Recursive Topk Split Reduction (#9807)
Implements multi-level Topk Split Reduction. Split reduction is now controlled by a list of reduction ratios, denoting to how much to split each successive application of the reduction parallelization.
This enables better optimization of larger Topk reductions: a higher reduction ratio leads to larger final final linear reductions which can easily eclipse the perf gained from splitting the first Topk
EX:
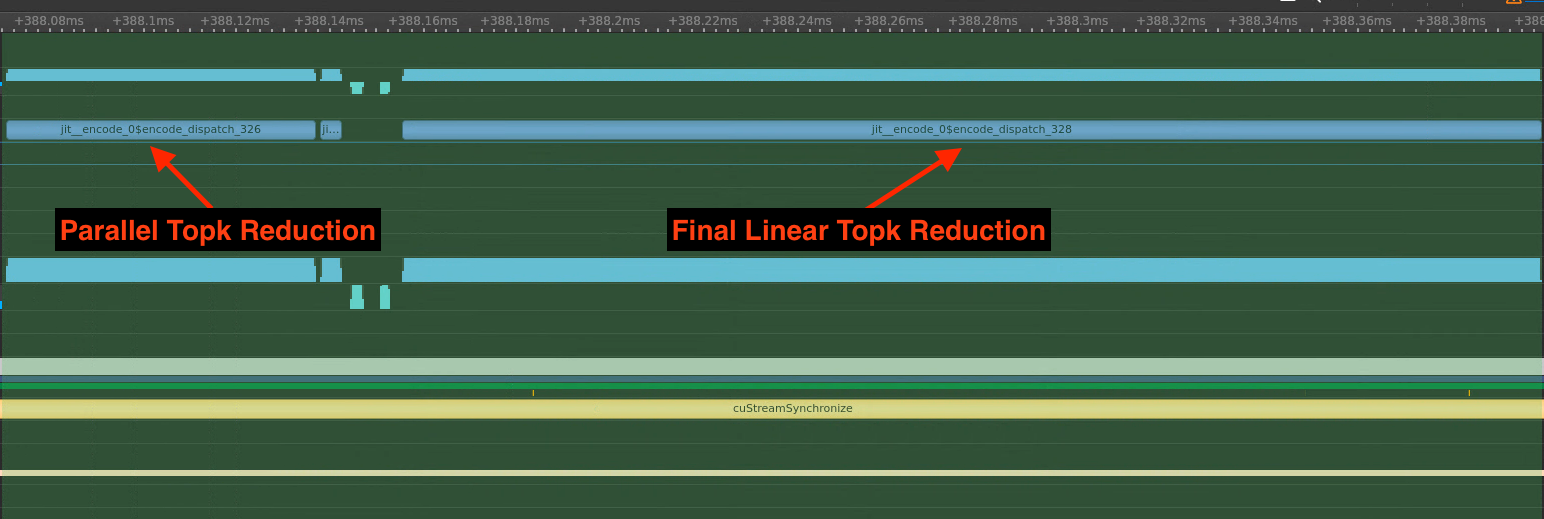
Related to #9383
diff --git a/compiler/src/iree/compiler/Dialect/Flow/Transforms/SplitReduction.cpp b/compiler/src/iree/compiler/Dialect/Flow/Transforms/SplitReduction.cpp
index d6f1768..7555028 100644
--- a/compiler/src/iree/compiler/Dialect/Flow/Transforms/SplitReduction.cpp
+++ b/compiler/src/iree/compiler/Dialect/Flow/Transforms/SplitReduction.cpp
@@ -28,9 +28,10 @@
"iree-flow-split-matmul-reduction", llvm::cl::desc("split ratio"),
llvm::cl::init(1));
-static llvm::cl::opt<int64_t> topkSplitReductionRatio(
- "iree-flow-topk-split-reduction", llvm::cl::desc("split ratio"),
- llvm::cl::init(1));
+static llvm::cl::list<int64_t> topkSplitReductionRatio(
+ "iree-flow-topk-split-reduction",
+ llvm::cl::desc("comma separated list of split ratios"),
+ llvm::cl::CommaSeparated);
namespace {
/// Pattern to wrap splitReduction transformation. This also propagates
@@ -81,7 +82,7 @@
void runOnOperation() override {
if (splitReductionRatio.getValue() <= 1 &&
- topkSplitReductionRatio.getValue() <= 1) {
+ topkSplitReductionRatio.empty()) {
return;
}
@@ -101,9 +102,15 @@
ArrayRef<StringAttr>{}, StringAttr::get(&getContext(), "SPLIT")));
LinalgExt::TopkSplitReductionControlFn splitReductionFn =
- [&](mlir::iree_compiler::IREE::LinalgExt::TopkOp topkOp) {
- return topkSplitReductionRatio.getValue();
- };
+ [&](int64_t splitReductionDepth) -> int64_t {
+ SmallVector<int64_t, 4> reductionRatios(topkSplitReductionRatio.begin(),
+ topkSplitReductionRatio.end());
+ if (splitReductionDepth >= reductionRatios.size()) {
+ return -1;
+ } else {
+ return reductionRatios[splitReductionDepth];
+ }
+ };
LinalgExt::populateTopkSplitReductionPattern(
patterns, splitReductionFn,
mlir::linalg::LinalgTransformationFilter(
@@ -122,6 +129,8 @@
});
funcOp->walk([&](LinalgExt::LinalgExtOp op) {
op->removeAttr(linalg::LinalgTransforms::kLinalgTransformMarker);
+ op->removeAttr(
+ mlir::iree_compiler::IREE::LinalgExt::kSplitReductionDepthMarker);
});
}
};
diff --git a/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.h b/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.h
index a456c1e..f8f76b6 100644
--- a/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.h
+++ b/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.h
@@ -26,8 +26,10 @@
/// Function signature to control reduction splitting. This returns the split
/// reduction ratio used to split the reduction dimension. The ratio is applied
/// to the reduction dimension of TopK. If the ratio value is less or equal to 1
-/// then nothing will be done.
-using TopkSplitReductionControlFn = std::function<int64_t(TopkOp topkOp)>;
+/// then nothing will be done. Input is the current depth of recursive split
+/// reduction, starting from 0 (first level).
+using TopkSplitReductionControlFn =
+ std::function<int64_t(int64_t splitReductionDepth)>;
/// Patterns to apply `topk split reduction` pass.
void populateTopkSplitReductionPattern(
@@ -38,6 +40,9 @@
std::unique_ptr<OperationPass<func::FuncOp>> createTopkSplitReductionPass();
+// Marker used as attribute the depth of the split reduction transformations.
+const StringLiteral kSplitReductionDepthMarker = "__split_reduction_depth__";
+
void registerPasses();
} // namespace LinalgExt
diff --git a/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.td b/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.td
index af2ff3b..8e2721f 100644
--- a/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.td
+++ b/llvm-external-projects/iree-dialects/include/iree-dialects/Dialect/LinalgExt/Passes/Passes.td
@@ -54,8 +54,8 @@
}];
let constructor = "mlir::iree_compiler::IREE::LinalgExt::createTopkSplitReductionPass()";
let options = [
- Option<"splitRatio", "split-ratio", "int", /*default=*/"1",
- "Split reduction ratio">,
+ ListOption<"splitRatios", "split-ratios", "int",
+ "List of split reduction ratios">,
];
}
diff --git a/llvm-external-projects/iree-dialects/lib/Dialect/LinalgExt/Passes/SplitReduction.cpp b/llvm-external-projects/iree-dialects/lib/Dialect/LinalgExt/Passes/SplitReduction.cpp
index 5cdd93d..37b2bb7 100644
--- a/llvm-external-projects/iree-dialects/lib/Dialect/LinalgExt/Passes/SplitReduction.cpp
+++ b/llvm-external-projects/iree-dialects/lib/Dialect/LinalgExt/Passes/SplitReduction.cpp
@@ -68,7 +68,8 @@
LogicalResult shouldParallelTopk(iree_compiler::IREE::LinalgExt::TopkOp topkOp,
PatternRewriter &rewriter, int64_t kDimOrig,
- int64_t splitReductionRatio) {
+ int64_t splitReductionRatio,
+ int64_t splitReductionDepth) {
// Determine if we should split the reduction. Requires aligned static shapes
// and no input indicies.
auto valuesOrigType = topkOp.getInputType();
@@ -76,9 +77,9 @@
return rewriter.notifyMatchFailure(topkOp,
"cannot split dynamic dimension");
}
- if (topkOp.indices()) {
- return rewriter.notifyMatchFailure(topkOp,
- "input indices aren't supported");
+ if (topkOp.indices() && splitReductionDepth == 0) {
+ return rewriter.notifyMatchFailure(
+ topkOp, "input indices aren't supported for first split");
}
if (splitReductionRatio <= 1) {
return rewriter.notifyMatchFailure(topkOp, "reduction ratio <= 1");
@@ -115,6 +116,17 @@
Value valuesExpanded = rewriter.create<tensor::ExpandShapeOp>(
loc, valuesExpandedType, valuesOrig, reassociationIndices);
+ // Expand input indices shape for parallel processing if they exist
+ Optional<Value> indicesExpanded;
+ if (Optional<Value> inputIndices = topkOp.indices()) {
+ // Type inputElementType = inputIndices->getType().cast<ShapedType>();
+ Type indicesExpandedType =
+ RankedTensorType::get(expandedShape, indicesElementType);
+ indicesExpanded = rewriter.create<tensor::ExpandShapeOp>(
+ loc, indicesExpandedType, inputIndices.getValue(),
+ reassociationIndices);
+ }
+
// Define the expanded output types
SmallVector<int64_t> expandedResultShape = expandedShape;
expandedResultShape[kDimParallel] = kSize;
@@ -162,6 +174,9 @@
SmallVector<Type> parallelTopkResultTypes = {outputValuesExpandedType,
outputIndicesExpandedType};
SmallVector<Value> parallelTopkIns = {valuesExpanded};
+ if (indicesExpanded) {
+ parallelTopkIns.push_back(indicesExpanded.getValue());
+ }
SmallVector<Value> parallelTopkOuts = {negInfTensor, posInfTensor};
// Parallel topk
@@ -253,6 +268,22 @@
return reductionTopkOp;
}
+int64_t getSplitReductionDepth(TopkOp topkOp) {
+ auto attr =
+ topkOp->template getAttrOfType<IntegerAttr>(kSplitReductionDepthMarker);
+ if (attr) {
+ return attr.getInt();
+ } else {
+ return 0;
+ }
+}
+
+void setSplitReductionDepth(TopkOp topkOp, PatternRewriter &rewriter,
+ int64_t depth) {
+ topkOp->setAttr(kSplitReductionDepthMarker,
+ rewriter.getI64IntegerAttr(depth));
+}
+
struct TopkOpSplitReduction : public OpRewritePattern<TopkOp> {
using OpRewritePattern::OpRewritePattern;
@@ -286,13 +317,14 @@
int64_t kDimParallel = kDimOrig + 1;
int64_t kSize =
topkOp.getResult(0).getType().cast<ShapedType>().getDimSize(kDimOrig);
- int64_t splitReductionRatio = splitReductionFn(topkOp);
+ int64_t splitReductionDepth = getSplitReductionDepth(topkOp);
+ int64_t splitReductionRatio = splitReductionFn(splitReductionDepth);
SmallVector<ReassociationIndices> reassociationIndices =
getReassociationIndices(topkOp.getInputRank(), splitDimParallel);
// Determine if should compute parallel topk
- LogicalResult shouldParallelTopkResult =
- shouldParallelTopk(topkOp, rewriter, kDimOrig, splitReductionRatio);
+ LogicalResult shouldParallelTopkResult = shouldParallelTopk(
+ topkOp, rewriter, kDimOrig, splitReductionRatio, splitReductionDepth);
if (shouldParallelTopkResult.failed()) {
return shouldParallelTopkResult;
}
@@ -302,14 +334,19 @@
loc, rewriter, topkOp, reassociationIndices, splitReductionRatio,
splitDimParallel, kDimParallel, kSize);
- // Update parallel indices to correct offsets
- Value parallelIndices = parallelTopkOp.getResult(1);
- SmallVector<int64_t> expandedShape = getExpandedShape(
- topkOp.values().getType().cast<ShapedType>().getShape(),
- splitReductionRatio, splitDimParallel);
- int64_t kDimParallelSize = expandedShape[kDimParallel];
- Value updatedParallelIndices = offsetParallelIndices(
- loc, rewriter, parallelIndices, kDimParallelSize, splitDimParallel);
+ // Update parallel indices to correct offsets if input indices weren't
+ // provided. If input indices were provided, no offsetting is needed as
+ // original original indices are already known.
+ Value updatedParallelIndices = parallelTopkOp.getResult(1);
+ if (!topkOp.indices()) {
+ Value parallelIndices = parallelTopkOp.getResult(1);
+ SmallVector<int64_t> expandedShape = getExpandedShape(
+ topkOp.values().getType().cast<ShapedType>().getShape(),
+ splitReductionRatio, splitDimParallel);
+ int64_t kDimParallelSize = expandedShape[kDimParallel];
+ updatedParallelIndices = offsetParallelIndices(
+ loc, rewriter, parallelIndices, kDimParallelSize, splitDimParallel);
+ }
// Topk final reduction
TopkOp reductionTopkOp = computeReductionTopk(
@@ -319,7 +356,7 @@
// Replace and update result
rewriter.replaceOp(topkOp, reductionTopkOp.getResults());
filter.replaceLinalgTransformationFilter(rewriter, parallelTopkOp);
- filter.replaceLinalgTransformationFilter(rewriter, reductionTopkOp);
+ setSplitReductionDepth(reductionTopkOp, rewriter, splitReductionDepth + 1);
return success();
}
@@ -344,15 +381,21 @@
}
void runOnOperation() override {
- if (splitRatio.getValue() <= 1) {
+ if (splitRatios.empty()) {
return;
}
-
RewritePatternSet patterns(&getContext());
TopkSplitReductionControlFn splitReductionFn =
- [&](mlir::iree_compiler::IREE::LinalgExt::TopkOp topkOp) {
- return splitRatio.getValue();
- };
+ [&](int64_t splitReductionDepth) -> int64_t {
+ SmallVector<int64_t, 4> reductionRatios(splitRatios.begin(),
+ splitRatios.end());
+ if (splitReductionDepth >= reductionRatios.size()) {
+ return -1;
+ } else {
+ return reductionRatios[splitReductionDepth];
+ }
+ };
+
patterns.add<TopkOpSplitReduction>(
patterns.getContext(), splitReductionFn,
mlir::linalg::LinalgTransformationFilter(
@@ -362,6 +405,13 @@
std::move(patterns)))) {
return signalPassFailure();
}
+
+ // Remove all the markers at the end.
+ auto funcOp = getOperation();
+ funcOp->walk([&](TopkOp op) {
+ op->removeAttr(linalg::LinalgTransforms::kLinalgTransformMarker);
+ op->removeAttr(kSplitReductionDepthMarker);
+ });
}
};
} // namespace
diff --git a/llvm-external-projects/iree-dialects/test/Dialect/iree_linalg_ext/split-reduction.mlir b/llvm-external-projects/iree-dialects/test/Dialect/iree_linalg_ext/split-reduction.mlir
index 493c3ec..2411342 100644
--- a/llvm-external-projects/iree-dialects/test/Dialect/iree_linalg_ext/split-reduction.mlir
+++ b/llvm-external-projects/iree-dialects/test/Dialect/iree_linalg_ext/split-reduction.mlir
@@ -1,5 +1,6 @@
-// RUN: iree-dialects-opt --iree-linalg-ext-topk-split-reduction='split-ratio=3' %s | FileCheck %s --check-prefix SINGLE
-// RUN: iree-dialects-opt --iree-linalg-ext-topk-split-reduction='split-ratio=4' %s | FileCheck %s --check-prefix MULTIPLE
+// RUN: iree-dialects-opt --iree-linalg-ext-topk-split-reduction='split-ratios=3' %s | FileCheck %s --check-prefix SINGLE
+// RUN: iree-dialects-opt --iree-linalg-ext-topk-split-reduction='split-ratios=4' %s | FileCheck %s --check-prefix MULTIPLE
+// RUN: iree-dialects-opt --iree-linalg-ext-topk-split-reduction='split-ratios=40,10' %s | FileCheck %s --check-prefix DOUBLE
func.func @topk_split_reduction_1d(%input_values: tensor<30xf32>, %out_values: tensor<3xf32>, %out_indices: tensor<3xi32>) -> (tensor<3xf32>, tensor<3xi32>) {
%0:2 = iree_linalg_ext.topk
@@ -26,7 +27,7 @@
// SINGLE: %[[D2:.*]] = linalg.init_tensor [3, 3] : tensor<3x3xi32>
// SINGLE: %[[D3:.*]] = linalg.fill ins(%[[CNEG]] : f32) outs(%[[D1]] : tensor<3x3xf32>) -> tensor<3x3xf32>
// SINGLE: %[[D4:.*]] = linalg.fill ins(%[[CPOS]] : i32) outs(%[[D2]] : tensor<3x3xi32>) -> tensor<3x3xi32>
-// SINGLE: %[[D5:.*]]:2 = iree_linalg_ext.topk {__internal_linalg_transform__ = "SPLIT_REDUCTION"} dimension(1) ins(%[[D0]] : tensor<3x10xf32>) outs(%[[D3]], %[[D4]] : tensor<3x3xf32>, tensor<3x3xi32>) {
+// SINGLE: %[[D5:.*]]:2 = iree_linalg_ext.topk dimension(1) ins(%[[D0]] : tensor<3x10xf32>) outs(%[[D3]], %[[D4]] : tensor<3x3xf32>, tensor<3x3xi32>) {
// SINGLE: ^bb0(%[[ARG3:.*]]: f32, %[[ARG4:.*]]: f32):
// SINGLE: %[[D10:.*]] = arith.cmpf ogt, %[[ARG3]], %[[ARG4]] : f32
// SINGLE: iree_linalg_ext.yield %[[D10]] : i1
@@ -41,7 +42,7 @@
// SINGLE: } -> tensor<3x3xi32>
// SINGLE: %[[D7:.*]] = tensor.collapse_shape %[[D5:.*]]#0 {{\[\[}}0, 1]] : tensor<3x3xf32> into tensor<9xf32>
// SINGLE: %[[D8:.*]] = tensor.collapse_shape %[[D6:.*]] {{\[\[}}0, 1]] : tensor<3x3xi32> into tensor<9xi32>
-// SINGLE: %[[D9:.*]]:2 = iree_linalg_ext.topk {__internal_linalg_transform__ = "SPLIT_REDUCTION"} dimension(0) ins(%[[D7]], %[[D8]] : tensor<9xf32>, tensor<9xi32>) outs(%[[ARG1]], %[[ARG2]] : tensor<3xf32>, tensor<3xi32>) {
+// SINGLE: %[[D9:.*]]:2 = iree_linalg_ext.topk dimension(0) ins(%[[D7]], %[[D8]] : tensor<9xf32>, tensor<9xi32>) outs(%[[ARG1]], %[[ARG2]] : tensor<3xf32>, tensor<3xi32>) {
// SINGLE: ^bb0(%[[ARG3:.*]]: f32, %[[ARG4:.*]]: f32):
// SINGLE: %[[D10:.*]] = arith.cmpf ogt, %[[ARG3]], %[[ARG4]] : f32
// SINGLE: iree_linalg_ext.yield %[[D10]] : i1
@@ -76,7 +77,7 @@
// MULTIPLE: %[[D2:.*]] = linalg.init_tensor [3, 10, 4, 4, 8] : tensor<3x10x4x4x8xi32>
// MULTIPLE: %[[D3:.*]] = linalg.fill ins(%[[CNEG]] : f32) outs(%[[D1]] : tensor<3x10x4x4x8xf32>) -> tensor<3x10x4x4x8xf32>
// MULTIPLE: %[[D4:.*]] = linalg.fill ins(%[[CPOS]] : i32) outs(%[[D2]] : tensor<3x10x4x4x8xi32>) -> tensor<3x10x4x4x8xi32>
-// MULTIPLE: %[[D5:.*]]:2 = iree_linalg_ext.topk {__internal_linalg_transform__ = "SPLIT_REDUCTION"} dimension(3) ins(%[[D0]] : tensor<3x10x4x10x8xf32>) outs(%[[D3]], %[[D4]] : tensor<3x10x4x4x8xf32>, tensor<3x10x4x4x8xi32>) {
+// MULTIPLE: %[[D5:.*]]:2 = iree_linalg_ext.topk dimension(3) ins(%[[D0]] : tensor<3x10x4x10x8xf32>) outs(%[[D3]], %[[D4]] : tensor<3x10x4x4x8xf32>, tensor<3x10x4x4x8xi32>) {
// MULTIPLE: ^bb0(%[[ARG3:.*]]: f32, %[[ARG4:.*]]: f32):
// MULTIPLE: %[[D10:.*]] = arith.cmpf ogt, %[[ARG3]], %[[ARG4]] : f32
// MULTIPLE: iree_linalg_ext.yield %[[D10]] : i1
@@ -91,10 +92,73 @@
// MULTIPLE: } -> tensor<3x10x4x4x8xi32>
// MULTIPLE: %[[D7:.*]] = tensor.collapse_shape %[[D5:.*]]#0 {{\[\[}}0], [1], [2, 3], [4]] : tensor<3x10x4x4x8xf32> into tensor<3x10x16x8xf32>
// MULTIPLE: %[[D8:.*]] = tensor.collapse_shape %[[D6:.*]] {{\[\[}}0], [1], [2, 3], [4]] : tensor<3x10x4x4x8xi32> into tensor<3x10x16x8xi32>
-// MULTIPLE: %[[D9:.*]]:2 = iree_linalg_ext.topk {__internal_linalg_transform__ = "SPLIT_REDUCTION"} dimension(2) ins(%[[D7]], %[[D8]] : tensor<3x10x16x8xf32>, tensor<3x10x16x8xi32>) outs(%[[ARG1]], %[[ARG2]] : tensor<3x10x4x8xf32>, tensor<3x10x4x8xi32>) {
+// MULTIPLE: %[[D9:.*]]:2 = iree_linalg_ext.topk dimension(2) ins(%[[D7]], %[[D8]] : tensor<3x10x16x8xf32>, tensor<3x10x16x8xi32>) outs(%[[ARG1]], %[[ARG2]] : tensor<3x10x4x8xf32>, tensor<3x10x4x8xi32>) {
// MULTIPLE: ^bb0(%[[ARG3:.*]]: f32, %[[ARG4:.*]]: f32):
// MULTIPLE: %[[D10:.*]] = arith.cmpf ogt, %[[ARG3]], %[[ARG4]] : f32
// MULTIPLE: iree_linalg_ext.yield %[[D10]] : i1
// MULTIPLE: } -> tensor<3x10x4x8xf32>, tensor<3x10x4x8xi32>
// MULTIPLE: return %[[D9:.*]]#0, %[[D9]]#1 : tensor<3x10x4x8xf32>, tensor<3x10x4x8xi32>
// MULTIPLE: }
+
+// -----
+
+func.func @topk_split_reduction_double(%input_values: tensor<400xf32>, %out_values: tensor<3xf32>, %out_indices: tensor<3xi32>) -> (tensor<3xf32>, tensor<3xi32>) {
+ %0:2 = iree_linalg_ext.topk
+ dimension(0)
+ ins(%input_values: tensor<400xf32>)
+ outs(%out_values, %out_indices : tensor<3xf32>, tensor<3xi32>) {
+ ^bb0(%arg0: f32, %arg1: f32): // no predecessors
+ %0 = arith.cmpf ogt, %arg0, %arg1 : f32
+ iree_linalg_ext.yield %0 : i1
+ } -> tensor<3xf32>, tensor<3xi32>
+ return %0#0, %0#1 : tensor<3xf32>, tensor<3xi32>
+}
+
+// DOUBLE-DAG: #[[MAP0:.+]] = affine_map<(d0, d1) -> (d0, d1)>
+// DOUBLE-LABEL: func.func @topk_split_reduction_double(
+// DOUBLE-SAME: %[[ARG0:.*]]: tensor<400xf32>,
+// DOUBLE-SAME: %[[ARG1:.*]]: tensor<3xf32>,
+// DOUBLE-SAME: %[[ARG2:.*]]: tensor<3xi32>) -> (tensor<3xf32>, tensor<3xi32>) {
+// DOUBLE-DAG: %[[CNEG:.*]] = arith.constant 0xFF800000 : f32
+// DOUBLE-DAG: %[[CPOS:.*]] = arith.constant 2147483647 : i32
+// DOUBLE-DAG: %[[C10:.*]] = arith.constant 10 : i32
+// DOUBLE: %[[D0:.*]] = tensor.expand_shape %[[ARG0]] {{\[\[}}0, 1]] : tensor<400xf32> into tensor<40x10xf32>
+// DOUBLE: %[[D1:.*]] = linalg.init_tensor [40, 3] : tensor<40x3xf32>
+// DOUBLE: %[[D2:.*]] = linalg.init_tensor [40, 3] : tensor<40x3xi32>
+// DOUBLE: %[[D3:.*]] = linalg.fill ins(%[[CNEG]] : f32) outs(%[[D1]] : tensor<40x3xf32>) -> tensor<40x3xf32>
+// DOUBLE: %[[D4:.*]] = linalg.fill ins(%[[CPOS]] : i32) outs(%[[D2]] : tensor<40x3xi32>) -> tensor<40x3xi32>
+// DOUBLE: %[[D5:.*]]:2 = iree_linalg_ext.topk dimension(1) ins(%[[D0]] : tensor<40x10xf32>) outs(%[[D3]], %[[D4]] : tensor<40x3xf32>, tensor<40x3xi32>) {
+// DOUBLE: ^bb0(%[[ARG3:.*]]: f32, %[[ARG4:.*]]: f32):
+// DOUBLE: %[[D19:.*]] = arith.cmpf ogt, %[[ARG3]], %[[ARG4]] : f32
+// DOUBLE: iree_linalg_ext.yield %[[D19]] : i1
+// DOUBLE: } -> tensor<40x3xf32>, tensor<40x3xi32>
+// DOUBLE: %[[D6:.*]] = linalg.generic {indexing_maps = [#[[MAP0]]], iterator_types = ["parallel", "parallel"]} outs(%[[D5:.*]]#1 : tensor<40x3xi32>) {
+// DOUBLE: ^bb0(%[[ARG3:.*]]: i32):
+// DOUBLE: %[[D19:.*]] = linalg.index 0 : index
+// DOUBLE: %[[D20:.*]] = arith.index_cast %[[D19]] : index to i32
+// DOUBLE: %[[D21:.*]] = arith.muli %[[D20]], %[[C10]] : i32
+// DOUBLE: %[[D22:.*]] = arith.addi %[[D21]], %[[ARG3]] : i32
+// DOUBLE: linalg.yield %[[D22]] : i32
+// DOUBLE: } -> tensor<40x3xi32>
+// DOUBLE: %[[D7:.*]] = tensor.collapse_shape %[[D5:.*]]#0 {{\[\[}}0, 1]] : tensor<40x3xf32> into tensor<120xf32>
+// DOUBLE: %[[D8:.*]] = tensor.collapse_shape %[[D6:.*]] {{\[\[}}0, 1]] : tensor<40x3xi32> into tensor<120xi32>
+// DOUBLE: %[[D9:.*]] = tensor.expand_shape %[[D7]] {{\[\[}}0, 1]] : tensor<120xf32> into tensor<10x12xf32>
+// DOUBLE: %[[D10:.*]] = tensor.expand_shape %[[D8]] {{\[\[}}0, 1]] : tensor<120xi32> into tensor<10x12xi32>
+// DOUBLE: %[[D11:.*]] = linalg.init_tensor [10, 3] : tensor<10x3xf32>
+// DOUBLE: %[[D12:.*]] = linalg.init_tensor [10, 3] : tensor<10x3xi32>
+// DOUBLE: %[[D13:.*]] = linalg.fill ins(%[[CNEG]] : f32) outs(%[[D11]] : tensor<10x3xf32>) -> tensor<10x3xf32>
+// DOUBLE: %[[D14:.*]] = linalg.fill ins(%[[CPOS]] : i32) outs(%[[D12]] : tensor<10x3xi32>) -> tensor<10x3xi32>
+// DOUBLE: %[[D15:.*]]:2 = iree_linalg_ext.topk dimension(1) ins(%[[D9]], %[[D10]] : tensor<10x12xf32>, tensor<10x12xi32>) outs(%[[D13]], %[[D14]] : tensor<10x3xf32>, tensor<10x3xi32>) {
+// DOUBLE: ^bb0(%[[ARG3:.*]]: f32, %[[ARG4:.*]]: f32):
+// DOUBLE: %[[D19:.*]] = arith.cmpf ogt, %[[ARG3]], %[[ARG4]] : f32
+// DOUBLE: iree_linalg_ext.yield %[[D19]] : i1
+// DOUBLE: } -> tensor<10x3xf32>, tensor<10x3xi32>
+// DOUBLE: %[[D16:.*]] = tensor.collapse_shape %[[D15:.*]]#0 {{\[\[}}0, 1]] : tensor<10x3xf32> into tensor<30xf32>
+// DOUBLE: %[[D17:.*]] = tensor.collapse_shape %[[D15:.*]]#1 {{\[\[}}0, 1]] : tensor<10x3xi32> into tensor<30xi32>
+// DOUBLE: %[[D18:.*]]:2 = iree_linalg_ext.topk dimension(0) ins(%[[D16]], %[[D17]] : tensor<30xf32>, tensor<30xi32>) outs(%[[ARG1]], %[[ARG2]] : tensor<3xf32>, tensor<3xi32>) {
+// DOUBLE: ^bb0(%[[ARG3:.*]]: f32, %[[ARG4:.*]]: f32):
+// DOUBLE: %[[D10:.*]] = arith.cmpf ogt, %[[ARG3]], %[[ARG4]] : f32
+// DOUBLE: iree_linalg_ext.yield %[[D10]] : i1
+// DOUBLE: } -> tensor<3xf32>, tensor<3xi32>
+// DOUBLE: return %[[D18:.*]]#0, %[[D18]]#1 : tensor<3xf32>, tensor<3xi32>
+// DOUBLE: }
diff --git a/tests/e2e/linalg_ext_ops/BUILD b/tests/e2e/linalg_ext_ops/BUILD
index 5b4de0b..ce036c9 100644
--- a/tests/e2e/linalg_ext_ops/BUILD
+++ b/tests/e2e/linalg_ext_ops/BUILD
@@ -39,17 +39,9 @@
iree_check_single_backend_test_suite(
name = "check_cuda-topk-split-reduction",
- srcs = enforce_glob(
- [
- "top-k.mlir",
- ],
- include = ["*.mlir"],
- exclude = [
- "reverse.mlir",
- "scan.mlir",
- "sort.mlir",
- ],
- ),
+ srcs = [
+ "top-k.mlir",
+ ],
compiler_flags = ["--iree-flow-topk-split-reduction=2"],
driver = "cuda",
tags = [
@@ -64,6 +56,24 @@
)
iree_check_single_backend_test_suite(
+ name = "check_cuda-topk-split-reduction-double",
+ srcs = [
+ "top-k.mlir",
+ ],
+ compiler_flags = ["--iree-flow-topk-split-reduction=3,2"],
+ driver = "cuda",
+ tags = [
+ # CUDA cuInit fails with sanitizer on.
+ "noasan",
+ "nomsan",
+ "notsan",
+ "noubsan",
+ "requires-gpu-nvidia",
+ ],
+ target_backend = "cuda",
+)
+
+iree_check_single_backend_test_suite(
name = "check_dylib-llvm-aot_dylib",
srcs = enforce_glob(
# keep sorted
diff --git a/tests/e2e/linalg_ext_ops/CMakeLists.txt b/tests/e2e/linalg_ext_ops/CMakeLists.txt
index 4706bbf..4c6577d 100644
--- a/tests/e2e/linalg_ext_ops/CMakeLists.txt
+++ b/tests/e2e/linalg_ext_ops/CMakeLists.txt
@@ -51,6 +51,25 @@
iree_check_single_backend_test_suite(
NAME
+ check_cuda-topk-split-reduction-double
+ SRCS
+ "top-k.mlir"
+ TARGET_BACKEND
+ "cuda"
+ DRIVER
+ "cuda"
+ COMPILER_FLAGS
+ "--iree-flow-topk-split-reduction=3,2"
+ LABELS
+ "noasan"
+ "nomsan"
+ "notsan"
+ "noubsan"
+ "requires-gpu-nvidia"
+)
+
+iree_check_single_backend_test_suite(
+ NAME
check_dylib-llvm-aot_dylib
SRCS
"reverse.mlir"
diff --git a/tests/e2e/linalg_ext_ops/top-k.mlir b/tests/e2e/linalg_ext_ops/top-k.mlir
index a99e2f9..0987719 100644
--- a/tests/e2e/linalg_ext_ops/top-k.mlir
+++ b/tests/e2e/linalg_ext_ops/top-k.mlir
@@ -189,3 +189,35 @@
return
}
+
+func.func @topk_1d_dim0_max_double() {
+ %input_values = util.unfoldable_constant dense<[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, 17.0, 18.0]> : tensor<18xf32>
+ %input_indices = util.unfoldable_constant dense<[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]> : tensor<18xi32>
+
+ %out_values_empty = linalg.init_tensor [3] : tensor<3xf32>
+ %out_indices_empty = linalg.init_tensor [3] : tensor<3xi32>
+ %neg_inf = arith.constant 0xFF800000 : f32
+ %c0 = arith.constant 0 : i32
+ %out_values = linalg.fill ins(%neg_inf : f32) outs(%out_values_empty : tensor<3xf32>) -> tensor<3xf32>
+ %out_indices = linalg.fill ins(%c0 : i32) outs(%out_indices_empty : tensor<3xi32>) -> tensor<3xi32>
+ %0:2 = iree_linalg_ext.topk
+ dimension(0)
+ ins(%input_values, %input_indices : tensor<18xf32> , tensor<18xi32>)
+ outs(%out_values, %out_indices : tensor<3xf32>, tensor<3xi32>) {
+ ^bb0(%arg0 : f32, %arg1 : f32):
+ %0 = arith.cmpf ogt, %arg0, %arg1 : f32
+ iree_linalg_ext.yield %0 : i1
+ } -> tensor<3xf32>, tensor<3xi32>
+
+ check.expect_almost_eq_const(
+ %0#0,
+ dense<[18.0, 17.0, 16.0]> : tensor<3xf32>
+ ) : tensor<3xf32>
+
+ check.expect_eq_const(
+ %0#1,
+ dense<[17, 16, 15]> : tensor<3xi32>
+ ) : tensor<3xi32>
+
+ return
+}
{kind=link}