice(
+ op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ break;
+ case kTfLiteInt8:
+ reference_ops::StridedSlice(op_params,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+} // namespace strided_slice
+
+TfLiteRegistration Register_STRIDED_SLICE() {
+ return {/*init=*/strided_slice::Init,
+ /*free=*/nullptr,
+ /*prepare=*/strided_slice::Prepare,
+ /*invoke=*/strided_slice::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/strided_slice_test.cc b/tensorflow/lite/micro/kernels/strided_slice_test.cc
new file mode 100644
index 0000000..2225be1
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/strided_slice_test.cc
@@ -0,0 +1,1072 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void ValidateStridedSliceGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* golden, T* output, int output_len,
+ TfLiteStridedSliceParams* params,
+ const bool expect_prepare_err, int num_invoke,
+ float tolerance = 1e-5) {
+ int inputs_array_data[] = {4, 0, 1, 2, 3};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 4};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration =
+ tflite::ops::micro::Register_STRIDED_SLICE();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, reinterpret_cast<void*>(params));
+ if (expect_prepare_err) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError, runner.InitAndPrepare());
+ return;
+ } else {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ }
+
+ for (int i = 0; i < num_invoke; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+ }
+
+ for (int i = 0; i < output_len; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output[i], 1e-5f);
+ }
+}
+
+void TestStridedSliceFloat(const int* input_shape, const int* begin_shape,
+ const int* end_shape, const int* strides_shape,
+ TfLiteStridedSliceParams* builtin_data,
+ float* input_data, const int32_t* begin_data,
+ const int32_t* end_data, const int32_t* strides_data,
+ const int* output_shape, float* output_data,
+ const float* expected_output,
+ bool expect_prepare_err, int num_invoke = 1) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_shape);
+ TfLiteIntArray* begin_dims = IntArrayFromInts(begin_shape);
+ TfLiteIntArray* end_dims = IntArrayFromInts(end_shape);
+ TfLiteIntArray* strides_dims = IntArrayFromInts(strides_shape);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_shape);
+ constexpr int inputs_size = 4;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(begin_data, begin_dims),
+ CreateTensor(end_data, end_dims),
+ CreateTensor(strides_data, strides_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateStridedSliceGoldens(tensors, tensors_size, expected_output,
+ output_data, ElementCount(*output_dims),
+ builtin_data, expect_prepare_err, num_invoke,
+ 1.0);
+}
+
+template <typename T>
+void TestStridedSliceQuantized(
+ const int* input_shape, const int* begin_shape, const int* end_shape,
+ const int* strides_shape, TfLiteStridedSliceParams* builtin_data,
+ const T* input_data, const int32_t* begin_data, const int32_t* end_data,
+ const int32_t* strides_data, const int* output_shape, T* output_data,
+ const T* expected_output, bool expect_prepare_err, int num_invoke = 1) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_shape);
+ TfLiteIntArray* begin_dims = IntArrayFromInts(begin_shape);
+ TfLiteIntArray* end_dims = IntArrayFromInts(end_shape);
+ TfLiteIntArray* strides_dims = IntArrayFromInts(strides_shape);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_shape);
+ constexpr int inputs_size = 4;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ int zero_point =
+ std::numeric_limits<T>::max() + std::numeric_limits<T>::min() / 2;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_dims, 1.0, zero_point),
+ CreateTensor(begin_data, begin_dims),
+ CreateTensor(end_data, end_dims),
+ CreateTensor(strides_data, strides_dims),
+ CreateQuantizedTensor(output_data, output_dims, 1.0, zero_point),
+ };
+
+ ValidateStridedSliceGoldens(tensors, tensors_size, expected_output,
+ output_data, ElementCount(*output_dims),
+ builtin_data, expect_prepare_err, num_invoke,
+ 1.0);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(UnsupportedInputSize) {
+ const int input_shape[] = {5, 2, 2, 2, 2, 2};
+ const int begin_shape[] = {1, 5};
+ const int end_shape[] = {1, 5};
+ const int strides_shape[] = {1, 5};
+ const int output_shape[] = {0};
+ float input_data[] = {};
+ int32_t begin_data[] = {};
+ int32_t end_data[] = {};
+ int32_t strides_data[] = {};
+ float golden[] = {};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, true);
+}
+
+TF_LITE_MICRO_TEST(In1D) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {1};
+ int32_t end_data[] = {3};
+ int32_t strides_data[] = {1};
+ float golden[] = {2, 3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_EmptyOutput) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 0};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {10};
+ int32_t end_data[] = {3};
+ int32_t strides_data[] = {1};
+ float golden[] = {};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_NegativeBegin) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {-3};
+ int32_t end_data[] = {3};
+ int32_t strides_data[] = {1};
+ float golden[] = {2, 3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_OutOfRangeBegin) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 3};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {-5};
+ int32_t end_data[] = {3};
+ int32_t strides_data[] = {1};
+ float golden[] = {1, 2, 3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_NegativeEnd) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 1};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {1};
+ int32_t end_data[] = {-2};
+ int32_t strides_data[] = {1};
+ float golden[] = {2};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_OutOfRangeEnd) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 3};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {-3};
+ int32_t end_data[] = {5};
+ int32_t strides_data[] = {1};
+ float golden[] = {2, 3, 4};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_BeginMask) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 3};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {1};
+ int32_t end_data[] = {3};
+ int32_t strides_data[] = {1};
+ float golden[] = {1, 2, 3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {1, 0, 0, 0, 0};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_NegativeBeginNegativeStride) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 1};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {-2};
+ int32_t end_data[] = {-3};
+ int32_t strides_data[] = {-1};
+ float golden[] = {3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_OutOfRangeBeginNegativeStride) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 1};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {5};
+ int32_t end_data[] = {2};
+ int32_t strides_data[] = {-1};
+ float golden[] = {4};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_NegativeEndNegativeStride) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {2};
+ int32_t end_data[] = {-4};
+ int32_t strides_data[] = {-1};
+ float golden[] = {3, 2};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_OutOfRangeEndNegativeStride) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {-3};
+ int32_t end_data[] = {-5};
+ int32_t strides_data[] = {-1};
+ float golden[] = {2, 1};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_EndMask) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 3};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {1};
+ int32_t end_data[] = {3};
+ int32_t strides_data[] = {1};
+ float golden[] = {2, 3, 4};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {0, 1, 0, 0, 0};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_NegStride) {
+ const int input_shape[] = {1, 3};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 3};
+ float input_data[] = {1, 2, 3};
+ int32_t begin_data[] = {-1};
+ int32_t end_data[] = {-4};
+ int32_t strides_data[] = {-1};
+ float golden[] = {3, 2, 1};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_EvenLenStride2) {
+ const int input_shape[] = {1, 2};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 1};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {0};
+ int32_t end_data[] = {4};
+ int32_t strides_data[] = {2};
+ float golden[] = {1};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_OddLenStride2) {
+ const int input_shape[] = {1, 3};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4};
+ int32_t begin_data[] = {0};
+ int32_t end_data[] = {3};
+ int32_t strides_data[] = {2};
+ float golden[] = {1, 3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_Identity) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 2, 3};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {0, 0};
+ int32_t end_data[] = {2, 3};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {1, 2, 3, 4, 5, 6};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 1, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {1, 0};
+ int32_t end_data[] = {2, 2};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {4, 5};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_Stride2) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 1, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {0, 0};
+ int32_t end_data[] = {2, 3};
+ int32_t strides_data[] = {2, 2};
+ float golden[] = {1, 3};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_NegStride) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 1, 3};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {1, -1};
+ int32_t end_data[] = {2, -4};
+ int32_t strides_data[] = {2, -1};
+ float golden[] = {6, 5, 4};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_BeginMask) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 2, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {1, 0};
+ int32_t end_data[] = {2, 2};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {1, 2, 4, 5};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {1, 0, 0, 0, 0};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_EndMask) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 1, 3};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {1, 0};
+ int32_t end_data[] = {2, 2};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {4, 5, 6};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {0, 2, 0, 0, 0};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_NegStrideBeginMask) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 1, 3};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {1, -2};
+ int32_t end_data[] = {2, -4};
+ int32_t strides_data[] = {1, -1};
+ float golden[] = {6, 5, 4};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {2, 0, 0, 0, 0};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_NegStrideEndMask) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 1, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {1, -2};
+ int32_t end_data[] = {2, -3};
+ int32_t strides_data[] = {1, -1};
+ float golden[] = {5, 4};
+ float output_data[8];
+
+ TfLiteStridedSliceParams builtin_data = {0, 2, 0, 0, 0};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_Identity) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {3, 2, 3, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {2, 3, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_NegStride) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {3, 2, 3, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {2, 3, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_Strided2) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {3, 1, 2, 1};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {2, 3, 2};
+ int32_t strides_data[] = {2, 2, 2};
+ float golden[] = {1, 5};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_ShrinkAxisMask1) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {3, 2, 3, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {2, 3, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_ShrinkAxisMask1_NegativeSlice) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {0};
+ float input_data[] = {0, 1, 2, 3};
+ int32_t begin_data[] = {-1};
+ int32_t end_data[] = {0};
+ int32_t strides_data[] = {1};
+ float golden[] = {3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 1};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_ShrinkAxis3_NegativeSlice) {
+ const int input_shape[] = {2, 4, 1};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {0};
+ float input_data[] = {0, 1, 2, 3};
+ int32_t begin_data[] = {-2, -1};
+ int32_t end_data[] = {-1, 0};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {2};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 3};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_ShrinkAxis2_BeginEndAxis1_NegativeSlice) {
+ const int input_shape[] = {2, 4, 1};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {1, 4};
+ float input_data[] = {0, 1, 2, 3};
+ int32_t begin_data[] = {0, -1};
+ int32_t end_data[] = {0, 0};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {0, 1, 2, 3};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {1, 1, 0, 0, 2};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In1D_BeginMaskShrinkAxisMask1) {
+ const int input_shape[] = {1, 4};
+ const int begin_shape[] = {1, 1};
+ const int end_shape[] = {1, 1};
+ const int strides_shape[] = {1, 1};
+ const int output_shape[] = {0};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {1};
+ int32_t end_data[] = {1};
+ int32_t strides_data[] = {1};
+ float golden[] = {1};
+ float output_data[4];
+
+ TfLiteStridedSliceParams builtin_data = {1, 0, 0, 0, 1};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_ShrinkAxisMask1) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {1, 3};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {0, 0};
+ int32_t end_data[] = {1, 3};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {1, 2, 3};
+ float output_data[6];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 1};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_ShrinkAxisMask2) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {0, 0};
+ int32_t end_data[] = {2, 1};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {1, 4};
+ float output_data[6];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 2};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In2D_ShrinkAxisMask3) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {0};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {0, 0};
+ int32_t end_data[] = {1, 1};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {1};
+ float output_data[6];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 3};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis1) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {2, 3, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {1, 3, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 2, 3, 4, 5, 6};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 1};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis2) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {2, 2, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {2, 1, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 2, 7, 8};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 2};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis3) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {1, 1, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 2};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 3};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis4) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {2, 2, 3};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {2, 3, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 3, 5, 7, 9, 11};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 4};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis5) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {1, 3};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {1, 3, 1};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 3, 5};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 5};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis6) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {1, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {2, 1, 1};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1, 7};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 6};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis7) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {0};
+ float input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {1, 1, 1};
+ int32_t strides_data[] = {1, 1, 1};
+ float golden[] = {1};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 7};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+// This tests catches a very subtle bug that was fixed by cl/188403234.
+TF_LITE_MICRO_TEST(RunTwice) {
+ const int input_shape[] = {2, 2, 3};
+ const int begin_shape[] = {1, 2};
+ const int end_shape[] = {1, 2};
+ const int strides_shape[] = {1, 2};
+ const int output_shape[] = {2, 2, 2};
+ float input_data[] = {1, 2, 3, 4, 5, 6};
+ int32_t begin_data[] = {1, 0};
+ int32_t end_data[] = {2, 2};
+ int32_t strides_data[] = {1, 1};
+ float golden[] = {1, 2, 4, 5};
+ float output_data[16];
+
+ TfLiteStridedSliceParams builtin_data = {1, 0, 0, 0, 0};
+
+ tflite::testing::TestStridedSliceFloat(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false, 2);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis1Uint8) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {2, 3, 2};
+ uint8_t input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {1, 3, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ uint8_t golden[] = {1, 2, 3, 4, 5, 6};
+ uint8_t output_data[12];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 1};
+
+ tflite::testing::TestStridedSliceQuantized(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TEST(In3D_IdentityShrinkAxis1int8) {
+ const int input_shape[] = {3, 2, 3, 2};
+ const int begin_shape[] = {1, 3};
+ const int end_shape[] = {1, 3};
+ const int strides_shape[] = {1, 3};
+ const int output_shape[] = {2, 3, 2};
+ int8_t input_data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
+ int32_t begin_data[] = {0, 0, 0};
+ int32_t end_data[] = {1, 3, 2};
+ int32_t strides_data[] = {1, 1, 1};
+ int8_t golden[] = {1, 2, 3, 4, 5, 6};
+ int8_t output_data[12];
+
+ TfLiteStridedSliceParams builtin_data = {0, 0, 0, 0, 1};
+
+ tflite::testing::TestStridedSliceQuantized(
+ input_shape, begin_shape, end_shape, strides_shape, &builtin_data,
+ input_data, begin_data, end_data, strides_data, output_shape, output_data,
+ golden, false);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/sub.cc b/tensorflow/lite/micro/kernels/sub.cc
new file mode 100644
index 0000000..2cc61a9
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/sub.cc
@@ -0,0 +1,256 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/sub.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace sub {
+
+constexpr int kInputTensor1 = 0;
+constexpr int kInputTensor2 = 1;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ bool requires_broadcast;
+
+ // These fields are used in both the general 8-bit -> 8bit quantized path,
+ // and the special 16-bit -> 16bit quantized path
+ int input1_shift;
+ int input2_shift;
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+
+ // These fields are used only in the general 8-bit -> 8bit quantized path
+ int32_t input1_multiplier;
+ int32_t input2_multiplier;
+ int32_t output_multiplier;
+ int output_shift;
+ int left_shift;
+ int32_t input1_offset;
+ int32_t input2_offset;
+ int32_t output_offset;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteSubParams* params,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2, TfLiteTensor* output,
+ OpData* data) {
+ data->requires_broadcast = !HaveSameShapes(input1, input2);
+
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ // 8bit -> 8bit general quantized path, with general rescalings
+ data->input1_offset = -input1->params.zero_point;
+ data->input2_offset = -input2->params.zero_point;
+ data->output_offset = output->params.zero_point;
+ data->left_shift = 20;
+ const float twice_max_input_scale =
+ 2 * std::max(input1->params.scale, input2->params.scale);
+ const double real_input1_multiplier =
+ static_cast<double>(input1->params.scale / twice_max_input_scale);
+ const double real_input2_multiplier =
+ static_cast<double>(input2->params.scale / twice_max_input_scale);
+ const double real_output_multiplier =
+ static_cast<double>(twice_max_input_scale /
+ ((1 << data->left_shift) * output->params.scale));
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_input1_multiplier, &data->input1_multiplier, &data->input1_shift);
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_input2_multiplier, &data->input2_multiplier, &data->input2_shift);
+
+ QuantizeMultiplierSmallerThanOneExp(
+ real_output_multiplier, &data->output_multiplier, &data->output_shift);
+
+ TF_LITE_ENSURE_STATUS(CalculateActivationRangeQuantized(
+ context, params->activation, output, &data->output_activation_min,
+ &data->output_activation_max));
+ }
+
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ auto* params = reinterpret_cast<TfLiteSubParams*>(node->builtin_data);
+
+ const TfLiteTensor* input1 = GetInput(context, node, kInputTensor1);
+ TF_LITE_ENSURE(context, input1 != nullptr);
+ const TfLiteTensor* input2 = GetInput(context, node, kInputTensor2);
+ TF_LITE_ENSURE(context, input2 != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_STATUS(
+ CalculateOpData(context, params, input1, input2, output, data));
+ return kTfLiteOk;
+}
+
+void EvalSub(TfLiteContext* context, TfLiteNode* node, TfLiteSubParams* params,
+ const OpData* data, const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2, TfLiteEvalTensor* output) {
+ float output_activation_min, output_activation_max;
+ CalculateActivationRange(params->activation, &output_activation_min,
+ &output_activation_max);
+ tflite::ArithmeticParams op_params;
+ SetActivationParams(output_activation_min, output_activation_max, &op_params);
+ if (data->requires_broadcast) {
+ tflite::reference_ops::BroadcastSubSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<float>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<float>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ } else {
+ tflite::reference_ops::SubWithActivation(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<float>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<float>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ }
+}
+
+TfLiteStatus EvalSubQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLiteSubParams* params, const OpData* data,
+ const TfLiteEvalTensor* input1,
+ const TfLiteEvalTensor* input2,
+ TfLiteEvalTensor* output) {
+ if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ tflite::ArithmeticParams op_params;
+ op_params.left_shift = data->left_shift;
+ op_params.input1_offset = data->input1_offset;
+ op_params.input1_multiplier = data->input1_multiplier;
+ op_params.input1_shift = data->input1_shift;
+ op_params.input2_offset = data->input2_offset;
+ op_params.input2_multiplier = data->input2_multiplier;
+ op_params.input2_shift = data->input2_shift;
+ op_params.output_offset = data->output_offset;
+ op_params.output_multiplier = data->output_multiplier;
+ op_params.output_shift = data->output_shift;
+ SetActivationParams(data->output_activation_min,
+ data->output_activation_max, &op_params);
+ bool need_broadcast = reference_ops::ProcessBroadcastShapes(
+ tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorShape(input2), &op_params);
+
+ if (output->type == kTfLiteInt8) {
+ if (need_broadcast) {
+ tflite::reference_ops::BroadcastSubSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<int8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ } else {
+ tflite::reference_ops::Sub(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<int8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<int8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ }
+ } else {
+ if (need_broadcast) {
+ tflite::reference_ops::BroadcastSubSlow(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<uint8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<uint8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ } else {
+ tflite::reference_ops::Sub(
+ op_params, tflite::micro::GetTensorShape(input1),
+ tflite::micro::GetTensorData<uint8_t>(input1),
+ tflite::micro::GetTensorShape(input2),
+ tflite::micro::GetTensorData<uint8_t>(input2),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+ }
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = reinterpret_cast<TfLiteSubParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input1 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor1);
+ const TfLiteEvalTensor* input2 =
+ tflite::micro::GetEvalInput(context, node, kInputTensor2);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ if (output->type == kTfLiteFloat32) {
+ EvalSub(context, node, params, &data, input1, input2, output);
+ } else if (output->type == kTfLiteUInt8 || output->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_OK(context, EvalSubQuantized(context, node, params, &data,
+ input1, input2, output));
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(output->type), output->type);
+ return kTfLiteError;
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace sub
+
+TfLiteRegistration Register_SUB() {
+ return {/*init=*/sub::Init,
+ /*free=*/nullptr,
+ /*prepare=*/sub::Prepare,
+ /*invoke=*/sub::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/sub_test.cc b/tensorflow/lite/micro/kernels/sub_test.cc
new file mode 100644
index 0000000..83da86f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/sub_test.cc
@@ -0,0 +1,493 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <cstdint>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Shapes and values for mixed broadcast tests.
+const int broadcast_output_dims_count = 36;
+const int broadcast_num_shapes = 4;
+
+const int broadcast_input1_shape[] = {4, 2, 3, 1, 2};
+const float broadcast_input1_values[] = {-0.3, 2.3, 0.9, 0.5, 0.8, -1.1,
+ 1.2, 2.8, -1.6, 0.0, 0.7, -2.2};
+const float broadcast_input2_values[] = {-0.2, -0.3, 0.4, -0.5, -1.0, -0.9};
+const float
+ broadcast_goldens[broadcast_num_shapes][broadcast_output_dims_count] = {
+ {-0.1, 2.6, -0.7, 2.8, 0.7, 3.2, 1.1, 0.8, 0.5, 1.0, 1.9, 1.4,
+ 1.0, -0.8, 0.4, -0.6, 1.8, -0.2, 1.4, 3.1, 0.8, 3.3, 2.2, 3.7,
+ -1.4, 0.3, -2.0, 0.5, -0.6, 0.9, 0.9, -1.9, 0.3, -1.7, 1.7, -1.3},
+ {-0.1, 2.6, 0.5, 1.0, 1.8, -0.2, 1.4, 3.1, -2.0, 0.5, 1.7, -1.3},
+ {-0.1, 2.5, 0.0, 2.6, -0.7, 1.9, 1.1, 0.7, 1.2, 0.8, 0.5, 0.1,
+ 1.0, -0.9, 1.1, -0.8, 0.4, -1.5, 1.7, 3.3, 2.2, 3.8, 2.1, 3.7,
+ -1.1, 0.5, -0.6, 1.0, -0.7, 0.9, 1.2, -1.7, 1.7, -1.2, 1.6, -1.3},
+ {-0.1, 2.5, 1.2, 0.8, 0.4, -1.5, 1.7, 3.3, -0.6, 1.0, 1.6, -1.3},
+};
+
+const int broadcast_max_shape_size = 5;
+const int broadcast_input2_shapes[broadcast_num_shapes]
+ [broadcast_max_shape_size] = {
+ {4, 1, 1, 3, 2},
+ {4, 1, 3, 1, 2},
+ {4, 2, 1, 3, 1},
+ {4, 2, 3, 1, 1},
+};
+const int broadcast_output_shapes[broadcast_num_shapes]
+ [broadcast_max_shape_size] = {
+ {4, 2, 3, 3, 2},
+ {4, 2, 3, 1, 2},
+ {4, 2, 3, 3, 2},
+ {4, 2, 3, 1, 2},
+};
+
+template <typename T>
+void ValidateSubGoldens(TfLiteTensor* tensors, int tensors_size,
+ const T* golden, T* output, int output_size,
+ TfLiteFusedActivation activation,
+ float tolerance = 1e-5) {
+ TfLiteSubParams builtin_data;
+ builtin_data.activation = activation;
+
+ int inputs_array_data[] = {2, 0, 1};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 2};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_SUB();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, &builtin_data);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_size; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(golden[i], output[i], tolerance);
+ }
+}
+
+void TestSubFloat(const int* input1_dims_data, const float* input1_data,
+ const int* input2_dims_data, const float* input2_data,
+ const int* output_dims_data, const float* expected_output,
+ TfLiteFusedActivation activation, float* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input1_data, input1_dims),
+ CreateTensor(input2_data, input2_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateSubGoldens(tensors, tensors_size, expected_output, output_data,
+ ElementCount(*output_dims), activation);
+}
+
+template <typename T>
+void TestSubQuantized(const int* input1_dims_data, const float* input1_data,
+ T* input1_quantized, float input1_scale,
+ int input1_zero_point, const int* input2_dims_data,
+ const float* input2_data, T* input2_quantized,
+ float input2_scale, int input2_zero_point,
+ const int* output_dims_data, const float* golden,
+ T* golden_quantized, float output_scale,
+ int output_zero_point, TfLiteFusedActivation activation,
+ T* output_data) {
+ TfLiteIntArray* input1_dims = IntArrayFromInts(input1_dims_data);
+ TfLiteIntArray* input2_dims = IntArrayFromInts(input2_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+
+ constexpr int inputs_size = 2;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ tflite::testing::CreateQuantizedTensor(input1_data, input1_quantized,
+ input1_dims, input1_scale,
+ input1_zero_point),
+ tflite::testing::CreateQuantizedTensor(input2_data, input2_quantized,
+ input2_dims, input2_scale,
+ input2_zero_point),
+ tflite::testing::CreateQuantizedTensor(output_data, output_dims,
+ output_scale, output_zero_point),
+ };
+ tflite::Quantize(golden, golden_quantized, ElementCount(*output_dims),
+ output_scale, output_zero_point);
+
+ ValidateSubGoldens(tensors, tensors_size, golden_quantized, output_data,
+ ElementCount(*output_dims), activation);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatSubNoActivation) {
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8};
+ const float input2_values[] = {0.1, 0.2, 0.3, 0.5};
+ const float golden_values[] = {-2.1, 0.0, 0.4, 0.3};
+ float output_data[output_dims_count];
+ tflite::testing::TestSubFloat(inout_shape, input1_values, inout_shape,
+ input2_values, inout_shape, golden_values,
+ kTfLiteActNone, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatSubActivationRelu1) {
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.0, 0.2, 2.0, 0.8};
+ const float input2_values[] = {2.0, 0.2, 0.3, 0.5};
+ const float golden_values[] = {-1.0, 0.0, 1.0, 0.3};
+
+ float output_data[output_dims_count];
+ tflite::testing::TestSubFloat(inout_shape, input1_values, inout_shape,
+ input2_values, inout_shape, golden_values,
+ kTfLiteActReluN1To1, output_data);
+}
+
+TF_LITE_MICRO_TEST(FloatSubVariousInputShapes) {
+ const int output_dims_count = 6;
+ float output_data[output_dims_count];
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const float input2_values[] = {0.1, 0.2, 0.3, 0.5, 1.1, 0.1};
+ const float expected_output[] = {-2.1, 0.0, 0.4, 0.3, 0.0, 1.9};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestSubFloat(test_shapes[i], input1_values, test_shapes[i],
+ input2_values, test_shapes[i],
+ expected_output, kTfLiteActNone, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(FloatSubWithScalarBroadcast) {
+ const int output_dims_count = 6;
+ float output_data[output_dims_count];
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const int input2_shape[] = {0};
+ const float input2_values[] = {0.1};
+ const float expected_output[] = {-2.1, 0.1, 0.6, 0.7, 1.0, 1.9};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestSubFloat(test_shapes[i], input1_values, input2_shape,
+ input2_values, test_shapes[i],
+ expected_output, kTfLiteActNone, output_data);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubNoActivationUint8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {125, 129, 135};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {-1.01, -1.99, -2.99, -4.02};
+ const float golden_values[] = {-1, 1, 3, 5};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ tflite::testing::TestSubQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActNone, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubNoActivationInt8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {-10, 4, 13};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {-1.01, -1.99, -2.99, -4.02};
+ const float golden_values[] = {-1, 1, 3, 5};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ tflite::testing::TestSubQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActNone, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubActivationRelu1Uint8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {125, 129, 135};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {-1.01, -1.99, -2.99, -4.02};
+ const float golden_values[] = {-1, 1, 1, 1};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ tflite::testing::TestSubQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActReluN1To1, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubActivationRelu1Int8) {
+ const float scales[] = {0.25, 0.5, 1.0};
+ const int zero_points[] = {-10, 4, 13};
+ const int output_dims_count = 4;
+ const int inout_shape[] = {4, 1, 2, 2, 1};
+ const float input1_values[] = {-2.01, -1.01, -0.01, 0.98};
+ const float input2_values[] = {-1.01, -1.99, -2.99, -4.02};
+ const float golden_values[] = {-1, 1, 1, 1};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ tflite::testing::TestSubQuantized(
+ inout_shape, input1_values, input1_quantized, scales[0], zero_points[0],
+ inout_shape, input2_values, input2_quantized, scales[1], zero_points[1],
+ inout_shape, golden_values, golden_quantized, scales[2], zero_points[2],
+ kTfLiteActReluN1To1, output);
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubVariousInputShapesUint8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {120, 130, 139};
+ const int output_dims_count = 6;
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const float input2_values[] = {-0.1, -0.2, -0.3, -0.5, -1.1, -0.1};
+ const float golden_values[] = {-1.9, 0.4, 1.0, 1.3, 2.2, 2.1};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; i++) {
+ tflite::testing::TestSubQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], test_shapes[i], input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden_values,
+ golden_quantized, scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubVariousInputShapesInt8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {-9, 5, 14};
+ const int output_dims_count = 6;
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const float input2_values[] = {-0.1, -0.2, -0.3, -0.5, -1.1, -0.1};
+ const float golden_values[] = {-1.9, 0.4, 1.0, 1.3, 2.2, 2.1};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; i++) {
+ tflite::testing::TestSubQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], test_shapes[i], input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden_values,
+ golden_quantized, scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubWithScalarBroadcastUint8) {
+ const int output_dims_count = 6;
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const int input2_shape[] = {0};
+ const float input2_values[] = {-0.1};
+ const float golden[] = {-1.9, 0.3, 0.8, 0.9, 1.2, 2.1};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float scales[] = {0.1, 0.1, 0.1};
+ const int zero_points[] = {120, 131, 139};
+
+ uint8_t input1_quantized[output_dims_count];
+ uint8_t input2_quantized[output_dims_count];
+ uint8_t golden_quantized[output_dims_count];
+ uint8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestSubQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], input2_shape, input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden, golden_quantized,
+ scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+TF_LITE_MICRO_TEST(QuantizedSubWithScalarBroadcastFloat) {
+ float output_float[tflite::testing::broadcast_output_dims_count];
+
+ for (int i = 0; i < tflite::testing::broadcast_num_shapes; ++i) {
+ tflite::testing::TestSubFloat(tflite::testing::broadcast_input1_shape,
+ tflite::testing::broadcast_input1_values,
+ tflite::testing::broadcast_input2_shapes[i],
+ tflite::testing::broadcast_input2_values,
+ tflite::testing::broadcast_output_shapes[i],
+ tflite::testing::broadcast_goldens[i],
+ kTfLiteActNone, output_float);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubWithScalarBroadcastInt8) {
+ const int output_dims_count = 6;
+
+ const float input1_values[] = {-2.0, 0.2, 0.7, 0.8, 1.1, 2.0};
+ const int input2_shape[] = {0};
+ const float input2_values[] = {-0.1};
+ const float golden[] = {-1.9, 0.3, 0.8, 0.9, 1.2, 2.1};
+
+ constexpr int num_shapes = 4;
+ constexpr int max_shape_size = 5;
+ const int test_shapes[num_shapes][max_shape_size] = {
+ {1, 6},
+ {2, 2, 3},
+ {3, 2, 1, 3},
+ {4, 1, 3, 1, 2},
+ };
+
+ const float scales[] = {0.1, 0.05, 0.05};
+ const int zero_points[] = {-8, 4, 12};
+
+ int8_t input1_quantized[output_dims_count];
+ int8_t input2_quantized[output_dims_count];
+ int8_t golden_quantized[output_dims_count];
+ int8_t output[output_dims_count];
+
+ for (int i = 0; i < num_shapes; ++i) {
+ tflite::testing::TestSubQuantized(
+ test_shapes[i], input1_values, input1_quantized, scales[0],
+ zero_points[0], input2_shape, input2_values, input2_quantized,
+ scales[1], zero_points[1], test_shapes[i], golden, golden_quantized,
+ scales[2], zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubWithMixedBroadcastUint8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {127, 131, 139};
+ uint8_t input1_quantized[tflite::testing::broadcast_output_dims_count];
+ uint8_t input2_quantized[tflite::testing::broadcast_output_dims_count];
+ uint8_t golden_quantized[tflite::testing::broadcast_output_dims_count];
+ uint8_t output[tflite::testing::broadcast_output_dims_count];
+
+ for (int i = 0; i < tflite::testing::broadcast_num_shapes; ++i) {
+ tflite::testing::TestSubQuantized(
+ tflite::testing::broadcast_input1_shape,
+ tflite::testing::broadcast_input1_values, input1_quantized, scales[0],
+ zero_points[0], tflite::testing::broadcast_input2_shapes[i],
+ tflite::testing::broadcast_input2_values, input2_quantized, scales[1],
+ zero_points[1], tflite::testing::broadcast_output_shapes[i],
+ tflite::testing::broadcast_goldens[i], golden_quantized, scales[2],
+ zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TEST(QuantizedSubWithMixedBroadcastInt8) {
+ const float scales[] = {0.1, 0.05, 0.1};
+ const int zero_points[] = {-10, -5, 7};
+ int8_t input1_quantized[tflite::testing::broadcast_output_dims_count];
+ int8_t input2_quantized[tflite::testing::broadcast_output_dims_count];
+ int8_t golden_quantized[tflite::testing::broadcast_output_dims_count];
+ int8_t output[tflite::testing::broadcast_output_dims_count];
+
+ for (int i = 0; i < tflite::testing::broadcast_num_shapes; ++i) {
+ tflite::testing::TestSubQuantized(
+ tflite::testing::broadcast_input1_shape,
+ tflite::testing::broadcast_input1_values, input1_quantized, scales[0],
+ zero_points[0], tflite::testing::broadcast_input2_shapes[i],
+ tflite::testing::broadcast_input2_values, input2_quantized, scales[1],
+ zero_points[1], tflite::testing::broadcast_output_shapes[i],
+ tflite::testing::broadcast_goldens[i], golden_quantized, scales[2],
+ zero_points[2], kTfLiteActNone, output);
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/svdf.cc b/tensorflow/lite/micro/kernels/svdf.cc
new file mode 100644
index 0000000..cd22e31
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/svdf.cc
@@ -0,0 +1,97 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/svdf.h"
+
+#include <math.h>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/activation_utils.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace {
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = reinterpret_cast<TfLiteSVDFParams*>(node->builtin_data);
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kSvdfInputTensor);
+ const TfLiteEvalTensor* weights_feature =
+ tflite::micro::GetEvalInput(context, node, kSvdfWeightsFeatureTensor);
+ const TfLiteEvalTensor* weights_time =
+ tflite::micro::GetEvalInput(context, node, kSvdfWeightsTimeTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 5)
+ ? tflite::micro::GetEvalInput(context, node, kSvdfBiasTensor)
+ : nullptr;
+ TfLiteEvalTensor* activation_state = tflite::micro::GetMutableEvalInput(
+ context, node, kSvdfInputActivationStateTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kSvdfOutputTensor);
+
+ switch (weights_feature->type) {
+ case kTfLiteFloat32: {
+ EvalFloatSvdfReference(
+ context, node, input, weights_feature, weights_time, bias, params,
+ data.scratch_tensor_index, activation_state, output);
+ return kTfLiteOk;
+ break;
+ }
+
+ case kTfLiteInt8: {
+ EvalIntegerSvdfReference(context, node, input, weights_feature,
+ weights_time, bias, params, activation_state,
+ output, data);
+ return kTfLiteOk;
+ break;
+ }
+
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s not currently supported.",
+ TfLiteTypeGetName(weights_feature->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_SVDF() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/PrepareSvdf,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/svdf.h b/tensorflow/lite/micro/kernels/svdf.h
new file mode 100644
index 0000000..d04787b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/svdf.h
@@ -0,0 +1,71 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_SVDF_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_SVDF_H_
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+struct OpData {
+ int32_t effective_scale_1_a;
+ int32_t effective_scale_2_a;
+ // b versions of each scale are kept at int since the numbers are just the
+ // shift value - typically between [-32, 32].
+ int effective_scale_1_b;
+ int effective_scale_2_b;
+ int scratch_tensor_index;
+ int scratch_output_tensor_index;
+
+ // Cached tensor zero point values for quantized operations.
+ int input_zero_point;
+ int output_zero_point;
+};
+
+// Input tensors.
+extern const int kSvdfInputTensor;
+extern const int kSvdfWeightsFeatureTensor;
+extern const int kSvdfWeightsTimeTensor;
+extern const int kSvdfBiasTensor;
+// This is a variable tensor, and will be modified by this op.
+extern const int kSvdfInputActivationStateTensor;
+
+// Output tensor.
+extern const int kSvdfOutputTensor;
+
+// TensorflowLite Micro-specific reference implementation for Integer SVDF.
+void EvalIntegerSvdfReference(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input_tensor,
+ const TfLiteEvalTensor* weights_feature_tensor,
+ const TfLiteEvalTensor* weights_time_tensor,
+ const TfLiteEvalTensor* bias_tensor,
+ const TfLiteSVDFParams* params,
+ TfLiteEvalTensor* activation_state_tensor,
+ TfLiteEvalTensor* output_tensor,
+ const OpData& data);
+
+void EvalFloatSvdfReference(
+ TfLiteContext* context, TfLiteNode* node, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* weights_feature,
+ const TfLiteEvalTensor* weights_time, const TfLiteEvalTensor* bias,
+ const TfLiteSVDFParams* params, int scratch_tensor_index,
+ TfLiteEvalTensor* activation_state, TfLiteEvalTensor* output);
+
+TfLiteStatus PrepareSvdf(TfLiteContext* context, TfLiteNode* node);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_SVDF_H_
diff --git a/tensorflow/lite/micro/kernels/svdf_common.cc b/tensorflow/lite/micro/kernels/svdf_common.cc
new file mode 100644
index 0000000..12e697b
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/svdf_common.cc
@@ -0,0 +1,469 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <math.h>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/activation_utils.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/svdf.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+
+/**
+ * This version of SVDF is specific to TFLite Micro. It contains the following
+ * differences between the TFLite version:
+ *
+ * 1.) Scratch tensor allocation - scratch tensors must be known ahead of time
+ * for the Micro interpreter.
+ * 2.) Output dimensions - the TFLite version determines output size and runtime
+ * and resizes the output tensor. Micro runtime does not support tensor
+ * resizing.
+ */
+
+const int kSvdfInputTensor = 0;
+const int kSvdfWeightsFeatureTensor = 1;
+const int kSvdfWeightsTimeTensor = 2;
+const int kSvdfBiasTensor = 3;
+const int kSvdfInputActivationStateTensor =
+ 4; // This is a variable tensor, and will be modified by this op.
+const int kSvdfOutputTensor = 0;
+
+void EvalIntegerSvdfReference(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input_tensor,
+ const TfLiteEvalTensor* weights_feature_tensor,
+ const TfLiteEvalTensor* weights_time_tensor,
+ const TfLiteEvalTensor* bias_tensor,
+ const TfLiteSVDFParams* params,
+ TfLiteEvalTensor* activation_state_tensor,
+ TfLiteEvalTensor* output_tensor,
+ const OpData& data) {
+ const int n_rank = params->rank;
+ const int n_batch = input_tensor->dims->data[0];
+ const int n_input = input_tensor->dims->data[1];
+ const int n_filter = weights_feature_tensor->dims->data[0];
+ const int n_unit = n_filter / n_rank;
+ const int n_memory = weights_time_tensor->dims->data[1];
+
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer != nullptr);
+
+ int32_t* scratch_tensor = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, data.scratch_tensor_index));
+ int32_t* scratch_output_tensor = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, data.scratch_output_tensor_index));
+
+ // Shift states.
+ int16_t* const state_ptr =
+ tflite::micro::GetTensorData<int16_t>(activation_state_tensor);
+
+ // Left shift the activation_state.
+ {
+ int16_t* new_state_start = state_ptr;
+ const int16_t* old_state_start = state_ptr + 1;
+ const int16_t* old_state_end = state_ptr + n_batch * n_filter * n_memory;
+ while (old_state_start != old_state_end) {
+ *new_state_start++ = *old_state_start++;
+ }
+ }
+
+ // Note: no need to clear the latest activation, matmul is not accumulative.
+
+ // Feature matmul.
+ {
+ int16_t* state =
+ tflite::micro::GetTensorData<int16_t>(activation_state_tensor);
+ const int8_t* input = tflite::micro::GetTensorData<int8_t>(input_tensor);
+ const int8_t* weight_feature =
+ tflite::micro::GetTensorData<int8_t>(weights_feature_tensor);
+ const int32_t output_max = std::numeric_limits<int16_t>::max();
+ const int32_t output_min = std::numeric_limits<int16_t>::min();
+ int16_t* result_in_batch = state + (n_memory - 1);
+ for (int b = 0; b < n_batch; b++) {
+ const int8_t* matrix_ptr = weight_feature;
+ for (int r = 0; r < n_filter; r++) {
+ int32_t dot_prod = 0;
+ const int8_t* vector_in_batch = input + b * n_input;
+ for (int c = 0; c < n_input; c++) {
+ dot_prod +=
+ *matrix_ptr++ * (*vector_in_batch++ - data.input_zero_point);
+ }
+ dot_prod = MultiplyByQuantizedMultiplier(
+ dot_prod, data.effective_scale_1_a, data.effective_scale_1_b);
+ dot_prod = std::min(std::max(output_min, dot_prod), output_max);
+ // This assumes state is symmetrically quantized. Otherwise last bit of
+ // state should be initialized to its zero point and accumulate the
+ // dot_prod.
+ // Equivalent as the following:
+ // result_in_batch = zero point, which happens to be zero.
+ // result_in_batch += dot_prod_56.
+ *result_in_batch = dot_prod;
+ result_in_batch += n_memory;
+ }
+ }
+ }
+
+ // Time.
+ {
+ for (int b = 0; b < n_batch; ++b) {
+ int32_t* scratch_ptr_batch = scratch_tensor + b * n_filter;
+
+ // Perform batched vector dot product:
+ const int16_t* vector1_ptr =
+ tflite::micro::GetTensorData<int16_t>(weights_time_tensor);
+ const int16_t* vector2_ptr =
+ tflite::micro::GetTensorData<int16_t>(activation_state_tensor) +
+ b * n_memory * n_filter;
+
+ for (int i = 0; i < n_filter; i++) {
+ *scratch_ptr_batch = 0;
+ for (int j = 0; j < n_memory; j++) {
+ *scratch_ptr_batch += *vector1_ptr++ * *vector2_ptr++;
+ }
+ scratch_ptr_batch++;
+ }
+ }
+ }
+
+ // Reduce, add bias, rescale, activation.
+ {
+ // Add bias.
+ if (bias_tensor) {
+ // Vector batch assign:
+ const int32_t* bias_data =
+ tflite::micro::GetTensorData<int32_t>(bias_tensor);
+ for (int i = 0; i < n_batch; ++i) {
+ int32_t* output_ptr = scratch_output_tensor + i * n_unit;
+ const int32_t* bias_ptr = bias_data;
+ for (int j = 0; j < n_unit; ++j) {
+ *output_ptr++ = *bias_ptr++;
+ }
+ }
+ } else {
+ int32_t* output_ptr = scratch_output_tensor;
+ for (int i = 0; i < n_batch * n_unit; ++i) {
+ *output_ptr++ = 0;
+ }
+ }
+
+ // Reduce.
+ for (int b = 0; b < n_batch; ++b) {
+ int32_t* output_temp_ptr = scratch_output_tensor + b * n_unit;
+ int32_t* scratch_ptr_batch = scratch_tensor + b * n_filter;
+
+ // Reduction sum vector
+ for (int i = 0; i < n_unit; ++i) {
+ for (int j = 0; j < n_rank; ++j) {
+ output_temp_ptr[i] += *scratch_ptr_batch++;
+ }
+ }
+ }
+
+ // Rescale.
+ const int32_t output_max = std::numeric_limits<int8_t>::max();
+ const int32_t output_min = std::numeric_limits<int8_t>::min();
+ for (int i = 0; i < n_batch * n_unit; ++i) {
+ int32_t x1 = scratch_output_tensor[i];
+ int32_t x2 = MultiplyByQuantizedMultiplier(x1, data.effective_scale_2_a,
+ data.effective_scale_2_b);
+ int32_t x3 = x2 + data.output_zero_point;
+ int32_t x4 = std::min(std::max(output_min, x3), output_max);
+ tflite::micro::GetTensorData<int8_t>(output_tensor)[i] =
+ static_cast<int8_t>(x4);
+ }
+ }
+}
+static inline void ApplyTimeWeightsBiasAndActivation(
+ int batch_size, int memory_size, int num_filters, int num_units, int rank,
+ const float* const __restrict__ weights_time_ptr,
+ const float* const __restrict__ bias_ptr, TfLiteFusedActivation activation,
+ float* const __restrict__ state_ptr, float* const __restrict__ scratch_ptr,
+ float* const __restrict__ output_ptr) {
+ // Compute matmul(activation_state, weights_time).
+ for (int b = 0; b < batch_size; ++b) {
+ // Perform batched vector dot product:
+ float* scratch_ptr_batch = scratch_ptr + b * num_filters;
+ const float* vector1_ptr = weights_time_ptr;
+ const float* vector2_ptr = state_ptr + b * memory_size * num_filters;
+ for (int i = 0; i < num_filters; ++i) {
+ *scratch_ptr_batch = 0.f;
+ for (int j = 0; j < memory_size; ++j) {
+ *scratch_ptr_batch += *vector1_ptr++ * *vector2_ptr++;
+ }
+ scratch_ptr_batch++;
+ }
+ }
+
+ // Initialize output with bias if provided.
+ if (bias_ptr) {
+ // VectorBatchVectorAssign
+ for (int i = 0; i < batch_size; ++i) {
+ float* output_data = output_ptr + i * num_units;
+ const float* bias_data = bias_ptr;
+ for (int j = 0; j < num_units; ++j) {
+ *output_data++ = *bias_data++;
+ }
+ }
+ } else {
+ float* output_data = output_ptr;
+ for (int i = 0; i < batch_size * num_units; ++i) {
+ *output_data++ = 0.0f;
+ }
+ }
+
+ // Reduction sum.
+ for (int b = 0; b < batch_size; ++b) {
+ float* output_ptr_batch = output_ptr + b * num_units;
+ float* scratch_ptr_batch = scratch_ptr + b * num_filters;
+
+ // Reduction sum vector
+ for (int i = 0; i < num_units; ++i) {
+ for (int j = 0; j < rank; j++) {
+ output_ptr_batch[i] += *scratch_ptr_batch++;
+ }
+ }
+ }
+
+ // Apply activation.
+ for (int b = 0; b < batch_size; ++b) {
+ float* output_ptr_batch = output_ptr + b * num_units;
+ for (int i = 0; i < num_units; ++i) {
+ *output_ptr_batch =
+ tflite::ops::micro::ActivationValFloat(activation, *output_ptr_batch);
+ ++output_ptr_batch;
+ }
+ }
+}
+
+void EvalFloatSvdfReference(
+ TfLiteContext* context, TfLiteNode* node, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* weights_feature,
+ const TfLiteEvalTensor* weights_time, const TfLiteEvalTensor* bias,
+ const TfLiteSVDFParams* params, int scratch_tensor_index,
+ TfLiteEvalTensor* activation_state, TfLiteEvalTensor* output) {
+ const int rank = params->rank;
+ const int batch_size = input->dims->data[0];
+ const int input_size = input->dims->data[1];
+ const int num_filters = weights_feature->dims->data[0];
+ const int num_units = num_filters / rank;
+ const int memory_size = weights_time->dims->data[1];
+
+ const float* weights_feature_ptr =
+ tflite::micro::GetTensorData<float>(weights_feature);
+ const float* weights_time_ptr =
+ tflite::micro::GetTensorData<float>(weights_time);
+ const float* bias_ptr = tflite::micro::GetTensorData<float>(bias);
+ const float* input_ptr = tflite::micro::GetTensorData<float>(input);
+
+ float* state_ptr = tflite::micro::GetTensorData<float>(activation_state);
+
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer != nullptr);
+
+ float* scratch_ptr = static_cast<float*>(
+ context->GetScratchBuffer(context, scratch_tensor_index));
+
+ float* output_ptr = tflite::micro::GetTensorData<float>(output);
+
+ // Left shift the activation_state.
+ {
+ float* new_state_start = state_ptr;
+ const float* old_state_start = state_ptr + 1;
+ const float* old_state_end =
+ state_ptr + batch_size * num_filters * memory_size;
+ while (old_state_start != old_state_end) {
+ *new_state_start++ = *old_state_start++;
+ }
+ }
+
+ // Note: no need to clear the latest activation, matmul is not accumulative.
+
+ // Compute conv1d(inputs, weights_feature).
+ // The activation_state's rightmost column is used to save current cycle
+ // activation. This is achieved by starting at state_ptr[memory_size - 1] and
+ // having the stride equal to memory_size.
+
+ // Perform batched matrix vector multiply operation:
+ {
+ const float* matrix = weights_feature_ptr;
+ const float* vector = input_ptr;
+ float* result = &state_ptr[memory_size - 1];
+ float* result_in_batch = result;
+ for (int i = 0; i < batch_size; ++i) {
+ const float* matrix_ptr = matrix;
+ for (int j = 0; j < num_filters; ++j) {
+ float dot_prod = 0.0f;
+ const float* vector_in_batch = vector + i * input_size;
+ for (int k = 0; k < input_size; ++k) {
+ dot_prod += *matrix_ptr++ * *vector_in_batch++;
+ }
+ *result_in_batch = dot_prod;
+ result_in_batch += memory_size;
+ }
+ }
+ }
+
+ ApplyTimeWeightsBiasAndActivation(
+ batch_size, memory_size, num_filters, num_units, rank, weights_time_ptr,
+ bias_ptr, params->activation, state_ptr, scratch_ptr, output_ptr);
+}
+
+TfLiteStatus PrepareSvdf(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ const auto* params = static_cast<const TfLiteSVDFParams*>(node->builtin_data);
+
+ // Validate Tensor Inputs (dtype depends on quantization):
+ // [0] = Input, {2, batch_size, input_size}
+ // [1] = Weights Feature, {2, num_filters, input_size}
+ // [2] = Weights Time, {2, num_filters, memory_size}
+ // [3] = Bias (optional), {1, num_units}
+ // [4] = Activation State (variable),
+ // {2, batch_size, memory_size * num_filters}
+ const TfLiteTensor* input = GetInput(context, node, kSvdfInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* weights_feature =
+ GetInput(context, node, kSvdfWeightsFeatureTensor);
+ TF_LITE_ENSURE(context, weights_feature != nullptr);
+ const TfLiteTensor* weights_time =
+ GetInput(context, node, kSvdfWeightsTimeTensor);
+ TF_LITE_ENSURE(context, weights_time != nullptr);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kSvdfBiasTensor);
+ const TfLiteTensor* activation_state =
+ GetInput(context, node, kSvdfInputActivationStateTensor);
+ TF_LITE_ENSURE(context, activation_state != nullptr);
+
+ // Define input constants based on input tensor definition above:
+ const int rank = params->rank;
+ const int input_size = input->dims->data[1];
+ const int batch_size = input->dims->data[0];
+ const int num_filters = weights_feature->dims->data[0];
+ TF_LITE_ENSURE_EQ(context, num_filters % rank, 0);
+ const int num_units = num_filters / rank;
+ const int memory_size = weights_time->dims->data[1];
+
+ // Validate Input Tensor:
+ TF_LITE_ENSURE(context,
+ input->type == kTfLiteFloat32 || input->type == kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), 2);
+
+ // Validate Tensor Output:
+ // [0] = float/int8_t, {2, batch_size, num_units}
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+ TfLiteTensor* output = GetOutput(context, node, kSvdfOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(output), 2);
+ TF_LITE_ENSURE_EQ(context, output->dims->data[0], batch_size);
+ TF_LITE_ENSURE_EQ(context, output->dims->data[1], num_units);
+
+ // Validate Weights Feature Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(weights_feature), 2);
+ TF_LITE_ENSURE_EQ(context, weights_feature->dims->data[1], input_size);
+
+ // Validate Weights Time Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(weights_time), 2);
+ TF_LITE_ENSURE_EQ(context, weights_time->dims->data[0], num_filters);
+ TF_LITE_ENSURE_EQ(context, weights_time->dims->data[1], memory_size);
+
+ // Validate Optional Bias Input Tensor:
+ if (bias != nullptr) {
+ TF_LITE_ENSURE_EQ(context, bias->dims->data[0], num_units);
+ }
+
+ // Validate Activation State Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(activation_state), 2);
+ TF_LITE_ENSURE_EQ(context, activation_state->dims->data[0], batch_size);
+ TF_LITE_ENSURE_EQ(context, activation_state->dims->data[1],
+ memory_size * num_filters);
+ // Since is_variable is not part of TFLiteEvalTensor, check is_variable here.
+ TF_LITE_ENSURE_EQ(context, activation_state->is_variable, true);
+
+ TF_LITE_ENSURE_EQ(context, node->inputs->size, 5);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, weights_feature->type, kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, weights_time->type, kTfLiteInt16);
+ TF_LITE_ENSURE_EQ(context, activation_state->type, kTfLiteInt16);
+ if (bias != nullptr) {
+ TF_LITE_ENSURE_EQ(context, bias->type, kTfLiteInt32);
+ }
+
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, kTfLiteInt8);
+
+ const double effective_scale_1 = static_cast<double>(
+ input->params.scale * weights_feature->params.scale /
+ activation_state->params.scale);
+ const double effective_scale_2 =
+ static_cast<double>(activation_state->params.scale *
+ weights_time->params.scale / output->params.scale);
+
+ // TODO(b/162018098): Use TF_LITE_ENSURE_NEAR when it is ready.
+ TF_LITE_ENSURE(
+ context,
+ std::abs(static_cast<double>(bias->params.scale) -
+ static_cast<double>(activation_state->params.scale *
+ weights_time->params.scale)) < 1e-5);
+
+ QuantizeMultiplier(effective_scale_1, &(data->effective_scale_1_a),
+ &(data->effective_scale_1_b));
+ QuantizeMultiplier(effective_scale_2, &(data->effective_scale_2_a),
+ &(data->effective_scale_2_b));
+
+ data->input_zero_point = input->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ TFLITE_DCHECK(context->RequestScratchBufferInArena != nullptr);
+
+ const TfLiteStatus scratch_status = context->RequestScratchBufferInArena(
+ context, batch_size * num_filters * sizeof(int32_t),
+ &(data->scratch_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_status);
+
+ const TfLiteStatus scratch_output_status =
+ context->RequestScratchBufferInArena(
+ context, batch_size * num_units * sizeof(int32_t),
+ &(data->scratch_output_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_output_status);
+ } else {
+ TF_LITE_ENSURE_EQ(context, weights_feature->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_EQ(context, weights_time->type, kTfLiteFloat32);
+ TF_LITE_ENSURE_EQ(context, activation_state->type, kTfLiteFloat32);
+ if (bias != nullptr) {
+ TF_LITE_ENSURE_EQ(context, bias->type, kTfLiteFloat32);
+ }
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, kTfLiteFloat32);
+
+ TFLITE_DCHECK(context->RequestScratchBufferInArena != nullptr);
+ const TfLiteStatus scratch_status = context->RequestScratchBufferInArena(
+ context, batch_size * num_filters * sizeof(float),
+ &(data->scratch_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_status);
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/svdf_test.cc b/tensorflow/lite/micro/kernels/svdf_test.cc
new file mode 100644
index 0000000..2f3b06e
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/svdf_test.cc
@@ -0,0 +1,928 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+namespace tflite {
+namespace testing {
+namespace {
+
+// naming as follows: <tensor name>_<input size>x<batch size>x<batch count>
+
+// 10 inputs each with shape {2, 2}.
+const float input_data_2x2x10[] = {
+ 0.12609188, -0.46347019, 0.35867718, 0.36897406,
+
+ 0.14278367, -1.64410412, -0.57290924, 0.12729003,
+
+ 0.49837467, 0.19278903, 0.17660543, 0.52949083,
+
+ -0.11186574, 0.13164264, -0.72674477, -0.5683046,
+
+ -0.68892461, 0.37783599, -0.63690937, 0.44483393,
+
+ -0.81299269, -0.86831826, -0.95760226, 1.82078898,
+
+ -1.45006323, -0.82251364, -1.65087092, -1.89238167,
+
+ 0.03966608, -0.24936394, 2.06740379, -1.51439476,
+
+ 0.11771342, -0.23761693, 0.31088525, -1.55601168,
+
+ -0.89477462, 1.67204106, -0.6230064, 0.29819036,
+};
+
+// Feature filter of shape {8, 2}.
+const float feature_weights_data_2x2x10[] = {
+ -0.31930989, 0.0079667, 0.39296314, 0.37613347, 0.12416199, 0.15785322,
+ 0.27901134, 0.3905206, 0.21931258, -0.36137494, -0.10640851, 0.31053296,
+ -0.36118156, -0.0976817, -0.36916667, 0.22197971};
+
+// Time filter of shape {8, 10}.
+const float time_weights_data_2x2x10[] = {
+ -0.31930989, 0.37613347, 0.27901134, -0.36137494, -0.36118156,
+ 0.22197971, 0.27557442, -0.06634006, 0.0079667, 0.12416199,
+
+ 0.3905206, -0.10640851, -0.0976817, 0.15294972, 0.39635518,
+ -0.02702999, 0.39296314, 0.15785322, 0.21931258, 0.31053296,
+
+ -0.36916667, 0.38031587, -0.21580373, 0.27072677, 0.23622236,
+ 0.34936687, 0.18174365, 0.35907319, -0.17493086, 0.324846,
+
+ -0.10781813, 0.27201805, 0.14324132, -0.23681851, -0.27115166,
+ -0.01580888, -0.14943552, 0.15465137, 0.09784451, -0.0337657,
+
+ -0.14884081, 0.19931212, -0.36002168, 0.34663299, -0.11405486,
+ 0.12672701, 0.39463779, -0.07886535, -0.06384811, 0.08249187,
+
+ -0.26816407, -0.19905911, 0.29211238, 0.31264046, -0.28664589,
+ 0.05698794, 0.11613581, 0.14078894, 0.02187902, -0.21781836,
+
+ -0.15567942, 0.08693647, -0.38256618, 0.36580828, -0.22922277,
+ -0.0226903, 0.12878349, -0.28122205, -0.10850525, -0.11955214,
+
+ 0.27179423, -0.04710215, 0.31069002, 0.22672787, 0.09580326,
+ 0.08682203, 0.1258215, 0.1851041, 0.29228821, 0.12366763};
+
+// Activation state with shape {2, 80}. These initial values must be copied into
+// a mutable activation state tensor.
+
+const float initial_activation_state_data_2x2x10[] = {
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
+
+// Bias with shape {8}
+const float bias_data_2x2x10[] = {0, 0, 0, 0, 0, 0, 0, 0};
+
+// 10 outputs each of shape {2, 4}
+const float golden_output_2x2x10[] = {
+ -0.044205, -0.013757, 0.050369, -0.018447,
+ 0.073010, 0.025142, -0.021154, 0.013551,
+
+ -0.209613, -0.062421, 0.150209, -0.108334,
+ 0.028256, -0.006950, -0.030885, 0.009603,
+
+ -0.076800, -0.037075, -0.087198, -0.155183,
+ 0.091069, 0.098446, -0.016083, 0.106475,
+
+ -0.082123, -0.162238, -0.084434, -0.141074,
+ -0.029340, -0.090685, 0.053302, -0.030604,
+
+ -0.201440, 0.088424, 0.139877, 0.012416,
+ -0.113212, 0.103893, -0.100842, 0.122780,
+
+ -0.166632, -0.116705, 0.175298, -0.047163,
+ 0.313077, -0.166485, -0.285860, 0.129069,
+
+ -0.625911, 0.046134, 0.138081, -0.129581,
+ -0.521455, -0.061579, 0.230289, 0.114963,
+
+ -0.216693, -0.161643, -0.179177, -0.052599,
+ -0.213239, 0.029502, 0.260858, 0.275045,
+
+ -0.213689, -0.323608, -0.285635, -0.317687,
+ -0.324092, -0.317972, -0.208450, -0.462504,
+
+ -0.255126, -0.218576, -0.041528, 0.179421,
+ -0.440583, 0.072127, -0.284136, 0.241570};
+
+// Simulated real-world inputs, weights and expected outputs.
+
+// Input of shape {1x16}
+const float input_data_16x1x1[] = {
+ -0.488494, 2.023762, -2.233117, -0.488494, 3.559030, 9.490748,
+ -3.210106, -1.953977, -0.279140, 0.907204, 1.674838, 0.000000,
+ -0.279140, -0.628064, -0.069785, -0.628064,
+};
+
+// Feature filter of shape {64, 16}.
+const float feature_weights_data_16x1x1[] = {
+ 0.173588, 0.173588, -0.024798, 0.193426, -0.099193, 0.044637, 0.183507,
+ 0.183507, 0.044637, 0.198386, -0.069435, 0.084314, 0.312458, 0.024798,
+ 0.173588, -0.049596, -0.352135, -0.550521, -0.009919, -0.099193, -0.074395,
+ -0.128951, 0.193426, 0.357095, -0.317418, -0.119032, -0.218225, -0.004960,
+ -0.386853, -0.133911, 0.252942, -0.019839, -0.024798, -0.054556, -0.069435,
+ -0.128951, 0.029758, -0.099193, -0.312458, -0.029758, 0.064475, 0.183507,
+ 0.114072, -0.178547, -0.247982, -0.119032, 0.243023, -0.119032, -0.034718,
+ -0.178547, 0.019839, 0.128951, -0.223184, -0.009919, -0.213265, 0.168628,
+ -0.143830, -0.322377, -0.218225, -0.193426, -0.252942, -0.049596, 0.064475,
+ -0.267821, -0.580279, -0.099193, 0.213265, 0.119032, -0.119032, -0.178547,
+ 0.610037, 0.109112, 0.049596, -0.014879, -0.049596, -0.193426, 0.039677,
+ -0.148789, -0.114072, -0.158709, -0.158709, 0.094233, 0.099193, -0.114072,
+ 0.104153, -0.123991, 0.198386, -0.173588, 0.089274, -0.247982, -0.054556,
+ 0.123991, 0.183507, 0.114072, 0.188467, 0.302539, 0.044637, 0.039677,
+ -0.099193, 0.168628, -0.024798, -0.054556, -0.109112, 0.014879, -0.009919,
+ 0.069435, -0.396772, -0.287660, -0.079354, -0.104153, 0.054556, 0.089274,
+ -0.099193, 0.114072, 0.034718, 0.119032, 0.282700, -0.119032, -0.505884,
+ -0.233104, -0.114072, -0.257902, -0.233104, -0.178547, 0.153749, 0.128951,
+ 0.143830, -0.188467, -0.183507, 0.104153, -0.024798, 0.193426, -0.287660,
+ 0.168628, -0.009919, 0.119032, -0.024798, -0.099193, -0.203346, 0.099193,
+ 0.084314, -0.168628, 0.123991, -0.148789, 0.114072, -0.029758, 0.228144,
+ -0.238063, 0.089274, -0.064475, 0.307498, -0.188467, -0.004960, -0.252942,
+ -0.173588, -0.158709, -0.044637, -0.009919, 0.312458, -0.262861, 0.059516,
+ 0.158709, 0.069435, -0.282700, 0.074395, -0.322377, -0.183507, -0.123991,
+ -0.233104, 0.009919, 0.252942, -0.243023, 0.555481, -0.099193, -0.119032,
+ -0.441409, 0.148789, 0.084314, -0.168628, -0.183507, 0.188467, 0.024798,
+ -0.302539, 0.223184, 0.143830, -0.193426, -0.054556, -0.218225, -0.297579,
+ 0.104153, 0.272781, -0.034718, 0.114072, -0.059516, 0.044637, 0.342216,
+ 0.421570, 0.138870, -0.024798, -0.039677, -0.163668, -0.034718, 0.396772,
+ -0.128951, -0.044637, -0.173588, 0.302539, 0.079354, 0.049596, 0.133911,
+ -0.029758, -0.312458, -0.029758, 0.079354, 0.128951, 0.252942, 0.213265,
+ 0.014879, 0.287660, 0.178547, 0.297579, 0.352135, 0.401732, 0.024798,
+ -0.277740, -0.411651, -0.069435, 0.342216, -0.158709, -0.104153, -0.009919,
+ 0.223184, 0.228144, -0.019839, 0.059516, -0.104153, -0.510844, 0.029758,
+ -0.406691, 0.089274, 0.421570, 0.163668, -0.143830, -0.019839, -0.039677,
+ 0.104153, -0.044637, -0.128951, 0.203346, 0.079354, -0.069435, 0.094233,
+ -0.138870, 0.466207, -0.163668, 0.049596, 0.029758, 0.267821, 0.029758,
+ -0.049596, 0.009919, 0.004960, -0.099193, 0.094233, -0.262861, 0.089274,
+ -0.302539, 0.332297, -0.307498, -0.014879, 0.168628, -0.094233, -0.272781,
+ 0.034718, -0.133911, -0.228144, 0.094233, 0.257902, -0.228144, 0.153749,
+ -0.054556, -0.252942, 0.054556, 0.218225, -0.054556, 0.302539, 0.282700,
+ 0.054556, -0.044637, -0.133911, 0.233104, -0.049596, 0.411651, 0.044637,
+ -0.297579, -0.029758, -0.114072, 0.114072, -0.580279, 0.079354, -0.024798,
+ -0.347175, -0.128951, -0.099193, 0.238063, -0.104153, -0.009919, 0.158709,
+ -0.034718, 0.123991, -0.163668, 0.059516, 0.342216, 0.009919, 0.064475,
+ -0.307498, -0.520763, -0.238063, 0.163668, 0.362054, 0.034718, -0.178547,
+ -0.104153, -0.257902, 0.322377, 0.054556, 0.148789, -0.178547, 0.084314,
+ 0.004960, 0.257902, 0.029758, 0.079354, -0.223184, -0.193426, 0.282700,
+ 0.000000, -0.019839, -0.114072, 0.491005, -0.193426, -0.029758, -0.243023,
+ 0.009919, 0.089274, -0.277740, -0.089274, 0.104153, 0.337256, 0.138870,
+ -0.307498, -0.054556, 0.352135, 0.133911, -0.044637, 0.133911, -0.089274,
+ -0.357095, -0.272781, 0.069435, 0.059516, -0.109112, 0.148789, -0.044637,
+ -0.019839, -0.153749, 0.123991, -0.223184, 0.322377, 0.074395, -0.312458,
+ 0.024798, -0.223184, 0.109112, -0.138870, 0.218225, -0.074395, -0.406691,
+ 0.009919, -0.198386, -0.009919, 0.416611, 0.178547, 0.148789, 0.133911,
+ -0.004960, 0.069435, -0.054556, -0.044637, 0.297579, 0.059516, -0.456288,
+ -0.148789, -0.004960, 0.054556, 0.094233, -0.104153, 0.198386, -0.302539,
+ 0.133911, 0.411651, 0.054556, 0.525723, -0.089274, 0.079354, 0.238063,
+ 0.079354, -0.039677, 0.039677, 0.029758, 0.332297, -0.014879, -0.367014,
+ -0.143830, -0.123991, -0.064475, 0.014879, 0.173588, -0.168628, 0.386853,
+ 0.009919, 0.173588, 0.163668, 0.123991, 0.163668, 0.198386, 0.203346,
+ -0.401732, -0.009919, 0.272781, -0.173588, 0.044637, 0.238063, 0.133911,
+ 0.049596, 0.208305, -0.024798, 0.049596, -0.049596, 0.034718, -0.446368,
+ 0.466207, -0.089274, -0.099193, -0.128951, -0.228144, 0.014879, -0.252942,
+ 0.074395, -0.223184, -0.168628, -0.292619, 0.178547, 0.153749, -0.014879,
+ 0.054556, 0.000000, 0.193426, 0.158709, 0.178547, -0.327337, -0.138870,
+ -0.114072, 0.168628, 0.297579, -0.109112, -0.029758, -0.029758, -0.416611,
+ 0.059516, 0.000000, -0.168628, -0.322377, 0.238063, -0.128951, -0.029758,
+ 0.500925, 0.292619, 0.123991, -0.099193, 0.074395, 0.317418, -0.148789,
+ 0.064475, -0.104153, -0.044637, -0.094233, 0.188467, -0.044637, 0.213265,
+ -0.233104, -0.049596, 0.004960, -0.198386, 0.287660, -0.148789, -0.257902,
+ 0.004960, -0.218225, -0.044637, -0.386853, -0.243023, -0.163668, 0.094233,
+ 0.029758, -0.019839, -0.009919, -0.143830, -0.158709, 0.158709, -0.243023,
+ -0.039677, -0.297579, 0.069435, 0.049596, 0.302539, 0.059516, 0.074395,
+ -0.019839, 0.352135, -0.019839, -0.138870, -0.178547, -0.243023, 0.233104,
+ 0.252942, -0.228144, -0.049596, 0.173588, 0.173588, -0.074395, -0.034718,
+ -0.292619, 0.362054, 0.183507, 0.243023, -0.203346, -0.044637, 0.054556,
+ 0.059516, -0.158709, -0.158709, 0.000000, 0.327337, 0.119032, 0.034718,
+ -0.044637, -0.089274, 0.089274, -0.233104, 0.000000, -0.317418, 0.371974,
+ 0.213265, 0.307498, -0.178547, -0.367014, 0.039677, -0.059516, 0.168628,
+ -0.014879, 0.143830, 0.123991, -0.084314, -0.332297, -0.416611, 0.183507,
+ 0.109112, -0.039677, 0.014879, 0.292619, -0.213265, -0.054556, 0.004960,
+ 0.123991, 0.119032, 0.000000, -0.332297, -0.312458, -0.198386, -0.213265,
+ 0.119032, 0.322377, 0.168628, 0.104153, -0.262861, 0.327337, -0.049596,
+ -0.228144, -0.074395, 0.168628, 0.123991, 0.396772, 0.044637, 0.322377,
+ 0.193426, 0.267821, -0.178547, 0.297579, 0.148789, -0.218225, -0.138870,
+ 0.044637, 0.049596, 0.133911, 0.064475, 0.069435, 0.064475, -0.158709,
+ -0.044637, -0.173588, 0.267821, 0.327337, 0.079354, -0.228144, 0.029758,
+ 0.014879, 0.198386, -0.109112, -0.133911, 0.431490, 0.099193, 0.421570,
+ 0.233104, -0.054556, 0.054556, -0.317418, -0.133911, -0.123991, -0.287660,
+ 0.342216, -0.049596, -0.153749, 0.228144, -0.213265, 0.262861, 0.406691,
+ -0.084314, -0.004960, 0.193426, 0.188467, -0.099193, -0.223184, 0.163668,
+ -0.257902, -0.153749, 0.441409, 0.099193, 0.128951, -0.089274, -0.208305,
+ -0.009919, -0.004960, -0.109112, 0.024798, -0.119032, 0.019839, 0.391812,
+ -0.024798, 0.198386, 0.327337, -0.505884, -0.099193, 0.510844, -0.148789,
+ 0.094233, -0.153749, -0.039677, 0.352135, 0.272781, -0.228144, -0.287660,
+ -0.272781, 0.148789, 0.277740, 0.074395, 0.109112, -0.064475, 0.044637,
+ 0.074395, -0.292619, 0.153749, -0.064475, -0.114072, 0.198386, -0.039677,
+ -0.128951, -0.004960, 0.257902, -0.228144, -0.094233, 0.064475, 0.014879,
+ 0.188467, -0.416611, 0.099193, 0.362054, -0.208305, 0.198386, -0.079354,
+ 0.009919, 0.119032, 0.332297, 0.243023, -0.168628, 0.158709, 0.039677,
+ 0.143830, 0.277740, -0.168628, 0.009919, 0.099193, -0.004960, -0.257902,
+ -0.297579, 0.208305, -0.104153, 0.119032, 0.247982, 0.381893, -0.223184,
+ -0.367014, -0.327337, -0.168628, -0.094233, 0.208305, -0.019839, 0.183507,
+ 0.084314, 0.133911, 0.109112, -0.148789, -0.183507, -0.411651, -0.024798,
+ -0.114072, -0.029758, -0.009919, 0.173588, -0.059516, -0.049596, 0.039677,
+ 0.317418, 0.138870, -0.247982, -0.084314, 0.158709, 0.054556, -0.084314,
+ -0.049596, 0.074395, 0.019839, -0.282700, -0.119032, -0.262861, 0.163668,
+ -0.069435, -0.064475, -0.059516, 0.094233, 0.123991, -0.079354, -0.272781,
+ -0.267821, 0.233104, 0.114072, -0.218225, 0.540602, 0.089274, 0.262861,
+ 0.079354, 0.267821, -0.119032, -0.109112, -0.128951, 0.128951, -0.044637,
+ -0.272781, 0.277740, 0.297579, -0.054556, -0.084314, -0.049596, 0.123991,
+ 0.059516, 0.238063, -0.168628, -0.009919, 0.163668, -0.307498, 0.109112,
+ -0.064475, 0.218225, -0.168628, -0.004960, -0.168628, 0.119032, 0.094233,
+ -0.183507, -0.089274, -0.292619, -0.094233, 0.064475, -0.183507, -0.168628,
+ 0.089274, 0.074395, -0.367014, -0.024798, -0.069435, 0.119032, -0.302539,
+ -0.376933, -0.123991, -0.009919, -0.069435, -0.208305, -0.119032, 0.014879,
+ -0.183507, -0.238063, 0.163668, -0.332297, -0.148789, -0.391812, -0.024798,
+ -0.133911, -0.059516, -0.123991, 0.123991, -0.292619, -0.044637, 0.059516,
+ -0.069435, 0.049596, -0.069435, 0.034718, 0.158709, -0.347175, -0.044637,
+ 0.352135, -0.347175, -0.282700, -0.054556, 0.307498, 0.029758, 0.357095,
+ -0.148789, 0.208305, -0.317418, 0.009919, 0.004960, -0.243023, 0.049596,
+ -0.099193, 0.213265, -0.342216, 0.158709, 0.123991, -0.332297, 0.386853,
+ -0.262861, -0.208305, 0.123991, -0.044637, 0.148789, 0.084314, -0.297579,
+ -0.307498, -0.163668, 0.337256, -0.014879, 0.074395, 0.178547, -0.004960,
+ -0.257902, -0.019839, -0.228144, -0.034718, -0.277740, -0.158709, -0.119032,
+ -0.153749, 0.629876, 0.277740, 0.178547, -0.267821, -0.004960, 0.247982,
+ 0.084314, -0.094233, 0.000000, -0.039677, 0.332297, 0.178547, 0.009919,
+ -0.213265, -0.208305, -0.044637, 0.019839, 0.218225, -0.297579, 0.014879,
+ -0.247982, -0.004960, -0.128951, 0.421570, -0.059516, 0.362054, -0.203346,
+ -0.143830, -0.099193, -0.024798, 0.094233, -0.123991, 0.163668, 0.109112,
+ -0.104153, -0.233104, 0.009919, -0.218225, 0.376933, 0.104153, -0.059516,
+ 0.049596, -0.054556, 0.019839, -0.044637, -0.019839, 0.371974, -0.019839,
+ 0.104153, 0.168628, -0.024798, -0.272781, -0.158709, 0.223184, 0.044637,
+ 0.039677, -0.168628, -0.287660, -0.109112, 0.094233, -0.089274, -0.148789,
+ 0.178547, -0.039677, -0.089274, -0.049596, -0.024798, 0.064475, -0.158709,
+ 0.089274, 0.029758, -0.247982, 0.362054, 0.024798, -0.004960, -0.099193,
+ 0.173588, -0.059516, 0.188467, -0.629876, 0.094233, 0.371974, 0.069435,
+ 0.252942, -0.357095, -0.272781, -0.367014, 0.014879, -0.049596, -0.262861,
+ 0.009919, -0.094233, -0.094233, 0.059516, 0.223184, 0.133911, 0.411651,
+ -0.044637, -0.044637, 0.109112, 0.228144, 0.386853, -0.233104, 0.069435,
+ 0.228144, -0.302539, 0.029758, 0.089274, 0.044637, -0.238063, -0.138870,
+ -0.158709, -0.019839, 0.049596, 0.039677, 0.000000, -0.069435, 0.109112,
+ -0.213265, -0.188467, -0.262861, -0.267821, -0.094233, 0.133911, 0.391812,
+ 0.123991, -0.317418, 0.233104, -0.029758, -0.099193, -0.193426, 0.074395,
+ -0.009919, 0.252942, 0.322377, -0.530683, 0.208305, 0.252942, 0.203346,
+ -0.069435, -0.262861};
+
+// Time filter of shape {64, 8}.
+const float time_weights_data_16x1x1[] = {
+ -0.052026, 0.043107, 0.053512, 0.013378, 0.011892, -0.182834, -0.108511,
+ 0.153105, 0.050539, -0.173915, 0.145672, 0.208103, -0.221481, 0.108511,
+ -0.496475, 0.181347, -0.016351, -0.132294, -0.234859, -0.243778, 0.028243,
+ -0.228914, -0.130808, -0.167969, -0.041621, -0.306209, -0.193239, -0.028243,
+ -0.057972, -0.057972, -0.497962, 0.054999, 0.181347, 0.047566, -0.099592,
+ -0.111484, -0.130808, -0.071350, 0.380532, 0.010405, 0.041621, 0.052026,
+ 0.022297, 0.081755, 0.098106, 0.099592, -0.584176, -0.023783, 0.062431,
+ -0.090674, -0.279453, -0.486070, -0.273507, 0.004459, -0.062431, 0.095133,
+ 0.056485, 0.022297, -0.105538, -0.184320, 0.358235, 0.254183, 0.049053,
+ 0.084728, 0.218508, 0.078782, -0.136754, -0.017837, -0.124862, -0.118916,
+ -0.001486, 0.043107, 0.254183, 0.087701, 0.261616, 0.309182, -0.404315,
+ -0.040134, -0.046080, -0.052026, -0.034188, -0.475665, -0.025270, -0.049053,
+ -0.046080, -0.062431, 0.020810, 0.040134, -0.135267, -0.169456, -0.050539,
+ -0.576743, 0.034188, 0.075809, 0.101079, 0.136754, 0.083241, 0.077296,
+ -0.050539, 0.761064, -0.335938, -0.080268, 0.025270, 0.257156, 0.227427,
+ 0.252697, 0.065404, 0.115943, 0.222968, -0.026756, -0.054999, 0.107025,
+ -0.093646, 0.041621, -0.092160, -0.474178, -0.016351, 0.004459, 0.049053,
+ 0.019324, 0.019324, 0.074323, 0.038648, -0.613905, 0.182834, 0.075809,
+ 0.028243, 0.019324, 0.010405, -0.011892, 0.001486, -0.492016, -0.224454,
+ -0.474178, -0.147159, 0.002973, 0.102565, 0.136754, -0.267561, -0.001486,
+ -0.095133, -0.040134, 0.066890, 0.074323, 0.104052, 0.532150, 0.090674,
+ 0.072836, -0.053512, -0.004459, 0.020810, 0.046080, 0.062431, 0.477151,
+ 0.133781, -0.029729, -0.026756, 0.031215, 0.156077, 0.096619, 0.251210,
+ 0.352289, 0.657012, 0.047566, -0.014865, -0.072836, -0.016351, 0.008919,
+ -0.053512, 0.016351, 0.300263, 0.047566, 0.020810, 0.169456, 0.001486,
+ 0.007432, 0.111484, 0.044594, -0.188779, -0.096619, 0.074323, -0.040134,
+ 0.160537, 0.138240, 0.184320, 0.377559, -0.092160, -0.049053, 0.056485,
+ -0.032702, 0.001486, -0.083241, -0.472692, -0.114457, -0.117430, -0.075809,
+ 0.026756, 0.163510, 0.172428, 0.127835, -0.199185, -0.218508, -0.057972,
+ -0.132294, -0.162023, -0.019324, -0.245265, -0.395396, -0.254183, 0.084728,
+ 0.248238, 0.191752, 0.221481, 0.173915, 0.173915, -0.208103, -0.077296,
+ 0.384991, -0.313641, -0.313641, -0.147159, -0.090674, 0.035675, 0.059458,
+ -0.010405, 0.019324, 0.087701, 0.016351, 0.037161, 0.469719, -0.074323,
+ 0.092160, 0.026756, 0.090674, 0.098106, 0.004459, -0.034188, 0.492016,
+ -0.367154, -0.093646, -0.063917, 0.041621, 0.017837, 0.026756, -0.062431,
+ -0.350803, 0.425125, 0.002973, 0.083241, 0.075809, 0.016351, 0.047566,
+ -0.185807, -0.107025, -0.098106, -0.144186, 0.255670, 0.020810, 0.105538,
+ 0.029729, 0.129321, 0.156077, 0.141213, 0.334452, 0.147159, -0.066890,
+ 0.035675, 0.115943, 0.240805, 0.328506, 0.162023, -0.237832, 0.218508,
+ 0.233373, 0.214049, 0.099592, 0.026756, -0.322560, -0.236346, -0.166483,
+ 0.225941, 0.109997, -0.147159, 0.147159, -0.266075, 0.111484, 0.078782,
+ -0.120403, 0.022297, -0.075809, -0.148645, -0.251210, -0.176888, -0.044594,
+ -0.023783, 0.016351, 0.026756, -0.013378, -0.069863, -0.112970, 0.013378,
+ 0.086214, 0.014865, 0.352289, -0.240805, -0.135267, -0.114457, -0.472692,
+ 0.334452, 0.095133, 0.047566, 0.130808, -0.068377, -0.007432, -0.130808,
+ -0.121889, -0.053512, -0.245265, -0.371613, -0.083241, 0.000000, -0.028243,
+ 0.029729, -0.093646, -0.004459, -0.038648, -0.108511, -0.475665, -0.169456,
+ -0.047566, -0.010405, -0.114457, -0.353776, -0.034188, -0.044594, 0.041621,
+ -0.047566, -0.107025, 0.004459, 0.053512, 0.047566, -0.358235, -0.193239,
+ 0.040134, -0.096619, -0.054999, 0.099592, 0.032702, 0.205130, -0.170942,
+ -0.237832, -0.405801, -0.126348, -0.072836, -0.203644, -0.169456, -0.093646,
+ -0.074323, 0.078782, 0.607959, -0.437017, -0.164996, -0.166483, 0.043107,
+ -0.016351, 0.258643, 0.065404, -0.057972, 0.017837, 0.080268, 0.050539,
+ -0.013378, -0.215536, -0.524718, 0.260129, 0.040134, -0.002973, -0.046080,
+ 0.020810, 0.025270, 0.145672, 0.515799, 0.233373, 0.011892, 0.139727,
+ 0.126348, 0.065404, -0.007432, -0.008919, 0.035675, 0.083241, 0.040134,
+ -0.005946, 0.503907, -0.490529, -0.181347, -0.092160, -0.038648, 0.019324,
+ 0.133781, -0.011892, 0.041621, 0.062431, -0.062431, -0.040134, -0.092160,
+ -0.111484, -0.133781, -0.130808, -0.484583, -0.248238, 0.037161, -0.092160,
+ -0.056485, -0.041621, 0.112970, 0.248238, 0.438503, 0.258643, -0.013378,
+ 0.004459, 0.043107, 0.040134, 0.017837, 0.101079, 0.264589, 0.212563,
+ 0.014865, 0.285399, 0.153105, 0.170942, 0.358235, 0.334452, 0.086214,
+ 0.132294, 0.098106, -0.001486, 0.107025, 0.200671, -0.026756, 0.344857,
+ 0.227427, -0.041621, 0.098106, 0.063917, -0.093646, 0.130808, 0.285399,
+ -0.319587, 0.035675, -0.017837, -0.319587, 0.016351, -0.098106, -0.017837,
+ 0.083241, 0.074323, -0.054999, 0.276480, 0.316614, -0.099592, -0.059458,
+ 0.156077, -0.043107, 0.035675, 0.056485, -0.022297, 0.017837, -0.001486,
+ 0.340398, 0.492016, 0.004459, 0.057972, -0.150132, -0.206617, -0.257156,
+ -0.248238, -0.080268, -0.164996, 0.352289, -0.054999, -0.056485, 0.010405,
+ -0.049053, -0.041621, -0.099592, 0.013378, -0.089187, 0.057972, -0.413234,
+ 0.217022, 0.013378, -0.080268, -0.035675, 0.035675, 0.007432, 0.002973,
+ -0.469719, 0.141213, 0.136754, 0.153105, 0.130808, -0.104052, -0.508367,
+ -0.291345, -0.072836, -0.019324, -0.252697, -0.214049, -0.214049, 0.130808,
+ 0.484583};
+
+// Bias of shape {64}
+const float bias_data_16x1x1[] = {
+ -0.245395, -0.083545, -0.262522, -0.407912, -0.560898, -0.364789, -0.037964,
+ -0.378594, 0.178152, 0.400380, -0.301349, -0.240913, -0.159454, -0.158757,
+ -0.073665, 0.455906, -0.061232, 0.318907, -0.226993, -0.344644, 0.140316,
+ 0.559608, 0.109774, 0.437391, 0.113849, -0.162068, 0.039572, 0.569472,
+ 0.460205, 0.113459, 0.370469, 0.176811, 0.203063, -0.296975, -0.271655,
+ 0.059862, -0.159912, -0.077310, -0.338314, -0.195477, -0.256762, 0.233834,
+ 0.083172, 0.029040, -0.236288, -0.267054, -0.166627, 0.188319, -0.271391,
+ -0.222920, 0.106463, 0.263614, 0.384986, -0.125957, -0.095890, 0.363686,
+ -0.036990, -0.358884, -0.178254, 0.305596, 0.390088, -0.189437, 0.613409,
+ 0.399639};
+
+// Activation state with shape {64, 8}. These initial values must be copied into
+// a mutable activation state tensor.
+const float initial_activation_state_data_16x1x1[] = {
+ -0.582275, -0.586623, -1.262373, -1.277279, -1.542175, -1.271999, -1.429757,
+ -1.184425, -0.462094, -1.443421, 0.230736, -0.494701, -0.354955, -2.534061,
+ -4.277471, -4.218467, 0.403711, -0.248748, -0.330111, -0.467683, 0.549047,
+ 0.733511, -0.230115, 0.793136, -1.126353, -0.984123, -0.081984, -0.222351,
+ 0.692830, 0.517060, 1.367958, 2.118860, -0.116766, -0.826365, -2.402700,
+ -2.313884, -2.898954, -2.076005, -2.405185, -2.755481, 0.329490, 0.085400,
+ -1.485966, -2.034702, -2.161405, -1.269515, -1.151818, -1.823841, 0.561469,
+ 1.109273, 1.693411, -0.082605, -0.069252, -1.225107, -1.330693, -1.411435,
+ 0.253406, -0.357439, -1.593415, -0.879779, -1.111136, 1.821357, 2.471952,
+ 1.236908, -4.014127, -2.810448, -2.944604, -1.930980, -1.566398, -0.838166,
+ -0.319242, 0.749349, 1.156476, 0.658670, 1.997437, 2.080663, 2.912618,
+ 2.677224, 2.642442, 2.796163, -0.272349, -0.473273, 3.120063, 2.747097,
+ 3.595510, 1.874150, 2.049919, 2.093396, -1.049959, 0.277939, -1.255541,
+ -1.052443, -1.810177, -0.883505, -0.538178, 0.524203, -1.017662, -0.269244,
+ 0.039129, -0.227941, -0.114592, -2.018243, -2.548968, -0.706804, 0.890959,
+ 0.102480, 0.349986, 0.405885, 1.287216, 0.756181, 0.319242, -0.641590,
+ -3.841774, -2.716042, -4.342065, -3.826557, -2.924729, -1.643724, -1.237839,
+ -0.597492, -1.954892, -1.215169, -1.528201, -1.018904, -0.863941, -0.293467,
+ 0.039439, 0.672023, 1.408019, 1.362679, 1.467644, 1.006171, 0.310236,
+ -0.249990, -1.048406, -0.752144, -1.831605, -1.058033, -1.096541, -0.293467,
+ 0.051551, 0.232600, 0.088816, 2.570395, 0.704009, 2.465120, 3.010751,
+ 2.139357, 0.630410, 1.006171, 1.545281, 1.486898, -1.162998, -2.344317,
+ -4.593918, -3.522842, -2.872247, -1.416714, -0.642521, -0.230115, 0.315205,
+ -0.368930, -0.162726, 0.396879, 0.505570, 0.534451, 0.554947, 1.270447,
+ 0.388805, 0.531967, -1.243119, -0.671713, -1.214859, -0.238189, 0.016459,
+ -1.164550, 0.609603, 3.293348, 2.600208, 1.454290, -1.034121, -1.760179,
+ -1.192500, -0.613951, 3.449553, 2.912618, 1.917937, 1.435968, 0.879158,
+ 1.118279, 0.102791, -0.502465, -0.239121, -0.092853, 1.786265, 1.943091,
+ 2.547104, 2.630641, 2.585302, 2.965411, -0.945615, -2.538720, -2.474126,
+ -1.088156, 0.056209, 0.864873, 0.170490, 0.457435, 0.545941, 0.752765,
+ 1.569503, 1.129459, 0.662086, -0.527929, -0.810838, -1.662978, 1.285042,
+ 1.653040, 4.130893, 2.961995, 4.147041, 3.256393, 3.881524, 2.522571,
+ -0.875431, -1.112378, 2.105817, 2.180970, 3.121926, 1.577577, 1.639376,
+ 2.906407, -0.142230, 0.421101, 2.212335, 2.311399, 3.993321, 3.651719,
+ 4.206666, 4.678387, -1.304917, -1.130701, -2.543067, -2.500212, -2.197118,
+ -1.197158, -0.949652, -0.282908, 0.320795, -1.543728, 1.290322, 1.788128,
+ 3.957297, 3.205774, 2.892432, 2.297114, 0.138814, -0.139435, 0.936920,
+ 0.344707, 0.723263, -1.772290, -3.138385, -2.287177, -2.405806, -1.859864,
+ -4.572801, -3.410424, -3.855748, -2.239663, -2.269786, -1.582857, 4.238342,
+ 3.858543, 2.499901, 1.087535, 0.290051, -0.026086, -0.880400, -2.602692,
+ -1.404292, 0.253096, -0.665502, -1.443421, -0.925119, -0.096580, 1.115484,
+ 1.846200, -1.604284, -1.244671, -0.464888, 0.326385, 0.168006, -0.262723,
+ -0.744691, 0.953379, -0.407127, -0.349986, -1.154302, 0.831023, 1.590931,
+ 2.538720, 2.063583, 3.697680, -0.752455, -1.293117, -1.330693, -1.869802,
+ -0.592523, 0.631652, 1.198089, -0.481347, 3.738983, 4.153252, 2.782499,
+ 2.244321, 0.709289, 1.650245, 1.700865, 0.385078, 2.192460, 2.610456,
+ 4.009780, 3.492719, 2.574743, 2.116687, 1.856138, 1.205853, 2.722563,
+ 4.075305, 5.415935, 3.009198, 2.715421, 1.571056, 0.897170, -2.430339,
+ 0.749970, 0.425760, -0.302783, 0.817359, 1.031636, 1.913589, 2.686229,
+ 1.631923, -1.459259, -1.793097, -1.187531, -1.553355, -0.844998, -1.296843,
+ -1.805519, -0.486627, 0.909591, 2.082837, -1.473855, -2.456735, -3.851401,
+ -2.760139, -3.060438, -2.605487, -2.138735, -2.441519, -1.333177, -1.353984,
+ -0.245642, -0.588486, 0.033850, 2.084700, 0.076084, 0.690035, 0.747797,
+ 0.594697, -1.016109, -1.348083, -1.201195, -1.088466, 2.045571, 2.460772,
+ 0.717984, 0.041613, -0.721711, 1.134738, 2.322269, 1.112378, -0.307441,
+ -0.581033, -0.868599, -0.018633, 0.856488, 0.919839, 0.303094, -0.433213,
+ 0.811148, -0.508986, -1.060828, -1.227591, -1.566087, -1.117968, -1.385038,
+ -2.011101, -0.490353, -1.849616, -0.594697, -1.055859, 1.110205, 0.622646,
+ 0.145957, 0.359303, 1.012072, 0.774814, -0.400295, -1.484103, -2.007374,
+ -1.441247, -0.997787, -0.581033, -0.545941, -0.306510, 0.693451, 0.087264,
+ -0.227320, -1.211753, -1.532859, -1.688753, 0.065215, 0.134777, 0.608051,
+ -0.393152, -0.214588, -0.635689, -1.499320, 0.069562, -1.555839, -2.633126,
+ -2.966032, -1.550870, -0.101549, 0.874189, 0.436318, 0.299367, 2.289972,
+ 2.339659, 2.602071, 1.564535, 0.019254, -0.583207, -1.295912, -2.424749,
+ -1.221070, -1.175109, -0.577306, -0.102791, 1.877876, 2.568222, 2.173827,
+ 3.131243, 2.637784, 2.088737, 3.679047, 3.218506, 2.483442, 1.650556,
+ 1.363611, -0.027328, 1.486898, -0.721711, -3.684327, -3.006093, -3.777491,
+ -2.327548, -2.737470, -4.549510, -0.060867, 0.127635, 0.680408, 0.581344,
+ 0.320174, -0.403090, -0.838166, 0.293777, -0.995613, -0.165521, -0.419859,
+ 1.110515, 1.203679, 1.749931, 2.467294, 4.276539, 0.031055, -0.967664,
+ 1.167035, 1.865144, 3.221923, 3.248630, 4.121266, 4.187723, 0.749039,
+ -1.571056, 0.785994, 1.568572, 3.759479, 3.588678, 4.116608, 3.864444,
+ -0.290051, -0.271107, 0.375140, 0.537556, 0.536314, 0.095959, 0.054656,
+ 0.088816};
+
+// One output with shape {1, 64}
+const float golden_output_16x1x1[] = {
+ -0.087914, 1.145864, -0.418088, -1.556392, -0.925298, 0.205252, 0.289119,
+ 1.331180, -0.218010, 0.963057, -2.225886, 1.248478, 1.448983, 0.355467,
+ 1.682174, 0.803739, 0.449738, 0.543566, 1.916269, -2.975136, 0.222774,
+ 0.241589, -0.104216, 1.561748, 0.936818, -0.089907, -0.520117, -0.870353,
+ 1.606074, 0.895770, 0.521297, -0.369994, -0.889351, -2.809309, 2.404628,
+ 1.069754, -0.195456, -1.105652, 1.272715, -1.233177, 1.271416, -1.691805,
+ -1.058125, -0.716227, 0.052540, 1.262483, 0.540555, 1.735760, -0.539197,
+ -0.014367, -0.243002, 1.072254, 0.528985, -0.731151, -1.262649, 2.338702,
+ -0.603093, 0.970736, -3.567897, 0.035085, -0.201711, -0.550400, 1.545573,
+ -1.805005};
+
+// One output with shape {1, 64}
+const float golden_output_relu_16x1x1[] = {
+ 0.000000, 1.145864, 0.000000, 0.000000, 0.000000, 0.205252, 0.289119,
+ 1.331180, 0.000000, 0.963057, 0.000000, 1.248478, 1.448983, 0.355467,
+ 1.682174, 0.803739, 0.449738, 0.543566, 1.916269, 0.000000, 0.222774,
+ 0.241589, 0.000000, 1.561748, 0.936818, 0.000000, 0.000000, 0.000000,
+ 1.606074, 0.895770, 0.521297, 0.000000, 0.000000, 0.000000, 2.404628,
+ 1.069754, 0.000000, 0.000000, 1.272715, 0.000000, 1.271416, 0.000000,
+ 0.000000, 0.000000, 0.052540, 1.262483, 0.540555, 1.735760, 0.000000,
+ 0.000000, 0.000000, 1.072254, 0.528985, 0.000000, 0.000000, 2.338702,
+ 0.000000, 0.970736, 0.000000, 0.035085, 0.000000, 0.000000, 1.545573,
+ 0.000000};
+
+template <typename T>
+void ValidateSVDFGoldens(const int batch_size, const int num_units,
+ const int input_size, const int rank,
+ TfLiteTensor* tensors, const int tensor_count,
+ TfLiteFusedActivation activaiton,
+ const T* input_sequences_data,
+ const int input_sequences_len, T* output_data,
+ const T* expected_output, float tolerance = 1e-5f) {
+ TfLiteSVDFParams params;
+ params.rank = rank;
+ params.activation = activaiton;
+
+ int inputs_array_data[] = {5, 0, 1, 2, 3, 4};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+
+ int outputs_array_data[] = {1, 5};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_SVDF();
+ micro::KernelRunner runner(registration, tensors, tensor_count, inputs_array,
+ outputs_array, ¶ms);
+
+ TfLiteStatus init_and_prepare_status = runner.InitAndPrepare();
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, init_and_prepare_status);
+
+ // Abort early to make it clear init and prepare failed.
+ if (init_and_prepare_status != kTfLiteOk) {
+ return;
+ }
+
+ int num_inputs = input_sequences_len / (input_size * batch_size);
+
+ for (int i = 0; i < num_inputs; ++i) {
+ const T* input_batch_start =
+ input_sequences_data + i * input_size * batch_size;
+
+ memcpy(tensors[0].data.raw, input_batch_start, tensors[0].bytes);
+ TfLiteStatus status = runner.Invoke();
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, status);
+
+ // Only validate outputs when invoke has succeeded.
+ if (status == kTfLiteOk) {
+ int output_idx = 0;
+ int golden_idx = i * batch_size * num_units;
+ for (int j = golden_idx; j < golden_idx + batch_size * num_units; ++j) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output[j], output_data[output_idx],
+ tolerance);
+ output_idx++;
+ }
+ }
+ }
+}
+
+#if !defined(XTENSA) // Needed to avoid build errors from unused functions.
+void TestSVDF(const int batch_size, const int num_units, const int input_size,
+ const int memory_size, const int rank,
+ TfLiteFusedActivation activation, float* input_data,
+ const float* feature_weights_data, const float* time_weights_data,
+ float* activation_state_data, const float* bias_data,
+ float* scratch_data, float* output_data,
+ const float* input_sequences_data, int input_sequences_len,
+ const float* expected_output, float tolerance = 1e-5f) {
+ const int num_filters = num_units * rank;
+
+ const int input_dims_arg[] = {2, batch_size, input_size};
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_arg);
+
+ const int feature_weights_dims_args[] = {2, num_filters, input_size};
+ TfLiteIntArray* feature_weights_dims =
+ IntArrayFromInts(feature_weights_dims_args);
+
+ const int time_weights_dims_args[] = {2, num_filters, memory_size};
+ TfLiteIntArray* time_weights_dims = IntArrayFromInts(time_weights_dims_args);
+
+ const int activation_state_dims_args[] = {2, batch_size,
+ memory_size * num_filters};
+ TfLiteIntArray* activation_state_dims =
+ IntArrayFromInts(activation_state_dims_args);
+
+ const int bias_dims_args[] = {1, num_units};
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_args);
+
+ const int output_dims_args[] = {2, batch_size, num_units};
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_args);
+
+ const int tensor_count = 6; // 5 inputs, 1 output
+ TfLiteTensor tensors[] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(feature_weights_data, feature_weights_dims),
+ CreateTensor(time_weights_data, time_weights_dims),
+ CreateTensor(bias_data, bias_dims),
+ CreateTensor(activation_state_data, activation_state_dims,
+ /*is_variable=*/true),
+ CreateTensor(output_data, output_dims),
+ };
+
+ ValidateSVDFGoldens(batch_size, num_units, input_size, rank, tensors,
+ tensor_count, activation, input_sequences_data,
+ input_sequences_len, output_data, expected_output,
+ tolerance);
+}
+#endif
+
+// The pattern to this method's arguemnts is:
+// <kernel metadata>
+// for each tensor in
+// {input, feature weights, time weights, bias, activation state, output}:
+// <tensor float values> <tensor quantized buffer> <tensor quantization data>
+inline void TestIntegerSVDF(
+ const int batch_size, const int num_units, const int input_size,
+ const int memory_size, const int rank, TfLiteFusedActivation activation,
+ int8_t* input_quantized, float input_scale, int input_zero_point,
+ const float* feature_weights_data, int8_t* feature_weights_quantized,
+ const float feature_weights_scale, const float* time_weights_data,
+ int16_t* time_weights_quantized, float time_weights_scale,
+ const float* bias_data, int32_t* bias_quantized,
+ const float* initial_activation_state_data,
+ int16_t* activation_state_quantized, float activation_state_scale,
+ int8_t* output_data, float output_scale, int output_zero_point,
+ const float* input_sequences_data, int8_t* input_sequences_quantized,
+ const int input_sequences_len, const float* golden_output,
+ int8_t* golden_output_quantized, int golden_output_len) {
+ const int num_filters = num_units * rank;
+
+ const int input_dims_arg[] = {2, batch_size, input_size};
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_arg);
+
+ const int feature_weights_dims_args[] = {2, num_filters, input_size};
+ TfLiteIntArray* feature_weights_dims =
+ IntArrayFromInts(feature_weights_dims_args);
+
+ const int time_weights_dims_args[] = {2, num_filters, memory_size};
+ TfLiteIntArray* time_weights_dims = IntArrayFromInts(time_weights_dims_args);
+
+ const int bias_dims_data[] = {1, num_units};
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+
+ const int activation_state_dims_args[] = {2, batch_size,
+ memory_size * num_filters};
+ TfLiteIntArray* activation_state_dims =
+ IntArrayFromInts(activation_state_dims_args);
+
+ const int output_dims_args[] = {2, batch_size, num_units};
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_args);
+
+ const int tensor_count = 6; // 5 inputs, 1 output
+
+ TfLiteTensor tensors[] = {
+ CreateQuantizedTensor(input_quantized, input_dims, input_scale,
+ input_zero_point),
+ CreateQuantizedTensor(feature_weights_data, feature_weights_quantized,
+ feature_weights_dims, feature_weights_scale, 0),
+ CreateQuantizedTensor(time_weights_data, time_weights_quantized,
+ time_weights_dims, time_weights_scale, 0),
+ CreateQuantizedBiasTensor(bias_data, bias_quantized, bias_dims,
+ time_weights_scale, activation_state_scale),
+ CreateQuantizedTensor(initial_activation_state_data,
+ activation_state_quantized, activation_state_dims,
+ activation_state_scale, 0,
+ /*is_variable=*/true),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point)};
+
+ tflite::Quantize(golden_output, golden_output_quantized, golden_output_len,
+ output_scale, output_zero_point);
+ tflite::Quantize(input_sequences_data, input_sequences_quantized,
+ input_sequences_len, input_scale, input_zero_point);
+
+ ValidateSVDFGoldens(batch_size, num_units, input_size, rank, tensors,
+ tensor_count, activation, input_sequences_quantized,
+ input_sequences_len, output_data, golden_output_quantized,
+ /*tolerance*/ 1);
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+#if !defined(XTENSA) // TODO(b/170332589): xtensa kernels are less general than
+ // reference kernels and we ifdef out test cases that are
+ // currently known to fail.
+TF_LITE_MICRO_TEST(SvdfFloat2x2Input2x4OutputShouldMatchGolden) {
+ constexpr int batch_size = 2;
+ constexpr int num_units = 4;
+ constexpr int input_size = 2;
+ constexpr int memory_size = 10;
+ constexpr int rank = 2;
+ constexpr int num_filters = num_units * rank;
+
+ const int input_size_dims_count = batch_size * input_size;
+ float input_data[input_size_dims_count];
+
+ const int activation_state_dims_count =
+ batch_size * memory_size * num_filters;
+ float activation_state_data[activation_state_dims_count];
+
+ memcpy(activation_state_data,
+ tflite::testing::initial_activation_state_data_2x2x10,
+ sizeof(tflite::testing::initial_activation_state_data_2x2x10));
+
+ const int scratch_dims_count = batch_size * num_filters;
+ float scratch_data[scratch_dims_count];
+
+ const int output_dims_count = batch_size * num_units;
+ float output_data[output_dims_count];
+
+ tflite::testing::TestSVDF(
+ batch_size, num_units, input_size, memory_size, rank, kTfLiteActNone,
+ input_data, tflite::testing::feature_weights_data_2x2x10,
+ tflite::testing::time_weights_data_2x2x10, activation_state_data,
+ tflite::testing::bias_data_2x2x10, scratch_data, output_data,
+ tflite::testing::input_data_2x2x10,
+ sizeof(tflite::testing::input_data_2x2x10) / sizeof(float),
+ tflite::testing::golden_output_2x2x10);
+}
+#endif
+
+TF_LITE_MICRO_TEST(SvdfQuantized2x2Input2x4OutputShouldMatchGolden) {
+ constexpr int batch_size = 2;
+ constexpr int num_units = 4;
+ constexpr int input_size = 2;
+ constexpr int memory_size = 10;
+ constexpr int rank = 2;
+ constexpr int num_filters = num_units * rank;
+
+ const int input_size_dims_count = batch_size * input_size;
+
+ const int activation_state_dims_count =
+ batch_size * memory_size * num_filters;
+
+ const int output_dims_count = batch_size * num_units;
+ int8_t output_data[output_dims_count];
+
+ float input_scale = 2.5f / INT8_MAX; // Range is [-2.5, 2.5]
+ float feature_weights_scale = 1.f / INT8_MAX; // Range is [-1, 1]
+ float time_weights_scale = 1.f / INT16_MAX; // Range is [-1, 1]
+ float activation_state_scale = 16.f / INT16_MAX; // Range is [-16, 16]
+ float output_scale = 1.f / INT8_MAX; // Range is [-1, 1]
+
+ int input_zero_point = 0;
+ int output_zero_point = 0;
+
+ int8_t input_quantized[input_size_dims_count];
+ int8_t input_sequences_quantized[sizeof(tflite::testing::input_data_2x2x10) /
+ sizeof(float)];
+ int8_t feature_weights_quantized
+ [sizeof(tflite::testing::feature_weights_data_2x2x10) / sizeof(float)];
+ int16_t
+ time_weights_quantized[sizeof(tflite::testing::time_weights_data_2x2x10) /
+ sizeof(float)];
+ int16_t activation_state_quantized[activation_state_dims_count];
+ int32_t
+ bias_quantized[sizeof(tflite::testing::bias_data_2x2x10) / sizeof(float)];
+ int8_t golden_quantized[sizeof(tflite::testing::golden_output_2x2x10) /
+ sizeof(float)];
+
+ tflite::testing::TestIntegerSVDF(
+ batch_size, num_units, input_size, memory_size, rank, kTfLiteActRelu,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::feature_weights_data_2x2x10, feature_weights_quantized,
+ feature_weights_scale, tflite::testing::time_weights_data_2x2x10,
+ time_weights_quantized, time_weights_scale,
+ tflite::testing::bias_data_2x2x10, bias_quantized,
+ tflite::testing::initial_activation_state_data_2x2x10,
+ activation_state_quantized, activation_state_scale, output_data,
+ output_scale, output_zero_point, tflite::testing::input_data_2x2x10,
+ input_sequences_quantized,
+ sizeof(tflite::testing::input_data_2x2x10) / sizeof(float),
+ tflite::testing::golden_output_2x2x10, golden_quantized,
+ sizeof(tflite::testing::golden_output_2x2x10) / sizeof(float));
+}
+
+#if !defined(XTENSA) // TODO(b/170332589): xtensa kernels are less general than
+ // reference kernels and we ifdef out test cases that are
+ // currently known to fail.
+TF_LITE_MICRO_TEST(SvdfFloat1x16Input64x1OutputShouldMatchGolden) {
+ constexpr int batch_size = 1;
+ constexpr int num_units = 64;
+ constexpr int input_size = 16;
+ constexpr int memory_size = 8;
+ constexpr int rank = 1;
+ constexpr int num_filters = num_units * rank;
+ constexpr int activation_state_dims_count =
+ batch_size * memory_size * num_filters;
+ constexpr int output_dims_count = batch_size * num_units;
+ constexpr int input_dims_count = batch_size * input_size;
+
+ float input_data[input_dims_count];
+ float output_data[output_dims_count];
+ float scratch_buffer[batch_size * num_filters];
+ float activation_state_data_mutable[activation_state_dims_count];
+
+ // Initialize activation state to starting values.
+ memcpy(activation_state_data_mutable,
+ tflite::testing::initial_activation_state_data_16x1x1,
+ sizeof(tflite::testing::initial_activation_state_data_16x1x1));
+
+ tflite::testing::TestSVDF(
+ batch_size, num_units, input_size, memory_size, rank, kTfLiteActNone,
+ input_data, tflite::testing::feature_weights_data_16x1x1,
+ tflite::testing::time_weights_data_16x1x1, activation_state_data_mutable,
+ tflite::testing::bias_data_16x1x1, scratch_buffer, output_data,
+ tflite::testing::input_data_16x1x1, input_size,
+ tflite::testing::golden_output_16x1x1);
+}
+
+TF_LITE_MICRO_TEST(SvdfFloat1x16Input64x1OutputReluShouldMatchGolden) {
+ constexpr int batch_size = 1;
+ constexpr int num_units = 64;
+ constexpr int input_size = 16;
+ constexpr int memory_size = 8;
+ constexpr int rank = 1;
+ constexpr int num_filters = num_units * rank;
+ constexpr int activation_state_dims_count =
+ batch_size * memory_size * num_filters;
+ constexpr int output_dims_count = batch_size * num_units;
+ constexpr int input_dims_count = batch_size * input_size;
+
+ float input_data[input_dims_count];
+ float output_data[output_dims_count];
+ float scratch_buffer[batch_size * num_filters];
+ float activation_state_data_mutable[activation_state_dims_count];
+
+ // Initialize activation state to starting values.
+ memcpy(activation_state_data_mutable,
+ tflite::testing::initial_activation_state_data_16x1x1,
+ sizeof(tflite::testing::initial_activation_state_data_16x1x1));
+
+ tflite::testing::TestSVDF(
+ batch_size, num_units, input_size, memory_size, rank, kTfLiteActRelu,
+ input_data, tflite::testing::feature_weights_data_16x1x1,
+ tflite::testing::time_weights_data_16x1x1, activation_state_data_mutable,
+ tflite::testing::bias_data_16x1x1, scratch_buffer, output_data,
+ tflite::testing::input_data_16x1x1, input_size,
+ tflite::testing::golden_output_relu_16x1x1);
+}
+#endif
+
+TF_LITE_MICRO_TEST(SvdfQuantized1x16Input64x1OutputShouldMatchGolden) {
+ constexpr int batch_size = 1;
+ constexpr int num_units = 64;
+ constexpr int input_size = 16;
+ constexpr int memory_size = 8;
+ constexpr int rank = 1;
+ constexpr int num_filters = num_units * rank;
+ constexpr int activation_state_dims_count =
+ batch_size * memory_size * num_filters;
+ constexpr int output_dims_count = batch_size * num_units;
+ constexpr int input_dims_count = batch_size * input_size;
+
+ int8_t output_data[output_dims_count];
+
+ float input_scale = 0.10075444;
+ float feature_weights_scale = 0.00649388;
+ float time_weights_scale = 0.001571355;
+ float activation_state_scale = 0.00045896982;
+ float output_scale = 0.051445257;
+
+ int input_zero_point = 2;
+ int output_zero_point = 0;
+
+ int8_t input_quantized[input_dims_count];
+ int8_t input_sequences_quantized[sizeof(tflite::testing::input_data_16x1x1) /
+ sizeof(float)];
+ int8_t feature_weights_quantized
+ [sizeof(tflite::testing::feature_weights_data_16x1x1) / sizeof(float)];
+ int16_t
+ time_weights_quantized[sizeof(tflite::testing::time_weights_data_16x1x1) /
+ sizeof(float)];
+ int16_t activation_state_quantized[activation_state_dims_count];
+ int32_t
+ bias_quantized[sizeof(tflite::testing::bias_data_16x1x1) / sizeof(float)];
+ int8_t golden_quantized[sizeof(tflite::testing::golden_output_16x1x1) /
+ sizeof(float)];
+
+ tflite::testing::TestIntegerSVDF(
+ batch_size, num_units, input_size, memory_size, rank, kTfLiteActNone,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::feature_weights_data_16x1x1, feature_weights_quantized,
+ feature_weights_scale, tflite::testing::time_weights_data_16x1x1,
+ time_weights_quantized, time_weights_scale,
+ tflite::testing::bias_data_16x1x1, bias_quantized,
+ tflite::testing::initial_activation_state_data_16x1x1,
+ activation_state_quantized, activation_state_scale, output_data,
+ output_scale, output_zero_point, tflite::testing::input_data_16x1x1,
+ input_sequences_quantized,
+ sizeof(tflite::testing::input_data_16x1x1) / sizeof(float),
+ tflite::testing::golden_output_16x1x1, golden_quantized,
+ sizeof(tflite::testing::golden_output_16x1x1) / sizeof(float));
+}
+
+TF_LITE_MICRO_TEST(SvdfQuantized1x16Input64x1OutputReluShouldMatchGolden) {
+ constexpr int batch_size = 1;
+ constexpr int num_units = 64;
+ constexpr int input_size = 16;
+ constexpr int memory_size = 8;
+ constexpr int rank = 1;
+ constexpr int num_filters = num_units * rank;
+ constexpr int activation_state_dims_count =
+ batch_size * memory_size * num_filters;
+ constexpr int output_dims_count = batch_size * num_units;
+ constexpr int input_dims_count = batch_size * input_size;
+
+ int8_t output_data[output_dims_count];
+
+ float input_scale = 0.10075444;
+ float feature_weights_scale = 0.00649388;
+ float time_weights_scale = 0.001571355;
+ float activation_state_scale = 0.00045896982;
+ float output_scale = 0.051445257;
+
+ int input_zero_point = 2;
+ int output_zero_point = -128;
+
+ int8_t input_quantized[input_dims_count];
+ int8_t input_sequences_quantized[sizeof(tflite::testing::input_data_16x1x1) /
+ sizeof(float)];
+ int8_t feature_weights_quantized
+ [sizeof(tflite::testing::feature_weights_data_16x1x1) / sizeof(float)];
+ int16_t
+ time_weights_quantized[sizeof(tflite::testing::time_weights_data_16x1x1) /
+ sizeof(float)];
+ int16_t activation_state_quantized[activation_state_dims_count];
+ int32_t
+ bias_quantized[sizeof(tflite::testing::bias_data_16x1x1) / sizeof(float)];
+ int8_t golden_quantized[sizeof(tflite::testing::golden_output_relu_16x1x1) /
+ sizeof(float)];
+
+ tflite::testing::TestIntegerSVDF(
+ batch_size, num_units, input_size, memory_size, rank, kTfLiteActRelu,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::feature_weights_data_16x1x1, feature_weights_quantized,
+ feature_weights_scale, tflite::testing::time_weights_data_16x1x1,
+ time_weights_quantized, time_weights_scale,
+ tflite::testing::bias_data_16x1x1, bias_quantized,
+ tflite::testing::initial_activation_state_data_16x1x1,
+ activation_state_quantized, activation_state_scale, output_data,
+ output_scale, output_zero_point, tflite::testing::input_data_16x1x1,
+ input_sequences_quantized,
+ sizeof(tflite::testing::input_data_16x1x1) / sizeof(float),
+ tflite::testing::golden_output_relu_16x1x1, golden_quantized,
+ sizeof(tflite::testing::golden_output_relu_16x1x1) / sizeof(float));
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/tanh.cc b/tensorflow/lite/micro/kernels/tanh.cc
new file mode 100644
index 0000000..7743a87
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/tanh.cc
@@ -0,0 +1,158 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/tanh.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/tanh.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace activations {
+namespace {
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+struct OpData {
+ int32_t input_zero_point;
+ int32_t input_range_radius;
+ int32_t input_multiplier;
+ int input_left_shift;
+};
+
+void* TanhInit(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus CalculateArithmeticOpData(TfLiteContext* context, TfLiteNode* node,
+ OpData* data) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+
+ TF_LITE_ENSURE_TYPES_EQ(context, input->type, output->type);
+
+ if (input->type == kTfLiteUInt8 || input->type == kTfLiteInt8) {
+ static constexpr int kInputIntegerBits = 4;
+ const double input_real_multiplier =
+ static_cast<double>(input->params.scale) *
+ static_cast<double>(1 << (31 - kInputIntegerBits));
+
+ const double q = std::frexp(input_real_multiplier, &data->input_left_shift);
+ data->input_multiplier = static_cast<int32_t>(TfLiteRound(q * (1ll << 31)));
+
+ data->input_range_radius =
+ CalculateInputRadius(kInputIntegerBits, data->input_left_shift, 31);
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus TanhPrepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ data->input_zero_point = input->params.zero_point;
+ return CalculateArithmeticOpData(context, node, data);
+}
+
+} // namespace
+
+TfLiteStatus TanhEval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ reference_ops::Tanh(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output));
+ return kTfLiteOk;
+ } break;
+ case kTfLiteInt16: {
+ TanhParams params;
+ params.input_left_shift = data.input_left_shift;
+ reference_ops::Tanh(params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int16_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ return kTfLiteOk;
+ } break;
+ case kTfLiteUInt8: {
+ TanhParams params;
+ params.input_zero_point = data.input_zero_point;
+ params.input_range_radius = data.input_range_radius;
+ params.input_multiplier = data.input_multiplier;
+ params.input_left_shift = data.input_left_shift;
+ reference_ops::Tanh(params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+
+ return kTfLiteOk;
+ } break;
+ case kTfLiteInt8: {
+ reference_integer_ops::Tanh(
+ data.input_zero_point, data.input_range_radius, data.input_multiplier,
+ data.input_left_shift, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+ } break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+}
+
+} // namespace activations
+
+TfLiteRegistration Register_TANH() {
+ return {/*init=*/activations::TanhInit,
+ /*free=*/nullptr,
+ /*prepare=*/activations::TanhPrepare,
+ /*invoke=*/activations::TanhEval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/tanh_test.cc b/tensorflow/lite/micro/kernels/tanh_test.cc
new file mode 100644
index 0000000..20401f3
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/tanh_test.cc
@@ -0,0 +1,224 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int tanh_vec_size = 90;
+
+const float tanh_input_vec_fp[tanh_vec_size] = {
+ -8.0000000000, -7.8181818182, -7.6363636364, -7.4545454545, -7.2727272727,
+ -7.0909090909, -6.9090909091, -6.7272727273, -6.5454545455, -6.3636363636,
+ -6.1818181818, -6.0000000000, -5.8181818182, -5.6363636364, -5.4545454545,
+ -5.2727272727, -5.0909090909, -4.9090909091, -4.7272727273, -4.5454545455,
+ -4.3636363636, -4.1818181818, -4.0000000000, -3.8181818182, -3.6363636364,
+ -3.4545454545, -3.2727272727, -3.0909090909, -2.9090909091, -2.7272727273,
+ -2.5454545455, -2.3636363636, -2.1818181818, -2.0000000000, -1.8181818182,
+ -1.6363636364, -1.4545454545, -1.2727272727, -1.0909090909, -0.9090909091,
+ -0.7272727273, -0.5454545455, -0.3636363636, -0.1818181818, 0.0000000000,
+ 0.1818181818, 0.3636363636, 0.5454545455, 0.7272727273, 0.9090909091,
+ 1.0909090909, 1.2727272727, 1.4545454545, 1.6363636364, 1.8181818182,
+ 2.0000000000, 2.1818181818, 2.3636363636, 2.5454545455, 2.7272727273,
+ 2.9090909091, 3.0909090909, 3.2727272727, 3.4545454545, 3.6363636364,
+ 3.8181818182, 4.0000000000, 4.1818181818, 4.3636363636, 4.5454545455,
+ 4.7272727273, 4.9090909091, 5.0909090909, 5.2727272727, 5.4545454545,
+ 5.6363636364, 5.8181818182, 6.0000000000, 6.1818181818, 6.3636363636,
+ 6.5454545455, 6.7272727273, 6.9090909091, 7.0909090909, 7.2727272727,
+ 7.4545454545, 7.6363636364, 7.8181818182, 8.0000000000};
+
+const float tanh_output_vec_fp[tanh_vec_size] = {
+ -0.9999997749, -0.9999996762, -0.9999995342, -0.9999993300, -0.9999990361,
+ -0.9999986134, -0.9999980053, -0.9999971306, -0.9999958722, -0.9999940619,
+ -0.9999914578, -0.9999877117, -0.9999823226, -0.9999745703, -0.9999634183,
+ -0.9999473758, -0.9999242982, -0.9998911009, -0.9998433469, -0.9997746542,
+ -0.9996758446, -0.9995337191, -0.9993292997, -0.9990353053, -0.9986125310,
+ -0.9980046622, -0.9971308601, -0.9958751909, -0.9940716137, -0.9914827859,
+ -0.9877703933, -0.9824541388, -0.9748561217, -0.9640275801, -0.9486568273,
+ -0.9269625051, -0.8965880154, -0.8545351057, -0.7972097087, -0.7206956332,
+ -0.6213939966, -0.4971057414, -0.3484130125, -0.1798408185, 0.0000000000,
+ 0.1798408185, 0.3484130125, 0.4971057414, 0.6213939966, 0.7206956332,
+ 0.7972097087, 0.8545351057, 0.8965880154, 0.9269625051, 0.9486568273,
+ 0.9640275801, 0.9748561217, 0.9824541388, 0.9877703933, 0.9914827859,
+ 0.9940716137, 0.9958751909, 0.9971308601, 0.9980046622, 0.9986125310,
+ 0.9990353053, 0.9993292997, 0.9995337191, 0.9996758446, 0.9997746542,
+ 0.9998433469, 0.9998911009, 0.9999242982, 0.9999473758, 0.9999634183,
+ 0.9999745703, 0.9999823226, 0.9999877117, 0.9999914578, 0.9999940619,
+ 0.9999958722, 0.9999971306, 0.9999980053, 0.9999986134, 0.9999990361,
+ 0.9999993300, 0.9999995342, 0.9999996762, 0.9999997749};
+
+void TestTanhFloat(const int input_dims_data[], const float* input_data,
+ const float* expected_output_data,
+ const int output_dims_data[], float* output_data,
+ const float tolerance) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_TANH();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i],
+ tolerance);
+ }
+}
+
+template <typename T>
+void TestTanhQuantized(const int input_dims_data[], const float* input_data,
+ T* input_quantized, float input_scale,
+ int input_zero_point, const float* expected_output_data,
+ T* expected_output_quantized,
+ const int output_dims_data[], float output_scale,
+ int output_zero_point, T* output_quantized,
+ const int tolerance) {
+ static_assert(sizeof(T) == 1, "Valid only for 8bit data types");
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_elements_count = ElementCount(*output_dims);
+
+ tflite::Quantize(expected_output_data, expected_output_quantized,
+ output_elements_count, output_scale, output_zero_point);
+
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedTensor(output_quantized, output_dims, output_scale,
+ output_zero_point)};
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_TANH();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_elements_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_quantized[i], output_quantized[i],
+ tolerance);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SimpleTestTanhFloat) {
+ using tflite::testing::tanh_input_vec_fp;
+ using tflite::testing::tanh_output_vec_fp;
+ using tflite::testing::tanh_vec_size;
+
+ const int input_shape[] = {2, 1, tanh_vec_size};
+ const int output_shape[] = {2, 1, tanh_vec_size};
+
+ float output_data[tanh_vec_size];
+ tflite::testing::TestTanhFloat( //
+ input_shape, // Input shape.
+ tanh_input_vec_fp, // Input data
+ tanh_output_vec_fp, // Expected results.
+ output_shape, // Output shape.
+ output_data, 1e-7 /* tolerance */);
+}
+
+TF_LITE_MICRO_TEST(SimpleTestTanhUInt8) {
+ using tflite::testing::tanh_input_vec_fp;
+ using tflite::testing::tanh_output_vec_fp;
+ using tflite::testing::tanh_vec_size;
+
+ const float input_scale = 16 / 256.f;
+ const int input_zero_point = 128;
+ const float output_scale = 1.99999955f / 256.f;
+ const int output_zero_point = 128;
+
+ const int input_shape[] = {2, 1, tanh_vec_size};
+ const int output_shape[] = {2, 1, tanh_vec_size};
+
+ uint8_t input_quantized[tanh_vec_size];
+ uint8_t expected_output_quantized[tanh_vec_size];
+ uint8_t output_quantized[tanh_vec_size];
+ tflite::testing::TestTanhQuantized<uint8_t>( //
+ input_shape, // Input shape.
+ tanh_input_vec_fp, input_quantized, // Input data.
+ input_scale, input_zero_point, // Input quantized info.
+ tanh_output_vec_fp, expected_output_quantized, // Expected results.
+ output_shape, // Output shape.
+ output_scale, output_zero_point, // Output quantized info.
+ output_quantized, // Operation results
+ 2 // Tolerance.
+ );
+}
+
+TF_LITE_MICRO_TEST(SimpleTestTanhUInt8) {
+ using tflite::testing::tanh_input_vec_fp;
+ using tflite::testing::tanh_output_vec_fp;
+ using tflite::testing::tanh_vec_size;
+
+ const float input_scale = 16 / 256.f;
+ const int input_zero_point = 0;
+ const float output_scale = 1.99999955f / 256.f;
+ const int output_zero_point = 0;
+
+ const int input_shape[] = {2, 1, tanh_vec_size};
+ const int output_shape[] = {2, 1, tanh_vec_size};
+
+ int8_t input_quantized[tanh_vec_size];
+ int8_t expected_output_quantized[tanh_vec_size];
+ int8_t output_quantized[tanh_vec_size];
+ tflite::testing::TestTanhQuantized<int8_t>( //
+ input_shape, // Input shape.
+ tanh_input_vec_fp, input_quantized, // Input data.
+ input_scale, input_zero_point, // Input quantized info.
+ tanh_output_vec_fp, expected_output_quantized, // Expected results.
+ output_shape, // Output shape.
+ output_scale, output_zero_point, // Output quantized info.
+ output_quantized, // Operation results
+ 2 // Tolerance.
+ );
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/test_data_generation/BUILD b/tensorflow/lite/micro/kernels/test_data_generation/BUILD
new file mode 100644
index 0000000..b728b54
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/test_data_generation/BUILD
@@ -0,0 +1,34 @@
+load("@bazel_skylib//rules:build_test.bzl", "build_test")
+
+package(
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+cc_binary(
+ name = "generate_detection_postprocess_flexbuffers_data",
+ srcs = [
+ "generate_detection_postprocess_flexbuffers_data.cc",
+ ],
+ deps = [
+ "@flatbuffers",
+ ],
+)
+
+cc_binary(
+ name = "generate_circular_buffer_flexbuffers_data",
+ srcs = [
+ "generate_circular_buffer_flexbuffers_data.cc",
+ ],
+ deps = [
+ "@flatbuffers",
+ ],
+)
+
+build_test(
+ name = "build_test",
+ targets = [
+ ":generate_circular_buffer_flexbuffers_data",
+ ":generate_detection_postprocess_flexbuffers_data",
+ ],
+)
diff --git a/tensorflow/lite/micro/kernels/test_data_generation/README.md b/tensorflow/lite/micro/kernels/test_data_generation/README.md
new file mode 100644
index 0000000..9c71701
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/test_data_generation/README.md
@@ -0,0 +1,14 @@
+# Background
+
+As a Custom operator, detection_postprocess is using Flexbuffers library. In the
+unit test there is a need to use flexbuffers::Builder since the operator itself
+use flexbuffers::Map. However flexbuffers::Builder can not be used for most
+targets (basically only on X86), since it is using std::vector and std::map.
+Therefore the flexbuffers::Builder data is pregenerated on X86.
+
+# How to generate new data:
+
+~~~
+ ```g++ -I../../../micro/tools/make/downloads/flatbuffers/include generate_flexbuffers_data.cc && ./a.out > ../flexbuffers_generated_data.cc```
+
+~~~
diff --git a/tensorflow/lite/micro/kernels/test_data_generation/generate_circular_buffer_flexbuffers_data.cc b/tensorflow/lite/micro/kernels/test_data_generation/generate_circular_buffer_flexbuffers_data.cc
new file mode 100644
index 0000000..38abb63
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/test_data_generation/generate_circular_buffer_flexbuffers_data.cc
@@ -0,0 +1,61 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "flatbuffers/flexbuffers.h"
+
+const char* license =
+ "/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.\n"
+ "Licensed under the Apache License, Version 2.0 (the \"License\");\n"
+ "you may not use this file except in compliance with the License.\n"
+ "You may obtain a copy of the License at\n\n"
+ " http://www.apache.org/licenses/LICENSE-2.0\n\n"
+ "Unless required by applicable law or agreed to in writing, software\n"
+ "distributed under the License is distributed on an \"AS IS\" BASIS,\n"
+ "WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n"
+ "See the License for the specific language governing permissions and\n"
+ "limitations under the License.\n"
+ "======================================================================="
+ "=======*/\n";
+
+void generate(const char* name) {
+ flexbuffers::Builder fbb;
+ fbb.Map([&]() { fbb.Int("cycles_max", 1); });
+ fbb.Finish();
+
+ // fbb.GetBuffer returns std::Vector<uint8_t> but TfLite passes char arrays
+ // for the raw data, and so we reinterpret_cast.
+ const uint8_t* init_data =
+ reinterpret_cast<const uint8_t*>(fbb.GetBuffer().data());
+ int fbb_size = fbb.GetBuffer().size();
+
+ printf("const int g_gen_data_size_%s = %d;\n", name, fbb_size);
+ printf("const unsigned char g_gen_data_%s[] = { ", name);
+ for (size_t i = 0; i < fbb_size; i++) {
+ printf("0x%02x, ", init_data[i]);
+ }
+ printf("};\n");
+}
+
+int main() {
+ printf("%s\n", license);
+ printf("// This file is generated. See:\n");
+ printf("// third_party/tensorflow/lite/micro/kernels/test_data_generation/");
+ printf("README.md\n");
+ printf("\n");
+ printf(
+ "#include \"third_party/tensorflow/lite/micro/kernels/"
+ "circular_buffer_flexbuffers_generated_data.h\"");
+ printf("\n\n");
+ generate("circular_buffer_config");
+}
diff --git a/tensorflow/lite/micro/kernels/test_data_generation/generate_detection_postprocess_flexbuffers_data.cc b/tensorflow/lite/micro/kernels/test_data_generation/generate_detection_postprocess_flexbuffers_data.cc
new file mode 100644
index 0000000..f4e6900
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/test_data_generation/generate_detection_postprocess_flexbuffers_data.cc
@@ -0,0 +1,75 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "flatbuffers/flexbuffers.h"
+
+const char* license =
+ "/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.\n"
+ "Licensed under the Apache License, Version 2.0 (the \"License\");\n"
+ "you may not use this file except in compliance with the License.\n"
+ "You may obtain a copy of the License at\n\n"
+ " http://www.apache.org/licenses/LICENSE-2.0\n\n"
+ "Unless required by applicable law or agreed to in writing, software\n"
+ "distributed under the License is distributed on an \"AS IS\" BASIS,\n"
+ "WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n"
+ "See the License for the specific language governing permissions and\n"
+ "limitations under the License.\n"
+ "======================================================================="
+ "=======*/\n";
+
+void generate(const char* name, bool use_regular_nms) {
+ flexbuffers::Builder fbb;
+ fbb.Map([&]() {
+ fbb.Int("max_detections", 3);
+ fbb.Int("max_classes_per_detection", 1);
+ fbb.Int("detections_per_class", 1);
+ fbb.Bool("use_regular_nms", use_regular_nms);
+ fbb.Float("nms_score_threshold", 0.0);
+ fbb.Float("nms_iou_threshold", 0.5);
+ fbb.Int("num_classes", 2);
+ fbb.Float("y_scale", 10.0);
+ fbb.Float("x_scale", 10.0);
+ fbb.Float("h_scale", 5.0);
+ fbb.Float("w_scale", 5.0);
+ });
+ fbb.Finish();
+
+ // fbb.GetBuffer returns std::Vector<uint8_t> but TfLite passes char arrays
+ // for the raw data, and so we reinterpret_cast.
+ const uint8_t* init_data =
+ reinterpret_cast<const uint8_t*>(fbb.GetBuffer().data());
+ int fbb_size = fbb.GetBuffer().size();
+
+ printf("const int g_gen_data_size_%s = %d;\n", name, fbb_size);
+ printf("const unsigned char g_gen_data_%s[] = { ", name);
+ for (size_t i = 0; i < fbb_size; i++) {
+ printf("0x%02x, ", init_data[i]);
+ }
+ printf("};\n");
+}
+
+int main() {
+ printf("%s\n", license);
+ printf("// This file is generated. See:\n");
+ printf("// tensorflow/lite/micro/kernels/detection_postprocess_test/");
+ printf("README.md\n");
+ printf("\n");
+ printf(
+ "#include "
+ "\"tensorflow/lite/micro/kernels/"
+ "detection_postprocess_flexbuffers_generated_data.h\"");
+ printf("\n\n");
+ generate("none_regular_nms", false);
+ generate("regular_nms", true);
+}
diff --git a/tensorflow/lite/micro/kernels/transpose.cc b/tensorflow/lite/micro/kernels/transpose.cc
new file mode 100644
index 0000000..d11d26e
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/transpose.cc
@@ -0,0 +1,181 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include <stdint.h>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/optimized/optimized_ops.h"
+#include "tensorflow/lite/kernels/internal/reference/reference_ops.h"
+#include "tensorflow/lite/kernels/internal/tensor.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/internal/types.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace builtin {
+namespace transpose {
+
+// This file has two implementations of Transpose.
+enum KernelType {
+ kReference,
+ kGenericOptimized,
+};
+
+struct TransposeContext {
+ TransposeContext(TfLiteContext* context, TfLiteNode* node) {
+ input = GetInput(context, node, 0);
+ perm = GetInput(context, node, 1);
+ output = GetOutput(context, node, 0);
+ }
+ const TfLiteTensor* input;
+ const TfLiteTensor* perm;
+ TfLiteTensor* output;
+};
+
+TfLiteStatus ResizeOutputTensor(TfLiteContext* context,
+ TransposeContext* op_context) {
+ int dims = NumDimensions(op_context->input);
+ const int* perm_data = GetTensorData<int32_t>(op_context->perm);
+
+ // Ensure validity of the permutations tensor as a 1D tensor.
+ TF_LITE_ENSURE_EQ(context, NumDimensions(op_context->perm), 1);
+ TF_LITE_ENSURE_EQ(context, op_context->perm->dims->data[0], dims);
+ for (int idx = 0; idx < dims; ++idx) {
+ TF_LITE_ENSURE_MSG(context, (perm_data[idx] >= 0 && perm_data[idx] < dims),
+ "Transpose op permutations array is out of bounds.");
+ }
+
+ // Determine size of output tensor.
+ TfLiteIntArray* input_size = op_context->input->dims;
+ TfLiteIntArray* output_size = TfLiteIntArrayCopy(input_size);
+ for (int idx = 0; idx < dims; ++idx) {
+ output_size->data[idx] = input_size->data[perm_data[idx]];
+ }
+
+ return context->ResizeTensor(context, op_context->output, output_size);
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 2);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+
+ TransposeContext op_context(context, node);
+
+ // Ensure validity of input tensor.
+ TF_LITE_ENSURE_MSG(context, NumDimensions(op_context.input) <= 5,
+ "Transpose op only supports 1D-5D input arrays.");
+ TF_LITE_ENSURE_TYPES_EQ(context, op_context.input->type,
+ op_context.output->type);
+
+ if (!IsConstantTensor(op_context.perm)) {
+ SetTensorToDynamic(op_context.output);
+ return kTfLiteOk;
+ }
+ return ResizeOutputTensor(context, &op_context);
+}
+
+template <KernelType kernel_type>
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TransposeContext op_context(context, node);
+
+ // Resize the output tensor if the output tensor is dynamic.
+ if (IsDynamicTensor(op_context.output)) {
+ TF_LITE_ENSURE_OK(context, ResizeOutputTensor(context, &op_context));
+ }
+
+ const int* perm_data = GetTensorData<int32_t>(op_context.perm);
+ const int size = op_context.perm->dims->data[0];
+ TransposeParams params;
+ params.perm_count = size;
+ for (int i = 0; i < size; ++i) {
+ params.perm[i] = perm_data[i];
+ }
+
+#define TF_LITE_TRANSPOSE(type, scalar) \
+ type::Transpose(params, GetTensorShape(op_context.input), \
+ GetTensorData<scalar>(op_context.input), \
+ GetTensorShape(op_context.output), \
+ GetTensorData<scalar>(op_context.output))
+
+ // Transpose kernel only does rearranging values not numeric evaluations on
+ // each cell. It's safe to implement per size of scalar type and this trick
+ // keeps the total code size in a reasonable range.
+ switch (op_context.input->type) {
+ case kTfLiteFloat32:
+ case kTfLiteInt32:
+ if (kernel_type == kGenericOptimized) {
+ TF_LITE_TRANSPOSE(optimized_ops, int32_t);
+ } else {
+ TF_LITE_TRANSPOSE(reference_ops, int32_t);
+ }
+ break;
+ case kTfLiteUInt8:
+ case kTfLiteInt8:
+ if (kernel_type == kGenericOptimized) {
+ TF_LITE_TRANSPOSE(optimized_ops, int8_t);
+ } else {
+ TF_LITE_TRANSPOSE(reference_ops, int8_t);
+ }
+ break;
+ case kTfLiteInt16:
+ TF_LITE_TRANSPOSE(reference_ops, int16_t);
+ break;
+ case kTfLiteInt64:
+ TF_LITE_TRANSPOSE(reference_ops, int64_t);
+ break;
+ case kTfLiteBool:
+ if (sizeof(bool) == 1) {
+ if (kernel_type == kGenericOptimized) {
+ TF_LITE_TRANSPOSE(optimized_ops, int8_t);
+ } else {
+ TF_LITE_TRANSPOSE(reference_ops, int8_t);
+ }
+ } else {
+ TF_LITE_TRANSPOSE(reference_ops, bool);
+ }
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "Type %s is currently not supported by Transpose.",
+ TfLiteTypeGetName(op_context.input->type));
+ return kTfLiteError;
+ }
+#undef TF_LITE_TRANSPOSE
+
+ return kTfLiteOk;
+}
+
+} // namespace transpose
+
+TfLiteRegistration* Register_TRANSPOSE_REF() {
+ static TfLiteRegistration r = {nullptr, nullptr, transpose::Prepare,
+ transpose::Eval<transpose::kReference>};
+ return &r;
+}
+
+TfLiteRegistration* Register_TRANSPOSE_GENERIC_OPTIMIZED() {
+ static TfLiteRegistration r = {nullptr, nullptr, transpose::Prepare,
+ transpose::Eval<transpose::kGenericOptimized>};
+ return &r;
+}
+
+TfLiteRegistration* Register_TRANSPOSE() {
+ return Register_TRANSPOSE_GENERIC_OPTIMIZED();
+}
+
+} // namespace builtin
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/transpose_conv.cc b/tensorflow/lite/micro/kernels/transpose_conv.cc
new file mode 100644
index 0000000..c49a998
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/transpose_conv.cc
@@ -0,0 +1,269 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/transpose_conv.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/transpose_conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+// For the TfLite transpose_conv implementation, input tensor 0 corresponds to
+// the OutputShapeTensor. However, since TFLM does not support dynamic tensors,
+// the TFLM implementation ignores input tensor 0 and the only inputs we care
+// about are kFilterTensor, kInputTensor and kBiasTensor.
+constexpr int kFilterTensor = 1;
+constexpr int kInputTensor = 2;
+constexpr int kBiasTensor = 3;
+constexpr int kOutputTensor = 0;
+
+// Conv is quantized along dimension 0:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+constexpr int kConvQuantizedDimension = 0;
+
+struct OpData {
+ ConvParams params;
+
+ // A scratch buffer is required for quantized implementations.
+ int scratch_buffer_index;
+
+ // Multiplier and shift arrays are required for the int8 implementation.
+ int32_t* per_channel_output_multiplier;
+ int32_t* per_channel_output_shift;
+};
+
+inline PaddingType RuntimePaddingType(TfLitePadding padding) {
+ switch (padding) {
+ case TfLitePadding::kTfLitePaddingSame:
+ return PaddingType::kSame;
+ case TfLitePadding::kTfLitePaddingValid:
+ return PaddingType::kValid;
+ case TfLitePadding::kTfLitePaddingUnknown:
+ default:
+ return PaddingType::kNone;
+ }
+}
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteConvParams* params, int width,
+ int height, int filter_width, int filter_height,
+ int out_width, int out_height,
+ const TfLiteType data_type, OpData* data) {
+ bool has_bias = node->inputs->size == 4;
+ // Check number of inputs/outputs
+ TF_LITE_ENSURE(context, has_bias || node->inputs->size == 3);
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+
+ // Matching GetWindowedOutputSize in TensorFlow.
+ auto padding = params->padding;
+ TfLitePaddingValues padding_values = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width,
+ params->dilation_height_factor, params->dilation_width_factor, height,
+ width, filter_height, filter_width, padding, &out_height, &out_width);
+
+ data->params.padding_type = RuntimePaddingType(padding);
+ data->params.padding_values.width = padding_values.width;
+ data->params.padding_values.height = padding_values.height;
+
+ // Note that quantized inference requires that all tensors have their
+ // parameters set. This is usually done during quantized training.
+ if (data_type != kTfLiteFloat32) {
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ int output_channels = filter->dims->data[kConvQuantizedDimension];
+
+ TF_LITE_ENSURE_STATUS(tflite::PopulateConvolutionQuantizationParams(
+ context, input, filter, bias, output, params->activation,
+ &data->params.output_multiplier, &data->params.output_shift,
+ &data->params.quantized_activation_min,
+ &data->params.quantized_activation_max,
+ data->per_channel_output_multiplier,
+ reinterpret_cast<int*>(data->per_channel_output_shift),
+ output_channels));
+ }
+ return kTfLiteOk;
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const auto params = static_cast<const TfLiteConvParams*>(node->builtin_data);
+
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+
+ int input_width = input->dims->data[2];
+ int input_height = input->dims->data[1];
+ int filter_width = filter->dims->data[2];
+ int filter_height = filter->dims->data[1];
+ int output_width = output->dims->data[2];
+ int output_height = output->dims->data[1];
+
+ // Dynamically allocate per-channel quantization parameters.
+ const int num_channels = filter->dims->data[kConvQuantizedDimension];
+ data->per_channel_output_multiplier =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->per_channel_output_shift =
+ static_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ // Quantized kernels use an int32 scratch buffer.
+ if (input->type == kTfLiteUInt8 || input->type == kTfLiteInt8) {
+ TFLITE_DCHECK(context->RequestScratchBufferInArena != nullptr);
+ TFLITE_DCHECK(context->RequestScratchBufferInArena(
+ context,
+ GetTensorShape(output).FlatSize() * sizeof(int32_t),
+ &(data->scratch_buffer_index)) == kTfLiteOk);
+ }
+
+ // All per-channel quantized tensors need valid zero point and scale arrays.
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+
+ const auto* affine_quantization =
+ static_cast<TfLiteAffineQuantization*>(filter->quantization.params);
+ TF_LITE_ENSURE(context, affine_quantization);
+ TF_LITE_ENSURE(context, affine_quantization->scale);
+ TF_LITE_ENSURE(context, affine_quantization->zero_point);
+
+ TF_LITE_ENSURE(context,
+ affine_quantization->scale->size == 1 ||
+ affine_quantization->scale->size ==
+ filter->dims->data[kConvQuantizedDimension]);
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size,
+ affine_quantization->zero_point->size);
+ }
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(
+ context, node, params, input_width, input_height, filter_width,
+ filter_height, output_width, output_height, input->type, data));
+
+ // Offsets (zero points)
+ data->params.input_offset = -input->params.zero_point;
+ data->params.weights_offset = -filter->params.zero_point;
+ data->params.output_offset = output->params.zero_point;
+
+ // Stride + dilation
+ data->params.stride_width = params->stride_width;
+ data->params.stride_height = params->stride_height;
+ data->params.dilation_width_factor = params->dilation_width_factor;
+ data->params.dilation_height_factor = params->dilation_height_factor;
+
+ float output_activation_min, output_activation_max;
+ CalculateActivationRange(params->activation, &output_activation_min,
+ &output_activation_max);
+ data->params.float_activation_min = output_activation_min;
+ data->params.float_activation_max = output_activation_max;
+ return kTfLiteOk;
+} // namespace conv
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFilterTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 4)
+ ? tflite::micro::GetEvalInput(context, node, kBiasTensor)
+ : nullptr;
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ TF_LITE_ENSURE_EQ(context, input->type, output->type);
+ TF_LITE_ENSURE_MSG(context, input->type == filter->type,
+ "Hybrid models are not supported on TFLite Micro.");
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteFloat32: {
+ reference_ops::TransposeConv(
+ data.params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<float>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<float>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<float>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<float>(output),
+ tflite::micro::GetTensorShape(nullptr), nullptr);
+ break;
+ }
+ case kTfLiteInt8: {
+ int32_t* scratch_buffer = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, data.scratch_buffer_index));
+ reference_integer_ops::TransposeConv(
+ data.params, data.per_channel_output_multiplier,
+ data.per_channel_output_shift, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output),
+ tflite::micro::GetTensorShape(nullptr), nullptr, scratch_buffer);
+ break;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_TRANSPOSE_CONV() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/transpose_conv_test.cc b/tensorflow/lite/micro/kernels/transpose_conv_test.cc
new file mode 100644
index 0000000..b6b798c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/transpose_conv_test.cc
@@ -0,0 +1,296 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/kernels/conv_test.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+// Common inputs and outputs.
+constexpr int kInputElements = 32;
+static const int kInputShape[] = {4, 1, 4, 4, 2};
+static const float kInputData[kInputElements] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
+ 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32};
+
+constexpr int kFilterElements = 18;
+static const int kFilterShape[] = {4, 1, 3, 3, 2};
+static const float kFilterData[kFilterElements] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18};
+
+constexpr int kBiasElements = 1;
+static const int kBiasShape[] = {4, 1, 1, 1, 1};
+static const float kBiasData[kBiasElements] = {0};
+
+constexpr int kOutputElements = 16;
+static const int kOutputShape[] = {4, 1, 4, 4, 1};
+static const float kGoldenData[kOutputElements] = {
+ 184, 412, 568, 528, 678, 1347, 1689, 1434,
+ 1494, 2715, 3057, 2442, 1968, 3352, 3652, 2760};
+
+// Transpose conv uses TfLiteConvParams.
+static TfLiteConvParams common_conv_params = {kTfLitePaddingSame, // padding
+ 1, // stride_width
+ 1, // stride_height
+ kTfLiteActNone,
+ 1,
+ 1};
+
+template <typename T>
+TfLiteStatus InvokeTransposeConv(TfLiteTensor* tensors, int tensors_size,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ T* output_data) {
+ int inputs_array_data[] = {4, 0, 1, 2, 3};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 4};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::Register_TRANSPOSE_CONV();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array, conv_params);
+
+ const char* init_data = reinterpret_cast<const char*>(conv_params);
+ TfLiteStatus status = runner.InitAndPrepare(init_data);
+ if (status != kTfLiteOk) {
+ return status;
+ }
+ return runner.Invoke();
+}
+
+template <typename T>
+TfLiteStatus ValidateTransposeConvGoldens(TfLiteTensor* tensors,
+ int tensors_size,
+ const T* expected_output_data,
+ int output_length,
+ TfLiteConvParams* conv_params,
+ T* output_data, float tolerance) {
+ TfLiteStatus status = InvokeTransposeConv(
+ tensors, tensors_size, output_length, conv_params, output_data);
+ if (status != kTfLiteOk) {
+ return status;
+ }
+ for (int i = 0; i < output_length; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i],
+ tolerance);
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus TestTransposeConvFloat(
+ const int* input_dims_data, const float* input_data,
+ const int* filter_dims_data, const float* filter_data,
+ const int* bias_dims_data, const float* bias_data,
+ const int* output_dims_data, const float* expected_output_data,
+ TfLiteConvParams* conv_params, float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ const int output_shape_dims_data[] = {1, 0};
+ int32_t* output_shape = nullptr;
+ TfLiteIntArray* output_shape_dims = IntArrayFromInts(output_shape_dims_data);
+
+ constexpr int inputs_size = 4;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(output_shape, output_shape_dims),
+ CreateTensor(filter_data, filter_dims),
+ CreateTensor(input_data, input_dims),
+ CreateTensor(bias_data, bias_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ return ValidateTransposeConvGoldens(tensors, tensors_size,
+ expected_output_data, output_dims_count,
+ conv_params, output_data, 0.001f);
+}
+
+TfLiteStatus TestTransposeConvQuantized(
+ const int* input_dims_data, const float* input_data,
+ int8_t* input_quantized, float input_scale, int input_zero_point,
+ const int* filter_dims_data, const float* filter_data,
+ int8_t* filter_quantized, float filter_scale, const int* bias_dims_data,
+ const float* bias_data, int32_t* bias_quantized, float* bias_scales,
+ int* bias_zero_points, const int* output_dims_data,
+ const float* expected_output_data, int8_t* expected_output_quantized,
+ float output_scale, int output_zero_point, TfLiteConvParams* conv_params,
+ int8_t* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(filter_dims_data);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(bias_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ int filter_zero_points[5];
+ float filter_scales[5];
+ TfLiteAffineQuantization filter_quant;
+ TfLiteTensor filter_tensor = CreateSymmetricPerChannelQuantizedTensor(
+ filter_data, filter_quantized, filter_dims, filter_scales,
+ filter_zero_points, &filter_quant, 0 /* quantized dimension */);
+ tflite::Quantize(expected_output_data, expected_output_quantized,
+ output_dims_count, output_scale, 0);
+
+ const int output_shape_dims_data[] = {1, 0};
+ int32_t* output_shape = nullptr;
+ TfLiteIntArray* output_shape_dims = IntArrayFromInts(output_shape_dims_data);
+
+ constexpr int inputs_size = 4;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(output_shape, output_shape_dims), filter_tensor,
+ CreateQuantizedTensor(input_data, input_quantized, input_dims,
+ input_scale, input_zero_point),
+ CreateQuantizedBiasTensor(bias_data, bias_quantized, bias_dims,
+ input_scale, filter_scale),
+ CreateQuantizedTensor(output_data, output_dims, output_scale,
+ output_zero_point)};
+
+ return ValidateTransposeConvGoldens(
+ tensors, tensors_size, expected_output_quantized, output_dims_count,
+ conv_params, output_data, 1.0f);
+}
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(SimpleTestFloat) {
+ float output_data[tflite::testing::kOutputElements];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestTransposeConvFloat(
+ tflite::testing::kInputShape, tflite::testing::kInputData,
+ tflite::testing::kFilterShape, tflite::testing::kFilterData,
+ tflite::testing::kBiasShape, tflite::testing::kBiasData,
+ tflite::testing::kOutputShape, tflite::testing::kGoldenData,
+ &tflite::testing::common_conv_params, output_data));
+}
+
+TF_LITE_MICRO_TEST(SimpleTestQuantizedPerChannel) {
+ int8_t output_data[tflite::testing::kOutputElements];
+
+ const float input_scale = 0.5f;
+ const float output_scale = 1.0f;
+ const float filter_scale = 1.0f;
+ const int input_zero_point = 0;
+ const int output_zero_point = 0;
+
+ int8_t input_quantized[tflite::testing::kInputElements];
+ int8_t filter_quantized[tflite::testing::kFilterElements];
+ int32_t bias_quantized[tflite::testing::kBiasElements];
+ int8_t golden_quantized[tflite::testing::kOutputElements];
+ int zero_points[tflite::testing::kBiasElements + 1];
+ float scales[tflite::testing::kBiasElements + 1];
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::testing::TestTransposeConvQuantized(
+ tflite::testing::kInputShape, tflite::testing::kInputData,
+ input_quantized, input_scale, input_zero_point,
+ tflite::testing::kFilterShape, tflite::testing::kFilterData,
+ filter_quantized, filter_scale, tflite::testing::kBiasShape,
+ tflite::testing::kBiasData, bias_quantized, scales, zero_points,
+ tflite::testing::kOutputShape, tflite::testing::kGoldenData,
+ golden_quantized, output_scale, output_zero_point,
+ &tflite::testing::common_conv_params, output_data));
+}
+
+TF_LITE_MICRO_TEST(InputOutputDifferentTypeIsError) {
+ using tflite::testing::CreateQuantizedTensor;
+ using tflite::testing::CreateTensor;
+ using tflite::testing::IntArrayFromInts;
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(tflite::testing::kInputShape);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(tflite::testing::kFilterShape);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(tflite::testing::kBiasShape);
+ TfLiteIntArray* output_dims = IntArrayFromInts(tflite::testing::kOutputShape);
+ const int output_dims_count = tflite::ElementCount(*output_dims);
+ constexpr int inputs_size = 4;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+
+ int8_t output_data[tflite::testing::kOutputElements];
+
+ const int output_shape_dims_data[] = {1, 0};
+ int32_t* output_shape = nullptr;
+ TfLiteIntArray* output_shape_dims = IntArrayFromInts(output_shape_dims_data);
+
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(output_shape, output_shape_dims),
+ CreateTensor(tflite::testing::kInputData, input_dims),
+ CreateTensor(tflite::testing::kFilterData, filter_dims),
+ CreateTensor(tflite::testing::kBiasData, bias_dims),
+ CreateQuantizedTensor(output_data, output_dims, /*scale=*/1.0f,
+ /*zero_point=*/0),
+ };
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError, tflite::testing::InvokeTransposeConv(
+ tensors, tensors_size, output_dims_count,
+ &tflite::testing::common_conv_params, output_data));
+}
+
+TF_LITE_MICRO_TEST(HybridModeIsError) {
+ using tflite::testing::CreateQuantizedTensor;
+ using tflite::testing::CreateTensor;
+ using tflite::testing::IntArrayFromInts;
+
+ TfLiteIntArray* input_dims = IntArrayFromInts(tflite::testing::kInputShape);
+ TfLiteIntArray* filter_dims = IntArrayFromInts(tflite::testing::kFilterShape);
+ TfLiteIntArray* bias_dims = IntArrayFromInts(tflite::testing::kBiasShape);
+ TfLiteIntArray* output_dims = IntArrayFromInts(tflite::testing::kOutputShape);
+ const int output_dims_count = tflite::ElementCount(*output_dims);
+
+ constexpr int inputs_size = 4;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+
+ int8_t filter_data[tflite::testing::kFilterElements] = {};
+ float output_data[tflite::testing::kOutputElements];
+
+ const int output_shape_dims_data[] = {1, 0};
+ int32_t* output_shape = nullptr;
+ TfLiteIntArray* output_shape_dims = IntArrayFromInts(output_shape_dims_data);
+
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(output_shape, output_shape_dims),
+ CreateTensor(tflite::testing::kInputData, input_dims),
+ CreateQuantizedTensor(filter_data, filter_dims,
+ /*scale=*/1.0f,
+ /*zero_point=*/0),
+ CreateTensor(tflite::testing::kBiasData, bias_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError, tflite::testing::InvokeTransposeConv(
+ tensors, tensors_size, output_dims_count,
+ &tflite::testing::common_conv_params, output_data));
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/unpack.cc b/tensorflow/lite/micro/kernels/unpack.cc
new file mode 100644
index 0000000..557cc57
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/unpack.cc
@@ -0,0 +1,121 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace unpack {
+namespace {
+
+constexpr int kInputTensor = 0;
+
+template <typename T>
+TfLiteStatus UnpackImpl(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input, int output_count,
+ int axis) {
+ const TfLiteEvalTensor* output0 =
+ tflite::micro::GetEvalOutput(context, node, 0);
+ const TfLiteIntArray* input_dims = input->dims;
+ const TfLiteIntArray* output_dims = output0->dims;
+ const int dimensions = input_dims->size;
+
+ if (axis < 0) {
+ axis += input->dims->size;
+ }
+
+ TFLITE_DCHECK_LT(axis, dimensions);
+
+ int outer_size = 1;
+ for (int i = 0; i < axis; ++i) {
+ outer_size *= input_dims->data[i];
+ }
+ int copy_size = 1;
+ for (int i = axis + 1; i < dimensions; ++i) {
+ copy_size *= input_dims->data[i];
+ }
+ int output_size = 1;
+ for (int i = 0; i < output_dims->size; ++i) {
+ output_size *= output_dims->data[i];
+ }
+ TFLITE_DCHECK_EQ(output_size, copy_size * outer_size);
+
+ const T* input_data = tflite::micro::GetTensorData<T>(input);
+
+ for (int i = 0; i < output_count; ++i) {
+ TfLiteEvalTensor* t = tflite::micro::GetEvalOutput(context, node, i);
+ T* output_data = tflite::micro::GetTensorData<T>(t);
+ for (int k = 0; k < outer_size; ++k) {
+ T* output_ptr = output_data + copy_size * k;
+ int loc = k * output_count * copy_size + i * copy_size;
+ const T* input_ptr = input_data + loc;
+ for (int j = 0; j < copy_size; ++j) output_ptr[j] = input_ptr[j];
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TfLiteUnpackParams* data =
+ reinterpret_cast<TfLiteUnpackParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+
+ switch (input->type) {
+ case kTfLiteFloat32: {
+ return UnpackImpl<float>(context, node, input, data->num, data->axis);
+ }
+ case kTfLiteInt32: {
+ return UnpackImpl<int32_t>(context, node, input, data->num, data->axis);
+ }
+ case kTfLiteUInt8: {
+ return UnpackImpl<uint8_t>(context, node, input, data->num, data->axis);
+ }
+ case kTfLiteInt8: {
+ return UnpackImpl<int8_t>(context, node, input, data->num, data->axis);
+ }
+ default: {
+ TF_LITE_KERNEL_LOG(context, "Type '%s' is not supported by unpack.",
+ TfLiteTypeGetName(input->type));
+ return kTfLiteError;
+ }
+ }
+
+ return kTfLiteOk;
+}
+} // namespace
+} // namespace unpack
+
+TfLiteRegistration Register_UNPACK() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/nullptr,
+ /*invoke=*/unpack::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/unpack_test.cc b/tensorflow/lite/micro/kernels/unpack_test.cc
new file mode 100644
index 0000000..90773a7
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/unpack_test.cc
@@ -0,0 +1,373 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/debug_log.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+
+void TestUnpackThreeOutputsFloat(
+ const int* input_dims_data, const float* input_data, int axis,
+ const int* output1_dims_data, const float* expected_output1_data,
+ const int* output2_dims_data, const float* expected_output2_data,
+ const int* output3_dims_data, const float* expected_output3_data,
+ float* output1_data, float* output2_data, float* output3_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output1_dims = IntArrayFromInts(output1_dims_data);
+ TfLiteIntArray* output2_dims = IntArrayFromInts(output2_dims_data);
+ TfLiteIntArray* output3_dims = IntArrayFromInts(output3_dims_data);
+ const int output1_dims_count = ElementCount(*output1_dims);
+ const int output2_dims_count = ElementCount(*output2_dims);
+ const int output3_dims_count = ElementCount(*output3_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 3;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output1_data, output1_dims),
+ CreateTensor(output2_data, output2_dims),
+ CreateTensor(output3_data, output3_dims)};
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output1_dims_count; ++i) {
+ output1_data[i] = 23;
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ output2_data[i] = 23;
+ }
+
+ for (int i = 0; i < output3_dims_count; ++i) {
+ output3_data[i] = 23;
+ }
+
+ TfLiteUnpackParams builtin_data = {
+ .num = 3,
+ .axis = axis,
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {3, 1, 2, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_UNPACK();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output1_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output1_data[i], output1_data[i], 1e-5f);
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output2_data[i], output2_data[i], 1e-5f);
+ }
+
+ for (int i = 0; i < output3_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output3_data[i], output3_data[i], 1e-5f);
+ }
+}
+
+void TestUnpackOneOutputFloat(const int* input_dims_data,
+ const float* input_data, int axis,
+ const int* output_dims_data,
+ const float* expected_output_data,
+ float* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(output_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 1;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims)};
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output_dims_count; ++i) {
+ output_data[i] = 23;
+ }
+
+ TfLiteUnpackParams builtin_data = {
+ .num = 1,
+ .axis = axis,
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_UNPACK();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_NEAR(expected_output_data[i], output_data[i], 1e-5f);
+ }
+}
+
+void TestUnpackThreeOutputsQuantized(
+ const int* input_dims_data, const uint8_t* input_data, int axis,
+ const int* output1_dims_data, const uint8_t* expected_output1_data,
+ const int* output2_dims_data, const uint8_t* expected_output2_data,
+ const int* output3_dims_data, const uint8_t* expected_output3_data,
+ uint8_t* output1_data, uint8_t* output2_data, uint8_t* output3_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output1_dims = IntArrayFromInts(output1_dims_data);
+ TfLiteIntArray* output2_dims = IntArrayFromInts(output2_dims_data);
+ TfLiteIntArray* output3_dims = IntArrayFromInts(output3_dims_data);
+ const int output1_dims_count = ElementCount(*output1_dims);
+ const int output2_dims_count = ElementCount(*output2_dims);
+ const int output3_dims_count = ElementCount(*output3_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 3;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {
+ // CreateQuantizedTensor needs min/max values as input, but these values
+ // don't matter as to the functionality of UNPACK, so just set as 0
+ // and 10.
+ CreateQuantizedTensor(input_data, input_dims, 0, 10),
+ CreateQuantizedTensor(output1_data, output1_dims, 0, 10),
+ CreateQuantizedTensor(output2_data, output2_dims, 0, 10),
+ CreateQuantizedTensor(output3_data, output3_dims, 0, 10)};
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output1_dims_count; ++i) {
+ output1_data[i] = 23;
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ output2_data[i] = 23;
+ }
+
+ for (int i = 0; i < output3_dims_count; ++i) {
+ output3_data[i] = 23;
+ }
+
+ TfLiteUnpackParams builtin_data = {
+ .num = 3,
+ .axis = axis,
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {3, 1, 2, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_UNPACK();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output1_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output1_data[i], output1_data[i]);
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output2_data[i], output2_data[i]);
+ }
+
+ for (int i = 0; i < output3_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output3_data[i], output3_data[i]);
+ }
+}
+
+void TestUnpackThreeOutputsQuantized32(
+ const int* input_dims_data, const int32_t* input_data, int axis,
+ const int* output1_dims_data, const int32_t* expected_output1_data,
+ const int* output2_dims_data, const int32_t* expected_output2_data,
+ const int* output3_dims_data, const int32_t* expected_output3_data,
+ int32_t* output1_data, int32_t* output2_data, int32_t* output3_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output1_dims = IntArrayFromInts(output1_dims_data);
+ TfLiteIntArray* output2_dims = IntArrayFromInts(output2_dims_data);
+ TfLiteIntArray* output3_dims = IntArrayFromInts(output3_dims_data);
+ const int output1_dims_count = ElementCount(*output1_dims);
+ const int output2_dims_count = ElementCount(*output2_dims);
+ const int output3_dims_count = ElementCount(*output3_dims);
+
+ constexpr int input_size = 1;
+ constexpr int output_size = 3;
+ constexpr int tensors_size = input_size + output_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output1_data, output1_dims),
+ CreateTensor(output2_data, output2_dims),
+ CreateTensor(output3_data, output3_dims)};
+
+ // Place a unique value in the uninitialized output buffer.
+ for (int i = 0; i < output1_dims_count; ++i) {
+ output1_data[i] = 23;
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ output2_data[i] = 23;
+ }
+
+ for (int i = 0; i < output3_dims_count; ++i) {
+ output3_data[i] = 23;
+ }
+
+ TfLiteUnpackParams builtin_data = {
+ .num = 3,
+ .axis = axis,
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {3, 1, 2, 3};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = tflite::ops::micro::Register_UNPACK();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ reinterpret_cast<void*>(&builtin_data));
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output1_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output1_data[i], output1_data[i]);
+ }
+
+ for (int i = 0; i < output2_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output2_data[i], output2_data[i]);
+ }
+
+ for (int i = 0; i < output3_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output3_data[i], output3_data[i]);
+ }
+}
+
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(UnpackFloatThreeOutputs) {
+ const int input_shape[] = {2, 3, 2};
+ const float input_values[] = {1, 2, 3, 4, 5, 6};
+ const int output1_shape[] = {1, 2};
+ const float output1_golden[] = {1, 2};
+ const int output2_shape[] = {1, 2};
+ const float output2_golden[] = {3, 4};
+ const int output3_shape[] = {1, 2};
+ const float output3_golden[] = {5, 6};
+ constexpr int output1_dims_count = 2;
+ constexpr int output2_dims_count = 2;
+ constexpr int output3_dims_count = 2;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ float output3_data[output3_dims_count];
+ tflite::testing::TestUnpackThreeOutputsFloat(
+ input_shape, input_values, 0, output1_shape, output1_golden,
+ output2_shape, output2_golden, output3_shape, output3_golden,
+ output1_data, output2_data, output3_data);
+}
+
+TF_LITE_MICRO_TEST(UnpackFloatThreeOutputsNegativeAxisTwo) {
+ const int input_shape[] = {2, 3, 2};
+ const float input_values[] = {1, 2, 3, 4, 5, 6};
+ const int output1_shape[] = {1, 2};
+ const float output1_golden[] = {1, 2};
+ const int output2_shape[] = {1, 2};
+ const float output2_golden[] = {3, 4};
+ const int output3_shape[] = {1, 2};
+ const float output3_golden[] = {5, 6};
+ constexpr int output1_dims_count = 2;
+ constexpr int output2_dims_count = 2;
+ constexpr int output3_dims_count = 2;
+ float output1_data[output1_dims_count];
+ float output2_data[output2_dims_count];
+ float output3_data[output3_dims_count];
+ tflite::testing::TestUnpackThreeOutputsFloat(
+ input_shape, input_values, -2, output1_shape, output1_golden,
+ output2_shape, output2_golden, output3_shape, output3_golden,
+ output1_data, output2_data, output3_data);
+}
+
+TF_LITE_MICRO_TEST(UnpackFloatOneOutput) {
+ const int input_shape[] = {2, 1, 6};
+ const float input_values[] = {1, 2, 3, 4, 5, 6};
+ const int output_shape[] = {1, 6};
+ const float golden[] = {1, 2, 3, 4, 5, 6};
+ constexpr int output_dims_count = 6;
+ float output_data[output_dims_count];
+ tflite::testing::TestUnpackOneOutputFloat(input_shape, input_values, 0,
+ output_shape, golden, output_data);
+}
+
+TF_LITE_MICRO_TEST(UnpackQuantizedThreeOutputs) {
+ const int input_shape[] = {2, 3, 2};
+ const uint8_t input_values[] = {1, 2, 3, 4, 5, 6};
+ const int output1_shape[] = {1, 2};
+ const uint8_t output1_golden[] = {1, 2};
+ const int output2_shape[] = {1, 2};
+ const uint8_t output2_golden[] = {3, 4};
+ const int output3_shape[] = {1, 2};
+ const uint8_t output3_golden[] = {5, 6};
+ constexpr int output1_dims_count = 2;
+ constexpr int output2_dims_count = 2;
+ constexpr int output3_dims_count = 2;
+ uint8_t output1_data[output1_dims_count];
+ uint8_t output2_data[output2_dims_count];
+ uint8_t output3_data[output3_dims_count];
+ tflite::testing::TestUnpackThreeOutputsQuantized(
+ input_shape, input_values, 0, output1_shape, output1_golden,
+ output2_shape, output2_golden, output3_shape, output3_golden,
+ output1_data, output2_data, output3_data);
+}
+
+TF_LITE_MICRO_TEST(UnpackQuantized32ThreeOutputs) {
+ const int input_shape[] = {2, 3, 2};
+ const int32_t input_values[] = {1, 2, 3, 4, 5, 6};
+ const int output1_shape[] = {1, 2};
+ const int32_t output1_golden[] = {1, 2};
+ const int output2_shape[] = {1, 2};
+ const int32_t output2_golden[] = {3, 4};
+ const int output3_shape[] = {1, 2};
+ const int32_t output3_golden[] = {5, 6};
+ constexpr int output1_dims_count = 2;
+ constexpr int output2_dims_count = 2;
+ constexpr int output3_dims_count = 2;
+ int32_t output1_data[output1_dims_count];
+ int32_t output2_data[output2_dims_count];
+ int32_t output3_data[output3_dims_count];
+ tflite::testing::TestUnpackThreeOutputsQuantized32(
+ input_shape, input_values, 0, output1_shape, output1_golden,
+ output2_shape, output2_golden, output3_shape, output3_golden,
+ output1_data, output2_data, output3_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/kernels/vexriscv/README.md b/tensorflow/lite/micro/kernels/vexriscv/README.md
new file mode 100644
index 0000000..228f179
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/vexriscv/README.md
@@ -0,0 +1,49 @@
+# VexRISC-V
+
+## Maintainers
+
+* [danielyou0230](https://github.com/danielyou0230)
+* [tal-x](https://github.com/tcal-x)
+
+## Background
+
+The optimized kernels for
+[VexRISC-V](https://github.com/SpinalHDL/VexRiscv)/[Litex](https://github.com/enjoy-digital/litex)
+are used to run Tensorflow Lite Micro in Zephyr on either
+
+* Digilent Arty board (e.g. Arty A7)
+* [Renode](https://github.com/renode/renode): Open source simulation framework
+ (no hardware required)
+
+To run on Digilent Arty board (FPGA,) you'll also need a soft-CPU gateware for
+the FPGA, please see
+[Tensorflow lite demo running in Zephyr on Litex/VexRiscv SoC](https://github.com/antmicro/litex-vexriscv-tensorflow-lite-demo)
+by Antmicro for more details.
+
+For general utilities, please refer to `utils/` under this directory, see
+[README](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/kernels/vexriscv/utils/README.md)
+for available utilities
+
+## Info
+
+To use VexRISC-V optimized kernels instead of reference kernel add
+`TAGS=vexriscv` to the make command. The kernels that doesn't have optimization
+for a certain micro architecture fallback to use TFLM reference kernels.
+
+# Example
+
+To compile the binary file with VexRISC-V optimizations, one can use the
+following command
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile \
+TAGS=vexriscv \
+TARGET=zephyr_vexriscv \
+person_detection_int8_bin
+```
+
+## Optimized kernels
+
+The following kernels are optimized specific to VexRISCV
+
+* [DepthwiseConv2D](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/kernels/vexriscv/doc/DepthwiseConv2D_int8.md)
diff --git a/tensorflow/lite/micro/kernels/vexriscv/depthwise_conv.cc b/tensorflow/lite/micro/kernels/vexriscv/depthwise_conv.cc
new file mode 100644
index 0000000..ef41504
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/vexriscv/depthwise_conv.cc
@@ -0,0 +1,527 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace ops {
+namespace micro {
+namespace depthwise_conv {
+namespace vexriscv {
+
+constexpr int kChannelStep = 32;
+
+inline void DepthwiseConvPerChannel(
+ const DepthwiseParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ // Get parameters.
+ // TODO(b/141565753): Re-introduce ScopedProfilingLabel on Micro.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t input_offset = params.input_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ // Check dimensions of the tensors.
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int m = 0; m < depth_multiplier; ++m) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ // Divide channels to chunks of size kChannelStep
+ for (int begin_ch = 0; begin_ch < input_depth;
+ begin_ch += kChannelStep) {
+ // Allocate a partial result accumulator for each channel
+ // in current chunks
+ int32_t acc[kChannelStep] = {0};
+ // Calculate the last channel for current chunk
+ const int steps =
+ std::min(input_depth, begin_ch + kChannelStep) - begin_ch;
+
+ // Accumulate partial results to acc for a small chunk of channels
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+
+ if (!is_point_inside_image) {
+ continue;
+ }
+
+ for (int offset_ch = 0; offset_ch < steps; ++offset_ch) {
+ const int in_channel = begin_ch + offset_ch;
+ const int output_channel = m + in_channel * depth_multiplier;
+
+ int32_t input_val = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, output_channel)];
+ // Accumulate with 32 bits accumulator.
+ // In the nudging process during model quantization, we force
+ // real value of 0.0 be represented by a quantized value. This
+ // guarantees that the input_offset is a int8_t, even though
+ // it is represented using int32_t. int32_t += int8_t *
+ // (int8_t - int8_t) so the highest value we can get from each
+ // accumulation is [-127, 127] * ([-128, 127] -
+ // [-128, 127]), which is [-32512, 32512]. log2(32512)
+ // = 14.98, which means we can accumulate at least 2^16
+ // multiplications without overflow. The accumulator is
+ // applied to a filter so the accumulation logic will hold as
+ // long as the filter size (filter_y * filter_x * in_channel)
+ // does not exceed 2^16, which is the case in all the models
+ // we have seen so far.
+ // TODO(jianlijianli): Add a check to make sure the
+ // accumulator depth is smaller than 2^16.
+ acc[offset_ch] += filter_val * (input_val + input_offset);
+ }
+ }
+ }
+
+ // Add bias / activations for current chunk of channels
+ for (int offset_ch = 0; offset_ch < steps; ++offset_ch) {
+ const int in_channel = begin_ch + offset_ch;
+ const int output_channel = m + in_channel * depth_multiplier;
+
+ int32_t value = acc[offset_ch];
+ if (bias_data) {
+ value += bias_data[output_channel];
+ }
+
+ value = MultiplyByQuantizedMultiplier(
+ value, output_multiplier[output_channel],
+ output_shift[output_channel]);
+ value += output_offset;
+ value = std::max(value, output_activation_min);
+ value = std::min(value, output_activation_max);
+
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ output_channel)] = static_cast<int8_t>(value);
+ }
+ }
+ }
+ }
+ }
+ }
+}
+
+inline void DepthwiseConv(
+ const DepthwiseParams& params, const RuntimeShape& input_shape,
+ const uint8_t* input_data, const RuntimeShape& filter_shape,
+ const uint8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ uint8_t* output_data) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ for (int m = 0; m < depth_multiplier; m++) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ // Divide channels to chunks of size kChannelStep
+ for (int begin_ch = 0; begin_ch < input_depth;
+ begin_ch += kChannelStep) {
+ // Allocate a partial result accumulator for each channel
+ // in current chunks
+ int32_t acc[kChannelStep] = {0};
+ // Calculate the last channel for current chunk
+ const int steps =
+ std::min(input_depth, begin_ch + kChannelStep) - begin_ch;
+
+ // Accumulate partial results to acc for a small chunk of channels
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+
+ if (!is_point_inside_image) {
+ continue;
+ }
+
+ for (int offset_ch = 0; offset_ch < steps; ++offset_ch) {
+ const int in_channel = begin_ch + offset_ch;
+ const int output_channel = m + in_channel * depth_multiplier;
+
+ int32_t input_val = input_data[Offset(
+ input_shape, batch, in_y, in_x, in_channel)];
+ int32_t filter_val = filter_data[Offset(
+ filter_shape, 0, filter_y, filter_x, output_channel)];
+ acc[offset_ch] +=
+ (filter_val + filter_offset) * (input_val + input_offset);
+ }
+ }
+ }
+
+ // Add bias / activations for current chunk of channels
+ for (int offset_ch = 0; offset_ch < steps; ++offset_ch) {
+ const int in_channel = begin_ch + offset_ch;
+ const int output_channel = m + in_channel * depth_multiplier;
+
+ int32_t value = acc[offset_ch];
+ if (bias_data) {
+ value += bias_data[output_channel];
+ }
+
+ value = MultiplyByQuantizedMultiplier(value, output_multiplier,
+ output_shift);
+ value += output_offset;
+ value = std::max(value, output_activation_min);
+ value = std::min(value, output_activation_max);
+
+ output_data[Offset(output_shape, batch, out_y, out_x,
+ output_channel)] = static_cast<uint8_t>(value);
+ }
+ }
+ }
+ }
+ }
+ }
+}
+
+} // namespace vexriscv
+
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kFilterTensor = 1;
+constexpr int kBiasTensor = 2;
+constexpr int kOutputTensor = 0;
+
+// Depthwise conv is quantized along dimension 3:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+constexpr int kDepthwiseConvQuantizedDimension = 3;
+
+struct OpData {
+ TfLitePaddingValues padding;
+
+ // Cached tensor zero point values for quantized operations.
+ int32_t input_zero_point;
+ int32_t filter_zero_point;
+ int32_t output_zero_point;
+
+ // The scaling factor from input to output (aka the 'real multiplier') can
+ // be represented as a fixed point multiplier plus a left shift.
+ int32_t output_multiplier;
+ int output_shift;
+
+ // Per channel output multiplier and shift.
+ int32_t* per_channel_output_multiplier;
+ int32_t* per_channel_output_shift;
+ // The range of the fused activation layer. For example for kNone and
+ // uint8_t these would be 0 and 255.
+ int32_t output_activation_min;
+ int32_t output_activation_max;
+};
+
+TfLiteStatus CalculateOpData(TfLiteContext* context, TfLiteNode* node,
+ TfLiteDepthwiseConvParams* params, int width,
+ int height, int filter_width, int filter_height,
+ const TfLiteType data_type, OpData* data) {
+ bool has_bias = node->inputs->size == 3;
+ // Check number of inputs/outputs
+ TF_LITE_ENSURE(context, has_bias || node->inputs->size == 2);
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+
+ int unused_output_height, unused_output_width;
+ data->padding = ComputePaddingHeightWidth(
+ params->stride_height, params->stride_width, 1, 1, height, width,
+ filter_height, filter_width, params->padding, &unused_output_height,
+ &unused_output_width);
+
+ // Note that quantized inference requires that all tensors have their
+ // parameters set. This is usually done during quantized training.
+ if (data_type != kTfLiteFloat32) {
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ int num_channels = filter->dims->data[kDepthwiseConvQuantizedDimension];
+
+ return tflite::PopulateConvolutionQuantizationParams(
+ context, input, filter, bias, output, params->activation,
+ &data->output_multiplier, &data->output_shift,
+ &data->output_activation_min, &data->output_activation_max,
+ data->per_channel_output_multiplier,
+ reinterpret_cast<int*>(data->per_channel_output_shift), num_channels);
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* params =
+ reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* filter = GetInput(context, node, kFilterTensor);
+
+ const TfLiteType data_type = input->type;
+ int width = SizeOfDimension(input, 2);
+ int height = SizeOfDimension(input, 1);
+ int filter_width = SizeOfDimension(filter, 2);
+ int filter_height = SizeOfDimension(filter, 1);
+
+ // Per channel quantization is only needed for int8_t inference. For other
+ // quantized types, only a single scale and zero point is needed.
+ const int num_channels = filter->dims->data[kDepthwiseConvQuantizedDimension];
+ // Dynamically allocate per-channel quantization parameters.
+ data->per_channel_output_multiplier =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+ data->per_channel_output_shift =
+ reinterpret_cast<int32_t*>(context->AllocatePersistentBuffer(
+ context, num_channels * sizeof(int32_t)));
+
+ // All per-channel quantized tensors need valid zero point and scale arrays.
+ if (input->type == kTfLiteInt8) {
+ TF_LITE_ENSURE_EQ(context, filter->quantization.type,
+ kTfLiteAffineQuantization);
+
+ const auto* affine_quantization =
+ reinterpret_cast<TfLiteAffineQuantization*>(
+ filter->quantization.params);
+ TF_LITE_ENSURE(context, affine_quantization);
+ TF_LITE_ENSURE(context, affine_quantization->scale);
+ TF_LITE_ENSURE(context, affine_quantization->zero_point);
+ TF_LITE_ENSURE(
+ context, affine_quantization->scale->size == 1 ||
+ affine_quantization->scale->size ==
+ filter->dims->data[kDepthwiseConvQuantizedDimension]);
+ TF_LITE_ENSURE_EQ(context, affine_quantization->scale->size,
+ affine_quantization->zero_point->size);
+ }
+
+ TF_LITE_ENSURE_STATUS(CalculateOpData(context, node, params, width, height,
+ filter_width, filter_height, data_type,
+ data));
+
+ data->input_zero_point = input->params.zero_point;
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ return kTfLiteOk;
+}
+
+void EvalQuantizedPerChannel(TfLiteContext* context, TfLiteNode* node,
+ TfLiteDepthwiseConvParams* params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ DepthwiseParams op_params;
+ op_params.padding_type = PaddingType::kSame;
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params->stride_width;
+ op_params.stride_height = params->stride_height;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.depth_multiplier = params->depth_multiplier;
+ op_params.input_offset = -data.input_zero_point;
+ op_params.weights_offset = 0;
+ op_params.output_offset = data.output_zero_point;
+ // TODO(b/130439627): Use calculated value for clamping.
+ op_params.quantized_activation_min = std::numeric_limits<int8_t>::min();
+ op_params.quantized_activation_max = std::numeric_limits<int8_t>::max();
+
+ vexriscv::DepthwiseConvPerChannel(
+ op_params, data.per_channel_output_multiplier,
+ data.per_channel_output_shift, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+}
+
+void EvalQuantized(TfLiteContext* context, TfLiteNode* node,
+ TfLiteDepthwiseConvParams* params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter, const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ const int32_t input_offset = -data.input_zero_point;
+ const int32_t filter_offset = -data.filter_zero_point;
+ const int32_t output_offset = data.output_zero_point;
+
+ tflite::DepthwiseParams op_params;
+ // Padding type is ignored, but still set.
+ op_params.padding_type = PaddingType::kSame;
+ op_params.padding_values.width = data.padding.width;
+ op_params.padding_values.height = data.padding.height;
+ op_params.stride_width = params->stride_width;
+ op_params.stride_height = params->stride_height;
+ op_params.dilation_width_factor = params->dilation_width_factor;
+ op_params.dilation_height_factor = params->dilation_height_factor;
+ op_params.depth_multiplier = params->depth_multiplier;
+ op_params.quantized_activation_min = data.output_activation_min;
+ op_params.quantized_activation_max = data.output_activation_max;
+ op_params.input_offset = input_offset;
+ op_params.weights_offset = filter_offset;
+ op_params.output_offset = output_offset;
+ op_params.output_multiplier = data.output_multiplier;
+ // Legacy ops used mixed left and right shifts. Now all are +ve-means-left.
+ op_params.output_shift = -data.output_shift;
+
+ vexriscv::DepthwiseConv(op_params, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<uint8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<uint8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<uint8_t>(output));
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* params =
+ reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFilterTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kBiasTensor)
+ : nullptr;
+
+ // TODO(aselle): Consider whether float conv and quantized conv should be
+ // separate ops to avoid dispatch overhead here.
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteInt8:
+ EvalQuantizedPerChannel(context, node, params, data, input, filter, bias,
+ output);
+ break;
+ case kTfLiteUInt8:
+ EvalQuantized(context, node, params, data, input, filter, bias, output);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace depthwise_conv
+
+TfLiteRegistration Register_DEPTHWISE_CONV_2D() {
+ return {/*init=*/depthwise_conv::Init,
+ /*free=*/nullptr,
+ /*prepare=*/depthwise_conv::Prepare,
+ /*invoke=*/depthwise_conv::Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace micro
+} // namespace ops
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/vexriscv/doc/DepthwiseConv2D_int8.md b/tensorflow/lite/micro/kernels/vexriscv/doc/DepthwiseConv2D_int8.md
new file mode 100644
index 0000000..f4de0d9
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/vexriscv/doc/DepthwiseConv2D_int8.md
@@ -0,0 +1,237 @@
+# Design of DepthwiseConv2D for VexRISCV
+
+* Author: Daniel You (Google SWE intern, Summer 2020)
+* Github Profile: [danielyou0230](https://github.com/danielyou0230)
+* Last Update: August 28, 2020
+* [PR#42715](https://github.com/tensorflow/tensorflow/pull/42715) (see
+ experiment results in the PR message)
+
+## Overview
+
+The kernel is optimized based on the reference kernel in Tensorflow Lite.
+Different from the straightforward implementation, this implementation takes
+memory layout in TF Lite (`NHWC`) into account, which leverages memory hierarchy
+to reduce memory miss count, to be more specific, it performs depthwise
+convolution for every channel in a fixed spatial position (iterate `C`-axis
+first, then `W`-axis, `H`-axis, and `N`-axis).
+
+## Objective
+
+With the debut of Artificial Intelligence (AI) products and services, our lives
+have been changed ever since. While much of those applications are cloud-based
+implementations, there are still many cases where AI algorithms have to be run
+on resource constrained devices. Current machine learning frameworks are still
+not well optimized for those platforms, thereby preventing more complicated
+applications running on them with acceptable performance.
+
+This design focuses on improving the performance of kernels in TensorFlow Lite
+Micro, to be more specific, this design involves one of the most popular kernels
+among the models deployed on edge devices: DepthwiseConv2D (see
+[TensorFlow Python API](https://www.tensorflow.org/api_docs/python/tf/keras/layers/DepthwiseConv2D);
+[discussion on MobileNetV1](https://groups.google.com/g/keras-users/c/sec8pYjJwwE)
+on Google groups.) The goal is to reduce the inference time on those devices
+which can in turn save more energy on them or more importantly, enable more
+complex applications running on them.
+
+## Background
+
+Existing works aim to optimize on-CPU performance focus on leveraging CPU
+specific instruction like SIMD instructions in RISC-V Vector and other
+counterparts like AVX and SSE intrinsics. An implementation released by Facebook
+([pytorch/FBGEMM](https://github.com/pytorch/FBGEMM/tree/master/src))
+demonstrated the potential that can be achieved with the aforementioned vector
+instructions.
+
+The alternative approach is to optimize on GPUs. Modern GPUs are well-known for
+having great performance in matrix multiplication and parallel computation (e.g.
+CUDA from Nvidia). Those powerful GPUs enable machine learning researchers to
+explore a wide variety of models and solve complicated problems. For resource
+constrained embedded processors, however, incorporating a GPU may not fit the
+limited hardware and power budget for their applications. Unlike running
+TensorFlow Python APIs on desktop or servers, TensorFlow Lite and TensorFlow
+Lite Micro are made to efficiently run inference on those devices, which enables
+the possibilities to make machine learning applications ubiquitous in our life.
+
+## Requirements and scale
+
+After detailed analysis on memory access patterns in existing implementations, I
+found existing code under-utilizes the memory hierarchy, specifically, the SRAM
+cache, to reduce excessive memory access time, which would be approximately 100
+times slower if memory access were optimized
+([Latency Numbers Every Programmer Should Know](https://gist.github.com/jboner/2841832),
+[The Effect Of CPU Caches And Memory Access Patterns](http://kejser.org/the-effect-of-cpu-caches-and-memory-access-patterns/).)
+Therefore, this design aims to improve the memory access pattern to better fit
+the memory layout of the TensorFlow Lite C++ library. Any integer-based models
+with DepthwiseConv2D layers using TensorFlow Lite Micro will benefit from this
+change.
+
+To begin with, the memory layout of tensors in TensorFlow Lite C++ library uses
+`NHWC` format `(n, height, width, channel)` and flattened to an 1-d tensor, the
+index of `(n, h, w, c)` in the tensor can then be calculated with `((n * H + h)
+* W + w) * C + c`. The reference implementation is depicted as follows:
+
+```
+for i-th input among N inputs
+ for c-th input channel
+ for (y, x) in input that are convolving with the filter
+ access element (i, y, x, c) in the input
+```
+
+Thus, if the current element is `(i, y, x, c)` at index `((i * H + y) * W + x) *
+C + c`, next element will be `(i, y, x + 1, c)` at index `((i * H + y) * W + (x
++ 1)) * C + c`, the difference of indices between two consecutive accesses is
+`C` (illustrated below,) which is apparently not a sequential access.
+
+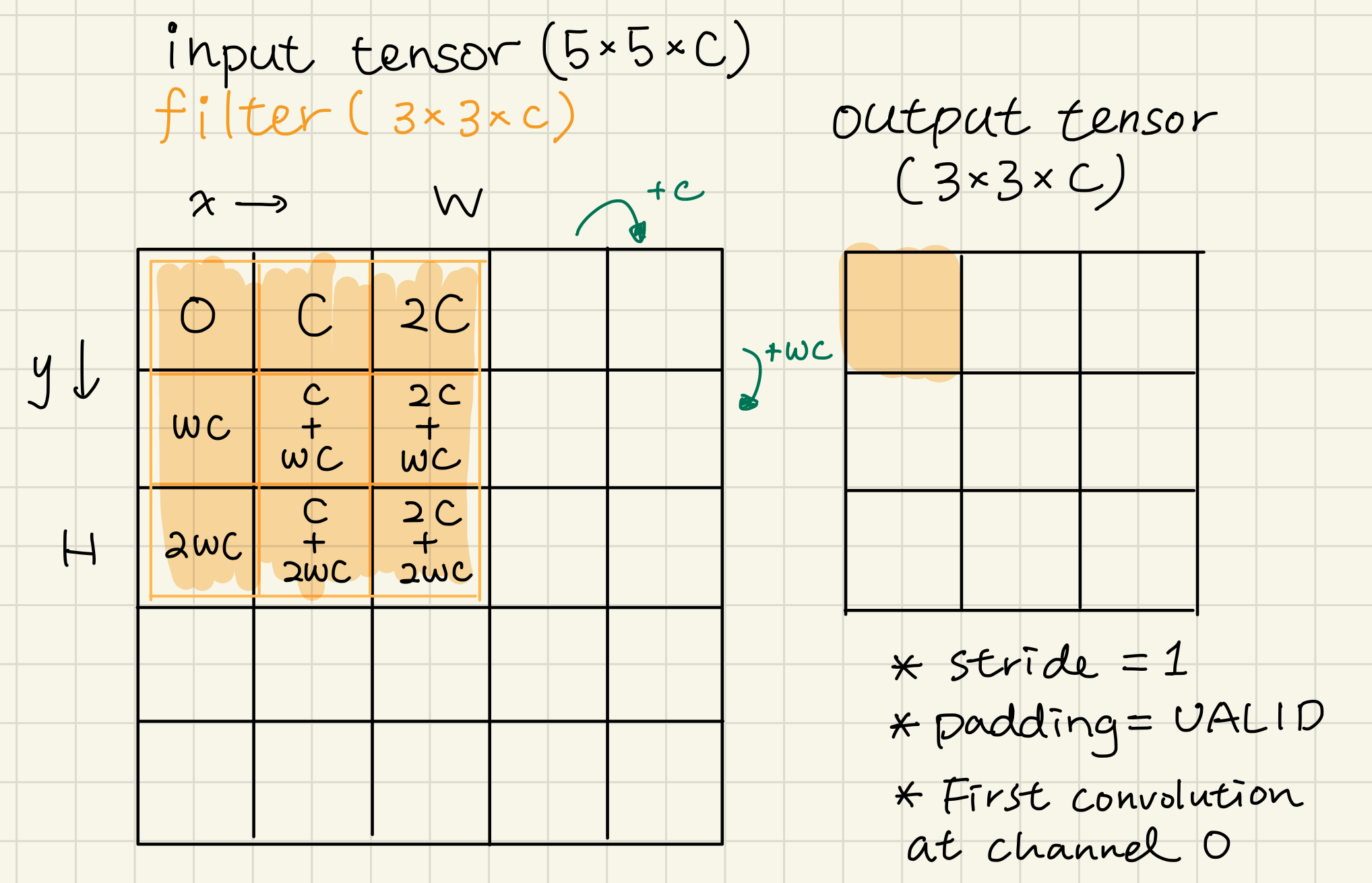
+
+In response to the poor memory access pattern in the reference, it would be
+beneficial to implement DepthwiseConv2D in a depth-centric manner, namely,
+accessing elements at a fixed spatial location `(y, x)` for each channel. The
+access order then becomes sequential on the 1-d tensor because the layout of
+tensors are in the format of `NHWC`.
+
+## Design ideas
+
+Instead of accessing the memory in a non-sequential manner, this design proposes
+to change the access pattern to be consistent with the memory layout in the
+current TensorFlow Lite C++ library. The idea can be broken down into two major
+parts:
+
+* Relating sequential memory access to DepthwiseConv2D
+* Depthwise convolution with sequential memory access scheme
+
+### Relating sequential memory access to DepthwiseConv2D
+
+Contrary to the reference implementation, the proposed solution re-orders the
+calculation to access the elements sequentially in the tensor, namely, `(0, 1,
+2, ..., H * W * C - 1)`. This can be done by interchanging the order of two
+inner loops: `for i-th input for (y, x) in input that are convolving with the
+filter for c-th input channel access element (i, y, x, c) in the input`
+
+In this case, if the current element is `(i, y, x, c)` at index `((i * H + y) *
+W + x) * C + c`, the next element will be `((i * H + y) * W + x) * C + (c + 1)`,
+the difference of between two consecutive access becomes `1`, thereby fully
+re-using the data in a cache block.
+
+### Depthwise convolution with sequential memory access scheme
+
+In the existing TF Lite reference implementation, each element in the output is
+calculated by performing `(filter_h * filter_w)` multiplications and additions
+in a row. With the proposed design, memory access patterns can be greatly
+improved by re-ordering the calculations.
+
+Rather than calculating the results in a row, this design rearranges the
+operations. To calculate the output at a specific spatial location for all
+channels (see the colored cells in the output tensor in the figure below) the
+resulting order of calculations is illustrated below, the involving input/filter
+locations are represented as `(spatial index, channel)`
+
+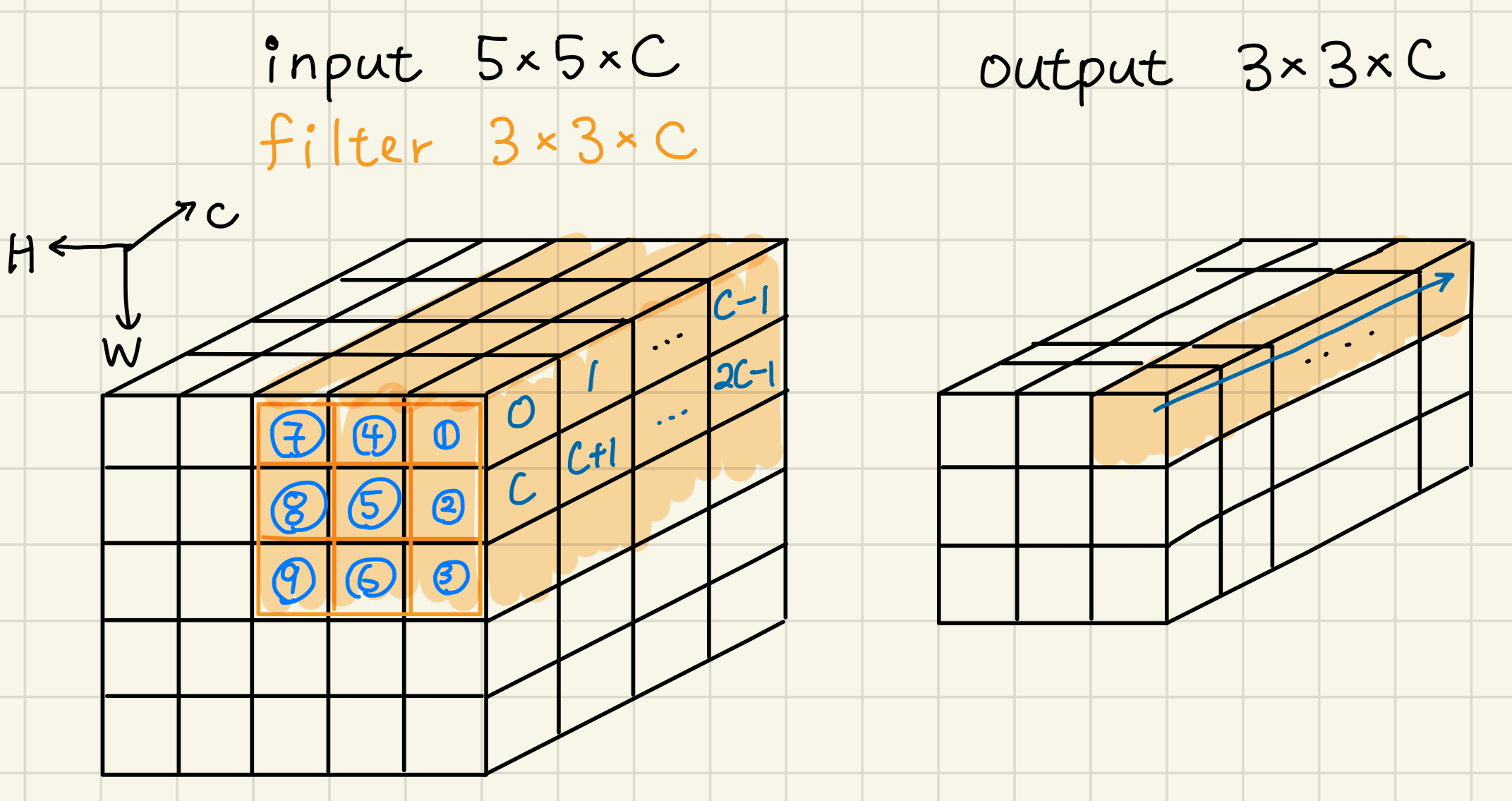
+
+The calculation for each element at the output is completed when it reaches the
+bold coordinates in the table. From the table, this scheme only gets partial
+results until it reaches the last location (i.e., `(#9, 0)` to `(#9, C-1)`).
+Ideally, we can use the output tensor directly as an accumulator, no extra space
+is needed at runtime. Yet, since the output tensor is limited (8 bits) in an
+integer model, accumulating intermediate values at the output tensor will cause
+overflow: the product of two `int8` values is in the range of `int16` and there
+are `H * W` values to be accumulated, the range of the value before quantization
+is `H * W * MAX_INT16`. Therefore, an `int32` accumulator is adequate as long as
+the number of accumulations `(H*W*C)` does not exceed `2^16`. To address
+overflow when accumulating at output tensor and provide better memory access
+pattern, an `int32` array of size equals to number of channels (`C`) as
+accumulators is enough, since those `C` calculations are done once a set of
+spatial locations (`#1` to `#9`) are convolved, we don't have to allocate an
+array with size equals to the output tensor to accumulate the values.
+
+Original | Optimized
+:-------------: | :-------------:
+(#1, 0) | (#1, 0)
+(#2, 0) | (#1, 1)
+... | ...
+**(#9, 0)** | (#1, C - 1)
+(#1, 1) | (#2, 0)
+... | ...
+**(#9, 1)** | **(#9, 0)**
+... | ...
+**(#9, C - 1)** | **(#9, C - 1)**
+
+If we implement this idea, i.e. allocating a temporary array with size equals to
+`C`, we can follow the loop structure shown below, this would work just fine,
+but as we can see in the routine, it involves allocating an `int32` array of
+**size in proportional to the input channel**, which is not preferable in those
+resource limited devices because we cannot assure there will always be enough
+memory given any application or model.
+
+```
+for i-th input among N inputs
+ for each (out_y, out_x)
+ for m < depth_multiplier; step_size = 1
+ calculate origin (in_y_origin, in_x_origin) to perform convolution
+
+ // Accumulate partial results in buffer given a origin
+ create an int32 buffer of size output_channel as accumulators
+
+ for each (filter_y, filter_x)
+ calculate (in_y, in_x) to perform convolution
+ for in_ch < in_channel; step_size = 1
+ calculate out_ch
+ // accumulate partial results
+ buffer[ch_offset] += input[indexOf(i, y, x, in_ch)] *
+ filter[indexOf(0, f_y, f_x, out_ch)]
+
+ for in_ch < in_channel; step_size = 1
+ calculate out_ch
+ // Add bias / activation / requantize
+ value = postAccumulation(buffer[out_ch])
+ output[indexOf(i, out_y, out_x, out_ch)] = value
+```
+
+Instead, we can further breakdown the structure into chunks, namely, we can add
+an additional nested loop inside to iterate `K` channels a time until all
+channels are processed, the modified loop structure is depicted below and the
+visualization is shown in the figure below the loop.
+
+```
+for i-th input among N inputs
+ for each (out_y, out_x)
+ for m < depth_multiplier; step_size = 1
+ calculate origin (in_y_origin, in_x_origin) to perform convolution
+
+ // Accumulate partial results in buffer for K channels given a origin
+ for ch < input_ch; step_size = K
+ create an int32 buffer of size K as accumulator for current chunk
+
+ for each (filter_y, filter_x)
+ calculate (in_y, in_x) to perform convolution
+ for ch_offset < channel_step; step_size = 1
+ calculate in_ch and out_ch
+ // accumulate partial results
+ buffer[ch_offset] += input[indexOf(i, y, x, in_ch)] *
+ filter[indexOf(0, f_y, f_x, out_ch)]
+
+ for ch_offset < channel_step; step_size = 1
+ // Add bias / activation / requantize
+ value = postAccumulation(buffer[ch_offset])
+ output[indexOf(i, out_y, out_x, out_ch)] = value
+```
+
+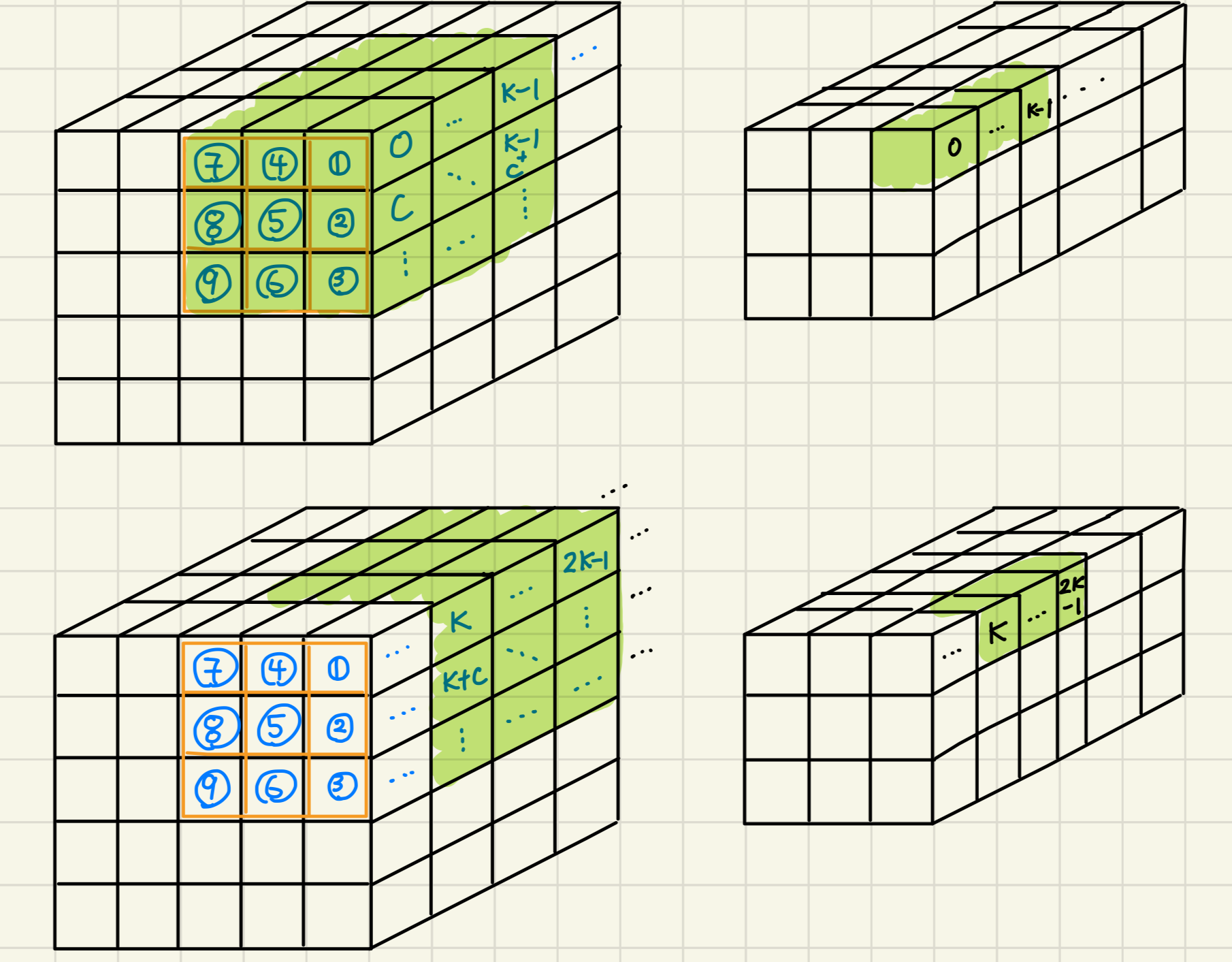
+
+The final problem is how the choice of `K`, according to the soft-CPU
+configuration, we have a cache size of 4KB and each memory block is 32 bytes.
+Combined with the input format we use (`int8`) whenever the OS fetches a block
+of input tensor, it loads 32 `int8` to the cache. To fully utilize that block,
+we can choose the size of the buffer to accommodate 32 partial results (128
+byte, or 4 blocks,) most applications keep the number of channels to be power of
+2s (except for the input,) 32 is a reasonable value to perform depthwise
+convolution for both small and large numbers of channels in the model.
+
+## Alternatives considered
+
+An alternative design is to dynamically allocate a buffer for each channel (an
+`int32` array of size equals to number of output channels.) This approach is
+easier to implement since after `H * W * C` calculations, we can requantize
+those `C` values and store them into the output tensor. However, we are running
+on memory constrained devices, dynamic allocation is not encouraged by the
+upstream developers.
diff --git a/tensorflow/lite/micro/kernels/vexriscv/utils/README.md b/tensorflow/lite/micro/kernels/vexriscv/utils/README.md
new file mode 100644
index 0000000..16f5661
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/vexriscv/utils/README.md
@@ -0,0 +1,133 @@
+# VexRISC-V utils
+
+This directory contains scripts for some utilities when debugging with TFLM
+applications.
+
+## log_parser.py
+
+This script is used to analyze the function call stack obtained when a
+application is running on Renode with GDB session attached or with Renode's
+logging set to true (include the following line in your `*.resc` file of enter
+this command in Renode every time you launch an simulator.)
+
+```
+sysbus.cpu LogFunctionNames true
+```
+
+Also, make sure you check out Antmicro's repo
+[antmicro/litex-vexriscv-tensorflow-lite-demo](https://github.com/antmicro/litex-vexriscv-tensorflow-lite-demo)
+for the guide to run TensorFlow Lite Micro examples on Renode.
+
+In the following guide with GDB, we will be using the example gdb script
+described here
+[Cobbled-together Profiler](https://xobs.io/cobbled-together-profiler/)
+
+### Launch Renode console
+
+Include (`include` or `i` for short) the renode script (`*.resc`), DO NOT start
+the simulation yet.
+
+The symbol `@` is the path where Renode is installed, you can navigate to
+anywhere on the disk as long as you follow the linux syntax (`../` for parent
+directory, etc.), here I install Renode under home (`/home/$USER` or `~/`)
+directory and I put the demo repository litex-vexriscv-tensorflow-lite-demo
+under home directory.
+
+```
+i @../litex-vexriscv-tensorflow-lite-demo/renode/litex-vexriscv-tflite.resc
+```
+
+### Start GDB server on Renode on port 8833
+
+```
+machine StartGdbServer 8833
+```
+
+### Launch GDB
+
+First you need to find a proper GDB executable for your target architecture,
+here, we will follow Antmicro's repo and use the riscv GDB executable from
+zephyr
+
+Usage: `[GDB] -x [GDB_SCRIPT] [TFLM_BINARY]`
+
+Example: `/opt/zephyr-sdk/riscv64-zephyr-elf/bin/riscv64-zephyr-elf-gdb \ -x
+profiling.gdb \
+../tensorflow/tensorflow/lite/micro/tools/make/gen/zephyr_vexriscv_x86_64/magic_wand/build/zephyr/zephyr.elf`
+
+### Connect GDB to Renode's gdbserver on the same port
+
+```
+(gdb) target remote :8833
+(gdb) monitor start
+(gdb) continue
+
+# Run the function in the GDB script with required parameter
+(gdb) poor_profile 1000
+```
+
+### Interrupt the gdb script regularly with a shell command
+
+```
+for i in $(seq 1000); do echo $i...; killall -INT riscv64-zephyr-elf-gdb; sleep 5; done
+```
+
+### Interpreting the log
+
+#### Parse and visualize the log
+
+```
+# The following command is used to parse and visualize the log file
+# obtained from GDB and only keep top 7 most frequent functions in the
+# image, for detail usage of the script, please refer to the source code
+
+python log_parser.py [INPUT] --regex=gdb_regex.json --visualize --top=7 --source=gdb
+```
+
+Since we are redirecting the gdb interrupt messages to the file
+`<path-you-run-gdb>/profile.txt` (see the gdb script,) we can now parse the log
+and visualize it. (set the image title with argument `--title`)
+
+```
+python log_parser.py profile.txt --regex=gdb_regex.json --visualize --top=7 --title=magic_wand
+```
+
+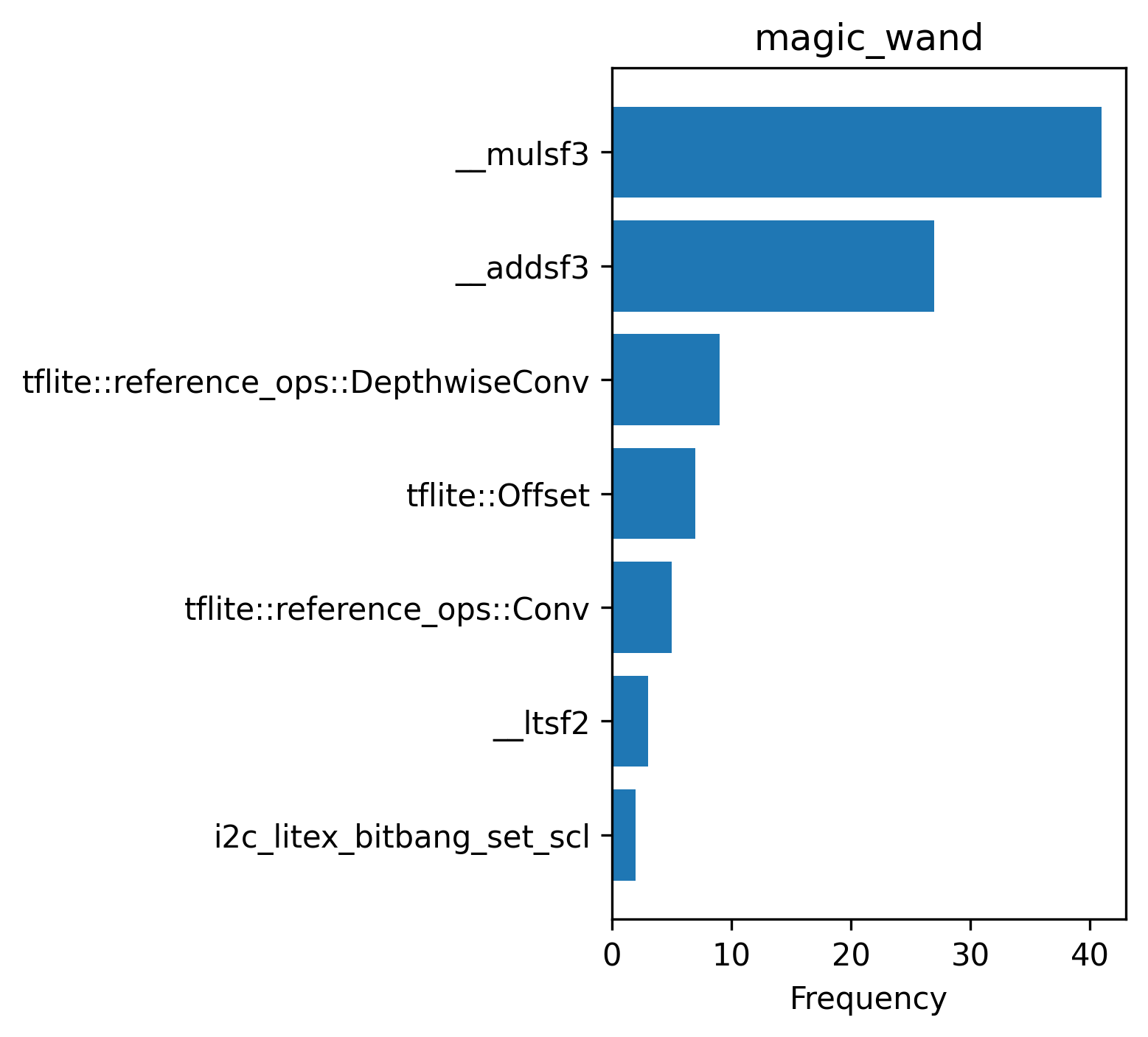
+
+#### Get the statistic of the function call hierarchy
+
+To get a more detail view of how the entire function call stack looks like and
+how many time the function is called with the exact same call stack, we can add
+another option `--full-trace` to the script and it will generate a `*.json` file
+for the complete call stack trace. `python log_parser.py profile.txt
+--regex=gdb_regex.json --visualize --top=7 --full-trace`
+
+```
+# In the `*.json` file
+root
+|-- fcn0
+| |-- [stack0, stack1, ...] # List of function call stacks, see below
+|
+|-- fcn1
+| |-- [stack0, stack1, ...]
+...
+```
+
+```
+# Each stack* object contains the following information
+stack*
+|-- counts: 5 # Number of occurrences with the exact same call stack
+|-- [list of functions in the call stack]
+```
+
+
+
+### Customizing `*.json` used in the script
+
+The regular expression used in this script is configured with a standard
+`*.json` file with the following content:
+
+* `base`: Base regular expression to clean up the log, this is set to clean up
+ the ANSI color codes in GDB
+* `custom`: A series of other regular expressions (the script will run them in
+ order) to extract the information from the log
diff --git a/tensorflow/lite/micro/kernels/vexriscv/utils/gdb_regex.json b/tensorflow/lite/micro/kernels/vexriscv/utils/gdb_regex.json
new file mode 100644
index 0000000..22a986f
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/vexriscv/utils/gdb_regex.json
@@ -0,0 +1,9 @@
+{
+ "base": "(\\x1b\\[\\d?\\d?m)",
+ "custom": [
+ "(\\w+ in ([^()])*)",
+ "tflite[^()]*",
+ "(\\w+) \\(",
+ "#\\d+ (.*) \\("
+ ]
+}
\ No newline at end of file
diff --git a/tensorflow/lite/micro/kernels/vexriscv/utils/log_parser.py b/tensorflow/lite/micro/kernels/vexriscv/utils/log_parser.py
new file mode 100644
index 0000000..2294088
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/vexriscv/utils/log_parser.py
@@ -0,0 +1,340 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+r"""Analyze function call stack from GDB or Renode
+
+See README for detail usage
+
+Example usage:
+
+python log_parser.py profile.txt --regex=gdb_regex.json --visualize --top=7
+
+* To add a title in the graph, use the optional argument --title to set it
+
+Example usage:
+
+python log_parser.py profile.txt --regex=gdb_regex.json \
+--visualize --top=7 --title=magic_wand
+
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import collections
+import json
+import os
+import re
+import matplotlib.pyplot as plt
+
+
+def readlines(filename):
+ """
+ Arg:
+ filename(str):
+
+ Return:
+ (list of str):
+ """
+ with open(filename, "r") as f:
+ content = f.read().splitlines()
+
+ return content
+
+
+def writelines(data, filename):
+ # Write parsed log to file
+ with open(filename, "w") as f:
+ for line in data:
+ f.write(line + "\n")
+
+
+def load_regex_parser(filename):
+ """
+ Arg:
+ filename: string for the input json file containing regex
+ """
+ assert filename is not None
+
+ with open(filename, "r") as f:
+ content = json.load(f)
+
+ regex_parser = {}
+ for key, val in content.items():
+ if isinstance(val, list):
+ regexs = []
+ for pattern in val:
+ regexs.append(re.compile(pattern))
+
+ regex_parser[key] = regexs
+ else:
+ regex_parser[key] = re.compile(val)
+
+ return regex_parser
+
+
+def gdb_log_parser(data, output, re_file, ignore_list=None, full_trace=False):
+ """
+ Args:
+ data: list of strings of logs from GDB
+ output: string of output filename
+ re_file: path to the regex *.json file
+ ignore_list: list of string (functions) to ignore
+ full_trace: bool to generate full stack trace of the log
+ """
+ regex_parser = load_regex_parser(re_file)
+
+ trace = collections.defaultdict(list)
+ stack = []
+ processed = []
+ for line in data:
+ # Skip invalid lines
+ if not line.startswith("#"):
+ continue
+
+ # Skip redundant lines
+ if not full_trace and not line.startswith("#0"):
+ continue
+
+ # Remove ANSI color symbols
+ # line = ANSI_CLEANER.sub("", line)
+ line = regex_parser["base"].sub("", line)
+
+ # Extract function names with regex
+ find = None
+ for r in regex_parser["custom"]:
+ find = r.findall(line)
+
+ if len(find) != 0:
+ break
+
+ if find is None or len(find) == 0:
+ continue
+
+ # Extract content from `re.findall` results
+ target = find[0][0] if isinstance(find[0], tuple) else find[0]
+
+ # Extract function name from `$ADDR in $NAME`, e.g.
+ # `0x40002998 in __addsf3` -> `__addsf3`
+ if " in " in target:
+ target = target.split()[-1]
+
+ # Remove leading/trailing spaces
+ target = target.strip()
+
+ if full_trace:
+ if line.startswith("#0") and stack:
+ # Encode the trace to string
+ temp = "/".join(stack)
+ trace[stack[0]].append(temp)
+
+ # Clear up previous stack
+ stack.clear()
+
+ stack.append(target)
+
+ if not line.startswith("#0"):
+ continue
+
+ if ignore_list and target in ignore_list:
+ continue
+
+ # Strip the string before adding into parsed list
+ processed.append(target)
+
+ print("Extracted {} lines".format(len(processed)))
+
+ # Write parsed log to file
+ writelines(processed, output)
+
+ if full_trace:
+ content = {}
+ for top, paths in trace.items():
+ content[top] = []
+ counter = collections.Counter(paths)
+
+ for path, counts in counter.items():
+ info = {"counts": counts, "path": path.split("/")}
+ content[top].append(info)
+
+ name = os.path.splitext(output)[0]
+ with open(name + ".json", "w") as f:
+ json.dump(content, f, sort_keys=True, indent=4)
+
+ print("Parsed the log to `{}`".format(output))
+
+
+def renode_log_parser(data, output, ignore_list=None):
+ """
+ Args:
+ data: list of strings of logs from Renode
+ output: string of output filename
+ ignore_list: list of string (functions) to ignore
+ """
+ message = "Entering function"
+ extractor = re.compile(r"{} (.*) at".format(message))
+
+ ignore_count = 0
+ processed = []
+ for idx, line in enumerate(data):
+ print("Processing {:.2f}%".format((idx + 1) / len(data) * 100.), end="\r")
+
+ if message not in line:
+ continue
+
+ find = extractor.findall(line)
+
+ # Skip invalid find or unnamed functions
+ if len(find) == 0 or len(find[0].split()) == 0:
+ continue
+
+ entry = find[0].split()[0]
+
+ if ignore_list and entry in ignore_list:
+ ignore_count += 1
+ continue
+
+ processed.append(entry)
+
+ print("Extracted {} lines ({:.2f}%); {} lines are ignored ({:.2f}%)".format(
+ len(processed),
+ len(processed) / len(data) * 100., ignore_count,
+ ignore_count / len(data) * 100.))
+
+ # Write parsed log to file
+ writelines(processed, output)
+
+ print("Parsed the log to `{}`".format(output))
+
+
+def parse_log(filename,
+ output=None,
+ re_file=None,
+ source="gdb",
+ ignore=None,
+ full_trace=False):
+ """
+ Args:
+ filename(str)
+ output(str)
+ """
+ data = readlines(filename)
+ print("Raw log: {} lines".format(len(data)))
+
+ ignore_list = None
+ if ignore is not None:
+ ignore_list = set(readlines(ignore))
+ print("* {} patterns in the ignore list".format(len(ignore_list)))
+
+ name, ext = None, None
+ if output is None:
+ name, ext = os.path.splitext(filename)
+ output = "{}-parsed{}".format(name, ext)
+
+ if source == "gdb":
+ gdb_log_parser(data, output, re_file, ignore_list, full_trace)
+ elif source == "renode":
+ renode_log_parser(data, output, ignore_list=ignore_list)
+ else:
+ raise NotImplementedError
+
+
+def visualize_log(filename, top=None, title=None, show=False, save=True):
+ """
+ Arg:
+ filename(str)
+ """
+ data = readlines(filename)
+ print("Parsed log: {} lines".format(len(data)))
+
+ x, y = get_frequency(data)
+
+ if top is not None:
+ top *= -1
+ x, y = x[top:], y[top:]
+
+ plt.figure(figsize=(3, 5))
+ plt.barh(x, y)
+ plt.xlabel("Frequency")
+
+ if title:
+ plt.title(title)
+
+ if show:
+ plt.show()
+
+ if save:
+ fig_name = "{}.png".format(os.path.splitext(filename)[0])
+ plt.savefig(fname=fig_name, bbox_inches="tight", dpi=300)
+ print("Figure saved in {}".format(fig_name))
+
+
+def get_frequency(data):
+ """
+ Arg:
+ data(list of str):
+
+ Return:
+ keys(list of str):
+ vals(list of str):
+ """
+ counter = collections.Counter(data)
+
+ keys = [pair[0] for pair in sorted(counter.items(), key=lambda x: x[1])]
+ vals = sorted(counter.values())
+
+ return keys, vals
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("input", type=str, help="Input raw log file.")
+ parser.add_argument("--output",
+ type=str,
+ help="Parsed log file. Default: [NAME]-parsed.[EXT]")
+ parser.add_argument("--regex",
+ type=str,
+ help="Path to the regex files for parsing GDB log.")
+ parser.add_argument("--visualize",
+ action="store_true",
+ help="Parse and visualize")
+ parser.add_argument("--top", type=int, help="Top # to visualize")
+ parser.add_argument("--source",
+ type=str,
+ default="gdb",
+ choices=["gdb", "renode"],
+ help="Source of where the log is captured")
+ parser.add_argument(
+ "--ignore",
+ type=str,
+ help="List of functions (one for each line in the file) to \
+ ignore after parsing.")
+ parser.add_argument("--full-trace", action="store_true", help="")
+ parser.add_argument("--title",
+ type=str,
+ help="Set title for the visualized image")
+
+ args = parser.parse_args()
+
+ if args.output is None:
+ fname, extension = os.path.splitext(args.input)
+ args.output = "{}-parsed{}".format(fname, extension)
+
+ parse_log(args.input, args.output, args.regex, args.source, args.ignore,
+ args.full_trace)
+
+ if args.visualize:
+ visualize_log(args.output, top=args.top, title=args.title)
diff --git a/tensorflow/lite/micro/kernels/xtensa/conv.cc b/tensorflow/lite/micro/kernels/xtensa/conv.cc
new file mode 100644
index 0000000..7d18411
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/conv.cc
@@ -0,0 +1,512 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/conv.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/conv.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h"
+#include "tensorflow/lite/micro/kernels/xtensa/xtensa.h"
+
+namespace tflite {
+namespace {
+
+struct OpData {
+ OpDataConv reference_op_data;
+
+#if defined(FUSION_F1)
+ int scratch_tensor_index;
+#endif // defined(FUSION_F1)
+};
+
+#if defined(HIFIMINI)
+void EvalHifiMini(const ConvParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int32_t input_offset = params.input_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ const int batches = input_shape.Dims(0);
+
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int filter_depth = filter_shape.Dims(3);
+
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int output_depth = output_shape.Dims(3);
+
+ ae_p24x2s input_offset_24x2 = AE_MOVPA24(input_offset);
+ ae_q56s output_offset_56 = AE_CVTQ48A32S(output_offset);
+ ae_q56s output_activation_min_56 = AE_CVTQ48A32S(output_activation_min);
+ ae_q56s output_activation_max_56 = AE_CVTQ48A32S(output_activation_max);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
+ ae_q56s acc_56 = AE_ZEROQ56();
+
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ for (int filter_x = 0; filter_x < filter_width; filter_x += 2) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+ if (is_point_inside_image) {
+ // Find current input index, minus 2 for Xtensa load
+ // alignments:
+ // TODO(b/147322595): Consider doing these offset calculations
+ // with intrinsics:
+ int input_idx =
+ ((batch * input_height + in_y) * input_width + in_x) *
+ input_depth * 2 -
+ 2;
+ const int8_t* input_vals_offset_ptr = input_data + input_idx;
+ for (int i = 0; i < input_depth; i += 2) {
+ // Load signed 2x 8bit values and right shift into 24bit
+ // alignment:
+ ae_p24x2s input_vals_24x2;
+ AE_LP8X2F_IU(input_vals_24x2, input_vals_offset_ptr, 2);
+ input_vals_24x2 = AE_P24X2S_SRAI(input_vals_24x2, 16);
+
+ // Add input offset (24bit aligned):
+ input_vals_24x2 =
+ AE_P24S_ADDS_P24X2S(input_vals_24x2, input_offset_24x2);
+
+ // Find current filter index, minus 2 for Xtensa load
+ // alignments:
+ int filter_idx =
+ ((out_channel * filter_height + filter_y) * filter_width +
+ filter_x) *
+ filter_depth +
+ i - 2;
+ const int8_t* filter_vals_offset_ptr =
+ filter_data + filter_idx;
+
+ // Load signed 2x 8bit values and right shift into 24bit
+ // alignment:
+ ae_p24x2s filter_vals_24x2;
+ AE_LP8X2F_IU(filter_vals_24x2, filter_vals_offset_ptr, 2);
+ filter_vals_24x2 = AE_P24X2S_SRAI(filter_vals_24x2, 16);
+
+ // Multiply and accumulate into 48bit bit space:
+ AE_MULAAP24S_HH_LL(acc_56, filter_vals_24x2, input_vals_24x2);
+ }
+ }
+ }
+ }
+
+ // Left shift from 48bit alignment to 32bit:
+ acc_56 = AE_Q56S_SLAI(acc_56, 16);
+
+ if (bias_data) {
+ // Load and add bias at 32bit alignment:
+ ae_q56s bias_56 = AE_CVTQ48A32S(bias_data[out_channel]);
+ acc_56 = AE_ADDQ56(acc_56, bias_56);
+ }
+
+ // Shift from 32bit alignment to 24bit alignment and place back on
+ // the PR register:
+ acc_56 = AE_Q56S_SLAI(acc_56, 8);
+ ae_p24x2s acc_24x2 = AE_TRUNCP24Q48(acc_56);
+
+ // Apply quantized multiplier and accumulate result at 48bit
+ // alignment. Convert the (unsigned) 32-bit multiplier down to a
+ // 24-bit multiplier.
+ acc_56 = MultiplyByQuantizedMultiplier(
+ acc_24x2, output_multiplier[out_channel] >> 8,
+ output_shift[out_channel]);
+
+ // Add output offset, cap activation, and assign to the output:
+ acc_56 = AE_ADDQ56(acc_56, output_offset_56);
+ acc_56 = AE_MINQ56S(acc_56, output_activation_max_56);
+ acc_56 = AE_MAXQ56S(acc_56, output_activation_min_56);
+
+ int output_idx =
+ ((batch * output_height + out_y) * output_width + out_x) *
+ output_depth +
+ out_channel;
+ output_data[output_idx] = static_cast<int8_t>(AE_TRUNCA32Q48(acc_56));
+ }
+ }
+ }
+ }
+}
+
+// TODO(b/154240772): Move shared code into common methods.
+inline void Conv1x32Input32x32FilterHifiMini(
+ const int input_offset, const int output_offset,
+ const int quantized_activation_min, const int quantized_activation_max,
+ const int32_t* output_multiplier, const int32_t* output_shift,
+ const RuntimeShape& input_shape, const int8_t* input_data,
+ const RuntimeShape& filter_shape, const int8_t* filter_data,
+ const RuntimeShape& bias_shape, const int32_t* bias_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ ae_p24x2s input_offset_24x2 = AE_MOVPA24(input_offset);
+ ae_q56s output_offset_56 = AE_CVTQ48A32S(output_offset);
+ ae_q56s output_activation_max_56 = AE_CVTQ48A32S(quantized_activation_max);
+ ae_q56s output_activation_min_56 = AE_CVTQ48A32S(quantized_activation_min);
+
+ constexpr int kChannels = 32;
+ constexpr int kFilterDepth = 32;
+ for (int ch = 0; ch < kChannels; ch++) {
+ ae_q56s acc_56 = AE_ZEROQ56();
+ const int8_t* input_vals_ptr = input_data - 2;
+ for (int i = 0; i < kFilterDepth; i += 2) {
+ // Load signed 2x 8bit values and right shift into 24bit
+ // alignment:
+ ae_p24x2s input_vals_24x2;
+ AE_LP8X2F_IU(input_vals_24x2, input_vals_ptr, 2);
+ input_vals_24x2 = AE_P24X2S_SRAI(input_vals_24x2, 16);
+
+ // Add input offset (24bit aligned):
+ input_vals_24x2 = AE_P24S_ADDS_P24X2S(input_vals_24x2, input_offset_24x2);
+ // Find current filter index, minus 2 for Xtensa load
+ // alignments:
+ const int filter_idx = ch * kFilterDepth + i - 2;
+ const int8_t* filter_vals_offset_ptr = filter_data + filter_idx;
+
+ // Load signed 2x 8bit values and right shift into 24bit
+ // alignment:
+ ae_p24x2s filter_vals_24x2;
+ AE_LP8X2F_IU(filter_vals_24x2, filter_vals_offset_ptr, 2);
+ filter_vals_24x2 = AE_P24X2S_SRAI(filter_vals_24x2, 16);
+
+ // Multiply and accumulate into 48bit bit space:
+ AE_MULAAP24S_HH_LL(acc_56, filter_vals_24x2, input_vals_24x2);
+ }
+ // Left shift from 48bit alignment to 32bit:
+ acc_56 = AE_Q56S_SLAI(acc_56, 16);
+ if (bias_data) {
+ // Load and add bias at 32bit alignment:
+ ae_q56s bias_56 = AE_CVTQ48A32S(bias_data[ch]);
+ acc_56 = AE_ADDQ56(acc_56, bias_56);
+ }
+
+ // Shift from 32bit alignment to 24bit alignment and place back on
+ // the PR register:
+ acc_56 = AE_Q56S_SLAI(acc_56, 8);
+ ae_p24x2s acc_24x2 = AE_TRUNCP24Q48(acc_56);
+
+ // Apply quantized multiplier and accumulate result at 48bit alignment.
+ // Convert the (unsigned) 32-bit multiplier down to a 24-bit multiplier.
+ acc_56 = MultiplyByQuantizedMultiplier(acc_24x2, output_multiplier[ch] >> 8,
+ output_shift[ch]);
+
+ // Add output offset, cap activation, and assign to the output:
+ acc_56 = AE_ADDQ56(acc_56, output_offset_56);
+ acc_56 = AE_MINQ56S(acc_56, output_activation_max_56);
+ acc_56 = AE_MAXQ56S(acc_56, output_activation_min_56);
+
+ output_data[ch] = static_cast<int8_t>(AE_TRUNCA32Q48(acc_56));
+ }
+}
+#endif // defined(HIFIMINI)
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_OK(context, ConvPrepare(context, node));
+
+#if defined(FUSION_F1)
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const auto params = static_cast<const TfLiteConvParams*>(node->builtin_data);
+
+ // Calculate scratch memory requirements and request scratch buffer
+ TfLiteTensor* output = GetOutput(context, node, kConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ const TfLiteTensor* input = GetInput(context, node, kConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+
+ const RuntimeShape& input_shape = GetTensorShape(input);
+ const RuntimeShape& filter_shape = GetTensorShape(filter);
+ const RuntimeShape& output_shape = GetTensorShape(output);
+ const int input_height = input_shape.Dims(1);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_channels = output_shape.Dims(3);
+ const int stride_height = params->stride_height;
+ const int pad_height = data->reference_op_data.padding.height;
+
+ TF_LITE_ENSURE_EQ(context, input->type, kTfLiteInt8);
+
+ int required_scratch = 0;
+ // Dilation is currently not supported on HiFi 4 NN Library
+ if ((params->dilation_width_factor == 1) &&
+ (params->dilation_height_factor == 1)) {
+ required_scratch = xa_nn_conv2d_std_getsize(
+ input_height, input_depth, filter_height, filter_width, stride_height,
+ pad_height, output_height, output_channels, PREC_ASYM8S);
+ TF_LITE_ENSURE(context, required_scratch > 0);
+ }
+ TF_LITE_ENSURE_OK(
+ context, context->RequestScratchBufferInArena(
+ context, required_scratch, &data->scratch_tensor_index));
+#endif // defined(FUSION_F1)
+ return kTfLiteOk;
+}
+
+#if defined(FUSION_F1)
+TfLiteStatus EvalHifi4(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteConvParams& params, const OpData& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias, TfLiteEvalTensor* output,
+ TfLiteEvalTensor* im2col) {
+ const RuntimeShape& input_shape = tflite::micro::GetTensorShape(input);
+ const RuntimeShape& filter_shape = tflite::micro::GetTensorShape(filter);
+ /* Dilation is currently not supported on HiFi 4 NN Library */
+ if ((params.dilation_width_factor == 1) &&
+ (params.dilation_height_factor == 1) &&
+ input_shape.Dims(1) >= filter_shape.Dims(1) &&
+ input_shape.Dims(2) >= filter_shape.Dims(2)) {
+ const int32_t input_offset = -data.reference_op_data.input_zero_point;
+ const int32_t output_offset = data.reference_op_data.output_zero_point;
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int pad_width = data.reference_op_data.padding.width;
+ const int pad_height = data.reference_op_data.padding.height;
+ const int32_t output_activation_min =
+ data.reference_op_data.output_activation_min;
+ const int32_t output_activation_max =
+ data.reference_op_data.output_activation_max;
+
+ const RuntimeShape& output_shape = tflite::micro::GetTensorShape(output);
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int input_depth = MatchingDim(input_shape, 3, filter_shape, 3);
+ const int output_depth = MatchingDim(filter_shape, 0, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+
+ const int8_t* input_data = tflite::micro::GetTensorData<int8_t>(input);
+ const int8_t* filter_data = tflite::micro::GetTensorData<int8_t>(filter);
+ const int32_t* bias_data = tflite::micro::GetTensorData<int32_t>(bias);
+ int8_t* output_data = tflite::micro::GetTensorData<int8_t>(output);
+
+ int output_data_format = 0;
+ int out_length = output_height * output_width * output_depth;
+
+ if (filter_height == 1 && filter_width == 1) {
+ for (int batch = 0; batch < batches; ++batch) {
+ int8_t* p_out_temp;
+ p_out_temp = &output_data[batch * out_length];
+
+ TF_LITE_ENSURE_EQ(
+ context,
+
+ xa_nn_conv2d_pointwise_per_chan_sym8sxasym8s(
+ p_out_temp, const_cast<WORD8*>(filter_data),
+ const_cast<WORD8*>(&input_data[batch * input_height *
+ input_width * input_depth]),
+ const_cast<WORD32*>(bias_data), input_height, input_width,
+ input_depth, output_depth, input_offset,
+ data.reference_op_data.per_channel_output_multiplier,
+ data.reference_op_data.per_channel_output_shift, output_offset,
+ output_data_format),
+ 0);
+
+ TF_LITE_ENSURE_EQ(context,
+ xa_nn_vec_activation_min_max_8_8(
+ p_out_temp, p_out_temp, output_activation_min,
+ output_activation_max, out_length),
+ 0);
+ }
+ } else {
+ void* p_scratch = static_cast<void*>(
+ context->GetScratchBuffer(context, data.scratch_tensor_index));
+
+ for (int batch = 0; batch < batches; ++batch) {
+ int8_t* p_out_temp;
+ p_out_temp = &output_data[batch * out_length];
+
+ {
+ TF_LITE_ENSURE_EQ(
+ context,
+ xa_nn_conv2d_std_per_chan_sym8sxasym8s(
+ p_out_temp,
+ &input_data[batch * input_height * input_width * input_depth],
+ const_cast<int8_t*>(filter_data), // filter_data,
+ bias_data, input_height, input_width, input_depth,
+ filter_height, filter_width, output_depth, stride_width,
+ stride_height, pad_width, pad_height, output_height,
+ output_width, input_offset,
+ data.reference_op_data.per_channel_output_multiplier,
+ data.reference_op_data.per_channel_output_shift,
+ output_offset, output_data_format,
+ static_cast<void*>(p_scratch)),
+ 0);
+ }
+
+ TF_LITE_ENSURE_EQ(context,
+ xa_nn_vec_activation_min_max_8_8(
+ p_out_temp, p_out_temp, output_activation_min,
+ output_activation_max, out_length),
+ 0);
+ }
+ }
+ return kTfLiteOk;
+ }
+
+ reference_integer_ops::ConvPerChannel(
+ ConvParamsQuantized(params, data.reference_op_data),
+ data.reference_op_data.per_channel_output_multiplier,
+ data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+}
+#endif // defined(FUSION_F1)
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto& params =
+ *(reinterpret_cast<TfLiteConvParams*>(node->builtin_data));
+ const auto& op_data = *(reinterpret_cast<OpData*>(node->user_data));
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kConvOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kConvInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kConvWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kConvBiasTensor)
+ : nullptr;
+
+#if defined(HIFIMINI)
+ int* input_dims = input->dims->data;
+ int* filter_dims = filter->dims->data;
+ if (input_dims[0] == 1 && input_dims[1] == 1 && input_dims[2] == 1 &&
+ input_dims[3] == 32 && filter_dims[0] == 32 && filter_dims[1] == 1 &&
+ filter_dims[2] == 1 && filter_dims[3] == 32) {
+ Conv1x32Input32x32FilterHifiMini(
+ -op_data.reference_op_data.input_zero_point,
+ op_data.reference_op_data.output_zero_point,
+ op_data.reference_op_data.output_activation_min,
+ op_data.reference_op_data.output_activation_max,
+ op_data.reference_op_data.per_channel_output_multiplier,
+ op_data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+ }
+#endif // defined(HIFIMINI)
+
+ switch (input->type) {
+ case kTfLiteInt8: {
+#if defined(HIFIMINI)
+ EvalHifiMini(ConvParamsQuantized(params, op_data.reference_op_data),
+ op_data.reference_op_data.per_channel_output_multiplier,
+ op_data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#elif defined(FUSION_F1)
+ EvalHifi4(context, node, params, op_data, input, filter, bias, output,
+ nullptr);
+#else
+ reference_integer_ops::ConvPerChannel(
+ ConvParamsQuantized(params, op_data.reference_op_data),
+ op_data.reference_op_data.per_channel_output_multiplier,
+ op_data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#endif
+ break;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+} // namespace
+
+TfLiteRegistration Register_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/xtensa/depthwise_conv.cc b/tensorflow/lite/micro/kernels/xtensa/depthwise_conv.cc
new file mode 100644
index 0000000..49fef8c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/depthwise_conv.cc
@@ -0,0 +1,541 @@
+/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/depthwise_conv.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h"
+#include "tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/padding.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h"
+#include "tensorflow/lite/micro/kernels/xtensa/xtensa.h"
+
+namespace tflite {
+namespace {
+
+struct OpData {
+ OpDataConv reference_op_data;
+
+#if defined(FUSION_F1)
+ int scratch_tensor_index;
+#endif // defined(FUSION_F1)
+};
+
+#if defined(HIFIMINI)
+inline void EvalHifiMini(
+ const DepthwiseParams& params, const int32_t* output_multiplier,
+ const int32_t* output_shift, const RuntimeShape& input_shape,
+ const int8_t* input_data, const RuntimeShape& filter_shape,
+ const int8_t* filter_data, const RuntimeShape& bias_shape,
+ const int32_t* bias_data, const RuntimeShape& output_shape,
+ int8_t* output_data) {
+ // TODO(b/154032858): Investigate removing extra copies.
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int dilation_width_factor = params.dilation_width_factor;
+ const int dilation_height_factor = params.dilation_height_factor;
+ const int pad_width = params.padding_values.width;
+ const int pad_height = params.padding_values.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t input_offset = params.input_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ const int batches = input_shape.Dims(0);
+
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int filter_depth = filter_shape.Dims(3);
+
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ const int output_depth = output_shape.Dims(3);
+
+ ae_p24x2s input_offset_24x2 = AE_MOVPA24(input_offset);
+ ae_q56s output_offset_56 = AE_CVTQ48A32S(output_offset);
+ ae_q56s output_activation_min_56 = AE_CVTQ48A32S(output_activation_min);
+ ae_q56s output_activation_max_56 = AE_CVTQ48A32S(output_activation_max);
+
+ for (int batch = 0; batch < batches; ++batch) {
+ for (int out_y = 0; out_y < output_height; ++out_y) {
+ const int in_y_origin = (out_y * stride_height) - pad_height;
+ for (int out_x = 0; out_x < output_width; ++out_x) {
+ const int in_x_origin = (out_x * stride_width) - pad_width;
+ for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
+ for (int m = 0; m < depth_multiplier; ++m) {
+ const int output_channel = m + in_channel * depth_multiplier;
+ ae_q56s acc_56 = AE_ZEROQ56();
+ for (int filter_y = 0; filter_y < filter_height; ++filter_y) {
+ const int in_y = in_y_origin + dilation_height_factor * filter_y;
+ for (int filter_x = 0; filter_x < filter_width; ++filter_x) {
+ const int in_x = in_x_origin + dilation_width_factor * filter_x;
+ // Zero padding by omitting the areas outside the image.
+ const bool is_point_inside_image =
+ (in_x >= 0) && (in_x < input_width) && (in_y >= 0) &&
+ (in_y < input_height);
+
+ if (is_point_inside_image) {
+ // Find current input index, minus 2 for Xtensa load
+ // alignments:
+ // TODO(b/147322595): Consider doing these offset calculations
+ // with intrinsics:
+ int input_idx =
+ ((batch * input_height + in_y) * input_width + in_x) *
+ input_depth +
+ (in_channel);
+ int32_t input_val = input_data[input_idx];
+
+ // Find current filter index, minus 2 for Xtensa load
+ // alignments:
+ int filter_idx =
+ ((filter_y)*filter_width + filter_x) * filter_depth +
+ (output_channel);
+ int32_t filter_val = filter_data[filter_idx];
+
+ // Load 8bit value as int32_t into a 24x24 register and right
+ // shift into 24bit space. Note: value is duplicated in the HH
+ // and LL register - but all calculations are done on the HH
+ // side.
+ ae_p24x2s input_val_24x2 = AE_MOVPA24(input_val);
+
+ // Add input offset (24bit aligned):
+ input_val_24x2 =
+ AE_P24S_ADDS_P24X2S(input_val_24x2, input_offset_24x2);
+
+ // Load filter 8bit value into 24bit alignment:
+ ae_p24x2s filter_val_24x2 = AE_MOVPA24(filter_val);
+
+ // Multiply and accumulate the HH side of each 24x24 PR
+ // register:
+ AE_MULAS56P24S_HH(acc_56, filter_val_24x2, input_val_24x2);
+ }
+ }
+ }
+
+ // Left shift from 48bit alignment to 32bit:
+ acc_56 = AE_Q56S_SLAI(acc_56, 16);
+
+ if (bias_data) {
+ // Load and add bias at 32bit alignment:
+ ae_q56s bias_56 = AE_CVTQ48A32S(bias_data[output_channel]);
+ acc_56 = AE_ADDQ56(acc_56, bias_56);
+ }
+
+ // Shift from 32bit alignment to 24bit alignment and place back on
+ // the PR register:
+ acc_56 = AE_Q56S_SLAI(acc_56, 8);
+ ae_p24x2s acc_24x2 = AE_TRUNCP24Q48(acc_56);
+
+ // Apply quantized multiplier and accumulate result at 48bit
+ // alignment:
+ acc_56 = MultiplyByQuantizedMultiplier(
+ acc_24x2, output_multiplier[output_channel],
+ output_shift[output_channel]);
+
+ // Add output offset, cap activation, and assign to the output:
+ acc_56 = AE_ADDQ56(acc_56, output_offset_56);
+ acc_56 = AE_MINQ56S(acc_56, output_activation_max_56);
+ acc_56 = AE_MAXQ56S(acc_56, output_activation_min_56);
+
+ int output_idx =
+ ((batch * output_height + out_y) * output_width + out_x) *
+ output_depth +
+ output_channel;
+ output_data[output_idx] =
+ static_cast<int8_t>(AE_TRUNCA32Q48(acc_56));
+ }
+ }
+ }
+ }
+ }
+}
+
+constexpr int kConvolutionalKernelWidth = 4;
+constexpr int kConvolutionalKernelDepth = 32;
+inline void DepthwiseConv4x32MatchingInputAndFilterHifiMini(
+ const int input_offset, const int output_offset,
+ const int quantized_activation_min, const int quantized_activation_max,
+ const int32_t* output_multiplier, const int32_t* output_shift,
+ const RuntimeShape& input_shape, const int8_t* input_data,
+ const RuntimeShape& filter_shape, const int8_t* filter_data,
+ const RuntimeShape& bias_shape, const int32_t* bias_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ // Convert the (unsigned) 32-bit multiplier down to a 24-bit multiplier.
+ const int32_t mult = output_multiplier[0] >> 8;
+ const int32_t shift = output_shift[0];
+ ae_p24x2s input_offset_24x2 = AE_MOVPA24(input_offset);
+ ae_q56s output_offset_56 = AE_CVTQ48A32S(output_offset);
+ ae_q56s output_activation_min_56 = AE_CVTQ48A32S(quantized_activation_min);
+ ae_q56s output_activation_max_56 = AE_CVTQ48A32S(quantized_activation_max);
+
+ const int num_blocks =
+ kConvolutionalKernelDepth / 2; // Based on the 24x2 register size.
+ const int stride_elements =
+ (kConvolutionalKernelDepth / kConvolutionalKernelWidth);
+
+ const int8_t* input_0_ptr = (const int8_t*)(input_data - 2);
+ const int8_t* weight_0_ptr = (const int8_t*)(filter_data - 2);
+ // Apply the kernels in blocks of 4 for all the channels.
+ const int8_t* input_1_ptr = input_0_ptr + stride_elements * 4;
+ const int8_t* input_2_ptr = input_1_ptr + stride_elements * 4;
+ const int8_t* input_3_ptr = input_2_ptr + stride_elements * 4;
+
+ const int8_t* weight_1_ptr = weight_0_ptr + stride_elements * 4;
+ const int8_t* weight_2_ptr = weight_1_ptr + stride_elements * 4;
+ const int8_t* weight_3_ptr = weight_2_ptr + stride_elements * 4;
+
+ for (int i = 0; i < num_blocks; ++i) {
+ ae_q56s block_0_acc = AE_ZEROQ56();
+ ae_q56s block_1_acc = AE_ZEROQ56();
+
+ // Load all the weights.
+ ae_p24x2s weight_0, weight_1, weight_2, weight_3;
+ AE_LP8X2F_IU(weight_0, weight_0_ptr, 2);
+ AE_LP8X2F_IU(weight_1, weight_1_ptr, 2);
+ AE_LP8X2F_IU(weight_2, weight_2_ptr, 2);
+ AE_LP8X2F_IU(weight_3, weight_3_ptr, 2);
+
+ // Load all the inputs.
+ ae_p24x2s input_0, input_1, input_2, input_3;
+ AE_LP8X2F_IU(input_0, input_0_ptr, 2);
+ AE_LP8X2F_IU(input_1, input_1_ptr, 2);
+ AE_LP8X2F_IU(input_2, input_2_ptr, 2);
+ AE_LP8X2F_IU(input_3, input_3_ptr, 2);
+
+ // Shift inputs to 8 bit alignment and add offsets.
+ input_0 = AE_P24X2S_SRAI(input_0, 16);
+ input_1 = AE_P24X2S_SRAI(input_1, 16);
+ input_2 = AE_P24X2S_SRAI(input_2, 16);
+ input_3 = AE_P24X2S_SRAI(input_3, 16);
+
+ input_0 = AE_P24S_ADDS_P24X2S(input_0, input_offset_24x2);
+ input_1 = AE_P24S_ADDS_P24X2S(input_1, input_offset_24x2);
+ input_2 = AE_P24S_ADDS_P24X2S(input_2, input_offset_24x2);
+ input_3 = AE_P24S_ADDS_P24X2S(input_3, input_offset_24x2);
+
+ // Do the multiplies across all channels. Resulting accumulators are 32bit
+ // aligned (24 bit aligned weights * 8 bit aligned inputs).
+ AE_MULAS56P24S_HH(block_0_acc, input_0, weight_0);
+ AE_MULAS56P24S_HH(block_0_acc, input_1, weight_1);
+ AE_MULAS56P24S_HH(block_0_acc, input_2, weight_2);
+ AE_MULAS56P24S_HH(block_0_acc, input_3, weight_3);
+
+ AE_MULAS56P24S_LL(block_1_acc, input_0, weight_0);
+ AE_MULAS56P24S_LL(block_1_acc, input_1, weight_1);
+ AE_MULAS56P24S_LL(block_1_acc, input_2, weight_2);
+ AE_MULAS56P24S_LL(block_1_acc, input_3, weight_3);
+
+ int ch_0 = i * 2;
+ int ch_1 = i * 2 + 1;
+
+ // Load and add bias at 32bit alignment:
+ ae_q56s bias_56_0 = AE_CVTQ48A32S(bias_data[ch_0]);
+ ae_q56s bias_56_1 = AE_CVTQ48A32S(bias_data[ch_1]);
+ block_0_acc = AE_ADDQ56(block_0_acc, bias_56_0);
+ block_1_acc = AE_ADDQ56(block_1_acc, bias_56_1);
+
+ // Shift from 32bit alignment to 24bit alignment and place back on
+ // the PR register:
+ block_0_acc = AE_Q56S_SLAI(block_0_acc, 8);
+ block_1_acc = AE_Q56S_SLAI(block_1_acc, 8);
+ ae_p24x2s acc_24x2_0 = AE_TRUNCP24Q48(block_0_acc);
+ ae_p24x2s acc_24x2_1 = AE_TRUNCP24Q48(block_1_acc);
+
+ // Apply quantized multiplier and accumulate result at 48bit
+ // alignment:
+ block_0_acc = MultiplyByQuantizedMultiplier(acc_24x2_0, mult, shift);
+ // Apply quantized multiplier and accumulate result at 48bit
+ // alignment:
+ block_1_acc = MultiplyByQuantizedMultiplier(acc_24x2_1, mult, shift);
+
+ // Add output offset, cap activation, and assign to the output:
+ block_0_acc = AE_ADDQ56(block_0_acc, output_offset_56);
+ block_1_acc = AE_ADDQ56(block_1_acc, output_offset_56);
+ block_0_acc = AE_MINQ56S(block_0_acc, output_activation_max_56);
+ block_1_acc = AE_MINQ56S(block_1_acc, output_activation_max_56);
+ block_0_acc = AE_MAXQ56S(block_0_acc, output_activation_min_56);
+ block_1_acc = AE_MAXQ56S(block_1_acc, output_activation_min_56);
+
+ output_data[ch_0] = static_cast<int8_t>(AE_TRUNCA32Q48(block_0_acc));
+ output_data[ch_1] = static_cast<int8_t>(AE_TRUNCA32Q48(block_1_acc));
+ }
+}
+#endif // defined(HIFIMINI)
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_OK(context, DepthwiseConvPrepare(context, node));
+
+#if defined(FUSION_F1)
+ OpData* data = static_cast<OpData*>(node->user_data);
+ const auto& params =
+ *(static_cast<const TfLiteDepthwiseConvParams*>(node->builtin_data));
+
+ // Calculate scratch memory requirements and request scratch buffer
+ TfLiteTensor* output = GetOutput(context, node, kConvOutputTensor);
+ TF_LITE_ENSURE(context, output != nullptr);
+ const TfLiteTensor* input = GetInput(context, node, kConvInputTensor);
+ TF_LITE_ENSURE(context, input != nullptr);
+ const TfLiteTensor* filter = GetInput(context, node, kConvWeightsTensor);
+ TF_LITE_ENSURE(context, filter != nullptr);
+
+ TF_LITE_ENSURE_EQ(context, input->type, kTfLiteInt8);
+
+ const RuntimeShape& input_shape = GetTensorShape(input);
+ const RuntimeShape& filter_shape = GetTensorShape(filter);
+ const RuntimeShape& output_shape = GetTensorShape(output);
+
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+
+ const int depth_multiplier = params.depth_multiplier;
+ const int stride_height = params.stride_height;
+ const int stride_width = params.stride_width;
+ const int pad_width = data->reference_op_data.padding.width;
+ const int pad_height = data->reference_op_data.padding.height;
+
+ int required_scratch = 0;
+ // Dilation is currently not supported on HiFi 4 NN Library
+ if ((params.dilation_width_factor == 1) &&
+ (params.dilation_height_factor == 1)) {
+ required_scratch = xa_nn_conv2d_depthwise_getsize(
+ input_height, input_width, input_depth, filter_height, filter_width,
+ depth_multiplier, stride_width, stride_height, pad_width, pad_height,
+ output_height, output_width, PREC_ASYM8S, 0 /* NHWC */);
+ TF_LITE_ENSURE(context, required_scratch > 0);
+ }
+ TF_LITE_ENSURE_OK(
+ context, context->RequestScratchBufferInArena(
+ context, required_scratch, &data->scratch_tensor_index));
+#endif // defined(FUISON_F1)
+ return kTfLiteOk;
+}
+
+#if defined(FUSION_F1)
+TfLiteStatus EvalHifi4(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteDepthwiseConvParams& params,
+ const OpData& data, const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias, TfLiteEvalTensor* output) {
+ // If dilation is not required use the optimized NN Library kernel.
+ // Otherwise call the reference implementation.
+ if ((params.dilation_width_factor == 1) &&
+ (params.dilation_height_factor == 1)) {
+ const int stride_width = params.stride_width;
+ const int stride_height = params.stride_height;
+ const int pad_width = data.reference_op_data.padding.width;
+ const int pad_height = data.reference_op_data.padding.height;
+ const int depth_multiplier = params.depth_multiplier;
+ const int32_t output_activation_min =
+ data.reference_op_data.output_activation_min;
+ const int32_t output_activation_max =
+ data.reference_op_data.output_activation_max;
+ TFLITE_DCHECK_LE(output_activation_min, output_activation_max);
+
+ const RuntimeShape& input_shape = tflite::micro::GetTensorShape(input);
+ const RuntimeShape& filter_shape = tflite::micro::GetTensorShape(filter);
+ const RuntimeShape& output_shape = tflite::micro::GetTensorShape(output);
+ const RuntimeShape& bias_shape = tflite::micro::GetTensorShape(bias);
+ TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(filter_shape.DimensionsCount(), 4);
+ TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
+
+ const int batches = MatchingDim(input_shape, 0, output_shape, 0);
+ const int output_depth = MatchingDim(filter_shape, 3, output_shape, 3);
+ const int input_height = input_shape.Dims(1);
+ const int input_width = input_shape.Dims(2);
+ const int input_depth = input_shape.Dims(3);
+ const int filter_height = filter_shape.Dims(1);
+ const int filter_width = filter_shape.Dims(2);
+ const int output_height = output_shape.Dims(1);
+ const int output_width = output_shape.Dims(2);
+ TFLITE_DCHECK_EQ(output_depth, input_depth * depth_multiplier);
+ TFLITE_DCHECK_EQ(bias_shape.FlatSize(), output_depth);
+
+ const int8_t* input_data = tflite::micro::GetTensorData<int8_t>(input);
+ const int8_t* filter_data = tflite::micro::GetTensorData<int8_t>(filter);
+ const int32_t* bias_data = tflite::micro::GetTensorData<int32_t>(bias);
+ int8_t* output_data = tflite::micro::GetTensorData<int8_t>(output);
+
+ int32_t input_data_format = 0;
+ int32_t output_data_format = 0;
+
+ uint8_t* p_scratch = static_cast<uint8_t*>(
+ context->GetScratchBuffer(context, data.scratch_tensor_index));
+
+ for (int i = 0; i < batches; i++) {
+ TF_LITE_ENSURE_EQ(
+ context,
+ xa_nn_conv2d_depthwise_per_chan_sym8sxasym8s(
+ &output_data[i * output_height * output_width * output_depth],
+ filter_data,
+ &input_data[i * input_height * input_width * input_depth],
+ bias_data, input_height, input_width, input_depth, filter_height,
+ filter_width, depth_multiplier, stride_width, stride_height,
+ pad_width, pad_height, output_height, output_width,
+ -data.reference_op_data.input_zero_point,
+ data.reference_op_data.per_channel_output_multiplier,
+ data.reference_op_data.per_channel_output_shift,
+ data.reference_op_data.output_zero_point, input_data_format,
+ output_data_format, p_scratch),
+ 0);
+ }
+
+ int out_length = batches * output_height * output_width * output_depth;
+ TF_LITE_ENSURE_EQ(context,
+ xa_nn_vec_activation_min_max_8_8(
+ output_data, output_data, output_activation_min,
+ output_activation_max, out_length),
+ 0);
+
+ return kTfLiteOk;
+ }
+
+ reference_integer_ops::DepthwiseConvPerChannel(
+ DepthwiseConvParamsQuantized(params, data.reference_op_data),
+ data.reference_op_data.per_channel_output_multiplier,
+ data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+
+ return kTfLiteOk;
+}
+#endif // defined(FUSION_F1)
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto& params =
+ *(reinterpret_cast<TfLiteDepthwiseConvParams*>(node->builtin_data));
+ const auto& op_data = *(reinterpret_cast<OpData*>(node->user_data));
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kDepthwiseConvOutputTensor);
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kDepthwiseConvInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kDepthwiseConvWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3)
+ ? tflite::micro::GetEvalInput(context, node, kDepthwiseConvBiasTensor)
+ : nullptr;
+
+#if defined(HIFIMINI)
+ // Handle special case for streaming model.
+ int* input_dims = input->dims->data;
+ int* filter_dims = filter->dims->data;
+ if (input_dims[0] == 1 && input_dims[1] == 4 && input_dims[2] == 1 &&
+ input_dims[3] == 32 && filter_dims[0] == 1 && filter_dims[1] == 4 &&
+ filter_dims[2] == 1 && filter_dims[3] == 32) {
+ DepthwiseConv4x32MatchingInputAndFilterHifiMini(
+ -op_data.reference_op_data.input_zero_point,
+ op_data.reference_op_data.output_zero_point,
+ std::numeric_limits<int8_t>::min(), std::numeric_limits<int8_t>::max(),
+ op_data.reference_op_data.per_channel_output_multiplier,
+ op_data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+ return kTfLiteOk;
+ }
+#endif // defined(HIFIMINI)
+
+ switch (input->type) { // Already know in/out types are same.
+ case kTfLiteInt8: {
+#if defined(HIFIMINI)
+ EvalHifiMini(
+ DepthwiseConvParamsQuantized(params, op_data.reference_op_data),
+ op_data.reference_op_data.per_channel_output_multiplier,
+ op_data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#elif defined(FUSION_F1)
+ EvalHifi4(context, node, params, op_data, input, filter, bias, output);
+#else
+ reference_integer_ops::DepthwiseConvPerChannel(
+ DepthwiseConvParamsQuantized(params, op_data.reference_op_data),
+ op_data.reference_op_data.per_channel_output_multiplier,
+ op_data.reference_op_data.per_channel_output_shift,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#endif
+ break;
+ }
+ default:
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+} // namespace
+
+TfLiteRegistration Register_DEPTHWISE_CONV_2D() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h b/tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h
new file mode 100644
index 0000000..2f8a4bd
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h
@@ -0,0 +1,140 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_XTENSA_HIFIMINI_FIXEDPOINT_UTILS_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_XTENSA_HIFIMINI_FIXEDPOINT_UTILS_H_
+
+#include <algorithm>
+#include <cmath>
+#include <cstdint>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/micro/kernels/xtensa/xtensa.h"
+
+namespace tflite {
+
+#if defined(HIFIMINI)
+
+// INT24 MIN/MAX
+#define INT24_MIN -8388608
+#define INT24_MAX 8388607
+
+// Multiply 24bit value by a quantized multiplier (w/ shift) and returns a 48bit
+// aligned value in the QR register.
+inline ae_q56s MultiplyByQuantizedMultiplier(ae_p24x2s x_24x2,
+ int32_t quantized_multiplier,
+ int shift) {
+ // A value with 1 sign bit, N integer bits and M fractional bits is
+ // represented as QN+1.M since the sign bit is included in the integer bits.
+ //
+ // The Q notation in this method explains the values represented in each
+ // variable, along with an implicit division since the quantized_multiplier
+ // represents a value between 0.5 and 1.0 (Q1.X-1 where X is the bit precision
+ // of the type).
+ //
+ // Load the quantized multiplier into the PR register.
+ // NOTE: This method assumes that this param has been calculated for 24bit
+ // space - not 32bits.
+ // Q32.0 / 2^23 -> Q24.0 / 2^23 representing a Q1.23 multiplier.
+ ae_p24x2s quantized_multiplier_24x2 = AE_MOVPA24(quantized_multiplier);
+ // Shift right by 23 - 16 bits minus the specified shift. This is because we
+ // keep 16 fractional bits until the end to perform rounding. Subtract shift
+ // since shift is a left shift, and the 23-16 is a right shift.
+ int shift_amount = 7 - shift;
+
+ // Find the product of x and the quantized_multiplier.
+ // Q24.0 / 2^23 * Q24.0 = Q48.0 / 2^23
+ // Q48.0 / 2^23 >> 7 = Q48.0 / 2^16
+ ae_q56s result_56 = AE_MULP24S_HH(x_24x2, quantized_multiplier_24x2);
+
+ // Shift right if shift amount is positive, left if shift amount is negative.
+ if (shift_amount >= 0) {
+ result_56 = AE_Q56S_SRA(result_56, shift_amount);
+ } else {
+ result_56 = AE_Q56S_SLA(result_56, -shift_amount);
+ }
+
+ // Round off the bottom 16 bits.
+ // Q48.0 / 2^16 -> Q32.0 aligned to 48 bits.
+ result_56 = AE_ROUNDSQ32SYM(result_56);
+ return result_56;
+}
+
+// Multiply 32bit value by a quantized multiplier (w/ shift) and returns a 48bit
+// aligned value in the QR register.
+inline ae_q56s MultiplyByQuantizedMultiplierResult48Bit(
+ int32_t x, int32_t quantized_multiplier, int shift) {
+ // Convert x into a 2x24bit PR register file. If x is outside the numerical
+ // limits of a 24bit integer, the "fractional" or lower 8bits are discarded.
+ // If x is within the range of a 24 bit integer, the "signed" or upper 8bits
+ // are discarded.
+ ae_p24x2s x_24x2;
+ if (x > INT24_MIN && x < INT24_MAX) {
+ x_24x2 = AE_MOVPA24(x);
+ } else {
+ x_24x2 = static_cast<ae_p24s>(*reinterpret_cast<ae_p24f*>(&x));
+ shift += 8;
+ }
+
+ return MultiplyByQuantizedMultiplier(x_24x2, quantized_multiplier, shift);
+}
+
+// Calculate quantization params for 24bit runtimes.
+inline void QuantizeMultiplierForInt24(float multiplier,
+ int32_t* quantized_multiplier,
+ int* shift) {
+ if (multiplier == 0.0f) {
+ *quantized_multiplier = 0;
+ *shift = 0;
+ return;
+ }
+
+ // Special cased to 24bit:
+ const float q = std::frexp(multiplier, shift);
+ auto q_fixed = static_cast<int64_t>(std::round(q * (1 << 23)));
+
+ TFLITE_CHECK(q_fixed <= (1 << 23));
+ if (q_fixed == (1 << 23)) {
+ q_fixed /= 2;
+ ++*shift;
+ }
+ TFLITE_CHECK_LE(q_fixed, INT24_MAX);
+
+ // Ensure shift does not exceed 24-bit range.
+ TFLITE_CHECK_LE(*shift, 23);
+ if (*shift < -23) {
+ *shift = 0;
+ q_fixed = 0;
+ }
+ *quantized_multiplier = static_cast<int32_t>(q_fixed);
+}
+
+// Convert a floating point number to a Q representation for 24 bit integers.
+inline int CreateQConstantForInt24(int integer_bits, float f) {
+ const float min_bounds = static_cast<float>(INT24_MIN);
+ const float max_bounds = static_cast<float>(INT24_MAX);
+
+ int fractional_bits = 23 - integer_bits;
+ float raw = std::round(f * static_cast<float>(1 << fractional_bits));
+ raw = std::max(raw, min_bounds);
+ raw = std::min(raw, max_bounds);
+ return static_cast<int>(raw);
+}
+
+#endif // defined(HIFIMINI)
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_XTENSA_HIFIMINI_FIXEDPOINT_UTILS_H_
diff --git a/tensorflow/lite/micro/kernels/xtensa/fully_connected.cc b/tensorflow/lite/micro/kernels/xtensa/fully_connected.cc
new file mode 100644
index 0000000..c5904ce
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/fully_connected.cc
@@ -0,0 +1,283 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/fully_connected.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h"
+#include "tensorflow/lite/micro/kernels/xtensa/xtensa.h"
+
+namespace tflite {
+namespace {
+
+#if defined(HIFIMINI)
+void FullyConnected(const FullyConnectedParams& params,
+ const RuntimeShape& input_shape, const int8_t* input_data,
+ const RuntimeShape& filter_shape, const int8_t* filter_data,
+ const RuntimeShape& bias_shape, const int32_t* bias_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ // TODO(b/154032858): Investigate removing extra copies.
+ const int32_t input_offset = params.input_offset;
+ const int32_t filter_offset = params.weights_offset;
+ const int32_t output_offset = params.output_offset;
+ const int32_t output_multiplier = params.output_multiplier;
+ const int output_shift = params.output_shift;
+ const int32_t output_activation_min = params.quantized_activation_min;
+ const int32_t output_activation_max = params.quantized_activation_max;
+
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ const int batches = output_shape.Dims(0);
+ const int output_depth = output_shape.Dims(1);
+ const int accum_depth = filter_shape.Dims(filter_dim_count - 1);
+ const int accum_depth_iters = accum_depth / 2;
+
+ ae_p24x2s offsets_input_24x2 = AE_MOVPA24(input_offset);
+ ae_p24x2s offsets_filter_24x2 = AE_MOVPA24(filter_offset);
+ ae_q56s output_offset_56 = AE_CVTQ48A32S(output_offset);
+ ae_q56s output_activation_max_56 = AE_CVTQ48A32S(output_activation_max);
+ ae_q56s output_activation_min_56 = AE_CVTQ48A32S(output_activation_min);
+
+ for (int b = 0; b < batches; ++b) {
+ for (int out_c = 0; out_c < output_depth; ++out_c) {
+ // Load intrinsics advance pointer before loading so backoff data pointers
+ // by two before loading:
+ const int8_t* input_ptr = (input_data + b * accum_depth) - 2;
+ const int8_t* filter_ptr = (filter_data + out_c * accum_depth) - 2;
+
+ // Main accumulator register entry for loop:
+ ae_q56s sum_56 = AE_ZEROQ56();
+
+ for (int d = 0; d < accum_depth_iters; d++) {
+ // Load the signed 8bit values into the PR register:
+ ae_p24x2s input_24x2;
+ ae_p24x2s filter_24x2;
+ AE_LP8X2F_IU(input_24x2, input_ptr, 2);
+ AE_LP8X2F_IU(filter_24x2, filter_ptr, 2);
+
+ // Right shift the signed 8bit values to expand to signed 24bit values:
+ input_24x2 = AE_P24X2S_SRAI(input_24x2, 16);
+ filter_24x2 = AE_P24X2S_SRAI(filter_24x2, 16);
+
+ // Add offsets to data values (24 bit aligned):
+ input_24x2 = AE_P24S_ADDS_P24X2S(offsets_input_24x2, input_24x2);
+ filter_24x2 = AE_P24S_ADDS_P24X2S(offsets_filter_24x2, filter_24x2);
+
+ // 24x2 signed integer dual MAC w/ addition into 56bit accumulator (48
+ // bit aligned):
+ AE_MULAAP24S_HH_LL(sum_56, input_24x2, filter_24x2);
+ }
+
+ // Left shift to get back into 32bit space (right padded to 48bit):
+ sum_56 = AE_Q56S_SLAI(sum_56, 16);
+
+ // Add bias data if needed:
+ if (bias_data) {
+ ae_q56s bias_56 = AE_CVTQ48A32S(bias_data[out_c]);
+ sum_56 = AE_ADDQ56(sum_56, bias_56);
+ }
+
+ // Shift left into 24bit space and place back on PR register:
+ sum_56 = AE_Q56S_SLAI(sum_56, 8);
+ ae_p24x2s sum_24x2 = AE_TRUNCP24Q48(sum_56);
+
+ // MultiplyByQuantizedMultiplier returns a 48bit aligned value
+ sum_56 = MultiplyByQuantizedMultiplier(sum_24x2, output_multiplier,
+ output_shift);
+
+ // Add output_offset and cap min/max values:
+ sum_56 = AE_ADDQ56(sum_56, output_offset_56);
+ sum_56 = AE_MINQ56S(sum_56, output_activation_max_56);
+ sum_56 = AE_MAXQ56S(sum_56, output_activation_min_56);
+
+ output_data[out_c + output_depth * b] =
+ static_cast<int8_t>(AE_TRUNCA32Q48(sum_56));
+ }
+ }
+}
+#endif
+
+TfLiteStatus CalculateOpData(TfLiteContext* context,
+ TfLiteFusedActivation activation,
+ TfLiteType data_type, const TfLiteTensor* input,
+ const TfLiteTensor* filter,
+ const TfLiteTensor* bias, TfLiteTensor* output,
+ OpDataFullyConnected* data) {
+ double real_multiplier = 0.0;
+ TF_LITE_ENSURE_STATUS(GetQuantizedConvolutionMultipler(
+ context, input, filter, bias, output, &real_multiplier));
+#if defined(HIFIMINI)
+ QuantizeMultiplierForInt24(real_multiplier, &data->output_multiplier,
+ &data->output_shift);
+#else
+ QuantizeMultiplier(real_multiplier, &data->output_multiplier,
+ &data->output_shift);
+#endif
+ data->input_zero_point = input->params.zero_point;
+ data->filter_zero_point = filter->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ return CalculateActivationRangeQuantized(context, activation, output,
+ &data->output_activation_min,
+ &data->output_activation_max);
+}
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context,
+ sizeof(OpDataFullyConnected));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+
+ auto* data = static_cast<OpDataFullyConnected*>(node->user_data);
+ const auto* params =
+ reinterpret_cast<TfLiteFullyConnectedParams*>(node->builtin_data);
+
+ const TfLiteTensor* input =
+ GetInput(context, node, kFullyConnectedInputTensor);
+ const TfLiteTensor* filter =
+ GetInput(context, node, kFullyConnectedWeightsTensor);
+ const TfLiteTensor* bias =
+ GetOptionalInputTensor(context, node, kFullyConnectedBiasTensor);
+ TfLiteTensor* output = GetOutput(context, node, kFullyConnectedOutputTensor);
+
+ if (input->type != kTfLiteInt8) {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+
+ // Filter weights will always be symmetric quantized since we only support
+ // int8 quantization.
+ TFLITE_DCHECK(filter->params.zero_point == 0);
+
+ TFLITE_DCHECK(GetTensorShape(output).DimensionsCount() == 2);
+
+ return CalculateOpData(context, params->activation, input->type, input,
+ filter, bias, output, data);
+}
+
+TfLiteStatus EvalQuantizedInt8(TfLiteContext* context, TfLiteNode* node,
+ const OpDataFullyConnected& data,
+ const TfLiteEvalTensor* input,
+ const TfLiteEvalTensor* filter,
+ const TfLiteEvalTensor* bias,
+ TfLiteEvalTensor* output) {
+ // TODO(b/154032858): Investigate removing extra copies (i.e.
+ // data.ToQuantizedParams), and also passing by value.
+ //
+ // TODO(b/155656675): Consider passing OpDataFullyConnected by value
+ // once it is also passed to the FullyConnected function. Until it is copied
+ // to a local op_param variable, we do not get any latency improvements from
+ // passing by value.
+#if defined(HIFIMINI)
+ FullyConnected(FullyConnectedParamsQuantized(data),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#elif defined(FUSION_F1)
+ const RuntimeShape& output_shape = tflite::micro::GetTensorShape(output);
+ const int num_batches = output_shape.Dims(0);
+ const int output_depth = output_shape.Dims(1);
+
+ const RuntimeShape& filter_shape = tflite::micro::GetTensorShape(filter);
+ const int filter_dim_count = filter_shape.DimensionsCount();
+ const int accum_depth = filter_shape.Dims(filter_dim_count - 1);
+
+ FullyConnectedParams op_params = FullyConnectedParamsQuantized(data);
+ for (int b = 0; b < num_batches; ++b) {
+ TF_LITE_ENSURE_EQ(
+ context,
+ xa_nn_fully_connected_sym8sxasym8s_asym8s(
+ (tflite::micro::GetTensorData<int8_t>(output) + b * output_depth),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ (tflite::micro::GetTensorData<int8_t>(input) + b * accum_depth),
+ tflite::micro::GetTensorData<int32_t>(bias), accum_depth,
+ output_depth, op_params.input_offset, op_params.output_multiplier,
+ op_params.output_shift, op_params.output_offset),
+ 0);
+ }
+
+ int8_t* output_arr = tflite::micro::GetTensorData<int8_t>(output);
+ TF_LITE_ENSURE_EQ(context,
+ xa_nn_vec_activation_min_max_8_8(
+ output_arr, output_arr, data.output_activation_min,
+ data.output_activation_max, num_batches * output_depth),
+ 0);
+ return kTfLiteOk;
+#else
+ reference_integer_ops::FullyConnected(
+ FullyConnectedParamsQuantized(data), tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(filter),
+ tflite::micro::GetTensorData<int8_t>(filter),
+ tflite::micro::GetTensorShape(bias),
+ tflite::micro::GetTensorData<int32_t>(bias),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#endif
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const auto& data =
+ *(static_cast<const OpDataFullyConnected*>(node->user_data));
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedInputTensor);
+ const TfLiteEvalTensor* filter =
+ tflite::micro::GetEvalInput(context, node, kFullyConnectedWeightsTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 3) ? tflite::micro::GetEvalInput(
+ context, node, kFullyConnectedBiasTensor)
+ : nullptr;
+
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kFullyConnectedOutputTensor);
+
+ return EvalQuantizedInt8(context, node, data, input, filter, bias, output);
+}
+
+} // namespace
+
+TfLiteRegistration Register_FULLY_CONNECTED() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/xtensa/quantize.cc b/tensorflow/lite/micro/kernels/xtensa/quantize.cc
new file mode 100644
index 0000000..cbb5826
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/quantize.cc
@@ -0,0 +1,241 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/kernels/internal/reference/quantize.h"
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/requantize.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/quantize.h"
+#include "tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h"
+#include "tensorflow/lite/micro/kernels/xtensa/xtensa.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+
+namespace tflite {
+namespace {
+
+#if defined(HIFIMINI)
+struct OpData {
+ int32_t zero_point = 0;
+ int scale_multiplier = 0;
+
+ // Use 32-bit multiplier and scale for requantize version of this operator
+ // to preserve compatibility with reference op.
+ int32_t requantize_output_multiplier;
+ int requantize_output_shift;
+ int32_t input_zero_point = 0;
+};
+
+void AffineQuantize(int scale_multiplier, const int32_t zero_point,
+ const RuntimeShape& input_shape, const int16_t* input_data,
+ const RuntimeShape& output_shape, int8_t* output_data) {
+ const int flat_size = MatchingFlatSize(input_shape, output_shape);
+ ae_q56s min_val_56 = AE_CVTQ48A32S(INT16_MIN);
+ ae_q56s max_val_56 = AE_CVTQ48A32S(INT16_MAX);
+ ae_q56s zero_point_56 = AE_CVTQ48A32S(zero_point);
+
+ const ae_p16x2s* input_data_ptr = (const ae_p16x2s*)(input_data - 2);
+
+ ae_p24x2s scale_multiplier_24x2 = AE_MOVPA24(scale_multiplier);
+
+ int iters = flat_size / 2;
+ for (int i = 0; i < iters; i++) {
+ // Load two 16bit pairs into the 2x24bit register PR:
+ // Values need to be right shifted 8 bits to align from upper 16bits to a
+ // 24bit value:
+ ae_p24x2s inputs_24x2;
+ AE_LP16X2F_IU(inputs_24x2, input_data_ptr, 4);
+ inputs_24x2 = AE_P24X2S_SRAI(inputs_24x2, 8);
+
+ // Q0.23 * Q16.0 == Q16.23
+ {
+ ae_q56s sum_56 = AE_MULP24S_HH(scale_multiplier_24x2, inputs_24x2);
+
+ // Q16.23 -> Q16.0
+ // Shift right only 7 bits (23 - 16). This truncated shift aligns the
+ // 16bit value at the truncation line for 32bit in the QR register. The
+ // lower 16 bits will be used for rounding in AE_ROUNDSQ32SYM.
+ sum_56 = AE_Q56S_SRAI(sum_56, 7);
+
+ // Round and truncate 32 bits
+ sum_56 = AE_ROUNDSQ32SYM(sum_56);
+
+ // Add offset (zero_point_56 is already aligned at 32bits.
+ sum_56 = AE_ADDQ56(sum_56, zero_point_56);
+
+ // Saturate:
+ sum_56 = AE_MINQ56S(sum_56, max_val_56);
+ sum_56 = AE_MAXQ56S(sum_56, min_val_56);
+
+ output_data[i * 2] = static_cast<int16_t>(AE_TRUNCA32Q48(sum_56));
+ }
+ {
+ ae_q56s sum_56 = AE_MULP24S_LL(scale_multiplier_24x2, inputs_24x2);
+
+ // Q16.23 -> Q16.0
+ // Shift right only 7 bits (23 - 16). This truncated shift aligns the
+ // 16bit value at the truncation line for 32bit in the QR register. The
+ // lower 16 bits will be used for rounding in AE_ROUNDSQ32SYM.
+ sum_56 = AE_Q56S_SRAI(sum_56, 23 - 16);
+
+ // Round and truncate 32 bits
+ sum_56 = AE_ROUNDSQ32SYM(sum_56);
+
+ // Add offset (zero_point_56 is already aligned at 32bits.
+ sum_56 = AE_ADDQ56(sum_56, zero_point_56);
+
+ // Saturate:
+ sum_56 = AE_MINQ56S(sum_56, max_val_56);
+ sum_56 = AE_MAXQ56S(sum_56, min_val_56);
+
+ output_data[i * 2 + 1] = static_cast<int16_t>(AE_TRUNCA32Q48(sum_56));
+ }
+ }
+}
+
+#endif // defined(HIFIMINI)
+
+#if defined(HIFIMINI) || defined(FUSION_F1)
+TfLiteStatus EvalXtensa(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+#if defined(HIFIMINI)
+ auto* op_data = static_cast<OpData*>(node->user_data);
+#elif defined(FUSION_F1)
+ auto* op_data = static_cast<OpDataQuantizeReference*>(node->user_data);
+#endif
+
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+
+ if (output->type == kTfLiteInt8 && input->type == kTfLiteInt16) {
+#if defined(HIFIMINI)
+ AffineQuantize(op_data->scale_multiplier, op_data->zero_point,
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int16_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int8_t>(output));
+#elif defined(FUSION_F1)
+ int size = ElementCount(*input->dims);
+ TF_LITE_ENSURE_EQ(
+ context,
+ xa_nn_elm_quantize_asym16s_asym8s(
+ tflite::micro::GetTensorData<int8_t>(output),
+ tflite::micro::GetTensorData<int16_t>(input),
+ op_data->input_zero_point, op_data->quantization_params.zero_point,
+ op_data->requantize_output_shift,
+ op_data->requantize_output_multiplier, size),
+ 0);
+#else
+ static_assert(false, "Unsupported xtensa architecture.");
+#endif
+ } else if (output->type == kTfLiteInt32 &&
+ (input->type == kTfLiteInt16 || input->type == kTfLiteInt8)) {
+ int size = ElementCount(*input->dims);
+
+ // This ifdef is only needed because the hifimini code is not following the
+ // convention of the rest of the codebase. Ideally we would be using the
+ // same structs as much as possible and reduce the need for such ifdefs.
+#if defined(HIFIMINI)
+ int32_t zero_point = op_data->zero_point;
+#elif defined(FUSION_F1)
+ int32_t zero_point = op_data->quantization_params.zero_point;
+#endif
+ if (input->type == kTfLiteInt16) {
+ reference_ops::Requantize(tflite::micro::GetTensorData<int16_t>(input),
+ size, op_data->requantize_output_multiplier,
+ op_data->requantize_output_shift,
+ op_data->input_zero_point, zero_point,
+ tflite::micro::GetTensorData<int32_t>(output));
+ } else {
+ reference_ops::Requantize(tflite::micro::GetTensorData<int8_t>(input),
+ size, op_data->requantize_output_multiplier,
+ op_data->requantize_output_shift,
+ op_data->input_zero_point, zero_point,
+ tflite::micro::GetTensorData<int32_t>(output));
+ }
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Input %s, output %s not supported.",
+ TfLiteTypeGetName(input->type),
+ TfLiteTypeGetName(output->type));
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+#endif // defined(HIFIMINI) || defined(FUSION_F1)
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+#if defined(HIFIMINI)
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+#else
+ return context->AllocatePersistentBuffer(context,
+ sizeof(OpDataQuantizeReference));
+#endif
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->user_data != nullptr);
+
+ TfLiteTensor* output = GetOutput(context, node, 0);
+ const TfLiteTensor* input = GetInput(context, node, 0);
+
+#if defined(HIFIMINI)
+ auto* op_data = static_cast<OpData*>(node->user_data);
+ // TODO(b/155682734): Fix dangerous input/output scale ratio assumptions.
+ op_data->scale_multiplier =
+ CreateQConstantForInt24(0, input->params.scale / output->params.scale);
+ op_data->zero_point = output->params.zero_point;
+#else
+ auto* op_data = static_cast<OpDataQuantizeReference*>(node->user_data);
+ op_data->quantization_params.zero_point = output->params.zero_point;
+ op_data->quantization_params.scale =
+ static_cast<double>(output->params.scale);
+#endif
+
+ op_data->input_zero_point = input->params.zero_point;
+
+ double effective_scale = static_cast<double>(input->params.scale) /
+ static_cast<double>(output->params.scale);
+ QuantizeMultiplier(effective_scale, &op_data->requantize_output_multiplier,
+ &op_data->requantize_output_shift);
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+#if defined(HIFIMINI) || defined(FUSION_F1)
+ return EvalXtensa(context, node);
+#else
+ return EvalQuantizeReference(context, node);
+#endif
+}
+
+} // namespace
+
+TfLiteRegistration Register_QUANTIZE() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/xtensa/softmax.cc b/tensorflow/lite/micro/kernels/xtensa/softmax.cc
new file mode 100644
index 0000000..aeb940c
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/softmax.cc
@@ -0,0 +1,302 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/softmax.h"
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/reference/softmax.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/xtensa/xtensa.h"
+
+namespace tflite {
+namespace {
+
+#if defined(HIFIMINI)
+struct OpData {
+ uint16_t* exp_lut;
+};
+#elif defined(FUSION_F1)
+struct OpData {
+ SoftmaxParams params;
+ int scratch_tensor_index;
+};
+#endif
+
+#if defined(HIFIMINI)
+// Number of unique int8_t and int16_t values. Used in exponent lookup table
+// computation.
+constexpr int kInt8Range =
+ std::numeric_limits<int8_t>::max() - std::numeric_limits<int8_t>::min() + 1;
+constexpr int kInt16Range = std::numeric_limits<int16_t>::max() -
+ std::numeric_limits<int16_t>::min() + 1;
+// Each 16-bit precalculated exponent is expressed as a Q0.16 fixedpoint
+// value. We special-case e^0 since 1.0 requires 1 integer bit to
+// express.
+constexpr int kExpFractionalBits = 16;
+// e^0 expressed as Q1.15 exceeds the int16_t range, so it must be handled
+// specially.
+constexpr int kMaxExponentValue = (1 << kExpFractionalBits);
+
+// Quantized softmax with int8_t input and int16_t output.
+// Passing OpData by value does not have much savings in this op, but following
+// that as a best practice, at least for the xtensa kernels. See b/155656675 for
+// more details.
+TfLiteStatus SoftmaxHifimini(OpData op_data, const RuntimeShape& input_shape,
+ const int8_t* input_data,
+ const RuntimeShape& output_shape,
+ int16_t* output_data) {
+ // The last dimension is depth. Outer size is the total input size
+ // divided by depth.
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+
+ for (int i = 0; i < outer_size; ++i) {
+ int8_t max_in_row = std::numeric_limits<int8_t>::min();
+ for (int c = 0; c < depth; ++c) {
+ max_in_row = std::max(max_in_row, input_data[i * depth + c]);
+ }
+
+ uint32_t sum_of_exps = 0;
+ for (int c = 0; c < depth; ++c) {
+ TFLITE_DCHECK(max_in_row >= input_data[i * depth + c]);
+ uint8_t input_diff = max_in_row - input_data[i * depth + c];
+
+ sum_of_exps +=
+ input_diff == 0 ? kMaxExponentValue : op_data.exp_lut[input_diff];
+ }
+
+ // Ensure we cannot overflow the full_range_output value. We need to
+ // guarantee that kInt16Range * max(input_data) / sum_of_exps < kInt16Range.
+ TFLITE_DCHECK(sum_of_exps >= kMaxExponentValue);
+
+ for (int c = 0; c < depth; ++c) {
+ uint8_t input_diff = max_in_row - input_data[i * depth + c];
+ // Special case for diff == 0
+ uint32_t unscaled_output =
+ input_diff == 0 ? kMaxExponentValue : op_data.exp_lut[input_diff];
+ int64_t scaled_output = static_cast<int64_t>(unscaled_output) *
+ static_cast<int64_t>(kInt16Range);
+ int32_t full_range_output =
+ scaled_output / sum_of_exps + std::numeric_limits<int16_t>::min();
+ // Round up if remainder exceeds half of the divider value.
+ uint32_t remainder = scaled_output % sum_of_exps;
+ if (remainder * 2 >= sum_of_exps) {
+ full_range_output++;
+ }
+ output_data[i * depth + c] = static_cast<int16_t>(std::max(
+ std::min(full_range_output,
+ static_cast<int32_t>(std::numeric_limits<int16_t>::max())),
+ static_cast<int32_t>(std::numeric_limits<int16_t>::min())));
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus CalculateSoftmaxOpDataHifimini(TfLiteContext* context,
+ const TfLiteTensor* input,
+ TfLiteTensor* output,
+ const TfLiteSoftmaxParams* params,
+ OpData* op_data) {
+ if (input->type == kTfLiteUInt8 || input->type == kTfLiteInt8) {
+ if (input->type == kTfLiteUInt8) {
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point, 0);
+ } else {
+ if (output->type == kTfLiteInt16) {
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point,
+ std::numeric_limits<int16_t>::min());
+ // NOTE: Current int16_t softmax output does not require symmetric
+ // scaling
+ // - so no need to verify scale here.
+ } else {
+ TF_LITE_ENSURE_EQ(context, output->params.zero_point,
+ std::numeric_limits<int8_t>::min());
+ TF_LITE_ENSURE(context, output->params.scale == 1.f / 256);
+ }
+ }
+
+ // Precompute e^(-x * input_scale * beta) for every possible int8_t input.
+ // This computation is used for every iteration of Softmax. We must compute
+ // using pre-scaled inputs to avoid introducing additional error, while
+ // restricting our input range to the int8_t range. This is valid since beta
+ // and input scale are constant for a given op in the graph. Skip index 0
+ // since that is a special case which requires 1 integer bit instead of 0.
+ for (int i = 1; i <= kInt8Range; i++) {
+ float scaled_input = i * input->params.scale;
+ float exp_value =
+ std::exp((-scaled_input) * static_cast<float>(params->beta));
+
+ float exponent_scaled =
+ std::round(exp_value * static_cast<float>(1 << kExpFractionalBits));
+ op_data->exp_lut[i] = static_cast<uint16_t>(exponent_scaled);
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus PrepareHifimini(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = static_cast<TfLiteSoftmaxParams*>(node->builtin_data);
+
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ TfLiteTensor* output = GetOutput(context, node, 0);
+ TF_LITE_ENSURE(context, NumDimensions(input) >= 1);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* op_data = static_cast<OpData*>(node->user_data);
+
+ // Allocate an array to precompute exponents over all int8_t inputs, applying
+ // the scale and beta before calculating exp. It is mandatory to apply beta
+ // and scale here, since each softmax op may have different beta and scale
+ // values. Beta and scale will remain constant for a given softmax op.
+ op_data->exp_lut = static_cast<uint16_t*>(context->AllocatePersistentBuffer(
+ context, (kInt8Range + 1) * sizeof(uint16_t)));
+ TF_LITE_ENSURE(context, op_data->exp_lut != nullptr);
+
+ TF_LITE_ENSURE_STATUS(
+ CalculateSoftmaxOpDataHifimini(context, input, output, params, op_data));
+
+ return kTfLiteOk;
+}
+#endif // defined(HIFIMINI)
+
+#if defined(FUSION_F1)
+TfLiteStatus PrepareHifi4(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_OK(context, SoftmaxPrepare(context, node));
+
+ // Calculate scratch memory requirements and request scratch buffer
+ const TfLiteTensor* input = GetInput(context, node, 0);
+ const TfLiteTensor* output = GetOutput(context, node, 0);
+
+ const RuntimeShape& input_shape = GetTensorShape(input);
+ const RuntimeShape& output_shape = GetTensorShape(output);
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+
+ if (input->type == kTfLiteInt8) {
+ int required_scratch =
+ get_softmax_scratch_size(PREC_ASYM8S, PREC_ASYM8S, depth);
+ TF_LITE_ENSURE(context, required_scratch > 0);
+
+ auto* data = static_cast<OpData*>(node->user_data);
+ TF_LITE_ENSURE_OK(
+ context, context->RequestScratchBufferInArena(
+ context, required_scratch, &(data->scratch_tensor_index)));
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus EvalHifi4(const OpData* op_data, const TfLiteEvalTensor* input,
+ TfLiteEvalTensor* output, TfLiteContext* context) {
+ const RuntimeShape& input_shape = tflite::micro::GetTensorShape(input);
+ const int8_t* input_data = tflite::micro::GetTensorData<int8_t>(input);
+ const RuntimeShape& output_shape = tflite::micro::GetTensorShape(output);
+ int16_t* output_data = tflite::micro::GetTensorData<int16_t>(output);
+ const int trailing_dim = input_shape.DimensionsCount() - 1;
+ const int outer_size =
+ MatchingFlatSizeSkipDim(input_shape, trailing_dim, output_shape);
+ const int depth =
+ MatchingDim(input_shape, trailing_dim, output_shape, trailing_dim);
+
+ void* p_scratch = static_cast<void*>(
+ context->GetScratchBuffer(context, op_data->scratch_tensor_index));
+
+ for (int i = 0; i < outer_size; ++i) {
+ int err = xa_nn_vec_softmax_asym8s_16(
+ &output_data[i * depth], &input_data[i * depth],
+ op_data->params.diff_min, op_data->params.input_left_shift,
+ op_data->params.input_multiplier, depth, p_scratch);
+ TF_LITE_ENSURE(context, err == 0);
+ }
+ return kTfLiteOk;
+}
+
+#endif // defined(FUSION_F1)
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+#if defined(HIFIMINI) || defined(FUSION_F1)
+ TFLITE_DCHECK(context->AllocatePersistentBuffer != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+#else
+ return SoftmaxInit(context, buffer, length);
+#endif
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+#if defined(HIFIMINI)
+ return PrepareHifimini(context, node);
+#elif defined(FUSION_F1)
+ return PrepareHifi4(context, node);
+#else
+ return SoftmaxPrepare(context, node);
+#endif
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input = tflite::micro::GetEvalInput(context, node, 0);
+ TfLiteEvalTensor* output = tflite::micro::GetEvalOutput(context, node, 0);
+ TFLITE_DCHECK(node->user_data != nullptr);
+
+ if (input->type == kTfLiteInt8 && output->type == kTfLiteInt16) {
+#if defined(HIFIMINI)
+ return SoftmaxHifimini(*static_cast<OpData*>(node->user_data),
+ tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+#elif defined(FUSION_F1)
+ return EvalHifi4(static_cast<OpData*>(node->user_data), input, output,
+ context);
+#else
+ SoftmaxParams op_data = *static_cast<SoftmaxParams*>(node->user_data);
+ tflite::reference_ops::Softmax(
+ op_data, tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorData<int8_t>(input),
+ tflite::micro::GetTensorShape(output),
+ tflite::micro::GetTensorData<int16_t>(output));
+ return kTfLiteOk;
+#endif
+ } else {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+}
+
+} // namespace
+
+TfLiteRegistration Register_SOFTMAX() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/xtensa/svdf.cc b/tensorflow/lite/micro/kernels/xtensa/svdf.cc
new file mode 100644
index 0000000..6aea649
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/svdf.cc
@@ -0,0 +1,499 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/kernels/svdf.h"
+
+#include <cmath>
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/common.h"
+#include "tensorflow/lite/kernels/internal/quantization_util.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/kernels/activation_utils.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/xtensa/fixedpoint_utils.h"
+#include "tensorflow/lite/micro/kernels/xtensa/xtensa.h"
+
+namespace tflite {
+namespace {
+
+// Input tensors.
+constexpr int kInputTensor = 0;
+constexpr int kWeightsFeatureTensor = 1;
+constexpr int kWeightsTimeTensor = 2;
+constexpr int kBiasTensor = 3;
+// This is a variable tensor, and will be modified by this op.
+constexpr int kInputActivationStateTensor = 4;
+
+// Output tensor.
+constexpr int kOutputTensor = 0;
+
+#if defined(HIFIMINI)
+/**
+ * This version of SVDF is specific to TFLite Micro. It contains only a full
+ * integer receipe with optimizations for the Xtensa HiFiMini platform.
+ *
+ * Note: passing OpData by value might seem like an oversight but it helps
+ * reduce the latency. See b/155656675 for more details.
+ */
+void EvalIntegerSvdfHifimini(TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input_tensor,
+ const TfLiteEvalTensor* weights_feature_tensor,
+ const TfLiteEvalTensor* weights_time_tensor,
+ const TfLiteEvalTensor* bias_tensor,
+ const TfLiteSVDFParams* params,
+ TfLiteEvalTensor* activation_state_tensor,
+ TfLiteEvalTensor* output_tensor, OpData data) {
+ const int n_rank = params->rank;
+ const int n_batch = input_tensor->dims->data[0];
+ const int n_input = input_tensor->dims->data[1];
+ const int n_filter = weights_feature_tensor->dims->data[0];
+ const int n_unit = n_filter / n_rank;
+ const int n_memory = weights_time_tensor->dims->data[1];
+
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer != nullptr);
+
+ int32_t* scratch_tensor = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, data.scratch_tensor_index));
+ TFLITE_DCHECK(scratch_tensor != nullptr);
+ int32_t* scratch_output_tensor = static_cast<int32_t*>(
+ context->GetScratchBuffer(context, data.scratch_output_tensor_index));
+ TFLITE_DCHECK(scratch_output_tensor != nullptr);
+
+ // Shift states.
+ int16_t* const state_ptr =
+ tflite::micro::GetTensorData<int16_t>(activation_state_tensor);
+
+ // Left shift the activation_state.
+ {
+ int16_t* new_state_start = state_ptr;
+ const int16_t* old_state_start = state_ptr + 1;
+ const int16_t* old_state_end = state_ptr + n_batch * n_filter * n_memory;
+ while (old_state_start != old_state_end) {
+ *new_state_start++ = *old_state_start++;
+ }
+ }
+
+ // Note: no need to clear the latest activation, matmul is not accumulative.
+
+ // Feature matmul.
+ {
+ const int8_t* input = tflite::micro::GetTensorData<int8_t>(input_tensor);
+ const int8_t* weight_feature =
+ tflite::micro::GetTensorData<int8_t>(weights_feature_tensor);
+ int16_t* result_in_batch = state_ptr + (n_memory - 1);
+
+ ae_q56s output_int16_max_56 = AE_CVTQ48A32S(INT16_MAX);
+ ae_q56s output_int16_min_56 = AE_CVTQ48A32S(INT16_MIN);
+ ae_p24x2s input_zp_24x2 = AE_MOVPA24(data.input_zero_point);
+
+ for (int b = 0; b < n_batch; b++) {
+ const int8_t* weight_feature_ptr = weight_feature - 2;
+
+ for (int r = 0; r < n_filter; r++) {
+ ae_q56s dot_prod_56 = AE_ZEROQ56();
+
+ const int8_t* input_batch_ptr = input + b * n_input;
+ const int8_t* offset_input_batch_ptr = input_batch_ptr - 2;
+
+ int num_iters = n_input / 2;
+ for (int c = 0; c < num_iters; c++) {
+ // Load 2 sets of values:
+ ae_p24x2s weight_feature_ptr_24x2;
+ ae_p24x2s input_batch_ptr_24x2;
+ AE_LP8X2F_IU(weight_feature_ptr_24x2, weight_feature_ptr, 2);
+ AE_LP8X2F_IU(input_batch_ptr_24x2, offset_input_batch_ptr, 2);
+
+ // Right shift the signed 8bit values to expand to signed 24bit
+ // values:
+ weight_feature_ptr_24x2 = AE_P24X2S_SRAI(weight_feature_ptr_24x2, 16);
+ input_batch_ptr_24x2 = AE_P24X2S_SRAI(input_batch_ptr_24x2, 16);
+
+ // First subtract input_zp from input_batch_ptr_24x2:
+ input_batch_ptr_24x2 =
+ AE_SUBSP24S(input_batch_ptr_24x2, input_zp_24x2);
+
+ // Multiply accum:
+ AE_MULAAP24S_HH_LL(dot_prod_56, weight_feature_ptr_24x2,
+ input_batch_ptr_24x2);
+ }
+
+ // Left shift 48bit value into 24bit space and place on the PR register:
+ dot_prod_56 = AE_Q56S_SLAI(dot_prod_56, 24);
+ ae_p24x2s dot_prod_24x2 = AE_TRUNCP24Q48(dot_prod_56);
+
+ dot_prod_56 = MultiplyByQuantizedMultiplier(
+ dot_prod_24x2, data.effective_scale_1_a, data.effective_scale_1_b);
+
+ // Cap min/max and convert to int32_t:
+ dot_prod_56 = AE_MAXQ56S(dot_prod_56, output_int16_min_56);
+ dot_prod_56 = AE_MINQ56S(dot_prod_56, output_int16_max_56);
+ // Truncate immediately since the QR register is already 32 bit aligned:
+ // This assumes state is symmetrically quantized. Otherwise last bit of
+ // state should be initialized to its zero point and accumulate the
+ // dot_prod.
+ // Equivalent as the following:
+ // result_in_batch = zero point, which happens to be zero.
+ // result_in_batch += dot_prod_56.
+ *result_in_batch = AE_TRUNCA32Q48(dot_prod_56);
+ result_in_batch += n_memory;
+ }
+ }
+ }
+
+ // Time.
+ {
+ for (int b = 0; b < n_batch; ++b) {
+ int32_t* scratch_ptr_batch = scratch_tensor + b * n_filter;
+
+ // Perform batched vector dot product:
+ const int16_t* vector1_ptr =
+ tflite::micro::GetTensorData<int16_t>(weights_time_tensor);
+ const int16_t* vector2_ptr = state_ptr + b * n_memory * n_filter;
+
+ const ae_p16x2s* offset_vector1 =
+ reinterpret_cast<const ae_p16x2s*>(vector1_ptr - 2);
+ const ae_p16x2s* offset_vector2 =
+ reinterpret_cast<const ae_p16x2s*>(vector2_ptr - 2);
+
+ for (int i = 0; i < n_filter; i++) {
+ *scratch_ptr_batch = 0;
+
+ ae_q56s sum_56 = AE_ZEROQ56();
+ int num_iters = n_memory / 2;
+ for (int j = 0; j < num_iters; j++) {
+ ae_p24x2s vector1_24x2;
+ ae_p24x2s vector2_24x2;
+ AE_LP16X2F_IU(vector1_24x2, offset_vector1, 4);
+ AE_LP16X2F_IU(vector2_24x2, offset_vector2, 4);
+ AE_MULAAP24S_HH_LL(sum_56, vector1_24x2, vector2_24x2);
+ }
+ // Truncate directly since values are already 32bit aligned:
+ *scratch_ptr_batch = AE_TRUNCA32Q48(sum_56);
+ scratch_ptr_batch++;
+ }
+ }
+ }
+
+ // Reduce, add bias, rescale, activation.
+ {
+ // Add bias.
+ if (bias_tensor) {
+ // Vector batch assign:
+ const int32_t* bias_data =
+ tflite::micro::GetTensorData<int32_t>(bias_tensor);
+ for (int i = 0; i < n_batch; ++i) {
+ int32_t* output_ptr = scratch_output_tensor + i * n_unit;
+ const int32_t* bias_ptr = bias_data;
+ for (int j = 0; j < n_unit; ++j) {
+ *output_ptr++ = *bias_ptr++;
+ }
+ }
+ } else {
+ int32_t* output_ptr = scratch_output_tensor;
+ for (int i = 0; i < n_batch * n_unit; ++i) {
+ *output_ptr++ = 0;
+ }
+ }
+
+ // Reduce.
+ for (int b = 0; b < n_batch; ++b) {
+ int32_t* output_temp_ptr = scratch_output_tensor + b * n_unit;
+ int32_t* scratch_ptr_batch = scratch_tensor + b * n_filter;
+
+ // Reduction sum vector
+ for (int i = 0; i < n_unit; ++i) {
+ for (int j = 0; j < n_rank; ++j) {
+ output_temp_ptr[i] += *scratch_ptr_batch++;
+ }
+ }
+ }
+
+ // Rescale.
+ ae_q56s output_int8_max_56 = AE_CVTQ48A32S(INT8_MAX);
+ ae_q56s output_int8_min_56 = AE_CVTQ48A32S(INT8_MIN);
+ ae_q56s output_zp_56 = AE_CVTQ48A32S(data.output_zero_point);
+ for (int i = 0; i < n_batch * n_unit; ++i) {
+ ae_q56s x_56 = MultiplyByQuantizedMultiplierResult48Bit(
+ scratch_output_tensor[i], data.effective_scale_2_a,
+ data.effective_scale_2_b);
+ // Add output adjustment:
+ x_56 = AE_ADDQ56(x_56, output_zp_56);
+ // Cap min/max and convert to int32_t (already aligned to 32bit):
+ x_56 = AE_MAXQ56S(x_56, output_int8_min_56);
+ x_56 = AE_MINQ56S(x_56, output_int8_max_56);
+ tflite::micro::GetTensorData<int8_t>(output_tensor)[i] =
+ static_cast<int8_t>(AE_TRUNCA32Q48(x_56));
+ }
+ }
+}
+
+#elif defined(FUSION_F1)
+
+TfLiteStatus EvalIntegerSvdfHifi4(
+ TfLiteContext* context, TfLiteNode* node,
+ const TfLiteEvalTensor* input_tensor,
+ const TfLiteEvalTensor* weights_feature_tensor,
+ const TfLiteEvalTensor* weights_time_tensor,
+ const TfLiteEvalTensor* bias_tensor, const TfLiteSVDFParams* params,
+ TfLiteEvalTensor* activation_state_tensor, TfLiteEvalTensor* output_tensor,
+ const OpData& data) {
+ const int n_rank = params->rank;
+ const int n_batch = input_tensor->dims->data[0];
+ const int n_input = input_tensor->dims->data[1];
+ const int n_filter = weights_feature_tensor->dims->data[0];
+ const int n_unit = n_filter / n_rank;
+ const int n_memory = weights_time_tensor->dims->data[1];
+
+ TFLITE_DCHECK(context != nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer != nullptr);
+
+ // Shift states.
+ int16_t* const state_ptr =
+ tflite::micro::GetTensorData<int16_t>(activation_state_tensor);
+
+ // Left shift the activation_state.
+ int num_bytes = sizeof(*state_ptr) * (n_batch * n_filter * n_memory - 1);
+ xa_nn_memmove_16(state_ptr, state_ptr + 1, num_bytes);
+
+ // Note: no need to clear the latest activation, matmul is not accumulative.
+
+ // Feature matmul.
+ const int8_t* input = tflite::micro::GetTensorData<int8_t>(input_tensor);
+ const int8_t* weight_feature =
+ tflite::micro::GetTensorData<int8_t>(weights_feature_tensor);
+ int16_t* result_in_batch = state_ptr + (n_memory - 1);
+
+ for (int b = 0; b < n_batch; b++) {
+ TF_LITE_ENSURE_EQ(context,
+ xa_nn_matXvec_out_stride_sym8sxasym8s_16(
+ &result_in_batch[b * n_filter * n_memory],
+ weight_feature, &input[b * n_input], NULL, n_filter,
+ n_input, n_input, n_memory, -data.input_zero_point,
+ (data.effective_scale_1_a), data.effective_scale_1_b),
+ 0);
+ }
+
+ // Time weights dot product + activation
+ for (int b = 0; b < n_batch; ++b) {
+ const int16_t* vector1_ptr =
+ tflite::micro::GetTensorData<int16_t>(weights_time_tensor);
+ const int16_t* vector2_ptr =
+ tflite::micro::GetTensorData<int16_t>(activation_state_tensor) +
+ b * n_memory * n_filter;
+ const int32_t* bias_ptr =
+ tflite::micro::GetTensorData<int32_t>(bias_tensor);
+ int8_t* output_ptr =
+ tflite::micro::GetTensorData<int8_t>(output_tensor) + b * n_unit;
+
+ TF_LITE_ENSURE_EQ(
+ context,
+ xa_nn_dot_prod_16x16_asym8s(
+ output_ptr, vector1_ptr, vector2_ptr, bias_ptr, n_memory * n_rank,
+ (data.effective_scale_2_a), data.effective_scale_2_b,
+ data.output_zero_point, n_unit),
+ 0);
+ }
+ return kTfLiteOk;
+}
+#endif // defined(FUSION_F1) || defined(HIFIMINI)
+
+void* Init(TfLiteContext* context, const char* buffer, size_t length) {
+ TFLITE_DCHECK(context != nullptr);
+ return context->AllocatePersistentBuffer(context, sizeof(OpData));
+}
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TFLITE_DCHECK(node->builtin_data != nullptr);
+ const auto* params = static_cast<const TfLiteSVDFParams*>(node->builtin_data);
+
+ // Validate Tensor Inputs (dtype depends on quantization):
+ // [0] = Input, {2, batch_size, input_size}
+ // [1] = Weights Feature, {2, num_filters, input_size}
+ // [2] = Weights Time, {2, num_filters, memory_size}
+ // [3] = Bias (optional), {1, num_units}
+ // [4] = Activation State (variable),
+ // {2, batch_size, memory_size * num_filters}
+ const TfLiteTensor* input = GetInput(context, node, kInputTensor);
+ const TfLiteTensor* weights_feature =
+ GetInput(context, node, kWeightsFeatureTensor);
+ const TfLiteTensor* weights_time =
+ GetInput(context, node, kWeightsTimeTensor);
+ const TfLiteTensor* bias = GetOptionalInputTensor(context, node, kBiasTensor);
+ const TfLiteTensor* activation_state =
+ GetInput(context, node, kInputActivationStateTensor);
+
+ // Define input constants based on input tensor definition above:
+ const int rank = params->rank;
+ const int input_size = input->dims->data[1];
+ const int batch_size = input->dims->data[0];
+
+#if defined(HIFIMINI)
+ // Ensure the input size is a multiple of two. This is necessary since
+ // optimized kernels access the memory in chunks of two, and all accesses
+ // must be aligned to 16 bits.
+ // TODO(b/153202598): Remove when padding is allowed in TFLite tensors.
+ TF_LITE_ENSURE_EQ(context, input_size % 2, 0);
+#endif // defined(HIFIMINI)
+
+ const int num_filters = weights_feature->dims->data[0];
+ TF_LITE_ENSURE_EQ(context, num_filters % rank, 0);
+ const int num_units = num_filters / rank;
+ const int memory_size = weights_time->dims->data[1];
+
+ if (input->type != kTfLiteInt8) {
+ TF_LITE_KERNEL_LOG(context, "Type %s (%d) not supported.",
+ TfLiteTypeGetName(input->type), input->type);
+ return kTfLiteError;
+ }
+
+ // Validate Input Tensor:
+ TF_LITE_ENSURE(context, input->type == kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(input), 2);
+
+ // Validate Tensor Output:
+ // [0] = float/int8_t, {2, batch_size, num_units}
+ TF_LITE_ENSURE_EQ(context, node->outputs->size, 1);
+ TfLiteTensor* output = GetOutput(context, node, kOutputTensor);
+ TF_LITE_ENSURE_EQ(context, NumDimensions(output), 2);
+ TF_LITE_ENSURE_EQ(context, output->dims->data[0], batch_size);
+ TF_LITE_ENSURE_EQ(context, output->dims->data[1], num_units);
+
+ // Validate Weights Feature Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(weights_feature), 2);
+ TF_LITE_ENSURE_EQ(context, weights_feature->dims->data[1], input_size);
+
+ // Validate Weights Time Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(weights_time), 2);
+ TF_LITE_ENSURE_EQ(context, weights_time->dims->data[0], num_filters);
+ TF_LITE_ENSURE_EQ(context, weights_time->dims->data[1], memory_size);
+
+ // Validate Optional Bias Input Tensor:
+ if (bias != nullptr) {
+ TF_LITE_ENSURE_EQ(context, bias->dims->data[0], num_units);
+ TF_LITE_ENSURE_EQ(context, bias->type, kTfLiteInt32);
+ }
+
+ // Validate Activation State Input Tensor:
+ TF_LITE_ENSURE_EQ(context, NumDimensions(activation_state), 2);
+ TF_LITE_ENSURE_EQ(context, activation_state->dims->data[0], batch_size);
+ TF_LITE_ENSURE_EQ(context, activation_state->dims->data[1],
+ memory_size * num_filters);
+
+ TF_LITE_ENSURE_EQ(context, node->inputs->size, 5);
+ TF_LITE_ENSURE_EQ(context, weights_feature->type, kTfLiteInt8);
+ TF_LITE_ENSURE_EQ(context, weights_time->type, kTfLiteInt16);
+ TF_LITE_ENSURE_EQ(context, activation_state->type, kTfLiteInt16);
+
+ // Validate output tensor:
+ TF_LITE_ENSURE_TYPES_EQ(context, output->type, kTfLiteInt8);
+
+ const double effective_scale_1 =
+ static_cast<double>(input->params.scale * weights_feature->params.scale /
+ activation_state->params.scale);
+ const double effective_scale_2 =
+ static_cast<double>(activation_state->params.scale *
+ weights_time->params.scale / output->params.scale);
+
+ TF_LITE_ENSURE_NEAR(context, static_cast<double>(bias->params.scale),
+ static_cast<double>(activation_state->params.scale *
+ weights_time->params.scale),
+ 1e-5);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ OpData* data = static_cast<OpData*>(node->user_data);
+
+#if defined(HIFIMINI)
+ QuantizeMultiplierForInt24(effective_scale_1, &data->effective_scale_1_a,
+ &data->effective_scale_1_b);
+ QuantizeMultiplierForInt24(effective_scale_2, &data->effective_scale_2_a,
+ &data->effective_scale_2_b);
+#else
+ QuantizeMultiplier(effective_scale_1, &(data->effective_scale_1_a),
+ &(data->effective_scale_1_b));
+ QuantizeMultiplier(effective_scale_2, &(data->effective_scale_2_a),
+ &(data->effective_scale_2_b));
+#endif
+
+ data->input_zero_point = input->params.zero_point;
+ data->output_zero_point = output->params.zero_point;
+
+ const TfLiteStatus scratch_status = context->RequestScratchBufferInArena(
+ context, batch_size * num_filters * sizeof(int32_t),
+ &(data->scratch_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_status);
+ const TfLiteStatus scratch_output_status =
+ context->RequestScratchBufferInArena(
+ context, batch_size * num_units * sizeof(int32_t),
+ &(data->scratch_output_tensor_index));
+ TF_LITE_ENSURE_OK(context, scratch_output_status);
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ auto* params = static_cast<TfLiteSVDFParams*>(node->builtin_data);
+
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ const TfLiteEvalTensor* weights_feature =
+ tflite::micro::GetEvalInput(context, node, kWeightsFeatureTensor);
+ const TfLiteEvalTensor* weights_time =
+ tflite::micro::GetEvalInput(context, node, kWeightsTimeTensor);
+ const TfLiteEvalTensor* bias =
+ (NumInputs(node) == 5)
+ ? tflite::micro::GetEvalInput(context, node, kBiasTensor)
+ : nullptr;
+ TfLiteEvalTensor* activation_state = tflite::micro::GetMutableEvalInput(
+ context, node, kInputActivationStateTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+
+ TFLITE_DCHECK(node->user_data != nullptr);
+ const OpData& data = *(static_cast<const OpData*>(node->user_data));
+
+#if defined(HIFIMINI)
+ EvalIntegerSvdfHifimini(context, node, input, weights_feature, weights_time,
+ bias, params, activation_state, output, data);
+ return kTfLiteOk;
+#elif defined(FUSION_F1)
+ return EvalIntegerSvdfHifi4(context, node, input, weights_feature,
+ weights_time, bias, params, activation_state,
+ output, data);
+#else
+ EvalIntegerSvdfReference(context, node, input, weights_feature, weights_time,
+ bias, params, activation_state, output, data);
+ return kTfLiteOk;
+#endif
+}
+
+} // namespace
+
+TfLiteRegistration Register_SVDF() {
+ return {/*init=*/Init,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/xtensa/xtensa.h b/tensorflow/lite/micro/kernels/xtensa/xtensa.h
new file mode 100644
index 0000000..0ced325
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/xtensa/xtensa.h
@@ -0,0 +1,29 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_KERNELS_XTENSA_XTENSA_H_
+#define TENSORFLOW_LITE_MICRO_KERNELS_XTENSA_XTENSA_H_
+
+#if defined(HIFIMINI)
+#include <xtensa/tie/xt_hifi2.h>
+#elif defined(FUSION_F1)
+#include "include/nnlib/xa_nnlib_api.h"
+#include "include/nnlib/xa_nnlib_standards.h"
+
+#define ALIGNED_SIZE(x, bytes) (((x) + (bytes - 1)) & (~(bytes - 1)))
+#define ALIGN_PTR(x, bytes) ((((unsigned)(x)) + (bytes - 1)) & (~(bytes - 1)))
+#endif
+
+#endif // TENSORFLOW_LITE_MICRO_KERNELS_XTENSA_XTENSA_H_
diff --git a/tensorflow/lite/micro/kernels/zeros_like.cc b/tensorflow/lite/micro/kernels/zeros_like.cc
new file mode 100644
index 0000000..ce40392
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/zeros_like.cc
@@ -0,0 +1,89 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/kernels/kernel_util.h"
+
+namespace tflite {
+namespace {
+
+constexpr int kInputTensor = 0;
+constexpr int kOutputTensor = 0;
+
+TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) {
+ TF_LITE_ENSURE_EQ(context, NumInputs(node), 1);
+ TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1);
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kOutputTensor, &output));
+ output->type = input->type;
+
+ return kTfLiteOk;
+}
+
+template <typename T>
+void resetZeros(T* out, const int num_elements) {
+ for (int i = 0; i < num_elements; ++i) {
+ out[i] = static_cast<T>(0);
+ }
+}
+
+TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteEvalTensor* input =
+ tflite::micro::GetEvalInput(context, node, kInputTensor);
+ TfLiteEvalTensor* output =
+ tflite::micro::GetEvalOutput(context, node, kOutputTensor);
+ int flat_size = MatchingFlatSize(tflite::micro::GetTensorShape(input),
+ tflite::micro::GetTensorShape(output));
+ switch (input->type) {
+ case kTfLiteInt64:
+ resetZeros(tflite::micro::GetTensorData<int64_t>(output), flat_size);
+ break;
+ case kTfLiteInt32:
+ resetZeros(tflite::micro::GetTensorData<int32_t>(output), flat_size);
+ break;
+ case kTfLiteInt8:
+ resetZeros(tflite::micro::GetTensorData<int8_t>(output), flat_size);
+ break;
+ case kTfLiteFloat32:
+ resetZeros(tflite::micro::GetTensorData<float>(output), flat_size);
+ break;
+ default:
+ TF_LITE_KERNEL_LOG(context,
+ "ZerosLike only currently supports int64, int32, "
+ "and float32, got %d.",
+ input->type);
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+} // namespace
+
+TfLiteRegistration Register_ZEROS_LIKE() {
+ return {/*init=*/nullptr,
+ /*free=*/nullptr,
+ /*prepare=*/Prepare,
+ /*invoke=*/Eval,
+ /*profiling_string=*/nullptr,
+ /*builtin_code=*/0,
+ /*custom_name=*/nullptr,
+ /*version=*/0};
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/kernels/zeros_like_test.cc b/tensorflow/lite/micro/kernels/zeros_like_test.cc
new file mode 100644
index 0000000..68b7807
--- /dev/null
+++ b/tensorflow/lite/micro/kernels/zeros_like_test.cc
@@ -0,0 +1,101 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/c/builtin_op_data.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/kernels/kernel_runner.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+template <typename T>
+void TestZerosLike(const int* input_dims_data, const T* input_data,
+ const T* expected_output_data, T* output_data) {
+ TfLiteIntArray* input_dims = IntArrayFromInts(input_dims_data);
+ TfLiteIntArray* output_dims = IntArrayFromInts(input_dims_data);
+ const int output_dims_count = ElementCount(*output_dims);
+ constexpr int inputs_size = 1;
+ constexpr int outputs_size = 1;
+ constexpr int tensors_size = inputs_size + outputs_size;
+ TfLiteTensor tensors[tensors_size] = {
+ CreateTensor(input_data, input_dims),
+ CreateTensor(output_data, output_dims),
+ };
+
+ int inputs_array_data[] = {1, 0};
+ TfLiteIntArray* inputs_array = IntArrayFromInts(inputs_array_data);
+ int outputs_array_data[] = {1, 1};
+ TfLiteIntArray* outputs_array = IntArrayFromInts(outputs_array_data);
+
+ const TfLiteRegistration registration = Register_ZEROS_LIKE();
+ micro::KernelRunner runner(registration, tensors, tensors_size, inputs_array,
+ outputs_array,
+ /*builtin_data=*/nullptr);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.InitAndPrepare());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, runner.Invoke());
+
+ for (int i = 0; i < output_dims_count; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_output_data[i], output_data[i]);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestZerosLikeFloat) {
+ float output_data[6];
+ const int input_dims[] = {2, 2, 3};
+ const float input_values[] = {-2.0, -1.0, 0.0, 1.0, 2.0, 3.0};
+ const float golden[] = {0.0, 0.0, 0.0, 0.0, 0.0, 0.0};
+ tflite::testing::TestZerosLike<float>(input_dims, input_values, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(TestZerosLikeInt8) {
+ int8_t output_data[6];
+ const int input_dims[] = {3, 1, 2, 3};
+ const int8_t input_values[] = {-2, -1, 0, 1, 2, 3};
+ const int8_t golden[] = {0, 0, 0, 0, 0, 0};
+ tflite::testing::TestZerosLike<int8_t>(input_dims, input_values, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(TestZerosLikeInt32) {
+ int32_t output_data[4];
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const int32_t input_values[] = {-2, -1, 0, 3};
+ const int32_t golden[] = {0, 0, 0, 0};
+ tflite::testing::TestZerosLike<int32_t>(input_dims, input_values, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TEST(TestZerosLikeInt64) {
+ int64_t output_data[4];
+ const int input_dims[] = {4, 1, 2, 2, 1};
+ const int64_t input_values[] = {-2, -1, 0, 3};
+ const int64_t golden[] = {0, 0, 0, 0};
+ tflite::testing::TestZerosLike<int64_t>(input_dims, input_values, golden,
+ output_data);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/mbed/debug_log.cc b/tensorflow/lite/micro/mbed/debug_log.cc
new file mode 100644
index 0000000..57e74bf
--- /dev/null
+++ b/tensorflow/lite/micro/mbed/debug_log.cc
@@ -0,0 +1,24 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include <mbed.h>
+
+// On mbed platforms, we set up a serial port and write to it for debug logging.
+extern "C" void DebugLog(const char* s) {
+ static Serial pc(USBTX, USBRX);
+ pc.printf("%s", s);
+}
diff --git a/tensorflow/lite/micro/memory_arena_threshold_test.cc b/tensorflow/lite/micro/memory_arena_threshold_test.cc
new file mode 100644
index 0000000..c828210
--- /dev/null
+++ b/tensorflow/lite/micro/memory_arena_threshold_test.cc
@@ -0,0 +1,256 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include <stdint.h>
+
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/recording_micro_allocator.h"
+#include "tensorflow/lite/micro/recording_micro_interpreter.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/micro/testing/test_conv_model.h"
+
+/**
+ * Tests to ensure arena memory allocation does not regress by more than 3%.
+ */
+
+namespace {
+
+// Ensure memory doesn't expand more that 3%:
+constexpr float kAllocationThreshold = 0.03;
+
+// TODO(b/160617245): Record persistent allocations to provide a more accurate
+// number here.
+constexpr float kAllocationTailMiscCeiling = 2 * 1024;
+
+const bool kIs64BitSystem = (sizeof(void*) == 8);
+
+constexpr int kKeywordModelTensorArenaSize = 22 * 1024;
+uint8_t keyword_model_tensor_arena[kKeywordModelTensorArenaSize];
+
+constexpr int kKeywordModelTensorCount = 54;
+constexpr int kKeywordModelNodeAndRegistrationCount = 15;
+
+// NOTE: These values are measured on x86-64:
+// TODO(b/158651472): Consider auditing these values on non-64 bit systems.
+//
+// Run this test with '--copt=-DTF_LITE_STATIC_MEMORY' to get optimized memory
+// runtime values:
+#ifdef TF_LITE_STATIC_MEMORY
+constexpr int kKeywordModelTotalSize = 14384;
+constexpr int kKeywordModelTailSize = 13712;
+constexpr int kKeywordModelPersistentTfLiteTensorDataSize = 128;
+constexpr int kKeywordModelPersistentBufferDataSize = 572;
+#else
+constexpr int kKeywordModelTotalSize = 14832;
+constexpr int kKeywordModelTailSize = 14160;
+constexpr int kKeywordModelPersistentTfLiteTensorDataSize = 224;
+constexpr int kKeywordModelPersistentBufferDataSize = 564;
+#endif
+constexpr int kKeywordModelHeadSize = 672;
+constexpr int kKeywordModelTfLiteTensorVariableBufferDataSize = 10240;
+constexpr int kKeywordModelPersistentTfLiteTensorQuantizationData = 64;
+constexpr int kKeywordModelOpRuntimeDataSize = 148;
+
+constexpr int kTestConvModelArenaSize = 12 * 1024;
+uint8_t test_conv_tensor_arena[kTestConvModelArenaSize];
+
+constexpr int kTestConvModelTensorCount = 15;
+constexpr int kTestConvModelNodeAndRegistrationCount = 7;
+
+// NOTE: These values are measured on x86-64:
+// TODO(b/158651472): Consider auditing these values on non-64 bit systems.
+#ifdef TF_LITE_STATIC_MEMORY
+constexpr int kTestConvModelTotalSize = 9744;
+constexpr int kTestConvModelTailSize = 2000;
+constexpr int kTestConvModelPersistentTfLiteTensorDataSize = 128;
+constexpr int kTestConvModelPersistentBufferDataSize = 672;
+#else
+constexpr int kTestConvModelTotalSize = 10016;
+constexpr int kTestConvModelTailSize = 2272;
+constexpr int kTestConvModelPersistentTfLiteTensorDataSize = 224;
+constexpr int kTestConvModelPersistentBufferDataSize = 680;
+#endif
+constexpr int kTestConvModelHeadSize = 7744;
+constexpr int kTestConvModelOpRuntimeDataSize = 136;
+constexpr int kTestConvModelPersistentTfLiteTensorQuantizationData = 0;
+
+struct ModelAllocationThresholds {
+ size_t tensor_count = 0;
+ size_t node_and_registration_count = 0;
+ size_t total_alloc_size = 0;
+ size_t head_alloc_size = 0;
+ size_t tail_alloc_size = 0;
+ size_t tensor_variable_buffer_data_size = 0;
+ size_t persistent_tflite_tensor_data_size = 0;
+ size_t persistent_tflite_tensor_quantization_data_size = 0;
+ size_t op_runtime_data_size = 0;
+ size_t persistent_buffer_data = 0;
+};
+
+void EnsureAllocatedSizeThreshold(const char* allocation_type, size_t actual,
+ size_t expected) {
+ // TODO(b/158651472): Better auditing of non-64 bit systems:
+ if (kIs64BitSystem) {
+ // 64-bit systems should check floor and ceiling to catch memory savings:
+ TF_LITE_MICRO_EXPECT_NEAR(actual, expected,
+ expected * kAllocationThreshold);
+ if (actual != expected) {
+ TF_LITE_REPORT_ERROR(tflite::GetMicroErrorReporter(),
+ "%s threshold failed: %d != %d", allocation_type,
+ actual, expected);
+ }
+ } else {
+ // Non-64 bit systems should just expect allocation does not exceed the
+ // ceiling:
+ TF_LITE_MICRO_EXPECT_LE(actual, expected + expected * kAllocationThreshold);
+ }
+}
+
+void ValidateModelAllocationThresholds(
+ const tflite::RecordingMicroAllocator& allocator,
+ const ModelAllocationThresholds& thresholds) {
+ allocator.PrintAllocations();
+
+ EnsureAllocatedSizeThreshold(
+ "Total", allocator.GetSimpleMemoryAllocator()->GetUsedBytes(),
+ thresholds.total_alloc_size);
+ EnsureAllocatedSizeThreshold(
+ "Head", allocator.GetSimpleMemoryAllocator()->GetHeadUsedBytes(),
+ thresholds.head_alloc_size);
+ EnsureAllocatedSizeThreshold(
+ "Tail", allocator.GetSimpleMemoryAllocator()->GetTailUsedBytes(),
+ thresholds.tail_alloc_size);
+ EnsureAllocatedSizeThreshold(
+ "TfLiteEvalTensor",
+ allocator
+ .GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteEvalTensorData)
+ .used_bytes,
+ sizeof(TfLiteEvalTensor) * thresholds.tensor_count);
+ EnsureAllocatedSizeThreshold(
+ "VariableBufferData",
+ allocator
+ .GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteTensorVariableBufferData)
+ .used_bytes,
+ thresholds.tensor_variable_buffer_data_size);
+ EnsureAllocatedSizeThreshold(
+ "PersistentTfLiteTensor",
+ allocator
+ .GetRecordedAllocation(
+ tflite::RecordedAllocationType::kPersistentTfLiteTensorData)
+ .used_bytes,
+ thresholds.persistent_tflite_tensor_data_size);
+ EnsureAllocatedSizeThreshold(
+ "PersistentTfliteTensorQuantizationData",
+ allocator
+ .GetRecordedAllocation(tflite::RecordedAllocationType::
+ kPersistentTfLiteTensorQuantizationData)
+ .used_bytes,
+ thresholds.persistent_tflite_tensor_quantization_data_size);
+ EnsureAllocatedSizeThreshold(
+ "PersistentBufferData",
+ allocator
+ .GetRecordedAllocation(
+ tflite::RecordedAllocationType::kPersistentBufferData)
+ .used_bytes,
+ thresholds.persistent_buffer_data);
+ EnsureAllocatedSizeThreshold(
+ "NodeAndRegistration",
+ allocator
+ .GetRecordedAllocation(
+ tflite::RecordedAllocationType::kNodeAndRegistrationArray)
+ .used_bytes,
+ sizeof(tflite::NodeAndRegistration) *
+ thresholds.node_and_registration_count);
+ EnsureAllocatedSizeThreshold(
+ "OpData",
+ allocator.GetRecordedAllocation(tflite::RecordedAllocationType::kOpData)
+ .used_bytes,
+ thresholds.op_runtime_data_size);
+
+ // Ensure tail allocation recording is not missing any large chunks:
+ size_t tail_est_length = sizeof(TfLiteEvalTensor) * thresholds.tensor_count +
+ thresholds.tensor_variable_buffer_data_size +
+ sizeof(tflite::NodeAndRegistration) *
+ thresholds.node_and_registration_count +
+ thresholds.op_runtime_data_size;
+ TF_LITE_MICRO_EXPECT_LE(thresholds.tail_alloc_size - tail_est_length,
+ kAllocationTailMiscCeiling);
+}
+
+} // namespace
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestKeywordModelMemoryThreshold) {
+ tflite::AllOpsResolver all_ops_resolver;
+ tflite::RecordingMicroInterpreter interpreter(
+ tflite::GetModel(g_keyword_scrambled_model_data), all_ops_resolver,
+ keyword_model_tensor_arena, kKeywordModelTensorArenaSize,
+ tflite::GetMicroErrorReporter());
+
+ interpreter.AllocateTensors();
+
+ ModelAllocationThresholds thresholds;
+ thresholds.tensor_count = kKeywordModelTensorCount;
+ thresholds.node_and_registration_count =
+ kKeywordModelNodeAndRegistrationCount;
+ thresholds.total_alloc_size = kKeywordModelTotalSize;
+ thresholds.head_alloc_size = kKeywordModelHeadSize;
+ thresholds.tail_alloc_size = kKeywordModelTailSize;
+ thresholds.tensor_variable_buffer_data_size =
+ kKeywordModelTfLiteTensorVariableBufferDataSize;
+ thresholds.op_runtime_data_size = kKeywordModelOpRuntimeDataSize;
+ thresholds.persistent_buffer_data = kKeywordModelPersistentBufferDataSize;
+ thresholds.persistent_tflite_tensor_data_size =
+ kKeywordModelPersistentTfLiteTensorDataSize;
+ thresholds.persistent_tflite_tensor_quantization_data_size =
+ kKeywordModelPersistentTfLiteTensorQuantizationData;
+
+ ValidateModelAllocationThresholds(interpreter.GetMicroAllocator(),
+ thresholds);
+}
+
+TF_LITE_MICRO_TEST(TestConvModelMemoryThreshold) {
+ tflite::AllOpsResolver all_ops_resolver;
+ tflite::RecordingMicroInterpreter interpreter(
+ tflite::GetModel(kTestConvModelData), all_ops_resolver,
+ test_conv_tensor_arena, kTestConvModelArenaSize,
+ tflite::GetMicroErrorReporter());
+
+ interpreter.AllocateTensors();
+
+ ModelAllocationThresholds thresholds;
+ thresholds.tensor_count = kTestConvModelTensorCount;
+ thresholds.node_and_registration_count =
+ kTestConvModelNodeAndRegistrationCount;
+ thresholds.total_alloc_size = kTestConvModelTotalSize;
+ thresholds.head_alloc_size = kTestConvModelHeadSize;
+ thresholds.tail_alloc_size = kTestConvModelTailSize;
+ thresholds.op_runtime_data_size = kTestConvModelOpRuntimeDataSize;
+ thresholds.persistent_buffer_data = kTestConvModelPersistentBufferDataSize;
+ thresholds.persistent_tflite_tensor_data_size =
+ kTestConvModelPersistentTfLiteTensorDataSize;
+ thresholds.persistent_tflite_tensor_quantization_data_size =
+ kTestConvModelPersistentTfLiteTensorQuantizationData;
+
+ ValidateModelAllocationThresholds(interpreter.GetMicroAllocator(),
+ thresholds);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/memory_helpers.cc b/tensorflow/lite/micro/memory_helpers.cc
new file mode 100644
index 0000000..2d8f759
--- /dev/null
+++ b/tensorflow/lite/micro/memory_helpers.cc
@@ -0,0 +1,167 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+#include <cstddef>
+#include <cstdint>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/core/api/flatbuffer_conversions.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+uint8_t* AlignPointerUp(uint8_t* data, size_t alignment) {
+ std::uintptr_t data_as_uintptr_t = reinterpret_cast<std::uintptr_t>(data);
+ uint8_t* aligned_result = reinterpret_cast<uint8_t*>(
+ ((data_as_uintptr_t + (alignment - 1)) / alignment) * alignment);
+ return aligned_result;
+}
+
+uint8_t* AlignPointerDown(uint8_t* data, size_t alignment) {
+ std::uintptr_t data_as_uintptr_t = reinterpret_cast<std::uintptr_t>(data);
+ uint8_t* aligned_result =
+ reinterpret_cast<uint8_t*>((data_as_uintptr_t / alignment) * alignment);
+ return aligned_result;
+}
+
+size_t AlignSizeUp(size_t size, size_t alignment) {
+ size_t aligned_size = (((size + (alignment - 1)) / alignment) * alignment);
+ return aligned_size;
+}
+
+TfLiteStatus TfLiteTypeSizeOf(TfLiteType type, size_t* size) {
+ switch (type) {
+ case kTfLiteFloat16:
+ *size = sizeof(int16_t);
+ break;
+ case kTfLiteFloat32:
+ *size = sizeof(float);
+ break;
+ case kTfLiteFloat64:
+ *size = sizeof(double);
+ break;
+ case kTfLiteInt16:
+ *size = sizeof(int16_t);
+ break;
+ case kTfLiteInt32:
+ *size = sizeof(int32_t);
+ break;
+ case kTfLiteUInt32:
+ *size = sizeof(uint32_t);
+ break;
+ case kTfLiteUInt8:
+ *size = sizeof(uint8_t);
+ break;
+ case kTfLiteInt8:
+ *size = sizeof(int8_t);
+ break;
+ case kTfLiteInt64:
+ *size = sizeof(int64_t);
+ break;
+ case kTfLiteUInt64:
+ *size = sizeof(uint64_t);
+ break;
+ case kTfLiteBool:
+ *size = sizeof(bool);
+ break;
+ case kTfLiteComplex64:
+ *size = sizeof(float) * 2;
+ break;
+ case kTfLiteComplex128:
+ *size = sizeof(double) * 2;
+ break;
+ default:
+ return kTfLiteError;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus BytesRequiredForTensor(const tflite::Tensor& flatbuffer_tensor,
+ size_t* bytes, size_t* type_size,
+ ErrorReporter* error_reporter) {
+ int element_count = 1;
+ // If flatbuffer_tensor.shape == nullptr, then flatbuffer_tensor is a scalar
+ // so has 1 element.
+ if (flatbuffer_tensor.shape() != nullptr) {
+ for (size_t n = 0; n < flatbuffer_tensor.shape()->Length(); ++n) {
+ element_count *= flatbuffer_tensor.shape()->Get(n);
+ }
+ }
+
+ TfLiteType tf_lite_type;
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(flatbuffer_tensor.type(),
+ &tf_lite_type, error_reporter));
+ TF_LITE_ENSURE_STATUS(TfLiteTypeSizeOf(tf_lite_type, type_size));
+ *bytes = element_count * (*type_size);
+ return kTfLiteOk;
+}
+
+TfLiteStatus TfLiteEvalTensorByteLength(const TfLiteEvalTensor* eval_tensor,
+ size_t* out_bytes) {
+ TFLITE_DCHECK(out_bytes != nullptr);
+
+ int element_count = 1;
+ // If eval_tensor->dims == nullptr, then tensor is a scalar so has 1 element.
+ if (eval_tensor->dims != nullptr) {
+ for (int n = 0; n < eval_tensor->dims->size; ++n) {
+ element_count *= eval_tensor->dims->data[n];
+ }
+ }
+ size_t type_size;
+ TF_LITE_ENSURE_STATUS(TfLiteTypeSizeOf(eval_tensor->type, &type_size));
+ *out_bytes = element_count * type_size;
+ return kTfLiteOk;
+}
+
+TfLiteStatus AllocateOutputDimensionsFromInput(TfLiteContext* context,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2,
+ TfLiteTensor* output) {
+ const TfLiteTensor* input = nullptr;
+
+ TF_LITE_ENSURE(context, input1->dims != nullptr);
+ TF_LITE_ENSURE(context, input2->dims != nullptr);
+ TF_LITE_ENSURE(context, output->dims->size == 0);
+
+ input = input1->dims->size > input2->dims->size ? input1 : input2;
+ TF_LITE_ENSURE(context, output->type == input->type);
+
+ size_t size = 0;
+ TfLiteTypeSizeOf(input->type, &size);
+ const int dimensions_count = tflite::GetTensorShape(input).DimensionsCount();
+ for (int i = 0; i < dimensions_count; i++) {
+ size *= input->dims->data[i];
+ }
+
+ output->bytes = size;
+
+ output->dims =
+ reinterpret_cast<TfLiteIntArray*>(context->AllocatePersistentBuffer(
+ context, TfLiteIntArrayGetSizeInBytes(size)));
+
+ output->dims->size = input->dims->size;
+ for (int i = 0; i < dimensions_count; i++) {
+ output->dims->data[i] = input->dims->data[i];
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/memory_helpers.h b/tensorflow/lite/micro/memory_helpers.h
new file mode 100644
index 0000000..8f5526c
--- /dev/null
+++ b/tensorflow/lite/micro/memory_helpers.h
@@ -0,0 +1,59 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MEMORY_HELPERS_H_
+#define TENSORFLOW_LITE_MICRO_MEMORY_HELPERS_H_
+
+#include <cstddef>
+#include <cstdint>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+// Returns the next pointer address aligned to the given alignment.
+uint8_t* AlignPointerUp(uint8_t* data, size_t alignment);
+
+// Returns the previous pointer address aligned to the given alignment.
+uint8_t* AlignPointerDown(uint8_t* data, size_t alignment);
+
+// Returns an increased size that's a multiple of alignment.
+size_t AlignSizeUp(size_t size, size_t alignment);
+
+// Returns size in bytes for a given TfLiteType.
+TfLiteStatus TfLiteTypeSizeOf(TfLiteType type, size_t* size);
+
+// How many bytes are needed to hold a tensor's contents.
+TfLiteStatus BytesRequiredForTensor(const tflite::Tensor& flatbuffer_tensor,
+ size_t* bytes, size_t* type_size,
+ ErrorReporter* error_reporter);
+
+// How many bytes are used in a TfLiteEvalTensor instance. The byte length is
+// returned in out_bytes.
+TfLiteStatus TfLiteEvalTensorByteLength(const TfLiteEvalTensor* eval_tensor,
+ size_t* out_bytes);
+
+// Deduce output dimensions from input and allocate given size.
+// Useful for operators with two inputs where the largest input should equal the
+// output dimension.
+TfLiteStatus AllocateOutputDimensionsFromInput(TfLiteContext* context,
+ const TfLiteTensor* input1,
+ const TfLiteTensor* input2,
+ TfLiteTensor* output);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MEMORY_HELPERS_H_
diff --git a/tensorflow/lite/micro/memory_helpers_test.cc b/tensorflow/lite/micro/memory_helpers_test.cc
new file mode 100644
index 0000000..230539c
--- /dev/null
+++ b/tensorflow/lite/micro/memory_helpers_test.cc
@@ -0,0 +1,233 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace {
+
+// This just needs to be big enough to handle the array of 5 ints allocated
+// in TestAllocateOutputDimensionsFromInput below.
+const int kGlobalPersistentBufferLength = 100;
+char global_persistent_buffer[kGlobalPersistentBufferLength];
+
+// Only need to handle a single allocation at a time for output dimensions
+// in TestAllocateOutputDimensionsFromInput.
+void* FakeAllocatePersistentBuffer(TfLiteContext* context, size_t bytes) {
+ return reinterpret_cast<void*>(global_persistent_buffer);
+}
+
+} // namespace
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestAlignPointerUp) {
+ uint8_t* input0 = reinterpret_cast<uint8_t*>(0);
+
+ uint8_t* input0_aligned1 = tflite::AlignPointerUp(input0, 1);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned1);
+
+ uint8_t* input0_aligned2 = tflite::AlignPointerUp(input0, 2);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned2);
+
+ uint8_t* input0_aligned3 = tflite::AlignPointerUp(input0, 3);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned3);
+
+ uint8_t* input0_aligned16 = tflite::AlignPointerUp(input0, 16);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned16);
+
+ uint8_t* input23 = reinterpret_cast<uint8_t*>(23);
+
+ uint8_t* input23_aligned1 = tflite::AlignPointerUp(input23, 1);
+ TF_LITE_MICRO_EXPECT(input23 == input23_aligned1);
+
+ uint8_t* input23_aligned2 = tflite::AlignPointerUp(input23, 2);
+ uint8_t* expected23_aligned2 = reinterpret_cast<uint8_t*>(24);
+ TF_LITE_MICRO_EXPECT(expected23_aligned2 == input23_aligned2);
+
+ uint8_t* input23_aligned3 = tflite::AlignPointerUp(input23, 3);
+ uint8_t* expected23_aligned3 = reinterpret_cast<uint8_t*>(24);
+ TF_LITE_MICRO_EXPECT(expected23_aligned3 == input23_aligned3);
+
+ uint8_t* input23_aligned16 = tflite::AlignPointerUp(input23, 16);
+ uint8_t* expected23_aligned16 = reinterpret_cast<uint8_t*>(32);
+ TF_LITE_MICRO_EXPECT(expected23_aligned16 == input23_aligned16);
+}
+
+TF_LITE_MICRO_TEST(TestAlignPointerDown) {
+ uint8_t* input0 = reinterpret_cast<uint8_t*>(0);
+
+ uint8_t* input0_aligned1 = tflite::AlignPointerDown(input0, 1);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned1);
+
+ uint8_t* input0_aligned2 = tflite::AlignPointerDown(input0, 2);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned2);
+
+ uint8_t* input0_aligned3 = tflite::AlignPointerDown(input0, 3);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned3);
+
+ uint8_t* input0_aligned16 = tflite::AlignPointerDown(input0, 16);
+ TF_LITE_MICRO_EXPECT(input0 == input0_aligned16);
+
+ uint8_t* input23 = reinterpret_cast<uint8_t*>(23);
+
+ uint8_t* input23_aligned1 = tflite::AlignPointerDown(input23, 1);
+ TF_LITE_MICRO_EXPECT(input23 == input23_aligned1);
+
+ uint8_t* input23_aligned2 = tflite::AlignPointerDown(input23, 2);
+ uint8_t* expected23_aligned2 = reinterpret_cast<uint8_t*>(22);
+ TF_LITE_MICRO_EXPECT(expected23_aligned2 == input23_aligned2);
+
+ uint8_t* input23_aligned3 = tflite::AlignPointerDown(input23, 3);
+ uint8_t* expected23_aligned3 = reinterpret_cast<uint8_t*>(21);
+ TF_LITE_MICRO_EXPECT(expected23_aligned3 == input23_aligned3);
+
+ uint8_t* input23_aligned16 = tflite::AlignPointerDown(input23, 16);
+ uint8_t* expected23_aligned16 = reinterpret_cast<uint8_t*>(16);
+ TF_LITE_MICRO_EXPECT(expected23_aligned16 == input23_aligned16);
+}
+
+TF_LITE_MICRO_TEST(TestAlignSizeUp) {
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), tflite::AlignSizeUp(1, 1));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(2), tflite::AlignSizeUp(1, 2));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(3), tflite::AlignSizeUp(1, 3));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(16), tflite::AlignSizeUp(1, 16));
+
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(23), tflite::AlignSizeUp(23, 1));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(24), tflite::AlignSizeUp(23, 2));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(24), tflite::AlignSizeUp(23, 3));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(32), tflite::AlignSizeUp(23, 16));
+}
+
+TF_LITE_MICRO_TEST(TestTypeSizeOf) {
+ size_t size;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteFloat16, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(int16_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteFloat32, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(float), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteFloat64, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(double), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteInt16, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(int16_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteInt32, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(int32_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteUInt32, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(uint32_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteUInt8, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(uint8_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteInt8, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(int8_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteInt64, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(int64_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteUInt64, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(uint64_t), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteBool, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(bool), size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteComplex64, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(float) * 2, size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ tflite::TfLiteTypeSizeOf(kTfLiteComplex128, &size));
+ TF_LITE_MICRO_EXPECT_EQ(sizeof(double) * 2, size);
+
+ TF_LITE_MICRO_EXPECT_NE(
+ kTfLiteOk, tflite::TfLiteTypeSizeOf(static_cast<TfLiteType>(-1), &size));
+}
+
+TF_LITE_MICRO_TEST(TestBytesRequiredForTensor) {
+ const tflite::Tensor* tensor100 =
+ tflite::testing::Create1dFlatbufferTensor(100);
+ size_t bytes;
+ size_t type_size;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, tflite::BytesRequiredForTensor(
+ *tensor100, &bytes, &type_size,
+ tflite::GetMicroErrorReporter()));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(400), bytes);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), type_size);
+
+ const tflite::Tensor* tensor200 =
+ tflite::testing::Create1dFlatbufferTensor(200);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, tflite::BytesRequiredForTensor(
+ *tensor200, &bytes, &type_size,
+ tflite::GetMicroErrorReporter()));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(800), bytes);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), type_size);
+}
+
+TF_LITE_MICRO_TEST(TestAllocateOutputDimensionsFromInput) {
+ constexpr int kDimsLen = 4;
+ const int input1_dims[] = {1, 1};
+ const int input2_dims[] = {kDimsLen, 5, 5, 5, 5};
+ int output_dims[] = {0, 0, 0, 0, 0};
+ TfLiteTensor input_tensor1 = tflite::testing::CreateTensor<int32_t>(
+ nullptr, tflite::testing::IntArrayFromInts(input1_dims));
+ TfLiteTensor input_tensor2 = tflite::testing::CreateTensor<int32_t>(
+ nullptr, tflite::testing::IntArrayFromInts(input2_dims));
+ TfLiteTensor output_tensor = tflite::testing::CreateTensor<int32_t>(
+ nullptr, tflite::testing::IntArrayFromInts(output_dims));
+ TfLiteContext context;
+ // Only need to allocate space for output_tensor.dims. Use a simple
+ // fake allocator.
+ context.AllocatePersistentBuffer = FakeAllocatePersistentBuffer;
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::AllocateOutputDimensionsFromInput(
+ &context, &input_tensor1, &input_tensor2, &output_tensor));
+
+ TF_LITE_MICRO_EXPECT_EQ(output_tensor.bytes, input_tensor2.bytes);
+ for (int i = 0; i < kDimsLen; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(input_tensor2.dims->data[i],
+ output_tensor.dims->data[i]);
+ // Reset output dims for next iteration.
+ output_tensor.dims->data[i] = 0;
+ }
+ // Output tensor size must be 0 to allocate output dimensions from input.
+ output_tensor.dims->size = 0;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::AllocateOutputDimensionsFromInput(
+ &context, &input_tensor2, &input_tensor1, &output_tensor));
+ for (int i = 0; i < kDimsLen; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(input_tensor2.dims->data[i],
+ output_tensor.dims->data[i]);
+ }
+ TF_LITE_MICRO_EXPECT_EQ(output_tensor.bytes, input_tensor2.bytes);
+}
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/memory_planner/BUILD b/tensorflow/lite/micro/memory_planner/BUILD
new file mode 100644
index 0000000..9b74dd7
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/BUILD
@@ -0,0 +1,77 @@
+load(
+ "//tensorflow/lite/micro:build_def.bzl",
+ "micro_copts",
+)
+
+package(
+ default_visibility = ["//visibility:public"],
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+cc_library(
+ name = "memory_planner",
+ hdrs = [
+ "memory_planner.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/core/api",
+ ],
+)
+
+cc_library(
+ name = "linear_memory_planner",
+ srcs = [
+ "linear_memory_planner.cc",
+ ],
+ hdrs = [
+ "linear_memory_planner.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":memory_planner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_compatibility",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ ],
+)
+
+cc_library(
+ name = "greedy_memory_planner",
+ srcs = [
+ "greedy_memory_planner.cc",
+ ],
+ hdrs = [
+ "greedy_memory_planner.h",
+ ],
+ copts = micro_copts(),
+ deps = [
+ ":memory_planner",
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/micro:micro_compatibility",
+ ],
+)
+
+cc_test(
+ name = "linear_memory_planner_test",
+ srcs = [
+ "linear_memory_planner_test.cc",
+ ],
+ deps = [
+ ":linear_memory_planner",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
+
+cc_test(
+ name = "greedy_memory_planner_test",
+ srcs = [
+ "greedy_memory_planner_test.cc",
+ ],
+ deps = [
+ ":greedy_memory_planner",
+ "//tensorflow/lite/micro/testing:micro_test",
+ ],
+)
diff --git a/tensorflow/lite/micro/memory_planner/greedy_memory_planner.cc b/tensorflow/lite/micro/memory_planner/greedy_memory_planner.cc
new file mode 100644
index 0000000..39991ab
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/greedy_memory_planner.cc
@@ -0,0 +1,437 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/memory_planner/greedy_memory_planner.h"
+
+namespace tflite {
+
+// Simple stable in-place sort function. Not time-efficient for large arrays.
+// Would normally be in an anonymous namespace to keep it private, but we want
+// to be able to test it externally.
+void ReverseSortInPlace(int* values, int* ids, int size) {
+ bool any_swapped;
+ do {
+ any_swapped = false;
+ for (int i = 1; i < size; ++i) {
+ if (values[i - 1] < values[i]) {
+ const int value_temp = values[i - 1];
+ values[i - 1] = values[i];
+ values[i] = value_temp;
+ const int id_temp = ids[i - 1];
+ ids[i - 1] = ids[i];
+ ids[i] = id_temp;
+ any_swapped = true;
+ }
+ }
+ } while (any_swapped);
+}
+
+GreedyMemoryPlanner::GreedyMemoryPlanner(unsigned char* scratch_buffer,
+ int scratch_buffer_size)
+ : buffer_count_(0), need_to_calculate_offsets_(true) {
+ // Allocate the arrays we need within the scratch buffer arena.
+ max_buffer_count_ = scratch_buffer_size / per_buffer_size();
+
+ unsigned char* next_free = scratch_buffer;
+ requirements_ = reinterpret_cast<BufferRequirements*>(next_free);
+ next_free += sizeof(BufferRequirements) * max_buffer_count_;
+
+ buffer_sizes_sorted_ = reinterpret_cast<int*>(next_free);
+ next_free += sizeof(int) * max_buffer_count_;
+
+ buffer_ids_sorted_ = reinterpret_cast<int*>(next_free);
+ next_free += sizeof(int) * max_buffer_count_;
+
+ buffers_sorted_by_offset_ = reinterpret_cast<ListEntry*>(next_free);
+ next_free += sizeof(ListEntry) * max_buffer_count_;
+
+ buffer_offsets_ = reinterpret_cast<int*>(next_free);
+}
+
+GreedyMemoryPlanner::~GreedyMemoryPlanner() {
+ // We don't own the scratch buffer, so don't deallocate anything.
+}
+
+TfLiteStatus GreedyMemoryPlanner::AddBuffer(
+ tflite::ErrorReporter* error_reporter, int size, int first_time_used,
+ int last_time_used) {
+ if (buffer_count_ >= max_buffer_count_) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Too many buffers (max is %d)",
+ max_buffer_count_);
+ return kTfLiteError;
+ }
+ BufferRequirements* current = &requirements_[buffer_count_];
+ current->size = size;
+ current->first_time_used = first_time_used;
+ current->last_time_used = last_time_used;
+ current->offline_offset = kOnlinePlannedBuffer;
+ ++buffer_count_;
+ need_to_calculate_offsets_ = true;
+ return kTfLiteOk;
+}
+
+TfLiteStatus GreedyMemoryPlanner::AddBuffer(
+ tflite::ErrorReporter* error_reporter, int size, int first_time_used,
+ int last_time_used, int offline_offset) {
+ BufferRequirements* current = &requirements_[buffer_count_];
+ if (AddBuffer(error_reporter, size, first_time_used, last_time_used) !=
+ kTfLiteOk) {
+ return kTfLiteError;
+ }
+ current->offline_offset = offline_offset;
+ return kTfLiteOk;
+}
+
+bool GreedyMemoryPlanner::DoesEntryOverlapInTime(
+ const GreedyMemoryPlanner::ListEntry* entry, const int first_time_used,
+ const int last_time_used) const {
+ const BufferRequirements* entry_requirements =
+ &requirements_[entry->requirements_index];
+ if (entry_requirements->first_time_used > last_time_used) {
+ return false;
+ }
+ if (first_time_used > entry_requirements->last_time_used) {
+ return false;
+ }
+ return true;
+}
+
+GreedyMemoryPlanner::ListEntry*
+GreedyMemoryPlanner::NextSimultaneouslyActiveBuffer(
+ const GreedyMemoryPlanner::ListEntry* start, const int first_time_used,
+ const int last_time_used) {
+ ListEntry* result = nullptr;
+ ListEntry* candidate_next_entry;
+ if (start == nullptr) {
+ candidate_next_entry = &buffers_sorted_by_offset_[first_entry_index_];
+ } else {
+ if (start->next_entry_index == -1) {
+ return nullptr;
+ }
+ candidate_next_entry = &buffers_sorted_by_offset_[start->next_entry_index];
+ }
+ do {
+ if (DoesEntryOverlapInTime(candidate_next_entry, first_time_used,
+ last_time_used)) {
+ result = candidate_next_entry;
+ break;
+ }
+ if (candidate_next_entry->next_entry_index == -1) {
+ break;
+ }
+ candidate_next_entry =
+ &buffers_sorted_by_offset_[candidate_next_entry->next_entry_index];
+ } while (true);
+ return result;
+}
+
+void GreedyMemoryPlanner::CalculateOffsetsIfNeeded() {
+ if (!need_to_calculate_offsets_ || (buffer_count_ == 0)) {
+ return;
+ }
+ need_to_calculate_offsets_ = false;
+
+ // Start off by ordering the buffers in descending order of size.
+ // This helps find a more compact layout. Intuitively, you can think
+ // about putting the large buffers in place first, and then the
+ // smaller buffers can fit in the gaps, rather than fragmenting the
+ // gaps with small buffers at the beginning. Add offline planned offsets
+ // first in the list, since they have a predetermined offset.
+ int idx_from_tail = buffer_count_;
+ int idx_from_head = 0;
+ for (int i = 0; i < buffer_count_; ++i) {
+ if (requirements_[i].offline_offset == kOnlinePlannedBuffer) {
+ idx_from_tail--;
+ buffer_sizes_sorted_[idx_from_tail] = requirements_[i].size;
+ buffer_ids_sorted_[idx_from_tail] = i;
+ buffer_offsets_[i] = -1;
+ } else {
+ buffer_sizes_sorted_[idx_from_head] = requirements_[i].size;
+ buffer_ids_sorted_[idx_from_head] = i;
+ buffer_offsets_[i] = requirements_[i].offline_offset;
+ idx_from_head++;
+ }
+ }
+
+ // This sorting algorithm is naive, and may end up taking a very long time
+ // with hundreds of buffers. Do not sort the offline planned offsets.
+ ReverseSortInPlace(&buffer_sizes_sorted_[idx_from_head],
+ &buffer_ids_sorted_[idx_from_head],
+ buffer_count_ - idx_from_head);
+
+ // Initialize the first entry to the first buffer in
+ // buffer_ids_sorted_.
+ // - If there are no offline planned offsets, the largest buffer will be
+ // first, and the buffers will be handled in size order.
+ // - If offline offsets are present, these will be handled first in order
+ // for the greedy algorithm to utilized gaps in the offline plan.
+ first_entry_index_ = 0;
+ next_free_entry_ = 1;
+ ListEntry* first_entry = &buffers_sorted_by_offset_[first_entry_index_];
+ first_entry->next_entry_index = -1; // to mark the entry as end of list
+ int buffer_id = buffer_ids_sorted_[0];
+ first_entry->requirements_index = buffer_id;
+ if (requirements_[buffer_id].offline_offset == kOnlinePlannedBuffer) {
+ buffer_offsets_[buffer_id] = 0;
+ }
+ first_entry->offset = buffer_offsets_[buffer_id];
+
+ // Work through the rest of the buffers to find a good gap to place each one.
+ for (int i = 1; i < buffer_count_; ++i) {
+ // The id is the order the buffer was originally added by the client.
+ buffer_id = buffer_ids_sorted_[i];
+ // Look at what size and time range the buffer needs to be active.
+ BufferRequirements* wanted_requirements = &requirements_[buffer_id];
+ const int wanted_size = wanted_requirements->size;
+ const int wanted_first_time_used = wanted_requirements->first_time_used;
+ const int wanted_last_time_used = wanted_requirements->last_time_used;
+
+ // Find the first buffer that's active in our time range. All placed
+ // buffers are stored in the order of their starting position in the arena
+ // so that it's easy to find the next buffer in memory, and so the gap.
+ // The candidate_entry variable holds the buffer that we're considering
+ // placing the current buffer after.
+
+ int candidate_offset = 0;
+ // Loop through the offset-ordered list of buffers, looking for gaps.
+ if (wanted_requirements->offline_offset == kOnlinePlannedBuffer) {
+ ListEntry* prior_entry = nullptr;
+ while (true) {
+ // Find out what the next active buffer is.
+ ListEntry* next_entry = NextSimultaneouslyActiveBuffer(
+ prior_entry, wanted_first_time_used, wanted_last_time_used);
+
+ if (prior_entry) {
+ BufferRequirements* candidate_requirements =
+ &requirements_[prior_entry->requirements_index];
+ const int prior_entry_offset =
+ prior_entry->offset + candidate_requirements->size;
+ if (prior_entry_offset > candidate_offset) {
+ candidate_offset = prior_entry_offset;
+ }
+ }
+ if (next_entry == nullptr) {
+ // We're at the end of the list, so we can always append the buffer
+ // here.
+ break;
+ }
+ // Find out how much space there is between us and the next buffer.
+ const int gap = next_entry->offset - candidate_offset;
+ if (gap >= wanted_size) {
+ // This entry has a big enough gap between it and the next, so
+ // use it!
+ break;
+ }
+ // The gap wasn't big enough, so move on to another candidate.
+ prior_entry = next_entry;
+ }
+ } else {
+ // Offline planned offset are to be considered constant
+ candidate_offset = wanted_requirements->offline_offset;
+ }
+ // At this point, we've either found a gap (possibly at the end of the
+ // list) and want to place the buffer there, or there are no other active
+ // buffers in this time range and so we can put it at offset zero.
+ // Record the buffer's offset in our plan.
+ buffer_offsets_[buffer_id] = candidate_offset;
+ // Add the newly-placed buffer to our offset-ordered list, so that
+ // subsequent passes can fit in their buffers around it.
+ ListEntry* new_entry = &buffers_sorted_by_offset_[next_free_entry_];
+ new_entry->offset = candidate_offset;
+ new_entry->requirements_index = buffer_id;
+ const int new_entry_index = next_free_entry_;
+ ++next_free_entry_;
+
+ if (first_entry->offset > candidate_offset) {
+ // The new entry offset is smaller than the first entry offset =>
+ // replace the first entry
+ first_entry = new_entry;
+ first_entry->next_entry_index = first_entry_index_;
+ first_entry_index_ = new_entry_index;
+ } else {
+ ListEntry* current_entry = first_entry;
+ // Make sure that we insert the buffer at the correct place in the
+ // buffer-offset-ordered list
+ while (true) {
+ const int next_entry_index = current_entry->next_entry_index;
+ if (next_entry_index == -1) {
+ // We're at the end of the list, so just add the new entry here.
+ current_entry->next_entry_index = new_entry_index;
+ new_entry->next_entry_index = -1;
+ break;
+ }
+ // not at the end of the list -> take a look at next entry
+ ListEntry* next_entry = &buffers_sorted_by_offset_[next_entry_index];
+ if (next_entry->offset > candidate_offset) {
+ // We're at the right spot to do an insertion and retain the sorting
+ // order, so place the new entry here.
+ new_entry->next_entry_index = current_entry->next_entry_index;
+ current_entry->next_entry_index = new_entry_index;
+ break;
+ }
+ current_entry = next_entry;
+ }
+ }
+ }
+}
+
+size_t GreedyMemoryPlanner::GetMaximumMemorySize() {
+ CalculateOffsetsIfNeeded();
+ if (buffer_count_ == 0) {
+ return 0;
+ }
+ ListEntry* entry = &buffers_sorted_by_offset_[first_entry_index_];
+ size_t max_size = 0;
+ while (entry) {
+ BufferRequirements* requirements =
+ &requirements_[entry->requirements_index];
+ // TODO(b/148246793): Update all size and offset variables types from
+ // int to size_t
+ const size_t current_size = entry->offset + requirements->size;
+ if (current_size > max_size) {
+ max_size = current_size;
+ }
+ if (entry->next_entry_index == -1) {
+ break;
+ }
+ entry = &buffers_sorted_by_offset_[entry->next_entry_index];
+ }
+ return max_size;
+}
+
+void GreedyMemoryPlanner::PrintMemoryPlan(ErrorReporter* error_reporter) {
+ CalculateOffsetsIfNeeded();
+
+ for (int i = 0; i < buffer_count_; ++i) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "Planner buffer ID: %d, calculated offset: %d, size required: %d, "
+ "first_time_created: %d, "
+ "last_time_used: %d",
+ i, buffer_offsets_[i], requirements_[i].size,
+ requirements_[i].first_time_used, requirements_[i].last_time_used);
+ }
+
+ constexpr int kLineWidth = 80;
+ int max_size = kLineWidth;
+ int max_time = 0;
+ for (int i = 0; i < buffer_count_; ++i) {
+ BufferRequirements* requirements = &requirements_[i];
+ const int offset = buffer_offsets_[i];
+ const int last_time_used = requirements->last_time_used;
+ const int size = offset + requirements->size;
+ if (size > max_size) {
+ max_size = size;
+ }
+ if (last_time_used > max_time) {
+ max_time = last_time_used;
+ }
+ }
+
+ char line[kLineWidth + 1];
+ for (int t = 0; t <= max_time; ++t) {
+ for (int c = 0; c < kLineWidth; ++c) {
+ line[c] = '.';
+ }
+ for (int i = 0; i < buffer_count_; ++i) {
+ BufferRequirements* requirements = &requirements_[i];
+ if ((t < requirements->first_time_used) ||
+ (t > requirements->last_time_used)) {
+ continue;
+ }
+ const int offset = buffer_offsets_[i];
+ if (offset == -1) {
+ continue;
+ }
+ const int size = requirements->size;
+ const int line_start = (offset * kLineWidth) / max_size;
+ const int line_end = ((offset + size) * kLineWidth) / max_size;
+ for (int n = line_start; n < line_end; ++n) {
+ if (line[n] == '.') {
+ char display;
+ if (i < 10) {
+ display = '0' + i;
+ } else if (i < 36) {
+ display = 'a' + (i - 10);
+ } else if (i < 62) {
+ display = 'A' + (i - 36);
+ } else {
+ display = '*';
+ }
+ line[n] = display;
+ } else {
+ line[n] = '!';
+ }
+ }
+ }
+ line[kLineWidth] = 0;
+ TF_LITE_REPORT_ERROR(error_reporter, "%s", (const char*)line);
+ }
+}
+
+int GreedyMemoryPlanner::GetBufferCount() { return buffer_count_; }
+
+TfLiteStatus GreedyMemoryPlanner::GetOffsetForBuffer(
+ tflite::ErrorReporter* error_reporter, int buffer_index, int* offset) {
+ CalculateOffsetsIfNeeded();
+ if ((buffer_index < 0) || (buffer_index >= buffer_count_)) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "buffer index %d is outside range 0 to %d",
+ buffer_index, buffer_count_);
+ return kTfLiteError;
+ }
+ *offset = buffer_offsets_[buffer_index];
+ return kTfLiteOk;
+}
+
+bool GreedyMemoryPlanner::DoAnyBuffersOverlap(ErrorReporter* error_reporter) {
+ CalculateOffsetsIfNeeded();
+ bool were_overlaps_found = false;
+ for (int i = 0; i < buffer_count_; ++i) {
+ BufferRequirements* a_requirements = &requirements_[i];
+ const int a_start_offset = buffer_offsets_[i];
+ const int a_first_time_used = a_requirements->first_time_used;
+ const int a_last_time_used = a_requirements->last_time_used;
+ const int a_end_offset = a_start_offset + a_requirements->size;
+ for (int j = 0; j < buffer_count_; ++j) {
+ if (i == j) {
+ continue;
+ }
+ BufferRequirements* b_requirements = &requirements_[j];
+ const int b_start_offset = buffer_offsets_[j];
+ const int b_first_time_used = b_requirements->first_time_used;
+ const int b_last_time_used = b_requirements->last_time_used;
+ const int b_end_offset = b_start_offset + b_requirements->size;
+ if ((a_first_time_used > b_last_time_used) ||
+ (b_first_time_used > a_last_time_used)) {
+ // Buffers don't overlap in time.
+ continue;
+ }
+ if ((a_start_offset >= b_end_offset) ||
+ (b_start_offset >= a_end_offset)) {
+ // No overlap in memory.
+ continue;
+ }
+ were_overlaps_found = true;
+ TF_LITE_REPORT_ERROR(
+ error_reporter, "Overlap: %d (%d=>%d, %d->%d) vs %d (%d=>%d, %d->%d)",
+ i, a_first_time_used, a_last_time_used, a_start_offset, a_end_offset,
+ j, b_first_time_used, b_last_time_used, b_start_offset, b_end_offset);
+ }
+ }
+ return were_overlaps_found;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/memory_planner/greedy_memory_planner.h b/tensorflow/lite/micro/memory_planner/greedy_memory_planner.h
new file mode 100644
index 0000000..f5f26a8
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/greedy_memory_planner.h
@@ -0,0 +1,163 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_GREEDY_MEMORY_PLANNER_H_
+#define TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_GREEDY_MEMORY_PLANNER_H_
+
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/memory_planner/memory_planner.h"
+
+namespace tflite {
+
+constexpr int kOnlinePlannedBuffer = -1;
+
+// A memory planner that uses a greedy algorithm to arrange buffers in memory
+// to minimize the overall arena size needed.
+//
+// The algorithm works like this:
+// - The client enters the buffer information through AddBuffer().
+// - When a function like GetOffsetForBuffer() is called, the
+// CalculateOffsetsIfNeeded() method is invoked.
+// - If an up to date plan is not already present, one will be calculated.
+// - The buffers are sorted in descending order of size.
+// - The largest buffer is placed at offset zero.
+// - The rest of the buffers are looped through in descending size order.
+// - The other buffers that need to be in memory at the same time are found.
+// - The first gap between simultaneously active buffers that the current
+// buffer fits into will be used.
+// - If no large-enough gap is found, the current buffer is placed after the
+// last buffer that's simultaneously active.
+// - This continues until all buffers are placed, and the offsets stored.
+//
+// This is not guaranteed to produce the best placement, since that's an
+// NP-Complete problem, but in practice it should produce one that's decent.
+class GreedyMemoryPlanner : public MemoryPlanner {
+ public:
+ // You need to pass in an area of memory to be used for planning. This memory
+ // needs to have a lifetime as long as the planner, but isn't owned by this
+ // object, so management should be handled by the client. This is so it can be
+ // stack or globally allocated if necessary on devices without dynamic memory
+ // allocation. How many buffers can be planned for will depend on the size of
+ // this scratch memory, so you should enlarge it if you see an error when
+ // calling AddBuffer(). The memory can be reused once you're done with the
+ // planner, as long as you copy the calculated offsets to another location.
+ // Each buffer requires about 36 bytes of scratch.
+ GreedyMemoryPlanner(unsigned char* scratch_buffer, int scratch_buffer_size);
+ ~GreedyMemoryPlanner() override;
+
+ // Record details of a buffer we want to place.
+ TfLiteStatus AddBuffer(ErrorReporter* error_reporter, int size,
+ int first_time_used, int last_time_used) override;
+
+ // Record details of an offline planned buffer offset we want to place.
+ // offline_offset is the buffer offset from the start of the arena.
+ TfLiteStatus AddBuffer(ErrorReporter* error_reporter, int size,
+ int first_time_used, int last_time_used,
+ int offline_offset);
+
+ // Returns the high-water mark of used memory. This is the minimum size of a
+ // memory arena you'd need to allocate to hold these buffers.
+ size_t GetMaximumMemorySize() override;
+
+ // How many buffers have been recorded.
+ int GetBufferCount() override;
+
+ // Where a given buffer should be placed in the memory arena.
+ // This information is stored in the memory arena itself, so once the arena
+ // is used for inference, it will be overwritten.
+ TfLiteStatus GetOffsetForBuffer(ErrorReporter* error_reporter,
+ int buffer_index, int* offset) override;
+
+ // Prints an ascii-art diagram of the buffer layout plan.
+ void PrintMemoryPlan(ErrorReporter* error_reporter);
+
+ // Debug method to check whether any buffer allocations are overlapping. This
+ // is an O(N^2) complexity operation, so only use for testing.
+ bool DoAnyBuffersOverlap(ErrorReporter* error_reporter);
+
+ // Used to store a list of buffers ordered by their offset.
+ struct ListEntry {
+ int offset;
+ int requirements_index;
+ int next_entry_index;
+ };
+
+ // Number of bytes required in order to plan a buffer.
+ static size_t per_buffer_size() {
+ const int per_buffer_size =
+ sizeof(BufferRequirements) + // requirements_
+ sizeof(int) + // buffer_sizes_sorted_
+ sizeof(int) + // buffer_ids_sorted_
+ sizeof(ListEntry) + // buffers_sorted_by_offset_
+ sizeof(int); // buffer_offsets_;
+ return per_buffer_size;
+ }
+
+ private:
+ // Whether a buffer is active in a given time range.
+ bool DoesEntryOverlapInTime(const ListEntry* entry, const int first_time_used,
+ const int last_time_used) const;
+
+ // Walks the list to return the next buffer that is active in a given time
+ // range, or a null pointer if there are none.
+ ListEntry* NextSimultaneouslyActiveBuffer(const ListEntry* start,
+ const int first_time_used,
+ const int last_time_used);
+
+ // If there isn't an up to date plan, calculate a new one.
+ void CalculateOffsetsIfNeeded();
+
+ // How many buffers we can plan for, based on the arena size we're given in
+ // the constructor.
+ int max_buffer_count_;
+
+ // The number of buffers added so far.
+ int buffer_count_;
+
+ // Records the client-provided information about each buffer.
+ struct BufferRequirements {
+ int size;
+ int offline_offset;
+ int first_time_used;
+ int last_time_used;
+ };
+
+ // Working arrays used during the layout algorithm.
+ BufferRequirements* requirements_;
+ // buffer_sizes_sorted_ and buffer_ids_sorted_ are sorted according to:
+ // {
+ // offline planned buffers,
+ // online planned buffers sorted by size
+ // }
+ int* buffer_sizes_sorted_;
+ int* buffer_ids_sorted_;
+ ListEntry* buffers_sorted_by_offset_;
+ int next_free_entry_; // Index of the next free entry of
+ // buffers_sorted_by_offset_
+ int first_entry_index_; // Index of the first entry (smallest offset) of
+ // buffers_sorted_by_offset_
+
+ // Stores the outcome of the plan, the location of each buffer in the arena.
+ int* buffer_offsets_;
+
+ // Whether buffers have been added since the last plan was calculated.
+ bool need_to_calculate_offsets_;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_GREEDY_MEMORY_PLANNER_H_
diff --git a/tensorflow/lite/micro/memory_planner/greedy_memory_planner_test.cc b/tensorflow/lite/micro/memory_planner/greedy_memory_planner_test.cc
new file mode 100644
index 0000000..48b1785
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/greedy_memory_planner_test.cc
@@ -0,0 +1,273 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/memory_planner/greedy_memory_planner.h"
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+// We don't declare this in the header since it's not a public interface, but we
+// need to call it to test it, so declare it here instead.
+void ReverseSortInPlace(int* values, int* ids, int size);
+} // namespace tflite
+
+namespace {
+constexpr int kScratchBufferSize = 4096;
+unsigned char g_scratch_buffer[kScratchBufferSize];
+} // namespace
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestReverseSortInPlace) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ constexpr int a_size = 10;
+ int a_values[a_size] = {10, 9, 8, 7, 6, 5, 4, 3, 2, 1};
+ int a_ids[a_size] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
+ const int a_expected_values[a_size] = {10, 9, 8, 7, 6, 5, 4, 3, 2, 1};
+ const int a_expected_ids[a_size] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
+ tflite::ReverseSortInPlace(a_values, a_ids, a_size);
+ for (int i = 0; i < a_size; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(a_expected_values[i], a_values[i]);
+ TF_LITE_MICRO_EXPECT_EQ(a_expected_ids[i], a_ids[i]);
+ }
+
+ constexpr int b_size = 10;
+ int b_values[b_size] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
+ int b_ids[b_size] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
+ const int b_expected_values[b_size] = {10, 9, 8, 7, 6, 5, 4, 3, 2, 1};
+ const int b_expected_ids[b_size] = {9, 8, 7, 6, 5, 4, 3, 2, 1, 0};
+ tflite::ReverseSortInPlace(b_values, b_ids, b_size);
+ for (int i = 0; i < b_size; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(b_expected_values[i], b_values[i]);
+ TF_LITE_MICRO_EXPECT_EQ(b_expected_ids[i], b_ids[i]);
+ }
+
+ constexpr int c_size = 100;
+ int c_values[c_size] = {
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
+ int c_ids[c_size] = {
+ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
+ 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
+ 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
+ 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67,
+ 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84,
+ 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99};
+ const int c_expected_values[c_size] = {
+ 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9,
+ 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
+ 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
+ 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
+ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
+ const int c_expected_ids[c_size] = {
+ 9, 19, 29, 39, 49, 59, 69, 79, 89, 99, 8, 18, 28, 38, 48, 58, 68,
+ 78, 88, 98, 7, 17, 27, 37, 47, 57, 67, 77, 87, 97, 6, 16, 26, 36,
+ 46, 56, 66, 76, 86, 96, 5, 15, 25, 35, 45, 55, 65, 75, 85, 95, 4,
+ 14, 24, 34, 44, 54, 64, 74, 84, 94, 3, 13, 23, 33, 43, 53, 63, 73,
+ 83, 93, 2, 12, 22, 32, 42, 52, 62, 72, 82, 92, 1, 11, 21, 31, 41,
+ 51, 61, 71, 81, 91, 0, 10, 20, 30, 40, 50, 60, 70, 80, 90};
+ tflite::ReverseSortInPlace(c_values, c_ids, c_size);
+ for (int i = 0; i < c_size; ++i) {
+ TF_LITE_MICRO_EXPECT_EQ(c_expected_values[i], c_values[i]);
+ TF_LITE_MICRO_EXPECT_EQ(c_expected_ids[i], c_ids[i]);
+ }
+}
+
+TF_LITE_MICRO_TEST(TestGreedyBasics) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ tflite::GreedyMemoryPlanner planner(g_scratch_buffer, kScratchBufferSize);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 10, 0, 1));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 20, 2, 3));
+
+ TF_LITE_MICRO_EXPECT_EQ(false,
+ planner.DoAnyBuffersOverlap(µ_error_reporter));
+
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(20),
+ planner.GetMaximumMemorySize());
+
+ int offset = -1;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 0, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(0, offset);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 1, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(0, offset);
+}
+
+TF_LITE_MICRO_TEST(TestGreedyMedium) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ tflite::GreedyMemoryPlanner planner(g_scratch_buffer, kScratchBufferSize);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 10, 0, 1));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 20, 1, 2));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 30, 2, 3));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 40, 3, 4));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 50, 0, 1));
+
+ int offset = -1;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 0, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(50, offset);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 1, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(70, offset);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 2, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(40, offset);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 3, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(0, offset);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 4, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(0, offset);
+
+ planner.PrintMemoryPlan(µ_error_reporter);
+
+ TF_LITE_MICRO_EXPECT_EQ(false,
+ planner.DoAnyBuffersOverlap(µ_error_reporter));
+
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(90),
+ planner.GetMaximumMemorySize());
+}
+
+TF_LITE_MICRO_TEST(TestPersonDetectionModel) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ tflite::GreedyMemoryPlanner planner(g_scratch_buffer, kScratchBufferSize);
+ // These buffer sizes and time ranges are taken from the 250KB MobileNet model
+ // used in the person detection example.
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 9216, 0, 29));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 3, 28, 29));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 256, 27, 28));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 26, 27));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 25, 26));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 24, 25));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 1152, 23, 24));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 22, 23));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 21, 22));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 20, 21));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 19, 20));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 18, 19));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 17, 18));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 16, 17));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 15, 16));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 14, 15));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 13, 14));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 12, 13));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 11, 12));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 9216, 10, 11));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 9216, 9, 10));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 9216, 8, 9));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 4608, 7, 8));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 6, 7));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 5, 6));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 4, 5));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 9216, 3, 4));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 36864, 2, 3));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 1, 2));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 0, 1));
+
+ planner.PrintMemoryPlan(µ_error_reporter);
+
+ TF_LITE_MICRO_EXPECT_EQ(false,
+ planner.DoAnyBuffersOverlap(µ_error_reporter));
+
+ // The sum of all the buffers is 241,027 bytes, so we at least expect the plan
+ // to come up with something smaller than this.
+ TF_LITE_MICRO_EXPECT_GT(static_cast<size_t>(241027),
+ planner.GetMaximumMemorySize());
+}
+
+TF_LITE_MICRO_TEST(TestOverlapCase) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ tflite::GreedyMemoryPlanner planner(g_scratch_buffer, kScratchBufferSize);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 100, 0, 1));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 50, 2, 3));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 20, 1, 2));
+
+ planner.PrintMemoryPlan(µ_error_reporter);
+
+ TF_LITE_MICRO_EXPECT_EQ(false,
+ planner.DoAnyBuffersOverlap(µ_error_reporter));
+
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(120),
+ planner.GetMaximumMemorySize());
+}
+
+TF_LITE_MICRO_TEST(TestSmallScratch) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ constexpr int scratch_buffer_size = 40;
+ unsigned char scratch_buffer[scratch_buffer_size];
+ tflite::GreedyMemoryPlanner planner(scratch_buffer, scratch_buffer_size);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 100, 0, 1));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError,
+ planner.AddBuffer(µ_error_reporter, 50, 2, 3));
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/memory_planner/linear_memory_planner.cc b/tensorflow/lite/micro/memory_planner/linear_memory_planner.cc
new file mode 100644
index 0000000..d25a4f2
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/linear_memory_planner.cc
@@ -0,0 +1,54 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/memory_planner/linear_memory_planner.h"
+
+namespace tflite {
+
+LinearMemoryPlanner::LinearMemoryPlanner()
+ : current_buffer_count_(0), next_free_offset_(0) {}
+LinearMemoryPlanner::~LinearMemoryPlanner() {}
+
+TfLiteStatus LinearMemoryPlanner::AddBuffer(
+ tflite::ErrorReporter* error_reporter, int size, int first_time_used,
+ int last_time_used) {
+ if (current_buffer_count_ >= kMaxBufferCount) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Too many buffers (max is %d)",
+ kMaxBufferCount);
+ return kTfLiteError;
+ }
+ buffer_offsets_[current_buffer_count_] = next_free_offset_;
+ next_free_offset_ += size;
+ ++current_buffer_count_;
+ return kTfLiteOk;
+}
+
+size_t LinearMemoryPlanner::GetMaximumMemorySize() { return next_free_offset_; }
+
+int LinearMemoryPlanner::GetBufferCount() { return current_buffer_count_; }
+
+TfLiteStatus LinearMemoryPlanner::GetOffsetForBuffer(
+ tflite::ErrorReporter* error_reporter, int buffer_index, int* offset) {
+ if ((buffer_index < 0) || (buffer_index >= current_buffer_count_)) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "buffer index %d is outside range 0 to %d",
+ buffer_index, current_buffer_count_);
+ return kTfLiteError;
+ }
+ *offset = buffer_offsets_[buffer_index];
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/memory_planner/linear_memory_planner.h b/tensorflow/lite/micro/memory_planner/linear_memory_planner.h
new file mode 100644
index 0000000..4d77e77
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/linear_memory_planner.h
@@ -0,0 +1,50 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_LINEAR_MEMORY_PLANNER_H_
+#define TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_LINEAR_MEMORY_PLANNER_H_
+
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/memory_planner/memory_planner.h"
+
+namespace tflite {
+
+// The simplest possible memory planner that just lays out all buffers at
+// increasing offsets without trying to reuse memory.
+class LinearMemoryPlanner : public MemoryPlanner {
+ public:
+ LinearMemoryPlanner();
+ ~LinearMemoryPlanner() override;
+
+ TfLiteStatus AddBuffer(tflite::ErrorReporter* error_reporter, int size,
+ int first_time_used, int last_time_used) override;
+
+ size_t GetMaximumMemorySize() override;
+ int GetBufferCount() override;
+ TfLiteStatus GetOffsetForBuffer(tflite::ErrorReporter* error_reporter,
+ int buffer_index, int* offset) override;
+
+ private:
+ static constexpr int kMaxBufferCount = 1024;
+ size_t buffer_offsets_[kMaxBufferCount];
+ int current_buffer_count_;
+ size_t next_free_offset_;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_LINEAR_MEMORY_PLANNER_H_
diff --git a/tensorflow/lite/micro/memory_planner/linear_memory_planner_test.cc b/tensorflow/lite/micro/memory_planner/linear_memory_planner_test.cc
new file mode 100644
index 0000000..dc13684
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/linear_memory_planner_test.cc
@@ -0,0 +1,124 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/memory_planner/linear_memory_planner.h"
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestBasics) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ tflite::LinearMemoryPlanner planner;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 10, 0, 1));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 20, 1, 2));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(30),
+ planner.GetMaximumMemorySize());
+
+ int offset = -1;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 0, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(0, offset);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.GetOffsetForBuffer(µ_error_reporter, 1, &offset));
+ TF_LITE_MICRO_EXPECT_EQ(10, offset);
+}
+
+TF_LITE_MICRO_TEST(TestErrorHandling) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ tflite::LinearMemoryPlanner planner;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 10, 0, 1));
+
+ int offset = -1;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError, planner.GetOffsetForBuffer(
+ µ_error_reporter, 1, &offset));
+}
+
+TF_LITE_MICRO_TEST(TestPersonDetectionModel) {
+ tflite::MicroErrorReporter micro_error_reporter;
+
+ tflite::LinearMemoryPlanner planner;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 9216, 0, 29));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 3, 28, 29));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 256, 27, 28));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 26, 27));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 25, 26));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 24, 25));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 1152, 23, 24));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 22, 23));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 21, 22));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 20, 21));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 19, 20));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 18, 19));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 17, 18));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 16, 17));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 15, 16));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 14, 15));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 13, 14));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 4608, 12, 13));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 2304, 11, 12));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 9216, 10, 11));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 9216, 9, 10));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 9216, 8, 9));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 4608, 7, 8));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 6, 7));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 5, 6));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 4, 5));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ planner.AddBuffer(µ_error_reporter, 9216, 3, 4));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 36864, 2, 3));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 1, 2));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, planner.AddBuffer(µ_error_reporter, 18432, 0, 1));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(241027),
+ planner.GetMaximumMemorySize());
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/memory_planner/memory_planner.h b/tensorflow/lite/micro/memory_planner/memory_planner.h
new file mode 100644
index 0000000..2c39fbe
--- /dev/null
+++ b/tensorflow/lite/micro/memory_planner/memory_planner.h
@@ -0,0 +1,71 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_MEMORY_PLANNER_H_
+#define TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_MEMORY_PLANNER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+
+namespace tflite {
+
+// Interface class for planning the layout of memory buffers during the
+// execution of a graph.
+// It's designed to be used by a client that iterates in any order through the
+// buffers it wants to lay out, and then calls the getter functions for
+// information about the calculated layout. For example:
+//
+// SomeMemoryPlanner planner;
+// planner.AddBuffer(reporter, 100, 0, 1); // Buffer 0
+// planner.AddBuffer(reporter, 50, 2, 3); // Buffer 1
+// planner.AddBuffer(reporter, 50, 2, 3); // Buffer 2
+//
+// int offset0;
+// TF_EXPECT_OK(planner.GetOffsetForBuffer(reporter, 0, &offset0));
+// int offset1;
+// TF_EXPECT_OK(planner.GetOffsetForBuffer(reporter, 1, &offset1));
+// int offset2;
+// TF_EXPECT_OK(planner.GetOffsetForBuffer(reporter, 2, &offset2));
+// const int arena_size_needed = planner.GetMaximumMemorySize();
+//
+// The goal is for applications to be able to experiment with different layout
+// strategies without changing their client code, by swapping out classes that
+// implement this interface.=
+class MemoryPlanner {
+ public:
+ MemoryPlanner() {}
+ virtual ~MemoryPlanner() {}
+
+ // Pass information about a buffer's size and lifetime to the layout
+ // algorithm. The order this is called implicitly assigns an index to the
+ // result, so the buffer information that's passed into the N-th call of
+ // this method will be used as the buffer_index argument to
+ // GetOffsetForBuffer().
+ virtual TfLiteStatus AddBuffer(tflite::ErrorReporter* error_reporter,
+ int size, int first_time_used,
+ int last_time_used) = 0;
+
+ // The largest contiguous block of memory that's needed to hold the layout.
+ virtual size_t GetMaximumMemorySize() = 0;
+ // How many buffers have been added to the planner.
+ virtual int GetBufferCount() = 0;
+ // Calculated layout offset for the N-th buffer added to the planner.
+ virtual TfLiteStatus GetOffsetForBuffer(tflite::ErrorReporter* error_reporter,
+ int buffer_index, int* offset) = 0;
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MEMORY_PLANNER_MEMORY_PLANNER_H_
diff --git a/tensorflow/lite/micro/micro_allocator.cc b/tensorflow/lite/micro/micro_allocator.cc
new file mode 100644
index 0000000..fabcdd4
--- /dev/null
+++ b/tensorflow/lite/micro/micro_allocator.cc
@@ -0,0 +1,1142 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_allocator.h"
+
+#include <cstddef>
+#include <cstdint>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/core/api/flatbuffer_conversions.h"
+#include "tensorflow/lite/core/api/op_resolver.h"
+#include "tensorflow/lite/core/api/tensor_utils.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+#include "tensorflow/lite/micro/memory_planner/greedy_memory_planner.h"
+#include "tensorflow/lite/micro/memory_planner/memory_planner.h"
+#include "tensorflow/lite/micro/micro_op_resolver.h"
+#include "tensorflow/lite/micro/simple_memory_allocator.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+#include "tensorflow/lite/schema/schema_utils.h"
+
+namespace tflite {
+
+namespace {
+
+// Maximum number of scratch buffer requests per operator. Operator kernels that
+// request more than this value will receive an exception.
+constexpr size_t kMaxScratchBuffersPerOp = 12;
+
+// Sentinel value used as a placeholder to mark a ScratchBufferRequest request
+// needs a node id assignment.
+constexpr int kUnassignedScratchBufferRequestIndex = -1;
+
+// Used to hold information used during allocation calculations.
+struct AllocationInfo {
+ size_t bytes;
+ void** output_ptr;
+ int first_created;
+ int last_used;
+ int32_t offline_offset;
+ bool needs_allocating;
+};
+
+// We align tensor buffers to 16-byte boundaries, since this is a common
+// requirement for SIMD extensions.
+constexpr int kBufferAlignment = 16;
+constexpr char kOfflineMemAllocMetadata[] = "OfflineMemoryAllocation";
+const TfLiteIntArray kZeroLengthIntArray = {};
+
+class MicroBuiltinDataAllocator : public BuiltinDataAllocator {
+ public:
+ explicit MicroBuiltinDataAllocator(SimpleMemoryAllocator* memory_allocator)
+ : memory_allocator_(memory_allocator) {}
+
+ void* Allocate(size_t size, size_t alignment_hint) override {
+ return memory_allocator_->AllocateFromTail(size, alignment_hint);
+ }
+ void Deallocate(void* data) override {
+ // Do not deallocate, builtin data needs to be available for the life time
+ // of the model.
+ }
+
+ private:
+ SimpleMemoryAllocator* memory_allocator_;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+#if !defined(__clang__)
+// Helper function to check flatbuffer metadata correctness. This function is
+// not called by default. Hence it's not linked in to the final binary code.
+TfLiteStatus CheckOfflinePlannedOffsets(const Model* model,
+ ErrorReporter* error_reporter) {
+ // Suppress compile warning for unused function
+ (void)CheckOfflinePlannedOffsets;
+
+ if (model->metadata()) {
+ for (size_t i = 0; i < model->metadata()->size(); ++i) {
+ auto metadata = model->metadata()->Get(i);
+ if (strncmp(metadata->name()->c_str(), kOfflineMemAllocMetadata,
+ strlen(kOfflineMemAllocMetadata)) == 0) {
+ auto* subgraphs = model->subgraphs();
+ const SubGraph* subgraph = (*subgraphs)[0];
+ const flatbuffers::Vector<flatbuffers::Offset<Tensor>>* tensors =
+ subgraph->tensors();
+ const flatbuffers::Vector<flatbuffers::Offset<Buffer>>* buffers =
+ model->buffers();
+ int nbr_tflite_tensors = tensors->size();
+ auto* buffer = (*buffers)[metadata->buffer()];
+ auto* array = buffer->data();
+ const uint32_t* metadata_buffer = (uint32_t*)array->data();
+ int version = metadata_buffer[0];
+ int subgraph_idx = metadata_buffer[1];
+ const int nbr_offline_offsets = metadata_buffer[2];
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ int* offline_planner_offsets = (int*)&metadata_buffer[3];
+#endif
+
+ TF_LITE_REPORT_ERROR(error_reporter, "==== Model metadata info: =====");
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Offline planner metadata found, version %d, "
+ "subgraph %d, nbr offline offsets %d",
+ version, subgraph_idx, nbr_offline_offsets);
+ for (int j = 0; j < nbr_offline_offsets; ++j) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "Offline planner tensor index %d, offline offset: %d", j,
+ offline_planner_offsets[j]);
+ }
+
+ if (version != 1) {
+ TF_LITE_REPORT_ERROR(error_reporter, "Version not supported! (%d)\n",
+ version);
+ return kTfLiteError;
+ }
+ if (subgraph_idx != 0) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Only 1 subgraph supported! Subgraph idx (%d)\n",
+ subgraph_idx);
+ return kTfLiteError;
+ }
+ if (nbr_tflite_tensors != nbr_offline_offsets) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Nbr of offline buffer offsets (%d) in metadata "
+ "not equal nbr tensors (%d)\n",
+ nbr_offline_offsets, nbr_tflite_tensors);
+ return kTfLiteError;
+ }
+ }
+ }
+ }
+ return kTfLiteOk;
+}
+#endif
+
+// A helper class to construct AllocationInfo array. This array contains the
+// lifetime of tensors / scratch_buffer and will be used to calculate the memory
+// plan. Methods need to be called in order from `Init`, `Add*`, to `Finish`.
+class AllocationInfoBuilder {
+ public:
+ AllocationInfoBuilder(AllocationInfo* info, size_t tensor_count,
+ size_t scratch_buffer_count, ErrorReporter* reporter)
+ : info_(info),
+ tensor_count_(tensor_count),
+ buffer_count_(scratch_buffer_count),
+ reporter_(reporter) {}
+
+ // Check if model contains offline planned buffer offsets.
+ // - If there's no metadata available, offline_planner_offsets is not set
+ // - If there's metadata available, offline_planner_offsets will point to the
+ // first offset in the metadata buffer list.
+ TfLiteStatus GetOfflinePlannedOffsets(
+ const Model* model, const int32_t** offline_planner_offsets);
+
+ // Add allocaiton information for the tensors.
+ TfLiteStatus AddTensors(const SubGraph* subgraph,
+ const int32_t* offline_offsets,
+ TfLiteEvalTensor* eval_tensors);
+
+ // Add allocation information for the scratch buffers.
+ TfLiteStatus AddScratchBuffers(
+ internal::ScratchBufferRequest* scratch_buffer_requests,
+ ScratchBufferHandle* scratch_buffer_handles);
+
+ // Returns a pointer to the built AllocationInfo array.
+ const AllocationInfo* Finish() const { return info_; }
+
+ private:
+ AllocationInfo* info_ = nullptr;
+ size_t tensor_count_ = 0;
+ size_t buffer_count_ = 0;
+ ErrorReporter* reporter_ = nullptr;
+};
+
+TfLiteStatus AllocationInfoBuilder::AddTensors(const SubGraph* subgraph,
+ const int32_t* offline_offsets,
+ TfLiteEvalTensor* eval_tensors) {
+ TFLITE_DCHECK(eval_tensors != nullptr);
+
+ // Set up allocation info for all tensors.
+ for (size_t i = 0; i < tensor_count_; ++i) {
+ AllocationInfo* current = &info_[i];
+ current->output_ptr = &(eval_tensors[i].data.data);
+
+ TF_LITE_ENSURE_STATUS(
+ TfLiteEvalTensorByteLength(&eval_tensors[i], ¤t->bytes));
+
+ current->first_created = -1;
+ current->last_used = -1;
+ current->needs_allocating = (eval_tensors[i].data.data == nullptr) &&
+ (!subgraph->tensors()->Get(i)->is_variable());
+ if (offline_offsets) {
+ current->offline_offset = offline_offsets[i];
+ } else {
+ current->offline_offset = kOnlinePlannedBuffer;
+ }
+ }
+
+ for (size_t i = 0; i < subgraph->inputs()->size(); ++i) {
+ const int tensor_index = subgraph->inputs()->Get(i);
+ AllocationInfo* current = &info_[tensor_index];
+ current->first_created = 0;
+ }
+
+ // Mark all outputs as persistent to the end of the invocation.
+ for (size_t i = 0; i < subgraph->outputs()->size(); ++i) {
+ const int tensor_index = subgraph->outputs()->Get(i);
+ AllocationInfo* current = &info_[tensor_index];
+ current->last_used = subgraph->operators()->size() - 1;
+ }
+
+ // Figure out when the first and last use of each tensor is.
+ for (int i = (subgraph->operators()->size() - 1); i >= 0; --i) {
+ const auto* op = subgraph->operators()->Get(i);
+ for (size_t n = 0; n < op->inputs()->size(); ++n) {
+ const int tensor_index = op->inputs()->Get(n);
+ AllocationInfo* current = &info_[tensor_index];
+ if (((current->last_used == -1) || (current->last_used < i))) {
+ current->last_used = i;
+ }
+ }
+ for (size_t n = 0; n < op->outputs()->size(); ++n) {
+ const int tensor_index = op->outputs()->Get(n);
+ AllocationInfo* current = &info_[tensor_index];
+ if ((current->first_created == -1) || (current->first_created > i)) {
+ current->first_created = i;
+ }
+ }
+ }
+
+ // Sanity check for valid tensor lifetime.
+ for (size_t i = 0; i < tensor_count_; ++i) {
+ AllocationInfo* current = &info_[i];
+ // Even though tensor appears to be read only it may still need to be
+ // allocated.
+ const bool appears_read_only =
+ (current->first_created == -1) && (current->last_used != -1);
+ const bool has_partial_lifetime =
+ !appears_read_only &&
+ ((current->first_created == -1) || (current->last_used == -1));
+ if (has_partial_lifetime && current->needs_allocating) {
+ TF_LITE_REPORT_ERROR(
+ reporter_,
+ "Logic error in memory planner, tensor %d has an invalid lifetime: "
+ "first_created: %d, last_used: %d",
+ i, current->first_created, current->last_used);
+ return kTfLiteError;
+ }
+ }
+ return kTfLiteOk;
+}
+
+// Get offline tensors allocation plan. See
+// micro/docs/memory_management.md for more info.
+TfLiteStatus AllocationInfoBuilder::GetOfflinePlannedOffsets(
+ const Model* model, const int32_t** offline_planner_offsets) {
+ if (model->metadata()) {
+ for (size_t i = 0; i < model->metadata()->size(); ++i) {
+ auto metadata = model->metadata()->Get(i);
+ if (strncmp(metadata->name()->c_str(), kOfflineMemAllocMetadata,
+ strlen(kOfflineMemAllocMetadata)) == 0) {
+ const flatbuffers::Vector<flatbuffers::Offset<Buffer>>* buffers =
+ model->buffers();
+ auto* buffer = (*buffers)[metadata->buffer()];
+ auto* array = buffer->data();
+ const uint32_t* metadata_buffer =
+ reinterpret_cast<const uint32_t*>(array->data());
+ const size_t nbr_tensors = static_cast<size_t>(metadata_buffer[2]);
+ *offline_planner_offsets =
+ reinterpret_cast<const int32_t*>(&metadata_buffer[3]);
+
+ if (tensor_count_ != nbr_tensors) {
+ TF_LITE_REPORT_ERROR(reporter_,
+ "Nbr of offline buffer offsets (%d) in metadata "
+ "not equal nbr tensors (%d)\n",
+ nbr_tensors, tensor_count_);
+ return kTfLiteError;
+ }
+ }
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus AllocationInfoBuilder::AddScratchBuffers(
+ internal::ScratchBufferRequest* scratch_buffer_requests,
+ ScratchBufferHandle* scratch_buffer_handles) {
+ // Set up allocation info for buffers.
+ for (size_t i = tensor_count_; i < tensor_count_ + buffer_count_; ++i) {
+ internal::ScratchBufferRequest* current_request =
+ &(scratch_buffer_requests[i - tensor_count_]);
+ ScratchBufferHandle* current_handle =
+ &(scratch_buffer_handles[i - tensor_count_]);
+
+ AllocationInfo* current = &info_[i];
+ current->output_ptr = reinterpret_cast<void**>(¤t_handle->data);
+ current->bytes = current_request->bytes;
+ current->first_created = current_request->node_idx;
+ current->last_used = current_request->node_idx;
+ current->offline_offset = kOnlinePlannedBuffer;
+ current->needs_allocating = true;
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus CreatePlan(ErrorReporter* error_reporter,
+ GreedyMemoryPlanner* planner,
+ const AllocationInfo* allocation_info,
+ size_t allocation_info_size) {
+ // Add the tensors to our allocation plan.
+ for (size_t i = 0; i < allocation_info_size; ++i) {
+ const AllocationInfo* current = &allocation_info[i];
+ if (current->needs_allocating) {
+ size_t aligned_bytes_required =
+ AlignSizeUp(current->bytes, kBufferAlignment);
+ if (current->offline_offset == kOnlinePlannedBuffer) {
+ TF_LITE_ENSURE_STATUS(
+ planner->AddBuffer(error_reporter, aligned_bytes_required,
+ current->first_created, current->last_used));
+ } else {
+ TF_LITE_ENSURE_STATUS(planner->AddBuffer(
+ error_reporter, aligned_bytes_required, current->first_created,
+ current->last_used, current->offline_offset));
+ }
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus CommitPlan(ErrorReporter* error_reporter, MemoryPlanner* planner,
+ uint8_t* starting_point,
+ const AllocationInfo* allocation_info,
+ size_t allocation_info_size) {
+ // Figure out the actual memory addresses for each buffer, based on the plan.
+ int planner_index = 0;
+ for (size_t i = 0; i < allocation_info_size; ++i) {
+ const AllocationInfo* current = &allocation_info[i];
+ if (current->needs_allocating) {
+ int offset = -1;
+ TF_LITE_ENSURE_STATUS(
+ planner->GetOffsetForBuffer(error_reporter, planner_index, &offset));
+ *current->output_ptr = reinterpret_cast<void*>(starting_point + offset);
+ ++planner_index;
+ }
+ }
+ return kTfLiteOk;
+}
+} // namespace
+
+namespace internal {
+
+// Handles architecture safe mapping of flatbuffer vectors to a TfLite*Array
+// struct. Matching types are required (e.g. float and TfLiteFloatArray).
+// Big-endian systems will always allocate dimension array data in the tail
+// (persistent) section.
+template <typename kFlatBufferVectorType, typename kTfLiteArrayType>
+TfLiteStatus FlatBufferVectorToTfLiteTypeArray(
+ SimpleMemoryAllocator* allocator, ErrorReporter* error_reporter,
+ const flatbuffers::Vector<kFlatBufferVectorType>* flatbuffer_array,
+ kTfLiteArrayType** result) {
+ TFLITE_DCHECK(error_reporter != nullptr);
+ TFLITE_DCHECK(flatbuffer_array != nullptr);
+ // TODO(b/159668691): Consider adding type assertion or breaking this function
+ // into multiple functions for each type. std::is_same is c++11 and has a
+ // special updated constructor in c++17 that requires a string argument.
+ if (FLATBUFFERS_LITTLEENDIAN) {
+ // On little-endian machines, TfLite*Array happens to have the same memory
+ // layout as flatbuffers:Vector<kFlatBufferVectorType>, so we can
+ // reinterpret_cast the flatbuffer vector and avoid a copy and malloc.
+ *result = const_cast<kTfLiteArrayType*>(
+ reinterpret_cast<const kTfLiteArrayType*>(flatbuffer_array));
+ } else {
+ // Big-endian architecture can not use the same memory layout as
+ // flatbuffers::Vector<kFlatBufferVectorType>. Allocate from the tail and
+ // copy values from the flatbuffer into the newly allocated chunk.
+ kTfLiteArrayType* array =
+ reinterpret_cast<kTfLiteArrayType*>(allocator->AllocateFromTail(
+ TfLiteIntArrayGetSizeInBytes(flatbuffer_array->Length()),
+ alignof(kTfLiteArrayType)));
+ if (array == nullptr) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter,
+ "Failed to allocate %d bytes of memory to copy an array.",
+ TfLiteIntArrayGetSizeInBytes(flatbuffer_array->Length()));
+ return kTfLiteError;
+ }
+ array->size = flatbuffer_array->Length();
+ for (int i = 0; i < array->size; ++i) {
+ array->data[i] = flatbuffer_array->Get(i);
+ }
+ *result = array;
+ }
+ return kTfLiteOk;
+}
+
+// Returns a pointer to any buffer associated with the flatbuffer tensor. Can
+// return nullptr if no buffer is found.
+void* GetFlatbufferTensorBuffer(
+ const tflite::Tensor& flatbuffer_tensor,
+ const flatbuffers::Vector<flatbuffers::Offset<Buffer>>* buffers) {
+ // We need to figure out where the actual contents of this tensor are stored
+ // in memory. We'll check to see if there's a serialized buffer (pretty much
+ // the same as a constant op in TensorFlow) associated with this tensor first,
+ // and if there is update the runtime structure to point to its location in
+ // memory.
+ // First see if there's any buffer information in the serialized tensor.
+ // TODO(b/170379532): Add better unit tests to validate flatbuffer values.
+ void* out_buffer = nullptr;
+ if (auto* buffer = (*buffers)[flatbuffer_tensor.buffer()]) {
+ // If we've found a buffer, does it have any data?
+ if (auto* array = buffer->data()) {
+ // If it has any data, is the data size larger than zero?
+ if (array->size()) {
+ // We've found a buffer with valid data, so update the runtime tensor
+ // data structure to point to it.
+ out_buffer = const_cast<void*>(static_cast<const void*>(array->data()));
+ }
+ }
+ // TODO(petewarden): It's not clear in what circumstances we could have a
+ // buffer in the serialized tensor, but it doesn't have any data in it. Is
+ // that a validly-generated file, and if so what does it mean, or is it an
+ // error condition? It would be good to tighten up the specification to make
+ // it less ambiguous.
+ }
+ return out_buffer;
+}
+
+TfLiteStatus InitializeTfLiteTensorFromFlatbuffer(
+ SimpleMemoryAllocator* allocator, bool allocate_temp,
+ const tflite::Tensor& flatbuffer_tensor,
+ const flatbuffers::Vector<flatbuffers::Offset<Buffer>>* buffers,
+ ErrorReporter* error_reporter, TfLiteTensor* result) {
+ TFLITE_DCHECK(result != nullptr);
+
+ *result = {};
+ // Make sure the serialized type is one we know how to deal with, and convert
+ // it from a flatbuffer enum into a constant used by the kernel C API.
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(flatbuffer_tensor.type(),
+ &result->type, error_reporter));
+ // Make sure we remember if the serialized tensor is designated as a variable.
+ result->is_variable = flatbuffer_tensor.is_variable();
+
+ result->data.data = GetFlatbufferTensorBuffer(flatbuffer_tensor, buffers);
+
+ // TODO(petewarden): Some of these paths aren't getting enough testing
+ // coverage, so we should figure out some tests that exercise them.
+ if (result->data.data == nullptr) {
+ // The tensor contents haven't been set from a serialized buffer, so
+ // make a note that they will be allocated from memory. The actual
+ // allocation won't happen until later.
+ result->allocation_type = kTfLiteArenaRw;
+ } else {
+ // We set the data from a serialized buffer, so record tha.
+ result->allocation_type = kTfLiteMmapRo;
+ }
+
+ // Figure out what the size in bytes of the buffer is and store it.
+ size_t type_size;
+ TF_LITE_ENSURE_STATUS(BytesRequiredForTensor(
+ flatbuffer_tensor, &result->bytes, &type_size, error_reporter));
+
+ if (flatbuffer_tensor.shape() == nullptr) {
+ // flatbuffer_tensor.shape() can return a nullptr in the case of a scalar
+ // tensor.
+ result->dims = const_cast<TfLiteIntArray*>(&kZeroLengthIntArray);
+ } else {
+ // TFLM doesn't allow reshaping the tensor which requires dynamic memory
+ // allocation so it is safe to drop the const qualifier. In the future, if
+ // we really want to update the tensor shape, we can always pass in a new
+ // TfLiteIntArray - especially we have to do so if the dimension is
+ TF_LITE_ENSURE_STATUS(FlatBufferVectorToTfLiteTypeArray(
+ allocator, error_reporter, flatbuffer_tensor.shape(), &(result->dims)));
+ }
+
+ // Copy the quantization information from the serialized data.
+ const auto* src_quantization = flatbuffer_tensor.quantization();
+ if (src_quantization && src_quantization->scale() &&
+ (src_quantization->scale()->size() > 0) &&
+ src_quantization->zero_point() &&
+ (src_quantization->zero_point()->size() > 0)) {
+ // Always populate the TfLiteTensor.params field, even if there are
+ // per-channel quantization parameters.
+ result->params.scale = src_quantization->scale()->Get(0);
+ // Note that the zero_point field in the FlatBuffers schema is a 64-bit
+ // integer, but the zero_point field in the TfLiteQuantizationParams struct
+ // is a 32-bit integer.
+ result->params.zero_point =
+ static_cast<int32_t>(src_quantization->zero_point()->Get(0));
+
+ // Populate per-channel quantization params.
+ int channels = src_quantization->scale()->size();
+ TfLiteAffineQuantization* quantization =
+ allocate_temp
+ ? reinterpret_cast<TfLiteAffineQuantization*>(
+ allocator->AllocateTemp(sizeof(TfLiteAffineQuantization),
+ alignof(TfLiteAffineQuantization)))
+ : reinterpret_cast<TfLiteAffineQuantization*>(
+ allocator->AllocateFromTail(
+ sizeof(TfLiteAffineQuantization),
+ alignof(TfLiteAffineQuantization)));
+ if (quantization == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Unable to allocate TfLiteAffineQuantization.\n");
+ return kTfLiteError;
+ }
+
+ // TODO(b/153688719): Reduce tail allocation by using a global zero-point
+ // buffer. This value can not be reused from the flatbuffer since the
+ // zero_point is stored as a int64_t.
+ quantization->zero_point =
+ allocate_temp
+ ? reinterpret_cast<TfLiteIntArray*>(allocator->AllocateTemp(
+ TfLiteIntArrayGetSizeInBytes(channels),
+ alignof(TfLiteIntArray)))
+ : reinterpret_cast<TfLiteIntArray*>(allocator->AllocateFromTail(
+ TfLiteIntArrayGetSizeInBytes(channels),
+ alignof(TfLiteIntArray)));
+ if (quantization->zero_point == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Unable to allocate quantization->zero_point.\n");
+ return kTfLiteError;
+ }
+
+ TF_LITE_ENSURE_STATUS(FlatBufferVectorToTfLiteTypeArray(
+ allocator, error_reporter, src_quantization->scale(),
+ &quantization->scale));
+
+ quantization->zero_point->size = channels;
+ int* zero_point_data = quantization->zero_point->data;
+ for (int i = 0; i < channels; i++) {
+ zero_point_data[i] = src_quantization->zero_point()->Get(i);
+ }
+ // TODO(rocky): Need to add a micro_allocator test case that fails when
+ // this is not copied:
+ quantization->quantized_dimension = src_quantization->quantized_dimension();
+
+ result->quantization = {kTfLiteAffineQuantization, quantization};
+ }
+ return kTfLiteOk;
+}
+
+TfLiteStatus InitializeTfLiteEvalTensorFromFlatbuffer(
+ SimpleMemoryAllocator* allocator, const tflite::Tensor& flatbuffer_tensor,
+ const flatbuffers::Vector<flatbuffers::Offset<Buffer>>* buffers,
+ ErrorReporter* error_reporter, TfLiteEvalTensor* result) {
+ *result = {};
+ // Make sure the serialized type is one we know how to deal with, and convert
+ // it from a flatbuffer enum into a constant used by the kernel C API.
+ TF_LITE_ENSURE_STATUS(ConvertTensorType(flatbuffer_tensor.type(),
+ &result->type, error_reporter));
+
+ result->data.data = GetFlatbufferTensorBuffer(flatbuffer_tensor, buffers);
+
+ if (flatbuffer_tensor.shape() == nullptr) {
+ // flatbuffer_tensor.shape() can return a nullptr in the case of a scalar
+ // tensor.
+ result->dims = const_cast<TfLiteIntArray*>(&kZeroLengthIntArray);
+ } else {
+ TF_LITE_ENSURE_STATUS(FlatBufferVectorToTfLiteTypeArray(
+ allocator, error_reporter, flatbuffer_tensor.shape(), &(result->dims)));
+ }
+ return kTfLiteOk;
+}
+
+} // namespace internal
+
+MicroAllocator::MicroAllocator(SimpleMemoryAllocator* memory_allocator,
+ ErrorReporter* error_reporter)
+ : memory_allocator_(memory_allocator),
+ error_reporter_(error_reporter),
+ model_is_allocating_(false) {}
+
+MicroAllocator::~MicroAllocator() {}
+
+MicroAllocator* MicroAllocator::Create(uint8_t* tensor_arena, size_t arena_size,
+ ErrorReporter* error_reporter) {
+ uint8_t* aligned_arena = AlignPointerUp(tensor_arena, kBufferAlignment);
+ size_t aligned_arena_size = tensor_arena + arena_size - aligned_arena;
+ return Create(SimpleMemoryAllocator::Create(error_reporter, aligned_arena,
+ aligned_arena_size),
+ error_reporter);
+}
+
+MicroAllocator* MicroAllocator::Create(SimpleMemoryAllocator* memory_allocator,
+ ErrorReporter* error_reporter) {
+ TFLITE_DCHECK(memory_allocator != nullptr);
+ TFLITE_DCHECK(error_reporter != nullptr);
+
+ uint8_t* allocator_buffer = memory_allocator->AllocateFromTail(
+ sizeof(MicroAllocator), alignof(MicroAllocator));
+ MicroAllocator* allocator =
+ new (allocator_buffer) MicroAllocator(memory_allocator, error_reporter);
+ return allocator;
+}
+
+TfLiteStatus MicroAllocator::StartModelAllocation(
+ const Model* model, const MicroOpResolver& op_resolver,
+ NodeAndRegistration** node_and_registrations,
+ TfLiteEvalTensor** eval_tensors) {
+ TFLITE_DCHECK(model != nullptr);
+
+ if (model_is_allocating_) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "MicroAllocator: Model allocation started before "
+ "finishing previously allocated model");
+ return kTfLiteError;
+ }
+
+ model_is_allocating_ = true;
+
+ TF_LITE_ENSURE_STATUS(InitScratchBufferData());
+ TF_LITE_ENSURE_STATUS(AllocateTfLiteEvalTensors(model, eval_tensors));
+ TF_LITE_ENSURE_STATUS(
+ AllocateNodeAndRegistrations(model, node_and_registrations));
+ TF_LITE_ENSURE_STATUS(PrepareNodeAndRegistrationDataFromFlatbuffer(
+ model, op_resolver, *node_and_registrations));
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus MicroAllocator::FinishModelAllocation(
+ const Model* model, TfLiteEvalTensor* eval_tensors,
+ ScratchBufferHandle** scratch_buffer_handles) {
+ if (!model_is_allocating_) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "MicroAllocator: Model allocation finished before "
+ "starting allocating model");
+ return kTfLiteError;
+ }
+
+ const SubGraph* subgraph = GetSubGraphFromModel(model);
+ TFLITE_DCHECK(subgraph != nullptr);
+
+ TF_LITE_ENSURE_STATUS(AllocateScratchBufferHandles(
+ scratch_buffer_handles, scratch_buffer_request_count_));
+ TF_LITE_ENSURE_STATUS(CommitStaticMemoryPlan(model, subgraph, eval_tensors,
+ *scratch_buffer_handles));
+ TF_LITE_ENSURE_STATUS(AllocateVariables(subgraph, eval_tensors));
+
+ model_is_allocating_ = false;
+ return kTfLiteOk;
+}
+
+void* MicroAllocator::AllocatePersistentBuffer(size_t bytes) {
+ return memory_allocator_->AllocateFromTail(bytes, kBufferAlignment);
+}
+
+TfLiteStatus MicroAllocator::RequestScratchBufferInArena(size_t bytes,
+ int* buffer_idx) {
+ // All scratch buffer requests are stored in the head section of the arena
+ // when a model is in the prepare phase. First align a scratch buffer request
+ // pointer to the start of the head:
+ internal::ScratchBufferRequest* requests = GetScratchBufferRequests();
+
+ // Count the number of requested scratch buffers for the current node:
+ size_t current_node_request_count = 0;
+ for (size_t i = 0; i < scratch_buffer_request_count_; ++i) {
+ if (requests[i].node_idx == kUnassignedScratchBufferRequestIndex) {
+ ++current_node_request_count;
+ }
+ }
+
+ // First, ensure that the per-kernel request has not exceeded the limit:
+ if (current_node_request_count >= kMaxScratchBuffersPerOp) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Scratch buffer request exeeds limit per operator (%d)",
+ kMaxScratchBuffersPerOp);
+ return kTfLiteError;
+ }
+
+ // Initialize and assign values for the request at the current index:
+ internal::ScratchBufferRequest* current_request =
+ &requests[scratch_buffer_request_count_];
+ *current_request = {};
+ // Assign -1 as a sentinel value that will be updated when the node finishes
+ // allocating:
+ current_request->bytes = bytes;
+ current_request->node_idx = kUnassignedScratchBufferRequestIndex;
+
+ // Assign the current request index to the out-param:
+ *buffer_idx = scratch_buffer_request_count_;
+
+ // Bump the request count to prepare for the next request:
+ ++scratch_buffer_request_count_;
+ return kTfLiteOk;
+}
+
+TfLiteStatus MicroAllocator::FinishPrepareNodeAllocations(int node_id) {
+ // When a node has finished preparing, all temp allocations performed by the
+ // kernel should be cleaned up:
+ ResetTempAllocations();
+
+ // Find and update any new scratch buffer requests for the current node:
+ internal::ScratchBufferRequest* requests = GetScratchBufferRequests();
+
+ for (size_t i = 0; i < scratch_buffer_request_count_; ++i) {
+ // A request with a node_idx of -1 is a sentinel value used to indicate this
+ // was a new request for the current node. The allocator finally knows the
+ // node index at this point. Assign the value and update the list of new
+ // requests so the head section can be adjusted to allow for the next kernel
+ // to allocate at most kMaxScratchBuffersPerOp requests:
+ if (requests[i].node_idx == kUnassignedScratchBufferRequestIndex) {
+ requests[i].node_idx = node_id;
+ }
+ }
+
+ // Ensure that the head is re-adjusted to allow for another at-most
+ // kMaxScratchBuffersPerOp scratch buffer requests in the next operator:
+ TF_LITE_ENSURE_STATUS(memory_allocator_->SetHeadBufferSize(
+ sizeof(internal::ScratchBufferRequest) *
+ (scratch_buffer_request_count_ + kMaxScratchBuffersPerOp),
+ alignof(internal::ScratchBufferRequest)));
+
+ return kTfLiteOk;
+}
+
+size_t MicroAllocator::used_bytes() const {
+ return memory_allocator_->GetUsedBytes();
+}
+
+TfLiteStatus MicroAllocator::AllocateNodeAndRegistrations(
+ const Model* model, NodeAndRegistration** node_and_registrations) {
+ TFLITE_DCHECK(node_and_registrations);
+
+ const SubGraph* subgraph = GetSubGraphFromModel(model);
+ TFLITE_DCHECK(subgraph != nullptr);
+
+ NodeAndRegistration* output = reinterpret_cast<NodeAndRegistration*>(
+ memory_allocator_->AllocateFromTail(
+ sizeof(NodeAndRegistration) * subgraph->operators()->size(),
+ alignof(NodeAndRegistration)));
+ if (output == nullptr) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Failed to allocate memory for node_and_registrations.");
+ return kTfLiteError;
+ }
+ *node_and_registrations = output;
+ return kTfLiteOk;
+}
+
+TfLiteStatus MicroAllocator::PrepareNodeAndRegistrationDataFromFlatbuffer(
+ const Model* model, const MicroOpResolver& op_resolver,
+ NodeAndRegistration* node_and_registrations) {
+ TFLITE_DCHECK(model != nullptr);
+ TFLITE_DCHECK(node_and_registrations != nullptr);
+
+ const SubGraph* subgraph = GetSubGraphFromModel(model);
+ TFLITE_DCHECK(subgraph != nullptr);
+
+ TfLiteStatus status = kTfLiteOk;
+ auto* opcodes = model->operator_codes();
+ MicroBuiltinDataAllocator builtin_data_allocator(memory_allocator_);
+ for (size_t i = 0; i < subgraph->operators()->size(); ++i) {
+ const auto* op = subgraph->operators()->Get(i);
+ const size_t index = op->opcode_index();
+ if (index >= opcodes->size()) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Missing registration for opcode_index %d\n", index);
+ return kTfLiteError;
+ }
+ auto* opcode = (*opcodes)[index];
+ status =
+ GetRegistrationFromOpCode(opcode, op_resolver, error_reporter_,
+ &(node_and_registrations[i].registration));
+ if (status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to get registration from op code %s\n ",
+ EnumNameBuiltinOperator(GetBuiltinCode(opcode)));
+ return status;
+ }
+ const auto* registration = node_and_registrations[i].registration;
+ if (registration == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_, "Skipping op for opcode_index %d\n",
+ index);
+ return kTfLiteError;
+ }
+ BuiltinOperator op_type =
+ static_cast<BuiltinOperator>(registration->builtin_code);
+
+ const char* custom_data = nullptr;
+ size_t custom_data_size = 0;
+ unsigned char* builtin_data = nullptr;
+
+ if (op_type == BuiltinOperator_CUSTOM) {
+ // Custom Ops may or may not have a non-null custom_options field.
+ if (op->custom_options() != nullptr) {
+ custom_data =
+ reinterpret_cast<const char*>(op->custom_options()->data());
+ custom_data_size = op->custom_options()->size();
+ }
+ } else {
+ if (op->custom_options() != nullptr) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Unsupported behavior: found builtin operator %s with custom "
+ "options.\n",
+ EnumNameBuiltinOperator(op_type));
+ return kTfLiteError;
+ }
+
+ MicroOpResolver::BuiltinParseFunction parser =
+ op_resolver.GetOpDataParser(op_type);
+ if (parser == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_, "Did not find a parser for %s",
+ EnumNameBuiltinOperator(op_type));
+
+ return kTfLiteError;
+ }
+ TF_LITE_ENSURE_STATUS(parser(op, error_reporter_, &builtin_data_allocator,
+ (void**)(&builtin_data)));
+ }
+
+ TfLiteIntArray* inputs_array;
+ TF_LITE_ENSURE_STATUS(internal::FlatBufferVectorToTfLiteTypeArray(
+ memory_allocator_, error_reporter_, op->inputs(), &inputs_array));
+
+ TfLiteIntArray* outputs_array;
+ TF_LITE_ENSURE_STATUS(internal::FlatBufferVectorToTfLiteTypeArray(
+ memory_allocator_, error_reporter_, op->outputs(), &outputs_array));
+
+ TfLiteNode* node = &(node_and_registrations[i].node);
+ *node = {};
+ node->inputs = inputs_array;
+ node->outputs = outputs_array;
+ node->builtin_data = reinterpret_cast<void*>(builtin_data);
+ node->custom_initial_data = custom_data;
+ node->custom_initial_data_size = custom_data_size;
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteTensor* MicroAllocator::AllocatePersistentTfLiteTensor(
+ const Model* model, TfLiteEvalTensor* eval_tensors, int tensor_index) {
+ const SubGraph* subgraph = GetSubGraphFromModel(model);
+ TFLITE_DCHECK(subgraph != nullptr);
+
+ // This value is allocated from persistent arena space. It is guaranteed to be
+ // around for the lifetime of the application.
+ TfLiteTensor* tensor =
+ AllocatePersistentTfLiteTensorInternal(model, eval_tensors, tensor_index);
+
+ // Populate any fields from the flatbuffer, since this TfLiteTensor struct is
+ // allocated in the persistent section of the arena, ensure that additional
+ // allocations also take place in that section of the arena.
+ if (PopulateTfLiteTensorFromFlatbuffer(model, subgraph, tensor, tensor_index,
+ /*allocate_temp=*/false) !=
+ kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to populate a persistent TfLiteTensor struct "
+ "from flatbuffer data!");
+ return nullptr;
+ }
+
+ if (eval_tensors != nullptr) {
+ // Tensor buffers that are allocated at runtime (e.g. non-weight buffers)
+ // and not located in the flatbuffer are stored on the pre-allocated list of
+ // TfLiteEvalTensors structs. These structs are the source of truth, simply
+ // point the corresponding buffer to the new TfLiteTensor data value.
+ tensor->data.data = eval_tensors[tensor_index].data.data;
+ }
+ return tensor;
+}
+
+TfLiteTensor* MicroAllocator::AllocateTempTfLiteTensor(
+ const Model* model, TfLiteEvalTensor* eval_tensors, int tensor_index) {
+ const SubGraph* subgraph = GetSubGraphFromModel(model);
+ TFLITE_DCHECK(subgraph != nullptr);
+
+ // This value is allocated from temporary arena space. It is guaranteed to be
+ // around for at least the scope of the calling function. Since this struct
+ // allocation takes place in temp space, no need to own or cleanup.
+ TfLiteTensor* tensor =
+ reinterpret_cast<TfLiteTensor*>(memory_allocator_->AllocateTemp(
+ sizeof(TfLiteTensor), alignof(TfLiteTensor)));
+
+ // Populate any fields from the flatbuffer, since this TfLiteTensor struct is
+ // allocated in the temp section of the arena, ensure that additional
+ // allocations also take place in that section of the arena.
+ if (PopulateTfLiteTensorFromFlatbuffer(model, subgraph, tensor, tensor_index,
+ /*allocate_temp=*/true) != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Failed to populate a temp TfLiteTensor struct from flatbuffer data!");
+ return nullptr;
+ }
+
+ if (eval_tensors != nullptr) {
+ // Tensor buffers that are allocated at runtime (e.g. non-weight buffers)
+ // and not located in the flatbuffer are stored on the pre-allocated list of
+ // TfLiteEvalTensors structs. These structs are the source of truth, simply
+ // point the corresponding buffer to the new TfLiteTensor data value.
+ tensor->data.data = eval_tensors[tensor_index].data.data;
+ }
+ return tensor;
+}
+
+void MicroAllocator::ResetTempAllocations() {
+ memory_allocator_->ResetTempAllocations();
+}
+
+TfLiteStatus MicroAllocator::AllocateTfLiteEvalTensors(
+ const Model* model, TfLiteEvalTensor** eval_tensors) {
+ TFLITE_DCHECK(eval_tensors != nullptr);
+
+ const SubGraph* subgraph = GetSubGraphFromModel(model);
+ TFLITE_DCHECK(subgraph != nullptr);
+
+ size_t alloc_count = subgraph->tensors()->size();
+ TfLiteEvalTensor* tensors =
+ reinterpret_cast<TfLiteEvalTensor*>(memory_allocator_->AllocateFromTail(
+ sizeof(TfLiteEvalTensor) * alloc_count, alignof(TfLiteEvalTensor)));
+ if (tensors == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to allocate memory for context->eval_tensors, "
+ "%d bytes required",
+ sizeof(TfLiteEvalTensor) * alloc_count);
+ return kTfLiteError;
+ }
+
+ for (size_t i = 0; i < alloc_count; ++i) {
+ TfLiteStatus status = internal::InitializeTfLiteEvalTensorFromFlatbuffer(
+ memory_allocator_, *subgraph->tensors()->Get(i), model->buffers(),
+ error_reporter_, &tensors[i]);
+ if (status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter_, "Failed to initialize tensor %d",
+ i);
+ return kTfLiteError;
+ }
+ }
+ *eval_tensors = tensors;
+ return kTfLiteOk;
+}
+
+TfLiteStatus MicroAllocator::AllocateVariables(const SubGraph* subgraph,
+ TfLiteEvalTensor* eval_tensors) {
+ for (size_t i = 0; i < subgraph->tensors()->size(); ++i) {
+ auto* tensor = subgraph->tensors()->Get(i);
+ if (tensor->is_variable()) {
+ size_t buffer_size;
+ TF_LITE_ENSURE_STATUS(
+ TfLiteEvalTensorByteLength(&eval_tensors[i], &buffer_size));
+
+ eval_tensors[i].data.data =
+ memory_allocator_->AllocateFromTail(buffer_size, kBufferAlignment);
+
+ if (eval_tensors[i].data.data == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to allocate variable tensor of size %d",
+ buffer_size);
+ return kTfLiteError;
+ }
+ }
+ }
+ return kTfLiteOk;
+}
+
+TfLiteTensor* MicroAllocator::AllocatePersistentTfLiteTensorInternal(
+ const Model* model, TfLiteEvalTensor* eval_tensors, int tensor_index) {
+ return reinterpret_cast<TfLiteTensor*>(memory_allocator_->AllocateFromTail(
+ sizeof(TfLiteTensor), alignof(TfLiteTensor)));
+}
+
+TfLiteStatus MicroAllocator::PopulateTfLiteTensorFromFlatbuffer(
+ const Model* model, const SubGraph* subgraph, TfLiteTensor* tensor,
+ int tensor_index, bool allocate_temp) {
+ // TODO(b/162311891): This method serves as a stub to ensure quantized
+ // allocations in the tail can be recorded. Once the interpreter has APIs for
+ // accessing buffers on TfLiteEvalTensor this method can be dropped.
+ return internal::InitializeTfLiteTensorFromFlatbuffer(
+ memory_allocator_, allocate_temp, *subgraph->tensors()->Get(tensor_index),
+ model->buffers(), error_reporter_, tensor);
+}
+
+ErrorReporter* MicroAllocator::error_reporter() const {
+ return error_reporter_;
+}
+
+const SubGraph* MicroAllocator::GetSubGraphFromModel(const Model* model) {
+ auto* subgraphs = model->subgraphs();
+ if (subgraphs->size() != 1) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Only 1 subgraph is currently supported.\n");
+ return nullptr;
+ }
+ return (*subgraphs)[0];
+}
+
+TfLiteStatus MicroAllocator::CommitStaticMemoryPlan(
+ const Model* model, const SubGraph* subgraph,
+ TfLiteEvalTensor* eval_tensors,
+ ScratchBufferHandle* scratch_buffer_handles) {
+ size_t head_usage = 0;
+ // Create static memory plan
+ // 1. Calculate AllocationInfo to know the lifetime of each tensor/buffer.
+ // 2. Add them into the planner (such as the GreedyMemoryPlanner).
+ // 3. Static memory planning using the planner.
+ // 4. Set tensor/buffer pointers based on the offsets from the previous step.
+ //
+ // Note that AllocationInfo is only needed for creating the plan. It will be
+ // allocated from the temp section and cleaned up at the bottom of this
+ // function.
+
+ size_t allocation_info_count =
+ subgraph->tensors()->size() + scratch_buffer_request_count_;
+ size_t bytes = sizeof(AllocationInfo) * allocation_info_count;
+
+ // Allocate an array of AllocationInfo structs from the temp section. This
+ // struct will be used by AllocationInfoBuilder to find buffer usage.
+ AllocationInfo* allocation_info = reinterpret_cast<AllocationInfo*>(
+ memory_allocator_->AllocateTemp(bytes, alignof(AllocationInfo)));
+ if (allocation_info == nullptr) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Failed to allocate memory for allocation_info, %d bytes required",
+ bytes);
+ return kTfLiteError;
+ }
+
+ // Use the AllocationInfoBuilder class to help determine where buffers are
+ // used in the subgraph.
+ AllocationInfoBuilder builder(allocation_info, subgraph->tensors()->size(),
+ scratch_buffer_request_count_, error_reporter_);
+
+ const int32_t* offline_planner_offsets = nullptr;
+ TF_LITE_ENSURE_STATUS(
+ builder.GetOfflinePlannedOffsets(model, &offline_planner_offsets));
+ TF_LITE_ENSURE_STATUS(
+ builder.AddTensors(subgraph, offline_planner_offsets, eval_tensors));
+
+ internal::ScratchBufferRequest* scratch_buffer_requests =
+ GetScratchBufferRequests();
+
+ TF_LITE_ENSURE_STATUS(builder.AddScratchBuffers(scratch_buffer_requests,
+ scratch_buffer_handles));
+
+ // Remaining arena size that memory planner can use for calculating offsets.
+ size_t remaining_arena_size =
+ memory_allocator_->GetAvailableMemory(kBufferAlignment);
+ uint8_t* planner_arena =
+ memory_allocator_->AllocateTemp(remaining_arena_size, kBufferAlignment);
+ TF_LITE_ENSURE(error_reporter_, planner_arena != nullptr);
+ GreedyMemoryPlanner planner(planner_arena, remaining_arena_size);
+ TF_LITE_ENSURE_STATUS(CreatePlan(error_reporter_, &planner, allocation_info,
+ allocation_info_count));
+
+ // Reset all temp allocations used above:
+ memory_allocator_->ResetTempAllocations();
+
+ size_t actual_available_arena_size =
+ memory_allocator_->GetAvailableMemory(kBufferAlignment);
+
+ // Make sure we have enough arena size.
+ if (planner.GetMaximumMemorySize() > actual_available_arena_size) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Arena size is too small for all buffers. Needed %u but only "
+ "%u was available.",
+ planner.GetMaximumMemorySize(), actual_available_arena_size);
+ return kTfLiteError;
+ }
+ // Commit the plan.
+ TF_LITE_ENSURE_STATUS(CommitPlan(error_reporter_, &planner,
+ memory_allocator_->GetHeadBuffer(),
+ allocation_info, allocation_info_count));
+ head_usage = planner.GetMaximumMemorySize();
+
+ // The head is used to store memory plans for one model at a time during the
+ // model preparation stage, and is re-purposed to store scratch buffer handles
+ // during model invocation. The head must be as large as the greater of the
+ // largest model memory plan's size and the total space required for all
+ // scratch buffer handles.
+ if (max_head_buffer_usage_ < head_usage) {
+ max_head_buffer_usage_ = head_usage;
+ }
+
+ // The head is used for storing scratch buffer allocations before finalizing a
+ // memory plan in this function. Ensure that the head is set to the largest
+ // memory plan sent through the allocator:
+ TF_LITE_ENSURE_STATUS(memory_allocator_->SetHeadBufferSize(
+ max_head_buffer_usage_, kBufferAlignment));
+ return kTfLiteOk;
+}
+
+TfLiteStatus MicroAllocator::AllocateScratchBufferHandles(
+ ScratchBufferHandle** scratch_buffer_handles, size_t handle_count) {
+ TFLITE_DCHECK(scratch_buffer_handles != nullptr);
+
+ if (scratch_buffer_request_count_ == 0) {
+ // No scratch buffer requests were requested during model allocation.
+ return kTfLiteOk;
+ }
+
+ // Allocate a consecutive block of memory store the scratch buffer handles.
+ // This alignment ensures quick lookup during inference time for the model:
+ *scratch_buffer_handles = reinterpret_cast<ScratchBufferHandle*>(
+ memory_allocator_->AllocateFromTail(
+ sizeof(ScratchBufferHandle) * handle_count,
+ alignof(ScratchBufferHandle)));
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus MicroAllocator::InitScratchBufferData() {
+ // A model is preparing to allocate resources, ensure that scratch buffer
+ // request counter is cleared:
+ scratch_buffer_request_count_ = 0;
+
+ // All requests will be stored in the head section. Each kernel is allowed at
+ // most kMaxScratchBuffersPerOp requests. Adjust the head to reserve at most
+ // that many requests to begin:
+ TF_LITE_ENSURE_STATUS(memory_allocator_->SetHeadBufferSize(
+ sizeof(internal::ScratchBufferRequest) * kMaxScratchBuffersPerOp,
+ alignof(internal::ScratchBufferRequest)));
+
+ return kTfLiteOk;
+}
+
+internal::ScratchBufferRequest* MicroAllocator::GetScratchBufferRequests() {
+ return reinterpret_cast<internal::ScratchBufferRequest*>(
+ AlignPointerUp(memory_allocator_->GetHeadBuffer(),
+ alignof(internal::ScratchBufferRequest)));
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/micro_allocator.h b/tensorflow/lite/micro/micro_allocator.h
new file mode 100644
index 0000000..39a12ea
--- /dev/null
+++ b/tensorflow/lite/micro/micro_allocator.h
@@ -0,0 +1,279 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_ALLOCATOR_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_ALLOCATOR_H_
+
+#include <cstddef>
+#include <cstdint>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/micro_op_resolver.h"
+#include "tensorflow/lite/micro/simple_memory_allocator.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+namespace internal {
+
+// Sets up all of the data structure members for a TfLiteTensor based on the
+// contents of a serialized tensor in the flatbuffer.
+// TODO(b/162311891): Drop this method when the interpreter has an API for
+// returning buffers on TfLiteEvalTensor.
+TfLiteStatus InitializeTfLiteTensorFromFlatbuffer(
+ SimpleMemoryAllocator* allocator, bool allocate_temp,
+ const tflite::Tensor& flatbuffer_tensor,
+ const flatbuffers::Vector<flatbuffers::Offset<Buffer>>* buffers,
+ ErrorReporter* error_reporter, TfLiteTensor* result);
+
+// Holds placeholder information for a scratch buffer request from a kernel.
+// This struct is only used during the model prepare stage. Each request from a
+// kernel is stored in the head section. During the prepare stage, the head
+// section will at least hold kMaxScratchBuffersPerOp number of requests plus
+// any requests from previous kernel requests.
+//
+// When the memory plan is finalized, these structs are no longer used in favor
+// of a sequential, array of ScratchBufferHandle allocations in the tail
+// section. These allocations are indexed by the request API defined in the
+// TfLiteContext struct.
+typedef struct {
+ // Number of bytes required by the buffer. The actual allocated size might be
+ // greater than `bytes` due to buffer alignment.
+ size_t bytes;
+ // Node where the buffer is allocated for. This provides useful information to
+ // determine the lifetime of the buffer. In AllocationInfo, this buffer will
+ // have `before` = node_idx and `after` = node_idx.
+ int node_idx;
+} ScratchBufferRequest;
+
+} // namespace internal
+
+typedef struct {
+ TfLiteNode node;
+ const TfLiteRegistration* registration;
+} NodeAndRegistration;
+
+// Holds a pointer to a buffer for a scratch buffer requested by a kernel during
+// the model prepare stage. This struct is allocated in-place and allows for
+// quick pointer-indexed lookup for speed during model inference.
+typedef struct {
+ // Pointer to location of the scratch buffer:
+ uint8_t* data;
+} ScratchBufferHandle;
+
+// Allocator responsible for allocating memory for all intermediate tensors
+// necessary to invoke a model.
+//
+// The lifetime of the model, tensor arena and error reporter must be at
+// least as long as that of the allocator object, since the allocator needs
+// them to be accessible during its entire lifetime.
+//
+// The MicroAllocator simply plans out additional allocations that are required
+// to standup a model for inference in TF Micro. This class currently relies on
+// an additional allocator - SimpleMemoryAllocator - for all allocations from an
+// arena. These allocations are divided into head (non-persistent) and tail
+// (persistent) regions:
+//
+// Memory layout to help understand how it works
+// This information could change in the future version.
+// ************** .memory_allocator->GetBuffer()
+// Tensors/Scratch buffers (head)
+// ************** .head_watermark
+// unused memory
+// ************** .memory_allocator->GetBuffer() + ->GetMaxBufferSize()
+// - ->GetDataSize()
+// persistent area (tail)
+// ************** .memory_allocator->GetBuffer() + ->GetMaxBufferSize()
+class MicroAllocator {
+ public:
+ // Creates a MicroAllocator instance from a given tensor arena. This arena
+ // will be managed by the created instance.
+ // Note: Please use __declspec(align(16)) to make sure tensor_arena is 16
+ // bytes aligned, otherwise some head room will be wasted.
+ // TODO(b/157615197): Cleanup constructor + factory usage.
+ static MicroAllocator* Create(uint8_t* tensor_arena, size_t arena_size,
+ ErrorReporter* error_reporter);
+
+ // Creates a MicroAllocator instance using the provided SimpleMemoryAllocator
+ // intance. This allocator instance will use the SimpleMemoryAllocator
+ // instance to manage allocations internally.
+ static MicroAllocator* Create(SimpleMemoryAllocator* memory_allocator,
+ ErrorReporter* error_reporter);
+
+ // Begin allocating internal resources required for model inference.
+ // This method will run through the flatbuffer data supplied in the model to
+ // properly allocate tensor, node, and op registration data. This method is
+ // expected to be followed with a call to FinishModelAllocation() before
+ // resuming allocation with another model. All persistent tensor buffers are
+ // stored in the out-param eval_tensors. This value is allocated from the
+ // persistent memory arena and will be used to host runtime tensor buffers.
+ TfLiteStatus StartModelAllocation(
+ const Model* model, const MicroOpResolver& op_resolver,
+ NodeAndRegistration** node_and_registrations,
+ TfLiteEvalTensor** eval_tensors);
+
+ // Finish allocating internal resources required for model inference.
+ // This method will plan non-persistent buffers and commit a memory plan to
+ // the 'head' section of the memory arena. All variable tensor data will also
+ // be allocated. This method should be called after assigning model resources
+ // in StartModelAllocation(). The eval_tensors pointer should be the value
+ // passed into this class during StartModelAllocation(). Scratch buffer
+ // handles are stored in the out-param `scratch_buffer_handles`. This value
+ // will be used in `GetScratchBuffer` call to retrieve scratch buffers.
+ TfLiteStatus FinishModelAllocation(
+ const Model* model, TfLiteEvalTensor* eval_tensors,
+ ScratchBufferHandle** scratch_buffer_handles);
+
+ // Allocates a TfLiteTensor struct and populates the returned value with
+ // properties from the model flatbuffer. This struct is allocated from
+ // persistent arena memory is only guaranteed for the lifetime of the
+ // application. The eval_tensors pointer should be the value passed into this
+ // class during StartModelAllocation() and contains the source-of-truth for
+ // buffers.
+ virtual TfLiteTensor* AllocatePersistentTfLiteTensor(
+ const Model* model, TfLiteEvalTensor* eval_tensors, int tensor_index);
+
+ // Allocates a TfLiteTensor struct and populates the returned value with
+ // properties from the model flatbuffer. This struct is allocated from
+ // temporary arena memory is only guaranteed until a call is made to
+ // ResetTempAllocations(). The eval_tensors pointer should be the value passed
+ // into this class during StartModelAllocation() and contains the
+ // source-of-truth for buffers.
+ virtual TfLiteTensor* AllocateTempTfLiteTensor(const Model* model,
+ TfLiteEvalTensor* eval_tensors,
+ int tensor_index);
+
+ // Resets all temporary allocations. This method should be called after a
+ // chain of temp allocations (e.g. chain of TfLiteTensor objects via
+ // AllocateTfLiteTensor()).
+ virtual void ResetTempAllocations();
+
+ // Allocates persistent buffer which has the same life time as the allocator.
+ // The memory is immediately available and is allocated from the tail of the
+ // arena.
+ virtual void* AllocatePersistentBuffer(size_t bytes);
+
+ // Register a scratch buffer of size `bytes` for Node with `node_id`.
+ // This method only requests a buffer with a given size to be used after a
+ // model has finished allocation via FinishModelAllocation(). All requested
+ // buffers will be accessible by the out-param in that method.
+ TfLiteStatus RequestScratchBufferInArena(size_t bytes, int* buffer_idx);
+
+ // Finish allocating a specific NodeAndRegistration prepare block (kernel
+ // entry for a model) with a given node ID. This call ensures that any scratch
+ // buffer requests and temporary allocations are handled and ready for the
+ // next node prepare block.
+ TfLiteStatus FinishPrepareNodeAllocations(int node_id);
+
+ // Returns the arena usage in bytes, only available after
+ // `FinishModelAllocation`. Otherwise, it will return 0.
+ size_t used_bytes() const;
+
+ protected:
+ MicroAllocator(SimpleMemoryAllocator* memory_allocator,
+ ErrorReporter* error_reporter);
+ virtual ~MicroAllocator();
+
+ // Allocates an array in the arena to hold pointers to the node and
+ // registration pointers required to represent the inference graph of the
+ // model.
+ virtual TfLiteStatus AllocateNodeAndRegistrations(
+ const Model* model, NodeAndRegistration** node_and_registrations);
+
+ // Populates node and registration pointers representing the inference graph
+ // of the model from values inside the flatbuffer (loaded from the TfLiteModel
+ // instance). Persistent data (e.g. operator data) is allocated from the
+ // arena.
+ virtual TfLiteStatus PrepareNodeAndRegistrationDataFromFlatbuffer(
+ const Model* model, const MicroOpResolver& op_resolver,
+ NodeAndRegistration* node_and_registrations);
+
+ // Allocates the list of persistent TfLiteEvalTensors that are used for the
+ // "eval" phase of model inference. These structs will be the source of truth
+ // for all tensor buffers. Allocation results are stored in the out-param
+ // eval_tensors.
+ virtual TfLiteStatus AllocateTfLiteEvalTensors(
+ const Model* model, TfLiteEvalTensor** eval_tensors);
+
+ // Allocates persistent tensor buffers for variable tensors in the subgraph.
+ virtual TfLiteStatus AllocateVariables(const SubGraph* subgraph,
+ TfLiteEvalTensor* eval_tensors);
+
+ // Allocate and return a persistent TfLiteTensor.
+ // TODO(b/162311891): Drop this method when the interpreter has an API for
+ // accessing TfLiteEvalTensor structs.
+ virtual TfLiteTensor* AllocatePersistentTfLiteTensorInternal(
+ const Model* model, TfLiteEvalTensor* eval_tensors, int tensor_index);
+
+ // Populates a TfLiteTensor struct with data from the model flatbuffer. Any
+ // quantization data is allocated from either the tail (persistent) or temp
+ // sections of the arena based on the allocation flag.
+ virtual TfLiteStatus PopulateTfLiteTensorFromFlatbuffer(
+ const Model* model, const SubGraph* subgraph, TfLiteTensor* tensor,
+ int tensor_index, bool allocate_temp);
+
+ ErrorReporter* error_reporter() const;
+
+ // Returns the first subgraph from the model.
+ const SubGraph* GetSubGraphFromModel(const Model* model);
+
+ private:
+ // Commits a memory plan for all non-persistent buffer allocations in the
+ // 'head' section of the memory arena. The eval_tensors pointer is the list of
+ // pre-allocated TfLiteEvalTensor structs that will point to the buffers that
+ // will be allocated into the head section in this function call. The
+ // scratch_buffer_handles pointer is the array of pre-allocated
+ // ScratchBufferHandle structs that will point to allocated buffers also in
+ // the head section.
+ virtual TfLiteStatus CommitStaticMemoryPlan(
+ const Model* model, const SubGraph* subgraph,
+ TfLiteEvalTensor* eval_tensors,
+ ScratchBufferHandle* scratch_buffer_handles);
+
+ // Allocates an array of ScratchBufferHandle structs in the tail section for a
+ // given number of handles.
+ virtual TfLiteStatus AllocateScratchBufferHandles(
+ ScratchBufferHandle** scratch_buffer_handles, size_t handle_count);
+
+ // Clears all internal scratch buffer request counts and resets the head to
+ // prepare for kernels to request scratch buffer data when a model is
+ // preparing.
+ TfLiteStatus InitScratchBufferData();
+
+ // Returns the pointer for the array of ScratchBufferRequest allocations in
+ // the head section.
+ internal::ScratchBufferRequest* GetScratchBufferRequests();
+
+ // A simple memory allocator that always allocate from the arena tail or head.
+ SimpleMemoryAllocator* memory_allocator_;
+
+ ErrorReporter* error_reporter_;
+ bool model_is_allocating_;
+
+ // Holds the number of ScratchBufferRequest instances stored in the head
+ // section when a model is allocating.
+ size_t scratch_buffer_request_count_ = 0;
+
+ // Holds the byte length of the memory plan with the largest head usage. Used
+ // to ensure that multi-tenant allocations can share the head for buffers.
+ size_t max_head_buffer_usage_ = 0;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+#endif // TENSORFLOW_LITE_MICRO_MICRO_ALLOCATOR_H_
diff --git a/tensorflow/lite/micro/micro_allocator_test.cc b/tensorflow/lite/micro/micro_allocator_test.cc
new file mode 100644
index 0000000..53bc55f
--- /dev/null
+++ b/tensorflow/lite/micro/micro_allocator_test.cc
@@ -0,0 +1,853 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_allocator.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/micro/memory_helpers.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/simple_memory_allocator.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/micro/testing/test_conv_model.h"
+
+namespace tflite {
+namespace testing {
+namespace {
+
+constexpr int kExpectedAlignment = 4;
+constexpr int t0 = 0;
+constexpr int t1 = 1;
+constexpr int t2 = 2;
+constexpr int t3 = 3;
+constexpr int t4 = 4;
+constexpr int t5 = 5;
+
+void VerifyMockTfLiteTensor(TfLiteTensor* tensor, bool is_variable = false) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, tensor->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(is_variable, tensor->is_variable);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), tensor->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensor->data.raw);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(0),
+ (reinterpret_cast<std::uintptr_t>(tensor->data.raw) %
+ kExpectedAlignment));
+}
+
+void VerifyMockWeightTfLiteTensor(TfLiteTensor* tensor) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteUInt8, tensor->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), tensor->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensor->data.raw);
+}
+
+void VerifyMockTfLiteEvalTensor(TfLiteEvalTensor* tensor) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, tensor->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->data[0]);
+ size_t buffer_size;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::TfLiteEvalTensorByteLength(tensor, &buffer_size));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), buffer_size);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensor->data.raw);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(0),
+ (reinterpret_cast<std::uintptr_t>(tensor->data.raw) %
+ kExpectedAlignment));
+}
+
+void VerifyMockWeightTfLiteEvalTensor(TfLiteEvalTensor* tensor) {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteUInt8, tensor->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, tensor->dims->data[0]);
+ size_t buffer_size;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::TfLiteEvalTensorByteLength(tensor, &buffer_size));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), buffer_size);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, tensor->data.raw);
+}
+
+void VerifyMockTensor(const Model* model, MicroAllocator* allocator,
+ TfLiteEvalTensor* eval_tensors, int tensor_idx,
+ bool is_variable = false) {
+ VerifyMockTfLiteTensor(allocator->AllocatePersistentTfLiteTensor(
+ model, eval_tensors, tensor_idx),
+ is_variable);
+ VerifyMockTfLiteEvalTensor(&eval_tensors[tensor_idx]);
+}
+
+void VerifyMockWeightTensor(const Model* model, MicroAllocator* allocator,
+ TfLiteEvalTensor* eval_tensors, int tensor_idx) {
+ VerifyMockWeightTfLiteTensor(allocator->AllocatePersistentTfLiteTensor(
+ model, eval_tensors, tensor_idx));
+ VerifyMockWeightTfLiteEvalTensor(&eval_tensors[tensor_idx]);
+}
+
+void EnsureUniqueVariableTensorBuffer(const Model* model,
+ TfLiteEvalTensor* eval_tensors,
+ const int variable_tensor_idx) {
+ for (size_t i = 0; i < GetModelTensorCount(model); i++) {
+ if (i != static_cast<size_t>(variable_tensor_idx)) {
+ TF_LITE_MICRO_EXPECT_NE(eval_tensors[variable_tensor_idx].data.raw,
+ eval_tensors[i].data.raw);
+ }
+ }
+}
+
+void VerifyRegistrationAndNodeAllocation(
+ NodeAndRegistration* node_and_registration, size_t count) {
+ for (size_t i = 0; i < count; i++) {
+ TF_LITE_MICRO_EXPECT_NE(nullptr, node_and_registration[i].registration);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, node_and_registration[i].node.inputs);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, node_and_registration[i].node.outputs);
+ }
+}
+
+} // namespace
+} // namespace testing
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestInitializeRuntimeTensor) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator* simple_allocator =
+ tflite::SimpleMemoryAllocator::Create(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ const tflite::Tensor* tensor = tflite::testing::Create1dFlatbufferTensor(100);
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>>* buffers =
+ tflite::testing::CreateFlatbufferBuffers();
+
+ TfLiteTensor allocated_tensor;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::internal::InitializeTfLiteTensorFromFlatbuffer(
+ simple_allocator, /*allocate_temp=*/false, *tensor, buffers,
+ tflite::GetMicroErrorReporter(), &allocated_tensor));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, allocated_tensor.type);
+ TF_LITE_MICRO_EXPECT_EQ(1, allocated_tensor.dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(100, allocated_tensor.dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(400), allocated_tensor.bytes);
+ TF_LITE_MICRO_EXPECT(nullptr == allocated_tensor.data.i32);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteArenaRw, allocated_tensor.allocation_type);
+
+ simple_allocator->~SimpleMemoryAllocator();
+}
+
+// TODO(b/162311891): Drop this test when InitializeTfLiteTensorFromFlatbuffer()
+// always allocates from temp (interpreter returns buffers from
+// TfLiteEvalTensor):
+TF_LITE_MICRO_TEST(TestInitializeTempRuntimeTensor) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator* simple_allocator =
+ tflite::SimpleMemoryAllocator::Create(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ const tflite::Tensor* tensor = tflite::testing::Create1dFlatbufferTensor(100);
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>>* buffers =
+ tflite::testing::CreateFlatbufferBuffers();
+
+ TfLiteTensor allocated_temp_tensor;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, tflite::internal::InitializeTfLiteTensorFromFlatbuffer(
+ simple_allocator, /*allocate_temp=*/true, *tensor, buffers,
+ tflite::GetMicroErrorReporter(), &allocated_temp_tensor));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, allocated_temp_tensor.type);
+ TF_LITE_MICRO_EXPECT_EQ(1, allocated_temp_tensor.dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(100, allocated_temp_tensor.dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(400),
+ allocated_temp_tensor.bytes);
+ TF_LITE_MICRO_EXPECT(nullptr == allocated_temp_tensor.data.i32);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteArenaRw,
+ allocated_temp_tensor.allocation_type);
+
+ simple_allocator->~SimpleMemoryAllocator();
+}
+
+TF_LITE_MICRO_TEST(TestInitializeQuantizedTensor) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator* simple_allocator =
+ tflite::SimpleMemoryAllocator::Create(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ const tflite::Tensor* tensor =
+ tflite::testing::CreateQuantizedFlatbufferTensor(100);
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>>* buffers =
+ tflite::testing::CreateFlatbufferBuffers();
+
+ TfLiteTensor allocated_tensor;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::internal::InitializeTfLiteTensorFromFlatbuffer(
+ simple_allocator, /*allocate_temp=*/false, *tensor, buffers,
+ tflite::GetMicroErrorReporter(), &allocated_tensor));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, allocated_tensor.type);
+ TF_LITE_MICRO_EXPECT_EQ(1, allocated_tensor.dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(100, allocated_tensor.dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(400), allocated_tensor.bytes);
+ TF_LITE_MICRO_EXPECT(nullptr == allocated_tensor.data.i32);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteArenaRw, allocated_tensor.allocation_type);
+
+ simple_allocator->~SimpleMemoryAllocator();
+}
+
+TF_LITE_MICRO_TEST(TestMissingQuantization) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator* simple_allocator =
+ tflite::SimpleMemoryAllocator::Create(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ const tflite::Tensor* tensor =
+ tflite::testing::CreateMissingQuantizationFlatbufferTensor(100);
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>>* buffers =
+ tflite::testing::CreateFlatbufferBuffers();
+
+ TfLiteTensor allocated_tensor;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ tflite::internal::InitializeTfLiteTensorFromFlatbuffer(
+ simple_allocator, /*allocate_temp=*/false, *tensor, buffers,
+ tflite::GetMicroErrorReporter(), &allocated_tensor));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, allocated_tensor.type);
+ TF_LITE_MICRO_EXPECT_EQ(1, allocated_tensor.dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(100, allocated_tensor.dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(400), allocated_tensor.bytes);
+ TF_LITE_MICRO_EXPECT(nullptr == allocated_tensor.data.i32);
+}
+
+TF_LITE_MICRO_TEST(TestFailsWhenModelStartsTwice) {
+ const tflite::Model* model = tflite::testing::GetSimpleMockModel();
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT(nullptr != allocator);
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+}
+
+TF_LITE_MICRO_TEST(TestFailsWithWrongSequence) {
+ const tflite::Model* model = tflite::testing::GetSimpleMockModel();
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(nullptr, allocator);
+
+ // We can't finish allocation before it ever got started.
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ // Start twice is not allowed.
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteError,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+}
+
+TF_LITE_MICRO_TEST(TestMockModelAllocation) {
+ const tflite::Model* model = tflite::testing::GetSimpleMockModel();
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT(nullptr != allocator);
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ size_t model_tensor_size = tflite::testing::GetModelTensorCount(model);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), model_tensor_size);
+
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 0);
+ tflite::testing::VerifyMockWeightTensor(model, allocator, eval_tensors, 1);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 2);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 3);
+
+ TF_LITE_MICRO_EXPECT_NE(eval_tensors[1].data.raw, eval_tensors[0].data.raw);
+ TF_LITE_MICRO_EXPECT_NE(eval_tensors[2].data.raw, eval_tensors[0].data.raw);
+ TF_LITE_MICRO_EXPECT_NE(eval_tensors[1].data.raw, eval_tensors[2].data.raw);
+ TF_LITE_MICRO_EXPECT_NE(eval_tensors[3].data.raw, eval_tensors[0].data.raw);
+ TF_LITE_MICRO_EXPECT_NE(eval_tensors[3].data.raw, eval_tensors[1].data.raw);
+ TF_LITE_MICRO_EXPECT_NE(eval_tensors[3].data.raw, eval_tensors[2].data.raw);
+ TF_LITE_MICRO_EXPECT_LE(allocator->used_bytes(), 856 + 100);
+
+ // SimpleMockModel has 2 operators:
+ tflite::testing::VerifyRegistrationAndNodeAllocation(node_and_registration,
+ /*count=*/2);
+}
+
+TF_LITE_MICRO_TEST(TestMultiTenantAllocation) {
+ // The `OpResolver` is shared among different models in this test for
+ // simplicity but in practice you could have different `OpResolver`.
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ // Create a shared allocator.
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(nullptr, allocator);
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+
+ // Allocate for model 1. We use ComplexMockModel here to cover the code path
+ // allocatig variables.
+ const tflite::Model* model1 = tflite::testing::GetComplexMockModel();
+ tflite::NodeAndRegistration* node_and_registration1;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model1, op_resolver,
+ &node_and_registration1, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model1, eval_tensors,
+ &scratch_buffer_handles));
+ const size_t single_model_used_bytes = allocator->used_bytes();
+
+ // Allocate for model 2.
+ const tflite::Model* model2 = tflite::testing::GetComplexMockModel();
+ tflite::NodeAndRegistration* node_and_registration2;
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model2, op_resolver,
+ &node_and_registration2, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model2, eval_tensors,
+ &scratch_buffer_handles));
+
+ // Allocation for two instances of the same model takes less memory as `head`
+ // of the arena is reused.
+ TF_LITE_MICRO_EXPECT_LE(allocator->used_bytes(), 2 * single_model_used_bytes);
+}
+
+TF_LITE_MICRO_TEST(TestAllocationForModelsWithBranches) {
+ const tflite::Model* model = tflite::testing::GetSimpleModelWithBranch();
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(nullptr, allocator);
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ uint8_t* start = eval_tensors[0].data.uint8;
+ // Check test_helpers.cc BuildSimpleModelWithBranch for model structure.
+ // t0 is the first tensor, so place it in offset 0.
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[0].data.uint8 - start);
+ // bytes = 2 * 2 * 3 * sizeof(float32) = 48, same for other tensors.
+ size_t buffer_size;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, tflite::TfLiteEvalTensorByteLength(
+ &eval_tensors[0], &buffer_size));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(48), buffer_size);
+ // t1 can't reuse any memory, as n0 requires both t0 and t1.
+ TF_LITE_MICRO_EXPECT_EQ(96, eval_tensors[1].data.uint8 - start);
+ // t2 can't reuse any memory, as n1 requires both t0 and t2. Also n2 requires
+ // both t1 and t2.
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[2].data.uint8 - start);
+ // t3 reuses the same memory from t0 as t0 is not an input to any node.
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[3].data.uint8 - start);
+
+ // SimpleModelWithBranch has 3 operators:
+ tflite::testing::VerifyRegistrationAndNodeAllocation(node_and_registration,
+ /*count=*/3);
+}
+
+TF_LITE_MICRO_TEST(TestAllocationForComplexModelAllocation) {
+ const tflite::Model* model = tflite::testing::GetComplexMockModel();
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ constexpr size_t arena_size = 2048;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT(nullptr != allocator);
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ size_t model_tensor_size = tflite::testing::GetModelTensorCount(model);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(10), model_tensor_size);
+
+ // NOTE: Tensor indexes match the values in GetComplexMockModel().
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 0);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 1,
+ /*is_variable=*/true);
+ tflite::testing::VerifyMockWeightTensor(model, allocator, eval_tensors, 2);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 3);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 4,
+ /*is_variable=*/true);
+ tflite::testing::VerifyMockWeightTensor(model, allocator, eval_tensors, 5);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 6);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 7,
+ /*is_variable=*/true);
+ tflite::testing::VerifyMockWeightTensor(model, allocator, eval_tensors, 8);
+ tflite::testing::VerifyMockTensor(model, allocator, eval_tensors, 9);
+
+ // // Ensure that variable tensors have unique address
+ tflite::testing::EnsureUniqueVariableTensorBuffer(model, eval_tensors, 1);
+ tflite::testing::EnsureUniqueVariableTensorBuffer(model, eval_tensors, 4);
+ tflite::testing::EnsureUniqueVariableTensorBuffer(model, eval_tensors, 7);
+
+ // ComplexMockModel has 3 operators:
+ tflite::testing::VerifyRegistrationAndNodeAllocation(node_and_registration,
+ /*count=*/3);
+}
+
+TF_LITE_MICRO_TEST(OfflinePlannerBranchesAllOnline) {
+ int version = 1;
+ int subgraph = 0;
+ constexpr int number_tensors = 4;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ const int32_t metadata_buffer[tflite::testing::kOfflinePlannerHeaderSize +
+ number_tensors] = {version, subgraph,
+ number_tensors, // header
+ // memory offsets:
+ -1, -1, -1, -1};
+
+ // The structure is identical to the one in
+ // TestAllocationForModelsWithBranches
+ int number_connections = 3;
+ tflite::testing::NodeConnection node_list[3] = {{
+ {0}, // input
+ {1} // output
+ },
+ {
+ {0}, // input
+ {2} // output
+ },
+ {
+ {1, 2}, // input1, input2
+ {3} // output
+ }};
+
+ const tflite::Model* model = tflite::testing::GetModelWithOfflinePlanning(
+ number_tensors, metadata_buffer, node_list, number_connections);
+
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ // Since all of the tensors are online planned and the model structure is
+ // identical to that in TestAllocationForModelsWithBranches,
+ // the offsets be should identical to that test.
+ uint8_t* start = eval_tensors[0].data.uint8;
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[0].data.uint8 - start);
+
+ size_t buffer_size;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, tflite::TfLiteEvalTensorByteLength(
+ &eval_tensors[0], &buffer_size));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(48), buffer_size);
+ TF_LITE_MICRO_EXPECT_EQ(96, eval_tensors[1].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[2].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[3].data.uint8 - start);
+}
+
+TF_LITE_MICRO_TEST(OfflinePlannerBasic) {
+ constexpr int number_tensors = 4;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ const int32_t metadata_buffer[tflite::testing::kOfflinePlannerHeaderSize +
+ number_tensors] = {1, 0, number_tensors,
+ /*t0=*/0,
+ /*t1=*/48,
+ /*t2=*/0,
+ /*t3=*/48};
+ constexpr int number_connections = 3;
+ tflite::testing::NodeConnection node_list[number_connections] = {
+ {/*input=*/{tflite::testing::t0},
+ /*output=*/{tflite::testing::t1}},
+ {/*input=*/{tflite::testing::t1},
+ /*output=*/{tflite::testing::t2}},
+ {/*input=*/{tflite::testing::t2},
+ /*output=*/{tflite::testing::t3}}};
+
+ const tflite::Model* model = tflite::testing::GetModelWithOfflinePlanning(
+ number_tensors, metadata_buffer, node_list, number_connections);
+
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ uint8_t* start = eval_tensors[0].data.uint8;
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[0].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[1].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[2].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[3].data.uint8 - start);
+}
+
+TF_LITE_MICRO_TEST(OfflinePlannerOverlappingAllocation) {
+ constexpr int number_tensors = 4;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ const int32_t metadata_buffer[tflite::testing::kOfflinePlannerHeaderSize +
+ number_tensors] = {/*version=*/1,
+ /*subgraph=*/0,
+ number_tensors,
+ /*t0=*/0,
+ /*t1=*/0,
+ /*t2=*/48,
+ /*t3=*/-1};
+
+ int number_connections = 2;
+ tflite::testing::NodeConnection node_list[2] = {
+ {/*input, scratch=*/{tflite::testing::t0, tflite::testing::t1},
+ /*output=*/{tflite::testing::t2}},
+ {/*input=*/{tflite::testing::t2},
+ /*output=*/{tflite::testing::t3}},
+ };
+
+ const tflite::Model* model = tflite::testing::GetModelWithOfflinePlanning(
+ number_tensors, metadata_buffer, node_list, number_connections);
+
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ uint8_t* start = eval_tensors[0].data.uint8;
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[0].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[1].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[2].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[3].data.uint8 - start);
+ // TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(48), context.tensors[0].bytes);
+}
+
+TF_LITE_MICRO_TEST(OfflinePlannerOfflineOnline) {
+ constexpr int number_tensors = 5;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ const int32_t metadata_buffer[tflite::testing::kOfflinePlannerHeaderSize +
+ number_tensors] = {/*version=*/1,
+ /*subgraph=*/0,
+ number_tensors,
+ /*t0=*/0,
+ /*t1=*/48,
+ /*t2=*/-1,
+ /*t3=*/0,
+ /*t4=*/-1};
+
+ constexpr int number_connections = 2;
+ tflite::testing::NodeConnection node_list[number_connections] = {
+ {
+ /*input, scratch=*/{tflite::testing::t0, tflite::testing::t1},
+ /*output=*/{tflite::testing::t2},
+ },
+ {
+ /*input=*/{tflite::testing::t2},
+ /*output1, output2=*/{tflite::testing::t3, tflite::testing::t4},
+ },
+ };
+
+ const tflite::Model* model = tflite::testing::GetModelWithOfflinePlanning(
+ number_tensors, metadata_buffer, node_list, number_connections);
+
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ uint8_t* start = eval_tensors[0].data.uint8;
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[0].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[1].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(96, eval_tensors[2].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[4].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[3].data.uint8 - start);
+}
+
+TF_LITE_MICRO_TEST(TestAllocatePersistentTfLiteTensor) {
+ const tflite::Model* model = tflite::GetModel(kTestConvModelData);
+ constexpr size_t arena_size = 1024 * 12;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(allocator, nullptr);
+
+ TfLiteTensor* tensor1 = allocator->AllocatePersistentTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, /*tensor_index=*/1);
+ TF_LITE_MICRO_EXPECT_NE(tensor1, nullptr);
+ TF_LITE_MICRO_EXPECT_NE(tensor1->quantization.params, nullptr);
+ TF_LITE_MICRO_EXPECT_FALSE(tensor1->is_variable);
+
+ TfLiteTensor* tensor2 = allocator->AllocatePersistentTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, /*tensor_index=*/2);
+ TF_LITE_MICRO_EXPECT_NE(tensor2, nullptr);
+ TF_LITE_MICRO_EXPECT_NE(tensor2->quantization.params, nullptr);
+ TF_LITE_MICRO_EXPECT_FALSE(tensor2->is_variable);
+
+ // The address of tensor1 should be higher than the address of tensor2 since
+ // persistent allocations take place in the tail which grows downward.
+ TF_LITE_MICRO_EXPECT_GT(tensor1, tensor2);
+}
+
+TF_LITE_MICRO_TEST(TestAllocateSingleTempTfLiteTensor) {
+ const tflite::Model* model = tflite::testing::GetSimpleMockModel();
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(allocator, nullptr);
+
+ TfLiteTensor* tensor1 = allocator->AllocateTempTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, /*tensor_index=*/1);
+ TF_LITE_MICRO_EXPECT_NE(tensor1, nullptr);
+}
+
+TF_LITE_MICRO_TEST(TestAllocateChainOfTfLiteTensor) {
+ const tflite::Model* model = tflite::testing::GetSimpleMockModel();
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(allocator, nullptr);
+
+ TfLiteTensor* tensor1 = allocator->AllocateTempTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, /*tensor_index=*/1);
+ TF_LITE_MICRO_EXPECT_NE(tensor1, nullptr);
+
+ TfLiteTensor* tensor2 = allocator->AllocateTempTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, /*tensor_index=*/2);
+ TF_LITE_MICRO_EXPECT_NE(tensor2, nullptr);
+
+ // The address of tensor2 should be higher than the address of tensor1
+ // (chained allocations):
+ TF_LITE_MICRO_EXPECT_GT(tensor2, tensor1);
+}
+
+TF_LITE_MICRO_TEST(TestAllocateTfLiteTensorWithReset) {
+ const tflite::Model* model = tflite::testing::GetSimpleMockModel();
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT(allocator != nullptr);
+
+ TfLiteTensor* tensor1 = allocator->AllocateTempTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, /*tensor_index=*/1);
+ TF_LITE_MICRO_EXPECT(tensor1 != nullptr);
+
+ allocator->ResetTempAllocations();
+
+ TfLiteTensor* tensor2 = allocator->AllocateTempTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, /*tensor_index=*/2);
+ TF_LITE_MICRO_EXPECT(tensor2 != nullptr);
+
+ // The address of tensor2 should be equal than the address of tensor1 since
+ // allocations were not chained:
+ TF_LITE_MICRO_EXPECT(tensor2 == tensor1);
+}
+
+TF_LITE_MICRO_TEST(TestOperatorInputsNotInSubgraphInputs) {
+ constexpr int number_tensors = 5;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ const int32_t metadata_buffer[tflite::testing::kOfflinePlannerHeaderSize +
+ number_tensors] = {/*version=*/1,
+ /*subgraph=*/0,
+ number_tensors,
+ /*t0=*/0,
+ /*t1=*/0,
+ /*t2=*/0,
+ /*t3=*/48,
+ /*t4=*/-1};
+
+ constexpr int number_connections = 2;
+ tflite::testing::NodeConnection node_list[number_connections] = {
+ {// t0: input (actual input part of subgraph inputs as
+ // well as operator inputs)
+ // t1: scratch1 (only in operator inputs)
+ // t2: scratch2 (only in operator inputs)
+ {tflite::testing::t0, tflite::testing::t1, tflite::testing::t2},
+ /*t3: output=*/{tflite::testing::t3}},
+ {/*t3: input=*/{tflite::testing::t3},
+ /*t4: output=*/{tflite::testing::t4}},
+ };
+
+ const tflite::Model* model = tflite::testing::GetModelWithOfflinePlanning(
+ number_tensors, metadata_buffer, node_list, number_connections,
+ /*Only first tensor (t0) is in subgraph input list=*/1);
+
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ uint8_t* start = eval_tensors[0].data.uint8;
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[0].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[1].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[2].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[3].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[4].data.uint8 - start);
+}
+
+TF_LITE_MICRO_TEST(TestTypicalFirstOpAndSecondOpWithScratchTensors) {
+ constexpr int number_tensors = 6;
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ tflite::NodeAndRegistration* node_and_registration;
+ const int32_t metadata_buffer[tflite::testing::kOfflinePlannerHeaderSize +
+ number_tensors] = {/*version=*/1,
+ /*subgraph=*/0,
+ number_tensors,
+ /*t0=*/0,
+ /*t1=*/0,
+ /*t2=*/0,
+ /*t3=*/0,
+ /*t4=*/48,
+ /*t5=*/-1};
+
+ constexpr int number_connections = 3;
+ tflite::testing::NodeConnection node_list[number_connections] = {
+ {/*t0: input (subgraph and operator input)=*/{tflite::testing::t0},
+ /*t1: output=*/{tflite::testing::t1}},
+ {// t1: input
+ // t2: scratch1 (only in operator inputs)
+ // t3: scratch2 (only in operator inputs)
+ {tflite::testing::t1, tflite::testing::t2, tflite::testing::t3},
+
+ /*t4: output=*/{tflite::testing::t4}},
+ {/*t4: input=*/{tflite::testing::t4},
+ /*t5: output=*/{tflite::testing::t5}},
+ };
+
+ const tflite::Model* model = tflite::testing::GetModelWithOfflinePlanning(
+ number_tensors, metadata_buffer, node_list, number_connections,
+ /*Only first tensor (t0) is in subgraph input list=*/1);
+
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ constexpr size_t arena_size = 4096;
+ uint8_t arena[arena_size];
+ tflite::MicroAllocator* allocator = tflite::MicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk,
+ allocator->StartModelAllocation(model, op_resolver,
+ &node_and_registration, &eval_tensors));
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles));
+
+ uint8_t* start = eval_tensors[0].data.uint8;
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[0].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[1].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[2].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[3].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(48, eval_tensors[4].data.uint8 - start);
+ TF_LITE_MICRO_EXPECT_EQ(0, eval_tensors[5].data.uint8 - start);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/micro_error_reporter.cc b/tensorflow/lite/micro/micro_error_reporter.cc
new file mode 100644
index 0000000..5aba058
--- /dev/null
+++ b/tensorflow/lite/micro/micro_error_reporter.cc
@@ -0,0 +1,68 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+#include <cstdarg>
+#include <cstdint>
+#include <new>
+
+#if !defined(TF_LITE_STRIP_ERROR_STRINGS)
+#include "tensorflow/lite/micro/debug_log.h"
+#include "tensorflow/lite/micro/micro_string.h"
+#endif
+
+namespace {
+uint8_t micro_error_reporter_buffer[sizeof(tflite::MicroErrorReporter)];
+tflite::MicroErrorReporter* error_reporter_ = nullptr;
+
+void Log(const char* format, va_list args) {
+#if !defined(TF_LITE_STRIP_ERROR_STRINGS)
+ // Only pulling in the implementation of this function for builds where we
+ // expect to make use of it to be extra cautious about not increasing the code
+ // size.
+ static constexpr int kMaxLogLen = 256;
+ char log_buffer[kMaxLogLen];
+ MicroVsnprintf(log_buffer, kMaxLogLen, format, args);
+ DebugLog(log_buffer);
+ DebugLog("\r\n");
+#endif
+}
+
+} // namespace
+
+#if !defined(TF_LITE_STRIP_ERROR_STRINGS)
+void MicroPrintf(const char* format, ...) {
+ va_list args;
+ va_start(args, format);
+ Log(format, args);
+ va_end(args);
+}
+#endif
+
+namespace tflite {
+ErrorReporter* GetMicroErrorReporter() {
+ if (error_reporter_ == nullptr) {
+ error_reporter_ = new (micro_error_reporter_buffer) MicroErrorReporter();
+ }
+ return error_reporter_;
+}
+
+int MicroErrorReporter::Report(const char* format, va_list args) {
+ Log(format, args);
+ return 0;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/micro_error_reporter.h b/tensorflow/lite/micro/micro_error_reporter.h
new file mode 100644
index 0000000..ac45224
--- /dev/null
+++ b/tensorflow/lite/micro/micro_error_reporter.h
@@ -0,0 +1,49 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_ERROR_REPORTER_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_ERROR_REPORTER_H_
+
+#include <cstdarg>
+
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/micro/compatibility.h"
+
+#if !defined(TF_LITE_STRIP_ERROR_STRINGS)
+// This function can be used independent of the MicroErrorReporter to get
+// printf-like functionalitys and are common to all target platforms.
+void MicroPrintf(const char* format, ...);
+#else
+// We use a #define to ensure that the strings are completely stripped, to
+// prevent an unnecessary increase in the binary size.
+#define MicroPrintf(format, ...)
+#endif
+
+namespace tflite {
+
+// Get a pointer to a singleton global error reporter.
+ErrorReporter* GetMicroErrorReporter();
+
+class MicroErrorReporter : public ErrorReporter {
+ public:
+ ~MicroErrorReporter() override {}
+ int Report(const char* format, va_list args) override;
+
+ private:
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_ERROR_REPORTER_H_
diff --git a/tensorflow/lite/micro/micro_error_reporter_test.cc b/tensorflow/lite/micro/micro_error_reporter_test.cc
new file mode 100644
index 0000000..b67a716
--- /dev/null
+++ b/tensorflow/lite/micro/micro_error_reporter_test.cc
@@ -0,0 +1,28 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+
+int main(int argc, char** argv) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ tflite::MicroErrorReporter micro_error_reporter;
+ tflite::ErrorReporter* error_reporter = µ_error_reporter;
+ TF_LITE_REPORT_ERROR(error_reporter, "Number: %d", 42);
+ TF_LITE_REPORT_ERROR(error_reporter, "Badly-formed format string %");
+ TF_LITE_REPORT_ERROR(error_reporter,
+ "Another % badly-formed %% format string");
+ TF_LITE_REPORT_ERROR(error_reporter, "~~~%s~~~", "ALL TESTS PASSED");
+#endif // !defined(TF_LITE_STRIP_ERROR_STRINGS)
+}
diff --git a/tensorflow/lite/micro/micro_interpreter.cc b/tensorflow/lite/micro/micro_interpreter.cc
new file mode 100644
index 0000000..f01ed64
--- /dev/null
+++ b/tensorflow/lite/micro/micro_interpreter.cc
@@ -0,0 +1,409 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/micro/micro_interpreter.h"
+
+#include <cstdarg>
+#include <cstddef>
+#include <cstdint>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/core/api/tensor_utils.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+#include "tensorflow/lite/micro/micro_allocator.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_op_resolver.h"
+#include "tensorflow/lite/micro/micro_profiler.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+namespace {
+
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+const char* OpNameFromRegistration(const TfLiteRegistration* registration) {
+ if (registration->builtin_code == BuiltinOperator_CUSTOM) {
+ return registration->custom_name;
+ } else {
+ return EnumNameBuiltinOperator(BuiltinOperator(registration->builtin_code));
+ }
+}
+#endif // !defined(TF_LITE_STRIP_ERROR_STRINGS)
+
+} // namespace
+
+namespace internal {
+
+ContextHelper::ContextHelper(ErrorReporter* error_reporter,
+ MicroAllocator* allocator, const Model* model)
+ : allocator_(allocator), error_reporter_(error_reporter), model_(model) {}
+
+void* ContextHelper::AllocatePersistentBuffer(TfLiteContext* ctx,
+ size_t bytes) {
+ return reinterpret_cast<ContextHelper*>(ctx->impl_)
+ ->allocator_->AllocatePersistentBuffer(bytes);
+}
+
+TfLiteStatus ContextHelper::RequestScratchBufferInArena(TfLiteContext* ctx,
+ size_t bytes,
+ int* buffer_idx) {
+ ContextHelper* helper = reinterpret_cast<ContextHelper*>(ctx->impl_);
+ return helper->allocator_->RequestScratchBufferInArena(bytes, buffer_idx);
+}
+
+void* ContextHelper::GetScratchBuffer(TfLiteContext* ctx, int buffer_idx) {
+ ContextHelper* helper = reinterpret_cast<ContextHelper*>(ctx->impl_);
+ ScratchBufferHandle* handle = helper->scratch_buffer_handles_ + buffer_idx;
+ return handle->data;
+}
+
+void ContextHelper::ReportOpError(struct TfLiteContext* context,
+ const char* format, ...) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ ContextHelper* helper = static_cast<ContextHelper*>(context->impl_);
+ va_list args;
+ va_start(args, format);
+ TF_LITE_REPORT_ERROR(helper->error_reporter_, format, args);
+ va_end(args);
+#endif
+}
+
+TfLiteTensor* ContextHelper::GetTensor(const struct TfLiteContext* context,
+ int tensor_idx) {
+ ContextHelper* helper = static_cast<ContextHelper*>(context->impl_);
+ return helper->allocator_->AllocateTempTfLiteTensor(
+ helper->model_, helper->eval_tensors_, tensor_idx);
+}
+
+TfLiteEvalTensor* ContextHelper::GetEvalTensor(
+ const struct TfLiteContext* context, int tensor_idx) {
+ ContextHelper* helper = reinterpret_cast<ContextHelper*>(context->impl_);
+ return &helper->eval_tensors_[tensor_idx];
+}
+
+void ContextHelper::SetTfLiteEvalTensors(TfLiteEvalTensor* eval_tensors) {
+ eval_tensors_ = eval_tensors;
+}
+
+void ContextHelper::SetScratchBufferHandles(
+ ScratchBufferHandle* scratch_buffer_handles) {
+ scratch_buffer_handles_ = scratch_buffer_handles;
+}
+
+} // namespace internal
+
+MicroInterpreter::MicroInterpreter(const Model* model,
+ const MicroOpResolver& op_resolver,
+ uint8_t* tensor_arena,
+ size_t tensor_arena_size,
+ ErrorReporter* error_reporter,
+ MicroProfiler* profiler)
+ : model_(model),
+ op_resolver_(op_resolver),
+ error_reporter_(error_reporter),
+ allocator_(*MicroAllocator::Create(tensor_arena, tensor_arena_size,
+ error_reporter)),
+ tensors_allocated_(false),
+ initialization_status_(kTfLiteError),
+ eval_tensors_(nullptr),
+ context_helper_(error_reporter_, &allocator_, model),
+ input_tensors_(nullptr),
+ output_tensors_(nullptr) {
+ Init(profiler);
+}
+
+MicroInterpreter::MicroInterpreter(const Model* model,
+ const MicroOpResolver& op_resolver,
+ MicroAllocator* allocator,
+ ErrorReporter* error_reporter,
+ MicroProfiler* profiler)
+ : model_(model),
+ op_resolver_(op_resolver),
+ error_reporter_(error_reporter),
+ allocator_(*allocator),
+ tensors_allocated_(false),
+ initialization_status_(kTfLiteError),
+ eval_tensors_(nullptr),
+ context_helper_(error_reporter_, &allocator_, model),
+ input_tensors_(nullptr),
+ output_tensors_(nullptr) {
+ Init(profiler);
+}
+
+MicroInterpreter::~MicroInterpreter() {
+ if (node_and_registrations_ != nullptr) {
+ for (size_t i = 0; i < subgraph_->operators()->size(); ++i) {
+ TfLiteNode* node = &(node_and_registrations_[i].node);
+ const TfLiteRegistration* registration =
+ node_and_registrations_[i].registration;
+ // registration is allocated outside the interpreter, so double check to
+ // make sure it's not nullptr;
+ if (registration != nullptr && registration->free != nullptr) {
+ registration->free(&context_, node->user_data);
+ }
+ }
+ }
+}
+
+void MicroInterpreter::Init(MicroProfiler* profiler) {
+ const flatbuffers::Vector<flatbuffers::Offset<SubGraph>>* subgraphs =
+ model_->subgraphs();
+ if (subgraphs->size() != 1) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Only 1 subgraph is currently supported.\n");
+ initialization_status_ = kTfLiteError;
+ return;
+ }
+ subgraph_ = (*subgraphs)[0];
+
+ context_.impl_ = static_cast<void*>(&context_helper_);
+ context_.ReportError = context_helper_.ReportOpError;
+ context_.GetTensor = context_helper_.GetTensor;
+ context_.GetEvalTensor = context_helper_.GetEvalTensor;
+ context_.recommended_num_threads = 1;
+ context_.profiler = profiler;
+
+ initialization_status_ = kTfLiteOk;
+}
+
+TfLiteStatus MicroInterpreter::AllocateTensors() {
+ if (allocator_.StartModelAllocation(model_, op_resolver_,
+ &node_and_registrations_,
+ &eval_tensors_) != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed starting model allocation.\n");
+ initialization_status_ = kTfLiteError;
+ return kTfLiteError;
+ }
+
+ // Update the pointer now that TfLiteEvalTensor allocation has completed on
+ // the context helper.
+ // TODO(b/16157777): This call would not be needed if ContextHelper rolled
+ // into the interpreter.
+ context_helper_.SetTfLiteEvalTensors(eval_tensors_);
+ context_.tensors_size = subgraph_->tensors()->size();
+
+ // Only allow AllocatePersistentBuffer in Init stage.
+ context_.AllocatePersistentBuffer = context_helper_.AllocatePersistentBuffer;
+ context_.RequestScratchBufferInArena = nullptr;
+ context_.GetScratchBuffer = nullptr;
+
+ for (size_t i = 0; i < subgraph_->operators()->size(); ++i) {
+ auto* node = &(node_and_registrations_[i].node);
+ auto* registration = node_and_registrations_[i].registration;
+ size_t init_data_size;
+ const char* init_data;
+ if (registration->builtin_code == BuiltinOperator_CUSTOM) {
+ init_data = reinterpret_cast<const char*>(node->custom_initial_data);
+ init_data_size = node->custom_initial_data_size;
+ } else {
+ init_data = reinterpret_cast<const char*>(node->builtin_data);
+ init_data_size = 0;
+ }
+ if (registration->init) {
+ node->user_data =
+ registration->init(&context_, init_data, init_data_size);
+ }
+ }
+
+ // Both AllocatePersistentBuffer and RequestScratchBufferInArena is
+ // available in Prepare stage.
+ context_.RequestScratchBufferInArena =
+ context_helper_.RequestScratchBufferInArena;
+ for (size_t i = 0; i < subgraph_->operators()->size(); ++i) {
+ auto* node = &(node_and_registrations_[i].node);
+ auto* registration = node_and_registrations_[i].registration;
+ if (registration->prepare) {
+ TfLiteStatus prepare_status = registration->prepare(&context_, node);
+ if (prepare_status != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Node %s (number %df) failed to prepare with status %d",
+ OpNameFromRegistration(registration), i, prepare_status);
+ return kTfLiteError;
+ }
+ }
+ allocator_.FinishPrepareNodeAllocations(/*node_id=*/i);
+ }
+
+ // Prepare is done, we're ready for Invoke. Memory allocation is no longer
+ // allowed. Kernels can only fetch scratch buffers via GetScratchBuffer.
+ context_.AllocatePersistentBuffer = nullptr;
+ context_.RequestScratchBufferInArena = nullptr;
+ context_.GetScratchBuffer = context_helper_.GetScratchBuffer;
+
+ TF_LITE_ENSURE_OK(&context_,
+ allocator_.FinishModelAllocation(model_, eval_tensors_,
+ &scratch_buffer_handles_));
+ // TODO(b/16157777): Remove this when ContextHelper is rolled into this class.
+ context_helper_.SetScratchBufferHandles(scratch_buffer_handles_);
+
+ // TODO(b/162311891): Drop these allocations when the interpreter supports
+ // handling buffers from TfLiteEvalTensor.
+ input_tensors_ =
+ reinterpret_cast<TfLiteTensor**>(allocator_.AllocatePersistentBuffer(
+ sizeof(TfLiteTensor*) * inputs_size()));
+ if (input_tensors_ == nullptr) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Failed to allocate memory for context->input_tensors_, "
+ "%d bytes required",
+ sizeof(TfLiteTensor*) * inputs_size());
+ return kTfLiteError;
+ }
+
+ for (size_t i = 0; i < inputs_size(); ++i) {
+ input_tensors_[i] = allocator_.AllocatePersistentTfLiteTensor(
+ model_, eval_tensors_, inputs().Get(i));
+ if (input_tensors_[i] == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to initialize input tensor %d", i);
+ return kTfLiteError;
+ }
+ }
+
+ // TODO(b/162311891): Drop these allocations when the interpreter supports
+ // handling buffers from TfLiteEvalTensor.
+ output_tensors_ =
+ reinterpret_cast<TfLiteTensor**>(allocator_.AllocatePersistentBuffer(
+ sizeof(TfLiteTensor*) * outputs_size()));
+ if (output_tensors_ == nullptr) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Failed to allocate memory for context->output_tensors_, "
+ "%d bytes required",
+ sizeof(TfLiteTensor*) * outputs_size());
+ return kTfLiteError;
+ }
+
+ for (size_t i = 0; i < outputs_size(); ++i) {
+ output_tensors_[i] = allocator_.AllocatePersistentTfLiteTensor(
+ model_, eval_tensors_, outputs().Get(i));
+ if (output_tensors_[i] == nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to initialize output tensor %d", i);
+ return kTfLiteError;
+ }
+ }
+
+ TF_LITE_ENSURE_STATUS(ResetVariableTensors());
+
+ tensors_allocated_ = true;
+ return kTfLiteOk;
+}
+
+TfLiteStatus MicroInterpreter::Invoke() {
+ if (initialization_status_ != kTfLiteOk) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Invoke() called after initialization failed\n");
+ return kTfLiteError;
+ }
+
+ // Ensure tensors are allocated before the interpreter is invoked to avoid
+ // difficult to debug segfaults.
+ if (!tensors_allocated_) {
+ TF_LITE_ENSURE_OK(&context_, AllocateTensors());
+ }
+
+ for (size_t i = 0; i < subgraph_->operators()->size(); ++i) {
+ auto* node = &(node_and_registrations_[i].node);
+ auto* registration = node_and_registrations_[i].registration;
+
+// This ifdef is needed (even though ScopedMicroProfiler itself is a no-op with
+// -DTF_LITE_STRIP_ERROR_STRINGS) because the function OpNameFromRegistration is
+// only defined for builds with the error strings.
+#if !defined(TF_LITE_STRIP_ERROR_STRINGS)
+ ScopedMicroProfiler scoped_profiler(
+ OpNameFromRegistration(registration),
+ reinterpret_cast<MicroProfiler*>(context_.profiler));
+#endif
+
+ TFLITE_DCHECK(registration->invoke);
+ TfLiteStatus invoke_status = registration->invoke(&context_, node);
+
+ // All TfLiteTensor structs used in the kernel are allocated from temp
+ // memory in the allocator. This creates a chain of allocations in the
+ // temp section. The call below resets the chain of allocations to
+ // prepare for the next call.
+ allocator_.ResetTempAllocations();
+
+ if (invoke_status == kTfLiteError) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Node %s (number %d) failed to invoke with status %d",
+ OpNameFromRegistration(registration), i, invoke_status);
+ return kTfLiteError;
+ } else if (invoke_status != kTfLiteOk) {
+ return invoke_status;
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+TfLiteTensor* MicroInterpreter::input(size_t index) {
+ const size_t length = inputs_size();
+ if (index >= length) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Input index %d out of range (length is %d)", index,
+ length);
+ return nullptr;
+ }
+ return input_tensors_[index];
+}
+
+TfLiteTensor* MicroInterpreter::output(size_t index) {
+ const size_t length = outputs_size();
+ if (index >= length) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Output index %d out of range (length is %d)", index,
+ length);
+ return nullptr;
+ }
+ return output_tensors_[index];
+}
+
+TfLiteTensor* MicroInterpreter::tensor(size_t index) {
+ const size_t length = tensors_size();
+ if (index >= length) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Tensor index %d out of range (length is %d)", index,
+ length);
+ return nullptr;
+ }
+ return allocator_.AllocatePersistentTfLiteTensor(model_, eval_tensors_,
+ index);
+}
+
+TfLiteStatus MicroInterpreter::ResetVariableTensors() {
+ for (size_t i = 0; i < subgraph_->tensors()->size(); ++i) {
+ auto* tensor = subgraph_->tensors()->Get(i);
+ if (tensor->is_variable()) {
+ size_t buffer_size;
+ TF_LITE_ENSURE_STATUS(
+ TfLiteEvalTensorByteLength(&eval_tensors_[i], &buffer_size));
+
+ int value = 0;
+ if (tensor->type() == tflite::TensorType_INT8) {
+ value = tensor->quantization()->zero_point()->Get(0);
+ }
+ memset(eval_tensors_[i].data.raw, value, buffer_size);
+ }
+ }
+
+ return kTfLiteOk;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/micro_interpreter.h b/tensorflow/lite/micro/micro_interpreter.h
new file mode 100644
index 0000000..39fb09b
--- /dev/null
+++ b/tensorflow/lite/micro/micro_interpreter.h
@@ -0,0 +1,210 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_INTERPRETER_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_INTERPRETER_H_
+
+#include <cstddef>
+#include <cstdint>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/micro/micro_allocator.h"
+#include "tensorflow/lite/micro/micro_op_resolver.h"
+#include "tensorflow/lite/micro/micro_profiler.h"
+#include "tensorflow/lite/portable_type_to_tflitetype.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+// Copied from tensorflow/lite/version.h to avoid a dependency chain into
+// tensorflow/core.
+#define TFLITE_SCHEMA_VERSION (3)
+
+namespace tflite {
+
+namespace internal {
+
+// A helper class to encapsulate the implementation of APIs in Context.
+// context->impl_ points to an instance of this class.
+// Check tensorflow/lite/c/common.h for detailed descriptions.
+// TODO(b/16157777): Consider rolling this class into MicroInterpreter.
+class ContextHelper {
+ public:
+ explicit ContextHelper(ErrorReporter* error_reporter,
+ MicroAllocator* allocator, const Model* model);
+
+ // Functions that will be assigned to function pointers on TfLiteContext:
+ static void* AllocatePersistentBuffer(TfLiteContext* ctx, size_t bytes);
+ static TfLiteStatus RequestScratchBufferInArena(TfLiteContext* ctx,
+ size_t bytes,
+ int* buffer_idx);
+ static void* GetScratchBuffer(TfLiteContext* ctx, int buffer_idx);
+ static void ReportOpError(struct TfLiteContext* context, const char* format,
+ ...);
+ static TfLiteTensor* GetTensor(const struct TfLiteContext* context,
+ int tensor_idx);
+ static TfLiteEvalTensor* GetEvalTensor(const struct TfLiteContext* context,
+ int tensor_idx);
+
+ // Sets the pointer to a list of TfLiteEvalTensor instances.
+ void SetTfLiteEvalTensors(TfLiteEvalTensor* eval_tensors);
+
+ // Sets the pointer to a list of ScratchBufferHandle instances.
+ void SetScratchBufferHandles(ScratchBufferHandle* scratch_buffer_handles);
+
+ private:
+ MicroAllocator* allocator_ = nullptr;
+ ErrorReporter* error_reporter_ = nullptr;
+ const Model* model_ = nullptr;
+ TfLiteEvalTensor* eval_tensors_ = nullptr;
+ ScratchBufferHandle* scratch_buffer_handles_ = nullptr;
+};
+
+} // namespace internal
+
+class MicroInterpreter {
+ public:
+ // The lifetime of the model, op resolver, tensor arena, error reporter and
+ // profiler must be at least as long as that of the interpreter object, since
+ // the interpreter may need to access them at any time. This means that you
+ // should usually create them with the same scope as each other, for example
+ // having them all allocated on the stack as local variables through a
+ // top-level function. The interpreter doesn't do any deallocation of any of
+ // the pointed-to objects, ownership remains with the caller.
+ MicroInterpreter(const Model* model, const MicroOpResolver& op_resolver,
+ uint8_t* tensor_arena, size_t tensor_arena_size,
+ ErrorReporter* error_reporter,
+ MicroProfiler* profiler = nullptr);
+
+ // Create an interpreter instance using an existing MicroAllocator instance.
+ // This constructor should be used when creating an allocator that needs to
+ // have allocation handled in more than one interpreter or for recording
+ // allocations inside the interpreter. The lifetime of the allocator must be
+ // as long as that of the interpreter object.
+ MicroInterpreter(const Model* model, const MicroOpResolver& op_resolver,
+ MicroAllocator* allocator, ErrorReporter* error_reporter,
+ MicroProfiler* profiler = nullptr);
+
+ ~MicroInterpreter();
+
+ // Runs through the model and allocates all necessary input, output and
+ // intermediate tensors.
+ TfLiteStatus AllocateTensors();
+
+ // In order to support partial graph runs for strided models, this can return
+ // values other than kTfLiteOk and kTfLiteError.
+ // TODO(b/149795762): Add this to the TfLiteStatus enum.
+ TfLiteStatus Invoke();
+
+ size_t tensors_size() const { return context_.tensors_size; }
+ TfLiteTensor* tensor(size_t tensor_index);
+ template <class T>
+ T* typed_tensor(int tensor_index) {
+ if (TfLiteTensor* tensor_ptr = tensor(tensor_index)) {
+ if (tensor_ptr->type == typeToTfLiteType<T>()) {
+ return GetTensorData<T>(tensor_ptr);
+ }
+ }
+ return nullptr;
+ }
+
+ TfLiteTensor* input(size_t index);
+ size_t inputs_size() const { return subgraph_->inputs()->Length(); }
+ const flatbuffers::Vector<int32_t>& inputs() const {
+ return *subgraph_->inputs();
+ }
+ TfLiteTensor* input_tensor(size_t index) { return input(index); }
+ template <class T>
+ T* typed_input_tensor(int tensor_index) {
+ if (TfLiteTensor* tensor_ptr = input_tensor(tensor_index)) {
+ if (tensor_ptr->type == typeToTfLiteType<T>()) {
+ return GetTensorData<T>(tensor_ptr);
+ }
+ }
+ return nullptr;
+ }
+
+ TfLiteTensor* output(size_t index);
+ size_t outputs_size() const { return subgraph_->outputs()->Length(); }
+ const flatbuffers::Vector<int32_t>& outputs() const {
+ return *subgraph_->outputs();
+ }
+ TfLiteTensor* output_tensor(size_t index) { return output(index); }
+ template <class T>
+ T* typed_output_tensor(int tensor_index) {
+ if (TfLiteTensor* tensor_ptr = output_tensor(tensor_index)) {
+ if (tensor_ptr->type == typeToTfLiteType<T>()) {
+ return GetTensorData<T>(tensor_ptr);
+ }
+ }
+ return nullptr;
+ }
+
+ // Reset all variable tensors to the default value.
+ TfLiteStatus ResetVariableTensors();
+
+ TfLiteStatus initialization_status() const { return initialization_status_; }
+
+ size_t operators_size() const { return subgraph_->operators()->size(); }
+
+ // For debugging only.
+ const NodeAndRegistration node_and_registration(int node_index) const {
+ return node_and_registrations_[node_index];
+ }
+
+ // For debugging only.
+ // Returns the actual used arena in bytes. This method gives the optimal arena
+ // size. It's only available after `AllocateTensors` has been called.
+ // Note that normally `tensor_arena` requires 16 bytes alignment to fully
+ // utilize the space. If it's not the case, the optimial arena size would be
+ // arena_used_bytes() + 16.
+ size_t arena_used_bytes() const { return allocator_.used_bytes(); }
+
+ protected:
+ const MicroAllocator& allocator() const { return allocator_; }
+ const TfLiteContext& context() const { return context_; }
+
+ private:
+ // TODO(b/158263161): Consider switching to Create() function to enable better
+ // error reporting during initialization.
+ void Init(MicroProfiler* profiler);
+
+ NodeAndRegistration* node_and_registrations_ = nullptr;
+
+ const Model* model_;
+ const MicroOpResolver& op_resolver_;
+ ErrorReporter* error_reporter_;
+ TfLiteContext context_ = {};
+ MicroAllocator& allocator_;
+ bool tensors_allocated_;
+
+ TfLiteStatus initialization_status_;
+
+ const SubGraph* subgraph_ = nullptr;
+ TfLiteEvalTensor* eval_tensors_ = nullptr;
+ ScratchBufferHandle* scratch_buffer_handles_ = nullptr;
+
+ // TODO(b/16157777): Drop this reference:
+ internal::ContextHelper context_helper_;
+
+ // TODO(b/162311891): Clean these pointers up when this class supports buffers
+ // from TfLiteEvalTensor.
+ TfLiteTensor** input_tensors_;
+ TfLiteTensor** output_tensors_;
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_INTERPRETER_H_
diff --git a/tensorflow/lite/micro/micro_interpreter_test.cc b/tensorflow/lite/micro/micro_interpreter_test.cc
new file mode 100644
index 0000000..5b775f6
--- /dev/null
+++ b/tensorflow/lite/micro/micro_interpreter_test.cc
@@ -0,0 +1,555 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_interpreter.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/core/api/flatbuffer_conversions.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_profiler.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/micro/recording_micro_allocator.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace {
+
+class MockProfiler : public MicroProfiler {
+ public:
+ MockProfiler() : event_starts_(0), event_ends_(0) {}
+
+ uint32_t BeginEvent(const char* tag) override {
+ event_starts_++;
+ return 0;
+ }
+
+ void EndEvent(uint32_t event_handle) override { event_ends_++; }
+
+ int event_starts() { return event_starts_; }
+ int event_ends() { return event_ends_; }
+
+ private:
+ int event_starts_;
+ int event_ends_;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestInterpreter) {
+ const tflite::Model* model = tflite::testing::GetSimpleMockModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size = 2000;
+ uint8_t allocator_buffer[allocator_buffer_size];
+
+ // Create a new scope so that we can test the destructor.
+ {
+ tflite::MicroInterpreter interpreter(model, op_resolver, allocator_buffer,
+ allocator_buffer_size,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);
+ TF_LITE_MICRO_EXPECT_LE(interpreter.arena_used_bytes(), 928 + 100);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), interpreter.inputs_size());
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(2), interpreter.outputs_size());
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), interpreter.tensors_size());
+
+ TfLiteTensor* input = interpreter.input(0);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, input->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), input->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input->data.i32);
+ input->data.i32[0] = 21;
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter.Invoke());
+
+ TfLiteTensor* output = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, output);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), output->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, output->data.i32);
+ TF_LITE_MICRO_EXPECT_EQ(42, output->data.i32[0]);
+
+ output = interpreter.output(1);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, output);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), output->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, output->data.i32);
+ TF_LITE_MICRO_EXPECT_EQ(42, output->data.i32[0]);
+ }
+
+ TF_LITE_MICRO_EXPECT_EQ(tflite::testing::MockCustom::freed_, true);
+}
+
+TF_LITE_MICRO_TEST(TestMultiTenantInterpreter) {
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+ constexpr size_t arena_size = 8192;
+ uint8_t arena[arena_size];
+
+ size_t simple_model_head_usage = 0, complex_model_head_usage = 0;
+
+ // Get simple_model_head_usage.
+ {
+ tflite::RecordingMicroAllocator* allocator =
+ tflite::RecordingMicroAllocator::Create(
+ arena, arena_size, tflite::GetMicroErrorReporter());
+ const tflite::Model* model0 = tflite::testing::GetSimpleMockModel();
+ tflite::MicroInterpreter interpreter0(model0, op_resolver, allocator,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter0.AllocateTensors());
+ simple_model_head_usage =
+ allocator->GetSimpleMemoryAllocator()->GetHeadUsedBytes();
+
+ TfLiteTensor* input = interpreter0.input(0);
+ TfLiteTensor* output = interpreter0.output(0);
+ input->data.i32[0] = 21;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter0.Invoke());
+ TF_LITE_MICRO_EXPECT_EQ(42, output->data.i32[0]);
+ }
+
+ // Shared allocator for various models.
+ tflite::RecordingMicroAllocator* allocator =
+ tflite::RecordingMicroAllocator::Create(arena, arena_size,
+ tflite::GetMicroErrorReporter());
+
+ // Get complex_model_head_usage. No head space reuse since it's the first
+ // model allocated in the `allocator`.
+ const tflite::Model* model1 = tflite::testing::GetComplexMockModel();
+ tflite::MicroInterpreter interpreter1(model1, op_resolver, allocator,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter1.AllocateTensors());
+ TfLiteTensor* input1 = interpreter1.input(0);
+ TfLiteTensor* output1 = interpreter1.output(0);
+ complex_model_head_usage =
+ allocator->GetSimpleMemoryAllocator()->GetHeadUsedBytes();
+
+ // Allocate simple model from the same `allocator`. Some head space will
+ // be reused thanks to multi-tenant TFLM support. Also makes sure that
+ // the output is correct.
+ const tflite::Model* model2 = tflite::testing::GetSimpleMockModel();
+ tflite::MicroInterpreter interpreter2(model2, op_resolver, allocator,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter2.AllocateTensors());
+ TfLiteTensor* input2 = interpreter2.input(0);
+ TfLiteTensor* output2 = interpreter2.output(0);
+ // Verify that 1 + 1 < 2.
+ size_t multi_tenant_head_usage =
+ allocator->GetSimpleMemoryAllocator()->GetHeadUsedBytes();
+ TF_LITE_MICRO_EXPECT_LE(multi_tenant_head_usage,
+ complex_model_head_usage + simple_model_head_usage);
+
+ // Now we have model1 and model2 sharing the same `allocator`.
+ // Let's make sure that they can produce correct results.
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, input1->type);
+ input1->data.i32[0] = 10;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter1.Invoke());
+ // Output tensor for the first model.
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output1->type);
+ TF_LITE_MICRO_EXPECT_EQ(10, output1->data.i32[0]);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, input2->type);
+ input2->data.i32[0] = 21;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter2.Invoke());
+ // Output for the second model.
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output2->type);
+ TF_LITE_MICRO_EXPECT_EQ(42, output2->data.i32[0]);
+
+ // Allocate another complex model from the `allocator` will not increase
+ // head space usage.
+ const tflite::Model* model3 = tflite::testing::GetComplexMockModel();
+ tflite::MicroInterpreter interpreter3(model3, op_resolver, allocator,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter3.AllocateTensors());
+ TfLiteTensor* input3 = interpreter3.input(0);
+ TfLiteTensor* output3 = interpreter3.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, input3->type);
+ input3->data.i32[0] = 10;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter3.Invoke());
+ // Output tensor for the third model.
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output3->type);
+ TF_LITE_MICRO_EXPECT_EQ(10, output3->data.i32[0]);
+ // No increase on the head usage as we're reusing the space.
+ TF_LITE_MICRO_EXPECT_EQ(
+ multi_tenant_head_usage,
+ allocator->GetSimpleMemoryAllocator()->GetHeadUsedBytes());
+}
+
+TF_LITE_MICRO_TEST(TestKernelMemoryPlanning) {
+ const tflite::Model* model = tflite::testing::GetSimpleStatefulModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size = 4096;
+ uint8_t allocator_buffer[allocator_buffer_size];
+
+ tflite::RecordingMicroAllocator* allocator =
+ tflite::RecordingMicroAllocator::Create(allocator_buffer,
+ allocator_buffer_size,
+ tflite::GetMicroErrorReporter());
+
+ // Make sure kernel memory planning works in multi-tenant context.
+ for (int i = 0; i < 3; i++) {
+ tflite::MicroInterpreter interpreter(model, op_resolver, allocator,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), interpreter.inputs_size());
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(2), interpreter.outputs_size());
+
+ TfLiteTensor* input = interpreter.input(0);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(3, input->dims->data[0]);
+ input->data.uint8[0] = 2;
+ input->data.uint8[1] = 3;
+ input->data.uint8[2] = 1;
+
+ uint8_t expected_median = 2;
+
+ {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter.Invoke());
+ TfLiteTensor* median = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(expected_median, median->data.uint8[0]);
+ TfLiteTensor* invoke_count = interpreter.output(1);
+ TF_LITE_MICRO_EXPECT_EQ(1, invoke_count->data.i32[0]);
+ }
+
+ {
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter.Invoke());
+ TfLiteTensor* median = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_EQ(expected_median, median->data.uint8[0]);
+ TfLiteTensor* invoke_count = interpreter.output(1);
+ TF_LITE_MICRO_EXPECT_EQ(2, invoke_count->data.i32[0]);
+ }
+ }
+}
+
+TF_LITE_MICRO_TEST(TestVariableTensorReset) {
+ const tflite::Model* model = tflite::testing::GetComplexMockModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size =
+ 3072 /* optimal arena size at the time of writting. */ +
+ 16 /* alignment */ + 100 /* some headroom */;
+ uint8_t allocator_buffer[allocator_buffer_size];
+ tflite::MicroInterpreter interpreter(model, op_resolver, allocator_buffer,
+ allocator_buffer_size,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);
+ TF_LITE_MICRO_EXPECT_LE(interpreter.arena_used_bytes(), 2096 + 100);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), interpreter.inputs_size());
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), interpreter.outputs_size());
+
+ // Assign hard-code values:
+ for (size_t i = 0; i < interpreter.tensors_size(); ++i) {
+ TfLiteTensor* cur_tensor = interpreter.tensor(i);
+ int buffer_length = tflite::ElementCount(*cur_tensor->dims);
+ // Assign all buffers to non-zero values. Variable tensors will be assigned
+ // 2 here and will be verified that they have been reset after the API call.
+ int buffer_value = cur_tensor->is_variable ? 2 : 1;
+ switch (cur_tensor->type) {
+ case kTfLiteInt32: {
+ int32_t* buffer = tflite::GetTensorData<int32_t>(cur_tensor);
+ for (int j = 0; j < buffer_length; ++j) {
+ buffer[j] = static_cast<int32_t>(buffer_value);
+ }
+ break;
+ }
+ case kTfLiteUInt8: {
+ uint8_t* buffer = tflite::GetTensorData<uint8_t>(cur_tensor);
+ for (int j = 0; j < buffer_length; ++j) {
+ buffer[j] = static_cast<uint8_t>(buffer_value);
+ }
+ break;
+ }
+ default:
+ TF_LITE_MICRO_FAIL("Unsupported dtype");
+ }
+ }
+
+ interpreter.ResetVariableTensors();
+
+ // Ensure only variable tensors have been reset to zero:
+ for (size_t i = 0; i < interpreter.tensors_size(); ++i) {
+ TfLiteTensor* cur_tensor = interpreter.tensor(i);
+ int buffer_length = tflite::ElementCount(*cur_tensor->dims);
+ // Variable tensors should be zero (not the value assigned in the for loop
+ // above).
+ int buffer_value = cur_tensor->is_variable ? 0 : 1;
+ switch (cur_tensor->type) {
+ case kTfLiteInt32: {
+ int32_t* buffer = tflite::GetTensorData<int32_t>(cur_tensor);
+ for (int j = 0; j < buffer_length; ++j) {
+ TF_LITE_MICRO_EXPECT_EQ(buffer_value, buffer[j]);
+ }
+ break;
+ }
+ case kTfLiteUInt8: {
+ uint8_t* buffer = tflite::GetTensorData<uint8_t>(cur_tensor);
+ for (int j = 0; j < buffer_length; ++j) {
+ TF_LITE_MICRO_EXPECT_EQ(buffer_value, buffer[j]);
+ }
+ break;
+ }
+ default:
+ TF_LITE_MICRO_FAIL("Unsupported dtype");
+ }
+ }
+}
+
+// The interpreter initialization requires multiple steps and this test case
+// ensures that simply creating and destructing an interpreter object is ok.
+// b/147830765 has one example of a change that caused trouble for this simple
+// case.
+TF_LITE_MICRO_TEST(TestIncompleteInitialization) {
+ const tflite::Model* model = tflite::testing::GetComplexMockModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size = 2048;
+ uint8_t allocator_buffer[allocator_buffer_size];
+
+ tflite::MicroInterpreter interpreter(model, op_resolver, allocator_buffer,
+ allocator_buffer_size,
+ tflite::GetMicroErrorReporter());
+}
+
+// Test that an interpreter with a supplied profiler correctly calls the
+// profiler each time an operator is invoked.
+TF_LITE_MICRO_TEST(InterpreterWithProfilerShouldProfileOps) {
+ const tflite::Model* model = tflite::testing::GetComplexMockModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size = 2048;
+ uint8_t allocator_buffer[allocator_buffer_size];
+ tflite::MockProfiler profiler;
+ tflite::MicroInterpreter interpreter(
+ model, op_resolver, allocator_buffer, allocator_buffer_size,
+ tflite::GetMicroErrorReporter(), &profiler);
+
+ TF_LITE_MICRO_EXPECT_EQ(profiler.event_starts(), 0);
+ TF_LITE_MICRO_EXPECT_EQ(profiler.event_ends(), 0);
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.Invoke(), kTfLiteOk);
+#ifndef NDEBUG
+ TF_LITE_MICRO_EXPECT_EQ(profiler.event_starts(), 3);
+ TF_LITE_MICRO_EXPECT_EQ(profiler.event_ends(), 3);
+#else // Profile events will not occur on release builds.
+ TF_LITE_MICRO_EXPECT_EQ(profiler.event_starts(), 0);
+ TF_LITE_MICRO_EXPECT_EQ(profiler.event_ends(), 0);
+#endif
+}
+
+TF_LITE_MICRO_TEST(TestIncompleteInitializationAllocationsWithSmallArena) {
+ const tflite::Model* model = tflite::testing::GetComplexMockModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size = 512;
+ uint8_t allocator_buffer[allocator_buffer_size];
+
+ tflite::RecordingMicroAllocator* allocator =
+ tflite::RecordingMicroAllocator::Create(allocator_buffer,
+ allocator_buffer_size,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(nullptr, allocator);
+
+ tflite::MicroInterpreter interpreter(model, op_resolver, allocator,
+ tflite::GetMicroErrorReporter());
+
+ // Interpreter fails because arena is too small:
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.Invoke(), kTfLiteError);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(192),
+ allocator->GetSimpleMemoryAllocator()->GetHeadUsedBytes());
+
+ // Ensure allocations are zero (ignore tail since some internal structs are
+ // initialized with this space):
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(0),
+ allocator
+ ->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteEvalTensorData)
+ .used_bytes);
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(0),
+ allocator
+ ->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteTensorVariableBufferData)
+ .used_bytes);
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(0),
+ allocator->GetRecordedAllocation(tflite::RecordedAllocationType::kOpData)
+ .used_bytes);
+}
+
+TF_LITE_MICRO_TEST(TestInterpreterDoesNotAllocateUntilInvoke) {
+ const tflite::Model* model = tflite::testing::GetComplexMockModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size = 1024 * 10;
+ uint8_t allocator_buffer[allocator_buffer_size];
+
+ tflite::RecordingMicroAllocator* allocator =
+ tflite::RecordingMicroAllocator::Create(allocator_buffer,
+ allocator_buffer_size,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(nullptr, allocator);
+
+ tflite::MicroInterpreter interpreter(model, op_resolver, allocator,
+ tflite::GetMicroErrorReporter());
+
+ // Ensure allocations are zero (ignore tail since some internal structs are
+ // initialized with this space):
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(0),
+ allocator->GetSimpleMemoryAllocator()->GetHeadUsedBytes());
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(0),
+ allocator
+ ->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteTensorVariableBufferData)
+ .used_bytes);
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(0),
+ allocator
+ ->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteEvalTensorData)
+ .used_bytes);
+ TF_LITE_MICRO_EXPECT_EQ(
+ static_cast<size_t>(0),
+ allocator->GetRecordedAllocation(tflite::RecordedAllocationType::kOpData)
+ .used_bytes);
+
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.Invoke(), kTfLiteOk);
+ allocator->PrintAllocations();
+
+ // Allocation sizes vary based on platform - check that allocations are now
+ // non-zero:
+ TF_LITE_MICRO_EXPECT_GT(
+ allocator->GetSimpleMemoryAllocator()->GetHeadUsedBytes(),
+ static_cast<size_t>(0));
+ TF_LITE_MICRO_EXPECT_GT(
+ allocator
+ ->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteEvalTensorData)
+ .used_bytes,
+ 0);
+
+ TF_LITE_MICRO_EXPECT_GT(
+ allocator
+ ->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteTensorVariableBufferData)
+ .used_bytes,
+ static_cast<size_t>(0));
+
+ // TODO(b/160160549): This check is mostly meaningless right now because the
+ // operator creation in our mock models is inconsistent. Revisit what
+ // this check should be once the mock models are properly created.
+ TF_LITE_MICRO_EXPECT_EQ(
+ allocator->GetRecordedAllocation(tflite::RecordedAllocationType::kOpData)
+ .used_bytes,
+ static_cast<size_t>(0));
+}
+
+TF_LITE_MICRO_TEST(TestInterpreterMultipleInputs) {
+ const tflite::Model* model = tflite::testing::GetSimpleMultipleInputsModel();
+ TF_LITE_MICRO_EXPECT_NE(nullptr, model);
+
+ tflite::AllOpsResolver op_resolver = tflite::testing::GetOpResolver();
+
+ constexpr size_t allocator_buffer_size = 2000;
+ uint8_t allocator_buffer[allocator_buffer_size];
+
+ // Create a new scope so that we can test the destructor.
+ {
+ tflite::MicroInterpreter interpreter(model, op_resolver, allocator_buffer,
+ allocator_buffer_size,
+ tflite::GetMicroErrorReporter());
+
+ TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);
+ TF_LITE_MICRO_EXPECT_LE(interpreter.arena_used_bytes(), 928 + 100);
+
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(3), interpreter.inputs_size());
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), interpreter.outputs_size());
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), interpreter.tensors_size());
+
+ TfLiteTensor* input = interpreter.input(0);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, input->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), input->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input->data.i32);
+ input->data.i32[0] = 21;
+
+ TfLiteTensor* input1 = interpreter.input(1);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input1);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt8, input1->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, input1->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, input1->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1), input1->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input1->data.i32);
+ input1->data.i32[0] = 21;
+
+ TfLiteTensor* input2 = interpreter.input(2);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input2);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, input2->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, input2->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, input2->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), input2->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, input2->data.i32);
+ input2->data.i32[0] = 24;
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, interpreter.Invoke());
+
+ TfLiteTensor* output = interpreter.output(0);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, output);
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteInt32, output->type);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->size);
+ TF_LITE_MICRO_EXPECT_EQ(1, output->dims->data[0]);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(4), output->bytes);
+ TF_LITE_MICRO_EXPECT_NE(nullptr, output->data.i32);
+ TF_LITE_MICRO_EXPECT_EQ(66, output->data.i32[0]);
+ }
+
+ TF_LITE_MICRO_EXPECT_EQ(tflite::testing::MultipleInputs::freed_, true);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/micro_mutable_op_resolver.h b/tensorflow/lite/micro/micro_mutable_op_resolver.h
new file mode 100644
index 0000000..95c4b56
--- /dev/null
+++ b/tensorflow/lite/micro/micro_mutable_op_resolver.h
@@ -0,0 +1,561 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_MUTABLE_OP_RESOLVER_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_MUTABLE_OP_RESOLVER_H_
+
+#include <cstdio>
+#include <cstring>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/core/api/flatbuffer_conversions.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/kernels/ethosu.h"
+#include "tensorflow/lite/micro/kernels/fully_connected.h"
+#include "tensorflow/lite/micro/kernels/micro_ops.h"
+#include "tensorflow/lite/micro/micro_op_resolver.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+TfLiteRegistration* Register_DETECTION_POSTPROCESS();
+
+template <unsigned int tOpCount>
+class MicroMutableOpResolver : public MicroOpResolver {
+ public:
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+
+ explicit MicroMutableOpResolver(ErrorReporter* error_reporter = nullptr)
+ : error_reporter_(error_reporter) {}
+
+ const TfLiteRegistration* FindOp(tflite::BuiltinOperator op) const override {
+ if (op == BuiltinOperator_CUSTOM) return nullptr;
+
+ for (unsigned int i = 0; i < registrations_len_; ++i) {
+ const TfLiteRegistration& registration = registrations_[i];
+ if (registration.builtin_code == op) {
+ return ®istration;
+ }
+ }
+ return nullptr;
+ }
+
+ const TfLiteRegistration* FindOp(const char* op) const override {
+ for (unsigned int i = 0; i < registrations_len_; ++i) {
+ const TfLiteRegistration& registration = registrations_[i];
+ if ((registration.builtin_code == BuiltinOperator_CUSTOM) &&
+ (strcmp(registration.custom_name, op) == 0)) {
+ return ®istration;
+ }
+ }
+ return nullptr;
+ }
+
+ MicroOpResolver::BuiltinParseFunction GetOpDataParser(
+ BuiltinOperator op) const override {
+ TFLITE_DCHECK(num_buitin_ops_ <= tOpCount);
+ for (unsigned int i = 0; i < num_buitin_ops_; ++i) {
+ if (builtin_codes_[i] == op) return builtin_parsers_[i];
+ }
+ return nullptr;
+ }
+
+ // Registers a Custom Operator with the MicroOpResolver.
+ //
+ // Only the first call for a given name will be successful. i.e. if this
+ // function is called again for a previously added Custom Operator, the
+ // MicroOpResolver will be unchanged and this function will return
+ // kTfLiteError.
+ TfLiteStatus AddCustom(const char* name, TfLiteRegistration* registration) {
+ if (registrations_len_ >= tOpCount) {
+ if (error_reporter_) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Couldn't register custom op '%s', resolver size is too small (%d)",
+ name, tOpCount);
+ }
+ return kTfLiteError;
+ }
+
+ if (FindOp(name) != nullptr) {
+ if (error_reporter_ != nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Calling AddCustom for the same op more than once "
+ "is not supported (Op: %s).",
+ name);
+ }
+ return kTfLiteError;
+ }
+
+ TfLiteRegistration* new_registration = ®istrations_[registrations_len_];
+ registrations_len_ += 1;
+
+ *new_registration = *registration;
+ new_registration->builtin_code = BuiltinOperator_CUSTOM;
+ new_registration->custom_name = name;
+ return kTfLiteOk;
+ }
+
+ // The Add* functions below add the various Builtin operators to the
+ // MicroMutableOpResolver object.
+
+ TfLiteStatus AddAbs() {
+ return AddBuiltin(BuiltinOperator_ABS, tflite::ops::micro::Register_ABS(),
+ ParseAbs);
+ }
+
+ TfLiteStatus AddAdd() {
+ return AddBuiltin(BuiltinOperator_ADD, tflite::ops::micro::Register_ADD(),
+ ParseAdd);
+ }
+
+ TfLiteStatus AddAddN() {
+ return AddBuiltin(BuiltinOperator_ADD_N, tflite::Register_ADD_N(),
+ ParseAddN);
+ }
+
+ TfLiteStatus AddArgMax() {
+ return AddBuiltin(BuiltinOperator_ARG_MAX,
+ tflite::ops::micro::Register_ARG_MAX(), ParseArgMax);
+ }
+
+ TfLiteStatus AddArgMin() {
+ return AddBuiltin(BuiltinOperator_ARG_MIN,
+ tflite::ops::micro::Register_ARG_MIN(), ParseArgMin);
+ }
+
+ TfLiteStatus AddAveragePool2D() {
+ return AddBuiltin(BuiltinOperator_AVERAGE_POOL_2D,
+ tflite::ops::micro::Register_AVERAGE_POOL_2D(),
+ ParsePool);
+ }
+
+ TfLiteStatus AddBatchToSpaceNd() {
+ return AddBuiltin(BuiltinOperator_BATCH_TO_SPACE_ND,
+ Register_BATCH_TO_SPACE_ND(), ParseBatchToSpaceNd);
+ }
+
+ TfLiteStatus AddCast() {
+ return AddBuiltin(BuiltinOperator_CAST, Register_CAST(), ParseCast);
+ }
+
+ TfLiteStatus AddCeil() {
+ return AddBuiltin(BuiltinOperator_CEIL, tflite::ops::micro::Register_CEIL(),
+ ParseCeil);
+ }
+
+ TfLiteStatus AddCircularBuffer() {
+ return AddCustom("CIRCULAR_BUFFER",
+ tflite::ops::micro::Register_CIRCULAR_BUFFER());
+ }
+
+ TfLiteStatus AddConcatenation() {
+ return AddBuiltin(BuiltinOperator_CONCATENATION,
+ tflite::ops::micro::Register_CONCATENATION(),
+ ParseConcatenation);
+ }
+
+ TfLiteStatus AddConv2D() {
+ return AddBuiltin(BuiltinOperator_CONV_2D, Register_CONV_2D(), ParseConv2D);
+ }
+
+ TfLiteStatus AddCos() {
+ return AddBuiltin(BuiltinOperator_COS, tflite::ops::micro::Register_COS(),
+ ParseCos);
+ }
+
+ TfLiteStatus AddCumSum() {
+ return AddBuiltin(BuiltinOperator_CUMSUM, tflite::Register_CUMSUM(),
+ ParseCumsum);
+ }
+
+ TfLiteStatus AddDepthwiseConv2D() {
+ return AddBuiltin(BuiltinOperator_DEPTHWISE_CONV_2D,
+ Register_DEPTHWISE_CONV_2D(), ParseDepthwiseConv2D);
+ }
+
+ TfLiteStatus AddDequantize() {
+ return AddBuiltin(BuiltinOperator_DEQUANTIZE,
+ tflite::ops::micro::Register_DEQUANTIZE(),
+ ParseDequantize);
+ }
+
+ TfLiteStatus AddDetectionPostprocess() {
+ return AddCustom("TFLite_Detection_PostProcess",
+ tflite::Register_DETECTION_POSTPROCESS());
+ }
+
+ TfLiteStatus AddElu() {
+ return AddBuiltin(BuiltinOperator_ELU, tflite::Register_ELU(), ParseElu);
+ }
+
+ TfLiteStatus AddEqual() {
+ return AddBuiltin(BuiltinOperator_EQUAL,
+ tflite::ops::micro::Register_EQUAL(), ParseEqual);
+ }
+
+ TfLiteStatus AddEthosU() {
+ TfLiteRegistration* registration = tflite::Register_ETHOSU();
+ if (registration) {
+ return AddCustom(tflite::GetString_ETHOSU(), registration);
+ }
+ return kTfLiteOk;
+ }
+
+ TfLiteStatus AddExp() {
+ return AddBuiltin(BuiltinOperator_EXP, Register_EXP(), ParseExp);
+ }
+
+ TfLiteStatus AddExpandDims() {
+ return AddBuiltin(BuiltinOperator_EXPAND_DIMS, Register_EXPAND_DIMS(),
+ ParseExpandDims);
+ }
+
+ TfLiteStatus AddFill() {
+ return AddBuiltin(BuiltinOperator_FILL, tflite::Register_FILL(), ParseFill);
+ }
+
+ TfLiteStatus AddFloor() {
+ return AddBuiltin(BuiltinOperator_FLOOR,
+ tflite::ops::micro::Register_FLOOR(), ParseFloor);
+ }
+
+ TfLiteStatus AddFloorDiv() {
+ return AddBuiltin(BuiltinOperator_FLOOR_DIV, tflite::Register_FLOOR_DIV(),
+ ParseFloorDiv);
+ }
+
+ TfLiteStatus AddFloorMod() {
+ return AddBuiltin(BuiltinOperator_FLOOR_MOD, tflite::Register_FLOOR_MOD(),
+ ParseFloorMod);
+ }
+
+ TfLiteStatus AddFullyConnected(
+ const TfLiteRegistration& registration = Register_FULLY_CONNECTED()) {
+ return AddBuiltin(BuiltinOperator_FULLY_CONNECTED, registration,
+ ParseFullyConnected);
+ }
+
+ TfLiteStatus AddGreater() {
+ return AddBuiltin(BuiltinOperator_GREATER,
+ tflite::ops::micro::Register_GREATER(), ParseGreater);
+ }
+
+ TfLiteStatus AddGreaterEqual() {
+ return AddBuiltin(BuiltinOperator_GREATER_EQUAL,
+ tflite::ops::micro::Register_GREATER_EQUAL(),
+ ParseGreaterEqual);
+ }
+
+ TfLiteStatus AddHardSwish() {
+ return AddBuiltin(BuiltinOperator_HARD_SWISH,
+ tflite::ops::micro::Register_HARD_SWISH(),
+ ParseHardSwish);
+ }
+
+ TfLiteStatus AddL2Normalization() {
+ return AddBuiltin(BuiltinOperator_L2_NORMALIZATION,
+ tflite::ops::micro::Register_L2_NORMALIZATION(),
+ ParseL2Normalization);
+ }
+
+ TfLiteStatus AddL2Pool2D() {
+ return AddBuiltin(BuiltinOperator_L2_POOL_2D, tflite::Register_L2_POOL_2D(),
+ ParsePool);
+ }
+
+ TfLiteStatus AddLeakyRelu() {
+ return AddBuiltin(BuiltinOperator_LEAKY_RELU, tflite::Register_LEAKY_RELU(),
+ ParseLeakyRelu);
+ }
+
+ TfLiteStatus AddLess() {
+ return AddBuiltin(BuiltinOperator_LESS, tflite::ops::micro::Register_LESS(),
+ ParseLess);
+ }
+
+ TfLiteStatus AddLessEqual() {
+ return AddBuiltin(BuiltinOperator_LESS_EQUAL,
+ tflite::ops::micro::Register_LESS_EQUAL(),
+ ParseLessEqual);
+ }
+
+ TfLiteStatus AddLog() {
+ return AddBuiltin(BuiltinOperator_LOG, tflite::ops::micro::Register_LOG(),
+ ParseLog);
+ }
+
+ TfLiteStatus AddLogicalAnd() {
+ return AddBuiltin(BuiltinOperator_LOGICAL_AND,
+ tflite::ops::micro::Register_LOGICAL_AND(),
+ ParseLogicalAnd);
+ }
+
+ TfLiteStatus AddLogicalNot() {
+ return AddBuiltin(BuiltinOperator_LOGICAL_NOT,
+ tflite::ops::micro::Register_LOGICAL_NOT(),
+ ParseLogicalNot);
+ }
+
+ TfLiteStatus AddLogicalOr() {
+ return AddBuiltin(BuiltinOperator_LOGICAL_OR,
+ tflite::ops::micro::Register_LOGICAL_OR(),
+ ParseLogicalOr);
+ }
+
+ TfLiteStatus AddLogistic() {
+ return AddBuiltin(BuiltinOperator_LOGISTIC,
+ tflite::ops::micro::Register_LOGISTIC(), ParseLogistic);
+ }
+
+ TfLiteStatus AddMaximum() {
+ return AddBuiltin(BuiltinOperator_MAXIMUM,
+ tflite::ops::micro::Register_MAXIMUM(), ParseMaximum);
+ }
+
+ TfLiteStatus AddMaxPool2D() {
+ return AddBuiltin(BuiltinOperator_MAX_POOL_2D,
+ tflite::ops::micro::Register_MAX_POOL_2D(), ParsePool);
+ }
+
+ TfLiteStatus AddMean() {
+ return AddBuiltin(BuiltinOperator_MEAN, tflite::ops::micro::Register_MEAN(),
+ ParseReducer);
+ }
+
+ TfLiteStatus AddMinimum() {
+ return AddBuiltin(BuiltinOperator_MINIMUM,
+ tflite::ops::micro::Register_MINIMUM(), ParseMinimum);
+ }
+
+ TfLiteStatus AddMul() {
+ return AddBuiltin(BuiltinOperator_MUL, tflite::ops::micro::Register_MUL(),
+ ParseMul);
+ }
+
+ TfLiteStatus AddNeg() {
+ return AddBuiltin(BuiltinOperator_NEG, tflite::ops::micro::Register_NEG(),
+ ParseNeg);
+ }
+
+ TfLiteStatus AddNotEqual() {
+ return AddBuiltin(BuiltinOperator_NOT_EQUAL,
+ tflite::ops::micro::Register_NOT_EQUAL(), ParseNotEqual);
+ }
+
+ TfLiteStatus AddPack() {
+ return AddBuiltin(BuiltinOperator_PACK, tflite::ops::micro::Register_PACK(),
+ ParsePack);
+ }
+
+ TfLiteStatus AddPad() {
+ return AddBuiltin(BuiltinOperator_PAD, tflite::ops::micro::Register_PAD(),
+ ParsePad);
+ }
+
+ TfLiteStatus AddPadV2() {
+ return AddBuiltin(BuiltinOperator_PADV2,
+ tflite::ops::micro::Register_PADV2(), ParsePadV2);
+ }
+
+ TfLiteStatus AddPrelu() {
+ return AddBuiltin(BuiltinOperator_PRELU,
+ tflite::ops::micro::Register_PRELU(), ParsePrelu);
+ }
+
+ TfLiteStatus AddQuantize() {
+ return AddBuiltin(BuiltinOperator_QUANTIZE, Register_QUANTIZE(),
+ ParseQuantize);
+ }
+
+ TfLiteStatus AddReduceMax() {
+ return AddBuiltin(BuiltinOperator_REDUCE_MAX,
+ tflite::ops::micro::Register_REDUCE_MAX(), ParseReducer);
+ }
+
+ TfLiteStatus AddRelu() {
+ return AddBuiltin(BuiltinOperator_RELU, tflite::ops::micro::Register_RELU(),
+ ParseRelu);
+ }
+
+ TfLiteStatus AddRelu6() {
+ return AddBuiltin(BuiltinOperator_RELU6,
+ tflite::ops::micro::Register_RELU6(), ParseRelu6);
+ }
+
+ TfLiteStatus AddReshape() {
+ return AddBuiltin(BuiltinOperator_RESHAPE,
+ tflite::ops::micro::Register_RESHAPE(), ParseReshape);
+ }
+
+ TfLiteStatus AddResizeNearestNeighbor() {
+ return AddBuiltin(BuiltinOperator_RESIZE_NEAREST_NEIGHBOR,
+ tflite::ops::micro::Register_RESIZE_NEAREST_NEIGHBOR(),
+ ParseResizeNearestNeighbor);
+ }
+
+ TfLiteStatus AddRound() {
+ return AddBuiltin(BuiltinOperator_ROUND,
+ tflite::ops::micro::Register_ROUND(), ParseRound);
+ }
+
+ TfLiteStatus AddRsqrt() {
+ return AddBuiltin(BuiltinOperator_RSQRT,
+ tflite::ops::micro::Register_RSQRT(), ParseRsqrt);
+ }
+
+ TfLiteStatus AddShape() {
+ return AddBuiltin(BuiltinOperator_SHAPE, Register_SHAPE(), ParseShape);
+ }
+
+ TfLiteStatus AddSin() {
+ return AddBuiltin(BuiltinOperator_SIN, tflite::ops::micro::Register_SIN(),
+ ParseSin);
+ }
+
+ TfLiteStatus AddSoftmax() {
+ return AddBuiltin(BuiltinOperator_SOFTMAX, Register_SOFTMAX(),
+ ParseSoftmax);
+ }
+
+ TfLiteStatus AddSpaceToBatchNd() {
+ return AddBuiltin(BuiltinOperator_SPACE_TO_BATCH_ND,
+ Register_SPACE_TO_BATCH_ND(), ParseSpaceToBatchNd);
+ }
+
+ TfLiteStatus AddSplit() {
+ return AddBuiltin(BuiltinOperator_SPLIT,
+ tflite::ops::micro::Register_SPLIT(), ParseSplit);
+ }
+
+ TfLiteStatus AddSplitV() {
+ return AddBuiltin(BuiltinOperator_SPLIT_V,
+ tflite::ops::micro::Register_SPLIT_V(), ParseSplitV);
+ }
+
+ TfLiteStatus AddSqueeze() {
+ return AddBuiltin(BuiltinOperator_SQUEEZE, Register_SQUEEZE(),
+ ParseSqueeze);
+ }
+
+ TfLiteStatus AddSqrt() {
+ return AddBuiltin(BuiltinOperator_SQRT, tflite::ops::micro::Register_SQRT(),
+ ParseSqrt);
+ }
+
+ TfLiteStatus AddSquare() {
+ return AddBuiltin(BuiltinOperator_SQUARE,
+ tflite::ops::micro::Register_SQUARE(), ParseSquare);
+ }
+
+ TfLiteStatus AddStridedSlice() {
+ return AddBuiltin(BuiltinOperator_STRIDED_SLICE,
+ tflite::ops::micro::Register_STRIDED_SLICE(),
+ ParseStridedSlice);
+ }
+
+ TfLiteStatus AddSub() {
+ return AddBuiltin(BuiltinOperator_SUB, tflite::ops::micro::Register_SUB(),
+ ParseSub);
+ }
+
+ TfLiteStatus AddSvdf() {
+ return AddBuiltin(BuiltinOperator_SVDF, Register_SVDF(), ParseSvdf);
+ }
+
+ TfLiteStatus AddTanh() {
+ return AddBuiltin(BuiltinOperator_TANH, tflite::ops::micro::Register_TANH(),
+ ParseTanh);
+ }
+
+ TfLiteStatus AddTransposeConv() {
+ return AddBuiltin(BuiltinOperator_TRANSPOSE_CONV,
+ tflite::Register_TRANSPOSE_CONV(), ParseTransposeConv);
+ }
+
+ TfLiteStatus AddUnpack() {
+ return AddBuiltin(BuiltinOperator_UNPACK,
+ tflite::ops::micro::Register_UNPACK(), ParseUnpack);
+ }
+
+ TfLiteStatus AddZerosLike() {
+ return AddBuiltin(BuiltinOperator_ZEROS_LIKE, Register_ZEROS_LIKE(),
+ ParseZerosLike);
+ }
+
+ unsigned int GetRegistrationLength() { return registrations_len_; }
+
+ private:
+ TfLiteStatus AddBuiltin(tflite::BuiltinOperator op,
+ const TfLiteRegistration& registration,
+ MicroOpResolver::BuiltinParseFunction parser) {
+ if (op == BuiltinOperator_CUSTOM) {
+ if (error_reporter_ != nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Invalid parameter BuiltinOperator_CUSTOM to the "
+ "AddBuiltin function.");
+ }
+ return kTfLiteError;
+ }
+
+ if (FindOp(op) != nullptr) {
+ if (error_reporter_ != nullptr) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Calling AddBuiltin with the same op more than "
+ "once is not supported (Op: #%d).",
+ op);
+ }
+ return kTfLiteError;
+ }
+
+ if (registrations_len_ >= tOpCount) {
+ if (error_reporter_) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Couldn't register builtin op #%d, resolver size "
+ "is too small (%d).",
+ op, tOpCount);
+ }
+ return kTfLiteError;
+ }
+
+ registrations_[registrations_len_] = registration;
+ // Strictly speaking, the builtin_code is not necessary for TFLM but filling
+ // it in regardless.
+ registrations_[registrations_len_].builtin_code = op;
+ registrations_len_++;
+
+ builtin_codes_[num_buitin_ops_] = op;
+ builtin_parsers_[num_buitin_ops_] = parser;
+ num_buitin_ops_++;
+
+ return kTfLiteOk;
+ }
+
+ TfLiteRegistration registrations_[tOpCount];
+ unsigned int registrations_len_ = 0;
+
+ // Arrays (and counter) to store the builtin codes and their corresponding
+ // parse functions as these are registered with the Op Resolver.
+ BuiltinOperator builtin_codes_[tOpCount];
+ MicroOpResolver::BuiltinParseFunction builtin_parsers_[tOpCount];
+ unsigned int num_buitin_ops_ = 0;
+
+ ErrorReporter* error_reporter_;
+};
+
+}; // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_MUTABLE_OP_RESOLVER_H_
diff --git a/tensorflow/lite/micro/micro_mutable_op_resolver_test.cc b/tensorflow/lite/micro/micro_mutable_op_resolver_test.cc
new file mode 100644
index 0000000..efe41ff
--- /dev/null
+++ b/tensorflow/lite/micro/micro_mutable_op_resolver_test.cc
@@ -0,0 +1,132 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
+
+#include "tensorflow/lite/micro/micro_op_resolver.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+namespace tflite {
+namespace {
+void* MockInit(TfLiteContext* context, const char* buffer, size_t length) {
+ // Do nothing.
+ return nullptr;
+}
+
+void MockFree(TfLiteContext* context, void* buffer) {
+ // Do nothing.
+}
+
+TfLiteStatus MockPrepare(TfLiteContext* context, TfLiteNode* node) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus MockInvoke(TfLiteContext* context, TfLiteNode* node) {
+ return kTfLiteOk;
+}
+
+class MockErrorReporter : public ErrorReporter {
+ public:
+ MockErrorReporter() : has_been_called_(false) {}
+ int Report(const char* format, va_list args) override {
+ has_been_called_ = true;
+ return 0;
+ };
+
+ bool HasBeenCalled() { return has_been_called_; }
+
+ void ResetState() { has_been_called_ = false; }
+
+ private:
+ bool has_been_called_;
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace
+} // namespace tflite
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestOperations) {
+ using tflite::BuiltinOperator_CONV_2D;
+ using tflite::BuiltinOperator_RELU;
+ using tflite::MicroMutableOpResolver;
+ using tflite::OpResolver;
+
+ static TfLiteRegistration r = {};
+ r.init = tflite::MockInit;
+ r.free = tflite::MockFree;
+ r.prepare = tflite::MockPrepare;
+ r.invoke = tflite::MockInvoke;
+
+ MicroMutableOpResolver<1> micro_op_resolver;
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ micro_op_resolver.AddCustom("mock_custom", &r));
+
+ // Only one AddCustom per operator should return kTfLiteOk.
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError,
+ micro_op_resolver.AddCustom("mock_custom", &r));
+
+ tflite::MicroOpResolver* resolver = µ_op_resolver;
+
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1),
+ micro_op_resolver.GetRegistrationLength());
+
+ const TfLiteRegistration* registration =
+ resolver->FindOp(BuiltinOperator_RELU);
+ TF_LITE_MICRO_EXPECT(nullptr == registration);
+
+ registration = resolver->FindOp("mock_custom");
+ TF_LITE_MICRO_EXPECT(nullptr != registration);
+ TF_LITE_MICRO_EXPECT(nullptr == registration->init(nullptr, nullptr, 0));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->prepare(nullptr, nullptr));
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, registration->invoke(nullptr, nullptr));
+
+ registration = resolver->FindOp("nonexistent_custom");
+ TF_LITE_MICRO_EXPECT(nullptr == registration);
+}
+
+TF_LITE_MICRO_TEST(TestErrorReporting) {
+ using tflite::BuiltinOperator_CONV_2D;
+ using tflite::BuiltinOperator_RELU;
+ using tflite::MicroMutableOpResolver;
+
+ static TfLiteRegistration r = {};
+ r.init = tflite::MockInit;
+ r.free = tflite::MockFree;
+ r.prepare = tflite::MockPrepare;
+ r.invoke = tflite::MockInvoke;
+
+ tflite::MockErrorReporter mock_reporter;
+ MicroMutableOpResolver<1> micro_op_resolver(&mock_reporter);
+ TF_LITE_MICRO_EXPECT_EQ(false, mock_reporter.HasBeenCalled());
+ mock_reporter.ResetState();
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,
+ micro_op_resolver.AddCustom("mock_custom_0", &r));
+ TF_LITE_MICRO_EXPECT_EQ(false, mock_reporter.HasBeenCalled());
+ mock_reporter.ResetState();
+
+ // Attempting to Add more operators than the class template parameter for
+ // MicroMutableOpResolver should result in errors.
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError, micro_op_resolver.AddRelu());
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError,
+ micro_op_resolver.AddCustom("mock_custom_1", &r));
+ TF_LITE_MICRO_EXPECT_EQ(true, mock_reporter.HasBeenCalled());
+ mock_reporter.ResetState();
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/micro_op_resolver.h b/tensorflow/lite/micro/micro_op_resolver.h
new file mode 100644
index 0000000..757b6b8
--- /dev/null
+++ b/tensorflow/lite/micro/micro_op_resolver.h
@@ -0,0 +1,73 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_OP_RESOLVER_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_OP_RESOLVER_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/core/api/flatbuffer_conversions.h"
+#include "tensorflow/lite/core/api/op_resolver.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+// This is an interface for the OpResolver for TFLiteMicro. The differences from
+// the TFLite OpResolver base class are to:
+// * explicitly remove support for Op versions
+// * allow for finer grained registration of the Builtin Ops to reduce code
+// size for TFLiteMicro.
+//
+// We need an interface class instead of directly using MicroMutableOpResolver
+// because MicroMutableOpResolver is a class template with the number of
+// registered Ops as the template parameter.
+class MicroOpResolver : public OpResolver {
+ public:
+ typedef TfLiteStatus (*BuiltinParseFunction)(const Operator* op,
+ ErrorReporter* error_reporter,
+ BuiltinDataAllocator* allocator,
+ void** builtin_data);
+
+ // Returns the Op registration struct corresponding to the enum code from the
+ // flatbuffer schema. Returns nullptr if the op is not found or if op ==
+ // BuiltinOperator_CUSTOM.
+ virtual const TfLiteRegistration* FindOp(BuiltinOperator op) const = 0;
+
+ // Returns the Op registration struct corresponding to the custom operator by
+ // name.
+ virtual const TfLiteRegistration* FindOp(const char* op) const = 0;
+
+ // This implementation exists for compatibility with the OpResolver base class
+ // and disregards the version parameter.
+ const TfLiteRegistration* FindOp(BuiltinOperator op,
+ int version) const final {
+ return FindOp(op);
+ }
+
+ // This implementation exists for compatibility with the OpResolver base class
+ // and disregards the version parameter.
+ const TfLiteRegistration* FindOp(const char* op, int version) const final {
+ return FindOp(op);
+ }
+
+ // Returns the operator specific parsing function for the OpData for a
+ // BuiltinOperator (if registered), else nullptr.
+ virtual BuiltinParseFunction GetOpDataParser(BuiltinOperator op) const = 0;
+
+ ~MicroOpResolver() override {}
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_OP_RESOLVER_H_
diff --git a/tensorflow/lite/micro/micro_profiler.cc b/tensorflow/lite/micro/micro_profiler.cc
new file mode 100644
index 0000000..792d8ae
--- /dev/null
+++ b/tensorflow/lite/micro/micro_profiler.cc
@@ -0,0 +1,58 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/micro/micro_profiler.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/micro_time.h"
+
+namespace tflite {
+
+uint32_t MicroProfiler::BeginEvent(const char* tag) {
+ if (num_events_ == kMaxEvents) {
+ num_events_ = 0;
+ }
+
+ tags_[num_events_] = tag;
+ start_ticks_[num_events_] = GetCurrentTimeTicks();
+ end_ticks_[num_events_] = start_ticks_[num_events_] - 1;
+ return num_events_++;
+}
+
+void MicroProfiler::EndEvent(uint32_t event_handle) {
+ TFLITE_DCHECK(event_handle < kMaxEvents);
+ end_ticks_[event_handle] = GetCurrentTimeTicks();
+}
+
+int32_t MicroProfiler::GetTotalTicks() const {
+ int32_t ticks = 0;
+ for (int i = 0; i < num_events_; ++i) {
+ ticks += end_ticks_[i] - start_ticks_[i];
+ }
+ return ticks;
+}
+
+void MicroProfiler::Log() const {
+#if !defined(TF_LITE_STRIP_ERROR_STRINGS)
+ for (int i = 0; i < num_events_; ++i) {
+ int32_t ticks = end_ticks_[i] - start_ticks_[i];
+ MicroPrintf("%s took %d ticks (%d ms).", tags_[i], ticks, TicksToMs(ticks));
+ }
+#endif
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/micro_profiler.h b/tensorflow/lite/micro/micro_profiler.h
new file mode 100644
index 0000000..a75375b
--- /dev/null
+++ b/tensorflow/lite/micro/micro_profiler.h
@@ -0,0 +1,118 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_PROFILER_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_PROFILER_H_
+
+#include <cstdint>
+
+#include "tensorflow/lite/micro/compatibility.h"
+
+namespace tflite {
+
+// MicroProfiler creates a common way to gain fine-grained insight into runtime
+// performance. Bottleck operators can be identified along with slow code
+// sections. This can be used in conjunction with running the relevant micro
+// benchmark to evaluate end-to-end performance.
+class MicroProfiler {
+ public:
+ MicroProfiler() = default;
+ virtual ~MicroProfiler() = default;
+
+ // Marks the start of a new event and returns an event handle that can be used
+ // to mark the end of the event via EndEvent. The lifetime of the tag
+ // parameter must exceed that of the MicroProfiler.
+ virtual uint32_t BeginEvent(const char* tag);
+
+ // Marks the end of an event associated with event_handle. It is the
+ // responsibility of the caller to ensure than EndEvent is called once and
+ // only once per event_handle.
+ //
+ // If EndEvent is called more than once for the same event_handle, the last
+ // call will be used as the end of event marker.If EndEvent is called 0 times
+ // for a particular event_handle, the duration of that event will be 0 ticks.
+ virtual void EndEvent(uint32_t event_handle);
+
+ // Clears all the events that have been currently profiled.
+ void ClearEvents() { num_events_ = 0; }
+
+ // Returns the sum of the ticks taken across all the events. This number
+ // is only meaningful if all of the events are disjoint (the end time of
+ // event[i] <= start time of event[i+1]).
+ int32_t GetTotalTicks() const;
+
+ // Prints the profiling information of each of the events.
+ void Log() const;
+
+ private:
+ // Maximum number of events that this class can keep track of. If we call
+ // AddEvent more than kMaxEvents number of times, then the oldest event's
+ // profiling information will be overwritten.
+ static constexpr int kMaxEvents = 50;
+
+ const char* tags_[kMaxEvents];
+ int32_t start_ticks_[kMaxEvents];
+ int32_t end_ticks_[kMaxEvents];
+ int num_events_ = 0;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE;
+};
+
+#if defined(NDEBUG)
+// For release builds, the ScopedMicroProfiler is a noop.
+//
+// This is done because the ScipedProfiler is used as part of the
+// MicroInterpreter and we want to ensure zero overhead for the release builds.
+class ScopedMicroProfiler {
+ public:
+ explicit ScopedMicroProfiler(const char* tag, MicroProfiler* profiler) {}
+};
+
+#else
+
+// This class can be used to add events to a MicroProfiler object that span the
+// lifetime of the ScopedMicroProfiler object.
+// Usage example:
+//
+// MicroProfiler profiler();
+// ...
+// {
+// ScopedMicroProfiler scoped_profiler("custom_tag", profiler);
+// work_to_profile();
+// }
+class ScopedMicroProfiler {
+ public:
+ explicit ScopedMicroProfiler(const char* tag, MicroProfiler* profiler)
+ : profiler_(profiler) {
+ if (profiler_ != nullptr) {
+ event_handle_ = profiler_->BeginEvent(tag);
+ }
+ }
+
+ ~ScopedMicroProfiler() {
+ if (profiler_ != nullptr) {
+ profiler_->EndEvent(event_handle_);
+ }
+ }
+
+ private:
+ uint32_t event_handle_ = 0;
+ MicroProfiler* profiler_ = nullptr;
+};
+#endif // !defined(NDEBUG)
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_PROFILER_H_
diff --git a/tensorflow/lite/micro/micro_string.cc b/tensorflow/lite/micro/micro_string.cc
new file mode 100644
index 0000000..ad769f6
--- /dev/null
+++ b/tensorflow/lite/micro/micro_string.cc
@@ -0,0 +1,309 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Implements debug logging for numbers by converting them into strings and then
+// calling the main DebugLog(char*) function. These are separated into a
+// different file so that platforms can just implement the string output version
+// of DebugLog() and then get the numerical variations without requiring any
+// more code.
+
+#include "tensorflow/lite/micro/micro_string.h"
+
+#include <cstdarg>
+#include <cstdint>
+#include <cstring>
+
+namespace {
+
+// Int formats can need up to 10 bytes for the value plus a single byte for the
+// sign.
+constexpr int kMaxIntCharsNeeded = 10 + 1;
+// Hex formats can need up to 8 bytes for the value plus two bytes for the "0x".
+constexpr int kMaxHexCharsNeeded = 8 + 2;
+
+// Float formats can need up to 7 bytes for the fraction plus 3 bytes for "x2^"
+// plus 3 bytes for the exponent and a single sign bit.
+constexpr float kMaxFloatCharsNeeded = 7 + 3 + 3 + 1;
+
+// All input buffers to the number conversion functions must be this long.
+const int kFastToBufferSize = 48;
+
+// Reverses a zero-terminated string in-place.
+char* ReverseStringInPlace(char* start, char* end) {
+ char* p1 = start;
+ char* p2 = end - 1;
+ while (p1 < p2) {
+ char tmp = *p1;
+ *p1++ = *p2;
+ *p2-- = tmp;
+ }
+ return start;
+}
+
+// Appends a string to a string, in-place. You need to pass in the maximum
+// string length as the second argument.
+char* StrCatStr(char* main, int main_max_length, const char* to_append) {
+ char* current = main;
+ while (*current != 0) {
+ ++current;
+ }
+ char* current_end = main + (main_max_length - 1);
+ while ((*to_append != 0) && (current < current_end)) {
+ *current = *to_append;
+ ++current;
+ ++to_append;
+ }
+ *current = 0;
+ return current;
+}
+
+// Populates the provided buffer with an ASCII representation of the number.
+char* FastUInt32ToBufferLeft(uint32_t i, char* buffer, int base) {
+ char* start = buffer;
+ do {
+ int32_t digit = i % base;
+ char character;
+ if (digit < 10) {
+ character = '0' + digit;
+ } else {
+ character = 'a' + (digit - 10);
+ }
+ *buffer++ = character;
+ i /= base;
+ } while (i > 0);
+ *buffer = 0;
+ ReverseStringInPlace(start, buffer);
+ return buffer;
+}
+
+// Populates the provided buffer with an ASCII representation of the number.
+char* FastInt32ToBufferLeft(int32_t i, char* buffer) {
+ uint32_t u = i;
+ if (i < 0) {
+ *buffer++ = '-';
+ u = -u;
+ }
+ return FastUInt32ToBufferLeft(u, buffer, 10);
+}
+
+// Converts a number to a string and appends it to another.
+char* StrCatInt32(char* main, int main_max_length, int32_t number) {
+ char number_string[kFastToBufferSize];
+ FastInt32ToBufferLeft(number, number_string);
+ return StrCatStr(main, main_max_length, number_string);
+}
+
+// Converts a number to a string and appends it to another.
+char* StrCatUInt32(char* main, int main_max_length, uint32_t number, int base) {
+ char number_string[kFastToBufferSize];
+ FastUInt32ToBufferLeft(number, number_string, base);
+ return StrCatStr(main, main_max_length, number_string);
+}
+
+// Populates the provided buffer with ASCII representation of the float number.
+// Avoids the use of any floating point instructions (since these aren't
+// supported on many microcontrollers) and as a consequence prints values with
+// power-of-two exponents.
+char* FastFloatToBufferLeft(float f, char* buffer) {
+ char* current = buffer;
+ char* current_end = buffer + (kFastToBufferSize - 1);
+ // Access the bit fields of the floating point value to avoid requiring any
+ // float instructions. These constants are derived from IEEE 754.
+ const uint32_t sign_mask = 0x80000000;
+ const uint32_t exponent_mask = 0x7f800000;
+ const int32_t exponent_shift = 23;
+ const int32_t exponent_bias = 127;
+ const uint32_t fraction_mask = 0x007fffff;
+ uint32_t u;
+ memcpy(&u, &f, sizeof(int32_t));
+ const int32_t exponent =
+ ((u & exponent_mask) >> exponent_shift) - exponent_bias;
+ const uint32_t fraction = (u & fraction_mask);
+ // Expect ~0x2B1B9D3 for fraction.
+ if (u & sign_mask) {
+ *current = '-';
+ current += 1;
+ }
+ *current = 0;
+ // These are special cases for infinities and not-a-numbers.
+ if (exponent == 128) {
+ if (fraction == 0) {
+ current = StrCatStr(current, (current_end - current), "Inf");
+ return current;
+ } else {
+ current = StrCatStr(current, (current_end - current), "NaN");
+ return current;
+ }
+ }
+ // 0x007fffff (8388607) represents 0.99... for the fraction, so to print the
+ // correct decimal digits we need to scale our value before passing it to the
+ // conversion function. This scale should be 10000000/8388608 = 1.1920928955.
+ // We can approximate this using multiply-adds and right-shifts using the
+ // values in this array. The 1. portion of the number string is printed out
+ // in a fixed way before the fraction, below.
+ const int32_t scale_shifts_size = 13;
+ const int8_t scale_shifts[13] = {3, 4, 8, 11, 13, 14, 17,
+ 18, 19, 20, 21, 22, 23};
+ uint32_t scaled_fraction = fraction;
+ for (int i = 0; i < scale_shifts_size; ++i) {
+ scaled_fraction += (fraction >> scale_shifts[i]);
+ }
+ *current = '1';
+ current += 1;
+ *current = '.';
+ current += 1;
+ *current = 0;
+
+ // Prepend leading zeros to fill in all 7 bytes of the fraction. Truncate
+ // zeros off the end of the fraction. Every fractional value takes 7 bytes.
+ // For example, 2500 would be written into the buffer as 0002500 since it
+ // represents .00025.
+ constexpr int kMaxFractionalDigits = 7;
+
+ // Abort early if there is not enough space in the buffer.
+ if (current_end - current <= kMaxFractionalDigits) {
+ return current;
+ }
+
+ // Pre-fill buffer with zeros to ensure zero-truncation works properly.
+ for (int i = 1; i < kMaxFractionalDigits; i++) {
+ *(current + i) = '0';
+ }
+
+ // Track how large the fraction is to add leading zeros.
+ char* previous = current;
+ current = StrCatUInt32(current, (current_end - current), scaled_fraction, 10);
+ int fraction_digits = current - previous;
+ int leading_zeros = kMaxFractionalDigits - fraction_digits;
+
+ // Overwrite the null terminator from StrCatUInt32 to ensure zero-trunctaion
+ // works properly.
+ *current = '0';
+
+ // Shift fraction values and prepend zeros if necessary.
+ if (leading_zeros != 0) {
+ for (int i = 0; i < fraction_digits; i++) {
+ current--;
+ *(current + leading_zeros) = *current;
+ *current = '0';
+ }
+ current += kMaxFractionalDigits;
+ }
+
+ // Truncate trailing zeros for cleaner logs. Ensure we leave at least one
+ // fractional character for the case when scaled_fraction is 0.
+ while (*(current - 1) == '0' && (current - 1) > previous) {
+ current--;
+ }
+ *current = 0;
+ current = StrCatStr(current, (current_end - current), "*2^");
+ current = StrCatInt32(current, (current_end - current), exponent);
+ return current;
+}
+
+int FormatInt32(char* output, int32_t i) {
+ return static_cast<int>(FastInt32ToBufferLeft(i, output) - output);
+}
+
+int FormatUInt32(char* output, uint32_t i) {
+ return static_cast<int>(FastUInt32ToBufferLeft(i, output, 10) - output);
+}
+
+int FormatHex(char* output, uint32_t i) {
+ return static_cast<int>(FastUInt32ToBufferLeft(i, output, 16) - output);
+}
+
+int FormatFloat(char* output, float i) {
+ return static_cast<int>(FastFloatToBufferLeft(i, output) - output);
+}
+
+} // namespace
+
+extern "C" int MicroVsnprintf(char* output, int len, const char* format,
+ va_list args) {
+ int output_index = 0;
+ const char* current = format;
+ // One extra character must be left for the null terminator.
+ const int usable_length = len - 1;
+ while (*current != '\0' && output_index < usable_length) {
+ if (*current == '%') {
+ current++;
+ switch (*current) {
+ case 'd':
+ // Cut off log message if format could exceed log buffer length.
+ if (usable_length - output_index < kMaxIntCharsNeeded) {
+ output[output_index++] = '\0';
+ return output_index;
+ }
+ output_index +=
+ FormatInt32(&output[output_index], va_arg(args, int32_t));
+ current++;
+ break;
+ case 'u':
+ if (usable_length - output_index < kMaxIntCharsNeeded) {
+ output[output_index++] = '\0';
+ return output_index;
+ }
+ output_index +=
+ FormatUInt32(&output[output_index], va_arg(args, uint32_t));
+ current++;
+ break;
+ case 'x':
+ if (usable_length - output_index < kMaxHexCharsNeeded) {
+ output[output_index++] = '\0';
+ return output_index;
+ }
+ output[output_index++] = '0';
+ output[output_index++] = 'x';
+ output_index +=
+ FormatHex(&output[output_index], va_arg(args, uint32_t));
+ current++;
+ break;
+ case 'f':
+ if (usable_length - output_index < kMaxFloatCharsNeeded) {
+ output[output_index++] = '\0';
+ return output_index;
+ }
+ output_index +=
+ FormatFloat(&output[output_index], va_arg(args, double));
+ current++;
+ break;
+ case '%':
+ output[output_index++] = *current++;
+ break;
+ case 's':
+ char* string = va_arg(args, char*);
+ int string_idx = 0;
+ while (string_idx + output_index < usable_length &&
+ string[string_idx] != '\0') {
+ output[output_index++] = string[string_idx++];
+ }
+ current++;
+ }
+ } else {
+ output[output_index++] = *current++;
+ }
+ }
+ output[output_index++] = '\0';
+ return output_index;
+}
+
+extern "C" int MicroSnprintf(char* output, int len, const char* format, ...) {
+ va_list args;
+ va_start(args, format);
+ int bytes_written = MicroVsnprintf(output, len, format, args);
+ va_end(args);
+ return bytes_written;
+}
diff --git a/tensorflow/lite/micro/micro_string.h b/tensorflow/lite/micro/micro_string.h
new file mode 100644
index 0000000..59303e8
--- /dev/null
+++ b/tensorflow/lite/micro/micro_string.h
@@ -0,0 +1,33 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_STRING_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_STRING_H_
+
+#include <cstdarg>
+
+// Implements simple string formatting for numeric types. Returns the number of
+// bytes written to output.
+extern "C" {
+// Functionally equivalent to vsnprintf, trimmed down for TFLite Micro.
+// MicroSnprintf() is implemented using MicroVsnprintf().
+int MicroVsnprintf(char* output, int len, const char* format, va_list args);
+// Functionally equavalent to snprintf, trimmed down for TFLite Micro.
+// For example, MicroSnprintf(buffer, 10, "int %d", 10) will put the string
+// "int 10" in the buffer.
+// Floating point values are logged in exponent notation (1.XXX*2^N).
+int MicroSnprintf(char* output, int len, const char* format, ...);
+}
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_STRING_H_
diff --git a/tensorflow/lite/micro/micro_string_test.cc b/tensorflow/lite/micro/micro_string_test.cc
new file mode 100644
index 0000000..f69812c
--- /dev/null
+++ b/tensorflow/lite/micro/micro_string_test.cc
@@ -0,0 +1,151 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_string.h"
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FormatPositiveIntShouldMatchExpected) {
+ const int kBufferLen = 32;
+ char buffer[kBufferLen];
+ const char golden[] = "Int: 55";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Int: %d", 55);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(FormatNegativeIntShouldMatchExpected) {
+ const int kBufferLen = 32;
+ char buffer[kBufferLen];
+ const char golden[] = "Int: -55";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Int: %d", -55);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(FormatUnsignedIntShouldMatchExpected) {
+ const int kBufferLen = 32;
+ char buffer[kBufferLen];
+ const char golden[] = "UInt: 12345";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "UInt: %u", 12345);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(FormatHexShouldMatchExpected) {
+ const int kBufferLen = 32;
+ char buffer[kBufferLen];
+ const char golden[] = "Hex: 0x12345";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Hex: %x", 0x12345);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(FormatFloatShouldMatchExpected) {
+ const int kBufferLen = 32;
+ char buffer[kBufferLen];
+ const char golden[] = "Float: 1.0*2^4";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Float: %f", 16.);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(BadlyFormattedStringShouldProduceReasonableString) {
+ const int kBufferLen = 32;
+ char buffer[kBufferLen];
+ const char golden[] = "Test Badly % formated % string";
+ int bytes_written =
+ MicroSnprintf(buffer, kBufferLen, "Test Badly %% formated %% string%");
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(IntFormatOverrunShouldTruncate) {
+ const int kBufferLen = 8;
+ char buffer[kBufferLen];
+ const char golden[] = "Int: ";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Int: %d", 12345);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(UnsignedIntFormatOverrunShouldTruncate) {
+ const int kBufferLen = 8;
+ char buffer[kBufferLen];
+ const char golden[] = "UInt: ";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "UInt: %u", 12345);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(HexFormatOverrunShouldTruncate) {
+ const int kBufferLen = 8;
+ char buffer[kBufferLen];
+ const char golden[] = "Hex: ";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Hex: %x", 0x12345);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(FloatFormatOverrunShouldTruncate) {
+ const int kBufferLen = 12;
+ char buffer[kBufferLen];
+ const char golden[] = "Float: ";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Float: %x", 12345.);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(FloatFormatShouldPrintFractionCorrectly) {
+ const int kBufferLen = 24;
+ char buffer[kBufferLen];
+ const char golden[] = "Float: 1.0625*2^0";
+ // Add small offset to float value to account for float rounding error.
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Float: %f", 1.0625001);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(FloatFormatShouldPrintFractionCorrectlyNoLeadingZeros) {
+ const int kBufferLen = 24;
+ char buffer[kBufferLen];
+ const char golden[] = "Float: 1.6332993*2^-1";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "Float: %f", 0.816650);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(StringFormatOverrunShouldTruncate) {
+ const int kBufferLen = 10;
+ char buffer[kBufferLen];
+ const char golden[] = "String: h";
+ int bytes_written =
+ MicroSnprintf(buffer, kBufferLen, "String: %s", "hello world");
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TEST(StringFormatWithExactOutputSizeOverrunShouldTruncate) {
+ const int kBufferLen = 10;
+ char buffer[kBufferLen];
+ const char golden[] = "format st";
+ int bytes_written = MicroSnprintf(buffer, kBufferLen, "format str");
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<int>(sizeof(golden)), bytes_written);
+ TF_LITE_MICRO_EXPECT_STRING_EQ(golden, buffer);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/micro_time.cc b/tensorflow/lite/micro/micro_time.cc
new file mode 100644
index 0000000..d7c51f9
--- /dev/null
+++ b/tensorflow/lite/micro/micro_time.cc
@@ -0,0 +1,59 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Reference implementation of timer functions. Platforms are not required to
+// implement these timer methods, but they are required to enable profiling.
+
+// On platforms that have a POSIX stack or C library, it can be written using
+// methods from <sys/time.h> or clock() from <time.h>.
+
+// To add an equivalent function for your own platform, create your own
+// implementation file, and place it in a subfolder with named after the OS
+// you're targeting. For example, see the Cortex M bare metal version in
+// tensorflow/lite/micro/bluepill/micro_time.cc or the mbed one on
+// tensorflow/lite/micro/mbed/micro_time.cc.
+
+#include "tensorflow/lite/micro/micro_time.h"
+
+#if defined(TF_LITE_USE_CTIME)
+#include <ctime>
+#endif
+
+namespace tflite {
+
+#if !defined(TF_LITE_USE_CTIME)
+
+// Reference implementation of the ticks_per_second() function that's required
+// for a platform to support Tensorflow Lite for Microcontrollers profiling.
+// This returns 0 by default because timing is an optional feature that builds
+// without errors on platforms that do not need it.
+int32_t ticks_per_second() { return 0; }
+
+// Reference implementation of the GetCurrentTimeTicks() function that's
+// required for a platform to support Tensorflow Lite for Microcontrollers
+// profiling. This returns 0 by default because timing is an optional feature
+// that builds without errors on platforms that do not need it.
+int32_t GetCurrentTimeTicks() { return 0; }
+
+#else // defined(TF_LITE_USE_CTIME)
+
+// For platforms that support ctime, we implment the micro_time interface in
+// this central location.
+int32_t ticks_per_second() { return CLOCKS_PER_SEC; }
+
+int32_t GetCurrentTimeTicks() { return clock(); }
+#endif
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/micro_time.h b/tensorflow/lite/micro/micro_time.h
new file mode 100644
index 0000000..fac9069
--- /dev/null
+++ b/tensorflow/lite/micro/micro_time.h
@@ -0,0 +1,36 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_TIME_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_TIME_H_
+
+#include <cstdint>
+
+namespace tflite {
+
+// These functions should be implemented by each target platform, and provide an
+// accurate tick count along with how many ticks there are per second.
+int32_t ticks_per_second();
+
+// Return time in ticks. The meaning of a tick varies per platform.
+int32_t GetCurrentTimeTicks();
+
+inline int32_t TicksToMs(int32_t ticks) {
+ return static_cast<int32_t>(1000.0f * static_cast<float>(ticks) /
+ static_cast<float>(ticks_per_second()));
+}
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_TIME_H_
diff --git a/tensorflow/lite/micro/micro_time_test.cc b/tensorflow/lite/micro/micro_time_test.cc
new file mode 100644
index 0000000..d7e4131
--- /dev/null
+++ b/tensorflow/lite/micro/micro_time_test.cc
@@ -0,0 +1,48 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_time.h"
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestBasicTimerFunctionality) {
+ int32_t ticks_per_second = tflite::ticks_per_second();
+
+ // Retry enough times to guarantee a tick advance, while not taking too long
+ // to complete. With 1e6 retries, assuming each loop takes tens of cycles,
+ // this will retry for less than 10 seconds on a 10MHz platform.
+ constexpr int kMaxRetries = 1e6;
+ int start_time = tflite::GetCurrentTimeTicks();
+
+ if (ticks_per_second != 0) {
+ for (int i = 0; i < kMaxRetries; i++) {
+ if (tflite::GetCurrentTimeTicks() - start_time > 0) {
+ break;
+ }
+ }
+ }
+
+ // Ensure the timer is increasing. This works for the overflow case too, since
+ // (MIN_INT + x) - (MAX_INT - y) == x + y + 1. For example,
+ // 0x80000001(min int + 1) - 0x7FFFFFFE(max int - 1) = 0x00000003 == 3.
+ // GetTicksPerSecond() == 0 means the timer is not implemented on this
+ // platform.
+ TF_LITE_MICRO_EXPECT(ticks_per_second == 0 ||
+ tflite::GetCurrentTimeTicks() - start_time > 0);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/micro_utils.cc b/tensorflow/lite/micro/micro_utils.cc
new file mode 100644
index 0000000..9615236
--- /dev/null
+++ b/tensorflow/lite/micro/micro_utils.cc
@@ -0,0 +1,80 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_utils.h"
+
+#include <cmath>
+#include <cstdint>
+#include <limits>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/op_macros.h"
+
+namespace tflite {
+
+int ElementCount(const TfLiteIntArray& dims) {
+ int result = 1;
+ for (int i = 0; i < dims.size; ++i) {
+ result *= dims.data[i];
+ }
+ return result;
+}
+
+void SignedSymmetricPerChannelQuantize(const float* values,
+ TfLiteIntArray* dims,
+ int quantized_dimension,
+ int8_t* quantized_values,
+ float* scaling_factors) {
+ int input_size = ElementCount(*dims);
+ int channel_count = dims->data[quantized_dimension];
+ int per_channel_size = input_size / channel_count;
+
+ int stride;
+ int channel_stride;
+ if (quantized_dimension == 0) {
+ stride = 1;
+ channel_stride = per_channel_size;
+ } else if (quantized_dimension == 3) {
+ stride = channel_count;
+ channel_stride = 1;
+ } else {
+ TF_LITE_FATAL("quantized dimension must be 0 or 3");
+ }
+
+ // Calculate scales for each channel.
+ for (int channel = 0; channel < channel_count; channel++) {
+ float min = 0;
+ float max = 0;
+
+ for (int i = 0; i < per_channel_size; i++) {
+ int idx = channel * channel_stride + i * stride;
+ min = fminf(min, values[idx]);
+ max = fmaxf(max, values[idx]);
+ }
+ scaling_factors[channel] =
+ fmaxf(fabs(min), fabs(max)) / std::numeric_limits<int8_t>::max();
+ for (int i = 0; i < per_channel_size; i++) {
+ int idx = channel * channel_stride + i * stride;
+ const int32_t quantized_value =
+ static_cast<int32_t>(roundf(values[idx] / scaling_factors[channel]));
+ // Clamp: just in case some odd numeric offset.
+ quantized_values[idx] =
+ fminf(std::numeric_limits<int8_t>::max(),
+ fmaxf(std::numeric_limits<int8_t>::min() + 1, quantized_value));
+ }
+ }
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/micro_utils.h b/tensorflow/lite/micro/micro_utils.h
new file mode 100644
index 0000000..b9a3121
--- /dev/null
+++ b/tensorflow/lite/micro/micro_utils.h
@@ -0,0 +1,134 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_MICRO_UTILS_H_
+#define TENSORFLOW_LITE_MICRO_MICRO_UTILS_H_
+
+#include <algorithm>
+#include <cmath>
+#include <cstdint>
+
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+// Returns number of elements in the shape array.
+
+int ElementCount(const TfLiteIntArray& dims);
+
+// Converts a float value into a quantized value. Note that large values (close
+// to max int and min int) may see significant error due to a lack of floating
+// point granularity for large values.
+template <typename T>
+T FloatToQuantizedType(const float value, const float scale, int zero_point) {
+ int32_t result = round(value / scale) + zero_point;
+ result =
+ std::max(static_cast<int32_t>(std::numeric_limits<T>::min()), result);
+ result =
+ std::min(static_cast<int32_t>(std::numeric_limits<T>::max()), result);
+ return result;
+}
+
+template <typename T>
+T FloatToSymmetricQuantizedType(const float value, const float scale) {
+ int32_t result = round(value / scale);
+ result =
+ std::max(static_cast<int32_t>(std::numeric_limits<T>::min() + 1), result);
+ result =
+ std::min(static_cast<int32_t>(std::numeric_limits<T>::max()), result);
+ return result;
+}
+
+// Helper methods to quantize arrays of floats to the desired format.
+//
+// There are several key flavors of quantization in TfLite:
+// asymmetric symmetric per channel
+// int8_t | X | X | X |
+// uint8_t | X | X | |
+// int16_t | X | | |
+// int32_t | | X | X |
+//
+// The per-op quantization spec can be found here:
+// https://www.tensorflow.org/lite/performance/quantization_spec
+template <typename T>
+void Quantize(const float* input, T* output, int num_elements, float scale,
+ int zero_point) {
+ for (int i = 0; i < num_elements; i++) {
+ output[i] = FloatToQuantizedType<T>(input[i], scale, zero_point);
+ }
+}
+
+template <typename T>
+void SymmetricQuantize(const float* input, T* output, int num_elements,
+ float scale) {
+ for (int i = 0; i < num_elements; i++) {
+ output[i] = FloatToSymmetricQuantizedType<T>(input[i], scale);
+ }
+}
+
+template <typename T>
+void SymmetricPerChannelQuantize(const float* input, T* output,
+ int num_elements, int num_channels,
+ float* scales) {
+ int elements_per_channel = num_elements / num_channels;
+ for (int i = 0; i < num_channels; i++) {
+ for (int j = 0; j < elements_per_channel; j++) {
+ output[i * elements_per_channel + j] = FloatToSymmetricQuantizedType<T>(
+ input[i * elements_per_channel + j], scales[i]);
+ }
+ }
+}
+
+void SignedSymmetricPerChannelQuantize(const float* values,
+ TfLiteIntArray* dims,
+ int quantized_dimension,
+ int8_t* quantized_values,
+ float* scaling_factor);
+
+// Quantizes inputs based on the values provided, choosing the smallest range
+// which includes all input values.
+template <typename T>
+void SymmetricQuantizeCalculateScales(const float* values, TfLiteIntArray* dims,
+ T* output, float* scale) {
+ int input_size = ElementCount(*dims);
+
+ float min = 0;
+ float max = 0;
+ for (int i = 0; i < input_size; i++) {
+ min = fminf(min, values[i]);
+ max = fmaxf(max, values[i]);
+ }
+ *scale = fmaxf(std::abs(min), std::abs(max)) / std::numeric_limits<T>::max();
+ for (int i = 0; i < input_size; i++) {
+ const int32_t quantized_value =
+ static_cast<int32_t>(roundf(values[i] / *scale));
+ // Clamp: just in case some odd numeric offset.
+ quantized_value = fminf(std::numeric_limits<T>::max(), quantized_value);
+ quantized_value = fmaxf(std::numeric_limits<T>::min() + 1, quantized_value);
+ output[i] = quantized_value;
+ }
+}
+
+template <typename T>
+void Dequantize(const T* values, const int size, const float scale,
+ int zero_point, float* dequantized_values) {
+ for (int i = 0; i < size; ++i) {
+ dequantized_values[i] = (values[i] - zero_point) * scale;
+ }
+}
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_MICRO_UTILS_H_
diff --git a/tensorflow/lite/micro/micro_utils_test.cc b/tensorflow/lite/micro/micro_utils_test.cc
new file mode 100644
index 0000000..d74004e
--- /dev/null
+++ b/tensorflow/lite/micro/micro_utils_test.cc
@@ -0,0 +1,120 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/micro_utils.h"
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(FloatToAsymmetricQuantizedUInt8Test) {
+ using tflite::FloatToQuantizedType;
+ // [0, 127.5] -> zero_point=0, scale=0.5
+ TF_LITE_MICRO_EXPECT_EQ(0, FloatToQuantizedType<uint8_t>(0, 0.5, 0));
+ TF_LITE_MICRO_EXPECT_EQ(254, FloatToQuantizedType<uint8_t>(127, 0.5, 0));
+ TF_LITE_MICRO_EXPECT_EQ(255, FloatToQuantizedType<uint8_t>(127.5, 0.5, 0));
+ // [-10, 245] -> zero_point=10, scale=1.0
+ TF_LITE_MICRO_EXPECT_EQ(0, FloatToQuantizedType<uint8_t>(-10, 1.0, 10));
+ TF_LITE_MICRO_EXPECT_EQ(1, FloatToQuantizedType<uint8_t>(-9, 1.0, 10));
+ TF_LITE_MICRO_EXPECT_EQ(128, FloatToQuantizedType<uint8_t>(118, 1.0, 10));
+ TF_LITE_MICRO_EXPECT_EQ(253, FloatToQuantizedType<uint8_t>(243, 1.0, 10));
+ TF_LITE_MICRO_EXPECT_EQ(254, FloatToQuantizedType<uint8_t>(244, 1.0, 10));
+ TF_LITE_MICRO_EXPECT_EQ(255, FloatToQuantizedType<uint8_t>(245, 1.0, 10));
+}
+
+TF_LITE_MICRO_TEST(FloatToAsymmetricQuantizedInt8Test) {
+ using tflite::FloatToQuantizedType;
+ // [-64, 63.5] -> zero_point=0, scale=0.5
+ TF_LITE_MICRO_EXPECT_EQ(2, FloatToQuantizedType<int8_t>(1, 0.5, 0));
+ TF_LITE_MICRO_EXPECT_EQ(4, FloatToQuantizedType<int8_t>(2, 0.5, 0));
+ TF_LITE_MICRO_EXPECT_EQ(6, FloatToQuantizedType<int8_t>(3, 0.5, 0));
+ TF_LITE_MICRO_EXPECT_EQ(-10, FloatToQuantizedType<int8_t>(-5, 0.5, 0));
+ TF_LITE_MICRO_EXPECT_EQ(-128, FloatToQuantizedType<int8_t>(-64, 0.5, 0));
+ TF_LITE_MICRO_EXPECT_EQ(127, FloatToQuantizedType<int8_t>(63.5, 0.5, 0));
+ // [-127, 128] -> zero_point=-1, scale=1.0
+ TF_LITE_MICRO_EXPECT_EQ(0, FloatToQuantizedType<int8_t>(1, 1.0, -1));
+ TF_LITE_MICRO_EXPECT_EQ(-1, FloatToQuantizedType<int8_t>(0, 1.0, -1));
+ TF_LITE_MICRO_EXPECT_EQ(126, FloatToQuantizedType<int8_t>(127, 1.0, -1));
+ TF_LITE_MICRO_EXPECT_EQ(127, FloatToQuantizedType<int8_t>(128, 1.0, -1));
+ TF_LITE_MICRO_EXPECT_EQ(-127, FloatToQuantizedType<int8_t>(-126, 1.0, -1));
+ TF_LITE_MICRO_EXPECT_EQ(-128, FloatToQuantizedType<int8_t>(-127, 1.0, -1));
+}
+
+TF_LITE_MICRO_TEST(FloatToSymmetricQuantizedInt8Test) {
+ using tflite::FloatToSymmetricQuantizedType;
+ // [-64, 63.5] -> zero_point=0, scale=0.5
+ TF_LITE_MICRO_EXPECT_EQ(2, FloatToSymmetricQuantizedType<int8_t>(1, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(4, FloatToSymmetricQuantizedType<int8_t>(2, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(6, FloatToSymmetricQuantizedType<int8_t>(3, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(-10, FloatToSymmetricQuantizedType<int8_t>(-5, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(-127,
+ FloatToSymmetricQuantizedType<int8_t>(-64, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(127,
+ FloatToSymmetricQuantizedType<int8_t>(63.5, 0.5));
+ // [-127, 128] -> zero_point=-1, scale=1.0
+ TF_LITE_MICRO_EXPECT_EQ(1, FloatToSymmetricQuantizedType<int8_t>(1, 1.0));
+ TF_LITE_MICRO_EXPECT_EQ(0, FloatToSymmetricQuantizedType<int8_t>(0, 1.0));
+ TF_LITE_MICRO_EXPECT_EQ(127, FloatToSymmetricQuantizedType<int8_t>(127, 1.0));
+ TF_LITE_MICRO_EXPECT_EQ(127, FloatToSymmetricQuantizedType<int8_t>(128, 1.0));
+ TF_LITE_MICRO_EXPECT_EQ(-126,
+ FloatToSymmetricQuantizedType<int8_t>(-126, 1.0));
+ TF_LITE_MICRO_EXPECT_EQ(-127,
+ FloatToSymmetricQuantizedType<int8_t>(-127, 1.0));
+}
+
+TF_LITE_MICRO_TEST(FloatToAsymmetricQuantizedInt32Test) {
+ using tflite::FloatToSymmetricQuantizedType;
+ TF_LITE_MICRO_EXPECT_EQ(0, FloatToSymmetricQuantizedType<int32_t>(0, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(2, FloatToSymmetricQuantizedType<int32_t>(1, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(-2, FloatToSymmetricQuantizedType<int32_t>(-1, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(-100,
+ FloatToSymmetricQuantizedType<int32_t>(-50, 0.5));
+ TF_LITE_MICRO_EXPECT_EQ(100, FloatToSymmetricQuantizedType<int32_t>(50, 0.5));
+}
+
+TF_LITE_MICRO_TEST(AsymmetricQuantizeInt8) {
+ float values[] = {-10.3, -3.1, -2.1, -1.9, -0.9, 0.1, 0.9, 1.85, 2.9, 4.1};
+ int8_t goldens[] = {-20, -5, -3, -3, -1, 1, 3, 5, 7, 9};
+ constexpr int length = sizeof(values) / sizeof(float);
+ int8_t quantized[length];
+ tflite::Quantize(values, quantized, length, 0.5, 1);
+ for (int i = 0; i < length; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(quantized[i], goldens[i]);
+ }
+}
+
+TF_LITE_MICRO_TEST(AsymmetricQuantizeUInt8) {
+ float values[] = {-10.3, -3.1, -2.1, -1.9, -0.9, 0.1, 0.9, 1.85, 2.9, 4.1};
+ uint8_t goldens[] = {106, 121, 123, 123, 125, 127, 129, 131, 133, 135};
+ constexpr int length = sizeof(values) / sizeof(float);
+ uint8_t quantized[length];
+ tflite::Quantize(values, quantized, length, 0.5, 127);
+ for (int i = 0; i < length; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(quantized[i], goldens[i]);
+ }
+}
+
+TF_LITE_MICRO_TEST(SymmetricQuantizeInt32) {
+ float values[] = {-10.3, -3.1, -2.1, -1.9, -0.9, 0.1, 0.9, 1.85, 2.9, 4.1};
+ int32_t goldens[] = {-21, -6, -4, -4, -2, 0, 2, 4, 6, 8};
+ constexpr int length = sizeof(values) / sizeof(float);
+ int32_t quantized[length];
+ tflite::SymmetricQuantize(values, quantized, length, 0.5);
+ for (int i = 0; i < length; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(quantized[i], goldens[i]);
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/openmvcam/debug_log.cc b/tensorflow/lite/micro/openmvcam/debug_log.cc
new file mode 100644
index 0000000..00b5f18
--- /dev/null
+++ b/tensorflow/lite/micro/openmvcam/debug_log.cc
@@ -0,0 +1,36 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include <stdio.h>
+#include <string.h>
+
+// These are set by openmv py_tf.c code to redirect printing to an error message
+// buffer...
+
+char* py_tf_putchar_buffer = NULL;
+size_t py_tf_putchar_buffer_len = 0;
+
+extern "C" void DebugLog(const char* s) {
+ for (size_t i = 0, j = strlen(s); i < j; i++) {
+ if (py_tf_putchar_buffer_len) {
+ *py_tf_putchar_buffer++ = s[i];
+ py_tf_putchar_buffer_len--;
+ } else {
+ putchar(s[i]);
+ }
+ }
+}
diff --git a/tensorflow/lite/micro/recording_micro_allocator.cc b/tensorflow/lite/micro/recording_micro_allocator.cc
new file mode 100644
index 0000000..6bb5297
--- /dev/null
+++ b/tensorflow/lite/micro/recording_micro_allocator.cc
@@ -0,0 +1,244 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/recording_micro_allocator.h"
+
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/micro_allocator.h"
+#include "tensorflow/lite/micro/recording_simple_memory_allocator.h"
+
+namespace tflite {
+
+RecordingMicroAllocator::RecordingMicroAllocator(
+ RecordingSimpleMemoryAllocator* recording_memory_allocator,
+ ErrorReporter* error_reporter)
+ : MicroAllocator(recording_memory_allocator, error_reporter),
+ recording_memory_allocator_(recording_memory_allocator) {}
+
+RecordingMicroAllocator* RecordingMicroAllocator::Create(
+ uint8_t* tensor_arena, size_t arena_size, ErrorReporter* error_reporter) {
+ TFLITE_DCHECK(error_reporter != nullptr);
+
+ RecordingSimpleMemoryAllocator* simple_memory_allocator =
+ RecordingSimpleMemoryAllocator::Create(error_reporter, tensor_arena,
+ arena_size);
+ TFLITE_DCHECK(simple_memory_allocator != nullptr);
+
+ uint8_t* allocator_buffer = simple_memory_allocator->AllocateFromTail(
+ sizeof(RecordingMicroAllocator), alignof(RecordingMicroAllocator));
+ RecordingMicroAllocator* allocator = new (allocator_buffer)
+ RecordingMicroAllocator(simple_memory_allocator, error_reporter);
+ return allocator;
+}
+
+RecordedAllocation RecordingMicroAllocator::GetRecordedAllocation(
+ RecordedAllocationType allocation_type) const {
+ switch (allocation_type) {
+ case RecordedAllocationType::kTfLiteEvalTensorData:
+ return recorded_tflite_eval_tensor_data_;
+ case RecordedAllocationType::kPersistentTfLiteTensorData:
+ return recorded_persistent_tflite_tensor_data_;
+ case RecordedAllocationType::kPersistentTfLiteTensorQuantizationData:
+ return recorded_persistent_tflite_tensor_quantization_data_;
+ case RecordedAllocationType::kPersistentBufferData:
+ return recorded_persistent_buffer_data_;
+ case RecordedAllocationType::kTfLiteTensorVariableBufferData:
+ return recorded_tflite_tensor_variable_buffer_data_;
+ case RecordedAllocationType::kNodeAndRegistrationArray:
+ return recorded_node_and_registration_array_data_;
+ case RecordedAllocationType::kOpData:
+ return recorded_op_data_;
+ }
+ TF_LITE_REPORT_ERROR(error_reporter(), "Invalid allocation type supplied: %d",
+ allocation_type);
+ return RecordedAllocation();
+}
+
+const RecordingSimpleMemoryAllocator*
+RecordingMicroAllocator::GetSimpleMemoryAllocator() const {
+ return recording_memory_allocator_;
+}
+
+void RecordingMicroAllocator::PrintAllocations() const {
+ TF_LITE_REPORT_ERROR(
+ error_reporter(),
+ "[RecordingMicroAllocator] Arena allocation total %d bytes",
+ recording_memory_allocator_->GetUsedBytes());
+ TF_LITE_REPORT_ERROR(
+ error_reporter(),
+ "[RecordingMicroAllocator] Arena allocation head %d bytes",
+ recording_memory_allocator_->GetHeadUsedBytes());
+ TF_LITE_REPORT_ERROR(
+ error_reporter(),
+ "[RecordingMicroAllocator] Arena allocation tail %d bytes",
+ recording_memory_allocator_->GetTailUsedBytes());
+ PrintRecordedAllocation(RecordedAllocationType::kTfLiteEvalTensorData,
+ "TfLiteEvalTensor data", "allocations");
+ PrintRecordedAllocation(RecordedAllocationType::kPersistentTfLiteTensorData,
+ "Persistent TfLiteTensor data", "tensors");
+ PrintRecordedAllocation(
+ RecordedAllocationType::kPersistentTfLiteTensorQuantizationData,
+ "Persistent TfLiteTensor quantization data", "allocations");
+ PrintRecordedAllocation(RecordedAllocationType::kPersistentBufferData,
+ "Persistent buffer data", "allocations");
+ PrintRecordedAllocation(
+ RecordedAllocationType::kTfLiteTensorVariableBufferData,
+ "TfLiteTensor variable buffer data", "allocations");
+ PrintRecordedAllocation(RecordedAllocationType::kNodeAndRegistrationArray,
+ "NodeAndRegistration struct",
+ "NodeAndRegistration structs");
+ PrintRecordedAllocation(RecordedAllocationType::kOpData,
+ "Operator runtime data", "OpData structs");
+}
+
+void* RecordingMicroAllocator::AllocatePersistentBuffer(size_t bytes) {
+ RecordedAllocation allocations = SnapshotAllocationUsage();
+ void* buffer = MicroAllocator::AllocatePersistentBuffer(bytes);
+ RecordAllocationUsage(allocations, recorded_persistent_buffer_data_);
+
+ return buffer;
+}
+
+void RecordingMicroAllocator::PrintRecordedAllocation(
+ RecordedAllocationType allocation_type, const char* allocation_name,
+ const char* allocation_description) const {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ RecordedAllocation allocation = GetRecordedAllocation(allocation_type);
+ if (allocation.used_bytes > 0 || allocation.requested_bytes > 0) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter(),
+ "[RecordingMicroAllocator] '%s' used %d bytes with alignment overhead "
+ "(requested %d bytes for %d %s)",
+ allocation_name, allocation.used_bytes, allocation.requested_bytes,
+ allocation.count, allocation_description);
+ }
+#endif
+}
+
+TfLiteStatus RecordingMicroAllocator::AllocateNodeAndRegistrations(
+ const Model* model, NodeAndRegistration** node_and_registrations) {
+ RecordedAllocation allocations = SnapshotAllocationUsage();
+
+ TfLiteStatus status = MicroAllocator::AllocateNodeAndRegistrations(
+ model, node_and_registrations);
+
+ RecordAllocationUsage(allocations,
+ recorded_node_and_registration_array_data_);
+ // The allocation count in SimpleMemoryAllocator will only be 1. To provide
+ // better logging, decrement by 1 and add in the actual number of operators
+ // used in the graph:
+ // The allocation for this recording will always be 1. This is because the
+ // parent class mallocs one large allocation for the number of nodes in the
+ // graph (e.g. sizeof(NodeAndRegistration) * num_nodes).
+ // To prevent extra overhead and potential for fragmentation, manually adjust
+ // the accounting by decrementing by 1 and adding the actual number of nodes
+ // used in the graph:
+ recorded_node_and_registration_array_data_.count +=
+ GetSubGraphFromModel(model)->operators()->size() - 1;
+ return status;
+}
+
+TfLiteStatus
+RecordingMicroAllocator::PrepareNodeAndRegistrationDataFromFlatbuffer(
+ const Model* model, const MicroOpResolver& op_resolver,
+ NodeAndRegistration* node_and_registrations) {
+ RecordedAllocation allocations = SnapshotAllocationUsage();
+
+ TfLiteStatus status =
+ MicroAllocator::PrepareNodeAndRegistrationDataFromFlatbuffer(
+ model, op_resolver, node_and_registrations);
+
+ RecordAllocationUsage(allocations, recorded_op_data_);
+ return status;
+}
+
+TfLiteStatus RecordingMicroAllocator::AllocateTfLiteEvalTensors(
+ const Model* model, TfLiteEvalTensor** eval_tensors) {
+ RecordedAllocation allocations = SnapshotAllocationUsage();
+
+ TfLiteStatus status =
+ MicroAllocator::AllocateTfLiteEvalTensors(model, eval_tensors);
+
+ RecordAllocationUsage(allocations, recorded_tflite_eval_tensor_data_);
+ // The allocation for this recording will always be 1. This is because the
+ // parent class mallocs one large allocation for the number of tensors in the
+ // graph (e.g. sizeof(TfLiteEvalTensor) * num_tensors).
+ // To prevent extra overhead and potential for fragmentation, manually adjust
+ // the accounting by decrementing by 1 and adding the actual number of tensors
+ // used in the graph:
+ recorded_tflite_eval_tensor_data_.count +=
+ GetSubGraphFromModel(model)->tensors()->size() - 1;
+ return status;
+}
+
+TfLiteStatus RecordingMicroAllocator::AllocateVariables(
+ const SubGraph* subgraph, TfLiteEvalTensor* eval_tensors) {
+ RecordedAllocation allocations = SnapshotAllocationUsage();
+
+ TfLiteStatus status =
+ MicroAllocator::AllocateVariables(subgraph, eval_tensors);
+
+ RecordAllocationUsage(allocations,
+ recorded_tflite_tensor_variable_buffer_data_);
+ return status;
+}
+
+TfLiteTensor* RecordingMicroAllocator::AllocatePersistentTfLiteTensorInternal(
+ const Model* model, TfLiteEvalTensor* eval_tensors, int tensor_index) {
+ RecordedAllocation allocations = SnapshotAllocationUsage();
+
+ TfLiteTensor* result = MicroAllocator::AllocatePersistentTfLiteTensorInternal(
+ model, eval_tensors, tensor_index);
+
+ RecordAllocationUsage(allocations, recorded_persistent_tflite_tensor_data_);
+ return result;
+}
+
+TfLiteStatus RecordingMicroAllocator::PopulateTfLiteTensorFromFlatbuffer(
+ const Model* model, const SubGraph* subgraph, TfLiteTensor* tensor,
+ int tensor_index, bool allocate_temp) {
+ RecordedAllocation allocations = SnapshotAllocationUsage();
+
+ TfLiteStatus status = MicroAllocator::PopulateTfLiteTensorFromFlatbuffer(
+ model, subgraph, tensor, tensor_index, allocate_temp);
+
+ RecordAllocationUsage(allocations,
+ recorded_persistent_tflite_tensor_quantization_data_);
+ return status;
+}
+
+RecordedAllocation RecordingMicroAllocator::SnapshotAllocationUsage() const {
+ return {/*requested_bytes=*/recording_memory_allocator_->GetRequestedBytes(),
+ /*used_bytes=*/recording_memory_allocator_->GetUsedBytes(),
+ /*count=*/recording_memory_allocator_->GetAllocatedCount()};
+}
+
+void RecordingMicroAllocator::RecordAllocationUsage(
+ const RecordedAllocation& snapshotted_allocation,
+ RecordedAllocation& recorded_allocation) {
+ recorded_allocation.requested_bytes +=
+ recording_memory_allocator_->GetRequestedBytes() -
+ snapshotted_allocation.requested_bytes;
+ recorded_allocation.used_bytes +=
+ recording_memory_allocator_->GetUsedBytes() -
+ snapshotted_allocation.used_bytes;
+ recorded_allocation.count +=
+ recording_memory_allocator_->GetAllocatedCount() -
+ snapshotted_allocation.count;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/recording_micro_allocator.h b/tensorflow/lite/micro/recording_micro_allocator.h
new file mode 100644
index 0000000..47246e1
--- /dev/null
+++ b/tensorflow/lite/micro/recording_micro_allocator.h
@@ -0,0 +1,125 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_RECORDING_MICRO_ALLOCATOR_H_
+#define TENSORFLOW_LITE_MICRO_RECORDING_MICRO_ALLOCATOR_H_
+
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/micro_allocator.h"
+#include "tensorflow/lite/micro/recording_simple_memory_allocator.h"
+
+namespace tflite {
+
+// List of buckets currently recorded by this class. Each type keeps a list of
+// allocated information during model initialization.
+// TODO(b/169834511): Add tracking for scratch buffer allocations.
+enum class RecordedAllocationType {
+ kTfLiteEvalTensorData,
+ kPersistentTfLiteTensorData,
+ kPersistentTfLiteTensorQuantizationData,
+ kPersistentBufferData,
+ kTfLiteTensorVariableBufferData,
+ kNodeAndRegistrationArray,
+ kOpData,
+};
+
+// Container for holding information about allocation recordings by a given
+// type. Each recording contains the number of bytes requested, the actual bytes
+// allocated (can defer from requested by alignment), and the number of items
+// allocated.
+struct RecordedAllocation {
+ size_t requested_bytes;
+ size_t used_bytes;
+ size_t count;
+};
+
+// Utility subclass of MicroAllocator that records all allocations
+// inside the arena. A summary of allocations can be logged through the
+// ErrorReporter by invoking LogAllocations(). This special allocator requires
+// an instance of RecordingSimpleMemoryAllocator to capture allocations in the
+// head and tail. Arena allocation recording can be retrieved by type through
+// the GetRecordedAllocation() function. This class should only be used for
+// auditing memory usage or integration testing.
+class RecordingMicroAllocator : public MicroAllocator {
+ public:
+ static RecordingMicroAllocator* Create(uint8_t* tensor_arena,
+ size_t arena_size,
+ ErrorReporter* error_reporter);
+
+ // Returns the recorded allocations information for a given allocation type.
+ RecordedAllocation GetRecordedAllocation(
+ RecordedAllocationType allocation_type) const;
+
+ const RecordingSimpleMemoryAllocator* GetSimpleMemoryAllocator() const;
+
+ // Logs out through the ErrorReporter all allocation recordings by type
+ // defined in RecordedAllocationType.
+ void PrintAllocations() const;
+
+ void* AllocatePersistentBuffer(size_t bytes) override;
+
+ protected:
+ TfLiteStatus AllocateNodeAndRegistrations(
+ const Model* model,
+ NodeAndRegistration** node_and_registrations) override;
+ TfLiteStatus PrepareNodeAndRegistrationDataFromFlatbuffer(
+ const Model* model, const MicroOpResolver& op_resolver,
+ NodeAndRegistration* node_and_registrations) override;
+ TfLiteStatus AllocateTfLiteEvalTensors(
+ const Model* model, TfLiteEvalTensor** eval_tensors) override;
+ TfLiteStatus AllocateVariables(const SubGraph* subgraph,
+ TfLiteEvalTensor* eval_tensors) override;
+ // TODO(b/162311891): Once all kernels have been updated to the new API drop
+ // this method. It is only used to record TfLiteTensor persistent allocations.
+ TfLiteTensor* AllocatePersistentTfLiteTensorInternal(
+ const Model* model, TfLiteEvalTensor* eval_tensors,
+ int tensor_index) override;
+ // TODO(b/162311891): Once all kernels have been updated to the new API drop
+ // this function since all allocations for quantized data will take place in
+ // the temp section.
+ TfLiteStatus PopulateTfLiteTensorFromFlatbuffer(const Model* model,
+ const SubGraph* subgraph,
+ TfLiteTensor* tensor,
+ int tensor_index,
+ bool allocate_temp) override;
+
+ private:
+ RecordingMicroAllocator(RecordingSimpleMemoryAllocator* memory_allocator,
+ ErrorReporter* error_reporter);
+
+ void PrintRecordedAllocation(RecordedAllocationType allocation_type,
+ const char* allocation_name,
+ const char* allocation_description) const;
+
+ RecordedAllocation SnapshotAllocationUsage() const;
+ void RecordAllocationUsage(const RecordedAllocation& snapshotted_allocation,
+ RecordedAllocation& recorded_allocation);
+
+ const RecordingSimpleMemoryAllocator* recording_memory_allocator_;
+
+ RecordedAllocation recorded_tflite_eval_tensor_data_ = {};
+ RecordedAllocation recorded_persistent_tflite_tensor_data_ = {};
+ RecordedAllocation recorded_persistent_tflite_tensor_quantization_data_ = {};
+ RecordedAllocation recorded_persistent_buffer_data_ = {};
+ RecordedAllocation recorded_tflite_tensor_variable_buffer_data_ = {};
+ RecordedAllocation recorded_node_and_registration_array_data_ = {};
+ RecordedAllocation recorded_op_data_ = {};
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_RECORDING_MICRO_ALLOCATOR_H_
diff --git a/tensorflow/lite/micro/recording_micro_allocator_test.cc b/tensorflow/lite/micro/recording_micro_allocator_test.cc
new file mode 100644
index 0000000..b5f4080
--- /dev/null
+++ b/tensorflow/lite/micro/recording_micro_allocator_test.cc
@@ -0,0 +1,283 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/recording_micro_allocator.h"
+
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+#include "tensorflow/lite/micro/testing/test_conv_model.h"
+
+#define TF_LITE_TENSOR_STRUCT_SIZE sizeof(TfLiteTensor)
+#define TF_LITE_EVAL_TENSOR_STRUCT_SIZE sizeof(TfLiteEvalTensor)
+#define TF_LITE_AFFINE_QUANTIZATION_SIZE sizeof(TfLiteAffineQuantization)
+#define NODE_AND_REGISTRATION_STRUCT_SIZE sizeof(tflite::NodeAndRegistration)
+
+// TODO(b/158303868): Move tests into anonymous namespace.
+namespace {
+
+constexpr int kTestConvArenaSize = 1024 * 12;
+
+} // namespace
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestRecordsTfLiteEvalTensorArrayData) {
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ tflite::AllOpsResolver all_ops_resolver;
+ tflite::NodeAndRegistration* node_and_registration;
+ const tflite::Model* model = tflite::GetModel(kTestConvModelData);
+ uint8_t arena[kTestConvArenaSize];
+
+ tflite::RecordingMicroAllocator* micro_allocator =
+ tflite::RecordingMicroAllocator::Create(arena, kTestConvArenaSize,
+ tflite::GetMicroErrorReporter());
+ // TODO(b/158102673): ugly workaround for not having fatal assertions. Same
+ // throughout this file.
+ TF_LITE_MICRO_EXPECT_NE(micro_allocator, nullptr);
+ if (micro_allocator == nullptr) return 1;
+
+ TfLiteStatus status;
+ status = micro_allocator->StartModelAllocation(
+ model, all_ops_resolver, &node_and_registration, &eval_tensors);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ status = micro_allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ micro_allocator->PrintAllocations();
+
+ tflite::RecordedAllocation recorded_allocation =
+ micro_allocator->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteEvalTensorData);
+
+ micro_allocator->PrintAllocations();
+
+ size_t tensors_count = tflite::testing::GetModelTensorCount(model);
+
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.count, tensors_count);
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.requested_bytes,
+ tensors_count * TF_LITE_EVAL_TENSOR_STRUCT_SIZE);
+ TF_LITE_MICRO_EXPECT_GE(recorded_allocation.used_bytes,
+ tensors_count * TF_LITE_EVAL_TENSOR_STRUCT_SIZE);
+}
+
+TF_LITE_MICRO_TEST(TestRecordsNodeAndRegistrationArrayData) {
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ tflite::AllOpsResolver all_ops_resolver;
+ tflite::NodeAndRegistration* node_and_registration;
+ const tflite::Model* model = tflite::GetModel(kTestConvModelData);
+ uint8_t arena[kTestConvArenaSize];
+
+ tflite::RecordingMicroAllocator* micro_allocator =
+ tflite::RecordingMicroAllocator::Create(arena, kTestConvArenaSize,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(micro_allocator, nullptr);
+ if (micro_allocator == nullptr) return 1;
+
+ TfLiteStatus status;
+ status = micro_allocator->StartModelAllocation(
+ model, all_ops_resolver, &node_and_registration, &eval_tensors);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ status = micro_allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ size_t num_ops = model->subgraphs()->Get(0)->operators()->size();
+ tflite::RecordedAllocation recorded_allocation =
+ micro_allocator->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kNodeAndRegistrationArray);
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.count, num_ops);
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.requested_bytes,
+ num_ops * NODE_AND_REGISTRATION_STRUCT_SIZE);
+ TF_LITE_MICRO_EXPECT_GE(recorded_allocation.used_bytes,
+ num_ops * NODE_AND_REGISTRATION_STRUCT_SIZE);
+}
+
+TF_LITE_MICRO_TEST(TestRecordsMultiTenantAllocations) {
+ TfLiteEvalTensor* eval_tensors = nullptr;
+ tflite::ScratchBufferHandle* scratch_buffer_handles = nullptr;
+ tflite::AllOpsResolver all_ops_resolver;
+ tflite::NodeAndRegistration* node_and_registration;
+ const tflite::Model* model = tflite::GetModel(kTestConvModelData);
+
+ // Double the arena size to allocate two models inside of it:
+ uint8_t arena[kTestConvArenaSize * 2];
+
+ TfLiteStatus status;
+
+ tflite::RecordingMicroAllocator* micro_allocator =
+ tflite::RecordingMicroAllocator::Create(arena, kTestConvArenaSize * 2,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(micro_allocator, nullptr);
+ if (micro_allocator == nullptr) return 1;
+
+ // First allocation with the model in the arena:
+ status = micro_allocator->StartModelAllocation(
+ model, all_ops_resolver, &node_and_registration, &eval_tensors);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ status = micro_allocator->FinishModelAllocation(model, eval_tensors,
+ &scratch_buffer_handles);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ // Second allocation with the same model in the arena:
+ status = micro_allocator->StartModelAllocation(
+ model, all_ops_resolver, &node_and_registration, &eval_tensors);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ status = kTfLiteOk, micro_allocator->FinishModelAllocation(
+ model, eval_tensors, &scratch_buffer_handles);
+ TF_LITE_MICRO_EXPECT_EQ(status, kTfLiteOk);
+ if (status != kTfLiteOk) return 1;
+
+ size_t tensors_count = tflite::testing::GetModelTensorCount(model);
+
+ tflite::RecordedAllocation recorded_allocation =
+ micro_allocator->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kTfLiteEvalTensorData);
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.count, tensors_count * 2);
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.requested_bytes,
+ tensors_count * TF_LITE_EVAL_TENSOR_STRUCT_SIZE * 2);
+ TF_LITE_MICRO_EXPECT_GE(recorded_allocation.used_bytes,
+ tensors_count * TF_LITE_EVAL_TENSOR_STRUCT_SIZE * 2);
+}
+
+TF_LITE_MICRO_TEST(TestRecordsPersistentTfLiteTensorData) {
+ const tflite::Model* model = tflite::GetModel(kTestConvModelData);
+ uint8_t arena[kTestConvArenaSize];
+
+ tflite::RecordingMicroAllocator* micro_allocator =
+ tflite::RecordingMicroAllocator::Create(arena, kTestConvArenaSize,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(micro_allocator, nullptr);
+ if (micro_allocator == nullptr) return 1;
+
+ TfLiteTensor* tensor = micro_allocator->AllocatePersistentTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, 0);
+ TF_LITE_MICRO_EXPECT_NE(tensor, nullptr);
+ if (tensor == nullptr) return 1;
+
+ tflite::RecordedAllocation recorded_allocation =
+ micro_allocator->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kPersistentTfLiteTensorData);
+
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.count, static_cast<size_t>(1));
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.requested_bytes,
+ TF_LITE_TENSOR_STRUCT_SIZE);
+ TF_LITE_MICRO_EXPECT_GE(recorded_allocation.used_bytes,
+ TF_LITE_TENSOR_STRUCT_SIZE);
+}
+
+TF_LITE_MICRO_TEST(TestRecordsPersistentTfLiteTensorQuantizationData) {
+ const tflite::Model* model = tflite::GetModel(kTestConvModelData);
+ uint8_t arena[kTestConvArenaSize];
+
+ tflite::RecordingMicroAllocator* micro_allocator =
+ tflite::RecordingMicroAllocator::Create(arena, kTestConvArenaSize,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(micro_allocator, nullptr);
+ if (micro_allocator == nullptr) return 1;
+
+ TfLiteTensor* tensor = micro_allocator->AllocatePersistentTfLiteTensor(
+ model, /*eval_tensors=*/nullptr, 0);
+ TF_LITE_MICRO_EXPECT_NE(tensor, nullptr);
+ if (tensor == nullptr) return 1;
+
+ // Walk the model subgraph to find all tensors with quantization params and
+ // keep a tally.
+ size_t quantized_channel_bytes = 0;
+ const tflite::Tensor* cur_tensor =
+ model->subgraphs()->Get(0)->tensors()->Get(0);
+ const tflite::QuantizationParameters* quantization_params =
+ cur_tensor->quantization();
+ if (quantization_params && quantization_params->scale() &&
+ quantization_params->scale()->size() > 0 &&
+ quantization_params->zero_point() &&
+ quantization_params->zero_point()->size() > 0) {
+ size_t num_channels = quantization_params->scale()->size();
+ quantized_channel_bytes += TfLiteIntArrayGetSizeInBytes(num_channels);
+ }
+
+ // Calculate the expected allocation bytes with subgraph quantization data:
+ size_t expected_requested_bytes =
+ TF_LITE_AFFINE_QUANTIZATION_SIZE + quantized_channel_bytes;
+
+ tflite::RecordedAllocation recorded_allocation =
+ micro_allocator->GetRecordedAllocation(
+ tflite::RecordedAllocationType::
+ kPersistentTfLiteTensorQuantizationData);
+
+ // Each quantized tensors has 2 mallocs (quant struct, zero point dimensions):
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.count, static_cast<size_t>(2));
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.requested_bytes,
+ expected_requested_bytes);
+ TF_LITE_MICRO_EXPECT_GE(recorded_allocation.used_bytes,
+ expected_requested_bytes);
+}
+
+TF_LITE_MICRO_TEST(TestRecordsPersistentBufferData) {
+ uint8_t arena[kTestConvArenaSize];
+
+ tflite::RecordingMicroAllocator* micro_allocator =
+ tflite::RecordingMicroAllocator::Create(arena, kTestConvArenaSize,
+ tflite::GetMicroErrorReporter());
+ TF_LITE_MICRO_EXPECT_NE(micro_allocator, nullptr);
+ if (micro_allocator == nullptr) return 1;
+
+ void* buffer = micro_allocator->AllocatePersistentBuffer(/*bytes=*/100);
+ TF_LITE_MICRO_EXPECT_NE(buffer, nullptr);
+ if (buffer == nullptr) return 1;
+
+ tflite::RecordedAllocation recorded_allocation =
+ micro_allocator->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kPersistentBufferData);
+
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.count, static_cast<size_t>(1));
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.requested_bytes,
+ static_cast<size_t>(100));
+ TF_LITE_MICRO_EXPECT_GE(recorded_allocation.used_bytes,
+ static_cast<size_t>(100));
+
+ buffer = micro_allocator->AllocatePersistentBuffer(/*bytes=*/50);
+ TF_LITE_MICRO_EXPECT_NE(buffer, nullptr);
+ if (buffer == nullptr) return 1;
+
+ recorded_allocation = micro_allocator->GetRecordedAllocation(
+ tflite::RecordedAllocationType::kPersistentBufferData);
+
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.count, static_cast<size_t>(2));
+ TF_LITE_MICRO_EXPECT_EQ(recorded_allocation.requested_bytes,
+ static_cast<size_t>(150));
+ TF_LITE_MICRO_EXPECT_GE(recorded_allocation.used_bytes,
+ static_cast<size_t>(150));
+}
+
+// TODO(b/158124094): Find a way to audit OpData allocations on
+// cross-architectures.
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/recording_micro_interpreter.h b/tensorflow/lite/micro/recording_micro_interpreter.h
new file mode 100644
index 0000000..0a579b0
--- /dev/null
+++ b/tensorflow/lite/micro/recording_micro_interpreter.h
@@ -0,0 +1,65 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_RECORDING_MICRO_INTERPRETER_H_
+#define TENSORFLOW_LITE_MICRO_RECORDING_MICRO_INTERPRETER_H_
+
+#include "tensorflow/lite/micro/micro_interpreter.h"
+#include "tensorflow/lite/micro/recording_micro_allocator.h"
+
+namespace tflite {
+
+// Utility subclass that enables internal recordings of the MicroInterpreter.
+// This class should be used to audit and analyze memory arena usage for a given
+// model and interpreter.
+//
+// After construction and the first Invoke() or AllocateTensors() call - the
+// memory usage is recorded and available through the GetMicroAllocator()
+// function. See RecordingMicroAlloctor for more details on what is currently
+// recorded from arena allocations.
+//
+// It is recommended for users to increase the tensor arena size by at least 1kb
+// to ensure enough additional memory is available for internal recordings.
+class RecordingMicroInterpreter : public MicroInterpreter {
+ public:
+ RecordingMicroInterpreter(const Model* model,
+ const MicroOpResolver& op_resolver,
+ uint8_t* tensor_arena, size_t tensor_arena_size,
+ ErrorReporter* error_reporter)
+ : MicroInterpreter(model, op_resolver,
+ RecordingMicroAllocator::Create(
+ tensor_arena, tensor_arena_size, error_reporter),
+ error_reporter),
+ recording_micro_allocator_(
+ static_cast<const RecordingMicroAllocator&>(allocator())) {}
+
+ RecordingMicroInterpreter(const Model* model,
+ const MicroOpResolver& op_resolver,
+ RecordingMicroAllocator* allocator,
+ ErrorReporter* error_reporter)
+ : MicroInterpreter(model, op_resolver, allocator, error_reporter),
+ recording_micro_allocator_(*allocator) {}
+
+ const RecordingMicroAllocator& GetMicroAllocator() const {
+ return recording_micro_allocator_;
+ }
+
+ private:
+ const RecordingMicroAllocator& recording_micro_allocator_;
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_RECORDING_MICRO_INTERPRETER_H_
diff --git a/tensorflow/lite/micro/recording_simple_memory_allocator.cc b/tensorflow/lite/micro/recording_simple_memory_allocator.cc
new file mode 100644
index 0000000..ef30aca
--- /dev/null
+++ b/tensorflow/lite/micro/recording_simple_memory_allocator.cc
@@ -0,0 +1,84 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/recording_simple_memory_allocator.h"
+
+#include <new>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+
+namespace tflite {
+
+RecordingSimpleMemoryAllocator::RecordingSimpleMemoryAllocator(
+ ErrorReporter* error_reporter, uint8_t* buffer_head, size_t buffer_size)
+ : SimpleMemoryAllocator(error_reporter, buffer_head, buffer_size),
+ requested_head_bytes_(0),
+ requested_tail_bytes_(0),
+ used_bytes_(0),
+ alloc_count_(0) {}
+
+RecordingSimpleMemoryAllocator::~RecordingSimpleMemoryAllocator() {}
+
+RecordingSimpleMemoryAllocator* RecordingSimpleMemoryAllocator::Create(
+ ErrorReporter* error_reporter, uint8_t* buffer_head, size_t buffer_size) {
+ TFLITE_DCHECK(error_reporter != nullptr);
+ TFLITE_DCHECK(buffer_head != nullptr);
+ RecordingSimpleMemoryAllocator tmp =
+ RecordingSimpleMemoryAllocator(error_reporter, buffer_head, buffer_size);
+
+ uint8_t* allocator_buffer =
+ tmp.AllocateFromTail(sizeof(RecordingSimpleMemoryAllocator),
+ alignof(RecordingSimpleMemoryAllocator));
+ // Use the default copy constructor to populate internal states.
+ return new (allocator_buffer) RecordingSimpleMemoryAllocator(tmp);
+}
+
+size_t RecordingSimpleMemoryAllocator::GetRequestedBytes() const {
+ return requested_head_bytes_ + requested_tail_bytes_;
+}
+
+size_t RecordingSimpleMemoryAllocator::GetUsedBytes() const {
+ return used_bytes_;
+}
+
+size_t RecordingSimpleMemoryAllocator::GetAllocatedCount() const {
+ return alloc_count_;
+}
+
+TfLiteStatus RecordingSimpleMemoryAllocator::SetHeadBufferSize(
+ size_t size, size_t alignment) {
+ const uint8_t* previous_head = head();
+ TfLiteStatus status =
+ SimpleMemoryAllocator::SetHeadBufferSize(size, alignment);
+ if (status == kTfLiteOk) {
+ used_bytes_ += head() - previous_head;
+ requested_head_bytes_ = size;
+ }
+ return status;
+}
+
+uint8_t* RecordingSimpleMemoryAllocator::AllocateFromTail(size_t size,
+ size_t alignment) {
+ const uint8_t* previous_tail = tail();
+ uint8_t* result = SimpleMemoryAllocator::AllocateFromTail(size, alignment);
+ if (result != nullptr) {
+ used_bytes_ += previous_tail - tail();
+ requested_tail_bytes_ += size;
+ alloc_count_++;
+ }
+ return result;
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/recording_simple_memory_allocator.h b/tensorflow/lite/micro/recording_simple_memory_allocator.h
new file mode 100644
index 0000000..3526716
--- /dev/null
+++ b/tensorflow/lite/micro/recording_simple_memory_allocator.h
@@ -0,0 +1,64 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_RECORDING_SIMPLE_MEMORY_ALLOCATOR_H_
+#define TENSORFLOW_LITE_MICRO_RECORDING_SIMPLE_MEMORY_ALLOCATOR_H_
+
+#include "tensorflow/lite/micro/compatibility.h"
+#include "tensorflow/lite/micro/simple_memory_allocator.h"
+
+namespace tflite {
+
+// Utility class used to log allocations of a SimpleMemoryAllocator. Should only
+// be used in debug/evaluation settings or unit tests to evaluate allocation
+// usage.
+class RecordingSimpleMemoryAllocator : public SimpleMemoryAllocator {
+ public:
+ RecordingSimpleMemoryAllocator(ErrorReporter* error_reporter,
+ uint8_t* buffer_head, size_t buffer_size);
+ // TODO(b/157615197): Cleanup constructors/destructor and use factory
+ // functions.
+ ~RecordingSimpleMemoryAllocator() override;
+
+ static RecordingSimpleMemoryAllocator* Create(ErrorReporter* error_reporter,
+ uint8_t* buffer_head,
+ size_t buffer_size);
+
+ // Returns the number of bytes requested from the head or tail.
+ size_t GetRequestedBytes() const;
+
+ // Returns the number of bytes actually allocated from the head or tail. This
+ // value will be >= to the number of requested bytes due to padding and
+ // alignment.
+ size_t GetUsedBytes() const;
+
+ // Returns the number of alloc calls from the head or tail.
+ size_t GetAllocatedCount() const;
+
+ TfLiteStatus SetHeadBufferSize(size_t size, size_t alignment) override;
+ uint8_t* AllocateFromTail(size_t size, size_t alignment) override;
+
+ private:
+ size_t requested_head_bytes_;
+ size_t requested_tail_bytes_;
+ size_t used_bytes_;
+ size_t alloc_count_;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_RECORDING_SIMPLE_MEMORY_ALLOCATOR_H_
diff --git a/tensorflow/lite/micro/recording_simple_memory_allocator_test.cc b/tensorflow/lite/micro/recording_simple_memory_allocator_test.cc
new file mode 100644
index 0000000..cf9078c
--- /dev/null
+++ b/tensorflow/lite/micro/recording_simple_memory_allocator_test.cc
@@ -0,0 +1,138 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/recording_simple_memory_allocator.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestRecordsTailAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::RecordingSimpleMemoryAllocator allocator(
+ tflite::GetMicroErrorReporter(), arena, arena_size);
+
+ uint8_t* result = allocator.AllocateFromTail(/*size=*/10, /*alignment=*/1);
+ TF_LITE_MICRO_EXPECT_NE(result, nullptr);
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(10));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(10));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(1));
+
+ result = allocator.AllocateFromTail(/*size=*/20, /*alignment=*/1);
+ TF_LITE_MICRO_EXPECT_NE(result, nullptr);
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(30));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(30));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(2));
+}
+
+TF_LITE_MICRO_TEST(TestRecordsMisalignedTailAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::RecordingSimpleMemoryAllocator allocator(
+ tflite::GetMicroErrorReporter(), arena, arena_size);
+
+ uint8_t* result = allocator.AllocateFromTail(/*size=*/10, /*alignment=*/12);
+ TF_LITE_MICRO_EXPECT_NE(result, nullptr);
+ // Validate used bytes in 8 byte range that can included alignment of 12:
+ TF_LITE_MICRO_EXPECT_GE(allocator.GetUsedBytes(), static_cast<size_t>(10));
+ TF_LITE_MICRO_EXPECT_LE(allocator.GetUsedBytes(), static_cast<size_t>(20));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(10));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(1));
+}
+
+TF_LITE_MICRO_TEST(TestDoesNotRecordFailedTailAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::RecordingSimpleMemoryAllocator allocator(
+ tflite::GetMicroErrorReporter(), arena, arena_size);
+
+ uint8_t* result = allocator.AllocateFromTail(/*size=*/2048, /*alignment=*/1);
+ TF_LITE_MICRO_EXPECT(result == nullptr);
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(0));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(0));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(0));
+}
+
+TF_LITE_MICRO_TEST(TestRecordsHeadSizeAdjustment) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::RecordingSimpleMemoryAllocator allocator(
+ tflite::GetMicroErrorReporter(), arena, arena_size);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/5, /*alignment=*/1));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(5));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(5));
+ // Head adjustments do not count as an allocation:
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(0));
+
+ uint8_t* result = allocator.AllocateFromTail(/*size=*/15, /*alignment=*/1);
+ TF_LITE_MICRO_EXPECT_NE(result, nullptr);
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(20));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(20));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(1));
+}
+
+TF_LITE_MICRO_TEST(TestRecordsMisalignedHeadSizeAdjustments) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::RecordingSimpleMemoryAllocator allocator(
+ tflite::GetMicroErrorReporter(), arena, arena_size);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/10, /*alignment=*/12));
+ // Validate used bytes in 8 byte range that can included alignment of 12:
+ TF_LITE_MICRO_EXPECT_GE(allocator.GetUsedBytes(), static_cast<size_t>(10));
+ TF_LITE_MICRO_EXPECT_LE(allocator.GetUsedBytes(), static_cast<size_t>(20));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(10));
+ // Head adjustments do not count as an allocation:
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(0));
+}
+
+TF_LITE_MICRO_TEST(TestDoesNotRecordFailedTailAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::RecordingSimpleMemoryAllocator allocator(
+ tflite::GetMicroErrorReporter(), arena, arena_size);
+
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError, allocator.SetHeadBufferSize(
+ /*size=*/2048, /*alignment=*/1));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(0));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetRequestedBytes(),
+ static_cast<size_t>(0));
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAllocatedCount(),
+ static_cast<size_t>(0));
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/riscv32_mcu/README.md b/tensorflow/lite/micro/riscv32_mcu/README.md
new file mode 100644
index 0000000..5477d7a
--- /dev/null
+++ b/tensorflow/lite/micro/riscv32_mcu/README.md
@@ -0,0 +1,7 @@
+# RISC-V MCU
+
+This folder contains TFLite kernel operations optimized for RISC-V micro
+controllers.
+
+It is designed to be portable even to 'bare metal', so it follows the same
+design goals as the micro experimental port.
diff --git a/tensorflow/lite/micro/riscv32_mcu/debug_log.cc b/tensorflow/lite/micro/riscv32_mcu/debug_log.cc
new file mode 100644
index 0000000..f9459b8
--- /dev/null
+++ b/tensorflow/lite/micro/riscv32_mcu/debug_log.cc
@@ -0,0 +1,21 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+// TODO(b/121324430): Add test for DebugLog functions
+// TODO(b/121275099): Remove dependency on debug_log once the platform supports
+// printf
+
+#include <stdio.h>
+
+extern "C" void DebugLog(const char* s) { puts(s); }
diff --git a/tensorflow/lite/micro/simple_memory_allocator.cc b/tensorflow/lite/micro/simple_memory_allocator.cc
new file mode 100644
index 0000000..08b6789
--- /dev/null
+++ b/tensorflow/lite/micro/simple_memory_allocator.cc
@@ -0,0 +1,149 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/simple_memory_allocator.h"
+
+#include <cstddef>
+#include <cstdint>
+#include <new>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/micro/memory_helpers.h"
+
+namespace tflite {
+
+SimpleMemoryAllocator::SimpleMemoryAllocator(ErrorReporter* error_reporter,
+ uint8_t* buffer_head,
+ uint8_t* buffer_tail)
+ : error_reporter_(error_reporter),
+ buffer_head_(buffer_head),
+ buffer_tail_(buffer_tail),
+ head_(buffer_head),
+ tail_(buffer_tail),
+ temp_(buffer_head_) {}
+
+SimpleMemoryAllocator::SimpleMemoryAllocator(ErrorReporter* error_reporter,
+ uint8_t* buffer,
+ size_t buffer_size)
+ : SimpleMemoryAllocator(error_reporter, buffer, buffer + buffer_size) {}
+
+/* static */
+SimpleMemoryAllocator* SimpleMemoryAllocator::Create(
+ ErrorReporter* error_reporter, uint8_t* buffer_head, size_t buffer_size) {
+ TFLITE_DCHECK(error_reporter != nullptr);
+ TFLITE_DCHECK(buffer_head != nullptr);
+ SimpleMemoryAllocator tmp =
+ SimpleMemoryAllocator(error_reporter, buffer_head, buffer_size);
+
+ // Allocate enough bytes from the buffer to create a SimpleMemoryAllocator.
+ // The new instance will use the current adjusted tail buffer from the tmp
+ // allocator instance.
+ uint8_t* allocator_buffer = tmp.AllocateFromTail(
+ sizeof(SimpleMemoryAllocator), alignof(SimpleMemoryAllocator));
+ // Use the default copy constructor to populate internal states.
+ return new (allocator_buffer) SimpleMemoryAllocator(tmp);
+}
+
+SimpleMemoryAllocator::~SimpleMemoryAllocator() {}
+
+TfLiteStatus SimpleMemoryAllocator::SetHeadBufferSize(size_t size,
+ size_t alignment) {
+ if (head_ != temp_) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Internal error: SetHeadBufferSize() needs to be called "
+ "after ResetTempAllocations().");
+ return kTfLiteError;
+ }
+
+ uint8_t* const aligned_result = AlignPointerUp(buffer_head_, alignment);
+ const size_t available_memory = tail_ - aligned_result;
+ if (available_memory < size) {
+ TF_LITE_REPORT_ERROR(
+ error_reporter_,
+ "Failed to set head size. Requested: %u, available %u, missing: %u",
+ size, available_memory, size - available_memory);
+ return kTfLiteError;
+ }
+ head_ = aligned_result + size;
+ temp_ = head_;
+
+ return kTfLiteOk;
+}
+
+uint8_t* SimpleMemoryAllocator::AllocateFromTail(size_t size,
+ size_t alignment) {
+ uint8_t* const aligned_result = AlignPointerDown(tail_ - size, alignment);
+ if (aligned_result < head_) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ const size_t missing_memory = head_ - aligned_result;
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to allocate tail memory. Requested: %u, "
+ "available %u, missing: %u",
+ size, size - missing_memory, missing_memory);
+#endif
+ return nullptr;
+ }
+ tail_ = aligned_result;
+ return aligned_result;
+}
+
+uint8_t* SimpleMemoryAllocator::AllocateTemp(size_t size, size_t alignment) {
+ uint8_t* const aligned_result = AlignPointerUp(temp_, alignment);
+ const size_t available_memory = tail_ - aligned_result;
+ if (available_memory < size) {
+ TF_LITE_REPORT_ERROR(error_reporter_,
+ "Failed to allocate temp memory. Requested: %u, "
+ "available %u, missing: %u",
+ size, available_memory, size - available_memory);
+ return nullptr;
+ }
+ temp_ = aligned_result + size;
+ return aligned_result;
+}
+
+void SimpleMemoryAllocator::ResetTempAllocations() { temp_ = head_; }
+
+uint8_t* SimpleMemoryAllocator::GetHeadBuffer() const { return buffer_head_; }
+
+size_t SimpleMemoryAllocator::GetHeadUsedBytes() const {
+ return head_ - buffer_head_;
+}
+
+size_t SimpleMemoryAllocator::GetTailUsedBytes() const {
+ return buffer_tail_ - tail_;
+}
+
+size_t SimpleMemoryAllocator::GetAvailableMemory(size_t alignment) const {
+ uint8_t* const aligned_temp = AlignPointerUp(temp_, alignment);
+ uint8_t* const aligned_tail = AlignPointerDown(tail_, alignment);
+ return aligned_tail - aligned_temp;
+}
+
+size_t SimpleMemoryAllocator::GetUsedBytes() const {
+ return GetBufferSize() - (tail_ - temp_);
+}
+
+size_t SimpleMemoryAllocator::GetBufferSize() const {
+ return buffer_tail_ - buffer_head_;
+}
+
+uint8_t* SimpleMemoryAllocator::head() const { return head_; }
+
+uint8_t* SimpleMemoryAllocator::tail() const { return tail_; }
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/simple_memory_allocator.h b/tensorflow/lite/micro/simple_memory_allocator.h
new file mode 100644
index 0000000..35adaf1
--- /dev/null
+++ b/tensorflow/lite/micro/simple_memory_allocator.h
@@ -0,0 +1,112 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_SIMPLE_MEMORY_ALLOCATOR_H_
+#define TENSORFLOW_LITE_MICRO_SIMPLE_MEMORY_ALLOCATOR_H_
+
+#include <cstddef>
+#include <cstdint>
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/micro/compatibility.h"
+
+namespace tflite {
+
+// TODO(petewarden): This allocator never frees up or reuses any memory, even
+// though we have enough information about lifetimes of the tensors to do so.
+// This makes it pretty wasteful, so we should use a more intelligent method.
+class SimpleMemoryAllocator {
+ public:
+ // TODO(b/157615197): Cleanup constructors/destructor and use factory
+ // functions.
+ SimpleMemoryAllocator(ErrorReporter* error_reporter, uint8_t* buffer_head,
+ uint8_t* buffer_tail);
+ SimpleMemoryAllocator(ErrorReporter* error_reporter, uint8_t* buffer,
+ size_t buffer_size);
+ virtual ~SimpleMemoryAllocator();
+
+ // Creates a new SimpleMemoryAllocator from a given buffer head and size.
+ static SimpleMemoryAllocator* Create(ErrorReporter* error_reporter,
+ uint8_t* buffer_head,
+ size_t buffer_size);
+
+ // Adjusts the head (lowest address and moving upwards) memory allocation to a
+ // given size. Calls to this method will also invalidate all temporary
+ // allocation values (it sets the location of temp space at the end of the
+ // head section). This call will fail if a chain of allocations through
+ // AllocateTemp() have not been cleaned up with a call to
+ // ResetTempAllocations().
+ virtual TfLiteStatus SetHeadBufferSize(size_t size, size_t alignment);
+
+ // Allocates memory starting at the tail of the arena (highest address and
+ // moving downwards).
+ virtual uint8_t* AllocateFromTail(size_t size, size_t alignment);
+
+ // Allocates a temporary buffer from the head of the arena (lowest address and
+ // moving upwards) but does not update the actual head allocation size or
+ // position. The returned buffer is guaranteed until either
+ // ResetTempAllocations() is called or another call to AllocateFromHead().
+ // Repeat calls to this function will create a chain of temp allocations. All
+ // calls to AllocateTemp() must end with a call to ResetTempAllocations(). If
+ // AllocateFromHead() is called before a call to ResetTempAllocations(), it
+ // will fail with an error message.
+ virtual uint8_t* AllocateTemp(size_t size, size_t alignment);
+
+ // Resets a chain of temporary allocations back to the current head of the
+ // arena (lowest address).
+ virtual void ResetTempAllocations();
+
+ // Returns a pointer to the buffer currently assigned to the head section.
+ // This buffer is set by calling SetHeadSize().
+ uint8_t* GetHeadBuffer() const;
+
+ // Returns the size of the head section in bytes.
+ size_t GetHeadUsedBytes() const;
+
+ // Returns the size of all allocations in the tail section in bytes.
+ size_t GetTailUsedBytes() const;
+
+ // Returns the number of bytes available with a given alignment. This number
+ // takes in account any temporary allocations.
+ size_t GetAvailableMemory(size_t alignment) const;
+
+ // Returns the number of used bytes in the allocator. This number takes in
+ // account any temporary allocations.
+ size_t GetUsedBytes() const;
+
+ protected:
+ // Returns a pointer to the current end of the head buffer.
+ uint8_t* head() const;
+
+ // Returns a pointer to the current end of the tail buffer.
+ uint8_t* tail() const;
+
+ private:
+ size_t GetBufferSize() const;
+
+ ErrorReporter* error_reporter_;
+ uint8_t* buffer_head_;
+ uint8_t* buffer_tail_;
+ uint8_t* head_;
+ uint8_t* tail_;
+ uint8_t* temp_;
+
+ TF_LITE_REMOVE_VIRTUAL_DELETE
+};
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_SIMPLE_MEMORY_ALLOCATOR_H_
diff --git a/tensorflow/lite/micro/simple_memory_allocator_test.cc b/tensorflow/lite/micro/simple_memory_allocator_test.cc
new file mode 100644
index 0000000..5b7c260
--- /dev/null
+++ b/tensorflow/lite/micro/simple_memory_allocator_test.cc
@@ -0,0 +1,272 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/simple_memory_allocator.h"
+
+#include <cstdint>
+
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(TestEnsureHeadSizeSimpleAlignment) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/100, /*alignment=*/1));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(100),
+ allocator.GetHeadUsedBytes());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/10, /*alignment=*/1));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(10),
+ allocator.GetHeadUsedBytes());
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/1000, /*alignment=*/1));
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(1000),
+ allocator.GetHeadUsedBytes());
+}
+
+TF_LITE_MICRO_TEST(TestAdjustHeadSizeMisalignment) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ // First head adjustment of 100 bytes (aligned 12):
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/100, /*alignment=*/12));
+
+ // Offset alignment of 12 can lead to allocation within 8 byte range of
+ // requested bytes based to arena alignment at runtime:
+ TF_LITE_MICRO_EXPECT_GE(allocator.GetHeadUsedBytes(), 100);
+ TF_LITE_MICRO_EXPECT_LE(allocator.GetHeadUsedBytes(), 100 + 11);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/10, /*alignment=*/12));
+ TF_LITE_MICRO_EXPECT_GE(allocator.GetHeadUsedBytes(), 10);
+ TF_LITE_MICRO_EXPECT_LE(allocator.GetHeadUsedBytes(), 100 + 11);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/1000, /*alignment=*/12));
+ TF_LITE_MICRO_EXPECT_GE(allocator.GetHeadUsedBytes(), 1000);
+ TF_LITE_MICRO_EXPECT_LE(allocator.GetHeadUsedBytes(), 1000 + 11);
+}
+
+TF_LITE_MICRO_TEST(TestAdjustHeadSizeMisalignedHandlesCorrectBytesAvailable) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ // First head adjustment of 100 bytes (aligned 12):
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/100, /*alignment=*/12));
+
+ // allocator.GetAvailableMemory() should also report the actual amount of
+ // memory available based on a requested offset (12):
+ size_t aligned_available_bytes =
+ allocator.GetAvailableMemory(/*alignment=*/12);
+ TF_LITE_MICRO_EXPECT_LE(aligned_available_bytes, arena_size - 100);
+ TF_LITE_MICRO_EXPECT_GE(aligned_available_bytes, arena_size - 100 - 24);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/10, /*alignment=*/12));
+ aligned_available_bytes = allocator.GetAvailableMemory(/*alignment=*/12);
+
+ TF_LITE_MICRO_EXPECT_LE(aligned_available_bytes, arena_size - 10);
+ TF_LITE_MICRO_EXPECT_GE(aligned_available_bytes, arena_size - 10 - 24);
+
+ TF_LITE_MICRO_EXPECT_EQ(
+ kTfLiteOk, allocator.SetHeadBufferSize(/*size=*/1000, /*alignment=*/12));
+ aligned_available_bytes = allocator.GetAvailableMemory(/*alignment=*/12);
+ TF_LITE_MICRO_EXPECT_LE(aligned_available_bytes, arena_size - 1000);
+ TF_LITE_MICRO_EXPECT_GE(aligned_available_bytes, arena_size - 1000 - 24);
+}
+
+TF_LITE_MICRO_TEST(TestGetAvailableMemory) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ constexpr size_t allocation_size = 100;
+ allocator.SetHeadBufferSize(/*size=*/allocation_size,
+ /*alignment=*/1);
+ allocator.AllocateFromTail(/*size=*/allocation_size,
+ /*alignment=*/1);
+
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAvailableMemory(/*alignment=*/1),
+ arena_size - allocation_size * 2);
+}
+
+TF_LITE_MICRO_TEST(TestGetAvailableMemoryWithTempAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ constexpr size_t allocation_size = 100;
+ allocator.AllocateTemp(/*size=*/allocation_size,
+ /*alignment=*/1);
+
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAvailableMemory(/*alignment=*/1),
+ arena_size - allocation_size);
+
+ // Reset temp allocations and ensure GetAvailableMemory() is back to the
+ // starting size:
+ allocator.ResetTempAllocations();
+
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetAvailableMemory(/*alignment=*/1),
+ arena_size);
+}
+
+TF_LITE_MICRO_TEST(TestGetUsedBytes) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(0));
+
+ constexpr size_t allocation_size = 100;
+ allocator.SetHeadBufferSize(/*size=*/allocation_size,
+ /*alignment=*/1);
+ allocator.AllocateFromTail(/*size=*/allocation_size,
+ /*alignment=*/1);
+
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), allocation_size * 2);
+}
+
+TF_LITE_MICRO_TEST(TestGetUsedBytesTempAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ constexpr size_t allocation_size = 100;
+ allocator.AllocateTemp(/*size=*/allocation_size,
+ /*alignment=*/1);
+
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), allocation_size);
+
+ // Reset temp allocations and ensure GetUsedBytes() is back to the starting
+ // size:
+ allocator.ResetTempAllocations();
+
+ TF_LITE_MICRO_EXPECT_EQ(allocator.GetUsedBytes(), static_cast<size_t>(0));
+}
+
+TF_LITE_MICRO_TEST(TestJustFits) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ uint8_t* result = allocator.AllocateFromTail(arena_size, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != result);
+}
+
+TF_LITE_MICRO_TEST(TestAligned) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ uint8_t* result = allocator.AllocateFromTail(1, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != result);
+
+ result = allocator.AllocateFromTail(16, 4);
+ TF_LITE_MICRO_EXPECT(nullptr != result);
+ TF_LITE_MICRO_EXPECT_EQ(static_cast<size_t>(0),
+ reinterpret_cast<std::uintptr_t>(result) & 3);
+}
+
+TF_LITE_MICRO_TEST(TestMultipleTooLarge) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ uint8_t* result = allocator.AllocateFromTail(768, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != result);
+
+ result = allocator.AllocateFromTail(768, 1);
+ TF_LITE_MICRO_EXPECT(nullptr == result);
+}
+
+TF_LITE_MICRO_TEST(TestTempAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ uint8_t* temp1 = allocator.AllocateTemp(100, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != temp1);
+
+ uint8_t* temp2 = allocator.AllocateTemp(100, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != temp2);
+
+ // Expect that the next micro allocation is 100 bytes away from each other.
+ TF_LITE_MICRO_EXPECT_EQ(temp2 - temp1, 100);
+}
+
+TF_LITE_MICRO_TEST(TestResetTempAllocations) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ uint8_t* temp1 = allocator.AllocateTemp(100, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != temp1);
+
+ allocator.ResetTempAllocations();
+
+ uint8_t* temp2 = allocator.AllocateTemp(100, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != temp2);
+
+ // Reset temp allocations should have the same start address:
+ TF_LITE_MICRO_EXPECT_EQ(temp2 - temp1, 0);
+}
+
+TF_LITE_MICRO_TEST(TestEnsureHeadSizeWithoutResettingTemp) {
+ constexpr size_t arena_size = 1024;
+ uint8_t arena[arena_size];
+ tflite::SimpleMemoryAllocator allocator(tflite::GetMicroErrorReporter(),
+ arena, arena_size);
+
+ uint8_t* temp = allocator.AllocateTemp(100, 1);
+ TF_LITE_MICRO_EXPECT(nullptr != temp);
+
+ // Adjustment to head should fail since temp allocation was not followed by a
+ // call to ResetTempAllocations().
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteError, allocator.SetHeadBufferSize(100, 1));
+
+ allocator.ResetTempAllocations();
+
+ // Reduce head size back to zero.
+ TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, allocator.SetHeadBufferSize(0, 1));
+
+ // The most recent head allocation should be in the same location as the
+ // original temp allocation pointer.
+ TF_LITE_MICRO_EXPECT(temp == allocator.GetHeadBuffer());
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/sparkfun_edge/debug_log.cc b/tensorflow/lite/micro/sparkfun_edge/debug_log.cc
new file mode 100644
index 0000000..f1babc1
--- /dev/null
+++ b/tensorflow/lite/micro/sparkfun_edge/debug_log.cc
@@ -0,0 +1,21 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+// This file is empty to ensure that a specialized implementation of
+// debug_log.h is used (instead of the default implementation from
+// tensorflow/lite/micro/debug_log.cc).
+//
+// The actual target-specific implementation of debug_log.h is in
+// system_setup.cc since that allows us to consolidate all the target-specific
+// specializations into one source file.
diff --git a/tensorflow/lite/micro/sparkfun_edge/micro_time.cc b/tensorflow/lite/micro/sparkfun_edge/micro_time.cc
new file mode 100644
index 0000000..a7db6e4
--- /dev/null
+++ b/tensorflow/lite/micro/sparkfun_edge/micro_time.cc
@@ -0,0 +1,21 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+// This file is empty to ensure that a specialized implementation of
+// micro_time.h is used (instead of the default implementation from
+// tensorflow/lite/micro/micro_time.cc).
+//
+// The actual target-specific implementation of micro_time.h is in
+// system_setup.cc since that allows us to consolidate all the target-specific
+// specializations into one source file.
diff --git a/tensorflow/lite/micro/sparkfun_edge/system_setup.cc b/tensorflow/lite/micro/sparkfun_edge/system_setup.cc
new file mode 100644
index 0000000..995a3bb
--- /dev/null
+++ b/tensorflow/lite/micro/sparkfun_edge/system_setup.cc
@@ -0,0 +1,99 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/system_setup.h"
+
+#include "tensorflow/lite/micro/debug_log.h"
+#include "tensorflow/lite/micro/micro_time.h"
+
+// These are headers from Ambiq's Apollo3 SDK.
+#include "am_bsp.h" // NOLINT
+#include "am_mcu_apollo.h" // NOLINT
+#include "am_util.h" // NOLINT
+
+namespace {
+
+// Select CTIMER 1 as benchmarking timer on Sparkfun Edge. This timer must not
+// be used elsewhere.
+constexpr int kTimerNum = 1;
+
+// Clock set to operate at 12MHz.
+constexpr int kClocksPerSecond = 12e6;
+
+// Enables 96MHz burst mode on Sparkfun Edge. Enable in timer since most
+// benchmarks and profilers want maximum performance for debugging.
+void BurstModeEnable() {
+ am_hal_clkgen_control(AM_HAL_CLKGEN_CONTROL_SYSCLK_MAX, 0);
+
+ // Set the default cache configuration
+ am_hal_cachectrl_config(&am_hal_cachectrl_defaults);
+ am_hal_cachectrl_enable();
+
+ am_hal_burst_avail_e eBurstModeAvailable;
+ am_hal_burst_mode_e eBurstMode;
+
+ // Check that the Burst Feature is available.
+ int status = am_hal_burst_mode_initialize(&eBurstModeAvailable);
+ if (status != AM_HAL_STATUS_SUCCESS ||
+ eBurstModeAvailable != AM_HAL_BURST_AVAIL) {
+ DebugLog("Failed to initialize burst mode.\n");
+ return;
+ }
+
+ status = am_hal_burst_mode_enable(&eBurstMode);
+
+ if (status != AM_HAL_STATUS_SUCCESS || eBurstMode != AM_HAL_BURST_MODE) {
+ DebugLog("Failed to Enable Burst Mode operation\n");
+ }
+}
+
+} // namespace
+
+// Implementation for the DebugLog() function that prints to the UART on the
+// SparkFun Edge microcontroller. The same should work for other targets using
+// the Ambiq Apollo 3.
+extern "C" void DebugLog(const char* s) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ am_util_stdio_printf("%s", s);
+#endif
+}
+
+namespace tflite {
+
+// Calling this method enables a timer that runs for eternity. The user is
+// responsible for avoiding trampling on this timer's config, otherwise timing
+// measurements may no longer be valid.
+void InitializeTarget() {
+ am_bsp_uart_printf_enable();
+
+ BurstModeEnable();
+ am_hal_ctimer_config_t timer_config;
+ // Operate as a 32-bit timer.
+ timer_config.ui32Link = 1;
+ // Set timer A to continuous mode at 12MHz.
+ timer_config.ui32TimerAConfig =
+ AM_HAL_CTIMER_FN_CONTINUOUS | AM_HAL_CTIMER_HFRC_12MHZ;
+
+ am_hal_ctimer_stop(kTimerNum, AM_HAL_CTIMER_BOTH);
+ am_hal_ctimer_clear(kTimerNum, AM_HAL_CTIMER_BOTH);
+ am_hal_ctimer_config(kTimerNum, &timer_config);
+ am_hal_ctimer_start(kTimerNum, AM_HAL_CTIMER_TIMERA);
+}
+
+int32_t ticks_per_second() { return kClocksPerSecond; }
+
+int32_t GetCurrentTimeTicks() { return CTIMERn(kTimerNum)->TMR0; }
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/spresense/compiler_specific.cc b/tensorflow/lite/micro/spresense/compiler_specific.cc
new file mode 100644
index 0000000..304052a
--- /dev/null
+++ b/tensorflow/lite/micro/spresense/compiler_specific.cc
@@ -0,0 +1,21 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+extern "C" {
+
+char dummy[16];
+char* _impure_ptr = &dummy[0];
+void __assert_func(const char*, int, const char*, const char*) {}
+}
diff --git a/tensorflow/lite/micro/spresense/debug_log.cc b/tensorflow/lite/micro/spresense/debug_log.cc
new file mode 100644
index 0000000..e31f77b
--- /dev/null
+++ b/tensorflow/lite/micro/spresense/debug_log.cc
@@ -0,0 +1,20 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include <stdio.h>
+
+extern "C" void DebugLog(const char* s) { printf(s); }
diff --git a/tensorflow/lite/micro/stm32f4/debug_log.cc b/tensorflow/lite/micro/stm32f4/debug_log.cc
new file mode 100644
index 0000000..7d61d10
--- /dev/null
+++ b/tensorflow/lite/micro/stm32f4/debug_log.cc
@@ -0,0 +1,25 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+extern "C" void DebugLog(const char* s) {
+ asm("mov r0, #0x04\n" // SYS_WRITE0
+ "mov r1, %[str]\n"
+ "bkpt #0xAB\n"
+ :
+ : [str] "r"(s)
+ : "r0", "r1");
+}
diff --git a/tensorflow/lite/micro/stm32f4HAL/debug_log.cc b/tensorflow/lite/micro/stm32f4HAL/debug_log.cc
new file mode 100644
index 0000000..117c101
--- /dev/null
+++ b/tensorflow/lite/micro/stm32f4HAL/debug_log.cc
@@ -0,0 +1,47 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include <stm32f4xx_hal.h>
+#include <stm32f4xx_hal_uart.h>
+
+#include <cstdio>
+
+extern UART_HandleTypeDef DEBUG_UART_HANDLE;
+
+#ifdef __cplusplus
+extern "C" {
+#endif
+
+#ifdef __GNUC__
+int __io_putchar(int ch) {
+ HAL_UART_Transmit(&DEBUG_UART_HANDLE, (uint8_t*)&ch, 1, HAL_MAX_DELAY);
+
+ return ch;
+}
+#else
+int fputc(int ch, FILE* f) {
+ HAL_UART_Transmit(&DEBUG_UART_HANDLE, (uint8_t*)&ch, 1, HAL_MAX_DELAY);
+
+ return ch;
+}
+#endif /* __GNUC__ */
+
+void DebugLog(const char* s) { fprintf(stderr, "%s", s); }
+
+#ifdef __cplusplus
+}
+#endif
diff --git a/tensorflow/lite/micro/system_setup.cc b/tensorflow/lite/micro/system_setup.cc
new file mode 100644
index 0000000..db4a100
--- /dev/null
+++ b/tensorflow/lite/micro/system_setup.cc
@@ -0,0 +1,25 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/system_setup.h"
+
+namespace tflite {
+
+// To add an equivalent function for your own platform, create your own
+// implementation file, and place it in a subfolder named after the target. See
+// tensorflow/lite/micro/debug_log.cc for a similar example.
+void InitializeTarget() {}
+
+} // namespace tflite
diff --git a/tensorflow/lite/micro/system_setup.h b/tensorflow/lite/micro/system_setup.h
new file mode 100644
index 0000000..71ab13a
--- /dev/null
+++ b/tensorflow/lite/micro/system_setup.h
@@ -0,0 +1,27 @@
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_SYSTEM_SETUP_H_
+#define TENSORFLOW_LITE_MICRO_SYSTEM_SETUP_H_
+
+namespace tflite {
+
+// This should called during initialization of TFLM binaries and tests. It can
+// be specialized if there is a need for custom target-specific intialization.
+// For more information, see tensorflow/lite/micro/system_setup.cc.
+void InitializeTarget();
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_SYSTEM_SETUP_H_
diff --git a/tensorflow/lite/micro/test_helpers.cc b/tensorflow/lite/micro/test_helpers.cc
new file mode 100644
index 0000000..f73073f
--- /dev/null
+++ b/tensorflow/lite/micro/test_helpers.cc
@@ -0,0 +1,1079 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/test_helpers.h"
+
+#include <cstdarg>
+#include <cstddef>
+#include <cstdint>
+#include <initializer_list>
+#include <new>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/core/api/error_reporter.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/kernels/kernel_util.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+// TODO(b/170464050): Use TFLM test only version of schema_utils.
+
+namespace tflite {
+namespace testing {
+namespace {
+
+class StackAllocator : public flatbuffers::Allocator {
+ public:
+ StackAllocator() : data_(data_backing_), data_size_(0) {}
+
+ uint8_t* allocate(size_t size) override {
+ TFLITE_DCHECK((data_size_ + size) <= kStackAllocatorSize);
+ uint8_t* result = data_;
+ data_ += size;
+ data_size_ += size;
+ return result;
+ }
+
+ void deallocate(uint8_t* p, size_t) override {}
+
+ static StackAllocator& instance() {
+ // Avoid using true dynamic memory allocation to be portable to bare metal.
+ static char inst_memory[sizeof(StackAllocator)];
+ static StackAllocator* inst = new (inst_memory) StackAllocator;
+ return *inst;
+ }
+
+ static constexpr size_t kStackAllocatorSize = 8192;
+
+ private:
+ uint8_t data_backing_[kStackAllocatorSize];
+ uint8_t* data_;
+ int data_size_;
+};
+
+flatbuffers::FlatBufferBuilder* BuilderInstance() {
+ static char inst_memory[sizeof(flatbuffers::FlatBufferBuilder)];
+ static flatbuffers::FlatBufferBuilder* inst =
+ new (inst_memory) flatbuffers::FlatBufferBuilder(
+ StackAllocator::kStackAllocatorSize, &StackAllocator::instance());
+ return inst;
+}
+
+// A wrapper around FlatBuffer API to help build model easily.
+class ModelBuilder {
+ public:
+ typedef int32_t Tensor;
+ typedef int Operator;
+ typedef int Node;
+
+ // `builder` needs to be available until BuildModel is called.
+ explicit ModelBuilder(flatbuffers::FlatBufferBuilder* builder)
+ : builder_(builder) {}
+
+ // Registers an operator that will be used in the model.
+ Operator RegisterOp(BuiltinOperator op, const char* custom_code);
+
+ // Adds a tensor to the model.
+ Tensor AddTensor(TensorType type, std::initializer_list<int32_t> shape) {
+ return AddTensorImpl(type, /* is_variable */ false, shape);
+ }
+
+ // Adds a variable tensor to the model.
+ Tensor AddVariableTensor(TensorType type,
+ std::initializer_list<int32_t> shape) {
+ return AddTensorImpl(type, /* is_variable */ true, shape);
+ }
+
+ // Adds a node to the model with given input and output Tensors.
+ Node AddNode(Operator op, std::initializer_list<Tensor> inputs,
+ std::initializer_list<Tensor> outputs);
+
+ void AddMetadata(const char* description_string,
+ const int32_t* metadata_buffer_data, size_t num_elements);
+
+ // Constructs the flatbuffer model using `builder_` and return a pointer to
+ // it. The returned model has the same lifetime as `builder_`.
+ // Note the default value of 0 for num_subgraph_inputs means all tensor inputs
+ // are in subgraph input list.
+ const Model* BuildModel(std::initializer_list<Tensor> inputs,
+ std::initializer_list<Tensor> outputs,
+ size_t num_subgraph_inputs = 0);
+
+ private:
+ // Adds a tensor to the model.
+ Tensor AddTensorImpl(TensorType type, bool is_variable,
+ std::initializer_list<int32_t> shape);
+
+ flatbuffers::FlatBufferBuilder* builder_;
+
+ static constexpr int kMaxOperatorCodes = 10;
+ flatbuffers::Offset<tflite::OperatorCode> operator_codes_[kMaxOperatorCodes];
+ int next_operator_code_id_ = 0;
+
+ static constexpr int kMaxOperators = 50;
+ flatbuffers::Offset<tflite::Operator> operators_[kMaxOperators];
+ int next_operator_id_ = 0;
+
+ static constexpr int kMaxTensors = 50;
+ flatbuffers::Offset<tflite::Tensor> tensors_[kMaxTensors];
+
+ static constexpr int kMaxMetadataBuffers = 10;
+
+ static constexpr int kMaxMetadatas = 10;
+ flatbuffers::Offset<Metadata> metadata_[kMaxMetadatas];
+
+ flatbuffers::Offset<Buffer> metadata_buffers_[kMaxMetadataBuffers];
+
+ int nbr_of_metadata_buffers_ = 0;
+
+ int next_tensor_id_ = 0;
+};
+
+ModelBuilder::Operator ModelBuilder::RegisterOp(BuiltinOperator op,
+ const char* custom_code) {
+ TFLITE_DCHECK(next_operator_code_id_ <= kMaxOperatorCodes);
+ operator_codes_[next_operator_code_id_] = tflite::CreateOperatorCodeDirect(
+ *builder_, /*deprecated_builtin_code=*/0, custom_code, /*version=*/0, op);
+ next_operator_code_id_++;
+ return next_operator_code_id_ - 1;
+}
+
+ModelBuilder::Node ModelBuilder::AddNode(
+ ModelBuilder::Operator op,
+ std::initializer_list<ModelBuilder::Tensor> inputs,
+ std::initializer_list<ModelBuilder::Tensor> outputs) {
+ TFLITE_DCHECK(next_operator_id_ <= kMaxOperators);
+ operators_[next_operator_id_] = tflite::CreateOperator(
+ *builder_, op, builder_->CreateVector(inputs.begin(), inputs.size()),
+ builder_->CreateVector(outputs.begin(), outputs.size()),
+ BuiltinOptions_NONE);
+ next_operator_id_++;
+ return next_operator_id_ - 1;
+}
+
+void ModelBuilder::AddMetadata(const char* description_string,
+ const int32_t* metadata_buffer_data,
+ size_t num_elements) {
+ metadata_[ModelBuilder::nbr_of_metadata_buffers_] =
+ CreateMetadata(*builder_, builder_->CreateString(description_string),
+ 1 + ModelBuilder::nbr_of_metadata_buffers_);
+
+ metadata_buffers_[nbr_of_metadata_buffers_] = tflite::CreateBuffer(
+ *builder_, builder_->CreateVector((uint8_t*)metadata_buffer_data,
+ sizeof(uint32_t) * num_elements));
+
+ ModelBuilder::nbr_of_metadata_buffers_++;
+}
+
+const Model* ModelBuilder::BuildModel(
+ std::initializer_list<ModelBuilder::Tensor> inputs,
+ std::initializer_list<ModelBuilder::Tensor> outputs,
+ size_t num_subgraph_inputs) {
+ // Model schema requires an empty buffer at idx 0.
+ size_t buffer_size = 1 + ModelBuilder::nbr_of_metadata_buffers_;
+ flatbuffers::Offset<Buffer> buffers[kMaxMetadataBuffers];
+ buffers[0] = tflite::CreateBuffer(*builder_);
+
+ // Place the metadata buffers first in the buffer since the indices for them
+ // have already been set in AddMetadata()
+ for (int i = 1; i < ModelBuilder::nbr_of_metadata_buffers_ + 1; ++i) {
+ buffers[i] = metadata_buffers_[i - 1];
+ }
+
+ // TFLM only supports single subgraph.
+ constexpr size_t subgraphs_size = 1;
+
+ // Find out number of subgraph inputs.
+ if (num_subgraph_inputs == 0) {
+ // This is the default case.
+ num_subgraph_inputs = inputs.size();
+ } else {
+ // A non-zero value of num_subgraph_inputs means that some of
+ // the operator input tensors are not subgraph inputs.
+ TFLITE_DCHECK(num_subgraph_inputs <= inputs.size());
+ }
+
+ const flatbuffers::Offset<SubGraph> subgraphs[subgraphs_size] = {
+ tflite::CreateSubGraph(
+ *builder_, builder_->CreateVector(tensors_, next_tensor_id_),
+ builder_->CreateVector(inputs.begin(), num_subgraph_inputs),
+ builder_->CreateVector(outputs.begin(), outputs.size()),
+ builder_->CreateVector(operators_, next_operator_id_),
+ builder_->CreateString("test_subgraph"))};
+
+ flatbuffers::Offset<Model> model_offset;
+ if (ModelBuilder::nbr_of_metadata_buffers_ > 0) {
+ model_offset = tflite::CreateModel(
+ *builder_, 0,
+ builder_->CreateVector(operator_codes_, next_operator_code_id_),
+ builder_->CreateVector(subgraphs, subgraphs_size),
+ builder_->CreateString("teset_model"),
+ builder_->CreateVector(buffers, buffer_size), 0,
+ builder_->CreateVector(metadata_,
+ ModelBuilder::nbr_of_metadata_buffers_));
+ } else {
+ model_offset = tflite::CreateModel(
+ *builder_, 0,
+ builder_->CreateVector(operator_codes_, next_operator_code_id_),
+ builder_->CreateVector(subgraphs, subgraphs_size),
+ builder_->CreateString("teset_model"),
+ builder_->CreateVector(buffers, buffer_size));
+ }
+
+ tflite::FinishModelBuffer(*builder_, model_offset);
+ void* model_pointer = builder_->GetBufferPointer();
+ const Model* model = flatbuffers::GetRoot<Model>(model_pointer);
+ return model;
+}
+
+ModelBuilder::Tensor ModelBuilder::AddTensorImpl(
+ TensorType type, bool is_variable, std::initializer_list<int32_t> shape) {
+ TFLITE_DCHECK(next_tensor_id_ <= kMaxTensors);
+ tensors_[next_tensor_id_] = tflite::CreateTensor(
+ *builder_, builder_->CreateVector(shape.begin(), shape.size()), type,
+ /* buffer */ 0, /* name */ 0, /* quantization */ 0,
+ /* is_variable */ is_variable,
+ /* sparsity */ 0);
+ next_tensor_id_++;
+ return next_tensor_id_ - 1;
+}
+
+const Model* BuildSimpleStatefulModel() {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* fb_builder = BuilderInstance();
+
+ ModelBuilder model_builder(fb_builder);
+
+ const int op_id =
+ model_builder.RegisterOp(BuiltinOperator_CUSTOM, "simple_stateful_op");
+ const int input_tensor = model_builder.AddTensor(TensorType_UINT8, {3});
+ const int median_tensor = model_builder.AddTensor(TensorType_UINT8, {3});
+ const int invoke_count_tensor =
+ model_builder.AddTensor(TensorType_INT32, {1});
+
+ model_builder.AddNode(op_id, {input_tensor},
+ {median_tensor, invoke_count_tensor});
+ return model_builder.BuildModel({input_tensor},
+ {median_tensor, invoke_count_tensor});
+}
+
+const Model* BuildSimpleModelWithBranch() {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* fb_builder = BuilderInstance();
+
+ ModelBuilder model_builder(fb_builder);
+ /* Model structure
+ | t0
+ +------|
+ | v
+ | +---------+
+ | | n0 |
+ | | |
+ | +---------+
+ v +
+ |
+ +---------+ | t1
+ | n1 | |
+ | | |
+ +---------+ |
+ | |
+ t2 | v
+ | +---------+
+ +-->| n2 |
+ | |
+ +-------|-+
+ |t3
+ v
+ */
+ const int op_id =
+ model_builder.RegisterOp(BuiltinOperator_CUSTOM, "mock_custom");
+ const int t0 = model_builder.AddTensor(TensorType_FLOAT32, {2, 2, 3});
+ const int t1 = model_builder.AddTensor(TensorType_FLOAT32, {2, 2, 3});
+ const int t2 = model_builder.AddTensor(TensorType_FLOAT32, {2, 2, 3});
+ const int t3 = model_builder.AddTensor(TensorType_FLOAT32, {2, 2, 3});
+ model_builder.AddNode(op_id, {t0}, {t1}); // n0
+ model_builder.AddNode(op_id, {t0}, {t2}); // n1
+ model_builder.AddNode(op_id, {t1, t2}, {t3}); // n2
+ return model_builder.BuildModel({t0}, {t3});
+}
+
+const Model* BuildModelWithOfflinePlanning(int number_of_tensors,
+ const int32_t* metadata_buffer,
+ NodeConnection* node_conn,
+ int num_conns,
+ int num_subgraph_inputs) {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* fb_builder = BuilderInstance();
+
+ ModelBuilder model_builder(fb_builder);
+
+ const int op_id =
+ model_builder.RegisterOp(BuiltinOperator_CUSTOM, "mock_custom");
+
+ for (int i = 0; i < number_of_tensors; ++i) {
+ model_builder.AddTensor(TensorType_FLOAT32, {2, 2, 3});
+ }
+
+ for (int i = 0; i < num_conns; ++i) {
+ model_builder.AddNode(op_id, node_conn[i].input, node_conn[i].output);
+ }
+
+ model_builder.AddMetadata(
+ "OfflineMemoryAllocation", metadata_buffer,
+ number_of_tensors + tflite::testing::kOfflinePlannerHeaderSize);
+
+ return model_builder.BuildModel(
+ node_conn[0].input, node_conn[num_conns - 1].output, num_subgraph_inputs);
+}
+
+const Model* BuildSimpleMockModel() {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* builder = BuilderInstance();
+
+ constexpr size_t buffer_data_size = 1;
+ const uint8_t buffer_data[buffer_data_size] = {21};
+ constexpr size_t buffers_size = 2;
+ const Offset<Buffer> buffers[buffers_size] = {
+ CreateBuffer(*builder),
+ CreateBuffer(*builder,
+ builder->CreateVector(buffer_data, buffer_data_size))};
+ constexpr size_t tensor_shape_size = 1;
+ const int32_t tensor_shape[tensor_shape_size] = {1};
+ constexpr size_t tensors_size = 4;
+ const Offset<Tensor> tensors[tensors_size] = {
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0,
+ builder->CreateString("test_input_tensor"), 0, false),
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_UINT8, 1,
+ builder->CreateString("test_weight_tensor"), 0, false),
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0,
+ builder->CreateString("test_output_tensor"), 0, false),
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0,
+ builder->CreateString("test_output2_tensor"), 0, false),
+ };
+ constexpr size_t inputs_size = 1;
+ const int32_t inputs[inputs_size] = {0};
+ constexpr size_t outputs_size = 2;
+ const int32_t outputs[outputs_size] = {2, 3};
+ constexpr size_t operator_inputs_size = 2;
+ const int32_t operator_inputs[operator_inputs_size] = {0, 1};
+ constexpr size_t operator_outputs_size = 1;
+ const int32_t operator_outputs[operator_outputs_size] = {2};
+ const int32_t operator2_outputs[operator_outputs_size] = {3};
+ constexpr size_t operators_size = 2;
+ const Offset<Operator> operators[operators_size] = {
+ CreateOperator(
+ *builder, 0,
+ builder->CreateVector(operator_inputs, operator_inputs_size),
+ builder->CreateVector(operator_outputs, operator_outputs_size),
+ BuiltinOptions_NONE),
+ CreateOperator(
+ *builder, 0,
+ builder->CreateVector(operator_inputs, operator_inputs_size),
+ builder->CreateVector(operator2_outputs, operator_outputs_size),
+ BuiltinOptions_NONE),
+ };
+ constexpr size_t subgraphs_size = 1;
+ const Offset<SubGraph> subgraphs[subgraphs_size] = {
+ CreateSubGraph(*builder, builder->CreateVector(tensors, tensors_size),
+ builder->CreateVector(inputs, inputs_size),
+ builder->CreateVector(outputs, outputs_size),
+ builder->CreateVector(operators, operators_size),
+ builder->CreateString("test_subgraph"))};
+ constexpr size_t operator_codes_size = 1;
+ const Offset<OperatorCode> operator_codes[operator_codes_size] = {
+ CreateOperatorCodeDirect(*builder, /*deprecated_builtin_code=*/0,
+ "mock_custom",
+ /*version=*/0, BuiltinOperator_CUSTOM)};
+ const Offset<Model> model_offset = CreateModel(
+ *builder, 0, builder->CreateVector(operator_codes, operator_codes_size),
+ builder->CreateVector(subgraphs, subgraphs_size),
+ builder->CreateString("test_model"),
+ builder->CreateVector(buffers, buffers_size));
+ FinishModelBuffer(*builder, model_offset);
+ void* model_pointer = builder->GetBufferPointer();
+ const Model* model = flatbuffers::GetRoot<Model>(model_pointer);
+ return model;
+}
+
+const Model* BuildComplexMockModel() {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* builder = BuilderInstance();
+
+ constexpr size_t buffer_data_size = 1;
+ const uint8_t buffer_data_1[buffer_data_size] = {21};
+ const uint8_t buffer_data_2[buffer_data_size] = {21};
+ const uint8_t buffer_data_3[buffer_data_size] = {21};
+ constexpr size_t buffers_size = 7;
+ const Offset<Buffer> buffers[buffers_size] = {
+ // Op 1 buffers:
+ CreateBuffer(*builder),
+ CreateBuffer(*builder),
+ CreateBuffer(*builder,
+ builder->CreateVector(buffer_data_1, buffer_data_size)),
+ // Op 2 buffers:
+ CreateBuffer(*builder),
+ CreateBuffer(*builder,
+ builder->CreateVector(buffer_data_2, buffer_data_size)),
+ // Op 3 buffers:
+ CreateBuffer(*builder),
+ CreateBuffer(*builder,
+ builder->CreateVector(buffer_data_3, buffer_data_size)),
+ };
+ constexpr size_t tensor_shape_size = 1;
+ const int32_t tensor_shape[tensor_shape_size] = {1};
+
+ constexpr size_t tensors_size = 10;
+ const Offset<Tensor> tensors[tensors_size] = {
+ // Op 1 inputs:
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0, builder->CreateString("test_input_tensor_1"), 0,
+ false /* is_variable */),
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 1, builder->CreateString("test_variable_tensor_1"),
+ 0, true /* is_variable */),
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_UINT8, 2, builder->CreateString("test_weight_tensor_1"), 0,
+ false /* is_variable */),
+ // Op 1 output / Op 2 input:
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0, builder->CreateString("test_output_tensor_1"), 0,
+ false /* is_variable */),
+ // Op 2 inputs:
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 1, builder->CreateString("test_variable_tensor_2"),
+ 0, true /* is_variable */),
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_UINT8, 2, builder->CreateString("test_weight_tensor_2"), 0,
+ false /* is_variable */),
+ // Op 2 output / Op 3 input:
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0, builder->CreateString("test_output_tensor_2"), 0,
+ false /* is_variable */),
+ // Op 3 inputs:
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 1, builder->CreateString("test_variable_tensor_3"),
+ 0, true /* is_variable */),
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_UINT8, 2, builder->CreateString("test_weight_tensor_3"), 0,
+ false /* is_variable */),
+ // Op 3 output:
+ CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0, builder->CreateString("test_output_tensor_3"), 0,
+ false /* is_variable */),
+ };
+
+ constexpr size_t operators_size = 3;
+ Offset<Operator> operators[operators_size];
+ {
+ // Set Op 1 attributes:
+ constexpr size_t operator_inputs_size = 3;
+ const int32_t operator_inputs[operator_inputs_size] = {0, 1, 2};
+ constexpr size_t operator_outputs_size = 1;
+ const int32_t operator_outputs[operator_outputs_size] = {3};
+
+ operators[0] = {CreateOperator(
+ *builder, 0,
+ builder->CreateVector(operator_inputs, operator_inputs_size),
+ builder->CreateVector(operator_outputs, operator_outputs_size),
+ BuiltinOptions_NONE)};
+ }
+
+ {
+ // Set Op 2 attributes
+ constexpr size_t operator_inputs_size = 3;
+ const int32_t operator_inputs[operator_inputs_size] = {3, 4, 5};
+ constexpr size_t operator_outputs_size = 1;
+ const int32_t operator_outputs[operator_outputs_size] = {6};
+
+ operators[1] = {CreateOperator(
+ *builder, 0,
+ builder->CreateVector(operator_inputs, operator_inputs_size),
+ builder->CreateVector(operator_outputs, operator_outputs_size),
+ BuiltinOptions_NONE)};
+ }
+
+ {
+ // Set Op 3 attributes
+ constexpr size_t operator_inputs_size = 3;
+ const int32_t operator_inputs[operator_inputs_size] = {6, 7, 8};
+ constexpr size_t operator_outputs_size = 1;
+ const int32_t operator_outputs[operator_outputs_size] = {9};
+
+ operators[2] = {CreateOperator(
+ *builder, 0,
+ builder->CreateVector(operator_inputs, operator_inputs_size),
+ builder->CreateVector(operator_outputs, operator_outputs_size),
+ BuiltinOptions_NONE)};
+ }
+
+ constexpr size_t inputs_size = 1;
+ const int32_t inputs[inputs_size] = {0};
+ constexpr size_t outputs_size = 1;
+ const int32_t outputs[outputs_size] = {9};
+
+ constexpr size_t subgraphs_size = 1;
+ const Offset<SubGraph> subgraphs[subgraphs_size] = {
+ CreateSubGraph(*builder, builder->CreateVector(tensors, tensors_size),
+ builder->CreateVector(inputs, inputs_size),
+ builder->CreateVector(outputs, outputs_size),
+ builder->CreateVector(operators, operators_size),
+ builder->CreateString("test_subgraph"))};
+
+ constexpr size_t operator_codes_size = 1;
+ const Offset<OperatorCode> operator_codes[operator_codes_size] = {
+ CreateOperatorCodeDirect(*builder, /*deprecated_builtin_code=*/0,
+ "mock_custom",
+ /*version=*/0, BuiltinOperator_CUSTOM)};
+
+ const Offset<Model> model_offset = CreateModel(
+ *builder, 0, builder->CreateVector(operator_codes, operator_codes_size),
+ builder->CreateVector(subgraphs, subgraphs_size),
+ builder->CreateString("test_model"),
+ builder->CreateVector(buffers, buffers_size));
+
+ FinishModelBuffer(*builder, model_offset);
+ void* model_pointer = builder->GetBufferPointer();
+ const Model* model = flatbuffers::GetRoot<Model>(model_pointer);
+ return model;
+}
+
+const Model* BuildSimpleMultipleInputsModel() {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* builder = BuilderInstance();
+
+ constexpr size_t buffers_size = 1;
+ const Offset<Buffer> buffers[buffers_size] = {
+ CreateBuffer(*builder),
+ };
+ constexpr size_t tensor_shape_size = 1;
+ const int32_t tensor_shape[tensor_shape_size] = {1};
+ constexpr size_t tensors_size = 4;
+ const Offset<Tensor> tensors[tensors_size] = {
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0,
+ builder->CreateString("test_input_tensor1"), 0, false),
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT8, 0,
+ builder->CreateString("test_input_tensor2"), 0, false),
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0,
+ builder->CreateString("test_input_tensor3"), 0, false),
+ CreateTensor(*builder,
+ builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0,
+ builder->CreateString("test_output_tensor"), 0, false),
+ };
+ constexpr size_t inputs_size = 3;
+ const int32_t inputs[inputs_size] = {0, 1, 2};
+ constexpr size_t outputs_size = 1;
+ const int32_t outputs[outputs_size] = {3};
+ constexpr size_t operator_inputs_size = 3;
+ const int32_t operator_inputs[operator_inputs_size] = {0, 1, 2};
+ constexpr size_t operator_outputs_size = 1;
+ const int32_t operator_outputs[operator_outputs_size] = {3};
+ constexpr size_t operators_size = 1;
+ const Offset<Operator> operators[operators_size] = {
+ CreateOperator(
+ *builder, 0,
+ builder->CreateVector(operator_inputs, operator_inputs_size),
+ builder->CreateVector(operator_outputs, operator_outputs_size),
+ BuiltinOptions_NONE),
+ };
+ constexpr size_t subgraphs_size = 1;
+ const Offset<SubGraph> subgraphs[subgraphs_size] = {
+ CreateSubGraph(*builder, builder->CreateVector(tensors, tensors_size),
+ builder->CreateVector(inputs, inputs_size),
+ builder->CreateVector(outputs, outputs_size),
+ builder->CreateVector(operators, operators_size),
+ builder->CreateString("test_subgraph"))};
+ constexpr size_t operator_codes_size = 1;
+ const Offset<OperatorCode> operator_codes[operator_codes_size] = {
+ CreateOperatorCodeDirect(*builder, /*deprecated_builtin_code=*/0,
+ "multiple_inputs_op",
+ /*version=*/0, BuiltinOperator_CUSTOM)};
+ const Offset<Model> model_offset = CreateModel(
+ *builder, 0, builder->CreateVector(operator_codes, operator_codes_size),
+ builder->CreateVector(subgraphs, subgraphs_size),
+ builder->CreateString("test_model"),
+ builder->CreateVector(buffers, buffers_size));
+ FinishModelBuffer(*builder, model_offset);
+ void* model_pointer = builder->GetBufferPointer();
+ const Model* model = flatbuffers::GetRoot<Model>(model_pointer);
+ return model;
+}
+
+} // namespace
+
+const TfLiteRegistration* SimpleStatefulOp::getRegistration() {
+ return GetMutableRegistration();
+}
+
+TfLiteRegistration* SimpleStatefulOp::GetMutableRegistration() {
+ static TfLiteRegistration r;
+ r.init = Init;
+ r.prepare = Prepare;
+ r.invoke = Invoke;
+ return &r;
+}
+
+void* SimpleStatefulOp::Init(TfLiteContext* context, const char* buffer,
+ size_t length) {
+ TFLITE_DCHECK(context->AllocateBufferForEval == nullptr);
+ TFLITE_DCHECK(context->GetScratchBuffer == nullptr);
+ TFLITE_DCHECK(context->RequestScratchBufferInArena == nullptr);
+
+ void* raw = context->AllocatePersistentBuffer(context, sizeof(OpData));
+ OpData* data = reinterpret_cast<OpData*>(raw);
+ *data = {};
+ return raw;
+}
+
+TfLiteStatus SimpleStatefulOp::Prepare(TfLiteContext* context,
+ TfLiteNode* node) {
+ OpData* data = reinterpret_cast<OpData*>(node->user_data);
+
+ // Make sure that the input is in uint8_t with at least 1 data entry.
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ if (input->type != kTfLiteUInt8) return kTfLiteError;
+ if (NumElements(input->dims) == 0) return kTfLiteError;
+
+ // Allocate a temporary buffer with the same size of input for sorting.
+ TF_LITE_ENSURE_STATUS(context->RequestScratchBufferInArena(
+ context, sizeof(uint8_t) * NumElements(input->dims),
+ &data->sorting_buffer));
+ // We can interleave scratch / persistent buffer allocation.
+ data->invoke_count = reinterpret_cast<int*>(
+ context->AllocatePersistentBuffer(context, sizeof(int)));
+ *data->invoke_count = 0;
+
+ return kTfLiteOk;
+}
+
+TfLiteStatus SimpleStatefulOp::Invoke(TfLiteContext* context,
+ TfLiteNode* node) {
+ OpData* data = reinterpret_cast<OpData*>(node->user_data);
+ *data->invoke_count += 1;
+
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, kInputTensor, &input));
+ const uint8_t* input_data = GetTensorData<uint8_t>(input);
+ int size = NumElements(input->dims);
+
+ uint8_t* sorting_buffer = reinterpret_cast<uint8_t*>(
+ context->GetScratchBuffer(context, data->sorting_buffer));
+ // Copy inputs data to the sorting buffer. We don't want to mutate the input
+ // tensor as it might be used by a another node.
+ for (int i = 0; i < size; i++) {
+ sorting_buffer[i] = input_data[i];
+ }
+
+ // In place insertion sort on `sorting_buffer`.
+ for (int i = 1; i < size; i++) {
+ for (int j = i; j > 0 && sorting_buffer[j] < sorting_buffer[j - 1]; j--) {
+ std::swap(sorting_buffer[j], sorting_buffer[j - 1]);
+ }
+ }
+
+ TfLiteTensor* median;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kMedianTensor, &median));
+ uint8_t* median_data = GetTensorData<uint8_t>(median);
+ TfLiteTensor* invoke_count;
+ TF_LITE_ENSURE_OK(context,
+ GetOutputSafe(context, node, kInvokeCount, &invoke_count));
+ int32_t* invoke_count_data = GetTensorData<int32_t>(invoke_count);
+
+ median_data[0] = sorting_buffer[size / 2];
+ invoke_count_data[0] = *data->invoke_count;
+ return kTfLiteOk;
+}
+
+const TfLiteRegistration* MockCustom::getRegistration() {
+ return GetMutableRegistration();
+}
+
+TfLiteRegistration* MockCustom::GetMutableRegistration() {
+ static TfLiteRegistration r;
+ r.init = Init;
+ r.prepare = Prepare;
+ r.invoke = Invoke;
+ r.free = Free;
+ return &r;
+}
+
+void* MockCustom::Init(TfLiteContext* context, const char* buffer,
+ size_t length) {
+ // We don't support delegate in TFL micro. This is a weak check to test if
+ // context struct being zero-initialized.
+ TFLITE_DCHECK(context->ReplaceNodeSubsetsWithDelegateKernels == nullptr);
+ freed_ = false;
+ // Do nothing.
+ return nullptr;
+}
+
+void MockCustom::Free(TfLiteContext* context, void* buffer) { freed_ = true; }
+
+TfLiteStatus MockCustom::Prepare(TfLiteContext* context, TfLiteNode* node) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus MockCustom::Invoke(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, 0, &input));
+ const int32_t* input_data = input->data.i32;
+ const TfLiteTensor* weight;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, 1, &weight));
+ const uint8_t* weight_data = weight->data.uint8;
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context, GetOutputSafe(context, node, 0, &output));
+ int32_t* output_data = output->data.i32;
+ output_data[0] =
+ 0; // Catch output tensor sharing memory with an input tensor
+ output_data[0] = input_data[0] + weight_data[0];
+ return kTfLiteOk;
+}
+
+bool MockCustom::freed_ = false;
+
+const TfLiteRegistration* MultipleInputs::getRegistration() {
+ return GetMutableRegistration();
+}
+
+TfLiteRegistration* MultipleInputs::GetMutableRegistration() {
+ static TfLiteRegistration r;
+ r.init = Init;
+ r.prepare = Prepare;
+ r.invoke = Invoke;
+ r.free = Free;
+ return &r;
+}
+
+void* MultipleInputs::Init(TfLiteContext* context, const char* buffer,
+ size_t length) {
+ // We don't support delegate in TFL micro. This is a weak check to test if
+ // context struct being zero-initialized.
+ TFLITE_DCHECK(context->ReplaceNodeSubsetsWithDelegateKernels == nullptr);
+ freed_ = false;
+ // Do nothing.
+ return nullptr;
+}
+
+void MultipleInputs::Free(TfLiteContext* context, void* buffer) {
+ freed_ = true;
+}
+
+TfLiteStatus MultipleInputs::Prepare(TfLiteContext* context, TfLiteNode* node) {
+ return kTfLiteOk;
+}
+
+TfLiteStatus MultipleInputs::Invoke(TfLiteContext* context, TfLiteNode* node) {
+ const TfLiteTensor* input;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, 0, &input));
+ const int32_t* input_data = input->data.i32;
+ const TfLiteTensor* input1;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, 1, &input1));
+ const int32_t* input_data1 = input1->data.i32;
+ const TfLiteTensor* input2;
+ TF_LITE_ENSURE_OK(context, GetInputSafe(context, node, 2, &input2));
+ const int32_t* input_data2 = input2->data.i32;
+
+ TfLiteTensor* output;
+ TF_LITE_ENSURE_OK(context, GetOutputSafe(context, node, 0, &output));
+ int32_t* output_data = output->data.i32;
+ output_data[0] =
+ 0; // Catch output tensor sharing memory with an input tensor
+ output_data[0] = input_data[0] + input_data1[0] + input_data2[0];
+ return kTfLiteOk;
+}
+
+bool MultipleInputs::freed_ = false;
+
+AllOpsResolver GetOpResolver() {
+ AllOpsResolver op_resolver;
+ op_resolver.AddCustom("mock_custom", MockCustom::GetMutableRegistration());
+ op_resolver.AddCustom("simple_stateful_op",
+ SimpleStatefulOp::GetMutableRegistration());
+ op_resolver.AddCustom("multiple_inputs_op",
+ MultipleInputs::GetMutableRegistration());
+ return op_resolver;
+}
+
+const Model* GetSimpleMockModel() {
+ static Model* model = nullptr;
+ if (!model) {
+ model = const_cast<Model*>(BuildSimpleMockModel());
+ }
+ return model;
+}
+
+const Model* GetSimpleMultipleInputsModel() {
+ static Model* model = nullptr;
+ if (!model) {
+ model = const_cast<Model*>(BuildSimpleMultipleInputsModel());
+ }
+ return model;
+}
+
+const Model* GetComplexMockModel() {
+ static Model* model = nullptr;
+ if (!model) {
+ model = const_cast<Model*>(BuildComplexMockModel());
+ }
+ return model;
+}
+
+const Model* GetSimpleModelWithBranch() {
+ static Model* model = nullptr;
+ if (!model) {
+ model = const_cast<Model*>(BuildSimpleModelWithBranch());
+ }
+ return model;
+}
+
+const Model* GetModelWithOfflinePlanning(int num_tensors,
+ const int32_t* metadata_buffer,
+ NodeConnection* node_conn,
+ int num_conns,
+ int num_subgraph_inputs) {
+ const Model* model = BuildModelWithOfflinePlanning(
+ num_tensors, metadata_buffer, node_conn, num_conns, num_subgraph_inputs);
+ return model;
+}
+
+const Model* GetSimpleStatefulModel() {
+ static Model* model = nullptr;
+ if (!model) {
+ model = const_cast<Model*>(BuildSimpleStatefulModel());
+ }
+ return model;
+}
+
+const Tensor* Create1dFlatbufferTensor(int size, bool is_variable) {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* builder = BuilderInstance();
+ constexpr size_t tensor_shape_size = 1;
+ const int32_t tensor_shape[tensor_shape_size] = {size};
+ const Offset<Tensor> tensor_offset = CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0, builder->CreateString("test_tensor"), 0,
+ is_variable);
+ builder->Finish(tensor_offset);
+ void* tensor_pointer = builder->GetBufferPointer();
+ const Tensor* tensor = flatbuffers::GetRoot<Tensor>(tensor_pointer);
+ return tensor;
+}
+
+const Tensor* CreateQuantizedFlatbufferTensor(int size) {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* builder = BuilderInstance();
+ const Offset<QuantizationParameters> quant_params =
+ CreateQuantizationParameters(
+ *builder,
+ /*min=*/builder->CreateVector<float>({0.1f}),
+ /*max=*/builder->CreateVector<float>({0.2f}),
+ /*scale=*/builder->CreateVector<float>({0.3f}),
+ /*zero_point=*/builder->CreateVector<int64_t>({100ll}));
+
+ constexpr size_t tensor_shape_size = 1;
+ const int32_t tensor_shape[tensor_shape_size] = {size};
+ const Offset<Tensor> tensor_offset = CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0, builder->CreateString("test_tensor"), quant_params,
+ false);
+ builder->Finish(tensor_offset);
+ void* tensor_pointer = builder->GetBufferPointer();
+ const Tensor* tensor = flatbuffers::GetRoot<Tensor>(tensor_pointer);
+ return tensor;
+}
+
+const Tensor* CreateMissingQuantizationFlatbufferTensor(int size) {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* builder = BuilderInstance();
+ const Offset<QuantizationParameters> quant_params =
+ CreateQuantizationParameters(*builder, 0, 0, 0, 0,
+ QuantizationDetails_NONE, 0, 0);
+ constexpr size_t tensor_shape_size = 1;
+ const int32_t tensor_shape[tensor_shape_size] = {size};
+ const Offset<Tensor> tensor_offset = CreateTensor(
+ *builder, builder->CreateVector(tensor_shape, tensor_shape_size),
+ TensorType_INT32, 0, builder->CreateString("test_tensor"), quant_params,
+ false);
+ builder->Finish(tensor_offset);
+ void* tensor_pointer = builder->GetBufferPointer();
+ const Tensor* tensor = flatbuffers::GetRoot<Tensor>(tensor_pointer);
+ return tensor;
+}
+
+const flatbuffers::Vector<flatbuffers::Offset<Buffer>>*
+CreateFlatbufferBuffers() {
+ using flatbuffers::Offset;
+ flatbuffers::FlatBufferBuilder* builder = BuilderInstance();
+ constexpr size_t buffers_size = 1;
+ const Offset<Buffer> buffers[buffers_size] = {
+ CreateBuffer(*builder),
+ };
+ const flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<Buffer>>>
+ buffers_offset = builder->CreateVector(buffers, buffers_size);
+ builder->Finish(buffers_offset);
+ void* buffers_pointer = builder->GetBufferPointer();
+ const flatbuffers::Vector<flatbuffers::Offset<Buffer>>* result =
+ flatbuffers::GetRoot<flatbuffers::Vector<flatbuffers::Offset<Buffer>>>(
+ buffers_pointer);
+ return result;
+}
+
+int TestStrcmp(const char* a, const char* b) {
+ if ((a == nullptr) || (b == nullptr)) {
+ return -1;
+ }
+ while ((*a != 0) && (*a == *b)) {
+ a++;
+ b++;
+ }
+ return *reinterpret_cast<const unsigned char*>(a) -
+ *reinterpret_cast<const unsigned char*>(b);
+}
+
+// Wrapper to forward kernel errors to the interpreter's error reporter.
+void ReportOpError(struct TfLiteContext* context, const char* format, ...) {
+#ifndef TF_LITE_STRIP_ERROR_STRINGS
+ ErrorReporter* error_reporter = static_cast<ErrorReporter*>(context->impl_);
+ va_list args;
+ va_start(args, format);
+ TF_LITE_REPORT_ERROR(error_reporter, format, args);
+ va_end(args);
+#endif
+}
+
+// Create a TfLiteIntArray from an array of ints. The first element in the
+// supplied array must be the size of the array expressed as an int.
+TfLiteIntArray* IntArrayFromInts(const int* int_array) {
+ return const_cast<TfLiteIntArray*>(
+ reinterpret_cast<const TfLiteIntArray*>(int_array));
+}
+
+// Create a TfLiteFloatArray from an array of floats. The first element in the
+// supplied array must be the size of the array expressed as a float.
+TfLiteFloatArray* FloatArrayFromFloats(const float* floats) {
+ static_assert(sizeof(float) == sizeof(int),
+ "assumes sizeof(float) == sizeof(int) to perform casting");
+ int size = static_cast<int>(floats[0]);
+ *reinterpret_cast<int32_t*>(const_cast<float*>(floats)) = size;
+ return reinterpret_cast<TfLiteFloatArray*>(const_cast<float*>(floats));
+}
+
+TfLiteTensor CreateQuantizedBiasTensor(const float* data, int32_t* quantized,
+ TfLiteIntArray* dims, float input_scale,
+ float weights_scale, bool is_variable) {
+ float bias_scale = input_scale * weights_scale;
+ tflite::SymmetricQuantize(data, quantized, ElementCount(*dims), bias_scale);
+
+ // Quantized int32_t tensors always have a zero point of 0, since the range of
+ // int32_t values is large, and because zero point costs extra cycles during
+ // processing.
+ TfLiteTensor result =
+ CreateQuantizedTensor(quantized, dims, bias_scale, 0, is_variable);
+ return result;
+}
+
+// Quantizes int32_t bias tensor with per-channel weights determined by input
+// scale multiplied by weight scale for each channel.
+TfLiteTensor CreatePerChannelQuantizedBiasTensor(
+ const float* input, int32_t* quantized, TfLiteIntArray* dims,
+ float input_scale, float* weight_scales, float* scales, int* zero_points,
+ TfLiteAffineQuantization* affine_quant, int quantized_dimension,
+ bool is_variable) {
+ int input_size = ElementCount(*dims);
+ int num_channels = dims->data[quantized_dimension];
+ // First element is reserved for array length
+ zero_points[0] = num_channels;
+ scales[0] = static_cast<float>(num_channels);
+ float* scales_array = &scales[1];
+ for (int i = 0; i < num_channels; i++) {
+ scales_array[i] = input_scale * weight_scales[i];
+ zero_points[i + 1] = 0;
+ }
+
+ SymmetricPerChannelQuantize<int32_t>(input, quantized, input_size,
+ num_channels, scales_array);
+
+ affine_quant->scale = FloatArrayFromFloats(scales);
+ affine_quant->zero_point = IntArrayFromInts(zero_points);
+ affine_quant->quantized_dimension = quantized_dimension;
+
+ TfLiteTensor result = CreateTensor(quantized, dims, is_variable);
+ result.quantization = {kTfLiteAffineQuantization, affine_quant};
+ return result;
+}
+
+TfLiteTensor CreateSymmetricPerChannelQuantizedTensor(
+ const float* input, int8_t* quantized, TfLiteIntArray* dims, float* scales,
+ int* zero_points, TfLiteAffineQuantization* affine_quant,
+ int quantized_dimension, bool is_variable) {
+ int channel_count = dims->data[quantized_dimension];
+ scales[0] = static_cast<float>(channel_count);
+ zero_points[0] = channel_count;
+
+ SignedSymmetricPerChannelQuantize(input, dims, quantized_dimension, quantized,
+ &scales[1]);
+
+ for (int i = 0; i < channel_count; i++) {
+ zero_points[i + 1] = 0;
+ }
+
+ affine_quant->scale = FloatArrayFromFloats(scales);
+ affine_quant->zero_point = IntArrayFromInts(zero_points);
+ affine_quant->quantized_dimension = quantized_dimension;
+
+ TfLiteTensor result = CreateTensor(quantized, dims, is_variable);
+ result.quantization = {kTfLiteAffineQuantization, affine_quant};
+ return result;
+}
+
+size_t GetModelTensorCount(const Model* model) {
+ auto* subgraphs = model->subgraphs();
+ if (subgraphs) {
+ return (*subgraphs)[0]->tensors()->size();
+ }
+ return 0;
+}
+
+} // namespace testing
+} // namespace tflite
diff --git a/tensorflow/lite/micro/test_helpers.h b/tensorflow/lite/micro/test_helpers.h
new file mode 100644
index 0000000..4c8b7c2
--- /dev/null
+++ b/tensorflow/lite/micro/test_helpers.h
@@ -0,0 +1,241 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_TEST_HELPERS_H_
+#define TENSORFLOW_LITE_MICRO_TEST_HELPERS_H_
+
+// Useful functions for writing tests.
+
+#include <cstdint>
+#include <limits>
+
+#include "flatbuffers/flatbuffers.h" // from @flatbuffers
+#include "tensorflow/lite//kernels/internal/tensor_ctypes.h"
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+#include "tensorflow/lite/micro/all_ops_resolver.h"
+#include "tensorflow/lite/micro/micro_utils.h"
+#include "tensorflow/lite/portable_type_to_tflitetype.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+namespace testing {
+
+constexpr int kOfflinePlannerHeaderSize = 3;
+
+struct NodeConnection_ {
+ std::initializer_list<int32_t> input;
+ std::initializer_list<int32_t> output;
+};
+typedef struct NodeConnection_ NodeConnection;
+
+// A simple operator that returns the median of the input with the number of
+// times the kernel was invoked. The implementation below is deliberately
+// complicated, just to demonstrate how kernel memory planning works.
+class SimpleStatefulOp {
+ static constexpr int kBufferNotAllocated = 0;
+ // Inputs:
+ static constexpr int kInputTensor = 0;
+ // Outputs:
+ static constexpr int kMedianTensor = 0;
+ static constexpr int kInvokeCount = 1;
+ struct OpData {
+ int* invoke_count = nullptr;
+ int sorting_buffer = kBufferNotAllocated;
+ };
+
+ public:
+ static const TfLiteRegistration* getRegistration();
+ static TfLiteRegistration* GetMutableRegistration();
+ static void* Init(TfLiteContext* context, const char* buffer, size_t length);
+ static TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node);
+ static TfLiteStatus Invoke(TfLiteContext* context, TfLiteNode* node);
+};
+
+class MockCustom {
+ public:
+ static const TfLiteRegistration* getRegistration();
+ static TfLiteRegistration* GetMutableRegistration();
+ static void* Init(TfLiteContext* context, const char* buffer, size_t length);
+ static void Free(TfLiteContext* context, void* buffer);
+ static TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node);
+ static TfLiteStatus Invoke(TfLiteContext* context, TfLiteNode* node);
+
+ static bool freed_;
+};
+
+// A simple operator with the purpose of testing multiple inputs. It returns
+// the sum of the inputs.
+class MultipleInputs {
+ public:
+ static const TfLiteRegistration* getRegistration();
+ static TfLiteRegistration* GetMutableRegistration();
+ static void* Init(TfLiteContext* context, const char* buffer, size_t length);
+ static void Free(TfLiteContext* context, void* buffer);
+ static TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node);
+ static TfLiteStatus Invoke(TfLiteContext* context, TfLiteNode* node);
+
+ static bool freed_;
+};
+
+// Returns an Op Resolver that can be used in the testing code.
+AllOpsResolver GetOpResolver();
+
+// Returns a simple example flatbuffer TensorFlow Lite model. Contains 1 input,
+// 1 layer of weights, 1 output Tensor, and 1 operator.
+const Model* GetSimpleMockModel();
+
+// Returns a flatbuffer TensorFlow Lite model with more inputs, variable
+// tensors, and operators.
+const Model* GetComplexMockModel();
+
+// Returns a simple flatbuffer model with two branches.
+const Model* GetSimpleModelWithBranch();
+
+// Returns a simple example flatbuffer TensorFlow Lite model. Contains 3 inputs,
+// 1 output Tensor, and 1 operator.
+const Model* GetSimpleMultipleInputsModel();
+
+// Returns a simple flatbuffer model with offline planned tensors
+// @param[in] num_tensors Number of tensors in the model.
+// @param[in] metadata_buffer Metadata for offline planner.
+// @param[in] node_con List of connections, i.e. operators
+// in the model.
+// @param[in] num_conns Number of connections.
+// @param[in] num_subgraph_inputs How many of the input tensors are in
+// the subgraph inputs. The default value
+// of 0 means all of the input tensors
+// are in the subgraph input list. There
+// must be at least 1 input tensor in the
+// subgraph input list.
+const Model* GetModelWithOfflinePlanning(int num_tensors,
+ const int32_t* metadata_buffer,
+ NodeConnection* node_conn,
+ int num_conns,
+ int num_subgraph_inputs = 0);
+
+// Returns a flatbuffer model with `simple_stateful_op`
+const Model* GetSimpleStatefulModel();
+
+// Builds a one-dimensional flatbuffer tensor of the given size.
+const Tensor* Create1dFlatbufferTensor(int size, bool is_variable = false);
+
+// Builds a one-dimensional flatbuffer tensor of the given size with
+// quantization metadata.
+const Tensor* CreateQuantizedFlatbufferTensor(int size);
+
+// Creates a one-dimensional tensor with no quantization metadata.
+const Tensor* CreateMissingQuantizationFlatbufferTensor(int size);
+
+// Creates a vector of flatbuffer buffers.
+const flatbuffers::Vector<flatbuffers::Offset<Buffer>>*
+CreateFlatbufferBuffers();
+
+// Performs a simple string comparison without requiring standard C library.
+int TestStrcmp(const char* a, const char* b);
+
+// Wrapper to forward kernel errors to the interpreter's error reporter.
+void ReportOpError(struct TfLiteContext* context, const char* format, ...);
+
+void PopulateContext(TfLiteTensor* tensors, int tensors_size,
+ TfLiteContext* context);
+
+// Create a TfLiteIntArray from an array of ints. The first element in the
+// supplied array must be the size of the array expressed as an int.
+TfLiteIntArray* IntArrayFromInts(const int* int_array);
+
+// Create a TfLiteFloatArray from an array of floats. The first element in the
+// supplied array must be the size of the array expressed as a float.
+TfLiteFloatArray* FloatArrayFromFloats(const float* floats);
+
+template <typename T>
+TfLiteTensor CreateTensor(const T* data, TfLiteIntArray* dims,
+ const bool is_variable = false) {
+ TfLiteTensor result;
+ result.dims = dims;
+ result.params = {};
+ result.quantization = {kTfLiteNoQuantization, nullptr};
+ result.is_variable = is_variable;
+ result.allocation_type = kTfLiteMemNone;
+ result.type = typeToTfLiteType<T>();
+ // Const cast is used to allow passing in const and non-const arrays within a
+ // single CreateTensor method. A Const array should be used for immutable
+ // input tensors and non-const array should be used for mutable and output
+ // tensors.
+ result.data.data = const_cast<T*>(data);
+ result.quantization = {kTfLiteAffineQuantization, nullptr};
+ result.bytes = ElementCount(*dims) * sizeof(T);
+ return result;
+}
+
+template <typename T>
+TfLiteTensor CreateQuantizedTensor(const T* data, TfLiteIntArray* dims,
+ const float scale, const int zero_point = 0,
+ const bool is_variable = false) {
+ TfLiteTensor result = CreateTensor(data, dims, is_variable);
+ result.params = {scale, zero_point};
+ result.quantization = {kTfLiteAffineQuantization, nullptr};
+ return result;
+}
+
+template <typename T>
+TfLiteTensor CreateQuantizedTensor(const float* input, T* quantized,
+ TfLiteIntArray* dims, float scale,
+ int zero_point, bool is_variable = false) {
+ int input_size = ElementCount(*dims);
+ tflite::Quantize(input, quantized, input_size, scale, zero_point);
+ return CreateQuantizedTensor(quantized, dims, scale, zero_point, is_variable);
+}
+
+TfLiteTensor CreateQuantizedBiasTensor(const float* data, int32_t* quantized,
+ TfLiteIntArray* dims, float input_scale,
+ float weights_scale,
+ bool is_variable = false);
+
+// Quantizes int32_t bias tensor with per-channel weights determined by input
+// scale multiplied by weight scale for each channel.
+TfLiteTensor CreatePerChannelQuantizedBiasTensor(
+ const float* input, int32_t* quantized, TfLiteIntArray* dims,
+ float input_scale, float* weight_scales, float* scales, int* zero_points,
+ TfLiteAffineQuantization* affine_quant, int quantized_dimension,
+ bool is_variable = false);
+
+TfLiteTensor CreateSymmetricPerChannelQuantizedTensor(
+ const float* input, int8_t* quantized, TfLiteIntArray* dims, float* scales,
+ int* zero_points, TfLiteAffineQuantization* affine_quant,
+ int quantized_dimension, bool is_variable = false);
+
+// Returns the number of tensors in the default subgraph for a tflite::Model.
+size_t GetModelTensorCount(const Model* model);
+
+// Derives the quantization scaling factor from a min and max range.
+template <typename T>
+inline float ScaleFromMinMax(const float min, const float max) {
+ return (max - min) /
+ static_cast<float>((std::numeric_limits<T>::max() * 1.0) -
+ std::numeric_limits<T>::min());
+}
+
+// Derives the quantization zero point from a min and max range.
+template <typename T>
+inline int ZeroPointFromMinMax(const float min, const float max) {
+ return static_cast<int>(std::numeric_limits<T>::min()) +
+ static_cast<int>(-min / ScaleFromMinMax<T>(min, max) + 0.5f);
+}
+
+} // namespace testing
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_MICRO_TEST_HELPERS_H_
diff --git a/tensorflow/lite/micro/testing/BUILD b/tensorflow/lite/micro/testing/BUILD
new file mode 100644
index 0000000..6d8c74d
--- /dev/null
+++ b/tensorflow/lite/micro/testing/BUILD
@@ -0,0 +1,74 @@
+package(
+ features = ["-layering_check"],
+ licenses = ["notice"],
+)
+
+package_group(
+ name = "micro",
+ packages = ["//tensorflow/lite/micro/..."],
+)
+
+package_group(
+ name = "microfrontend",
+ packages = ["//tensorflow/lite/experimental/microfrontend/..."],
+)
+
+cc_library(
+ name = "micro_test",
+ hdrs = [
+ "micro_test.h",
+ ],
+ visibility = [
+ ":micro",
+ ":microfrontend",
+ ],
+ deps = [
+ "//tensorflow/lite/c:common",
+ "//tensorflow/lite/core/api",
+ "//tensorflow/lite/micro:micro_error_reporter",
+ "//tensorflow/lite/micro:micro_framework",
+ "//tensorflow/lite/micro:micro_utils",
+ "//tensorflow/lite/micro:system_setup",
+ "//tensorflow/lite/micro:test_helpers",
+ ],
+)
+
+cc_test(
+ name = "util_test",
+ srcs = [
+ "util_test.cc",
+ ],
+ deps = [
+ ":micro_test",
+ ],
+)
+
+cc_library(
+ name = "test_conv_model",
+ srcs = [
+ "test_conv_model.cc",
+ ],
+ hdrs = [
+ "test_conv_model.h",
+ ],
+ visibility = [
+ ":micro",
+ ],
+)
+
+py_binary(
+ name = "generate_test_models",
+ srcs = ["generate_test_models.py"],
+ python_version = "PY3",
+ srcs_version = "PY3ONLY",
+ tags = [
+ "no_oss", # TODO(b/174680668): Exclude python targets from OSS.
+ "nomicro_static", # TF dep incompatible w/ TF_LITE_STATIC_MEMORY.
+ "noubsan", # TODO(b/144512025): Fix raw_to_bitmap_test to fix ubsan failure.
+ ],
+ deps = [
+ "//tensorflow:tensorflow_py",
+ "//third_party/py/numpy",
+ "@absl_py//absl:app",
+ ],
+)
diff --git a/tensorflow/lite/micro/testing/Dockerfile.riscv b/tensorflow/lite/micro/testing/Dockerfile.riscv
new file mode 100644
index 0000000..4f7ac55
--- /dev/null
+++ b/tensorflow/lite/micro/testing/Dockerfile.riscv
@@ -0,0 +1,24 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+# This docker configuration file lets you emulate a Hifive1 board
+# on an x86 desktop or laptop, which can be useful for debugging and
+# automated testing.
+FROM antmicro/renode:latest
+
+LABEL maintainer="Pete Warden <petewarden@google.com>"
+
+RUN apt-get update
+RUN apt-get install -y curl git unzip make g++
\ No newline at end of file
diff --git a/tensorflow/lite/micro/testing/bluepill.resc b/tensorflow/lite/micro/testing/bluepill.resc
new file mode 100644
index 0000000..78af665
--- /dev/null
+++ b/tensorflow/lite/micro/testing/bluepill.resc
@@ -0,0 +1,25 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+using sysbus
+
+mach create
+machine LoadPlatformDescription @platforms/cpus/stm32f103.repl
+
+# These lines are needed to show the results of DebugLog calls in the output.
+machine LoadPlatformDescriptionFromString "uartSemihosting: UART.SemihostingUart @ cpu"
+showAnalyzer cpu.uartSemihosting Antmicro.Renode.Analyzers.LoggingUartAnalyzer
+cpu.uartSemihosting CreateFileBackend $logfile true
+
diff --git a/tensorflow/lite/micro/testing/bluepill_nontest.resc b/tensorflow/lite/micro/testing/bluepill_nontest.resc
new file mode 100644
index 0000000..c345014
--- /dev/null
+++ b/tensorflow/lite/micro/testing/bluepill_nontest.resc
@@ -0,0 +1,22 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+mach create
+# Load platform specification
+machine LoadPlatformDescription @platforms/cpus/stm32f103.repl
+# Create additional semihosting interface peripheral
+machine LoadPlatformDescriptionFromString "uartSemihosting: UART.SemihostingUart @ cpu"
+showAnalyzer sysbus.cpu.uartSemihosting
+
diff --git a/tensorflow/lite/micro/testing/generate_test_models.py b/tensorflow/lite/micro/testing/generate_test_models.py
new file mode 100644
index 0000000..ff48614
--- /dev/null
+++ b/tensorflow/lite/micro/testing/generate_test_models.py
@@ -0,0 +1,80 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Python utility script to generate unit test model data."""
+
+# Steps to regenerate model test data:
+# TODO(b/158011574): Do these steps in the script here instead of manually.
+# 1.) Run this script
+# 2.) Hexdump the model into a .h/.cc file:
+# xxd -i /tmp/tf_micro_conv_test_model.tflite > /tmp/temp.cc
+# 3.) Copy/replace contents of temp.cc into desired header/source files (e.g.
+# test_conv_model.h/.cc
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from absl import app
+import numpy as np
+import tensorflow.compat.v2 as tf
+
+
+def generate_conv_model():
+ """Creates a basic Keras model and converts to tflite.
+
+ This model does not make any relevant classifications. It only exists to
+ generate a model that is designed to run on embedded devices.
+ """
+ input_shape = (16, 16, 1)
+
+ model = tf.keras.models.Sequential()
+ model.add(
+ tf.keras.layers.Conv2D(16, 3, activation="relu", input_shape=input_shape))
+ model.add(tf.keras.layers.Conv2D(32, 3, activation="relu"))
+ model.add(tf.keras.layers.MaxPooling2D(2))
+ model.add(tf.keras.layers.Flatten())
+ model.add(tf.keras.layers.Dense(10))
+ model.compile(
+ optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
+ model.summary()
+
+ # Test with random data
+ data_x = np.random.rand(12, 16, 16, 1)
+ data_y = np.random.randint(2, size=(12, 10))
+ model.fit(data_x, data_y, epochs=5)
+
+ def representative_dataset_gen():
+ for _ in range(12):
+ yield [np.random.rand(16, 16).reshape(1, 16, 16, 1).astype(np.float32)]
+
+ # Now convert to a TFLite model with full int8 quantization:
+ converter = tf.lite.TFLiteConverter.from_keras_model(model)
+ converter.optimizations = [tf.lite.Optimize.DEFAULT]
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
+ converter.inference_input_type = tf.int8
+ converter.inference_output_type = tf.int8
+ converter.representative_dataset = representative_dataset_gen
+
+ tflite_model = converter.convert()
+ open("/tmp/tf_micro_conv_test_model.int8.tflite", "wb").write(tflite_model)
+
+
+def main(argv):
+ del argv # Unused for now
+ generate_conv_model()
+
+
+if __name__ == "__main__":
+ app.run(main)
diff --git a/tensorflow/lite/micro/testing/leon_commands b/tensorflow/lite/micro/testing/leon_commands
new file mode 100644
index 0000000..5deb5f5
--- /dev/null
+++ b/tensorflow/lite/micro/testing/leon_commands
@@ -0,0 +1,3 @@
+run
+quit
+
diff --git a/tensorflow/lite/micro/testing/micro_test.h b/tensorflow/lite/micro/testing/micro_test.h
new file mode 100644
index 0000000..229dfa6
--- /dev/null
+++ b/tensorflow/lite/micro/testing/micro_test.h
@@ -0,0 +1,240 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// An ultra-lightweight testing framework designed for use with microcontroller
+// applications. Its only dependency is on TensorFlow Lite's ErrorReporter
+// interface, where log messages are output. This is designed to be usable even
+// when no standard C or C++ libraries are available, and without any dynamic
+// memory allocation or reliance on global constructors.
+//
+// To build a test, you use syntax similar to gunit, but with some extra
+// decoration to create a hidden 'main' function containing each of the tests to
+// be run. Your code should look something like:
+// ----------------------------------------------------------------------------
+// #include "path/to/this/header"
+//
+// TF_LITE_MICRO_TESTS_BEGIN
+//
+// TF_LITE_MICRO_TEST(SomeTest) {
+// TF_LITE_LOG_EXPECT_EQ(true, true);
+// }
+//
+// TF_LITE_MICRO_TESTS_END
+// ----------------------------------------------------------------------------
+// If you compile this for your platform, you'll get a normal binary that you
+// should be able to run. Executing it will output logging information like this
+// to stderr (or whatever equivalent is available and written to by
+// ErrorReporter):
+// ----------------------------------------------------------------------------
+// Testing SomeTest
+// 1/1 tests passed
+// ~~~ALL TESTS PASSED~~~
+// ----------------------------------------------------------------------------
+// This is designed to be human-readable, so you can just run tests manually,
+// but the string "~~~ALL TESTS PASSED~~~" should only appear if all of the
+// tests do pass. This makes it possible to integrate with automated test
+// systems by scanning the output logs and looking for that magic value.
+//
+// This framework is intended to be a rudimentary alternative to no testing at
+// all on systems that struggle to run more conventional approaches, so use with
+// caution!
+
+#ifndef TENSORFLOW_LITE_MICRO_TESTING_MICRO_TEST_H_
+#define TENSORFLOW_LITE_MICRO_TESTING_MICRO_TEST_H_
+
+#include "tensorflow/lite/c/common.h"
+#include "tensorflow/lite/micro/micro_error_reporter.h"
+#include "tensorflow/lite/micro/system_setup.h"
+
+namespace micro_test {
+extern int tests_passed;
+extern int tests_failed;
+extern bool is_test_complete;
+extern bool did_test_fail;
+} // namespace micro_test
+
+namespace tflite {
+
+// This additional helper function is used (instead of directly calling
+// tflite::InitializeTarget from the TF_LITE_MICRO_TESTS_BEGIN macro) to avoid
+// adding a dependency from every bazel test target to micro:system_setp (which
+// is the target that implements InitializeTarget().
+//
+// The underlying issue here is that the use of the macros results in
+// dependencies that can be containted within the micro/testing:micro_test
+// target bleeding on to all the tests.
+inline void InitializeTest() { InitializeTarget(); }
+} // namespace tflite
+
+#define TF_LITE_MICRO_TESTS_BEGIN \
+ namespace micro_test { \
+ int tests_passed; \
+ int tests_failed; \
+ bool is_test_complete; \
+ bool did_test_fail; \
+ } \
+ \
+ int main(int argc, char** argv) { \
+ micro_test::tests_passed = 0; \
+ micro_test::tests_failed = 0; \
+ tflite::InitializeTest();
+
+#define TF_LITE_MICRO_TESTS_END \
+ MicroPrintf("%d/%d tests passed", micro_test::tests_passed, \
+ (micro_test::tests_failed + micro_test::tests_passed)); \
+ if (micro_test::tests_failed == 0) { \
+ MicroPrintf("~~~ALL TESTS PASSED~~~\n"); \
+ return kTfLiteOk; \
+ } else { \
+ MicroPrintf("~~~SOME TESTS FAILED~~~\n"); \
+ return kTfLiteError; \
+ } \
+ }
+
+// TODO(petewarden): I'm going to hell for what I'm doing to this poor for loop.
+#define TF_LITE_MICRO_TEST(name) \
+ MicroPrintf("Testing " #name); \
+ for (micro_test::is_test_complete = false, \
+ micro_test::did_test_fail = false; \
+ !micro_test::is_test_complete; micro_test::is_test_complete = true, \
+ micro_test::tests_passed += (micro_test::did_test_fail) ? 0 : 1, \
+ micro_test::tests_failed += (micro_test::did_test_fail) ? 1 : 0)
+
+#define TF_LITE_MICRO_EXPECT(x) \
+ do { \
+ if (!(x)) { \
+ MicroPrintf(#x " failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+// TODO(b/139142772): this macro is used with types other than ints even though
+// the printf specifier is %d.
+#define TF_LITE_MICRO_EXPECT_EQ(x, y) \
+ do { \
+ auto vx = x; \
+ auto vy = y; \
+ if ((vx) != (vy)) { \
+ MicroPrintf(#x " == " #y " failed at %s:%d (%d vs %d)", __FILE__, \
+ __LINE__, static_cast<int>(vx), static_cast<int>(vy)); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_NE(x, y) \
+ do { \
+ if ((x) == (y)) { \
+ MicroPrintf(#x " != " #y " failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+// TODO(wangtz): Making it more generic once needed.
+#define TF_LITE_MICRO_ARRAY_ELEMENT_EXPECT_NEAR(arr1, idx1, arr2, idx2, \
+ epsilon) \
+ do { \
+ auto delta = ((arr1)[(idx1)] > (arr2)[(idx2)]) \
+ ? ((arr1)[(idx1)] - (arr2)[(idx2)]) \
+ : ((arr2)[(idx2)] - (arr1)[(idx1)]); \
+ if (delta > epsilon) { \
+ MicroPrintf(#arr1 "[%d] (%f) near " #arr2 "[%d] (%f) failed at %s:%d", \
+ static_cast<int>(idx1), static_cast<float>((arr1)[(idx1)]), \
+ static_cast<int>(idx2), static_cast<float>((arr2)[(idx2)]), \
+ __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+// The check vx != vy is needed to properly handle the case where both
+// x and y evaluate to infinity. See #46960 for more details.
+#define TF_LITE_MICRO_EXPECT_NEAR(x, y, epsilon) \
+ do { \
+ auto vx = (x); \
+ auto vy = (y); \
+ auto delta = ((vx) > (vy)) ? ((vx) - (vy)) : ((vy) - (vx)); \
+ if (vx != vy && delta > epsilon) { \
+ MicroPrintf(#x " (%f) near " #y " (%f) failed at %s:%d", \
+ static_cast<double>(vx), static_cast<double>(vy), __FILE__, \
+ __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_GT(x, y) \
+ do { \
+ if ((x) <= (y)) { \
+ MicroPrintf(#x " > " #y " failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_LT(x, y) \
+ do { \
+ if ((x) >= (y)) { \
+ MicroPrintf(#x " < " #y " failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_GE(x, y) \
+ do { \
+ if ((x) < (y)) { \
+ MicroPrintf(#x " >= " #y " failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_LE(x, y) \
+ do { \
+ if ((x) > (y)) { \
+ MicroPrintf(#x " <= " #y " failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_TRUE(x) \
+ do { \
+ if (!(x)) { \
+ MicroPrintf(#x " was not true failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_FALSE(x) \
+ do { \
+ if (x) { \
+ MicroPrintf(#x " was not false failed at %s:%d", __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } while (false)
+
+#define TF_LITE_MICRO_FAIL(msg) \
+ do { \
+ MicroPrintf("FAIL: %s", msg, __FILE__, __LINE__); \
+ micro_test::did_test_fail = true; \
+ } while (false)
+
+#define TF_LITE_MICRO_EXPECT_STRING_EQ(string1, string2) \
+ do { \
+ for (int i = 0; string1[i] != '\0' && string2[i] != '\0'; i++) { \
+ if (string1[i] != string2[i]) { \
+ MicroPrintf("FAIL: %s did not match %s", string1, string2, __FILE__, \
+ __LINE__); \
+ micro_test::did_test_fail = true; \
+ } \
+ } \
+ } while (false)
+
+#endif // TENSORFLOW_LITE_MICRO_TESTING_MICRO_TEST_H_
diff --git a/tensorflow/lite/micro/testing/robot.resource.txt b/tensorflow/lite/micro/testing/robot.resource.txt
new file mode 100644
index 0000000..e06720c
--- /dev/null
+++ b/tensorflow/lite/micro/testing/robot.resource.txt
@@ -0,0 +1,26 @@
+*** Variables ***
+${UART} sysbus.cpu.uartSemihosting
+
+*** Keywords ***
+Teardown With Custom Message
+ Test Teardown
+ [Documentation] Replace robot fail message with whole UART output
+ ${UART_LOGS} Get File ${UART_LOG}
+ Set Test Message UART OUTPUT:\n\n${UART_LOGS}
+ Remove File ${UART_LOG}
+
+Create Platform
+ Execute Command $logfile=@${UART_LOG}
+ Execute Script ${RESC}
+ Provides ready-platform
+
+Test Binary
+ [Arguments] ${BIN}
+ Requires ready-platform
+ Execute Command sysbus LoadELF ${BIN}
+
+ Create Terminal Tester ${UART} timeout=2
+ Start Emulation
+
+ Wait For Line On Uart ${UART_LINE_ON_SUCCESS}
+
diff --git a/tensorflow/lite/micro/testing/sifive_fe310.resc b/tensorflow/lite/micro/testing/sifive_fe310.resc
new file mode 100644
index 0000000..676197c
--- /dev/null
+++ b/tensorflow/lite/micro/testing/sifive_fe310.resc
@@ -0,0 +1,35 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+:name: SiFive-FE310
+:description: This script runs Zephyr RTOS shell sample on SiFive-FE310 platform.
+
+$name?="SiFive-FE310"
+
+using sysbus
+mach create $name
+machine LoadPlatformDescription @platforms/cpus/sifive-fe310.repl
+
+$bin?=@/workspace/tensorflow/lite/micro/tools/make/gen/riscv32_mcu_riscv32_mcu/bin/micro_speech_test
+
+showAnalyzer uart0 Antmicro.Renode.Analyzers.LoggingUartAnalyzer
+logFile @/tmp/renode_riscv_log.txt
+
+sysbus LoadELF $bin
+
+sysbus Tag <0x10008000 4> "PRCI_HFROSCCFG" 0xFFFFFFFF
+sysbus Tag <0x10008008 4> "PRCI_PLLCFG" 0xFFFFFFFF
+
+cpu PerformanceInMips 320
diff --git a/tensorflow/lite/micro/testing/stm32f4.resc b/tensorflow/lite/micro/testing/stm32f4.resc
new file mode 100644
index 0000000..024c948
--- /dev/null
+++ b/tensorflow/lite/micro/testing/stm32f4.resc
@@ -0,0 +1,25 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+using sysbus
+
+mach create
+machine LoadPlatformDescription @platforms/cpus/stm32f4.repl
+
+# These lines are needed to show the results of DebugLog calls in the output.
+machine LoadPlatformDescriptionFromString "uartSemihosting: UART.SemihostingUart @ cpu"
+showAnalyzer cpu.uartSemihosting Antmicro.Renode.Analyzers.LoggingUartAnalyzer
+cpu.uartSemihosting CreateFileBackend $logfile true
+
diff --git a/tensorflow/lite/micro/testing/test_conv_model.cc b/tensorflow/lite/micro/testing/test_conv_model.cc
new file mode 100644
index 0000000..358479c
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_conv_model.cc
@@ -0,0 +1,1799 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/testing/test_conv_model.h"
+
+extern const unsigned char kTestConvModelData[] = {
+ 0x24, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x12, 0x00, 0x1c, 0x00, 0x04, 0x00,
+ 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00, 0x00, 0x00, 0x18, 0x00,
+ 0x12, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0xb4, 0x52, 0x00, 0x00,
+ 0x3c, 0x42, 0x00, 0x00, 0x24, 0x42, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x0c, 0x00, 0x04, 0x00, 0x08, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x13, 0x00, 0x00, 0x00,
+ 0x6d, 0x69, 0x6e, 0x5f, 0x72, 0x75, 0x6e, 0x74, 0x69, 0x6d, 0x65, 0x5f,
+ 0x76, 0x65, 0x72, 0x73, 0x69, 0x6f, 0x6e, 0x00, 0x0f, 0x00, 0x00, 0x00,
+ 0xd4, 0x41, 0x00, 0x00, 0xc0, 0x41, 0x00, 0x00, 0x64, 0x41, 0x00, 0x00,
+ 0xc0, 0x40, 0x00, 0x00, 0x7c, 0x40, 0x00, 0x00, 0x58, 0x40, 0x00, 0x00,
+ 0x44, 0x13, 0x00, 0x00, 0xa0, 0x12, 0x00, 0x00, 0x8c, 0x00, 0x00, 0x00,
+ 0x80, 0x00, 0x00, 0x00, 0x6c, 0x00, 0x00, 0x00, 0x58, 0x00, 0x00, 0x00,
+ 0x44, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0xd6, 0xbe, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x31, 0x2e, 0x35, 0x2e, 0x30, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x94, 0xb2, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xa4, 0xb2, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0xb4, 0xb2, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0xc4, 0xb2, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xd4, 0xb2, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x00, 0x46, 0xbf, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x12, 0x00, 0x00, 0x7d, 0x6a, 0x24, 0xa1, 0xf6, 0xca, 0x70, 0x2f,
+ 0x8e, 0xb1, 0xe8, 0x15, 0x42, 0x08, 0x32, 0xf6, 0xe9, 0xfb, 0xa0, 0xda,
+ 0xe4, 0xf1, 0x0a, 0x9d, 0x72, 0x66, 0x88, 0x37, 0xe9, 0x9e, 0x08, 0x54,
+ 0x61, 0x51, 0x40, 0x93, 0x4d, 0xcf, 0xe2, 0x08, 0x36, 0xad, 0xb1, 0x8e,
+ 0xfc, 0xe4, 0x02, 0xd1, 0x9a, 0x1e, 0x05, 0x67, 0xa3, 0x3b, 0xa6, 0xde,
+ 0x5d, 0x2a, 0xcc, 0x8c, 0x3c, 0x2e, 0xd2, 0x15, 0xc2, 0x60, 0xab, 0xea,
+ 0x73, 0xe4, 0x88, 0xc1, 0x66, 0x21, 0xb0, 0xe5, 0x5b, 0x55, 0xda, 0x69,
+ 0x2d, 0x0c, 0x66, 0x07, 0x74, 0x36, 0xcd, 0x79, 0x81, 0xf9, 0x5c, 0x2c,
+ 0xb5, 0x93, 0xab, 0x76, 0xa1, 0x1f, 0x20, 0x90, 0x89, 0xe1, 0x41, 0xc7,
+ 0x32, 0xc2, 0xa3, 0x03, 0x77, 0x86, 0x79, 0xf7, 0x89, 0xc1, 0xb1, 0x42,
+ 0x2a, 0x75, 0xc7, 0xc1, 0x2f, 0xbb, 0xf6, 0xe8, 0x23, 0x99, 0x9b, 0x74,
+ 0x9c, 0xe5, 0x91, 0x15, 0xc6, 0x08, 0x0e, 0xae, 0x7c, 0xd3, 0x27, 0x54,
+ 0xfb, 0xa7, 0x49, 0x65, 0x52, 0x2f, 0x63, 0x33, 0x8b, 0x5f, 0x67, 0x21,
+ 0x25, 0xe0, 0xcf, 0x95, 0x03, 0x05, 0x19, 0x0c, 0x3d, 0xfc, 0x95, 0x42,
+ 0xa9, 0x26, 0x27, 0x54, 0xa3, 0x71, 0xb4, 0x70, 0x7a, 0x40, 0x0d, 0xc1,
+ 0x72, 0x04, 0x81, 0x3b, 0xb9, 0xb7, 0xd2, 0xc1, 0x4e, 0xf8, 0xff, 0xca,
+ 0x66, 0xc1, 0xbe, 0xb9, 0x09, 0xbd, 0xb9, 0x2c, 0x5b, 0x97, 0xc3, 0xa8,
+ 0xf6, 0xc4, 0x23, 0x93, 0x2e, 0xf6, 0xce, 0x2e, 0xdb, 0xfb, 0x8f, 0xb0,
+ 0xc8, 0xba, 0xfa, 0x97, 0xfd, 0xc0, 0x0a, 0xc8, 0x2c, 0xf3, 0x4c, 0x4d,
+ 0x8b, 0x3b, 0x47, 0x11, 0xfb, 0xe8, 0x96, 0xe3, 0xcc, 0xef, 0xe4, 0xb5,
+ 0x07, 0xa1, 0xb7, 0xa9, 0xf7, 0x98, 0x71, 0x59, 0x9b, 0x5a, 0x7b, 0x88,
+ 0xe4, 0xcf, 0x9b, 0x55, 0x26, 0xce, 0x59, 0x73, 0x66, 0x17, 0x9c, 0x74,
+ 0x02, 0xfc, 0x24, 0x01, 0xde, 0x44, 0x98, 0xe3, 0x8b, 0x18, 0x02, 0x42,
+ 0xf5, 0x0f, 0xbc, 0xcb, 0xf7, 0x37, 0xb1, 0xd5, 0xb4, 0x7c, 0x0a, 0x6a,
+ 0x59, 0x59, 0xc9, 0x11, 0xd8, 0x0f, 0xf9, 0xab, 0x40, 0xdd, 0x14, 0xf9,
+ 0x30, 0xaa, 0xf1, 0x8c, 0x6d, 0xbc, 0x4c, 0x5b, 0x71, 0x95, 0xfd, 0x41,
+ 0x4c, 0xf3, 0xb4, 0x7f, 0x1c, 0xb6, 0x4b, 0x12, 0x3b, 0x6e, 0xc1, 0xce,
+ 0x6f, 0xf8, 0x57, 0xb7, 0x5e, 0x2a, 0x36, 0x32, 0x3d, 0x85, 0xc6, 0xbf,
+ 0xd7, 0xab, 0x95, 0x45, 0x62, 0xae, 0xb8, 0xa6, 0x03, 0xcc, 0x21, 0x25,
+ 0x18, 0x5a, 0xa8, 0x03, 0x27, 0x33, 0x47, 0xb1, 0x7e, 0x0e, 0xbd, 0xc3,
+ 0x24, 0x25, 0x78, 0x28, 0xa4, 0xe3, 0x5b, 0x08, 0xbf, 0x04, 0xa2, 0xae,
+ 0x90, 0x4c, 0x96, 0x78, 0xa8, 0xb1, 0xb8, 0x54, 0x89, 0x25, 0x2d, 0x35,
+ 0x93, 0x95, 0xa5, 0xd3, 0x1a, 0xe6, 0x00, 0x8b, 0xfe, 0x36, 0x0f, 0xd2,
+ 0x6e, 0xff, 0x86, 0x93, 0x48, 0xb8, 0x08, 0x39, 0x1f, 0x3a, 0x2d, 0xe7,
+ 0x47, 0x5e, 0x05, 0x66, 0x7a, 0xb8, 0xe4, 0xda, 0xbc, 0x5b, 0x57, 0xdf,
+ 0xd9, 0x0a, 0xb9, 0x48, 0x5d, 0x0c, 0x57, 0xed, 0x8d, 0xbb, 0x8d, 0x4b,
+ 0x0e, 0xb8, 0xea, 0x02, 0x06, 0x2f, 0xfd, 0x28, 0x0d, 0x0b, 0xf4, 0xf4,
+ 0x52, 0x81, 0x77, 0x15, 0x87, 0x53, 0x28, 0xef, 0xbe, 0xc6, 0x4c, 0x45,
+ 0x3e, 0x1a, 0x6e, 0xbd, 0x10, 0xd8, 0x9a, 0x72, 0x1f, 0x14, 0xe2, 0x37,
+ 0x08, 0xaf, 0xfa, 0xce, 0xd3, 0x84, 0x23, 0x43, 0x8c, 0x5c, 0xce, 0x1b,
+ 0xf7, 0xf3, 0xb0, 0x3b, 0xfd, 0x33, 0xf8, 0x09, 0xf1, 0x41, 0xa5, 0xa8,
+ 0x86, 0x8d, 0x56, 0xde, 0xf6, 0x68, 0xe3, 0x4c, 0x97, 0xa6, 0xc3, 0x66,
+ 0x9b, 0xa9, 0x8a, 0xbd, 0x59, 0x45, 0xfb, 0xdf, 0xa1, 0x42, 0x10, 0x1c,
+ 0x55, 0x22, 0x53, 0xe1, 0x32, 0x33, 0xf9, 0xfa, 0xc2, 0x70, 0x0f, 0x49,
+ 0x15, 0xa7, 0x21, 0xbc, 0x56, 0x35, 0x09, 0x06, 0xe6, 0x5e, 0xc4, 0xc1,
+ 0x64, 0x93, 0x59, 0x3b, 0x8e, 0xb7, 0x52, 0x6c, 0x4d, 0xa1, 0xb7, 0xee,
+ 0x14, 0xc2, 0x01, 0x25, 0xbb, 0x5e, 0xe0, 0xc6, 0xa4, 0x4f, 0xb5, 0x20,
+ 0x88, 0xe0, 0xd7, 0x5e, 0x26, 0x5b, 0x9f, 0xf7, 0xb5, 0x26, 0x5b, 0xfc,
+ 0xf3, 0x3e, 0xf3, 0x57, 0x6f, 0x9e, 0x9e, 0x51, 0x07, 0x6e, 0xc0, 0x53,
+ 0x17, 0x89, 0x79, 0xf0, 0x91, 0xb2, 0x54, 0x30, 0x1f, 0x97, 0x95, 0xfc,
+ 0x02, 0x2d, 0x0c, 0x06, 0xb0, 0x82, 0xad, 0x20, 0xc2, 0xdc, 0x78, 0xbc,
+ 0xbe, 0x5b, 0x88, 0xa0, 0xdd, 0x45, 0x49, 0x26, 0xec, 0xb4, 0xa5, 0x8b,
+ 0x7f, 0xdd, 0x40, 0xcf, 0x9e, 0xbe, 0x46, 0x4d, 0x36, 0xab, 0x0a, 0x34,
+ 0x1a, 0x2a, 0xd0, 0xd3, 0x83, 0x96, 0xff, 0x88, 0xa4, 0xd8, 0x48, 0x75,
+ 0x2f, 0xcb, 0x3c, 0xc3, 0xbb, 0xc7, 0x2f, 0xe9, 0xf9, 0xa3, 0xde, 0x9d,
+ 0xbb, 0x5e, 0x37, 0x29, 0xf6, 0x75, 0xcc, 0x85, 0xeb, 0xf9, 0x73, 0xf7,
+ 0xdc, 0x31, 0x8c, 0x56, 0x52, 0x4a, 0x44, 0xa4, 0x2a, 0x2a, 0x51, 0x49,
+ 0x77, 0x6d, 0x35, 0x0a, 0xf9, 0x44, 0xaa, 0x36, 0x05, 0xef, 0x1e, 0x6b,
+ 0xe5, 0x65, 0x6b, 0xaa, 0xc1, 0x41, 0x9c, 0x62, 0xd0, 0x70, 0x78, 0xff,
+ 0x88, 0xe8, 0x5f, 0x3c, 0x2e, 0x00, 0x6c, 0xe3, 0xdb, 0xc3, 0x54, 0x66,
+ 0xa9, 0xf4, 0xe2, 0x4c, 0x91, 0x11, 0xc8, 0x3c, 0x39, 0x9b, 0x31, 0x81,
+ 0xc7, 0x11, 0x22, 0x62, 0xb7, 0x26, 0xa0, 0x0c, 0x2e, 0x6c, 0xe7, 0x34,
+ 0x3b, 0x1f, 0x27, 0xb3, 0xe5, 0x4f, 0xc9, 0x71, 0xb2, 0x18, 0x99, 0x59,
+ 0x95, 0xc6, 0x35, 0x4c, 0x5d, 0xa3, 0x59, 0xd1, 0x8b, 0x71, 0xea, 0xe7,
+ 0x30, 0x3f, 0xe7, 0x8c, 0x1a, 0x59, 0xeb, 0xc5, 0x5d, 0xbd, 0xe6, 0x00,
+ 0x67, 0x02, 0xfb, 0xca, 0x8d, 0xdf, 0x71, 0xb6, 0xed, 0xc7, 0xd2, 0xf2,
+ 0x72, 0x1b, 0xd3, 0x63, 0x51, 0x1f, 0x04, 0xe9, 0xf9, 0xe2, 0x38, 0x13,
+ 0x48, 0x63, 0x19, 0x66, 0x2b, 0x48, 0xc8, 0x1b, 0x9d, 0x19, 0x5a, 0x57,
+ 0x44, 0x2d, 0x30, 0xb5, 0xce, 0x3b, 0xcc, 0xae, 0xc4, 0x5e, 0x4e, 0x96,
+ 0x62, 0x5c, 0x53, 0x1f, 0xbf, 0xbd, 0xc8, 0x9d, 0xcf, 0x81, 0xb3, 0x1e,
+ 0xb0, 0x22, 0xd5, 0xbe, 0x60, 0x65, 0xd9, 0xeb, 0x11, 0x74, 0x8c, 0x24,
+ 0x18, 0x67, 0x45, 0xd3, 0xf8, 0x3f, 0xc5, 0xdf, 0xac, 0x65, 0xd4, 0x0c,
+ 0x82, 0x63, 0xd6, 0x43, 0x94, 0xa0, 0x3b, 0xff, 0x03, 0x0f, 0xbb, 0xe4,
+ 0x4d, 0x3b, 0x41, 0x9f, 0xf4, 0x1a, 0xa9, 0xdb, 0x15, 0x5b, 0x9a, 0x92,
+ 0xcb, 0xd5, 0xb8, 0x33, 0x5e, 0xea, 0x28, 0x3d, 0x2d, 0x30, 0x20, 0xcd,
+ 0xb6, 0x23, 0x18, 0x0e, 0x10, 0x2a, 0xa9, 0xe1, 0xad, 0xbc, 0x96, 0xd1,
+ 0xf9, 0xf3, 0x95, 0x4f, 0x2a, 0x0b, 0x91, 0xff, 0xf0, 0x96, 0x14, 0x00,
+ 0xaa, 0xfb, 0x1a, 0x44, 0x21, 0x9b, 0xe8, 0x71, 0x31, 0x9e, 0xd6, 0x58,
+ 0x7f, 0x02, 0x36, 0x5e, 0x92, 0x8d, 0x93, 0x99, 0xac, 0xb6, 0x87, 0x39,
+ 0xda, 0x47, 0xef, 0x70, 0xd4, 0xf7, 0x8d, 0x2a, 0xbd, 0x08, 0x40, 0x4d,
+ 0xec, 0xeb, 0x4e, 0x1b, 0x85, 0x5d, 0x55, 0x64, 0x4c, 0xf3, 0x5e, 0x8f,
+ 0x68, 0x1e, 0x5e, 0x64, 0xc3, 0xb8, 0x92, 0x24, 0x41, 0x98, 0x78, 0x09,
+ 0x85, 0x87, 0x17, 0x2c, 0x88, 0x9e, 0x62, 0x86, 0x4f, 0x44, 0x71, 0x9c,
+ 0xa8, 0x73, 0xb3, 0x14, 0x1f, 0x3c, 0x96, 0x6b, 0xab, 0xad, 0x43, 0xdf,
+ 0x67, 0x34, 0x66, 0x30, 0x1d, 0x15, 0xd3, 0xe7, 0xd5, 0x8b, 0x00, 0xaa,
+ 0x11, 0x77, 0xea, 0x36, 0xc9, 0x49, 0x99, 0x93, 0x01, 0x6e, 0x00, 0x4a,
+ 0x93, 0x08, 0x2c, 0x44, 0x01, 0x91, 0xe0, 0x91, 0xdd, 0xab, 0x70, 0x4b,
+ 0xe7, 0xbf, 0x2d, 0x0f, 0xd4, 0x52, 0xa0, 0xf1, 0x5d, 0xa0, 0xcc, 0xb9,
+ 0x1b, 0xa2, 0x62, 0xeb, 0x23, 0x1e, 0x8e, 0xbb, 0x2b, 0xb6, 0xc5, 0x3a,
+ 0xdf, 0x32, 0x99, 0xde, 0x2e, 0x94, 0xcf, 0x98, 0x99, 0x34, 0x59, 0x60,
+ 0xcf, 0x57, 0xe0, 0xb0, 0xd9, 0x89, 0xaa, 0xc2, 0x4f, 0x1e, 0x38, 0x88,
+ 0xca, 0x32, 0x93, 0x9b, 0xa3, 0x2b, 0x17, 0x0b, 0x40, 0x5e, 0x69, 0xbd,
+ 0x14, 0x15, 0xca, 0x1a, 0x21, 0xdf, 0xa8, 0x4e, 0x14, 0x5e, 0x18, 0x40,
+ 0xe3, 0x4e, 0x04, 0x1f, 0xe5, 0x81, 0x53, 0x11, 0xae, 0x5e, 0x30, 0xe5,
+ 0xda, 0xd7, 0xf1, 0x3b, 0x72, 0x1b, 0xa5, 0xe3, 0x13, 0xad, 0x40, 0x54,
+ 0xae, 0xf0, 0xbc, 0x2b, 0xc1, 0x1a, 0x9c, 0xdd, 0xe1, 0xd0, 0x12, 0x10,
+ 0xfd, 0x59, 0xce, 0x36, 0x60, 0x86, 0xa0, 0xa7, 0xee, 0xe1, 0x02, 0xe6,
+ 0xf8, 0xf0, 0x5c, 0x4f, 0xa3, 0xa4, 0xe4, 0x09, 0xb9, 0xc3, 0x84, 0xe3,
+ 0x8d, 0x97, 0x21, 0x62, 0xf3, 0x11, 0x47, 0xb1, 0x4a, 0xce, 0x5b, 0x89,
+ 0xde, 0x86, 0xb5, 0x0e, 0xba, 0xbc, 0x8c, 0xcf, 0x54, 0x38, 0x3a, 0xc6,
+ 0xaf, 0x8c, 0x4d, 0x9d, 0xff, 0x58, 0x9b, 0xe8, 0x32, 0xb7, 0xa2, 0x29,
+ 0xad, 0x91, 0x3a, 0xa5, 0xc7, 0x54, 0xff, 0xd8, 0x47, 0x4f, 0x8f, 0x38,
+ 0x91, 0x12, 0x76, 0xa3, 0x2e, 0xf7, 0xdd, 0xba, 0xa7, 0xd4, 0x49, 0xe5,
+ 0xd1, 0x74, 0xe9, 0x2a, 0x29, 0xe4, 0x64, 0xb9, 0x58, 0x98, 0x0c, 0xe5,
+ 0x1f, 0xb2, 0x0e, 0x33, 0xea, 0xf8, 0x2e, 0xb1, 0x22, 0x46, 0xc2, 0x67,
+ 0x2d, 0xfe, 0x2e, 0xd3, 0xcf, 0xbc, 0x64, 0x7b, 0x75, 0x24, 0x53, 0x1c,
+ 0x42, 0x8c, 0x0b, 0x99, 0x9e, 0xa7, 0xa6, 0xb9, 0xfb, 0x5d, 0x86, 0x9f,
+ 0xe9, 0x04, 0x62, 0xb2, 0x42, 0x81, 0xa2, 0x0d, 0x60, 0x83, 0x40, 0xbb,
+ 0x21, 0x10, 0xdf, 0xaa, 0xe6, 0x6c, 0x72, 0xc5, 0xb1, 0xad, 0x9f, 0xd2,
+ 0x91, 0xf8, 0xb6, 0x56, 0xfb, 0x2e, 0xb3, 0xc4, 0x12, 0xd9, 0x86, 0x29,
+ 0x6c, 0x55, 0x88, 0x72, 0xba, 0xfb, 0x9b, 0xb9, 0x6f, 0x2d, 0x7d, 0x75,
+ 0xd0, 0x9d, 0xaf, 0x44, 0xb6, 0xbd, 0x7b, 0xec, 0x78, 0xf1, 0xbf, 0x66,
+ 0xe8, 0x79, 0x66, 0x16, 0x5e, 0xf9, 0x68, 0x89, 0x5b, 0xde, 0x8f, 0xf9,
+ 0xeb, 0x04, 0x0b, 0x6a, 0x71, 0xa1, 0x3b, 0x46, 0x03, 0xb4, 0x29, 0xa9,
+ 0x31, 0xf4, 0xc5, 0xd3, 0x43, 0x6d, 0x88, 0x43, 0xa8, 0xef, 0xb7, 0xd7,
+ 0x75, 0x6b, 0x83, 0x35, 0xb6, 0x2f, 0xe0, 0x5f, 0xf2, 0x14, 0xcd, 0xd0,
+ 0x06, 0xb3, 0x5e, 0x8b, 0xdb, 0x86, 0x11, 0x94, 0x2f, 0xfb, 0x92, 0x19,
+ 0x52, 0x7f, 0xcb, 0xe5, 0x22, 0x27, 0x5f, 0xe4, 0x68, 0xb2, 0xcb, 0xc7,
+ 0xb8, 0xec, 0xfd, 0x9e, 0x39, 0x9c, 0x5b, 0xe4, 0xae, 0xca, 0x83, 0x19,
+ 0xcf, 0xf0, 0x01, 0xe3, 0xfc, 0xb0, 0x28, 0xda, 0x79, 0x84, 0xfb, 0xfe,
+ 0xa5, 0xb6, 0xb3, 0xd2, 0x73, 0xd3, 0x11, 0xe5, 0xdf, 0x7a, 0xd7, 0x82,
+ 0x78, 0x25, 0x06, 0x5b, 0x0f, 0x89, 0x9d, 0x0b, 0x9b, 0xd1, 0x1b, 0xc5,
+ 0xb7, 0x67, 0xef, 0x7c, 0xa2, 0xa3, 0xca, 0x27, 0xd0, 0x59, 0xb9, 0x99,
+ 0x86, 0xa9, 0xf6, 0x9a, 0x28, 0xf0, 0xbb, 0x42, 0xd2, 0xa0, 0xa8, 0x01,
+ 0x29, 0xa1, 0x0c, 0x1b, 0x33, 0x1b, 0x9c, 0xcb, 0xe4, 0x6c, 0x61, 0x0a,
+ 0xc4, 0xd7, 0x6c, 0xec, 0x86, 0xb3, 0xd2, 0xaa, 0x8c, 0xab, 0x1a, 0xf4,
+ 0x03, 0x2e, 0x2b, 0x42, 0xbe, 0xc1, 0x31, 0x1d, 0x57, 0x47, 0xdc, 0x7b,
+ 0xb5, 0x8f, 0x8b, 0xdf, 0x06, 0xad, 0x3f, 0xf4, 0x4f, 0xb5, 0x52, 0x07,
+ 0x4e, 0x25, 0xb3, 0x73, 0x34, 0x92, 0x6a, 0x89, 0x93, 0x28, 0x8b, 0x96,
+ 0x9d, 0xdb, 0xb4, 0x77, 0x81, 0x76, 0x86, 0xd2, 0xa5, 0x94, 0x76, 0x35,
+ 0xc9, 0x66, 0x4e, 0xd8, 0xc5, 0xc3, 0xc9, 0x34, 0xaf, 0xad, 0x4a, 0x7c,
+ 0x92, 0x24, 0xb1, 0x7d, 0x7d, 0xac, 0xf6, 0xcb, 0x8f, 0x36, 0xc1, 0xb2,
+ 0x63, 0x78, 0x99, 0x33, 0x23, 0x68, 0x6e, 0x71, 0x6a, 0xcc, 0x05, 0xf9,
+ 0x41, 0x92, 0x30, 0xf0, 0xb1, 0xb4, 0xa6, 0x46, 0x86, 0x62, 0xd9, 0xd9,
+ 0x94, 0x8a, 0xb2, 0x9c, 0x68, 0xff, 0xf4, 0x3a, 0x2e, 0xaf, 0xee, 0xcf,
+ 0x04, 0x94, 0x53, 0x35, 0x25, 0xf9, 0xaa, 0x74, 0x93, 0xf3, 0x63, 0xc0,
+ 0xd2, 0x22, 0x30, 0x8c, 0xde, 0xa6, 0xb1, 0xb4, 0xa1, 0x56, 0x07, 0x06,
+ 0x71, 0xa2, 0x9e, 0x42, 0x31, 0xa3, 0x1e, 0xa6, 0x9a, 0xbc, 0x9f, 0x5b,
+ 0x12, 0x3c, 0xc2, 0x74, 0xf9, 0x61, 0x71, 0xef, 0x73, 0x86, 0xc2, 0x3b,
+ 0x25, 0x8a, 0x31, 0x72, 0x27, 0xac, 0xa4, 0x72, 0xf3, 0xbb, 0x78, 0x2c,
+ 0x94, 0xed, 0xa8, 0x3a, 0x42, 0x98, 0x34, 0xda, 0x3e, 0x60, 0x1c, 0x4a,
+ 0xec, 0x6b, 0x4e, 0x5f, 0x2a, 0x62, 0xb9, 0xad, 0xc9, 0xd9, 0x38, 0x90,
+ 0xa7, 0x3b, 0xd3, 0x1a, 0xbb, 0x81, 0x0d, 0x33, 0xd9, 0x16, 0x35, 0x8e,
+ 0xc3, 0x88, 0x36, 0xfa, 0x3e, 0xa8, 0x4f, 0x30, 0x9d, 0xf1, 0x08, 0xea,
+ 0x40, 0x1b, 0x87, 0x4d, 0x23, 0x8e, 0x8e, 0xb0, 0xe2, 0xf0, 0x27, 0xc1,
+ 0xdc, 0x0d, 0xe2, 0x8f, 0x93, 0xef, 0x8b, 0xd1, 0x19, 0xa5, 0xbe, 0xd7,
+ 0x5a, 0x8a, 0x38, 0x62, 0x43, 0xba, 0x74, 0xf8, 0xae, 0x11, 0x1f, 0x1d,
+ 0xa4, 0x6e, 0x70, 0x94, 0x91, 0x14, 0xf4, 0xff, 0xbe, 0x39, 0xb4, 0x33,
+ 0xc2, 0x87, 0x74, 0x1b, 0xfd, 0x9a, 0xa8, 0x64, 0x09, 0x4b, 0x7f, 0x95,
+ 0x0a, 0xcb, 0x6b, 0x15, 0x54, 0x1d, 0xc6, 0x03, 0x1d, 0x1b, 0x25, 0x56,
+ 0x15, 0xb5, 0xd7, 0xe5, 0xd6, 0xf3, 0x28, 0xa4, 0xde, 0x1b, 0x39, 0x0d,
+ 0x59, 0x26, 0x12, 0xe4, 0x32, 0xf2, 0x25, 0xeb, 0xc0, 0xdb, 0x58, 0xe5,
+ 0xce, 0x64, 0x6f, 0x70, 0x74, 0xc1, 0xc9, 0xbd, 0x75, 0xef, 0x16, 0x02,
+ 0xdf, 0x27, 0x09, 0xc8, 0xb8, 0x37, 0x8f, 0x44, 0x0d, 0x58, 0x48, 0xf5,
+ 0xc2, 0x53, 0x21, 0x28, 0x16, 0xa4, 0x56, 0x02, 0xdf, 0xa7, 0x97, 0xa4,
+ 0x5c, 0x48, 0x75, 0x51, 0x89, 0x0b, 0xa7, 0x4d, 0xd9, 0x9e, 0x04, 0x4e,
+ 0x5d, 0x6c, 0xe5, 0x1f, 0x68, 0x88, 0xcc, 0xb7, 0x9a, 0x20, 0x05, 0x83,
+ 0x82, 0x6c, 0xfd, 0xdb, 0x07, 0x6c, 0xec, 0x61, 0xaa, 0x36, 0x57, 0x68,
+ 0x01, 0xf2, 0x70, 0xfe, 0xe6, 0x4d, 0xe1, 0xa9, 0xb6, 0xb6, 0x52, 0xe6,
+ 0x20, 0x52, 0x0f, 0x27, 0x9a, 0x1c, 0x2d, 0x20, 0x9b, 0xd4, 0x07, 0xd3,
+ 0xf6, 0x85, 0x4b, 0xf2, 0x52, 0x4d, 0x4c, 0xd7, 0xf0, 0x32, 0x5d, 0x2e,
+ 0xef, 0xa2, 0xd0, 0xcd, 0x48, 0x89, 0xbc, 0x9f, 0xcb, 0x37, 0x02, 0x29,
+ 0xa5, 0xdb, 0xab, 0xfa, 0x1d, 0xf4, 0x53, 0x78, 0x30, 0xde, 0x2c, 0x5c,
+ 0x35, 0x7f, 0x3d, 0xe1, 0xe0, 0xce, 0xdb, 0x13, 0xca, 0x2a, 0xae, 0xdf,
+ 0x1c, 0xb1, 0xb6, 0xb9, 0x6a, 0x9f, 0x28, 0xb0, 0x54, 0x5a, 0x00, 0xdd,
+ 0x76, 0x14, 0xfb, 0x17, 0xc2, 0x2a, 0x45, 0xa2, 0x18, 0xbb, 0x8a, 0x3e,
+ 0xbe, 0x0e, 0xa5, 0x1b, 0x3c, 0x70, 0x56, 0x10, 0x98, 0xec, 0xc6, 0x3a,
+ 0x95, 0x2a, 0x96, 0x6a, 0x44, 0xef, 0xd9, 0x9c, 0x2a, 0x45, 0xb4, 0x15,
+ 0xf8, 0x2e, 0x03, 0x5d, 0x8c, 0x79, 0xfb, 0xb0, 0x53, 0x71, 0xcd, 0x0d,
+ 0xf4, 0xe2, 0xfc, 0x3b, 0x71, 0xee, 0x30, 0xf2, 0x29, 0xd3, 0xaa, 0x18,
+ 0x7a, 0x45, 0x1d, 0x99, 0x6d, 0x2f, 0x1f, 0x2d, 0x32, 0x23, 0x48, 0xc2,
+ 0x69, 0x33, 0x3d, 0x04, 0xa7, 0xa3, 0x96, 0xb5, 0x76, 0x5b, 0x4e, 0xb7,
+ 0x3c, 0x10, 0x58, 0x17, 0xf4, 0x5f, 0xec, 0x51, 0x6d, 0x5a, 0x3b, 0x7f,
+ 0x1e, 0x0e, 0xbb, 0xbf, 0x77, 0x43, 0xf7, 0xa4, 0x57, 0xc0, 0x33, 0xac,
+ 0xc1, 0xe3, 0x3e, 0x1f, 0x65, 0x3c, 0x62, 0x19, 0x46, 0x2d, 0x7b, 0x2d,
+ 0x07, 0x44, 0x48, 0xf4, 0x91, 0xdf, 0x59, 0x32, 0x10, 0xf7, 0x12, 0xe2,
+ 0xe5, 0x39, 0x70, 0x37, 0xa4, 0x79, 0x9a, 0x17, 0x19, 0xe8, 0x90, 0xe7,
+ 0x37, 0x0d, 0xb6, 0x6d, 0x58, 0xe6, 0x7e, 0x57, 0x76, 0x8a, 0xe8, 0xd0,
+ 0x76, 0x30, 0x25, 0xda, 0xb6, 0xdf, 0x59, 0x3c, 0x6c, 0x20, 0x65, 0x88,
+ 0xd2, 0x60, 0x5e, 0x39, 0xb6, 0x6b, 0xac, 0xa2, 0x25, 0xc6, 0xa7, 0xb1,
+ 0x2f, 0xbb, 0x1d, 0x23, 0xee, 0x02, 0x08, 0x1d, 0xd6, 0x6c, 0x0e, 0xbc,
+ 0xea, 0xd2, 0xc2, 0x70, 0x34, 0xe9, 0x96, 0xd3, 0xf3, 0xf4, 0x8e, 0x94,
+ 0x6f, 0x86, 0x76, 0xe7, 0x38, 0x08, 0x6f, 0x47, 0xf5, 0xcd, 0xab, 0xad,
+ 0x7a, 0x39, 0x10, 0x9a, 0xa8, 0x44, 0xba, 0x2d, 0x7f, 0x05, 0x1e, 0xb7,
+ 0x44, 0xd8, 0x10, 0x05, 0xd1, 0x8d, 0x98, 0x09, 0x14, 0xbb, 0x6b, 0x2b,
+ 0xf7, 0xeb, 0x9f, 0xa5, 0x65, 0x4b, 0x21, 0xff, 0xaf, 0xe8, 0x2e, 0x34,
+ 0x52, 0x38, 0xcf, 0xd5, 0x51, 0x29, 0x2c, 0x91, 0x43, 0x3a, 0x49, 0x42,
+ 0xdd, 0xfb, 0x0e, 0xd2, 0x77, 0x8f, 0x65, 0x93, 0x3e, 0x52, 0x22, 0x58,
+ 0xd6, 0xf9, 0xd9, 0x58, 0xd4, 0x06, 0xa9, 0x0c, 0x79, 0x9f, 0x1b, 0xa5,
+ 0x45, 0x61, 0xd8, 0x4e, 0xbf, 0x4b, 0x51, 0xe2, 0xfb, 0x6f, 0x58, 0xee,
+ 0xc5, 0xa5, 0x11, 0xbd, 0x99, 0x25, 0x14, 0xac, 0x94, 0x0e, 0xd1, 0xf7,
+ 0x54, 0xb6, 0x05, 0x8c, 0xc3, 0x57, 0xa5, 0x3c, 0x3c, 0xa6, 0x83, 0x47,
+ 0x38, 0xd1, 0x6a, 0xab, 0x12, 0xc0, 0xd3, 0x7f, 0x96, 0x55, 0xd7, 0xf4,
+ 0x3a, 0xd0, 0x08, 0x85, 0x5f, 0x3d, 0x65, 0x8e, 0xbb, 0xea, 0x34, 0xf3,
+ 0x53, 0x96, 0x71, 0x08, 0x9b, 0x50, 0xe9, 0x4b, 0xce, 0x8a, 0x2f, 0xef,
+ 0xe4, 0xb2, 0x72, 0x68, 0xcb, 0x88, 0xa8, 0xd9, 0xd9, 0xa2, 0xfc, 0x62,
+ 0xe8, 0x8b, 0x23, 0x2b, 0xbc, 0xf0, 0x9e, 0xb4, 0xd0, 0x40, 0x8b, 0x45,
+ 0xff, 0x6d, 0x37, 0x01, 0xa6, 0x4b, 0x62, 0xe0, 0x3b, 0x4e, 0x18, 0x67,
+ 0xb3, 0x97, 0x04, 0xa0, 0x2a, 0xf2, 0x11, 0x79, 0x38, 0xb4, 0xb2, 0xed,
+ 0x64, 0xc1, 0x1e, 0xfe, 0xc4, 0xf4, 0xe2, 0x4d, 0x94, 0xb4, 0x17, 0x52,
+ 0x1a, 0x63, 0xe6, 0x56, 0x8a, 0x41, 0x0a, 0x5b, 0xa2, 0x1c, 0x59, 0xef,
+ 0x17, 0x64, 0xf9, 0xf7, 0x2c, 0xa4, 0xfd, 0x66, 0xf7, 0xe3, 0xae, 0xa0,
+ 0x54, 0x36, 0x64, 0x26, 0x84, 0x51, 0x49, 0xd5, 0x3a, 0x5e, 0x2c, 0xc5,
+ 0xca, 0xde, 0x8e, 0xe7, 0x25, 0x59, 0xb3, 0x9a, 0xb2, 0xf0, 0xff, 0xf1,
+ 0x83, 0xe5, 0x70, 0xc3, 0xef, 0x63, 0x66, 0x31, 0x04, 0x4d, 0x42, 0xf1,
+ 0xd9, 0x4c, 0x5e, 0x29, 0x92, 0x37, 0x8d, 0xd1, 0x18, 0x2a, 0x9e, 0x3c,
+ 0xcc, 0x05, 0xb9, 0xc4, 0xb6, 0xe7, 0x2a, 0x09, 0x3a, 0x68, 0xb5, 0x61,
+ 0x60, 0x36, 0x11, 0x02, 0x92, 0xf8, 0xa0, 0x56, 0x9b, 0xe8, 0xfe, 0xac,
+ 0x87, 0xcc, 0xaf, 0xb9, 0x62, 0xa7, 0x1e, 0x99, 0xb8, 0x9f, 0x47, 0xf7,
+ 0xa5, 0x12, 0x47, 0x66, 0xeb, 0xd6, 0x3a, 0x6f, 0xb3, 0x26, 0x63, 0xe2,
+ 0xec, 0x0c, 0xba, 0x7d, 0xc2, 0x9b, 0xb2, 0x10, 0x62, 0x03, 0x3f, 0x20,
+ 0xed, 0x7a, 0xce, 0x47, 0xd0, 0x50, 0x5b, 0x5c, 0x66, 0xbf, 0x01, 0x09,
+ 0x84, 0x0b, 0x71, 0xa8, 0x1f, 0x8d, 0xe1, 0x05, 0x09, 0xb4, 0xd5, 0x34,
+ 0xf1, 0xba, 0x31, 0xc6, 0x76, 0x8e, 0x00, 0x96, 0x3d, 0x6b, 0xe4, 0x66,
+ 0x3a, 0x22, 0xcd, 0x7f, 0x9d, 0xf8, 0x64, 0xfc, 0x76, 0x42, 0x88, 0x0e,
+ 0x32, 0xa5, 0xd0, 0x69, 0x56, 0xe2, 0xa5, 0x6f, 0xbb, 0xfa, 0xd8, 0xde,
+ 0xb4, 0x23, 0xa9, 0xc7, 0x9a, 0xc1, 0x99, 0xa7, 0x7f, 0x79, 0x58, 0xe1,
+ 0xe7, 0xc5, 0x56, 0x36, 0xc0, 0xfb, 0x8d, 0x8f, 0xe4, 0x6c, 0x96, 0x89,
+ 0xcb, 0xb0, 0xb0, 0x6e, 0xee, 0x20, 0x46, 0xd3, 0x43, 0x83, 0xac, 0x39,
+ 0x7c, 0x25, 0xba, 0x69, 0x3a, 0x58, 0x8a, 0x48, 0x0a, 0xf7, 0xb7, 0xfc,
+ 0x58, 0x7b, 0x93, 0x8b, 0xcd, 0x81, 0x7e, 0x94, 0xe0, 0xdf, 0xb1, 0xca,
+ 0xf6, 0x60, 0x54, 0xa9, 0x6e, 0xc6, 0x7f, 0xac, 0xfb, 0x62, 0xfe, 0xd9,
+ 0xd5, 0xf4, 0x6c, 0x62, 0x65, 0xf6, 0x0b, 0x24, 0x49, 0x1d, 0x55, 0xd6,
+ 0x4c, 0x0b, 0x5a, 0xf1, 0x2e, 0x78, 0x7a, 0x4e, 0xc1, 0xd0, 0xdb, 0xfe,
+ 0xd2, 0x84, 0x60, 0x68, 0x51, 0x8e, 0x3f, 0xf1, 0xa8, 0x90, 0xbf, 0xda,
+ 0x86, 0xda, 0x41, 0xd8, 0x90, 0x7b, 0xc3, 0xc8, 0x9e, 0xa5, 0x77, 0x06,
+ 0x56, 0x02, 0x13, 0x59, 0xaa, 0x89, 0xf9, 0xd5, 0x3c, 0x1d, 0xe2, 0xa9,
+ 0xb1, 0xc8, 0x02, 0x5a, 0x1c, 0xae, 0x72, 0x66, 0xdf, 0xb4, 0x1a, 0xb7,
+ 0xd2, 0x4d, 0xda, 0x4f, 0xc9, 0xed, 0x88, 0x7d, 0x9b, 0xc4, 0x4a, 0x8c,
+ 0x5e, 0x77, 0xaf, 0xd6, 0xd3, 0xbb, 0x38, 0xd2, 0xfa, 0x85, 0xe4, 0xdd,
+ 0xe7, 0x6e, 0xcb, 0x0b, 0x34, 0x1e, 0xa8, 0xfd, 0xf4, 0xd2, 0xc3, 0xdd,
+ 0xe0, 0xa6, 0xb1, 0x78, 0x16, 0x85, 0x2b, 0x1b, 0x22, 0xa6, 0xd5, 0x93,
+ 0x4f, 0xa1, 0xd5, 0x10, 0x96, 0xab, 0x38, 0xa7, 0x3c, 0xf2, 0xbd, 0xd9,
+ 0x7c, 0x59, 0x71, 0x25, 0x6f, 0x7c, 0xce, 0x73, 0x8e, 0x4e, 0xfb, 0x5a,
+ 0x30, 0x24, 0x53, 0xc5, 0xa3, 0x20, 0x13, 0x03, 0xfc, 0x7a, 0xaf, 0x1f,
+ 0x71, 0x5d, 0x6b, 0xce, 0x2e, 0x92, 0x16, 0x4d, 0xab, 0x96, 0x10, 0xc0,
+ 0xf6, 0x3c, 0xfe, 0x51, 0x89, 0x4d, 0x39, 0x45, 0x2c, 0x92, 0x5a, 0x86,
+ 0x24, 0xce, 0xbc, 0x75, 0xc6, 0x7f, 0x0e, 0xc2, 0xd1, 0xe7, 0x6a, 0x75,
+ 0x30, 0x59, 0xfb, 0xbf, 0x6b, 0xcf, 0x60, 0x90, 0x07, 0x73, 0xb1, 0x47,
+ 0x6e, 0x5d, 0xcd, 0x44, 0xac, 0xee, 0x2a, 0xdb, 0x16, 0x5a, 0x1a, 0xaf,
+ 0xba, 0xf8, 0x64, 0xdd, 0xdd, 0xed, 0x46, 0x4b, 0x67, 0xf3, 0xf8, 0x2d,
+ 0x22, 0xe9, 0x25, 0x74, 0x4c, 0x70, 0xe0, 0x3d, 0xbc, 0x11, 0xd3, 0x56,
+ 0xec, 0x86, 0x39, 0x89, 0x4c, 0xf2, 0xbc, 0x39, 0xdc, 0xde, 0x5f, 0x3b,
+ 0x42, 0xcb, 0xf6, 0x0c, 0x49, 0x8c, 0x66, 0x76, 0x58, 0x28, 0xe8, 0x47,
+ 0x59, 0x40, 0x11, 0xef, 0xb5, 0x9d, 0x93, 0xe5, 0x39, 0x56, 0x62, 0x0d,
+ 0xd0, 0xdd, 0xbb, 0x51, 0xff, 0x87, 0xa3, 0xd1, 0x9e, 0x0e, 0x0c, 0xbd,
+ 0x8e, 0xfc, 0xa5, 0x44, 0xc7, 0x6d, 0x35, 0x1d, 0x69, 0x14, 0x5b, 0x0d,
+ 0x45, 0xff, 0x85, 0x2d, 0xd1, 0x14, 0xf4, 0x5e, 0x5b, 0x49, 0x85, 0xad,
+ 0x69, 0xf1, 0x34, 0x9e, 0x7a, 0xf3, 0xed, 0x2d, 0xf2, 0x5f, 0x70, 0x5a,
+ 0xc1, 0xca, 0x63, 0xb5, 0xec, 0x49, 0xfc, 0x88, 0xcb, 0x0f, 0x81, 0x1d,
+ 0xd4, 0x2f, 0x18, 0xf6, 0xfe, 0x71, 0x51, 0xe2, 0x25, 0x71, 0x48, 0xa4,
+ 0xb2, 0x9f, 0x4f, 0xc0, 0xa5, 0x24, 0x12, 0x5b, 0xf8, 0xf2, 0xcf, 0x6e,
+ 0x52, 0x52, 0x6a, 0xee, 0x7d, 0xa5, 0x9b, 0xdb, 0x9c, 0xc9, 0x35, 0x30,
+ 0x1a, 0xf0, 0x7d, 0xcc, 0x98, 0x73, 0x09, 0x16, 0x8c, 0x05, 0x8d, 0x70,
+ 0xa3, 0x15, 0xd6, 0x7a, 0xa0, 0x7c, 0xd5, 0xcc, 0xd3, 0x29, 0x32, 0x2e,
+ 0xa5, 0xde, 0xf6, 0xd3, 0xa4, 0x03, 0x59, 0x6c, 0x05, 0x2d, 0x0e, 0x8b,
+ 0xb7, 0x1f, 0xa0, 0x57, 0x5c, 0x76, 0xde, 0x81, 0xcb, 0x64, 0xb9, 0x73,
+ 0xc1, 0x3b, 0x26, 0xba, 0x16, 0xdb, 0xe6, 0x40, 0x23, 0xa4, 0xe9, 0x24,
+ 0x48, 0xb8, 0x73, 0x23, 0x67, 0xbf, 0x26, 0xca, 0x95, 0x4f, 0xa0, 0x60,
+ 0x95, 0xa2, 0x0f, 0x29, 0xed, 0x5d, 0x71, 0x66, 0x94, 0xa3, 0xd0, 0x2a,
+ 0x4e, 0x17, 0x32, 0x18, 0xe6, 0xd6, 0x75, 0x84, 0xa5, 0x2a, 0x72, 0x18,
+ 0x60, 0x85, 0xde, 0x66, 0x22, 0x52, 0xf6, 0x45, 0xd6, 0xf0, 0xed, 0x93,
+ 0x0f, 0x5a, 0xa9, 0x12, 0x2a, 0xc4, 0xa8, 0x3d, 0x97, 0xc9, 0xc7, 0x84,
+ 0x71, 0x14, 0xb3, 0x54, 0xb6, 0xf7, 0x92, 0x7a, 0xc0, 0x6e, 0x02, 0xf7,
+ 0x48, 0xdb, 0x7c, 0xc1, 0x45, 0x21, 0xdb, 0x1b, 0x51, 0xc3, 0xea, 0xc0,
+ 0x19, 0x31, 0xe4, 0x6c, 0x20, 0x5f, 0x08, 0xe7, 0x88, 0xf7, 0xc0, 0x6e,
+ 0xee, 0x5f, 0x20, 0x33, 0x68, 0xef, 0xc5, 0x33, 0x1b, 0x40, 0x66, 0xc5,
+ 0xa3, 0x68, 0xdb, 0xbc, 0x8a, 0xb7, 0x54, 0xdb, 0xc7, 0xc5, 0x2c, 0x42,
+ 0x65, 0x51, 0xab, 0x56, 0x94, 0x73, 0xec, 0xd9, 0x95, 0xfa, 0x6a, 0x56,
+ 0xef, 0x22, 0x95, 0xa4, 0x75, 0x46, 0xee, 0x60, 0x8b, 0x25, 0xa6, 0x92,
+ 0x0a, 0x8e, 0xc1, 0x39, 0x97, 0x69, 0xa9, 0x19, 0x97, 0xf1, 0x0f, 0x61,
+ 0xc2, 0x40, 0x7d, 0x62, 0xe9, 0x5e, 0x22, 0x1f, 0x27, 0xe5, 0xc7, 0xe7,
+ 0xa4, 0x35, 0x5d, 0x90, 0xc7, 0x38, 0x38, 0x2d, 0xb0, 0x1e, 0x29, 0x0f,
+ 0x4f, 0x08, 0x8b, 0xdd, 0x69, 0x3c, 0x5c, 0x03, 0xbe, 0x9a, 0x76, 0xba,
+ 0x91, 0xf5, 0x57, 0x07, 0x39, 0xfe, 0x09, 0xfc, 0x01, 0x7b, 0x37, 0xc4,
+ 0x73, 0x7f, 0x76, 0x50, 0x76, 0xae, 0x6e, 0x4b, 0x22, 0x2c, 0x3b, 0xe7,
+ 0x77, 0x19, 0x9a, 0x92, 0x26, 0xdf, 0xc4, 0xe6, 0xd8, 0x57, 0xc1, 0x7f,
+ 0x65, 0x0b, 0xfb, 0xfa, 0xdd, 0xd2, 0x8c, 0xc7, 0xb1, 0x72, 0x2a, 0xb2,
+ 0x5a, 0xfa, 0xb2, 0x84, 0xb1, 0xec, 0x79, 0x9e, 0xde, 0xd8, 0x2f, 0xdf,
+ 0x3b, 0x39, 0x0b, 0xac, 0xfa, 0xb8, 0x07, 0x38, 0xff, 0x2e, 0x22, 0x2b,
+ 0xc9, 0x31, 0x3b, 0x09, 0x05, 0xd2, 0x06, 0xc4, 0x2d, 0x22, 0x1c, 0x21,
+ 0x70, 0x03, 0x93, 0xd1, 0x3a, 0x8d, 0x94, 0x60, 0xfe, 0x99, 0x13, 0xc3,
+ 0x00, 0x03, 0x41, 0xfa, 0x50, 0x79, 0x31, 0xeb, 0xf0, 0xf4, 0x06, 0x7a,
+ 0x19, 0xe8, 0x90, 0xdf, 0x61, 0x4d, 0x5f, 0xe3, 0x99, 0x1b, 0xca, 0xbf,
+ 0xcf, 0xae, 0xca, 0xfa, 0x84, 0x63, 0x88, 0x56, 0x1d, 0x52, 0x5a, 0x21,
+ 0xf9, 0xcd, 0xa3, 0x30, 0x16, 0xb9, 0x0d, 0xe1, 0x87, 0x08, 0x78, 0xa2,
+ 0xdb, 0x7e, 0x16, 0x82, 0x48, 0x48, 0x17, 0x1a, 0xa8, 0x3f, 0xc7, 0x4d,
+ 0xfd, 0x99, 0x2b, 0x36, 0xbf, 0x08, 0xb9, 0xeb, 0xa6, 0xbf, 0xb6, 0xa0,
+ 0x9e, 0x26, 0x15, 0xac, 0xd2, 0x65, 0xc9, 0x36, 0x41, 0xe3, 0x59, 0x4e,
+ 0xdc, 0x7b, 0x58, 0x3b, 0x47, 0x0b, 0xc9, 0xf3, 0xb3, 0xf9, 0x81, 0x33,
+ 0x39, 0xca, 0xf8, 0x97, 0x2d, 0x9b, 0x24, 0x33, 0x69, 0xbe, 0x1b, 0x81,
+ 0x59, 0x59, 0x17, 0xed, 0x7d, 0x5b, 0xbe, 0xda, 0xeb, 0x4e, 0x5d, 0x5d,
+ 0x70, 0x13, 0x3c, 0x4b, 0x4a, 0xfc, 0xa4, 0xbe, 0xa0, 0x5d, 0xa2, 0xed,
+ 0xe8, 0x8d, 0xf8, 0xf2, 0xa5, 0xdd, 0xd4, 0x49, 0x45, 0x04, 0xef, 0x18,
+ 0x9f, 0xa1, 0xf7, 0xc4, 0x3b, 0xc2, 0x6b, 0xe0, 0x45, 0xa8, 0x76, 0x39,
+ 0x49, 0x32, 0xec, 0xc3, 0xcb, 0x45, 0x46, 0xd2, 0x4b, 0x3a, 0x55, 0xe5,
+ 0xce, 0x08, 0xc4, 0x84, 0xe5, 0xd9, 0xb3, 0xf3, 0xc4, 0xa8, 0xe9, 0x88,
+ 0x83, 0xd5, 0x56, 0xe1, 0xa6, 0xef, 0x41, 0x55, 0xb0, 0x3f, 0xa3, 0xc1,
+ 0xbe, 0x3b, 0x83, 0xd6, 0x92, 0x90, 0x38, 0xd3, 0xf3, 0x75, 0xf6, 0x49,
+ 0x95, 0xee, 0xa9, 0xed, 0xaa, 0xf8, 0xb9, 0x14, 0x0e, 0x6a, 0x48, 0x9d,
+ 0xc5, 0x48, 0x3b, 0x5e, 0x61, 0xd3, 0x8c, 0x4a, 0x10, 0x12, 0x7c, 0x0a,
+ 0xf7, 0xaf, 0x62, 0x2d, 0xd3, 0x89, 0x8d, 0x75, 0x19, 0x6b, 0x62, 0x4b,
+ 0x1a, 0x04, 0xc7, 0xd3, 0x32, 0x17, 0x2f, 0x5f, 0x29, 0xfa, 0xb1, 0x8d,
+ 0x78, 0xe7, 0x27, 0xf6, 0x67, 0x7e, 0x17, 0xa3, 0x18, 0xdc, 0x13, 0x08,
+ 0x1e, 0x4b, 0xc7, 0x8e, 0xf6, 0xba, 0x90, 0xb3, 0x32, 0x42, 0x37, 0x6b,
+ 0x60, 0xa9, 0x23, 0xb5, 0x89, 0x57, 0x7b, 0xdb, 0x98, 0x35, 0x1f, 0x95,
+ 0x86, 0xa5, 0x83, 0x36, 0xd1, 0x8c, 0x8e, 0xc0, 0x77, 0x5c, 0x40, 0x8e,
+ 0xec, 0xdf, 0x25, 0x69, 0x0a, 0x83, 0x8f, 0xdf, 0x91, 0x52, 0x31, 0xab,
+ 0xd5, 0x61, 0x37, 0xbd, 0x83, 0x1d, 0x4c, 0x8b, 0xa1, 0x4a, 0x81, 0x8b,
+ 0xa0, 0xf4, 0x41, 0xbd, 0x54, 0x36, 0x36, 0x56, 0x6d, 0x4c, 0xe7, 0xd9,
+ 0xc7, 0x09, 0xd9, 0x4b, 0xf0, 0x54, 0x45, 0x3c, 0x62, 0x47, 0x17, 0x54,
+ 0x1f, 0x55, 0x2f, 0x74, 0xdc, 0x11, 0xe9, 0xa3, 0xb5, 0x75, 0xe9, 0x10,
+ 0xde, 0x62, 0xa9, 0x24, 0x39, 0xd4, 0x17, 0xbb, 0x15, 0xe4, 0x48, 0x09,
+ 0x26, 0x6a, 0xbd, 0x3b, 0x10, 0xa1, 0x55, 0xe5, 0x99, 0x53, 0x1e, 0xd2,
+ 0xee, 0x7c, 0x54, 0xd8, 0x06, 0x8b, 0x1e, 0xe7, 0x3f, 0x08, 0x38, 0x9b,
+ 0x2e, 0x41, 0xdf, 0x0b, 0x7e, 0x83, 0x7f, 0x04, 0x38, 0xa5, 0x1f, 0x46,
+ 0x8b, 0x94, 0x28, 0x9f, 0xb8, 0x8c, 0x41, 0xfe, 0x96, 0xe2, 0x24, 0xd1,
+ 0x97, 0xa4, 0xcb, 0xba, 0xfa, 0x19, 0xc9, 0x57, 0x30, 0x0f, 0x88, 0x58,
+ 0xa9, 0x67, 0x31, 0x74, 0x51, 0x34, 0x03, 0xbc, 0xff, 0x3b, 0x12, 0x61,
+ 0x84, 0x63, 0x74, 0xec, 0x4d, 0xda, 0xa3, 0x56, 0xc3, 0xe5, 0x5e, 0x4a,
+ 0x03, 0x26, 0x88, 0x1a, 0x1d, 0x7f, 0xe8, 0x3f, 0x61, 0x78, 0xb6, 0xc5,
+ 0x66, 0xb7, 0xb4, 0xc1, 0xe7, 0x82, 0xc1, 0x44, 0xdf, 0xf9, 0x30, 0x30,
+ 0xe1, 0xd0, 0xf8, 0xf5, 0x40, 0x5a, 0x72, 0x29, 0xef, 0x30, 0xe1, 0x01,
+ 0xca, 0x1b, 0xb0, 0xa6, 0xa3, 0x17, 0x2b, 0x58, 0x03, 0xda, 0x25, 0x0f,
+ 0xdc, 0x49, 0x7c, 0xc5, 0x8f, 0x2d, 0x83, 0xca, 0x43, 0x08, 0xc0, 0x36,
+ 0x70, 0x1e, 0x42, 0xfd, 0xac, 0x4d, 0x31, 0xcf, 0x68, 0x4a, 0xda, 0xd8,
+ 0xcb, 0xee, 0xaa, 0xfc, 0xcf, 0xcc, 0xe6, 0xb2, 0x77, 0x8b, 0x83, 0x5b,
+ 0xd5, 0x3d, 0x55, 0xba, 0x03, 0x45, 0xce, 0x51, 0x78, 0x36, 0xcb, 0xcd,
+ 0x9a, 0x0f, 0x58, 0xbe, 0x15, 0x10, 0xdb, 0x3f, 0x1d, 0x28, 0x27, 0x11,
+ 0x69, 0xca, 0x95, 0x68, 0xa8, 0xc8, 0xff, 0x0c, 0x3f, 0xd5, 0x11, 0x91,
+ 0x35, 0x45, 0x35, 0x9d, 0x1c, 0x58, 0xa2, 0xe5, 0xab, 0x83, 0x95, 0x10,
+ 0x44, 0xd4, 0xc0, 0x27, 0xf4, 0xc2, 0x72, 0x0f, 0x1a, 0x3d, 0x1c, 0xf2,
+ 0x7f, 0xb9, 0x54, 0xf2, 0x41, 0x24, 0xa8, 0x67, 0x30, 0xa0, 0x57, 0x67,
+ 0x00, 0xa8, 0x06, 0x60, 0xc3, 0x74, 0x6d, 0x54, 0x90, 0x5e, 0xad, 0x71,
+ 0x41, 0x50, 0xab, 0x9d, 0xba, 0x34, 0x1a, 0xfd, 0x19, 0x21, 0x0e, 0x87,
+ 0xb7, 0x22, 0xe6, 0xca, 0xb9, 0x0d, 0x3c, 0x4f, 0xad, 0x16, 0xf1, 0xa5,
+ 0x6d, 0xba, 0x6d, 0x7b, 0xbe, 0x7b, 0xe3, 0x95, 0xec, 0x1b, 0x8b, 0x6e,
+ 0xb0, 0xdc, 0x5c, 0xfd, 0x31, 0x73, 0x85, 0x02, 0x63, 0xc6, 0xcc, 0x04,
+ 0x29, 0xa5, 0xf4, 0x1f, 0xcb, 0x90, 0xf7, 0x83, 0x0d, 0x36, 0xbf, 0x31,
+ 0xc0, 0xfc, 0x26, 0x15, 0x87, 0xc8, 0x15, 0x88, 0xc9, 0x79, 0x11, 0x67,
+ 0x23, 0x53, 0xca, 0x03, 0x7a, 0x02, 0xe5, 0xfc, 0xb3, 0x38, 0xf3, 0x5d,
+ 0xfc, 0x91, 0x6f, 0x59, 0x26, 0xae, 0xd8, 0x45, 0xfa, 0xc4, 0x5b, 0xa2,
+ 0xfb, 0x2c, 0xc5, 0x36, 0xc6, 0x0d, 0x7b, 0x4e, 0xd2, 0x7f, 0x61, 0xc5,
+ 0xcc, 0x74, 0xd3, 0x41, 0xd4, 0x8a, 0xaf, 0xcb, 0x32, 0x50, 0xca, 0xeb,
+ 0x59, 0x0a, 0x05, 0x25, 0xe0, 0x5f, 0x30, 0x2b, 0x5d, 0x9b, 0xf7, 0xe8,
+ 0x14, 0x14, 0xb5, 0xfe, 0xd5, 0x2f, 0x94, 0x84, 0x5b, 0xc7, 0x4f, 0x82,
+ 0x01, 0x50, 0xbf, 0x54, 0xe2, 0x7d, 0xeb, 0x0c, 0x85, 0xc8, 0x99, 0x45,
+ 0x50, 0x8e, 0x4e, 0x10, 0x12, 0x01, 0x17, 0x41, 0xf3, 0x21, 0x4a, 0xee,
+ 0xaf, 0x0f, 0x76, 0x44, 0xe2, 0x8e, 0xf8, 0x36, 0x25, 0xab, 0x0d, 0x8f,
+ 0xb1, 0x0a, 0xbf, 0x63, 0x0e, 0xf2, 0x0c, 0x9d, 0x39, 0xa1, 0x98, 0x98,
+ 0x69, 0x91, 0xd1, 0x9b, 0xe8, 0xcf, 0x16, 0x65, 0x02, 0xc9, 0x67, 0x72,
+ 0x71, 0x7c, 0xfb, 0x41, 0x2d, 0xe4, 0xd3, 0xfb, 0x44, 0x8a, 0x7a, 0x88,
+ 0x32, 0x62, 0x26, 0x63, 0xfe, 0x5b, 0x0c, 0x4f, 0x6c, 0xad, 0x2f, 0x64,
+ 0x6f, 0xc9, 0xda, 0x95, 0x10, 0xbe, 0xd1, 0xfa, 0x8b, 0x67, 0x64, 0x35,
+ 0x2d, 0xed, 0xca, 0xf3, 0x12, 0xb7, 0x06, 0xc3, 0xa9, 0x8e, 0x3f, 0x09,
+ 0x4d, 0x1f, 0x50, 0x3a, 0x97, 0xb7, 0xa7, 0xce, 0x4d, 0x46, 0xf1, 0x61,
+ 0xc1, 0x06, 0x95, 0x0d, 0x07, 0xa2, 0xbc, 0xed, 0xeb, 0x45, 0xb4, 0x69,
+ 0x05, 0x7a, 0x30, 0x47, 0xa3, 0xbf, 0x81, 0xa9, 0xa7, 0xf0, 0x53, 0x36,
+ 0x31, 0x37, 0x13, 0xe5, 0x0e, 0xd6, 0xe6, 0xc7, 0x17, 0x17, 0x21, 0x6d,
+ 0x36, 0xd0, 0xf6, 0x2a, 0xea, 0x2d, 0x32, 0x0e, 0x90, 0x03, 0x30, 0x4d,
+ 0x30, 0x31, 0xaa, 0x79, 0x2d, 0xae, 0x2e, 0xb0, 0x13, 0xad, 0x63, 0x69,
+ 0x67, 0xd8, 0xf3, 0x6e, 0xa4, 0x34, 0xcf, 0x02, 0x10, 0xdd, 0x76, 0xfa,
+ 0xa7, 0xb0, 0x92, 0xea, 0x47, 0xbd, 0xff, 0xf9, 0xac, 0x8a, 0x1f, 0x31,
+ 0xf8, 0x05, 0xd4, 0xce, 0x23, 0xad, 0x32, 0x8c, 0x6c, 0x92, 0x85, 0xb9,
+ 0x74, 0xa6, 0xab, 0x6e, 0x76, 0xfd, 0x3e, 0x8a, 0xac, 0xa3, 0xd1, 0xb7,
+ 0x40, 0x53, 0x87, 0x28, 0xfc, 0xbc, 0x8a, 0x52, 0x8e, 0x2e, 0x59, 0x2c,
+ 0x5f, 0x3f, 0xcb, 0xd8, 0xbe, 0x37, 0xfd, 0xdc, 0xc0, 0x34, 0x85, 0x67,
+ 0x28, 0x9f, 0x1d, 0x05, 0x05, 0x94, 0xed, 0x6f, 0x54, 0x7a, 0x51, 0x9a,
+ 0xaa, 0xca, 0xe1, 0x41, 0x10, 0xf0, 0x9d, 0x38, 0x9c, 0x5e, 0x95, 0xe3,
+ 0x7e, 0x62, 0xe2, 0x31, 0x81, 0x28, 0x4a, 0x3c, 0x5e, 0x04, 0x11, 0xe2,
+ 0x6a, 0x45, 0x6f, 0x68, 0x96, 0x5b, 0xbf, 0x22, 0xd8, 0x29, 0x91, 0x76,
+ 0xe1, 0xb2, 0x5f, 0xfc, 0x89, 0x90, 0x87, 0xf8, 0xb8, 0x3f, 0xd5, 0x11,
+ 0xe7, 0x36, 0x47, 0x71, 0xb9, 0x52, 0x97, 0x8e, 0x62, 0x8b, 0x05, 0x31,
+ 0xe5, 0xd9, 0xa2, 0xc3, 0x1a, 0xb5, 0xda, 0xc7, 0xa5, 0x37, 0x06, 0x67,
+ 0x41, 0x1f, 0x6e, 0xa3, 0xc2, 0xb4, 0x96, 0x64, 0xfc, 0x46, 0x85, 0x95,
+ 0x4e, 0xd8, 0x2a, 0x4b, 0xaa, 0x1e, 0xec, 0xd5, 0xed, 0x81, 0x23, 0x68,
+ 0x0f, 0x5d, 0x0b, 0x95, 0x29, 0xd4, 0x36, 0x4d, 0x8c, 0x32, 0x73, 0x6a,
+ 0xb7, 0xad, 0xb8, 0x9c, 0xad, 0x76, 0x09, 0xad, 0xb9, 0xea, 0x2d, 0x17,
+ 0x3c, 0x33, 0x87, 0x7f, 0x62, 0x74, 0x77, 0xc9, 0xd6, 0x3d, 0x17, 0xbc,
+ 0xff, 0x57, 0x10, 0xec, 0x7a, 0xb7, 0x89, 0x05, 0x26, 0xf1, 0xb2, 0x53,
+ 0xa1, 0x91, 0xc5, 0x2a, 0xfb, 0x5a, 0xce, 0x5d, 0xd1, 0x6b, 0xbc, 0xb7,
+ 0x39, 0x09, 0x43, 0xdf, 0x20, 0xd3, 0xc1, 0x74, 0x8d, 0xf4, 0x0b, 0x2a,
+ 0xc7, 0xe8, 0xa1, 0x5f, 0xb2, 0xfe, 0x1a, 0x96, 0x3a, 0x92, 0xbc, 0x8f,
+ 0x85, 0xe2, 0x22, 0x73, 0x3f, 0x49, 0xb3, 0x6b, 0x90, 0xbd, 0xcb, 0x3f,
+ 0x36, 0x6c, 0x3d, 0xe3, 0x00, 0x00, 0x00, 0x00, 0x56, 0xd1, 0xff, 0xff,
+ 0x04, 0x00, 0x00, 0x00, 0x90, 0x00, 0x00, 0x00, 0x1f, 0x05, 0x81, 0x3f,
+ 0x25, 0x68, 0xde, 0x72, 0x88, 0x26, 0x66, 0x2d, 0xe4, 0xc8, 0x81, 0xf8,
+ 0x5d, 0x98, 0xa2, 0xc2, 0x02, 0x62, 0x63, 0x47, 0xe6, 0x61, 0x7f, 0xee,
+ 0xca, 0x3f, 0x81, 0xd7, 0x1e, 0xa9, 0xbf, 0x66, 0x59, 0x7f, 0xc3, 0x35,
+ 0x03, 0xae, 0xe5, 0xf2, 0x4d, 0x81, 0x82, 0x78, 0x5e, 0xaf, 0xaa, 0xd1,
+ 0x27, 0x41, 0x19, 0x93, 0xa8, 0x9b, 0x78, 0x4e, 0x95, 0x89, 0x7f, 0xce,
+ 0x49, 0xd0, 0x45, 0xb5, 0x7f, 0x1d, 0xe9, 0xee, 0x7f, 0x91, 0xf4, 0x0a,
+ 0x67, 0x7d, 0x75, 0xff, 0x38, 0x81, 0x27, 0x90, 0x14, 0xa5, 0x99, 0x40,
+ 0x5b, 0xe6, 0x9a, 0x81, 0x75, 0x22, 0x5f, 0x18, 0x81, 0x34, 0xb7, 0x54,
+ 0x2e, 0x8d, 0x81, 0x36, 0x0e, 0x5e, 0xc0, 0x5f, 0xd4, 0xc6, 0x34, 0x81,
+ 0xc8, 0xb9, 0xe2, 0xa9, 0x77, 0x81, 0x44, 0xb4, 0x06, 0x24, 0x81, 0x74,
+ 0x1c, 0xeb, 0xfb, 0xdd, 0x25, 0x81, 0x14, 0x09, 0x2d, 0xba, 0x11, 0x4b,
+ 0x07, 0x13, 0xf1, 0xae, 0x81, 0xaf, 0xa3, 0x87, 0x00, 0x00, 0x00, 0x00,
+ 0xf6, 0xd1, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x00, 0x2d, 0x00, 0x00,
+ 0x8a, 0x29, 0x03, 0xe6, 0x24, 0x2a, 0xd6, 0x21, 0xb6, 0xb1, 0x2d, 0x3a,
+ 0xff, 0xd6, 0x27, 0xd7, 0x18, 0x42, 0xc1, 0xb4, 0xf8, 0xfd, 0xdf, 0x45,
+ 0x09, 0x91, 0xcb, 0xfe, 0xe9, 0xb5, 0x24, 0xf1, 0xc0, 0x69, 0xd0, 0x64,
+ 0xa8, 0xeb, 0x12, 0x71, 0xe3, 0xb4, 0xbe, 0xb4, 0x93, 0xbf, 0x8a, 0x8b,
+ 0xf3, 0x4d, 0x13, 0x3b, 0x6f, 0x6f, 0x32, 0x12, 0x98, 0x95, 0xb9, 0x63,
+ 0xcd, 0xa5, 0x23, 0xa4, 0xb8, 0x2e, 0x74, 0x75, 0xbc, 0xe4, 0xc7, 0x46,
+ 0x96, 0xd4, 0x47, 0xa0, 0x65, 0xec, 0xea, 0xcf, 0xd0, 0xdc, 0xe9, 0x8b,
+ 0xcc, 0x1d, 0x2f, 0x0d, 0x0a, 0x9c, 0x6e, 0x99, 0x97, 0x97, 0xcc, 0x00,
+ 0xd2, 0x8e, 0xbc, 0x3c, 0x9a, 0xf1, 0x32, 0x0e, 0xf3, 0xd6, 0x27, 0x1c,
+ 0xea, 0xab, 0xca, 0x4d, 0x69, 0x32, 0x30, 0x5f, 0x18, 0xd7, 0xb7, 0x4a,
+ 0xcb, 0x8e, 0xb2, 0x96, 0x39, 0xa3, 0xc7, 0x42, 0xca, 0x60, 0x9b, 0xad,
+ 0x8e, 0xb7, 0x54, 0x32, 0xea, 0xfd, 0x58, 0xfa, 0xf8, 0x02, 0xef, 0x2f,
+ 0xec, 0x3c, 0x2a, 0x1a, 0x6a, 0x08, 0xa4, 0x4b, 0xec, 0x30, 0x90, 0xaf,
+ 0x13, 0x98, 0xcd, 0x48, 0xfd, 0x5f, 0x56, 0x68, 0x17, 0x9e, 0x87, 0xb1,
+ 0x2b, 0x16, 0xd3, 0x3c, 0xe0, 0xe8, 0x0e, 0xa6, 0xc4, 0x24, 0xd3, 0x05,
+ 0x75, 0xda, 0x22, 0x44, 0xb5, 0x41, 0xd2, 0xa5, 0x99, 0xf1, 0x5e, 0xbe,
+ 0x15, 0xb7, 0x33, 0x54, 0x9a, 0x97, 0x5b, 0x35, 0x77, 0x2b, 0x18, 0x46,
+ 0x2f, 0x92, 0xc5, 0x97, 0x2d, 0x4c, 0xa6, 0xf8, 0x9e, 0xc3, 0xe0, 0x0a,
+ 0x52, 0xf9, 0x97, 0xc7, 0xd6, 0x36, 0xdd, 0x38, 0xaa, 0xf3, 0x05, 0x30,
+ 0xc3, 0xe5, 0xaf, 0x54, 0xdc, 0xc4, 0xf2, 0x01, 0x9e, 0xe6, 0xc1, 0x89,
+ 0xee, 0xd8, 0x5f, 0xfe, 0xf0, 0x70, 0x3c, 0xc4, 0x40, 0xa4, 0xd4, 0xee,
+ 0xaf, 0x3d, 0xe6, 0xcd, 0x31, 0x16, 0x31, 0x3b, 0xa0, 0x0e, 0xc4, 0x71,
+ 0xbf, 0xbd, 0x39, 0x89, 0x0f, 0x36, 0xba, 0xd8, 0xa2, 0x49, 0x01, 0xab,
+ 0xf4, 0x07, 0x99, 0xc7, 0xb1, 0x0c, 0x33, 0x9d, 0x71, 0xf1, 0x15, 0x4b,
+ 0x60, 0xe0, 0xed, 0x59, 0x0a, 0x34, 0xd9, 0xa2, 0x45, 0x99, 0x4a, 0x60,
+ 0xd3, 0xdc, 0x37, 0x56, 0x32, 0x4c, 0xea, 0xdc, 0xcf, 0xe6, 0x22, 0x27,
+ 0x17, 0xea, 0x75, 0x3f, 0x69, 0xd4, 0xcf, 0x53, 0x92, 0x98, 0xf4, 0xfe,
+ 0x13, 0xa8, 0xe2, 0xb2, 0x48, 0x5f, 0x64, 0xab, 0x2b, 0x61, 0x97, 0xf5,
+ 0xc5, 0xb6, 0xef, 0x32, 0x4e, 0x47, 0x26, 0x42, 0x48, 0x9c, 0x5b, 0x24,
+ 0xa3, 0xcb, 0x70, 0xc7, 0x31, 0x6c, 0xc8, 0x4d, 0x5c, 0x02, 0xca, 0x71,
+ 0x1e, 0x56, 0xdb, 0x27, 0x66, 0x5d, 0x4f, 0x0b, 0x09, 0x57, 0xbe, 0x72,
+ 0x17, 0x3b, 0xce, 0xdd, 0xd2, 0x20, 0x13, 0x67, 0x32, 0x04, 0xee, 0xc4,
+ 0x66, 0x23, 0x0e, 0x97, 0x5e, 0x21, 0x30, 0xb2, 0xe4, 0x16, 0x06, 0x57,
+ 0xc3, 0x9b, 0x29, 0x5b, 0x76, 0xd0, 0x36, 0xac, 0xe6, 0xa2, 0x91, 0x57,
+ 0x96, 0x4e, 0x1c, 0x6f, 0x4a, 0x03, 0x50, 0x55, 0x6d, 0xaf, 0x9a, 0x29,
+ 0xc9, 0x61, 0x6c, 0x18, 0x4c, 0xb9, 0xd5, 0x41, 0xf8, 0x75, 0x2b, 0xc3,
+ 0x0e, 0x69, 0x9f, 0x45, 0x93, 0x2f, 0xa6, 0xf9, 0x30, 0x65, 0x05, 0x13,
+ 0xe3, 0x00, 0x54, 0x0e, 0xa4, 0xb5, 0x89, 0x6d, 0x4d, 0x11, 0x3d, 0x2a,
+ 0x29, 0x99, 0xd9, 0xdf, 0x75, 0xce, 0x01, 0x21, 0xbc, 0x26, 0xb3, 0x22,
+ 0xf9, 0xb0, 0x45, 0x5c, 0xf8, 0xea, 0xb2, 0x08, 0x1a, 0xf7, 0xa0, 0x70,
+ 0x65, 0xa8, 0xab, 0xe1, 0x92, 0xcc, 0xcc, 0x1f, 0x0e, 0x36, 0x60, 0xb7,
+ 0xea, 0xcb, 0x3d, 0xf6, 0x98, 0xbf, 0xcd, 0x00, 0xc9, 0x16, 0x1e, 0xdb,
+ 0x58, 0x24, 0xb1, 0xd8, 0xaf, 0x01, 0x00, 0xfa, 0x15, 0xf4, 0x37, 0x05,
+ 0xd7, 0x17, 0x2a, 0xd2, 0xe8, 0xe4, 0x0c, 0x50, 0xfa, 0xe8, 0xd6, 0x99,
+ 0xa9, 0x58, 0x61, 0x38, 0xee, 0x22, 0x3c, 0x53, 0xcf, 0x64, 0x8e, 0xad,
+ 0x4d, 0xd6, 0xc3, 0xc3, 0xdd, 0xb0, 0xb3, 0xf7, 0xdd, 0x37, 0xfd, 0xf3,
+ 0x2b, 0x6a, 0xe2, 0xd4, 0xfc, 0x0c, 0x74, 0xca, 0x37, 0x2f, 0xd2, 0xf8,
+ 0x5b, 0xf1, 0x8c, 0x32, 0xa0, 0xdc, 0x2c, 0xa8, 0x36, 0x2f, 0xbe, 0x45,
+ 0x9b, 0x42, 0x95, 0x15, 0x5e, 0x08, 0xb1, 0x61, 0xec, 0xa2, 0xdf, 0x5f,
+ 0xca, 0xf8, 0x62, 0x73, 0xfd, 0x66, 0xc8, 0x51, 0x2a, 0x69, 0x3c, 0x8f,
+ 0x75, 0xa4, 0x6f, 0xbe, 0xc1, 0x5c, 0x66, 0xe2, 0x60, 0x92, 0xd7, 0x0e,
+ 0xee, 0x1b, 0xc7, 0x39, 0x8b, 0x56, 0x6c, 0xc6, 0x20, 0xfa, 0xec, 0x96,
+ 0xa5, 0x0f, 0x74, 0x42, 0x32, 0x12, 0x11, 0xdf, 0x02, 0xfe, 0x42, 0x1c,
+ 0xfe, 0xf1, 0x72, 0xaf, 0x47, 0x3b, 0x62, 0xe3, 0x27, 0x29, 0xf0, 0xec,
+ 0x39, 0xd2, 0xdd, 0xb6, 0xe9, 0xbe, 0x5f, 0x66, 0x67, 0x6c, 0xc9, 0xa1,
+ 0xf0, 0x25, 0x9a, 0x1b, 0xa8, 0xa0, 0x15, 0xcb, 0x61, 0x98, 0x98, 0xfd,
+ 0xef, 0xba, 0x74, 0x9b, 0x54, 0xf3, 0x6d, 0xe1, 0xa4, 0xcf, 0xb5, 0xe7,
+ 0xba, 0x0f, 0xd1, 0x41, 0xd8, 0x63, 0x94, 0x09, 0xcd, 0x4f, 0xb1, 0x31,
+ 0x49, 0x5e, 0x54, 0xb1, 0x28, 0x39, 0x8e, 0x13, 0x48, 0x2e, 0x20, 0xb0,
+ 0xf7, 0x18, 0x9a, 0xea, 0xf2, 0x9b, 0xde, 0x8f, 0x16, 0xc8, 0x9e, 0x31,
+ 0xca, 0x94, 0x28, 0x26, 0x0d, 0x8c, 0x0f, 0x09, 0x69, 0xc5, 0x2a, 0x38,
+ 0xae, 0x6b, 0xfb, 0x4f, 0xbb, 0xf4, 0x14, 0xea, 0x8d, 0x13, 0xc0, 0x09,
+ 0xe2, 0xfb, 0xfb, 0x09, 0xa1, 0xfc, 0x49, 0xff, 0x0f, 0x52, 0x3e, 0xe8,
+ 0xda, 0xfe, 0xe1, 0x67, 0x8f, 0x21, 0xcf, 0xaf, 0xb7, 0xe2, 0xcf, 0x09,
+ 0x15, 0x10, 0x51, 0x72, 0x8f, 0x42, 0x09, 0x9d, 0xea, 0x27, 0x2d, 0x25,
+ 0x9f, 0x54, 0x50, 0xfa, 0xdf, 0x9f, 0x41, 0xe8, 0xd2, 0x66, 0xd8, 0x28,
+ 0xfb, 0x8b, 0xe4, 0x42, 0x03, 0x92, 0xf9, 0xcd, 0xcc, 0xb0, 0xc0, 0x52,
+ 0x53, 0x6d, 0xcd, 0xed, 0x16, 0xad, 0x3c, 0x3d, 0xf9, 0x3b, 0x05, 0xbb,
+ 0xac, 0x9e, 0xa3, 0x4b, 0x17, 0xb4, 0xc7, 0xdd, 0xd4, 0xd3, 0x0c, 0x10,
+ 0x0d, 0xd8, 0x9c, 0xdb, 0xa4, 0x60, 0x06, 0x89, 0x4b, 0x06, 0x4c, 0x9f,
+ 0xc4, 0x47, 0xc8, 0xaf, 0xab, 0x02, 0x23, 0x89, 0x6e, 0xf2, 0x9d, 0x2b,
+ 0x6b, 0x9a, 0xa4, 0xee, 0x16, 0x0b, 0x3c, 0x76, 0xd4, 0xf0, 0x17, 0x90,
+ 0xca, 0xf5, 0xc8, 0xbf, 0xcb, 0xb1, 0x02, 0x69, 0x34, 0x71, 0x59, 0x5d,
+ 0x0e, 0x56, 0xd8, 0x41, 0x0a, 0xa5, 0x0a, 0x16, 0xbc, 0x93, 0x63, 0xf9,
+ 0xd9, 0xab, 0x3e, 0x75, 0x1e, 0xd3, 0xf3, 0x56, 0xf5, 0x14, 0xee, 0x65,
+ 0xf3, 0x2f, 0x72, 0x03, 0xcb, 0x69, 0x90, 0x91, 0x0d, 0x31, 0x8e, 0x3e,
+ 0xe9, 0xb0, 0xe6, 0x2e, 0x37, 0x5d, 0xb0, 0x38, 0x52, 0xe6, 0x23, 0x24,
+ 0x36, 0xb2, 0xe9, 0xa5, 0xa0, 0xae, 0xed, 0xfd, 0x95, 0xa5, 0xcf, 0x4a,
+ 0xe3, 0xbd, 0xe7, 0x29, 0xd0, 0x57, 0x3e, 0xf1, 0xdf, 0xc8, 0xc7, 0x26,
+ 0xf6, 0xc7, 0x4b, 0xc8, 0x6a, 0x4a, 0xed, 0x49, 0x60, 0x2d, 0x1c, 0xe3,
+ 0x8b, 0x10, 0x24, 0xfc, 0xef, 0xbb, 0x1e, 0x24, 0xbb, 0x40, 0xeb, 0x99,
+ 0xba, 0xe1, 0x4a, 0xd4, 0x1f, 0x69, 0x47, 0xa4, 0x8f, 0x48, 0x05, 0x17,
+ 0xcb, 0xee, 0x55, 0xca, 0xe5, 0xe3, 0x60, 0xec, 0xfa, 0xe6, 0xd1, 0x28,
+ 0xc5, 0xa8, 0x04, 0xd8, 0xce, 0x13, 0x2b, 0x99, 0x2b, 0xc7, 0x94, 0x9d,
+ 0xda, 0xd7, 0x6f, 0x31, 0xfe, 0xee, 0x6c, 0x9b, 0xf1, 0x70, 0xd2, 0xee,
+ 0xc4, 0xba, 0xb7, 0xbe, 0xd3, 0x37, 0xdc, 0x43, 0x4e, 0x30, 0x4a, 0x67,
+ 0xf2, 0x45, 0x29, 0xe1, 0x8b, 0xb8, 0x6d, 0xca, 0xec, 0xb9, 0xd6, 0xd3,
+ 0xdd, 0xcb, 0xde, 0xdb, 0xa9, 0x4d, 0xdd, 0x3d, 0x41, 0xae, 0x99, 0x89,
+ 0xce, 0x70, 0x50, 0x61, 0x07, 0xf3, 0xca, 0x24, 0x56, 0x76, 0x3f, 0xe0,
+ 0x6e, 0xbe, 0xa7, 0xc6, 0xac, 0x6c, 0xf1, 0x8c, 0xa2, 0x0e, 0xc4, 0x2a,
+ 0x48, 0x30, 0x8b, 0xc9, 0xc0, 0x5a, 0xb2, 0x2b, 0xbd, 0xa2, 0xcc, 0xf7,
+ 0x25, 0x16, 0xc3, 0xde, 0x1b, 0x8d, 0x23, 0x8c, 0xb6, 0xc4, 0xaa, 0x4a,
+ 0x0b, 0x66, 0x25, 0x35, 0xb3, 0x9a, 0x74, 0x27, 0x63, 0xea, 0xef, 0x92,
+ 0x12, 0x8c, 0x58, 0xd9, 0x3a, 0x55, 0xd6, 0x61, 0x29, 0x9f, 0xbc, 0x28,
+ 0xbd, 0x30, 0xcd, 0x43, 0xe6, 0x36, 0x36, 0x66, 0x20, 0x8c, 0x9e, 0x23,
+ 0xfe, 0x6d, 0xf0, 0xbc, 0x61, 0xcd, 0x58, 0xd8, 0xe0, 0x2e, 0xe4, 0xcf,
+ 0x61, 0xf7, 0xd5, 0x6b, 0x54, 0x33, 0xb3, 0x2c, 0x60, 0xa8, 0x59, 0x21,
+ 0x5d, 0xaa, 0x65, 0x9e, 0xdc, 0xa3, 0xc9, 0xc4, 0x9d, 0x4d, 0x95, 0x29,
+ 0xf6, 0x2b, 0xcd, 0xc9, 0xb9, 0x9d, 0x46, 0xa0, 0x89, 0xf4, 0x4e, 0x52,
+ 0x55, 0xe2, 0x13, 0x98, 0xf0, 0xef, 0x27, 0xc3, 0xc9, 0xd1, 0xe1, 0xee,
+ 0x07, 0x1b, 0x9d, 0x8a, 0x5b, 0x9d, 0x06, 0x26, 0x61, 0x2a, 0x55, 0x6f,
+ 0x54, 0x22, 0xd5, 0x06, 0x20, 0xed, 0x06, 0x4d, 0xa2, 0xb3, 0xaa, 0x4f,
+ 0x1f, 0x3e, 0xd2, 0x0d, 0x6a, 0xab, 0x6d, 0xee, 0x8f, 0x09, 0xb2, 0xd9,
+ 0x39, 0x46, 0x0f, 0xe7, 0x51, 0x70, 0x51, 0xdb, 0x09, 0xf8, 0x8e, 0xbb,
+ 0x06, 0x98, 0x49, 0x69, 0xb7, 0x9e, 0xa0, 0xbc, 0x16, 0x5f, 0x96, 0xad,
+ 0xe9, 0x76, 0x9f, 0x71, 0xe2, 0x1b, 0x91, 0x73, 0xd9, 0x74, 0x6a, 0x70,
+ 0x48, 0x71, 0x47, 0x3b, 0x0c, 0xd5, 0x96, 0xe3, 0x6e, 0xdb, 0xbb, 0x9c,
+ 0x44, 0x5c, 0xe5, 0x07, 0x73, 0x31, 0xd1, 0x55, 0x07, 0xff, 0x5f, 0xb1,
+ 0x55, 0x9d, 0x0d, 0xbf, 0x32, 0x53, 0xf9, 0xfe, 0xcd, 0xc8, 0xe0, 0x56,
+ 0x18, 0x8f, 0x4b, 0x51, 0xd1, 0x23, 0x2e, 0x9f, 0xb9, 0xee, 0xf3, 0xfd,
+ 0x26, 0x02, 0xf6, 0x54, 0xd5, 0x3e, 0x13, 0xc1, 0xc1, 0xe4, 0xa8, 0xb4,
+ 0x5f, 0x5c, 0xa0, 0x9f, 0xb5, 0x19, 0xbb, 0x4e, 0xd6, 0xf8, 0x18, 0x9b,
+ 0xeb, 0x9e, 0x58, 0x9d, 0x00, 0x51, 0x24, 0x28, 0x70, 0x55, 0xf7, 0xb9,
+ 0x5a, 0x59, 0x50, 0xc5, 0x72, 0xab, 0x6b, 0x13, 0x95, 0xfb, 0xe4, 0xc2,
+ 0x05, 0x96, 0xf3, 0x48, 0xef, 0x02, 0x67, 0xd5, 0x8f, 0x5b, 0x8e, 0xb6,
+ 0xbe, 0xc1, 0x3d, 0x8e, 0x22, 0xee, 0x49, 0xc7, 0xbe, 0xfb, 0x2d, 0x51,
+ 0x45, 0x44, 0xca, 0x94, 0x8e, 0xce, 0xb5, 0x9a, 0x29, 0xc7, 0x52, 0xde,
+ 0x2c, 0xdf, 0xcc, 0x43, 0xc7, 0xd7, 0x51, 0xb7, 0x07, 0xf0, 0x9b, 0x9d,
+ 0x33, 0x98, 0x62, 0xfa, 0xc9, 0x13, 0x0b, 0xcd, 0xdf, 0xbd, 0xff, 0x8e,
+ 0x13, 0x44, 0xda, 0x62, 0xc0, 0xd1, 0x8d, 0x57, 0x0e, 0xec, 0x53, 0x8a,
+ 0x04, 0xcf, 0x0f, 0x5a, 0xd7, 0x3c, 0x4b, 0x17, 0xda, 0x3b, 0xf0, 0x30,
+ 0xbf, 0xea, 0x40, 0xa6, 0x36, 0xed, 0xda, 0xf7, 0x40, 0x6b, 0xf1, 0x1e,
+ 0x61, 0xa0, 0x8b, 0x5d, 0xfa, 0xa8, 0x6a, 0xca, 0xfd, 0x6a, 0x06, 0xb4,
+ 0xf5, 0xb6, 0xc7, 0xbe, 0xdf, 0xac, 0x17, 0x00, 0x4a, 0x91, 0x8d, 0x97,
+ 0x5b, 0xc8, 0xcb, 0xd4, 0xc8, 0x20, 0x0b, 0x53, 0xee, 0x2b, 0x25, 0xb8,
+ 0xa1, 0x24, 0xa1, 0xa0, 0x17, 0x60, 0xd9, 0xf7, 0x2d, 0x00, 0x6c, 0x70,
+ 0x44, 0x0d, 0x60, 0xe7, 0x95, 0x1e, 0x8a, 0x1b, 0x29, 0xcf, 0xb5, 0xc1,
+ 0xbe, 0xd0, 0xe5, 0xeb, 0xd8, 0x71, 0x88, 0x34, 0xcb, 0xbd, 0x32, 0x52,
+ 0xa7, 0xcf, 0x6d, 0x9b, 0xef, 0xf2, 0xe4, 0x68, 0x6f, 0xfe, 0xb9, 0x17,
+ 0x31, 0xa0, 0x3e, 0xfc, 0xae, 0xf6, 0x54, 0xe3, 0x33, 0x24, 0xd1, 0xfc,
+ 0xb7, 0x37, 0x8f, 0xd3, 0x4f, 0xf2, 0x59, 0x53, 0xea, 0xaf, 0x71, 0xc5,
+ 0xb1, 0xdb, 0xf9, 0xed, 0xc0, 0x46, 0x56, 0xfc, 0x09, 0x90, 0xf7, 0x09,
+ 0x5a, 0x12, 0x71, 0xad, 0xa6, 0x0f, 0xba, 0x4c, 0x2f, 0xd7, 0x61, 0xcb,
+ 0xf2, 0xab, 0x44, 0x67, 0x43, 0xd0, 0x41, 0xd5, 0xba, 0xff, 0x26, 0x50,
+ 0x5b, 0x97, 0x91, 0xc4, 0x8f, 0x2a, 0x64, 0x3c, 0x06, 0x2e, 0x26, 0x8e,
+ 0x5f, 0xb1, 0xba, 0x74, 0x16, 0xeb, 0xee, 0x6e, 0xe1, 0x68, 0xcc, 0x09,
+ 0xed, 0xa5, 0x5d, 0xf7, 0xef, 0xd6, 0xfa, 0x9f, 0x39, 0xe1, 0x5c, 0x38,
+ 0xbd, 0x1b, 0xe6, 0x8a, 0xfa, 0xea, 0xbc, 0x14, 0x4c, 0x31, 0xa8, 0x9d,
+ 0x64, 0xa6, 0xec, 0xf0, 0xf8, 0xa2, 0x0a, 0x6c, 0xb9, 0xc5, 0x3d, 0x40,
+ 0x48, 0x41, 0x1d, 0xf2, 0xab, 0xd4, 0xdf, 0xfb, 0x55, 0x9e, 0xa5, 0xac,
+ 0xe9, 0xf0, 0x46, 0x96, 0xc5, 0x4d, 0x5f, 0x5f, 0x64, 0x00, 0x69, 0x48,
+ 0x0e, 0xa3, 0xb5, 0x5d, 0x45, 0xce, 0x57, 0xc4, 0x45, 0xdb, 0xc6, 0x13,
+ 0x4b, 0xa7, 0xa0, 0xd5, 0x31, 0xb4, 0xd4, 0x0f, 0x4f, 0x29, 0x40, 0xc0,
+ 0xaa, 0xb7, 0x54, 0x21, 0xd5, 0x3a, 0x01, 0xbc, 0xa8, 0x58, 0xb5, 0x3f,
+ 0xa6, 0x1a, 0x06, 0xb5, 0x07, 0xd3, 0xb6, 0xff, 0x6e, 0x74, 0x08, 0x16,
+ 0x45, 0xaf, 0xd9, 0xc5, 0x4a, 0x0d, 0xd2, 0x8a, 0xd1, 0x6c, 0xba, 0x5a,
+ 0xd0, 0xee, 0x57, 0x10, 0xa4, 0x1a, 0xf4, 0x92, 0x97, 0xe0, 0xd7, 0xa8,
+ 0xff, 0x47, 0xed, 0x56, 0x6b, 0x91, 0x77, 0x5d, 0xa6, 0xcf, 0xed, 0x96,
+ 0xc5, 0x5a, 0xe3, 0x0b, 0x1d, 0xc0, 0xcc, 0xa1, 0x71, 0x95, 0xa8, 0xec,
+ 0xef, 0x33, 0x91, 0xd6, 0x53, 0x1f, 0xef, 0x43, 0xa9, 0x42, 0x2a, 0xc7,
+ 0xf6, 0x15, 0x60, 0xc2, 0xde, 0xeb, 0xac, 0xf8, 0x55, 0x27, 0x14, 0xf1,
+ 0xf8, 0x69, 0x55, 0xc8, 0x69, 0x1f, 0xf3, 0xc2, 0x71, 0xe8, 0x75, 0xa9,
+ 0x1a, 0x91, 0xc5, 0x1e, 0xe3, 0x52, 0x24, 0x5f, 0x60, 0xb5, 0xf1, 0xe6,
+ 0xdd, 0x4b, 0x1b, 0xdd, 0x3a, 0xad, 0x58, 0x36, 0x9c, 0xb3, 0x25, 0x9e,
+ 0x28, 0xd4, 0x3b, 0x6a, 0x64, 0xe7, 0x57, 0x54, 0xad, 0x4d, 0x44, 0xfc,
+ 0x54, 0xd3, 0xa3, 0x96, 0x4e, 0xee, 0xde, 0x23, 0x30, 0x30, 0x1f, 0x57,
+ 0x2f, 0xd6, 0xb4, 0xfa, 0x5c, 0x1b, 0x4a, 0x1b, 0x96, 0x58, 0x9a, 0xc7,
+ 0x25, 0xd0, 0x9c, 0xf3, 0x2b, 0x16, 0x58, 0x62, 0x0c, 0x5b, 0x45, 0x96,
+ 0xb0, 0xc2, 0x3e, 0xca, 0x0a, 0xb5, 0x0f, 0x06, 0xa8, 0xa3, 0xb2, 0x0a,
+ 0x6a, 0xc5, 0xb7, 0xf8, 0x69, 0xfa, 0xc1, 0xa8, 0xbc, 0x17, 0x6c, 0x92,
+ 0x06, 0x50, 0x74, 0x4b, 0x02, 0xc8, 0x4d, 0x9c, 0x3e, 0x94, 0x6f, 0xef,
+ 0x3e, 0xd9, 0x71, 0xa6, 0x3a, 0x70, 0x6a, 0x14, 0x0e, 0x06, 0xbe, 0x40,
+ 0x2b, 0xa1, 0xbb, 0x05, 0x71, 0x05, 0xbd, 0xd5, 0x2d, 0xd9, 0xe2, 0xf6,
+ 0xb4, 0x32, 0x33, 0xac, 0x0f, 0x9a, 0xe3, 0xaf, 0xf4, 0x44, 0x21, 0x59,
+ 0x91, 0x0d, 0xd0, 0xf1, 0x47, 0x9e, 0x00, 0x38, 0xa2, 0x1d, 0x61, 0x54,
+ 0xd2, 0x18, 0x9d, 0xe4, 0x4f, 0xf3, 0xbd, 0x04, 0xdb, 0x4d, 0x59, 0x8c,
+ 0xfa, 0x12, 0xdd, 0xe4, 0xb5, 0x32, 0x3b, 0xf8, 0x93, 0xae, 0x3b, 0xa9,
+ 0xb3, 0xe9, 0x57, 0x30, 0x49, 0x6d, 0xaa, 0x35, 0x12, 0xce, 0x16, 0x98,
+ 0x3c, 0xd0, 0xed, 0xe8, 0xa6, 0xbc, 0xa6, 0xe6, 0x66, 0x0f, 0xb3, 0x12,
+ 0x95, 0x19, 0x56, 0x23, 0xb1, 0x30, 0x5d, 0xb3, 0x4c, 0x5f, 0x0c, 0xef,
+ 0x24, 0x12, 0xe0, 0x97, 0xf3, 0x3e, 0x9c, 0x49, 0xff, 0xa6, 0x6f, 0xa6,
+ 0xd2, 0x58, 0xbe, 0x3f, 0x30, 0xdd, 0x65, 0xd0, 0x40, 0xe1, 0xaf, 0x09,
+ 0xf1, 0xf4, 0x0f, 0x1a, 0xe5, 0xef, 0x51, 0x50, 0x38, 0x5d, 0xb0, 0x1e,
+ 0xed, 0x19, 0x8d, 0x4e, 0x20, 0xa1, 0x65, 0x07, 0x5b, 0x23, 0x0c, 0x14,
+ 0xd3, 0x18, 0xa3, 0xda, 0x58, 0x9f, 0x10, 0x00, 0xbd, 0xb5, 0x95, 0x07,
+ 0x1d, 0x0f, 0xf9, 0x2a, 0xe4, 0x35, 0x3c, 0x60, 0xad, 0xb2, 0x13, 0x3b,
+ 0xd5, 0x9e, 0xeb, 0xc7, 0x09, 0x6e, 0x53, 0xff, 0x95, 0xf3, 0xc1, 0x9b,
+ 0xcd, 0x21, 0x15, 0x3b, 0x5f, 0xfe, 0x4e, 0xaf, 0x3f, 0xf8, 0xe3, 0xa8,
+ 0x35, 0xee, 0x44, 0x33, 0xc7, 0x8c, 0x9c, 0x1c, 0x33, 0x55, 0x3c, 0x4a,
+ 0xa4, 0x35, 0xf6, 0xf0, 0x32, 0x8e, 0xed, 0x6d, 0x06, 0xff, 0x8d, 0x24,
+ 0x05, 0x72, 0x4c, 0xa2, 0x97, 0x25, 0x93, 0x3d, 0x79, 0x18, 0x22, 0x15,
+ 0xec, 0x5c, 0xc4, 0x10, 0x65, 0xec, 0x90, 0x6d, 0x28, 0xba, 0x93, 0xb5,
+ 0x2f, 0x53, 0xe4, 0x00, 0x9c, 0x39, 0xf5, 0x4c, 0xde, 0x51, 0x39, 0xc3,
+ 0xd8, 0x03, 0xc3, 0x97, 0xe1, 0xa8, 0x3e, 0x06, 0x26, 0x4d, 0xd9, 0x49,
+ 0x75, 0xbb, 0xd5, 0x69, 0x20, 0xfb, 0x85, 0x12, 0xc9, 0xac, 0xfc, 0x05,
+ 0xad, 0x57, 0xa9, 0x58, 0xcd, 0xfd, 0xbe, 0x64, 0x31, 0x50, 0x4d, 0xa4,
+ 0x93, 0xb6, 0x23, 0x3b, 0xfd, 0xd9, 0xdb, 0x46, 0xdd, 0x1f, 0x07, 0x54,
+ 0xc2, 0xc2, 0xd6, 0xad, 0xf6, 0x21, 0x39, 0xa1, 0x96, 0x53, 0x12, 0x46,
+ 0x5a, 0xc8, 0xf3, 0xf8, 0xe2, 0xa3, 0xd0, 0x29, 0x3f, 0x30, 0xca, 0x0b,
+ 0x57, 0xab, 0xcf, 0x1e, 0x08, 0x59, 0x3d, 0x41, 0x6a, 0xf7, 0xb2, 0xfc,
+ 0xff, 0x33, 0x46, 0xd1, 0x1a, 0xa6, 0x91, 0x54, 0xca, 0x27, 0x5a, 0x94,
+ 0x13, 0xf4, 0xf0, 0xcf, 0x58, 0xe0, 0x96, 0x50, 0xda, 0xe6, 0x91, 0xc7,
+ 0x8d, 0x14, 0x5b, 0xc1, 0xeb, 0x4a, 0x96, 0xf1, 0xa5, 0x43, 0xf6, 0x29,
+ 0x91, 0xb9, 0xb9, 0x67, 0x3f, 0x31, 0xd7, 0x08, 0xe6, 0x2b, 0xfb, 0x43,
+ 0x56, 0x39, 0x4e, 0xf9, 0x02, 0x8e, 0x96, 0x1f, 0xa3, 0x3c, 0xae, 0x55,
+ 0x03, 0x05, 0x9a, 0x39, 0xbe, 0xf7, 0x67, 0xa1, 0x6b, 0x2f, 0x42, 0x45,
+ 0x9b, 0x45, 0x8f, 0x53, 0x1f, 0x96, 0x42, 0x54, 0xd2, 0x5b, 0xf0, 0x17,
+ 0x94, 0x41, 0xaf, 0xd4, 0xc6, 0x37, 0x5f, 0xc0, 0xbd, 0xe3, 0x44, 0x8d,
+ 0xc1, 0x69, 0x64, 0x2a, 0xe7, 0x08, 0xe5, 0x18, 0x92, 0x53, 0xfc, 0xed,
+ 0xd3, 0x69, 0x94, 0x6b, 0x10, 0x0b, 0x5e, 0x91, 0x38, 0x4b, 0xa5, 0x19,
+ 0x3a, 0x6a, 0x2e, 0x5a, 0xa2, 0x6f, 0x34, 0x2c, 0x7b, 0x5d, 0x53, 0x33,
+ 0x77, 0x46, 0xf8, 0x4a, 0xa2, 0x8d, 0x55, 0x67, 0xa8, 0xbd, 0xc6, 0x3c,
+ 0x5d, 0x47, 0xeb, 0x99, 0xed, 0xdc, 0xae, 0xcf, 0xec, 0xbe, 0x40, 0x60,
+ 0xfc, 0x36, 0x5c, 0x93, 0x95, 0x64, 0xd8, 0x47, 0x14, 0xe2, 0x1e, 0xa2,
+ 0xd4, 0xd4, 0xdf, 0xd9, 0x23, 0x18, 0xf2, 0x99, 0xe8, 0xe4, 0x2a, 0x3b,
+ 0xec, 0x2e, 0x28, 0xa8, 0x04, 0x74, 0x04, 0xa4, 0x32, 0xa6, 0x49, 0xf9,
+ 0x33, 0x6c, 0xa8, 0x1d, 0xb2, 0xbb, 0x57, 0xe4, 0xcf, 0xf2, 0x9e, 0x74,
+ 0x8d, 0xf7, 0x22, 0xaa, 0x0d, 0x8a, 0x2f, 0x34, 0x72, 0x33, 0xec, 0xdf,
+ 0x46, 0x57, 0x6c, 0x97, 0x94, 0xad, 0x06, 0x88, 0xeb, 0x20, 0xec, 0x79,
+ 0x44, 0xe1, 0xbc, 0xf8, 0xbd, 0xeb, 0x99, 0xe3, 0xaf, 0xfe, 0xc5, 0xb5,
+ 0xfa, 0x31, 0x75, 0x62, 0xff, 0x2a, 0x2a, 0x1b, 0xce, 0xad, 0xa8, 0xc8,
+ 0x3c, 0x54, 0x23, 0xf9, 0x9e, 0x2d, 0xe2, 0xa4, 0x4f, 0x5b, 0x4d, 0xb8,
+ 0x4f, 0xc6, 0xb3, 0xc6, 0xef, 0x66, 0x54, 0x31, 0xab, 0xd3, 0xf0, 0xb9,
+ 0xfa, 0xb6, 0x15, 0xe6, 0xdb, 0x4b, 0x51, 0x4d, 0x77, 0xa5, 0x3d, 0x4e,
+ 0xd9, 0xc9, 0xdb, 0x95, 0x31, 0x1d, 0x4d, 0x37, 0xe0, 0x34, 0xd3, 0xf3,
+ 0x20, 0x6b, 0xb8, 0x16, 0x0b, 0x4e, 0x55, 0x96, 0x56, 0x1e, 0xa7, 0xe8,
+ 0xc6, 0x3a, 0x08, 0x49, 0xa1, 0x16, 0x46, 0xc9, 0x43, 0xcb, 0x8f, 0x28,
+ 0x4a, 0x78, 0xaa, 0xf9, 0x6c, 0x74, 0xc8, 0x0b, 0xce, 0x13, 0x2c, 0xef,
+ 0xfe, 0x73, 0x42, 0xa7, 0xbc, 0x3d, 0xc9, 0xf2, 0xaf, 0x1c, 0x32, 0xdb,
+ 0xb2, 0x15, 0x70, 0x6b, 0x9b, 0x6e, 0x6f, 0x6e, 0xf7, 0x95, 0xea, 0x3e,
+ 0xd0, 0xb1, 0x2a, 0xbe, 0x8c, 0x66, 0x4e, 0xe9, 0x29, 0xe3, 0x35, 0xde,
+ 0xbf, 0x44, 0xbc, 0x5e, 0x56, 0x8b, 0xb3, 0xd4, 0xdf, 0xf5, 0x4e, 0x2e,
+ 0xeb, 0xe6, 0x8e, 0x58, 0xe2, 0xfd, 0xe7, 0x27, 0xff, 0x07, 0x49, 0x20,
+ 0xdd, 0xcf, 0xe4, 0xd7, 0x5c, 0x5f, 0x1f, 0xcc, 0xeb, 0x29, 0xeb, 0x34,
+ 0xac, 0xd6, 0xb6, 0xf8, 0xae, 0xdf, 0x11, 0x58, 0xd5, 0xea, 0xf1, 0x76,
+ 0xe5, 0x4d, 0x51, 0x72, 0xd4, 0x5e, 0x1e, 0x0f, 0xfd, 0x2e, 0xbe, 0x8e,
+ 0x07, 0x1a, 0x1f, 0x99, 0x4d, 0x73, 0x70, 0xe1, 0x41, 0xb4, 0x20, 0x10,
+ 0x75, 0x0f, 0xc8, 0x69, 0x5f, 0x6c, 0x20, 0x2b, 0xc8, 0xfd, 0xe9, 0x4c,
+ 0xf4, 0x6f, 0x6a, 0xe0, 0x1a, 0xb5, 0xec, 0x2e, 0xf5, 0x25, 0x6d, 0x56,
+ 0x56, 0xb9, 0x42, 0xca, 0x70, 0x72, 0xe5, 0x41, 0x07, 0x4f, 0x41, 0x25,
+ 0xea, 0x0a, 0x5d, 0xe1, 0x0a, 0xd5, 0x6f, 0x35, 0x50, 0xcc, 0x27, 0x53,
+ 0x5f, 0x31, 0x1c, 0xee, 0xae, 0x26, 0xc8, 0xc4, 0x4f, 0x9b, 0xf5, 0xf6,
+ 0x4d, 0x19, 0xb9, 0xc4, 0x55, 0xcd, 0xe5, 0x8a, 0xe9, 0x45, 0xec, 0xf2,
+ 0xf9, 0x33, 0x4d, 0xba, 0x57, 0x8f, 0xd6, 0xf5, 0xf7, 0x92, 0xb3, 0xd3,
+ 0x65, 0x39, 0x07, 0x04, 0x92, 0x2f, 0x70, 0x99, 0x97, 0x96, 0x60, 0xe5,
+ 0x92, 0x60, 0xc3, 0x72, 0x1e, 0xc7, 0xe6, 0x1d, 0xbb, 0x5b, 0xd5, 0x64,
+ 0x1b, 0x36, 0x45, 0xb8, 0xcb, 0x42, 0xe7, 0x26, 0x45, 0x65, 0xc8, 0x04,
+ 0x1c, 0x05, 0x9b, 0x48, 0xe3, 0x93, 0x8e, 0xb2, 0x1c, 0x6a, 0xab, 0x60,
+ 0xc2, 0xa6, 0x1a, 0x71, 0xd5, 0x2c, 0xb8, 0xe9, 0x9e, 0x66, 0x8d, 0xb6,
+ 0xb1, 0x99, 0x90, 0x9c, 0x1b, 0xc9, 0x44, 0x6d, 0x31, 0xbb, 0x62, 0x6e,
+ 0x46, 0xcc, 0xd7, 0x47, 0x3a, 0x40, 0x63, 0x33, 0x34, 0x4f, 0x50, 0x3c,
+ 0x94, 0x97, 0xe9, 0xe8, 0x3a, 0xf7, 0x2d, 0x2d, 0x9c, 0xb6, 0x5d, 0x52,
+ 0xbd, 0xa9, 0x2d, 0x42, 0xfc, 0xe8, 0x70, 0x09, 0x48, 0xd0, 0x36, 0x0b,
+ 0x3d, 0x2b, 0x9f, 0xe2, 0x4c, 0xdf, 0xf3, 0x57, 0x73, 0x55, 0xf7, 0x34,
+ 0xb8, 0x6b, 0x44, 0x6f, 0xf6, 0x6d, 0xcf, 0x93, 0x09, 0x14, 0xac, 0x8f,
+ 0xde, 0xce, 0x5f, 0x05, 0x04, 0x9f, 0xc7, 0x05, 0x5f, 0xdd, 0x2e, 0xfc,
+ 0x53, 0xec, 0x9e, 0xdb, 0xa8, 0xa2, 0xc7, 0x53, 0x5c, 0x9a, 0x4d, 0xb6,
+ 0x6f, 0xa5, 0xc6, 0xf3, 0xc5, 0xa4, 0x56, 0x62, 0xdc, 0x75, 0xe4, 0x0b,
+ 0xb0, 0xcc, 0x38, 0xde, 0x2d, 0xbb, 0xbc, 0x0b, 0xc6, 0xab, 0xac, 0xac,
+ 0x46, 0xce, 0x1e, 0xe6, 0x47, 0x6c, 0x6e, 0x8e, 0x00, 0x00, 0xa0, 0xae,
+ 0x1e, 0x1d, 0xaa, 0x22, 0xaf, 0x34, 0xc7, 0x26, 0x37, 0x01, 0x46, 0x25,
+ 0x9c, 0x5f, 0x92, 0xef, 0xda, 0x07, 0x64, 0x62, 0xe4, 0xf7, 0x4c, 0xa2,
+ 0x41, 0xf1, 0x10, 0xe0, 0xe5, 0x73, 0x72, 0xe1, 0xf8, 0x66, 0x19, 0x58,
+ 0xa9, 0xdf, 0xb1, 0x41, 0xcb, 0xb3, 0xc4, 0xe6, 0x21, 0xbe, 0x17, 0x26,
+ 0xa9, 0x68, 0x96, 0xde, 0x5d, 0xba, 0x8f, 0x1b, 0x09, 0x00, 0x39, 0x0e,
+ 0xc2, 0x8d, 0x31, 0x61, 0xfe, 0x9e, 0x60, 0x05, 0xf3, 0x72, 0xdf, 0x78,
+ 0x14, 0x5a, 0x1b, 0x74, 0xa1, 0x23, 0xa7, 0x6e, 0x93, 0x76, 0xfa, 0x4a,
+ 0x73, 0xa1, 0x3b, 0xda, 0x0b, 0x06, 0xdd, 0xfc, 0x2f, 0xef, 0x0a, 0x38,
+ 0x03, 0xbf, 0xbb, 0x12, 0x29, 0x6b, 0xec, 0x68, 0xc7, 0xa6, 0xf9, 0x72,
+ 0xbc, 0xdb, 0xeb, 0x4e, 0x8f, 0x5f, 0x3a, 0xa9, 0x06, 0x4e, 0x3c, 0xf4,
+ 0x3b, 0xe0, 0x98, 0x9b, 0x77, 0x57, 0x0f, 0x39, 0x08, 0x43, 0x3f, 0x9b,
+ 0x76, 0x11, 0xd3, 0x38, 0xb6, 0x1f, 0x1e, 0xfe, 0xbb, 0x16, 0x37, 0x24,
+ 0x15, 0xf7, 0x8e, 0x61, 0x3d, 0xf5, 0x60, 0xab, 0x46, 0x49, 0xd6, 0xb2,
+ 0x8e, 0x35, 0xd5, 0x66, 0x20, 0x1f, 0xad, 0xf5, 0x95, 0xc3, 0x3e, 0xaa,
+ 0xda, 0x12, 0x1f, 0x33, 0xf4, 0xc0, 0xd9, 0x9e, 0x09, 0x76, 0x8b, 0x2f,
+ 0x35, 0xe2, 0x58, 0x09, 0x36, 0xf1, 0x03, 0xbc, 0xc2, 0x54, 0x67, 0x29,
+ 0x00, 0x3b, 0xf0, 0x24, 0xdf, 0xa0, 0x92, 0x71, 0xc3, 0x98, 0xe8, 0x5d,
+ 0xbe, 0xc7, 0xe8, 0x6f, 0x2f, 0x05, 0x89, 0x9f, 0xa1, 0x63, 0x29, 0x12,
+ 0x94, 0xff, 0xc7, 0x4c, 0xec, 0x98, 0x0e, 0xb8, 0xeb, 0x9e, 0x6d, 0x1e,
+ 0x4f, 0x4a, 0x1e, 0x41, 0xb0, 0xf9, 0x40, 0x8b, 0xdd, 0xd9, 0xa6, 0x1b,
+ 0xd4, 0x6d, 0xaf, 0x5b, 0x14, 0x68, 0xfd, 0x96, 0x5d, 0x0d, 0xad, 0x46,
+ 0x03, 0xf8, 0xd7, 0x13, 0x1d, 0xf3, 0x47, 0xbe, 0x46, 0x3d, 0xc7, 0xdd,
+ 0xa9, 0x60, 0x05, 0x15, 0xef, 0x9d, 0xa4, 0xb8, 0xde, 0xf2, 0x41, 0xe2,
+ 0x07, 0x1d, 0xcb, 0xe8, 0xf3, 0x9c, 0x9c, 0x5e, 0xcd, 0xec, 0x53, 0x39,
+ 0xf2, 0x62, 0x3b, 0x69, 0x3a, 0x29, 0xc7, 0xb3, 0x57, 0xce, 0x58, 0xd6,
+ 0x55, 0xf8, 0xc2, 0xf1, 0x16, 0xf3, 0x33, 0x3f, 0xf2, 0xaa, 0x63, 0x42,
+ 0x27, 0x01, 0x22, 0x5a, 0x1e, 0x8d, 0xa5, 0x33, 0x34, 0x29, 0x12, 0xf6,
+ 0x07, 0x22, 0xfd, 0xbb, 0x72, 0x60, 0x2a, 0xf5, 0xec, 0x71, 0xfe, 0xd7,
+ 0xc1, 0xf5, 0xdf, 0x97, 0x3e, 0x4a, 0x9a, 0x97, 0x6f, 0x56, 0xf1, 0xd4,
+ 0xba, 0x29, 0x09, 0x46, 0x3f, 0x10, 0xdc, 0x2d, 0xb2, 0x04, 0x32, 0x38,
+ 0xa3, 0xc7, 0x75, 0x95, 0x16, 0xd6, 0x12, 0x44, 0x7a, 0xd3, 0x18, 0xb3,
+ 0x51, 0x72, 0x63, 0xb8, 0xae, 0x9b, 0xf1, 0xec, 0x17, 0xe4, 0x2d, 0xed,
+ 0x29, 0x05, 0x63, 0xd7, 0x01, 0xf4, 0xf5, 0xc1, 0x6d, 0x13, 0x5f, 0x5c,
+ 0x73, 0x11, 0xc9, 0x53, 0xf4, 0xda, 0x90, 0xa2, 0x1c, 0x0b, 0x1d, 0x37,
+ 0x28, 0xa1, 0x06, 0x65, 0xd3, 0x49, 0x5d, 0x07, 0x1f, 0x93, 0xa9, 0x98,
+ 0xc5, 0xa5, 0x13, 0xc5, 0xac, 0xda, 0x64, 0x25, 0x77, 0x9a, 0xd5, 0xa9,
+ 0xe9, 0x3a, 0x77, 0x62, 0xac, 0xf2, 0x76, 0xf4, 0x03, 0xb6, 0x03, 0x6e,
+ 0xef, 0x97, 0x13, 0x1c, 0xd1, 0xb9, 0x73, 0x12, 0xf7, 0x10, 0xbd, 0x1c,
+ 0xa1, 0xe7, 0xed, 0xd7, 0xa0, 0xd7, 0x53, 0xa1, 0x21, 0xf1, 0x5f, 0x1e,
+ 0xec, 0x36, 0x0d, 0x2c, 0xce, 0x74, 0x4a, 0x0c, 0x97, 0x5a, 0x76, 0x62,
+ 0x18, 0x9c, 0xc3, 0xc1, 0xc4, 0x5e, 0xf1, 0xfa, 0xe6, 0x4b, 0x15, 0xda,
+ 0xfa, 0xfd, 0xe9, 0x98, 0x09, 0xc3, 0x67, 0x63, 0x1f, 0x28, 0x37, 0xf0,
+ 0x59, 0x4b, 0x4b, 0xa3, 0xd1, 0x41, 0x94, 0xa6, 0x05, 0xb0, 0x93, 0xee,
+ 0x41, 0xa4, 0xce, 0xee, 0xea, 0xc4, 0x43, 0x6e, 0xab, 0x65, 0x70, 0xe3,
+ 0x4d, 0xf1, 0x02, 0xf5, 0x0f, 0xd5, 0x5e, 0xfd, 0x03, 0xcd, 0x22, 0x27,
+ 0x90, 0xf4, 0x98, 0xa2, 0xc0, 0xb4, 0xd5, 0x04, 0xfa, 0x75, 0x22, 0x4c,
+ 0xe7, 0xdd, 0xef, 0x3a, 0x1d, 0xb6, 0x00, 0x58, 0xcd, 0x5a, 0xbc, 0x12,
+ 0xea, 0x5a, 0xda, 0xa9, 0x18, 0x0e, 0xff, 0x51, 0xc4, 0xaf, 0xc8, 0x95,
+ 0xfb, 0x92, 0xdf, 0x99, 0xc9, 0x4e, 0xfe, 0xb1, 0xb0, 0xca, 0xa1, 0xba,
+ 0x90, 0xc8, 0x07, 0x34, 0x52, 0x6d, 0xd8, 0x05, 0x72, 0x2e, 0xee, 0x98,
+ 0xc0, 0x1e, 0x25, 0xb3, 0xa2, 0xb4, 0x9c, 0xa5, 0xdc, 0xd3, 0xb1, 0xdf,
+ 0x17, 0xd9, 0xda, 0xe9, 0x5d, 0x41, 0xca, 0xc7, 0xe4, 0x94, 0x0d, 0x67,
+ 0xba, 0x9c, 0xcf, 0x52, 0xf0, 0x00, 0x54, 0xe0, 0xbd, 0x3c, 0xc7, 0xb9,
+ 0x6a, 0x11, 0xc6, 0xd1, 0x62, 0xc3, 0xcf, 0xc2, 0x6a, 0x44, 0xeb, 0x41,
+ 0x43, 0x54, 0xe2, 0xf5, 0xc4, 0x11, 0xd7, 0x6a, 0xf2, 0x76, 0xa9, 0x16,
+ 0xae, 0xe2, 0x11, 0xfb, 0x04, 0x3d, 0xee, 0xd1, 0x98, 0x30, 0x0b, 0x6b,
+ 0x8a, 0x6f, 0x45, 0xb7, 0x01, 0x64, 0x46, 0x32, 0x61, 0xd5, 0x05, 0xfa,
+ 0xb1, 0x14, 0x54, 0x39, 0x13, 0x9b, 0xd5, 0x1d, 0x5c, 0xad, 0xd0, 0x5e,
+ 0x6d, 0xb3, 0xa1, 0xb3, 0xc5, 0x8d, 0xf8, 0x12, 0xd9, 0x5f, 0x94, 0x27,
+ 0xdf, 0x30, 0xc8, 0x0e, 0x3a, 0x46, 0x70, 0x5c, 0x4c, 0xaa, 0x24, 0xc3,
+ 0x50, 0x62, 0x52, 0xc8, 0x63, 0x64, 0xc9, 0x49, 0x74, 0x1c, 0xd2, 0x49,
+ 0x0f, 0x20, 0x69, 0x53, 0x97, 0x34, 0xc0, 0x92, 0x48, 0x28, 0x7b, 0x64,
+ 0xca, 0xea, 0x07, 0x6c, 0x63, 0x3e, 0xb6, 0xdb, 0xd5, 0x52, 0x9d, 0x7a,
+ 0x5f, 0x46, 0xc1, 0xb9, 0x3e, 0xe2, 0xe9, 0xeb, 0x04, 0x65, 0xc0, 0x74,
+ 0x4b, 0x07, 0x6a, 0x19, 0x4a, 0x9d, 0x05, 0xa0, 0xba, 0xae, 0x74, 0xef,
+ 0x62, 0x09, 0x57, 0x36, 0xe5, 0x9c, 0x54, 0x59, 0x3d, 0x04, 0xf0, 0xfb,
+ 0x6f, 0x89, 0x13, 0x1f, 0x1f, 0x88, 0x03, 0x6b, 0x0c, 0xeb, 0x53, 0xac,
+ 0x3a, 0x18, 0xa4, 0x93, 0xcc, 0x4f, 0xf5, 0x92, 0x44, 0x23, 0x9e, 0x67,
+ 0xf0, 0xf5, 0x2f, 0xb9, 0xc9, 0x34, 0x76, 0x97, 0x1d, 0x94, 0x75, 0x3f,
+ 0x47, 0x97, 0xe0, 0x30, 0xcc, 0xff, 0xd2, 0x7a, 0x3b, 0x04, 0xa7, 0xa5,
+ 0x62, 0x9e, 0xe4, 0x8f, 0xd8, 0x62, 0xee, 0x1d, 0x1c, 0xff, 0xad, 0x18,
+ 0xc9, 0x66, 0x47, 0x36, 0xfb, 0x2e, 0x74, 0x2a, 0xe7, 0x5f, 0xb2, 0x12,
+ 0xd2, 0x9e, 0xae, 0x2b, 0x92, 0xb8, 0x53, 0x66, 0x22, 0x5c, 0xa8, 0xaf,
+ 0x4f, 0x29, 0xab, 0x64, 0x50, 0x09, 0xe9, 0x2f, 0x2e, 0x62, 0x2e, 0x0e,
+ 0x8a, 0xd6, 0xeb, 0xa7, 0x5d, 0x3e, 0x9e, 0xe1, 0x39, 0x52, 0x13, 0x57,
+ 0x54, 0x5c, 0x78, 0xed, 0xb3, 0xfc, 0x5f, 0xa1, 0xf3, 0x2a, 0x77, 0x90,
+ 0xa9, 0x09, 0xa1, 0x05, 0x3b, 0xa9, 0x6a, 0xf5, 0xc4, 0xfa, 0x97, 0x79,
+ 0x64, 0x57, 0x1a, 0xf1, 0x74, 0xe5, 0x16, 0x93, 0xa9, 0xef, 0xe6, 0xdf,
+ 0x36, 0xd2, 0xd0, 0xe6, 0xb8, 0xdd, 0xe9, 0x13, 0x4c, 0xcd, 0x22, 0x98,
+ 0xc1, 0x94, 0xbb, 0x04, 0x2a, 0x4a, 0x69, 0x10, 0x5a, 0xcb, 0x1d, 0x9e,
+ 0xc4, 0x3d, 0x6d, 0x0e, 0xe0, 0x12, 0xb4, 0xe1, 0x6c, 0x55, 0x6f, 0xa3,
+ 0xf5, 0x1b, 0x0c, 0xe5, 0x1c, 0x99, 0x8b, 0x23, 0x23, 0xbc, 0x33, 0xe4,
+ 0xd4, 0x15, 0xfd, 0xcc, 0x90, 0x87, 0xb5, 0x0e, 0x24, 0xba, 0x20, 0x1b,
+ 0xcf, 0x67, 0x98, 0x1a, 0x35, 0xe7, 0xc3, 0x95, 0x29, 0xd6, 0xd2, 0x4f,
+ 0xe4, 0x14, 0xd5, 0xa1, 0x93, 0xff, 0x24, 0x0e, 0xfc, 0xb7, 0xd6, 0xde,
+ 0x05, 0xc5, 0x2f, 0xaa, 0x92, 0xd4, 0xd8, 0xac, 0x8f, 0x67, 0x45, 0xdb,
+ 0x36, 0x19, 0x15, 0x09, 0x9a, 0x3f, 0x2a, 0x56, 0xd5, 0xa9, 0x26, 0xb6,
+ 0xcb, 0x19, 0xf3, 0x6a, 0xbb, 0xba, 0xba, 0xa3, 0x68, 0x90, 0x0f, 0xb1,
+ 0x98, 0x14, 0x33, 0xd8, 0x12, 0xdf, 0xef, 0xe5, 0x01, 0x93, 0xab, 0xf8,
+ 0x93, 0x40, 0xbd, 0xa0, 0x01, 0x34, 0x54, 0xfd, 0xa0, 0xc4, 0xc3, 0xf3,
+ 0x6b, 0x90, 0x30, 0xc1, 0xbe, 0xd8, 0xbb, 0xab, 0x71, 0xaa, 0xe5, 0x3b,
+ 0x2d, 0x5d, 0x6e, 0x00, 0x34, 0xa8, 0x02, 0x34, 0xa9, 0x67, 0x95, 0xcd,
+ 0xed, 0xa2, 0x25, 0x55, 0xc9, 0x03, 0x1c, 0x30, 0xe7, 0xdf, 0xe6, 0xe7,
+ 0x2b, 0x5a, 0x9a, 0xcd, 0xa8, 0xf0, 0x4e, 0xe4, 0xd7, 0x90, 0x5f, 0x4e,
+ 0xbf, 0x5d, 0x68, 0x12, 0x1c, 0x4c, 0x68, 0x03, 0x9c, 0x49, 0xcb, 0xe6,
+ 0xc4, 0xfd, 0xad, 0xd5, 0xa8, 0xd8, 0xda, 0x2f, 0x13, 0xbc, 0x42, 0x61,
+ 0xa5, 0x0a, 0x1a, 0xe9, 0x5e, 0x5c, 0x01, 0x7c, 0xca, 0x73, 0x6f, 0x32,
+ 0xc1, 0x96, 0x24, 0x9d, 0x12, 0x20, 0x11, 0x6a, 0xf6, 0xbc, 0xff, 0x6a,
+ 0xc1, 0x58, 0x0d, 0xb9, 0xad, 0xc5, 0xde, 0x69, 0x37, 0xbe, 0xd9, 0x93,
+ 0xcc, 0x2b, 0xe9, 0x13, 0x45, 0xa0, 0x6c, 0x3f, 0x44, 0x34, 0xaf, 0x43,
+ 0x6d, 0xae, 0xef, 0xb2, 0x65, 0x03, 0xc1, 0xef, 0x10, 0x1e, 0xd8, 0x6e,
+ 0xb5, 0xb9, 0x03, 0xd8, 0x6e, 0x2f, 0x53, 0xe6, 0xc0, 0xaf, 0x44, 0xd2,
+ 0xd8, 0x15, 0x56, 0x15, 0x59, 0xd6, 0xd4, 0xe4, 0x1a, 0x25, 0xd5, 0xcf,
+ 0xe7, 0x6a, 0x55, 0xd4, 0xf8, 0x42, 0x4c, 0xcb, 0x9a, 0x48, 0x4d, 0x27,
+ 0x61, 0x4c, 0x36, 0x2b, 0xcb, 0x10, 0xba, 0xf7, 0xe3, 0x23, 0x27, 0xc5,
+ 0x6a, 0x1b, 0x94, 0x69, 0x64, 0xb1, 0x8c, 0xdb, 0xd4, 0x0d, 0x32, 0x3e,
+ 0x58, 0x73, 0xa8, 0x2f, 0x3d, 0x22, 0xd9, 0x0d, 0x2a, 0x52, 0xf0, 0xdd,
+ 0xeb, 0x21, 0x42, 0xc7, 0x59, 0x96, 0x09, 0x93, 0x5a, 0x70, 0xc3, 0x21,
+ 0x5f, 0xce, 0xc2, 0xdd, 0xcf, 0x61, 0xed, 0x1c, 0xfb, 0x2f, 0x57, 0xf7,
+ 0x31, 0xb8, 0x3e, 0x92, 0x29, 0xd4, 0x47, 0x6a, 0x19, 0x66, 0x00, 0xc2,
+ 0xc4, 0x6c, 0xb5, 0xc5, 0x68, 0x24, 0xa8, 0x64, 0x26, 0x72, 0x43, 0x20,
+ 0x9f, 0xf1, 0x3f, 0xac, 0x64, 0xb5, 0x12, 0x26, 0x13, 0x76, 0x52, 0x05,
+ 0xda, 0x57, 0xe3, 0x53, 0x73, 0x30, 0x21, 0x27, 0x75, 0x8d, 0x37, 0xd1,
+ 0x77, 0x40, 0x97, 0x2a, 0xb7, 0x0b, 0x2e, 0x9e, 0x4c, 0x36, 0x75, 0x44,
+ 0x15, 0xdb, 0x96, 0x70, 0xf9, 0x33, 0x9a, 0x1e, 0x6e, 0x13, 0x05, 0x38,
+ 0x2c, 0xbf, 0x0a, 0xdd, 0x2b, 0x2b, 0x38, 0x77, 0xa9, 0x00, 0x2d, 0x5e,
+ 0xee, 0x4b, 0xf3, 0x20, 0x7a, 0x90, 0x97, 0x44, 0xdf, 0x55, 0xfd, 0x50,
+ 0xe3, 0x24, 0x25, 0xa9, 0xd9, 0x3f, 0x6d, 0x09, 0x32, 0x67, 0xb5, 0x43,
+ 0xf1, 0xc7, 0xa7, 0xfb, 0x92, 0xde, 0xc3, 0xbf, 0x64, 0x6b, 0x35, 0xda,
+ 0x08, 0x94, 0x68, 0xb0, 0xc8, 0x3f, 0xb5, 0x9f, 0x15, 0x05, 0xff, 0x6c,
+ 0xbc, 0x22, 0x61, 0xf4, 0x67, 0xf8, 0x1f, 0x2e, 0x91, 0xc8, 0x12, 0xdc,
+ 0xcb, 0x22, 0x05, 0xb8, 0xab, 0x0d, 0x0e, 0xd7, 0x04, 0x8e, 0x32, 0x0e,
+ 0xfe, 0x72, 0x79, 0xc3, 0xba, 0xd8, 0x68, 0x3e, 0x5d, 0xab, 0xa0, 0xf8,
+ 0x26, 0x57, 0xe4, 0x20, 0x91, 0x0a, 0xde, 0x52, 0x95, 0xbc, 0xb7, 0x71,
+ 0x50, 0xe4, 0x3f, 0x07, 0x4c, 0xa8, 0x6a, 0xb6, 0xa0, 0x95, 0xe2, 0x31,
+ 0x8f, 0x5f, 0xfa, 0xdd, 0xee, 0x02, 0x23, 0x56, 0xf1, 0xdd, 0x1a, 0xa6,
+ 0xa0, 0x2d, 0x46, 0x36, 0x6c, 0x79, 0xe8, 0x67, 0x43, 0xdd, 0xe7, 0x2e,
+ 0x25, 0xda, 0x35, 0x6f, 0x63, 0xf1, 0x2c, 0x6c, 0x61, 0xaa, 0xb7, 0x51,
+ 0x91, 0xa1, 0x7c, 0x54, 0x9a, 0xf6, 0x3c, 0x3f, 0xa8, 0xba, 0x4d, 0xee,
+ 0xb6, 0xab, 0xa5, 0x05, 0xc6, 0xb6, 0xe8, 0x2f, 0x1b, 0x99, 0xb0, 0x45,
+ 0x3e, 0xc3, 0x50, 0x26, 0x0b, 0x10, 0x61, 0x5a, 0xc6, 0x25, 0x2d, 0x07,
+ 0xb6, 0x28, 0x59, 0xf3, 0xb4, 0x02, 0x61, 0xa0, 0xd0, 0x0a, 0xae, 0xd6,
+ 0x3c, 0xcc, 0x5f, 0xfb, 0xc0, 0xfd, 0xeb, 0x7b, 0xe2, 0x66, 0xc5, 0x98,
+ 0x70, 0x50, 0x31, 0x3a, 0x12, 0x45, 0xf4, 0x1c, 0xba, 0xa6, 0x92, 0x51,
+ 0xae, 0x68, 0xec, 0xb0, 0x1a, 0xd9, 0x45, 0x00, 0xd6, 0x9e, 0xad, 0x64,
+ 0xfe, 0xd9, 0xfb, 0xcc, 0x57, 0xff, 0x9e, 0xa3, 0x71, 0xe7, 0x7a, 0xaf,
+ 0x26, 0x31, 0x31, 0x6a, 0x41, 0xa4, 0x4d, 0x68, 0xbc, 0xcb, 0xfa, 0xb4,
+ 0x3a, 0x1c, 0x3a, 0x8f, 0xcd, 0xc1, 0x95, 0xb2, 0x46, 0x72, 0xf7, 0xfc,
+ 0x20, 0xe2, 0x2f, 0x0f, 0xbd, 0x74, 0xe1, 0x2a, 0xd5, 0xf6, 0xe9, 0xe1,
+ 0x45, 0x7d, 0x95, 0xb0, 0x49, 0xce, 0xe8, 0x53, 0x69, 0x46, 0x9d, 0x03,
+ 0x5f, 0x15, 0x2e, 0x92, 0x4c, 0xb7, 0xf1, 0x43, 0x67, 0x8a, 0x43, 0xc6,
+ 0x90, 0xec, 0xb5, 0x5d, 0xd5, 0x64, 0x16, 0x6e, 0xf0, 0xad, 0x4e, 0xf0,
+ 0x56, 0xe8, 0x77, 0xd5, 0x47, 0x47, 0x41, 0xc9, 0x98, 0x3a, 0xcb, 0xe0,
+ 0x01, 0x77, 0x93, 0x15, 0xe0, 0xd3, 0x93, 0xbe, 0xe1, 0x97, 0xe0, 0x21,
+ 0x60, 0x2b, 0xf1, 0x4a, 0x62, 0x29, 0x11, 0xe9, 0x61, 0x55, 0xc4, 0x57,
+ 0x04, 0xa8, 0xb3, 0xb3, 0x61, 0xd7, 0xa6, 0xce, 0x50, 0xd2, 0xc3, 0x38,
+ 0xda, 0xc2, 0x23, 0x67, 0x37, 0x09, 0xa7, 0xfd, 0x29, 0xdc, 0xcc, 0x52,
+ 0x65, 0xea, 0x3f, 0xcc, 0x67, 0x5e, 0x3b, 0xd4, 0x59, 0x59, 0x12, 0x9b,
+ 0xf1, 0xd2, 0x43, 0x46, 0x54, 0xcd, 0xb9, 0xbe, 0x71, 0xb6, 0x6d, 0x6a,
+ 0x62, 0xc5, 0x59, 0xc1, 0x21, 0xf7, 0x4c, 0x91, 0x64, 0xe0, 0xd7, 0xd9,
+ 0x34, 0x60, 0x0d, 0xb2, 0x93, 0xd8, 0xd3, 0x01, 0x8b, 0xf3, 0x9c, 0x6c,
+ 0xff, 0x63, 0xca, 0xd2, 0xf4, 0x76, 0xe3, 0x60, 0x52, 0x5c, 0x0e, 0xa3,
+ 0x13, 0xc8, 0xd9, 0xa7, 0x13, 0x6d, 0x1b, 0x29, 0xc0, 0xb1, 0x54, 0x31,
+ 0x33, 0x55, 0x44, 0x0a, 0x0a, 0x96, 0x3f, 0xf0, 0xb2, 0x64, 0x23, 0xa1,
+ 0xc8, 0x08, 0x01, 0x94, 0x2f, 0xc8, 0x0a, 0xfb, 0x93, 0x38, 0xe4, 0xc1,
+ 0xd9, 0xea, 0x46, 0x96, 0xdd, 0x5d, 0x62, 0xfc, 0xb0, 0x4d, 0x17, 0xe8,
+ 0xa0, 0xd4, 0x35, 0x98, 0x65, 0xb0, 0x27, 0x97, 0xbc, 0xe8, 0x48, 0x38,
+ 0x90, 0x9b, 0x6e, 0xf1, 0xd2, 0x17, 0x1b, 0xbf, 0x03, 0xc6, 0xa3, 0x42,
+ 0xaf, 0xdc, 0x44, 0x9d, 0x9e, 0x69, 0x67, 0x33, 0x61, 0xfb, 0x96, 0xfa,
+ 0xff, 0xf4, 0xa8, 0x3c, 0xb6, 0x42, 0xd2, 0x4c, 0xc0, 0xa8, 0x2a, 0x4b,
+ 0x37, 0x78, 0x41, 0x94, 0xf6, 0x04, 0xb9, 0x54, 0xe4, 0x2b, 0xfc, 0xed,
+ 0xf5, 0xf7, 0x62, 0x23, 0x44, 0xc4, 0xd7, 0x5a, 0xeb, 0xc2, 0x3d, 0x4c,
+ 0x41, 0x22, 0xa0, 0xe3, 0x22, 0xbc, 0x91, 0x69, 0x37, 0x3f, 0x94, 0xfd,
+ 0x07, 0xa7, 0x6e, 0x53, 0x27, 0xdc, 0xb0, 0x14, 0x8d, 0x0a, 0x08, 0x31,
+ 0xba, 0xf0, 0xd0, 0xda, 0xa6, 0x7a, 0xc0, 0x4c, 0x9d, 0x3b, 0x8f, 0xee,
+ 0x11, 0xc7, 0x9f, 0xc9, 0xcc, 0x4c, 0x26, 0x51, 0xb4, 0x10, 0xde, 0xc2,
+ 0xa3, 0xe0, 0xaa, 0x7c, 0x9c, 0x27, 0x8d, 0x04, 0x8e, 0xfc, 0xe4, 0x68,
+ 0x93, 0xf9, 0x67, 0x28, 0xa0, 0xe6, 0xca, 0xbd, 0x5a, 0x64, 0x98, 0x9f,
+ 0xe3, 0x7b, 0x16, 0x5d, 0x61, 0xcc, 0x4c, 0x64, 0x04, 0x1b, 0xcc, 0xa6,
+ 0xa2, 0x31, 0x28, 0xa2, 0xac, 0xd0, 0xce, 0x40, 0x19, 0xe7, 0xf9, 0xea,
+ 0xc5, 0x98, 0x50, 0x16, 0x38, 0xad, 0x58, 0x21, 0x2e, 0x10, 0x48, 0x4f,
+ 0xe7, 0xc0, 0xc0, 0x6c, 0xcd, 0xe2, 0xc3, 0xcd, 0xc5, 0xfc, 0x26, 0x91,
+ 0xea, 0xcf, 0x52, 0x97, 0x9f, 0xdc, 0x2c, 0x45, 0xd8, 0x50, 0xf8, 0x75,
+ 0xa2, 0x93, 0x52, 0x2b, 0x23, 0xd3, 0x30, 0x9d, 0xa7, 0xf7, 0xbb, 0xc2,
+ 0xd2, 0xb7, 0x9d, 0xec, 0xf9, 0x9a, 0xec, 0x3e, 0xc0, 0xce, 0x64, 0xb8,
+ 0xf5, 0x41, 0x4e, 0x06, 0xa1, 0x25, 0xf2, 0x40, 0xee, 0x07, 0xec, 0x6d,
+ 0x9a, 0xd0, 0x5c, 0xdd, 0xe9, 0xf5, 0x56, 0xf9, 0x2e, 0xf5, 0xdb, 0x69,
+ 0xc9, 0x3e, 0xb5, 0x0c, 0xbc, 0x29, 0xa4, 0xa9, 0x55, 0x9b, 0xf6, 0xab,
+ 0x1f, 0x55, 0x9d, 0x25, 0xd2, 0xde, 0x3f, 0xa0, 0xe5, 0x1c, 0xb3, 0x90,
+ 0x2f, 0x6c, 0xaf, 0xb5, 0x6d, 0x23, 0x15, 0xab, 0x91, 0x55, 0x5f, 0x02,
+ 0x20, 0x22, 0x8e, 0xc1, 0x4a, 0x63, 0xa6, 0x5e, 0x85, 0x99, 0x58, 0xdc,
+ 0xde, 0xb0, 0x76, 0x9f, 0x21, 0x4d, 0xe9, 0x47, 0xcc, 0x3f, 0x02, 0x91,
+ 0x75, 0x67, 0xe5, 0x6a, 0x2c, 0xc3, 0x69, 0x95, 0x2d, 0x74, 0x77, 0xf7,
+ 0x1d, 0xe1, 0x12, 0x2b, 0xcf, 0x4c, 0x7b, 0xcf, 0xbe, 0x24, 0x1d, 0x07,
+ 0x34, 0xd3, 0x67, 0xa8, 0xb9, 0x76, 0x2a, 0x3e, 0xfd, 0xb5, 0xcd, 0xf6,
+ 0x29, 0x07, 0x4e, 0x17, 0xcf, 0x28, 0xdd, 0x90, 0x4b, 0x17, 0x24, 0x55,
+ 0xdc, 0x78, 0xe5, 0xf4, 0x97, 0x31, 0x3d, 0xfa, 0x96, 0xe2, 0x99, 0x61,
+ 0xb1, 0xcb, 0xa4, 0x7b, 0x4e, 0x5d, 0x6a, 0xf8, 0xb2, 0x79, 0xfc, 0xa9,
+ 0xd9, 0x27, 0x46, 0xdd, 0x52, 0xdf, 0x24, 0x66, 0x1c, 0xa6, 0xbc, 0x18,
+ 0x13, 0x72, 0x38, 0x53, 0xac, 0x1b, 0x67, 0x1f, 0x30, 0xae, 0x5a, 0xf3,
+ 0x55, 0xd0, 0xe1, 0x23, 0x9a, 0x46, 0xa4, 0xbb, 0x68, 0x73, 0x30, 0xda,
+ 0xb7, 0x3b, 0xff, 0xd1, 0x0d, 0xe0, 0xf7, 0xda, 0x36, 0x3a, 0x7a, 0x19,
+ 0xf5, 0x2e, 0xf4, 0xda, 0xa4, 0x09, 0x94, 0xb8, 0x18, 0xad, 0x6b, 0xf6,
+ 0x64, 0xbf, 0x2a, 0x04, 0xc6, 0xde, 0x0f, 0x45, 0x27, 0x3a, 0x3d, 0x61,
+ 0xf5, 0xde, 0x38, 0x1d, 0x23, 0x23, 0x70, 0x00, 0xfc, 0x0c, 0x5c, 0x96,
+ 0xc1, 0x21, 0x78, 0x25, 0x24, 0x71, 0xd1, 0xe2, 0xe9, 0x1a, 0x2f, 0x48,
+ 0x4d, 0x09, 0x24, 0x27, 0xe4, 0xe7, 0x42, 0x76, 0x92, 0x93, 0x7a, 0x62,
+ 0x76, 0xc6, 0xd7, 0xdf, 0xe4, 0x5e, 0x0e, 0xfc, 0x4e, 0x0a, 0x65, 0x63,
+ 0x51, 0x90, 0xfd, 0x92, 0x5f, 0x9a, 0x49, 0xa9, 0x6c, 0xb1, 0xb6, 0xe6,
+ 0xab, 0xf7, 0xb9, 0x39, 0xc0, 0xed, 0x1d, 0x65, 0x9c, 0x24, 0x21, 0xc1,
+ 0x0d, 0xd6, 0x9a, 0xbe, 0xd4, 0x74, 0xa2, 0x70, 0xab, 0x0b, 0x45, 0xf0,
+ 0xc9, 0xaa, 0xf1, 0x49, 0x0b, 0x6c, 0x20, 0xdc, 0x37, 0x2b, 0x13, 0x68,
+ 0x48, 0x0e, 0xd8, 0xd1, 0x67, 0xd8, 0xa3, 0x7e, 0xd7, 0xb7, 0x50, 0xc8,
+ 0x14, 0x58, 0x6a, 0x04, 0xa5, 0x70, 0x22, 0x2d, 0x41, 0xea, 0x28, 0xb7,
+ 0xf0, 0xde, 0xc4, 0xe4, 0x5b, 0x4d, 0xc1, 0x33, 0x9e, 0x14, 0x32, 0xa8,
+ 0x9b, 0xc8, 0xd9, 0x5b, 0x95, 0x2a, 0x91, 0x9d, 0xe8, 0x15, 0x19, 0x9b,
+ 0x38, 0xf3, 0x35, 0x69, 0x3e, 0xd3, 0x4b, 0xcc, 0xf2, 0x94, 0x5a, 0xaf,
+ 0x91, 0xa4, 0xa1, 0x03, 0x48, 0x5f, 0x6d, 0x16, 0x56, 0x03, 0x5a, 0xcb,
+ 0x99, 0x19, 0x45, 0x9c, 0xba, 0xc9, 0xbc, 0x5b, 0x0f, 0xf5, 0xde, 0x70,
+ 0xa3, 0x70, 0x0d, 0x3f, 0x3e, 0x5c, 0x4d, 0x5a, 0x1a, 0x46, 0x1b, 0x44,
+ 0x4a, 0x73, 0xfa, 0xb1, 0xc4, 0x42, 0x7b, 0x0c, 0x15, 0x0d, 0x35, 0xc4,
+ 0xa3, 0xea, 0x17, 0xa0, 0x0b, 0xfb, 0x4d, 0x1b, 0x2f, 0x96, 0x1f, 0xaa,
+ 0xc0, 0xad, 0xdc, 0xf3, 0xb2, 0xb1, 0x44, 0x1f, 0x39, 0xc7, 0x33, 0x18,
+ 0xad, 0xe1, 0x50, 0x7d, 0xf9, 0x2a, 0x90, 0xf2, 0x06, 0xce, 0x07, 0xae,
+ 0x9f, 0xbc, 0x4d, 0xae, 0x30, 0xdd, 0x47, 0xa2, 0xd3, 0x6d, 0x0c, 0xc6,
+ 0xb7, 0xae, 0xf5, 0x38, 0xa3, 0x00, 0x59, 0x6a, 0x00, 0x04, 0xd2, 0x77,
+ 0x0a, 0x58, 0xc9, 0xaf, 0x1b, 0x59, 0x29, 0xf3, 0xdd, 0x58, 0xcf, 0xa1,
+ 0x6d, 0xb4, 0x66, 0x23, 0x9f, 0x9b, 0x41, 0x2a, 0xc8, 0x28, 0x34, 0x77,
+ 0x3a, 0x1f, 0xa5, 0xde, 0x4b, 0x3f, 0xc7, 0x19, 0xf5, 0xdb, 0x98, 0xc4,
+ 0x6c, 0x2f, 0x34, 0x20, 0xc9, 0x52, 0x16, 0x60, 0xbc, 0x04, 0xd5, 0xff,
+ 0x4b, 0x07, 0x28, 0x5a, 0x3a, 0x48, 0x5b, 0x96, 0xee, 0x1f, 0xf1, 0xb4,
+ 0x9b, 0xb5, 0x64, 0xde, 0x1c, 0xd5, 0x3c, 0x1b, 0x98, 0x11, 0xc7, 0x0b,
+ 0x97, 0x00, 0x2f, 0x8f, 0xf9, 0x24, 0x4d, 0xba, 0x75, 0x6a, 0xce, 0xd8,
+ 0x7a, 0xee, 0x02, 0xd5, 0x19, 0xd6, 0x26, 0x40, 0xa7, 0x78, 0x76, 0x1a,
+ 0x17, 0xc2, 0xe6, 0x5a, 0x6e, 0x24, 0xb1, 0x17, 0xf8, 0x9f, 0xdc, 0x64,
+ 0xf0, 0x59, 0xc5, 0xfc, 0x4c, 0xbb, 0x3d, 0x3f, 0x70, 0x2c, 0x0d, 0xf5,
+ 0x6c, 0x96, 0x46, 0x1a, 0x1e, 0x5f, 0xd1, 0x3a, 0x00, 0x9a, 0x9d, 0x63,
+ 0xe6, 0xd1, 0xa2, 0x5a, 0x4a, 0x50, 0xa8, 0xd5, 0x91, 0x90, 0x69, 0x58,
+ 0x65, 0x00, 0xc7, 0xf1, 0xa6, 0x45, 0xfd, 0x5a, 0xe6, 0x05, 0x4b, 0xb2,
+ 0x3a, 0xdf, 0xa9, 0xd9, 0xe5, 0xa6, 0xe5, 0xe2, 0x5b, 0x3b, 0x2f, 0x57,
+ 0x6c, 0xc4, 0x06, 0xe1, 0x8e, 0x15, 0x98, 0xc8, 0x5e, 0x63, 0xba, 0x37,
+ 0xe6, 0x91, 0x5f, 0x1c, 0x5b, 0x77, 0xb5, 0x91, 0x07, 0x3a, 0xa6, 0x67,
+ 0x6d, 0xdf, 0x15, 0x62, 0x6b, 0x3b, 0xed, 0xa2, 0xc7, 0x46, 0x52, 0x8f,
+ 0xf2, 0x9f, 0x69, 0x00, 0xb8, 0x49, 0xcf, 0xd4, 0xf0, 0x95, 0x51, 0xda,
+ 0x0f, 0x4e, 0x0d, 0x11, 0x2f, 0x27, 0x73, 0xe9, 0x13, 0xcb, 0xa1, 0xfc,
+ 0x6b, 0x45, 0xf0, 0xfd, 0xc7, 0x17, 0xaa, 0x0c, 0xac, 0x98, 0xc4, 0x6c,
+ 0xf0, 0x32, 0x45, 0x67, 0xfe, 0x6f, 0x2e, 0xfb, 0xec, 0x19, 0xda, 0xbd,
+ 0x93, 0x5f, 0x50, 0xc2, 0x22, 0x9a, 0x3a, 0x5b, 0x31, 0xf5, 0x4e, 0x91,
+ 0xa6, 0xea, 0x67, 0xdd, 0x69, 0xf4, 0xd7, 0xea, 0x02, 0xbe, 0x55, 0x52,
+ 0xb9, 0x30, 0x21, 0xe5, 0xfc, 0x9a, 0x93, 0xd6, 0x6c, 0x33, 0x06, 0xb9,
+ 0xe3, 0xb0, 0x6a, 0xff, 0x9e, 0xc2, 0x5e, 0x1d, 0xd6, 0xdb, 0xa1, 0x60,
+ 0x34, 0x5d, 0x08, 0xf9, 0xeb, 0xd6, 0x1f, 0x90, 0xf1, 0xf4, 0x07, 0x47,
+ 0xbf, 0xd9, 0xc9, 0xe8, 0xcf, 0xce, 0xa5, 0x1d, 0xb0, 0xd9, 0xbe, 0xc7,
+ 0xfb, 0xcc, 0xac, 0x3e, 0x92, 0x59, 0x0d, 0x1d, 0x65, 0x16, 0xa3, 0xdc,
+ 0x9b, 0x72, 0x22, 0x46, 0x04, 0xca, 0xb3, 0x5a, 0x2f, 0x3d, 0x99, 0x5c,
+ 0xb5, 0xb9, 0x30, 0xe3, 0xde, 0x8c, 0xba, 0xc7, 0x4c, 0xe5, 0x34, 0x6e,
+ 0xf4, 0x75, 0xf4, 0x38, 0x01, 0xf1, 0x61, 0xb8, 0x2b, 0xc3, 0x6f, 0xae,
+ 0xd1, 0x0a, 0x9d, 0x48, 0xc9, 0xe7, 0xc3, 0xe7, 0xc9, 0xe1, 0x6f, 0x96,
+ 0xa0, 0xc2, 0x91, 0xfd, 0xad, 0x99, 0x48, 0xde, 0xfc, 0xa3, 0x6e, 0xe3,
+ 0x94, 0x0e, 0xb5, 0xf6, 0x24, 0x8b, 0xce, 0x70, 0x3c, 0xdc, 0xe2, 0x66,
+ 0x9f, 0xe3, 0x6b, 0xc5, 0xd1, 0x97, 0x38, 0x12, 0x46, 0x37, 0xd6, 0x9a,
+ 0x4c, 0x6d, 0x4a, 0x2d, 0xc3, 0x28, 0x20, 0x2f, 0x55, 0x67, 0x17, 0x71,
+ 0xd3, 0x5c, 0xdc, 0xa3, 0x23, 0x60, 0x25, 0x2d, 0xe0, 0xc2, 0xed, 0xee,
+ 0x67, 0x9f, 0x26, 0xfb, 0x2f, 0x63, 0xf2, 0x6a, 0x23, 0x45, 0x26, 0x2c,
+ 0x33, 0x8a, 0xf2, 0xd1, 0xb2, 0x77, 0x99, 0x98, 0xd6, 0x18, 0xfe, 0xf3,
+ 0xff, 0xa4, 0x36, 0x03, 0xf4, 0xf5, 0xb1, 0xca, 0xa3, 0x5f, 0xe2, 0xc6,
+ 0xb2, 0x55, 0x2c, 0xaa, 0x64, 0xef, 0x28, 0x3a, 0x9e, 0x98, 0x01, 0x57,
+ 0x49, 0x98, 0x61, 0x4f, 0x42, 0x57, 0x00, 0x19, 0xb9, 0xa8, 0xec, 0xed,
+ 0x2b, 0x63, 0xf3, 0x0c, 0x3a, 0x1f, 0x10, 0xab, 0xe9, 0x6e, 0x61, 0x69,
+ 0xd1, 0x2d, 0xf3, 0x1f, 0xaa, 0x00, 0x57, 0xe2, 0xab, 0x74, 0xcd, 0xff,
+ 0x97, 0x2c, 0x3b, 0x67, 0xae, 0xa3, 0xfc, 0x69, 0xa9, 0x4e, 0x42, 0x07,
+ 0xfc, 0xbf, 0x36, 0x1a, 0xef, 0x6d, 0x6d, 0x14, 0x61, 0x30, 0x27, 0x98,
+ 0xfa, 0xf8, 0xc9, 0x70, 0xb4, 0xaa, 0x53, 0x48, 0x72, 0x3f, 0x58, 0x69,
+ 0x8d, 0x08, 0xc8, 0x09, 0x2b, 0xfc, 0x1d, 0xa1, 0x92, 0xae, 0x62, 0xa0,
+ 0xea, 0x05, 0x40, 0xac, 0x9c, 0xaf, 0x0e, 0xf4, 0x1e, 0x45, 0x33, 0xee,
+ 0x31, 0x39, 0x08, 0x4b, 0x54, 0x02, 0x2d, 0x03, 0x1c, 0xe6, 0x2d, 0x0c,
+ 0xd0, 0x92, 0x44, 0xd6, 0xa1, 0x57, 0x4e, 0x17, 0xde, 0xe6, 0x4f, 0x6a,
+ 0x07, 0x9f, 0x58, 0xe2, 0x27, 0xdb, 0xa9, 0x0c, 0x19, 0x56, 0xa3, 0xb4,
+ 0xc4, 0xe8, 0xa3, 0x52, 0x9f, 0x6a, 0xc9, 0xb1, 0xda, 0xe9, 0xef, 0x12,
+ 0xc1, 0x6d, 0x5b, 0x04, 0x20, 0x93, 0xac, 0xf4, 0x38, 0x95, 0xdb, 0x50,
+ 0xa6, 0x2e, 0x5c, 0x3f, 0x2d, 0x32, 0x50, 0x03, 0x73, 0x64, 0x3a, 0xd5,
+ 0xfd, 0x98, 0x1c, 0x57, 0xc3, 0xe7, 0xf7, 0x14, 0x13, 0x15, 0x2a, 0xa2,
+ 0x5f, 0xa0, 0x67, 0xdd, 0x67, 0x00, 0x09, 0xc6, 0xfe, 0xad, 0x06, 0x4c,
+ 0x5e, 0x9a, 0x5b, 0x55, 0x06, 0x8c, 0x9a, 0x2a, 0x51, 0x0e, 0x4f, 0x15,
+ 0xcc, 0xe1, 0x53, 0x9c, 0x43, 0x37, 0xc1, 0x3e, 0x02, 0x4b, 0x98, 0x6f,
+ 0x9b, 0x60, 0x31, 0x2c, 0x2b, 0x9d, 0xda, 0xe0, 0x1d, 0xe4, 0x49, 0x66,
+ 0x65, 0x18, 0xfb, 0x24, 0x97, 0xe0, 0x2d, 0xf5, 0x44, 0x23, 0x09, 0x01,
+ 0xf9, 0xf5, 0x29, 0xff, 0x01, 0x36, 0xb9, 0x0e, 0x9b, 0xb3, 0x23, 0x1e,
+ 0xe5, 0x12, 0xbb, 0x3a, 0x04, 0x14, 0xb8, 0x23, 0x43, 0x95, 0xc1, 0x9d,
+ 0x57, 0x45, 0x46, 0x4c, 0x8f, 0x35, 0x25, 0x5f, 0x2b, 0xd9, 0xc6, 0xdd,
+ 0x61, 0xb8, 0xbb, 0x4d, 0x49, 0xef, 0x6e, 0x0c, 0x50, 0x07, 0xc9, 0x9b,
+ 0x2e, 0xb7, 0xbe, 0x23, 0xc3, 0xcf, 0x9d, 0xeb, 0x13, 0xc8, 0xeb, 0x72,
+ 0x51, 0x71, 0x69, 0x35, 0xf3, 0xce, 0x35, 0x45, 0x02, 0xba, 0x44, 0x5d,
+ 0xaf, 0xd0, 0xe5, 0x1d, 0x9b, 0x18, 0xbb, 0x62, 0xce, 0xaf, 0x40, 0x48,
+ 0x40, 0x2a, 0x5d, 0xcd, 0xa7, 0x2b, 0x8f, 0xf4, 0x4a, 0x4c, 0xe1, 0x59,
+ 0x40, 0x63, 0x33, 0xae, 0xd8, 0x9d, 0x4d, 0x11, 0x3d, 0x2d, 0x11, 0xc6,
+ 0x8c, 0xa9, 0xab, 0xa2, 0x08, 0xb8, 0xbf, 0x09, 0x66, 0xbc, 0xd7, 0xab,
+ 0xce, 0x0d, 0xe0, 0x9e, 0x51, 0x2f, 0x5c, 0xc7, 0x21, 0xb9, 0xcf, 0xc4,
+ 0x8b, 0xc0, 0x4b, 0x04, 0x1b, 0xfd, 0x43, 0xcf, 0xa4, 0x72, 0x62, 0x04,
+ 0x0b, 0x1f, 0x9f, 0x35, 0x9d, 0xa9, 0x19, 0x71, 0x06, 0xda, 0x03, 0x0f,
+ 0xcc, 0x3a, 0xf4, 0x3a, 0xaf, 0x07, 0x0f, 0xf2, 0x3e, 0x4a, 0xd3, 0x41,
+ 0x6a, 0x90, 0x35, 0x39, 0x4c, 0x1d, 0x2f, 0x05, 0xff, 0xcf, 0xc0, 0xbe,
+ 0x0f, 0xaf, 0x90, 0x4e, 0x45, 0x8c, 0x78, 0x4d, 0x6b, 0xf2, 0x47, 0x26,
+ 0xe9, 0x0d, 0xee, 0xd3, 0x97, 0x44, 0xaf, 0x6f, 0x95, 0x30, 0x9c, 0x08,
+ 0xe5, 0x18, 0x9e, 0xad, 0xd2, 0x2a, 0x0c, 0x21, 0x67, 0x50, 0x28, 0x4f,
+ 0x31, 0x9c, 0xee, 0xb2, 0x95, 0xbd, 0xef, 0xc0, 0xd0, 0x0d, 0xd4, 0x6e,
+ 0xff, 0x93, 0x12, 0xc3, 0x51, 0x41, 0xe4, 0x6c, 0x19, 0x09, 0xd7, 0x0a,
+ 0xe0, 0xea, 0x0a, 0xe7, 0xa8, 0x4b, 0x60, 0xd6, 0x0c, 0x4d, 0xb5, 0x29,
+ 0x01, 0x74, 0xf9, 0x40, 0x8c, 0x6b, 0x11, 0xf6, 0xe4, 0xc9, 0x3c, 0x1a,
+ 0xf7, 0xce, 0x2c, 0xd8, 0xe3, 0x0e, 0xc5, 0xb9, 0x6c, 0x40, 0x44, 0xc9,
+ 0x04, 0xf6, 0x5c, 0xe1, 0x9f, 0xc7, 0xe0, 0x68, 0xe7, 0x6a, 0x92, 0xe7,
+ 0xb2, 0x12, 0x72, 0x3f, 0xfd, 0xc3, 0x06, 0xeb, 0x0a, 0xab, 0x6d, 0xad,
+ 0x03, 0x0b, 0x5d, 0xcc, 0x49, 0x04, 0x52, 0x19, 0xd4, 0x9d, 0x67, 0xbf,
+ 0xd3, 0xf4, 0x22, 0x76, 0x99, 0x52, 0xf5, 0xb5, 0x15, 0x38, 0x58, 0x57,
+ 0x9a, 0xa2, 0xd1, 0xbb, 0x3a, 0x07, 0xe2, 0xd6, 0x8d, 0x69, 0x9e, 0x5c,
+ 0xf4, 0xba, 0xda, 0x4a, 0x4d, 0x73, 0xdc, 0x32, 0xfd, 0xe1, 0x3a, 0x16,
+ 0xf1, 0x09, 0x26, 0x3b, 0x2a, 0xa9, 0xa7, 0x2c, 0xd3, 0xcf, 0x6b, 0xc5,
+ 0xb5, 0xbc, 0x71, 0xb6, 0x9e, 0xa0, 0x6a, 0x69, 0xa5, 0xeb, 0x54, 0x87,
+ 0xe9, 0x4f, 0x69, 0x39, 0xc5, 0x54, 0x28, 0x55, 0xb9, 0xff, 0x5d, 0x9e,
+ 0x17, 0x8e, 0x8c, 0xd5, 0x14, 0x5c, 0xa7, 0x33, 0x5a, 0x2f, 0x2d, 0x37,
+ 0x0e, 0xf2, 0x54, 0x64, 0x9d, 0xdf, 0x49, 0xab, 0xd3, 0x0f, 0xbd, 0xad,
+ 0x19, 0xb9, 0xcf, 0x0f, 0x40, 0x62, 0x4b, 0x93, 0xd7, 0xf4, 0x3b, 0xee,
+ 0x2b, 0x97, 0xe3, 0x55, 0xb3, 0x5b, 0x3f, 0x93, 0xa5, 0xf1, 0x40, 0x99,
+ 0xa1, 0x69, 0xbd, 0xf3, 0xf0, 0xb1, 0x6e, 0x5c, 0xba, 0x4a, 0xc4, 0x51,
+ 0x8e, 0xe1, 0x5c, 0xb8, 0x92, 0xb5, 0x43, 0xc4, 0x9e, 0x38, 0x0d, 0xfb,
+ 0x60, 0xb3, 0xe6, 0x0f, 0x55, 0x94, 0x01, 0xaf, 0xaa, 0xc3, 0x6d, 0xea,
+ 0xb2, 0xfc, 0xb0, 0x06, 0x29, 0x0f, 0xd3, 0x95, 0xb9, 0xf1, 0x8b, 0xce,
+ 0xd3, 0x5d, 0x16, 0xbf, 0x5c, 0x24, 0xc5, 0x36, 0x98, 0x8c, 0x5b, 0x43,
+ 0xe7, 0xfe, 0x77, 0xda, 0xc5, 0xd8, 0xf6, 0x72, 0xba, 0xcf, 0x9c, 0x18,
+ 0x58, 0xb8, 0xe4, 0x1d, 0xf6, 0xfb, 0x3b, 0xb4, 0x1f, 0xea, 0xa3, 0xe3,
+ 0xd5, 0xbe, 0x3f, 0xd5, 0xf9, 0xc4, 0x00, 0x8e, 0x17, 0x22, 0x3d, 0x96,
+ 0xd8, 0xb6, 0xa5, 0xf6, 0xcd, 0x55, 0x48, 0x8b, 0x1b, 0x38, 0x9c, 0xd7,
+ 0x6d, 0x40, 0x2a, 0x5f, 0xcf, 0xcb, 0x67, 0xa4, 0x8c, 0xf4, 0x8f, 0x70,
+ 0x34, 0xeb, 0x70, 0xcd, 0xee, 0x1c, 0xbd, 0xae, 0xd1, 0xc1, 0xf8, 0x62,
+ 0x45, 0xb5, 0x5d, 0xe6, 0x0b, 0xd4, 0x3d, 0x23, 0xf0, 0x27, 0x44, 0x56,
+ 0x32, 0x4d, 0xb1, 0x6c, 0x5d, 0x33, 0x94, 0x77, 0xe3, 0xac, 0x54, 0x56,
+ 0x24, 0x05, 0x26, 0x4a, 0xf0, 0x59, 0xfb, 0x1f, 0xa4, 0x0f, 0xbe, 0x9e,
+ 0xbc, 0x76, 0x9d, 0x5a, 0xed, 0x15, 0x97, 0x4e, 0x05, 0x8a, 0x8b, 0xff,
+ 0xc7, 0x9b, 0x67, 0x32, 0x12, 0x41, 0x04, 0xcb, 0x24, 0xae, 0x9e, 0xcc,
+ 0xd6, 0xc6, 0x67, 0x53, 0xfa, 0x29, 0x37, 0x73, 0xc6, 0xdf, 0xf2, 0x56,
+ 0x72, 0x06, 0x03, 0xaa, 0x5d, 0x07, 0xac, 0x38, 0xb9, 0x2a, 0x61, 0x02,
+ 0x24, 0xcf, 0x54, 0x3f, 0x98, 0xb0, 0x5c, 0xba, 0xe3, 0x15, 0x27, 0x52,
+ 0x63, 0x43, 0x12, 0x62, 0x33, 0x02, 0xb8, 0x69, 0x52, 0x70, 0x6c, 0xc0,
+ 0x23, 0x37, 0x65, 0x4b, 0xc9, 0xea, 0x98, 0x06, 0xde, 0x3d, 0x59, 0x72,
+ 0x94, 0x48, 0x60, 0xeb, 0xe7, 0xaa, 0x68, 0x72, 0x22, 0x15, 0x39, 0xf0,
+ 0x47, 0x43, 0xeb, 0x37, 0xb1, 0x3b, 0x9e, 0x05, 0x12, 0xdb, 0x74, 0x18,
+ 0xfe, 0x11, 0xcb, 0xae, 0xe0, 0xed, 0x1c, 0xe3, 0x19, 0x71, 0x56, 0xa6,
+ 0x04, 0xe6, 0x20, 0x62, 0xfd, 0xb1, 0x57, 0x44, 0xca, 0x3f, 0xdf, 0x51,
+ 0x23, 0x76, 0x3b, 0x70, 0x27, 0x33, 0x62, 0x74, 0x94, 0xff, 0x70, 0xcc,
+ 0xd4, 0xbf, 0x67, 0x12, 0x17, 0x5f, 0x71, 0xf8, 0x8f, 0x09, 0xca, 0xb5,
+ 0x49, 0x38, 0xcf, 0x1f, 0x94, 0x9a, 0xe6, 0x76, 0x0e, 0xa6, 0x5a, 0x2c,
+ 0x36, 0x61, 0x41, 0x2d, 0x14, 0x2f, 0x35, 0xa2, 0xaa, 0x2d, 0xd5, 0x54,
+ 0x3c, 0x4e, 0xa0, 0x63, 0xa9, 0x9e, 0xe9, 0x65, 0x62, 0xcf, 0x5a, 0x1a,
+ 0xb9, 0x70, 0xf7, 0xf1, 0x8a, 0xc7, 0x19, 0x6e, 0x34, 0xa0, 0xbb, 0x1b,
+ 0x76, 0x9b, 0x60, 0x20, 0xfd, 0xff, 0xe1, 0x40, 0x5e, 0xd7, 0x49, 0xd3,
+ 0x3c, 0x0f, 0x52, 0xae, 0x37, 0x38, 0x1d, 0xd5, 0xd0, 0xe7, 0xd6, 0xfc,
+ 0x06, 0x3b, 0x50, 0x06, 0x9c, 0xb4, 0x37, 0x9a, 0x53, 0x09, 0x56, 0xa4,
+ 0xa8, 0x64, 0x70, 0xa7, 0xaf, 0xb9, 0xd9, 0x19, 0xbc, 0x5b, 0x04, 0x07,
+ 0x68, 0xc0, 0xa4, 0xc0, 0x3d, 0x32, 0x36, 0x94, 0x24, 0xd3, 0x36, 0x1f,
+ 0xfc, 0xd8, 0x26, 0x49, 0x94, 0xd2, 0x1e, 0x8b, 0x0c, 0x70, 0x6e, 0xd7,
+ 0xd2, 0x37, 0x8f, 0x13, 0xef, 0x41, 0xdb, 0x53, 0xb5, 0xba, 0xe5, 0xe3,
+ 0x0c, 0xcd, 0xa3, 0xfa, 0x74, 0x16, 0xd9, 0x42, 0x10, 0xa3, 0xe6, 0x26,
+ 0xd6, 0x74, 0xbc, 0x17, 0x9b, 0x2e, 0x4c, 0xe2, 0x13, 0x49, 0x0f, 0xc9,
+ 0xc2, 0x34, 0xae, 0x5b, 0x6b, 0x46, 0xbc, 0xc4, 0x62, 0xa0, 0x4a, 0x18,
+ 0x62, 0x69, 0x1c, 0xc3, 0x78, 0x36, 0xfa, 0xd9, 0x8d, 0xd0, 0xf9, 0x4f,
+ 0x56, 0x90, 0x4b, 0xca, 0xc4, 0xdd, 0x64, 0x2c, 0xd1, 0x3c, 0xa8, 0xbe,
+ 0x62, 0x8f, 0x2a, 0x11, 0x93, 0x71, 0x75, 0x70, 0x43, 0xd0, 0x5f, 0xfb,
+ 0x36, 0x2b, 0x35, 0x26, 0xda, 0xda, 0x25, 0x3c, 0x17, 0xf2, 0xb7, 0x36,
+ 0xd7, 0x8d, 0xd1, 0xbc, 0x2f, 0xe7, 0xf8, 0x55, 0x42, 0x2e, 0xe1, 0xc0,
+ 0x4a, 0xee, 0x3d, 0x5b, 0xc9, 0x69, 0x15, 0xc5, 0x42, 0x03, 0x2c, 0x46,
+ 0x02, 0x94, 0x91, 0xfb, 0x0f, 0x98, 0x8d, 0x32, 0xdf, 0x0b, 0x19, 0xda,
+ 0x9f, 0x96, 0x6e, 0x2d, 0xc4, 0xa1, 0x92, 0xc1, 0x73, 0x2f, 0x23, 0x9f,
+ 0x55, 0xc5, 0xb4, 0x8c, 0xef, 0xf3, 0xa2, 0x94, 0x8f, 0x6c, 0xd8, 0xb1,
+ 0x9d, 0x0d, 0x17, 0x93, 0x21, 0xd7, 0xae, 0xa8, 0x41, 0xd3, 0xf1, 0x9a,
+ 0xe3, 0x36, 0xca, 0x5f, 0xa4, 0xd9, 0xaf, 0x34, 0xbf, 0xe6, 0x9e, 0x4c,
+ 0xf0, 0xd1, 0xb0, 0x8c, 0x8e, 0x76, 0x3d, 0xb3, 0xf7, 0xd9, 0xfb, 0xbf,
+ 0x72, 0xae, 0xa8, 0x39, 0x00, 0xe5, 0x53, 0x17, 0x6c, 0x4e, 0x06, 0x22,
+ 0xc0, 0x10, 0xe7, 0x4d, 0xff, 0x75, 0x03, 0x01, 0x18, 0x46, 0xfd, 0xde,
+ 0x1e, 0x95, 0x46, 0xb8, 0x5b, 0x36, 0xbc, 0x1d, 0x95, 0x05, 0x8f, 0x5d,
+ 0x38, 0x41, 0x25, 0x2c, 0x9b, 0x34, 0x75, 0x9b, 0xf0, 0x8b, 0xaf, 0x0d,
+ 0x2e, 0xc2, 0x1a, 0x03, 0x61, 0xbe, 0xe8, 0x49, 0xbc, 0x9b, 0x45, 0xfb,
+ 0x35, 0x2b, 0x6c, 0xa1, 0x96, 0xa0, 0x08, 0x0e, 0xca, 0x01, 0xc0, 0x97,
+ 0xfa, 0xdf, 0x11, 0x1a, 0x0d, 0xf9, 0xc2, 0x5a, 0xe1, 0x4c, 0xb5, 0x37,
+ 0xff, 0x91, 0xb6, 0x96, 0xbf, 0x62, 0x04, 0x59, 0x69, 0x01, 0x68, 0x66,
+ 0x52, 0x66, 0x4a, 0x49, 0xe9, 0xe6, 0xe4, 0x44, 0x92, 0x5e, 0xaf, 0xf5,
+ 0x24, 0xdb, 0x6f, 0x21, 0xf9, 0x21, 0x58, 0x5f, 0xc4, 0xf0, 0x30, 0x90,
+ 0x68, 0xff, 0x58, 0x5c, 0xbd, 0x6f, 0x58, 0x77, 0xe0, 0x03, 0x68, 0x2a,
+ 0x1a, 0xa4, 0xd6, 0x9d, 0xd0, 0x38, 0x5a, 0xbd, 0x52, 0xa8, 0xc5, 0xf0,
+ 0xbc, 0xf2, 0x04, 0x49, 0x0e, 0x1b, 0x1b, 0x93, 0xc0, 0x65, 0xca, 0x05,
+ 0x42, 0x11, 0x03, 0xd6, 0xd5, 0x2c, 0x4c, 0xcd, 0xed, 0xb4, 0x54, 0xa4,
+ 0x3d, 0x46, 0x64, 0x4c, 0xc4, 0x8f, 0x0a, 0x95, 0x6a, 0x4f, 0xfb, 0x2e,
+ 0x1d, 0x5a, 0x8a, 0xcb, 0x31, 0x94, 0x21, 0x54, 0x51, 0xf5, 0x4e, 0x3e,
+ 0x32, 0x00, 0x12, 0x8e, 0x4c, 0x8c, 0x17, 0x90, 0xea, 0x8d, 0xfe, 0xc3,
+ 0xfe, 0x69, 0x10, 0xd9, 0x1c, 0x60, 0x91, 0xb6, 0xbb, 0x11, 0xb7, 0x77,
+ 0x1c, 0x69, 0xec, 0xb5, 0x28, 0x1e, 0x4b, 0xc8, 0xac, 0xe2, 0xe7, 0xe4,
+ 0xca, 0x1c, 0x6a, 0x16, 0xb8, 0x0a, 0x1c, 0xcb, 0xbd, 0x0e, 0x61, 0xf6,
+ 0x30, 0xa0, 0xb0, 0x11, 0x57, 0xd0, 0xa0, 0xe5, 0x63, 0xb4, 0x5e, 0x65,
+ 0x54, 0xbd, 0x2b, 0xcf, 0x92, 0xb3, 0xe2, 0xad, 0xba, 0x6b, 0xd8, 0x8b,
+ 0xd4, 0xc9, 0x49, 0x6b, 0xe9, 0x6f, 0x30, 0x9a, 0x8d, 0x1a, 0xd2, 0x73,
+ 0xed, 0x01, 0x20, 0x76, 0x59, 0x3b, 0x63, 0x15, 0xf7, 0x4a, 0x93, 0xf5,
+ 0xe8, 0xaa, 0x77, 0xf7, 0xee, 0x16, 0x26, 0x6d, 0x6d, 0x1e, 0xb3, 0x04,
+ 0xd1, 0x36, 0x6d, 0xdb, 0xe1, 0xee, 0xdf, 0x69, 0x0e, 0x28, 0x3b, 0x5a,
+ 0x37, 0x51, 0x61, 0x10, 0x58, 0xd0, 0x58, 0x75, 0x63, 0x5b, 0x76, 0x3e,
+ 0x55, 0x0a, 0x07, 0x3e, 0xfe, 0xb9, 0x6e, 0x4c, 0xfc, 0x1b, 0x8a, 0xa5,
+ 0x03, 0x1a, 0xb9, 0x04, 0x22, 0x60, 0x33, 0x66, 0xda, 0xb7, 0x1c, 0x3a,
+ 0xb6, 0x92, 0x45, 0x01, 0xc2, 0x73, 0x49, 0x6a, 0x9a, 0x54, 0x10, 0xe2,
+ 0x36, 0x45, 0xbd, 0x1d, 0x33, 0x2a, 0xd2, 0xc9, 0x70, 0x63, 0x39, 0xcf,
+ 0xf7, 0x76, 0x70, 0x37, 0xde, 0x23, 0x4c, 0xd2, 0xa1, 0x37, 0x2c, 0x52,
+ 0xae, 0xa3, 0xfb, 0x45, 0xd0, 0xb9, 0x46, 0x3e, 0x2a, 0xe8, 0xe9, 0x64,
+ 0xe1, 0x16, 0x30, 0x08, 0x36, 0xcd, 0x9e, 0x15, 0x44, 0xdd, 0x27, 0xa9,
+ 0x1c, 0x29, 0xf1, 0xa7, 0x20, 0x21, 0x59, 0x61, 0x4c, 0xbe, 0x5e, 0x20,
+ 0x36, 0xca, 0xb8, 0x6d, 0xb5, 0x0c, 0x29, 0x41, 0xa1, 0xd3, 0x8a, 0x2b,
+ 0x34, 0xd2, 0x5b, 0x92, 0x12, 0x1f, 0x36, 0x9f, 0x5d, 0x02, 0x2a, 0xca,
+ 0xac, 0x5b, 0x29, 0x8b, 0x51, 0x3a, 0x65, 0xf5, 0xdf, 0x60, 0x6c, 0x0c,
+ 0xa7, 0x95, 0x3d, 0x52, 0x13, 0xb4, 0xbd, 0x8c, 0xf1, 0xac, 0xba, 0x3c,
+ 0x24, 0x6c, 0xc0, 0xdb, 0xa8, 0x5b, 0xd4, 0xdb, 0xf5, 0xcd, 0xaf, 0xdf,
+ 0x2f, 0xe2, 0x71, 0xcc, 0x00, 0x3a, 0x87, 0xdc, 0x23, 0xdf, 0xa7, 0xb0,
+ 0xb6, 0xcb, 0xff, 0x1c, 0xe7, 0xfe, 0xa8, 0xa8, 0xea, 0xad, 0x37, 0x58,
+ 0xfd, 0x58, 0x01, 0xa5, 0xe4, 0x5d, 0xdf, 0x4a, 0x10, 0x0b, 0xc3, 0x5e,
+ 0xd1, 0x0d, 0x4c, 0x21, 0x0e, 0x51, 0x95, 0x99, 0x58, 0xdf, 0x6d, 0xa8,
+ 0x8e, 0xf7, 0x51, 0xa6, 0x53, 0x44, 0x6b, 0xb3, 0x00, 0x64, 0xe1, 0x6f,
+ 0x3d, 0x19, 0x40, 0x30, 0x46, 0x95, 0x9b, 0x39, 0xa5, 0x0d, 0x77, 0xaa,
+ 0xb1, 0x57, 0x57, 0x08, 0xe0, 0xab, 0xd1, 0xd5, 0x25, 0x59, 0x11, 0x2f,
+ 0x62, 0xbf, 0x50, 0x95, 0x02, 0x18, 0xdb, 0x2d, 0xbc, 0xdb, 0xfa, 0x3d,
+ 0x45, 0xab, 0xb5, 0x2e, 0x8e, 0x9b, 0x49, 0xe5, 0x50, 0xbd, 0x1f, 0x1c,
+ 0x64, 0xd8, 0x9d, 0x0c, 0x0c, 0xe8, 0xf3, 0x54, 0x49, 0x95, 0x3d, 0x71,
+ 0xa1, 0x16, 0x98, 0x08, 0x16, 0x37, 0x6a, 0x95, 0xa3, 0xaa, 0xb6, 0xf7,
+ 0x0e, 0x99, 0x2a, 0x0b, 0x68, 0x49, 0xd1, 0xa4, 0x33, 0x3e, 0x57, 0xfc,
+ 0xc3, 0x5a, 0xa9, 0x1e, 0xbf, 0xf1, 0x19, 0x2d, 0xee, 0xfa, 0x01, 0xa8,
+ 0x64, 0x0d, 0x74, 0x54, 0xed, 0x4d, 0xab, 0xad, 0x23, 0x25, 0xde, 0xef,
+ 0xb4, 0x54, 0xfe, 0x3f, 0xba, 0xe0, 0x0e, 0x76, 0x1b, 0x1a, 0xa9, 0xe3,
+ 0x53, 0xbd, 0xde, 0x65, 0x6b, 0x08, 0x6d, 0x71, 0x45, 0xb4, 0xf8, 0x9a,
+ 0x06, 0x3d, 0xae, 0x87, 0x25, 0x51, 0x9d, 0x46, 0x33, 0xf3, 0x77, 0x6d,
+ 0xb6, 0x5d, 0xbe, 0x08, 0xfc, 0xf5, 0x31, 0xa1, 0xd5, 0x22, 0x19, 0xcd,
+ 0x66, 0x82, 0x19, 0xf5, 0xf5, 0x29, 0x28, 0x83, 0xa5, 0xa3, 0x30, 0x50,
+ 0xa1, 0xfb, 0xf6, 0x36, 0x31, 0xbf, 0xb5, 0xc4, 0xe7, 0x99, 0xd5, 0x4f,
+ 0xf5, 0xb0, 0xf5, 0x9a, 0x12, 0x4e, 0x1b, 0xdb, 0x4d, 0x21, 0x6d, 0xda,
+ 0xeb, 0x6a, 0x11, 0x55, 0xa2, 0xe2, 0x6a, 0xe9, 0xe8, 0x01, 0xa1, 0x97,
+ 0x68, 0xc2, 0x30, 0xd2, 0xfa, 0x60, 0xec, 0x4d, 0x54, 0x5b, 0x9e, 0x2d,
+ 0x97, 0xca, 0x1b, 0xc2, 0xb2, 0x14, 0x3f, 0xaf, 0x23, 0x54, 0xe8, 0x0c,
+ 0x3c, 0xed, 0x50, 0x32, 0xff, 0x3a, 0x8c, 0xe6, 0xdc, 0x17, 0xad, 0x65,
+ 0x05, 0x35, 0x28, 0xc9, 0x77, 0x21, 0xb1, 0x9a, 0xec, 0xf1, 0xd6, 0x53,
+ 0xb9, 0xb3, 0xe0, 0x41, 0x11, 0x85, 0x2e, 0x1a, 0xb5, 0xad, 0xab, 0x9b,
+ 0xae, 0x69, 0xa0, 0xb1, 0xa0, 0x07, 0x72, 0x8f, 0x4a, 0xd9, 0x5e, 0x1f,
+ 0x29, 0x9e, 0x4d, 0x0b, 0x9a, 0x82, 0xfe, 0x26, 0xc5, 0x17, 0x5b, 0x51,
+ 0x46, 0xf2, 0xf7, 0x27, 0xba, 0x06, 0x91, 0x0e, 0xc2, 0x07, 0xb3, 0x1b,
+ 0x54, 0xad, 0xb5, 0xf5, 0x02, 0xc1, 0x39, 0x6a, 0x2a, 0xd7, 0x46, 0xbf,
+ 0x3d, 0x39, 0x4e, 0x8e, 0xb1, 0x58, 0xf4, 0x90, 0xa7, 0x08, 0x0e, 0x99,
+ 0x64, 0x33, 0x3e, 0x1e, 0x09, 0xb7, 0x88, 0xa0, 0x29, 0xb2, 0x0b, 0x5c,
+ 0x15, 0xd4, 0x36, 0x55, 0x42, 0x48, 0xe7, 0x47, 0xf9, 0xb5, 0x05, 0xcd,
+ 0x40, 0xde, 0x92, 0x27, 0x11, 0x3b, 0xad, 0x3e, 0x9b, 0x95, 0x38, 0xad,
+ 0x11, 0xd5, 0x9d, 0x1d, 0x38, 0x60, 0xde, 0x31, 0xe3, 0x40, 0xb2, 0xf2,
+ 0x8e, 0xb4, 0x03, 0xaa, 0x51, 0x15, 0xe4, 0x36, 0x4d, 0x43, 0x05, 0xbc,
+ 0x36, 0x82, 0xdf, 0xfc, 0xfd, 0x23, 0x4d, 0xad, 0x9f, 0xf4, 0xce, 0xfb,
+ 0xaf, 0x46, 0xb3, 0x59, 0x98, 0x91, 0x85, 0x4a, 0xa7, 0x67, 0x70, 0xbd,
+ 0xca, 0x12, 0x9b, 0x6b, 0x00, 0xe5, 0x82, 0x3c, 0x37, 0x99, 0x8d, 0x6b,
+ 0x32, 0xaf, 0x08, 0x05, 0x36, 0xd6, 0xd7, 0xfb, 0x65, 0xce, 0x4e, 0x9f,
+ 0xd5, 0xd1, 0x3a, 0x42, 0xb0, 0x31, 0x62, 0xd0, 0xe2, 0xe5, 0x37, 0xc1,
+ 0x6d, 0x8a, 0x24, 0xa4, 0x19, 0xc2, 0x59, 0x3c, 0x44, 0xef, 0x96, 0xf6,
+ 0x35, 0x00, 0xe7, 0xe6, 0x2e, 0x82, 0xa5, 0x4a, 0x2f, 0xa2, 0xfe, 0x1f,
+ 0x53, 0x52, 0x31, 0x97, 0x47, 0x37, 0x15, 0x26, 0xa7, 0x8d, 0xd3, 0x21,
+ 0x6a, 0x98, 0x6d, 0xf1, 0xe6, 0x29, 0xf8, 0x9d, 0xaf, 0x5f, 0x3e, 0x3a,
+ 0xbc, 0x65, 0xb2, 0xd8, 0x41, 0xbc, 0xd6, 0x39, 0x3c, 0xc7, 0x2f, 0x2e,
+ 0xa3, 0x08, 0x9a, 0x21, 0x05, 0xe0, 0x4c, 0x06, 0x4d, 0x82, 0x68, 0x5d,
+ 0x4a, 0x9e, 0xca, 0xee, 0x3d, 0x28, 0x45, 0x0e, 0xff, 0xdd, 0xe6, 0x46,
+ 0xbc, 0xf8, 0x19, 0x5b, 0xda, 0xf4, 0x14, 0xd1, 0x4f, 0x02, 0x6e, 0xf6,
+ 0x01, 0x2d, 0xd6, 0xb6, 0x8b, 0xf5, 0x9c, 0x4e, 0xee, 0xe7, 0xc8, 0x10,
+ 0x05, 0xb6, 0x6d, 0x8d, 0x49, 0xe2, 0x04, 0xec, 0x4d, 0x61, 0x67, 0xc2,
+ 0x19, 0x27, 0xab, 0xe1, 0x0d, 0x29, 0xab, 0xf2, 0xa0, 0xf9, 0x69, 0x0d,
+ 0x81, 0x29, 0x4d, 0x40, 0x6d, 0xd7, 0xda, 0xb7, 0x9e, 0x0b, 0x90, 0x9c,
+ 0x9b, 0xeb, 0x59, 0x2c, 0xc9, 0xa4, 0x85, 0x95, 0xe2, 0xda, 0x2d, 0xe4,
+ 0x60, 0x9a, 0x64, 0x21, 0xbf, 0x1d, 0x57, 0x4d, 0x3e, 0xa0, 0x35, 0x0f,
+ 0xce, 0xd7, 0xe1, 0x44, 0x63, 0x9e, 0xe8, 0x8e, 0xbd, 0xc8, 0xc1, 0x65,
+ 0xe1, 0xd2, 0x09, 0x45, 0xd3, 0xbd, 0x13, 0xb2, 0x1f, 0x46, 0x32, 0xa6,
+ 0xcd, 0xa3, 0x44, 0x4c, 0x52, 0xa7, 0xe7, 0x54, 0xea, 0xe6, 0xa0, 0xce,
+ 0x02, 0x8b, 0x69, 0xdb, 0xde, 0xef, 0x5f, 0xcb, 0x6f, 0x6e, 0x0f, 0xf5,
+ 0x68, 0x42, 0xf4, 0x37, 0x08, 0x1f, 0x87, 0x55, 0xb4, 0xbc, 0x8a, 0x84,
+ 0x84, 0x10, 0xc6, 0x36, 0x3e, 0x8a, 0x6b, 0x4e, 0xd5, 0xc8, 0x64, 0xcb,
+ 0xb5, 0xc0, 0xfe, 0x99, 0x66, 0xaa, 0xb1, 0x50, 0xa7, 0x70, 0xd9, 0xa6,
+ 0x17, 0x2d, 0xd4, 0xad, 0xdf, 0xf2, 0x2f, 0xac, 0xae, 0xae, 0x12, 0xcf,
+ 0x5b, 0x09, 0xf2, 0x2d, 0xb4, 0x21, 0xc9, 0xd1, 0x58, 0xdb, 0x4e, 0x9b,
+ 0xe0, 0x32, 0x08, 0xe4, 0x4a, 0xe6, 0x9c, 0x61, 0x25, 0x90, 0x08, 0xf2,
+ 0xb1, 0xc1, 0x3c, 0x25, 0x0b, 0x5a, 0x03, 0x40, 0xdb, 0x06, 0x5f, 0xd2,
+ 0x60, 0x8e, 0x0a, 0x5b, 0xc8, 0xa2, 0xcd, 0xac, 0xb3, 0x54, 0x0b, 0xb6,
+ 0x05, 0x45, 0xd7, 0xa8, 0x8a, 0xfa, 0x8a, 0xba, 0x09, 0x53, 0x81, 0xd7,
+ 0xf5, 0x40, 0x61, 0x46, 0xf2, 0x22, 0xe4, 0x21, 0xb4, 0x26, 0x41, 0x10,
+ 0x25, 0x4d, 0x93, 0xc2, 0xa2, 0xae, 0xc3, 0xaa, 0xbe, 0x71, 0xa6, 0xaa,
+ 0xf7, 0xb1, 0xbf, 0x02, 0x22, 0xe9, 0xd7, 0xfb, 0xaa, 0x1d, 0x5d, 0xf5,
+ 0xe7, 0x5b, 0x63, 0xf2, 0xe6, 0x5c, 0xd6, 0x24, 0x6d, 0xb5, 0xca, 0xa3,
+ 0xe7, 0x57, 0x1a, 0xa5, 0xf7, 0x95, 0xc5, 0x92, 0x51, 0x65, 0x68, 0xc5,
+ 0xe6, 0x27, 0xa9, 0x94, 0x8a, 0xb6, 0xec, 0x0d, 0x9c, 0x51, 0xdf, 0x22,
+ 0xca, 0xdf, 0x5a, 0xf5, 0xe4, 0xad, 0xf4, 0xfc, 0x1f, 0x68, 0x9f, 0xdb,
+ 0x40, 0x4e, 0x6a, 0x1e, 0x5a, 0xd8, 0x6c, 0xd6, 0xef, 0xad, 0x64, 0xe7,
+ 0xcb, 0xfc, 0x44, 0xae, 0xa5, 0x62, 0x65, 0xad, 0x2e, 0x6a, 0x46, 0xcf,
+ 0x0d, 0xd0, 0x46, 0x5e, 0x87, 0x37, 0xb6, 0xab, 0x70, 0x52, 0xee, 0x5a,
+ 0xa7, 0x13, 0xa3, 0xc3, 0x4b, 0x62, 0xe7, 0x31, 0x10, 0xed, 0x39, 0x1c,
+ 0x4a, 0xe3, 0xc1, 0x57, 0xcb, 0x45, 0xe4, 0x89, 0xee, 0x0e, 0x24, 0xc1,
+ 0xa6, 0xac, 0xd4, 0x0e, 0x9b, 0xe0, 0x26, 0x28, 0x08, 0x2b, 0xe1, 0xc9,
+ 0x42, 0x37, 0xa3, 0x46, 0xcc, 0x5d, 0x89, 0x10, 0x1f, 0x23, 0xcb, 0x1c,
+ 0x67, 0xe2, 0x6d, 0xaa, 0x66, 0xa5, 0xf5, 0xea, 0x94, 0x2b, 0x8c, 0xf6,
+ 0xf4, 0xd3, 0xfb, 0x9c, 0x96, 0x0a, 0x87, 0xaf, 0x5c, 0x19, 0xb4, 0x3b,
+ 0x26, 0xb2, 0x48, 0x55, 0x97, 0xfd, 0x3a, 0xec, 0x06, 0xe4, 0x58, 0x99,
+ 0x9a, 0x26, 0x4f, 0xe0, 0x9c, 0x67, 0x09, 0x05, 0x5b, 0x72, 0x8e, 0xd6,
+ 0xe4, 0x4e, 0xe2, 0x63, 0xb0, 0x9c, 0xf6, 0x92, 0xd3, 0x05, 0x3f, 0xb0,
+ 0x04, 0x5f, 0x02, 0x97, 0xf4, 0x42, 0x1d, 0x3b, 0x5c, 0x44, 0x00, 0x95,
+ 0x8b, 0xf5, 0x06, 0x40, 0xbd, 0xb8, 0xf7, 0x4b, 0x4a, 0xfa, 0xf0, 0x04,
+ 0x04, 0xd0, 0xa5, 0xb9, 0x3a, 0xa0, 0x2d, 0x0c, 0x1b, 0xec, 0x5a, 0x14,
+ 0xc8, 0x1d, 0x93, 0x86, 0xfd, 0x16, 0x68, 0xf8, 0x16, 0x9b, 0xb4, 0x88,
+ 0x99, 0x63, 0x0e, 0xd5, 0x20, 0x07, 0x43, 0x28, 0x26, 0xba, 0xf9, 0x97,
+ 0xed, 0x6b, 0x40, 0xb8, 0x07, 0x73, 0x59, 0xd5, 0x55, 0xa8, 0x64, 0x14,
+ 0x1c, 0xc5, 0xc0, 0x1f, 0x8d, 0x09, 0xae, 0x9c, 0x66, 0xa1, 0x94, 0xca,
+ 0x14, 0x46, 0xed, 0x46, 0x46, 0x25, 0x63, 0x5b, 0x2b, 0x95, 0x85, 0x05,
+ 0xc2, 0xb7, 0xeb, 0x06, 0x30, 0x5a, 0xf6, 0x22, 0x4e, 0x47, 0x1e, 0x0e,
+ 0x0c, 0xad, 0xd5, 0x11, 0xa8, 0x6a, 0x89, 0xd5, 0x49, 0xd4, 0xfa, 0x43,
+ 0xb0, 0x32, 0xb0, 0xb9, 0xb3, 0xda, 0x3f, 0x4f, 0xac, 0x4c, 0xc1, 0xa7,
+ 0x9f, 0xc2, 0xc2, 0x04, 0x70, 0xa2, 0x08, 0x01, 0xeb, 0x10, 0xa4, 0xa5,
+ 0x4c, 0xcd, 0xb3, 0x81, 0x4e, 0xbe, 0x6c, 0x51, 0x44, 0xf8, 0x82, 0xbd,
+ 0x42, 0x34, 0xfb, 0xdb, 0xb4, 0x32, 0xd2, 0x93, 0x63, 0x5e, 0xf6, 0x07,
+ 0x6e, 0x2c, 0xc2, 0xcf, 0xf4, 0x5d, 0x84, 0xe9, 0x5e, 0x5c, 0xa8, 0x39,
+ 0x28, 0x4a, 0xed, 0x15, 0x1b, 0xea, 0xe6, 0xde, 0x85, 0x92, 0x86, 0xe7,
+ 0x83, 0x4b, 0x87, 0xf7, 0x23, 0x60, 0xe2, 0x22, 0xd3, 0x32, 0x16, 0x4e,
+ 0x2f, 0xde, 0x01, 0x8b, 0x48, 0xea, 0xcd, 0x8a, 0x8b, 0xbc, 0xc6, 0x64,
+ 0xb2, 0x67, 0x47, 0xf5, 0x98, 0xf8, 0xca, 0xf1, 0x83, 0x66, 0xd7, 0x9a,
+ 0xef, 0xca, 0x20, 0xc2, 0xec, 0x8c, 0x38, 0xb1, 0x37, 0x13, 0x93, 0x92,
+ 0xba, 0xa1, 0xee, 0x6a, 0x57, 0x43, 0xaa, 0xdc, 0xdf, 0xa4, 0x3f, 0xc6,
+ 0xb6, 0xd6, 0x68, 0x54, 0xab, 0x36, 0xe9, 0x0f, 0x6f, 0xd5, 0xa1, 0x1b,
+ 0xa1, 0x02, 0xc9, 0x41, 0xef, 0x4f, 0x86, 0xcc, 0x1a, 0xfa, 0xd2, 0xdd,
+ 0x87, 0x04, 0xe0, 0x27, 0x38, 0xcf, 0x91, 0x95, 0xb4, 0x02, 0x10, 0x1d,
+ 0xc3, 0xcc, 0x6f, 0xaf, 0xbc, 0x94, 0x64, 0x47, 0xbc, 0x37, 0xde, 0xe3,
+ 0x2e, 0x89, 0x03, 0xb6, 0xd3, 0x28, 0x4a, 0x5e, 0x6d, 0x1e, 0xc5, 0x1a,
+ 0xa5, 0x0c, 0x92, 0xf7, 0xe2, 0x19, 0xe7, 0x39, 0xf0, 0xf2, 0x49, 0x8b,
+ 0xe6, 0x99, 0xd8, 0x4b, 0x0d, 0x6e, 0x3f, 0x57, 0x89, 0x9e, 0x0d, 0x34,
+ 0x4b, 0x52, 0xcd, 0x18, 0x57, 0xc7, 0x8e, 0x48, 0x03, 0x65, 0xd4, 0xdd,
+ 0xdf, 0x04, 0xf5, 0x39, 0x5e, 0x97, 0xbc, 0xc0, 0xc5, 0x91, 0xe7, 0x9d,
+ 0xbe, 0x28, 0x4c, 0xe7, 0xf4, 0xa0, 0x34, 0xee, 0xba, 0xa7, 0x8d, 0x52,
+ 0xc4, 0x07, 0x14, 0xd2, 0x93, 0xb0, 0x1d, 0x61, 0x53, 0x23, 0xc3, 0xe1,
+ 0xd2, 0xbf, 0xe1, 0xd6, 0x1f, 0x27, 0xcc, 0x8c, 0xe7, 0x0b, 0x09, 0x4f,
+ 0xe6, 0xa2, 0x41, 0xf4, 0x31, 0xbe, 0x95, 0x17, 0xfb, 0x50, 0xa4, 0xa4,
+ 0x51, 0x3c, 0x6f, 0xf8, 0x6a, 0xba, 0xac, 0xe4, 0x1e, 0x38, 0x78, 0x18,
+ 0x58, 0x31, 0x69, 0xc9, 0x52, 0xb0, 0xfc, 0x71, 0x54, 0xad, 0xe2, 0x8e,
+ 0xa2, 0xf2, 0x8e, 0x58, 0x11, 0x1d, 0xcc, 0x30, 0x74, 0x55, 0x41, 0x02,
+ 0x9b, 0x2a, 0x2f, 0x17, 0x97, 0xe4, 0x1a, 0xd0, 0xd5, 0x8f, 0x60, 0x10,
+ 0xdb, 0xc2, 0x69, 0x94, 0x0d, 0xaf, 0x44, 0xd0, 0x95, 0x3d, 0x50, 0xf4,
+ 0x27, 0x5e, 0xdc, 0x56, 0x5f, 0xa7, 0x4c, 0x41, 0xe5, 0x9e, 0xc8, 0x31,
+ 0xb0, 0x8e, 0x3f, 0xde, 0xdc, 0x42, 0x24, 0x93, 0x98, 0xce, 0x69, 0x90,
+ 0x98, 0x73, 0x06, 0xb9, 0x8e, 0xa4, 0x8d, 0x97, 0xb1, 0x41, 0x33, 0x64,
+ 0x5a, 0xae, 0xe8, 0x2f, 0x5f, 0x99, 0x64, 0x3e, 0xea, 0xd4, 0xbe, 0xa2,
+ 0x52, 0x2d, 0xc7, 0x56, 0x46, 0xfb, 0x33, 0xd8, 0xde, 0xe6, 0x74, 0xf6,
+ 0x2e, 0x2a, 0x26, 0xa1, 0x07, 0xcd, 0x3c, 0xca, 0x39, 0x74, 0x61, 0x4a,
+ 0x53, 0xf7, 0x8c, 0xd7, 0x3c, 0x4f, 0x4f, 0xd9, 0x14, 0x74, 0x56, 0xa8,
+ 0x3b, 0x3b, 0xe4, 0xe5, 0x70, 0x2e, 0xda, 0xde, 0xcd, 0x65, 0x4f, 0x2e,
+ 0xb6, 0x76, 0x17, 0x59, 0x6a, 0xaf, 0x0a, 0x24, 0x8c, 0x99, 0x0b, 0x2a,
+ 0xac, 0x46, 0x74, 0x2c, 0x3b, 0x40, 0x20, 0xad, 0x30, 0xab, 0x63, 0x34,
+ 0x8f, 0x30, 0x22, 0x50, 0x5c, 0xf8, 0x73, 0x21, 0x3e, 0xeb, 0x16, 0x44,
+ 0x30, 0xb9, 0x59, 0x0f, 0xf0, 0xe5, 0xb6, 0x6a, 0xde, 0x32, 0x03, 0x28,
+ 0x3c, 0xc8, 0xc2, 0x8d, 0x6b, 0x72, 0x2f, 0x3e, 0x2b, 0x99, 0xc1, 0xa6,
+ 0xdf, 0x5a, 0x91, 0x2d, 0x40, 0x39, 0xb2, 0x24, 0x27, 0x25, 0x26, 0x51,
+ 0xbb, 0xb5, 0x6a, 0x47, 0x38, 0x94, 0x2c, 0x3e, 0xa0, 0x96, 0x19, 0xf7,
+ 0x99, 0x0c, 0x34, 0x41, 0xb9, 0x0d, 0xad, 0x37, 0xa6, 0x0c, 0x38, 0x9c,
+ 0xee, 0x03, 0x68, 0x62, 0x76, 0x64, 0x18, 0x63, 0x62, 0x10, 0xd6, 0x2a,
+ 0xca, 0xdb, 0x73, 0x9b, 0x93, 0x35, 0x29, 0xb0, 0xec, 0x6c, 0xa8, 0x1f,
+ 0xa6, 0xac, 0xf8, 0xd8, 0xfa, 0x98, 0xc3, 0x02, 0xf0, 0xf5, 0x66, 0x2c,
+ 0xfc, 0x75, 0xc7, 0xb0, 0x76, 0xfe, 0x0f, 0x92, 0x9b, 0xce, 0xc5, 0xe8,
+ 0x9a, 0x5e, 0x8f, 0x16, 0x26, 0x8c, 0x97, 0x20, 0x97, 0x36, 0xca, 0x56,
+ 0xed, 0xf2, 0x05, 0x53, 0xf7, 0x9f, 0x23, 0xbb, 0x1e, 0xdc, 0x5a, 0x94,
+ 0x0b, 0x1d, 0x0e, 0x55, 0xc7, 0x34, 0xff, 0xd9, 0xa3, 0x37, 0x69, 0x63,
+ 0x9f, 0x00, 0x0f, 0xa1, 0x5c, 0x1f, 0x50, 0x56, 0x25, 0xf0, 0xb8, 0x0e,
+ 0x92, 0x70, 0xcd, 0xa0, 0xca, 0x2a, 0xce, 0xa5, 0x21, 0xe7, 0x5b, 0x10,
+ 0x13, 0xd5, 0x9b, 0x9f, 0x60, 0x1b, 0x3f, 0x21, 0xa9, 0x27, 0xd9, 0xeb,
+ 0xdc, 0xe8, 0x05, 0x8e, 0x09, 0x27, 0x4b, 0x8b, 0xb1, 0x3b, 0x07, 0xb1,
+ 0xe9, 0x55, 0xc4, 0xab, 0x5d, 0x74, 0x11, 0xcf, 0x98, 0x5d, 0x47, 0x58,
+ 0x9d, 0x08, 0xec, 0x0b, 0x31, 0x69, 0x98, 0xad, 0xd0, 0x93, 0x09, 0xc7,
+ 0xcc, 0xe3, 0x64, 0x67, 0xef, 0xce, 0x98, 0xf3, 0xc2, 0x69, 0xd4, 0x47,
+ 0x4d, 0xf7, 0x1a, 0x10, 0xa9, 0x18, 0x35, 0x94, 0xc8, 0xe1, 0xd2, 0xf5,
+ 0xb5, 0xb4, 0x0b, 0xd7, 0x28, 0xa8, 0x97, 0x9b, 0xbf, 0x90, 0xe5, 0xc6,
+ 0xde, 0xf7, 0x4f, 0x33, 0xaf, 0x36, 0xe2, 0xa8, 0x65, 0x56, 0xdd, 0xe8,
+ 0x79, 0xae, 0x68, 0xc1, 0xf3, 0x5b, 0x26, 0x59, 0x53, 0x00, 0x43, 0x4c,
+ 0x3e, 0xf9, 0x24, 0xc4, 0x8d, 0x73, 0x00, 0x6c, 0xb2, 0x97, 0x56, 0x90,
+ 0x42, 0xde, 0xba, 0xd6, 0x3a, 0x6d, 0x39, 0x9d, 0xbe, 0x1c, 0xca, 0x24,
+ 0xbb, 0xba, 0x06, 0xf0, 0x59, 0x74, 0x32, 0x99, 0x1b, 0x02, 0xad, 0xc1,
+ 0x8b, 0xd4, 0x0b, 0xd8, 0xb7, 0xe7, 0xbd, 0xbd, 0x68, 0x56, 0xc1, 0x1e,
+ 0xda, 0xa4, 0xfe, 0x6b, 0x94, 0xf3, 0xda, 0x9a, 0x33, 0x01, 0x97, 0xb6,
+ 0x39, 0xc4, 0xe7, 0x57, 0xee, 0xcf, 0x0e, 0xce, 0x40, 0x7a, 0xd4, 0x4d,
+ 0x30, 0x6a, 0x57, 0x8f, 0x97, 0x92, 0x59, 0xeb, 0xf2, 0x18, 0x8c, 0x77,
+ 0xd9, 0x8f, 0x72, 0xff, 0xd5, 0xb2, 0x1f, 0x2e, 0xba, 0xb6, 0x46, 0x1a,
+ 0x33, 0xe0, 0x74, 0x2a, 0xd7, 0xdb, 0xc7, 0x07, 0x37, 0x2f, 0x55, 0xe2,
+ 0x70, 0x43, 0xc2, 0xbc, 0x33, 0x03, 0xc9, 0xd4, 0x4e, 0x6e, 0x3e, 0xc9,
+ 0x67, 0x55, 0xf8, 0x6d, 0x63, 0x9f, 0x6b, 0x3f, 0x5b, 0xc7, 0xe9, 0xb8,
+ 0x31, 0x04, 0x0b, 0x71, 0x15, 0xcd, 0x34, 0xe4, 0xaf, 0x74, 0x73, 0xea,
+ 0xbf, 0x20, 0x00, 0x75, 0xd7, 0xa7, 0xf7, 0x9c, 0xf5, 0xa1, 0x28, 0xc7,
+ 0xfe, 0x6b, 0xa2, 0x36, 0xdc, 0xd4, 0xf0, 0xd7, 0x42, 0x4e, 0xe4, 0x3f,
+ 0x00, 0x09, 0x3c, 0x5e, 0x1f, 0xc8, 0xfd, 0xb9, 0xd8, 0x90, 0xdb, 0xf4,
+ 0x41, 0x0b, 0xda, 0x68, 0xe1, 0xe4, 0xb9, 0xfb, 0x36, 0x37, 0xa9, 0x5f,
+ 0xc9, 0xb6, 0xb8, 0xa4, 0xda, 0x41, 0xaa, 0xab, 0xa8, 0xc8, 0xd3, 0xc6,
+ 0x6a, 0xbe, 0x03, 0x77, 0xcc, 0x1a, 0x8d, 0x0d, 0xe8, 0xcc, 0x58, 0x46,
+ 0x71, 0x33, 0x19, 0x62, 0xe5, 0xc4, 0xe3, 0x4a, 0x1d, 0xf7, 0x96, 0xd4,
+ 0x08, 0xe5, 0xa8, 0x18, 0x40, 0x2d, 0xc5, 0xd7, 0xa7, 0x31, 0xa2, 0x5f,
+ 0x60, 0xde, 0x21, 0xe5, 0xaa, 0x65, 0x93, 0x0d, 0xdb, 0x55, 0x54, 0x88,
+ 0xbd, 0x53, 0x8e, 0xe0, 0xa6, 0x23, 0xcd, 0x1d, 0xb7, 0xbd, 0x2a, 0x8c,
+ 0x0e, 0x67, 0x65, 0xab, 0xda, 0xe9, 0x3b, 0x12, 0xf6, 0x97, 0x4b, 0xe8,
+ 0x16, 0xf7, 0x09, 0xb6, 0x45, 0x97, 0x16, 0xec, 0xd9, 0xdc, 0x8d, 0x01,
+ 0xba, 0xb0, 0xb6, 0xdd, 0x59, 0x60, 0xbf, 0x92, 0x92, 0xc3, 0x21, 0x41,
+ 0x46, 0xcb, 0x5e, 0x6e, 0x99, 0x10, 0x41, 0x45, 0x9a, 0xb9, 0xe0, 0x6d,
+ 0x22, 0x68, 0xd3, 0x5a, 0xaa, 0x6e, 0xb4, 0xc6, 0x42, 0xa2, 0xad, 0xf1,
+ 0xf7, 0x0b, 0x3d, 0x29, 0x38, 0xa2, 0x11, 0xf8, 0x57, 0x25, 0xb8, 0x8f,
+ 0xbc, 0x65, 0xac, 0x0d, 0xf0, 0xb7, 0x5c, 0x95, 0xfb, 0x5d, 0xdb, 0x54,
+ 0x3d, 0x3e, 0xd6, 0x4f, 0x2a, 0xfe, 0x43, 0xfc, 0x1c, 0xca, 0xb9, 0xb3,
+ 0x95, 0x06, 0x90, 0xd9, 0x5d, 0x43, 0xc4, 0xe9, 0xbb, 0x17, 0xd6, 0xaf,
+ 0xf2, 0xb0, 0x24, 0x9d, 0x27, 0xdf, 0xaf, 0xf7, 0x6f, 0xd1, 0x4c, 0xbe,
+ 0xd0, 0x1d, 0x16, 0x3f, 0xf5, 0x23, 0xdb, 0x52, 0xc4, 0x3b, 0x99, 0x3d,
+ 0xd5, 0xdc, 0x0b, 0x54, 0x3b, 0xfd, 0x9d, 0x36, 0xf6, 0xd9, 0x63, 0xd4,
+ 0xc0, 0x8f, 0x9d, 0x00, 0xa6, 0x1e, 0x41, 0x72, 0x18, 0xa6, 0xc5, 0xd0,
+ 0xb6, 0xdd, 0x10, 0x61, 0x45, 0xe0, 0xdc, 0xcc, 0x92, 0xd3, 0x05, 0x54,
+ 0x26, 0x2c, 0xcf, 0x94, 0x67, 0xa5, 0xae, 0x62, 0x97, 0x4e, 0x10, 0x2b,
+ 0xf4, 0x65, 0x89, 0x21, 0x98, 0xad, 0x25, 0x6a, 0x01, 0xa9, 0x4f, 0x57,
+ 0x2b, 0xbe, 0x3b, 0xcc, 0x34, 0x89, 0xc3, 0xd2, 0xa0, 0xc5, 0x72, 0xd9,
+ 0x39, 0x3f, 0x45, 0x62, 0x73, 0xda, 0xf3, 0xe7, 0xbf, 0xfd, 0xfe, 0x5b,
+ 0xe0, 0xc5, 0x9f, 0xf9, 0xbe, 0x2b, 0x9a, 0xf7, 0xc2, 0xe9, 0x59, 0x73,
+ 0xc4, 0x0a, 0xfe, 0x73, 0x5b, 0x34, 0xb9, 0xfc, 0x45, 0xb7, 0x4d, 0x39,
+ 0xc2, 0xcd, 0x5f, 0x33, 0x91, 0xab, 0x48, 0x57, 0x0a, 0x27, 0xf3, 0xd4,
+ 0xf3, 0xb4, 0x57, 0x04, 0xeb, 0x8a, 0xb2, 0xd4, 0x06, 0x60, 0x09, 0x48,
+ 0x58, 0xf8, 0x1f, 0x06, 0x8c, 0x2d, 0x55, 0x2b, 0x8d, 0xbb, 0x37, 0xbb,
+ 0xc5, 0xa3, 0x05, 0x38, 0xf7, 0x47, 0x0a, 0xd9, 0xa8, 0x5a, 0x5b, 0x75,
+ 0x58, 0xa3, 0x35, 0x01, 0x1a, 0x5c, 0xe3, 0x97, 0xef, 0x04, 0xd9, 0x28,
+ 0x93, 0xc9, 0x59, 0xfc, 0xc1, 0x9b, 0x25, 0xe8, 0x44, 0x05, 0x17, 0xdc,
+ 0xe1, 0xb2, 0x06, 0xd6, 0x08, 0xe0, 0x00, 0xe0, 0x06, 0xaf, 0xb6, 0xf8,
+ 0x63, 0x6c, 0x54, 0x29, 0x7a, 0x25, 0x0c, 0xc4, 0xe7, 0x6c, 0x2b, 0xe8,
+ 0xe9, 0x06, 0xa4, 0x9e, 0xb0, 0x38, 0xd4, 0xf1, 0x46, 0xb3, 0x93, 0x54,
+ 0xa7, 0xa1, 0xcd, 0x65, 0x43, 0xe8, 0xc3, 0x03, 0x60, 0x9c, 0x39, 0x02,
+ 0xea, 0xc5, 0x0c, 0x96, 0xd2, 0x05, 0x0d, 0x1f, 0xc7, 0x04, 0xc4, 0xa3,
+ 0xc4, 0xc0, 0xa9, 0x0b, 0xc7, 0xa1, 0x3f, 0xdc, 0x35, 0x51, 0x4d, 0xc8,
+ 0xc2, 0x87, 0x99, 0x3c, 0x46, 0xb3, 0x4e, 0xc9, 0xbf, 0xb3, 0x34, 0x8b,
+ 0xb7, 0x6f, 0xe5, 0x95, 0x9b, 0x17, 0x20, 0x56, 0xa6, 0x64, 0x4c, 0x77,
+ 0xdc, 0x0e, 0x28, 0xc3, 0xef, 0xf4, 0x28, 0x47, 0xd4, 0x0c, 0x6a, 0xe1,
+ 0x75, 0x63, 0xc9, 0xae, 0xe9, 0x36, 0x57, 0xfd, 0x08, 0x2f, 0xb2, 0x0b,
+ 0x48, 0xd4, 0x04, 0x24, 0x2f, 0x17, 0x03, 0x9e, 0xfe, 0xfd, 0x67, 0x0e,
+ 0xbe, 0x66, 0xcf, 0x2c, 0xaa, 0x4f, 0x1c, 0x32, 0x2e, 0xa0, 0xfb, 0x55,
+ 0x40, 0x15, 0x5d, 0x51, 0xca, 0xbe, 0xff, 0xb2, 0xb2, 0x2b, 0x47, 0xee,
+ 0x37, 0xc8, 0x65, 0xad, 0xda, 0xb9, 0x3a, 0x75, 0x3a, 0x98, 0x1f, 0xcf,
+ 0xd7, 0x48, 0x56, 0xa2, 0xed, 0xb4, 0x46, 0x60, 0x30, 0x6a, 0x19, 0x5b,
+ 0x38, 0xc8, 0x0d, 0x3a, 0xc3, 0xe1, 0x34, 0x6e, 0x39, 0x5f, 0xf2, 0x4d,
+ 0x78, 0x02, 0xba, 0x3c, 0x71, 0x70, 0x75, 0x6c, 0xb0, 0xfa, 0x38, 0xe3,
+ 0x6b, 0x42, 0x1e, 0x23, 0xcd, 0xe6, 0xf8, 0xc5, 0x9c, 0x24, 0x3d, 0x98,
+ 0xa8, 0xbb, 0x4a, 0x07, 0x8c, 0xb6, 0xfa, 0x13, 0xd0, 0xfc, 0xc5, 0xdc,
+ 0xb2, 0xcd, 0x65, 0x59, 0xc2, 0x3a, 0x24, 0x47, 0x1c, 0x53, 0x92, 0x57,
+ 0x21, 0xf3, 0x26, 0x9b, 0xe9, 0xa5, 0x95, 0x9a, 0xd6, 0xa5, 0xe2, 0xda,
+ 0x0e, 0xb7, 0xab, 0x9e, 0xee, 0xe3, 0xef, 0x59, 0xd2, 0x88, 0x32, 0x1f,
+ 0x0d, 0xbf, 0xf2, 0xa4, 0x3b, 0xd7, 0xd5, 0xf2, 0xa4, 0xae, 0x65, 0xab,
+ 0xb3, 0x72, 0xf6, 0x3b, 0xe8, 0xc5, 0x2b, 0xad, 0xcc, 0xbe, 0x02, 0x95,
+ 0x63, 0x95, 0x2c, 0x22, 0x74, 0x3a, 0x1b, 0xd5, 0xd1, 0x1d, 0xf8, 0x69,
+ 0x03, 0x98, 0x70, 0x66, 0x43, 0xb5, 0x6d, 0xd0, 0x27, 0x6a, 0x1c, 0xfc,
+ 0xf9, 0xaf, 0x71, 0x9b, 0x8c, 0xcb, 0xf8, 0xbd, 0x18, 0xad, 0x5f, 0xb7,
+ 0xbc, 0xfb, 0xbd, 0xde, 0xb9, 0xdc, 0x54, 0x65, 0x3b, 0xaf, 0xa7, 0x92,
+ 0xbe, 0x62, 0xdc, 0x25, 0x50, 0x48, 0x78, 0xd4, 0xed, 0xed, 0x96, 0x3f,
+ 0x53, 0xc5, 0xb5, 0x5f, 0xac, 0xa7, 0x5c, 0x92, 0xd9, 0xfe, 0x3b, 0xcd,
+ 0xbb, 0x29, 0xa0, 0xe0, 0x1e, 0xb0, 0x92, 0xad, 0x6b, 0x45, 0x29, 0x59,
+ 0xff, 0x5d, 0x5a, 0xfe, 0x8f, 0x63, 0x86, 0x6d, 0xa4, 0x4a, 0x53, 0xc4,
+ 0x3e, 0x39, 0xbf, 0xe5, 0x20, 0xbc, 0xd1, 0xdf, 0x59, 0x9c, 0x3a, 0x72,
+ 0x3b, 0x8f, 0xb2, 0x40, 0xe5, 0x9e, 0xa5, 0x02, 0x35, 0xd0, 0x4d, 0x6f,
+ 0x7d, 0xd5, 0x4c, 0xde, 0x51, 0x0a, 0x9a, 0x57, 0x43, 0x43, 0xe5, 0x97,
+ 0x95, 0x4b, 0xb2, 0x6c, 0xaf, 0x92, 0x4e, 0x52, 0x06, 0x0b, 0x72, 0x60,
+ 0x9e, 0x5c, 0xa1, 0xe3, 0x9b, 0xb3, 0x8c, 0x32, 0xcd, 0xc1, 0x4a, 0x88,
+ 0xd6, 0x3d, 0xed, 0xe8, 0x42, 0x5d, 0x53, 0xdd, 0x00, 0x52, 0x26, 0x2e,
+ 0xd5, 0x41, 0xf2, 0xfc, 0x51, 0x40, 0x45, 0xe4, 0x00, 0xe3, 0x1c, 0xfb,
+ 0x32, 0x33, 0x22, 0xed, 0x15, 0x12, 0x9b, 0xc4, 0x89, 0xd0, 0x0e, 0x95,
+ 0xad, 0xfd, 0x04, 0x2e, 0xee, 0x73, 0x06, 0xee, 0x23, 0xe2, 0xd3, 0x3d,
+ 0x44, 0x62, 0x35, 0xdc, 0x18, 0x9d, 0xf4, 0x9d, 0x92, 0x00, 0x4e, 0x8e,
+ 0x4e, 0x24, 0xa1, 0x2c, 0xb2, 0xb2, 0x3f, 0xfc, 0xe4, 0x27, 0x43, 0x3b,
+ 0x59, 0xb4, 0x13, 0xff, 0x57, 0xdf, 0x3d, 0xee, 0x1a, 0xab, 0x8c, 0x51,
+ 0xd9, 0x96, 0x1f, 0x2b, 0x66, 0x67, 0x42, 0xb6, 0x91, 0xfe, 0x8f, 0x4d,
+ 0xa6, 0xd3, 0x3b, 0x51, 0x45, 0x35, 0xab, 0xe5, 0x6e, 0x07, 0xed, 0x24,
+ 0x95, 0x3d, 0x6a, 0x47, 0x3f, 0x4e, 0xe4, 0x13, 0x5f, 0xfc, 0x19, 0xe8,
+ 0x09, 0x4b, 0x3d, 0xdf, 0x4f, 0xb4, 0xb4, 0xc1, 0x74, 0x31, 0xff, 0x13,
+ 0x00, 0xaf, 0x07, 0x16, 0xb6, 0x57, 0xfe, 0x6a, 0x37, 0x05, 0x62, 0x01,
+ 0xa0, 0xfa, 0xe2, 0xe5, 0x57, 0xcb, 0xa4, 0x5a, 0x57, 0xee, 0xd1, 0x5f,
+ 0x14, 0x23, 0xbe, 0xef, 0x9b, 0x91, 0x0f, 0x97, 0xa8, 0xf2, 0x36, 0xf7,
+ 0xc3, 0xb6, 0xbe, 0xe5, 0x59, 0x2b, 0x3c, 0xb3, 0x5d, 0x9f, 0x1e, 0x3b,
+ 0xd3, 0xf7, 0xee, 0x2e, 0xc0, 0x73, 0x6f, 0x2e, 0xfd, 0xc7, 0x3f, 0xfd,
+ 0x9c, 0xac, 0xbd, 0xa1, 0x8e, 0xcc, 0x59, 0x41, 0xa4, 0x41, 0xd3, 0x39,
+ 0x28, 0x67, 0x96, 0x14, 0x42, 0xc3, 0x38, 0x96, 0x0d, 0xfc, 0x68, 0x3d,
+ 0x2e, 0x2f, 0x46, 0x24, 0x66, 0x0d, 0xa6, 0x72, 0xc7, 0x27, 0x66, 0x3c,
+ 0xad, 0x55, 0xae, 0xbd, 0x34, 0xb4, 0x3b, 0x60, 0x73, 0xa5, 0xaa, 0xd4,
+ 0x56, 0x0b, 0x61, 0xf5, 0x5c, 0x66, 0x2e, 0x9d, 0x33, 0xfe, 0xfe, 0x7b,
+ 0x21, 0xbc, 0x36, 0xec, 0x0f, 0x03, 0x28, 0xa4, 0xd6, 0x05, 0x21, 0x30,
+ 0xf8, 0x3c, 0xd9, 0x3b, 0xaf, 0x5d, 0x92, 0x25, 0xce, 0xac, 0x28, 0xe1,
+ 0xd1, 0x02, 0x3c, 0x49, 0xe6, 0xed, 0xb7, 0x0e, 0xe7, 0xe7, 0x1e, 0x56,
+ 0xbf, 0x5d, 0xfd, 0xed, 0xdb, 0x4d, 0x63, 0x03, 0x8c, 0x06, 0x30, 0xfa,
+ 0x62, 0x78, 0x3f, 0x6e, 0x63, 0x1e, 0xa6, 0x4b, 0x96, 0xe9, 0xe4, 0x2d,
+ 0x16, 0x51, 0xf2, 0xf1, 0xa7, 0x2a, 0xeb, 0x15, 0xb5, 0xb1, 0x04, 0x9a,
+ 0xde, 0x77, 0xde, 0xcf, 0xcc, 0x21, 0xd9, 0x30, 0xf1, 0xea, 0xb9, 0xb0,
+ 0x39, 0xe1, 0x6f, 0xc7, 0x0a, 0xbd, 0x64, 0x75, 0x59, 0xbf, 0x3c, 0xbf,
+ 0xd0, 0xdb, 0x00, 0xfa, 0x2e, 0x36, 0xcc, 0xb5, 0xd1, 0x20, 0x46, 0xb0,
+ 0xd7, 0xfc, 0xb1, 0x5b, 0x54, 0x9f, 0xe2, 0xe1, 0xd0, 0x18, 0xa3, 0x51,
+ 0x62, 0x24, 0x0f, 0xa1, 0xa1, 0x9a, 0x47, 0x33, 0xca, 0xb9, 0x26, 0xb6,
+ 0x0b, 0x46, 0xd4, 0xb5, 0xc6, 0xbb, 0x72, 0x1e, 0x60, 0xeb, 0xb4, 0x9d,
+ 0x9f, 0x09, 0x10, 0x12, 0xce, 0x68, 0xa3, 0xb6, 0x8c, 0xce, 0xd7, 0x26,
+ 0x55, 0xb5, 0x90, 0x08, 0x9f, 0xf2, 0xa8, 0xc0, 0x56, 0xd8, 0xf6, 0x29,
+ 0x60, 0xe0, 0x73, 0x52, 0x22, 0x6f, 0x35, 0x4e, 0xe7, 0xc5, 0xa3, 0x95,
+ 0xcd, 0xd0, 0x8e, 0xd3, 0x95, 0xe3, 0x03, 0x04, 0x00, 0x54, 0xeb, 0xef,
+ 0x27, 0x11, 0xef, 0x38, 0x56, 0x6f, 0xa0, 0xe5, 0x72, 0x2a, 0x97, 0x23,
+ 0x56, 0xe2, 0x93, 0x21, 0x3f, 0xe2, 0xd6, 0x12, 0xcd, 0x61, 0x50, 0x44,
+ 0xd3, 0xe3, 0x8d, 0x3f, 0x24, 0x90, 0x6c, 0x53, 0xad, 0x1c, 0xad, 0x03,
+ 0x0f, 0x89, 0x63, 0xf9, 0xb9, 0xbc, 0xe2, 0x56, 0xdd, 0x16, 0xcf, 0x2d,
+ 0xa1, 0xda, 0xf9, 0x3f, 0xec, 0xbf, 0xb1, 0xb6, 0xe1, 0xdf, 0x3f, 0x11,
+ 0x02, 0x76, 0xe9, 0xe2, 0x9f, 0xa2, 0x02, 0xce, 0x3e, 0xf9, 0xcf, 0x4f,
+ 0xd9, 0x5f, 0x72, 0x5d, 0x51, 0xa7, 0x1d, 0x98, 0xeb, 0x8e, 0x97, 0x98,
+ 0x39, 0x58, 0x52, 0x11, 0xed, 0x95, 0x3c, 0x94, 0xf0, 0x6c, 0xa2, 0x3e,
+ 0x5f, 0x5f, 0x05, 0x98, 0xf1, 0x73, 0xab, 0xc7, 0xa8, 0x4b, 0x92, 0x73,
+ 0xda, 0x59, 0x1d, 0x56, 0x11, 0xc2, 0x38, 0x43, 0xdb, 0x4b, 0xbe, 0x08,
+ 0xdd, 0xf2, 0x5d, 0x47, 0x26, 0xdc, 0x16, 0xf9, 0x62, 0xf8, 0x92, 0x19,
+ 0x5c, 0x6f, 0x2b, 0xe1, 0x15, 0x66, 0xfa, 0xdb, 0x3a, 0xe0, 0x92, 0x9c,
+ 0x70, 0x91, 0x3f, 0xb8, 0xb0, 0x01, 0xc1, 0x44, 0xf6, 0x62, 0x47, 0x37,
+ 0xe9, 0xd9, 0x4c, 0x0f, 0x99, 0x6a, 0xc4, 0x60, 0x26, 0x2f, 0xc6, 0x43,
+ 0x50, 0x62, 0xee, 0x44, 0x21, 0xbd, 0xad, 0x50, 0x2d, 0x58, 0x78, 0xea,
+ 0x5a, 0x5f, 0x5c, 0xf7, 0x28, 0xa9, 0xdf, 0x0e, 0xd3, 0x67, 0xdf, 0x1f,
+ 0x4c, 0xd3, 0xe9, 0x5e, 0x0f, 0xa3, 0xb7, 0x56, 0xa5, 0x4e, 0x5f, 0x2a,
+ 0xb6, 0x14, 0x5e, 0x2f, 0x16, 0x71, 0x48, 0x59, 0x77, 0x6b, 0xf9, 0x6c,
+ 0x79, 0xba, 0xc4, 0x26, 0x30, 0x44, 0x61, 0x62, 0x60, 0xef, 0x35, 0x95,
+ 0xe3, 0x77, 0xd5, 0xc8, 0x44, 0xa4, 0xf8, 0x95, 0xba, 0xd1, 0x73, 0x6f,
+ 0x92, 0xf2, 0xd3, 0x98, 0x4c, 0x8f, 0xe0, 0x2e, 0x27, 0xaa, 0x2f, 0x63,
+ 0x00, 0x00, 0x00, 0x00, 0x06, 0xff, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff, 0x80, 0x04, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x26, 0xff, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00,
+ 0x0e, 0xfe, 0xff, 0xff, 0xbb, 0xfd, 0xff, 0xff, 0xe1, 0x05, 0x00, 0x00,
+ 0x4b, 0x0f, 0x00, 0x00, 0x8e, 0x15, 0x00, 0x00, 0x7f, 0x04, 0x00, 0x00,
+ 0x02, 0x02, 0x00, 0x00, 0x53, 0xe6, 0xff, 0xff, 0xa6, 0x04, 0x00, 0x00,
+ 0xdf, 0x07, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x66, 0xff, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,
+ 0x80, 0x00, 0x00, 0x00, 0x7f, 0xfd, 0xff, 0xff, 0x3e, 0xf8, 0xff, 0xff,
+ 0xae, 0x03, 0x00, 0x00, 0x5c, 0xfe, 0xff, 0xff, 0x82, 0xfa, 0xff, 0xff,
+ 0xbd, 0xf8, 0xff, 0xff, 0x04, 0xfe, 0xff, 0xff, 0x8c, 0xfe, 0xff, 0xff,
+ 0x9b, 0xf8, 0xff, 0xff, 0x51, 0x02, 0x00, 0x00, 0x19, 0xfe, 0xff, 0xff,
+ 0x54, 0xfe, 0xff, 0xff, 0x8f, 0xff, 0xff, 0xff, 0xe7, 0xfd, 0xff, 0xff,
+ 0xc2, 0x07, 0x00, 0x00, 0x36, 0x06, 0x00, 0x00, 0x57, 0xfd, 0xff, 0xff,
+ 0xa3, 0x03, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00, 0x79, 0x03, 0x00, 0x00,
+ 0x9b, 0xf7, 0xff, 0xff, 0xc7, 0x04, 0x00, 0x00, 0xbf, 0x06, 0x00, 0x00,
+ 0x86, 0xfe, 0xff, 0xff, 0x20, 0xfb, 0xff, 0xff, 0x90, 0xfc, 0xff, 0xff,
+ 0x16, 0x00, 0x00, 0x00, 0x8e, 0xff, 0xff, 0xff, 0xa0, 0x03, 0x00, 0x00,
+ 0xc7, 0xff, 0xff, 0xff, 0x51, 0x01, 0x00, 0x00, 0x24, 0xf8, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x04, 0x00, 0x06, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0xee, 0x01, 0x00, 0x00,
+ 0xda, 0x02, 0x00, 0x00, 0xa9, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
+ 0xc4, 0xfe, 0xff, 0xff, 0xfa, 0xfc, 0xff, 0xff, 0xc0, 0xff, 0xff, 0xff,
+ 0x6a, 0xff, 0xff, 0xff, 0x92, 0x02, 0x00, 0x00, 0xa4, 0xff, 0xff, 0xff,
+ 0xfd, 0xfe, 0xff, 0xff, 0x4e, 0xfd, 0xff, 0xff, 0x87, 0x00, 0x00, 0x00,
+ 0x19, 0xfe, 0xff, 0xff, 0x17, 0xff, 0xff, 0xff, 0xa0, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0xf4, 0xf3, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x04, 0xf4, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x4d, 0x4c, 0x49, 0x52,
+ 0x20, 0x43, 0x6f, 0x6e, 0x76, 0x65, 0x72, 0x74, 0x65, 0x64, 0x2e, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00,
+ 0x18, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00,
+ 0x0e, 0x00, 0x00, 0x00, 0xf8, 0x01, 0x00, 0x00, 0xec, 0x01, 0x00, 0x00,
+ 0xe0, 0x01, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x6d, 0x61, 0x69, 0x6e, 0x00, 0x00, 0x00, 0x00,
+ 0x07, 0x00, 0x00, 0x00, 0xa4, 0x01, 0x00, 0x00, 0x4c, 0x01, 0x00, 0x00,
+ 0xfc, 0x00, 0x00, 0x00, 0xa8, 0x00, 0x00, 0x00, 0x70, 0x00, 0x00, 0x00,
+ 0x38, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x82, 0xfe, 0xff, 0xff,
+ 0x05, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x08, 0x00,
+ 0x0c, 0x00, 0x10, 0x00, 0x07, 0x00, 0x14, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x08, 0x03, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xc8, 0xf4, 0xff, 0xff,
+ 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x0b, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0xe6, 0xfe, 0xff, 0xff, 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x0e, 0x00, 0x1a, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00,
+ 0x07, 0x00, 0x14, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x05,
+ 0x01, 0x00, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x07, 0x00,
+ 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x01, 0x02, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0a, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00,
+ 0xc2, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01, 0x24, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xb4, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x01, 0x01, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x0e, 0x00, 0x14, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0c, 0x00,
+ 0x07, 0x00, 0x10, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01,
+ 0x30, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x10, 0x00, 0x06, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x07, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x01, 0x01, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x10, 0x00, 0x04, 0x00,
+ 0x08, 0x00, 0x0c, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0d, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0d, 0x00, 0x00, 0x00, 0x0f, 0x00, 0x00, 0x00, 0xb8, 0x0d, 0x00, 0x00,
+ 0x64, 0x0c, 0x00, 0x00, 0x64, 0x0a, 0x00, 0x00, 0xe8, 0x09, 0x00, 0x00,
+ 0x9c, 0x09, 0x00, 0x00, 0x20, 0x09, 0x00, 0x00, 0x6c, 0x07, 0x00, 0x00,
+ 0x78, 0x04, 0x00, 0x00, 0x74, 0x03, 0x00, 0x00, 0x68, 0x02, 0x00, 0x00,
+ 0xbc, 0x01, 0x00, 0x00, 0x28, 0x01, 0x00, 0x00, 0xa4, 0x00, 0x00, 0x00,
+ 0x54, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xc8, 0xff, 0xff, 0xff,
+ 0x28, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff, 0x0a, 0x00, 0x00, 0x00,
+ 0x08, 0x00, 0x00, 0x00, 0x49, 0x64, 0x65, 0x6e, 0x74, 0x69, 0x74, 0x79,
+ 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0a, 0x00, 0x00, 0x00, 0x14, 0x00, 0x10, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0c, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,
+ 0x10, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x69,
+ 0x6e, 0x70, 0x75, 0x74, 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x30, 0xf3, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09,
+ 0x6c, 0x00, 0x00, 0x00, 0x0d, 0x00, 0x00, 0x00, 0x50, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0xff, 0xff, 0xff, 0xff, 0x0a, 0x00, 0x00, 0x00, 0x14, 0xf3, 0xff, 0xff,
+ 0x2c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x13, 0xc2, 0x47, 0x3b,
+ 0x01, 0x00, 0x00, 0x00, 0x8d, 0xf4, 0xad, 0x3e, 0x01, 0x00, 0x00, 0x00,
+ 0x15, 0x00, 0xe0, 0xbe, 0x0d, 0x00, 0x00, 0x00, 0x49, 0x64, 0x65, 0x6e,
+ 0x74, 0x69, 0x74, 0x79, 0x5f, 0x69, 0x6e, 0x74, 0x38, 0x00, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00,
+ 0xb0, 0xf3, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0x7c, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x54, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,
+ 0x80, 0x04, 0x00, 0x00, 0x94, 0xf3, 0xff, 0xff, 0x30, 0x00, 0x00, 0x00,
+ 0x24, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x6c, 0x02, 0xa5, 0x3a,
+ 0x01, 0x00, 0x00, 0x00, 0x6a, 0x5d, 0xa4, 0x3e, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x1a, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,
+ 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x66, 0x6c, 0x61, 0x74, 0x74,
+ 0x65, 0x6e, 0x2f, 0x52, 0x65, 0x73, 0x68, 0x61, 0x70, 0x65, 0x00, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x80, 0x04, 0x00, 0x00,
+ 0x40, 0xf4, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0x8c, 0x00, 0x00, 0x00,
+ 0x0b, 0x00, 0x00, 0x00, 0x5c, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,
+ 0x06, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x2c, 0xf4, 0xff, 0xff, 0x30, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x6c, 0x02, 0xa5, 0x3a, 0x01, 0x00, 0x00, 0x00,
+ 0x6a, 0x5d, 0xa4, 0x3e, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,
+ 0x61, 0x6c, 0x2f, 0x6d, 0x61, 0x78, 0x5f, 0x70, 0x6f, 0x6f, 0x6c, 0x69,
+ 0x6e, 0x67, 0x32, 0x64, 0x2f, 0x4d, 0x61, 0x78, 0x50, 0x6f, 0x6f, 0x6c,
+ 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0xe8, 0xf4, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0xec, 0x00, 0x00, 0x00,
+ 0x0a, 0x00, 0x00, 0x00, 0x5c, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,
+ 0x0c, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0xd4, 0xf4, 0xff, 0xff, 0x30, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x6c, 0x02, 0xa5, 0x3a, 0x01, 0x00, 0x00, 0x00,
+ 0x6a, 0x5d, 0xa4, 0x3e, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x83, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,
+ 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x31, 0x2f,
+ 0x52, 0x65, 0x6c, 0x75, 0x3b, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74,
+ 0x69, 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x31,
+ 0x2f, 0x42, 0x69, 0x61, 0x73, 0x41, 0x64, 0x64, 0x3b, 0x73, 0x65, 0x71,
+ 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76,
+ 0x32, 0x64, 0x5f, 0x31, 0x2f, 0x43, 0x6f, 0x6e, 0x76, 0x32, 0x44, 0x3b,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63,
+ 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x31, 0x2f, 0x42, 0x69, 0x61, 0x73,
+ 0x41, 0x64, 0x64, 0x2f, 0x52, 0x65, 0x61, 0x64, 0x56, 0x61, 0x72, 0x69,
+ 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x2f, 0x72, 0x65, 0x73, 0x6f, 0x75,
+ 0x72, 0x63, 0x65, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x0c, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0xf0, 0xf5, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0xe4, 0x00, 0x00, 0x00,
+ 0x09, 0x00, 0x00, 0x00, 0x5c, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xff, 0xff, 0xff, 0xff,
+ 0x0e, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xdc, 0xf5, 0xff, 0xff, 0x30, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,
+ 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x15, 0xa1, 0x10, 0x3b, 0x01, 0x00, 0x00, 0x00,
+ 0x74, 0x10, 0x10, 0x3f, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x7b, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,
+ 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f, 0x52, 0x65,
+ 0x6c, 0x75, 0x3b, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61,
+ 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f, 0x42, 0x69, 0x61,
+ 0x73, 0x41, 0x64, 0x64, 0x3b, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74,
+ 0x69, 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f, 0x43,
+ 0x6f, 0x6e, 0x76, 0x32, 0x44, 0x3b, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e,
+ 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f,
+ 0x42, 0x69, 0x61, 0x73, 0x41, 0x64, 0x64, 0x2f, 0x52, 0x65, 0x61, 0x64,
+ 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x2f, 0x72,
+ 0x65, 0x73, 0x6f, 0x75, 0x72, 0x63, 0x65, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x3a, 0xf8, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09,
+ 0xd4, 0x02, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0xac, 0x02, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0xc4, 0xf6, 0xff, 0xff, 0x1c, 0x02, 0x00, 0x00,
+ 0x94, 0x01, 0x00, 0x00, 0x0c, 0x01, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0xb9, 0x37, 0x74, 0x3a, 0x8b, 0xfe, 0x77, 0x3a, 0x54, 0xc7, 0x75, 0x3a,
+ 0xc4, 0x11, 0x78, 0x3a, 0xb9, 0x90, 0x74, 0x3a, 0x3b, 0x97, 0x7b, 0x3a,
+ 0xe8, 0x57, 0x75, 0x3a, 0x0c, 0x0e, 0x74, 0x3a, 0x76, 0x8b, 0x79, 0x3a,
+ 0x2b, 0x7b, 0x6d, 0x3a, 0x17, 0xad, 0x71, 0x3a, 0xe4, 0x9b, 0x77, 0x3a,
+ 0x0b, 0xab, 0x7a, 0x3a, 0x9e, 0x12, 0x75, 0x3a, 0x8c, 0xcf, 0x79, 0x3a,
+ 0xa0, 0x5a, 0x79, 0x3a, 0x74, 0xc3, 0x78, 0x3a, 0x0e, 0xa9, 0x74, 0x3a,
+ 0x6b, 0xf8, 0x6f, 0x3a, 0x53, 0xeb, 0x72, 0x3a, 0xff, 0xe2, 0x73, 0x3a,
+ 0x3b, 0x38, 0x78, 0x3a, 0xed, 0x9e, 0x76, 0x3a, 0x77, 0xbc, 0x6d, 0x3a,
+ 0x4f, 0xf5, 0x71, 0x3a, 0x17, 0xc9, 0x74, 0x3a, 0x87, 0x84, 0x6b, 0x3a,
+ 0x4b, 0xc5, 0x78, 0x3a, 0xdd, 0x02, 0x75, 0x3a, 0x0e, 0xcf, 0x78, 0x3a,
+ 0x14, 0x40, 0x75, 0x3a, 0x2e, 0xca, 0x72, 0x3a, 0x20, 0x00, 0x00, 0x00,
+ 0x95, 0x2f, 0xef, 0x3d, 0x47, 0x1c, 0xf0, 0x3d, 0xc5, 0xdb, 0xf3, 0x3d,
+ 0x2e, 0x57, 0xe7, 0x3d, 0x98, 0xa7, 0xf2, 0x3d, 0x98, 0x89, 0xe4, 0x3d,
+ 0x38, 0x6d, 0xf3, 0x3d, 0x3f, 0x38, 0xe2, 0x3d, 0x91, 0x6f, 0xf0, 0x3d,
+ 0x35, 0xa0, 0xeb, 0x3d, 0x42, 0x3d, 0xeb, 0x3d, 0xed, 0x89, 0xe7, 0x3d,
+ 0xb5, 0xb5, 0xf8, 0x3d, 0x79, 0x28, 0xf3, 0x3d, 0xed, 0xdb, 0xf7, 0x3d,
+ 0xeb, 0x67, 0xf7, 0x3d, 0xed, 0xd1, 0xf6, 0x3d, 0xbc, 0xbf, 0xf2, 0x3d,
+ 0x7a, 0x18, 0xee, 0x3d, 0x7c, 0x05, 0xf1, 0x3d, 0x63, 0x69, 0xe8, 0x3d,
+ 0xbb, 0xc0, 0xf1, 0x3d, 0xaf, 0xb1, 0xf4, 0x3d, 0xfe, 0xe0, 0xeb, 0x3d,
+ 0xb6, 0x60, 0xec, 0x3d, 0x8c, 0x32, 0xf0, 0x3d, 0x7e, 0xad, 0xe9, 0x3d,
+ 0xc0, 0xd3, 0xf6, 0x3d, 0xd7, 0x18, 0xf3, 0x3d, 0x40, 0x53, 0xf0, 0x3d,
+ 0x2c, 0xdc, 0xf1, 0x3d, 0x9a, 0xe4, 0xf0, 0x3d, 0x20, 0x00, 0x00, 0x00,
+ 0x4a, 0x4f, 0xf2, 0xbd, 0x8e, 0x0e, 0xf6, 0xbd, 0x74, 0x46, 0xec, 0xbd,
+ 0xa0, 0x21, 0xf6, 0xbd, 0x8e, 0x27, 0xf0, 0xbd, 0x0d, 0xa0, 0xf9, 0xbd,
+ 0x0c, 0x97, 0xec, 0xbd, 0xf0, 0x25, 0xf2, 0xbd, 0x5f, 0x98, 0xf7, 0xbd,
+ 0x27, 0x8d, 0xe8, 0xbd, 0xbd, 0xc9, 0xef, 0xbd, 0xac, 0xac, 0xf5, 0xbd,
+ 0x5a, 0x94, 0xed, 0xbd, 0x5a, 0x64, 0xf1, 0xbd, 0x2a, 0xa7, 0xe9, 0xbd,
+ 0x3c, 0x93, 0xf3, 0xbd, 0xf8, 0x2b, 0xf3, 0xbd, 0xf6, 0x35, 0xed, 0xbd,
+ 0x94, 0xf4, 0xed, 0xbd, 0x70, 0x94, 0xe9, 0xbd, 0x39, 0xfb, 0xf1, 0xbd,
+ 0xcb, 0x47, 0xf6, 0xbd, 0x88, 0xb9, 0xe7, 0xbd, 0x49, 0x62, 0xe9, 0xbd,
+ 0x64, 0x11, 0xf0, 0xbd, 0x85, 0xdf, 0xf2, 0xbd, 0x5c, 0x61, 0xe8, 0xbd,
+ 0x22, 0x46, 0xf3, 0xbd, 0x5a, 0x8e, 0xf0, 0xbd, 0x70, 0xdd, 0xf6, 0xbd,
+ 0x94, 0x55, 0xf3, 0xbd, 0x57, 0xba, 0xf0, 0xbd, 0x1a, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63,
+ 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x31, 0x2f, 0x43, 0x6f, 0x6e, 0x76,
+ 0x32, 0x44, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x2a, 0xfb, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0x94, 0x01, 0x00, 0x00,
+ 0x07, 0x00, 0x00, 0x00, 0x6c, 0x01, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0xb4, 0xf9, 0xff, 0xff, 0x1c, 0x01, 0x00, 0x00, 0xd4, 0x00, 0x00, 0x00,
+ 0x8c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xe6, 0x69, 0xc5, 0x3a, 0xa0, 0x8d, 0xa8, 0x3a, 0xfe, 0x5c, 0xc1, 0x3a,
+ 0x84, 0x01, 0xcb, 0x3a, 0xa2, 0xc2, 0xb5, 0x3a, 0x42, 0x01, 0xd1, 0x3a,
+ 0xd7, 0x01, 0xcc, 0x3a, 0x20, 0xd8, 0xc7, 0x3a, 0x28, 0x80, 0xa4, 0x3a,
+ 0xd9, 0x25, 0xbe, 0x3a, 0x39, 0x6f, 0xc4, 0x3a, 0x59, 0x6c, 0xcb, 0x3a,
+ 0xb8, 0x0a, 0xc2, 0x3a, 0x73, 0x3f, 0xca, 0x3a, 0xb9, 0xed, 0xc5, 0x3a,
+ 0xe9, 0x9f, 0xc1, 0x3a, 0x10, 0x00, 0x00, 0x00, 0x5b, 0x2e, 0x2f, 0x3e,
+ 0x3e, 0xd9, 0x06, 0x3e, 0x44, 0xda, 0x3f, 0x3e, 0xd3, 0x09, 0x22, 0x3e,
+ 0x1d, 0x57, 0x34, 0x3e, 0xa4, 0xb6, 0x44, 0x3e, 0xd3, 0x69, 0x4a, 0x3e,
+ 0x70, 0x48, 0x46, 0x3e, 0x28, 0x37, 0x23, 0x3e, 0xe6, 0xdb, 0x06, 0x3e,
+ 0x3c, 0x1d, 0x34, 0x3e, 0x36, 0xba, 0x16, 0x3e, 0x24, 0xa4, 0x34, 0x3e,
+ 0xf4, 0xfb, 0x37, 0x3e, 0xd6, 0x7b, 0x8a, 0x3d, 0x00, 0x85, 0xe3, 0x3d,
+ 0x10, 0x00, 0x00, 0x00, 0x12, 0xdf, 0x43, 0xbe, 0x85, 0x3c, 0x27, 0xbe,
+ 0x54, 0xcd, 0x0d, 0xbe, 0x81, 0x6b, 0x49, 0xbe, 0x33, 0xb1, 0xe7, 0xbd,
+ 0x3f, 0x5f, 0x4f, 0xbe, 0xa1, 0x63, 0x3e, 0xbe, 0xbb, 0xa7, 0xea, 0xbd,
+ 0x2d, 0x8c, 0x0e, 0xbe, 0x8d, 0xa9, 0x3c, 0xbe, 0x5b, 0xe6, 0x42, 0xbe,
+ 0x80, 0xd5, 0x49, 0xbe, 0xa3, 0x86, 0x40, 0xbe, 0xf4, 0xaa, 0x48, 0xbe,
+ 0xde, 0x61, 0x44, 0xbe, 0xa9, 0x1c, 0x40, 0xbe, 0x18, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63,
+ 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x2f, 0x43, 0x6f, 0x6e, 0x76, 0x32, 0x44,
+ 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0xda, 0xfc, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0x64, 0x00, 0x00, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x64, 0xfb, 0xff, 0xff, 0x2c, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x07, 0x72, 0x1e, 0x3a, 0x01, 0x00, 0x00, 0x00, 0x32, 0xe2, 0x9b, 0x3d,
+ 0x01, 0x00, 0x00, 0x00, 0x23, 0x35, 0x9d, 0xbd, 0x17, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64,
+ 0x65, 0x6e, 0x73, 0x65, 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x00,
+ 0x02, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x80, 0x04, 0x00, 0x00,
+ 0x52, 0xfd, 0xff, 0xff, 0x00, 0x00, 0x00, 0x02, 0x38, 0x00, 0x00, 0x00,
+ 0x05, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x04, 0x00, 0x04, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x66,
+ 0x6c, 0x61, 0x74, 0x74, 0x65, 0x6e, 0x2f, 0x43, 0x6f, 0x6e, 0x73, 0x74,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,
+ 0x9a, 0xfd, 0xff, 0xff, 0x00, 0x00, 0x00, 0x02, 0x68, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x8c, 0xfd, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0xfc, 0x41, 0x4c, 0x35, 0x30, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x64,
+ 0x65, 0x6e, 0x73, 0x65, 0x2f, 0x42, 0x69, 0x61, 0x73, 0x41, 0x64, 0x64,
+ 0x2f, 0x52, 0x65, 0x61, 0x64, 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c,
+ 0x65, 0x4f, 0x70, 0x2f, 0x72, 0x65, 0x73, 0x6f, 0x75, 0x72, 0x63, 0x65,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00,
+ 0x12, 0xfe, 0xff, 0xff, 0x00, 0x00, 0x00, 0x02, 0xdc, 0x01, 0x00, 0x00,
+ 0x03, 0x00, 0x00, 0x00, 0x9c, 0x01, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x04, 0xfe, 0xff, 0xff, 0x0c, 0x01, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x20, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x03, 0xf9, 0x09, 0x36, 0x3a, 0x1b, 0x0c, 0x36, 0xc6, 0xda, 0x0a, 0x36,
+ 0x16, 0x26, 0x0c, 0x36, 0x4b, 0x2b, 0x0a, 0x36, 0x60, 0x23, 0x0e, 0x36,
+ 0xd3, 0x9b, 0x0a, 0x36, 0x78, 0xe1, 0x09, 0x36, 0x78, 0xfb, 0x0c, 0x36,
+ 0xb6, 0x2a, 0x06, 0x36, 0x6f, 0x89, 0x08, 0x36, 0x7e, 0xe3, 0x0b, 0x36,
+ 0xf0, 0x9d, 0x0d, 0x36, 0xae, 0x74, 0x0a, 0x36, 0xef, 0x21, 0x0d, 0x36,
+ 0xe0, 0xdf, 0x0c, 0x36, 0x79, 0x8a, 0x0c, 0x36, 0x0a, 0x39, 0x0a, 0x36,
+ 0xbb, 0x92, 0x07, 0x36, 0x39, 0x3d, 0x09, 0x36, 0x25, 0xc9, 0x09, 0x36,
+ 0xd1, 0x3b, 0x0c, 0x36, 0x93, 0x54, 0x0b, 0x36, 0x9a, 0x4f, 0x06, 0x36,
+ 0x3c, 0xb2, 0x08, 0x36, 0x23, 0x4b, 0x0a, 0x36, 0xbe, 0x0e, 0x05, 0x36,
+ 0x83, 0x8b, 0x0c, 0x36, 0xc7, 0x6b, 0x0a, 0x36, 0x07, 0x91, 0x0c, 0x36,
+ 0x5d, 0x8e, 0x0a, 0x36, 0x7f, 0x2a, 0x09, 0x36, 0x33, 0x00, 0x00, 0x00,
+ 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63,
+ 0x6f, 0x6e, 0x76, 0x32, 0x64, 0x5f, 0x31, 0x2f, 0x42, 0x69, 0x61, 0x73,
+ 0x41, 0x64, 0x64, 0x2f, 0x52, 0x65, 0x61, 0x64, 0x56, 0x61, 0x72, 0x69,
+ 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x2f, 0x72, 0x65, 0x73, 0x6f, 0x75,
+ 0x72, 0x63, 0x65, 0x00, 0x01, 0x00, 0x00, 0x00, 0x20, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x08, 0x00, 0x07, 0x00, 0x0c, 0x00,
+ 0x10, 0x00, 0x14, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x02,
+ 0x2c, 0x01, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0xec, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x90, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0xe1, 0x22, 0xc6, 0x36, 0x90, 0x2b, 0xa9, 0x36, 0x2d, 0x12, 0xc2, 0x36,
+ 0xbc, 0xbf, 0xcb, 0x36, 0xf2, 0x6c, 0xb6, 0x36, 0x19, 0xc5, 0xd1, 0x36,
+ 0xff, 0xc0, 0xcc, 0x36, 0x62, 0x93, 0xc8, 0x36, 0x4c, 0x1a, 0xa5, 0x36,
+ 0x05, 0xd8, 0xbe, 0x36, 0x49, 0x27, 0xc5, 0x36, 0xf5, 0x2a, 0xcc, 0x36,
+ 0x8a, 0xc0, 0xc2, 0x36, 0xf5, 0xfc, 0xca, 0x36, 0x2f, 0xa7, 0xc6, 0x36,
+ 0x57, 0x55, 0xc2, 0x36, 0x31, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,
+ 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x2f, 0x63, 0x6f, 0x6e, 0x76, 0x32,
+ 0x64, 0x2f, 0x42, 0x69, 0x61, 0x73, 0x41, 0x64, 0x64, 0x2f, 0x52, 0x65,
+ 0x61, 0x64, 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70,
+ 0x2f, 0x72, 0x65, 0x73, 0x6f, 0x75, 0x72, 0x63, 0x65, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x14, 0x00, 0x1c, 0x00,
+ 0x08, 0x00, 0x07, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x18, 0x00, 0x14, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,
+ 0x88, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x68, 0x00, 0x00, 0x00,
+ 0x28, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0xff, 0xff, 0xff, 0xff, 0x10, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x14, 0x00, 0x04, 0x00, 0x08, 0x00,
+ 0x0c, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,
+ 0x24, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,
+ 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xf0, 0x77, 0x80, 0x3b,
+ 0x01, 0x00, 0x00, 0x00, 0xf0, 0xee, 0x7f, 0x3f, 0x01, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x00, 0x11, 0x00, 0x00, 0x00, 0x63, 0x6f, 0x6e, 0x76,
+ 0x32, 0x64, 0x5f, 0x69, 0x6e, 0x70, 0x75, 0x74, 0x5f, 0x69, 0x6e, 0x74,
+ 0x38, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x10, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x70, 0x00, 0x00, 0x00, 0x54, 0x00, 0x00, 0x00,
+ 0x40, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,
+ 0x04, 0x00, 0x00, 0x00, 0xca, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x06,
+ 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x07, 0x00,
+ 0x06, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x72, 0xe6, 0xff, 0xff, 0xff,
+ 0x00, 0x00, 0x00, 0x09, 0x04, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00,
+ 0x06, 0x00, 0x05, 0x00, 0x06, 0x00, 0x00, 0x00, 0x00, 0x16, 0x0a, 0x00,
+ 0x0e, 0x00, 0x07, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0a, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x11, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00,
+ 0x0c, 0x00, 0x07, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0a, 0x00, 0x00, 0x00,
+ 0x00, 0x00, 0x00, 0x03, 0x03, 0x00, 0x00, 0x00};
+
+const unsigned int kTestConvModelDataSize = 21344;
diff --git a/tensorflow/lite/micro/testing/test_conv_model.h b/tensorflow/lite/micro/testing/test_conv_model.h
new file mode 100644
index 0000000..2103196
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_conv_model.h
@@ -0,0 +1,23 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#ifndef TENSORFLOW_LITE_MICRO_TESTING_TEST_CONV_MODEL_H_
+#define TENSORFLOW_LITE_MICRO_TESTING_TEST_CONV_MODEL_H_
+
+// See generate_test_models.py for updating the contents of this model:
+extern const unsigned char kTestConvModelData[];
+extern const unsigned int kTestConvModelDataSize;
+
+#endif // TENSORFLOW_LITE_MICRO_TESTING_TEST_CONV_MODEL_H_
diff --git a/tensorflow/lite/micro/testing/test_ecm3531_binary.sh b/tensorflow/lite/micro/testing/test_ecm3531_binary.sh
new file mode 100755
index 0000000..1647cf8
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_ecm3531_binary.sh
@@ -0,0 +1,16 @@
+#!/bin/bash -e
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
diff --git a/tensorflow/lite/micro/testing/test_hexagon_binary.sh b/tensorflow/lite/micro/testing/test_hexagon_binary.sh
new file mode 100755
index 0000000..98b3c50
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_hexagon_binary.sh
@@ -0,0 +1,41 @@
+#!/bin/bash -e
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests a Qualcomm Hexagon binary by parsing the log output.
+#
+# First argument is the binary location.
+# Second argument is a regular expression that's required to be in the output
+# logs for the test to pass.
+
+declare -r TEST_TMPDIR=/tmp/test_hexagon_binary/
+declare -r MICRO_LOG_PATH=${TEST_TMPDIR}/$1
+declare -r MICRO_LOG_FILENAME=${MICRO_LOG_PATH}/logs.txt
+mkdir -p ${MICRO_LOG_PATH}
+
+hexagon-elfcopy $1 $1.elf
+hexagon-sim $1.elf 2>&1 | tee ${MICRO_LOG_FILENAME}
+
+if [[ ${2} != "non_test_binary" ]]
+then
+ if grep -q "$2" ${MICRO_LOG_FILENAME}
+ then
+ echo "$1: PASS"
+ exit 0
+ else
+ echo "$1: FAIL - '$2' not found in logs."
+ exit 1
+ fi
+fi
diff --git a/tensorflow/lite/micro/testing/test_leon_binary.sh b/tensorflow/lite/micro/testing/test_leon_binary.sh
new file mode 100755
index 0000000..5163c45
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_leon_binary.sh
@@ -0,0 +1,47 @@
+#!/bin/bash -e
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests a LEON 3 ELF binary by executing it using the TSIM emulator and parsing
+# the log output.
+#
+# First argument is the binary location.
+# Second argument is a regular expression that's required to be in the output
+# logs for the test to pass.
+
+declare -r ROOT_DIR=`pwd`
+declare -r TEST_TMPDIR=/tmp/test_leon_binary/
+declare -r MICRO_LOG_PATH=${TEST_TMPDIR}/$1
+declare -r MICRO_LOG_FILENAME=${MICRO_LOG_PATH}/logs.txt
+declare -r LEON_
+mkdir -p ${MICRO_LOG_PATH}
+
+# Get the location of this script file as an absolute path
+SCRIPT_PATH="`dirname \"$BASH_SOURCE\"`"
+SCRIPT_PATH="`( cd \"$SCRIPT_PATH\" && pwd )`"
+LEON_COMMANDS="$SCRIPT_PATH/leon_commands"
+TSIM_PATH="tensorflow/lite/micro/tools/make/downloads/tsim/tsim/linux-x64/tsim-leon3"
+
+${TSIM_PATH} $1 -c ${LEON_COMMANDS} 2>&1 | tee ${MICRO_LOG_FILENAME}
+
+if grep -q "$2" ${MICRO_LOG_FILENAME}
+then
+ echo "$1: PASS"
+ exit 0
+else
+ echo "$1: FAIL - '$2' not found in logs."
+ exit 1
+fi
+
diff --git a/tensorflow/lite/micro/testing/test_with_arm_corstone_300.sh b/tensorflow/lite/micro/testing/test_with_arm_corstone_300.sh
new file mode 100755
index 0000000..c5293e5
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_with_arm_corstone_300.sh
@@ -0,0 +1,48 @@
+#!/bin/bash -e
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+#
+# Parameters:
+# ${1} - path to a binary to test or directory (all *_test will be run).
+# ${2} - String that is checked for pass/fail.
+# ${3} - target (e.g. cortex_m_generic.)
+
+set -e
+
+BINARY_TO_TEST=${1}
+PASS_STRING=${2}
+TARGET=${3}
+
+RESULTS_DIRECTORY=/tmp/${TARGET}_logs
+MICRO_LOG_FILENAME=${RESULTS_DIRECTORY}/logs.txt
+mkdir -p ${RESULTS_DIRECTORY}
+
+FVP="FVP_Corstone_SSE-300_Ethos-U55 "
+FVP+="--cpulimit 1 "
+FVP+="-C mps3_board.visualisation.disable-visualisation=1 "
+FVP+="-C mps3_board.telnetterminal0.start_telnet=0 "
+FVP+='-C mps3_board.uart0.out_file="-" '
+FVP+='-C mps3_board.uart0.unbuffered_output=1'
+${FVP} ${BINARY_TO_TEST} | tee ${MICRO_LOG_FILENAME}
+
+if grep -q "$PASS_STRING" ${MICRO_LOG_FILENAME}
+then
+ echo "$BINARY_TO_TEST: PASS"
+ exit 0
+else
+ echo "$BINARY_TO_TEST: FAIL - '$PASS_STRING' not found in logs."
+ exit 1
+fi
diff --git a/tensorflow/lite/micro/testing/test_with_renode.sh b/tensorflow/lite/micro/testing/test_with_renode.sh
new file mode 100755
index 0000000..4f5418e
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_with_renode.sh
@@ -0,0 +1,110 @@
+#!/bin/bash -e
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+#
+# Parameters:
+# ${1} - path to a binary to test or directory (all *_test will be run).
+# ${2} - String that is checked for pass/fail.
+# ${3} - target (bluepill, stm32f4 etc.)
+
+set -e
+
+PASS_STRING=${2}
+TARGET=${3}
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+TFLM_ROOT_DIR=${SCRIPT_DIR}/..
+
+# The renode script for the board being emulated.
+RESC_PATH=${TFLM_ROOT_DIR}/testing/${TARGET}.resc
+
+# Robot file with definition of custom keywords used in test suite.
+ROBOT_RESOURCE=${TFLM_ROOT_DIR}/testing/robot.resource.txt
+
+# Renode's entrypoint for using the Robot Framework.
+RENODE_TEST_SCRIPT=${TFLM_ROOT_DIR}/tools/make/downloads/renode/test.sh
+
+if [ ! -f "${RENODE_TEST_SCRIPT}" ]; then
+ echo "The renode test script: ${RENODE_TEST_SCRIPT} does not exist. Please " \
+ "make sure that you have correctly installed Renode for TFLM. See " \
+ "tensorflow/lite/micro/docs/renode.md for more details."
+ exit 1
+fi
+
+if ! ${RENODE_TEST_SCRIPT} &> /dev/null
+then
+ echo "The following command failed: ${RENODE_TEST_SCRIPT}. Please " \
+ "make sure that you have correctly installed Renode for TFLM. See " \
+ "tensorflow/lite/micro/docs/renode.md for more details."
+ exit 1
+fi
+
+# Files generated by this script will go in the RESULTS_DIRECTORY. These include:
+# 1. UART_LOG: Output log from the renode uart.
+# 2. html and xml files generated by the Robot Framework.
+# 3. ROBOT_SCRIPT: Generated test suite.
+#
+# Note that with the current approach (in generated ROBOT_SCRIPT), multiple test
+# binaries are run in a the same test suite and UART_LOG only has logs from the last test
+# binary since it is deleted prior to running each test binary. If some test fails
+# the UART_LOG will be printed to console log before being deleted.
+RESULTS_DIRECTORY=/tmp/renode_${TARGET}_logs
+mkdir -p ${RESULTS_DIRECTORY}
+
+UART_LOG=${RESULTS_DIRECTORY}/uart_log.txt
+
+ROBOT_SCRIPT=${RESULTS_DIRECTORY}/${TARGET}.robot
+
+echo -e "*** Settings ***\n" \
+ "Suite Setup Setup\n" \
+ "Suite Teardown Teardown\n" \
+ "Test Setup Reset Emulation\n" \
+ "Test Teardown Teardown With Custom Message\n" \
+ "Resource \${RENODEKEYWORDS}\n" \
+ "Resource ${ROBOT_RESOURCE}\n" \
+ "Default Tags tensorflow\n" \
+ "\n" \
+ "*** Variables ***\n" \
+ "\${RESC} undefined_RESC\n" \
+ "\${UART_LOG} /tmp/uart.log\n" \
+ "\${UART_LINE_ON_SUCCESS} ${PASS_STRING}\n" \
+ "\${CREATE_SNAPSHOT_ON_FAIL} False\n" \
+ "\n" \
+ "*** Test Cases ***\n" \
+ "Should Create Platform\n" \
+ " Create Platform\n" > $ROBOT_SCRIPT
+
+declare -a FILES
+if [[ -d ${1} ]]; then
+ FILES=`ls -1 ${1}/*_test`
+else
+ FILES=${1}
+fi
+
+for binary in ${FILES}
+do
+ echo -e "Should Run $(basename ${binary})\n"\
+ " Test Binary @$(realpath ${binary})\n" >> ${ROBOT_SCRIPT}
+done
+
+ROBOT_COMMAND="${RENODE_TEST_SCRIPT} ${ROBOT_SCRIPT} \
+ -r ${RESULTS_DIRECTORY} \
+ --variable RESC:${RESC_PATH} \
+ --variable UART_LOG:${UART_LOG}"
+
+echo "${ROBOT_COMMAND}"
+echo ""
+${ROBOT_COMMAND}
diff --git a/tensorflow/lite/micro/testing/test_xcore_binary.sh b/tensorflow/lite/micro/testing/test_xcore_binary.sh
new file mode 100755
index 0000000..e059968
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_xcore_binary.sh
@@ -0,0 +1,47 @@
+#!/bin/bash -e
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests an XS3 binary by executing it using the XSIM simulator and parsing
+# the log output.
+#
+# First argument is the binary location.
+# Second argument is a regular expression that's required to be in the output
+# logs for the test to pass.
+
+declare -r ROOT_DIR=`pwd`
+declare -r TEST_TMPDIR=/tmp/test_xcore_binary/
+declare -r MICRO_LOG_PATH=${TEST_TMPDIR}/$1
+declare -r MICRO_LOG_FILENAME=${MICRO_LOG_PATH}/logs.txt
+declare -r XCORE_
+mkdir -p ${MICRO_LOG_PATH}
+
+# Get the location of this script file as an absolute path
+SCRIPT_PATH="`dirname \"$BASH_SOURCE\"`"
+SCRIPT_PATH="`( cd \"$SCRIPT_PATH\" && pwd )`"
+XSIM_FLAGS=""
+
+
+xsim $1 ${XSIM_FLAGS} 2>&1 | tee ${MICRO_LOG_FILENAME}
+
+if grep -q "$2" ${MICRO_LOG_FILENAME}
+then
+ echo "$1: PASS"
+ exit 0
+else
+ echo "$1: FAIL - '$2' not found in logs."
+ exit 1
+fi
+
diff --git a/tensorflow/lite/micro/testing/test_xtensa_binary.sh b/tensorflow/lite/micro/testing/test_xtensa_binary.sh
new file mode 100755
index 0000000..9141d2f
--- /dev/null
+++ b/tensorflow/lite/micro/testing/test_xtensa_binary.sh
@@ -0,0 +1,40 @@
+#!/bin/bash -e
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests an Xtensa binary by parsing the log output.
+#
+# First argument is the binary location.
+#
+# Second argument is a regular expression that's required to be in the output
+# logs for the test to pass.
+
+declare -r TEST_TMPDIR=/tmp/test_xtensa_binary/
+declare -r MICRO_LOG_PATH=${TEST_TMPDIR}/$1
+declare -r MICRO_LOG_FILENAME=${MICRO_LOG_PATH}/logs.txt
+mkdir -p ${MICRO_LOG_PATH}
+
+xt-run $1 2>&1 | tee ${MICRO_LOG_FILENAME}
+
+if [[ ${2} != "non_test_binary" ]]
+then
+ if grep -q "$2" ${MICRO_LOG_FILENAME}
+ then
+ exit 0
+ else
+ exit 1
+ fi
+fi
+
diff --git a/tensorflow/lite/micro/testing/util_test.cc b/tensorflow/lite/micro/testing/util_test.cc
new file mode 100644
index 0000000..1720c81
--- /dev/null
+++ b/tensorflow/lite/micro/testing/util_test.cc
@@ -0,0 +1,29 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(ArgumentsExecutedOnlyOnce) {
+ float count = 0.;
+ // Make sure either argument is executed once after macro expansion.
+ TF_LITE_MICRO_EXPECT_NEAR(0, count++, 0.1f);
+ TF_LITE_MICRO_EXPECT_NEAR(1, count++, 0.1f);
+ TF_LITE_MICRO_EXPECT_NEAR(count++, 2, 0.1f);
+ TF_LITE_MICRO_EXPECT_NEAR(count++, 3, 0.1f);
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/testing_helpers_test.cc b/tensorflow/lite/micro/testing_helpers_test.cc
new file mode 100644
index 0000000..7ef669f
--- /dev/null
+++ b/tensorflow/lite/micro/testing_helpers_test.cc
@@ -0,0 +1,106 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/test_helpers.h"
+#include "tensorflow/lite/micro/testing/micro_test.h"
+
+TF_LITE_MICRO_TESTS_BEGIN
+
+TF_LITE_MICRO_TEST(CreateQuantizedBiasTensor) {
+ float input_scale = 0.5;
+ float weight_scale = 0.5;
+ constexpr int tensor_size = 12;
+ int dims_arr[] = {4, 2, 3, 2, 1};
+ int32_t quantized[tensor_size];
+ float pre_quantized[] = {-10, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 10};
+ int32_t expected_quantized_values[] = {-40, -20, -16, -12, -8, -4,
+ 0, 4, 8, 12, 16, 40};
+ TfLiteIntArray* dims = tflite::testing::IntArrayFromInts(dims_arr);
+
+ TfLiteTensor result = tflite::testing::CreateQuantizedBiasTensor(
+ pre_quantized, quantized, dims, input_scale, weight_scale);
+
+ TF_LITE_MICRO_EXPECT_EQ(result.bytes, tensor_size * sizeof(int32_t));
+ TF_LITE_MICRO_EXPECT(result.dims == dims);
+ TF_LITE_MICRO_EXPECT_EQ(result.params.scale, input_scale * weight_scale);
+ for (int i = 0; i < tensor_size; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_quantized_values[i], result.data.i32[i]);
+ }
+}
+
+TF_LITE_MICRO_TEST(CreatePerChannelQuantizedBiasTensor) {
+ float input_scale = 0.5;
+ float weight_scales[] = {0.5, 1, 2, 4};
+ constexpr int tensor_size = 12;
+ const int channels = 4;
+ int dims_arr[] = {4, 4, 3, 1, 1};
+ int32_t quantized[tensor_size];
+ float scales[channels + 1];
+ int zero_points[] = {4, 0, 0, 0, 0};
+ float pre_quantized[] = {-10, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 10};
+ int32_t expected_quantized_values[] = {-40, -20, -16, -6, -4, -2,
+ 0, 1, 2, 2, 2, 5};
+ TfLiteIntArray* dims = tflite::testing::IntArrayFromInts(dims_arr);
+
+ TfLiteAffineQuantization quant;
+ TfLiteTensor result = tflite::testing::CreatePerChannelQuantizedBiasTensor(
+ pre_quantized, quantized, dims, input_scale, weight_scales, scales,
+ zero_points, &quant, 0);
+
+ // Values in scales array start at index 1 since index 0 is dedicated to
+ // tracking the tensor size.
+ for (int i = 0; i < channels; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(scales[i + 1], input_scale * weight_scales[i]);
+ }
+
+ TF_LITE_MICRO_EXPECT_EQ(result.bytes, tensor_size * sizeof(int32_t));
+ TF_LITE_MICRO_EXPECT(result.dims == dims);
+ for (int i = 0; i < tensor_size; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_quantized_values[i], result.data.i32[i]);
+ }
+}
+
+TF_LITE_MICRO_TEST(CreateSymmetricPerChannelQuantizedTensor) {
+ const int tensor_size = 12;
+ constexpr int channels = 2;
+ const int dims_arr[] = {4, channels, 3, 2, 1};
+ int8_t quantized[12];
+ const float pre_quantized[] = {-127, -55, -4, -3, -2, -1,
+ 0, 1, 2, 3, 4, 63.5};
+ const int8_t expected_quantized_values[] = {-127, -55, -4, -3, -2, -1,
+ 0, 2, 4, 6, 8, 127};
+ float expected_scales[] = {1.0, 0.5};
+ TfLiteIntArray* dims = tflite::testing::IntArrayFromInts(dims_arr);
+
+ int zero_points[channels + 1];
+ float scales[channels + 1];
+ TfLiteAffineQuantization quant;
+ TfLiteTensor result =
+ tflite::testing::CreateSymmetricPerChannelQuantizedTensor(
+ pre_quantized, quantized, dims, scales, zero_points, &quant, 0);
+
+ TF_LITE_MICRO_EXPECT_EQ(result.bytes, tensor_size * sizeof(int8_t));
+ TF_LITE_MICRO_EXPECT(result.dims == dims);
+ TfLiteFloatArray* result_scales =
+ static_cast<TfLiteAffineQuantization*>(result.quantization.params)->scale;
+ for (int i = 0; i < channels; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(result_scales->data[i], expected_scales[i]);
+ }
+ for (int i = 0; i < tensor_size; i++) {
+ TF_LITE_MICRO_EXPECT_EQ(expected_quantized_values[i], result.data.int8[i]);
+ }
+}
+
+TF_LITE_MICRO_TESTS_END
diff --git a/tensorflow/lite/micro/tools/ci_build/ci_build_micro_projects.sh b/tensorflow/lite/micro/tools/ci_build/ci_build_micro_projects.sh
new file mode 100755
index 0000000..96fcc0c
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/ci_build_micro_projects.sh
@@ -0,0 +1,38 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Creates the project file distributions for the TensorFlow Lite Micro test and
+# example targets aimed at embedded platforms.
+#
+# Usage: ci_build_micro_projects.sh <TARGET OS> <TAGS>
+#
+# For example:
+# ci_build_micro_projects.sh mbed "CMSIS disco_f746ng"
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+pwd
+
+make -f tensorflow/lite/micro/tools/make/Makefile \
+ TARGET=${1} \
+ TAGS="${2}" \
+ generate_projects
+
+# Needed to solve CI build bug triggered by files added to source tree.
+make -f tensorflow/lite/micro/tools/make/Makefile clean_downloads
diff --git a/tensorflow/lite/micro/tools/ci_build/helper_functions.sh b/tensorflow/lite/micro/tools/ci_build/helper_functions.sh
new file mode 100644
index 0000000..13f843c
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/helper_functions.sh
@@ -0,0 +1,50 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+
+# Collection of helper functions that can be used in the different continuous
+# integration scripts.
+
+function die() {
+ echo "$@" 1>&2 ; exit 1;
+}
+
+# A small utility to run the command and only print logs if the command fails.
+# On success, all logs are hidden. This helps to keep the log output clean and
+# makes debugging easier.
+function readable_run {
+ # Disable debug mode to avoid printing of variables here.
+ set +x
+ result=$("$@" 2>&1) || die "$result"
+ echo "$@"
+ echo "Command completed successfully at $(date)"
+ set -x
+}
+
+# Check if the regex ${1} is to be found in the pathspec ${2}.
+# An optional error messsage can be passed with ${3}
+function check_contents() {
+ GREP_OUTPUT=$(git grep -E -rn ${1} -- ${2})
+
+ if [ "${GREP_OUTPUT}" ]; then
+ echo "=============================================="
+ echo "Found matches for ${1} that are not permitted."
+ echo "${3}"
+ echo "=============================================="
+ echo "${GREP_OUTPUT}"
+ return 1
+ fi
+}
diff --git a/tensorflow/lite/micro/tools/ci_build/install_arduino_cli.sh b/tensorflow/lite/micro/tools/ci_build/install_arduino_cli.sh
new file mode 100755
index 0000000..3275534
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/install_arduino_cli.sh
@@ -0,0 +1,32 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Installs the latest arduino-cli tool in /tmp/arduino-cli
+
+set -e
+
+cd /tmp
+
+rm -rf arduino-cli*
+curl -L -O "https://github.com/arduino/arduino-cli/releases/download/0.4.0/arduino-cli_0.4.0_Linux_64bit.tar.gz"
+tar xzf arduino-cli_0.4.0_Linux_64bit.tar.gz
+
+# To use with MacOS, replace the previous two lines with:
+# curl -L -O "https://github.com/arduino/arduino-cli/releases/download/0.4.0/arduino-cli_0.4.0_MacOS_64bit.tar.gz"
+# tar xzf arduino-cli_0.4.0_MacOS_64bit.tar.gz
+
+/tmp/arduino-cli core update-index
+/tmp/arduino-cli core install arduino:mbed
diff --git a/tensorflow/lite/micro/tools/ci_build/install_mbed_cli.sh b/tensorflow/lite/micro/tools/ci_build/install_mbed_cli.sh
new file mode 100755
index 0000000..801a0f5
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/install_mbed_cli.sh
@@ -0,0 +1,18 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Installs the latest Mbed command-line toolchain.
+pip install mbed-cli
diff --git a/tensorflow/lite/micro/tools/ci_build/test_all.sh b/tensorflow/lite/micro/tools/ci_build/test_all.sh
new file mode 100755
index 0000000..9e391a5
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_all.sh
@@ -0,0 +1,117 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Creates the project file distributions for the TensorFlow Lite Micro test and
+# example targets aimed at embedded platforms.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+pwd
+
+echo "Starting to run micro tests at `date`"
+
+make -f tensorflow/lite/micro/tools/make/Makefile clean_downloads DISABLE_DOWNLOADS=true
+make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=cmsis_nn clean DISABLE_DOWNLOADS=true
+if [ -d tensorflow/lite/micro/tools/make/downloads ]; then
+ echo "ERROR: Downloads directory should not exist, but it does."
+ exit 1
+fi
+
+# Check that an incorrect optimized kernel directory results in an error.
+# Without such an error, an incorrect optimized kernel directory can result in
+# an unexpected fallback to reference kernels and which can be hard to debug. We
+# add some complexity to the CI to make sure that we do not repeat the same
+# mistake as described in http://b/183546742.
+INCORRECT_CMD="make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=does_not_exist clean"
+EXT_LIBS_INC=tensorflow/lite/micro/tools/make/ext_libs/does_not_exist.inc
+touch ${EXT_LIBS_INC}
+if ${INCORRECT_CMD} &> /dev/null ; then
+ echo "'${INCORRECT_CMD}' should have failed but it did not have any errors."
+ rm -f ${EXT_LIBS_INC}
+ exit 1
+fi
+rm -f ${EXT_LIBS_INC}
+
+echo "Running code style checks at `date`"
+tensorflow/lite/micro/tools/ci_build/test_code_style.sh PRESUBMIT
+
+# Add all the test scripts for the various supported platforms here. This
+# enables running all the tests together has part of the continuous integration
+# pipeline and reduces duplication associated with setting up the docker
+# environment.
+
+if [[ ${1} == "GITHUB_PRESUBMIT" ]]; then
+ # We enable bazel as part of the github CI only. This is because the same
+ # checks are already part of the internal CI and there isn't a good reason to
+ # duplicate them.
+ #
+ # Another reason is that the bazel checks involve some patching of TF
+ # workspace and BUILD files and this is an experiment to see what the
+ # trade-off should be between the maintenance overhead, increased CI time from
+ # the unnecessary TF downloads.
+ #
+ # See https://github.com/tensorflow/tensorflow/issues/46465 and
+ # http://b/177672856 for more context.
+ echo "Running bazel tests at `date`"
+ tensorflow/lite/micro/tools/ci_build/test_bazel.sh
+
+ # Enabling FVP for github CI only. This is because it currently adds ~4mins to each
+ # Kokoro run and is only relevant for external changes. Given all the other TFLM CI
+ # coverage, it is unlikely that an internal change would break only the corstone build.
+ echo "Running cortex_m_corstone_300 tests at `date`"
+ tensorflow/lite/micro/tools/ci_build/test_cortex_m_corstone_300.sh
+
+ # Only running project generation v2 prototype as part of the github CI while
+ # it is under development. See
+ # https://github.com/tensorflow/tensorflow/issues/47413 for more context.
+ echo "Running project_generation test at `date`"
+ tensorflow/lite/micro/tools/ci_build/test_project_generation.sh
+fi
+
+echo "Running x86 tests at `date`"
+tensorflow/lite/micro/tools/ci_build/test_x86.sh
+
+echo "Running bluepill tests at `date`"
+tensorflow/lite/micro/tools/ci_build/test_bluepill.sh
+
+# TODO(b/174189223): Skipping mbed tests due to:
+# https://github.com/tensorflow/tensorflow/issues/45164
+# echo "Running mbed tests at `date`"
+# tensorflow/lite/micro/tools/ci_build/test_mbed.sh PRESUBMIT
+
+echo "Running Sparkfun tests at `date`"
+tensorflow/lite/micro/tools/ci_build/test_sparkfun.sh
+
+echo "Running stm32f4 tests at `date`"
+tensorflow/lite/micro/tools/ci_build/test_stm32f4.sh PRESUBMIT
+
+echo "Running Arduino tests at `date`"
+tensorflow/lite/micro/tools/ci_build/test_arduino.sh
+
+echo "Running cortex_m_generic tests at `date`"
+tensorflow/lite/micro/tools/ci_build/test_cortex_m_generic.sh
+
+if [[ ${1} == "GITHUB_PRESUBMIT" ]]; then
+ # This is needed to prevent rsync errors with the TFLM github Kokoro build.
+ # See https://github.com/tensorflow/tensorflow/issues/48254 for additional
+ # context.
+ make -f tensorflow/lite/micro/tools/make/Makefile clean_downloads DISABLE_DOWNLOADS=true
+fi
+
+echo "Finished all micro tests at `date`"
diff --git a/tensorflow/lite/micro/tools/ci_build/test_all_new.sh b/tensorflow/lite/micro/tools/ci_build/test_all_new.sh
new file mode 100755
index 0000000..b85e96f
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_all_new.sh
@@ -0,0 +1,60 @@
+#!/usr/bin/env bash
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+pwd
+
+echo "Starting to run micro tests at `date`"
+
+make -f tensorflow/lite/micro/tools/make/Makefile clean_downloads DISABLE_DOWNLOADS=true
+make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=cmsis_nn clean DISABLE_DOWNLOADS=true
+if [ -d tensorflow/lite/micro/tools/make/downloads ]; then
+ echo "ERROR: Downloads directory should not exist, but it does."
+ exit 1
+fi
+
+echo "Running code style checks at `date`"
+tensorflow/lite/micro/tools/ci_build/test_code_style.sh PRESUBMIT
+
+# Add all the test scripts for the various supported platforms here. This
+# enables running all the tests together has part of the continuous integration
+# pipeline and reduces duplication associated with setting up the docker
+# environment.
+
+if [[ ${1} == "GITHUB_PRESUBMIT" ]]; then
+ # We enable bazel as part of the github CI only. This is because the same
+ # checks are already part of the internal CI and there isn't a good reason to
+ # duplicate them.
+ #
+ # Another reason is that the bazel checks involve some patching of TF
+ # workspace and BUILD files and this is an experiment to see what the
+ # trade-off should be between the maintenance overhead, increased CI time from
+ # the unnecessary TF downloads.
+ #
+ # See https://github.com/tensorflow/tensorflow/issues/46465 and
+ # http://b/177672856 for more context.
+ echo "Running bazel tests at `date`"
+ tensorflow/lite/micro/tools/ci_build/test_bazel.sh
+fi
+
+echo "Running x86 tests at `date`"
+tensorflow/lite/micro/tools/ci_build/test_x86.sh
+
+echo "Finished all micro tests at `date`"
diff --git a/tensorflow/lite/micro/tools/ci_build/test_arc.sh b/tensorflow/lite/micro/tools/ci_build/test_arc.sh
new file mode 100644
index 0000000..de8f7c5
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_arc.sh
@@ -0,0 +1,36 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests the microcontroller code using arc platform.
+# These tests require a metaware compiler.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+
+TARGET_ARCH=arc
+
+# TODO(b/143715361): downloading first to allow for parallel builds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile TARGET_ARCH=${TARGET_ARCH} third_party_downloads
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET_ARCH=${TARGET_ARCH} generate_hello_world_test_make_project
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET_ARCH=${TARGET_ARCH} generate_person_detection_test_make_project
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET_ARCH=${TARGET_ARCH} hello_world_test
diff --git a/tensorflow/lite/micro/tools/ci_build/test_arduino.sh b/tensorflow/lite/micro/tools/ci_build/test_arduino.sh
new file mode 100755
index 0000000..da4858e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_arduino.sh
@@ -0,0 +1,42 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Creates the project file distributions for the TensorFlow Lite Micro test and
+# example targets aimed at embedded platforms.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+
+TARGET=arduino
+OPTIMIZED_KERNEL_DIR=cmsis_nn
+
+# TODO(b/143715361): parallel builds do not work with generated files right now.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile \
+ TARGET=${TARGET} \
+ OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} \
+ generate_arduino_zip
+
+readable_run tensorflow/lite/micro/tools/ci_build/install_arduino_cli.sh
+
+readable_run tensorflow/lite/micro/tools/ci_build/test_arduino_library.sh \
+ tensorflow/lite/micro/tools/make/gen/arduino_x86_64_default/prj/tensorflow_lite.zip
diff --git a/tensorflow/lite/micro/tools/ci_build/test_arduino_library.sh b/tensorflow/lite/micro/tools/ci_build/test_arduino_library.sh
new file mode 100755
index 0000000..3856cb8
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_arduino_library.sh
@@ -0,0 +1,65 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests an individual Arduino library. Because libraries need to be installed
+# globally, this can cause problems with previously-installed modules, so we
+# recommend that you only run this within a VM.
+
+set -e
+
+ARDUINO_HOME_DIR=${HOME}/Arduino
+ARDUINO_LIBRARIES_DIR=${ARDUINO_HOME_DIR}/libraries
+ARDUINO_CLI_TOOL=/tmp/arduino-cli
+# Necessary due to bug in arduino-cli that allows it to build files in pwd
+TEMP_BUILD_DIR=/tmp/tflite-arduino-build
+
+LIBRARY_ZIP=${1}
+
+rm -rf ${TEMP_BUILD_DIR}
+
+mkdir -p "${ARDUINO_HOME_DIR}/libraries"
+mkdir -p ${TEMP_BUILD_DIR}
+
+unzip -o -q ${LIBRARY_ZIP} -d "${ARDUINO_LIBRARIES_DIR}"
+
+# Installs all dependencies for Arduino
+InstallLibraryDependencies () {
+ # Required by magic_wand
+ ${ARDUINO_CLI_TOOL} lib install Arduino_LSM9DS1@1.1.0
+
+ # Required by person_detection
+ ${ARDUINO_CLI_TOOL} lib install JPEGDecoder@1.8.0
+ # Patch to ensure works with nano33ble. This hack (deleting the entire
+ # contents of the file) works with 1.8.0. If we bump the version, may need a
+ # different patch.
+ > ${ARDUINO_LIBRARIES_DIR}/JPEGDecoder/src/User_Config.h
+
+ # Arducam, not available through Arduino library manager. This specific
+ # commit is tested to work; if we bump the commit, we need to ensure that
+ # the defines in ArduCAM/memorysaver.h are correct.
+ wget -O /tmp/arducam-master.zip https://github.com/ArduCAM/Arduino/archive/e216049ba304048ec9bb29adfc2cc24c16f589b1/master.zip
+ unzip -o /tmp/arducam-master.zip -d /tmp
+ cp -r /tmp/Arduino-e216049ba304048ec9bb29adfc2cc24c16f589b1/ArduCAM "${ARDUINO_LIBRARIES_DIR}"
+}
+
+InstallLibraryDependencies
+
+for f in ${ARDUINO_LIBRARIES_DIR}/tensorflow_lite/examples/*/*.ino; do
+ ${ARDUINO_CLI_TOOL} compile --build-cache-path ${TEMP_BUILD_DIR} --build-path ${TEMP_BUILD_DIR} --fqbn arduino:mbed:nano33ble $f
+done
+
+rm -rf ${ARDUINO_LIBRARIES_DIR}
+rm -rf ${TEMP_BUILD_DIR}
diff --git a/tensorflow/lite/micro/tools/ci_build/test_bazel.sh b/tensorflow/lite/micro/tools/ci_build/test_bazel.sh
new file mode 100755
index 0000000..0911c2a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_bazel.sh
@@ -0,0 +1,54 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+# This script can be used to initiate a bazel build with a reduced set of
+# downloads, but still sufficient to test all the TFLM targets.
+#
+# This is primarily intended for use from a Docker image as part of the TFLM
+# github continuous integration system. There are still a number of downloads
+# (e.g. java) that are not necessary and it may be possible to further reduce
+# the set of external libraries and downloads.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+CC=clang readable_run bazel test tensorflow/lite/micro/... \
+ --test_tag_filters=-no_oss --build_tag_filters=-no_oss \
+ --test_output=errors
+
+CC=clang readable_run bazel test tensorflow/lite/micro/... \
+ --config=msan \
+ --test_tag_filters=-no_oss,-nomsan --build_tag_filters=-no_oss,-nomsan \
+ --test_output=errors
+
+CC=clang readable_run bazel test tensorflow/lite/micro/... \
+ --config=asan \
+ --test_tag_filters=-no_oss,-noasan --build_tag_filters=-no_oss,-noasan \
+ --test_output=errors
+
+# TODO(b/178621680): enable ubsan once bazel + clang + ubsan errors are fixed.
+#CC=clang readable_run bazel test tensorflow/lite/micro/... --config=ubsan --test_tag_filters=-no_oss,-noubsan --build_tag_filters=-no_oss,-noubsan
+
+CC=clang readable_run bazel test tensorflow/lite/micro/... \
+ --test_tag_filters=-no_oss --build_tag_filters=-no_oss \
+ --copt=-DTF_LITE_STATIC_MEMORY \
+ --test_output=errors
+
diff --git a/tensorflow/lite/micro/tools/ci_build/test_bluepill.sh b/tensorflow/lite/micro/tools/ci_build/test_bluepill.sh
new file mode 100755
index 0000000..5f5d7c1
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_bluepill.sh
@@ -0,0 +1,47 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests the microcontroller code for bluepill platform
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+pwd
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+
+TARGET=bluepill
+
+# TODO(b/143715361): downloading first to allow for parallel builds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} third_party_downloads
+
+# check that the release build is ok.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} OPTIMIZATION_LEVEL=-O3 BUILD_TYPE=release build
+
+# Next, build w/o release so that we can run the tests and get additional
+# debugging info on failures.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} OPTIMIZATION_LEVEL=-Os test
+
+# We use Renode differently when running the full test suite (make test) vs an
+# individual test. So, we test only of the kernels individually as well to have
+# both of the Renode variations be part of the CI.
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} test_kernel_add_test
diff --git a/tensorflow/lite/micro/tools/ci_build/test_code_style.sh b/tensorflow/lite/micro/tools/ci_build/test_code_style.sh
new file mode 100755
index 0000000..23ad7a7
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_code_style.sh
@@ -0,0 +1,142 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+# explicitly call third_party_downloads since we need pigweed for the license
+# and clang-format checks.
+make -f tensorflow/lite/micro/tools/make/Makefile third_party_downloads
+
+# Explicitly disable exit on error so that we can report all the style errors in
+# one pass and clean up the temporary git repository even when one of the
+# scripts fail with an error code.
+set +e
+
+# The pigweed scripts only work from a git repository and the Tensorflow CI
+# infrastructure does not always guarantee that. As an ugly workaround, we
+# create our own git repo when running on the CI servers.
+pushd tensorflow/lite/
+if [[ ${1} == "PRESUBMIT" ]]; then
+ git init .
+ git config user.email "tflm@google.com"
+ git config user.name "TensorflowLite Micro"
+ git add *
+ git commit -a -m "Commit for a temporary repository." > /dev/null
+fi
+
+############################################################
+# License Check
+############################################################
+micro/tools/make/downloads/pigweed/pw_presubmit/py/pw_presubmit/pigweed_presubmit.py \
+ kernels/internal/reference/ \
+ micro/ \
+ -p copyright_notice \
+ -e kernels/internal/reference/integer_ops/ \
+ -e kernels/internal/reference/reference_ops.h \
+ -e tools/make/downloads \
+ -e tools/make/targets/ecm3531 \
+ -e BUILD\
+ -e leon_commands \
+ -e "\.bzl" \
+ -e "\.h5" \
+ -e "\.ipynb" \
+ -e "\.inc" \
+ -e "\.patch" \
+ -e "\.properties" \
+ -e "\.txt" \
+ -e "\.tpl" \
+ --output-directory /tmp
+
+LICENSE_CHECK_RESULT=$?
+
+############################################################
+# Formatting Check
+############################################################
+# We are currently ignoring Python files (with yapf as the formatter) because
+# that needs additional setup. We are also ignoring the markdown files to allow
+# for a more gradual rollout of this presubmit check.
+micro/tools/make/downloads/pigweed/pw_presubmit/py/pw_presubmit/format_code.py \
+ kernels/internal/reference/ \
+ micro/ \
+ -e kernels/internal/reference/integer_ops/ \
+ -e kernels/internal/reference/reference_ops.h \
+ -e "\.inc" \
+ -e "\.md" \
+ -e "\.py"
+
+CLANG_FORMAT_RESULT=$?
+
+#############################################################################
+# Avoided specific-code snippets for TFLM
+#############################################################################
+
+CHECK_CONTENTS_PATHSPEC=\
+"micro "\
+":(exclude)micro/tools/ci_build/test_code_style.sh"
+
+# See https://github.com/tensorflow/tensorflow/issues/46297 for more context.
+check_contents "gtest|gmock" "${CHECK_CONTENTS_PATHSPEC}" \
+ "These matches can likely be deleted."
+GTEST_RESULT=$?
+
+# See http://b/175657165 for more context.
+ERROR_REPORTER_MESSAGE=\
+"TF_LITE_REPORT_ERROR should be used instead, so that log strings can be "\
+"removed to save space, if needed."
+
+check_contents "error_reporter.*Report\(|context->ReportError\(" \
+ "${CHECK_CONTENTS_PATHSPEC}" "${ERROR_REPORTER_MESSAGE}"
+ERROR_REPORTER_RESULT=$?
+
+# See http://b/175657165 for more context.
+ASSERT_PATHSPEC=\
+"${CHECK_CONTENTS_PATHSPEC}"\
+" :(exclude)micro/examples/micro_speech/esp/ringbuf.c"\
+" :(exclude)*\.ipynb"\
+" :(exclude)*\.py"\
+" :(exclude)*zephyr_riscv/Makefile.inc"
+
+check_contents "\<assert\>" "${ASSERT_PATHSPEC}" \
+ "assert should not be used in TFLM code.."
+ASSERT_RESULT=$?
+
+###########################################################################
+# All checks are complete, clean up.
+###########################################################################
+
+popd
+if [[ ${1} == "PRESUBMIT" ]]; then
+ rm -rf tensorflow/lite/.git
+fi
+
+# Re-enable exit on error now that we are done with the temporary git repo.
+set -e
+
+if [[ ${LICENSE_CHECK_RESULT} != 0 || \
+ ${CLANG_FORMAT_RESULT} != 0 || \
+ ${GTEST_RESULT} != 0 || \
+ ${ERROR_REPORTER_RESULT} != 0 || \
+ ${ASSERT_RESULT} != 0 \
+ ]]
+then
+ exit 1
+fi
diff --git a/tensorflow/lite/micro/tools/ci_build/test_cortex_m_corstone_300.sh b/tensorflow/lite/micro/tools/ci_build/test_cortex_m_corstone_300.sh
new file mode 100755
index 0000000..6a0c817
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_cortex_m_corstone_300.sh
@@ -0,0 +1,37 @@
+#!/usr/bin/env bash
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests Arm Cortex-M55 microprocessor code with CMSIS-NN optimizied kernels using FVP based on Arm Corstone-300 software.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+TARGET=cortex_m_corstone_300
+TARGET_ARCH=cortex-m55
+OPTIMIZED_KERNEL_DIR=cmsis_nn
+
+# TODO(b/143715361): downloading first to allow for parallel builds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} TARGET_ARCH=${TARGET_ARCH} third_party_downloads
+
+# Avoid running tests in parallel.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} TARGET_ARCH=${TARGET_ARCH} build
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} TARGET_ARCH=${TARGET_ARCH} test
diff --git a/tensorflow/lite/micro/tools/ci_build/test_cortex_m_generic.sh b/tensorflow/lite/micro/tools/ci_build/test_cortex_m_generic.sh
new file mode 100755
index 0000000..369f4da
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_cortex_m_generic.sh
@@ -0,0 +1,47 @@
+#!/usr/bin/env bash
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests the microcontroller code using a Cortex-M4/M4F platform.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+TARGET=cortex_m_generic
+OPTIMIZED_KERNEL_DIR=cmsis_nn
+
+# TODO(b/143715361): downloading first to allow for parallel builds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} TARGET_ARCH=cortex-m4 third_party_downloads
+
+# Build for Cortex-M4 (no FPU) without CMSIS
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j$(nproc) -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} TARGET_ARCH=cortex-m4 microlite
+
+# Build for Cortex-M4F (FPU present) without CMSIS
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j$(nproc) -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} TARGET_ARCH=cortex-m4+fp microlite
+
+# Build for Cortex-M4 (no FPU) with CMSIS
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j$(nproc) -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} TARGET_ARCH=cortex-m4 microlite
+
+# Build for Cortex-M4 (FPU present) with CMSIS
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j$(nproc) -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} TARGET_ARCH=cortex-m4+fp microlite
diff --git a/tensorflow/lite/micro/tools/ci_build/test_esp32.sh b/tensorflow/lite/micro/tools/ci_build/test_esp32.sh
new file mode 100755
index 0000000..fd4044b
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_esp32.sh
@@ -0,0 +1,59 @@
+#!/usr/bin/env bash
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests the microcontroller code for esp32 platform
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+pwd
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+TARGET=esp
+
+# setup esp-idf and toolchains
+echo "Checking out esp-idf..."
+readable_run git clone --recursive --single-branch --branch release/v4.2 https://github.com/espressif/esp-idf.git
+export IDF_PATH="${ROOT_DIR}"/esp-idf
+cd $IDF_PATH
+readable_run ./install.sh
+readable_run . ./export.sh
+cd "${ROOT_DIR}"
+
+# clean all
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+
+# generate examples
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} generate_hello_world_esp_project
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} generate_person_detection_esp_project
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} generate_micro_speech_esp_project
+
+# build examples
+cd "${ROOT_DIR}"/tensorflow/lite/micro/tools/make/gen/esp_xtensa-esp32/prj/hello_world/esp-idf
+readable_run idf.py build
+
+cd "${ROOT_DIR}"/tensorflow/lite/micro/tools/make/gen/esp_xtensa-esp32/prj/person_detection/esp-idf
+readable_run git clone https://github.com/espressif/esp32-camera.git components/esp32-camera
+cd components/esp32-camera/
+readable_run git checkout eacd640b8d379883bff1251a1005ebf3cf1ed95c
+cd ../../
+readable_run idf.py build
+
+cd "${ROOT_DIR}"/tensorflow/lite/micro/tools/make/gen/esp_xtensa-esp32/prj/micro_speech/esp-idf
+readable_run idf.py build
diff --git a/tensorflow/lite/micro/tools/ci_build/test_mbed.sh b/tensorflow/lite/micro/tools/ci_build/test_mbed.sh
new file mode 100755
index 0000000..fa4506f
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_mbed.sh
@@ -0,0 +1,69 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+#
+# This script takes a single argument to differentiate between running it as
+# part of presubmit checks or not.
+#
+# This will generate a subset of targets:
+# test_mbed.sh PRESUBMIT
+#
+# This will run generate all the targets:
+# test_mbed.sh
+#
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+pwd
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+
+TARGET=mbed
+
+# We limit the number of projects that we build as part of the presubmit checks
+# to keep the overall time low, but build everything as part of the nightly
+# builds.
+if [[ ${1} == "PRESUBMIT" ]]; then
+ PROJECTS="generate_hello_world_mbed_project generate_micro_speech_mbed_project"
+else
+ PROJECTS=generate_projects
+fi
+
+make -f tensorflow/lite/micro/tools/make/Makefile \
+ TARGET=${TARGET} \
+ TAGS="disco_f746ng" \
+ ${PROJECTS}
+
+readable_run tensorflow/lite/micro/tools/ci_build/install_mbed_cli.sh
+
+for PROJECT_PATH in tensorflow/lite/micro/tools/make/gen/mbed_*/prj/*/mbed; do
+ PROJECT_PARENT_DIR=$(dirname ${PROJECT_PATH})
+ PROJECT_NAME=$(basename ${PROJECT_PARENT_DIR})
+ # Don't try to build and package up test projects, because there are too many.
+ if [[ ${PROJECT_NAME} == *"_test" ]]; then
+ continue
+ fi
+ cp -r ${PROJECT_PATH} ${PROJECT_PARENT_DIR}/${PROJECT_NAME}
+ pushd ${PROJECT_PARENT_DIR}
+ zip -q -r ${PROJECT_NAME}.zip ${PROJECT_NAME}
+ popd
+ readable_run tensorflow/lite/micro/tools/ci_build/test_mbed_library.sh ${PROJECT_PATH}
+done
diff --git a/tensorflow/lite/micro/tools/ci_build/test_mbed_library.sh b/tensorflow/lite/micro/tools/ci_build/test_mbed_library.sh
new file mode 100755
index 0000000..c1ec1e6
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_mbed_library.sh
@@ -0,0 +1,34 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests an individual Arduino library. Because libraries need to be installed
+# globally, this can cause problems with previously-installed modules, so we
+# recommend that you only run this within a VM.
+
+set -e
+
+PATH=`pwd`/tensorflow/lite/micro/tools/make/downloads/gcc_embedded/bin:${PATH}
+cd "${1}"
+
+mbed config root .
+mbed deploy
+
+python -c 'import fileinput, glob;
+for filename in glob.glob("mbed-os/tools/profiles/*.json"):
+ for line in fileinput.input(filename, inplace=True):
+ print(line.replace("\"-std=gnu++98\"","\"-std=c++11\", \"-fpermissive\""))'
+
+mbed compile -m DISCO_F746NG -t GCC_ARM
diff --git a/tensorflow/lite/micro/tools/ci_build/test_project_generation.sh b/tensorflow/lite/micro/tools/ci_build/test_project_generation.sh
new file mode 100755
index 0000000..bd0a5ac
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_project_generation.sh
@@ -0,0 +1,52 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+# This script can be used to initiate a bazel build with a reduced set of
+# downloads, but still sufficient to test all the TFLM targets.
+#
+# This is primarily intended for use from a Docker image as part of the TFLM
+# github continuous integration system. There are still a number of downloads
+# (e.g. java) that are not necessary and it may be possible to further reduce
+# the set of external libraries and downloads.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+TEST_OUTPUT_DIR="/tmp/tflm_project_gen"
+rm -rf ${TEST_OUTPUT_DIR}
+
+TEST_OUTPUT_DIR_CMSIS="/tmp/tflm_project_gen_cmsis"
+rm -rf ${TEST_OUTPUT_DIR_CMSIS}
+
+readable_run \
+ python3 tensorflow/lite/micro/tools/project_generation/create_tflm_tree.py \
+ ${TEST_OUTPUT_DIR} \
+ -e hello_world
+
+readable_run cp tensorflow/lite/micro/tools/project_generation/Makefile ${TEST_OUTPUT_DIR}
+
+pushd ${TEST_OUTPUT_DIR} > /dev/null
+readable_run make -j8 examples
+popd > /dev/null
+
+readable_run python3 tensorflow/lite/micro/tools/project_generation/create_tflm_tree.py \
+ --makefile_options="TARGET=cortex_m_generic OPTIMIZED_KERNEL_DIR=cmsis_nn TARGET_ARCH=cortex-m4" \
+ ${TEST_OUTPUT_DIR_CMSIS}
diff --git a/tensorflow/lite/micro/tools/ci_build/test_sparkfun.sh b/tensorflow/lite/micro/tools/ci_build/test_sparkfun.sh
new file mode 100755
index 0000000..ad7d294
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_sparkfun.sh
@@ -0,0 +1,36 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests the microcontroller code using native x86 execution.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+TARGET=sparkfun_edge
+
+# TODO(b/143715361): downloading first to allow for parallel builds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} third_party_downloads
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} build
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile TARGET=${TARGET} OPTIMIZED_KERNEL_DIR=cmsis_nn build
diff --git a/tensorflow/lite/micro/tools/ci_build/test_stm32f4.sh b/tensorflow/lite/micro/tools/ci_build/test_stm32f4.sh
new file mode 100755
index 0000000..8354563
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_stm32f4.sh
@@ -0,0 +1,42 @@
+#!/usr/bin/env bash
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests the microcontroller code for stm32f4
+
+set -e
+
+TARGET=stm32f4
+OPTIMIZED_KERNEL_DIR=cmsis_nn
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+pwd
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+
+# TODO(b/143715361): downloading first to allow for parallel builds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} third_party_downloads
+
+# First make sure that the release build succeeds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile BUILD_TYPE=release OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} build
+
+# Next, build w/o release so that we can run the tests and get additional
+# debugging info on failures.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile OPTIMIZED_KERNEL_DIR=${OPTIMIZED_KERNEL_DIR} TARGET=${TARGET} test
diff --git a/tensorflow/lite/micro/tools/ci_build/test_x86.sh b/tensorflow/lite/micro/tools/ci_build/test_x86.sh
new file mode 100755
index 0000000..363aba8
--- /dev/null
+++ b/tensorflow/lite/micro/tools/ci_build/test_x86.sh
@@ -0,0 +1,47 @@
+#!/usr/bin/env bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Tests the microcontroller code using native x86 execution.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/ci_build/helper_functions.sh
+
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+
+# TODO(b/143715361): downloading first to allow for parallel builds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile third_party_downloads
+
+# Next, build w/o TF_LITE_STATIC_MEMORY to catch additional errors.
+# TODO(b/160955687): We run the tests w/o TF_LITE_STATIC_MEMORY to make the
+# internal and open source CI consistent. See b/160955687#comment7 for more
+# details.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile BUILD_TYPE=no_tf_lite_static_memory test
+
+# Next, make sure that the release build succeeds.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -j8 -f tensorflow/lite/micro/tools/make/Makefile BUILD_TYPE=release build
+
+# Next, build w/o release so that we can run the tests and get additional
+# debugging info on failures.
+readable_run make -f tensorflow/lite/micro/tools/make/Makefile clean
+readable_run make -s -j8 -f tensorflow/lite/micro/tools/make/Makefile test
+
diff --git a/tensorflow/lite/micro/tools/dev_setup/pre-push.tflm b/tensorflow/lite/micro/tools/dev_setup/pre-push.tflm
new file mode 100755
index 0000000..140f1aa
--- /dev/null
+++ b/tensorflow/lite/micro/tools/dev_setup/pre-push.tflm
@@ -0,0 +1,17 @@
+#!/bin/sh
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+tensorflow/lite/micro/tools/ci_build/test_code_style.sh
diff --git a/tensorflow/lite/micro/tools/make/.gitignore b/tensorflow/lite/micro/tools/make/.gitignore
new file mode 100644
index 0000000..752f078
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/.gitignore
@@ -0,0 +1,2 @@
+downloads
+gen
diff --git a/tensorflow/lite/micro/tools/make/Makefile b/tensorflow/lite/micro/tools/make/Makefile
new file mode 100644
index 0000000..1bd65a7
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/Makefile
@@ -0,0 +1,873 @@
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+ifneq (3.82,$(firstword $(sort $(MAKE_VERSION) 3.82)))
+ $(error "Requires make version 3.82 or later (current is $(MAKE_VERSION))")
+endif
+
+# root directory of tensorflow
+TENSORFLOW_ROOT :=
+MAKEFILE_DIR := tensorflow/lite/micro/tools/make
+
+# Override this on make command line to parse third party downloads during project generation
+# make -f tensorflow/lite/micro/tools/make/Makefile PARSE_THIRD_PARTY=true TARGET=apollo3evb generate_hello_world_make_project
+PARSE_THIRD_PARTY :=
+
+
+# Pull in some convenience functions.
+include $(MAKEFILE_DIR)/helper_functions.inc
+
+# Try to figure out the host system
+HOST_OS :=
+ifeq ($(OS),Windows_NT)
+ HOST_OS = windows
+else
+ UNAME_S := $(shell uname -s)
+ ifeq ($(UNAME_S),Linux)
+ HOST_OS := linux
+ endif
+ ifeq ($(UNAME_S),Darwin)
+ HOST_OS := osx
+ endif
+endif
+
+# Determine the host architecture, with any ix86 architecture being labelled x86_32
+HOST_ARCH := $(shell if uname -m | grep -Eq 'i[345678]86'; then echo x86_32; else echo $(shell uname -m); fi)
+
+# Override these on the make command line to target a specific architecture. For example:
+# make -f tensorflow/lite/Makefile TARGET=rpi TARGET_ARCH=armv7l
+TARGET := $(HOST_OS)
+TARGET_ARCH := $(HOST_ARCH)
+
+# Default compiler and tool names:
+TOOLCHAIN:=gcc
+CXX_TOOL := g++
+CC_TOOL := gcc
+AR_TOOL := ar
+
+ifneq ($(TAGS),)
+ $(error The TAGS command line option is no longer supported in the TFLM Makefile.)
+endif
+
+# Specify which specialized kernel implementation should be pulled in.
+OPTIMIZED_KERNEL_DIR :=
+
+# Specify which co-processor's kernel implementation should be pulled in.
+# If the same kernel is implemented in both kernels/OPTIMIZED_KERNEL_DIR and
+# kernels/CO_PROCESSOR, then the implementation from kernels/CO_PROCESSOR will
+# be used.
+CO_PROCESSOR :=
+
+# This is obviously horrible. We need to generate these 3 versions of the
+# include directories from one source.
+INCLUDES := \
+-I. \
+-I$(MAKEFILE_DIR)/downloads/gemmlowp \
+-I$(MAKEFILE_DIR)/downloads/flatbuffers/include \
+-I$(MAKEFILE_DIR)/downloads/ruy
+
+# Same list of paths, but now relative to the generated project files.
+GENERATED_PROJECT_INCLUDES := \
+-I. \
+-I./third_party/gemmlowp \
+-I./third_party/flatbuffers/include \
+-I./third_party/ruy
+
+# Same list of paths, but now in the format the generate_keil_project.py
+# script expects them.
+PROJECT_INCLUDES := \
+. \
+third_party/gemmlowp \
+third_party/flatbuffers/include \
+third_party/ruy
+
+TEST_SCRIPT :=
+
+MICROLITE_LIBS := -lm
+
+# For the target, optimized_kernel_dir, and co-processor as specified on the
+# command line we add -D<tag> to the cflags to allow for #idefs in the code.
+#
+# We apply the following transformations (via the tr command):
+# 1. Convert to uppercase (TARGET=xtensa -> -DXTENSA)
+
+ADDITIONAL_DEFINES := -D$(shell echo $(TARGET) | tr [a-z] [A-Z])
+
+ifneq ($(OPTIMIZED_KERNEL_DIR),)
+ ADDITIONAL_DEFINES += -D$(shell echo $(OPTIMIZED_KERNEL_DIR) | tr [a-z] [A-Z])
+endif
+
+ifneq ($(CO_PROCESSOR),)
+ ADDITIONAL_DEFINES += -D$(shell echo $(CO_PROCESSOR) | tr [a-z] [A-Z])
+endif
+
+OPTIMIZATION_LEVEL := -O3
+
+CC_WARNINGS := \
+ -Werror \
+ -Wsign-compare \
+ -Wdouble-promotion \
+ -Wshadow \
+ -Wunused-variable \
+ -Wmissing-field-initializers \
+ -Wunused-function \
+ -Wswitch \
+ -Wvla \
+ -Wall \
+ -Wextra \
+ -Wstrict-aliasing \
+ -Wno-unused-parameter
+
+COMMON_FLAGS := \
+ -fno-unwind-tables \
+ -ffunction-sections \
+ -fdata-sections \
+ -fmessage-length=0 \
+ -DTF_LITE_STATIC_MEMORY \
+ -DTF_LITE_DISABLE_X86_NEON \
+ $(OPTIMIZATION_LEVEL) \
+ $(CC_WARNINGS) \
+ $(ADDITIONAL_DEFINES)
+
+ifeq ($(TARGET), $(HOST_OS))
+ # If we are not doing a cross-compilation then -DTF_LITE_USE_CTIME is what we
+ # want to have by default.
+ COMMON_FLAGS += -DTF_LITE_USE_CTIME
+endif
+
+CXXFLAGS := \
+ -std=c++11 \
+ -fno-rtti \
+ -fno-exceptions \
+ -fno-threadsafe-statics \
+ $(COMMON_FLAGS)
+
+CCFLAGS := \
+ -std=c11 \
+ $(COMMON_FLAGS)
+
+ARFLAGS := -r
+
+ifeq ($(TOOLCHAIN), gcc)
+ ifneq ($(TARGET), osx)
+ # GCC on MacOS uses an LLVM backend so we avoid the additional linker flags
+ # that are unsupported with LLVM.
+ LDFLAGS += \
+ -Wl,--fatal-warnings \
+ -Wl,--gc-sections
+ endif
+endif
+
+# override these in the makefile.inc for specific compiler targets
+TARGET_TOOLCHAIN_PREFIX :=
+TARGET_TOOLCHAIN_ROOT :=
+
+# Specifying BUILD_TYPE=<blah> as part of the make command gives us a few
+# options to choose from.
+#
+# If BUILD_TYPE is not specified, the default build (which should be suitable
+# most of the time) has all of the error checking logic at the expense of a
+# latency increase of ~5-10% relative to BUILD_TYPE=release_with_logs.
+#
+# This default build is most suited for usual development and testing as is
+# highlighted by the discussion on this github pull request:
+# https://github.com/tensorflow/tensorflow/pull/42314#issuecomment-694360567
+BUILD_TYPE := default
+ifeq ($(BUILD_TYPE), debug)
+ # Specifying BUILD_TYPE=debug adds debug symbols to the binary (and makes it
+ # larger) and should be used to run a binary with gdb.
+ CXXFLAGS += -g
+ CCFLAGS += -g
+else ifeq ($(BUILD_TYPE), release)
+ # The 'release' build results in the smallest binary (by virtue of removing
+ # strings from log messages, DCHECKs ...).
+ #
+ # The down-side is that we currently do not have a good mechanism to allow
+ # for logging that is not related to errors (e.g. profiling information, or
+ # logs that help determine if tests pass or fail). As a result, we are unable
+ # to run tests or benchmarks with BUILD_TYPE=release (which is a bit
+ # counter-intuitive). TODO(b/158205789): A global error reporter might help.
+ #
+ # For a close approximation of the release build use
+ # BUILD_TYPE=release_with_logs.
+ CXXFLAGS += -DNDEBUG -DTF_LITE_STRIP_ERROR_STRINGS
+ CCFLAGS += -DNDEBUG -DTF_LITE_STRIP_ERROR_STRINGS
+else ifeq ($(BUILD_TYPE), release_with_logs)
+ # The latency with BUILD_TYPE=release_with_logs will be close to the 'release'
+ # build and there will still be error logs. This build type may be preferable
+ # for profiling and benchmarking.
+ CXXFLAGS += -DNDEBUG
+ CCFLAGS += -DNDEBUG
+else ifeq ($(BUILD_TYPE), no_tf_lite_static_memory)
+ # This build should not be used to run any binaries/tests since
+ # TF_LITE_STATIC_MEMORY should be defined for all micro builds. However,
+ # having a build without TF_LITE_STATIC_MEMORY is useful to catch errors in
+ # code that is shared between TfLite Mobile and TfLite Micro. See this issue
+ # for more details:
+ # https://github.com/tensorflow/tensorflow/issues/43076
+ CXXFLAGS := $(filter-out -DTF_LITE_STATIC_MEMORY, $(CXXFLAGS))
+ CCFLAGS := $(filter-out -DTF_LITE_STATIC_MEMORY, $(CCFLAGS))
+endif
+
+# This library is the main target for this makefile. It will contain a minimal
+# runtime that can be linked in to other programs.
+MICROLITE_LIB_NAME := libtensorflow-microlite.a
+
+# These two must be defined before we include the target specific Makefile.inc
+# because we filter out the examples that are not supported for those targets.
+# See targets/xtensa_xpg_makefile.inc for an example.
+#
+# We limit max depth of directories to search to not include target specific
+# Makefiles that are included directly by the main example Makefile. See
+# examples/micro_speech/Makefile.inc for an example. At the same time, we
+# search till an arbitrary depth for files named Makefile_internal.inc as a way
+# to bypass this check and allow for deeper directory structures.
+MICRO_LITE_EXAMPLE_TESTS := $(shell find tensorflow/lite/micro/examples/ -maxdepth 2 -name Makefile.inc)
+MICRO_LITE_EXAMPLE_TESTS += $(shell find tensorflow/lite/micro/examples/ -name Makefile_internal.inc)
+
+# Image recognition experimental uses uint8 quantization and is no longer
+# supported (See #44912 for more details). We should consider deleting
+# the image_recognition_experimental example.
+EXCLUDED_EXAMPLE_TESTS := \
+ tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc
+MICRO_LITE_EXAMPLE_TESTS := $(filter-out $(EXCLUDED_EXAMPLE_TESTS), $(MICRO_LITE_EXAMPLE_TESTS))
+
+MICRO_LITE_BENCHMARKS := $(wildcard tensorflow/lite/micro/benchmarks/Makefile.inc)
+
+# TODO(b/152645559): move all benchmarks to benchmarks directory.
+MICROLITE_BENCHMARK_SRCS := \
+$(wildcard tensorflow/lite/micro/benchmarks/*benchmark.cc)
+
+MICROLITE_TEST_SRCS := \
+tensorflow/lite/micro/memory_arena_threshold_test.cc \
+tensorflow/lite/micro/memory_helpers_test.cc \
+tensorflow/lite/micro/micro_allocator_test.cc \
+tensorflow/lite/micro/micro_error_reporter_test.cc \
+tensorflow/lite/micro/micro_interpreter_test.cc \
+tensorflow/lite/micro/micro_mutable_op_resolver_test.cc \
+tensorflow/lite/micro/micro_string_test.cc \
+tensorflow/lite/micro/micro_time_test.cc \
+tensorflow/lite/micro/micro_utils_test.cc \
+tensorflow/lite/micro/recording_micro_allocator_test.cc \
+tensorflow/lite/micro/recording_simple_memory_allocator_test.cc \
+tensorflow/lite/micro/simple_memory_allocator_test.cc \
+tensorflow/lite/micro/testing_helpers_test.cc \
+tensorflow/lite/micro/kernels/activations_test.cc \
+tensorflow/lite/micro/kernels/add_test.cc \
+tensorflow/lite/micro/kernels/add_n_test.cc \
+tensorflow/lite/micro/kernels/arg_min_max_test.cc \
+tensorflow/lite/micro/kernels/batch_to_space_nd_test.cc \
+tensorflow/lite/micro/kernels/cast_test.cc \
+tensorflow/lite/micro/kernels/ceil_test.cc \
+tensorflow/lite/micro/kernels/circular_buffer_test.cc \
+tensorflow/lite/micro/kernels/comparisons_test.cc \
+tensorflow/lite/micro/kernels/concatenation_test.cc \
+tensorflow/lite/micro/kernels/conv_test.cc \
+tensorflow/lite/micro/kernels/cumsum_test.cc \
+tensorflow/lite/micro/kernels/depthwise_conv_test.cc \
+tensorflow/lite/micro/kernels/dequantize_test.cc \
+tensorflow/lite/micro/kernels/detection_postprocess_test.cc \
+tensorflow/lite/micro/kernels/elementwise_test.cc \
+tensorflow/lite/micro/kernels/elu_test.cc \
+tensorflow/lite/micro/kernels/exp_test.cc \
+tensorflow/lite/micro/kernels/expand_dims_test.cc \
+tensorflow/lite/micro/kernels/fill_test.cc \
+tensorflow/lite/micro/kernels/floor_test.cc \
+tensorflow/lite/micro/kernels/floor_div_test.cc \
+tensorflow/lite/micro/kernels/floor_mod_test.cc \
+tensorflow/lite/micro/kernels/fully_connected_test.cc \
+tensorflow/lite/micro/kernels/hard_swish_test.cc \
+tensorflow/lite/micro/kernels/l2norm_test.cc \
+tensorflow/lite/micro/kernels/l2_pool_2d_test.cc \
+tensorflow/lite/micro/kernels/leaky_relu_test.cc \
+tensorflow/lite/micro/kernels/logical_test.cc \
+tensorflow/lite/micro/kernels/logistic_test.cc \
+tensorflow/lite/micro/kernels/maximum_minimum_test.cc \
+tensorflow/lite/micro/kernels/mul_test.cc \
+tensorflow/lite/micro/kernels/neg_test.cc \
+tensorflow/lite/micro/kernels/pack_test.cc \
+tensorflow/lite/micro/kernels/pad_test.cc \
+tensorflow/lite/micro/kernels/pooling_test.cc \
+tensorflow/lite/micro/kernels/prelu_test.cc \
+tensorflow/lite/micro/kernels/quantization_util_test.cc \
+tensorflow/lite/micro/kernels/quantize_test.cc \
+tensorflow/lite/micro/kernels/reduce_test.cc \
+tensorflow/lite/micro/kernels/reshape_test.cc \
+tensorflow/lite/micro/kernels/resize_nearest_neighbor_test.cc \
+tensorflow/lite/micro/kernels/round_test.cc \
+tensorflow/lite/micro/kernels/shape_test.cc \
+tensorflow/lite/micro/kernels/softmax_test.cc \
+tensorflow/lite/micro/kernels/space_to_batch_nd_test.cc \
+tensorflow/lite/micro/kernels/split_test.cc \
+tensorflow/lite/micro/kernels/split_v_test.cc \
+tensorflow/lite/micro/kernels/squeeze_test.cc \
+tensorflow/lite/micro/kernels/strided_slice_test.cc \
+tensorflow/lite/micro/kernels/sub_test.cc \
+tensorflow/lite/micro/kernels/svdf_test.cc \
+tensorflow/lite/micro/kernels/tanh_test.cc \
+tensorflow/lite/micro/kernels/transpose_conv_test.cc \
+tensorflow/lite/micro/kernels/unpack_test.cc \
+tensorflow/lite/micro/kernels/zeros_like_test.cc \
+tensorflow/lite/micro/memory_planner/greedy_memory_planner_test.cc \
+tensorflow/lite/micro/memory_planner/linear_memory_planner_test.cc
+
+MICROLITE_CC_KERNEL_SRCS := \
+tensorflow/lite/micro/kernels/activations.cc \
+tensorflow/lite/micro/kernels/add.cc \
+tensorflow/lite/micro/kernels/add_n.cc \
+tensorflow/lite/micro/kernels/arg_min_max.cc \
+tensorflow/lite/micro/kernels/batch_to_space_nd.cc \
+tensorflow/lite/micro/kernels/cast.cc \
+tensorflow/lite/micro/kernels/ceil.cc \
+tensorflow/lite/micro/kernels/circular_buffer.cc \
+tensorflow/lite/micro/kernels/comparisons.cc \
+tensorflow/lite/micro/kernels/concatenation.cc \
+tensorflow/lite/micro/kernels/conv.cc \
+tensorflow/lite/micro/kernels/conv_common.cc \
+tensorflow/lite/micro/kernels/cumsum.cc \
+tensorflow/lite/micro/kernels/depthwise_conv.cc \
+tensorflow/lite/micro/kernels/depthwise_conv_common.cc \
+tensorflow/lite/micro/kernels/dequantize.cc \
+tensorflow/lite/micro/kernels/detection_postprocess.cc \
+tensorflow/lite/micro/kernels/elementwise.cc \
+tensorflow/lite/micro/kernels/elu.cc \
+tensorflow/lite/micro/kernels/ethosu.cc \
+tensorflow/lite/micro/kernels/exp.cc \
+tensorflow/lite/micro/kernels/expand_dims.cc \
+tensorflow/lite/micro/kernels/fill.cc \
+tensorflow/lite/micro/kernels/floor.cc \
+tensorflow/lite/micro/kernels/floor_div.cc \
+tensorflow/lite/micro/kernels/floor_mod.cc \
+tensorflow/lite/micro/kernels/fully_connected.cc \
+tensorflow/lite/micro/kernels/fully_connected_common.cc \
+tensorflow/lite/micro/kernels/hard_swish.cc \
+tensorflow/lite/micro/kernels/kernel_runner.cc \
+tensorflow/lite/micro/kernels/kernel_util.cc \
+tensorflow/lite/micro/kernels/l2norm.cc \
+tensorflow/lite/micro/kernels/l2_pool_2d.cc \
+tensorflow/lite/micro/kernels/leaky_relu.cc \
+tensorflow/lite/micro/kernels/logical.cc \
+tensorflow/lite/micro/kernels/logistic.cc \
+tensorflow/lite/micro/kernels/maximum_minimum.cc \
+tensorflow/lite/micro/kernels/mul.cc \
+tensorflow/lite/micro/kernels/neg.cc \
+tensorflow/lite/micro/kernels/pack.cc \
+tensorflow/lite/micro/kernels/pad.cc \
+tensorflow/lite/micro/kernels/pooling.cc \
+tensorflow/lite/micro/kernels/prelu.cc \
+tensorflow/lite/micro/kernels/quantize.cc \
+tensorflow/lite/micro/kernels/quantize_common.cc \
+tensorflow/lite/micro/kernels/reduce.cc \
+tensorflow/lite/micro/kernels/reshape.cc \
+tensorflow/lite/micro/kernels/resize_nearest_neighbor.cc \
+tensorflow/lite/micro/kernels/round.cc \
+tensorflow/lite/micro/kernels/shape.cc \
+tensorflow/lite/micro/kernels/softmax.cc \
+tensorflow/lite/micro/kernels/softmax_common.cc \
+tensorflow/lite/micro/kernels/space_to_batch_nd.cc \
+tensorflow/lite/micro/kernels/split.cc \
+tensorflow/lite/micro/kernels/split_v.cc \
+tensorflow/lite/micro/kernels/squeeze.cc \
+tensorflow/lite/micro/kernels/strided_slice.cc \
+tensorflow/lite/micro/kernels/sub.cc \
+tensorflow/lite/micro/kernels/svdf.cc \
+tensorflow/lite/micro/kernels/svdf_common.cc \
+tensorflow/lite/micro/kernels/tanh.cc \
+tensorflow/lite/micro/kernels/transpose_conv.cc \
+tensorflow/lite/micro/kernels/unpack.cc \
+tensorflow/lite/micro/kernels/zeros_like.cc
+
+MICROLITE_TEST_HDRS := \
+$(wildcard tensorflow/lite/micro/testing/*.h)
+
+MICROLITE_CC_BASE_SRCS := \
+$(wildcard tensorflow/lite/micro/*.cc) \
+$(wildcard tensorflow/lite/micro/memory_planner/*.cc) \
+tensorflow/lite/c/common.c \
+tensorflow/lite/core/api/error_reporter.cc \
+tensorflow/lite/core/api/flatbuffer_conversions.cc \
+tensorflow/lite/core/api/op_resolver.cc \
+tensorflow/lite/core/api/tensor_utils.cc \
+tensorflow/lite/kernels/internal/quantization_util.cc \
+tensorflow/lite/kernels/kernel_util.cc \
+tensorflow/lite/schema/schema_utils.cc
+
+MICROLITE_CC_SRCS := $(filter-out $(MICROLITE_TEST_SRCS), $(MICROLITE_CC_BASE_SRCS))
+MICROLITE_CC_SRCS := $(filter-out $(MICROLITE_BENCHMARK_SRCS), $(MICROLITE_CC_SRCS))
+
+MICROLITE_CC_HDRS := \
+$(wildcard tensorflow/lite/micro/*.h) \
+$(wildcard tensorflow/lite/micro/benchmarks/*model_data.h) \
+$(wildcard tensorflow/lite/micro/kernels/*.h) \
+$(wildcard tensorflow/lite/micro/memory_planner/*.h) \
+LICENSE \
+tensorflow/lite/c/builtin_op_data.h \
+tensorflow/lite/c/c_api_types.h \
+tensorflow/lite/c/common.h \
+tensorflow/lite/core/api/error_reporter.h \
+tensorflow/lite/core/api/flatbuffer_conversions.h \
+tensorflow/lite/core/api/op_resolver.h \
+tensorflow/lite/core/api/tensor_utils.h \
+tensorflow/lite/kernels/internal/common.h \
+tensorflow/lite/kernels/internal/compatibility.h \
+tensorflow/lite/kernels/internal/optimized/neon_check.h \
+tensorflow/lite/kernels/internal/quantization_util.h \
+tensorflow/lite/kernels/internal/reference/add.h \
+tensorflow/lite/kernels/internal/reference/add_n.h \
+tensorflow/lite/kernels/internal/reference/arg_min_max.h \
+tensorflow/lite/kernels/internal/reference/batch_to_space_nd.h \
+tensorflow/lite/kernels/internal/reference/binary_function.h \
+tensorflow/lite/kernels/internal/reference/ceil.h \
+tensorflow/lite/kernels/internal/reference/comparisons.h \
+tensorflow/lite/kernels/internal/reference/concatenation.h \
+tensorflow/lite/kernels/internal/reference/conv.h \
+tensorflow/lite/kernels/internal/reference/cumsum.h \
+tensorflow/lite/kernels/internal/reference/depthwiseconv_float.h \
+tensorflow/lite/kernels/internal/reference/depthwiseconv_uint8.h \
+tensorflow/lite/kernels/internal/reference/dequantize.h \
+tensorflow/lite/kernels/internal/reference/elu.h \
+tensorflow/lite/kernels/internal/reference/exp.h \
+tensorflow/lite/kernels/internal/reference/fill.h \
+tensorflow/lite/kernels/internal/reference/floor.h \
+tensorflow/lite/kernels/internal/reference/floor_div.h \
+tensorflow/lite/kernels/internal/reference/floor_mod.h \
+tensorflow/lite/kernels/internal/reference/fully_connected.h \
+tensorflow/lite/kernels/internal/reference/hard_swish.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/add.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/conv.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/depthwise_conv.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/fully_connected.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/logistic.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/l2normalization.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/mean.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/mul.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/pooling.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/tanh.h \
+tensorflow/lite/kernels/internal/reference/integer_ops/transpose_conv.h \
+tensorflow/lite/kernels/internal/reference/l2normalization.h \
+tensorflow/lite/kernels/internal/reference/leaky_relu.h \
+tensorflow/lite/kernels/internal/reference/maximum_minimum.h \
+tensorflow/lite/kernels/internal/reference/mul.h \
+tensorflow/lite/kernels/internal/reference/neg.h \
+tensorflow/lite/kernels/internal/reference/pad.h \
+tensorflow/lite/kernels/internal/reference/pooling.h \
+tensorflow/lite/kernels/internal/reference/prelu.h \
+tensorflow/lite/kernels/internal/reference/process_broadcast_shapes.h \
+tensorflow/lite/kernels/internal/reference/quantize.h \
+tensorflow/lite/kernels/internal/reference/reduce.h \
+tensorflow/lite/kernels/internal/reference/requantize.h \
+tensorflow/lite/kernels/internal/reference/resize_nearest_neighbor.h \
+tensorflow/lite/kernels/internal/reference/round.h \
+tensorflow/lite/kernels/internal/reference/softmax.h \
+tensorflow/lite/kernels/internal/reference/space_to_batch_nd.h \
+tensorflow/lite/kernels/internal/reference/sub.h \
+tensorflow/lite/kernels/internal/reference/logistic.h \
+tensorflow/lite/kernels/internal/reference/strided_slice.h \
+tensorflow/lite/kernels/internal/reference/tanh.h \
+tensorflow/lite/kernels/internal/reference/transpose_conv.h \
+tensorflow/lite/kernels/internal/cppmath.h \
+tensorflow/lite/kernels/internal/max.h \
+tensorflow/lite/kernels/internal/min.h \
+tensorflow/lite/kernels/internal/portable_tensor.h \
+tensorflow/lite/kernels/internal/strided_slice_logic.h \
+tensorflow/lite/kernels/internal/tensor_ctypes.h \
+tensorflow/lite/kernels/internal/types.h \
+tensorflow/lite/kernels/kernel_util.h \
+tensorflow/lite/kernels/op_macros.h \
+tensorflow/lite/kernels/padding.h \
+tensorflow/lite/portable_type_to_tflitetype.h \
+tensorflow/lite/schema/schema_generated.h \
+tensorflow/lite/schema/schema_utils.h
+
+# For project generation v1, the headers that are common to all targets need to
+# have a third_party prefix. Other third_party headers (e.g. CMSIS) do not have
+# this requirement and are added to THIRD_PARTY_CC_HDRS with full path from the
+# tensorflow root. This inconsistency may also be the reason why (for
+# example) these different third party libraries are fund in different paths in
+# the Arduino output tree.
+#
+# The convention with the (under development) project generation v2 is for all
+# third party paths to be relative to the root of the git repository. We are
+# keeping backwards compatibility between v1 and v2 by having a
+# THIRD_PARTY_CC_HDRS_BASE variable and adding in a third_party prefix to
+# THIRD_PARTY_CC_HDRS later on in the Makefile logic.
+# TODO(#47413): remove this additional logic once we are ready to switch over to
+# project generation v2.
+THIRD_PARTY_CC_HDRS :=
+
+# TODO(b/165940489): Figure out how to avoid including fixed point
+# platform-specific headers.
+THIRD_PARTY_CC_HDRS_BASE := \
+gemmlowp/fixedpoint/fixedpoint.h \
+gemmlowp/fixedpoint/fixedpoint_neon.h \
+gemmlowp/fixedpoint/fixedpoint_sse.h \
+gemmlowp/internal/detect_platform.h \
+gemmlowp/LICENSE \
+flatbuffers/include/flatbuffers/base.h \
+flatbuffers/include/flatbuffers/stl_emulation.h \
+flatbuffers/include/flatbuffers/flatbuffers.h \
+flatbuffers/include/flatbuffers/flexbuffers.h \
+flatbuffers/include/flatbuffers/util.h \
+flatbuffers/LICENSE.txt \
+ruy/ruy/profiler/instrumentation.h
+
+MAKE_PROJECT_FILES := \
+ Makefile \
+ README_MAKE.md \
+ .vscode/tasks.json
+
+MBED_PROJECT_FILES := \
+ README_MBED.md \
+ mbed-os.lib \
+ mbed_app.json
+
+KEIL_PROJECT_FILES := \
+ README_KEIL.md \
+ keil_project.uvprojx
+
+ARDUINO_PROJECT_FILES := \
+ library.properties
+
+ESP_PROJECT_FILES := \
+ README_ESP.md \
+ CMakeLists.txt \
+ main/CMakeLists.txt \
+ components/tfmicro/CMakeLists.txt
+
+ALL_PROJECT_TARGETS :=
+
+ARDUINO_LIBRARY_TARGETS :=
+ARDUINO_LIBRARY_ZIPS :=
+
+# For some invocations of the makefile, it is useful to avoid downloads. This
+# can be achieved by explicitly passing in DISABLE_DOWNLOADS=true on the command
+# line. Note that for target-specific downloads (e.g. CMSIS) there will need to
+# be corresponding checking in the respecitve included makefiles (e.g.
+# ext_libs/cmsis_nn.inc)
+DISABLE_DOWNLOADS :=
+
+ifneq ($(DISABLE_DOWNLOADS), true)
+ # The download scripts require that the downloads directory already exist for
+ # improved error checking. To accomodate that, we first create a downloads
+ # directory.
+ $(shell mkdir -p ${MAKEFILE_DIR}/downloads)
+
+ # Directly download the flatbuffers library.
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/flatbuffers_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the flatbuffers download: $(DOWNLOAD_RESULT))
+ endif
+
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/pigweed_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the pigweed download: $(DOWNLOAD_RESULT))
+ endif
+
+ include $(MAKEFILE_DIR)/third_party_downloads.inc
+ THIRD_PARTY_DOWNLOADS :=
+ $(eval $(call add_third_party_download,$(GEMMLOWP_URL),$(GEMMLOWP_MD5),gemmlowp,))
+ $(eval $(call add_third_party_download,$(RUY_URL),$(RUY_MD5),ruy,))
+ $(eval $(call add_third_party_download,$(PERSON_MODEL_URL),$(PERSON_MODEL_MD5),person_model_grayscale,))
+ $(eval $(call add_third_party_download,$(PERSON_MODEL_INT8_URL),$(PERSON_MODEL_INT8_MD5),person_model_int8,))
+endif
+
+# The target-specific makefile must have a name that is exactly
+# TARGET_makefile.inc and is only needed for cross-compilation (i.e. when TARGET
+# is different from the HOST_OS).
+# There are also some other targets like arduino and CHRE that are also special
+# in that they do no have a <target>_makefile but are still used to create a
+# directory for the generated artifacts. We are using a workaround right now and
+# will be separating the project generation from the Makefile in the future.
+TARGETS_WITHOUT_MAKEFILES := \
+$(HOST_OS) \
+arduino
+
+# This specific string needs to be outputted for a test to be recognized as
+# having passed.
+TEST_PASS_STRING:='~~~ALL TESTS PASSED~~~'
+
+# ${TARGET}_makefile.inc can set this to true to allow it to defined a custom
+# implementation for `make test`. See bluepill_makefile as an example.
+TARGET_SPECIFIC_MAKE_TEST:=0
+
+ifeq ($(findstring $(TARGET),$(TARGETS_WITHOUT_MAKEFILES)),)
+ include $(MAKEFILE_DIR)/targets/$(TARGET)_makefile.inc
+endif
+
+ifneq ($(OPTIMIZED_KERNEL_DIR),)
+ # Check that OPTIMIZED_KERNEL_DIR is valid to avoid unexpected fallback to
+ # reference kernels. See http://b/183546742 for more context.
+ PATH_TO_OPTIMIZED_KERNELS := tensorflow/lite/micro/kernels/$(OPTIMIZED_KERNEL_DIR)
+ RESULT := $(shell $(MAKEFILE_DIR)/check_optimized_kernel_dir.sh $(PATH_TO_OPTIMIZED_KERNELS))
+ ifneq ($(RESULT), SUCCESS)
+ $(error Incorrect OPTIMIZED_KERNEL_DIR: $(RESULT))
+ endif
+
+ include $(MAKEFILE_DIR)/ext_libs/$(OPTIMIZED_KERNEL_DIR).inc
+ # Specialize for the optimized kernels
+ MICROLITE_CC_KERNEL_SRCS := $(call substitute_specialized_implementations,$(MICROLITE_CC_KERNEL_SRCS),$(OPTIMIZED_KERNEL_DIR))
+endif
+
+# If a co-processor is specified on the command line with
+# CO_PROCESSOR=<co_processor> then we will include ext_libs/<co_processor>.inc
+# and find additional kernel sources in kernels/<co_processor>/
+#
+# That the co-processor specialization of the kernel sources happens after the
+# optimized_kernel_dir means that if there is an implementation of the same
+# kernel in both directories, the one from co_processor will be used.
+ifneq ($(CO_PROCESSOR),)
+ include $(MAKEFILE_DIR)/ext_libs/$(CO_PROCESSOR).inc
+ # Specialize for the coprocessor kernels.
+ MICROLITE_CC_KERNEL_SRCS := $(call substitute_specialized_implementations,$(MICROLITE_CC_KERNEL_SRCS),$(CO_PROCESSOR))
+endif
+
+# TODO(#47413): Remove this logic once we are switched over to the newer version
+# of project generation (v2). Project generation v1 needs the "base" third party
+# headers to have a prefix of third_party/. In order to support v2 prototyping
+# without a lot of changes with the v1 system, we are manually adding in this
+# prefix, and also making a copy in THIRD_PARTY_CC_HDRS_V2 that will be used in
+# the list_third_party_headers target.
+THIRD_PARTY_CC_HDRS_V2 := $(THIRD_PARTY_CC_HDRS)
+THIRD_PARTY_CC_HDRS += $(addprefix third_party/,$(THIRD_PARTY_CC_HDRS_BASE))
+
+# Specialize for debug_log. micro_time etc.
+MICROLITE_CC_SRCS := $(call substitute_specialized_implementations,$(MICROLITE_CC_SRCS),$(TARGET))
+MICROLITE_CC_SRCS += $(MICROLITE_CC_KERNEL_SRCS)
+
+ALL_SRCS := \
+ $(MICROLITE_CC_SRCS) \
+ $(MICROLITE_TEST_SRCS)
+
+# Where compiled objects are stored.
+
+GENDIR := $(MAKEFILE_DIR)/gen/$(TARGET)_$(TARGET_ARCH)_$(BUILD_TYPE)/
+OBJDIR := $(GENDIR)obj/
+BINDIR := $(GENDIR)bin/
+LIBDIR := $(GENDIR)lib/
+PRJDIR := $(GENDIR)prj/
+
+MICROLITE_LIB_PATH := $(LIBDIR)$(MICROLITE_LIB_NAME)
+
+CXX := $(TARGET_TOOLCHAIN_ROOT)${TARGET_TOOLCHAIN_PREFIX}${CXX_TOOL}
+CC := $(TARGET_TOOLCHAIN_ROOT)${TARGET_TOOLCHAIN_PREFIX}${CC_TOOL}
+AR := $(TARGET_TOOLCHAIN_ROOT)${TARGET_TOOLCHAIN_PREFIX}${AR_TOOL}
+
+# The default Makefile target(all) must appear before any target,
+# which is compiled if there's no command-line arguments.
+all: $(MICROLITE_LIB_PATH)
+
+# Load the examples.
+include $(MICRO_LITE_EXAMPLE_TESTS)
+
+# Load the benchmarks.
+include $(MICRO_LITE_BENCHMARKS)
+
+# Create rules for downloading third-party dependencies.
+THIRD_PARTY_TARGETS :=
+$(foreach DOWNLOAD,$(THIRD_PARTY_DOWNLOADS),$(eval $(call create_download_rule,$(DOWNLOAD))))
+third_party_downloads: $(THIRD_PARTY_TARGETS)
+
+MICROLITE_LIB_OBJS := $(addprefix $(OBJDIR), \
+$(patsubst %.cc,%.o,$(patsubst %.c,%.o,$(MICROLITE_CC_SRCS))))
+
+MICROLITE_LIB_OBJS += $(addprefix $(OBJDIR), \
+$(patsubst %.S,%.o,$(patsubst %.cc,%.o,$(patsubst %.c,%.o,$(THIRD_PARTY_CC_SRCS)))))
+
+# For normal manually-created TensorFlow C++ source files.
+$(OBJDIR)%.o: %.cc $(THIRD_PARTY_TARGETS)
+ @mkdir -p $(dir $@)
+ $(CXX) $(CXXFLAGS) $(INCLUDES) -c $< -o $@
+
+# For normal manually-created TensorFlow C source files.
+$(OBJDIR)%.o: %.c $(THIRD_PARTY_TARGETS)
+ @mkdir -p $(dir $@)
+ $(CC) $(CCFLAGS) $(INCLUDES) -c $< -o $@
+
+# For normal manually-created TensorFlow ASM source files.
+$(OBJDIR)%.o: %.S $(THIRD_PARTY_TARGETS)
+ @mkdir -p $(dir $@)
+ $(CC) $(CCFLAGS) $(INCLUDES) -c $< -o $@
+
+microlite: $(MICROLITE_LIB_PATH)
+
+# Hack for generating schema file bypassing flatbuffer parsing
+tensorflow/lite/schema/schema_generated.h:
+ @cp -u tensorflow/lite/schema/schema_generated.h.oss tensorflow/lite/schema/schema_generated.h
+
+# Gathers together all the objects we've compiled into a single '.a' archive.
+$(MICROLITE_LIB_PATH): tensorflow/lite/schema/schema_generated.h $(MICROLITE_LIB_OBJS)
+ @mkdir -p $(dir $@)
+ $(AR) $(ARFLAGS) $(MICROLITE_LIB_PATH) $(MICROLITE_LIB_OBJS)
+
+$(BINDIR)%_test : $(OBJDIR)%_test.o $(MICROLITE_LIB_PATH)
+ @mkdir -p $(dir $@)
+ $(CXX) $(CXXFLAGS) $(INCLUDES) \
+ -o $@ $< \
+ $(MICROLITE_LIB_PATH) $(LDFLAGS) $(MICROLITE_LIBS)
+
+$(BINDIR)%.test_target: $(BINDIR)%_test
+ @test -f $(TEST_SCRIPT) || (echo 'Unable to find the test script. Is the software emulation available in $(TARGET)?'; exit 1)
+ $(TEST_SCRIPT) $< $(TEST_PASS_STRING)
+
+# snease: Add %.bin rule here since BINDIR is now defined
+# These are microcontroller-specific rules for converting the ELF output
+# of the linker into a binary image that can be loaded directly.
+OBJCOPY := ${TARGET_TOOLCHAIN_ROOT}$(TARGET_TOOLCHAIN_PREFIX)objcopy
+$(BINDIR)%.bin: $(BINDIR)%
+ @mkdir -p $(dir $@)
+ $(OBJCOPY) $< $@ -O binary
+
+
+# Some tests have additional dependencies (beyond libtensorflow-microlite.a) and
+# those need to be explicitly specified with their own individual call to the
+# microlite_test helper function. For these tests, we also need to make sure to
+# not add targets for them if they have been excluded as part of the target
+# specific Makefile.
+EXPLICITLY_SPECIFIED_TEST:= tensorflow/lite/micro/kernels/detection_postprocess_test.cc
+ifneq ($(findstring $(EXPLICITLY_SPECIFIED_TEST),$(MICROLITE_TEST_SRCS)),)
+ MICROLITE_TEST_SRCS := $(filter-out $(EXPLICITLY_SPECIFIED_TEST), $(MICROLITE_TEST_SRCS))
+ EXPLICITLY_SPECIFIED_TEST_SRCS := \
+ $(EXPLICITLY_SPECIFIED_TEST) \
+ tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.cc
+ EXPLICITLY_SPECIFIED_TEST_HDRS := \
+ tensorflow/lite/micro/kernels/detection_postprocess_flexbuffers_generated_data.h
+ $(eval $(call microlite_test,kernel_detection_postprocess_test,\
+ $(EXPLICITLY_SPECIFIED_TEST_SRCS),$(EXPLICITLY_SPECIFIED_TEST_HDRS)))
+endif
+
+EXPLICITLY_SPECIFIED_TEST:= tensorflow/lite/micro/kernels/circular_buffer_test.cc
+ifneq ($(findstring $(EXPLICITLY_SPECIFIED_TEST),$(MICROLITE_TEST_SRCS)),)
+ MICROLITE_TEST_SRCS := $(filter-out $(EXPLICITLY_SPECIFIED_TEST), $(MICROLITE_TEST_SRCS))
+ EXPLICITLY_SPECIFIED_TEST_SRCS := \
+ $(EXPLICITLY_SPECIFIED_TEST) \
+ tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.cc
+ EXPLICITLY_SPECIFIED_TEST_HDRS := \
+ tensorflow/lite/micro/kernels/circular_buffer_flexbuffers_generated_data.h
+ $(eval $(call microlite_test,kernel_circular_buffer_test,\
+ $(EXPLICITLY_SPECIFIED_TEST_SRCS),$(EXPLICITLY_SPECIFIED_TEST_HDRS)))
+endif
+
+EXPLICITLY_SPECIFIED_TEST:= tensorflow/lite/micro/memory_arena_threshold_test.cc
+ifneq ($(findstring $(EXPLICITLY_SPECIFIED_TEST),$(MICROLITE_TEST_SRCS)),)
+ MICROLITE_TEST_SRCS := $(filter-out $(EXPLICITLY_SPECIFIED_TEST), $(MICROLITE_TEST_SRCS))
+ EXPLICITLY_SPECIFIED_TEST_SRCS := \
+ $(EXPLICITLY_SPECIFIED_TEST) \
+ tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.cc \
+ tensorflow/lite/micro/testing/test_conv_model.cc
+ EXPLICITLY_SPECIFIED_TEST_HDRS := \
+ tensorflow/lite/micro/benchmarks/keyword_scrambled_model_data.h \
+ tensorflow/lite/micro/testing/test_conv_model.h
+ $(eval $(call microlite_test,memory_arena_threshold_test,\
+ $(EXPLICITLY_SPECIFIED_TEST_SRCS),$(EXPLICITLY_SPECIFIED_TEST_HDRS)))
+endif
+
+EXPLICITLY_SPECIFIED_TEST:= tensorflow/lite/micro/micro_allocator_test.cc
+ifneq ($(findstring $(EXPLICITLY_SPECIFIED_TEST),$(MICROLITE_TEST_SRCS)),)
+ MICROLITE_TEST_SRCS := $(filter-out $(EXPLICITLY_SPECIFIED_TEST), $(MICROLITE_TEST_SRCS))
+ EXPLICITLY_SPECIFIED_TEST_SRCS := \
+ $(EXPLICITLY_SPECIFIED_TEST) \
+ tensorflow/lite/micro/testing/test_conv_model.cc
+ EXPLICITLY_SPECIFIED_TEST_HDRS := \
+ tensorflow/lite/micro/testing/test_conv_model.h
+ $(eval $(call microlite_test,micro_allocator_test,\
+ $(EXPLICITLY_SPECIFIED_TEST_SRCS),$(EXPLICITLY_SPECIFIED_TEST_HDRS)))
+endif
+
+EXPLICITLY_SPECIFIED_TEST:= tensorflow/lite/micro/recording_micro_allocator_test.cc
+ifneq ($(findstring $(EXPLICITLY_SPECIFIED_TEST),$(MICROLITE_TEST_SRCS)),)
+ MICROLITE_TEST_SRCS := $(filter-out $(EXPLICITLY_SPECIFIED_TEST), $(MICROLITE_TEST_SRCS))
+ EXPLICITLY_SPECIFIED_TEST_SRCS := \
+ $(EXPLICITLY_SPECIFIED_TEST) \
+ tensorflow/lite/micro/testing/test_conv_model.cc
+ EXPLICITLY_SPECIFIED_TEST_HDRS := \
+ tensorflow/lite/micro/testing/test_conv_model.h
+ $(eval $(call microlite_test,recording_micro_allocator_test,\
+ $(EXPLICITLY_SPECIFIED_TEST_SRCS),$(EXPLICITLY_SPECIFIED_TEST_HDRS)))
+endif
+
+EXPLICITLY_SPECIFIED_TEST:= tensorflow/lite/micro/kernels/conv_test.cc
+ifneq ($(findstring $(EXPLICITLY_SPECIFIED_TEST),$(MICROLITE_TEST_SRCS)),)
+ MICROLITE_TEST_SRCS := $(filter-out $(EXPLICITLY_SPECIFIED_TEST), $(MICROLITE_TEST_SRCS))
+ EXPLICITLY_SPECIFIED_TEST_SRCS := \
+ $(EXPLICITLY_SPECIFIED_TEST) \
+ tensorflow/lite/micro/kernels/conv_test_common.cc
+ EXPLICITLY_SPECIFIED_TEST_HDRS := \
+ tensorflow/lite/micro/kernels/conv_test.h
+ $(eval $(call microlite_test,kernel_conv_test,\
+ $(EXPLICITLY_SPECIFIED_TEST_SRCS),$(EXPLICITLY_SPECIFIED_TEST_HDRS)))
+endif
+
+EXPLICITLY_SPECIFIED_TEST:= tensorflow/lite/micro/kernels/transpose_conv_test.cc
+ifneq ($(findstring $(EXPLICITLY_SPECIFIED_TEST),$(MICROLITE_TEST_SRCS)),)
+ MICROLITE_TEST_SRCS := $(filter-out $(EXPLICITLY_SPECIFIED_TEST), $(MICROLITE_TEST_SRCS))
+ EXPLICITLY_SPECIFIED_TEST_SRCS := \
+ $(EXPLICITLY_SPECIFIED_TEST) \
+ tensorflow/lite/micro/kernels/conv_test_common.cc
+ EXPLICITLY_SPECIFIED_TEST_HDRS := \
+ tensorflow/lite/micro/kernels/conv_test.h
+ $(eval $(call microlite_test,kernel_transpose_conv_test,\
+ $(EXPLICITLY_SPECIFIED_TEST_SRCS),$(EXPLICITLY_SPECIFIED_TEST_HDRS)))
+endif
+
+
+# For all the tests that do not have any additional dependencies, we can
+# add a make target in a common way.
+$(foreach TEST_TARGET,$(filter-out tensorflow/lite/micro/kernels/%,$(MICROLITE_TEST_SRCS)),\
+$(eval $(call microlite_test,$(notdir $(basename $(TEST_TARGET))),$(TEST_TARGET))))
+
+$(foreach TEST_TARGET,$(filter tensorflow/lite/micro/kernels/%,$(MICROLITE_TEST_SRCS)),\
+$(eval $(call microlite_test,kernel_$(notdir $(basename $(TEST_TARGET))),$(TEST_TARGET))))
+
+
+
+ifeq ($(TARGET_SPECIFIC_MAKE_TEST),0)
+test: $(MICROLITE_TEST_TARGETS)
+endif
+
+# Just build the test targets
+build: $(MICROLITE_BUILD_TARGETS)
+
+generate_projects: $(ALL_PROJECT_TARGETS)
+
+ARDUINO_PROJECT_TARGETS := $(foreach TARGET,$(ALL_PROJECT_TARGETS),$(if $(findstring _arduino,$(TARGET)),$(TARGET),))
+
+generate_arduino_zip: $(ARDUINO_PROJECT_TARGETS) $(ARDUINO_LIBRARY_ZIPS)
+ python tensorflow/lite/micro/tools/make/merge_arduino_zips.py $(PRJDIR)/tensorflow_lite.zip $(ARDUINO_LIBRARY_ZIPS)
+
+list_library_sources:
+ @echo $(MICROLITE_CC_SRCS)
+
+list_library_headers:
+ @echo $(MICROLITE_CC_HDRS)
+
+list_third_party_sources:
+ @echo $(THIRD_PARTY_CC_SRCS)
+
+list_third_party_headers:
+ @echo $(addprefix $(MAKEFILE_DIR)/downloads/,$(THIRD_PARTY_CC_HDRS_BASE)) $(THIRD_PARTY_CC_HDRS_V2)
+
+# Gets rid of all generated files.
+clean:
+ rm -rf $(MAKEFILE_DIR)/gen
+
+# Removes third-party downloads.
+clean_downloads:
+ rm -rf $(MAKEFILE_DIR)/downloads
+
+$(DEPDIR)/%.d: ;
+.PRECIOUS: $(DEPDIR)/%.d
+.PRECIOUS: $(BINDIR)%_test
+
+-include $(patsubst %,$(DEPDIR)/%.d,$(basename $(ALL_SRCS)))
diff --git a/tensorflow/lite/micro/tools/make/arm_gcc_download.sh b/tensorflow/lite/micro/tools/make/arm_gcc_download.sh
new file mode 100755
index 0000000..e69df9e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/arm_gcc_download.sh
@@ -0,0 +1,73 @@
+#!/bin/bash
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/make/bash_helpers.sh
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+DOWNLOADED_GCC_PATH=${DOWNLOADS_DIR}/gcc_embedded
+
+if [ -d ${DOWNLOADED_GCC_PATH} ]; then
+ echo >&2 "${DOWNLOADED_GCC_PATH} already exists, skipping the download."
+else
+
+ UNAME_S=`uname -s`
+ if [ ${UNAME_S} == Linux ]; then
+ GCC_URL="https://developer.arm.com/-/media/Files/downloads/gnu-rm/10-2020q4/gcc-arm-none-eabi-10-2020-q4-major-x86_64-linux.tar.bz2"
+ EXPECTED_MD5="8312c4c91799885f222f663fc81f9a31"
+ elif [ ${UNAME_S} == Darwin ]; then
+ GCC_URL="https://developer.arm.com/-/media/Files/downloads/gnu-rm/10-2020q4/gcc-arm-none-eabi-10-2020-q4-major-mac.tar.bz2"
+ EXPECTED_MD5="e588d21be5a0cc9caa60938d2422b058"
+ else
+ echo "OS type ${UNAME_S} not supported."
+ exit 1
+ fi
+
+ TEMPFILE=$(mktemp -d)/temp_file
+ wget ${GCC_URL} -O ${TEMPFILE} >&2
+ check_md5 ${TEMPFILE} ${EXPECTED_MD5}
+
+ mkdir ${DOWNLOADED_GCC_PATH}
+ tar -C ${DOWNLOADED_GCC_PATH} --strip-components=1 -xjf ${TEMPFILE} >&2
+ echo >&2 "Unpacked to directory: ${DOWNLOADED_GCC_PATH}"
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/bash_helpers.sh b/tensorflow/lite/micro/tools/make/bash_helpers.sh
new file mode 100755
index 0000000..8075c5f
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/bash_helpers.sh
@@ -0,0 +1,49 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+
+# Compute the MD5 sum.
+#
+# Parameter(s):
+# ${1} - path to the file
+function compute_md5() {
+ UNAME_S=`uname -s`
+ if [ ${UNAME_S} == Linux ]; then
+ tflm_md5sum=md5sum
+ elif [ ${UNAME_S} == Darwin ]; then
+ tflm_md5sum='md5 -r'
+ else
+ tflm_md5sum=md5sum
+ fi
+ ${tflm_md5sum} ${1} | awk '{print $1}'
+}
+
+# Check that MD5 sum matches expected value.
+#
+# Parameter(s):
+# ${1} - path to the file
+# ${2} - expected md5
+function check_md5() {
+ MD5=`compute_md5 ${1}`
+
+ if [[ ${MD5} != ${2} ]]
+ then
+ echo "Bad checksum. Expected: ${2}, Got: ${MD5}"
+ exit 1
+ fi
+
+}
+
diff --git a/tensorflow/lite/micro/tools/make/check_optimized_kernel_dir.sh b/tensorflow/lite/micro/tools/make/check_optimized_kernel_dir.sh
new file mode 100755
index 0000000..d4e2b7a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/check_optimized_kernel_dir.sh
@@ -0,0 +1,43 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - OPTIMIZED_KERNEL_PATH (relative to TF root) to the optimized kernel implementations.
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+OPTIMIZED_KERNEL_PATH=${1}
+if [ ! -d ${OPTIMIZED_KERNEL_PATH} ]; then
+ echo "The optimized kernel directory: ${OPTIMIZED_KERNEL_PATH} does not exist."
+ exit 1
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/corstone_300_download.sh b/tensorflow/lite/micro/tools/make/corstone_300_download.sh
new file mode 100755
index 0000000..4ac60bb
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/corstone_300_download.sh
@@ -0,0 +1,70 @@
+#!/bin/bash
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/make/bash_helpers.sh
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+DOWNLOADED_CORSTONE_PATH=${DOWNLOADS_DIR}/corstone300
+
+if [ -d ${DOWNLOADED_CORSTONE_PATH} ]; then
+ echo >&2 "${DOWNLOADED_CORSTONE_PATH} already exists, skipping the download."
+else
+ UNAME_S=`uname -s`
+ if [ ${UNAME_S} == Linux ]; then
+ CORSTONE_URL=https://developer.arm.com/-/media/Arm%20Developer%20Community/Downloads/OSS/FVP/Corstone-300/FVP_Corstone_SSE-300_Ethos-U55_11.12_57.tgz
+ EXPECTED_MD5=08cc89b02a41917c2224f390f3ac0b47
+ else
+ echo "OS type ${UNAME_S} not supported."
+ exit 1
+ fi
+
+ TEMPFILE=$(mktemp -d)/temp_file
+ wget ${CORSTONE_URL} -O ${TEMPFILE} >&2
+ check_md5 ${TEMPFILE} ${EXPECTED_MD5}
+
+ TEMPDIR=$(mktemp -d)
+ tar -C ${TEMPDIR} -xvzf ${TEMPFILE} >&2
+ mkdir ${DOWNLOADED_CORSTONE_PATH}
+ ${TEMPDIR}/FVP_Corstone_SSE-300_Ethos-U55.sh --i-agree-to-the-contained-eula --no-interactive -d ${DOWNLOADED_CORSTONE_PATH} >&2
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/download_and_extract.sh b/tensorflow/lite/micro/tools/make/download_and_extract.sh
new file mode 100755
index 0000000..de85553
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/download_and_extract.sh
@@ -0,0 +1,213 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+# Utility script that handles downloading, extracting, and patching third-party
+# library dependencies for TensorFlow Lite for Microcontrollers.
+# Called with four arguments:
+# 1 - URL to download from.
+# 2 - MD5 checksum to verify the package's integrity. Use md5sum to create one.
+# 3 - Path to new folder to unpack the library into.
+# 4 - Optional patching action name.
+
+set -e
+
+# Patches the Ambiq Micro SDK to work around build issues.
+patch_am_sdk() {
+ local am_dir="${1}"
+ if [ ! -f ${am_dir}/VERSION.txt ]; then
+ echo "Could not find ${am_dir}, skipping AmbiqMicro SDK patch";
+ return;
+ fi
+
+ local src_dir=${am_dir}/boards/apollo3_evb/examples/hello_world/gcc
+ local dest_dir=${am_dir}/boards/apollo3_evb/examples/hello_world/gcc_patched
+
+ rm -rf ${dest_dir}
+ mkdir ${dest_dir}
+
+ cp "${src_dir}/startup_gcc.c" "${dest_dir}/startup_gcc.c"
+ cp "${src_dir}/hello_world.ld" "${dest_dir}/apollo3evb.ld"
+
+ sed -i -e '114s/1024/1024\*20/g' "${dest_dir}/startup_gcc.c"
+ #sed -i -e 's/main/_main/g' "${dest_dir}/startup_gcc.c"
+
+ sed -i -e '3s/hello_world.ld/apollo3evb.ld/g' "${dest_dir}/apollo3evb.ld"
+ sed -i -e '3s/startup_gnu/startup_gcc/g' "${dest_dir}/apollo3evb.ld"
+ sed -i -e $'22s/\*(.text\*)/\*(.text\*)\\\n\\\n\\\t\/\* These are the C++ global constructors. Stick them all here and\\\n\\\t \* then walk through the array in main() calling them all.\\\n\\\t \*\/\\\n\\\t_init_array_start = .;\\\n\\\tKEEP (\*(SORT(.init_array\*)))\\\n\\\t_init_array_end = .;\\\n\\\n\\\t\/\* XXX Currently not doing anything for global destructors. \*\/\\\n/g' "${dest_dir}/apollo3evb.ld"
+ sed -i -e $'70s/} > SRAM/} > SRAM\\\n \/\* Add this to satisfy reference to symbol "end" from libnosys.a(sbrk.o)\\\n \* to denote the HEAP start.\\\n \*\/\\\n end = .;/g' "${dest_dir}/apollo3evb.ld"
+
+ # Add a delay after establishing serial connection
+ sed -ir -E $'s/ with serial\.Serial\(args\.port, args\.baud, timeout=12\) as ser:/ with serial.Serial(args.port, args.baud, timeout=12) as ser:\\\n # Patched.\\\n import time\\\n time.sleep(0.25)\\\n # End patch./g' "${am_dir}/tools/apollo3_scripts/uart_wired_update.py"
+
+ # Add CPP include guards to "am_hal_iom.h"
+ sed -i -e '57a\
+ #ifdef __cplusplus // Patch\
+ extern "C" {\
+ #endif // End patch
+ ' "${am_dir}/mcu/apollo3/hal/am_hal_iom.h"
+
+ sed -i -e '836a\
+ #ifdef __cplusplus // Patch\
+ }\
+ #endif // End patch
+ ' "${am_dir}/mcu/apollo3/hal/am_hal_iom.h"
+
+ echo "Finished preparing Apollo3 files"
+}
+
+# Fixes issues with KissFFT.
+patch_kissfft() {
+ sed -i -E $'s@#ifdef FIXED_POINT@// Patched automatically by download_dependencies.sh so default is 16 bit.\\\n#ifndef FIXED_POINT\\\n#define FIXED_POINT (16)\\\n#endif\\\n// End patch.\\\n\\\n#ifdef FIXED_POINT@g' tensorflow/lite/micro/tools/make/downloads/kissfft/kiss_fft.h
+
+ sed -i -E '/^#include <sys\/types.h>/d' tensorflow/lite/micro/tools/make/downloads/kissfft/kiss_fft.h
+ # Fix for https://github.com/mborgerding/kissfft/issues/20
+ sed -i -E $'s@#ifdef FIXED_POINT@#ifdef FIXED_POINT\\\n#include <stdint.h> /* Patched. */@g' tensorflow/lite/micro/tools/make/downloads/kissfft/kiss_fft.h
+
+ sed -i -E "s@#define KISS_FFT_MALLOC malloc@#define KISS_FFT_MALLOC(X) (void*)(0) /* Patched. */@g" tensorflow/lite/micro/tools/make/downloads/kissfft/kiss_fft.h
+ sed -i -E "s@#define KISS_FFT_FREE free@#define KISS_FFT_FREE(X) /* Patched. */@g" tensorflow/lite/micro/tools/make/downloads/kissfft/kiss_fft.h
+ sed -ir -E "s@(fprintf.*\);)@/* \1 */@g" tensorflow/lite/micro/tools/make/downloads/kissfft/tools/kiss_fftr.c
+ sed -ir -E "s@(exit.*\);)@return; /* \1 */@g" tensorflow/lite/micro/tools/make/downloads/kissfft/tools/kiss_fftr.c
+ echo "Finished patching kissfft"
+}
+
+# Create a header file containing an array with the first 10 images from the
+# CIFAR10 test dataset.
+patch_cifar10_dataset() {
+ xxd -l 30730 -i ${1}/test_batch.bin ${1}/../../../../examples/image_recognition_experimental/first_10_cifar_images.h
+ sed -i -E "s/unsigned char/const unsigned char/g" ${1}/../../../../examples/image_recognition_experimental/first_10_cifar_images.h
+}
+
+build_embarc_mli() {
+ make -j 4 -C ${1}/lib/make TCF_FILE=${2}
+}
+
+setup_zephyr() {
+ command -v virtualenv >/dev/null 2>&1 || {
+ echo >&2 "The required 'virtualenv' tool isn't installed. Try 'pip install virtualenv'."; exit 1;
+ }
+ virtualenv -p python3 ${1}/venv-zephyr
+ . ${1}/venv-zephyr/bin/activate
+ python ${1}/venv-zephyr/bin/pip install -r ${1}/scripts/requirements.txt
+ west init -m https://github.com/zephyrproject-rtos/zephyr.git
+ deactivate
+}
+
+# Main function handling the download, verify, extract, and patch process.
+download_and_extract() {
+ local usage="Usage: download_and_extract URL MD5 DIR [ACTION] [ACTION_PARAM]"
+ local url="${1:?${usage}}"
+ local expected_md5="${2:?${usage}}"
+ local dir="${3:?${usage}}"
+ local action=${4}
+ local action_param1=${5} # optional action parameter
+ local tempdir=$(mktemp -d)
+ local tempdir2=$(mktemp -d)
+ local tempfile=${tempdir}/temp_file
+ local curl_retries=5
+
+ # Destionation already downloaded.
+ if [ -d ${dir} ]; then
+ exit 0
+ fi
+
+ command -v curl >/dev/null 2>&1 || {
+ echo >&2 "The required 'curl' tool isn't installed. Try 'apt-get install curl'."; exit 1;
+ }
+
+ echo "downloading ${url}" >&2
+ mkdir -p "${dir}"
+ # We've been seeing occasional 56 errors from valid URLs, so set up a retry
+ # loop to attempt to recover from them.
+ for (( i=1; i<=$curl_retries; ++i )); do
+ # We have to use this approach because we normally halt the script when
+ # there's an error, and instead we want to catch errors so we can retry.
+ set +ex
+ curl -LsS --fail --retry 5 "${url}" > ${tempfile}
+ CURL_RESULT=$?
+ set -ex
+
+ # Was the command successful? If so, continue.
+ if [[ $CURL_RESULT -eq 0 ]]; then
+ break
+ fi
+
+ # Keep trying if we see the '56' error code.
+ if [[ ( $CURL_RESULT -ne 56 ) || ( $i -eq $curl_retries ) ]]; then
+ echo "Error $CURL_RESULT downloading '${url}'"
+ exit 1
+ fi
+ sleep 2
+ done
+
+ # Check that the file was downloaded correctly using a checksum.
+ DOWNLOADED_MD5=$(openssl dgst -md5 ${tempfile} | sed 's/.* //g')
+ if [ ${expected_md5} != ${DOWNLOADED_MD5} ]; then
+ echo "Checksum error for '${url}'. Expected ${expected_md5} but found ${DOWNLOADED_MD5}"
+ exit 1
+ fi
+
+ # delete anything after the '?' in a url that may mask true file extension
+ url=$(echo "${url}" | sed "s/\?.*//")
+
+ if [[ "${url}" == *gz ]]; then
+ tar -C "${dir}" --strip-components=1 -xzf ${tempfile}
+ elif [[ "${url}" == *tar.xz ]]; then
+ tar -C "${dir}" --strip-components=1 -xf ${tempfile}
+ elif [[ "${url}" == *bz2 ]]; then
+ curl -Ls "${url}" > ${tempdir}/tarred.bz2
+ tar -C "${dir}" --strip-components=1 -xjf ${tempfile}
+ elif [[ "${url}" == *zip ]]; then
+ unzip ${tempfile} -d ${tempdir2} 2>&1 1>/dev/null
+ # If the zip file contains nested directories, extract the files from the
+ # inner directory.
+ if [ $(find $tempdir2/* -maxdepth 0 | wc -l) = 1 ] && [ -d $tempdir2/* ]; then
+ # unzip has no strip components, so unzip to a temp dir, and move the
+ # files we want from the tempdir to destination.
+ cp -R ${tempdir2}/*/* ${dir}/
+ else
+ cp -R ${tempdir2}/* ${dir}/
+ fi
+ else
+ echo "Error unsupported archive type. Failed to extract tool after download."
+ exit 1
+ fi
+ rm -rf ${tempdir2} ${tempdir}
+
+ # Delete any potential BUILD files, which would interfere with Bazel builds.
+ find "${dir}" -type f -name '*BUILD' -delete
+
+ if [[ ${action} == "patch_am_sdk" ]]; then
+ patch_am_sdk ${dir}
+ elif [[ ${action} == "patch_kissfft" ]]; then
+ patch_kissfft ${dir}
+ elif [[ ${action} == "patch_cifar10_dataset" ]]; then
+ patch_cifar10_dataset ${dir}
+ elif [[ ${action} == "build_embarc_mli" ]]; then
+ if [[ "${action_param1}" == *.tcf ]]; then
+ cp ${action_param1} ${dir}/hw/arc.tcf
+ build_embarc_mli ${dir} ../../hw/arc.tcf
+ else
+ build_embarc_mli ${dir} ${action_param1}
+ fi
+ elif [[ ${action} == "setup_zephyr" ]]; then
+ setup_zephyr ${dir}
+ elif [[ ${action} ]]; then
+ echo "Unknown action '${action}'"
+ exit 1
+ fi
+}
+
+download_and_extract "$1" "$2" "$3" "$4" "$5"
diff --git a/tensorflow/lite/micro/tools/make/ethos_u_core_platform_download.sh b/tensorflow/lite/micro/tools/make/ethos_u_core_platform_download.sh
new file mode 100755
index 0000000..d00800a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ethos_u_core_platform_download.sh
@@ -0,0 +1,80 @@
+#!/bin/bash
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/make/bash_helpers.sh
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+DOWNLOADED_ETHOS_U_CORE_PLATFORM_PATH=${DOWNLOADS_DIR}/ethos_u_core_platform
+
+if [ -d ${DOWNLOADED_ETHOS_U_CORE_PLATFORM_PATH} ]; then
+ echo >&2 "${DOWNLOADED_ETHOS_U_CORE_PLATFORM_PATH} already exists, skipping the download."
+else
+ UNAME_S=`uname -s`
+ if [ ${UNAME_S} == Linux ]; then
+ ETHOS_U_CORE_PLATFORM_URL=https://git.mlplatform.org/ml/ethos-u/ethos-u-core-platform.git/snapshot/ethos-u-core-platform-6663630bb3feea222fd38278a962297c08d0b320.tar.gz
+ EXPECTED_MD5=11683ce5cbf4e4d1003ca93a85ad0b08
+ else
+ echo "OS type ${UNAME_S} not supported."
+ exit 1
+ fi
+
+ TEMPFILE=$(mktemp -d)/temp_file
+ wget ${ETHOS_U_CORE_PLATFORM_URL} -O ${TEMPFILE} >&2
+ check_md5 ${TEMPFILE} ${EXPECTED_MD5}
+
+ mkdir ${DOWNLOADED_ETHOS_U_CORE_PLATFORM_PATH}
+ tar xzf ${TEMPFILE} --strip-components=1 -C ${DOWNLOADED_ETHOS_U_CORE_PLATFORM_PATH} >&2
+
+ # Run C preprocessor on linker file to get rid of ifdefs and make sure compiler is downloaded first.
+ COMPILER=${DOWNLOADS_DIR}/gcc_embedded/bin/arm-none-eabi-gcc
+ if [ ! -f ${COMPILER} ]; then
+ RETURN_VALUE=`./tensorflow/lite/micro/tools/make/arm_gcc_download.sh ${DOWNLOADS_DIR}`
+ if [ "SUCCESS" != "${RETURN_VALUE}" ]; then
+ echo "The script ./tensorflow/lite/micro/tools/make/arm_gcc_download.sh failed."
+ exit 1
+ fi
+ fi
+ LINKER_PATH=${DOWNLOADED_ETHOS_U_CORE_PLATFORM_PATH}/targets/corstone-300
+ ${COMPILER} -E -x c -P -o ${LINKER_PATH}/platform_parsed.ld ${LINKER_PATH}/platform.ld
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/arc_mli.inc b/tensorflow/lite/micro/tools/make/ext_libs/arc_mli.inc
new file mode 100644
index 0000000..28a42b4
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/arc_mli.inc
@@ -0,0 +1,104 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Settings for embARC MLI library for ARC platform.
+
+ifeq ($(TARGET_ARCH), arc)
+
+# MLI Library is used by default for ARC platform whenever it is possible.
+# To use TFLM reference implementation MLI should be intentionally turned off
+# by passing 'no_arc_mli' tag (make -f <tflm_main_makefile> ARC_TAGS=no_arc_mli ...)
+ifeq ($(filter no_arc_mli,$(ARC_TAGS)),)
+
+ALL_TAGS += arc_mli
+
+ifeq ($(BUILD_ARC_MLI),true)
+ MLI_LIB_DIR ?= arc_mli_$(basename $(TCF_FILE_NAME))
+
+ $(eval $(call add_third_party_download,$(EMBARC_MLI_URL),$(EMBARC_MLI_MD5),$(MLI_LIB_DIR),build_embarc_mli,$(TCF_FILE)))
+
+ MLI_INCLUDE_FOLDER = $(MLI_LIB_DIR)/include
+ MLI_LIB = third_party/$(MLI_LIB_DIR)/bin/libmli.a
+ MICROLITE_LIBS += $(MAKEFILE_DIR)/downloads/$(MLI_LIB_DIR)/bin/libmli.a
+
+ THIRD_PARTY_CC_HDRS += \
+ third_party/$(MLI_LIB_DIR)/LICENSE
+else
+ifneq ($(ARC_MLI_PRE_COMPILED_TARGET),)
+ MLI_LIB_DIR ?= arc_mli_package
+ $(eval $(call add_third_party_download,$(EMBARC_MLI_PRE_COMPILED_URL),$(EMBARC_MLI_PRE_COMPILED_MD5),$(MLI_LIB_DIR),))
+
+ MLI_INCLUDE_FOLDER = $(MLI_LIB_DIR)/include
+ MLI_LIB = third_party/$(MLI_LIB_DIR)/bin/$(ARC_MLI_PRE_COMPILED_TARGET)/release/libmli.a
+ MICROLITE_LIBS += $(MAKEFILE_DIR)/downloads/$(MLI_LIB_DIR)/bin/$(ARC_MLI_PRE_COMPILED_TARGET)/release/libmli.a
+
+ THIRD_PARTY_CC_HDRS += \
+ third_party/$(MLI_LIB_DIR)/LICENSE
+else
+$(error Target for pre compiled ARC MLI library is not defined)
+endif
+endif
+
+ THIRD_PARTY_CC_HDRS += $(MLI_LIB)
+ GENERATED_PROJECT_LIBS += $(MLI_LIB)
+
+ INCLUDES += \
+ -I$(MAKEFILE_DIR)/downloads/$(MLI_INCLUDE_FOLDER) \
+ -I$(MAKEFILE_DIR)/downloads/$(MLI_INCLUDE_FOLDER)/api
+
+ GENERATED_PROJECT_INCLUDES += \
+ -I. \
+ -I./third_party/$(MLI_INCLUDE_FOLDER) \
+ -I./third_party/$(MLI_INCLUDE_FOLDER)/api
+
+
+ THIRD_PARTY_CC_HDRS += \
+ third_party/$(MLI_INCLUDE_FOLDER)/mli_api.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/mli_config.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/mli_types.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/api/mli_helpers_api.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/api/mli_kernels_api.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/api/mli_krn_avepool_spec_api.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/api/mli_krn_conv2d_spec_api.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/api/mli_krn_depthwise_conv2d_spec_api.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/api/mli_krn_maxpool_spec_api.h \
+ third_party/$(MLI_INCLUDE_FOLDER)/api/mli_mov_api.h
+
+ MICROLITE_CC_HDRS += tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.h
+ MICROLITE_CC_SRCS += tensorflow/lite/micro/kernels/arc_mli/scratch_buffers.cc
+ MICROLITE_CC_HDRS += tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.h
+ MICROLITE_CC_SRCS += tensorflow/lite/micro/kernels/arc_mli/scratch_buf_mgr.cc
+ MICROLITE_CC_HDRS += tensorflow/lite/micro/kernels/arc_mli/mli_slicers.h
+ MICROLITE_CC_SRCS += tensorflow/lite/micro/kernels/arc_mli/mli_slicers.cc
+ MICROLITE_CC_HDRS += tensorflow/lite/micro/kernels/arc_mli/mli_tf_utils.h
+
+
+ MICROLITE_TEST_SRCS += $(wildcard tensorflow/lite/micro/kernels/arc_mli/*test.cc)
+
+ ARC_MLI_TESTS := conv depthwise_conv pooling fully_connected
+ ARC_MLI_TESTS += $(foreach TEST,$(ARC_MLI_TESTS), $(TEST)_slicing)
+
+generate_arc_mli_test_projects: $(foreach TEST,$(ARC_MLI_TESTS), generate_kernel_$(TEST)_test_make_project)
+
+ ARC_EXTRA_APP_SETTINGS += \
+ \nMLI_ONLY ?= false\n\
+ \nifeq \($(DLR)\(MLI_ONLY\), true\)\
+ \nCCFLAGS += -DTF_LITE_STRIP_REFERENCE_IMPL\
+ \nCXXFLAGS += -DTF_LITE_STRIP_REFERENCE_IMPL\
+ \nendif\n
+
+
+
+endif # no_embarc_mli
+endif # TARGET_ARCH
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/ceva.inc b/tensorflow/lite/micro/tools/make/ext_libs/ceva.inc
new file mode 100644
index 0000000..e69de29
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/ceva.inc
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/cmsis_download.sh b/tensorflow/lite/micro/tools/make/ext_libs/cmsis_download.sh
new file mode 100755
index 0000000..fdb02a3
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/cmsis_download.sh
@@ -0,0 +1,65 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/make/bash_helpers.sh
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+DOWNLOADED_CMSIS_PATH=${DOWNLOADS_DIR}/cmsis
+
+if [ -d ${DOWNLOADED_CMSIS_PATH} ]; then
+ echo >&2 "${DOWNLOADED_CMSIS_PATH} already exists, skipping the download."
+else
+
+ ZIP_PREFIX="0d7e4fa7131241a17e23dfae18140e0b2e77728f"
+ CMSIS_URL="http://github.com/ARM-software/CMSIS_5/archive/${ZIP_PREFIX}.zip"
+ CMSIS_MD5="630bb4a0acd3d2f3ccdd8bcccb9d6400"
+
+ # wget is much faster than git clone of the entire repo. So we wget a specific
+ # version and can then apply a patch, as needed.
+ wget ${CMSIS_URL} -O /tmp/${ZIP_PREFIX}.zip >&2
+ check_md5 /tmp/${ZIP_PREFIX}.zip ${CMSIS_MD5}
+
+ unzip -qo /tmp/${ZIP_PREFIX}.zip -d /tmp >&2
+ mv /tmp/CMSIS_5-${ZIP_PREFIX} ${DOWNLOADED_CMSIS_PATH}
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/cmsis_nn.inc b/tensorflow/lite/micro/tools/make/ext_libs/cmsis_nn.inc
new file mode 100644
index 0000000..7ca2ff5
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/cmsis_nn.inc
@@ -0,0 +1,63 @@
+# Enable u-arch specfic behaviours
+ifneq (,$(filter $(TARGET_ARCH), x86_64))
+ # CMSIS-NN optimizations not supported
+endif
+
+ifneq ($(DISABLE_DOWNLOADS), true)
+ # Unless an external path is provided we force a download during the first
+ # phase of make.
+ CMSIS_DEFAULT_DOWNLOAD_PATH := $(MAKEFILE_DIR)/downloads/cmsis
+ CMSIS_PATH := $(CMSIS_DEFAULT_DOWNLOAD_PATH)
+ ifeq ($(CMSIS_PATH), $(CMSIS_DEFAULT_DOWNLOAD_PATH))
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/cmsis_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the CMSIS download: $(DOWNLOAD_RESULT))
+ endif
+ endif
+endif
+
+THIRD_PARTY_CC_SRCS += \
+ $(call recursive_find,$(CMSIS_PATH)/CMSIS/NN/Source,*.c)
+THIRD_PARTY_CC_HDRS += \
+ $(call recursive_find,$(CMSIS_PATH)/CMSIS/NN/Include,*.h)
+
+# Note all the headers from CMSIS/Core/Include are needed to ensure that the
+# project generation scripts copy over the compiler specific implementations of
+# the various intrinisics.
+THIRD_PARTY_CC_HDRS += \
+ $(CMSIS_PATH)/LICENSE.txt \
+ $(wildcard $(CMSIS_PATH)/CMSIS/Core/Include/*.h) \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/arm_common_tables.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/arm_helium_utils.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/arm_math.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/arm_math_memory.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/arm_math_types.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/basic_math_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/bayes_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/complex_math_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/controller_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/distance_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/fast_math_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/filtering_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/interpolation_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/matrix_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/none.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/statistics_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/support_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/svm_defines.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/svm_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/transform_functions.h \
+ $(CMSIS_PATH)/CMSIS/DSP/Include/dsp/utils.h
+
+# We add -I$(CMSIS_PATH) to enable the code in the TFLM repo (mostly in the
+# tensorflow/lite/micro/kernels/cmsis_nn) to use include paths relative to
+# the CMSIS code-base.
+#
+# The CMSIS code itself uses includes such as #include "arm_math.h" and so
+# we add $(CMSIS_PATH)/CMSIS/Core/Include etc. to be able to build the CMSIS
+# code without any modifications.
+INCLUDES += \
+ -I$(CMSIS_PATH) \
+ -I$(CMSIS_PATH)/CMSIS/Core/Include \
+ -I$(CMSIS_PATH)/CMSIS/DSP/Include \
+ -I$(CMSIS_PATH)/CMSIS/NN/Include
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/ethos_u.inc b/tensorflow/lite/micro/tools/make/ext_libs/ethos_u.inc
new file mode 100644
index 0000000..67f5a8e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/ethos_u.inc
@@ -0,0 +1,43 @@
+# Arm Compiler will not link the Math library (see below), therefore we're filtering it out.
+# See Fatal error: L6450U: Cannot find library m:
+# "Arm Compiler is designed to run in a bare metal environment,
+# and automatically includes implementations of these functions,
+# and so no such flag is necessary."
+# https://developer.arm.com/documentation/100891/0611/troubleshooting/general-troubleshooting-advice
+MICROLITE_LIBS := $(filter-out -lm,$(MICROLITE_LIBS))
+
+ifneq (,$(filter $(TARGET_ARCH), x86_64))
+ $(error target architecture x86_64 not supported)
+endif
+
+# Unless an external path is provided we force a download during the first phase of make so
+# that the files exist prior to the call to recursive_find below. add_third_party_download
+# prevents the use of wildcards and recursive_find in selecting which files to add to THIRD_PARTY_SRCS.
+ETHOSU_DEFAULT_DOWNLOAD_DRIVER_PATH := $(MAKEFILE_DIR)/downloads/ethos_u_core_driver
+ETHOSU_DRIVER_PATH := $(ETHOSU_DEFAULT_DOWNLOAD_DRIVER_PATH)
+ifeq ($(ETHOSU_DRIVER_PATH), $(ETHOSU_DEFAULT_DOWNLOAD_DRIVER_PATH))
+ $(call $(or $(shell $(DOWNLOAD_SCRIPT) $(ETHOSU_URL) $(ETHOSU_MD5) $(ETHOSU_DRIVER_PATH) >&2 && echo SUCCESS), $(error $(DOWNLOAD_SCRIPT) failed)))
+endif
+
+THIRD_PARTY_CC_HDRS += $(call recursive_find,$(ETHOSU_DRIVER_PATH)/include,*.h)
+ifeq (,$(ETHOSU_DRIVER_LIBS))
+ THIRD_PARTY_CC_SRCS += $(call recursive_find,$(ETHOSU_DRIVER_PATH)/src,*.c)
+else
+ MICROLITE_LIBS += $(ETHOSU_DRIVER_LIBS)
+endif
+
+# Currently there is a dependency to CMSIS even without OPTIMIZED_KERNEL_DIR=cmsis_nn.
+CMSIS_DEFAULT_DOWNLOAD_PATH := $(MAKEFILE_DIR)/downloads/cmsis
+CMSIS_PATH := $(CMSIS_DEFAULT_DOWNLOAD_PATH)
+ifeq ($(CMSIS_PATH), $(CMSIS_DEFAULT_DOWNLOAD_PATH))
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/cmsis_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the CMSIS download: $(DOWNLOAD_RESULT))
+ endif
+endif
+
+THIRD_PARTY_CC_HDRS += $(CMSIS_PATH)/CMSIS/Core/Include/cmsis_compiler.h
+
+INCLUDES += -I$(ETHOSU_DRIVER_PATH)/include \
+ -I$(CMSIS_PATH)/CMSIS/Core/Include
+GENERATED_PROJECT_INCLUDES += -I./$(ETHOSU_DRIVER_PATH)/include
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/hexagon.inc b/tensorflow/lite/micro/tools/make/ext_libs/hexagon.inc
new file mode 100644
index 0000000..983f107
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/hexagon.inc
@@ -0,0 +1,7 @@
+HEXAGON_TFLM_LIB_PATH = tensorflow/lite/micro/kernels/hexagon/lib/
+HEXAGON_TFLM_INC_PATH = tensorflow/lite/micro/kernels/hexagon/inc/
+
+HEXAGON_TFLM_CORE_LIB_NAME = hexagon_tflm_core.a
+HEXAGON_TFLM_CORE_LIB_FULLNAME = $(HEXAGON_TFLM_LIB_PATH)$(HEXAGON_TFLM_CORE_LIB_NAME)
+MICROLITE_LIBS += $(HEXAGON_TFLM_CORE_LIB_FULLNAME)
+INCLUDES += -I$(HEXAGON_TFLM_INC_PATH)
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/stm32_bare_lib_download.sh b/tensorflow/lite/micro/tools/make/ext_libs/stm32_bare_lib_download.sh
new file mode 100755
index 0000000..7b3fe49
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/stm32_bare_lib_download.sh
@@ -0,0 +1,51 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+DOWNLOADED_STM32_BARE_LIB_PATH=${DOWNLOADS_DIR}/stm32_bare_lib
+
+if [ -d ${DOWNLOADED_STM32_BARE_LIB_PATH} ]; then
+ echo >&2 "${DOWNLOADED_STM32_BARE_LIB_PATH} already exists, skipping the download."
+else
+ git clone https://github.com/google/stm32_bare_lib.git ${DOWNLOADED_STM32_BARE_LIB_PATH} >&2
+ pushd ${DOWNLOADED_STM32_BARE_LIB_PATH} > /dev/null
+ git checkout aaabdeb0d6098322a0874b29f6ed547a39b3929f >&2
+ popd > /dev/null
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/vexriscv.inc b/tensorflow/lite/micro/tools/make/ext_libs/vexriscv.inc
new file mode 100644
index 0000000..e69de29
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/vexriscv.inc
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/xtensa.inc b/tensorflow/lite/micro/tools/make/ext_libs/xtensa.inc
new file mode 100644
index 0000000..f0c021f
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/xtensa.inc
@@ -0,0 +1,39 @@
+ifeq ($(TARGET_ARCH), $(findstring $(TARGET_ARCH), "fusion_f1 hifi4"))
+
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/xtensa_download.sh ${MAKEFILE_DIR}/downloads hifi4)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the xtensa download: $(DOWNLOAD_RESULT))
+ endif
+
+ # TODO(b/161489252): -Wno-shadow is only needed for xannlib. But since we do
+ # not have separate cflags (or the concept of modular build targets) with the
+ # Makefile, -Wno-shadow will be used for everything.
+
+ PLATFORM_FLAGS = \
+ -DNNLIB_V2 \
+ -Wno-shadow
+
+ CCFLAGS += $(PLATFORM_FLAGS)
+ CXXFLAGS += $(PLATFORM_FLAGS)
+
+ NNLIB_PATH := $(MAKEFILE_DIR)/downloads/xa_nnlib_hifi4
+
+ THIRD_PARTY_CC_SRCS += \
+ $(shell find $(NNLIB_PATH) -name "*.c")
+
+ EXCLUDED_NNLIB_SRCS = \
+ $(NNLIB_PATH)/algo/layers/cnn/src/xa_nn_cnn_api.c \
+ $(NNLIB_PATH)/algo/layers/gru/src/xa_nn_gru_api.c \
+ $(NNLIB_PATH)/algo/layers/lstm/src/xa_nn_lstm_api.c
+
+ THIRD_PARTY_CC_SRCS := $(filter-out $(EXCLUDED_NNLIB_SRCS), $(THIRD_PARTY_CC_SRCS))
+
+ INCLUDES += \
+ -I$(NNLIB_PATH)/ \
+ -I$(NNLIB_PATH)/algo/kernels/ \
+ -I$(NNLIB_PATH)/include/nnlib/ \
+ -I$(NNLIB_PATH)/include/ \
+ -I$(NNLIB_PATH)/algo/common/include/ \
+ -I$(NNLIB_PATH)/algo/ndsp/hifi4/include/
+
+endif
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/xtensa_download.sh b/tensorflow/lite/micro/tools/make/ext_libs/xtensa_download.sh
new file mode 100755
index 0000000..3d0b6a0
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/xtensa_download.sh
@@ -0,0 +1,80 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Downloads necessary to build with OPTIMIZED_KERNEL_DIR=xtensa.
+#
+# Called with four arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+# 2 - Xtensa variant to download for (e.g. hifi4)
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+if [[ ${2} == "hifi4" ]]; then
+ LIBRARY_URL="http://github.com/foss-xtensa/nnlib-hifi4/raw/master/archive/xa_nnlib_hifi4_02_11_2021.zip"
+ LIBRARY_DIRNAME="xa_nnlib_hifi4"
+ LIBRARY_MD5="8b934f61ffe0a966644849602810fb1b"
+else
+ echo "Attempting to download an unsupported xtensa variant: ${2}"
+ exit 1
+fi
+
+LIBRARY_INSTALL_PATH=${DOWNLOADS_DIR}/${LIBRARY_DIRNAME}
+
+if [ -d ${LIBRARY_INSTALL_PATH} ]; then
+ echo >&2 "${LIBRARY_INSTALL_PATH} already exists, skipping the download."
+else
+ TMP_ZIP_ARCHIVE_NAME="${LIBRARY_DIRNAME}.zip"
+ wget ${LIBRARY_URL} -O /tmp/${TMP_ZIP_ARCHIVE_NAME} >&2
+ MD5=`md5sum /tmp/${TMP_ZIP_ARCHIVE_NAME} | awk '{print $1}'`
+
+ if [[ ${MD5} != ${LIBRARY_MD5} ]]
+ then
+ echo "Bad checksum. Expected: ${LIBRARY_MD5}, Got: ${MD5}"
+ exit 1
+ fi
+
+ unzip -qo /tmp/${TMP_ZIP_ARCHIVE_NAME} -d ${DOWNLOADS_DIR} >&2
+
+ pushd ${DOWNLOADS_DIR}/xa_nnlib_hifi4/ >&2
+ git init . >&2
+ git config user.email "tflm@google.com"
+ git config user.name "TensorflowLite Micro"
+ git add *
+ git commit -a -m "Commit for a temporary repository." > /dev/null
+ git apply ../../ext_libs/xtensa_patch.patch
+ popd >&2
+
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/ext_libs/xtensa_patch.patch b/tensorflow/lite/micro/tools/make/ext_libs/xtensa_patch.patch
new file mode 100644
index 0000000..cad2381
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/ext_libs/xtensa_patch.patch
@@ -0,0 +1,34 @@
+diff --git a/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise.c b/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise.c
+index 3e29856..320987b 100644
+--- a/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise.c
++++ b/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise.c
+@@ -249,8 +249,6 @@ WORD32 xa_nn_conv2d_depthwise_getsize
+ XA_NNLIB_CHK_COND((kernel_height <= 0), -1);
+ XA_NNLIB_CHK_COND((kernel_width <= 0), -1);
+ XA_NNLIB_CHK_COND((channels_multiplier <= 0), -1);
+- XA_NNLIB_CHK_COND((x_stride <= 0 || x_stride > kernel_width), -1);
+- XA_NNLIB_CHK_COND((y_stride <= 0 || y_stride > kernel_height), -1);
+ XA_NNLIB_CHK_COND((x_padding < 0), -1);
+ XA_NNLIB_CHK_COND((y_padding < 0), -1);
+ XA_NNLIB_CHK_COND((output_height <= 0), -1);
+diff --git a/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise_sym8sxasym8s.c b/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise_sym8sxasym8s.c
+index e719da1..5b7390f 100644
+--- a/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise_sym8sxasym8s.c
++++ b/algo/kernels/cnn/hifi4/xa_nn_conv2d_depthwise_sym8sxasym8s.c
+@@ -659,7 +659,6 @@ WORD32 xa_nn_conv2d_depthwise_per_chan_sym8sxasym8s
+ XA_NNLIB_ARG_CHK_COND((input_channels <= 0), -1);
+ XA_NNLIB_ARG_CHK_COND((kernel_height <= 0 || kernel_width <= 0), -1);
+ XA_NNLIB_ARG_CHK_COND((kernel_height > input_height), -1);
+- XA_NNLIB_ARG_CHK_COND((kernel_width > input_width), -1);
+ XA_NNLIB_ARG_CHK_COND((channels_multiplier <= 0), -1);
+ XA_NNLIB_ARG_CHK_COND((y_stride <= 0 || x_stride <= 0), -1);
+ XA_NNLIB_ARG_CHK_COND((y_padding < 0 || x_padding < 0), -1);
+@@ -671,8 +670,6 @@ WORD32 xa_nn_conv2d_depthwise_per_chan_sym8sxasym8s
+ XA_NNLIB_ARG_CHK_COND((inp_data_format != 0 && inp_data_format != 1), -1);
+ XA_NNLIB_ARG_CHK_COND((out_data_format != 0), -1);
+ /* Implementation dependent checks */
+- XA_NNLIB_ARG_CHK_COND((y_stride > kernel_height), -1);
+- XA_NNLIB_ARG_CHK_COND((x_stride > kernel_width), -1);
+
+ if(inp_data_format == 0)
+ {
diff --git a/tensorflow/lite/micro/tools/make/fix_arduino_subfolders.py b/tensorflow/lite/micro/tools/make/fix_arduino_subfolders.py
new file mode 100755
index 0000000..0c6d06c
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/fix_arduino_subfolders.py
@@ -0,0 +1,110 @@
+# Lint as: python2, python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Moves source files to match Arduino library conventions."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import glob
+import os
+
+import six
+
+
+def rename_example_subfolder_files(library_dir):
+ """Moves source files in example subfolders to equivalents at root."""
+ patterns = ['*.h', '*.cpp', '*.c']
+ for pattern in patterns:
+ search_path = os.path.join(library_dir, 'examples/*/*', pattern)
+ for source_file_path in glob.glob(search_path):
+ source_file_dir = os.path.dirname(source_file_path)
+ source_file_base = os.path.basename(source_file_path)
+ new_source_file_path = source_file_dir + '_' + source_file_base
+ os.rename(source_file_path, new_source_file_path)
+
+
+def move_person_data(library_dir):
+ """Moves the downloaded person model into the examples folder."""
+ old_person_data_path = os.path.join(
+ library_dir, 'src/tensorflow/lite/micro/tools/make/downloads/' +
+ 'person_model_int8/person_detect_model_data.cpp')
+ new_person_data_path = os.path.join(
+ library_dir, 'examples/person_detection/person_detect_model_data.cpp')
+ if os.path.exists(old_person_data_path):
+ os.rename(old_person_data_path, new_person_data_path)
+ # Update include.
+ with open(new_person_data_path, 'r') as source_file:
+ file_contents = source_file.read()
+ file_contents = file_contents.replace(
+ six.ensure_str('#include "tensorflow/lite/micro/examples/' +
+ 'person_detection/person_detect_model_data.h"'),
+ '#include "person_detect_model_data.h"')
+ with open(new_person_data_path, 'w') as source_file:
+ source_file.write(file_contents)
+
+
+def move_image_data_experimental(library_dir):
+ """Moves the downloaded image detection model into the examples folder."""
+ old_image_data_path = os.path.join(
+ library_dir, 'src/tensorflow/lite/micro/tools/make/downloads/' +
+ 'image_recognition_model/image_recognition_model.cpp')
+ new_image_data_path = os.path.join(
+ library_dir,
+ 'examples/image_recognition_experimental/image_recognition_model.cpp')
+ if os.path.exists(old_image_data_path):
+ os.rename(old_image_data_path, new_image_data_path)
+ # Update include.
+ with open(new_image_data_path, 'r') as source_file:
+ file_contents = source_file.read()
+ file_contents = file_contents.replace(
+ six.ensure_str('#include "tensorflow/lite/micro/examples/' +
+ 'image_recognition_example/image_recognition_model.h"'),
+ '#include "image_recognition_model.h"')
+ with open(new_image_data_path, 'w') as source_file:
+ source_file.write(file_contents)
+
+
+def rename_example_main_inos(library_dir):
+ """Makes sure the .ino sketch files match the example name."""
+ search_path = os.path.join(library_dir, 'examples/*', 'main.ino')
+ for ino_path in glob.glob(search_path):
+ example_path = os.path.dirname(ino_path)
+ example_name = os.path.basename(example_path)
+ new_ino_path = os.path.join(example_path, example_name + '.ino')
+ os.rename(ino_path, new_ino_path)
+
+
+def main(unparsed_args):
+ """Control the rewriting of source files."""
+ library_dir = unparsed_args[0]
+ rename_example_subfolder_files(library_dir)
+ rename_example_main_inos(library_dir)
+ move_person_data(library_dir)
+ move_image_data_experimental(library_dir)
+
+
+def parse_args():
+ """Converts the raw arguments into accessible flags."""
+ parser = argparse.ArgumentParser()
+ _, unparsed_args = parser.parse_known_args()
+
+ main(unparsed_args)
+
+
+if __name__ == '__main__':
+ parse_args()
diff --git a/tensorflow/lite/micro/tools/make/fix_arduino_subfolders_test.sh b/tensorflow/lite/micro/tools/make/fix_arduino_subfolders_test.sh
new file mode 100755
index 0000000..e55e61a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/fix_arduino_subfolders_test.sh
@@ -0,0 +1,75 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Bash unit tests for the TensorFlow Lite Micro project generator.
+
+set -e
+
+LIBRARY_DIR=${TEST_TMPDIR}/library
+mkdir -p ${LIBRARY_DIR}
+
+EXAMPLES_SUBDIR_CPP=${LIBRARY_DIR}/examples/something/foo/fish.cpp
+mkdir -p `dirname ${EXAMPLES_SUBDIR_CPP}`
+touch ${EXAMPLES_SUBDIR_CPP}
+
+EXAMPLES_SUBDIR_HEADER=${LIBRARY_DIR}/examples/something/foo/fish.h
+mkdir -p `dirname ${EXAMPLES_SUBDIR_HEADER}`
+touch ${EXAMPLES_SUBDIR_HEADER}
+
+TENSORFLOW_SRC_DIR=${LIBRARY_DIR}/src/
+PERSON_DATA_FILE=${TENSORFLOW_SRC_DIR}tensorflow/lite/micro/tools/make/downloads/person_model_int8/person_detect_model_data.cpp
+mkdir -p `dirname ${PERSON_DATA_FILE}`
+echo '#include "tensorflow/lite/micro/examples/person_detection/person_detect_model_data.h"' > ${PERSON_DATA_FILE}
+mkdir -p ${LIBRARY_DIR}/examples/person_detection
+
+EXAMPLE_INO_FILE=${LIBRARY_DIR}/examples/something/main.ino
+mkdir -p `dirname ${EXAMPLE_INO_FILE}`
+touch ${EXAMPLE_INO_FILE}
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/fix_arduino_subfolders \
+ ${LIBRARY_DIR}
+
+EXPECTED_EXAMPLES_SUBDIR_CPP=${LIBRARY_DIR}/examples/something/foo_fish.cpp
+if [[ ! -f ${EXPECTED_EXAMPLES_SUBDIR_CPP} ]]; then
+ echo "${EXPECTED_EXAMPLES_SUBDIR_CPP} wasn't created."
+ exit 1
+fi
+
+EXPECTED_EXAMPLES_SUBDIR_HEADER=${LIBRARY_DIR}/examples/something/foo_fish.h
+if [[ ! -f ${EXPECTED_EXAMPLES_SUBDIR_HEADER} ]]; then
+ echo "${EXPECTED_EXAMPLES_SUBDIR_HEADER} wasn't created."
+ exit 1
+fi
+
+EXPECTED_PERSON_DATA_FILE=${LIBRARY_DIR}/examples/person_detection/person_detect_model_data.cpp
+if [[ ! -f ${EXPECTED_PERSON_DATA_FILE} ]]; then
+ echo "${EXPECTED_PERSON_DATA_FILE} wasn't created."
+ exit 1
+fi
+
+if ! grep -q '#include "person_detect_model_data.h"' ${EXPECTED_PERSON_DATA_FILE}; then
+ echo "ERROR: No person_detect_model_data.h include found in output '${EXPECTED_PERSON_DATA_FILE}'"
+ exit 1
+fi
+
+EXPECTED_EXAMPLE_INO_FILE=${LIBRARY_DIR}/examples/something/something.ino
+if [[ ! -f ${EXPECTED_EXAMPLE_INO_FILE} ]]; then
+ echo "${EXPECTED_EXAMPLE_INO_FILE} wasn't created."
+ exit 1
+fi
+
+echo
+echo "SUCCESS: fix_arduino_subfolders test PASSED"
diff --git a/tensorflow/lite/micro/tools/make/flatbuffers_download.sh b/tensorflow/lite/micro/tools/make/flatbuffers_download.sh
new file mode 100755
index 0000000..5e9b49a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/flatbuffers_download.sh
@@ -0,0 +1,110 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/make/bash_helpers.sh
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+# TODO(b/173239141): Patch flatbuffers to avoid pulling in extra symbols from
+# strtod that are not used at runtime but are still problematic on the
+# Bluepill platform.
+#
+# Parameter(s):
+# $1 - full path to the downloaded flexbuffers.h that will be patched in-place.
+function patch_to_avoid_strtod() {
+ local input_flexbuffers_path="$1"
+ local temp_flexbuffers_path="$(mktemp)"
+ local string_to_num_line=`awk '/StringToNumber/{ print NR; }' ${input_flexbuffers_path}`
+ local case_string_line=$((${string_to_num_line} - 2))
+
+ head -n ${case_string_line} ${input_flexbuffers_path} > ${temp_flexbuffers_path}
+
+ echo "#if 1" >> ${temp_flexbuffers_path}
+ echo "#pragma GCC diagnostic push" >> ${temp_flexbuffers_path}
+ echo "#pragma GCC diagnostic ignored \"-Wnull-dereference\"" >> ${temp_flexbuffers_path}
+ echo " // TODO(b/173239141): Patched via micro/tools/make/flexbuffers_download.sh" >> ${temp_flexbuffers_path}
+ echo " // Introduce a segfault for an unsupported code path for TFLM." >> ${temp_flexbuffers_path}
+ echo " return *(static_cast<double*>(nullptr));" >> ${temp_flexbuffers_path}
+ echo "#pragma GCC diagnostic pop" >> ${temp_flexbuffers_path}
+ echo "#else" >> ${temp_flexbuffers_path}
+ echo " // This is the original code" >> ${temp_flexbuffers_path}
+ sed -n -e $((${string_to_num_line} - 1)),$((${string_to_num_line} + 1))p ${input_flexbuffers_path} >> ${temp_flexbuffers_path}
+ echo "#endif" >> ${temp_flexbuffers_path}
+
+ local total_num_lines=`wc -l ${input_flexbuffers_path} | awk '{print $1}'`
+ sed -n -e $((${string_to_num_line} + 2)),${total_num_lines}p ${input_flexbuffers_path} >> ${temp_flexbuffers_path}
+ mv ${input_flexbuffers_path} ${input_flexbuffers_path}.orig
+ mv ${temp_flexbuffers_path} ${input_flexbuffers_path}
+}
+
+# The BUILD files in the downloaded folder result in an error with:
+# bazel build tensorflow/lite/micro/...
+#
+# Parameters:
+# $1 - path to the downloaded flatbuffers code.
+function delete_build_files() {
+ rm -f `find ${1} -name BUILD`
+ rm -f `find ${1} -name BUILD.bazel`
+}
+
+DOWNLOADED_FLATBUFFERS_PATH=${DOWNLOADS_DIR}/flatbuffers
+
+if [ -d ${DOWNLOADED_FLATBUFFERS_PATH} ]; then
+ echo >&2 "${DOWNLOADED_FLATBUFFERS_PATH} already exists, skipping the download."
+else
+ ZIP_PREFIX="dca12522a9f9e37f126ab925fd385c807ab4f84e"
+ FLATBUFFERS_URL="http://mirror.tensorflow.org/github.com/google/flatbuffers/archive/${ZIP_PREFIX}.zip"
+ FLATBUFFERS_MD5="aa9adc93eb9b33fa1a2a90969e48baee"
+
+ TMPDIR="$(mktemp -d)"
+ TMPFILE="${TMPDIR}/${ZIP_PREFIX}.zip"
+ wget ${FLATBUFFERS_URL} -O "$TMPFILE" >&2
+ check_md5 "${TMPFILE}" ${FLATBUFFERS_MD5}
+
+ unzip -qo "$TMPFILE" -d "${TMPDIR}" >&2
+ mv "${TMPDIR}/flatbuffers-${ZIP_PREFIX}" ${DOWNLOADED_FLATBUFFERS_PATH}
+ rm -rf "${TMPDIR}"
+
+ patch_to_avoid_strtod ${DOWNLOADED_FLATBUFFERS_PATH}/include/flatbuffers/flexbuffers.h
+ delete_build_files ${DOWNLOADED_FLATBUFFERS_PATH}
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/generate_keil_project.py b/tensorflow/lite/micro/tools/make/generate_keil_project.py
new file mode 100644
index 0000000..a022be3
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/generate_keil_project.py
@@ -0,0 +1,122 @@
+# Lint as: python2, python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Generates a Keil uVision project file from a template."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import os.path
+import re
+
+import six
+
+
+def sanitize_xml(unsanitized):
+ """Uses a allowlist to avoid generating bad XML."""
+ return re.sub(r'[^a-zA-Z0-9+_\-/\\.]', '', six.ensure_str(unsanitized))
+
+
+def main(unused_args, flags):
+ """Generates a Keil project file from a template source."""
+ with open(flags.input_template, 'r') as input_template_file:
+ template_file_text = input_template_file.read()
+
+ template_file_text = re.sub(r'%{EXECUTABLE}%',
+ six.ensure_str(flags.executable),
+ template_file_text)
+
+ srcs_list = six.ensure_str(flags.srcs).split(' ')
+ hdrs_list = six.ensure_str(flags.hdrs).split(' ')
+ all_srcs_list = srcs_list + hdrs_list
+ all_srcs_list.sort()
+
+ replace_srcs = ''
+ for src in all_srcs_list:
+ if not src:
+ continue
+ ext = os.path.splitext(src)[1]
+ # These extension indexes are used by uVision to keep track of the type
+ # of files. I determined them by experimentation, since the file format
+ # isn't documented.
+ if ext == '.h':
+ ext_index = '5'
+ elif ext == '.c':
+ ext_index = '1'
+ elif ext == '.cc' or ext == '.cpp':
+ ext_index = '8'
+ else:
+ ext_index = '5'
+ basename = sanitize_xml(os.path.basename(src))
+ clean_src = sanitize_xml(src)
+ replace_srcs += ' <File>\n'
+ replace_srcs += ' <FileName>' + basename + '</FileName>\n'
+ replace_srcs += ' <FileType>' + ext_index + '</FileType>\n'
+ replace_srcs += ' <FilePath>' + clean_src + '</FilePath>\n'
+ replace_srcs += ' </File>\n'
+ template_file_text = re.sub(r'%{SRCS}%', replace_srcs,
+ six.ensure_str(template_file_text))
+
+ include_paths = re.sub(' ', ';', six.ensure_str(flags.include_paths))
+ template_file_text = re.sub(r'%{INCLUDE_PATHS}%', include_paths,
+ template_file_text)
+
+ with open(flags.output_file, 'w') as output_file:
+ output_file.write(template_file_text)
+
+
+def parse_args():
+ """Converts the raw arguments into accessible flags."""
+ parser = argparse.ArgumentParser()
+ parser.register('type', 'bool', lambda v: v.lower() == 'true')
+ parser.add_argument(
+ '--input_template',
+ type=str,
+ default='',
+ help='Path to template project file to build from.')
+ parser.add_argument(
+ '--output_file',
+ type=str,
+ default='',
+ help='Path to write the completed project file to.')
+ parser.add_argument(
+ '--executable',
+ type=str,
+ default='',
+ help='Name of the executable the project will build.')
+ parser.add_argument(
+ '--hdrs',
+ type=str,
+ default='',
+ help='Space-separated list of C or C++ source files to compile.')
+ parser.add_argument(
+ '--srcs',
+ type=str,
+ default='',
+ help='Space-separated list of C or C++ header files to include.')
+ parser.add_argument(
+ '--include_paths',
+ type=str,
+ default='',
+ help='Space-separated list of paths to look for header files on.')
+ flags, unparsed = parser.parse_known_args()
+
+ main(unparsed, flags)
+
+
+if __name__ == '__main__':
+ parse_args()
diff --git a/tensorflow/lite/micro/tools/make/generate_keil_project_test.sh b/tensorflow/lite/micro/tools/make/generate_keil_project_test.sh
new file mode 100755
index 0000000..359e5a8
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/generate_keil_project_test.sh
@@ -0,0 +1,69 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Bash unit tests for the TensorFlow Lite Micro project generator.
+
+set -e
+
+INPUT_TEMPLATE=${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/templates/keil_project.uvprojx.tpl
+OUTPUT_FILE=${TEST_TMPDIR}/keil_project.uvprojx
+EXECUTABLE=test_executable
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/generate_keil_project \
+ --input_template=${INPUT_TEMPLATE} \
+ --output_file=${OUTPUT_FILE} \
+ --executable=${EXECUTABLE} \
+ --hdrs="foo.h bar.h" \
+ --srcs="foo.c bar.cc some/bad<xml.cc" \
+ --include_paths=". include"
+
+if ! grep -q "${EXECUTABLE}" ${OUTPUT_FILE}; then
+ echo "ERROR: No executable name '${EXECUTABLE}' found in project file '${OUTPUT_FILE}'."
+ exit 1
+fi
+
+if ! grep -q "foo\.h" ${OUTPUT_FILE}; then
+ echo "ERROR: No header 'foo.h' found in project file '${OUTPUT_FILE}'."
+ exit 1
+fi
+
+if ! grep -q "bar\.h" ${OUTPUT_FILE}; then
+ echo "ERROR: No header 'bar.h' found in project file '${OUTPUT_FILE}'."
+ exit 1
+fi
+
+if ! grep -q "foo\.c" ${OUTPUT_FILE}; then
+ echo "ERROR: No source 'foo.c' found in project file '${OUTPUT_FILE}'."
+ exit 1
+fi
+
+if ! grep -q "bar\.cc" ${OUTPUT_FILE}; then
+ echo "ERROR: No source 'bar.cc' found in project file '${OUTPUT_FILE}'."
+ exit 1
+fi
+
+if ! grep -q "some/badxml\.cc" ${OUTPUT_FILE}; then
+ echo "ERROR: No source 'some/badxml.cc' found in project file '${OUTPUT_FILE}'."
+ exit 1
+fi
+
+if ! grep -q "\.;include" ${OUTPUT_FILE}; then
+ echo "ERROR: No include paths '.;include' found in project file '${OUTPUT_FILE}'."
+ exit 1
+fi
+
+echo
+echo "SUCCESS: generate_keil_project test PASSED"
diff --git a/tensorflow/lite/micro/tools/make/helper_functions.inc b/tensorflow/lite/micro/tools/make/helper_functions.inc
new file mode 100644
index 0000000..c102ee2
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/helper_functions.inc
@@ -0,0 +1,591 @@
+DOWNLOAD_SCRIPT := $(MAKEFILE_DIR)/download_and_extract.sh
+
+# Reverses a space-separated list of words.
+reverse = $(if $(1),$(call reverse,$(wordlist 2,$(words $(1)),$(1)))) $(firstword $(1))
+
+# Get macros only (i.e. the ones starting with -D) from two lists and remove duplicates
+getmacros = $(patsubst -D%,%,$(filter -D%,$(sort $(filter -D%, $(1)) $(filter -D%, $(2)))))
+
+# Look for platform or target-specific implementation files to replace reference
+# implementations with, given a tag. These are expected to occur in subfolders
+# of a directory where a reference implementation exists, and have the same
+# interface and header file. For example,
+# tensorflow/lite/micro/examples/micro_speech/audio_provider.cc
+# defines a module for supplying audio data, but since no platform or OS can be
+# presumed, it just always returns zeroes for its samples. The MacOS-specific
+# tensorflow/lite/micro/examples/micro_speech/osx/audio_provider.cc
+# has an implementation that relies on CoreAudio, and there are equivalent
+# versions for other operating systems.
+# The specific implementation yielded by the first tag in the list that produces
+# a match is returned, else the reference version if none of the tags produce a
+# match.
+# All lists of source files are put through this substitution process with the
+# tags of their target OS and architecture, so that implementations can be added
+# by simply placing them in the file tree, with no changes to the build files
+# needed.
+# One confusing thing about this implementation is that we're using wildcard to
+# act as a 'does file exist?' function, rather than expanding an expression.
+# Wildcard will return an empty string if given a plain file path with no actual
+# wildcards, if the file doesn't exist, so taking the first word of the list
+# between that and the reference path will pick the specialized one if it's
+# available.
+# Another fix is that originally if neither file existed(either the original or
+# a specialized version) this would return an empty string.Because this is
+# sometimes called on third party library files before they've been downloaded,
+# this caused mysterious errors, so an initial if conditional was added so that
+# specializations are only looked for if the original file exists.
+substitute_specialized_implementation = \
+ $(if $(wildcard $(1)),$(firstword $(wildcard $(dir $(1))$(2)/$(notdir $(1))) $(wildcard $(1))),$(1))
+substitute_specialized_implementations = \
+ $(foreach source,$(1),$(call substitute_specialized_implementation,$(source),$(2)))
+
+# Tests and project generation targets use this entrypoint for to get the
+# specialized sources. It should be avoided for any new functionality.
+# The only argument is a list of file paths.
+specialize = $(call substitute_specialized_implementations,$(1),$(TARGET))
+
+# TODO(b/143904317): It would be better to have the dependency be
+# THIRD_PARTY_TARGETS instead of third_party_downloads. However, that does not
+# quite work for the generate_project functions.
+#
+# Creates a set of rules to build a standalone makefile project for an
+# executable, including all of the source and header files required in a
+# separate folder and a simple makefile.
+# Arguments are:
+# 1 - Project type (make, mbed, etc).
+# 2 - Project file template name.
+# 3 - Name of executable.
+# 4 - List of C/C++ source files needed to build the target.
+# 5 - List of C/C++ header files needed to build the target.
+# 6 - Linker flags required.
+# 7 - C++ compilation flags needed.
+# 8 - C compilation flags needed.
+# 9 - Target Toolchian root directory
+# 10 - Target Toolchain prefix
+# Calling eval on the output will create a <Name>_makefile target that you
+# can invoke to create the standalone project.
+define generate_project
+$(PRJDIR)$(3)/$(1)/%: % third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(3)/cmake/boards/%: tensorflow/lite/micro/examples/$(3)/zephyr_riscv/boards/%
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(3)/cmake/%: tensorflow/lite/micro/examples/$(3)/zephyr_riscv/%
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(3)/$(1)/third_party/%: tensorflow/lite/micro/tools/make/downloads/% third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(3)/$(1)/%: tensorflow/lite/micro/tools/make/templates/%.tpl
+ @mkdir -p $$(dir $$@)
+ @sed -E 's#\%\{SRCS\}\%#$(4)#g' $$< | \
+ sed -E 's#\%\{EXECUTABLE\}\%#$(3)#g' | \
+ sed -E 's#\%\{LINKER_FLAGS\}\%#$(6)#g' | \
+ sed -E 's#\%\{CXX_FLAGS\}\%#$(7)#g' | \
+ sed -E 's#\%\{CC_FLAGS\}\%#$(8)#g' | \
+ sed -E 's#\%\{TARGET_TOOLCHAIN_ROOT\}\%#$(9)#g' | \
+ sed -E 's#\%\{TARGET_TOOLCHAIN_PREFIX\}\%#$(10)#g' > $$@
+
+$(PRJDIR)$(3)/$(1)/keil_project.uvprojx: tensorflow/lite/micro/tools/make/templates/keil_project.uvprojx.tpl
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/generate_keil_project.py \
+ --input_template=$$< --output_file=$$@ --executable=$(3) \
+ --srcs="$(4)" --hdrs="$(5)" --include_paths="$$(PROJECT_INCLUDES)"
+
+$(PRJDIR)$(3)/$(1)/.vscode/tasks.json : tensorflow/lite/micro/tools/make/templates/tasks.json.$(1).tpl
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+generate_$(3)_$(1)_project: $(addprefix $(PRJDIR)$(3)/$(1)/, $(4) $(5) $(2))
+ifeq (mbed, $(1))
+ $(eval macrolist := $(call getmacros, $7, $8))
+ $(eval jsonfilename := $(PRJDIR)$(3)/$(1)/mbed_app)
+ @awk 'FNR==NR{ if (/}/) p=NR; next} 1; FNR==(p-1){ n=split("$(macrolist)",a," "); print(" ,\"macros\": [");for (i=1; i <= n; i++){ printf(" \"%s\"", a[i]); if(i<n){printf(",\n")}}printf("\n ]\n")}' \
+ $(jsonfilename).json $(jsonfilename).json > $(jsonfilename).tmp && mv $(jsonfilename).tmp $(jsonfilename).json
+endif
+
+list_$(3)_$(1)_files:
+ @echo $(4) $(5)
+
+ALL_PROJECT_TARGETS += generate_$(3)_$(1)_project
+endef
+
+# Creates a set of rules to build a standalone makefile project for the ARC platform
+# including all of the source and header files required in a
+# separate folder and a simple makefile.
+# Arguments are:
+# 1 - Project type (make, mbed, etc).
+# 2 - Project file template name.
+# 3 - Name of executable.
+# 4 - List of C/C++ source files needed to build the target.
+# 5 - List of C/C++ header files needed to build the target.
+# 6 - Linker flags required.
+# 7 - C++ compilation flags needed.
+# 8 - C compilation flags needed.
+
+# Calling eval on the output will create a <Name>_makefile target that you
+# can invoke to create the standalone project.
+define generate_arc_project
+
+ifeq ($(TARGET_ARCH), arc)
+
+$(PRJDIR)$(3)/$(1)/Makefile: tensorflow/lite/micro/tools/make/templates/arc/arc_app_makefile.tpl
+ @mkdir -p $$(dir $$@)
+ @sed -E 's#\%\{SRCS\}\%#$(4)#g' $$< | \
+ sed -E 's#\%\{CC\}\%#$(CC_TOOL)#g' | \
+ sed -E 's#\%\{CXX\}\%#$(CXX_TOOL)#g' | \
+ sed -E 's#\%\{LD\}\%#$(LD_TOOL)#g' | \
+ sed -E 's#\%\{EXECUTABLE\}\%#$(3).elf#g' | \
+ sed -E 's#\%\{LINKER_FLAGS\}\%#$(6)#g' | \
+ sed -E 's#\%\{CXX_FLAGS\}\%#$(7)#g' | \
+ sed -E 's#\%\{CC_FLAGS\}\%#$(8)#g' | \
+ sed -E 's#\%\{EXTRA_APP_SETTINGS\}\%#$(ARC_EXTRA_APP_SETTINGS)#g' | \
+ sed -E 's#\%\{EXTRA_APP_RULES\}\%#$(ARC_EXTRA_APP_RULES)#g' | \
+ sed -E 's#\%\{BIN_DEPEND\}\%#$(ARC_BIN_DEPEND)#g' | \
+ sed -E 's#\%\{BIN_RULE\}\%#$(ARC_BIN_RULE)#g' | \
+ sed -E 's#\%\{EXTRA_RM_TARGETS\}\%#$(ARC_EXTRA_RM_TARGETS)#g' | \
+ sed -E 's#\%\{APP_RUN_CMD\}\%#$(ARC_APP_RUN_CMD)#g' | \
+ sed -E 's#\%\{APP_DEBUG_CMD\}\%#$(ARC_APP_DEBUG_CMD)#g' | \
+ sed -E 's#\%\{EXTRA_EXECUTE_RULES\}\%#$(ARC_EXTRA_EXECUTE_RULES)#g' > $$@
+
+$(PRJDIR)$(3)/$(1)/%: tensorflow/lite/micro/tools/make/templates/arc/%.tpl
+ @cp $$< $$@
+
+$(foreach var,$(ARC_TARGET_COPY_FILES), $(eval $(call path_changing_copy_file,\
+ $(PRJDIR)$(3)/$(1)/$(word 1, $(subst !, ,$(var))),\
+ $(word 2, $(subst !, ,$(var))))))
+
+endif
+endef
+
+
+define generate_ceva_bx1_project
+ifeq ($(TARGET), ceva)
+ifeq ($(TARGET_ARCH), CEVA_BX1)
+
+$(PRJDIR)$(3)/$(1)/Makefile: tensorflow/lite/micro/tools/make/templates/ceva/ceva_app_makefile_v18.0.5.tpl
+ @mkdir -p $$(dir $$@)
+ @sed -E 's#\%\{SRCS\}\%#$(4)#g' $$< | \
+ sed -E 's#\%\{CC\}\%#$(CC_TOOL)#g' | \
+ sed -E 's#\%\{CXX\}\%#$(CXX_TOOL)#g' | \
+ sed -E 's#\%\{LD\}\%#$(LD_TOOL)#g' | \
+ sed -E 's#\%\{EXECUTABLE\}\%#$(3).elf#g' | \
+ sed -E 's#\%\{LD_FLAGS\}\%#$(6)#g' | \
+ sed -E 's#\%\{CXX_FLAGS\}\%#$(7)#g' | \
+ sed -E 's#\%\{CC_FLAGS\}\%#$(8)#g' > $$@
+
+$(PRJDIR)$(3)/$(1)/%: tensorflow/lite/micro/tools/make/templates/ceva/%.tpl
+ @cp $$< $$@
+
+$(foreach var,$(CEVA_TARGET_FILES_DIRS),$(eval $(call path_changing_copy_file,$(PRJDIR)$(3)/$(1),$(var))))
+
+endif
+endif
+endef
+
+define generate_ceva_sp500_project
+ifeq ($(TARGET), ceva)
+ifeq ($(TARGET_ARCH), CEVA_SP500)
+
+$(PRJDIR)$(3)/$(1)/Makefile: tensorflow/lite/micro/tools/make/templates/ceva_SP500/ceva_app_makefile.tpl
+ @mkdir -p $$(dir $$@)
+ @sed -E 's#\%\{SRCS\}\%#$(4)#g' $$< | \
+ sed -E 's#\%\{CC\}\%#$(CC_TOOL)#g' | \
+ sed -E 's#\%\{CXX\}\%#$(CXX_TOOL)#g' | \
+ sed -E 's#\%\{LD\}\%#$(LD_TOOL)#g' | \
+ sed -E 's#\%\{EXECUTABLE\}\%#$(3).elf#g' | \
+ sed -E 's#\%\{LD_FLAGS\}\%#$(6)#g' | \
+ sed -E 's#\%\{CXX_FLAGS\}\%#$(7)#g' | \
+ sed -E 's#\%\{CC_FLAGS\}\%#$(8)#g' | \
+ sed -E 's#\%\{EXTRA_APP_SETTINGS\}\%#$(ARC_EXTRA_APP_SETTINGS)#g' | \
+ sed -E 's#\%\{EXTRA_APP_RULES\}\%#$(ARC_EXTRA_APP_RULES)#g' | \
+ sed -E 's#\%\{BIN_DEPEND\}\%#$(ARC_BIN_DEPEND)#g' | \
+ sed -E 's#\%\{BIN_RULE\}\%#$(ARC_BIN_RULE)#g' | \
+ sed -E 's#\%\{EXTRA_RM_TARGETS\}\%#$(ARC_EXTRA_RM_TARGETS)#g' | \
+ sed -E 's#\%\{APP_RUN_CMD\}\%#$(ARC_APP_RUN_CMD)#g' | \
+ sed -E 's#\%\{APP_DEBUG_CMD\}\%#$(ARC_APP_DEBUG_CMD)#g' | \
+ sed -E 's#\%\{EXTRA_EXECUTE_RULES\}\%#$(ARC_EXTRA_EXECUTE_RULES)#g' > $$@
+
+$(PRJDIR)$(3)/$(1)/%: tensorflow/lite/micro/tools/make/templates/ceva_SP500/%.tpl
+ @cp $$< $$@
+
+$(foreach var,$(CEVA_TARGET_FILES_DIRS),$(eval $(call path_changing_copy_file,$(PRJDIR)$(3)/$(1),$(var))))
+
+endif
+endif
+endef
+
+
+
+
+
+# Creates a set of rules to build a standalone Arduino project for an
+# executable, including all of the source and header files required in a
+# separate folder and a simple makefile.
+# Arguments are:
+# 1 - Project file template names.
+# 2 - Name of executable.
+# 3 - List of C/C++ source files needed to build the target.
+# 4 - List of C/C++ header files needed to build the target.
+# 5 - Linker flags required.
+# 6 - C++ compilation flags needed.
+# 7 - C compilation flags needed.
+# Calling eval on the output will create a <Name>_makefile target that you
+# can invoke to create the standalone project.
+define generate_arduino_project
+
+$(PRJDIR)$(2)/arduino/examples/%.c: tensorflow/lite/micro/examples/%.c
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --is_example_source \
+ --source_path="$$<" \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/examples/%.cpp: tensorflow/lite/micro/examples/%.cc
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --is_example_source \
+ --source_path="$$<" \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/examples/%.h: tensorflow/lite/micro/examples/%.h
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --is_example_source \
+ --source_path="$$<" \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/examples/%/main.ino: tensorflow/lite/micro/examples/%/main_functions.cc
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --is_example_ino \
+ --source_path="$$<" \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/src/%.cpp: %.cc
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/src/%.h: %.h third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/LICENSE: LICENSE
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/arduino/src/%: % third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/src/third_party/%: tensorflow/lite/micro/tools/make/downloads/% third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/src/third_party/%.cpp: tensorflow/lite/micro/tools/make/downloads/%.cc third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --third_party_headers="$(4)" < $$< > $$@
+
+$(PRJDIR)$(2)/arduino/src/third_party/flatbuffers/include/flatbuffers/base.h: tensorflow/lite/micro/tools/make/downloads/flatbuffers/include/flatbuffers/base.h third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --third_party_headers="$(4)" < $$< | \
+ sed -E 's/utility\.h/utility/g' > $$@
+
+$(PRJDIR)$(2)/arduino/src/third_party/kissfft/kiss_fft.h: tensorflow/lite/micro/tools/make/downloads/kissfft/kiss_fft.h third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=arduino \
+ --third_party_headers="$(4)" < $$< | \
+ sed -E 's@#include <string.h>@//#include <string.h> /* Patched by helper_functions.inc for Arduino compatibility */@g' > $$@
+
+$(PRJDIR)$(2)/arduino/%: tensorflow/lite/micro/tools/make/templates/%
+ @mkdir -p $$(dir $$@)
+ @sed -E 's#\%\{SRCS\}\%#$(3)#g' $$< | \
+ sed -E 's#\%\{EXECUTABLE\}\%#$(2)#g' | \
+ sed -E 's#\%\{LINKER_FLAGS\}\%#$(5)#g' | \
+ sed -E 's#\%\{CXX_FLAGS\}\%#$(6)#g' | \
+ sed -E 's#\%\{CC_FLAGS\}\%#$(7)#g' > $$@
+
+$(PRJDIR)$(2)/arduino/examples/$(2)/$(2).ino: tensorflow/lite/micro/tools/make/templates/arduino_example.ino
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/arduino/src/TensorFlowLite.h: tensorflow/lite/micro/tools/make/templates/TensorFlowLite.h
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+# This would be cleaner if we broke up the list of dependencies into variables,
+# but these get hard to define with the evaluation approach used to define make
+# functions.
+generate_$(2)_arduino_project: \
+$(addprefix $(PRJDIR)$(2)/arduino/, \
+$(patsubst tensorflow/%,src/tensorflow/%,\
+$(patsubst examples/%/main_functions.cpp,examples/%/main.ino,\
+$(patsubst examples/%_test.cpp,examples/%_test.ino,\
+$(patsubst tensorflow/lite/micro/examples/%,examples/%,\
+$(patsubst third_party/%,src/third_party/%,\
+$(patsubst %.cc,%.cpp,$(3)))))))) \
+$(addprefix $(PRJDIR)$(2)/arduino/, \
+$(patsubst tensorflow/%,src/tensorflow/%,\
+$(patsubst tensorflow/lite/micro/examples/%,examples/%,\
+$(patsubst third_party/%,src/third_party/%,$(4))))) \
+$(addprefix $(PRJDIR)$(2)/arduino/,$(1)) \
+$(PRJDIR)$(2)/arduino/src/TensorFlowLite.h
+
+generate_$(2)_arduino_library_zip: generate_$(2)_arduino_project
+ cp -r $(PRJDIR)$(2)/arduino $(PRJDIR)$(2)/tensorflow_lite
+ python tensorflow/lite/micro/tools/make/fix_arduino_subfolders.py $(PRJDIR)$(2)/tensorflow_lite
+ @cd $(PRJDIR)$(2) && zip -q -r tensorflow_lite.zip tensorflow_lite
+
+ALL_PROJECT_TARGETS += $(if $(findstring _test,$(2)),,generate_$(2)_arduino_library_zip)
+
+ ARDUINO_LIBRARY_ZIPS += $(if $(findstring _mock,$(2)),,$(if $(findstring _test,$(2)),,$(PRJDIR)$(2)/tensorflow_lite.zip))
+
+endef
+
+# Creates a set of rules to build a standalone ESP-IDF project for an
+# executable, including all of the source and header files required in a
+# separate folder.
+# Arguments are:
+# 1 - Project file template names.
+# 2 - Name of executable.
+# 3 - List of C/C++ source files needed to build the TF Micro component.
+# 4 - List of C/C++ header files needed to build the TF Micro component.
+# 5 - List of C/C++ source files needed to build this particular project.
+# 6 - List of C/C++ header files needed to build this particular project.
+# 7 - Linker flags required.
+# 8 - C++ compilation flags needed.
+# 9 - C compilation flags needed.
+# 10 - List of includes.
+define generate_esp_project
+$(PRJDIR)$(2)/esp-idf/LICENSE: LICENSE
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/esp-idf/%: tensorflow/lite/micro/examples/$(2)/esp/%
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/esp-idf/main/%.cc: tensorflow/lite/micro/examples/$(2)/%.cc
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=esp \
+ --is_example_source \
+ --source_path="$$<" \
+ < $$< > $$@
+
+$(PRJDIR)$(2)/esp-idf/main/%.h: tensorflow/lite/micro/examples/$(2)/%.h
+ @mkdir -p $$(dir $$@)
+ @python tensorflow/lite/micro/tools/make/transform_source.py \
+ --platform=esp \
+ --is_example_source \
+ --source_path="$$<" \
+ < $$< > $$@
+
+$(PRJDIR)$(2)/esp-idf/main/%: tensorflow/lite/micro/examples/$(2)/%
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/esp-idf/components/tfmicro/%: % third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/esp-idf/components/tfmicro/third_party/%: tensorflow/lite/micro/tools/make/downloads/% third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/esp-idf/sdkconfig.defaults: tensorflow/lite/micro/examples/$(2)/esp/sdkconfig.defaults
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+
+$(PRJDIR)$(2)/esp-idf/%: tensorflow/lite/micro/tools/make/templates/esp/%.tpl
+# Split the sources into 2 components:
+# - Main component contains only the example's sources, relative from its dir.
+# - TFL Micro component contains everything but the example sources.
+ $(eval MAIN_SRCS := $(filter tensorflow/lite/micro/examples/%,$(5)))
+ $(eval MAIN_SRCS_RELATIVE := $(patsubst tensorflow/lite/micro/examples/$(2)/%,%,$(MAIN_SRCS)))
+ $(eval TFLM_SRCS := $(filter-out tensorflow/lite/micro/examples/%,$(5)) $(3))
+
+ @mkdir -p $$(dir $$@)
+ @sed -E 's#\%\{COMPONENT_SRCS\}\%#$(TFLM_SRCS)#g' $$< | \
+ sed -E 's#\%\{MAIN_SRCS\}\%#$(MAIN_SRCS_RELATIVE)#g' | \
+ sed -E 's#\%\{EXECUTABLE\}\%#$(2)#g' | \
+ sed -E 's#\%\{COMPONENT_INCLUDES\}\%#$(10)#g' | \
+ sed -E 's#\%\{LINKER_FLAGS\}\%#$(7)#g' | \
+ sed -E 's#\%\{CXX_FLAGS\}\%#$(8)#g' | \
+ sed -E 's#\%\{CC_FLAGS\}\%#$(9)#g' > $$@
+
+generate_$(2)_esp_project: \
+$(addprefix $(PRJDIR)$(2)/esp-idf/,\
+$(patsubst tensorflow/%,components/tfmicro/tensorflow/%,\
+$(patsubst third_party/%,components/tfmicro/third_party/%,\
+$(patsubst tensorflow/lite/micro/examples/$(2)/%,main/%,$(3) $(4) $(5) $(6))))) \
+$(addprefix $(PRJDIR)$(2)/esp-idf/,$(1))
+
+ALL_PROJECT_TARGETS += generate_$(2)_esp_project
+endef
+
+# Specialized version of generate_project for TF Lite Micro test targets that
+# automatically includes standard library files, so you just need to pass the
+# test name and any extra source files required.
+# Arguments are:
+# 1 - Name of test.
+# 2 - C/C++ source files implementing the test.
+# 3 - C/C++ header files needed for the test.
+# Calling eval on the output will create targets that you can invoke to
+# generate the standalone project.
+define generate_microlite_projects
+$(call generate_project,make,$(MAKE_PROJECT_FILES) $($(1)_MAKE_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(LDFLAGS) $(MICROLITE_LIBS),$(CXXFLAGS) $(GENERATED_PROJECT_INCLUDES), $(CCFLAGS) $(GENERATED_PROJECT_INCLUDES),$(TARGET_TOOLCHAIN_ROOT),$(TARGET_TOOLCHAIN_PREFIX))
+$(call generate_arc_project,make,$(MAKE_PROJECT_FILES) $($(1)_MAKE_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(LDFLAGS) $(GENERATED_PROJECT_LIBS),$(CXXFLAGS) $(GENERATED_PROJECT_INCLUDES), $(CCFLAGS) $(GENERATED_PROJECT_INCLUDES))
+$(call generate_ceva_bx1_project,make,$(MAKE_PROJECT_FILES) $($(1)_MAKE_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(LDFLAGS) $(GENERATED_PROJECT_LIBS),$(CXXFLAGS) $(GENERATED_PROJECT_INCLUDES), $(CCFLAGS) $(GENERATED_PROJECT_INCLUDES))
+$(call generate_ceva_sp500_project,make,$(MAKE_PROJECT_FILES) $($(1)_MAKE_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(LDFLAGS) $(GENERATED_PROJECT_LIBS),$(CXXFLAGS) $(GENERATED_PROJECT_INCLUDES), $(CCFLAGS) $(GENERATED_PROJECT_INCLUDES))
+$(call generate_project,mbed,$(MBED_PROJECT_FILES) $($(1)_MBED_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(MICROLITE_LIBS),$(CXXFLAGS),$(CCFLAGS),$(TARGET_TOOLCHAIN_ROOT),$(TARGET_TOOLCHAIN_PREFIX))
+$(call generate_project,keil,$(KEIL_PROJECT_FILES) $($(1)_KEIL_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(MICROLITE_LIBS),$(CXXFLAGS),$(CCFLAGS),$(TARGET_TOOLCHAIN_ROOT),$(TARGET_TOOLCHAIN_PREFIX))
+ifeq (,$(findstring _benchmark,$(1)))
+ $(call generate_arduino_project,$(ARDUINO_PROJECT_FILES) $($(1)_ARDUINO_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(MICROLITE_LIBS),$(CXXFLAGS),$(CCFLAGS))
+endif
+$(call generate_esp_project,$(ESP_PROJECT_FILES) $($(1)_ESP_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS),$(2),$(3),$(MICROLITE_LIBS),$(CXXFLAGS),$(CCFLAGS),$(PROJECT_INCLUDES))
+endef
+
+# Handles the details of generating a binary target, including specializing
+# for the current platform, and generating project file targets.
+#
+# Note that while the function is called microlite_test, it is used for both
+# test and non-test binaries.
+
+# Files that end with _test are added as test targets (i.e. can be executed with
+# make test_<target>. ALl others can be executed with make run_<target>
+#
+# Arguments are:
+# 1 - Name of target.
+# 2 - C/C++ source files
+# 3 - C/C++ header files
+# 4 - if "exclude", then the non-test target will be excluded from
+# MICROLITE_BUILD_TARGETS. This exception is needed because not all the
+# microlite_test targets (e.g. the examples) are buildable on all platforms.
+# Calling eval on the output will create the targets that you need.
+define microlite_test
+ifeq (,$(findstring _test, $(1)))
+ $(eval $(call generate_project_third_party_parsing))
+endif
+
+$(1)_LOCAL_SRCS := $(2)
+$(1)_LOCAL_SRCS := $$(call specialize,$$($(1)_LOCAL_SRCS))
+ALL_SRCS += $$($(1)_LOCAL_SRCS)
+$(1)_LOCAL_HDRS := $(3)
+$(1)_LOCAL_OBJS := $$(addprefix $$(OBJDIR), \
+$$(patsubst %.cc,%.o,$$(patsubst %.c,%.o,$$($(1)_LOCAL_SRCS))))
+$(1)_BINARY := $$(BINDIR)$(1)
+$$($(1)_BINARY): $$($(1)_LOCAL_OBJS) $$(MICROLITE_LIB_PATH)
+ @mkdir -p $$(dir $$@)
+ $$(CXX) $$(CXXFLAGS) $$(INCLUDES) \
+ -o $$($(1)_BINARY) $$($(1)_LOCAL_OBJS) \
+ $$(MICROLITE_LIB_PATH) $$(LDFLAGS) $$(MICROLITE_LIBS)
+$(1): $$($(1)_BINARY)
+$(1)_bin: $$($(1)_BINARY).bin
+
+ifneq (,$(findstring _test,$(1)))
+ MICROLITE_TEST_TARGETS += test_$(1)
+ MICROLITE_BUILD_TARGETS += $$($(1)_BINARY)
+
+test_$(1): $$($(1)_BINARY)
+ $$(TEST_SCRIPT) $$($(1)_BINARY) $$(TEST_PASS_STRING) $$(TARGET)
+
+else
+ ifeq ($(findstring exclude,$(4)),)
+ MICROLITE_BUILD_TARGETS += $$($(1)_BINARY)
+ endif
+
+run_$(1): $$($(1)_BINARY)
+ $$(TEST_SCRIPT) $$($(1)_BINARY) non_test_binary $$(TARGET)
+endif
+
+$(eval $(call generate_microlite_projects,$(1),$(call specialize,$(2)),$(3)))
+endef
+
+# Adds a dependency for a third-party library that needs to be downloaded from
+# an external source.
+# Arguments are:
+# 1 - URL to download archive file from (can be .zip, .tgz, or .bz).
+# 2 - MD5 sum of archive, to check integrity. Use md5sum tool to generate.
+# 3 - Folder name to unpack library into, inside tf/l/x/m/t/downloads root.
+# 4 - Optional patching action, must match clause in download_and_extract.sh.
+# 5 - Optional patching action parameter
+# These arguments are packed into a single '!' separated string, so no element
+# can contain a '!'.
+define add_third_party_download
+THIRD_PARTY_DOWNLOADS += $(1)!$(2)!tensorflow/lite/micro/tools/make/downloads/$(3)!$(4)!$(5)
+endef
+
+# Unpacks an entry in a list of strings created by add_third_party_download, and
+# defines a dependency rule to download the library. The download_and_extract.sh
+# script is used to handle to downloading and unpacking.
+# 1 - Information about the library, separated by '!'s.
+define create_download_rule
+$(word 3, $(subst !, ,$(1))):
+ $(DOWNLOAD_SCRIPT) $(subst !, ,$(1))
+THIRD_PARTY_TARGETS += $(word 3, $(subst !, ,$(1)))
+endef
+
+# Recursively find all files of given pattern
+# Arguments are:
+# 1 - Starting path
+# 2 - File pattern, e.g: *.h
+recursive_find = $(wildcard $(1)$(2)) $(foreach dir,$(wildcard $(1)*),$(call recursive_find,$(dir)/,$(2)))
+
+
+# Modifies the Makefile to include all third party Srcs so that generate
+# projects will create a Makefile that can be immediatley compiled without
+# modification
+define generate_project_third_party_parsing
+
+ifeq ($$(PARSE_THIRD_PARTY), true)
+# Get generated src includes with update path to third party
+THIRD_PARTY_CC_SRCS += $$(filter $$(MAKEFILE_DIR)/downloads/%, $$(MICROLITE_CC_SRCS))
+MICROLITE_CC_SRCS := $$(filter-out $$(THIRD_PARTY_CC_SRCS), $$(MICROLITE_CC_SRCS))
+THIRD_PARTY_CC_SRCS := $$(sort $$(patsubst $$(MAKEFILE_DIR)/downloads/%, third_party/%, $$(THIRD_PARTY_CC_SRCS)))
+
+# Get generated project includes from the includes with update path to third_party
+GENERATED_PROJECT_INCLUDES += $$(filter -I$$(MAKEFILE_DIR)/downloads/%, $$(INCLUDES))
+GENERATED_PROJECT_INCLUDES := $$(patsubst -I$$(MAKEFILE_DIR)/downloads/%, -Ithird_party/%, $$(GENERATED_PROJECT_INCLUDES))
+GENERATED_PROJECT_INCLUDES += $$(filter -isystem$$(MAKEFILE_DIR)/downloads/%, $$(INCLUDES))
+GENERATED_PROJECT_INCLUDES := $$(sort $$(patsubst -isystem$$(MAKEFILE_DIR)/downloads/%, -isystemthird_party/%, $$(GENERATED_PROJECT_INCLUDES)))
+
+# We dont copy the libraries, we just want to make sure we link to them correctly.
+MICROLITE_LIBS := $$(sort $$(patsubst $$(MAKEFILE_DIR)/downloads/%, $$(TENSORFLOW_ROOT)$$(MAKEFILE_DIR)/downloads/%, $$(MICROLITE_LIBS)))
+LDFLAGS := $$(sort $$(patsubst $$(MAKEFILE_DIR)/downloads/%, $$(TENSORFLOW_ROOT)$$(MAKEFILE_DIR)/downloads/%, $$(LDFLAGS)))
+
+# Copy all third party headers that are mentioned in includes
+THIRD_PARTY_CC_HDRS += $$(filter $$(MAKEFILE_DIR)/downloads/%, $$(MICROLITE_CC_HDRS))
+MICROLITE_CC_HDRS:= $$(sort $$(filter-out $$(THIRD_PARTY_CC_HDRS), $$(MICROLITE_CC_HDRS)))
+THIRD_PARTY_CC_HDRS := $$(sort $$(patsubst $$(MAKEFILE_DIR)/downloads/%, third_party/%, $$(THIRD_PARTY_CC_HDRS)))
+
+# Copy all third party headers that are mentioned in includes
+INCLUDE_HDRS := $$(wildcard $$(addsuffix /*.h,$$(filter $$(MAKEFILE_DIR)/downloads/%, $$(patsubst -I%,%,$$(INCLUDES)))))
+INCLUDE_HDRS += $$(wildcard $$(addsuffix /*.h,$$(filter $$(MAKEFILE_DIR)/downloads/%, $$(patsubst -isystem%,%,$$(INCLUDES)))))
+INCLUDE_HDRS := $$(sort $$(INCLUDE_HDRS))
+THIRD_PARTY_CC_HDRS += $ $$(sort $(patsubst $$(MAKEFILE_DIR)/downloads/%, third_party/%, $$(INCLUDE_HDRS)))
+endif
+
+endef
diff --git a/tensorflow/lite/micro/tools/make/merge_arduino_zips.py b/tensorflow/lite/micro/tools/make/merge_arduino_zips.py
new file mode 100644
index 0000000..503fce2
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/merge_arduino_zips.py
@@ -0,0 +1,48 @@
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Resolves non-system C/C++ includes to their full paths to help Arduino."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import shutil
+import tempfile
+import zipfile
+
+
+def main(unparsed_args):
+ """Merges multiple Arduino zipfiles into a single result."""
+ output_zip_path = unparsed_args[0]
+ input_zip_paths = unparsed_args[1::]
+ working_dir = tempfile.mkdtemp()
+ for input_zip_path in input_zip_paths:
+ with zipfile.ZipFile(input_zip_path, 'r') as input_zip:
+ input_zip.extractall(path=working_dir)
+ output_path_without_zip = output_zip_path.replace('.zip', '')
+ shutil.make_archive(output_path_without_zip, 'zip', working_dir)
+
+
+def parse_args():
+ """Converts the raw arguments into accessible flags."""
+ parser = argparse.ArgumentParser()
+ _, unparsed_args = parser.parse_known_args()
+
+ main(unparsed_args)
+
+
+if __name__ == '__main__':
+ parse_args()
diff --git a/tensorflow/lite/micro/tools/make/merge_arduino_zips_test.sh b/tensorflow/lite/micro/tools/make/merge_arduino_zips_test.sh
new file mode 100755
index 0000000..7fe5663
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/merge_arduino_zips_test.sh
@@ -0,0 +1,70 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Bash unit tests for the TensorFlow Lite Micro project generator.
+
+set -e
+
+INPUT1_DIR=${TEST_TMPDIR}/input1
+mkdir -p ${INPUT1_DIR}
+touch ${INPUT1_DIR}/a.txt
+touch ${INPUT1_DIR}/b.txt
+mkdir ${INPUT1_DIR}/sub1/
+touch ${INPUT1_DIR}/sub1/c.txt
+mkdir ${INPUT1_DIR}/sub2/
+touch ${INPUT1_DIR}/sub2/d.txt
+INPUT1_ZIP=${TEST_TMPDIR}/input1.zip
+pushd ${INPUT1_DIR}
+zip -q -r ${INPUT1_ZIP} *
+popd
+
+INPUT2_DIR=${TEST_TMPDIR}/input2
+mkdir -p ${INPUT2_DIR}
+touch ${INPUT2_DIR}/a.txt
+touch ${INPUT2_DIR}/e.txt
+mkdir ${INPUT2_DIR}/sub1/
+touch ${INPUT2_DIR}/sub1/f.txt
+mkdir ${INPUT2_DIR}/sub3/
+touch ${INPUT2_DIR}/sub3/g.txt
+INPUT2_ZIP=${TEST_TMPDIR}/input2.zip
+pushd ${INPUT2_DIR}
+zip -q -r ${INPUT2_ZIP} *
+popd
+
+OUTPUT_DIR=${TEST_TMPDIR}/output/
+OUTPUT_ZIP=${OUTPUT_DIR}/output.zip
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/merge_arduino_zips \
+ ${OUTPUT_ZIP} ${INPUT1_ZIP} ${INPUT2_ZIP}
+
+if [[ ! -f ${OUTPUT_ZIP} ]]; then
+ echo "${OUTPUT_ZIP} wasn't created."
+fi
+
+pushd ${OUTPUT_DIR}
+unzip -q ${OUTPUT_ZIP}
+popd
+
+for EXPECTED_FILE in a.txt b.txt sub1/c.txt sub2/d.txt e.txt sub1/f.txt sub3/g.txt
+do
+ if [[ ! -f ${OUTPUT_DIR}/${EXPECTED_FILE} ]]; then
+ echo "${OUTPUT_DIR}/${EXPECTED_FILE} wasn't created."
+ exit 1
+ fi
+done
+
+echo
+echo "SUCCESS: merge_arduino_zips test PASSED"
diff --git a/tensorflow/lite/micro/tools/make/pigweed.patch b/tensorflow/lite/micro/tools/make/pigweed.patch
new file mode 100644
index 0000000..89dba14
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/pigweed.patch
@@ -0,0 +1,117 @@
+diff --git a/pw_presubmit/py/pw_presubmit/build.py b/pw_presubmit/py/pw_presubmit/build.py
+index 4a370e33..224ad9c6 100644
+--- a/pw_presubmit/py/pw_presubmit/build.py
++++ b/pw_presubmit/py/pw_presubmit/build.py
+@@ -20,7 +20,6 @@ from pathlib import Path
+ import re
+ from typing import Container, Dict, Iterable, List, Mapping, Set, Tuple
+
+-from pw_package import package_manager
+ from pw_presubmit import call, log_run, plural, PresubmitFailure, tools
+
+ _LOG = logging.getLogger(__name__)
+diff --git a/pw_presubmit/py/pw_presubmit/format_code.py b/pw_presubmit/py/pw_presubmit/format_code.py
+index 19d09546..dae2e813 100755
+--- a/pw_presubmit/py/pw_presubmit/format_code.py
++++ b/pw_presubmit/py/pw_presubmit/format_code.py
+@@ -229,8 +229,7 @@ def print_format_check(errors: Dict[Path, str],
+ except ValueError:
+ return Path(path).resolve()
+
+- message = (f' pw format --fix {path_relative_to_cwd(path)}'
+- for path in errors)
++ message = (f' tensorflow/lite/{__file__} --fix {path}' for path in errors)
+ _LOG.warning('To fix formatting, run:\n\n%s\n', '\n'.join(message))
+
+
+diff --git a/pw_presubmit/py/pw_presubmit/pigweed_presubmit.py b/pw_presubmit/py/pw_presubmit/pigweed_presubmit.py
+index 794967db..061db7ea 100755
+--- a/pw_presubmit/py/pw_presubmit/pigweed_presubmit.py
++++ b/pw_presubmit/py/pw_presubmit/pigweed_presubmit.py
+@@ -220,8 +220,8 @@ def clang_tidy(ctx: PresubmitContext):
+
+
+ # The first line must be regex because of the '20\d\d' date
+-COPYRIGHT_FIRST_LINE = r'Copyright 20\d\d The Pigweed Authors'
+-COPYRIGHT_COMMENTS = r'(#|//| \*|REM|::)'
++COPYRIGHT_FIRST_LINE = r'Copyright 20\d\d The TensorFlow Authors. All Rights Reserved.'
++COPYRIGHT_COMMENTS = r'(#|//|\*|REM|::|/\*)'
+ COPYRIGHT_BLOCK_COMMENTS = (
+ # HTML comments
+ (r'<!--', r'-->'), )
+@@ -232,21 +232,23 @@ COPYRIGHT_FIRST_LINE_EXCEPTIONS = (
+ '@echo off',
+ '# -*-',
+ ':',
++ '# Lint as',
++ '# coding=utf-8'
+ )
+
+ COPYRIGHT_LINES = tuple("""\
+
+-Licensed under the Apache License, Version 2.0 (the "License"); you may not
+-use this file except in compliance with the License. You may obtain a copy of
+-the License at
++Licensed under the Apache License, Version 2.0 (the "License");
++you may not use this file except in compliance with the License.
++You may obtain a copy of the License at
+
+- https://www.apache.org/licenses/LICENSE-2.0
++ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+-distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
+-WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
+-License for the specific language governing permissions and limitations under
+-the License.
++distributed under the License is distributed on an "AS IS" BASIS,
++WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
++See the License for the specific language governing permissions and
++limitations under the License.
+ """.splitlines())
+
+ _EXCLUDE_FROM_COPYRIGHT_NOTICE: Sequence[str] = (
+@@ -344,6 +346,11 @@ def copyright_notice(ctx: PresubmitContext):
+ errors.append(path)
+ continue
+
++ # Special handling for TFLM style of copyright+license in the cc
++ # files.
++ if comment == '/*':
++ comment = ''
++
+ if end_block_comment:
+ expected_lines = COPYRIGHT_LINES + (end_block_comment, )
+ else:
+@@ -354,6 +361,10 @@ def copyright_notice(ctx: PresubmitContext):
+ expected_line = expected + '\n'
+ elif comment:
+ expected_line = (comment + ' ' + expected).rstrip() + '\n'
++ else:
++ # Special handling for TFLM style of copyright+license in
++ # the cc files.
++ expected_line = (expected).rstrip() + '\n'
+
+ if expected_line != actual:
+ _LOG.warning(' bad line: %r', actual)
+@@ -475,6 +486,10 @@ BROKEN = (
+ gn_nanopb_build,
+ )
+
++COPYRIGHT_NOTICE = (
++ copyright_notice,
++)
++
+ QUICK = (
+ commit_message_format,
+ init_cipd,
+@@ -509,7 +524,8 @@ FULL = (
+ build_env_setup,
+ )
+
+-PROGRAMS = Programs(broken=BROKEN, quick=QUICK, full=FULL)
++PROGRAMS = Programs(broken=BROKEN, quick=QUICK, full=FULL,
++ copyright_notice=COPYRIGHT_NOTICE)
+
+
+ def parse_args() -> argparse.Namespace:
diff --git a/tensorflow/lite/micro/tools/make/pigweed_download.sh b/tensorflow/lite/micro/tools/make/pigweed_download.sh
new file mode 100755
index 0000000..9991ee8
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/pigweed_download.sh
@@ -0,0 +1,65 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+# The BUILD files in the downloaded folder result in an error with:
+# bazel build tensorflow/lite/micro/...
+#
+# Parameters:
+# $1 - path to the downloaded flatbuffers code.
+function delete_build_files() {
+ rm -f `find ${1} -name BUILD`
+}
+
+DOWNLOADED_PIGWEED_PATH=${DOWNLOADS_DIR}/pigweed
+
+if [ -d ${DOWNLOADED_PIGWEED_PATH} ]; then
+ echo >&2 "${DOWNLOADED_PIGWEED_PATH} already exists, skipping the download."
+else
+ git clone https://pigweed.googlesource.com/pigweed/pigweed ${DOWNLOADED_PIGWEED_PATH} >&2
+ pushd ${DOWNLOADED_PIGWEED_PATH} > /dev/null
+ git checkout 47268dff45019863e20438ca3746c6c62df6ef09 >&2
+
+ # Patch for TFLM specific changes that are not currently upstreamed.
+ git apply ../../pigweed.patch
+ popd > /dev/null
+
+ delete_build_files ${DOWNLOADED_PIGWEED_PATH}
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/renode_download.sh b/tensorflow/lite/micro/tools/make/renode_download.sh
new file mode 100755
index 0000000..9acacb1
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/renode_download.sh
@@ -0,0 +1,67 @@
+#!/bin/bash
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Called with following arguments:
+# 1 - Path to the downloads folder which is typically
+# tensorflow/lite/micro/tools/make/downloads
+#
+# This script is called from the Makefile and uses the following convention to
+# enable determination of sucess/failure:
+#
+# - If the script is successful, the only output on stdout should be SUCCESS.
+# The makefile checks for this particular string.
+#
+# - Any string on stdout that is not SUCCESS will be shown in the makefile as
+# the cause for the script to have failed.
+#
+# - Any other informational prints should be on stderr.
+
+set -e
+
+SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
+ROOT_DIR=${SCRIPT_DIR}/../../../../..
+cd "${ROOT_DIR}"
+
+source tensorflow/lite/micro/tools/make/bash_helpers.sh
+
+DOWNLOADS_DIR=${1}
+if [ ! -d ${DOWNLOADS_DIR} ]; then
+ echo "The top-level downloads directory: ${DOWNLOADS_DIR} does not exist."
+ exit 1
+fi
+
+DOWNLOADED_RENODE_PATH=${DOWNLOADS_DIR}/renode
+
+if [ -d ${DOWNLOADED_RENODE_PATH} ]; then
+ echo >&2 "${DOWNLOADED_RENODE_PATH} already exists, skipping the download."
+else
+ LINUX_PORTABLE_URL="https://github.com/renode/renode/releases/download/v1.11.0/renode-1.11.0.linux-portable.tar.gz"
+ TEMP_ARCHIVE="/tmp/renode.tar.gz"
+
+ echo >&2 "Downloading from url: ${LINUX_PORTABLE_URL}"
+ wget ${LINUX_PORTABLE_URL} -O ${TEMP_ARCHIVE} >&2
+
+ EXPECTED_MD5="8415361f5caa843f1e31b59c50b2858f"
+ check_md5 ${TEMP_ARCHIVE} ${EXPECTED_MD5}
+
+ mkdir ${DOWNLOADED_RENODE_PATH}
+ tar xzf ${TEMP_ARCHIVE} --strip-components=1 --directory "${DOWNLOADED_RENODE_PATH}" >&2
+ echo >&2 "Unpacked to directory: ${DOWNLOADED_RENODE_PATH}"
+
+ pip3 install -r ${DOWNLOADED_RENODE_PATH}/tests/requirements.txt >&2
+fi
+
+echo "SUCCESS"
diff --git a/tensorflow/lite/micro/tools/make/targets/apollo3evb/.gitignore b/tensorflow/lite/micro/tools/make/targets/apollo3evb/.gitignore
new file mode 100644
index 0000000..cb646e2
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/apollo3evb/.gitignore
@@ -0,0 +1,4 @@
+startup_gcc.c
+am_*.c
+libam*.a
+
diff --git a/tensorflow/lite/micro/tools/make/targets/apollo3evb/apollo3evb.ld b/tensorflow/lite/micro/tools/make/targets/apollo3evb/apollo3evb.ld
new file mode 100644
index 0000000..6ae8f1f
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/apollo3evb/apollo3evb.ld
@@ -0,0 +1,94 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+/******************************************************************************
+ *
+ * apollo3evb.ld - Linker script for applications using startup_gcc.c
+ *
+ *****************************************************************************/
+ENTRY(Reset_Handler)
+
+MEMORY
+{
+ FLASH (rx) : ORIGIN = 0x0000C000, LENGTH = 960K
+ SRAM (rwx) : ORIGIN = 0x10000000, LENGTH = 384K
+}
+
+SECTIONS
+{
+ .text :
+ {
+ . = ALIGN(4);
+ KEEP(*(.isr_vector))
+ KEEP(*(.patch))
+ *(.text)
+ *(.text*)
+
+ /* These are the C++ global constructors. Stick them all here and
+ * then walk through the array in main() calling them all.
+ */
+ _init_array_start = .;
+ KEEP (*(SORT(.init_array*)))
+ _init_array_end = .;
+
+ /* XXX Currently not doing anything for global destructors. */
+
+ *(.rodata)
+ *(.rodata*)
+ . = ALIGN(4);
+ _etext = .;
+ } > FLASH
+
+ /* User stack section initialized by startup code. */
+ .stack (NOLOAD):
+ {
+ . = ALIGN(8);
+ *(.stack)
+ *(.stack*)
+ . = ALIGN(8);
+ } > SRAM
+
+ .data :
+ {
+ . = ALIGN(4);
+ _sdata = .;
+ *(.data)
+ *(.data*)
+ . = ALIGN(4);
+ _edata = .;
+ } > SRAM AT>FLASH
+
+ /* used by startup to initialize data */
+ _init_data = LOADADDR(.data);
+
+ .bss :
+ {
+ . = ALIGN(4);
+ _sbss = .;
+ *(.bss)
+ *(.bss*)
+ *(COMMON)
+ . = ALIGN(4);
+ _ebss = .;
+ } > SRAM
+ /* Add this to satisfy reference to symbol 'end' from libnosys.a(sbrk.o)
+ * to denote the HEAP start.
+ */
+ end = .;
+
+ .ARM.attributes 0 : { *(.ARM.attributes) }
+}
+
+
diff --git a/tensorflow/lite/micro/tools/make/targets/apollo3evb/prep_apollo3_files.sh b/tensorflow/lite/micro/tools/make/targets/apollo3evb/prep_apollo3_files.sh
new file mode 100755
index 0000000..ae764c8
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/apollo3evb/prep_apollo3_files.sh
@@ -0,0 +1,35 @@
+#!/bin/bash
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+AP3_DIR="tensorflow/lite/micro/tools/make/downloads/Apollo3-SDK-2018.08.13"
+if [ ! -d $AP3_DIR ]; then
+ echo "Apollo 3 SDK does not exist"
+ echo "Either the SDK has not been downloaded, or this script is not being run from the root of the repository"
+else
+ DEST_DIR="tensorflow/lite/micro/tools/make/targets/apollo3evb"
+ cp "$AP3_DIR/boards/apollo3_evb/examples/hello_world/gcc/startup_gcc.c" "$DEST_DIR"
+ cp "$AP3_DIR/boards/apollo3_evb/examples/hello_world/gcc/hello_world.ld" "$DEST_DIR/apollo3evb.ld"
+ sed -i -e '131s/1024/1024\*20/g' "$DEST_DIR/startup_gcc.c"
+ sed -i -e 's/main/_main/g' "$DEST_DIR/startup_gcc.c"
+ sed -i -e '3s/hello_world.ld/apollo3evb.ld/g' "$DEST_DIR/apollo3evb.ld"
+ sed -i -e '3s/startup_gnu/startup_gcc/g' "$DEST_DIR/apollo3evb.ld"
+ sed -i -e '6s/am_reset_isr/Reset_Handler/g' "$DEST_DIR/apollo3evb.ld"
+ sed -i -e '22s/\*(.text\*)/\*(.text\*)\n\n\t\/\* These are the C++ global constructors. Stick them all here and\n\t \* then walk through the array in main() calling them all.\n\t \*\/\n\t_init_array_start = .;\n\tKEEP (\*(SORT(.init_array\*)))\n\t_init_array_end = .;\n\n\t\/\* XXX Currently not doing anything for global destructors. \*\/\n/g' "$DEST_DIR/apollo3evb.ld"
+ sed -i -e "70s/} > SRAM/} > SRAM\n \/\* Add this to satisfy reference to symbol 'end' from libnosys.a(sbrk.o)\n \* to denote the HEAP start.\n \*\/\n end = .;/g" "$DEST_DIR/apollo3evb.ld"
+ echo "Finished preparing Apollo3 files"
+
+
+fi
diff --git a/tensorflow/lite/micro/tools/make/targets/apollo3evb_makefile.inc b/tensorflow/lite/micro/tools/make/targets/apollo3evb_makefile.inc
new file mode 100644
index 0000000..d0198f9
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/apollo3evb_makefile.inc
@@ -0,0 +1,143 @@
+export PATH := $(MAKEFILE_DIR)/downloads/gcc_embedded/bin/:$(PATH)
+TARGET_ARCH := cortex-m4
+TARGET_TOOLCHAIN_PREFIX := arm-none-eabi-
+TARGET_TOOLCHAIN_ROOT := $(TENSORFLOW_ROOT)$(MAKEFILE_DIR)/downloads/gcc_embedded/bin/
+# Download the Ambiq Apollo3 SDK and set this variable to find the header
+# files:
+APOLLO3_SDK := $(MAKEFILE_DIR)/downloads/$(AM_SDK_DEST)
+# Need a pointer to the GNU ARM toolchain for crtbegin.o for the fp functions
+# with the hard interfaces.
+GCC_ARM := $(MAKEFILE_DIR)/downloads/gcc_embedded/
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/arm_gcc_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the GCC download: $(DOWNLOAD_RESULT))
+endif
+
+$(eval $(call add_third_party_download,$(AM_SDK_URL),$(AM_SDK_MD5),$(AM_SDK_DEST),patch_am_sdk))
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/cmsis_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the CMSIS download: $(DOWNLOAD_RESULT))
+endif
+
+ifeq ($(findstring sparkfun,$(TARGET)), sparkfun)
+ $(eval $(call add_third_party_download,$(SF_BSPS_URL),$(SF_BSPS_MD5),$(AM_SDK_DEST)/$(SF_BSPS_DEST),))
+ # Make sure that we download the full Ambiq SDK before the SparkFun BSPs.
+$(MAKEFILE_DIR)/downloads/$(AM_SDK_DEST)/$(SF_BSPS_DEST): $(MAKEFILE_DIR)/downloads/$(AM_SDK_DEST)
+endif
+
+PLATFORM_FLAGS = \
+ -DPART_apollo3 \
+ -DAM_PACKAGE_BGA \
+ -DAM_PART_APOLLO3 \
+ -DGEMMLOWP_ALLOW_SLOW_SCALAR_FALLBACK \
+ -DTF_LITE_STATIC_MEMORY \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -D __FPU_PRESENT=1 \
+ -DARM_MATH_CM4 \
+ -fno-rtti \
+ -fmessage-length=0 \
+ -fno-exceptions \
+ -fno-unwind-tables \
+ -ffunction-sections \
+ -fdata-sections \
+ -funsigned-char \
+ -MMD \
+ -mcpu=cortex-m4 \
+ -mthumb \
+ -mfpu=fpv4-sp-d16 \
+ -mfloat-abi=hard \
+ -std=gnu++11 \
+ -Wvla \
+ -Wall \
+ -Wextra \
+ -Wno-missing-field-initializers \
+ -Wno-strict-aliasing \
+ -Wno-type-limits \
+ -Wno-unused-function \
+ -Wno-unused-parameter \
+ -fno-delete-null-pointer-checks \
+ -fno-threadsafe-statics \
+ -fomit-frame-pointer \
+ -fno-use-cxa-atexit \
+ -nostdlib \
+ -ggdb \
+ -O3
+CXXFLAGS += $(PLATFORM_FLAGS)
+CCFLAGS += $(PLATFORM_FLAGS)
+LDFLAGS += \
+ -mthumb -mcpu=cortex-m4 -mfpu=fpv4-sp-d16 -mfloat-abi=hard \
+ -nostartfiles -static \
+ -Wl,--gc-sections -Wl,--entry,Reset_Handler \
+ -Wl,--start-group -lm -lc -lgcc -Wl,--end-group \
+ -fno-exceptions \
+ -nostdlib --specs=nano.specs -t -lstdc++ -lc -lnosys -lm \
+ -Wl,-T,$(TENSORFLOW_ROOT)$(APOLLO3_SDK)/boards/apollo3_evb/examples/hello_world/gcc_patched/apollo3evb.ld \
+ -Wl,-Map=$(TENSORFLOW_ROOT)$(MAKEFILE_DIR)/gen/$(TARGET).map,--cref
+BUILD_TYPE := micro
+ifeq ($(TARGET), apollo3evb)
+ BOARD_BSP_PATH := $(APOLLO3_SDK)/boards/apollo3_evb/bsp
+endif
+ifeq ($(findstring sparkfun,$(TARGET)), sparkfun)
+ BOARD_BSP_PATH := $(APOLLO3_SDK)/$(SF_BSPS_DEST)/$(subst sparkfun_,,$(TARGET))/bsp
+ INCLUDES+= \
+ -I$(APOLLO3_SDK)/$(SF_BSPS_DEST)/common/third_party/hm01b0
+endif
+MICROLITE_LIBS := \
+ $(BOARD_BSP_PATH)/gcc/bin/libam_bsp.a \
+ $(APOLLO3_SDK)/mcu/apollo3/hal/gcc/bin/libam_hal.a \
+ $(GCC_ARM)/lib/gcc/arm-none-eabi/10.2.1/thumb/v7e-m+fp/hard/crtbegin.o \
+ -lm
+INCLUDES += \
+ -isystem$(MAKEFILE_DIR)/downloads/cmsis/CMSIS/Core/Include/ \
+ -isystem$(MAKEFILE_DIR)/downloads/cmsis/CMSIS/DSP/Include/ \
+ -I$(GCC_ARM)/arm-none-eabi/ \
+ -I$(APOLLO3_SDK)/mcu/apollo3/ \
+ -I$(APOLLO3_SDK)/mcu/apollo3/regs \
+ -I$(APOLLO3_SDK)/mcu/apollo3/hal \
+ -I$(APOLLO3_SDK)/CMSIS/AmbiqMicro/Include/ \
+ -I$(BOARD_BSP_PATH) \
+ -I$(APOLLO3_SDK)/devices/ \
+ -I$(APOLLO3_SDK)/utils/ \
+
+
+# The startup_gcc.c file is an altered version of the examples/hello_world/gcc/startup_gcc.c
+# file from Ambiq:
+# - Increase the stack size from 1k to 20k
+# - Change the application entry call from main() to _main()
+# The am_*.c files should be copied from the Ambiq Apollo3 SDK
+# _main.c contains application and target specific initialization, like
+# setting clock speed, default uart setups, etc. and an implementation
+# of the DebugLog interfaces.
+MICROLITE_CC_SRCS += \
+ $(APOLLO3_SDK)/boards/apollo3_evb/examples/hello_world/gcc_patched/startup_gcc.c \
+ $(APOLLO3_SDK)/utils/am_util_delay.c \
+ $(APOLLO3_SDK)/utils/am_util_faultisr.c \
+ $(APOLLO3_SDK)/utils/am_util_id.c \
+ $(APOLLO3_SDK)/utils/am_util_stdio.c \
+ $(APOLLO3_SDK)/devices/am_devices_led.c
+
+CMSIS_SRC_DIR := $(MAKEFILE_DIR)/downloads/cmsis/CMSIS/DSP/Source
+THIRD_PARTY_CC_SRCS := \
+$(CMSIS_SRC_DIR)/BasicMathFunctions/arm_dot_prod_q15.c \
+$(CMSIS_SRC_DIR)/BasicMathFunctions/arm_mult_q15.c \
+$(CMSIS_SRC_DIR)/TransformFunctions/arm_rfft_init_q15.c \
+$(CMSIS_SRC_DIR)/TransformFunctions/arm_rfft_q15.c \
+$(CMSIS_SRC_DIR)/TransformFunctions/arm_bitreversal2.c \
+$(CMSIS_SRC_DIR)/TransformFunctions/arm_cfft_q15.c \
+$(CMSIS_SRC_DIR)/TransformFunctions/arm_cfft_radix4_q15.c \
+$(CMSIS_SRC_DIR)/CommonTables/arm_const_structs.c \
+$(CMSIS_SRC_DIR)/CommonTables/arm_common_tables.c \
+$(CMSIS_SRC_DIR)/StatisticsFunctions/arm_mean_q15.c \
+$(CMSIS_SRC_DIR)/StatisticsFunctions/arm_max_q7.c
+
+MICRO_SPEECH_TEST_SRCS += \
+ $(AP3_MICRO_DIR)/_main.c
+
+TEST_SCRIPT := tensorflow/lite/micro/testing/test_apollo3evb_binary.sh
+# These are tests that don't currently work on the Apollo3 board.
+EXCLUDED_TESTS := \
+ tensorflow/lite/micro/micro_interpreter_test.cc \
+ tensorflow/lite/micro/simple_tensor_allocator_test.cc
+MICROLITE_TEST_SRCS := $(filter-out $(EXCLUDED_TESTS), $(MICROLITE_TEST_SRCS))
diff --git a/tensorflow/lite/micro/tools/make/targets/arc/README.md b/tensorflow/lite/micro/tools/make/targets/arc/README.md
new file mode 100644
index 0000000..420f06e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/arc/README.md
@@ -0,0 +1,339 @@
+# Building TensorFlow Lite for Microcontrollers for Synopsys DesignWare ARC EM/HS Processors
+
+## Maintainers
+
+* [dzakhar](https://github.com/dzakhar)
+* [JaccovG](https://github.com/JaccovG)
+
+## Introduction
+
+This document contains the general information on building and running
+TensorFlow Lite Micro for targets based on the Synopsys ARC EM/HS Processors.
+
+## Table of Contents
+
+- [Install the Synopsys DesignWare ARC MetaWare Development Toolkit](#install-the-synopsys-designware-arc-metaWare-development-toolkit)
+- [ARC EM Software Development Platform (ARC EM SDP)](#ARC-EM-Software-Development-Platform-ARC-EM-SDP)
+- [Custom ARC EM or HS Platform](#Custom-ARC-EMHS-Platform)
+
+## Install the Synopsys DesignWare ARC MetaWare Development Toolkit
+
+The Synopsys DesignWare ARC MetaWare Development Toolkit (MWDT) is required to
+build and run Tensorflow Lite Micro applications for all ARC EM/HS targets.
+
+To license MWDT, please see further details
+[here](https://www.synopsys.com/dw/ipdir.php?ds=sw_metaware)
+
+To request an evaluation version of MWDT, please use the
+[Synopsys Eval Portal](https://eval.synopsys.com/) and follow the link for the
+MetaWare Development Toolkit (Important: Do not confuse this with MetaWare EV
+Development Toolkit or MetaWare Lite options also available on this page)
+
+Run the downloaded installer and follow the instructions to set up the toolchain
+on your platform.
+
+TensorFlow Lite for Microcontrollers builds are divided into two phases:
+Application Project Generation and Application Project Building/Running. The
+former phase requires \*nix environment while the latter does not.
+
+For basic project generation targeting
+[ARC EM Software Development Platform](#ARC-EM-Software-Development-Platform-ARC-EM-SDP),
+MetaWare is NOT required for the Project Generation Phase. However, it is
+required in case the following: - For project generation for custom (not EM SDP)
+targets - To build microlib target library with all required TFLM objects for
+external use
+
+Please consider the above when choosing whether to install Windows or Linux or
+both versions of MWDT
+
+## ARC EM Software Development Platform (ARC EM SDP)
+
+This section describes how to deploy on an
+[ARC EM SDP board](https://www.synopsys.com/dw/ipdir.php?ds=arc-em-software-development-platform)
+
+### Initial Setup
+
+To use the EM SDP, you need the following hardware and software:
+
+#### ARC EM SDP
+
+More information on the platform, including ordering information, can be found
+[here](https://www.synopsys.com/dw/ipdir.php?ds=arc-em-software-development-platform).
+
+#### MetaWare Development Toolkit
+
+See
+[Install the Synopsys DesignWare ARC MetaWare Development Toolkit](#install-the-synopsys-designware-arc-metaWare-development-toolkit)
+section for instructions on toolchain installation.
+
+#### Digilent Adept 2 System Software Package
+
+If you wish to use the MetaWare Debugger to debug your code, you need to also
+install the Digilent Adept 2 software, which includes the necessary drivers for
+connecting to the targets. This is available from official
+[Digilent site](https://reference.digilentinc.com/reference/software/adept/start?redirect=1#software_downloads).
+You should install the “System” component, and Runtime. Utilities and SDK are
+NOT required.
+
+Digilent installation is NOT required if you plan to deploy to EM SDP via the SD
+card instead of using the debugger.
+
+#### Make Tool
+
+A `'make'` tool is required for both phases of deploying Tensorflow Lite Micro
+applications on ARC EM SDP: 1. Application project generation 2. Working with
+generated application (build and run)
+
+For the first phase you need an environment and make tool compatible with
+Tensorflow Lite for Micro build system. At the moment of this writing, this
+requires make >=3.82 and a *nix-like environment which supports shell and native
+commands for file manipulations. MWDT toolkit is not required for this phase.
+
+For the second phase, requirements are less strict. The gmake version delivered
+with MetaWare Development Toolkit is sufficient. There are no shell and *nix
+command dependencies, so Windows can be used
+
+#### Serial Terminal Emulation Application
+
+The Debug UART port of the EM SDP is used to print application output. The USB
+connection provides both the debug channel and RS232 transport. You can use any
+terminal emulation program (like [PuTTY](https://www.putty.org/)) to view UART
+output from the EM SDP.
+
+#### microSD Card
+
+If you want to self-boot your application (start it independently from a
+debugger connection), you also need a microSD card with a minimum size of 512 MB
+and a way to write to the card from your development host. Note that the card
+must be formatted as FAT32 with default cluster size (but less than 32 Kbytes)
+
+### Connect the Board
+
+1. Make sure Boot switches of the board (S3) are configured in the next way:
+
+Switch # | Switch position
+:------: | :-------------:
+1 | Low (0)
+2 | Low (0)
+3 | High (1)
+4 | Low (0)
+
+1. Connect the power supply included in the product package to the ARC EM SDP.
+2. Connect the USB cable to connector J10 on the ARC EM SDP (near the RST and
+ CFG buttons) and to an available USB port on your development host.
+3. Determine the COM port assigned to the USB Serial Port (on Windows, using
+ Device Manager is an easy way to do this)
+4. Execute the serial terminal application you installed in the previous step
+ and open the serial connection with the early defined COM port (speed 115200
+ baud; 8 bits; 1 stop bit; no parity).
+5. Push the CFG button on the board. After a few seconds you should see the
+ boot log in the terminal which begins as follows:
+
+```
+U-Boot <Versioning info>
+
+CPU: ARC EM11D v5.0 at 40 MHz
+Subsys:ARC Data Fusion IP Subsystem
+Model: snps,emsdp
+Board: ARC EM Software Development Platform v1.0
+…
+```
+
+### Generate Application Project for ARC EM SDP
+
+Before building an example or test application, you need to generate a TFLM
+project for this application from TensorFlow sources and external dependencies.
+To generate it for ARC EM SDP board you need to set `TARGET=arc_emsdp` on the
+make command line. For instance, to build the Person Detect test application,
+use a shell to execute the following command from the root directory of the
+TensorFlow repo:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile generate_person_detection_test_int8_make_project TARGET=arc_emsdp OPTIMIZED_KERNEL_DIR=arc_mli
+```
+
+The application project will be generated into
+*tensorflow/lite/micro/tools/make/gen/arc_emsdp_arc/prj/person_detection_test_int8/make*
+
+Info on generating and building example applications for EM SDP
+(*tensorflow/lite/micro/examples*) can be found in the appropriate readme file
+placed in the same directory with the examples. In general, it’s the same
+process which described in this Readme.
+
+The
+[embARC MLI Library](https://github.com/foss-for-synopsys-dwc-arc-processors/embarc_mli)
+is used by default to speed up execution of some kernels for asymmetrically
+quantized layers. Kernels which use MLI-based implementations are kept in the
+*tensorflow/lite/micro/kernels/arc_mli* folder. For applications which may not
+benefit from MLI library, the project can be generated without these
+implementations by adding `ARC_TAGS=no_arc_mli` in the command line. This can
+reduce code size when the optimized kernels are not required.
+
+For more options on embARC MLI usage see
+[kernels/arc_mli/README.md](/tensorflow/lite/micro/kernels/arc_mli/README.md).
+
+### Build the Application
+
+You may need to adjust the following commands in order to use the appropriate
+make tool available in your environment (ie: `make` or `gmake`)
+
+1. Open command shell and change the working directory to the location which
+ contains the generated project, as described in the previous section
+
+2. Clean previous build artifacts (optional)
+
+ make clean
+
+3. Build application
+
+ make app
+
+### Run the Application on the Board Using MetaWare Debugger
+
+In case you do not have access to the MetaWare Debugger or have chosen not to
+install the Digilent drivers, you can skip to the next section.
+
+To run the application from the console, use the following command:
+
+```
+ make run
+```
+
+If application runs in an infinite loop, type `Ctrl+C` several times to exit the
+debugger.
+
+To run the application in the GUI debugger, use the following command:
+
+```
+ make debug
+```
+
+In both cases you will see the application output in the serial terminal.
+
+### Run the Application on the Board from the microSD Card
+
+1. Use the following command in the same command shell you used for building
+ the application, as described in the previous step
+
+```
+ make flash
+```
+
+1. Copy the content of the created *./bin* folder into the root of microSD
+ card. Note that the card must be formatted as FAT32 with default cluster
+ size (but less than 32 Kbytes)
+
+2. Plug in the microSD card into the J11 connector.
+
+3. Push the RST button. If a red LED is lit beside RST button, push the CFG
+ button.
+
+4. Using serial terminal, create uboot environment file to automatically run
+ the application on start-up. Type or copy next sequence of commands into
+ serial terminal one-by-another:
+
+```
+ setenv loadaddr 0x10800000
+ setenv bootfile app.elf
+ setenv bootdelay 1
+ setenv bootcmd fatload mmc 0 \$\{loadaddr\} \$\{bootfile\} \&\& bootelf
+ saveenv
+```
+
+1. Reset the board (see step 4 above)
+
+You will see the application output in the serial terminal.
+
+## Custom ARC EM/HS Platform
+
+This section describes how to deploy on a Custom ARC EM/HS platform defined only
+by a TCF (Tool Configuration File, created at CPU configuration time) and
+optional LCF (Linker Command File). In this case, the real hardware is unknown,
+and applications can be run only in the nSIM simulator included with the
+MetaWare toolkit
+
+### Initial Setup
+
+To with custom ARC EM/HS platform, you need the following : * Synopsys MetaWare
+Development Toolkit version 2019.12 or higher * Make tool (make or gmake)
+
+See
+[Install the Synopsys DesignWare ARC MetaWare Development Toolkit](#install-the-synopsys-designware-arc-metaWare-development-toolkit)
+section for instructions on toolchain installation. See
+[MetaWare Development Toolkit](#MetaWare-Development-Toolkit) and
+[Make Tool](#Make-Tool) sections for instructions on toolchain installation and
+comments about make versions.
+
+### Generate Application Project
+
+Before building the application itself, you need to generate the project for
+this application from TensorFlow sources and external dependencies. To generate
+it for a custom TCF you need to set the following variables in the make command
+line: * TARGET=arc_custom * TCF_FILE=<path to TCF file> * (optional)
+LCF_FILE=<path to LCF file>
+
+If you don’t supply an external LCF, the one embedded in the TCF will be used
+instead
+
+For instance, to build **Person Detection** test application, use the following
+command from the root directory of the TensorFlow repo:
+
+```
+make -f tensorflow/lite/micro/tools/make/Makefile generate_person_detection_test_int8_make_project TARGET=arc_custom OPTIMIZED_KERNEL_DIR=arc_mli TCF_FILE=<path_to_tcf_file> LCF_FILE=<path_to_lcf_file>
+```
+
+The application project will be generated into
+*tensorflow/lite/micro/tools/make/gen/<tcf_file_basename>_arc/prj/person_detection_test_int8/make*
+
+The
+[embARC MLI Library](https://github.com/foss-for-synopsys-dwc-arc-processors/embarc_mli)
+is used by default to speed up execution of some kernels for asymmetrically
+quantized layers. Kernels which use MLI-based implementations are kept in the
+*tensorflow/lite/micro/kernels/arc_mli* folder. For applications which may not
+benefit from MLI library, the project can be generated without these
+implementations by adding `ARC_TAGS=no_arc_mli` in the command line. This can
+reduce code size when the optimized kernels are not required.
+
+For more options on embARC MLI usage see
+[kernels/arc_mli/README.md](/tensorflow/lite/micro/kernels/arc_mli/README.md).
+
+### Build the Application
+
+You may need to adjust the following commands in order to use the appropriate
+make tool available in your environment (ie: `make` or `gmake`)
+
+1. Open command shell and change the working directory to the location which
+ contains the generated project, as described in the previous section
+
+2. Clean previous build artifacts (optional)
+
+ make clean
+
+3. Build application
+
+ make app
+
+### Run the Application with MetaWare Debugger on the nSim Simulator.
+
+To run application from the console, use the following command:
+
+```
+ make run
+```
+
+If application runs in an infinite loop, type `Ctrl+C` several times to exit the
+debugger.
+
+To run the application in the GUI debugger, use the following command:
+
+```
+ make debug
+```
+
+You will see the application output in the same console where you ran it.
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository,
+and third-party dependencies are covered by their respective licenses, in the
+third_party folder of this package.
diff --git a/tensorflow/lite/micro/tools/make/targets/arc/arc_common.inc b/tensorflow/lite/micro/tools/make/targets/arc/arc_common.inc
new file mode 100644
index 0000000..51ae86e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/arc/arc_common.inc
@@ -0,0 +1,141 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Common Settings for ARC platform and its projects.
+# Might be reused across different targets
+
+ifeq ($(TARGET_ARCH), arc)
+
+ DLR := $$$$
+
+ # List of pairs <dst>!<src>. Each of pairs declares destination file in generated project tree,
+ # and source file in user environment. Destination and source are separated by '!' symbol
+ # likewise to "add_third_party_download" define in helper_functions.inc
+ ARC_TARGET_COPY_FILES ?=
+
+ # For the following variables see arc_app_makefile.tpl for usage
+
+ # Additional text into application settings section of arc makefile project
+ ARC_EXTRA_APP_SETTINGS ?=
+
+ # Additional text into application general rules of arc makefile project
+ ARC_EXTRA_APP_RULES ?=
+
+ # additional arguments for RM command of "clean" target rule ("make clean" command)
+ ARC_EXTRA_RM_TARGETS ?=
+
+ # Dependencies of "flash" target rule ("make flash" command)
+ ARC_BIN_DEPEND ?=
+
+ # Commands in "flash" target rule ("make flash" command)
+ ARC_BIN_RULE ?= \t$(DLR)\(error Flash rule isnt defined for this ARC target\)
+
+ # Command to run app on "make run" command of generated project
+ ARC_APP_RUN_CMD ?=
+
+ # Command to run app on "make debug" command of generated project
+ ARC_APP_DEBUG_CMD ?=
+
+ # Additional text into application execution rules of arc makefile project
+ ARC_EXTRA_EXECUTE_RULES ?=
+
+# We overwrite project generator to exclude everything not relevant to ARC platform.
+# ARC targets cannot work with non-ARC development tools.
+# Basic make project is updated to be applicable for general ARC platform
+define generate_microlite_projects
+$(call generate_project,make,$(MAKE_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(LDFLAGS) $(MICROLITE_LIBS),$(CXXFLAGS) $(GENERATED_PROJECT_INCLUDES), $(CCFLAGS) $(GENERATED_PROJECT_INCLUDES),$(TARGET_TOOLCHAIN_ROOT),$(TARGET_TOOLCHAIN_PREFIX))
+$(call generate_arc_project,make,$(MAKE_PROJECT_FILES),$(1),$(MICROLITE_CC_SRCS) $(THIRD_PARTY_CC_SRCS) $(2),$(MICROLITE_CC_HDRS) $(THIRD_PARTY_CC_HDRS) $(MICROLITE_TEST_HDRS) $(3),$(LDFLAGS) $(GENERATED_PROJECT_LIBS),$(CXXFLAGS) $(GENERATED_PROJECT_INCLUDES), $(CCFLAGS) $(GENERATED_PROJECT_INCLUDES))
+endef
+
+# Copy rule generator to do file copies with changing paths in generated project
+# Arguments are:
+# 1 - Path to file in generated project (destination).
+# 2 - Path to files in the source repo (source).
+# Used in helper_functions.inc for arc projects to copy files
+define path_changing_copy_file
+$(1) : $(2) third_party_downloads
+ @mkdir -p $$(dir $$@)
+ @cp $$< $$@
+endef
+
+# These are microcontroller-specific rules for converting the ELF output
+# of the linker into a binary image that can be loaded directly.
+# Not applicable for ARC, leaving it empty.
+$(BINDIR)%.bin:
+
+
+ifeq ($(ARC_TOOLCHAIN), mwdt)
+ CC_TOOL := ccac
+ AR_TOOL := arac
+ CXX_TOOL := ccac
+ LD_TOOL := ccac
+
+ ARC_APP_RUN_CMD = mdb -run -jit -tcf=$(TCF_FILE_NAME) $(DLR)\(DBG_ARGS\)
+ ARC_APP_DEBUG_CMD = mdb -OK -jit -tcf=$(TCF_FILE_NAME) $(DLR)\(DBG_ARGS\)
+
+ # The variable TCF_FILE stores path to Tool Configuration File (*.tcf).
+ # This file is used by MWDT toolchain to properly compile/run code
+ TCF_FILE ?=
+
+ LCF_FILE ?=
+
+ BUILD_ARC_MLI ?= true
+
+# The variable TCF_FILE_NAME stores the TCF file name (including .tcf extension),
+# this variable is used later to add the option to the linker/compiler flags.
+# This condition also handles the case when the user/makefile specifies
+# the configuration bundled with MWDT (usually without .tcf extension) and that doesn't require copying.
+ifneq (,$(findstring .tcf,$(TCF_FILE)))
+ TCF_FILE_NAME = $(notdir $(TCF_FILE))
+ ARC_TARGET_COPY_FILES += $(notdir $(TCF_FILE))!$(TCF_FILE)
+ MAKE_PROJECT_FILES += $(TCF_FILE_NAME)
+else
+ TCF_FILE_NAME = $(TCF_FILE)
+endif
+
+ PLATFORM_FLAGS = -tcf=$(TCF_FILE_NAME) -tcf_core_config
+
+ PLATFORM_FLAGS += -Hnocopyr -Hpurge -Hdense_prologue -Hon=Long_enums -fslp-vectorize-aggressive -ffunction-sections -fdata-sections
+
+ # Use compact CRT. It requires pre-defined heap size
+ PLATFORM_FLAGS += -Hcl -Hcrt_fast_memcpy -Hcrt_fast_memset
+
+ PLATFORM_LDFLAGS = -tcf=$(TCF_FILE_NAME)
+
+ PLATFORM_LDFLAGS += -Hnocopyr -m -Hldopt=-Coutput=memory.map -Hheap=24K
+
+ifneq ($(LCF_FILE), )
+ PLATFORM_LDFLAGS += $(notdir $(LCF_FILE))
+ ARC_TARGET_COPY_FILES += $(notdir $(LCF_FILE))!$(LCF_FILE)
+ MAKE_PROJECT_FILES += $(notdir $(LCF_FILE))
+endif
+
+ CXXFLAGS := $(filter-out -std=c++11,$(CXXFLAGS))
+ CCFLAGS := $(filter-out -std=c11,$(CCFLAGS))
+
+ ldflags_to_remove = -Wl,--fatal-warnings -Wl,--gc-sections
+ LDFLAGS := $(filter-out $(ldflags_to_remove),$(LDFLAGS))
+
+ MICROLITE_LIBS := $(filter-out -lm,$(MICROLITE_LIBS))
+
+ CXXFLAGS += $(PLATFORM_FLAGS)
+ CCFLAGS += $(PLATFORM_FLAGS)
+ LDFLAGS += $(PLATFORM_LDFLAGS)
+
+endif # ARC_TOOLCHAIN
+
+else
+ $(error "Only ARC target architecture supported (TARGET_ARCH=arc)")
+
+endif # TARGET_ARCH
diff --git a/tensorflow/lite/micro/tools/make/targets/arc/emsdp/emsdp.lcf b/tensorflow/lite/micro/tools/make/targets/arc/emsdp/emsdp.lcf
new file mode 100644
index 0000000..0655a4a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/arc/emsdp/emsdp.lcf
@@ -0,0 +1,78 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Common EMSDP LCF File for applications
+#
+# external SRAM memory is used for code, because some TFLM applications includes the whole
+# set of supported kernels which doesn't fit to ICCM0.
+# It could slow performance a bit. Smaller applications can use ICCM0 instead.
+#
+# External PSRAM is used for potentially big sections. In particular:
+# - rodata_in data which typically includes protobuf with model.
+# - other .data which typically includes tensor arena.
+#
+# stack and heap are kept in DCCM which is the closest memory to the core
+
+# CCMWRAP memory regions indicate unusable portions of the address space
+# due to CCM memory wrapping into upper addresses beyond its size
+
+MEMORY {
+ PSRAM : ORIGIN = 0x10000400, LENGTH = (0x01000000 >> 1) - 0x400
+ SRAM : ORIGIN = 0x20000000, LENGTH = 0x00040000
+ IVT : ORIGIN = 0x60000000, LENGTH = 0x400
+ ICCM0 : ORIGIN = 0x60000400, LENGTH = (0x00020000 - 0x400)
+# CCMWRAP0: ORIGIN = 0x60020000, LENGTH = 0x0ffe0000
+ DCCM : ORIGIN = 0x80000000, LENGTH = 0x00020000
+# CCMWRAP1: ORIGIN = 0x80020000, LENGTH = 0x0ffe0000
+ XCCM : ORIGIN = 0x90000000, LENGTH = 0x00004000
+# CCMWRAP2: ORIGIN = 0x90004000, LENGTH = 0x0fffc000
+ YCCM : ORIGIN = 0xa0000000, LENGTH = 0x00004000
+# CCMWRAP3: ORIGIN = 0xa0004000, LENGTH = 0x0fffc000
+ }
+
+SECTIONS {
+
+ GROUP BLOCK(4) : {
+ .vectors (TEXT) SIZE(DEFINED _IVTSIZE?_IVTSIZE:756): {} = FILL(0xa5a5a5a5,4)
+ } > IVT
+
+ GROUP BLOCK(4): {
+ .text? : { *('.text$crt*') }
+ * (TEXT): {}
+ * (LIT): {}
+ * (DATA): {}
+ * (BSS): {}
+ } > PSRAM
+
+ GROUP BLOCK(4): {
+ .Zdata? : {}
+ .stack ALIGN(4) SIZE(DEFINED _STACKSIZE?_STACKSIZE:32K): {}
+ .heap? ALIGN(4) SIZE(DEFINED _HEAPSIZE?_HEAPSIZE:24K): {}
+ } > DCCM
+
+ GROUP BLOCK(4): {
+ .Xdata? : {}
+ } > XCCM
+
+ GROUP BLOCK(4): {
+ .Ydata? : {}
+ } > YCCM
+
+ GROUP BLOCK(4): {
+ .debug_log? : {}
+ } > SRAM
+}
+
+
diff --git a/tensorflow/lite/micro/tools/make/targets/arc/emsdp/emsdp_v2.lcf b/tensorflow/lite/micro/tools/make/targets/arc/emsdp/emsdp_v2.lcf
new file mode 100644
index 0000000..a15bce1
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/arc/emsdp/emsdp_v2.lcf
@@ -0,0 +1,78 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+#
+# Difference with common EMSDP LCF file (to reduce data access time):
+# - move data from external PSRAM to DCCM
+# - move text from SRAM to ICCM
+#
+# CCMWRAP memory regions indicate unusable portions of the address space
+# due to CCM memory wrapping into upper addresses beyond its size
+
+MEMORY {
+ PSRAM : ORIGIN = 0x10000400, LENGTH = (0x01000000 >> 1) - 0x400
+ SRAM : ORIGIN = 0x20000000, LENGTH = 0x00040000
+ IVT : ORIGIN = 0x60000000, LENGTH = 0x400
+ ICCM0 : ORIGIN = 0x60000400, LENGTH = (0x00020000 - 0x400)
+# CCMWRAP0: ORIGIN = 0x60020000, LENGTH = 0x0ffe0000
+ DCCM : ORIGIN = 0x80000000, LENGTH = 0x00020000
+# CCMWRAP1: ORIGIN = 0x80020000, LENGTH = 0x0ffe0000
+ XCCM : ORIGIN = 0x90000000, LENGTH = 0x00004000
+# CCMWRAP2: ORIGIN = 0x90004000, LENGTH = 0x0fffc000
+ YCCM : ORIGIN = 0xa0000000, LENGTH = 0x00004000
+# CCMWRAP3: ORIGIN = 0xa0004000, LENGTH = 0x0fffc000
+ }
+
+SECTIONS {
+
+ GROUP BLOCK(4) : {
+ .vectors (TEXT) SIZE(DEFINED _IVTSIZE?_IVTSIZE:756): {} = FILL(0xa5a5a5a5,4)
+ } > IVT
+
+ GROUP BLOCK(4): {
+ .text? : { *('.text$crt*') }
+ * (TEXT): {}
+ * (LIT): {}
+ } > ICCM0
+
+ GROUP BLOCK(4): {
+ .rodata_in_data? : {}
+ } > PSRAM
+
+ GROUP BLOCK(4): {
+ .debug_log? : {}
+ } > SRAM
+
+ GROUP BLOCK(4): {
+ /* _SDA_BASE_ computed implicitly */
+ .sdata?: {}
+ .sbss?: {}
+ * (DATA): {}
+ * (BSS): {}
+ .Zdata? : {}
+ .stack ALIGN(4) SIZE(DEFINED _STACKSIZE?_STACKSIZE:8K): {}
+ .heap? ALIGN(4) SIZE(DEFINED _HEAPSIZE?_HEAPSIZE:8K): {}
+ } > DCCM
+
+ GROUP BLOCK(4): {
+ .Xdata? : {}
+ } > XCCM
+
+ GROUP BLOCK(4): {
+ .Ydata? : {}
+ } > YCCM
+}
+
+
diff --git a/tensorflow/lite/micro/tools/make/targets/arc_custom_makefile.inc b/tensorflow/lite/micro/tools/make/targets/arc_custom_makefile.inc
new file mode 100644
index 0000000..9332bc9
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/arc_custom_makefile.inc
@@ -0,0 +1,36 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Settings for not pre-defined ARC processors.
+# User need to specify ARC target with Tool Configuration File (*.tcf).
+# Path to this file must be passed through TCF_FILE variable.
+# Otherwise, default em7d_voice_audio configuration is used
+
+TARGET_ARCH := arc
+ARC_TOOLCHAIN := mwdt
+
+# Overriding TARGET variable to change name of project folder according
+# to specified Tool Configuration File (*.tcf) passed through TCF_FILE variable
+# or default em7d_voice_audio configuration.
+ifneq ($(TCF_FILE), )
+ override TARGET = $(basename $(notdir $(TCF_FILE)))
+else
+ $(warning TCF_FILE variable is not specified. Use default em7d_voice_audio configuration)
+ override TARGET = em7d_voice_audio
+ TCF_FILE = em7d_voice_audio
+endif
+
+include $(MAKEFILE_DIR)/targets/arc/arc_common.inc
+
+MAKE_PROJECT_FILES := $(filter-out README_MAKE.md, $(MAKE_PROJECT_FILES)) README_ARC.md
diff --git a/tensorflow/lite/micro/tools/make/targets/arc_emsdp_makefile.inc b/tensorflow/lite/micro/tools/make/targets/arc_emsdp_makefile.inc
new file mode 100644
index 0000000..b83f9aa
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/arc_emsdp_makefile.inc
@@ -0,0 +1,62 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Settings for EMSDP target (ARC processor)
+
+TARGET_ARCH := arc
+ARC_TOOLCHAIN := mwdt
+
+
+BUILD_ARC_MLI := false
+ARC_MLI_PRE_COMPILED_TARGET := emsdp_em11d_em9d_dfss
+
+ifneq ($(filter no_arc_mli,$(ARC_TAGS)),)
+ MLI_LIB_DIR = arc_mli_package
+ $(eval $(call add_third_party_download,$(EMBARC_MLI_PRE_COMPILED_URL),$(EMBARC_MLI_PRE_COMPILED_MD5),$(MLI_LIB_DIR),))
+else ifeq ($(BUILD_ARC_MLI), true)
+ MLI_LIB_DIR = arc_mli_$(ARC_MLI_PRE_COMPILED_TARGET)
+endif
+
+TCF_FILE = $(PWD)/$(MAKEFILE_DIR)/downloads/$(MLI_LIB_DIR)/hw/emsdp_em11d_em9d_dfss.tcf
+LCF_FILE = $(PWD)/$(MAKEFILE_DIR)/targets/arc/emsdp/emsdp.lcf
+
+
+include $(MAKEFILE_DIR)/targets/arc/arc_common.inc
+
+ ARC_EXTRA_APP_SETTINGS = \
+ BIN_DIR = .$(DLR)\(PS\)bin\n\
+ BIN_FILE = $(DLR)\(BIN_DIR\)$(DLR)\(PS\)app.elf\n
+
+ ARC_EXTRA_APP_RULES = \
+ $(DLR)\(BIN_FILE\): $(DLR)\(BIN_DIR\) $(DLR)\(OUT_NAME\)\
+ \n\t\@$(DLR)\(CP\) $(DLR)\(OUT_NAME\) $(DLR)\(BIN_FILE\)\
+ \n \
+ \n$(DLR)\(BIN_DIR\):\
+ \n\t\@$(DLR)\(MKDIR\) $(DLR)\(BIN_DIR\)\
+
+ ARC_EXTRA_RM_TARGETS = $(DLR)\(BIN_DIR\)
+
+ ARC_BIN_DEPEND = $(DLR)\(BIN_DIR\) $(DLR)\(BIN_FILE\)
+ ARC_BIN_RULE = \t@echo Copy content of $(DLR)\(BIN_DIR\) into the root of SD card and follow instructions
+
+ ARC_APP_RUN_CMD = mdb -run -digilent -nooptions $(DLR)\(DBG_ARGS\)
+ ARC_APP_DEBUG_CMD = mdb -OK -digilent -nooptions $(DLR)\(DBG_ARGS\)
+ ARC_EXTRA_EXECUTE_RULES =
+
+MAKE_PROJECT_FILES := $(filter-out README_MAKE.md, $(MAKE_PROJECT_FILES)) README_ARC_EMSDP.md
+
+# for default EMSDP configuration we can use em9d_va rt libs
+# for better performance runtime should be built for emsdp configuration
+# No hostlink library for smaller codesize purpose
+PLATFORM_LDFLAGS += -Hlib=em9d_voice_audio -Hhostlib=
diff --git a/tensorflow/lite/micro/tools/make/targets/bluepill/bluepill.lds b/tensorflow/lite/micro/tools/make/targets/bluepill/bluepill.lds
new file mode 100644
index 0000000..b5d823a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/bluepill/bluepill.lds
@@ -0,0 +1,104 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+/* Copied and modified from:
+ https://github.com/google/stm32_bare_lib/blob/master/stm32_linker_layout.lds
+
+ Modifications:
+ * increased the flash size to 512K and RAM to 256K. This far exceeds the
+ actual hardware but enables running the tests in the emulator.
+*/
+
+/*
+ * 0x00000000 - 0x07ffffff - aliased to flash or sys memory depending on BOOT jumpers.
+ * 0x08000000 - 0x080fffff - Flash.
+ * 0x1ffff000 - 0x1ffff7ff - Boot firmware in system memory.
+ * 0x1ffff800 - 0x1fffffff - Option bytes.
+ * 0x20000000 - 0x2003ffff - SRAM.
+ * 0x40000000 - 0x40023400 - Peripherals
+ */
+
+/* Define main entry point */
+ENTRY(_main)
+
+MEMORY {
+RAM (xrw) : ORIGIN = 0x20000000, LENGTH = 256K
+FLASH (rx) : ORIGIN = 0x8000000, LENGTH = 1024K
+}
+
+/* Compute where the stack ends rather than hard coding it */
+_ld_stack_end_addr = ORIGIN(RAM) + LENGTH(RAM);
+_ld_min_stack_size = 0x200;
+
+SECTIONS {
+
+/* interrupt vector goes to top of flash */
+
+.interrupt_vector : {
+ . = ALIGN(4);
+ KEEP(*(.interrupt_vector))
+ . = ALIGN(4);
+} >FLASH
+
+/* read only .text and .rodata go to flash */
+
+.text : {
+ . = ALIGN(4);
+ KEEP(*(.text.interrupt_handler))
+ *(.text*)
+} >FLASH
+
+.rodata : {
+ . = ALIGN(4);
+ *(.rodata*)
+ . = ALIGN(4);
+} >FLASH
+
+/* read mwrite data needs to be stored in flash but copied to ram */
+.data : {
+ . = ALIGN(4);
+ _ld_data_load_dest_start = .; /* export where to load from */
+ *(.data*)
+ . = ALIGN(4);
+ _ld_data_load_dest_stop = .; /* export where to load from */
+} >RAM AT> FLASH
+_ld_data_load_source = LOADADDR(.data);
+
+/* unitialized data section needs zero initialization */
+.bss :
+{
+ . = ALIGN(4);
+ _ld_bss_data_start = .;
+ *(.bss*)
+ . = ALIGN(4);
+ _ld_bss_data_stop = .;
+} >RAM
+
+._user_heap_stack :
+{
+ . = ALIGN(8);
+ . += _ld_min_stack_size;
+ PROVIDE(end = .);
+ . = ALIGN(8);
+} >RAM
+
+/DISCARD/ :
+{
+ libc.a (*)
+ libm.a (*)
+ libgcc.a (*)
+}
+
+} /* SECTIONS */
diff --git a/tensorflow/lite/micro/tools/make/targets/bluepill_makefile.inc b/tensorflow/lite/micro/tools/make/targets/bluepill_makefile.inc
new file mode 100644
index 0000000..572b389
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/bluepill_makefile.inc
@@ -0,0 +1,84 @@
+export PATH := $(MAKEFILE_DIR)/downloads/gcc_embedded/bin/:$(PATH)
+TARGET_ARCH := cortex-m3
+TARGET_TOOLCHAIN_PREFIX := arm-none-eabi-
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/arm_gcc_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the GCC download: $(DOWNLOAD_RESULT))
+endif
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/renode_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the renode download: $(DOWNLOAD_RESULT))
+endif
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/cmsis_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the CMSIS download: $(DOWNLOAD_RESULT))
+endif
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/stm32_bare_lib_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the STM32 Bare Lib download: $(DOWNLOAD_RESULT))
+endif
+
+PLATFORM_FLAGS = \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -mcpu=cortex-m3 \
+ -mthumb \
+ -Wno-vla \
+ -Wno-strict-aliasing \
+ -Wno-shadow \
+ -Wno-type-limits \
+ -fomit-frame-pointer \
+ -nostdlib
+
+# TODO(b/168334217): Currently we always add -DNDEBUG because the build is
+# broken w/o it. Remove this workaround once the issue is resolved.
+PLATFORM_FLAGS += -DNDEBUG
+
+# TODO(#46937): Remove once initialization of global variables is sorted out.
+PLATFORM_FLAGS += -DRENODE
+
+CXXFLAGS += $(PLATFORM_FLAGS) -fno-use-cxa-atexit
+CCFLAGS += $(PLATFORM_FLAGS)
+
+LDFLAGS += \
+ -T $(MAKEFILE_DIR)/targets/bluepill/bluepill.lds \
+ -Wl,-Map=$(MAKEFILE_DIR)/gen/$(TARGET).map,--cref
+
+# Additional include paths needed for the stm_32_bare_lib only.
+INCLUDES += \
+ -isystem$(MAKEFILE_DIR)/downloads/cmsis/CMSIS/Core/Include/ \
+ -I$(MAKEFILE_DIR)/downloads/stm32_bare_lib/include
+
+MICROLITE_CC_SRCS += \
+ $(wildcard $(MAKEFILE_DIR)/downloads/stm32_bare_lib/source/*.c) \
+ $(wildcard $(MAKEFILE_DIR)/downloads/stm32_bare_lib/source/*.cc)
+EXCLUDED_SRCS := \
+ $(MAKEFILE_DIR)/downloads/stm32_bare_lib/source/debug_log.c
+MICROLITE_CC_SRCS := $(filter-out $(EXCLUDED_SRCS), $(MICROLITE_CC_SRCS))
+
+# TODO(b/158651472): Fix the memory_arena_threshold_test
+# TODO(b/143286954): Figure out why some tests fail and enable once the issues
+# are resolved.
+EXCLUDED_TESTS := \
+ tensorflow/lite/micro/micro_interpreter_test.cc \
+ tensorflow/lite/micro/micro_allocator_test.cc \
+ tensorflow/lite/micro/memory_helpers_test.cc \
+ tensorflow/lite/micro/memory_arena_threshold_test.cc
+MICROLITE_TEST_SRCS := $(filter-out $(EXCLUDED_TESTS), $(MICROLITE_TEST_SRCS))
+
+EXCLUDED_EXAMPLE_TESTS := \
+ tensorflow/lite/micro/examples/magic_wand/Makefile.inc \
+ tensorflow/lite/micro/examples/micro_speech/Makefile.inc \
+ tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc
+MICRO_LITE_EXAMPLE_TESTS := $(filter-out $(EXCLUDED_EXAMPLE_TESTS), $(MICRO_LITE_EXAMPLE_TESTS))
+
+TEST_SCRIPT := tensorflow/lite/micro/testing/test_with_renode.sh
+
+# We are setting this variable to non-zero to allow us to have a custom
+# implementation of `make test` for bluepill
+TARGET_SPECIFIC_MAKE_TEST := 1
+test: build
+ $(TEST_SCRIPT) $(BINDIR) $(TEST_PASS_STRING) $(TARGET)
diff --git a/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM.ld b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM.ld
new file mode 100755
index 0000000..666c59a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM.ld
@@ -0,0 +1,234 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+OUTPUT(a.elf)
+
+/* By default, program starts from reset address (the default location of the interrupt table) */
+ENTRY(__cxd_inttbl_start)
+
+/** Memory configuration parameters.
+ * The parameters become application symbols and can be referred from application
+ */
+__internal_code_start = DEFINED(__internal_code_start) ? __internal_code_start : 0x00000000;
+__internal_code_size = DEFINED(__internal_code_size ) ? __internal_code_size : 256k;
+__internal_data_start = DEFINED(__internal_data_start) ? __internal_data_start : 0x00000000;
+__internal_data_size = DEFINED(__internal_data_size ) ? __internal_data_size : 512k;
+__external_start = DEFINED(__external_start ) ? __external_start : 0x40000000;
+__external_size = DEFINED(__external_size ) ? __external_size : 0x40000000;
+__rom_start = DEFINED(__rom_start ) ? __rom_start : 0xC0000000;
+__rom_size = DEFINED(__rom_size ) ? __rom_size : 1024M;
+
+__malloc_size = DEFINED(__malloc_size ) ? __malloc_size : 32k;
+__stack_size = DEFINED(__stack_size ) ? __stack_size : 32k;
+__arg_sect_size = DEFINED(__arg_sect_size ) ? __arg_sect_size : 512;
+
+MEMORY {
+ INTERNAL_CODE (rx) : ORIGIN = __internal_code_start, LENGTH = __internal_code_size
+ INTERNAL_DATA (rw) : ORIGIN = __internal_data_start, LENGTH = __internal_data_size
+ EXTERNAL (rwx) : ORIGIN = __external_start , LENGTH = __external_size
+ ROM (rx) : ORIGIN = __rom_start , LENGTH = __rom_size
+}
+
+SECTIONS {
+ .inttbl : ALIGN(0x20) {
+ /** The interrupt vector table. Contains the NMI
+ * and maskable interrupt handlers
+ */
+ . = 0x0;
+ KEEP(*(.inttbl))
+ . = ALIGN(0x20);
+ KEEP(*(.sinttbl))
+ } >INTERNAL_CODE
+
+ .data.internal : ALIGN(0x20) {
+ PROVIDE(__data_internal_start = ABSOLUTE(.));
+ /* Don't map any data at address zero to avoid issues with C NULL
+ * pointer checks
+ */
+ . += 0x4;
+
+ PROVIDE(__data_start = ABSOLUTE(.));
+ *(.data .data.*)
+ PROVIDE(__data_end = ABSOLUTE(.));
+ PROVIDE(__data_size = ABSOLUTE(+__data_end - __data_start));
+
+ PROVIDE(__sdata_start = ABSOLUTE(.));
+ *(.sdata .sdata.*)
+ PROVIDE(__sdata_end = ABSOLUTE(.));
+ PROVIDE(__sdata_size = ABSOLUTE(+__sdata_end - __sdata_start));
+
+ PROVIDE(__data_internal_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_size = ABSOLUTE(__data_internal_end - __data_internal_start));
+ } >INTERNAL_DATA
+
+ .data.internal.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_internal_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_internal_size);
+ } >INTERNAL_DATA
+
+ .data.internal.ro : ALIGN(0x20) {
+ PROVIDE(__data_internal_ro_start = ABSOLUTE(.));
+ PROVIDE(__rodata_start = ABSOLUTE(.));
+ *(.rodata .rodata.*)
+ PROVIDE(__rodata_end = ABSOLUTE(.));
+ PROVIDE(__rodata_size = ABSOLUTE(+__rodata_end - __rodata_start));
+
+ PROVIDE(__data_internal_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_ro_size = ABSOLUTE(__data_internal_ro_end - __data_internal_ro_start));
+ } >INTERNAL_DATA
+
+ .cst.call : ALIGN(4) {
+ PROVIDE(__cst_call_start = ABSOLUTE(.));
+ *(.cst.call)
+ PROVIDE(__cst_call_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .cst.mov : ALIGN(4) {
+ PROVIDE(__cst_mov_start = ABSOLUTE(.));
+ *(.cst.mov)
+ PROVIDE(__cst_mov_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .bss (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__bss_start = ABSOLUTE(.));
+ *(.bss .bss.*)
+ PROVIDE(__common_start = ABSOLUTE(.));
+ *(COMMON)
+ PROVIDE(__common_end = ABSOLUTE(.));
+ PROVIDE(__common_size = ABSOLUTE(+__common_end - __common_start));
+ PROVIDE(__bss_end = ABSOLUTE(.));
+ PROVIDE(__bss_size = ABSOLUTE(+__bss_end - __bss_start));
+ } >INTERNAL_DATA
+
+ __STACK_SECT (NOLOAD) : ALIGN(0x10) {
+ __stack_start = ABSOLUTE(.);
+ . = . + __stack_size;
+ __stack_end = ABSOLUTE(.);
+ } >INTERNAL_DATA
+
+ .text : ALIGN(0x20) {
+ PROVIDE(__text_start = ABSOLUTE(.));
+ /* The __call_saved* functions need to be placed at low addresses for
+ * calling with absolute call instructions
+ */
+ *(.text.__call_saved*)
+ *(.text .text.*)
+ PROVIDE(__text_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ .data.external : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_start = ABSOLUTE(.));
+
+ PROVIDE(__data1_start = ABSOLUTE(.));
+ *(.data1 .data1.*)
+ PROVIDE(__data1_end = ABSOLUTE(.));
+
+ PROVIDE(__sdata1_start = ABSOLUTE(.));
+ *(.sdata1 .sdata1.*)
+ PROVIDE(__sdata1_end = ABSOLUTE(.));
+ PROVIDE(__sdata1_size = ABSOLUTE(+__sdata1_end - __sdata1_start));
+
+ PROVIDE(__data_external_end = ABSOLUTE(.));
+ PROVIDE(__data_external_size = ABSOLUTE(__data_external_end - __data_external_start));
+ } >EXTERNAL
+
+ .data.external.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_external_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_external_size);
+ } >EXTERNAL
+
+ .data.external.ro : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_ro_start = ABSOLUTE(.));
+
+ PROVIDE(__rodata1_start = ABSOLUTE(.));
+ *(.rodata1 .rodata1.*)
+ PROVIDE(__rodata1_end = ABSOLUTE(.));
+ PROVIDE(__rodata1_size = ABSOLUTE(+__rodata1_end - __rodata1_start));
+
+ /* Constructors and destructors are called once per program invocation,
+ * so are never in the hot path; they shouldn't waste space in limited
+ * internal memory so we place them in slower, external memory */
+
+ . = ALIGN(4); /* constructors must be aligned on a word boundary */
+ PROVIDE(__init_array_start = ABSOLUTE(.));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array.*) SORT_BY_INIT_PRIORITY(.ctors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array*) SORT_BY_INIT_PRIORITY(.ctors*)));
+ PROVIDE(__init_array_end = ABSOLUTE(.));
+
+ PROVIDE(__fini_array_start = ABSOLUTE(.));
+ /* destructors are run in reverse order of their priority */
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array.*) SORT_BY_INIT_PRIORITY(.dtors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array*) SORT_BY_INIT_PRIORITY(.dtors*)));
+ PROVIDE(__fini_array_end = ABSOLUTE(.));
+
+ PROVIDE(__data_external_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_external_ro_size = ABSOLUTE(__data_external_ro_end - __data_external_ro_start));
+ } >EXTERNAL
+
+ .bss1 (NOLOAD) : ALIGN(0x20) {
+ /**
+ * `.bss1` is for large zero-initialized symbols that do not fit in
+ * internal data
+ */
+ PROVIDE(__bss1_start = ABSOLUTE(.));
+ *(.bss1 .bss1.*)
+ PROVIDE(__large_common_start = ABSOLUTE(.));
+ *(LARGE_COMMON)
+ PROVIDE(__large_common_end = ABSOLUTE(.));
+ PROVIDE(__large_common_size = ABSOLUTE(+__large_common_end - __large_common_start));
+ PROVIDE(__bss1_end = ABSOLUTE(.));
+ PROVIDE(__bss1_size = ABSOLUTE(+__bss1_end - __bss1_start));
+ } >EXTERNAL
+
+ /* Program arguments are loaded by `_start` routine from `__arg_sect_start`.
+ * When the user has set a zero size for the section, argc, and argv
+ * will be zero and NULL, respectively.
+ * Although likely small, they are on the slow path so by default they
+ * go at the end of external memory
+ */
+ __ARG_SECT (NOLOAD) : ALIGN(0x4) {
+ __arg_sect_start = .;
+ . = . + (__arg_sect_size ? __arg_sect_size + 4 : 0);
+ __arg_sect_end = .;
+ } >EXTERNAL
+
+ __MALLOC_SECT (NOLOAD) : ALIGN(0x10) {
+ PROVIDE(__malloc_start = ABSOLUTE(.));
+ . = . + __malloc_size;
+ PROVIDE(__malloc_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ data_internal_loadable_addr = __data_internal_clone_start;
+ data_external_loadable_addr = __data_external_clone_start;
+
+ /DISCARD/ : {
+ /* Note: The CEVA Debugger and Restriction Checker use information
+ * stored in the ".note.CEVA-arch" section. Do NOT discard this section
+ * for projects in development phase. This section has no effect on the
+ * applications footprint */
+ *(.comment)
+ *(.note.GNU-stack)
+ /* The X-DSP ABI uses a custom relocation format stored in its own
+ * section. These are left in the binary by default but are unneeded. */
+ *(.ceva_reloc)
+ }
+
+}
diff --git a/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.2.ld b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.2.ld
new file mode 100755
index 0000000..dce5330
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.2.ld
@@ -0,0 +1,205 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+OUTPUT(a.elf)
+
+/* By default, program starts from reset address (the default location of the interrupt table) */
+ENTRY(__cxd_inttbl_start)
+
+/** Memory configuration parameters.
+ * The parameters become application symbols and can be referred from application
+ */
+__internal_code_start = DEFINED(__internal_code_start) ? __internal_code_start : 0x00000000;
+__internal_code_size = DEFINED(__internal_code_size ) ? __internal_code_size : 256k;
+__internal_data_start = DEFINED(__internal_data_start) ? __internal_data_start : 0x00000000;
+__internal_data_size = DEFINED(__internal_data_size ) ? __internal_data_size : 512k;
+__external_start = DEFINED(__external_start ) ? __external_start : 0x40000000;
+__external_size = DEFINED(__external_size ) ? __external_size : 0x40000000;
+__rom_start = DEFINED(__rom_start ) ? __rom_start : 0xC0000000;
+__rom_size = DEFINED(__rom_size ) ? __rom_size : 1024M;
+
+__malloc_size = DEFINED(__malloc_size ) ? __malloc_size : 64k;
+__stack_size = DEFINED(__stack_size ) ? __stack_size : 64k;
+__arg_sect_size = DEFINED(__arg_sect_size ) ? __arg_sect_size : 512;
+
+MEMORY {
+ INTERNAL_CODE (rx) : ORIGIN = __internal_code_start, LENGTH = __internal_code_size
+ INTERNAL_DATA (rw) : ORIGIN = __internal_data_start, LENGTH = __internal_data_size
+ EXTERNAL (rwx) : ORIGIN = __external_start , LENGTH = __external_size
+ ROM (rx) : ORIGIN = __rom_start , LENGTH = __rom_size
+}
+
+SECTIONS {
+ .inttbl : ALIGN(0x20) {
+ /** The interrupt vector resides at address zero and contains the NMI
+ * and maskable interrupt handlers
+ */
+ . = 0x0;
+ KEEP(*(.inttbl))
+ . = ALIGN(0x20);
+ KEEP(*(.sinttbl))
+ } >INTERNAL_CODE AT>ROM
+
+ .data.internal : ALIGN(0x20) {
+ PROVIDE(__data_internal_start = ABSOLUTE(.));
+ /* Don't map any data at address zero to avoid issues with C NULL
+ * pointer checks
+ */
+ . += 0x4;
+
+ PROVIDE(__data_start = ABSOLUTE(.));
+ *(.data .data.*)
+ PROVIDE(__data_end = ABSOLUTE(.));
+ PROVIDE(__data_size = +__data_end - __data_start);
+
+ PROVIDE(__sdata_start = ABSOLUTE(.));
+ *(.sdata .sdata.*)
+ PROVIDE(__sdata_end = ABSOLUTE(.));
+ PROVIDE(__sdata_size = +__sdata_end - __sdata_start);
+
+ PROVIDE(__rodata_start = ABSOLUTE(.));
+ *(.rodata .rodata.*)
+ PROVIDE(__rodata_end = ABSOLUTE(.));
+ PROVIDE(__rodata_size = +__rodata_end - __rodata_start);
+
+ PROVIDE(__data_internal_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_size = __data_internal_end - __data_internal_start);
+ } >INTERNAL_DATA AT>ROM
+
+ .cst.call : ALIGN(4) {
+ PROVIDE(__cst_call_start = ABSOLUTE(.));
+ *(.cst.call)
+ PROVIDE(__cst_call_end = ABSOLUTE(.));
+ } >INTERNAL_DATA AT>ROM
+
+ .cst.mov : ALIGN(4) {
+ PROVIDE(__cst_mov_start = ABSOLUTE(.));
+ *(.cst.mov)
+ PROVIDE(__cst_mov_end = ABSOLUTE(.));
+ } >INTERNAL_DATA AT>ROM
+
+ .bss (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__bss_start = ABSOLUTE(.));
+ *(.bss .bss.*)
+ PROVIDE(__common_start = ABSOLUTE(.));
+ *(COMMON)
+ PROVIDE(__common_end = ABSOLUTE(.));
+ PROVIDE(__common_size = +__common_end - __common_start);
+ PROVIDE(__bss_end = ABSOLUTE(.));
+ PROVIDE(__bss_size = +__bss_end - __bss_start);
+ } >INTERNAL_DATA
+
+ __STACK_SECT (NOLOAD) : ALIGN(0x10) {
+ __stack_start = ABSOLUTE(.);
+ . = . + __stack_size;
+ __stack_end = ABSOLUTE(.);
+ } >INTERNAL_DATA
+
+ .text : ALIGN(0x20) {
+ PROVIDE(__text_start = ABSOLUTE(.));
+ /* The __call_saved* functions need to be placed at low addresses for
+ * calling with absolute call instructions
+ */
+ *(.text.__call_saved*)
+ *(.text .text.*)
+ PROVIDE(__text_end = ABSOLUTE(.));
+ } >EXTERNAL AT>ROM
+
+ .data.external : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_start = ABSOLUTE(.));
+
+ PROVIDE(__data1_start = ABSOLUTE(.));
+ *(.data1 .data1.*)
+ PROVIDE(__data1_end = ABSOLUTE(.));
+
+ PROVIDE(__sdata1_start = ABSOLUTE(.));
+ *(.sdata1 .sdata1.*)
+ PROVIDE(__sdata1_end = ABSOLUTE(.));
+ PROVIDE(__sdata1_size = +__sdata1_end - __sdata1_start);
+
+ PROVIDE(__rodata1_start = ABSOLUTE(.));
+ *(.rodata1 .rodata1.*)
+ PROVIDE(__rodata1_end = ABSOLUTE(.));
+ PROVIDE(__rodata1_size = +__rodata1_end - __rodata1_start);
+
+ /* Constructors and destructors are called once per program invocation,
+ * so are never in the hot path; they shouldn't waste space in limited
+ * internal memory so we place them in slower, external memory
+ */
+
+ . = ALIGN(4); /* constructors must be aligned on a word boundary */
+ PROVIDE(__init_array_start = ABSOLUTE(.));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array.*) SORT_BY_INIT_PRIORITY(.ctors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array*) SORT_BY_INIT_PRIORITY(.ctors*)));
+ PROVIDE(__init_array_end = ABSOLUTE(.));
+
+ PROVIDE(__fini_array_start = ABSOLUTE(.));
+ /* destructors are run in reverse order of their priority */
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array.*) SORT_BY_INIT_PRIORITY(.dtors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array*) SORT_BY_INIT_PRIORITY(.dtors*)));
+ PROVIDE(__fini_array_end = ABSOLUTE(.));
+
+ PROVIDE(__data_external_end = ABSOLUTE(.));
+ PROVIDE(__data_external_size = __data_external_end - __data_external_start);
+ } >EXTERNAL AT>ROM
+
+ .bss1 (NOLOAD) : ALIGN(0x20) {
+ /**
+ * `.bss1` is for large zero-initialized symbols that do not fit in
+ * internal data
+ */
+ PROVIDE(__bss1_start = ABSOLUTE(.));
+ *(.bss1 .bss1.*)
+ PROVIDE(__large_common_start = ABSOLUTE(.));
+ *(LARGE_COMMON)
+ PROVIDE(__large_common_end = ABSOLUTE(.));
+ PROVIDE(__large_common_size = +__large_common_end - __large_common_start);
+ PROVIDE(__bss1_end = ABSOLUTE(.));
+ PROVIDE(__bss1_size = +__bss1_end - __bss1_start);
+ } >EXTERNAL
+
+ /* Program arguments are loaded by `_start` routine from `__arg_sect_start`.
+ * When the user has set a zero size for the section, argc, and argv
+ * will be zero and NULL, respectively.
+ * Although likely small, they are on the slow path so by default they
+ * go at the end of external memory
+ */
+ __ARG_SECT (NOLOAD) : ALIGN(0x4) {
+ __arg_sect_start = .;
+ . = . + (__arg_sect_size ? __arg_sect_size + 4 : 0);
+ __arg_sect_end = .;
+ } >EXTERNAL
+
+ __MALLOC_SECT (NOLOAD) : ALIGN(0x10) {
+ PROVIDE(__malloc_start = ABSOLUTE(.));
+ . = . + __malloc_size;
+ PROVIDE(__malloc_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ /DISCARD/ : {
+ /* Discarding .note.CEVA-arch saves a fair amount of space but
+ * confounds the restriction checker. YMMV */
+ /* *(.note.CEVA-arch) */
+ *(.comment)
+ *(.note.GNU-stack)
+ /* The X-DSP ABI uses a custom relocation format stored in its own
+ * section. These are left in the binary by default but are unneeded. */
+ *(.ceva_reloc)
+ }
+
+}
diff --git a/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.3.ld b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.3.ld
new file mode 100755
index 0000000..0fa2044
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.3.ld
@@ -0,0 +1,235 @@
+
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+OUTPUT(a.elf)
+
+/* By default, program starts from reset address (the default location of the interrupt table) */
+ENTRY(__cxd_inttbl_start)
+
+/** Memory configuration parameters.
+ * The parameters become application symbols and can be referred from application
+ */
+__internal_code_start = DEFINED(__internal_code_start) ? __internal_code_start : 0x00000000;
+__internal_code_size = DEFINED(__internal_code_size ) ? __internal_code_size : 256k;
+__internal_data_start = DEFINED(__internal_data_start) ? __internal_data_start : 0x00000000;
+__internal_data_size = DEFINED(__internal_data_size ) ? __internal_data_size : 512k;
+__external_start = DEFINED(__external_start ) ? __external_start : 0x40000000;
+__external_size = DEFINED(__external_size ) ? __external_size : 0x40000000;
+__rom_start = DEFINED(__rom_start ) ? __rom_start : 0xC0000000;
+__rom_size = DEFINED(__rom_size ) ? __rom_size : 1024M;
+
+__malloc_size = DEFINED(__malloc_size ) ? __malloc_size : 32k;
+__stack_size = DEFINED(__stack_size ) ? __stack_size : 32k;
+__arg_sect_size = DEFINED(__arg_sect_size ) ? __arg_sect_size : 512;
+
+MEMORY {
+ INTERNAL_CODE (rx) : ORIGIN = __internal_code_start, LENGTH = __internal_code_size
+ INTERNAL_DATA (rw) : ORIGIN = __internal_data_start, LENGTH = __internal_data_size
+ EXTERNAL (rwx) : ORIGIN = __external_start , LENGTH = __external_size
+ ROM (rx) : ORIGIN = __rom_start , LENGTH = __rom_size
+}
+
+SECTIONS {
+ .inttbl : ALIGN(0x20) {
+ /** The interrupt vector table. Contains the NMI
+ * and maskable interrupt handlers
+ */
+ . = 0x0;
+ KEEP(*(.inttbl))
+ . = ALIGN(0x20);
+ KEEP(*(.sinttbl))
+ } >INTERNAL_CODE
+
+ .data.internal : ALIGN(0x20) {
+ PROVIDE(__data_internal_start = ABSOLUTE(.));
+ /* Don't map any data at address zero to avoid issues with C NULL
+ * pointer checks
+ */
+ . += 0x4;
+
+ PROVIDE(__data_start = ABSOLUTE(.));
+ *(.data .data.*)
+ PROVIDE(__data_end = ABSOLUTE(.));
+ PROVIDE(__data_size = ABSOLUTE(+__data_end - __data_start));
+
+ PROVIDE(__sdata_start = ABSOLUTE(.));
+ *(.sdata .sdata.*)
+ PROVIDE(__sdata_end = ABSOLUTE(.));
+ PROVIDE(__sdata_size = ABSOLUTE(+__sdata_end - __sdata_start));
+
+ PROVIDE(__data_internal_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_size = ABSOLUTE(__data_internal_end - __data_internal_start));
+ } >INTERNAL_DATA
+
+ .data.internal.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_internal_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_internal_size);
+ } >INTERNAL_DATA
+
+ .data.internal.ro : ALIGN(0x20) {
+ PROVIDE(__data_internal_ro_start = ABSOLUTE(.));
+ PROVIDE(__rodata_start = ABSOLUTE(.));
+ *(.rodata .rodata.*)
+ PROVIDE(__rodata_end = ABSOLUTE(.));
+ PROVIDE(__rodata_size = ABSOLUTE(+__rodata_end - __rodata_start));
+
+ PROVIDE(__data_internal_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_ro_size = ABSOLUTE(__data_internal_ro_end - __data_internal_ro_start));
+ } >INTERNAL_DATA
+
+ .cst.call : ALIGN(4) {
+ PROVIDE(__cst_call_start = ABSOLUTE(.));
+ *(.cst.call)
+ PROVIDE(__cst_call_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .cst.mov : ALIGN(4) {
+ PROVIDE(__cst_mov_start = ABSOLUTE(.));
+ *(.cst.mov)
+ PROVIDE(__cst_mov_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .bss (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__bss_start = ABSOLUTE(.));
+ *(.bss .bss.*)
+ PROVIDE(__common_start = ABSOLUTE(.));
+ *(COMMON)
+ PROVIDE(__common_end = ABSOLUTE(.));
+ PROVIDE(__common_size = ABSOLUTE(+__common_end - __common_start));
+ PROVIDE(__bss_end = ABSOLUTE(.));
+ PROVIDE(__bss_size = ABSOLUTE(+__bss_end - __bss_start));
+ } >INTERNAL_DATA
+
+ __STACK_SECT (NOLOAD) : ALIGN(0x10) {
+ __stack_start = ABSOLUTE(.);
+ . = . + __stack_size;
+ __stack_end = ABSOLUTE(.);
+ } >INTERNAL_DATA
+
+ .text : ALIGN(0x20) {
+ PROVIDE(__text_start = ABSOLUTE(.));
+ /* The __call_saved* functions need to be placed at low addresses for
+ * calling with absolute call instructions
+ */
+ *(.text.__call_saved*)
+ *(.text .text.*)
+ PROVIDE(__text_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ .data.external : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_start = ABSOLUTE(.));
+
+ PROVIDE(__data1_start = ABSOLUTE(.));
+ *(.data1 .data1.*)
+ PROVIDE(__data1_end = ABSOLUTE(.));
+
+ PROVIDE(__sdata1_start = ABSOLUTE(.));
+ *(.sdata1 .sdata1.*)
+ PROVIDE(__sdata1_end = ABSOLUTE(.));
+ PROVIDE(__sdata1_size = ABSOLUTE(+__sdata1_end - __sdata1_start));
+
+ PROVIDE(__data_external_end = ABSOLUTE(.));
+ PROVIDE(__data_external_size = ABSOLUTE(__data_external_end - __data_external_start));
+ } >EXTERNAL
+
+ .data.external.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_external_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_external_size);
+ } >EXTERNAL
+
+ .data.external.ro : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_ro_start = ABSOLUTE(.));
+
+ PROVIDE(__rodata1_start = ABSOLUTE(.));
+ *(.rodata1 .rodata1.*)
+ PROVIDE(__rodata1_end = ABSOLUTE(.));
+ PROVIDE(__rodata1_size = ABSOLUTE(+__rodata1_end - __rodata1_start));
+
+ /* Constructors and destructors are called once per program invocation,
+ * so are never in the hot path; they shouldn't waste space in limited
+ * internal memory so we place them in slower, external memory */
+
+ . = ALIGN(4); /* constructors must be aligned on a word boundary */
+ PROVIDE(__init_array_start = ABSOLUTE(.));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array.*) SORT_BY_INIT_PRIORITY(.ctors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array*) SORT_BY_INIT_PRIORITY(.ctors*)));
+ PROVIDE(__init_array_end = ABSOLUTE(.));
+
+ PROVIDE(__fini_array_start = ABSOLUTE(.));
+ /* destructors are run in reverse order of their priority */
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array.*) SORT_BY_INIT_PRIORITY(.dtors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array*) SORT_BY_INIT_PRIORITY(.dtors*)));
+ PROVIDE(__fini_array_end = ABSOLUTE(.));
+
+ PROVIDE(__data_external_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_external_ro_size = ABSOLUTE(__data_external_ro_end - __data_external_ro_start));
+ } >EXTERNAL
+
+ .bss1 (NOLOAD) : ALIGN(0x20) {
+ /**
+ * `.bss1` is for large zero-initialized symbols that do not fit in
+ * internal data
+ */
+ PROVIDE(__bss1_start = ABSOLUTE(.));
+ *(.bss1 .bss1.*)
+ PROVIDE(__large_common_start = ABSOLUTE(.));
+ *(LARGE_COMMON)
+ PROVIDE(__large_common_end = ABSOLUTE(.));
+ PROVIDE(__large_common_size = ABSOLUTE(+__large_common_end - __large_common_start));
+ PROVIDE(__bss1_end = ABSOLUTE(.));
+ PROVIDE(__bss1_size = ABSOLUTE(+__bss1_end - __bss1_start));
+ } >EXTERNAL
+
+ /* Program arguments are loaded by `_start` routine from `__arg_sect_start`.
+ * When the user has set a zero size for the section, argc, and argv
+ * will be zero and NULL, respectively.
+ * Although likely small, they are on the slow path so by default they
+ * go at the end of external memory
+ */
+ __ARG_SECT (NOLOAD) : ALIGN(0x4) {
+ __arg_sect_start = .;
+ . = . + (__arg_sect_size ? __arg_sect_size + 4 : 0);
+ __arg_sect_end = .;
+ } >EXTERNAL
+
+ __MALLOC_SECT (NOLOAD) : ALIGN(0x10) {
+ PROVIDE(__malloc_start = ABSOLUTE(.));
+ . = . + __malloc_size;
+ PROVIDE(__malloc_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ data_internal_loadable_addr = __data_internal_clone_start;
+ data_external_loadable_addr = __data_external_clone_start;
+
+ /DISCARD/ : {
+ /* Note: The CEVA Debugger and Restriction Checker use information
+ * stored in the ".note.CEVA-arch" section. Do NOT discard this section
+ * for projects in development phase. This section has no effect on the
+ * applications footprint */
+ *(.comment)
+ *(.note.GNU-stack)
+ /* The X-DSP ABI uses a custom relocation format stored in its own
+ * section. These are left in the binary by default but are unneeded. */
+ *(.ceva_reloc)
+ }
+
+}
diff --git a/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.5.ld b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.5.ld
new file mode 100755
index 0000000..127ed82
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_BX1_TFLM_18.0.5.ld
@@ -0,0 +1,235 @@
+
+/* Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+OUTPUT(a.elf)
+
+/* By default, program starts from reset address (the default location of the interrupt table) */
+ENTRY(__cxd_inttbl_start)
+
+/** Memory configuration parameters.
+ * The parameters become application symbols and can be referred from application
+ */
+__internal_code_start = DEFINED(__internal_code_start) ? __internal_code_start : 0x00000000;
+__internal_code_size = DEFINED(__internal_code_size ) ? __internal_code_size : 256k;
+__internal_data_start = DEFINED(__internal_data_start) ? __internal_data_start : 0x00000000;
+__internal_data_size = DEFINED(__internal_data_size ) ? __internal_data_size : 512k;
+__external_start = DEFINED(__external_start ) ? __external_start : 0x40000000;
+__external_size = DEFINED(__external_size ) ? __external_size : 0x40000000;
+__rom_start = DEFINED(__rom_start ) ? __rom_start : 0xC0000000;
+__rom_size = DEFINED(__rom_size ) ? __rom_size : 1024M;
+
+__malloc_size = DEFINED(__malloc_size ) ? __malloc_size : 32k;
+__stack_size = DEFINED(__stack_size ) ? __stack_size : 32k;
+__arg_sect_size = DEFINED(__arg_sect_size ) ? __arg_sect_size : 512;
+
+MEMORY {
+ INTERNAL_CODE (rx) : ORIGIN = __internal_code_start, LENGTH = __internal_code_size
+ INTERNAL_DATA (rw) : ORIGIN = __internal_data_start, LENGTH = __internal_data_size
+ EXTERNAL (rwx) : ORIGIN = __external_start , LENGTH = __external_size
+ ROM (rx) : ORIGIN = __rom_start , LENGTH = __rom_size
+}
+
+SECTIONS {
+ .inttbl : ALIGN(0x20) {
+ /** The interrupt vector table. Contains the NMI
+ * and maskable interrupt handlers
+ */
+ . = 0x0;
+ KEEP(*(.inttbl))
+ . = ALIGN(0x20);
+ KEEP(*(.sinttbl))
+ } >INTERNAL_CODE
+
+ .data.internal : ALIGN(0x20) {
+ PROVIDE(__data_internal_start = ABSOLUTE(.));
+ /* Don't map any data at address zero to avoid issues with C NULL
+ * pointer checks
+ */
+ . += 0x4;
+
+ PROVIDE(__data_start = ABSOLUTE(.));
+ *(.data .data.*)
+ PROVIDE(__data_end = ABSOLUTE(.));
+ PROVIDE(__data_size = ABSOLUTE(+__data_end - __data_start));
+
+ PROVIDE(__sdata_start = ABSOLUTE(.));
+ *(.sdata .sdata.*)
+ PROVIDE(__sdata_end = ABSOLUTE(.));
+ PROVIDE(__sdata_size = ABSOLUTE(+__sdata_end - __sdata_start));
+
+ PROVIDE(__data_internal_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_size = ABSOLUTE(__data_internal_end - __data_internal_start));
+ } >INTERNAL_DATA
+
+ .data.internal.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_internal_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_internal_size);
+ } >INTERNAL_DATA
+
+ .data.internal.ro : ALIGN(0x20) {
+ PROVIDE(__data_internal_ro_start = ABSOLUTE(.));
+ PROVIDE(__rodata_start = ABSOLUTE(.));
+ *(.rodata .rodata.*)
+ PROVIDE(__rodata_end = ABSOLUTE(.));
+ PROVIDE(__rodata_size = ABSOLUTE(+__rodata_end - __rodata_start));
+
+ PROVIDE(__data_internal_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_ro_size = ABSOLUTE(__data_internal_ro_end - __data_internal_ro_start));
+ } >INTERNAL_DATA
+
+ .cst.call : ALIGN(4) {
+ PROVIDE(__cst_call_start = ABSOLUTE(.));
+ *(.cst.call)
+ PROVIDE(__cst_call_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .cst.mov : ALIGN(4) {
+ PROVIDE(__cst_mov_start = ABSOLUTE(.));
+ *(.cst.mov)
+ PROVIDE(__cst_mov_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .bss (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__bss_start = ABSOLUTE(.));
+ *(.bss .bss.*)
+ PROVIDE(__common_start = ABSOLUTE(.));
+ *(COMMON)
+ PROVIDE(__common_end = ABSOLUTE(.));
+ PROVIDE(__common_size = ABSOLUTE(+__common_end - __common_start));
+ PROVIDE(__bss_end = ABSOLUTE(.));
+ PROVIDE(__bss_size = ABSOLUTE(+__bss_end - __bss_start));
+ } >INTERNAL_DATA
+
+ __STACK_SECT (NOLOAD) : ALIGN(0x10) {
+ __stack_start = ABSOLUTE(.);
+ . = . + __stack_size;
+ __stack_end = ABSOLUTE(.);
+ } >INTERNAL_DATA
+
+ .text : ALIGN(0x20) {
+ PROVIDE(__text_start = ABSOLUTE(.));
+ /* The __call_saved* functions need to be placed at low addresses for
+ * calling with absolute call instructions
+ */
+ *(.text.__call_saved*)
+ *(.text .text.*)
+ PROVIDE(__text_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ .data.external : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_start = ABSOLUTE(.));
+
+ PROVIDE(__data1_start = ABSOLUTE(.));
+ *(.data1 .data1.*)
+ PROVIDE(__data1_end = ABSOLUTE(.));
+
+ PROVIDE(__sdata1_start = ABSOLUTE(.));
+ *(.sdata1 .sdata1.*)
+ PROVIDE(__sdata1_end = ABSOLUTE(.));
+ PROVIDE(__sdata1_size = ABSOLUTE(+__sdata1_end - __sdata1_start));
+
+ PROVIDE(__data_external_end = ABSOLUTE(.));
+ PROVIDE(__data_external_size = ABSOLUTE(__data_external_end - __data_external_start));
+ } >EXTERNAL
+
+ .data.external.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_external_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_external_size);
+ } >EXTERNAL
+
+ .data.external.ro : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_ro_start = ABSOLUTE(.));
+
+ PROVIDE(__rodata1_start = ABSOLUTE(.));
+ *(.rodata1 .rodata1.*)
+ PROVIDE(__rodata1_end = ABSOLUTE(.));
+ PROVIDE(__rodata1_size = ABSOLUTE(+__rodata1_end - __rodata1_start));
+
+ /* Constructors and destructors are called once per program invocation,
+ * so are never in the hot path; they shouldn't waste space in limited
+ * internal memory so we place them in slower, external memory */
+
+ . = ALIGN(4); /* constructors must be aligned on a word boundary */
+ PROVIDE(__init_array_start = ABSOLUTE(.));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array.*) SORT_BY_INIT_PRIORITY(.ctors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array*) SORT_BY_INIT_PRIORITY(.ctors*)));
+ PROVIDE(__init_array_end = ABSOLUTE(.));
+
+ PROVIDE(__fini_array_start = ABSOLUTE(.));
+ /* destructors are run in reverse order of their priority */
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array.*) SORT_BY_INIT_PRIORITY(.dtors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array*) SORT_BY_INIT_PRIORITY(.dtors*)));
+ PROVIDE(__fini_array_end = ABSOLUTE(.));
+
+ PROVIDE(__data_external_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_external_ro_size = ABSOLUTE(__data_external_ro_end - __data_external_ro_start));
+ } >EXTERNAL
+
+ .bss1 (NOLOAD) : ALIGN(0x20) {
+ /**
+ * `.bss1` is for large zero-initialized symbols that do not fit in
+ * internal data
+ */
+ PROVIDE(__bss1_start = ABSOLUTE(.));
+ *(.bss1 .bss1.*)
+ PROVIDE(__large_common_start = ABSOLUTE(.));
+ *(LARGE_COMMON)
+ PROVIDE(__large_common_end = ABSOLUTE(.));
+ PROVIDE(__large_common_size = ABSOLUTE(+__large_common_end - __large_common_start));
+ PROVIDE(__bss1_end = ABSOLUTE(.));
+ PROVIDE(__bss1_size = ABSOLUTE(+__bss1_end - __bss1_start));
+ } >EXTERNAL
+
+ /* Program arguments are loaded by `_start` routine from `__arg_sect_start`.
+ * When the user has set a zero size for the section, argc, and argv
+ * will be zero and NULL, respectively.
+ * Although likely small, they are on the slow path so by default they
+ * go at the end of external memory
+ */
+ __ARG_SECT (NOLOAD) : ALIGN(0x4) {
+ __arg_sect_start = .;
+ . = . + (__arg_sect_size ? __arg_sect_size + 4 : 0);
+ __arg_sect_end = .;
+ } >EXTERNAL
+
+ __MALLOC_SECT (NOLOAD) : ALIGN(0x10) {
+ PROVIDE(__malloc_start = ABSOLUTE(.));
+ . = . + __malloc_size;
+ PROVIDE(__malloc_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ data_internal_loadable_addr = __data_internal_clone_start;
+ data_external_loadable_addr = __data_external_clone_start;
+
+ /DISCARD/ : {
+ /* Note: The CEVA Debugger and Restriction Checker use information
+ * stored in the ".note.CEVA-arch" section. Do NOT discard this section
+ * for projects in development phase. This section has no effect on the
+ * applications footprint */
+ *(.comment)
+ *(.note.GNU-stack)
+ /* The X-DSP ABI uses a custom relocation format stored in its own
+ * section. These are left in the binary by default but are unneeded. */
+ *(.ceva_reloc)
+ }
+
+}
diff --git a/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_SP500_TFLM.ld b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_SP500_TFLM.ld
new file mode 100755
index 0000000..244859a
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ceva/CEVA_SP500_TFLM.ld
@@ -0,0 +1,235 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+
+OUTPUT(a.elf)
+
+/* By default, program starts from reset address (the default location of the interrupt table) */
+ENTRY(__cxd_inttbl_start)
+
+/** Memory configuration parameters.
+ * The parameters become application symbols and can be referred from application
+ */
+__internal_data_start = DEFINED(__internal_data_start) ? __internal_data_start : 0x00000000;
+__internal_data_size = DEFINED(__internal_data_size ) ? __internal_data_size : 256k;
+__external_start = DEFINED(__external_start ) ? __external_start : 0x20000000;
+__external_size = DEFINED(__external_size ) ? __external_size : 0x60000000;
+__rom_start = DEFINED(__rom_start ) ? __rom_start : 0xC0000000;
+__rom_size = DEFINED(__rom_size ) ? __rom_size : 1024M;
+
+__malloc_size = DEFINED(__malloc_size ) ? __malloc_size : 16k;
+__stack_size = DEFINED(__stack_size ) ? __stack_size : 16k;
+__arg_sect_size = DEFINED(__arg_sect_size ) ? __arg_sect_size : 512;
+
+MEMORY {
+ INTERNAL_DATA (rw) : ORIGIN = __internal_data_start, LENGTH = __internal_data_size
+ EXTERNAL (rwx) : ORIGIN = __external_start , LENGTH = __external_size
+ ROM (rx) : ORIGIN = __rom_start , LENGTH = __rom_size
+}
+
+SECTIONS {
+ .inttbl : ALIGN(0x20) {
+ /** The interrupt vector table. Contains the NMI
+ * and maskable interrupt handlers
+ */
+ . = 0x0;
+ KEEP(*(.inttbl))
+ . = ALIGN(0x20);
+ KEEP(*(.sinttbl))
+ } >EXTERNAL
+
+ .data.internal : ALIGN(0x20) {
+ PROVIDE(__data_internal_start = ABSOLUTE(.));
+ /* Don't map any data at address zero to avoid issues with C NULL
+ * pointer checks
+ */
+ . += 0x4;
+
+ PROVIDE(__data_start = ABSOLUTE(.));
+ *(.data .data.*)
+ PROVIDE(__data_end = ABSOLUTE(.));
+ PROVIDE(__data_size = ABSOLUTE(+__data_end - __data_start));
+
+ PROVIDE(__sdata_start = ABSOLUTE(.));
+ *(.sdata .sdata.*)
+ PROVIDE(__sdata_end = ABSOLUTE(.));
+ PROVIDE(__sdata_size = ABSOLUTE(+__sdata_end - __sdata_start));
+
+ PROVIDE(__data_internal_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_size = ABSOLUTE(__data_internal_end - __data_internal_start));
+ } >INTERNAL_DATA
+
+ .data.internal.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_internal_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_internal_size);
+ } >INTERNAL_DATA
+
+ .data.internal.ro : ALIGN(0x20) {
+ PROVIDE(__data_internal_ro_start = ABSOLUTE(.));
+ PROVIDE(__rodata_start = ABSOLUTE(.));
+ *(.rodata .rodata.*)
+ PROVIDE(__rodata_end = ABSOLUTE(.));
+ PROVIDE(__rodata_size = ABSOLUTE(+__rodata_end - __rodata_start));
+
+ PROVIDE(__data_internal_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_internal_ro_size = ABSOLUTE(__data_internal_ro_end - __data_internal_ro_start));
+ } >INTERNAL_DATA
+
+ .cst.call : ALIGN(4) {
+ PROVIDE(__cst_call_start = ABSOLUTE(.));
+ *(.cst.call)
+ PROVIDE(__cst_call_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .cst.mov : ALIGN(4) {
+ PROVIDE(__cst_mov_start = ABSOLUTE(.));
+ *(.cst.mov)
+ PROVIDE(__cst_mov_end = ABSOLUTE(.));
+ } >INTERNAL_DATA
+
+ .bss (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__bss_start = ABSOLUTE(.));
+ *(.bss .bss.*)
+ PROVIDE(__common_start = ABSOLUTE(.));
+ *(COMMON)
+ PROVIDE(__common_end = ABSOLUTE(.));
+ PROVIDE(__common_size = ABSOLUTE(+__common_end - __common_start));
+ PROVIDE(__bss_end = ABSOLUTE(.));
+ PROVIDE(__bss_size = ABSOLUTE(+__bss_end - __bss_start));
+ } >INTERNAL_DATA
+
+ __STACK_SECT (NOLOAD) : ALIGN(0x10) {
+ __stack_start = ABSOLUTE(.);
+ . = . + __stack_size;
+ __stack_end = ABSOLUTE(.);
+ } >INTERNAL_DATA
+
+ .text : ALIGN(0x20) {
+ PROVIDE(__text_start = ABSOLUTE(.));
+ /* The __call_saved* functions need to be placed at low addresses for
+ * calling with absolute call instructions
+ */
+ *(.text.__call_saved*)
+ *(.text .text.*)
+ /* Program sections in external memory should be aligned to the fetch line width
+ */
+ . = ALIGN(0x20);
+ PROVIDE(__text_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ .data.external : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_start = ABSOLUTE(.));
+
+ PROVIDE(__data1_start = ABSOLUTE(.));
+ *(.data1 .data1.*)
+ PROVIDE(__data1_end = ABSOLUTE(.));
+
+ PROVIDE(__sdata1_start = ABSOLUTE(.));
+ *(.sdata1 .sdata1.*)
+ PROVIDE(__sdata1_end = ABSOLUTE(.));
+ PROVIDE(__sdata1_size = ABSOLUTE(+__sdata1_end - __sdata1_start));
+
+ PROVIDE(__data_external_end = ABSOLUTE(.));
+ PROVIDE(__data_external_size = ABSOLUTE(__data_external_end - __data_external_start));
+ } >EXTERNAL
+
+ .data.external.clone (NOLOAD) : ALIGN(0x20) {
+ PROVIDE(__data_external_clone_start = ABSOLUTE(.));
+ . = ABSOLUTE(. + __data_external_size);
+ } >EXTERNAL
+
+ .data.external.ro : ALIGN(0x20) {
+ /** .data1, .rodata1, .sdata1 are all for large symbols which cannot
+ * fit in limited internal memory. We put them in external memory by
+ * default. */
+ PROVIDE(__data_external_ro_start = ABSOLUTE(.));
+
+ PROVIDE(__rodata1_start = ABSOLUTE(.));
+ *(.rodata1 .rodata1.*)
+ PROVIDE(__rodata1_end = ABSOLUTE(.));
+ PROVIDE(__rodata1_size = ABSOLUTE(+__rodata1_end - __rodata1_start));
+
+ /* Constructors and destructors are called once per program invocation,
+ * so are never in the hot path; they shouldn't waste space in limited
+ * internal memory so we place them in slower, external memory */
+
+ . = ALIGN(4); /* constructors must be aligned on a word boundary */
+ PROVIDE(__init_array_start = ABSOLUTE(.));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array.*) SORT_BY_INIT_PRIORITY(.ctors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.init_array*) SORT_BY_INIT_PRIORITY(.ctors*)));
+ PROVIDE(__init_array_end = ABSOLUTE(.));
+
+ PROVIDE(__fini_array_start = ABSOLUTE(.));
+ /* destructors are run in reverse order of their priority */
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array.*) SORT_BY_INIT_PRIORITY(.dtors.*)));
+ KEEP(*(SORT_BY_INIT_PRIORITY(.fini_array*) SORT_BY_INIT_PRIORITY(.dtors*)));
+ PROVIDE(__fini_array_end = ABSOLUTE(.));
+
+ PROVIDE(__data_external_ro_end = ABSOLUTE(.));
+ PROVIDE(__data_external_ro_size = ABSOLUTE(__data_external_ro_end - __data_external_ro_start));
+ } >EXTERNAL
+
+ .bss1 (NOLOAD) : ALIGN(0x20) {
+ /**
+ * `.bss1` is for large zero-initialized symbols that do not fit in
+ * internal data
+ */
+ PROVIDE(__bss1_start = ABSOLUTE(.));
+ *(.bss1 .bss1.*)
+ PROVIDE(__large_common_start = ABSOLUTE(.));
+ *(LARGE_COMMON)
+ PROVIDE(__large_common_end = ABSOLUTE(.));
+ PROVIDE(__large_common_size = ABSOLUTE(+__large_common_end - __large_common_start));
+ PROVIDE(__bss1_end = ABSOLUTE(.));
+ PROVIDE(__bss1_size = ABSOLUTE(+__bss1_end - __bss1_start));
+ } >EXTERNAL
+
+ /* Program arguments are loaded by `_start` routine from `__arg_sect_start`.
+ * When the user has set a zero size for the section, argc, and argv
+ * will be zero and NULL, respectively.
+ * Although likely small, they are on the slow path so by default they
+ * go at the end of external memory
+ */
+ __ARG_SECT (NOLOAD) : ALIGN(0x4) {
+ __arg_sect_start = .;
+ . = . + (__arg_sect_size ? __arg_sect_size + 4 : 0);
+ __arg_sect_end = .;
+ } >EXTERNAL
+
+ __MALLOC_SECT (NOLOAD) : ALIGN(0x10) {
+ PROVIDE(__malloc_start = ABSOLUTE(.));
+ . = . + __malloc_size;
+ PROVIDE(__malloc_end = ABSOLUTE(.));
+ } >EXTERNAL
+
+ data_internal_loadable_addr = __data_internal_clone_start;
+ data_external_loadable_addr = __data_external_clone_start;
+
+ /DISCARD/ : {
+ /* Note: The CEVA Debugger and Restriction Checker use information
+ * stored in the ".note.CEVA-arch" section. Do NOT discard this section
+ * for projects in development phase. This section has no effect on the
+ * applications footprint */
+ *(.comment)
+ *(.note.GNU-stack)
+ /* The X-DSP ABI uses a custom relocation format stored in its own
+ * section. These are left in the binary by default but are unneeded. */
+ *(.ceva_reloc)
+ }
+
+}
diff --git a/tensorflow/lite/micro/tools/make/targets/ceva_makefile.inc b/tensorflow/lite/micro/tools/make/targets/ceva_makefile.inc
new file mode 100755
index 0000000..46bf587
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ceva_makefile.inc
@@ -0,0 +1,88 @@
+TARGET_ARCH :=
+
+ifeq ($(TARGET_ARCH), )
+ $(error TARGET_ARCH must be specified on the command line)
+endif
+
+# Create a cflag based on the specified TARGET_ARCH. For example:
+# TARGET_ARCH=CEVA_BX1 --> -DCEVA_BX1
+# TARGET_ARCH=CEVA_SP500 --> -DCEVA_SP500
+TARGET_ARCH_DEFINES := -D$(shell echo $(TARGET_ARCH) | tr [a-z] [A-Z])
+
+TARGET_TOOLCHAIN_PREFIX := ceva
+CXX_TOOL = clang++
+CC_TOOL = clang
+LD_TOOL = ceva-elf-ld
+LD = ceva-elf-ld
+
+PLATFORM_ARGS += \
+$(TARGET_ARCH_DEFINES) \
+ -fmessage-length=0 \
+ -fpermissive \
+ -O4 \
+ -g3 \
+ -Wall \
+ -pedantic \
+ -D_LIBCPP_INLINE_VISIBILITY="" \
+ -D_LIBCPP_EXTERN_TEMPLATE_INLINE_VISIBILITY=""
+
+
+CXXFLAGS := -std=c++11 -DTF_LITE_STATIC_MEMORY
+CCFLAGS := -std=c11 -DTF_LITE_STATIC_MEMORY
+
+ifeq ($(TARGET_ARCH), CEVA_BX1)
+PLATFORM_ARGS += \
+ --target=cevabx1-elf \
+ -mcpu=cevabx1v1.0.0 \
+ -m32x32 \
+ -mgetbits \
+ -mloop-buffer-size=10 \
+ -mfp=1 \
+ -mdpfp=1
+
+
+LDFLAGS += \
+ -T \
+ CEVA_TFLM.ld \
+ --no-relax \
+ --no-gc-sections \
+ -defsym \
+ __internal_data_size=512k \
+ -defsym \
+ __internal_code_size=256k \
+
+endif
+
+ifeq ($(TARGET_ARCH), CEVA_SP500)
+PLATFORM_ARGS = \
+ -pedantic \
+ -Wa,--no-rstr-check \
+ --target=senspro-elf \
+ -mcpu=sensprov1.0.0 \
+ -mvu=1 \
+ -mno-vld2 \
+ -mvmpyv5 \
+ -mvmpyext -mnonlinear=1 -mno-vbnn -mvhist \
+ -mlvu=1 \
+ -mfp=2 \
+ -mdpfp=2 \
+ -mvfp=1
+
+ LDFLAGS += \
+--no-relax --no-gc-sections \
+ -defsym __internal_code_size=0k \
+ -defsym __internal_data_size=512k
+
+endif
+
+CXXFLAGS += $(PLATFORM_ARGS)
+CCFLAGS += $(PLATFORM_ARGS)
+
+MICROLITE_CC_HDRS += \
+ tensorflow/lite/micro/kernels/ceva/ceva_tflm_lib.h \
+ tensorflow/lite/micro/kernels/ceva/types.h \
+ tensorflow/lite/micro/kernels/ceva/ceva_common.h
+
+
+MICROLITE_CC_SRCS += \
+ tensorflow/lite/micro/kernels/ceva/ceva_common.cc
diff --git a/tensorflow/lite/micro/tools/make/targets/chre_makefile.inc b/tensorflow/lite/micro/tools/make/targets/chre_makefile.inc
new file mode 100644
index 0000000..3665b26
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/chre_makefile.inc
@@ -0,0 +1,34 @@
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Remove flexbuffers library and detection postprocess kernel from chre build
+# due to string dependencies.
+EXCLUDED_CC_SRCS := \
+ tensorflow/lite/micro/kernels/circular_buffer.cc \
+ tensorflow/lite/micro/kernels/detection_postprocess.cc \
+ tensorflow/lite/micro/kernels/flexbuffers_generated_data.cc
+
+EXCLUDED_TESTS := \
+ tensorflow/lite/micro/kernels/detection_postprocess_test.cc
+
+EXCLUDED_HDRS := \
+ third_party/flatbuffers/include/flatbuffers/flexbuffers.h
+
+EXCLUDED_KERNEL_HDRS := \
+ tensorflow/lite/micro/kernels/flexbuffers_generated_data.h
+
+MICROLITE_CC_KERNEL_SRCS := $(filter-out $(EXCLUDED_CC_SRCS),$(MICROLITE_CC_KERNEL_SRCS))
+MICROLITE_TEST_SRCS := $(filter-out $(EXCLUDED_TESTS),$(MICROLITE_TEST_SRCS))
+THIRD_PARTY_CC_HDRS := $(filter-out $(EXCLUDED_HDRS),$(THIRD_PARTY_CC_HDRS))
+MICROLITE_CC_HDRS := $(filter-out $(EXCLUDED_KERNEL_HDRS),$(MICROLITE_CC_HDRS))
diff --git a/tensorflow/lite/micro/tools/make/targets/cortex_m_corstone_300_makefile.inc b/tensorflow/lite/micro/tools/make/targets/cortex_m_corstone_300_makefile.inc
new file mode 100644
index 0000000..af2222b
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/cortex_m_corstone_300_makefile.inc
@@ -0,0 +1,167 @@
+# ARM Cortex M makefile targeted for a FVP based on Arm Corstone-300 software.
+# For more info see: tensorflow/lite/micro/cortex_m_corstone_300/README.md
+
+export PATH := $(MAKEFILE_DIR)/downloads/corstone300/models/Linux64_GCC-6.4:$(PATH)
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/corstone_300_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the Arm Corstone-300 software download: $(DOWNLOAD_RESULT))
+endif
+
+ETHOS_U_CORE_PLATFORM := ${PWD}/$(MAKEFILE_DIR)/downloads/ethos_u_core_platform/targets/corstone-300
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ethos_u_core_platform_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the Ethos-U Core Platform software download: $(DOWNLOAD_RESULT))
+endif
+
+# This target has dependencies to CMSIS-Device so just in case running without OPTIMIZED_KERNEL_DIR=cmsis_nn.
+CMSIS_DEFAULT_DOWNLOAD_PATH := $(MAKEFILE_DIR)/downloads/cmsis
+CMSIS_PATH := $(CMSIS_DEFAULT_DOWNLOAD_PATH)
+ifeq ($(CMSIS_PATH), $(CMSIS_DEFAULT_DOWNLOAD_PATH))
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/cmsis_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the CMSIS download: $(DOWNLOAD_RESULT))
+ endif
+endif
+
+FLOAT := soft
+GCC_TARGET_ARCH := $(TARGET_ARCH)
+
+ifeq ($(TARGET_ARCH), cortex-m0)
+ CORE=M0
+
+else ifeq ($(TARGET_ARCH), cortex-m3)
+ CORE=M3
+
+else ifeq ($(TARGET_ARCH), cortex-m33)
+ CORE=M33
+ FLOAT=hard
+ CMSIS_ARM_FEATURES := _DSP_DP
+
+else ifeq ($(TARGET_ARCH), cortex-m33+nodsp)
+ CORE=M33
+
+else ifeq ($(TARGET_ARCH), cortex-m4)
+ CORE=M4
+ GCC_TARGET_ARCH := cortex-m4+nofp
+
+else ifeq ($(TARGET_ARCH), cortex-m4+fp)
+ CORE=M4
+ FLOAT=hard
+ GCC_TARGET_ARCH := cortex-m4
+ CMSIS_ARM_FEATURES := _FP
+
+else ifeq ($(TARGET_ARCH), cortex-m55)
+ CORE=M55
+ FLOAT=hard
+
+else ifeq ($(TARGET_ARCH), cortex-m55+nodsp+nofp)
+ CORE=M55
+
+else ifeq ($(TARGET_ARCH), cortex-m55+nofp)
+ CORE=M55
+
+else ifeq ($(TARGET_ARCH), cortex-m7)
+ CORE=M7
+ GCC_TARGET_ARCH := cortex-m7+nofp
+
+else ifeq ($(TARGET_ARCH), cortex-m7+fp)
+ CORE=M7
+ FLOAT=hard
+ GCC_TARGET_ARCH := cortex-m7
+ CMSIS_ARM_FEATURES := _DP
+
+else
+ $(error "TARGET_ARCH=$(TARGET_ARCH) is not supported")
+endif
+
+ifneq ($(filter cortex-m55%,$(TARGET_ARCH)),)
+ # soft-abi=soft disables MVE - use softfp instead for M55.
+ ifeq ($(FLOAT),soft)
+ FLOAT=softfp
+ endif
+endif
+
+ifeq ($(TOOLCHAIN), gcc)
+ export PATH := $(MAKEFILE_DIR)/downloads/gcc_embedded/bin/:$(PATH)
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/arm_gcc_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the GCC download: $(DOWNLOAD_RESULT))
+ endif
+ TARGET_TOOLCHAIN_PREFIX := arm-none-eabi-
+
+ FLAGS_GCC = -mcpu=$(GCC_TARGET_ARCH) -mfpu=auto
+ CXXFLAGS += $(FLAGS_GCC)
+ CCFLAGS += $(FLAGS_GCC)
+
+ LDFLAGS += \
+ --specs=nosys.specs \
+ -T $(ETHOS_U_CORE_PLATFORM)/platform_parsed.ld \
+ -Wl,-Map=${TENSORFLOW_ROOT}$(MAKEFILE_DIR)/gen/$(TARGET).map,--cref \
+ -Wl,--gc-sections \
+ --entry Reset_Handler
+
+else
+ $(error "TOOLCHAIN=$(TOOLCHAIN) is not supported.")
+endif
+
+# TODO(#47718): resolve warnings.
+OMIT_ERRORS = \
+ -Wno-implicit-fallthrough \
+ -Wno-strict-aliasing
+
+PLATFORM_FLAGS = \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -mthumb \
+ -mfloat-abi=$(FLOAT) \
+ -funsigned-char \
+ -mlittle-endian \
+ ${OMIT_ERRORS} \
+ -fomit-frame-pointer \
+ -MD \
+ -DCPU_$(CORE)=1
+
+# Common + C/C++ flags
+CXXFLAGS += $(PLATFORM_FLAGS)
+CCFLAGS += $(PLATFORM_FLAGS)
+
+ARM_CPU := $(subst cortex-m,ARMCM,$(GCC_TARGET_ARCH))
+ARM_CPU := $(subst +nofp,,$(ARM_CPU))
+CXXFLAGS += -D$(ARM_CPU)$(CMSIS_ARM_FEATURES)
+CCFLAGS += -D$(ARM_CPU)$(CMSIS_ARM_FEATURES)
+
+THIRD_PARTY_CC_SRCS += \
+ $(ETHOS_U_CORE_PLATFORM)/retarget.c \
+ $(ETHOS_U_CORE_PLATFORM)/uart.c
+
+CMSIS_DEFAULT_DOWNLOAD_PATH := $(MAKEFILE_DIR)/downloads/cmsis
+CMSIS_PATH := $(CMSIS_DEFAULT_DOWNLOAD_PATH)
+THIRD_PARTY_CC_SRCS += \
+ $(CMSIS_PATH)/Device/ARM/$(ARM_CPU)/Source/system_$(ARM_CPU).c \
+ $(CMSIS_PATH)/Device/ARM/$(ARM_CPU)/Source/startup_$(ARM_CPU).c
+INCLUDES += \
+ -I$(CMSIS_PATH)/Device/ARM/$(ARM_CPU)/Include \
+ -I$(CMSIS_PATH)/CMSIS/Core/Include
+
+# TODO(#47071): Examine why Micro benchmarks fails.
+MICRO_LITE_BENCHMARKS := $(filter-out tensorflow/lite/micro/benchmarks/Makefile.inc, $(MICRO_LITE_BENCHMARKS))
+
+# TODO(#47070): Examine why some tests fail here.
+EXCLUDED_TESTS := \
+ tensorflow/lite/micro/micro_interpreter_test.cc \
+ tensorflow/lite/micro/micro_allocator_test.cc \
+ tensorflow/lite/micro/memory_helpers_test.cc \
+ tensorflow/lite/micro/micro_error_reporter_test.cc \
+ tensorflow/lite/micro/output_handler_test.cc \
+ tensorflow/lite/micro/memory_arena_threshold_test.cc \
+ tensorflow/lite/micro/recording_micro_allocator_test.cc \
+ tensorflow/lite/micro/kernels/circular_buffer_test.cc
+MICROLITE_TEST_SRCS := $(filter-out $(EXCLUDED_TESTS), $(MICROLITE_TEST_SRCS))
+EXCLUDED_EXAMPLE_TESTS := \
+ tensorflow/lite/micro/examples/magic_wand/Makefile.inc \
+ tensorflow/lite/micro/examples/micro_speech/Makefile.inc \
+ tensorflow/lite/micro/examples/person_detection/Makefile.inc \
+ tensorflow/lite/micro/examples/hello_world/Makefile.inc \
+ tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc
+MICRO_LITE_EXAMPLE_TESTS := $(filter-out $(EXCLUDED_EXAMPLE_TESTS), $(MICRO_LITE_EXAMPLE_TESTS))
+
+TEST_SCRIPT := tensorflow/lite/micro/testing/test_with_arm_corstone_300.sh
diff --git a/tensorflow/lite/micro/tools/make/targets/cortex_m_generic_makefile.inc b/tensorflow/lite/micro/tools/make/targets/cortex_m_generic_makefile.inc
new file mode 100644
index 0000000..8fc6fca
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/cortex_m_generic_makefile.inc
@@ -0,0 +1,145 @@
+# Generic Makefile target for ARM Cortex M builds.
+# For more info see: tensorflow/lite/micro/cortex_m_generic/README.md
+
+FLOAT := soft
+GCC_TARGET_ARCH := $(TARGET_ARCH)
+
+ifeq ($(TARGET_ARCH), cortex-m0)
+ CORE=M0
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M0
+
+else ifeq ($(TARGET_ARCH), cortex-m3)
+ CORE=M3
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M3
+
+else ifeq ($(TARGET_ARCH), cortex-m33)
+ CORE=M33
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M33
+ TARGET_SPECIFIC_FLAGS += -D__DSP_PRESENT=1 -D__FPU_PRESENT=1 -D__VTOR_PRESENT=1 -D__FPU_USED=1
+ FLOAT=hard
+
+else ifeq ($(TARGET_ARCH), cortex-m33+nodsp)
+ CORE=M33
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M33.no_dsp.no_fp
+
+else ifeq ($(TARGET_ARCH), cortex-m4)
+ CORE=M4
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M4.no_fp
+ GCC_TARGET_ARCH := cortex-m4+nofp
+
+else ifeq ($(TARGET_ARCH), cortex-m4+fp)
+ CORE=M4
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M4
+ TARGET_SPECIFIC_FLAGS += -D__FPU_PRESENT=1
+ FLOAT=hard
+ GCC_TARGET_ARCH := cortex-m4
+
+else ifeq ($(TARGET_ARCH), cortex-m55)
+ CORE=M55
+ ARM_LDFLAGS := -Wl,--cpu=8.1-M.Main.mve.fp
+ TARGET_SPECIFIC_FLAGS += -D__DSP_PRESENT=1 -D__FPU_PRESENT=1
+ FLOAT=hard
+
+else ifeq ($(TARGET_ARCH), cortex-m55+nodsp+nofp)
+ CORE=M55
+ ARM_LDFLAGS := -Wl,--cpu=8.1-M.Main.mve.no_dsp.no_fp
+
+else ifeq ($(TARGET_ARCH), cortex-m55+nofp)
+ CORE=M55
+ ARM_LDFLAGS := -Wl,--cpu=8.1-M.Main.mve.no_fp
+ TARGET_SPECIFIC_FLAGS += -D__DSP_PRESENT=1
+
+else ifeq ($(TARGET_ARCH), cortex-m7)
+ CORE=M7
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M7.no_fp
+ GCC_TARGET_ARCH := cortex-m7+nofp
+
+else ifeq ($(TARGET_ARCH), cortex-m7+fp)
+ CORE=M7
+ ARM_LDFLAGS := -Wl,--cpu=Cortex-M7
+ FLOAT=hard
+ GCC_TARGET_ARCH := cortex-m7
+
+else
+ $(error "TARGET_ARCH=$(TARGET_ARCH) is not supported")
+endif
+
+ifneq ($(filter cortex-m55%,$(TARGET_ARCH)),)
+ # soft-abi=soft disables MVE - use softfp instead for M55.
+ ifeq ($(FLOAT),soft)
+ FLOAT=softfp
+ endif
+endif
+
+# Toolchain specfic flags
+ifeq ($(TOOLCHAIN), armclang)
+ CXX_TOOL := armclang
+ CC_TOOL := armclang
+ AR_TOOL := armar
+ LD := armlink
+
+ FLAGS_ARMC = \
+ --target=arm-arm-none-eabi \
+ -mcpu=$(TARGET_ARCH)
+
+ CXXFLAGS += $(FLAGS_ARMC)
+ CCFLAGS += $(FLAGS_ARMC)
+ LDFLAGS += $(ARM_LDFLAGS)
+
+ # Arm Compiler will not link the Math library (see below), therefore we're filtering it out.
+ # See Fatal error: L6450U: Cannot find library m:
+ # "Arm Compiler is designed to run in a bare metal environment,
+ # and automatically includes implementations of these functions,
+ # and so no such flag is necessary."
+ # https://developer.arm.com/documentation/100891/0611/troubleshooting/general-troubleshooting-advice
+ MICROLITE_LIBS := $(filter-out -lm,$(MICROLITE_LIBS))
+
+else ifeq ($(TOOLCHAIN), gcc)
+ export PATH := $(MAKEFILE_DIR)/downloads/gcc_embedded/bin/:$(PATH)
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/arm_gcc_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the GCC download: $(DOWNLOAD_RESULT))
+ endif
+
+ TARGET_TOOLCHAIN_PREFIX := arm-none-eabi-
+
+ FLAGS_GCC = -mcpu=$(GCC_TARGET_ARCH) -mfpu=auto
+ CXXFLAGS += $(FLAGS_GCC)
+ CCFLAGS += $(FLAGS_GCC)
+
+else
+ $(error "TOOLCHAIN=$(TOOLCHAIN) is not supported.")
+endif
+
+# TODO(#47718): resolve warnings.
+OMIT_ERRORS = \
+ -Wno-implicit-fallthrough \
+ -Wno-strict-aliasing \
+ -Wno-unused-variable
+
+PLATFORM_FLAGS = \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -mthumb \
+ -mfloat-abi=$(FLOAT) \
+ -funsigned-char \
+ -mlittle-endian \
+ ${OMIT_ERRORS} \
+ -Wno-type-limits \
+ -Wno-unused-private-field \
+ -fomit-frame-pointer \
+ -MD \
+ -DCPU_$(CORE)=1 \
+ $(TARGET_SPECIFIC_FLAGS)
+
+# Common + C/C++ flags
+CXXFLAGS += $(PLATFORM_FLAGS)
+CCFLAGS += $(PLATFORM_FLAGS)
+
+# Needed for the project generation interface.
+MICROLITE_CC_HDRS := \
+ tensorflow/lite/micro/cortex_m_generic/debug_log_callback.h
+
+EXCLUDED_EXAMPLE_TESTS := \
+ tensorflow/lite/micro/examples/micro_speech/Makefile.inc
+MICRO_LITE_EXAMPLE_TESTS := $(filter-out $(EXCLUDED_EXAMPLE_TESTS), $(MICRO_LITE_EXAMPLE_TESTS))
+
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/README.md b/tensorflow/lite/micro/tools/make/targets/ecm3531/README.md
new file mode 100644
index 0000000..14ea7c3
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/README.md
@@ -0,0 +1,9 @@
+Compiling instructions here
+https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro
+
+CONTACT INFORMATION:
+
+Contact info@etacompute.com for more information on obtaining the Eta Compute
+SDK and evaluation board.
+
+www.etacompute.com
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/_main.c b/tensorflow/lite/micro/tools/make/targets/ecm3531/_main.c
new file mode 100644
index 0000000..e3d0b88
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/_main.c
@@ -0,0 +1,90 @@
+/* Copyright 2015 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+/* This is file contains the entry point to the application and is called after
+ startup.
+ The GPIOs, Uart and timer are initialized and Tensorflow is invoked with the
+ call to main().
+ Tensorflow will print out if the tests have passed or failed and the
+ execution time is also
+ printed. */
+
+#include <inttypes.h>
+#include <stdint.h>
+#include <stdio.h>
+#include <string.h>
+
+#include "eta_bsp.h"
+#include "eta_chip.h"
+#include "eta_csp.h"
+#include "eta_csp_buck.h"
+#include "eta_csp_gpio.h"
+#include "eta_csp_io.h"
+#include "eta_csp_pwr.h"
+#include "eta_csp_rtc.h"
+#include "eta_csp_socctrl.h"
+#include "eta_csp_sys_clock.h"
+#include "eta_csp_timer.h"
+#include "eta_csp_uart.h"
+
+tUart g_sUart0 = {eUartNum0, eUartBaud115200};
+tUart g_sUart1 = {eUartNum1, eUartBaud115200};
+
+int init_main(int);
+void EtaPrintExecutionTime(uint64_t);
+
+//*****************************************************************************
+//
+// The entry point for the application.
+//
+//*****************************************************************************
+extern int main(int argc, char** argv);
+
+int _main(void) {
+ uint64_t time_ms;
+
+ EtaCspInit(); // initialize csp registers
+ EtaCspGpioInit(); // initialize gpios
+ EtaCspUartInit(&g_sUart1, eUartNum0, eUartBaud115200,
+ eUartFlowControlHardware); // initialize Uart
+ EtaCspBuckInit(ETA_BSP_VDD_IO_SETTING, eBuckAo600Mv, eBuckM3Frequency60Mhz,
+ eBuckMemVoltage900Mv); // set M3 freq
+ EtaCspTimerInitMs(); // start timer
+ main(0, NULL); // Call to Tensorflow; this will print if test was successful.
+ time_ms = EtaCspTimerCountGetMs(); // read time
+ EtaPrintExecutionTime(time_ms); // print execution time
+}
+
+void EtaPrintExecutionTime(uint64_t time_ms) {
+ uint8_t c;
+ int k1;
+ char time_string[] = "00000";
+
+ EtaCspIoPrintf("Execution time (msec) = ");
+ if (time_ms < 100000) // Convert time to a string
+ {
+ for (k1 = 0; k1 < 5; k1++) {
+ c = time_ms % 10;
+ time_ms = time_ms / 10;
+ time_string[k1] = (char)(0x30 + c);
+ }
+ for (k1 = 4; k1 >= 0; k1--) { // print out 1 char at a time
+ EtaCspUartPutc(&g_sUart1, time_string[k1]);
+ }
+ } else {
+ EtaCspIoPrintf("Execution time exceeds 100 sec\n");
+ }
+ EtaCspIoPrintf("\n\n");
+}
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/ecm3531.lds b/tensorflow/lite/micro/tools/make/targets/ecm3531/ecm3531.lds
new file mode 100644
index 0000000..58cb5eb
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/ecm3531.lds
@@ -0,0 +1,84 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+/*
+ * linker script for use with ECM3531
+ * All sections must map to 128KBytes of SRAM beginning at 0x10000000
+ *
+ */
+
+ /*
+ * Indicate to the linker the entry point.
+ */
+ENTRY(ResetISR)
+
+/*
+ * SRAM is at 0x10000000 of length 0x00020000
+ */
+MEMORY
+{
+ SRAM (RWX) : ORIGIN = 0x10000000, LENGTH = 0x00020000
+}
+
+SECTIONS
+{
+ .text :
+ {
+ _text = .;
+ KEEP(*(.vectors))
+ . = ALIGN(0x4);
+ *(.text*)
+ . = ALIGN(0x4);
+ *(.rodata*)
+ . = ALIGN(0x4);
+ _etext = .;
+ } > SRAM= 0
+ .dummy :
+ {
+ . = ALIGN(0x4);
+ _eftext = .;
+ } > SRAM
+ .datax :
+ {
+ _datax = .;
+ KEEP(*(.mainStack))
+ . += 16384;
+ _edatax = .;
+ _stack_top = .;
+ . += 4;
+ } > SRAM
+ .data :
+ AT (ADDR(.text) + SIZEOF(.text) )
+ {
+ _data = .;
+ *(.data*)
+ KEEP(*(.mainHeap))
+ _edata = .;
+ } > SRAM
+
+ .bss :
+ {
+ _bss = .;
+ *(.bss*)
+ *(COMMON)
+ _ebss = .;
+ } > SRAM
+ .ARM.exidx :
+ {
+ *(.ARM.exidx*)
+ }
+
+}
+
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/ecm3531_flash.lds b/tensorflow/lite/micro/tools/make/targets/ecm3531/ecm3531_flash.lds
new file mode 100644
index 0000000..7b95754
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/ecm3531_flash.lds
@@ -0,0 +1,85 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+
+/*
+ * linker script for use with ECM3531 chip.
+ * .text and .ro map to FLASH all else to SRAM.
+ *
+ */
+
+ /*
+ * Indicate to the linker the entry point.
+ */
+ENTRY(ResetISR)
+
+/*
+ * FLASH is at 0x01000000 of length 0x00080000 512KB
+ * SRAM is at 0x10000000 of length 0x00020000 128KB
+ */
+MEMORY
+{
+ FLASH (RX) : ORIGIN = 0x01000000, LENGTH = 0x00080000
+ SRAM (RWX) : ORIGIN = 0x10000000, LENGTH = 0x00020000
+}
+
+SECTIONS
+{
+ .text :
+ {
+ _text = .;
+ KEEP(*(.vectors))
+ . = ALIGN(0x4);
+ *(.text*)
+ . = ALIGN(0x4);
+ *(.rodata*)
+ . = ALIGN(0x4);
+ _etext = .;
+ } > FLASH= 0
+ .dummy :
+ {
+ . = ALIGN(0x4);
+ _eftext = .;
+ } > FLASH
+/* put the stack at the bottom of SRAM*/
+ .datax (NOLOAD) :
+ {
+ _datax = .;
+ KEEP(*(.mainStack))
+ . = ALIGN(0x4);
+ . += 16384;
+ _edatax = .;
+ _stack_top = .;
+ } > SRAM
+ .data :
+ {
+ _data = .;
+ *(.data*)
+ KEEP(*(.mainHeap))
+ _edata = .;
+ } > SRAM AT > FLASH
+
+ .bss (NOLOAD) :
+ {
+ _bss = .;
+ *(.bss*)
+ *(COMMON)
+ _ebss = .;
+ } > SRAM
+
+
+
+}
+
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/flash_erase b/tensorflow/lite/micro/tools/make/targets/ecm3531/flash_erase
new file mode 100755
index 0000000..66b506e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/flash_erase
@@ -0,0 +1,47 @@
+#!/usr/bin/python3
+#Usage: cd to the directory tensorflow/lite/micro/tools/make/targets/ecm3531 and type ./flash_erase to erase the flash.
+#
+#
+# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+#==============================================================================
+
+
+import os
+import telnetlib
+
+def send_ocd_cmd(line):
+ ocd_sock.write(bytes(line,encoding = 'utf-8'))
+ print(ocd_sock.read_until(b'> ').decode('utf-8'), end='')
+
+def get_ocd_response():
+ print(ocd_sock.read_until(b'> ').decode('utf-8'), end='')
+
+#get hooked up to openocd daemon
+ocd_sock = telnetlib.Telnet(host='localhost', port=4444)
+get_ocd_response() # clean it out
+
+#ocd comand
+ocd_commands = ["halt\n",
+ "flash erase_sector 0 0 127\n",
+ "mww 0x1001fff8 0\n",
+ "mdw 0x01000000 16\n",
+ "reset\n"]
+
+# OK now do what we came here for!!!
+for x in ocd_commands:
+ print(x)
+ send_ocd_cmd(x)
+
+
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/flash_program b/tensorflow/lite/micro/tools/make/targets/ecm3531/flash_program
new file mode 100755
index 0000000..8f72ac3
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/flash_program
@@ -0,0 +1,53 @@
+#!/usr/bin/python3
+#Usage: cd to the directory tensorflow/lite/micro/tools/make/targets/ecm3531 and type ./flash_program executable_name to load an executable from the directory tensorflow/lite/micro/tools/make/gen/ecm3531_cortex-m3/bin/ into flash
+#
+#
+# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+#==============================================================================
+
+
+import sys, getopt
+import os
+import telnetlib
+
+def send_ocd_cmd(line):
+ ocd_sock.write(bytes(line,encoding = 'utf-8'))
+ print(ocd_sock.read_until(b'> ').decode('utf-8'), end='')
+
+def get_ocd_response():
+ print(ocd_sock.read_until(b'> ').decode('utf-8'), end='')
+
+#get hooked up to openocd daemon
+ocd_sock = telnetlib.Telnet(host='localhost', port=4444)
+get_ocd_response() # clean it out
+
+# git path to project elf file
+cur_dir = os.getcwd()
+#elf_file = cur_dir + '/../../gen/ecm3531_cortex-m3/bin/' + 'micro_speech'
+elf_file = cur_dir + '/../../gen/ecm3531_cortex-m3/bin/' + sys.argv[1]
+print("elf_file = ",elf_file)
+
+
+# use these to download and run the elf fle
+ocd_commands = ["halt\n",
+ "flash erase_sector 0 0 127\n",
+ "flash write_image {}\n".format(elf_file),
+ "mww 0x1001fff8 0\n",
+ "reset\n"]
+
+# OK now do what we came here for!!!
+for x in ocd_commands:
+ print(x)
+ send_ocd_cmd(x)
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/load_program b/tensorflow/lite/micro/tools/make/targets/ecm3531/load_program
new file mode 100755
index 0000000..a6bf6fe
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/load_program
@@ -0,0 +1,55 @@
+#!/usr/bin/python3
+#Usage: cd to the directory tensorflow/lite/micro/tools/make/targets/ecm3531 and type ./load_prgram executable_name to load an executable from the directory tensorflow/lite/micro/tools/make/gen/ecm3531_cortex-m3/bin/
+#
+#
+# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
+#
+#Licensed under the Apache License, Version 2.0 (the "License");
+#you may not use this file except in compliance with the License.
+#You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+#Unless required by applicable law or agreed to in writing, software
+#distributed under the License is distributed on an "AS IS" BASIS,
+#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+#See the License for the specific language governing permissions and
+#limitations under the License.
+#==============================================================================
+
+
+import sys, getopt
+import os
+import telnetlib
+
+def send_ocd_cmd(line):
+ ocd_sock.write(bytes(line,encoding = 'utf-8'))
+ print(ocd_sock.read_until(b'> ').decode('utf-8'), end='')
+
+def get_ocd_response():
+ print(ocd_sock.read_until(b'> ').decode('utf-8'), end='')
+
+#get hooked up to openocd daemon
+ocd_sock = telnetlib.Telnet(host='localhost', port=4444)
+get_ocd_response() # clean it out
+
+# git path to project elf file
+cur_dir = os.getcwd()
+#elf_file = cur_dir + '/../../gen/ecm3531_cortex-m3/bin/' + 'preprocessor_test'
+elf_file = cur_dir + '/../../gen/ecm3531_cortex-m3/bin/' + sys.argv[1]
+print("elf_file = ",elf_file)
+
+
+# use these to download and run the elf fle
+ocd_commands = ["halt\n",
+ "load_image {}\n".format(elf_file),
+ "mww 0x1001FFF8 0xDEADBEEF\n",
+ "mww 0x1001FFFC 0xC369A517\n",
+ "reset\n"]
+
+# OK now do what we came here for!!!
+for x in ocd_commands:
+ print(x)
+ send_ocd_cmd(x)
+
+
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531/startup.c b/tensorflow/lite/micro/tools/make/targets/ecm3531/startup.c
new file mode 100644
index 0000000..5a1af2b
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531/startup.c
@@ -0,0 +1,433 @@
+/* Copyright 2015 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+/* This file is called at power up time to initialize the chip. It in turn
+calls _main() which is the entry point into the application */
+
+#include <stdint.h>
+
+#include "eta_chip.h"
+#include "memio.h"
+
+#ifndef NULL
+#define NULL (0)
+#endif
+
+//*****************************************************************************
+//
+// Macro for hardware access, both direct and via the bit-band region.
+//
+//*****************************************************************************
+
+int _main(int argc, char* argv[]);
+void set_vtor(void);
+void* startup_get_my_pc(void);
+
+//*****************************************************************************
+// Forward DECLS for interrupt service routines (ISR)
+//*****************************************************************************
+extern void ResetISR(void) __attribute__((weak, alias("default_ResetISR")));
+extern void NmiSR(void) __attribute__((weak, alias("default_NmiSR")));
+extern void FaultISR(void) __attribute__((weak, alias("default_FaultISR")));
+
+extern void DebugMonitor_ISR(void)
+ __attribute__((weak, alias("default_DebugMonitor_ISR")));
+extern void SVCall_ISR(void) __attribute__((weak, alias("default_SVCall_ISR")));
+extern void PENDSV_ISR(void) __attribute__((weak, alias("default_PENDSV_ISR")));
+
+extern void SYSTICK_ISR(void)
+ __attribute__((weak, alias("default_SYSTICK_ISR")));
+
+extern void GPIO0_ISR(void) __attribute__((weak, alias("default_GPIO0_ISR")));
+extern void GPIO1_ISR(void) __attribute__((weak, alias("default_GPIO1_ISR")));
+extern void TIMER0_ISR(void) __attribute__((weak, alias("default_TIMER0_ISR")));
+extern void TIMER1_ISR(void) __attribute__((weak, alias("default_TIMER1_ISR")));
+extern void UART0_ISR(void) __attribute__((weak, alias("default_UART0_ISR")));
+extern void UART1_ISR(void) __attribute__((weak, alias("default_UART1_ISR")));
+extern void SPI0_ISR(void) __attribute__((weak, alias("default_SPI0_ISR")));
+extern void SPI1_ISR(void) __attribute__((weak, alias("default_SPI1_ISR")));
+extern void I2C0_ISR(void) __attribute__((weak, alias("default_I2C0_ISR")));
+extern void I2C1_ISR(void) __attribute__((weak, alias("default_I2C1_ISR")));
+extern void RTC0_ISR(void) __attribute__((weak, alias("default_RTC0_ISR")));
+extern void RTC1_ISR(void) __attribute__((weak, alias("default_RTC1_ISR")));
+extern void DSP_ISR(void) __attribute__((weak, alias("default_DSP_ISR")));
+extern void ADC_ISR(void) __attribute__((weak, alias("default_ADC_ISR")));
+extern void SW0_ISR(void) __attribute__((weak, alias("default_SW0_ISR")));
+extern void SW1_ISR(void) __attribute__((weak, alias("default_SW1_ISR")));
+extern void PWM_ISR(void) __attribute__((weak, alias("default_PWM_ISR")));
+extern void WDT_ISR(void) __attribute__((weak, alias("default_WDT_ISR")));
+extern void RTC_TMR_ISR(void)
+ __attribute__((weak, alias("default_RTC_TMR_ISR")));
+
+extern void SW2_ISR(void) __attribute__((weak, alias("default_SW1_ISR")));
+extern void SW3_ISR(void) __attribute__((weak, alias("default_SW1_ISR")));
+extern void SW4_ISR(void) __attribute__((weak, alias("default_SW1_ISR")));
+extern void SW5_ISR(void) __attribute__((weak, alias("default_SW1_ISR")));
+extern void SW6_ISR(void) __attribute__((weak, alias("default_SW1_ISR")));
+
+extern void IntDefaultHandler(void) __attribute__((weak));
+
+//*****************************************************************************
+//
+// Reserve space for the system stack.
+//
+//*****************************************************************************
+extern uint32_t _stack_top;
+//__attribute__ ((section(".mainStack"), used))
+// static uint32_t pui32Stack[2048];
+#define STARTUP_STACK_TOP (&_stack_top)
+
+//*****************************************************************************
+// VECTOR TABLE
+//*****************************************************************************
+__attribute__((section(".vectors"), used)) void (*const gVectors[])(void) = {
+ //(void (*)(void))((uint32_t)pui32Stack + sizeof(pui32Stack)), // Stack
+ // pointer
+ (void*)STARTUP_STACK_TOP,
+ ResetISR, // Reset handler
+ NmiSR, // The NMI handler
+ FaultISR, // The hard fault handler
+ IntDefaultHandler, // 4 The MPU fault handler
+ IntDefaultHandler, // 5 The bus fault handler
+ IntDefaultHandler, // 6 The usage fault handler
+ 0, // 7 Reserved
+ 0, // 8 Reserved
+ 0, // 9 Reserved
+ 0, // 10 Reserved
+ SVCall_ISR, // 11 SVCall handler
+ DebugMonitor_ISR, // 12 Debug monitor handler
+ 0, // 13 Reserved
+ PENDSV_ISR, // 14 The PendSV handler
+ SYSTICK_ISR, // 15 The SysTick handler
+
+ // external interrupt service routines (ISR)
+ GPIO0_ISR, // 16 GPIO Port A [ 0]
+ GPIO1_ISR, // 17 GPIO Port B [ 1]
+ TIMER0_ISR, // 18 Timer 0 [ 2]
+ TIMER1_ISR, // 19 Timer 1 [ 3]
+ UART0_ISR, // 20 UART 0 [ 4]
+ UART1_ISR, // 21 UART 1 [ 5]
+ SPI0_ISR, // 22 SPI0 [ 6]
+ SPI1_ISR, // 23 SPI1 [ 7]
+ I2C0_ISR, // 24 I2C 0 [ 8]
+ I2C1_ISR, // 25 I2C 1 [ 9]
+ RTC0_ISR, // 26 RTC 0 [10]
+ RTC1_ISR, // 27 RTC 1 [11]
+ DSP_ISR, // 28 DSP MAILBOX [12]
+ ADC_ISR, // 29 ADC [13]
+ PWM_ISR, // 32 PWM [14]
+ WDT_ISR, // 33 WDT [15]
+ RTC_TMR_ISR, // 34 RTC [16]
+
+ SW0_ISR, // 30 Software Interrupt 0 [17]
+ SW1_ISR, // 31 Software Interrupt 1 [18]
+ SW2_ISR, // 35 Software Interrupt 2 [19]
+ SW3_ISR, // 36 Software Interrupt 3 [20]
+ SW4_ISR, // 37 Software Interrupt 4 [21]
+ SW5_ISR, // 38 Software Interrupt 5 [22]
+ SW6_ISR, // 39 Software Interrupt 6 [23]
+
+};
+
+//*****************************************************************************
+//
+// The following are constructs created by the linker, indicating where the
+// the "data" and "bss" segments reside in memory. The initializers for the
+// for the "data" segment resides immediately following the "text" segment.
+//
+//*****************************************************************************
+extern uint32_t _etext;
+extern uint32_t _eftext;
+extern uint32_t _data;
+extern uint32_t _edata;
+extern uint32_t _bss;
+extern uint32_t _ebss;
+
+//
+// And here are the weak interrupt handlers.
+//
+void default_NmiSR(void) {
+ __asm(" movs r0, #2");
+ while (1) {
+ }
+}
+
+void default_FaultISR(void) {
+ __asm(" movs r0, #3");
+ MEMIO32(0x1001FFF0) = 0xbad0beef; // near the top of 128KB of SRAM
+ MEMIO32(0x1001FFF4) = 0xbad1beef; // near the top of 128KB of SRAM
+ while (1) {
+ __asm(" BKPT #1");
+ }
+}
+
+void IntDefaultHandler(void) {
+ __asm(" movs r0, #20");
+ while (1) {
+ __asm(" BKPT #1");
+ }
+}
+
+void default_SVCall_ISR(void) {
+ __asm(" movs r0, #11");
+ while (1) {
+ __asm(" BKPT #11");
+ }
+}
+
+void default_DebugMonitor_ISR(void) {
+ __asm(" movs r0, #12");
+ while (1) {
+ __asm(" BKPT #12");
+ }
+}
+
+void default_PENDSV_ISR(void) {
+ __asm(" movs r0, #14");
+ while (1) {
+ __asm(" BKPT #14");
+ }
+}
+
+void default_SYSTICK_ISR(void) {
+ __asm(" movs r0, #15");
+ while (1) {
+ __asm(" BKPT #15");
+ }
+}
+
+//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+void default_SPI0_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_SPI1_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_I2C0_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_I2C1_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_UART0_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_UART1_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_GPIO0_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_GPIO1_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_ADC_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_DSP_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_TIMER0_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_TIMER1_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_RTC0_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_RTC1_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_PWM_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_WDT_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_RTC_TMR_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_SW0_ISR(void) {
+ __asm(" movs r0, #16");
+ while (1) {
+ __asm(" BKPT #16");
+ }
+}
+
+void default_SW1_ISR(void) {
+ __asm(" movs r0, #17");
+ while (1) {
+ __asm(" BKPT #17");
+ }
+}
+
+////////////////////////////////////////////////////////////////////////////////
+// Reset ISR
+////////////////////////////////////////////////////////////////////////////////
+void default_ResetISR(void) {
+ int rc;
+ bool bRunningInFlash;
+
+ set_vtor();
+
+ bRunningInFlash =
+ ((((uint32_t)startup_get_my_pc()) & 0xFF000000) == 0x01000000);
+
+ if ((!REG_RTC_AO_CSR.BF.WARM_START_MODE) || bRunningInFlash) {
+ //
+ // Copy any .ro bytes to .data so that initialized global variables
+ // are actually properly initialized.
+ //
+ __asm(
+ " ldr r0, =_eftext\n"
+ " ldr r1, =_data\n"
+ " ldr r2, =_edata\n"
+ "ro_copy_loop:\n"
+ " ldr r3, [r0], #4\n"
+ " str r3, [r1], #4\n"
+ " cmp r1, r2\n"
+ " ble ro_copy_loop\n");
+
+ //
+ // Zero fill the .bss section.
+ //
+ __asm(
+ " ldr r0, =_bss\n"
+ " ldr r1, =_ebss\n"
+ " mov r2, #0\n"
+ "bss_zero_loop:\n"
+ " cmp r0, r1\n"
+ " it lt\n"
+ " strlt r2, [r0], #4\n"
+ " blt bss_zero_loop\n");
+ }
+
+ //
+ // call the main routine barefoot, i.e. without the normal CRTC0 entry
+ // point.
+ //
+ rc = _main(0, NULL);
+
+ //
+ // If main ever returns, trap it here and wake up the debugger if it is
+ // connected.
+ //
+ while (1) // for FPGA/real chip use
+ {
+ __asm(" BKPT #1");
+ }
+}
+
+////////////////////////////////////////////////////////////////////////////////
+// get my PC
+////////////////////////////////////////////////////////////////////////////////
+void* startup_get_my_pc(void) {
+ void* pc;
+ asm("mov %0, pc" : "=r"(pc));
+ return pc;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+// get my SP
+////////////////////////////////////////////////////////////////////////////////
+void* startup_get_my_sp(void) {
+ void* sp;
+ asm("mov %0, sp" : "=r"(sp));
+ return sp;
+}
+
+////////////////////////////////////////////////////////////////////////////////
+// Set VTOR based on PC
+////////////////////////////////////////////////////////////////////////////////
+void set_vtor(void) {
+ __asm(
+ " ldr r0, =0xe000ed08\n"
+ " ldr r1, =0xFF000000\n"
+ " mov r2, lr\n"
+ " and r1, r2\n"
+ " str r1, [r0]\n");
+
+ return;
+}
diff --git a/tensorflow/lite/micro/tools/make/targets/ecm3531_makefile.inc b/tensorflow/lite/micro/tools/make/targets/ecm3531_makefile.inc
new file mode 100644
index 0000000..709f060
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/ecm3531_makefile.inc
@@ -0,0 +1,121 @@
+# Settings for eta ecm3531 platform
+ifeq ($(TARGET), ecm3531)
+ TARGET_ARCH := cortex-m3
+ TARGET_TOOLCHAIN_PREFIX := arm-none-eabi-
+ ETA_SDK := /home/hari/TensaiSDK-v0.0.17/soc/
+ GCC_ARM := /home/hari/Downloads/gcc-arm-none-eabi-7-2018-q2-update/
+
+#Pick the appropriate lds file depending whether you are running frof SRAM of flash
+ ETA_LDS_FILE := ecm3531.lds
+# ETA_LDS_FILE := ecm3531_flash.lds
+
+ ifeq ($(wildcard $(ETA_SDK)),)
+ $(error Path to ETA SDK is not set (ETA_SDK))
+ endif
+
+ ifeq ($(wildcard $(GCC_ARM)),)
+ $(error Path to gcc arm compiler is not set (GCC_ARM))
+ endif
+
+ PLATFORM_FLAGS = \
+ -DARM_MATH_CM3 \
+ -DFIRMWARE_BUILD \
+ -DGEMMLOWP_ALLOW_SLOW_SCALAR_FALLBACK \
+ -DTF_LITE_STATIC_MEMORY \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -fno-rtti \
+ -fmessage-length=0 \
+ -fno-exceptions \
+ -fno-unwind-tables \
+ -ffunction-sections \
+ -fdata-sections \
+ -funsigned-char \
+ -MMD \
+ -mcpu=cortex-m3 \
+ -mthumb \
+ -mlittle-endian \
+ -mno-unaligned-access \
+ -std=gnu++11 \
+ -Wvla \
+ -Wall \
+ -Wextra \
+ -Wsign-compare \
+ -Wdouble-promotion \
+ -Wshadow \
+ -Wunused-variable \
+ -Wmissing-field-initializers \
+ -Wno-unused-parameter \
+ -Wno-write-strings \
+ -Wunused-function \
+ -fno-delete-null-pointer-checks \
+ -fno-threadsafe-statics \
+ -fomit-frame-pointer \
+ -fpermissive \
+ -fno-use-cxa-atexit \
+ -nostdlib \
+ -g \
+ -Os
+ CXXFLAGS += $(PLATFORM_FLAGS)
+ CCFLAGS += $(PLATFORM_FLAGS)
+# Adding the --specs=nano.specs flag causes the linker to use libc_nano.a
+# instead of libc.a. This gets rid of lots of errors with various pieces
+# of the exception unwinding code not being found. Not clear why it is
+# trying to link in this code to begin with, though.
+ LDFLAGS += \
+ -mthumb -mcpu=cortex-m3 \
+ -nostartfiles -static \
+ -Wl,--gc-sections -Wl,--entry,ResetISR \
+ -Wl,--start-group -lm -lc -lgcc -Wl,--end-group \
+ -fno-exceptions \
+ -nostdlib --specs=nano.specs -t -lstdc++ -lc -lnosys -lm \
+ -Wl,-T,$(MAKEFILE_DIR)/targets/ecm3531/$(ETA_LDS_FILE) \
+ -Wl,-Map=$(MAKEFILE_DIR)/targets/ecm3531/ecm3531.map,--cref
+ BUILD_TYPE := micro
+ MICROLITE_LIBS := \
+ $(GCC_ARM)/lib/gcc/arm-none-eabi/7.3.1/thumb/v7e-m/fpv4-sp/softfp/crtbegin.o \
+ -lm
+ ECM3531_INCLUDES := \
+ -I$(GCC_ARM)/arm-none-eabi/include/ \
+ -I$(ETA_SDK)/ecm3531/boards/eta_evb/projects/m3/common/inc/ \
+ -I$(ETA_SDK)/ecm3531/m3/reg/inc/ \
+ -I$(ETA_SDK)/ecm3531/m3/csp/inc/ \
+ -I$(ETA_SDK)/ecm3531/common/csp/inc/ \
+ -I$(ETA_SDK)/common/inc/ \
+ -I$(ETA_SDK)/../utils/inc/ \
+ -I$(ETA_SDK)/ecm3531/boards/eta_evb/eta_bsp/inc
+
+ INCLUDES += $(ECM3531_INCLUDES)
+ GENERATED_PROJECT_INCLUDES += $(ECM3531_INCLUDES)
+
+ # _main.c contains application and target specific initialization, like
+ # setting clock speed, default uart setups, etc. and an implementation
+#of the DebugLog interfaces.
+ MICROLITE_CC_SRCS += \
+ $(MAKEFILE_DIR)/targets/ecm3531/startup.c \
+ $(MAKEFILE_DIR)/targets/ecm3531/_main.c \
+ $(wildcard $(ETA_SDK)/ecm3531/boards/eta_evb/projects/m3/common/src/*.c) \
+ $(wildcard $(ETA_SDK)/ecm3531/m3/csp/src/*.c) \
+ $(wildcard $(ETA_SDK)/ecm3531/m3/csp/src/*.s)
+
+ # The linker script isn't a header, but it needs to get copied to the gen/
+ # directory for generated projects. This is similar to the behavior needed
+ # for headers.
+ MICROLITE_CC_HDRS += \
+ $(MAKEFILE_DIR)/targets/ecm3531/$(ETA_LDS_FILE)
+
+ TEST_SCRIPT := tensorflow/lite/micro/testing/test_ecm3531_binary.sh
+ # These are tests that don't currently work on the blue pill.
+ EXCLUDED_TESTS := \
+ tensorflow/lite/micro/micro_interpreter_test.cc \
+ tensorflow/lite/micro/simple_tensor_allocator_test.cc
+ MICROLITE_TEST_SRCS := $(filter-out $(EXCLUDED_TESTS), $(MICROLITE_TEST_SRCS))
+
+# These are microcontroller-specific rules for converting the ELF output
+# of the linker into a binary image that can be loaded directly.
+ OBJCOPY := $(TARGET_TOOLCHAIN_PREFIX)objcopy
+
+ $(BINDIR)/%.bin: $(BINDIR)/%
+ @mkdir -p $(dir $@)
+ $(OBJCOPY) $< $@ -O binary
+
+endif
diff --git a/tensorflow/lite/micro/tools/make/targets/esp_makefile.inc b/tensorflow/lite/micro/tools/make/targets/esp_makefile.inc
new file mode 100644
index 0000000..afc78e7
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/esp_makefile.inc
@@ -0,0 +1,5 @@
+# Settings for Espressif ESP32
+
+TARGET_ARCH := xtensa-esp32
+CCFLAGS := $(filter-out -std=c11,$(CCFLAGS))
+CFLAGS += -std=c11
diff --git a/tensorflow/lite/micro/tools/make/targets/hexagon/download_hexagon.sh b/tensorflow/lite/micro/tools/make/targets/hexagon/download_hexagon.sh
new file mode 100644
index 0000000..e1fa9d5
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/hexagon/download_hexagon.sh
@@ -0,0 +1,40 @@
+#!/bin/bash
+
+# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+
+# Explanation and background can be found in:
+# https://docs.google.com/document/d/1SlU5OcHEjdgs02ZCupo21mlLBJ6tE6D46FxUrQl8xUc/edit#heading=h.fshpxalu2qt4
+
+# Usage: ./tensorflow/lite/micro/tools/make/targets/hexagon/download_hexagon.sh <path-to-hexagon_tflm_core.a>
+
+# Clone hexagon kernels to temp directory and check out known-good commit.
+HEXAGON_DIR=/tmp/hexagon_optimized
+
+if [ ! -d ${HEXAGON_DIR} ]; then
+ mkdir -p ${HEXAGON_DIR}
+ git clone -b release_v2 https://source.codeaurora.org/quic/embedded_ai/tensorflow ${HEXAGON_DIR}
+fi
+
+pushd ${HEXAGON_DIR} > /dev/null
+git checkout 2d052806c211144875c89315a4fc6f1393064cf6
+popd > /dev/null
+
+# Copy optimized kernels from checkout, copy prebuilt lib.
+rm -rf tensorflow/lite/micro/kernels/hexagon
+cp -R ${HEXAGON_DIR}/tensorflow/lite/micro/kernels/hexagon tensorflow/lite/micro/kernels/hexagon
+mkdir tensorflow/lite/micro/kernels/hexagon/lib
+cp ${1} tensorflow/lite/micro/kernels/hexagon/lib/
diff --git a/tensorflow/lite/micro/tools/make/targets/hexagon_makefile.inc b/tensorflow/lite/micro/tools/make/targets/hexagon_makefile.inc
new file mode 100644
index 0000000..ee71e3c
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/hexagon_makefile.inc
@@ -0,0 +1,99 @@
+# Settings for Hexagon toolchain.
+# REQUIRED:
+# - Hexagon SDK 3.5 Toolkit (for qurt, posix libs).
+# HEXAGON_SDK_ROOT environment variable must be set to location of
+# Hexagon_SDK/<version>/ on your machine.
+# - Hexagon Tools root (for hexagon-clang++, hexagon-sim).
+# The tool folder may be a part of the Hexagon SDK
+# (e.g. $(HEXAGON_SDK_ROOT)/tools/HEXAGON_Tools) or installed
+# separately.
+# HEXAGON_ROOT environment variable must be set to location of
+# HEXAGON_Tools on your machine.
+# - HEXAGON_TOOL_VER: The Hexagon tool version (installed under HEXAGON_ROOT).
+# For example: 8.3.07
+# - HEXAGON_CPU_VER: The CPU version to use, will cause a compiler exception
+# without providing a version. Valid values may vary depending on tools
+# version, but generally in the range: v55-v67
+#
+# Unlike other targets, there is not currently a way to automatically download
+# the Hexagon SDK. For this reason, users are required to manually download
+# and configure the SDK.
+
+TARGET_ARCH := hexagon
+
+ifndef HEXAGON_SDK_ROOT
+ $(error HEXAGON_SDK_ROOT is undefined)
+endif
+
+ifndef HEXAGON_TOOL_VER
+ $(error HEXAGON_TOOL_VER is undefined)
+endif
+
+ifndef HEXAGON_ROOT
+ $(error HEXAGON_ROOT is undefined)
+endif
+
+ifndef HEXAGON_CPU_VER
+ $(error HEXAGON_CPU_VER is undefined)
+endif
+
+HEXAGON_LPI_BUILD :=
+
+PLATFORM_ARGS = \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -DTF_LITE_USE_CTIME \
+ -DHEXAGON_ASM \
+ -DMALLOC_IN_STDLIB \
+ -DPTHREAD_STUBS \
+ -DUSE_PREALLOCATED_BUFFER \
+ -D_HAS_C9X \
+ -DTF_LITE_USE_CTIME \
+ -MMD \
+ -DHEXAGON \
+ -Wall \
+ -Wextra \
+ -Wno-missing-field-initializers \
+ -Wno-sign-compare \
+ -Wno-unused-parameter \
+ -Wno-write-strings \
+ -Wunused-function \
+ -Wno-unused-private-field \
+ -Wvla \
+ -fdata-sections \
+ -ffunction-sections \
+ -fmessage-length=0 \
+ -fno-delete-null-pointer-checks \
+ -fno-exceptions \
+ -fno-register-global-dtors-with-atexit \
+ -fno-rtti \
+ -fno-short-enums \
+ -fno-threadsafe-statics \
+ -fno-unwind-tables \
+ -fno-use-cxa-atexit \
+ -fomit-frame-pointer \
+ -fpermissive \
+ -funsigned-char \
+ -mcpu=$(HEXAGON_CPU_VER) \
+ -m$(HEXAGON_CPU_VER)
+
+# See http://b/183462077 for more details on why we need -G0 for an LPI build.
+ifeq ($(HEXAGON_LPI_BUILD), true)
+ PLATFORM_ARGS += -G0
+endif
+
+export PATH := $(HEXAGON_ROOT)/$(HEXAGON_TOOL_VER)/Tools/bin:$(PATH)
+TARGET_TOOLCHAIN_PREFIX := hexagon-
+CXX_TOOL := clang++
+CC_TOOL := clang
+
+CXXFLAGS += $(PLATFORM_ARGS)
+CCFLAGS += $(PLATFORM_ARGS)
+LDFLAGS += \
+ -Wl,--gc-sections -lhexagon \
+ $(HEXAGON_ROOT)/$(HEXAGON_TOOL_VER)/Tools/target/hexagon/lib/v66/libstdc++.a
+
+INCLUDES += \
+ -I$(HEXAGON_SDK_ROOT)/libs/common/qurt/computev66/include/posix \
+ -I$(HEXAGON_SDK_ROOT)/libs/common/qurt/computev66/include/qurt
+
+TEST_SCRIPT := tensorflow/lite/micro/testing/test_hexagon_binary.sh
diff --git a/tensorflow/lite/micro/tools/make/targets/himax_we1_evb_makefile.inc b/tensorflow/lite/micro/tools/make/targets/himax_we1_evb_makefile.inc
new file mode 100644
index 0000000..f01bfe7
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/himax_we1_evb_makefile.inc
@@ -0,0 +1,93 @@
+# Settings for himax WE_1 evb.
+
+CC_TOOL = ccac
+AR_TOOL = arac
+CXX_TOOL = ccac
+LD_TOOL := ccac
+TARGET_ARCH := arc
+#ARC_TOOLCHAIN := mwdt
+
+BUILD_ARC_MLI := false
+ARC_MLI_PRE_COMPILED_TARGET := himax_arcem9d_r16
+
+include $(MAKEFILE_DIR)/targets/arc/arc_common.inc
+
+#download SDK & MLI
+HIMAX_WE1_SDK_NAME := himax_we1_sdk
+$(eval $(call add_third_party_download,$(HIMAX_WE1_SDK_URL),$(HIMAX_WE1_SDK_MD5),$(HIMAX_WE1_SDK_NAME),))
+
+#export path of toolchain
+#export PATH := $(MAKEFILE_DIR)/downloads/$(HIMAX_WE1_SDK_NAME)/image_gen_linux_v3/:$(PATH)
+
+TCF_FILE := $(PWD)/$(MAKEFILE_DIR)/downloads/$(HIMAX_WE1_SDK_NAME)/arcem9d_wei_r16.tcf
+LCF_FILE := $(PWD)/$(MAKEFILE_DIR)/downloads/$(HIMAX_WE1_SDK_NAME)/memory.lcf
+ARCLIB_FILE := $(PWD)/$(MAKEFILE_DIR)/downloads/$(HIMAX_WE1_SDK_NAME)/libembarc.a
+LIB_HEADER_FILE := $(PWD)/$(MAKEFILE_DIR)/downloads/$(HIMAX_WE1_SDK_NAME)/hx_drv_tflm.h
+
+
+DEFAULT_HEAPSZ := 8192
+DEFAULT_STACKSZ := 8192
+
+TCF_FILE_NAME = $(notdir $(TCF_FILE))
+ARC_TARGET_COPY_FILES += $(notdir $(TCF_FILE))!$(TCF_FILE)
+MAKE_PROJECT_FILES += $(TCF_FILE_NAME)
+
+
+
+LCF_FILE_NAME = $(notdir $(LCF_FILE))
+ARC_TARGET_COPY_FILES += $(notdir $(LCF_FILE))!$(LCF_FILE)
+MAKE_PROJECT_FILES += $(LCF_FILE_NAME)
+
+ARCLIB_FILE_NAME = $(notdir $(ARCLIB_FILE))
+ARC_TARGET_COPY_FILES += $(notdir $(ARCLIB_FILE))!$(ARCLIB_FILE)
+MAKE_PROJECT_FILES += $(ARCLIB_FILE_NAME)
+
+LIB_HEADER_FILE_NAME = $(notdir $(LIB_HEADER_FILE))
+ARC_TARGET_COPY_FILES += $(notdir $(LIB_HEADER_FILE))!$(LIB_HEADER_FILE)
+MAKE_PROJECT_FILES += $(LIB_HEADER_FILE_NAME)
+
+
+# Need a pointer to the TCF and lcf file
+
+PLATFORM_FLAGS = \
+ -DNDEBUG \
+ -g \
+ -DCPU_ARC \
+ -Hnosdata \
+ -DTF_LITE_STATIC_MEMORY \
+ -tcf=$(TCF_FILE_NAME) \
+ -Hnocopyr \
+ -Hpurge \
+ -Hcl \
+ -fslp-vectorize-aggressive \
+ -ffunction-sections \
+ -fdata-sections \
+ -tcf_core_config \
+
+CXXFLAGS += -fno-rtti -DSCRATCH_MEM_Z_SIZE=0x10000 $(PLATFORM_FLAGS)
+CCFLAGS += $(PLATFORM_FLAGS)
+
+INCLUDES+= \
+ -I $(MAKEFILE_DIR)/downloads/$(WEI_SDK_NAME) \
+ -I $(MAKEFILE_DIR)/downloads/kissfft
+
+GENERATED_PROJECT_INCLUDES += \
+ -I. \
+ -I./third_party/kissfft
+
+LDFLAGS += \
+ -Hheap=8192 \
+ -tcf=$(TCF_FILE_NAME) \
+ -Hnocopyr \
+ -m \
+ -Hldopt=-Coutput=$(TARGET).map \
+ $(LCF_FILE_NAME) \
+ -Hldopt=-Bgrouplib $(ARCLIB_FILE_NAME)
+
+CXXFLAGS := $(filter-out -std=c++11,$(CXXFLAGS))
+CCFLAGS := $(filter-out -std=c11,$(CCFLAGS))
+
+ldflags_to_remove = -Wl,--fatal-warnings -Wl,--gc-sections
+LDFLAGS := $(filter-out $(ldflags_to_remove),$(LDFLAGS))
+
+MICROLITE_LIBS := $(filter-out -lm,$(MICROLITE_LIBS))
diff --git a/tensorflow/lite/micro/tools/make/targets/leon_makefile.inc b/tensorflow/lite/micro/tools/make/targets/leon_makefile.inc
new file mode 100644
index 0000000..fce0551
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/leon_makefile.inc
@@ -0,0 +1,14 @@
+# Settings for SparcV8 based LEON processors from Gaisler Aeroflex
+ifeq ($(TARGET), leon)
+ PLATFORM_FLAGS = -O3 -mcpu=leon3
+ CXXFLAGS += -std=c++11 $(PLATFORM_FLAGS)
+ CCFLAGS += $(PLATFORM_FLAGS)
+ TARGET_ARCH := leon
+ TARGET_TOOLCHAIN_PREFIX := tensorflow/lite/micro/tools/make/downloads/leon_bcc2/bin/sparc-gaisler-elf-
+ TEST_SCRIPT := tensorflow/lite/micro/testing/test_leon_binary.sh
+ GCC_LEON := $(MAKEFILE_DIR)/downloads/leon_bcc2/
+
+ $(eval $(call add_third_party_download,$(LEON_BCC2_URL),$(LEON_BCC2_MD5),leon_bcc2,))
+ $(eval $(call add_third_party_download,$(TSIM_URL),$(TSIM_MD5),tsim,))
+
+endif
diff --git a/tensorflow/lite/micro/tools/make/targets/mbed_makefile.inc b/tensorflow/lite/micro/tools/make/targets/mbed_makefile.inc
new file mode 100644
index 0000000..6d7d853
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/mbed_makefile.inc
@@ -0,0 +1,11 @@
+# Settings for mbed platforms.
+ifeq ($(TARGET), mbed)
+ TARGET_ARCH := cortex-m4
+ $(eval $(call add_third_party_download,$(CMSIS_URL),$(CMSIS_MD5),cmsis,))
+ $(eval $(call add_third_party_download,$(CUST_CMSIS_URL),$(CUST_CMSIS_MD5),CMSIS_ext,))
+
+ DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/arm_gcc_download.sh ${MAKEFILE_DIR}/downloads)
+ ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the GCC download: $(DOWNLOAD_RESULT))
+ endif
+endif
diff --git a/tensorflow/lite/micro/tools/make/targets/mcu_riscv_makefile.inc b/tensorflow/lite/micro/tools/make/targets/mcu_riscv_makefile.inc
new file mode 100644
index 0000000..9c87a10
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/mcu_riscv_makefile.inc
@@ -0,0 +1,69 @@
+# Settings for RISCV 32-bit MCU toolchain.
+ifeq ($(TARGET), riscv32_mcu)
+ TARGET_ARCH := riscv32_mcu
+ TARGET_TOOLCHAIN_PREFIX := riscv64-unknown-elf-
+
+ $(eval $(call add_third_party_download,$(RISCV_TOOLCHAIN_URL),$(RISCV_TOOLCHAIN_MD5),riscv_toolchain,))
+ $(eval $(call add_third_party_download,$(SIFIVE_FE310_LIB_URL),$(SIFIVE_FE310_LIB_MD5),sifive_fe310_lib,))
+
+ PLATFORM_FLAGS = \
+ -march=rv32imac \
+ -mabi=ilp32 \
+ -mcmodel=medany \
+ -mexplicit-relocs \
+ -fno-builtin-printf \
+ -fno-exceptions \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -DTF_LITE_USE_GLOBAL_CMATH_FUNCTIONS \
+ -fno-unwind-tables \
+ -ffunction-sections \
+ -fdata-sections \
+ -funsigned-char \
+ -Wvla \
+ -Wall \
+ -Wextra \
+ -Wsign-compare \
+ -Wdouble-promotion \
+ -Wshadow \
+ -Wunused-variable \
+ -Wmissing-field-initializers \
+ -Wno-unused-parameter \
+ -Wno-write-strings \
+ -Wunused-function \
+ -fno-delete-null-pointer-checks \
+ -fno-threadsafe-statics \
+ -fomit-frame-pointer \
+ -fno-use-cxa-atexit \
+ -Os
+
+ CXXFLAGS += $(PLATFORM_FLAGS) \
+ -fpermissive \
+ -fno-rtti \
+ --std=gnu++11
+
+ CCFLAGS += $(PLATFORM_FLAGS)
+
+ BUILD_TYPE := micro
+
+ INCLUDES += \
+ -I$(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/include \
+ -I$(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/drivers/ \
+ -I$(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env \
+ -I$(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/freedom-e300-hifive1
+
+ MICROLITE_CC_SRCS += \
+ $(wildcard tensorflow/lite/micro/riscv32_mcu/*.cc)
+
+ LDFLAGS += \
+ -T$(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env/freedom-e300-hifive1/flash.lds \
+ -nostartfiles \
+ -L$(MAKEFILE_DIR)/downloads/sifive_fe310_lib/bsp/env \
+ --specs=nano.specs
+
+# These are microcontroller-specific rules for converting the ELF output
+# of the linker into a binary image that can be loaded directly.
+ OBJCOPY := $(TARGET_TOOLCHAIN_PREFIX)objcopy
+ $(BINDIR)/%.bin: $(BINDIR)/%
+ @mkdir -p $(dir $@)
+ $(OBJCOPY) $< $@ -O binary
+endif
diff --git a/tensorflow/lite/micro/tools/make/targets/sparkfun_edge_makefile.inc b/tensorflow/lite/micro/tools/make/targets/sparkfun_edge_makefile.inc
new file mode 100644
index 0000000..0a4e532
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/sparkfun_edge_makefile.inc
@@ -0,0 +1,2 @@
+include $(MAKEFILE_DIR)/targets/apollo3evb_makefile.inc
+
diff --git a/tensorflow/lite/micro/tools/make/targets/spresense_makefile.inc b/tensorflow/lite/micro/tools/make/targets/spresense_makefile.inc
new file mode 100644
index 0000000..39363fb
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/spresense_makefile.inc
@@ -0,0 +1,100 @@
+# Settings for Spresense based platforms
+# For spresense, Tensorflow lite Microcontroller is used as a library.
+
+# This setting makefile accept 4 optional parameters on the make command line.
+# These options below are needed for build an example of Tensorflow Microcontroller.
+# But just build a library, no need to add those options.
+#
+# SPRESENSE_DEFS : This is the file path to Make.defs which includes configuration
+# parameters of spresense.
+# SPRESENSE_CONFIG_H : This is the file path to config.h which includes configuration
+# parameters for source code.
+# SPRESENSE_CURDIR : This is the directory path of externals/tensorflow in spresense
+# source repository.
+# SPRESENSE_APP_TFMAKE : This is the file path to makefile.inc for additional source code
+# in spresense to use tensorflow.
+
+# Evacuate Compiler flags to avoid override them with loading Spresense Config
+TMP_CXXFLAGS := $(CXXFLAGS)
+TMP_CCLAGS := $(CCFLAGS)
+
+# Define empty variable for add spresense specific settings
+SPRESENSE_PLATFORM_FLAGS :=
+
+ifneq ($(SPRESENSE_DEFS),)
+
+# Load Spresense Config
+include $(SPRESENSE_DEFS)
+
+SPRESENSE_PLATFORM_FLAGS := \
+ -DSPRESENSE_CONFIG_H="\"$(SPRESENSE_CONFIG_H)\"" \
+ -I$(SPRESENSE_CURDIR)/wrapper_include
+
+# Load application for Tensorflow lite micro in Spresense
+ifneq ($(SPRESENSE_APP_TFMAKE),)
+ifeq ($(CONFIG_EXTERNALS_TENSORFLOW_EXAMPLE_NONE),y)
+-include $(SPRESENSE_APP_TFMAKE)
+endif
+endif
+
+endif
+
+TARGET_ARCH := cortex-m4
+TARGET_TOOLCHAIN_PREFIX := arm-none-eabi-
+
+PLATFORM_FLAGS = \
+ $(SPRESENSE_PLATFORM_FLAGS) \
+ -DGEMMLOWP_ALLOW_SLOW_SCALAR_FALLBACK \
+ -DTF_LITE_STATIC_MEMORY \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -fmessage-length=0 \
+ -fno-exceptions \
+ -fno-unwind-tables \
+ -ffunction-sections \
+ -fdata-sections \
+ -funsigned-char \
+ -MMD \
+ -mcpu=cortex-m4 \
+ -mabi=aapcs \
+ -mthumb \
+ -mfpu=fpv4-sp-d16 \
+ -mfloat-abi=hard \
+ -Wall \
+ -Wextra \
+ -Wno-shadow \
+ -Wno-vla \
+ -Wno-strict-aliasing \
+ -Wno-type-limits \
+ -Wno-unused-parameter \
+ -Wno-missing-field-initializers \
+ -Wno-write-strings \
+ -Wno-sign-compare \
+ -Wunused-function \
+ -fno-delete-null-pointer-checks \
+ -fomit-frame-pointer \
+ -Os
+
+CXXFLAGS := $(TMP_CXXFLAGS) $(PLATFORM_FLAGS) -std=gnu++11 -fno-rtti -fno-use-cxa-atexit
+CCFLAGS := $(TMP_CCFLAGS) $(PLATFORM_FLAGS)
+
+BUILD_TYPE := micro
+
+INCLUDES += -isystem$(MAKEFILE_DIR)/downloads/cmsis/CMSIS/Core/Include/
+
+THIRD_PARTY_CC_SRCS := \
+ $(THIRD_PARTY_CC_SRCS) \
+ $(MAKEFILE_DIR)/../../spresense/compiler_specific.cc \
+
+# TODO: Now Spresense environment is not support tests.
+# So remove every tests.
+MICROLITE_TEST_SRCS :=
+MICRO_LITE_EXAMPLE_TESTS :=
+
+# These are microcontroller-specific rules for converting the ELF output
+# of the linker into a binary image that can be loaded directly.
+OBJCOPY := $(TARGET_TOOLCHAIN_PREFIX)objcopy
+
+$(BINDIR)/%.bin: $(BINDIR)/%
+ @mkdir -p $(dir $@)
+ $(OBJCOPY) $< $@ -O binary
+
diff --git a/tensorflow/lite/micro/tools/make/targets/stm32f4/stm32f4.lds b/tensorflow/lite/micro/tools/make/targets/stm32f4/stm32f4.lds
new file mode 100644
index 0000000..b7603d9
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/stm32f4/stm32f4.lds
@@ -0,0 +1,89 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+/* Define main entry point */
+ENTRY(_main)
+
+/* 256K of RAM and 2048K of FLASH. Source: */
+/* https://github.com/renode/renode/blob/master/platforms/cpus/stm32f4.repl*/
+MEMORY {
+ RAM (xrw) : ORIGIN = 0x20000000, LENGTH = 256K
+ FLASH (rx) : ORIGIN = 0x8000000, LENGTH = 2048K
+}
+
+/* Compute where the stack ends rather than hard coding it */
+_ld_stack_end_addr = ORIGIN(RAM) + LENGTH(RAM);
+_ld_min_stack_size = 0x200;
+
+SECTIONS {
+
+/* interrupt vector goes to top of flash */
+
+.interrupt_vector : {
+ . = ALIGN(4);
+ KEEP(*(.interrupt_vector))
+ . = ALIGN(4);
+} >FLASH
+
+/* read only .text and .rodata go to flash */
+
+.text : {
+ . = ALIGN(4);
+ KEEP(*(.text.interrupt_handler))
+ *(.text*)
+} >FLASH
+
+.rodata : {
+ . = ALIGN(4);
+ *(.rodata*)
+ . = ALIGN(4);
+} >FLASH
+
+/* read mwrite data needs to be stored in flash but copied to ram */
+.data : {
+ . = ALIGN(4);
+ _ld_data_load_dest_start = .; /* export where to load from */
+ *(.data*)
+ . = ALIGN(4);
+ _ld_data_load_dest_stop = .; /* export where to load from */
+} >RAM AT> FLASH
+_ld_data_load_source = LOADADDR(.data);
+
+/* unitialized data section needs zero initialization */
+.bss :
+{
+ . = ALIGN(4);
+ _ld_bss_data_start = .;
+ *(.bss*)
+ . = ALIGN(4);
+ _ld_bss_data_stop = .;
+} >RAM
+
+._user_heap_stack :
+{
+ . = ALIGN(8);
+ . += _ld_min_stack_size;
+ PROVIDE(end = .);
+ . = ALIGN(8);
+} >RAM
+
+/DISCARD/ :
+{
+ libc.a (*)
+ libm.a (*)
+ libgcc.a (*)
+}
+
+} /* SECTIONS */
diff --git a/tensorflow/lite/micro/tools/make/targets/stm32f4_makefile.inc b/tensorflow/lite/micro/tools/make/targets/stm32f4_makefile.inc
new file mode 100644
index 0000000..0903f27
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/stm32f4_makefile.inc
@@ -0,0 +1,105 @@
+# Settings for stm32f4 based platforms
+
+export PATH := $(MAKEFILE_DIR)/downloads/gcc_embedded/bin/:$(PATH)
+TARGET_ARCH := cortex-m4
+TARGET_TOOLCHAIN_PREFIX := arm-none-eabi-
+TARGET_TOOLCHAIN_ROOT := $(TENSORFLOW_ROOT)$(MAKEFILE_DIR)/downloads/gcc_embedded/bin/
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/arm_gcc_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the GCC download: $(DOWNLOAD_RESULT))
+endif
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/renode_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the renode download: $(DOWNLOAD_RESULT))
+endif
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/cmsis_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the CMSIS download: $(DOWNLOAD_RESULT))
+endif
+
+DOWNLOAD_RESULT := $(shell $(MAKEFILE_DIR)/ext_libs/stm32_bare_lib_download.sh ${MAKEFILE_DIR}/downloads)
+ifneq ($(DOWNLOAD_RESULT), SUCCESS)
+ $(error Something went wrong with the STM32 Bare Lib download: $(DOWNLOAD_RESULT))
+endif
+
+# TODO(b/161478030): change -Wno-vla to -Wvla and remove -Wno-shadow once
+# we have a solution for fixing / avoiding being tripped up by these warnings.
+PLATFORM_FLAGS = \
+ -DGEMMLOWP_ALLOW_SLOW_SCALAR_FALLBACK \
+ -DTF_LITE_STATIC_MEMORY \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -fmessage-length=0 \
+ -fno-exceptions \
+ -fno-unwind-tables \
+ -ffunction-sections \
+ -fdata-sections \
+ -funsigned-char \
+ -MMD \
+ -mcpu=cortex-m4 \
+ -mthumb \
+ -Wall \
+ -Wextra \
+ -Wno-shadow \
+ -Wno-vla \
+ -Wno-strict-aliasing \
+ -Wno-type-limits \
+ -Wno-unused-parameter \
+ -Wno-missing-field-initializers \
+ -Wno-write-strings \
+ -Wno-sign-compare \
+ -Wunused-function \
+ -fno-delete-null-pointer-checks \
+ -fomit-frame-pointer \
+ -g \
+ -Os
+
+# TODO(#46937): Remove once initialization of global variables is sorted out.
+PLATFORM_FLAGS += -DRENODE
+
+CXXFLAGS += $(PLATFORM_FLAGS) -std=gnu++11 -fno-rtti -fno-use-cxa-atexit
+CCFLAGS += $(PLATFORM_FLAGS)
+LDFLAGS += \
+ --specs=nosys.specs \
+ -T ${TENSORFLOW_ROOT}$(MAKEFILE_DIR)/targets/stm32f4/stm32f4.lds \
+ -Wl,-Map=${TENSORFLOW_ROOT}$(MAKEFILE_DIR)/gen/$(TARGET).map,--cref \
+ -Wl,--gc-sections
+BUILD_TYPE := micro
+MICROLITE_LIBS := \
+ -lm
+INCLUDES += \
+ -isystem$(MAKEFILE_DIR)/downloads/cmsis/CMSIS/Core/Include/ \
+ -I$(MAKEFILE_DIR)/downloads/stm32_bare_lib/include/
+THIRD_PARTY_CC_SRCS += \
+ $(wildcard $(MAKEFILE_DIR)/downloads/stm32_bare_lib/source/*.c) \
+ $(wildcard $(MAKEFILE_DIR)/downloads/stm32_bare_lib/source/*.cc)
+EXCLUDED_SRCS := \
+ $(MAKEFILE_DIR)/downloads/stm32_bare_lib/source/debug_log.c
+THIRD_PARTY_CC_SRCS := $(filter-out $(EXCLUDED_SRCS), $(THIRD_PARTY_CC_SRCS))
+MICROLITE_CC_SRCS := $(filter-out $(EXCLUDED_SRCS), $(MICROLITE_CC_SRCS))
+
+# TODO(b/158324045): Examine why some tests fail here.
+EXCLUDED_TESTS := \
+ tensorflow/lite/micro/micro_interpreter_test.cc \
+ tensorflow/lite/micro/micro_allocator_test.cc \
+ tensorflow/lite/micro/memory_helpers_test.cc \
+ tensorflow/lite/micro/memory_arena_threshold_test.cc \
+ tensorflow/lite/micro/recording_micro_allocator_test.cc
+MICROLITE_TEST_SRCS := $(filter-out $(EXCLUDED_TESTS), $(MICROLITE_TEST_SRCS))
+
+EXCLUDED_EXAMPLE_TESTS := \
+ tensorflow/lite/micro/examples/magic_wand/Makefile.inc \
+ tensorflow/lite/micro/examples/micro_speech/Makefile.inc \
+ tensorflow/lite/micro/examples/person_detection/Makefile.inc \
+ tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc
+MICRO_LITE_EXAMPLE_TESTS := $(filter-out $(EXCLUDED_EXAMPLE_TESTS), $(MICRO_LITE_EXAMPLE_TESTS))
+
+TEST_SCRIPT := tensorflow/lite/micro/testing/test_with_renode.sh
+
+# We are setting this variable to non-zero to allow us to have a custom
+# implementation of `make test` for bluepill
+TARGET_SPECIFIC_MAKE_TEST := 1
+test: build
+ $(TEST_SCRIPT) $(BINDIR) $(TEST_PASS_STRING) $(TARGET)
diff --git a/tensorflow/lite/micro/tools/make/targets/xcore_makefile.inc b/tensorflow/lite/micro/tools/make/targets/xcore_makefile.inc
new file mode 100644
index 0000000..9a0f746
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/xcore_makefile.inc
@@ -0,0 +1,24 @@
+# Settings for XMOS XS3 based processors (xcore.ai, ...)
+
+#IMPORTANT: to set up environment variables correctly run the following from the top tensorflow directory:
+# $ make -f tensorflow/lite/micro/tools/make/Makefile TARGET="xcore" clean clean_downloads test
+# $ pushd tensorflow/lite/micro/tools/make/downloads/xtimecomposer/xTIMEcomposer/15.0.0/ && source SetEnv && popd
+# $ make -f tensorflow/lite/micro/tools/make/Makefile TARGET="xcore" test
+
+ifeq ($(TARGET), xcore)
+ XTIME_URL := "https://www.xmos.com/download/Tools-15---Linux-64%2815.0.0_rc1%29.tgz?key=132D-9DC9-E913-0229-ECE6-D5AB-F511-2B19"
+ XTIME_MD5 := "8f6543c8ac4af7583edf75e62df322a2"
+ $(eval $(call add_third_party_download,$(XTIME_URL),$(XTIME_MD5),xtimecomposer))
+ PLATFORM_FLAGS = -target=XU316-1024-FB265-C32 -mcmodel=large -Os -DXCORE -Wno-xcore-fptrgroup -report
+ CXX_TOOL := xcc
+ CC_TOOL := xcc
+ AR_TOOL := xmosar
+ override CXXFLAGS := -std=c++11 -g -DTF_LITE_STATIC_MEMORY -DNDEBUG
+ override CXXFLAGS += $(PLATFORM_FLAGS)
+ override CCFLAGS := -g -DTF_LITE_STATIC_MEMORY -DNDEBUG
+ override CCFLAGS += $(PLATFORM_FLAGS)
+ TARGET_ARCH := xcore
+ #TARGET_TOOLCHAIN_PREFIX := tensorflow/lite/micro/tools/make/downloads/xtimecomposer/bin/
+ TEST_SCRIPT := tensorflow/lite/micro/testing/test_xcore_binary.sh
+ #GCC_XCORE := $(MAKEFILE_DIR)/downloads/xtimecomposer/bin/
+endif
diff --git a/tensorflow/lite/micro/tools/make/targets/xtensa_makefile.inc b/tensorflow/lite/micro/tools/make/targets/xtensa_makefile.inc
new file mode 100644
index 0000000..1a111d4
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/xtensa_makefile.inc
@@ -0,0 +1,90 @@
+# Settings for Xtensa toolchain for the hifimini kernels.
+# REQUIRED:
+# Environment variables:
+# - XTENSA_BASE must be set to location of
+# the Xtensa developer tools installation directory.
+# Command line arguments:
+# - XTENSA_TOOLS_VERSION: For example: RI-2019.2-linux
+# - XTENSA_CORE: The name of the Xtensa core to use
+# For example: hifimini
+
+TARGET_ARCH :=
+XTENSA_USE_LIBC :=
+
+ifndef XTENSA_BASE
+ $(error XTENSA_BASE is undefined)
+endif
+
+ifndef XTENSA_TOOLS_VERSION
+ $(error XTENSA_TOOLS_VERSION is undefined)
+endif
+
+ifndef XTENSA_CORE
+ $(error XTENSA_CORE is undefined)
+endif
+
+ifeq ($(TARGET_ARCH), )
+ $(error TARGET_ARCH must be specified on the command line)
+endif
+
+# Create a cflag based on the specified TARGET_ARCH. For example:
+# TARGET_ARCH=hifimini --> -DHIFIMINI
+# TARGET_ARCH=fusion_f1 --> -DFUSION_F1
+TARGET_ARCH_DEFINES := -D$(shell echo $(TARGET_ARCH) | tr [a-z] [A-Z])
+
+PLATFORM_FLAGS = \
+ -DTF_LITE_MCU_DEBUG_LOG \
+ -DTF_LITE_USE_CTIME \
+ --xtensa-core=$(XTENSA_CORE) \
+ -mcoproc \
+ -DMAX_RFFT_PWR=9 \
+ -DMIN_RFFT_PWR=MAX_RFFT_PWR \
+ $(TARGET_ARCH_DEFINES)
+
+ifeq ($(BUILD_TYPE), release)
+ PLATFORM_FLAGS += -Wno-unused-private-field
+endif
+
+export PATH := $(XTENSA_BASE)/tools/$(XTENSA_TOOLS_VERSION)/XtensaTools/bin:$(PATH)
+TARGET_TOOLCHAIN_PREFIX := xt-
+CXX_TOOL := clang++
+CC_TOOL := clang
+
+# Unused exception related symbols make their way into a binary that links
+# against TFLM as described in https://github.com/tensorflow/tensorflow/issues/47575.
+# We have two options to avoid this. The first involves using -stdlib=libc++ and
+# the second involves stubbing out and modifying some of the files in the Xtensa
+# toolchain to prevent inclusion of the exception handling code
+# (http://b/182209217#comment3). This Makefile supports building TFLM in a way
+# that is compatible with either of the two approaches.
+ifeq ($(XTENSA_USE_LIBC), true)
+ PLATFORM_FLAGS += -stdlib=libc++
+else
+ # TODO(b/150240249): Do not filter-out -fno-rtti once that works for the
+ # Xtensa toolchain.
+ CXXFLAGS := $(filter-out -fno-rtti, $(CXXFLAGS))
+endif
+
+CXXFLAGS += $(PLATFORM_FLAGS)
+CCFLAGS += $(PLATFORM_FLAGS)
+
+TEST_SCRIPT := tensorflow/lite/micro/testing/test_xtensa_binary.sh
+
+# TODO(b/158651472): Fix the memory_arena_threshold_test
+# TODO(b/174707181): Fix the micro_interpreter_test
+EXCLUDED_TESTS := \
+ tensorflow/lite/micro/micro_interpreter_test.cc \
+ tensorflow/lite/micro/memory_arena_threshold_test.cc
+MICROLITE_TEST_SRCS := $(filter-out $(EXCLUDED_TESTS), $(MICROLITE_TEST_SRCS))
+
+# TODO(b/156962140): This manually maintained list of excluded examples is
+# quite error prone.
+EXCLUDED_EXAMPLE_TESTS := \
+ tensorflow/lite/micro/examples/hello_world/Makefile.inc \
+ tensorflow/lite/micro/examples/image_recognition_experimental/Makefile.inc \
+ tensorflow/lite/micro/examples/magic_wand/Makefile.inc \
+ tensorflow/lite/micro/examples/micro_speech/Makefile.inc \
+ tensorflow/lite/micro/examples/network_tester/Makefile.inc \
+ tensorflow/lite/micro/examples/person_detection/Makefile.inc
+MICRO_LITE_EXAMPLE_TESTS := $(filter-out $(EXCLUDED_EXAMPLE_TESTS), $(MICRO_LITE_EXAMPLE_TESTS))
+
diff --git a/tensorflow/lite/micro/tools/make/targets/zephyr_vexriscv_makefile.inc b/tensorflow/lite/micro/tools/make/targets/zephyr_vexriscv_makefile.inc
new file mode 100644
index 0000000..728a26e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/targets/zephyr_vexriscv_makefile.inc
@@ -0,0 +1,3 @@
+$(eval $(call add_third_party_download,$(ZEPHYR_URL),$(ZEPHYR_MD5),zephyr,setup_zephyr))
+export ZEPHYR_SDK_INSTALL_DIR?=/opt/zephyr-sdk
+export ZEPHYR_BASE?=$(realpath $(MAKEFILE_DIR)/downloads/zephyr)
diff --git a/tensorflow/lite/micro/tools/make/templates/AUDIO_DISCO_F746NG.lib.tpl b/tensorflow/lite/micro/tools/make/templates/AUDIO_DISCO_F746NG.lib.tpl
new file mode 100644
index 0000000..11dae1e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/AUDIO_DISCO_F746NG.lib.tpl
@@ -0,0 +1 @@
+https://os.mbed.com/teams/ST/code/AUDIO_DISCO_F746NG/#7046ce26b7ed
diff --git a/tensorflow/lite/micro/tools/make/templates/BSP_DISCO_F746NG.lib.tpl b/tensorflow/lite/micro/tools/make/templates/BSP_DISCO_F746NG.lib.tpl
new file mode 100644
index 0000000..48dc131
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/BSP_DISCO_F746NG.lib.tpl
@@ -0,0 +1 @@
+https://os.mbed.com/teams/ST/code/BSP_DISCO_F746NG/#df2ea349c37a
diff --git a/tensorflow/lite/micro/tools/make/templates/LCD_DISCO_F746NG.lib.tpl b/tensorflow/lite/micro/tools/make/templates/LCD_DISCO_F746NG.lib.tpl
new file mode 100644
index 0000000..899a504
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/LCD_DISCO_F746NG.lib.tpl
@@ -0,0 +1 @@
+http://os.mbed.com/teams/ST/code/LCD_DISCO_F746NG/#d44525b1de98
diff --git a/tensorflow/lite/micro/tools/make/templates/Makefile.tpl b/tensorflow/lite/micro/tools/make/templates/Makefile.tpl
new file mode 100644
index 0000000..6078b92
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/Makefile.tpl
@@ -0,0 +1,57 @@
+TARGET_TOOLCHAIN_ROOT := %{TARGET_TOOLCHAIN_ROOT}%
+TARGET_TOOLCHAIN_PREFIX := %{TARGET_TOOLCHAIN_PREFIX}%
+
+# These are microcontroller-specific rules for converting the ELF output
+# of the linker into a binary image that can be loaded directly.
+CXX := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)g++'
+CC := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)gcc'
+AS := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)as'
+AR := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)ar'
+LD := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)ld'
+NM := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)nm'
+OBJDUMP := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)objdump'
+OBJCOPY := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)objcopy'
+SIZE := '$(TARGET_TOOLCHAIN_ROOT)$(TARGET_TOOLCHAIN_PREFIX)size'
+
+RM = rm -f
+ARFLAGS := -csr
+SRCS := \
+%{SRCS}%
+
+OBJS := \
+$(patsubst %.cc,%.o,$(patsubst %.c,%.o,$(SRCS)))
+
+LIBRARY_OBJS := $(filter-out tensorflow/lite/micro/examples/%, $(OBJS))
+
+CXXFLAGS += %{CXX_FLAGS}%
+CCFLAGS += %{CC_FLAGS}%
+
+LDFLAGS += %{LINKER_FLAGS}%
+
+
+# library to be generated
+MICROLITE_LIB = libtensorflow-microlite.a
+
+%.o: %.cc
+ $(CXX) $(CXXFLAGS) $(INCLUDES) -c $< -o $@
+
+%.o: %.c
+ $(CC) $(CCFLAGS) $(INCLUDES) -c $< -o $@
+
+%{EXECUTABLE}% : $(OBJS)
+ $(CXX) $(CXXFLAGS) -o $@ $(OBJS) $(LDFLAGS)
+
+
+# Creates a tensorflow-litemicro.a which excludes any example code.
+$(MICROLITE_LIB): tensorflow/lite/schema/schema_generated.h $(LIBRARY_OBJS)
+ @mkdir -p $(dir $@)
+ $(AR) $(ARFLAGS) $(MICROLITE_LIB) $(LIBRARY_OBJS)
+
+all: %{EXECUTABLE}%
+
+lib: $(MICROLITE_LIB)
+
+clean:
+ -$(RM) $(OBJS)
+ -$(RM) %{EXECUTABLE}%
+ -$(RM) ${MICROLITE_LIB}
diff --git a/tensorflow/lite/micro/tools/make/templates/README_KEIL.md.tpl b/tensorflow/lite/micro/tools/make/templates/README_KEIL.md.tpl
new file mode 100644
index 0000000..5b4560e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/README_KEIL.md.tpl
@@ -0,0 +1,5 @@
+# TensorFlow Lite Micro Keil Project
+
+This folder has been autogenerated by TensorFlow, and contains source, header,
+and project files needed to build a single TensorFlow Lite Micro target using
+the Keil uVision IDE.
diff --git a/tensorflow/lite/micro/tools/make/templates/README_MAKE.md.tpl b/tensorflow/lite/micro/tools/make/templates/README_MAKE.md.tpl
new file mode 100644
index 0000000..f9f6a9c
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/README_MAKE.md.tpl
@@ -0,0 +1,29 @@
+# TensorFlow Lite Micro Make Project
+
+This folder has been autogenerated by TensorFlow, and contains source, header,
+and project files needed to build a single TensorFlow Lite Micro target using
+the make tool.
+
+## Usage
+
+To build this, run:
+
+```
+make
+```
+
+This should attempt to build the target locally on your platform, using the
+standard Makefile variables like CFLAGS, CC, CXX, and so on.
+
+## Project Generation
+
+See
+[tensorflow/lite/micro](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro)
+for details on how projects like this can be generated from the main source
+tree.
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository,
+and third party dependencies are covered by their respective licenses, in the
+third_party folder of this package.
diff --git a/tensorflow/lite/micro/tools/make/templates/README_MBED.md.tpl b/tensorflow/lite/micro/tools/make/templates/README_MBED.md.tpl
new file mode 100644
index 0000000..2685cbe
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/README_MBED.md.tpl
@@ -0,0 +1,48 @@
+# TensorFlow Lite Micro Mbed Project
+
+This folder has been autogenerated by TensorFlow, and contains source, header,
+and project files needed to build a single TensorFlow Lite Micro target using
+the Mbed command line interface.
+
+## Usage
+
+To load the dependencies this code requires, run:
+
+```
+mbed config root .
+mbed deploy
+```
+
+TensorFlow requires C++ 11, so you'll need to update your profiles to reflect
+this. Here's a short Python command that does that:
+
+```
+python -c 'import fileinput, glob;
+for filename in glob.glob("mbed-os/tools/profiles/*.json"):
+ for line in fileinput.input(filename, inplace=True):
+ print line.replace("\"-std=gnu++98\"","\"-std=c++11\", \"-fpermissive\"")'
+```
+
+With that setting updated, you should now be able to compile:
+
+```
+mbed compile -m auto -t GCC_ARM
+```
+
+If this works, it will give you a .bin file that you can flash onto the device
+you're targeting. For example, using a Discovery STM3246G board, you can deploy
+it by copying the bin to the volume mounted as a USB drive, just by dragging
+over the file.
+
+## Project Generation
+
+See
+[tensorflow/lite/micro](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro)
+for details on how projects like this can be generated from the main source
+tree.
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository,
+and third party dependencies are covered by their respective licenses, in the
+third_party folder of this package.
diff --git a/tensorflow/lite/micro/tools/make/templates/SDRAM_DISCO_F746NG.lib.tpl b/tensorflow/lite/micro/tools/make/templates/SDRAM_DISCO_F746NG.lib.tpl
new file mode 100644
index 0000000..e2ccd7b
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/SDRAM_DISCO_F746NG.lib.tpl
@@ -0,0 +1 @@
+https://os.mbed.com/teams/ST/code/SDRAM_DISCO_F746NG/#370f402a2219
diff --git a/tensorflow/lite/micro/tools/make/templates/TensorFlowLite.h b/tensorflow/lite/micro/tools/make/templates/TensorFlowLite.h
new file mode 100644
index 0000000..3ba9a5d
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/TensorFlowLite.h
@@ -0,0 +1,22 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_MICRO_TOOLS_MAKE_TEMPLATES_TENSORFLOWLITE_H_
+#define TENSORFLOW_LITE_MICRO_TOOLS_MAKE_TEMPLATES_TENSORFLOWLITE_H_
+
+// This header is deliberately empty, and is only present because including it
+// in a .ino sketch forces the Arduino toolchain to build the rest of the
+// library.
+
+#endif // TENSORFLOW_LITE_MICRO_TOOLS_MAKE_TEMPLATES_TENSORFLOWLITE_H_
diff --git a/tensorflow/lite/micro/tools/make/templates/arc/README_ARC.md.tpl b/tensorflow/lite/micro/tools/make/templates/arc/README_ARC.md.tpl
new file mode 100644
index 0000000..0ddaf3e
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/arc/README_ARC.md.tpl
@@ -0,0 +1,45 @@
+# TensorFlow Lite Micro ARC Make Project
+
+This folder has been autogenerated by TensorFlow, and contains sources, headers, and project files needed to build a single TensorFlow Lite Micro application using make tool and a Synopsys DesignWare ARC processor compatible toolchain, specifically the ARC MetaWare Development Toolkit (MWDT).
+
+This project has been generated for a target defined by TCF file only (Tool Configuration File). The real target board is unspecified, and applications can be run only in the nSIM simulator included with MWDT.
+
+See
+[tensorflow/lite/micro](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro)
+for details on how projects like this can be generated from the main source tree.
+
+## Usage
+
+See [Custom ARC EM/HS Platform](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/tools/make/targets/arc/README.md#Custom-ARC-EMHS-Platform) section for more detailed information on requirements and usage of this project.
+
+The Makefile contains all the information on building and running the project. One can modify it to satisfy specific needs. Next actions are available out of the box. You may need to adjust the following commands in order to use the appropriate make tool available in your environment, ie: `make` or `gmake`
+
+1. Build the application.
+
+ make app
+
+2. Build the application passing additional flags to compiler.
+
+ make app EXT_CFLAGS=[additional compiler flags]
+
+3. Build the application and stripout TFLM reference kernel fallback implementations in order to reduce code size. This only has an effect in case the project was generated with MLI support. See more info in [EmbARC MLI Library Based Optimizations](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/kernels/arc_mli/README.md). `false` is the default value.
+
+ make app MLI_ONLY=[true|false]
+
+4. Delete all artifacts created during build.
+
+ make clean
+
+5. Run the application with the nSIM simulator in console mode.
+
+ make run
+
+6. Run the application with the nSIM simulator, but using the MetaWare Debugger GUI for further execution/debugging capabilities.
+
+ make debug
+
+
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository, and third party dependencies are covered by their respective licenses, in the third_party folder of this package.
diff --git a/tensorflow/lite/micro/tools/make/templates/arc/README_ARC_EMSDP.md.tpl b/tensorflow/lite/micro/tools/make/templates/arc/README_ARC_EMSDP.md.tpl
new file mode 100644
index 0000000..7664502
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/arc/README_ARC_EMSDP.md.tpl
@@ -0,0 +1,48 @@
+# TensorFlow Lite Micro ARC Make Project for EM SDP Board.
+
+This folder has been autogenerated by TensorFlow, and contains source, header, and project files needed to build a single TensorFlow Lite Micro target using make tool and a Synopsys DesignWare ARC processor compatible toolchain, specifically the ARC MetaWare Development Toolkit (MWDT).
+
+This project has been generated for the ARC EM Software Development Platform (EM SDP). The built application can be run only on this platform.
+
+See
+[tensorflow/lite/micro](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro)
+for details on how projects like this can be generated from the main source tree.
+
+## Usage
+
+See [ARC EM Software Development Platform](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/tools/make/targets/arc/README.md#ARC-EM-Software-Development-Platform-ARC-EM-SDP) section for more detailed information on requirements and usage of this project.
+
+The Makefile contains all the information on building and running the project. One can modify it to satisfy specific needs. Next actions are available out of the box. You may need to adjust the following commands in order to use the appropriate make tool available in your environment, ie: `make` or `gmake`:
+
+1. Build the application.
+
+ make app
+
+2. Build the application passing additional flags to compiler.
+
+ make app EXT_CFLAGS=[additional compiler flags]
+
+3. Build the application and stripout TFLM reference kernel fallback implementations in order to reduce code size. This only has an effect in case the project was generated with MLI support. See more info in [EmbARC MLI Library Based Optimizations](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/kernels/arc_mli/README.md). `false` is the default value.
+
+ make app MLI_ONLY=[true|false]
+
+4. Delete all artifacts created during build.
+
+ make clean
+
+5. Run the application with the nSIM simulator in console mode.
+
+ make run
+
+6. Load the application and open MetaWare Debugger GUI for further execution/debugging.
+
+ make debug
+
+7. Generate necessary artefacts for self-booting execution from flash. See [reference to Run the application on the board from the micro SD card](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/tools/make/targets/arc/README.md#Run-the-Application-on-the-Board-from-the-microSD-Card).
+
+ make flash
+
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository, and third party dependencies are covered by their respective licenses, in the third_party folder of this package.
diff --git a/tensorflow/lite/micro/tools/make/templates/arc/arc_app_makefile.tpl b/tensorflow/lite/micro/tools/make/templates/arc/arc_app_makefile.tpl
new file mode 100644
index 0000000..a1a3ab7
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/arc/arc_app_makefile.tpl
@@ -0,0 +1,114 @@
+#=============================================================
+# OS-specific definitions
+#=============================================================
+COMMA=,
+OPEN_PAREN=(
+CLOSE_PAREN=)
+BACKSLASH=\$(nullstring)
+ifneq ($(ComSpec)$(COMSPEC),)
+ O_SYS=Windows
+ RM=del /F /Q
+ MKDIR=mkdir
+ CP=copy /Y
+ TYPE=type
+ PS=$(BACKSLASH)
+ Q=
+ coQ=\$(nullstring)
+ fix_platform_path = $(subst /,$(PS), $(1))
+ DEV_NULL = nul
+else
+ O_SYS=Unix
+ RM=rm -rf
+ MKDIR=mkdir -p
+ CP=cp
+ TYPE=cat
+ PS=/
+ Q=$(BACKSLASH)
+ coQ=
+ fix_platform_path=$(1)
+ DEV_NULL=/dev/null
+endif
+
+#=============================================================
+# Toolchain definitions
+#=============================================================
+CC = %{CC}%
+CXX = %{CXX}%
+LD = %{LD}%
+
+
+#=============================================================
+# Applications settings
+#=============================================================
+OUT_NAME = %{EXECUTABLE}%
+
+DBG_ARGS ?=
+
+RUN_ARGS ?=
+
+EXT_CFLAGS ?=
+
+CXXFLAGS += %{CXX_FLAGS}%
+
+CCFLAGS += %{CC_FLAGS}%
+
+LDFLAGS += %{LINKER_FLAGS}%
+
+%{EXTRA_APP_SETTINGS}%
+
+
+#=============================================================
+# Files and directories
+#=============================================================
+SRCS := \
+%{SRCS}%
+
+OBJS := \
+$(patsubst %.cc,%.o,$(patsubst %.c,%.o,$(SRCS)))
+
+
+#=============================================================
+# Common rules
+#=============================================================
+.PHONY: all app flash clean run debug
+
+%.o: %.cc
+ $(CXX) $(CXXFLAGS) $(EXT_CFLAGS) $(INCLUDES) -c $< -o $@
+
+%.o: %.c
+ $(CC) $(CCFLAGS) $(EXT_CFLAGS) $(INCLUDES) -c $< -o $@
+
+$(OUT_NAME): $(OBJS)
+ $(LD) $(CXXFLAGS) -o $@ -Ccrossref $(OBJS) $(LDFLAGS)
+
+%{EXTRA_APP_RULES}%
+
+
+#=================================================================
+# Global rules
+#=================================================================
+all: $(OUT_NAME)
+
+app: $(OUT_NAME)
+
+flash: %{BIN_DEPEND}%
+%{BIN_RULE}%
+
+clean:
+ -@$(RM) $(call fix_platform_path,$(OBJS))
+ -@$(RM) $(OUT_NAME) %{EXTRA_RM_TARGETS}%
+
+#=================================================================
+# Execution rules
+#=================================================================
+
+APP_RUN := %{APP_RUN_CMD}%
+APP_DEBUG := %{APP_DEBUG_CMD}%
+
+run: $(OUT_NAME)
+ $(APP_RUN) $(OUT_NAME) $(RUN_ARGS)
+
+debug: $(OUT_NAME)
+ $(APP_DEBUG) $(OUT_NAME) $(RUN_ARGS)
+
+%{EXTRA_EXECUTE_RULES}%
diff --git a/tensorflow/lite/micro/tools/make/templates/arduino_example.ino b/tensorflow/lite/micro/tools/make/templates/arduino_example.ino
new file mode 100644
index 0000000..ac8813f
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/arduino_example.ino
@@ -0,0 +1,42 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+// Template sketch that calls into the detailed TensorFlow Lite example code.
+
+// Include an empty header so that Arduino knows to build the TF Lite library.
+#include <TensorFlowLite.h>
+
+// TensorFlow Lite defines its own main function
+extern int tflite_micro_main(int argc, char* argv[]);
+
+// So the example works with or without a serial connection,
+// wait to see one for 5 seconds before giving up.
+void waitForSerial() {
+ int start = millis();
+ while(!Serial) {
+ int diff = millis() - start;
+ if (diff > 5000) break;
+ }
+}
+
+// Runs once when the program starts
+void setup() {
+ waitForSerial();
+ tflite_micro_main(0, NULL);
+}
+
+// Leave the loop unused
+void loop() {
+}
\ No newline at end of file
diff --git a/tensorflow/lite/micro/tools/make/templates/ceva/ceva_app_makefile_v18.0.5.tpl b/tensorflow/lite/micro/tools/make/templates/ceva/ceva_app_makefile_v18.0.5.tpl
new file mode 100755
index 0000000..537b557
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/ceva/ceva_app_makefile_v18.0.5.tpl
@@ -0,0 +1,69 @@
+
+TARGET_TOOLCHAIN_ROOT := /home/yaire/CEVA-ToolBox/V18.05/BX/
+
+CC = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/clang
+CXX = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/clang++
+LD = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/ceva-elf-ld
+AS = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/ceva-elf-as
+TOOLS_OBJS := \
+${TARGET_TOOLCHAIN_ROOT}/cevatools/lib/clang/9.0.1/cevabx1-unknown-unknown-elf/rtlv1.0.0-fp1-dpfp1/lib/crt0.o ${TARGET_TOOLCHAIN_ROOT}/cevatools/lib/clang/9.0.1/cevabx1-unknown-unknown-elf/rtlv1.0.0-fp1-dpfp1/lib/crtn.o
+
+TOOLS_LIBS := \
+-lc++ -lc++abi -lc -lcompiler-rt
+
+ LDFLAGS += \
+ -T \
+ ../../../../../targets/ceva/CEVA_BX1_TFLM_18.0.5.ld \
+ --no-relax \
+ --no-gc-sections \
+ -defsym \
+ __internal_data_size=512k \
+ -defsym \
+ __internal_code_size=256k \
+ -L${TARGET_TOOLCHAIN_ROOT}cevatools/lib/clang/9.0.1/cevabx1-unknown-unknown-elf/rtlv1.0.0-fp1-dpfp1/lib/ \
+ -lc++ -lc++abi -lc -lcompiler-rt -lCEVA_TFLM_lib -lceva_dsp_lib
+
+
+OUT_NAME = %{EXECUTABLE}%
+
+CXXFLAGS += %{CXX_FLAGS}%
+CCFLAGS += %{CC_FLAGS}%
+
+#=============================================================
+# Files and directories
+#=============================================================
+SRCS := \
+%{SRCS}%
+
+OBJS := \
+$(patsubst %.cc,%.o,$(patsubst %.c,%.o,$(SRCS)))
+
+
+#=============================================================
+# Common rules
+#=============================================================
+.PHONY: all app flash clean run debug
+
+%.o: %.cc
+ $(CXX) $(CXXFLAGS) $(EXT_CFLAGS) $(INCLUDES) -c $< -o $@
+
+%.o: %.c
+ $(CC) $(CCFLAGS) $(EXT_CFLAGS) $(INCLUDES) -c $< -o $@
+
+$(OUT_NAME): $(OBJS)
+ $(LD) -o $@ $(OBJS) $(TOOLS_OBJS) ${TOOLS_LIBS} $(LDFLAGS)
+
+
+
+#=================================================================
+# Global rules
+#=================================================================
+all: $(OUT_NAME)
+
+app: $(OUT_NAME)
+
+clean:
+ -@$(RM) $(call fix_platform_path,$(OBJS))
+ -@$(RM) $(OUT_NAME) %{EXTRA_RM_TARGETS}%
+
+
diff --git a/tensorflow/lite/micro/tools/make/templates/ceva_SP500/ceva_app_makefile.tpl b/tensorflow/lite/micro/tools/make/templates/ceva_SP500/ceva_app_makefile.tpl
new file mode 100755
index 0000000..238f86d
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/ceva_SP500/ceva_app_makefile.tpl
@@ -0,0 +1,68 @@
+
+TARGET_TOOLCHAIN_ROOT := /home/yaire/CEVA-ToolBox/V20/SensPro
+#CC = %{CC_TOOL}%
+#CXX = %{CXX_TOOL}%
+#LD = %{LD_TOOL}%
+CC = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/clang
+CXX = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/clang++
+LD = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/ceva-elf-ld
+AS = ${TARGET_TOOLCHAIN_ROOT}/cevatools/bin/ceva-elf-as
+TOOLS_OBJS := \
+${TARGET_TOOLCHAIN_ROOT}/cevatools/lib/clang/7.1.0/senspro-unknown-unknown-elf/rtlv1.0.0-fp2-dpfp2/lib/crt0.o ${TARGET_TOOLCHAIN_ROOT}/cevatools/lib/clang/7.1.0/senspro-unknown-unknown-elf/rtlv1.0.0-fp2-dpfp2/lib/crtn.o
+TOOLS_LIBS := \
+-lc++ -lc++abi -lc -lcompiler-rt
+
+ LDFLAGS += \
+ -T \
+ ../../../../../targets/ceva/CEVA_SP500_TFLM.ld \
+ --no-relax \
+ --no-gc-sections \
+ -defsym __internal_code_size=0k \
+ -defsym __internal_data_size=512k \
+ -L${TARGET_TOOLCHAIN_ROOT}/cevatools/lib/clang/7.1.0/senspro-unknown-unknown-elf/rtlv1.0.0-fp2-dpfp2/lib/ \
+ -lc++ -lc++abi -lc -lcompiler-rt
+
+
+OUT_NAME = %{EXECUTABLE}%
+
+CXXFLAGS += %{CXX_FLAGS}%
+CCFLAGS += %{CC_FLAGS}%
+
+#=============================================================
+# Files and directories
+#=============================================================
+SRCS := \
+%{SRCS}%
+
+OBJS := \
+$(patsubst %.cc,%.o,$(patsubst %.c,%.o,$(SRCS)))
+
+
+#=============================================================
+# Common rules
+#=============================================================
+.PHONY: all app flash clean run debug
+
+%.o: %.cc
+ $(CXX) $(CXXFLAGS) $(EXT_CFLAGS) $(INCLUDES) -c $< -o $@
+
+%.o: %.c
+ $(CC) $(CCFLAGS) $(EXT_CFLAGS) $(INCLUDES) -c $< -o $@
+
+$(OUT_NAME): $(OBJS)
+ $(LD) -o $@ $(OBJS) $(TOOLS_OBJS) ${TOOLS_LIBS} $(LDFLAGS)
+
+%{EXTRA_APP_RULES}%
+
+
+#=================================================================
+# Global rules
+#=================================================================
+all: $(OUT_NAME)
+
+app: $(OUT_NAME)
+
+clean:
+ -@$(RM) $(call fix_platform_path,$(OBJS))
+ -@$(RM) $(OUT_NAME) %{EXTRA_RM_TARGETS}%
+
diff --git a/tensorflow/lite/micro/tools/make/templates/esp/CMakeLists.txt.tpl b/tensorflow/lite/micro/tools/make/templates/esp/CMakeLists.txt.tpl
new file mode 100644
index 0000000..02966a4
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/esp/CMakeLists.txt.tpl
@@ -0,0 +1,3 @@
+cmake_minimum_required(VERSION 3.5)
+include($ENV{IDF_PATH}/tools/cmake/project.cmake)
+project(%{EXECUTABLE}%)
diff --git a/tensorflow/lite/micro/tools/make/templates/esp/README_ESP.md.tpl b/tensorflow/lite/micro/tools/make/templates/esp/README_ESP.md.tpl
new file mode 100644
index 0000000..6847893
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/esp/README_ESP.md.tpl
@@ -0,0 +1,58 @@
+# TensorFlow Lite Micro ESP-IDF Project
+
+This folder has been autogenerated by TensorFlow, and contains source, header,
+and project files needed to build a single TensorFlow Lite Micro target using
+Espressif's [ESP-IDF](https://docs.espressif.com/projects/esp-idf/en/latest/).
+
+## Usage
+
+### Install the ESP IDF
+
+Follow the instructions of the
+[ESP-IDF get started guide](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html)
+to setup the toolchain and the ESP-IDF itself.
+
+The next steps assume that the
+[IDF environment variables are set](https://docs.espressif.com/projects/esp-idf/en/latest/get-started/index.html#step-4-set-up-the-environment-variables) :
+ * The `IDF_PATH` environment variable is set.
+ * `idf.py` and Xtensa-esp32 tools (e.g., `xtensa-esp32-elf-gcc`) are in `$PATH`.
+
+## Build the example
+
+To build this, run:
+
+```
+idf.py build
+```
+
+### Load and run the example
+
+To flash (replace `/dev/ttyUSB0` with the device serial port):
+```
+idf.py --port /dev/ttyUSB0 flash
+```
+
+Monitor the serial output:
+```
+idf.py --port /dev/ttyUSB0 monitor
+```
+
+Use `Ctrl+]` to exit.
+
+The previous two commands can be combined:
+```
+idf.py --port /dev/ttyUSB0 flash monitor
+```
+
+## Project Generation
+
+See
+[tensorflow/lite/micro](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro)
+for details on how projects like this can be generated from the main source
+tree.
+
+## License
+
+TensorFlow's code is covered by the Apache2 License included in the repository,
+and third party dependencies are covered by their respective licenses, in the
+third_party folder of this package.
diff --git a/tensorflow/lite/micro/tools/make/templates/esp/components/tfmicro/CMakeLists.txt.tpl b/tensorflow/lite/micro/tools/make/templates/esp/components/tfmicro/CMakeLists.txt.tpl
new file mode 100644
index 0000000..a342517
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/esp/components/tfmicro/CMakeLists.txt.tpl
@@ -0,0 +1,38 @@
+
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+#
+# This component was generated for the '%{EXECUTABLE}%' TF Micro example.
+#
+
+# Make sure that the IDF Path environment variable is defined
+if(NOT DEFINED ENV{IDF_PATH})
+ message(FATAL_ERROR "The IDF_PATH environment variable must point to the location of the ESP-IDF.")
+endif()
+
+idf_component_register(
+ SRCS %{COMPONENT_SRCS}%
+ INCLUDE_DIRS %{COMPONENT_INCLUDES}%)
+
+# Reduce the level of paranoia to be able to compile TF sources
+target_compile_options(${COMPONENT_LIB} PRIVATE
+ -Wno-maybe-uninitialized
+ -Wno-missing-field-initializers
+ -Wno-type-limits)
+
+target_compile_options(${COMPONENT_LIB} PRIVATE %{CC_FLAGS}%)
+target_compile_options(${COMPONENT_LIB} PRIVATE $<$<COMPILE_LANGUAGE:CXX>: %{CXX_FLAGS}% >)
+target_compile_options(${COMPONENT_LIB} INTERFACE $<$<IN_LIST:-DTF_LITE_STATIC_MEMORY,$<TARGET_PROPERTY:${COMPONENT_LIB},COMPILE_OPTIONS>>:-DTF_LITE_STATIC_MEMORY>)
+target_link_libraries(${COMPONENT_LIB} PRIVATE %{LINKER_FLAGS}%)
diff --git a/tensorflow/lite/micro/tools/make/templates/esp/main/CMakeLists.txt.tpl b/tensorflow/lite/micro/tools/make/templates/esp/main/CMakeLists.txt.tpl
new file mode 100644
index 0000000..da2aee2
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/esp/main/CMakeLists.txt.tpl
@@ -0,0 +1,8 @@
+
+#
+# Main component of TF Micro project '%{EXECUTABLE}%'.
+#
+
+idf_component_register(
+ SRCS %{MAIN_SRCS}%
+ INCLUDE_DIRS "")
diff --git a/tensorflow/lite/micro/tools/make/templates/keil_project.uvprojx.tpl b/tensorflow/lite/micro/tools/make/templates/keil_project.uvprojx.tpl
new file mode 100644
index 0000000..440d4b6
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/keil_project.uvprojx.tpl
@@ -0,0 +1,418 @@
+<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
+<Project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="project_projx.xsd">
+
+ <SchemaVersion>2.1</SchemaVersion>
+
+ <Targets>
+ <Target>
+ <TargetName>%{EXECUTABLE}%</TargetName>
+ <ToolsetNumber>0x4</ToolsetNumber>
+ <ToolsetName>ARM-ADS</ToolsetName>
+ <pCCUsed>6100001::V6.10.1::.\ARMCLANG</pCCUsed>
+ <uAC6>1</uAC6>
+ <TargetOption>
+ <TargetCommonOption>
+ <Device>STM32F746NGHx</Device>
+ <Vendor>STMicroelectronics</Vendor>
+ <PackID>Keil.STM32F7xx_DFP.2.11.0</PackID>
+ <PackURL>http://www.keil.com/pack</PackURL>
+ <Cpu>IRAM(0x20010000,0x40000) IRAM2(0x20000000,0x10000) IROM(0x08000000,0x100000) IROM2(0x00200000,0x100000) CPUTYPE("Cortex-M7") FPU3(SFPU) CLOCK(12000000) ELITTLE</Cpu>
+ <FlashUtilSpec></FlashUtilSpec>
+ <StartupFile></StartupFile>
+ <FlashDriverDll>UL2CM3(-S0 -C0 -P0 -FD20010000 -FC1000 -FN2 -FF0STM32F7x_1024 -FS08000000 -FL0100000 -FF1STM32F7xTCM_1024 -FS1200000 -FL1100000 -FP0($$Device:STM32F746NGHx$CMSIS\Flash\STM32F7x_1024.FLM) -FP1($$Device:STM32F746NGHx$CMSIS\Flash\STM32F7xTCM_1024.FLM))</FlashDriverDll>
+ <DeviceId>0</DeviceId>
+ <RegisterFile>$$Device:STM32F746NGHx$Drivers\CMSIS\Device\ST\STM32F7xx\Include\stm32f7xx.h</RegisterFile>
+ <MemoryEnv></MemoryEnv>
+ <Cmp></Cmp>
+ <Asm></Asm>
+ <Linker></Linker>
+ <OHString></OHString>
+ <InfinionOptionDll></InfinionOptionDll>
+ <SLE66CMisc></SLE66CMisc>
+ <SLE66AMisc></SLE66AMisc>
+ <SLE66LinkerMisc></SLE66LinkerMisc>
+ <SFDFile>$$Device:STM32F746NGHx$CMSIS\SVD\STM32F7x6_v1r1.svd</SFDFile>
+ <bCustSvd>0</bCustSvd>
+ <UseEnv>0</UseEnv>
+ <BinPath></BinPath>
+ <IncludePath></IncludePath>
+ <LibPath></LibPath>
+ <RegisterFilePath></RegisterFilePath>
+ <DBRegisterFilePath></DBRegisterFilePath>
+ <TargetStatus>
+ <Error>0</Error>
+ <ExitCodeStop>0</ExitCodeStop>
+ <ButtonStop>0</ButtonStop>
+ <NotGenerated>0</NotGenerated>
+ <InvalidFlash>1</InvalidFlash>
+ </TargetStatus>
+ <OutputDirectory>.\Objects\</OutputDirectory>
+ <OutputName>%{EXECUTABLE}%</OutputName>
+ <CreateExecutable>1</CreateExecutable>
+ <CreateLib>0</CreateLib>
+ <CreateHexFile>0</CreateHexFile>
+ <DebugInformation>1</DebugInformation>
+ <BrowseInformation>1</BrowseInformation>
+ <ListingPath>.\Listings\</ListingPath>
+ <HexFormatSelection>1</HexFormatSelection>
+ <Merge32K>0</Merge32K>
+ <CreateBatchFile>0</CreateBatchFile>
+ <BeforeCompile>
+ <RunUserProg1>0</RunUserProg1>
+ <RunUserProg2>0</RunUserProg2>
+ <UserProg1Name></UserProg1Name>
+ <UserProg2Name></UserProg2Name>
+ <UserProg1Dos16Mode>0</UserProg1Dos16Mode>
+ <UserProg2Dos16Mode>0</UserProg2Dos16Mode>
+ <nStopU1X>0</nStopU1X>
+ <nStopU2X>0</nStopU2X>
+ </BeforeCompile>
+ <BeforeMake>
+ <RunUserProg1>0</RunUserProg1>
+ <RunUserProg2>0</RunUserProg2>
+ <UserProg1Name></UserProg1Name>
+ <UserProg2Name></UserProg2Name>
+ <UserProg1Dos16Mode>0</UserProg1Dos16Mode>
+ <UserProg2Dos16Mode>0</UserProg2Dos16Mode>
+ <nStopB1X>0</nStopB1X>
+ <nStopB2X>0</nStopB2X>
+ </BeforeMake>
+ <AfterMake>
+ <RunUserProg1>0</RunUserProg1>
+ <RunUserProg2>0</RunUserProg2>
+ <UserProg1Name></UserProg1Name>
+ <UserProg2Name></UserProg2Name>
+ <UserProg1Dos16Mode>0</UserProg1Dos16Mode>
+ <UserProg2Dos16Mode>0</UserProg2Dos16Mode>
+ <nStopA1X>0</nStopA1X>
+ <nStopA2X>0</nStopA2X>
+ </AfterMake>
+ <SelectedForBatchBuild>0</SelectedForBatchBuild>
+ <SVCSIdString></SVCSIdString>
+ </TargetCommonOption>
+ <CommonProperty>
+ <UseCPPCompiler>0</UseCPPCompiler>
+ <RVCTCodeConst>0</RVCTCodeConst>
+ <RVCTZI>0</RVCTZI>
+ <RVCTOtherData>0</RVCTOtherData>
+ <ModuleSelection>0</ModuleSelection>
+ <IncludeInBuild>1</IncludeInBuild>
+ <AlwaysBuild>0</AlwaysBuild>
+ <GenerateAssemblyFile>0</GenerateAssemblyFile>
+ <AssembleAssemblyFile>0</AssembleAssemblyFile>
+ <PublicsOnly>0</PublicsOnly>
+ <StopOnExitCode>3</StopOnExitCode>
+ <CustomArgument></CustomArgument>
+ <IncludeLibraryModules></IncludeLibraryModules>
+ <ComprImg>1</ComprImg>
+ </CommonProperty>
+ <DllOption>
+ <SimDllName>SARMCM3.DLL</SimDllName>
+ <SimDllArguments> -REMAP -MPU</SimDllArguments>
+ <SimDlgDll>DCM.DLL</SimDlgDll>
+ <SimDlgDllArguments>-pCM7</SimDlgDllArguments>
+ <TargetDllName>SARMCM3.DLL</TargetDllName>
+ <TargetDllArguments> -MPU</TargetDllArguments>
+ <TargetDlgDll>TCM.DLL</TargetDlgDll>
+ <TargetDlgDllArguments>-pCM7</TargetDlgDllArguments>
+ </DllOption>
+ <DebugOption>
+ <OPTHX>
+ <HexSelection>1</HexSelection>
+ <HexRangeLowAddress>0</HexRangeLowAddress>
+ <HexRangeHighAddress>0</HexRangeHighAddress>
+ <HexOffset>0</HexOffset>
+ <Oh166RecLen>16</Oh166RecLen>
+ </OPTHX>
+ </DebugOption>
+ <Utilities>
+ <Flash1>
+ <UseTargetDll>1</UseTargetDll>
+ <UseExternalTool>0</UseExternalTool>
+ <RunIndependent>0</RunIndependent>
+ <UpdateFlashBeforeDebugging>1</UpdateFlashBeforeDebugging>
+ <Capability>1</Capability>
+ <DriverSelection>-1</DriverSelection>
+ </Flash1>
+ <bUseTDR>1</bUseTDR>
+ <Flash2>BIN\UL2CM3.DLL</Flash2>
+ <Flash3></Flash3>
+ <Flash4></Flash4>
+ <pFcarmOut></pFcarmOut>
+ <pFcarmGrp></pFcarmGrp>
+ <pFcArmRoot></pFcArmRoot>
+ <FcArmLst>0</FcArmLst>
+ </Utilities>
+ <TargetArmAds>
+ <ArmAdsMisc>
+ <GenerateListings>0</GenerateListings>
+ <asHll>1</asHll>
+ <asAsm>1</asAsm>
+ <asMacX>1</asMacX>
+ <asSyms>1</asSyms>
+ <asFals>1</asFals>
+ <asDbgD>1</asDbgD>
+ <asForm>1</asForm>
+ <ldLst>0</ldLst>
+ <ldmm>1</ldmm>
+ <ldXref>1</ldXref>
+ <BigEnd>0</BigEnd>
+ <AdsALst>1</AdsALst>
+ <AdsACrf>1</AdsACrf>
+ <AdsANop>0</AdsANop>
+ <AdsANot>0</AdsANot>
+ <AdsLLst>1</AdsLLst>
+ <AdsLmap>1</AdsLmap>
+ <AdsLcgr>1</AdsLcgr>
+ <AdsLsym>1</AdsLsym>
+ <AdsLszi>1</AdsLszi>
+ <AdsLtoi>1</AdsLtoi>
+ <AdsLsun>1</AdsLsun>
+ <AdsLven>1</AdsLven>
+ <AdsLsxf>1</AdsLsxf>
+ <RvctClst>0</RvctClst>
+ <GenPPlst>0</GenPPlst>
+ <AdsCpuType>"Cortex-M7"</AdsCpuType>
+ <RvctDeviceName></RvctDeviceName>
+ <mOS>0</mOS>
+ <uocRom>0</uocRom>
+ <uocRam>0</uocRam>
+ <hadIROM>1</hadIROM>
+ <hadIRAM>1</hadIRAM>
+ <hadXRAM>0</hadXRAM>
+ <uocXRam>0</uocXRam>
+ <RvdsVP>2</RvdsVP>
+ <RvdsMve>0</RvdsMve>
+ <hadIRAM2>1</hadIRAM2>
+ <hadIROM2>1</hadIROM2>
+ <StupSel>8</StupSel>
+ <useUlib>0</useUlib>
+ <EndSel>0</EndSel>
+ <uLtcg>0</uLtcg>
+ <nSecure>0</nSecure>
+ <RoSelD>4</RoSelD>
+ <RwSelD>4</RwSelD>
+ <CodeSel>0</CodeSel>
+ <OptFeed>0</OptFeed>
+ <NoZi1>0</NoZi1>
+ <NoZi2>0</NoZi2>
+ <NoZi3>0</NoZi3>
+ <NoZi4>0</NoZi4>
+ <NoZi5>0</NoZi5>
+ <Ro1Chk>0</Ro1Chk>
+ <Ro2Chk>0</Ro2Chk>
+ <Ro3Chk>0</Ro3Chk>
+ <Ir1Chk>1</Ir1Chk>
+ <Ir2Chk>0</Ir2Chk>
+ <Ra1Chk>0</Ra1Chk>
+ <Ra2Chk>0</Ra2Chk>
+ <Ra3Chk>0</Ra3Chk>
+ <Im1Chk>1</Im1Chk>
+ <Im2Chk>1</Im2Chk>
+ <OnChipMemories>
+ <Ocm1>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </Ocm1>
+ <Ocm2>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </Ocm2>
+ <Ocm3>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </Ocm3>
+ <Ocm4>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </Ocm4>
+ <Ocm5>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </Ocm5>
+ <Ocm6>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </Ocm6>
+ <IRAM>
+ <Type>0</Type>
+ <StartAddress>0x20010000</StartAddress>
+ <Size>0x40000</Size>
+ </IRAM>
+ <IROM>
+ <Type>1</Type>
+ <StartAddress>0x8000000</StartAddress>
+ <Size>0x100000</Size>
+ </IROM>
+ <XRAM>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </XRAM>
+ <OCR_RVCT1>
+ <Type>1</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </OCR_RVCT1>
+ <OCR_RVCT2>
+ <Type>1</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </OCR_RVCT2>
+ <OCR_RVCT3>
+ <Type>1</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </OCR_RVCT3>
+ <OCR_RVCT4>
+ <Type>1</Type>
+ <StartAddress>0x8000000</StartAddress>
+ <Size>0x100000</Size>
+ </OCR_RVCT4>
+ <OCR_RVCT5>
+ <Type>1</Type>
+ <StartAddress>0x200000</StartAddress>
+ <Size>0x100000</Size>
+ </OCR_RVCT5>
+ <OCR_RVCT6>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </OCR_RVCT6>
+ <OCR_RVCT7>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </OCR_RVCT7>
+ <OCR_RVCT8>
+ <Type>0</Type>
+ <StartAddress>0x0</StartAddress>
+ <Size>0x0</Size>
+ </OCR_RVCT8>
+ <OCR_RVCT9>
+ <Type>0</Type>
+ <StartAddress>0x20010000</StartAddress>
+ <Size>0x40000</Size>
+ </OCR_RVCT9>
+ <OCR_RVCT10>
+ <Type>0</Type>
+ <StartAddress>0x20000000</StartAddress>
+ <Size>0x10000</Size>
+ </OCR_RVCT10>
+ </OnChipMemories>
+ <RvctStartVector></RvctStartVector>
+ </ArmAdsMisc>
+ <Cads>
+ <interw>1</interw>
+ <Optim>7</Optim>
+ <oTime>0</oTime>
+ <SplitLS>0</SplitLS>
+ <OneElfS>1</OneElfS>
+ <Strict>0</Strict>
+ <EnumInt>0</EnumInt>
+ <PlainCh>0</PlainCh>
+ <Ropi>0</Ropi>
+ <Rwpi>0</Rwpi>
+ <wLevel>3</wLevel>
+ <uThumb>0</uThumb>
+ <uSurpInc>0</uSurpInc>
+ <uC99>0</uC99>
+ <uGnu>1</uGnu>
+ <useXO>0</useXO>
+ <v6Lang>3</v6Lang>
+ <v6LangP>3</v6LangP>
+ <vShortEn>1</vShortEn>
+ <vShortWch>1</vShortWch>
+ <v6Lto>0</v6Lto>
+ <v6WtE>0</v6WtE>
+ <v6Rtti>0</v6Rtti>
+ <VariousControls>
+ <MiscControls></MiscControls>
+ <Define></Define>
+ <Undefine></Undefine>
+ <IncludePath>%{INCLUDE_PATHS}%</IncludePath>
+ </VariousControls>
+ </Cads>
+ <Aads>
+ <interw>1</interw>
+ <Ropi>0</Ropi>
+ <Rwpi>0</Rwpi>
+ <thumb>0</thumb>
+ <SplitLS>0</SplitLS>
+ <SwStkChk>0</SwStkChk>
+ <NoWarn>0</NoWarn>
+ <uSurpInc>0</uSurpInc>
+ <useXO>0</useXO>
+ <uClangAs>0</uClangAs>
+ <VariousControls>
+ <MiscControls></MiscControls>
+ <Define></Define>
+ <Undefine></Undefine>
+ <IncludePath></IncludePath>
+ </VariousControls>
+ </Aads>
+ <LDads>
+ <umfTarg>0</umfTarg>
+ <Ropi>0</Ropi>
+ <Rwpi>0</Rwpi>
+ <noStLib>0</noStLib>
+ <RepFail>1</RepFail>
+ <useFile>0</useFile>
+ <TextAddressRange>0x08000000</TextAddressRange>
+ <DataAddressRange>0x20010000</DataAddressRange>
+ <pXoBase></pXoBase>
+ <ScatterFile></ScatterFile>
+ <IncludeLibs></IncludeLibs>
+ <IncludeLibsPath></IncludeLibsPath>
+ <Misc></Misc>
+ <LinkerInputFile></LinkerInputFile>
+ <DisabledWarnings></DisabledWarnings>
+ </LDads>
+ </TargetArmAds>
+ </TargetOption>
+ <Groups>
+ <Group>
+ <GroupName>Source</GroupName>
+ <Files>
+%{SRCS}%
+ </Files>
+ </Group>
+ <Group>
+ <GroupName>::Compiler</GroupName>
+ </Group>
+ </Groups>
+ </Target>
+ </Targets>
+
+ <RTE>
+ <apis/>
+ <components>
+ <component Cbundle="ARM Compiler" Cclass="Compiler" Cgroup="I/O" Csub="STDERR" Cvariant="ITM" Cvendor="Keil" Cversion="1.2.0" condition="ARMCC Cortex-M with ITM">
+ <package name="ARM_Compiler" schemaVersion="1.4.9" url="http://www.keil.com/pack/" vendor="Keil" version="1.6.0"/>
+ <targetInfos>
+ <targetInfo name="%{EXECUTABLE}%"/>
+ </targetInfos>
+ </component>
+ <component Cbundle="ARM Compiler" Cclass="Compiler" Cgroup="I/O" Csub="STDIN" Cvariant="ITM" Cvendor="Keil" Cversion="1.2.0" condition="ARMCC Cortex-M with ITM">
+ <package name="ARM_Compiler" schemaVersion="1.4.9" url="http://www.keil.com/pack/" vendor="Keil" version="1.6.0"/>
+ <targetInfos>
+ <targetInfo name="%{EXECUTABLE}%"/>
+ </targetInfos>
+ </component>
+ <component Cbundle="ARM Compiler" Cclass="Compiler" Cgroup="I/O" Csub="STDOUT" Cvariant="ITM" Cvendor="Keil" Cversion="1.2.0" condition="ARMCC Cortex-M with ITM">
+ <package name="ARM_Compiler" schemaVersion="1.4.9" url="http://www.keil.com/pack/" vendor="Keil" version="1.6.0"/>
+ <targetInfos>
+ <targetInfo name="%{EXECUTABLE}%"/>
+ </targetInfos>
+ </component>
+ </components>
+ <files/>
+ </RTE>
+
+</Project>
diff --git a/tensorflow/lite/micro/tools/make/templates/library.properties b/tensorflow/lite/micro/tools/make/templates/library.properties
new file mode 100644
index 0000000..e44286f
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/library.properties
@@ -0,0 +1,11 @@
+name=Arduino_TensorFlowLite
+version=2.4.0-ALPHA
+author=TensorFlow Authors
+maintainer=Pete Warden <petewarden@google.com>
+sentence=Allows you to run machine learning models locally on your device.
+paragraph=This library runs TensorFlow machine learning models on microcontrollers, allowing you to build AI/ML applications powered by deep learning and neural networks. With the included examples, you can recognize speech, detect people using a camera, and recognise "magic wand" gestures using an accelerometer. The examples work best with the Arduino Nano 33 BLE Sense board, which has a microphone and accelerometer.
+category=Data Processing
+url=https://www.tensorflow.org/lite/microcontrollers/overview
+ldflags=-lm
+includes=TensorFlowLite.h
+precompiled=full
diff --git a/tensorflow/lite/micro/tools/make/templates/mbed-os.lib.tpl b/tensorflow/lite/micro/tools/make/templates/mbed-os.lib.tpl
new file mode 100644
index 0000000..ed924d7
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/mbed-os.lib.tpl
@@ -0,0 +1 @@
+https://github.com/ARMmbed/mbed-os/#532654ebb31c7bf79601042a6fa976b85532ef47
diff --git a/tensorflow/lite/micro/tools/make/templates/mbed_app.json.tpl b/tensorflow/lite/micro/tools/make/templates/mbed_app.json.tpl
new file mode 100644
index 0000000..0f54c73
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/mbed_app.json.tpl
@@ -0,0 +1,8 @@
+{
+ "config": {
+ "main-stack-size": {
+ "value": 65536
+ }
+ },
+ "requires": ["bare-metal"]
+}
diff --git a/tensorflow/lite/micro/tools/make/templates/tasks.json.make.tpl b/tensorflow/lite/micro/tools/make/templates/tasks.json.make.tpl
new file mode 100644
index 0000000..141994d
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/tasks.json.make.tpl
@@ -0,0 +1,16 @@
+{
+ // See https://go.microsoft.com/fwlink/?LinkId=733558
+ // for the documentation about the tasks.json format
+ "version": "2.0.0",
+ "tasks": [
+ {
+ "label": "Make Build",
+ "type": "shell",
+ "command": "make",
+ "group": {
+ "kind": "build",
+ "isDefault": true
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/tensorflow/lite/micro/tools/make/templates/tasks.json.mbed.tpl b/tensorflow/lite/micro/tools/make/templates/tasks.json.mbed.tpl
new file mode 100644
index 0000000..616f3b2
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/tasks.json.mbed.tpl
@@ -0,0 +1,39 @@
+{
+ // See https://go.microsoft.com/fwlink/?LinkId=733558
+ // for the documentation about the tasks.json format
+ "version": "2.0.0",
+ "tasks": [
+ {
+ "label": "Mbed Config Root",
+ "type": "shell",
+ "command": "mbed config root .",
+ },
+ {
+ "label": "Mbed Deploy",
+ "type": "shell",
+ "command": "mbed deploy",
+ },
+ {
+ "label": "Mbed Patch C++11",
+ "type": "shell",
+ "command": "python",
+ "args": [
+ "-c",
+ "import fileinput, glob;\nfor filename in glob.glob(\"mbed-os/tools/profiles/*.json\"):\n for line in fileinput.input(filename, inplace=True):\n print line.replace(\"\\\"-std=gnu++98\\\"\",\"\\\"-std=c++11\\\", \\\"-fpermissive\\\"\")"
+ ]
+ },
+ {
+ "label": "Mbed Init",
+ "dependsOn": ["Mbed Config Root", "Mbed Deploy", "Mbed Patch C++11"]
+ },
+ {
+ "label": "Mbed build",
+ "type": "shell",
+ "command": "mbed compile -m auto -t GCC_ARM",
+ "group": {
+ "kind": "build",
+ "isDefault": true
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/tensorflow/lite/micro/tools/make/templates/zephyr_cmake_project.cmake.tpl b/tensorflow/lite/micro/tools/make/templates/zephyr_cmake_project.cmake.tpl
new file mode 100644
index 0000000..dc1eee5
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/templates/zephyr_cmake_project.cmake.tpl
@@ -0,0 +1,16 @@
+cmake_minimum_required(VERSION 3.13.1)
+include($ENV{ZEPHYR_BASE}/cmake/app/boilerplate.cmake NO_POLICY_SCOPE)
+project(tf_lite_magic_wand)
+
+# -fno-threadsafe-statics -- disables the mutex around initialization of local static variables
+set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} %{CXX_FLAGS}% -fno-threadsafe-statics -Wno-sign-compare -Wno-narrowing")
+set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} %{CC_FLAGS}%")
+set(CMAKE_EXE_LINKER_FLAGS "%{LINKER_FLAGS}%")
+
+target_sources(app PRIVATE
+ %{SRCS}%
+ )
+
+target_include_directories(app PRIVATE
+ %{INCLUDE_DIRS}%
+ )
diff --git a/tensorflow/lite/micro/tools/make/third_party_downloads.inc b/tensorflow/lite/micro/tools/make/third_party_downloads.inc
new file mode 100644
index 0000000..a395b53
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/third_party_downloads.inc
@@ -0,0 +1,67 @@
+# Add URLs and MD5 checksums for third-party libraries here.
+# We use mirror.tensorflow.org to cache copies of third-party files,
+# but this is just an optimization applied manually by TensorFlow
+# engineers, so add non-mirrored URLs if you need to update this
+# in a pull request and we'll periodically copy them and update
+# the URL.
+
+GEMMLOWP_URL := "https://github.com/google/gemmlowp/archive/719139ce755a0f31cbf1c37f7f98adcc7fc9f425.zip"
+GEMMLOWP_MD5 := "7e8191b24853d75de2af87622ad293ba"
+
+LEON_BCC2_URL := "http://mirror.tensorflow.org/www.gaisler.com/anonftp/bcc2/bin/bcc-2.0.7-gcc-linux64.tar.xz"
+LEON_BCC2_MD5 := "cdf78082be4882da2a92c9baa82fe765"
+
+TSIM_URL := "http://mirror.tensorflow.org/www.gaisler.com/anonftp/tsim/tsim-eval-2.0.63.tar.gz"
+TSIM_MD5 := "afa0095d3ed989a949e1467f94e41d2f"
+
+AM_SDK_URL := "http://mirror.tensorflow.org/s3.asia.ambiqmicro.com/downloads/AmbiqSuite-Rel2.2.0.zip"
+AM_SDK_MD5 := "7605fa2d4d97e6bb7a1190c92b66b597"
+AM_SDK_DEST := AmbiqSuite-Rel2.2.0
+
+SF_BSPS_URL := "http://mirror.tensorflow.org/github.com/sparkfun/SparkFun_Apollo3_AmbiqSuite_BSPs/archive/v0.0.7.zip"
+SF_BSPS_MD5 := "34199f7e754735661d1c8a70a40ca7a3"
+SF_BSPS_DEST := boards_sfe
+
+ifeq ($(HOST_OS),osx)
+ RISCV_TOOLCHAIN_URL := "http://mirror.tensorflow.org/static.dev.sifive.com/dev-tools/riscv64-unknown-elf-gcc-8.1.0-2019.01.0-x86_64-apple-darwin.tar.gz"
+ RISCV_TOOLCHAIN_MD5 := "2ac2fa00618b9ab7fa0c7d0ec173de94"
+else
+ RISCV_TOOLCHAIN_URL := "http://mirror.tensorflow.org/static.dev.sifive.com/dev-tools/riscv64-unknown-elf-gcc-20181030-x86_64-linux-ubuntu14.tar.gz"
+ RISCV_TOOLCHAIN_MD5="2366b7afe36a54dc94fb0ff8a0830934"
+endif
+
+SIFIVE_FE310_LIB_URL := "http://mirror.tensorflow.org/github.com/sifive/freedom-e-sdk/archive/baeeb8fd497a99b3c141d7494309ec2e64f19bdf.zip"
+SIFIVE_FE310_LIB_MD5 := "06ee24c4956f8e21670ab3395861fe64"
+
+KISSFFT_URL="http://mirror.tensorflow.org/github.com/mborgerding/kissfft/archive/v130.zip"
+KISSFFT_MD5="438ba1fef5783cc5f5f201395cc477ca"
+
+RUY_URL="https://github.com/google/ruy/archive/38a9266b832767a3f535a74a9e0cf39f7892e594.zip"
+RUY_MD5="4cbc3104b27b718c819b2082beb732c5"
+
+CIFAR10_DATASET_URL="http://mirror.tensorflow.org/www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz"
+CIFAR10_DATASET_MD5="c32a1d4ab5d03f1284b67883e8d87530"
+
+IMAGE_RECOGNITION_MODEL_URL := "https://storage.googleapis.com/download.tensorflow.org/models/tflite/cifar_image_recognition_model_2020_05_27.zip"
+IMAGE_RECOGNITION_MODEL_MD5 := "1f4607b05ac45b8a6146fb883dbc2d7b"
+
+PERSON_MODEL_URL := "https://storage.googleapis.com/download.tensorflow.org/data/tf_lite_micro_person_data_grayscale_2020_05_27.zip"
+PERSON_MODEL_MD5 := "55b85f76e2995153e660391d4a209ef1"
+
+PERSON_MODEL_INT8_URL := "https://storage.googleapis.com/download.tensorflow.org/data/tf_lite_micro_person_data_int8_grayscale_2020_12_1.zip"
+PERSON_MODEL_INT8_MD5 := "e765cc76889db8640cfe876a37e4ec00"
+
+EMBARC_MLI_URL := "https://github.com/foss-for-synopsys-dwc-arc-processors/embarc_mli/archive/ef7dd3c4e37d74a908f30713a7d0121387d3c678.zip"
+EMBARC_MLI_MD5 := "65c4ff3f4a2963e90fd014f97c69f451"
+
+EMBARC_MLI_PRE_COMPILED_URL := "https://github.com/foss-for-synopsys-dwc-arc-processors/embarc_mli/releases/download/Release_1.1/embARC_MLI_package.zip"
+EMBARC_MLI_PRE_COMPILED_MD5 := "173990c2dde4efef6a2c95b92d1f0244"
+
+ZEPHYR_URL := "http://mirror.tensorflow.org/github.com/antmicro/zephyr/archive/55e36b9.zip"
+ZEPHYR_MD5 := "755622eb4812fde918a6382b65d50c3b"
+
+ETHOSU_URL := "https://git.mlplatform.org/ml/ethos-u/ethos-u-core-driver.git/snapshot/ethos-u-core-driver-2b201c340788ac582cec160b7217c2b5405b04f9.tar.gz"
+ETHOSU_MD5 := "0c148b90a1ee01de398892eb3a63e717"
+
+HIMAX_WE1_SDK_URL ="https://www.himax.com.tw/we-i/himax_we1_sdk_v04.zip"
+HIMAX_WE1_SDK_MD5 ="40b3ccb3c2e41210fe5c970d61e7e7d3"
diff --git a/tensorflow/lite/micro/tools/make/transform_arduino_source.py b/tensorflow/lite/micro/tools/make/transform_arduino_source.py
new file mode 100644
index 0000000..c6a49b7
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/transform_arduino_source.py
@@ -0,0 +1,137 @@
+# Lint as: python2, python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Resolves non-system C/C++ includes to their full paths to help Arduino."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import re
+import sys
+
+import six
+
+
+def replace_includes(line, supplied_headers_list):
+ """Updates any includes to reference the new Arduino library paths."""
+ include_match = re.match(r'(.*#include.*")(.*)(")', line)
+ if include_match:
+ path = include_match.group(2)
+ for supplied_header in supplied_headers_list:
+ if six.ensure_str(supplied_header).endswith(path):
+ path = supplied_header
+ break
+ line = include_match.group(1) + six.ensure_str(path) + include_match.group(
+ 3)
+ return line
+
+
+def replace_main(line):
+ """Updates any occurrences of a bare main definition to the Arduino equivalent."""
+ main_match = re.match(r'(.*int )(main)(\(.*)', line)
+ if main_match:
+ line = main_match.group(1) + 'tflite_micro_main' + main_match.group(3)
+ return line
+
+
+def check_ino_functions(input_text):
+ """Ensures the required functions exist."""
+ # We're moving to an Arduino-friendly structure for all our examples, so they
+ # have to have a setup() and loop() function, just like their IDE expects.
+ if not re.search(r'void setup\(\) \{', input_text):
+ raise Exception(
+ 'All examples must have a setup() function for Arduino compatibility\n'
+ + input_text)
+ if not re.search(r'void loop\(\) \{', input_text):
+ raise Exception(
+ 'All examples must have a loop() function for Arduino compatibility')
+ return input_text
+
+
+def add_example_ino_library_include(input_text):
+ """Makes sure the example includes the header that loads the library."""
+ return re.sub(r'#include ', '#include <TensorFlowLite.h>\n\n#include ',
+ input_text, 1)
+
+
+def replace_example_includes(line, _):
+ """Updates any includes for local example files."""
+ # Because the export process moves the example source and header files out of
+ # their default locations into the top-level 'examples' folder in the Arduino
+ # library, we have to update any include references to match.
+ dir_path = 'tensorflow/lite/micro/examples/'
+ include_match = re.match(
+ r'(.*#include.*")' + six.ensure_str(dir_path) + r'([^/]+)/(.*")', line)
+ if include_match:
+ flattened_name = re.sub(r'/', '_', include_match.group(3))
+ line = include_match.group(1) + flattened_name
+ return line
+
+
+def main(unused_args, flags):
+ """Transforms the input source file to work when exported to Arduino."""
+ input_file_lines = sys.stdin.read().split('\n')
+
+ supplied_headers_list = six.ensure_str(flags.third_party_headers).split(' ')
+
+ output_lines = []
+ for line in input_file_lines:
+ line = replace_includes(line, supplied_headers_list)
+ if flags.is_example_ino or flags.is_example_source:
+ line = replace_example_includes(line, flags.source_path)
+ else:
+ line = replace_main(line)
+ output_lines.append(line)
+ output_text = '\n'.join(output_lines)
+
+ if flags.is_example_ino:
+ output_text = check_ino_functions(output_text)
+ output_text = add_example_ino_library_include(output_text)
+
+ sys.stdout.write(output_text)
+
+
+def parse_args():
+ """Converts the raw arguments into accessible flags."""
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--third_party_headers',
+ type=str,
+ default='',
+ help='Space-separated list of headers to resolve.')
+ parser.add_argument(
+ '--is_example_ino',
+ dest='is_example_ino',
+ action='store_true',
+ help='Whether the destination is an example main ino.')
+ parser.add_argument(
+ '--is_example_source',
+ dest='is_example_source',
+ action='store_true',
+ help='Whether the destination is an example cpp or header file.')
+ parser.add_argument(
+ '--source_path',
+ type=str,
+ default='',
+ help='The relative path of the source code file.')
+ flags, unparsed = parser.parse_known_args()
+
+ main(unparsed, flags)
+
+
+if __name__ == '__main__':
+ parse_args()
diff --git a/tensorflow/lite/micro/tools/make/transform_arduino_source_test.sh b/tensorflow/lite/micro/tools/make/transform_arduino_source_test.sh
new file mode 100755
index 0000000..00889b2
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/transform_arduino_source_test.sh
@@ -0,0 +1,154 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Bash unit tests for the TensorFlow Lite Micro project generator.
+
+set -e
+
+INPUT_REGULAR_FILE=${TEST_TMPDIR}/input_regular.cc
+cat << EOF > ${INPUT_REGULAR_FILE}
+#include <stdio.h>
+#include "foo.h"
+#include "bar/fish.h"
+#include "baz.h"
+#ifndef __ANDROID__
+ #include "something.h"
+#endif // __ANDROID__
+
+int main(int argc, char** argv) {
+ fprintf(stderr, "Hello World!\n");
+ return 0;
+}
+EOF
+
+OUTPUT_REGULAR_FILE=${TEST_TMPDIR}/output_regular.cc
+THIRD_PARTY_HEADERS="subdir/foo.h subdir_2/include/bar/fish.h subdir_3/something.h"
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/transform_source \
+ --platform=arduino \
+ --third_party_headers="${THIRD_PARTY_HEADERS}" \
+ < ${INPUT_REGULAR_FILE} \
+ > ${OUTPUT_REGULAR_FILE}
+
+if ! grep -q '#include <stdio.h>' ${OUTPUT_REGULAR_FILE}; then
+ echo "ERROR: No stdio.h include found in output '${OUTPUT_REGULAR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "subdir/foo.h"' ${OUTPUT_REGULAR_FILE}; then
+ echo "ERROR: No subdir/foo.h include found in output '${OUTPUT_REGULAR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "subdir_2/include/bar/fish.h"' ${OUTPUT_REGULAR_FILE}; then
+ echo "ERROR: No subdir_2/include/bar/fish.h include found in output '${OUTPUT_REGULAR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "baz.h"' ${OUTPUT_REGULAR_FILE}; then
+ echo "ERROR: No baz.h include found in output '${OUTPUT_REGULAR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "subdir_3/something.h"' ${OUTPUT_REGULAR_FILE}; then
+ echo "ERROR: No subdir_3/something.h include found in output '${OUTPUT_REGULAR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q 'int tflite_micro_main(' ${OUTPUT_REGULAR_FILE}; then
+ echo "ERROR: No int tflite_micro_main() definition found in output '${OUTPUT_REGULAR_FILE}'"
+ exit 1
+fi
+
+
+INPUT_EXAMPLE_INO_FILE=${TEST_TMPDIR}/input_example_ino.cc
+cat << EOF > ${INPUT_EXAMPLE_INO_FILE}
+#include <stdio.h>
+#include "foo.h"
+#include "tensorflow/lite/micro/examples/something/foo/fish.h"
+#include "baz.h"
+
+void setup() {
+}
+
+void loop() {
+}
+EOF
+
+OUTPUT_EXAMPLE_INO_FILE=${TEST_TMPDIR}/output_regular.cc
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/transform_source \
+ --platform=arduino \
+ --third_party_headers="${THIRD_PARTY_HEADERS}" \
+ --is_example_ino \
+ < ${INPUT_EXAMPLE_INO_FILE} \
+ > ${OUTPUT_EXAMPLE_INO_FILE}
+
+if ! grep -q '#include <TensorFlowLite.h>' ${OUTPUT_EXAMPLE_INO_FILE}; then
+ echo "ERROR: No TensorFlowLite.h include found in output '${OUTPUT_EXAMPLE_INO_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "foo_fish.h"' ${OUTPUT_EXAMPLE_INO_FILE}; then
+ echo "ERROR: No foo/fish.h include found in output '${OUTPUT_EXAMPLE_INO_FILE}'"
+ exit 1
+fi
+
+INPUT_EXAMPLE_SOURCE_FILE=${TEST_TMPDIR}/input_example_source.h
+cat << EOF > ${INPUT_EXAMPLE_SOURCE_FILE}
+#include <stdio.h>
+#include "foo.h"
+#include "foo/fish.h"
+#include "baz.h"
+#include "tensorflow/lite/micro/examples/something/cube/tri.h"
+
+void setup() {
+}
+
+void loop() {
+}
+
+int main(int argc, char* argv[]) {
+ setup();
+ while (true) {
+ loop();
+ }
+}
+EOF
+
+OUTPUT_EXAMPLE_SOURCE_FILE=${TEST_TMPDIR}/output_example_source.h
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/transform_source \
+ --platform=arduino \
+ --third_party_headers="${THIRD_PARTY_HEADERS}" \
+ --is_example_source \
+ --source_path="foo/input_example_source.h" \
+ < ${INPUT_EXAMPLE_SOURCE_FILE} \
+ > ${OUTPUT_EXAMPLE_SOURCE_FILE}
+
+if ! grep -q '#include "foo/fish.h"' ${OUTPUT_EXAMPLE_SOURCE_FILE}; then
+ echo "ERROR: No foo/fish.h include found in output '${OUTPUT_EXAMPLE_SOURCE_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "cube_tri.h"' ${OUTPUT_EXAMPLE_SOURCE_FILE}; then
+ echo "ERROR: No cube_tri.h include found in output '${OUTPUT_EXAMPLE_SOURCE_FILE}'"
+ exit 1
+fi
+
+
+echo
+echo "SUCCESS: transform_arduino_source test PASSED"
diff --git a/tensorflow/lite/micro/tools/make/transform_esp_source_test.sh b/tensorflow/lite/micro/tools/make/transform_esp_source_test.sh
new file mode 100755
index 0000000..b1bbbfb
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/transform_esp_source_test.sh
@@ -0,0 +1,108 @@
+#!/bin/bash
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Bash unit tests for the TensorFlow Lite Micro project generator.
+
+set -e
+
+INPUT_EXAMPLE_FILE=${TEST_TMPDIR}/input_example.cc
+cat << EOF > ${INPUT_EXAMPLE_FILE}
+#include <stdio.h>
+#include "baz.h"
+#include "tensorflow/lite/micro/examples/something/foo/fish.h"
+
+main() {
+ fprintf(stderr, "Hello World!\n");
+ return 0;
+}
+EOF
+
+OUTPUT_EXAMPLE_FILE=${TEST_TMPDIR}/output_example.cc
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/transform_source \
+ --platform=esp \
+ --is_example_source \
+ --source_path="tensorflow/lite/micro/examples/something/input_example.cc" \
+ < ${INPUT_EXAMPLE_FILE} \
+ > ${OUTPUT_EXAMPLE_FILE}
+
+if ! grep -q '#include <stdio.h>' ${OUTPUT_EXAMPLE_FILE}; then
+ echo "ERROR: No stdio.h include found in output '${OUTPUT_EXAMPLE_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "baz.h"' ${OUTPUT_EXAMPLE_FILE}; then
+ echo "ERROR: No baz.h include found in output '${OUTPUT_EXAMPLE_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "foo/fish.h"' ${OUTPUT_EXAMPLE_FILE}; then
+ echo "ERROR: No foo/fish.h include found in output '${OUTPUT_EXAMPLE_FILE}'"
+ exit 1
+fi
+
+
+#
+# Example file in a sub directory.
+#
+
+mkdir -p "${TEST_TMPDIR}/subdir"
+INPUT_EXAMPLE_SUBDIR_FILE=${TEST_TMPDIR}/subdir/input_example.cc
+cat << EOF > ${INPUT_EXAMPLE_SUBDIR_FILE}
+#include <stdio.h>
+#include "baz.h"
+#include "tensorflow/lite/micro/examples/something/subdir/input_example.h"
+#include "tensorflow/lite/micro/examples/something/bleh.h"
+#include "tensorflow/lite/micro/examples/something/foo/fish.h"
+EOF
+
+OUTPUT_EXAMPLE_SUBDIR_FILE=${TEST_TMPDIR}/output_example.cc
+
+${TEST_SRCDIR}/tensorflow/lite/micro/tools/make/transform_source \
+ --platform=esp \
+ --is_example_source \
+ --source_path="tensorflow/lite/micro/examples/something/subdir/input_example.cc" \
+ < ${INPUT_EXAMPLE_SUBDIR_FILE} \
+ > ${OUTPUT_EXAMPLE_SUBDIR_FILE}
+
+if ! grep -q '#include <stdio.h>' ${OUTPUT_EXAMPLE_SUBDIR_FILE}; then
+ echo "ERROR: No stdio.h include found in output '${OUTPUT_EXAMPLE_SUBDIR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "baz.h"' ${OUTPUT_EXAMPLE_SUBDIR_FILE}; then
+ echo "ERROR: No baz.h include found in output '${OUTPUT_EXAMPLE_SUBDIR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "input_example.h"' ${OUTPUT_EXAMPLE_SUBDIR_FILE}; then
+ echo "ERROR: No input_example.h include found in output '${OUTPUT_EXAMPLE_SUBDIR_FILE}'"
+ cat ${OUTPUT_EXAMPLE_SUBDIR_FILE}
+ exit 1
+fi
+
+if ! grep -q '#include "../bleh.h"' ${OUTPUT_EXAMPLE_SUBDIR_FILE}; then
+ echo "ERROR: No ../bleh.h include found in output '${OUTPUT_EXAMPLE_SUBDIR_FILE}'"
+ exit 1
+fi
+
+if ! grep -q '#include "../foo/fish.h"' ${OUTPUT_EXAMPLE_SUBDIR_FILE}; then
+ echo "ERROR: No ../foo/fish.h include found in output '${OUTPUT_EXAMPLE_SUBDIR_FILE}'"
+ exit 1
+fi
+
+echo
+echo "SUCCESS: transform_esp_source test PASSED"
diff --git a/tensorflow/lite/micro/tools/make/transform_source.py b/tensorflow/lite/micro/tools/make/transform_source.py
new file mode 100644
index 0000000..e023b6d
--- /dev/null
+++ b/tensorflow/lite/micro/tools/make/transform_source.py
@@ -0,0 +1,205 @@
+# Lint as: python2, python3
+# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Resolves non-system C/C++ includes to their full paths.
+
+Used to generate Arduino and ESP-IDF examples.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import os
+import re
+import sys
+
+import six
+
+
+EXAMPLE_DIR_PATH = 'tensorflow/lite/micro/examples/'
+
+
+def replace_arduino_includes(line, supplied_headers_list):
+ """Updates any includes to reference the new Arduino library paths."""
+ include_match = re.match(r'(.*#include.*")(.*)(")', line)
+ if include_match:
+ path = include_match.group(2)
+ for supplied_header in supplied_headers_list:
+ if six.ensure_str(supplied_header).endswith(path):
+ path = supplied_header
+ break
+ line = include_match.group(1) + six.ensure_str(path) + include_match.group(
+ 3)
+ return line
+
+
+def replace_arduino_main(line):
+ """Updates any occurrences of a bare main definition to the Arduino equivalent."""
+ main_match = re.match(r'(.*int )(main)(\(.*)', line)
+ if main_match:
+ line = main_match.group(1) + 'tflite_micro_main' + main_match.group(3)
+ return line
+
+
+def check_ino_functions(input_text):
+ """Ensures the required functions exist."""
+ # We're moving to an Arduino-friendly structure for all our examples, so they
+ # have to have a setup() and loop() function, just like their IDE expects.
+ if not re.search(r'void setup\(\) \{', input_text):
+ raise Exception(
+ 'All examples must have a setup() function for Arduino compatibility\n'
+ + input_text)
+ if not re.search(r'void loop\(\) \{', input_text):
+ raise Exception(
+ 'All examples must have a loop() function for Arduino compatibility')
+ return input_text
+
+
+def add_example_ino_library_include(input_text):
+ """Makes sure the example includes the header that loads the library."""
+ return re.sub(r'#include ', '#include <TensorFlowLite.h>\n\n#include ',
+ input_text, 1)
+
+
+def replace_arduino_example_includes(line, _):
+ """Updates any includes for local example files."""
+ # Because the export process moves the example source and header files out of
+ # their default locations into the top-level 'examples' folder in the Arduino
+ # library, we have to update any include references to match.
+ dir_path = 'tensorflow/lite/micro/examples/'
+ include_match = re.match(
+ r'(.*#include.*")' + six.ensure_str(dir_path) + r'([^/]+)/(.*")', line)
+ if include_match:
+ flattened_name = re.sub(r'/', '_', include_match.group(3))
+ line = include_match.group(1) + flattened_name
+ return line
+
+
+def replace_esp_example_includes(line, source_path):
+ """Updates any includes for local example files."""
+ # Because the export process moves the example source and header files out of
+ # their default locations into the top-level 'main' folder in the ESP-IDF
+ # project, we have to update any include references to match.
+ include_match = re.match(r'.*#include.*"(' + EXAMPLE_DIR_PATH + r'.*)"', line)
+
+ if include_match:
+ # Compute the target path relative from the source's directory
+ target_path = include_match.group(1)
+ source_dirname = os.path.dirname(source_path)
+ rel_to_target = os.path.relpath(target_path, start=source_dirname)
+
+ line = '#include "%s"' % rel_to_target
+ return line
+
+
+def transform_arduino_sources(input_lines, flags):
+ """Transform sources for the Arduino platform.
+
+ Args:
+ input_lines: A sequence of lines from the input file to process.
+ flags: Flags indicating which transformation(s) to apply.
+
+ Returns:
+ The transformed output as a string.
+ """
+ supplied_headers_list = six.ensure_str(flags.third_party_headers).split(' ')
+
+ output_lines = []
+ for line in input_lines:
+ line = replace_arduino_includes(line, supplied_headers_list)
+ if flags.is_example_ino or flags.is_example_source:
+ line = replace_arduino_example_includes(line, flags.source_path)
+ else:
+ line = replace_arduino_main(line)
+ output_lines.append(line)
+ output_text = '\n'.join(output_lines)
+
+ if flags.is_example_ino:
+ output_text = check_ino_functions(output_text)
+ output_text = add_example_ino_library_include(output_text)
+
+ return output_text
+
+
+def transform_esp_sources(input_lines, flags):
+ """Transform sources for the ESP-IDF platform.
+
+ Args:
+ input_lines: A sequence of lines from the input file to process.
+ flags: Flags indicating which transformation(s) to apply.
+
+ Returns:
+ The transformed output as a string.
+ """
+ output_lines = []
+ for line in input_lines:
+ if flags.is_example_source:
+ line = replace_esp_example_includes(line, flags.source_path)
+ output_lines.append(line)
+
+ output_text = '\n'.join(output_lines)
+ return output_text
+
+
+def main(unused_args, flags):
+ """Transforms the input source file to work when exported as example."""
+ input_file_lines = sys.stdin.read().split('\n')
+
+ output_text = ''
+ if flags.platform == 'arduino':
+ output_text = transform_arduino_sources(input_file_lines, flags)
+ elif flags.platform == 'esp':
+ output_text = transform_esp_sources(input_file_lines, flags)
+
+ sys.stdout.write(output_text)
+
+
+def parse_args():
+ """Converts the raw arguments into accessible flags."""
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--platform',
+ choices=['arduino', 'esp'],
+ required=True,
+ help='Target platform.')
+ parser.add_argument(
+ '--third_party_headers',
+ type=str,
+ default='',
+ help='Space-separated list of headers to resolve.')
+ parser.add_argument(
+ '--is_example_ino',
+ dest='is_example_ino',
+ action='store_true',
+ help='Whether the destination is an example main ino.')
+ parser.add_argument(
+ '--is_example_source',
+ dest='is_example_source',
+ action='store_true',
+ help='Whether the destination is an example cpp or header file.')
+ parser.add_argument(
+ '--source_path',
+ type=str,
+ default='',
+ help='The relative path of the source code file.')
+ flags, unparsed = parser.parse_known_args()
+
+ main(unparsed, flags)
+
+
+if __name__ == '__main__':
+ parse_args()
diff --git a/tensorflow/lite/micro/tools/project_generation/Makefile b/tensorflow/lite/micro/tools/project_generation/Makefile
new file mode 100644
index 0000000..fb2abb8
--- /dev/null
+++ b/tensorflow/lite/micro/tools/project_generation/Makefile
@@ -0,0 +1,68 @@
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#
+# Simple Makefile that serves as a smokes-check for project generation on x86.
+#
+# Execute the following command after copying this Makefile to the root of the
+# TFLM tree created with the project generation script:
+# make -j8 examples
+
+CXX := clang++
+CXXFLAGS := \
+ -std=c++11
+
+CC := clang
+CCFLAGS := \
+ -std=c11
+
+INCLUDES := \
+ -I. \
+ -I./third_party/gemmlowp \
+ -I./third_party/flatbuffers/include \
+ -I./third_party/ruy
+
+AR := ar
+ARFLAGS := -r
+
+GENDIR := gen
+OBJDIR := $(GENDIR)/obj
+BINDIR := $(GENDIR)/bin
+LIB := $(GENDIR)/libtflm.a
+
+TFLM_CC_SRCS := $(shell find tensorflow -name "*.cc" -o -name "*.c")
+OBJS := $(addprefix $(OBJDIR)/, $(patsubst %.c,%.o,$(patsubst %.cc,%.o,$(TFLM_CC_SRCS))))
+
+$(OBJDIR)/%.o: %.cc
+ @mkdir -p $(dir $@)
+ $(CXX) $(CXXFLAGS) $(INCLUDES) -c $< -o $@
+
+$(OBJDIR)/%.o: %.c
+ @mkdir -p $(dir $@)
+ $(CC) $(CCFLAGS) $(INCLUDES) -c $< -o $@
+
+$(LIB): $(OBJS)
+ @mkdir -p $(dir $@)
+ $(AR) $(ARFLAGS) $(LIB) $(OBJS)
+
+clean:
+ rm -rf $(GENDIR)
+
+libtflm: $(LIB)
+
+hello_world: libtflm
+ @mkdir -p $(BINDIR)
+ $(CXX) $(CXXFLAGS) $(wildcard examples/hello_world/*.cc) $(INCLUDES) $(LIB) -o $(BINDIR)/$@
+
+examples: hello_world
diff --git a/tensorflow/lite/micro/tools/project_generation/create_tflm_tree.py b/tensorflow/lite/micro/tools/project_generation/create_tflm_tree.py
new file mode 100644
index 0000000..1c4c77b
--- /dev/null
+++ b/tensorflow/lite/micro/tools/project_generation/create_tflm_tree.py
@@ -0,0 +1,167 @@
+# Copyright 2021 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Starting point for writing scripts to integrate TFLM with external IDEs.
+
+This script can be used to output a tree containing only the sources and headers
+needed to use TFLM for a specific configuration (e.g. target and
+optimized_kernel_implementation). This should serve as a starting
+point to integrate TFLM with external IDEs.
+
+The goal is for this script to be an interface that is maintained by the TFLM
+team and any additional scripting needed for integration with a particular IDE
+should be written external to the TFLM repository and built to work on top of
+the output tree generated with this script.
+
+We will add more documentation for a desired end-to-end integration workflow as
+we get further along in our prototyping. See this github issue for more details:
+ https://github.com/tensorflow/tensorflow/issues/47413
+"""
+
+import argparse
+import fileinput
+import os
+import shutil
+import subprocess
+
+
+def _get_dirs(file_list):
+ dirs = set()
+ for filepath in file_list:
+ dirs.add(os.path.dirname(filepath))
+ return dirs
+
+
+def _get_file_list(key, makefile_options):
+ params_list = [
+ "make", "-f", "tensorflow/lite/micro/tools/make/Makefile", key
+ ] + makefile_options.split()
+ process = subprocess.Popen(
+ params_list, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ stdout, stderr = process.communicate()
+
+ if process.returncode != 0:
+ raise RuntimeError("%s failed with \n\n %s" %
+ (" ".join(params_list), stderr.decode()))
+
+ return [bytepath.decode() for bytepath in stdout.split()]
+
+
+def _add_third_party_code(prefix_dir, makefile_options):
+ files = []
+ files.extend(_get_file_list("list_third_party_sources", makefile_options))
+ files.extend(_get_file_list("list_third_party_headers", makefile_options))
+
+ # The list_third_party_* rules give path relative to the root of the git repo.
+ # However, in the output tree, we would like for the third_party code to be a tree
+ # under prefix_dir/third_party, with the path to the tflm_download directory
+ # removed. The path manipulation logic that follows removes the downloads
+ # directory prefix, and adds the third_party prefix to create a list of
+ # destination directories for each of the third party files.
+ tflm_download_path = "tensorflow/lite/micro/tools/make/downloads"
+ dest_dir_list = [
+ os.path.join(prefix_dir, "third_party",
+ os.path.relpath(os.path.dirname(f), tflm_download_path))
+ for f in files
+ ]
+
+ for dest_dir, filepath in zip(dest_dir_list, files):
+ os.makedirs(dest_dir, exist_ok=True)
+ shutil.copy(filepath, dest_dir)
+
+
+def _add_tflm_code(prefix_dir, makefile_options):
+ files = []
+ files.extend(_get_file_list("list_library_sources", makefile_options))
+ files.extend(_get_file_list("list_library_headers", makefile_options))
+
+ for dirname in _get_dirs(files):
+ os.makedirs(os.path.join(prefix_dir, dirname), exist_ok=True)
+
+ for filepath in files:
+ shutil.copy(filepath, os.path.join(prefix_dir, os.path.dirname(filepath)))
+
+
+def _create_tflm_tree(prefix_dir, makefile_options):
+ _add_tflm_code(prefix_dir, makefile_options)
+ _add_third_party_code(prefix_dir, makefile_options)
+
+
+# For examples, we are explicitly making a deicision to not have any source
+# specialization based on the TARGET and OPTIMIZED_KERNEL_DIR. The thinking
+# here is that any target-specific sources should not be part of the TFLM
+# tree. Rather, this function will return an examples directory structure for
+# x86 and it will be the responsibility of the target-specific examples
+# repository to provide all the additional sources (and remove the unnecessary
+# sources) for the examples to run on that specific target.
+def _create_examples_tree(prefix_dir, examples_list):
+ files = []
+ for e in examples_list:
+ files.extend(_get_file_list("list_%s_example_sources" % (e), ""))
+ files.extend(_get_file_list("list_%s_example_headers" % (e), ""))
+
+ # The get_file_list gives path relative to the root of the git repo (where the
+ # examples are in tensorflow/lite/micro/examples). However, in the output
+ # tree, we would like for the examples to be under prefix_dir/examples.
+ tflm_examples_path = "tensorflow/lite/micro/examples"
+
+ dest_file_list = [
+ os.path.join(prefix_dir, "examples",
+ os.path.relpath(f, tflm_examples_path)) for f in files
+ ]
+
+ for dest_file, filepath in zip(dest_file_list, files):
+ dest_dir = os.path.dirname(dest_file)
+ os.makedirs(dest_dir, exist_ok=True)
+ shutil.copy(filepath, dest_dir)
+
+ # Since we are changing the directory structure for the examples, we will also
+ # need to modify the paths in the code.
+ for filepath in dest_file_list:
+ # We need a trailing forward slash because what we care about is replacing
+ # the include paths.
+ text_to_replace = os.path.join(
+ tflm_examples_path, os.path.basename(os.path.dirname(filepath))) + "/"
+
+ with fileinput.FileInput(filepath, inplace=True) as f:
+ for line in f:
+ # end="" prevents an extra newline from getting added as part of the
+ # in-place find and replace.
+ print(line.replace(text_to_replace, ""), end="")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(
+ description="Starting script for TFLM project generation")
+ parser.add_argument(
+ "output_dir", help="Output directory for generated TFLM tree")
+ parser.add_argument(
+ "--makefile_options",
+ default="",
+ help="Additional TFLM Makefile options. For example: "
+ "--makefile_options=\"TARGET=<target> "
+ "OPTIMIZED_KERNEL_DIR=<optimized_kernel_dir> "
+ "TARGET_ARCH=corex-m4\"")
+ parser.add_argument(
+ "--examples",
+ "-e",
+ action="append",
+ help="Examples to add to the output tree. For example: "
+ "-e hello_world -e micro_speech")
+ args = parser.parse_args()
+
+ _create_tflm_tree(args.output_dir, args.makefile_options)
+
+ if args.examples is not None:
+ _create_examples_tree(args.output_dir, args.examples)
diff --git a/tensorflow/lite/micro/xcore/README.md b/tensorflow/lite/micro/xcore/README.md
new file mode 100644
index 0000000..796b73a
--- /dev/null
+++ b/tensorflow/lite/micro/xcore/README.md
@@ -0,0 +1,30 @@
+# Quickstart to install tools and run unit tests:
+
+```
+$ make -f tensorflow/lite/micro/tools/make/Makefile TARGET="xcore" clean clean_downloads && make -f tensorflow/lite/micro/tools/make/Makefile TARGET="xcore" test_greedy_memory_planner_test || true && pushd tensorflow/lite/micro/tools/make/downloads/xtimecomposer/xTIMEcomposer/15.0.0/ && source SetEnv && popd && make -f tensorflow/lite/micro/tools/make/Makefile TARGET="xcore" test
+```
+
+(add -jN to the final make command to run builds / tests in N parallel threads)
+
+# Background information:
+
+* To start from a fresh repo (this will also remove non-xcore builds and
+ downloads): `$ make -f tensorflow/lite/micro/tools/make/Makefile
+ TARGET="xcore" clean clean_downloads`
+* To force xcore.ai tools download from a clean repo: `$ make -f
+ tensorflow/lite/micro/tools/make/Makefile TARGET="xcore"
+ test_greedy_memory_planner_test` (this will fail to build the test, but if
+ it succeeds because you already have tools it will exit quickly)
+
+* To set up environment variables correctly run the following from the top
+ tensorflow directory: `$ make -f tensorflow/lite/micro/tools/make/Makefile
+ TARGET="xcore" test $ pushd
+ ./tensorflow/lite/micro/tools/make/downloads/xtimecomposer/xTIMEcomposer/15.0.0/
+ && source SetEnv && popd $ make -f tensorflow/lite/micro/tools/make/Makefile
+ TARGET="xcore" test`
+
+* Assuming tools are already set up the following are the most commonly used
+ commands: `$ make -f tensorflow/lite/micro/tools/make/Makefile
+ TARGET="xcore" build $ make -f tensorflow/lite/micro/tools/make/Makefile
+ TARGET="xcore" test $ make -f tensorflow/lite/micro/tools/make/Makefile
+ TARGET="xcore" < name_of_example i.e. hello_world_test >`
diff --git a/tensorflow/lite/micro/xcore/debug_log.cc b/tensorflow/lite/micro/xcore/debug_log.cc
new file mode 100644
index 0000000..b964706
--- /dev/null
+++ b/tensorflow/lite/micro/xcore/debug_log.cc
@@ -0,0 +1,19 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+
+#include "tensorflow/lite/micro/debug_log.h"
+
+#include <cstdio>
+extern "C" void DebugLog(const char* s) { printf("%s", s); }
diff --git a/tensorflow/lite/portable_type_to_tflitetype.h b/tensorflow/lite/portable_type_to_tflitetype.h
new file mode 100644
index 0000000..83a0ac6
--- /dev/null
+++ b/tensorflow/lite/portable_type_to_tflitetype.h
@@ -0,0 +1,74 @@
+/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_PORTABLE_TYPE_TO_TFLITETYPE_H_
+#define TENSORFLOW_LITE_PORTABLE_TYPE_TO_TFLITETYPE_H_
+
+// Most of the definitions have been moved to this subheader so that Micro
+// can include it without relying on <string> and <complex>, which isn't
+// available on all platforms.
+
+// Arduino build defines abs as a macro here. That is invalid C++, and breaks
+// libc++'s <complex> header, undefine it.
+#ifdef abs
+#undef abs
+#endif
+
+#include <stdint.h>
+
+#include "tensorflow/lite/c/common.h"
+
+namespace tflite {
+
+// Map statically from a C++ type to a TfLiteType. Used in interpreter for
+// safe casts.
+// Example:
+// typeToTfLiteType<bool>() -> kTfLiteBool
+template <typename T>
+constexpr TfLiteType typeToTfLiteType() {
+ return kTfLiteNoType;
+}
+// Map from TfLiteType to the corresponding C++ type.
+// Example:
+// TfLiteTypeToType<kTfLiteBool>::Type -> bool
+template <TfLiteType TFLITE_TYPE_ENUM>
+struct TfLiteTypeToType {}; // Specializations below
+
+// Template specialization for both typeToTfLiteType and TfLiteTypeToType.
+#define MATCH_TYPE_AND_TFLITE_TYPE(CPP_TYPE, TFLITE_TYPE_ENUM) \
+ template <> \
+ constexpr TfLiteType typeToTfLiteType<CPP_TYPE>() { \
+ return TFLITE_TYPE_ENUM; \
+ } \
+ template <> \
+ struct TfLiteTypeToType<TFLITE_TYPE_ENUM> { \
+ using Type = CPP_TYPE; \
+ }
+
+// No string mapping is included here, since the TF Lite packed representation
+// doesn't correspond to a C++ type well.
+MATCH_TYPE_AND_TFLITE_TYPE(int32_t, kTfLiteInt32);
+MATCH_TYPE_AND_TFLITE_TYPE(uint32_t, kTfLiteUInt32);
+MATCH_TYPE_AND_TFLITE_TYPE(int16_t, kTfLiteInt16);
+MATCH_TYPE_AND_TFLITE_TYPE(int64_t, kTfLiteInt64);
+MATCH_TYPE_AND_TFLITE_TYPE(float, kTfLiteFloat32);
+MATCH_TYPE_AND_TFLITE_TYPE(unsigned char, kTfLiteUInt8);
+MATCH_TYPE_AND_TFLITE_TYPE(int8_t, kTfLiteInt8);
+MATCH_TYPE_AND_TFLITE_TYPE(bool, kTfLiteBool);
+MATCH_TYPE_AND_TFLITE_TYPE(TfLiteFloat16, kTfLiteFloat16);
+MATCH_TYPE_AND_TFLITE_TYPE(double, kTfLiteFloat64);
+MATCH_TYPE_AND_TFLITE_TYPE(uint64_t, kTfLiteUInt64);
+
+} // namespace tflite
+#endif // TENSORFLOW_LITE_PORTABLE_TYPE_TO_TFLITETYPE_H_
diff --git a/tensorflow/lite/schema/BUILD b/tensorflow/lite/schema/BUILD
new file mode 100644
index 0000000..df17b03
--- /dev/null
+++ b/tensorflow/lite/schema/BUILD
@@ -0,0 +1,32 @@
+package(
+ default_visibility = [
+ "//visibility:public",
+ ],
+ licenses = ["notice"],
+)
+
+
+# The name schema_fbs is unchanged from upstream TF so that sync'ing shared
+# TfLite/TFLM code does not require a change in the name for this BUILD target.
+# For upstream TFL code, schema_fbs is a flatbuffer_cc_library whereas it is a
+# standard cc_library (with the generated schems header) in the TFLM code.
+cc_library(
+ name = "schema_fbs",
+ hdrs = ["schema_generated.h"],
+ deps = [
+ "@flatbuffers//:runtime_cc",
+ ],
+)
+
+cc_library(
+ name = "schema_utils",
+ srcs = ["schema_utils.cc"],
+ hdrs = ["schema_utils.h"],
+ deps = [
+ ":schema_fbs",
+ "//tensorflow/lite/kernels/internal:compatibility",
+ "@flatbuffers//:runtime_cc",
+ ],
+)
+
+
diff --git a/tensorflow/lite/schema/schema_generated.h b/tensorflow/lite/schema/schema_generated.h
new file mode 100755
index 0000000..ee1387c
--- /dev/null
+++ b/tensorflow/lite/schema/schema_generated.h
@@ -0,0 +1,17891 @@
+/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+// automatically generated by the FlatBuffers compiler, do not modify
+
+
+#ifndef FLATBUFFERS_GENERATED_SCHEMA_TFLITE_H_
+#define FLATBUFFERS_GENERATED_SCHEMA_TFLITE_H_
+
+#include "flatbuffers/flatbuffers.h"
+
+namespace tflite {
+
+struct CustomQuantization;
+struct CustomQuantizationT;
+
+struct QuantizationParameters;
+struct QuantizationParametersT;
+
+struct Int32Vector;
+struct Int32VectorT;
+
+struct Uint16Vector;
+struct Uint16VectorT;
+
+struct Uint8Vector;
+struct Uint8VectorT;
+
+struct DimensionMetadata;
+struct DimensionMetadataT;
+
+struct SparsityParameters;
+struct SparsityParametersT;
+
+struct Tensor;
+struct TensorT;
+
+struct Conv2DOptions;
+struct Conv2DOptionsT;
+
+struct Conv3DOptions;
+struct Conv3DOptionsT;
+
+struct Pool2DOptions;
+struct Pool2DOptionsT;
+
+struct DepthwiseConv2DOptions;
+struct DepthwiseConv2DOptionsT;
+
+struct ConcatEmbeddingsOptions;
+struct ConcatEmbeddingsOptionsT;
+
+struct LSHProjectionOptions;
+struct LSHProjectionOptionsT;
+
+struct SVDFOptions;
+struct SVDFOptionsT;
+
+struct RNNOptions;
+struct RNNOptionsT;
+
+struct SequenceRNNOptions;
+struct SequenceRNNOptionsT;
+
+struct BidirectionalSequenceRNNOptions;
+struct BidirectionalSequenceRNNOptionsT;
+
+struct FullyConnectedOptions;
+struct FullyConnectedOptionsT;
+
+struct SoftmaxOptions;
+struct SoftmaxOptionsT;
+
+struct ConcatenationOptions;
+struct ConcatenationOptionsT;
+
+struct AddOptions;
+struct AddOptionsT;
+
+struct MulOptions;
+struct MulOptionsT;
+
+struct L2NormOptions;
+struct L2NormOptionsT;
+
+struct LocalResponseNormalizationOptions;
+struct LocalResponseNormalizationOptionsT;
+
+struct LSTMOptions;
+struct LSTMOptionsT;
+
+struct UnidirectionalSequenceLSTMOptions;
+struct UnidirectionalSequenceLSTMOptionsT;
+
+struct BidirectionalSequenceLSTMOptions;
+struct BidirectionalSequenceLSTMOptionsT;
+
+struct ResizeBilinearOptions;
+struct ResizeBilinearOptionsT;
+
+struct ResizeNearestNeighborOptions;
+struct ResizeNearestNeighborOptionsT;
+
+struct CallOptions;
+struct CallOptionsT;
+
+struct PadOptions;
+struct PadOptionsT;
+
+struct PadV2Options;
+struct PadV2OptionsT;
+
+struct ReshapeOptions;
+struct ReshapeOptionsT;
+
+struct SpaceToBatchNDOptions;
+struct SpaceToBatchNDOptionsT;
+
+struct BatchToSpaceNDOptions;
+struct BatchToSpaceNDOptionsT;
+
+struct SkipGramOptions;
+struct SkipGramOptionsT;
+
+struct SpaceToDepthOptions;
+struct SpaceToDepthOptionsT;
+
+struct DepthToSpaceOptions;
+struct DepthToSpaceOptionsT;
+
+struct SubOptions;
+struct SubOptionsT;
+
+struct DivOptions;
+struct DivOptionsT;
+
+struct TopKV2Options;
+struct TopKV2OptionsT;
+
+struct EmbeddingLookupSparseOptions;
+struct EmbeddingLookupSparseOptionsT;
+
+struct GatherOptions;
+struct GatherOptionsT;
+
+struct TransposeOptions;
+struct TransposeOptionsT;
+
+struct ExpOptions;
+struct ExpOptionsT;
+
+struct CosOptions;
+struct CosOptionsT;
+
+struct ReducerOptions;
+struct ReducerOptionsT;
+
+struct SqueezeOptions;
+struct SqueezeOptionsT;
+
+struct SplitOptions;
+struct SplitOptionsT;
+
+struct SplitVOptions;
+struct SplitVOptionsT;
+
+struct StridedSliceOptions;
+struct StridedSliceOptionsT;
+
+struct LogSoftmaxOptions;
+struct LogSoftmaxOptionsT;
+
+struct CastOptions;
+struct CastOptionsT;
+
+struct DequantizeOptions;
+struct DequantizeOptionsT;
+
+struct MaximumMinimumOptions;
+struct MaximumMinimumOptionsT;
+
+struct TileOptions;
+struct TileOptionsT;
+
+struct ArgMaxOptions;
+struct ArgMaxOptionsT;
+
+struct ArgMinOptions;
+struct ArgMinOptionsT;
+
+struct GreaterOptions;
+struct GreaterOptionsT;
+
+struct GreaterEqualOptions;
+struct GreaterEqualOptionsT;
+
+struct LessOptions;
+struct LessOptionsT;
+
+struct LessEqualOptions;
+struct LessEqualOptionsT;
+
+struct NegOptions;
+struct NegOptionsT;
+
+struct SelectOptions;
+struct SelectOptionsT;
+
+struct SliceOptions;
+struct SliceOptionsT;
+
+struct TransposeConvOptions;
+struct TransposeConvOptionsT;
+
+struct ExpandDimsOptions;
+struct ExpandDimsOptionsT;
+
+struct SparseToDenseOptions;
+struct SparseToDenseOptionsT;
+
+struct EqualOptions;
+struct EqualOptionsT;
+
+struct NotEqualOptions;
+struct NotEqualOptionsT;
+
+struct ShapeOptions;
+struct ShapeOptionsT;
+
+struct RankOptions;
+struct RankOptionsT;
+
+struct PowOptions;
+struct PowOptionsT;
+
+struct FakeQuantOptions;
+struct FakeQuantOptionsT;
+
+struct PackOptions;
+struct PackOptionsT;
+
+struct LogicalOrOptions;
+struct LogicalOrOptionsT;
+
+struct OneHotOptions;
+struct OneHotOptionsT;
+
+struct AbsOptions;
+struct AbsOptionsT;
+
+struct HardSwishOptions;
+struct HardSwishOptionsT;
+
+struct LogicalAndOptions;
+struct LogicalAndOptionsT;
+
+struct LogicalNotOptions;
+struct LogicalNotOptionsT;
+
+struct UnpackOptions;
+struct UnpackOptionsT;
+
+struct FloorDivOptions;
+struct FloorDivOptionsT;
+
+struct SquareOptions;
+struct SquareOptionsT;
+
+struct ZerosLikeOptions;
+struct ZerosLikeOptionsT;
+
+struct FillOptions;
+struct FillOptionsT;
+
+struct FloorModOptions;
+struct FloorModOptionsT;
+
+struct RangeOptions;
+struct RangeOptionsT;
+
+struct LeakyReluOptions;
+struct LeakyReluOptionsT;
+
+struct SquaredDifferenceOptions;
+struct SquaredDifferenceOptionsT;
+
+struct MirrorPadOptions;
+struct MirrorPadOptionsT;
+
+struct UniqueOptions;
+struct UniqueOptionsT;
+
+struct ReverseV2Options;
+struct ReverseV2OptionsT;
+
+struct AddNOptions;
+struct AddNOptionsT;
+
+struct GatherNdOptions;
+struct GatherNdOptionsT;
+
+struct WhereOptions;
+struct WhereOptionsT;
+
+struct ReverseSequenceOptions;
+struct ReverseSequenceOptionsT;
+
+struct MatrixDiagOptions;
+struct MatrixDiagOptionsT;
+
+struct QuantizeOptions;
+struct QuantizeOptionsT;
+
+struct MatrixSetDiagOptions;
+struct MatrixSetDiagOptionsT;
+
+struct IfOptions;
+struct IfOptionsT;
+
+struct CallOnceOptions;
+struct CallOnceOptionsT;
+
+struct WhileOptions;
+struct WhileOptionsT;
+
+struct NonMaxSuppressionV4Options;
+struct NonMaxSuppressionV4OptionsT;
+
+struct NonMaxSuppressionV5Options;
+struct NonMaxSuppressionV5OptionsT;
+
+struct ScatterNdOptions;
+struct ScatterNdOptionsT;
+
+struct SelectV2Options;
+struct SelectV2OptionsT;
+
+struct DensifyOptions;
+struct DensifyOptionsT;
+
+struct SegmentSumOptions;
+struct SegmentSumOptionsT;
+
+struct BatchMatMulOptions;
+struct BatchMatMulOptionsT;
+
+struct CumsumOptions;
+struct CumsumOptionsT;
+
+struct BroadcastToOptions;
+struct BroadcastToOptionsT;
+
+struct Rfft2dOptions;
+struct Rfft2dOptionsT;
+
+struct HashtableOptions;
+struct HashtableOptionsT;
+
+struct HashtableFindOptions;
+struct HashtableFindOptionsT;
+
+struct HashtableImportOptions;
+struct HashtableImportOptionsT;
+
+struct HashtableSizeOptions;
+struct HashtableSizeOptionsT;
+
+struct OperatorCode;
+struct OperatorCodeT;
+
+struct Operator;
+struct OperatorT;
+
+struct SubGraph;
+struct SubGraphT;
+
+struct Buffer;
+struct BufferT;
+
+struct Metadata;
+struct MetadataT;
+
+struct TensorMap;
+struct TensorMapT;
+
+struct SignatureDef;
+struct SignatureDefT;
+
+struct Model;
+struct ModelT;
+
+enum TensorType {
+ TensorType_FLOAT32 = 0,
+ TensorType_FLOAT16 = 1,
+ TensorType_INT32 = 2,
+ TensorType_UINT8 = 3,
+ TensorType_INT64 = 4,
+ TensorType_STRING = 5,
+ TensorType_BOOL = 6,
+ TensorType_INT16 = 7,
+ TensorType_COMPLEX64 = 8,
+ TensorType_INT8 = 9,
+ TensorType_FLOAT64 = 10,
+ TensorType_COMPLEX128 = 11,
+ TensorType_UINT64 = 12,
+ TensorType_RESOURCE = 13,
+ TensorType_VARIANT = 14,
+ TensorType_UINT32 = 15,
+ TensorType_MIN = TensorType_FLOAT32,
+ TensorType_MAX = TensorType_UINT32
+};
+
+inline const TensorType (&EnumValuesTensorType())[16] {
+ static const TensorType values[] = {
+ TensorType_FLOAT32,
+ TensorType_FLOAT16,
+ TensorType_INT32,
+ TensorType_UINT8,
+ TensorType_INT64,
+ TensorType_STRING,
+ TensorType_BOOL,
+ TensorType_INT16,
+ TensorType_COMPLEX64,
+ TensorType_INT8,
+ TensorType_FLOAT64,
+ TensorType_COMPLEX128,
+ TensorType_UINT64,
+ TensorType_RESOURCE,
+ TensorType_VARIANT,
+ TensorType_UINT32
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesTensorType() {
+ static const char * const names[17] = {
+ "FLOAT32",
+ "FLOAT16",
+ "INT32",
+ "UINT8",
+ "INT64",
+ "STRING",
+ "BOOL",
+ "INT16",
+ "COMPLEX64",
+ "INT8",
+ "FLOAT64",
+ "COMPLEX128",
+ "UINT64",
+ "RESOURCE",
+ "VARIANT",
+ "UINT32",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameTensorType(TensorType e) {
+ if (flatbuffers::IsOutRange(e, TensorType_FLOAT32, TensorType_UINT32)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesTensorType()[index];
+}
+
+enum QuantizationDetails {
+ QuantizationDetails_NONE = 0,
+ QuantizationDetails_CustomQuantization = 1,
+ QuantizationDetails_MIN = QuantizationDetails_NONE,
+ QuantizationDetails_MAX = QuantizationDetails_CustomQuantization
+};
+
+inline const QuantizationDetails (&EnumValuesQuantizationDetails())[2] {
+ static const QuantizationDetails values[] = {
+ QuantizationDetails_NONE,
+ QuantizationDetails_CustomQuantization
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesQuantizationDetails() {
+ static const char * const names[3] = {
+ "NONE",
+ "CustomQuantization",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameQuantizationDetails(QuantizationDetails e) {
+ if (flatbuffers::IsOutRange(e, QuantizationDetails_NONE, QuantizationDetails_CustomQuantization)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesQuantizationDetails()[index];
+}
+
+template<typename T> struct QuantizationDetailsTraits {
+ static const QuantizationDetails enum_value = QuantizationDetails_NONE;
+};
+
+template<> struct QuantizationDetailsTraits<tflite::CustomQuantization> {
+ static const QuantizationDetails enum_value = QuantizationDetails_CustomQuantization;
+};
+
+struct QuantizationDetailsUnion {
+ QuantizationDetails type;
+ void *value;
+
+ QuantizationDetailsUnion() : type(QuantizationDetails_NONE), value(nullptr) {}
+ QuantizationDetailsUnion(QuantizationDetailsUnion&& u) FLATBUFFERS_NOEXCEPT :
+ type(QuantizationDetails_NONE), value(nullptr)
+ { std::swap(type, u.type); std::swap(value, u.value); }
+ QuantizationDetailsUnion(const QuantizationDetailsUnion &) FLATBUFFERS_NOEXCEPT;
+ QuantizationDetailsUnion &operator=(const QuantizationDetailsUnion &u) FLATBUFFERS_NOEXCEPT
+ { QuantizationDetailsUnion t(u); std::swap(type, t.type); std::swap(value, t.value); return *this; }
+ QuantizationDetailsUnion &operator=(QuantizationDetailsUnion &&u) FLATBUFFERS_NOEXCEPT
+ { std::swap(type, u.type); std::swap(value, u.value); return *this; }
+ ~QuantizationDetailsUnion() { Reset(); }
+
+ void Reset();
+
+#ifndef FLATBUFFERS_CPP98_STL
+ template <typename T>
+ void Set(T&& val) {
+ using RT = typename std::remove_reference<T>::type;
+ Reset();
+ type = QuantizationDetailsTraits<typename RT::TableType>::enum_value;
+ if (type != QuantizationDetails_NONE) {
+ value = new RT(std::forward<T>(val));
+ }
+ }
+#endif // FLATBUFFERS_CPP98_STL
+
+ static void *UnPack(const void *obj, QuantizationDetails type, const flatbuffers::resolver_function_t *resolver);
+ flatbuffers::Offset<void> Pack(flatbuffers::FlatBufferBuilder &_fbb, const flatbuffers::rehasher_function_t *_rehasher = nullptr) const;
+
+ tflite::CustomQuantizationT *AsCustomQuantization() {
+ return type == QuantizationDetails_CustomQuantization ?
+ reinterpret_cast<tflite::CustomQuantizationT *>(value) : nullptr;
+ }
+ const tflite::CustomQuantizationT *AsCustomQuantization() const {
+ return type == QuantizationDetails_CustomQuantization ?
+ reinterpret_cast<const tflite::CustomQuantizationT *>(value) : nullptr;
+ }
+};
+
+bool VerifyQuantizationDetails(flatbuffers::Verifier &verifier, const void *obj, QuantizationDetails type);
+bool VerifyQuantizationDetailsVector(flatbuffers::Verifier &verifier, const flatbuffers::Vector<flatbuffers::Offset<void>> *values, const flatbuffers::Vector<uint8_t> *types);
+
+enum DimensionType {
+ DimensionType_DENSE = 0,
+ DimensionType_SPARSE_CSR = 1,
+ DimensionType_MIN = DimensionType_DENSE,
+ DimensionType_MAX = DimensionType_SPARSE_CSR
+};
+
+inline const DimensionType (&EnumValuesDimensionType())[2] {
+ static const DimensionType values[] = {
+ DimensionType_DENSE,
+ DimensionType_SPARSE_CSR
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesDimensionType() {
+ static const char * const names[3] = {
+ "DENSE",
+ "SPARSE_CSR",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameDimensionType(DimensionType e) {
+ if (flatbuffers::IsOutRange(e, DimensionType_DENSE, DimensionType_SPARSE_CSR)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesDimensionType()[index];
+}
+
+enum SparseIndexVector {
+ SparseIndexVector_NONE = 0,
+ SparseIndexVector_Int32Vector = 1,
+ SparseIndexVector_Uint16Vector = 2,
+ SparseIndexVector_Uint8Vector = 3,
+ SparseIndexVector_MIN = SparseIndexVector_NONE,
+ SparseIndexVector_MAX = SparseIndexVector_Uint8Vector
+};
+
+inline const SparseIndexVector (&EnumValuesSparseIndexVector())[4] {
+ static const SparseIndexVector values[] = {
+ SparseIndexVector_NONE,
+ SparseIndexVector_Int32Vector,
+ SparseIndexVector_Uint16Vector,
+ SparseIndexVector_Uint8Vector
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesSparseIndexVector() {
+ static const char * const names[5] = {
+ "NONE",
+ "Int32Vector",
+ "Uint16Vector",
+ "Uint8Vector",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameSparseIndexVector(SparseIndexVector e) {
+ if (flatbuffers::IsOutRange(e, SparseIndexVector_NONE, SparseIndexVector_Uint8Vector)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesSparseIndexVector()[index];
+}
+
+template<typename T> struct SparseIndexVectorTraits {
+ static const SparseIndexVector enum_value = SparseIndexVector_NONE;
+};
+
+template<> struct SparseIndexVectorTraits<tflite::Int32Vector> {
+ static const SparseIndexVector enum_value = SparseIndexVector_Int32Vector;
+};
+
+template<> struct SparseIndexVectorTraits<tflite::Uint16Vector> {
+ static const SparseIndexVector enum_value = SparseIndexVector_Uint16Vector;
+};
+
+template<> struct SparseIndexVectorTraits<tflite::Uint8Vector> {
+ static const SparseIndexVector enum_value = SparseIndexVector_Uint8Vector;
+};
+
+struct SparseIndexVectorUnion {
+ SparseIndexVector type;
+ void *value;
+
+ SparseIndexVectorUnion() : type(SparseIndexVector_NONE), value(nullptr) {}
+ SparseIndexVectorUnion(SparseIndexVectorUnion&& u) FLATBUFFERS_NOEXCEPT :
+ type(SparseIndexVector_NONE), value(nullptr)
+ { std::swap(type, u.type); std::swap(value, u.value); }
+ SparseIndexVectorUnion(const SparseIndexVectorUnion &) FLATBUFFERS_NOEXCEPT;
+ SparseIndexVectorUnion &operator=(const SparseIndexVectorUnion &u) FLATBUFFERS_NOEXCEPT
+ { SparseIndexVectorUnion t(u); std::swap(type, t.type); std::swap(value, t.value); return *this; }
+ SparseIndexVectorUnion &operator=(SparseIndexVectorUnion &&u) FLATBUFFERS_NOEXCEPT
+ { std::swap(type, u.type); std::swap(value, u.value); return *this; }
+ ~SparseIndexVectorUnion() { Reset(); }
+
+ void Reset();
+
+#ifndef FLATBUFFERS_CPP98_STL
+ template <typename T>
+ void Set(T&& val) {
+ using RT = typename std::remove_reference<T>::type;
+ Reset();
+ type = SparseIndexVectorTraits<typename RT::TableType>::enum_value;
+ if (type != SparseIndexVector_NONE) {
+ value = new RT(std::forward<T>(val));
+ }
+ }
+#endif // FLATBUFFERS_CPP98_STL
+
+ static void *UnPack(const void *obj, SparseIndexVector type, const flatbuffers::resolver_function_t *resolver);
+ flatbuffers::Offset<void> Pack(flatbuffers::FlatBufferBuilder &_fbb, const flatbuffers::rehasher_function_t *_rehasher = nullptr) const;
+
+ tflite::Int32VectorT *AsInt32Vector() {
+ return type == SparseIndexVector_Int32Vector ?
+ reinterpret_cast<tflite::Int32VectorT *>(value) : nullptr;
+ }
+ const tflite::Int32VectorT *AsInt32Vector() const {
+ return type == SparseIndexVector_Int32Vector ?
+ reinterpret_cast<const tflite::Int32VectorT *>(value) : nullptr;
+ }
+ tflite::Uint16VectorT *AsUint16Vector() {
+ return type == SparseIndexVector_Uint16Vector ?
+ reinterpret_cast<tflite::Uint16VectorT *>(value) : nullptr;
+ }
+ const tflite::Uint16VectorT *AsUint16Vector() const {
+ return type == SparseIndexVector_Uint16Vector ?
+ reinterpret_cast<const tflite::Uint16VectorT *>(value) : nullptr;
+ }
+ tflite::Uint8VectorT *AsUint8Vector() {
+ return type == SparseIndexVector_Uint8Vector ?
+ reinterpret_cast<tflite::Uint8VectorT *>(value) : nullptr;
+ }
+ const tflite::Uint8VectorT *AsUint8Vector() const {
+ return type == SparseIndexVector_Uint8Vector ?
+ reinterpret_cast<const tflite::Uint8VectorT *>(value) : nullptr;
+ }
+};
+
+bool VerifySparseIndexVector(flatbuffers::Verifier &verifier, const void *obj, SparseIndexVector type);
+bool VerifySparseIndexVectorVector(flatbuffers::Verifier &verifier, const flatbuffers::Vector<flatbuffers::Offset<void>> *values, const flatbuffers::Vector<uint8_t> *types);
+
+enum BuiltinOperator {
+ BuiltinOperator_ADD = 0,
+ BuiltinOperator_AVERAGE_POOL_2D = 1,
+ BuiltinOperator_CONCATENATION = 2,
+ BuiltinOperator_CONV_2D = 3,
+ BuiltinOperator_DEPTHWISE_CONV_2D = 4,
+ BuiltinOperator_DEPTH_TO_SPACE = 5,
+ BuiltinOperator_DEQUANTIZE = 6,
+ BuiltinOperator_EMBEDDING_LOOKUP = 7,
+ BuiltinOperator_FLOOR = 8,
+ BuiltinOperator_FULLY_CONNECTED = 9,
+ BuiltinOperator_HASHTABLE_LOOKUP = 10,
+ BuiltinOperator_L2_NORMALIZATION = 11,
+ BuiltinOperator_L2_POOL_2D = 12,
+ BuiltinOperator_LOCAL_RESPONSE_NORMALIZATION = 13,
+ BuiltinOperator_LOGISTIC = 14,
+ BuiltinOperator_LSH_PROJECTION = 15,
+ BuiltinOperator_LSTM = 16,
+ BuiltinOperator_MAX_POOL_2D = 17,
+ BuiltinOperator_MUL = 18,
+ BuiltinOperator_RELU = 19,
+ BuiltinOperator_RELU_N1_TO_1 = 20,
+ BuiltinOperator_RELU6 = 21,
+ BuiltinOperator_RESHAPE = 22,
+ BuiltinOperator_RESIZE_BILINEAR = 23,
+ BuiltinOperator_RNN = 24,
+ BuiltinOperator_SOFTMAX = 25,
+ BuiltinOperator_SPACE_TO_DEPTH = 26,
+ BuiltinOperator_SVDF = 27,
+ BuiltinOperator_TANH = 28,
+ BuiltinOperator_CONCAT_EMBEDDINGS = 29,
+ BuiltinOperator_SKIP_GRAM = 30,
+ BuiltinOperator_CALL = 31,
+ BuiltinOperator_CUSTOM = 32,
+ BuiltinOperator_EMBEDDING_LOOKUP_SPARSE = 33,
+ BuiltinOperator_PAD = 34,
+ BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_RNN = 35,
+ BuiltinOperator_GATHER = 36,
+ BuiltinOperator_BATCH_TO_SPACE_ND = 37,
+ BuiltinOperator_SPACE_TO_BATCH_ND = 38,
+ BuiltinOperator_TRANSPOSE = 39,
+ BuiltinOperator_MEAN = 40,
+ BuiltinOperator_SUB = 41,
+ BuiltinOperator_DIV = 42,
+ BuiltinOperator_SQUEEZE = 43,
+ BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_LSTM = 44,
+ BuiltinOperator_STRIDED_SLICE = 45,
+ BuiltinOperator_BIDIRECTIONAL_SEQUENCE_RNN = 46,
+ BuiltinOperator_EXP = 47,
+ BuiltinOperator_TOPK_V2 = 48,
+ BuiltinOperator_SPLIT = 49,
+ BuiltinOperator_LOG_SOFTMAX = 50,
+ BuiltinOperator_DELEGATE = 51,
+ BuiltinOperator_BIDIRECTIONAL_SEQUENCE_LSTM = 52,
+ BuiltinOperator_CAST = 53,
+ BuiltinOperator_PRELU = 54,
+ BuiltinOperator_MAXIMUM = 55,
+ BuiltinOperator_ARG_MAX = 56,
+ BuiltinOperator_MINIMUM = 57,
+ BuiltinOperator_LESS = 58,
+ BuiltinOperator_NEG = 59,
+ BuiltinOperator_PADV2 = 60,
+ BuiltinOperator_GREATER = 61,
+ BuiltinOperator_GREATER_EQUAL = 62,
+ BuiltinOperator_LESS_EQUAL = 63,
+ BuiltinOperator_SELECT = 64,
+ BuiltinOperator_SLICE = 65,
+ BuiltinOperator_SIN = 66,
+ BuiltinOperator_TRANSPOSE_CONV = 67,
+ BuiltinOperator_SPARSE_TO_DENSE = 68,
+ BuiltinOperator_TILE = 69,
+ BuiltinOperator_EXPAND_DIMS = 70,
+ BuiltinOperator_EQUAL = 71,
+ BuiltinOperator_NOT_EQUAL = 72,
+ BuiltinOperator_LOG = 73,
+ BuiltinOperator_SUM = 74,
+ BuiltinOperator_SQRT = 75,
+ BuiltinOperator_RSQRT = 76,
+ BuiltinOperator_SHAPE = 77,
+ BuiltinOperator_POW = 78,
+ BuiltinOperator_ARG_MIN = 79,
+ BuiltinOperator_FAKE_QUANT = 80,
+ BuiltinOperator_REDUCE_PROD = 81,
+ BuiltinOperator_REDUCE_MAX = 82,
+ BuiltinOperator_PACK = 83,
+ BuiltinOperator_LOGICAL_OR = 84,
+ BuiltinOperator_ONE_HOT = 85,
+ BuiltinOperator_LOGICAL_AND = 86,
+ BuiltinOperator_LOGICAL_NOT = 87,
+ BuiltinOperator_UNPACK = 88,
+ BuiltinOperator_REDUCE_MIN = 89,
+ BuiltinOperator_FLOOR_DIV = 90,
+ BuiltinOperator_REDUCE_ANY = 91,
+ BuiltinOperator_SQUARE = 92,
+ BuiltinOperator_ZEROS_LIKE = 93,
+ BuiltinOperator_FILL = 94,
+ BuiltinOperator_FLOOR_MOD = 95,
+ BuiltinOperator_RANGE = 96,
+ BuiltinOperator_RESIZE_NEAREST_NEIGHBOR = 97,
+ BuiltinOperator_LEAKY_RELU = 98,
+ BuiltinOperator_SQUARED_DIFFERENCE = 99,
+ BuiltinOperator_MIRROR_PAD = 100,
+ BuiltinOperator_ABS = 101,
+ BuiltinOperator_SPLIT_V = 102,
+ BuiltinOperator_UNIQUE = 103,
+ BuiltinOperator_CEIL = 104,
+ BuiltinOperator_REVERSE_V2 = 105,
+ BuiltinOperator_ADD_N = 106,
+ BuiltinOperator_GATHER_ND = 107,
+ BuiltinOperator_COS = 108,
+ BuiltinOperator_WHERE = 109,
+ BuiltinOperator_RANK = 110,
+ BuiltinOperator_ELU = 111,
+ BuiltinOperator_REVERSE_SEQUENCE = 112,
+ BuiltinOperator_MATRIX_DIAG = 113,
+ BuiltinOperator_QUANTIZE = 114,
+ BuiltinOperator_MATRIX_SET_DIAG = 115,
+ BuiltinOperator_ROUND = 116,
+ BuiltinOperator_HARD_SWISH = 117,
+ BuiltinOperator_IF = 118,
+ BuiltinOperator_WHILE = 119,
+ BuiltinOperator_NON_MAX_SUPPRESSION_V4 = 120,
+ BuiltinOperator_NON_MAX_SUPPRESSION_V5 = 121,
+ BuiltinOperator_SCATTER_ND = 122,
+ BuiltinOperator_SELECT_V2 = 123,
+ BuiltinOperator_DENSIFY = 124,
+ BuiltinOperator_SEGMENT_SUM = 125,
+ BuiltinOperator_BATCH_MATMUL = 126,
+ BuiltinOperator_PLACEHOLDER_FOR_GREATER_OP_CODES = 127,
+ BuiltinOperator_CUMSUM = 128,
+ BuiltinOperator_CALL_ONCE = 129,
+ BuiltinOperator_BROADCAST_TO = 130,
+ BuiltinOperator_RFFT2D = 131,
+ BuiltinOperator_CONV_3D = 132,
+ BuiltinOperator_IMAG = 133,
+ BuiltinOperator_REAL = 134,
+ BuiltinOperator_COMPLEX_ABS = 135,
+ BuiltinOperator_HASHTABLE = 136,
+ BuiltinOperator_HASHTABLE_FIND = 137,
+ BuiltinOperator_HASHTABLE_IMPORT = 138,
+ BuiltinOperator_HASHTABLE_SIZE = 139,
+ BuiltinOperator_REDUCE_ALL = 140,
+ BuiltinOperator_MIN = BuiltinOperator_ADD,
+ BuiltinOperator_MAX = BuiltinOperator_REDUCE_ALL
+};
+
+inline const BuiltinOperator (&EnumValuesBuiltinOperator())[141] {
+ static const BuiltinOperator values[] = {
+ BuiltinOperator_ADD,
+ BuiltinOperator_AVERAGE_POOL_2D,
+ BuiltinOperator_CONCATENATION,
+ BuiltinOperator_CONV_2D,
+ BuiltinOperator_DEPTHWISE_CONV_2D,
+ BuiltinOperator_DEPTH_TO_SPACE,
+ BuiltinOperator_DEQUANTIZE,
+ BuiltinOperator_EMBEDDING_LOOKUP,
+ BuiltinOperator_FLOOR,
+ BuiltinOperator_FULLY_CONNECTED,
+ BuiltinOperator_HASHTABLE_LOOKUP,
+ BuiltinOperator_L2_NORMALIZATION,
+ BuiltinOperator_L2_POOL_2D,
+ BuiltinOperator_LOCAL_RESPONSE_NORMALIZATION,
+ BuiltinOperator_LOGISTIC,
+ BuiltinOperator_LSH_PROJECTION,
+ BuiltinOperator_LSTM,
+ BuiltinOperator_MAX_POOL_2D,
+ BuiltinOperator_MUL,
+ BuiltinOperator_RELU,
+ BuiltinOperator_RELU_N1_TO_1,
+ BuiltinOperator_RELU6,
+ BuiltinOperator_RESHAPE,
+ BuiltinOperator_RESIZE_BILINEAR,
+ BuiltinOperator_RNN,
+ BuiltinOperator_SOFTMAX,
+ BuiltinOperator_SPACE_TO_DEPTH,
+ BuiltinOperator_SVDF,
+ BuiltinOperator_TANH,
+ BuiltinOperator_CONCAT_EMBEDDINGS,
+ BuiltinOperator_SKIP_GRAM,
+ BuiltinOperator_CALL,
+ BuiltinOperator_CUSTOM,
+ BuiltinOperator_EMBEDDING_LOOKUP_SPARSE,
+ BuiltinOperator_PAD,
+ BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_RNN,
+ BuiltinOperator_GATHER,
+ BuiltinOperator_BATCH_TO_SPACE_ND,
+ BuiltinOperator_SPACE_TO_BATCH_ND,
+ BuiltinOperator_TRANSPOSE,
+ BuiltinOperator_MEAN,
+ BuiltinOperator_SUB,
+ BuiltinOperator_DIV,
+ BuiltinOperator_SQUEEZE,
+ BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_LSTM,
+ BuiltinOperator_STRIDED_SLICE,
+ BuiltinOperator_BIDIRECTIONAL_SEQUENCE_RNN,
+ BuiltinOperator_EXP,
+ BuiltinOperator_TOPK_V2,
+ BuiltinOperator_SPLIT,
+ BuiltinOperator_LOG_SOFTMAX,
+ BuiltinOperator_DELEGATE,
+ BuiltinOperator_BIDIRECTIONAL_SEQUENCE_LSTM,
+ BuiltinOperator_CAST,
+ BuiltinOperator_PRELU,
+ BuiltinOperator_MAXIMUM,
+ BuiltinOperator_ARG_MAX,
+ BuiltinOperator_MINIMUM,
+ BuiltinOperator_LESS,
+ BuiltinOperator_NEG,
+ BuiltinOperator_PADV2,
+ BuiltinOperator_GREATER,
+ BuiltinOperator_GREATER_EQUAL,
+ BuiltinOperator_LESS_EQUAL,
+ BuiltinOperator_SELECT,
+ BuiltinOperator_SLICE,
+ BuiltinOperator_SIN,
+ BuiltinOperator_TRANSPOSE_CONV,
+ BuiltinOperator_SPARSE_TO_DENSE,
+ BuiltinOperator_TILE,
+ BuiltinOperator_EXPAND_DIMS,
+ BuiltinOperator_EQUAL,
+ BuiltinOperator_NOT_EQUAL,
+ BuiltinOperator_LOG,
+ BuiltinOperator_SUM,
+ BuiltinOperator_SQRT,
+ BuiltinOperator_RSQRT,
+ BuiltinOperator_SHAPE,
+ BuiltinOperator_POW,
+ BuiltinOperator_ARG_MIN,
+ BuiltinOperator_FAKE_QUANT,
+ BuiltinOperator_REDUCE_PROD,
+ BuiltinOperator_REDUCE_MAX,
+ BuiltinOperator_PACK,
+ BuiltinOperator_LOGICAL_OR,
+ BuiltinOperator_ONE_HOT,
+ BuiltinOperator_LOGICAL_AND,
+ BuiltinOperator_LOGICAL_NOT,
+ BuiltinOperator_UNPACK,
+ BuiltinOperator_REDUCE_MIN,
+ BuiltinOperator_FLOOR_DIV,
+ BuiltinOperator_REDUCE_ANY,
+ BuiltinOperator_SQUARE,
+ BuiltinOperator_ZEROS_LIKE,
+ BuiltinOperator_FILL,
+ BuiltinOperator_FLOOR_MOD,
+ BuiltinOperator_RANGE,
+ BuiltinOperator_RESIZE_NEAREST_NEIGHBOR,
+ BuiltinOperator_LEAKY_RELU,
+ BuiltinOperator_SQUARED_DIFFERENCE,
+ BuiltinOperator_MIRROR_PAD,
+ BuiltinOperator_ABS,
+ BuiltinOperator_SPLIT_V,
+ BuiltinOperator_UNIQUE,
+ BuiltinOperator_CEIL,
+ BuiltinOperator_REVERSE_V2,
+ BuiltinOperator_ADD_N,
+ BuiltinOperator_GATHER_ND,
+ BuiltinOperator_COS,
+ BuiltinOperator_WHERE,
+ BuiltinOperator_RANK,
+ BuiltinOperator_ELU,
+ BuiltinOperator_REVERSE_SEQUENCE,
+ BuiltinOperator_MATRIX_DIAG,
+ BuiltinOperator_QUANTIZE,
+ BuiltinOperator_MATRIX_SET_DIAG,
+ BuiltinOperator_ROUND,
+ BuiltinOperator_HARD_SWISH,
+ BuiltinOperator_IF,
+ BuiltinOperator_WHILE,
+ BuiltinOperator_NON_MAX_SUPPRESSION_V4,
+ BuiltinOperator_NON_MAX_SUPPRESSION_V5,
+ BuiltinOperator_SCATTER_ND,
+ BuiltinOperator_SELECT_V2,
+ BuiltinOperator_DENSIFY,
+ BuiltinOperator_SEGMENT_SUM,
+ BuiltinOperator_BATCH_MATMUL,
+ BuiltinOperator_PLACEHOLDER_FOR_GREATER_OP_CODES,
+ BuiltinOperator_CUMSUM,
+ BuiltinOperator_CALL_ONCE,
+ BuiltinOperator_BROADCAST_TO,
+ BuiltinOperator_RFFT2D,
+ BuiltinOperator_CONV_3D,
+ BuiltinOperator_IMAG,
+ BuiltinOperator_REAL,
+ BuiltinOperator_COMPLEX_ABS,
+ BuiltinOperator_HASHTABLE,
+ BuiltinOperator_HASHTABLE_FIND,
+ BuiltinOperator_HASHTABLE_IMPORT,
+ BuiltinOperator_HASHTABLE_SIZE,
+ BuiltinOperator_REDUCE_ALL
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesBuiltinOperator() {
+ static const char * const names[142] = {
+ "ADD",
+ "AVERAGE_POOL_2D",
+ "CONCATENATION",
+ "CONV_2D",
+ "DEPTHWISE_CONV_2D",
+ "DEPTH_TO_SPACE",
+ "DEQUANTIZE",
+ "EMBEDDING_LOOKUP",
+ "FLOOR",
+ "FULLY_CONNECTED",
+ "HASHTABLE_LOOKUP",
+ "L2_NORMALIZATION",
+ "L2_POOL_2D",
+ "LOCAL_RESPONSE_NORMALIZATION",
+ "LOGISTIC",
+ "LSH_PROJECTION",
+ "LSTM",
+ "MAX_POOL_2D",
+ "MUL",
+ "RELU",
+ "RELU_N1_TO_1",
+ "RELU6",
+ "RESHAPE",
+ "RESIZE_BILINEAR",
+ "RNN",
+ "SOFTMAX",
+ "SPACE_TO_DEPTH",
+ "SVDF",
+ "TANH",
+ "CONCAT_EMBEDDINGS",
+ "SKIP_GRAM",
+ "CALL",
+ "CUSTOM",
+ "EMBEDDING_LOOKUP_SPARSE",
+ "PAD",
+ "UNIDIRECTIONAL_SEQUENCE_RNN",
+ "GATHER",
+ "BATCH_TO_SPACE_ND",
+ "SPACE_TO_BATCH_ND",
+ "TRANSPOSE",
+ "MEAN",
+ "SUB",
+ "DIV",
+ "SQUEEZE",
+ "UNIDIRECTIONAL_SEQUENCE_LSTM",
+ "STRIDED_SLICE",
+ "BIDIRECTIONAL_SEQUENCE_RNN",
+ "EXP",
+ "TOPK_V2",
+ "SPLIT",
+ "LOG_SOFTMAX",
+ "DELEGATE",
+ "BIDIRECTIONAL_SEQUENCE_LSTM",
+ "CAST",
+ "PRELU",
+ "MAXIMUM",
+ "ARG_MAX",
+ "MINIMUM",
+ "LESS",
+ "NEG",
+ "PADV2",
+ "GREATER",
+ "GREATER_EQUAL",
+ "LESS_EQUAL",
+ "SELECT",
+ "SLICE",
+ "SIN",
+ "TRANSPOSE_CONV",
+ "SPARSE_TO_DENSE",
+ "TILE",
+ "EXPAND_DIMS",
+ "EQUAL",
+ "NOT_EQUAL",
+ "LOG",
+ "SUM",
+ "SQRT",
+ "RSQRT",
+ "SHAPE",
+ "POW",
+ "ARG_MIN",
+ "FAKE_QUANT",
+ "REDUCE_PROD",
+ "REDUCE_MAX",
+ "PACK",
+ "LOGICAL_OR",
+ "ONE_HOT",
+ "LOGICAL_AND",
+ "LOGICAL_NOT",
+ "UNPACK",
+ "REDUCE_MIN",
+ "FLOOR_DIV",
+ "REDUCE_ANY",
+ "SQUARE",
+ "ZEROS_LIKE",
+ "FILL",
+ "FLOOR_MOD",
+ "RANGE",
+ "RESIZE_NEAREST_NEIGHBOR",
+ "LEAKY_RELU",
+ "SQUARED_DIFFERENCE",
+ "MIRROR_PAD",
+ "ABS",
+ "SPLIT_V",
+ "UNIQUE",
+ "CEIL",
+ "REVERSE_V2",
+ "ADD_N",
+ "GATHER_ND",
+ "COS",
+ "WHERE",
+ "RANK",
+ "ELU",
+ "REVERSE_SEQUENCE",
+ "MATRIX_DIAG",
+ "QUANTIZE",
+ "MATRIX_SET_DIAG",
+ "ROUND",
+ "HARD_SWISH",
+ "IF",
+ "WHILE",
+ "NON_MAX_SUPPRESSION_V4",
+ "NON_MAX_SUPPRESSION_V5",
+ "SCATTER_ND",
+ "SELECT_V2",
+ "DENSIFY",
+ "SEGMENT_SUM",
+ "BATCH_MATMUL",
+ "PLACEHOLDER_FOR_GREATER_OP_CODES",
+ "CUMSUM",
+ "CALL_ONCE",
+ "BROADCAST_TO",
+ "RFFT2D",
+ "CONV_3D",
+ "IMAG",
+ "REAL",
+ "COMPLEX_ABS",
+ "HASHTABLE",
+ "HASHTABLE_FIND",
+ "HASHTABLE_IMPORT",
+ "HASHTABLE_SIZE",
+ "REDUCE_ALL",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameBuiltinOperator(BuiltinOperator e) {
+ if (flatbuffers::IsOutRange(e, BuiltinOperator_ADD, BuiltinOperator_REDUCE_ALL)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesBuiltinOperator()[index];
+}
+
+enum BuiltinOptions {
+ BuiltinOptions_NONE = 0,
+ BuiltinOptions_Conv2DOptions = 1,
+ BuiltinOptions_DepthwiseConv2DOptions = 2,
+ BuiltinOptions_ConcatEmbeddingsOptions = 3,
+ BuiltinOptions_LSHProjectionOptions = 4,
+ BuiltinOptions_Pool2DOptions = 5,
+ BuiltinOptions_SVDFOptions = 6,
+ BuiltinOptions_RNNOptions = 7,
+ BuiltinOptions_FullyConnectedOptions = 8,
+ BuiltinOptions_SoftmaxOptions = 9,
+ BuiltinOptions_ConcatenationOptions = 10,
+ BuiltinOptions_AddOptions = 11,
+ BuiltinOptions_L2NormOptions = 12,
+ BuiltinOptions_LocalResponseNormalizationOptions = 13,
+ BuiltinOptions_LSTMOptions = 14,
+ BuiltinOptions_ResizeBilinearOptions = 15,
+ BuiltinOptions_CallOptions = 16,
+ BuiltinOptions_ReshapeOptions = 17,
+ BuiltinOptions_SkipGramOptions = 18,
+ BuiltinOptions_SpaceToDepthOptions = 19,
+ BuiltinOptions_EmbeddingLookupSparseOptions = 20,
+ BuiltinOptions_MulOptions = 21,
+ BuiltinOptions_PadOptions = 22,
+ BuiltinOptions_GatherOptions = 23,
+ BuiltinOptions_BatchToSpaceNDOptions = 24,
+ BuiltinOptions_SpaceToBatchNDOptions = 25,
+ BuiltinOptions_TransposeOptions = 26,
+ BuiltinOptions_ReducerOptions = 27,
+ BuiltinOptions_SubOptions = 28,
+ BuiltinOptions_DivOptions = 29,
+ BuiltinOptions_SqueezeOptions = 30,
+ BuiltinOptions_SequenceRNNOptions = 31,
+ BuiltinOptions_StridedSliceOptions = 32,
+ BuiltinOptions_ExpOptions = 33,
+ BuiltinOptions_TopKV2Options = 34,
+ BuiltinOptions_SplitOptions = 35,
+ BuiltinOptions_LogSoftmaxOptions = 36,
+ BuiltinOptions_CastOptions = 37,
+ BuiltinOptions_DequantizeOptions = 38,
+ BuiltinOptions_MaximumMinimumOptions = 39,
+ BuiltinOptions_ArgMaxOptions = 40,
+ BuiltinOptions_LessOptions = 41,
+ BuiltinOptions_NegOptions = 42,
+ BuiltinOptions_PadV2Options = 43,
+ BuiltinOptions_GreaterOptions = 44,
+ BuiltinOptions_GreaterEqualOptions = 45,
+ BuiltinOptions_LessEqualOptions = 46,
+ BuiltinOptions_SelectOptions = 47,
+ BuiltinOptions_SliceOptions = 48,
+ BuiltinOptions_TransposeConvOptions = 49,
+ BuiltinOptions_SparseToDenseOptions = 50,
+ BuiltinOptions_TileOptions = 51,
+ BuiltinOptions_ExpandDimsOptions = 52,
+ BuiltinOptions_EqualOptions = 53,
+ BuiltinOptions_NotEqualOptions = 54,
+ BuiltinOptions_ShapeOptions = 55,
+ BuiltinOptions_PowOptions = 56,
+ BuiltinOptions_ArgMinOptions = 57,
+ BuiltinOptions_FakeQuantOptions = 58,
+ BuiltinOptions_PackOptions = 59,
+ BuiltinOptions_LogicalOrOptions = 60,
+ BuiltinOptions_OneHotOptions = 61,
+ BuiltinOptions_LogicalAndOptions = 62,
+ BuiltinOptions_LogicalNotOptions = 63,
+ BuiltinOptions_UnpackOptions = 64,
+ BuiltinOptions_FloorDivOptions = 65,
+ BuiltinOptions_SquareOptions = 66,
+ BuiltinOptions_ZerosLikeOptions = 67,
+ BuiltinOptions_FillOptions = 68,
+ BuiltinOptions_BidirectionalSequenceLSTMOptions = 69,
+ BuiltinOptions_BidirectionalSequenceRNNOptions = 70,
+ BuiltinOptions_UnidirectionalSequenceLSTMOptions = 71,
+ BuiltinOptions_FloorModOptions = 72,
+ BuiltinOptions_RangeOptions = 73,
+ BuiltinOptions_ResizeNearestNeighborOptions = 74,
+ BuiltinOptions_LeakyReluOptions = 75,
+ BuiltinOptions_SquaredDifferenceOptions = 76,
+ BuiltinOptions_MirrorPadOptions = 77,
+ BuiltinOptions_AbsOptions = 78,
+ BuiltinOptions_SplitVOptions = 79,
+ BuiltinOptions_UniqueOptions = 80,
+ BuiltinOptions_ReverseV2Options = 81,
+ BuiltinOptions_AddNOptions = 82,
+ BuiltinOptions_GatherNdOptions = 83,
+ BuiltinOptions_CosOptions = 84,
+ BuiltinOptions_WhereOptions = 85,
+ BuiltinOptions_RankOptions = 86,
+ BuiltinOptions_ReverseSequenceOptions = 87,
+ BuiltinOptions_MatrixDiagOptions = 88,
+ BuiltinOptions_QuantizeOptions = 89,
+ BuiltinOptions_MatrixSetDiagOptions = 90,
+ BuiltinOptions_HardSwishOptions = 91,
+ BuiltinOptions_IfOptions = 92,
+ BuiltinOptions_WhileOptions = 93,
+ BuiltinOptions_DepthToSpaceOptions = 94,
+ BuiltinOptions_NonMaxSuppressionV4Options = 95,
+ BuiltinOptions_NonMaxSuppressionV5Options = 96,
+ BuiltinOptions_ScatterNdOptions = 97,
+ BuiltinOptions_SelectV2Options = 98,
+ BuiltinOptions_DensifyOptions = 99,
+ BuiltinOptions_SegmentSumOptions = 100,
+ BuiltinOptions_BatchMatMulOptions = 101,
+ BuiltinOptions_CumsumOptions = 102,
+ BuiltinOptions_CallOnceOptions = 103,
+ BuiltinOptions_BroadcastToOptions = 104,
+ BuiltinOptions_Rfft2dOptions = 105,
+ BuiltinOptions_Conv3DOptions = 106,
+ BuiltinOptions_HashtableOptions = 107,
+ BuiltinOptions_HashtableFindOptions = 108,
+ BuiltinOptions_HashtableImportOptions = 109,
+ BuiltinOptions_HashtableSizeOptions = 110,
+ BuiltinOptions_MIN = BuiltinOptions_NONE,
+ BuiltinOptions_MAX = BuiltinOptions_HashtableSizeOptions
+};
+
+inline const BuiltinOptions (&EnumValuesBuiltinOptions())[111] {
+ static const BuiltinOptions values[] = {
+ BuiltinOptions_NONE,
+ BuiltinOptions_Conv2DOptions,
+ BuiltinOptions_DepthwiseConv2DOptions,
+ BuiltinOptions_ConcatEmbeddingsOptions,
+ BuiltinOptions_LSHProjectionOptions,
+ BuiltinOptions_Pool2DOptions,
+ BuiltinOptions_SVDFOptions,
+ BuiltinOptions_RNNOptions,
+ BuiltinOptions_FullyConnectedOptions,
+ BuiltinOptions_SoftmaxOptions,
+ BuiltinOptions_ConcatenationOptions,
+ BuiltinOptions_AddOptions,
+ BuiltinOptions_L2NormOptions,
+ BuiltinOptions_LocalResponseNormalizationOptions,
+ BuiltinOptions_LSTMOptions,
+ BuiltinOptions_ResizeBilinearOptions,
+ BuiltinOptions_CallOptions,
+ BuiltinOptions_ReshapeOptions,
+ BuiltinOptions_SkipGramOptions,
+ BuiltinOptions_SpaceToDepthOptions,
+ BuiltinOptions_EmbeddingLookupSparseOptions,
+ BuiltinOptions_MulOptions,
+ BuiltinOptions_PadOptions,
+ BuiltinOptions_GatherOptions,
+ BuiltinOptions_BatchToSpaceNDOptions,
+ BuiltinOptions_SpaceToBatchNDOptions,
+ BuiltinOptions_TransposeOptions,
+ BuiltinOptions_ReducerOptions,
+ BuiltinOptions_SubOptions,
+ BuiltinOptions_DivOptions,
+ BuiltinOptions_SqueezeOptions,
+ BuiltinOptions_SequenceRNNOptions,
+ BuiltinOptions_StridedSliceOptions,
+ BuiltinOptions_ExpOptions,
+ BuiltinOptions_TopKV2Options,
+ BuiltinOptions_SplitOptions,
+ BuiltinOptions_LogSoftmaxOptions,
+ BuiltinOptions_CastOptions,
+ BuiltinOptions_DequantizeOptions,
+ BuiltinOptions_MaximumMinimumOptions,
+ BuiltinOptions_ArgMaxOptions,
+ BuiltinOptions_LessOptions,
+ BuiltinOptions_NegOptions,
+ BuiltinOptions_PadV2Options,
+ BuiltinOptions_GreaterOptions,
+ BuiltinOptions_GreaterEqualOptions,
+ BuiltinOptions_LessEqualOptions,
+ BuiltinOptions_SelectOptions,
+ BuiltinOptions_SliceOptions,
+ BuiltinOptions_TransposeConvOptions,
+ BuiltinOptions_SparseToDenseOptions,
+ BuiltinOptions_TileOptions,
+ BuiltinOptions_ExpandDimsOptions,
+ BuiltinOptions_EqualOptions,
+ BuiltinOptions_NotEqualOptions,
+ BuiltinOptions_ShapeOptions,
+ BuiltinOptions_PowOptions,
+ BuiltinOptions_ArgMinOptions,
+ BuiltinOptions_FakeQuantOptions,
+ BuiltinOptions_PackOptions,
+ BuiltinOptions_LogicalOrOptions,
+ BuiltinOptions_OneHotOptions,
+ BuiltinOptions_LogicalAndOptions,
+ BuiltinOptions_LogicalNotOptions,
+ BuiltinOptions_UnpackOptions,
+ BuiltinOptions_FloorDivOptions,
+ BuiltinOptions_SquareOptions,
+ BuiltinOptions_ZerosLikeOptions,
+ BuiltinOptions_FillOptions,
+ BuiltinOptions_BidirectionalSequenceLSTMOptions,
+ BuiltinOptions_BidirectionalSequenceRNNOptions,
+ BuiltinOptions_UnidirectionalSequenceLSTMOptions,
+ BuiltinOptions_FloorModOptions,
+ BuiltinOptions_RangeOptions,
+ BuiltinOptions_ResizeNearestNeighborOptions,
+ BuiltinOptions_LeakyReluOptions,
+ BuiltinOptions_SquaredDifferenceOptions,
+ BuiltinOptions_MirrorPadOptions,
+ BuiltinOptions_AbsOptions,
+ BuiltinOptions_SplitVOptions,
+ BuiltinOptions_UniqueOptions,
+ BuiltinOptions_ReverseV2Options,
+ BuiltinOptions_AddNOptions,
+ BuiltinOptions_GatherNdOptions,
+ BuiltinOptions_CosOptions,
+ BuiltinOptions_WhereOptions,
+ BuiltinOptions_RankOptions,
+ BuiltinOptions_ReverseSequenceOptions,
+ BuiltinOptions_MatrixDiagOptions,
+ BuiltinOptions_QuantizeOptions,
+ BuiltinOptions_MatrixSetDiagOptions,
+ BuiltinOptions_HardSwishOptions,
+ BuiltinOptions_IfOptions,
+ BuiltinOptions_WhileOptions,
+ BuiltinOptions_DepthToSpaceOptions,
+ BuiltinOptions_NonMaxSuppressionV4Options,
+ BuiltinOptions_NonMaxSuppressionV5Options,
+ BuiltinOptions_ScatterNdOptions,
+ BuiltinOptions_SelectV2Options,
+ BuiltinOptions_DensifyOptions,
+ BuiltinOptions_SegmentSumOptions,
+ BuiltinOptions_BatchMatMulOptions,
+ BuiltinOptions_CumsumOptions,
+ BuiltinOptions_CallOnceOptions,
+ BuiltinOptions_BroadcastToOptions,
+ BuiltinOptions_Rfft2dOptions,
+ BuiltinOptions_Conv3DOptions,
+ BuiltinOptions_HashtableOptions,
+ BuiltinOptions_HashtableFindOptions,
+ BuiltinOptions_HashtableImportOptions,
+ BuiltinOptions_HashtableSizeOptions
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesBuiltinOptions() {
+ static const char * const names[112] = {
+ "NONE",
+ "Conv2DOptions",
+ "DepthwiseConv2DOptions",
+ "ConcatEmbeddingsOptions",
+ "LSHProjectionOptions",
+ "Pool2DOptions",
+ "SVDFOptions",
+ "RNNOptions",
+ "FullyConnectedOptions",
+ "SoftmaxOptions",
+ "ConcatenationOptions",
+ "AddOptions",
+ "L2NormOptions",
+ "LocalResponseNormalizationOptions",
+ "LSTMOptions",
+ "ResizeBilinearOptions",
+ "CallOptions",
+ "ReshapeOptions",
+ "SkipGramOptions",
+ "SpaceToDepthOptions",
+ "EmbeddingLookupSparseOptions",
+ "MulOptions",
+ "PadOptions",
+ "GatherOptions",
+ "BatchToSpaceNDOptions",
+ "SpaceToBatchNDOptions",
+ "TransposeOptions",
+ "ReducerOptions",
+ "SubOptions",
+ "DivOptions",
+ "SqueezeOptions",
+ "SequenceRNNOptions",
+ "StridedSliceOptions",
+ "ExpOptions",
+ "TopKV2Options",
+ "SplitOptions",
+ "LogSoftmaxOptions",
+ "CastOptions",
+ "DequantizeOptions",
+ "MaximumMinimumOptions",
+ "ArgMaxOptions",
+ "LessOptions",
+ "NegOptions",
+ "PadV2Options",
+ "GreaterOptions",
+ "GreaterEqualOptions",
+ "LessEqualOptions",
+ "SelectOptions",
+ "SliceOptions",
+ "TransposeConvOptions",
+ "SparseToDenseOptions",
+ "TileOptions",
+ "ExpandDimsOptions",
+ "EqualOptions",
+ "NotEqualOptions",
+ "ShapeOptions",
+ "PowOptions",
+ "ArgMinOptions",
+ "FakeQuantOptions",
+ "PackOptions",
+ "LogicalOrOptions",
+ "OneHotOptions",
+ "LogicalAndOptions",
+ "LogicalNotOptions",
+ "UnpackOptions",
+ "FloorDivOptions",
+ "SquareOptions",
+ "ZerosLikeOptions",
+ "FillOptions",
+ "BidirectionalSequenceLSTMOptions",
+ "BidirectionalSequenceRNNOptions",
+ "UnidirectionalSequenceLSTMOptions",
+ "FloorModOptions",
+ "RangeOptions",
+ "ResizeNearestNeighborOptions",
+ "LeakyReluOptions",
+ "SquaredDifferenceOptions",
+ "MirrorPadOptions",
+ "AbsOptions",
+ "SplitVOptions",
+ "UniqueOptions",
+ "ReverseV2Options",
+ "AddNOptions",
+ "GatherNdOptions",
+ "CosOptions",
+ "WhereOptions",
+ "RankOptions",
+ "ReverseSequenceOptions",
+ "MatrixDiagOptions",
+ "QuantizeOptions",
+ "MatrixSetDiagOptions",
+ "HardSwishOptions",
+ "IfOptions",
+ "WhileOptions",
+ "DepthToSpaceOptions",
+ "NonMaxSuppressionV4Options",
+ "NonMaxSuppressionV5Options",
+ "ScatterNdOptions",
+ "SelectV2Options",
+ "DensifyOptions",
+ "SegmentSumOptions",
+ "BatchMatMulOptions",
+ "CumsumOptions",
+ "CallOnceOptions",
+ "BroadcastToOptions",
+ "Rfft2dOptions",
+ "Conv3DOptions",
+ "HashtableOptions",
+ "HashtableFindOptions",
+ "HashtableImportOptions",
+ "HashtableSizeOptions",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameBuiltinOptions(BuiltinOptions e) {
+ if (flatbuffers::IsOutRange(e, BuiltinOptions_NONE, BuiltinOptions_HashtableSizeOptions)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesBuiltinOptions()[index];
+}
+
+template<typename T> struct BuiltinOptionsTraits {
+ static const BuiltinOptions enum_value = BuiltinOptions_NONE;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::Conv2DOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_Conv2DOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::DepthwiseConv2DOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_DepthwiseConv2DOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ConcatEmbeddingsOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ConcatEmbeddingsOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LSHProjectionOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LSHProjectionOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::Pool2DOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_Pool2DOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SVDFOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SVDFOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::RNNOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_RNNOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::FullyConnectedOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_FullyConnectedOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SoftmaxOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SoftmaxOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ConcatenationOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ConcatenationOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::AddOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_AddOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::L2NormOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_L2NormOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LocalResponseNormalizationOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LocalResponseNormalizationOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LSTMOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LSTMOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ResizeBilinearOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ResizeBilinearOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::CallOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_CallOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ReshapeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ReshapeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SkipGramOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SkipGramOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SpaceToDepthOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SpaceToDepthOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::EmbeddingLookupSparseOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_EmbeddingLookupSparseOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::MulOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_MulOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::PadOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_PadOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::GatherOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_GatherOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::BatchToSpaceNDOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_BatchToSpaceNDOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SpaceToBatchNDOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SpaceToBatchNDOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::TransposeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_TransposeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ReducerOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ReducerOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SubOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SubOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::DivOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_DivOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SqueezeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SqueezeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SequenceRNNOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SequenceRNNOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::StridedSliceOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_StridedSliceOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ExpOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ExpOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::TopKV2Options> {
+ static const BuiltinOptions enum_value = BuiltinOptions_TopKV2Options;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SplitOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SplitOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LogSoftmaxOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LogSoftmaxOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::CastOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_CastOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::DequantizeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_DequantizeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::MaximumMinimumOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_MaximumMinimumOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ArgMaxOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ArgMaxOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LessOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LessOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::NegOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_NegOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::PadV2Options> {
+ static const BuiltinOptions enum_value = BuiltinOptions_PadV2Options;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::GreaterOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_GreaterOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::GreaterEqualOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_GreaterEqualOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LessEqualOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LessEqualOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SelectOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SelectOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SliceOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SliceOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::TransposeConvOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_TransposeConvOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SparseToDenseOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SparseToDenseOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::TileOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_TileOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ExpandDimsOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ExpandDimsOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::EqualOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_EqualOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::NotEqualOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_NotEqualOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ShapeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ShapeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::PowOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_PowOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ArgMinOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ArgMinOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::FakeQuantOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_FakeQuantOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::PackOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_PackOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LogicalOrOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LogicalOrOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::OneHotOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_OneHotOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LogicalAndOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LogicalAndOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LogicalNotOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LogicalNotOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::UnpackOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_UnpackOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::FloorDivOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_FloorDivOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SquareOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SquareOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ZerosLikeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ZerosLikeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::FillOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_FillOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::BidirectionalSequenceLSTMOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_BidirectionalSequenceLSTMOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::BidirectionalSequenceRNNOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_BidirectionalSequenceRNNOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::UnidirectionalSequenceLSTMOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_UnidirectionalSequenceLSTMOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::FloorModOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_FloorModOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::RangeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_RangeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ResizeNearestNeighborOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ResizeNearestNeighborOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::LeakyReluOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_LeakyReluOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SquaredDifferenceOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SquaredDifferenceOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::MirrorPadOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_MirrorPadOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::AbsOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_AbsOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SplitVOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SplitVOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::UniqueOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_UniqueOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ReverseV2Options> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ReverseV2Options;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::AddNOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_AddNOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::GatherNdOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_GatherNdOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::CosOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_CosOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::WhereOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_WhereOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::RankOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_RankOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ReverseSequenceOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ReverseSequenceOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::MatrixDiagOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_MatrixDiagOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::QuantizeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_QuantizeOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::MatrixSetDiagOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_MatrixSetDiagOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::HardSwishOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_HardSwishOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::IfOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_IfOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::WhileOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_WhileOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::DepthToSpaceOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_DepthToSpaceOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::NonMaxSuppressionV4Options> {
+ static const BuiltinOptions enum_value = BuiltinOptions_NonMaxSuppressionV4Options;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::NonMaxSuppressionV5Options> {
+ static const BuiltinOptions enum_value = BuiltinOptions_NonMaxSuppressionV5Options;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::ScatterNdOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_ScatterNdOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SelectV2Options> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SelectV2Options;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::DensifyOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_DensifyOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::SegmentSumOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_SegmentSumOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::BatchMatMulOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_BatchMatMulOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::CumsumOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_CumsumOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::CallOnceOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_CallOnceOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::BroadcastToOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_BroadcastToOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::Rfft2dOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_Rfft2dOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::Conv3DOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_Conv3DOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::HashtableOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_HashtableOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::HashtableFindOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_HashtableFindOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::HashtableImportOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_HashtableImportOptions;
+};
+
+template<> struct BuiltinOptionsTraits<tflite::HashtableSizeOptions> {
+ static const BuiltinOptions enum_value = BuiltinOptions_HashtableSizeOptions;
+};
+
+struct BuiltinOptionsUnion {
+ BuiltinOptions type;
+ void *value;
+
+ BuiltinOptionsUnion() : type(BuiltinOptions_NONE), value(nullptr) {}
+ BuiltinOptionsUnion(BuiltinOptionsUnion&& u) FLATBUFFERS_NOEXCEPT :
+ type(BuiltinOptions_NONE), value(nullptr)
+ { std::swap(type, u.type); std::swap(value, u.value); }
+ BuiltinOptionsUnion(const BuiltinOptionsUnion &) FLATBUFFERS_NOEXCEPT;
+ BuiltinOptionsUnion &operator=(const BuiltinOptionsUnion &u) FLATBUFFERS_NOEXCEPT
+ { BuiltinOptionsUnion t(u); std::swap(type, t.type); std::swap(value, t.value); return *this; }
+ BuiltinOptionsUnion &operator=(BuiltinOptionsUnion &&u) FLATBUFFERS_NOEXCEPT
+ { std::swap(type, u.type); std::swap(value, u.value); return *this; }
+ ~BuiltinOptionsUnion() { Reset(); }
+
+ void Reset();
+
+#ifndef FLATBUFFERS_CPP98_STL
+ template <typename T>
+ void Set(T&& val) {
+ using RT = typename std::remove_reference<T>::type;
+ Reset();
+ type = BuiltinOptionsTraits<typename RT::TableType>::enum_value;
+ if (type != BuiltinOptions_NONE) {
+ value = new RT(std::forward<T>(val));
+ }
+ }
+#endif // FLATBUFFERS_CPP98_STL
+
+ static void *UnPack(const void *obj, BuiltinOptions type, const flatbuffers::resolver_function_t *resolver);
+ flatbuffers::Offset<void> Pack(flatbuffers::FlatBufferBuilder &_fbb, const flatbuffers::rehasher_function_t *_rehasher = nullptr) const;
+
+ tflite::Conv2DOptionsT *AsConv2DOptions() {
+ return type == BuiltinOptions_Conv2DOptions ?
+ reinterpret_cast<tflite::Conv2DOptionsT *>(value) : nullptr;
+ }
+ const tflite::Conv2DOptionsT *AsConv2DOptions() const {
+ return type == BuiltinOptions_Conv2DOptions ?
+ reinterpret_cast<const tflite::Conv2DOptionsT *>(value) : nullptr;
+ }
+ tflite::DepthwiseConv2DOptionsT *AsDepthwiseConv2DOptions() {
+ return type == BuiltinOptions_DepthwiseConv2DOptions ?
+ reinterpret_cast<tflite::DepthwiseConv2DOptionsT *>(value) : nullptr;
+ }
+ const tflite::DepthwiseConv2DOptionsT *AsDepthwiseConv2DOptions() const {
+ return type == BuiltinOptions_DepthwiseConv2DOptions ?
+ reinterpret_cast<const tflite::DepthwiseConv2DOptionsT *>(value) : nullptr;
+ }
+ tflite::ConcatEmbeddingsOptionsT *AsConcatEmbeddingsOptions() {
+ return type == BuiltinOptions_ConcatEmbeddingsOptions ?
+ reinterpret_cast<tflite::ConcatEmbeddingsOptionsT *>(value) : nullptr;
+ }
+ const tflite::ConcatEmbeddingsOptionsT *AsConcatEmbeddingsOptions() const {
+ return type == BuiltinOptions_ConcatEmbeddingsOptions ?
+ reinterpret_cast<const tflite::ConcatEmbeddingsOptionsT *>(value) : nullptr;
+ }
+ tflite::LSHProjectionOptionsT *AsLSHProjectionOptions() {
+ return type == BuiltinOptions_LSHProjectionOptions ?
+ reinterpret_cast<tflite::LSHProjectionOptionsT *>(value) : nullptr;
+ }
+ const tflite::LSHProjectionOptionsT *AsLSHProjectionOptions() const {
+ return type == BuiltinOptions_LSHProjectionOptions ?
+ reinterpret_cast<const tflite::LSHProjectionOptionsT *>(value) : nullptr;
+ }
+ tflite::Pool2DOptionsT *AsPool2DOptions() {
+ return type == BuiltinOptions_Pool2DOptions ?
+ reinterpret_cast<tflite::Pool2DOptionsT *>(value) : nullptr;
+ }
+ const tflite::Pool2DOptionsT *AsPool2DOptions() const {
+ return type == BuiltinOptions_Pool2DOptions ?
+ reinterpret_cast<const tflite::Pool2DOptionsT *>(value) : nullptr;
+ }
+ tflite::SVDFOptionsT *AsSVDFOptions() {
+ return type == BuiltinOptions_SVDFOptions ?
+ reinterpret_cast<tflite::SVDFOptionsT *>(value) : nullptr;
+ }
+ const tflite::SVDFOptionsT *AsSVDFOptions() const {
+ return type == BuiltinOptions_SVDFOptions ?
+ reinterpret_cast<const tflite::SVDFOptionsT *>(value) : nullptr;
+ }
+ tflite::RNNOptionsT *AsRNNOptions() {
+ return type == BuiltinOptions_RNNOptions ?
+ reinterpret_cast<tflite::RNNOptionsT *>(value) : nullptr;
+ }
+ const tflite::RNNOptionsT *AsRNNOptions() const {
+ return type == BuiltinOptions_RNNOptions ?
+ reinterpret_cast<const tflite::RNNOptionsT *>(value) : nullptr;
+ }
+ tflite::FullyConnectedOptionsT *AsFullyConnectedOptions() {
+ return type == BuiltinOptions_FullyConnectedOptions ?
+ reinterpret_cast<tflite::FullyConnectedOptionsT *>(value) : nullptr;
+ }
+ const tflite::FullyConnectedOptionsT *AsFullyConnectedOptions() const {
+ return type == BuiltinOptions_FullyConnectedOptions ?
+ reinterpret_cast<const tflite::FullyConnectedOptionsT *>(value) : nullptr;
+ }
+ tflite::SoftmaxOptionsT *AsSoftmaxOptions() {
+ return type == BuiltinOptions_SoftmaxOptions ?
+ reinterpret_cast<tflite::SoftmaxOptionsT *>(value) : nullptr;
+ }
+ const tflite::SoftmaxOptionsT *AsSoftmaxOptions() const {
+ return type == BuiltinOptions_SoftmaxOptions ?
+ reinterpret_cast<const tflite::SoftmaxOptionsT *>(value) : nullptr;
+ }
+ tflite::ConcatenationOptionsT *AsConcatenationOptions() {
+ return type == BuiltinOptions_ConcatenationOptions ?
+ reinterpret_cast<tflite::ConcatenationOptionsT *>(value) : nullptr;
+ }
+ const tflite::ConcatenationOptionsT *AsConcatenationOptions() const {
+ return type == BuiltinOptions_ConcatenationOptions ?
+ reinterpret_cast<const tflite::ConcatenationOptionsT *>(value) : nullptr;
+ }
+ tflite::AddOptionsT *AsAddOptions() {
+ return type == BuiltinOptions_AddOptions ?
+ reinterpret_cast<tflite::AddOptionsT *>(value) : nullptr;
+ }
+ const tflite::AddOptionsT *AsAddOptions() const {
+ return type == BuiltinOptions_AddOptions ?
+ reinterpret_cast<const tflite::AddOptionsT *>(value) : nullptr;
+ }
+ tflite::L2NormOptionsT *AsL2NormOptions() {
+ return type == BuiltinOptions_L2NormOptions ?
+ reinterpret_cast<tflite::L2NormOptionsT *>(value) : nullptr;
+ }
+ const tflite::L2NormOptionsT *AsL2NormOptions() const {
+ return type == BuiltinOptions_L2NormOptions ?
+ reinterpret_cast<const tflite::L2NormOptionsT *>(value) : nullptr;
+ }
+ tflite::LocalResponseNormalizationOptionsT *AsLocalResponseNormalizationOptions() {
+ return type == BuiltinOptions_LocalResponseNormalizationOptions ?
+ reinterpret_cast<tflite::LocalResponseNormalizationOptionsT *>(value) : nullptr;
+ }
+ const tflite::LocalResponseNormalizationOptionsT *AsLocalResponseNormalizationOptions() const {
+ return type == BuiltinOptions_LocalResponseNormalizationOptions ?
+ reinterpret_cast<const tflite::LocalResponseNormalizationOptionsT *>(value) : nullptr;
+ }
+ tflite::LSTMOptionsT *AsLSTMOptions() {
+ return type == BuiltinOptions_LSTMOptions ?
+ reinterpret_cast<tflite::LSTMOptionsT *>(value) : nullptr;
+ }
+ const tflite::LSTMOptionsT *AsLSTMOptions() const {
+ return type == BuiltinOptions_LSTMOptions ?
+ reinterpret_cast<const tflite::LSTMOptionsT *>(value) : nullptr;
+ }
+ tflite::ResizeBilinearOptionsT *AsResizeBilinearOptions() {
+ return type == BuiltinOptions_ResizeBilinearOptions ?
+ reinterpret_cast<tflite::ResizeBilinearOptionsT *>(value) : nullptr;
+ }
+ const tflite::ResizeBilinearOptionsT *AsResizeBilinearOptions() const {
+ return type == BuiltinOptions_ResizeBilinearOptions ?
+ reinterpret_cast<const tflite::ResizeBilinearOptionsT *>(value) : nullptr;
+ }
+ tflite::CallOptionsT *AsCallOptions() {
+ return type == BuiltinOptions_CallOptions ?
+ reinterpret_cast<tflite::CallOptionsT *>(value) : nullptr;
+ }
+ const tflite::CallOptionsT *AsCallOptions() const {
+ return type == BuiltinOptions_CallOptions ?
+ reinterpret_cast<const tflite::CallOptionsT *>(value) : nullptr;
+ }
+ tflite::ReshapeOptionsT *AsReshapeOptions() {
+ return type == BuiltinOptions_ReshapeOptions ?
+ reinterpret_cast<tflite::ReshapeOptionsT *>(value) : nullptr;
+ }
+ const tflite::ReshapeOptionsT *AsReshapeOptions() const {
+ return type == BuiltinOptions_ReshapeOptions ?
+ reinterpret_cast<const tflite::ReshapeOptionsT *>(value) : nullptr;
+ }
+ tflite::SkipGramOptionsT *AsSkipGramOptions() {
+ return type == BuiltinOptions_SkipGramOptions ?
+ reinterpret_cast<tflite::SkipGramOptionsT *>(value) : nullptr;
+ }
+ const tflite::SkipGramOptionsT *AsSkipGramOptions() const {
+ return type == BuiltinOptions_SkipGramOptions ?
+ reinterpret_cast<const tflite::SkipGramOptionsT *>(value) : nullptr;
+ }
+ tflite::SpaceToDepthOptionsT *AsSpaceToDepthOptions() {
+ return type == BuiltinOptions_SpaceToDepthOptions ?
+ reinterpret_cast<tflite::SpaceToDepthOptionsT *>(value) : nullptr;
+ }
+ const tflite::SpaceToDepthOptionsT *AsSpaceToDepthOptions() const {
+ return type == BuiltinOptions_SpaceToDepthOptions ?
+ reinterpret_cast<const tflite::SpaceToDepthOptionsT *>(value) : nullptr;
+ }
+ tflite::EmbeddingLookupSparseOptionsT *AsEmbeddingLookupSparseOptions() {
+ return type == BuiltinOptions_EmbeddingLookupSparseOptions ?
+ reinterpret_cast<tflite::EmbeddingLookupSparseOptionsT *>(value) : nullptr;
+ }
+ const tflite::EmbeddingLookupSparseOptionsT *AsEmbeddingLookupSparseOptions() const {
+ return type == BuiltinOptions_EmbeddingLookupSparseOptions ?
+ reinterpret_cast<const tflite::EmbeddingLookupSparseOptionsT *>(value) : nullptr;
+ }
+ tflite::MulOptionsT *AsMulOptions() {
+ return type == BuiltinOptions_MulOptions ?
+ reinterpret_cast<tflite::MulOptionsT *>(value) : nullptr;
+ }
+ const tflite::MulOptionsT *AsMulOptions() const {
+ return type == BuiltinOptions_MulOptions ?
+ reinterpret_cast<const tflite::MulOptionsT *>(value) : nullptr;
+ }
+ tflite::PadOptionsT *AsPadOptions() {
+ return type == BuiltinOptions_PadOptions ?
+ reinterpret_cast<tflite::PadOptionsT *>(value) : nullptr;
+ }
+ const tflite::PadOptionsT *AsPadOptions() const {
+ return type == BuiltinOptions_PadOptions ?
+ reinterpret_cast<const tflite::PadOptionsT *>(value) : nullptr;
+ }
+ tflite::GatherOptionsT *AsGatherOptions() {
+ return type == BuiltinOptions_GatherOptions ?
+ reinterpret_cast<tflite::GatherOptionsT *>(value) : nullptr;
+ }
+ const tflite::GatherOptionsT *AsGatherOptions() const {
+ return type == BuiltinOptions_GatherOptions ?
+ reinterpret_cast<const tflite::GatherOptionsT *>(value) : nullptr;
+ }
+ tflite::BatchToSpaceNDOptionsT *AsBatchToSpaceNDOptions() {
+ return type == BuiltinOptions_BatchToSpaceNDOptions ?
+ reinterpret_cast<tflite::BatchToSpaceNDOptionsT *>(value) : nullptr;
+ }
+ const tflite::BatchToSpaceNDOptionsT *AsBatchToSpaceNDOptions() const {
+ return type == BuiltinOptions_BatchToSpaceNDOptions ?
+ reinterpret_cast<const tflite::BatchToSpaceNDOptionsT *>(value) : nullptr;
+ }
+ tflite::SpaceToBatchNDOptionsT *AsSpaceToBatchNDOptions() {
+ return type == BuiltinOptions_SpaceToBatchNDOptions ?
+ reinterpret_cast<tflite::SpaceToBatchNDOptionsT *>(value) : nullptr;
+ }
+ const tflite::SpaceToBatchNDOptionsT *AsSpaceToBatchNDOptions() const {
+ return type == BuiltinOptions_SpaceToBatchNDOptions ?
+ reinterpret_cast<const tflite::SpaceToBatchNDOptionsT *>(value) : nullptr;
+ }
+ tflite::TransposeOptionsT *AsTransposeOptions() {
+ return type == BuiltinOptions_TransposeOptions ?
+ reinterpret_cast<tflite::TransposeOptionsT *>(value) : nullptr;
+ }
+ const tflite::TransposeOptionsT *AsTransposeOptions() const {
+ return type == BuiltinOptions_TransposeOptions ?
+ reinterpret_cast<const tflite::TransposeOptionsT *>(value) : nullptr;
+ }
+ tflite::ReducerOptionsT *AsReducerOptions() {
+ return type == BuiltinOptions_ReducerOptions ?
+ reinterpret_cast<tflite::ReducerOptionsT *>(value) : nullptr;
+ }
+ const tflite::ReducerOptionsT *AsReducerOptions() const {
+ return type == BuiltinOptions_ReducerOptions ?
+ reinterpret_cast<const tflite::ReducerOptionsT *>(value) : nullptr;
+ }
+ tflite::SubOptionsT *AsSubOptions() {
+ return type == BuiltinOptions_SubOptions ?
+ reinterpret_cast<tflite::SubOptionsT *>(value) : nullptr;
+ }
+ const tflite::SubOptionsT *AsSubOptions() const {
+ return type == BuiltinOptions_SubOptions ?
+ reinterpret_cast<const tflite::SubOptionsT *>(value) : nullptr;
+ }
+ tflite::DivOptionsT *AsDivOptions() {
+ return type == BuiltinOptions_DivOptions ?
+ reinterpret_cast<tflite::DivOptionsT *>(value) : nullptr;
+ }
+ const tflite::DivOptionsT *AsDivOptions() const {
+ return type == BuiltinOptions_DivOptions ?
+ reinterpret_cast<const tflite::DivOptionsT *>(value) : nullptr;
+ }
+ tflite::SqueezeOptionsT *AsSqueezeOptions() {
+ return type == BuiltinOptions_SqueezeOptions ?
+ reinterpret_cast<tflite::SqueezeOptionsT *>(value) : nullptr;
+ }
+ const tflite::SqueezeOptionsT *AsSqueezeOptions() const {
+ return type == BuiltinOptions_SqueezeOptions ?
+ reinterpret_cast<const tflite::SqueezeOptionsT *>(value) : nullptr;
+ }
+ tflite::SequenceRNNOptionsT *AsSequenceRNNOptions() {
+ return type == BuiltinOptions_SequenceRNNOptions ?
+ reinterpret_cast<tflite::SequenceRNNOptionsT *>(value) : nullptr;
+ }
+ const tflite::SequenceRNNOptionsT *AsSequenceRNNOptions() const {
+ return type == BuiltinOptions_SequenceRNNOptions ?
+ reinterpret_cast<const tflite::SequenceRNNOptionsT *>(value) : nullptr;
+ }
+ tflite::StridedSliceOptionsT *AsStridedSliceOptions() {
+ return type == BuiltinOptions_StridedSliceOptions ?
+ reinterpret_cast<tflite::StridedSliceOptionsT *>(value) : nullptr;
+ }
+ const tflite::StridedSliceOptionsT *AsStridedSliceOptions() const {
+ return type == BuiltinOptions_StridedSliceOptions ?
+ reinterpret_cast<const tflite::StridedSliceOptionsT *>(value) : nullptr;
+ }
+ tflite::ExpOptionsT *AsExpOptions() {
+ return type == BuiltinOptions_ExpOptions ?
+ reinterpret_cast<tflite::ExpOptionsT *>(value) : nullptr;
+ }
+ const tflite::ExpOptionsT *AsExpOptions() const {
+ return type == BuiltinOptions_ExpOptions ?
+ reinterpret_cast<const tflite::ExpOptionsT *>(value) : nullptr;
+ }
+ tflite::TopKV2OptionsT *AsTopKV2Options() {
+ return type == BuiltinOptions_TopKV2Options ?
+ reinterpret_cast<tflite::TopKV2OptionsT *>(value) : nullptr;
+ }
+ const tflite::TopKV2OptionsT *AsTopKV2Options() const {
+ return type == BuiltinOptions_TopKV2Options ?
+ reinterpret_cast<const tflite::TopKV2OptionsT *>(value) : nullptr;
+ }
+ tflite::SplitOptionsT *AsSplitOptions() {
+ return type == BuiltinOptions_SplitOptions ?
+ reinterpret_cast<tflite::SplitOptionsT *>(value) : nullptr;
+ }
+ const tflite::SplitOptionsT *AsSplitOptions() const {
+ return type == BuiltinOptions_SplitOptions ?
+ reinterpret_cast<const tflite::SplitOptionsT *>(value) : nullptr;
+ }
+ tflite::LogSoftmaxOptionsT *AsLogSoftmaxOptions() {
+ return type == BuiltinOptions_LogSoftmaxOptions ?
+ reinterpret_cast<tflite::LogSoftmaxOptionsT *>(value) : nullptr;
+ }
+ const tflite::LogSoftmaxOptionsT *AsLogSoftmaxOptions() const {
+ return type == BuiltinOptions_LogSoftmaxOptions ?
+ reinterpret_cast<const tflite::LogSoftmaxOptionsT *>(value) : nullptr;
+ }
+ tflite::CastOptionsT *AsCastOptions() {
+ return type == BuiltinOptions_CastOptions ?
+ reinterpret_cast<tflite::CastOptionsT *>(value) : nullptr;
+ }
+ const tflite::CastOptionsT *AsCastOptions() const {
+ return type == BuiltinOptions_CastOptions ?
+ reinterpret_cast<const tflite::CastOptionsT *>(value) : nullptr;
+ }
+ tflite::DequantizeOptionsT *AsDequantizeOptions() {
+ return type == BuiltinOptions_DequantizeOptions ?
+ reinterpret_cast<tflite::DequantizeOptionsT *>(value) : nullptr;
+ }
+ const tflite::DequantizeOptionsT *AsDequantizeOptions() const {
+ return type == BuiltinOptions_DequantizeOptions ?
+ reinterpret_cast<const tflite::DequantizeOptionsT *>(value) : nullptr;
+ }
+ tflite::MaximumMinimumOptionsT *AsMaximumMinimumOptions() {
+ return type == BuiltinOptions_MaximumMinimumOptions ?
+ reinterpret_cast<tflite::MaximumMinimumOptionsT *>(value) : nullptr;
+ }
+ const tflite::MaximumMinimumOptionsT *AsMaximumMinimumOptions() const {
+ return type == BuiltinOptions_MaximumMinimumOptions ?
+ reinterpret_cast<const tflite::MaximumMinimumOptionsT *>(value) : nullptr;
+ }
+ tflite::ArgMaxOptionsT *AsArgMaxOptions() {
+ return type == BuiltinOptions_ArgMaxOptions ?
+ reinterpret_cast<tflite::ArgMaxOptionsT *>(value) : nullptr;
+ }
+ const tflite::ArgMaxOptionsT *AsArgMaxOptions() const {
+ return type == BuiltinOptions_ArgMaxOptions ?
+ reinterpret_cast<const tflite::ArgMaxOptionsT *>(value) : nullptr;
+ }
+ tflite::LessOptionsT *AsLessOptions() {
+ return type == BuiltinOptions_LessOptions ?
+ reinterpret_cast<tflite::LessOptionsT *>(value) : nullptr;
+ }
+ const tflite::LessOptionsT *AsLessOptions() const {
+ return type == BuiltinOptions_LessOptions ?
+ reinterpret_cast<const tflite::LessOptionsT *>(value) : nullptr;
+ }
+ tflite::NegOptionsT *AsNegOptions() {
+ return type == BuiltinOptions_NegOptions ?
+ reinterpret_cast<tflite::NegOptionsT *>(value) : nullptr;
+ }
+ const tflite::NegOptionsT *AsNegOptions() const {
+ return type == BuiltinOptions_NegOptions ?
+ reinterpret_cast<const tflite::NegOptionsT *>(value) : nullptr;
+ }
+ tflite::PadV2OptionsT *AsPadV2Options() {
+ return type == BuiltinOptions_PadV2Options ?
+ reinterpret_cast<tflite::PadV2OptionsT *>(value) : nullptr;
+ }
+ const tflite::PadV2OptionsT *AsPadV2Options() const {
+ return type == BuiltinOptions_PadV2Options ?
+ reinterpret_cast<const tflite::PadV2OptionsT *>(value) : nullptr;
+ }
+ tflite::GreaterOptionsT *AsGreaterOptions() {
+ return type == BuiltinOptions_GreaterOptions ?
+ reinterpret_cast<tflite::GreaterOptionsT *>(value) : nullptr;
+ }
+ const tflite::GreaterOptionsT *AsGreaterOptions() const {
+ return type == BuiltinOptions_GreaterOptions ?
+ reinterpret_cast<const tflite::GreaterOptionsT *>(value) : nullptr;
+ }
+ tflite::GreaterEqualOptionsT *AsGreaterEqualOptions() {
+ return type == BuiltinOptions_GreaterEqualOptions ?
+ reinterpret_cast<tflite::GreaterEqualOptionsT *>(value) : nullptr;
+ }
+ const tflite::GreaterEqualOptionsT *AsGreaterEqualOptions() const {
+ return type == BuiltinOptions_GreaterEqualOptions ?
+ reinterpret_cast<const tflite::GreaterEqualOptionsT *>(value) : nullptr;
+ }
+ tflite::LessEqualOptionsT *AsLessEqualOptions() {
+ return type == BuiltinOptions_LessEqualOptions ?
+ reinterpret_cast<tflite::LessEqualOptionsT *>(value) : nullptr;
+ }
+ const tflite::LessEqualOptionsT *AsLessEqualOptions() const {
+ return type == BuiltinOptions_LessEqualOptions ?
+ reinterpret_cast<const tflite::LessEqualOptionsT *>(value) : nullptr;
+ }
+ tflite::SelectOptionsT *AsSelectOptions() {
+ return type == BuiltinOptions_SelectOptions ?
+ reinterpret_cast<tflite::SelectOptionsT *>(value) : nullptr;
+ }
+ const tflite::SelectOptionsT *AsSelectOptions() const {
+ return type == BuiltinOptions_SelectOptions ?
+ reinterpret_cast<const tflite::SelectOptionsT *>(value) : nullptr;
+ }
+ tflite::SliceOptionsT *AsSliceOptions() {
+ return type == BuiltinOptions_SliceOptions ?
+ reinterpret_cast<tflite::SliceOptionsT *>(value) : nullptr;
+ }
+ const tflite::SliceOptionsT *AsSliceOptions() const {
+ return type == BuiltinOptions_SliceOptions ?
+ reinterpret_cast<const tflite::SliceOptionsT *>(value) : nullptr;
+ }
+ tflite::TransposeConvOptionsT *AsTransposeConvOptions() {
+ return type == BuiltinOptions_TransposeConvOptions ?
+ reinterpret_cast<tflite::TransposeConvOptionsT *>(value) : nullptr;
+ }
+ const tflite::TransposeConvOptionsT *AsTransposeConvOptions() const {
+ return type == BuiltinOptions_TransposeConvOptions ?
+ reinterpret_cast<const tflite::TransposeConvOptionsT *>(value) : nullptr;
+ }
+ tflite::SparseToDenseOptionsT *AsSparseToDenseOptions() {
+ return type == BuiltinOptions_SparseToDenseOptions ?
+ reinterpret_cast<tflite::SparseToDenseOptionsT *>(value) : nullptr;
+ }
+ const tflite::SparseToDenseOptionsT *AsSparseToDenseOptions() const {
+ return type == BuiltinOptions_SparseToDenseOptions ?
+ reinterpret_cast<const tflite::SparseToDenseOptionsT *>(value) : nullptr;
+ }
+ tflite::TileOptionsT *AsTileOptions() {
+ return type == BuiltinOptions_TileOptions ?
+ reinterpret_cast<tflite::TileOptionsT *>(value) : nullptr;
+ }
+ const tflite::TileOptionsT *AsTileOptions() const {
+ return type == BuiltinOptions_TileOptions ?
+ reinterpret_cast<const tflite::TileOptionsT *>(value) : nullptr;
+ }
+ tflite::ExpandDimsOptionsT *AsExpandDimsOptions() {
+ return type == BuiltinOptions_ExpandDimsOptions ?
+ reinterpret_cast<tflite::ExpandDimsOptionsT *>(value) : nullptr;
+ }
+ const tflite::ExpandDimsOptionsT *AsExpandDimsOptions() const {
+ return type == BuiltinOptions_ExpandDimsOptions ?
+ reinterpret_cast<const tflite::ExpandDimsOptionsT *>(value) : nullptr;
+ }
+ tflite::EqualOptionsT *AsEqualOptions() {
+ return type == BuiltinOptions_EqualOptions ?
+ reinterpret_cast<tflite::EqualOptionsT *>(value) : nullptr;
+ }
+ const tflite::EqualOptionsT *AsEqualOptions() const {
+ return type == BuiltinOptions_EqualOptions ?
+ reinterpret_cast<const tflite::EqualOptionsT *>(value) : nullptr;
+ }
+ tflite::NotEqualOptionsT *AsNotEqualOptions() {
+ return type == BuiltinOptions_NotEqualOptions ?
+ reinterpret_cast<tflite::NotEqualOptionsT *>(value) : nullptr;
+ }
+ const tflite::NotEqualOptionsT *AsNotEqualOptions() const {
+ return type == BuiltinOptions_NotEqualOptions ?
+ reinterpret_cast<const tflite::NotEqualOptionsT *>(value) : nullptr;
+ }
+ tflite::ShapeOptionsT *AsShapeOptions() {
+ return type == BuiltinOptions_ShapeOptions ?
+ reinterpret_cast<tflite::ShapeOptionsT *>(value) : nullptr;
+ }
+ const tflite::ShapeOptionsT *AsShapeOptions() const {
+ return type == BuiltinOptions_ShapeOptions ?
+ reinterpret_cast<const tflite::ShapeOptionsT *>(value) : nullptr;
+ }
+ tflite::PowOptionsT *AsPowOptions() {
+ return type == BuiltinOptions_PowOptions ?
+ reinterpret_cast<tflite::PowOptionsT *>(value) : nullptr;
+ }
+ const tflite::PowOptionsT *AsPowOptions() const {
+ return type == BuiltinOptions_PowOptions ?
+ reinterpret_cast<const tflite::PowOptionsT *>(value) : nullptr;
+ }
+ tflite::ArgMinOptionsT *AsArgMinOptions() {
+ return type == BuiltinOptions_ArgMinOptions ?
+ reinterpret_cast<tflite::ArgMinOptionsT *>(value) : nullptr;
+ }
+ const tflite::ArgMinOptionsT *AsArgMinOptions() const {
+ return type == BuiltinOptions_ArgMinOptions ?
+ reinterpret_cast<const tflite::ArgMinOptionsT *>(value) : nullptr;
+ }
+ tflite::FakeQuantOptionsT *AsFakeQuantOptions() {
+ return type == BuiltinOptions_FakeQuantOptions ?
+ reinterpret_cast<tflite::FakeQuantOptionsT *>(value) : nullptr;
+ }
+ const tflite::FakeQuantOptionsT *AsFakeQuantOptions() const {
+ return type == BuiltinOptions_FakeQuantOptions ?
+ reinterpret_cast<const tflite::FakeQuantOptionsT *>(value) : nullptr;
+ }
+ tflite::PackOptionsT *AsPackOptions() {
+ return type == BuiltinOptions_PackOptions ?
+ reinterpret_cast<tflite::PackOptionsT *>(value) : nullptr;
+ }
+ const tflite::PackOptionsT *AsPackOptions() const {
+ return type == BuiltinOptions_PackOptions ?
+ reinterpret_cast<const tflite::PackOptionsT *>(value) : nullptr;
+ }
+ tflite::LogicalOrOptionsT *AsLogicalOrOptions() {
+ return type == BuiltinOptions_LogicalOrOptions ?
+ reinterpret_cast<tflite::LogicalOrOptionsT *>(value) : nullptr;
+ }
+ const tflite::LogicalOrOptionsT *AsLogicalOrOptions() const {
+ return type == BuiltinOptions_LogicalOrOptions ?
+ reinterpret_cast<const tflite::LogicalOrOptionsT *>(value) : nullptr;
+ }
+ tflite::OneHotOptionsT *AsOneHotOptions() {
+ return type == BuiltinOptions_OneHotOptions ?
+ reinterpret_cast<tflite::OneHotOptionsT *>(value) : nullptr;
+ }
+ const tflite::OneHotOptionsT *AsOneHotOptions() const {
+ return type == BuiltinOptions_OneHotOptions ?
+ reinterpret_cast<const tflite::OneHotOptionsT *>(value) : nullptr;
+ }
+ tflite::LogicalAndOptionsT *AsLogicalAndOptions() {
+ return type == BuiltinOptions_LogicalAndOptions ?
+ reinterpret_cast<tflite::LogicalAndOptionsT *>(value) : nullptr;
+ }
+ const tflite::LogicalAndOptionsT *AsLogicalAndOptions() const {
+ return type == BuiltinOptions_LogicalAndOptions ?
+ reinterpret_cast<const tflite::LogicalAndOptionsT *>(value) : nullptr;
+ }
+ tflite::LogicalNotOptionsT *AsLogicalNotOptions() {
+ return type == BuiltinOptions_LogicalNotOptions ?
+ reinterpret_cast<tflite::LogicalNotOptionsT *>(value) : nullptr;
+ }
+ const tflite::LogicalNotOptionsT *AsLogicalNotOptions() const {
+ return type == BuiltinOptions_LogicalNotOptions ?
+ reinterpret_cast<const tflite::LogicalNotOptionsT *>(value) : nullptr;
+ }
+ tflite::UnpackOptionsT *AsUnpackOptions() {
+ return type == BuiltinOptions_UnpackOptions ?
+ reinterpret_cast<tflite::UnpackOptionsT *>(value) : nullptr;
+ }
+ const tflite::UnpackOptionsT *AsUnpackOptions() const {
+ return type == BuiltinOptions_UnpackOptions ?
+ reinterpret_cast<const tflite::UnpackOptionsT *>(value) : nullptr;
+ }
+ tflite::FloorDivOptionsT *AsFloorDivOptions() {
+ return type == BuiltinOptions_FloorDivOptions ?
+ reinterpret_cast<tflite::FloorDivOptionsT *>(value) : nullptr;
+ }
+ const tflite::FloorDivOptionsT *AsFloorDivOptions() const {
+ return type == BuiltinOptions_FloorDivOptions ?
+ reinterpret_cast<const tflite::FloorDivOptionsT *>(value) : nullptr;
+ }
+ tflite::SquareOptionsT *AsSquareOptions() {
+ return type == BuiltinOptions_SquareOptions ?
+ reinterpret_cast<tflite::SquareOptionsT *>(value) : nullptr;
+ }
+ const tflite::SquareOptionsT *AsSquareOptions() const {
+ return type == BuiltinOptions_SquareOptions ?
+ reinterpret_cast<const tflite::SquareOptionsT *>(value) : nullptr;
+ }
+ tflite::ZerosLikeOptionsT *AsZerosLikeOptions() {
+ return type == BuiltinOptions_ZerosLikeOptions ?
+ reinterpret_cast<tflite::ZerosLikeOptionsT *>(value) : nullptr;
+ }
+ const tflite::ZerosLikeOptionsT *AsZerosLikeOptions() const {
+ return type == BuiltinOptions_ZerosLikeOptions ?
+ reinterpret_cast<const tflite::ZerosLikeOptionsT *>(value) : nullptr;
+ }
+ tflite::FillOptionsT *AsFillOptions() {
+ return type == BuiltinOptions_FillOptions ?
+ reinterpret_cast<tflite::FillOptionsT *>(value) : nullptr;
+ }
+ const tflite::FillOptionsT *AsFillOptions() const {
+ return type == BuiltinOptions_FillOptions ?
+ reinterpret_cast<const tflite::FillOptionsT *>(value) : nullptr;
+ }
+ tflite::BidirectionalSequenceLSTMOptionsT *AsBidirectionalSequenceLSTMOptions() {
+ return type == BuiltinOptions_BidirectionalSequenceLSTMOptions ?
+ reinterpret_cast<tflite::BidirectionalSequenceLSTMOptionsT *>(value) : nullptr;
+ }
+ const tflite::BidirectionalSequenceLSTMOptionsT *AsBidirectionalSequenceLSTMOptions() const {
+ return type == BuiltinOptions_BidirectionalSequenceLSTMOptions ?
+ reinterpret_cast<const tflite::BidirectionalSequenceLSTMOptionsT *>(value) : nullptr;
+ }
+ tflite::BidirectionalSequenceRNNOptionsT *AsBidirectionalSequenceRNNOptions() {
+ return type == BuiltinOptions_BidirectionalSequenceRNNOptions ?
+ reinterpret_cast<tflite::BidirectionalSequenceRNNOptionsT *>(value) : nullptr;
+ }
+ const tflite::BidirectionalSequenceRNNOptionsT *AsBidirectionalSequenceRNNOptions() const {
+ return type == BuiltinOptions_BidirectionalSequenceRNNOptions ?
+ reinterpret_cast<const tflite::BidirectionalSequenceRNNOptionsT *>(value) : nullptr;
+ }
+ tflite::UnidirectionalSequenceLSTMOptionsT *AsUnidirectionalSequenceLSTMOptions() {
+ return type == BuiltinOptions_UnidirectionalSequenceLSTMOptions ?
+ reinterpret_cast<tflite::UnidirectionalSequenceLSTMOptionsT *>(value) : nullptr;
+ }
+ const tflite::UnidirectionalSequenceLSTMOptionsT *AsUnidirectionalSequenceLSTMOptions() const {
+ return type == BuiltinOptions_UnidirectionalSequenceLSTMOptions ?
+ reinterpret_cast<const tflite::UnidirectionalSequenceLSTMOptionsT *>(value) : nullptr;
+ }
+ tflite::FloorModOptionsT *AsFloorModOptions() {
+ return type == BuiltinOptions_FloorModOptions ?
+ reinterpret_cast<tflite::FloorModOptionsT *>(value) : nullptr;
+ }
+ const tflite::FloorModOptionsT *AsFloorModOptions() const {
+ return type == BuiltinOptions_FloorModOptions ?
+ reinterpret_cast<const tflite::FloorModOptionsT *>(value) : nullptr;
+ }
+ tflite::RangeOptionsT *AsRangeOptions() {
+ return type == BuiltinOptions_RangeOptions ?
+ reinterpret_cast<tflite::RangeOptionsT *>(value) : nullptr;
+ }
+ const tflite::RangeOptionsT *AsRangeOptions() const {
+ return type == BuiltinOptions_RangeOptions ?
+ reinterpret_cast<const tflite::RangeOptionsT *>(value) : nullptr;
+ }
+ tflite::ResizeNearestNeighborOptionsT *AsResizeNearestNeighborOptions() {
+ return type == BuiltinOptions_ResizeNearestNeighborOptions ?
+ reinterpret_cast<tflite::ResizeNearestNeighborOptionsT *>(value) : nullptr;
+ }
+ const tflite::ResizeNearestNeighborOptionsT *AsResizeNearestNeighborOptions() const {
+ return type == BuiltinOptions_ResizeNearestNeighborOptions ?
+ reinterpret_cast<const tflite::ResizeNearestNeighborOptionsT *>(value) : nullptr;
+ }
+ tflite::LeakyReluOptionsT *AsLeakyReluOptions() {
+ return type == BuiltinOptions_LeakyReluOptions ?
+ reinterpret_cast<tflite::LeakyReluOptionsT *>(value) : nullptr;
+ }
+ const tflite::LeakyReluOptionsT *AsLeakyReluOptions() const {
+ return type == BuiltinOptions_LeakyReluOptions ?
+ reinterpret_cast<const tflite::LeakyReluOptionsT *>(value) : nullptr;
+ }
+ tflite::SquaredDifferenceOptionsT *AsSquaredDifferenceOptions() {
+ return type == BuiltinOptions_SquaredDifferenceOptions ?
+ reinterpret_cast<tflite::SquaredDifferenceOptionsT *>(value) : nullptr;
+ }
+ const tflite::SquaredDifferenceOptionsT *AsSquaredDifferenceOptions() const {
+ return type == BuiltinOptions_SquaredDifferenceOptions ?
+ reinterpret_cast<const tflite::SquaredDifferenceOptionsT *>(value) : nullptr;
+ }
+ tflite::MirrorPadOptionsT *AsMirrorPadOptions() {
+ return type == BuiltinOptions_MirrorPadOptions ?
+ reinterpret_cast<tflite::MirrorPadOptionsT *>(value) : nullptr;
+ }
+ const tflite::MirrorPadOptionsT *AsMirrorPadOptions() const {
+ return type == BuiltinOptions_MirrorPadOptions ?
+ reinterpret_cast<const tflite::MirrorPadOptionsT *>(value) : nullptr;
+ }
+ tflite::AbsOptionsT *AsAbsOptions() {
+ return type == BuiltinOptions_AbsOptions ?
+ reinterpret_cast<tflite::AbsOptionsT *>(value) : nullptr;
+ }
+ const tflite::AbsOptionsT *AsAbsOptions() const {
+ return type == BuiltinOptions_AbsOptions ?
+ reinterpret_cast<const tflite::AbsOptionsT *>(value) : nullptr;
+ }
+ tflite::SplitVOptionsT *AsSplitVOptions() {
+ return type == BuiltinOptions_SplitVOptions ?
+ reinterpret_cast<tflite::SplitVOptionsT *>(value) : nullptr;
+ }
+ const tflite::SplitVOptionsT *AsSplitVOptions() const {
+ return type == BuiltinOptions_SplitVOptions ?
+ reinterpret_cast<const tflite::SplitVOptionsT *>(value) : nullptr;
+ }
+ tflite::UniqueOptionsT *AsUniqueOptions() {
+ return type == BuiltinOptions_UniqueOptions ?
+ reinterpret_cast<tflite::UniqueOptionsT *>(value) : nullptr;
+ }
+ const tflite::UniqueOptionsT *AsUniqueOptions() const {
+ return type == BuiltinOptions_UniqueOptions ?
+ reinterpret_cast<const tflite::UniqueOptionsT *>(value) : nullptr;
+ }
+ tflite::ReverseV2OptionsT *AsReverseV2Options() {
+ return type == BuiltinOptions_ReverseV2Options ?
+ reinterpret_cast<tflite::ReverseV2OptionsT *>(value) : nullptr;
+ }
+ const tflite::ReverseV2OptionsT *AsReverseV2Options() const {
+ return type == BuiltinOptions_ReverseV2Options ?
+ reinterpret_cast<const tflite::ReverseV2OptionsT *>(value) : nullptr;
+ }
+ tflite::AddNOptionsT *AsAddNOptions() {
+ return type == BuiltinOptions_AddNOptions ?
+ reinterpret_cast<tflite::AddNOptionsT *>(value) : nullptr;
+ }
+ const tflite::AddNOptionsT *AsAddNOptions() const {
+ return type == BuiltinOptions_AddNOptions ?
+ reinterpret_cast<const tflite::AddNOptionsT *>(value) : nullptr;
+ }
+ tflite::GatherNdOptionsT *AsGatherNdOptions() {
+ return type == BuiltinOptions_GatherNdOptions ?
+ reinterpret_cast<tflite::GatherNdOptionsT *>(value) : nullptr;
+ }
+ const tflite::GatherNdOptionsT *AsGatherNdOptions() const {
+ return type == BuiltinOptions_GatherNdOptions ?
+ reinterpret_cast<const tflite::GatherNdOptionsT *>(value) : nullptr;
+ }
+ tflite::CosOptionsT *AsCosOptions() {
+ return type == BuiltinOptions_CosOptions ?
+ reinterpret_cast<tflite::CosOptionsT *>(value) : nullptr;
+ }
+ const tflite::CosOptionsT *AsCosOptions() const {
+ return type == BuiltinOptions_CosOptions ?
+ reinterpret_cast<const tflite::CosOptionsT *>(value) : nullptr;
+ }
+ tflite::WhereOptionsT *AsWhereOptions() {
+ return type == BuiltinOptions_WhereOptions ?
+ reinterpret_cast<tflite::WhereOptionsT *>(value) : nullptr;
+ }
+ const tflite::WhereOptionsT *AsWhereOptions() const {
+ return type == BuiltinOptions_WhereOptions ?
+ reinterpret_cast<const tflite::WhereOptionsT *>(value) : nullptr;
+ }
+ tflite::RankOptionsT *AsRankOptions() {
+ return type == BuiltinOptions_RankOptions ?
+ reinterpret_cast<tflite::RankOptionsT *>(value) : nullptr;
+ }
+ const tflite::RankOptionsT *AsRankOptions() const {
+ return type == BuiltinOptions_RankOptions ?
+ reinterpret_cast<const tflite::RankOptionsT *>(value) : nullptr;
+ }
+ tflite::ReverseSequenceOptionsT *AsReverseSequenceOptions() {
+ return type == BuiltinOptions_ReverseSequenceOptions ?
+ reinterpret_cast<tflite::ReverseSequenceOptionsT *>(value) : nullptr;
+ }
+ const tflite::ReverseSequenceOptionsT *AsReverseSequenceOptions() const {
+ return type == BuiltinOptions_ReverseSequenceOptions ?
+ reinterpret_cast<const tflite::ReverseSequenceOptionsT *>(value) : nullptr;
+ }
+ tflite::MatrixDiagOptionsT *AsMatrixDiagOptions() {
+ return type == BuiltinOptions_MatrixDiagOptions ?
+ reinterpret_cast<tflite::MatrixDiagOptionsT *>(value) : nullptr;
+ }
+ const tflite::MatrixDiagOptionsT *AsMatrixDiagOptions() const {
+ return type == BuiltinOptions_MatrixDiagOptions ?
+ reinterpret_cast<const tflite::MatrixDiagOptionsT *>(value) : nullptr;
+ }
+ tflite::QuantizeOptionsT *AsQuantizeOptions() {
+ return type == BuiltinOptions_QuantizeOptions ?
+ reinterpret_cast<tflite::QuantizeOptionsT *>(value) : nullptr;
+ }
+ const tflite::QuantizeOptionsT *AsQuantizeOptions() const {
+ return type == BuiltinOptions_QuantizeOptions ?
+ reinterpret_cast<const tflite::QuantizeOptionsT *>(value) : nullptr;
+ }
+ tflite::MatrixSetDiagOptionsT *AsMatrixSetDiagOptions() {
+ return type == BuiltinOptions_MatrixSetDiagOptions ?
+ reinterpret_cast<tflite::MatrixSetDiagOptionsT *>(value) : nullptr;
+ }
+ const tflite::MatrixSetDiagOptionsT *AsMatrixSetDiagOptions() const {
+ return type == BuiltinOptions_MatrixSetDiagOptions ?
+ reinterpret_cast<const tflite::MatrixSetDiagOptionsT *>(value) : nullptr;
+ }
+ tflite::HardSwishOptionsT *AsHardSwishOptions() {
+ return type == BuiltinOptions_HardSwishOptions ?
+ reinterpret_cast<tflite::HardSwishOptionsT *>(value) : nullptr;
+ }
+ const tflite::HardSwishOptionsT *AsHardSwishOptions() const {
+ return type == BuiltinOptions_HardSwishOptions ?
+ reinterpret_cast<const tflite::HardSwishOptionsT *>(value) : nullptr;
+ }
+ tflite::IfOptionsT *AsIfOptions() {
+ return type == BuiltinOptions_IfOptions ?
+ reinterpret_cast<tflite::IfOptionsT *>(value) : nullptr;
+ }
+ const tflite::IfOptionsT *AsIfOptions() const {
+ return type == BuiltinOptions_IfOptions ?
+ reinterpret_cast<const tflite::IfOptionsT *>(value) : nullptr;
+ }
+ tflite::WhileOptionsT *AsWhileOptions() {
+ return type == BuiltinOptions_WhileOptions ?
+ reinterpret_cast<tflite::WhileOptionsT *>(value) : nullptr;
+ }
+ const tflite::WhileOptionsT *AsWhileOptions() const {
+ return type == BuiltinOptions_WhileOptions ?
+ reinterpret_cast<const tflite::WhileOptionsT *>(value) : nullptr;
+ }
+ tflite::DepthToSpaceOptionsT *AsDepthToSpaceOptions() {
+ return type == BuiltinOptions_DepthToSpaceOptions ?
+ reinterpret_cast<tflite::DepthToSpaceOptionsT *>(value) : nullptr;
+ }
+ const tflite::DepthToSpaceOptionsT *AsDepthToSpaceOptions() const {
+ return type == BuiltinOptions_DepthToSpaceOptions ?
+ reinterpret_cast<const tflite::DepthToSpaceOptionsT *>(value) : nullptr;
+ }
+ tflite::NonMaxSuppressionV4OptionsT *AsNonMaxSuppressionV4Options() {
+ return type == BuiltinOptions_NonMaxSuppressionV4Options ?
+ reinterpret_cast<tflite::NonMaxSuppressionV4OptionsT *>(value) : nullptr;
+ }
+ const tflite::NonMaxSuppressionV4OptionsT *AsNonMaxSuppressionV4Options() const {
+ return type == BuiltinOptions_NonMaxSuppressionV4Options ?
+ reinterpret_cast<const tflite::NonMaxSuppressionV4OptionsT *>(value) : nullptr;
+ }
+ tflite::NonMaxSuppressionV5OptionsT *AsNonMaxSuppressionV5Options() {
+ return type == BuiltinOptions_NonMaxSuppressionV5Options ?
+ reinterpret_cast<tflite::NonMaxSuppressionV5OptionsT *>(value) : nullptr;
+ }
+ const tflite::NonMaxSuppressionV5OptionsT *AsNonMaxSuppressionV5Options() const {
+ return type == BuiltinOptions_NonMaxSuppressionV5Options ?
+ reinterpret_cast<const tflite::NonMaxSuppressionV5OptionsT *>(value) : nullptr;
+ }
+ tflite::ScatterNdOptionsT *AsScatterNdOptions() {
+ return type == BuiltinOptions_ScatterNdOptions ?
+ reinterpret_cast<tflite::ScatterNdOptionsT *>(value) : nullptr;
+ }
+ const tflite::ScatterNdOptionsT *AsScatterNdOptions() const {
+ return type == BuiltinOptions_ScatterNdOptions ?
+ reinterpret_cast<const tflite::ScatterNdOptionsT *>(value) : nullptr;
+ }
+ tflite::SelectV2OptionsT *AsSelectV2Options() {
+ return type == BuiltinOptions_SelectV2Options ?
+ reinterpret_cast<tflite::SelectV2OptionsT *>(value) : nullptr;
+ }
+ const tflite::SelectV2OptionsT *AsSelectV2Options() const {
+ return type == BuiltinOptions_SelectV2Options ?
+ reinterpret_cast<const tflite::SelectV2OptionsT *>(value) : nullptr;
+ }
+ tflite::DensifyOptionsT *AsDensifyOptions() {
+ return type == BuiltinOptions_DensifyOptions ?
+ reinterpret_cast<tflite::DensifyOptionsT *>(value) : nullptr;
+ }
+ const tflite::DensifyOptionsT *AsDensifyOptions() const {
+ return type == BuiltinOptions_DensifyOptions ?
+ reinterpret_cast<const tflite::DensifyOptionsT *>(value) : nullptr;
+ }
+ tflite::SegmentSumOptionsT *AsSegmentSumOptions() {
+ return type == BuiltinOptions_SegmentSumOptions ?
+ reinterpret_cast<tflite::SegmentSumOptionsT *>(value) : nullptr;
+ }
+ const tflite::SegmentSumOptionsT *AsSegmentSumOptions() const {
+ return type == BuiltinOptions_SegmentSumOptions ?
+ reinterpret_cast<const tflite::SegmentSumOptionsT *>(value) : nullptr;
+ }
+ tflite::BatchMatMulOptionsT *AsBatchMatMulOptions() {
+ return type == BuiltinOptions_BatchMatMulOptions ?
+ reinterpret_cast<tflite::BatchMatMulOptionsT *>(value) : nullptr;
+ }
+ const tflite::BatchMatMulOptionsT *AsBatchMatMulOptions() const {
+ return type == BuiltinOptions_BatchMatMulOptions ?
+ reinterpret_cast<const tflite::BatchMatMulOptionsT *>(value) : nullptr;
+ }
+ tflite::CumsumOptionsT *AsCumsumOptions() {
+ return type == BuiltinOptions_CumsumOptions ?
+ reinterpret_cast<tflite::CumsumOptionsT *>(value) : nullptr;
+ }
+ const tflite::CumsumOptionsT *AsCumsumOptions() const {
+ return type == BuiltinOptions_CumsumOptions ?
+ reinterpret_cast<const tflite::CumsumOptionsT *>(value) : nullptr;
+ }
+ tflite::CallOnceOptionsT *AsCallOnceOptions() {
+ return type == BuiltinOptions_CallOnceOptions ?
+ reinterpret_cast<tflite::CallOnceOptionsT *>(value) : nullptr;
+ }
+ const tflite::CallOnceOptionsT *AsCallOnceOptions() const {
+ return type == BuiltinOptions_CallOnceOptions ?
+ reinterpret_cast<const tflite::CallOnceOptionsT *>(value) : nullptr;
+ }
+ tflite::BroadcastToOptionsT *AsBroadcastToOptions() {
+ return type == BuiltinOptions_BroadcastToOptions ?
+ reinterpret_cast<tflite::BroadcastToOptionsT *>(value) : nullptr;
+ }
+ const tflite::BroadcastToOptionsT *AsBroadcastToOptions() const {
+ return type == BuiltinOptions_BroadcastToOptions ?
+ reinterpret_cast<const tflite::BroadcastToOptionsT *>(value) : nullptr;
+ }
+ tflite::Rfft2dOptionsT *AsRfft2dOptions() {
+ return type == BuiltinOptions_Rfft2dOptions ?
+ reinterpret_cast<tflite::Rfft2dOptionsT *>(value) : nullptr;
+ }
+ const tflite::Rfft2dOptionsT *AsRfft2dOptions() const {
+ return type == BuiltinOptions_Rfft2dOptions ?
+ reinterpret_cast<const tflite::Rfft2dOptionsT *>(value) : nullptr;
+ }
+ tflite::Conv3DOptionsT *AsConv3DOptions() {
+ return type == BuiltinOptions_Conv3DOptions ?
+ reinterpret_cast<tflite::Conv3DOptionsT *>(value) : nullptr;
+ }
+ const tflite::Conv3DOptionsT *AsConv3DOptions() const {
+ return type == BuiltinOptions_Conv3DOptions ?
+ reinterpret_cast<const tflite::Conv3DOptionsT *>(value) : nullptr;
+ }
+ tflite::HashtableOptionsT *AsHashtableOptions() {
+ return type == BuiltinOptions_HashtableOptions ?
+ reinterpret_cast<tflite::HashtableOptionsT *>(value) : nullptr;
+ }
+ const tflite::HashtableOptionsT *AsHashtableOptions() const {
+ return type == BuiltinOptions_HashtableOptions ?
+ reinterpret_cast<const tflite::HashtableOptionsT *>(value) : nullptr;
+ }
+ tflite::HashtableFindOptionsT *AsHashtableFindOptions() {
+ return type == BuiltinOptions_HashtableFindOptions ?
+ reinterpret_cast<tflite::HashtableFindOptionsT *>(value) : nullptr;
+ }
+ const tflite::HashtableFindOptionsT *AsHashtableFindOptions() const {
+ return type == BuiltinOptions_HashtableFindOptions ?
+ reinterpret_cast<const tflite::HashtableFindOptionsT *>(value) : nullptr;
+ }
+ tflite::HashtableImportOptionsT *AsHashtableImportOptions() {
+ return type == BuiltinOptions_HashtableImportOptions ?
+ reinterpret_cast<tflite::HashtableImportOptionsT *>(value) : nullptr;
+ }
+ const tflite::HashtableImportOptionsT *AsHashtableImportOptions() const {
+ return type == BuiltinOptions_HashtableImportOptions ?
+ reinterpret_cast<const tflite::HashtableImportOptionsT *>(value) : nullptr;
+ }
+ tflite::HashtableSizeOptionsT *AsHashtableSizeOptions() {
+ return type == BuiltinOptions_HashtableSizeOptions ?
+ reinterpret_cast<tflite::HashtableSizeOptionsT *>(value) : nullptr;
+ }
+ const tflite::HashtableSizeOptionsT *AsHashtableSizeOptions() const {
+ return type == BuiltinOptions_HashtableSizeOptions ?
+ reinterpret_cast<const tflite::HashtableSizeOptionsT *>(value) : nullptr;
+ }
+};
+
+bool VerifyBuiltinOptions(flatbuffers::Verifier &verifier, const void *obj, BuiltinOptions type);
+bool VerifyBuiltinOptionsVector(flatbuffers::Verifier &verifier, const flatbuffers::Vector<flatbuffers::Offset<void>> *values, const flatbuffers::Vector<uint8_t> *types);
+
+enum Padding {
+ Padding_SAME = 0,
+ Padding_VALID = 1,
+ Padding_MIN = Padding_SAME,
+ Padding_MAX = Padding_VALID
+};
+
+inline const Padding (&EnumValuesPadding())[2] {
+ static const Padding values[] = {
+ Padding_SAME,
+ Padding_VALID
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesPadding() {
+ static const char * const names[3] = {
+ "SAME",
+ "VALID",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNamePadding(Padding e) {
+ if (flatbuffers::IsOutRange(e, Padding_SAME, Padding_VALID)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesPadding()[index];
+}
+
+enum ActivationFunctionType {
+ ActivationFunctionType_NONE = 0,
+ ActivationFunctionType_RELU = 1,
+ ActivationFunctionType_RELU_N1_TO_1 = 2,
+ ActivationFunctionType_RELU6 = 3,
+ ActivationFunctionType_TANH = 4,
+ ActivationFunctionType_SIGN_BIT = 5,
+ ActivationFunctionType_MIN = ActivationFunctionType_NONE,
+ ActivationFunctionType_MAX = ActivationFunctionType_SIGN_BIT
+};
+
+inline const ActivationFunctionType (&EnumValuesActivationFunctionType())[6] {
+ static const ActivationFunctionType values[] = {
+ ActivationFunctionType_NONE,
+ ActivationFunctionType_RELU,
+ ActivationFunctionType_RELU_N1_TO_1,
+ ActivationFunctionType_RELU6,
+ ActivationFunctionType_TANH,
+ ActivationFunctionType_SIGN_BIT
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesActivationFunctionType() {
+ static const char * const names[7] = {
+ "NONE",
+ "RELU",
+ "RELU_N1_TO_1",
+ "RELU6",
+ "TANH",
+ "SIGN_BIT",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameActivationFunctionType(ActivationFunctionType e) {
+ if (flatbuffers::IsOutRange(e, ActivationFunctionType_NONE, ActivationFunctionType_SIGN_BIT)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesActivationFunctionType()[index];
+}
+
+enum LSHProjectionType {
+ LSHProjectionType_UNKNOWN = 0,
+ LSHProjectionType_SPARSE = 1,
+ LSHProjectionType_DENSE = 2,
+ LSHProjectionType_MIN = LSHProjectionType_UNKNOWN,
+ LSHProjectionType_MAX = LSHProjectionType_DENSE
+};
+
+inline const LSHProjectionType (&EnumValuesLSHProjectionType())[3] {
+ static const LSHProjectionType values[] = {
+ LSHProjectionType_UNKNOWN,
+ LSHProjectionType_SPARSE,
+ LSHProjectionType_DENSE
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesLSHProjectionType() {
+ static const char * const names[4] = {
+ "UNKNOWN",
+ "SPARSE",
+ "DENSE",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameLSHProjectionType(LSHProjectionType e) {
+ if (flatbuffers::IsOutRange(e, LSHProjectionType_UNKNOWN, LSHProjectionType_DENSE)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesLSHProjectionType()[index];
+}
+
+enum FullyConnectedOptionsWeightsFormat {
+ FullyConnectedOptionsWeightsFormat_DEFAULT = 0,
+ FullyConnectedOptionsWeightsFormat_SHUFFLED4x16INT8 = 1,
+ FullyConnectedOptionsWeightsFormat_MIN = FullyConnectedOptionsWeightsFormat_DEFAULT,
+ FullyConnectedOptionsWeightsFormat_MAX = FullyConnectedOptionsWeightsFormat_SHUFFLED4x16INT8
+};
+
+inline const FullyConnectedOptionsWeightsFormat (&EnumValuesFullyConnectedOptionsWeightsFormat())[2] {
+ static const FullyConnectedOptionsWeightsFormat values[] = {
+ FullyConnectedOptionsWeightsFormat_DEFAULT,
+ FullyConnectedOptionsWeightsFormat_SHUFFLED4x16INT8
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesFullyConnectedOptionsWeightsFormat() {
+ static const char * const names[3] = {
+ "DEFAULT",
+ "SHUFFLED4x16INT8",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameFullyConnectedOptionsWeightsFormat(FullyConnectedOptionsWeightsFormat e) {
+ if (flatbuffers::IsOutRange(e, FullyConnectedOptionsWeightsFormat_DEFAULT, FullyConnectedOptionsWeightsFormat_SHUFFLED4x16INT8)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesFullyConnectedOptionsWeightsFormat()[index];
+}
+
+enum LSTMKernelType {
+ LSTMKernelType_FULL = 0,
+ LSTMKernelType_BASIC = 1,
+ LSTMKernelType_MIN = LSTMKernelType_FULL,
+ LSTMKernelType_MAX = LSTMKernelType_BASIC
+};
+
+inline const LSTMKernelType (&EnumValuesLSTMKernelType())[2] {
+ static const LSTMKernelType values[] = {
+ LSTMKernelType_FULL,
+ LSTMKernelType_BASIC
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesLSTMKernelType() {
+ static const char * const names[3] = {
+ "FULL",
+ "BASIC",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameLSTMKernelType(LSTMKernelType e) {
+ if (flatbuffers::IsOutRange(e, LSTMKernelType_FULL, LSTMKernelType_BASIC)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesLSTMKernelType()[index];
+}
+
+enum CombinerType {
+ CombinerType_SUM = 0,
+ CombinerType_MEAN = 1,
+ CombinerType_SQRTN = 2,
+ CombinerType_MIN = CombinerType_SUM,
+ CombinerType_MAX = CombinerType_SQRTN
+};
+
+inline const CombinerType (&EnumValuesCombinerType())[3] {
+ static const CombinerType values[] = {
+ CombinerType_SUM,
+ CombinerType_MEAN,
+ CombinerType_SQRTN
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesCombinerType() {
+ static const char * const names[4] = {
+ "SUM",
+ "MEAN",
+ "SQRTN",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameCombinerType(CombinerType e) {
+ if (flatbuffers::IsOutRange(e, CombinerType_SUM, CombinerType_SQRTN)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesCombinerType()[index];
+}
+
+enum MirrorPadMode {
+ MirrorPadMode_REFLECT = 0,
+ MirrorPadMode_SYMMETRIC = 1,
+ MirrorPadMode_MIN = MirrorPadMode_REFLECT,
+ MirrorPadMode_MAX = MirrorPadMode_SYMMETRIC
+};
+
+inline const MirrorPadMode (&EnumValuesMirrorPadMode())[2] {
+ static const MirrorPadMode values[] = {
+ MirrorPadMode_REFLECT,
+ MirrorPadMode_SYMMETRIC
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesMirrorPadMode() {
+ static const char * const names[3] = {
+ "REFLECT",
+ "SYMMETRIC",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameMirrorPadMode(MirrorPadMode e) {
+ if (flatbuffers::IsOutRange(e, MirrorPadMode_REFLECT, MirrorPadMode_SYMMETRIC)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesMirrorPadMode()[index];
+}
+
+enum CustomOptionsFormat {
+ CustomOptionsFormat_FLEXBUFFERS = 0,
+ CustomOptionsFormat_MIN = CustomOptionsFormat_FLEXBUFFERS,
+ CustomOptionsFormat_MAX = CustomOptionsFormat_FLEXBUFFERS
+};
+
+inline const CustomOptionsFormat (&EnumValuesCustomOptionsFormat())[1] {
+ static const CustomOptionsFormat values[] = {
+ CustomOptionsFormat_FLEXBUFFERS
+ };
+ return values;
+}
+
+inline const char * const *EnumNamesCustomOptionsFormat() {
+ static const char * const names[2] = {
+ "FLEXBUFFERS",
+ nullptr
+ };
+ return names;
+}
+
+inline const char *EnumNameCustomOptionsFormat(CustomOptionsFormat e) {
+ if (flatbuffers::IsOutRange(e, CustomOptionsFormat_FLEXBUFFERS, CustomOptionsFormat_FLEXBUFFERS)) return "";
+ const size_t index = static_cast<size_t>(e);
+ return EnumNamesCustomOptionsFormat()[index];
+}
+
+struct CustomQuantizationT : public flatbuffers::NativeTable {
+ typedef CustomQuantization TableType;
+ std::vector<uint8_t> custom;
+ CustomQuantizationT() {
+ }
+};
+
+struct CustomQuantization FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef CustomQuantizationT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_CUSTOM = 4
+ };
+ const flatbuffers::Vector<uint8_t> *custom() const {
+ return GetPointer<const flatbuffers::Vector<uint8_t> *>(VT_CUSTOM);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_CUSTOM) &&
+ verifier.VerifyVector(custom()) &&
+ verifier.EndTable();
+ }
+ CustomQuantizationT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(CustomQuantizationT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<CustomQuantization> Pack(flatbuffers::FlatBufferBuilder &_fbb, const CustomQuantizationT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct CustomQuantizationBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_custom(flatbuffers::Offset<flatbuffers::Vector<uint8_t>> custom) {
+ fbb_.AddOffset(CustomQuantization::VT_CUSTOM, custom);
+ }
+ explicit CustomQuantizationBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ CustomQuantizationBuilder &operator=(const CustomQuantizationBuilder &);
+ flatbuffers::Offset<CustomQuantization> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<CustomQuantization>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<CustomQuantization> CreateCustomQuantization(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<uint8_t>> custom = 0) {
+ CustomQuantizationBuilder builder_(_fbb);
+ builder_.add_custom(custom);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<CustomQuantization> CreateCustomQuantizationDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<uint8_t> *custom = nullptr) {
+ if (custom) { _fbb.ForceVectorAlignment(custom->size(), sizeof(uint8_t), 16); }
+ auto custom__ = custom ? _fbb.CreateVector<uint8_t>(*custom) : 0;
+ return tflite::CreateCustomQuantization(
+ _fbb,
+ custom__);
+}
+
+flatbuffers::Offset<CustomQuantization> CreateCustomQuantization(flatbuffers::FlatBufferBuilder &_fbb, const CustomQuantizationT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct QuantizationParametersT : public flatbuffers::NativeTable {
+ typedef QuantizationParameters TableType;
+ std::vector<float> min;
+ std::vector<float> max;
+ std::vector<float> scale;
+ std::vector<int64_t> zero_point;
+ tflite::QuantizationDetailsUnion details;
+ int32_t quantized_dimension;
+ QuantizationParametersT()
+ : quantized_dimension(0) {
+ }
+};
+
+struct QuantizationParameters FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef QuantizationParametersT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_MIN = 4,
+ VT_MAX = 6,
+ VT_SCALE = 8,
+ VT_ZERO_POINT = 10,
+ VT_DETAILS_TYPE = 12,
+ VT_DETAILS = 14,
+ VT_QUANTIZED_DIMENSION = 16
+ };
+ const flatbuffers::Vector<float> *min() const {
+ return GetPointer<const flatbuffers::Vector<float> *>(VT_MIN);
+ }
+ const flatbuffers::Vector<float> *max() const {
+ return GetPointer<const flatbuffers::Vector<float> *>(VT_MAX);
+ }
+ const flatbuffers::Vector<float> *scale() const {
+ return GetPointer<const flatbuffers::Vector<float> *>(VT_SCALE);
+ }
+ const flatbuffers::Vector<int64_t> *zero_point() const {
+ return GetPointer<const flatbuffers::Vector<int64_t> *>(VT_ZERO_POINT);
+ }
+ tflite::QuantizationDetails details_type() const {
+ return static_cast<tflite::QuantizationDetails>(GetField<uint8_t>(VT_DETAILS_TYPE, 0));
+ }
+ const void *details() const {
+ return GetPointer<const void *>(VT_DETAILS);
+ }
+ template<typename T> const T *details_as() const;
+ const tflite::CustomQuantization *details_as_CustomQuantization() const {
+ return details_type() == tflite::QuantizationDetails_CustomQuantization ? static_cast<const tflite::CustomQuantization *>(details()) : nullptr;
+ }
+ int32_t quantized_dimension() const {
+ return GetField<int32_t>(VT_QUANTIZED_DIMENSION, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_MIN) &&
+ verifier.VerifyVector(min()) &&
+ VerifyOffset(verifier, VT_MAX) &&
+ verifier.VerifyVector(max()) &&
+ VerifyOffset(verifier, VT_SCALE) &&
+ verifier.VerifyVector(scale()) &&
+ VerifyOffset(verifier, VT_ZERO_POINT) &&
+ verifier.VerifyVector(zero_point()) &&
+ VerifyField<uint8_t>(verifier, VT_DETAILS_TYPE) &&
+ VerifyOffset(verifier, VT_DETAILS) &&
+ VerifyQuantizationDetails(verifier, details(), details_type()) &&
+ VerifyField<int32_t>(verifier, VT_QUANTIZED_DIMENSION) &&
+ verifier.EndTable();
+ }
+ QuantizationParametersT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(QuantizationParametersT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<QuantizationParameters> Pack(flatbuffers::FlatBufferBuilder &_fbb, const QuantizationParametersT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+template<> inline const tflite::CustomQuantization *QuantizationParameters::details_as<tflite::CustomQuantization>() const {
+ return details_as_CustomQuantization();
+}
+
+struct QuantizationParametersBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_min(flatbuffers::Offset<flatbuffers::Vector<float>> min) {
+ fbb_.AddOffset(QuantizationParameters::VT_MIN, min);
+ }
+ void add_max(flatbuffers::Offset<flatbuffers::Vector<float>> max) {
+ fbb_.AddOffset(QuantizationParameters::VT_MAX, max);
+ }
+ void add_scale(flatbuffers::Offset<flatbuffers::Vector<float>> scale) {
+ fbb_.AddOffset(QuantizationParameters::VT_SCALE, scale);
+ }
+ void add_zero_point(flatbuffers::Offset<flatbuffers::Vector<int64_t>> zero_point) {
+ fbb_.AddOffset(QuantizationParameters::VT_ZERO_POINT, zero_point);
+ }
+ void add_details_type(tflite::QuantizationDetails details_type) {
+ fbb_.AddElement<uint8_t>(QuantizationParameters::VT_DETAILS_TYPE, static_cast<uint8_t>(details_type), 0);
+ }
+ void add_details(flatbuffers::Offset<void> details) {
+ fbb_.AddOffset(QuantizationParameters::VT_DETAILS, details);
+ }
+ void add_quantized_dimension(int32_t quantized_dimension) {
+ fbb_.AddElement<int32_t>(QuantizationParameters::VT_QUANTIZED_DIMENSION, quantized_dimension, 0);
+ }
+ explicit QuantizationParametersBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ QuantizationParametersBuilder &operator=(const QuantizationParametersBuilder &);
+ flatbuffers::Offset<QuantizationParameters> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<QuantizationParameters>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<QuantizationParameters> CreateQuantizationParameters(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<float>> min = 0,
+ flatbuffers::Offset<flatbuffers::Vector<float>> max = 0,
+ flatbuffers::Offset<flatbuffers::Vector<float>> scale = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int64_t>> zero_point = 0,
+ tflite::QuantizationDetails details_type = tflite::QuantizationDetails_NONE,
+ flatbuffers::Offset<void> details = 0,
+ int32_t quantized_dimension = 0) {
+ QuantizationParametersBuilder builder_(_fbb);
+ builder_.add_quantized_dimension(quantized_dimension);
+ builder_.add_details(details);
+ builder_.add_zero_point(zero_point);
+ builder_.add_scale(scale);
+ builder_.add_max(max);
+ builder_.add_min(min);
+ builder_.add_details_type(details_type);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<QuantizationParameters> CreateQuantizationParametersDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<float> *min = nullptr,
+ const std::vector<float> *max = nullptr,
+ const std::vector<float> *scale = nullptr,
+ const std::vector<int64_t> *zero_point = nullptr,
+ tflite::QuantizationDetails details_type = tflite::QuantizationDetails_NONE,
+ flatbuffers::Offset<void> details = 0,
+ int32_t quantized_dimension = 0) {
+ auto min__ = min ? _fbb.CreateVector<float>(*min) : 0;
+ auto max__ = max ? _fbb.CreateVector<float>(*max) : 0;
+ auto scale__ = scale ? _fbb.CreateVector<float>(*scale) : 0;
+ auto zero_point__ = zero_point ? _fbb.CreateVector<int64_t>(*zero_point) : 0;
+ return tflite::CreateQuantizationParameters(
+ _fbb,
+ min__,
+ max__,
+ scale__,
+ zero_point__,
+ details_type,
+ details,
+ quantized_dimension);
+}
+
+flatbuffers::Offset<QuantizationParameters> CreateQuantizationParameters(flatbuffers::FlatBufferBuilder &_fbb, const QuantizationParametersT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct Int32VectorT : public flatbuffers::NativeTable {
+ typedef Int32Vector TableType;
+ std::vector<int32_t> values;
+ Int32VectorT() {
+ }
+};
+
+struct Int32Vector FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef Int32VectorT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_VALUES = 4
+ };
+ const flatbuffers::Vector<int32_t> *values() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_VALUES);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_VALUES) &&
+ verifier.VerifyVector(values()) &&
+ verifier.EndTable();
+ }
+ Int32VectorT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(Int32VectorT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Int32Vector> Pack(flatbuffers::FlatBufferBuilder &_fbb, const Int32VectorT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct Int32VectorBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_values(flatbuffers::Offset<flatbuffers::Vector<int32_t>> values) {
+ fbb_.AddOffset(Int32Vector::VT_VALUES, values);
+ }
+ explicit Int32VectorBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ Int32VectorBuilder &operator=(const Int32VectorBuilder &);
+ flatbuffers::Offset<Int32Vector> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Int32Vector>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Int32Vector> CreateInt32Vector(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> values = 0) {
+ Int32VectorBuilder builder_(_fbb);
+ builder_.add_values(values);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Int32Vector> CreateInt32VectorDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<int32_t> *values = nullptr) {
+ auto values__ = values ? _fbb.CreateVector<int32_t>(*values) : 0;
+ return tflite::CreateInt32Vector(
+ _fbb,
+ values__);
+}
+
+flatbuffers::Offset<Int32Vector> CreateInt32Vector(flatbuffers::FlatBufferBuilder &_fbb, const Int32VectorT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct Uint16VectorT : public flatbuffers::NativeTable {
+ typedef Uint16Vector TableType;
+ std::vector<uint16_t> values;
+ Uint16VectorT() {
+ }
+};
+
+struct Uint16Vector FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef Uint16VectorT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_VALUES = 4
+ };
+ const flatbuffers::Vector<uint16_t> *values() const {
+ return GetPointer<const flatbuffers::Vector<uint16_t> *>(VT_VALUES);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_VALUES) &&
+ verifier.VerifyVector(values()) &&
+ verifier.EndTable();
+ }
+ Uint16VectorT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(Uint16VectorT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Uint16Vector> Pack(flatbuffers::FlatBufferBuilder &_fbb, const Uint16VectorT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct Uint16VectorBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_values(flatbuffers::Offset<flatbuffers::Vector<uint16_t>> values) {
+ fbb_.AddOffset(Uint16Vector::VT_VALUES, values);
+ }
+ explicit Uint16VectorBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ Uint16VectorBuilder &operator=(const Uint16VectorBuilder &);
+ flatbuffers::Offset<Uint16Vector> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Uint16Vector>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Uint16Vector> CreateUint16Vector(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<uint16_t>> values = 0) {
+ Uint16VectorBuilder builder_(_fbb);
+ builder_.add_values(values);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Uint16Vector> CreateUint16VectorDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<uint16_t> *values = nullptr) {
+ if (values) { _fbb.ForceVectorAlignment(values->size(), sizeof(uint16_t), 4); }
+ auto values__ = values ? _fbb.CreateVector<uint16_t>(*values) : 0;
+ return tflite::CreateUint16Vector(
+ _fbb,
+ values__);
+}
+
+flatbuffers::Offset<Uint16Vector> CreateUint16Vector(flatbuffers::FlatBufferBuilder &_fbb, const Uint16VectorT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct Uint8VectorT : public flatbuffers::NativeTable {
+ typedef Uint8Vector TableType;
+ std::vector<uint8_t> values;
+ Uint8VectorT() {
+ }
+};
+
+struct Uint8Vector FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef Uint8VectorT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_VALUES = 4
+ };
+ const flatbuffers::Vector<uint8_t> *values() const {
+ return GetPointer<const flatbuffers::Vector<uint8_t> *>(VT_VALUES);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_VALUES) &&
+ verifier.VerifyVector(values()) &&
+ verifier.EndTable();
+ }
+ Uint8VectorT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(Uint8VectorT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Uint8Vector> Pack(flatbuffers::FlatBufferBuilder &_fbb, const Uint8VectorT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct Uint8VectorBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_values(flatbuffers::Offset<flatbuffers::Vector<uint8_t>> values) {
+ fbb_.AddOffset(Uint8Vector::VT_VALUES, values);
+ }
+ explicit Uint8VectorBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ Uint8VectorBuilder &operator=(const Uint8VectorBuilder &);
+ flatbuffers::Offset<Uint8Vector> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Uint8Vector>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Uint8Vector> CreateUint8Vector(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<uint8_t>> values = 0) {
+ Uint8VectorBuilder builder_(_fbb);
+ builder_.add_values(values);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Uint8Vector> CreateUint8VectorDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<uint8_t> *values = nullptr) {
+ if (values) { _fbb.ForceVectorAlignment(values->size(), sizeof(uint8_t), 4); }
+ auto values__ = values ? _fbb.CreateVector<uint8_t>(*values) : 0;
+ return tflite::CreateUint8Vector(
+ _fbb,
+ values__);
+}
+
+flatbuffers::Offset<Uint8Vector> CreateUint8Vector(flatbuffers::FlatBufferBuilder &_fbb, const Uint8VectorT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct DimensionMetadataT : public flatbuffers::NativeTable {
+ typedef DimensionMetadata TableType;
+ tflite::DimensionType format;
+ int32_t dense_size;
+ tflite::SparseIndexVectorUnion array_segments;
+ tflite::SparseIndexVectorUnion array_indices;
+ DimensionMetadataT()
+ : format(tflite::DimensionType_DENSE),
+ dense_size(0) {
+ }
+};
+
+struct DimensionMetadata FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef DimensionMetadataT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FORMAT = 4,
+ VT_DENSE_SIZE = 6,
+ VT_ARRAY_SEGMENTS_TYPE = 8,
+ VT_ARRAY_SEGMENTS = 10,
+ VT_ARRAY_INDICES_TYPE = 12,
+ VT_ARRAY_INDICES = 14
+ };
+ tflite::DimensionType format() const {
+ return static_cast<tflite::DimensionType>(GetField<int8_t>(VT_FORMAT, 0));
+ }
+ int32_t dense_size() const {
+ return GetField<int32_t>(VT_DENSE_SIZE, 0);
+ }
+ tflite::SparseIndexVector array_segments_type() const {
+ return static_cast<tflite::SparseIndexVector>(GetField<uint8_t>(VT_ARRAY_SEGMENTS_TYPE, 0));
+ }
+ const void *array_segments() const {
+ return GetPointer<const void *>(VT_ARRAY_SEGMENTS);
+ }
+ template<typename T> const T *array_segments_as() const;
+ const tflite::Int32Vector *array_segments_as_Int32Vector() const {
+ return array_segments_type() == tflite::SparseIndexVector_Int32Vector ? static_cast<const tflite::Int32Vector *>(array_segments()) : nullptr;
+ }
+ const tflite::Uint16Vector *array_segments_as_Uint16Vector() const {
+ return array_segments_type() == tflite::SparseIndexVector_Uint16Vector ? static_cast<const tflite::Uint16Vector *>(array_segments()) : nullptr;
+ }
+ const tflite::Uint8Vector *array_segments_as_Uint8Vector() const {
+ return array_segments_type() == tflite::SparseIndexVector_Uint8Vector ? static_cast<const tflite::Uint8Vector *>(array_segments()) : nullptr;
+ }
+ tflite::SparseIndexVector array_indices_type() const {
+ return static_cast<tflite::SparseIndexVector>(GetField<uint8_t>(VT_ARRAY_INDICES_TYPE, 0));
+ }
+ const void *array_indices() const {
+ return GetPointer<const void *>(VT_ARRAY_INDICES);
+ }
+ template<typename T> const T *array_indices_as() const;
+ const tflite::Int32Vector *array_indices_as_Int32Vector() const {
+ return array_indices_type() == tflite::SparseIndexVector_Int32Vector ? static_cast<const tflite::Int32Vector *>(array_indices()) : nullptr;
+ }
+ const tflite::Uint16Vector *array_indices_as_Uint16Vector() const {
+ return array_indices_type() == tflite::SparseIndexVector_Uint16Vector ? static_cast<const tflite::Uint16Vector *>(array_indices()) : nullptr;
+ }
+ const tflite::Uint8Vector *array_indices_as_Uint8Vector() const {
+ return array_indices_type() == tflite::SparseIndexVector_Uint8Vector ? static_cast<const tflite::Uint8Vector *>(array_indices()) : nullptr;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FORMAT) &&
+ VerifyField<int32_t>(verifier, VT_DENSE_SIZE) &&
+ VerifyField<uint8_t>(verifier, VT_ARRAY_SEGMENTS_TYPE) &&
+ VerifyOffset(verifier, VT_ARRAY_SEGMENTS) &&
+ VerifySparseIndexVector(verifier, array_segments(), array_segments_type()) &&
+ VerifyField<uint8_t>(verifier, VT_ARRAY_INDICES_TYPE) &&
+ VerifyOffset(verifier, VT_ARRAY_INDICES) &&
+ VerifySparseIndexVector(verifier, array_indices(), array_indices_type()) &&
+ verifier.EndTable();
+ }
+ DimensionMetadataT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(DimensionMetadataT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<DimensionMetadata> Pack(flatbuffers::FlatBufferBuilder &_fbb, const DimensionMetadataT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+template<> inline const tflite::Int32Vector *DimensionMetadata::array_segments_as<tflite::Int32Vector>() const {
+ return array_segments_as_Int32Vector();
+}
+
+template<> inline const tflite::Uint16Vector *DimensionMetadata::array_segments_as<tflite::Uint16Vector>() const {
+ return array_segments_as_Uint16Vector();
+}
+
+template<> inline const tflite::Uint8Vector *DimensionMetadata::array_segments_as<tflite::Uint8Vector>() const {
+ return array_segments_as_Uint8Vector();
+}
+
+template<> inline const tflite::Int32Vector *DimensionMetadata::array_indices_as<tflite::Int32Vector>() const {
+ return array_indices_as_Int32Vector();
+}
+
+template<> inline const tflite::Uint16Vector *DimensionMetadata::array_indices_as<tflite::Uint16Vector>() const {
+ return array_indices_as_Uint16Vector();
+}
+
+template<> inline const tflite::Uint8Vector *DimensionMetadata::array_indices_as<tflite::Uint8Vector>() const {
+ return array_indices_as_Uint8Vector();
+}
+
+struct DimensionMetadataBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_format(tflite::DimensionType format) {
+ fbb_.AddElement<int8_t>(DimensionMetadata::VT_FORMAT, static_cast<int8_t>(format), 0);
+ }
+ void add_dense_size(int32_t dense_size) {
+ fbb_.AddElement<int32_t>(DimensionMetadata::VT_DENSE_SIZE, dense_size, 0);
+ }
+ void add_array_segments_type(tflite::SparseIndexVector array_segments_type) {
+ fbb_.AddElement<uint8_t>(DimensionMetadata::VT_ARRAY_SEGMENTS_TYPE, static_cast<uint8_t>(array_segments_type), 0);
+ }
+ void add_array_segments(flatbuffers::Offset<void> array_segments) {
+ fbb_.AddOffset(DimensionMetadata::VT_ARRAY_SEGMENTS, array_segments);
+ }
+ void add_array_indices_type(tflite::SparseIndexVector array_indices_type) {
+ fbb_.AddElement<uint8_t>(DimensionMetadata::VT_ARRAY_INDICES_TYPE, static_cast<uint8_t>(array_indices_type), 0);
+ }
+ void add_array_indices(flatbuffers::Offset<void> array_indices) {
+ fbb_.AddOffset(DimensionMetadata::VT_ARRAY_INDICES, array_indices);
+ }
+ explicit DimensionMetadataBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ DimensionMetadataBuilder &operator=(const DimensionMetadataBuilder &);
+ flatbuffers::Offset<DimensionMetadata> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<DimensionMetadata>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<DimensionMetadata> CreateDimensionMetadata(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::DimensionType format = tflite::DimensionType_DENSE,
+ int32_t dense_size = 0,
+ tflite::SparseIndexVector array_segments_type = tflite::SparseIndexVector_NONE,
+ flatbuffers::Offset<void> array_segments = 0,
+ tflite::SparseIndexVector array_indices_type = tflite::SparseIndexVector_NONE,
+ flatbuffers::Offset<void> array_indices = 0) {
+ DimensionMetadataBuilder builder_(_fbb);
+ builder_.add_array_indices(array_indices);
+ builder_.add_array_segments(array_segments);
+ builder_.add_dense_size(dense_size);
+ builder_.add_array_indices_type(array_indices_type);
+ builder_.add_array_segments_type(array_segments_type);
+ builder_.add_format(format);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<DimensionMetadata> CreateDimensionMetadata(flatbuffers::FlatBufferBuilder &_fbb, const DimensionMetadataT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SparsityParametersT : public flatbuffers::NativeTable {
+ typedef SparsityParameters TableType;
+ std::vector<int32_t> traversal_order;
+ std::vector<int32_t> block_map;
+ std::vector<std::unique_ptr<tflite::DimensionMetadataT>> dim_metadata;
+ SparsityParametersT() {
+ }
+};
+
+struct SparsityParameters FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SparsityParametersT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_TRAVERSAL_ORDER = 4,
+ VT_BLOCK_MAP = 6,
+ VT_DIM_METADATA = 8
+ };
+ const flatbuffers::Vector<int32_t> *traversal_order() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_TRAVERSAL_ORDER);
+ }
+ const flatbuffers::Vector<int32_t> *block_map() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_BLOCK_MAP);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::DimensionMetadata>> *dim_metadata() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::DimensionMetadata>> *>(VT_DIM_METADATA);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_TRAVERSAL_ORDER) &&
+ verifier.VerifyVector(traversal_order()) &&
+ VerifyOffset(verifier, VT_BLOCK_MAP) &&
+ verifier.VerifyVector(block_map()) &&
+ VerifyOffset(verifier, VT_DIM_METADATA) &&
+ verifier.VerifyVector(dim_metadata()) &&
+ verifier.VerifyVectorOfTables(dim_metadata()) &&
+ verifier.EndTable();
+ }
+ SparsityParametersT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SparsityParametersT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SparsityParameters> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SparsityParametersT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SparsityParametersBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_traversal_order(flatbuffers::Offset<flatbuffers::Vector<int32_t>> traversal_order) {
+ fbb_.AddOffset(SparsityParameters::VT_TRAVERSAL_ORDER, traversal_order);
+ }
+ void add_block_map(flatbuffers::Offset<flatbuffers::Vector<int32_t>> block_map) {
+ fbb_.AddOffset(SparsityParameters::VT_BLOCK_MAP, block_map);
+ }
+ void add_dim_metadata(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::DimensionMetadata>>> dim_metadata) {
+ fbb_.AddOffset(SparsityParameters::VT_DIM_METADATA, dim_metadata);
+ }
+ explicit SparsityParametersBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SparsityParametersBuilder &operator=(const SparsityParametersBuilder &);
+ flatbuffers::Offset<SparsityParameters> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SparsityParameters>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SparsityParameters> CreateSparsityParameters(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> traversal_order = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> block_map = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::DimensionMetadata>>> dim_metadata = 0) {
+ SparsityParametersBuilder builder_(_fbb);
+ builder_.add_dim_metadata(dim_metadata);
+ builder_.add_block_map(block_map);
+ builder_.add_traversal_order(traversal_order);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<SparsityParameters> CreateSparsityParametersDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<int32_t> *traversal_order = nullptr,
+ const std::vector<int32_t> *block_map = nullptr,
+ const std::vector<flatbuffers::Offset<tflite::DimensionMetadata>> *dim_metadata = nullptr) {
+ auto traversal_order__ = traversal_order ? _fbb.CreateVector<int32_t>(*traversal_order) : 0;
+ auto block_map__ = block_map ? _fbb.CreateVector<int32_t>(*block_map) : 0;
+ auto dim_metadata__ = dim_metadata ? _fbb.CreateVector<flatbuffers::Offset<tflite::DimensionMetadata>>(*dim_metadata) : 0;
+ return tflite::CreateSparsityParameters(
+ _fbb,
+ traversal_order__,
+ block_map__,
+ dim_metadata__);
+}
+
+flatbuffers::Offset<SparsityParameters> CreateSparsityParameters(flatbuffers::FlatBufferBuilder &_fbb, const SparsityParametersT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct TensorT : public flatbuffers::NativeTable {
+ typedef Tensor TableType;
+ std::vector<int32_t> shape;
+ tflite::TensorType type;
+ uint32_t buffer;
+ std::string name;
+ std::unique_ptr<tflite::QuantizationParametersT> quantization;
+ bool is_variable;
+ std::unique_ptr<tflite::SparsityParametersT> sparsity;
+ std::vector<int32_t> shape_signature;
+ TensorT()
+ : type(tflite::TensorType_FLOAT32),
+ buffer(0),
+ is_variable(false) {
+ }
+};
+
+struct Tensor FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef TensorT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_SHAPE = 4,
+ VT_TYPE = 6,
+ VT_BUFFER = 8,
+ VT_NAME = 10,
+ VT_QUANTIZATION = 12,
+ VT_IS_VARIABLE = 14,
+ VT_SPARSITY = 16,
+ VT_SHAPE_SIGNATURE = 18
+ };
+ const flatbuffers::Vector<int32_t> *shape() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_SHAPE);
+ }
+ tflite::TensorType type() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_TYPE, 0));
+ }
+ uint32_t buffer() const {
+ return GetField<uint32_t>(VT_BUFFER, 0);
+ }
+ const flatbuffers::String *name() const {
+ return GetPointer<const flatbuffers::String *>(VT_NAME);
+ }
+ const tflite::QuantizationParameters *quantization() const {
+ return GetPointer<const tflite::QuantizationParameters *>(VT_QUANTIZATION);
+ }
+ bool is_variable() const {
+ return GetField<uint8_t>(VT_IS_VARIABLE, 0) != 0;
+ }
+ const tflite::SparsityParameters *sparsity() const {
+ return GetPointer<const tflite::SparsityParameters *>(VT_SPARSITY);
+ }
+ const flatbuffers::Vector<int32_t> *shape_signature() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_SHAPE_SIGNATURE);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_SHAPE) &&
+ verifier.VerifyVector(shape()) &&
+ VerifyField<int8_t>(verifier, VT_TYPE) &&
+ VerifyField<uint32_t>(verifier, VT_BUFFER) &&
+ VerifyOffset(verifier, VT_NAME) &&
+ verifier.VerifyString(name()) &&
+ VerifyOffset(verifier, VT_QUANTIZATION) &&
+ verifier.VerifyTable(quantization()) &&
+ VerifyField<uint8_t>(verifier, VT_IS_VARIABLE) &&
+ VerifyOffset(verifier, VT_SPARSITY) &&
+ verifier.VerifyTable(sparsity()) &&
+ VerifyOffset(verifier, VT_SHAPE_SIGNATURE) &&
+ verifier.VerifyVector(shape_signature()) &&
+ verifier.EndTable();
+ }
+ TensorT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(TensorT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Tensor> Pack(flatbuffers::FlatBufferBuilder &_fbb, const TensorT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct TensorBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_shape(flatbuffers::Offset<flatbuffers::Vector<int32_t>> shape) {
+ fbb_.AddOffset(Tensor::VT_SHAPE, shape);
+ }
+ void add_type(tflite::TensorType type) {
+ fbb_.AddElement<int8_t>(Tensor::VT_TYPE, static_cast<int8_t>(type), 0);
+ }
+ void add_buffer(uint32_t buffer) {
+ fbb_.AddElement<uint32_t>(Tensor::VT_BUFFER, buffer, 0);
+ }
+ void add_name(flatbuffers::Offset<flatbuffers::String> name) {
+ fbb_.AddOffset(Tensor::VT_NAME, name);
+ }
+ void add_quantization(flatbuffers::Offset<tflite::QuantizationParameters> quantization) {
+ fbb_.AddOffset(Tensor::VT_QUANTIZATION, quantization);
+ }
+ void add_is_variable(bool is_variable) {
+ fbb_.AddElement<uint8_t>(Tensor::VT_IS_VARIABLE, static_cast<uint8_t>(is_variable), 0);
+ }
+ void add_sparsity(flatbuffers::Offset<tflite::SparsityParameters> sparsity) {
+ fbb_.AddOffset(Tensor::VT_SPARSITY, sparsity);
+ }
+ void add_shape_signature(flatbuffers::Offset<flatbuffers::Vector<int32_t>> shape_signature) {
+ fbb_.AddOffset(Tensor::VT_SHAPE_SIGNATURE, shape_signature);
+ }
+ explicit TensorBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ TensorBuilder &operator=(const TensorBuilder &);
+ flatbuffers::Offset<Tensor> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Tensor>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Tensor> CreateTensor(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> shape = 0,
+ tflite::TensorType type = tflite::TensorType_FLOAT32,
+ uint32_t buffer = 0,
+ flatbuffers::Offset<flatbuffers::String> name = 0,
+ flatbuffers::Offset<tflite::QuantizationParameters> quantization = 0,
+ bool is_variable = false,
+ flatbuffers::Offset<tflite::SparsityParameters> sparsity = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> shape_signature = 0) {
+ TensorBuilder builder_(_fbb);
+ builder_.add_shape_signature(shape_signature);
+ builder_.add_sparsity(sparsity);
+ builder_.add_quantization(quantization);
+ builder_.add_name(name);
+ builder_.add_buffer(buffer);
+ builder_.add_shape(shape);
+ builder_.add_is_variable(is_variable);
+ builder_.add_type(type);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Tensor> CreateTensorDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<int32_t> *shape = nullptr,
+ tflite::TensorType type = tflite::TensorType_FLOAT32,
+ uint32_t buffer = 0,
+ const char *name = nullptr,
+ flatbuffers::Offset<tflite::QuantizationParameters> quantization = 0,
+ bool is_variable = false,
+ flatbuffers::Offset<tflite::SparsityParameters> sparsity = 0,
+ const std::vector<int32_t> *shape_signature = nullptr) {
+ auto shape__ = shape ? _fbb.CreateVector<int32_t>(*shape) : 0;
+ auto name__ = name ? _fbb.CreateString(name) : 0;
+ auto shape_signature__ = shape_signature ? _fbb.CreateVector<int32_t>(*shape_signature) : 0;
+ return tflite::CreateTensor(
+ _fbb,
+ shape__,
+ type,
+ buffer,
+ name__,
+ quantization,
+ is_variable,
+ sparsity,
+ shape_signature__);
+}
+
+flatbuffers::Offset<Tensor> CreateTensor(flatbuffers::FlatBufferBuilder &_fbb, const TensorT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct Conv2DOptionsT : public flatbuffers::NativeTable {
+ typedef Conv2DOptions TableType;
+ tflite::Padding padding;
+ int32_t stride_w;
+ int32_t stride_h;
+ tflite::ActivationFunctionType fused_activation_function;
+ int32_t dilation_w_factor;
+ int32_t dilation_h_factor;
+ Conv2DOptionsT()
+ : padding(tflite::Padding_SAME),
+ stride_w(0),
+ stride_h(0),
+ fused_activation_function(tflite::ActivationFunctionType_NONE),
+ dilation_w_factor(1),
+ dilation_h_factor(1) {
+ }
+};
+
+struct Conv2DOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef Conv2DOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_PADDING = 4,
+ VT_STRIDE_W = 6,
+ VT_STRIDE_H = 8,
+ VT_FUSED_ACTIVATION_FUNCTION = 10,
+ VT_DILATION_W_FACTOR = 12,
+ VT_DILATION_H_FACTOR = 14
+ };
+ tflite::Padding padding() const {
+ return static_cast<tflite::Padding>(GetField<int8_t>(VT_PADDING, 0));
+ }
+ int32_t stride_w() const {
+ return GetField<int32_t>(VT_STRIDE_W, 0);
+ }
+ int32_t stride_h() const {
+ return GetField<int32_t>(VT_STRIDE_H, 0);
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ int32_t dilation_w_factor() const {
+ return GetField<int32_t>(VT_DILATION_W_FACTOR, 1);
+ }
+ int32_t dilation_h_factor() const {
+ return GetField<int32_t>(VT_DILATION_H_FACTOR, 1);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_PADDING) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_W) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_H) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<int32_t>(verifier, VT_DILATION_W_FACTOR) &&
+ VerifyField<int32_t>(verifier, VT_DILATION_H_FACTOR) &&
+ verifier.EndTable();
+ }
+ Conv2DOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(Conv2DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Conv2DOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const Conv2DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct Conv2DOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_padding(tflite::Padding padding) {
+ fbb_.AddElement<int8_t>(Conv2DOptions::VT_PADDING, static_cast<int8_t>(padding), 0);
+ }
+ void add_stride_w(int32_t stride_w) {
+ fbb_.AddElement<int32_t>(Conv2DOptions::VT_STRIDE_W, stride_w, 0);
+ }
+ void add_stride_h(int32_t stride_h) {
+ fbb_.AddElement<int32_t>(Conv2DOptions::VT_STRIDE_H, stride_h, 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(Conv2DOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_dilation_w_factor(int32_t dilation_w_factor) {
+ fbb_.AddElement<int32_t>(Conv2DOptions::VT_DILATION_W_FACTOR, dilation_w_factor, 1);
+ }
+ void add_dilation_h_factor(int32_t dilation_h_factor) {
+ fbb_.AddElement<int32_t>(Conv2DOptions::VT_DILATION_H_FACTOR, dilation_h_factor, 1);
+ }
+ explicit Conv2DOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ Conv2DOptionsBuilder &operator=(const Conv2DOptionsBuilder &);
+ flatbuffers::Offset<Conv2DOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Conv2DOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Conv2DOptions> CreateConv2DOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::Padding padding = tflite::Padding_SAME,
+ int32_t stride_w = 0,
+ int32_t stride_h = 0,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ int32_t dilation_w_factor = 1,
+ int32_t dilation_h_factor = 1) {
+ Conv2DOptionsBuilder builder_(_fbb);
+ builder_.add_dilation_h_factor(dilation_h_factor);
+ builder_.add_dilation_w_factor(dilation_w_factor);
+ builder_.add_stride_h(stride_h);
+ builder_.add_stride_w(stride_w);
+ builder_.add_fused_activation_function(fused_activation_function);
+ builder_.add_padding(padding);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<Conv2DOptions> CreateConv2DOptions(flatbuffers::FlatBufferBuilder &_fbb, const Conv2DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct Conv3DOptionsT : public flatbuffers::NativeTable {
+ typedef Conv3DOptions TableType;
+ tflite::Padding padding;
+ int32_t stride_d;
+ int32_t stride_w;
+ int32_t stride_h;
+ tflite::ActivationFunctionType fused_activation_function;
+ int32_t dilation_d_factor;
+ int32_t dilation_w_factor;
+ int32_t dilation_h_factor;
+ Conv3DOptionsT()
+ : padding(tflite::Padding_SAME),
+ stride_d(0),
+ stride_w(0),
+ stride_h(0),
+ fused_activation_function(tflite::ActivationFunctionType_NONE),
+ dilation_d_factor(1),
+ dilation_w_factor(1),
+ dilation_h_factor(1) {
+ }
+};
+
+struct Conv3DOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef Conv3DOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_PADDING = 4,
+ VT_STRIDE_D = 6,
+ VT_STRIDE_W = 8,
+ VT_STRIDE_H = 10,
+ VT_FUSED_ACTIVATION_FUNCTION = 12,
+ VT_DILATION_D_FACTOR = 14,
+ VT_DILATION_W_FACTOR = 16,
+ VT_DILATION_H_FACTOR = 18
+ };
+ tflite::Padding padding() const {
+ return static_cast<tflite::Padding>(GetField<int8_t>(VT_PADDING, 0));
+ }
+ int32_t stride_d() const {
+ return GetField<int32_t>(VT_STRIDE_D, 0);
+ }
+ int32_t stride_w() const {
+ return GetField<int32_t>(VT_STRIDE_W, 0);
+ }
+ int32_t stride_h() const {
+ return GetField<int32_t>(VT_STRIDE_H, 0);
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ int32_t dilation_d_factor() const {
+ return GetField<int32_t>(VT_DILATION_D_FACTOR, 1);
+ }
+ int32_t dilation_w_factor() const {
+ return GetField<int32_t>(VT_DILATION_W_FACTOR, 1);
+ }
+ int32_t dilation_h_factor() const {
+ return GetField<int32_t>(VT_DILATION_H_FACTOR, 1);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_PADDING) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_D) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_W) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_H) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<int32_t>(verifier, VT_DILATION_D_FACTOR) &&
+ VerifyField<int32_t>(verifier, VT_DILATION_W_FACTOR) &&
+ VerifyField<int32_t>(verifier, VT_DILATION_H_FACTOR) &&
+ verifier.EndTable();
+ }
+ Conv3DOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(Conv3DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Conv3DOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const Conv3DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct Conv3DOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_padding(tflite::Padding padding) {
+ fbb_.AddElement<int8_t>(Conv3DOptions::VT_PADDING, static_cast<int8_t>(padding), 0);
+ }
+ void add_stride_d(int32_t stride_d) {
+ fbb_.AddElement<int32_t>(Conv3DOptions::VT_STRIDE_D, stride_d, 0);
+ }
+ void add_stride_w(int32_t stride_w) {
+ fbb_.AddElement<int32_t>(Conv3DOptions::VT_STRIDE_W, stride_w, 0);
+ }
+ void add_stride_h(int32_t stride_h) {
+ fbb_.AddElement<int32_t>(Conv3DOptions::VT_STRIDE_H, stride_h, 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(Conv3DOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_dilation_d_factor(int32_t dilation_d_factor) {
+ fbb_.AddElement<int32_t>(Conv3DOptions::VT_DILATION_D_FACTOR, dilation_d_factor, 1);
+ }
+ void add_dilation_w_factor(int32_t dilation_w_factor) {
+ fbb_.AddElement<int32_t>(Conv3DOptions::VT_DILATION_W_FACTOR, dilation_w_factor, 1);
+ }
+ void add_dilation_h_factor(int32_t dilation_h_factor) {
+ fbb_.AddElement<int32_t>(Conv3DOptions::VT_DILATION_H_FACTOR, dilation_h_factor, 1);
+ }
+ explicit Conv3DOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ Conv3DOptionsBuilder &operator=(const Conv3DOptionsBuilder &);
+ flatbuffers::Offset<Conv3DOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Conv3DOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Conv3DOptions> CreateConv3DOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::Padding padding = tflite::Padding_SAME,
+ int32_t stride_d = 0,
+ int32_t stride_w = 0,
+ int32_t stride_h = 0,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ int32_t dilation_d_factor = 1,
+ int32_t dilation_w_factor = 1,
+ int32_t dilation_h_factor = 1) {
+ Conv3DOptionsBuilder builder_(_fbb);
+ builder_.add_dilation_h_factor(dilation_h_factor);
+ builder_.add_dilation_w_factor(dilation_w_factor);
+ builder_.add_dilation_d_factor(dilation_d_factor);
+ builder_.add_stride_h(stride_h);
+ builder_.add_stride_w(stride_w);
+ builder_.add_stride_d(stride_d);
+ builder_.add_fused_activation_function(fused_activation_function);
+ builder_.add_padding(padding);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<Conv3DOptions> CreateConv3DOptions(flatbuffers::FlatBufferBuilder &_fbb, const Conv3DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct Pool2DOptionsT : public flatbuffers::NativeTable {
+ typedef Pool2DOptions TableType;
+ tflite::Padding padding;
+ int32_t stride_w;
+ int32_t stride_h;
+ int32_t filter_width;
+ int32_t filter_height;
+ tflite::ActivationFunctionType fused_activation_function;
+ Pool2DOptionsT()
+ : padding(tflite::Padding_SAME),
+ stride_w(0),
+ stride_h(0),
+ filter_width(0),
+ filter_height(0),
+ fused_activation_function(tflite::ActivationFunctionType_NONE) {
+ }
+};
+
+struct Pool2DOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef Pool2DOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_PADDING = 4,
+ VT_STRIDE_W = 6,
+ VT_STRIDE_H = 8,
+ VT_FILTER_WIDTH = 10,
+ VT_FILTER_HEIGHT = 12,
+ VT_FUSED_ACTIVATION_FUNCTION = 14
+ };
+ tflite::Padding padding() const {
+ return static_cast<tflite::Padding>(GetField<int8_t>(VT_PADDING, 0));
+ }
+ int32_t stride_w() const {
+ return GetField<int32_t>(VT_STRIDE_W, 0);
+ }
+ int32_t stride_h() const {
+ return GetField<int32_t>(VT_STRIDE_H, 0);
+ }
+ int32_t filter_width() const {
+ return GetField<int32_t>(VT_FILTER_WIDTH, 0);
+ }
+ int32_t filter_height() const {
+ return GetField<int32_t>(VT_FILTER_HEIGHT, 0);
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_PADDING) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_W) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_H) &&
+ VerifyField<int32_t>(verifier, VT_FILTER_WIDTH) &&
+ VerifyField<int32_t>(verifier, VT_FILTER_HEIGHT) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ verifier.EndTable();
+ }
+ Pool2DOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(Pool2DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Pool2DOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const Pool2DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct Pool2DOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_padding(tflite::Padding padding) {
+ fbb_.AddElement<int8_t>(Pool2DOptions::VT_PADDING, static_cast<int8_t>(padding), 0);
+ }
+ void add_stride_w(int32_t stride_w) {
+ fbb_.AddElement<int32_t>(Pool2DOptions::VT_STRIDE_W, stride_w, 0);
+ }
+ void add_stride_h(int32_t stride_h) {
+ fbb_.AddElement<int32_t>(Pool2DOptions::VT_STRIDE_H, stride_h, 0);
+ }
+ void add_filter_width(int32_t filter_width) {
+ fbb_.AddElement<int32_t>(Pool2DOptions::VT_FILTER_WIDTH, filter_width, 0);
+ }
+ void add_filter_height(int32_t filter_height) {
+ fbb_.AddElement<int32_t>(Pool2DOptions::VT_FILTER_HEIGHT, filter_height, 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(Pool2DOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ explicit Pool2DOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ Pool2DOptionsBuilder &operator=(const Pool2DOptionsBuilder &);
+ flatbuffers::Offset<Pool2DOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Pool2DOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Pool2DOptions> CreatePool2DOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::Padding padding = tflite::Padding_SAME,
+ int32_t stride_w = 0,
+ int32_t stride_h = 0,
+ int32_t filter_width = 0,
+ int32_t filter_height = 0,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE) {
+ Pool2DOptionsBuilder builder_(_fbb);
+ builder_.add_filter_height(filter_height);
+ builder_.add_filter_width(filter_width);
+ builder_.add_stride_h(stride_h);
+ builder_.add_stride_w(stride_w);
+ builder_.add_fused_activation_function(fused_activation_function);
+ builder_.add_padding(padding);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<Pool2DOptions> CreatePool2DOptions(flatbuffers::FlatBufferBuilder &_fbb, const Pool2DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct DepthwiseConv2DOptionsT : public flatbuffers::NativeTable {
+ typedef DepthwiseConv2DOptions TableType;
+ tflite::Padding padding;
+ int32_t stride_w;
+ int32_t stride_h;
+ int32_t depth_multiplier;
+ tflite::ActivationFunctionType fused_activation_function;
+ int32_t dilation_w_factor;
+ int32_t dilation_h_factor;
+ DepthwiseConv2DOptionsT()
+ : padding(tflite::Padding_SAME),
+ stride_w(0),
+ stride_h(0),
+ depth_multiplier(0),
+ fused_activation_function(tflite::ActivationFunctionType_NONE),
+ dilation_w_factor(1),
+ dilation_h_factor(1) {
+ }
+};
+
+struct DepthwiseConv2DOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef DepthwiseConv2DOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_PADDING = 4,
+ VT_STRIDE_W = 6,
+ VT_STRIDE_H = 8,
+ VT_DEPTH_MULTIPLIER = 10,
+ VT_FUSED_ACTIVATION_FUNCTION = 12,
+ VT_DILATION_W_FACTOR = 14,
+ VT_DILATION_H_FACTOR = 16
+ };
+ tflite::Padding padding() const {
+ return static_cast<tflite::Padding>(GetField<int8_t>(VT_PADDING, 0));
+ }
+ int32_t stride_w() const {
+ return GetField<int32_t>(VT_STRIDE_W, 0);
+ }
+ int32_t stride_h() const {
+ return GetField<int32_t>(VT_STRIDE_H, 0);
+ }
+ int32_t depth_multiplier() const {
+ return GetField<int32_t>(VT_DEPTH_MULTIPLIER, 0);
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ int32_t dilation_w_factor() const {
+ return GetField<int32_t>(VT_DILATION_W_FACTOR, 1);
+ }
+ int32_t dilation_h_factor() const {
+ return GetField<int32_t>(VT_DILATION_H_FACTOR, 1);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_PADDING) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_W) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_H) &&
+ VerifyField<int32_t>(verifier, VT_DEPTH_MULTIPLIER) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<int32_t>(verifier, VT_DILATION_W_FACTOR) &&
+ VerifyField<int32_t>(verifier, VT_DILATION_H_FACTOR) &&
+ verifier.EndTable();
+ }
+ DepthwiseConv2DOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(DepthwiseConv2DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<DepthwiseConv2DOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const DepthwiseConv2DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct DepthwiseConv2DOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_padding(tflite::Padding padding) {
+ fbb_.AddElement<int8_t>(DepthwiseConv2DOptions::VT_PADDING, static_cast<int8_t>(padding), 0);
+ }
+ void add_stride_w(int32_t stride_w) {
+ fbb_.AddElement<int32_t>(DepthwiseConv2DOptions::VT_STRIDE_W, stride_w, 0);
+ }
+ void add_stride_h(int32_t stride_h) {
+ fbb_.AddElement<int32_t>(DepthwiseConv2DOptions::VT_STRIDE_H, stride_h, 0);
+ }
+ void add_depth_multiplier(int32_t depth_multiplier) {
+ fbb_.AddElement<int32_t>(DepthwiseConv2DOptions::VT_DEPTH_MULTIPLIER, depth_multiplier, 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(DepthwiseConv2DOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_dilation_w_factor(int32_t dilation_w_factor) {
+ fbb_.AddElement<int32_t>(DepthwiseConv2DOptions::VT_DILATION_W_FACTOR, dilation_w_factor, 1);
+ }
+ void add_dilation_h_factor(int32_t dilation_h_factor) {
+ fbb_.AddElement<int32_t>(DepthwiseConv2DOptions::VT_DILATION_H_FACTOR, dilation_h_factor, 1);
+ }
+ explicit DepthwiseConv2DOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ DepthwiseConv2DOptionsBuilder &operator=(const DepthwiseConv2DOptionsBuilder &);
+ flatbuffers::Offset<DepthwiseConv2DOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<DepthwiseConv2DOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<DepthwiseConv2DOptions> CreateDepthwiseConv2DOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::Padding padding = tflite::Padding_SAME,
+ int32_t stride_w = 0,
+ int32_t stride_h = 0,
+ int32_t depth_multiplier = 0,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ int32_t dilation_w_factor = 1,
+ int32_t dilation_h_factor = 1) {
+ DepthwiseConv2DOptionsBuilder builder_(_fbb);
+ builder_.add_dilation_h_factor(dilation_h_factor);
+ builder_.add_dilation_w_factor(dilation_w_factor);
+ builder_.add_depth_multiplier(depth_multiplier);
+ builder_.add_stride_h(stride_h);
+ builder_.add_stride_w(stride_w);
+ builder_.add_fused_activation_function(fused_activation_function);
+ builder_.add_padding(padding);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<DepthwiseConv2DOptions> CreateDepthwiseConv2DOptions(flatbuffers::FlatBufferBuilder &_fbb, const DepthwiseConv2DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ConcatEmbeddingsOptionsT : public flatbuffers::NativeTable {
+ typedef ConcatEmbeddingsOptions TableType;
+ int32_t num_channels;
+ std::vector<int32_t> num_columns_per_channel;
+ std::vector<int32_t> embedding_dim_per_channel;
+ ConcatEmbeddingsOptionsT()
+ : num_channels(0) {
+ }
+};
+
+struct ConcatEmbeddingsOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ConcatEmbeddingsOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NUM_CHANNELS = 4,
+ VT_NUM_COLUMNS_PER_CHANNEL = 6,
+ VT_EMBEDDING_DIM_PER_CHANNEL = 8
+ };
+ int32_t num_channels() const {
+ return GetField<int32_t>(VT_NUM_CHANNELS, 0);
+ }
+ const flatbuffers::Vector<int32_t> *num_columns_per_channel() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_NUM_COLUMNS_PER_CHANNEL);
+ }
+ const flatbuffers::Vector<int32_t> *embedding_dim_per_channel() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_EMBEDDING_DIM_PER_CHANNEL);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_NUM_CHANNELS) &&
+ VerifyOffset(verifier, VT_NUM_COLUMNS_PER_CHANNEL) &&
+ verifier.VerifyVector(num_columns_per_channel()) &&
+ VerifyOffset(verifier, VT_EMBEDDING_DIM_PER_CHANNEL) &&
+ verifier.VerifyVector(embedding_dim_per_channel()) &&
+ verifier.EndTable();
+ }
+ ConcatEmbeddingsOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ConcatEmbeddingsOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ConcatEmbeddingsOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ConcatEmbeddingsOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ConcatEmbeddingsOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_num_channels(int32_t num_channels) {
+ fbb_.AddElement<int32_t>(ConcatEmbeddingsOptions::VT_NUM_CHANNELS, num_channels, 0);
+ }
+ void add_num_columns_per_channel(flatbuffers::Offset<flatbuffers::Vector<int32_t>> num_columns_per_channel) {
+ fbb_.AddOffset(ConcatEmbeddingsOptions::VT_NUM_COLUMNS_PER_CHANNEL, num_columns_per_channel);
+ }
+ void add_embedding_dim_per_channel(flatbuffers::Offset<flatbuffers::Vector<int32_t>> embedding_dim_per_channel) {
+ fbb_.AddOffset(ConcatEmbeddingsOptions::VT_EMBEDDING_DIM_PER_CHANNEL, embedding_dim_per_channel);
+ }
+ explicit ConcatEmbeddingsOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ConcatEmbeddingsOptionsBuilder &operator=(const ConcatEmbeddingsOptionsBuilder &);
+ flatbuffers::Offset<ConcatEmbeddingsOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ConcatEmbeddingsOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ConcatEmbeddingsOptions> CreateConcatEmbeddingsOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t num_channels = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> num_columns_per_channel = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> embedding_dim_per_channel = 0) {
+ ConcatEmbeddingsOptionsBuilder builder_(_fbb);
+ builder_.add_embedding_dim_per_channel(embedding_dim_per_channel);
+ builder_.add_num_columns_per_channel(num_columns_per_channel);
+ builder_.add_num_channels(num_channels);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<ConcatEmbeddingsOptions> CreateConcatEmbeddingsOptionsDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t num_channels = 0,
+ const std::vector<int32_t> *num_columns_per_channel = nullptr,
+ const std::vector<int32_t> *embedding_dim_per_channel = nullptr) {
+ auto num_columns_per_channel__ = num_columns_per_channel ? _fbb.CreateVector<int32_t>(*num_columns_per_channel) : 0;
+ auto embedding_dim_per_channel__ = embedding_dim_per_channel ? _fbb.CreateVector<int32_t>(*embedding_dim_per_channel) : 0;
+ return tflite::CreateConcatEmbeddingsOptions(
+ _fbb,
+ num_channels,
+ num_columns_per_channel__,
+ embedding_dim_per_channel__);
+}
+
+flatbuffers::Offset<ConcatEmbeddingsOptions> CreateConcatEmbeddingsOptions(flatbuffers::FlatBufferBuilder &_fbb, const ConcatEmbeddingsOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LSHProjectionOptionsT : public flatbuffers::NativeTable {
+ typedef LSHProjectionOptions TableType;
+ tflite::LSHProjectionType type;
+ LSHProjectionOptionsT()
+ : type(tflite::LSHProjectionType_UNKNOWN) {
+ }
+};
+
+struct LSHProjectionOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LSHProjectionOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_TYPE = 4
+ };
+ tflite::LSHProjectionType type() const {
+ return static_cast<tflite::LSHProjectionType>(GetField<int8_t>(VT_TYPE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_TYPE) &&
+ verifier.EndTable();
+ }
+ LSHProjectionOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LSHProjectionOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LSHProjectionOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LSHProjectionOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LSHProjectionOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_type(tflite::LSHProjectionType type) {
+ fbb_.AddElement<int8_t>(LSHProjectionOptions::VT_TYPE, static_cast<int8_t>(type), 0);
+ }
+ explicit LSHProjectionOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LSHProjectionOptionsBuilder &operator=(const LSHProjectionOptionsBuilder &);
+ flatbuffers::Offset<LSHProjectionOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LSHProjectionOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LSHProjectionOptions> CreateLSHProjectionOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::LSHProjectionType type = tflite::LSHProjectionType_UNKNOWN) {
+ LSHProjectionOptionsBuilder builder_(_fbb);
+ builder_.add_type(type);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LSHProjectionOptions> CreateLSHProjectionOptions(flatbuffers::FlatBufferBuilder &_fbb, const LSHProjectionOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SVDFOptionsT : public flatbuffers::NativeTable {
+ typedef SVDFOptions TableType;
+ int32_t rank;
+ tflite::ActivationFunctionType fused_activation_function;
+ bool asymmetric_quantize_inputs;
+ SVDFOptionsT()
+ : rank(0),
+ fused_activation_function(tflite::ActivationFunctionType_NONE),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct SVDFOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SVDFOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_RANK = 4,
+ VT_FUSED_ACTIVATION_FUNCTION = 6,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 8
+ };
+ int32_t rank() const {
+ return GetField<int32_t>(VT_RANK, 0);
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_RANK) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ SVDFOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SVDFOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SVDFOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SVDFOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SVDFOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_rank(int32_t rank) {
+ fbb_.AddElement<int32_t>(SVDFOptions::VT_RANK, rank, 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(SVDFOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(SVDFOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit SVDFOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SVDFOptionsBuilder &operator=(const SVDFOptionsBuilder &);
+ flatbuffers::Offset<SVDFOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SVDFOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SVDFOptions> CreateSVDFOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t rank = 0,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ bool asymmetric_quantize_inputs = false) {
+ SVDFOptionsBuilder builder_(_fbb);
+ builder_.add_rank(rank);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SVDFOptions> CreateSVDFOptions(flatbuffers::FlatBufferBuilder &_fbb, const SVDFOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct RNNOptionsT : public flatbuffers::NativeTable {
+ typedef RNNOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ bool asymmetric_quantize_inputs;
+ RNNOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct RNNOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef RNNOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 6
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ RNNOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(RNNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<RNNOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const RNNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct RNNOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(RNNOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(RNNOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit RNNOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ RNNOptionsBuilder &operator=(const RNNOptionsBuilder &);
+ flatbuffers::Offset<RNNOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<RNNOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<RNNOptions> CreateRNNOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ bool asymmetric_quantize_inputs = false) {
+ RNNOptionsBuilder builder_(_fbb);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<RNNOptions> CreateRNNOptions(flatbuffers::FlatBufferBuilder &_fbb, const RNNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SequenceRNNOptionsT : public flatbuffers::NativeTable {
+ typedef SequenceRNNOptions TableType;
+ bool time_major;
+ tflite::ActivationFunctionType fused_activation_function;
+ bool asymmetric_quantize_inputs;
+ SequenceRNNOptionsT()
+ : time_major(false),
+ fused_activation_function(tflite::ActivationFunctionType_NONE),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct SequenceRNNOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SequenceRNNOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_TIME_MAJOR = 4,
+ VT_FUSED_ACTIVATION_FUNCTION = 6,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 8
+ };
+ bool time_major() const {
+ return GetField<uint8_t>(VT_TIME_MAJOR, 0) != 0;
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_TIME_MAJOR) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ SequenceRNNOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SequenceRNNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SequenceRNNOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SequenceRNNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SequenceRNNOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_time_major(bool time_major) {
+ fbb_.AddElement<uint8_t>(SequenceRNNOptions::VT_TIME_MAJOR, static_cast<uint8_t>(time_major), 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(SequenceRNNOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(SequenceRNNOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit SequenceRNNOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SequenceRNNOptionsBuilder &operator=(const SequenceRNNOptionsBuilder &);
+ flatbuffers::Offset<SequenceRNNOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SequenceRNNOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SequenceRNNOptions> CreateSequenceRNNOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool time_major = false,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ bool asymmetric_quantize_inputs = false) {
+ SequenceRNNOptionsBuilder builder_(_fbb);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_fused_activation_function(fused_activation_function);
+ builder_.add_time_major(time_major);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SequenceRNNOptions> CreateSequenceRNNOptions(flatbuffers::FlatBufferBuilder &_fbb, const SequenceRNNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct BidirectionalSequenceRNNOptionsT : public flatbuffers::NativeTable {
+ typedef BidirectionalSequenceRNNOptions TableType;
+ bool time_major;
+ tflite::ActivationFunctionType fused_activation_function;
+ bool merge_outputs;
+ bool asymmetric_quantize_inputs;
+ BidirectionalSequenceRNNOptionsT()
+ : time_major(false),
+ fused_activation_function(tflite::ActivationFunctionType_NONE),
+ merge_outputs(false),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct BidirectionalSequenceRNNOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef BidirectionalSequenceRNNOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_TIME_MAJOR = 4,
+ VT_FUSED_ACTIVATION_FUNCTION = 6,
+ VT_MERGE_OUTPUTS = 8,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 10
+ };
+ bool time_major() const {
+ return GetField<uint8_t>(VT_TIME_MAJOR, 0) != 0;
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool merge_outputs() const {
+ return GetField<uint8_t>(VT_MERGE_OUTPUTS, 0) != 0;
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_TIME_MAJOR) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<uint8_t>(verifier, VT_MERGE_OUTPUTS) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ BidirectionalSequenceRNNOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(BidirectionalSequenceRNNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<BidirectionalSequenceRNNOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceRNNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct BidirectionalSequenceRNNOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_time_major(bool time_major) {
+ fbb_.AddElement<uint8_t>(BidirectionalSequenceRNNOptions::VT_TIME_MAJOR, static_cast<uint8_t>(time_major), 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(BidirectionalSequenceRNNOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_merge_outputs(bool merge_outputs) {
+ fbb_.AddElement<uint8_t>(BidirectionalSequenceRNNOptions::VT_MERGE_OUTPUTS, static_cast<uint8_t>(merge_outputs), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(BidirectionalSequenceRNNOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit BidirectionalSequenceRNNOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ BidirectionalSequenceRNNOptionsBuilder &operator=(const BidirectionalSequenceRNNOptionsBuilder &);
+ flatbuffers::Offset<BidirectionalSequenceRNNOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<BidirectionalSequenceRNNOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<BidirectionalSequenceRNNOptions> CreateBidirectionalSequenceRNNOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool time_major = false,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ bool merge_outputs = false,
+ bool asymmetric_quantize_inputs = false) {
+ BidirectionalSequenceRNNOptionsBuilder builder_(_fbb);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_merge_outputs(merge_outputs);
+ builder_.add_fused_activation_function(fused_activation_function);
+ builder_.add_time_major(time_major);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<BidirectionalSequenceRNNOptions> CreateBidirectionalSequenceRNNOptions(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceRNNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct FullyConnectedOptionsT : public flatbuffers::NativeTable {
+ typedef FullyConnectedOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ tflite::FullyConnectedOptionsWeightsFormat weights_format;
+ bool keep_num_dims;
+ bool asymmetric_quantize_inputs;
+ FullyConnectedOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE),
+ weights_format(tflite::FullyConnectedOptionsWeightsFormat_DEFAULT),
+ keep_num_dims(false),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct FullyConnectedOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef FullyConnectedOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4,
+ VT_WEIGHTS_FORMAT = 6,
+ VT_KEEP_NUM_DIMS = 8,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 10
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ tflite::FullyConnectedOptionsWeightsFormat weights_format() const {
+ return static_cast<tflite::FullyConnectedOptionsWeightsFormat>(GetField<int8_t>(VT_WEIGHTS_FORMAT, 0));
+ }
+ bool keep_num_dims() const {
+ return GetField<uint8_t>(VT_KEEP_NUM_DIMS, 0) != 0;
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<int8_t>(verifier, VT_WEIGHTS_FORMAT) &&
+ VerifyField<uint8_t>(verifier, VT_KEEP_NUM_DIMS) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ FullyConnectedOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(FullyConnectedOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<FullyConnectedOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const FullyConnectedOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct FullyConnectedOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(FullyConnectedOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_weights_format(tflite::FullyConnectedOptionsWeightsFormat weights_format) {
+ fbb_.AddElement<int8_t>(FullyConnectedOptions::VT_WEIGHTS_FORMAT, static_cast<int8_t>(weights_format), 0);
+ }
+ void add_keep_num_dims(bool keep_num_dims) {
+ fbb_.AddElement<uint8_t>(FullyConnectedOptions::VT_KEEP_NUM_DIMS, static_cast<uint8_t>(keep_num_dims), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(FullyConnectedOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit FullyConnectedOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ FullyConnectedOptionsBuilder &operator=(const FullyConnectedOptionsBuilder &);
+ flatbuffers::Offset<FullyConnectedOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<FullyConnectedOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<FullyConnectedOptions> CreateFullyConnectedOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ tflite::FullyConnectedOptionsWeightsFormat weights_format = tflite::FullyConnectedOptionsWeightsFormat_DEFAULT,
+ bool keep_num_dims = false,
+ bool asymmetric_quantize_inputs = false) {
+ FullyConnectedOptionsBuilder builder_(_fbb);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_keep_num_dims(keep_num_dims);
+ builder_.add_weights_format(weights_format);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<FullyConnectedOptions> CreateFullyConnectedOptions(flatbuffers::FlatBufferBuilder &_fbb, const FullyConnectedOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SoftmaxOptionsT : public flatbuffers::NativeTable {
+ typedef SoftmaxOptions TableType;
+ float beta;
+ SoftmaxOptionsT()
+ : beta(0.0f) {
+ }
+};
+
+struct SoftmaxOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SoftmaxOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_BETA = 4
+ };
+ float beta() const {
+ return GetField<float>(VT_BETA, 0.0f);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<float>(verifier, VT_BETA) &&
+ verifier.EndTable();
+ }
+ SoftmaxOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SoftmaxOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SoftmaxOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SoftmaxOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SoftmaxOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_beta(float beta) {
+ fbb_.AddElement<float>(SoftmaxOptions::VT_BETA, beta, 0.0f);
+ }
+ explicit SoftmaxOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SoftmaxOptionsBuilder &operator=(const SoftmaxOptionsBuilder &);
+ flatbuffers::Offset<SoftmaxOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SoftmaxOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SoftmaxOptions> CreateSoftmaxOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ float beta = 0.0f) {
+ SoftmaxOptionsBuilder builder_(_fbb);
+ builder_.add_beta(beta);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SoftmaxOptions> CreateSoftmaxOptions(flatbuffers::FlatBufferBuilder &_fbb, const SoftmaxOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ConcatenationOptionsT : public flatbuffers::NativeTable {
+ typedef ConcatenationOptions TableType;
+ int32_t axis;
+ tflite::ActivationFunctionType fused_activation_function;
+ ConcatenationOptionsT()
+ : axis(0),
+ fused_activation_function(tflite::ActivationFunctionType_NONE) {
+ }
+};
+
+struct ConcatenationOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ConcatenationOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_AXIS = 4,
+ VT_FUSED_ACTIVATION_FUNCTION = 6
+ };
+ int32_t axis() const {
+ return GetField<int32_t>(VT_AXIS, 0);
+ }
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_AXIS) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ verifier.EndTable();
+ }
+ ConcatenationOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ConcatenationOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ConcatenationOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ConcatenationOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ConcatenationOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_axis(int32_t axis) {
+ fbb_.AddElement<int32_t>(ConcatenationOptions::VT_AXIS, axis, 0);
+ }
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(ConcatenationOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ explicit ConcatenationOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ConcatenationOptionsBuilder &operator=(const ConcatenationOptionsBuilder &);
+ flatbuffers::Offset<ConcatenationOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ConcatenationOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ConcatenationOptions> CreateConcatenationOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t axis = 0,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE) {
+ ConcatenationOptionsBuilder builder_(_fbb);
+ builder_.add_axis(axis);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ConcatenationOptions> CreateConcatenationOptions(flatbuffers::FlatBufferBuilder &_fbb, const ConcatenationOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct AddOptionsT : public flatbuffers::NativeTable {
+ typedef AddOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ bool pot_scale_int16;
+ AddOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE),
+ pot_scale_int16(true) {
+ }
+};
+
+struct AddOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef AddOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4,
+ VT_POT_SCALE_INT16 = 6
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool pot_scale_int16() const {
+ return GetField<uint8_t>(VT_POT_SCALE_INT16, 1) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<uint8_t>(verifier, VT_POT_SCALE_INT16) &&
+ verifier.EndTable();
+ }
+ AddOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(AddOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<AddOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const AddOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct AddOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(AddOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_pot_scale_int16(bool pot_scale_int16) {
+ fbb_.AddElement<uint8_t>(AddOptions::VT_POT_SCALE_INT16, static_cast<uint8_t>(pot_scale_int16), 1);
+ }
+ explicit AddOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ AddOptionsBuilder &operator=(const AddOptionsBuilder &);
+ flatbuffers::Offset<AddOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<AddOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<AddOptions> CreateAddOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ bool pot_scale_int16 = true) {
+ AddOptionsBuilder builder_(_fbb);
+ builder_.add_pot_scale_int16(pot_scale_int16);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<AddOptions> CreateAddOptions(flatbuffers::FlatBufferBuilder &_fbb, const AddOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct MulOptionsT : public flatbuffers::NativeTable {
+ typedef MulOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ MulOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE) {
+ }
+};
+
+struct MulOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef MulOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ verifier.EndTable();
+ }
+ MulOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(MulOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<MulOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const MulOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct MulOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(MulOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ explicit MulOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ MulOptionsBuilder &operator=(const MulOptionsBuilder &);
+ flatbuffers::Offset<MulOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<MulOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<MulOptions> CreateMulOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE) {
+ MulOptionsBuilder builder_(_fbb);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<MulOptions> CreateMulOptions(flatbuffers::FlatBufferBuilder &_fbb, const MulOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct L2NormOptionsT : public flatbuffers::NativeTable {
+ typedef L2NormOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ L2NormOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE) {
+ }
+};
+
+struct L2NormOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef L2NormOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ verifier.EndTable();
+ }
+ L2NormOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(L2NormOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<L2NormOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const L2NormOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct L2NormOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(L2NormOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ explicit L2NormOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ L2NormOptionsBuilder &operator=(const L2NormOptionsBuilder &);
+ flatbuffers::Offset<L2NormOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<L2NormOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<L2NormOptions> CreateL2NormOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE) {
+ L2NormOptionsBuilder builder_(_fbb);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<L2NormOptions> CreateL2NormOptions(flatbuffers::FlatBufferBuilder &_fbb, const L2NormOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LocalResponseNormalizationOptionsT : public flatbuffers::NativeTable {
+ typedef LocalResponseNormalizationOptions TableType;
+ int32_t radius;
+ float bias;
+ float alpha;
+ float beta;
+ LocalResponseNormalizationOptionsT()
+ : radius(0),
+ bias(0.0f),
+ alpha(0.0f),
+ beta(0.0f) {
+ }
+};
+
+struct LocalResponseNormalizationOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LocalResponseNormalizationOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_RADIUS = 4,
+ VT_BIAS = 6,
+ VT_ALPHA = 8,
+ VT_BETA = 10
+ };
+ int32_t radius() const {
+ return GetField<int32_t>(VT_RADIUS, 0);
+ }
+ float bias() const {
+ return GetField<float>(VT_BIAS, 0.0f);
+ }
+ float alpha() const {
+ return GetField<float>(VT_ALPHA, 0.0f);
+ }
+ float beta() const {
+ return GetField<float>(VT_BETA, 0.0f);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_RADIUS) &&
+ VerifyField<float>(verifier, VT_BIAS) &&
+ VerifyField<float>(verifier, VT_ALPHA) &&
+ VerifyField<float>(verifier, VT_BETA) &&
+ verifier.EndTable();
+ }
+ LocalResponseNormalizationOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LocalResponseNormalizationOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LocalResponseNormalizationOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LocalResponseNormalizationOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LocalResponseNormalizationOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_radius(int32_t radius) {
+ fbb_.AddElement<int32_t>(LocalResponseNormalizationOptions::VT_RADIUS, radius, 0);
+ }
+ void add_bias(float bias) {
+ fbb_.AddElement<float>(LocalResponseNormalizationOptions::VT_BIAS, bias, 0.0f);
+ }
+ void add_alpha(float alpha) {
+ fbb_.AddElement<float>(LocalResponseNormalizationOptions::VT_ALPHA, alpha, 0.0f);
+ }
+ void add_beta(float beta) {
+ fbb_.AddElement<float>(LocalResponseNormalizationOptions::VT_BETA, beta, 0.0f);
+ }
+ explicit LocalResponseNormalizationOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LocalResponseNormalizationOptionsBuilder &operator=(const LocalResponseNormalizationOptionsBuilder &);
+ flatbuffers::Offset<LocalResponseNormalizationOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LocalResponseNormalizationOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LocalResponseNormalizationOptions> CreateLocalResponseNormalizationOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t radius = 0,
+ float bias = 0.0f,
+ float alpha = 0.0f,
+ float beta = 0.0f) {
+ LocalResponseNormalizationOptionsBuilder builder_(_fbb);
+ builder_.add_beta(beta);
+ builder_.add_alpha(alpha);
+ builder_.add_bias(bias);
+ builder_.add_radius(radius);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LocalResponseNormalizationOptions> CreateLocalResponseNormalizationOptions(flatbuffers::FlatBufferBuilder &_fbb, const LocalResponseNormalizationOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LSTMOptionsT : public flatbuffers::NativeTable {
+ typedef LSTMOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ float cell_clip;
+ float proj_clip;
+ tflite::LSTMKernelType kernel_type;
+ bool asymmetric_quantize_inputs;
+ LSTMOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE),
+ cell_clip(0.0f),
+ proj_clip(0.0f),
+ kernel_type(tflite::LSTMKernelType_FULL),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct LSTMOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LSTMOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4,
+ VT_CELL_CLIP = 6,
+ VT_PROJ_CLIP = 8,
+ VT_KERNEL_TYPE = 10,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 12
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ float cell_clip() const {
+ return GetField<float>(VT_CELL_CLIP, 0.0f);
+ }
+ float proj_clip() const {
+ return GetField<float>(VT_PROJ_CLIP, 0.0f);
+ }
+ tflite::LSTMKernelType kernel_type() const {
+ return static_cast<tflite::LSTMKernelType>(GetField<int8_t>(VT_KERNEL_TYPE, 0));
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<float>(verifier, VT_CELL_CLIP) &&
+ VerifyField<float>(verifier, VT_PROJ_CLIP) &&
+ VerifyField<int8_t>(verifier, VT_KERNEL_TYPE) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ LSTMOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LSTMOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LSTMOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LSTMOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LSTMOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(LSTMOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_cell_clip(float cell_clip) {
+ fbb_.AddElement<float>(LSTMOptions::VT_CELL_CLIP, cell_clip, 0.0f);
+ }
+ void add_proj_clip(float proj_clip) {
+ fbb_.AddElement<float>(LSTMOptions::VT_PROJ_CLIP, proj_clip, 0.0f);
+ }
+ void add_kernel_type(tflite::LSTMKernelType kernel_type) {
+ fbb_.AddElement<int8_t>(LSTMOptions::VT_KERNEL_TYPE, static_cast<int8_t>(kernel_type), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(LSTMOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit LSTMOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LSTMOptionsBuilder &operator=(const LSTMOptionsBuilder &);
+ flatbuffers::Offset<LSTMOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LSTMOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LSTMOptions> CreateLSTMOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ float cell_clip = 0.0f,
+ float proj_clip = 0.0f,
+ tflite::LSTMKernelType kernel_type = tflite::LSTMKernelType_FULL,
+ bool asymmetric_quantize_inputs = false) {
+ LSTMOptionsBuilder builder_(_fbb);
+ builder_.add_proj_clip(proj_clip);
+ builder_.add_cell_clip(cell_clip);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_kernel_type(kernel_type);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LSTMOptions> CreateLSTMOptions(flatbuffers::FlatBufferBuilder &_fbb, const LSTMOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct UnidirectionalSequenceLSTMOptionsT : public flatbuffers::NativeTable {
+ typedef UnidirectionalSequenceLSTMOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ float cell_clip;
+ float proj_clip;
+ bool time_major;
+ bool asymmetric_quantize_inputs;
+ UnidirectionalSequenceLSTMOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE),
+ cell_clip(0.0f),
+ proj_clip(0.0f),
+ time_major(false),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct UnidirectionalSequenceLSTMOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef UnidirectionalSequenceLSTMOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4,
+ VT_CELL_CLIP = 6,
+ VT_PROJ_CLIP = 8,
+ VT_TIME_MAJOR = 10,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 12
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ float cell_clip() const {
+ return GetField<float>(VT_CELL_CLIP, 0.0f);
+ }
+ float proj_clip() const {
+ return GetField<float>(VT_PROJ_CLIP, 0.0f);
+ }
+ bool time_major() const {
+ return GetField<uint8_t>(VT_TIME_MAJOR, 0) != 0;
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<float>(verifier, VT_CELL_CLIP) &&
+ VerifyField<float>(verifier, VT_PROJ_CLIP) &&
+ VerifyField<uint8_t>(verifier, VT_TIME_MAJOR) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ UnidirectionalSequenceLSTMOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(UnidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<UnidirectionalSequenceLSTMOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const UnidirectionalSequenceLSTMOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct UnidirectionalSequenceLSTMOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(UnidirectionalSequenceLSTMOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_cell_clip(float cell_clip) {
+ fbb_.AddElement<float>(UnidirectionalSequenceLSTMOptions::VT_CELL_CLIP, cell_clip, 0.0f);
+ }
+ void add_proj_clip(float proj_clip) {
+ fbb_.AddElement<float>(UnidirectionalSequenceLSTMOptions::VT_PROJ_CLIP, proj_clip, 0.0f);
+ }
+ void add_time_major(bool time_major) {
+ fbb_.AddElement<uint8_t>(UnidirectionalSequenceLSTMOptions::VT_TIME_MAJOR, static_cast<uint8_t>(time_major), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(UnidirectionalSequenceLSTMOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit UnidirectionalSequenceLSTMOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ UnidirectionalSequenceLSTMOptionsBuilder &operator=(const UnidirectionalSequenceLSTMOptionsBuilder &);
+ flatbuffers::Offset<UnidirectionalSequenceLSTMOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<UnidirectionalSequenceLSTMOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<UnidirectionalSequenceLSTMOptions> CreateUnidirectionalSequenceLSTMOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ float cell_clip = 0.0f,
+ float proj_clip = 0.0f,
+ bool time_major = false,
+ bool asymmetric_quantize_inputs = false) {
+ UnidirectionalSequenceLSTMOptionsBuilder builder_(_fbb);
+ builder_.add_proj_clip(proj_clip);
+ builder_.add_cell_clip(cell_clip);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_time_major(time_major);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<UnidirectionalSequenceLSTMOptions> CreateUnidirectionalSequenceLSTMOptions(flatbuffers::FlatBufferBuilder &_fbb, const UnidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct BidirectionalSequenceLSTMOptionsT : public flatbuffers::NativeTable {
+ typedef BidirectionalSequenceLSTMOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ float cell_clip;
+ float proj_clip;
+ bool merge_outputs;
+ bool time_major;
+ bool asymmetric_quantize_inputs;
+ BidirectionalSequenceLSTMOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE),
+ cell_clip(0.0f),
+ proj_clip(0.0f),
+ merge_outputs(false),
+ time_major(true),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct BidirectionalSequenceLSTMOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef BidirectionalSequenceLSTMOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4,
+ VT_CELL_CLIP = 6,
+ VT_PROJ_CLIP = 8,
+ VT_MERGE_OUTPUTS = 10,
+ VT_TIME_MAJOR = 12,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 14
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ float cell_clip() const {
+ return GetField<float>(VT_CELL_CLIP, 0.0f);
+ }
+ float proj_clip() const {
+ return GetField<float>(VT_PROJ_CLIP, 0.0f);
+ }
+ bool merge_outputs() const {
+ return GetField<uint8_t>(VT_MERGE_OUTPUTS, 0) != 0;
+ }
+ bool time_major() const {
+ return GetField<uint8_t>(VT_TIME_MAJOR, 1) != 0;
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<float>(verifier, VT_CELL_CLIP) &&
+ VerifyField<float>(verifier, VT_PROJ_CLIP) &&
+ VerifyField<uint8_t>(verifier, VT_MERGE_OUTPUTS) &&
+ VerifyField<uint8_t>(verifier, VT_TIME_MAJOR) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ BidirectionalSequenceLSTMOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(BidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<BidirectionalSequenceLSTMOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceLSTMOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct BidirectionalSequenceLSTMOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(BidirectionalSequenceLSTMOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_cell_clip(float cell_clip) {
+ fbb_.AddElement<float>(BidirectionalSequenceLSTMOptions::VT_CELL_CLIP, cell_clip, 0.0f);
+ }
+ void add_proj_clip(float proj_clip) {
+ fbb_.AddElement<float>(BidirectionalSequenceLSTMOptions::VT_PROJ_CLIP, proj_clip, 0.0f);
+ }
+ void add_merge_outputs(bool merge_outputs) {
+ fbb_.AddElement<uint8_t>(BidirectionalSequenceLSTMOptions::VT_MERGE_OUTPUTS, static_cast<uint8_t>(merge_outputs), 0);
+ }
+ void add_time_major(bool time_major) {
+ fbb_.AddElement<uint8_t>(BidirectionalSequenceLSTMOptions::VT_TIME_MAJOR, static_cast<uint8_t>(time_major), 1);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(BidirectionalSequenceLSTMOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit BidirectionalSequenceLSTMOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ BidirectionalSequenceLSTMOptionsBuilder &operator=(const BidirectionalSequenceLSTMOptionsBuilder &);
+ flatbuffers::Offset<BidirectionalSequenceLSTMOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<BidirectionalSequenceLSTMOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<BidirectionalSequenceLSTMOptions> CreateBidirectionalSequenceLSTMOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ float cell_clip = 0.0f,
+ float proj_clip = 0.0f,
+ bool merge_outputs = false,
+ bool time_major = true,
+ bool asymmetric_quantize_inputs = false) {
+ BidirectionalSequenceLSTMOptionsBuilder builder_(_fbb);
+ builder_.add_proj_clip(proj_clip);
+ builder_.add_cell_clip(cell_clip);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_time_major(time_major);
+ builder_.add_merge_outputs(merge_outputs);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<BidirectionalSequenceLSTMOptions> CreateBidirectionalSequenceLSTMOptions(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ResizeBilinearOptionsT : public flatbuffers::NativeTable {
+ typedef ResizeBilinearOptions TableType;
+ bool align_corners;
+ bool half_pixel_centers;
+ ResizeBilinearOptionsT()
+ : align_corners(false),
+ half_pixel_centers(false) {
+ }
+};
+
+struct ResizeBilinearOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ResizeBilinearOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_ALIGN_CORNERS = 8,
+ VT_HALF_PIXEL_CENTERS = 10
+ };
+ bool align_corners() const {
+ return GetField<uint8_t>(VT_ALIGN_CORNERS, 0) != 0;
+ }
+ bool half_pixel_centers() const {
+ return GetField<uint8_t>(VT_HALF_PIXEL_CENTERS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_ALIGN_CORNERS) &&
+ VerifyField<uint8_t>(verifier, VT_HALF_PIXEL_CENTERS) &&
+ verifier.EndTable();
+ }
+ ResizeBilinearOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ResizeBilinearOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ResizeBilinearOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ResizeBilinearOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ResizeBilinearOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_align_corners(bool align_corners) {
+ fbb_.AddElement<uint8_t>(ResizeBilinearOptions::VT_ALIGN_CORNERS, static_cast<uint8_t>(align_corners), 0);
+ }
+ void add_half_pixel_centers(bool half_pixel_centers) {
+ fbb_.AddElement<uint8_t>(ResizeBilinearOptions::VT_HALF_PIXEL_CENTERS, static_cast<uint8_t>(half_pixel_centers), 0);
+ }
+ explicit ResizeBilinearOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ResizeBilinearOptionsBuilder &operator=(const ResizeBilinearOptionsBuilder &);
+ flatbuffers::Offset<ResizeBilinearOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ResizeBilinearOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ResizeBilinearOptions> CreateResizeBilinearOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool align_corners = false,
+ bool half_pixel_centers = false) {
+ ResizeBilinearOptionsBuilder builder_(_fbb);
+ builder_.add_half_pixel_centers(half_pixel_centers);
+ builder_.add_align_corners(align_corners);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ResizeBilinearOptions> CreateResizeBilinearOptions(flatbuffers::FlatBufferBuilder &_fbb, const ResizeBilinearOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ResizeNearestNeighborOptionsT : public flatbuffers::NativeTable {
+ typedef ResizeNearestNeighborOptions TableType;
+ bool align_corners;
+ bool half_pixel_centers;
+ ResizeNearestNeighborOptionsT()
+ : align_corners(false),
+ half_pixel_centers(false) {
+ }
+};
+
+struct ResizeNearestNeighborOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ResizeNearestNeighborOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_ALIGN_CORNERS = 4,
+ VT_HALF_PIXEL_CENTERS = 6
+ };
+ bool align_corners() const {
+ return GetField<uint8_t>(VT_ALIGN_CORNERS, 0) != 0;
+ }
+ bool half_pixel_centers() const {
+ return GetField<uint8_t>(VT_HALF_PIXEL_CENTERS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_ALIGN_CORNERS) &&
+ VerifyField<uint8_t>(verifier, VT_HALF_PIXEL_CENTERS) &&
+ verifier.EndTable();
+ }
+ ResizeNearestNeighborOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ResizeNearestNeighborOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ResizeNearestNeighborOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ResizeNearestNeighborOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ResizeNearestNeighborOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_align_corners(bool align_corners) {
+ fbb_.AddElement<uint8_t>(ResizeNearestNeighborOptions::VT_ALIGN_CORNERS, static_cast<uint8_t>(align_corners), 0);
+ }
+ void add_half_pixel_centers(bool half_pixel_centers) {
+ fbb_.AddElement<uint8_t>(ResizeNearestNeighborOptions::VT_HALF_PIXEL_CENTERS, static_cast<uint8_t>(half_pixel_centers), 0);
+ }
+ explicit ResizeNearestNeighborOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ResizeNearestNeighborOptionsBuilder &operator=(const ResizeNearestNeighborOptionsBuilder &);
+ flatbuffers::Offset<ResizeNearestNeighborOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ResizeNearestNeighborOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ResizeNearestNeighborOptions> CreateResizeNearestNeighborOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool align_corners = false,
+ bool half_pixel_centers = false) {
+ ResizeNearestNeighborOptionsBuilder builder_(_fbb);
+ builder_.add_half_pixel_centers(half_pixel_centers);
+ builder_.add_align_corners(align_corners);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ResizeNearestNeighborOptions> CreateResizeNearestNeighborOptions(flatbuffers::FlatBufferBuilder &_fbb, const ResizeNearestNeighborOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct CallOptionsT : public flatbuffers::NativeTable {
+ typedef CallOptions TableType;
+ uint32_t subgraph;
+ CallOptionsT()
+ : subgraph(0) {
+ }
+};
+
+struct CallOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef CallOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_SUBGRAPH = 4
+ };
+ uint32_t subgraph() const {
+ return GetField<uint32_t>(VT_SUBGRAPH, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint32_t>(verifier, VT_SUBGRAPH) &&
+ verifier.EndTable();
+ }
+ CallOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(CallOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<CallOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const CallOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct CallOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_subgraph(uint32_t subgraph) {
+ fbb_.AddElement<uint32_t>(CallOptions::VT_SUBGRAPH, subgraph, 0);
+ }
+ explicit CallOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ CallOptionsBuilder &operator=(const CallOptionsBuilder &);
+ flatbuffers::Offset<CallOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<CallOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<CallOptions> CreateCallOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ uint32_t subgraph = 0) {
+ CallOptionsBuilder builder_(_fbb);
+ builder_.add_subgraph(subgraph);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<CallOptions> CreateCallOptions(flatbuffers::FlatBufferBuilder &_fbb, const CallOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct PadOptionsT : public flatbuffers::NativeTable {
+ typedef PadOptions TableType;
+ PadOptionsT() {
+ }
+};
+
+struct PadOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef PadOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ PadOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(PadOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<PadOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const PadOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct PadOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit PadOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ PadOptionsBuilder &operator=(const PadOptionsBuilder &);
+ flatbuffers::Offset<PadOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<PadOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<PadOptions> CreatePadOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ PadOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<PadOptions> CreatePadOptions(flatbuffers::FlatBufferBuilder &_fbb, const PadOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct PadV2OptionsT : public flatbuffers::NativeTable {
+ typedef PadV2Options TableType;
+ PadV2OptionsT() {
+ }
+};
+
+struct PadV2Options FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef PadV2OptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ PadV2OptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(PadV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<PadV2Options> Pack(flatbuffers::FlatBufferBuilder &_fbb, const PadV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct PadV2OptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit PadV2OptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ PadV2OptionsBuilder &operator=(const PadV2OptionsBuilder &);
+ flatbuffers::Offset<PadV2Options> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<PadV2Options>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<PadV2Options> CreatePadV2Options(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ PadV2OptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<PadV2Options> CreatePadV2Options(flatbuffers::FlatBufferBuilder &_fbb, const PadV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ReshapeOptionsT : public flatbuffers::NativeTable {
+ typedef ReshapeOptions TableType;
+ std::vector<int32_t> new_shape;
+ ReshapeOptionsT() {
+ }
+};
+
+struct ReshapeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ReshapeOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NEW_SHAPE = 4
+ };
+ const flatbuffers::Vector<int32_t> *new_shape() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_NEW_SHAPE);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_NEW_SHAPE) &&
+ verifier.VerifyVector(new_shape()) &&
+ verifier.EndTable();
+ }
+ ReshapeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ReshapeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ReshapeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReshapeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ReshapeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_new_shape(flatbuffers::Offset<flatbuffers::Vector<int32_t>> new_shape) {
+ fbb_.AddOffset(ReshapeOptions::VT_NEW_SHAPE, new_shape);
+ }
+ explicit ReshapeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ReshapeOptionsBuilder &operator=(const ReshapeOptionsBuilder &);
+ flatbuffers::Offset<ReshapeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ReshapeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ReshapeOptions> CreateReshapeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> new_shape = 0) {
+ ReshapeOptionsBuilder builder_(_fbb);
+ builder_.add_new_shape(new_shape);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<ReshapeOptions> CreateReshapeOptionsDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<int32_t> *new_shape = nullptr) {
+ auto new_shape__ = new_shape ? _fbb.CreateVector<int32_t>(*new_shape) : 0;
+ return tflite::CreateReshapeOptions(
+ _fbb,
+ new_shape__);
+}
+
+flatbuffers::Offset<ReshapeOptions> CreateReshapeOptions(flatbuffers::FlatBufferBuilder &_fbb, const ReshapeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SpaceToBatchNDOptionsT : public flatbuffers::NativeTable {
+ typedef SpaceToBatchNDOptions TableType;
+ SpaceToBatchNDOptionsT() {
+ }
+};
+
+struct SpaceToBatchNDOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SpaceToBatchNDOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ SpaceToBatchNDOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SpaceToBatchNDOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SpaceToBatchNDOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToBatchNDOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SpaceToBatchNDOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit SpaceToBatchNDOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SpaceToBatchNDOptionsBuilder &operator=(const SpaceToBatchNDOptionsBuilder &);
+ flatbuffers::Offset<SpaceToBatchNDOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SpaceToBatchNDOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SpaceToBatchNDOptions> CreateSpaceToBatchNDOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ SpaceToBatchNDOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SpaceToBatchNDOptions> CreateSpaceToBatchNDOptions(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToBatchNDOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct BatchToSpaceNDOptionsT : public flatbuffers::NativeTable {
+ typedef BatchToSpaceNDOptions TableType;
+ BatchToSpaceNDOptionsT() {
+ }
+};
+
+struct BatchToSpaceNDOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef BatchToSpaceNDOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ BatchToSpaceNDOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(BatchToSpaceNDOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<BatchToSpaceNDOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const BatchToSpaceNDOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct BatchToSpaceNDOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit BatchToSpaceNDOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ BatchToSpaceNDOptionsBuilder &operator=(const BatchToSpaceNDOptionsBuilder &);
+ flatbuffers::Offset<BatchToSpaceNDOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<BatchToSpaceNDOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<BatchToSpaceNDOptions> CreateBatchToSpaceNDOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ BatchToSpaceNDOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<BatchToSpaceNDOptions> CreateBatchToSpaceNDOptions(flatbuffers::FlatBufferBuilder &_fbb, const BatchToSpaceNDOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SkipGramOptionsT : public flatbuffers::NativeTable {
+ typedef SkipGramOptions TableType;
+ int32_t ngram_size;
+ int32_t max_skip_size;
+ bool include_all_ngrams;
+ SkipGramOptionsT()
+ : ngram_size(0),
+ max_skip_size(0),
+ include_all_ngrams(false) {
+ }
+};
+
+struct SkipGramOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SkipGramOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NGRAM_SIZE = 4,
+ VT_MAX_SKIP_SIZE = 6,
+ VT_INCLUDE_ALL_NGRAMS = 8
+ };
+ int32_t ngram_size() const {
+ return GetField<int32_t>(VT_NGRAM_SIZE, 0);
+ }
+ int32_t max_skip_size() const {
+ return GetField<int32_t>(VT_MAX_SKIP_SIZE, 0);
+ }
+ bool include_all_ngrams() const {
+ return GetField<uint8_t>(VT_INCLUDE_ALL_NGRAMS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_NGRAM_SIZE) &&
+ VerifyField<int32_t>(verifier, VT_MAX_SKIP_SIZE) &&
+ VerifyField<uint8_t>(verifier, VT_INCLUDE_ALL_NGRAMS) &&
+ verifier.EndTable();
+ }
+ SkipGramOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SkipGramOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SkipGramOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SkipGramOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SkipGramOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_ngram_size(int32_t ngram_size) {
+ fbb_.AddElement<int32_t>(SkipGramOptions::VT_NGRAM_SIZE, ngram_size, 0);
+ }
+ void add_max_skip_size(int32_t max_skip_size) {
+ fbb_.AddElement<int32_t>(SkipGramOptions::VT_MAX_SKIP_SIZE, max_skip_size, 0);
+ }
+ void add_include_all_ngrams(bool include_all_ngrams) {
+ fbb_.AddElement<uint8_t>(SkipGramOptions::VT_INCLUDE_ALL_NGRAMS, static_cast<uint8_t>(include_all_ngrams), 0);
+ }
+ explicit SkipGramOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SkipGramOptionsBuilder &operator=(const SkipGramOptionsBuilder &);
+ flatbuffers::Offset<SkipGramOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SkipGramOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SkipGramOptions> CreateSkipGramOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t ngram_size = 0,
+ int32_t max_skip_size = 0,
+ bool include_all_ngrams = false) {
+ SkipGramOptionsBuilder builder_(_fbb);
+ builder_.add_max_skip_size(max_skip_size);
+ builder_.add_ngram_size(ngram_size);
+ builder_.add_include_all_ngrams(include_all_ngrams);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SkipGramOptions> CreateSkipGramOptions(flatbuffers::FlatBufferBuilder &_fbb, const SkipGramOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SpaceToDepthOptionsT : public flatbuffers::NativeTable {
+ typedef SpaceToDepthOptions TableType;
+ int32_t block_size;
+ SpaceToDepthOptionsT()
+ : block_size(0) {
+ }
+};
+
+struct SpaceToDepthOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SpaceToDepthOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_BLOCK_SIZE = 4
+ };
+ int32_t block_size() const {
+ return GetField<int32_t>(VT_BLOCK_SIZE, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_BLOCK_SIZE) &&
+ verifier.EndTable();
+ }
+ SpaceToDepthOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SpaceToDepthOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SpaceToDepthOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToDepthOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SpaceToDepthOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_block_size(int32_t block_size) {
+ fbb_.AddElement<int32_t>(SpaceToDepthOptions::VT_BLOCK_SIZE, block_size, 0);
+ }
+ explicit SpaceToDepthOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SpaceToDepthOptionsBuilder &operator=(const SpaceToDepthOptionsBuilder &);
+ flatbuffers::Offset<SpaceToDepthOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SpaceToDepthOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SpaceToDepthOptions> CreateSpaceToDepthOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t block_size = 0) {
+ SpaceToDepthOptionsBuilder builder_(_fbb);
+ builder_.add_block_size(block_size);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SpaceToDepthOptions> CreateSpaceToDepthOptions(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToDepthOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct DepthToSpaceOptionsT : public flatbuffers::NativeTable {
+ typedef DepthToSpaceOptions TableType;
+ int32_t block_size;
+ DepthToSpaceOptionsT()
+ : block_size(0) {
+ }
+};
+
+struct DepthToSpaceOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef DepthToSpaceOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_BLOCK_SIZE = 4
+ };
+ int32_t block_size() const {
+ return GetField<int32_t>(VT_BLOCK_SIZE, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_BLOCK_SIZE) &&
+ verifier.EndTable();
+ }
+ DepthToSpaceOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(DepthToSpaceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<DepthToSpaceOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const DepthToSpaceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct DepthToSpaceOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_block_size(int32_t block_size) {
+ fbb_.AddElement<int32_t>(DepthToSpaceOptions::VT_BLOCK_SIZE, block_size, 0);
+ }
+ explicit DepthToSpaceOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ DepthToSpaceOptionsBuilder &operator=(const DepthToSpaceOptionsBuilder &);
+ flatbuffers::Offset<DepthToSpaceOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<DepthToSpaceOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<DepthToSpaceOptions> CreateDepthToSpaceOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t block_size = 0) {
+ DepthToSpaceOptionsBuilder builder_(_fbb);
+ builder_.add_block_size(block_size);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<DepthToSpaceOptions> CreateDepthToSpaceOptions(flatbuffers::FlatBufferBuilder &_fbb, const DepthToSpaceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SubOptionsT : public flatbuffers::NativeTable {
+ typedef SubOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ bool pot_scale_int16;
+ SubOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE),
+ pot_scale_int16(true) {
+ }
+};
+
+struct SubOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SubOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4,
+ VT_POT_SCALE_INT16 = 6
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool pot_scale_int16() const {
+ return GetField<uint8_t>(VT_POT_SCALE_INT16, 1) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ VerifyField<uint8_t>(verifier, VT_POT_SCALE_INT16) &&
+ verifier.EndTable();
+ }
+ SubOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SubOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SubOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SubOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SubOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(SubOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ void add_pot_scale_int16(bool pot_scale_int16) {
+ fbb_.AddElement<uint8_t>(SubOptions::VT_POT_SCALE_INT16, static_cast<uint8_t>(pot_scale_int16), 1);
+ }
+ explicit SubOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SubOptionsBuilder &operator=(const SubOptionsBuilder &);
+ flatbuffers::Offset<SubOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SubOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SubOptions> CreateSubOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE,
+ bool pot_scale_int16 = true) {
+ SubOptionsBuilder builder_(_fbb);
+ builder_.add_pot_scale_int16(pot_scale_int16);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SubOptions> CreateSubOptions(flatbuffers::FlatBufferBuilder &_fbb, const SubOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct DivOptionsT : public flatbuffers::NativeTable {
+ typedef DivOptions TableType;
+ tflite::ActivationFunctionType fused_activation_function;
+ DivOptionsT()
+ : fused_activation_function(tflite::ActivationFunctionType_NONE) {
+ }
+};
+
+struct DivOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef DivOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_FUSED_ACTIVATION_FUNCTION = 4
+ };
+ tflite::ActivationFunctionType fused_activation_function() const {
+ return static_cast<tflite::ActivationFunctionType>(GetField<int8_t>(VT_FUSED_ACTIVATION_FUNCTION, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_FUSED_ACTIVATION_FUNCTION) &&
+ verifier.EndTable();
+ }
+ DivOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(DivOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<DivOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const DivOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct DivOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_fused_activation_function(tflite::ActivationFunctionType fused_activation_function) {
+ fbb_.AddElement<int8_t>(DivOptions::VT_FUSED_ACTIVATION_FUNCTION, static_cast<int8_t>(fused_activation_function), 0);
+ }
+ explicit DivOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ DivOptionsBuilder &operator=(const DivOptionsBuilder &);
+ flatbuffers::Offset<DivOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<DivOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<DivOptions> CreateDivOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::ActivationFunctionType fused_activation_function = tflite::ActivationFunctionType_NONE) {
+ DivOptionsBuilder builder_(_fbb);
+ builder_.add_fused_activation_function(fused_activation_function);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<DivOptions> CreateDivOptions(flatbuffers::FlatBufferBuilder &_fbb, const DivOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct TopKV2OptionsT : public flatbuffers::NativeTable {
+ typedef TopKV2Options TableType;
+ TopKV2OptionsT() {
+ }
+};
+
+struct TopKV2Options FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef TopKV2OptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ TopKV2OptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(TopKV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<TopKV2Options> Pack(flatbuffers::FlatBufferBuilder &_fbb, const TopKV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct TopKV2OptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit TopKV2OptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ TopKV2OptionsBuilder &operator=(const TopKV2OptionsBuilder &);
+ flatbuffers::Offset<TopKV2Options> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<TopKV2Options>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<TopKV2Options> CreateTopKV2Options(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ TopKV2OptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<TopKV2Options> CreateTopKV2Options(flatbuffers::FlatBufferBuilder &_fbb, const TopKV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct EmbeddingLookupSparseOptionsT : public flatbuffers::NativeTable {
+ typedef EmbeddingLookupSparseOptions TableType;
+ tflite::CombinerType combiner;
+ EmbeddingLookupSparseOptionsT()
+ : combiner(tflite::CombinerType_SUM) {
+ }
+};
+
+struct EmbeddingLookupSparseOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef EmbeddingLookupSparseOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_COMBINER = 4
+ };
+ tflite::CombinerType combiner() const {
+ return static_cast<tflite::CombinerType>(GetField<int8_t>(VT_COMBINER, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_COMBINER) &&
+ verifier.EndTable();
+ }
+ EmbeddingLookupSparseOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(EmbeddingLookupSparseOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<EmbeddingLookupSparseOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const EmbeddingLookupSparseOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct EmbeddingLookupSparseOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_combiner(tflite::CombinerType combiner) {
+ fbb_.AddElement<int8_t>(EmbeddingLookupSparseOptions::VT_COMBINER, static_cast<int8_t>(combiner), 0);
+ }
+ explicit EmbeddingLookupSparseOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ EmbeddingLookupSparseOptionsBuilder &operator=(const EmbeddingLookupSparseOptionsBuilder &);
+ flatbuffers::Offset<EmbeddingLookupSparseOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<EmbeddingLookupSparseOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<EmbeddingLookupSparseOptions> CreateEmbeddingLookupSparseOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::CombinerType combiner = tflite::CombinerType_SUM) {
+ EmbeddingLookupSparseOptionsBuilder builder_(_fbb);
+ builder_.add_combiner(combiner);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<EmbeddingLookupSparseOptions> CreateEmbeddingLookupSparseOptions(flatbuffers::FlatBufferBuilder &_fbb, const EmbeddingLookupSparseOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct GatherOptionsT : public flatbuffers::NativeTable {
+ typedef GatherOptions TableType;
+ int32_t axis;
+ int32_t batch_dims;
+ GatherOptionsT()
+ : axis(0),
+ batch_dims(0) {
+ }
+};
+
+struct GatherOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef GatherOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_AXIS = 4,
+ VT_BATCH_DIMS = 6
+ };
+ int32_t axis() const {
+ return GetField<int32_t>(VT_AXIS, 0);
+ }
+ int32_t batch_dims() const {
+ return GetField<int32_t>(VT_BATCH_DIMS, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_AXIS) &&
+ VerifyField<int32_t>(verifier, VT_BATCH_DIMS) &&
+ verifier.EndTable();
+ }
+ GatherOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(GatherOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<GatherOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const GatherOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct GatherOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_axis(int32_t axis) {
+ fbb_.AddElement<int32_t>(GatherOptions::VT_AXIS, axis, 0);
+ }
+ void add_batch_dims(int32_t batch_dims) {
+ fbb_.AddElement<int32_t>(GatherOptions::VT_BATCH_DIMS, batch_dims, 0);
+ }
+ explicit GatherOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ GatherOptionsBuilder &operator=(const GatherOptionsBuilder &);
+ flatbuffers::Offset<GatherOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<GatherOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<GatherOptions> CreateGatherOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t axis = 0,
+ int32_t batch_dims = 0) {
+ GatherOptionsBuilder builder_(_fbb);
+ builder_.add_batch_dims(batch_dims);
+ builder_.add_axis(axis);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<GatherOptions> CreateGatherOptions(flatbuffers::FlatBufferBuilder &_fbb, const GatherOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct TransposeOptionsT : public flatbuffers::NativeTable {
+ typedef TransposeOptions TableType;
+ TransposeOptionsT() {
+ }
+};
+
+struct TransposeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef TransposeOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ TransposeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(TransposeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<TransposeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const TransposeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct TransposeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit TransposeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ TransposeOptionsBuilder &operator=(const TransposeOptionsBuilder &);
+ flatbuffers::Offset<TransposeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<TransposeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<TransposeOptions> CreateTransposeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ TransposeOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<TransposeOptions> CreateTransposeOptions(flatbuffers::FlatBufferBuilder &_fbb, const TransposeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ExpOptionsT : public flatbuffers::NativeTable {
+ typedef ExpOptions TableType;
+ ExpOptionsT() {
+ }
+};
+
+struct ExpOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ExpOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ ExpOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ExpOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ExpOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ExpOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ExpOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit ExpOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ExpOptionsBuilder &operator=(const ExpOptionsBuilder &);
+ flatbuffers::Offset<ExpOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ExpOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ExpOptions> CreateExpOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ ExpOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ExpOptions> CreateExpOptions(flatbuffers::FlatBufferBuilder &_fbb, const ExpOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct CosOptionsT : public flatbuffers::NativeTable {
+ typedef CosOptions TableType;
+ CosOptionsT() {
+ }
+};
+
+struct CosOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef CosOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ CosOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(CosOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<CosOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const CosOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct CosOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit CosOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ CosOptionsBuilder &operator=(const CosOptionsBuilder &);
+ flatbuffers::Offset<CosOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<CosOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<CosOptions> CreateCosOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ CosOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<CosOptions> CreateCosOptions(flatbuffers::FlatBufferBuilder &_fbb, const CosOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ReducerOptionsT : public flatbuffers::NativeTable {
+ typedef ReducerOptions TableType;
+ bool keep_dims;
+ ReducerOptionsT()
+ : keep_dims(false) {
+ }
+};
+
+struct ReducerOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ReducerOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_KEEP_DIMS = 4
+ };
+ bool keep_dims() const {
+ return GetField<uint8_t>(VT_KEEP_DIMS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_KEEP_DIMS) &&
+ verifier.EndTable();
+ }
+ ReducerOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ReducerOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ReducerOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReducerOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ReducerOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_keep_dims(bool keep_dims) {
+ fbb_.AddElement<uint8_t>(ReducerOptions::VT_KEEP_DIMS, static_cast<uint8_t>(keep_dims), 0);
+ }
+ explicit ReducerOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ReducerOptionsBuilder &operator=(const ReducerOptionsBuilder &);
+ flatbuffers::Offset<ReducerOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ReducerOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ReducerOptions> CreateReducerOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool keep_dims = false) {
+ ReducerOptionsBuilder builder_(_fbb);
+ builder_.add_keep_dims(keep_dims);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ReducerOptions> CreateReducerOptions(flatbuffers::FlatBufferBuilder &_fbb, const ReducerOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SqueezeOptionsT : public flatbuffers::NativeTable {
+ typedef SqueezeOptions TableType;
+ std::vector<int32_t> squeeze_dims;
+ SqueezeOptionsT() {
+ }
+};
+
+struct SqueezeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SqueezeOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_SQUEEZE_DIMS = 4
+ };
+ const flatbuffers::Vector<int32_t> *squeeze_dims() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_SQUEEZE_DIMS);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_SQUEEZE_DIMS) &&
+ verifier.VerifyVector(squeeze_dims()) &&
+ verifier.EndTable();
+ }
+ SqueezeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SqueezeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SqueezeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SqueezeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SqueezeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_squeeze_dims(flatbuffers::Offset<flatbuffers::Vector<int32_t>> squeeze_dims) {
+ fbb_.AddOffset(SqueezeOptions::VT_SQUEEZE_DIMS, squeeze_dims);
+ }
+ explicit SqueezeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SqueezeOptionsBuilder &operator=(const SqueezeOptionsBuilder &);
+ flatbuffers::Offset<SqueezeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SqueezeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SqueezeOptions> CreateSqueezeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> squeeze_dims = 0) {
+ SqueezeOptionsBuilder builder_(_fbb);
+ builder_.add_squeeze_dims(squeeze_dims);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<SqueezeOptions> CreateSqueezeOptionsDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<int32_t> *squeeze_dims = nullptr) {
+ auto squeeze_dims__ = squeeze_dims ? _fbb.CreateVector<int32_t>(*squeeze_dims) : 0;
+ return tflite::CreateSqueezeOptions(
+ _fbb,
+ squeeze_dims__);
+}
+
+flatbuffers::Offset<SqueezeOptions> CreateSqueezeOptions(flatbuffers::FlatBufferBuilder &_fbb, const SqueezeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SplitOptionsT : public flatbuffers::NativeTable {
+ typedef SplitOptions TableType;
+ int32_t num_splits;
+ SplitOptionsT()
+ : num_splits(0) {
+ }
+};
+
+struct SplitOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SplitOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NUM_SPLITS = 4
+ };
+ int32_t num_splits() const {
+ return GetField<int32_t>(VT_NUM_SPLITS, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_NUM_SPLITS) &&
+ verifier.EndTable();
+ }
+ SplitOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SplitOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SplitOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SplitOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SplitOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_num_splits(int32_t num_splits) {
+ fbb_.AddElement<int32_t>(SplitOptions::VT_NUM_SPLITS, num_splits, 0);
+ }
+ explicit SplitOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SplitOptionsBuilder &operator=(const SplitOptionsBuilder &);
+ flatbuffers::Offset<SplitOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SplitOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SplitOptions> CreateSplitOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t num_splits = 0) {
+ SplitOptionsBuilder builder_(_fbb);
+ builder_.add_num_splits(num_splits);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SplitOptions> CreateSplitOptions(flatbuffers::FlatBufferBuilder &_fbb, const SplitOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SplitVOptionsT : public flatbuffers::NativeTable {
+ typedef SplitVOptions TableType;
+ int32_t num_splits;
+ SplitVOptionsT()
+ : num_splits(0) {
+ }
+};
+
+struct SplitVOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SplitVOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NUM_SPLITS = 4
+ };
+ int32_t num_splits() const {
+ return GetField<int32_t>(VT_NUM_SPLITS, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_NUM_SPLITS) &&
+ verifier.EndTable();
+ }
+ SplitVOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SplitVOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SplitVOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SplitVOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SplitVOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_num_splits(int32_t num_splits) {
+ fbb_.AddElement<int32_t>(SplitVOptions::VT_NUM_SPLITS, num_splits, 0);
+ }
+ explicit SplitVOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SplitVOptionsBuilder &operator=(const SplitVOptionsBuilder &);
+ flatbuffers::Offset<SplitVOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SplitVOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SplitVOptions> CreateSplitVOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t num_splits = 0) {
+ SplitVOptionsBuilder builder_(_fbb);
+ builder_.add_num_splits(num_splits);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SplitVOptions> CreateSplitVOptions(flatbuffers::FlatBufferBuilder &_fbb, const SplitVOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct StridedSliceOptionsT : public flatbuffers::NativeTable {
+ typedef StridedSliceOptions TableType;
+ int32_t begin_mask;
+ int32_t end_mask;
+ int32_t ellipsis_mask;
+ int32_t new_axis_mask;
+ int32_t shrink_axis_mask;
+ StridedSliceOptionsT()
+ : begin_mask(0),
+ end_mask(0),
+ ellipsis_mask(0),
+ new_axis_mask(0),
+ shrink_axis_mask(0) {
+ }
+};
+
+struct StridedSliceOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef StridedSliceOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_BEGIN_MASK = 4,
+ VT_END_MASK = 6,
+ VT_ELLIPSIS_MASK = 8,
+ VT_NEW_AXIS_MASK = 10,
+ VT_SHRINK_AXIS_MASK = 12
+ };
+ int32_t begin_mask() const {
+ return GetField<int32_t>(VT_BEGIN_MASK, 0);
+ }
+ int32_t end_mask() const {
+ return GetField<int32_t>(VT_END_MASK, 0);
+ }
+ int32_t ellipsis_mask() const {
+ return GetField<int32_t>(VT_ELLIPSIS_MASK, 0);
+ }
+ int32_t new_axis_mask() const {
+ return GetField<int32_t>(VT_NEW_AXIS_MASK, 0);
+ }
+ int32_t shrink_axis_mask() const {
+ return GetField<int32_t>(VT_SHRINK_AXIS_MASK, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_BEGIN_MASK) &&
+ VerifyField<int32_t>(verifier, VT_END_MASK) &&
+ VerifyField<int32_t>(verifier, VT_ELLIPSIS_MASK) &&
+ VerifyField<int32_t>(verifier, VT_NEW_AXIS_MASK) &&
+ VerifyField<int32_t>(verifier, VT_SHRINK_AXIS_MASK) &&
+ verifier.EndTable();
+ }
+ StridedSliceOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(StridedSliceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<StridedSliceOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const StridedSliceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct StridedSliceOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_begin_mask(int32_t begin_mask) {
+ fbb_.AddElement<int32_t>(StridedSliceOptions::VT_BEGIN_MASK, begin_mask, 0);
+ }
+ void add_end_mask(int32_t end_mask) {
+ fbb_.AddElement<int32_t>(StridedSliceOptions::VT_END_MASK, end_mask, 0);
+ }
+ void add_ellipsis_mask(int32_t ellipsis_mask) {
+ fbb_.AddElement<int32_t>(StridedSliceOptions::VT_ELLIPSIS_MASK, ellipsis_mask, 0);
+ }
+ void add_new_axis_mask(int32_t new_axis_mask) {
+ fbb_.AddElement<int32_t>(StridedSliceOptions::VT_NEW_AXIS_MASK, new_axis_mask, 0);
+ }
+ void add_shrink_axis_mask(int32_t shrink_axis_mask) {
+ fbb_.AddElement<int32_t>(StridedSliceOptions::VT_SHRINK_AXIS_MASK, shrink_axis_mask, 0);
+ }
+ explicit StridedSliceOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ StridedSliceOptionsBuilder &operator=(const StridedSliceOptionsBuilder &);
+ flatbuffers::Offset<StridedSliceOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<StridedSliceOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<StridedSliceOptions> CreateStridedSliceOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t begin_mask = 0,
+ int32_t end_mask = 0,
+ int32_t ellipsis_mask = 0,
+ int32_t new_axis_mask = 0,
+ int32_t shrink_axis_mask = 0) {
+ StridedSliceOptionsBuilder builder_(_fbb);
+ builder_.add_shrink_axis_mask(shrink_axis_mask);
+ builder_.add_new_axis_mask(new_axis_mask);
+ builder_.add_ellipsis_mask(ellipsis_mask);
+ builder_.add_end_mask(end_mask);
+ builder_.add_begin_mask(begin_mask);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<StridedSliceOptions> CreateStridedSliceOptions(flatbuffers::FlatBufferBuilder &_fbb, const StridedSliceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LogSoftmaxOptionsT : public flatbuffers::NativeTable {
+ typedef LogSoftmaxOptions TableType;
+ LogSoftmaxOptionsT() {
+ }
+};
+
+struct LogSoftmaxOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LogSoftmaxOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ LogSoftmaxOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LogSoftmaxOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LogSoftmaxOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogSoftmaxOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LogSoftmaxOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit LogSoftmaxOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LogSoftmaxOptionsBuilder &operator=(const LogSoftmaxOptionsBuilder &);
+ flatbuffers::Offset<LogSoftmaxOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LogSoftmaxOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LogSoftmaxOptions> CreateLogSoftmaxOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ LogSoftmaxOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LogSoftmaxOptions> CreateLogSoftmaxOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogSoftmaxOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct CastOptionsT : public flatbuffers::NativeTable {
+ typedef CastOptions TableType;
+ tflite::TensorType in_data_type;
+ tflite::TensorType out_data_type;
+ CastOptionsT()
+ : in_data_type(tflite::TensorType_FLOAT32),
+ out_data_type(tflite::TensorType_FLOAT32) {
+ }
+};
+
+struct CastOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef CastOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_IN_DATA_TYPE = 4,
+ VT_OUT_DATA_TYPE = 6
+ };
+ tflite::TensorType in_data_type() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_IN_DATA_TYPE, 0));
+ }
+ tflite::TensorType out_data_type() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_OUT_DATA_TYPE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_IN_DATA_TYPE) &&
+ VerifyField<int8_t>(verifier, VT_OUT_DATA_TYPE) &&
+ verifier.EndTable();
+ }
+ CastOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(CastOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<CastOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const CastOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct CastOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_in_data_type(tflite::TensorType in_data_type) {
+ fbb_.AddElement<int8_t>(CastOptions::VT_IN_DATA_TYPE, static_cast<int8_t>(in_data_type), 0);
+ }
+ void add_out_data_type(tflite::TensorType out_data_type) {
+ fbb_.AddElement<int8_t>(CastOptions::VT_OUT_DATA_TYPE, static_cast<int8_t>(out_data_type), 0);
+ }
+ explicit CastOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ CastOptionsBuilder &operator=(const CastOptionsBuilder &);
+ flatbuffers::Offset<CastOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<CastOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<CastOptions> CreateCastOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::TensorType in_data_type = tflite::TensorType_FLOAT32,
+ tflite::TensorType out_data_type = tflite::TensorType_FLOAT32) {
+ CastOptionsBuilder builder_(_fbb);
+ builder_.add_out_data_type(out_data_type);
+ builder_.add_in_data_type(in_data_type);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<CastOptions> CreateCastOptions(flatbuffers::FlatBufferBuilder &_fbb, const CastOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct DequantizeOptionsT : public flatbuffers::NativeTable {
+ typedef DequantizeOptions TableType;
+ DequantizeOptionsT() {
+ }
+};
+
+struct DequantizeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef DequantizeOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ DequantizeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(DequantizeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<DequantizeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const DequantizeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct DequantizeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit DequantizeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ DequantizeOptionsBuilder &operator=(const DequantizeOptionsBuilder &);
+ flatbuffers::Offset<DequantizeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<DequantizeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<DequantizeOptions> CreateDequantizeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ DequantizeOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<DequantizeOptions> CreateDequantizeOptions(flatbuffers::FlatBufferBuilder &_fbb, const DequantizeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct MaximumMinimumOptionsT : public flatbuffers::NativeTable {
+ typedef MaximumMinimumOptions TableType;
+ MaximumMinimumOptionsT() {
+ }
+};
+
+struct MaximumMinimumOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef MaximumMinimumOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ MaximumMinimumOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(MaximumMinimumOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<MaximumMinimumOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const MaximumMinimumOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct MaximumMinimumOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit MaximumMinimumOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ MaximumMinimumOptionsBuilder &operator=(const MaximumMinimumOptionsBuilder &);
+ flatbuffers::Offset<MaximumMinimumOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<MaximumMinimumOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<MaximumMinimumOptions> CreateMaximumMinimumOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ MaximumMinimumOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<MaximumMinimumOptions> CreateMaximumMinimumOptions(flatbuffers::FlatBufferBuilder &_fbb, const MaximumMinimumOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct TileOptionsT : public flatbuffers::NativeTable {
+ typedef TileOptions TableType;
+ TileOptionsT() {
+ }
+};
+
+struct TileOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef TileOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ TileOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(TileOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<TileOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const TileOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct TileOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit TileOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ TileOptionsBuilder &operator=(const TileOptionsBuilder &);
+ flatbuffers::Offset<TileOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<TileOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<TileOptions> CreateTileOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ TileOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<TileOptions> CreateTileOptions(flatbuffers::FlatBufferBuilder &_fbb, const TileOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ArgMaxOptionsT : public flatbuffers::NativeTable {
+ typedef ArgMaxOptions TableType;
+ tflite::TensorType output_type;
+ ArgMaxOptionsT()
+ : output_type(tflite::TensorType_FLOAT32) {
+ }
+};
+
+struct ArgMaxOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ArgMaxOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_OUTPUT_TYPE = 4
+ };
+ tflite::TensorType output_type() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_OUTPUT_TYPE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_OUTPUT_TYPE) &&
+ verifier.EndTable();
+ }
+ ArgMaxOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ArgMaxOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ArgMaxOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ArgMaxOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ArgMaxOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_output_type(tflite::TensorType output_type) {
+ fbb_.AddElement<int8_t>(ArgMaxOptions::VT_OUTPUT_TYPE, static_cast<int8_t>(output_type), 0);
+ }
+ explicit ArgMaxOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ArgMaxOptionsBuilder &operator=(const ArgMaxOptionsBuilder &);
+ flatbuffers::Offset<ArgMaxOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ArgMaxOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ArgMaxOptions> CreateArgMaxOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::TensorType output_type = tflite::TensorType_FLOAT32) {
+ ArgMaxOptionsBuilder builder_(_fbb);
+ builder_.add_output_type(output_type);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ArgMaxOptions> CreateArgMaxOptions(flatbuffers::FlatBufferBuilder &_fbb, const ArgMaxOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ArgMinOptionsT : public flatbuffers::NativeTable {
+ typedef ArgMinOptions TableType;
+ tflite::TensorType output_type;
+ ArgMinOptionsT()
+ : output_type(tflite::TensorType_FLOAT32) {
+ }
+};
+
+struct ArgMinOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ArgMinOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_OUTPUT_TYPE = 4
+ };
+ tflite::TensorType output_type() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_OUTPUT_TYPE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_OUTPUT_TYPE) &&
+ verifier.EndTable();
+ }
+ ArgMinOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ArgMinOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ArgMinOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ArgMinOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_output_type(tflite::TensorType output_type) {
+ fbb_.AddElement<int8_t>(ArgMinOptions::VT_OUTPUT_TYPE, static_cast<int8_t>(output_type), 0);
+ }
+ explicit ArgMinOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ArgMinOptionsBuilder &operator=(const ArgMinOptionsBuilder &);
+ flatbuffers::Offset<ArgMinOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ArgMinOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ArgMinOptions> CreateArgMinOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::TensorType output_type = tflite::TensorType_FLOAT32) {
+ ArgMinOptionsBuilder builder_(_fbb);
+ builder_.add_output_type(output_type);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ArgMinOptions> CreateArgMinOptions(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct GreaterOptionsT : public flatbuffers::NativeTable {
+ typedef GreaterOptions TableType;
+ GreaterOptionsT() {
+ }
+};
+
+struct GreaterOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef GreaterOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ GreaterOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(GreaterOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<GreaterOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const GreaterOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct GreaterOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit GreaterOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ GreaterOptionsBuilder &operator=(const GreaterOptionsBuilder &);
+ flatbuffers::Offset<GreaterOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<GreaterOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<GreaterOptions> CreateGreaterOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ GreaterOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<GreaterOptions> CreateGreaterOptions(flatbuffers::FlatBufferBuilder &_fbb, const GreaterOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct GreaterEqualOptionsT : public flatbuffers::NativeTable {
+ typedef GreaterEqualOptions TableType;
+ GreaterEqualOptionsT() {
+ }
+};
+
+struct GreaterEqualOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef GreaterEqualOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ GreaterEqualOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(GreaterEqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<GreaterEqualOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const GreaterEqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct GreaterEqualOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit GreaterEqualOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ GreaterEqualOptionsBuilder &operator=(const GreaterEqualOptionsBuilder &);
+ flatbuffers::Offset<GreaterEqualOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<GreaterEqualOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<GreaterEqualOptions> CreateGreaterEqualOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ GreaterEqualOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<GreaterEqualOptions> CreateGreaterEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const GreaterEqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LessOptionsT : public flatbuffers::NativeTable {
+ typedef LessOptions TableType;
+ LessOptionsT() {
+ }
+};
+
+struct LessOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LessOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ LessOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LessOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LessOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LessOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LessOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit LessOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LessOptionsBuilder &operator=(const LessOptionsBuilder &);
+ flatbuffers::Offset<LessOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LessOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LessOptions> CreateLessOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ LessOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LessOptions> CreateLessOptions(flatbuffers::FlatBufferBuilder &_fbb, const LessOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LessEqualOptionsT : public flatbuffers::NativeTable {
+ typedef LessEqualOptions TableType;
+ LessEqualOptionsT() {
+ }
+};
+
+struct LessEqualOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LessEqualOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ LessEqualOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LessEqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LessEqualOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LessEqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LessEqualOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit LessEqualOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LessEqualOptionsBuilder &operator=(const LessEqualOptionsBuilder &);
+ flatbuffers::Offset<LessEqualOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LessEqualOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LessEqualOptions> CreateLessEqualOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ LessEqualOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LessEqualOptions> CreateLessEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const LessEqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct NegOptionsT : public flatbuffers::NativeTable {
+ typedef NegOptions TableType;
+ NegOptionsT() {
+ }
+};
+
+struct NegOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef NegOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ NegOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(NegOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<NegOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const NegOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct NegOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit NegOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ NegOptionsBuilder &operator=(const NegOptionsBuilder &);
+ flatbuffers::Offset<NegOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<NegOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<NegOptions> CreateNegOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ NegOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<NegOptions> CreateNegOptions(flatbuffers::FlatBufferBuilder &_fbb, const NegOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SelectOptionsT : public flatbuffers::NativeTable {
+ typedef SelectOptions TableType;
+ SelectOptionsT() {
+ }
+};
+
+struct SelectOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SelectOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ SelectOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SelectOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SelectOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SelectOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SelectOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit SelectOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SelectOptionsBuilder &operator=(const SelectOptionsBuilder &);
+ flatbuffers::Offset<SelectOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SelectOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SelectOptions> CreateSelectOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ SelectOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SelectOptions> CreateSelectOptions(flatbuffers::FlatBufferBuilder &_fbb, const SelectOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SliceOptionsT : public flatbuffers::NativeTable {
+ typedef SliceOptions TableType;
+ SliceOptionsT() {
+ }
+};
+
+struct SliceOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SliceOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ SliceOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SliceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SliceOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SliceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SliceOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit SliceOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SliceOptionsBuilder &operator=(const SliceOptionsBuilder &);
+ flatbuffers::Offset<SliceOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SliceOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SliceOptions> CreateSliceOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ SliceOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SliceOptions> CreateSliceOptions(flatbuffers::FlatBufferBuilder &_fbb, const SliceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct TransposeConvOptionsT : public flatbuffers::NativeTable {
+ typedef TransposeConvOptions TableType;
+ tflite::Padding padding;
+ int32_t stride_w;
+ int32_t stride_h;
+ TransposeConvOptionsT()
+ : padding(tflite::Padding_SAME),
+ stride_w(0),
+ stride_h(0) {
+ }
+};
+
+struct TransposeConvOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef TransposeConvOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_PADDING = 4,
+ VT_STRIDE_W = 6,
+ VT_STRIDE_H = 8
+ };
+ tflite::Padding padding() const {
+ return static_cast<tflite::Padding>(GetField<int8_t>(VT_PADDING, 0));
+ }
+ int32_t stride_w() const {
+ return GetField<int32_t>(VT_STRIDE_W, 0);
+ }
+ int32_t stride_h() const {
+ return GetField<int32_t>(VT_STRIDE_H, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_PADDING) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_W) &&
+ VerifyField<int32_t>(verifier, VT_STRIDE_H) &&
+ verifier.EndTable();
+ }
+ TransposeConvOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(TransposeConvOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<TransposeConvOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const TransposeConvOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct TransposeConvOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_padding(tflite::Padding padding) {
+ fbb_.AddElement<int8_t>(TransposeConvOptions::VT_PADDING, static_cast<int8_t>(padding), 0);
+ }
+ void add_stride_w(int32_t stride_w) {
+ fbb_.AddElement<int32_t>(TransposeConvOptions::VT_STRIDE_W, stride_w, 0);
+ }
+ void add_stride_h(int32_t stride_h) {
+ fbb_.AddElement<int32_t>(TransposeConvOptions::VT_STRIDE_H, stride_h, 0);
+ }
+ explicit TransposeConvOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ TransposeConvOptionsBuilder &operator=(const TransposeConvOptionsBuilder &);
+ flatbuffers::Offset<TransposeConvOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<TransposeConvOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<TransposeConvOptions> CreateTransposeConvOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::Padding padding = tflite::Padding_SAME,
+ int32_t stride_w = 0,
+ int32_t stride_h = 0) {
+ TransposeConvOptionsBuilder builder_(_fbb);
+ builder_.add_stride_h(stride_h);
+ builder_.add_stride_w(stride_w);
+ builder_.add_padding(padding);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<TransposeConvOptions> CreateTransposeConvOptions(flatbuffers::FlatBufferBuilder &_fbb, const TransposeConvOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ExpandDimsOptionsT : public flatbuffers::NativeTable {
+ typedef ExpandDimsOptions TableType;
+ ExpandDimsOptionsT() {
+ }
+};
+
+struct ExpandDimsOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ExpandDimsOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ ExpandDimsOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ExpandDimsOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ExpandDimsOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ExpandDimsOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ExpandDimsOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit ExpandDimsOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ExpandDimsOptionsBuilder &operator=(const ExpandDimsOptionsBuilder &);
+ flatbuffers::Offset<ExpandDimsOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ExpandDimsOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ExpandDimsOptions> CreateExpandDimsOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ ExpandDimsOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ExpandDimsOptions> CreateExpandDimsOptions(flatbuffers::FlatBufferBuilder &_fbb, const ExpandDimsOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SparseToDenseOptionsT : public flatbuffers::NativeTable {
+ typedef SparseToDenseOptions TableType;
+ bool validate_indices;
+ SparseToDenseOptionsT()
+ : validate_indices(false) {
+ }
+};
+
+struct SparseToDenseOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SparseToDenseOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_VALIDATE_INDICES = 4
+ };
+ bool validate_indices() const {
+ return GetField<uint8_t>(VT_VALIDATE_INDICES, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_VALIDATE_INDICES) &&
+ verifier.EndTable();
+ }
+ SparseToDenseOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SparseToDenseOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SparseToDenseOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SparseToDenseOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SparseToDenseOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_validate_indices(bool validate_indices) {
+ fbb_.AddElement<uint8_t>(SparseToDenseOptions::VT_VALIDATE_INDICES, static_cast<uint8_t>(validate_indices), 0);
+ }
+ explicit SparseToDenseOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SparseToDenseOptionsBuilder &operator=(const SparseToDenseOptionsBuilder &);
+ flatbuffers::Offset<SparseToDenseOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SparseToDenseOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SparseToDenseOptions> CreateSparseToDenseOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool validate_indices = false) {
+ SparseToDenseOptionsBuilder builder_(_fbb);
+ builder_.add_validate_indices(validate_indices);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SparseToDenseOptions> CreateSparseToDenseOptions(flatbuffers::FlatBufferBuilder &_fbb, const SparseToDenseOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct EqualOptionsT : public flatbuffers::NativeTable {
+ typedef EqualOptions TableType;
+ EqualOptionsT() {
+ }
+};
+
+struct EqualOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef EqualOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ EqualOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(EqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<EqualOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const EqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct EqualOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit EqualOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ EqualOptionsBuilder &operator=(const EqualOptionsBuilder &);
+ flatbuffers::Offset<EqualOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<EqualOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<EqualOptions> CreateEqualOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ EqualOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<EqualOptions> CreateEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const EqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct NotEqualOptionsT : public flatbuffers::NativeTable {
+ typedef NotEqualOptions TableType;
+ NotEqualOptionsT() {
+ }
+};
+
+struct NotEqualOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef NotEqualOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ NotEqualOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(NotEqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<NotEqualOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const NotEqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct NotEqualOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit NotEqualOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ NotEqualOptionsBuilder &operator=(const NotEqualOptionsBuilder &);
+ flatbuffers::Offset<NotEqualOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<NotEqualOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<NotEqualOptions> CreateNotEqualOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ NotEqualOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<NotEqualOptions> CreateNotEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const NotEqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ShapeOptionsT : public flatbuffers::NativeTable {
+ typedef ShapeOptions TableType;
+ tflite::TensorType out_type;
+ ShapeOptionsT()
+ : out_type(tflite::TensorType_FLOAT32) {
+ }
+};
+
+struct ShapeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ShapeOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_OUT_TYPE = 4
+ };
+ tflite::TensorType out_type() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_OUT_TYPE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_OUT_TYPE) &&
+ verifier.EndTable();
+ }
+ ShapeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ShapeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ShapeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ShapeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ShapeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_out_type(tflite::TensorType out_type) {
+ fbb_.AddElement<int8_t>(ShapeOptions::VT_OUT_TYPE, static_cast<int8_t>(out_type), 0);
+ }
+ explicit ShapeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ShapeOptionsBuilder &operator=(const ShapeOptionsBuilder &);
+ flatbuffers::Offset<ShapeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ShapeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ShapeOptions> CreateShapeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::TensorType out_type = tflite::TensorType_FLOAT32) {
+ ShapeOptionsBuilder builder_(_fbb);
+ builder_.add_out_type(out_type);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ShapeOptions> CreateShapeOptions(flatbuffers::FlatBufferBuilder &_fbb, const ShapeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct RankOptionsT : public flatbuffers::NativeTable {
+ typedef RankOptions TableType;
+ RankOptionsT() {
+ }
+};
+
+struct RankOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef RankOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ RankOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(RankOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<RankOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const RankOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct RankOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit RankOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ RankOptionsBuilder &operator=(const RankOptionsBuilder &);
+ flatbuffers::Offset<RankOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<RankOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<RankOptions> CreateRankOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ RankOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<RankOptions> CreateRankOptions(flatbuffers::FlatBufferBuilder &_fbb, const RankOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct PowOptionsT : public flatbuffers::NativeTable {
+ typedef PowOptions TableType;
+ PowOptionsT() {
+ }
+};
+
+struct PowOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef PowOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ PowOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(PowOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<PowOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const PowOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct PowOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit PowOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ PowOptionsBuilder &operator=(const PowOptionsBuilder &);
+ flatbuffers::Offset<PowOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<PowOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<PowOptions> CreatePowOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ PowOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<PowOptions> CreatePowOptions(flatbuffers::FlatBufferBuilder &_fbb, const PowOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct FakeQuantOptionsT : public flatbuffers::NativeTable {
+ typedef FakeQuantOptions TableType;
+ float min;
+ float max;
+ int32_t num_bits;
+ bool narrow_range;
+ FakeQuantOptionsT()
+ : min(0.0f),
+ max(0.0f),
+ num_bits(0),
+ narrow_range(false) {
+ }
+};
+
+struct FakeQuantOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef FakeQuantOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_MIN = 4,
+ VT_MAX = 6,
+ VT_NUM_BITS = 8,
+ VT_NARROW_RANGE = 10
+ };
+ float min() const {
+ return GetField<float>(VT_MIN, 0.0f);
+ }
+ float max() const {
+ return GetField<float>(VT_MAX, 0.0f);
+ }
+ int32_t num_bits() const {
+ return GetField<int32_t>(VT_NUM_BITS, 0);
+ }
+ bool narrow_range() const {
+ return GetField<uint8_t>(VT_NARROW_RANGE, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<float>(verifier, VT_MIN) &&
+ VerifyField<float>(verifier, VT_MAX) &&
+ VerifyField<int32_t>(verifier, VT_NUM_BITS) &&
+ VerifyField<uint8_t>(verifier, VT_NARROW_RANGE) &&
+ verifier.EndTable();
+ }
+ FakeQuantOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(FakeQuantOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<FakeQuantOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct FakeQuantOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_min(float min) {
+ fbb_.AddElement<float>(FakeQuantOptions::VT_MIN, min, 0.0f);
+ }
+ void add_max(float max) {
+ fbb_.AddElement<float>(FakeQuantOptions::VT_MAX, max, 0.0f);
+ }
+ void add_num_bits(int32_t num_bits) {
+ fbb_.AddElement<int32_t>(FakeQuantOptions::VT_NUM_BITS, num_bits, 0);
+ }
+ void add_narrow_range(bool narrow_range) {
+ fbb_.AddElement<uint8_t>(FakeQuantOptions::VT_NARROW_RANGE, static_cast<uint8_t>(narrow_range), 0);
+ }
+ explicit FakeQuantOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ FakeQuantOptionsBuilder &operator=(const FakeQuantOptionsBuilder &);
+ flatbuffers::Offset<FakeQuantOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<FakeQuantOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<FakeQuantOptions> CreateFakeQuantOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ float min = 0.0f,
+ float max = 0.0f,
+ int32_t num_bits = 0,
+ bool narrow_range = false) {
+ FakeQuantOptionsBuilder builder_(_fbb);
+ builder_.add_num_bits(num_bits);
+ builder_.add_max(max);
+ builder_.add_min(min);
+ builder_.add_narrow_range(narrow_range);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<FakeQuantOptions> CreateFakeQuantOptions(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct PackOptionsT : public flatbuffers::NativeTable {
+ typedef PackOptions TableType;
+ int32_t values_count;
+ int32_t axis;
+ PackOptionsT()
+ : values_count(0),
+ axis(0) {
+ }
+};
+
+struct PackOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef PackOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_VALUES_COUNT = 4,
+ VT_AXIS = 6
+ };
+ int32_t values_count() const {
+ return GetField<int32_t>(VT_VALUES_COUNT, 0);
+ }
+ int32_t axis() const {
+ return GetField<int32_t>(VT_AXIS, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_VALUES_COUNT) &&
+ VerifyField<int32_t>(verifier, VT_AXIS) &&
+ verifier.EndTable();
+ }
+ PackOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(PackOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<PackOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const PackOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct PackOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_values_count(int32_t values_count) {
+ fbb_.AddElement<int32_t>(PackOptions::VT_VALUES_COUNT, values_count, 0);
+ }
+ void add_axis(int32_t axis) {
+ fbb_.AddElement<int32_t>(PackOptions::VT_AXIS, axis, 0);
+ }
+ explicit PackOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ PackOptionsBuilder &operator=(const PackOptionsBuilder &);
+ flatbuffers::Offset<PackOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<PackOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<PackOptions> CreatePackOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t values_count = 0,
+ int32_t axis = 0) {
+ PackOptionsBuilder builder_(_fbb);
+ builder_.add_axis(axis);
+ builder_.add_values_count(values_count);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<PackOptions> CreatePackOptions(flatbuffers::FlatBufferBuilder &_fbb, const PackOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LogicalOrOptionsT : public flatbuffers::NativeTable {
+ typedef LogicalOrOptions TableType;
+ LogicalOrOptionsT() {
+ }
+};
+
+struct LogicalOrOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LogicalOrOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ LogicalOrOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LogicalOrOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LogicalOrOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogicalOrOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LogicalOrOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit LogicalOrOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LogicalOrOptionsBuilder &operator=(const LogicalOrOptionsBuilder &);
+ flatbuffers::Offset<LogicalOrOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LogicalOrOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LogicalOrOptions> CreateLogicalOrOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ LogicalOrOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LogicalOrOptions> CreateLogicalOrOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogicalOrOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct OneHotOptionsT : public flatbuffers::NativeTable {
+ typedef OneHotOptions TableType;
+ int32_t axis;
+ OneHotOptionsT()
+ : axis(0) {
+ }
+};
+
+struct OneHotOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef OneHotOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_AXIS = 4
+ };
+ int32_t axis() const {
+ return GetField<int32_t>(VT_AXIS, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_AXIS) &&
+ verifier.EndTable();
+ }
+ OneHotOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(OneHotOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<OneHotOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const OneHotOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct OneHotOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_axis(int32_t axis) {
+ fbb_.AddElement<int32_t>(OneHotOptions::VT_AXIS, axis, 0);
+ }
+ explicit OneHotOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ OneHotOptionsBuilder &operator=(const OneHotOptionsBuilder &);
+ flatbuffers::Offset<OneHotOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<OneHotOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<OneHotOptions> CreateOneHotOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t axis = 0) {
+ OneHotOptionsBuilder builder_(_fbb);
+ builder_.add_axis(axis);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<OneHotOptions> CreateOneHotOptions(flatbuffers::FlatBufferBuilder &_fbb, const OneHotOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct AbsOptionsT : public flatbuffers::NativeTable {
+ typedef AbsOptions TableType;
+ AbsOptionsT() {
+ }
+};
+
+struct AbsOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef AbsOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ AbsOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(AbsOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<AbsOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const AbsOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct AbsOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit AbsOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ AbsOptionsBuilder &operator=(const AbsOptionsBuilder &);
+ flatbuffers::Offset<AbsOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<AbsOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<AbsOptions> CreateAbsOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ AbsOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<AbsOptions> CreateAbsOptions(flatbuffers::FlatBufferBuilder &_fbb, const AbsOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct HardSwishOptionsT : public flatbuffers::NativeTable {
+ typedef HardSwishOptions TableType;
+ HardSwishOptionsT() {
+ }
+};
+
+struct HardSwishOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef HardSwishOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ HardSwishOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(HardSwishOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<HardSwishOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const HardSwishOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct HardSwishOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit HardSwishOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ HardSwishOptionsBuilder &operator=(const HardSwishOptionsBuilder &);
+ flatbuffers::Offset<HardSwishOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<HardSwishOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<HardSwishOptions> CreateHardSwishOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ HardSwishOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<HardSwishOptions> CreateHardSwishOptions(flatbuffers::FlatBufferBuilder &_fbb, const HardSwishOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LogicalAndOptionsT : public flatbuffers::NativeTable {
+ typedef LogicalAndOptions TableType;
+ LogicalAndOptionsT() {
+ }
+};
+
+struct LogicalAndOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LogicalAndOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ LogicalAndOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LogicalAndOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LogicalAndOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogicalAndOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LogicalAndOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit LogicalAndOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LogicalAndOptionsBuilder &operator=(const LogicalAndOptionsBuilder &);
+ flatbuffers::Offset<LogicalAndOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LogicalAndOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LogicalAndOptions> CreateLogicalAndOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ LogicalAndOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LogicalAndOptions> CreateLogicalAndOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogicalAndOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LogicalNotOptionsT : public flatbuffers::NativeTable {
+ typedef LogicalNotOptions TableType;
+ LogicalNotOptionsT() {
+ }
+};
+
+struct LogicalNotOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LogicalNotOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ LogicalNotOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LogicalNotOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LogicalNotOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogicalNotOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LogicalNotOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit LogicalNotOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LogicalNotOptionsBuilder &operator=(const LogicalNotOptionsBuilder &);
+ flatbuffers::Offset<LogicalNotOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LogicalNotOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LogicalNotOptions> CreateLogicalNotOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ LogicalNotOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LogicalNotOptions> CreateLogicalNotOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogicalNotOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct UnpackOptionsT : public flatbuffers::NativeTable {
+ typedef UnpackOptions TableType;
+ int32_t num;
+ int32_t axis;
+ UnpackOptionsT()
+ : num(0),
+ axis(0) {
+ }
+};
+
+struct UnpackOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef UnpackOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NUM = 4,
+ VT_AXIS = 6
+ };
+ int32_t num() const {
+ return GetField<int32_t>(VT_NUM, 0);
+ }
+ int32_t axis() const {
+ return GetField<int32_t>(VT_AXIS, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_NUM) &&
+ VerifyField<int32_t>(verifier, VT_AXIS) &&
+ verifier.EndTable();
+ }
+ UnpackOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(UnpackOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<UnpackOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct UnpackOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_num(int32_t num) {
+ fbb_.AddElement<int32_t>(UnpackOptions::VT_NUM, num, 0);
+ }
+ void add_axis(int32_t axis) {
+ fbb_.AddElement<int32_t>(UnpackOptions::VT_AXIS, axis, 0);
+ }
+ explicit UnpackOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ UnpackOptionsBuilder &operator=(const UnpackOptionsBuilder &);
+ flatbuffers::Offset<UnpackOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<UnpackOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<UnpackOptions> CreateUnpackOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t num = 0,
+ int32_t axis = 0) {
+ UnpackOptionsBuilder builder_(_fbb);
+ builder_.add_axis(axis);
+ builder_.add_num(num);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<UnpackOptions> CreateUnpackOptions(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct FloorDivOptionsT : public flatbuffers::NativeTable {
+ typedef FloorDivOptions TableType;
+ FloorDivOptionsT() {
+ }
+};
+
+struct FloorDivOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef FloorDivOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ FloorDivOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(FloorDivOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<FloorDivOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct FloorDivOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit FloorDivOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ FloorDivOptionsBuilder &operator=(const FloorDivOptionsBuilder &);
+ flatbuffers::Offset<FloorDivOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<FloorDivOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<FloorDivOptions> CreateFloorDivOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ FloorDivOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<FloorDivOptions> CreateFloorDivOptions(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SquareOptionsT : public flatbuffers::NativeTable {
+ typedef SquareOptions TableType;
+ SquareOptionsT() {
+ }
+};
+
+struct SquareOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SquareOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ SquareOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SquareOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SquareOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SquareOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SquareOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit SquareOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SquareOptionsBuilder &operator=(const SquareOptionsBuilder &);
+ flatbuffers::Offset<SquareOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SquareOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SquareOptions> CreateSquareOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ SquareOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SquareOptions> CreateSquareOptions(flatbuffers::FlatBufferBuilder &_fbb, const SquareOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ZerosLikeOptionsT : public flatbuffers::NativeTable {
+ typedef ZerosLikeOptions TableType;
+ ZerosLikeOptionsT() {
+ }
+};
+
+struct ZerosLikeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ZerosLikeOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ ZerosLikeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ZerosLikeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ZerosLikeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ZerosLikeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ZerosLikeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit ZerosLikeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ZerosLikeOptionsBuilder &operator=(const ZerosLikeOptionsBuilder &);
+ flatbuffers::Offset<ZerosLikeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ZerosLikeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ZerosLikeOptions> CreateZerosLikeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ ZerosLikeOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ZerosLikeOptions> CreateZerosLikeOptions(flatbuffers::FlatBufferBuilder &_fbb, const ZerosLikeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct FillOptionsT : public flatbuffers::NativeTable {
+ typedef FillOptions TableType;
+ FillOptionsT() {
+ }
+};
+
+struct FillOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef FillOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ FillOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(FillOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<FillOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const FillOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct FillOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit FillOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ FillOptionsBuilder &operator=(const FillOptionsBuilder &);
+ flatbuffers::Offset<FillOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<FillOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<FillOptions> CreateFillOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ FillOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<FillOptions> CreateFillOptions(flatbuffers::FlatBufferBuilder &_fbb, const FillOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct FloorModOptionsT : public flatbuffers::NativeTable {
+ typedef FloorModOptions TableType;
+ FloorModOptionsT() {
+ }
+};
+
+struct FloorModOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef FloorModOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ FloorModOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(FloorModOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<FloorModOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const FloorModOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct FloorModOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit FloorModOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ FloorModOptionsBuilder &operator=(const FloorModOptionsBuilder &);
+ flatbuffers::Offset<FloorModOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<FloorModOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<FloorModOptions> CreateFloorModOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ FloorModOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<FloorModOptions> CreateFloorModOptions(flatbuffers::FlatBufferBuilder &_fbb, const FloorModOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct RangeOptionsT : public flatbuffers::NativeTable {
+ typedef RangeOptions TableType;
+ RangeOptionsT() {
+ }
+};
+
+struct RangeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef RangeOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ RangeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(RangeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<RangeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const RangeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct RangeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit RangeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ RangeOptionsBuilder &operator=(const RangeOptionsBuilder &);
+ flatbuffers::Offset<RangeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<RangeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<RangeOptions> CreateRangeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ RangeOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<RangeOptions> CreateRangeOptions(flatbuffers::FlatBufferBuilder &_fbb, const RangeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct LeakyReluOptionsT : public flatbuffers::NativeTable {
+ typedef LeakyReluOptions TableType;
+ float alpha;
+ LeakyReluOptionsT()
+ : alpha(0.0f) {
+ }
+};
+
+struct LeakyReluOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef LeakyReluOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_ALPHA = 4
+ };
+ float alpha() const {
+ return GetField<float>(VT_ALPHA, 0.0f);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<float>(verifier, VT_ALPHA) &&
+ verifier.EndTable();
+ }
+ LeakyReluOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(LeakyReluOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<LeakyReluOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const LeakyReluOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct LeakyReluOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_alpha(float alpha) {
+ fbb_.AddElement<float>(LeakyReluOptions::VT_ALPHA, alpha, 0.0f);
+ }
+ explicit LeakyReluOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ LeakyReluOptionsBuilder &operator=(const LeakyReluOptionsBuilder &);
+ flatbuffers::Offset<LeakyReluOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<LeakyReluOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<LeakyReluOptions> CreateLeakyReluOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ float alpha = 0.0f) {
+ LeakyReluOptionsBuilder builder_(_fbb);
+ builder_.add_alpha(alpha);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<LeakyReluOptions> CreateLeakyReluOptions(flatbuffers::FlatBufferBuilder &_fbb, const LeakyReluOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SquaredDifferenceOptionsT : public flatbuffers::NativeTable {
+ typedef SquaredDifferenceOptions TableType;
+ SquaredDifferenceOptionsT() {
+ }
+};
+
+struct SquaredDifferenceOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SquaredDifferenceOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ SquaredDifferenceOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SquaredDifferenceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SquaredDifferenceOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SquaredDifferenceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SquaredDifferenceOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit SquaredDifferenceOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SquaredDifferenceOptionsBuilder &operator=(const SquaredDifferenceOptionsBuilder &);
+ flatbuffers::Offset<SquaredDifferenceOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SquaredDifferenceOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SquaredDifferenceOptions> CreateSquaredDifferenceOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ SquaredDifferenceOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SquaredDifferenceOptions> CreateSquaredDifferenceOptions(flatbuffers::FlatBufferBuilder &_fbb, const SquaredDifferenceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct MirrorPadOptionsT : public flatbuffers::NativeTable {
+ typedef MirrorPadOptions TableType;
+ tflite::MirrorPadMode mode;
+ MirrorPadOptionsT()
+ : mode(tflite::MirrorPadMode_REFLECT) {
+ }
+};
+
+struct MirrorPadOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef MirrorPadOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_MODE = 4
+ };
+ tflite::MirrorPadMode mode() const {
+ return static_cast<tflite::MirrorPadMode>(GetField<int8_t>(VT_MODE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_MODE) &&
+ verifier.EndTable();
+ }
+ MirrorPadOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(MirrorPadOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<MirrorPadOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const MirrorPadOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct MirrorPadOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_mode(tflite::MirrorPadMode mode) {
+ fbb_.AddElement<int8_t>(MirrorPadOptions::VT_MODE, static_cast<int8_t>(mode), 0);
+ }
+ explicit MirrorPadOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ MirrorPadOptionsBuilder &operator=(const MirrorPadOptionsBuilder &);
+ flatbuffers::Offset<MirrorPadOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<MirrorPadOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<MirrorPadOptions> CreateMirrorPadOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::MirrorPadMode mode = tflite::MirrorPadMode_REFLECT) {
+ MirrorPadOptionsBuilder builder_(_fbb);
+ builder_.add_mode(mode);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<MirrorPadOptions> CreateMirrorPadOptions(flatbuffers::FlatBufferBuilder &_fbb, const MirrorPadOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct UniqueOptionsT : public flatbuffers::NativeTable {
+ typedef UniqueOptions TableType;
+ tflite::TensorType idx_out_type;
+ UniqueOptionsT()
+ : idx_out_type(tflite::TensorType_INT32) {
+ }
+};
+
+struct UniqueOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef UniqueOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_IDX_OUT_TYPE = 4
+ };
+ tflite::TensorType idx_out_type() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_IDX_OUT_TYPE, 2));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_IDX_OUT_TYPE) &&
+ verifier.EndTable();
+ }
+ UniqueOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(UniqueOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<UniqueOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const UniqueOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct UniqueOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_idx_out_type(tflite::TensorType idx_out_type) {
+ fbb_.AddElement<int8_t>(UniqueOptions::VT_IDX_OUT_TYPE, static_cast<int8_t>(idx_out_type), 2);
+ }
+ explicit UniqueOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ UniqueOptionsBuilder &operator=(const UniqueOptionsBuilder &);
+ flatbuffers::Offset<UniqueOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<UniqueOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<UniqueOptions> CreateUniqueOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ tflite::TensorType idx_out_type = tflite::TensorType_INT32) {
+ UniqueOptionsBuilder builder_(_fbb);
+ builder_.add_idx_out_type(idx_out_type);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<UniqueOptions> CreateUniqueOptions(flatbuffers::FlatBufferBuilder &_fbb, const UniqueOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ReverseV2OptionsT : public flatbuffers::NativeTable {
+ typedef ReverseV2Options TableType;
+ ReverseV2OptionsT() {
+ }
+};
+
+struct ReverseV2Options FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ReverseV2OptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ ReverseV2OptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ReverseV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ReverseV2Options> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReverseV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ReverseV2OptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit ReverseV2OptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ReverseV2OptionsBuilder &operator=(const ReverseV2OptionsBuilder &);
+ flatbuffers::Offset<ReverseV2Options> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ReverseV2Options>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ReverseV2Options> CreateReverseV2Options(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ ReverseV2OptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ReverseV2Options> CreateReverseV2Options(flatbuffers::FlatBufferBuilder &_fbb, const ReverseV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct AddNOptionsT : public flatbuffers::NativeTable {
+ typedef AddNOptions TableType;
+ AddNOptionsT() {
+ }
+};
+
+struct AddNOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef AddNOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ AddNOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(AddNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<AddNOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const AddNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct AddNOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit AddNOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ AddNOptionsBuilder &operator=(const AddNOptionsBuilder &);
+ flatbuffers::Offset<AddNOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<AddNOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<AddNOptions> CreateAddNOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ AddNOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<AddNOptions> CreateAddNOptions(flatbuffers::FlatBufferBuilder &_fbb, const AddNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct GatherNdOptionsT : public flatbuffers::NativeTable {
+ typedef GatherNdOptions TableType;
+ GatherNdOptionsT() {
+ }
+};
+
+struct GatherNdOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef GatherNdOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ GatherNdOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(GatherNdOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<GatherNdOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const GatherNdOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct GatherNdOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit GatherNdOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ GatherNdOptionsBuilder &operator=(const GatherNdOptionsBuilder &);
+ flatbuffers::Offset<GatherNdOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<GatherNdOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<GatherNdOptions> CreateGatherNdOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ GatherNdOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<GatherNdOptions> CreateGatherNdOptions(flatbuffers::FlatBufferBuilder &_fbb, const GatherNdOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct WhereOptionsT : public flatbuffers::NativeTable {
+ typedef WhereOptions TableType;
+ WhereOptionsT() {
+ }
+};
+
+struct WhereOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef WhereOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ WhereOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(WhereOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<WhereOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const WhereOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct WhereOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit WhereOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ WhereOptionsBuilder &operator=(const WhereOptionsBuilder &);
+ flatbuffers::Offset<WhereOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<WhereOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<WhereOptions> CreateWhereOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ WhereOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<WhereOptions> CreateWhereOptions(flatbuffers::FlatBufferBuilder &_fbb, const WhereOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ReverseSequenceOptionsT : public flatbuffers::NativeTable {
+ typedef ReverseSequenceOptions TableType;
+ int32_t seq_dim;
+ int32_t batch_dim;
+ ReverseSequenceOptionsT()
+ : seq_dim(0),
+ batch_dim(0) {
+ }
+};
+
+struct ReverseSequenceOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ReverseSequenceOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_SEQ_DIM = 4,
+ VT_BATCH_DIM = 6
+ };
+ int32_t seq_dim() const {
+ return GetField<int32_t>(VT_SEQ_DIM, 0);
+ }
+ int32_t batch_dim() const {
+ return GetField<int32_t>(VT_BATCH_DIM, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_SEQ_DIM) &&
+ VerifyField<int32_t>(verifier, VT_BATCH_DIM) &&
+ verifier.EndTable();
+ }
+ ReverseSequenceOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ReverseSequenceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ReverseSequenceOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReverseSequenceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ReverseSequenceOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_seq_dim(int32_t seq_dim) {
+ fbb_.AddElement<int32_t>(ReverseSequenceOptions::VT_SEQ_DIM, seq_dim, 0);
+ }
+ void add_batch_dim(int32_t batch_dim) {
+ fbb_.AddElement<int32_t>(ReverseSequenceOptions::VT_BATCH_DIM, batch_dim, 0);
+ }
+ explicit ReverseSequenceOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ReverseSequenceOptionsBuilder &operator=(const ReverseSequenceOptionsBuilder &);
+ flatbuffers::Offset<ReverseSequenceOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ReverseSequenceOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ReverseSequenceOptions> CreateReverseSequenceOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t seq_dim = 0,
+ int32_t batch_dim = 0) {
+ ReverseSequenceOptionsBuilder builder_(_fbb);
+ builder_.add_batch_dim(batch_dim);
+ builder_.add_seq_dim(seq_dim);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ReverseSequenceOptions> CreateReverseSequenceOptions(flatbuffers::FlatBufferBuilder &_fbb, const ReverseSequenceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct MatrixDiagOptionsT : public flatbuffers::NativeTable {
+ typedef MatrixDiagOptions TableType;
+ MatrixDiagOptionsT() {
+ }
+};
+
+struct MatrixDiagOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef MatrixDiagOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ MatrixDiagOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(MatrixDiagOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<MatrixDiagOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const MatrixDiagOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct MatrixDiagOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit MatrixDiagOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ MatrixDiagOptionsBuilder &operator=(const MatrixDiagOptionsBuilder &);
+ flatbuffers::Offset<MatrixDiagOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<MatrixDiagOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<MatrixDiagOptions> CreateMatrixDiagOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ MatrixDiagOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<MatrixDiagOptions> CreateMatrixDiagOptions(flatbuffers::FlatBufferBuilder &_fbb, const MatrixDiagOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct QuantizeOptionsT : public flatbuffers::NativeTable {
+ typedef QuantizeOptions TableType;
+ QuantizeOptionsT() {
+ }
+};
+
+struct QuantizeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef QuantizeOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ QuantizeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(QuantizeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<QuantizeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const QuantizeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct QuantizeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit QuantizeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ QuantizeOptionsBuilder &operator=(const QuantizeOptionsBuilder &);
+ flatbuffers::Offset<QuantizeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<QuantizeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<QuantizeOptions> CreateQuantizeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ QuantizeOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<QuantizeOptions> CreateQuantizeOptions(flatbuffers::FlatBufferBuilder &_fbb, const QuantizeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct MatrixSetDiagOptionsT : public flatbuffers::NativeTable {
+ typedef MatrixSetDiagOptions TableType;
+ MatrixSetDiagOptionsT() {
+ }
+};
+
+struct MatrixSetDiagOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef MatrixSetDiagOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ MatrixSetDiagOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(MatrixSetDiagOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<MatrixSetDiagOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const MatrixSetDiagOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct MatrixSetDiagOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit MatrixSetDiagOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ MatrixSetDiagOptionsBuilder &operator=(const MatrixSetDiagOptionsBuilder &);
+ flatbuffers::Offset<MatrixSetDiagOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<MatrixSetDiagOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<MatrixSetDiagOptions> CreateMatrixSetDiagOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ MatrixSetDiagOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<MatrixSetDiagOptions> CreateMatrixSetDiagOptions(flatbuffers::FlatBufferBuilder &_fbb, const MatrixSetDiagOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct IfOptionsT : public flatbuffers::NativeTable {
+ typedef IfOptions TableType;
+ int32_t then_subgraph_index;
+ int32_t else_subgraph_index;
+ IfOptionsT()
+ : then_subgraph_index(0),
+ else_subgraph_index(0) {
+ }
+};
+
+struct IfOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef IfOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_THEN_SUBGRAPH_INDEX = 4,
+ VT_ELSE_SUBGRAPH_INDEX = 6
+ };
+ int32_t then_subgraph_index() const {
+ return GetField<int32_t>(VT_THEN_SUBGRAPH_INDEX, 0);
+ }
+ int32_t else_subgraph_index() const {
+ return GetField<int32_t>(VT_ELSE_SUBGRAPH_INDEX, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_THEN_SUBGRAPH_INDEX) &&
+ VerifyField<int32_t>(verifier, VT_ELSE_SUBGRAPH_INDEX) &&
+ verifier.EndTable();
+ }
+ IfOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(IfOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<IfOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const IfOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct IfOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_then_subgraph_index(int32_t then_subgraph_index) {
+ fbb_.AddElement<int32_t>(IfOptions::VT_THEN_SUBGRAPH_INDEX, then_subgraph_index, 0);
+ }
+ void add_else_subgraph_index(int32_t else_subgraph_index) {
+ fbb_.AddElement<int32_t>(IfOptions::VT_ELSE_SUBGRAPH_INDEX, else_subgraph_index, 0);
+ }
+ explicit IfOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ IfOptionsBuilder &operator=(const IfOptionsBuilder &);
+ flatbuffers::Offset<IfOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<IfOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<IfOptions> CreateIfOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t then_subgraph_index = 0,
+ int32_t else_subgraph_index = 0) {
+ IfOptionsBuilder builder_(_fbb);
+ builder_.add_else_subgraph_index(else_subgraph_index);
+ builder_.add_then_subgraph_index(then_subgraph_index);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<IfOptions> CreateIfOptions(flatbuffers::FlatBufferBuilder &_fbb, const IfOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct CallOnceOptionsT : public flatbuffers::NativeTable {
+ typedef CallOnceOptions TableType;
+ int32_t init_subgraph_index;
+ CallOnceOptionsT()
+ : init_subgraph_index(0) {
+ }
+};
+
+struct CallOnceOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef CallOnceOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_INIT_SUBGRAPH_INDEX = 4
+ };
+ int32_t init_subgraph_index() const {
+ return GetField<int32_t>(VT_INIT_SUBGRAPH_INDEX, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_INIT_SUBGRAPH_INDEX) &&
+ verifier.EndTable();
+ }
+ CallOnceOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(CallOnceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<CallOnceOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const CallOnceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct CallOnceOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_init_subgraph_index(int32_t init_subgraph_index) {
+ fbb_.AddElement<int32_t>(CallOnceOptions::VT_INIT_SUBGRAPH_INDEX, init_subgraph_index, 0);
+ }
+ explicit CallOnceOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ CallOnceOptionsBuilder &operator=(const CallOnceOptionsBuilder &);
+ flatbuffers::Offset<CallOnceOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<CallOnceOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<CallOnceOptions> CreateCallOnceOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t init_subgraph_index = 0) {
+ CallOnceOptionsBuilder builder_(_fbb);
+ builder_.add_init_subgraph_index(init_subgraph_index);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<CallOnceOptions> CreateCallOnceOptions(flatbuffers::FlatBufferBuilder &_fbb, const CallOnceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct WhileOptionsT : public flatbuffers::NativeTable {
+ typedef WhileOptions TableType;
+ int32_t cond_subgraph_index;
+ int32_t body_subgraph_index;
+ WhileOptionsT()
+ : cond_subgraph_index(0),
+ body_subgraph_index(0) {
+ }
+};
+
+struct WhileOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef WhileOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_COND_SUBGRAPH_INDEX = 4,
+ VT_BODY_SUBGRAPH_INDEX = 6
+ };
+ int32_t cond_subgraph_index() const {
+ return GetField<int32_t>(VT_COND_SUBGRAPH_INDEX, 0);
+ }
+ int32_t body_subgraph_index() const {
+ return GetField<int32_t>(VT_BODY_SUBGRAPH_INDEX, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_COND_SUBGRAPH_INDEX) &&
+ VerifyField<int32_t>(verifier, VT_BODY_SUBGRAPH_INDEX) &&
+ verifier.EndTable();
+ }
+ WhileOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(WhileOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<WhileOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const WhileOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct WhileOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_cond_subgraph_index(int32_t cond_subgraph_index) {
+ fbb_.AddElement<int32_t>(WhileOptions::VT_COND_SUBGRAPH_INDEX, cond_subgraph_index, 0);
+ }
+ void add_body_subgraph_index(int32_t body_subgraph_index) {
+ fbb_.AddElement<int32_t>(WhileOptions::VT_BODY_SUBGRAPH_INDEX, body_subgraph_index, 0);
+ }
+ explicit WhileOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ WhileOptionsBuilder &operator=(const WhileOptionsBuilder &);
+ flatbuffers::Offset<WhileOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<WhileOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<WhileOptions> CreateWhileOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t cond_subgraph_index = 0,
+ int32_t body_subgraph_index = 0) {
+ WhileOptionsBuilder builder_(_fbb);
+ builder_.add_body_subgraph_index(body_subgraph_index);
+ builder_.add_cond_subgraph_index(cond_subgraph_index);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<WhileOptions> CreateWhileOptions(flatbuffers::FlatBufferBuilder &_fbb, const WhileOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct NonMaxSuppressionV4OptionsT : public flatbuffers::NativeTable {
+ typedef NonMaxSuppressionV4Options TableType;
+ NonMaxSuppressionV4OptionsT() {
+ }
+};
+
+struct NonMaxSuppressionV4Options FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef NonMaxSuppressionV4OptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ NonMaxSuppressionV4OptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(NonMaxSuppressionV4OptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<NonMaxSuppressionV4Options> Pack(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV4OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct NonMaxSuppressionV4OptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit NonMaxSuppressionV4OptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ NonMaxSuppressionV4OptionsBuilder &operator=(const NonMaxSuppressionV4OptionsBuilder &);
+ flatbuffers::Offset<NonMaxSuppressionV4Options> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<NonMaxSuppressionV4Options>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<NonMaxSuppressionV4Options> CreateNonMaxSuppressionV4Options(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ NonMaxSuppressionV4OptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<NonMaxSuppressionV4Options> CreateNonMaxSuppressionV4Options(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV4OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct NonMaxSuppressionV5OptionsT : public flatbuffers::NativeTable {
+ typedef NonMaxSuppressionV5Options TableType;
+ NonMaxSuppressionV5OptionsT() {
+ }
+};
+
+struct NonMaxSuppressionV5Options FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef NonMaxSuppressionV5OptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ NonMaxSuppressionV5OptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(NonMaxSuppressionV5OptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<NonMaxSuppressionV5Options> Pack(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV5OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct NonMaxSuppressionV5OptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit NonMaxSuppressionV5OptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ NonMaxSuppressionV5OptionsBuilder &operator=(const NonMaxSuppressionV5OptionsBuilder &);
+ flatbuffers::Offset<NonMaxSuppressionV5Options> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<NonMaxSuppressionV5Options>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<NonMaxSuppressionV5Options> CreateNonMaxSuppressionV5Options(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ NonMaxSuppressionV5OptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<NonMaxSuppressionV5Options> CreateNonMaxSuppressionV5Options(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV5OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ScatterNdOptionsT : public flatbuffers::NativeTable {
+ typedef ScatterNdOptions TableType;
+ ScatterNdOptionsT() {
+ }
+};
+
+struct ScatterNdOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ScatterNdOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ ScatterNdOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ScatterNdOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<ScatterNdOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ScatterNdOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ScatterNdOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit ScatterNdOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ScatterNdOptionsBuilder &operator=(const ScatterNdOptionsBuilder &);
+ flatbuffers::Offset<ScatterNdOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<ScatterNdOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<ScatterNdOptions> CreateScatterNdOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ ScatterNdOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<ScatterNdOptions> CreateScatterNdOptions(flatbuffers::FlatBufferBuilder &_fbb, const ScatterNdOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SelectV2OptionsT : public flatbuffers::NativeTable {
+ typedef SelectV2Options TableType;
+ SelectV2OptionsT() {
+ }
+};
+
+struct SelectV2Options FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SelectV2OptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ SelectV2OptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SelectV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SelectV2Options> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SelectV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SelectV2OptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit SelectV2OptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SelectV2OptionsBuilder &operator=(const SelectV2OptionsBuilder &);
+ flatbuffers::Offset<SelectV2Options> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SelectV2Options>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SelectV2Options> CreateSelectV2Options(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ SelectV2OptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SelectV2Options> CreateSelectV2Options(flatbuffers::FlatBufferBuilder &_fbb, const SelectV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct DensifyOptionsT : public flatbuffers::NativeTable {
+ typedef DensifyOptions TableType;
+ DensifyOptionsT() {
+ }
+};
+
+struct DensifyOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef DensifyOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ DensifyOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(DensifyOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<DensifyOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const DensifyOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct DensifyOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit DensifyOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ DensifyOptionsBuilder &operator=(const DensifyOptionsBuilder &);
+ flatbuffers::Offset<DensifyOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<DensifyOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<DensifyOptions> CreateDensifyOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ DensifyOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<DensifyOptions> CreateDensifyOptions(flatbuffers::FlatBufferBuilder &_fbb, const DensifyOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SegmentSumOptionsT : public flatbuffers::NativeTable {
+ typedef SegmentSumOptions TableType;
+ SegmentSumOptionsT() {
+ }
+};
+
+struct SegmentSumOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SegmentSumOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ SegmentSumOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SegmentSumOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SegmentSumOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SegmentSumOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SegmentSumOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit SegmentSumOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SegmentSumOptionsBuilder &operator=(const SegmentSumOptionsBuilder &);
+ flatbuffers::Offset<SegmentSumOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SegmentSumOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SegmentSumOptions> CreateSegmentSumOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ SegmentSumOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<SegmentSumOptions> CreateSegmentSumOptions(flatbuffers::FlatBufferBuilder &_fbb, const SegmentSumOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct BatchMatMulOptionsT : public flatbuffers::NativeTable {
+ typedef BatchMatMulOptions TableType;
+ bool adj_x;
+ bool adj_y;
+ bool asymmetric_quantize_inputs;
+ BatchMatMulOptionsT()
+ : adj_x(false),
+ adj_y(false),
+ asymmetric_quantize_inputs(false) {
+ }
+};
+
+struct BatchMatMulOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef BatchMatMulOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_ADJ_X = 4,
+ VT_ADJ_Y = 6,
+ VT_ASYMMETRIC_QUANTIZE_INPUTS = 8
+ };
+ bool adj_x() const {
+ return GetField<uint8_t>(VT_ADJ_X, 0) != 0;
+ }
+ bool adj_y() const {
+ return GetField<uint8_t>(VT_ADJ_Y, 0) != 0;
+ }
+ bool asymmetric_quantize_inputs() const {
+ return GetField<uint8_t>(VT_ASYMMETRIC_QUANTIZE_INPUTS, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_ADJ_X) &&
+ VerifyField<uint8_t>(verifier, VT_ADJ_Y) &&
+ VerifyField<uint8_t>(verifier, VT_ASYMMETRIC_QUANTIZE_INPUTS) &&
+ verifier.EndTable();
+ }
+ BatchMatMulOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(BatchMatMulOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<BatchMatMulOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const BatchMatMulOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct BatchMatMulOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_adj_x(bool adj_x) {
+ fbb_.AddElement<uint8_t>(BatchMatMulOptions::VT_ADJ_X, static_cast<uint8_t>(adj_x), 0);
+ }
+ void add_adj_y(bool adj_y) {
+ fbb_.AddElement<uint8_t>(BatchMatMulOptions::VT_ADJ_Y, static_cast<uint8_t>(adj_y), 0);
+ }
+ void add_asymmetric_quantize_inputs(bool asymmetric_quantize_inputs) {
+ fbb_.AddElement<uint8_t>(BatchMatMulOptions::VT_ASYMMETRIC_QUANTIZE_INPUTS, static_cast<uint8_t>(asymmetric_quantize_inputs), 0);
+ }
+ explicit BatchMatMulOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ BatchMatMulOptionsBuilder &operator=(const BatchMatMulOptionsBuilder &);
+ flatbuffers::Offset<BatchMatMulOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<BatchMatMulOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<BatchMatMulOptions> CreateBatchMatMulOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool adj_x = false,
+ bool adj_y = false,
+ bool asymmetric_quantize_inputs = false) {
+ BatchMatMulOptionsBuilder builder_(_fbb);
+ builder_.add_asymmetric_quantize_inputs(asymmetric_quantize_inputs);
+ builder_.add_adj_y(adj_y);
+ builder_.add_adj_x(adj_x);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<BatchMatMulOptions> CreateBatchMatMulOptions(flatbuffers::FlatBufferBuilder &_fbb, const BatchMatMulOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct CumsumOptionsT : public flatbuffers::NativeTable {
+ typedef CumsumOptions TableType;
+ bool exclusive;
+ bool reverse;
+ CumsumOptionsT()
+ : exclusive(false),
+ reverse(false) {
+ }
+};
+
+struct CumsumOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef CumsumOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_EXCLUSIVE = 4,
+ VT_REVERSE = 6
+ };
+ bool exclusive() const {
+ return GetField<uint8_t>(VT_EXCLUSIVE, 0) != 0;
+ }
+ bool reverse() const {
+ return GetField<uint8_t>(VT_REVERSE, 0) != 0;
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint8_t>(verifier, VT_EXCLUSIVE) &&
+ VerifyField<uint8_t>(verifier, VT_REVERSE) &&
+ verifier.EndTable();
+ }
+ CumsumOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(CumsumOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<CumsumOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const CumsumOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct CumsumOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_exclusive(bool exclusive) {
+ fbb_.AddElement<uint8_t>(CumsumOptions::VT_EXCLUSIVE, static_cast<uint8_t>(exclusive), 0);
+ }
+ void add_reverse(bool reverse) {
+ fbb_.AddElement<uint8_t>(CumsumOptions::VT_REVERSE, static_cast<uint8_t>(reverse), 0);
+ }
+ explicit CumsumOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ CumsumOptionsBuilder &operator=(const CumsumOptionsBuilder &);
+ flatbuffers::Offset<CumsumOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<CumsumOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<CumsumOptions> CreateCumsumOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ bool exclusive = false,
+ bool reverse = false) {
+ CumsumOptionsBuilder builder_(_fbb);
+ builder_.add_reverse(reverse);
+ builder_.add_exclusive(exclusive);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<CumsumOptions> CreateCumsumOptions(flatbuffers::FlatBufferBuilder &_fbb, const CumsumOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct BroadcastToOptionsT : public flatbuffers::NativeTable {
+ typedef BroadcastToOptions TableType;
+ BroadcastToOptionsT() {
+ }
+};
+
+struct BroadcastToOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef BroadcastToOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ BroadcastToOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(BroadcastToOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<BroadcastToOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const BroadcastToOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct BroadcastToOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit BroadcastToOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ BroadcastToOptionsBuilder &operator=(const BroadcastToOptionsBuilder &);
+ flatbuffers::Offset<BroadcastToOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<BroadcastToOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<BroadcastToOptions> CreateBroadcastToOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ BroadcastToOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<BroadcastToOptions> CreateBroadcastToOptions(flatbuffers::FlatBufferBuilder &_fbb, const BroadcastToOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct Rfft2dOptionsT : public flatbuffers::NativeTable {
+ typedef Rfft2dOptions TableType;
+ Rfft2dOptionsT() {
+ }
+};
+
+struct Rfft2dOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef Rfft2dOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ Rfft2dOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(Rfft2dOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Rfft2dOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const Rfft2dOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct Rfft2dOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit Rfft2dOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ Rfft2dOptionsBuilder &operator=(const Rfft2dOptionsBuilder &);
+ flatbuffers::Offset<Rfft2dOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Rfft2dOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Rfft2dOptions> CreateRfft2dOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ Rfft2dOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<Rfft2dOptions> CreateRfft2dOptions(flatbuffers::FlatBufferBuilder &_fbb, const Rfft2dOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct HashtableOptionsT : public flatbuffers::NativeTable {
+ typedef HashtableOptions TableType;
+ int32_t table_id;
+ tflite::TensorType key_dtype;
+ tflite::TensorType value_dtype;
+ HashtableOptionsT()
+ : table_id(0),
+ key_dtype(tflite::TensorType_FLOAT32),
+ value_dtype(tflite::TensorType_FLOAT32) {
+ }
+};
+
+struct HashtableOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef HashtableOptionsT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_TABLE_ID = 4,
+ VT_KEY_DTYPE = 6,
+ VT_VALUE_DTYPE = 8
+ };
+ int32_t table_id() const {
+ return GetField<int32_t>(VT_TABLE_ID, 0);
+ }
+ tflite::TensorType key_dtype() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_KEY_DTYPE, 0));
+ }
+ tflite::TensorType value_dtype() const {
+ return static_cast<tflite::TensorType>(GetField<int8_t>(VT_VALUE_DTYPE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int32_t>(verifier, VT_TABLE_ID) &&
+ VerifyField<int8_t>(verifier, VT_KEY_DTYPE) &&
+ VerifyField<int8_t>(verifier, VT_VALUE_DTYPE) &&
+ verifier.EndTable();
+ }
+ HashtableOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(HashtableOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<HashtableOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct HashtableOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_table_id(int32_t table_id) {
+ fbb_.AddElement<int32_t>(HashtableOptions::VT_TABLE_ID, table_id, 0);
+ }
+ void add_key_dtype(tflite::TensorType key_dtype) {
+ fbb_.AddElement<int8_t>(HashtableOptions::VT_KEY_DTYPE, static_cast<int8_t>(key_dtype), 0);
+ }
+ void add_value_dtype(tflite::TensorType value_dtype) {
+ fbb_.AddElement<int8_t>(HashtableOptions::VT_VALUE_DTYPE, static_cast<int8_t>(value_dtype), 0);
+ }
+ explicit HashtableOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ HashtableOptionsBuilder &operator=(const HashtableOptionsBuilder &);
+ flatbuffers::Offset<HashtableOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<HashtableOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<HashtableOptions> CreateHashtableOptions(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int32_t table_id = 0,
+ tflite::TensorType key_dtype = tflite::TensorType_FLOAT32,
+ tflite::TensorType value_dtype = tflite::TensorType_FLOAT32) {
+ HashtableOptionsBuilder builder_(_fbb);
+ builder_.add_table_id(table_id);
+ builder_.add_value_dtype(value_dtype);
+ builder_.add_key_dtype(key_dtype);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<HashtableOptions> CreateHashtableOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct HashtableFindOptionsT : public flatbuffers::NativeTable {
+ typedef HashtableFindOptions TableType;
+ HashtableFindOptionsT() {
+ }
+};
+
+struct HashtableFindOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef HashtableFindOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ HashtableFindOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(HashtableFindOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<HashtableFindOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableFindOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct HashtableFindOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit HashtableFindOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ HashtableFindOptionsBuilder &operator=(const HashtableFindOptionsBuilder &);
+ flatbuffers::Offset<HashtableFindOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<HashtableFindOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<HashtableFindOptions> CreateHashtableFindOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ HashtableFindOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<HashtableFindOptions> CreateHashtableFindOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableFindOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct HashtableImportOptionsT : public flatbuffers::NativeTable {
+ typedef HashtableImportOptions TableType;
+ HashtableImportOptionsT() {
+ }
+};
+
+struct HashtableImportOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef HashtableImportOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ HashtableImportOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(HashtableImportOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<HashtableImportOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableImportOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct HashtableImportOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit HashtableImportOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ HashtableImportOptionsBuilder &operator=(const HashtableImportOptionsBuilder &);
+ flatbuffers::Offset<HashtableImportOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<HashtableImportOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<HashtableImportOptions> CreateHashtableImportOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ HashtableImportOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<HashtableImportOptions> CreateHashtableImportOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableImportOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct HashtableSizeOptionsT : public flatbuffers::NativeTable {
+ typedef HashtableSizeOptions TableType;
+ HashtableSizeOptionsT() {
+ }
+};
+
+struct HashtableSizeOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef HashtableSizeOptionsT NativeTableType;
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ verifier.EndTable();
+ }
+ HashtableSizeOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(HashtableSizeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<HashtableSizeOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableSizeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct HashtableSizeOptionsBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ explicit HashtableSizeOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ HashtableSizeOptionsBuilder &operator=(const HashtableSizeOptionsBuilder &);
+ flatbuffers::Offset<HashtableSizeOptions> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<HashtableSizeOptions>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<HashtableSizeOptions> CreateHashtableSizeOptions(
+ flatbuffers::FlatBufferBuilder &_fbb) {
+ HashtableSizeOptionsBuilder builder_(_fbb);
+ return builder_.Finish();
+}
+
+flatbuffers::Offset<HashtableSizeOptions> CreateHashtableSizeOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableSizeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct OperatorCodeT : public flatbuffers::NativeTable {
+ typedef OperatorCode TableType;
+ int8_t deprecated_builtin_code;
+ std::string custom_code;
+ int32_t version;
+ tflite::BuiltinOperator builtin_code;
+ OperatorCodeT()
+ : deprecated_builtin_code(0),
+ version(1),
+ builtin_code(tflite::BuiltinOperator_ADD) {
+ }
+};
+
+struct OperatorCode FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef OperatorCodeT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_DEPRECATED_BUILTIN_CODE = 4,
+ VT_CUSTOM_CODE = 6,
+ VT_VERSION = 8,
+ VT_BUILTIN_CODE = 10
+ };
+ int8_t deprecated_builtin_code() const {
+ return GetField<int8_t>(VT_DEPRECATED_BUILTIN_CODE, 0);
+ }
+ const flatbuffers::String *custom_code() const {
+ return GetPointer<const flatbuffers::String *>(VT_CUSTOM_CODE);
+ }
+ int32_t version() const {
+ return GetField<int32_t>(VT_VERSION, 1);
+ }
+ tflite::BuiltinOperator builtin_code() const {
+ return static_cast<tflite::BuiltinOperator>(GetField<int32_t>(VT_BUILTIN_CODE, 0));
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<int8_t>(verifier, VT_DEPRECATED_BUILTIN_CODE) &&
+ VerifyOffset(verifier, VT_CUSTOM_CODE) &&
+ verifier.VerifyString(custom_code()) &&
+ VerifyField<int32_t>(verifier, VT_VERSION) &&
+ VerifyField<int32_t>(verifier, VT_BUILTIN_CODE) &&
+ verifier.EndTable();
+ }
+ OperatorCodeT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(OperatorCodeT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<OperatorCode> Pack(flatbuffers::FlatBufferBuilder &_fbb, const OperatorCodeT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct OperatorCodeBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_deprecated_builtin_code(int8_t deprecated_builtin_code) {
+ fbb_.AddElement<int8_t>(OperatorCode::VT_DEPRECATED_BUILTIN_CODE, deprecated_builtin_code, 0);
+ }
+ void add_custom_code(flatbuffers::Offset<flatbuffers::String> custom_code) {
+ fbb_.AddOffset(OperatorCode::VT_CUSTOM_CODE, custom_code);
+ }
+ void add_version(int32_t version) {
+ fbb_.AddElement<int32_t>(OperatorCode::VT_VERSION, version, 1);
+ }
+ void add_builtin_code(tflite::BuiltinOperator builtin_code) {
+ fbb_.AddElement<int32_t>(OperatorCode::VT_BUILTIN_CODE, static_cast<int32_t>(builtin_code), 0);
+ }
+ explicit OperatorCodeBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ OperatorCodeBuilder &operator=(const OperatorCodeBuilder &);
+ flatbuffers::Offset<OperatorCode> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<OperatorCode>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<OperatorCode> CreateOperatorCode(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int8_t deprecated_builtin_code = 0,
+ flatbuffers::Offset<flatbuffers::String> custom_code = 0,
+ int32_t version = 1,
+ tflite::BuiltinOperator builtin_code = tflite::BuiltinOperator_ADD) {
+ OperatorCodeBuilder builder_(_fbb);
+ builder_.add_builtin_code(builtin_code);
+ builder_.add_version(version);
+ builder_.add_custom_code(custom_code);
+ builder_.add_deprecated_builtin_code(deprecated_builtin_code);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<OperatorCode> CreateOperatorCodeDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ int8_t deprecated_builtin_code = 0,
+ const char *custom_code = nullptr,
+ int32_t version = 1,
+ tflite::BuiltinOperator builtin_code = tflite::BuiltinOperator_ADD) {
+ auto custom_code__ = custom_code ? _fbb.CreateString(custom_code) : 0;
+ return tflite::CreateOperatorCode(
+ _fbb,
+ deprecated_builtin_code,
+ custom_code__,
+ version,
+ builtin_code);
+}
+
+flatbuffers::Offset<OperatorCode> CreateOperatorCode(flatbuffers::FlatBufferBuilder &_fbb, const OperatorCodeT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct OperatorT : public flatbuffers::NativeTable {
+ typedef Operator TableType;
+ uint32_t opcode_index;
+ std::vector<int32_t> inputs;
+ std::vector<int32_t> outputs;
+ tflite::BuiltinOptionsUnion builtin_options;
+ std::vector<uint8_t> custom_options;
+ tflite::CustomOptionsFormat custom_options_format;
+ std::vector<bool> mutating_variable_inputs;
+ std::vector<int32_t> intermediates;
+ OperatorT()
+ : opcode_index(0),
+ custom_options_format(tflite::CustomOptionsFormat_FLEXBUFFERS) {
+ }
+};
+
+struct Operator FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef OperatorT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_OPCODE_INDEX = 4,
+ VT_INPUTS = 6,
+ VT_OUTPUTS = 8,
+ VT_BUILTIN_OPTIONS_TYPE = 10,
+ VT_BUILTIN_OPTIONS = 12,
+ VT_CUSTOM_OPTIONS = 14,
+ VT_CUSTOM_OPTIONS_FORMAT = 16,
+ VT_MUTATING_VARIABLE_INPUTS = 18,
+ VT_INTERMEDIATES = 20
+ };
+ uint32_t opcode_index() const {
+ return GetField<uint32_t>(VT_OPCODE_INDEX, 0);
+ }
+ const flatbuffers::Vector<int32_t> *inputs() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_INPUTS);
+ }
+ const flatbuffers::Vector<int32_t> *outputs() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_OUTPUTS);
+ }
+ tflite::BuiltinOptions builtin_options_type() const {
+ return static_cast<tflite::BuiltinOptions>(GetField<uint8_t>(VT_BUILTIN_OPTIONS_TYPE, 0));
+ }
+ const void *builtin_options() const {
+ return GetPointer<const void *>(VT_BUILTIN_OPTIONS);
+ }
+ template<typename T> const T *builtin_options_as() const;
+ const tflite::Conv2DOptions *builtin_options_as_Conv2DOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_Conv2DOptions ? static_cast<const tflite::Conv2DOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::DepthwiseConv2DOptions *builtin_options_as_DepthwiseConv2DOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_DepthwiseConv2DOptions ? static_cast<const tflite::DepthwiseConv2DOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ConcatEmbeddingsOptions *builtin_options_as_ConcatEmbeddingsOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ConcatEmbeddingsOptions ? static_cast<const tflite::ConcatEmbeddingsOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LSHProjectionOptions *builtin_options_as_LSHProjectionOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LSHProjectionOptions ? static_cast<const tflite::LSHProjectionOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::Pool2DOptions *builtin_options_as_Pool2DOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_Pool2DOptions ? static_cast<const tflite::Pool2DOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SVDFOptions *builtin_options_as_SVDFOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SVDFOptions ? static_cast<const tflite::SVDFOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::RNNOptions *builtin_options_as_RNNOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_RNNOptions ? static_cast<const tflite::RNNOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::FullyConnectedOptions *builtin_options_as_FullyConnectedOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_FullyConnectedOptions ? static_cast<const tflite::FullyConnectedOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SoftmaxOptions *builtin_options_as_SoftmaxOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SoftmaxOptions ? static_cast<const tflite::SoftmaxOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ConcatenationOptions *builtin_options_as_ConcatenationOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ConcatenationOptions ? static_cast<const tflite::ConcatenationOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::AddOptions *builtin_options_as_AddOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_AddOptions ? static_cast<const tflite::AddOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::L2NormOptions *builtin_options_as_L2NormOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_L2NormOptions ? static_cast<const tflite::L2NormOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LocalResponseNormalizationOptions *builtin_options_as_LocalResponseNormalizationOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LocalResponseNormalizationOptions ? static_cast<const tflite::LocalResponseNormalizationOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LSTMOptions *builtin_options_as_LSTMOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LSTMOptions ? static_cast<const tflite::LSTMOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ResizeBilinearOptions *builtin_options_as_ResizeBilinearOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ResizeBilinearOptions ? static_cast<const tflite::ResizeBilinearOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::CallOptions *builtin_options_as_CallOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_CallOptions ? static_cast<const tflite::CallOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ReshapeOptions *builtin_options_as_ReshapeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ReshapeOptions ? static_cast<const tflite::ReshapeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SkipGramOptions *builtin_options_as_SkipGramOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SkipGramOptions ? static_cast<const tflite::SkipGramOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SpaceToDepthOptions *builtin_options_as_SpaceToDepthOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SpaceToDepthOptions ? static_cast<const tflite::SpaceToDepthOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::EmbeddingLookupSparseOptions *builtin_options_as_EmbeddingLookupSparseOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_EmbeddingLookupSparseOptions ? static_cast<const tflite::EmbeddingLookupSparseOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::MulOptions *builtin_options_as_MulOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_MulOptions ? static_cast<const tflite::MulOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::PadOptions *builtin_options_as_PadOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_PadOptions ? static_cast<const tflite::PadOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::GatherOptions *builtin_options_as_GatherOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_GatherOptions ? static_cast<const tflite::GatherOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::BatchToSpaceNDOptions *builtin_options_as_BatchToSpaceNDOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_BatchToSpaceNDOptions ? static_cast<const tflite::BatchToSpaceNDOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SpaceToBatchNDOptions *builtin_options_as_SpaceToBatchNDOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SpaceToBatchNDOptions ? static_cast<const tflite::SpaceToBatchNDOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::TransposeOptions *builtin_options_as_TransposeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_TransposeOptions ? static_cast<const tflite::TransposeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ReducerOptions *builtin_options_as_ReducerOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ReducerOptions ? static_cast<const tflite::ReducerOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SubOptions *builtin_options_as_SubOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SubOptions ? static_cast<const tflite::SubOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::DivOptions *builtin_options_as_DivOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_DivOptions ? static_cast<const tflite::DivOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SqueezeOptions *builtin_options_as_SqueezeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SqueezeOptions ? static_cast<const tflite::SqueezeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SequenceRNNOptions *builtin_options_as_SequenceRNNOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SequenceRNNOptions ? static_cast<const tflite::SequenceRNNOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::StridedSliceOptions *builtin_options_as_StridedSliceOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_StridedSliceOptions ? static_cast<const tflite::StridedSliceOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ExpOptions *builtin_options_as_ExpOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ExpOptions ? static_cast<const tflite::ExpOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::TopKV2Options *builtin_options_as_TopKV2Options() const {
+ return builtin_options_type() == tflite::BuiltinOptions_TopKV2Options ? static_cast<const tflite::TopKV2Options *>(builtin_options()) : nullptr;
+ }
+ const tflite::SplitOptions *builtin_options_as_SplitOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SplitOptions ? static_cast<const tflite::SplitOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LogSoftmaxOptions *builtin_options_as_LogSoftmaxOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LogSoftmaxOptions ? static_cast<const tflite::LogSoftmaxOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::CastOptions *builtin_options_as_CastOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_CastOptions ? static_cast<const tflite::CastOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::DequantizeOptions *builtin_options_as_DequantizeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_DequantizeOptions ? static_cast<const tflite::DequantizeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::MaximumMinimumOptions *builtin_options_as_MaximumMinimumOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_MaximumMinimumOptions ? static_cast<const tflite::MaximumMinimumOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ArgMaxOptions *builtin_options_as_ArgMaxOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ArgMaxOptions ? static_cast<const tflite::ArgMaxOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LessOptions *builtin_options_as_LessOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LessOptions ? static_cast<const tflite::LessOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::NegOptions *builtin_options_as_NegOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_NegOptions ? static_cast<const tflite::NegOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::PadV2Options *builtin_options_as_PadV2Options() const {
+ return builtin_options_type() == tflite::BuiltinOptions_PadV2Options ? static_cast<const tflite::PadV2Options *>(builtin_options()) : nullptr;
+ }
+ const tflite::GreaterOptions *builtin_options_as_GreaterOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_GreaterOptions ? static_cast<const tflite::GreaterOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::GreaterEqualOptions *builtin_options_as_GreaterEqualOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_GreaterEqualOptions ? static_cast<const tflite::GreaterEqualOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LessEqualOptions *builtin_options_as_LessEqualOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LessEqualOptions ? static_cast<const tflite::LessEqualOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SelectOptions *builtin_options_as_SelectOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SelectOptions ? static_cast<const tflite::SelectOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SliceOptions *builtin_options_as_SliceOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SliceOptions ? static_cast<const tflite::SliceOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::TransposeConvOptions *builtin_options_as_TransposeConvOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_TransposeConvOptions ? static_cast<const tflite::TransposeConvOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SparseToDenseOptions *builtin_options_as_SparseToDenseOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SparseToDenseOptions ? static_cast<const tflite::SparseToDenseOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::TileOptions *builtin_options_as_TileOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_TileOptions ? static_cast<const tflite::TileOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ExpandDimsOptions *builtin_options_as_ExpandDimsOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ExpandDimsOptions ? static_cast<const tflite::ExpandDimsOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::EqualOptions *builtin_options_as_EqualOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_EqualOptions ? static_cast<const tflite::EqualOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::NotEqualOptions *builtin_options_as_NotEqualOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_NotEqualOptions ? static_cast<const tflite::NotEqualOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ShapeOptions *builtin_options_as_ShapeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ShapeOptions ? static_cast<const tflite::ShapeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::PowOptions *builtin_options_as_PowOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_PowOptions ? static_cast<const tflite::PowOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ArgMinOptions *builtin_options_as_ArgMinOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ArgMinOptions ? static_cast<const tflite::ArgMinOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::FakeQuantOptions *builtin_options_as_FakeQuantOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_FakeQuantOptions ? static_cast<const tflite::FakeQuantOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::PackOptions *builtin_options_as_PackOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_PackOptions ? static_cast<const tflite::PackOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LogicalOrOptions *builtin_options_as_LogicalOrOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LogicalOrOptions ? static_cast<const tflite::LogicalOrOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::OneHotOptions *builtin_options_as_OneHotOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_OneHotOptions ? static_cast<const tflite::OneHotOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LogicalAndOptions *builtin_options_as_LogicalAndOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LogicalAndOptions ? static_cast<const tflite::LogicalAndOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LogicalNotOptions *builtin_options_as_LogicalNotOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LogicalNotOptions ? static_cast<const tflite::LogicalNotOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::UnpackOptions *builtin_options_as_UnpackOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_UnpackOptions ? static_cast<const tflite::UnpackOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::FloorDivOptions *builtin_options_as_FloorDivOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_FloorDivOptions ? static_cast<const tflite::FloorDivOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SquareOptions *builtin_options_as_SquareOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SquareOptions ? static_cast<const tflite::SquareOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ZerosLikeOptions *builtin_options_as_ZerosLikeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ZerosLikeOptions ? static_cast<const tflite::ZerosLikeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::FillOptions *builtin_options_as_FillOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_FillOptions ? static_cast<const tflite::FillOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::BidirectionalSequenceLSTMOptions *builtin_options_as_BidirectionalSequenceLSTMOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_BidirectionalSequenceLSTMOptions ? static_cast<const tflite::BidirectionalSequenceLSTMOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::BidirectionalSequenceRNNOptions *builtin_options_as_BidirectionalSequenceRNNOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_BidirectionalSequenceRNNOptions ? static_cast<const tflite::BidirectionalSequenceRNNOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::UnidirectionalSequenceLSTMOptions *builtin_options_as_UnidirectionalSequenceLSTMOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_UnidirectionalSequenceLSTMOptions ? static_cast<const tflite::UnidirectionalSequenceLSTMOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::FloorModOptions *builtin_options_as_FloorModOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_FloorModOptions ? static_cast<const tflite::FloorModOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::RangeOptions *builtin_options_as_RangeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_RangeOptions ? static_cast<const tflite::RangeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ResizeNearestNeighborOptions *builtin_options_as_ResizeNearestNeighborOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ResizeNearestNeighborOptions ? static_cast<const tflite::ResizeNearestNeighborOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::LeakyReluOptions *builtin_options_as_LeakyReluOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_LeakyReluOptions ? static_cast<const tflite::LeakyReluOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SquaredDifferenceOptions *builtin_options_as_SquaredDifferenceOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SquaredDifferenceOptions ? static_cast<const tflite::SquaredDifferenceOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::MirrorPadOptions *builtin_options_as_MirrorPadOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_MirrorPadOptions ? static_cast<const tflite::MirrorPadOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::AbsOptions *builtin_options_as_AbsOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_AbsOptions ? static_cast<const tflite::AbsOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SplitVOptions *builtin_options_as_SplitVOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SplitVOptions ? static_cast<const tflite::SplitVOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::UniqueOptions *builtin_options_as_UniqueOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_UniqueOptions ? static_cast<const tflite::UniqueOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ReverseV2Options *builtin_options_as_ReverseV2Options() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ReverseV2Options ? static_cast<const tflite::ReverseV2Options *>(builtin_options()) : nullptr;
+ }
+ const tflite::AddNOptions *builtin_options_as_AddNOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_AddNOptions ? static_cast<const tflite::AddNOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::GatherNdOptions *builtin_options_as_GatherNdOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_GatherNdOptions ? static_cast<const tflite::GatherNdOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::CosOptions *builtin_options_as_CosOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_CosOptions ? static_cast<const tflite::CosOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::WhereOptions *builtin_options_as_WhereOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_WhereOptions ? static_cast<const tflite::WhereOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::RankOptions *builtin_options_as_RankOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_RankOptions ? static_cast<const tflite::RankOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::ReverseSequenceOptions *builtin_options_as_ReverseSequenceOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ReverseSequenceOptions ? static_cast<const tflite::ReverseSequenceOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::MatrixDiagOptions *builtin_options_as_MatrixDiagOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_MatrixDiagOptions ? static_cast<const tflite::MatrixDiagOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::QuantizeOptions *builtin_options_as_QuantizeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_QuantizeOptions ? static_cast<const tflite::QuantizeOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::MatrixSetDiagOptions *builtin_options_as_MatrixSetDiagOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_MatrixSetDiagOptions ? static_cast<const tflite::MatrixSetDiagOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::HardSwishOptions *builtin_options_as_HardSwishOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_HardSwishOptions ? static_cast<const tflite::HardSwishOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::IfOptions *builtin_options_as_IfOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_IfOptions ? static_cast<const tflite::IfOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::WhileOptions *builtin_options_as_WhileOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_WhileOptions ? static_cast<const tflite::WhileOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::DepthToSpaceOptions *builtin_options_as_DepthToSpaceOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_DepthToSpaceOptions ? static_cast<const tflite::DepthToSpaceOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::NonMaxSuppressionV4Options *builtin_options_as_NonMaxSuppressionV4Options() const {
+ return builtin_options_type() == tflite::BuiltinOptions_NonMaxSuppressionV4Options ? static_cast<const tflite::NonMaxSuppressionV4Options *>(builtin_options()) : nullptr;
+ }
+ const tflite::NonMaxSuppressionV5Options *builtin_options_as_NonMaxSuppressionV5Options() const {
+ return builtin_options_type() == tflite::BuiltinOptions_NonMaxSuppressionV5Options ? static_cast<const tflite::NonMaxSuppressionV5Options *>(builtin_options()) : nullptr;
+ }
+ const tflite::ScatterNdOptions *builtin_options_as_ScatterNdOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_ScatterNdOptions ? static_cast<const tflite::ScatterNdOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SelectV2Options *builtin_options_as_SelectV2Options() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SelectV2Options ? static_cast<const tflite::SelectV2Options *>(builtin_options()) : nullptr;
+ }
+ const tflite::DensifyOptions *builtin_options_as_DensifyOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_DensifyOptions ? static_cast<const tflite::DensifyOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::SegmentSumOptions *builtin_options_as_SegmentSumOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_SegmentSumOptions ? static_cast<const tflite::SegmentSumOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::BatchMatMulOptions *builtin_options_as_BatchMatMulOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_BatchMatMulOptions ? static_cast<const tflite::BatchMatMulOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::CumsumOptions *builtin_options_as_CumsumOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_CumsumOptions ? static_cast<const tflite::CumsumOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::CallOnceOptions *builtin_options_as_CallOnceOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_CallOnceOptions ? static_cast<const tflite::CallOnceOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::BroadcastToOptions *builtin_options_as_BroadcastToOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_BroadcastToOptions ? static_cast<const tflite::BroadcastToOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::Rfft2dOptions *builtin_options_as_Rfft2dOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_Rfft2dOptions ? static_cast<const tflite::Rfft2dOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::Conv3DOptions *builtin_options_as_Conv3DOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_Conv3DOptions ? static_cast<const tflite::Conv3DOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::HashtableOptions *builtin_options_as_HashtableOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_HashtableOptions ? static_cast<const tflite::HashtableOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::HashtableFindOptions *builtin_options_as_HashtableFindOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_HashtableFindOptions ? static_cast<const tflite::HashtableFindOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::HashtableImportOptions *builtin_options_as_HashtableImportOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_HashtableImportOptions ? static_cast<const tflite::HashtableImportOptions *>(builtin_options()) : nullptr;
+ }
+ const tflite::HashtableSizeOptions *builtin_options_as_HashtableSizeOptions() const {
+ return builtin_options_type() == tflite::BuiltinOptions_HashtableSizeOptions ? static_cast<const tflite::HashtableSizeOptions *>(builtin_options()) : nullptr;
+ }
+ const flatbuffers::Vector<uint8_t> *custom_options() const {
+ return GetPointer<const flatbuffers::Vector<uint8_t> *>(VT_CUSTOM_OPTIONS);
+ }
+ tflite::CustomOptionsFormat custom_options_format() const {
+ return static_cast<tflite::CustomOptionsFormat>(GetField<int8_t>(VT_CUSTOM_OPTIONS_FORMAT, 0));
+ }
+ const flatbuffers::Vector<uint8_t> *mutating_variable_inputs() const {
+ return GetPointer<const flatbuffers::Vector<uint8_t> *>(VT_MUTATING_VARIABLE_INPUTS);
+ }
+ const flatbuffers::Vector<int32_t> *intermediates() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_INTERMEDIATES);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint32_t>(verifier, VT_OPCODE_INDEX) &&
+ VerifyOffset(verifier, VT_INPUTS) &&
+ verifier.VerifyVector(inputs()) &&
+ VerifyOffset(verifier, VT_OUTPUTS) &&
+ verifier.VerifyVector(outputs()) &&
+ VerifyField<uint8_t>(verifier, VT_BUILTIN_OPTIONS_TYPE) &&
+ VerifyOffset(verifier, VT_BUILTIN_OPTIONS) &&
+ VerifyBuiltinOptions(verifier, builtin_options(), builtin_options_type()) &&
+ VerifyOffset(verifier, VT_CUSTOM_OPTIONS) &&
+ verifier.VerifyVector(custom_options()) &&
+ VerifyField<int8_t>(verifier, VT_CUSTOM_OPTIONS_FORMAT) &&
+ VerifyOffset(verifier, VT_MUTATING_VARIABLE_INPUTS) &&
+ verifier.VerifyVector(mutating_variable_inputs()) &&
+ VerifyOffset(verifier, VT_INTERMEDIATES) &&
+ verifier.VerifyVector(intermediates()) &&
+ verifier.EndTable();
+ }
+ OperatorT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(OperatorT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Operator> Pack(flatbuffers::FlatBufferBuilder &_fbb, const OperatorT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+template<> inline const tflite::Conv2DOptions *Operator::builtin_options_as<tflite::Conv2DOptions>() const {
+ return builtin_options_as_Conv2DOptions();
+}
+
+template<> inline const tflite::DepthwiseConv2DOptions *Operator::builtin_options_as<tflite::DepthwiseConv2DOptions>() const {
+ return builtin_options_as_DepthwiseConv2DOptions();
+}
+
+template<> inline const tflite::ConcatEmbeddingsOptions *Operator::builtin_options_as<tflite::ConcatEmbeddingsOptions>() const {
+ return builtin_options_as_ConcatEmbeddingsOptions();
+}
+
+template<> inline const tflite::LSHProjectionOptions *Operator::builtin_options_as<tflite::LSHProjectionOptions>() const {
+ return builtin_options_as_LSHProjectionOptions();
+}
+
+template<> inline const tflite::Pool2DOptions *Operator::builtin_options_as<tflite::Pool2DOptions>() const {
+ return builtin_options_as_Pool2DOptions();
+}
+
+template<> inline const tflite::SVDFOptions *Operator::builtin_options_as<tflite::SVDFOptions>() const {
+ return builtin_options_as_SVDFOptions();
+}
+
+template<> inline const tflite::RNNOptions *Operator::builtin_options_as<tflite::RNNOptions>() const {
+ return builtin_options_as_RNNOptions();
+}
+
+template<> inline const tflite::FullyConnectedOptions *Operator::builtin_options_as<tflite::FullyConnectedOptions>() const {
+ return builtin_options_as_FullyConnectedOptions();
+}
+
+template<> inline const tflite::SoftmaxOptions *Operator::builtin_options_as<tflite::SoftmaxOptions>() const {
+ return builtin_options_as_SoftmaxOptions();
+}
+
+template<> inline const tflite::ConcatenationOptions *Operator::builtin_options_as<tflite::ConcatenationOptions>() const {
+ return builtin_options_as_ConcatenationOptions();
+}
+
+template<> inline const tflite::AddOptions *Operator::builtin_options_as<tflite::AddOptions>() const {
+ return builtin_options_as_AddOptions();
+}
+
+template<> inline const tflite::L2NormOptions *Operator::builtin_options_as<tflite::L2NormOptions>() const {
+ return builtin_options_as_L2NormOptions();
+}
+
+template<> inline const tflite::LocalResponseNormalizationOptions *Operator::builtin_options_as<tflite::LocalResponseNormalizationOptions>() const {
+ return builtin_options_as_LocalResponseNormalizationOptions();
+}
+
+template<> inline const tflite::LSTMOptions *Operator::builtin_options_as<tflite::LSTMOptions>() const {
+ return builtin_options_as_LSTMOptions();
+}
+
+template<> inline const tflite::ResizeBilinearOptions *Operator::builtin_options_as<tflite::ResizeBilinearOptions>() const {
+ return builtin_options_as_ResizeBilinearOptions();
+}
+
+template<> inline const tflite::CallOptions *Operator::builtin_options_as<tflite::CallOptions>() const {
+ return builtin_options_as_CallOptions();
+}
+
+template<> inline const tflite::ReshapeOptions *Operator::builtin_options_as<tflite::ReshapeOptions>() const {
+ return builtin_options_as_ReshapeOptions();
+}
+
+template<> inline const tflite::SkipGramOptions *Operator::builtin_options_as<tflite::SkipGramOptions>() const {
+ return builtin_options_as_SkipGramOptions();
+}
+
+template<> inline const tflite::SpaceToDepthOptions *Operator::builtin_options_as<tflite::SpaceToDepthOptions>() const {
+ return builtin_options_as_SpaceToDepthOptions();
+}
+
+template<> inline const tflite::EmbeddingLookupSparseOptions *Operator::builtin_options_as<tflite::EmbeddingLookupSparseOptions>() const {
+ return builtin_options_as_EmbeddingLookupSparseOptions();
+}
+
+template<> inline const tflite::MulOptions *Operator::builtin_options_as<tflite::MulOptions>() const {
+ return builtin_options_as_MulOptions();
+}
+
+template<> inline const tflite::PadOptions *Operator::builtin_options_as<tflite::PadOptions>() const {
+ return builtin_options_as_PadOptions();
+}
+
+template<> inline const tflite::GatherOptions *Operator::builtin_options_as<tflite::GatherOptions>() const {
+ return builtin_options_as_GatherOptions();
+}
+
+template<> inline const tflite::BatchToSpaceNDOptions *Operator::builtin_options_as<tflite::BatchToSpaceNDOptions>() const {
+ return builtin_options_as_BatchToSpaceNDOptions();
+}
+
+template<> inline const tflite::SpaceToBatchNDOptions *Operator::builtin_options_as<tflite::SpaceToBatchNDOptions>() const {
+ return builtin_options_as_SpaceToBatchNDOptions();
+}
+
+template<> inline const tflite::TransposeOptions *Operator::builtin_options_as<tflite::TransposeOptions>() const {
+ return builtin_options_as_TransposeOptions();
+}
+
+template<> inline const tflite::ReducerOptions *Operator::builtin_options_as<tflite::ReducerOptions>() const {
+ return builtin_options_as_ReducerOptions();
+}
+
+template<> inline const tflite::SubOptions *Operator::builtin_options_as<tflite::SubOptions>() const {
+ return builtin_options_as_SubOptions();
+}
+
+template<> inline const tflite::DivOptions *Operator::builtin_options_as<tflite::DivOptions>() const {
+ return builtin_options_as_DivOptions();
+}
+
+template<> inline const tflite::SqueezeOptions *Operator::builtin_options_as<tflite::SqueezeOptions>() const {
+ return builtin_options_as_SqueezeOptions();
+}
+
+template<> inline const tflite::SequenceRNNOptions *Operator::builtin_options_as<tflite::SequenceRNNOptions>() const {
+ return builtin_options_as_SequenceRNNOptions();
+}
+
+template<> inline const tflite::StridedSliceOptions *Operator::builtin_options_as<tflite::StridedSliceOptions>() const {
+ return builtin_options_as_StridedSliceOptions();
+}
+
+template<> inline const tflite::ExpOptions *Operator::builtin_options_as<tflite::ExpOptions>() const {
+ return builtin_options_as_ExpOptions();
+}
+
+template<> inline const tflite::TopKV2Options *Operator::builtin_options_as<tflite::TopKV2Options>() const {
+ return builtin_options_as_TopKV2Options();
+}
+
+template<> inline const tflite::SplitOptions *Operator::builtin_options_as<tflite::SplitOptions>() const {
+ return builtin_options_as_SplitOptions();
+}
+
+template<> inline const tflite::LogSoftmaxOptions *Operator::builtin_options_as<tflite::LogSoftmaxOptions>() const {
+ return builtin_options_as_LogSoftmaxOptions();
+}
+
+template<> inline const tflite::CastOptions *Operator::builtin_options_as<tflite::CastOptions>() const {
+ return builtin_options_as_CastOptions();
+}
+
+template<> inline const tflite::DequantizeOptions *Operator::builtin_options_as<tflite::DequantizeOptions>() const {
+ return builtin_options_as_DequantizeOptions();
+}
+
+template<> inline const tflite::MaximumMinimumOptions *Operator::builtin_options_as<tflite::MaximumMinimumOptions>() const {
+ return builtin_options_as_MaximumMinimumOptions();
+}
+
+template<> inline const tflite::ArgMaxOptions *Operator::builtin_options_as<tflite::ArgMaxOptions>() const {
+ return builtin_options_as_ArgMaxOptions();
+}
+
+template<> inline const tflite::LessOptions *Operator::builtin_options_as<tflite::LessOptions>() const {
+ return builtin_options_as_LessOptions();
+}
+
+template<> inline const tflite::NegOptions *Operator::builtin_options_as<tflite::NegOptions>() const {
+ return builtin_options_as_NegOptions();
+}
+
+template<> inline const tflite::PadV2Options *Operator::builtin_options_as<tflite::PadV2Options>() const {
+ return builtin_options_as_PadV2Options();
+}
+
+template<> inline const tflite::GreaterOptions *Operator::builtin_options_as<tflite::GreaterOptions>() const {
+ return builtin_options_as_GreaterOptions();
+}
+
+template<> inline const tflite::GreaterEqualOptions *Operator::builtin_options_as<tflite::GreaterEqualOptions>() const {
+ return builtin_options_as_GreaterEqualOptions();
+}
+
+template<> inline const tflite::LessEqualOptions *Operator::builtin_options_as<tflite::LessEqualOptions>() const {
+ return builtin_options_as_LessEqualOptions();
+}
+
+template<> inline const tflite::SelectOptions *Operator::builtin_options_as<tflite::SelectOptions>() const {
+ return builtin_options_as_SelectOptions();
+}
+
+template<> inline const tflite::SliceOptions *Operator::builtin_options_as<tflite::SliceOptions>() const {
+ return builtin_options_as_SliceOptions();
+}
+
+template<> inline const tflite::TransposeConvOptions *Operator::builtin_options_as<tflite::TransposeConvOptions>() const {
+ return builtin_options_as_TransposeConvOptions();
+}
+
+template<> inline const tflite::SparseToDenseOptions *Operator::builtin_options_as<tflite::SparseToDenseOptions>() const {
+ return builtin_options_as_SparseToDenseOptions();
+}
+
+template<> inline const tflite::TileOptions *Operator::builtin_options_as<tflite::TileOptions>() const {
+ return builtin_options_as_TileOptions();
+}
+
+template<> inline const tflite::ExpandDimsOptions *Operator::builtin_options_as<tflite::ExpandDimsOptions>() const {
+ return builtin_options_as_ExpandDimsOptions();
+}
+
+template<> inline const tflite::EqualOptions *Operator::builtin_options_as<tflite::EqualOptions>() const {
+ return builtin_options_as_EqualOptions();
+}
+
+template<> inline const tflite::NotEqualOptions *Operator::builtin_options_as<tflite::NotEqualOptions>() const {
+ return builtin_options_as_NotEqualOptions();
+}
+
+template<> inline const tflite::ShapeOptions *Operator::builtin_options_as<tflite::ShapeOptions>() const {
+ return builtin_options_as_ShapeOptions();
+}
+
+template<> inline const tflite::PowOptions *Operator::builtin_options_as<tflite::PowOptions>() const {
+ return builtin_options_as_PowOptions();
+}
+
+template<> inline const tflite::ArgMinOptions *Operator::builtin_options_as<tflite::ArgMinOptions>() const {
+ return builtin_options_as_ArgMinOptions();
+}
+
+template<> inline const tflite::FakeQuantOptions *Operator::builtin_options_as<tflite::FakeQuantOptions>() const {
+ return builtin_options_as_FakeQuantOptions();
+}
+
+template<> inline const tflite::PackOptions *Operator::builtin_options_as<tflite::PackOptions>() const {
+ return builtin_options_as_PackOptions();
+}
+
+template<> inline const tflite::LogicalOrOptions *Operator::builtin_options_as<tflite::LogicalOrOptions>() const {
+ return builtin_options_as_LogicalOrOptions();
+}
+
+template<> inline const tflite::OneHotOptions *Operator::builtin_options_as<tflite::OneHotOptions>() const {
+ return builtin_options_as_OneHotOptions();
+}
+
+template<> inline const tflite::LogicalAndOptions *Operator::builtin_options_as<tflite::LogicalAndOptions>() const {
+ return builtin_options_as_LogicalAndOptions();
+}
+
+template<> inline const tflite::LogicalNotOptions *Operator::builtin_options_as<tflite::LogicalNotOptions>() const {
+ return builtin_options_as_LogicalNotOptions();
+}
+
+template<> inline const tflite::UnpackOptions *Operator::builtin_options_as<tflite::UnpackOptions>() const {
+ return builtin_options_as_UnpackOptions();
+}
+
+template<> inline const tflite::FloorDivOptions *Operator::builtin_options_as<tflite::FloorDivOptions>() const {
+ return builtin_options_as_FloorDivOptions();
+}
+
+template<> inline const tflite::SquareOptions *Operator::builtin_options_as<tflite::SquareOptions>() const {
+ return builtin_options_as_SquareOptions();
+}
+
+template<> inline const tflite::ZerosLikeOptions *Operator::builtin_options_as<tflite::ZerosLikeOptions>() const {
+ return builtin_options_as_ZerosLikeOptions();
+}
+
+template<> inline const tflite::FillOptions *Operator::builtin_options_as<tflite::FillOptions>() const {
+ return builtin_options_as_FillOptions();
+}
+
+template<> inline const tflite::BidirectionalSequenceLSTMOptions *Operator::builtin_options_as<tflite::BidirectionalSequenceLSTMOptions>() const {
+ return builtin_options_as_BidirectionalSequenceLSTMOptions();
+}
+
+template<> inline const tflite::BidirectionalSequenceRNNOptions *Operator::builtin_options_as<tflite::BidirectionalSequenceRNNOptions>() const {
+ return builtin_options_as_BidirectionalSequenceRNNOptions();
+}
+
+template<> inline const tflite::UnidirectionalSequenceLSTMOptions *Operator::builtin_options_as<tflite::UnidirectionalSequenceLSTMOptions>() const {
+ return builtin_options_as_UnidirectionalSequenceLSTMOptions();
+}
+
+template<> inline const tflite::FloorModOptions *Operator::builtin_options_as<tflite::FloorModOptions>() const {
+ return builtin_options_as_FloorModOptions();
+}
+
+template<> inline const tflite::RangeOptions *Operator::builtin_options_as<tflite::RangeOptions>() const {
+ return builtin_options_as_RangeOptions();
+}
+
+template<> inline const tflite::ResizeNearestNeighborOptions *Operator::builtin_options_as<tflite::ResizeNearestNeighborOptions>() const {
+ return builtin_options_as_ResizeNearestNeighborOptions();
+}
+
+template<> inline const tflite::LeakyReluOptions *Operator::builtin_options_as<tflite::LeakyReluOptions>() const {
+ return builtin_options_as_LeakyReluOptions();
+}
+
+template<> inline const tflite::SquaredDifferenceOptions *Operator::builtin_options_as<tflite::SquaredDifferenceOptions>() const {
+ return builtin_options_as_SquaredDifferenceOptions();
+}
+
+template<> inline const tflite::MirrorPadOptions *Operator::builtin_options_as<tflite::MirrorPadOptions>() const {
+ return builtin_options_as_MirrorPadOptions();
+}
+
+template<> inline const tflite::AbsOptions *Operator::builtin_options_as<tflite::AbsOptions>() const {
+ return builtin_options_as_AbsOptions();
+}
+
+template<> inline const tflite::SplitVOptions *Operator::builtin_options_as<tflite::SplitVOptions>() const {
+ return builtin_options_as_SplitVOptions();
+}
+
+template<> inline const tflite::UniqueOptions *Operator::builtin_options_as<tflite::UniqueOptions>() const {
+ return builtin_options_as_UniqueOptions();
+}
+
+template<> inline const tflite::ReverseV2Options *Operator::builtin_options_as<tflite::ReverseV2Options>() const {
+ return builtin_options_as_ReverseV2Options();
+}
+
+template<> inline const tflite::AddNOptions *Operator::builtin_options_as<tflite::AddNOptions>() const {
+ return builtin_options_as_AddNOptions();
+}
+
+template<> inline const tflite::GatherNdOptions *Operator::builtin_options_as<tflite::GatherNdOptions>() const {
+ return builtin_options_as_GatherNdOptions();
+}
+
+template<> inline const tflite::CosOptions *Operator::builtin_options_as<tflite::CosOptions>() const {
+ return builtin_options_as_CosOptions();
+}
+
+template<> inline const tflite::WhereOptions *Operator::builtin_options_as<tflite::WhereOptions>() const {
+ return builtin_options_as_WhereOptions();
+}
+
+template<> inline const tflite::RankOptions *Operator::builtin_options_as<tflite::RankOptions>() const {
+ return builtin_options_as_RankOptions();
+}
+
+template<> inline const tflite::ReverseSequenceOptions *Operator::builtin_options_as<tflite::ReverseSequenceOptions>() const {
+ return builtin_options_as_ReverseSequenceOptions();
+}
+
+template<> inline const tflite::MatrixDiagOptions *Operator::builtin_options_as<tflite::MatrixDiagOptions>() const {
+ return builtin_options_as_MatrixDiagOptions();
+}
+
+template<> inline const tflite::QuantizeOptions *Operator::builtin_options_as<tflite::QuantizeOptions>() const {
+ return builtin_options_as_QuantizeOptions();
+}
+
+template<> inline const tflite::MatrixSetDiagOptions *Operator::builtin_options_as<tflite::MatrixSetDiagOptions>() const {
+ return builtin_options_as_MatrixSetDiagOptions();
+}
+
+template<> inline const tflite::HardSwishOptions *Operator::builtin_options_as<tflite::HardSwishOptions>() const {
+ return builtin_options_as_HardSwishOptions();
+}
+
+template<> inline const tflite::IfOptions *Operator::builtin_options_as<tflite::IfOptions>() const {
+ return builtin_options_as_IfOptions();
+}
+
+template<> inline const tflite::WhileOptions *Operator::builtin_options_as<tflite::WhileOptions>() const {
+ return builtin_options_as_WhileOptions();
+}
+
+template<> inline const tflite::DepthToSpaceOptions *Operator::builtin_options_as<tflite::DepthToSpaceOptions>() const {
+ return builtin_options_as_DepthToSpaceOptions();
+}
+
+template<> inline const tflite::NonMaxSuppressionV4Options *Operator::builtin_options_as<tflite::NonMaxSuppressionV4Options>() const {
+ return builtin_options_as_NonMaxSuppressionV4Options();
+}
+
+template<> inline const tflite::NonMaxSuppressionV5Options *Operator::builtin_options_as<tflite::NonMaxSuppressionV5Options>() const {
+ return builtin_options_as_NonMaxSuppressionV5Options();
+}
+
+template<> inline const tflite::ScatterNdOptions *Operator::builtin_options_as<tflite::ScatterNdOptions>() const {
+ return builtin_options_as_ScatterNdOptions();
+}
+
+template<> inline const tflite::SelectV2Options *Operator::builtin_options_as<tflite::SelectV2Options>() const {
+ return builtin_options_as_SelectV2Options();
+}
+
+template<> inline const tflite::DensifyOptions *Operator::builtin_options_as<tflite::DensifyOptions>() const {
+ return builtin_options_as_DensifyOptions();
+}
+
+template<> inline const tflite::SegmentSumOptions *Operator::builtin_options_as<tflite::SegmentSumOptions>() const {
+ return builtin_options_as_SegmentSumOptions();
+}
+
+template<> inline const tflite::BatchMatMulOptions *Operator::builtin_options_as<tflite::BatchMatMulOptions>() const {
+ return builtin_options_as_BatchMatMulOptions();
+}
+
+template<> inline const tflite::CumsumOptions *Operator::builtin_options_as<tflite::CumsumOptions>() const {
+ return builtin_options_as_CumsumOptions();
+}
+
+template<> inline const tflite::CallOnceOptions *Operator::builtin_options_as<tflite::CallOnceOptions>() const {
+ return builtin_options_as_CallOnceOptions();
+}
+
+template<> inline const tflite::BroadcastToOptions *Operator::builtin_options_as<tflite::BroadcastToOptions>() const {
+ return builtin_options_as_BroadcastToOptions();
+}
+
+template<> inline const tflite::Rfft2dOptions *Operator::builtin_options_as<tflite::Rfft2dOptions>() const {
+ return builtin_options_as_Rfft2dOptions();
+}
+
+template<> inline const tflite::Conv3DOptions *Operator::builtin_options_as<tflite::Conv3DOptions>() const {
+ return builtin_options_as_Conv3DOptions();
+}
+
+template<> inline const tflite::HashtableOptions *Operator::builtin_options_as<tflite::HashtableOptions>() const {
+ return builtin_options_as_HashtableOptions();
+}
+
+template<> inline const tflite::HashtableFindOptions *Operator::builtin_options_as<tflite::HashtableFindOptions>() const {
+ return builtin_options_as_HashtableFindOptions();
+}
+
+template<> inline const tflite::HashtableImportOptions *Operator::builtin_options_as<tflite::HashtableImportOptions>() const {
+ return builtin_options_as_HashtableImportOptions();
+}
+
+template<> inline const tflite::HashtableSizeOptions *Operator::builtin_options_as<tflite::HashtableSizeOptions>() const {
+ return builtin_options_as_HashtableSizeOptions();
+}
+
+struct OperatorBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_opcode_index(uint32_t opcode_index) {
+ fbb_.AddElement<uint32_t>(Operator::VT_OPCODE_INDEX, opcode_index, 0);
+ }
+ void add_inputs(flatbuffers::Offset<flatbuffers::Vector<int32_t>> inputs) {
+ fbb_.AddOffset(Operator::VT_INPUTS, inputs);
+ }
+ void add_outputs(flatbuffers::Offset<flatbuffers::Vector<int32_t>> outputs) {
+ fbb_.AddOffset(Operator::VT_OUTPUTS, outputs);
+ }
+ void add_builtin_options_type(tflite::BuiltinOptions builtin_options_type) {
+ fbb_.AddElement<uint8_t>(Operator::VT_BUILTIN_OPTIONS_TYPE, static_cast<uint8_t>(builtin_options_type), 0);
+ }
+ void add_builtin_options(flatbuffers::Offset<void> builtin_options) {
+ fbb_.AddOffset(Operator::VT_BUILTIN_OPTIONS, builtin_options);
+ }
+ void add_custom_options(flatbuffers::Offset<flatbuffers::Vector<uint8_t>> custom_options) {
+ fbb_.AddOffset(Operator::VT_CUSTOM_OPTIONS, custom_options);
+ }
+ void add_custom_options_format(tflite::CustomOptionsFormat custom_options_format) {
+ fbb_.AddElement<int8_t>(Operator::VT_CUSTOM_OPTIONS_FORMAT, static_cast<int8_t>(custom_options_format), 0);
+ }
+ void add_mutating_variable_inputs(flatbuffers::Offset<flatbuffers::Vector<uint8_t>> mutating_variable_inputs) {
+ fbb_.AddOffset(Operator::VT_MUTATING_VARIABLE_INPUTS, mutating_variable_inputs);
+ }
+ void add_intermediates(flatbuffers::Offset<flatbuffers::Vector<int32_t>> intermediates) {
+ fbb_.AddOffset(Operator::VT_INTERMEDIATES, intermediates);
+ }
+ explicit OperatorBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ OperatorBuilder &operator=(const OperatorBuilder &);
+ flatbuffers::Offset<Operator> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Operator>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Operator> CreateOperator(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ uint32_t opcode_index = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> inputs = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> outputs = 0,
+ tflite::BuiltinOptions builtin_options_type = tflite::BuiltinOptions_NONE,
+ flatbuffers::Offset<void> builtin_options = 0,
+ flatbuffers::Offset<flatbuffers::Vector<uint8_t>> custom_options = 0,
+ tflite::CustomOptionsFormat custom_options_format = tflite::CustomOptionsFormat_FLEXBUFFERS,
+ flatbuffers::Offset<flatbuffers::Vector<uint8_t>> mutating_variable_inputs = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> intermediates = 0) {
+ OperatorBuilder builder_(_fbb);
+ builder_.add_intermediates(intermediates);
+ builder_.add_mutating_variable_inputs(mutating_variable_inputs);
+ builder_.add_custom_options(custom_options);
+ builder_.add_builtin_options(builtin_options);
+ builder_.add_outputs(outputs);
+ builder_.add_inputs(inputs);
+ builder_.add_opcode_index(opcode_index);
+ builder_.add_custom_options_format(custom_options_format);
+ builder_.add_builtin_options_type(builtin_options_type);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Operator> CreateOperatorDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ uint32_t opcode_index = 0,
+ const std::vector<int32_t> *inputs = nullptr,
+ const std::vector<int32_t> *outputs = nullptr,
+ tflite::BuiltinOptions builtin_options_type = tflite::BuiltinOptions_NONE,
+ flatbuffers::Offset<void> builtin_options = 0,
+ const std::vector<uint8_t> *custom_options = nullptr,
+ tflite::CustomOptionsFormat custom_options_format = tflite::CustomOptionsFormat_FLEXBUFFERS,
+ const std::vector<uint8_t> *mutating_variable_inputs = nullptr,
+ const std::vector<int32_t> *intermediates = nullptr) {
+ auto inputs__ = inputs ? _fbb.CreateVector<int32_t>(*inputs) : 0;
+ auto outputs__ = outputs ? _fbb.CreateVector<int32_t>(*outputs) : 0;
+ auto custom_options__ = custom_options ? _fbb.CreateVector<uint8_t>(*custom_options) : 0;
+ auto mutating_variable_inputs__ = mutating_variable_inputs ? _fbb.CreateVector<uint8_t>(*mutating_variable_inputs) : 0;
+ auto intermediates__ = intermediates ? _fbb.CreateVector<int32_t>(*intermediates) : 0;
+ return tflite::CreateOperator(
+ _fbb,
+ opcode_index,
+ inputs__,
+ outputs__,
+ builtin_options_type,
+ builtin_options,
+ custom_options__,
+ custom_options_format,
+ mutating_variable_inputs__,
+ intermediates__);
+}
+
+flatbuffers::Offset<Operator> CreateOperator(flatbuffers::FlatBufferBuilder &_fbb, const OperatorT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SubGraphT : public flatbuffers::NativeTable {
+ typedef SubGraph TableType;
+ std::vector<std::unique_ptr<tflite::TensorT>> tensors;
+ std::vector<int32_t> inputs;
+ std::vector<int32_t> outputs;
+ std::vector<std::unique_ptr<tflite::OperatorT>> operators;
+ std::string name;
+ SubGraphT() {
+ }
+};
+
+struct SubGraph FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SubGraphT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_TENSORS = 4,
+ VT_INPUTS = 6,
+ VT_OUTPUTS = 8,
+ VT_OPERATORS = 10,
+ VT_NAME = 12
+ };
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Tensor>> *tensors() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::Tensor>> *>(VT_TENSORS);
+ }
+ const flatbuffers::Vector<int32_t> *inputs() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_INPUTS);
+ }
+ const flatbuffers::Vector<int32_t> *outputs() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_OUTPUTS);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Operator>> *operators() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::Operator>> *>(VT_OPERATORS);
+ }
+ const flatbuffers::String *name() const {
+ return GetPointer<const flatbuffers::String *>(VT_NAME);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_TENSORS) &&
+ verifier.VerifyVector(tensors()) &&
+ verifier.VerifyVectorOfTables(tensors()) &&
+ VerifyOffset(verifier, VT_INPUTS) &&
+ verifier.VerifyVector(inputs()) &&
+ VerifyOffset(verifier, VT_OUTPUTS) &&
+ verifier.VerifyVector(outputs()) &&
+ VerifyOffset(verifier, VT_OPERATORS) &&
+ verifier.VerifyVector(operators()) &&
+ verifier.VerifyVectorOfTables(operators()) &&
+ VerifyOffset(verifier, VT_NAME) &&
+ verifier.VerifyString(name()) &&
+ verifier.EndTable();
+ }
+ SubGraphT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SubGraphT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SubGraph> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SubGraphT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SubGraphBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_tensors(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Tensor>>> tensors) {
+ fbb_.AddOffset(SubGraph::VT_TENSORS, tensors);
+ }
+ void add_inputs(flatbuffers::Offset<flatbuffers::Vector<int32_t>> inputs) {
+ fbb_.AddOffset(SubGraph::VT_INPUTS, inputs);
+ }
+ void add_outputs(flatbuffers::Offset<flatbuffers::Vector<int32_t>> outputs) {
+ fbb_.AddOffset(SubGraph::VT_OUTPUTS, outputs);
+ }
+ void add_operators(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Operator>>> operators) {
+ fbb_.AddOffset(SubGraph::VT_OPERATORS, operators);
+ }
+ void add_name(flatbuffers::Offset<flatbuffers::String> name) {
+ fbb_.AddOffset(SubGraph::VT_NAME, name);
+ }
+ explicit SubGraphBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SubGraphBuilder &operator=(const SubGraphBuilder &);
+ flatbuffers::Offset<SubGraph> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SubGraph>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SubGraph> CreateSubGraph(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Tensor>>> tensors = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> inputs = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> outputs = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Operator>>> operators = 0,
+ flatbuffers::Offset<flatbuffers::String> name = 0) {
+ SubGraphBuilder builder_(_fbb);
+ builder_.add_name(name);
+ builder_.add_operators(operators);
+ builder_.add_outputs(outputs);
+ builder_.add_inputs(inputs);
+ builder_.add_tensors(tensors);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<SubGraph> CreateSubGraphDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<flatbuffers::Offset<tflite::Tensor>> *tensors = nullptr,
+ const std::vector<int32_t> *inputs = nullptr,
+ const std::vector<int32_t> *outputs = nullptr,
+ const std::vector<flatbuffers::Offset<tflite::Operator>> *operators = nullptr,
+ const char *name = nullptr) {
+ auto tensors__ = tensors ? _fbb.CreateVector<flatbuffers::Offset<tflite::Tensor>>(*tensors) : 0;
+ auto inputs__ = inputs ? _fbb.CreateVector<int32_t>(*inputs) : 0;
+ auto outputs__ = outputs ? _fbb.CreateVector<int32_t>(*outputs) : 0;
+ auto operators__ = operators ? _fbb.CreateVector<flatbuffers::Offset<tflite::Operator>>(*operators) : 0;
+ auto name__ = name ? _fbb.CreateString(name) : 0;
+ return tflite::CreateSubGraph(
+ _fbb,
+ tensors__,
+ inputs__,
+ outputs__,
+ operators__,
+ name__);
+}
+
+flatbuffers::Offset<SubGraph> CreateSubGraph(flatbuffers::FlatBufferBuilder &_fbb, const SubGraphT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct BufferT : public flatbuffers::NativeTable {
+ typedef Buffer TableType;
+ std::vector<uint8_t> data;
+ BufferT() {
+ }
+};
+
+struct Buffer FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef BufferT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_DATA = 4
+ };
+ const flatbuffers::Vector<uint8_t> *data() const {
+ return GetPointer<const flatbuffers::Vector<uint8_t> *>(VT_DATA);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_DATA) &&
+ verifier.VerifyVector(data()) &&
+ verifier.EndTable();
+ }
+ BufferT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(BufferT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Buffer> Pack(flatbuffers::FlatBufferBuilder &_fbb, const BufferT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct BufferBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_data(flatbuffers::Offset<flatbuffers::Vector<uint8_t>> data) {
+ fbb_.AddOffset(Buffer::VT_DATA, data);
+ }
+ explicit BufferBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ BufferBuilder &operator=(const BufferBuilder &);
+ flatbuffers::Offset<Buffer> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Buffer>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Buffer> CreateBuffer(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<uint8_t>> data = 0) {
+ BufferBuilder builder_(_fbb);
+ builder_.add_data(data);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Buffer> CreateBufferDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<uint8_t> *data = nullptr) {
+ if (data) { _fbb.ForceVectorAlignment(data->size(), sizeof(uint8_t), 16); }
+ auto data__ = data ? _fbb.CreateVector<uint8_t>(*data) : 0;
+ return tflite::CreateBuffer(
+ _fbb,
+ data__);
+}
+
+flatbuffers::Offset<Buffer> CreateBuffer(flatbuffers::FlatBufferBuilder &_fbb, const BufferT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct MetadataT : public flatbuffers::NativeTable {
+ typedef Metadata TableType;
+ std::string name;
+ uint32_t buffer;
+ MetadataT()
+ : buffer(0) {
+ }
+};
+
+struct Metadata FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef MetadataT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NAME = 4,
+ VT_BUFFER = 6
+ };
+ const flatbuffers::String *name() const {
+ return GetPointer<const flatbuffers::String *>(VT_NAME);
+ }
+ uint32_t buffer() const {
+ return GetField<uint32_t>(VT_BUFFER, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_NAME) &&
+ verifier.VerifyString(name()) &&
+ VerifyField<uint32_t>(verifier, VT_BUFFER) &&
+ verifier.EndTable();
+ }
+ MetadataT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(MetadataT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Metadata> Pack(flatbuffers::FlatBufferBuilder &_fbb, const MetadataT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct MetadataBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_name(flatbuffers::Offset<flatbuffers::String> name) {
+ fbb_.AddOffset(Metadata::VT_NAME, name);
+ }
+ void add_buffer(uint32_t buffer) {
+ fbb_.AddElement<uint32_t>(Metadata::VT_BUFFER, buffer, 0);
+ }
+ explicit MetadataBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ MetadataBuilder &operator=(const MetadataBuilder &);
+ flatbuffers::Offset<Metadata> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Metadata>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Metadata> CreateMetadata(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::String> name = 0,
+ uint32_t buffer = 0) {
+ MetadataBuilder builder_(_fbb);
+ builder_.add_buffer(buffer);
+ builder_.add_name(name);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Metadata> CreateMetadataDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const char *name = nullptr,
+ uint32_t buffer = 0) {
+ auto name__ = name ? _fbb.CreateString(name) : 0;
+ return tflite::CreateMetadata(
+ _fbb,
+ name__,
+ buffer);
+}
+
+flatbuffers::Offset<Metadata> CreateMetadata(flatbuffers::FlatBufferBuilder &_fbb, const MetadataT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct TensorMapT : public flatbuffers::NativeTable {
+ typedef TensorMap TableType;
+ std::string name;
+ uint32_t tensor_index;
+ TensorMapT()
+ : tensor_index(0) {
+ }
+};
+
+struct TensorMap FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef TensorMapT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_NAME = 4,
+ VT_TENSOR_INDEX = 6
+ };
+ const flatbuffers::String *name() const {
+ return GetPointer<const flatbuffers::String *>(VT_NAME);
+ }
+ uint32_t tensor_index() const {
+ return GetField<uint32_t>(VT_TENSOR_INDEX, 0);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_NAME) &&
+ verifier.VerifyString(name()) &&
+ VerifyField<uint32_t>(verifier, VT_TENSOR_INDEX) &&
+ verifier.EndTable();
+ }
+ TensorMapT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(TensorMapT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<TensorMap> Pack(flatbuffers::FlatBufferBuilder &_fbb, const TensorMapT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct TensorMapBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_name(flatbuffers::Offset<flatbuffers::String> name) {
+ fbb_.AddOffset(TensorMap::VT_NAME, name);
+ }
+ void add_tensor_index(uint32_t tensor_index) {
+ fbb_.AddElement<uint32_t>(TensorMap::VT_TENSOR_INDEX, tensor_index, 0);
+ }
+ explicit TensorMapBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ TensorMapBuilder &operator=(const TensorMapBuilder &);
+ flatbuffers::Offset<TensorMap> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<TensorMap>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<TensorMap> CreateTensorMap(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::String> name = 0,
+ uint32_t tensor_index = 0) {
+ TensorMapBuilder builder_(_fbb);
+ builder_.add_tensor_index(tensor_index);
+ builder_.add_name(name);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<TensorMap> CreateTensorMapDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const char *name = nullptr,
+ uint32_t tensor_index = 0) {
+ auto name__ = name ? _fbb.CreateString(name) : 0;
+ return tflite::CreateTensorMap(
+ _fbb,
+ name__,
+ tensor_index);
+}
+
+flatbuffers::Offset<TensorMap> CreateTensorMap(flatbuffers::FlatBufferBuilder &_fbb, const TensorMapT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct SignatureDefT : public flatbuffers::NativeTable {
+ typedef SignatureDef TableType;
+ std::vector<std::unique_ptr<tflite::TensorMapT>> inputs;
+ std::vector<std::unique_ptr<tflite::TensorMapT>> outputs;
+ std::string method_name;
+ std::string key;
+ SignatureDefT() {
+ }
+};
+
+struct SignatureDef FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef SignatureDefT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_INPUTS = 4,
+ VT_OUTPUTS = 6,
+ VT_METHOD_NAME = 8,
+ VT_KEY = 10
+ };
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>> *inputs() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>> *>(VT_INPUTS);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>> *outputs() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>> *>(VT_OUTPUTS);
+ }
+ const flatbuffers::String *method_name() const {
+ return GetPointer<const flatbuffers::String *>(VT_METHOD_NAME);
+ }
+ const flatbuffers::String *key() const {
+ return GetPointer<const flatbuffers::String *>(VT_KEY);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyOffset(verifier, VT_INPUTS) &&
+ verifier.VerifyVector(inputs()) &&
+ verifier.VerifyVectorOfTables(inputs()) &&
+ VerifyOffset(verifier, VT_OUTPUTS) &&
+ verifier.VerifyVector(outputs()) &&
+ verifier.VerifyVectorOfTables(outputs()) &&
+ VerifyOffset(verifier, VT_METHOD_NAME) &&
+ verifier.VerifyString(method_name()) &&
+ VerifyOffset(verifier, VT_KEY) &&
+ verifier.VerifyString(key()) &&
+ verifier.EndTable();
+ }
+ SignatureDefT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(SignatureDefT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<SignatureDef> Pack(flatbuffers::FlatBufferBuilder &_fbb, const SignatureDefT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct SignatureDefBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_inputs(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>>> inputs) {
+ fbb_.AddOffset(SignatureDef::VT_INPUTS, inputs);
+ }
+ void add_outputs(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>>> outputs) {
+ fbb_.AddOffset(SignatureDef::VT_OUTPUTS, outputs);
+ }
+ void add_method_name(flatbuffers::Offset<flatbuffers::String> method_name) {
+ fbb_.AddOffset(SignatureDef::VT_METHOD_NAME, method_name);
+ }
+ void add_key(flatbuffers::Offset<flatbuffers::String> key) {
+ fbb_.AddOffset(SignatureDef::VT_KEY, key);
+ }
+ explicit SignatureDefBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ SignatureDefBuilder &operator=(const SignatureDefBuilder &);
+ flatbuffers::Offset<SignatureDef> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<SignatureDef>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<SignatureDef> CreateSignatureDef(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>>> inputs = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::TensorMap>>> outputs = 0,
+ flatbuffers::Offset<flatbuffers::String> method_name = 0,
+ flatbuffers::Offset<flatbuffers::String> key = 0) {
+ SignatureDefBuilder builder_(_fbb);
+ builder_.add_key(key);
+ builder_.add_method_name(method_name);
+ builder_.add_outputs(outputs);
+ builder_.add_inputs(inputs);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<SignatureDef> CreateSignatureDefDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ const std::vector<flatbuffers::Offset<tflite::TensorMap>> *inputs = nullptr,
+ const std::vector<flatbuffers::Offset<tflite::TensorMap>> *outputs = nullptr,
+ const char *method_name = nullptr,
+ const char *key = nullptr) {
+ auto inputs__ = inputs ? _fbb.CreateVector<flatbuffers::Offset<tflite::TensorMap>>(*inputs) : 0;
+ auto outputs__ = outputs ? _fbb.CreateVector<flatbuffers::Offset<tflite::TensorMap>>(*outputs) : 0;
+ auto method_name__ = method_name ? _fbb.CreateString(method_name) : 0;
+ auto key__ = key ? _fbb.CreateString(key) : 0;
+ return tflite::CreateSignatureDef(
+ _fbb,
+ inputs__,
+ outputs__,
+ method_name__,
+ key__);
+}
+
+flatbuffers::Offset<SignatureDef> CreateSignatureDef(flatbuffers::FlatBufferBuilder &_fbb, const SignatureDefT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+struct ModelT : public flatbuffers::NativeTable {
+ typedef Model TableType;
+ uint32_t version;
+ std::vector<std::unique_ptr<tflite::OperatorCodeT>> operator_codes;
+ std::vector<std::unique_ptr<tflite::SubGraphT>> subgraphs;
+ std::string description;
+ std::vector<std::unique_ptr<tflite::BufferT>> buffers;
+ std::vector<int32_t> metadata_buffer;
+ std::vector<std::unique_ptr<tflite::MetadataT>> metadata;
+ std::vector<std::unique_ptr<tflite::SignatureDefT>> signature_defs;
+ ModelT()
+ : version(0) {
+ }
+};
+
+struct Model FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table {
+ typedef ModelT NativeTableType;
+ enum FlatBuffersVTableOffset FLATBUFFERS_VTABLE_UNDERLYING_TYPE {
+ VT_VERSION = 4,
+ VT_OPERATOR_CODES = 6,
+ VT_SUBGRAPHS = 8,
+ VT_DESCRIPTION = 10,
+ VT_BUFFERS = 12,
+ VT_METADATA_BUFFER = 14,
+ VT_METADATA = 16,
+ VT_SIGNATURE_DEFS = 18
+ };
+ uint32_t version() const {
+ return GetField<uint32_t>(VT_VERSION, 0);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::OperatorCode>> *operator_codes() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::OperatorCode>> *>(VT_OPERATOR_CODES);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::SubGraph>> *subgraphs() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::SubGraph>> *>(VT_SUBGRAPHS);
+ }
+ const flatbuffers::String *description() const {
+ return GetPointer<const flatbuffers::String *>(VT_DESCRIPTION);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>> *buffers() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>> *>(VT_BUFFERS);
+ }
+ const flatbuffers::Vector<int32_t> *metadata_buffer() const {
+ return GetPointer<const flatbuffers::Vector<int32_t> *>(VT_METADATA_BUFFER);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::Metadata>> *metadata() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::Metadata>> *>(VT_METADATA);
+ }
+ const flatbuffers::Vector<flatbuffers::Offset<tflite::SignatureDef>> *signature_defs() const {
+ return GetPointer<const flatbuffers::Vector<flatbuffers::Offset<tflite::SignatureDef>> *>(VT_SIGNATURE_DEFS);
+ }
+ bool Verify(flatbuffers::Verifier &verifier) const {
+ return VerifyTableStart(verifier) &&
+ VerifyField<uint32_t>(verifier, VT_VERSION) &&
+ VerifyOffset(verifier, VT_OPERATOR_CODES) &&
+ verifier.VerifyVector(operator_codes()) &&
+ verifier.VerifyVectorOfTables(operator_codes()) &&
+ VerifyOffset(verifier, VT_SUBGRAPHS) &&
+ verifier.VerifyVector(subgraphs()) &&
+ verifier.VerifyVectorOfTables(subgraphs()) &&
+ VerifyOffset(verifier, VT_DESCRIPTION) &&
+ verifier.VerifyString(description()) &&
+ VerifyOffset(verifier, VT_BUFFERS) &&
+ verifier.VerifyVector(buffers()) &&
+ verifier.VerifyVectorOfTables(buffers()) &&
+ VerifyOffset(verifier, VT_METADATA_BUFFER) &&
+ verifier.VerifyVector(metadata_buffer()) &&
+ VerifyOffset(verifier, VT_METADATA) &&
+ verifier.VerifyVector(metadata()) &&
+ verifier.VerifyVectorOfTables(metadata()) &&
+ VerifyOffset(verifier, VT_SIGNATURE_DEFS) &&
+ verifier.VerifyVector(signature_defs()) &&
+ verifier.VerifyVectorOfTables(signature_defs()) &&
+ verifier.EndTable();
+ }
+ ModelT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ void UnPackTo(ModelT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const;
+ static flatbuffers::Offset<Model> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ModelT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+};
+
+struct ModelBuilder {
+ flatbuffers::FlatBufferBuilder &fbb_;
+ flatbuffers::uoffset_t start_;
+ void add_version(uint32_t version) {
+ fbb_.AddElement<uint32_t>(Model::VT_VERSION, version, 0);
+ }
+ void add_operator_codes(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::OperatorCode>>> operator_codes) {
+ fbb_.AddOffset(Model::VT_OPERATOR_CODES, operator_codes);
+ }
+ void add_subgraphs(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::SubGraph>>> subgraphs) {
+ fbb_.AddOffset(Model::VT_SUBGRAPHS, subgraphs);
+ }
+ void add_description(flatbuffers::Offset<flatbuffers::String> description) {
+ fbb_.AddOffset(Model::VT_DESCRIPTION, description);
+ }
+ void add_buffers(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>>> buffers) {
+ fbb_.AddOffset(Model::VT_BUFFERS, buffers);
+ }
+ void add_metadata_buffer(flatbuffers::Offset<flatbuffers::Vector<int32_t>> metadata_buffer) {
+ fbb_.AddOffset(Model::VT_METADATA_BUFFER, metadata_buffer);
+ }
+ void add_metadata(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Metadata>>> metadata) {
+ fbb_.AddOffset(Model::VT_METADATA, metadata);
+ }
+ void add_signature_defs(flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::SignatureDef>>> signature_defs) {
+ fbb_.AddOffset(Model::VT_SIGNATURE_DEFS, signature_defs);
+ }
+ explicit ModelBuilder(flatbuffers::FlatBufferBuilder &_fbb)
+ : fbb_(_fbb) {
+ start_ = fbb_.StartTable();
+ }
+ ModelBuilder &operator=(const ModelBuilder &);
+ flatbuffers::Offset<Model> Finish() {
+ const auto end = fbb_.EndTable(start_);
+ auto o = flatbuffers::Offset<Model>(end);
+ return o;
+ }
+};
+
+inline flatbuffers::Offset<Model> CreateModel(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ uint32_t version = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::OperatorCode>>> operator_codes = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::SubGraph>>> subgraphs = 0,
+ flatbuffers::Offset<flatbuffers::String> description = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Buffer>>> buffers = 0,
+ flatbuffers::Offset<flatbuffers::Vector<int32_t>> metadata_buffer = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::Metadata>>> metadata = 0,
+ flatbuffers::Offset<flatbuffers::Vector<flatbuffers::Offset<tflite::SignatureDef>>> signature_defs = 0) {
+ ModelBuilder builder_(_fbb);
+ builder_.add_signature_defs(signature_defs);
+ builder_.add_metadata(metadata);
+ builder_.add_metadata_buffer(metadata_buffer);
+ builder_.add_buffers(buffers);
+ builder_.add_description(description);
+ builder_.add_subgraphs(subgraphs);
+ builder_.add_operator_codes(operator_codes);
+ builder_.add_version(version);
+ return builder_.Finish();
+}
+
+inline flatbuffers::Offset<Model> CreateModelDirect(
+ flatbuffers::FlatBufferBuilder &_fbb,
+ uint32_t version = 0,
+ const std::vector<flatbuffers::Offset<tflite::OperatorCode>> *operator_codes = nullptr,
+ const std::vector<flatbuffers::Offset<tflite::SubGraph>> *subgraphs = nullptr,
+ const char *description = nullptr,
+ const std::vector<flatbuffers::Offset<tflite::Buffer>> *buffers = nullptr,
+ const std::vector<int32_t> *metadata_buffer = nullptr,
+ const std::vector<flatbuffers::Offset<tflite::Metadata>> *metadata = nullptr,
+ const std::vector<flatbuffers::Offset<tflite::SignatureDef>> *signature_defs = nullptr) {
+ auto operator_codes__ = operator_codes ? _fbb.CreateVector<flatbuffers::Offset<tflite::OperatorCode>>(*operator_codes) : 0;
+ auto subgraphs__ = subgraphs ? _fbb.CreateVector<flatbuffers::Offset<tflite::SubGraph>>(*subgraphs) : 0;
+ auto description__ = description ? _fbb.CreateString(description) : 0;
+ auto buffers__ = buffers ? _fbb.CreateVector<flatbuffers::Offset<tflite::Buffer>>(*buffers) : 0;
+ auto metadata_buffer__ = metadata_buffer ? _fbb.CreateVector<int32_t>(*metadata_buffer) : 0;
+ auto metadata__ = metadata ? _fbb.CreateVector<flatbuffers::Offset<tflite::Metadata>>(*metadata) : 0;
+ auto signature_defs__ = signature_defs ? _fbb.CreateVector<flatbuffers::Offset<tflite::SignatureDef>>(*signature_defs) : 0;
+ return tflite::CreateModel(
+ _fbb,
+ version,
+ operator_codes__,
+ subgraphs__,
+ description__,
+ buffers__,
+ metadata_buffer__,
+ metadata__,
+ signature_defs__);
+}
+
+flatbuffers::Offset<Model> CreateModel(flatbuffers::FlatBufferBuilder &_fbb, const ModelT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr);
+
+inline CustomQuantizationT *CustomQuantization::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new CustomQuantizationT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void CustomQuantization::UnPackTo(CustomQuantizationT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = custom(); if (_e) { _o->custom.resize(_e->size()); std::copy(_e->begin(), _e->end(), _o->custom.begin()); } }
+}
+
+inline flatbuffers::Offset<CustomQuantization> CustomQuantization::Pack(flatbuffers::FlatBufferBuilder &_fbb, const CustomQuantizationT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateCustomQuantization(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<CustomQuantization> CreateCustomQuantization(flatbuffers::FlatBufferBuilder &_fbb, const CustomQuantizationT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const CustomQuantizationT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ _fbb.ForceVectorAlignment(_o->custom.size(), sizeof(uint8_t), 16);
+ auto _custom = _o->custom.size() ? _fbb.CreateVector(_o->custom) : 0;
+ return tflite::CreateCustomQuantization(
+ _fbb,
+ _custom);
+}
+
+inline QuantizationParametersT *QuantizationParameters::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new QuantizationParametersT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void QuantizationParameters::UnPackTo(QuantizationParametersT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = min(); if (_e) { _o->min.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->min[_i] = _e->Get(_i); } } }
+ { auto _e = max(); if (_e) { _o->max.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->max[_i] = _e->Get(_i); } } }
+ { auto _e = scale(); if (_e) { _o->scale.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->scale[_i] = _e->Get(_i); } } }
+ { auto _e = zero_point(); if (_e) { _o->zero_point.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->zero_point[_i] = _e->Get(_i); } } }
+ { auto _e = details_type(); _o->details.type = _e; }
+ { auto _e = details(); if (_e) _o->details.value = tflite::QuantizationDetailsUnion::UnPack(_e, details_type(), _resolver); }
+ { auto _e = quantized_dimension(); _o->quantized_dimension = _e; }
+}
+
+inline flatbuffers::Offset<QuantizationParameters> QuantizationParameters::Pack(flatbuffers::FlatBufferBuilder &_fbb, const QuantizationParametersT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateQuantizationParameters(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<QuantizationParameters> CreateQuantizationParameters(flatbuffers::FlatBufferBuilder &_fbb, const QuantizationParametersT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const QuantizationParametersT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _min = _o->min.size() ? _fbb.CreateVector(_o->min) : 0;
+ auto _max = _o->max.size() ? _fbb.CreateVector(_o->max) : 0;
+ auto _scale = _o->scale.size() ? _fbb.CreateVector(_o->scale) : 0;
+ auto _zero_point = _o->zero_point.size() ? _fbb.CreateVector(_o->zero_point) : 0;
+ auto _details_type = _o->details.type;
+ auto _details = _o->details.Pack(_fbb);
+ auto _quantized_dimension = _o->quantized_dimension;
+ return tflite::CreateQuantizationParameters(
+ _fbb,
+ _min,
+ _max,
+ _scale,
+ _zero_point,
+ _details_type,
+ _details,
+ _quantized_dimension);
+}
+
+inline Int32VectorT *Int32Vector::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new Int32VectorT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Int32Vector::UnPackTo(Int32VectorT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = values(); if (_e) { _o->values.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->values[_i] = _e->Get(_i); } } }
+}
+
+inline flatbuffers::Offset<Int32Vector> Int32Vector::Pack(flatbuffers::FlatBufferBuilder &_fbb, const Int32VectorT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateInt32Vector(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Int32Vector> CreateInt32Vector(flatbuffers::FlatBufferBuilder &_fbb, const Int32VectorT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const Int32VectorT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _values = _o->values.size() ? _fbb.CreateVector(_o->values) : 0;
+ return tflite::CreateInt32Vector(
+ _fbb,
+ _values);
+}
+
+inline Uint16VectorT *Uint16Vector::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new Uint16VectorT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Uint16Vector::UnPackTo(Uint16VectorT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = values(); if (_e) { _o->values.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->values[_i] = _e->Get(_i); } } }
+}
+
+inline flatbuffers::Offset<Uint16Vector> Uint16Vector::Pack(flatbuffers::FlatBufferBuilder &_fbb, const Uint16VectorT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateUint16Vector(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Uint16Vector> CreateUint16Vector(flatbuffers::FlatBufferBuilder &_fbb, const Uint16VectorT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const Uint16VectorT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ _fbb.ForceVectorAlignment(_o->values.size(), sizeof(uint16_t), 4);
+ auto _values = _o->values.size() ? _fbb.CreateVector(_o->values) : 0;
+ return tflite::CreateUint16Vector(
+ _fbb,
+ _values);
+}
+
+inline Uint8VectorT *Uint8Vector::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new Uint8VectorT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Uint8Vector::UnPackTo(Uint8VectorT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = values(); if (_e) { _o->values.resize(_e->size()); std::copy(_e->begin(), _e->end(), _o->values.begin()); } }
+}
+
+inline flatbuffers::Offset<Uint8Vector> Uint8Vector::Pack(flatbuffers::FlatBufferBuilder &_fbb, const Uint8VectorT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateUint8Vector(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Uint8Vector> CreateUint8Vector(flatbuffers::FlatBufferBuilder &_fbb, const Uint8VectorT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const Uint8VectorT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ _fbb.ForceVectorAlignment(_o->values.size(), sizeof(uint8_t), 4);
+ auto _values = _o->values.size() ? _fbb.CreateVector(_o->values) : 0;
+ return tflite::CreateUint8Vector(
+ _fbb,
+ _values);
+}
+
+inline DimensionMetadataT *DimensionMetadata::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new DimensionMetadataT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void DimensionMetadata::UnPackTo(DimensionMetadataT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = format(); _o->format = _e; }
+ { auto _e = dense_size(); _o->dense_size = _e; }
+ { auto _e = array_segments_type(); _o->array_segments.type = _e; }
+ { auto _e = array_segments(); if (_e) _o->array_segments.value = tflite::SparseIndexVectorUnion::UnPack(_e, array_segments_type(), _resolver); }
+ { auto _e = array_indices_type(); _o->array_indices.type = _e; }
+ { auto _e = array_indices(); if (_e) _o->array_indices.value = tflite::SparseIndexVectorUnion::UnPack(_e, array_indices_type(), _resolver); }
+}
+
+inline flatbuffers::Offset<DimensionMetadata> DimensionMetadata::Pack(flatbuffers::FlatBufferBuilder &_fbb, const DimensionMetadataT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateDimensionMetadata(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<DimensionMetadata> CreateDimensionMetadata(flatbuffers::FlatBufferBuilder &_fbb, const DimensionMetadataT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const DimensionMetadataT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _format = _o->format;
+ auto _dense_size = _o->dense_size;
+ auto _array_segments_type = _o->array_segments.type;
+ auto _array_segments = _o->array_segments.Pack(_fbb);
+ auto _array_indices_type = _o->array_indices.type;
+ auto _array_indices = _o->array_indices.Pack(_fbb);
+ return tflite::CreateDimensionMetadata(
+ _fbb,
+ _format,
+ _dense_size,
+ _array_segments_type,
+ _array_segments,
+ _array_indices_type,
+ _array_indices);
+}
+
+inline SparsityParametersT *SparsityParameters::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SparsityParametersT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SparsityParameters::UnPackTo(SparsityParametersT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = traversal_order(); if (_e) { _o->traversal_order.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->traversal_order[_i] = _e->Get(_i); } } }
+ { auto _e = block_map(); if (_e) { _o->block_map.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->block_map[_i] = _e->Get(_i); } } }
+ { auto _e = dim_metadata(); if (_e) { _o->dim_metadata.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->dim_metadata[_i] = std::unique_ptr<tflite::DimensionMetadataT>(_e->Get(_i)->UnPack(_resolver)); } } }
+}
+
+inline flatbuffers::Offset<SparsityParameters> SparsityParameters::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SparsityParametersT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSparsityParameters(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SparsityParameters> CreateSparsityParameters(flatbuffers::FlatBufferBuilder &_fbb, const SparsityParametersT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SparsityParametersT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _traversal_order = _o->traversal_order.size() ? _fbb.CreateVector(_o->traversal_order) : 0;
+ auto _block_map = _o->block_map.size() ? _fbb.CreateVector(_o->block_map) : 0;
+ auto _dim_metadata = _o->dim_metadata.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::DimensionMetadata>> (_o->dim_metadata.size(), [](size_t i, _VectorArgs *__va) { return CreateDimensionMetadata(*__va->__fbb, __va->__o->dim_metadata[i].get(), __va->__rehasher); }, &_va ) : 0;
+ return tflite::CreateSparsityParameters(
+ _fbb,
+ _traversal_order,
+ _block_map,
+ _dim_metadata);
+}
+
+inline TensorT *Tensor::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new TensorT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Tensor::UnPackTo(TensorT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = shape(); if (_e) { _o->shape.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->shape[_i] = _e->Get(_i); } } }
+ { auto _e = type(); _o->type = _e; }
+ { auto _e = buffer(); _o->buffer = _e; }
+ { auto _e = name(); if (_e) _o->name = _e->str(); }
+ { auto _e = quantization(); if (_e) _o->quantization = std::unique_ptr<tflite::QuantizationParametersT>(_e->UnPack(_resolver)); }
+ { auto _e = is_variable(); _o->is_variable = _e; }
+ { auto _e = sparsity(); if (_e) _o->sparsity = std::unique_ptr<tflite::SparsityParametersT>(_e->UnPack(_resolver)); }
+ { auto _e = shape_signature(); if (_e) { _o->shape_signature.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->shape_signature[_i] = _e->Get(_i); } } }
+}
+
+inline flatbuffers::Offset<Tensor> Tensor::Pack(flatbuffers::FlatBufferBuilder &_fbb, const TensorT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateTensor(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Tensor> CreateTensor(flatbuffers::FlatBufferBuilder &_fbb, const TensorT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const TensorT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _shape = _o->shape.size() ? _fbb.CreateVector(_o->shape) : 0;
+ auto _type = _o->type;
+ auto _buffer = _o->buffer;
+ auto _name = _o->name.empty() ? 0 : _fbb.CreateString(_o->name);
+ auto _quantization = _o->quantization ? CreateQuantizationParameters(_fbb, _o->quantization.get(), _rehasher) : 0;
+ auto _is_variable = _o->is_variable;
+ auto _sparsity = _o->sparsity ? CreateSparsityParameters(_fbb, _o->sparsity.get(), _rehasher) : 0;
+ auto _shape_signature = _o->shape_signature.size() ? _fbb.CreateVector(_o->shape_signature) : 0;
+ return tflite::CreateTensor(
+ _fbb,
+ _shape,
+ _type,
+ _buffer,
+ _name,
+ _quantization,
+ _is_variable,
+ _sparsity,
+ _shape_signature);
+}
+
+inline Conv2DOptionsT *Conv2DOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new Conv2DOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Conv2DOptions::UnPackTo(Conv2DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = padding(); _o->padding = _e; }
+ { auto _e = stride_w(); _o->stride_w = _e; }
+ { auto _e = stride_h(); _o->stride_h = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = dilation_w_factor(); _o->dilation_w_factor = _e; }
+ { auto _e = dilation_h_factor(); _o->dilation_h_factor = _e; }
+}
+
+inline flatbuffers::Offset<Conv2DOptions> Conv2DOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const Conv2DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateConv2DOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Conv2DOptions> CreateConv2DOptions(flatbuffers::FlatBufferBuilder &_fbb, const Conv2DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const Conv2DOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _padding = _o->padding;
+ auto _stride_w = _o->stride_w;
+ auto _stride_h = _o->stride_h;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _dilation_w_factor = _o->dilation_w_factor;
+ auto _dilation_h_factor = _o->dilation_h_factor;
+ return tflite::CreateConv2DOptions(
+ _fbb,
+ _padding,
+ _stride_w,
+ _stride_h,
+ _fused_activation_function,
+ _dilation_w_factor,
+ _dilation_h_factor);
+}
+
+inline Conv3DOptionsT *Conv3DOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new Conv3DOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Conv3DOptions::UnPackTo(Conv3DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = padding(); _o->padding = _e; }
+ { auto _e = stride_d(); _o->stride_d = _e; }
+ { auto _e = stride_w(); _o->stride_w = _e; }
+ { auto _e = stride_h(); _o->stride_h = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = dilation_d_factor(); _o->dilation_d_factor = _e; }
+ { auto _e = dilation_w_factor(); _o->dilation_w_factor = _e; }
+ { auto _e = dilation_h_factor(); _o->dilation_h_factor = _e; }
+}
+
+inline flatbuffers::Offset<Conv3DOptions> Conv3DOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const Conv3DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateConv3DOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Conv3DOptions> CreateConv3DOptions(flatbuffers::FlatBufferBuilder &_fbb, const Conv3DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const Conv3DOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _padding = _o->padding;
+ auto _stride_d = _o->stride_d;
+ auto _stride_w = _o->stride_w;
+ auto _stride_h = _o->stride_h;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _dilation_d_factor = _o->dilation_d_factor;
+ auto _dilation_w_factor = _o->dilation_w_factor;
+ auto _dilation_h_factor = _o->dilation_h_factor;
+ return tflite::CreateConv3DOptions(
+ _fbb,
+ _padding,
+ _stride_d,
+ _stride_w,
+ _stride_h,
+ _fused_activation_function,
+ _dilation_d_factor,
+ _dilation_w_factor,
+ _dilation_h_factor);
+}
+
+inline Pool2DOptionsT *Pool2DOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new Pool2DOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Pool2DOptions::UnPackTo(Pool2DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = padding(); _o->padding = _e; }
+ { auto _e = stride_w(); _o->stride_w = _e; }
+ { auto _e = stride_h(); _o->stride_h = _e; }
+ { auto _e = filter_width(); _o->filter_width = _e; }
+ { auto _e = filter_height(); _o->filter_height = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+}
+
+inline flatbuffers::Offset<Pool2DOptions> Pool2DOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const Pool2DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreatePool2DOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Pool2DOptions> CreatePool2DOptions(flatbuffers::FlatBufferBuilder &_fbb, const Pool2DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const Pool2DOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _padding = _o->padding;
+ auto _stride_w = _o->stride_w;
+ auto _stride_h = _o->stride_h;
+ auto _filter_width = _o->filter_width;
+ auto _filter_height = _o->filter_height;
+ auto _fused_activation_function = _o->fused_activation_function;
+ return tflite::CreatePool2DOptions(
+ _fbb,
+ _padding,
+ _stride_w,
+ _stride_h,
+ _filter_width,
+ _filter_height,
+ _fused_activation_function);
+}
+
+inline DepthwiseConv2DOptionsT *DepthwiseConv2DOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new DepthwiseConv2DOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void DepthwiseConv2DOptions::UnPackTo(DepthwiseConv2DOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = padding(); _o->padding = _e; }
+ { auto _e = stride_w(); _o->stride_w = _e; }
+ { auto _e = stride_h(); _o->stride_h = _e; }
+ { auto _e = depth_multiplier(); _o->depth_multiplier = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = dilation_w_factor(); _o->dilation_w_factor = _e; }
+ { auto _e = dilation_h_factor(); _o->dilation_h_factor = _e; }
+}
+
+inline flatbuffers::Offset<DepthwiseConv2DOptions> DepthwiseConv2DOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const DepthwiseConv2DOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateDepthwiseConv2DOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<DepthwiseConv2DOptions> CreateDepthwiseConv2DOptions(flatbuffers::FlatBufferBuilder &_fbb, const DepthwiseConv2DOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const DepthwiseConv2DOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _padding = _o->padding;
+ auto _stride_w = _o->stride_w;
+ auto _stride_h = _o->stride_h;
+ auto _depth_multiplier = _o->depth_multiplier;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _dilation_w_factor = _o->dilation_w_factor;
+ auto _dilation_h_factor = _o->dilation_h_factor;
+ return tflite::CreateDepthwiseConv2DOptions(
+ _fbb,
+ _padding,
+ _stride_w,
+ _stride_h,
+ _depth_multiplier,
+ _fused_activation_function,
+ _dilation_w_factor,
+ _dilation_h_factor);
+}
+
+inline ConcatEmbeddingsOptionsT *ConcatEmbeddingsOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ConcatEmbeddingsOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ConcatEmbeddingsOptions::UnPackTo(ConcatEmbeddingsOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = num_channels(); _o->num_channels = _e; }
+ { auto _e = num_columns_per_channel(); if (_e) { _o->num_columns_per_channel.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->num_columns_per_channel[_i] = _e->Get(_i); } } }
+ { auto _e = embedding_dim_per_channel(); if (_e) { _o->embedding_dim_per_channel.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->embedding_dim_per_channel[_i] = _e->Get(_i); } } }
+}
+
+inline flatbuffers::Offset<ConcatEmbeddingsOptions> ConcatEmbeddingsOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ConcatEmbeddingsOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateConcatEmbeddingsOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ConcatEmbeddingsOptions> CreateConcatEmbeddingsOptions(flatbuffers::FlatBufferBuilder &_fbb, const ConcatEmbeddingsOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ConcatEmbeddingsOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _num_channels = _o->num_channels;
+ auto _num_columns_per_channel = _o->num_columns_per_channel.size() ? _fbb.CreateVector(_o->num_columns_per_channel) : 0;
+ auto _embedding_dim_per_channel = _o->embedding_dim_per_channel.size() ? _fbb.CreateVector(_o->embedding_dim_per_channel) : 0;
+ return tflite::CreateConcatEmbeddingsOptions(
+ _fbb,
+ _num_channels,
+ _num_columns_per_channel,
+ _embedding_dim_per_channel);
+}
+
+inline LSHProjectionOptionsT *LSHProjectionOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LSHProjectionOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LSHProjectionOptions::UnPackTo(LSHProjectionOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = type(); _o->type = _e; }
+}
+
+inline flatbuffers::Offset<LSHProjectionOptions> LSHProjectionOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LSHProjectionOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLSHProjectionOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LSHProjectionOptions> CreateLSHProjectionOptions(flatbuffers::FlatBufferBuilder &_fbb, const LSHProjectionOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LSHProjectionOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _type = _o->type;
+ return tflite::CreateLSHProjectionOptions(
+ _fbb,
+ _type);
+}
+
+inline SVDFOptionsT *SVDFOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SVDFOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SVDFOptions::UnPackTo(SVDFOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = rank(); _o->rank = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<SVDFOptions> SVDFOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SVDFOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSVDFOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SVDFOptions> CreateSVDFOptions(flatbuffers::FlatBufferBuilder &_fbb, const SVDFOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SVDFOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _rank = _o->rank;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateSVDFOptions(
+ _fbb,
+ _rank,
+ _fused_activation_function,
+ _asymmetric_quantize_inputs);
+}
+
+inline RNNOptionsT *RNNOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new RNNOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void RNNOptions::UnPackTo(RNNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<RNNOptions> RNNOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const RNNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateRNNOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<RNNOptions> CreateRNNOptions(flatbuffers::FlatBufferBuilder &_fbb, const RNNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const RNNOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateRNNOptions(
+ _fbb,
+ _fused_activation_function,
+ _asymmetric_quantize_inputs);
+}
+
+inline SequenceRNNOptionsT *SequenceRNNOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SequenceRNNOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SequenceRNNOptions::UnPackTo(SequenceRNNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = time_major(); _o->time_major = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<SequenceRNNOptions> SequenceRNNOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SequenceRNNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSequenceRNNOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SequenceRNNOptions> CreateSequenceRNNOptions(flatbuffers::FlatBufferBuilder &_fbb, const SequenceRNNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SequenceRNNOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _time_major = _o->time_major;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateSequenceRNNOptions(
+ _fbb,
+ _time_major,
+ _fused_activation_function,
+ _asymmetric_quantize_inputs);
+}
+
+inline BidirectionalSequenceRNNOptionsT *BidirectionalSequenceRNNOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new BidirectionalSequenceRNNOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void BidirectionalSequenceRNNOptions::UnPackTo(BidirectionalSequenceRNNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = time_major(); _o->time_major = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = merge_outputs(); _o->merge_outputs = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<BidirectionalSequenceRNNOptions> BidirectionalSequenceRNNOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceRNNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateBidirectionalSequenceRNNOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<BidirectionalSequenceRNNOptions> CreateBidirectionalSequenceRNNOptions(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceRNNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const BidirectionalSequenceRNNOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _time_major = _o->time_major;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _merge_outputs = _o->merge_outputs;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateBidirectionalSequenceRNNOptions(
+ _fbb,
+ _time_major,
+ _fused_activation_function,
+ _merge_outputs,
+ _asymmetric_quantize_inputs);
+}
+
+inline FullyConnectedOptionsT *FullyConnectedOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new FullyConnectedOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void FullyConnectedOptions::UnPackTo(FullyConnectedOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = weights_format(); _o->weights_format = _e; }
+ { auto _e = keep_num_dims(); _o->keep_num_dims = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<FullyConnectedOptions> FullyConnectedOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const FullyConnectedOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateFullyConnectedOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<FullyConnectedOptions> CreateFullyConnectedOptions(flatbuffers::FlatBufferBuilder &_fbb, const FullyConnectedOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const FullyConnectedOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _weights_format = _o->weights_format;
+ auto _keep_num_dims = _o->keep_num_dims;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateFullyConnectedOptions(
+ _fbb,
+ _fused_activation_function,
+ _weights_format,
+ _keep_num_dims,
+ _asymmetric_quantize_inputs);
+}
+
+inline SoftmaxOptionsT *SoftmaxOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SoftmaxOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SoftmaxOptions::UnPackTo(SoftmaxOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = beta(); _o->beta = _e; }
+}
+
+inline flatbuffers::Offset<SoftmaxOptions> SoftmaxOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SoftmaxOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSoftmaxOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SoftmaxOptions> CreateSoftmaxOptions(flatbuffers::FlatBufferBuilder &_fbb, const SoftmaxOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SoftmaxOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _beta = _o->beta;
+ return tflite::CreateSoftmaxOptions(
+ _fbb,
+ _beta);
+}
+
+inline ConcatenationOptionsT *ConcatenationOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ConcatenationOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ConcatenationOptions::UnPackTo(ConcatenationOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = axis(); _o->axis = _e; }
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+}
+
+inline flatbuffers::Offset<ConcatenationOptions> ConcatenationOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ConcatenationOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateConcatenationOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ConcatenationOptions> CreateConcatenationOptions(flatbuffers::FlatBufferBuilder &_fbb, const ConcatenationOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ConcatenationOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _axis = _o->axis;
+ auto _fused_activation_function = _o->fused_activation_function;
+ return tflite::CreateConcatenationOptions(
+ _fbb,
+ _axis,
+ _fused_activation_function);
+}
+
+inline AddOptionsT *AddOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new AddOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void AddOptions::UnPackTo(AddOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = pot_scale_int16(); _o->pot_scale_int16 = _e; }
+}
+
+inline flatbuffers::Offset<AddOptions> AddOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const AddOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateAddOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<AddOptions> CreateAddOptions(flatbuffers::FlatBufferBuilder &_fbb, const AddOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const AddOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _pot_scale_int16 = _o->pot_scale_int16;
+ return tflite::CreateAddOptions(
+ _fbb,
+ _fused_activation_function,
+ _pot_scale_int16);
+}
+
+inline MulOptionsT *MulOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new MulOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void MulOptions::UnPackTo(MulOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+}
+
+inline flatbuffers::Offset<MulOptions> MulOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const MulOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateMulOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<MulOptions> CreateMulOptions(flatbuffers::FlatBufferBuilder &_fbb, const MulOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const MulOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ return tflite::CreateMulOptions(
+ _fbb,
+ _fused_activation_function);
+}
+
+inline L2NormOptionsT *L2NormOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new L2NormOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void L2NormOptions::UnPackTo(L2NormOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+}
+
+inline flatbuffers::Offset<L2NormOptions> L2NormOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const L2NormOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateL2NormOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<L2NormOptions> CreateL2NormOptions(flatbuffers::FlatBufferBuilder &_fbb, const L2NormOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const L2NormOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ return tflite::CreateL2NormOptions(
+ _fbb,
+ _fused_activation_function);
+}
+
+inline LocalResponseNormalizationOptionsT *LocalResponseNormalizationOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LocalResponseNormalizationOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LocalResponseNormalizationOptions::UnPackTo(LocalResponseNormalizationOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = radius(); _o->radius = _e; }
+ { auto _e = bias(); _o->bias = _e; }
+ { auto _e = alpha(); _o->alpha = _e; }
+ { auto _e = beta(); _o->beta = _e; }
+}
+
+inline flatbuffers::Offset<LocalResponseNormalizationOptions> LocalResponseNormalizationOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LocalResponseNormalizationOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLocalResponseNormalizationOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LocalResponseNormalizationOptions> CreateLocalResponseNormalizationOptions(flatbuffers::FlatBufferBuilder &_fbb, const LocalResponseNormalizationOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LocalResponseNormalizationOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _radius = _o->radius;
+ auto _bias = _o->bias;
+ auto _alpha = _o->alpha;
+ auto _beta = _o->beta;
+ return tflite::CreateLocalResponseNormalizationOptions(
+ _fbb,
+ _radius,
+ _bias,
+ _alpha,
+ _beta);
+}
+
+inline LSTMOptionsT *LSTMOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LSTMOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LSTMOptions::UnPackTo(LSTMOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = cell_clip(); _o->cell_clip = _e; }
+ { auto _e = proj_clip(); _o->proj_clip = _e; }
+ { auto _e = kernel_type(); _o->kernel_type = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<LSTMOptions> LSTMOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LSTMOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLSTMOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LSTMOptions> CreateLSTMOptions(flatbuffers::FlatBufferBuilder &_fbb, const LSTMOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LSTMOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _cell_clip = _o->cell_clip;
+ auto _proj_clip = _o->proj_clip;
+ auto _kernel_type = _o->kernel_type;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateLSTMOptions(
+ _fbb,
+ _fused_activation_function,
+ _cell_clip,
+ _proj_clip,
+ _kernel_type,
+ _asymmetric_quantize_inputs);
+}
+
+inline UnidirectionalSequenceLSTMOptionsT *UnidirectionalSequenceLSTMOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new UnidirectionalSequenceLSTMOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void UnidirectionalSequenceLSTMOptions::UnPackTo(UnidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = cell_clip(); _o->cell_clip = _e; }
+ { auto _e = proj_clip(); _o->proj_clip = _e; }
+ { auto _e = time_major(); _o->time_major = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<UnidirectionalSequenceLSTMOptions> UnidirectionalSequenceLSTMOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const UnidirectionalSequenceLSTMOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateUnidirectionalSequenceLSTMOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<UnidirectionalSequenceLSTMOptions> CreateUnidirectionalSequenceLSTMOptions(flatbuffers::FlatBufferBuilder &_fbb, const UnidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const UnidirectionalSequenceLSTMOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _cell_clip = _o->cell_clip;
+ auto _proj_clip = _o->proj_clip;
+ auto _time_major = _o->time_major;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateUnidirectionalSequenceLSTMOptions(
+ _fbb,
+ _fused_activation_function,
+ _cell_clip,
+ _proj_clip,
+ _time_major,
+ _asymmetric_quantize_inputs);
+}
+
+inline BidirectionalSequenceLSTMOptionsT *BidirectionalSequenceLSTMOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new BidirectionalSequenceLSTMOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void BidirectionalSequenceLSTMOptions::UnPackTo(BidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = cell_clip(); _o->cell_clip = _e; }
+ { auto _e = proj_clip(); _o->proj_clip = _e; }
+ { auto _e = merge_outputs(); _o->merge_outputs = _e; }
+ { auto _e = time_major(); _o->time_major = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<BidirectionalSequenceLSTMOptions> BidirectionalSequenceLSTMOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceLSTMOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateBidirectionalSequenceLSTMOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<BidirectionalSequenceLSTMOptions> CreateBidirectionalSequenceLSTMOptions(flatbuffers::FlatBufferBuilder &_fbb, const BidirectionalSequenceLSTMOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const BidirectionalSequenceLSTMOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _cell_clip = _o->cell_clip;
+ auto _proj_clip = _o->proj_clip;
+ auto _merge_outputs = _o->merge_outputs;
+ auto _time_major = _o->time_major;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateBidirectionalSequenceLSTMOptions(
+ _fbb,
+ _fused_activation_function,
+ _cell_clip,
+ _proj_clip,
+ _merge_outputs,
+ _time_major,
+ _asymmetric_quantize_inputs);
+}
+
+inline ResizeBilinearOptionsT *ResizeBilinearOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ResizeBilinearOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ResizeBilinearOptions::UnPackTo(ResizeBilinearOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = align_corners(); _o->align_corners = _e; }
+ { auto _e = half_pixel_centers(); _o->half_pixel_centers = _e; }
+}
+
+inline flatbuffers::Offset<ResizeBilinearOptions> ResizeBilinearOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ResizeBilinearOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateResizeBilinearOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ResizeBilinearOptions> CreateResizeBilinearOptions(flatbuffers::FlatBufferBuilder &_fbb, const ResizeBilinearOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ResizeBilinearOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _align_corners = _o->align_corners;
+ auto _half_pixel_centers = _o->half_pixel_centers;
+ return tflite::CreateResizeBilinearOptions(
+ _fbb,
+ _align_corners,
+ _half_pixel_centers);
+}
+
+inline ResizeNearestNeighborOptionsT *ResizeNearestNeighborOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ResizeNearestNeighborOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ResizeNearestNeighborOptions::UnPackTo(ResizeNearestNeighborOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = align_corners(); _o->align_corners = _e; }
+ { auto _e = half_pixel_centers(); _o->half_pixel_centers = _e; }
+}
+
+inline flatbuffers::Offset<ResizeNearestNeighborOptions> ResizeNearestNeighborOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ResizeNearestNeighborOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateResizeNearestNeighborOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ResizeNearestNeighborOptions> CreateResizeNearestNeighborOptions(flatbuffers::FlatBufferBuilder &_fbb, const ResizeNearestNeighborOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ResizeNearestNeighborOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _align_corners = _o->align_corners;
+ auto _half_pixel_centers = _o->half_pixel_centers;
+ return tflite::CreateResizeNearestNeighborOptions(
+ _fbb,
+ _align_corners,
+ _half_pixel_centers);
+}
+
+inline CallOptionsT *CallOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new CallOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void CallOptions::UnPackTo(CallOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = subgraph(); _o->subgraph = _e; }
+}
+
+inline flatbuffers::Offset<CallOptions> CallOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const CallOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateCallOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<CallOptions> CreateCallOptions(flatbuffers::FlatBufferBuilder &_fbb, const CallOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const CallOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _subgraph = _o->subgraph;
+ return tflite::CreateCallOptions(
+ _fbb,
+ _subgraph);
+}
+
+inline PadOptionsT *PadOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new PadOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void PadOptions::UnPackTo(PadOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<PadOptions> PadOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const PadOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreatePadOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<PadOptions> CreatePadOptions(flatbuffers::FlatBufferBuilder &_fbb, const PadOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const PadOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreatePadOptions(
+ _fbb);
+}
+
+inline PadV2OptionsT *PadV2Options::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new PadV2OptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void PadV2Options::UnPackTo(PadV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<PadV2Options> PadV2Options::Pack(flatbuffers::FlatBufferBuilder &_fbb, const PadV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreatePadV2Options(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<PadV2Options> CreatePadV2Options(flatbuffers::FlatBufferBuilder &_fbb, const PadV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const PadV2OptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreatePadV2Options(
+ _fbb);
+}
+
+inline ReshapeOptionsT *ReshapeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ReshapeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ReshapeOptions::UnPackTo(ReshapeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = new_shape(); if (_e) { _o->new_shape.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->new_shape[_i] = _e->Get(_i); } } }
+}
+
+inline flatbuffers::Offset<ReshapeOptions> ReshapeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReshapeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateReshapeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ReshapeOptions> CreateReshapeOptions(flatbuffers::FlatBufferBuilder &_fbb, const ReshapeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ReshapeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _new_shape = _o->new_shape.size() ? _fbb.CreateVector(_o->new_shape) : 0;
+ return tflite::CreateReshapeOptions(
+ _fbb,
+ _new_shape);
+}
+
+inline SpaceToBatchNDOptionsT *SpaceToBatchNDOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SpaceToBatchNDOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SpaceToBatchNDOptions::UnPackTo(SpaceToBatchNDOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<SpaceToBatchNDOptions> SpaceToBatchNDOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToBatchNDOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSpaceToBatchNDOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SpaceToBatchNDOptions> CreateSpaceToBatchNDOptions(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToBatchNDOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SpaceToBatchNDOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateSpaceToBatchNDOptions(
+ _fbb);
+}
+
+inline BatchToSpaceNDOptionsT *BatchToSpaceNDOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new BatchToSpaceNDOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void BatchToSpaceNDOptions::UnPackTo(BatchToSpaceNDOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<BatchToSpaceNDOptions> BatchToSpaceNDOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const BatchToSpaceNDOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateBatchToSpaceNDOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<BatchToSpaceNDOptions> CreateBatchToSpaceNDOptions(flatbuffers::FlatBufferBuilder &_fbb, const BatchToSpaceNDOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const BatchToSpaceNDOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateBatchToSpaceNDOptions(
+ _fbb);
+}
+
+inline SkipGramOptionsT *SkipGramOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SkipGramOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SkipGramOptions::UnPackTo(SkipGramOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = ngram_size(); _o->ngram_size = _e; }
+ { auto _e = max_skip_size(); _o->max_skip_size = _e; }
+ { auto _e = include_all_ngrams(); _o->include_all_ngrams = _e; }
+}
+
+inline flatbuffers::Offset<SkipGramOptions> SkipGramOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SkipGramOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSkipGramOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SkipGramOptions> CreateSkipGramOptions(flatbuffers::FlatBufferBuilder &_fbb, const SkipGramOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SkipGramOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _ngram_size = _o->ngram_size;
+ auto _max_skip_size = _o->max_skip_size;
+ auto _include_all_ngrams = _o->include_all_ngrams;
+ return tflite::CreateSkipGramOptions(
+ _fbb,
+ _ngram_size,
+ _max_skip_size,
+ _include_all_ngrams);
+}
+
+inline SpaceToDepthOptionsT *SpaceToDepthOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SpaceToDepthOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SpaceToDepthOptions::UnPackTo(SpaceToDepthOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = block_size(); _o->block_size = _e; }
+}
+
+inline flatbuffers::Offset<SpaceToDepthOptions> SpaceToDepthOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToDepthOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSpaceToDepthOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SpaceToDepthOptions> CreateSpaceToDepthOptions(flatbuffers::FlatBufferBuilder &_fbb, const SpaceToDepthOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SpaceToDepthOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _block_size = _o->block_size;
+ return tflite::CreateSpaceToDepthOptions(
+ _fbb,
+ _block_size);
+}
+
+inline DepthToSpaceOptionsT *DepthToSpaceOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new DepthToSpaceOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void DepthToSpaceOptions::UnPackTo(DepthToSpaceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = block_size(); _o->block_size = _e; }
+}
+
+inline flatbuffers::Offset<DepthToSpaceOptions> DepthToSpaceOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const DepthToSpaceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateDepthToSpaceOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<DepthToSpaceOptions> CreateDepthToSpaceOptions(flatbuffers::FlatBufferBuilder &_fbb, const DepthToSpaceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const DepthToSpaceOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _block_size = _o->block_size;
+ return tflite::CreateDepthToSpaceOptions(
+ _fbb,
+ _block_size);
+}
+
+inline SubOptionsT *SubOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SubOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SubOptions::UnPackTo(SubOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+ { auto _e = pot_scale_int16(); _o->pot_scale_int16 = _e; }
+}
+
+inline flatbuffers::Offset<SubOptions> SubOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SubOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSubOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SubOptions> CreateSubOptions(flatbuffers::FlatBufferBuilder &_fbb, const SubOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SubOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ auto _pot_scale_int16 = _o->pot_scale_int16;
+ return tflite::CreateSubOptions(
+ _fbb,
+ _fused_activation_function,
+ _pot_scale_int16);
+}
+
+inline DivOptionsT *DivOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new DivOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void DivOptions::UnPackTo(DivOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = fused_activation_function(); _o->fused_activation_function = _e; }
+}
+
+inline flatbuffers::Offset<DivOptions> DivOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const DivOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateDivOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<DivOptions> CreateDivOptions(flatbuffers::FlatBufferBuilder &_fbb, const DivOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const DivOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _fused_activation_function = _o->fused_activation_function;
+ return tflite::CreateDivOptions(
+ _fbb,
+ _fused_activation_function);
+}
+
+inline TopKV2OptionsT *TopKV2Options::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new TopKV2OptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void TopKV2Options::UnPackTo(TopKV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<TopKV2Options> TopKV2Options::Pack(flatbuffers::FlatBufferBuilder &_fbb, const TopKV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateTopKV2Options(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<TopKV2Options> CreateTopKV2Options(flatbuffers::FlatBufferBuilder &_fbb, const TopKV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const TopKV2OptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateTopKV2Options(
+ _fbb);
+}
+
+inline EmbeddingLookupSparseOptionsT *EmbeddingLookupSparseOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new EmbeddingLookupSparseOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void EmbeddingLookupSparseOptions::UnPackTo(EmbeddingLookupSparseOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = combiner(); _o->combiner = _e; }
+}
+
+inline flatbuffers::Offset<EmbeddingLookupSparseOptions> EmbeddingLookupSparseOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const EmbeddingLookupSparseOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateEmbeddingLookupSparseOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<EmbeddingLookupSparseOptions> CreateEmbeddingLookupSparseOptions(flatbuffers::FlatBufferBuilder &_fbb, const EmbeddingLookupSparseOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const EmbeddingLookupSparseOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _combiner = _o->combiner;
+ return tflite::CreateEmbeddingLookupSparseOptions(
+ _fbb,
+ _combiner);
+}
+
+inline GatherOptionsT *GatherOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new GatherOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void GatherOptions::UnPackTo(GatherOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = axis(); _o->axis = _e; }
+ { auto _e = batch_dims(); _o->batch_dims = _e; }
+}
+
+inline flatbuffers::Offset<GatherOptions> GatherOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const GatherOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateGatherOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<GatherOptions> CreateGatherOptions(flatbuffers::FlatBufferBuilder &_fbb, const GatherOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const GatherOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _axis = _o->axis;
+ auto _batch_dims = _o->batch_dims;
+ return tflite::CreateGatherOptions(
+ _fbb,
+ _axis,
+ _batch_dims);
+}
+
+inline TransposeOptionsT *TransposeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new TransposeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void TransposeOptions::UnPackTo(TransposeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<TransposeOptions> TransposeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const TransposeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateTransposeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<TransposeOptions> CreateTransposeOptions(flatbuffers::FlatBufferBuilder &_fbb, const TransposeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const TransposeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateTransposeOptions(
+ _fbb);
+}
+
+inline ExpOptionsT *ExpOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ExpOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ExpOptions::UnPackTo(ExpOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<ExpOptions> ExpOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ExpOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateExpOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ExpOptions> CreateExpOptions(flatbuffers::FlatBufferBuilder &_fbb, const ExpOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ExpOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateExpOptions(
+ _fbb);
+}
+
+inline CosOptionsT *CosOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new CosOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void CosOptions::UnPackTo(CosOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<CosOptions> CosOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const CosOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateCosOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<CosOptions> CreateCosOptions(flatbuffers::FlatBufferBuilder &_fbb, const CosOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const CosOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateCosOptions(
+ _fbb);
+}
+
+inline ReducerOptionsT *ReducerOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ReducerOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ReducerOptions::UnPackTo(ReducerOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = keep_dims(); _o->keep_dims = _e; }
+}
+
+inline flatbuffers::Offset<ReducerOptions> ReducerOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReducerOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateReducerOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ReducerOptions> CreateReducerOptions(flatbuffers::FlatBufferBuilder &_fbb, const ReducerOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ReducerOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _keep_dims = _o->keep_dims;
+ return tflite::CreateReducerOptions(
+ _fbb,
+ _keep_dims);
+}
+
+inline SqueezeOptionsT *SqueezeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SqueezeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SqueezeOptions::UnPackTo(SqueezeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = squeeze_dims(); if (_e) { _o->squeeze_dims.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->squeeze_dims[_i] = _e->Get(_i); } } }
+}
+
+inline flatbuffers::Offset<SqueezeOptions> SqueezeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SqueezeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSqueezeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SqueezeOptions> CreateSqueezeOptions(flatbuffers::FlatBufferBuilder &_fbb, const SqueezeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SqueezeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _squeeze_dims = _o->squeeze_dims.size() ? _fbb.CreateVector(_o->squeeze_dims) : 0;
+ return tflite::CreateSqueezeOptions(
+ _fbb,
+ _squeeze_dims);
+}
+
+inline SplitOptionsT *SplitOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SplitOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SplitOptions::UnPackTo(SplitOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = num_splits(); _o->num_splits = _e; }
+}
+
+inline flatbuffers::Offset<SplitOptions> SplitOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SplitOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSplitOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SplitOptions> CreateSplitOptions(flatbuffers::FlatBufferBuilder &_fbb, const SplitOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SplitOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _num_splits = _o->num_splits;
+ return tflite::CreateSplitOptions(
+ _fbb,
+ _num_splits);
+}
+
+inline SplitVOptionsT *SplitVOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SplitVOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SplitVOptions::UnPackTo(SplitVOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = num_splits(); _o->num_splits = _e; }
+}
+
+inline flatbuffers::Offset<SplitVOptions> SplitVOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SplitVOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSplitVOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SplitVOptions> CreateSplitVOptions(flatbuffers::FlatBufferBuilder &_fbb, const SplitVOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SplitVOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _num_splits = _o->num_splits;
+ return tflite::CreateSplitVOptions(
+ _fbb,
+ _num_splits);
+}
+
+inline StridedSliceOptionsT *StridedSliceOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new StridedSliceOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void StridedSliceOptions::UnPackTo(StridedSliceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = begin_mask(); _o->begin_mask = _e; }
+ { auto _e = end_mask(); _o->end_mask = _e; }
+ { auto _e = ellipsis_mask(); _o->ellipsis_mask = _e; }
+ { auto _e = new_axis_mask(); _o->new_axis_mask = _e; }
+ { auto _e = shrink_axis_mask(); _o->shrink_axis_mask = _e; }
+}
+
+inline flatbuffers::Offset<StridedSliceOptions> StridedSliceOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const StridedSliceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateStridedSliceOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<StridedSliceOptions> CreateStridedSliceOptions(flatbuffers::FlatBufferBuilder &_fbb, const StridedSliceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const StridedSliceOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _begin_mask = _o->begin_mask;
+ auto _end_mask = _o->end_mask;
+ auto _ellipsis_mask = _o->ellipsis_mask;
+ auto _new_axis_mask = _o->new_axis_mask;
+ auto _shrink_axis_mask = _o->shrink_axis_mask;
+ return tflite::CreateStridedSliceOptions(
+ _fbb,
+ _begin_mask,
+ _end_mask,
+ _ellipsis_mask,
+ _new_axis_mask,
+ _shrink_axis_mask);
+}
+
+inline LogSoftmaxOptionsT *LogSoftmaxOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LogSoftmaxOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LogSoftmaxOptions::UnPackTo(LogSoftmaxOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<LogSoftmaxOptions> LogSoftmaxOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogSoftmaxOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLogSoftmaxOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LogSoftmaxOptions> CreateLogSoftmaxOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogSoftmaxOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LogSoftmaxOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateLogSoftmaxOptions(
+ _fbb);
+}
+
+inline CastOptionsT *CastOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new CastOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void CastOptions::UnPackTo(CastOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = in_data_type(); _o->in_data_type = _e; }
+ { auto _e = out_data_type(); _o->out_data_type = _e; }
+}
+
+inline flatbuffers::Offset<CastOptions> CastOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const CastOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateCastOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<CastOptions> CreateCastOptions(flatbuffers::FlatBufferBuilder &_fbb, const CastOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const CastOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _in_data_type = _o->in_data_type;
+ auto _out_data_type = _o->out_data_type;
+ return tflite::CreateCastOptions(
+ _fbb,
+ _in_data_type,
+ _out_data_type);
+}
+
+inline DequantizeOptionsT *DequantizeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new DequantizeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void DequantizeOptions::UnPackTo(DequantizeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<DequantizeOptions> DequantizeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const DequantizeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateDequantizeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<DequantizeOptions> CreateDequantizeOptions(flatbuffers::FlatBufferBuilder &_fbb, const DequantizeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const DequantizeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateDequantizeOptions(
+ _fbb);
+}
+
+inline MaximumMinimumOptionsT *MaximumMinimumOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new MaximumMinimumOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void MaximumMinimumOptions::UnPackTo(MaximumMinimumOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<MaximumMinimumOptions> MaximumMinimumOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const MaximumMinimumOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateMaximumMinimumOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<MaximumMinimumOptions> CreateMaximumMinimumOptions(flatbuffers::FlatBufferBuilder &_fbb, const MaximumMinimumOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const MaximumMinimumOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateMaximumMinimumOptions(
+ _fbb);
+}
+
+inline TileOptionsT *TileOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new TileOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void TileOptions::UnPackTo(TileOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<TileOptions> TileOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const TileOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateTileOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<TileOptions> CreateTileOptions(flatbuffers::FlatBufferBuilder &_fbb, const TileOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const TileOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateTileOptions(
+ _fbb);
+}
+
+inline ArgMaxOptionsT *ArgMaxOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ArgMaxOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ArgMaxOptions::UnPackTo(ArgMaxOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = output_type(); _o->output_type = _e; }
+}
+
+inline flatbuffers::Offset<ArgMaxOptions> ArgMaxOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ArgMaxOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateArgMaxOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ArgMaxOptions> CreateArgMaxOptions(flatbuffers::FlatBufferBuilder &_fbb, const ArgMaxOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ArgMaxOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _output_type = _o->output_type;
+ return tflite::CreateArgMaxOptions(
+ _fbb,
+ _output_type);
+}
+
+inline ArgMinOptionsT *ArgMinOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ArgMinOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ArgMinOptions::UnPackTo(ArgMinOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = output_type(); _o->output_type = _e; }
+}
+
+inline flatbuffers::Offset<ArgMinOptions> ArgMinOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateArgMinOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ArgMinOptions> CreateArgMinOptions(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ArgMinOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _output_type = _o->output_type;
+ return tflite::CreateArgMinOptions(
+ _fbb,
+ _output_type);
+}
+
+inline GreaterOptionsT *GreaterOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new GreaterOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void GreaterOptions::UnPackTo(GreaterOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<GreaterOptions> GreaterOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const GreaterOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateGreaterOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<GreaterOptions> CreateGreaterOptions(flatbuffers::FlatBufferBuilder &_fbb, const GreaterOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const GreaterOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateGreaterOptions(
+ _fbb);
+}
+
+inline GreaterEqualOptionsT *GreaterEqualOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new GreaterEqualOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void GreaterEqualOptions::UnPackTo(GreaterEqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<GreaterEqualOptions> GreaterEqualOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const GreaterEqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateGreaterEqualOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<GreaterEqualOptions> CreateGreaterEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const GreaterEqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const GreaterEqualOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateGreaterEqualOptions(
+ _fbb);
+}
+
+inline LessOptionsT *LessOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LessOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LessOptions::UnPackTo(LessOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<LessOptions> LessOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LessOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLessOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LessOptions> CreateLessOptions(flatbuffers::FlatBufferBuilder &_fbb, const LessOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LessOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateLessOptions(
+ _fbb);
+}
+
+inline LessEqualOptionsT *LessEqualOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LessEqualOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LessEqualOptions::UnPackTo(LessEqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<LessEqualOptions> LessEqualOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LessEqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLessEqualOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LessEqualOptions> CreateLessEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const LessEqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LessEqualOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateLessEqualOptions(
+ _fbb);
+}
+
+inline NegOptionsT *NegOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new NegOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void NegOptions::UnPackTo(NegOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<NegOptions> NegOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const NegOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateNegOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<NegOptions> CreateNegOptions(flatbuffers::FlatBufferBuilder &_fbb, const NegOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const NegOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateNegOptions(
+ _fbb);
+}
+
+inline SelectOptionsT *SelectOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SelectOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SelectOptions::UnPackTo(SelectOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<SelectOptions> SelectOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SelectOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSelectOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SelectOptions> CreateSelectOptions(flatbuffers::FlatBufferBuilder &_fbb, const SelectOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SelectOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateSelectOptions(
+ _fbb);
+}
+
+inline SliceOptionsT *SliceOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SliceOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SliceOptions::UnPackTo(SliceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<SliceOptions> SliceOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SliceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSliceOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SliceOptions> CreateSliceOptions(flatbuffers::FlatBufferBuilder &_fbb, const SliceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SliceOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateSliceOptions(
+ _fbb);
+}
+
+inline TransposeConvOptionsT *TransposeConvOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new TransposeConvOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void TransposeConvOptions::UnPackTo(TransposeConvOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = padding(); _o->padding = _e; }
+ { auto _e = stride_w(); _o->stride_w = _e; }
+ { auto _e = stride_h(); _o->stride_h = _e; }
+}
+
+inline flatbuffers::Offset<TransposeConvOptions> TransposeConvOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const TransposeConvOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateTransposeConvOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<TransposeConvOptions> CreateTransposeConvOptions(flatbuffers::FlatBufferBuilder &_fbb, const TransposeConvOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const TransposeConvOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _padding = _o->padding;
+ auto _stride_w = _o->stride_w;
+ auto _stride_h = _o->stride_h;
+ return tflite::CreateTransposeConvOptions(
+ _fbb,
+ _padding,
+ _stride_w,
+ _stride_h);
+}
+
+inline ExpandDimsOptionsT *ExpandDimsOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ExpandDimsOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ExpandDimsOptions::UnPackTo(ExpandDimsOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<ExpandDimsOptions> ExpandDimsOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ExpandDimsOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateExpandDimsOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ExpandDimsOptions> CreateExpandDimsOptions(flatbuffers::FlatBufferBuilder &_fbb, const ExpandDimsOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ExpandDimsOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateExpandDimsOptions(
+ _fbb);
+}
+
+inline SparseToDenseOptionsT *SparseToDenseOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SparseToDenseOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SparseToDenseOptions::UnPackTo(SparseToDenseOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = validate_indices(); _o->validate_indices = _e; }
+}
+
+inline flatbuffers::Offset<SparseToDenseOptions> SparseToDenseOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SparseToDenseOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSparseToDenseOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SparseToDenseOptions> CreateSparseToDenseOptions(flatbuffers::FlatBufferBuilder &_fbb, const SparseToDenseOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SparseToDenseOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _validate_indices = _o->validate_indices;
+ return tflite::CreateSparseToDenseOptions(
+ _fbb,
+ _validate_indices);
+}
+
+inline EqualOptionsT *EqualOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new EqualOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void EqualOptions::UnPackTo(EqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<EqualOptions> EqualOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const EqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateEqualOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<EqualOptions> CreateEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const EqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const EqualOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateEqualOptions(
+ _fbb);
+}
+
+inline NotEqualOptionsT *NotEqualOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new NotEqualOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void NotEqualOptions::UnPackTo(NotEqualOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<NotEqualOptions> NotEqualOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const NotEqualOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateNotEqualOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<NotEqualOptions> CreateNotEqualOptions(flatbuffers::FlatBufferBuilder &_fbb, const NotEqualOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const NotEqualOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateNotEqualOptions(
+ _fbb);
+}
+
+inline ShapeOptionsT *ShapeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ShapeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ShapeOptions::UnPackTo(ShapeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = out_type(); _o->out_type = _e; }
+}
+
+inline flatbuffers::Offset<ShapeOptions> ShapeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ShapeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateShapeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ShapeOptions> CreateShapeOptions(flatbuffers::FlatBufferBuilder &_fbb, const ShapeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ShapeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _out_type = _o->out_type;
+ return tflite::CreateShapeOptions(
+ _fbb,
+ _out_type);
+}
+
+inline RankOptionsT *RankOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new RankOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void RankOptions::UnPackTo(RankOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<RankOptions> RankOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const RankOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateRankOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<RankOptions> CreateRankOptions(flatbuffers::FlatBufferBuilder &_fbb, const RankOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const RankOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateRankOptions(
+ _fbb);
+}
+
+inline PowOptionsT *PowOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new PowOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void PowOptions::UnPackTo(PowOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<PowOptions> PowOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const PowOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreatePowOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<PowOptions> CreatePowOptions(flatbuffers::FlatBufferBuilder &_fbb, const PowOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const PowOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreatePowOptions(
+ _fbb);
+}
+
+inline FakeQuantOptionsT *FakeQuantOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new FakeQuantOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void FakeQuantOptions::UnPackTo(FakeQuantOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = min(); _o->min = _e; }
+ { auto _e = max(); _o->max = _e; }
+ { auto _e = num_bits(); _o->num_bits = _e; }
+ { auto _e = narrow_range(); _o->narrow_range = _e; }
+}
+
+inline flatbuffers::Offset<FakeQuantOptions> FakeQuantOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateFakeQuantOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<FakeQuantOptions> CreateFakeQuantOptions(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const FakeQuantOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _min = _o->min;
+ auto _max = _o->max;
+ auto _num_bits = _o->num_bits;
+ auto _narrow_range = _o->narrow_range;
+ return tflite::CreateFakeQuantOptions(
+ _fbb,
+ _min,
+ _max,
+ _num_bits,
+ _narrow_range);
+}
+
+inline PackOptionsT *PackOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new PackOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void PackOptions::UnPackTo(PackOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = values_count(); _o->values_count = _e; }
+ { auto _e = axis(); _o->axis = _e; }
+}
+
+inline flatbuffers::Offset<PackOptions> PackOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const PackOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreatePackOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<PackOptions> CreatePackOptions(flatbuffers::FlatBufferBuilder &_fbb, const PackOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const PackOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _values_count = _o->values_count;
+ auto _axis = _o->axis;
+ return tflite::CreatePackOptions(
+ _fbb,
+ _values_count,
+ _axis);
+}
+
+inline LogicalOrOptionsT *LogicalOrOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LogicalOrOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LogicalOrOptions::UnPackTo(LogicalOrOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<LogicalOrOptions> LogicalOrOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogicalOrOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLogicalOrOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LogicalOrOptions> CreateLogicalOrOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogicalOrOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LogicalOrOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateLogicalOrOptions(
+ _fbb);
+}
+
+inline OneHotOptionsT *OneHotOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new OneHotOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void OneHotOptions::UnPackTo(OneHotOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = axis(); _o->axis = _e; }
+}
+
+inline flatbuffers::Offset<OneHotOptions> OneHotOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const OneHotOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateOneHotOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<OneHotOptions> CreateOneHotOptions(flatbuffers::FlatBufferBuilder &_fbb, const OneHotOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const OneHotOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _axis = _o->axis;
+ return tflite::CreateOneHotOptions(
+ _fbb,
+ _axis);
+}
+
+inline AbsOptionsT *AbsOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new AbsOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void AbsOptions::UnPackTo(AbsOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<AbsOptions> AbsOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const AbsOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateAbsOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<AbsOptions> CreateAbsOptions(flatbuffers::FlatBufferBuilder &_fbb, const AbsOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const AbsOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateAbsOptions(
+ _fbb);
+}
+
+inline HardSwishOptionsT *HardSwishOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new HardSwishOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void HardSwishOptions::UnPackTo(HardSwishOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<HardSwishOptions> HardSwishOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const HardSwishOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateHardSwishOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<HardSwishOptions> CreateHardSwishOptions(flatbuffers::FlatBufferBuilder &_fbb, const HardSwishOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const HardSwishOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateHardSwishOptions(
+ _fbb);
+}
+
+inline LogicalAndOptionsT *LogicalAndOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LogicalAndOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LogicalAndOptions::UnPackTo(LogicalAndOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<LogicalAndOptions> LogicalAndOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogicalAndOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLogicalAndOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LogicalAndOptions> CreateLogicalAndOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogicalAndOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LogicalAndOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateLogicalAndOptions(
+ _fbb);
+}
+
+inline LogicalNotOptionsT *LogicalNotOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LogicalNotOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LogicalNotOptions::UnPackTo(LogicalNotOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<LogicalNotOptions> LogicalNotOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LogicalNotOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLogicalNotOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LogicalNotOptions> CreateLogicalNotOptions(flatbuffers::FlatBufferBuilder &_fbb, const LogicalNotOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LogicalNotOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateLogicalNotOptions(
+ _fbb);
+}
+
+inline UnpackOptionsT *UnpackOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new UnpackOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void UnpackOptions::UnPackTo(UnpackOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = num(); _o->num = _e; }
+ { auto _e = axis(); _o->axis = _e; }
+}
+
+inline flatbuffers::Offset<UnpackOptions> UnpackOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateUnpackOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<UnpackOptions> CreateUnpackOptions(flatbuffers::FlatBufferBuilder &_fbb, const UnpackOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const UnpackOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _num = _o->num;
+ auto _axis = _o->axis;
+ return tflite::CreateUnpackOptions(
+ _fbb,
+ _num,
+ _axis);
+}
+
+inline FloorDivOptionsT *FloorDivOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new FloorDivOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void FloorDivOptions::UnPackTo(FloorDivOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<FloorDivOptions> FloorDivOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateFloorDivOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<FloorDivOptions> CreateFloorDivOptions(flatbuffers::FlatBufferBuilder &_fbb, const FloorDivOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const FloorDivOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateFloorDivOptions(
+ _fbb);
+}
+
+inline SquareOptionsT *SquareOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SquareOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SquareOptions::UnPackTo(SquareOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<SquareOptions> SquareOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SquareOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSquareOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SquareOptions> CreateSquareOptions(flatbuffers::FlatBufferBuilder &_fbb, const SquareOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SquareOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateSquareOptions(
+ _fbb);
+}
+
+inline ZerosLikeOptionsT *ZerosLikeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ZerosLikeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ZerosLikeOptions::UnPackTo(ZerosLikeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<ZerosLikeOptions> ZerosLikeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ZerosLikeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateZerosLikeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ZerosLikeOptions> CreateZerosLikeOptions(flatbuffers::FlatBufferBuilder &_fbb, const ZerosLikeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ZerosLikeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateZerosLikeOptions(
+ _fbb);
+}
+
+inline FillOptionsT *FillOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new FillOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void FillOptions::UnPackTo(FillOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<FillOptions> FillOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const FillOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateFillOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<FillOptions> CreateFillOptions(flatbuffers::FlatBufferBuilder &_fbb, const FillOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const FillOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateFillOptions(
+ _fbb);
+}
+
+inline FloorModOptionsT *FloorModOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new FloorModOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void FloorModOptions::UnPackTo(FloorModOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<FloorModOptions> FloorModOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const FloorModOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateFloorModOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<FloorModOptions> CreateFloorModOptions(flatbuffers::FlatBufferBuilder &_fbb, const FloorModOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const FloorModOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateFloorModOptions(
+ _fbb);
+}
+
+inline RangeOptionsT *RangeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new RangeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void RangeOptions::UnPackTo(RangeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<RangeOptions> RangeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const RangeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateRangeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<RangeOptions> CreateRangeOptions(flatbuffers::FlatBufferBuilder &_fbb, const RangeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const RangeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateRangeOptions(
+ _fbb);
+}
+
+inline LeakyReluOptionsT *LeakyReluOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new LeakyReluOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void LeakyReluOptions::UnPackTo(LeakyReluOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = alpha(); _o->alpha = _e; }
+}
+
+inline flatbuffers::Offset<LeakyReluOptions> LeakyReluOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const LeakyReluOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateLeakyReluOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<LeakyReluOptions> CreateLeakyReluOptions(flatbuffers::FlatBufferBuilder &_fbb, const LeakyReluOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const LeakyReluOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _alpha = _o->alpha;
+ return tflite::CreateLeakyReluOptions(
+ _fbb,
+ _alpha);
+}
+
+inline SquaredDifferenceOptionsT *SquaredDifferenceOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SquaredDifferenceOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SquaredDifferenceOptions::UnPackTo(SquaredDifferenceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<SquaredDifferenceOptions> SquaredDifferenceOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SquaredDifferenceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSquaredDifferenceOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SquaredDifferenceOptions> CreateSquaredDifferenceOptions(flatbuffers::FlatBufferBuilder &_fbb, const SquaredDifferenceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SquaredDifferenceOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateSquaredDifferenceOptions(
+ _fbb);
+}
+
+inline MirrorPadOptionsT *MirrorPadOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new MirrorPadOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void MirrorPadOptions::UnPackTo(MirrorPadOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = mode(); _o->mode = _e; }
+}
+
+inline flatbuffers::Offset<MirrorPadOptions> MirrorPadOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const MirrorPadOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateMirrorPadOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<MirrorPadOptions> CreateMirrorPadOptions(flatbuffers::FlatBufferBuilder &_fbb, const MirrorPadOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const MirrorPadOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _mode = _o->mode;
+ return tflite::CreateMirrorPadOptions(
+ _fbb,
+ _mode);
+}
+
+inline UniqueOptionsT *UniqueOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new UniqueOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void UniqueOptions::UnPackTo(UniqueOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = idx_out_type(); _o->idx_out_type = _e; }
+}
+
+inline flatbuffers::Offset<UniqueOptions> UniqueOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const UniqueOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateUniqueOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<UniqueOptions> CreateUniqueOptions(flatbuffers::FlatBufferBuilder &_fbb, const UniqueOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const UniqueOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _idx_out_type = _o->idx_out_type;
+ return tflite::CreateUniqueOptions(
+ _fbb,
+ _idx_out_type);
+}
+
+inline ReverseV2OptionsT *ReverseV2Options::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ReverseV2OptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ReverseV2Options::UnPackTo(ReverseV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<ReverseV2Options> ReverseV2Options::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReverseV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateReverseV2Options(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ReverseV2Options> CreateReverseV2Options(flatbuffers::FlatBufferBuilder &_fbb, const ReverseV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ReverseV2OptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateReverseV2Options(
+ _fbb);
+}
+
+inline AddNOptionsT *AddNOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new AddNOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void AddNOptions::UnPackTo(AddNOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<AddNOptions> AddNOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const AddNOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateAddNOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<AddNOptions> CreateAddNOptions(flatbuffers::FlatBufferBuilder &_fbb, const AddNOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const AddNOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateAddNOptions(
+ _fbb);
+}
+
+inline GatherNdOptionsT *GatherNdOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new GatherNdOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void GatherNdOptions::UnPackTo(GatherNdOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<GatherNdOptions> GatherNdOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const GatherNdOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateGatherNdOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<GatherNdOptions> CreateGatherNdOptions(flatbuffers::FlatBufferBuilder &_fbb, const GatherNdOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const GatherNdOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateGatherNdOptions(
+ _fbb);
+}
+
+inline WhereOptionsT *WhereOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new WhereOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void WhereOptions::UnPackTo(WhereOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<WhereOptions> WhereOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const WhereOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateWhereOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<WhereOptions> CreateWhereOptions(flatbuffers::FlatBufferBuilder &_fbb, const WhereOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const WhereOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateWhereOptions(
+ _fbb);
+}
+
+inline ReverseSequenceOptionsT *ReverseSequenceOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ReverseSequenceOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ReverseSequenceOptions::UnPackTo(ReverseSequenceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = seq_dim(); _o->seq_dim = _e; }
+ { auto _e = batch_dim(); _o->batch_dim = _e; }
+}
+
+inline flatbuffers::Offset<ReverseSequenceOptions> ReverseSequenceOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ReverseSequenceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateReverseSequenceOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ReverseSequenceOptions> CreateReverseSequenceOptions(flatbuffers::FlatBufferBuilder &_fbb, const ReverseSequenceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ReverseSequenceOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _seq_dim = _o->seq_dim;
+ auto _batch_dim = _o->batch_dim;
+ return tflite::CreateReverseSequenceOptions(
+ _fbb,
+ _seq_dim,
+ _batch_dim);
+}
+
+inline MatrixDiagOptionsT *MatrixDiagOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new MatrixDiagOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void MatrixDiagOptions::UnPackTo(MatrixDiagOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<MatrixDiagOptions> MatrixDiagOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const MatrixDiagOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateMatrixDiagOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<MatrixDiagOptions> CreateMatrixDiagOptions(flatbuffers::FlatBufferBuilder &_fbb, const MatrixDiagOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const MatrixDiagOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateMatrixDiagOptions(
+ _fbb);
+}
+
+inline QuantizeOptionsT *QuantizeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new QuantizeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void QuantizeOptions::UnPackTo(QuantizeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<QuantizeOptions> QuantizeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const QuantizeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateQuantizeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<QuantizeOptions> CreateQuantizeOptions(flatbuffers::FlatBufferBuilder &_fbb, const QuantizeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const QuantizeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateQuantizeOptions(
+ _fbb);
+}
+
+inline MatrixSetDiagOptionsT *MatrixSetDiagOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new MatrixSetDiagOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void MatrixSetDiagOptions::UnPackTo(MatrixSetDiagOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<MatrixSetDiagOptions> MatrixSetDiagOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const MatrixSetDiagOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateMatrixSetDiagOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<MatrixSetDiagOptions> CreateMatrixSetDiagOptions(flatbuffers::FlatBufferBuilder &_fbb, const MatrixSetDiagOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const MatrixSetDiagOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateMatrixSetDiagOptions(
+ _fbb);
+}
+
+inline IfOptionsT *IfOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new IfOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void IfOptions::UnPackTo(IfOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = then_subgraph_index(); _o->then_subgraph_index = _e; }
+ { auto _e = else_subgraph_index(); _o->else_subgraph_index = _e; }
+}
+
+inline flatbuffers::Offset<IfOptions> IfOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const IfOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateIfOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<IfOptions> CreateIfOptions(flatbuffers::FlatBufferBuilder &_fbb, const IfOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const IfOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _then_subgraph_index = _o->then_subgraph_index;
+ auto _else_subgraph_index = _o->else_subgraph_index;
+ return tflite::CreateIfOptions(
+ _fbb,
+ _then_subgraph_index,
+ _else_subgraph_index);
+}
+
+inline CallOnceOptionsT *CallOnceOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new CallOnceOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void CallOnceOptions::UnPackTo(CallOnceOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = init_subgraph_index(); _o->init_subgraph_index = _e; }
+}
+
+inline flatbuffers::Offset<CallOnceOptions> CallOnceOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const CallOnceOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateCallOnceOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<CallOnceOptions> CreateCallOnceOptions(flatbuffers::FlatBufferBuilder &_fbb, const CallOnceOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const CallOnceOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _init_subgraph_index = _o->init_subgraph_index;
+ return tflite::CreateCallOnceOptions(
+ _fbb,
+ _init_subgraph_index);
+}
+
+inline WhileOptionsT *WhileOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new WhileOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void WhileOptions::UnPackTo(WhileOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = cond_subgraph_index(); _o->cond_subgraph_index = _e; }
+ { auto _e = body_subgraph_index(); _o->body_subgraph_index = _e; }
+}
+
+inline flatbuffers::Offset<WhileOptions> WhileOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const WhileOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateWhileOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<WhileOptions> CreateWhileOptions(flatbuffers::FlatBufferBuilder &_fbb, const WhileOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const WhileOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _cond_subgraph_index = _o->cond_subgraph_index;
+ auto _body_subgraph_index = _o->body_subgraph_index;
+ return tflite::CreateWhileOptions(
+ _fbb,
+ _cond_subgraph_index,
+ _body_subgraph_index);
+}
+
+inline NonMaxSuppressionV4OptionsT *NonMaxSuppressionV4Options::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new NonMaxSuppressionV4OptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void NonMaxSuppressionV4Options::UnPackTo(NonMaxSuppressionV4OptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<NonMaxSuppressionV4Options> NonMaxSuppressionV4Options::Pack(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV4OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateNonMaxSuppressionV4Options(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<NonMaxSuppressionV4Options> CreateNonMaxSuppressionV4Options(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV4OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const NonMaxSuppressionV4OptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateNonMaxSuppressionV4Options(
+ _fbb);
+}
+
+inline NonMaxSuppressionV5OptionsT *NonMaxSuppressionV5Options::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new NonMaxSuppressionV5OptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void NonMaxSuppressionV5Options::UnPackTo(NonMaxSuppressionV5OptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<NonMaxSuppressionV5Options> NonMaxSuppressionV5Options::Pack(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV5OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateNonMaxSuppressionV5Options(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<NonMaxSuppressionV5Options> CreateNonMaxSuppressionV5Options(flatbuffers::FlatBufferBuilder &_fbb, const NonMaxSuppressionV5OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const NonMaxSuppressionV5OptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateNonMaxSuppressionV5Options(
+ _fbb);
+}
+
+inline ScatterNdOptionsT *ScatterNdOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ScatterNdOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void ScatterNdOptions::UnPackTo(ScatterNdOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<ScatterNdOptions> ScatterNdOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ScatterNdOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateScatterNdOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<ScatterNdOptions> CreateScatterNdOptions(flatbuffers::FlatBufferBuilder &_fbb, const ScatterNdOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ScatterNdOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateScatterNdOptions(
+ _fbb);
+}
+
+inline SelectV2OptionsT *SelectV2Options::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SelectV2OptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SelectV2Options::UnPackTo(SelectV2OptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<SelectV2Options> SelectV2Options::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SelectV2OptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSelectV2Options(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SelectV2Options> CreateSelectV2Options(flatbuffers::FlatBufferBuilder &_fbb, const SelectV2OptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SelectV2OptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateSelectV2Options(
+ _fbb);
+}
+
+inline DensifyOptionsT *DensifyOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new DensifyOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void DensifyOptions::UnPackTo(DensifyOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<DensifyOptions> DensifyOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const DensifyOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateDensifyOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<DensifyOptions> CreateDensifyOptions(flatbuffers::FlatBufferBuilder &_fbb, const DensifyOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const DensifyOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateDensifyOptions(
+ _fbb);
+}
+
+inline SegmentSumOptionsT *SegmentSumOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SegmentSumOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SegmentSumOptions::UnPackTo(SegmentSumOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<SegmentSumOptions> SegmentSumOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SegmentSumOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSegmentSumOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SegmentSumOptions> CreateSegmentSumOptions(flatbuffers::FlatBufferBuilder &_fbb, const SegmentSumOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SegmentSumOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateSegmentSumOptions(
+ _fbb);
+}
+
+inline BatchMatMulOptionsT *BatchMatMulOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new BatchMatMulOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void BatchMatMulOptions::UnPackTo(BatchMatMulOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = adj_x(); _o->adj_x = _e; }
+ { auto _e = adj_y(); _o->adj_y = _e; }
+ { auto _e = asymmetric_quantize_inputs(); _o->asymmetric_quantize_inputs = _e; }
+}
+
+inline flatbuffers::Offset<BatchMatMulOptions> BatchMatMulOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const BatchMatMulOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateBatchMatMulOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<BatchMatMulOptions> CreateBatchMatMulOptions(flatbuffers::FlatBufferBuilder &_fbb, const BatchMatMulOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const BatchMatMulOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _adj_x = _o->adj_x;
+ auto _adj_y = _o->adj_y;
+ auto _asymmetric_quantize_inputs = _o->asymmetric_quantize_inputs;
+ return tflite::CreateBatchMatMulOptions(
+ _fbb,
+ _adj_x,
+ _adj_y,
+ _asymmetric_quantize_inputs);
+}
+
+inline CumsumOptionsT *CumsumOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new CumsumOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void CumsumOptions::UnPackTo(CumsumOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = exclusive(); _o->exclusive = _e; }
+ { auto _e = reverse(); _o->reverse = _e; }
+}
+
+inline flatbuffers::Offset<CumsumOptions> CumsumOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const CumsumOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateCumsumOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<CumsumOptions> CreateCumsumOptions(flatbuffers::FlatBufferBuilder &_fbb, const CumsumOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const CumsumOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _exclusive = _o->exclusive;
+ auto _reverse = _o->reverse;
+ return tflite::CreateCumsumOptions(
+ _fbb,
+ _exclusive,
+ _reverse);
+}
+
+inline BroadcastToOptionsT *BroadcastToOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new BroadcastToOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void BroadcastToOptions::UnPackTo(BroadcastToOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<BroadcastToOptions> BroadcastToOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const BroadcastToOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateBroadcastToOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<BroadcastToOptions> CreateBroadcastToOptions(flatbuffers::FlatBufferBuilder &_fbb, const BroadcastToOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const BroadcastToOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateBroadcastToOptions(
+ _fbb);
+}
+
+inline Rfft2dOptionsT *Rfft2dOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new Rfft2dOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Rfft2dOptions::UnPackTo(Rfft2dOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<Rfft2dOptions> Rfft2dOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const Rfft2dOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateRfft2dOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Rfft2dOptions> CreateRfft2dOptions(flatbuffers::FlatBufferBuilder &_fbb, const Rfft2dOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const Rfft2dOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateRfft2dOptions(
+ _fbb);
+}
+
+inline HashtableOptionsT *HashtableOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new HashtableOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void HashtableOptions::UnPackTo(HashtableOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = table_id(); _o->table_id = _e; }
+ { auto _e = key_dtype(); _o->key_dtype = _e; }
+ { auto _e = value_dtype(); _o->value_dtype = _e; }
+}
+
+inline flatbuffers::Offset<HashtableOptions> HashtableOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateHashtableOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<HashtableOptions> CreateHashtableOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const HashtableOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _table_id = _o->table_id;
+ auto _key_dtype = _o->key_dtype;
+ auto _value_dtype = _o->value_dtype;
+ return tflite::CreateHashtableOptions(
+ _fbb,
+ _table_id,
+ _key_dtype,
+ _value_dtype);
+}
+
+inline HashtableFindOptionsT *HashtableFindOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new HashtableFindOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void HashtableFindOptions::UnPackTo(HashtableFindOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<HashtableFindOptions> HashtableFindOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableFindOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateHashtableFindOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<HashtableFindOptions> CreateHashtableFindOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableFindOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const HashtableFindOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateHashtableFindOptions(
+ _fbb);
+}
+
+inline HashtableImportOptionsT *HashtableImportOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new HashtableImportOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void HashtableImportOptions::UnPackTo(HashtableImportOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<HashtableImportOptions> HashtableImportOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableImportOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateHashtableImportOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<HashtableImportOptions> CreateHashtableImportOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableImportOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const HashtableImportOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateHashtableImportOptions(
+ _fbb);
+}
+
+inline HashtableSizeOptionsT *HashtableSizeOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new HashtableSizeOptionsT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void HashtableSizeOptions::UnPackTo(HashtableSizeOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+}
+
+inline flatbuffers::Offset<HashtableSizeOptions> HashtableSizeOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const HashtableSizeOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateHashtableSizeOptions(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<HashtableSizeOptions> CreateHashtableSizeOptions(flatbuffers::FlatBufferBuilder &_fbb, const HashtableSizeOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const HashtableSizeOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ return tflite::CreateHashtableSizeOptions(
+ _fbb);
+}
+
+inline OperatorCodeT *OperatorCode::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new OperatorCodeT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void OperatorCode::UnPackTo(OperatorCodeT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = deprecated_builtin_code(); _o->deprecated_builtin_code = _e; }
+ { auto _e = custom_code(); if (_e) _o->custom_code = _e->str(); }
+ { auto _e = version(); _o->version = _e; }
+ { auto _e = builtin_code(); _o->builtin_code = _e; }
+}
+
+inline flatbuffers::Offset<OperatorCode> OperatorCode::Pack(flatbuffers::FlatBufferBuilder &_fbb, const OperatorCodeT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateOperatorCode(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<OperatorCode> CreateOperatorCode(flatbuffers::FlatBufferBuilder &_fbb, const OperatorCodeT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const OperatorCodeT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _deprecated_builtin_code = _o->deprecated_builtin_code;
+ auto _custom_code = _o->custom_code.empty() ? 0 : _fbb.CreateString(_o->custom_code);
+ auto _version = _o->version;
+ auto _builtin_code = _o->builtin_code;
+ return tflite::CreateOperatorCode(
+ _fbb,
+ _deprecated_builtin_code,
+ _custom_code,
+ _version,
+ _builtin_code);
+}
+
+inline OperatorT *Operator::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new OperatorT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Operator::UnPackTo(OperatorT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = opcode_index(); _o->opcode_index = _e; }
+ { auto _e = inputs(); if (_e) { _o->inputs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->inputs[_i] = _e->Get(_i); } } }
+ { auto _e = outputs(); if (_e) { _o->outputs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->outputs[_i] = _e->Get(_i); } } }
+ { auto _e = builtin_options_type(); _o->builtin_options.type = _e; }
+ { auto _e = builtin_options(); if (_e) _o->builtin_options.value = tflite::BuiltinOptionsUnion::UnPack(_e, builtin_options_type(), _resolver); }
+ { auto _e = custom_options(); if (_e) { _o->custom_options.resize(_e->size()); std::copy(_e->begin(), _e->end(), _o->custom_options.begin()); } }
+ { auto _e = custom_options_format(); _o->custom_options_format = _e; }
+ { auto _e = mutating_variable_inputs(); if (_e) { _o->mutating_variable_inputs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->mutating_variable_inputs[_i] = _e->Get(_i) != 0; } } }
+ { auto _e = intermediates(); if (_e) { _o->intermediates.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->intermediates[_i] = _e->Get(_i); } } }
+}
+
+inline flatbuffers::Offset<Operator> Operator::Pack(flatbuffers::FlatBufferBuilder &_fbb, const OperatorT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateOperator(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Operator> CreateOperator(flatbuffers::FlatBufferBuilder &_fbb, const OperatorT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const OperatorT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _opcode_index = _o->opcode_index;
+ auto _inputs = _o->inputs.size() ? _fbb.CreateVector(_o->inputs) : 0;
+ auto _outputs = _o->outputs.size() ? _fbb.CreateVector(_o->outputs) : 0;
+ auto _builtin_options_type = _o->builtin_options.type;
+ auto _builtin_options = _o->builtin_options.Pack(_fbb);
+ auto _custom_options = _o->custom_options.size() ? _fbb.CreateVector(_o->custom_options) : 0;
+ auto _custom_options_format = _o->custom_options_format;
+ auto _mutating_variable_inputs = _o->mutating_variable_inputs.size() ? _fbb.CreateVector(_o->mutating_variable_inputs) : 0;
+ auto _intermediates = _o->intermediates.size() ? _fbb.CreateVector(_o->intermediates) : 0;
+ return tflite::CreateOperator(
+ _fbb,
+ _opcode_index,
+ _inputs,
+ _outputs,
+ _builtin_options_type,
+ _builtin_options,
+ _custom_options,
+ _custom_options_format,
+ _mutating_variable_inputs,
+ _intermediates);
+}
+
+inline SubGraphT *SubGraph::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SubGraphT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SubGraph::UnPackTo(SubGraphT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = tensors(); if (_e) { _o->tensors.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->tensors[_i] = std::unique_ptr<tflite::TensorT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = inputs(); if (_e) { _o->inputs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->inputs[_i] = _e->Get(_i); } } }
+ { auto _e = outputs(); if (_e) { _o->outputs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->outputs[_i] = _e->Get(_i); } } }
+ { auto _e = operators(); if (_e) { _o->operators.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->operators[_i] = std::unique_ptr<tflite::OperatorT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = name(); if (_e) _o->name = _e->str(); }
+}
+
+inline flatbuffers::Offset<SubGraph> SubGraph::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SubGraphT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSubGraph(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SubGraph> CreateSubGraph(flatbuffers::FlatBufferBuilder &_fbb, const SubGraphT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SubGraphT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _tensors = _o->tensors.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::Tensor>> (_o->tensors.size(), [](size_t i, _VectorArgs *__va) { return CreateTensor(*__va->__fbb, __va->__o->tensors[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _inputs = _o->inputs.size() ? _fbb.CreateVector(_o->inputs) : 0;
+ auto _outputs = _o->outputs.size() ? _fbb.CreateVector(_o->outputs) : 0;
+ auto _operators = _o->operators.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::Operator>> (_o->operators.size(), [](size_t i, _VectorArgs *__va) { return CreateOperator(*__va->__fbb, __va->__o->operators[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _name = _o->name.empty() ? 0 : _fbb.CreateString(_o->name);
+ return tflite::CreateSubGraph(
+ _fbb,
+ _tensors,
+ _inputs,
+ _outputs,
+ _operators,
+ _name);
+}
+
+inline BufferT *Buffer::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new BufferT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Buffer::UnPackTo(BufferT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = data(); if (_e) { _o->data.resize(_e->size()); std::copy(_e->begin(), _e->end(), _o->data.begin()); } }
+}
+
+inline flatbuffers::Offset<Buffer> Buffer::Pack(flatbuffers::FlatBufferBuilder &_fbb, const BufferT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateBuffer(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Buffer> CreateBuffer(flatbuffers::FlatBufferBuilder &_fbb, const BufferT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const BufferT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ _fbb.ForceVectorAlignment(_o->data.size(), sizeof(uint8_t), 16);
+ auto _data = _o->data.size() ? _fbb.CreateVector(_o->data) : 0;
+ return tflite::CreateBuffer(
+ _fbb,
+ _data);
+}
+
+inline MetadataT *Metadata::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new MetadataT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Metadata::UnPackTo(MetadataT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = name(); if (_e) _o->name = _e->str(); }
+ { auto _e = buffer(); _o->buffer = _e; }
+}
+
+inline flatbuffers::Offset<Metadata> Metadata::Pack(flatbuffers::FlatBufferBuilder &_fbb, const MetadataT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateMetadata(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Metadata> CreateMetadata(flatbuffers::FlatBufferBuilder &_fbb, const MetadataT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const MetadataT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _name = _o->name.empty() ? 0 : _fbb.CreateString(_o->name);
+ auto _buffer = _o->buffer;
+ return tflite::CreateMetadata(
+ _fbb,
+ _name,
+ _buffer);
+}
+
+inline TensorMapT *TensorMap::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new TensorMapT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void TensorMap::UnPackTo(TensorMapT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = name(); if (_e) _o->name = _e->str(); }
+ { auto _e = tensor_index(); _o->tensor_index = _e; }
+}
+
+inline flatbuffers::Offset<TensorMap> TensorMap::Pack(flatbuffers::FlatBufferBuilder &_fbb, const TensorMapT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateTensorMap(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<TensorMap> CreateTensorMap(flatbuffers::FlatBufferBuilder &_fbb, const TensorMapT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const TensorMapT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _name = _o->name.empty() ? 0 : _fbb.CreateString(_o->name);
+ auto _tensor_index = _o->tensor_index;
+ return tflite::CreateTensorMap(
+ _fbb,
+ _name,
+ _tensor_index);
+}
+
+inline SignatureDefT *SignatureDef::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new SignatureDefT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void SignatureDef::UnPackTo(SignatureDefT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = inputs(); if (_e) { _o->inputs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->inputs[_i] = std::unique_ptr<tflite::TensorMapT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = outputs(); if (_e) { _o->outputs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->outputs[_i] = std::unique_ptr<tflite::TensorMapT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = method_name(); if (_e) _o->method_name = _e->str(); }
+ { auto _e = key(); if (_e) _o->key = _e->str(); }
+}
+
+inline flatbuffers::Offset<SignatureDef> SignatureDef::Pack(flatbuffers::FlatBufferBuilder &_fbb, const SignatureDefT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateSignatureDef(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<SignatureDef> CreateSignatureDef(flatbuffers::FlatBufferBuilder &_fbb, const SignatureDefT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const SignatureDefT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _inputs = _o->inputs.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::TensorMap>> (_o->inputs.size(), [](size_t i, _VectorArgs *__va) { return CreateTensorMap(*__va->__fbb, __va->__o->inputs[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _outputs = _o->outputs.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::TensorMap>> (_o->outputs.size(), [](size_t i, _VectorArgs *__va) { return CreateTensorMap(*__va->__fbb, __va->__o->outputs[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _method_name = _o->method_name.empty() ? 0 : _fbb.CreateString(_o->method_name);
+ auto _key = _o->key.empty() ? 0 : _fbb.CreateString(_o->key);
+ return tflite::CreateSignatureDef(
+ _fbb,
+ _inputs,
+ _outputs,
+ _method_name,
+ _key);
+}
+
+inline ModelT *Model::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
+ auto _o = new ModelT();
+ UnPackTo(_o, _resolver);
+ return _o;
+}
+
+inline void Model::UnPackTo(ModelT *_o, const flatbuffers::resolver_function_t *_resolver) const {
+ (void)_o;
+ (void)_resolver;
+ { auto _e = version(); _o->version = _e; }
+ { auto _e = operator_codes(); if (_e) { _o->operator_codes.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->operator_codes[_i] = std::unique_ptr<tflite::OperatorCodeT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = subgraphs(); if (_e) { _o->subgraphs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->subgraphs[_i] = std::unique_ptr<tflite::SubGraphT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = description(); if (_e) _o->description = _e->str(); }
+ { auto _e = buffers(); if (_e) { _o->buffers.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->buffers[_i] = std::unique_ptr<tflite::BufferT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = metadata_buffer(); if (_e) { _o->metadata_buffer.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->metadata_buffer[_i] = _e->Get(_i); } } }
+ { auto _e = metadata(); if (_e) { _o->metadata.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->metadata[_i] = std::unique_ptr<tflite::MetadataT>(_e->Get(_i)->UnPack(_resolver)); } } }
+ { auto _e = signature_defs(); if (_e) { _o->signature_defs.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->signature_defs[_i] = std::unique_ptr<tflite::SignatureDefT>(_e->Get(_i)->UnPack(_resolver)); } } }
+}
+
+inline flatbuffers::Offset<Model> Model::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ModelT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
+ return CreateModel(_fbb, _o, _rehasher);
+}
+
+inline flatbuffers::Offset<Model> CreateModel(flatbuffers::FlatBufferBuilder &_fbb, const ModelT *_o, const flatbuffers::rehasher_function_t *_rehasher) {
+ (void)_rehasher;
+ (void)_o;
+ struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ModelT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va;
+ auto _version = _o->version;
+ auto _operator_codes = _o->operator_codes.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::OperatorCode>> (_o->operator_codes.size(), [](size_t i, _VectorArgs *__va) { return CreateOperatorCode(*__va->__fbb, __va->__o->operator_codes[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _subgraphs = _o->subgraphs.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::SubGraph>> (_o->subgraphs.size(), [](size_t i, _VectorArgs *__va) { return CreateSubGraph(*__va->__fbb, __va->__o->subgraphs[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _description = _o->description.empty() ? 0 : _fbb.CreateString(_o->description);
+ auto _buffers = _o->buffers.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::Buffer>> (_o->buffers.size(), [](size_t i, _VectorArgs *__va) { return CreateBuffer(*__va->__fbb, __va->__o->buffers[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _metadata_buffer = _o->metadata_buffer.size() ? _fbb.CreateVector(_o->metadata_buffer) : 0;
+ auto _metadata = _o->metadata.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::Metadata>> (_o->metadata.size(), [](size_t i, _VectorArgs *__va) { return CreateMetadata(*__va->__fbb, __va->__o->metadata[i].get(), __va->__rehasher); }, &_va ) : 0;
+ auto _signature_defs = _o->signature_defs.size() ? _fbb.CreateVector<flatbuffers::Offset<tflite::SignatureDef>> (_o->signature_defs.size(), [](size_t i, _VectorArgs *__va) { return CreateSignatureDef(*__va->__fbb, __va->__o->signature_defs[i].get(), __va->__rehasher); }, &_va ) : 0;
+ return tflite::CreateModel(
+ _fbb,
+ _version,
+ _operator_codes,
+ _subgraphs,
+ _description,
+ _buffers,
+ _metadata_buffer,
+ _metadata,
+ _signature_defs);
+}
+
+inline bool VerifyQuantizationDetails(flatbuffers::Verifier &verifier, const void *obj, QuantizationDetails type) {
+ switch (type) {
+ case QuantizationDetails_NONE: {
+ return true;
+ }
+ case QuantizationDetails_CustomQuantization: {
+ auto ptr = reinterpret_cast<const tflite::CustomQuantization *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ default: return true;
+ }
+}
+
+inline bool VerifyQuantizationDetailsVector(flatbuffers::Verifier &verifier, const flatbuffers::Vector<flatbuffers::Offset<void>> *values, const flatbuffers::Vector<uint8_t> *types) {
+ if (!values || !types) return !values && !types;
+ if (values->size() != types->size()) return false;
+ for (flatbuffers::uoffset_t i = 0; i < values->size(); ++i) {
+ if (!VerifyQuantizationDetails(
+ verifier, values->Get(i), types->GetEnum<QuantizationDetails>(i))) {
+ return false;
+ }
+ }
+ return true;
+}
+
+inline void *QuantizationDetailsUnion::UnPack(const void *obj, QuantizationDetails type, const flatbuffers::resolver_function_t *resolver) {
+ switch (type) {
+ case QuantizationDetails_CustomQuantization: {
+ auto ptr = reinterpret_cast<const tflite::CustomQuantization *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ default: return nullptr;
+ }
+}
+
+inline flatbuffers::Offset<void> QuantizationDetailsUnion::Pack(flatbuffers::FlatBufferBuilder &_fbb, const flatbuffers::rehasher_function_t *_rehasher) const {
+ switch (type) {
+ case QuantizationDetails_CustomQuantization: {
+ auto ptr = reinterpret_cast<const tflite::CustomQuantizationT *>(value);
+ return CreateCustomQuantization(_fbb, ptr, _rehasher).Union();
+ }
+ default: return 0;
+ }
+}
+
+inline QuantizationDetailsUnion::QuantizationDetailsUnion(const QuantizationDetailsUnion &u) FLATBUFFERS_NOEXCEPT : type(u.type), value(nullptr) {
+ switch (type) {
+ case QuantizationDetails_CustomQuantization: {
+ value = new tflite::CustomQuantizationT(*reinterpret_cast<tflite::CustomQuantizationT *>(u.value));
+ break;
+ }
+ default:
+ break;
+ }
+}
+
+inline void QuantizationDetailsUnion::Reset() {
+ switch (type) {
+ case QuantizationDetails_CustomQuantization: {
+ auto ptr = reinterpret_cast<tflite::CustomQuantizationT *>(value);
+ delete ptr;
+ break;
+ }
+ default: break;
+ }
+ value = nullptr;
+ type = QuantizationDetails_NONE;
+}
+
+inline bool VerifySparseIndexVector(flatbuffers::Verifier &verifier, const void *obj, SparseIndexVector type) {
+ switch (type) {
+ case SparseIndexVector_NONE: {
+ return true;
+ }
+ case SparseIndexVector_Int32Vector: {
+ auto ptr = reinterpret_cast<const tflite::Int32Vector *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case SparseIndexVector_Uint16Vector: {
+ auto ptr = reinterpret_cast<const tflite::Uint16Vector *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case SparseIndexVector_Uint8Vector: {
+ auto ptr = reinterpret_cast<const tflite::Uint8Vector *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ default: return true;
+ }
+}
+
+inline bool VerifySparseIndexVectorVector(flatbuffers::Verifier &verifier, const flatbuffers::Vector<flatbuffers::Offset<void>> *values, const flatbuffers::Vector<uint8_t> *types) {
+ if (!values || !types) return !values && !types;
+ if (values->size() != types->size()) return false;
+ for (flatbuffers::uoffset_t i = 0; i < values->size(); ++i) {
+ if (!VerifySparseIndexVector(
+ verifier, values->Get(i), types->GetEnum<SparseIndexVector>(i))) {
+ return false;
+ }
+ }
+ return true;
+}
+
+inline void *SparseIndexVectorUnion::UnPack(const void *obj, SparseIndexVector type, const flatbuffers::resolver_function_t *resolver) {
+ switch (type) {
+ case SparseIndexVector_Int32Vector: {
+ auto ptr = reinterpret_cast<const tflite::Int32Vector *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case SparseIndexVector_Uint16Vector: {
+ auto ptr = reinterpret_cast<const tflite::Uint16Vector *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case SparseIndexVector_Uint8Vector: {
+ auto ptr = reinterpret_cast<const tflite::Uint8Vector *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ default: return nullptr;
+ }
+}
+
+inline flatbuffers::Offset<void> SparseIndexVectorUnion::Pack(flatbuffers::FlatBufferBuilder &_fbb, const flatbuffers::rehasher_function_t *_rehasher) const {
+ switch (type) {
+ case SparseIndexVector_Int32Vector: {
+ auto ptr = reinterpret_cast<const tflite::Int32VectorT *>(value);
+ return CreateInt32Vector(_fbb, ptr, _rehasher).Union();
+ }
+ case SparseIndexVector_Uint16Vector: {
+ auto ptr = reinterpret_cast<const tflite::Uint16VectorT *>(value);
+ return CreateUint16Vector(_fbb, ptr, _rehasher).Union();
+ }
+ case SparseIndexVector_Uint8Vector: {
+ auto ptr = reinterpret_cast<const tflite::Uint8VectorT *>(value);
+ return CreateUint8Vector(_fbb, ptr, _rehasher).Union();
+ }
+ default: return 0;
+ }
+}
+
+inline SparseIndexVectorUnion::SparseIndexVectorUnion(const SparseIndexVectorUnion &u) FLATBUFFERS_NOEXCEPT : type(u.type), value(nullptr) {
+ switch (type) {
+ case SparseIndexVector_Int32Vector: {
+ value = new tflite::Int32VectorT(*reinterpret_cast<tflite::Int32VectorT *>(u.value));
+ break;
+ }
+ case SparseIndexVector_Uint16Vector: {
+ value = new tflite::Uint16VectorT(*reinterpret_cast<tflite::Uint16VectorT *>(u.value));
+ break;
+ }
+ case SparseIndexVector_Uint8Vector: {
+ value = new tflite::Uint8VectorT(*reinterpret_cast<tflite::Uint8VectorT *>(u.value));
+ break;
+ }
+ default:
+ break;
+ }
+}
+
+inline void SparseIndexVectorUnion::Reset() {
+ switch (type) {
+ case SparseIndexVector_Int32Vector: {
+ auto ptr = reinterpret_cast<tflite::Int32VectorT *>(value);
+ delete ptr;
+ break;
+ }
+ case SparseIndexVector_Uint16Vector: {
+ auto ptr = reinterpret_cast<tflite::Uint16VectorT *>(value);
+ delete ptr;
+ break;
+ }
+ case SparseIndexVector_Uint8Vector: {
+ auto ptr = reinterpret_cast<tflite::Uint8VectorT *>(value);
+ delete ptr;
+ break;
+ }
+ default: break;
+ }
+ value = nullptr;
+ type = SparseIndexVector_NONE;
+}
+
+inline bool VerifyBuiltinOptions(flatbuffers::Verifier &verifier, const void *obj, BuiltinOptions type) {
+ switch (type) {
+ case BuiltinOptions_NONE: {
+ return true;
+ }
+ case BuiltinOptions_Conv2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Conv2DOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_DepthwiseConv2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::DepthwiseConv2DOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ConcatEmbeddingsOptions: {
+ auto ptr = reinterpret_cast<const tflite::ConcatEmbeddingsOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LSHProjectionOptions: {
+ auto ptr = reinterpret_cast<const tflite::LSHProjectionOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_Pool2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Pool2DOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SVDFOptions: {
+ auto ptr = reinterpret_cast<const tflite::SVDFOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_RNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::RNNOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_FullyConnectedOptions: {
+ auto ptr = reinterpret_cast<const tflite::FullyConnectedOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SoftmaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::SoftmaxOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ConcatenationOptions: {
+ auto ptr = reinterpret_cast<const tflite::ConcatenationOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_AddOptions: {
+ auto ptr = reinterpret_cast<const tflite::AddOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_L2NormOptions: {
+ auto ptr = reinterpret_cast<const tflite::L2NormOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LocalResponseNormalizationOptions: {
+ auto ptr = reinterpret_cast<const tflite::LocalResponseNormalizationOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::LSTMOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ResizeBilinearOptions: {
+ auto ptr = reinterpret_cast<const tflite::ResizeBilinearOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_CallOptions: {
+ auto ptr = reinterpret_cast<const tflite::CallOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ReshapeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReshapeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SkipGramOptions: {
+ auto ptr = reinterpret_cast<const tflite::SkipGramOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SpaceToDepthOptions: {
+ auto ptr = reinterpret_cast<const tflite::SpaceToDepthOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_EmbeddingLookupSparseOptions: {
+ auto ptr = reinterpret_cast<const tflite::EmbeddingLookupSparseOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_MulOptions: {
+ auto ptr = reinterpret_cast<const tflite::MulOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_PadOptions: {
+ auto ptr = reinterpret_cast<const tflite::PadOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_GatherOptions: {
+ auto ptr = reinterpret_cast<const tflite::GatherOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_BatchToSpaceNDOptions: {
+ auto ptr = reinterpret_cast<const tflite::BatchToSpaceNDOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SpaceToBatchNDOptions: {
+ auto ptr = reinterpret_cast<const tflite::SpaceToBatchNDOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_TransposeOptions: {
+ auto ptr = reinterpret_cast<const tflite::TransposeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ReducerOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReducerOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SubOptions: {
+ auto ptr = reinterpret_cast<const tflite::SubOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_DivOptions: {
+ auto ptr = reinterpret_cast<const tflite::DivOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SqueezeOptions: {
+ auto ptr = reinterpret_cast<const tflite::SqueezeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SequenceRNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::SequenceRNNOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_StridedSliceOptions: {
+ auto ptr = reinterpret_cast<const tflite::StridedSliceOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ExpOptions: {
+ auto ptr = reinterpret_cast<const tflite::ExpOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_TopKV2Options: {
+ auto ptr = reinterpret_cast<const tflite::TopKV2Options *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SplitOptions: {
+ auto ptr = reinterpret_cast<const tflite::SplitOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LogSoftmaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogSoftmaxOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_CastOptions: {
+ auto ptr = reinterpret_cast<const tflite::CastOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_DequantizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::DequantizeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_MaximumMinimumOptions: {
+ auto ptr = reinterpret_cast<const tflite::MaximumMinimumOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ArgMaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::ArgMaxOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LessOptions: {
+ auto ptr = reinterpret_cast<const tflite::LessOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_NegOptions: {
+ auto ptr = reinterpret_cast<const tflite::NegOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_PadV2Options: {
+ auto ptr = reinterpret_cast<const tflite::PadV2Options *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_GreaterOptions: {
+ auto ptr = reinterpret_cast<const tflite::GreaterOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_GreaterEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::GreaterEqualOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LessEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::LessEqualOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SelectOptions: {
+ auto ptr = reinterpret_cast<const tflite::SelectOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SliceOptions: {
+ auto ptr = reinterpret_cast<const tflite::SliceOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_TransposeConvOptions: {
+ auto ptr = reinterpret_cast<const tflite::TransposeConvOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SparseToDenseOptions: {
+ auto ptr = reinterpret_cast<const tflite::SparseToDenseOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_TileOptions: {
+ auto ptr = reinterpret_cast<const tflite::TileOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ExpandDimsOptions: {
+ auto ptr = reinterpret_cast<const tflite::ExpandDimsOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_EqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::EqualOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_NotEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::NotEqualOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ShapeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ShapeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_PowOptions: {
+ auto ptr = reinterpret_cast<const tflite::PowOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ArgMinOptions: {
+ auto ptr = reinterpret_cast<const tflite::ArgMinOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_FakeQuantOptions: {
+ auto ptr = reinterpret_cast<const tflite::FakeQuantOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_PackOptions: {
+ auto ptr = reinterpret_cast<const tflite::PackOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LogicalOrOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalOrOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_OneHotOptions: {
+ auto ptr = reinterpret_cast<const tflite::OneHotOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LogicalAndOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalAndOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LogicalNotOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalNotOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_UnpackOptions: {
+ auto ptr = reinterpret_cast<const tflite::UnpackOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_FloorDivOptions: {
+ auto ptr = reinterpret_cast<const tflite::FloorDivOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SquareOptions: {
+ auto ptr = reinterpret_cast<const tflite::SquareOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ZerosLikeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ZerosLikeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_FillOptions: {
+ auto ptr = reinterpret_cast<const tflite::FillOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_BidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::BidirectionalSequenceLSTMOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_BidirectionalSequenceRNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::BidirectionalSequenceRNNOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_UnidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::UnidirectionalSequenceLSTMOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_FloorModOptions: {
+ auto ptr = reinterpret_cast<const tflite::FloorModOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_RangeOptions: {
+ auto ptr = reinterpret_cast<const tflite::RangeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ResizeNearestNeighborOptions: {
+ auto ptr = reinterpret_cast<const tflite::ResizeNearestNeighborOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_LeakyReluOptions: {
+ auto ptr = reinterpret_cast<const tflite::LeakyReluOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SquaredDifferenceOptions: {
+ auto ptr = reinterpret_cast<const tflite::SquaredDifferenceOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_MirrorPadOptions: {
+ auto ptr = reinterpret_cast<const tflite::MirrorPadOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_AbsOptions: {
+ auto ptr = reinterpret_cast<const tflite::AbsOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SplitVOptions: {
+ auto ptr = reinterpret_cast<const tflite::SplitVOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_UniqueOptions: {
+ auto ptr = reinterpret_cast<const tflite::UniqueOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ReverseV2Options: {
+ auto ptr = reinterpret_cast<const tflite::ReverseV2Options *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_AddNOptions: {
+ auto ptr = reinterpret_cast<const tflite::AddNOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_GatherNdOptions: {
+ auto ptr = reinterpret_cast<const tflite::GatherNdOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_CosOptions: {
+ auto ptr = reinterpret_cast<const tflite::CosOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_WhereOptions: {
+ auto ptr = reinterpret_cast<const tflite::WhereOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_RankOptions: {
+ auto ptr = reinterpret_cast<const tflite::RankOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ReverseSequenceOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReverseSequenceOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_MatrixDiagOptions: {
+ auto ptr = reinterpret_cast<const tflite::MatrixDiagOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_QuantizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::QuantizeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_MatrixSetDiagOptions: {
+ auto ptr = reinterpret_cast<const tflite::MatrixSetDiagOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_HardSwishOptions: {
+ auto ptr = reinterpret_cast<const tflite::HardSwishOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_IfOptions: {
+ auto ptr = reinterpret_cast<const tflite::IfOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_WhileOptions: {
+ auto ptr = reinterpret_cast<const tflite::WhileOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_DepthToSpaceOptions: {
+ auto ptr = reinterpret_cast<const tflite::DepthToSpaceOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_NonMaxSuppressionV4Options: {
+ auto ptr = reinterpret_cast<const tflite::NonMaxSuppressionV4Options *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_NonMaxSuppressionV5Options: {
+ auto ptr = reinterpret_cast<const tflite::NonMaxSuppressionV5Options *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_ScatterNdOptions: {
+ auto ptr = reinterpret_cast<const tflite::ScatterNdOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SelectV2Options: {
+ auto ptr = reinterpret_cast<const tflite::SelectV2Options *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_DensifyOptions: {
+ auto ptr = reinterpret_cast<const tflite::DensifyOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_SegmentSumOptions: {
+ auto ptr = reinterpret_cast<const tflite::SegmentSumOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_BatchMatMulOptions: {
+ auto ptr = reinterpret_cast<const tflite::BatchMatMulOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_CumsumOptions: {
+ auto ptr = reinterpret_cast<const tflite::CumsumOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_CallOnceOptions: {
+ auto ptr = reinterpret_cast<const tflite::CallOnceOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_BroadcastToOptions: {
+ auto ptr = reinterpret_cast<const tflite::BroadcastToOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_Rfft2dOptions: {
+ auto ptr = reinterpret_cast<const tflite::Rfft2dOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_Conv3DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Conv3DOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_HashtableOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_HashtableFindOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableFindOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_HashtableImportOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableImportOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ case BuiltinOptions_HashtableSizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableSizeOptions *>(obj);
+ return verifier.VerifyTable(ptr);
+ }
+ default: return true;
+ }
+}
+
+inline bool VerifyBuiltinOptionsVector(flatbuffers::Verifier &verifier, const flatbuffers::Vector<flatbuffers::Offset<void>> *values, const flatbuffers::Vector<uint8_t> *types) {
+ if (!values || !types) return !values && !types;
+ if (values->size() != types->size()) return false;
+ for (flatbuffers::uoffset_t i = 0; i < values->size(); ++i) {
+ if (!VerifyBuiltinOptions(
+ verifier, values->Get(i), types->GetEnum<BuiltinOptions>(i))) {
+ return false;
+ }
+ }
+ return true;
+}
+
+inline void *BuiltinOptionsUnion::UnPack(const void *obj, BuiltinOptions type, const flatbuffers::resolver_function_t *resolver) {
+ switch (type) {
+ case BuiltinOptions_Conv2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Conv2DOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_DepthwiseConv2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::DepthwiseConv2DOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ConcatEmbeddingsOptions: {
+ auto ptr = reinterpret_cast<const tflite::ConcatEmbeddingsOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LSHProjectionOptions: {
+ auto ptr = reinterpret_cast<const tflite::LSHProjectionOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_Pool2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Pool2DOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SVDFOptions: {
+ auto ptr = reinterpret_cast<const tflite::SVDFOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_RNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::RNNOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_FullyConnectedOptions: {
+ auto ptr = reinterpret_cast<const tflite::FullyConnectedOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SoftmaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::SoftmaxOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ConcatenationOptions: {
+ auto ptr = reinterpret_cast<const tflite::ConcatenationOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_AddOptions: {
+ auto ptr = reinterpret_cast<const tflite::AddOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_L2NormOptions: {
+ auto ptr = reinterpret_cast<const tflite::L2NormOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LocalResponseNormalizationOptions: {
+ auto ptr = reinterpret_cast<const tflite::LocalResponseNormalizationOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::LSTMOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ResizeBilinearOptions: {
+ auto ptr = reinterpret_cast<const tflite::ResizeBilinearOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_CallOptions: {
+ auto ptr = reinterpret_cast<const tflite::CallOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ReshapeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReshapeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SkipGramOptions: {
+ auto ptr = reinterpret_cast<const tflite::SkipGramOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SpaceToDepthOptions: {
+ auto ptr = reinterpret_cast<const tflite::SpaceToDepthOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_EmbeddingLookupSparseOptions: {
+ auto ptr = reinterpret_cast<const tflite::EmbeddingLookupSparseOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_MulOptions: {
+ auto ptr = reinterpret_cast<const tflite::MulOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_PadOptions: {
+ auto ptr = reinterpret_cast<const tflite::PadOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_GatherOptions: {
+ auto ptr = reinterpret_cast<const tflite::GatherOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_BatchToSpaceNDOptions: {
+ auto ptr = reinterpret_cast<const tflite::BatchToSpaceNDOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SpaceToBatchNDOptions: {
+ auto ptr = reinterpret_cast<const tflite::SpaceToBatchNDOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_TransposeOptions: {
+ auto ptr = reinterpret_cast<const tflite::TransposeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ReducerOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReducerOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SubOptions: {
+ auto ptr = reinterpret_cast<const tflite::SubOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_DivOptions: {
+ auto ptr = reinterpret_cast<const tflite::DivOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SqueezeOptions: {
+ auto ptr = reinterpret_cast<const tflite::SqueezeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SequenceRNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::SequenceRNNOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_StridedSliceOptions: {
+ auto ptr = reinterpret_cast<const tflite::StridedSliceOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ExpOptions: {
+ auto ptr = reinterpret_cast<const tflite::ExpOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_TopKV2Options: {
+ auto ptr = reinterpret_cast<const tflite::TopKV2Options *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SplitOptions: {
+ auto ptr = reinterpret_cast<const tflite::SplitOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LogSoftmaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogSoftmaxOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_CastOptions: {
+ auto ptr = reinterpret_cast<const tflite::CastOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_DequantizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::DequantizeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_MaximumMinimumOptions: {
+ auto ptr = reinterpret_cast<const tflite::MaximumMinimumOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ArgMaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::ArgMaxOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LessOptions: {
+ auto ptr = reinterpret_cast<const tflite::LessOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_NegOptions: {
+ auto ptr = reinterpret_cast<const tflite::NegOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_PadV2Options: {
+ auto ptr = reinterpret_cast<const tflite::PadV2Options *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_GreaterOptions: {
+ auto ptr = reinterpret_cast<const tflite::GreaterOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_GreaterEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::GreaterEqualOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LessEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::LessEqualOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SelectOptions: {
+ auto ptr = reinterpret_cast<const tflite::SelectOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SliceOptions: {
+ auto ptr = reinterpret_cast<const tflite::SliceOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_TransposeConvOptions: {
+ auto ptr = reinterpret_cast<const tflite::TransposeConvOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SparseToDenseOptions: {
+ auto ptr = reinterpret_cast<const tflite::SparseToDenseOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_TileOptions: {
+ auto ptr = reinterpret_cast<const tflite::TileOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ExpandDimsOptions: {
+ auto ptr = reinterpret_cast<const tflite::ExpandDimsOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_EqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::EqualOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_NotEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::NotEqualOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ShapeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ShapeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_PowOptions: {
+ auto ptr = reinterpret_cast<const tflite::PowOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ArgMinOptions: {
+ auto ptr = reinterpret_cast<const tflite::ArgMinOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_FakeQuantOptions: {
+ auto ptr = reinterpret_cast<const tflite::FakeQuantOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_PackOptions: {
+ auto ptr = reinterpret_cast<const tflite::PackOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LogicalOrOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalOrOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_OneHotOptions: {
+ auto ptr = reinterpret_cast<const tflite::OneHotOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LogicalAndOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalAndOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LogicalNotOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalNotOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_UnpackOptions: {
+ auto ptr = reinterpret_cast<const tflite::UnpackOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_FloorDivOptions: {
+ auto ptr = reinterpret_cast<const tflite::FloorDivOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SquareOptions: {
+ auto ptr = reinterpret_cast<const tflite::SquareOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ZerosLikeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ZerosLikeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_FillOptions: {
+ auto ptr = reinterpret_cast<const tflite::FillOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_BidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::BidirectionalSequenceLSTMOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_BidirectionalSequenceRNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::BidirectionalSequenceRNNOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_UnidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::UnidirectionalSequenceLSTMOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_FloorModOptions: {
+ auto ptr = reinterpret_cast<const tflite::FloorModOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_RangeOptions: {
+ auto ptr = reinterpret_cast<const tflite::RangeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ResizeNearestNeighborOptions: {
+ auto ptr = reinterpret_cast<const tflite::ResizeNearestNeighborOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_LeakyReluOptions: {
+ auto ptr = reinterpret_cast<const tflite::LeakyReluOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SquaredDifferenceOptions: {
+ auto ptr = reinterpret_cast<const tflite::SquaredDifferenceOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_MirrorPadOptions: {
+ auto ptr = reinterpret_cast<const tflite::MirrorPadOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_AbsOptions: {
+ auto ptr = reinterpret_cast<const tflite::AbsOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SplitVOptions: {
+ auto ptr = reinterpret_cast<const tflite::SplitVOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_UniqueOptions: {
+ auto ptr = reinterpret_cast<const tflite::UniqueOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ReverseV2Options: {
+ auto ptr = reinterpret_cast<const tflite::ReverseV2Options *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_AddNOptions: {
+ auto ptr = reinterpret_cast<const tflite::AddNOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_GatherNdOptions: {
+ auto ptr = reinterpret_cast<const tflite::GatherNdOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_CosOptions: {
+ auto ptr = reinterpret_cast<const tflite::CosOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_WhereOptions: {
+ auto ptr = reinterpret_cast<const tflite::WhereOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_RankOptions: {
+ auto ptr = reinterpret_cast<const tflite::RankOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ReverseSequenceOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReverseSequenceOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_MatrixDiagOptions: {
+ auto ptr = reinterpret_cast<const tflite::MatrixDiagOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_QuantizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::QuantizeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_MatrixSetDiagOptions: {
+ auto ptr = reinterpret_cast<const tflite::MatrixSetDiagOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_HardSwishOptions: {
+ auto ptr = reinterpret_cast<const tflite::HardSwishOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_IfOptions: {
+ auto ptr = reinterpret_cast<const tflite::IfOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_WhileOptions: {
+ auto ptr = reinterpret_cast<const tflite::WhileOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_DepthToSpaceOptions: {
+ auto ptr = reinterpret_cast<const tflite::DepthToSpaceOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_NonMaxSuppressionV4Options: {
+ auto ptr = reinterpret_cast<const tflite::NonMaxSuppressionV4Options *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_NonMaxSuppressionV5Options: {
+ auto ptr = reinterpret_cast<const tflite::NonMaxSuppressionV5Options *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_ScatterNdOptions: {
+ auto ptr = reinterpret_cast<const tflite::ScatterNdOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SelectV2Options: {
+ auto ptr = reinterpret_cast<const tflite::SelectV2Options *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_DensifyOptions: {
+ auto ptr = reinterpret_cast<const tflite::DensifyOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_SegmentSumOptions: {
+ auto ptr = reinterpret_cast<const tflite::SegmentSumOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_BatchMatMulOptions: {
+ auto ptr = reinterpret_cast<const tflite::BatchMatMulOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_CumsumOptions: {
+ auto ptr = reinterpret_cast<const tflite::CumsumOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_CallOnceOptions: {
+ auto ptr = reinterpret_cast<const tflite::CallOnceOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_BroadcastToOptions: {
+ auto ptr = reinterpret_cast<const tflite::BroadcastToOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_Rfft2dOptions: {
+ auto ptr = reinterpret_cast<const tflite::Rfft2dOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_Conv3DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Conv3DOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_HashtableOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_HashtableFindOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableFindOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_HashtableImportOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableImportOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ case BuiltinOptions_HashtableSizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableSizeOptions *>(obj);
+ return ptr->UnPack(resolver);
+ }
+ default: return nullptr;
+ }
+}
+
+inline flatbuffers::Offset<void> BuiltinOptionsUnion::Pack(flatbuffers::FlatBufferBuilder &_fbb, const flatbuffers::rehasher_function_t *_rehasher) const {
+ switch (type) {
+ case BuiltinOptions_Conv2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Conv2DOptionsT *>(value);
+ return CreateConv2DOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_DepthwiseConv2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::DepthwiseConv2DOptionsT *>(value);
+ return CreateDepthwiseConv2DOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ConcatEmbeddingsOptions: {
+ auto ptr = reinterpret_cast<const tflite::ConcatEmbeddingsOptionsT *>(value);
+ return CreateConcatEmbeddingsOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LSHProjectionOptions: {
+ auto ptr = reinterpret_cast<const tflite::LSHProjectionOptionsT *>(value);
+ return CreateLSHProjectionOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_Pool2DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Pool2DOptionsT *>(value);
+ return CreatePool2DOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SVDFOptions: {
+ auto ptr = reinterpret_cast<const tflite::SVDFOptionsT *>(value);
+ return CreateSVDFOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_RNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::RNNOptionsT *>(value);
+ return CreateRNNOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_FullyConnectedOptions: {
+ auto ptr = reinterpret_cast<const tflite::FullyConnectedOptionsT *>(value);
+ return CreateFullyConnectedOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SoftmaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::SoftmaxOptionsT *>(value);
+ return CreateSoftmaxOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ConcatenationOptions: {
+ auto ptr = reinterpret_cast<const tflite::ConcatenationOptionsT *>(value);
+ return CreateConcatenationOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_AddOptions: {
+ auto ptr = reinterpret_cast<const tflite::AddOptionsT *>(value);
+ return CreateAddOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_L2NormOptions: {
+ auto ptr = reinterpret_cast<const tflite::L2NormOptionsT *>(value);
+ return CreateL2NormOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LocalResponseNormalizationOptions: {
+ auto ptr = reinterpret_cast<const tflite::LocalResponseNormalizationOptionsT *>(value);
+ return CreateLocalResponseNormalizationOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::LSTMOptionsT *>(value);
+ return CreateLSTMOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ResizeBilinearOptions: {
+ auto ptr = reinterpret_cast<const tflite::ResizeBilinearOptionsT *>(value);
+ return CreateResizeBilinearOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_CallOptions: {
+ auto ptr = reinterpret_cast<const tflite::CallOptionsT *>(value);
+ return CreateCallOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ReshapeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReshapeOptionsT *>(value);
+ return CreateReshapeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SkipGramOptions: {
+ auto ptr = reinterpret_cast<const tflite::SkipGramOptionsT *>(value);
+ return CreateSkipGramOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SpaceToDepthOptions: {
+ auto ptr = reinterpret_cast<const tflite::SpaceToDepthOptionsT *>(value);
+ return CreateSpaceToDepthOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_EmbeddingLookupSparseOptions: {
+ auto ptr = reinterpret_cast<const tflite::EmbeddingLookupSparseOptionsT *>(value);
+ return CreateEmbeddingLookupSparseOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_MulOptions: {
+ auto ptr = reinterpret_cast<const tflite::MulOptionsT *>(value);
+ return CreateMulOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_PadOptions: {
+ auto ptr = reinterpret_cast<const tflite::PadOptionsT *>(value);
+ return CreatePadOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_GatherOptions: {
+ auto ptr = reinterpret_cast<const tflite::GatherOptionsT *>(value);
+ return CreateGatherOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_BatchToSpaceNDOptions: {
+ auto ptr = reinterpret_cast<const tflite::BatchToSpaceNDOptionsT *>(value);
+ return CreateBatchToSpaceNDOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SpaceToBatchNDOptions: {
+ auto ptr = reinterpret_cast<const tflite::SpaceToBatchNDOptionsT *>(value);
+ return CreateSpaceToBatchNDOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_TransposeOptions: {
+ auto ptr = reinterpret_cast<const tflite::TransposeOptionsT *>(value);
+ return CreateTransposeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ReducerOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReducerOptionsT *>(value);
+ return CreateReducerOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SubOptions: {
+ auto ptr = reinterpret_cast<const tflite::SubOptionsT *>(value);
+ return CreateSubOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_DivOptions: {
+ auto ptr = reinterpret_cast<const tflite::DivOptionsT *>(value);
+ return CreateDivOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SqueezeOptions: {
+ auto ptr = reinterpret_cast<const tflite::SqueezeOptionsT *>(value);
+ return CreateSqueezeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SequenceRNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::SequenceRNNOptionsT *>(value);
+ return CreateSequenceRNNOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_StridedSliceOptions: {
+ auto ptr = reinterpret_cast<const tflite::StridedSliceOptionsT *>(value);
+ return CreateStridedSliceOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ExpOptions: {
+ auto ptr = reinterpret_cast<const tflite::ExpOptionsT *>(value);
+ return CreateExpOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_TopKV2Options: {
+ auto ptr = reinterpret_cast<const tflite::TopKV2OptionsT *>(value);
+ return CreateTopKV2Options(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SplitOptions: {
+ auto ptr = reinterpret_cast<const tflite::SplitOptionsT *>(value);
+ return CreateSplitOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LogSoftmaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogSoftmaxOptionsT *>(value);
+ return CreateLogSoftmaxOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_CastOptions: {
+ auto ptr = reinterpret_cast<const tflite::CastOptionsT *>(value);
+ return CreateCastOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_DequantizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::DequantizeOptionsT *>(value);
+ return CreateDequantizeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_MaximumMinimumOptions: {
+ auto ptr = reinterpret_cast<const tflite::MaximumMinimumOptionsT *>(value);
+ return CreateMaximumMinimumOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ArgMaxOptions: {
+ auto ptr = reinterpret_cast<const tflite::ArgMaxOptionsT *>(value);
+ return CreateArgMaxOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LessOptions: {
+ auto ptr = reinterpret_cast<const tflite::LessOptionsT *>(value);
+ return CreateLessOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_NegOptions: {
+ auto ptr = reinterpret_cast<const tflite::NegOptionsT *>(value);
+ return CreateNegOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_PadV2Options: {
+ auto ptr = reinterpret_cast<const tflite::PadV2OptionsT *>(value);
+ return CreatePadV2Options(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_GreaterOptions: {
+ auto ptr = reinterpret_cast<const tflite::GreaterOptionsT *>(value);
+ return CreateGreaterOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_GreaterEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::GreaterEqualOptionsT *>(value);
+ return CreateGreaterEqualOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LessEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::LessEqualOptionsT *>(value);
+ return CreateLessEqualOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SelectOptions: {
+ auto ptr = reinterpret_cast<const tflite::SelectOptionsT *>(value);
+ return CreateSelectOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SliceOptions: {
+ auto ptr = reinterpret_cast<const tflite::SliceOptionsT *>(value);
+ return CreateSliceOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_TransposeConvOptions: {
+ auto ptr = reinterpret_cast<const tflite::TransposeConvOptionsT *>(value);
+ return CreateTransposeConvOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SparseToDenseOptions: {
+ auto ptr = reinterpret_cast<const tflite::SparseToDenseOptionsT *>(value);
+ return CreateSparseToDenseOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_TileOptions: {
+ auto ptr = reinterpret_cast<const tflite::TileOptionsT *>(value);
+ return CreateTileOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ExpandDimsOptions: {
+ auto ptr = reinterpret_cast<const tflite::ExpandDimsOptionsT *>(value);
+ return CreateExpandDimsOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_EqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::EqualOptionsT *>(value);
+ return CreateEqualOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_NotEqualOptions: {
+ auto ptr = reinterpret_cast<const tflite::NotEqualOptionsT *>(value);
+ return CreateNotEqualOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ShapeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ShapeOptionsT *>(value);
+ return CreateShapeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_PowOptions: {
+ auto ptr = reinterpret_cast<const tflite::PowOptionsT *>(value);
+ return CreatePowOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ArgMinOptions: {
+ auto ptr = reinterpret_cast<const tflite::ArgMinOptionsT *>(value);
+ return CreateArgMinOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_FakeQuantOptions: {
+ auto ptr = reinterpret_cast<const tflite::FakeQuantOptionsT *>(value);
+ return CreateFakeQuantOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_PackOptions: {
+ auto ptr = reinterpret_cast<const tflite::PackOptionsT *>(value);
+ return CreatePackOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LogicalOrOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalOrOptionsT *>(value);
+ return CreateLogicalOrOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_OneHotOptions: {
+ auto ptr = reinterpret_cast<const tflite::OneHotOptionsT *>(value);
+ return CreateOneHotOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LogicalAndOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalAndOptionsT *>(value);
+ return CreateLogicalAndOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LogicalNotOptions: {
+ auto ptr = reinterpret_cast<const tflite::LogicalNotOptionsT *>(value);
+ return CreateLogicalNotOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_UnpackOptions: {
+ auto ptr = reinterpret_cast<const tflite::UnpackOptionsT *>(value);
+ return CreateUnpackOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_FloorDivOptions: {
+ auto ptr = reinterpret_cast<const tflite::FloorDivOptionsT *>(value);
+ return CreateFloorDivOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SquareOptions: {
+ auto ptr = reinterpret_cast<const tflite::SquareOptionsT *>(value);
+ return CreateSquareOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ZerosLikeOptions: {
+ auto ptr = reinterpret_cast<const tflite::ZerosLikeOptionsT *>(value);
+ return CreateZerosLikeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_FillOptions: {
+ auto ptr = reinterpret_cast<const tflite::FillOptionsT *>(value);
+ return CreateFillOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_BidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::BidirectionalSequenceLSTMOptionsT *>(value);
+ return CreateBidirectionalSequenceLSTMOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_BidirectionalSequenceRNNOptions: {
+ auto ptr = reinterpret_cast<const tflite::BidirectionalSequenceRNNOptionsT *>(value);
+ return CreateBidirectionalSequenceRNNOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_UnidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<const tflite::UnidirectionalSequenceLSTMOptionsT *>(value);
+ return CreateUnidirectionalSequenceLSTMOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_FloorModOptions: {
+ auto ptr = reinterpret_cast<const tflite::FloorModOptionsT *>(value);
+ return CreateFloorModOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_RangeOptions: {
+ auto ptr = reinterpret_cast<const tflite::RangeOptionsT *>(value);
+ return CreateRangeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ResizeNearestNeighborOptions: {
+ auto ptr = reinterpret_cast<const tflite::ResizeNearestNeighborOptionsT *>(value);
+ return CreateResizeNearestNeighborOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_LeakyReluOptions: {
+ auto ptr = reinterpret_cast<const tflite::LeakyReluOptionsT *>(value);
+ return CreateLeakyReluOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SquaredDifferenceOptions: {
+ auto ptr = reinterpret_cast<const tflite::SquaredDifferenceOptionsT *>(value);
+ return CreateSquaredDifferenceOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_MirrorPadOptions: {
+ auto ptr = reinterpret_cast<const tflite::MirrorPadOptionsT *>(value);
+ return CreateMirrorPadOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_AbsOptions: {
+ auto ptr = reinterpret_cast<const tflite::AbsOptionsT *>(value);
+ return CreateAbsOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SplitVOptions: {
+ auto ptr = reinterpret_cast<const tflite::SplitVOptionsT *>(value);
+ return CreateSplitVOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_UniqueOptions: {
+ auto ptr = reinterpret_cast<const tflite::UniqueOptionsT *>(value);
+ return CreateUniqueOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ReverseV2Options: {
+ auto ptr = reinterpret_cast<const tflite::ReverseV2OptionsT *>(value);
+ return CreateReverseV2Options(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_AddNOptions: {
+ auto ptr = reinterpret_cast<const tflite::AddNOptionsT *>(value);
+ return CreateAddNOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_GatherNdOptions: {
+ auto ptr = reinterpret_cast<const tflite::GatherNdOptionsT *>(value);
+ return CreateGatherNdOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_CosOptions: {
+ auto ptr = reinterpret_cast<const tflite::CosOptionsT *>(value);
+ return CreateCosOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_WhereOptions: {
+ auto ptr = reinterpret_cast<const tflite::WhereOptionsT *>(value);
+ return CreateWhereOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_RankOptions: {
+ auto ptr = reinterpret_cast<const tflite::RankOptionsT *>(value);
+ return CreateRankOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ReverseSequenceOptions: {
+ auto ptr = reinterpret_cast<const tflite::ReverseSequenceOptionsT *>(value);
+ return CreateReverseSequenceOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_MatrixDiagOptions: {
+ auto ptr = reinterpret_cast<const tflite::MatrixDiagOptionsT *>(value);
+ return CreateMatrixDiagOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_QuantizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::QuantizeOptionsT *>(value);
+ return CreateQuantizeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_MatrixSetDiagOptions: {
+ auto ptr = reinterpret_cast<const tflite::MatrixSetDiagOptionsT *>(value);
+ return CreateMatrixSetDiagOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_HardSwishOptions: {
+ auto ptr = reinterpret_cast<const tflite::HardSwishOptionsT *>(value);
+ return CreateHardSwishOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_IfOptions: {
+ auto ptr = reinterpret_cast<const tflite::IfOptionsT *>(value);
+ return CreateIfOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_WhileOptions: {
+ auto ptr = reinterpret_cast<const tflite::WhileOptionsT *>(value);
+ return CreateWhileOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_DepthToSpaceOptions: {
+ auto ptr = reinterpret_cast<const tflite::DepthToSpaceOptionsT *>(value);
+ return CreateDepthToSpaceOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_NonMaxSuppressionV4Options: {
+ auto ptr = reinterpret_cast<const tflite::NonMaxSuppressionV4OptionsT *>(value);
+ return CreateNonMaxSuppressionV4Options(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_NonMaxSuppressionV5Options: {
+ auto ptr = reinterpret_cast<const tflite::NonMaxSuppressionV5OptionsT *>(value);
+ return CreateNonMaxSuppressionV5Options(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_ScatterNdOptions: {
+ auto ptr = reinterpret_cast<const tflite::ScatterNdOptionsT *>(value);
+ return CreateScatterNdOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SelectV2Options: {
+ auto ptr = reinterpret_cast<const tflite::SelectV2OptionsT *>(value);
+ return CreateSelectV2Options(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_DensifyOptions: {
+ auto ptr = reinterpret_cast<const tflite::DensifyOptionsT *>(value);
+ return CreateDensifyOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_SegmentSumOptions: {
+ auto ptr = reinterpret_cast<const tflite::SegmentSumOptionsT *>(value);
+ return CreateSegmentSumOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_BatchMatMulOptions: {
+ auto ptr = reinterpret_cast<const tflite::BatchMatMulOptionsT *>(value);
+ return CreateBatchMatMulOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_CumsumOptions: {
+ auto ptr = reinterpret_cast<const tflite::CumsumOptionsT *>(value);
+ return CreateCumsumOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_CallOnceOptions: {
+ auto ptr = reinterpret_cast<const tflite::CallOnceOptionsT *>(value);
+ return CreateCallOnceOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_BroadcastToOptions: {
+ auto ptr = reinterpret_cast<const tflite::BroadcastToOptionsT *>(value);
+ return CreateBroadcastToOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_Rfft2dOptions: {
+ auto ptr = reinterpret_cast<const tflite::Rfft2dOptionsT *>(value);
+ return CreateRfft2dOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_Conv3DOptions: {
+ auto ptr = reinterpret_cast<const tflite::Conv3DOptionsT *>(value);
+ return CreateConv3DOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_HashtableOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableOptionsT *>(value);
+ return CreateHashtableOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_HashtableFindOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableFindOptionsT *>(value);
+ return CreateHashtableFindOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_HashtableImportOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableImportOptionsT *>(value);
+ return CreateHashtableImportOptions(_fbb, ptr, _rehasher).Union();
+ }
+ case BuiltinOptions_HashtableSizeOptions: {
+ auto ptr = reinterpret_cast<const tflite::HashtableSizeOptionsT *>(value);
+ return CreateHashtableSizeOptions(_fbb, ptr, _rehasher).Union();
+ }
+ default: return 0;
+ }
+}
+
+inline BuiltinOptionsUnion::BuiltinOptionsUnion(const BuiltinOptionsUnion &u) FLATBUFFERS_NOEXCEPT : type(u.type), value(nullptr) {
+ switch (type) {
+ case BuiltinOptions_Conv2DOptions: {
+ value = new tflite::Conv2DOptionsT(*reinterpret_cast<tflite::Conv2DOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_DepthwiseConv2DOptions: {
+ value = new tflite::DepthwiseConv2DOptionsT(*reinterpret_cast<tflite::DepthwiseConv2DOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ConcatEmbeddingsOptions: {
+ value = new tflite::ConcatEmbeddingsOptionsT(*reinterpret_cast<tflite::ConcatEmbeddingsOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LSHProjectionOptions: {
+ value = new tflite::LSHProjectionOptionsT(*reinterpret_cast<tflite::LSHProjectionOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_Pool2DOptions: {
+ value = new tflite::Pool2DOptionsT(*reinterpret_cast<tflite::Pool2DOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SVDFOptions: {
+ value = new tflite::SVDFOptionsT(*reinterpret_cast<tflite::SVDFOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_RNNOptions: {
+ value = new tflite::RNNOptionsT(*reinterpret_cast<tflite::RNNOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_FullyConnectedOptions: {
+ value = new tflite::FullyConnectedOptionsT(*reinterpret_cast<tflite::FullyConnectedOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SoftmaxOptions: {
+ value = new tflite::SoftmaxOptionsT(*reinterpret_cast<tflite::SoftmaxOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ConcatenationOptions: {
+ value = new tflite::ConcatenationOptionsT(*reinterpret_cast<tflite::ConcatenationOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_AddOptions: {
+ value = new tflite::AddOptionsT(*reinterpret_cast<tflite::AddOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_L2NormOptions: {
+ value = new tflite::L2NormOptionsT(*reinterpret_cast<tflite::L2NormOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LocalResponseNormalizationOptions: {
+ value = new tflite::LocalResponseNormalizationOptionsT(*reinterpret_cast<tflite::LocalResponseNormalizationOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LSTMOptions: {
+ value = new tflite::LSTMOptionsT(*reinterpret_cast<tflite::LSTMOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ResizeBilinearOptions: {
+ value = new tflite::ResizeBilinearOptionsT(*reinterpret_cast<tflite::ResizeBilinearOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_CallOptions: {
+ value = new tflite::CallOptionsT(*reinterpret_cast<tflite::CallOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ReshapeOptions: {
+ value = new tflite::ReshapeOptionsT(*reinterpret_cast<tflite::ReshapeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SkipGramOptions: {
+ value = new tflite::SkipGramOptionsT(*reinterpret_cast<tflite::SkipGramOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SpaceToDepthOptions: {
+ value = new tflite::SpaceToDepthOptionsT(*reinterpret_cast<tflite::SpaceToDepthOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_EmbeddingLookupSparseOptions: {
+ value = new tflite::EmbeddingLookupSparseOptionsT(*reinterpret_cast<tflite::EmbeddingLookupSparseOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_MulOptions: {
+ value = new tflite::MulOptionsT(*reinterpret_cast<tflite::MulOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_PadOptions: {
+ value = new tflite::PadOptionsT(*reinterpret_cast<tflite::PadOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_GatherOptions: {
+ value = new tflite::GatherOptionsT(*reinterpret_cast<tflite::GatherOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_BatchToSpaceNDOptions: {
+ value = new tflite::BatchToSpaceNDOptionsT(*reinterpret_cast<tflite::BatchToSpaceNDOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SpaceToBatchNDOptions: {
+ value = new tflite::SpaceToBatchNDOptionsT(*reinterpret_cast<tflite::SpaceToBatchNDOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_TransposeOptions: {
+ value = new tflite::TransposeOptionsT(*reinterpret_cast<tflite::TransposeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ReducerOptions: {
+ value = new tflite::ReducerOptionsT(*reinterpret_cast<tflite::ReducerOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SubOptions: {
+ value = new tflite::SubOptionsT(*reinterpret_cast<tflite::SubOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_DivOptions: {
+ value = new tflite::DivOptionsT(*reinterpret_cast<tflite::DivOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SqueezeOptions: {
+ value = new tflite::SqueezeOptionsT(*reinterpret_cast<tflite::SqueezeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SequenceRNNOptions: {
+ value = new tflite::SequenceRNNOptionsT(*reinterpret_cast<tflite::SequenceRNNOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_StridedSliceOptions: {
+ value = new tflite::StridedSliceOptionsT(*reinterpret_cast<tflite::StridedSliceOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ExpOptions: {
+ value = new tflite::ExpOptionsT(*reinterpret_cast<tflite::ExpOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_TopKV2Options: {
+ value = new tflite::TopKV2OptionsT(*reinterpret_cast<tflite::TopKV2OptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SplitOptions: {
+ value = new tflite::SplitOptionsT(*reinterpret_cast<tflite::SplitOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LogSoftmaxOptions: {
+ value = new tflite::LogSoftmaxOptionsT(*reinterpret_cast<tflite::LogSoftmaxOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_CastOptions: {
+ value = new tflite::CastOptionsT(*reinterpret_cast<tflite::CastOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_DequantizeOptions: {
+ value = new tflite::DequantizeOptionsT(*reinterpret_cast<tflite::DequantizeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_MaximumMinimumOptions: {
+ value = new tflite::MaximumMinimumOptionsT(*reinterpret_cast<tflite::MaximumMinimumOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ArgMaxOptions: {
+ value = new tflite::ArgMaxOptionsT(*reinterpret_cast<tflite::ArgMaxOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LessOptions: {
+ value = new tflite::LessOptionsT(*reinterpret_cast<tflite::LessOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_NegOptions: {
+ value = new tflite::NegOptionsT(*reinterpret_cast<tflite::NegOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_PadV2Options: {
+ value = new tflite::PadV2OptionsT(*reinterpret_cast<tflite::PadV2OptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_GreaterOptions: {
+ value = new tflite::GreaterOptionsT(*reinterpret_cast<tflite::GreaterOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_GreaterEqualOptions: {
+ value = new tflite::GreaterEqualOptionsT(*reinterpret_cast<tflite::GreaterEqualOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LessEqualOptions: {
+ value = new tflite::LessEqualOptionsT(*reinterpret_cast<tflite::LessEqualOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SelectOptions: {
+ value = new tflite::SelectOptionsT(*reinterpret_cast<tflite::SelectOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SliceOptions: {
+ value = new tflite::SliceOptionsT(*reinterpret_cast<tflite::SliceOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_TransposeConvOptions: {
+ value = new tflite::TransposeConvOptionsT(*reinterpret_cast<tflite::TransposeConvOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SparseToDenseOptions: {
+ value = new tflite::SparseToDenseOptionsT(*reinterpret_cast<tflite::SparseToDenseOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_TileOptions: {
+ value = new tflite::TileOptionsT(*reinterpret_cast<tflite::TileOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ExpandDimsOptions: {
+ value = new tflite::ExpandDimsOptionsT(*reinterpret_cast<tflite::ExpandDimsOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_EqualOptions: {
+ value = new tflite::EqualOptionsT(*reinterpret_cast<tflite::EqualOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_NotEqualOptions: {
+ value = new tflite::NotEqualOptionsT(*reinterpret_cast<tflite::NotEqualOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ShapeOptions: {
+ value = new tflite::ShapeOptionsT(*reinterpret_cast<tflite::ShapeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_PowOptions: {
+ value = new tflite::PowOptionsT(*reinterpret_cast<tflite::PowOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ArgMinOptions: {
+ value = new tflite::ArgMinOptionsT(*reinterpret_cast<tflite::ArgMinOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_FakeQuantOptions: {
+ value = new tflite::FakeQuantOptionsT(*reinterpret_cast<tflite::FakeQuantOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_PackOptions: {
+ value = new tflite::PackOptionsT(*reinterpret_cast<tflite::PackOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LogicalOrOptions: {
+ value = new tflite::LogicalOrOptionsT(*reinterpret_cast<tflite::LogicalOrOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_OneHotOptions: {
+ value = new tflite::OneHotOptionsT(*reinterpret_cast<tflite::OneHotOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LogicalAndOptions: {
+ value = new tflite::LogicalAndOptionsT(*reinterpret_cast<tflite::LogicalAndOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LogicalNotOptions: {
+ value = new tflite::LogicalNotOptionsT(*reinterpret_cast<tflite::LogicalNotOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_UnpackOptions: {
+ value = new tflite::UnpackOptionsT(*reinterpret_cast<tflite::UnpackOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_FloorDivOptions: {
+ value = new tflite::FloorDivOptionsT(*reinterpret_cast<tflite::FloorDivOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SquareOptions: {
+ value = new tflite::SquareOptionsT(*reinterpret_cast<tflite::SquareOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ZerosLikeOptions: {
+ value = new tflite::ZerosLikeOptionsT(*reinterpret_cast<tflite::ZerosLikeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_FillOptions: {
+ value = new tflite::FillOptionsT(*reinterpret_cast<tflite::FillOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_BidirectionalSequenceLSTMOptions: {
+ value = new tflite::BidirectionalSequenceLSTMOptionsT(*reinterpret_cast<tflite::BidirectionalSequenceLSTMOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_BidirectionalSequenceRNNOptions: {
+ value = new tflite::BidirectionalSequenceRNNOptionsT(*reinterpret_cast<tflite::BidirectionalSequenceRNNOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_UnidirectionalSequenceLSTMOptions: {
+ value = new tflite::UnidirectionalSequenceLSTMOptionsT(*reinterpret_cast<tflite::UnidirectionalSequenceLSTMOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_FloorModOptions: {
+ value = new tflite::FloorModOptionsT(*reinterpret_cast<tflite::FloorModOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_RangeOptions: {
+ value = new tflite::RangeOptionsT(*reinterpret_cast<tflite::RangeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ResizeNearestNeighborOptions: {
+ value = new tflite::ResizeNearestNeighborOptionsT(*reinterpret_cast<tflite::ResizeNearestNeighborOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_LeakyReluOptions: {
+ value = new tflite::LeakyReluOptionsT(*reinterpret_cast<tflite::LeakyReluOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SquaredDifferenceOptions: {
+ value = new tflite::SquaredDifferenceOptionsT(*reinterpret_cast<tflite::SquaredDifferenceOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_MirrorPadOptions: {
+ value = new tflite::MirrorPadOptionsT(*reinterpret_cast<tflite::MirrorPadOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_AbsOptions: {
+ value = new tflite::AbsOptionsT(*reinterpret_cast<tflite::AbsOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SplitVOptions: {
+ value = new tflite::SplitVOptionsT(*reinterpret_cast<tflite::SplitVOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_UniqueOptions: {
+ value = new tflite::UniqueOptionsT(*reinterpret_cast<tflite::UniqueOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ReverseV2Options: {
+ value = new tflite::ReverseV2OptionsT(*reinterpret_cast<tflite::ReverseV2OptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_AddNOptions: {
+ value = new tflite::AddNOptionsT(*reinterpret_cast<tflite::AddNOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_GatherNdOptions: {
+ value = new tflite::GatherNdOptionsT(*reinterpret_cast<tflite::GatherNdOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_CosOptions: {
+ value = new tflite::CosOptionsT(*reinterpret_cast<tflite::CosOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_WhereOptions: {
+ value = new tflite::WhereOptionsT(*reinterpret_cast<tflite::WhereOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_RankOptions: {
+ value = new tflite::RankOptionsT(*reinterpret_cast<tflite::RankOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ReverseSequenceOptions: {
+ value = new tflite::ReverseSequenceOptionsT(*reinterpret_cast<tflite::ReverseSequenceOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_MatrixDiagOptions: {
+ value = new tflite::MatrixDiagOptionsT(*reinterpret_cast<tflite::MatrixDiagOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_QuantizeOptions: {
+ value = new tflite::QuantizeOptionsT(*reinterpret_cast<tflite::QuantizeOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_MatrixSetDiagOptions: {
+ value = new tflite::MatrixSetDiagOptionsT(*reinterpret_cast<tflite::MatrixSetDiagOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_HardSwishOptions: {
+ value = new tflite::HardSwishOptionsT(*reinterpret_cast<tflite::HardSwishOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_IfOptions: {
+ value = new tflite::IfOptionsT(*reinterpret_cast<tflite::IfOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_WhileOptions: {
+ value = new tflite::WhileOptionsT(*reinterpret_cast<tflite::WhileOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_DepthToSpaceOptions: {
+ value = new tflite::DepthToSpaceOptionsT(*reinterpret_cast<tflite::DepthToSpaceOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_NonMaxSuppressionV4Options: {
+ value = new tflite::NonMaxSuppressionV4OptionsT(*reinterpret_cast<tflite::NonMaxSuppressionV4OptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_NonMaxSuppressionV5Options: {
+ value = new tflite::NonMaxSuppressionV5OptionsT(*reinterpret_cast<tflite::NonMaxSuppressionV5OptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_ScatterNdOptions: {
+ value = new tflite::ScatterNdOptionsT(*reinterpret_cast<tflite::ScatterNdOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SelectV2Options: {
+ value = new tflite::SelectV2OptionsT(*reinterpret_cast<tflite::SelectV2OptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_DensifyOptions: {
+ value = new tflite::DensifyOptionsT(*reinterpret_cast<tflite::DensifyOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_SegmentSumOptions: {
+ value = new tflite::SegmentSumOptionsT(*reinterpret_cast<tflite::SegmentSumOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_BatchMatMulOptions: {
+ value = new tflite::BatchMatMulOptionsT(*reinterpret_cast<tflite::BatchMatMulOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_CumsumOptions: {
+ value = new tflite::CumsumOptionsT(*reinterpret_cast<tflite::CumsumOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_CallOnceOptions: {
+ value = new tflite::CallOnceOptionsT(*reinterpret_cast<tflite::CallOnceOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_BroadcastToOptions: {
+ value = new tflite::BroadcastToOptionsT(*reinterpret_cast<tflite::BroadcastToOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_Rfft2dOptions: {
+ value = new tflite::Rfft2dOptionsT(*reinterpret_cast<tflite::Rfft2dOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_Conv3DOptions: {
+ value = new tflite::Conv3DOptionsT(*reinterpret_cast<tflite::Conv3DOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_HashtableOptions: {
+ value = new tflite::HashtableOptionsT(*reinterpret_cast<tflite::HashtableOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_HashtableFindOptions: {
+ value = new tflite::HashtableFindOptionsT(*reinterpret_cast<tflite::HashtableFindOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_HashtableImportOptions: {
+ value = new tflite::HashtableImportOptionsT(*reinterpret_cast<tflite::HashtableImportOptionsT *>(u.value));
+ break;
+ }
+ case BuiltinOptions_HashtableSizeOptions: {
+ value = new tflite::HashtableSizeOptionsT(*reinterpret_cast<tflite::HashtableSizeOptionsT *>(u.value));
+ break;
+ }
+ default:
+ break;
+ }
+}
+
+inline void BuiltinOptionsUnion::Reset() {
+ switch (type) {
+ case BuiltinOptions_Conv2DOptions: {
+ auto ptr = reinterpret_cast<tflite::Conv2DOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_DepthwiseConv2DOptions: {
+ auto ptr = reinterpret_cast<tflite::DepthwiseConv2DOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ConcatEmbeddingsOptions: {
+ auto ptr = reinterpret_cast<tflite::ConcatEmbeddingsOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LSHProjectionOptions: {
+ auto ptr = reinterpret_cast<tflite::LSHProjectionOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_Pool2DOptions: {
+ auto ptr = reinterpret_cast<tflite::Pool2DOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SVDFOptions: {
+ auto ptr = reinterpret_cast<tflite::SVDFOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_RNNOptions: {
+ auto ptr = reinterpret_cast<tflite::RNNOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_FullyConnectedOptions: {
+ auto ptr = reinterpret_cast<tflite::FullyConnectedOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SoftmaxOptions: {
+ auto ptr = reinterpret_cast<tflite::SoftmaxOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ConcatenationOptions: {
+ auto ptr = reinterpret_cast<tflite::ConcatenationOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_AddOptions: {
+ auto ptr = reinterpret_cast<tflite::AddOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_L2NormOptions: {
+ auto ptr = reinterpret_cast<tflite::L2NormOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LocalResponseNormalizationOptions: {
+ auto ptr = reinterpret_cast<tflite::LocalResponseNormalizationOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LSTMOptions: {
+ auto ptr = reinterpret_cast<tflite::LSTMOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ResizeBilinearOptions: {
+ auto ptr = reinterpret_cast<tflite::ResizeBilinearOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_CallOptions: {
+ auto ptr = reinterpret_cast<tflite::CallOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ReshapeOptions: {
+ auto ptr = reinterpret_cast<tflite::ReshapeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SkipGramOptions: {
+ auto ptr = reinterpret_cast<tflite::SkipGramOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SpaceToDepthOptions: {
+ auto ptr = reinterpret_cast<tflite::SpaceToDepthOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_EmbeddingLookupSparseOptions: {
+ auto ptr = reinterpret_cast<tflite::EmbeddingLookupSparseOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_MulOptions: {
+ auto ptr = reinterpret_cast<tflite::MulOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_PadOptions: {
+ auto ptr = reinterpret_cast<tflite::PadOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_GatherOptions: {
+ auto ptr = reinterpret_cast<tflite::GatherOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_BatchToSpaceNDOptions: {
+ auto ptr = reinterpret_cast<tflite::BatchToSpaceNDOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SpaceToBatchNDOptions: {
+ auto ptr = reinterpret_cast<tflite::SpaceToBatchNDOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_TransposeOptions: {
+ auto ptr = reinterpret_cast<tflite::TransposeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ReducerOptions: {
+ auto ptr = reinterpret_cast<tflite::ReducerOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SubOptions: {
+ auto ptr = reinterpret_cast<tflite::SubOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_DivOptions: {
+ auto ptr = reinterpret_cast<tflite::DivOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SqueezeOptions: {
+ auto ptr = reinterpret_cast<tflite::SqueezeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SequenceRNNOptions: {
+ auto ptr = reinterpret_cast<tflite::SequenceRNNOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_StridedSliceOptions: {
+ auto ptr = reinterpret_cast<tflite::StridedSliceOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ExpOptions: {
+ auto ptr = reinterpret_cast<tflite::ExpOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_TopKV2Options: {
+ auto ptr = reinterpret_cast<tflite::TopKV2OptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SplitOptions: {
+ auto ptr = reinterpret_cast<tflite::SplitOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LogSoftmaxOptions: {
+ auto ptr = reinterpret_cast<tflite::LogSoftmaxOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_CastOptions: {
+ auto ptr = reinterpret_cast<tflite::CastOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_DequantizeOptions: {
+ auto ptr = reinterpret_cast<tflite::DequantizeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_MaximumMinimumOptions: {
+ auto ptr = reinterpret_cast<tflite::MaximumMinimumOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ArgMaxOptions: {
+ auto ptr = reinterpret_cast<tflite::ArgMaxOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LessOptions: {
+ auto ptr = reinterpret_cast<tflite::LessOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_NegOptions: {
+ auto ptr = reinterpret_cast<tflite::NegOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_PadV2Options: {
+ auto ptr = reinterpret_cast<tflite::PadV2OptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_GreaterOptions: {
+ auto ptr = reinterpret_cast<tflite::GreaterOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_GreaterEqualOptions: {
+ auto ptr = reinterpret_cast<tflite::GreaterEqualOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LessEqualOptions: {
+ auto ptr = reinterpret_cast<tflite::LessEqualOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SelectOptions: {
+ auto ptr = reinterpret_cast<tflite::SelectOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SliceOptions: {
+ auto ptr = reinterpret_cast<tflite::SliceOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_TransposeConvOptions: {
+ auto ptr = reinterpret_cast<tflite::TransposeConvOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SparseToDenseOptions: {
+ auto ptr = reinterpret_cast<tflite::SparseToDenseOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_TileOptions: {
+ auto ptr = reinterpret_cast<tflite::TileOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ExpandDimsOptions: {
+ auto ptr = reinterpret_cast<tflite::ExpandDimsOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_EqualOptions: {
+ auto ptr = reinterpret_cast<tflite::EqualOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_NotEqualOptions: {
+ auto ptr = reinterpret_cast<tflite::NotEqualOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ShapeOptions: {
+ auto ptr = reinterpret_cast<tflite::ShapeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_PowOptions: {
+ auto ptr = reinterpret_cast<tflite::PowOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ArgMinOptions: {
+ auto ptr = reinterpret_cast<tflite::ArgMinOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_FakeQuantOptions: {
+ auto ptr = reinterpret_cast<tflite::FakeQuantOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_PackOptions: {
+ auto ptr = reinterpret_cast<tflite::PackOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LogicalOrOptions: {
+ auto ptr = reinterpret_cast<tflite::LogicalOrOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_OneHotOptions: {
+ auto ptr = reinterpret_cast<tflite::OneHotOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LogicalAndOptions: {
+ auto ptr = reinterpret_cast<tflite::LogicalAndOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LogicalNotOptions: {
+ auto ptr = reinterpret_cast<tflite::LogicalNotOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_UnpackOptions: {
+ auto ptr = reinterpret_cast<tflite::UnpackOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_FloorDivOptions: {
+ auto ptr = reinterpret_cast<tflite::FloorDivOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SquareOptions: {
+ auto ptr = reinterpret_cast<tflite::SquareOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ZerosLikeOptions: {
+ auto ptr = reinterpret_cast<tflite::ZerosLikeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_FillOptions: {
+ auto ptr = reinterpret_cast<tflite::FillOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_BidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<tflite::BidirectionalSequenceLSTMOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_BidirectionalSequenceRNNOptions: {
+ auto ptr = reinterpret_cast<tflite::BidirectionalSequenceRNNOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_UnidirectionalSequenceLSTMOptions: {
+ auto ptr = reinterpret_cast<tflite::UnidirectionalSequenceLSTMOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_FloorModOptions: {
+ auto ptr = reinterpret_cast<tflite::FloorModOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_RangeOptions: {
+ auto ptr = reinterpret_cast<tflite::RangeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ResizeNearestNeighborOptions: {
+ auto ptr = reinterpret_cast<tflite::ResizeNearestNeighborOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_LeakyReluOptions: {
+ auto ptr = reinterpret_cast<tflite::LeakyReluOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SquaredDifferenceOptions: {
+ auto ptr = reinterpret_cast<tflite::SquaredDifferenceOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_MirrorPadOptions: {
+ auto ptr = reinterpret_cast<tflite::MirrorPadOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_AbsOptions: {
+ auto ptr = reinterpret_cast<tflite::AbsOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SplitVOptions: {
+ auto ptr = reinterpret_cast<tflite::SplitVOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_UniqueOptions: {
+ auto ptr = reinterpret_cast<tflite::UniqueOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ReverseV2Options: {
+ auto ptr = reinterpret_cast<tflite::ReverseV2OptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_AddNOptions: {
+ auto ptr = reinterpret_cast<tflite::AddNOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_GatherNdOptions: {
+ auto ptr = reinterpret_cast<tflite::GatherNdOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_CosOptions: {
+ auto ptr = reinterpret_cast<tflite::CosOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_WhereOptions: {
+ auto ptr = reinterpret_cast<tflite::WhereOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_RankOptions: {
+ auto ptr = reinterpret_cast<tflite::RankOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ReverseSequenceOptions: {
+ auto ptr = reinterpret_cast<tflite::ReverseSequenceOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_MatrixDiagOptions: {
+ auto ptr = reinterpret_cast<tflite::MatrixDiagOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_QuantizeOptions: {
+ auto ptr = reinterpret_cast<tflite::QuantizeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_MatrixSetDiagOptions: {
+ auto ptr = reinterpret_cast<tflite::MatrixSetDiagOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_HardSwishOptions: {
+ auto ptr = reinterpret_cast<tflite::HardSwishOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_IfOptions: {
+ auto ptr = reinterpret_cast<tflite::IfOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_WhileOptions: {
+ auto ptr = reinterpret_cast<tflite::WhileOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_DepthToSpaceOptions: {
+ auto ptr = reinterpret_cast<tflite::DepthToSpaceOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_NonMaxSuppressionV4Options: {
+ auto ptr = reinterpret_cast<tflite::NonMaxSuppressionV4OptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_NonMaxSuppressionV5Options: {
+ auto ptr = reinterpret_cast<tflite::NonMaxSuppressionV5OptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_ScatterNdOptions: {
+ auto ptr = reinterpret_cast<tflite::ScatterNdOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SelectV2Options: {
+ auto ptr = reinterpret_cast<tflite::SelectV2OptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_DensifyOptions: {
+ auto ptr = reinterpret_cast<tflite::DensifyOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_SegmentSumOptions: {
+ auto ptr = reinterpret_cast<tflite::SegmentSumOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_BatchMatMulOptions: {
+ auto ptr = reinterpret_cast<tflite::BatchMatMulOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_CumsumOptions: {
+ auto ptr = reinterpret_cast<tflite::CumsumOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_CallOnceOptions: {
+ auto ptr = reinterpret_cast<tflite::CallOnceOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_BroadcastToOptions: {
+ auto ptr = reinterpret_cast<tflite::BroadcastToOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_Rfft2dOptions: {
+ auto ptr = reinterpret_cast<tflite::Rfft2dOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_Conv3DOptions: {
+ auto ptr = reinterpret_cast<tflite::Conv3DOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_HashtableOptions: {
+ auto ptr = reinterpret_cast<tflite::HashtableOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_HashtableFindOptions: {
+ auto ptr = reinterpret_cast<tflite::HashtableFindOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_HashtableImportOptions: {
+ auto ptr = reinterpret_cast<tflite::HashtableImportOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ case BuiltinOptions_HashtableSizeOptions: {
+ auto ptr = reinterpret_cast<tflite::HashtableSizeOptionsT *>(value);
+ delete ptr;
+ break;
+ }
+ default: break;
+ }
+ value = nullptr;
+ type = BuiltinOptions_NONE;
+}
+
+inline const tflite::Model *GetModel(const void *buf) {
+ return flatbuffers::GetRoot<tflite::Model>(buf);
+}
+
+inline const tflite::Model *GetSizePrefixedModel(const void *buf) {
+ return flatbuffers::GetSizePrefixedRoot<tflite::Model>(buf);
+}
+
+inline const char *ModelIdentifier() {
+ return "TFL3";
+}
+
+inline bool ModelBufferHasIdentifier(const void *buf) {
+ return flatbuffers::BufferHasIdentifier(
+ buf, ModelIdentifier());
+}
+
+inline bool VerifyModelBuffer(
+ flatbuffers::Verifier &verifier) {
+ return verifier.VerifyBuffer<tflite::Model>(ModelIdentifier());
+}
+
+inline bool VerifySizePrefixedModelBuffer(
+ flatbuffers::Verifier &verifier) {
+ return verifier.VerifySizePrefixedBuffer<tflite::Model>(ModelIdentifier());
+}
+
+inline const char *ModelExtension() {
+ return "tflite";
+}
+
+inline void FinishModelBuffer(
+ flatbuffers::FlatBufferBuilder &fbb,
+ flatbuffers::Offset<tflite::Model> root) {
+ fbb.Finish(root, ModelIdentifier());
+}
+
+inline void FinishSizePrefixedModelBuffer(
+ flatbuffers::FlatBufferBuilder &fbb,
+ flatbuffers::Offset<tflite::Model> root) {
+ fbb.FinishSizePrefixed(root, ModelIdentifier());
+}
+
+inline std::unique_ptr<tflite::ModelT> UnPackModel(
+ const void *buf,
+ const flatbuffers::resolver_function_t *res = nullptr) {
+ return std::unique_ptr<tflite::ModelT>(GetModel(buf)->UnPack(res));
+}
+
+inline std::unique_ptr<tflite::ModelT> UnPackSizePrefixedModel(
+ const void *buf,
+ const flatbuffers::resolver_function_t *res = nullptr) {
+ return std::unique_ptr<tflite::ModelT>(GetSizePrefixedModel(buf)->UnPack(res));
+}
+
+} // namespace tflite
+
+#endif // FLATBUFFERS_GENERATED_SCHEMA_TFLITE_H_
diff --git a/tensorflow/lite/schema/schema_utils.cc b/tensorflow/lite/schema/schema_utils.cc
new file mode 100644
index 0000000..fc19290
--- /dev/null
+++ b/tensorflow/lite/schema/schema_utils.cc
@@ -0,0 +1,62 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#include "tensorflow/lite/schema/schema_utils.h"
+
+#include <algorithm>
+
+#include "tensorflow/lite/kernels/internal/compatibility.h"
+
+namespace tflite {
+
+// The following GetBuiltinCode methods are the utility methods for reading
+// builtin operatore code, ensuring compatibility issues between v3 and v3a
+// schema. Always the maximum value of the two fields always will be the correct
+// value as follows:
+//
+// - Supporting schema version v3 models
+//
+// The `builtin_code` field is not available in the v3 models. Flatbuffer
+// library will feed zero value, which is the default value in the v3a schema.
+// The actual builtin operatore code value will exist in the
+// `deprecated_builtin_code` field. At the same time, it implies that
+// `deprecated_builtin_code` >= `builtin_code` and the maximum value of the two
+// fields will be same with `deprecated_builtin_code'.
+//
+// - Supporting builtin operator codes beyonds 127
+//
+// New builtin operators, whose operator code is larger than 127, can not be
+// assigned to the `deprecated_builtin_code` field. In such cases, the
+// value of the `builtin_code` field should be used for the builtin operator
+// code. In the case, the maximum value of the two fields will be the value of
+// the `builtin_code` as the right value.
+
+BuiltinOperator GetBuiltinCode(const OperatorCode* op_code) {
+ // Caller should guarantee that the given argument value is not a nullptr.
+ TFLITE_DCHECK(op_code != nullptr);
+
+ return std::max(
+ op_code->builtin_code(),
+ static_cast<BuiltinOperator>(op_code->deprecated_builtin_code()));
+}
+
+BuiltinOperator GetBuiltinCode(const OperatorCodeT* op_code) {
+ // Caller should guarantee that the given argument value is not a nullptr.
+ TFLITE_DCHECK(op_code != nullptr);
+
+ return std::max(op_code->builtin_code, static_cast<BuiltinOperator>(
+ op_code->deprecated_builtin_code));
+}
+
+} // namespace tflite
diff --git a/tensorflow/lite/schema/schema_utils.h b/tensorflow/lite/schema/schema_utils.h
new file mode 100644
index 0000000..9cca36c
--- /dev/null
+++ b/tensorflow/lite/schema/schema_utils.h
@@ -0,0 +1,33 @@
+/* Copyright 2020 The TensorFlow Authors. All Rights Reserved.
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+==============================================================================*/
+#ifndef TENSORFLOW_LITE_SCHEMA_SCHEMA_UTILS_H_
+#define TENSORFLOW_LITE_SCHEMA_SCHEMA_UTILS_H_
+
+#include "flatbuffers/flatbuffers.h"
+#include "tensorflow/lite/schema/schema_generated.h"
+
+namespace tflite {
+
+// The following methods are introduced to resolve op builtin code shortage
+// problem. The new builtin operator will be assigned to the extended builtin
+// code field in the flatbuffer schema. Those methods helps to hide builtin code
+// details.
+BuiltinOperator GetBuiltinCode(const OperatorCode *op_code);
+
+BuiltinOperator GetBuiltinCode(const OperatorCodeT *op_code);
+
+} // namespace tflite
+
+#endif // TENSORFLOW_LITE_SCHEMA_SCHEMA_UTILS_H_
diff --git a/tensorflow/tensorflow.bzl b/tensorflow/tensorflow.bzl
new file mode 100644
index 0000000..4876c6e
--- /dev/null
+++ b/tensorflow/tensorflow.bzl
@@ -0,0 +1,11 @@
+def if_not_windows(a):
+ return select({
+ clean_dep("//tensorflow:windows"): [],
+ "//conditions:default": a,
+ })
+
+def clean_dep(dep):
+ return str(Label(dep))
+
+def get_compatible_with_portable():
+ return []
diff --git a/tensorflow/workspace.bzl b/tensorflow/workspace.bzl
new file mode 100644
index 0000000..9f5424b
--- /dev/null
+++ b/tensorflow/workspace.bzl
@@ -0,0 +1,42 @@
+load("//third_party/flatbuffers:workspace.bzl", flatbuffers = "repo")
+load("//third_party/kissfft:workspace.bzl", kissfft = "repo")
+load("//third_party/ruy:workspace.bzl", ruy = "repo")
+load("//third_party:repo.bzl", "tf_http_archive")
+
+def initialize_third_party():
+ """ Load third party repositories. See above load() statements. """
+ flatbuffers()
+ kissfft()
+ ruy()
+
+# Sanitize a dependency so that it works correctly from code that includes
+# TensorFlow as a submodule.
+def clean_dep(dep):
+ return str(Label(dep))
+
+def tf_repositories(path_prefix = "", tf_repo_name = ""):
+ """All external dependencies for TF builds."""
+ # https://github.com/bazelbuild/bazel-skylib/releases
+ tf_http_archive(
+ name = "bazel_skylib",
+ sha256 = "1dde365491125a3db70731e25658dfdd3bc5dbdfd11b840b3e987ecf043c7ca0",
+ urls = [
+ "https://storage.googleapis.com/mirror.tensorflow.org/github.com/bazelbuild/bazel-skylib/releases/download/0.9.0/bazel_skylib-0.9.0.tar.gz",
+ "https://github.com/bazelbuild/bazel-skylib/releases/download/0.9.0/bazel_skylib-0.9.0.tar.gz",
+ ],
+ )
+
+ tf_http_archive(
+ name = "gemmlowp",
+ sha256 = "43146e6f56cb5218a8caaab6b5d1601a083f1f31c06ff474a4378a7d35be9cfb", # SHARED_GEMMLOWP_SHA
+ strip_prefix = "gemmlowp-fda83bdc38b118cc6b56753bd540caa49e570745",
+ urls = [
+ "https://storage.googleapis.com/mirror.tensorflow.org/github.com/google/gemmlowp/archive/fda83bdc38b118cc6b56753bd540caa49e570745.zip",
+ "https://github.com/google/gemmlowp/archive/fda83bdc38b118cc6b56753bd540caa49e570745.zip",
+ ],
+ )
+
+ initialize_third_party()
+
+def workspace():
+ tf_repositories()
diff --git a/third_party/BUILD b/third_party/BUILD
new file mode 100644
index 0000000..5b01f6e
--- /dev/null
+++ b/third_party/BUILD
@@ -0,0 +1 @@
+licenses(["notice"])
diff --git a/third_party/flatbuffers/BUILD b/third_party/flatbuffers/BUILD
new file mode 100644
index 0000000..82bab3f
--- /dev/null
+++ b/third_party/flatbuffers/BUILD
@@ -0,0 +1 @@
+# This empty BUILD file is required to make Bazel treat this directory as a package.
diff --git a/third_party/flatbuffers/BUILD.bazel b/third_party/flatbuffers/BUILD.bazel
new file mode 100644
index 0000000..a8c5139
--- /dev/null
+++ b/third_party/flatbuffers/BUILD.bazel
@@ -0,0 +1,102 @@
+package(default_visibility = ["//visibility:public"])
+
+licenses(["notice"])
+
+exports_files(["LICENSE.txt"])
+
+licenses(["notice"])
+
+config_setting(
+ name = "freebsd",
+ values = {"cpu": "freebsd"},
+)
+
+config_setting(
+ name = "windows",
+ values = {"cpu": "x64_windows"},
+)
+
+load("@rules_cc//cc:defs.bzl", "cc_binary", "cc_library")
+
+# Public flatc library to compile flatbuffer files at runtime.
+cc_library(
+ name = "flatbuffers",
+ hdrs = ["//:public_headers"],
+ linkstatic = 1,
+ strip_include_prefix = "/include",
+ visibility = ["//visibility:public"],
+ deps = ["//src:flatbuffers"],
+)
+
+# Public C++ headers for the Flatbuffers library.
+filegroup(
+ name = "public_headers",
+ srcs = [
+ "include/flatbuffers/base.h",
+ "include/flatbuffers/code_generators.h",
+ "include/flatbuffers/flatbuffers.h",
+ "include/flatbuffers/flexbuffers.h",
+ "include/flatbuffers/hash.h",
+ "include/flatbuffers/idl.h",
+ "include/flatbuffers/minireflect.h",
+ "include/flatbuffers/reflection.h",
+ "include/flatbuffers/reflection_generated.h",
+ "include/flatbuffers/registry.h",
+ "include/flatbuffers/stl_emulation.h",
+ "include/flatbuffers/util.h",
+ ],
+ visibility = ["//:__subpackages__"],
+)
+
+# Public flatc compiler library.
+cc_library(
+ name = "flatc_library",
+ linkstatic = 1,
+ visibility = ["//visibility:public"],
+ deps = [
+ "@flatbuffers//src:flatc_library",
+ ],
+)
+
+# Public flatc compiler.
+cc_binary(
+ name = "flatc",
+ linkopts = select({
+ ":freebsd": [
+ "-lm",
+ ],
+ ":windows": [],
+ "//conditions:default": [
+ "-lm",
+ "-ldl",
+ ],
+ }),
+ visibility = ["//visibility:public"],
+ deps = [
+ "@flatbuffers//src:flatc",
+ ],
+)
+
+filegroup(
+ name = "flatc_headers",
+ srcs = [
+ "include/flatbuffers/flatc.h",
+ ],
+ visibility = ["//:__subpackages__"],
+)
+
+# Library used by flatbuffer_cc_library rules.
+cc_library(
+ name = "runtime_cc",
+ hdrs = [
+ "include/flatbuffers/base.h",
+ "include/flatbuffers/flatbuffers.h",
+ "include/flatbuffers/flexbuffers.h",
+ "include/flatbuffers/stl_emulation.h",
+ "include/flatbuffers/util.h",
+ ],
+ linkstatic = 1,
+ strip_include_prefix = "/include",
+ visibility = ["//visibility:public"],
+)
+
diff --git a/third_party/flatbuffers/BUILD.system b/third_party/flatbuffers/BUILD.system
new file mode 100644
index 0000000..8fe4d7a
--- /dev/null
+++ b/third_party/flatbuffers/BUILD.system
@@ -0,0 +1,43 @@
+licenses(["notice"]) # Apache 2.0
+
+filegroup(
+ name = "LICENSE.txt",
+ visibility = ["//visibility:public"],
+)
+
+# Public flatc library to compile flatbuffer files at runtime.
+cc_library(
+ name = "flatbuffers",
+ linkopts = ["-lflatbuffers"],
+ visibility = ["//visibility:public"],
+)
+
+# Public flatc compiler library.
+cc_library(
+ name = "flatc_library",
+ linkopts = ["-lflatbuffers"],
+ visibility = ["//visibility:public"],
+)
+
+genrule(
+ name = "lnflatc",
+ outs = ["flatc.bin"],
+ cmd = "ln -s $$(which flatc) $@",
+)
+
+# Public flatc compiler.
+sh_binary(
+ name = "flatc",
+ srcs = ["flatc.bin"],
+ visibility = ["//visibility:public"],
+)
+
+cc_library(
+ name = "runtime_cc",
+ visibility = ["//visibility:public"],
+)
+
+py_library(
+ name = "runtime_py",
+ visibility = ["//visibility:public"],
+)
diff --git a/third_party/flatbuffers/build_defs.bzl b/third_party/flatbuffers/build_defs.bzl
new file mode 100644
index 0000000..d409f83
--- /dev/null
+++ b/third_party/flatbuffers/build_defs.bzl
@@ -0,0 +1,638 @@
+"""BUILD rules for generating flatbuffer files."""
+
+load("@build_bazel_rules_android//android:rules.bzl", "android_library")
+
+flatc_path = "@flatbuffers//:flatc"
+zip_files = "//tensorflow/lite/tools:zip_files"
+
+DEFAULT_INCLUDE_PATHS = [
+ "./",
+ "$(GENDIR)",
+ "$(BINDIR)",
+]
+
+DEFAULT_FLATC_ARGS = [
+ "--no-union-value-namespacing",
+ "--gen-object-api",
+]
+
+def flatbuffer_library_public(
+ name,
+ srcs,
+ outs,
+ language_flag,
+ out_prefix = "",
+ includes = [],
+ include_paths = [],
+ compatible_with = [],
+ flatc_args = DEFAULT_FLATC_ARGS,
+ reflection_name = "",
+ reflection_visibility = None,
+ output_to_bindir = False):
+ """Generates code files for reading/writing the given flatbuffers in the requested language using the public compiler.
+
+ Outs:
+ filegroup(name): all generated source files.
+ Fileset([reflection_name]): (Optional) all generated reflection binaries.
+
+ Args:
+ name: Rule name.
+ srcs: Source .fbs files. Sent in order to the compiler.
+ outs: Output files from flatc.
+ language_flag: Target language flag. One of [-c, -j, -js].
+ out_prefix: Prepend this path to the front of all generated files except on
+ single source targets. Usually is a directory name.
+ includes: Optional, list of filegroups of schemas that the srcs depend on.
+ include_paths: Optional, list of paths the includes files can be found in.
+ compatible_with: Optional, passed to genrule for environments this rule
+ can be built for.
+ flatc_args: Optional, list of additional arguments to pass to flatc.
+ reflection_name: Optional, if set this will generate the flatbuffer
+ reflection binaries for the schemas.
+ reflection_visibility: The visibility of the generated reflection Fileset.
+ output_to_bindir: Passed to genrule for output to bin directory.
+ """
+ include_paths_cmd = ["-I %s" % (s) for s in include_paths]
+
+ # '$(@D)' when given a single source target will give the appropriate
+ # directory. Appending 'out_prefix' is only necessary when given a build
+ # target with multiple sources.
+ output_directory = (
+ ("-o $(@D)/%s" % (out_prefix)) if len(srcs) > 1 else ("-o $(@D)")
+ )
+ genrule_cmd = " ".join([
+ "for f in $(SRCS); do",
+ "$(location %s)" % (flatc_path),
+ " ".join(flatc_args),
+ " ".join(include_paths_cmd),
+ language_flag,
+ output_directory,
+ "$$f;",
+ "done",
+ ])
+ native.genrule(
+ name = name,
+ srcs = srcs,
+ outs = outs,
+ output_to_bindir = output_to_bindir,
+ compatible_with = compatible_with,
+ tools = includes + [flatc_path],
+ cmd = genrule_cmd,
+ message = "Generating flatbuffer files for %s:" % (name),
+ )
+ if reflection_name:
+ reflection_genrule_cmd = " ".join([
+ "for f in $(SRCS); do",
+ "$(location %s)" % (flatc_path),
+ "-b --schema",
+ " ".join(flatc_args),
+ " ".join(include_paths_cmd),
+ language_flag,
+ output_directory,
+ "$$f;",
+ "done",
+ ])
+ reflection_outs = [
+ (out_prefix + "%s.bfbs") % (s.replace(".fbs", "").split("/")[-1])
+ for s in srcs
+ ]
+ native.genrule(
+ name = "%s_srcs" % reflection_name,
+ srcs = srcs,
+ outs = reflection_outs,
+ output_to_bindir = output_to_bindir,
+ compatible_with = compatible_with,
+ tools = includes + [flatc_path],
+ cmd = reflection_genrule_cmd,
+ message = "Generating flatbuffer reflection binary for %s:" % (name),
+ )
+ # TODO(b/114456773): Make bazel rules proper and supported by flatbuffer
+ # Have to comment this since FilesetEntry is not supported in bazel
+ # skylark.
+ # native.Fileset(
+ # name = reflection_name,
+ # out = "%s_out" % reflection_name,
+ # entries = [
+ # native.FilesetEntry(files = reflection_outs),
+ # ],
+ # visibility = reflection_visibility,
+ # compatible_with = compatible_with,
+ # )
+
+def flatbuffer_cc_library(
+ name,
+ srcs,
+ srcs_filegroup_name = "",
+ out_prefix = "",
+ includes = [],
+ include_paths = [],
+ compatible_with = [],
+ flatc_args = DEFAULT_FLATC_ARGS,
+ visibility = None,
+ srcs_filegroup_visibility = None,
+ gen_reflections = False):
+ '''A cc_library with the generated reader/writers for the given flatbuffer definitions.
+
+ Outs:
+ filegroup([name]_srcs): all generated .h files.
+ filegroup(srcs_filegroup_name if specified, or [name]_includes if not):
+ Other flatbuffer_cc_library's can pass this in for their `includes`
+ parameter, if they depend on the schemas in this library.
+ Fileset([name]_reflection): (Optional) all generated reflection binaries.
+ cc_library([name]): library with sources and flatbuffers deps.
+
+ Remarks:
+ ** Because the genrule used to call flatc does not have any trivial way of
+ computing the output list of files transitively generated by includes and
+ --gen-includes (the default) being defined for flatc, the --gen-includes
+ flag will not work as expected. The way around this is to add a dependency
+ to the flatbuffer_cc_library defined alongside the flatc included Fileset.
+ For example you might define:
+
+ flatbuffer_cc_library(
+ name = "my_fbs",
+ srcs = [ "schemas/foo.fbs" ],
+ includes = [ "//third_party/bazz:bazz_fbs_includes" ],
+ )
+
+ In which foo.fbs includes a few files from the Fileset defined at
+ //third_party/bazz:bazz_fbs_includes. When compiling the library that
+ includes foo_generated.h, and therefore has my_fbs as a dependency, it
+ will fail to find any of the bazz *_generated.h files unless you also
+ add bazz's flatbuffer_cc_library to your own dependency list, e.g.:
+
+ cc_library(
+ name = "my_lib",
+ deps = [
+ ":my_fbs",
+ "//third_party/bazz:bazz_fbs"
+ ],
+ )
+
+ Happy dependent Flatbuffering!
+
+ Args:
+ name: Rule name.
+ srcs: Source .fbs files. Sent in order to the compiler.
+ srcs_filegroup_name: Name of the output filegroup that holds srcs. Pass this
+ filegroup into the `includes` parameter of any other
+ flatbuffer_cc_library that depends on this one's schemas.
+ out_prefix: Prepend this path to the front of all generated files. Usually
+ is a directory name.
+ includes: Optional, list of filegroups of schemas that the srcs depend on.
+ ** SEE REMARKS BELOW **
+ include_paths: Optional, list of paths the includes files can be found in.
+ compatible_with: Optional, passed to genrule for environments this rule
+ can be built for
+ flatc_args: Optional list of additional arguments to pass to flatc
+ (e.g. --gen-mutable).
+ visibility: The visibility of the generated cc_library. By default, use the
+ default visibility of the project.
+ srcs_filegroup_visibility: The visibility of the generated srcs filegroup.
+ By default, use the value of the visibility parameter above.
+ gen_reflections: Optional, if true this will generate the flatbuffer
+ reflection binaries for the schemas.
+ '''
+ output_headers = [
+ (out_prefix + "%s_generated.h") % (s.replace(".fbs", "").split("/")[-1])
+ for s in srcs
+ ]
+ reflection_name = "%s_reflection" % name if gen_reflections else ""
+
+ flatbuffer_library_public(
+ name = "%s_srcs" % (name),
+ srcs = srcs,
+ outs = output_headers,
+ language_flag = "-c",
+ out_prefix = out_prefix,
+ includes = includes,
+ include_paths = include_paths,
+ compatible_with = compatible_with,
+ flatc_args = flatc_args,
+ reflection_name = reflection_name,
+ reflection_visibility = visibility,
+ )
+ native.cc_library(
+ name = name,
+ hdrs = output_headers,
+ srcs = output_headers,
+ features = [
+ "-parse_headers",
+ ],
+ deps = [
+ "@flatbuffers//:runtime_cc",
+ ],
+ includes = ["."],
+ linkstatic = 1,
+ visibility = visibility,
+ compatible_with = compatible_with,
+ )
+
+ # A filegroup for the `srcs`. That is, all the schema files for this
+ # Flatbuffer set.
+ native.filegroup(
+ name = srcs_filegroup_name if srcs_filegroup_name else "%s_includes" % (name),
+ srcs = srcs,
+ visibility = srcs_filegroup_visibility if srcs_filegroup_visibility != None else visibility,
+ compatible_with = compatible_with,
+ )
+
+# Custom provider to track dependencies transitively.
+FlatbufferInfo = provider(
+ fields = {
+ "transitive_srcs": "flatbuffer schema definitions.",
+ },
+)
+
+def _flatbuffer_schemas_aspect_impl(target, ctx):
+ _ignore = [target]
+ transitive_srcs = depset()
+ if hasattr(ctx.rule.attr, "deps"):
+ for dep in ctx.rule.attr.deps:
+ if FlatbufferInfo in dep:
+ transitive_srcs = depset(dep[FlatbufferInfo].transitive_srcs, transitive = [transitive_srcs])
+ if hasattr(ctx.rule.attr, "srcs"):
+ for src in ctx.rule.attr.srcs:
+ if FlatbufferInfo in src:
+ transitive_srcs = depset(src[FlatbufferInfo].transitive_srcs, transitive = [transitive_srcs])
+ for f in src.files:
+ if f.extension == "fbs":
+ transitive_srcs = depset([f], transitive = [transitive_srcs])
+ return [FlatbufferInfo(transitive_srcs = transitive_srcs)]
+
+# An aspect that runs over all dependencies and transitively collects
+# flatbuffer schema files.
+_flatbuffer_schemas_aspect = aspect(
+ attr_aspects = [
+ "deps",
+ "srcs",
+ ],
+ implementation = _flatbuffer_schemas_aspect_impl,
+)
+
+# Rule to invoke the flatbuffer compiler.
+def _gen_flatbuffer_srcs_impl(ctx):
+ outputs = ctx.attr.outputs
+ include_paths = ctx.attr.include_paths
+ if ctx.attr.no_includes:
+ no_includes_statement = ["--no-includes"]
+ else:
+ no_includes_statement = []
+
+ # Need to generate all files in a directory.
+ if not outputs:
+ outputs = [ctx.actions.declare_directory("{}_all".format(ctx.attr.name))]
+ output_directory = outputs[0].path
+ else:
+ outputs = [ctx.actions.declare_file(output) for output in outputs]
+ output_directory = outputs[0].dirname
+
+ deps = depset(ctx.files.srcs + ctx.files.deps, transitive = [
+ dep[FlatbufferInfo].transitive_srcs
+ for dep in ctx.attr.deps
+ if FlatbufferInfo in dep
+ ])
+
+ include_paths_cmd_line = []
+ for s in include_paths:
+ include_paths_cmd_line.extend(["-I", s])
+
+ for src in ctx.files.srcs:
+ ctx.actions.run(
+ inputs = deps,
+ outputs = outputs,
+ executable = ctx.executable._flatc,
+ arguments = [
+ ctx.attr.language_flag,
+ "-o",
+ output_directory,
+ # Allow for absolute imports and referencing of generated files.
+ "-I",
+ "./",
+ "-I",
+ ctx.genfiles_dir.path,
+ "-I",
+ ctx.bin_dir.path,
+ ] + no_includes_statement +
+ include_paths_cmd_line + [
+ "--no-union-value-namespacing",
+ "--gen-object-api",
+ src.path,
+ ],
+ progress_message = "Generating flatbuffer files for {}:".format(src),
+ use_default_shell_env = True,
+ )
+ return [
+ DefaultInfo(files = depset(outputs)),
+ ]
+
+_gen_flatbuffer_srcs = rule(
+ _gen_flatbuffer_srcs_impl,
+ attrs = {
+ "srcs": attr.label_list(
+ allow_files = [".fbs"],
+ mandatory = True,
+ ),
+ "outputs": attr.string_list(
+ default = [],
+ mandatory = False,
+ ),
+ "deps": attr.label_list(
+ default = [],
+ mandatory = False,
+ aspects = [_flatbuffer_schemas_aspect],
+ ),
+ "include_paths": attr.string_list(
+ default = [],
+ mandatory = False,
+ ),
+ "language_flag": attr.string(
+ mandatory = True,
+ ),
+ "no_includes": attr.bool(
+ default = False,
+ mandatory = False,
+ ),
+ "_flatc": attr.label(
+ default = Label("@flatbuffers//:flatc"),
+ executable = True,
+ cfg = "host",
+ ),
+ },
+ output_to_genfiles = True,
+)
+
+def flatbuffer_py_strip_prefix_srcs(name, srcs = [], strip_prefix = ""):
+ """Strips path prefix.
+
+ Args:
+ name: Rule name. (required)
+ srcs: Source .py files. (required)
+ strip_prefix: Path that needs to be stripped from the srcs filepaths. (required)
+ """
+ for src in srcs:
+ native.genrule(
+ name = name + "_" + src.replace(".", "_").replace("/", "_"),
+ srcs = [src],
+ outs = [src.replace(strip_prefix, "")],
+ cmd = "cp $< $@",
+ )
+
+def _concat_flatbuffer_py_srcs_impl(ctx):
+ # Merge all generated python files. The files are concatenated and import
+ # statements are removed. Finally we import the flatbuffer runtime library.
+ # IMPORTANT: Our Windows shell does not support "find ... -exec" properly.
+ # If you're changing the commandline below, please build wheels and run smoke
+ # tests on all the three operating systems.
+ command = "echo 'import flatbuffers\n' > %s; "
+ command += "for f in $(find %s -name '*.py' | sort); do cat $f | sed '/import flatbuffers/d' >> %s; done "
+ ctx.actions.run_shell(
+ inputs = ctx.attr.deps[0].files,
+ outputs = [ctx.outputs.out],
+ command = command % (
+ ctx.outputs.out.path,
+ ctx.attr.deps[0].files.to_list()[0].path,
+ ctx.outputs.out.path,
+ ),
+ )
+
+_concat_flatbuffer_py_srcs = rule(
+ _concat_flatbuffer_py_srcs_impl,
+ attrs = {
+ "deps": attr.label_list(mandatory = True),
+ },
+ output_to_genfiles = True,
+ outputs = {"out": "%{name}.py"},
+)
+
+def flatbuffer_py_library(
+ name,
+ srcs,
+ deps = [],
+ include_paths = []):
+ """A py_library with the generated reader/writers for the given schema.
+
+ This rule assumes that the schema files define non-conflicting names, so that
+ they can be merged in a single file. This is e.g. the case if only a single
+ namespace is used.
+ The rule call the flatbuffer compiler for all schema files and merges the
+ generated python files into a single file that is wrapped in a py_library.
+
+ Args:
+ name: Rule name. (required)
+ srcs: List of source .fbs files. (required)
+ deps: List of dependencies.
+ include_paths: Optional, list of paths the includes files can be found in.
+ """
+ all_srcs = "{}_srcs".format(name)
+ _gen_flatbuffer_srcs(
+ name = all_srcs,
+ srcs = srcs,
+ language_flag = "--python",
+ deps = deps,
+ include_paths = include_paths,
+ )
+ all_srcs_no_include = "{}_srcs_no_include".format(name)
+ _gen_flatbuffer_srcs(
+ name = all_srcs_no_include,
+ srcs = srcs,
+ language_flag = "--python",
+ deps = deps,
+ no_includes = True,
+ include_paths = include_paths,
+ )
+ concat_py_srcs = "{}_generated".format(name)
+ _concat_flatbuffer_py_srcs(
+ name = concat_py_srcs,
+ deps = [
+ ":{}".format(all_srcs_no_include),
+ ],
+ )
+ native.py_library(
+ name = name,
+ srcs = [
+ ":{}".format(concat_py_srcs),
+ ],
+ srcs_version = "PY3",
+ deps = deps + [
+ "@flatbuffers//:runtime_py",
+ ],
+ )
+
+def flatbuffer_java_library(
+ name,
+ srcs,
+ custom_package = "",
+ package_prefix = "",
+ include_paths = DEFAULT_INCLUDE_PATHS,
+ flatc_args = DEFAULT_FLATC_ARGS,
+ visibility = None):
+ """A java library with the generated reader/writers for the given flatbuffer definitions.
+
+ Args:
+ name: Rule name. (required)
+ srcs: List of source .fbs files including all includes. (required)
+ custom_package: Package name of generated Java files. If not specified
+ namespace in the schema files will be used. (optional)
+ package_prefix: like custom_package, but prefixes to the existing
+ namespace. (optional)
+ include_paths: List of paths that includes files can be found in. (optional)
+ flatc_args: List of additional arguments to pass to flatc. (optional)
+ visibility: Visibility setting for the java_library rule. (optional)
+ """
+ out_srcjar = "java_%s_all.srcjar" % name
+ flatbuffer_java_srcjar(
+ name = "%s_srcjar" % name,
+ srcs = srcs,
+ out = out_srcjar,
+ custom_package = custom_package,
+ flatc_args = flatc_args,
+ include_paths = include_paths,
+ package_prefix = package_prefix,
+ )
+
+ native.filegroup(
+ name = "%s.srcjar" % name,
+ srcs = [out_srcjar],
+ )
+
+ native.java_library(
+ name = name,
+ srcs = [out_srcjar],
+ javacopts = ["-source 7 -target 7"],
+ deps = [
+ "@flatbuffers//:runtime_java",
+ ],
+ visibility = visibility,
+ )
+
+def flatbuffer_java_srcjar(
+ name,
+ srcs,
+ out,
+ custom_package = "",
+ package_prefix = "",
+ include_paths = DEFAULT_INCLUDE_PATHS,
+ flatc_args = DEFAULT_FLATC_ARGS):
+ """Generate flatbuffer Java source files.
+
+ Args:
+ name: Rule name. (required)
+ srcs: List of source .fbs files including all includes. (required)
+ out: Output file name. (required)
+ custom_package: Package name of generated Java files. If not specified
+ namespace in the schema files will be used. (optional)
+ package_prefix: like custom_package, but prefixes to the existing
+ namespace. (optional)
+ include_paths: List of paths that includes files can be found in. (optional)
+ flatc_args: List of additional arguments to pass to flatc. (optional)
+ """
+ command_fmt = """set -e
+ tmpdir=$(@D)
+ schemas=$$tmpdir/schemas
+ java_root=$$tmpdir/java
+ rm -rf $$schemas
+ rm -rf $$java_root
+ mkdir -p $$schemas
+ mkdir -p $$java_root
+
+ for src in $(SRCS); do
+ dest=$$schemas/$$src
+ rm -rf $$(dirname $$dest)
+ mkdir -p $$(dirname $$dest)
+ if [ -z "{custom_package}" ] && [ -z "{package_prefix}" ]; then
+ cp -f $$src $$dest
+ else
+ if [ -z "{package_prefix}" ]; then
+ sed -e "s/namespace\\s.*/namespace {custom_package};/" $$src > $$dest
+ else
+ sed -e "s/namespace \\([^;]\\+\\);/namespace {package_prefix}.\\1;/" $$src > $$dest
+ fi
+ fi
+ done
+
+ flatc_arg_I="-I $$tmpdir/schemas"
+ for include_path in {include_paths}; do
+ flatc_arg_I="$$flatc_arg_I -I $$schemas/$$include_path"
+ done
+
+ flatc_additional_args=
+ for arg in {flatc_args}; do
+ flatc_additional_args="$$flatc_additional_args $$arg"
+ done
+
+ for src in $(SRCS); do
+ $(location {flatc_path}) $$flatc_arg_I --java $$flatc_additional_args -o $$java_root $$schemas/$$src
+ done
+
+ $(location {zip_files}) -export_zip_path=$@ -file_directory=$$java_root
+ """
+ genrule_cmd = command_fmt.format(
+ package_name = native.package_name(),
+ custom_package = custom_package,
+ package_prefix = package_prefix,
+ flatc_path = flatc_path,
+ zip_files = zip_files,
+ include_paths = " ".join(include_paths),
+ flatc_args = " ".join(flatc_args),
+ )
+
+ native.genrule(
+ name = name,
+ srcs = srcs,
+ outs = [out],
+ tools = [flatc_path, zip_files],
+ cmd = genrule_cmd,
+ )
+
+def flatbuffer_android_library(
+ name,
+ srcs,
+ custom_package = "",
+ package_prefix = "",
+ include_paths = DEFAULT_INCLUDE_PATHS,
+ flatc_args = DEFAULT_FLATC_ARGS,
+ visibility = None):
+ """An android_library with the generated reader/writers for the given flatbuffer definitions.
+
+ Args:
+ name: Rule name. (required)
+ srcs: List of source .fbs files including all includes. (required)
+ custom_package: Package name of generated Java files. If not specified
+ namespace in the schema files will be used. (optional)
+ package_prefix: like custom_package, but prefixes to the existing
+ namespace. (optional)
+ include_paths: List of paths that includes files can be found in. (optional)
+ flatc_args: List of additional arguments to pass to flatc. (optional)
+ visibility: Visibility setting for the android_library rule. (optional)
+ """
+ out_srcjar = "android_%s_all.srcjar" % name
+ flatbuffer_java_srcjar(
+ name = "%s_srcjar" % name,
+ srcs = srcs,
+ out = out_srcjar,
+ custom_package = custom_package,
+ flatc_args = flatc_args,
+ include_paths = include_paths,
+ package_prefix = package_prefix,
+ )
+
+ native.filegroup(
+ name = "%s.srcjar" % name,
+ srcs = [out_srcjar],
+ )
+
+ # To support org.checkerframework.dataflow.qual.Pure.
+ checkerframework_annotations = [
+ "@org_checkerframework_qual",
+ ] if "--java-checkerframework" in flatc_args else []
+
+ android_library(
+ name = name,
+ srcs = [out_srcjar],
+ javacopts = ["-source 7 -target 7"],
+ visibility = visibility,
+ deps = [
+ "@flatbuffers//:runtime_android",
+ ] + checkerframework_annotations,
+ )
diff --git a/third_party/flatbuffers/workspace.bzl b/third_party/flatbuffers/workspace.bzl
new file mode 100644
index 0000000..e3cc5b5
--- /dev/null
+++ b/third_party/flatbuffers/workspace.bzl
@@ -0,0 +1,19 @@
+"""Loads the Flatbuffers library, used by TF Lite."""
+
+load("//third_party:repo.bzl", "tf_http_archive")
+
+def repo():
+ tf_http_archive(
+ name = "flatbuffers",
+ strip_prefix = "flatbuffers-1.12.0",
+ sha256 = "62f2223fb9181d1d6338451375628975775f7522185266cd5296571ac152bc45",
+ urls = [
+ "https://storage.googleapis.com/mirror.tensorflow.org/github.com/google/flatbuffers/archive/v1.12.0.tar.gz",
+ "https://github.com/google/flatbuffers/archive/v1.12.0.tar.gz",
+ ],
+ build_file = "//third_party/flatbuffers:BUILD.bazel",
+ system_build_file = "//third_party/flatbuffers:BUILD.system",
+ link_files = {
+ "//third_party/flatbuffers:build_defs.bzl": "build_defs.bzl",
+ },
+ )
diff --git a/third_party/kissfft/BUILD b/third_party/kissfft/BUILD
new file mode 100644
index 0000000..82bab3f
--- /dev/null
+++ b/third_party/kissfft/BUILD
@@ -0,0 +1 @@
+# This empty BUILD file is required to make Bazel treat this directory as a package.
diff --git a/third_party/kissfft/BUILD.bazel b/third_party/kissfft/BUILD.bazel
new file mode 100644
index 0000000..60c30e7
--- /dev/null
+++ b/third_party/kissfft/BUILD.bazel
@@ -0,0 +1,23 @@
+package(
+ default_visibility = ["//visibility:public"],
+)
+
+licenses(["notice"]) # Apache 2.0
+
+exports_files(["COPYING"])
+
+cc_library(
+ name = "kiss_fftr_16",
+ srcs = [
+ "kiss_fft.c",
+ "tools/kiss_fftr.c",
+ ],
+ hdrs = [
+ "_kiss_fft_guts.h",
+ "kiss_fft.h",
+ "tools/kiss_fftr.h",
+ ],
+ copts = [
+ "-DFIXED_POINT=16",
+ ],
+)
diff --git a/third_party/kissfft/workspace.bzl b/third_party/kissfft/workspace.bzl
new file mode 100644
index 0000000..9d68d5a
--- /dev/null
+++ b/third_party/kissfft/workspace.bzl
@@ -0,0 +1,15 @@
+"""Loads the kissfft library, used by TF Lite."""
+
+load("//third_party:repo.bzl", "tf_http_archive")
+
+def repo():
+ tf_http_archive(
+ name = "kissfft",
+ strip_prefix = "kissfft-36dbc057604f00aacfc0288ddad57e3b21cfc1b8",
+ sha256 = "42b7ef406d5aa2d57a7b3b56fc44e8ad3011581692458a69958a911071efdcf2",
+ urls = [
+ "https://storage.googleapis.com/mirror.tensorflow.org/github.com/mborgerding/kissfft/archive/36dbc057604f00aacfc0288ddad57e3b21cfc1b8.tar.gz",
+ "https://github.com/mborgerding/kissfft/archive/36dbc057604f00aacfc0288ddad57e3b21cfc1b8.tar.gz",
+ ],
+ build_file = "//third_party/kissfft:BUILD.bazel",
+ )
diff --git a/third_party/repo.bzl b/third_party/repo.bzl
new file mode 100644
index 0000000..38a8805
--- /dev/null
+++ b/third_party/repo.bzl
@@ -0,0 +1,117 @@
+# Copyright 2017 The TensorFlow Authors. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Utilities for defining TensorFlow Bazel dependencies."""
+
+def _get_env_var(ctx, name):
+ if name in ctx.os.environ:
+ return ctx.os.environ[name]
+ else:
+ return None
+
+# Checks if we should use the system lib instead of the bundled one
+def _use_system_lib(ctx, name):
+ syslibenv = _get_env_var(ctx, "TF_SYSTEM_LIBS")
+ if not syslibenv:
+ return False
+ return name in [n.strip() for n in syslibenv.split(",")]
+
+def _get_link_dict(ctx, link_files, build_file):
+ if build_file:
+ # Use BUILD.bazel because it takes precedence over BUILD.
+ link_files = dict(link_files, **{build_file: "BUILD.bazel"})
+ return {ctx.path(v): Label(k) for k, v in link_files.items()}
+
+def _tf_http_archive_impl(ctx):
+ # Construct all labels early on to prevent rule restart. We want the
+ # attributes to be strings instead of labels because they refer to files
+ # in the TensorFlow repository, not files in repos depending on TensorFlow.
+ # See also https://github.com/bazelbuild/bazel/issues/10515.
+ link_dict = _get_link_dict(ctx, ctx.attr.link_files, ctx.attr.build_file)
+
+ if _use_system_lib(ctx, ctx.attr.name):
+ link_dict.update(_get_link_dict(
+ ctx = ctx,
+ link_files = ctx.attr.system_link_files,
+ build_file = ctx.attr.system_build_file,
+ ))
+ else:
+ patch_file = ctx.attr.patch_file
+ patch_file = Label(patch_file) if patch_file else None
+ ctx.download_and_extract(
+ url = ctx.attr.urls,
+ sha256 = ctx.attr.sha256,
+ type = ctx.attr.type,
+ stripPrefix = ctx.attr.strip_prefix,
+ )
+ if patch_file:
+ ctx.patch(patch_file, strip = 1)
+
+ for path, label in link_dict.items():
+ ctx.delete(path)
+ ctx.symlink(label, path)
+
+_tf_http_archive = repository_rule(
+ implementation = _tf_http_archive_impl,
+ attrs = {
+ "sha256": attr.string(mandatory = True),
+ "urls": attr.string_list(mandatory = True),
+ "strip_prefix": attr.string(),
+ "type": attr.string(),
+ "patch_file": attr.string(),
+ "build_file": attr.string(),
+ "system_build_file": attr.string(),
+ "link_files": attr.string_dict(),
+ "system_link_files": attr.string_dict(),
+ },
+ environ = ["TF_SYSTEM_LIBS"],
+)
+
+def tf_http_archive(name, sha256, urls, **kwargs):
+ """Downloads and creates Bazel repos for dependencies.
+
+ This is a swappable replacement for both http_archive() and
+ new_http_archive() that offers some additional features. It also helps
+ ensure best practices are followed.
+
+ File arguments are relative to the TensorFlow repository by default. Dependent
+ repositories that use this rule should refer to files either with absolute
+ labels (e.g. '@foo//:bar') or from a label created in their repository (e.g.
+ 'str(Label("//:bar"))').
+ """
+ if len(urls) < 2:
+ fail("tf_http_archive(urls) must have redundant URLs.")
+
+ if not any([mirror in urls[0] for mirror in (
+ "mirror.tensorflow.org",
+ "mirror.bazel.build",
+ "storage.googleapis.com",
+ )]):
+ fail("The first entry of tf_http_archive(urls) must be a mirror " +
+ "URL, preferrably mirror.tensorflow.org. Even if you don't have " +
+ "permission to mirror the file, please put the correctly " +
+ "formatted mirror URL there anyway, because someone will come " +
+ "along shortly thereafter and mirror the file.")
+
+ if native.existing_rule(name):
+ print("\n\033[1;33mWarning:\033[0m skipping import of repository '" +
+ name + "' because it already exists.\n")
+ return
+
+ _tf_http_archive(
+ name = name,
+ sha256 = sha256,
+ urls = urls,
+ **kwargs
+ )
diff --git a/third_party/ruy/BUILD b/third_party/ruy/BUILD
new file mode 100644
index 0000000..4c36181
--- /dev/null
+++ b/third_party/ruy/BUILD
@@ -0,0 +1,8 @@
+# Ruy is not BLAS
+
+package(
+ default_visibility = ["//visibility:public"],
+ licenses = ["notice"],
+)
+
+exports_files(["LICENSE"])
diff --git a/third_party/ruy/workspace.bzl b/third_party/ruy/workspace.bzl
new file mode 100644
index 0000000..5076962
--- /dev/null
+++ b/third_party/ruy/workspace.bzl
@@ -0,0 +1,15 @@
+"""Loads the ruy library, used by TensorFlow Lite."""
+
+load("//third_party:repo.bzl", "tf_http_archive")
+
+def repo():
+ tf_http_archive(
+ name = "ruy",
+ sha256 = "da5ec0cc07472bdb21589b0b51c8f3d7f75d2ed6230b794912adf213838d289a",
+ strip_prefix = "ruy-54774a7a2cf85963777289193629d4bd42de4a59",
+ urls = [
+ "https://storage.googleapis.com/mirror.tensorflow.org/github.com/google/ruy/archive/54774a7a2cf85963777289193629d4bd42de4a59.zip",
+ "https://github.com/google/ruy/archive/54774a7a2cf85963777289193629d4bd42de4a59.zip",
+ ],
+ build_file = "//third_party/ruy:BUILD",
+ )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}